├── .gitignore
├── .travis.yml
├── README.md
├── akka-demo
├── README.md
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── akka
│ ├── HelloWorldApp.scala
│ └── PingPongApp.scala
├── analysis-demo
├── README.md
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── analysis
│ └── analysisApp.scala
├── breeze-demo
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── breeze
│ └── BreezeApp.scala
├── file-demo
├── README.md
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── file
│ └── FileApp.scala
├── hive-json-demo
├── README.md
├── pom.xml
└── src
│ ├── main
│ ├── java
│ │ └── cn.thinkjoy.utils4s.hive.json
│ │ │ └── JSONSerDe.java
│ └── scala
│ │ └── cn
│ │ └── thinkjoy
│ │ └── utils4s
│ │ └── hive
│ │ └── json
│ │ └── App.scala
│ └── resources
│ └── create_table.sql
├── json4s-demo
├── README.md
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── json4s
│ └── Json4sDemo.scala
├── lamma-demo
├── README.md
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── lamma
│ └── BasicOper.scala
├── log-demo
├── README.md
├── pom.xml
└── src
│ └── main
│ ├── resources
│ └── log4j.properties
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── log4s
│ ├── App.scala
│ ├── Logging.scala
│ └── LoggingTest.scala
├── manger-tools
├── python
│ └── es
│ │ ├── __init__.py
│ │ ├── check_index.py
│ │ ├── del_expired_index.py
│ │ ├── del_many_index.py
│ │ ├── delindex.py
│ │ ├── expired_index.xml
│ │ ├── index_list.xml
│ │ ├── logger.py
│ │ ├── mail.py
│ │ └── test.json
└── shell
│ ├── kafka-reassign-replica.sh
│ ├── manger.sh
│ └── start_daily.sh
├── nscala-time-demo
├── README.md
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── nscala_time
│ └── BasicOper.scala
├── picture
├── covAndcon.png
├── datacube.jpg
└── spark_streaming_config.png
├── pom.xml
├── resources-demo
├── README.md
├── pom.xml
└── src
│ └── main
│ ├── resources
│ ├── test.properties
│ └── test.xml
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── resources
│ └── ResourcesApp.scala
├── scala-demo
├── README.md
├── md
│ ├── 偏函数(PartialFunction)、偏应用函数(Partial Applied Function).md
│ ├── 函数参数传名调用、传值调用.md
│ └── 协变逆变上界下界.md
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ ├── S99
│ ├── P01.scala
│ ├── P02.scala
│ ├── P03.scala
│ ├── P04.scala
│ ├── P05.scala
│ ├── P06.scala
│ ├── P07.scala
│ ├── P08.scala
│ ├── P09.scala
│ ├── P10.scala
│ └── P11.scala
│ └── scala
│ ├── CaseClass.scala
│ ├── CovariantAndContravariant.scala
│ ├── EnumerationApp.scala
│ ├── ExtractorApp.scala
│ ├── FileSysCommandApp.scala
│ ├── FutureAndPromise.scala
│ ├── FutureApp.scala
│ ├── HighOrderFunction.scala
│ ├── MapApp.scala
│ ├── PatternMatching.scala
│ ├── TestApp.scala
│ └── TraitApp.scala
├── spark-analytics-demo
├── pom.xml
└── src
│ └── main
│ ├── resources
│ └── block_1.csv
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── spark
│ └── analytics
│ ├── DataCleaningApp.scala
│ ├── NAStatCounter.scala
│ └── StatsWithMissing.scala
├── spark-core-demo
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── spark
│ └── core
│ └── GroupByKeyAndReduceByKeyApp.scala
├── spark-dataframe-demo
├── README.md
├── pom.xml
└── src
│ └── main
│ ├── resources
│ ├── a.json
│ ├── b.txt
│ └── hive-site.xml
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── spark
│ └── dataframe
│ ├── RollupApp.scala
│ ├── SparkDataFrameApp.scala
│ ├── SparkDataFrameUDFApp.scala
│ ├── SparkSQLSupport.scala
│ ├── UdfTestApp.scala
│ └── udf
│ ├── AccessLogParser.scala
│ ├── AccessLogRecord.scala
│ └── LogAnalytics.scala
├── spark-knowledge
├── README.md
├── images
│ ├── MapReduce-v3.png
│ ├── Spark-Heap-Usage.png
│ ├── Spark-Memory-Management-1.6.0.png
│ ├── data-frame.png
│ ├── goupByKey.001.jpg
│ ├── groupByKey.png
│ ├── kafka
│ │ └── system_components_on_white_v2.png
│ ├── rdd-dataframe-dataset
│ │ ├── filter-down.png
│ │ └── rdd-dataframe.png
│ ├── reduceByKey.png
│ ├── spark-streaming-kafka
│ │ ├── spark-kafka-direct-api.png
│ │ ├── spark-metadata-checkpointing.png
│ │ ├── spark-reliable-source-reliable-receiver.png
│ │ ├── spark-wal.png
│ │ └── spark-wall-at-least-once-delivery.png
│ ├── spark_sort_shuffle.png
│ ├── spark_tungsten_sort_shuffle.png
│ └── zepplin
│ │ ├── helium.png
│ │ └── z-manager-zeppelin.png
├── md
│ ├── RDD、DataFrame和DataSet的区别.md
│ ├── confluent_platform2.0.md
│ ├── hash-shuffle.md
│ ├── sort-shuffle.md
│ ├── spark-dataframe-parquet.md
│ ├── spark_sql选择parquet存储方式的五个原因.md
│ ├── spark_streaming使用kafka保证数据零丢失.md
│ ├── spark从关系数据库加载数据.md
│ ├── spark内存概述.md
│ ├── spark实践总结.md
│ ├── spark统一内存管理.md
│ ├── tungsten-sort-shuffle.md
│ ├── zeppelin搭建.md
│ ├── 使用spark进行数据挖掘--音乐推荐.md
│ └── 利用spark进行数据挖掘-数据清洗.md
└── resources
│ └── zeppelin
│ ├── interpreter.json
│ └── zeppelin-env.sh
├── spark-streaming-demo
├── README.md
├── md
│ ├── mapWithState.md
│ └── spark-streaming-kafka测试用例.md
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── sparkstreaming
│ ├── MapWithStateApp.scala
│ ├── SparkStreamingDataFrameDemo.scala
│ └── SparkStreamingDemo.scala
├── spark-timeseries-demo
├── README.md
├── data
│ └── ticker.tsv
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── spark
│ └── timeseries
│ └── TimeSeriesApp.scala
├── toc_gen.py
├── twitter-util-demo
├── README.md
├── pom.xml
└── src
│ └── main
│ └── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── twitter
│ └── util
│ └── core
│ └── TimeApp.scala
└── unittest-demo
├── README.md
├── pom.xml
└── src
├── main
└── scala
│ └── cn
│ └── thinkjoy
│ └── utils4s
│ └── unittest
│ └── App.scala
└── test
└── scala
└── cn
└── thinkjoy
└── utils4s
└── scala
├── StackSpec.scala
└── UnitSpec.scala
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea
2 | demo.iml
3 | logs/*
4 | */*.iml
5 | */target
6 | target
7 | checkpoint
8 | derby.log
9 | metastore_db/
10 |
--------------------------------------------------------------------------------
/.travis.yml:
--------------------------------------------------------------------------------
1 | language: scala
2 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | utils4s
2 |
3 | 公众号:
4 | 
5 |
6 | [](https://travis-ci.org/jacksu/utils4s)[](https://gitter.im/jacksu/utils4s?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
7 |
8 | * [utils4s](#id1)
9 | * [scala语法学习](#id2)
10 | * [common库](#id21)
11 | * [BigData库](#id22)
12 | * [Spark](#id221)
13 | * [Spark core](#id2211)
14 | * [Spark Streaming](#id2212)
15 | * [Spark SQL](#id2213)
16 | * [Spark 机器学习](#id2213)
17 | * [Spark Zeppelin](#id2214)
18 | * [Spark 其它](#id2215)
19 | * [ES](#id222)
20 | * [贡献代码步骤](#id23)
21 | * [贡献者](#id24)
22 |
23 | **Issues 中包含我们平时阅读的关于scala、spark好的文章,欢迎推荐**
24 |
25 | utils4s包含各种scala通用、好玩的工具库demo和使用文档,通过简单的代码演示和操作文档,各种库信手拈来。
26 |
27 | **同时欢迎大家贡献各种好玩的、经常使用的工具库。**
28 |
29 | [开源中国地址](http://git.oschina.net/jack.su/utils4s)
30 |
31 | QQ交流群 `432290475(已满),请加530066027`  或者点击上面gitter图标也可以参与讨论
32 |
33 | [作者博客专注大数据、分布式系统、机器学习,欢迎交流](http://www.jianshu.com/users/92a1227beb27/latest_articles)
34 |
35 | 微博:[**jacksu_**](http://weibo.com/jack4s)
36 |
37 |
或者点击上面gitter图标也可以参与讨论
32 |
33 | [作者博客专注大数据、分布式系统、机器学习,欢迎交流](http://www.jianshu.com/users/92a1227beb27/latest_articles)
34 |
35 | 微博:[**jacksu_**](http://weibo.com/jack4s)
36 |
37 | scala语法学习
38 |
39 | 说明:scala语法学习过程中,用例代码都放在scala-demo模块下。
40 |
41 | [利用IntelliJ IDEA与Maven开始你的Scala之旅](https://www.jianshu.com/p/ecc6eb298b8f)
42 |
43 | [快学scala电子书](http://vdisk.weibo.com/s/C7NmUN3g8gH46)(推荐入门级书)
44 |
45 | [scala理解的比较深](http://hongjiang.info/scala/)
46 |
47 | [scala99问题](http://aperiodic.net/phil/scala/s-99/)
48 |
49 | [scala初学者指南](https://windor.gitbooks.io/beginners-guide-to-scala/content/introduction.html)(这可不是初学者可以理解的欧,还是写过一些程序后再看)
50 |
51 | [scala初学者指南英文版](http://danielwestheide.com/scala/neophytes.html)
52 |
53 | [scala学习用例](scala-demo)
54 |
55 | [scala入门笔记](http://blog.djstudy.net/2016/01/24/scala-rumen-biji/)
56 |
57 | [Databricks风格](https://github.com/databricks/scala-style-guide)
58 |
59 | [scala/java 通过maven编译(Mixed Java/Scala Projects)](http://davidb.github.io/scala-maven-plugin/example_java.html)
60 |
61 | common库
62 |
63 | [日志操作](log-demo)([log4s](https://github.com/Log4s/log4s))
64 |
65 | [单元测试](unittest-demo)([scalatest](http://www.scalatest.org))
66 |
67 | [日期操作](lamma-demo)([lama](http://www.lamma.io/doc/quick_start))(注:只支持日期操作,不支持时间操作)
68 |
69 | [日期时间操作](nscala-time-demo)([nscala-time](https://github.com/nscala-time/nscala-time))(注:没有每月多少天,每月最后一天,以及每年多少天)
70 |
71 | [json解析](json4s-demo)([json4s](https://github.com/json4s/json4s))
72 |
73 | [resources下文件加载用例](resources-demo)
74 |
75 | [文件操作](file-demo)([better-files](https://github.com/pathikrit/better-files))
76 |
77 | [单位换算](analysis-demo)([squants](https://github.com/garyKeorkunian/squants))
78 |
79 | [线性代数和向量计算](breeze-demo)([breeze](https://github.com/scalanlp/breeze))
80 |
81 | [分布式并行实现库akka](akka-demo)([akka](http://akka.io))
82 |
83 | [Twitter工具库](twitter-util-demo)([twitter util](https://github.com/twitter/util))
84 |
85 | [日常脚本工具](manger-tools)
86 |
87 | BigData库
88 |
89 | Spark
90 |
91 | Spark core
92 | [spark远程调试源代码](http://hadoop1989.com/2016/02/01/Spark-Remote-Debug/)
93 |
94 | [spark介绍](http://litaotao.github.io/introduction-to-spark)
95 |
96 | [一个不错的spark学习互动课程](http://www.hubwiz.com/class/5449c691e564e50960f1b7a9)
97 |
98 | [spark 设计与实现](http://spark-internals.books.yourtion.com/index.html)
99 |
100 | [aliyun-spark-deploy-tool](https://github.com/aliyun/aliyun-spark-deploy-tool)---Spark on ECS
101 | Spark Streaming
102 |
103 | [Spark Streaming使用Kafka保证数据零丢失](spark-knowledge/md/spark_streaming使用Kafka保证数据零丢失.md)
104 |
105 | [spark streaming测试用例](sparkstreaming-demo)
106 |
107 | [spark streaming源码解析](https://github.com/proflin/CoolplaySpark)
108 |
109 | [基于spark streaming的聚合分析(Sparkta)](https://github.com/Stratio/Sparkta)
110 |
111 | Spark SQL
112 |
113 | [spark DataFrame测试用例](spark-dataframe-demo)
114 |
115 | [Hive Json加载](hive-json-demo)
116 |
117 | [SparkSQL架构设计和代码分析](https://github.com/marsishandsome/SparkSQL-Internal)
118 |
119 | Spark 机器学习
120 |
121 | [spark机器学习源码解析](https://github.com/endymecy/spark-ml-source-analysis)
122 |
123 | [KeyStoneML](http://keystone-ml.org)
124 | KeystoneML is a software framework, written in Scala, from the UC Berkeley AMPLab designed to simplify the construction of large scale, end-to-end, machine learning pipelines with Apache Spark.
125 |
126 | [spark TS](spark-timeseries-demo)
127 |
128 | Spark zeppelin
129 |
130 | [**Z-Manager**](https://github.com/NFLabs/z-manager)--Simplify getting Zeppelin up and running
131 |
132 | [**zeppelin**](https://github.com/apache/incubator-zeppelin)--a web-based notebook that enables interactive data analytics. You can make beautiful data-driven, interactive and collaborative documents with SQL, Scala and more.
133 |
134 | [**helium**](http://s.apache.org/helium)--Brings Zeppelin to data analytics application platform
135 |
136 | Spark 其它
137 |
138 | [spark专题在简书](http://www.jianshu.com/collection/6157554bfdd9)
139 |
140 | [databricks spark知识库](https://aiyanbo.gitbooks.io/databricks-spark-knowledge-base-zh-cn/content/)
141 |
142 | [spark学习知识总结](spark-knowledge)
143 |
144 | [Spark library for doing exploratory data analysis in a scalable way](https://github.com/vicpara/exploratory-data-analysis/)
145 |
146 | [图处理(cassovary)](https://github.com/twitter/cassovary)
147 |
148 | [基于spark进行地理位置分析(gagellan)](https://github.com/harsha2010/magellan)
149 |
150 | [spark summit east 2016 ppt](http://vdisk.weibo.com/s/BP8uNBea_C2Af?from=page_100505_profile&wvr=6)
151 |
152 | ES
153 |
154 | [ES 非阻塞scala客户端](https://github.com/sksamuel/elastic4s)
155 |
156 | Beam
157 | [Apache Beam:下一代的数据处理标准](http://geek.csdn.net/news/detail/134167)
158 | 贡献代码步骤
159 | 1. 首先 fork 我的项目
160 | 2. 把 fork 过去的项目也就是你的项目 clone 到你的本地
161 | 3. 运行 git remote add jacksu git@github.com:jacksu/utils4s.git 把我的库添加为远端库
162 | 4. 运行 git pull jacksu master 拉取并合并到本地
163 | 5. coding
164 | 6. commit后push到自己的库( git push origin master )
165 | 7. 登陆Github在你首页可以看到一个 pull request 按钮,点击它,填写一些说明信息,然后提交即可。
166 | 1~3是初始化操作,执行一次即可。在coding前必须执行第4步同步我的库(这样避免冲突),然后执行5~7既可。
167 |
168 | 贡献者
169 | [jjcipher](https://github.com/jjcipher)
170 |
171 |
--------------------------------------------------------------------------------
/akka-demo/README.md:
--------------------------------------------------------------------------------
1 |
2 | ##参考
3 |
4 | [一个超简单的akka actor例子](http://colobu.com/2015/02/26/simple-scala-akka-actor-examples/)
5 |
6 | [akka 学习资料](https://github.com/hustnn/AkkaLearning)
--------------------------------------------------------------------------------
/akka-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.akka
11 | akka-demo
12 | 2008
13 |
14 |
15 | com.typesafe.akka
16 | akka-actor_${soft.scala.version}
17 | 2.3.14
18 |
19 |
20 |
21 |
22 |
--------------------------------------------------------------------------------
/akka-demo/src/main/scala/cn/thinkjoy/utils4s/akka/HelloWorldApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.akka
2 |
3 | import akka.actor.{Props, ActorSystem, Actor}
4 |
5 | /**
6 | * Created by jacksu on 15/12/26.
7 | */
8 |
9 | class HelloActor extends Actor{
10 | def receive = {
11 | case "hello" => println("您好!")
12 | case _ => println("您是?")
13 | }
14 | }
15 |
16 | object HelloWorldApp {
17 | def main(args: Array[String]) {
18 | val system = ActorSystem("HelloSystem")
19 | // 缺省的Actor构造函数
20 | val helloActor = system.actorOf(Props[HelloActor], name = "helloactor")
21 | helloActor ! "hello"
22 | helloActor ! "喂"
23 | }
24 | }
25 |
--------------------------------------------------------------------------------
/akka-demo/src/main/scala/cn/thinkjoy/utils4s/akka/PingPongApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.akka
2 |
3 | import akka.actor._
4 | /**
5 | * Created by jacksu on 15/12/26.
6 | */
7 |
8 | case object PingMessage
9 | case object PongMessage
10 | case object StartMessage
11 | case object StopMessage
12 |
13 | class Ping(pong: ActorRef) extends Actor {
14 | var count = 0
15 | def incrementAndPrint { count += 1; println("ping") }
16 | def receive = {
17 | case StartMessage =>
18 | incrementAndPrint
19 | pong ! PingMessage
20 | case PongMessage =>
21 | if (count > 9) {
22 | sender ! StopMessage
23 | println("ping stopped")
24 | context.stop(self)
25 | } else {
26 | incrementAndPrint
27 | sender ! PingMessage
28 | }
29 | }
30 | }
31 |
32 | class Pong extends Actor {
33 | def receive = {
34 | case PingMessage =>
35 | println(" pong")
36 | sender ! PongMessage
37 | case StopMessage =>
38 | println("pong stopped")
39 | context.stop(self)
40 | context.system.shutdown()
41 | }
42 | }
43 | object PingPongApp {
44 | def main(args: Array[String]) {
45 | val system = ActorSystem("PingPongSystem")
46 | val pong = system.actorOf(Props[Pong], name = "pong")
47 | val ping = system.actorOf(Props(new Ping(pong)), name = "ping")
48 | // start them going
49 | ping ! StartMessage
50 | }
51 | }
52 |
--------------------------------------------------------------------------------
/analysis-demo/README.md:
--------------------------------------------------------------------------------
1 | ##单位换算以及不同单位进行运算
2 |
3 | *已经两年没有更新*
4 |
5 | ###转换
6 |
7 | ```scala
8 | (Hours(2) + Days(1) + Seconds(1)).toSeconds //93601.0
9 | ```
10 | ###toString
11 |
12 | ```scala
13 | Days(1) toString time.Seconds //86400.0 s
14 | ```
15 |
16 | ###toTuple
17 |
18 | ```scala
19 | Days(1) toTuple time.Seconds //(86400.0,s)
20 | ```
21 |
22 | **测试不支持map**
23 |
24 | ##精度判断
25 |
26 | ```scala
27 | implicit val tolerance = Watts(.1) // implicit Power: 0.1 W
28 | val load = Kilowatts(2.0) // Power: 2.0 kW
29 | val reading = Kilowatts(1.9999) // Power: 1.9999 kW
30 |
31 | // uses implicit tolerance
32 | load =~ reading // true
33 | ```
34 |
35 | ###向量
36 | ```scala
37 | val vector: QuantityVector[Length] = QuantityVector(Kilometers(1.2), Kilometers(4.3), Kilometers(2.3))
38 | val magnitude: Length = vector.magnitude // returns the scalar value of the vector
39 | println(magnitude)
40 | val normalized = vector.normalize(Kilometers) // returns a corresponding vector scaled to 1 of the given unit
41 | println(normalized)
42 |
43 | val vector2: QuantityVector[Length] = QuantityVector(Kilometers(1.2), Kilometers(4.3), Kilometers(2.3))
44 | val vectorSum = vector + vector2 // returns the sum of two vectors
45 | println(vectorSum)
46 | val vectorDiff = vector - vector2 // return the difference of two vectors
47 | println(vectorDiff)
48 | val vectorScaled = vector * 5 // returns vector scaled 5 times
49 | println(vectorScaled)
50 | val vectorReduced = vector / 5 // returns vector reduced 5 time
51 | println(vectorReduced)
52 | val vectorDouble = vector / space.Meters(5) // returns vector reduced and converted to DoubleVector
53 | println(vectorDouble)
54 | val dotProduct = vector * vectorDouble // returns the Dot Product of vector and vectorDouble
55 | println(dotProduct)
56 |
57 | val crossProduct = vector crossProduct vectorDouble // currently only supported for 3-dimensional vectors
58 | println(crossProduct)
59 | ```
60 | result
61 |
62 | ```scala
63 | 5.021951811795888 km
64 | QuantityVector(ArrayBuffer(0.2389509188800581 km, 0.8562407926535415 km, 0.45798926118677796 km))
65 | QuantityVector(ArrayBuffer(2.4 km, 8.6 km, 4.6 km))
66 | QuantityVector(ArrayBuffer(0.0 km, 0.0 km, 0.0 km))
67 | QuantityVector(ArrayBuffer(6.0 km, 21.5 km, 11.5 km))
68 | QuantityVector(ArrayBuffer(0.24 km, 0.86 km, 0.45999999999999996 km))
69 | DoubleVector(ArrayBuffer(240.0, 860.0, 459.99999999999994))
70 | 5044.0 km
71 | QuantityVector(WrappedArray(0.0 km, 1.1368683772161603E-13 km, 0.0 km))
72 | ```
73 | ###Money and Price
74 |
75 | ###参考
76 | [squants](https://github.com/garyKeorkunian/squants)
--------------------------------------------------------------------------------
/analysis-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.analysis
11 | analysis-demo
12 | 2008
13 |
14 |
15 | 0.5.3
16 |
17 |
18 |
19 | com.squants
20 | squants_${soft.scala.version}
21 | ${squants.version}
22 |
23 |
24 |
25 |
26 |
--------------------------------------------------------------------------------
/analysis-demo/src/main/scala/cn/thinkjoy/utils4s/analysis/analysisApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.analysis
2 |
3 | import squants.energy.Power
4 | import squants.energy._
5 | import squants.space._
6 | import squants._
7 | import squants.time._
8 | import squants.market._
9 |
10 | /**
11 | * Created by jacksu on 15/11/16.
12 | */
13 |
14 | object analysisApp {
15 | def main(args: Array[String]) {
16 | val load1: Power = Kilowatts(12) // returns Power(12, Kilowatts) or 12 kW
17 | val load2: Power = Megawatts(0.023) // Power: 0.023 MW
18 | val sum = load1 + load2 // Power: 35 kW - unit on left side is preserved
19 | println("%06.2f".format(sum.toMegawatts))
20 | val ratio = Days(1) / Hours(3)
21 | println(ratio)
22 | val seconds = (Hours(2) + Days(1) + time.Seconds(1)).toSeconds
23 | println(seconds)
24 | println(Days(1).toSeconds)
25 |
26 | //toString
27 | println(Days(1) toString time.Seconds)
28 |
29 | //totuple
30 | println(Days(1) toTuple time.Seconds)
31 |
32 | //Approximations
33 | implicit val tolerance = Watts(.1) // implicit Power: 0.1 W
34 | val load = Kilowatts(2.0) // Power: 2.0 kW
35 | val reading = Kilowatts(1.9999)
36 | println(load =~ reading)
37 |
38 | //vectors
39 | val vector: QuantityVector[Length] = QuantityVector(Kilometers(1.2), Kilometers(4.3), Kilometers(2.3))
40 | val magnitude: Length = vector.magnitude // returns the scalar value of the vector
41 | println(magnitude)
42 | val normalized = vector.normalize(Kilometers) // returns a corresponding vector scaled to 1 of the given unit
43 | println(normalized)
44 |
45 | val vector2: QuantityVector[Length] = QuantityVector(Kilometers(1.2), Kilometers(4.3), Kilometers(2.3))
46 | val vectorSum = vector + vector2 // returns the sum of two vectors
47 | println(vectorSum)
48 | val vectorDiff = vector - vector2 // return the difference of two vectors
49 | println(vectorDiff)
50 | val vectorScaled = vector * 5 // returns vector scaled 5 times
51 | println(vectorScaled)
52 | val vectorReduced = vector / 5 // returns vector reduced 5 time
53 | println(vectorReduced)
54 | val vectorDouble = vector / space.Meters(5) // returns vector reduced and converted to DoubleVector
55 | println(vectorDouble)
56 | val dotProduct = vector * vectorDouble // returns the Dot Product of vector and vectorDouble
57 | println(dotProduct)
58 |
59 | val crossProduct = vector crossProduct vectorDouble // currently only supported for 3-dimensional vectors
60 | println(crossProduct)
61 |
62 | //money
63 | val tenBucks = USD(10)
64 | println(tenBucks)
65 | val tenyuan = CNY(10)
66 | println(tenyuan)
67 | val hongkong = HKD(10)
68 | println(hongkong)
69 |
70 | //price
71 | val energyPrice = USD(102.20) / MegawattHours(1)
72 | println(energyPrice)
73 | }
74 | }
75 |
--------------------------------------------------------------------------------
/breeze-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.breeze
11 | breeze-demo
12 | 2008
13 |
14 |
15 |
16 | org.scalanlp
17 | breeze_${soft.scala.version}
18 | 0.10
19 |
20 |
21 |
22 |
--------------------------------------------------------------------------------
/breeze-demo/src/main/scala/cn/thinkjoy/utils4s/breeze/BreezeApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.breeze
2 |
3 | //包含线性代数包(linear algebra)
4 | import breeze.linalg._
5 |
6 | /**
7 | * jacksu
8 | *
9 | */
10 | object BreezeApp {
11 | def main(args: Array[String]) {
12 | //=========两种矢量的区别,dense分配内存,sparse不分配=========
13 | //DenseVector(0.0, 0.0, 0.0, 0.0, 0.0)
14 | //底层是Array
15 | val x = DenseVector.zeros[Double](5)
16 | println(x)
17 |
18 | //SparseVector
19 | val y = SparseVector.zeros[Double](5)
20 | println(y)
21 |
22 | //===========操作对应的值===============
23 | //DenseVector(0.0, 2.0, 0.0, 0.0, 0.0)
24 | x(1)=2
25 | println(x)
26 |
27 | //SparseVector((1,2.0))
28 | y(1)=2
29 | println(y)
30 |
31 | //===========slice==========
32 | //DenseVector(0.5, 0.5)
33 | println(x(3 to 4):=.5)
34 | //DenseVector(0.0, 2.0, 0.0, 0.5, 0.5)
35 | println(x)
36 | println(x(1))
37 |
38 | //==========DenseMatrix===========
39 | /**
40 | * 0 0 0 0 0
41 | * 0 0 0 0 0
42 | * 0 0 0 0 0
43 | * 0 0 0 0 0
44 | * 0 0 0 0 0
45 | */
46 | val m=DenseMatrix.zeros[Int](5,5)
47 | println(m)
48 |
49 | /**
50 | * 向量是列式的
51 | * 0 0 0 0 1
52 | * 0 0 0 0 2
53 | * 0 0 0 0 3
54 | * 0 0 0 0 4
55 | * 0 0 0 0 5
56 | */
57 | m(::,4):=DenseVector(1,2,3,4,5)
58 | println(m)
59 | //5
60 | println(max(m))
61 | //15
62 | println(sum(m))
63 | //DenseVector(1.0, 1.5, 2.0)
64 | println(linspace(1,2,3))
65 |
66 | //==========对角线============
67 | /**
68 | * 1.0 0.0 0.0
69 | * 0.0 1.0 0.0
70 | * 0.0 0.0 1.0
71 | */
72 | println(DenseMatrix.eye[Double](3))
73 | /**
74 | * 1.0 0.0 0.0
75 | * 0.0 2.0 0.0
76 | * 0.0 0.0 3.0
77 | */
78 | println(diag(DenseVector(1.0,2.0,3.0)))
79 | }
80 | }
81 |
--------------------------------------------------------------------------------
/file-demo/README.md:
--------------------------------------------------------------------------------
1 | 文件基本操作
2 |
3 | **需要java8**
--------------------------------------------------------------------------------
/file-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.file
11 | file-demo
12 | 2008
13 |
14 | 2.13.0
15 |
16 |
17 |
18 |
19 | com.github.pathikrit
20 | better-files_${soft.scala.version}
21 | ${better.file.version}
22 | compile
23 |
24 |
25 |
26 |
--------------------------------------------------------------------------------
/file-demo/src/main/scala/cn/thinkjoy/utils4s/file/FileApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.file
2 |
3 | import better.files._
4 | import java.io.{File=>JFile}
5 |
6 | /**
7 | * Hello world!
8 | *
9 | */
10 | object FileApp{
11 | def main(args: Array[String]) {
12 | //TODO
13 | println("需要java8,需要继续跟")
14 | }
15 |
16 | }
17 |
--------------------------------------------------------------------------------
/hive-json-demo/README.md:
--------------------------------------------------------------------------------
1 |
2 | 实现json文件加载为hive表
3 |
4 | ##参考
5 | [Hive-JSON-Serde](https://github.com/rcongiu/Hive-JSON-Serde)
6 | [Serde](http://blog.csdn.net/xiao_jun_0820/article/details/38119123#)
7 |
--------------------------------------------------------------------------------
/hive-json-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.hive.json
11 | hive-json-demo
12 | 2008
13 |
14 |
15 |
16 | org.apache.hadoop
17 | hadoop-common
18 | 2.6.0
19 | compile
20 |
21 |
22 | org.apache.hive
23 | hive-serde
24 | 1.1.0
25 | compile
26 |
27 |
28 |
29 |
--------------------------------------------------------------------------------
/hive-json-demo/src/main/scala/cn/thinkjoy/utils4s/hive/json/App.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.hive.json
2 |
3 | /**
4 | * Hello world!
5 | *
6 | */
7 | object App {
8 | println( "Hello World!" )
9 | }
10 |
--------------------------------------------------------------------------------
/hive-json-demo/src/resources/create_table.sql:
--------------------------------------------------------------------------------
1 | /**
2 | create table weixiao_follower_info(
3 | requestTime BIGINT,
4 | requestParams STRUCT,
5 | requestUrl STRING)
6 | row format serde "com.besttone.hive.serde.JSONSerDe"
7 | WITH SERDEPROPERTIES(
8 | "input.invalid.ignore"="true",
9 | "requestTime"="$.requestTime",
10 | "requestParams.timestamp"="$.requestParams.timestamp",
11 | "requestParams.phone"="$.requestParams.phone",
12 | "requestParams.cardName"="$.requestParams.cardName",
13 | "requestParams.provinceCode"="$.requestParams.provinceCode",
14 | "requestParams.cityCode"="$.requestParams.cityCode",
15 | "requestUrl"="$.requestUrl");
16 | **/
17 |
18 | //暂时发现patition有问题
19 | CREATE EXTERNAL TABLE weixiao_follower_info(
20 | uid STRING,
21 | schoolCode STRING,
22 | attend STRING,
23 | app STRING,
24 | suite STRING,
25 | timestamp STRING)
26 | ROW FORMAT serde "cn.thinkjoy.utils4s.hive.json.JSONSerDe"
27 | WITH SERDEPROPERTIES(
28 | "input.invalid.ignore"="true",
29 | "uid"="$.uid",
30 | "schoolCode"="$.schoolCode",
31 | "attend."="$.attend",
32 | "app"="$.app",
33 | "suite"="$.suite",
34 | "timestamp"="$.timestamp");
35 |
36 | load data inpath '/tmp/weixiao_user_guanzhu_log/20151217/20/' INTO TABLE weixiao_follower_info partition(dt='20151217',hour='20')
37 | select * from weixiao_follower_info where cast(timestamp as bigint)>=unix_timestamp('2015121720','yyyyMMddHH')*1000;
--------------------------------------------------------------------------------
/json4s-demo/README.md:
--------------------------------------------------------------------------------
1 | #json4s
2 | json的各种形式的相互转化图如下:
3 | 
4 |
5 | 其中的关键是AST,AST有如下的语法树:
6 | ```scala
7 | sealed abstract class JValue
8 | case object JNothing extends JValue // 'zero' for JValue
9 | case object JNull extends JValue
10 | case class JString(s: String) extends JValue
11 | case class JDouble(num: Double) extends JValue
12 | case class JDecimal(num: BigDecimal) extends JValue
13 | case class JInt(num: BigInt) extends JValue
14 | case class JBool(value: Boolean) extends JValue
15 | case class JObject(obj: List[JField]) extends JValue
16 | case class JArray(arr: List[JValue]) extends JValue
17 |
18 | type JField = (String, JValue)
19 | ```
20 |
21 | > * String -> AST
22 | ```scala
23 | val ast=parse(""" {"name":"test", "numbers" : [1, 2, 3, 4] } """)
24 | result: JObject(List((name,JString(test)), (numbers,JArray(List(JInt(1), JInt(2), JInt(3), JInt(4))))))
25 | ```
26 | > * Json DSL -> AST
27 | ```scala
28 | import org.json4s.JsonDSL._
29 | //DSL implicit AST
30 | val json2 = ("name" -> "joe") ~ ("age" -> Some(35))
31 | println(json2)
32 | result:JObject(List((name,JString(joe)), (age,JInt(35))))
33 | ```
34 | > * AST -> String
35 | ```scala
36 | val str=compact(render(json2))
37 | println(str)
38 | result:{"name":"joe","age":35}
39 | //pretty
40 | val pretty=pretty(render(json2))
41 | println(pretty)
42 | result:
43 | {
44 | "name" : "joe",
45 | "age" : 35
46 | }
47 | ```
48 |
49 | > * AST operation
50 | ```scala
51 | val json4 = parse( """
52 | { "name": "joe",
53 | "children": [
54 | {
55 | "name": "Mary",
56 | "age": 5
57 | },
58 | {
59 | "name": "Mazy",
60 | "age": 3
61 | }
62 | ]
63 | }
64 | """)
65 | //注意\和\\的区别
66 | //{"name":"joe","name":"Mary","name":"Mazy"}
67 | println(compact(render(json4 \\ "name")))
68 | //"joe"
69 | println(compact(render(json4 \ "name")))
70 | //[{"name":"Mary","age":5},{"name":"Mazy","age":3}]
71 | println(compact(render(json4 \\ "children")))
72 | //["Mary","Mazy"]
73 | println(compact(render(json4 \ "children" \ "name")))
74 | //{"name":"joe"}
75 | println(compact(render(json4 findField {
76 | case JField("name", _) => true
77 | case _ => false
78 | })))
79 | //{"name":"joe","name":"Mary","name":"Mazy"}
80 | println(compact(render(json4 filterField {
81 | case JField("name", _) => true
82 | case _ => false
83 | })))
84 | ```
85 |
86 | > * AST -> case class
87 | ```scala
88 | implicit val formats = DefaultFormats
89 | val json5 = parse("""{"first_name":"Mary"}""")
90 | case class Person(`firstName`: String)
91 | val json6=json5 transformField {
92 | case ("first_name", x) => ("firstName", x)
93 | }
94 | println(json6.extract[Person])
95 | println(json5.camelizeKeys.extract[Person])
96 | result:
97 | Person(Mary)
98 | Person(Mary)
99 | ```
100 |
101 | 参考:
102 | [json4s](https://github.com/json4s/json4s)
--------------------------------------------------------------------------------
/json4s-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.json4s
11 | json4s-demo
12 | 2008
13 |
14 |
15 |
16 | org.json4s
17 | json4s-jackson_${soft.scala.version}
18 | 3.3.0
19 |
20 |
21 |
--------------------------------------------------------------------------------
/json4s-demo/src/main/scala/cn/thinkjoy/utils4s/json4s/Json4sDemo.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.json4s
2 |
3 | import org.json4s._
4 | import org.json4s.jackson.JsonMethods._
5 |
6 |
7 | object Json4sDemo {
8 | def main(args: Array[String]) {
9 | //=========== 通过字符串解析为json AST ==============
10 | val json1 = """ {"name":"test", "numbers" : [1, 2, 3, 4] } """
11 | println(parse(json1))
12 |
13 | //============= 通过DSL解析为json AST ===========
14 | import org.json4s.JsonDSL._
15 | //DSL implicit AST
16 | val json2 = ("name" -> "joe") ~ ("age" -> Some(35))
17 | println(json2)
18 | println(render(json2))
19 |
20 | case class Winner(id: Long, numbers: List[Int])
21 | case class Lotto(id: Long, winningNumbers: List[Int], winners: List[Winner], drawDate: Option[java.util.Date])
22 | val winners = List(Winner(23, List(2, 45, 34, 23, 3, 5)), Winner(54, List(52, 3, 12, 11, 18, 22)))
23 | val lotto = Lotto(5, List(2, 45, 34, 23, 7, 5, 3), winners, None)
24 | val json3 =
25 | ("lotto" ->
26 | ("lotto-id" -> lotto.id) ~
27 | ("winning-numbers" -> lotto.winningNumbers) ~
28 | ("draw-date" -> lotto.drawDate.map(_.toString)) ~
29 | ("winners" ->
30 | lotto.winners.map { w =>
31 | (("winner-id" -> w.id) ~
32 | ("numbers" -> w.numbers))
33 | }))
34 | println(render(json3))
35 |
36 |
37 | //=================== 转化为String =============
38 | //println(compact(json1))
39 | println(compact(json2))
40 | //render用默认方式格式化空字符
41 | println(compact(render(json2)))
42 | println(compact(render(json3)))
43 |
44 | //println(pretty(json1))
45 | println(pretty(render(json2)))
46 | println(pretty(render(json3)))
47 |
48 |
49 | //=========== querying json ===============
50 | val json4 = parse( """
51 | { "name": "joe",
52 | "children": [
53 | {
54 | "name": "Mary",
55 | "age": 5
56 | },
57 | {
58 | "name": "Mazy",
59 | "age": 3
60 | }
61 | ]
62 | }
63 | """)
64 | // TODO name:"joe"
65 | val ages = for {
66 | JObject(child) <- json4
67 | JField("age", JInt(age)) <- child
68 | if age > 4
69 | } yield age
70 | val name = for{
71 | JString(name) <- json4
72 | } yield name
73 | println(ages)
74 | //List(joe, Mary, Mazy)
75 | println(name)
76 | //{"name":"joe","name":"Mary","name":"Mazy"}
77 | println(compact(render(json4 \\ "name")))
78 | //"joe"
79 | println(compact(render(json4 \ "name")))
80 | //[{"name":"Mary","age":5},{"name":"Mazy","age":3}]
81 | println(compact(render(json4 \\ "children")))
82 | //["Mary","Mazy"]
83 | println(compact(render(json4 \ "children" \ "name")))
84 | //{"name":"joe"}
85 | println(compact(render(json4 findField {
86 | case JField("name", _) => true
87 | case _ => false
88 | })))
89 | //{"name":"joe","name":"Mary","name":"Mazy"}
90 | println(compact(render(json4 filterField {
91 | case JField("name", _) => true
92 | case _ => false
93 | })))
94 |
95 | //============== extract value =================
96 | implicit val formats = DefaultFormats
97 | val json5 = parse("""{"first_name":"Mary"}""")
98 | case class Person(`firstName`: String)
99 | val json6=json5 transformField {
100 | case ("first_name", x) => ("firstName", x)
101 | }
102 | println(json6.extract[Person])
103 | println(json5.camelizeKeys.extract[Person])
104 |
105 | //================ xml 2 json ===================
106 | import org.json4s.Xml.{toJson, toXml}
107 | val xml =
108 |
109 |
110 | 1
111 | Harry
112 |
113 |
114 | 2
115 | David
116 |
117 |
118 |
119 | val json = toJson(xml)
120 | println(pretty(render(json)))
121 | println(pretty(render(json transformField {
122 | case ("id", JString(s)) => ("id", JInt(s.toInt))
123 | case ("user", x: JObject) => ("user", JArray(x :: Nil))
124 | })))
125 | //================ json 2 xml ===================
126 | println(toXml(json))
127 | }
128 | }
129 |
--------------------------------------------------------------------------------
/lamma-demo/README.md:
--------------------------------------------------------------------------------
1 | #lamma-demo
2 | 日期相关的操作全部具有,唯一的缺点就是没有时间的操作
--------------------------------------------------------------------------------
/lamma-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s
11 | lamma-demo
12 | 2008
13 |
14 |
15 |
16 | io.lamma
17 | lamma_${soft.scala.version}
18 | 2.2.3
19 |
20 |
21 |
22 |
--------------------------------------------------------------------------------
/lamma-demo/src/main/scala/cn/thinkjoy/utils4s/lamma/BasicOper.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.lamma
2 |
3 | import io.lamma._
4 |
5 | /**
6 | * test
7 | *
8 | */
9 | object BasicOper {
10 | def main(args: Array[String]): Unit = {
11 | //============== create date ===========
12 | println(Date(2014, 7, 7).toISOString) //2014-07-07
13 | println(Date("2014-07-7").toISOInt) //20140707
14 | println(Date.today())
15 |
16 | //============== compare two date ===========
17 | println(Date(2014, 7, 7) < Date(2014, 7, 8))
18 | println((2014, 7, 7) <(2014, 7, 8))
19 | println(Date("2014-07-7") > Date("2014-7-8"))
20 | println(Date("2014-07-10") - Date("2014-7-8"))
21 |
22 | // ========== manipulate dates =============
23 | println(Date(2014, 7, 7) + 1)
24 | println((2014, 7, 7) + 30)
25 | println(Date("2014-07-7") + 1)
26 | println(Date("2014-07-7") - 1)
27 | println(Date("2014-07-7") + (2 weeks))
28 | println(Date("2014-07-7") + (2 months))
29 | println(Date("2014-07-7") + (2 years))
30 |
31 | // ========== week related ops ============
32 | println(Date("2014-07-7").dayOfWeek) //MONDAY
33 | println(Date("2014-07-7").withDayOfWeek(Monday).toISOString) //这周的星期一 2014-07-07
34 | println(Date("2014-07-7").next(Monday))
35 | println(Date(2014, 7, 8).daysOfWeek(0)) //默认星期一是一周第一天
36 |
37 | // ========== month related ops ============
38 | println(Date("2014-07-7").maxDayOfMonth)
39 | println(Date("2014-07-7").lastDayOfMonth)
40 | println(Date("2014-07-7").firstDayOfMonth)
41 | println(Date("2014-07-7").sameWeekdaysOfMonth)
42 | println(Date("2014-07-7").dayOfMonth)
43 |
44 | // ========== year related ops ============
45 | println(Date("2014-07-7").maxDayOfYear)
46 | println(Date("2014-07-7").dayOfYear)
47 | }
48 | }
49 |
--------------------------------------------------------------------------------
/log-demo/README.md:
--------------------------------------------------------------------------------
1 | #log-demo
2 | log4s可以作为日志库,使用需要log4j.prperties作为配置文件
--------------------------------------------------------------------------------
/log-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 |
10 | 4.0.0
11 | cn.thinkjoy.utils4s.log4s
12 | log-demo
13 | pom
14 | 2008
15 |
16 |
17 |
18 |
19 | org.slf4j
20 | slf4j-log4j12
21 | 1.7.2
22 |
23 |
24 | org.log4s
25 | log4s_${soft.scala.version}
26 | 1.2.0
27 | compile
28 |
29 |
30 |
31 |
32 |
--------------------------------------------------------------------------------
/log-demo/src/main/resources/log4j.properties:
--------------------------------------------------------------------------------
1 | # This is the configuring for logging displayed in the Application Server
2 | log4j.rootCategory=INFO,stdout,file
3 |
4 | #standard
5 | log4j.appender.stdout=org.apache.log4j.ConsoleAppender
6 | log4j.appender.stdout.Target = System.out
7 | log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
8 | log4j.appender.stdout.layout.ConversionPattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %p [%c] line:%L [%F][%M][%t] - %m%n
9 |
10 | #file configure
11 | log4j.appender.file=org.apache.log4j.DailyRollingFileAppender
12 | log4j.appender.file.encoding=UTF-8
13 | log4j.appender.file.Threshold = INFO
14 | log4j.appender.file.File=logs/log.log
15 | log4j.appender.file.layout=org.apache.log4j.PatternLayout
16 | log4j.appender.file.layout.ConversionPattern= %d{yyyy-MM-dd HH:mm:ss,SSS} %p line:%L [%F][%M] - %m%n
--------------------------------------------------------------------------------
/log-demo/src/main/scala/cn/thinkjoy/utils4s/log4s/App.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.log4s
2 |
3 | import org.log4s._
4 |
5 | /**
6 | * Hello world!
7 | *
8 | */
9 |
10 | object App {
11 |
12 | def main(args: Array[String]) {
13 | val test=new LoggingTest
14 | test.logPrint()
15 |
16 | val loggerName = this.getClass.getName
17 | val log=getLogger(loggerName)
18 | log.debug("debug log")
19 | log.info("info log")
20 | log.warn("warn log")
21 | log.error("error log")
22 |
23 | }
24 |
25 | }
26 |
--------------------------------------------------------------------------------
/log-demo/src/main/scala/cn/thinkjoy/utils4s/log4s/Logging.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.log4s
2 |
3 | import org.log4s._
4 |
5 | /**
6 | * Created by jacksu on 15/11/13.
7 | */
8 | trait Logging {
9 | private val clazz=this.getClass
10 | lazy val logger=getLogger(clazz)
11 | }
12 |
--------------------------------------------------------------------------------
/log-demo/src/main/scala/cn/thinkjoy/utils4s/log4s/LoggingTest.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.log4s
2 |
3 | import org.log4s._
4 |
5 | /**
6 | * Created by jacksu on 15/9/24.
7 | */
8 |
9 |
10 | class LoggingTest extends Logging{
11 | def logPrint(): Unit ={
12 | logger.debug("debug log")
13 | logger.info("info log")
14 | logger.warn("warn log")
15 | logger.error("error log")
16 | }
17 | }
18 |
--------------------------------------------------------------------------------
/manger-tools/python/es/__init__.py:
--------------------------------------------------------------------------------
1 | __author__ = 'jacksu'
2 |
--------------------------------------------------------------------------------
/manger-tools/python/es/check_index.py:
--------------------------------------------------------------------------------
1 | #! /usr/local/bin/python3
2 | # coding = utf-8
3 |
4 | __author__ = 'jacksu'
5 |
6 | import os
7 | import sys
8 | import xml.etree.ElementTree as ET
9 | from calendar import datetime
10 | import requests
11 | sys.path.append('.')
12 | import logger
13 | import mail
14 |
15 |
16 | if __name__ == '__main__':
17 | if len(sys.argv) != 2: # 参数判断
18 | print("example: " + sys.argv[0] + " index_list.conf")
19 | sys.exit(1)
20 | if not os.path.exists(sys.argv[1]): # 文件存在判断
21 | print("conf file does not exist")
22 | sys.exit(1)
23 |
24 | logger=logger.getLogger()
25 | logger.info("Start time: " + datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
26 | tree = ET.parse(sys.argv[1])
27 | root = tree.getroot()
28 | list = []
29 | for hosts in root.findall("host"):
30 | logger.debug(hosts)
31 | auth_flag = hosts.get("auth")
32 | logger.debug(auth_flag)
33 | if "true" == auth_flag:
34 | auth = (hosts.get("user"), hosts.get("password"))
35 | logger.info(auth)
36 | top_url = hosts.get("url")
37 | logger.info(top_url)
38 | for child in hosts.findall("index"):
39 | prefix = child.find("name").text
40 | period = child.find("period").text
41 | type = child.find("period").get("type")
42 | logger.debug(type)
43 | if "day" == type:
44 | suffix = (datetime.datetime.now() - datetime.timedelta(days=int(period))).strftime('%Y.%m.%d')
45 | elif "month" == type:
46 | suffix = datetime.datetime.now().strftime('%Y%m')
47 | index = prefix + suffix
48 | logger.debug(index)
49 | url = top_url + index
50 | if "true" == auth_flag:
51 | result = requests.head(url, auth=auth)
52 | else:
53 | result = requests.head(url)
54 | if result.status_code != 200:
55 | list.append(index)
56 | if 0 != len(list):
57 | logger.debug("send mail")
58 | mail.send_mail('xbsu@thinkjoy.cn', 'xbsu@thinkjoy.cn', 'ES 索引错误', str(list))
59 | logger.info("End time: " + datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
60 |
--------------------------------------------------------------------------------
/manger-tools/python/es/del_expired_index.py:
--------------------------------------------------------------------------------
1 | #! /usr/local/bin/python3
2 | # coding = utf-8
3 |
4 | __author__ = 'jacksu'
5 |
6 | import os
7 | import sys
8 | import xml.etree.ElementTree as ET
9 | from calendar import datetime
10 | import requests
11 | import logger
12 |
13 | if __name__ == '__main__':
14 | if len(sys.argv) != 2:
15 | print("example: " + sys.argv[0] + " expired_index.conf")
16 | sys.exit(1)
17 | if not os.path.exists(sys.argv[1]):
18 | print("conf file does not exist")
19 | sys.exit(1)
20 | logger = logger.getLogger()
21 | logger.info("Start time: " + datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
22 | tree = ET.parse(sys.argv[1])
23 | root = tree.getroot()
24 | # conn = httplib.HTTPConnection("http://es_admin:password@10.253.2.125:9200/")
25 | for host in root.findall("host"):
26 |
27 | top_url = host.get("url")
28 | logger.info(top_url)
29 | for index in host.findall("index"):
30 | prefix = index.find("name").text
31 | period = index.find("period").text
32 | suffix = (datetime.datetime.now() - datetime.timedelta(days=int(period))).strftime('%Y.%m.%d')
33 | index = prefix + "-" + suffix
34 | logger.debug(index)
35 | url = top_url + index
36 | if "true" == host.get("auth"):
37 | auth = (host.get("user"), host.get("password"))
38 | logger.info("auth: " + str(auth))
39 | result = requests.delete(url, auth=auth)
40 | else:
41 | result = requests.delete(url)
42 | logger.debug(result.json())
43 | logger.debug(result.status_code)
44 | logger.info("End time: " + datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
45 |
--------------------------------------------------------------------------------
/manger-tools/python/es/del_many_index.py:
--------------------------------------------------------------------------------
1 | #! /usr/local/bin/python3
2 | # coding = utf-8
3 |
4 | import datetime
5 | import sys
6 | sys.path.append('.')
7 | from delindex import delindex
8 |
9 | __author__ = 'jacksu'
10 |
11 |
12 | def str_2_date(str):
13 | return datetime.datetime.strptime(str, "%Y%m%d")
14 |
15 |
16 | def nextdate(str):
17 | return (datetime.datetime.strptime(str,'%Y%m%d') + datetime.timedelta(days=1)).strftime('%Y%m%d')
18 |
19 | def formatdate(str):
20 | return datetime.datetime.strptime(str, "%Y%m%d").strftime('%Y.%m.%d')
21 |
22 | if __name__ == '__main__':
23 | if len(sys.argv) != 4:
24 | print("example: " + sys.argv[0] + " index_prefix start_date end_date")
25 | sys.exit(1)
26 |
27 | prefix = sys.argv[1]
28 | begin = sys.argv[2]
29 | end = sys.argv[3]
30 |
31 | print("Start time: " + datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
32 |
33 | while str_2_date(begin) <= str_2_date(end):
34 | index = prefix + "-" + formatdate(begin)
35 | print(index)
36 | if not delindex(index):
37 | print("delete index error: " + index)
38 | begin = str(nextdate(begin))
39 | print("End time: " + datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
--------------------------------------------------------------------------------
/manger-tools/python/es/delindex.py:
--------------------------------------------------------------------------------
1 | #! /usr/local/bin/python3
2 | # coding = utf-8
3 |
4 | import sys
5 | import requests
6 | import datetime
7 |
8 | __author__ = 'jacksu'
9 |
10 |
11 | def delindex(index):
12 | auth = ("es_admin", "password")
13 | print(auth)
14 | top_url = "http://10.253.2.125:9200/"
15 | print(top_url)
16 | url = top_url + index
17 | result = requests.delete(url, auth=auth)
18 | if result.status_code != 200:
19 | return False
20 | return True
21 |
22 |
23 | if __name__ == '__main__':
24 | if len(sys.argv) != 2:
25 | print("example: " + sys.argv[0] + " index")
26 | sys.exit(1)
27 |
28 | index = sys.argv[1]
29 |
30 | print("Start time: " + datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
31 |
32 | if not delindex(index):
33 | print("delete index error: " + index)
34 | print("End time: " + datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
35 |
--------------------------------------------------------------------------------
/manger-tools/python/es/expired_index.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | logstash-qky-pro
5 | 15
6 |
7 |
8 |
9 |
10 | .marvel-
11 | 10
12 |
13 |
14 |
15 |
--------------------------------------------------------------------------------
/manger-tools/python/es/index_list.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | logstash-qky-pro-
5 | 1
6 |
7 |
8 | logstash-ucenter-oper-log-
9 | 1
10 |
11 |
12 | logstash-zhiliao_uc_access-
13 | 1
14 |
15 |
16 |
17 |
18 | yzt_errornotes_
19 | 0
20 |
21 |
22 |
23 |
--------------------------------------------------------------------------------
/manger-tools/python/es/logger.py:
--------------------------------------------------------------------------------
1 | #! /usr/local/bin/python3
2 | # coding = utf-8
3 |
4 | __author__ = 'jacksu'
5 |
6 | import logging
7 | import logging.handlers
8 |
9 |
10 | def getLogger():
11 | logging.basicConfig(level=logging.DEBUG,
12 | format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
13 | datefmt='%a, %d %b %Y %H:%M:%S',
14 | filemode='w')
15 | return logging.getLogger()
16 |
--------------------------------------------------------------------------------
/manger-tools/python/es/mail.py:
--------------------------------------------------------------------------------
1 | #! /usr/local/bin/python3
2 | # coding = utf-8
3 |
4 | import email
5 | import smtplib
6 | import email.mime.multipart
7 | import email.mime.text
8 |
9 | __author__ = 'jacksu'
10 |
11 |
12 |
13 |
14 | def send_mail(from_list, to_list, sub, content):
15 | msg = email.mime.multipart.MIMEMultipart()
16 | msg['from'] = from_list
17 | msg['to'] = to_list
18 | msg['subject'] = sub
19 | content = content
20 | txt = email.mime.text.MIMEText(content)
21 | msg.attach(txt)
22 |
23 | smtp = smtplib.SMTP('localhost')
24 | smtp.sendmail(from_list, to_list, str(msg))
25 | smtp.quit()
--------------------------------------------------------------------------------
/manger-tools/shell/kafka-reassign-replica.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ###################
4 | #修改Kafka中数据的replica数
5 | # Created by jacksu on 16/2/26.
6 |
7 | if [ $# -ne 2 ]
8 | then
9 | echo "exampl: $0 zookeeperURL TOPIC [replicaNum]"
10 | exit 1
11 | fi
12 |
13 | ZKURL=$1
14 | TOPIC=$2
15 |
16 | if [ $# -gt 2 ]
17 | then
18 | REPNUM=$3
19 | else
20 | REPNUM=2
21 | fi
22 |
23 | echo "replica num:$REPNUM"
24 |
25 | export PATH=$PATH
26 | KAFKAPATH="/opt/kafka"
27 |
28 | PARTITIONS=$(${KAFKAPATH}/bin/kafka-topics.sh --zookeeper $ZKURL --topic $TOPIC --describe | grep PartitionCount | awk '{print $2}' | awk -F":" '{print $2}')
29 |
30 |
31 | REPLICA=$(seq -s, 0 `expr $REPNUM - 1`)
32 | PARTITIONS=$(expr $PARTITIONS - 2)
33 | FILE=partition-to-move.json
34 |
35 | ##输出头
36 | echo "{" > $FILE
37 | echo "\"partitions\":" >> $FILE
38 | echo "[" >> $FILE
39 |
40 | if [ $PARTITIONS -gt 0 ]
41 | then
42 | for i in `seq 0 $PARTITIONS`
43 | do
44 | echo "{\"topic\": \"$TOPIC\", \"partition\": $i,\"replicas\": [$REPLICA]}," >> $FILE
45 | done
46 | elif [ $PARTITIONS -eq 0 ]
47 | then
48 | echo "{\"topic\": \"$TOPIC\", \"partition\": 0,\"replicas\": [$REPLICA]}," >> $FILE
49 | fi
50 | PARTITIONS=$(expr $PARTITIONS + 1)
51 |
52 | ##输出尾
53 | echo "{\"topic\": \"$TOPIC\", \"partition\": $PARTITIONS,\"replicas\": [$REPLICA]}" >> $FILE
54 | echo "]" >> $FILE
55 | echo "}" >> $FILE
56 |
57 |
58 | $KAFKAPATH/bin/kafka-reassign-partitions.sh --zookeeper $ZKURL -reassignment-json-file $FILE -execute
59 |
--------------------------------------------------------------------------------
/manger-tools/shell/manger.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ###################
4 | #主要用于程序启动和停止时,只需要修改函数start中COMMAND
5 | #COMMAND赋值为你要操作的程序即可
6 | # Created by jacksu on 16/1/15.
7 |
8 | BASE_NAME=`dirname $0`
9 | NAME=`basename $0 | awk -F '.' '{print $1}'`
10 |
11 | function print_usage(){
12 | echo "manger.sh [OPTION]"
13 | echo " --help|-h"
14 | echo " --daemon|-d 默认后台运行"
15 | echo " --logdir|-l 日志目录"
16 | echo " --conf 配置文件"
17 | echo " --workdir"
18 | }
19 |
20 | # Print an error message and exit
21 | function die() {
22 | echo -e "\nError: $@\n" 1>&2
23 | print_usage
24 | exit 1
25 | }
26 |
27 | for i in "$@"
28 | do
29 | case "$1" in
30 | start|stop|restart|status)
31 | ACTION="$1"
32 | ;;
33 | --workdir)
34 | WORK_DIR="$2"
35 | shift
36 | ;;
37 | --fwdir)
38 | FWDIR="$2"
39 | shift
40 | ;;
41 | --logdir)
42 | LOG_DIR="$2"
43 | shift
44 | ;;
45 | --jars)
46 | JARS="$2"
47 | shift
48 | ;;
49 | --conf)
50 | CONFIG_DIR="$2"
51 | shift
52 | ;;
53 | --jvmflags)
54 | JVM_FLAGS="$2"
55 | shift
56 | ;;
57 | --help|-h)
58 | print_usage
59 | exit 0
60 | ;;
61 | *)
62 | ;;
63 | esac
64 | shift
65 | done
66 |
67 | PID="$BASE_NAME/.${NAME}_pid"
68 |
69 | if [ -f "$PID" ]; then
70 | PID_VALUE=`cat $PID` > /dev/null 2>&1
71 | else
72 | PID_VALUE=""
73 | fi
74 |
75 | if [ ! -d "$LOG_DIR" ]; then
76 | mkdir "$LOG_DIR"
77 | fi
78 |
79 | function start(){
80 | echo "now is starting"
81 |
82 | #TODO 添加需要执行的命令
83 | COMMAND=""
84 | COMMAND+=""
85 |
86 | echo "Running command:"
87 | echo "$COMMAND"
88 | nohup $COMMAND & echo $! > $PID
89 | }
90 |
91 | function stop() {
92 | if [ -f "$PID" ]; then
93 | if kill -0 $PID_VALUE > /dev/null 2>&1; then
94 | echo 'now is stopping'
95 | kill $PID_VALUE
96 | sleep 1
97 | if kill -0 $PID_VALUE > /dev/null 2>&1; then
98 | echo "Did not stop gracefully, killing with kill -9"
99 | kill -9 $PID_VALUE
100 | fi
101 | else
102 | echo "Process $PID_VALUE is not running"
103 | fi
104 | else
105 | echo "No pid file found"
106 | fi
107 | }
108 |
109 | # Check the status of the process
110 | function status() {
111 | if [ -f "$PID" ]; then
112 | echo "Looking into file: $PID"
113 | if kill -0 $PID_VALUE > /dev/null 2>&1; then
114 | echo "The process is running with status: "
115 | ps -ef | grep -v grep | grep $PID_VALUE
116 | else
117 | echo "The process is not running"
118 | exit 1
119 | fi
120 | else
121 | echo "No pid file found"
122 | exit 1
123 | fi
124 | }
125 |
126 |
127 | case "$ACTION" in
128 | "start")
129 | start
130 | ;;
131 | "status")
132 | status
133 | ;;
134 | "restart")
135 | stop
136 | echo "Sleeping..."
137 | sleep 1
138 | start
139 | ;;
140 | "stop")
141 | stop
142 | ;;
143 | *)
144 | print_usage
145 | exit 1
146 | ;;
147 | esac
--------------------------------------------------------------------------------
/manger-tools/shell/start_daily.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # Created by xbsu on 16/1/6.
4 |
5 | if [ $# -ne 2 ]
6 | then
7 | echo "exampl: $0 20160101 20160102"
8 | exit 1
9 | fi
10 |
11 | BEGIN_DATE=$1
12 | END_DATE=$2
13 |
14 | export PATH=$PATH
15 |
16 | DB_HOST=""
17 | DB_USER=""
18 | DB_PASS=""
19 | DB_DB=""
20 | MYSQL="mysql -u${DB_USER} -p${DB_PASS} -h${DB_HOST} -D${DB_DB} --skip-column-name -e"
21 |
22 |
23 | ##################main####################
24 | echo "======Start time `date`==========="
25 |
26 | while [ $BEGIN_DATE -le $END_DATE ]; do
27 | FORMAT_DATE=`date -d "$BEGIN_DATE" +"%Y-%m-%d"`
28 | echo "fromat date $FORMAT_DATE"
29 | ##TODO something
30 | SQL=""
31 | $MYSQL $SQL
32 | BEGIN_DATE=`date -d "$BEGIN_DATE UTC +1 day" +"%Y%m%d"`
33 | done
34 |
35 | echo "======End time `date`==========="
36 |
--------------------------------------------------------------------------------
/nscala-time-demo/README.md:
--------------------------------------------------------------------------------
1 | #nscala-time
2 |
3 | 有时间的操作,文档不全,不知道每月的最大一天是什么,暂时还不知道如何使用scala for操作日期段,如下使用。
4 |
5 | ```scala
6 | //不可以这样
7 | for(current<-DateTime.parse("2014-07-7") to DateTime.parse("2014-07-8")){
8 | println(current)
9 | }
10 | ```
11 |
12 |
13 | 谢谢jjcipher,补全demo
--------------------------------------------------------------------------------
/nscala-time-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.nscala-time
11 | nscala-time-demo
12 | pom
13 | 2008
14 |
15 |
16 |
17 | com.github.nscala-time
18 | nscala-time_${soft.scala.version}
19 | 2.2.0
20 |
21 |
22 |
23 |
--------------------------------------------------------------------------------
/nscala-time-demo/src/main/scala/cn/thinkjoy/utils4s/nscala_time/BasicOper.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.nscala_time
2 |
3 | import com.github.nscala_time.time._
4 | import com.github.nscala_time.time.Imports._
5 | import org.joda.time.PeriodType
6 |
7 | /**
8 | * Hello world!
9 | *
10 | */
11 | object BasicOper {
12 | def main(args: Array[String]) {
13 | //================= create date ===================
14 | println(DateTime.now())
15 | val yesterday = (DateTime.now() - 1.days).toString(StaticDateTimeFormat.forPattern("yyyy-MM-dd HH:mm:ss"))
16 | println(yesterday)
17 | println(DateTime.parse("2014-07-7"))
18 | println(DateTime.parse("20140707", DateTimeFormat.forPattern("yyyyMMdd")))
19 | println(DateTime.parse("20140707", DateTimeFormat.forPattern("yyyyMMdd")).toLocalDate)
20 | println(DateTime.parse("20140707", DateTimeFormat.forPattern("yyyyMMdd")).toLocalTime)
21 |
22 | //============== compare two date ===========
23 | println(DateTime.parse("2014-07-7") < DateTime.parse("2014-07-8"))
24 | //println((DateTime.parse("2014-07-9").toLocalDate - DateTime.parse("2014-07-8").toLocalDate))
25 |
26 |
27 | // Find the time difference between two dates
28 | val newYear2016 = new DateTime withDate(2016, 1, 1)
29 | val daysToYear2016 = (newYear2016 to DateTime.now toPeriod PeriodType.days).getDays // 到2016年一月ㄧ日還有幾天
30 |
31 | // ========== manipulate dates =============
32 | println(DateTime.parse("2014-07-7") + 1.days)
33 | println((DateTime.parse("2014-07-7") + 1.day).toLocalDate)
34 | println(DateTime.parse("2014-07-7") - 1.days)
35 | println(DateTime.parse("2014-07-7") + (2 weeks))
36 | println(DateTime.parse("2014-07-7") + (2 months))
37 | println(DateTime.parse("2014-07-7") + (2 years))
38 |
39 | // ========== manipulate times =============
40 | println(DateTime.now() + 1.hour)
41 | println(DateTime.now() + 1.hour + 1.minute + 2.seconds)
42 | println(DateTime.now().getHourOfDay)
43 | println(DateTime.now.getMinuteOfHour)
44 |
45 | // ========== week related ops =============
46 | println((DateTime.now()-1.days).getDayOfWeek)//星期一为第一天
47 | println(DateTime.now().withDayOfWeek(1).toLocalDate)//这周的星期一
48 | println((DateTime.now()+ 1.weeks).withDayOfWeek(1))//下周星期一
49 |
50 | // ========== month related ops =============
51 | println((DateTime.now()-1.days).getDayOfMonth)
52 | println(DateTime.now().getMonthOfYear)
53 | println(DateTime.now().plusMonths(1))
54 | println(DateTime.now().dayOfMonth().getMaximumValue()) // 這個月有多少天
55 |
56 | // ========== year related ops =============
57 | println((DateTime.now()-1.days).getDayOfYear)
58 | println(DateTime.now().dayOfYear().getMaximumValue()) // 今年有多少天
59 |
60 | }
61 | }
62 |
--------------------------------------------------------------------------------
/picture/covAndcon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/picture/covAndcon.png
--------------------------------------------------------------------------------
/picture/datacube.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/picture/datacube.jpg
--------------------------------------------------------------------------------
/picture/spark_streaming_config.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/picture/spark_streaming_config.png
--------------------------------------------------------------------------------
/pom.xml:
--------------------------------------------------------------------------------
1 |
2 |
5 | 4.0.0
6 |
7 | cn.thinkjoy.utils4s
8 | demo
9 | pom
10 | 1.0
11 |
12 |
13 | 2.11.7
14 | 2.11
15 |
16 |
17 |
18 |
19 | org.scala-lang
20 | scala-compiler
21 | ${scala.version}
22 | compile
23 |
24 |
25 | org.scalatest
26 | scalatest_${soft.scala.version}
27 | 2.1.5
28 | test
29 |
30 |
31 | org.scala-lang
32 | scala-xml
33 | 2.11.0-M4
34 |
35 |
36 |
37 |
38 | log-demo
39 | unittest-demo
40 | scala-demo
41 | lamma-demo
42 | nscala-time-demo
43 | json4s-demo
44 | spark-streaming-demo
45 | resources-demo
46 | file-demo
47 | analysis-demo
48 | twitter-util-demo
49 | spark-dataframe-demo
50 |
51 | breeze-demo
52 | hive-json-demo
53 | akka-demo
54 | spark-core-demo
55 | spark-analytics-demo
56 |
57 |
58 |
59 |
60 |
61 | org.scala-tools
62 | maven-scala-plugin
63 |
64 |
65 |
66 | compile
67 | testCompile
68 |
69 |
70 |
71 |
72 | ${scala.version}
73 |
74 | -target:jvm-1.7
75 |
76 |
77 |
78 |
79 | org.apache.maven.plugins
80 | maven-surefire-plugin
81 | 2.7
82 |
83 | true
84 |
85 |
86 |
87 | org.scalatest
88 | scalatest-maven-plugin
89 | 1.0
90 |
91 | ${project.build.directory}/surefire-reports
92 | .
93 | WDF TestSuite.txt
94 |
95 |
96 |
97 | test
98 |
99 | test
100 |
101 |
102 |
103 |
104 |
105 |
106 | maven-assembly-plugin
107 |
108 |
109 | jar-with-dependencies
110 |
111 |
112 |
113 |
114 | make-assembly
115 | package
116 |
117 | single
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 | org.scala-tools
128 | maven-scala-plugin
129 |
130 | ${scala.version}
131 |
132 |
133 |
134 |
135 |
--------------------------------------------------------------------------------
/resources-demo/README.md:
--------------------------------------------------------------------------------
1 | 通过加载properties和xml两种文件进行测试。
--------------------------------------------------------------------------------
/resources-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 |
10 | 4.0.0
11 | cn.thinkjoy.utils4s
12 | resources-demo
13 | 2008
14 |
15 |
16 | src/main/scala
17 | src/test/scala
18 |
19 |
20 |
--------------------------------------------------------------------------------
/resources-demo/src/main/resources/test.properties:
--------------------------------------------------------------------------------
1 | url.jack=https://github.com/jacksu
--------------------------------------------------------------------------------
/resources-demo/src/main/resources/test.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 | test
4 | https://github.com/jacksu
5 |
6 |
7 | test1
8 | https://github.com/jacksu
9 |
10 |
11 |
--------------------------------------------------------------------------------
/resources-demo/src/main/scala/cn/thinkjoy/utils4s/resources/ResourcesApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.resources
2 |
3 | import java.util.Properties
4 |
5 | import scala.io.Source
6 | import scala.xml.XML
7 |
8 | /**
9 | * Hello world!
10 | *
11 | */
12 | object ResourcesApp {
13 | def main(args: Array[String]): Unit = {
14 | val stream = getClass.getResourceAsStream("/test.properties")
15 | val prop=new Properties()
16 | prop.load(stream)
17 | println(prop.getProperty("url.jack"))
18 | //获取resources下面的文件
19 | val streamXml = getClass.getResourceAsStream("/test.xml")
20 | //val lines = Source.fromInputStream(streamXml).getLines.toList
21 | val xml=XML.load(streamXml)
22 | for (child <- xml \\ "collection" \\ "property"){
23 | println((child \\ "name").text)
24 | println((child \\ "url").text)
25 | }
26 |
27 | }
28 | }
29 |
--------------------------------------------------------------------------------
/scala-demo/README.md:
--------------------------------------------------------------------------------
1 | #scala-demo
2 |
3 | [协变、逆变、上界、下界](md/协变逆变上界下界.md)
4 |
5 | [提取器](https://windor.gitbooks.io/beginners-guide-to-scala/content/chp1-extractors.html)
6 |
7 | ## Future和Promise
8 |
9 | [Scala Future and Promise](http://colobu.com/2015/06/11/Scala-Future-and-Promise/)
10 |
11 | [Scala中使用Future进行并发处理](http://m.blog.csdn.net/blog/ratsniper/47177619)
12 |
13 | ##执行shell命令
14 | ```scala
15 | val source = Source.fromURL("http://www.baidu.com","UTF-8")
16 | println(source.mkString)
17 | import sys.process._
18 | "ls -la ." !
19 | val result = "ls -l ." #| "grep README" #| "wc -l" !!
20 | //!!必须空一行
21 |
22 | println(result)
23 | "grep baidu" #< new URL("http://www.baidu.com") !
24 | ```
25 |
26 | 学习scala的测试用例,参考于[scala练习](http://scala-exercises.47deg.com)
--------------------------------------------------------------------------------
/scala-demo/md/偏函数(PartialFunction)、偏应用函数(Partial Applied Function).md:
--------------------------------------------------------------------------------
1 | #偏函数(PartialFunction)、部分应用函数(Partial Applied Function)
2 |
3 | ##偏函数(PartialFunction)
4 |
5 | 偏函数是只对函数定义域的一个子集进行定义的函数。 scala中用scala.PartialFunction[-T, +S]类来表示
6 |
7 | scala可以通过模式匹配来定义偏函数, 下面这两种方式定义的函数, 都可以认为是偏函数, 因为他们都只对其定义域Int的部分值做了处理. 那么像p1哪有定义成PartialFunction的额外好处是, 你可以在调用前使用一个isDefinedAt方法, 来校验参数是否会得到处理. 或者在调用时使用一个orElse方法, 该方法接受另一个偏函数,用来定义当参数未被偏函数捕获时该怎么做. 也就是能够进行显示的声明. 在实际代码中最好使用PartialFunction来声明你确实是要定义一个偏函数, 而不是漏掉了什么.
8 |
9 | ```scala
10 | def p1:PartialFunction[Int, Int] = {
11 | case x if x > 1 => 1
12 | }
13 | p1.isDefinedAt(1)
14 |
15 | def p2 = (x:Int) => x match {
16 | case x if x > 1 => 1
17 | }
18 | ```
19 |
20 | ##部分应用函数(Partial Applied Function)
21 |
22 | 是指一个函数有N个参数, 而我们为其提供少于N个参数, 那就得到了一个部分应用函数.
23 |
24 | 比如我先定义一个函数
25 | ```scala
26 | def sum(a:Int,b:Int,c:Int) = a + b + c
27 | ```
28 | 那么就可以从这个函数衍生出一个偏函数是这样的:
29 | ```scala
30 | def p_sum = sum(1, _:Int, _:Int)
31 | ```
32 | 于是就可以这样调用p_sum(2,3), 相当于调用sum(1,2,3) 得到的结果是6. 这里的两个_分别对应函数sum对应位置的参数. 所以你也可以定义成
33 | ```scala
34 | def p_sum = sum (_:Int, 1, _:Int)
35 | ```
--------------------------------------------------------------------------------
/scala-demo/md/函数参数传名调用、传值调用.md:
--------------------------------------------------------------------------------
1 | 引言
2 | Scala的解释器在解析函数参数(function arguments)时有两种方式:先计算参数表达式的值(reduce the arguments),再应用到函数内部;或者是将未计算的参数表达式直接应用到函数内部。前者叫做传值调用(call-by-value),后者叫做传名调用(call-by-name)。
3 |
4 | ```scala
5 | package com.doggie
6 |
7 | object Add {
8 | def addByName(a: Int, b: => Int) = a + b
9 | def addByValue(a: Int, b: Int) = a + b
10 | }
11 | ```
12 |
13 |
14 | addByName是传名调用,addByValue是传值调用。语法上可以看出,使用传名调用时,在参数名称和参数类型中间有一个=》符号。
15 |
16 | 以a为2,b为2 + 2为例,他们在Scala解释器进行参数规约(reduction)时的顺序分别是这样的:
17 | ```scala
18 | addByName(2, 2 + 2)
19 | 2 + (2 + 2)
20 | 2 + 4
21 | 6
22 |
23 | addByValue(2, 2 + 2)
24 | addByValue(2, 4)
25 | 2 + 4
26 | 6
27 | ```
28 | 可以看出,在进入函数内部前,传值调用方式就已经将参数表达式的值计算完毕,而传名调用是在函数内部进行参数表达式的值计算的。
29 |
30 | 这就造成了一种现象,每次使用传名调用时,解释器都会计算一次表达式的值。对于有副作用(side-effect)的参数来说,这无疑造成了两种调用方式结果的不同。
31 |
32 | 酒鬼喝酒
33 | 举一个例子,假设有一只酒鬼,他最初有十元钱,每天喝酒都会花掉一元钱。设他有一个技能是数自己的钱,返回每天他口袋里钱的最新数目。
34 |
35 | 代码如下:
36 | ```scala
37 | package com.doggie
38 |
39 | object Drunkard {
40 | //最开始拥有的软妹币
41 | var money = 10
42 | //每天喝掉一个软妹币
43 | def drink: Unit = {
44 | money -= 1
45 | }
46 | //数钱时要算上被喝掉的软妹币
47 | def count: Int = {
48 | drink
49 | money
50 | }
51 | //每天都数钱
52 | def printByName(x: => Int): Unit = {
53 | for(i <- 0 until 5)
54 | println("每天算一算,酒鬼还剩" + x + "块钱!")
55 | }
56 | //第一天数一下记墙上,以后每天看墙上的余额
57 | def printByValue(x: Int): Unit = {
58 | for(i <- 0 until 5)
59 | println("只算第一天,酒鬼还剩" + x + "块钱!")
60 | }
61 |
62 | def main(args: Array[String]) = {
63 | printByName(count)
64 | printByValue(count)
65 | }
66 | }
67 | ```
68 |
69 | 我们使用成员变量money来表示酒鬼剩下的软妹币数量,每次发动drink技能就消耗一枚软妹币,在count中要计算因为drink消费掉的钱。我们定义了两种计算方式,printByName是传名调用,printByValue是传值调用。查看程序输出:
70 |
71 | ```scala
72 | 每天算一算,酒鬼还剩9块钱!
73 | 每天算一算,酒鬼还剩8块钱!
74 | 每天算一算,酒鬼还剩7块钱!
75 | 每天算一算,酒鬼还剩6块钱!
76 | 每天算一算,酒鬼还剩5块钱!
77 | 只算第一天,酒鬼还剩4块钱!
78 | 只算第一天,酒鬼还剩4块钱!
79 | 只算第一天,酒鬼还剩4块钱!
80 | 只算第一天,酒鬼还剩4块钱!
81 | 只算第一天,酒鬼还剩4块钱!
82 | ```
83 |
84 | 可以看到,酒鬼最初5天每天都会数一下口袋里的软妹币(call-by-name),得到了每天喝酒花钱之后剩下的软妹币数量,钱越来越少,他深感不能再这么堕落下去了。于是想出了一个聪明的方法,在第六天他将口袋里还剩下的余额数写在了墙上,以后每天看一下墙上的数字(call-by-value),就知道自己还剩多少钱了-___________________-
85 |
86 | 怎么样,这个酒鬼够不够聪明?
87 |
88 |
89 |
90 | 两者的比较
91 | 传值调用在进入函数体之前就对参数表达式进行了计算,这避免了函数内部多次使用参数时重复计算其值,在一定程度上提高了效率。
92 |
93 | 但是传名调用的一个优势在于,如果参数在函数体内部没有被使用到,那么它就不用计算参数表达式的值了。在这种情况下,传名调用的效率会高一点。
94 |
95 | 讲到这里,有些同学不开心了:你这不是耍我么?函数体内部不使用参数,干嘛还要传进去?
96 |
97 | 别着急,这里有一个例子:
98 |
99 | ```scala
100 | package com.doggie
101 |
102 | object WhyAlwaysMe {
103 | var flag: Boolean = true
104 | def useOrNotUse(x: Int, y: => Int) = {
105 | flag match{
106 | case true => x
107 | case false => x + y
108 | }
109 | }
110 | def main(args: Array[String]) =
111 | {
112 | println(useOrNotUse(1, 2))
113 | flag = false
114 | println(useOrNotUse(1, 2))
115 | }
116 | }
117 | ```
118 |
119 | You got it?
120 |
121 |
122 |
123 | 参考:
124 |
125 | http://stackoverflow.com/questions/13337338/call-by-name-vs-call-by-value-in-scala-clarification-needed
126 |
127 | http://www.cnblogs.com/nixil/archive/2012/05/31/2528068.html
128 |
129 | http://www.scala-lang.org/docu/files/ScalaByExample.pdf
130 |
131 | http://blog.csdn.net/asongoficeandfire/article/details/21889375
--------------------------------------------------------------------------------
/scala-demo/md/协变逆变上界下界.md:
--------------------------------------------------------------------------------
1 | 
2 | B是A的子类,A是B的父类。
3 | 当我们定义一个协变类型List[A+]时,List[Child]可以是List[Parent]的子类型。
4 | 当我们定义一个逆变类型List[-A]时,List[Child]可以是List[Parent]的父类型。
5 |
6 | ##Scala的协变
7 |
8 | 看下面的例子:
9 | ```scala
10 | class Animal {}
11 | class Bird extends Animal {}
12 | class Animal {}
13 | class Bird extends Animal {}
14 | //协变
15 | class Covariant[T](t:T){}
16 | val cov = new Covariant[Bird](new Bird)
17 | val cov2:Covariant[Animal] = cov
18 | ```
19 | cov不能赋值给cov2,因为Covariant定义成不变类型。
20 |
21 | 稍微改一下:
22 | ```scala
23 | class Animal {}
24 | class Bird extends Animal {}
25 | class Animal {}
26 | class Bird extends Animal {}
27 | //协变
28 | class Covariant[+T](t:T){}
29 | val cov = new Covariant[Bird](new Bird)
30 | val cov2:Covariant[Animal] = cov
31 | ```
32 | 因为Covariant定义成协变类型的,所以Covariant[Bird]是Covariant[Animal]的子类型,所以它可以被赋值给c2。
33 |
34 | ##Scala的逆变
35 |
36 | 将上面的例子改一下:
37 | ```scala
38 | class Animal {}
39 | class Bird extends Animal {}
40 | class Contravariant[-T](t: T) {
41 | }
42 | val c: Contravariant[Animal] = new Contravariant[Animal](new Animal)
43 | val c2: Contravariant[Bird] = c
44 | ```
45 | 这里Contravariant[-T]定义成逆变类型,所以Contravariant[Animal]被看作Contravariant[Animal]的子类型,故c可以被赋值给c2。
46 |
47 | ##下界lower bounds
48 |
49 | 如果协变类包含带类型参数的方法时:
50 | ```scala
51 | class Animal {}
52 | class Bird extends Animal {}
53 | class Consumer[+T](t: T) {
54 | def use(t: T) = {}
55 | }
56 | ```
57 | 编译会出错。出错信息为 "Covariant type T occurs in contravariant position in type T of value t"。
58 | 但是如果返回结果为类型参数则没有问题。
59 | ```scala
60 | class Animal {}
61 | class Bird extends Animal {}
62 | class Consumer[+T](t: T) {
63 | def get(): T = {new T}
64 | }
65 | ```
66 | 为了在方法的参数中使用类型参数,你需要定义下界:
67 | ```scala
68 | class Animal {}
69 | class Bird extends Animal {}
70 | class Consumer[+T](t: T) {
71 | def use[U >: T](u : U) = {println(u)}
72 | }
73 | ```
74 | 这个地方比较复杂, 简单的说就是Scala内部实现是, 把类中的每个可以放类型的地方都做了分类(+, –, 中立), 具体分类规则不说了 对于这里最外层类[+T]是协变, 但是到了方法的类型参数时, 该位置发生了翻转, 成为-逆变的位置, 所以你把T给他, 就会报错说你把一个协变类型放到了一个逆变的位置上
75 |
76 | 所以这里的处理的方法就是, 他要逆变, 就给他个逆变, 使用[U >: T], 其中T为下界, 表示T或T的超类, 这样Scala编译器就不报错了
77 | ##上界upper bounds
78 |
79 | 看一下逆变类中使用上界的例子:
80 | ```scala
81 | class Animal {}
82 | class Bird extends Animal {}
83 | class Consumer[-T](t: T) {
84 | def get[U <: T](): U = {new U}
85 | }
86 | ```
87 | 可以看到方法的返回值是协变的位置,方法的参数是逆变的位置。
88 | 因此协变类的类型参数可以用在方法的返回值的类型,在方法的参数类型上必须使用下界绑定 >:。
89 | 逆变类的类型参数可以用在方法的参数类型上,用做方法的返回值类型时必须使用上界绑定 <:。
90 |
91 | 综合协变,逆变,上界,下界
92 |
93 | 一个综合例子:
94 | ```scala
95 | class Animal {}
96 | class Bird extends Animal {}
97 | class Consumer[-S,+T]() {
98 | def m1[U >: T](u: U): T = {new T} //协变,下界
99 | def m2[U <: S](s: S): U = {new U} //逆变,上界
100 | }
101 | class Test extends App {
102 | val c:Consumer[Animal,Bird] = new Consumer[Animal,Bird]()
103 | val c2:Consumer[Bird,Animal] = c
104 | c2.m1(new Animal)
105 | c2.m2(new Bird)
106 | }
107 | ```
108 | ##View Bound <%
109 |
110 | Scala还有一种视图绑定的功能,如
111 | ```scala
112 | class Bird {def sing = {}}
113 | class Toy {}
114 | class Consumer[T <% Bird]() {
115 | def use(t: T) = t.sing
116 | }
117 | ```
118 | 或者类型参数在方法上:
119 | ```scala
120 | class Bird {def sing = {}}
121 | class Toy {}
122 | class Consumer() {
123 | def use[T <% Bird](t: T) = t.sing
124 | }
125 | class Test extends App {
126 | val c = new Consumer()
127 | c.use(new Toy)
128 | }
129 | ```
130 | 它要求T必须有一种隐式转换能转换成Bird,也就是 T => Bird,否则上面的代码会编译出错:
131 | No implicit view available from Toy => Bird.
132 | 加入一个隐式转换,编译通过。
133 | ```scala
134 | import scala.language.implicitConversions
135 | class Bird {def sing = {}}
136 | class Toy {}
137 | class Consumer() {
138 | def use[T <% Bird](t: T) = t.sing
139 | }
140 | class Test extends App {
141 | implicit def toy2Bird(t: Toy) = new Bird
142 | val c = new Consumer()
143 | c.use(new Toy)
144 | }
145 | ```
146 | ##Context Bound
147 |
148 | context bound在Scala 2.8.0中引入,也被称作type class pattern。
149 | view bound使用A <% String方式,context bound则需要参数化的类型,如Ordered[A]。
150 | 它声明了一个类型A,隐式地有一个类型B[A],语法如下:
151 | ```scala
152 | def f[A : B](a: A) = g(a) // where g requires an implicit value of type B[A]
153 | ```
154 | 更清晰的一个例子:
155 | ```scala
156 | def f[A : ClassManifest](n: Int) = new Array[A](n)
157 | ```
158 | 又比如
159 | ```scala
160 | def f[A : Ordering](a: A, b: A) = implicitly[Ordering[A]].compare(a, b)
161 | ```
162 |
163 | ##参考
164 | [Scala中的协变,逆变,上界,下界等](http://colobu.com/2015/05/19/Variance-lower-bounds-upper-bounds-in-Scala/)
165 |
166 | [Scala的协变和逆变上界与下界](http://oopsoutofmemory.github.io/scala/2014/11/19/scala-xie-bian-ni-bian-shang-jie-xia-jie-----li-jie-pian/)
167 |
168 | [协变点和逆变点](http://segmentfault.com/a/1190000003509191)
169 |
--------------------------------------------------------------------------------
/scala-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.scala
11 | scala-demo
12 | 2008
13 |
14 |
15 | src/main/scala
16 | src/test/scala
17 |
18 |
19 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/S99/P01.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.S99
2 |
3 | /**
4 | * Created by jacksu on 15/11/30.
5 | */
6 | object P01 {
7 | def last[A](ls: List[A]): A = ls.last
8 |
9 | def main(args: Array[String]) {
10 | println(last(List(1, 1, 2, 3, 5, 8)))
11 | }
12 | }
13 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/S99/P02.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.S99
2 |
3 | /**
4 | * Created by jacksu on 15/11/30.
5 | */
6 | object P02 {
7 | def penultimate[A](ls: List[A]): A = ls match {
8 | case h :: _ :: Nil => h
9 | case _ :: tail => penultimate(tail)
10 | case _ => throw new NoSuchElementException
11 | }
12 |
13 | def main(args: Array[String]) {
14 | println(penultimate(List(1, 1, 2, 3, 5, 8)))
15 | println(penultimate(List(1)))
16 | }
17 |
18 | }
19 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/S99/P03.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.S99
2 |
3 | /**
4 | * Created by jacksu on 15/12/1.
5 | */
6 | object P03 {
7 | def nth[A](n: Int, xs: List[A]): A = {
8 | if (xs.size <= n)
9 | throw new NoSuchElementException
10 | else
11 | xs(n)
12 | }
13 |
14 | def main(args: Array[String]) {
15 | println(nth(2, List(1, 1, 2, 3, 5, 8)))
16 | println(nth(6, List(1, 1, 2, 3, 5, 8)))
17 | }
18 | }
19 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/S99/P04.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.S99
2 |
3 | /**
4 | * Created by jacksu on 15/12/1.
5 | */
6 | object P04 {
7 | def length[A](xs: List[A]): Int = xs match {
8 | case Nil => 0
9 | case _ :: tail => 1 + length(tail)
10 | }
11 |
12 | def main(args: Array[String]) {
13 | println(length(List(1, 1, 2, 3, 5, 8)))
14 | }
15 | }
16 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/S99/P05.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.S99
2 |
3 | /**
4 | * Created by jacksu on 15/12/1.
5 | */
6 | object P05 {
7 | def reverse[A](xs:List[A]):List[A]= xs match{
8 | case head::Nil => List(head)
9 | case head::tail => reverse(tail):::List(head)
10 | }
11 |
12 | def main(args: Array[String]) {
13 | println(reverse(List(1, 1, 2, 3, 5, 8)))
14 | }
15 | }
16 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/S99/P06.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.S99
2 |
3 | /**
4 | * Created by jacksu on 15/12/1.
5 | */
6 | object P06 {
7 | def isPalindrome[A](xs:List[A]):Boolean={
8 | xs.reverse == xs
9 | }
10 |
11 | def main(args: Array[String]) {
12 | println(isPalindrome(List(1, 2, 3, 2, 1)))
13 | println(isPalindrome(List(2, 3, 2, 1)))
14 | }
15 | }
16 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/S99/P07.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.S99
2 |
3 | /**
4 | * Created by jacksu on 15/12/1.
5 | */
6 | object P07 {
7 | def flatten(xs:List[Any]):List[Any]=xs flatMap {
8 | case l:List[_]=> flatten(l)
9 | case e=> List(e)
10 | }
11 |
12 | def main(args: Array[String]) {
13 | println(flatten(List(List(1, 1), 2, List(3, List(5, 8)))))
14 | }
15 | }
16 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/S99/P08.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.S99
2 |
3 | /**
4 | * Created by jacksu on 15/12/2.
5 | */
6 | object P08 {
7 | /** result is vector
8 | def compress[A](xs: List[A]) = {
9 | for (i <- 0 until xs.length; j = i + 1
10 | if (j < xs.length && xs(i) != xs(j)|| j==xs.length)
11 | ) yield (xs(i))
12 | }
13 | **/
14 |
15 | def compress[A](xs:List[A]):List[A] = xs match{
16 | case Nil => Nil
17 | case head::tail => head::compress(tail.dropWhile(_ == head))
18 | }
19 |
20 | def main(args: Array[String]) {
21 | println(compress(List('a, 'a, 'a, 'a, 'b, 'c, 'c, 'a, 'a, 'd, 'e, 'e, 'e, 'e)))
22 | }
23 | }
24 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/S99/P09.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.S99
2 |
3 | /**
4 | * Created by jacksu on 15/12/2.
5 | */
6 | object P09 {
7 | def pack[A](xs: List[A]): List[Any] = xs match {
8 | case Nil => Nil
9 | case head :: tail => (head::tail.takeWhile(head == _)) :: pack(tail.dropWhile(_ == head))
10 | }
11 |
12 | def main(args: Array[String]) {
13 | println(pack(List('a, 'a, 'a, 'a, 'b, 'c, 'c, 'a, 'a, 'd, 'e, 'e, 'e, 'e)))
14 | }
15 | }
16 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/S99/P10.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.S99
2 |
3 | /**
4 | * Created by jacksu on 15/12/2.
5 | */
6 | object P10 {
7 | def encode[A](xs: List[A]): List[Any] = xs match {
8 | case Nil => Nil
9 | case head :: tail => (tail.takeWhile(_ == head).length+1, head) :: encode(tail.dropWhile(_ == head))
10 | }
11 |
12 | def main(args: Array[String]) {
13 | println(encode(List('a, 'a, 'a, 'a, 'b, 'c, 'c, 'a, 'a, 'd, 'e, 'e, 'e, 'e)))
14 | }
15 | }
16 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/S99/P11.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.S99
2 |
3 | /**
4 | * Created by jacksu on 15-12-6.
5 | */
6 | object P11 {
7 | def encodeModified[A](xs: List[A]): List[Any] = xs match {
8 | case Nil => Nil
9 | case head :: tail => {
10 | if (tail.takeWhile(_ == head).isEmpty)
11 | head :: encodeModified(tail.dropWhile(_ == head))
12 | else
13 | (tail.takeWhile(_ == head).length + 1, head) ::
14 | encodeModified(tail.dropWhile(_ == head))
15 | }
16 | }
17 |
18 | def main(args: Array[String]) {
19 | println(encodeModified(List('a, 'a, 'a, 'a, 'b, 'c, 'c, 'a, 'a, 'd, 'e, 'e, 'e, 'e)))
20 | }
21 | }
22 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/CaseClass.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | /**
4 | * Created by jacksu on 15/10/24.
5 | */
6 |
7 | abstract class Term
8 | case class Var(name: String) extends Term
9 | case class Fun(arg: String, body: Term) extends Term
10 | case class App(f: Term, v: Term) extends Term
11 | case class Dog(name: String, breed: String) // Doberman
12 |
13 | object CaseClass {
14 | def main(args: Array[String]) {
15 | def printTerm(term: Term) {
16 | term match {
17 | case Var(n) =>
18 | print(n)
19 | case Fun(x, b) =>
20 | print("^" + x + ".")
21 | printTerm(b)
22 | case App(f, v) =>
23 | Console.print("(")
24 | printTerm(f)
25 | print(" ")
26 | printTerm(v)
27 | print(")")
28 | }
29 | }
30 | def isIdentityFun(term: Term): Boolean = term match {
31 | case Fun(x, Var(y)) if x == y => true
32 | case _ => false
33 | }
34 | val id = Fun("x", Var("x"))
35 | val t = Fun("x", Fun("y", App(Var("x"), Var("y"))))
36 | printTerm(t)
37 | println
38 | println(isIdentityFun(id))
39 | println(isIdentityFun(t))
40 |
41 | val d1 = Dog("Scooby", "Doberman")
42 |
43 | val d2 = d1.copy(name = "Scooby Doo") // copy the case class but change the name in the copy
44 | println(d2.name)
45 |
46 | val d3=Dog.unapply(d2).get
47 | println(d3._1)
48 | }
49 | }
50 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/CovariantAndContravariant.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | /**
4 | * Created by jacksu on 15/11/19.
5 | */
6 | object CovariantAndContravariant {
7 | def main(args: Array[String]) {
8 |
9 | class Animal {println("Animal")}
10 | class Bird extends Animal {println("Bird")}
11 | //协变
12 | println("========协变==========")
13 | class Covariant[+T](t:T){}
14 | val cov = new Covariant[Bird](new Bird)
15 | val cov2:Covariant[Animal] = cov
16 | //逆变
17 | println("=========逆变==========")
18 | class Contravariant[-T](t: T) {
19 | }
20 | val c: Contravariant[Animal] = new Contravariant[Animal](new Animal)
21 | val c2: Contravariant[Bird] = c
22 | //上界
23 | println("===========上界=============")
24 | class UpperBoundAnimal{println("UpperBoundAnimal")}
25 | class UpperBoundBird extends UpperBoundAnimal{println("UpperBoundBird")}
26 | class UpperBoundBlueBird extends UpperBoundBird{println("UpperBoundBlueBird")}
27 | class UpperBound[-T](t:T){
28 | def use[S <: T](s:S){println("use")}
29 | }
30 | val upper=new UpperBound[UpperBoundAnimal](new UpperBoundAnimal)
31 | val upper2:UpperBound[UpperBoundBird]=upper
32 | upper2.use(new UpperBoundBird)
33 | upper.use(new UpperBoundBird)
34 | //upper2.use(new UpperBoundAnimal) //error
35 | upper.use(new UpperBoundAnimal)
36 | upper2.use(new UpperBoundBlueBird)
37 | upper.use(new UpperBoundBlueBird)
38 |
39 | //下界
40 | println("=========下界=============")
41 | class LowerBoundAnimal(){println("LowerBoundAnimal")}
42 | class LowerBoundBird extends LowerBoundAnimal(){println("LowerBoundBird")}
43 | class LowerBoundBlueBird extends LowerBoundBird(){println("LowerBoundBlueBird")}
44 | class LowerBound[+T](t:T){
45 | def use[S >: T](s:S){println("use")}
46 | }
47 | val lower=new LowerBound[LowerBoundBlueBird](new LowerBoundBlueBird)
48 | val lower2:LowerBound[LowerBoundBird] = lower
49 | lower2.use(new LowerBoundAnimal)
50 | lower2.use(new LowerBoundBird)
51 | //TODO 确定为什么下面这个是正确的
52 | lower2.use(new LowerBoundBlueBird)
53 | }
54 | }
55 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/EnumerationApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | /**
4 | * Created by jacksu on 15-12-4.
5 | */
6 | object EnumerationApp {
7 | object TrafficLightColor extends Enumeration{
8 | type TrafficLightColor = Value
9 | val Red = Value(0,"stop")
10 | val Yellow = Value(10)
11 | val Green = Value("go")
12 | }
13 |
14 | import TrafficLightColor._
15 |
16 | def doWhat(color:TrafficLightColor): Unit =color match{
17 | case Red => println("stop")
18 | }
19 | def main(args: Array[String]) {
20 | doWhat(TrafficLightColor(0))
21 | println(Green.id+","+Green)
22 | println(TrafficLightColor(0))
23 | println(TrafficLightColor(10))
24 | println(TrafficLightColor.withName("stop").id)
25 | }
26 | }
27 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/ExtractorApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | /**
4 | *
5 | * 提取器测试用例,模式匹配可以解构各种数据结构,包括 列表 、
6 | * 流 ,以及 样例类,归功于提取器。构造器从给定的参数列表创
7 | * 建一个对象, 而提取器却是从传递给它的对象中提取出构造该对象的参数
8 | * Created by jacksu on 15/11/24.
9 | */
10 |
11 | object ExtractorApp {
12 |
13 | case class User(firstName: String, lastName: String, score: Int)
14 |
15 | trait User1 {
16 | def name: String
17 |
18 | def score: Int
19 | }
20 |
21 | class FreeUser(
22 | val name: String,
23 | val score: Int,
24 | val upgradeProbability: Double
25 | ) extends User1
26 |
27 | class PremiumUser(
28 | val name: String,
29 | val score: Int
30 | ) extends User1
31 |
32 | object FreeUser {
33 | def unapply(user: FreeUser): Option[(String, Int, Double)] =
34 | Some((user.name, user.score, user.upgradeProbability))
35 | }
36 |
37 | object PremiumUser {
38 | def unapply(user: PremiumUser): Option[(String, Int)] =
39 | Some((user.name, user.score))
40 | }
41 |
42 | def main(args: Array[String]) {
43 | val user1 = User("jack", "su", 98)
44 | val user2 = User("jack", "su", 90)
45 | val xs = List(user1, user2)
46 | println(advance(xs))
47 |
48 | //多值提取
49 | val user: User1 = new FreeUser("Daniel", 3000, 0.7d)
50 | val str = user match {
51 | case FreeUser(name, _, p) =>
52 | if (p > 0.75) s"$name, what can we do for you today?"
53 | else s"Hello $name"
54 | case PremiumUser(name, _) =>
55 | s"Welcome back, dear $name"
56 | }
57 | println(str)
58 |
59 | //TODO 遇到bool提取添加
60 | }
61 |
62 | def advance(xs: List[User]) = xs match {
63 | case User(_, _, score1) :: User(_, _, score2) :: _ => score1 - score2
64 | case _ => 0
65 | }
66 | }
67 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/FileSysCommandApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | import java.net.URL
4 |
5 | import scala.io.Source
6 | import scala.sys.process.ProcessBuilder.URLBuilder
7 |
8 | /**
9 | * Created by jack on 15-12-5.
10 | */
11 |
12 | object FileSysCommandApp {
13 | def main(args: Array[String]) {
14 | val source = Source.fromURL("http://www.baidu.com","UTF-8")
15 | println(source.mkString)
16 | import sys.process._
17 | "ls -la ." !
18 | val result = "ls -l ." #| "grep README" #| "wc -l" !!
19 | //!!必须空一行
20 |
21 | println(result)
22 | "grep baidu" #< new URL("http://www.baidu.com") !
23 | }
24 |
25 | }
26 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/FutureAndPromise.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | import scala.concurrent.{Await, Future, Promise}
4 | import scala.concurrent.ExecutionContext.Implicits.global
5 | import scala.concurrent.duration._
6 | import scala.util.{Random, Failure, Success}
7 |
8 | /**
9 | * Created by jacksu on 15/11/28.
10 | */
11 |
12 | /**
13 | * 通过被推选的政客给他的投票者一个减税的承诺的例子说明
14 | */
15 |
16 | case class TaxCut(reduction: Int) {
17 | //println("reducing start now")
18 | //Thread.sleep(Random.nextInt(200))
19 | //println("reducing stop now")
20 | }
21 |
22 | object Government {
23 | val p = Promise[TaxCut]()
24 | val f = p.future
25 | //Promise 的完成和对返回的 Future 的处理发生在不同的线程
26 | def redeemCampaignPledge() = Future {
27 | println("Starting the new legislative period.")
28 | //do something
29 | Thread.sleep(Random.nextInt(200))
30 | p.success(TaxCut(20))
31 | //do something
32 | Thread.sleep(Random.nextInt(200))
33 | println("We reduced the taxes! You must reelect us!!!!1111")
34 | }
35 |
36 | }
37 |
38 | object FutureAndPromise {
39 |
40 | def main(args: Array[String]) {
41 | //实现承诺
42 | Government.redeemCampaignPledge()
43 | val taxCutF:Future[TaxCut] = Government.f
44 | println("Now that they're elected, let's see if they remember their promises...")
45 | taxCutF.onComplete {
46 | case Success(TaxCut(reduction)) =>
47 | println(s"A miracle! They really cut our taxes by $reduction percentage points!")
48 | case Failure(ex) =>
49 | println(s"They broke their promises! Again! Because of a ${ex.getMessage}")
50 | }
51 | Thread.sleep(1000)
52 | }
53 | }
54 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/FutureApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | import scala.concurrent.{TimeoutException, Await, Future}
4 | import scala.util.{Try, Failure, Success, Random}
5 | import scala.concurrent.duration._
6 | import scala.concurrent.ExecutionContext.Implicits.global
7 |
8 | /**
9 | * Created by jacksu on 15-11-27.
10 | */
11 |
12 | /**
13 | * 准备一杯卡布奇诺
14 | * 1 研磨所需的咖啡豆
15 | * 2 加热一些水
16 | * 3 用研磨好的咖啡豆和热水制做一杯咖啡
17 | * 4 打奶泡
18 | * 5 结合咖啡和奶泡做成卡布奇诺
19 | */
20 | object FutureApp {
21 | // Some type aliases, just for getting more meaningful method signatures:
22 | type CoffeeBeans = String
23 | type GroundCoffee = String
24 |
25 | case class Water(temperature: Int)
26 |
27 | type Milk = String
28 | type FrothedMilk = String
29 | type Espresso = String
30 | type Cappuccino = String
31 |
32 | // some exceptions for things that might go wrong in the individual steps
33 | // (we'll need some of them later, use the others when experimenting with the code):
34 | case class GrindingException(msg: String) extends Exception(msg)
35 |
36 | case class FrothingException(msg: String) extends Exception(msg)
37 |
38 | case class WaterBoilingException(msg: String) extends Exception(msg)
39 |
40 | case class BrewingException(msg: String) extends Exception(msg)
41 |
42 | def grind(beans: CoffeeBeans): Future[GroundCoffee] = Future {
43 | println("start grinding...")
44 | Thread.sleep(Random.nextInt(200))
45 | if (beans == "baked beans") throw GrindingException("are you joking?")
46 | println("finished grinding...")
47 | s"ground coffee of $beans"
48 | }
49 |
50 | def heatWater(water: Water): Future[Water] = Future {
51 | println("heating the water now")
52 | Thread.sleep(Random.nextInt(200))
53 | println("hot, it's hot!")
54 | water.copy(temperature = 85)
55 | }
56 |
57 | def frothMilk(milk: Milk): Future[FrothedMilk] = Future {
58 | println("milk frothing system engaged!")
59 | Thread.sleep(Random.nextInt(200))
60 | println("shutting down milk frothing system")
61 | s"frothed $milk"
62 | }
63 |
64 | def brew(coffee: GroundCoffee, heatedWater: Water): Future[Espresso] = Future {
65 | println("happy brewing :)")
66 | Thread.sleep(Random.nextInt(200))
67 | println("it's brewed!")
68 | "espresso"
69 | }
70 |
71 | def combine(espresso: Espresso, frothedMilk: FrothedMilk): Cappuccino = "cappuccino"
72 |
73 |
74 | def prepareCappuccinoSequentially(): Future[Cappuccino] = {
75 | for {
76 | ground <- grind("arabica beans")
77 | water <- heatWater(Water(25))
78 | foam <- frothMilk("milk")
79 | espresso <- brew(ground, water)
80 | } yield combine(espresso, foam)
81 | }
82 |
83 | def prepareCappuccino(): Future[Cappuccino] = {
84 | val groundCoffee = grind("arabica beans")
85 | val heatedWater = heatWater(Water(20))
86 | val frothedMilk = frothMilk("milk")
87 | for {
88 | ground <- groundCoffee
89 | water <- heatedWater
90 | foam <- frothedMilk
91 | espresso <- brew(ground, water)
92 | } yield combine(espresso, foam)
93 | }
94 |
95 |
96 | def main(args: Array[String]) {
97 |
98 | //回调函数
99 | grind("baked beans").onComplete {
100 | case Success(ground) => println(s"got my $ground")
101 | case Failure(ex) => println("This grinder needs a replacement, seriously!")
102 | }
103 | //Await.result(f,1 milli)
104 |
105 | //顺序,并且为了测试try,主线程等待结果的完成
106 | val result=Try(Await.result(prepareCappuccinoSequentially(), 1 second)) recover {
107 | case e:TimeoutException => "timeout error"
108 | }
109 | println(result.get)
110 | //并行
111 | Await.result(prepareCappuccino(), 1 second)
112 | //cap.collect()
113 | //Thread.sleep(Random.nextInt(2000))
114 |
115 | }
116 | }
117 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/HighOrderFunction.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | /**
4 | * Created by jacksu on 15/11/29.
5 | *
6 | *
7 | */
8 |
9 | case class Email(subject: String,
10 | text: String,
11 | sender: String,
12 | recipient: String)
13 |
14 | object Email {
15 | type EmailFilter = Email => Boolean
16 |
17 | def newMailsForUser(mails: Seq[Email], f: EmailFilter) = mails.filter(f)
18 |
19 | object EmailFilterFactory {
20 | //谓词函数
21 | def complement[A](predicate: A => Boolean) = (a: A) => !predicate(a)
22 |
23 | val sentByOneOf: Set[String] => EmailFilter =
24 | senders => email => senders.contains(email.sender)
25 | //val notSentByAnyOf: Set[String] => EmailFilter =
26 | // senders => email => !senders.contains(email.sender)
27 | //函数组合
28 | val notSentByAnyOf = sentByOneOf andThen (complement(_))
29 | //运行是有错误的
30 | //val notSentByAnyOf = (complement(_)) compose (sentByOneOf)
31 | type SizeChecker = Int => Boolean
32 | val sizeConstraint: SizeChecker => EmailFilter =
33 | f => email => f(email.text.size)
34 | val minimumSize: Int => EmailFilter =
35 | n => sizeConstraint(_ >= n)
36 | val maximumSize: Int => EmailFilter =
37 | n => sizeConstraint(_ <= n)
38 | }
39 |
40 | }
41 |
42 | object HighOrderFunction {
43 |
44 | def main(args: Array[String]) {
45 | val emailFilter: Email.EmailFilter = Email.EmailFilterFactory.notSentByAnyOf(Set("johndoe@example.com"))
46 | val mails = Email(
47 | subject = "It's me again, your stalker friend!",
48 | text = "Hello my friend! How are you?",
49 | sender = "johndoe@example.com",
50 | recipient = "me@example.com") :: Nil
51 | Email.newMailsForUser(mails, emailFilter) // returns an empty list
52 |
53 | }
54 | }
55 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/MapApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | /**
4 | * Created by jacksu on 15-12-7.
5 | */
6 |
7 | object MapApp {
8 | case class Key(name:String,oper:Long)
9 | case class A(key:Key,cType:Long,count:Long)
10 | val enumType=List(1,2)
11 |
12 | def decode(t:Long): List[Long] ={
13 | for(x<-enumType if((t&x) != 0)) yield x.toLong
14 | }
15 |
16 | def main(args: Array[String]) {
17 | val list=List(A(Key("1",2),1,1),A(Key("1",1),1,0),
18 | A(Key("1",2),2,0),A(Key("1",2),3,4))
19 | /**
20 | list.flatMap {
21 | case A(a, b, cType,c) => for (x <- decode(cType)) yield ((a,b,x),c)
22 | }.groupBy(_._1).mapValues(_.map(_._2).sum).map{
23 | case ((a,b,c),d) => A(a,b,c,d)
24 | }.foreach(println)
25 | **/
26 | list.foreach(println)
27 | println("==========================")
28 | list.flatMap {
29 | case A(a, cType,c) => for (x <- decode(cType)) yield ((a,x),c)
30 | }.groupBy(_._1).mapValues(_.map(_._2).sum).map{
31 | case ((a,c),d) => A(a,c,d)
32 | }.foreach(println)
33 | }
34 | }
35 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/PatternMatching.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | /**
4 | * Pattern Matching
5 | *
6 | */
7 |
8 | object PatternMatching {
9 | def matchTest(x: Int) = x match {
10 | case 1 => "One"
11 | case 2 => "Two"
12 | case _ => "Other"
13 | }
14 |
15 | def goldilocks(expr: Any) = expr match {
16 | case ("porridge", "Papa") => "Papa eating porridge"
17 | case ("porridge", _) => "Mama eating porridge"
18 | case ("porridge", "Baby") => "Baby eating porridge"
19 | case _ => "what?"
20 | }
21 |
22 | /**
23 | * 模式匹配代替表达式
24 | * @param expr
25 | * @return
26 | */
27 | def expression(expr: Any) = expr match {
28 | case ("porridge", bear) => bear + " said someone's been eating my porridge"
29 | case ("chair", bear) => bear + " said someone's been sitting in my chair"
30 | case ("bed", bear) => bear + " said someone's been sleeping in my bed"
31 | case _ => "what?"
32 | }
33 |
34 | def patternEquals(i: Int, j: Int) = j match {
35 | case `i` => true
36 | case _ => false
37 | }
38 |
39 | //模式匿名函数
40 | val transformFn:(String, Int)=>String = { case (w, _) => w }
41 |
42 | def main(args: Array[String]) {
43 |
44 | println(matchTest(3))
45 |
46 |
47 | val stuff = "blue"
48 | val myStuff = stuff match {
49 | case "red" => println("RED"); 1
50 | case "blue" => println("BLUE"); 2
51 | case "green" => println("GREEN"); 3
52 | case _ => println(stuff); 0 //case _ will trigger if all other cases fail.
53 | }
54 | assert(myStuff == 2)
55 |
56 | val complex = stuff match {
57 | case "red" => (255, 0, 0)
58 | case "green" => (0, 255, 0)
59 | case "blue" => (0, 0, 255)
60 | case _ => println(stuff); 0
61 | }
62 | assert(complex == (0,0,255))
63 |
64 | //模式匹配通配符
65 | assert(goldilocks(("porridge", "Mama")) == "Mama eating porridge")
66 |
67 | //模式匹配代替表达式
68 | println(expression( ("chair", "jack")))
69 |
70 | println(patternEquals(3,3))
71 |
72 | }
73 | }
74 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/TestApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | /**
4 | * 只是为我平时做一些测试使用
5 | * Created by xbsu on 15/12/25.
6 | */
7 | object TestApp {
8 | def getClickPoint(clickpoint: String) = {
9 | clickpoint.stripPrefix("(").stripSuffix(")").split(",")
10 | }
11 |
12 | def main(args: Array[String]) {
13 | getClickPoint("(2323,23)").foreach(println)
14 | }
15 | }
16 |
--------------------------------------------------------------------------------
/scala-demo/src/main/scala/cn/thinkjoy/utils4s/scala/TraitApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | import java.util.Date
4 |
5 | /**
6 | * Created by jack on 15-12-22.
7 | */
8 |
9 | trait Logger {
10 | def log(msg: String) {}
11 | }
12 |
13 | trait ConsoleLogger extends Logger {
14 | override def log(msg: String): Unit = {
15 | println(msg)
16 | }
17 | }
18 |
19 | trait TimeLogger extends Logger {
20 | override def log(msg: String) = {
21 | super.log(new Date() + "" + msg)
22 | }
23 | }
24 |
25 | trait ShortLogger extends Logger{
26 | //抽象字段
27 | val maxLength:Int
28 | override def log(msg:String): Unit ={
29 | if (msg.length balance) log("Insufficient funds")
40 | }
41 | }
42 |
43 | object TraitApp {
44 | def main(args: Array[String]) {
45 | //对象混入trait
46 | val account = new Account(1) with ConsoleLogger
47 | account.withdraw(2)
48 |
49 | //super.log调用的是下一个trait,具体是哪一个,要根据trait添加的顺序来决定
50 | val acc1= new Account(1) with ConsoleLogger with TimeLogger with ShortLogger{
51 | val maxLength=12
52 | }
53 | acc1.withdraw(2)
54 | val acc2=new Account(1) with ConsoleLogger with ShortLogger with TimeLogger{
55 | val maxLength=3
56 | }
57 | acc2.withdraw(2)
58 | }
59 | }
60 |
--------------------------------------------------------------------------------
/spark-analytics-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.spark.analytics
11 | spark-analytics
12 | 2008
13 |
14 | 1.4.0
15 |
16 |
17 |
18 | org.apache.hadoop
19 | hadoop-common
20 | 2.6.0
21 | compile
22 |
23 |
24 | org.apache.spark
25 | spark-core_${soft.scala.version}
26 | ${spark.version}
27 | compile
28 |
29 |
30 |
31 |
--------------------------------------------------------------------------------
/spark-analytics-demo/src/main/scala/cn/thinkjoy/utils4s/spark/analytics/DataCleaningApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.analytics
2 |
3 | import org.apache.spark.{SparkContext, SparkConf}
4 | import StatsWithMissing._
5 |
6 | /**
7 | * Created by jacksu on 16/1/27.
8 | */
9 | case class MatchData(id1: Int, id2: Int,
10 | scores: Array[Double], matched: Boolean)
11 |
12 | case class Scored(md: MatchData, score: Double)
13 |
14 | object DataCleaningApp {
15 | def main(args: Array[String]) {
16 |
17 | val conf = new SparkConf().setAppName("Dataleaning").setMaster("local")
18 | val sc = new SparkContext(conf)
19 | val noheader = sc.textFile("spark-analytics-demo/src/main/resources/block_1.csv").filter(!isHeader(_))
20 |
21 | val parsed = noheader.map(parse)
22 | //为了验证文件加载是否正确
23 | //println(parsed.first())
24 | //如果数据需要多次处理,就使用cache
25 | parsed.cache()
26 |
27 | val matchCounts = parsed.map(md => md.matched).countByValue()
28 | //Map不可以排序,只能转化为Seq
29 | val matchCountsSeq = matchCounts.toSeq
30 | matchCountsSeq.sortBy(_._2).reverse.foreach(println)
31 |
32 | val stats = (0 until 9).map(i => {
33 | parsed.map(_.scores(i)).filter(!_.isNaN).stats()
34 | })
35 | stats.foreach(println)
36 |
37 | //测试NAStatCounter
38 | val nas1 = NAStatCounter(10.0)
39 | nas1.add(2.1)
40 | val nas2 = NAStatCounter(Double.NaN)
41 | nas1.merge(nas2)
42 | println(nas1.toString)
43 | val nasRDD = parsed.map(md => {
44 | md.scores.map(d => NAStatCounter(d))
45 | })
46 | val reduced = nasRDD.reduce((n1, n2) => {
47 | n1.zip(n2).map { case (a, b) => a.merge(b) }
48 | })
49 | reduced.foreach(println)
50 |
51 | statsWithMissing(parsed.filter(_.matched).map(_.scores)).foreach(println)
52 |
53 | }
54 |
55 | /**
56 | * 判断是不是头
57 | * @param line
58 | * @return
59 | */
60 | def isHeader(line: String) = line.contains("id_1")
61 |
62 | /**
63 | * 字符串转化为double
64 | * @param s
65 | * @return
66 | */
67 | def toDouble(s: String) = {
68 | if ("?".equals(s)) Double.NaN else s.toDouble
69 | }
70 |
71 | /**
72 | * 解析每一行,用case class表示
73 | * @param line
74 | * @return
75 | */
76 | def parse(line: String) = {
77 | val pieces = line.split(',')
78 | val id1 = pieces(0).toInt
79 | val id2 = pieces(1).toInt
80 | val scores = pieces.slice(2, 11).map(toDouble _)
81 | val matched = pieces(11).toBoolean
82 | MatchData(id1, id2, scores, matched)
83 | }
84 | }
85 |
--------------------------------------------------------------------------------
/spark-analytics-demo/src/main/scala/cn/thinkjoy/utils4s/spark/analytics/NAStatCounter.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.analytics
2 |
3 | import org.apache.spark.util.StatCounter
4 |
5 | /**
6 | * Created by jack on 16/1/31.
7 | */
8 |
9 | /**
10 | * 主要统计记录数据缺失情况下的均值、方差、最小值、最大值
11 | */
12 | class NAStatCounter extends Serializable {
13 | val stats: StatCounter = new StatCounter()
14 | var missing: Long = 0
15 |
16 | def add(x: Double): NAStatCounter = {
17 | if (x.isNaN) {
18 | missing += 1
19 | } else {
20 | stats.merge(x)
21 | }
22 | this
23 | }
24 |
25 | def merge(other: NAStatCounter): NAStatCounter = {
26 | stats.merge(other.stats)
27 | missing += other.missing
28 | this
29 | }
30 |
31 | override def toString: String = {
32 | "stats: " + stats.toString + " NaN: " + missing
33 | }
34 | }
35 |
36 | object NAStatCounter {
37 | def apply(x: Double) = (new NAStatCounter).add(x)
38 | }
39 |
--------------------------------------------------------------------------------
/spark-analytics-demo/src/main/scala/cn/thinkjoy/utils4s/spark/analytics/StatsWithMissing.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.analytics
2 |
3 | import org.apache.spark.rdd.RDD
4 |
5 | /**
6 | * Created by jack on 16/1/31.
7 | */
8 | package object StatsWithMissing {
9 | /**
10 | * Double数组数据统计
11 | * @param rdd
12 | * @return
13 | */
14 | def statsWithMissing(rdd: RDD[Array[Double]]): Array[NAStatCounter] = {
15 | val nastats = rdd.mapPartitions((iter: Iterator[Array[Double]]) => {
16 | val nas: Array[NAStatCounter] = iter.next().map(d => NAStatCounter(d))
17 |
18 | iter.foreach(arr => {
19 | nas.zip(arr).foreach { case (n, d) => n.add(d) }
20 | })
21 | Iterator(nas)
22 | })
23 | nastats.reduce((n1, n2) => {
24 | n1.zip(n2).map { case (a, b) => a.merge(b) }
25 | })
26 | }
27 | }
28 |
29 |
--------------------------------------------------------------------------------
/spark-core-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.spark.core
11 | spark-core-demo
12 | 2008
13 |
14 | 1.4.0
15 |
16 |
17 |
18 | org.apache.hadoop
19 | hadoop-common
20 | 2.6.0
21 | compile
22 |
23 |
24 | org.apache.spark
25 | spark-core_${soft.scala.version}
26 | ${spark.version}
27 | compile
28 |
29 |
30 |
31 |
--------------------------------------------------------------------------------
/spark-core-demo/src/main/scala/cn/thinkjoy/utils4s/spark/core/GroupByKeyAndReduceByKeyApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.core
2 |
3 | import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
4 |
5 |
6 | object GroupByKeyAndReduceByKeyApp {
7 | def main(args: Array[String]) {
8 | val conf = new SparkConf().setAppName("GroupAndReduce").setMaster("local")
9 | val sc = new SparkContext(conf)
10 | val words = Array("one", "two", "two", "three", "three", "three")
11 | val wordsRDD = sc.parallelize(words)
12 |
13 | val wordsCountWithReduce = wordsRDD.
14 | map(word => (word, 1)).
15 | reduceByKey(_ + _).
16 | collect().
17 | foreach(println)
18 |
19 | val wordsCountWithGroup = wordsRDD.
20 | map(word => (word, 1)).
21 | groupByKey().
22 | map(w => (w._1, w._2.sum)).
23 | collect().
24 | foreach(println)
25 |
26 | //使用combineByKey计算wordcount
27 | wordsRDD.map(word=>(word,1)).combineByKey(
28 | (v: Int) => v,
29 | (c: Int, v: Int) => c+v,
30 | (c1: Int, c2: Int) => c1 + c2
31 | ).collect.foreach(println)
32 |
33 | //使用foldByKey计算wordcount
34 | println("=======foldByKey=========")
35 | wordsRDD.map(word=>(word,1)).foldByKey(0)(_+_).foreach(println)
36 |
37 | //使用aggregateByKey计算wordcount
38 | println("=======aggregateByKey============")
39 | wordsRDD.map(word=>(word,1)).aggregateByKey(0)((u:Int,v)=>u+v,_+_).foreach(println)
40 |
41 | var rdd1 = sc.makeRDD(Array(("A", 1), ("A", 2), ("B", 1), ("B", 2), ("B", 3), ("B", 4), ("C", 1)))
42 | rdd1.combineByKey(
43 | (v: Int) => v + "_",
44 | (c: String, v: Int) => c + "@" + v,
45 | (c1: String, c2: String) => c1 + "$" + c2,
46 | new HashPartitioner(2),
47 | mapSideCombine = false
48 | ).collect.foreach(println)
49 | }
50 | }
51 |
--------------------------------------------------------------------------------
/spark-dataframe-demo/README.md:
--------------------------------------------------------------------------------
1 | #DataFrame
2 |
3 | 1 通过HDFS文件建立临时表的通用方法
4 |
5 | 2 DataFrame UDF的测试
--------------------------------------------------------------------------------
/spark-dataframe-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.spark.dataframe
11 | spark-dataframe-demo
12 | 2008
13 |
14 |
15 | 1.6.0
16 |
17 |
18 |
19 | org.apache.hadoop
20 | hadoop-common
21 | 2.6.0
22 | compile
23 |
24 |
25 | org.apache.spark
26 | spark-core_${soft.scala.version}
27 | ${spark.version}
28 | compile
29 |
30 |
31 | org.apache.spark
32 | spark-sql_${soft.scala.version}
33 | ${spark.version}
34 | compile
35 |
36 |
37 | org.apache.spark
38 | spark-hive_${soft.scala.version}
39 | ${spark.version}
40 | compile
41 |
42 |
43 | org.apache.spark
44 | spark-core_${soft.scala.version}
45 |
46 |
47 |
48 |
49 | org.json4s
50 | json4s-jackson_${soft.scala.version}
51 | 3.3.0
52 |
53 |
54 |
55 |
56 |
57 | org.scalariform
58 | scalariform-maven-plugin
59 | 0.1.4
60 |
61 |
62 | process-sources
63 |
64 | format
65 |
66 |
67 | true
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
--------------------------------------------------------------------------------
/spark-dataframe-demo/src/main/resources/a.json:
--------------------------------------------------------------------------------
1 | {"name":{"last":"jack1"}}
2 | {"age":11}
3 | {"age":10,"name":{"last":"jack","first":"su"}}
--------------------------------------------------------------------------------
/spark-dataframe-demo/src/main/resources/b.txt:
--------------------------------------------------------------------------------
1 | 1 test1
2 | 2 test2
3 | 3 testtesttest
--------------------------------------------------------------------------------
/spark-dataframe-demo/src/main/resources/hive-site.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 | hive.metastore.uris
7 | thrift://vm10-136-3-214.ksc.com:9083
8 |
9 |
10 | hive.metastore.client.socket.timeout
11 | 300
12 |
13 |
14 | hive.metastore.warehouse.dir
15 | /user/hive/warehouse
16 |
17 |
18 | hive.warehouse.subdir.inherit.perms
19 | true
20 |
21 |
22 | hive.enable.spark.execution.engine
23 | false
24 |
25 |
26 | hive.conf.restricted.list
27 | hive.enable.spark.execution.engine
28 |
29 |
30 | mapred.reduce.tasks
31 | -1
32 |
33 |
34 | hive.exec.reducers.bytes.per.reducer
35 | 67108864
36 |
37 |
38 | hive.exec.copyfile.maxsize
39 | 33554432
40 |
41 |
42 | hive.exec.reducers.max
43 | 1099
44 |
45 |
46 | hive.metastore.execute.setugi
47 | true
48 |
49 |
50 | hive.support.concurrency
51 | true
52 |
53 |
54 | hive.zookeeper.quorum
55 | vm10-136-3-214.ksc.com
56 |
57 |
58 | hive.zookeeper.client.port
59 | 2181
60 |
61 |
62 | hbase.zookeeper.quorum
63 | vm10-136-3-214.ksc.com
64 |
65 |
66 | hbase.zookeeper.property.clientPort
67 | 2181
68 |
69 |
70 | hive.zookeeper.namespace
71 | hive_zookeeper_namespace_hive
72 |
73 |
74 | hive.cluster.delegation.token.store.class
75 | org.apache.hadoop.hive.thrift.MemoryTokenStore
76 |
77 |
78 | hive.server2.enable.doAs
79 | true
80 |
81 |
82 | hive.server2.use.SSL
83 | false
84 |
85 |
86 |
--------------------------------------------------------------------------------
/spark-dataframe-demo/src/main/scala/cn/thinkjoy/utils4s/spark/dataframe/RollupApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.dataframe
2 |
3 | import java.sql.Timestamp
4 | import java.sql.Date
5 |
6 | import org.apache.spark.{SparkConf, SparkContext}
7 | import org.apache.spark.sql.hive.HiveContext
8 | import org.apache.spark.sql._
9 |
10 | /**
11 | * 参考:http://zhangyi.farbox.com/post/kai-yuan-kuang-jia/rollup-in-spark
12 | * 数据pivot,比如统计商品四个季度的销售量,可以参考:https://databricks.com/blog/2016/02/09/reshaping-data-with-pivot-in-spark.html
13 | * Created by xbsu on 16/1/18.
14 | */
15 | object RollupApp {
16 |
17 | implicit class StringFuncs(str: String) {
18 | def toTimestamp = new Timestamp(Date.valueOf(str).getTime)
19 | }
20 |
21 | def main(args: Array[String]) {
22 | @transient
23 | val conf = new SparkConf().setAppName("test").setMaster("local")
24 |
25 | val sc = new SparkContext(conf)
26 |
27 | val sqlContext = new SQLContext(sc)
28 | import sqlContext.implicits._
29 | val sales = Seq(
30 | (1, "Widget Co", 1000.00, 0.00, "广东省", "深圳市", "2014-02-01".toTimestamp),
31 | (2, "Acme Widgets", 1000.00, 500.00, "四川省", "成都市", "2014-02-11".toTimestamp),
32 | (3, "Acme Widgets", 1000.00, 500.00, "四川省", "绵阳市", "2014-02-12".toTimestamp),
33 | (4, "Acme Widgets", 1000.00, 500.00, "四川省", "成都市", "2014-02-13".toTimestamp),
34 | (5, "Widget Co", 1000.00, 0.00, "广东省", "广州市", "2015-01-01".toTimestamp),
35 | (6, "Acme Widgets", 1000.00, 500.00, "四川省", "泸州市", "2015-01-11".toTimestamp),
36 | (7, "Widgetry", 1000.00, 200.00, "四川省", "成都市", "2015-02-11".toTimestamp),
37 | (8, "Widgets R Us", 3000.00, 0.0, "四川省", "绵阳市", "2015-02-19".toTimestamp),
38 | (9, "Widgets R Us", 2000.00, 0.0, "广东省", "深圳市", "2015-02-20".toTimestamp),
39 | (10, "Ye Olde Widgete", 3000.00, 0.0, "广东省", "深圳市", "2015-02-28".toTimestamp),
40 | (11, "Ye Olde Widgete", 3000.00, 0.0, "广东省", "广州市", "2015-02-28".toTimestamp))
41 |
42 | val saleDF = sqlContext.sparkContext.parallelize(sales, 4).toDF("id", "name", "sales", "discount", "province", "city", "saleDate")
43 | saleDF.registerTempTable("sales")
44 |
45 | val dataFrame = sqlContext.sql("select province,city,sales from sales")
46 | dataFrame.show
47 |
48 | val resultDF = dataFrame.rollup($"province", $"city").agg(Map("sales" -> "sum"))
49 | resultDF.show
50 |
51 | //可以通过groupBy实现rollup
52 | dataFrame.groupBy("province", "city").agg(Map("sales" -> "sum")).show()
53 | }
54 | }
55 |
--------------------------------------------------------------------------------
/spark-dataframe-demo/src/main/scala/cn/thinkjoy/utils4s/spark/dataframe/SparkDataFrameApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.dataframe
2 |
3 | import org.apache.spark.rdd.RDD
4 | import org.apache.spark.sql.Row
5 | import org.apache.spark.sql.hive.HiveContext
6 | import org.apache.spark.sql.types._
7 | import org.apache.spark.{ SparkContext, SparkConf }
8 |
9 | /**
10 | * Created by jack on 15-12-10.
11 | */
12 |
13 | object SparkDataFrameApp extends SparkSQLSupport("DataFrameApp") {
14 |
15 | def main(args: Array[String]) {
16 | //txt通用创建表测试
17 | val path = "spark-dataframe-demo/src/main/resources/b.txt"
18 | createTableFromStr(path, "people", "age name", f)
19 | sqlContext.sql("SELECT age,name FROM people").show()
20 |
21 | //json测试
22 | createTableFromJson("spark-dataframe-demo/src/main/resources/a.json",
23 | "test")
24 | sqlContext.sql("SELECT age,name.first FROM test").show()
25 |
26 | //parquet测试
27 | val test = sqlContext.read.json("spark-dataframe-demo/src/main/resources/a.json");
28 | test.write.parquet("spark-dataframe-demo/src/main/resources/parquet")
29 | val parquet = sqlContext.read.parquet("spark-dataframe-demo/src/main/resources/parquet")
30 | parquet.registerTempTable("parquet")
31 | sqlContext.sql("select * from parquet").collect().foreach(println)
32 |
33 | }
34 |
35 | /**
36 | * 对输入的内容转化为Row
37 | * @param line
38 | * @return
39 | */
40 | def f(line: RDD[String]): RDD[Row] = {
41 | line.map(_.split(" ")).map(array ⇒ Row(array(0), array(1)))
42 | }
43 |
44 | }
45 |
--------------------------------------------------------------------------------
/spark-dataframe-demo/src/main/scala/cn/thinkjoy/utils4s/spark/dataframe/SparkDataFrameUDFApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.dataframe
2 |
3 | import java.sql.{ Date, Timestamp }
4 | import java.util.Calendar
5 |
6 | import cn.thinkjoy.utils4s.spark.dataframe.SparkDataFrameApp._
7 | import org.apache.spark.SparkConf
8 | import org.apache.spark.rdd.RDD
9 | import org.apache.spark.sql.Row
10 | import org.apache.spark.sql.expressions.{ MutableAggregationBuffer, UserDefinedAggregateFunction }
11 | import org.apache.spark.sql.functions._
12 | import org.apache.spark.sql.types._
13 |
14 | /**
15 | * http://zhangyi.farbox.com/post/kai-yuan-kuang-jia/udf-and-udaf-in-spark
16 | * Created by xbsu on 16/1/18.
17 | */
18 | object SparkDataFrameUDFApp extends SparkSQLSupport("UDFApp") {
19 | def main(args: Array[String]) {
20 |
21 | val path = "spark-dataframe-demo/src/main/resources/b.txt"
22 | val df = createTableFromStr(path, "people", "age name", f)
23 | //使用udf 1.5.2只能使用sqlContext
24 | //TODO 查找sqlCOntext和hiveContext差别
25 |
26 | /**
27 | * UDF
28 | */
29 |
30 | //更详细解释:http://zhangyi.farbox.com/post/kai-yuan-kuang-jia/udf-and-udaf-in-spark
31 | sqlContext.udf.register("getSourceType", getSourceType(_: String))
32 | sqlContext.sql("SELECT base64(age),getSourceType(name) FROM people").show()
33 | //注册udf函数
34 | sqlContext.udf.register("longLength", lengthLongerThan _)
35 |
36 | sqlContext.sql("select * from people where longLength(name,10)").show()
37 |
38 | //若使用DataFrame的API,则可以以字符串的形式将UDF传入
39 | df.filter("longLength(name,10)").show()
40 |
41 | //DataFrame的API也可以接收Column对象,
42 | //可以用$符号来包裹一个字符串表示一个Column。
43 | //$是定义在SQLContext对象implicits中的一个隐式转换。
44 | //此时,UDF的定义也不相同,不能直接定义Scala函数,
45 | //而是要用定义在org.apache.spark.sql.functions中的udf方法来接收一个函数。
46 | //这种方式无需register
47 | import org.apache.spark.sql.functions._
48 | val longLength = udf((bookTitle: String, length: Int) ⇒ bookTitle.length > length)
49 | import sqlContext.implicits._
50 | //用$符号来包裹一个字符串表示一个Column
51 | df.filter(longLength($"name", lit(10))).show()
52 |
53 | /**
54 | * UDAF(User Defined Aggregate Function)
55 | * 例子:当我要对销量执行年度同比计算,就需要对当年和上一年的销量分别求和,
56 | * 然后再利用同比公式进行计算
57 | */
58 |
59 | val sales = Seq(
60 | (1, "Widget Co", 1000.00, 0.00, "AZ", "2014-01-01"),
61 | (2, "Acme Widgets", 2000.00, 500.00, "CA", "2014-02-01"),
62 | (3, "Widgetry", 1000.00, 200.00, "CA", "2015-01-11"),
63 | (4, "Widgets R Us", 2000.00, 0.0, "CA", "2015-02-19"),
64 | (5, "Ye Olde Widgete", 3000.00, 0.0, "MA", "2015-02-28"))
65 |
66 | val salesRows = sc.parallelize(sales, 4)
67 | val salesDF = salesRows.toDF("id", "name", "sales", "discount", "state", "saleDate")
68 | salesDF.registerTempTable("sales")
69 | val current = DateRange(Timestamp.valueOf("2015-01-01 00:00:00"), Timestamp.valueOf("2015-12-31 00:00:00"))
70 | val yearOnYear = new YearOnYearUDAF(current)
71 |
72 | sqlContext.udf.register("yearOnYear", yearOnYear)
73 | val dataFrame = sqlContext.sql("select yearOnYear(sales, saleDate) as yearOnYear from sales")
74 | dataFrame.show()
75 | }
76 |
77 | def lengthLongerThan(name: String, length: Int): Boolean = {
78 | name.length > length
79 | }
80 |
81 | /**
82 | * UDF验证
83 | * @param remark
84 | * @return
85 | */
86 | def getSourceType(remark: String): Int = {
87 | val typePattern = "yzt_web|iphone|IPHONE|ANDROID".r
88 | val logType = typePattern.findFirstIn(remark).getOrElse("")
89 |
90 | logType match {
91 | case "yzt_web" ⇒ 0
92 | case "ANDROID" ⇒ 1
93 | case "IPHONE" ⇒ 2
94 | case "iphone" ⇒ 2
95 | case _ ⇒ 404
96 | }
97 | }
98 |
99 | /**
100 | * 对输入的内容转化为Row
101 | * @param line
102 | * @return
103 | */
104 | def f(line: RDD[String]): RDD[Row] = {
105 | line.map(_.split(" ")).map(array ⇒ Row(array(0), array(1)))
106 | }
107 | }
108 |
109 | case class DateRange(startDate: Timestamp, endDate: Timestamp) {
110 | def in(targetDate: Date): Boolean = {
111 | targetDate.before(endDate) && targetDate.after(startDate)
112 | }
113 | }
114 |
115 | class YearOnYearUDAF(current: DateRange) extends UserDefinedAggregateFunction {
116 | //处理的列
117 | override def inputSchema: StructType = {
118 | StructType(StructField("metric", DoubleType) :: StructField("time", DateType) :: Nil)
119 | }
120 |
121 | //保存处理的中间结果
122 | override def bufferSchema: StructType = {
123 | StructType(StructField("sumOfCurrent", DoubleType) :: StructField("sumOfPrevious", DoubleType) :: Nil)
124 | }
125 |
126 | //update函数的第二个参数input: Row对应的并非DataFrame的行,而是被inputSchema投影了的行。
127 | //以本例而言,每一个input就应该只有两个Field的值。倘若我们在调用这个UDAF函数时,
128 | //分别传入了销量和销售日期两个列的话,则input(0)代表的就是销量,input(1)代表的就是销售日期。
129 | override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
130 | if (current.in(input.getAs[Date](1))) {
131 | buffer(0) = buffer.getAs[Double](0) + input.getAs[Double](0)
132 | }
133 | val previous = DateRange(subtractOneYear(current.startDate), subtractOneYear(current.endDate))
134 | if (previous.in(input.getAs[Date](1))) {
135 | buffer(1) = buffer.getAs[Double](1) + input.getAs[Double](0)
136 | }
137 | }
138 |
139 | private def subtractOneYear(targetDate: Timestamp): Timestamp = {
140 | val calendar = Calendar.getInstance()
141 | calendar.setTimeInMillis(targetDate.getTime)
142 | calendar.add(Calendar.YEAR, -1)
143 |
144 | val time = new Timestamp(calendar.getTimeInMillis)
145 | println(time.toString)
146 | time
147 | }
148 |
149 | //merge函数负责合并两个聚合运算的buffer,再将其存储到MutableAggregationBuffer中
150 | override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
151 | buffer1(0) = buffer1.getAs[Double](0) + buffer2.getAs[Double](0)
152 | buffer1(1) = buffer1.getAs[Double](1) + buffer2.getAs[Double](1)
153 | }
154 |
155 | //initialize就是对聚合运算中间结果的初始化,在我们这个例子中,两个求和的中间值都被初始化为0d:
156 | override def initialize(buffer: MutableAggregationBuffer): Unit = {
157 | buffer.update(0, 0d)
158 | buffer.update(1, 0d)
159 | }
160 |
161 | //deterministic是一个布尔值,用以标记针对给定的一组输入,UDAF是否总是生成相同的结果
162 | override def deterministic: Boolean = {
163 | true
164 | }
165 |
166 | //最终计算结果
167 | override def evaluate(buffer: Row): Any = {
168 | if (buffer.getDouble(1) == 0.0)
169 | 0.0
170 | else
171 | (buffer.getDouble(0) - buffer.getDouble(1)) / buffer.getDouble(1) * 100
172 | }
173 |
174 | //最终返回的类型
175 | override def dataType: DataType = DoubleType
176 | }
--------------------------------------------------------------------------------
/spark-dataframe-demo/src/main/scala/cn/thinkjoy/utils4s/spark/dataframe/SparkSQLSupport.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.dataframe
2 |
3 | import cn.thinkjoy.utils4s.spark.dataframe.SparkDataFrameApp._
4 | import org.apache.spark.rdd.RDD
5 | import org.apache.spark.sql.types.{ StringType, StructField, StructType }
6 | import org.apache.spark.sql.{ DataFrame, Row, SQLContext }
7 | import org.apache.spark.sql.hive.HiveContext
8 | import org.apache.spark.{ SparkContext, SparkConf }
9 |
10 | /**
11 | * Created by xbsu on 16/1/18.
12 | */
13 |
14 | //TODO 1.5.2 初步猜想hive依赖的环境是1.4.0导致的,后面需要验证,
15 | //HiveContext继承SQLContext,现在需要测试1.5.2新增支持的函数
16 |
17 | class SparkSQLSupport(val appName: String, val master: String = "local") {
18 | @transient
19 | val conf = new SparkConf().setAppName(appName).setMaster(master)
20 | @transient
21 | val sc = new SparkContext(conf)
22 |
23 | val hiveContext = new HiveContext(sc)
24 |
25 | val sqlContext = new SQLContext(sc)
26 |
27 | /**
28 | * 通过hdfs文件建表
29 | * @param path 文件所在路径
30 | * @param table 注册表名
31 | * @param schemaString 表的schema
32 | * @param f 内容转化函数
33 | */
34 | def createTableFromStr(
35 | path: String,
36 | table: String,
37 | schemaString: String,
38 | f: RDD[String] ⇒ RDD[Row]): DataFrame = {
39 |
40 | val people = sc.textFile(path)
41 | val schema =
42 | StructType(
43 | schemaString.split(" ").map(fieldName ⇒ StructField(fieldName, StringType, true)))
44 |
45 | // Convert records of the RDD (people) to Rows.
46 | //val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
47 | val rowRDD = f(people)
48 |
49 | // Apply the schema to the RDD.
50 | val peopleSchemaRDD = sqlContext.createDataFrame(rowRDD, schema)
51 |
52 | // Register the SchemaRDD as a table.
53 | peopleSchemaRDD.registerTempTable(table)
54 |
55 | peopleSchemaRDD
56 | }
57 |
58 | /**
59 | * 经过测试不需要指定schema,默认会补全字段
60 | * @param path
61 | * @param table
62 | */
63 | def createTableFromJson(
64 | path: String,
65 | table: String): Unit = {
66 |
67 | val peopleSchemaRDD = sqlContext.read.json(path)
68 |
69 | // Register the SchemaRDD as a table.
70 | peopleSchemaRDD.registerTempTable(table)
71 | }
72 |
73 | }
--------------------------------------------------------------------------------
/spark-dataframe-demo/src/main/scala/cn/thinkjoy/utils4s/spark/dataframe/UdfTestApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.dataframe
2 |
3 | import java.text.SimpleDateFormat
4 |
5 | import cn.thinkjoy.utils4s.spark.dataframe.udf.AccessLogParser
6 |
7 | /**
8 | * Created by xbsu on 16/2/5.
9 | */
10 | object UdfTestApp {
11 | def main(args: Array[String]) {
12 | val logAnalytics = new LogAnalytics
13 | println(logAnalytics.ip2City("120.132.74.17"))
14 |
15 | val rawRecord = """89.166.165.223 - - [25/Oct/2015:10:49:00 +0800] "GET /foo HTTP/1.1" 404 970 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.0.11) Firefox/3.0.11""""
16 |
17 | val parser = AccessLogParser
18 | val accessLogRecord = parser.parse(rawRecord) // an AccessLogRecord instance
19 | val logRecord = accessLogRecord.getOrElse(parser.nullObjectAccessLogRecord)
20 | println(s"******$logRecord******")
21 | val dateTime = logRecord.dateTime
22 | println(s"******$dateTime*****")
23 | val dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
24 | println(dateFormat.format(parser.parseDateField(dateTime).get))
25 |
26 | val agent = logRecord.userAgent
27 | println(s"agent:$agent")
28 | }
29 | }
30 |
--------------------------------------------------------------------------------
/spark-dataframe-demo/src/main/scala/cn/thinkjoy/utils4s/spark/dataframe/udf/AccessLogParser.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.dataframe.udf
2 |
3 | import java.text.SimpleDateFormat
4 | import java.util.Locale
5 | import scala.util.control.Exception._
6 | import java.util.regex.{ Matcher, Pattern }
7 |
8 | /**
9 | * Created by xbsu on 16/2/5.
10 | */
11 |
12 | class AccessLogParser extends Serializable {
13 | private val ddd = "\\d{1,3}" // at least 1 but not more than 3 times (possessive)
14 | private val ip = s"($ddd\\.$ddd\\.$ddd\\.$ddd)?" // like `123.456.7.89`
15 | private val client = "(\\S+)" // '\S' is 'non-whitespace character'
16 | private val user = "(\\S+)"
17 | private val dateTime = "(\\[.+?\\])" // like `[21/Jul/2009:02:48:13 -0700]`
18 | private val request = "\"(.*?)\"" // any number of any character, reluctant
19 | private val status = "(\\d{3})"
20 | private val bytes = "(\\S+)" // this can be a "-"
21 | private val referer = "\"(.*?)\""
22 | private val agent = "\"(.*?)\""
23 | private val regex = s"$ip $client $user $dateTime $request $status $bytes $referer $agent"
24 | private val p = Pattern.compile(regex)
25 |
26 | /**
27 | * note: group(0) is the entire record that was matched (skip it)
28 | * @param record Assumed to be an Apache access log combined record.
29 | * @return An AccessLogRecord instance wrapped in an Option.
30 | */
31 | def parseRecord(record: String): Option[AccessLogRecord] = {
32 | val matcher = p.matcher(record)
33 | if (matcher.find) {
34 | Some(buildAccessLogRecord(matcher))
35 | } else {
36 | None
37 | }
38 | }
39 |
40 | /**
41 | * Same as parseRecord, but returns a "Null Object" version of an AccessLogRecord
42 | * rather than an Option.
43 | *
44 | * @param record Assumed to be an Apache access log combined record.
45 | * @return An AccessLogRecord instance. This will be a "Null Object" version of an
46 | * AccessLogRecord if the parsing process fails. All fields in the Null Object
47 | * will be empty strings.
48 | */
49 | def parseRecordReturningNullObjectOnFailure(record: String): AccessLogRecord = {
50 | val matcher = p.matcher(record)
51 | if (matcher.find) {
52 | buildAccessLogRecord(matcher)
53 | } else {
54 | AccessLogParser.nullObjectAccessLogRecord
55 | }
56 | }
57 |
58 | private def buildAccessLogRecord(matcher: Matcher) = {
59 | AccessLogRecord(
60 | matcher.group(1),
61 | matcher.group(2),
62 | matcher.group(3),
63 | matcher.group(4),
64 | matcher.group(5),
65 | matcher.group(6),
66 | matcher.group(7),
67 | matcher.group(8),
68 | matcher.group(9))
69 | }
70 | }
71 |
72 | /**
73 | * A sample record:
74 | * 94.102.63.11 - - [21/Jul/2009:02:48:13 -0700] "GET / HTTP/1.1" 200 18209 "http://acme.com/foo.php" "Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)"
75 | */
76 | object AccessLogParser {
77 |
78 | val nullObjectAccessLogRecord = AccessLogRecord("", "", "", "", "", "", "", "", "")
79 |
80 | /**
81 | * @param request A String like "GET /the-uri-here HTTP/1.1"
82 | * @return A Tuple3(requestType, uri, httpVersion). requestType is GET, POST, etc.
83 | *
84 | * Returns a Tuple3 of three blank strings if the method fails.
85 | */
86 | def parseRequestField(request: String): Option[Tuple3[String, String, String]] = {
87 | val arr = request.split(" ")
88 | if (arr.size == 3) Some((arr(0), arr(1), arr(2))) else None
89 | }
90 |
91 | /**
92 | * @param field A String that looks like "[21/Jul/2009:02:48:13 -0700]"
93 | */
94 | def parseDateField(field: String): Option[java.util.Date] = {
95 | val dateRegex = "\\[(.*?) .*]"
96 | val datePattern = Pattern.compile(dateRegex)
97 | val dateMatcher = datePattern.matcher(field)
98 | if (dateMatcher.find) {
99 | val dateString = dateMatcher.group(1)
100 | println(s"***** DATE STRING $dateString ******")
101 | // HH is 0-23; kk is 1-24
102 | val dateFormat = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.ENGLISH)
103 | allCatch.opt(dateFormat.parse(dateString)) // return Option[Date]
104 | } else {
105 | None
106 | }
107 | }
108 |
109 | def parse(record: String): Option[AccessLogRecord] = (new AccessLogParser).parseRecord(record)
110 | }
111 |
112 |
--------------------------------------------------------------------------------
/spark-dataframe-demo/src/main/scala/cn/thinkjoy/utils4s/spark/dataframe/udf/AccessLogRecord.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.dataframe.udf
2 |
3 | /**
4 | * Created by jacksu on 16/2/5.
5 | */
6 |
7 | case class AccessLogRecord(
8 | clientIpAddress: String, // should be an ip address, but may also be the hostname if hostname-lookups are enabled
9 | rfc1413ClientIdentity: String, // typically `-`
10 | remoteUser: String, // typically `-`
11 | dateTime: String, // [day/month/year:hour:minute:second zone]
12 | request: String, // `GET /foo ...`
13 | httpStatusCode: String, // 200, 404, etc.
14 | bytesSent: String, // may be `-`
15 | referer: String, // where the visitor came from
16 | userAgent: String // long string to represent the browser and OS
17 | )
18 |
19 | case class UserAgent(
20 | family: String,
21 | major: Option[String] = None,
22 | minor: Option[String] = None,
23 | patch: Option[String] = None)
--------------------------------------------------------------------------------
/spark-dataframe-demo/src/main/scala/cn/thinkjoy/utils4s/spark/dataframe/udf/LogAnalytics.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.dataframe
2 |
3 | import org.apache.http.client.methods.HttpGet
4 | import org.apache.http.impl.client.{ HttpClients }
5 | import org.json4s.JsonAST.JString
6 | import org.json4s._
7 | import org.json4s.jackson.JsonMethods._
8 |
9 | /**
10 | * Created by xbsu on 16/2/4.
11 | */
12 |
13 | class LogAnalytics {
14 |
15 | /**
16 | * 通过IP返回IP所属城市
17 | * @param ip
18 | * @return
19 | */
20 | def ip2City(ip: String): String = {
21 | val location = ip2Location(ip)
22 | if (location.nonEmpty) {
23 | compact(render(parse(location) \ "city"))
24 | } else {
25 | ""
26 | }
27 | }
28 |
29 | /**
30 | * 通过IP返回IP所属城市
31 | * @param ip
32 | * @return
33 | */
34 | def ip2Province(ip: String): String = {
35 | val location = ip2Location(ip)
36 | if (location.nonEmpty) {
37 | compact(render(parse(location) \ "province"))
38 | } else {
39 | ""
40 | }
41 | }
42 |
43 | private def getRestContent(url: String): String = {
44 | val httpClient = HttpClients.createDefault()
45 | val httpResponse = httpClient.execute(new HttpGet(url))
46 | val entity = httpResponse.getEntity()
47 | var content = ""
48 | if (entity != null) {
49 | val inputStream = entity.getContent()
50 | content = scala.io.Source.fromInputStream(inputStream).getLines.mkString
51 | inputStream.close
52 | }
53 | httpClient.getConnectionManager().shutdown()
54 | return content
55 | }
56 |
57 | /**
58 | * 暂时没有超时,只是简单实现
59 | * @param ip
60 | * @return
61 | */
62 | private def ip2Location(ip: String): String = {
63 | val url = "http://int.dpool.sina.com.cn/iplookup/iplookup.php?format=js&ip=" + ip
64 | val result = scala.io.Source.fromURL(url).mkString.split("=")(1)
65 | if ((parse(result) \ "ret").equals(JInt(1))) {
66 | org.apache.commons.lang.StringEscapeUtils.unescapeJava(result)
67 | } else {
68 | println(result)
69 | ""
70 | }
71 | }
72 | }
73 |
--------------------------------------------------------------------------------
/spark-knowledge/README.md:
--------------------------------------------------------------------------------
1 | ##深入理解spark
2 |
3 | [spark内存概述](md/spark内存概述.md)
4 |
5 | [spark shuffle之hash shuffle](md/hash-shuffle.md)
6 |
7 | [spark shuffle之sort shuffle](md/sort-shuffle.md)
8 |
9 | [spark shuffle之tungsten sort shuffle](md/tungsten-sort-shuffle.md)
10 |
11 | [spark DataFrame parquet](md/spark-dataframe-parquet.md)
12 |
13 | [Spark Streaming使用Kafka保证数据零丢失](md/spark_streaming使用Kafka保证数据零丢失.md)
--------------------------------------------------------------------------------
/spark-knowledge/images/MapReduce-v3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/MapReduce-v3.png
--------------------------------------------------------------------------------
/spark-knowledge/images/Spark-Heap-Usage.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/Spark-Heap-Usage.png
--------------------------------------------------------------------------------
/spark-knowledge/images/Spark-Memory-Management-1.6.0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/Spark-Memory-Management-1.6.0.png
--------------------------------------------------------------------------------
/spark-knowledge/images/data-frame.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/data-frame.png
--------------------------------------------------------------------------------
/spark-knowledge/images/goupByKey.001.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/goupByKey.001.jpg
--------------------------------------------------------------------------------
/spark-knowledge/images/groupByKey.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/groupByKey.png
--------------------------------------------------------------------------------
/spark-knowledge/images/kafka/system_components_on_white_v2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/kafka/system_components_on_white_v2.png
--------------------------------------------------------------------------------
/spark-knowledge/images/rdd-dataframe-dataset/filter-down.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/rdd-dataframe-dataset/filter-down.png
--------------------------------------------------------------------------------
/spark-knowledge/images/rdd-dataframe-dataset/rdd-dataframe.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/rdd-dataframe-dataset/rdd-dataframe.png
--------------------------------------------------------------------------------
/spark-knowledge/images/reduceByKey.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/reduceByKey.png
--------------------------------------------------------------------------------
/spark-knowledge/images/spark-streaming-kafka/spark-kafka-direct-api.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/spark-streaming-kafka/spark-kafka-direct-api.png
--------------------------------------------------------------------------------
/spark-knowledge/images/spark-streaming-kafka/spark-metadata-checkpointing.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/spark-streaming-kafka/spark-metadata-checkpointing.png
--------------------------------------------------------------------------------
/spark-knowledge/images/spark-streaming-kafka/spark-reliable-source-reliable-receiver.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/spark-streaming-kafka/spark-reliable-source-reliable-receiver.png
--------------------------------------------------------------------------------
/spark-knowledge/images/spark-streaming-kafka/spark-wal.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/spark-streaming-kafka/spark-wal.png
--------------------------------------------------------------------------------
/spark-knowledge/images/spark-streaming-kafka/spark-wall-at-least-once-delivery.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/spark-streaming-kafka/spark-wall-at-least-once-delivery.png
--------------------------------------------------------------------------------
/spark-knowledge/images/spark_sort_shuffle.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/spark_sort_shuffle.png
--------------------------------------------------------------------------------
/spark-knowledge/images/spark_tungsten_sort_shuffle.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/spark_tungsten_sort_shuffle.png
--------------------------------------------------------------------------------
/spark-knowledge/images/zepplin/helium.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/zepplin/helium.png
--------------------------------------------------------------------------------
/spark-knowledge/images/zepplin/z-manager-zeppelin.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jacksu/utils4s/dde9292943202b70e26d5162a96998a3a863a189/spark-knowledge/images/zepplin/z-manager-zeppelin.png
--------------------------------------------------------------------------------
/spark-knowledge/md/RDD、DataFrame和DataSet的区别.md:
--------------------------------------------------------------------------------
1 | > RDD、DataFrame和DataSet是容易产生混淆的概念,必须对其相互之间对比,才可以知道其中异同。
2 |
3 | ##RDD和DataFrame
4 |
5 | 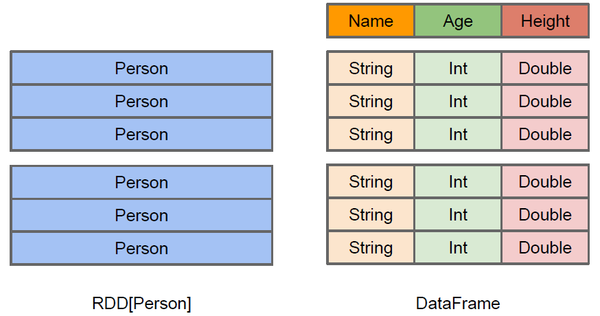
6 |
7 | 上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等。
8 |
9 | ###提升执行效率
10 |
11 | RDD API是函数式的,强调不变性,在大部分场景下倾向于创建新对象而不是修改老对象。这一特点虽然带来了干净整洁的API,却也使得Spark应用程序在运行期倾向于创建大量临时对象,对GC造成压力。在现有RDD API的基础之上,我们固然可以利用mapPartitions方法来重载RDD单个分片内的数据创建方式,用复用可变对象的方式来减小对象分配和GC的开销,但这牺牲了代码的可读性,而且要求开发者对Spark运行时机制有一定的了解,门槛较高。另一方面,Spark SQL在框架内部已经在各种可能的情况下尽量重用对象,这样做虽然在内部会打破了不变性,但在将数据返回给用户时,还会重新转为不可变数据。利用 DataFrame API进行开发,可以免费地享受到这些优化效果。
12 |
13 | ###减少数据读取
14 |
15 | 分析大数据,最快的方法就是 ——忽略它。这里的“忽略”并不是熟视无睹,而是根据查询条件进行恰当的剪枝。
16 |
17 | 上文讨论分区表时提到的分区剪 枝便是其中一种——当查询的过滤条件中涉及到分区列时,我们可以根据查询条件剪掉肯定不包含目标数据的分区目录,从而减少IO。
18 |
19 | 对于一些“智能”数据格 式,Spark SQL还可以根据数据文件中附带的统计信息来进行剪枝。简单来说,在这类数据格式中,数据是分段保存的,每段数据都带有最大值、最小值、null值数量等 一些基本的统计信息。当统计信息表名某一数据段肯定不包括符合查询条件的目标数据时,该数据段就可以直接跳过(例如某整数列a某段的最大值为100,而查询条件要求a > 200)。
20 |
21 | 此外,Spark SQL也可以充分利用RCFile、ORC、Parquet等列式存储格式的优势,仅扫描查询真正涉及的列,忽略其余列的数据。
22 |
23 | ###执行优化
24 |
25 | 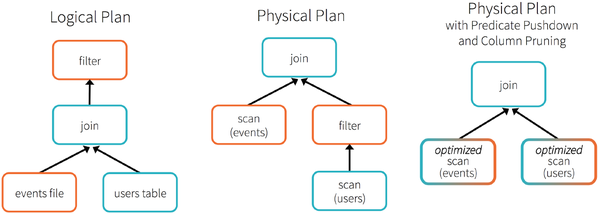
26 |
27 | 为了说明查询优化,我们来看上图展示的人口数据分析的示例。图中构造了两个DataFrame,将它们join之后又做了一次filter操作。如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一个较大的数据集。如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。而Spark SQL的查询优化器正是这样做的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。
28 |
29 | 得到的优化执行计划在转换成物 理执行计划的过程中,还可以根据具体的数据源的特性将过滤条件下推至数据源内。最右侧的物理执行计划中Filter之所以消失不见,就是因为溶入了用于执行最终的读取操作的表扫描节点内。
30 |
31 | 对于普通开发者而言,查询优化 器的意义在于,即便是经验并不丰富的程序员写出的次优的查询,也可以被尽量转换为高效的形式予以执行。
32 |
33 | ##RDD和DataSet
34 |
35 | * > DataSet以Catalyst逻辑执行计划表示,并且数据以编码的二进制形式被存储,不需要反序列化就可以执行sorting、shuffle等操作。
36 |
37 | * > DataSet创立需要一个显式的Encoder,把对象序列化为二进制,可以把对象的scheme映射为Spark
38 | SQl类型,然而RDD依赖于运行时反射机制。
39 |
40 | 通过上面两点,DataSet的性能比RDD的要好很多,可以参见[3]
41 |
42 | ##DataFrame和DataSet
43 |
44 | Dataset可以认为是DataFrame的一个特例,主要区别是Dataset每一个record存储的是一个强类型值而不是一个Row。因此具有如下三个特点:
45 |
46 | * > DataSet可以在编译时检查类型
47 |
48 | * > 并且是面向对象的编程接口。用wordcount举例:
49 |
50 | ```scala
51 | //DataFrame
52 |
53 | // Load a text file and interpret each line as a java.lang.String
54 | val ds = sqlContext.read.text("/home/spark/1.6/lines").as[String]
55 | val result = ds
56 | .flatMap(_.split(" ")) // Split on whitespace
57 | .filter(_ != "") // Filter empty words
58 | .toDF() // Convert to DataFrame to perform aggregation / sorting
59 | .groupBy($"value") // Count number of occurences of each word
60 | .agg(count("*") as "numOccurances")
61 | .orderBy($"numOccurances" desc) // Show most common words first
62 | ```
63 |
64 | ```scala
65 | //DataSet,完全使用scala编程,不要切换到DataFrame
66 |
67 | val wordCount =
68 | ds.flatMap(_.split(" "))
69 | .filter(_ != "")
70 | .groupBy(_.toLowerCase()) // Instead of grouping on a column expression (i.e. $"value") we pass a lambda function
71 | .count()
72 | ```
73 |
74 | * > 后面版本DataFrame会继承DataSet,DataFrame是面向Spark SQL的接口。
75 |
76 | DataFrame和DataSet可以相互转化,`df.as[ElementType]`这样可以把DataFrame转化为DataSet,`ds.toDF()`这样可以把DataSet转化为DataFrame。
77 |
78 | ##参考
79 | [1] [Spark SQL结构化分析](http://www.iteye.com/news/30658)
80 |
81 | [2] [解读2015之Spark篇:新生态系统的形成](http://www.infoq.com/cn/articles/2015-Review-Spark)
82 |
83 | [3] [Introducing Spark Datasets](https://databricks.com/blog/2016/01/04/introducing-spark-datasets.html)
84 |
85 | [4] [databricks example](https://docs.cloud.databricks.com/docs/spark/1.6/index.html#examples/Dataset%20Wordcount.html)
--------------------------------------------------------------------------------
/spark-knowledge/md/confluent_platform2.0.md:
--------------------------------------------------------------------------------
1 | #Confluent platform2.0
2 |
3 | 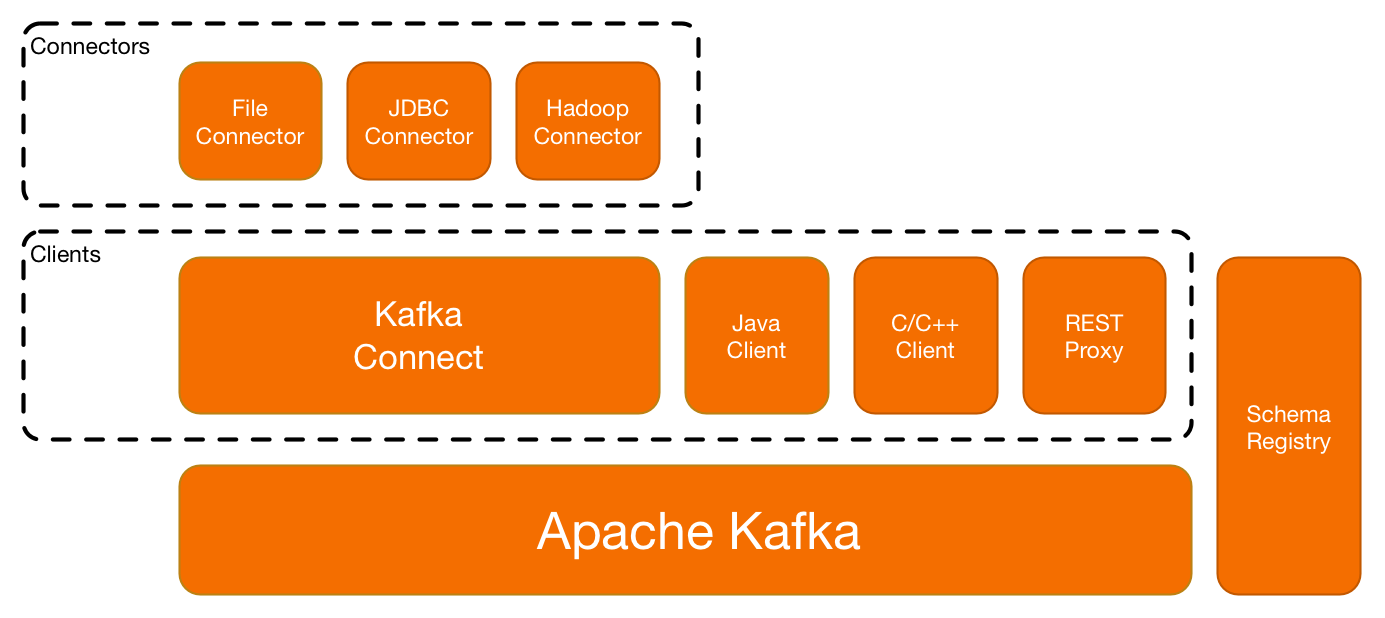
--------------------------------------------------------------------------------
/spark-knowledge/md/hash-shuffle.md:
--------------------------------------------------------------------------------
1 | 正如你所知,spark实现了多种shuffle方法,通过 spark.shuffle.manager来确定。暂时总共有三种:hash shuffle、sort shuffle和tungsten-sort shuffle,从1.2.0开始默认为sort shuffle。本节主要介绍hash shuffle。
2 |
3 | spark在1.2前默认为hash shuffle(spark.shuffle.manager = hash),但hash shuffle也经历了两个发展阶段。
4 | ##第一阶段
5 |
6 | 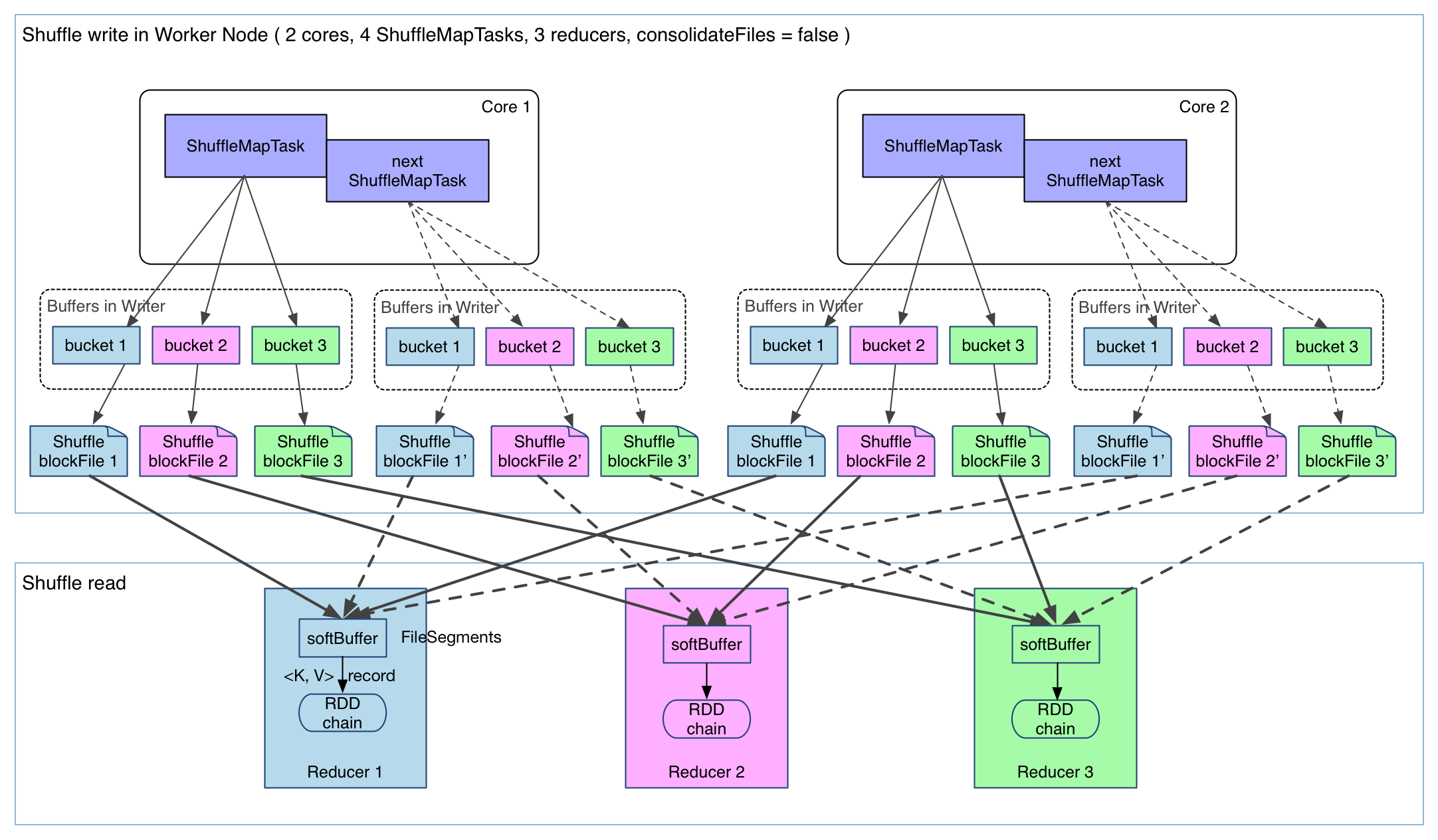
7 |
8 | 上图有 4 个 ShuffleMapTask 要在同一个 worker node 上运行,CPU core 数为 2,可以同时运行两个 task。每个 task 的执行结果(该 stage 的 finalRDD 中某个 partition 包含的 records)被逐一写到本地磁盘上。每个 task 包含 R 个缓冲区,R = reducer 个数(也就是下一个 stage 中 task 的个数),缓冲区被称为 bucket,其大小为spark.shuffle.file.buffer.kb ,默认是 32KB(Spark 1.1 版本以前是 100KB)。
9 |
10 | ##第二阶段
11 | 这样的实现很简单,但有几个问题:
12 |
13 | 1 产生的 *FileSegment* 过多。每个 ShuffleMapTask 产生 R(reducer 个数)个 FileSegment,M 个 ShuffleMapTask 就会产生 `M * R` 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
14 |
15 | 2 缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 M \* R 个 bucket。虽然一个 ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores R 个(一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了**cores \* R \* 32 KB**。对于 8 核 1000 个 reducer 来说,占用内存就是 256MB。
16 |
17 | spark.shuffle.consolidateFiles默认为false,如果为true,shuffleMapTask输出文件可以被合并。如图
18 |
19 | 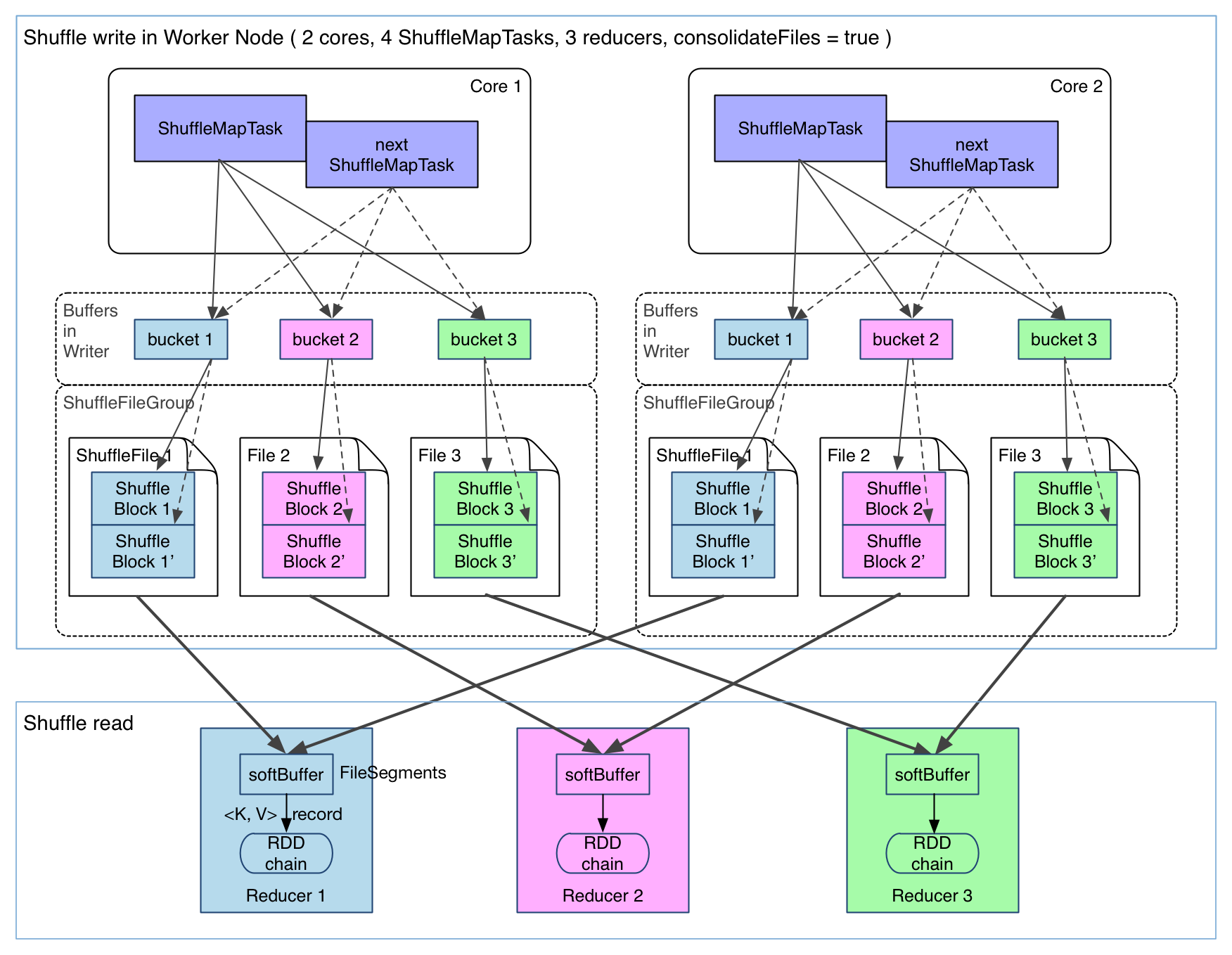
20 |
21 | 可以明显看出,在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的 ShuffleMapTask 形成 ShuffleBlock i,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成 ShuffleBlock i',每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行了。这样,每个 worker 持有的文件数降为 `cores * R`。**但是缓存空间占用大还没有解决**。
22 |
23 | ##总结
24 |
25 | ###优点
26 |
27 | 1. 快-不需要排序,也不需要维持hash表
28 | 2. 不需要额外空间用作排序
29 | 3. 不需要额外IO-数据写入磁盘只需一次,读取也只需一次
30 |
31 | ###缺点
32 |
33 | 1. 当partitions大时,输出大量的文件(cores * R),性能开始降低
34 | 2. 大量的文件写入,使文件系统开始变为随机写,性能比顺序写要降低100倍
35 | 3. 缓存空间占用比较大
36 |
37 | 当然,数据经过序列化、压缩写入文件,读取的时候,需要反序列化、解压缩。reduce fetch的时候有一个非常重要的参数`spark.reducer.maxSizeInFlight`,这里用 softBuffer 表示,默认大小为 48MB。一个 softBuffer 里面一般包含多个 FileSegment,但如果某个 FileSegment 特别大的话,这一个就可以填满甚至超过 softBuffer 的界限。如果增大,reduce请求的chunk就会变大,可以提高性能,但是增加了reduce的内存使用量。
38 |
39 | 如果排序在reduce不强制执行,那么reduce只返回一个依赖于map的迭代器。如果需要排序, 那么在reduce端,调用[ExternalSorter](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/util/collection/ExternalSorter.scala)。
40 |
41 | ##参考文献
42 |
43 | [spark Architecture:Shuffle](http://0x0fff.com/spark-architecture-shuffle/)
44 |
45 | [shuffle 过程](http://spark-internals.books.yourtion.com/markdown/4-shuffleDetails.html)
46 |
47 | [sort shuffle](https://github.com/hustnn/SparkShuffleComparison)
48 |
49 | [tungsten secret](https://github.com/hustnn/TungstenSecret)
--------------------------------------------------------------------------------
/spark-knowledge/md/sort-shuffle.md:
--------------------------------------------------------------------------------
1 | 正如你所知,spark实现了多种shuffle方法,通过 spark.shuffle.manager来确定。暂时总共有三种:hash shuffle、sort shuffle和tungsten-sort shuffle,从1.2.0开始默认为sort shuffle。本节主要介绍sort shuffle。
2 |
3 | 从1.2.0开始默认为sort shuffle(**spark.shuffle.manager** = sort),实现逻辑类似于Hadoop MapReduce,Hash Shuffle每一个reducers产生一个文件,但是Sort Shuffle只是产生一个按照reducer id排序可索引的文件,这样,只需获取有关文件中的相关数据块的位置信息,并fseek就可以读取指定reducer的数据。但对于rueducer数比较少的情况,Hash Shuffle明显要比Sort Shuffle快,因此Sort Shuffle有个“fallback”计划,对于reducers数少于 “spark.shuffle.sort.bypassMergeThreshold” (200 by default),我们使用fallback计划,hashing相关数据到分开的文件,然后合并这些文件为一个,具体实现为[BypassMergeSortShuffleWriter](https://github.com/apache/spark/blob/master/core/src/main/java/org/apache/spark/shuffle/sort/BypassMergeSortShuffleWriter.java)。
4 |
5 | 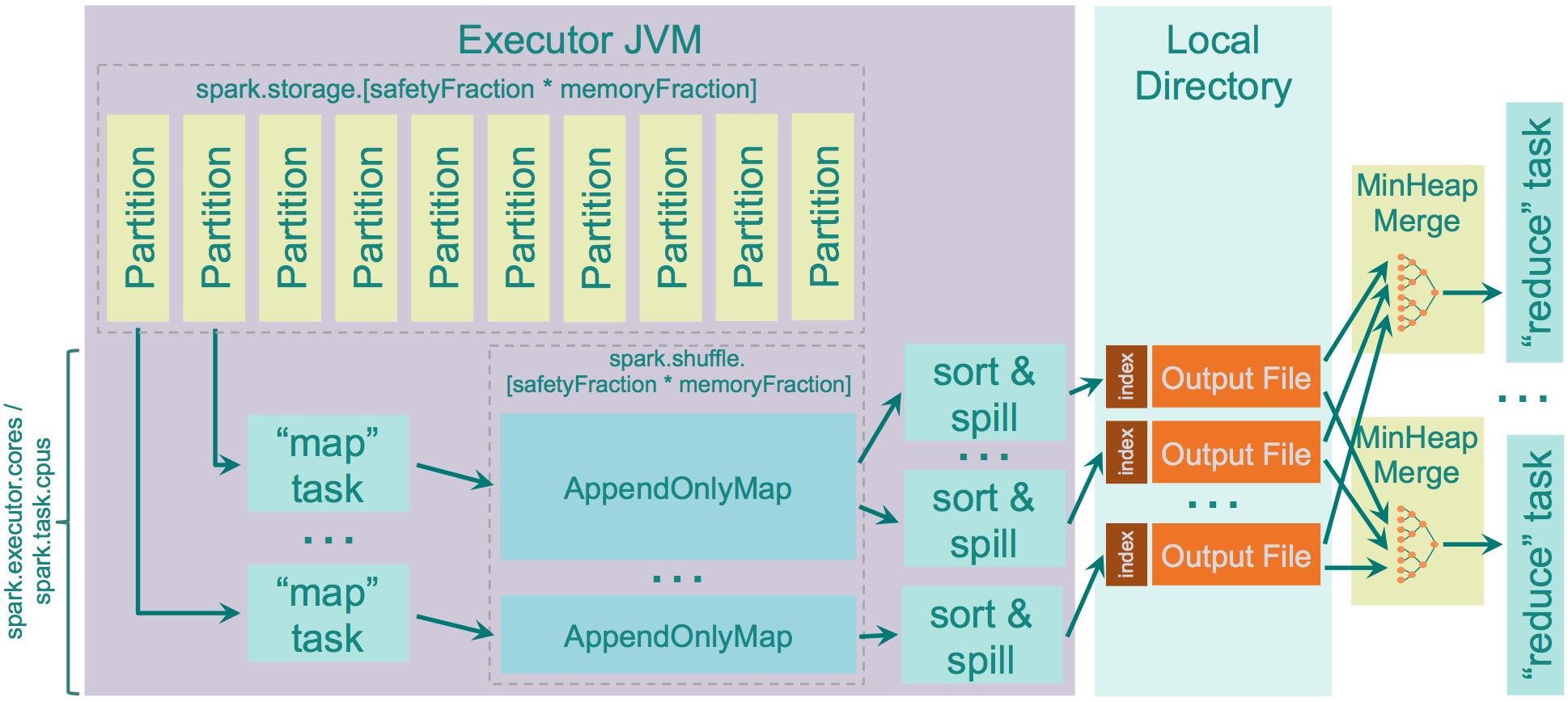
6 |
7 | 在map进行排序,在reduce端应用Timsort[1]进行合并。map端是否容许spill,通过**spark.shuffle.spill**来设置,默认是true。设置为false,如果没有足够的内存来存储map的输出,那么就会导致OOM错误,因此要慎用。
8 |
9 | 用于存储map输出的内存为:`“JVM Heap Size” \* spark.shuffle.memoryFraction \* spark.shuffle.safetyFraction`,默认为`“JVM Heap Size” \* 0.2 \* 0.8 = “JVM Heap Size” \* 0.16`。如果你在同一个执行程序中运行多个线程(设定`spark.executor.cores/ spark.task.cpus`超过1),每个map任务存储的空间为`“JVM Heap Size” * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction / spark.executor.cores * spark.task.cpus`, 默认2个cores,那么为`0.08 * “JVM Heap Size”`。
10 | spark使用[AppendOnlyMap](nch-1.5/core/src/main/scala/org/apache/spark/util/collection/AppendOnlyMap.scala)存储map输出的数据,利用开源hash函数[MurmurHash3](https://zh.wikipedia.org/wiki/Murmur哈希)和平方探测法把key和value保存在相同的array中。这种保存方法可以是spark进行combine。如果spill为true,会在spill前sort。
11 |
12 | Sort Shuffle内存的源码级别更详细说明可以参考[4],读写过程可以参考[5]
13 |
14 | ##优点
15 | 1. map创建文件量较少
16 | 2. 少量的IO随机操作,大部分是顺序读写
17 |
18 | ##缺点
19 | 1. 要比Hash Shuffle要慢,需要自己通过`spark.shuffle.sort.bypassMergeThreshold`来设置合适的值。
20 | 2. 如果使用SSD盘存储shuffle数据,那么Hash Shuffle可能更合适。
21 |
22 | ##参考
23 |
24 | [1][Timsort原理介绍](http://blog.csdn.net/yangzhongblog/article/details/8184707)
25 |
26 | [2][形式化方法的逆袭——如何找出Timsort算法和玉兔月球车中的Bug?](http://bindog.github.io/blog/2015/03/30/use-formal-method-to-find-the-bug-in-timsort-and-lunar-rover/)
27 |
28 | [3][Spark Architecture: Shuffle](http://0x0fff.com/spark-architecture-shuffle/)
29 |
30 | [4][Spark Sort Based Shuffle内存分析](http://www.jianshu.com/p/c83bb237caa8)
31 |
32 | [5][Spark Shuffle Write阶段磁盘文件分析](http://www.jianshu.com/p/2d837bf2dab6)
33 |
--------------------------------------------------------------------------------
/spark-knowledge/md/spark-dataframe-parquet.md:
--------------------------------------------------------------------------------
1 | Apache Parquet作为文件格式最近获得了显著关注,假设你有一个100列的表,大部分时间你只需要访问3-10列,行存储,不管你需要不需要它们,你必须扫描所有。Apache Parquet是列存储,如果需要3列,那么只有这3列被load。并且datatype、compression和quality非常好。
2 |
3 | 下面我们来介绍如何把一个表存储为Parquet和如何加载。
4 |
5 | 首先建立一个表格:
6 |
7 | | *first_name* | *last_name* | gender |
8 | | ------------- |:-------------:| :-----:|
9 | |Barack | Obama | M |
10 | |Bill | Clinton | M |
11 | |Hillary | Clinton | F |
12 |
13 |
14 | Spark SQL:
15 |
16 | ```scala
17 | val hc = new org.apache.spark.sql.hive.HiveContext(sc)
18 | import hc.implicits._
19 | case class Person(firstName: String, lastName: String, gender: String)
20 | val personRDD = sc.textFile("person").map(_.split("\t")).map(p => Person(p(0),p(1),p(2)))
21 | val person = personRDD.toDF
22 | person.registerTempTable("person")
23 | val males = hc.sql("select * from person where gender='M'")
24 | males.collect.foreach(println)
25 | ```
26 | 保存DF为Parquet格式:
27 |
28 | ```scala
29 | person.write.parquet("person.parquet")
30 | ```
31 |
32 | Hive中建立Parquet格式的表:
33 |
34 | ```hive
35 | create table person_parquet like person stored as parquet;
36 | insert overwrite table person_parquet select * from person;
37 | ```
38 |
39 | 加载Parquet文件不再需要case class。
40 |
41 | ```scala
42 | val personDF = hc.read.parquet("person.parquet")
43 | personDF.registerAsTempTable("pp")
44 | val males = hc.sql("select * from pp where gender='M'")
45 | males.collect.foreach(println)
46 | ```
47 | parquet文件的性能经过简单的group by操作测试,性能可以提高一倍多。
48 |
49 | Sometimes Parquet files pulled from other sources like Impala save String as binary. To fix that issue, add the following line right after creating SqlContext:
50 |
51 | ```scala
52 | sqlContext.setConf("spark.sql.parquet.binaryAsString","true")
53 | ```
54 |
55 | ##参考
56 |
57 | [http://www.infoobjects.com/spark-cookbook/](http://www.infoobjects.com/spark-cookbook/)
--------------------------------------------------------------------------------
/spark-knowledge/md/spark_sql选择parquet存储方式的五个原因.md:
--------------------------------------------------------------------------------
1 | #spark SQL选择parquet存储方式的五个原因
2 |
3 | > 1 采用parquet格式,spark SQL有10x的性能提升
4 |
5 | > 2 Spark SQL会工作比较好,因为读取数据量变小
6 |
7 | > 3 减少IO,会filter下推
8 |
9 | > 4 1.6.0中更高的扫描吞吐量,CPU使用较低,磁盘吞吐量比较高
10 |
11 | > 5 Efficient Spark execution graph
12 |
13 |
14 |
15 | ##参考
16 |
17 | [https://developer.ibm.com/hadoop/blog/2016/01/14/5-reasons-to-choose-parquet-for-spark-sql/](https://developer.ibm.com/hadoop/blog/2016/01/14/5-reasons-to-choose-parquet-for-spark-sql/)
--------------------------------------------------------------------------------
/spark-knowledge/md/spark_streaming使用kafka保证数据零丢失.md:
--------------------------------------------------------------------------------
1 | #Spark Streaming使用Kafka保证数据零丢失
2 |
3 | spark streaming从1.2开始提供了数据的零丢失,想享受这个特性,需要满足如下条件:
4 |
5 | 1.数据输入需要可靠的sources和可靠的receivers
6 |
7 | 2.应用metadata必须通过应用driver checkpoint
8 |
9 | 3.WAL(write ahead log)
10 |
11 | ##可靠的sources和receivers
12 |
13 | spark streaming可以通过多种方式作为数据sources(包括kafka),输入数据通过receivers接收,通过replication存储于spark中(为了faultolerance,默认复制到两个spark executors),如果数据复制完成,receivers可以知道(例如kafka中更新offsets到zookeeper中)。这样当receivers在接收数据过程中crash掉,不会有数据丢失,receivers没有复制的数据,当receiver恢复后重新接收。
14 |
15 | 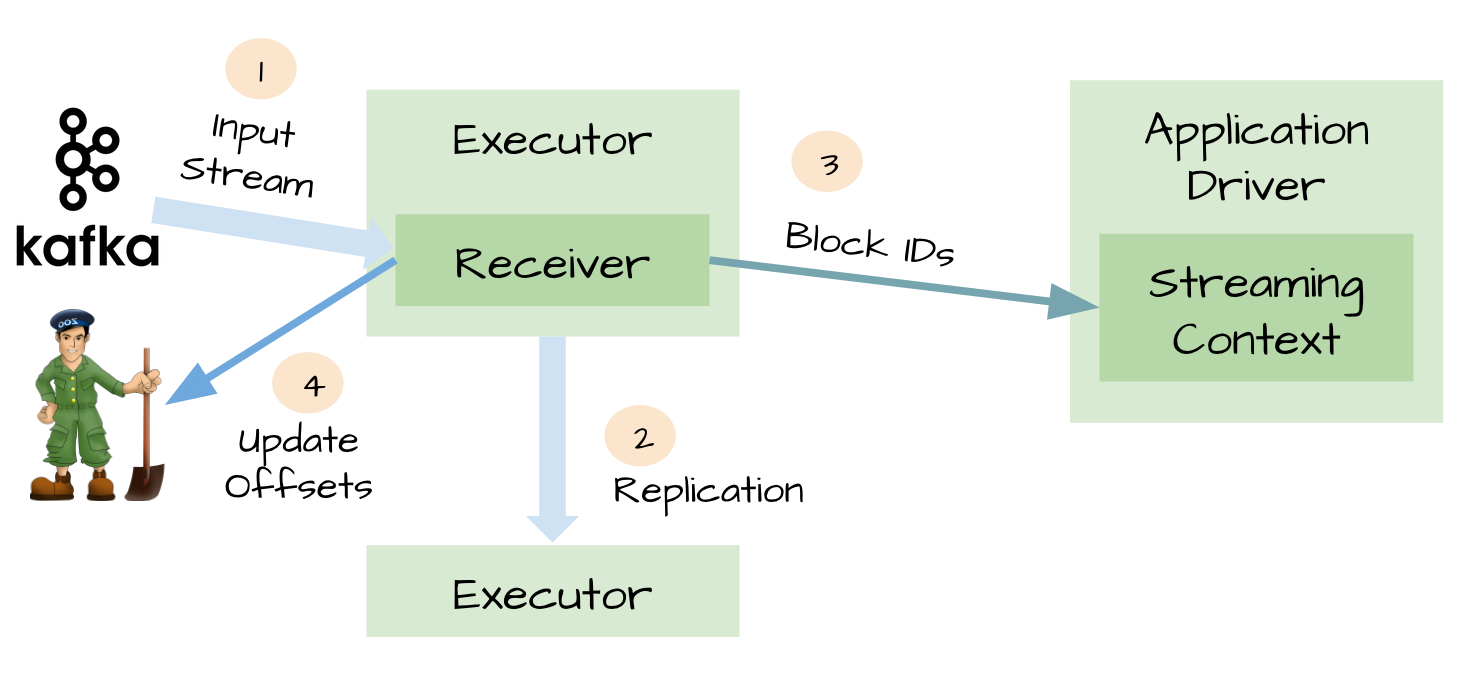
16 |
17 | ##metadata checkpoint
18 |
19 | 可靠的sources和receivers,可以使数据在receivers失败后恢复,然而在driver失败后恢复是比较复杂的,一种方法是通过checkpoint metadata到HDFS或者S3。metadata包括:
20 |
21 | * configuration
22 | * code
23 | * 一些排队等待处理但没有完成的RDD(仅仅是metadata,而不是data)
24 | 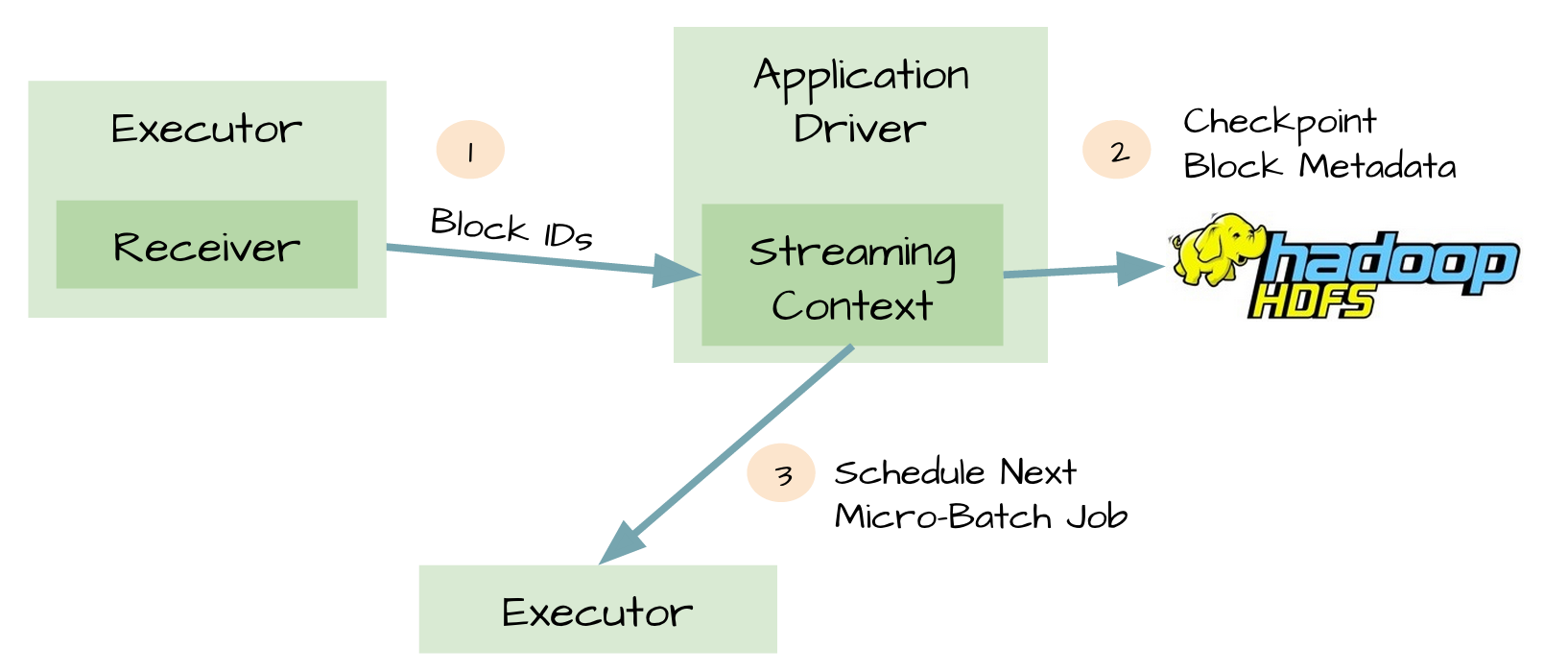
25 |
26 | 这样当driver失败时,可以通过metadata checkpoint,重构应用程序并知道执行到那个地方。
27 |
28 | ##数据可能丢失的场景
29 |
30 | 可靠的sources和receivers,以及metadata checkpoint也不可以保证数据的不丢失,例如:
31 |
32 | * 两个executor得到计算数据,并保存在他们的内存中
33 | * receivers知道数据已经输入
34 | * executors开始计算数据
35 | * driver突然失败
36 | * driver失败,那么executors都会被kill掉
37 | * 因为executor被kill掉,那么他们内存中得数据都会丢失,但是这些数据不再被处理
38 | * executor中的数据不可恢复
39 |
40 | ##WAL
41 |
42 | 为了避免上面情景的出现,spark streaming 1.2引入了WAL。所有接收的数据通过receivers写入HDFS或者S3中checkpoint目录,这样当driver失败后,executor中数据丢失后,可以通过checkpoint恢复。
43 | 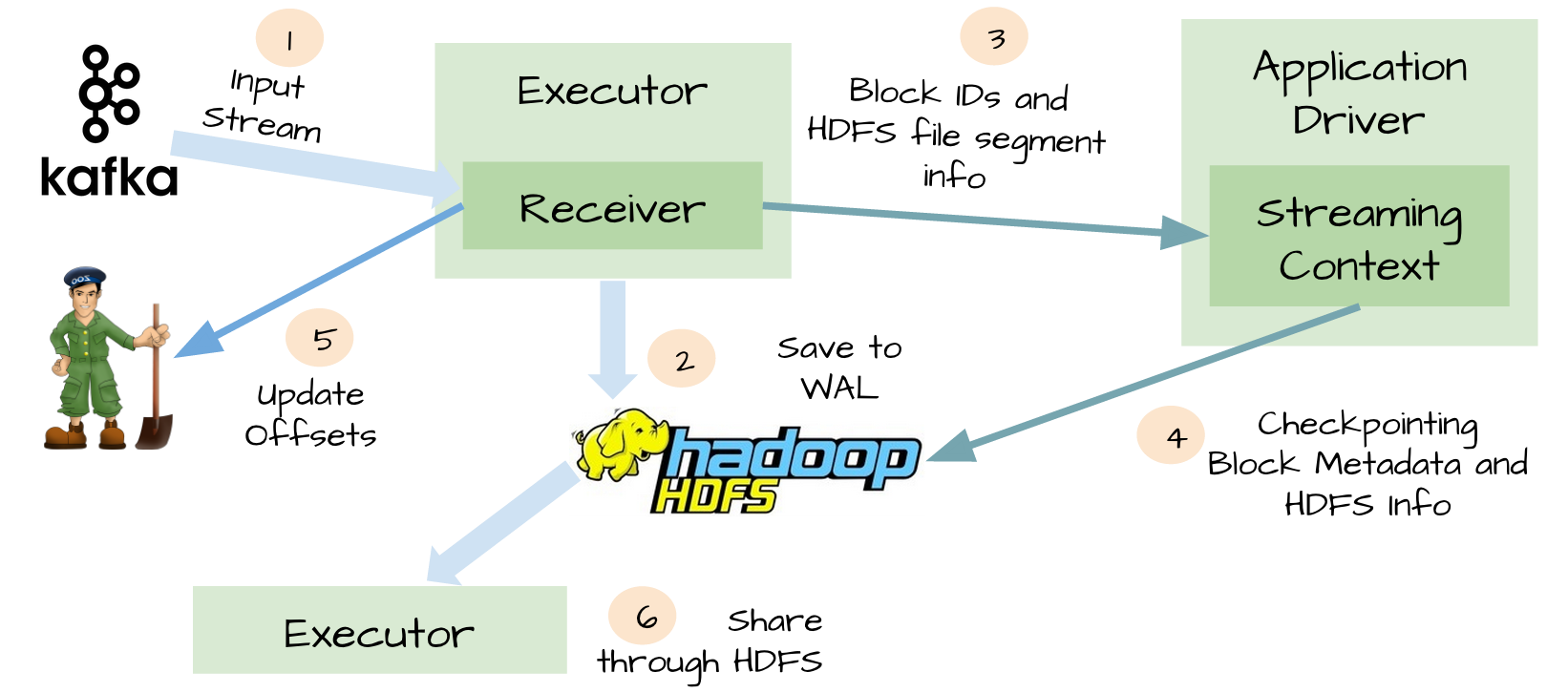
44 |
45 | ##At-Least-Once
46 | 尽管WAL可以保证数据零丢失,但是不能保证exactly-once,例如下面场景:
47 |
48 | * Receivers接收完数据并保存到HDFS或S3
49 | * 在更新offset前,receivers失败了
50 | 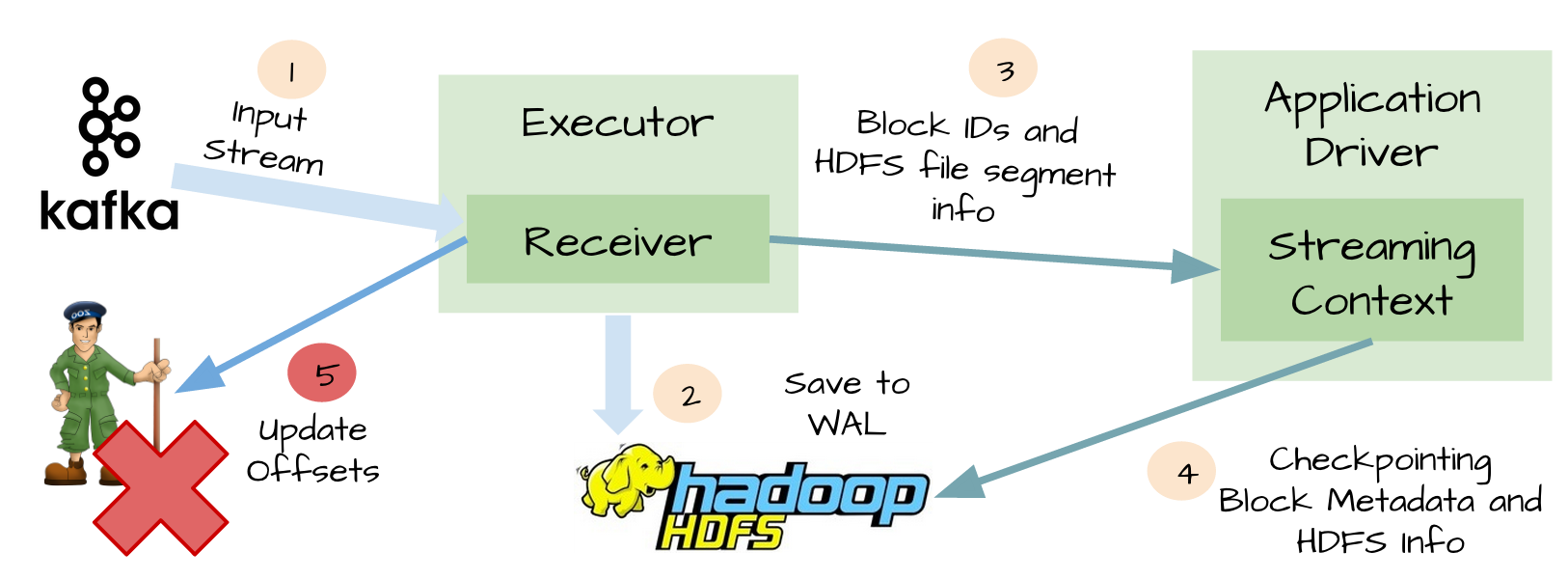
51 |
52 | * Spark Streaming以为数据接收成功,但是Kafka以为数据没有接收成功,因为offset没有更新到zookeeper
53 | * 随后receiver恢复了
54 | * 从WAL可以读取的数据重新消费一次,因为使用的kafka High-Level消费API,从zookeeper中保存的offsets开始消费
55 |
56 | ##WAL的缺点
57 | 通过上面描述,WAL有两个缺点:
58 |
59 | * 降低了receivers的性能,因为数据还要存储到HDFS等分布式文件系统
60 | * 对于一些resources,可能存在重复的数据,比如Kafka,在Kafka中存在一份数据,在Spark Streaming也存在一份(以WAL的形式存储在hadoop API兼容的文件系统中)
61 |
62 | ##Kafka direct API
63 | 为了WAL的性能损失和exactly-once,spark streaming1.3中使用Kafka direct API。非常巧妙,Spark driver计算下个batch的offsets,指导executor消费对应的topics和partitions。消费Kafka消息,就像消费文件系统文件一样。
64 |
65 | 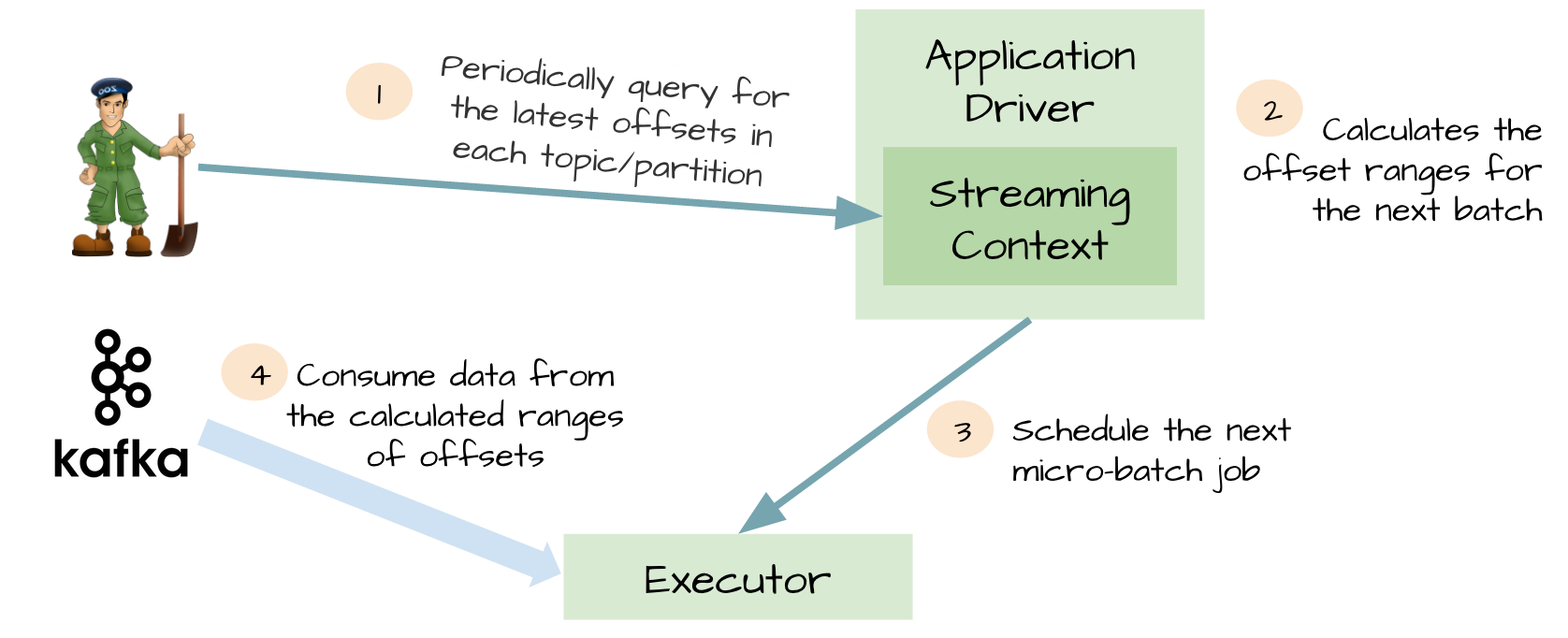
66 |
67 | 1.不再需要kafka receivers,executor直接通过Kafka API消费数据
68 |
69 | 2.WAL不再需要,如果从失败恢复,可以重新消费
70 |
71 | 3.exactly-once得到了保证,不会再从WAL中重复读取数据
72 |
73 | ##总结
74 |
75 | 主要说的是spark streaming通过各种方式来保证数据不丢失,并保证exactly-once,每个版本都是spark streaming越来越稳定,越来越向生产环境使用发展。
76 |
77 | ##参考
78 | [spark-streaming
79 | Recent Evolution of Zero Data Loss Guarantee in Spark Streaming With Kafka](http://getindata.com/blog/post/recent-evolution-of-zero-data-loss-guarantee-in-spark-streaming-with-kafka/)
80 |
81 | [Kafka direct API](http://www.jianshu.com/p/b4af851286e5)
82 |
83 | [spark streaming exactly-once](http://www.jianshu.com/p/885505daab29)
--------------------------------------------------------------------------------
/spark-knowledge/md/spark从关系数据库加载数据.md:
--------------------------------------------------------------------------------
1 | #Spark从关系数据库加载数据
2 |
3 | **整体思路是通过partition并行链接关系数据库。**
4 |
5 | 实现:
6 |
7 | ##1. 加载驱动程序
8 |
9 | 正确配置:
10 |
11 | ```scala
12 | --driver-class-path "driver_local_file_system_jdbc_driver1.jar:driver_local_file_system_jdbc_driver2.jar"
13 | --class "spark.executor.extraClassPath=executors_local_file_system_jdbc_driver1.jar:executors_local_file_system_jdbc_driver2.jar"
14 | ```
15 |
16 | 如果需要在NoteBook中执行任务,需要在启动前设置EXTRA_CLASSPATH,执行如下命令:
17 |
18 | ```scala
19 | export EXTRA_CLASSPATH=path_to_the_first_jar:path_to_the_second_jar
20 | ```
21 |
22 | ##2. 并行加载
23 |
24 | 有两种方式:
25 |
26 | 1)按照指定列进行统一分区
27 |
28 | 2)通过用户自定义谓词分区
29 |
30 | ###按照指定列进行统一分区
31 | **指定列必须是数字类型**
32 | 使用方法
33 |
34 | ```scala
35 | sqlctx.read.jdbc(url = "", table = "",
36 | columnName = "",
37 | lowerBound = minValue,
38 | upperBound = maxValue,
39 | numPartitions = 20,
40 | connectionProperties = new java.util.Properties()
41 | )
42 | ```
43 |
44 | ###通过用户自定义谓词分区
45 |
46 | 使用方法
47 |
48 | ```scala
49 | val predicates = Array("2015-06-20" -> "2015-06-30", "2015-07-01" -> "2015-07-10", "2015-07-11" -> "2015-07-20",
50 | "2015-07-21" -> "2015-07-31").map {
51 | case (start, end) => s"cast(DAT_TME as date) >= date '$start' " + "AND cast(DAT_TME as date) <= date '$end'"
52 | }
53 | sqlctx.read.jdbc(url = "", table = "", predicates = predicates, connectionProperties = new java.util.Properties())
54 | ```
55 |
56 | ##3.表格union
57 |
58 | ```scala
59 | def readTable(table: String): DataFrame
60 | List("", "", "").par.map(readTable).reduce(_ unionAll _)
61 | ```
62 |
63 | .par 表示readTable函数会并行调用,而不是线性顺序。
64 |
65 | ##4.映射为Case Class
66 |
67 | ```scala
68 | case class MyClass(a: Long, b: String, c: Int, d: String, e: String)
69 | dataframe.map {
70 | case Row(a: java.math.BigDecimal, b: String, c: Int, _: String, _: java.sql.Date,
71 | e: java.sql.Date, _: java.sql.Timestamp, _: java.sql.Timestamp, _: java.math.BigDecimal,
72 | _: String) => MyClass(a = a.longValue(), b = b, c = c, d = d.toString, e = e.toString)
73 | }
74 | ```
75 |
76 | 不可以处理包含null值的记录。可以通过
77 |
78 | ```scala
79 | dataframe.na.drop()
80 | ```
81 |
82 | 通过处理后,丢弃包含null的记录。
83 | #参考
84 |
85 | [利用tachyong优化任务从小时到秒](https://dzone.com/articles/Accelerate-In-Memory-Processing-with-Spark-from-Hours-to-Seconds-With-Tachyon)
--------------------------------------------------------------------------------
/spark-knowledge/md/spark内存概述.md:
--------------------------------------------------------------------------------
1 | #spark内存概述
2 |
3 | ##1.5以前
4 | spark进程是以JVM进程运行的,可以通过-Xmx和-Xms配置堆栈大小,它是如何使用堆栈呢?下面是spark内存分配图。
5 |
6 | 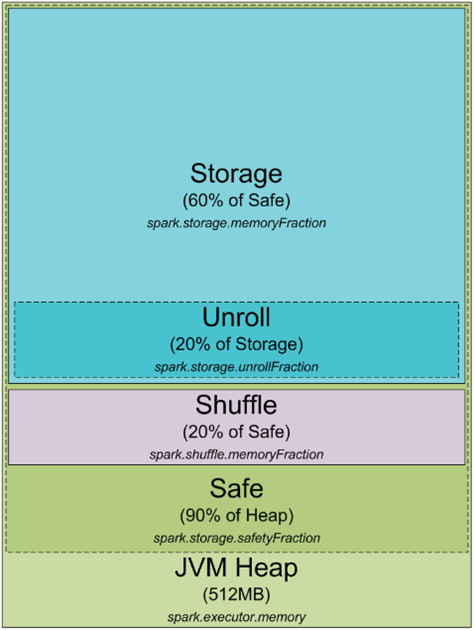
7 |
8 | ###storage memory
9 | spark默认JVM堆为512MB,为了避免OOM错误,只使用90%。通过spark.storage.safetyFraction来设置。spark通过内存来存储需要处理的数据,使用安全空间的60%,通过 spark.storage.memoryFraction来控制。如果我们想知道spark缓存数据可以使用多少空间?假设执行任务需要executors数为N,那么可使用空间为N\*90%\*60%\*512MB,但实际缓存数据的空间还要减去unroll memory。
10 | ###shuffle memory
11 | shuffle memory的内存为“Heap Size” \* spark.shuffle.safetyFraction \* spark.shuffle.memoryFraction。默认spark.shuffle.safetyFraction 是 0.8 ,spark.shuffle.memoryFraction是0.2 ,因此shuffle memory为 0.8\*0.2\*512MB = 0.16\*512MB,shuffle memory为shuffle用作数据的排序等。
12 | ###unroll memory
13 | unroll memory的内存为spark.storage.unrollFraction \* spark.storage.memoryFraction \* spark.storage.safetyFraction,即0.2 \* 0.6 \* 0.9 \* 512MB = 0.108 \* 512MB。unroll memory用作数据序列化和反序列化。
14 | ##1.6开始
15 | 提出了一个新的内存管理模型: Unified Memory Management。打破ExecutionMemory 和 StorageMemory 这种分明的界限。如果现在没有execution的需要,那么所有的内存都可以给storage用,反过来也是一样的。同时execution可以evict storage的部分内存,但是反过来不行。在新的内存管理框架上使用两个参数来控制spark.memory.fraction和spark.memory.storageFraction。
16 |
17 | ###参考文献
18 | [spark 框架](http://0x0fff.com/spark-architecture/)
19 |
20 | [Spark 1.6 内存管理模型( Unified Memory Management)分析](http://www.jianshu.com/p/b250797b452a)
21 |
--------------------------------------------------------------------------------
/spark-knowledge/md/spark实践总结.md:
--------------------------------------------------------------------------------
1 | #spark实践总结
2 |
3 | ##尽量少使用groupByKey
4 |
5 | [**测试源码**](https://github.com/jacksu/utils4s/blob/master/spark-core-demo/src/main/scala/cn/thinkjoy/utils4s/spark/core/GroupByKeyAndReduceByKeyApp.scala)
6 |
7 | 下面来看看groupByKey和reduceByKey的区别:
8 |
9 | ```scala
10 | val conf = new SparkConf().setAppName("GroupAndReduce").setMaster("local")
11 | val sc = new SparkContext(conf)
12 | val words = Array("one", "two", "two", "three", "three", "three")
13 | val wordsRDD = sc.parallelize(words).map(word => (word, 1))
14 | val wordsCountWithReduce = wordsRDD.
15 | reduceByKey(_ + _).
16 | collect().
17 | foreach(println)
18 | val wordsCountWithGroup = wordsRDD.
19 | groupByKey().
20 | map(w => (w._1, w._2.sum)).
21 | collect().
22 | foreach(println)
23 | ```
24 | 虽然两个函数都能得出正确的结果, 但reduceByKey函数更适合使用在大数据集上。 这是因为Spark知道它可以在每个分区移动数据之前将输出数据与一个共用的`key`结合。
25 |
26 | 借助下图可以理解在reduceByKey里发生了什么。 在数据对被搬移前,同一机器上同样的`key`是怎样被组合的( reduceByKey中的 lamdba 函数)。然后 lamdba 函数在每个分区上被再次调用来将所有值 reduce成最终结果。整个过程如下:
27 |
28 | 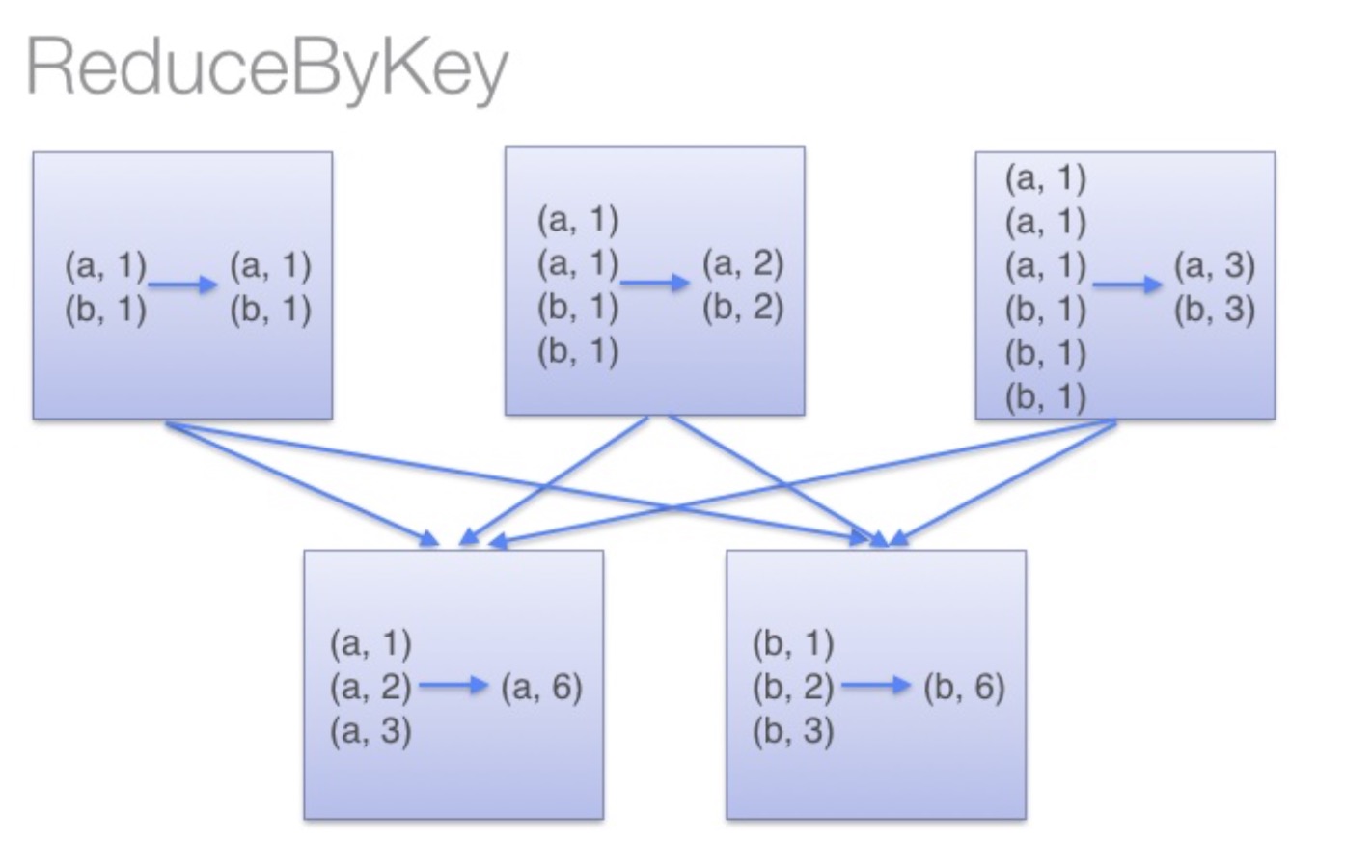
29 |
30 | 另一方面,当调用 groupByKey时,所有的键值对(key-value pair) 都会被移动,在网络上传输这些数据非常没必要,因此避免使用 GroupByKey。
31 |
32 | 为了确定将数据对移到哪个主机,Spark会对数据对的`key`调用一个分区算法。 当移动的数据量大于单台执行机器内存总量时`Spark`会把数据保存到磁盘上。 不过在保存时每次会处理一个`key`的数据,所以当单个 key 的键值对超过内存容量会存在内存溢出的异常。 这将会在之后发行的 Spark 版本中更加优雅地处理,这样的工作还可以继续完善。 尽管如此,仍应避免将数据保存到磁盘上,这会严重影响性能。
33 |
34 | 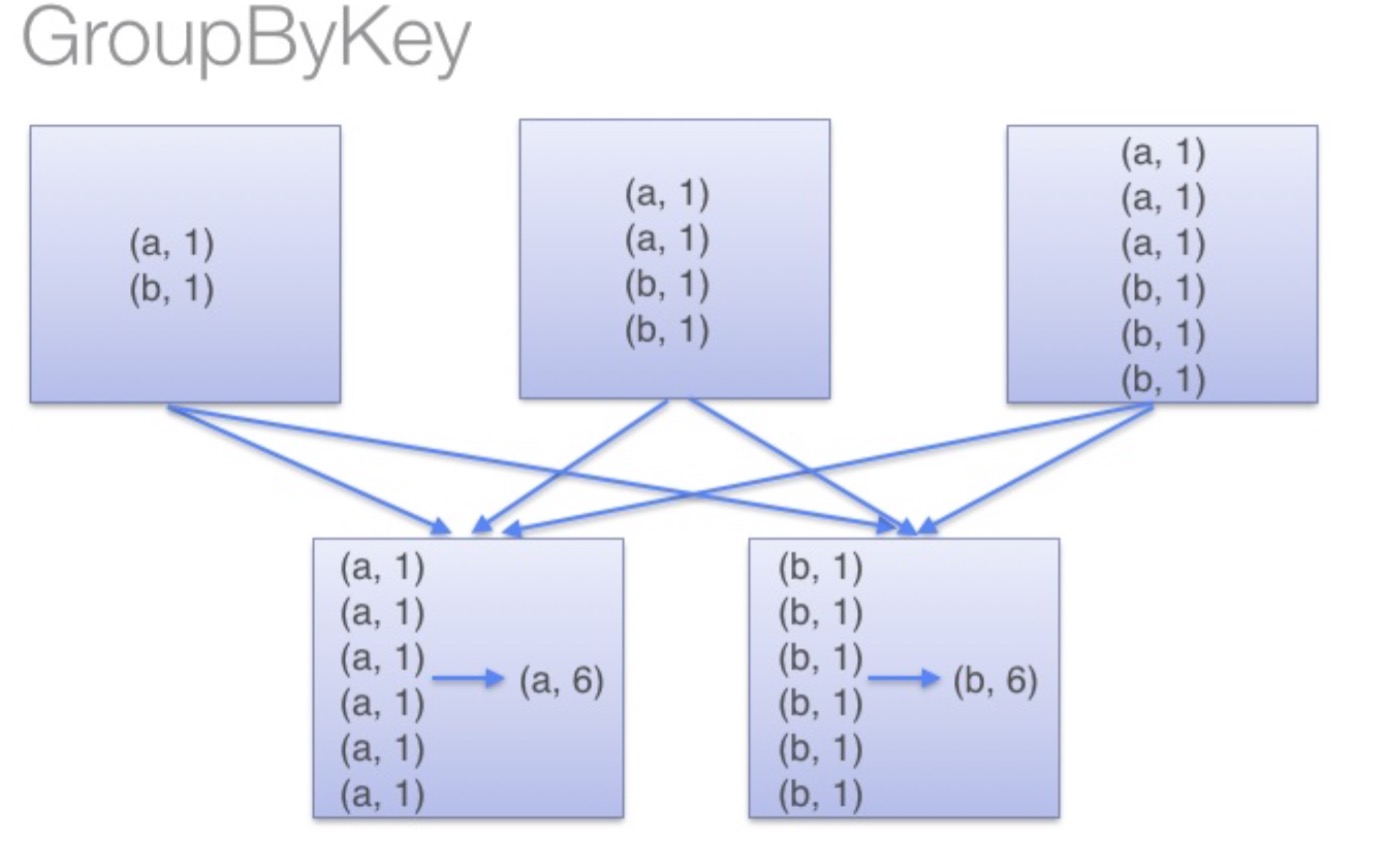
35 |
36 | 你可以想象一个非常大的数据集,在使用 reduceByKey 和 groupByKey 时他们的差别会被放大更多倍。
37 |
38 | 我们来看看两个函数的实现:
39 |
40 | ```scala
41 | def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
42 | combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
43 | }
44 | ```
45 |
46 | ```scala
47 | /**
48 | * Note: As currently implemented, groupByKey must be able to hold all the key-value pairs for any
49 | * key in memory. If a key has too many values, it can result in an [[OutOfMemoryError]].
50 | */
51 | def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
52 | // groupByKey shouldn't use map side combine because map side combine does not
53 | // reduce the amount of data shuffled and requires all map side data be inserted
54 | // into a hash table, leading to more objects in the old gen.
55 | val createCombiner = (v: V) => CompactBuffer(v)
56 | val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
57 | val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
58 | val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
59 | createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
60 | bufs.asInstanceOf[RDD[(K, Iterable[V])]]
61 | }
62 | ```
63 |
64 | **注意`mapSideCombine=false`,partitioner是`HashPartitioner`**,但是groupByKey对小数据量比较好,一个key对应的个数少于10个。
65 |
66 | 他们都调用了`combineByKeyWithClassTag`,我们再来看看`combineByKeyWithClassTag`的定义:
67 |
68 | ```scala
69 | def combineByKeyWithClassTag[C](
70 | createCombiner: V => C,
71 | mergeValue: (C, V) => C,
72 | mergeCombiners: (C, C) => C,
73 | partitioner: Partitioner,
74 | mapSideCombine: Boolean = true,
75 | serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)]
76 | ```
77 |
78 | combineByKey函数主要接受了三个函数作为参数,分别为createCombiner、mergeValue、mergeCombiners。这三个函数足以说明它究竟做了什么。理解了这三个函数,就可以很好地理解combineByKey。
79 |
80 | combineByKey是将RDD[(K,V)]combine为RDD[(K,C)],因此,首先需要提供一个函数,能够完成从V到C的combine,称之为combiner。如果V和C类型一致,则函数为V => V。倘若C是一个集合,例如Iterable[V],则createCombiner为V => Iterable[V]。
81 |
82 | mergeValue则是将原RDD中Pair的Value合并为操作后的C类型数据。合并操作的实现决定了结果的运算方式。所以,mergeValue更像是声明了一种合并方式,它是由整个combine运算的结果来导向的。函数的输入为原RDD中Pair的V,输出为结果RDD中Pair的C。
83 |
84 | 最后的mergeCombiners则会根据每个Key所对应的多个C,进行归并。
85 |
86 | 例如:
87 |
88 | ```scala
89 | var rdd1 = sc.makeRDD(Array(("A", 1), ("A", 2), ("B", 1), ("B", 2),("B",3),("B",4), ("C", 1)))
90 | rdd1.combineByKey(
91 | (v: Int) => v + "_",
92 | (c: String, v: Int) => c + "@" + v,
93 | (c1: String, c2: String) => c1 + "$" + c2
94 | ).collect.foreach(println)
95 | ```
96 |
97 | result不确定欧,单机执行不会调用mergeCombiners:
98 |
99 | ```scala
100 | (B,1_@2@3@4)
101 | (A,1_@2)
102 | (C,1_)
103 | ```
104 | 在集群情况下:
105 |
106 | ```scala
107 | (B,2_@3@4$1_)
108 | (A,1_@2)
109 | (C,1_)
110 | 或者
111 | (B,1_$2_@3@4)
112 | (A,1_@2)
113 | (C,1_)
114 |
115 | ```
116 |
117 | `mapSideCombine=false`时,再体验一下运行结果。
118 |
119 | 有许多函数比goupByKey好:
120 |
121 | 1. 当你combine元素时,可以使用`combineByKey`,但是输入值类型和输出可能不一样
122 | 2. `foldByKey`合并每一个 key 的所有值,在级联函数和“零值”中使用。
123 |
124 | ```scala
125 | //使用combineByKey计算wordcount
126 | wordsRDD.map(word=>(word,1)).combineByKey(
127 | (v: Int) => v,
128 | (c: Int, v: Int) => c+v,
129 | (c1: Int, c2: Int) => c1 + c2
130 | ).collect.foreach(println)
131 |
132 | //使用foldByKey计算wordcount
133 | println("=======foldByKey=========")
134 | wordsRDD.map(word=>(word,1)).foldByKey(0)(_+_).foreach(println)
135 |
136 | //使用aggregateByKey计算wordcount
137 | println("=======aggregateByKey============")
138 | wordsRDD.map(word=>(word,1)).aggregateByKey(0)((u:Int,v)=>u+v,_+_).foreach(println)
139 | ```
140 |
141 | `foldByKey`,`aggregateByKey`都是由combineByKey实现,并且`mapSideCombine=true`,因此可以使用这些函数替代goupByKey。
142 |
143 | ###参考
144 | [Spark中的combineByKey](http://zhangyi.farbox.com/post/kai-yuan-kuang-jia/combinebykey-in-spark )
145 |
146 | [databricks gitbooks](https://databricks.gitbooks.io/databricks-spark-knowledge-base/content/best_practices/prefer_reducebykey_over_groupbykey.html)
147 |
148 | [在Spark中尽量少使用GroupByKey函数](http://www.iteblog.com/archives/1357)
--------------------------------------------------------------------------------
/spark-knowledge/md/spark统一内存管理.md:
--------------------------------------------------------------------------------
1 | #spark统一内存管理
2 |
3 | spark从1.6.0开始内存管理发生了变化,原来的内存管理由[StaticMemoryManager](https://github.com/apache/spark/blob/branch-1.6/core/src/main/scala/org/apache/spark/memory/StaticMemoryManager.scala)实现,现在被称为`Legacy`,在1.5.x和1.6.0中运行相同代码的行为是不同的,为了兼容`Legacy`,可以通过`spark.memory.useLegacyMode`来设置,默认该参数是关闭的。
4 |
5 | 前面有一篇介绍spark内存管理的文章[spark内存概述](http://www.jianshu.com/p/f0f28af4bd83),现在介绍1.6.0的内存管理,由[UnifiedMemoryManager](https://github.com/apache/spark/blob/branch-1.6/core/src/main/scala/org/apache/spark/memory/UnifiedMemoryManager.scala)实现。
6 |
7 | 1.6.0的统一内存管理如下:
8 |
9 | 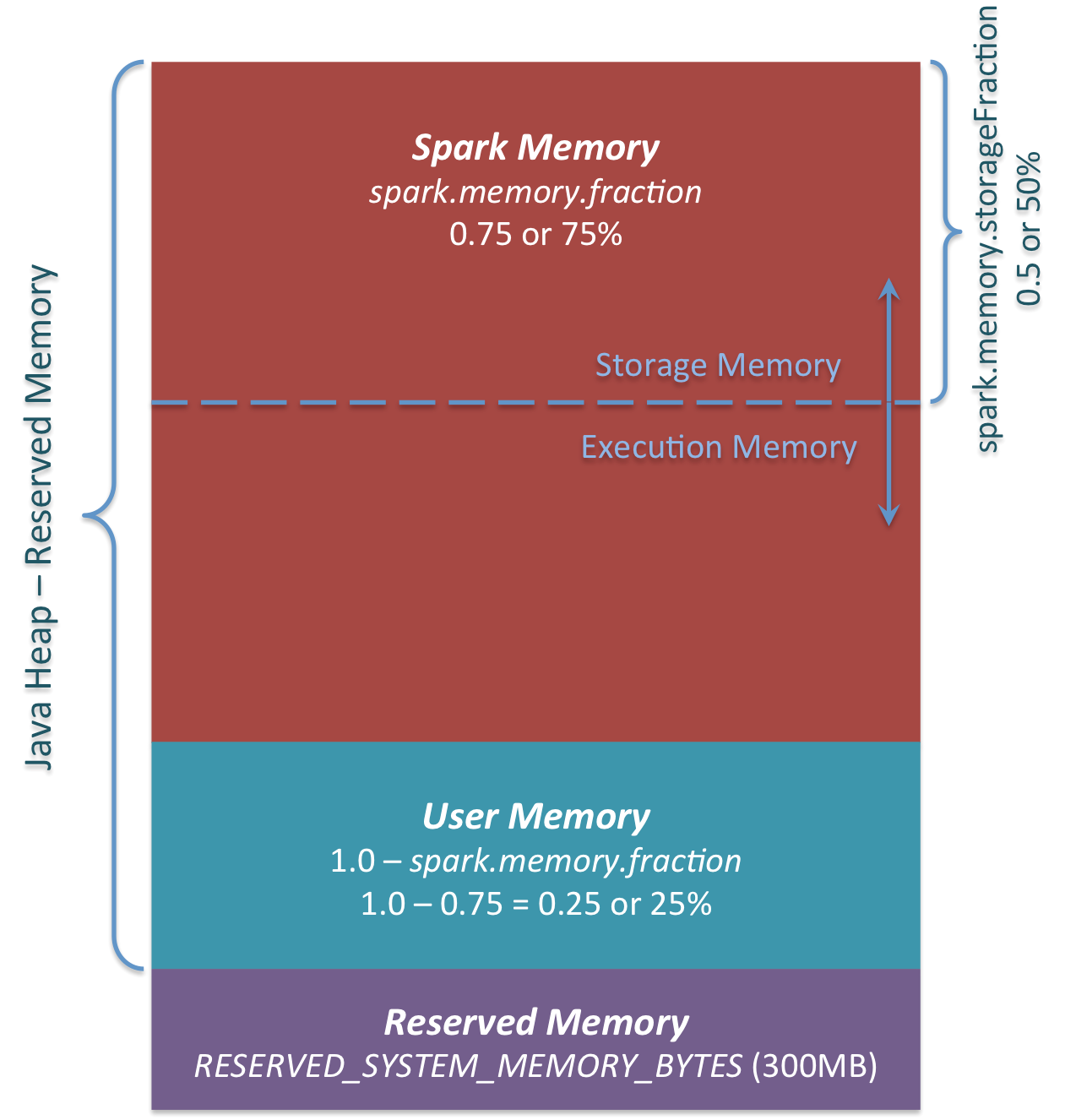
10 |
11 | 主要有三部分组成:
12 |
13 | **1 Reserved Memory**
14 |
15 | 这部分内存是预留给**系统**使用,是固定不变的。在1.6.0默认为300MB(`RESERVED_SYSTEM_MEMORY_BYTES = 300 * 1024 * 1024`),这一部分内存不计算在spark execution和storage中,除了重新编译spark和` spark.testing.reservedMemory`,Reserved Memory是不可以改变的,` spark.testing.reservedMemory`不推荐使用在实际运行环境中。是用来存储Spark internal objects,并且限制JVM的大小,如果executor的大小小于1.5 * Reserved Memory = 450MB ,那么就会报 “please use larger heap size”的错误,源码如下。
16 |
17 | ```scala
18 | val minSystemMemory = reservedMemory * 1.5
19 | if (systemMemory < minSystemMemory) {
20 | throw new IllegalArgumentException(s"System memory $systemMemory must " +
21 | s"be at least $minSystemMemory. Please use a larger heap size.")
22 | }
23 | ```
24 |
25 | **2 User Memory**
26 |
27 | 分配**Spark Memory**剩余的内存,用户可以根据需要使用。可以存储`RDD transformations`需要的数据结构,例如, 重写`spark aggregation`,使用`mapPartition transformation`,通过`hash table`来实现`aggregation`,这样使用的就是`User Memory`。在1.6.0中,计算方法为**`(“Java Heap” – “Reserved Memory”) * (1.0 – spark.memory.fraction)`**,默认为**` (“Java Heap” – 300MB) * 0.25`**,比如4GB的heap大小,那么`User Memory`的大小为949MB。由用户来决定存储的数据量,因此要遵守这个边界,不然会导致OOM。
28 |
29 |
30 | **3 Spark Memory**
31 |
32 | 计算方式是**`(“Java Heap” – “Reserved Memory”) * spark.memory.fraction`**,在1.6.0中,默认为**` (“Java Heap” – 300MB) * 0.75`**。例如推的大小为4GB,那么`Spark Memory`为2847MB。`Spark Memory`又分为`Storage Memory`和`Execution Memory`两部分。两个边界由`spark.memory.storageFraction`设定,默认为0.5。但是两部分可以动态变化,相互之间可以借用,如果一方使用完,可以向另一方借用。先看看两部分是如何使用的。
33 |
34 | * > **Storage Memory** 用来存储`spark cached data`也可作为临时空间存储序列化`unroll`,`broadcast variables`作为`cached block`存储,但是需要注意,这是[unroll](https://github.com/apache/spark/blob/branch-1.6/core/src/main/scala/org/apache/spark/storage/MemoryStore.scala#L249)源码,`unrolled block`如果内存不够,会存储在`driver`端。`broadcast variables`大部分存储级别为`MEMORY_AND_DISK`。
35 |
36 | * > **Execution Memory** 存储Spark task执行过程中需要的对象,例如,Shuffle中map端中间数据的存储,以及hash aggregation中的hash table。如果内存不足,该空间也容许spill到磁盘。
37 |
38 | `Execution Memory`不可以淘汰block,不然执行的时候就会fail,如果找不到block。`Storage Memory`中的内容可以淘汰。`Execution Memory`满足两种情况可以向`Storage Memory`借用空间:
39 |
40 | 1. `Storage Memory`还有free空间
41 |
42 | 2. `Storage Memory`大于初始化时的空间(`"Spark Memory" * spark.memory.storageFraction = (“Java Heap” – “Reserved Memory”) * spark.memory.fraction * spark.memory.storageFraction`)
43 |
44 | `Storage Memory`只有在`Execution Memory`有free空间时,才可以借用。
45 |
46 | ##参考
47 |
48 | [spark memory management](http://0x0fff.com/spark-memory-management/)
49 |
50 | [Spark Broadcast](http://www.kancloud.cn/kancloud/spark-internals/45238)
--------------------------------------------------------------------------------
/spark-knowledge/md/tungsten-sort-shuffle.md:
--------------------------------------------------------------------------------
1 | 正如你所知,spark实现了多种shuffle方法,通过 spark.shuffle.manager来确定。暂时总共有三种:hash shuffle、sort shuffle和tungsten-sort shuffle,从1.2.0开始默认为sort shuffle。本节主要介绍tungsten-sort。
2 |
3 | spark在1.4以后可以通过(spark.shuffle.manager = tungsten-sort)开启Tungsten-sort shuffle。如果Tungsten-sort 发现自己无法处理,则会自动使用 Sort Based Shuffle进行处理。
4 |
5 | Tungsten-sort优化点主要有:
6 |
7 | * > 直接在serialized binary data上操作,不需要反序列化,使用unsafe内存copy函数直接copy数据。
8 | * > 提供cache-efficient sorter [ShuffleExternalSorter](https://github.com/apache/spark/blob/master/core/src/main/java/org/apache/spark/shuffle/sort/ShuffleExternalSorter.java)排序压缩记录指针和partition ids,使用一个8bytes的指针,把排序转化成了一个指针数组的排序。
9 | * > spilling的时候不需要反序列化和序列化
10 | * > spill的merge过程也无需反序列化即可完成,但需要**shuffle.unsafe.fastMergeEnabled**的支持
11 |
12 | 当且仅当下面条件都满足时,才会使用新的Shuffle方式:
13 |
14 | * > Shuffle dependency 不能带有aggregation 或者输出需要排序
15 | * > Shuffle 的序列化器需要是 KryoSerializer 或者 Spark SQL's 自定义的一些序列化方式.
16 | * > Shuffle 文件的数量不能大于 16777216
17 | * > 序列化时,单条记录不能大于 128 MB
18 |
19 | 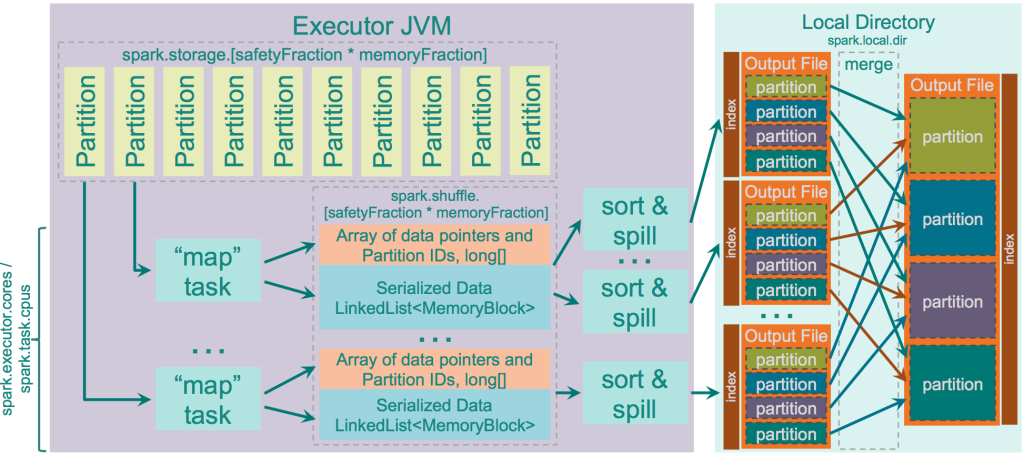
20 |
21 | ##优点
22 |
23 | 很多性能的优化
24 |
25 | ##缺点
26 |
27 | 1. 不可以在mapper端排序
28 | 2. 不稳定
29 | 3. 没有提供off-heap排序缓存
30 |
31 | ##参考
32 | [Spark Tungsten-sort Based Shuffle 分析](http://www.jianshu.com/p/d328c96aebfd)
33 |
34 | [探索Spark Tungsten的秘密](https://github.com/hustnn/TungstenSecret/tree/master)
--------------------------------------------------------------------------------
/spark-knowledge/md/zeppelin搭建.md:
--------------------------------------------------------------------------------
1 | zeppelin编译命令
2 | mvn clean package -Pspark-1.4 -Dhadoop.version=2.6.0-cdh5.4.1 -Phadoop-2.6 -Pvendor-repo -Pyarn -Ppyspark -DskipTests
3 |
4 | 配置文件为:
5 | [interpreter.json](../resources/zeppelin/interpreter.json)
6 |
7 | [zeppelin-env.sh](../resources/zeppelin/zeppelin-env.sh)
--------------------------------------------------------------------------------
/spark-knowledge/md/使用spark进行数据挖掘--音乐推荐.md:
--------------------------------------------------------------------------------
1 |
2 | [协同过滤定义](https://zh.wikipedia.org/wiki/協同過濾)
3 |
4 | [协同过滤算法介绍](http://www.infoq.com/cn/articles/recommendation-algorithm-overview-part02?utm_source=infoq&utm_medium=related_content_link&utm_campaign=relatedContent_articles_clk)
5 |
6 | [使用LFM(Latent factor model)隐语义模型进行Top-N推荐
7 | ](http://blog.csdn.net/harryhuang1990/article/details/9924377)
8 |
9 | [余弦相似](http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html)
10 |
11 |
--------------------------------------------------------------------------------
/spark-knowledge/md/利用spark进行数据挖掘-数据清洗.md:
--------------------------------------------------------------------------------
1 | 数据清洗是数据分析的第一步,也是最重要的一步。但是很多数据分析师不会做,因为相对于使用高深的机器学习算法进行数据挖掘得到最终结果来说,太单调乏味而且还不会产生出结果。大家多听过“garbage in,garbage out”,但是很多是通过得出偏差的结果后再回去进行数据清洗。应该在数据的整个生命周期都应该发现有意思的和有意义的结果,技巧和精力应用的越早,对产品的结果就越有信心。
2 |
3 | ##spark编程模型
4 |
5 | * > 在输入数据集上定义transformations
6 | * > 在transformated的数据集调用actions,把结果保存或者返回给driver memory
7 | * > 本地执行模仿分布式执行,帮助确定transformations和actions
8 |
9 | ##记录关联
10 |
11 | 记录关联(record linkage)包括实体解析、去重、合并分拆等。我们收集的数据大部分表示一个实体,比如用户、病人、商业地址和事件,他们有很多属性,例如name、address、phone等,我们需要通过这些属性来确定记录表示的是同一个实体,但是这些属性没有那么好,值可能表示形式不一样,类型不一样,甚至会缺失。如下表:
12 |
13 | | *Name* | *Address* | City | State | Phone|
14 | | :-------------: |:-------------------:| :-----:| :-----:| :-----:|
15 | |Josh’s Co ee Shop|1234 Sunset Boulevard |West Hollywood|CA|(213)-555-1212
16 | |Josh Cofee|1234 Sunset Blvd West |Hollywood|CA|555-1212|
|Coffee Chain #1234|1400 Sunset Blvd #2|Hollywood|CA|206-555-1212|
17 | |Coffee Chain Regional Office| 1400 Sunset Blvd Suite 2|Hollywood|CA|206-555-1212|
18 |
19 | 第一个实体和第二个是同一个,虽然看起来他们好像处在不同的城市。三表示咖啡店,四表示办公地点,但两个同时都给了公司总部的电话号码。因此进行记录关联是比较困难。
20 |
21 | ##例子
22 |
23 | 以病人的信息为例,处理数据的流程为:
24 |
25 | 1. 创建RDD,有两种方式:(1)通过外部数据源;(2)别的RDD通过transformation
26 | 2. 数据简单过滤(比如去掉第一行)
27 | 3. 用case class表示,这样每个字段都有名字
28 | 4. 如果数据后面会多次处理,那么最好调用cache
29 | 5. 做一些简单统计,比如个数,均值,方差等
30 | 6. 创建通用统计代码
--------------------------------------------------------------------------------
/spark-knowledge/resources/zeppelin/interpreter.json:
--------------------------------------------------------------------------------
1 | {
2 | "interpreterSettings": {
3 | "2AGQQSEAN": {
4 | "id": "2AGQQSEAN",
5 | "name": "sh",
6 | "group": "sh",
7 | "properties": {},
8 | "interpreterGroup": [
9 | {
10 | "class": "org.apache.zeppelin.shell.ShellInterpreter",
11 | "name": "sh"
12 | }
13 | ],
14 | "option": {
15 | "remote": true
16 | }
17 | },
18 | "2AHG28XSJ": {
19 | "id": "2AHG28XSJ",
20 | "name": "md",
21 | "group": "md",
22 | "properties": {},
23 | "interpreterGroup": [
24 | {
25 | "class": "org.apache.zeppelin.markdown.Markdown",
26 | "name": "md"
27 | }
28 | ],
29 | "option": {
30 | "remote": true
31 | }
32 | },
33 | "2AEJNH3KK": {
34 | "id": "2AEJNH3KK",
35 | "name": "spark",
36 | "group": "spark",
37 | "properties": {
38 | "spark.cores.max": "",
39 | "spark.yarn.jar": "",
40 | "master": "local[*]",
41 | "zeppelin.spark.maxResult": "10000",
42 | "zeppelin.dep.localrepo": "local-repo",
43 | "spark.app.name": "Zeppelin",
44 | "spark.executor.memory": "512m",
45 | "zeppelin.spark.useHiveContext": "false",
46 | "zeppelin.spark.concurrentSQL": "false",
47 | "args": "",
48 | "spark.home": "/opt/spark-1.5.2-bin-hadoop2.6",
49 | "zeppelin.pyspark.python": "python",
50 | "zeppelin.dep.additionalRemoteRepository": "spark-packages,http://dl.bintray.com/spark-packages/maven,false;"
51 | },
52 | "interpreterGroup": [
53 | {
54 | "class": "org.apache.zeppelin.spark.SparkInterpreter",
55 | "name": "spark"
56 | },
57 | {
58 | "class": "org.apache.zeppelin.spark.PySparkInterpreter",
59 | "name": "pyspark"
60 | },
61 | {
62 | "class": "org.apache.zeppelin.spark.SparkSqlInterpreter",
63 | "name": "sql"
64 | },
65 | {
66 | "class": "org.apache.zeppelin.spark.DepInterpreter",
67 | "name": "dep"
68 | }
69 | ],
70 | "option": {
71 | "remote": true
72 | }
73 | },
74 | "2AHCKV2A2": {
75 | "id": "2AHCKV2A2",
76 | "name": "spark-cluster",
77 | "group": "spark",
78 | "properties": {
79 | "spark.cores.max": "",
80 | "spark.yarn.jar": "",
81 | "master": "yarn-client",
82 | "zeppelin.spark.maxResult": "1000",
83 | "spark.executor.uri": "",
84 | "zeppelin.dep.localrepo": "local-repo",
85 | "spark.app.name": "zeppelin-root",
86 | "spark.executor.memory": "",
87 | "zeppelin.spark.useHiveContext": "true",
88 | "args": "",
89 | "spark.home": "/opt/cloudera/parcels/CDH/lib/spark/",
90 | "zeppelin.spark.concurrentSQL": "true",
91 | "zeppelin.pyspark.python": "python",
92 | "zeppelin.dep.additionalRemoteRepository": "spark-packages,http://dl.bintray.com/spark-packages/maven,false;"
93 | },
94 | "interpreterGroup": [
95 | {
96 | "class": "org.apache.zeppelin.spark.SparkInterpreter",
97 | "name": "spark"
98 | },
99 | {
100 | "class": "org.apache.zeppelin.spark.PySparkInterpreter",
101 | "name": "pyspark"
102 | },
103 | {
104 | "class": "org.apache.zeppelin.spark.SparkSqlInterpreter",
105 | "name": "sql"
106 | },
107 | {
108 | "class": "org.apache.zeppelin.spark.DepInterpreter",
109 | "name": "dep"
110 | }
111 | ],
112 | "option": {
113 | "remote": true
114 | }
115 | },
116 | "2AJ7D1X15": {
117 | "id": "2AJ7D1X15",
118 | "name": "test",
119 | "group": "sh",
120 | "properties": {},
121 | "interpreterGroup": [
122 | {
123 | "class": "org.apache.zeppelin.shell.ShellInterpreter",
124 | "name": "sh"
125 | }
126 | ],
127 | "option": {
128 | "remote": true
129 | }
130 | }
131 | },
132 | "interpreterBindings": {
133 | "2A94M5J1Z": [
134 | "2AHCKV2A2",
135 | "2AHG28XSJ",
136 | "2AGQQSEAN"
137 | ],
138 | "2BBWW24SA": [
139 | "2AEJNH3KK",
140 | "2AHG28XSJ",
141 | "2AGQQSEAN"
142 | ]
143 | }
144 | }
--------------------------------------------------------------------------------
/spark-knowledge/resources/zeppelin/zeppelin-env.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | #
3 | # Licensed to the Apache Software Foundation (ASF) under one or more
4 | # contributor license agreements. See the NOTICE file distributed with
5 | # this work for additional information regarding copyright ownership.
6 | # The ASF licenses this file to You under the Apache License, Version 2.0
7 | # (the "License"); you may not use this file except in compliance with
8 | # the License. You may obtain a copy of the License at
9 | #
10 | # http://www.apache.org/licenses/LICENSE-2.0
11 | #
12 | # Unless required by applicable law or agreed to in writing, software
13 | # distributed under the License is distributed on an "AS IS" BASIS,
14 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | # See the License for the specific language governing permissions and
16 | # limitations under the License.
17 | #
18 |
19 | # export JAVA_HOME=
20 | # export MASTER= # Spark master url. eg. spark://master_addr:7077. Leave empty if you want to use local mode
21 | # export ZEPPELIN_JAVA_OPTS # Additional jvm options. for example, export ZEPPELIN_JAVA_OPTS="-Dspark.executor.memory=8g -Dspark.cores.max=16"
22 | # export ZEPPELIN_MEM # Zeppelin jvm mem options Default -Xmx1024m -XX:MaxPermSize=512m
23 | # export ZEPPELIN_INTP_MEM # zeppelin interpreter process jvm mem options. Defualt = ZEPPELIN_MEM
24 | # export ZEPPELIN_INTP_JAVA_OPTS # zeppelin interpreter process jvm options. Default = ZEPPELIN_JAVA_OPTS
25 |
26 | # export ZEPPELIN_LOG_DIR # Where log files are stored. PWD by default.
27 | # export ZEPPELIN_PID_DIR # The pid files are stored. /tmp by default.
28 | # export ZEPPELIN_NOTEBOOK_DIR # Where notebook saved
29 | # export ZEPPELIN_IDENT_STRING # A string representing this instance of zeppelin. $USER by default.
30 | # export ZEPPELIN_NICENESS # The scheduling priority for daemons. Defaults to 0.
31 |
32 | # export ZEPPELIN_SPARK_USEHIVECONTEXT # Use HiveContext instead of SQLContext if set true. true by default.
33 | # export ZEPPELIN_SPARK_CONCURRENTSQL # Execute multiple SQL concurrently if set true. false by default.
34 | # export ZEPPELIN_SPARK_MAXRESULT # Max number of SparkSQL result to display. 1000 by default.
35 |
36 | # Options read in YARN client mode
37 | # export HADOOP_CONF_DIR # yarn-site.xml is located in configuration directory in HADOOP_CONF_DIR.
38 |
39 | # Pyspark (supported with Spark 1.2.1 and above)
40 | # To configure pyspark, you need to set spark distribution's path to 'spark.home' property in Interpreter setting screen in Zeppelin GUI
41 | # export PYSPARK_PYTHON # path to the python command. must be the same path on the driver(Zeppelin) and all workers.
42 | # export PYTHONPATH # extra PYTHONPATH.
43 |
44 |
45 |
46 | export HADOOP_CONF_DIR="/etc/hadoop/conf"
47 | export MESOS_NATIVE_JAVA_LIBRARY=""
48 | export PYTHONPATH="/opt/cloudera/parcels/CDH/lib/spark/python:/opt/cloudera/parcels/CDH/lib/spark/python/lib/py4j-0.8.2.1-src.zip"
49 | export SPARK_YARN_USER_ENV="PYTHONPATH=${PYTHONPATH}"
50 | export ZEPPELIN_PORT=8888
51 |
--------------------------------------------------------------------------------
/spark-streaming-demo/README.md:
--------------------------------------------------------------------------------
1 | #spark streaming
2 |
3 | 测试代码主要包含的内容如下:
4 |
5 | * [spark streaming kafka测试用例,可以在实际环境中使用](md/spark-streaming-kafka测试用例.md)
6 |
7 | * spark streaming和DataFrame结合使用测试用例
8 |
9 | * spark streaming中mapWithState测试
--------------------------------------------------------------------------------
/spark-streaming-demo/md/mapWithState.md:
--------------------------------------------------------------------------------
1 | mapWithState的延迟是updateStateByKey的6X,维持10X的keys的状态。导致这种情况的原因是:
2 |
3 | * > 避免处理没有新数据的keys
4 |
5 | * > 限制计算新数据keys的数量,这样可以减少每批次处理延迟
--------------------------------------------------------------------------------
/spark-streaming-demo/md/spark-streaming-kafka测试用例.md:
--------------------------------------------------------------------------------
1 | 从kafka读取数据,通过spark streaming处理,并确保可靠性,可在实际应用中使用。
2 |
3 | 接收模型
4 | ```scala
5 | val ssc:StreamingContext=???
6 | val kafkaParams:Map[String,String]=Map("group.id"->"test",...)
7 | val readParallelism=5
8 | val topics=Map("test"->1)
9 |
10 | //启动5个接收tasks
11 | val kafkaDStreams = (1 to readParallelism).map{_ =>
12 | KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](
13 | ssc, kafkaParams, topicMap, StorageLevel.MEMORY_AND_DISK_SER_2)
14 | }
15 |
16 | val unionDStream = ssc.union(kafkaDStreams)
17 |
18 | //一个DStream,20个partition
19 | val processingParallelism=20
20 | val processingDStream = unionDStream(processingParallelism)
21 |
22 | ```
23 |
24 | idea调试过程中,application配置文件的配置如下:
25 | 
26 |
27 | 测试命令
28 |
29 | ```scala
30 | spark-submit --master local[5] --class cn.thinkjoy.utils4s.sparkstreaming.SparkStreamingDemo sparkstreaming-demo-1.0-SNAPSHOT-jar-with-dependencies.jar 10.254.212.167,10.136.3.214/kafka test test 1 1
31 | ```
32 |
33 | 在实际环境中,只需去掉 `--master local[5]`
34 |
35 | ##参考
36 | [整合Kafka到Spark Streaming——代码示例和挑战](http://dataunion.org/6308.html)
--------------------------------------------------------------------------------
/spark-streaming-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.sparkstreaming
11 | spark-streaming-demo
12 | 2008
13 |
14 |
15 | 2.10.4
16 | 2.10
17 | 1.6.0
18 |
19 |
20 |
21 | org.apache.hadoop
22 | hadoop-common
23 | 2.6.0
24 | compile
25 |
26 |
27 | org.apache.spark
28 | spark-core_${soft.scala.version}
29 | ${spark.version}
30 | compile
31 |
32 |
33 | org.apache.spark
34 | spark-streaming_${soft.scala.version}
35 | ${spark.version}
36 | compile
37 |
38 |
39 | org.apache.spark
40 | spark-streaming-kafka_${soft.scala.version}
41 | ${spark.version}
42 | compile
43 |
44 |
45 | org.apache.spark
46 | spark-hive_${soft.scala.version}
47 | ${spark.version}
48 | compile
49 |
50 |
51 | org.apache.spark
52 | spark-core_${soft.scala.version}
53 |
54 |
55 |
56 |
57 |
58 |
59 |
--------------------------------------------------------------------------------
/spark-streaming-demo/src/main/scala/cn/thinkjoy/utils4s/sparkstreaming/MapWithStateApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.sparkstreaming
2 |
3 | import scala.util.Random
4 |
5 | import org.apache.spark._
6 | import org.apache.spark.streaming._
7 | import org.apache.spark.storage._
8 | import org.apache.spark.streaming.receiver.Receiver
9 |
10 | /**
11 | * 1.6中mapWitchState的测试
12 | * databricks的测试用例:https://docs.cloud.databricks.com/docs/spark/1.6/examples/Streaming%20mapWithState.html
13 | * databricks文章介绍:https://databricks.com/blog/2016/02/01/faster-stateful-stream-processing-in-spark-streaming.html
14 | * Created by xbsu on 16/2/3.
15 | */
16 |
17 | class DummySource(ratePerSec: Int) extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) {
18 |
19 | def onStart() {
20 | // Start the thread that receives data over a connection
21 | new Thread("Dummy Source") {
22 | override def run() {
23 | receive()
24 | }
25 | }.start()
26 | }
27 |
28 | def onStop() {
29 | // There is nothing much to do as the thread calling receive()
30 | // is designed to stop by itself isStopped() returns false
31 | }
32 |
33 | /** Create a socket connection and receive data until receiver is stopped */
34 | private def receive() {
35 | while (!isStopped()) {
36 | store("I am a dummy source " + Random.nextInt(10))
37 | Thread.sleep((1000.toDouble / ratePerSec).toInt)
38 | }
39 | }
40 | }
41 |
42 | object MapWithStateApp {
43 | def main(args: Array[String]) {
44 |
45 | val sparkConf = new SparkConf().setAppName("mapWithState").setMaster("local")
46 | val sc = new SparkContext(sparkConf)
47 | val batchIntervalSeconds = 2
48 | val eventsPerSecond = 10
49 | // Create a StreamingContext
50 | val ssc = new StreamingContext(sc, Seconds(batchIntervalSeconds))
51 |
52 | // Create a stream that generates 1000 lines per second
53 | val stream = ssc.receiverStream(new DummySource(eventsPerSecond))
54 |
55 | // Split the lines into words, and create a paired (key-value) dstream
56 | val wordStream = stream.flatMap {
57 | _.split(" ")
58 | }.map(word => (word, 1))
59 |
60 | val initialRDD = sc.parallelize(List(("dummy", 100L), ("source", 32L)))
61 | val stateSpec = StateSpec.function(trackStateFunc _)
62 | .initialState(initialRDD)
63 | .numPartitions(2)
64 | .timeout(Seconds(60))
65 |
66 | // This represents the emitted stream from the trackStateFunc. Since we emit every input record with the updated value,
67 | // this stream will contain the same # of records as the input dstream.
68 | val wordCountStateStream = wordStream.mapWithState(stateSpec)
69 | wordCountStateStream.print()
70 |
71 | // A snapshot of the state for the current batch. This dstream contains one entry per key.
72 | val stateSnapshotStream = wordCountStateStream.stateSnapshots()
73 | stateSnapshotStream.print()
74 | //stateSnapshotStream.foreachRDD { rdd =>
75 | // rdd.toDF("word", "count").registerTempTable("batch_word_count")
76 | //}
77 |
78 | // To make sure data is not deleted by the time we query it interactively
79 | //ssc.remember(Minutes(1))
80 |
81 | ssc.checkpoint("checkpoint")
82 |
83 | // Start the streaming context in the background.
84 | ssc.start()
85 |
86 | // This is to ensure that we wait for some time before the background streaming job starts.
87 | // This will put this cell on hold for 5 times the batchIntervalSeconds.
88 | ssc.awaitTerminationOrTimeout(batchIntervalSeconds * 2 * 1000)
89 | }
90 |
91 | /**
92 | * In this example:
93 | * - key is the word.
94 | * - value is '1'. Its type is 'Int'.
95 | * - state has the running count of the word. It's type is Long. The user can provide more custom classes as type too.
96 | * - The return value is the new (key, value) pair where value is the updated count.
97 | */
98 |
99 | def trackStateFunc(key: String, value: Option[Int], state: State[Long]): Option[(String, Long)] = {
100 | val sum = value.getOrElse(0).toLong + state.getOption.getOrElse(0L)
101 | val output = (key, sum)
102 | state.update(sum)
103 | Some(output)
104 | }
105 |
106 | }
107 |
--------------------------------------------------------------------------------
/spark-streaming-demo/src/main/scala/cn/thinkjoy/utils4s/sparkstreaming/SparkStreamingDataFrameDemo.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.sparkstreaming
2 |
3 | import kafka.serializer.StringDecoder
4 | import org.apache.spark.sql.SQLContext
5 | import org.apache.spark.storage.StorageLevel
6 | import org.apache.spark.streaming.kafka.KafkaUtils
7 | import org.apache.spark.streaming.{Minutes, Seconds, StreamingContext}
8 | import org.apache.spark.{SparkContext, SparkConf}
9 |
10 | /**
11 | * Created by jacksu on 16/1/4.
12 | */
13 | object SparkStreamingDataFrameDemo {
14 | def main(args: Array[String]) {
15 | if (args.length < 4) {
16 | System.err.println("Usage: KafkaWordCount ")
17 | System.exit(1)
18 | }
19 |
20 | val Array(zkQuorum, group, topics, numThreads, batch) = args
21 | val sparkConf = new SparkConf().setAppName("KafkaWordCount")
22 | val sc = new SparkContext(sparkConf)
23 | val ssc = new StreamingContext(sc, Seconds(batch.toInt))
24 | ssc.checkpoint("checkpoint")
25 |
26 | //numThreads 处理每个topic的线程数
27 | val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
28 | val kafkaParams = Map[String, String](
29 | "zookeeper.connect" -> zkQuorum, "group.id" -> group,
30 | "zookeeper.connection.timeout.ms" -> "10000",
31 | //auto.offset.reset设置为smallest,不然启动的时候为largest,只能收取实时消息
32 | "auto.offset.reset" -> "smallest"
33 | )
34 | //一般由两个以上接收线程,防止一个线程失败,但此处会分别统计
35 | val receiveNum = 2
36 | val lines = KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](
37 | ssc, kafkaParams, topicMap, StorageLevel.MEMORY_AND_DISK_SER_2)
38 | lines.map(_._2).flatMap(_.split(" ")).foreachRDD(rdd => {
39 | val sqlContext = SQLContext.getOrCreate(rdd.sparkContext)
40 | import sqlContext.implicits._
41 | val wordsDF = rdd.toDF("word")
42 | wordsDF.registerTempTable("words")
43 | val wordsCount = sqlContext.sql("select word,count(*) from words group by word")
44 | wordsCount.show()
45 | })
46 |
47 |
48 | //开始计算
49 | ssc.start()
50 | //等待计算结束
51 | ssc.awaitTermination()
52 | }
53 | }
54 |
--------------------------------------------------------------------------------
/spark-streaming-demo/src/main/scala/cn/thinkjoy/utils4s/sparkstreaming/SparkStreamingDemo.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.sparkstreaming
2 |
3 | import _root_.kafka.serializer.StringDecoder
4 | import org.apache.spark.storage.StorageLevel
5 | import org.apache.spark.streaming._
6 | import org.apache.spark.streaming.kafka.KafkaUtils
7 | import org.apache.spark.{SparkContext, SparkConf}
8 |
9 | /**
10 | * Created by jacksu on 15/11/12.
11 | */
12 |
13 | /**
14 | * Consumes messages from one or more topics in Kafka and does wordcount.
15 | * Usage: KafkaWordCount
16 | * is a list of one or more zookeeper servers that make quorum
17 | * is the name of kafka consumer group
18 | * is a list of one or more kafka topics to consume from
19 | * is the number of threads the kafka consumer should use
20 | *
21 | * Example:
22 | * `$ bin/run-example \
23 | * org.apache.spark.examples.streaming.KafkaWordCount zoo01,zoo02,zoo03 \
24 | * my-consumer-group topic1,topic2 1`
25 | */
26 | object SparkStreamingDemo {
27 |
28 | def main(args: Array[String]) {
29 | if (args.length < 4) {
30 | System.err.println("Usage: KafkaWordCount ")
31 | System.exit(1)
32 | }
33 |
34 | val Array(zkQuorum, group, topics, numThreads,batch) = args
35 | val sparkConf = new SparkConf().setAppName("KafkaWordCount")
36 | val sc = new SparkContext(sparkConf)
37 | val ssc = new StreamingContext(sc, Seconds(batch.toInt))
38 | ssc.checkpoint("checkpoint")
39 |
40 | //numThreads 处理每个topic的线程数
41 | val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
42 | val kafkaParams = Map[String, String](
43 | "zookeeper.connect" -> zkQuorum, "group.id" -> group,
44 | "zookeeper.connection.timeout.ms" -> "10000",
45 | //auto.offset.reset设置为smallest,不然启动的时候为largest,只能收取实时消息
46 | "auto.offset.reset" -> "smallest"
47 | )
48 | //一般由两个以上接收线程,防止一个线程失败,但此处会分别统计
49 | val receiveNum = 2
50 | (1 to receiveNum).map(_ => {
51 | val lines = KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](
52 | ssc, kafkaParams, topicMap, StorageLevel.MEMORY_AND_DISK_SER_2)
53 | lines.map(_._2).flatMap(_.split(" ")).map(x => (x, 1L))
54 | .reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2).print
55 | }
56 | )
57 |
58 | //开始计算
59 | ssc.start()
60 | //等待计算结束
61 | ssc.awaitTermination()
62 | }
63 |
64 | }
65 |
66 |
--------------------------------------------------------------------------------
/spark-timeseries-demo/README.md:
--------------------------------------------------------------------------------
1 |
2 | 时间数据展示有三种方式
3 |
4 | Observations DataFrame
5 |
6 | 
7 |
8 | Instants DataFrame
9 |
10 | 
11 |
12 | TimeSeriesRDD
13 |
14 | 
15 |
16 | 以股票数据为例,数据以tab分割,分别为年、月、日、股票代码、数量、价格
17 |
18 | ```scala
19 | 2015 8 14 ADP 194911 82.99
20 | 2015 9 14 NKE 224435 111.78
21 | 2015 9 18 DO 678664 20.18
22 | 2015 8 7 TGT 147406 78.96
23 | ```
24 |
25 | ##参考
26 | [spark-ts](http://blog.cloudera.com/blog/2015/12/spark-ts-a-new-library-for-analyzing-time-series-data-with-apache-spark/)
--------------------------------------------------------------------------------
/spark-timeseries-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.spark.timeseries
11 | spark-timeseries
12 | 2008
13 |
14 |
15 | 2.10.4
16 | 1.4.0
17 | 2.10
18 |
19 |
20 |
21 | org.apache.hadoop
22 | hadoop-common
23 | 2.6.0
24 | compile
25 |
26 |
27 | org.apache.spark
28 | spark-core_${soft.scala.version}
29 | ${spark.version}
30 | compile
31 |
32 |
33 | org.apache.spark
34 | spark-sql_${soft.scala.version}
35 | ${spark.version}
36 |
37 |
38 | org.apache.spark
39 | spark-mllib_${soft.scala.version}
40 | ${spark.version}
41 |
42 |
43 | com.cloudera.sparkts
44 | sparkts
45 | 0.1.0
46 |
47 |
48 | joda-time
49 | joda-time
50 | 2.3
51 |
52 |
53 |
--------------------------------------------------------------------------------
/spark-timeseries-demo/src/main/scala/cn/thinkjoy/utils4s/spark/timeseries/TimeSeriesApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.spark.timeseries
2 |
3 | import java.sql.Timestamp
4 |
5 | import com.cloudera.sparkts._
6 | import com.cloudera.sparkts.stats.TimeSeriesStatisticalTests
7 | import org.apache.spark.{SparkContext, SparkConf}
8 | import org.apache.spark.sql.{DataFrame, Row, SQLContext}
9 | import org.apache.spark.sql.types._
10 | import org.joda.time._
11 | import com.cloudera.sparkts.models.Autoregression
12 |
13 | /**
14 | * jacksu
15 | */
16 |
17 | object TimeSeriesApp {
18 |
19 | /**
20 | * Creates a Spark DataFrame of (timestamp, symbol, price) from a tab-separated file of stock
21 | * ticker data.
22 | */
23 | def loadObservations(sqlContext: SQLContext, path: String): DataFrame = {
24 | val rowRdd = sqlContext.sparkContext.textFile(path).map { line =>
25 | val tokens = line.split('\t')
26 | val dt = new DateTime(tokens(0).toInt, tokens(1).toInt, tokens(2).toInt, 0, 0)
27 | val symbol = tokens(3)
28 | val price = tokens(4).toDouble
29 | Row(new Timestamp(dt.getMillis), symbol, price)
30 | }
31 | val fields = Seq(
32 | StructField("timestamp", TimestampType, true),
33 | StructField("symbol", StringType, true),
34 | StructField("price", DoubleType, true)
35 | )
36 | val schema = StructType(fields)
37 | sqlContext.createDataFrame(rowRdd, schema)
38 | }
39 |
40 | def main(args: Array[String]): Unit = {
41 | val conf = new SparkConf().setAppName("Spark-TS Wiki Example").setMaster("local")
42 | conf.set("spark.io.compression.codec", "org.apache.spark.io.LZ4CompressionCodec")
43 | val sc = new SparkContext(conf)
44 | val sqlContext = new SQLContext(sc)
45 |
46 | val tickerObs = loadObservations(sqlContext, "spark-timeseries-demo/data/ticker.tsv")
47 |
48 | // Create an daily DateTimeIndex over August and September 2015
49 | val dtIndex = DateTimeIndex.uniform(
50 | new DateTime("2015-08-03"), new DateTime("2015-09-22"), new BusinessDayFrequency(1))
51 |
52 | // Align the ticker data on the DateTimeIndex to create a TimeSeriesRDD
53 | val tickerTsrdd = TimeSeriesRDD.timeSeriesRDDFromObservations(dtIndex, tickerObs,
54 | "timestamp", "symbol", "price")
55 |
56 | // Cache it in memory
57 | tickerTsrdd.cache()
58 |
59 | // Count the number of series (number of symbols)
60 | println("======"+tickerTsrdd.count()+"=======")
61 |
62 | // Impute missing values using linear interpolation
63 | val filled = tickerTsrdd.fill("linear")
64 |
65 | // Compute return rates 计算回报率
66 | val returnRates = filled.returnRates()
67 |
68 | // Compute Durbin-Watson stats for each series
69 | val dwStats = returnRates.mapValues(TimeSeriesStatisticalTests.dwtest(_))
70 |
71 | println(dwStats.map(_.swap).min)
72 | println(dwStats.map(_.swap).max)
73 | }
74 |
75 |
76 | }
77 |
--------------------------------------------------------------------------------
/toc_gen.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | """
5 | Generates table of content for markdown.
6 |
7 | Your title style must be like this:
8 | H1 title
9 | H2 title
10 | ...
11 | Generated TOC like this:
12 | * [H1 title](#h1)
13 | * [H2 title](#h2)
14 | ...
15 |
16 | usage: toc_gen.py [-h] [-S src] [-D des]
17 |
18 | Generates TOC for markdown file.
19 |
20 | optional arguments:
21 | -h, --help show this help message and exit
22 | -S src A path of source file.
23 | -D des A file path to store TOC.
24 | """
25 |
26 | from __future__ import print_function
27 |
28 | import os
29 | import argparse
30 | from HTMLParser import HTMLParser
31 |
32 | def get_toc(html):
33 |
34 | toc_list = []
35 |
36 | class MyHTMLParser(HTMLParser):
37 |
38 | _prefix = ''
39 | _id = ''
40 | _title = ''
41 |
42 | def handle_starttag(self, tag, attrs):
43 | if tag[-1].isdigit():
44 | space = (int(tag[-1]) - 1) * 4
45 | self._prefix = space * ' ' + '* '
46 | attrs = dict(attrs)
47 | if self._prefix and 'id' in attrs:
48 | self._id = '(#' + attrs['id'] + ')'
49 |
50 | def handle_data(self, data):
51 | if self._prefix:
52 | self._title = '[' + data.strip() + ']'
53 | toc_list.append(self._prefix + self._title + self._id)
54 | self._prefix = ''
55 | self._id = ''
56 | self._title = ''
57 |
58 | parser = MyHTMLParser()
59 | parser.feed(html)
60 | return '\n'.join(toc_list)
61 |
62 | def read(fpath):
63 | with open(fpath, 'r') as f:
64 | data = f.read()
65 | return data
66 |
67 | def write(fpath, toc):
68 | with open(fpath, 'w') as f:
69 | f.write(toc)
70 |
71 | def parse_args():
72 | parser = argparse.ArgumentParser(
73 | description = "Generates TOC for markdown file.")
74 | parser.add_argument(
75 | '-S',
76 | type = file_check,
77 | default = None,
78 | help = "A path of source file.",
79 | metavar = 'src',
80 | dest = 'src')
81 | parser.add_argument(
82 | '-D',
83 | type = path_check,
84 | default = None,
85 | help = "A file path to store TOC.",
86 | metavar = 'des',
87 | dest = 'des')
88 | args = parser.parse_args()
89 | return args.src, args.des
90 |
91 | def file_check(fpath):
92 | if os.path.isfile(fpath):
93 | return fpath
94 | raise argparse.ArgumentTypeError("Invalid source file path,"
95 | " {0} doesn't exists.".format(fpath))
96 |
97 | def path_check(fpath):
98 | if fpath is None: return
99 | path = os.path.dirname(fpath)
100 | if os.path.exists(path):
101 | return fpath
102 | raise argparse.ArgumentTypeError("Invalid destination file path,"
103 | " {0} doesn't exists.".format(fpath))
104 |
105 |
106 | def main():
107 | src, des = parse_args()
108 | toc = get_toc(read(src))
109 | if des:
110 | write(des, toc)
111 | print("TOC of '{0}' has been written to '{1}'".format(
112 | os.path.abspath(src),
113 | os.path.abspath(des)))
114 | else:
115 | print("TOC for '{0}':\n '{1}'".format(
116 | os.path.abspath(src),
117 | toc))
118 |
119 | if __name__ == '__main__':
120 | main()
121 |
--------------------------------------------------------------------------------
/twitter-util-demo/README.md:
--------------------------------------------------------------------------------
1 | #twitter util
2 |
3 | ##util-core
4 |
5 | ###time
6 | 依赖于
7 |
8 | * com.twitter.conversions.time
9 |
10 | * com.twiiter.util下的Duration和Time
--------------------------------------------------------------------------------
/twitter-util-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.twitter.util
11 | twitter-util-demo
12 | 2008
13 |
14 | 6.29.0
15 |
16 |
17 |
18 |
19 | com.twitter
20 | util-core_${soft.scala.version}
21 | ${twitter.util.version}
22 |
23 |
24 |
25 |
--------------------------------------------------------------------------------
/twitter-util-demo/src/main/scala/cn/thinkjoy/utils4s/twitter/util/core/TimeApp.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.twitter.util.core
2 |
3 | import com.twitter.conversions.time._
4 | import com.twitter.util._
5 |
6 | object TimeApp {
7 | def main(args: Array[String]) {
8 | val duration1 = 1.second
9 | val duration2 = 2.minutes
10 | //duration1.inMillis
11 | println( duration1.inMilliseconds )
12 | println((duration2-duration1).inSeconds)
13 | println((duration2-duration1).inMinutes)
14 | println(Time.now.format("yyyy-MM-dd"))
15 | println(Time.epoch)
16 | //just for test now
17 | val elapsed: () => Duration = Stopwatch.start()
18 | println(elapsed())
19 | }
20 |
21 | }
22 |
--------------------------------------------------------------------------------
/unittest-demo/README.md:
--------------------------------------------------------------------------------
1 | #unittest-demo
2 | scalatest库的简单使用
--------------------------------------------------------------------------------
/unittest-demo/pom.xml:
--------------------------------------------------------------------------------
1 |
3 |
4 | demo
5 | cn.thinkjoy.utils4s
6 | 1.0
7 | ../pom.xml
8 |
9 | 4.0.0
10 | cn.thinkjoy.utils4s.unittest
11 | unittest-demo
12 | 2008
13 |
14 |
15 |
16 | org.scalatest
17 | scalatest_${soft.scala.version}
18 | 2.1.5
19 | test
20 |
21 |
22 |
23 |
24 | src/main/scala
25 | src/test/scala
26 |
27 |
28 |
29 |
--------------------------------------------------------------------------------
/unittest-demo/src/main/scala/cn/thinkjoy/utils4s/unittest/App.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.unittest
2 |
3 | /**
4 | * Hello world!
5 | *
6 | */
7 | object App {
8 | def main(args: Array[String]) {
9 | println( "Hello World!" )
10 | }
11 |
12 | }
13 |
--------------------------------------------------------------------------------
/unittest-demo/src/test/scala/cn/thinkjoy/utils4s/scala/StackSpec.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | import scala.collection.mutable.Stack
4 |
5 | class StackSpec extends UnitSpec{
6 |
7 | "A Stack" should "pop values in last-in-first-out order" in {
8 | val stack = new Stack[Int]
9 | stack.push(1)
10 | stack.push(2)
11 | assert(stack.pop() === 2)
12 | assert(stack.pop() === 1)
13 | val a = 5
14 | val b = 3
15 | assertResult(2) {
16 | a - b
17 | }
18 | val someValue: Option[String] = Some("I am wrapped in something")
19 | someValue.get should be("I am wrapped in something")
20 | val left=1
21 | //assert(left===2,"Execution was attempted " + left + " times instead of 1 time")
22 | info("OK")
23 | }
24 |
25 | it should "throw NoSuchElementException if an empty stack is popped" in {
26 | val emptyStack = new Stack[String]
27 | intercept[NoSuchElementException] {
28 | emptyStack.pop()
29 | }
30 |
31 | }
32 | }
--------------------------------------------------------------------------------
/unittest-demo/src/test/scala/cn/thinkjoy/utils4s/scala/UnitSpec.scala:
--------------------------------------------------------------------------------
1 | package cn.thinkjoy.utils4s.scala
2 |
3 | import org.scalatest.{Matchers, FlatSpec}
4 |
5 | /**
6 | * Created by xbsu on 15/10/8.
7 | */
8 | abstract class UnitSpec extends FlatSpec with Matchers
9 |
--------------------------------------------------------------------------------