├── .gitattributes
├── .github
├── ISSUE_TEMPLATE
│ ├── bug-report.yml
│ ├── feature-request.yml
│ └── rfc.yml
├── PULL_REQUEST_TEMPLATE.md
└── workflows
│ ├── gh_pages.yml
│ ├── release.yml
│ └── schedule_test.yml
├── .gitignore
├── CGS.py
├── ComicSpider
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
│ ├── __init__.py
│ ├── basecomicspider.py
│ ├── comic90mh.py
│ ├── ehentai.py
│ ├── hitomi.py
│ ├── jm.py
│ ├── kaobei.py
│ ├── mangabz.py
│ └── wnacg.py
├── GUI
├── __init__.py
├── browser_window.py
├── conf_dialog.py
├── gui.py
├── hitomi_tools.py
├── mainwindow.py
├── src
│ ├── __init__.py
│ ├── material_ct.py
│ └── preview_format
│ │ ├── bootstrap.min.js
│ │ ├── index.html
│ │ ├── index_by_clip.html
│ │ ├── public.css
│ │ ├── public.js
│ │ ├── tasks_extend.js
│ │ └── tip_downloaded.js
├── thread
│ ├── __init__.py
│ └── other.py
└── uic
│ ├── __init__.py
│ ├── browser.py
│ ├── conf_dia.py
│ ├── qfluent
│ ├── __init__.py
│ ├── action_factory.py
│ ├── components.py
│ └── patch_uic.py
│ └── ui_mainwindow.py
├── LICENSE
├── README.md
├── assets
├── __init__.py
├── conf_sample.yml
├── config_icon.png
├── github_format.html
├── icon.png
└── res
│ ├── __init__.py
│ ├── locale
│ ├── en-US.yml
│ └── zh-CN.yml
│ └── transfer.py
├── crawl_only.py
├── deploy
├── __init__.py
├── env_record.json
├── launcher
│ ├── CGS.bat
│ └── mac
│ │ ├── CGS.bash
│ │ ├── __init__.py
│ │ ├── dos2unix.bash
│ │ └── init.bash
├── online_scripts
│ └── win.ps1
├── packer.py
├── pkg_mgr.py
└── update.py
├── docs
├── .vitepress
│ ├── config.ts
│ └── theme
│ │ ├── Layout.vue
│ │ ├── index.ts
│ │ └── style.css
├── _github
│ ├── README_en.md
│ ├── preset_preview.md
│ ├── preset_stable.md
│ └── release_notes.md
├── assets
│ └── img
│ │ ├── config
│ │ ├── conf_usage.png
│ │ └── conf_usage_en.png
│ │ ├── deploy
│ │ └── mac-app-move.jpg
│ │ ├── dev
│ │ └── branch.png
│ │ ├── faq
│ │ └── ditto_settings.png
│ │ ├── feature
│ │ └── browser_copyBtn.png
│ │ └── icons
│ │ └── website
│ │ ├── copy.png
│ │ ├── ehentai.png
│ │ ├── hitomi.png
│ │ ├── jm.png
│ │ ├── mangabz.png
│ │ └── wnacg.png
├── changelog
│ └── history.md
├── config
│ ├── index.md
│ └── other.md
├── deploy
│ ├── mac-required-reading.md
│ └── quick-start.md
├── dev
│ ├── contribute.md
│ ├── dev_spider.md
│ └── i18n.md
├── faq
│ ├── extra.md
│ ├── index.md
│ └── other.md
├── feature
│ ├── index.md
│ └── script.md
├── home
│ └── index.md
├── index.md
├── locate
│ └── en
│ │ ├── config
│ │ └── index.md
│ │ ├── deploy
│ │ ├── mac-required-reading.md
│ │ └── quick-start.md
│ │ └── index.md
├── package.json
└── public
│ ├── CGS-girl.png
│ └── _redirects
├── requirements
├── linux.txt
├── mac_arm64.txt
├── mac_x86_64.txt
├── script
│ ├── mac_arm64.txt
│ ├── mac_x86_64.txt
│ └── win.txt
└── win.txt
├── scrapy.cfg
├── utils
├── __init__.py
├── docs.py
├── preview
│ ├── __init__.py
│ └── el.py
├── processed_class.py
├── redViewer_tools.py
├── script
│ ├── __init__.py
│ ├── extra.py
│ └── image
│ │ ├── __init__.py
│ │ ├── expander.py
│ │ ├── kemono.py
│ │ ├── nekohouse.py
│ │ └── saucenao.py
├── sql
│ └── __init__.py
└── website
│ ├── __init__.py
│ ├── core.py
│ └── hitomi
│ ├── __init__.py
│ └── scape_dataset.py
└── variables
└── __init__.py
/.gitattributes:
--------------------------------------------------------------------------------
1 | # 核心配置:自动识别文本文件,并强制统一为 LF
2 | * text=auto eol=lf
3 |
4 | # 明确排除二进制文件(避免误处理)
5 | *.png binary
6 | *.jpg binary
7 | *.zip binary
8 | *.7z binary
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/bug-report.yml:
--------------------------------------------------------------------------------
1 | name: Bug Report 🐛
2 | description: 创建 Bug 报告以帮助我们改进 / Create a report to help us improve
3 | title: 🐛[Bug]
4 | assignees:
5 | - jasoneri
6 | labels: bug
7 | body:
8 | - type: textarea
9 | attributes:
10 | label: 🐛 描述(Description)
11 | description: >-
12 | 详细地描述 bug,让大家都能理解/Describe the bug in detail so that everyone can
13 | understand it
14 | validations:
15 | required: true
16 | - type: textarea
17 | attributes:
18 | label: 📷 复现步骤(Steps to Reproduce)
19 | description: >-
20 | 清晰描述复现步骤,让别人也能看到问题/Clearly describe the reproduction steps so that
21 | others can see the problem
22 | value: |-
23 | 1.
24 | 2.
25 | 3.
26 | validations:
27 | required: true
28 | - type: textarea
29 | attributes:
30 | label: ' 📄 [异常/日志]信息([Exception/Log] Information)'
31 | description: 如报错等其他信息可以贴在这里,或上传log文件/Other information such as crash can be posted here, or upload log file
32 | - type: markdown
33 | attributes:
34 | value: '## 🚑 **基本信息(Basic Information)**'
35 | - type: input
36 | attributes:
37 | label: 程序版本(Program version)
38 | description: >-
39 | 填写当前程序的版本号,在GUI主窗口的左上角图标右边 / Enter the current version, On top-left corner
40 | validations:
41 | required: true
42 | - type: dropdown
43 | attributes:
44 | label: 系统(OS)
45 | description: 在哪些系统中出现此问题/In which systems does this problem occur
46 | multiple: true
47 | options:
48 | - Windows10~+
49 | - Windows7~-
50 | - macOS
51 | validations:
52 | required: true
53 | - type: textarea
54 | attributes:
55 | label: 📄 配置文件(Configuration file)
56 | description: "上传配置文件`scripts/conf.yml` 或 配置窗口的截图 (github是公开的记得脱敏!下面字段的值使用马赛克等手段模糊化)
57 | /Upload configure file`scripts/conf.yml` or configure-dialog screenshots (remember desensitization! The value of below field must be blur)"
58 | placeholder: >-
59 | 储存路径, 代理,eh_cookies / sv_path, proxies, eh_cookies
60 | - type: textarea
61 | attributes:
62 | label: ' 🖼 其他截图(Screenshots)'
63 | description: 其他截图可以贴在这里/Screenshots of other situations can be posted here
64 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/feature-request.yml:
--------------------------------------------------------------------------------
1 | ---
2 | name: "Feature request 👑"
3 | description: 对程序的需求或建议 / Suggest an idea for program
4 | title: "👑[Feature Request]"
5 | labels: enhancement
6 | assignees:
7 | - jasoneri
8 | body:
9 | - type: textarea
10 | attributes:
11 | label: 🥰 需求描述(Description)
12 | placeholder: 详细地描述需求,让大家都能理解/escribe the requirements in detail so that everyone can understand them
13 | validations:
14 | required: true
15 | - type: textarea
16 | attributes:
17 | label: 🧐 解决方案(Solution)
18 | placeholder: 如果你有解决方案,在这里清晰地阐述/If you have a solution, explain it clearly here
19 | validations:
20 | required: true
21 | - type: textarea
22 | attributes:
23 | label: Additional context/其他信息
24 | placeholder: 如截图等其他信息可以贴在这里/Other information such as screenshots can be posted here
25 | validations:
26 | required: false
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/rfc.yml:
--------------------------------------------------------------------------------
1 | name: 功能提案
2 | description: Request for Comments
3 | title: "💡[RFC]"
4 | labels: ["RFC"]
5 | body:
6 | - type: markdown
7 | attributes:
8 | value: |
9 | 一份提案(RFC)定位为 **「在某功能/重构的具体开发前,用于开发者间 review 技术设计/方案的文档」**,
10 | 目的是让协作的开发者间清晰的知道「要做什么」和「具体会怎么做」,以及所有的开发者都能公开透明的参与讨论;
11 | 以便评估和讨论产生的影响 (遗漏的考虑、向后兼容性、与现有功能的冲突),
12 | 因此提案侧重在对解决问题的 **方案、设计、步骤** 的描述上。
13 |
14 | 如果仅希望讨论是否添加或改进某功能本身,请使用 -> [Issue: 功能改进](https://github.com/jasoneri/ComicGUISpider/issues/new?labels=feature+request&template=feature-request.yml&title=👑%5BFeature+Request%5D+)
15 | - type: textarea
16 | id: background
17 | attributes:
18 | label: 背景 or 问题
19 | description: 简单描述遇到的什么问题或需要改动什么。可以引用其他 issue、讨论、文档等。
20 | validations:
21 | required: true
22 | - type: textarea
23 | id: goal
24 | attributes:
25 | label: 🥰 目标 & 方案简述
26 | description: 简单描述提案此提案实现后,**预期的目标效果**,以及简单大致描述会采取的方案/步骤,可能会/不会产生什么影响。
27 | validations:
28 | required: true
29 | - type: textarea
30 | id: design
31 | attributes:
32 | label: 🧐 方案设计 & 实现步骤
33 | description: |
34 | 详细描述你设计的具体方案,可以考虑拆分列表或要点,一步步描述具体打算如何实现的步骤和相关细节。
35 | 这部份不需要一次性写完整,即使在创建完此提案 issue 后,依旧可以再次编辑修改。
36 | validations:
37 | required: false
38 | - type: textarea
39 | id: alternative
40 | attributes:
41 | label: 😸 替代方案 & 对比
42 | description: |
43 | [可选] 为来实现目标效果,还考虑过什么其他方案,有什么对比?
44 | validations:
45 | required: false
46 |
--------------------------------------------------------------------------------
/.github/PULL_REQUEST_TEMPLATE.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Description
4 |
5 |
6 | ## Related Issues
7 |
11 |
12 | ### Checklist:
13 |
14 | * [ ] Have you checked to ensure there aren't other open [Pull Requests](../../../pulls) for the same update/change?
15 | * [ ] Have you linted your code locally prior to submission?
16 | * [ ] Have you successfully ran app with your changes locally?
17 |
--------------------------------------------------------------------------------
/.github/workflows/gh_pages.yml:
--------------------------------------------------------------------------------
1 | name: Build to gh_pages
2 |
3 | on:
4 | pull_request:
5 | types:
6 | - closed
7 | workflow_dispatch:
8 |
9 | jobs:
10 | changes:
11 | if: |
12 | github.event.pull_request.merged == true &&
13 | github.event.pull_request.base.ref == 'GUI'
14 | runs-on: ubuntu-latest
15 | permissions:
16 | pull-requests: read
17 | outputs:
18 | docs: ${{ steps.filter.outputs.docs }}
19 | steps:
20 | - uses: dorny/paths-filter@v3
21 | id: filter
22 | with:
23 | filters: |
24 | docs:
25 | - 'docs/**'
26 |
27 | pages-deploy:
28 | needs: changes
29 | if: ${{ needs.changes.outputs.docs == 'true' }}
30 | runs-on: ubuntu-latest
31 | permissions:
32 | contents: write
33 |
34 | steps:
35 | - uses: actions/checkout@v4
36 | - name: Install dependencies
37 | run: |
38 | cd docs && npm install
39 | - name: Build VitePress docs
40 | run: |
41 | cd docs && npm run docs:build
42 | - name: Deploy to GitHub Pages
43 | uses: peaceiris/actions-gh-pages@v3
44 | with:
45 | github_token: ${{ secrets.GITHUB_TOKEN }}
46 | publish_dir: docs/.vitepress/dist
47 |
--------------------------------------------------------------------------------
/.github/workflows/release.yml:
--------------------------------------------------------------------------------
1 | name: Release
2 | on:
3 | push:
4 | tags:
5 | - 'v*.*.*'
6 | workflow_dispatch:
7 |
8 | jobs:
9 | prebuild-windows:
10 | runs-on: windows-latest
11 | defaults:
12 | run:
13 | shell: pwsh
14 | steps:
15 | - name: Checkout code
16 | uses: actions/checkout@v4
17 | with:
18 | fetch-depth: 1
19 | - name: Add PATH
20 | run: |
21 | $7zPath = "C:\Program Files\7-Zip"
22 | $PresetPath = "D:\build\CGS_preset"
23 | Add-Content $env:GITHUB_PATH "$7zPath"
24 | echo "presetP=D:\build\CGS_preset" >> $env:GITHUB_ENV
25 |
26 | - name: Download and Extract Preset
27 | run: |
28 | New-Item -ItemType Directory -Path D:\tmp -Force
29 | New-Item -ItemType Directory -Path D:\build -Force
30 | Invoke-WebRequest -Uri "https://github.com/jasoneri/imgur/releases/download/preset/CGS_preset.7z" -OutFile D:\tmp\CGS_preset.7z
31 | 7z x D:\tmp\CGS_preset.7z -o"$env:presetP" -spe -y
32 | Remove-Item -Path "D:\tmp\CGS_preset.7z" -Force -ErrorAction Stop
33 | - name: Put SourceCode in Preset
34 | run: |
35 | $sourcePath = $env:GITHUB_WORKSPACE
36 | $targetPath = "D:\build\CGS_preset\scripts"
37 | New-Item -ItemType Directory -Path $targetPath -Force
38 | Copy-Item -Path "$sourcePath\*" -Destination $targetPath -Recurse -Force
39 | - name: Install Dependencies
40 | working-directory: D:\build\CGS_preset
41 | run: irm https://raw.githubusercontent.com/jasoneri/ComicGUISpider/refs/heads/GUI/deploy/online_scripts/win.ps1 | iex
42 | - name: Rebuild Preset
43 | working-directory: D:\build\CGS_preset
44 | run: |
45 | Remove-Item -Path "D:\build\CGS_preset\scripts" -Recurse -Force
46 | 7z a -t7z -m0=lzma2 -mx9 -o$env:presetP CGS_preset
47 | Copy-Item -Path "D:\build\CGS_preset\CGS_preset.7z" -Destination "D:\tmp\CGS_preset.7z" -Force
48 |
49 | - name: Upload Preset
50 | uses: actions/upload-artifact@v4
51 | with:
52 | name: windows-preset
53 | path: D:\tmp\CGS_preset.7z
54 |
55 | build:
56 | runs-on: ubuntu-latest
57 | needs: [prebuild-windows]
58 | container:
59 | image: python:3.12
60 | volumes:
61 | - /tmp/build:/build
62 |
63 | steps:
64 | - name: Checkout code
65 | uses: actions/checkout@v4
66 | with:
67 | fetch-depth: 1
68 | path: src
69 |
70 | - name: Install dependencies
71 | run: python -m pip install pydos2unix py7zr tqdm loguru markdown pyyaml polib
72 |
73 | - name: Clean repository
74 | run: |
75 | mkdir -p /build/scripts
76 | mv src/* /build/scripts/
77 | rm -rf /build/scripts/.git
78 | find /build/scripts -name '__pycache__' -exec rm -rf {} +
79 | find /build/scripts -name '*.pyc' -delete
80 |
81 | - name: Download Windows Preset
82 | uses: actions/download-artifact@v4
83 | with:
84 | name: windows-preset
85 | path: /tmp/
86 |
87 | - name: Download macOS Preset
88 | run: |
89 | wget -O /tmp/CGS-macOS_preset.7z \
90 | https://github.com/jasoneri/imgur/releases/download/preset/CGS-macOS_preset.7z
91 |
92 | - name: Compose Release Notes
93 | id: compose_notes
94 | run: |
95 | TAG_NAME="${GITHUB_REF#refs/tags/}"
96 | echo "version: $TAG_NAME"
97 | base=$(cat /build/scripts/docs/_github/release_notes.md)
98 |
99 | case "$TAG_NAME" in
100 | *beta*)
101 | extra=$(cat /build/scripts/docs/_github/preset_preview.md)
102 | echo "is_beta=true" >> $GITHUB_OUTPUT
103 | ;;
104 | *)
105 | extra=$(cat /build/scripts/docs/_github/preset_stable.md)
106 | echo "is_beta=false" >> $GITHUB_OUTPUT
107 | ;;
108 | esac
109 |
110 | echo "$base\n$extra" > /build/full_body.md
111 |
112 | - name: Build packages
113 | working-directory: /build
114 | run: |
115 | python scripts/deploy/packer.py windows -v "${{ github.ref_name }}"
116 | python scripts/deploy/packer.py mac -v "${{ github.ref_name }}"
117 |
118 | - name: Create Release
119 | uses: softprops/action-gh-release@v1
120 | with:
121 | tag_name: ${{ github.ref }}
122 | name: ${{ github.ref_name }}
123 | prerelease: ${{ steps.compose_notes.outputs.is_beta == 'true' }}
124 | body_path: /build/full_body.md
125 | files: |
126 | /build/CGS.7z
127 | /build/CGS-macOS.7z
128 | env:
129 | GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
130 |
--------------------------------------------------------------------------------
/.github/workflows/schedule_test.yml:
--------------------------------------------------------------------------------
1 | name: Schedule Test Status
2 | permissions:
3 | contents: read
4 | pull-requests: write
5 | on:
6 | schedule:
7 | - cron: '0 4 */4 * *' # UTC 4 == +8 12:00
8 | workflow_dispatch:
9 |
10 | jobs:
11 | test-suite:
12 | runs-on: windows-latest
13 | env:
14 | PYTHONIOENCODING: utf-8
15 | defaults:
16 | run:
17 | shell: pwsh
18 | strategy:
19 | matrix:
20 | include:
21 | # - "ehentai" "jm" 使用本地 act 运行上传
22 | - crawler_name: "kaobei"
23 | params: "-w 1 -k 海贼王 -i 1 -i2 -1 -sp 50021"
24 | - crawler_name: "wnacg"
25 | params: "-w 3 -k ミモネル -i 2 -sp 50051"
26 | - crawler_name: "mangabz"
27 | params: "-w 5 -k 海贼王 -i 1 -i2 -1 -sp 50081"
28 | - crawler_name: "hitomi"
29 | params: "-w 6 -k artist/date/published/mimonel-japanese -i 1 -sp 50111"
30 |
31 | steps:
32 | - name: Checkout code
33 | uses: actions/checkout@v4
34 | with:
35 | fetch-depth: 1
36 | - name: Add PATH
37 | run: |
38 | $7zPath = "C:\Program Files\7-Zip"
39 | Add-Content $env:GITHUB_PATH "$7zPath"
40 | echo "runtimeP=D:\build\CGS" >> $env:GITHUB_ENV
41 | - name: Get Latest Release Tag
42 | id: get-latest-tag
43 | run: |
44 | $response = Invoke-WebRequest -Uri "https://api.github.com/repos/jasoneri/ComicGUISpider/releases?per_page=1" -Headers @{ "Accept" = "application/vnd.github.v3+json" }
45 | $latest_tag = ($response.Content | ConvertFrom-Json)[0].tag_name
46 | echo "latest_tag=$latest_tag" >> $env:GITHUB_OUTPUT
47 | - name: Download Latest CGS
48 | run: |
49 | New-Item -ItemType Directory -Path D:\tmp -Force
50 | New-Item -ItemType Directory -Path D:\build -Force
51 | Invoke-WebRequest -Uri "https://github.com/jasoneri/ComicGUISpider/releases/download/${{ steps.get-latest-tag.outputs.latest_tag }}/CGS.7z" -OutFile D:\tmp\CGS.7z
52 | 7z x D:\tmp\CGS.7z -o"$env:runtimeP" -spe -y
53 | Remove-Item -Path "D:\tmp\CGS.7z" -Force -ErrorAction Stop
54 | - name: Put SourceCode in CGS
55 | run: |
56 | $sourcePath = $env:GITHUB_WORKSPACE
57 | $targetPath = "D:\build\CGS\scripts"
58 | New-Item -ItemType Directory -Path $targetPath -Force
59 | Copy-Item -Path "$sourcePath\*" -Destination $targetPath -Recurse -Force
60 | - name: Run tests and Generate report
61 | working-directory: D:\build\CGS
62 | env:
63 | CRAWLER_NAME: ${{ matrix.crawler_name }}
64 | run: |
65 | $TODAY = (Get-Date -Format "MM-dd").ToString()
66 |
67 | $stdoutLog = $env:CRAWLER_NAME + "_stdout.log"
68 | $stderrLog = $env:CRAWLER_NAME+ "_stderr.log"
69 | $pythonArgs = "./scripts/crawl_only.py ${{ matrix.params }} -l INFO -dt"
70 | $timeoutSeconds = if ($env:CRAWLER_NAME -eq 'hitomi') { 120 } else { 60 }
71 |
72 | $process = Start-Process -FilePath "./runtime/python.exe" -ArgumentList $pythonArgs -NoNewWindow -PassThru -RedirectStandardOutput $stdoutLog -RedirectStandardError $stderrLog
73 | try {
74 | $process | Wait-Process -Timeout $timeoutSeconds -ErrorAction Stop
75 | $result = $process.ExitCode
76 | } catch [TimeoutException] {
77 | $process | Stop-Process -Force
78 | $result = 124
79 | }
80 | $logContent = Get-Content $stderrLog -Raw
81 | $item_count = if ($logContent -match "image/downloaded': (\d+)") { [int]$matches[1] } else { 0 }
82 | $statusData = @{
83 | schemaVersion = 1
84 | label = $TODAY
85 | message = $(if ($item_count -eq 0) { "fail" } else { "pass" })
86 | color = $(if ($item_count -eq 0) { "critical" } else { "success" })
87 | }
88 | $artifactPath = "D:\build\badges"
89 | New-Item -Path $artifactPath -ItemType Directory -Force | Out-Null
90 | $statusData | ConvertTo-Json -Compress | Out-File "$artifactPath\status_$env:CRAWLER_NAME.json" -Encoding utf8
91 | Get-ChildItem -Path $artifactPath -Recurse
92 | Copy-Item -Path $stderrLog -Destination "D:\build\badges\$stderrLog" -Force
93 |
94 | - name: Upload artifacts
95 | uses: actions/upload-artifact@v4
96 | with:
97 | name: badges-${{ matrix.crawler_name }}
98 | path: D:\build\badges/
99 |
100 | deploy-job:
101 | needs: test-suite
102 | runs-on: ubuntu-latest
103 | permissions:
104 | actions: write
105 | contents: read
106 | steps:
107 | - name: Download all artifacts
108 | uses: actions/download-artifact@v4
109 | with:
110 | path: /tmp/
111 | - name: Set up Node.js
112 | uses: actions/setup-node@v3
113 | with:
114 | node-version: '20'
115 | - name: Install wrangler
116 | run: |
117 | npm install -g wrangler
118 | - name: Merge artifacts
119 | run: |
120 | mkdir -p /tmp/merged-badges
121 | sudo find /tmp/ -type f -name 'status_*.json' -exec cp {} /tmp/merged-badges/ \;
122 |
123 | set +e
124 | for crawler in "ehentai" "jm"; do
125 | curl -s "https://cgs-status-badges.pages.dev/status_${crawler}.json" -o "/tmp/merged-badges/status_${crawler}.json" || true
126 | done
127 | - name: Deploy to CloudFlare Pages
128 | env:
129 | CLOUDFLARE_API_TOKEN: ${{ secrets.CLOUDFLARE_API_TOKEN }}
130 | CLOUDFLARE_ACCOUNT_ID: ${{ secrets.CLOUDFLARE_ACCOUNT_ID }}
131 | run: |
132 | wrangler pages deploy /tmp/merged-badges/ --project-name=cgs-status-badges --branch=main
133 | - name: Delete workflow runs
134 | uses: Mattraks/delete-workflow-runs@main
135 | with:
136 | token: ${{ secrets.GITHUB_TOKEN }}
137 | repository: ${{ github.repository }}
138 | retain_days: 0
139 | keep_minimum_runs: 5
140 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | ##----------idea----------
10 | *.iml
11 | .idea/
12 | *.ipr
13 | *.iws
14 |
15 | # Distribution / packaging
16 | .Python
17 | build/
18 | develop-eggs/
19 | dist/
20 | downloads/
21 | eggs/
22 | .eggs/
23 | lib/
24 | lib64/
25 | parts/
26 | sdist/
27 | var/
28 | wheels/
29 | pip-wheel-metadata/
30 | share/python-wheels/
31 | *.egg-info/
32 | .installed.cfg
33 | *.egg
34 | MANIFEST
35 | node_modules/
36 | docs/.vitepress/dist
37 | docs/.vitepress/cache
38 | package-lock.json
39 |
40 | # PyInstaller
41 | # Usually these files are written by a python script from a template
42 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
43 | *.manifest
44 | *.spec
45 |
46 | # Installer logs
47 | pip-log.txt
48 | pip-delete-this-directory.txt
49 |
50 | # GUI related
51 | *.ui
52 | source/
53 |
54 | # Unit test / coverage reports
55 | htmlcov/
56 | .tox/
57 | .nox/
58 | .coverage
59 | .coverage.*
60 | .cache
61 | nosetests.xml
62 | coverage.xml
63 | *.cover
64 | *.py,cover
65 | .hypothesis/
66 | .pytest_cache/
67 |
68 | # Translations
69 | *.po
70 | *.mo
71 | *.pot
72 |
73 | # Django stuff:
74 | *.log
75 | local_settings.py
76 | db.sqlite3
77 | db.sqlite3-journal
78 |
79 | # Flask stuff:
80 | instance/
81 | .webassets-cache
82 |
83 | # Scrapy stuff:
84 | .scrapy
85 |
86 | ##----------Other----------
87 | # osx
88 | *~
89 | .DS_Store
90 | gradle.properties
91 | comic/
92 |
93 | # Package Files #
94 | *.jar
95 | *.war
96 | *.nar
97 | *.ear
98 | ====.zip
99 | *.tar.gz
100 | ====.rar
101 | ====.exe
102 | *.xml
103 |
104 | ##----------Python----------
105 | *_origin.py
106 | setting.txt
107 | *.pyc
108 | *_info.txt
109 | private_*.json
110 | *test*.py
111 |
112 | # Sphinx documentation
113 | docs/_build/
114 | log/
115 |
116 | # PyBuilder
117 | target/
118 |
119 | # vscode
120 | .vscode
121 |
122 | # Jupyter Notebook
123 | .ipynb_checkpoints
124 |
125 | # IPython
126 | profile_default/
127 | ipython_config.py
128 |
129 | # pyenv
130 | .python-version
131 |
132 | # pipenv
133 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
134 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
135 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
136 | # install all needed dependencies.
137 | #Pipfile.lock
138 |
139 | # celery beat schedule file
140 | celerybeat-schedule
141 |
142 | # SageMath parsed files
143 | *.sage.py
144 |
145 | # Environments
146 | .env
147 | .venv
148 | env/
149 | venv/
150 | ENV/
151 | env.bak/
152 | venv.bak/
153 |
154 | # Spyder project settings
155 | .spyderproject
156 | .spyproject
157 |
158 | # Rope project settings
159 | .ropeproject
160 |
161 | # mkdocs documentation
162 | /site
163 |
164 | # mypy
165 | .mypy_cache/
166 | .dmypy.json
167 | dmypy.json
168 |
169 | # Pyre type checker
170 | .pyre/
171 |
172 | # self
173 | analyze/
174 | *.d
175 | *.zip
176 | *demo*.py
177 | __temp
178 | test/*
179 | .lh/
180 | assets/res/*.png
181 | # self/build
182 | *.ico
183 | *.qrc
184 | src/
185 | temp
186 | *-in.txt
187 | untitled*
188 | Pipfile
189 | Pipfile.lock
190 | codecov*
191 | *_local.yml
192 | *-lock.yaml
193 | *.hash
194 | # self/conf
195 | gitee_t.json
196 | conf.yml
197 | record.db
198 | hitomi.db
199 | # self/desc created html
200 | desc.html
201 | docs/*.html
202 | deploy/launcher/mac/*.html
203 | # self/bug-report
204 | _bug_log
205 | # ide
206 | .cursor
--------------------------------------------------------------------------------
/CGS.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import sys
3 | from multiprocessing import freeze_support
4 |
5 | from PyQt5.QtWidgets import QApplication
6 | from PyQt5.QtCore import Qt
7 |
8 | # 自己项目用到的
9 | from GUI.gui import SpiderGUI
10 | import GUI.src.material_ct
11 |
12 | # from multiprocessing.managers import RemoteError
13 | # sys.setrecursionlimit(5000)
14 |
15 |
16 | def start():
17 | freeze_support()
18 | QApplication.setHighDpiScaleFactorRoundingPolicy(Qt.HighDpiScaleFactorRoundingPolicy.PassThrough)
19 | QApplication.setAttribute(Qt.AA_EnableHighDpiScaling)
20 | QApplication.setAttribute(Qt.AA_UseHighDpiPixmaps)
21 | app = QApplication(sys.argv)
22 | app.setStyle("Fusion")
23 | ui = SpiderGUI()
24 | sys.excepthook = ui.hook_exception
25 | QApplication.processEvents()
26 | app.exec_()
27 |
28 |
29 | if __name__ == '__main__':
30 | start()
31 |
--------------------------------------------------------------------------------
/ComicSpider/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/ComicSpider/__init__.py
--------------------------------------------------------------------------------
/ComicSpider/items.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import scrapy
3 |
4 |
5 | class ComicspiderItem(scrapy.Item):
6 | title = scrapy.Field()
7 | section = scrapy.Field()
8 | page = scrapy.Field()
9 | image_urls = scrapy.Field()
10 | images = scrapy.Field()
11 | uuid = scrapy.Field()
12 | uuid_md5 = scrapy.Field() # 相当于group_id,并非此item的唯一标识
13 |
14 | @classmethod
15 | def get_group_infos(cls, resp_meta) -> dict:
16 | return {
17 | 'title': resp_meta.get('title'),
18 | 'section': resp_meta.get('section') or 'meaningless',
19 | 'uuid': resp_meta.get('uuid'),
20 | 'uuid_md5': resp_meta.get('uuid_md5'),
21 | }
22 |
--------------------------------------------------------------------------------
/ComicSpider/middlewares.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import re
3 |
4 | # Define here the models for your spider middleware
5 | #
6 | # See documentation in:
7 | # https://docs.scrapy.org/en/latest/topics/spider-middleware.html
8 |
9 | from scrapy import signals
10 | import random
11 | from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
12 |
13 |
14 | class ComicspiderDownloaderMiddleware(object):
15 | def __init__(self, USER_AGENTS, PROXIES):
16 | self.USER_AGENTS = USER_AGENTS
17 | self.PROXIES = PROXIES
18 |
19 | @classmethod
20 | def from_crawler(cls, crawler):
21 | USER_AGENTS, PROXIES = crawler.settings.get('UA'), crawler.settings.get('PROXY_CUST')
22 | s = cls(USER_AGENTS, PROXIES)
23 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
24 | return s
25 |
26 | def process_request(self, request, spider):
27 | return None
28 |
29 | def process_response(self, request, response, spider):
30 | # Called with the response returned from the downloader.
31 | if response.status != 200:
32 | request.headers['User-Agent'] = random.choice(self.USER_AGENTS)
33 | if self.PROXIES:
34 | proxy = random.choice(self.PROXIES)
35 | request.meta['proxy'] = f"{request.url.split(':')[0]}://{proxy}"
36 | return request
37 | return response
38 |
39 | def process_exception(self, request, exception, spider):
40 | if exception:
41 | spider.crawler.stats.inc_value('process_exception/count')
42 | spider.crawler.stats.set_value('process_exception/last_exception',
43 | f"[{type(exception).__name__}]{str(exception).replace('<', '')}")
44 | return None
45 |
46 | def spider_opened(self, spider):
47 | spider.logger.info(f'Spider opened: 【{spider.name}】')
48 |
49 |
50 | class UAMiddleware(ComicspiderDownloaderMiddleware):
51 | def process_request(self, request, spider):
52 | request.headers.update(getattr(spider, 'ua', {}))
53 | return None
54 |
55 |
56 | class UAKaobeiMiddleware(ComicspiderDownloaderMiddleware):
57 | def process_request(self, request, spider):
58 | if request.url.find(spider.pc_domain) != -1:
59 | ua = getattr(spider, 'ua', {})
60 | if request.url.endswith('/chapters'):
61 | ua.update({'Referer': f'https://{spider.pc_domain}/comic/{request.url.split("/")[-2]}'})
62 | else:
63 | ua.update({'Referer': "/".join(request.url.split("/")[:-2])})
64 | request.headers.update(ua)
65 | else:
66 | request.headers.update(getattr(spider, 'ua_mapi', {}))
67 | return None
68 |
69 |
70 | class MangabzUAMiddleware(UAMiddleware):
71 | def process_request(self, request, spider):
72 | if request.method == "POST":
73 | request.headers.update({
74 | "User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1",
75 | "Accept": "application/json, text/javascript, */*; q=0.01",
76 | "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
77 | "Accept-Encoding": "gzip, deflate, br",
78 | "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
79 | "X-Requested-With": "XMLHttpRequest",
80 | "Origin": "https://www.mangabz.com",
81 | "Connection": "keep-alive",
82 | "Sec-Fetch-Dest": "empty",
83 | "Sec-Fetch-Mode": "cors",
84 | "Sec-Fetch-Site": "same-origin",
85 | "Pragma": "no-cache",
86 | "Cache-Control": "no-cache",
87 | "TE": "trailers"
88 | })
89 | else:
90 | request.headers.update(getattr(spider, 'ua', {}))
91 | return None
92 |
93 |
94 | class ComicDlAllProxyMiddleware(ComicspiderDownloaderMiddleware):
95 | def process_request(self, request, spider):
96 | if self.PROXIES:
97 | proxy = random.choice(self.PROXIES)
98 | request.meta['proxy'] = f"http://{proxy}"
99 |
100 |
101 | class ComicDlProxyMiddleware(ComicspiderDownloaderMiddleware):
102 | """使用情况是“通常页需要over wall访问”,“图源cn就能访问”... 因此domain的都使用代理"""
103 | domain_regex: re.Pattern = None
104 |
105 | @classmethod
106 | def from_crawler(cls, crawler):
107 | _ = super(ComicDlProxyMiddleware, cls).from_crawler(crawler)
108 | _.domain_regex = re.compile(crawler.spider.domain)
109 | return _
110 |
111 | def process_request(self, request, spider):
112 | if bool(self.domain_regex.search(request.url)) and self.PROXIES:
113 | proxy = random.choice(self.PROXIES)
114 | request.meta['proxy'] = f"http://{proxy}"
115 |
116 |
117 | class DisableSystemProxyMiddleware(HttpProxyMiddleware):
118 | def _get_proxy(self, scheme, *args, **kwargs):
119 | return None, None
120 |
121 |
122 | class RefererMiddleware(ComicspiderDownloaderMiddleware):
123 | def process_request(self, request, spider):
124 | request.headers['Referer'] = spider.domain
125 | return None
126 |
--------------------------------------------------------------------------------
/ComicSpider/pipelines.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import os
3 | import re
4 | import pathlib
5 | import warnings
6 | from io import BytesIO
7 |
8 | import pillow_avif
9 | from itemadapter import ItemAdapter
10 | from scrapy.http import Request
11 | from scrapy.http.request import NO_CALLBACK
12 | from scrapy.pipelines.images import ImagesPipeline, ImageException
13 | from scrapy.exceptions import ScrapyDeprecationWarning
14 | from scrapy.utils.python import get_func_args
15 |
16 | from utils import conf
17 | from utils.website import JmUtils, set_author_ahead, MangabzUtils
18 | from utils.processed_class import TaskObj
19 | from assets import res
20 |
21 |
22 | class PageNamingMgr:
23 | img_sv_type = getattr(conf, 'img_sv_type', 'jpg')
24 | img_suffix_regex = re.compile(r'\.(jpg|png|gif|jpeg|bmp|webp|tiff|tif|ico|avif|svg)$')
25 |
26 | def __init__(self):
27 | self.digits_map = {}
28 |
29 | def __call__(self, taskid, page, info):
30 | if isinstance(page, str) and bool(self.img_suffix_regex.search(page)):
31 | return page
32 | elif not self.digits_map.get(taskid):
33 | self.digits_map[taskid] = len(str(info.spider.tasks[taskid].tasks_count))
34 | digits = self.digits_map[taskid]
35 | return f"{str(page).zfill(digits)}.{self.img_sv_type}"
36 |
37 |
38 | class ComicPipeline(ImagesPipeline):
39 | err_flag = 0
40 | _sub = re.compile(r'([|:<>?*"\\/])')
41 | _sub_index = re.compile(r"^\(.*?\)")
42 |
43 | def __init__(self, store_uri, download_func=None, settings=None):
44 | super(ComicPipeline, self).__init__(store_uri, download_func, settings)
45 | self.page_naming = PageNamingMgr()
46 |
47 | # 图片存储前调用
48 | def file_path(self, request, response=None, info=None, *, item=None):
49 | title = self._sub.sub('-', item.get('title'))
50 | section = self._sub.sub('-', item.get('section'))
51 | taskid = item.get('uuid_md5')
52 | page = self.page_naming(taskid, item.get('page'), info)
53 | spider = self.spiderinfo.spider
54 | basepath: pathlib.Path = spider.settings.get('SV_PATH')
55 | path = self.file_folder(basepath, section, spider, title, item)
56 | os.makedirs(path, exist_ok=True)
57 | fin = os.path.join(path, page)
58 | return fin
59 |
60 | def file_folder(self, basepath, section, spider, title, item):
61 | if spider.name in spider.settings.get('SPECIAL'):
62 | parent_p = basepath.joinpath(f"{res.SPIDER.ERO_BOOK_FOLDER}/web")
63 | _title = self._sub_index.sub('', set_author_ahead(title))
64 | path = parent_p.joinpath(f"{_title}[{item['uuid']}]" if conf.addUuid else _title)
65 | else:
66 | path = basepath.joinpath(f"{title}/{section}")
67 | if item['uuid_md5'] not in spider.tasks_path:
68 | spider.tasks_path[item['uuid_md5']] = path
69 | return path
70 |
71 | def image_downloaded(self, response, request, info, *, item=None):
72 | spider = info.spider
73 | try:
74 | super(ComicPipeline, self).image_downloaded(response, request, info, item=item)
75 | stats = spider.crawler.stats
76 | percent = int((stats.get_value('file_status_count/downloaded', default=0) / spider.total) * 100)
77 | spider.Q('BarQueue').send(int(percent)) # 后台打印百分比进度扔回GUI界面
78 | task_obj = TaskObj(item.get('uuid_md5'), item.get('page'), item['image_urls'][0])
79 | self.handle_task(spider, stats, task_obj)
80 | except Exception as e:
81 | spider.logger.error(f'traceback: {str(type(e))}:: {str(e)}')
82 |
83 | @staticmethod
84 | def handle_task(spider, stats, task_obj):
85 | _tasks = spider.tasks[task_obj.taskid]
86 | _tasks.downloaded.append(task_obj)
87 | curr_progress = int(len(_tasks.downloaded) / _tasks.tasks_count * 100)
88 | if conf.isDeduplicate and curr_progress >= 100:
89 | spider.sql_handler.add(task_obj.taskid)
90 | spider.Q('TasksQueue').send(task_obj, wait=True)
91 | stats.inc_value('image/downloaded')
92 |
93 | def item_completed(self, results, item, info):
94 | _item = super(ComicPipeline, self).item_completed(results, item, info)
95 | return _item
96 |
97 |
98 | class JmComicPipeline(ComicPipeline):
99 | def get_images(self, response, request, info, *, item=None):
100 | path = self.file_path(request, response=response, info=info, item=item)
101 | orig_image = JmUtils.JmImage.by_url(item['image_urls'][0]).convert_img(response.body)
102 |
103 | width, height = orig_image.size
104 | if width < self.min_width or height < self.min_height:
105 | raise ImageException(
106 | "Image too small "
107 | f"({width}x{height} < {self.min_width}x{self.min_height})"
108 | )
109 |
110 | image, buf = self.convert_image(
111 | orig_image, response_body=BytesIO(response.body)
112 | )
113 | yield path, image, buf
114 |
115 | for thumb_id, size in self.thumbs.items():
116 | thumb_path = self.thumb_path(
117 | request, thumb_id, response=response, info=info, item=item
118 | )
119 | thumb_image, thumb_buf = self.convert_image(image, size, buf)
120 | yield thumb_path, thumb_image, thumb_buf
121 |
122 |
123 | class MangabzComicPipeline(ComicPipeline):
124 |
125 | def get_media_requests(self, item, info):
126 | urls = ItemAdapter(item).get(self.images_urls_field, [])
127 | return [Request(u, callback=NO_CALLBACK, headers=MangabzUtils.image_ua) for u in urls]
128 |
--------------------------------------------------------------------------------
/ComicSpider/settings.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | # Scrapy settings for ComicSpider project
4 | #
5 | # For simplicity, this file contains only settings considered important or
6 | # commonly used. You can find more settings consulting the documentation:
7 | #
8 | # https://docs.scrapy.org/en/latest/topics/settings.html
9 | # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
10 | # https://docs.scrapy.org/en/latest/topics/spider-middleware.html
11 | from variables import SPECIAL_WEBSITES
12 | from utils import conf
13 |
14 | BOT_NAME = 'ComicSpider'
15 |
16 | SPIDER_MODULES = ['ComicSpider.spiders']
17 | NEWSPIDER_MODULE = 'ComicSpider.spiders'
18 |
19 |
20 | # Crawl responsibly by identifying yourself (and your website) on the user-agent
21 | #USER_AGENT = 'ComicSpider (+http://www.yourdomain.com)'
22 |
23 | # Obey robots.txt rules
24 | ROBOTSTXT_OBEY = False
25 | REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
26 | # Configure maximum concurrent requests performed by Scrapy (default: 16)
27 | #CONCURRENT_REQUESTS = 32
28 |
29 | # Configure a delay for requests for the same website (default: 0)
30 | # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
31 | # See also autothrottle settings and docs
32 | DOWNLOAD_DELAY = 0.5
33 | # The download delay setting will honor only one of:
34 | #CONCURRENT_REQUESTS_PER_DOMAIN = 16
35 | #CONCURRENT_REQUESTS_PER_IP = 16
36 |
37 | # Override the default request headers:
38 | DEFAULT_REQUEST_HEADERS = {
39 | 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
40 | 'Accept-Language': 'en',
41 | }
42 |
43 | DOWNLOADER_MIDDLEWARES = {
44 | 'ComicSpider.middlewares.ComicspiderDownloaderMiddleware': 5,
45 | }
46 |
47 | ITEM_PIPELINES = {
48 | 'ComicSpider.pipelines.ComicPipeline': 50
49 | }
50 |
51 | IMAGES_STORE = '/'
52 | SV_PATH, log_path, PROXY_CUST, LOG_LEVEL, CUSTOM_MAP = conf.settings
53 |
54 | UA = [r"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/101.0",
55 | r'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0',
56 | ]
57 |
58 | # 日志输出
59 | LOG_FILE = log_path.joinpath("scrapy.log")
60 | SPECIAL = SPECIAL_WEBSITES
61 |
--------------------------------------------------------------------------------
/ComicSpider/spiders/__init__.py:
--------------------------------------------------------------------------------
1 | # This package will contain the spiders of your Scrapy project
2 | #
3 | # Please refer to the documentation for information on how to create and manage
4 | # your spiders.
5 |
--------------------------------------------------------------------------------
/ComicSpider/spiders/comic90mh.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import re
3 | from .basecomicspider import BaseComicSpider, ComicspiderItem
4 |
5 | domain = "m.90mh.org" # 注意mk_page_tasks有域名转换
6 |
7 |
8 | class Comic90mhSpider(BaseComicSpider):
9 | name = 'comic90mh'
10 | search_url_head = f'http://{domain}/search/?keywords='
11 | mappings = {'更新': f'http://{domain}/update/',
12 | '排名': f'http://{domain}/rank/'}
13 |
14 | def frame_book(self, response):
15 | frame_results = {}
16 | example_b = r' {}、 《{}》 【{}】 [{}] [{}]'
17 | self.say(example_b.format('序号', '漫画名', '作者', '更新时间', '最新章节') + 'Preview
7 |
16 | {body}
17 |
18 |
19 |
--------------------------------------------------------------------------------
/GUI/src/preview_format/public.css:
--------------------------------------------------------------------------------
1 | .badge-on-img{position:absolute;right:-0.5em;box-shadow:0 0 3px rgba(0,0,0,0.03);opacity:0.7;min-width:1.5em;text-align:center;padding:0.25em;border-radius:0.25em;}
2 | .badge-on-img:hover {opacity: 0.9;}
--------------------------------------------------------------------------------
/GUI/src/preview_format/public.js:
--------------------------------------------------------------------------------
1 | // task-panel.js
2 | (() => {
3 | window.scanChecked = function () {
4 | var checkboxGroup = document.getElementsByName('img');
5 | var selectedValues = [];
6 | for (let i = 0; i < checkboxGroup.length; i++) {
7 | if (checkboxGroup[i].checked) {
8 | selectedValues.push(checkboxGroup[i].id);
9 | }
10 | }
11 | return selectedValues
12 | }
13 | window.get_curr_hml = function () {
14 | return document.documentElement.outerHTML;
15 | }
16 | document.addEventListener('DOMContentLoaded', function() {
17 | const containers = document.querySelectorAll('div[style*="position: relative"]');
18 | containers.forEach(container => {
19 | const badges = container.querySelectorAll('.badge-on-img');
20 | let verticalOffset = 0;
21 | badges.forEach(badge => {
22 | badge.style.removeProperty('top');
23 | badge.style.top = `${verticalOffset}px`;
24 | verticalOffset += badge.offsetHeight + 2;
25 | });
26 | });
27 | });
28 | })();
29 |
--------------------------------------------------------------------------------
/GUI/src/preview_format/tasks_extend.js:
--------------------------------------------------------------------------------
1 | // task-panel.js
2 | (() => {
3 | // 动态注入样式
4 | const style = document.createElement('style');
5 | style.textContent = `
6 | /* 分界线样式 */
7 | #panelDivider {
8 | margin: 1rem 0;
9 | border-width: 2px;
10 | border-color: #0d6efd;
11 | opacity: 0;
12 | transition: opacity 0.3s ease;
13 | }
14 | #panelDivider.visible {
15 | opacity: 1;
16 | }
17 | #taskPanel {
18 | max-height: 300px;
19 | overflow-y: auto;
20 | transition: all 0.3s ease;
21 | margin-bottom: 15px;
22 | box-shadow: 0 -2px 5px rgba(0,0,0,0.1); /* 投影增强层次 */
23 | direction: rtl; /* 滚动条左侧 */
24 | }
25 | #taskContainer {
26 | direction: ltr;
27 | }
28 | /* 滚动条样式 */
29 | #taskPanel::-webkit-scrollbar {
30 | width: 8px;
31 | background: #f1f1f1;
32 | }
33 | #taskPanel::-webkit-scrollbar-thumb {
34 | background: #888;
35 | border-radius: 4px;
36 | }
37 | #taskPanel::-webkit-scrollbar-thumb:hover {
38 | background: #555;
39 | }
40 | @supports (scrollbar-width: thin) {
41 | #taskPanel {
42 | scrollbar-width: thin;
43 | scrollbar-color: #888 #f1f1f1;
44 | }
45 | }
46 | /* 进度条完成 */
47 | .completed .progress-bar {
48 | background-color: #198754 !important;
49 | }
50 | /* 任务项样式 */
51 | .task-item {
52 | padding: 12px;
53 | border-bottom: 1px solid #dee2e6;
54 | }
55 | .task-progress {
56 | height: 20px;
57 | margin-top: 8px;
58 | }
59 | .task-count {
60 | font-family: monospace;
61 | font-size: 0.85em;
62 | color: #6c757d;
63 | }
64 | `;
65 | document.head.appendChild(style);
66 |
67 | // 初始化任务面板
68 | window.initTaskPanel = function () {
69 | // function initTaskPanel() {
70 | // 创建容器
71 | const container = document.createElement('div');
72 | container.innerHTML = `
73 |
78 | Hide tasks(0 )
79 |
80 |
83 | `;
84 | // 插入分隔线
85 | const divider = document.createElement('hr');
86 | divider.id = 'panelDivider';
87 | document.body.insertAdjacentElement('afterbegin', container);
88 | container.insertAdjacentElement('afterend', divider);
89 | // 事件监听
90 | const taskPanel = document.getElementById('taskPanel');
91 | const counterBtn = container.querySelector('button');
92 | if (taskPanel.classList.contains('show')) {
93 | divider.classList.add('visible');
94 | requestAnimationFrame(autoScroll);
95 | }
96 | taskPanel.addEventListener('shown.bs.collapse', () => {
97 | counterBtn.innerHTML = `Hide tasks (${taskCounter()} )`;
98 | divider.classList.add('visible');
99 | autoScroll(); // 展开时自动滚动
100 | });
101 | taskPanel.addEventListener('hidden.bs.collapse', () => {
102 | counterBtn.innerHTML = `Show tasks (${taskCounter()} )`;
103 | divider.classList.remove('visible');
104 | });
105 | window.scrollTo({top: 0, behavior: 'smooth'});
106 | }
107 |
108 | // 自动滚动优化
109 | function autoScroll() {
110 | const panel = document.getElementById('taskPanel');
111 | panel.scrollTo({
112 | top: panel.scrollHeight,
113 | behavior: 'smooth'
114 | });
115 | }
116 |
117 | // 添加任务
118 | window.addTask = function (uuid, title, task_count, title_url) {
119 | const container = document.getElementById('taskContainer');
120 | // if (document.getElementById(uuid)) return;
121 | const initialProgress = 0;
122 | const task = document.createElement('div');
123 | task.className = 'task-item';
124 | task.id = `task-${uuid}`;
125 | task.innerHTML = `
126 |
127 |
128 | ${title}
129 |
page: ${task_count}
130 |
132 |
138 | ${initialProgress}%
139 |
140 |
82 |
83 | etc..
100 |
101 |
102 | 由 [Weblate](https://hosted.weblate.org/engage/comicguispider/) 托管实现多语言的翻译
103 |
104 |
105 |
107 |
108 | ## 🔇免责声明
109 |
110 | 详见[License](LICENSE) 当你下载或使用本项目,将默许
111 |
112 | 本项目仅供交流和学习使用,请勿用此从事 违法/商业盈利 等,开发者团队拥有本项目的最终解释权
113 |
114 | ---
115 | 
116 |
--------------------------------------------------------------------------------
/assets/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 |
--------------------------------------------------------------------------------
/assets/conf_sample.yml:
--------------------------------------------------------------------------------
1 | ## 配置文件,使用方法详情至readme.md了解
2 |
3 | custom_map:
4 | 更新4: https://wnacg.com/albums-index-page-4.html
5 | 杂志: https://wnacg.com/albums-index-cate-10.html
6 | log_level: WARNING
7 | proxies: null
8 | sv_path: D:\Comic
--------------------------------------------------------------------------------
/assets/config_icon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/assets/config_icon.png
--------------------------------------------------------------------------------
/assets/icon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/assets/icon.png
--------------------------------------------------------------------------------
/assets/res/transfer.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | import pathlib
4 | import hashlib
5 | from datetime import datetime
6 | import yaml
7 | import polib
8 |
9 |
10 | def yaml_to_po(lang, yaml_file, po_file):
11 | with open(yaml_file, 'r', encoding='utf-8') as f:
12 | data = yaml.safe_load(f)
13 |
14 | po = polib.POFile()
15 | po.metadata = {
16 | 'Project-Id-Version': 'ComicGUISpider',
17 | 'POT-Creation-Date': datetime.now().strftime('%Y-%m-%d %H:%M%z'),
18 | 'Language': lang,
19 | 'MIME-Version': '1.0',
20 | 'Content-Type': 'text/plain; charset=utf-8',
21 | 'Content-Transfer-Encoding': '8bit',
22 | }
23 |
24 | def process_dict(data, prefix=''):
25 | for key, value in data.items():
26 | entry_id = f"{prefix}{key}" if prefix else key
27 | if isinstance(value, dict):
28 | process_dict(value, f"{entry_id}.")
29 | else:
30 | entry = polib.POEntry(
31 | msgid=entry_id,
32 | msgstr=str(value),
33 | )
34 | po.append(entry)
35 | process_dict(data)
36 | po.save(po_file)
37 |
38 | return po
39 |
40 | def compile_po_to_mo(po_file, mo_file):
41 | po = polib.pofile(po_file)
42 | po.save_as_mofile(mo_file)
43 |
44 |
45 | def main(base_dir, lang):
46 | locale_dir = base_dir / 'locale' / lang / 'LC_MESSAGES'
47 | locale_dir.mkdir(parents=True, exist_ok=True)
48 |
49 | yaml_file = base_dir / 'locale' / f'{lang}.yml'
50 | yaml_hash = base_dir / 'locale' / f'{lang}.hash'
51 | po_file = base_dir / 'locale' / lang / 'LC_MESSAGES' / 'res.po'
52 | mo_file = base_dir / 'locale' / lang / 'LC_MESSAGES' / 'res.mo'
53 |
54 | po = yaml_to_po(lang, yaml_file, po_file)
55 | compile_po_to_mo(po_file, mo_file)
56 | with open(yaml_hash, 'w', encoding='utf-8') as f:
57 | f.write(hashlib.sha256(yaml_file.read_bytes()).hexdigest())
58 |
59 |
60 | if __name__ == "__main__":
61 | main(pathlib.Path(__file__).parent, 'zh-CN')
62 | main(pathlib.Path(__file__).parent, 'en-US')
63 |
--------------------------------------------------------------------------------
/deploy/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | import os
4 | import platform
5 | import pathlib
6 | import subprocess
7 |
8 |
9 | class Env:
10 | default_sv_path = r"D:\Comic"
11 | default_clip_db = pathlib.Path.home().joinpath(r"AppData\Roaming\Ditto\Ditto.db")
12 | clip_sql = "SELECT `mText` FROM `MAIN` order by `LID` desc"
13 |
14 | def __init__(self, _p: pathlib.Path):
15 | self.proj_p = _p
16 | os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = str(
17 | proj_path.parent.joinpath(r"site-packages\PyQt5\Qt5\plugins\platforms"))
18 |
19 | def env_init(self):
20 | ...
21 |
22 | @staticmethod
23 | def open_folder(_p):
24 | os.startfile(_p)
25 |
26 | @staticmethod
27 | def open_file(_f):
28 | subprocess.run(["start", "", f"{_f}"], shell=True, check=True)
29 |
30 |
31 | proj_path = pathlib.Path(__file__).parent.parent
32 | curr_os_module = Env
33 | if platform.system().startswith("Darwin"):
34 | import sys
35 | sys.path.append(str(proj_path))
36 | from deploy.launcher.mac import macOS
37 | curr_os_module = macOS
38 | curr_os = curr_os_module(proj_path)
39 |
40 | if __name__ == '__main__':
41 | curr_os.env_init()
42 |
--------------------------------------------------------------------------------
/deploy/env_record.json:
--------------------------------------------------------------------------------
1 | ["execjs", "qfluentwidgets", "polib", "pillow_avif"]
--------------------------------------------------------------------------------
/deploy/launcher/CGS.bat:
--------------------------------------------------------------------------------
1 | @rem
2 | @echo off
3 |
4 | set "_root=%~dp0"
5 | set "_root=%_root:~0,-1%"
6 | cd "%_root%"
7 | @rem echo "%_root%
8 |
9 | set "_pyBin=%_root%\runtime"
10 | set "PATH=%_root%\site-packages;%_pyBin%;%PATH%"
11 |
12 | cd "%_root%\scripts" && python CGS.py
--------------------------------------------------------------------------------
/deploy/launcher/mac/CGS.bash:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | cd scripts;
3 | /usr/local/bin/python3.12 CGS.py;
--------------------------------------------------------------------------------
/deploy/launcher/mac/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | import pathlib
4 | import re
5 | import subprocess
6 |
7 | # 对应`冬青黑体简体中文`,想要换其他字体可聚焦搜索`字体册`,在目标字体右键`访达中显示`,可以看到字体文件,把字体名替换掉`font`的值即可
8 | # 字体册仅支持能访达/系统alias能搜索出的字体,如果是下载的字体文件,可以看`macOS.font_replace _repl`
9 | font = "Hiragino Sans GB"
10 |
11 |
12 | class macOS:
13 | default_sv_path = pathlib.Path.home().joinpath("Downloads/Comic")
14 | default_clip_db = pathlib.Path.home().joinpath(
15 | "Library/Containers/org.p0deje.Maccy/Data/Library/Application Support/Maccy/Storage.sqlite")
16 | clip_sql = "SELECT `ZTITLE` FROM `ZHISTORYITEM` order by `Z_PK` desc"
17 |
18 | def __init__(self, _p):
19 | self.proj_p = _p
20 |
21 | @staticmethod
22 | def open_folder(_p):
23 | subprocess.run(['open', _p])
24 |
25 | @staticmethod
26 | def open_file(_f):
27 | subprocess.run(['open', _f])
28 |
29 | def env_init(self):
30 | # 1. 更换字体
31 | self.font_replace()
32 | # 2. requirements.txt去掉window相关的包
33 | self.handle_requirements()
34 |
35 | def font_replace(self):
36 | def _repl(content):
37 | """下载的字体用绝对路径时可以用以下注释了的替换方法"""
38 | # font_path = "/Users/Shared/.../xxx.ttc"
39 | # if "QFontDatabase" not in content:
40 | # content = ("from PyQt5.QtGui import QFontDatabase\n"
41 | # f"font_path = '{font_path}'\n"
42 | # f"_id = QFontDatabase.addApplicationFont(font_path)\n") + content
43 | # new_content = re.sub(r'font = .*?\n.*?font\.setFamily\(".*?"\)',
44 | # f'font = QFontDatabase.font("{font}", "Regular", 11)', content, re.M)
45 | new_content = re.sub(r'font\.setFamily\(".*?"\)', f'font.setFamily("{font}")', content)
46 | return new_content
47 | uic_p = self.proj_p.joinpath("GUI/uic")
48 | for _f in ["conf_dia.py", "browser.py", "ui_mainwindow.py"]:
49 | self.file_content_replace(uic_p.joinpath(_f), _repl)
50 |
51 | def handle_requirements(self):
52 | self.file_content_replace(
53 | self.proj_p.joinpath('requirements.txt'),
54 | lambda content: re.sub(r'^(twisted-iocpsupport==.*|pywin32==.*)[\r\n]*', "", content, flags=re.MULTILINE)
55 | )
56 |
57 | @staticmethod
58 | def file_content_replace(file, repl_func):
59 | with open(file, 'r+', encoding='utf-8') as fp:
60 | content = fp.read()
61 | new_content = repl_func(content)
62 | fp.seek(0)
63 | fp.truncate()
64 | fp.write(new_content)
65 |
--------------------------------------------------------------------------------
/deploy/launcher/mac/dos2unix.bash:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | curr_p=$(cd "$(dirname "$0")";pwd)
3 | app_proj_p="/Applications/CGS.app/Contents/Resources/scripts"
4 | if [ ! -x /usr/local/bin/brew ]; then
5 | echo "not brew, downloading brew...";
6 | /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)";
7 | fi
8 | if [ ! -x /usr/local/bin/dos2unix ]; then
9 | echo "not dos2unix, downloading dos2unix...";
10 | brew install dos2unix;
11 | fi
12 | find $curr_p/../ -type f -name "*.bash" -exec sudo dos2unix {} +;
13 | find $curr_p/../ -type f -name "*.md" -exec sudo dos2unix {} +;
14 | find $curr_p/../ -type f -name "*.py" -exec sudo dos2unix {} +;
15 | find $curr_p/../ -type f -name "*.json" -exec sudo dos2unix {} +;
16 | find $curr_p/../ -type f -name "*.yml" -exec sudo dos2unix {} +;
17 | find $app_proj_p -type f -name "*.bash" -exec sudo dos2unix {} +;
18 | find $app_proj_p -type f -name "*.md" -exec sudo dos2unix {} +;
19 | find $app_proj_p -type f -name "*.py" -exec sudo dos2unix {} +;
20 | find $app_proj_p -type f -name "*.json" -exec sudo dos2unix {} +;
21 | find $app_proj_p -type f -name "*.yml" -exec sudo dos2unix {} +;
22 |
--------------------------------------------------------------------------------
/deploy/launcher/mac/init.bash:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # 将终端窗口置于最前
3 | osascript -e 'tell application "Terminal" to activate' -e 'tell application "System Events" to tell process "Terminal" to set frontmost to true'
4 |
5 | curr_p=$(cd "$(dirname "$0")";pwd);
6 | cd $curr_p/../../../;
7 | REQUIREMENTS="requirements/mac_x86_64.txt"
8 |
9 | # 检测是否为 Apple Silicon
10 | if [ "$(uname -m)" = "arm64" ]; then
11 | REQUIREMENTS="requirements/mac_arm64.txt"
12 | # 检测 Rosetta 2 是否已安装
13 | if ! arch -x86_64 echo > /dev/null 2>&1; then
14 | echo "检测到 Apple Silicon Mac,但未安装 Rosetta 2,正在安装..."
15 | /usr/sbin/softwareupdate --install-rosetta --agree-to-license
16 | fi
17 | fi
18 |
19 | PYTHON_PATH="/usr/local/bin/python3.12"
20 | # 确保安装的是 x86_64 版本的 Python
21 | if [ ! -x "$PYTHON_PATH" ]; then
22 | echo "无python3.12环境,正在初始化...";
23 | # 检测 Homebrew 安装路径
24 | if [ -x "/opt/homebrew/bin/brew" ]; then
25 | ARM_BREW_PATH="/opt/homebrew/bin/brew"
26 | fi
27 | if [ -x "/usr/local/bin/brew" ]; then
28 | INTEL_BREW_PATH="/usr/local/bin/brew"
29 | fi
30 | # 如果没有安装 Homebrew,则安装它
31 | if [ ! -x "$INTEL_BREW_PATH" ] && [ ! -x "$ARM_BREW_PATH" ]; then
32 | echo "未检测到 Homebrew,正在安装..."
33 | /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)";
34 | fi
35 | # 在 Apple Silicon Mac 上,通过 Rosetta 2 安装 x86_64 版的 Python
36 | if [ "$(uname -m)" = "arm64" ]; then
37 | if [ -x "$INTEL_BREW_PATH" ]; then
38 | echo "使用 Intel Homebrew 安装 Python..."
39 | "$INTEL_BREW_PATH" install python@3.12
40 | "$INTEL_BREW_PATH" link python@3.12
41 | else
42 | echo "通过 Rosetta 2 安装 Intel 版本的 Python..."
43 | arch -x86_64 /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
44 | arch -x86_64 /usr/local/bin/brew install python@3.12
45 | arch -x86_64 /usr/local/bin/brew link python@3.12
46 | fi
47 | else
48 | # 在 Intel Mac 上,直接安装
49 | if [ -x "$INTEL_BREW_PATH" ]; then
50 | "$INTEL_BREW_PATH" install python@3.12
51 | "$INTEL_BREW_PATH" link python@3.12
52 | fi
53 | fi
54 | fi
55 |
56 | "$PYTHON_PATH" deploy/__init__.py;
57 | echo "正在安装依赖(自动过滤macOS不兼容包)..."
58 | cat "$REQUIREMENTS" | grep -vE 'pywin32==|twisted-iocpsupport==' | "$PYTHON_PATH" -m pip install -r /dev/stdin \
59 | -i http://mirrors.aliyun.com/pypi/simple/ \
60 | --trusted-host mirrors.aliyun.com \
61 | --user \
62 | --break-system-packages;
63 |
64 | echo ""
65 | echo "===== 初始化完毕,请手动关闭终端窗口 ====="
66 | echo ""
--------------------------------------------------------------------------------
/deploy/online_scripts/win.ps1:
--------------------------------------------------------------------------------
1 | $IsPwsh = $PSVersionTable.PSEdition -eq "Core"
2 |
3 | $proj_p = Get-Location
4 |
5 | $python_exe = Join-Path $proj_p "runtime/python.exe"
6 | if (-not (Test-Path $python_exe)) {Write-Output "runtime/python.exe not found, need excute on unzipped path/请在解压的根目录下执行";pause;exit}
7 |
8 | $locale = if ($IsPwsh) { (Get-Culture).Name } else { [System.Threading.Thread]::CurrentThread.CurrentUICulture.Name }
9 |
10 | $targetUrl = if ($locale -eq "zh-CN") {"https://gitproxy.click/https://raw.githubusercontent.com/jasoneri/ComicGUISpider/refs/heads/GUI/deploy/pkg_mgr.py"} else {"https://raw.githubusercontent.com/jasoneri/ComicGUISpider/refs/heads/GUI/deploy/pkg_mgr.py"}
11 |
12 | $pyPath = "$proj_p\pkg_mgr.py"
13 | try {
14 | if ($PSVersionTable.PSVersion.Major -le 5) {
15 | Add-Type @"
16 | using System.Net;
17 | using System.Security.Cryptography.X509Certificates;
18 | public class TrustAllCertsPolicy : ICertificatePolicy {
19 | public bool CheckValidationResult(ServicePoint s, X509Certificate c, WebRequest r, int e) { return true; }
20 | }
21 | "@
22 | [Net.ServicePointManager]::CertificatePolicy = [TrustAllCertsPolicy]::new()
23 | }
24 | Invoke-WebRequest -Uri $targetUrl -OutFile $pyPath -UseBasicParsing
25 | }
26 | catch {
27 | Write-Output "install pkg_mgr.py failed/下载pkg_mgr.py失败";pause;exit
28 | }
29 | & "$python_exe" "$pyPath" -l $locale
30 | Remove-Item -Path $pyPath -Force
--------------------------------------------------------------------------------
/deploy/pkg_mgr.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import sys
3 | import importlib
4 | import platform
5 | import subprocess
6 | import pathlib
7 | import pip
8 |
9 | import httpx
10 | import tqdm
11 | from loguru import logger
12 |
13 | p = pathlib.Path(__file__).parent
14 | def which_env():
15 | os_type = platform.system()
16 | if os_type == "Darwin":
17 | # 判断Mac架构
18 | arch = platform.machine()
19 | if arch == "arm64":
20 | return "mac_arm64"
21 | elif arch == "x86_64":
22 | return "mac_x86_64"
23 | else:
24 | return "mac_x86_64"
25 | else:
26 | return "win"
27 |
28 |
29 | class PkgMgr:
30 | def __init__(self, locale="zh-CN", run_path=None, debug_signal=None):
31 | self.cli = httpx.Client()
32 | self.locale = locale
33 | self.run_path = run_path or p
34 | self.debug_signal = debug_signal
35 | if self.run_path.joinpath("scripts/CGS.py").exists():
36 | self.proj_p = self.run_path.joinpath("scripts")
37 | elif self.run_path.joinpath("CGS.py").exists():
38 | self.proj_p = self.run_path
39 | else:
40 | raise FileNotFoundError(f"CGS.py not found, unsure env. check your run path > [{self.run_path}].")
41 | self.env = which_env()
42 | self.set_assets()
43 |
44 | def github_speed(self, url):
45 | if self.locale == "zh-CN":
46 | url = "https://gitproxy.click/" + url
47 | return url
48 |
49 | def set_assets(self):
50 | requirements = f"requirements/{self.env}.txt"
51 | self.requirements_url = self.github_speed(f"https://raw.githubusercontent.com/jasoneri/ComicGUISpider/refs/heads/GUI/{requirements}")
52 | self.requirements = self.proj_p.joinpath(requirements)
53 |
54 | def print(self, *args, **kwargs):
55 | if self.debug_signal:
56 | self.debug_signal.emit(*args, **kwargs)
57 | print(*args, **kwargs)
58 |
59 | def dl(self):
60 | def _dl(url, out):
61 | with self.cli.stream("GET", url) as r:
62 | with open(out, "wb") as f:
63 | for chunk in tqdm.tqdm(r.iter_bytes(1000), desc=f"downloading {out.name}"):
64 | f.write(chunk)
65 | self.print(f"[downloaded] {out.name}")
66 |
67 | def _dl_uv():
68 | cmd = ["install", "uv"]
69 | if self.locale == "zh-CN":
70 | cmd.extend(["-i", "https://pypi.tuna.tsinghua.edu.cn/simple"])
71 | exitcode = pip.main(cmd)
72 | self.print(f"[pip install uv exitcode] {exitcode}")
73 |
74 | _dl_uv()
75 | _dl(self.requirements_url, self.requirements)
76 |
77 | def uv_install_pkgs(self):
78 | self.print("uv pip installing pkg...")
79 | uv = importlib.import_module("uv")
80 | cmd = [uv.find_uv_bin(), "pip", "install", "-r", str(self.requirements), "--python", sys.executable]
81 | if self.locale == "zh-CN":
82 | cmd.extend(["--index-url", "http://mirrors.aliyun.com/pypi/simple/", "--trusted-host", "mirrors.aliyun.com"])
83 | self.print("[uv_install_pkgs cmd]" + " ".join(cmd))
84 | process = subprocess.Popen(
85 | cmd, cwd=self.run_path,
86 | stdout=subprocess.PIPE, stderr=subprocess.STDOUT,
87 | text=True, bufsize=1, universal_newlines=True
88 | )
89 | full_output = []
90 | while True:
91 | line = process.stdout.readline()
92 | if not line:
93 | if process.poll() is not None:
94 | break # 进程结束且无输出时退出
95 | continue
96 | line = line.strip()
97 | full_output.append(line)
98 | # 实时发送信号
99 | self.print(line)
100 | # 读取剩余输出
101 | remaining = process.stdout.read()
102 | if remaining:
103 | for line in remaining.splitlines():
104 | cleaned_line = line.strip()
105 | full_output.append(cleaned_line)
106 | self.print(cleaned_line)
107 | # 等待进程结束
108 | exit_code = process.wait()
109 | if exit_code == 0:
110 | self.print("[!uv_install_pkgs done!]")
111 | return exit_code, full_output
112 |
113 | @logger.catch(reraise=True)
114 | def run(self):
115 | self.dl()
116 | exit_code, full_output = self.uv_install_pkgs()
117 | return exit_code, full_output
118 |
119 |
120 | if __name__ == "__main__":
121 | parser = argparse.ArgumentParser()
122 | parser.add_argument("-l", "--locale", default="zh-CN", help="locale")
123 | args = parser.parse_args()
124 | pkg_mgr = PkgMgr(args.locale)
125 | # pkg_mgr = PkgMgr("zh-CN")
126 | pkg_mgr.run()
127 |
--------------------------------------------------------------------------------
/docs/.vitepress/theme/Layout.vue:
--------------------------------------------------------------------------------
1 |
14 |
15 |
16 |
17 |
18 |
19 |
35 |
36 |
37 |
38 |
39 |
--------------------------------------------------------------------------------
/docs/.vitepress/theme/index.ts:
--------------------------------------------------------------------------------
1 | import DefaultTheme from 'vitepress/theme'
2 | import Layout from './Layout.vue'
3 | import './style.css'
4 |
5 | export default {
6 | extends: DefaultTheme,
7 | Layout
8 | }
--------------------------------------------------------------------------------
/docs/.vitepress/theme/style.css:
--------------------------------------------------------------------------------
1 | /**
2 | * Customize default theme styling by overriding CSS variables:
3 | * https://github.com/vuejs/vitepress/blob/main/src/client/theme-default/styles/vars.css
4 | */
5 |
6 | /**
7 | * Component: Home
8 | * -------------------------------------------------------------------------- */
9 |
10 | :root {
11 | --vp-home-hero-name-color: transparent;
12 | --vp-home-hero-name-background: -webkit-linear-gradient(
13 | 120deg,
14 | #eea320f4 60%,
15 | #441bd900
16 | );
17 |
18 | --vp-home-hero-image-background-image: -webkit-linear-gradient(
19 | 125deg,
20 | #f4c03bd5 40%,
21 | #fd3e94de 80%
22 | );
23 | --vp-home-hero-image-filter: blur(40px);
24 | }
25 |
--------------------------------------------------------------------------------
/docs/_github/README_en.md:
--------------------------------------------------------------------------------
1 |
20 |
21 | ▼ Demo ▼
22 |
23 | | Preview / Multi-select / Paging | Clipboard Tasks |
24 | |:-------------------------------------------------------------------------------:|:----------------------------------------------------------------------------:|
25 | |  | 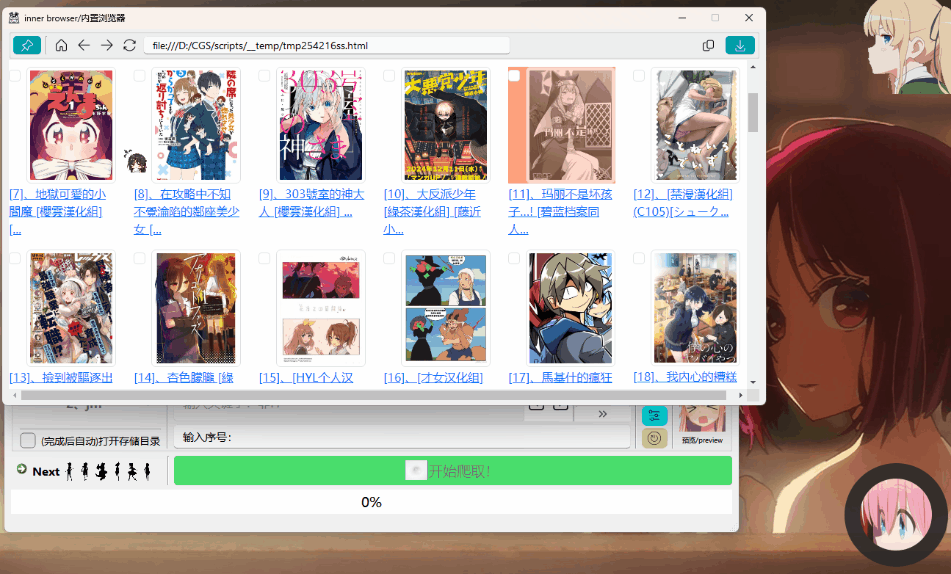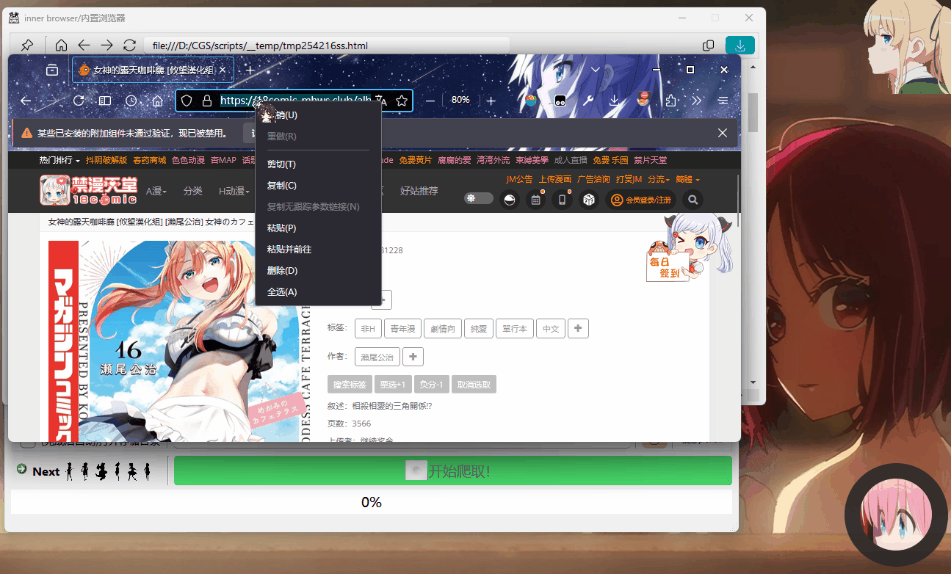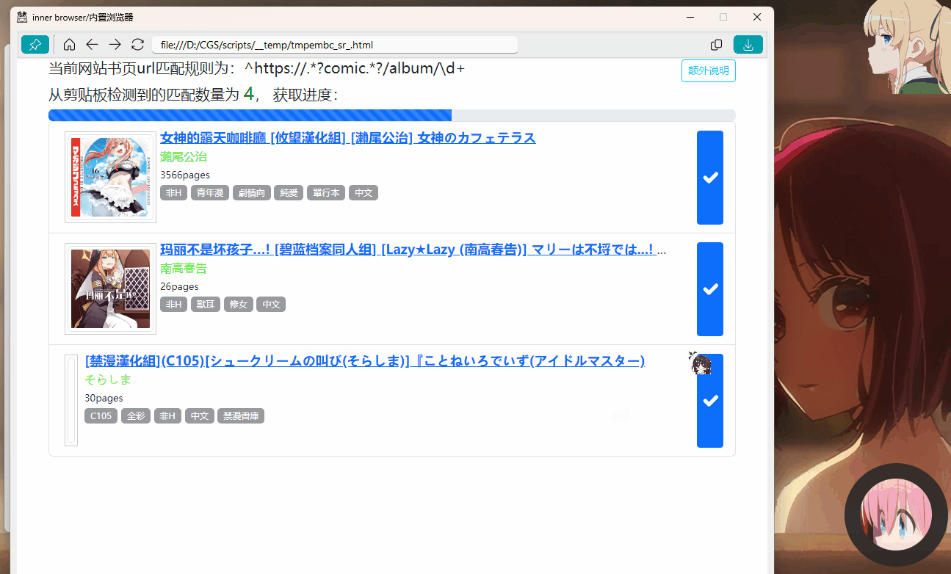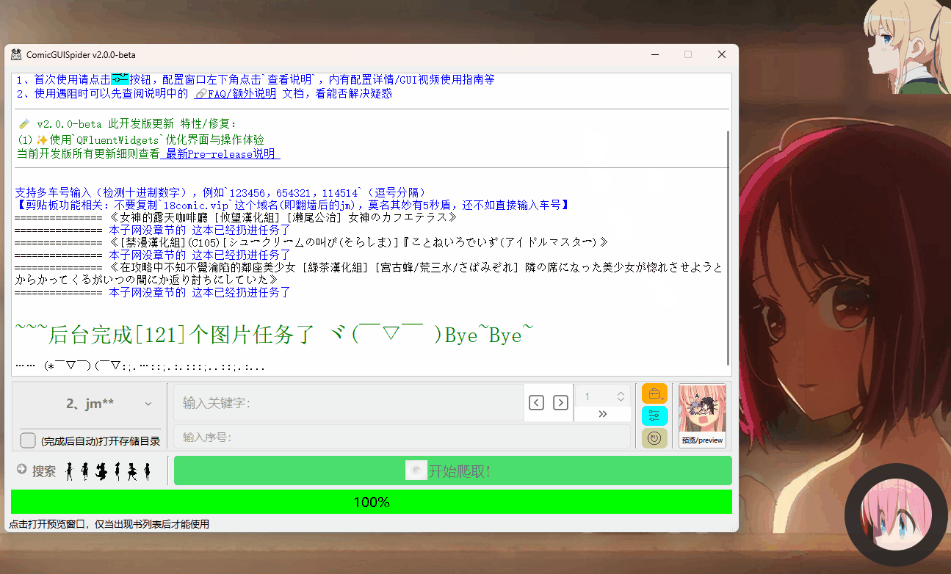 |
26 |
27 | ## 📑 Introduction
28 |
29 | ### Supported Websites
30 |
31 | | Website | locale | Notes | status儿童节
3 |
4 | ## 🐞 Fix
5 |
6 | ✅ 拷x恢复 🙊
7 | ✅ jm 发布页( WinError 10054 )问题处理详情看软件内 jm 提示,同时本地缓存统一改为48小时,🔜[相关参考指引](https://jasoneri.github.io/ComicGUISpider/faq/extra.html#_2-%E5%9F%9F%E5%90%8D%E7%9B%B8%E5%85%B3)
8 |
--------------------------------------------------------------------------------
/docs/assets/img/config/conf_usage.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/config/conf_usage.png
--------------------------------------------------------------------------------
/docs/assets/img/config/conf_usage_en.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/config/conf_usage_en.png
--------------------------------------------------------------------------------
/docs/assets/img/deploy/mac-app-move.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/deploy/mac-app-move.jpg
--------------------------------------------------------------------------------
/docs/assets/img/dev/branch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/dev/branch.png
--------------------------------------------------------------------------------
/docs/assets/img/faq/ditto_settings.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/faq/ditto_settings.png
--------------------------------------------------------------------------------
/docs/assets/img/feature/browser_copyBtn.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/feature/browser_copyBtn.png
--------------------------------------------------------------------------------
/docs/assets/img/icons/website/copy.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/icons/website/copy.png
--------------------------------------------------------------------------------
/docs/assets/img/icons/website/ehentai.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/icons/website/ehentai.png
--------------------------------------------------------------------------------
/docs/assets/img/icons/website/hitomi.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/icons/website/hitomi.png
--------------------------------------------------------------------------------
/docs/assets/img/icons/website/jm.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/icons/website/jm.png
--------------------------------------------------------------------------------
/docs/assets/img/icons/website/mangabz.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/icons/website/mangabz.png
--------------------------------------------------------------------------------
/docs/assets/img/icons/website/wnacg.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/assets/img/icons/website/wnacg.png
--------------------------------------------------------------------------------
/docs/changelog/history.md:
--------------------------------------------------------------------------------
1 | # 🕑 更新历史
2 |
3 | > [!Info] 此页面会忽略修复动作相关的记录,含引导意义的条目除外
4 |
5 | #### v2.2.0 | ~ 2025-05-20
6 |
7 | + hitomi 支持(部分)
8 | + Kemono 脚本集更新(下载引擎使用强大的 `Motrix-PRC`)
9 | + 页数命名优化:更改为纯数字补零命名,附带可选 [文件命名后缀修改](https://jasoneri.github.io/ComicGUISpider/config/#其他-yml-字段)
10 | + i18n 自动编译优化
11 | + 使用 astral-sh/uv 管理依赖
12 |
13 | #### v2.1.3 | ~ 2025-04-19
14 |
15 | + 支持 i18n
16 | + 增加贡献指南等,文档优化,并建成 github-pages 做官网
17 |
18 | ### v2.1.2 | ~ 2025-04-12
19 |
20 | + 更换看板娘
21 | + 版面增设各网站运行状态
22 |
23 | ### v2.1.0 | ~ 2025-03-29
24 |
25 | + 为预览窗口各封面右上增设badge
26 | + 将`requirements.txt`分别以`win`,`mac_x86_64`,`mac_arm64`编译
27 |
28 | ### v2.0.0 | ~ 2025-03-21
29 |
30 | + `使用说明`与`更新`在`v2.0.0`后将设置在配置窗口的左下按钮,绿色包可执行程序只保留主程序(macOS加个初始化.app)
31 | + 优化更新流程,贴近主流软件体验
32 | + ✨使用`QFluentWidgets`优化界面与操作体验
33 | + 搜索框右键选项`展开预设`, 序号输入框也有
34 | + 预览窗口改造了右键菜单,增设翻页进去菜单项,附带有`CGS`内的全局快捷键
35 | + 正确处理小数位级系统缩放,去掉`同步系统缩放`也有良好界面体验
36 | (操作参考[`v1.6.3`删代码部分](#v1-6-3-2025-02-13),后续若有反响则做成开关之类提供切换)
37 |
38 | ### v1.8.2 | ~ 2025-03-08
39 |
40 | + ✨预览窗口新增`复制`未完成任务按钮,配合剪贴板功能功能的流程,常用于进度卡死不动重下或补漏页
41 |
42 | ### v1.7.5 | ~ 2025-03-01
43 |
44 | + 序号输入扩展:输入框支持单个负数,例`-3`表示选择倒数三个
45 |
46 | ### v1.7.2 | ~ 2025-02-24
47 |
48 | + ✨新增`增加标识`开关勾选,为储存目录最后加上网站url上的作品id
49 | + ✨细化任务:预览窗口的`子任务进度`视图
50 | + 处理拷贝的隐藏漫画
51 | + 修正往后jm全程不走代理(如有jm需要走代理的场景请告知开发者)
52 |
53 | ### v1.6.3 | ~ 2025-02-13
54 |
55 | + ✨配置窗口新增`去重`勾选开关:分别有预览提示样式和自动过滤
56 | + ✨增加命令行工具(crawl_only.py)使用
57 | + 优化高分辨率(原开发环境为1080p);若显示不理想可桌面右键显示设置缩放改为100%,或在[`CGS.py`](https://github.com/jasoneri/ComicGUISpider/blob/GUI/CGS.py)中删除带`setAttribute(Qt.AA_` 的两行代码
58 |
59 | ### v1.6.2 | ~ 2024-12-08
60 |
61 | + ✨增加域名缓存机制(针对jm/wnacg发布页访问错误),每12小时才刷新可用域名,缓存文件为`scripts/__temp/xxx_domain.txt`,可删可改
62 | + 处理部分用户环境无法显示ui图标相关资源问题(如对比动图/视频仍有ui图标没显示,请反馈)
63 |
64 | ### v1.6.1 | ~ 2024-11-23
65 | + ✨新增读剪切板匹配生成任务功能
66 |
67 | ### v1.6.0 | ~ 2024-09-30
68 | + 🌐支持`Māngabz`
69 | + ✨支持`macOS`
70 | + 🌐支持`exhentai`
71 | + [`exhentai`]优化e绅士标题取名,优先使用副标题的中/日文作为目录名
72 | + ✨新增翻页功能
73 | + 翻页时保留选择状态
74 | + ✨新增预览功能
75 | > [!Info] 内置小型浏览器,无需打开电脑浏览器,视频3有介绍各种用法
76 |
77 | ### v1.5 | 上世纪 ~ 2024-08-05
78 | + ✨发布相关
79 | > [!Info] 发布开箱即用版,GUI视频使用指南
80 |
81 | + ✨脚本集说明(kemono,saucenao)
82 | + 新增`nekohouse`
83 | + 🌐支持`jm(禁漫)`
84 | + 支持车号输入
85 | + 🌐支持`拷贝漫画`
86 | + 在配置设了代理后能解锁部分漫画章节
87 | + 处理章节数量大于300
88 | + 🌐支持`wnacg`
89 |
--------------------------------------------------------------------------------
/docs/config/index.md:
--------------------------------------------------------------------------------
1 | # 🔨 主配置
2 |
3 | 
4 |
5 | ::: info 配置文件为初始使用后产生的 `scripts/conf.yml`
6 | 有关生效时间节点请查阅 [📒配置生效相关](../faq/extra.md#_1-配置生效相关)
7 | :::
8 | ::: warning 多行的编辑框输入为 `yaml` 格式(除了 eh_cookies ),冒号后要加一个⚠️ `空格` ⚠️
9 | :::
10 |
11 | ## 配置项 / 对应 `yml` 字段
12 |
13 | ### 存储路径 / `sv_path`
14 |
15 | 下载目录
16 | 目录结构里还有个 `web` 文件夹的情况是因为默认关联 [`redViewer`](https://github.com/jasoneri/redViewer) 项目所以这样设置的
17 |
18 | ### 日志等级 / `log_level`
19 |
20 | 后台运行过后会有 log 目录,GUI 与 后台 同级,报错时 GUI 会进行操作指引
21 |
22 | ### 去重 / `isDeduplicate`
23 |
24 | 勾选状态下,预览窗口会有已下载的样式提示
25 | 同时下载也会自动过滤已存在的记录
26 | > [!Info] 当前仅🔞网适用
27 |
28 | ### 增加标识 / `addUuid`
29 |
30 | 存储时目录最后增加标识,用以处理同一命名的不同作品等([对应逻辑](../faq/other.md#_1-去重,增加标识相关说明))
31 |
32 | ### 代理 / `proxies`
33 |
34 | 翻墙用
35 | > [!Warning] ⚠️ 已设置 jm 无论用全局还是怎样都只走本地原生ip
36 |
37 | > [!Info] 建议使用代理模式在此配置代理,而非全局代理模式,不然访问图源会吃走大量代理的流量
38 |
39 | ### 映射 / `custom_map`
40 |
41 | 搜索输入映射
42 | 当搜索与预设不满足使用时,先在此加入键值对,重启后在搜索框输入自定义键就会将对应网址结果输出,`🎥视频使用指南3`有介绍用法
43 |
44 | 1. 映射无需理会域名,前提是用在当前网站,只要满足 `不用映射时能访问` 和 `填入的不是无效的url`,
45 | 程序会内置替换成可用的域名,如非代理下映射的`wnacg.com`会自动被替换掉
46 | 2. 注意自制的映射有可能超出翻页规则范围,此时可通知开发者进行扩展
47 |
48 | ### 预设 / `completer`
49 |
50 | 自定义预设
51 | 鼠标悬停在输入框会有`序号对应网站`的提示(其实就是选择框的序号)
52 | `🎥视频使用指南3`有介绍用法
53 |
54 | ### eh_cookies / `eh_cookies`
55 |
56 | 使用`exhentai`时必需
57 | [🎬获取方法](https://jsd.vxo.im/gh/jasoneri/imgur@main/CGS/ehentai_get_cookies_new.gif)
58 | [🔗动图中的curl转换网站](https://tool.lu/curl/)
59 |
60 | ### 剪贴板db / `clip_db`
61 |
62 | ::: tip 前提:已阅 [`读剪贴板`功能说明](../feature/index#_4-1-读剪贴板)
63 | :::
64 |
65 | 读取剪贴板功能无法使用时可查看路径是否存在,通过以下查得正确路径后在此更改
66 |
67 | 1. ditto(win): 打开选项 → 数据库路径
68 | 2. maccy(macOS): [issue 搜索相关得知](https://github.com/p0deje/Maccy/issues/271)
69 |
70 | ### 读取条数 / `clip_read_num`
71 |
72 | 读取剪贴板软件条目数量
73 |
74 | ## 其他 `yml` 字段
75 |
76 | ::: info 此类字段没提供配置窗口便捷修改(或以后支持),不设时使用默认值
77 | :::
78 |
79 | ### `img_sv_type`
80 |
81 | 默认值: `jpg`
82 | 图片文件命名后缀
83 |
--------------------------------------------------------------------------------
/docs/config/other.md:
--------------------------------------------------------------------------------
1 | # 🔧 其他配置
2 |
3 | ## 1. 预览视窗的复制按钮相关
4 |
5 | 需要更改剪贴板软件的设置令功能得以使用正常
6 |
7 | ### [win] ditto
8 |
9 | 进ditto选项,点高级进页面后,查找图示的两个值将其改为150
10 |
11 | 
12 |
13 | ### [macOS] maccy
14 |
15 | 看了一圈Maccy设置没得改,所以用测试过能正常复制的最低延迟,300ms * 复制条数
16 |
--------------------------------------------------------------------------------
/docs/deploy/mac-required-reading.md:
--------------------------------------------------------------------------------
1 | # 💻 macOS( mac 操作系统) 部署
2 |
3 | > [!Info] WantHelp!
4 | > 寻找 `mac—arm64` 开发者维护 `mac` 应用(本渣配置台式开始跑不动 `mac` 虚拟机了) [查看详情](
5 | https://github.com/jasoneri/ComicGUISpider/issues/35)
6 |
7 | ## 🚩 前置架构相关
8 |
9 | 通过以下命令查看架构(一般英特尔芯片i系的即为`x86_64`, 苹果芯片m系的为`arm64`)
10 |
11 | ```bash
12 | python -c "import platform; print(platform.machine())"
13 | ```
14 |
15 | 1. `x86_64` 架构: 开发者虚拟机就是该架构,一般按下面流程走即可
16 | 2. `arm64` 架构: CGS-init.app 会自动安装`Rosetta 2`,下文中有列出一些[应对`CGS.app`无法打开](#针对弹窗报错的尝试)的处理方案
17 |
18 | ## 📑 绿色包说明
19 |
20 | macOS 仅需下载 `CGS-macOS`压缩包
21 |
22 | ::: details 解压后目录树(点击展开)
23 |
24 | ```text
25 | CGS-macOS
26 | ├── CGS.app # 既是 *主程序*,也可以当成代码目录文件夹打开,执行脚本 `scripts/deploy/launcher/mac/CGS.bash`
27 | | ├── Contents
28 | | ├── Resources
29 | | ├── scripts # 真实项目代码目录
30 | ├── CGS-init.app # 执行脚本 `scripts/deploy/launcher/mac/init.bash`
31 | └── CGS_macOS_first_guide.html # 用作刚解压时提供指引的一次性使用说明
32 | ```
33 |
34 | :::
35 | ::: warning macOS由于认证签名收费,app初次打开会有限制,正确操作如下
36 |
37 | 1. 对任一app右键打开,报错不要丢垃圾篓,直接取消
38 | 2. 再对同一app右键打开,此时弹出窗口有打开选项,能打开了
39 | 3. 后续就能双击打开,不用右键打开了
40 | :::
41 |
42 | ## ⛵️ 操作
43 |
44 | ::: warning 所有文档中包含`scripts`目录的
45 | 包括此mac部署说明,主说明README,release页面,issue的等等等等,
46 | 在app移至应用程序后的绝对路径皆指为`/Applications/CGS.app/Contents/Resources/scripts`
47 | :::
48 |
49 | ::: warning 以下初始化步骤严格按序执行
50 | :::
51 |
52 | | 初次化步骤 | 解析说明 |
53 | |:------:|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
54 | | 1 | 每次解压后,将`CGS.app`移至应用程序..` 三位版本的格式,每一位版本上的数字更新含义如下:
58 |
59 | - **Major**: 大版本更新,很可能有不兼容的 配置/API 修改
60 | - **Minor**: 向下兼容的功能性新增
61 | - **Patch**: 向下兼容的 Bug 修复 / 小优化修正
62 |
63 | ### 分支开发,主干发布
64 |
65 | ComicGUISpider 项目使用「分支开发,主干发布」的模式,
66 |
67 | [**`GUI`**](https://github.com/jasoneri/ComicGUISpider/commits/GUI) 分支是稳定版本的 **「主干分支」**,只用于修改版本号/打 tag 发版,不用于直接开发新功能或修复。
68 |
69 | 每一个 Minor 版本都有一个对应的 **「开发分支」** 用于开发新功能、与发布后维护修复问题,
70 |
71 | 开发分支的名字为 `.-dev`,如 `2.x-dev`, 你可以在仓库的 [All Branches 中搜索到它们](https://github.com/jasoneri/ComicGUISpider/branches/all?query=-dev)。
72 |
73 | ### Branch 生命周期
74 |
75 | 当一个 Minor 开发分支(以 `2.1-dev` 为例) 完成新功能开发,**首次**合入 GUI 分支后,
76 | - 发布 Minor 版本 (如 `2.1.0`)
77 | - 同时拉出**下一个** Minor 开发分支(`2.2-dev`),用于下一个版本新功能开发
78 | - 而**上一个**版本开发分支(`2.0-dev`)进入归档不再维护
79 | - 且这个 Minor 分支(`2.1-dev`)进入维护阶段,不再增加新功能/重构,只维护 Bugs 修复
80 | - Bug 修复到维护阶段的 Minor 分支(`2.1-dev`)后,会再往 GUI 分支合并,并发布 `Patch` 版本
81 |
82 | 根据这个流程,对于各位 Contributors 在开发贡献时选择 Git Branch 来说,则是:
83 | - 若「修复 Bug」,则基于**当前发布版本**的 Minor 分支开发修复,并 PR 到这个分支
84 | - 若「添加新功能/重构」,则基于**还未发布的下一个版本** Minor 分支开发,并 PR 到这个分支
85 |
86 | ::: info 「当前发布版本」为 [[Releases 页面]](https://github.com/jasoneri/ComicGUISpider/releases) 最新版本
87 | :::
88 |
89 | ### Git Workflow 一览
90 |
91 | > [!Info] 图中 commit timeline 从左到右 --->
92 |
93 | 
94 |
95 | ## Pull Request
96 |
97 | 请确保你根据上文的 Git 分支管理 章节选择了正确的 PR 目标分支,
98 |
99 | > [!Info] 若「修复 Bug」,则 PR 到**当前发布版本**的 Minor 维护分支
100 |
101 | > [!Info] 若「添加新功能/重构」,则 PR **下一个版本** Minor 开发分支
102 |
103 | - 一个 PR 应该只对应一件事,而不应引入不相关的更改;
104 |
105 | 对于不同的事情可以拆分提多个 PR,这能帮助开发组每次 review 只专注一个问题。
106 |
107 | - 在提 PR 的标题与描述中,最好对修改内容做简短的说明,包括原因和意图,
108 |
109 | 如果有相关的 issue 或 RFC,应该把它们链接到 PR 描述中,
110 |
111 | 这将帮助开发组 code review 时能最快了解上下文。
112 |
113 | - 确保勾选了「允许维护者编辑」(`Allow edits from maintainers`) 选项。这使我们可以直接进行较小的编辑/重构并节省大量时间。
114 |
115 | - 请确保本地通过了「单元测试」和「代码风格 Lint」,这也会在 PR 的 GitHub CI 上检查
116 | - 对于 bug fix 和新功能,通常开发组也会请求你添加对应改动的单元测试覆盖
117 |
118 | 开发组会在有时间的最快阶段 Review 贡献者提的 PR 并讨论或批准合并(Approve Merge)。
119 |
120 | ## 版本发布介绍
121 |
122 | 版本发布目前由开发组通过合并「PR」后,GUI 分支上修改版本号然后打 tag 自动触发打包与发布。
123 |
124 | 通常 Bug 修复的 PR 合并后会很快发版,通常不到一周;
125 |
126 | 而新功能的发版时间则会更长而且不定,你可以在我们的 [GitHub Project](https://github.com/jasoneri/ComicGUISpider/projects?query=is%3Aopen) 看板中看到开发进度,一个版本规划的新功能都开发完备后就会发版。
127 |
128 | ## 贡献文档
129 |
130 | 如果要为文档做贡献,请注意以下几点:
131 |
132 | - 文档皆存放在 docs 目录上,仅限 markdown
133 | - 需基于**当前发布版本**的 Minor 维护分支进行修改,并 PR 到这个分支
134 | - 请确保你的 PR 标题和描述中包含了你的修改的目的和意图
135 |
136 | 撰写文档请使用规范的书面化用语,遵照 Markdown 语法,以及 [中文文案排版指北](https://github.com/sparanoid/chinese-copywriting-guidelines) 中的规范。
137 |
--------------------------------------------------------------------------------
/docs/dev/dev_spider.md:
--------------------------------------------------------------------------------
1 | # ✒️ 其他网站的扩展开发指南
2 |
3 | Website crawler develope guide
4 |
5 | 基于 `Scrapy`
6 | 需切换到 **下一个版本** Minor 开发分支,PR 时提交到此分支
7 |
8 | ## 开发步骤
9 |
10 | ### 1. 爬虫代码
11 |
12 | 以 wnacg 为例
13 |
14 | ### WnacgSpider
15 |
16 | [`代码位置`](https://github.com/jasoneri/ComicGUISpider/blob/GUI/ComicSpider/spiders/wnacg.py)
17 |
18 | #### 类属性
19 |
20 | ✅ name: 爬虫名字,取目标网站域名的部分或标题,与分支名相同
21 | ✅ domain: 目标网站域名
22 | ✅ search_url_head: 搜索页url(去掉关键词),大部分网站都是以get形式直出的
23 | 🔳 custom_settings: `scrapy`客制设定。举例两个应用
24 | `wnacg`里的`ComicDlProxyMiddleware`, 配置里设了代理时 & 走目标网站域名情况下,会通过代理进行访问
25 | `jm`里的`JmComicPipeline`,禁漫的图片直接访问链接时是切割加密过的(可自行浏览器右键新建标签打开图像),这里做了解密还原了
26 | 🔳 ua: 若`custom_settings`设了 `UAMiddleware` 才会生效
27 | 🔳 mappings: 默认映射,与`更改配置`里的`映射`相叠加
28 | 🔳 frame_book_format: 影响传递给`self.parse_section`的`meta`组成
29 | 🔳 turn_page_search/turn_page_info: 翻页时需要,使用为`utils.processed_class.Url`, 参照已有案例即可 (注意`Url.set_next`,受传参个数影响)
30 |
31 | #### 类方法
32 |
33 | 🔳 @property search: 生成第一个请求的连接,可结合`mappings`进行复杂输入的转换
34 | 🔳 start_requests: 发出第一个请求,可在此进行`search`实现不了 或 不合其逻辑的操作
35 | ✅ frame_book: "搜索 > 书列表" 之间的清洗
36 | ✅ frame_section:
37 | 一跳页面:书页面 > 能直接获取该书的全页
38 | 二跳页面:书页面 > 章节列表 之间的清洗
39 | 🔳 parse_fin_page: (一跳页面不需要,二跳页面必须) 章节页面 > 直接获取该章节的全页
40 | 🔳 mk_page_tasks: 跟三跳页面相关,可以用巧妙方法绕过,初始先不管,二跳页面情况下参考`kaobei.py`
41 |
42 | #### 常用方法
43 |
44 | + self.say: 能将字符串(可使用部分html标签格式)打印在gui上
45 | + utils.processed_class.PreviewHtml: 通过`add`喂预览图链接,结束后用`created_temp_html`
46 | 生成临时html文件。实例详见`WnacgSpider.frame_book`
47 |
48 | ### WnacgUtils
49 |
50 | [`代码位置`](https://github.com/jasoneri/ComicGUISpider/blob/GUI/utils/website/__init__.py)
51 | 常规漫与🔞继承基类不同
52 |
53 | #### 类属性(Utils)
54 |
55 | ✅ name: 同爬虫名字
56 | ✅ uuid_regex: 将 作品id 从作品 预览url 中抽取的正则表达式
57 | 🔳 headers: 通用请求头
58 | 🔳 book_hea: 读剪贴板功能使用的请求头
59 | 🔳 book_url_regex: 读剪贴板功能使用所对应当前网站抽取 作品id 的正则表达式
60 |
61 | #### 类方法(Utils)
62 |
63 | 🔳 parse_publish_: 清洗发布页
64 | 🔳 parse_book: 清洗出读剪贴板功能的信息
65 | 🔳 test_index: 测试网络环境能否访问当前网站
66 |
67 | ::: tip 最后需要在 spider_utils_map 加上对应的 Utils
68 | :::
69 |
70 | ### 2. 其他代码
71 |
72 | #### [`variables/__init__.py`](https://github.com/jasoneri/ComicGUISpider/blob/GUI/variables/__init__.py)
73 |
74 | 1. `SPIDERS` - 爬虫名字:加入新序号(方面下面理解设为序号`3`²),值为爬虫名字`wnacg`
75 | 2. `DEFAULT_COMPLETER` - 默认预设:序号必须,值可空列表。用户配置会覆盖,但是可以先把做了开发的映射放进去
76 | 3. `STATUS_TIP` - 状态栏输入提示:序号必须,值可空字符串。鼠标悬停在搜索框时,最下状态栏会出现的文字
77 |
78 | > [!TIP] 如目标网站为🔞的
79 | > 还需在`SPECIAL_WEBSITES`加进 爬虫名字`wnacg` (此处影响存储位置)
80 | > 在`SPECIAL_WEBSITES_IDXES`加进 序号`3`² (此处影响gui逻辑)
81 |
82 | ### 3. ui 代码
83 |
84 | #### [`GUI/mainwindow.py`](https://github.com/jasoneri/ComicGUISpider/blob/GUI/GUI/mainwindow.py)
85 |
86 | 在最下方加入代码(需参考 `variables/__init__.py` 的 `SPIDERS` 避免使用重复序号导致覆盖)
87 |
88 | ```python
89 | self.chooseBox.addItem("")
90 | self.chooseBox.setItemText(3, _translate("MainWindow", "3、wnacg🔞")) # 🔞标识符不影响任何代码
91 | ```
92 |
93 | ---
94 |
95 | ### 4. 无GUI测试
96 |
97 | ```python
98 | python crawl_only.py -w 3 -k 首页 -i 1
99 | ```
100 |
101 | ### 5. GUI测试
102 |
103 | `python CGS.py`,对进行开发的网站测试流程是否正常,然后测试其他网站有没受影响
104 |
105 | > 注意: 当`ComicSpider/settings.py`里的`LOG_FILE`不为空时,控制台不会打印任何信息,只会在日志`log/scrapy.log`中输出,无论什么日志等级
106 | > 反之想让控制台输出时将其值置为空,在commit时需要改回来
107 |
--------------------------------------------------------------------------------
/docs/dev/i18n.md:
--------------------------------------------------------------------------------
1 | # 🌏 i18n guide
2 |
3 | 借助 [Weblate](https://hosted.weblate.org/engage/comicguispider/) 托管多语言的翻译
4 |
5 | Translation hosting by [Weblate](https://hosted.weblate.org/engage/comicguispider/)
6 |
7 | ## Development
8 |
9 | ### Ui
10 |
11 | 翻译仅需处理单个 yaml 文件如 [`en_US.yaml`](https://github.com/jasoneri/ComicGUISpider/blob/GUI//assets/res/locale/en-US.yml),
12 | 编译翻译的流程会在客户端使用时自动实现,除下文提及 Usage-ui 的一小点以外无需将精力放编译上
13 | 也可以阅读 [`transfer.py`](https://github.com/jasoneri/ComicGUISpider/blob/GUI//assets/res/transfer.py) 查看编译流程如何生成 res.mo
14 |
15 | Translation only needs to handle single yaml file such as [`en_US.yaml`](https://github.com/jasoneri/ComicGUISpider/blob/GUI//assets/res/locale/en-US.yml)
16 | The compilation process of translation will be automatically implemented when the client is used, except for a small point mentioned in Usage-ui, there is no need to focus on compilation
17 | You can also read [`transfer.py`](https://github.com/jasoneri/ComicGUISpider/blob/GUI//assets/res/transfer.py) to see how the res.mo is generated
18 |
19 | ### Documentation
20 |
21 | 文档皆存放在 `docs` 目录里,经由 Github-Action 做成 `github pages`
22 | 参考英文的存储路径为 `docs/locate/en/*`
23 |
24 | documents are stored in the `docs` directory, which will be made into `github pages` by Github-Action
25 | Reference English storage path is `docs/locate/en/*`
26 |
27 | ## Usage
28 |
29 | ### ui
30 |
31 | 软件在开启时,会通过 [`assets/res/__init__.py`](https://github.com/jasoneri/ComicGUISpider/blob/GUI//assets/res/__init__.py) 中的 `getUserLanguage` 函数获取当前机器的语言如 `Chinese (Simplified)_China.utf8`(ISO 639-1_ISO 3166-1.encoding),
32 | 检测转换成 RFC1766 标准如 `zh-CN` ,并加载 *.mo 模块进行语言切换。
33 |
34 | > [!Tip] 若进行了语言开发
35 | > 需在 `getUserLanguage` 中增加对应的 `RFC1766` 转换,否则默认使用 `en-US`
36 |
37 | The software will get the current machine language such as `Chinese (Simplified)_China.utf8` (ISO 639-1_ISO 3166-1.encoding)
38 | through the `getUserLanguage` function in [`assets/res/__init__.py`](https://github.com/jasoneri/ComicGUISpider/blob/GUI//assets/res/__init__.py) when it starts,
39 | machine language will convert to the RFC1766 standard such as `zh-CN`, and load the corresponding *.mo module for language switching.
40 |
41 | > [!Tip] If language development has been carried out
42 | > you need to add the corresponding `RFC1766` conversion in `getUserLanguage`, otherwise the default `en-US` is used
43 |
44 | ### crawler
45 |
46 | 对适用区域为🌏的网站发出的请求会基于 `Vars.ua_accept_language`
47 |
48 | Websites which applicable to 🌏 requests base on `Vars.ua_accept_language`
49 |
50 | ## Contant us
51 |
52 | 通过 [`issue`](https://github.com/jasoneri/ComicGUISpider/issues/new?template=feature-request.yml&labels=i18n) 进行反馈
53 |
54 | feedback by [`issue`](https://github.com/jasoneri/ComicGUISpider/issues/new?template=feature-request.yml&labels=i18n)
55 |
--------------------------------------------------------------------------------
/docs/faq/extra.md:
--------------------------------------------------------------------------------
1 |
2 | # 📒 额外使用说明
3 |
4 | ## 1. 配置生效相关
5 |
6 | 除少部分条目例如预设(只影响gui),能当即保存时立即生效(保存配置的操作与gui同一进程);
7 | 其余影响后台进程的配置条目在选择网站后定型(点选网站后`后台进程`即开始),
8 | 如果选网站后才反应过来改配置,需重启CGS方可生效
9 |
10 | ## 2. 域名相关
11 |
12 | 各网站的 `发布页`/`永久链接` 能在 `scripts/utils/website/__init__.py` 里找到
13 | (国内域名专用)域名缓存文件为 `scripts/__temp/xxx_domain.txt`(xxx = `wnacg`或`jm`),
14 | 再开程序会检测修改时间大于48小时则失效重新获取,处于48小时内则可对此文件删改或加个空格保存即时生效
15 |
16 | > [!Info] 手动改域名缓存文件示例
17 | > wnacg_domain.txt,没有则自建,内容填个 `www.wn01.uk` 即可
18 |
19 | > `发布页`/`永久链接`失效的情况下鼓励用户向开发者提供新可用网址,让软件能够持续使用
20 |
--------------------------------------------------------------------------------
/docs/faq/index.md:
--------------------------------------------------------------------------------
1 | # ❓ 常见问题
2 |
3 | ## 1. GUI
4 |
5 | ### 预览窗口页面显示异常/页面空白/图片加载等
6 |
7 | 刷新一下页面
8 | 有些是 JavaScript 没加载,有些是对方服务器问题
9 |
10 | ## 2. 爬虫
11 |
12 | ### 拷贝漫画部分无法出列表
13 |
14 | 拷贝有些漫画卷和话是分开的,api结构转换的当前是有结果的,但没做解析,如需前往群里反馈
15 |
16 | ### 拷贝/Māngabz多选书情况
17 |
18 | 多选书时,在章节序号输入时可以直接点击`开始爬取`跳过当前书的章节选择,只要出进度条即可
19 |
20 | ## 3. 其他
21 |
22 | ### ModuleNotFoundError: No module named 'xxx'
23 |
24 | win:
25 |
26 | 1. 在绿色包解压的目录打开 (powershell) 终端执行命令
27 |
28 | ``` bash
29 | irm https://gitproxy.click/https://raw.githubusercontent.com/jasoneri/ComicGUISpider/refs/heads/GUI/deploy/online_scripts/win.ps1 | iex
30 | ```
31 |
32 | ::: info 非绿色包的用户参考 [🚀 快速开始 > 部署](../deploy/quick-start#1-下载--部署) 的安装依赖命令示例
33 | :::
34 |
35 | macOS: 用`CGS-init`更新环境依赖
36 |
37 | ### 更新失败后程序无法打开
38 |
39 | ::: tip 最简单有效❗️
40 | 备份配置 scripts/conf.yml 与去重记录 scripts/record.db后 下载📦绿色包 覆盖更新
41 | :::
42 |
43 | 更新的报错日志已整合进 log/GUI.log 文件里,建议提 issue 并附上 log,帮助 CGS 进行优化
44 |
45 | 1. 回退到上一个正常版本: 找到对应版本的 `Source code (zip)` 源码包,解压后将全部源码覆盖到 scripts 目录下
46 | 删除 `scripts/deploy/version.json`,恢复正常使用
47 |
48 | 2. 安全使用最新版本: 将最新版本的 `Source code (zip)` 源码包,解压后将全部源码覆盖到 scripts 目录下
49 |
50 | 2.1 按上面 ModuleNotFoundError 的方法安装依赖
51 |
52 | ### 【win】弹出消息框报错而且一堆英文不是中文(非开发者预设报错)的时候
53 |
54 | 例如`Qxxx:xxxx`, `OpenGL`等,此前已优化过,如还有弹出框警告,
55 | 尝试在解压目录使用cmd运行`./CGS.bat > CGS-err.log 2>&1`,然后把`CGS-err.log`发群里反馈
56 |
57 | ---
58 |
59 | ::: warning 如果存在上述没有覆盖的问题
60 | 请带上 `log` 到 [issue](
61 | https://github.com/jasoneri/ComicGUISpider/issues/new?template=bug-report.yml
62 | ) 反馈 或 进群(右上角qq/discord)反馈。
63 | :::
64 |
65 |
66 |
--------------------------------------------------------------------------------
/docs/faq/other.md:
--------------------------------------------------------------------------------
1 | ## 1. 去重,增加标识相关说明
2 |
3 | ### 样例
4 |
5 | 1. http://jm-comic1.html “满开开花”
6 | 2. http://jm-comic2.html “满开开花”
7 | 3. http://wnacg-comic1.html “满开开花”
8 |
9 | > [!Info] 举例:其中 comic1 和 comic2 是 jm 的两个作品id,第三条 comic1 是 wnacg 的作品id
10 |
11 | #### 场景-原始
12 |
13 | 由于1和2同名,所以1下载后会被2覆盖,因为目录路径一样,3同理
14 |
15 | #### 场景-去重✅
16 |
17 | 选择1后得 md5('jm'+'comic1')=md5_1,查表 md5_1 不存在,下载,产生目录`储存目录.../满开开花`
18 | 再次下载1时查表发现 md5_1 已存在,不下载
19 | 选择2后得 md5('jm'+'comic2')=md5_2,查表 md5_2 不存在,下载,记录进表并将内容覆盖到`储存目录.../满开开花`
20 | 选择3后得 md5('wnacg'+'comic1')=md5_3,查表 md5_3 不存在,下载,记录进表并将内容覆盖到`储存目录.../满开开花`
21 |
22 | #### 场景-增加标识❌
23 |
24 | 无论去重还是不去重,目录存在就覆盖
25 |
26 | #### 场景-增加标识✅
27 |
28 | 将 spider_name 加唯一作品id加进命名尾部,例如下载上述三个得
29 |
30 | + `储存目录.../满开开花[jm-comic1]`
31 | + `储存目录.../满开开花[jm-comic2]`
32 | + `储存目录.../满开开花[wnacg-comic1]`
33 |
34 | ---------
35 |
36 | ### 其他
37 |
38 | #### 1. id实则自定义
39 |
40 | comic1 等 id 仅为示例,实际基于开发自定义
41 | 例如 md5('kaobei'+福利莲+第一话)=id 就可去做常规漫的去重,常规漫的任务细化就是此 id
42 |
43 | #### 2. 网站将同一内容的作品从 url 转移到 url2
44 |
45 | 考虑此情况实则并不常见,这种下重了也没所谓,少数情况
46 |
--------------------------------------------------------------------------------
/docs/feature/index.md:
--------------------------------------------------------------------------------
1 | # 🎸 常规功能
2 |
3 | ::: tip 欢迎提供功能建议,提交issue / PR / 此页下方评论区留言 等
4 | 例如打包 epub 格式 zip(需描述过程结果)
5 | :::
6 |
7 | ## 适用性
8 |
9 | > [!Info] 没列出的功能全网适用
10 |
11 | | | [拷贝](https://www.copy20.com/) | [Māngabz](https://mangabz.com) | [禁漫](https://18comic.vip/) | [wnacg](https://www.wnacg.com/) | [ExHentai](https://exhentai.org/) | [hitomi](https://hitomi.la/) |
12 | |:--------------------------------------|:-------------:|:---------:|:----:|:----------:|:----------:|:----------:|
13 | | 预览 | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ✔️ |
14 | | 翻页 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️
7 |
8 |
10 |
12 |
13 | ## 📑 简介
14 |
15 | **`CGS`** 是一个... 能简单使用的漫画下载软件!(忽略200字说明)
16 |
17 | ## 功能说明
18 |
19 | - 简易配置就能使用
20 | - 开预览后随便点点就能下载,还能基于预览窗口进网站看
21 | - 通过加减号,`0 全选`,`-3 选倒数三个` 等输入规则,能方便指定选择
22 | - 基于翻页保留,翻页就像已塞进了购物车一样
23 | - 虽然任务是顺序流,但内置重启很方便,加上多开更方便
24 | - 读剪贴板方式流,字如其名
25 | - 去重,加标识符等
26 |
27 | ## 致谢声明
28 |
29 | ### Credits
30 |
31 | Thanks to
32 | - [PyStand](https://github.com/skywind3000/PyStand) / [Platypus](https://github.com/sveinbjornt/Platypus) for providing win/macOS packaging.
33 | - [Ditto](https://github.com/sabrogden/Ditto) / [Maccy](https://github.com/p0deje/Maccy) for providing great win/macOS Clipboard Soft.
34 | - [PyQt-Fluent-Widgets](https://github.com/zhiyiYo/PyQt-Fluent-Widgets/) for providing elegant qfluent ui.
35 | - [VitePress](https://vitepress.dev) for providing a great documentation framework.
36 | - Every comic production team / translator team / fans.
37 |
38 | ## 贡献
39 |
40 | 欢迎提供 ISSUE 或者 PR
41 |
42 |
43 |
45 |
46 | ## 传播声明
47 |
48 | - **请勿**将 ComicGUISpider 用于商业用途。
49 | - **请勿**将 ComicGUISpider 制作为视频内容,于境内视频网站(版权利益方)传播。
50 | - **请勿**将 ComicGUISpider 用于任何违反法律法规的行为。
51 |
52 | ComicGUISpider 仅供学习交流使用。
53 |
54 | ## Licence
55 |
56 | [MIT licence](https://github.com/jasoneri/ComicGUISpider/blob/GUI/LICENSE)
57 |
--------------------------------------------------------------------------------
/docs/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | # https://vitepress.dev/reference/default-theme-home-page
3 | layout: home
4 |
5 | hero:
6 | name: "打开 CGS"
7 | text: "鼠标点几点轻松下漫画"
8 | tagline: 最自在
9 | image:
10 | src: /CGS-girl.png
11 | alt: CGS
12 | actions:
13 | - theme: brand
14 | text: 快速开始
15 | link: /deploy/quick-start
16 | - theme: alt
17 | text: 配置
18 | link: /config
19 | - theme: alt
20 | text: FAQ
21 | link: /faq
22 |
23 | features:
24 | - icon:
25 | src: ./assets/img/icons/website/copy.png
26 | title: '拷贝漫画 '
27 | details: 'Māngabz '
31 | details: 'jm '
35 | details: '绅士漫画 '
39 | details: 'exhentai '
43 | details: 'hitomi '
47 | details: '
51 |
52 |
55 |
56 |
57 | ## 功能说明
58 |
59 | - 简易配置就能使用
60 | - 开预览后随便点点就能下载,还能基于预览窗口进网站看
61 | - 通过加减号,`0 全选`,`-3 选倒数三个` 等输入规则,能方便指定选择
62 | - 基于翻页保留,翻页就像已塞进了购物车一样
63 | - 虽然任务是顺序流,但内置重启很方便,加上多开更方便
64 | - 读剪贴板方式流,字如其名
65 | - 去重,加标识符等
66 |
67 | ## 食用搭配(阅读器)
68 |
69 | 完全适配 CGS 而制,取(改)了独特的名字 `RedViewer (RV)`
70 | 加上最近对其手撕了几十个 commit 血改,还在更新中!所以再次推上
71 |
72 | [](https://github.com/jasoneri/redViewer)
73 |
74 | ## 致谢声明
75 |
76 | ### Credits
77 |
78 | Thanks to
79 | - [PyStand](https://github.com/skywind3000/PyStand) / [Platypus](https://github.com/sveinbjornt/Platypus) for providing win/macOS packaging.
80 | - [Ditto](https://github.com/sabrogden/Ditto) / [Maccy](https://github.com/p0deje/Maccy) for providing great win/macOS Clipboard Soft.
81 | - [PyQt-Fluent-Widgets](https://github.com/zhiyiYo/PyQt-Fluent-Widgets/) for providing elegant qfluent ui.
82 | - [VitePress](https://vitepress.dev) for providing a great documentation framework.
83 | - [astral-sh/uv](https://github.com/astral-sh/uv) for providing a great requirements manager.
84 | - Every comic production team / translator team / fans.
85 |
86 | ## 贡献
87 |
88 | 欢迎提供 ISSUE 或者 PR
89 |
90 |
91 |
93 |
94 | ## 传播声明
95 |
96 | - **请勿**将 ComicGUISpider 用于商业用途。
97 | - **请勿**将 ComicGUISpider 制作为视频内容,于境内视频网站(版权利益方)传播。
98 | - **请勿**将 ComicGUISpider 用于任何违反法律法规的行为。
99 |
100 | ComicGUISpider 仅供学习交流使用。
101 |
102 | ## Licence
103 |
104 | [MIT licence](https://github.com/jasoneri/ComicGUISpider/blob/GUI/LICENSE)
105 |
106 | ---
107 |
108 | 
109 |
--------------------------------------------------------------------------------
/docs/locate/en/config/index.md:
--------------------------------------------------------------------------------
1 | # 🔨 配置
2 |
3 | 
4 |
5 | ::: info config file is `scripts/conf.yml`, generated after initial use
6 | :::
7 | ::: warning The input box of multiple lines is in `yaml` format (except for eh_cookies), and a ⚠️ `space` ⚠️ is required after the `colon`
8 | :::
9 |
10 | ## Config Field / Corresponding `yml` Field
11 |
12 | ### Save Path / `sv_path`
13 |
14 | Download directory
15 | The `web` folder in the directory structure is because the default association with the [`redViewer`](https://github.com/jasoneri/redViewer) project is set like this
16 |
17 | ### LogLevel / `log_level`
18 |
19 | After the background runs, there will be a log directory, which is the same level as the GUI, and the GUI will give operation guidance when an error occurs
20 |
21 | ### Dedup / `isDeduplicate`
22 |
23 | When checked, there will be a style hint in the preview window for downloaded
24 | At the same time, the download will automatically filter out the existing records
25 | > [!Info] Currently only applicable in 🔞
26 |
27 | ### AddUuid / `addUuid`
28 |
29 | Add an identifier at the end of the directory when storing, which is used to handle different works with the same name
30 |
31 | ### Proxy / `proxies`
32 |
33 | Proxy
34 |
35 | > [!Info] It is recommended to configure the proxy here, rather than the global proxy mode, otherwise a lot of proxy traffic will be consumed when accessing the source
36 |
37 | ### Mapping / `custom_map`
38 |
39 | Search input mapping
40 | When the search does not meet the preset, first add the key-value pair here, and after restarting, the corresponding website results will be output when entering the custom key in the search box
41 |
42 | 1. Mapping does not need to care about the domain name, as long as it is used in the current website, as long as it meets `can access without mapping` and `the entered is not an invalid url`, the program will automatically replace it with a usable domain name, such as `wnacg.com` will be automatically replaced with the default domain name under non-proxy mapping
43 | 2. Note that the custom mapping may exceed the range of the paging rule, and at this time, it can be notified to the developer for expansion
44 |
45 | ### Preset / `completer`
46 |
47 | Custom preset
48 | There will be a `number corresponding to the website` prompt when the mouse hovers over the input box (in fact, it is the number of the choose-box)
49 |
50 | ### Eh Cookies / `eh_cookies`
51 |
52 | It is necessary to use `exhentai`
53 | [🎬 Method of acquisition](https://raw.githubusercontent.com/jasoneri/imgur/main/CGS/ehentai_get_cookies_new.gif)
54 | [🔗 Tool Website](https://tool.lu/en_US/curl/)
55 |
56 | ### ClipDb / `clip_db`
57 |
58 | ::: tip If function of read-clip wanted, Need Clipboard Soft be installed
59 | win: [🌐Ditto](https://github.com/sabrogden/Ditto)
60 | macOS: [🌐Maccy](https://github.com/p0deje/Maccy)
61 | :::
62 |
63 | When the clipboard reading function unusable, check whether the db exists, and fix it here after obtaining the correct path
64 |
65 | 1. ditto(win): Open options → Database path
66 | 2. maccy(macOS): [issue search for related information](https://github.com/p0deje/Maccy/issues/271)
67 |
68 | ### ClipEntries / `clip_read_num`
69 |
70 | Number of items read from the clipboard software
71 |
72 | ## Other `yml` Field
73 |
74 | ::: info The following fields are not displayed in the Config Dialog, set default value unless customize
75 | :::
76 |
77 | ### `img_sv_type`
78 |
79 | default: `jpg`
80 | image file name suffix
81 |
--------------------------------------------------------------------------------
/docs/locate/en/deploy/mac-required-reading.md:
--------------------------------------------------------------------------------
1 | # 💻 macOS Deploy
2 |
3 | ## 🚩 Architecture related
4 |
5 | Check the architecture with the following command (generally `x86_64` for Intel chips and `arm64` for Apple chips)
6 |
7 | ```bash
8 | python -c "import platform; print(platform.machine())"
9 | ```
10 |
11 | 1. `x86_64` architecture: The developer virtual machine is generally this architecture, and you can follow the process below
12 | 2. `arm64` architecture: CGS-init.app will automatically install `Rosetta 2`, and some [solutions to the error message](#trying-for-pop-up-error-messages) are listed below
13 |
14 | ## Portable Package
15 |
16 | macOS only needs to download the `CGS-macOS` compressed package
17 |
18 | ::: details Unzip directory tree (click to expand)
19 |
20 | ```
21 | CGS-macOS
22 | ├── CGS.app # Both the *main executor* and a code directory, it same as execute script `scripts/deploy/launcher/mac/CGS.bash`
23 | | ├── Contents
24 | | ├── Resources
25 | | ├── scripts # Real project code directory
26 | ├── CGS-init.app # Execute the script `scripts/deploy/launcher/mac/init.bash`
27 | └── CGS_macOS_first_guide.html # Used as a one-time guide for the first use after unzipping
28 | ```
29 |
30 | :::
31 |
32 | ## Operation
33 |
34 | ::: warning All documents containing the `scripts` directory
35 | Including this Deployment document, the main README, releases page, issue, etc.,
36 | The absolute-path in the app after moving to the application is `/Applications/CGS.app/Contents/Resources/scripts`
37 | :::
38 |
39 | ::: warning Execute the following initialization steps
40 | All `.app` must be opened with the right mouse button and clicked cancel the first time,
41 | then opened with the right mouse button to have an option to open,
42 | and then opened with a double-click from then on
43 | :::
44 |
45 | | | Explanation |
46 | |:------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
47 | | initialization | ⚠️following steps must be executed in strict order
50 | app move to Applications
52 |
53 | ## 🔰 Others
54 |
55 | ### Trying for pop-up error messages
56 |
57 | ```bash
58 | # arm64 CGS.app shows corrupted and cannot be opened
59 | /opt/homebrew/bin/python3.12 /Applications/CGS.app/Contents/Resources/scripts/CGS.py
60 | # or
61 | /usr/local/bin/python3.12 /Applications/CGS.app/Contents/Resources/scripts/CGS.py
62 | ```
63 |
64 | ::: info If both fail, you can try to find methods by chatgpt / feedback in the group
65 | :::
66 |
67 | ### Updating
68 |
69 | ⚠️ Configuration files / deduplication records are stored in `scripts`, please be careful not to lose them by directly overwriting when downloading packages
70 | If there are UI/Interface changes, it is recommended to run `CGS-init.app` to ensure that the font settings are correct
71 |
72 | ### Bug report / submit issue
73 |
74 | When running software on macOS and encountering errors that need to be reported as issues, in addition to selecting `macOS` in the system,
75 | you also need to specify the system version and architecture in the description
76 | (Developer development environment is `macOS Sonoma(14) / x86_64`)
77 |
--------------------------------------------------------------------------------
/docs/locate/en/deploy/quick-start.md:
--------------------------------------------------------------------------------
1 | # 🚀 Quick-Start
2 |
3 | ## 1. Download / Deploy
4 |
5 | + Directly download [📦portable-pkg](https://github.com/jasoneri/ComicGUISpider/releases/latest), and unzip
6 |
7 | ::: warning macOS
8 | need readed [macOS Deploy](./mac-required-reading.md) document
9 | :::
10 |
11 | + Or clone this project `git clone https://github.com/jasoneri/ComicGUISpider.git`
12 | ::: tip required list
13 | + `python3.12+`
14 | + install [`astral-sh/uv`](https://github.com/astral-sh/uv), instead `pip` of manage requiredments
15 |
16 | ```bash
17 | python -m pip install uv
18 | ```
19 |
20 | **Install command** (CGS's `requiredments/*.txt` base on compilation by uv)
21 |
22 | ```bash
23 | python -m uv pip install -r "requirements/win.txt"
24 | ```
25 |
26 | :::
27 |
28 | ::: warning ignore the `scripts` in scripts/xxx of the document, all document are based on the explanation of the 📦portable-pkg
29 | :::
30 |
31 | ## 2. Usage
32 |
33 | ### GUI
34 |
35 | `python CGS.py`
36 | Or using Portable-Applications
37 |
38 | ### CLI
39 |
40 | `python crawl_only.py --help`
41 | Or using env of portable environment:
42 | `.\runtime\python.exe .\scripts\crawl_only.py --help`
43 |
44 | ## 3. Configuration
45 |
46 | If you have needs of custom requirements, reference [🔨Configuration](../config/index.md) for settings
47 |
48 | ## 4. Update
49 |
50 | + CGS innerded an update module, you can click the `Update` button in the configuration window to update
51 | ::: info When `local version` < `latest stable version` < `latest dev version`
52 | You need to update to `latest stable version` before you can update to `latest dev version`
53 | :::
54 |
55 | + You can also choose to download the latest version manually to the releases, but you need to pay attention to the configuration files and duplicate records not being overwritten and lost
56 | ::: tip The configuration file is `scripts/conf.yml` and the duplicate record is `scripts/record.db`
57 | :::
58 |
--------------------------------------------------------------------------------
/docs/locate/en/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | # https://vitepress.dev/reference/default-theme-home-page
3 | layout: home
4 |
5 | hero:
6 | name: "CGS"
7 | text: "Easily dl Comic"
8 | tagline: have fun it
9 | image:
10 | src: /CGS-girl.png
11 | alt: CGS
12 | actions:
13 | - theme: brand
14 | text: Quick-start
15 | link: /locate/en/deploy/quick-start
16 | - theme: alt
17 | text: Config
18 | link: /locate/en/config
19 | ---
20 |
21 |
22 |
23 |
42 |
43 |
49 |
50 |
51 |
52 |
53 |
56 |
57 |
58 | ## Functional Description
59 |
60 | - Easy to use with simple configuration
61 | - Just click a few times after preview to download, and you can also browse the website on the preview window
62 | - Convenient to specify selection with input rules like `-3` (select the last three), `0` (select all), etc.
63 | - Based on page retention, flipping pages is like putting items in a shopping cart
64 | - Built-in restart is very convenient, and it is even more convenient with multiple launches
65 | - Read clipboard stream
66 | - De-duplication, add identifiers, etc.
67 |
68 | ### Credits
69 |
70 | Thanks to
71 | - [PyStand](https://github.com/skywind3000/PyStand) / [Platypus](https://github.com/sveinbjornt/Platypus) for providing win/macOS packaging.
72 | - [Ditto](https://github.com/sabrogden/Ditto) / [Maccy](https://github.com/p0deje/Maccy) for providing great win/macOS Clipboard Soft.
73 | - [PyQt-Fluent-Widgets](https://github.com/zhiyiYo/PyQt-Fluent-Widgets/) for providing elegant qfluent ui.
74 | - [VitePress](https://vitepress.dev) for providing a great documentation framework.
75 | - [astral-sh/uv](https://github.com/astral-sh/uv) for providing a great requirements manager.
76 | - Every comic production team / translator team / fans.
77 |
78 | ## contribution
79 |
80 | Welcome to provide ISSUE or PR
81 |
82 |
83 |
85 |
86 | ## Disclaimer
87 |
88 | - **Please do not** use ComicGUISpider for commercial purposes.
89 | - **Please do not** make ComicGUISpider into video content and disseminate it on domestic video websites (copyright holders).
90 | - **Please do not** use ComicGUISpider for any behavior that violates laws and regulations.
91 |
92 | ## Licence
93 |
94 | [MIT licence](https://github.com/jasoneri/ComicGUISpider/blob/GUI/LICENSE)
95 |
96 | ---
97 |
98 | 
99 |
--------------------------------------------------------------------------------
/docs/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "devDependencies": {
3 | "vitepress": "^1.6.3",
4 | "@vue/tsconfig": "^0.4.0",
5 | "@giscus/vue": "^3.1.1",
6 | "typescript": "4.9.5",
7 | "vue": "3.3.4"
8 | },
9 | "scripts": {
10 | "docs:dev": "vitepress dev",
11 | "docs:build": "rm _github/README_en.md && vitepress build && mkdir -p .vitepress/dist/assets/img/icons && cp -rf assets/img/icons/website .vitepress/dist/assets/img/icons/website",
12 | "docs:preview": "vitepress preview"
13 | },
14 | "type": "module"
15 | }
--------------------------------------------------------------------------------
/docs/public/CGS-girl.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/docs/public/CGS-girl.png
--------------------------------------------------------------------------------
/docs/public/_redirects:
--------------------------------------------------------------------------------
1 | /* /en/:splat 302 Language=en
2 | /* /zh/:splat 302
--------------------------------------------------------------------------------
/requirements/linux.txt:
--------------------------------------------------------------------------------
1 | # This file was autogenerated by uv via the following command:
2 | # uv pip compile requirements-in.txt --python-version 3.12 --python-platform linux -o linux.txt
3 | anyio==4.9.0
4 | # via httpx
5 | attrs==25.3.0
6 | # via
7 | # service-identity
8 | # twisted
9 | automat==25.4.16
10 | # via twisted
11 | brotli==1.1.0
12 | # via -r requirements-in.txt
13 | certifi==2025.4.26
14 | # via
15 | # httpcore
16 | # httpx
17 | # requests
18 | cffi==1.17.1
19 | # via
20 | # cryptography
21 | # xcffib
22 | charset-normalizer==3.4.1
23 | # via requests
24 | colorama==0.4.6
25 | # via -r requirements-in.txt
26 | constantly==23.10.4
27 | # via twisted
28 | cryptography==44.0.2
29 | # via
30 | # pyopenssl
31 | # scrapy
32 | # service-identity
33 | cssselect==1.3.0
34 | # via
35 | # parsel
36 | # scrapy
37 | darkdetect==0.8.0
38 | # via pyqt-fluent-widgets
39 | decorator==5.2.1
40 | # via jsonpath-rw
41 | defusedxml==0.7.1
42 | # via scrapy
43 | filelock==3.18.0
44 | # via tldextract
45 | h11==0.16.0
46 | # via httpcore
47 | h2==4.2.0
48 | # via httpx
49 | hpack==4.1.0
50 | # via h2
51 | httpcore==1.0.9
52 | # via httpx
53 | httpx==0.28.1
54 | # via -r requirements-in.txt
55 | hyperframe==6.1.0
56 | # via h2
57 | hyperlink==21.0.0
58 | # via twisted
59 | idna==3.10
60 | # via
61 | # anyio
62 | # httpx
63 | # hyperlink
64 | # requests
65 | # tldextract
66 | incremental==24.7.2
67 | # via twisted
68 | itemadapter==0.11.0
69 | # via
70 | # itemloaders
71 | # scrapy
72 | itemloaders==1.3.2
73 | # via scrapy
74 | jmespath==1.0.1
75 | # via
76 | # itemloaders
77 | # parsel
78 | jsonpath-rw==1.4.0
79 | # via -r requirements-in.txt
80 | loguru==0.7.3
81 | # via -r requirements-in.txt
82 | lxml==5.4.0
83 | # via
84 | # -r requirements-in.txt
85 | # parsel
86 | # scrapy
87 | markdown==3.8
88 | # via -r requirements-in.txt
89 | packaging==25.0
90 | # via
91 | # parsel
92 | # scrapy
93 | parsel==1.10.0
94 | # via
95 | # itemloaders
96 | # scrapy
97 | pillow==11.2.1
98 | # via -r requirements-in.txt
99 | pillow-avif-plugin==1.5.2
100 | # via -r requirements-in.txt
101 | ply==3.11
102 | # via jsonpath-rw
103 | polib==1.2.0
104 | # via -r requirements-in.txt
105 | protego==0.4.0
106 | # via scrapy
107 | pyasn1==0.6.1
108 | # via
109 | # pyasn1-modules
110 | # service-identity
111 | pyasn1-modules==0.4.2
112 | # via service-identity
113 | pycparser==2.22
114 | # via cffi
115 | pydispatcher==2.0.7
116 | # via scrapy
117 | pyexecjs==1.5.1
118 | # via -r requirements-in.txt
119 | pyopenssl==25.0.0
120 | # via scrapy
121 | pyqt-fluent-widgets==1.7.7
122 | # via -r requirements-in.txt
123 | pyqt5==5.15.11
124 | # via
125 | # -r requirements-in.txt
126 | # pyqt-fluent-widgets
127 | # pyqtwebengine
128 | pyqt5-frameless-window==0.6.0
129 | # via pyqt-fluent-widgets
130 | pyqt5-qt5==5.15.16
131 | # via pyqt5
132 | pyqt5-sip==12.17.0
133 | # via
134 | # pyqt5
135 | # pyqtwebengine
136 | pyqtwebengine==5.15.7
137 | # via -r requirements-in.txt
138 | pyqtwebengine-qt5==5.15.16
139 | # via pyqtwebengine
140 | pyyaml==6.0.2
141 | # via -r requirements-in.txt
142 | queuelib==1.8.0
143 | # via scrapy
144 | requests==2.32.3
145 | # via
146 | # requests-file
147 | # tldextract
148 | requests-file==2.1.0
149 | # via tldextract
150 | scrapy==2.12.0
151 | # via -r requirements-in.txt
152 | service-identity==24.2.0
153 | # via scrapy
154 | setuptools==80.1.0
155 | # via
156 | # incremental
157 | # zope-interface
158 | six==1.17.0
159 | # via
160 | # jsonpath-rw
161 | # pyexecjs
162 | sniffio==1.3.1
163 | # via anyio
164 | tldextract==5.3.0
165 | # via scrapy
166 | tqdm==4.67.1
167 | # via -r requirements-in.txt
168 | twisted==24.11.0
169 | # via scrapy
170 | typing-extensions==4.13.2
171 | # via
172 | # anyio
173 | # pyopenssl
174 | # twisted
175 | urllib3==2.4.0
176 | # via requests
177 | w3lib==2.3.1
178 | # via
179 | # parsel
180 | # scrapy
181 | xcffib==1.8.0
182 | # via pyqt5-frameless-window
183 | zope-interface==7.2
184 | # via
185 | # scrapy
186 | # twisted
187 |
--------------------------------------------------------------------------------
/requirements/script/mac_arm64.txt:
--------------------------------------------------------------------------------
1 | # This file was autogenerated by uv via the following command:
2 | # uv pip compile requirements-script-in.txt --python-version 3.12 --python-platform aarch64-apple-darwin -o mac_arm64.txt
3 | numpy==2.2.5
4 | # via pandas
5 | pandas==2.2.3
6 | # via -r requirements-script-in.txt
7 | python-dateutil==2.9.0.post0
8 | # via pandas
9 | pytz==2025.2
10 | # via pandas
11 | redis==6.0.0
12 | # via -r requirements-script-in.txt
13 | six==1.17.0
14 | # via python-dateutil
15 | tzdata==2025.2
16 | # via pandas
17 |
--------------------------------------------------------------------------------
/requirements/script/mac_x86_64.txt:
--------------------------------------------------------------------------------
1 | # This file was autogenerated by uv via the following command:
2 | # uv pip compile requirements-script-in.txt --python-version 3.12 --python-platform x86_64-apple-darwin -o mac_x86_64.txt
3 | numpy==2.2.5
4 | # via pandas
5 | pandas==2.2.3
6 | # via -r requirements-script-in.txt
7 | python-dateutil==2.9.0.post0
8 | # via pandas
9 | pytz==2025.2
10 | # via pandas
11 | redis==6.0.0
12 | # via -r requirements-script-in.txt
13 | six==1.17.0
14 | # via python-dateutil
15 | tzdata==2025.2
16 | # via pandas
17 |
--------------------------------------------------------------------------------
/requirements/script/win.txt:
--------------------------------------------------------------------------------
1 | # This file was autogenerated by uv via the following command:
2 | # uv pip compile requirements-script-in.txt --python-version 3.12 --python-platform windows -o win.txt
3 | numpy==2.2.5
4 | # via pandas
5 | pandas==2.2.3
6 | # via -r requirements-script-in.txt
7 | python-dateutil==2.9.0.post0
8 | # via pandas
9 | pytz==2025.2
10 | # via pandas
11 | redis==6.0.0
12 | # via -r requirements-script-in.txt
13 | six==1.17.0
14 | # via python-dateutil
15 | tzdata==2025.2
16 | # via pandas
17 |
--------------------------------------------------------------------------------
/requirements/win.txt:
--------------------------------------------------------------------------------
1 | # This file was autogenerated by uv via the following command:
2 | # uv pip compile requirements-in.txt --python-version 3.12 --python-platform windows -o win.txt
3 | anyio==4.9.0
4 | # via httpx
5 | attrs==25.3.0
6 | # via
7 | # service-identity
8 | # twisted
9 | automat==24.8.1
10 | # via twisted
11 | brotli==1.1.0
12 | # via -r requirements-in.txt
13 | certifi==2025.1.31
14 | # via
15 | # httpcore
16 | # httpx
17 | # requests
18 | cffi==1.17.1
19 | # via cryptography
20 | charset-normalizer==3.4.1
21 | # via requests
22 | colorama==0.4.6
23 | # via
24 | # -r requirements-in.txt
25 | # loguru
26 | # tqdm
27 | constantly==23.10.4
28 | # via twisted
29 | cryptography==44.0.2
30 | # via
31 | # pyopenssl
32 | # scrapy
33 | # service-identity
34 | cssselect==1.3.0
35 | # via
36 | # parsel
37 | # scrapy
38 | darkdetect==0.8.0
39 | # via pyqt-fluent-widgets
40 | decorator==5.2.1
41 | # via jsonpath-rw
42 | defusedxml==0.7.1
43 | # via scrapy
44 | filelock==3.18.0
45 | # via tldextract
46 | h11==0.16.0
47 | # via
48 | # -r requirements-in.txt
49 | # httpcore
50 | h2==4.2.0
51 | # via httpx
52 | hpack==4.1.0
53 | # via h2
54 | httpcore==1.0.9
55 | # via httpx
56 | httpx==0.28.1
57 | # via -r requirements-in.txt
58 | hyperframe==6.1.0
59 | # via h2
60 | hyperlink==21.0.0
61 | # via twisted
62 | idna==3.10
63 | # via
64 | # anyio
65 | # httpx
66 | # hyperlink
67 | # requests
68 | # tldextract
69 | incremental==24.7.2
70 | # via twisted
71 | itemadapter==0.11.0
72 | # via
73 | # itemloaders
74 | # scrapy
75 | itemloaders==1.3.2
76 | # via scrapy
77 | jmespath==1.0.1
78 | # via
79 | # itemloaders
80 | # parsel
81 | jsonpath-rw==1.4.0
82 | # via -r requirements-in.txt
83 | loguru==0.7.3
84 | # via -r requirements-in.txt
85 | lxml==5.3.1
86 | # via
87 | # -r requirements-in.txt
88 | # parsel
89 | # scrapy
90 | markdown==3.7
91 | # via -r requirements-in.txt
92 | packaging==24.2
93 | # via
94 | # parsel
95 | # scrapy
96 | parsel==1.10.0
97 | # via
98 | # itemloaders
99 | # scrapy
100 | pillow==11.1.0
101 | # via -r requirements-in.txt
102 | pillow-avif-plugin==1.5.2
103 | # via -r requirements-in.txt
104 | ply==3.11
105 | # via jsonpath-rw
106 | polib==1.2.0
107 | # via -r requirements-in.txt
108 | protego==0.4.0
109 | # via scrapy
110 | pyasn1==0.6.1
111 | # via
112 | # pyasn1-modules
113 | # service-identity
114 | pyasn1-modules==0.4.2
115 | # via service-identity
116 | pycparser==2.22
117 | # via cffi
118 | pydispatcher==2.0.7
119 | # via scrapy
120 | pyexecjs==1.5.1
121 | # via -r requirements-in.txt
122 | pyopenssl==25.0.0
123 | # via scrapy
124 | pyqt-fluent-widgets==1.7.6
125 | # via -r requirements-in.txt
126 | pyqt5==5.15.11
127 | # via
128 | # -r requirements-in.txt
129 | # pyqt-fluent-widgets
130 | # pyqtwebengine
131 | pyqt5-frameless-window==0.5.1
132 | # via pyqt-fluent-widgets
133 | pyqt5-qt5==5.15.2
134 | # via pyqt5
135 | pyqt5-sip==12.17.0
136 | # via
137 | # pyqt5
138 | # pyqtwebengine
139 | pyqtwebengine==5.15.7
140 | # via -r requirements-in.txt
141 | pyqtwebengine-qt5==5.15.2
142 | # via pyqtwebengine
143 | pywin32==310
144 | # via pyqt5-frameless-window
145 | pyyaml==6.0.2
146 | # via -r requirements-in.txt
147 | queuelib==1.7.0
148 | # via scrapy
149 | requests==2.32.3
150 | # via
151 | # requests-file
152 | # tldextract
153 | requests-file==2.1.0
154 | # via tldextract
155 | scrapy==2.12.0
156 | # via -r requirements-in.txt
157 | service-identity==24.2.0
158 | # via scrapy
159 | setuptools==80.7.1
160 | # via
161 | # -r requirements-in.txt
162 | # incremental
163 | # zope-interface
164 | six==1.17.0
165 | # via
166 | # jsonpath-rw
167 | # pyexecjs
168 | sniffio==1.3.1
169 | # via anyio
170 | tldextract==5.1.3
171 | # via scrapy
172 | tqdm==4.67.1
173 | # via -r requirements-in.txt
174 | twisted==24.11.0
175 | # via scrapy
176 | typing-extensions==4.13.0
177 | # via
178 | # anyio
179 | # pyopenssl
180 | # twisted
181 | urllib3==2.3.0
182 | # via requests
183 | uv==0.7.2
184 | # via -r requirements-in.txt
185 | w3lib==2.3.1
186 | # via
187 | # parsel
188 | # scrapy
189 | win32-setctime==1.2.0
190 | # via loguru
191 | zope-interface==7.2
192 | # via
193 | # scrapy
194 | # twisted
195 |
--------------------------------------------------------------------------------
/scrapy.cfg:
--------------------------------------------------------------------------------
1 | # Automatically created by: scrapy startproject
2 | #
3 | # For more information about the [deploy] section see:
4 | # https://scrapyd.readthedocs.io/en/latest/deploy.html
5 |
6 | [settings]
7 | default = ComicSpider.settings
8 |
9 | [deploy]
10 | #url = http://localhost:6800/
11 | project = ComicSpider
12 |
--------------------------------------------------------------------------------
/utils/docs.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | import markdown
4 | from utils import ori_path
5 |
6 |
7 | with open(ori_path.joinpath('assets/github_format.html'), 'r', encoding='utf-8') as f:
8 | github_markdown_format = f.read()
9 |
10 |
11 | class MarkdownConverter:
12 | github_markdown_format = github_markdown_format
13 | md = markdown.Markdown(extensions=['markdown.extensions.md_in_html',
14 | 'markdown.extensions.tables', 'markdown.extensions.fenced_code', 'markdown.extensions.nl2br',
15 | 'markdown.extensions.admonition'],
16 | output_format='html5')
17 |
18 | @classmethod
19 | def convert_html(cls, md_content):
20 | html_body = cls.md.convert(md_content)
21 | full_html = cls.github_markdown_format.replace('{content}', html_body)
22 | return full_html
23 |
24 | @classmethod
25 | def transfer_markdown(cls, _in, _out):
26 | with open(_in, 'r', encoding='utf-8') as f:
27 | _md_content = f.read()
28 | _html = cls.convert_html(_md_content)
29 | with open(_out, 'w', encoding='utf-8') as f:
30 | f.write(_html)
31 |
32 |
33 | class MdHtml(str):
34 | def cdn_replace(self, author, repo, branch):
35 | return MdHtml(self.replace("raw.githubusercontent.com", "jsd.vxo.im/gh")
36 | .replace(f"{author}/{repo}/{branch}", f"{author}/{repo}@{branch}"))
37 |
38 | @property
39 | def details_formatter(self):
40 | # before MarkdownConverter.convert_html()
41 | return MdHtml(self.replace("", ''))
42 |
--------------------------------------------------------------------------------
/utils/preview/__init__.py:
--------------------------------------------------------------------------------
1 | import tempfile
2 | from lxml import etree
3 | from utils import ori_path, temp_p
4 | from utils.sql import SqlUtils
5 | from utils.website import Uuid
6 | from utils.preview.el import El
7 |
8 |
9 | class PreviewHtml:
10 | format_path = ori_path.joinpath("GUI/src/preview_format")
11 |
12 | def __init__(self, url=None, custom_style=None):
13 | self.contents = []
14 | self.el = El(custom_style)
15 | self.url = url
16 |
17 | def add(self, *args, **badges_kw):
18 | """badges_kw support: pages, likes, lang, btype"""
19 | self.contents.append(self.el.create(*args, **badges_kw))
20 |
21 | @property
22 | def created_temp_html(self):
23 | temp_p.mkdir(exist_ok=True)
24 | with open(self.format_path.joinpath("index.html"), 'r', encoding='utf-8') as f:
25 | format_text = f.read()
26 | _content = "\n".join(self.contents)
27 | if self.url:
28 | _content += f'\nfor check current page
检查当前页数
{self.url}
p%s '
37 | likes = '♥️%s '
38 | lang = '%s '
39 | btype = '%s '
40 |
41 | def __init__(self, **badges_kw):
42 | self._content = []
43 | for attr, value in badges_kw.items():
44 | if value:
45 | self._content.append(getattr(self, attr) % value)
46 |
47 | def __str__(self):
48 | return r'i'
111 | return struct.unpack(fmt, binary)[0]
112 |
--------------------------------------------------------------------------------
/utils/website/hitomi/scape_dataset.py:
--------------------------------------------------------------------------------
1 | import re
2 | import json
3 | import sqlite3
4 | from contextlib import closing
5 | import httpx
6 | from lxml import html
7 |
8 | from assets import res
9 | from utils import ori_path, temp_p, conf
10 |
11 |
12 | BASE_URL = "https://hitomi.la/all{category}-{letter}.html"
13 | CATEGORIES = ['tags', 'artists', 'series', 'characters']
14 | LETTERS = [*[chr(i) for i in range(97, 123)], '123']
15 | db_p = ori_path.joinpath('assets/hitomi.db')
16 | proxy = (conf.proxies or [None])[0]
17 | client = httpx.Client(http2=True,
18 | headers={
19 | "accept": "*/*",
20 | "accept-language": res.Vars.ua_accept_language,
21 | "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:137.0) Gecko/20100101 Firefox/137.0",
22 | "referer": "https://hitomi.la/"
23 | }
24 | )
25 | if proxy:
26 | client.proxies = {'http://': 'http://{proxy}', 'https://': 'http://{proxy}'}
27 |
28 |
29 | def lstrip(text):
30 | if text.startswith("all"):
31 | return text[3:]
32 | return text
33 |
34 |
35 | class Db:
36 | data_tb = """
37 | CREATE TABLE IF NOT EXISTS `%s` (
38 | id INTEGER PRIMARY KEY AUTOINCREMENT,
39 | content TEXT NOT NULL UNIQUE,
40 | num INTEGER NOT NULL DEFAULT 1
41 | );
42 | """
43 | language_tb = """
44 | CREATE TABLE IF NOT EXISTS `language` (
45 | id INTEGER PRIMARY KEY AUTOINCREMENT,
46 | content TEXT NOT NULL UNIQUE
47 | );
48 | """
49 |
50 | @classmethod
51 | def create_tables(cls):
52 | with closing(sqlite3.connect(db_p)) as db_conn:
53 | cursor = db_conn.cursor()
54 | for category in CATEGORIES:
55 | for letter in LETTERS:
56 | table_name = f"all{lstrip(category)}-{letter}"
57 | cursor.execute(cls.data_tb % table_name)
58 | cursor.execute(cls.language_tb)
59 | db_conn.commit()
60 |
61 | @classmethod
62 | def recreate(cls, table_name):
63 | with closing(sqlite3.connect(db_p)) as db_conn:
64 | cursor = db_conn.cursor()
65 | cursor.execute(f"DROP TABLE IF EXISTS `{table_name}`")
66 | cursor.execute(cls.data_tb % table_name)
67 | db_conn.commit()
68 |
69 | regex = re.compile('.*/(.*?)-all')
70 | digit_regex = re.compile(r'\d+')
71 |
72 |
73 | def scrape_and_save():
74 | def scrape(category, letter):
75 | def get_content(_category, _letter):
76 | resp = client.get(BASE_URL.format(category=_category, letter=_letter), timeout=10)
77 | resp.raise_for_status()
78 | content = resp.content
79 | return content
80 | tree = html.fromstring(get_content(category, letter))
81 | lis = tree.xpath('//ul[@class="posts"]/li')
82 | items = [
83 | (regex.search(li.xpath('./a/@href')[0]).group(1),
84 | int(''.join(digit_regex.findall(li.xpath('.//text()')[-1]))))
85 | for li in lis
86 | ]
87 |
88 | table_name = f"all{category}-{letter}"
89 | if tb_rewrite_flag:
90 | Db.recreate(table_name)
91 | with closing(db_conn.cursor()) as cursor:
92 | cursor.executemany(
93 | f"INSERT OR IGNORE INTO `{table_name}` (content,num) VALUES (?,?)",
94 | [item for item in items if item[0].strip()]
95 | )
96 | db_conn.commit()
97 | print(f"[SUCCESS] {table_name} writen {cursor.rowcount} ")
98 | err = []
99 | init_err_f = temp_p.joinpath('hitomi_db_init_err.json')
100 | tb_rewrite_flag = False
101 | if init_err_f.exists():
102 | with open(init_err_f, 'r', encoding='utf-8') as f:
103 | tasks = json.load(f)
104 | tb_rewrite_flag = True
105 | if not tasks:
106 | tasks = [f'{category}-{letter}' for category in CATEGORIES for letter in LETTERS]
107 | with closing(sqlite3.connect(db_p)) as db_conn:
108 | for task in tasks:
109 | category, letter = task.split('-')
110 | category = lstrip(category)
111 | try:
112 | scrape(category, letter)
113 | except Exception as e:
114 | print(f"[ERROR] {task} {e}")
115 | err.append(f'{category}-{letter}')
116 | with open(init_err_f, 'w', encoding='utf-8') as f:
117 | json.dump(err, f, ensure_ascii=False, indent=4)
118 |
119 |
120 | def main():
121 | Db.create_tables()
122 | scrape_and_save()
123 |
--------------------------------------------------------------------------------
/variables/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | from assets import res
4 |
5 | SPIDERS = {
6 | 1: 'manga_copy', # 🇨🇳
7 | 2: 'jm', # 🇨🇳 🔞
8 | 3: 'wnacg', # 🇨🇳 🔞
9 | 4: 'ehentai', # 🌎 🔞
10 | 5: 'mangabz', # 🇨🇳
11 | 6: 'hitomi', # 🌎 🔞
12 | }
13 | SPECIAL_WEBSITES = ['wnacg', 'jm', 'ehentai', 'hitomi']
14 | SPECIAL_WEBSITES_IDXES = [2, 3, 4, 6]
15 | CN_PREVIEW_NEED_PROXIES_IDXES = [3, 4, 6]
16 |
17 | DEFAULT_COMPLETER = { # only take effect when init (mean value[completer] of conf.yml is null or not exist)
18 | 1: ['更新', '排名日', '排名周', '排名月', '排名总'],
19 | 2: ['C105', '更新周', '更新月', '点击周', '点击月', '评分周', '评分月', '评论周', '评论月', '收藏周', '收藏月'],
20 | 3: ['C105', '更新', '汉化'],
21 | 4: [res.EHentai.MAPPINGS_POPULAR, res.EHentai.MAPPINGS_INDEX, 'C105'],
22 | 5: ['更新', '人气'],
23 | 6: ['index-all', 'popular/week-all', 'popular/month-all']
24 | }
25 |
26 | STATUS_TIP = {
27 | 0: None,
28 | 1: f"manga_copy: {res.GUI.SearchInputStatusTip.manga_copy}",
29 | 2: f"jm: {res.GUI.SearchInputStatusTip.jm}",
30 | 3: f"wnacg: {res.GUI.SearchInputStatusTip.wnacg}",
31 | 4: f"ehentai: {res.GUI.SearchInputStatusTip.ehentai}",
32 | 5: f"mangabz: {res.GUI.SearchInputStatusTip.mangabz}",
33 | 6: f"hitomi: {res.GUI.SearchInputStatusTip.hitomi}"
34 | }
35 |
--------------------------------------------------------------------------------
 4 |
5 |
4 |
5 |  7 |
7 |  11 |
12 |
13 |
11 |
12 |
13 |  106 |
107 |
108 | ## 🔇免责声明
109 |
110 | 详见[License](LICENSE) 当你下载或使用本项目,将默许
111 |
112 | 本项目仅供交流和学习使用,请勿用此从事 违法/商业盈利 等,开发者团队拥有本项目的最终解释权
113 |
114 | ---
115 | 
116 |
--------------------------------------------------------------------------------
/assets/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 |
--------------------------------------------------------------------------------
/assets/conf_sample.yml:
--------------------------------------------------------------------------------
1 | ## 配置文件,使用方法详情至readme.md了解
2 |
3 | custom_map:
4 | 更新4: https://wnacg.com/albums-index-page-4.html
5 | 杂志: https://wnacg.com/albums-index-cate-10.html
6 | log_level: WARNING
7 | proxies: null
8 | sv_path: D:\Comic
--------------------------------------------------------------------------------
/assets/config_icon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/assets/config_icon.png
--------------------------------------------------------------------------------
/assets/icon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/assets/icon.png
--------------------------------------------------------------------------------
/assets/res/transfer.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | import pathlib
4 | import hashlib
5 | from datetime import datetime
6 | import yaml
7 | import polib
8 |
9 |
10 | def yaml_to_po(lang, yaml_file, po_file):
11 | with open(yaml_file, 'r', encoding='utf-8') as f:
12 | data = yaml.safe_load(f)
13 |
14 | po = polib.POFile()
15 | po.metadata = {
16 | 'Project-Id-Version': 'ComicGUISpider',
17 | 'POT-Creation-Date': datetime.now().strftime('%Y-%m-%d %H:%M%z'),
18 | 'Language': lang,
19 | 'MIME-Version': '1.0',
20 | 'Content-Type': 'text/plain; charset=utf-8',
21 | 'Content-Transfer-Encoding': '8bit',
22 | }
23 |
24 | def process_dict(data, prefix=''):
25 | for key, value in data.items():
26 | entry_id = f"{prefix}{key}" if prefix else key
27 | if isinstance(value, dict):
28 | process_dict(value, f"{entry_id}.")
29 | else:
30 | entry = polib.POEntry(
31 | msgid=entry_id,
32 | msgstr=str(value),
33 | )
34 | po.append(entry)
35 | process_dict(data)
36 | po.save(po_file)
37 |
38 | return po
39 |
40 | def compile_po_to_mo(po_file, mo_file):
41 | po = polib.pofile(po_file)
42 | po.save_as_mofile(mo_file)
43 |
44 |
45 | def main(base_dir, lang):
46 | locale_dir = base_dir / 'locale' / lang / 'LC_MESSAGES'
47 | locale_dir.mkdir(parents=True, exist_ok=True)
48 |
49 | yaml_file = base_dir / 'locale' / f'{lang}.yml'
50 | yaml_hash = base_dir / 'locale' / f'{lang}.hash'
51 | po_file = base_dir / 'locale' / lang / 'LC_MESSAGES' / 'res.po'
52 | mo_file = base_dir / 'locale' / lang / 'LC_MESSAGES' / 'res.mo'
53 |
54 | po = yaml_to_po(lang, yaml_file, po_file)
55 | compile_po_to_mo(po_file, mo_file)
56 | with open(yaml_hash, 'w', encoding='utf-8') as f:
57 | f.write(hashlib.sha256(yaml_file.read_bytes()).hexdigest())
58 |
59 |
60 | if __name__ == "__main__":
61 | main(pathlib.Path(__file__).parent, 'zh-CN')
62 | main(pathlib.Path(__file__).parent, 'en-US')
63 |
--------------------------------------------------------------------------------
/deploy/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | import os
4 | import platform
5 | import pathlib
6 | import subprocess
7 |
8 |
9 | class Env:
10 | default_sv_path = r"D:\Comic"
11 | default_clip_db = pathlib.Path.home().joinpath(r"AppData\Roaming\Ditto\Ditto.db")
12 | clip_sql = "SELECT `mText` FROM `MAIN` order by `LID` desc"
13 |
14 | def __init__(self, _p: pathlib.Path):
15 | self.proj_p = _p
16 | os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = str(
17 | proj_path.parent.joinpath(r"site-packages\PyQt5\Qt5\plugins\platforms"))
18 |
19 | def env_init(self):
20 | ...
21 |
22 | @staticmethod
23 | def open_folder(_p):
24 | os.startfile(_p)
25 |
26 | @staticmethod
27 | def open_file(_f):
28 | subprocess.run(["start", "", f"{_f}"], shell=True, check=True)
29 |
30 |
31 | proj_path = pathlib.Path(__file__).parent.parent
32 | curr_os_module = Env
33 | if platform.system().startswith("Darwin"):
34 | import sys
35 | sys.path.append(str(proj_path))
36 | from deploy.launcher.mac import macOS
37 | curr_os_module = macOS
38 | curr_os = curr_os_module(proj_path)
39 |
40 | if __name__ == '__main__':
41 | curr_os.env_init()
42 |
--------------------------------------------------------------------------------
/deploy/env_record.json:
--------------------------------------------------------------------------------
1 | ["execjs", "qfluentwidgets", "polib", "pillow_avif"]
--------------------------------------------------------------------------------
/deploy/launcher/CGS.bat:
--------------------------------------------------------------------------------
1 | @rem
2 | @echo off
3 |
4 | set "_root=%~dp0"
5 | set "_root=%_root:~0,-1%"
6 | cd "%_root%"
7 | @rem echo "%_root%
8 |
9 | set "_pyBin=%_root%\runtime"
10 | set "PATH=%_root%\site-packages;%_pyBin%;%PATH%"
11 |
12 | cd "%_root%\scripts" && python CGS.py
--------------------------------------------------------------------------------
/deploy/launcher/mac/CGS.bash:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | cd scripts;
3 | /usr/local/bin/python3.12 CGS.py;
--------------------------------------------------------------------------------
/deploy/launcher/mac/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | import pathlib
4 | import re
5 | import subprocess
6 |
7 | # 对应`冬青黑体简体中文`,想要换其他字体可聚焦搜索`字体册`,在目标字体右键`访达中显示`,可以看到字体文件,把字体名替换掉`font`的值即可
8 | # 字体册仅支持能访达/系统alias能搜索出的字体,如果是下载的字体文件,可以看`macOS.font_replace _repl`
9 | font = "Hiragino Sans GB"
10 |
11 |
12 | class macOS:
13 | default_sv_path = pathlib.Path.home().joinpath("Downloads/Comic")
14 | default_clip_db = pathlib.Path.home().joinpath(
15 | "Library/Containers/org.p0deje.Maccy/Data/Library/Application Support/Maccy/Storage.sqlite")
16 | clip_sql = "SELECT `ZTITLE` FROM `ZHISTORYITEM` order by `Z_PK` desc"
17 |
18 | def __init__(self, _p):
19 | self.proj_p = _p
20 |
21 | @staticmethod
22 | def open_folder(_p):
23 | subprocess.run(['open', _p])
24 |
25 | @staticmethod
26 | def open_file(_f):
27 | subprocess.run(['open', _f])
28 |
29 | def env_init(self):
30 | # 1. 更换字体
31 | self.font_replace()
32 | # 2. requirements.txt去掉window相关的包
33 | self.handle_requirements()
34 |
35 | def font_replace(self):
36 | def _repl(content):
37 | """下载的字体用绝对路径时可以用以下注释了的替换方法"""
38 | # font_path = "/Users/Shared/.../xxx.ttc"
39 | # if "QFontDatabase" not in content:
40 | # content = ("from PyQt5.QtGui import QFontDatabase\n"
41 | # f"font_path = '{font_path}'\n"
42 | # f"_id = QFontDatabase.addApplicationFont(font_path)\n") + content
43 | # new_content = re.sub(r'font = .*?\n.*?font\.setFamily\(".*?"\)',
44 | # f'font = QFontDatabase.font("{font}", "Regular", 11)', content, re.M)
45 | new_content = re.sub(r'font\.setFamily\(".*?"\)', f'font.setFamily("{font}")', content)
46 | return new_content
47 | uic_p = self.proj_p.joinpath("GUI/uic")
48 | for _f in ["conf_dia.py", "browser.py", "ui_mainwindow.py"]:
49 | self.file_content_replace(uic_p.joinpath(_f), _repl)
50 |
51 | def handle_requirements(self):
52 | self.file_content_replace(
53 | self.proj_p.joinpath('requirements.txt'),
54 | lambda content: re.sub(r'^(twisted-iocpsupport==.*|pywin32==.*)[\r\n]*', "", content, flags=re.MULTILINE)
55 | )
56 |
57 | @staticmethod
58 | def file_content_replace(file, repl_func):
59 | with open(file, 'r+', encoding='utf-8') as fp:
60 | content = fp.read()
61 | new_content = repl_func(content)
62 | fp.seek(0)
63 | fp.truncate()
64 | fp.write(new_content)
65 |
--------------------------------------------------------------------------------
/deploy/launcher/mac/dos2unix.bash:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | curr_p=$(cd "$(dirname "$0")";pwd)
3 | app_proj_p="/Applications/CGS.app/Contents/Resources/scripts"
4 | if [ ! -x /usr/local/bin/brew ]; then
5 | echo "not brew, downloading brew...";
6 | /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)";
7 | fi
8 | if [ ! -x /usr/local/bin/dos2unix ]; then
9 | echo "not dos2unix, downloading dos2unix...";
10 | brew install dos2unix;
11 | fi
12 | find $curr_p/../ -type f -name "*.bash" -exec sudo dos2unix {} +;
13 | find $curr_p/../ -type f -name "*.md" -exec sudo dos2unix {} +;
14 | find $curr_p/../ -type f -name "*.py" -exec sudo dos2unix {} +;
15 | find $curr_p/../ -type f -name "*.json" -exec sudo dos2unix {} +;
16 | find $curr_p/../ -type f -name "*.yml" -exec sudo dos2unix {} +;
17 | find $app_proj_p -type f -name "*.bash" -exec sudo dos2unix {} +;
18 | find $app_proj_p -type f -name "*.md" -exec sudo dos2unix {} +;
19 | find $app_proj_p -type f -name "*.py" -exec sudo dos2unix {} +;
20 | find $app_proj_p -type f -name "*.json" -exec sudo dos2unix {} +;
21 | find $app_proj_p -type f -name "*.yml" -exec sudo dos2unix {} +;
22 |
--------------------------------------------------------------------------------
/deploy/launcher/mac/init.bash:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # 将终端窗口置于最前
3 | osascript -e 'tell application "Terminal" to activate' -e 'tell application "System Events" to tell process "Terminal" to set frontmost to true'
4 |
5 | curr_p=$(cd "$(dirname "$0")";pwd);
6 | cd $curr_p/../../../;
7 | REQUIREMENTS="requirements/mac_x86_64.txt"
8 |
9 | # 检测是否为 Apple Silicon
10 | if [ "$(uname -m)" = "arm64" ]; then
11 | REQUIREMENTS="requirements/mac_arm64.txt"
12 | # 检测 Rosetta 2 是否已安装
13 | if ! arch -x86_64 echo > /dev/null 2>&1; then
14 | echo "检测到 Apple Silicon Mac,但未安装 Rosetta 2,正在安装..."
15 | /usr/sbin/softwareupdate --install-rosetta --agree-to-license
16 | fi
17 | fi
18 |
19 | PYTHON_PATH="/usr/local/bin/python3.12"
20 | # 确保安装的是 x86_64 版本的 Python
21 | if [ ! -x "$PYTHON_PATH" ]; then
22 | echo "无python3.12环境,正在初始化...";
23 | # 检测 Homebrew 安装路径
24 | if [ -x "/opt/homebrew/bin/brew" ]; then
25 | ARM_BREW_PATH="/opt/homebrew/bin/brew"
26 | fi
27 | if [ -x "/usr/local/bin/brew" ]; then
28 | INTEL_BREW_PATH="/usr/local/bin/brew"
29 | fi
30 | # 如果没有安装 Homebrew,则安装它
31 | if [ ! -x "$INTEL_BREW_PATH" ] && [ ! -x "$ARM_BREW_PATH" ]; then
32 | echo "未检测到 Homebrew,正在安装..."
33 | /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)";
34 | fi
35 | # 在 Apple Silicon Mac 上,通过 Rosetta 2 安装 x86_64 版的 Python
36 | if [ "$(uname -m)" = "arm64" ]; then
37 | if [ -x "$INTEL_BREW_PATH" ]; then
38 | echo "使用 Intel Homebrew 安装 Python..."
39 | "$INTEL_BREW_PATH" install python@3.12
40 | "$INTEL_BREW_PATH" link python@3.12
41 | else
42 | echo "通过 Rosetta 2 安装 Intel 版本的 Python..."
43 | arch -x86_64 /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
44 | arch -x86_64 /usr/local/bin/brew install python@3.12
45 | arch -x86_64 /usr/local/bin/brew link python@3.12
46 | fi
47 | else
48 | # 在 Intel Mac 上,直接安装
49 | if [ -x "$INTEL_BREW_PATH" ]; then
50 | "$INTEL_BREW_PATH" install python@3.12
51 | "$INTEL_BREW_PATH" link python@3.12
52 | fi
53 | fi
54 | fi
55 |
56 | "$PYTHON_PATH" deploy/__init__.py;
57 | echo "正在安装依赖(自动过滤macOS不兼容包)..."
58 | cat "$REQUIREMENTS" | grep -vE 'pywin32==|twisted-iocpsupport==' | "$PYTHON_PATH" -m pip install -r /dev/stdin \
59 | -i http://mirrors.aliyun.com/pypi/simple/ \
60 | --trusted-host mirrors.aliyun.com \
61 | --user \
62 | --break-system-packages;
63 |
64 | echo ""
65 | echo "===== 初始化完毕,请手动关闭终端窗口 ====="
66 | echo ""
--------------------------------------------------------------------------------
/deploy/online_scripts/win.ps1:
--------------------------------------------------------------------------------
1 | $IsPwsh = $PSVersionTable.PSEdition -eq "Core"
2 |
3 | $proj_p = Get-Location
4 |
5 | $python_exe = Join-Path $proj_p "runtime/python.exe"
6 | if (-not (Test-Path $python_exe)) {Write-Output "runtime/python.exe not found, need excute on unzipped path/请在解压的根目录下执行";pause;exit}
7 |
8 | $locale = if ($IsPwsh) { (Get-Culture).Name } else { [System.Threading.Thread]::CurrentThread.CurrentUICulture.Name }
9 |
10 | $targetUrl = if ($locale -eq "zh-CN") {"https://gitproxy.click/https://raw.githubusercontent.com/jasoneri/ComicGUISpider/refs/heads/GUI/deploy/pkg_mgr.py"} else {"https://raw.githubusercontent.com/jasoneri/ComicGUISpider/refs/heads/GUI/deploy/pkg_mgr.py"}
11 |
12 | $pyPath = "$proj_p\pkg_mgr.py"
13 | try {
14 | if ($PSVersionTable.PSVersion.Major -le 5) {
15 | Add-Type @"
16 | using System.Net;
17 | using System.Security.Cryptography.X509Certificates;
18 | public class TrustAllCertsPolicy : ICertificatePolicy {
19 | public bool CheckValidationResult(ServicePoint s, X509Certificate c, WebRequest r, int e) { return true; }
20 | }
21 | "@
22 | [Net.ServicePointManager]::CertificatePolicy = [TrustAllCertsPolicy]::new()
23 | }
24 | Invoke-WebRequest -Uri $targetUrl -OutFile $pyPath -UseBasicParsing
25 | }
26 | catch {
27 | Write-Output "install pkg_mgr.py failed/下载pkg_mgr.py失败";pause;exit
28 | }
29 | & "$python_exe" "$pyPath" -l $locale
30 | Remove-Item -Path $pyPath -Force
--------------------------------------------------------------------------------
/deploy/pkg_mgr.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import sys
3 | import importlib
4 | import platform
5 | import subprocess
6 | import pathlib
7 | import pip
8 |
9 | import httpx
10 | import tqdm
11 | from loguru import logger
12 |
13 | p = pathlib.Path(__file__).parent
14 | def which_env():
15 | os_type = platform.system()
16 | if os_type == "Darwin":
17 | # 判断Mac架构
18 | arch = platform.machine()
19 | if arch == "arm64":
20 | return "mac_arm64"
21 | elif arch == "x86_64":
22 | return "mac_x86_64"
23 | else:
24 | return "mac_x86_64"
25 | else:
26 | return "win"
27 |
28 |
29 | class PkgMgr:
30 | def __init__(self, locale="zh-CN", run_path=None, debug_signal=None):
31 | self.cli = httpx.Client()
32 | self.locale = locale
33 | self.run_path = run_path or p
34 | self.debug_signal = debug_signal
35 | if self.run_path.joinpath("scripts/CGS.py").exists():
36 | self.proj_p = self.run_path.joinpath("scripts")
37 | elif self.run_path.joinpath("CGS.py").exists():
38 | self.proj_p = self.run_path
39 | else:
40 | raise FileNotFoundError(f"CGS.py not found, unsure env. check your run path > [{self.run_path}].")
41 | self.env = which_env()
42 | self.set_assets()
43 |
44 | def github_speed(self, url):
45 | if self.locale == "zh-CN":
46 | url = "https://gitproxy.click/" + url
47 | return url
48 |
49 | def set_assets(self):
50 | requirements = f"requirements/{self.env}.txt"
51 | self.requirements_url = self.github_speed(f"https://raw.githubusercontent.com/jasoneri/ComicGUISpider/refs/heads/GUI/{requirements}")
52 | self.requirements = self.proj_p.joinpath(requirements)
53 |
54 | def print(self, *args, **kwargs):
55 | if self.debug_signal:
56 | self.debug_signal.emit(*args, **kwargs)
57 | print(*args, **kwargs)
58 |
59 | def dl(self):
60 | def _dl(url, out):
61 | with self.cli.stream("GET", url) as r:
62 | with open(out, "wb") as f:
63 | for chunk in tqdm.tqdm(r.iter_bytes(1000), desc=f"downloading {out.name}"):
64 | f.write(chunk)
65 | self.print(f"[downloaded] {out.name}")
66 |
67 | def _dl_uv():
68 | cmd = ["install", "uv"]
69 | if self.locale == "zh-CN":
70 | cmd.extend(["-i", "https://pypi.tuna.tsinghua.edu.cn/simple"])
71 | exitcode = pip.main(cmd)
72 | self.print(f"[pip install uv exitcode] {exitcode}")
73 |
74 | _dl_uv()
75 | _dl(self.requirements_url, self.requirements)
76 |
77 | def uv_install_pkgs(self):
78 | self.print("uv pip installing pkg...")
79 | uv = importlib.import_module("uv")
80 | cmd = [uv.find_uv_bin(), "pip", "install", "-r", str(self.requirements), "--python", sys.executable]
81 | if self.locale == "zh-CN":
82 | cmd.extend(["--index-url", "http://mirrors.aliyun.com/pypi/simple/", "--trusted-host", "mirrors.aliyun.com"])
83 | self.print("[uv_install_pkgs cmd]" + " ".join(cmd))
84 | process = subprocess.Popen(
85 | cmd, cwd=self.run_path,
86 | stdout=subprocess.PIPE, stderr=subprocess.STDOUT,
87 | text=True, bufsize=1, universal_newlines=True
88 | )
89 | full_output = []
90 | while True:
91 | line = process.stdout.readline()
92 | if not line:
93 | if process.poll() is not None:
94 | break # 进程结束且无输出时退出
95 | continue
96 | line = line.strip()
97 | full_output.append(line)
98 | # 实时发送信号
99 | self.print(line)
100 | # 读取剩余输出
101 | remaining = process.stdout.read()
102 | if remaining:
103 | for line in remaining.splitlines():
104 | cleaned_line = line.strip()
105 | full_output.append(cleaned_line)
106 | self.print(cleaned_line)
107 | # 等待进程结束
108 | exit_code = process.wait()
109 | if exit_code == 0:
110 | self.print("[!uv_install_pkgs done!]")
111 | return exit_code, full_output
112 |
113 | @logger.catch(reraise=True)
114 | def run(self):
115 | self.dl()
116 | exit_code, full_output = self.uv_install_pkgs()
117 | return exit_code, full_output
118 |
119 |
120 | if __name__ == "__main__":
121 | parser = argparse.ArgumentParser()
122 | parser.add_argument("-l", "--locale", default="zh-CN", help="locale")
123 | args = parser.parse_args()
124 | pkg_mgr = PkgMgr(args.locale)
125 | # pkg_mgr = PkgMgr("zh-CN")
126 | pkg_mgr.run()
127 |
--------------------------------------------------------------------------------
/docs/.vitepress/theme/Layout.vue:
--------------------------------------------------------------------------------
1 |
14 |
15 |
16 |
106 |
107 |
108 | ## 🔇免责声明
109 |
110 | 详见[License](LICENSE) 当你下载或使用本项目,将默许
111 |
112 | 本项目仅供交流和学习使用,请勿用此从事 违法/商业盈利 等,开发者团队拥有本项目的最终解释权
113 |
114 | ---
115 | 
116 |
--------------------------------------------------------------------------------
/assets/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 |
--------------------------------------------------------------------------------
/assets/conf_sample.yml:
--------------------------------------------------------------------------------
1 | ## 配置文件,使用方法详情至readme.md了解
2 |
3 | custom_map:
4 | 更新4: https://wnacg.com/albums-index-page-4.html
5 | 杂志: https://wnacg.com/albums-index-cate-10.html
6 | log_level: WARNING
7 | proxies: null
8 | sv_path: D:\Comic
--------------------------------------------------------------------------------
/assets/config_icon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/assets/config_icon.png
--------------------------------------------------------------------------------
/assets/icon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jasoneri/ComicGUISpider/940f80d32a862550fe7dfdef462d21f30e730c1a/assets/icon.png
--------------------------------------------------------------------------------
/assets/res/transfer.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | import pathlib
4 | import hashlib
5 | from datetime import datetime
6 | import yaml
7 | import polib
8 |
9 |
10 | def yaml_to_po(lang, yaml_file, po_file):
11 | with open(yaml_file, 'r', encoding='utf-8') as f:
12 | data = yaml.safe_load(f)
13 |
14 | po = polib.POFile()
15 | po.metadata = {
16 | 'Project-Id-Version': 'ComicGUISpider',
17 | 'POT-Creation-Date': datetime.now().strftime('%Y-%m-%d %H:%M%z'),
18 | 'Language': lang,
19 | 'MIME-Version': '1.0',
20 | 'Content-Type': 'text/plain; charset=utf-8',
21 | 'Content-Transfer-Encoding': '8bit',
22 | }
23 |
24 | def process_dict(data, prefix=''):
25 | for key, value in data.items():
26 | entry_id = f"{prefix}{key}" if prefix else key
27 | if isinstance(value, dict):
28 | process_dict(value, f"{entry_id}.")
29 | else:
30 | entry = polib.POEntry(
31 | msgid=entry_id,
32 | msgstr=str(value),
33 | )
34 | po.append(entry)
35 | process_dict(data)
36 | po.save(po_file)
37 |
38 | return po
39 |
40 | def compile_po_to_mo(po_file, mo_file):
41 | po = polib.pofile(po_file)
42 | po.save_as_mofile(mo_file)
43 |
44 |
45 | def main(base_dir, lang):
46 | locale_dir = base_dir / 'locale' / lang / 'LC_MESSAGES'
47 | locale_dir.mkdir(parents=True, exist_ok=True)
48 |
49 | yaml_file = base_dir / 'locale' / f'{lang}.yml'
50 | yaml_hash = base_dir / 'locale' / f'{lang}.hash'
51 | po_file = base_dir / 'locale' / lang / 'LC_MESSAGES' / 'res.po'
52 | mo_file = base_dir / 'locale' / lang / 'LC_MESSAGES' / 'res.mo'
53 |
54 | po = yaml_to_po(lang, yaml_file, po_file)
55 | compile_po_to_mo(po_file, mo_file)
56 | with open(yaml_hash, 'w', encoding='utf-8') as f:
57 | f.write(hashlib.sha256(yaml_file.read_bytes()).hexdigest())
58 |
59 |
60 | if __name__ == "__main__":
61 | main(pathlib.Path(__file__).parent, 'zh-CN')
62 | main(pathlib.Path(__file__).parent, 'en-US')
63 |
--------------------------------------------------------------------------------
/deploy/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | import os
4 | import platform
5 | import pathlib
6 | import subprocess
7 |
8 |
9 | class Env:
10 | default_sv_path = r"D:\Comic"
11 | default_clip_db = pathlib.Path.home().joinpath(r"AppData\Roaming\Ditto\Ditto.db")
12 | clip_sql = "SELECT `mText` FROM `MAIN` order by `LID` desc"
13 |
14 | def __init__(self, _p: pathlib.Path):
15 | self.proj_p = _p
16 | os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = str(
17 | proj_path.parent.joinpath(r"site-packages\PyQt5\Qt5\plugins\platforms"))
18 |
19 | def env_init(self):
20 | ...
21 |
22 | @staticmethod
23 | def open_folder(_p):
24 | os.startfile(_p)
25 |
26 | @staticmethod
27 | def open_file(_f):
28 | subprocess.run(["start", "", f"{_f}"], shell=True, check=True)
29 |
30 |
31 | proj_path = pathlib.Path(__file__).parent.parent
32 | curr_os_module = Env
33 | if platform.system().startswith("Darwin"):
34 | import sys
35 | sys.path.append(str(proj_path))
36 | from deploy.launcher.mac import macOS
37 | curr_os_module = macOS
38 | curr_os = curr_os_module(proj_path)
39 |
40 | if __name__ == '__main__':
41 | curr_os.env_init()
42 |
--------------------------------------------------------------------------------
/deploy/env_record.json:
--------------------------------------------------------------------------------
1 | ["execjs", "qfluentwidgets", "polib", "pillow_avif"]
--------------------------------------------------------------------------------
/deploy/launcher/CGS.bat:
--------------------------------------------------------------------------------
1 | @rem
2 | @echo off
3 |
4 | set "_root=%~dp0"
5 | set "_root=%_root:~0,-1%"
6 | cd "%_root%"
7 | @rem echo "%_root%
8 |
9 | set "_pyBin=%_root%\runtime"
10 | set "PATH=%_root%\site-packages;%_pyBin%;%PATH%"
11 |
12 | cd "%_root%\scripts" && python CGS.py
--------------------------------------------------------------------------------
/deploy/launcher/mac/CGS.bash:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | cd scripts;
3 | /usr/local/bin/python3.12 CGS.py;
--------------------------------------------------------------------------------
/deploy/launcher/mac/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | import pathlib
4 | import re
5 | import subprocess
6 |
7 | # 对应`冬青黑体简体中文`,想要换其他字体可聚焦搜索`字体册`,在目标字体右键`访达中显示`,可以看到字体文件,把字体名替换掉`font`的值即可
8 | # 字体册仅支持能访达/系统alias能搜索出的字体,如果是下载的字体文件,可以看`macOS.font_replace _repl`
9 | font = "Hiragino Sans GB"
10 |
11 |
12 | class macOS:
13 | default_sv_path = pathlib.Path.home().joinpath("Downloads/Comic")
14 | default_clip_db = pathlib.Path.home().joinpath(
15 | "Library/Containers/org.p0deje.Maccy/Data/Library/Application Support/Maccy/Storage.sqlite")
16 | clip_sql = "SELECT `ZTITLE` FROM `ZHISTORYITEM` order by `Z_PK` desc"
17 |
18 | def __init__(self, _p):
19 | self.proj_p = _p
20 |
21 | @staticmethod
22 | def open_folder(_p):
23 | subprocess.run(['open', _p])
24 |
25 | @staticmethod
26 | def open_file(_f):
27 | subprocess.run(['open', _f])
28 |
29 | def env_init(self):
30 | # 1. 更换字体
31 | self.font_replace()
32 | # 2. requirements.txt去掉window相关的包
33 | self.handle_requirements()
34 |
35 | def font_replace(self):
36 | def _repl(content):
37 | """下载的字体用绝对路径时可以用以下注释了的替换方法"""
38 | # font_path = "/Users/Shared/.../xxx.ttc"
39 | # if "QFontDatabase" not in content:
40 | # content = ("from PyQt5.QtGui import QFontDatabase\n"
41 | # f"font_path = '{font_path}'\n"
42 | # f"_id = QFontDatabase.addApplicationFont(font_path)\n") + content
43 | # new_content = re.sub(r'font = .*?\n.*?font\.setFamily\(".*?"\)',
44 | # f'font = QFontDatabase.font("{font}", "Regular", 11)', content, re.M)
45 | new_content = re.sub(r'font\.setFamily\(".*?"\)', f'font.setFamily("{font}")', content)
46 | return new_content
47 | uic_p = self.proj_p.joinpath("GUI/uic")
48 | for _f in ["conf_dia.py", "browser.py", "ui_mainwindow.py"]:
49 | self.file_content_replace(uic_p.joinpath(_f), _repl)
50 |
51 | def handle_requirements(self):
52 | self.file_content_replace(
53 | self.proj_p.joinpath('requirements.txt'),
54 | lambda content: re.sub(r'^(twisted-iocpsupport==.*|pywin32==.*)[\r\n]*', "", content, flags=re.MULTILINE)
55 | )
56 |
57 | @staticmethod
58 | def file_content_replace(file, repl_func):
59 | with open(file, 'r+', encoding='utf-8') as fp:
60 | content = fp.read()
61 | new_content = repl_func(content)
62 | fp.seek(0)
63 | fp.truncate()
64 | fp.write(new_content)
65 |
--------------------------------------------------------------------------------
/deploy/launcher/mac/dos2unix.bash:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | curr_p=$(cd "$(dirname "$0")";pwd)
3 | app_proj_p="/Applications/CGS.app/Contents/Resources/scripts"
4 | if [ ! -x /usr/local/bin/brew ]; then
5 | echo "not brew, downloading brew...";
6 | /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)";
7 | fi
8 | if [ ! -x /usr/local/bin/dos2unix ]; then
9 | echo "not dos2unix, downloading dos2unix...";
10 | brew install dos2unix;
11 | fi
12 | find $curr_p/../ -type f -name "*.bash" -exec sudo dos2unix {} +;
13 | find $curr_p/../ -type f -name "*.md" -exec sudo dos2unix {} +;
14 | find $curr_p/../ -type f -name "*.py" -exec sudo dos2unix {} +;
15 | find $curr_p/../ -type f -name "*.json" -exec sudo dos2unix {} +;
16 | find $curr_p/../ -type f -name "*.yml" -exec sudo dos2unix {} +;
17 | find $app_proj_p -type f -name "*.bash" -exec sudo dos2unix {} +;
18 | find $app_proj_p -type f -name "*.md" -exec sudo dos2unix {} +;
19 | find $app_proj_p -type f -name "*.py" -exec sudo dos2unix {} +;
20 | find $app_proj_p -type f -name "*.json" -exec sudo dos2unix {} +;
21 | find $app_proj_p -type f -name "*.yml" -exec sudo dos2unix {} +;
22 |
--------------------------------------------------------------------------------
/deploy/launcher/mac/init.bash:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # 将终端窗口置于最前
3 | osascript -e 'tell application "Terminal" to activate' -e 'tell application "System Events" to tell process "Terminal" to set frontmost to true'
4 |
5 | curr_p=$(cd "$(dirname "$0")";pwd);
6 | cd $curr_p/../../../;
7 | REQUIREMENTS="requirements/mac_x86_64.txt"
8 |
9 | # 检测是否为 Apple Silicon
10 | if [ "$(uname -m)" = "arm64" ]; then
11 | REQUIREMENTS="requirements/mac_arm64.txt"
12 | # 检测 Rosetta 2 是否已安装
13 | if ! arch -x86_64 echo > /dev/null 2>&1; then
14 | echo "检测到 Apple Silicon Mac,但未安装 Rosetta 2,正在安装..."
15 | /usr/sbin/softwareupdate --install-rosetta --agree-to-license
16 | fi
17 | fi
18 |
19 | PYTHON_PATH="/usr/local/bin/python3.12"
20 | # 确保安装的是 x86_64 版本的 Python
21 | if [ ! -x "$PYTHON_PATH" ]; then
22 | echo "无python3.12环境,正在初始化...";
23 | # 检测 Homebrew 安装路径
24 | if [ -x "/opt/homebrew/bin/brew" ]; then
25 | ARM_BREW_PATH="/opt/homebrew/bin/brew"
26 | fi
27 | if [ -x "/usr/local/bin/brew" ]; then
28 | INTEL_BREW_PATH="/usr/local/bin/brew"
29 | fi
30 | # 如果没有安装 Homebrew,则安装它
31 | if [ ! -x "$INTEL_BREW_PATH" ] && [ ! -x "$ARM_BREW_PATH" ]; then
32 | echo "未检测到 Homebrew,正在安装..."
33 | /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)";
34 | fi
35 | # 在 Apple Silicon Mac 上,通过 Rosetta 2 安装 x86_64 版的 Python
36 | if [ "$(uname -m)" = "arm64" ]; then
37 | if [ -x "$INTEL_BREW_PATH" ]; then
38 | echo "使用 Intel Homebrew 安装 Python..."
39 | "$INTEL_BREW_PATH" install python@3.12
40 | "$INTEL_BREW_PATH" link python@3.12
41 | else
42 | echo "通过 Rosetta 2 安装 Intel 版本的 Python..."
43 | arch -x86_64 /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
44 | arch -x86_64 /usr/local/bin/brew install python@3.12
45 | arch -x86_64 /usr/local/bin/brew link python@3.12
46 | fi
47 | else
48 | # 在 Intel Mac 上,直接安装
49 | if [ -x "$INTEL_BREW_PATH" ]; then
50 | "$INTEL_BREW_PATH" install python@3.12
51 | "$INTEL_BREW_PATH" link python@3.12
52 | fi
53 | fi
54 | fi
55 |
56 | "$PYTHON_PATH" deploy/__init__.py;
57 | echo "正在安装依赖(自动过滤macOS不兼容包)..."
58 | cat "$REQUIREMENTS" | grep -vE 'pywin32==|twisted-iocpsupport==' | "$PYTHON_PATH" -m pip install -r /dev/stdin \
59 | -i http://mirrors.aliyun.com/pypi/simple/ \
60 | --trusted-host mirrors.aliyun.com \
61 | --user \
62 | --break-system-packages;
63 |
64 | echo ""
65 | echo "===== 初始化完毕,请手动关闭终端窗口 ====="
66 | echo ""
--------------------------------------------------------------------------------
/deploy/online_scripts/win.ps1:
--------------------------------------------------------------------------------
1 | $IsPwsh = $PSVersionTable.PSEdition -eq "Core"
2 |
3 | $proj_p = Get-Location
4 |
5 | $python_exe = Join-Path $proj_p "runtime/python.exe"
6 | if (-not (Test-Path $python_exe)) {Write-Output "runtime/python.exe not found, need excute on unzipped path/请在解压的根目录下执行";pause;exit}
7 |
8 | $locale = if ($IsPwsh) { (Get-Culture).Name } else { [System.Threading.Thread]::CurrentThread.CurrentUICulture.Name }
9 |
10 | $targetUrl = if ($locale -eq "zh-CN") {"https://gitproxy.click/https://raw.githubusercontent.com/jasoneri/ComicGUISpider/refs/heads/GUI/deploy/pkg_mgr.py"} else {"https://raw.githubusercontent.com/jasoneri/ComicGUISpider/refs/heads/GUI/deploy/pkg_mgr.py"}
11 |
12 | $pyPath = "$proj_p\pkg_mgr.py"
13 | try {
14 | if ($PSVersionTable.PSVersion.Major -le 5) {
15 | Add-Type @"
16 | using System.Net;
17 | using System.Security.Cryptography.X509Certificates;
18 | public class TrustAllCertsPolicy : ICertificatePolicy {
19 | public bool CheckValidationResult(ServicePoint s, X509Certificate c, WebRequest r, int e) { return true; }
20 | }
21 | "@
22 | [Net.ServicePointManager]::CertificatePolicy = [TrustAllCertsPolicy]::new()
23 | }
24 | Invoke-WebRequest -Uri $targetUrl -OutFile $pyPath -UseBasicParsing
25 | }
26 | catch {
27 | Write-Output "install pkg_mgr.py failed/下载pkg_mgr.py失败";pause;exit
28 | }
29 | & "$python_exe" "$pyPath" -l $locale
30 | Remove-Item -Path $pyPath -Force
--------------------------------------------------------------------------------
/deploy/pkg_mgr.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import sys
3 | import importlib
4 | import platform
5 | import subprocess
6 | import pathlib
7 | import pip
8 |
9 | import httpx
10 | import tqdm
11 | from loguru import logger
12 |
13 | p = pathlib.Path(__file__).parent
14 | def which_env():
15 | os_type = platform.system()
16 | if os_type == "Darwin":
17 | # 判断Mac架构
18 | arch = platform.machine()
19 | if arch == "arm64":
20 | return "mac_arm64"
21 | elif arch == "x86_64":
22 | return "mac_x86_64"
23 | else:
24 | return "mac_x86_64"
25 | else:
26 | return "win"
27 |
28 |
29 | class PkgMgr:
30 | def __init__(self, locale="zh-CN", run_path=None, debug_signal=None):
31 | self.cli = httpx.Client()
32 | self.locale = locale
33 | self.run_path = run_path or p
34 | self.debug_signal = debug_signal
35 | if self.run_path.joinpath("scripts/CGS.py").exists():
36 | self.proj_p = self.run_path.joinpath("scripts")
37 | elif self.run_path.joinpath("CGS.py").exists():
38 | self.proj_p = self.run_path
39 | else:
40 | raise FileNotFoundError(f"CGS.py not found, unsure env. check your run path > [{self.run_path}].")
41 | self.env = which_env()
42 | self.set_assets()
43 |
44 | def github_speed(self, url):
45 | if self.locale == "zh-CN":
46 | url = "https://gitproxy.click/" + url
47 | return url
48 |
49 | def set_assets(self):
50 | requirements = f"requirements/{self.env}.txt"
51 | self.requirements_url = self.github_speed(f"https://raw.githubusercontent.com/jasoneri/ComicGUISpider/refs/heads/GUI/{requirements}")
52 | self.requirements = self.proj_p.joinpath(requirements)
53 |
54 | def print(self, *args, **kwargs):
55 | if self.debug_signal:
56 | self.debug_signal.emit(*args, **kwargs)
57 | print(*args, **kwargs)
58 |
59 | def dl(self):
60 | def _dl(url, out):
61 | with self.cli.stream("GET", url) as r:
62 | with open(out, "wb") as f:
63 | for chunk in tqdm.tqdm(r.iter_bytes(1000), desc=f"downloading {out.name}"):
64 | f.write(chunk)
65 | self.print(f"[downloaded] {out.name}")
66 |
67 | def _dl_uv():
68 | cmd = ["install", "uv"]
69 | if self.locale == "zh-CN":
70 | cmd.extend(["-i", "https://pypi.tuna.tsinghua.edu.cn/simple"])
71 | exitcode = pip.main(cmd)
72 | self.print(f"[pip install uv exitcode] {exitcode}")
73 |
74 | _dl_uv()
75 | _dl(self.requirements_url, self.requirements)
76 |
77 | def uv_install_pkgs(self):
78 | self.print("uv pip installing pkg...")
79 | uv = importlib.import_module("uv")
80 | cmd = [uv.find_uv_bin(), "pip", "install", "-r", str(self.requirements), "--python", sys.executable]
81 | if self.locale == "zh-CN":
82 | cmd.extend(["--index-url", "http://mirrors.aliyun.com/pypi/simple/", "--trusted-host", "mirrors.aliyun.com"])
83 | self.print("[uv_install_pkgs cmd]" + " ".join(cmd))
84 | process = subprocess.Popen(
85 | cmd, cwd=self.run_path,
86 | stdout=subprocess.PIPE, stderr=subprocess.STDOUT,
87 | text=True, bufsize=1, universal_newlines=True
88 | )
89 | full_output = []
90 | while True:
91 | line = process.stdout.readline()
92 | if not line:
93 | if process.poll() is not None:
94 | break # 进程结束且无输出时退出
95 | continue
96 | line = line.strip()
97 | full_output.append(line)
98 | # 实时发送信号
99 | self.print(line)
100 | # 读取剩余输出
101 | remaining = process.stdout.read()
102 | if remaining:
103 | for line in remaining.splitlines():
104 | cleaned_line = line.strip()
105 | full_output.append(cleaned_line)
106 | self.print(cleaned_line)
107 | # 等待进程结束
108 | exit_code = process.wait()
109 | if exit_code == 0:
110 | self.print("[!uv_install_pkgs done!]")
111 | return exit_code, full_output
112 |
113 | @logger.catch(reraise=True)
114 | def run(self):
115 | self.dl()
116 | exit_code, full_output = self.uv_install_pkgs()
117 | return exit_code, full_output
118 |
119 |
120 | if __name__ == "__main__":
121 | parser = argparse.ArgumentParser()
122 | parser.add_argument("-l", "--locale", default="zh-CN", help="locale")
123 | args = parser.parse_args()
124 | pkg_mgr = PkgMgr(args.locale)
125 | # pkg_mgr = PkgMgr("zh-CN")
126 | pkg_mgr.run()
127 |
--------------------------------------------------------------------------------
/docs/.vitepress/theme/Layout.vue:
--------------------------------------------------------------------------------
1 |
14 |
15 |
16 |  4 |
5 |
4 |
5 |  11 |
12 |
13 |
11 |
12 |
13 |  '
28 | - icon:
29 | src: ./assets/img/icons/website/mangabz.png
30 | title: 'Māngabz'
31 | details: '
'
28 | - icon:
29 | src: ./assets/img/icons/website/mangabz.png
30 | title: 'Māngabz'
31 | details: ' '
32 | - icon:
33 | src: ./assets/img/icons/website/jm.png
34 | title: 'jm'
35 | details: '
'
32 | - icon:
33 | src: ./assets/img/icons/website/jm.png
34 | title: 'jm'
35 | details: ' '
36 | - icon:
37 | src: ./assets/img/icons/website/wnacg.png
38 | title: '绅士漫画'
39 | details: '
'
36 | - icon:
37 | src: ./assets/img/icons/website/wnacg.png
38 | title: '绅士漫画'
39 | details: ' '
40 | - icon:
41 | src: ./assets/img/icons/website/ehentai.png
42 | title: 'exhentai'
43 | details: '
'
40 | - icon:
41 | src: ./assets/img/icons/website/ehentai.png
42 | title: 'exhentai'
43 | details: ' '
44 | - icon:
45 | src: ./assets/img/icons/website/hitomi.png
46 | title: 'hitomi'
47 | details: '
'
44 | - icon:
45 | src: ./assets/img/icons/website/hitomi.png
46 | title: 'hitomi'
47 | details: ' '
48 | ---
49 |
50 |
'
48 | ---
49 |
50 | 
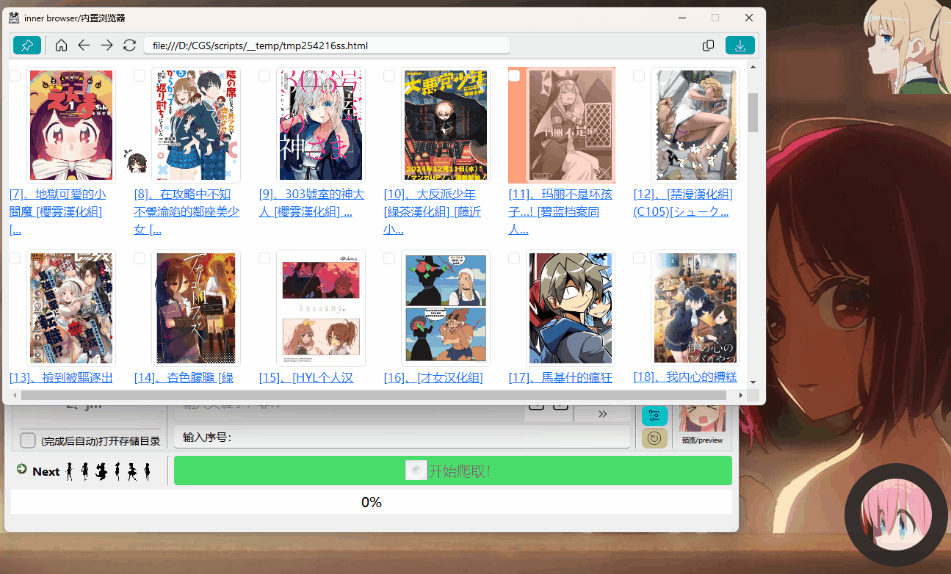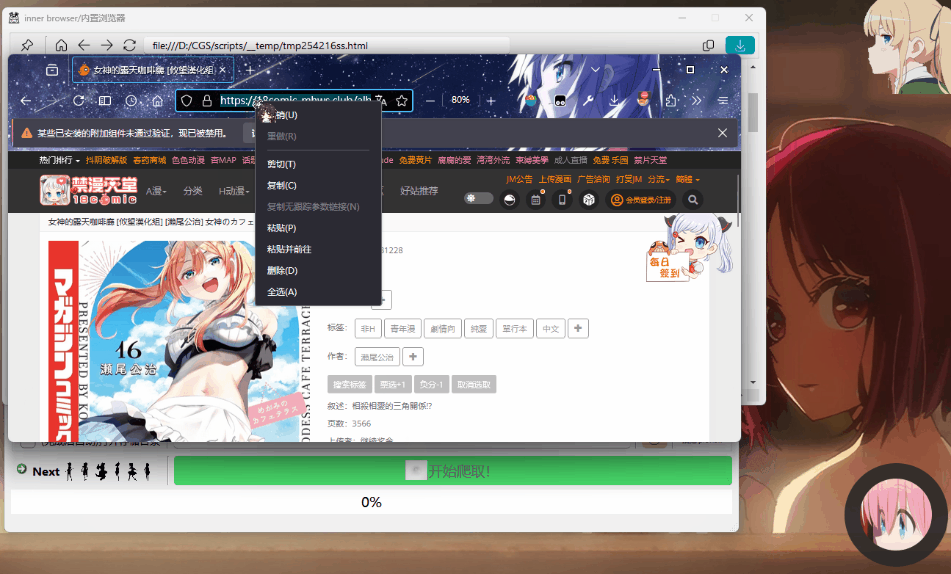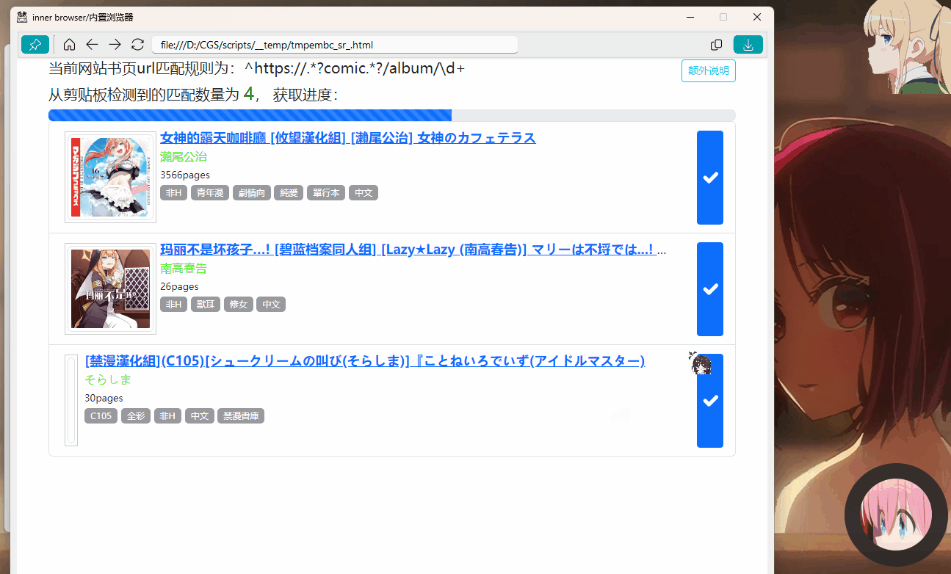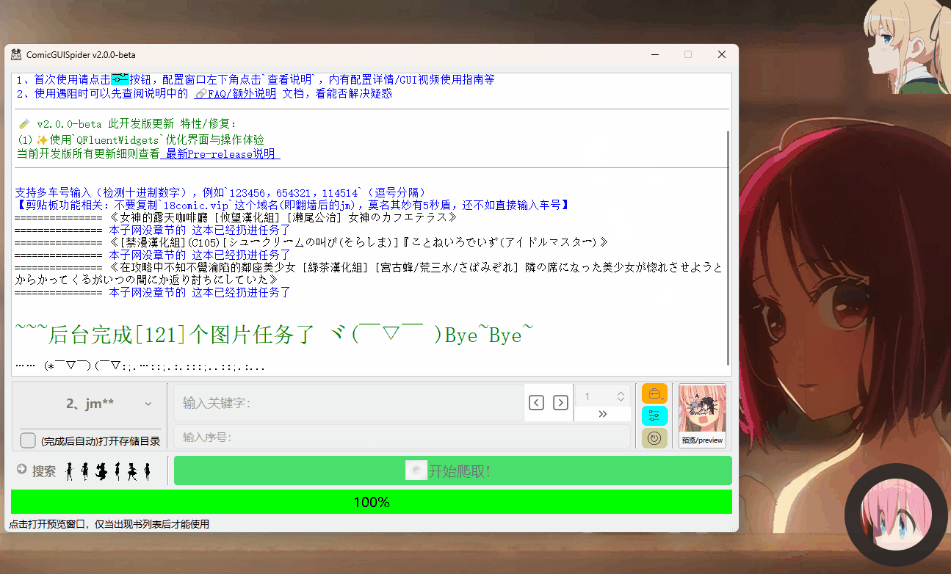



 88 |
88 |  91 |
91 |