├── docker
├── base
│ ├── config
│ │ ├── slaves
│ │ ├── start-hadoop.sh
│ │ ├── mapred-site.xml
│ │ ├── ssh_config
│ │ ├── core-site.xml
│ │ ├── hdfs-site.xml
│ │ ├── yarn-site.xml
│ │ └── hadoop-env.sh
│ └── Dockerfile
└── master
│ ├── bin
│ └── stackanswer_2.12-1.0.jar
│ ├── Dockerfile
│ └── config
│ ├── bootstrap.sh
│ ├── hive_job.sql
│ ├── hive-site.xml
│ └── spark-defaults.conf
├── src
├── StackAnswerScalaProject.zip
└── provisioning_data.py
├── .gitignore
├── start-cluster.sh
└── README.md
/docker/base/config/slaves:
--------------------------------------------------------------------------------
1 | hadoop-master
2 | hadoop-slave1
3 | hadoop-slave2
4 |
--------------------------------------------------------------------------------
/src/StackAnswerScalaProject.zip:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ivanrumo/KC_Practica_Big-Data-Architecture_docker/HEAD/src/StackAnswerScalaProject.zip
--------------------------------------------------------------------------------
/docker/master/bin/stackanswer_2.12-1.0.jar:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ivanrumo/KC_Practica_Big-Data-Architecture_docker/HEAD/docker/master/bin/stackanswer_2.12-1.0.jar
--------------------------------------------------------------------------------
/docker/base/config/start-hadoop.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | echo -e "\n"
4 |
5 | $HADOOP_HOME/sbin/start-dfs.sh
6 |
7 | echo -e "\n"
8 |
9 | $HADOOP_HOME/sbin/start-yarn.sh
10 |
11 | echo -e "\n"
12 |
13 |
--------------------------------------------------------------------------------
/docker/base/config/mapred-site.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | mapreduce.framework.name
5 | yarn
6 |
7 |
8 |
--------------------------------------------------------------------------------
/docker/base/config/ssh_config:
--------------------------------------------------------------------------------
1 | Host localhost
2 | StrictHostKeyChecking no
3 |
4 | Host 0.0.0.0
5 | StrictHostKeyChecking no
6 |
7 | Host hadoop-*
8 | StrictHostKeyChecking no
9 | UserKnownHostsFile=/dev/null
--------------------------------------------------------------------------------
/docker/base/config/core-site.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | fs.defaultFS
5 | hdfs://hadoop-master:9000/
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | notas
2 | src/.venv
3 | /data/locations_most_actives/000000_0
4 | /data/user_ids_answers
5 | /data/user_ids_names
6 | /data/users_most_actives/000000_0
7 | data/users_most_actives/_SUCCESS
8 | data/locations_most_actives/_SUCCESS
9 | prueba.sh
10 |
--------------------------------------------------------------------------------
/docker/base/config/hdfs-site.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | dfs.namenode.name.dir
5 | file:///root/hdfs/namenode
6 | NameNode directory for namespace and transaction logs storage.
7 |
8 |
9 | dfs.datanode.data.dir
10 | file:///root/hdfs/datanode
11 | DataNode directory
12 |
13 |
14 | dfs.replication
15 | 2
16 |
17 |
18 |
--------------------------------------------------------------------------------
/docker/master/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM irm/hadoop-cluster-base
2 | MAINTAINER irm
3 |
4 | WORKDIR /root
5 |
6 | # install Spark
7 | RUN wget http://apache.rediris.es/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz && \
8 | tar -xvf spark-2.4.4-bin-hadoop2.7.tgz && \
9 | mv spark-2.4.4-bin-hadoop2.7 /usr/local/spark && \
10 | rm spark-2.4.4-bin-hadoop2.7.tgz
11 |
12 | ENV PATH=$PATH:/usr/local/spark/bin
13 | ENV SPARK_HOME=/usr/local/spark
14 | ENV LD_LIBRARY_PATH=/usr/local/hadoop/lib/native:$LD_LIBRARY_PATH
15 |
16 | ADD config/spark-defaults.conf /usr/local/spark/conf
17 | RUN chown root:root /usr/local/spark/conf/spark-defaults.conf
18 |
19 | ADD bin/stackanswer_2.12-1.0.jar /usr/local/spark/jars
20 |
21 | ADD config/bootstrap.sh /etc/bootstrap.sh
22 | RUN chown root:root /etc/bootstrap.sh
23 | RUN chmod 700 /etc/bootstrap.sh
24 |
25 | ENV BOOTSTRAP /etc/bootstrap.sh
26 |
27 | VOLUME /data
28 |
29 | CMD ["/etc/bootstrap.sh", "-d"]
30 |
31 | EXPOSE 18080
32 |
--------------------------------------------------------------------------------
/docker/base/config/yarn-site.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | yarn.nodemanager.aux-services
5 | mapreduce_shuffle
6 |
7 |
8 | yarn.nodemanager.aux-services.mapreduce_shuffle.class
9 | org.apache.hadoop.mapred.ShuffleHandler
10 |
11 |
12 | yarn.resourcemanager.hostname
13 | hadoop-master
14 |
15 |
16 | yarn.scheduler.maximum-allocation-mb
17 | 2048
18 |
19 |
20 |
21 | yarn.nodemanager.pmem-check-enabled
22 | false
23 |
24 |
25 | yarn.nodemanager.vmem-check-enabled
26 | false
27 |
28 |
29 |
--------------------------------------------------------------------------------
/docker/master/config/bootstrap.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | service ssh start
4 |
5 | # start cluster
6 | $HADOOP_HOME/sbin/start-dfs.sh
7 | $HADOOP_HOME/sbin/start-yarn.sh
8 |
9 | # create paths and give permissions
10 | $HADOOP_HOME/bin/hdfs dfs -mkdir -p /user/root/input_answers
11 | $HADOOP_HOME/bin/hdfs dfs -mkdir -p /user/root/input_names
12 | $HADOOP_HOME/bin/hdfs dfs -copyFromLocal /data/user_ids_answers input_answers
13 | $HADOOP_HOME/bin/hdfs dfs -copyFromLocal /data/user_ids_names input_names
14 | $HADOOP_HOME/bin/hdfs dfs -mkdir /spark-logs
15 |
16 | # start spark history server
17 | $SPARK_HOME/sbin/start-history-server.sh
18 |
19 | # run the spark job
20 | spark-submit --deploy-mode cluster --master yarn \
21 | --class StackAnswer \
22 | $SPARK_HOME/jars/stackanswer_2.12-1.0.jar
23 |
24 | # copy results from hdfs to local
25 | $HADOOP_HOME/bin/hdfs dfs -copyToLocal /user/root/users_most_actives /data
26 | $HADOOP_HOME/bin/hdfs dfs -copyToLocal /user/root/locations_most_actives /data
27 |
28 | bash
--------------------------------------------------------------------------------
/docker/master/config/hive_job.sql:
--------------------------------------------------------------------------------
1 | CREATE TABLE IF NOT EXISTS users
2 | (user_id INT, name STRING, reputation INT, location STRING)
3 | row format delimited fields terminated by ',';
4 |
5 | LOAD DATA INPATH '/user/root/input_names/user_ids_names' INTO TABLE users;
6 |
7 | CREATE TABLE IF NOT EXISTS user_answers
8 | (user_id INT, n_answers INT) row format delimited fields terminated by '\t';
9 |
10 | LOAD DATA INPATH '/user/root/output/*' INTO TABLE user_answers;
11 |
12 | CREATE EXTERNAL TABLE IF NOT EXISTS users_most_actives(
13 | user_id INT, name STRING, n_answers INT)
14 | ROW FORMAT DELIMITED
15 | FIELDS TERMINATED BY ','
16 | STORED AS TEXTFILE
17 | LOCATION '/user/root/users_most_actives';
18 |
19 | INSERT OVERWRITE TABLE users_most_actives SELECT DISTINCT users.user_id, users.name, user_answers.n_answers
20 | FROM users JOIN user_answers ON users.user_id = user_answers.user_id
21 | ORDER BY n_answers DESC;
22 |
23 | CREATE EXTERNAL TABLE IF NOT EXISTS localtions_most_actives(
24 | location STRING, n_answers INT)
25 | ROW FORMAT DELIMITED
26 | FIELDS TERMINATED BY ','
27 | STORED AS TEXTFILE
28 | LOCATION '/user/root/locations_most_actives';
29 |
30 | INSERT OVERWRITE TABLE localtions_most_actives SELECT location, SUM(user_answers.n_answers) TOTAL
31 | FROM users JOIN user_answers ON users.user_id = user_answers.user_id
32 | GROUP BY location
33 | ORDER BY TOTAL DESC;
34 |
--------------------------------------------------------------------------------
/docker/master/config/hive-site.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | javax.jdo.option.ConnectionURL
5 | jdbc:derby:;databaseName=/usr/local/hive/metastore_db;create=true
6 | JDBC connect string for a JDBC metastore.
7 | To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
8 | For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
9 |
10 |
11 | hive.metastore.warehouse.dir
12 | /user/hive/warehouse
13 | location of default database for the warehouse
14 |
15 |
16 | hive.metastore.uris
17 |
18 | Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.
19 |
20 |
21 | javax.jdo.option.ConnectionDriverName
22 | org.apache.derby.jdbc.EmbeddedDriver
23 | Driver class name for a JDBC metastore
24 |
25 |
26 | javax.jdo.PersistenceManagerFactoryClass
27 | org.datanucleus.api.jdo.JDOPersistenceManagerFactory
28 | class implementing the jdo persistence
29 |
30 |
31 |
32 |
--------------------------------------------------------------------------------
/docker/master/config/spark-defaults.conf:
--------------------------------------------------------------------------------
1 | #
2 | # Licensed to the Apache Software Foundation (ASF) under one or more
3 | # contributor license agreements. See the NOTICE file distributed with
4 | # this work for additional information regarding copyright ownership.
5 | # The ASF licenses this file to You under the Apache License, Version 2.0
6 | # (the "License"); you may not use this file except in compliance with
7 | # the License. You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 | #
17 |
18 | # Default system properties included when running spark-submit.
19 | # This is useful for setting default environmental settings.
20 |
21 | # Example:
22 | # spark.master spark://master:7077
23 | # spark.eventLog.enabled true
24 | # spark.eventLog.dir hdfs://namenode:8021/directory
25 | # spark.serializer org.apache.spark.serializer.KryoSerializer
26 | # spark.driver.memory 5g
27 | # spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
28 |
29 | spark.master yarn
30 | spark.driver.memory 512m
31 | spark.yarn.am.memory 512m
32 | spark.executor.memory 512m
33 |
34 | spark.eventLog.enabled true
35 | spark.eventLog.dir hdfs://hadoop-master:9000/spark-logs
36 |
37 |
38 | spark.history.provider org.apache.spark.deploy.history.FsHistoryProvider
39 | spark.history.fs.logDirectory hdfs://hadoop-master:9000/spark-logs
40 | spark.history.fs.update.interval 10s
41 | spark.history.ui.port 18080
42 |
--------------------------------------------------------------------------------
/start-cluster.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # provisioning data
4 | #rm data/user_ids_names &> /dev/null
5 | #python src/provisioning_data.py
6 | sudo rm -rf data/locations_most_actives data/users_most_actives
7 |
8 | # create base hadoop cluster docker image
9 | docker build -f docker/base/Dockerfile -t irm/hadoop-cluster-base:latest docker/base
10 |
11 | # create master node hadoop cluster docker image
12 | docker build -f docker/master/Dockerfile -t irm/hadoop-cluster-master:latest docker/master
13 |
14 | echo "Starting cluster..."
15 |
16 | # the default node number is 3
17 | N=${1:-3}
18 |
19 | docker network create --driver=bridge hadoop &> /dev/null
20 |
21 | # start hadoop slave container
22 | i=1
23 | while [ $i -lt $N ]
24 | do
25 | port=$(( $i + 8042 ))
26 | docker rm -f hadoop-slave$i &> /dev/null
27 | echo "start hadoop-slave$i container..."
28 | docker run -itd \
29 | --net=hadoop \
30 | --name hadoop-slave$i \
31 | --hostname hadoop-slave$i \
32 | -p $((port)):8042 \
33 | irm/hadoop-cluster-base
34 | i=$(( $i + 1 ))
35 | done
36 |
37 |
38 |
39 | # start hadoop master container
40 | docker rm -f hadoop-master &> /dev/null
41 | echo "start hadoop-master container..."
42 | docker run -itd \
43 | --net=hadoop \
44 | -p 50070:50070 \
45 | -p 8088:8088 \
46 | -p 18080:18080 \
47 | --name hadoop-master \
48 | --hostname hadoop-master \
49 | -v $PWD/data:/data \
50 | irm/hadoop-cluster-master
51 |
52 | # get into hadoop master container
53 | #docker exec -it hadoop-master bash
54 |
55 | echo "Making jobs. Please wait"
56 |
57 | while [ ! -d data/locations_most_actives ]
58 | do
59 | sleep 10
60 | #echo "Waiting..."
61 | done
62 |
63 | echo "Stoping cluster..."
64 | docker stop hadoop-master
65 |
66 | i=1
67 | while [ $i -lt $N ]
68 | do
69 | docker stop hadoop-slave$i
70 |
71 | i=$(( $i + 1 ))
72 | done
73 |
--------------------------------------------------------------------------------
/docker/base/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM ubuntu:16.04
2 | MAINTAINER irm
3 |
4 | WORKDIR /root
5 |
6 | # install openssh-server, openjdk and wget
7 | RUN apt-get update && apt-get install -y openssh-server openjdk-8-jdk wget
8 |
9 | # install hadoop 2.7.2
10 | RUN wget http://apache.rediris.es/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz && \
11 | tar -xzvf hadoop-2.7.7.tar.gz && \
12 | mv hadoop-2.7.7 /usr/local/hadoop && \
13 | rm hadoop-2.7.7.tar.gz
14 |
15 | # set environment variable
16 | ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
17 | ENV HADOOP_HOME=/usr/local/hadoop
18 | ENV HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop/
19 | ENV YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop/
20 | ENV PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
21 |
22 | # ssh without key
23 | RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
24 | cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
25 |
26 | RUN mkdir -p ~/hdfs/namenode && \
27 | mkdir -p ~/hdfs/datanode && \
28 | mkdir $HADOOP_HOME/logs
29 |
30 | COPY config/* /tmp/
31 |
32 | RUN mv /tmp/ssh_config ~/.ssh/config && \
33 | mv /tmp/hadoop-env.sh /usr/local/hadoop/etc/hadoop/hadoop-env.sh && \
34 | mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
35 | mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
36 | mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
37 | mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
38 | mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
39 | mv /tmp/start-hadoop.sh ~/start-hadoop.sh
40 |
41 | RUN chmod +x ~/start-hadoop.sh && \
42 | chmod +x $HADOOP_HOME/sbin/start-dfs.sh && \
43 | chmod +x $HADOOP_HOME/sbin/start-yarn.sh
44 |
45 | # format namenode
46 | RUN /usr/local/hadoop/bin/hdfs namenode -format
47 |
48 | CMD [ "sh", "-c", "service ssh start; bash"]
49 |
50 | # Hdfs ports
51 | EXPOSE 9000 50010 50020 50070 50075 50090
52 | EXPOSE 9871 9870 9820 9869 9868 9867 9866 9865 9864
53 | # Mapred ports
54 | EXPOSE 19888
55 | #Yarn ports
56 | EXPOSE 8030 8031 8032 8033 8040 8042 8088 8188
57 | #Other ports
58 | EXPOSE 49707 2122
59 |
--------------------------------------------------------------------------------
/src/provisioning_data.py:
--------------------------------------------------------------------------------
1 | import requests
2 |
3 | from datetime import datetime, timedelta
4 | import time
5 | import os
6 |
7 | # obtenemos la fecha de hace 1 dia
8 | d = datetime.today() - timedelta(days=1)
9 |
10 | fromdate = int(d.timestamp())
11 |
12 | url_base = "https://api.stackexchange.com/2.2/answers?&order=asc&sort=activity&site=stackoverflow&pagesize=100&fromdate=" + str(
13 | fromdate)
14 | print(url_base)
15 | has_more = True
16 | pagina = 1
17 |
18 |
19 | with open('data/user_ids_answers', 'w') as f_user_ids_answers:
20 | while (has_more):
21 | url_request = url_base + "&page=" + str(pagina)
22 | response = requests.get(url_request)
23 |
24 | result = response.json()
25 |
26 | if (result.get('error_id')):
27 | print("Error: " + result.get('error_message'))
28 | break;
29 |
30 | for answer in result['items']:
31 | owner = answer['owner']
32 | if (owner.get('user_id')): # algunas peticiones no traen el user_id
33 | f_user_ids_answers.write(str(answer['owner']['user_id']) + "\n")
34 | #print(str(answer['owner']['user_id']) + "\n")
35 |
36 | print(end=".")
37 | #print("request")
38 |
39 | has_more = result['has_more']
40 | pagina = pagina + 1
41 | time.sleep(1)
42 |
43 |
44 | with open('data/user_ids_answers', 'r') as f_user_ids_answers:
45 | # El API de stackexchange nos permite
46 | # https://api.stackexchange.com/docs/users-by-ids
47 |
48 | i = 0
49 | users_url = ""
50 | for user_id in f_user_ids_answers:
51 | user_id = f_user_ids_answers.readline().rstrip()
52 |
53 | if (i >= 100):
54 | # quitamos el ultimo ; y hacemos la peticion para obtener los datos de los usuarios
55 | users_url = users_url[:-1]
56 | url = "https://api.stackexchange.com/2.2/users/" + users_url + "?pagesize=100&order=desc&sort=reputation&site=stackoverflow"
57 | # print(url)
58 | print(end=".")
59 | response = requests.get(url)
60 | result = response.json()
61 |
62 | with open('data/user_ids_names', 'a') as f_user_ids_names:
63 | if (result.get('error_id')):
64 | print("Error: " + result.get('error_message'))
65 | else:
66 | for user in result['items']:
67 | user_id = user['user_id']
68 | name = user.get('display_name')
69 | reputation = user.get('reputation')
70 | location = user.get('location')
71 | f_user_ids_names.write(
72 | str(user_id) + "," + name + "," + str(reputation) + "," + str(location) + "\n")
73 |
74 | i = 0
75 | users_url = ""
76 |
77 | users_url = users_url + str(user_id) + ";"
78 | i = i + 1
79 |
80 |
81 |
--------------------------------------------------------------------------------
/docker/base/config/hadoop-env.sh:
--------------------------------------------------------------------------------
1 | # Licensed to the Apache Software Foundation (ASF) under one
2 | # or more contributor license agreements. See the NOTICE file
3 | # distributed with this work for additional information
4 | # regarding copyright ownership. The ASF licenses this file
5 | # to you under the Apache License, Version 2.0 (the
6 | # "License"); you may not use this file except in compliance
7 | # with the License. You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 |
17 | # Set Hadoop-specific environment variables here.
18 |
19 | # The only required environment variable is JAVA_HOME. All others are
20 | # optional. When running a distributed configuration it is best to
21 | # set JAVA_HOME in this file, so that it is correctly defined on
22 | # remote nodes.
23 |
24 | # The java implementation to use.
25 | export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
26 |
27 | # The jsvc implementation to use. Jsvc is required to run secure datanodes
28 | # that bind to privileged ports to provide authentication of data transfer
29 | # protocol. Jsvc is not required if SASL is configured for authentication of
30 | # data transfer protocol using non-privileged ports.
31 | #export JSVC_HOME=${JSVC_HOME}
32 |
33 | export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
34 |
35 | # Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
36 | for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
37 | if [ "$HADOOP_CLASSPATH" ]; then
38 | export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
39 | else
40 | export HADOOP_CLASSPATH=$f
41 | fi
42 | done
43 |
44 | # The maximum amount of heap to use, in MB. Default is 1000.
45 | #export HADOOP_HEAPSIZE=
46 | #export HADOOP_NAMENODE_INIT_HEAPSIZE=""
47 |
48 | # Extra Java runtime options. Empty by default.
49 | export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
50 |
51 | # Command specific options appended to HADOOP_OPTS when specified
52 | export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
53 | export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
54 |
55 | export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
56 |
57 | export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
58 | export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
59 |
60 | # The following applies to multiple commands (fs, dfs, fsck, distcp etc)
61 | export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
62 | #HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
63 |
64 | # On secure datanodes, user to run the datanode as after dropping privileges.
65 | # This **MUST** be uncommented to enable secure HDFS if using privileged ports
66 | # to provide authentication of data transfer protocol. This **MUST NOT** be
67 | # defined if SASL is configured for authentication of data transfer protocol
68 | # using non-privileged ports.
69 | export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
70 |
71 | # Where log files are stored. $HADOOP_HOME/logs by default.
72 | #export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER
73 |
74 | # Where log files are stored in the secure data environment.
75 | export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
76 |
77 | ###
78 | # HDFS Mover specific parameters
79 | ###
80 | # Specify the JVM options to be used when starting the HDFS Mover.
81 | # These options will be appended to the options specified as HADOOP_OPTS
82 | # and therefore may override any similar flags set in HADOOP_OPTS
83 | #
84 | # export HADOOP_MOVER_OPTS=""
85 |
86 | ###
87 | # Advanced Users Only!
88 | ###
89 |
90 | # The directory where pid files are stored. /tmp by default.
91 | # NOTE: this should be set to a directory that can only be written to by
92 | # the user that will run the hadoop daemons. Otherwise there is the
93 | # potential for a symlink attack.
94 | export HADOOP_PID_DIR=${HADOOP_PID_DIR}
95 | export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
96 |
97 | # A string representing this instance of hadoop. $USER by default.
98 | export HADOOP_IDENT_STRING=$USER
99 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Creando un cluster de Hadoop y Spark con docker
2 |
3 | Seguimos la serie de artículos de nuestro cluster de Hadoop. En este caso voy a integrar [Apache Spark](https://spark.apache.org/) en el cluster y voy a incluir un script en Scala que usa el framewrok de Spark para realizar las mismas operaciones que realizamos con Hive en el artículo anterior.
4 |
5 | Recapitulando los anteriores artículos habíamos creado un cluster Hadoop para procesar unos ficheros. Creamos un Dockerfile para generar una imagen base. Con esta imagen creamos nos nodos slave del cluster. También creamos otro Dockerfile que se basa en la imagen base y con el que creamos la imagen del nodo master del cluster. En un primer lugar creamos un cluster de Hadoop, después incluimos hive y ahora vamos a incluir Spark.
6 |
7 | Como en artículo anterior nos modificamos los ficheros ya existentes y los cambios realizado los dejaré subidos [en una rama](https://github.com/ivanrumo/KC_Practica_Big-Data-Architecture_docker/tree/install_spark) del repositorio[ de Github](https://github.com/ivanrumo/KC_Practica_Big-Data-Architecture_docker) de los artículos.
8 |
9 | Empezamos modificando el Dockerfile de la imagen base. Se encuentra en la ruta docker/base/Dockerfile. Incluimos dos variables de entorno necesarias para que Spark encuentre las configuraciones de Hadoop y Yarn y pueda funcionar correctamente.
10 |
11 | ```yaml
12 | ENV HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop/
13 | ENV YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop/
14 | ```
15 |
16 | Así quedaría el fichero Dockerfile completo.
17 |
18 | ```yaml
19 | FROM ubuntu:16.04
20 | MAINTAINER irm
21 |
22 | WORKDIR /root
23 |
24 | # install openssh-server, openjdk and wget
25 | RUN apt-get update && apt-get install -y openssh-server openjdk-8-jdk wget
26 |
27 | # install hadoop 2.7.2
28 | RUN wget http://apache.rediris.es/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz && \
29 | tar -xzvf hadoop-2.7.7.tar.gz && \
30 | mv hadoop-2.7.7 /usr/local/hadoop && \
31 | rm hadoop-2.7.7.tar.gz
32 |
33 | # set environment variable
34 | ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
35 | ENV HADOOP_HOME=/usr/local/hadoop
36 | ENV HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop/
37 | ENV YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop/
38 | ENV PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
39 |
40 | # ssh without key
41 | RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
42 | cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
43 |
44 | RUN mkdir -p ~/hdfs/namenode && \
45 | mkdir -p ~/hdfs/datanode && \
46 | mkdir $HADOOP_HOME/logs
47 |
48 | COPY config/* /tmp/
49 |
50 | RUN mv /tmp/ssh_config ~/.ssh/config && \
51 | mv /tmp/hadoop-env.sh /usr/local/hadoop/etc/hadoop/hadoop-env.sh && \
52 | mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
53 | mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
54 | mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
55 | mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
56 | mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
57 | mv /tmp/start-hadoop.sh ~/start-hadoop.sh
58 |
59 | RUN chmod +x ~/start-hadoop.sh && \
60 | chmod +x $HADOOP_HOME/sbin/start-dfs.sh && \
61 | chmod +x $HADOOP_HOME/sbin/start-yarn.sh
62 |
63 | # format namenode
64 | RUN /usr/local/hadoop/bin/hdfs namenode -format
65 |
66 | CMD [ "sh", "-c", "service ssh start; bash"]
67 |
68 | # Hdfs ports
69 | EXPOSE 9000 50010 50020 50070 50075 50090
70 | EXPOSE 9871 9870 9820 9869 9868 9867 9866 9865 9864
71 | # Mapred ports
72 | EXPOSE 19888
73 | #Yarn ports
74 | EXPOSE 8030 8031 8032 8033 8040 8042 8088 8188
75 | #Other ports
76 | EXPOSE 49707 2122
77 | ```
78 |
79 | Ahora vamos con los cambios del Dockerfile de la imagen master. Quitamos la instalación de Hive e incluimos la instalación de Spark. Podríamos tener ambos a la vez en el mismo cluster, pero en este caso prefiero eliminar Hive del cluster ya que no lo vamos a utilizar:
80 |
81 | * Bajamos los binarios de Spark y lo descomprimimos.
82 | * Configuramos las variables de entorno
83 | * Añadimos el fichero de configuración de Spark
84 | * Añadimos el jar que va a ejecutar Spark para procesar los ficheros. Mas adelante vemos que hace exactamente.
85 | * Exponemos el puerto 18080 para poder acceder al Spark’s history server
86 |
87 | El fichero se encuentra en docker/master/Dockerfile
88 |
89 | ```yaml
90 | RUN wget http://apache.rediris.es/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz && \
91 | tar -xvf spark-2.4.0-bin-hadoop2.7.tgz && \
92 | mv spark-2.4.0-bin-hadoop2.7 /usr/local/spark && \
93 | rm spark-2.4.0-bin-hadoop2.7.tgz
94 |
95 | ENV PATH=$PATH:/usr/local/spark/bin
96 | ENV SPARK_HOME=/usr/local/spark
97 | ENV LD_LIBRARY_PATH=/usr/local/hadoop/lib/native:$LD_LIBRARY_PATH
98 |
99 | ADD config/spark-defaults.conf /usr/local/spark/conf
100 | RUN chown root:root /usr/local/spark/conf/spark-defaults.conf
101 |
102 | ADD bin/stackanswer_2.12-1.0.jar /usr/local/spark/jars
103 |
104 | EXPOSE 18080
105 | ```
106 |
107 | Así quedaría el fichero Dockerfile completo.
108 |
109 | ```yaml
110 | FROM irm/hadoop-cluster-base
111 | MAINTAINER irm
112 |
113 | WORKDIR /root
114 |
115 | # install Spark
116 | RUN wget http://apache.rediris.es/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz && \
117 | tar -xvf spark-2.4.4-bin-hadoop2.7.tgz && \
118 | mv spark-2.4.4-bin-hadoop2.7 /usr/local/spark && \
119 | rm spark-2.4.4-bin-hadoop2.7.tgz
120 |
121 | ENV PATH=$PATH:/usr/local/spark/bin
122 | ENV SPARK_HOME=/usr/local/spark
123 | ENV LD_LIBRARY_PATH=/usr/local/hadoop/lib/native:$LD_LIBRARY_PATH
124 |
125 | ADD config/spark-defaults.conf /usr/local/spark/conf
126 | RUN chown root:root /usr/local/spark/conf/spark-defaults.conf
127 |
128 | ADD bin/stackanswer_2.12-0.1.jar /usr/local/spark/jars
129 |
130 | ADD config/bootstrap.sh /etc/bootstrap.sh
131 | RUN chown root:root /etc/bootstrap.sh
132 | RUN chmod 700 /etc/bootstrap.sh
133 |
134 | ENV BOOTSTRAP /etc/bootstrap.sh
135 |
136 | VOLUME /data
137 |
138 | CMD ["/etc/bootstrap.sh", "-d"]
139 |
140 | EXPOSE 18080
141 | ```
142 |
143 | Seguimos con el fichero boostrap.sh. Este fichero se ejecuta al arrancar el contenedor del nodo master. En la versión anterior, este fichero configuraba directorios en el HDFS para hive, se inicializa el metastorage de Hive y ejecutaba un job de wordcount en Hadoop y un job de Hive. Todo eso se elimina en esta versión.
144 |
145 | Los cambios que incluimos son:
146 |
147 | * Arrancar el proceso del Spark’s history server
148 | * Crear el directorio de losg para Spark en el HDFS
149 | * Lanzar el job de Spark que procesará los ficheros de entrada.
150 |
151 | Este fichero se encuentra en la ruta docker/master/config/bootstrap.sh
152 |
153 | ```bash
154 | #!/bin/bash
155 |
156 | service ssh start
157 |
158 | # start cluster
159 | $HADOOP_HOME/sbin/start-dfs.sh
160 | $HADOOP_HOME/sbin/start-yarn.sh
161 |
162 | # create paths and give permissions
163 | $HADOOP_HOME/bin/hdfs dfs -mkdir -p /user/root/input_answers
164 | $HADOOP_HOME/bin/hdfs dfs -mkdir -p /user/root/input_names
165 | $HADOOP_HOME/bin/hdfs dfs -copyFromLocal /data/user_ids_answers input_answers
166 | $HADOOP_HOME/bin/hdfs dfs -copyFromLocal /data/user_ids_names input_names
167 | $HADOOP_HOME/bin/hdfs dfs -mkdir /spark-logs
168 |
169 | # start spark history server
170 | $SPARK_HOME/sbin/start-history-server.sh
171 |
172 | # run the spark job
173 | spark-submit --deploy-mode cluster --master yarn \
174 | --class StackAnswer \
175 | $SPARK_HOME/jars/stackanswer_2.12-0.1.jar
176 |
177 | # copy results from hdfs to local
178 | $HADOOP_HOME/bin/hdfs dfs -copyToLocal /user/root/users_most_actives /data
179 | $HADOOP_HOME/bin/hdfs dfs -copyToLocal /user/root/locations_most_actives /data
180 |
181 | bash
182 | ```
183 |
184 | Es el turno del script que realiza toda la magia. En este caso, solo incluimos mapeo de puerto de history server cuando creamos el contenedor del nodo master. Este sería el fichero completo:
185 |
186 | ```bash
187 | #!/bin/bash
188 |
189 | # provisioning data
190 | rm data/user_ids_names &> /dev/null
191 | python src/provisioning_data.py
192 | sudo rm -rf data/locations_most_actives data/users_most_actives
193 |
194 | # create base hadoop cluster docker image
195 | docker build -f docker/base/Dockerfile -t irm/hadoop-cluster-base:latest docker/base
196 |
197 | # create master node hadoop cluster docker image
198 | docker build -f docker/master/Dockerfile -t irm/hadoop-cluster-master:latest docker/master
199 |
200 | echo "Starting cluster..."
201 |
202 | # the default node number is 3
203 | N=${1:-3}
204 |
205 | docker network create --driver=bridge hadoop &> /dev/null
206 |
207 | # start hadoop slave container
208 | i=1
209 | while [ $i -lt $N ]
210 | do
211 | docker rm -f hadoop-slave$i &> /dev/null
212 | echo "start hadoop-slave$i container..."
213 | docker run -itd \
214 | --net=hadoop \
215 | --name hadoop-slave$i \
216 | --hostname hadoop-slave$i \
217 | irm/hadoop-cluster-base
218 | i=$(( $i + 1 ))
219 | done
220 |
221 | # start hadoop master container
222 | docker rm -f hadoop-master &> /dev/null
223 | echo "start hadoop-master container..."
224 | docker run -itd \
225 | --net=hadoop \
226 | -p 50070:50070 \
227 | -p 8088:8088 \
228 | -p 18080:18080 \
229 | --name hadoop-master \
230 | --hostname hadoop-master \
231 | -v $PWD/data:/data \
232 | irm/hadoop-cluster-master
233 |
234 | echo "Making jobs. Please wait"
235 |
236 | while [ ! -d data/locations_most_actives ]
237 | do
238 | sleep 10
239 | #echo "Waiting..."
240 | done
241 |
242 | echo "Stoping cluster..."
243 | docker stop hadoop-master
244 |
245 | i=1
246 | while [ $i -lt $N ]
247 | do
248 | docker stop hadoop-slave$i
249 |
250 | i=$(( $i + 1 ))
251 | done
252 | ```
253 |
254 | Para que Spark funcione correctamente debemos incluir unos parámetros nuevos en el fichero de configuración de Yarn.
255 |
256 | El fichero está en la ruta docker/base/config/yarn-site.xml
257 |
258 | ```xml
259 |
260 |
261 |
262 | yarn.nodemanager.aux-services
263 | mapreduce_shuffle
264 |
265 |
266 | yarn.nodemanager.aux-services.mapreduce_shuffle.class
267 | org.apache.hadoop.mapred.ShuffleHandler
268 |
269 |
270 | yarn.resourcemanager.hostname
271 | hadoop-master
272 |
273 |
274 | yarn.scheduler.maximum-allocation-mb
275 | 2048
276 |
277 |
278 | yarn.nodemanager.pmem-check-enabled
279 | false
280 |
281 |
282 | yarn.nodemanager.vmem-check-enabled
283 | false
284 |
285 |
286 | ```
287 |
288 | A continuación el fichero de configuración de Spark. En el configuramos la memoria disponible para la ejecución de Spark. Recordar que Spark necesita mucha memoria. Bueno, dependiendo del volumen de los conjuntos de datos que se vayan a procesar. Spark usa memoria para trabajar más rápido, por lo que es necesario asignar la memoria suficiente para que pueda funcionar correctamente. También se configuran las rutas de logs en HDFS y el puerto del history server.
289 |
290 | El fichero de logs se encuentra en la ruta docker/master/config/spark-defaults.conf
291 | ```yaml
292 | spark.master yarn
293 | spark.driver.memory 512m
294 | spark.yarn.am.memory 512m
295 | spark.executor.memory 512m
296 |
297 | spark.eventLog.enabled true
298 | spark.eventLog.dir hdfs://hadoop-master:9000/spark-logs
299 |
300 |
301 | spark.history.provider org.apache.spark.deploy.history.FsHistoryProvider
302 | spark.history.fs.logDirectory hdfs://hadoop-master:9000/spark-logs
303 | spark.history.fs.update.interval 10s
304 | spark.history.ui.port 18080
305 |
306 | ```
307 |
308 | Ahora es el turno del proceso de Scala que procesará los datos. Para trabajar con Scala he usado IntelliJ IDEA Community Edition con el plugin de Scala. En un futuro Post publicaré un tutorial para configurar el entorno de desarrollo con Scala, aunque haciendo un simple búsqueda hay mucho tutoriales. En src/StackAnswerScalaProject.zip he dejado el proyecto completo.
309 |
310 | Este proceso realiza las mismas acciones que se realizaban en el [post anterior](https://www.writecode.es/2019-02-25-cluster_hadoop_docker/) con Hadoop y Hive, pero ahora unicamente con Scala sobre Spark.
311 |
312 | ```scala
313 | import java.io.File
314 |
315 | import org.apache.spark.sql.types.{IntegerType, StringType, StructType}
316 | import org.apache.spark.sql.{SQLContext, SparkSession}
317 | import org.apache.spark.sql.functions._
318 |
319 | object StackAnswer {
320 |
321 |
322 | def main(args: Array[String]): Unit = {
323 | val namesFile = "hdfs:///user/root/input_names/user_ids_names"
324 | val answersFile = "hdfs:///user/root/input_answers/user_ids_answers"
325 | val pathWordCount = "hdfs:///user/root/user_ids_answers_wordcount"
326 | val pathUsersMostActives = "hdfs:///user/root/users_most_actives"
327 | val pathLocaltionsMostActives = "hdfs:///user/root/locations_most_actives"
328 |
329 | val spark = SparkSession
330 | .builder
331 | .appName("StackAnswer")
332 | .getOrCreate()
333 |
334 | // configuramos los logs para que solo muestre errores
335 | import org.apache.log4j.{Level, Logger}
336 | val rootLogger = Logger.getRootLogger()
337 | rootLogger.setLevel(Level.ERROR)
338 |
339 | import spark.implicits._
340 |
341 | // leemos el fichero con las respuestas y hacemos un count de los ids.
342 | val readFileDF = spark.sparkContext.textFile(answersFile).toDF
343 | val name_counts = readFileDF.groupBy("Value").count().orderBy($"count".desc)
344 |
345 | val name_countsC = name_counts.coalesce(1)
346 | name_countsC.write.csv(pathWordCount)
347 |
348 | // leemos el fichero de con los nombres de los usuarios y sus localizaciones
349 | val schemaNames = new StructType()
350 | .add("user_id", IntegerType,true)
351 | .add("name", StringType,true)
352 | .add("reputation", IntegerType, true)
353 | .add("location", StringType, true)
354 |
355 | val userDataDF = spark.read
356 | .option("sep", ",")
357 | .option("header", false)
358 | .schema(schemaNames)
359 | .csv(namesFile)
360 |
361 | // eliminamos las filas duplicadas
362 | val userDataCleanedDF = userDataDF.dropDuplicates()
363 |
364 | // hacemos un join de los datos
365 | val dataUsersAnswersDF = userDataCleanedDF.join(name_counts, userDataCleanedDF("user_id") === name_counts("Value"), "inner").drop("Value")
366 |
367 | val usersMostActivesDF = dataUsersAnswersDF.select($"user_id", $"name", $"count".as("n_answers")).coalesce(1)
368 | usersMostActivesDF.write.csv(pathUsersMostActives)
369 |
370 | val dataLocationsMostActivesDF = dataUsersAnswersDF
371 | .groupBy("location")
372 | .sum("count")
373 | .select($"location", $"sum(count)".as("n_answres"))
374 | .orderBy(desc("n_answres"))
375 | .coalesce(1)
376 | dataLocationsMostActivesDF.write.csv(pathLocaltionsMostActives)
377 | }
378 |
379 | }
380 | ```
381 |
382 | Dentro de IntelliJ generamos el fichero jar que usaremos para lanzar el trabajo de Spark. En el repositorio de GitHub el jar se encuentra en docker/master/bin/stackanswer_2.12-1.0.jar.
383 |
384 | El proceso se lanzará automáticamente al ejecutar el cluster. En la siguiente imagen podemos la ejecución del trabajo de Spark en el Yarn de nuestro cluster hadoop
385 |
386 | 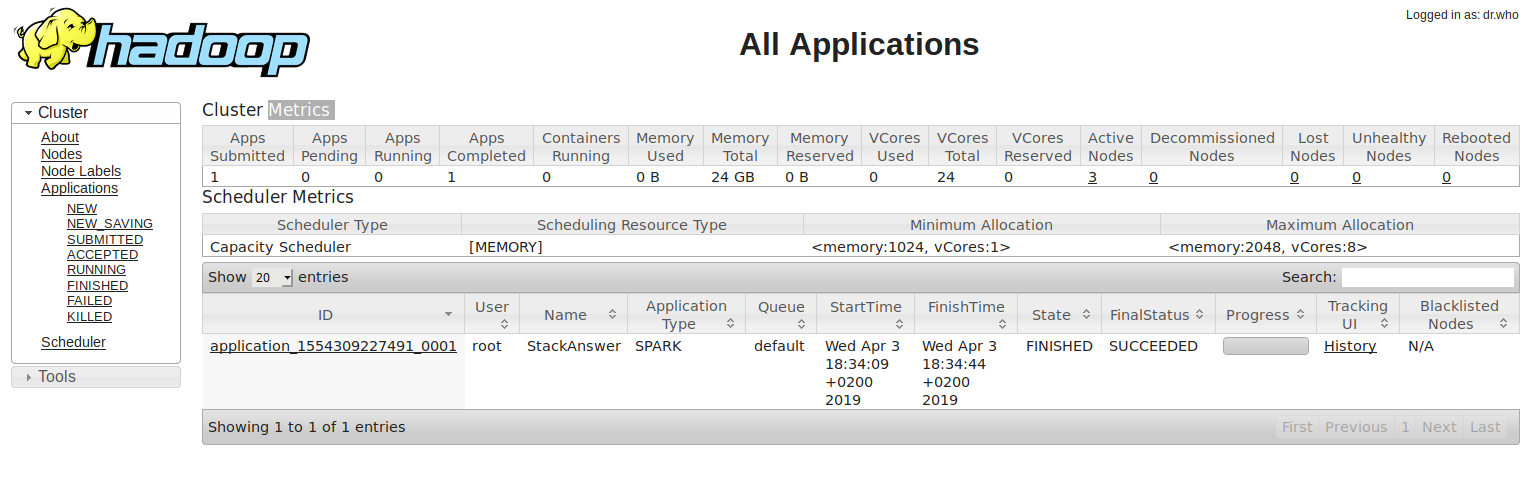
387 |
388 | En esta imagen se puede ver timeline de la ejecución en el History server de Spark
389 |
390 | 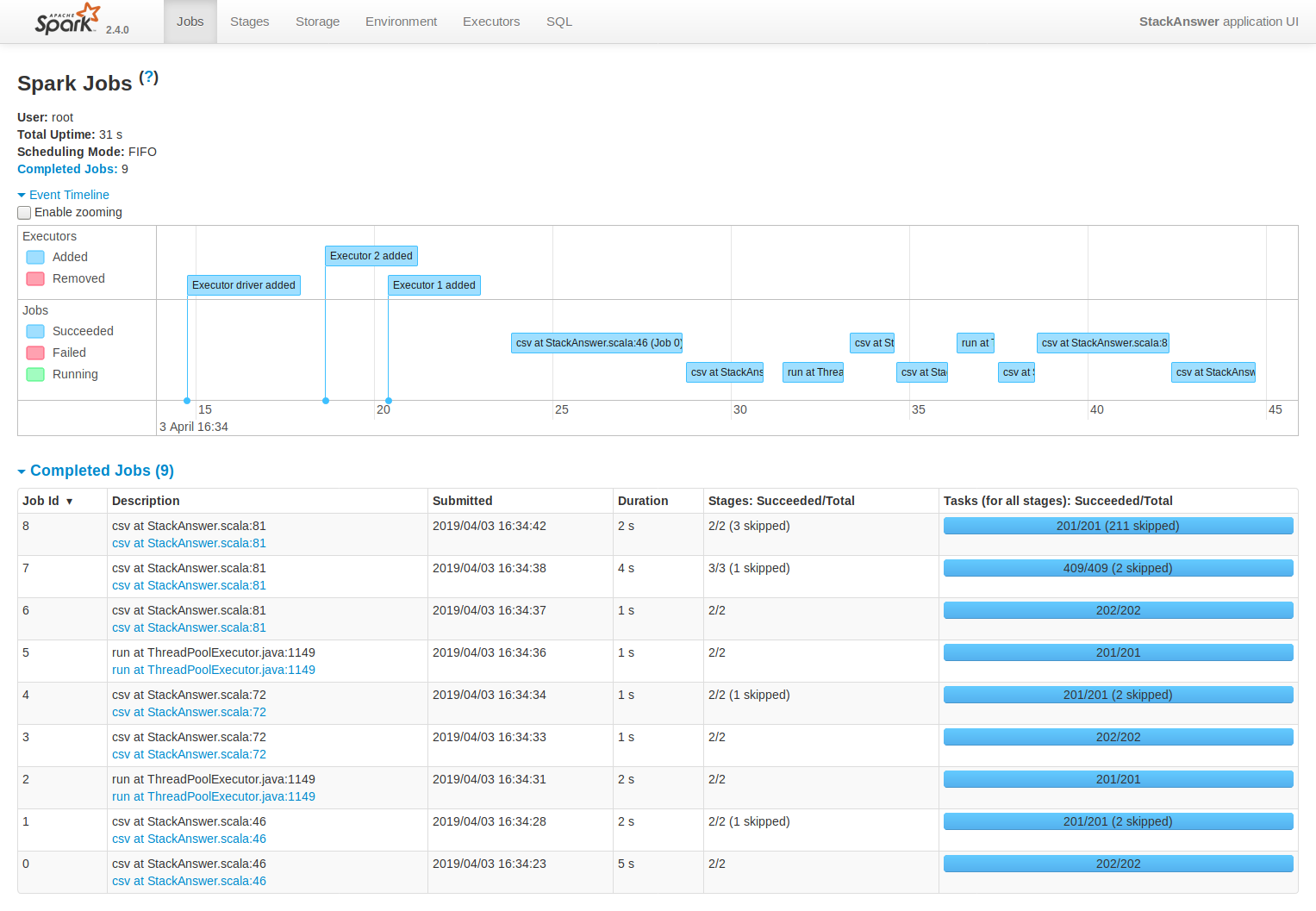
391 |
392 | Con esto estaría todo. Como hemos podido ver, teniendo un cluster Hadoop, incluir Spark para que ejecute trabajos dentro del cluster es bastante sencillo. Spark nos ofrece una velocidad de procesamiento muy superior a las operaciones de MapReduce de hadoop.
393 |
--------------------------------------------------------------------------------