The great majority of the projects about machine learning or data analysis I write about here on Bigish-Data have an initial step of scraping data from websites. And since I get a bunch of contact emails asking me to give them either the data I’ve scraped myself, or help with getting the code to work for themselves. Because of that, I figured I should write something here about the process of web scraping!
201 |There are plenty of other things to talk about when scraping, such as specifics on how to grab the data from a particular site, which Python libraries to use and how to use them, how to write code that would scrape the data in a daily job, where exactly to look as to how to get the data from random sites, etc. But since there are tons of other specific tutorials online, I’m going to talk about overall thoughts on how to scrape. There are three parts of this post – How to grab the data, how to save the data, and how to be nice.
202 |As is the case with everything, programming-wise, if you’re looking to learn scraping, you can’t just read tutorials and think to yourself that you know how to program. Pick a project, practice grabbing the data, and then write a blog post about what you learned.
203 |There definitely are tons of different thoughts on scraping, but these are the ones that I’ve learned from doing it a while. If you have questions, comments, and want to call me out, feel free to comment, or get in contact!
204 |Grabbing the Data
205 |The first step for scraping data from websites is to figure out where the sites keep their data, and what method they use to display the data on the browser. For this part of your project, I’ll suggest writing in a file named gather.py which should performs all these tasks.
206 |207 |
That being said, there are a few ways you’ll need to look for to see how to most easily get the data.
208 |Check if the site has an API First
209 |A ton of sites with interesting data have APIs for programmers to grab the data and write posts about the interesting-ness of the site. Genius does this very nicely, except for the song lyrics of course.
210 |And also if the site has an API, that means that they’re totally alright with programmers using their data, though pretty much every site doesn’t allow you to use its data to make money. Read their requirements and rules for using the site’s data, and if your project is allowed, API is the way to go.
211 |Figure out the URLs of all the data
212 |If there is no API, that means you’re going to have to figure out the urls where the site displays all the data you need.
213 |A common type you’ll see is that the data is displayed using IDs for the objects. If you’ve done web development in something like Rails, you’ll know exactly how that works. In this case, there probably is an index page that has links to all the different pages you’re trying to scrape, so you’ll have two scraping requirements. And like I’ve said, each site is different, but just know that these are possible requirements to get all the data you want.
214 |Check JSON loading of data
215 |If the site doesn’t have an API and you’re still going to want the data, check to see if the page that shows the data you’re looking for is by using JSON. If the page loads and it takes a second or a flash for the text to show up, it’s probably using that JSON.
216 |From there, right click the web page and click “Inspect” on Chrome to get the Developer Tools window to open, reload the web page, and check the Sources tab to see pages that end in .json. You’ll be able to see the URL it came from, then open a new tab and paste that URL and you’ll be able to see the JSON with your data!
217 |Quick example of how stats.nba.com generates their pages. If you just look at the HTML returned, you’ll see that it’s only AngularJS, meaning you can’t use the HTML to scrape the data. You’ll need to find the JS url that loads that data.
218 |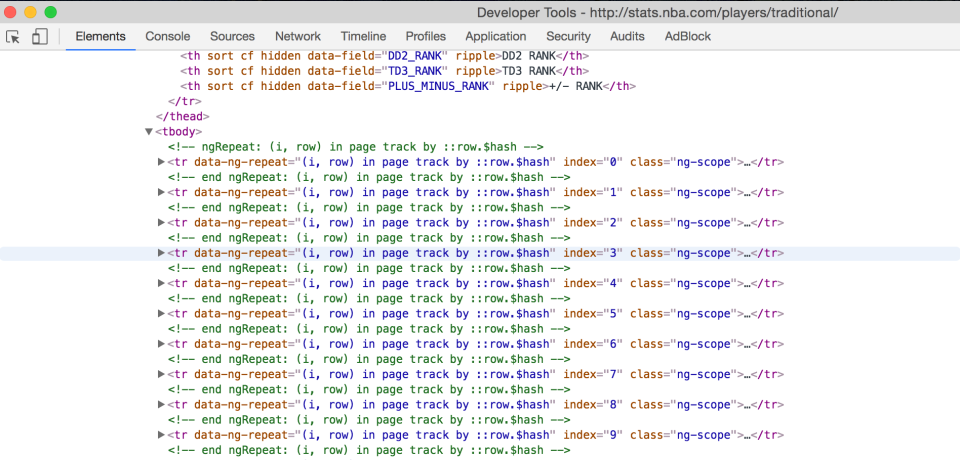
Looking at the network, I find a specific html file requested for over the Network.
220 |Then, by reloading the page and checking the files under the Network tab, I find the url that generates the data for the page. As you can see, it’s just a JS variable that has all the data for the players.
221 |
223 |
I won’t list the URL specifically here, but there are ways to change it to grab the data that you’re looking for.
224 |Fall back to HTML scraping
225 |If the site you’re looking for data from doesn’t have an API or use JSON to load the data, you’re going to fall back to grabbing the HTML pages. Which is the only technique that people think of when imagining web scraping!
226 |Like the JSON data, you’re going to have to use the Inspect feature of Chrome’s development tools, but in this case right click on the text that you’re trying to grab and analyze the classes and ids in order to grab that data.
227 |For example, if you’re looking to scrape a WordPress blog to do something like sentiment analysis of the posts, you’ll want to do something like this:
228 |
As for other sites, I won’t go into exactly how that’s to be done because the classes and ids vary, but odds are it’ll be structured similarly with specific classes and ids for the data part of the page. Practice HTML scraping a couple sites and you’ll see how that part is.
230 |Saving the Data
231 |After you have the data saved using gather.py, you’ll need to write code that scrapes the data. In case you didn’t guess this, a good name for that file is scrape.py.
232 |With this file, you’ll want to write the code that grabs the data and structures it for what you saved. How to save the data also depends on the type of scraping job you’re writing.
233 |CSV is probably a fine type of database initially
234 |There are two different types of scraping projects. First is just grabbing data that is consistent and doesn’t change that much over time. Like the PGA Tour stats I’ve scraped which change week by week for the current year but obviously don’t change when grabbing stats for every year in the past. Another example of this is how to get lyrics from Genius. Lyrics don’t change, and if you’re looking for other information about the songs, that doesn’t change much over time either.
235 |If you’re getting this kind of data, don’t worry about setting up a DB to save the data. All types of this have a limited amount and frankly, test files are also quick to analyze the data.
236 |Database is useful if you have data that keeps coming
237 |On the other hand, if the data you’re looking to scrape is updated continuously, you’re probably going to want a DB to store the data, especially if you have a service (Heroku, Amazon, etc.) that runs your scraping code at certain times.
238 |Another use for the DB is if you’re looking to scrape the data and then make a website that displays the data. Something like a script that checks Reddit comments to see how many Amazon products are mentioned and then displays them online.
239 |And obviously the benefit of storing the data in a database rather than local files is that querying to compare data you scraped is much easier than having to load all your files into variables and then analyze the data. Like everything I’ve mentioned here, types of methods depends on the site, data, and information you’re trying to gather.
240 |Be Nice
241 |Scrape with header that has your name and email so company knows it’s you.
242 |Some sites will get mad at you if you’re scraping their data. Even when the sites aren’t “nice”, you don’t want to do something “illegal”. An example of a way to do this:
243 |import requests
244 |
245 | from = "'From': %s" % 'contact@bigishdata.com'
246 | headers = {'user-agent' : 'Jack Schultz, bigishdata.com, contact@bigishdata.com'}
247 | html = requests.get(url, headers=headers)
248 | You can look up other options for the request header, but make sure it’s the same and that people who look at their server’s logs know who you are, just in case they want to get in contact.
249 |Make sure you don’t keep hitting the servers!!!!
250 |When you’re writing and running gather.py make sure you’re testing it in a way that doesn’t continuously hit the servers to gather the data! I’m talking about using JSON and HTML. As for API, you’ll also want to make sure you’re not hitting the end points time and time again, especially since they track who’s hitting the API and most only allow a certain number of requests per time period.
251 |Then when you’re running scrape.py, don’t hit their servers over and over as well. That script deals with gathering the data that you already got from their site.
252 |Basically, the only time you should continuously hit the servers is when you’re running your final code that gets and saves the data / files from the site.
253 |Gevent
254 |Now if you’re needing to scrape data from a bunch of different web pages, Gevent is the python library to use that will help run request jobs concurrently so you’ll be able to hit the API, grab the JSON, or grab the HTML pages quicker. Since for the most part, the longest code is the kind that hits their servers and then wait for the file to be returned.
255 |import gevent 256 | from gevent import monkey 257 | monkey.patch_all() 258 | ... #set the urls that you'll get the data from 259 | jobs = [gevent.spawn(gather_pages, pair[0], pair[1]) for pair in url_filenames] 260 | gevent.joinall(jobs)261 |
Again, as long as you’re not going too quickly destroy their servers by asking for thousands of pages at once, feel free to use Gevent. Especially since most sites have more than 50 requests at once.
262 |Practice, practice, practice
263 |With all that said, and what is the case with everything, if you want to web scrape, you gotta practice. Reading so many of the tutorials is interesting and does teach you things, but if you want to learn, write the code yourself and search for tutorials that help solve your bugs.
264 |And remember, be nice when grabbing the data.
265 | 686 |
707 |
--------------------------------------------------------------------------------
/scraping/requesting_html.py:
--------------------------------------------------------------------------------
1 | import helpers
2 |
3 | url = "https://bigishdata.com/2017/05/11/general-tips-for-web-scraping-with-python/"
4 | params = {} #used for ? values
5 | headers = {'user-agent' : 'Jack Schultz, bigishdata.com, contact@bigishdata.com'}
6 |
7 |
8 | import urllib2
9 | import urllib
10 | data = urllib.urlencode(params)
11 | req = urllib2.Request(url, data, headers)
12 | fstring = urllib2.urlopen(req).read()
13 | helpers.write_html('urllib2', fstring)
14 |
15 |
16 | import requests
17 | page = requests.get(url, headers=headers)
18 | fstring = page.text
19 | helpers.write_html('requests', fstring.encode('UTF-8'))
20 |
21 |
22 | import httplib
23 | #note that the url here is split into the base and the path
24 | conn = httplib.HTTPConnection("bigishdata.com")
25 | conn.request("GET", "/2017/05/11/general-tips-for-web-scraping-with-python/")
26 | response = conn.getresponse()
27 | helpers.write_html('httplib', response.read())
28 | conn.close()
29 |
--------------------------------------------------------------------------------
/scraping/requirements.txt:
--------------------------------------------------------------------------------
1 | PyDispatcher==2.0.5
2 | Scrapy==1.4.0
3 | Twisted==17.1.0
4 | beautifulsoup4==4.6.0
5 | certifi==2017.4.17
6 | chardet==3.0.3
7 | cssselect==1.0.1
8 | idna==2.5
9 | lxml==3.7.3
10 | parsel==1.2.0
11 | pyOpenSSL==17.0.0
12 | queuelib==1.4.2
13 | requests==2.17.3
14 | service-identity==17.0.0
15 | six==1.10.0
16 | urllib3==1.21.1
17 | virtualenv==15.1.0
18 | w3lib==1.17.0
19 | wsgiref==0.1.2
20 |
--------------------------------------------------------------------------------
/scraping/scraping_html.py:
--------------------------------------------------------------------------------
1 | import helpers
2 |
3 | with open('page.html', 'r') as f:
4 | page_string = f.read()
5 |
6 |
7 | ##
8 | ## BeautifulSoup
9 | ##
10 | from bs4 import BeautifulSoup as bs
11 | soup = bs(page_string, "html.parser")
12 | article = soup.find('div', {'class' : 'entry-content'})
13 |
14 | text = {}
15 | text['p'] = []
16 | text['h1'] = []
17 | text['h3'] = []
18 | text['pre'] = []
19 | text['imgsrc'] = []
20 | for tag in article.contents:
21 | #multiple if statements here to make is easier to read
22 | if tag is not None and tag.name is not None:
23 | if tag.name == "p":
24 | text['p'].append(tag.text)
25 | elif tag.name == 'h1':
26 | text['h1'].append(tag.text)
27 | elif tag.name == 'h3':
28 | text['h3'].append(tag.text)
29 | elif tag.name == 'pre':
30 | text['pre'].append(tag.text)
31 | for tag in article.findAll('img'):
32 | text['imgsrc'].append(tag['src'])
33 | helpers.write_data('bs', text)
34 |
35 | ##
36 | ## LXML
37 | ##
38 | import lxml.html
39 | page = lxml.html.fromstring(page_string)
40 | post = page.find_class('entry-content')[0] #0 since only one tag with that class
41 |
42 | text = {}
43 | text['p'] = []
44 | text['h1'] = []
45 | text['h3'] = []
46 | text['pre'] = []
47 | text['imgsrc'] = []
48 | #test_content is needed to get all of the text within the tag, not just on the top level
49 | for tag in post.findall('p'):
50 | text['p'].append(tag.text_content())
51 | for img in tag.findall('img'): #images in paragraphs, so need to check here
52 | text['imgsrc'].append(img.attrib['src'])
53 | for tag in post.findall('h1'):
54 | text['h1'].append(tag.text_content())
55 | for tag in post.findall('h3'):
56 | text['h3'].append(tag.text_content())
57 | for tag in post.findall('pre'):
58 | text['pre'].append(tag.text_content())
59 | helpers.write_data('lxml', text)
60 |
61 |
62 |
63 | ##
64 | ## HTMLParser
65 | ##
66 | from HTMLParser import HTMLParser
67 | import urllib
68 |
69 | desired_tags = (u'p', u'h1', u'h3', u'pre', u'img')
70 | class BigIshDataParser(HTMLParser):
71 | def __init__(self):
72 | HTMLParser.__init__(self)
73 | self.inside_entry_content = 0
74 | self.current_tag = None
75 | self.current_text = []
76 | self.overall_text = {}
77 | self.overall_text['p'] = []
78 | self.overall_text['h1'] = []
79 | self.overall_text['h3'] = []
80 | self.overall_text['pre'] = []
81 | self.overall_text['img'] = []
82 |
83 | def handle_starttag(self, tag, attributes):
84 | if self.inside_entry_content and tag in desired_tags:
85 | self.current_tag = tag
86 | if tag == 'div':
87 | for name, value in attributes:
88 | if name == 'class' and value == 'entry-content': #if this is correct div
89 | self.inside_entry_content += 1
90 | return #don't keep going through the attributes since there could be infinate, or just a ton of them
91 | if tag == 'img' and self.inside_entry_content: #need to deal with images here since they're only a start tag
92 | for attr in attributes:
93 | if attr[0] == 'src':
94 | self.overall_text['img'].append(attr[1])
95 | break
96 |
97 | def handle_endtag(self, tag):
98 | if tag == 'div' and self.inside_entry_content:
99 | self.inside_entry_content -= 1 #moving on down the divs
100 | if tag == self.current_tag:
101 | tstring = ''.join(self.current_text)
102 | self.overall_text[self.current_tag].append(tstring)
103 | self.current_text = []
104 | self.current_tag = None
105 |
106 | def handle_data(self, data):
107 | if self.inside_entry_content:
108 | self.current_text.append(data)
109 |
110 | p = BigIshDataParser()
111 | page_string = p.unescape(page_string.decode('UTF-8'))
112 | p.feed(page_string)
113 | helpers.write_data('htmlparser', p.overall_text)
114 | p.close()
115 |
116 |
117 |
--------------------------------------------------------------------------------
/scraping/selenium_test.py:
--------------------------------------------------------------------------------
1 | import helpers
2 |
3 | from selenium import webdriver
4 | from selenium.webdriver.common.keys import Keys
5 |
6 | url = 'https://bigishdata.com/2017/05/11/general-tips-for-web-scraping-with-python/'
7 |
8 | driver = webdriver.PhantomJS()
9 | driver.get(url)
10 | elem = driver.find_element_by_class_name('entry-content')
11 |
12 | text = {}
13 | desired_tags = (u'p', u'h1', u'h3', u'pre')
14 | for tag in desired_tags:
15 | tags = elem.find_elements_by_tag_name(tag)
16 | text[tag] = []
17 | for data in tags:
18 | text[tag].append(data.text)
19 |
20 | helpers.write_data('selenium', text)
21 |
--------------------------------------------------------------------------------
/sklearn_classify/classify.py:
--------------------------------------------------------------------------------
1 | import json
2 | from sklearn.feature_extraction.text import CountVectorizer
3 | from sklearn.feature_extraction.text import TfidfTransformer
4 | from sklearn.feature_extraction.text import TfidfVectorizer
5 | from pandas import DataFrame
6 | import numpy
7 | from sklearn.naive_bayes import MultinomialNB
8 | from sklearn.pipeline import Pipeline
9 | from sklearn.metrics import confusion_matrix, accuracy_score
10 |
11 |
12 | def print_confusion_matrix(matrix, class_labels):
13 | lines = ["" for i in range(len(class_labels)+1)]
14 | for index, c in enumerate(class_labels):
15 | lines[0] += "\t"
16 | lines[0] += c
17 | lines[index+1] += c
18 | for index, result in enumerate(matrix):
19 | for amount in result:
20 | lines[index+1] += "\t"
21 | lines[index+1] += str(amount)
22 | for line in lines:
23 | print line
24 |
25 | def initialize_conversion_matrix(num_labels):
26 | return [[0 for i in range(num_labels)] for y in range(num_labels)]
27 |
28 |
29 | '''
30 | counts = count_vectorizer.fit_transform(data['text'].values)
31 | bigram_counts = bigram_vectorizer.fit_transform(data['text'].values)
32 | tfidf_counts = tfidf_vectorizer.fit_transform(data['text'].values)
33 | '''
34 |
35 | labels = ["baby", "tool", "home", "pet", "food"]
36 |
37 | count_vectorizer = CountVectorizer(min_df=1)
38 | bigram_vectorizer = CountVectorizer(ngram_range=(1, 2), min_df=1)
39 | tfidf_vectorizer = TfidfVectorizer(min_df=1)
40 |
41 | classifier = MultinomialNB()
42 |
43 | pipeline = Pipeline([
44 | ('count_vectorizer', bigram_vectorizer),
45 | ('classifier', classifier)
46 | ])
47 |
48 | reviews = []
49 | for label in labels:
50 | filename = "train_%s.json" % label
51 | with open(filename, 'r') as f:
52 | for line in f:
53 | reviews.append({'text': json.loads(line)["reviewText"], 'class': label})
54 |
55 | data = DataFrame(reviews)
56 | data = data.reindex(numpy.random.permutation(data.index))
57 |
58 | pipeline.fit(data['text'].values, data['class'].values)
59 |
60 | test_reviews = []
61 | for index, label in enumerate(labels):
62 | filename = "test_%s.json" % label
63 | with open(filename, 'r') as f:
64 | for line in f:
65 | test_reviews.append({'text': json.loads(line)["reviewText"], 'class': label})
66 |
67 | test_examples = [review['text'] for review in test_reviews]
68 | test_labels = [review['class'] for review in test_reviews]
69 |
70 | #print pipeline.score(test_examples)
71 | guesses = pipeline.predict(test_examples)
72 |
73 | print accuracy_score(test_labels, guesses)
74 | print confusion_matrix(test_labels, guesses, labels=labels)
75 |
76 |
--------------------------------------------------------------------------------
/tourstats/analyze.py:
--------------------------------------------------------------------------------
1 | import csv
2 | import numpy as np
3 | from sklearn import linear_model
4 | import os
5 | from bokeh.plotting import figure, output_file, show,vplot
6 | from collections import Iterable, Sequence
7 |
8 | stat = 'Driving Distance'
9 | folder_path = 'stats_csv/%s' % (stat)
10 |
11 | key = 'AVG.'
12 |
13 | years = []
14 | yearly_data = []
15 | year_hash = {}
16 | for filename in os.listdir(folder_path):
17 | with open(folder_path + '/' + filename, 'rb') as csvfile:
18 | year = filename.split('.')[0]
19 | years.append(year)
20 | reader = csv.DictReader(csvfile)
21 | fieldnames = reader.fieldnames
22 |
23 | avgs = [float(row[key]) for row in reader]
24 | year_hash[year] = avgs
25 | yearly_data.append(avgs)
26 |
27 | int_years = [int(year) for year in years]
28 |
29 | yda = np.array(yearly_data)
30 |
31 | p = figure(tools="save", title="Max, Avg, Min Driving Distance Over Time")
32 | p.line(int_years, [np.average(asdf) for asdf in yda], line_color="red")#, fill_color="red", line_color="green", line_width=3, )
33 | p.line(int_years, [np.min(asdf) for asdf in yda], line_color="blue")#, fill_color="red", line_color="green", line_width=3, )
34 | p.line(int_years, [np.max(asdf) for asdf in yda], line_color="green")#, fill_color="red", line_color="green", line_width=3, )
35 | output_file("driving_distance.html", title="Max, Avg, Min Driving Distance Over Time")
36 | show(vplot(p))
37 |
38 | '''
39 | filename = '2015.csv'
40 | ind = []
41 | dep = []
42 | names = []
43 | with open(filename, 'rb') as csvfile:
44 | reader = csv.reader(csvfile)
45 | headings = reader.next()[1:-1] #headings
46 | for row in reader:
47 | names.append(row[0])
48 | ind.append(map(float, row[1:-3]))
49 | dep.append(float(row[-2]))
50 |
51 | npind = np.array(ind)
52 | npdep = np.array(dep)
53 |
54 | regr = linear_model.LinearRegression(normalize=True)
55 |
56 | regr.fit(npind, npdep)
57 |
58 | for name, coeff in zip(headings, regr.coef_):
59 | print "%s: %s" % (name, coeff)
60 |
61 | print("Residual sum of squares: %.2f"
62 | % np.mean((regr.predict(npind) - npdep) ** 2))
63 |
64 | for name, stats, money in zip(names, ind, dep):
65 | predicted = '{:20,.2f}'.format(np.dot(stats, regr.coef_))
66 | print "%s: %s, %s" % (name, predicted, '{:20,.2f}'.format(money))
67 |
68 | import csv
69 | from bokeh.plotting import figure, output_file, show, vplot
70 | years = range(2002,2016)
71 | years = [2002, 2015]
72 | for year in years:
73 | filename = "%s.csv" % year
74 | with open(filename, 'rb') as csvfile:
75 | reader = csv.DictReader(csvfile)
76 | fieldnames = reader.fieldnames
77 | distances = [float(row['driving_distance']) for row in reader if row['percentage_of_yardage_covered_by_tee_shots']]
78 | a = np.array(distances)
79 |
80 | hist, edges = np.histogram(a, density=True, bins=100)
81 |
82 | x = np.linspace(np.amin(a)-5, np.amax(a)+5, 1000)
83 | mu = np.mean(a)
84 | sigma = np.std(a)
85 | pdf = 1/(sigma * np.sqrt(2*np.pi)) * np.exp(-(x-mu)**2 / (2*sigma**2))
86 |
87 | p1 = figure(title="%s Driving Distance" % (year),tools="save", background_fill_color="#E8DDCB")
88 | p1.quad(top=hist, bottom=0, left=edges[:-1], right=edges[1:], fill_color="#036564", line_color="#033649")
89 | p1.line(x, pdf, line_color="#D95B43", line_width=8, alpha=0.7, legend="PDF")
90 |
91 | p1.legend.location = "top_left"
92 | p1.xaxis.axis_label = 'Driving Distance'
93 | p1.yaxis.axis_label = 'Pr(x)'
94 |
95 | output_file("%s_driving_distance.html" % (year), title="%s Driving Distance" % (year))
96 | show(vplot(p1))
97 |
98 |
99 | '''
100 |
--------------------------------------------------------------------------------
/tourstats/distance_vs_putts.csv:
--------------------------------------------------------------------------------
1 | Brian Gay,1.719,270.2
2 | Marc Leishman,1.723,288.3
3 | Rob Oppenheim,1.746,272.2
4 | Scott Stallings,1.798,287.3
5 | Chad Campbell,1.788,281.5
6 | Ian Poulter,1.835,276.2
7 | Cameron Percy,1.832,274.6
8 | Emiliano Grillo,1.779,286.2
9 | Smylie Kaufman,1.725,295.0
10 | Paul Casey,1.786,285.4
11 | Rickie Fowler,1.753,293.7
12 | Jason Dufner,1.756,282.7
13 | Ryo Ishikawa,1.723,297.4
14 | Charles Howell III,1.739,294.6
15 | Vaughn Taylor,1.715,272.9
16 | Jon Curran,1.738,267.1
17 | Matt Every,1.772,281.0
18 | Russell Knox,1.786,281.5
19 | Steven Bowditch,1.750,288.5
20 | Martin Piller,1.780,283.7
21 | Ben Crane,1.711,275.0
22 | David Lingmerth,1.729,284.1
23 | Bryce Molder,1.758,276.9
24 | Jim Herman,1.781,284.0
25 | D.H. Lee,1.762,276.4
26 | Chesson Hadley,1.812,288.3
27 | Robert Streb,1.808,285.4
28 | Matt Kuchar,1.725,281.2
29 | Mark Wilson,1.807,269.9
30 | Adam Hadwin,1.708,283.5
31 | Peter Malnati,1.735,277.3
32 | Billy Horschel,1.778,287.2
33 | Bud Cauley,1.762,282.6
34 | Jhonattan Vegas,1.791,288.1
35 | Rory Sabbatini,1.735,287.6
36 | D.A. Points,1.732,270.1
37 | Wes Roach,1.783,284.5
38 | Hiroshi Iwata,1.751,282.5
39 | Jonas Blixt,1.755,279.9
40 | Mark Hubbard,1.761,278.9
41 | Tyrone Van Aswegen,1.767,280.7
42 | Hideki Matsuyama,1.717,289.1
43 | Andres Gonzales,1.793,284.2
44 | Michael Kim,1.752,280.1
45 | Scott Brown,1.785,283.6
46 | Cameron Beckman,1.901,264.5
47 | Patrick Rodgers,1.791,295.6
48 | Danny Lee,1.741,283.2
49 | Stewart Cink,1.800,283.5
50 | Kyle Reifers,1.746,280.9
51 | David Toms,1.791,265.2
52 | William McGirt,1.727,277.5
53 | Charley Hoffman,1.769,296.5
54 | Will Wilcox,1.770,286.8
55 | Colt Knost,1.765,271.7
56 | Webb Simpson,1.746,288.9
57 | Brett Stegmaier,1.782,286.0
58 | Lucas Glover,1.763,283.8
59 | J.B. Holmes,1.761,306.0
60 | Patton Kizzire,1.728,283.5
61 | Brian Stuard,1.790,266.2
62 | Rory McIlroy,1.773,297.2
63 | Camilo Villegas,1.772,283.4
64 | Graeme McDowell,1.737,275.8
65 | Erik Compton,1.775,281.3
66 | Bill Haas,1.782,280.0
67 | Jonathan Byrd,1.763,275.1
68 | Ollie Schniederjans,1.802,295.5
69 | Tyler Aldridge,1.776,280.6
70 | Michael Putnam,1.825,278.8
71 | John Huh,1.741,274.1
72 | Vijay Singh,1.773,279.9
73 | Ken Duke,1.829,270.3
74 | Cameron Tringale,1.730,279.4
75 | Nick Watney,1.759,290.0
76 | Justin Thomas,1.742,293.9
77 | Nick Taylor,1.764,290.6
78 | Justin Rose,1.735,289.5
79 | Kyle Stanley,1.769,282.4
80 | Steve Wheatcroft,1.760,281.4
81 | Brendon de Jonge,1.784,283.1
82 | Cameron Smith,1.745,276.6
83 | Charlie Beljan,1.910,295.1
84 | Stuart Appleby,1.781,276.0
85 | Dustin Johnson,1.722,305.5
86 | Zach Johnson,1.755,281.8
87 | Charl Schwartzel,1.788,288.5
88 | Billy Hurley III,1.785,263.5
89 | Fabian Gomez,1.781,284.4
90 | Sung Kang,1.785,277.5
91 | Rhein Gibson,1.848,284.7
92 | Jason Day,1.765,297.4
93 | Andrew Loupe,1.701,296.4
94 | Luke Donald,1.781,270.8
95 | Alex Cejka,1.740,278.1
96 | Lucas Lee,1.818,265.7
97 | Justin Hicks,1.771,277.5
98 | Sam Saunders,1.810,284.8
99 | Tim Herron,1.825,269.1
100 | Brandt Snedeker,1.718,289.8
101 | Ryan Moore,1.715,281.0
102 | Justin Leonard,1.747,270.7
103 | Steve Stricker,1.661,268.9
104 | Tim Clark,1.796,270.2
105 | Hudson Swafford,1.786,292.6
106 | Carlos Ortiz,1.736,285.9
107 | George McNeill,1.744,277.8
108 | Jeff Overton,1.764,281.6
109 | John Senden,1.770,283.1
110 | Jimmy Walker,1.751,291.6
111 | Ben Martin,1.730,280.6
112 | Dicky Pride,1.807,268.5
113 | Hunter Stewart,1.782,283.3
114 | Brice Garnett,1.757,274.2
115 | Robert Garrigus,1.800,290.2
116 | Aaron Baddeley,1.722,281.7
117 | Jason Bohn,1.711,280.3
118 | James Hahn,1.759,286.4
119 | David Hearn,1.746,275.9
120 | Sean O'Hair,1.732,287.3
121 | Andrew Landry,1.819,278.2
122 | Shawn Stefani,1.824,287.3
123 | Graham DeLaet,1.741,288.7
124 | Brian Davis,1.783,263.8
125 | Chris Stroud,1.762,281.0
126 | Roberto Castro,1.774,279.9
127 | Russell Henley,1.762,290.2
128 | Blake Adams,1.805,270.3
129 | Andres Romero,1.727,278.4
130 | Phil Mickelson,1.718,287.0
131 | Martin Laird,1.751,290.8
132 | Derek Fathauer,1.755,282.3
133 | Retief Goosen,1.784,282.0
134 | Chris Kirk,1.824,279.7
135 | Davis Love III,1.773,283.8
136 | Morgan Hoffmann,1.754,289.2
137 | Will MacKenzie,1.783,279.1
138 | K.J. Choi,1.764,271.2
139 | Jordan Spieth,1.659,287.5
140 | Abraham Ancer,1.807,272.5
141 | John Merrick,1.804,276.1
142 | Dawie van der Walt,1.775,282.2
143 | Kevin Na,1.716,277.9
144 | Troy Merritt,1.743,283.2
145 | Sergio Garcia,1.746,282.4
146 | Whee Kim,1.847,282.4
147 | Brendan Steele,1.742,291.6
148 | Daniel Berger,1.764,290.7
149 | Boo Weekley,1.799,283.8
150 | Jason Kokrak,1.793,297.1
151 | Kevin Kisner,1.691,288.1
152 | J.J. Henry,1.811,283.9
153 | Darron Stiles,1.771,256.4
154 | Kelly Kraft,1.770,280.4
155 | Rod Pampling,1.845,273.7
156 | Johnson Wagner,1.788,280.0
157 | Chez Reavie,1.764,281.8
158 | Robert Allenby,1.851,274.9
159 | Francesco Molinari,1.751,279.2
160 | Jerry Kelly,1.787,273.2
161 | Gary Woodland,1.759,301.5
162 | Si Woo Kim,1.766,287.8
163 | Michael Thompson,1.747,284.2
164 | Steve Marino,1.806,283.6
165 | Scott Langley,1.820,277.0
166 | Thomas Aiken,1.834,275.5
167 | Alex Prugh,1.853,285.0
168 | Ricky Barnes,1.741,279.7
169 | Geoff Ogilvy,1.798,286.8
170 | Brooks Koepka,1.729,298.6
171 | Daniel Summerhays,1.728,284.2
172 | Scott Pinckney,1.814,291.2
173 | Ernie Els,1.801,283.3
174 | Jarrod Lyle,1.726,274.2
175 | Brian Harman,1.760,285.1
176 | Kevin Streelman,1.754,283.9
177 | Keegan Bradley,1.833,292.2
178 | Blayne Barber,1.795,279.2
179 | Hunter Mahan,1.759,293.3
180 | Derek Ernst,1.842,284.4
181 | Miguel Angel Carballo,1.774,284.3
182 | Zac Blair,1.776,271.0
183 | Seung-Yul Noh,1.730,288.7
184 | D.J. Trahan,1.762,282.4
185 | Brendon Todd,1.774,274.3
186 | Shane Lowry,1.780,288.3
187 | Freddie Jacobson,1.717,275.9
188 | Ryan Palmer,1.748,298.6
189 | Tim Wilkinson,1.773,275.6
190 | Chad Collins,1.775,273.8
191 | Harris English,1.778,290.8
192 | Tom Hoge,1.780,281.6
193 | Kevin Chappell,1.760,285.3
194 | Pat Perez,1.772,280.2
195 | Luke List,1.796,294.2
196 | Greg Owen,1.820,290.1
197 | Bronson Burgoon,1.791,285.6
198 | Matt Jones,1.752,289.8
199 | Shane Bertsch,1.781,275.5
200 | Andy Sullivan,1.806,276.9
201 | Adam Scott,1.726,289.5
202 | Jamie Lovemark,1.774,297.0
203 | Angel Cabrera,1.787,290.6
204 | Scott Piercy,1.765,294.1
205 | Nicholas Thompson,1.837,270.2
206 | Padraig Harrington,1.779,280.4
207 | Henrik Norlander,1.780,276.1
208 | Harold Varner III,1.779,291.8
209 | Tony Finau,1.784,300.9
210 | Patrick Reed,1.743,288.1
211 | Carl Pettersson,1.734,280.4
212 | Branden Grace,1.701,282.6
213 | Bo Van Pelt,1.871,278.5
214 | Bubba Watson,1.787,307.5
215 | Spencer Levin,1.732,277.8
216 | Jason Gore,1.730,281.2
217 | Anirban Lahiri,1.700,286.0
218 |
--------------------------------------------------------------------------------
/tourstats/driving_distance.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
686 |
707 |
--------------------------------------------------------------------------------
/scraping/requesting_html.py:
--------------------------------------------------------------------------------
1 | import helpers
2 |
3 | url = "https://bigishdata.com/2017/05/11/general-tips-for-web-scraping-with-python/"
4 | params = {} #used for ? values
5 | headers = {'user-agent' : 'Jack Schultz, bigishdata.com, contact@bigishdata.com'}
6 |
7 |
8 | import urllib2
9 | import urllib
10 | data = urllib.urlencode(params)
11 | req = urllib2.Request(url, data, headers)
12 | fstring = urllib2.urlopen(req).read()
13 | helpers.write_html('urllib2', fstring)
14 |
15 |
16 | import requests
17 | page = requests.get(url, headers=headers)
18 | fstring = page.text
19 | helpers.write_html('requests', fstring.encode('UTF-8'))
20 |
21 |
22 | import httplib
23 | #note that the url here is split into the base and the path
24 | conn = httplib.HTTPConnection("bigishdata.com")
25 | conn.request("GET", "/2017/05/11/general-tips-for-web-scraping-with-python/")
26 | response = conn.getresponse()
27 | helpers.write_html('httplib', response.read())
28 | conn.close()
29 |
--------------------------------------------------------------------------------
/scraping/requirements.txt:
--------------------------------------------------------------------------------
1 | PyDispatcher==2.0.5
2 | Scrapy==1.4.0
3 | Twisted==17.1.0
4 | beautifulsoup4==4.6.0
5 | certifi==2017.4.17
6 | chardet==3.0.3
7 | cssselect==1.0.1
8 | idna==2.5
9 | lxml==3.7.3
10 | parsel==1.2.0
11 | pyOpenSSL==17.0.0
12 | queuelib==1.4.2
13 | requests==2.17.3
14 | service-identity==17.0.0
15 | six==1.10.0
16 | urllib3==1.21.1
17 | virtualenv==15.1.0
18 | w3lib==1.17.0
19 | wsgiref==0.1.2
20 |
--------------------------------------------------------------------------------
/scraping/scraping_html.py:
--------------------------------------------------------------------------------
1 | import helpers
2 |
3 | with open('page.html', 'r') as f:
4 | page_string = f.read()
5 |
6 |
7 | ##
8 | ## BeautifulSoup
9 | ##
10 | from bs4 import BeautifulSoup as bs
11 | soup = bs(page_string, "html.parser")
12 | article = soup.find('div', {'class' : 'entry-content'})
13 |
14 | text = {}
15 | text['p'] = []
16 | text['h1'] = []
17 | text['h3'] = []
18 | text['pre'] = []
19 | text['imgsrc'] = []
20 | for tag in article.contents:
21 | #multiple if statements here to make is easier to read
22 | if tag is not None and tag.name is not None:
23 | if tag.name == "p":
24 | text['p'].append(tag.text)
25 | elif tag.name == 'h1':
26 | text['h1'].append(tag.text)
27 | elif tag.name == 'h3':
28 | text['h3'].append(tag.text)
29 | elif tag.name == 'pre':
30 | text['pre'].append(tag.text)
31 | for tag in article.findAll('img'):
32 | text['imgsrc'].append(tag['src'])
33 | helpers.write_data('bs', text)
34 |
35 | ##
36 | ## LXML
37 | ##
38 | import lxml.html
39 | page = lxml.html.fromstring(page_string)
40 | post = page.find_class('entry-content')[0] #0 since only one tag with that class
41 |
42 | text = {}
43 | text['p'] = []
44 | text['h1'] = []
45 | text['h3'] = []
46 | text['pre'] = []
47 | text['imgsrc'] = []
48 | #test_content is needed to get all of the text within the tag, not just on the top level
49 | for tag in post.findall('p'):
50 | text['p'].append(tag.text_content())
51 | for img in tag.findall('img'): #images in paragraphs, so need to check here
52 | text['imgsrc'].append(img.attrib['src'])
53 | for tag in post.findall('h1'):
54 | text['h1'].append(tag.text_content())
55 | for tag in post.findall('h3'):
56 | text['h3'].append(tag.text_content())
57 | for tag in post.findall('pre'):
58 | text['pre'].append(tag.text_content())
59 | helpers.write_data('lxml', text)
60 |
61 |
62 |
63 | ##
64 | ## HTMLParser
65 | ##
66 | from HTMLParser import HTMLParser
67 | import urllib
68 |
69 | desired_tags = (u'p', u'h1', u'h3', u'pre', u'img')
70 | class BigIshDataParser(HTMLParser):
71 | def __init__(self):
72 | HTMLParser.__init__(self)
73 | self.inside_entry_content = 0
74 | self.current_tag = None
75 | self.current_text = []
76 | self.overall_text = {}
77 | self.overall_text['p'] = []
78 | self.overall_text['h1'] = []
79 | self.overall_text['h3'] = []
80 | self.overall_text['pre'] = []
81 | self.overall_text['img'] = []
82 |
83 | def handle_starttag(self, tag, attributes):
84 | if self.inside_entry_content and tag in desired_tags:
85 | self.current_tag = tag
86 | if tag == 'div':
87 | for name, value in attributes:
88 | if name == 'class' and value == 'entry-content': #if this is correct div
89 | self.inside_entry_content += 1
90 | return #don't keep going through the attributes since there could be infinate, or just a ton of them
91 | if tag == 'img' and self.inside_entry_content: #need to deal with images here since they're only a start tag
92 | for attr in attributes:
93 | if attr[0] == 'src':
94 | self.overall_text['img'].append(attr[1])
95 | break
96 |
97 | def handle_endtag(self, tag):
98 | if tag == 'div' and self.inside_entry_content:
99 | self.inside_entry_content -= 1 #moving on down the divs
100 | if tag == self.current_tag:
101 | tstring = ''.join(self.current_text)
102 | self.overall_text[self.current_tag].append(tstring)
103 | self.current_text = []
104 | self.current_tag = None
105 |
106 | def handle_data(self, data):
107 | if self.inside_entry_content:
108 | self.current_text.append(data)
109 |
110 | p = BigIshDataParser()
111 | page_string = p.unescape(page_string.decode('UTF-8'))
112 | p.feed(page_string)
113 | helpers.write_data('htmlparser', p.overall_text)
114 | p.close()
115 |
116 |
117 |
--------------------------------------------------------------------------------
/scraping/selenium_test.py:
--------------------------------------------------------------------------------
1 | import helpers
2 |
3 | from selenium import webdriver
4 | from selenium.webdriver.common.keys import Keys
5 |
6 | url = 'https://bigishdata.com/2017/05/11/general-tips-for-web-scraping-with-python/'
7 |
8 | driver = webdriver.PhantomJS()
9 | driver.get(url)
10 | elem = driver.find_element_by_class_name('entry-content')
11 |
12 | text = {}
13 | desired_tags = (u'p', u'h1', u'h3', u'pre')
14 | for tag in desired_tags:
15 | tags = elem.find_elements_by_tag_name(tag)
16 | text[tag] = []
17 | for data in tags:
18 | text[tag].append(data.text)
19 |
20 | helpers.write_data('selenium', text)
21 |
--------------------------------------------------------------------------------
/sklearn_classify/classify.py:
--------------------------------------------------------------------------------
1 | import json
2 | from sklearn.feature_extraction.text import CountVectorizer
3 | from sklearn.feature_extraction.text import TfidfTransformer
4 | from sklearn.feature_extraction.text import TfidfVectorizer
5 | from pandas import DataFrame
6 | import numpy
7 | from sklearn.naive_bayes import MultinomialNB
8 | from sklearn.pipeline import Pipeline
9 | from sklearn.metrics import confusion_matrix, accuracy_score
10 |
11 |
12 | def print_confusion_matrix(matrix, class_labels):
13 | lines = ["" for i in range(len(class_labels)+1)]
14 | for index, c in enumerate(class_labels):
15 | lines[0] += "\t"
16 | lines[0] += c
17 | lines[index+1] += c
18 | for index, result in enumerate(matrix):
19 | for amount in result:
20 | lines[index+1] += "\t"
21 | lines[index+1] += str(amount)
22 | for line in lines:
23 | print line
24 |
25 | def initialize_conversion_matrix(num_labels):
26 | return [[0 for i in range(num_labels)] for y in range(num_labels)]
27 |
28 |
29 | '''
30 | counts = count_vectorizer.fit_transform(data['text'].values)
31 | bigram_counts = bigram_vectorizer.fit_transform(data['text'].values)
32 | tfidf_counts = tfidf_vectorizer.fit_transform(data['text'].values)
33 | '''
34 |
35 | labels = ["baby", "tool", "home", "pet", "food"]
36 |
37 | count_vectorizer = CountVectorizer(min_df=1)
38 | bigram_vectorizer = CountVectorizer(ngram_range=(1, 2), min_df=1)
39 | tfidf_vectorizer = TfidfVectorizer(min_df=1)
40 |
41 | classifier = MultinomialNB()
42 |
43 | pipeline = Pipeline([
44 | ('count_vectorizer', bigram_vectorizer),
45 | ('classifier', classifier)
46 | ])
47 |
48 | reviews = []
49 | for label in labels:
50 | filename = "train_%s.json" % label
51 | with open(filename, 'r') as f:
52 | for line in f:
53 | reviews.append({'text': json.loads(line)["reviewText"], 'class': label})
54 |
55 | data = DataFrame(reviews)
56 | data = data.reindex(numpy.random.permutation(data.index))
57 |
58 | pipeline.fit(data['text'].values, data['class'].values)
59 |
60 | test_reviews = []
61 | for index, label in enumerate(labels):
62 | filename = "test_%s.json" % label
63 | with open(filename, 'r') as f:
64 | for line in f:
65 | test_reviews.append({'text': json.loads(line)["reviewText"], 'class': label})
66 |
67 | test_examples = [review['text'] for review in test_reviews]
68 | test_labels = [review['class'] for review in test_reviews]
69 |
70 | #print pipeline.score(test_examples)
71 | guesses = pipeline.predict(test_examples)
72 |
73 | print accuracy_score(test_labels, guesses)
74 | print confusion_matrix(test_labels, guesses, labels=labels)
75 |
76 |
--------------------------------------------------------------------------------
/tourstats/analyze.py:
--------------------------------------------------------------------------------
1 | import csv
2 | import numpy as np
3 | from sklearn import linear_model
4 | import os
5 | from bokeh.plotting import figure, output_file, show,vplot
6 | from collections import Iterable, Sequence
7 |
8 | stat = 'Driving Distance'
9 | folder_path = 'stats_csv/%s' % (stat)
10 |
11 | key = 'AVG.'
12 |
13 | years = []
14 | yearly_data = []
15 | year_hash = {}
16 | for filename in os.listdir(folder_path):
17 | with open(folder_path + '/' + filename, 'rb') as csvfile:
18 | year = filename.split('.')[0]
19 | years.append(year)
20 | reader = csv.DictReader(csvfile)
21 | fieldnames = reader.fieldnames
22 |
23 | avgs = [float(row[key]) for row in reader]
24 | year_hash[year] = avgs
25 | yearly_data.append(avgs)
26 |
27 | int_years = [int(year) for year in years]
28 |
29 | yda = np.array(yearly_data)
30 |
31 | p = figure(tools="save", title="Max, Avg, Min Driving Distance Over Time")
32 | p.line(int_years, [np.average(asdf) for asdf in yda], line_color="red")#, fill_color="red", line_color="green", line_width=3, )
33 | p.line(int_years, [np.min(asdf) for asdf in yda], line_color="blue")#, fill_color="red", line_color="green", line_width=3, )
34 | p.line(int_years, [np.max(asdf) for asdf in yda], line_color="green")#, fill_color="red", line_color="green", line_width=3, )
35 | output_file("driving_distance.html", title="Max, Avg, Min Driving Distance Over Time")
36 | show(vplot(p))
37 |
38 | '''
39 | filename = '2015.csv'
40 | ind = []
41 | dep = []
42 | names = []
43 | with open(filename, 'rb') as csvfile:
44 | reader = csv.reader(csvfile)
45 | headings = reader.next()[1:-1] #headings
46 | for row in reader:
47 | names.append(row[0])
48 | ind.append(map(float, row[1:-3]))
49 | dep.append(float(row[-2]))
50 |
51 | npind = np.array(ind)
52 | npdep = np.array(dep)
53 |
54 | regr = linear_model.LinearRegression(normalize=True)
55 |
56 | regr.fit(npind, npdep)
57 |
58 | for name, coeff in zip(headings, regr.coef_):
59 | print "%s: %s" % (name, coeff)
60 |
61 | print("Residual sum of squares: %.2f"
62 | % np.mean((regr.predict(npind) - npdep) ** 2))
63 |
64 | for name, stats, money in zip(names, ind, dep):
65 | predicted = '{:20,.2f}'.format(np.dot(stats, regr.coef_))
66 | print "%s: %s, %s" % (name, predicted, '{:20,.2f}'.format(money))
67 |
68 | import csv
69 | from bokeh.plotting import figure, output_file, show, vplot
70 | years = range(2002,2016)
71 | years = [2002, 2015]
72 | for year in years:
73 | filename = "%s.csv" % year
74 | with open(filename, 'rb') as csvfile:
75 | reader = csv.DictReader(csvfile)
76 | fieldnames = reader.fieldnames
77 | distances = [float(row['driving_distance']) for row in reader if row['percentage_of_yardage_covered_by_tee_shots']]
78 | a = np.array(distances)
79 |
80 | hist, edges = np.histogram(a, density=True, bins=100)
81 |
82 | x = np.linspace(np.amin(a)-5, np.amax(a)+5, 1000)
83 | mu = np.mean(a)
84 | sigma = np.std(a)
85 | pdf = 1/(sigma * np.sqrt(2*np.pi)) * np.exp(-(x-mu)**2 / (2*sigma**2))
86 |
87 | p1 = figure(title="%s Driving Distance" % (year),tools="save", background_fill_color="#E8DDCB")
88 | p1.quad(top=hist, bottom=0, left=edges[:-1], right=edges[1:], fill_color="#036564", line_color="#033649")
89 | p1.line(x, pdf, line_color="#D95B43", line_width=8, alpha=0.7, legend="PDF")
90 |
91 | p1.legend.location = "top_left"
92 | p1.xaxis.axis_label = 'Driving Distance'
93 | p1.yaxis.axis_label = 'Pr(x)'
94 |
95 | output_file("%s_driving_distance.html" % (year), title="%s Driving Distance" % (year))
96 | show(vplot(p1))
97 |
98 |
99 | '''
100 |
--------------------------------------------------------------------------------
/tourstats/distance_vs_putts.csv:
--------------------------------------------------------------------------------
1 | Brian Gay,1.719,270.2
2 | Marc Leishman,1.723,288.3
3 | Rob Oppenheim,1.746,272.2
4 | Scott Stallings,1.798,287.3
5 | Chad Campbell,1.788,281.5
6 | Ian Poulter,1.835,276.2
7 | Cameron Percy,1.832,274.6
8 | Emiliano Grillo,1.779,286.2
9 | Smylie Kaufman,1.725,295.0
10 | Paul Casey,1.786,285.4
11 | Rickie Fowler,1.753,293.7
12 | Jason Dufner,1.756,282.7
13 | Ryo Ishikawa,1.723,297.4
14 | Charles Howell III,1.739,294.6
15 | Vaughn Taylor,1.715,272.9
16 | Jon Curran,1.738,267.1
17 | Matt Every,1.772,281.0
18 | Russell Knox,1.786,281.5
19 | Steven Bowditch,1.750,288.5
20 | Martin Piller,1.780,283.7
21 | Ben Crane,1.711,275.0
22 | David Lingmerth,1.729,284.1
23 | Bryce Molder,1.758,276.9
24 | Jim Herman,1.781,284.0
25 | D.H. Lee,1.762,276.4
26 | Chesson Hadley,1.812,288.3
27 | Robert Streb,1.808,285.4
28 | Matt Kuchar,1.725,281.2
29 | Mark Wilson,1.807,269.9
30 | Adam Hadwin,1.708,283.5
31 | Peter Malnati,1.735,277.3
32 | Billy Horschel,1.778,287.2
33 | Bud Cauley,1.762,282.6
34 | Jhonattan Vegas,1.791,288.1
35 | Rory Sabbatini,1.735,287.6
36 | D.A. Points,1.732,270.1
37 | Wes Roach,1.783,284.5
38 | Hiroshi Iwata,1.751,282.5
39 | Jonas Blixt,1.755,279.9
40 | Mark Hubbard,1.761,278.9
41 | Tyrone Van Aswegen,1.767,280.7
42 | Hideki Matsuyama,1.717,289.1
43 | Andres Gonzales,1.793,284.2
44 | Michael Kim,1.752,280.1
45 | Scott Brown,1.785,283.6
46 | Cameron Beckman,1.901,264.5
47 | Patrick Rodgers,1.791,295.6
48 | Danny Lee,1.741,283.2
49 | Stewart Cink,1.800,283.5
50 | Kyle Reifers,1.746,280.9
51 | David Toms,1.791,265.2
52 | William McGirt,1.727,277.5
53 | Charley Hoffman,1.769,296.5
54 | Will Wilcox,1.770,286.8
55 | Colt Knost,1.765,271.7
56 | Webb Simpson,1.746,288.9
57 | Brett Stegmaier,1.782,286.0
58 | Lucas Glover,1.763,283.8
59 | J.B. Holmes,1.761,306.0
60 | Patton Kizzire,1.728,283.5
61 | Brian Stuard,1.790,266.2
62 | Rory McIlroy,1.773,297.2
63 | Camilo Villegas,1.772,283.4
64 | Graeme McDowell,1.737,275.8
65 | Erik Compton,1.775,281.3
66 | Bill Haas,1.782,280.0
67 | Jonathan Byrd,1.763,275.1
68 | Ollie Schniederjans,1.802,295.5
69 | Tyler Aldridge,1.776,280.6
70 | Michael Putnam,1.825,278.8
71 | John Huh,1.741,274.1
72 | Vijay Singh,1.773,279.9
73 | Ken Duke,1.829,270.3
74 | Cameron Tringale,1.730,279.4
75 | Nick Watney,1.759,290.0
76 | Justin Thomas,1.742,293.9
77 | Nick Taylor,1.764,290.6
78 | Justin Rose,1.735,289.5
79 | Kyle Stanley,1.769,282.4
80 | Steve Wheatcroft,1.760,281.4
81 | Brendon de Jonge,1.784,283.1
82 | Cameron Smith,1.745,276.6
83 | Charlie Beljan,1.910,295.1
84 | Stuart Appleby,1.781,276.0
85 | Dustin Johnson,1.722,305.5
86 | Zach Johnson,1.755,281.8
87 | Charl Schwartzel,1.788,288.5
88 | Billy Hurley III,1.785,263.5
89 | Fabian Gomez,1.781,284.4
90 | Sung Kang,1.785,277.5
91 | Rhein Gibson,1.848,284.7
92 | Jason Day,1.765,297.4
93 | Andrew Loupe,1.701,296.4
94 | Luke Donald,1.781,270.8
95 | Alex Cejka,1.740,278.1
96 | Lucas Lee,1.818,265.7
97 | Justin Hicks,1.771,277.5
98 | Sam Saunders,1.810,284.8
99 | Tim Herron,1.825,269.1
100 | Brandt Snedeker,1.718,289.8
101 | Ryan Moore,1.715,281.0
102 | Justin Leonard,1.747,270.7
103 | Steve Stricker,1.661,268.9
104 | Tim Clark,1.796,270.2
105 | Hudson Swafford,1.786,292.6
106 | Carlos Ortiz,1.736,285.9
107 | George McNeill,1.744,277.8
108 | Jeff Overton,1.764,281.6
109 | John Senden,1.770,283.1
110 | Jimmy Walker,1.751,291.6
111 | Ben Martin,1.730,280.6
112 | Dicky Pride,1.807,268.5
113 | Hunter Stewart,1.782,283.3
114 | Brice Garnett,1.757,274.2
115 | Robert Garrigus,1.800,290.2
116 | Aaron Baddeley,1.722,281.7
117 | Jason Bohn,1.711,280.3
118 | James Hahn,1.759,286.4
119 | David Hearn,1.746,275.9
120 | Sean O'Hair,1.732,287.3
121 | Andrew Landry,1.819,278.2
122 | Shawn Stefani,1.824,287.3
123 | Graham DeLaet,1.741,288.7
124 | Brian Davis,1.783,263.8
125 | Chris Stroud,1.762,281.0
126 | Roberto Castro,1.774,279.9
127 | Russell Henley,1.762,290.2
128 | Blake Adams,1.805,270.3
129 | Andres Romero,1.727,278.4
130 | Phil Mickelson,1.718,287.0
131 | Martin Laird,1.751,290.8
132 | Derek Fathauer,1.755,282.3
133 | Retief Goosen,1.784,282.0
134 | Chris Kirk,1.824,279.7
135 | Davis Love III,1.773,283.8
136 | Morgan Hoffmann,1.754,289.2
137 | Will MacKenzie,1.783,279.1
138 | K.J. Choi,1.764,271.2
139 | Jordan Spieth,1.659,287.5
140 | Abraham Ancer,1.807,272.5
141 | John Merrick,1.804,276.1
142 | Dawie van der Walt,1.775,282.2
143 | Kevin Na,1.716,277.9
144 | Troy Merritt,1.743,283.2
145 | Sergio Garcia,1.746,282.4
146 | Whee Kim,1.847,282.4
147 | Brendan Steele,1.742,291.6
148 | Daniel Berger,1.764,290.7
149 | Boo Weekley,1.799,283.8
150 | Jason Kokrak,1.793,297.1
151 | Kevin Kisner,1.691,288.1
152 | J.J. Henry,1.811,283.9
153 | Darron Stiles,1.771,256.4
154 | Kelly Kraft,1.770,280.4
155 | Rod Pampling,1.845,273.7
156 | Johnson Wagner,1.788,280.0
157 | Chez Reavie,1.764,281.8
158 | Robert Allenby,1.851,274.9
159 | Francesco Molinari,1.751,279.2
160 | Jerry Kelly,1.787,273.2
161 | Gary Woodland,1.759,301.5
162 | Si Woo Kim,1.766,287.8
163 | Michael Thompson,1.747,284.2
164 | Steve Marino,1.806,283.6
165 | Scott Langley,1.820,277.0
166 | Thomas Aiken,1.834,275.5
167 | Alex Prugh,1.853,285.0
168 | Ricky Barnes,1.741,279.7
169 | Geoff Ogilvy,1.798,286.8
170 | Brooks Koepka,1.729,298.6
171 | Daniel Summerhays,1.728,284.2
172 | Scott Pinckney,1.814,291.2
173 | Ernie Els,1.801,283.3
174 | Jarrod Lyle,1.726,274.2
175 | Brian Harman,1.760,285.1
176 | Kevin Streelman,1.754,283.9
177 | Keegan Bradley,1.833,292.2
178 | Blayne Barber,1.795,279.2
179 | Hunter Mahan,1.759,293.3
180 | Derek Ernst,1.842,284.4
181 | Miguel Angel Carballo,1.774,284.3
182 | Zac Blair,1.776,271.0
183 | Seung-Yul Noh,1.730,288.7
184 | D.J. Trahan,1.762,282.4
185 | Brendon Todd,1.774,274.3
186 | Shane Lowry,1.780,288.3
187 | Freddie Jacobson,1.717,275.9
188 | Ryan Palmer,1.748,298.6
189 | Tim Wilkinson,1.773,275.6
190 | Chad Collins,1.775,273.8
191 | Harris English,1.778,290.8
192 | Tom Hoge,1.780,281.6
193 | Kevin Chappell,1.760,285.3
194 | Pat Perez,1.772,280.2
195 | Luke List,1.796,294.2
196 | Greg Owen,1.820,290.1
197 | Bronson Burgoon,1.791,285.6
198 | Matt Jones,1.752,289.8
199 | Shane Bertsch,1.781,275.5
200 | Andy Sullivan,1.806,276.9
201 | Adam Scott,1.726,289.5
202 | Jamie Lovemark,1.774,297.0
203 | Angel Cabrera,1.787,290.6
204 | Scott Piercy,1.765,294.1
205 | Nicholas Thompson,1.837,270.2
206 | Padraig Harrington,1.779,280.4
207 | Henrik Norlander,1.780,276.1
208 | Harold Varner III,1.779,291.8
209 | Tony Finau,1.784,300.9
210 | Patrick Reed,1.743,288.1
211 | Carl Pettersson,1.734,280.4
212 | Branden Grace,1.701,282.6
213 | Bo Van Pelt,1.871,278.5
214 | Bubba Watson,1.787,307.5
215 | Spencer Levin,1.732,277.8
216 | Jason Gore,1.730,281.2
217 | Anirban Lahiri,1.700,286.0
218 |
--------------------------------------------------------------------------------
/tourstats/driving_distance.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
Like this URL:
297 |296 | http://stats.nba.com/stats/leaguedashplayerstats?College=&Conference=&Country=&DateFrom=&DateTo=&Division=&DraftPick=&DraftYear=&GameScope=&GameSegment=&Height=&LastNGames=0&LeagueID=00&Location=&MeasureType=Base&Month=0&OpponentTeamID=0&Outcome=&PORound=0&PaceAdjust=N&PerMode=PerGame&Period=0&PlayerExperience=&PlayerPosition=&PlusMinus=N&Rank=N&Season=2016-17&SeasonSegment=&SeasonType=Playoffs&ShotClockRange=&StarterBench=&TeamID=0&VsConference=&VsDivision=&Weight=
LikeLike
298 |Pingback: General Tips for Web Scraping with Python – Full-Stack Feed
306 |Pingback: 2 – General Tips for Web Scraping with Python
309 |Pingback: This Week in Data Science (May 16, 2017) – Be Analytics
312 |Pingback: This Week in Data Science (May 16, 2017) – Cloud Data Architect
315 |Pingback: This Week in Data Science (May 16, 2017) - biva
318 |Pingback: This Week in Data Science (May 16, 2017) – Be Analytics
321 |