├── .gitignore
├── Code
├── FunctionList.py
├── README.md
├── datetime_demo.py
└── demo_1.py
├── Django
├── Django 1.10中文文档-第一个应用Part1-请求与响应.md
├── Django 1.10中文文档-第一个应用Part2-模型和管理站点.md
├── Django 1.10中文文档-第一个应用Part3-视图和模板.md
├── Django 1.10中文文档-第一个应用Part4-表单和通用视图.md
├── Django 1.10中文文档-第一个应用Part5-测试.md
├── Django 1.10中文文档-第一个应用Part6-静态文件.md
├── Django 1.10中文文档-第一个应用Part7-自定义管理站点.md
├── Django中六个常用的自定义装饰器.md
├── README.md
├── Ubuntu上通过nginx部署Django笔记.md
└── __init__.py
├── Docker
└── 使用GitHub Actions自动构建DockerHub镜像.md
├── Image
└── 2017060501.png
├── Linux
├── Linux笔记:使用Vim编辑器.md
└── README.md
├── MongoDB
└── Python中使用MongoDB.md
├── Pycharm
├── PyCharm 自定义文件和代码模板.md
├── Pycharm创建virtualenv方法.md
├── README.md
└── __init__.py
├── Python
├── Airflow笔记-MySqlOperator使用及conn配置.md
├── Docker容器化部署Python应用.md
├── Python NLP入门教程.md
├── Python判断文件是否存在的三种方法.md
├── Python图片验证码降噪 — 8邻域降噪.md
├── Python异步Web编程.md
├── Python标准库笔记(1) — string模块.md
├── Python标准库笔记(10) — itertools模块.md
├── Python标准库笔记(11) — operator模块.md
├── Python标准库笔记(2) — re模块.md
├── Python标准库笔记(3) — datetime模块.md
├── Python标准库笔记(4) — collections模块.md
├── Python标准库笔记(5) — sched模块.md
├── Python标准库笔记(6) — struct模块.md
├── Python标准库笔记(7) — copy模块.md
├── Python标准库笔记(8) — pprint模块.md
├── Python标准库笔记(9) — functools模块.md
├── Python正则表达式:最短匹配.md
├── Python爬虫—破解JS加密的Cookie.md
├── Python计算大文件行数方法及性能比较.md
├── Python魔术方法-Magic Method.md
├── README.md
├── python类中super()和__init__()的区别.md
├── 使用captcha模块生成图形验证码.md
└── 类属性的延迟计算.md
├── README.md
├── SSDB
├── README.md
├── SSDB图形界面管理工具:phpssdbadmin安装部署.md
├── SSDB安装配置记录.md
└── __init__.py
├── ZooKeeper
└── Python操作zookeeper—kazoo模块.md
├── test.py
├── uwsgi.log
├── 爬虫
├── Python Webdriver 重新使用已经打开的浏览器实例.md
├── Python检查xpath和csspath表达式是否合法.md
├── Python爬虫代理IP池.md
└── README.md
└── 算法记录
├── README.md
├── 常用样本相似性和距离度量方法.md
├── 曲线点抽稀算法-Python实现.md
└── 机器学习笔记—KNN算法.md
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea/
2 | *.pyc
3 | settings.py
--------------------------------------------------------------------------------
/Code/FunctionList.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | class FunctionalList:
3 | """
4 | 实现了内置类型list的功能,并丰富了一些其他方法: head, tail, init, last, drop, take
5 | """
6 |
7 | def __init__(self, values=None):
8 | if values is None:
9 | self.values = []
10 | else:
11 | self.values = values
12 |
13 | def __len__(self):
14 | return len(self.values)
15 |
16 | def __getitem__(self, key):
17 | return self.values[key]
18 |
19 | def __setitem__(self, key, value):
20 | self.values[key] = value
21 |
22 | def __delitem__(self, key):
23 | del self.values[key]
24 |
25 | def __iter__(self):
26 | return iter(self.values)
27 |
28 | def __reversed__(self):
29 | return FunctionalList(reversed(self.values))
30 |
31 | def append(self, value):
32 | self.values.append(value)
33 |
34 | def head(self):
35 | # 获取第一个元素
36 | return self.values[0]
37 |
38 | def tail(self):
39 | # 获取第一个元素之后的所有元素
40 | return self.values[1:]
41 |
42 | def init(self):
43 | # 获取最后一个元素之前的所有元素
44 | return self.values[:-1]
45 |
46 | def last(self):
47 | # 获取最后一个元素
48 | return self.values[-1]
49 |
50 | def drop(self, n):
51 | # 获取所有元素,除了前N个
52 | return self.values[n:]
53 |
54 | def take(self, n):
55 | # 获取前N个元素
56 | return self.values[:n]
57 |
58 |
--------------------------------------------------------------------------------
/Code/README.md:
--------------------------------------------------------------------------------
1 | * 笔记相关代码存放目录
--------------------------------------------------------------------------------
/Code/datetime_demo.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | -------------------------------------------------
4 | File Name: datetime.py
5 | Description : datetime模块
6 | Author : JHao
7 | date: 2017/4/6
8 | -------------------------------------------------
9 | Change Activity:
10 | 2017/4/6:
11 | -------------------------------------------------
12 | """
13 | __author__ = 'JHao'
14 |
15 | # region date类
16 | from datetime import date
17 |
18 | print 'today():', date.today() # 返回当前日期对象
19 |
20 | print 'fromtimestamp(1491448600):', date.fromtimestamp(1491448600) # 返回时间戳的日期对象
21 |
22 | print 'date.fromordinal(1):', date.fromordinal(1) # 返回对应公历序数的日期对象
23 |
24 | from datetime import date
25 |
26 | d = date(2017, 04, 06)
27 |
28 | print 'd.year:', d.year # 返回date对象的年份
29 |
30 | print 'd.month:', d.month # 返回date对象的月份
31 |
32 | print 'd.day:', d.day # 返回date对象的日
33 |
34 | print 'd.timetuple():', d.timetuple() # 返回date对象的struct_time结构
35 |
36 | print 'd.toordinal():', d.toordinal() # 返回公历日期的序数
37 |
38 | print 'd.weekday():', d.weekday() # 返回一星期中的第几天,星期一是0
39 |
40 | print 'd.isoweekday():', d.isoweekday() # 返回一星期中的第几天, 星期一1
41 |
42 | print 'd.isocalendar():', d.isocalendar() # 返回一个元组(年份, 这一年的第几周, 周几)
43 |
44 | print 'd.isoformat():', d.isoformat() # 以ISO 8601格式‘YYYY-MM-DD’返回date的字符串形式
45 |
46 | print 'd.ctime():', d.ctime() # 返回一个表示日期的字符串
47 |
48 | print 'd.strftime("%Y-%m-%d"):', d.strftime("%Y-%m-%d") # 返回指定格式的日期字符串
49 |
50 | print 'd.replace(year=2012, month=12) :', d.replace(year=2012, month=12) # 替换
51 |
52 | # endregion
53 |
54 | # region time类
55 | from datetime import time
56 |
57 | t = time(12, 10, 30, 50)
58 |
59 | print 't.hour:', t.hour # time对象小时数
60 |
61 | print 't.minute:', t.minute # time对象分钟数
62 |
63 | print 't.second:', t.second # time对象秒数
64 |
65 | print 't.microsecond:', t.microsecond # time对象微秒数
66 |
67 | print 't.isoformat():', t.isoformat() # 返回ISO 8601格式的时间字符串
68 |
69 | print 't.strftime("%H:%M:%S:%f"):', t.strftime("%H:%M:%S:%f") # 返回指定格式的时间格式
70 |
71 | print 't.replace(hour=23, minute=0):', t.replace(hour=23, minute=0) # 替换
72 |
73 | # endregion
74 |
75 | # region datetime类
76 | from datetime import datetime, time, date
77 |
78 | print 'datetime.today():', datetime.today() # 返回本地当前的时间datetime对象
79 |
80 | print 'datetime.now():', datetime.now() # 返回本地当前的日期和时间的datetime对象
81 |
82 | print 'datetime.utcnow():', datetime.utcnow() # 返回当前UTC日期和时间的datetime对象
83 |
84 | print 'datetime.fromtimestamp(1491468000):', datetime.fromtimestamp(1491468000) # 返回对应时间戳的datetime对象
85 |
86 | print 'datetime.fromordinal(699000):', datetime.fromordinal(699000) # 同date.fromordinal类似
87 |
88 | print 'datetime.combine(date(2012,12,12), time(12,12,12)):', datetime.combine(date(2012, 12, 12),
89 | time(23, 59, 59)) # 拼接date和time
90 |
91 | print 'datetime.strptime("2012-12-10", "%Y-%m-%d"):', datetime.strptime("2012-12-10",
92 | "%Y-%m-%d") # 将特定格式的日期时间字符串解析成datetime对象
93 |
94 | d = datetime(2017, 04, 06, 12, 10, 30)
95 |
96 | print 'd.date():', d.date() # 从datetime中拆分出date
97 |
98 | print 'd.time():', d.time() # 从datetime中拆分出time
99 |
100 | print 'd.timetz()', d.timetz() # 从datetime中拆分出具体时区属性的time
101 |
102 | print 'd.replace(year=2016):', d.replace(year=2016) # 替换
103 |
104 | print 'd.timetuple():', d.timetuple() # 时间数组,即struct_time结构
105 |
106 | print 'd.toordinal():', d.toordinal() # 和date.toordinal一样
107 |
108 | print 'd.weekday():', d.weekday() # 和date.weekday一样
109 |
110 | print 'd.isoweekday():', d.isoweekday() # 和date.isoweekday一样
111 |
112 | print 'd.isocalendar():', d.isocalendar() # 和date.isocalendar一样
113 |
114 | print 'd.isoformat():', d.isoformat() # 同上
115 |
116 | print 'd.ctime():', d.ctime() # 同上
117 |
118 | print 'd.strftime("%Y/%m/%d %H:%M:%S"):', d.strftime('%Y/%m/%d %H:%M:%S') # 同上
119 | # endregion
120 |
--------------------------------------------------------------------------------
/Code/demo_1.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | -------------------------------------------------
4 | File Name: demo_1.py.py
5 | Description : Python爬虫—破解JS加密的Cookie 快代理网站为例:http://www.kuaidaili.com/proxylist/1/
6 | Document:
7 | Author : JHao
8 | date: 2017/3/23
9 | -------------------------------------------------
10 | Change Activity:
11 | 2017/3/23: 破解JS加密的Cookie
12 | -------------------------------------------------
13 | """
14 | __author__ = 'JHao'
15 |
16 | import re
17 | import PyV8
18 | import requests
19 |
20 | TARGET_URL = "http://www.kuaidaili.com/proxylist/1/"
21 |
22 |
23 | def getHtml(url, cookie=None):
24 | header = {
25 | "Host": "www.kuaidaili.com",
26 | 'Connection': 'keep-alive',
27 | 'Cache-Control': 'max-age=0',
28 | 'Upgrade-Insecure-Requests': '1',
29 | 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36',
30 | 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
31 | 'Accept-Encoding': 'gzip, deflate, sdch',
32 | 'Accept-Language': 'zh-CN,zh;q=0.8',
33 | }
34 | html = requests.get(url=url, headers=header, timeout=30, cookies=cookie).content
35 | return html
36 |
37 |
38 | def executeJS(js_func_string, arg):
39 | ctxt = PyV8.JSContext()
40 | ctxt.enter()
41 | func = ctxt.eval("({js})".format(js=js_func_string))
42 | return func(arg)
43 |
44 |
45 | def parseCookie(string):
46 | string = string.replace("document.cookie='", "")
47 | clearance = string.split(';')[0]
48 | return {clearance.split('=')[0]: clearance.split('=')[1]}
49 |
50 |
51 | # 第一次访问获取动态加密的JS
52 | first_html = getHtml(TARGET_URL)
53 |
54 | # first_html = """
55 | #
56 | # """
57 |
58 | # 提取其中的JS加密函数
59 | js_func = ''.join(re.findall(r'(function .*?)', first_html))
60 |
61 | print 'get js func:\n', js_func
62 |
63 | # 提取其中执行JS函数的参数
64 | js_arg = ''.join(re.findall(r'setTimeout\(\"\D+\((\d+)\)\"', first_html))
65 |
66 | print 'get ja arg:\n', js_arg
67 |
68 | # 修改JS函数,使其返回Cookie内容
69 | js_func = js_func.replace('eval("qo=eval;qo(po);")', 'return po')
70 |
71 | # 执行JS获取Cookie
72 | cookie_str = executeJS(js_func, js_arg)
73 |
74 | # 将Cookie转换为字典格式
75 | cookie = parseCookie(cookie_str)
76 |
77 | print cookie
78 |
79 | # 带上Cookie再次访问url,获取正确数据
80 | print getHtml(TARGET_URL, cookie)[0:500]
81 |
--------------------------------------------------------------------------------
/Django/Django 1.10中文文档-第一个应用Part1-请求与响应.md:
--------------------------------------------------------------------------------
1 | 在本教程中,我们将引导您完成一个投票应用程序的创建,它包含下面两部分:
2 |
3 | * 一个可以进行投票和查看结果的公开站点;
4 |
5 | * 一个可以进行增删改查的后台admin管理界面;
6 |
7 | 我们假设你已经安装了Django。您可以通过运行以下命令来查看Django版本以及验证是否安装:
8 |
9 | ```
10 | python -m django --version
11 | ```
12 |
13 | 如果安装了Django,您应该将看到安装的版本。如果没有安装,你会得到一个错误,提示`No module named django`。
14 |
15 | 本教程是为Django 1.10和Python 3.4或更高版本编写的。如果Django版本不匹配,您可以去官网参考您的对应Django版本的教程,或者将Django更新到最新版本。
16 |
17 | 如果你仍然在使用Python 2.7,你需要稍微调整代码,注意代码中的注释。
18 |
19 | ## 创建project
20 |
21 | 如果这是你第一次使用Django,你将需要处理一些初始设置。也就是说,这会自动生成一些建立Django项目的代码,但是你需要设置一些配置,包括数据库配置,Django特定的选项和应用程序特定的设置等等。
22 |
23 | 从命令行,`cd`进入您将存放项目代码的目录,然后运行以下命令:
24 |
25 | ```
26 | django-admin startproject mysite # mysite为项目名
27 | ```
28 |
29 | 如果运行出错,请参见[Problems running django-admin](https://docs.djangoproject.com/en/1.10/faq/troubleshooting/#troubleshooting-django-admin)。这将在目录下生成一个mysite目录,也就是你的这个Django项目的根目录。它包含了一系列自动生成的目录和文件,具备各自专有的用途。
30 |
31 | > 注意: 在给项目命名的时候必须避开Django和Python的保留关键字。比如“django”(它会与Django本身冲突)或“test”(它与一个内置的Python包冲突)。
32 |
33 | > 这些代码应该放在哪儿? 如果你曾经学过普通的旧式的PHP(没有使用过现代的框架),你可能习惯于将代码放在Web服务器的文档根目录下(例如/var/www)。使用Django时,建议你不要这么做。 将Python代码放在你的Web服务器的根目录不是个好主意,因为这可能会有让其他人看到你的代码的风险。
34 |
35 | 一个新建立的项目结构大概如下:
36 | ```
37 | mysite/
38 | manage.py
39 | mysite/
40 | __init__.py
41 | settings.py
42 | urls.py
43 | wsgi.py
44 | ```
45 |
46 | 这些文件分别是:
47 |
48 | * 外层的mysite/根目录仅仅是项目的一个容器。它的命名对Django无关紧要;你可以把它重新命名为任何你喜欢的名字;
49 |
50 | * manage.py:一个命令行工具,可以使你用多种方式对Django项目进行交互。 你可以在[django-admin和manage.py](https://docs.djangoproject.com/en/1.10/ref/django-admin/)中读到关于manage.py的所有细节;
51 |
52 | * 内层的mysite/目录是你的项目的真正的Python包。它的名字是你引用内部文件的包名(例如 mysite.urls);
53 |
54 | * `mysite/__init__.py`:一个空文件,它告诉Python这个目录应该被看做一个Python包;
55 |
56 | * mysite/settings.py:该Django项目的配置文件。具体内容可以参见[Django settings](https://docs.djangoproject.com/en/1.10/topics/settings/);
57 |
58 | * mysite/urls.py: 路由文件,相当于你的Django站点的“目录”。 你可以在[URL转发器](https://docs.djangoproject.com/en/1.10/topics/http/urls/)中阅读到关于URL的更多内容;
59 |
60 | * mysite/wsgi.py:用于你的项目的与WSGI兼容的Web服务器入口。用作服务部署,更多细节请参见[如何利用WSGI进行部署](https://docs.djangoproject.com/en/1.10/howto/deployment/wsgi/)。
61 |
62 |
63 | ## 开发服务器
64 |
65 | 让我们验证一下你的Django项目是否工作。 进入外层的mysite目录,然后运行以下命令:
66 | ```
67 | python manage.py runserver
68 | ```
69 |
70 | 你将在看到如下输出:
71 | ```
72 | Performing system checks...
73 |
74 | System check identified no issues (0 silenced).
75 |
76 | You have 13 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
77 | Run 'python manage.py migrate' to apply them.
78 | January 09, 2017 - 16:22:02
79 | Django version 1.10.2, using settings 'Django_learn.settings'
80 | Starting development server at http://127.0.0.1:8000/
81 | Quit the server with CTRL-BREAK.
82 | ```
83 |
84 | > 注意:现在忽略有关未应用数据库迁移的警告;下面教程将很快处理数据库
85 |
86 | 这表明你已经启动了Django开发服务器,一个用纯Python写的轻量级Web服务器。 我们在Django中内置了它,这样你就可以在不配置用于生产环境的服务器(例如Apache)的情况下快速开发出产品,直到你准备好上线。
87 |
88 | 请注意:不要在任何生产环境使用这个服务器。它仅仅是用于在开发中使用。(我们的重点是编写Web框架,非Web服务器。)
89 |
90 | 既然服务器已经运行,请用你的浏览器访问 http://127.0.0.1:8000。 在淡蓝色背景下,你将看到一个“Welcome to Django”的页面。 It worked!
91 |
92 |
93 | ### 修改端口号
94 |
95 | 默认情况下,runserver命令在内部IP的8000端口启动开发服务器。
96 |
97 | 如果你需改变服务器的端口,把要使用的端口作为一个命令行参数传递给它。 例如,这个命令在8080端口启动服务器:
98 |
99 | ```
100 | python manage.py runserver 8080
101 | ```
102 |
103 | 如果你需改变服务器的IP地址,把IP地址和端口号放到一起。 因此若要监听所有的外网IP,请使用(如果你想在另外一台电脑上展示你的工作,会非常有用):
104 |
105 | ```
106 | python manage.py runserver 0.0.0.0:8000
107 | ```
108 |
109 | ### runserver的自动重载
110 |
111 | 在Debug模式下,开发服务器会根据需要自动重新载入Python代码。 你不必为了使更改的代码生效而重启服务器。 然而,一些行为比如添加文件,不会触发服务器的重启,所以在这种情况下你需要手动重启服务器。
112 |
113 | ## 创建投票app
114 |
115 | 你编写的每个Django应用都是遵循特定约定且包含一个Python包。 Django自带这个功能,它可以自动生成应用的基本目录结构(就像创建项目那样)
116 |
117 | project和app区别:
118 |
119 | * 一个app实现某个功能,比如博客、公共档案数据库或者简单的投票系统;
120 |
121 | * 一个project是配置文件和多个app的集合,他们组合成整个站点;
122 |
123 | * 一个project可以包含多个app;
124 |
125 | * 一个app可以属于多个project。
126 |
127 | app的存放位置可以是任何地点,但是通常我们将它们都放在与manage.py同级目录下,这样方便导入文件。
128 |
129 | 进入mysite目录,确保与manage.py文件处于同一级,并且键入以下命令来创建你的app:
130 |
131 | ```
132 | python manage.py startapp polls # polls为app的name
133 | ```
134 |
135 | 这将创建一个目录polls,它的结构如下:
136 |
137 | ```
138 | polls/
139 | __init__.py
140 | admin.py
141 | apps.py
142 | migrations/
143 | __init__.py
144 | models.py
145 | tests.py
146 | views.py
147 | ```
148 |
149 | ## 编写视图
150 |
151 | 让我们写第一个视图。打开文件polls/views.py,并输入以下Python代码:
152 | ```python
153 | # polls/views.py
154 | from django.http import HttpResponse
155 |
156 |
157 | def index(request):
158 | return HttpResponse("Hello, world. You're at the polls index.")
159 | ```
160 | 这是Django中最简单的视图。要调用视图,我们需要将它映射到一个URL,为此,我们需要一个URLconf。
161 |
162 | 要在polls目录中创建一个URLconf,在polls文件夹中创建一个名为urls.py的文件。您的应用目录现在应该像这样:
163 | ```
164 | polls/
165 | __init__.py
166 | admin.py
167 | apps.py
168 | migrations/
169 | __init__.py
170 | models.py
171 | tests.py
172 | urls.py
173 | views.py
174 | ```
175 |
176 | 编辑polls/urls.py文件:
177 | ```python
178 | # polls/urls.py
179 | from django.conf.urls import url
180 |
181 | from . import views
182 |
183 | urlpatterns = [
184 | url(r'^$', views.index, name='index'),
185 | ]
186 | ```
187 |
188 | 你可以看到项目根目录下的mysite目录也有个urls.py文件,下一步是让这个项目的主urls.py文件指向我们建立的polls这个app独有的urls.py文件,打开mysite/urls.py文件,你需要先导入include模块,代码如下:
189 | ```python
190 | from django.conf.urls import include, url
191 | from django.contrib import admin
192 |
193 | urlpatterns = [
194 | url(r'^polls/', include('polls.urls')),
195 | url(r'^admin/', admin.site.urls),
196 | ]
197 | ```
198 |
199 | include语法相当于二级路由策略,它将接收到的url地址去除了它前面的正则表达式,将剩下的字符串传递给下一级路由进行判断。
200 |
201 | include的背后是一种即插即用的思想。项目根路由不关心具体app的路由策略,只管往指定的二级路由转发,实现了解耦的特性。app所属的二级路由可以根据自己的需要随意编写,不会和其它的app路由发生冲突。app目录可以放置在任何位置,而不用修改路由。这是软件设计里很常见的一种模式。
202 |
203 | 您现在已将索引视图连接到URLconf。让我们验证它的工作,运行以下命令:
204 |
205 | ```
206 | python manage.py runserver
207 | ```
208 |
209 | 在浏览器中访问http//localhost8000/polls/,你应该看到文本“Hello, world. You're at the polls index.“,就如你在view.py中定义的那样。
210 |
211 | url()函数可以传递4个参数,其中2个是必须的:regex和view,以及2个可选的参数:kwargs和name。下面是具体的解释:
212 |
213 | ### url() 参数:regex
214 |
215 | regex是正则表达式的通用缩写,它是一种匹配字符串或url地址的语法。Django拿着用户请求的url地址,在urls.py文件中对urlpatterns列表中的每一项条目从头开始进行逐一对比,一旦遇到匹配项,立即执行该条目映射的视图函数或二级路由,其后的条目将不再继续匹配。因此,url路由的编写顺序至关重要!
216 |
217 | 需要注意的是,regex不会去匹配GET或POST参数或域名,例如对于https://www.example.com/myapp, regex只尝试匹配myapp/。对于https://www.example.com/myapp/?page=3, regex也只尝试匹配myapp/
218 |
219 | ### url() 参数:view
220 |
221 | 当正则表达式匹配到某个条目时,自动将封装的HttpRequest对象作为第一个参数,正则表达式“捕获”到的值作为第二个参数,传递给该条目指定的视图。如果是简单捕获,那么捕获值将作为一个位置参数进行传递,如果是命名捕获,那么将作为关键字参数进行传递。
222 |
223 | ### url() 参数:kwargs
224 |
225 | 任意数量的关键字参数可以作为一个字典传递给目标视图。
226 |
227 | ### url() argument: name
228 |
229 | 对你的URL进行命名,可以让你能够在Django的任意处,尤其是模板内显式地引用它。相当于给URL取了个全局变量名,你只需要修改这个全局变量的值,在整个Django中引用它的地方也将同样获得改变。这是极为古老、朴素和有用的设计思想,而且这种思想无处不在。
230 |
231 |
232 |
--------------------------------------------------------------------------------
/Django/Django 1.10中文文档-第一个应用Part3-视图和模板.md:
--------------------------------------------------------------------------------
1 | 本教程上接[Django 1.10中文文档-第一个应用Part2-模型和管理站点](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part2-%E6%A8%A1%E5%9E%8B%E5%92%8C%E7%AE%A1%E7%90%86%E7%AB%99%E7%82%B9.md)。我们将继续开发网页投票这个应用,主要讲如何创建一个对用户开放的界面。
2 |
3 | ## 概览
4 |
5 | 视图是Django应用中的一“类”网页,它通常使用一个特定的函数提供服务,并且具有一个特定的模板。例如,在博客应用中,可能有以下视图:
6 |
7 | * 博客首页 —— 显示最新发表的博客;
8 |
9 | * 博客“详细”页面 —— 每博客的链接页面;
10 |
11 | * 基于年份的归档页面 —— 显示特定年内所有月份发表过的博客;
12 |
13 | * 基于月份的归档页面 —— 显示特定月份内每天发表过博客;
14 |
15 | * 基于日期的归档页面 —— 显示特定日期内发表过的所有博客;
16 |
17 | * 评论:处理针对某篇博客发布的评论。
18 |
19 | 在我们的投票应用中,我们将建立下面的四个视图:
20 |
21 | * Question首页 —— 显示最新发布的几个Question;
22 |
23 | * Question“详细”页面 —— 显示单个Question的具体内容,提供一个投票的表单,但不显示该议题的当前投票结果;
24 |
25 | * Question“结果”页面 —— 显示特定的Question的投票结果;
26 |
27 | * 投票功能 —— 处理对Question中Choice的投票。
28 |
29 | 在Django中,网页的页面和其他内容都是由视图(views.py)来传递的(视图对WEB请求进行回应)。每个视图都是由一个Python函数(或者是基于类的视图的方法)表示。Django通过对比请求的URL地址来选择对应的视图。
30 |
31 | 在你平时的网页上,你可能经常会碰到类似“ME2/Sites/dirmod.asp?sid=&type=gen&mod=Core+Pages&gid=A6CD4967199A42D9B65B1B”的url。庆幸的是Django支持使用更加简介的URL模式(patterns),而不需要编写上面那种复杂的url。
32 |
33 | URL模式就是一种URL的通用模式 —— 例如: `/newsarchive///`。
34 |
35 | Django使用‘URLconfs’的配置来为URL匹配视图函数。 URLconf使用正则表达式将URL匹配到视图上。
36 |
37 | 本教程提供URLconfs基本使用,更多信息请参考[django.url](https://docs.djangoproject.com/en/1.10/ref/urlresolvers/#module-django.urls)
38 |
39 | ## 编辑视图
40 |
41 | 下面,让我们打开polls/views.py文件,添加下列代码:
42 | ```python
43 | # polls/views.py
44 | def detail(request, question_id):
45 | return HttpResponse("You're looking at question %s." % question_id)
46 |
47 | def results(request, question_id):
48 | response = "You're looking at the results of question %s."
49 | return HttpResponse(response % question_id)
50 |
51 | def vote(request, question_id):
52 | return HttpResponse("You're voting on question %s." % question_id)
53 | ```
54 | 然后,在polls/urls.py文件中加入下面的url模式,将其映射到我们上面新增的视图。
55 | ```python
56 | # polls/urls.py
57 | from django.conf.urls import url
58 |
59 | from . import views
60 |
61 | urlpatterns = [
62 | # ex: /polls/
63 | url(r'^$', views.index, name='index'),
64 | # ex: /polls/5/
65 | url(r'^(?P[0-9]+)/$', views.detail, name='detail'),
66 | # ex: /polls/5/results/
67 | url(r'^(?P[0-9]+)/results/$', views.results, name='results'),
68 | # ex: /polls/5/vote/
69 | url(r'^(?P[0-9]+)/vote/$', views.vote, name='vote'),
70 | ]
71 | ```
72 |
73 | 现在去浏览器中访问“/polls/34/”它将运行detail()方法,然后在页面中显示你在url里提供的ID。访问“/polls/34/results/”和“/polls/34/vote/”,将分别显示预定义的伪结果和投票页面。
74 |
75 | 上面访问的路由过程如下:当有人访问“/polls/34/”地址时,Django将首先加载mysite.urls模块,因为它是settings文件里设置的ROOT_URLCONF配置文件。在模块里找到urlpatterns变量,按顺序对各项进行正则匹配。当它匹配到了^polls/,就剥离出url中匹配的文本polls/,然后将剩下的文本“34/”,传递给“polls.urls”进行下一步的处理。在polls.urls,又匹配到了`r’^(?P[0-9]+)/$’`,最终结果就是调用该模式对应的detail()视图,将34作为参数传入:
76 | ```
77 | detail(request=, question_id='34')
78 | ```
79 | question_id='34'的部分来自`(?P [0-9])`。使用模式周围的括号“捕获”该模式匹配到的文本,并将其作为参数发送到视图函数;`?P` 定义一个名字用于标识匹配的模式;`[0-9]+`是匹配一串数字的正则表达。
80 |
81 | 因为URL模式是正则表达式,你如何使用它们没有什么限制。 不需要添加像.html这样繁琐的URL —— 除非你执意这么做,在这种情况下你可以这样做:
82 | ```
83 | url(r'^polls/latest\.html$', views.index),
84 | ```
85 | 但是,不要这样做。这比较愚蠢。
86 |
87 | ## 编写拥有实际功能的视图
88 |
89 | 每个视图函数只负责处理两件事中的一件:返回一个包含所请求页面内容的HttpResponse对象,或抛出一个诸如Http404异常。该如何去做这两件事,就看你自己的想法了。
90 |
91 | 您的视图可以从数据库读取记录,也可以不读取。它可以使用模板系统:如Django的或第三方Python模板系统 或不。可以生成PDF文件,输出XML,即时创建ZIP文件,任何你想要的,使用任何你想要的Python库。Django只要求返回的是一个[HttpResponse](https://docs.djangoproject.com/en/1.10/ref/request-response/#django.http.HttpResponse)。 或者抛出一个异常。
92 |
93 | 为了方便,让我们使用[Part1](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part1-%E8%AF%B7%E6%B1%82%E4%B8%8E%E5%93%8D%E5%BA%94.md)中介绍的Django自己的数据库API。 下面是一个新的index()视图,它显示系统中最新发布的5条questions记录,并用逗号分隔:
94 |
95 | ```python
96 | # polls/views.py
97 | from django.http import HttpResponse
98 |
99 | from .models import Question
100 |
101 |
102 | def index(request):
103 | latest_question_list = Question.objects.order_by('-pub_date')[:5]
104 | output = ', '.join([q.question_text for q in latest_question_list])
105 | return HttpResponse(output)
106 |
107 | # 保持其他的视图 (detail, results, vote) 不变
108 | ```
109 |
110 | 这里有一个问题:页面的设计被硬编码在视图中。 如果你想更改页面的外观,就得编辑这段Python代码。 因此,我们使用Django的模板系统,通过创建一个视图能够调用的模板,将页面的设计从Python中分离出来。
111 |
112 | 首先,在你的polls目录下创建一个叫做 templates的目录。Django将在这里查找模板。
113 |
114 | 项目的settings.py中的templates配置决定了Django如何加载渲染模板。将APP_DIRS设置为True。DjangoTemplates将在INSTALLED_APPS所包含的每个应用的目录下查找名为"templates"子目录。
115 |
116 | 在刚刚创建的templates目录中,创建另一个名为polls的目录,并在其中创建一个名为index.html的文件。换句话说,你的模板应该是polls/templates/polls/index.html。由于app_directories模板加载器如上所述工作,因此您可以在Django中简单地引用此模板为polls/index.html(省掉前面的路径)。
117 |
118 | > 模板命名空间: 如果我们把模板直接放在polls/templates中(而不是创建另一个polls子目录),但它实际上是一个坏主意。 Django将选择它找到的名字匹配的第一个模板,如果你在不同的应用程序中有一个相同名称的模板,Django将无法区分它们。我们需要能够将Django指向正确的一个,确保这一点的最简单的方法是通过命名空间。也就是说,将这些模板放在为应用程序本身命名的另一个目录中。
119 |
120 | 将以下的代码放入模板文件:
121 | ```
122 | # polls/templates/polls/index.html
123 |
124 | {% if latest_question_list %}
125 |
130 | {% else %}
131 | No polls are available.
132 | {% endif %}
133 | ```
134 | 现在更新polls/views.py中的index视图来使用模板:
135 | ```python
136 | # polls/views.py
137 |
138 | from django.http import HttpResponse
139 | from django.template import RequestContext, loader
140 |
141 | from .models import Question
142 |
143 |
144 | def index(request):
145 | latest_question_list = Question.objects.order_by('-pub_date')[:5]
146 | template = loader.get_template('polls/index.html')
147 | context = RequestContext(request, {
148 | 'latest_question_list': latest_question_list,
149 | })
150 | return HttpResponse(template.render(context))
151 | ```
152 |
153 | 该代码加载名为polls/index.html的模板,并传给它一个context。Context是一个字典,将模板变量的名字映射到Python对象。
154 |
155 | 然后你可以通过浏览器打开http://127.0.0.1:8000/polls 查看效果。
156 |
157 | ### 快捷方式:render()
158 |
159 | 常见的习惯是载入一个模板、填充一个context 然后返回一个含有模板渲染结果的HttpResponse对象。Django为此提供一个快捷方式。 下面是重写后的index()视图:
160 |
161 | ```python
162 | # polls/views.py
163 |
164 | from django.shortcuts import render
165 |
166 | from .models import Question
167 |
168 |
169 | def index(request):
170 | latest_question_list = Question.objects.order_by('-pub_date')[:5]
171 | context = {'latest_question_list': latest_question_list}
172 | return render(request, 'polls/index.html', context)
173 | ```
174 |
175 | 注意,一旦我们在所有这些视图中完成这个操作,我们不再需要import loader和HttpResponse(如果您仍然有detail, results, and vote方法,您将需要保留HttpResponse)。
176 |
177 | render()函数接受request对象作为其第一个参数,模板名称作为其第二个参数,字典作为其可选的第三个参数。它返回一个HttpResponse对象,含有用给定的context 渲染后的模板。
178 |
179 | ## 404错误
180 |
181 | 现在,让我们处理Question 详细页面的视图 —— 显示Question内容的页面:
182 | ```python
183 | # polls/views.py
184 |
185 | from django.http import Http404
186 | from django.shortcuts import render
187 |
188 | from .models import Question
189 | # ...
190 | def detail(request, question_id):
191 | try:
192 | question = Question.objects.get(pk=question_id)
193 | except Question.DoesNotExist:
194 | raise Http404("Question does not exist")
195 | return render(request, 'polls/detail.html', {'question': question})
196 | ```
197 | 这里的新概念:如果具有所请求的ID的问题不存在,则该视图引发Http404异常。
198 |
199 | 我们将在以后讨论你可以在polls/detail.html模板文件里放些什么代码,但如果你想快点运行上面的例子,仅仅只需要:
200 | ```
201 | # polls/templates/polls/detail.html
202 |
203 | {{ question }}
204 | ```
205 |
206 | ### 快捷方式:get_object_or_404()
207 |
208 | 一种常见的习惯是使用get()并在对象不存在时引发Http404。Django为此提供一个快捷方式。 下面是重写后的detail()视图:
209 | ```python
210 | # polls/views.py
211 |
212 | from django.shortcuts import get_object_or_404, render
213 |
214 | from .models import Question
215 | # ...
216 | def detail(request, question_id):
217 | question = get_object_or_404(Question, pk=question_id)
218 | return render(request, 'polls/detail.html', {'question': question})
219 | ```
220 |
221 | get_object_or_404() 函数将一个Django模型作为它的第一个参数,任意数量的关键字参数作为它的第二个参数,它会将这些关键字参数传递给模型管理器中的get() 函数。如果对象不存在,它就引发一个 Http404异常。
222 |
223 | > 为什么我们要使用一个辅助函数get_object_or_404()而不是在更高层自动捕获ObjectDoesNotExist异常,或者让模型的API 引发 Http404 而不是ObjectDoesNotExist?
224 | 因为那样做将会使模型层与视图层耦合在一起。 Django最重要的一个设计目标就是保持松耦合。 一些可控的耦合将会在django.shortcuts 模块中介绍。
225 |
226 | 还有一个get_list_or_404()函数,它的工作方式类似get_object_or_404() —— 差别在于它使用filter()而不是get()。如果列表为空则引发Http404。
227 |
228 | ## 使用模板系统
229 |
230 | 回到我们投票应用的detail()视图。 根据context 变量question,下面是polls/detail.html模板可能的样子:
231 | ```
232 | # polls/templates/polls/detail.html
233 |
234 | {{ question.question_text }}
235 |
236 | {% for choice in question.choice_set.all %}
237 | - {{ choice.choice_text }}
238 | {% endfor %}
239 |
240 | ```
241 |
242 | 模板系统使用点查找语法访问变量属性。在{{question.question_text}}的示例中,首先Django对对象问题进行字典查找。如果没有,它尝试一个属性查找 - 在这种情况下工作。如果属性查找失败,它将尝试列表索引查找。
243 |
244 | 方法调用发生在{% for %}循环中:question.choice_set.all被解释为Python的代码question.choice_set.all(),它返回一个由Choice对象组成的可迭代对象,并将其用于{% for %}标签。访问[模板指南](https://docs.djangoproject.com/en/1.10/topics/templates/)来了解更多关于模板的信息。
245 |
246 | ### 移除模板中硬编码的URLs
247 |
248 | 我们在polls/index.html模板中编写一个指向Question的链接时,链接中一部分是硬编码的:
249 | ```
250 | {{ question.question_text }}
251 | ```
252 |
253 | 这种硬编码、紧耦合的方法有一个问题,就是如果我们想在拥有许多模板文件的项目中修改URLs,那将会变得非常麻烦。 但是,因为你在polls.urls模块的url()函数中定义了name 参数,所以你可以通过使用{% url %}模板标签来移除对你的URL配置中定义的特定的URL的依赖:
254 | ```
255 | {{ question.question_text }}
256 | ```
257 |
258 | 它的工作原理是在polls.urls模块里查找指定的URL的定义。你可以看到名为‘detail’的URL的准确定义:
259 | ```
260 | ...
261 | # the 'name' value as called by the {% url %} template tag
262 | url(r'^(?P[0-9]+)/$', views.detail, name='detail'),
263 | ...
264 | ```
265 |
266 | 如果你想把polls应用中detail视图的URL改成其它样子比如 polls/specifics/12/,就可以不必在该模板(或者多个模板)中修改它,只需要修改 polls/urls.py:
267 | ```
268 | ...
269 | # added the word 'specifics'
270 | url(r'^specifics/(?P[0-9]+)/$', views.detail, name='detail'),
271 | ...
272 | ```
273 |
274 | ### URL name的命名空间
275 |
276 | 教程中的这个项目只有一个应用polls。在真实的Django项目中,可能会有五个、十个、二十个或者更多的应用。 Django如何区分它们URL的名字呢? 例如,polls 应用具有一个detail 视图,相同项目中的博客应用可能也有这样一个视图。当使用模板标签{% url %}时,人们该如何做才能使得Django知道为一个URL创建哪个应用的视图?
277 |
278 | 答案是在你的主URLconf下添加命名空间。 在mysite/urls.py文件中,添加命名空间将它修改成:
279 | ```python
280 | # mysite/urls.py
281 |
282 | from django.conf.urls import include, url
283 | from django.contrib import admin
284 |
285 | urlpatterns = [
286 | url(r'^polls/', include('polls.urls', namespace="polls")),
287 | url(r'^admin/', include(admin.site.urls)),
288 | ]
289 | ```
290 |
291 | 现在将你的polls/index.html改为具有命名空间的详细视图:
292 | ```
293 | # polls/templates/polls/index.html
294 |
295 | {{ question.question_text }}
296 | ```
297 |
--------------------------------------------------------------------------------
/Django/Django 1.10中文文档-第一个应用Part4-表单和通用视图.md:
--------------------------------------------------------------------------------
1 | >本教程接[Part3](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part3-%E8%A7%86%E5%9B%BE%E5%92%8C%E6%A8%A1%E6%9D%BF.md)开始。继续网页投票应用程序,并将重点介绍简单的表单处理和精简代码。
2 |
3 | ## 一个简单表单
4 |
5 | 更新一下在上一个教程中编写的投票详细页面的模板`polls/detail.html`,让它包含一个`HTML
21 | ```
22 |
23 | 关于上面的代码:
24 |
25 | * 在模板中Question的每个Choice都有一个单选按钮用于选择。每个单选按钮的value属性是对应的各个Choice的ID。每个单选按钮的name是"choice"。这意味着,当有人选择一个单选按钮并提交表单提交时,它将发送一个POST数据choice=#,其中# 为选择的Choice的ID。这是HTML表单的基本概念;
26 |
27 | * action表示你要发送的目的url,method表示提交数据的方式;
28 |
29 | * forloop.counter表示for循环的次数;
30 |
31 | * 由于我们发送了一个POST请求,就必须考虑一个跨站请求伪造的问题,简称CSRF(具体含义请百度)。Django为你提供了一个简单的方法来避免这个困扰,那就是在form表单内添加一条{% csrf_token %}标签,标签名不可更改,固定格式,位置任意,只要是在form表单内。
32 |
33 | 现在,创建一个Django视图来处理提交的数据,在Part3中已经创建了一个URLconf ,包含这一行:
34 |
35 | ```python
36 | # polls/urls.py
37 |
38 | url(r'^(?P[0-9]+)/vote/$', views.vote, name='vote'),
39 | ```
40 |
41 | 修改vote()函数。 将下面的代码添加到polls/views.py:
42 |
43 | ```python
44 | # polls/views.py
45 | from django.shortcuts import get_object_or_404, render
46 | from django.http import HttpResponseRedirect, HttpResponse
47 | from django.urls import reverse
48 |
49 | from .models import Choice, Question
50 | # ...
51 | def vote(request, question_id):
52 | p = get_object_or_404(Question, pk=question_id)
53 | try:
54 | selected_choice = p.choice_set.get(pk=request.POST['choice'])
55 | except (KeyError, Choice.DoesNotExist):
56 | # 出现异常重新显示投票表单
57 | return render(request, 'polls/detail.html', {
58 | 'question': p,
59 | 'error_message': "You didn't select a choice.",
60 | })
61 | else:
62 | selected_choice.votes += 1
63 | selected_choice.save()
64 | # 成功处理数据后,自动跳转到结果页面,防止用户连续多次提交。
65 | return HttpResponseRedirect(reverse('polls:results', args=(p.id,)))
66 | ```
67 |
68 | 上面代码里有些东西需要解释:
69 |
70 | * request.POST是一个类似字典的对象,允许你通过键名访问提交的数据。代码中`request.POST['choice']`返回被选择Choice的ID,并且值的类型永远是string字符串;
71 |
72 | * 如果在POST数据中没有提供choice,`request.POST['choice']`将引发一个KeyError。上面的`try ... except`就是用来检查KeyError,如果没有给出choice将重新显示Question表单和错误信息;
73 |
74 | * 在将Choice得票数加1之后,返回一个HttpResponseRedirect而不是常用的HttpResponse。HttpResponseRedirect只接收一个参数:用户将要被重定向的URL;
75 |
76 | * 在这个例子中,HttpResponseRedirect的构造函数中使用reverse()函数。这个函数可以避免在视图函数中硬编码URL。它需要我们给出想要跳转的视图的名字和该视图所对应的URL模式中需要给该视图提供的参数。 在本例中,使用在Part3中设定的URLconf,reverse()调用将返回一个这样的字符串:`'/polls/3/results/'`。
77 |
78 | 当对Question进行投票后,vote()视图将请求重定向到Question的结果界面。下面来编写这个视图:
79 |
80 | ```python
81 | #polls/views.py
82 |
83 | from django.shortcuts import get_object_or_404, render
84 |
85 |
86 | def results(request, question_id):
87 | question = get_object_or_404(Question, pk=question_id)
88 | return render(request, 'polls/results.html', {'question': question})
89 | ```
90 |
91 | 这和detail()视图几乎一模一样。唯一的不同是模板的名字。稍后再来优化这个问题。下面创建一个polls/results.html模板:
92 |
93 | ```html
94 | # polls/templates/polls/results.html
95 |
96 | {{ question.question_text }}
97 |
98 |
99 | {% for choice in question.choice_set.all %}
100 | - {{ choice.choice_text }} -- {{ choice.votes }} vote{{ choice.votes|pluralize }}
101 | {% endfor %}
102 |
103 |
104 | Vote again?
105 | ```
106 |
107 | 现在,在浏览器中访问/polls/1/然后为Question投票。应该看到一个投票结果页面,并且在每次投票后都会更新。 如果提交时没有选择任何Choice,应该会看到错误信息。
108 |
109 | >注: views()视图的代码确实有一个小问题。它首先从数据库中获取selected_choice对象,计算新的投票数值然后将其保写回数据库。如果您的网站的两位用户尝试在完全相同的时间投票,这可能会出错。这被称为竞争条件。如果您有兴趣,可以阅读[使用F()避免竞争条件](https://docs.djangoproject.com/en/1.10/ref/models/expressions/#avoiding-race-conditions-using-f),以了解如何解决此问题;
110 |
111 | ## 使用通用视图:减少代码冗余
112 |
113 | 上面的detail、index和results视图的代码非常相似,有点冗余,这是一个程序猿不能忍受的。他们都具有类似的业务逻辑,实现类似的功能:通过从URL传递过来的参数去数据库查询数据,加载一个模板,利用刚才的数据渲染模板,返回这个模板。由于这个过程是如此的常见,Django又很善解人意的帮你想办法偷懒了,它提供了一种快捷方式,名为`generic views`系统。
114 |
115 | Generic views会将常见的模式抽象化,可以使你在编写app时甚至不需要编写Python代码。
116 |
117 | 下面将投票应用转换成使用通用视图系统,这样可以删除许多冗余的代码。仅仅需要做以下几步来完成转换:
118 |
119 | * 修改URLconf;
120 |
121 | * 删除一些旧的无用的视图;
122 |
123 | * 采用基于通用视图的新视图。
124 |
125 | ## 改进URLconf
126 |
127 | ```python
128 | # polls/urls.py
129 |
130 | from django.conf.urls import url
131 |
132 | from . import views
133 |
134 | app_name = 'polls'
135 | urlpatterns = [
136 | url(r'^$', views.IndexView.as_view(), name='index'),
137 | url(r'^(?P[0-9]+)/$', views.DetailView.as_view(), name='detail'),
138 | url(r'^(?P[0-9]+)/results/$', views.ResultsView.as_view(), name='results'),
139 | url(r'^(?P[0-9]+)/vote/$', views.vote, name='vote'),
140 | ]
141 |
142 | ```
143 |
144 | 注意在第二个和第三个模式的正则表达式中,匹配的模式的名字由`` 变成 ``
145 |
146 | ## 改进视图
147 |
148 | 下面将删除旧的index、detail和 results 视图,并用Django的通用视图代替:
149 |
150 | ```python
151 | # polls/views.py
152 |
153 | from django.shortcuts import get_object_or_404, render
154 | from django.http import HttpResponseRedirect
155 | from django.urls import reverse
156 | from django.views import generic
157 |
158 | from .models import Choice, Question
159 |
160 |
161 | class IndexView(generic.ListView):
162 | template_name = 'polls/index.html'
163 | context_object_name = 'latest_question_list'
164 |
165 | def get_queryset(self):
166 | """Return the last five published questions."""
167 | return Question.objects.order_by('-pub_date')[:5]
168 |
169 |
170 | class DetailView(generic.DetailView):
171 | model = Question
172 | template_name = 'polls/detail.html'
173 |
174 |
175 | class ResultsView(generic.DetailView):
176 | model = Question
177 | template_name = 'polls/results.html'
178 |
179 |
180 | def vote(request, question_id):
181 | ... # same as above, no changes needed.
182 | ```
183 |
184 | 这里使用两个通用视图:[ListView](https://docs.djangoproject.com/en/1.10/ref/class-based-views/generic-display/#django.views.generic.list.ListView)和[DetailView](https://docs.djangoproject.com/en/1.10/ref/class-based-views/generic-display/#django.views.generic.list.ListView)。这两个视图分别代表“显示对象列表”和“显示特定类型对象的详细信息页面”的抽象概念。
185 |
186 | * 每个通用视图需要知道它将作用于哪个模型。 这由model 属性提供;
187 |
188 | * DetailView都是从URL中捕获名为"pk"的主键值,因此才需要把polls/urls.py中question_id改成了pk以使通用视图可以找到主键值。
189 |
190 | 默认情况下,DetailView泛型视图使用一个称作`/_detail.html`的模板。在本例中,实际使用的是`polls/question_detail.html`。template_name属性就是用来指定这个模板名的,用于代替自动生成的默认模板名。
191 |
192 | 在教程的前面部分,我们给模板提供了一个包含question和latest_question_list的上下文变量。而对于DetailView,question变量会被自动提供,因为我们使用了Django的模型(Question),Django会智能的选择合适的上下文变量。然而,对于ListView,自动生成的上下文变量是question_list。为了覆盖它,我们提供了context_object_name属性,指定说我们希望使用latest_question_list而不是question_list。
193 |
194 | 现在你可以运行开发服务器,然后试试基于泛型视图的应用程序了。
195 |
196 | 更多关于通用视图的详细信息,请查看[通用视图文档](https://docs.djangoproject.com/en/1.10/topics/class-based-views/)。
--------------------------------------------------------------------------------
/Django/Django 1.10中文文档-第一个应用Part6-静态文件.md:
--------------------------------------------------------------------------------
1 |
2 | 本教程上接[Part5](https://github.com/jhao104/django-chinese-docs-1.10/blob/master/intro/tutorial05/%E7%AC%AC%E4%B8%80%E4%B8%AADjango%E5%BA%94%E7%94%A8%2CPart5.md)。前面已经建立一个网页投票应用并且测试通过,现在主要讲述如何添加样式表和图片。
3 |
4 | 除由服务器生成的HTML文件外,网页应用一般还需要提供其它必要的文件——比如图片、JavaScript脚本和CSS样式表。这样才能为用户呈现出一个完整的网站。 在Django中,这些文件统称为“静态文件”。
5 |
6 | 如果是在小型项目中,这只是个小问题,因为你可以将它们放在网页服务器可以访问到的地方。 但是呢,在大一点的项目中——尤其是由多个应用组成的项目,处理每个应用提供的多个静态文件集合还是比较麻烦的。
7 |
8 | 但是Django提供了`django.contrib.staticfiles`:它收集每个应用(和任何你指定的地方)的静态文件到一个单独的位置,使得这些文件很容易维护。
9 |
10 | ## 自定义应用外观
11 |
12 | 首先在`polls`路径中创建一个`static`目录。Django会从这里搜索静态文件,这个和Django在`polls/templates/`中查找对应的模板文件的方式是一样的。
13 |
14 | Django有一个[STATICFILES_FINDERS](https://docs.djangoproject.com/en/1.10/ref/settings/#std:setting-STATICFILES_FINDERS)的查找器,它会告诉Django从哪里查找静态文件。 其中有个内建的查找器`AppDirectoriesFinder`,它的作用是在每个`INSTALLED_APPS`下查找“static”子目录下的静态文件。管理站点的静态文件也是使用相同的目录结构。
15 |
16 | 在你刚刚创建的static目录中,再创建一个polls目录并在它下面创建一个文件style.css。这样你的style.css样式表应该在polls/static/polls/style.css。因为根据`AppDirectoriesFinder`静态文件查找器的工作方式,Django会在polls/static找到polls/style.css这个静态文件,和访问模板的路径类似。
17 |
18 | >静态文件命名空间: 和模板类似,其实我们也可以直接将静态文件直接放在polls/static下面(而不是再创建一个polls子目录),但是这样是一个不好的行为。Django会自动使用它所找到的第一个符合要求的静态文件的文件名,如果你有在两个不同应用中存在两个同名的静态文件,那么Django是无法区分它们的。所以我们需要告诉Django该使用其中的哪一个,最简单的方法就是为它们添加命名空间。也就是将这些静态文件放进以它们所在的应用的名字命名的子目录下。
19 |
20 | 样式表中写入这些内容(polls/static/polls/style.css):
21 | ```css
22 | /*polls/static/polls/style.css*/
23 |
24 | li a {
25 | color: green;
26 | }
27 | ```
28 |
29 | 然后在`polls/templates/polls/index.html`中添加如下内容:
30 |
31 | ```html
32 | {% load static %}
33 |
34 |
35 | ```
36 |
37 | `{%static%}`模板标签用户生成静态文件的绝对URL。以上你在开发过程中所需要对静态文件做的所有处理。 浏览器中重新载入http://localhost:8000/polls/,你应该会看到Question的超链接变成了绿色(Django的风格),这也表明你的样式表成功引入了。
38 |
39 | ## 添加背景图片
40 |
41 | 下一步,我们将创建一个子目录来存放图片。在`polls/static/polls/`目录中创建一个`images`子目录。在这个目录中,放入一张图片background.gif。换句话,将你的图片放在polls/static/polls/images/background.gif。然后,在样式表中添加(polls/static/polls/style.css):
42 |
43 | ```css
44 | body {
45 | background: white url("images/background.gif") no-repeat right bottom;
46 | }
47 | ```
48 |
49 | 重新加载http://localhost:8000/polls/,你应该在屏幕的右下方看到载入的背景图片。
50 |
51 | > 警告:{% static %} 模板标签在不是由 Django 生成的静态文件(比如样式表)中是不可用的。在以后开发过程中应该使用相对路径来相互链接静态文件,因为这样你可以只改变STATIC_URL( static模板标签用它来生成URLs)而不用同时修改一大堆静态文件的路径。
52 |
53 | 这一上仅仅是基础。有关框架中包含的设置和其他更多详细信息,参见[静态文件howto](https://docs.djangoproject.com/en/1.10/howto/static-files/) 和[静态文件参考](https://docs.djangoproject.com/en/1.10/ref/contrib/staticfiles/)。[部署静态文件](https://docs.djangoproject.com/en/1.10/howto/static-files/deployment/)讲述如何在真实的服务器上使用静态文件。
54 |
55 | 当您对静态文件掌握的差不多了时,请阅读本教程的[第7部分](https://docs.djangoproject.com/en/1.10/intro/tutorial07/),了解如何自定义Django自动生成的管理站点。
56 |
57 | ## 快速通道
58 |
59 | * [Django 1.10中文文档-第一个应用Part1-请求与响应](https://my.oschina.net/jhao104/blog/821775)
60 | * [Django 1.10中文文档-第一个应用Part2-模型和管理站点](https://my.oschina.net/jhao104/blog/823947)
61 | * [Django 1.10中文文档-第一个应用Part3-视图和模板](https://my.oschina.net/jhao104/blog/827344)
62 | * [Django 1.10中文文档-第一个应用Part4-表单和通用视图](https://my.oschina.net/jhao104/blog/871727)
63 | * [Django 1.10中文文档-第一个应用Part5-测试](https://my.oschina.net/jhao104/blog/887023)
--------------------------------------------------------------------------------
/Django/Django 1.10中文文档-第一个应用Part7-自定义管理站点.md:
--------------------------------------------------------------------------------
1 | # 开发第一个Django应用,Part7
2 |
3 | 本教程上接[Part6](https://github.com/jhao104/django-chinese-docs-1.10/blob/master/intro/tutorial06/%E7%AC%AC%E4%B8%80%E4%B8%AADjango%E5%BA%94%E7%94%A8%2CPart6.md)。将继续完成这个投票应用,本节将着重讲解如果用Django自动生成后台管理网站。
4 |
5 | ## 自定义管理表单
6 |
7 | 通过`admin.site.register(Question)`注册了`Question`后,Django可以自动构建一个默认的表单。如果您需要自定义管理表单的外观和功能。你可以在注册时通过配置来实现。
8 |
9 | 现在先来试试重新排序表单上的字段。只需要将`admin.site.register(Question)`所在行替换为:
10 | ```python
11 | # polls/admin.py
12 |
13 | from django.contrib import admin
14 |
15 | from .models import Question
16 |
17 |
18 | class QuestionAdmin(admin.ModelAdmin):
19 | fields = ['pub_date', 'question_text']
20 |
21 | admin.site.register(Question, QuestionAdmin)
22 | ```
23 |
24 | 你可以参照上面的形式,创建一个模型类,将之作为第二个参数传入`admin.site.register()`。而且这种操作在任何时候都可以进行。
25 |
26 | 经过上面修改"Publication date"字段会在"Question"字段前面:
27 |
28 | 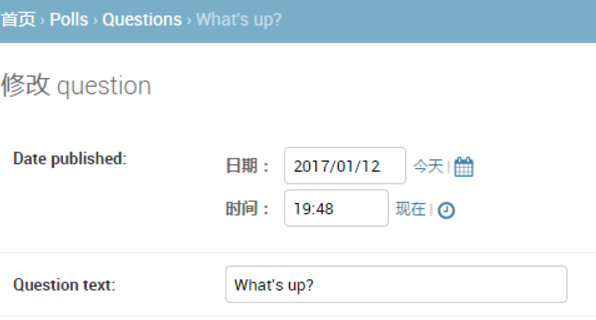
29 |
30 | 目前的表单只有两个字段可能看不出什么,但是对于一个字段很多的表单,设计一个直观合理的排序方式非常重要。并且在字段数据很多时,还可以将表单分割成多个字段的集合:
31 | ```python
32 | # polls/admin.py
33 | from django.contrib import admin
34 |
35 | from .models import Question
36 |
37 |
38 | class QuestionAdmin(admin.ModelAdmin):
39 | fieldsets = [
40 | (None, {'fields': ['question_text']}),
41 | ('Date information', {'fields': ['pub_date']}),
42 | ]
43 |
44 | admin.site.register(Question, QuestionAdmin)
45 | ```
46 |
47 | 字段集合中每一个元组的第一个元素是该字段集合的标题。它让页面看起来像下面的样子:
48 |
49 | 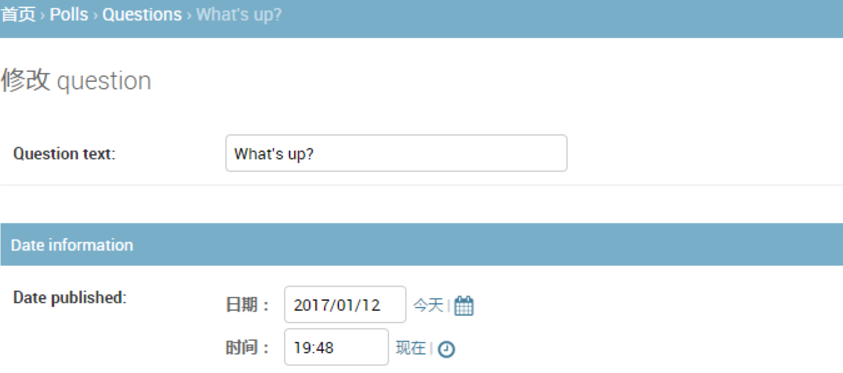
50 |
51 | ## 添加关联对象
52 |
53 | 现在Question的管理页面有了,但是一个Question应该有多个Choices。而此时管理页面并没有显示。现在有两个方法可以解决这个问题。一是就像刚刚Question一样也将Choice注册到admin界面。代码像这样:
54 | ```python
55 | # polls/admin.py
56 |
57 | from django.contrib import admin
58 |
59 | from .models import Choice, Question
60 | # ...
61 | admin.site.register(Choice)
62 | ```
63 |
64 | 现在Choice也可以在admin页面看见了,其中"Add choice"表单应该类似这样:
65 |
66 | 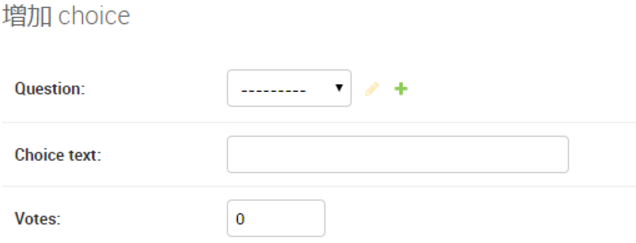
67 |
68 | 在这个表单中,Question字段是一个select选择框,包含了当前数据库中所有的Question实例。Django在admin站点中,自动地将所有的[外键](https://docs.djangoproject.com/en/1.11/ref/models/fields/#django.db.models.ForeignKey)关系展示为一个select框。在我们的例子中,目前只有一个question对象存在。
69 |
70 | 请注意图中的绿色加号,它连接到Question模型。每一个包含外键关系的对象都会有这个绿色加号。点击它,会弹出一个新增Question的表单,类似Question自己的添加表单。填入相关信息点击保存后,Django自动将该Question保存在数据库,并作为当前Choice的关联外键对象。通俗讲就是,新建一个Question并作为当前Choice的外键。
71 |
72 | 但是,实话说,这种创建方式的效率不怎么样。如果在创建Question对象的时候就可以直接添加一些Choice,那样操作将会变得简单些。
73 |
74 | 删除Choice模型对register()方法的调用。然后,编辑Question的注册代码如下:
75 | ```python
76 | # polls/admin.py
77 |
78 | from django.contrib import admin
79 |
80 | from .models import Choice, Question
81 |
82 |
83 | class ChoiceInline(admin.StackedInline):
84 | model = Choice
85 | extra = 3
86 |
87 |
88 | class QuestionAdmin(admin.ModelAdmin):
89 | fieldsets = [
90 | (None, {'fields': ['question_text']}),
91 | ('Date information', {'fields': ['pub_date'], 'classes': ['collapse']}),
92 | ]
93 | inlines = [ChoiceInline]
94 |
95 | admin.site.register(Question, QuestionAdmin)
96 | ```
97 |
98 | 上面的代码告诉Django:Choice对象将在Question管理页面进行编辑,默认情况,请提供3个Choice对象的编辑区域。
99 |
100 | 现在"增加question"页面变成了这样:
101 |
102 | 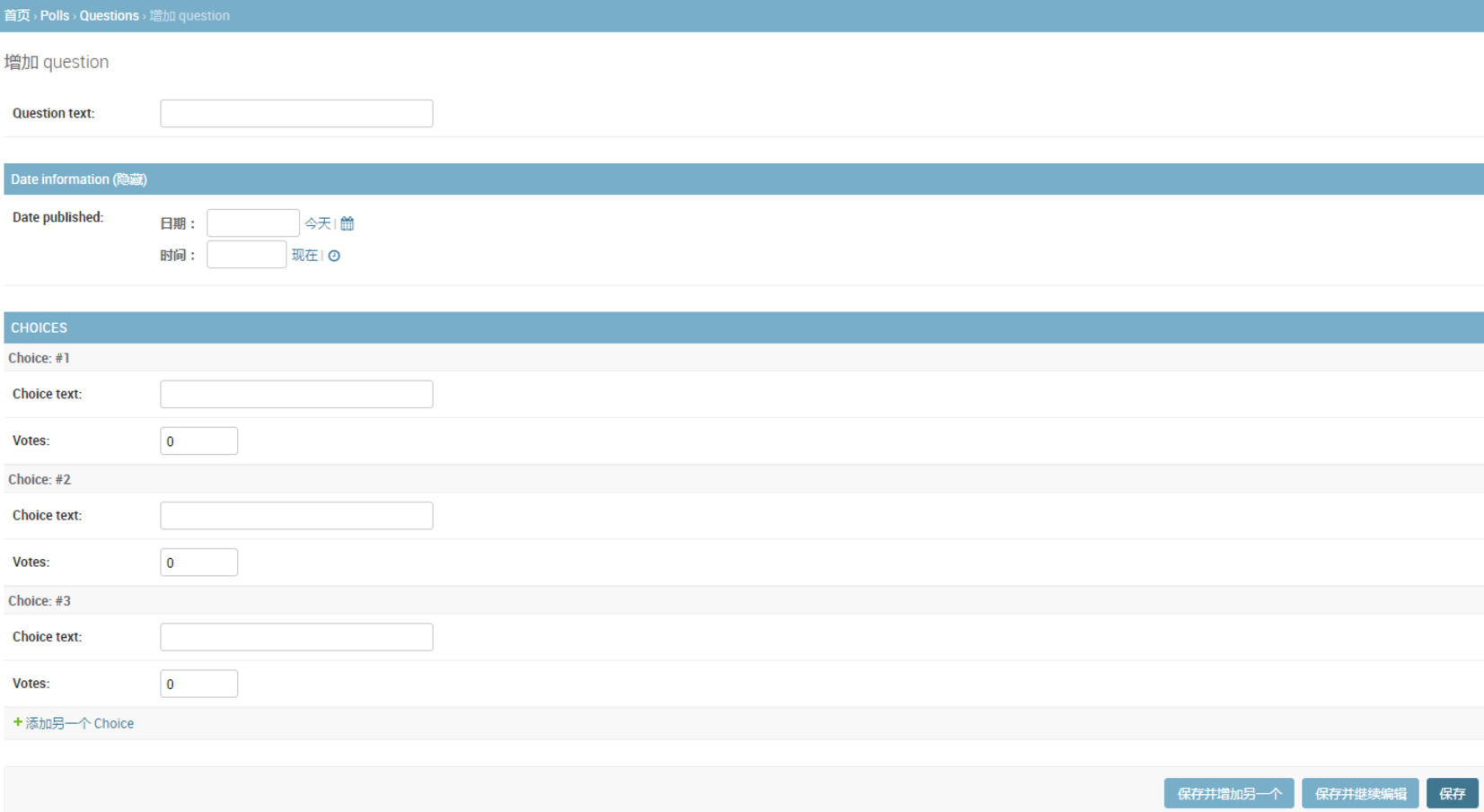
103 |
104 | 它的工作机制是:这里有3个插槽用于关联Choices,而且每当你重新返回一个已经存在的对象的“Change”页面,你又将获得3个新的额外的插槽可用。
105 |
106 | 在3个插槽的最后,还有一个“Add another Choice”链接。点击它,又可以获得一个新的插槽。如果你想删除新增的插槽,点击它右上方的X图标即可。但是,默认的三个插槽不可删除。下面是新增插槽的样子:
107 |
108 | 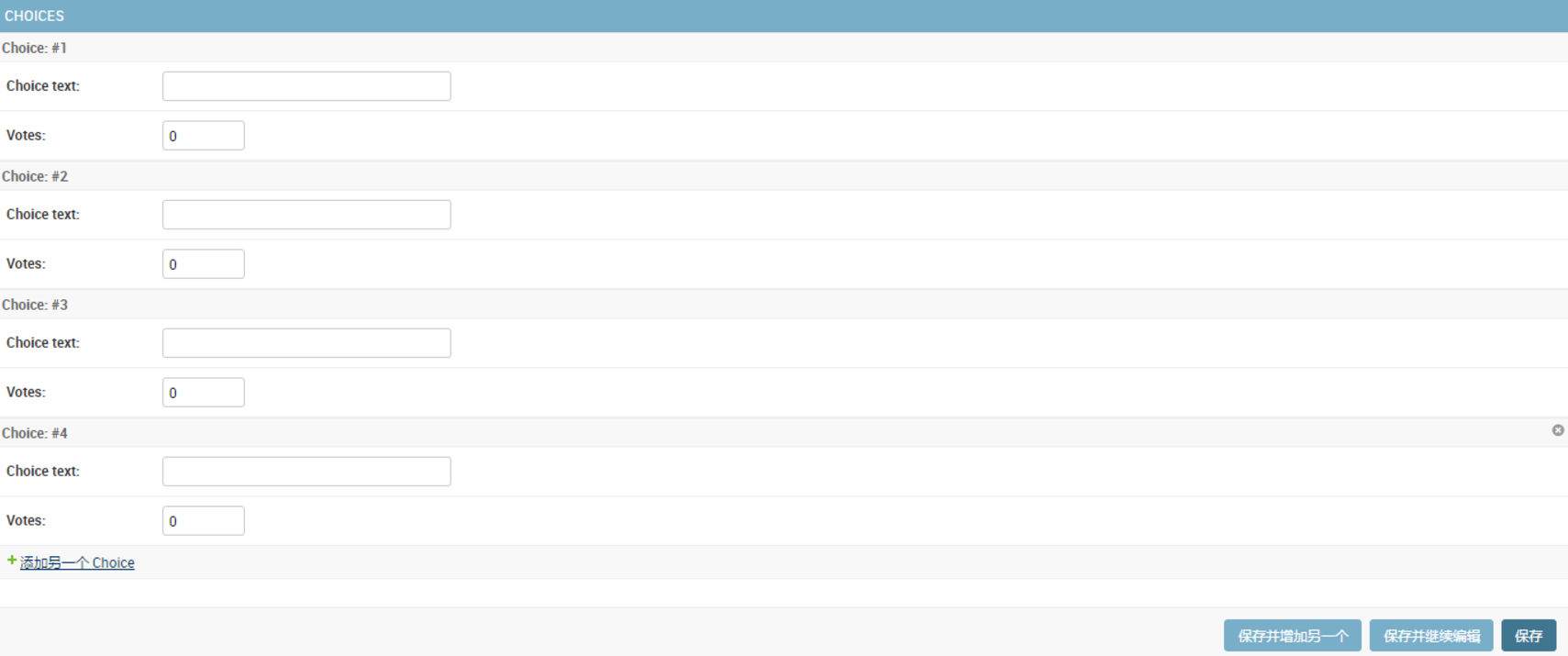
109 |
110 | 但是现在还有个小问题。上面页面中插槽纵队排列的方式需要占据大块的页面空间,看起来很不方便。为此,Django提供了一种扁平化的显示方式,你仅仅只需要将ChoiceInline继承的类改为admin.TabularInline:
111 | ```python
112 | # polls/admin.py
113 |
114 | class ChoiceInline(admin.TabularInline):
115 | #...
116 | ```
117 | 使用`TabularInline`代替`StackedInline``,相关的对象将以一种更紧凑的表格形式显示出来:
118 | 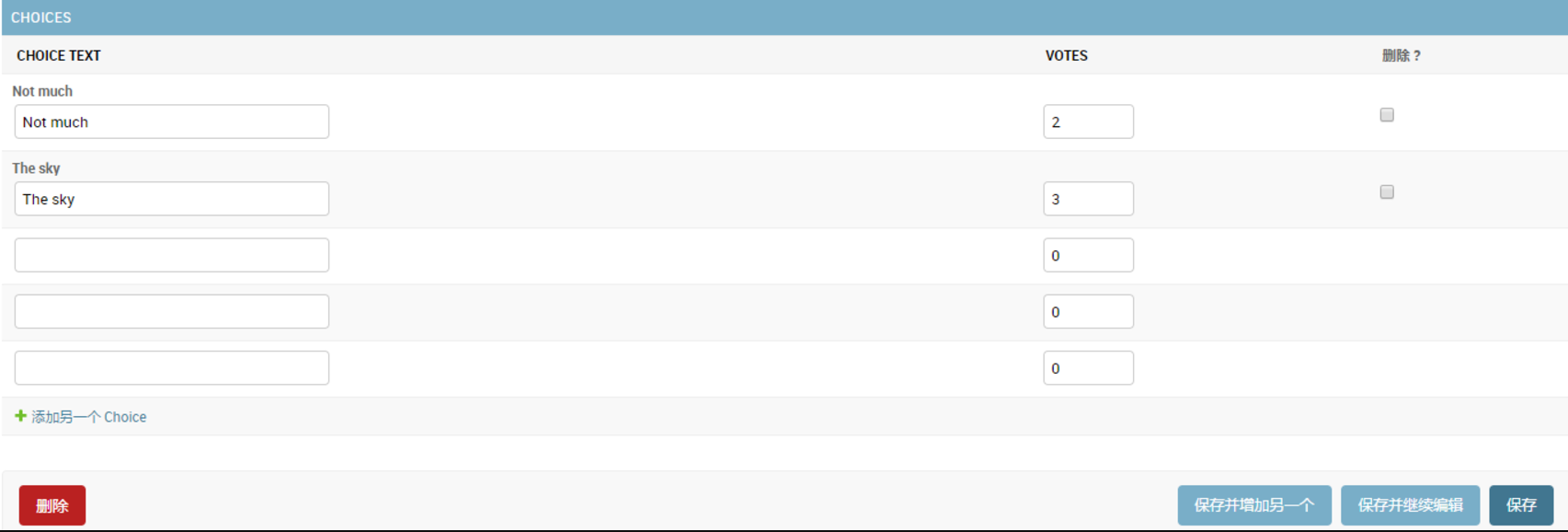
119 |
120 | 注意,这样多了一个"删除"选项,它允许你删除已经存在的Choice.
121 |
122 | ## 自定义修改列表
123 |
124 | 现在Question的管理页面看起来已经差不多了,下面来看看修改列表页面,也就是显示了所有question的页面,即下图这个页面:
125 | 
126 |
127 | Django默认只显示`str()`方法指定的内容。如果我们想要同时显示一些别的内容,可以使用list_display属性,它是一个由多个字段组成的元组,其中的每一个字段都会按顺序显示在页面上,代码如下:
128 |
129 | ```python
130 | # polls/admin.py
131 |
132 | class QuestionAdmin(admin.ModelAdmin):
133 | # ...
134 | list_display = ('question_text', 'pub_date')
135 | ```
136 | 同时,还可以把[Part2](https://github.com/jhao104/django-chinese-docs-1.10/blob/master/intro/tutorial02/%E5%BC%80%E5%8F%91%E7%AC%AC%E4%B8%80%E4%B8%AADjango%E5%BA%94%E7%94%A8%2CPart2.md)中的`was_published_recently()`方法也加入进来:
137 | ```python
138 | # polls/admin.py
139 |
140 | class QuestionAdmin(admin.ModelAdmin):
141 | # ...
142 | list_display = ('question_text', 'pub_date', 'was_published_recently')
143 | ```
144 |
145 | 现在question的修改列表页面看起来像这样:
146 | 
147 |
148 | 你可以点击其中一列的表头来让列表按照这列的值来进行排序,但是`was_published_recently`这列的表头不行,因为Django不支持按照随便一个方法的输出进行排序。另请注意,默认情况下,`was_published_recently`的列标题是方法的名称(下划线替换为空格),内容则是输出的字符串表示形式。
149 |
150 | 可以通过给方法提供一些属性来改进输出的样式,就如下面所示:
151 | ```python
152 | # polls/models.py
153 |
154 | class Question(models.Model):
155 | # ...
156 | def was_published_recently(self):
157 | now = timezone.now()
158 | return now - datetime.timedelta(days=1) <= self.pub_date <= now
159 | was_published_recently.admin_order_field = 'pub_date'
160 | was_published_recently.boolean = True
161 | was_published_recently.short_description = 'Published recently?'
162 | ```
163 | 关于这些方法属性的更多信息,请参见[list_display](https://docs.djangoproject.com/en/1.10/ref/contrib/admin/#django.contrib.admin.ModelAdmin.list_display)。
164 |
165 | 我们还可以对显示结果进行过滤,通过使用`list_filter`属性。在`QuestionAdmin`中添加下面的代码:
166 | ```python
167 | list_filter = ['pub_date']
168 | ```
169 |
170 | 它添加了一个“过滤器”侧边栏,这样就可以通过pubdate字段来过滤显示question:
171 | 
172 |
173 | 过滤器显示的筛选类型取决与你过滤的字段,由于`pub_data`是` DateTimeField`,所以Django就自动给出了“今天”、“过去7天”、“本月”、“今年”这几个选项。
174 |
175 | 这一切进展顺利。再添加一些搜索功能:
176 | ```python
177 | search_fields = ['question_text']
178 | ```
179 |
180 | 这行代码在修改列表的顶部添加了一个搜索框。 当进行搜索时,Django将在question_text字段中进行搜索。 你在search_fields中使用任意数量的字段,但由于它在后台使用LIKE进行查询,尽量不要添加太多的字段,不然会降低数据库查询能力。
181 |
182 | 修改列表自带分页功能,默认每页展示100条数据。
183 |
184 | ## 自定义管理站点外观
185 |
186 | 很明显,在每一个admin页面坐上顶端都显示“Django 管理”是感觉很荒诞,它仅仅是个占位文本。利用Django的模板系统,可以易修改它。
187 |
188 | 它可以用Django的模板系统轻松改变。 Django的管理站点是用Django自己制作出来的,它的界面代码使用的是Django自己的模板系统。
189 |
190 | ### 自定义项目模板
191 |
192 | 在项目的路劲下(包含manage.py的目录)创建一个名为`templates`目录。Templates可以放在你的文件系统中Django所能访问到的任何地方。(运行Web服务器的用户即是运行Django的用户)。然而,但是作为一个好的习惯,最好把模板放在本项目目录下。
193 |
194 | 在配置文件中(`mysite/settings.py`)在`TEMPLATES`中添加一个`DIRS`选项:
195 | ```python
196 | # mysite/settings.py
197 |
198 | TEMPLATES = [
199 | {
200 | 'BACKEND': 'django.template.backends.django.DjangoTemplates',
201 | 'DIRS': [os.path.join(BASE_DIR, 'templates')],
202 | 'APP_DIRS': True,
203 | 'OPTIONS': {
204 | 'context_processors': [
205 | 'django.template.context_processors.debug',
206 | 'django.template.context_processors.request',
207 | 'django.contrib.auth.context_processors.auth',
208 | 'django.contrib.messages.context_processors.messages',
209 | ],
210 | },
211 | },
212 | ]
213 | ```
214 |
215 | `DIRS`是在加载Django模板时检查的文件系统目录列表;它是一个搜索路径。
216 |
217 | > 模板组织方式:就像静态文件一样,我们可以把所有的模板都放在一起,形成一个大大的模板文件夹,并且工作正常。但是不建议这样!最好每一个模板都应该存放在它所属应用的模板目录内(例如polls/templates)而不是整个项目的模板目录(templates),因为这样每个应用才可以被方便和正确的重用。请参考[如何重用apps](> 模板组织方式:就像静态文件一样,我们可以把所有的模板都放在一起,形成一个大大的模板文件夹,并且工作正常。但是不建议这样!最好每一个模板都应该存放在它所属应用的模板目录内(例如polls/templates)而不是整个项目的模板目录(templates),因为这样每个应用才可以被方便和正确的重用。请参考[如何重用apps (0%)](https://docs.djangoproject.com/en/1.10/intro/reusable-apps/)。
218 |
219 | 接下来,在刚才创建的`templates`中创建一个`admin`目录,将`admin/base_site.html`模板文件拷贝到该目录内。这个html文件来自Django源码,它位于`django/contrib/admin/templates`目录内。
220 |
221 | > 如何找到Django源文件: 在命令行中运行下面代码: `python -c "import django; print(django.__path__)"`
222 |
223 | 然后替换文件中的`{{ site_header|default:_('Django administration') }}`(包括两个大括号),换成你想要命名的名字即可。编辑完成后应该类似下面的代码片段:
224 |
225 | ```python
226 | {% block branding %}
227 |
228 | {% endblock %}
229 | ```
230 |
231 | 这里仅仅是使用这种方法来教您如何覆盖模板。在实际的项目中,您可以使用[django.contrib.admin.AdminSite。siteheader](https://docs.djangoproject.com/en/1.10/ref/contrib/admin/#django.contrib.admin.AdminSite.site_header)属性更容易实现这个特殊的定制。
232 |
233 | 在这个模板文件中有许多类似这样的文本`{% block branding %}`、`{{ title }}`。`{%`和`{{`都是Django模板语法的一部分。当Django渲染`admin/base_site.html`的时候,这个模板语言将被生成最终的html页面,就像[Part3](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part3-%E8%A7%86%E5%9B%BE%E5%92%8C%E6%A8%A1%E6%9D%BF.md)中一样。
234 |
235 | 注意任何Django管理站点的默认模板都可以重写。 想要重写一个模板文件,只需要做和重写`base_site.html`相同的操作就行——将它从默认的目录拷贝到你自定义的目录中,然后修改它。
236 |
237 | ### 自定义应用模板
238 |
239 | 聪明的读者可能会问:但是`DIRS`默认是空的,Django是如何找到默认的admin模板呢?回答是,由于`APP_DIRS`被设置为`True``,Django将自动查找每一个应用路径下的templates/子目录(不要忘了django.contrib.admin也是一个应用)。
240 |
241 | 我们的投票应用不太复杂,因此不需要自定义admin模板。但是如果它变得越来越复杂,因为某些功能而需要修改Django的标准admin模板,那么修改的模板就比修改项目的模板更加明智。这样的话,你可以将投票应用加入到任何新的项目中,并且保证能够找到它所需要的自定义模板。更多关于Django如何加载模板文件的信息,请查看[模板加载 (0%)](https://docs.djangoproject.com/en/1.10/topics/templates/#template-loading)的文档。
242 |
243 | ### 自定义管理站点首页
244 |
245 | 在类似的情况下,您可能想要定制Django管理首页页面。默认情况下,管理站点首页显示所有`INSTALLED_APPS`内并在admin应用中注册过的app,以字母顺序进行排序。
246 |
247 | 要定制管理站点首页,需要重写`admin/index.html`模板,就像前面修改`base_site.html`模板的方法一样,从源码目录拷贝到你指定的目录内。编辑该文件,你会看到文件内使用了一个`app_list`模板变量。该变量包含了所有已经安装的Django应用。你可以硬编码链接到指定对象的admin页面,使用任何你认为好的方法,用于替代这个`app_list`。
248 |
249 |
--------------------------------------------------------------------------------
/Django/Django中六个常用的自定义装饰器.md:
--------------------------------------------------------------------------------
1 | ## 装饰器作用
2 |
3 | [decorator](https://docs.djangoproject.com/en/2.0/topics/http/decorators/)是当今最流行的设计模式之一,很多使用它的人并不知道它是一种设计模式。这种模式有什么特别之处? 有兴趣可以看看[Python Wiki](https://wiki.python.org/moin/DecoratorPattern)上例子,使用它可以很方便地修改对象行为,通过使用类似例中的接口将修改动作封装在装饰对象中。
4 |
5 | **decorator** 可以动态地修改函数、方法或类的功能,而无需创建子类或修改类的源代码。正因为如此,装饰器可以让代码将变得**更干净**、**更可读**、**更可维护**(这很重要!),并且减少了许多冗余但又不得不写的代码,使我们可以使用单个方法向多个类添加功能。
6 |
7 | 对于装饰器的重用性和易用性,Django里面的[@login_required](https://docs.djangoproject.com/en/2.0/topics/auth/default/#the-login-required-decorator)就是一个很好的例子。使用它只用一句代码就可以检查用户是否通过身份验证,并将未登录用户重定向到登录url。
8 |
9 | 该装饰器的使用方法如下:
10 | ```python
11 | from django.contrib.auth.decorators import login_required
12 |
13 | @login_required(login_url='/accounts/login/')
14 | def my_view(request):
15 | ...
16 | ```
17 |
18 | 每次用户试图访问 `my_view` 时,都会进入 `login_required` 中的代码。
19 |
20 | ## Django装饰器
21 |
22 | 下面介绍一些个人认为比较有用的,或者是之前使用过的具有积极效果的装饰器。事先声明,如要实现同样的业务场景,并不是只有本文中的方法。Django可以实现各种各样的装饰器,这完全根据您的需要进行定制。
23 |
24 | ### Group Required
25 |
26 | 有时需要保护一些视图,只允许某些用户组访问。这时就可以使用下面的装饰器来检查用户是否属于该用户组。
27 | ```python
28 | from django.contrib.auth.decorators import user_passes_test
29 |
30 |
31 | def group_required(*group_names):
32 | """Requires user membership in at least one of the groups passed in."""
33 |
34 | def in_groups(u):
35 | if u.is_authenticated():
36 | if bool(u.groups.filter(name__in=group_names)) | u.is_superuser:
37 | return True
38 | return False
39 | return user_passes_test(in_groups)
40 |
41 |
42 | # The way to use this decorator is:
43 | @group_required('admins', 'seller')
44 | def my_view(request, pk):
45 | ...
46 | ```
47 |
48 | 有关此装饰器更多的介绍,可以参考[这里](https://djangosnippets.org/snippets/1703/)。
49 |
50 | ### Anonymous required
51 |
52 | 这个装饰器是参考Django自带的 `login_required` 装饰器,但是功能是相反的情况,即用户必须是未登录的,否则用户将被重定向到 `settings.py` 中定义的地址。当我们想要已登录的用户不允许进入某些视图(比如登录)时,非常有用。
53 | ```python
54 | def anonymous_required(function=None, redirect_url=None):
55 |
56 | if not redirect_url:
57 | redirect_url = settings.LOGIN_REDIRECT_URL
58 |
59 | actual_decorator = user_passes_test(
60 | lambda u: u.is_anonymous(),
61 | login_url=redirect_url
62 | )
63 |
64 | if function:
65 | return actual_decorator(function)
66 | return actual_decorator
67 |
68 |
69 | # The way to use this decorator is:
70 | @anonymous_required
71 | def my_view(request, pk):
72 | ...
73 | ```
74 |
75 | 有关此装饰器更多的介绍,可以参考[这里](https://djangosnippets.org/snippets/2969/)。
76 |
77 | ### Superuser required
78 |
79 | 这个装饰器和上面的 `group_required` 类似, 但是它只允许超级用户才能访问视图。
80 | ```python
81 | from django.core.exceptions import PermissionDenied
82 |
83 |
84 | def superuser_only(function):
85 | """Limit view to superusers only."""
86 |
87 | def _inner(request, *args, **kwargs):
88 | if not request.user.is_superuser:
89 | raise PermissionDenied
90 | return function(request, *args, **kwargs)
91 |
92 | return _inner
93 |
94 |
95 | # The way to use this decorator is:
96 | @superuser_only
97 | def my_view(request):
98 | ...
99 | ```
100 |
101 | 有关此装饰器更多的介绍,可以参考[这里](https://djangosnippets.org/snippets/1575/)。
102 |
103 | ### Ajax required
104 |
105 | 这个装饰器用于检查请求是否是AJAX请求,在使用jQuery等Javascript框架时,这是一个非常有用的装饰器,也是一种保护应用程序的好方法。
106 |
107 | ```python
108 | from django.http import HttpResponseBadRequest
109 |
110 |
111 | def ajax_required(f):
112 | """
113 | AJAX request required decorator
114 | use it in your views:
115 |
116 | @ajax_required
117 | def my_view(request):
118 | ....
119 |
120 | """
121 |
122 | def wrap(request, *args, **kwargs):
123 | if not request.is_ajax():
124 | return HttpResponseBadRequest()
125 | return f(request, *args, **kwargs)
126 |
127 | wrap.__doc__ = f.__doc__
128 | wrap.__name__ = f.__name__
129 | return wrap
130 |
131 |
132 | # The way to use this decorator is:
133 | @ajax_required
134 | def my_view(request):
135 | ...
136 | ```
137 |
138 | 有关此装饰器更多的介绍,可以参考[这里](https://djangosnippets.org/snippets/771/)。
139 |
140 | ### Time it
141 |
142 | 如果您需要改进某个视图的响应时间,或者只想知道运行需要多长时间,那么这个装饰器非常有用。
143 |
144 | ```python
145 | def timeit(method):
146 |
147 | def timed(*args, **kw):
148 | ts = time.time()
149 | result = method(*args, **kw)
150 | te = time.time()
151 | print('%r (%r, %r) %2.2f sec' % (method.__name__, args, kw, te - ts))
152 | return result
153 |
154 | return timed
155 |
156 |
157 | # The way to use this decorator is:
158 | @timeit
159 | def my_view(request):
160 | ...
161 | ```
162 |
163 | 有关此装饰器更多的介绍,可以参考[这里](https://www.zopyx.com/andreas-jung/contents/a-python-decorator-for-measuring-the-execution-time-of-methods)。
164 |
165 | ### 自定义功能
166 |
167 | 下面这个装饰器只是一个示例,测试你能够轻松地检查某些权限或某些判断条件,并100%自己定制。
168 | 想象你有一个博客、购物论坛,如果用户需要有很多积分才能发表评论,这是一个避免垃圾信息的好方法。下面创建一个装饰器来检查用户是否已登录并拥有超过10个积分,这样才可以发表评论,否则将抛出一个Forbidden。
169 |
170 | ```python
171 | from django.http import HttpResponseForbidden
172 |
173 |
174 | logger = logging.getLogger(__name__)
175 |
176 |
177 | def user_can_write_a_review(func):
178 | """View decorator that checks a user is allowed to write a review, in negative case the decorator return Forbidden"""
179 |
180 | @functools.wraps(func)
181 | def wrapper(request, *args, **kwargs):
182 | if request.user.is_authenticated() and request.user.points < 10:
183 | logger.warning('The {} user has tried to write a review, but does not have enough points to do so'.format( request.user.pk))
184 | return HttpResponseForbidden()
185 |
186 | return func(request, *args, **kwargs)
187 |
188 | return wrapper
189 | ```
190 |
--------------------------------------------------------------------------------
/Django/README.md:
--------------------------------------------------------------------------------
1 | [欢迎光临我的博客小站](http://www.spiderpy.cn/blog/)
2 |
3 | * Django相关笔记
4 |
5 | * [Ubuntu上通过nginx部署Django笔记](https://github.com/jhao104/memory-notes/blob/master/Django/Ubuntu%E4%B8%8A%E9%80%9A%E8%BF%87nginx%E9%83%A8%E7%BD%B2Django%E7%AC%94%E8%AE%B0.md)
6 |
7 | * [Django中六个常用的自定义装饰器](https://github.com/jhao104/memory-notes/blob/master/Django/Django%E4%B8%AD%E5%85%AD%E4%B8%AA%E5%B8%B8%E7%94%A8%E7%9A%84%E8%87%AA%E5%AE%9A%E4%B9%89%E8%A3%85%E9%A5%B0%E5%99%A8.md)
8 |
9 | * [Django 1.10中文文档-第一个应用Part1-请求与响应](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part1-%E8%AF%B7%E6%B1%82%E4%B8%8E%E5%93%8D%E5%BA%94.md)
10 |
11 | * [Django 1.10中文文档-第一个应用Part2-模型和管理站点](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part2-%E6%A8%A1%E5%9E%8B%E5%92%8C%E7%AE%A1%E7%90%86%E7%AB%99%E7%82%B9.md)
12 |
13 | * [Django 1.10中文文档-第一个应用Part3-视图和模板](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part3-%E8%A7%86%E5%9B%BE%E5%92%8C%E6%A8%A1%E6%9D%BF.md)
14 |
15 | * [Django 1.10中文文档-第一个应用Part4-表单和通用视图](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part4-%E8%A1%A8%E5%8D%95%E5%92%8C%E9%80%9A%E7%94%A8%E8%A7%86%E5%9B%BE.md)
16 |
17 | * [Django 1.10中文文档-第一个应用Part5-测试](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part5-%E6%B5%8B%E8%AF%95.md)
18 |
19 | * [Django 1.10中文文档-第一个应用Part6-静态文件](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part6-%E9%9D%99%E6%80%81%E6%96%87%E4%BB%B6.md)
20 |
21 | * [Django 1.10中文文档-第一个应用Part7-自定义管理站点](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part7-%E8%87%AA%E5%AE%9A%E4%B9%89%E7%AE%A1%E7%90%86%E7%AB%99%E7%82%B9.md)
22 |
23 | * [Django 1.10中文文档-更多内容 点击](https://github.com/jhao104/django-chinese-doc)
--------------------------------------------------------------------------------
/Django/Ubuntu上通过nginx部署Django笔记.md:
--------------------------------------------------------------------------------
1 | > Django的部署可以有很多方式,采用nginx+uwsgi的方式是其中比较常见的一种方式。今天在Ubuntu上使用Nginx部署Django服务,虽然不是第一次搞这个了,但是发现还是跳进了好多坑,google了好久才搞定。想想还是把这个过程记录下来,免得下次再来踩同样的坑。
2 |
3 | ## 安装Nginx
4 |
5 | ```shell
6 | apt-get install nginx
7 | ```
8 |
9 | ubantu安装完Nginx后,文件结构大致为:
10 | 所有的配置文件都在 /etc/nginx下;
11 | 启动程序文件在 /usr/sbin/nginx下;
12 | 日志文件在 /var/log/nginx/下,分别是access.log和error.log;
13 | 并且在 /etc/init.d下创建了启动脚本nginx。
14 | ```shell
15 | sudo /etc/init.d/nginx start # 启动
16 | sudo /etc/init.d/nginx stop # 停止
17 | sudo /etc/init.d/nginx restart # 重启
18 | ```
19 |
20 |
21 | ## 安装uwsgi
22 |
23 | ```shell
24 | apt-get install python-dev
25 | pip install uwsgi
26 | ```
27 | 至于为什么要使用uwsgi,可以参见这边博客:[快速部署Python应用:Nginx+uWSGI配置详解(1)](http://developer.51cto.com/art/201010/229615.htm)。
28 | 这样大体的流程是:nginx作为服务器最前端,负责接收client的所有请求,统一管理。静态请求由Nginx自己处理。非静态请求通过uwsgi传递给Django,由Django来进行处理,从而完成一次WEB请求。
29 | 通信原理是:
30 | `the web client <-> the web server(nginx) <-> the socket <-> uwsgi <-> Django`
31 |
32 | ## 测试uwsgi
33 |
34 | 在Django项目下新建test.py文件,
35 | ```python
36 | # test.py
37 | def application(env, start_response):
38 | start_response('200 OK', [('Content-Type','text/html')])
39 | return ["Hello World"] # python2
40 | #return [b"Hello World"] # python3
41 | ```
42 | 然后执行shell命令:
43 | ```shell
44 | uwsgi --http :8001 --plugin python --wsgi-file test.py
45 | ```
46 | 加上--plugin python是告诉uWSGI在使用python插件,不然很有可能会出现类似这样的错误:
47 | ```shell
48 | uwsgi: unrecognized option '--wsgi-file'
49 | getopt_long() error
50 | ```
51 | 执行成功在浏览器中打开:http://localhost:8001显示Hello World说明uwsgi正常运行。
52 |
53 | ## 测试Django
54 |
55 | 首先得保证Django项目没有问题
56 | ```shell
57 | python manage.py runserver 0.0.0.0:8001
58 | ```
59 | 访问http://localhost:8001,项目运行正常。
60 | 然后链接Django和uwsgi,实现简单的web服务器,到Django项目目录下执行shell:
61 | ```shell
62 | uwsgi --http :8001 --plugin python --module blog.wsgi
63 | ```
64 | blog为你的项目名。访问http://localhost:8001,项目正常。注意这时项目的静态文件是不会被加载的,需要用nginx做静态文件代理。
65 |
66 | ## 配置uwsgi
67 | uwsgi支持通过配置文件的方式启动,可以接受更多的参数,高度可定制。我们在Django项目目录下新建uwsgi.ini
68 | ```
69 | [uwsgi]
70 | # Django-related settings
71 |
72 | socket = :8001
73 |
74 | # the base directory (full path)
75 | chdir = /home/ubuntu/blog
76 |
77 | # Django s wsgi file
78 | module = blog.wsgi
79 |
80 | # process-related settings
81 | # master
82 | master = true
83 |
84 | # maximum number of worker processes
85 | processes = 4
86 |
87 | # ... with appropriate permissions - may be needed
88 | # chmod-socket = 664
89 | # clear environment on exit
90 | vacuum = true
91 | ```
92 | 在shell中执行:
93 | ```shell
94 | sudo uwsgi --ini uwsgi.ini
95 | ```
96 | ps:如果实在不想配置nginx的话,单uwsgi就已经能完成部署了(把socket换成http),你可以把Django中的静态文件放到云平台中如七牛等等,这样你的Web也能被正常访问。
97 |
98 | ## 配置nginx
99 |
100 | nginx默认会读取`/etc/nginx/sites-enabled/default`文件中的配置,修改其配置如下:
101 |
102 | ```python
103 | server {
104 | # the port your site will be served on
105 | listen 80;
106 | # the domain name it will serve for
107 | server_name 127.0.0.1; # substitute your machine's IP address or FQDN
108 | charset utf-8;
109 |
110 | # max upload size
111 | client_max_body_size 75M; # adjust to taste
112 |
113 | # Django media
114 | location /media {
115 | alias /home/ubuntu/blog/media; # your Django project's media files - amend as required
116 | }
117 |
118 | location /static {
119 | alias /home/ubuntu/blog/static; # your Django project's static files - amend as required
120 | }
121 |
122 | # Finally, send all non-media requests to the Django server.
123 | location / {
124 | include uwsgi_params; # the uwsgi_params file you installed
125 | uwsgi_pass 127.0.0.1:8001;
126 | }
127 | }
128 | ```
129 | ## 收集Django静态文件
130 |
131 | 把Django自带的静态文件收集到同一个static中,不然访问Django的admin页面会找不到静态文件。在django的setting文件中,添加下面一行内容:
132 | ```python
133 | STATIC_ROOT = os.path.join(BASE_DIR, "static/")
134 | ```
135 | 然后到项目目录下执行:
136 |
137 | ```shell
138 | python manage.py collectstatic
139 | ```
140 |
141 | 修改配置文件
142 | ```python
143 | DEBUG = False
144 | ALLOWED_HOSTS = ['*']
145 | ```
146 | ## 运行
147 |
148 | 一切配置好后直接重启nginx即可。更加详细的说明请参见[官方文档](http://uwsgi-docs.readthedocs.io/en/latest/BuildSystem.html)
149 |
150 | ## 可能遇到的问题
151 |
152 | [如果监听80端口,部署后访问localhost自动跳转到nginx默认的欢迎界面](https://segmentfault.com/q/1010000007047896?_ea=1227923)
153 |
154 | [uwsgi: option ‘--http‘ is ambiguous](http://www.mamicode.com/info-detail-1442333.html)
155 |
156 | [把settings.py中的DEBUG设置为False前端页面显示不正常了](https://www.v2ex.com/t/184979)
--------------------------------------------------------------------------------
/Django/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | -------------------------------------------------
4 | File Name: __init__.py.py
5 | Description :
6 | Author : JHao
7 | date: 2016/11/12
8 | -------------------------------------------------
9 | Change Activity:
10 | 2016/11/12:
11 | -------------------------------------------------
12 | """
13 | __author__ = 'JHao'
14 |
15 | import sys
16 |
17 | reload(sys)
18 | sys.setdefaultencoding('utf-8')
19 |
20 | if __name__ == '__main__':
21 | pass
--------------------------------------------------------------------------------
/Docker/使用GitHub Actions自动构建DockerHub镜像.md:
--------------------------------------------------------------------------------
1 | DockerHub开启付费功能后,自动构建的功能不再免费开放了,这样Github的项目就不能再免费自动构建docker镜像并自动发布到DockerHub上。
2 |
3 | ## 前言
4 |
5 | 这里记录下使用 GitHub Actions持续集成服务自动构建发布镜像到DockerHub,目前GitHub Actions是免费开放的,所以Github上的项目都可以使用它来发布、测试、部署等等,非常方便。Github Actions [官方文档](https://docs.github.com/cn/actions)
6 |
7 | ## 配置
8 |
9 | 首先在项目中创建目录 `.github/workflows`, 然后在该目录中新建一个 `.yml` 文件,这里命名为 `docker-image.yml` 。 文件的名字没有实际意思,一个文件代表一个workflow任务。
10 |
11 | 文件内容如下(文件中`#`开头的为注释,是为方便理解加上去的):
12 |
13 | ```yaml
14 | # docker-image.yml
15 | name: Publish Docker image # workflow名称,可以在Github项目主页的【Actions】中看到所有的workflow
16 |
17 | on: # 配置触发workflow的事件
18 | push:
19 | branches: # master分支有push时触发此workflow
20 | - 'master'
21 | tags: # tag更新时触发此workflow
22 | - '*'
23 |
24 | jobs: # workflow中的job
25 |
26 | push_to_registry: # job的名字
27 | name: Push Docker image to Docker Hub
28 | runs-on: ubuntu-latest # job运行的基础环境
29 |
30 | steps: # 一个job由一个或多个step组成
31 | - name: Check out the repo
32 | uses: actions/checkout@v2 # 官方的action,获取代码
33 |
34 | - name: Log in to Docker Hub
35 | uses: docker/login-action@v1 # 三方的action操作, 执行docker login
36 | with:
37 | username: ${{ secrets.DOCKERHUB_USERNAME }} # 配置dockerhub的认证,在Github项目主页 【Settings】 -> 【Secrets】 添加对应变量
38 | password: ${{ secrets.DOCKERHUB_TOKEN }}
39 |
40 | - name: Extract metadata (tags, labels) for Docker
41 | id: meta
42 | uses: docker/metadata-action@v3 # 抽取项目信息,主要是镜像的tag
43 | with:
44 | images: jhao104/proxy_pool
45 |
46 | - name: Build and push Docker image
47 | uses: docker/build-push-action@v2 # docker build & push
48 | with:
49 | context: .
50 | push: true
51 | tags: ${{ steps.meta.outputs.tags }}
52 | labels: ${{ steps.meta.outputs.labels }}
53 | ```
54 |
55 | 配置中大部分我都加上了注释,需要特别说明的是 `steps` 中的 `uses` 。 我们以第二个step `Log in to Docker Hub` 为例,正常情况下,我们应该是运行 `run docker login **` 。
56 | 这里使用了一个 action [docker/login-action](https://github.com/marketplace/actions/docker-login),action 其实就是一系列step的组成,所以既然别人已经做好了,干嘛不直接用呢。所有可用的 action可以到 [这里](https://github.com/marketplace?type=actions) 查找。
57 |
58 | ## 使用
59 |
60 | 配置妥当之后,提交代码推送至github。按照本例中的配置,只要master分支有push事件或者tag有更新,就会触发Github Action,然后自动构建镜像推送至DockerHub。
61 |
62 | 可以在Github项目主页的【Actions】栏中查看每次执行详情,例如:
63 |
64 | 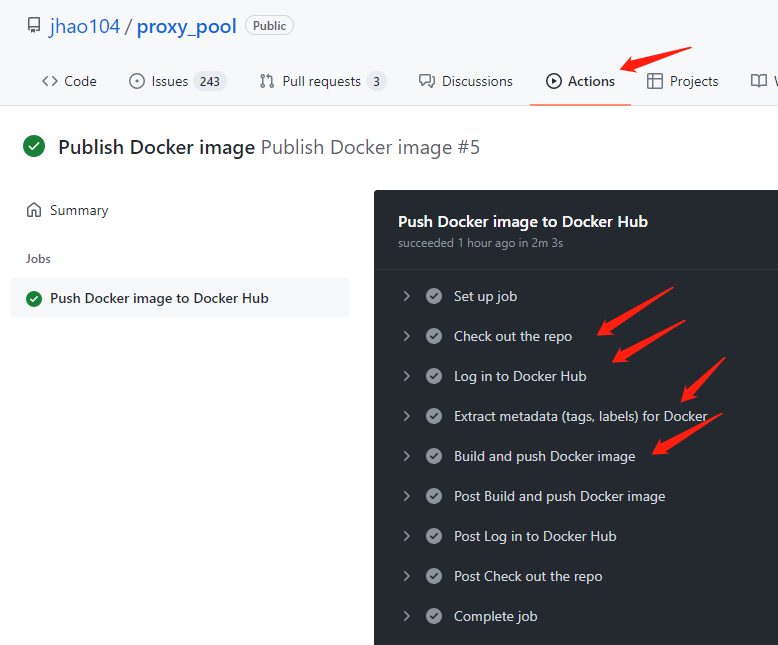
65 |
66 | 可以点击每一个step查看输出日志。
67 |
68 | 上面的配置注意两个部分,一是step 2的Dockerhub认证配置,你需要将你的Dockerhub用户名和Token(在Dockerhub页面生成)配置为Github项目主页的 【Settings】 -> 【Secrets】的变量。
69 | 二是,step 3中将`images`的名字改为你自己的,镜像的tag会自动抽取,默认情况下,如果是分支,镜像tag则为分支名,如果为github tag 则会推送 tag 和 `latest` 两个镜像,具体配置参见 [docker-metadata-action](https://github.com/marketplace/actions/docker-metadata-action) 。
70 |
71 |
--------------------------------------------------------------------------------
/Image/2017060501.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jhao104/memory-notes/c589b0b5504045f39b5b7fb6ffe407ec874bd091/Image/2017060501.png
--------------------------------------------------------------------------------
/Linux/Linux笔记:使用Vim编辑器.md:
--------------------------------------------------------------------------------
1 | Vi编辑器是Unix系统上早先的编辑器,在GNU项目将Vi编辑器移植到开源世界时,他们决定对其作一些改进。
2 | 于它不再是以前Unix中的那个原始的Vi编辑器了,开发人员也就将它重命名为Vi improved,或Vim。
3 | 为了方便使用,几乎所有Linux发行版都创建了一个名为vi的别名,指向vim程序。
4 |
5 | ## Vim基础
6 | Vim编辑器在内存缓冲区处理数据。只要键入vim命令和你要编辑的文件的名字,即可启动Vim编辑器。
7 | 如在启动Vim时未指定文件名,或者这个文件不存在,Vim会新开一段缓冲区域来编辑;如果命令指定了一个已有的文件的命令,Vim会将文件的整个内容都读到一块缓冲区域来准备编辑。
8 |
9 |
10 | Vim编辑器有两种操作模式:
11 |
12 | * 普通模式;
13 | * 插入模式
14 |
15 | 当打开要编辑的文件时,Vim编辑器会进入**普通模式**。在普通模式下,Vim编辑器会将按键解释成命令;
16 | 在编辑模式中,按下i键,进入**插入模式**。插入模式下,每个按键都将输入到光标位置的缓冲区。按Esc键即可退出插入模式;
17 |
18 | 在普通模式中,可以用方向键来在文本区域移动光标,如果是在一个没有定义方向键的终端上,还可以使用如下按键移动:
19 |
20 | |按键| 光标移动方式(普通模式下) |
21 | | ------------- |:-------------:|
22 | |h | 左移一个字符 |
23 | | j|下移一行 |
24 | |k | 上移一行 |
25 | | l| 右移一个字符 |
26 |
27 |
28 | 在大的文本文件中一行一行的移动会特别麻烦。幸而Vim提供了一些命令来帮助提高速度:
29 |
30 | | 按键 | 光标移动方式(普通模式下)|
31 | |---| --- |
32 | | PageDown(或Ctrl+F) | 下翻一屏数据|
33 | | PageUp(或Ctrl+B) | 上翻一屏数据|
34 | | G | 移动到缓冲区的最后一行|
35 | | *num* G | 移动到缓冲区的第*num*行|
36 | | gg | 移动缓冲区的第1行|
37 |
38 |
39 | Vim编辑器在普通模式下有个特别的功能叫**命令模式**。命令模式提供了一个可供输入额外命令来控制Vim中行为的交互式命令行。要进入命令模式,在普通模式下按下冒号键。光标会移动到消息行,冒号出现,等号输入命令。
40 | 在命令模式下有几个命令来将缓冲区的数据保存到文件中并退出Vim:
41 |
42 | | 命令 | 描述(命令模式下命令)|
43 | |---| --- |
44 | |q |如果未修改缓冲区的数据,退出|
45 | |q! |取消所有对缓冲区数据的的修改并退出|
46 | |w *filename*|将文件保存到另一个文件*filename*下|
47 | |wq |将缓冲区数据保存到文件中并退出|
48 |
49 | ## 编辑数据
50 |
51 | 在普通模式下,Vim编辑器提供了一些命令来编辑缓冲区中的数据。常用号命令有:
52 |
53 | | 命令 | 描述(普通模式下命令)|
54 | |---| --- |
55 | |x |删除当前光标所在位置的字符|
56 | |dd|删除当前光标所在行|
57 | |dw|删除当前光标所在位置的单词|
58 | |d$|删除当前光标所在位置至行尾的内容|
59 | |J |删除当前光标所在行行尾的换行符|
60 | |u |撤销前一个编辑命令|
61 | |a |在当前光标后追加数据|
62 | |A |在当前光标所在行行尾追加数据|
63 | |r *char*|用*char*替换当前光标所在位置的单个字符|
64 | |R *text*|用*text*覆盖当前光标所在位置的数据,直到按下ESC键|
65 |
66 | 有些编辑命令允许使用数据修饰来指定重复该命令多少次。比如,命令2x会删除从光标当前位置开始的两个字符,命令5dd会删除从光标当前所在行开始的向下5行。
67 |
68 | ## 复制和粘贴
69 |
70 | 现代编辑器的标准功能之一就是剪切或复制数据,Vim中剪切复制相对容易些。
71 |
72 | 上面已经有了删除数据的操作,Vim删除数据时,实际上它会将数据保存在单独的一个寄存器中。可以同p命令来取回数据。
73 |
74 | 简而言之,用dd删除一行文本,然后把光标移动到某个要放置该行文本的位置,之后用p命令。p命令会将文本插入到当前光标所在行之后。p命令可以和任何删除文本的命令一起搭配使用。
75 |
76 | Vim中复制命令是y(代表yank)。y命令和d命令有相同的第二字符(如yw表示复制单词,y$表示复制到行尾)。在复制文本后,输入p命令表示粘贴。
77 |
78 | 但是这样复制有个比较烦恼的问题,就是你没有看见到底复制了什么,除非粘贴出来才知道。Vim还有个功能解决了这个问题,**可视模式**会在移动光标时高亮文本,因此可以用可是模式来复制文本,方法如下:
79 |
80 | 移动光标到要开始复制的位置,按下v键,光标所在位置的文本会被高亮显示,移动光标覆盖想要复制的文本。覆盖后按y键来激活复制命令。现在寄存器中已经有了要复制的文本,使用p命令到合适的位置粘贴即可。
81 |
82 | ## 查找和替换
83 |
84 | 要查找某个字符串,在命令模式下,键入斜杠(/)加查找字符串(比如查找字符串class:/class),按下Enter键,光标会跑到消息行。在输入要查找的文本后,按下Enter键,Vim编辑器会有3中回应:
85 |
86 | * 如果光标当前位置之后有你要查找的文本,则光标会跳到该文本出现的第一个位置(按n键到达下一个);
87 | * 如果光标当前位置之后没有你要查找的文本,则光标会绕过文件末尾,显示在该文本出现的第一个位置(并用一条消息显示);
88 | * 输入一条错误消息,说明在文件中没有找到要找的文本
89 |
90 | 替换命令的格式是:
91 | ```
92 | :s/old/new
93 | ```
94 | Vim编辑会跳到old第一次出现的地方并用new来替换,可以对替换命令作一些修改来替换多处要替换的文本:
95 |
96 | | 命令 |描述
97 | |---| --- |
98 | |:s/old/new/g |一行命令替换所有old|
99 | |:n.ms/old/new/g |替换行号n和m之间的所有old|
100 | |:%s/old/new/g: |替换整个文件中的old|
101 | |:%s/old/new/gc: |替换整个文件中的old,但在每次出现时提示|
102 |
103 | ## 最后
104 | Vim包含了不少高级功能,由于每个Linux发行版都会包含它,所以应该至少了解一下Vim编辑器的一些基本用法。
105 |
--------------------------------------------------------------------------------
/Linux/README.md:
--------------------------------------------------------------------------------
1 | * Linux相关笔记
2 |
3 | * [Linux笔记:使用Vim编辑器](https://github.com/jhao104/memory-notes/blob/master/Linux/Linux%E7%AC%94%E8%AE%B0%EF%BC%9A%E4%BD%BF%E7%94%A8Vim%E7%BC%96%E8%BE%91%E5%99%A8.md)
--------------------------------------------------------------------------------
/MongoDB/Python中使用MongoDB.md:
--------------------------------------------------------------------------------
1 | > Python是开发社区中用于许多不同类型应用的强大编程语言。很多人都知道它是可以处理几乎任何任务的灵活语言。因此,在Python应用中需要一个什么样的与语言本身一样灵活的数据库呢?那就是NoSQL,比如MongoDB。
2 |
3 | > 英文原文:https://realpython.com/blog/python/introduction-to-mongodb-and-python
4 |
5 |
6 |
7 |
8 |
9 | ## 1、SQL vs NoSQL
10 |
11 | 如果你不是很熟悉NoSQL这个概念,MongoDB就是一个NoSQL数据库。近几年来它越来越受到整个行业的欢迎。NoSQL数据库提供了一个和关系型数据库非常不同的检索方式和存储数据功能。
12 |
13 | 在NoSQL出现的几十年来,SQL数据库是开发者寻求构建大型、可扩展系统的唯一选择之一。然而,越来越多的需求要求存储复杂数据结构的能力。这推动了NoSQL数据库的诞生,它允许开发者存储异构和无结构的数据。
14 |
15 | 当到数据库方案选择时,大多数人都问自己最后一个问题,“SQL或NoSQL的?”。无论是SQL和NoSQL都有自己的长处和弱点,你应该选择适合您的应用需求中最好的之一。这里是两者之间的一些区别:
16 |
17 | ### SQL
18 |
19 | * 模型是关系型的;
20 |
21 | * 数据被存放在表中;
22 |
23 | * 适用于每条记录都是相同类型并具有相同属性的情况;
24 |
25 | * 存储规范需要预定义结构;
26 |
27 | * 添加新的属性意味着你必须改变整体架构;
28 |
29 | * ACID事务支持;
30 |
31 | ### NoSQL
32 |
33 | * 模型是非关系型的;
34 |
35 | * 可以存储Json、键值对等(决定于NoSQL数据库类型);
36 |
37 | * 并不是每条记录都要有相同的结构;
38 |
39 | * 添加带有新属性的数据时,不会影响其他;
40 |
41 | * 支持ACID事务,根据使用的NoSQL的数据库而有所不同;
42 |
43 | * 一致性可以改变;
44 |
45 | * 横向扩展;
46 |
47 | 在两种类型的数据库之间还有许多其他的区别,但上面提到的是一些更重要的区别。根据您的具体情况,使用SQL数据库可能是首选,而在其他情况下,NoSQL的是更明显的选择。当选择一个数据库时,您应该谨慎考虑每个数据库的优势和劣势。
48 |
49 | NoSQL的一个好处是,有许多不同类型的数据库可供选择,并且每个都有自己的用例:
50 |
51 | * key-value存储:[DynamoDB](https://aws.amazon.com/cn/dynamodb/)
52 |
53 | * 文档存储:[CouchDB](http://couchdb.apache.org/),[MongoDB](https://www.mongodb.com/),[RethinkDB](https://www.rethinkdb.com/)
54 |
55 | * 列存储:[Cassandra](http://cassandra.apache.org/)
56 |
57 | * 数据结构: [Redis](https://redis.io/),[SSDB](http://ssdb.io/zh_cn/)
58 |
59 | 还有很多,但这些是一些更常见的类型。近年来,SQL和NoSQL数据库甚至已经开始合并。例如,PostgreSQL现在支持存储和查询JSON数据,很像MongoDB。有了这个,你可以用Postgres实现MongoDB一样的功能,但你仍然没有MongoDB的其他优势(如横向扩容和简单的界面,等等)。
60 |
61 | ## 2、MongoDB
62 |
63 | 现在,让我们将视线转移到本文的重点,并阐明的MongoDB的具体的一些情况。
64 |
65 | MongoDB是一个面向文档的,开源数据库程序,它平台无关。MongoDB像其他一些NoSQL数据库(但不是全部!)使用JSON结构的文档存储数据。这是使得数据非常灵活,不需要的Schema。
66 |
67 | 一些比较重要的特点是:
68 |
69 | * 支持多种标准查询类型,比如matching()、comparison (, )或者正则表达式;
70 |
71 | * 可以存储几乎任何类型的数据,无论是结构化,部分结构化,甚至是多态;
72 |
73 | * 要扩展和处理更多查询,只需添加更多的机器;
74 |
75 | * 它是高度灵活和敏捷,让您能够快速开发应用程序;
76 |
77 | * 作为基于文档的数据库意味着您可以在单个文档中存储有关您的模型的所有信息;
78 |
79 | * 您可以随时更改数据库的Schema;
80 |
81 | * 许多关系型数据库的功能也可以在MongoDB使用(如索引)。
82 |
83 | 在运行方面,MongoDB中有相当多的功能在其他数据库中是没有的:
84 |
85 |
86 | * 无论您需要独立服务器还是完整的独立服务器集群,MongoDB都可以根据需要进行扩展;
87 |
88 | * MongoDB还通过在各个分片上自动移动数据来提供负载均衡支持;
89 |
90 | * 它具有自动故障转移支持,如果主服务器Down掉,新的主服务器将自动启动并运行;
91 |
92 | * MongoDB的管理服务(MMS)可以用于监控和备份MongoDB的基础设施服务;
93 |
94 | * 不像关系数据库,由于内存映射文件,你将节省相当多的RAM。
95 |
96 | 虽然起初MongoDB似乎是解决我们许多问题的数据库,但它不是没有缺点的。MongoDB的一个常见缺点是缺少对ACID事务的支持,MongoDB在[特定场景下支持ACID事务](https://docs.mongodb.com/v3.4/core/write-operations-atomicity/),但不是在所有情况。在单文档级别,支持ACID事务(这是大多数事务发生的地方)。但是,由于MongoDB的分布式性质,不支持处理多个文档的事务。
97 |
98 | MongoDB还缺少对自然join查询支持。在MongoDB看来:文档意在包罗万象,这意味着,一般来说,它们不需要参考其他文档。在现实世界中,这并不总是有效的,因为我们使用的数据是关系性的。因此,许多人认为MongoDB应该被用作一个SQL数据库的补充数据库,但是当你使用MongoDB是,你会发现这是错误的。
99 |
100 | ## 3、PyMongo
101 |
102 | 现在我们已经描述了MongoDB的是什么,让我们来看看如何在Python中实际使用它。由MongoDB开发者发布的官方驱动程序[PyMongo](https://pypi.python.org/pypi/pymongo/),这里通过一些例子介绍,但你也应该查看[完整的文档](https://api.mongodb.com/python/current/),因为我们无法面面俱到。
103 |
104 | 当然第一件事就是安装,最简单的方式就是`pip`:
105 | ```shell
106 | pip install pymongo==3.4.0
107 | ```
108 |
109 | > 注:有关更全面的指南,请查看文档的[安装/升级](https://api.mongodb.com/python/3.4.0/installation.html)页面,并按照其中的步骤进行设置
110 |
111 | 完成设置后,启动的Python控制台并运行以下命令:
112 | ```shell
113 | >>> import pymongo
114 | ```
115 |
116 | 如果没有提出任何异常就说明安装成功了
117 |
118 | ### 建立连接
119 |
120 | 使用`MongoClient`对象建立连接:
121 |
122 | ```python
123 | from pymongo import MongoClient
124 | client = MongoClient()
125 | ```
126 |
127 | 使用上面的代码片段,将建立连接到默认主机(localhost)和端口(27017)。您还可以指定主机和/或使用端口:
128 |
129 | ```python
130 | client = MongoClient('localhost', 27017)
131 | ```
132 |
133 | 或者使用MongoURl格式:
134 |
135 | ```python
136 | client = MongoClient('mongodb://localhost:27017')
137 | ```
138 |
139 | ### 访问数据库
140 |
141 | 一旦你有一个连接的`MongoClient`实例,你可以在Mongo服务器中访问任何数据库。如果要访问一个数据库,你可以当作属性一样访问:
142 | ```python
143 | db = client.pymongo_test
144 | ```
145 |
146 | 或者你也可以使用字典形式的访问:
147 | ```python
148 | db = client['pymongo_test']
149 | ```
150 |
151 | 如果您的指定数据库已创建,实际上并不重要。通过指定此数据库名称并将数据保存到其中,您将自动创建数据库。
152 |
153 | ### 插入文档
154 |
155 | 在数据库中存储数据,就如同调用只是两行代码一样容易。第一行指定你将使用哪个集合。在MongoDB中术语中,一个集合是在数据库中存储在一起的一组文档(相当于SQL的表)。集合和文档类似于SQL表和行。第二行是使用集合插入数据insert_one()的方法:
156 |
157 | ```python
158 | posts = db.posts
159 | post_data = {
160 | 'title': 'Python and MongoDB',
161 | 'content': 'PyMongo is fun, you guys',
162 | 'author': 'Scott'
163 | }
164 | result = posts.insert_one(post_data)
165 | print('One post: {0}'.format(result.inserted_id))
166 | ```
167 |
168 |
169 | 我们甚至可以使用insert_one()同时插入很多文档,如果你有很多的文档添加到数据库中,可以使用方法insert_many()。此方法接受一个list参数:
170 |
171 | ```python
172 | post_1 = {
173 | 'title': 'Python and MongoDB',
174 | 'content': 'PyMongo is fun, you guys',
175 | 'author': 'Scott'
176 | }
177 | post_2 = {
178 | 'title': 'Virtual Environments',
179 | 'content': 'Use virtual environments, you guys',
180 | 'author': 'Scott'
181 | }
182 | post_3 = {
183 | 'title': 'Learning Python',
184 | 'content': 'Learn Python, it is easy',
185 | 'author': 'Bill'
186 | }
187 | new_result = posts.insert_many([post_1, post_2, post_3])
188 | print('Multiple posts: {0}'.format(new_result.inserted_ids))
189 | ```
190 |
191 | 你应该看到类似输出:
192 | ```python
193 | One post: 584d947dea542a13e9ec7ae6
194 | Multiple posts: [
195 | ObjectId('584d947dea542a13e9ec7ae7'),
196 | ObjectId('584d947dea542a13e9ec7ae8'),
197 | ObjectId('584d947dea542a13e9ec7ae9')
198 | ]
199 | ```
200 |
201 | > 注意: 不要担心,你和上面显示不一样。它们是在插入数据时,由Unix的纪元,机器标识符和其他唯一数据组成的动态标识。
202 |
203 | ### 检索文档
204 |
205 | 检索文档可以使用find_one()方法,比如要找到author为Bill的记录:
206 |
207 | ```python
208 | bills_post = posts.find_one({'author': 'Bill'})
209 | print(bills_post)
210 |
211 | 运行结果:
212 | {
213 | 'author': 'Bill',
214 | 'title': 'Learning Python',
215 | 'content': 'Learn Python, it is easy',
216 | '_id': ObjectId('584c4afdea542a766d254241')
217 | }
218 | ```
219 |
220 | 您可能已经注意到,这篇文章的ObjectId是设置的_id,这是以后可以使用唯一标识。如果需要查询多条记录可以使用find()方法:
221 |
222 | ```python
223 | scotts_posts = posts.find({'author': 'Scott'})
224 | print(scotts_posts)
225 |
226 | 结果:
227 |
228 |
229 | ```
230 | 他的主要区别在于文档数据不是作为数组直接返回给我们。相反,我们得到一个游标对象的实例。这Cursor是一个包含相当多的辅助方法,以帮助您处理数据的迭代对象。要获得每个文档,只需遍历结果:
231 |
232 | ```
233 | for post in scotts_posts:
234 | print(post)
235 | ```
236 |
237 | ### 4、MongoEngine
238 |
239 | 虽然PyMongo是非常容易使用,总体上是一个伟大的轮子,但是许多项目使用它都可能太低水平。简而言之,你必须编写很多自己的代码来持续地保存,检索和删除对象。PyMongo之上提供了一个更高的抽象一个库是MongoEngine。MongoEngine是一个对象文档映射器(ODM),它大致相当于一个基于SQL的对象关系映射器(ORM)。MongoEngine提供的抽象是基于类的,所以你创建的所有模型都是类。虽然有相当多的Python的库可以帮助您使用MongoDB,MongoEngine是一个更好的,因为它有一个很好的组合的功能,灵活性和社区支持。
240 |
241 |
242 | 使用pip安装:
243 | ```shell
244 | pip install mongoengine==0.10.7
245 | ```
246 |
247 | 连接:
248 | ```python
249 | from mongoengine import *
250 | connect('mongoengine_test', host='localhost', port=27017)
251 | ```
252 |
253 | 和pymongo不同。MongoEngine需要制定数据库名称。
254 |
255 | #### 定义文档
256 |
257 | 建立文档之前,需要定义文档中要存放数据的字段。与许多其他ORM类似,我们将通过继承Document类,并提供我们想要的数据类型来做到这一点:
258 |
259 | ````python
260 | import datetime
261 |
262 | class Post(Document):
263 | title = StringField(required=True, max_length=200)
264 | content = StringField(required=True)
265 | author = StringField(required=True, max_length=50)
266 | published = DateTimeField(default=datetime.datetime.now)
267 | ````
268 |
269 | 在这个简单的模型中,我们已经告诉MongoEngine,我们的Post实例有title、content、author、published。现在Document对象可以使用该信息来验证我们提供它的数据。
270 |
271 | 因此,如果我们试图保存Post的中没有title那么它会抛出一个Exception,让我们知道。我们甚至可以进一步利用这个并添加更多的限制:
272 |
273 | * required:设置必须;
274 |
275 | * default:如果没有其他值给出使用指定的默认值
276 |
277 | * unique:确保集合中没有其他document有此字段的值相同
278 |
279 | * choices:确保该字段的值等于数组中的给定值之一
280 |
281 | #### 保存文档
282 |
283 | 将文档保存到数据库中,我们将使用save()的方法。如果文档中的数据库已经存在,则所有的更改将在原子水平上对现有的文档进行。如果它不存在,但是,那么它会被创建。
284 |
285 | 这里是创建和保存一个文档的例子:
286 |
287 | ```python
288 | post_1 = Post(
289 | title='Sample Post',
290 | content='Some engaging content',
291 | author='Scott'
292 | )
293 | post_1.save() # This will perform an insert
294 | print(post_1.title)
295 | post_1.title = 'A Better Post Title'
296 | post_1.save() # This will perform an atomic edit on "title"
297 | print(post_1.title)
298 | ```
299 |
300 | 调用save()的时候需要注意几点:
301 |
302 | * PyMongo将在您调用.save()时执行验证,这意味着它将根据您在类中声明的模式检查要保存的数据,如果违反模式(或约束),则抛出异常并且不保存数据;
303 |
304 | * 由于Mongo不支持真正的事务,因此没有办法像在SQL数据库中那样“回滚”.save()调用。
305 |
306 | 当你保存的数据没有title时:
307 |
308 | ```python
309 | post_2 = Post(content='Content goes here', author='Michael')
310 | post_2.save()
311 |
312 |
313 | raise ValidationError(message, errors=errors)
314 | mongoengine.errors.ValidationError:
315 | ValidationError (Post:None) (Field is required: ['title'])
316 | ```
317 |
318 |
319 | #### 向对象的特性
320 |
321 | 使用MongoEngine是面向对象的,你也可以添加方法到你的子类文档。例如下面的示例,其中函数用于修改默认查询集(返回集合的所有对象)。通过使用它,我们可以对类应用默认过滤器,并只获取所需的对象
322 |
323 | ```python
324 | class Post(Document):
325 | title = StringField()
326 | published = BooleanField()
327 |
328 | @queryset_manager
329 | def live_posts(clazz, queryset):
330 | return queryset.filter(published=True)
331 |
332 | ```
333 |
334 | #### 关联其他文档
335 |
336 | 您还可以使用ReferenceField对象来创建从一个文档到另一个文档的引用。MongoEngine在访问时自动惰性处理引用。
337 |
338 | ```python
339 | class Author(Document):
340 | name = StringField()
341 |
342 | class Post(Document):
343 | author = ReferenceField(Author)
344 |
345 | Post.objects.first().author.name
346 | ```
347 |
348 | 在上面的代码中,使用文档"外键",我们可以很容易地找到第一篇文章的作者。其实还有比这里介绍的更多的字段类(和参数),所以一定要查看[文档字段](http://docs.mongoengine.org/apireference.html#fields)更多信息。
349 |
350 | 从所有这些示例中,您应该能够看到,MongoEngine非常适合管理几乎任何类型的应用程序的数据库对象。这些功能使得创建一个高效可扩展程序变得非常容易。如果你正在寻找更多关于MongoEngine的帮助,请务必查阅他们的[用户指南](http://docs.mongoengine.org/guide/index.html)。
351 |
352 |
353 |
--------------------------------------------------------------------------------
/Pycharm/PyCharm 自定义文件和代码模板.md:
--------------------------------------------------------------------------------
1 | PyCharm提供了文件和代码模板功能,可以利用此模板来快捷新建代码或文件。比如在PyCharm中新建一个html文件,新的文件并不是空的,而是会自动填充了一些基础的必备的内容,就像这样:
2 | ```html
3 |
4 |
5 |
6 |
7 | Title
8 |
9 |
10 |
11 |
12 |
13 | ```
14 | 系统自带的模板内容可能并不是想要的,自己可以修改增加个性化的内容,比如我新建一个名为main.py的Python文件,会自动填充这些内容:
15 |
16 | ```python
17 | # -*- coding: utf-8 -*-
18 | """
19 | -------------------------------------------------
20 | File Name: main.py
21 | Description :
22 | Author : JHao
23 | date: 2017/4/1
24 | -------------------------------------------------
25 | Change Activity:
26 | 2017/4/1:
27 | -------------------------------------------------
28 | """
29 | __author__ = 'JHao'
30 | ```
31 |
32 | File Name为文件名, Author是登录系统的用户名, 日期为当前系统日期。是不是感觉比默认的空白文件好多了。具体的修改步骤是: 【文件(File)】 --> 【设置(Settings)】如图操作, 在【编辑器(Editor)】中找到【文件和代码模板(File and Code Templates)】,选择你想要设置的文件类型进行编辑即可。
33 | 
34 | 我的模板是这样的:
35 | ```python
36 | # -*- coding: utf-8 -*-
37 | """
38 | -------------------------------------------------
39 | File Name: ${NAME}
40 | Description :
41 | Author : ${USER}
42 | date: ${DATE}
43 | -------------------------------------------------
44 | Change Activity:
45 | ${DATE}:
46 | -------------------------------------------------
47 | """
48 | __author__ = '${USER}'
49 | ```
50 |
51 | 附上模板变量:
52 | ```
53 | ${PROJECT_NAME} - 当前Project名称;
54 |
55 | ${NAME} - 在创建文件的对话框中指定的文件名;
56 |
57 | ${USER} - 当前用户名;
58 |
59 | ${DATE} - 当前系统日期;
60 |
61 | ${TIME} - 当前系统时间;
62 |
63 | ${YEAR} - 年;
64 |
65 | ${MONTH} - 月;
66 |
67 | ${DAY} - 日;
68 |
69 | ${HOUR} - 小时;
70 |
71 | ${MINUTE} - 分钟;
72 |
73 | ${PRODUCT_NAME} - 创建文件的IDE名称;
74 |
75 | ${MONTH_NAME_SHORT} - 英文月份缩写, 如: Jan, Feb, etc;
76 |
77 | ${MONTH_NAME_FULL} - 英文月份全称, 如: January, February, etc;
78 | ```
--------------------------------------------------------------------------------
/Pycharm/Pycharm创建virtualenv方法.md:
--------------------------------------------------------------------------------
1 |
2 | >Python的版本众多,在加上适用不同版本的Python Package。这导致在同时进行几个项目时,对库的依赖存在很大的问题。这个时候就牵涉到对Python以及依赖库的版本管理,方便进行开发,virtualenv就是用来解决这个问题的。下面介绍使用PyCharm创建Virtual Environment的方法。
3 |
4 | PyCharm可以使用[virtualenv](https://virtualenv.pypa.io/en/latest/index.html)中的功能来创建虚拟环境。PyCharm紧密集成了virtualenv,所以只需要在setting中配置即可创建虚拟环境。而且PyCharm捆绑了virtualenv,我们不需要单独安装。一般创建过程如下:
5 |
6 | * 1、打开Project Interpreters页面:文件(file)——>设置(setting)——>项目(Project)——>Project Interpreters;
7 | 
8 |
9 | * 2、选择项目,点击右边的配置按钮,选择**Create VirtualEnv**。这时会弹出**Create Virtual Environment**的对话框;
10 |
11 | * 3、配置新环境:
12 |
13 | * **Name**中填写新虚拟环境的名字,或者使用默认名字,方便以后安装第三方包和其他项目使用;
14 |
15 | * 在**Location**中填写新环境的文件目录;
16 |
17 | * 在**Base interpreter**下拉框中选择Python解释器;
18 |
19 | * 勾选**Inherit global site-packages**可以使用base interpreter中的第三方库,不选将和外界完全隔离;
20 |
21 | * 勾选**Make available to all projects**可将此虚拟环境提供给其他项目使用。
22 |
23 | * 4、点击OK,一切配置完毕。这样是不是比单独配置virtualenv简单的多。
24 | 
25 |
26 |
--------------------------------------------------------------------------------
/Pycharm/README.md:
--------------------------------------------------------------------------------
1 | [欢迎光临我的博客小站](http://www.spiderpy.cn/blog/)
2 |
3 | * PyCharm
4 |
5 | * [Pycharm创建virtualenv方法](https://github.com/jhao104/memory-notes/blob/master/Pycharm/Pycharm%E5%88%9B%E5%BB%BAvirtualenv%E6%96%B9%E6%B3%95.md)
6 | * [PyCharm 自定义文件和代码模板](https://github.com/jhao104/memory-notes/blob/master/Pycharm/PyCharm%20%E8%87%AA%E5%AE%9A%E4%B9%89%E6%96%87%E4%BB%B6%E5%92%8C%E4%BB%A3%E7%A0%81%E6%A8%A1%E6%9D%BF.md)
--------------------------------------------------------------------------------
/Pycharm/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | -------------------------------------------------
4 | File Name: __init__.py.py
5 | Description :
6 | Author : JHao
7 | date: 2016/11/14
8 | -------------------------------------------------
9 | Change Activity:
10 | 2016/11/14:
11 | -------------------------------------------------
12 | """
13 | __author__ = 'JHao'
14 |
15 | import sys
16 |
17 | reload(sys)
18 | sys.setdefaultencoding('utf-8')
19 |
20 | if __name__ == '__main__':
21 | pass
--------------------------------------------------------------------------------
/Python/Airflow笔记-MySqlOperator使用及conn配置.md:
--------------------------------------------------------------------------------
1 | ### 1. 依赖
2 | `MySqlOperator` 的数据库交互通过 `MySQLdb` 模块来实现, 使用前需要安装相关依赖:
3 | ```Shell
4 | pip install apache-airflow[mysql]
5 | ```
6 | ### 2. 使用
7 |
8 | 使用 `MySqlOperator` 执行sql任务的一个简单例子:
9 | ```Python
10 | from airflow import DAG
11 | from airflow.utils.dates import days_ago
12 | from airflow.operators.mysql_operator import MySqlOperator
13 |
14 | default_args = {
15 | 'owner': 'airflow',
16 | 'depends_on_past': False,
17 | 'start_date': days_ago(1),
18 | 'email': ['j_hao104@163.com'],
19 | 'email_on_failure': True,
20 | 'email_on_retry': False,
21 | }
22 |
23 | dag = DAG(
24 | 'MySqlOperatorExample',
25 | default_args=default_args,
26 | description='MySqlOperatorExample',
27 | schedule_interval="30 18 * * *")
28 |
29 | insert_sql = "insert into log SELECT * FROM temp_log"
30 |
31 |
32 | task = MySqlOperator(
33 | task_id='select_sql',
34 | sql=insert_sql,
35 | mysql_conn_id='mysql_conn',
36 | autocommit=True,
37 | dag=dag)
38 | ```
39 |
40 | ### 3. 参数
41 | `MySqlOperator` 接收几个参数:
42 |
43 | * `sql`: 待执行的sql语句;
44 | * `mysql_conn_id`: mysql数据库配置ID, Airflow的conn配置有两种配置方式,一是通过`os.environ`来配置环境变量实现,二是通过web界面配置到代码中,具体的配置方法会在下文描述;
45 | * `parameters`: 相当于`MySQLdb`库的`execute` 方法的第二参数,比如: `cur.execute('insert into UserInfo values(%s,%s)',('alex',18))`;
46 | * `autocommit`: 自动执行 `commit`;
47 | * `database`: 用于覆盖`conn`配置中的数据库名称, 这样方便于连接统一个mysql的不同数据库;
48 |
49 | ### 4. `conn`配置
50 |
51 | 
52 |
53 | 建议`conn`配置通过web界面来配置,这样不用硬编码到代码中,关于配置中的各个参数:
54 |
55 | * `Conn Id`: 对应 `MySqlOperator` 中的 `mysql_conn_id`;
56 | * `Host`: 数据库IP地址;
57 | * `Schema`: 库名, 可以被`MySqlOperator`中的`database`重写;
58 | * `Login`: 登录用户名;
59 | * `Password`: 登录密码;
60 | * `Port`: 数据库端口;
61 | * `Extra`: `MySQLdb.connect`的额外参数,包含`charset`、`cursor`、`ssl`、`local_infile`
62 |
63 | 其中`cursor`的值的对应关系为: `sscursor` —> `MySQLdb.cursors.SSCursor`; `dictcursor` —> `MySQLdb.cursors.DictCursor`; `ssdictcursor` —> `MySQLdb.cursors.SSDictCursor`
64 |
65 |
--------------------------------------------------------------------------------
/Python/Python判断文件是否存在的三种方法.md:
--------------------------------------------------------------------------------
1 | 通常在读写文件之前,需要判断文件或目录是否存在,不然某些处理方法可能会使程序出错。所以最好在做任何操作之前,先判断文件是否存在。
2 |
3 | 这里将介绍三种判断文件或文件夹是否存在的方法,分别使用`os模块`、`Try语句`、`pathlib模块`。
4 |
5 | ## 1.使用os模块
6 |
7 | os模块中的`os.path.exists()`方法用于检验文件是否存在。
8 |
9 | * 判断文件是否存在
10 |
11 | ```python
12 | import os
13 | os.path.exists(test_file.txt)
14 | #True
15 |
16 | os.path.exists(no_exist_file.txt)
17 | #False
18 | ```
19 |
20 | * 判断文件夹是否存在
21 |
22 | ```python
23 | import os
24 | os.path.exists(test_dir)
25 | #True
26 |
27 | os.path.exists(no_exist_dir)
28 | #False
29 | ```
30 |
31 | 可以看出用`os.path.exists()`方法,判断文件和文件夹是一样。
32 |
33 | 其实这种方法还是有个问题,假设你想检查文件“test_data”是否存在,但是当前路径下有个叫“test_data”的文件夹,这样就可能出现误判。为了避免这样的情况,可以这样:
34 |
35 | * 只检查文件
36 | ```
37 | import os
38 | os.path.isfile("test-data")
39 | ```
40 |
41 | 通过这个方法,如果文件"test-data"不存在将返回False,反之返回True。
42 |
43 | 即是文件存在,你可能还需要判断文件是否可进行读写操作。
44 |
45 | ## 判断文件是否可做读写操作
46 |
47 | 使用`os.access()`方法判断文件是否可进行读写操作。
48 |
49 | 语法:
50 |
51 | > os.access(path, mode)
52 |
53 | path为文件路径,mode为操作模式,有这么几种:
54 |
55 | * os.F_OK: 检查文件是否存在;
56 |
57 | * os.R_OK: 检查文件是否可读;
58 |
59 | * os.W_OK: 检查文件是否可以写入;
60 |
61 | * os.X_OK: 检查文件是否可以执行
62 |
63 | 该方法通过判断文件路径是否存在和各种访问模式的权限返回True或者False。
64 |
65 | ```python
66 | import os
67 | if os.access("/file/path/foo.txt", os.F_OK):
68 | print "Given file path is exist."
69 |
70 | if os.access("/file/path/foo.txt", os.R_OK):
71 | print "File is accessible to read"
72 |
73 | if os.access("/file/path/foo.txt", os.W_OK):
74 | print "File is accessible to write"
75 |
76 | if os.access("/file/path/foo.txt", os.X_OK):
77 | print "File is accessible to execute"
78 | ```
79 |
80 | ## 2.使用Try语句
81 |
82 | 可以在程序中直接使用`open()`方法来检查文件是否存在和可读写。
83 |
84 | 语法:
85 |
86 | >open()
87 |
88 | 如果你open的文件不存在,程序会抛出错误,使用try语句来捕获这个错误。
89 |
90 | 程序无法访问文件,可能有很多原因:
91 |
92 | * 如果你open的文件不存在,将抛出一个`FileNotFoundError`的异常;
93 |
94 | * 文件存在,但是没有权限访问,会抛出一个`PersmissionError`的异常。
95 |
96 | 所以可以使用下面的代码来判断文件是否存在:
97 |
98 | ```python
99 | try:
100 | f =open()
101 | f.close()
102 | except FileNotFoundError:
103 | print "File is not found."
104 | except PersmissionError:
105 | print "You don't have permission to access this file."
106 | ```
107 |
108 | 其实没有必要去这么细致的处理每个异常,上面的这两个异常都是`IOError`的子类。所以可以将程序简化一下:
109 |
110 | ```python
111 | try:
112 | f =open()
113 | f.close()
114 | except IOError:
115 | print "File is not accessible."
116 | ```
117 |
118 | 使用try语句进行判断,处理所有异常非常简单和优雅的。而且相比其他不需要引入其他外部模块。
119 |
120 | ## 3. 使用pathlib模块
121 |
122 | pathlib模块在Python3版本中是内建模块,但是在Python2中是需要单独安装三方模块。
123 |
124 | 使用pathlib需要先使用文件路径来创建path对象。此路径可以是文件名或目录路径。
125 |
126 | * 检查路径是否存在
127 |
128 | ```python
129 | path = pathlib.Path("path/file")
130 | path.exist()
131 | ```
132 |
133 | * 检查路径是否是文件
134 |
135 | ```python
136 | path = pathlib.Path("path/file")
137 | path.is_file()
138 | ```
139 |
140 |
141 |
142 |
--------------------------------------------------------------------------------
/Python/Python图片验证码降噪 — 8邻域降噪.md:
--------------------------------------------------------------------------------
1 | ### 简介
2 |
3 | 图片验证码识别的可以分为几个步骤,一般用 `Pillow` 库或 `OpenCV` 来实现,这几个过程是:
4 | * 1.灰度处理&二值化
5 | * 2.降噪
6 | * 3.字符分割
7 | * 4.标准化
8 | * 5.识别
9 |
10 | 所谓降噪就是把不需要的信息通通去除,比如背景,干扰线,干扰像素等等,只留下需要识别的字符,让图片变成2进制点阵,方便代入模型训练。
11 |
12 | ### 8邻域降噪
13 |
14 | `8邻域降噪` 的前提是将图片灰度化,即将彩色图像转化为灰度图像。以RGN色彩空间为例,彩色图像中每个像素的颜色由R 、G、B三个分量决定,每个分量由0到255种取值,这个一个像素点可以有一千多万种颜色变化。而灰度则是将三个分量转化成一个,使每个像素点只有0-255种取值,这样可以使后续的图像计算量变得少一些。
15 |
16 | 
17 |
18 | 以上面的灰度图片为例,图片越接近白色的点像素越接近255,越接近黑色的点像素越接近0,而且验证码字符肯定是非白色的。对于其中噪点大部分都是孤立的小点的,而且字符都是串联在一起的。`8邻域降噪` 的原理就是依次遍历图中所有非白色的点,计算其周围8个点中属于非白色点的个数,如果数量小于一个固定值,那么这个点就是噪点。对于不同类型的验证码这个阈值是不同的,所以可以在程序中配置,不断尝试找到最佳的阈值。
19 |
20 | 经过测试`8邻域降噪` 对于小的噪点的去除是很有效的,而且计算量不大,下图是阈值设置为4去噪后的结果:
21 |
22 | 
23 |
24 | ### Pillow实现
25 |
26 | 下面是使用 `Pillow` 模块的实现代码:
27 |
28 | ```python
29 | from PIL import Image
30 |
31 |
32 | def noise_remove_pil(image_name, k):
33 | """
34 | 8邻域降噪
35 | Args:
36 | image_name: 图片文件命名
37 | k: 判断阈值
38 |
39 | Returns:
40 |
41 | """
42 |
43 | def calculate_noise_count(img_obj, w, h):
44 | """
45 | 计算邻域非白色的个数
46 | Args:
47 | img_obj: img obj
48 | w: width
49 | h: height
50 | Returns:
51 | count (int)
52 | """
53 | count = 0
54 | width, height = img_obj.size
55 | for _w_ in [w - 1, w, w + 1]:
56 | for _h_ in [h - 1, h, h + 1]:
57 | if _w_ > width - 1:
58 | continue
59 | if _h_ > height - 1:
60 | continue
61 | if _w_ == w and _h_ == h:
62 | continue
63 | if img_obj.getpixel((_w_, _h_)) < 230: # 这里因为是灰度图像,设置小于230为非白色
64 | count += 1
65 | return count
66 |
67 | img = Image.open(image_name)
68 | # 灰度
69 | gray_img = img.convert('L')
70 |
71 | w, h = gray_img.size
72 | for _w in range(w):
73 | for _h in range(h):
74 | if _w == 0 or _h == 0:
75 | gray_img.putpixel((_w, _h), 255)
76 | continue
77 | # 计算邻域非白色的个数
78 | pixel = gray_img.getpixel((_w, _h))
79 | if pixel == 255:
80 | continue
81 |
82 | if calculate_noise_count(gray_img, _w, _h) < k:
83 | gray_img.putpixel((_w, _h), 255)
84 | return gray_img
85 |
86 |
87 | if __name__ == '__main__':
88 | image = noise_remove_pil("test.jpg", 4)
89 | image.show()
90 | ```
91 |
92 |
93 | ### OpenCV实现
94 |
95 | 使用`OpenCV`可以提高计算效率:
96 |
97 | ```python
98 | import cv2
99 |
100 |
101 | def noise_remove_cv2(image_name, k):
102 | """
103 | 8邻域降噪
104 | Args:
105 | image_name: 图片文件命名
106 | k: 判断阈值
107 |
108 | Returns:
109 |
110 | """
111 |
112 | def calculate_noise_count(img_obj, w, h):
113 | """
114 | 计算邻域非白色的个数
115 | Args:
116 | img_obj: img obj
117 | w: width
118 | h: height
119 | Returns:
120 | count (int)
121 | """
122 | count = 0
123 | width, height = img_obj.shape
124 | for _w_ in [w - 1, w, w + 1]:
125 | for _h_ in [h - 1, h, h + 1]:
126 | if _w_ > width - 1:
127 | continue
128 | if _h_ > height - 1:
129 | continue
130 | if _w_ == w and _h_ == h:
131 | continue
132 | if img_obj[_w_, _h_] < 230: # 二值化的图片设置为255
133 | count += 1
134 | return count
135 |
136 | img = cv2.imread(image_name, 1)
137 | # 灰度
138 | gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
139 | w, h = gray_img.shape
140 | for _w in range(w):
141 | for _h in range(h):
142 | if _w == 0 or _h == 0:
143 | gray_img[_w, _h] = 255
144 | continue
145 | # 计算邻域pixel值小于255的个数
146 | pixel = gray_img[_w, _h]
147 | if pixel == 255:
148 | continue
149 |
150 | if calculate_noise_count(gray_img, _w, _h) < k:
151 | gray_img[_w, _h] = 255
152 |
153 | return gray_img
154 |
155 |
156 | if __name__ == '__main__':
157 | image = noise_remove_cv2("test.jpg", 4)
158 | cv2.imshow('img', image)
159 | cv2.waitKey(10000)
160 | ```
--------------------------------------------------------------------------------
/Python/Python标准库笔记(1) — string模块.md:
--------------------------------------------------------------------------------
1 |
2 | >String模块包含大量实用常量和类,以及一些过时的遗留功能,并还可用作字符串操作。
3 |
4 | ## 1. 常用方法
5 |
6 | | 常用方法 | 描述 |
7 | |---|---|
8 | | str.capitalize() | 把字符串的首字母大写 |
9 | | str.center(width) | 将原字符串用空格填充成一个长度为width的字符串,原字符串内容居中 |
10 | | str.count(s) | 返回字符串s在str中出现的次数 |
11 | | str.decode(encoding='UTF-8',errors='strict') | 以指定编码格式解码字符串 |
12 | | str.encode(encoding='UTF-8',errors='strict') | 以指定编码格式编码字符串 |
13 | | str.endswith(s) | 判断字符串str是否以字符串s结尾 |
14 | | str.find(s) | 返回字符串s在字符串str中的位置索引,没有则返回-1 |
15 | | str.index(s)| 和find()方法一样,但是如果s不存在于str中则会抛出异常|
16 | | str.isalnum() | 如果str至少有一个字符并且都是字母或数字则返回True,否则返回False|
17 | | str.isalpha() | 如果str至少有一个字符并且都是字母则返回True,否则返回False|
18 | | str.isdigit() | 如果str只包含数字则返回 True 否则返回 False|
19 | | str.islower() | 如果str存在区分大小写的字符,并且都是小写则返回True 否则返回False|
20 | | str.isspace() | 如果str中只包含空格,则返回 True,否则返回 False|
21 | | str.istitle() | 如果str是标题化的(单词首字母大写)则返回True,否则返回False|
22 | | str.isupper() | 如果str存在区分大小写的字符,并且都是大写则返回True 否则返回False|
23 | | str.ljust(width) | 返回一个原字符串左对齐的并使用空格填充至长度width的新字符串 |
24 | | str.lower() | 转换str中所有大写字符为小写|
25 | | str.lstrip() | 去掉str左边的不可见字符|
26 | | str.partition(s)| 用s将str切分成三个值|
27 | | str.replace(a, b) | 将字符串str中的a替换成b|
28 | | str.rfind(s) | 类似于 find()函数,不过是从右边开始查找|
29 | | str.rindex(s) | 类似于 index(),不过是从右边开始|
30 | | str.rjust(width)| 返回一个原字符串右对齐的并使用空格填充至长度width的新字符串|
31 | | str.rpartition(s) | 类似于 partition()函数,不过是从右边开始查找|
32 | | str.rstrip() | 去掉str右边的不可见字符|
33 | | str.split(s) | 以s为分隔符切片str |
34 | | str.splitlines() | 按照行分隔,返回一个包含各行作为元素的列表 |
35 | | str.startswith(s) | 检查字符串str是否是以s开头,是则返回True,否则返回False |
36 | | str.strip() | 等于同时执行rstrip()和lstrip()|
37 | | str.title() | 返回"标题化"的str,所有单词都是以大写开始,其余字母均为小写|
38 | | str.upper() | 返回str所有字符为大写的字符串 |
39 | | str.zfill(width) |返回长度为 width 的字符串,原字符串str右对齐,前面填充0|
40 |
41 | ## 2.字符串常量
42 |
43 | | 常数 | 含义 |
44 | |---|---|
45 | | string.ascii_lowercase | 小写字母'abcdefghijklmnopqrstuvwxyz'|
46 | | string.ascii_uppercase | 大写的字母'ABCDEFGHIJKLMNOPQRSTUVWXYZ'|
47 | | string.ascii_letters | ascii_lowercase和ascii_uppercase常量的连接串 |
48 | | string.digits | 数字0到9的字符串:'0123456789'|
49 | | string.hexdigits| 字符串'0123456789abcdefABCDEF'|
50 | | string.letters| 字符串'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'|
51 | | string.lowercase|小写字母的字符串'abcdefghijklmnopqrstuvwxyz'|
52 | | string.octdigits| 字符串'01234567'|
53 | | string.punctuation| 所有标点字符|
54 | | string.printable| 可打印的字符的字符串。包含数字、字母、标点符号和空格|
55 | | string.uppercase | 大学字母的字符串'ABCDEFGHIJKLMNOPQRSTUVWXYZ'|
56 | | string.whitespace| 空白字符 '\t\n\x0b\x0c\r '|
57 |
58 | ## 3.字符串模板Template
59 |
60 | 通过string.Template可以为Python定制字符串的替换标准,下面是具体列子:
61 | ```python
62 | >>>from string import Template
63 | >>>s = Template('$who like $what')
64 | >>>print s.substitute(who='i', what='python')
65 | i like python
66 |
67 | >>>print s.safe_substitute(who='i') # 缺少key时不会抛错
68 | i like $what
69 |
70 | >>>Template('${who}LikePython').substitute(who='I') # 在字符串内时使用{}
71 | 'ILikePython'
72 | ```
73 |
74 | Template还有更加高级的用法,可以通过继承string.Template, 重写变量delimiter(定界符)和idpattern(替换格式), 定制不同形式的模板。
75 |
76 | ```python
77 | import string
78 |
79 | template_text = '''
80 | Delimiter : $de
81 | Replaced : %with_underscore
82 | Ingored : %notunderscored
83 | '''
84 |
85 | d = {'de': 'not replaced',
86 | 'with_underscore': 'replaced',
87 | 'notunderscored': 'not replaced'}
88 |
89 |
90 | class MyTemplate(string.Template):
91 | # 重写模板 定界符(delimiter)为"%", 替换模式(idpattern)必须包含下划线(_)
92 | delimiter = '%'
93 | idpattern = '[a-z]+_[a-z]+'
94 |
95 | print string.Template(template_text).safe_substitute(d) # 采用原来的Template渲染
96 |
97 | print MyTemplate(template_text).safe_substitute(d) # 使用重写后的MyTemplate渲染
98 |
99 | ```
100 |
101 | 输出:
102 | ```
103 |
104 | Delimiter : not replaced
105 | Replaced : %with_underscore
106 | Ingored : %notunderscored
107 |
108 |
109 | Delimiter : $de
110 | Replaced : replaced
111 | Ingored : %notunderscored
112 | ```
113 |
114 | 原生的Template只会渲染界定符为$的情况,重写后的MyTemplate会渲染界定符为%且替换格式带有下划线的情况。
115 |
116 | ## 4.常用字符串技巧
117 |
118 | * 1.反转字符串
119 |
120 | ```python
121 | >>> s = '1234567890'
122 | >>> print s[::-1]
123 | 0987654321
124 | ```
125 |
126 | * 2.关于字符串链接
127 |
128 | 尽量使用join()链接字符串,因为'+'号连接n个字符串需要申请n-1次内存,使用join()需要申请1次内存。
129 |
130 | * 3.固定长度分割字符串
131 |
132 | ```python
133 | >>> import re
134 | >>> s = '1234567890'
135 | >>> re.findall(r'.{1,3}', s) # 已三个长度分割字符串
136 | ['123', '456', '789', '0']
137 | ```
138 |
139 | * 4.使用()括号生成字符串
140 |
141 | ```
142 | sql = ('SELECT count() FROM table '
143 | 'WHERE id = "10" '
144 | 'GROUP BY sex')
145 |
146 | print sql
147 |
148 | SELECT count() FROM table WHERE id = "10" GROUP BY sex
149 | ```
150 |
151 | * 5.将print的字符串写到文件
152 |
153 | ```python
154 | >>> print >> open("somefile.txt", "w+"), "Hello World" # Hello World将写入文件somefile.txt
155 | ```
156 |
157 |
158 |
159 |
--------------------------------------------------------------------------------
/Python/Python标准库笔记(11) — operator模块.md:
--------------------------------------------------------------------------------
1 | > Operator——标准功能性操作符接口.
2 |
3 | 代码中使用迭代器时,有时必须要为一个简单表达式创建函数。有些情况这些函数可以用一个`lambda`函数实现,但是对于某些操作,根本没必要去写一个新的函数。因此`operator`模块定义了一些函数,这些函数对应于算术、比较和其他与标准对象API对应的操作。
4 |
5 | ### 1.逻辑操作符(Logical Operations)
6 |
7 | 下面函数用于确定一个值的布尔等价值,或者否定它创建相反的布尔值,或比较对象确定它们是否相同。
8 |
9 | ```python
10 | from operator import *
11 |
12 | a = -1
13 | b = 5
14 |
15 | print('a =', a)
16 | print('b =', b)
17 | print()
18 |
19 | print('not_(a) :', not_(a))
20 | print('truth(a) :', truth(a))
21 | print('is_(a, b) :', is_(a, b))
22 | print('is_not(a, b):', is_not(a, b))
23 | ```
24 |
25 | `not_()`后面有一个下划线,是因为`not`是Python关键字。`true()`使用的逻辑和`if`语句加表达式或将表达式转换为`bool.is_()`时相同的逻辑。`is_()`实现的是使用`is`关键字相同的检查,`is_not()`也执行相同的检查但返回相反的结果。
26 |
27 | ```python
28 | a = -1
29 | b = 5
30 |
31 | not_(a) : False
32 | truth(a) : True
33 | is_(a, b) : False
34 | is_not(a, b): True
35 | ```
36 |
37 | ### 2.比较操作符(Comparison Operators)
38 |
39 | 它支持所有富比较操作符:
40 |
41 | ```python
42 | from operator import *
43 |
44 | a = 1
45 | b = 5.0
46 |
47 | print('a =', a)
48 | print('b =', b)
49 |
50 | for func in (lt, le, eq, ne, ge, gt):
51 | print('{}(a, b): {}'.format(func.__name__, func(a, b)))
52 | ```
53 |
54 | 这些函数等价于使用`<`、`<=`、`==`、`>=`和`>`的表达式语法。
55 |
56 | ```python
57 | a = 1
58 | b = 5.0
59 | lt(a, b): True
60 | le(a, b): True
61 | eq(a, b): False
62 | ne(a, b): True
63 | ge(a, b): False
64 | gt(a, b): False
65 | ```
66 |
67 | ### 3.算术操作符(Arithmetic Operators)
68 |
69 | 它还支持用于操作数值的算术运算符:
70 |
71 | ```python
72 | from operator import *
73 |
74 | a = -1
75 | b = 5.0
76 | c = 2
77 | d = 6
78 |
79 | print('a =', a)
80 | print('b =', b)
81 | print('c =', c)
82 | print('d =', d)
83 |
84 | print('\n正数/负数:')
85 | print('abs(a):', abs(a))
86 | print('neg(a):', neg(a))
87 | print('neg(b):', neg(b))
88 | print('pos(a):', pos(a))
89 | print('pos(b):', pos(b))
90 |
91 | print('\n算术:')
92 | print('add(a, b) :', add(a, b))
93 | print('floordiv(a, b):', floordiv(a, b))
94 | print('floordiv(d, c):', floordiv(d, c))
95 | print('mod(a, b) :', mod(a, b))
96 | print('mul(a, b) :', mul(a, b))
97 | print('pow(c, d) :', pow(c, d))
98 | print('sub(b, a) :', sub(b, a))
99 | print('truediv(a, b) :', truediv(a, b))
100 | print('truediv(d, c) :', truediv(d, c))
101 |
102 | print('\n按位:')
103 | print('and_(c, d) :', and_(c, d))
104 | print('invert(c) :', invert(c))
105 | print('lshift(c, d):', lshift(c, d))
106 | print('or_(c, d) :', or_(c, d))
107 | print('rshift(d, c):', rshift(d, c))
108 | print('xor(c, d) :', xor(c, d))
109 | ```
110 |
111 | 有两种除法运算符:`floordiv()`(在3.0版本之前Python中实现的整数除法)和`truediv()`(浮点除法)。
112 |
113 | ```python
114 | a = -1
115 | b = 5.0
116 | c = 2
117 | d = 6
118 |
119 | 正数/负数:
120 | abs(a): 1
121 | neg(a): 1
122 | neg(b): -5.0
123 | pos(a): -1
124 | pos(b): 5.0
125 |
126 | 算术:
127 | add(a, b) : 4.0
128 | floordiv(a, b): -1.0
129 | floordiv(d, c): 3
130 | mod(a, b) : 4.0
131 | mul(a, b) : -5.0
132 | pow(c, d) : 64
133 | sub(b, a) : 6.0
134 | truediv(a, b) : -0.2
135 | truediv(d, c) : 3.0
136 |
137 | 按位:
138 | and_(c, d) : 2
139 | invert(c) : -3
140 | lshift(c, d): 128
141 | or_(c, d) : 6
142 | rshift(d, c): 1
143 | xor(c, d) : 4
144 | ```
145 |
146 | ### 4.序列操作符(Sequence Operators)
147 |
148 | 处理序列的操作符可以分为四种:构建序列、搜索条目、访问内容和从序列中删除条目:
149 |
150 | ```python
151 | from operator import *
152 |
153 | a = [1, 2, 3]
154 | b = ['a', 'b', 'c']
155 |
156 | print('a =', a)
157 | print('b =', b)
158 |
159 | print('\n构建序列:')
160 | print(' concat(a, b):', concat(a, b))
161 |
162 | print('\n搜索:')
163 | print(' contains(a, 1) :', contains(a, 1))
164 | print(' contains(b, "d"):', contains(b, "d"))
165 | print(' countOf(a, 1) :', countOf(a, 1))
166 | print(' countOf(b, "d") :', countOf(b, "d"))
167 | print(' indexOf(a, 5) :', indexOf(a, 1))
168 |
169 | print('\n访问:')
170 | print(' getitem(b, 1) :',
171 | getitem(b, 1))
172 | print(' getitem(b, slice(1, 3)) :',
173 | getitem(b, slice(1, 3)))
174 | print(' setitem(b, 1, "d") :', end=' ')
175 | setitem(b, 1, "d")
176 | print(b)
177 | print(' setitem(a, slice(1, 3), [4, 5]):', end=' ')
178 | setitem(a, slice(1, 3), [4, 5])
179 | print(a)
180 |
181 | print('\n删除:')
182 | print(' delitem(b, 1) :', end=' ')
183 | delitem(b, 1)
184 | print(b)
185 | print(' delitem(a, slice(1, 3)):', end=' ')
186 | delitem(a, slice(1, 3))
187 | print(a)
188 |
189 | ```
190 |
191 | 其中一些操作,如`setitem()`和`delitem()`,修改序列时属于原地操作,不返回值。
192 |
193 | ```python
194 | a = [1, 2, 3]
195 | b = ['a', 'b', 'c']
196 |
197 | 构建序列:
198 | concat(a, b): [1, 2, 3, 'a', 'b', 'c']
199 |
200 | 搜索:
201 | contains(a, 1) : True
202 | contains(b, "d"): False
203 | countOf(a, 1) : 1
204 | countOf(b, "d") : 0
205 | indexOf(a, 5) : 0
206 |
207 | 访问:
208 | getitem(b, 1) : b
209 | getitem(b, slice(1, 3)) : ['b', 'c']
210 | setitem(b, 1, "d") : ['a', 'd', 'c']
211 | setitem(a, slice(1, 3), [4, 5]): [1, 4, 5]
212 |
213 | 删除:
214 | delitem(b, 1) : ['a', 'c']
215 | delitem(a, slice(1, 3)): [1]
216 | ```
217 |
218 | ### 5.原地操作符(In-place Operators)
219 |
220 | 除了标准操作符之外,许多对象类型还支持通过特殊操作符(如`+=`)"原地"修改。原地操作符也有相同的功能:
221 |
222 | ```python
223 | from operator import *
224 |
225 | a = -1
226 | b = 5.0
227 | c = [1, 2, 3]
228 | d = ['a', 'b', 'c']
229 | print('a =', a)
230 | print('b =', b)
231 | print('c =', c)
232 | print('d =', d)
233 | print()
234 |
235 | iadd(a, b)
236 | print('a = iadd(a, b) =>', a)
237 | print()
238 |
239 | iconcat(c, d)
240 | print('c = iconcat(c, d) =>', c)
241 | ```
242 |
243 | 上面示例只演示了个别函数。有关详细信息,请参阅[标准库文档](https://docs.python.org/3/library/operator.html#inplace-operators)。
244 |
245 | ```python
246 | a = -1
247 | b = 5.0
248 | c = [1, 2, 3]
249 | d = ['a', 'b', 'c']
250 |
251 | a = iadd(a, b) => -1
252 |
253 | c = iconcat(c, d) => [1, 2, 3, 'a', 'b', 'c']
254 | ```
255 |
256 | ### 6.属性和内容"Getters"
257 |
258 | operator模块最出众的特性之一就是`getter`的概念。这些是在运行时构造的可调用对象,用于从序列中检索对象属性或内容。`getter`在处理迭代器或生成器序列时特别有用,因为它们的开销要小于`lambda`和Python函数。
259 |
260 | ```python
261 | from operator import *
262 |
263 |
264 | class MyObj:
265 | """attrgetter 演示类"""
266 |
267 | def __init__(self, arg):
268 | super().__init__()
269 | self.arg = arg
270 |
271 | def __repr__(self):
272 | return 'MyObj({})'.format(self.arg)
273 |
274 |
275 | l = [MyObj(i) for i in range(5)]
276 | print('objects :', l)
277 |
278 | # 从每个对象中提取'arg'属性
279 | g = attrgetter('arg')
280 | vals = [g(i) for i in l]
281 | print('arg values:', vals)
282 |
283 | # 使用arg排序
284 | l.reverse()
285 | print('reversed :', l)
286 | print('sorted :', sorted(l, key=g))
287 | ```
288 |
289 | 本例中的属性getters功能类似于:`lambda x, n='attrname': getattr(x, n)`:
290 |
291 | ```python
292 | objects : [MyObj(0), MyObj(1), MyObj(2), MyObj(3), MyObj(4)]
293 | arg values: [0, 1, 2, 3, 4]
294 | reversed : [MyObj(4), MyObj(3), MyObj(2), MyObj(1), MyObj(0)]
295 | sorted : [MyObj(0), MyObj(1), MyObj(2), MyObj(3), MyObj(4)]
296 |
297 | ```
298 |
299 | 而内容getters功能类似于`lambda x, y=5: x[y]`:
300 |
301 | ```python
302 | from operator import *
303 |
304 | l = [dict(val=-1 * i) for i in range(4)]
305 | print('Dictionaries:')
306 | print(' original:', l)
307 | g = itemgetter('val')
308 | vals = [g(i) for i in l]
309 | print(' values:', vals)
310 | print(' sorted:', sorted(l, key=g))
311 |
312 | print()
313 | l = [(i, i * -2) for i in range(4)]
314 | print('\nTuples:')
315 | print(' original:', l)
316 | g = itemgetter(1)
317 | vals = [g(i) for i in l]
318 | print(' values:', vals)
319 | print(' sorted:', sorted(l, key=g))
320 | ```
321 |
322 | 内容getters既可以处字典,也可以处理序列。
323 |
324 | ```python
325 | Dictionaries:
326 | original: [{'val': 0}, {'val': -1}, {'val': -2}, {'val': -3}]
327 | values: [0, -1, -2, -3]
328 | sorted: [{'val': -3}, {'val': -2}, {'val': -1}, {'val': 0}]
329 |
330 |
331 | Tuples:
332 | original: [(0, 0), (1, -2), (2, -4), (3, -6)]
333 | values: [0, -2, -4, -6]
334 | sorted: [(3, -6), (2, -4), (1, -2), (0, 0)]
335 | ```
336 |
337 | ### 7.自定义类中使用
338 |
339 | operator模块中的函数操作是通过标准的Python接口工作,因此它们也可以处理用户自定义的类和内置类型。
340 |
341 | ```python
342 | from operator import *
343 |
344 |
345 | class MyObj:
346 | """重载操作符例子"""
347 |
348 | def __init__(self, val):
349 | super(MyObj, self).__init__()
350 | self.val = val
351 |
352 | def __str__(self):
353 | return 'MyObj({})'.format(self.val)
354 |
355 | def __lt__(self, other):
356 | """小于比较"""
357 | print('Testing {} < {}'.format(self, other))
358 | return self.val < other.val
359 |
360 | def __add__(self, other):
361 | """add操作"""
362 | print('Adding {} + {}'.format(self, other))
363 | return MyObj(self.val + other.val)
364 |
365 |
366 | a = MyObj(1)
367 | b = MyObj(2)
368 |
369 | print('比较操作:')
370 | print(lt(a, b))
371 |
372 | print('\n算术运算:')
373 | print(add(a, b))
374 | ```
375 |
376 | ```python
377 | 比较操作:
378 | Testing MyObj(1) < MyObj(2)
379 | True
380 |
381 | 算术运算:
382 | Adding MyObj(1) + MyObj(2)
383 | MyObj(3)
384 | ```
--------------------------------------------------------------------------------
/Python/Python标准库笔记(2) — re模块.md:
--------------------------------------------------------------------------------
1 | re模块提供了一系列功能强大的正则表达式(regular expression)工具,它们允许你快速检查给定字符串是否与给定的模式匹配(match函数), 或者包含这个模式(search函数)。正则表达式是以紧凑(也很神秘)的语法写出的字符串模式。
2 |
3 | ## 1. 常用方法
4 |
5 | | 常用方法 | 描述 |
6 | |---|---|
7 | | match(pattern, string, flags=0) |如果字符串string的开头和正则表达式pattern匹配返回相应的MatchObject的实例,否则返回None|
8 | | search(pattern, string, flags=0) | 扫描string,如果有个位置可以匹配正则表达式pattern,就返回一个MatchObject的实例,否则返回None |
9 | | sub(pattern, repl, string, count=0, flags=0)| 将string里匹配pattern的部分,用repl替换掉,最多替换count次|
10 | | subn(pattern, repl, string, count=0, flags=0)| 和sub类似,subn返回的是一个替换后的字符串和匹配次数组成的元组|
11 | | split(pattern, string, maxsplit=0, flags=0)| 用pattern匹配到的字符串来分割string |
12 | | findall(pattern, string, flags=0) | 以列表的形式返回string里匹配pattern的字符串 |
13 | | compile(pattern, flags=0)compile(pattern, flags=0) | 把一个正则表达式pattern编译成正则对象,以便可以用正则对象的match和search方法 |
14 | | purge()| Clear the regular expression cache |
15 | | escape(string)| 把string中除了字母和数字以外的字符,都加上反斜杆 |
16 |
17 | ## 2. 特殊匹配符
18 |
19 | | 语法 | 说明
20 | |---|---|
21 | | . | 匹配除了换行符外的任何字符 |
22 | | ^ | 头匹配 |
23 | | $ | 尾匹配 |
24 | | * | 匹配前一个字符0次或多次|
25 | | + | 匹配前一个字符1次或多次|
26 | | ? | 匹配前一个字符0次或一次|
27 | | {m,n} | 匹配前一个字符m至n次|
28 | | \ |对任一特殊字符进行转义|
29 | | [] |用来表示一个字符集合|
30 | | \| |或,代表左右任意匹配一个|
31 |
32 | ## 3. 模块方法
33 |
34 | ### re.match(pattern, string, flags=0)
35 |
36 | 从字符串的开始匹配,如果pattern匹配到就返回一个Match对象实例(Match对象在后面描述),否则放回None。flags为匹配模式(会在下面描述),用于控制正则表达式的匹配方式。
37 | ```python
38 | import re
39 |
40 | a = 'abcdefg'
41 | print re.match(r'abc', a) # 匹配成功
42 | print re.match(r'abc', a).group()
43 | print re.match(r'cde', a) # 匹配失败
44 |
45 | >>><_sre.SRE_Match object at 0x0000000001D94578>
46 | >>>abc
47 | >>>None
48 |
49 | ```
50 |
51 | ### search(pattern, string, flags=0)
52 |
53 | 用于查找字符串中可以匹配成功的子串,如果找到就返回一个Match对象实例,否则返回None。
54 | ```python
55 | import re
56 |
57 | a = 'abcdefg'
58 | print re.search(r'bc', a)
59 | print re.search(r'bc', a).group()
60 | print re.search(r'123', a)
61 |
62 | >>><_sre.SRE_Match object at 0x0000000001D94578>
63 | >>>bc
64 | >>>None
65 | ```
66 |
67 | ### sub(pattern, repl, string, count=0, flags=0)
68 |
69 | 替换,将string里匹配pattern的部分,用repl替换掉,最多替换count次(剩余的匹配将不做处理),然后返回替换后的字符串。
70 | ```python
71 | import re
72 |
73 | a = 'a1b2c3'
74 | print re.sub(r'\d+', '0', a) # 将数字替换成'0'
75 | print re.sub(r'\s+', '0', a) # 将空白字符替换成'0'
76 |
77 | >>>a0b0c0
78 | >>>a1b2c3
79 | ```
80 |
81 | ### subn(pattern, repl, string, count=0, flags=0)
82 |
83 | 跟sub()函数一样,只是它返回的是一个元组,包含新字符串和匹配到的次数
84 |
85 | ```python
86 | import re
87 |
88 | a = 'a1b2c3'
89 | print re.subn(r'\d+', '0', a) # 将数字替换成'0'
90 |
91 | >>>('a0b0c0', 3)
92 | ```
93 |
94 | ### split(pattern, string, maxsplit=0, flags=0)
95 |
96 | 正则版的split(),用匹配pattern的子串来分割string,如果pattern里使用了圆括号,那么被pattern匹配到的串也将作为返回值列表的一部分,maxsplit为最多被分割的字符串。
97 |
98 | ```python
99 | import re
100 |
101 | a = 'a1b1c'
102 | print re.split(r'\d', a)
103 | print re.split(r'(\d)', a)
104 |
105 | >>>['a', 'b', 'c']
106 | >>>['a', '1', 'b', '1', 'c']
107 | ```
108 |
109 | ### findall(pattern, string, flags=0)
110 |
111 | 以列表的形式返回string里匹配pattern的不重叠的子串。
112 |
113 | ```python
114 | import re
115 |
116 | a = 'a1b2c3d4'
117 | print re.findall('\d', a)
118 |
119 | >>>['1', '2', '3', '4']
120 | ```
121 |
122 | ## 4. Match对象
123 |
124 | re.match()、re.search()成功匹配的话都会返回一个Match对象,它包含了很多此次匹配的信息,可以使用Match提供的属性或方法来获取这些信息。例如:
125 | ```
126 | >>>import re
127 |
128 | >>>str = 'he has 2 books and 1 pen'
129 | >>>ob = re.search('(\d+)', str)
130 |
131 | >>>print ob.string # 匹配时使用的文本
132 | he has 2 books and 1 pen
133 |
134 | >>>print ob.re # 匹配时使用的Pattern对象
135 | re.compile(r'(\d+)')
136 |
137 | >>>print ob.group() # 获得一个或多个分组截获的字符串
138 | 2
139 |
140 | >>>print ob.groups() # 以元组形式返回全部分组截获的字符串
141 | ('2',)
142 |
143 | ```
144 |
145 | ## 5.Pattern对象
146 |
147 | Pattern对象对象由re.compile()返回,它带有许多re模块的同名方法,而且方法作用类似一样的。例如:
148 | ```python
149 | >>>import re
150 | >>>pa = re.compile('(d\+)')
151 |
152 | >>>print pa.split('he has 2 books and 1 pen')
153 | ['he has ', '2', ' books and ', '1', ' pen']
154 |
155 | >>>print pa.findall('he has 2 books and 1 pen')
156 | ['2', '1']
157 |
158 | >>>print pa.sub('much', 'he has 2 books and 1 pen')
159 | he has much books and much pen
160 | ```
161 |
162 | ## 6.匹配模式
163 |
164 | 匹配模式取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M, 下面是常见的一些flag。
165 |
166 | * re.I(re.IGNORECASE): 忽略大小写
167 |
168 | ```python
169 | >>>pa = re.compile('abc', re.I)
170 | >>>pa.findall('AbCdEfG')
171 | >>>['AbC']
172 | ```
173 |
174 | * re.L(re.LOCALE):字符集本地化
175 |
176 | 这个功能是为了支持多语言版本的字符集使用环境的,比如在转义符`\w`,在英文环境下,它代表`[a-zA-Z0-9]`,即所以英文字符和数字。如果在一个法语环境下使用,有些法语字符串便匹配不上。加上这L选项和就可以匹配了。不过这个对于中文环境似乎没有什么用,它仍然不能匹配中文字符。
177 |
178 | * re.M(re.MULTILINE): 多行模式,改变'^'和'$'的行为
179 |
180 | ```python
181 | >>>pa = re.compile('^\d+')
182 | >>>pa.findall('123 456\n789 012\n345 678')
183 | >>>['123']
184 |
185 | >>>pa_m = re.compile('^\d+', re.M)
186 | >>>pa_m.findall('123 456\n789 012\n345 678')
187 | >>>['123', '789', '345']
188 | ```
189 |
190 |
191 | * re.S(re.DOTALL): 点任意匹配模式,改变'.'的行为
192 |
193 | `.`号将匹配所有的字符。缺省情况下`.`匹配除换行符`\n`外的所有字符,使用这一选项以后,点号就能匹配包括换行符的任何字符。
194 |
195 | * re.U(re.UNICODE): 根据Unicode字符集解析字符
196 |
197 | * re.X(re.VERBOSE): 详细模式
198 |
199 | ```python
200 | # 这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的
201 | a = re.compile(r"""\d + # the integral part
202 | \. # the decimal point
203 | \d * # some fractional digits""", re.X)
204 | b = re.compile(r"\d+\.\d*")
205 | # 但是在这个模式下,如果你想匹配一个空格,你必须用'/ '的形式('/'后面跟一个空格)
206 | ```
--------------------------------------------------------------------------------
/Python/Python标准库笔记(3) — datetime模块.md:
--------------------------------------------------------------------------------
1 | > datetime模块提供了简单和复杂的方式用于操纵日期和时间的类。虽然支持日期和时间运算,但实现的重点是为了输出格式化和操作高效地提取属性。
2 |
3 | ## 1. 模块内容
4 |
5 | | 内容 | 描述 |
6 | |---| --- |
7 | | 常量 ||
8 | | datetime.MINYEAR | date和datetime对象允许的最小年份|
9 | | datetime.MAXYEAR | date和datetime对象允许的最大年份|
10 | | 类 ||
11 | | datetime.date | 日期对象,属性(year, month, day) |
12 | | datetime.time | 时间对象,属性(hour, minute, second, microsecond, tzinfo)|
13 | | datetime.datetime | 日期时间对象,属性(date和time属性组合)|
14 | | datetime.timedelta | Difference between two datetime values(原文)|
15 | | datetime.tzinfo | 时区信息对象的抽象基类, datetime和time类使用它定制化时间调节 |
16 |
17 | ## 2. datetime.date类
18 | date对象表示理想化日历中的日期(年、月和日), 公历1年1月1日被称为第一天,依次往后推。
19 |
20 | * 类方法
21 |
22 | ```python
23 | from datetime import date
24 |
25 | print 'today():', date.today() # 返回当前日期对象
26 |
27 | print 'fromtimestamp(1491448600):', date.fromtimestamp(1491448600) # 返回时间戳的日期对象
28 |
29 | print 'date.fromordinal(1):', date.fromordinal(1) # 返回对应公历序数的日期对象
30 |
31 | # 输出
32 | today():2017-04-06
33 | fromtimestamp(1491448600):2017-04-06
34 | date.fromordinal(1): 0001-01-01
35 | ```
36 |
37 | * 对象方法和属性
38 |
39 | ```python
40 | from datetime import date
41 |
42 | d = date(2017, 04, 06)
43 |
44 | print 'd.year:', d.year # 返回date对象的年份
45 |
46 | print 'd.month:', d.month # 返回date对象的月份
47 |
48 | print 'd.day:', d.day # 返回date对象的日
49 |
50 | print 'd.timetuple():', d.timetuple() # 返回date对象的struct_time结构
51 |
52 | print 'd.toordinal():', d.toordinal() # 返回公历日期的序数
53 |
54 | print 'd.weekday():', d.weekday() # 返回一星期中的第几天,星期一是0
55 |
56 | print 'd.isoweekday():', d.isoweekday() # 返回一星期中的第几天, 星期一1
57 |
58 | print 'd.isocalendar():', d.isocalendar() # 返回一个元组(年份, 这一年的第几周, 周几)
59 |
60 | print 'd.isoformat():', d.isoformat() # 以ISO 8601格式‘YYYY-MM-DD’返回date的字符串形式
61 |
62 | print 'd.ctime():', d.ctime() # 返回一个表示日期的字符串
63 |
64 | print 'd.strftime("%Y-%m-%d"):', d.strftime("%Y-%m-%d") # 返回指定格式的日期字符串
65 |
66 | print 'd.replace(year=2012, month=12) :', d.replace(year=2012, month=12) # 替换
67 |
68 |
69 |
70 | # 输出
71 |
72 | d.year: 2017
73 | d.month: 4
74 | d.day: 6
75 | d.timetuple(): time.struct_time(tm_year=2017, tm_mon=4, tm_mday=6, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=96, tm_isdst=-1)
76 | d.toordinal(): 736425
77 | d.weekday(): 3
78 | d.isoweekday(): 4
79 | d.isocalendar(): (2017, 14, 4)
80 | d.isoformat(): 2017-04-06
81 | d.ctime(): Thu Apr 6 00:00:00 2017
82 | d.strftime("%Y-%m-%d"): 2017-04-06
83 | d.replace(year=2012, month=12) : 2012-12-06
84 | ```
85 |
86 | ## 3. datetime.time类
87 |
88 | 表示一个(当地)时间对象,与任何特定的日期无关,并且可以通过tzinfo(时区)对象进行调整。
89 |
90 | ```python
91 | from datetime import time
92 |
93 | t = time(12, 10, 30, 50)
94 |
95 | print 't.hour:', t.hour # time对象小时数
96 |
97 | print 't.minute:', t.minute # time对象分钟数
98 |
99 | print 't.second:', t.second # time对象秒数
100 |
101 | print 't.microsecond:', t.microsecond # time对象微秒数
102 |
103 | print 't.isoformat():', t.isoformat() # 返回ISO 8601格式的时间字符串
104 |
105 | print 't.strftime("%H:%M:%S:%f"):', t.strftime("%H:%M:%S:%f") # 返回指定格式的时间格式
106 |
107 | print 't.replace(hour=23, minute=0):', t.replace(hour=23, minute=0) # 替换
108 |
109 | # 输出
110 |
111 | t.hour: 12
112 | t.minute: 10
113 | t.second: 30
114 | t.microsecond: 50
115 | t.isoformat(): 12:10:30.000050
116 | t.strftime("%H:%M:%S:%f"): 12:10:30:000050
117 | t.replace(hour=23, minute=0): 23:00:30.000050
118 | ```
119 |
120 | ## 4. datetime.datetime类
121 |
122 | datetime对象包含date对象和time对象的所有信息
123 |
124 | * 类方法
125 |
126 | ```python
127 | from datetime import datetime, time, date
128 |
129 | print 'datetime.today():', datetime.today() # 返回本地当前的时间datetime对象
130 |
131 | print 'datetime.now():', datetime.now() # 返回本地当前的日期和时间的datetime对象
132 |
133 | print 'datetime.utcnow():', datetime.utcnow() # 返回当前UTC日期和时间的datetime对象
134 |
135 | print 'datetime.fromtimestamp(1491468000):', datetime.fromtimestamp(1491468000) # 返回对应时间戳的datetime对象
136 |
137 | print 'datetime.fromordinal(699000):', datetime.fromordinal(699000) # 同date.fromordinal类似
138 |
139 | print 'datetime.combine(date(2012,12,12), time(12,12,12)):', datetime.combine(date(2012, 12, 12), time(23, 59, 59)) # 拼接date和time
140 |
141 | print 'datetime.strptime("2012-12-10", "%Y-%m-%d"):', datetime.strptime("2012-12-10", "%Y-%m-%d") # 将特定格式的日期时间字符串解析成datetime对象
142 |
143 | # 输出
144 | datetime.today(): 2017-04-06 16:53:12.080000
145 | datetime.now(): 2017-04-06 16:53:12.080000
146 | datetime.utcnow(): 2017-04-06 08:53:12.080000
147 | datetime.fromtimestamp(1491468000): 2017-04-06 16:40:00
148 | datetime.fromordinal(699000): 1914-10-19 00:00:00
149 | datetime.combine(date(2012,12,12), time(12,12,12)): 2012-12-12 23:59:59
150 | datetime.strptime("2012-12-10", "%Y-%m-%d"): 2012-12-10 00:00:00
151 | ```
152 |
153 | * 对象方法和属性
154 |
155 | ```python
156 | from datetime import datetime
157 | d = datetime(2017, 04, 06, 12, 10, 30)
158 |
159 | print 'd.date():', d.date() # 从datetime中拆分出date
160 |
161 | print 'd.time():', d.time() # 从datetime中拆分出time
162 |
163 | print 'd.timetz()', d.timetz() # 从datetime中拆分出具体时区属性的time
164 |
165 | print 'd.replace(year=2016):', d.replace(year=2016) # 替换
166 |
167 | print 'd.timetuple():', d.timetuple() # 时间数组,即struct_time结构
168 |
169 | print 'd.toordinal():', d.toordinal() # 和date.toordinal一样
170 |
171 | print 'd.weekday():', d.weekday() # 和date.weekday一样
172 |
173 | print 'd.isoweekday():', d.isoweekday() # 和date.isoweekday一样
174 |
175 | print 'd.isocalendar():', d.isocalendar() # 和date.isocalendar一样
176 |
177 | print 'd.isoformat():', d.isoformat() # 同上
178 |
179 | print 'd.ctime():', d.ctime() # 同上
180 |
181 | print 'd.strftime("%Y/%m/%d %H:%M:%S"):', d.strftime('%Y/%m/%d %H:%M:%S') # 同上
182 |
183 | # 输出
184 | d.date(): 2017-04-06
185 | d.time(): 12:10:30
186 | d.timetz() 12:10:30
187 | d.replace(year=2016): 2016-04-06 12:10:30
188 | d.timetuple(): time.struct_time(tm_year=2017, tm_mon=4, tm_mday=6, tm_hour=12, tm_min=10, tm_sec=30, tm_wday=3, tm_yday=96, tm_isdst=-1)
189 | d.toordinal(): 736425
190 | d.weekday(): 3
191 | d.isoweekday(): 4
192 | d.isocalendar(): (2017, 14, 4)
193 | d.isoformat(): 2017-04-06T12:10:30
194 | d.ctime(): Thu Apr 6 12:10:30 2017
195 | d.strftime("%Y/%m/%d %H:%M:%S"): 2017/04/06 12:10:30
196 | ```
197 |
198 | ## 5. datetime.timedelta类
199 |
200 | timedelta对象表示一个时间段,即两个日期 (date) 或日期时间 (datetime) 之间的差。支持参数:weeks、days、hours、minutes、seconds、milliseconds、microseconds。但是据官方文档说其内部只存储days、seconds 和 microseconds,其他单位会做对应的时间转换。
201 |
202 |
203 | ```shell
204 | >>>from datetime import timedelta, date, datetime
205 | >>>d = date.today()
206 | >>>print d
207 | 2017-04-06
208 | >>>print d - timedelta(days=5) # 计算前5天
209 | 2017-04-01
210 |
211 | >>>dt = datetime.now()
212 | >>>print dt
213 | 2017-04-06 17:51:03.568000
214 | >>>print dt - timedelta(days=1, hours=5) # 计算前1天5小时
215 | 2017-04-05 12:51:03.568000
216 | ```
217 |
218 | ## 6. 格式字符串
219 | datetime、date、time 都提供了 strftime() 方法,该方法接收一个格式字符串,输出日期时间的字符串表示。支持的转换格式如下:
220 |
221 | | 字符 | 含义 | 例子 |
222 | |---|---|---|
223 | | %a | 英文星期的简写| Sun, Mon, ..., Sat |
224 | | %A |英文星期的全拼 | Sunday, Monday, ..., Saturday |
225 | | %w |星期几,星期天为0,星期六为6| 0, 1, ..., 6 |
226 | | %d | 这个月的第几天,以0填充的10进制|01, 02, ..., 31|
227 | | %b | 月份英文简写| Jan, Feb, ..., Dec|
228 | | %B | 月份英文全拼| January, February, ..., December|
229 | | %m | 月份数,以0填充的10进制|01, 02, ..., 12|
230 | | %y | 不带世纪的年份| 00, 01, ..., 99|
231 | | %Y | 带有世纪的年份| 1970, 1988, 2001, 2013|
232 | | %H | 24小时制的小时数| 00, 01, ..., 23|
233 | | %I | 12小时制的小时数|01, 02, ..., 12|
234 | | %p | AM或者PM|AM, PM|
235 | | %M | 分钟 |00, 01, ..., 59|
236 | | %S |秒数|00, 01, ..., 59|
237 | | %f | 微秒 |000000, 000001, ..., 999999|
238 | | %z | 与utc时间的间隔| (), +0000, -0400, +1030|
239 | | %Z | 时区 | (), UTC, EST, CST|
240 | | %j |当年的第几天|001, 002, ..., 366|
241 | | %U | 当年的第几周(星期天作为周的第一天) | 00, 01, ..., 53|
242 | | %W | 当年的第几周(星期一作为周的第一天)| 00, 01, ..., 53|
243 | | %c | 日期时间的字符串表示|Tue Aug 16 21:30:00 1988|
244 | | %X | 时间字符串表示 |21:30:00|
245 | | %x | 日期字符串表示 | 08/16/88|
246 | | %% |相当于转意等于一个%| % |
247 |
248 | ## 7. 常见应用
249 |
250 | * 时间戳转日期
251 |
252 | ```python
253 | >>>from datetime import datetime
254 | >>>timestamp = 1491550000
255 | >>>dt = datetime.fromtimestamp(timestamp)
256 | >>>print dt
257 | 2017-04-07 15:26:40
258 | >>>print dt.strftime('%Y-%m-%d')
259 | 2017-04-07
260 | ```
261 |
262 | * 字符串转日期
263 |
264 | ```python
265 | >>>from datetime import datetime
266 | >>>str = '2012-12-10'
267 | >>>dt =datetime.strptime(str, '%Y-%m-%d')
268 | >>>print dt.strftime('%Y/%m/%d')
269 | >>>2012/12/10
270 | ```
271 |
272 | * 计算前几天日期
273 |
274 | ```python
275 | >>>from datetime import datetime, timedelta
276 | >>>td = datetime.today()
277 | >>>print td
278 | 2017-04-07 16:27:52.111000
279 | >>>print dt.strftime('%Y/%m/%d')
280 | 2017-04-06 16:27:52.111000
281 | ```
282 |
--------------------------------------------------------------------------------
/Python/Python标准库笔记(4) — collections模块.md:
--------------------------------------------------------------------------------
1 | >这个模块提供几个非常有用的Python容器类型
2 |
3 | ## 1.容器
4 |
5 | | 名称 | 功能描述 |
6 | |---|---|
7 | | OrderedDict | 保持了key插入顺序的dict |
8 | | namedtuple | 生成可以使用名字来访问元素内容的tuple子类|
9 | | Counter | 计数器,主要用来计数 |
10 | | deque | 类似于list的容器,可以快速的在队列头部和尾部添加、删除元素|
11 | | defaultdict | dict的子类,带有默认值的字典|
12 |
13 | ## 2.OrderedDict
14 |
15 | `OrderedDict`类似于正常的词典,只是它记住了元素插入的顺序,当迭代它时,返回它会根据插入的顺序返回。
16 |
17 | * 和正常字典相比,它是"有序"的(插入的顺序)。
18 |
19 | ```python
20 | from collections import OrderedDict
21 |
22 | dict1 = dict() # 普通字典
23 | dict1['apple'] = 2
24 | dict1['banana'] = 1
25 | dict1['orange'] = 3
26 |
27 | dict2 = OrderedDict() # 有序字典
28 | dict2['apple'] = 2
29 | dict2['banana'] = 1
30 | dict2['orange'] = 3
31 |
32 | for key, value in dict1.items():
33 | print 'key:', key, ' value:', value
34 |
35 | for key, value in dict2.items():
36 | print 'key:', key, ' value:', value
37 | ```
38 | ````shell
39 | # ----输出结果-----
40 |
41 | # 普通字典
42 | key: orange value: 3
43 | key: apple value: 2
44 | key: banana value: 1
45 |
46 | # 有序字典
47 | key: apple value: 2
48 | key: banana value: 1
49 | key: orange value: 3
50 | ````
51 |
52 | * 如果重写已经存在的key,原始顺序保持不变,如果删除一个元素再重新插入,那么它会在末尾。
53 |
54 | ```python
55 | from collections import OrderedDict
56 |
57 | dict2 = OrderedDict()
58 | dict2['apple'] = 2
59 | dict2['banana'] = 1
60 | dict2['orange'] = 3
61 |
62 | # 直接重写apple的值,顺序不变
63 | dict2['apple'] = 0
64 |
65 | # 删除在重新写入banana, 顺序改变
66 | dict2.pop('banana')
67 | dict2['banana'] = 1
68 |
69 | print dict2
70 | ```
71 |
72 | ```shell
73 | # ----输出结果-----
74 | OrderedDict([('apple', 0), ('orange', 3), ('banana', 1)])
75 | ```
76 |
77 | * 可以使用排序函数,将普通字典变成OrderedDict。
78 |
79 | ```python
80 | from collections import OrderedDict
81 |
82 | d = {'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2}
83 | order_d = OrderedDict(sorted(d.items(), key=lambda t: t[1]))
84 |
85 | for key, value in order_d.items():
86 | print 'key:', key, ' value:', value
87 | ```
88 |
89 | ```shell
90 | # ----输出结果-----
91 | key: pear value: 1
92 | key: orange value: 2
93 | key: banana value: 3
94 | key: apple value: 4
95 | ```
96 |
97 | ## 3.namedtuple
98 |
99 | namedtuple就是命名的tuple,一般情况下的tuple是这样的(item1, item2, item3,...),所有的item都只能通过index访问,没有明确的称呼,而namedtuple就是事先把这些item命名,以后可以方便访问。
100 |
101 | ```python
102 | from collections import namedtuple
103 |
104 | # 定义一个namedtuple类型User,并包含name,sex和age属性。
105 | User = namedtuple('User', ['name', 'sex', 'age'])
106 |
107 | # 创建一个User对象
108 | user1 = User(name='name1', sex='male', age=18)
109 |
110 | # 也可以通过一个list来创建一个User对象,这里注意需要使用"_make"方法
111 | user2 = User._make(['name2', 'male', 21])
112 |
113 | print 'user1:', user1
114 |
115 | # 使用点号获取属性
116 | print 'name:', user1.name, ' sex:', user1.sex, ' age:', user1.age
117 |
118 | # 将User对象转换成字典,注意要使用"_asdict"
119 | print 'user1._asdict():', user1._asdict()
120 |
121 | # 字典转换成namedtuple
122 | name_dict = {'name': 'name3', 'sex': 'male', 'age': 20}
123 | print 'dict2namedtuple:', User(**name_dict)
124 |
125 | # 修改对象属性,注意要使用"_replace"方法
126 | print 'replace:', user1._replace(age=22)
127 | ```
128 |
129 | ```shell
130 | # ----输出结果-----
131 | user1: User(name='name1', sex='male', age=18)
132 | name: name1 sex: male age: 18
133 | user1._asdict(): OrderedDict([('name', 'name1'), ('sex', 'male'), ('age', 18)])
134 | dict2namedtuple: User(name='name3', sex='male', age=20)
135 | replace: User(name='name1', sex='male', age=22)
136 | ```
137 |
138 | ## 4.Counter
139 |
140 | Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。
141 |
142 | * Counter创建有如下几种方法
143 |
144 | ```python
145 | from collections import Counter
146 |
147 | print Counter('aabbcccd') # 从一个可iterable对象(list、tuple、dict、字符串等)创建
148 | print Counter(['a', 'a', 'c']) # 从一个可iterable对象(list、tuple、dict、字符串等)创建
149 | print Counter({'a': 4, 'b': 2}) # 从一个字典对象创建
150 | print Counter(a=4, b=2) # 从一组键值对创建
151 | ```
152 |
153 | ```shell
154 | # ----输出结果-----
155 | Counter({'c': 3, 'a': 2, 'b': 2, 'd': 1})
156 | Counter({'a': 2, 'c': 1})
157 | Counter({'a': 4, 'b': 2})
158 | Counter({'a': 4, 'b': 2})
159 | ```
160 |
161 | * 获取元素的计数时和dict类似, 但是这里的key不存在时返回0,而不是KeyError
162 |
163 | ```python
164 | >>> c = Counter("acda")
165 | >>> c["a"]
166 | 2
167 | >>> c["h"]
168 | 0
169 | ```
170 |
171 | * 可以使用update和subtract对计数器进行更新(增加和减少)
172 |
173 | ```python
174 | from collections import Counter
175 |
176 | c = Counter('aaabbc')
177 |
178 | print 'c:', c
179 |
180 | c.update("abc")
181 | print 'c.update("abc"):', c # 用另一个iterable对象update 也可传入一个Counter对象
182 |
183 | c.subtract("abc")
184 | print 'c.subtract("abc"):', c # 用另一个iterable对象subtract 也可传入一个Counter对象
185 | ```
186 |
187 | ```shell
188 | # ----输出结果-----
189 | c: Counter({'a': 3, 'b': 2, 'c': 1})
190 | c.update("abc"): Counter({'a': 4, 'b': 3, 'c': 2})
191 | c.subtract("abc"): Counter({'a': 3, 'b': 2, 'c': 1})
192 | ```
193 |
194 | * 返回计数次数top n的元素
195 |
196 | ```python
197 | from collections import Counter
198 |
199 | c = Counter('aaaabbcccddeeffg')
200 |
201 | print c.most_common(3)
202 | ```
203 |
204 | ```shell
205 | # ----输出结果-----
206 | [('a', 4), ('c', 3), ('b', 2)]
207 | ```
208 |
209 | * Counter还支持几个为数不多的数学运算+、-、&、|
210 |
211 | ```python
212 | from collections import Counter
213 |
214 | a = Counter(a=3, b=1)
215 | b = Counter(a=1, b=1)
216 |
217 | print 'a+b:', a + b # 加法,计数相加
218 | print 'a-b:', a - b # 减法,计数相减
219 | print 'b-a:', b - a # 只保留正计数
220 | print 'a&b:', a & b # 交集
221 | print 'a|b:', a | b # 并集
222 | ```
223 |
224 | ```shell
225 | # ----输出结果-----
226 | a+b: Counter({'a': 4, 'b': 2})
227 | a-b: Counter({'a': 2})
228 | b-a: Counter()
229 | a&b: Counter({'a': 1, 'b': 1})
230 | a|b: Counter({'a': 3, 'b': 1})
231 | ```
232 |
233 | ## 5.deque
234 |
235 | deque就是双端队列,是一种具有队列和栈的性质的数据结构,适合于在两端添加和删除,类似与序列的容器
236 |
237 | * 常用方法
238 |
239 | ```python
240 | from collections import deque
241 |
242 | d = deque([]) # 创建一个空的双队列
243 |
244 | d.append(item) # 在d的右边(末尾)添加项目item
245 |
246 | d.appendleft(item) # 从d的左边(开始)添加项目item
247 |
248 | d.clear() # 清空队列,也就是删除d中的所有项目
249 |
250 | d.extend(iterable) # 在d的右边(末尾)添加iterable中的所有项目
251 |
252 | d.extendleft(item) # 在d的左边(开始)添加item中的所有项目
253 |
254 | d.pop() # 删除并返回d中的最后一个(最右边的)项目。如果d为空,则引发IndexError
255 |
256 | d.popleft() # 删除并返回d中的第一个(最左边的)项目。如果d为空,则引发IndexError
257 |
258 | d.rotate(n=1)
259 | # 将d向右旋转n步(如果n<0,则向左旋转)
260 |
261 | d.count(n) # 在队列中统计元素的个数,n表示统计的元素
262 |
263 | d.remove(n) # 从队列中删除指定的值
264 |
265 | d.reverse() # 翻转队列
266 | ```
267 |
268 | ## 6.defaultdict
269 |
270 | 使用dict时,如果引用的Key不存在,就会抛出`KeyError`。如果希望key不存在时,返回一个默认值,就可以用defaultdict
271 |
272 | * 比如要统计字符串中每个单词的出现频率
273 |
274 | ```python
275 | from collections import defaultdict
276 |
277 | s = 'ilikepython'
278 |
279 | # 使用普通字典
280 | frequencies = {}
281 | for each in s:
282 | frequencies[each] += 1
283 |
284 | # 使用普通字典
285 | frequencie = defaultdict(int)
286 | for each in s:
287 | frequencie[each] += 1
288 | ```
289 |
290 | 第一段代码中会抛出一个`KeyError`的异常,而使用defaultdict则不会。defaultdict也可以接受一个函数作为参数来初始化:
291 |
292 | ```python
293 | >>> from collections import defaultdict
294 | >>> d = defaultdict(lambda : 0)
295 | >>> d['0']
296 | 0
297 | ```
298 |
299 |
--------------------------------------------------------------------------------
/Python/Python标准库笔记(5) — sched模块.md:
--------------------------------------------------------------------------------
1 | ## 事件调度
2 | `sched`模块内容很简单,只定义了一个类。它用来最为一个通用的事件调度模块。
3 |
4 | `class sched.scheduler(timefunc, delayfunc)`这个类定义了调度事件的通用接口,它需要外部传入两个参数,`timefunc`是一个没有参数的返回时间类型数字的函数(常用使用的如time模块里面的time),`delayfunc`应该是一个需要一个参数来调用、与timefunc的输出兼容、并且作用为延迟多个时间单位的函数(常用的如time模块的sleep)。
5 |
6 | 下面是一个列子:
7 | ```python
8 | import sched, time
9 |
10 | s = sched.scheduler(time.time, time.sleep) # 生成调度器
11 |
12 | def print_time():
13 | print "From print_time", time.time()
14 |
15 | def print_some_times():
16 | print time.time()
17 | s.enter(5, 1, print_time, ())
18 | # 加入调度事件
19 | # 四个参数分别是:
20 | # 间隔事件(具体值决定与delayfunc, 这里为秒);
21 | # 优先级(两个事件在同一时间到达的情况);
22 | # 触发的函数;
23 | # 函数参数;
24 | s.enter(10, 1, print_time, ())
25 |
26 | # 运行
27 | s.run()
28 | print time.time()
29 |
30 | if __name__ == '__main__':
31 | print_some_times()
32 | ```
33 | 看到的输出结果,隔5秒中执行第一个事件,隔10秒后执行第二个事件:
34 | ```python
35 | 1499259731.99
36 | From print_time 1499259736.99
37 | From print_time 1499259741.99
38 | 1499259741.99
39 | ```
40 |
41 | 在多线程场景中,会有线程安全问题,run()函数会阻塞主线程。官方建议使用`threading.Timer`类代替:
42 |
43 | ```python
44 | import time
45 | from threading import Timer
46 |
47 | def print_time():
48 | print "From print_time", time.time()
49 |
50 | def print_some_times():
51 | print time.time()
52 | Timer(5, print_time, ()).start()
53 | Timer(10, print_time, ()).start()
54 | time.sleep(11) # 阻塞主线程,等待调度程序执行完毕,再执行后面内容
55 | print time.time()
56 |
57 | if __name__ == '__main__':
58 | print_some_times()
59 | ```
60 |
61 | ## Scheduler对象方法
62 |
63 | scheduler对象拥有下面这些方法或属性:
64 |
65 | * scheduler.enterabs(time, priority, action, argument)
66 |
67 | 加入一个事件,`time`参数应该是一个与传递给构造函数的`timefunc`函数的返回值相兼容的数值类型。在同一时间到达的事件将按照`priority`顺序执行。
68 |
69 | 执行事件其实就是执行`action(argument)`。argument必须是一个包含`action`参数的序列。
70 |
71 | 返回值是一个事件,它可以用于稍后取消事件(请参见`cancel()`)。
72 |
73 | * scheduler.enter(delay, priority, action, argument)
74 |
75 | 安排一个事件来延迟`delay`个时间单位。除了时间外,其他参数、含义和返回值与`enterabs()`的值相同。其实内部`enterabs`就是用来被`enter`调用。
76 |
77 | * scheduler.cancel(event)
78 |
79 | 从队列中删除事件。如果事件不是当前队列中的事件,则该方法将跑出一个`ValueError`。
80 |
81 | * scheduler.empty()
82 |
83 | 判断队列是否为空。
84 |
85 | * scheduler.run()
86 |
87 | 运行所有预定的事件。这个函数将等待(使用传递给构造函数的`delayfunc()`函数),然后执行事件,直到不再有预定的事件。
88 |
89 | 任何`action`或`delayfunc`都可以引发异常。在这两种情况下,调度器将保持一个一致的状态并传播异常。如果一个异常是由`action`引起的,就不会再继续执行`run()`。
90 |
91 | * scheduler.queue
92 |
93 | 只读属性,返回一个即将到达的事件列表(按到达事件排序),每个事件都是有`time`、`priority`、`action`、`argument`组成的`namedtuple`。
94 |
95 |
--------------------------------------------------------------------------------
/Python/Python标准库笔记(6) — struct模块.md:
--------------------------------------------------------------------------------
1 | 该模块作用是完成Python数值和C语言结构体的Python字符串形式间的转换。这可以用于处理存储在文件中或从网络连接中存储的二进制数据,以及其他数据源。
2 |
3 | >用途: 在Python基本数据类型和二进制数据之间进行转换
4 |
5 | `struct`模块提供了用于在字节字符串和Python原生数据类型之间转换函数,比如数字和字符串。
6 |
7 | ### 模块函数和Struct类
8 | 它除了提供一个`Struct`类之外,还有许多模块级的函数用于处理结构化的值。这里有个格式符(Format specifiers)的概念,是指从字符串格式转换为已编译的表示形式,类似于正则表达式的处理方式。通常实例化`Struct`类,调用类方法来完成转换,比直接调用模块函数有效的多。下面的例子都是使用`Struct`类。
9 |
10 | ### Packing(打包)和Unpacking(解包)
11 |
12 | `Struct`支持将数据packing(打包)成字符串,并能从字符串中逆向unpacking(解压)出数据。
13 |
14 | 在本例中,格式指定器(specifier)需要一个整型或长整型,一个两个字节的string,和一个浮点数。格式符中的空格用于分隔各个指示器(indicators),在编译格式时会被忽略。
15 |
16 | ```python
17 | import struct
18 |
19 | import binascii
20 |
21 | values = (1, 'ab'.encode('utf-8'), 2.7)
22 | s = struct.Struct('I 2s f')
23 | packed_data = s.pack(*values)
24 |
25 | print('原始值:', values)
26 | print('格式符:', s.format)
27 | print('占用字节:', s.size)
28 | print('打包结果:', binascii.hexlify(packed_data))
29 | ```
30 | ```bash
31 | # output
32 | 原始值: (1, b'ab', 2.7)
33 | 格式符: b'I 2s f'
34 | 占用字节: 12
35 | 打包结果: b'0100000061620000cdcc2c40'
36 | ```
37 |
38 | 这个示例将打包的值转换为十六进制字节序列,用`binascii.hexlify()`方法打印出来。
39 |
40 | 使用`unpack()`方法解包。
41 |
42 | ```python
43 | import struct
44 | import binascii
45 |
46 | packed_data = binascii.unhexlify(b'0100000061620000cdcc2c40')
47 |
48 | s = struct.Struct('I 2s f')
49 | unpacked_data = s.unpack(packed_data)
50 | print('解包结果:', unpacked_data)
51 | ```
52 | ```bash
53 | # output
54 | 解包结果: (1, b'ab', 2.700000047683716)
55 | ```
56 |
57 | 将打包的值传给`unpack()`,基本上返回相同的值(浮点数会有差异)。
58 |
59 | ### 字节顺序/大小/对齐
60 |
61 | 默认情况下,pack是使用本地C库的字节顺序来编码的。格式化字符串的第一个字符可以用来表示填充数据的字节顺序、大小和对齐方式,如下表所描述的:
62 |
63 | | Character | Byte order | Size | Alignment |
64 | | ------------ | ------------ | ------------ | ------------ |
65 | | `@` | 本地 | 本地 | 本地 |
66 | | `=` | 本地 | standard | none |
67 | | `<` | little-endian(小字节序) | standard | none |
68 | | `>` | big-endian(大字节序) | standard | none |
69 | | `!` | network (= big-endian) | standard | none |
70 |
71 | 如果格式符中没有设置这些,那么默认将使用 `@`。
72 |
73 | 本地字节顺序是指字节顺序是由当前主机系统决定。比如:Intel x86和AMD64(x86-64)使用小字节序; Motorola 68000和 PowerPC G5使用大字节序。ARM和Intel安腾支持切换字节序。可以使用`sys.byteorder`查看当前系统的字节顺序。
74 |
75 | 本地大小(Size)和对齐(Alignment)是由c编译器的`sizeof`表达式确定的。它与本地字节顺序对应。
76 |
77 | 标准大小由格式符确定,下面会讲各个格式的标准大小。
78 |
79 | 示例:
80 | ```python
81 | import struct
82 | import binascii
83 |
84 | values = (1, 'ab'.encode('utf-8'), 2.7)
85 | print('原始值 : ', values)
86 |
87 | endianness = [
88 | ('@', 'native, native'),
89 | ('=', 'native, standard'),
90 | ('<', 'little-endian'),
91 | ('>', 'big-endian'),
92 | ('!', 'network'),
93 | ]
94 |
95 | for code, name in endianness:
96 | s = struct.Struct(code + ' I 2s f')
97 | packed_data = s.pack(*values)
98 | print()
99 | print('格式符 : ', s.format, 'for', name)
100 | print('占用字节: ', s.size)
101 | print('打包结果: ', binascii.hexlify(packed_data))
102 | print('解包结果: ', s.unpack(packed_data))
103 | ```
104 |
105 | ```python
106 | # output
107 | 原始值 : (1, b'ab', 2.7)
108 |
109 | 格式符 : b'@ I 2s f' for native, native
110 | 占用字节: 12
111 | 打包结果: b'0100000061620000cdcc2c40'
112 | 解包结果: (1, b'ab', 2.700000047683716)
113 |
114 | 格式符 : b'= I 2s f' for native, standard
115 | 占用字节: 10
116 | 打包结果: b'010000006162cdcc2c40'
117 | 解包结果: (1, b'ab', 2.700000047683716)
118 |
119 | 格式符 : b'< I 2s f' for little-endian
120 | 占用字节: 10
121 | 打包结果: b'010000006162cdcc2c40'
122 | 解包结果: (1, b'ab', 2.700000047683716)
123 |
124 | 格式符 : b'> I 2s f' for big-endian
125 | 占用字节: 10
126 | 打包结果: b'000000016162402ccccd'
127 | 解包结果: (1, b'ab', 2.700000047683716)
128 |
129 | 格式符 : b'! I 2s f' for network
130 | 占用字节: 10
131 | 打包结果: b'000000016162402ccccd'
132 | 解包结果: (1, b'ab', 2.700000047683716)
133 | ```
134 |
135 | ### 格式符
136 |
137 | 格式符对照表如下:
138 |
139 | | Format | C Type | Python type | Standard size | Notes |
140 | | --- | --- | --- | --- | --- |
141 | | `x` | pad byte | no value | | |
142 | | `c` | `char` | bytes of length 1 | 1 | |
143 | | `b` | `signed char` | integer | 1 | (1),(3) |
144 | | `B` | `unsigned char` | integer | 1 | (3) |
145 | | `?` | `_Bool` | bool | 1 | (1) |
146 | | `h` | `short` | integer | 2 | (3) |
147 | | `H` | `unsigned short` | integer | 2 | (3) |
148 | | `i` | `int` | integer | 4 | (3) |
149 | | `I` | `unsigned int` | integer | 4 | (3) |
150 | | `l` | `long` | integer | 4 | (3) |
151 | | `L` | `unsigned long` | integer | 4 | (3) |
152 | | `q` | `long long` | integer | 8 | (2), (3) |
153 | | `Q` | `unsigned long long` | integer | 8 | (2), (3) |
154 | | `n` | `ssize_t` | integer | (4) | |
155 | | `N` | `size_t` | integer | (4) | |
156 | | `f` | `float` | float | 4 | (5) |
157 | | `d` | `double` | float | 8 | (5) |
158 | | `s` | `char[]` | bytes | | |
159 | | `p` | `char[]` | bytes | | |
160 | | `P` | `void *` | integer | | (6) |
161 |
162 | ### 缓冲区
163 |
164 | 将数据打包成二进制通常是用在对性能要求很高的场景。
165 | 在这类场景中可以通过避免为每个打包结构分配新缓冲区的开销来优化。
166 | `pack_into()`和`unpack_from()`方法支持直接写入预先分配的缓冲区。
167 |
168 | ```python
169 | import array
170 | import binascii
171 | import ctypes
172 | import struct
173 |
174 | s = struct.Struct('I 2s f')
175 | values = (1, 'ab'.encode('utf-8'), 2.7)
176 | print('原始值:', values)
177 |
178 | print()
179 | print('使用ctypes模块string buffer')
180 |
181 | b = ctypes.create_string_buffer(s.size)
182 | print('原始buffer :', binascii.hexlify(b.raw))
183 | s.pack_into(b, 0, *values)
184 | print('打包结果写入 :', binascii.hexlify(b.raw))
185 | print('解包 :', s.unpack_from(b, 0))
186 |
187 | print()
188 | print('使用array模块')
189 |
190 | a = array.array('b', b'\0' * s.size)
191 | print('原始值 :', binascii.hexlify(a))
192 | s.pack_into(a, 0, *values)
193 | print('打包写入 :', binascii.hexlify(a))
194 | print('解包 :', s.unpack_from(a, 0))
195 | ```
196 |
197 | ```python
198 | # output
199 | 原始值: (1, b'ab', 2.7)
200 |
201 | 使用ctypes模块string buffer
202 | 原始buffer : b'000000000000000000000000'
203 | 打包结果写入 : b'0100000061620000cdcc2c40'
204 | 解包 : (1, b'ab', 2.700000047683716)
205 |
206 | 使用array模块
207 | 原始值 : b'000000000000000000000000'
208 | 打包写入 : b'0100000061620000cdcc2c40'
209 | 解包 : (1, b'ab', 2.700000047683716)
210 | ```
211 |
--------------------------------------------------------------------------------
/Python/Python标准库笔记(7) — copy模块.md:
--------------------------------------------------------------------------------
1 | > copy-对象拷贝模块;提供了浅拷贝和深拷贝复制对象的功能, 分别对应模块中的两个函数 `copy()` 和 `deepcopy()`。
2 |
3 | ## 1.浅拷贝(Shallow Copies)
4 |
5 | `copy()` 创建的 _浅拷贝_ 是一个新的容器,它包含了对原始对象的内容的引用。也就是说仅拷贝父对象,不会拷贝对象的内部的子对象。即浅复制只复制对象本身,没有复制该对象所引用的对象。比如,当创建一个列表对象的浅拷贝时,将构造一个新的列表,并将原始对象的元素添加给它。
6 |
7 | ```python
8 | import copy
9 |
10 |
11 | class MyClass:
12 |
13 | def __init__(self, name):
14 | self.name = name
15 |
16 | def __eq__(self, other):
17 | return self.name == other.name
18 |
19 | def __gt__(self, other):
20 | return self.name > other.name
21 |
22 |
23 | a = MyClass('a')
24 | my_list = [a]
25 | dup = copy.copy(my_list)
26 |
27 | print(' my_list:', my_list)
28 | print(' dup:', dup)
29 | print(' dup is my_list:', (dup is my_list))
30 | print(' dup == my_list:', (dup == my_list))
31 | print('dup[0] is my_list[0]:', (dup[0] is my_list[0]))
32 | print('dup[0] == my_list[0]:', (dup[0] == my_list[0]))
33 |
34 | ```
35 |
36 | ```python
37 | my_list: [<__main__.MyClass object at 0x0000026DFF98D128>]
38 | dup: [<__main__.MyClass object at 0x0000026DFF98D128>]
39 | dup is my_list: False
40 | dup == my_list: True
41 | dup[0] is my_list[0]: True
42 | dup[0] == my_list[0]: True
43 | ```
44 | 上面的浅拷贝实例中,`dup` 是由 `my_list` 拷贝而来, 但是 `MyClass` 实例不会拷贝,所以 `dup` 列表与 `my_list` 中引用的是同一个对象。
45 |
46 | ## 2.深拷贝(Deep Copies)
47 |
48 | `deepcopy()` 创建的 _深拷贝_ 是一个新的容器,它包含了对原始对象的内容的拷贝。深拷贝完全拷贝了父对象及其子对象。即创建一个新的组合对象,同时递归地拷贝所有子对象,新的组合对象与原对象没有任何关联。虽然实际上会共享不可变的子对象,但不影响它们的相互独立性。
49 |
50 | 将上面代码换成 `deepcopy()`,将会发现其中不同:
51 |
52 | ```python
53 | import copy
54 |
55 |
56 | class MyClass:
57 |
58 | def __init__(self, name):
59 | self.name = name
60 |
61 | def __eq__(self, other):
62 | return self.name == other.name
63 |
64 | def __gt__(self, other):
65 | return self.name > other.name
66 |
67 |
68 | a = MyClass('a')
69 | my_list = [a]
70 | dup = copy.deepcopy(my_list)
71 |
72 | print(' my_list:', my_list)
73 | print(' dup:', dup)
74 | print(' dup is my_list:', (dup is my_list))
75 | print(' dup == my_list:', (dup == my_list))
76 | print('dup[0] is my_list[0]:', (dup[0] is my_list[0]))
77 | print('dup[0] == my_list[0]:', (dup[0] == my_list[0]))
78 |
79 | ```
80 |
81 | ```python
82 | my_list: [<__main__.MyClass object at 0x000002442E47D128>]
83 | dup: [<__main__.MyClass object at 0x00000244352EF208>]
84 | dup is my_list: False
85 | dup == my_list: True
86 | dup[0] is my_list[0]: False
87 | dup[0] == my_list[0]: True
88 | ```
89 |
90 | 列表中的 `MyClass` 实例不再是同一个的对象引用,而是重新复制了一份, 但是当两个对象被比较时,它们的值仍然是相等的。
91 |
92 | ## 3.自定义拷贝行为
93 |
94 | 可以通过自定义 `__copy__()` 和 `__deepcopy__()` 方法来改变默认的拷贝行为。
95 |
96 | * `__copy()__` 是一个无参数方法,它返回一个浅拷贝对象;
97 |
98 | * `__deepcopy()__` 接受一个备忘(memo)字典参数,返回一个深拷贝对象。需要进行深拷贝的成员属性都应该传递给 `copy.deepcopy()` ,以及memo字典,以控制递归。(下面例子将解释memo字典)。
99 |
100 | 下面的示例演示如何调用这些方法:
101 | ```python
102 | import copy
103 |
104 |
105 | class MyClass:
106 |
107 | def __init__(self, name):
108 | self.name = name
109 |
110 | def __eq__(self, other):
111 | return self.name == other.name
112 |
113 | def __gt__(self, other):
114 | return self.name > other.name
115 |
116 | def __copy__(self):
117 | print('__copy__()')
118 | return MyClass(self.name)
119 |
120 | def __deepcopy__(self, memo):
121 | print('__deepcopy__({})'.format(memo))
122 | return MyClass(copy.deepcopy(self.name, memo))
123 |
124 |
125 | a = MyClass('a')
126 |
127 | sc = copy.copy(a)
128 | dc = copy.deepcopy(a)
129 | ```
130 |
131 | ```python
132 | __copy__()
133 | __deepcopy__({})
134 | ```
135 |
136 | memo字典用于跟踪已经拷贝的值,以避免无限递归。
137 |
138 | ## 4.深拷贝中的递归
139 |
140 | 为了避免拷贝时有递归数据结构的问题, `deepcopy()`` 使用一个字典来跟踪已经拷贝的对象。这个字典被传递给 `__deepcopy__()` 方法进行检查。
141 |
142 | 下面示例展示了一个相互关联的数据结构(有向图),如何通过实现 `__deepcopy__()` 方法来防止递归。
143 |
144 | ```python
145 | import copy
146 |
147 |
148 | class Graph:
149 |
150 | def __init__(self, name, connections):
151 | self.name = name
152 | self.connections = connections
153 |
154 | def add_connection(self, other):
155 | self.connections.append(other)
156 |
157 | def __repr__(self):
158 | return 'Graph(name={}, id={})'.format(
159 | self.name, id(self))
160 |
161 | def __deepcopy__(self, memo):
162 | print('\nCalling __deepcopy__ for {!r}'.format(self))
163 | if self in memo:
164 | existing = memo.get(self)
165 | print(' Already copied to {!r}'.format(existing))
166 | return existing
167 | print(' Memo dictionary:')
168 | if memo:
169 | for k, v in memo.items():
170 | print(' {}: {}'.format(k, v))
171 | else:
172 | print(' (empty)')
173 | dup = Graph(copy.deepcopy(self.name, memo), [])
174 | print(' Copying to new object {}'.format(dup))
175 | memo[self] = dup
176 | for c in self.connections:
177 | dup.add_connection(copy.deepcopy(c, memo))
178 | return dup
179 |
180 |
181 | root = Graph('root', [])
182 | a = Graph('a', [root])
183 | b = Graph('b', [a, root])
184 | root.add_connection(a)
185 | root.add_connection(b)
186 |
187 | dup = copy.deepcopy(root)
188 | ```
189 |
190 |
191 | `Graph` 类包括一些基本的有向图方法。可以用一个名称和它所连接的现有节点的列表来初始化一个实例。 `add_connection()` 方法用于设置双向连接。它也被深拷贝操作符使用。
192 |
193 | `__deepcopy__()` 方法打印了它的调用信息,并根据需要管理memo字典内容。它不会复制整个连接列表,而是创建一个新的列表,并将单个连接的副本添加进去。确保在每个新节点被复制时更新memo字典,并且避免递归或重复拷贝节点。与以前一样,该方法在完成时返回拷贝的对象。
194 |
195 | 
196 |
197 | ```python
198 | Calling __deepcopy__ for Graph(name=root, id=2115579269360)
199 | Memo dictionary:
200 | (empty)
201 | Copying to new object Graph(name=root, id=2115695211072)
202 |
203 | Calling __deepcopy__ for Graph(name=a, id=2115695210904)
204 | Memo dictionary:
205 | Graph(name=root, id=2115579269360): Graph(name=root, id=2115695211072)
206 | Copying to new object Graph(name=a, id=2115695211184)
207 |
208 | Calling __deepcopy__ for Graph(name=root, id=2115579269360)
209 | Already copied to Graph(name=root, id=2115695211072)
210 |
211 | Calling __deepcopy__ for Graph(name=b, id=2115695210960)
212 | Memo dictionary:
213 | Graph(name=root, id=2115579269360): Graph(name=root, id=2115695211072)
214 | Graph(name=a, id=2115695210904): Graph(name=a, id=2115695211184)
215 | 2115579269360: Graph(name=root, id=2115695211072)
216 | 2115695219408: [Graph(name=root, id=2115579269360), Graph(name=a, id=2115695210904)]
217 | 2115695210904: Graph(name=a, id=2115695211184)
218 | Copying to new object Graph(name=b, id=2115695211240)
219 | ```
220 |
221 | 第二次遇到根节点时,如果一个节点被已拷贝时, `__deepcopy__()` 检测递归,并从memo字典中重用现有的值,而不是创建一个新对象。
222 |
223 |
--------------------------------------------------------------------------------
/Python/Python标准库笔记(8) — pprint模块.md:
--------------------------------------------------------------------------------
1 | >pprint —— 更美观的打印数据结构
2 |
3 | `pprint` 模块包含一个“美观打印器(`PrettyPrinter`)”,用于产生美观的数据结构视图。格式化程序生成可以由解释器正确解析的数据结构,并且容易使人阅读。
4 |
5 | 下面所有的例子都将依赖定义在 `pprint_data.py` 中的 `data` 数据结构:
6 |
7 | ```python
8 | # pprint_data.py
9 |
10 | data = [
11 | (1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}),
12 | (2, {'e': 'E', 'f': 'F', 'g': 'G', 'h': 'H',
13 | 'i': 'I', 'j': 'J', 'k': 'K', 'l': 'L'}),
14 | (3, ['m', 'n']),
15 | (4, ['o', 'p', 'q']),
16 | (5, ['r', 's', 't''u', 'v', 'x', 'y', 'z']),
17 | ]
18 | ```
19 |
20 | ### 1.Printing
21 |
22 | 使用 `pprint` 模块的最简单方法是调用 `pprint()` 方法:
23 |
24 | ```python
25 | from pprint import pprint
26 |
27 | from pprint_data import data
28 |
29 | print('PRINT:')
30 | print(data)
31 | print()
32 | print('PPRINT:')
33 | pprint(data)
34 | ```
35 |
36 | `pprint(object, stream=None, indent=1, width=80, depth=None)` 格式化对象,并将其写入作为参数传入的stream(默认情况下为 `sys.stdout`)。
37 | ```python
38 | PRINT:
39 | [(1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}), (2, {'e': 'E', 'f': 'F', 'g': 'G', 'h': 'H', 'i': 'I', 'j': 'J', 'k': 'K', 'l': 'L'}), (3, ['m', 'n']), (4, ['o', 'p', 'q']), (5, ['r', 's', 'tu', 'v', 'x', 'y', 'z'])]
40 |
41 | PPRINT:
42 | [(1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}),
43 | (2,
44 | {'e': 'E',
45 | 'f': 'F',
46 | 'g': 'G',
47 | 'h': 'H',
48 | 'i': 'I',
49 | 'j': 'J',
50 | 'k': 'K',
51 | 'l': 'L'}),
52 | (3, ['m', 'n']),
53 | (4, ['o', 'p', 'q']),
54 | (5, ['r', 's', 'tu', 'v', 'x', 'y', 'z'])]
55 | ```
56 |
57 | ### 2.Formatting
58 |
59 | 如果仅仅是要格式化数据结构,而不直接将其写stream(例如,如果要写入日志),则可以使用 `pformat()` 来构建格式化的字符串表示:
60 |
61 | ```python
62 | import logging
63 | from pprint import pformat
64 | from pprint_data import data
65 |
66 | logging.basicConfig(
67 | level=logging.DEBUG,
68 | format='%(levelname)-8s %(message)s',
69 | )
70 | logging.debug('Logging pformatted data')
71 |
72 | formatted = pformat(data)
73 |
74 | for line in formatted.splitlines():
75 | logging.debug(line.rstrip())
76 | ```
77 |
78 | `pformat()` 将原数据结构转化为格式化的字符串形式。这里通过logging输出日志。
79 |
80 | ```python
81 | DEBUG Logging pformatted data
82 | DEBUG [(1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}),
83 | DEBUG (2,
84 | DEBUG {'e': 'E',
85 | DEBUG 'f': 'F',
86 | DEBUG 'g': 'G',
87 | DEBUG 'h': 'H',
88 | DEBUG 'i': 'I',
89 | DEBUG 'j': 'J',
90 | DEBUG 'k': 'K',
91 | DEBUG 'l': 'L'}),
92 | DEBUG (3, ['m', 'n']),
93 | DEBUG (4, ['o', 'p', 'q']),
94 | DEBUG (5, ['r', 's', 'tu', 'v', 'x', 'y', 'z'])]
95 | ```
96 |
97 | ### 3. 作用任意类
98 |
99 | `pprint` 的“美观打印器(`PrettyPrinter`)”不仅仅支持`list/dict`等,它也支持所有定义了 `__repr__` 方法的任意类。
100 |
101 | ```python
102 | from pprint import pprint
103 |
104 |
105 | class Node(object):
106 |
107 | def __init__(self, name, contents=[]):
108 | self.name = name
109 | self.contents = contents[:]
110 |
111 | def __repr__(self):
112 | return (
113 | 'node(' + repr(self.name) + ', ' +
114 | repr(self.contents) + ')'
115 | )
116 |
117 |
118 | trees = [
119 | Node('node-1'),
120 | Node('node-2', [Node('node-2-1')]),
121 | Node('node-3', [Node('node-3-1')]),
122 | ]
123 |
124 | pprint(trees)
125 | ```
126 |
127 | `PrettyPrinter` 会将这些嵌套对象组合起来返回完整的字符串表示。
128 | ```python
129 | [node('node-1', []),
130 | node('node-2', [node('node-2-1', [])]),
131 | node('node-3', [node('node-3-1', [])])]
132 | ```
133 |
134 | ### 4. 作用递归结构
135 |
136 | 当作用于递归数据结构时,会以引用原数据来源的方式表示,格式如 ``, `number`的值是对象的内存地址:
137 |
138 | ```python
139 | from pprint import pprint
140 |
141 | local_data = ['a', 'b', 1, 2]
142 | local_data.append(local_data)
143 |
144 | print('id(local_data) =>', id(local_data))
145 | print(local_data)
146 | pprint(local_data)
147 | ```
148 |
149 | 在上面代码中 `local_data` 将它自己添加到自己,变成了一个递归引用。
150 |
151 | ```python
152 | ('id(local_data) =>', 91945672L)
153 | ['a', 'b', 1, 2, [...]]
154 | ['a', 'b', 1, 2, ]
155 | ```
156 |
157 | ### 5. 限制嵌套层数
158 |
159 | 对于非常深的数据结构,可能并不需要输出所有层级细节。数据可能无法正确格式化,格式化的文本也可能因为太大而无法管理,或者可能某些数据是无关的。
160 |
161 | 使用 ``depth`` 参数来控制 `PrettyPrinter` 递归到嵌套数据结构的深度。输出中不包含的级别由省略号表示:
162 |
163 | ```python
164 | from pprint import pprint
165 |
166 | from pprint_data import data
167 |
168 | pprint(data, depth=1)
169 | pprint(data, depth=2)
170 | ```
171 |
172 | ```python
173 | [(...), (...), (...), (...), (...)]
174 | [(1, {...}), (2, {...}), (3, [...]), (4, [...]), (5, [...])]
175 | ```
176 |
177 | ### 6. 控制输出宽度
178 |
179 | 默认的输出宽度是80个字符长度, 可以使用 `pprint()` 的 ``width`` 参数来调整宽度:
180 |
181 | ```python
182 | from pprint import pprint
183 |
184 | from pprint_data import data
185 |
186 | for width in [80, 5]:
187 | print('WIDTH =', width)
188 | pprint(data, width=width)
189 | print()
190 | ```
191 |
192 | 当宽度太小而不能容纳格式化的数据结构时,如果这样做会导致无效的语法,则行不会被截断或包装:
193 | ```python
194 | ('WIDTH =', 80)
195 | [(1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}),
196 | (2,
197 | {'e': 'E',
198 | 'f': 'F',
199 | 'g': 'G',
200 | 'h': 'H',
201 | 'i': 'I',
202 | 'j': 'J',
203 | 'k': 'K',
204 | 'l': 'L'}),
205 | (3, ['m', 'n']),
206 | (4, ['o', 'p', 'q']),
207 | (5, ['r', 's', 'tu', 'v', 'x', 'y', 'z'])]
208 |
209 | ('WIDTH =', 5)
210 | [(1,
211 | {'a': 'A',
212 | 'b': 'B',
213 | 'c': 'C',
214 | 'd': 'D'}),
215 | (2,
216 | {'e': 'E',
217 | 'f': 'F',
218 | 'g': 'G',
219 | 'h': 'H',
220 | 'i': 'I',
221 | 'j': 'J',
222 | 'k': 'K',
223 | 'l': 'L'}),
224 | (3,
225 | ['m',
226 | 'n']),
227 | (4,
228 | ['o',
229 | 'p',
230 | 'q']),
231 | (5,
232 | ['r',
233 | 's',
234 | 'tu',
235 | 'v',
236 | 'x',
237 | 'y',
238 | 'z'])]
239 | ```
240 |
241 | `pprint()` 的 `compact` 参数表示,在每个单独的行上添加更多的数据,而不是跨行扩展复杂的数据结构(Py2版本无此参数):
242 |
243 | ```python
244 | from pprint import pprint
245 |
246 | from pprint_data import data
247 |
248 | print('DEFAULT:')
249 | pprint(data, compact=False)
250 | print('\nCOMPACT:')
251 | pprint(data, compact=True)
252 | ```
253 |
254 | ```python
255 | DEFAULT:
256 | [(1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}),
257 | (2,
258 | {'e': 'E',
259 | 'f': 'F',
260 | 'g': 'G',
261 | 'h': 'H',
262 | 'i': 'I',
263 | 'j': 'J',
264 | 'k': 'K',
265 | 'l': 'L'}),
266 | (3, ['m', 'n']),
267 | (4, ['o', 'p', 'q']),
268 | (5, ['r', 's', 'tu', 'v', 'x', 'y', 'z'])]
269 |
270 | COMPACT:
271 | [(1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}),
272 | (2,
273 | {'e': 'E',
274 | 'f': 'F',
275 | 'g': 'G',
276 | 'h': 'H',
277 | 'i': 'I',
278 | 'j': 'J',
279 | 'k': 'K',
280 | 'l': 'L'}),
281 | (3, ['m', 'n']), (4, ['o', 'p', 'q']),
282 | (5, ['r', 's', 'tu', 'v', 'x', 'y', 'z'])]
283 | ```
284 |
285 | 上面例子表明,设置 `compact` 后, 当数据结构不适合一行时,它就会被拆分(就像 `data` 列表中的第二项一样)。当多个元素可以在一行上时,就像第三个和第四个成员一样,会被放置在一行。
--------------------------------------------------------------------------------
/Python/Python正则表达式:最短匹配.md:
--------------------------------------------------------------------------------
1 | 最短匹配应用于:假如有一段文本,你只想匹配最短的可能,而不是最长。
2 | ## 例子
3 | 比如有一段html片段,```this is first labelthe second label```,如何匹配出每个a标签中的内容,下面来看下最短与最长的区别。
4 | ## 代码
5 | ```shell
6 | >>> import re
7 | >>> str = 'this is first labelthe second label'
8 |
9 | >>> print re.findall(r'(.*?)', str) # 最短匹配
10 | ['this is first label', 'the second label']
11 |
12 | >>> print re.findall(r'(.*)', str)
13 | ['this is first labelthe second label']
14 | ```
15 | ## 解释
16 | 例子中,模式```r'(.*?)```的意图是匹配被< a>和< /a>包含的文本,但是正则表达式中\*操作符是贪婪的,因此匹配操作会查找出最长的可能。
17 | 但是在*操作符后面加上?操作符,这样使得匹配变成非贪婪模式,从而得到最短匹配。
--------------------------------------------------------------------------------
/Python/Python计算大文件行数方法及性能比较.md:
--------------------------------------------------------------------------------
1 | 如何使用Python快速高效地统计出大文件的总行数, 下面是一些实现方法和性能的比较。
2 |
3 | * 1.readline读所有行
4 | 使用`readlines`方法读取所有行:
5 | ```python
6 | def readline_count(file_name):
7 | return len(open(file_name).readlines())
8 | ```
9 |
10 |
11 | * 2.依次读取每行
12 | 依次读取文件每行内容进行计数:
13 | ```python
14 | def simple_count(file_name):
15 | lines = 0
16 | for _ in open(file_name):
17 | lines += 1
18 | return lines
19 | ```
20 |
21 | * 3.sum计数
22 | 使用`sum`函数计数:
23 | ```python
24 | def sum_count(file_name):
25 | return sum(1 for _ in open(file_name))
26 | ```
27 | * 4.enumerate枚举计数:
28 | ```python
29 | def enumerate_count(file_name):
30 | with open(file_name) as f:
31 | for count, _ in enumerate(f, 1):
32 | pass
33 | return count
34 | ```
35 |
36 | * 5.buff count
37 | 每次读取固定大小,然后统计行数:
38 | ```python
39 | def buff_count(file_name):
40 | with open(file_name, 'rb') as f:
41 | count = 0
42 | buf_size = 1024 * 1024
43 | buf = f.read(buf_size)
44 | while buf:
45 | count += buf.count(b'\n')
46 | buf = f.read(buf_size)
47 | return count
48 | ```
49 | * 6.wc count
50 | 调用使用`wc`命令计算行:
51 | ```python
52 | def wc_count(file_name):
53 | import subprocess
54 | out = subprocess.getoutput("wc -l %s" % file_name)
55 | return int(out.split()[0])
56 | ```
57 | * 7.partial count
58 | 在buff_count基础上引入`partial`:
59 | ```python
60 | def partial_count(file_name):
61 | from functools import partial
62 | buffer = 1024 * 1024
63 | with open(file_name) as f:
64 | return sum(x.count('\n') for x in iter(partial(f.read, buffer), ''))
65 | ```
66 | * 8.iter count
67 | 在buff_count基础上引入`itertools`模块 :
68 | ```python
69 | def iter_count(file_name):
70 | from itertools import (takewhile, repeat)
71 | buffer = 1024 * 1024
72 | with open(file_name) as f:
73 | buf_gen = takewhile(lambda x: x, (f.read(buffer) for _ in repeat(None)))
74 | return sum(buf.count('\n') for buf in buf_gen)
75 | ```
76 | 下面是在我本机 4c8g python3.6的环境下,分别测试100m、500m、1g、10g大小文件运行的时间,单位秒:
77 |
78 | | 方法| 100M | 500M | 1G | 10G |
79 | | ----- | ----- | ----- | ----- | ----- |
80 | | readline_count | 0.25 | 1.82 | 3.27 | 45.04|
81 | | simple_count | 0.13 | 0.85 | 1.58 | 13.53 |
82 | | sum_count | 0.15 | 0.77 | 1.59 | 14.07 |
83 | | enumerate_count | 0.15 | 0.80 | 1.60 | 13.37|
84 | | buff_count | 0.13 | 0.62 | 1.18 | 10.21 |
85 | | wc_count | 0.09 | 0.53 | 0.99 | 9.47 |
86 | | partial_count | 0.12 | 0.55 | 1.11 | 8.92 |
87 | | iter_count | 0.08 | 0.42 | 0.83 | 8.33 |
88 |
89 |
--------------------------------------------------------------------------------
/Python/README.md:
--------------------------------------------------------------------------------
1 | [欢迎光临我的博客小站](http://www.spiderpy.cn/blog/)
2 |
3 | * Python相关笔记
4 |
5 | * [Python NLP入门教程](https://github.com/jhao104/memory-notes/blob/master/Python/Python%20NLP%E5%85%A5%E9%97%A8%E6%95%99%E7%A8%8B.md)
6 | * [Python异步Web编程](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E5%BC%82%E6%AD%A5Web%E7%BC%96%E7%A8%8B.md)
7 | * [Python检查xpath和csspath表达式是否合法](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A3%80%E6%9F%A5xpath%E5%92%8Ccsspath%E8%A1%A8%E8%BE%BE%E5%BC%8F%E6%98%AF%E5%90%A6%E5%90%88%E6%B3%95.md)
8 | * [python类中super()和__init__()的区别](https://github.com/jhao104/memory-notes/blob/master/Python/python%E7%B1%BB%E4%B8%ADsuper\(\)%E5%92%8C__init__\(\)%E7%9A%84%E5%8C%BA%E5%88%AB.md)
9 | * [Python判断文件是否存在的三种方法](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E5%88%A4%E6%96%AD%E6%96%87%E4%BB%B6%E6%98%AF%E5%90%A6%E5%AD%98%E5%9C%A8%E7%9A%84%E4%B8%89%E7%A7%8D%E6%96%B9%E6%B3%95.md)
10 | * [Python图片验证码降噪 — 8邻域降噪](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E5%9B%BE%E7%89%87%E9%AA%8C%E8%AF%81%E7%A0%81%E9%99%8D%E5%99%AA%20%E2%80%94%208%E9%82%BB%E5%9F%9F%E9%99%8D%E5%99%AA.md)
11 | * [Python魔术方法-Magic Method](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E9%AD%94%E6%9C%AF%E6%96%B9%E6%B3%95-Magic%20Method.md)
12 | * [Python操作zookeeper—kazoo模块](https://github.com/jhao104/memory-notes/blob/master/ZooKeeper/Python%E6%93%8D%E4%BD%9Czookeeper%E2%80%94kazoo%E6%A8%A1%E5%9D%97.md)
13 | * [Python正则表达式:最短匹配](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%EF%BC%9A%E6%9C%80%E7%9F%AD%E5%8C%B9%E9%85%8D.md)
14 | * [类属性的延迟计算](https://github.com/jhao104/memory-notes/blob/master/Python/%E7%B1%BB%E5%B1%9E%E6%80%A7%E7%9A%84%E5%BB%B6%E8%BF%9F%E8%AE%A1%E7%AE%97.md)
15 | * [使用captcha模块生成图形验证码](https://github.com/jhao104/memory-notes/blob/master/Python/%E4%BD%BF%E7%94%A8captcha%E6%A8%A1%E5%9D%97%E7%94%9F%E6%88%90%E5%9B%BE%E5%BD%A2%E9%AA%8C%E8%AF%81%E7%A0%81.md)
16 | * [Python标准库笔记(1) — string模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(1)%20%E2%80%94%20string%E6%A8%A1%E5%9D%97.md)
17 | * [Python标准库笔记(2) — re模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(2)%20%E2%80%94%20re%E6%A8%A1%E5%9D%97.md)
18 | * [Python标准库笔记(3) — datetime模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(3)%20%E2%80%94%20datetime%E6%A8%A1%E5%9D%97.md)
19 | * [Python标准库笔记(4) — collections模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(4)%20%E2%80%94%20collections%E6%A8%A1%E5%9D%97.md)
20 | * [Python标准库笔记(5) — sched模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(5)%20%E2%80%94%20sched%E6%A8%A1%E5%9D%97.md)
21 | * [Python标准库笔记(6) — struct模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(6)%20%E2%80%94%20struct%E6%A8%A1%E5%9D%97.md)
22 | * [Python标准库笔记(7) — copy模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(7)%20%E2%80%94%20copy%E6%A8%A1%E5%9D%97.md)
23 | * [Python标准库笔记(8) — pprint模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(8)%20%E2%80%94%20pprint%E6%A8%A1%E5%9D%97.md)
24 | * [Python标准库笔记(9) — functools模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(9)%20%E2%80%94%20functools%E6%A8%A1%E5%9D%97.md)
25 | * [Python标准库笔记(10) — itertools模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(10)%20%E2%80%94%20itertools%E6%A8%A1%E5%9D%97.md)
26 | * [Python标准库笔记(11) — operator模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(11)%20%E2%80%94%20operator%E6%A8%A1%E5%9D%97.md)
27 | * [Docker容器化部署Python应用](https://github.com/jhao104/memory-notes/blob/master/Python/Docker%E5%AE%B9%E5%99%A8%E5%8C%96%E9%83%A8%E7%BD%B2Python%E5%BA%94%E7%94%A8.md)
28 |
--------------------------------------------------------------------------------
/Python/python类中super()和__init__()的区别.md:
--------------------------------------------------------------------------------
1 | ##单继承时super()和__init__()实现的功能是类似的
2 | ```python
3 | class Base(object):
4 | def __init__(self):
5 | print 'Base create'
6 |
7 | class childA(Base):
8 | def __init__(self):
9 | print 'creat A ',
10 | Base.__init__(self)
11 |
12 |
13 | class childB(Base):
14 | def __init__(self):
15 | print 'creat B ',
16 | super(childB, self).__init__()
17 |
18 | base = Base()
19 |
20 | a = childA()
21 | b = childB()
22 | ```
23 |
24 | 输出结果:
25 | ```
26 | Base create
27 | creat A Base create
28 | creat B Base create
29 | ```
30 |
31 | 区别是使用super()继承时不用显式引用基类。
32 |
33 |
34 | ##super()只能用于新式类中
35 |
36 | 把基类改为旧式类,即不继承任何基类
37 | ```python
38 | class Base():
39 | def __init__(self):
40 | print 'Base create'
41 | ```
42 | 执行时,在初始化b时就会报错:
43 | ```python
44 | super(childB, self).__init__()
45 | TypeError: must be type, not classobj
46 | ```
47 |
48 |
49 | ##super不是父类,而是继承顺序的下一个类
50 | 在多重继承时会涉及继承顺序,super()相当于返回继承顺序的下一个类,而不是父类,类似于这样的功能:
51 | ```python
52 | def super(class_name, self):
53 | mro = self.__class__.mro()
54 | return mro[mro.index(class_name) + 1]
55 | ```
56 | mro()用来获得类的继承顺序。
57 | 例如:
58 | ```python
59 | class Base(object):
60 | def __init__(self):
61 | print 'Base create'
62 |
63 | class childA(Base):
64 | def __init__(self):
65 | print 'enter A '
66 | # Base.__init__(self)
67 | super(childA, self).__init__()
68 | print 'leave A'
69 |
70 |
71 | class childB(Base):
72 | def __init__(self):
73 | print 'enter B '
74 | # Base.__init__(self)
75 | super(childB, self).__init__()
76 | print 'leave B'
77 |
78 | class childC(childA, childB):
79 | pass
80 |
81 | c = childC()
82 | print c.__class__.__mro__
83 | ```
84 | 输出结果如下:
85 | ```
86 | enter A
87 | enter B
88 | Base create
89 | leave B
90 | leave A
91 | (, , , , )
92 | ```
93 | supder和父类没有关联,因此执行顺序是A —> B—>—>Base
94 |
95 | 执行过程相当于:初始化childC()时,先会去调用childA的构造方法中的 super(childA, self).\__init\__(), super(childA, self)返回当前类的继承顺序中childA后的一个类childB;然后再执行childB().\__init()\__,这样顺序执行下去。
96 |
97 | 在多重继承里,如果把childA()中的 super(childA, self).\__init\__() 换成Base.\__init\__(self),在执行时,继承childA后就会直接跳到Base类里,而略过了childB:
98 | ```
99 | enter A
100 | Base create
101 | leave A
102 | (, , , , )
103 | ```
104 | 从super()方法可以看出,super()的第一个参数可以是继承链中任意一个类的名字,
105 |
106 | 如果是本身就会依次继承下一个类;
107 |
108 | 如果是继承链里之前的类便会无限递归下去;
109 |
110 | 如果是继承链里之后的类便会忽略继承链汇总本身和传入类之间的类;
111 |
112 | 比如将childA()中的super改为:`super(childC, self).__init__()`,程序就会无限递归下去。
113 | 如:
114 | ```
115 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
116 | super(childC, self).__init__()
117 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
118 | super(childC, self).__init__()
119 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
120 | super(childC, self).__init__()
121 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
122 | super(childC, self).__init__()
123 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
124 | super(childC, self).__init__()
125 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
126 | super(childC, self).__init__()
127 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
128 | super(childC, self).__init__()
129 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
130 | super(childC, self).__init__()
131 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
132 | super(childC, self).__init__()
133 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
134 | super(childC, self).__init__()
135 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
136 | super(childC, self).__init__()
137 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
138 | super(childC, self).__init__()
139 | File "C:/Users/Administrator/Desktop/crawler/learn.py", line 10, in __init__
140 | super(childC, self).__init__()
141 | RuntimeError: maximum recursion depth exceeded while calling a Python object
142 | ```
143 |
144 |
145 | ##super()可以避免重复调用
146 | 如果childA基础Base, childB继承childA和Base,如果childB需要调用Base的__init__()方法时,就会导致__init__()被执行两次:
147 | ```python
148 | class Base(object):
149 | def __init__(self):
150 | print 'Base create'
151 |
152 | class childA(Base):
153 | def __init__(self):
154 | print 'enter A '
155 | Base.__init__(self)
156 | print 'leave A'
157 |
158 |
159 | class childB(childA, Base):
160 | def __init__(self):
161 | childA.__init__(self)
162 | Base.__init__(self)
163 |
164 | b = childB()
165 | ```
166 | Base的__init__()方法被执行了两次
167 | ```
168 | enter A
169 | Base create
170 | leave A
171 | Base create
172 | ```
173 | 使用super()是可避免重复调用
174 | ```python
175 | class Base(object):
176 | def __init__(self):
177 | print 'Base create'
178 |
179 | class childA(Base):
180 | def __init__(self):
181 | print 'enter A '
182 | super(childA, self).__init__()
183 | print 'leave A'
184 |
185 |
186 | class childB(childA, Base):
187 | def __init__(self):
188 | super(childB, self).__init__()
189 |
190 | b = childB()
191 | print b.__class__.mro()
192 | ```
193 | ```
194 | enter A
195 | Base create
196 | leave A
197 | [, , , ]
198 | ```
199 |
--------------------------------------------------------------------------------
/Python/使用captcha模块生成图形验证码.md:
--------------------------------------------------------------------------------
1 | captcha模块是专门用于生成图形验证码和语音验证码的Python三方库。图形验证码支持数字和英文单词。
2 |
3 | ## 安装
4 |
5 | ### 安装
6 | 可以直接使用 `pip` 安装,或者到[项目地址](https://github.com/lepture/captcha)下载安装。
7 |
8 | ### 模块支持
9 |
10 | 由于 `captcha` 模块内部是采用 `PIL` 模块生成图片,所以需要安装 `PIL` 模块才可以正常使用。
11 |
12 |
13 | ## 生成验证码
14 |
15 | ### 一般方法
16 |
17 | 使用其中 `image` 模块中的 `ImageCaptcha` 类生成图形验证码:
18 |
19 | ```python
20 | from captcha.image import ImageCaptcha
21 |
22 | img = ImageCaptcha()
23 | image = img.generate_image('python')
24 | image.show()
25 | image.save('python.jpg')
26 | ```
27 |
28 | 生成验证码如下:
29 |
30 | 
31 |
32 | `generate_image()` 方法接收一个字符串参数,将生成次字符串内容的验证码,返回的是 `PIL` 模块中的 `Image` 对象。可以使用 `PIL` 模块中 `Image` 对象的任何支持方法对其操作。例子中的 `image.show()` 和 `image.save()` 均是 `PIL` 模块的方法。
33 |
34 | ### 具体参数
35 |
36 | `ImageCaptcha(width=160, height=60, fonts=None, font_sizes=None)` 类实例化时,还可传入四个参数:
37 |
38 | * `width`: 生成验证码图片的宽度,默认为160个像素;
39 | * `height`: 生成验证码图片的高度,默认为60个像素;
40 | * `fonts`: 字体文件路径,用于生成验证码时的字体,默认使用模块自带 `DroidSansMono.ttf` 字体,你可以将字体文件放入list或者tuple传入,生成验证码时将随机使用;
41 | * `font_sizes`: 控制验证码字体大小,同`fonts`一样,接收一个list或者tuple,随机使用。
42 |
43 | ### 主要方法
44 |
45 | * `generate_image(chars)`
46 | 生成验证码的核心方法,生成`chars`内容的验证码图片的`Image`对象。
47 |
48 | * `create_captcha_image(chars, color, background)`
49 | `generate_image`的实现方法,可以通过重写此方法来实现自定义验证码样式。
50 |
51 | * `create_noise_dots(image, color, width=3, number=30)`
52 | 生成验证码干扰点。
53 |
54 | * `create_noise_curve(image, color)`
55 | 生成验证码干扰曲线
56 |
57 |
58 |
59 |
60 |
--------------------------------------------------------------------------------
/Python/类属性的延迟计算.md:
--------------------------------------------------------------------------------
1 | > 所谓类属性的延迟计算就是将类的属性定义成一个property,只在访问的时候才会计算,而且一旦被访问后,结果将会被缓存起来,不用每次都计算。
2 |
3 | ## 优点
4 | 构造一个延迟计算属性的主要目的是为了提升性能
5 |
6 | ## 实现
7 |
8 | ```
9 | class LazyProperty(object):
10 | def __init__(self, func):
11 | self.func = func
12 |
13 | def __get__(self, instance, owner):
14 | if instance is None:
15 | return self
16 | else:
17 | value = self.func(instance)
18 | setattr(instance, self.func.__name__, value)
19 | return value
20 |
21 |
22 | import math
23 |
24 |
25 | class Circle(object):
26 | def __init__(self, radius):
27 | self.radius = radius
28 |
29 | @LazyProperty
30 | def area(self):
31 | print 'Computing area'
32 | return math.pi * self.radius ** 2
33 |
34 | @LazyProperty
35 | def perimeter(self):
36 | print 'Computing perimeter'
37 | return 2 * math.pi * self.radius
38 | ```
39 |
40 | ## 说明
41 | 定义了一个延迟计算的装饰器类LazyProperty。Circle是用于测试的类,Circle类有是三个属性半径(radius)、面积(area)、周长(perimeter)。面积和周长的属性被LazyProperty装饰,下面来试试LazyProperty的魔法:
42 | ```
43 | >>> c = Circle(2)
44 | >>> print c.area
45 | Computing area
46 | 12.5663706144
47 | >>> print c.area
48 | 12.5663706144
49 | ```
50 | 在area()中每计算一次就会打印一次“Computing area”,而连续调用两次c.area后“Computing area”只被打印了一次。这得益于LazyProperty,只要调用一次后,无论后续调用多少次都不会重复计算。
51 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [欢迎光临我的博客小站](http://www.spiderpy.cn/blog/)
2 |
3 | # Good memory as bad written
4 |
5 | > 一些个人笔记,方便需要时查阅。喜欢的给个star
6 |
7 |
8 |
9 | * [Django](https://github.com/jhao104/memory-notes/tree/master/Django)
10 |
11 | * [Ubuntu上通过nginx部署Django笔记](https://github.com/jhao104/memory-notes/blob/master/Django/Ubuntu%E4%B8%8A%E9%80%9A%E8%BF%87nginx%E9%83%A8%E7%BD%B2Django%E7%AC%94%E8%AE%B0.md)
12 |
13 | * [Django中六个常用的自定义装饰器](https://github.com/jhao104/memory-notes/blob/master/Django/Django%E4%B8%AD%E5%85%AD%E4%B8%AA%E5%B8%B8%E7%94%A8%E7%9A%84%E8%87%AA%E5%AE%9A%E4%B9%89%E8%A3%85%E9%A5%B0%E5%99%A8.md)
14 |
15 | * [Django 1.10中文文档-第一个应用Part1-请求与响应](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part1-%E8%AF%B7%E6%B1%82%E4%B8%8E%E5%93%8D%E5%BA%94.md)
16 |
17 | * [Django 1.10中文文档-第一个应用Part2-模型和管理站点](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part2-%E6%A8%A1%E5%9E%8B%E5%92%8C%E7%AE%A1%E7%90%86%E7%AB%99%E7%82%B9.md)
18 |
19 | * [Django 1.10中文文档-第一个应用Part3-视图和模板](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part3-%E8%A7%86%E5%9B%BE%E5%92%8C%E6%A8%A1%E6%9D%BF.md)
20 |
21 | * [Django 1.10中文文档-第一个应用Part4-表单和通用视图](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part4-%E8%A1%A8%E5%8D%95%E5%92%8C%E9%80%9A%E7%94%A8%E8%A7%86%E5%9B%BE.md)
22 |
23 | * [Django 1.10中文文档-第一个应用Part5-测试](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part5-%E6%B5%8B%E8%AF%95.md)
24 |
25 | * [Django 1.10中文文档-第一个应用Part6-静态文件](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part6-%E9%9D%99%E6%80%81%E6%96%87%E4%BB%B6.md)
26 |
27 | * [Django 1.10中文文档-第一个应用Part7-自定义管理站点](https://github.com/jhao104/memory-notes/blob/master/Django/Django%201.10%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3-%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%BA%94%E7%94%A8Part7-%E8%87%AA%E5%AE%9A%E4%B9%89%E7%AE%A1%E7%90%86%E7%AB%99%E7%82%B9.md)
28 |
29 | * [Django 1.10中文文档-更多内容 点击](https://github.com/jhao104/django-chinese-doc)
30 |
31 | * [Linux](https://github.com/jhao104/memory-notes/tree/master/Linux)
32 |
33 | * [Linux笔记:使用Vim编辑器](https://github.com/jhao104/memory-notes/blob/master/Linux/Linux%E7%AC%94%E8%AE%B0%EF%BC%9A%E4%BD%BF%E7%94%A8Vim%E7%BC%96%E8%BE%91%E5%99%A8.md)
34 |
35 | * [PyCharm](https://github.com/jhao104/memory-notes/tree/master/Pycharm)
36 |
37 | * [Pycharm创建virtualenv方法](https://github.com/jhao104/memory-notes/blob/master/Pycharm/Pycharm%E5%88%9B%E5%BB%BAvirtualenv%E6%96%B9%E6%B3%95.md)
38 | * [PyCharm 自定义文件和代码模板](https://github.com/jhao104/memory-notes/blob/master/Pycharm/PyCharm%20%E8%87%AA%E5%AE%9A%E4%B9%89%E6%96%87%E4%BB%B6%E5%92%8C%E4%BB%A3%E7%A0%81%E6%A8%A1%E6%9D%BF.md)
39 |
40 |
41 | * [Python](https://github.com/jhao104/memory-notes/tree/master/Python)
42 |
43 | * [Python NLP入门教程](https://github.com/jhao104/memory-notes/blob/master/Python/Python%20NLP%E5%85%A5%E9%97%A8%E6%95%99%E7%A8%8B.md)
44 | * [Python异步Web编程](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E5%BC%82%E6%AD%A5Web%E7%BC%96%E7%A8%8B.md)
45 | * [python类中super()和__init__()的区别](https://github.com/jhao104/memory-notes/blob/master/Python/python%E7%B1%BB%E4%B8%ADsuper\(\)%E5%92%8C__init__\(\)%E7%9A%84%E5%8C%BA%E5%88%AB.md)
46 | * [Python判断文件是否存在的三种方法](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E5%88%A4%E6%96%AD%E6%96%87%E4%BB%B6%E6%98%AF%E5%90%A6%E5%AD%98%E5%9C%A8%E7%9A%84%E4%B8%89%E7%A7%8D%E6%96%B9%E6%B3%95.md)
47 | * [Python魔术方法-Magic Method](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E9%AD%94%E6%9C%AF%E6%96%B9%E6%B3%95-Magic%20Method.md)
48 | * [Python图片验证码降噪 — 8邻域降噪](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E5%9B%BE%E7%89%87%E9%AA%8C%E8%AF%81%E7%A0%81%E9%99%8D%E5%99%AA%20%E2%80%94%208%E9%82%BB%E5%9F%9F%E9%99%8D%E5%99%AA.md)
49 | * [Python操作zookeeper—kazoo模块](https://github.com/jhao104/memory-notes/blob/master/ZooKeeper/Python%E6%93%8D%E4%BD%9Czookeeper%E2%80%94kazoo%E6%A8%A1%E5%9D%97.md)
50 | * [Python正则表达式:最短匹配](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%EF%BC%9A%E6%9C%80%E7%9F%AD%E5%8C%B9%E9%85%8D.md)
51 | * [类属性的延迟计算](https://github.com/jhao104/memory-notes/blob/master/Python/%E7%B1%BB%E5%B1%9E%E6%80%A7%E7%9A%84%E5%BB%B6%E8%BF%9F%E8%AE%A1%E7%AE%97.md)
52 | * [使用captcha模块生成图形验证码](https://github.com/jhao104/memory-notes/blob/master/Python/%E4%BD%BF%E7%94%A8captcha%E6%A8%A1%E5%9D%97%E7%94%9F%E6%88%90%E5%9B%BE%E5%BD%A2%E9%AA%8C%E8%AF%81%E7%A0%81.md)
53 | * [Python标准库笔记(1) — string模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(1)%20%E2%80%94%20string%E6%A8%A1%E5%9D%97.md)
54 | * [Python标准库笔记(2) — re模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(2)%20%E2%80%94%20re%E6%A8%A1%E5%9D%97.md)
55 | * [Python标准库笔记(3) — datetime模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(3)%20%E2%80%94%20datetime%E6%A8%A1%E5%9D%97.md)
56 | * [Python标准库笔记(4) — collections模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(4)%20%E2%80%94%20collections%E6%A8%A1%E5%9D%97.md)
57 | * [Python标准库笔记(5) — sched模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(5)%20%E2%80%94%20sched%E6%A8%A1%E5%9D%97.md)
58 | * [Python标准库笔记(6) — struct模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(6)%20%E2%80%94%20struct%E6%A8%A1%E5%9D%97.md)
59 | * [Python标准库笔记(7) — copy模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(7)%20%E2%80%94%20copy%E6%A8%A1%E5%9D%97.md)
60 | * [Python标准库笔记(8) — pprint模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(8)%20%E2%80%94%20pprint%E6%A8%A1%E5%9D%97.md)
61 | * [Python标准库笔记(9) — functools模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(9)%20%E2%80%94%20functools%E6%A8%A1%E5%9D%97.md)
62 | * [Python标准库笔记(10) — itertools模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(10)%20%E2%80%94%20itertools%E6%A8%A1%E5%9D%97.md)
63 | * [Python标准库笔记(11) — operator模块](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E6%A0%87%E5%87%86%E5%BA%93%E7%AC%94%E8%AE%B0(11)%20%E2%80%94%20operator%E6%A8%A1%E5%9D%97.md)
64 | * [Docker容器化部署Python应用](https://github.com/jhao104/memory-notes/blob/master/Python/Docker%E5%AE%B9%E5%99%A8%E5%8C%96%E9%83%A8%E7%BD%B2Python%E5%BA%94%E7%94%A8.md)
65 | * [Airflow笔记-MySqlOperator使用及conn配置](https://github.com/jhao104/memory-notes/blob/master/Python/Airflow%E7%AC%94%E8%AE%B0-MySqlOperator%E4%BD%BF%E7%94%A8%E5%8F%8Aconn%E9%85%8D%E7%BD%AE.md)
66 |
67 | * [SSDB](https://github.com/jhao104/memory-notes/tree/master/SSDB)
68 |
69 | * [SSDB安装配置记录](https://github.com/jhao104/memory-notes/blob/master/SSDB/SSDB%E5%AE%89%E8%A3%85%E9%85%8D%E7%BD%AE%E8%AE%B0%E5%BD%95.md)
70 | * [SSDB图形界面管理工具:phpssdbadmin安装部署](https://github.com/jhao104/memory-notes/blob/master/SSDB/SSDB%E5%9B%BE%E5%BD%A2%E7%95%8C%E9%9D%A2%E7%AE%A1%E7%90%86%E5%B7%A5%E5%85%B7%EF%BC%9Aphpssdbadmin%E5%AE%89%E8%A3%85%E9%83%A8%E7%BD%B2.md)
71 |
72 | * [ZooKeeper](https://github.com/jhao104/memory-notes/tree/master/ZooKeeper)
73 |
74 | * [Python操作zookeeper—kazoo模块](https://github.com/jhao104/memory-notes/blob/master/ZooKeeper/Python%E6%93%8D%E4%BD%9Czookeeper%E2%80%94kazoo%E6%A8%A1%E5%9D%97.md)
75 |
76 | * [爬虫](https://github.com/jhao104/memory-notes/tree/master/%E7%88%AC%E8%99%AB)
77 |
78 | * [Python Webdriver 重新使用已经打开的浏览器实例](https://github.com/jhao104/memory-notes/blob/master/%E7%88%AC%E8%99%AB/Python%20Webdriver%20%E9%87%8D%E6%96%B0%E4%BD%BF%E7%94%A8%E5%B7%B2%E7%BB%8F%E6%89%93%E5%BC%80%E7%9A%84%E6%B5%8F%E8%A7%88%E5%99%A8%E5%AE%9E%E4%BE%8B.md)
79 | * [Python检查xpath和csspath表达式是否合法](https://github.com/jhao104/memory-notes/blob/master/%E7%88%AC%E8%99%AB/Python%E6%A3%80%E6%9F%A5xpath%E5%92%8Ccsspath%E8%A1%A8%E8%BE%BE%E5%BC%8F%E6%98%AF%E5%90%A6%E5%90%88%E6%B3%95.md)
80 | * [Python爬虫—破解JS加密的Cookie](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E7%88%AC%E8%99%AB%E2%80%94%E7%A0%B4%E8%A7%A3JS%E5%8A%A0%E5%AF%86%E7%9A%84Cookie.md)
81 | * [Python爬虫代理IP池](https://github.com/jhao104/memory-notes/blob/master/%E7%88%AC%E8%99%AB/Python%E7%88%AC%E8%99%AB%E4%BB%A3%E7%90%86IP%E6%B1%A0.md)
82 |
83 | * [算法记录](https://github.com/jhao104/memory-notes/tree/master/%E7%AE%97%E6%B3%95%E8%AE%B0%E5%BD%95)
84 |
85 | * [曲线点抽稀算法-Python实现](https://github.com/jhao104/memory-notes/blob/master/%E7%AE%97%E6%B3%95%E8%AE%B0%E5%BD%95/%E6%9B%B2%E7%BA%BF%E7%82%B9%E6%8A%BD%E7%A8%80%E7%AE%97%E6%B3%95-Python%E5%AE%9E%E7%8E%B0.md)
86 | * [常用样本相似性和距离度量方法](https://github.com/jhao104/memory-notes/blob/master/算法记录/常用样本相似性和距度量方法.md)
87 |
88 |
89 |
90 |
91 |
92 |
--------------------------------------------------------------------------------
/SSDB/README.md:
--------------------------------------------------------------------------------
1 | [欢迎光临我的博客小站](http://www.spiderpy.cn/blog/)
2 |
3 | * SSDB相关笔记
4 |
5 | * [SSDB安装配置记录](https://github.com/jhao104/memory-notes/blob/master/SSDB/SSDB%E5%AE%89%E8%A3%85%E9%85%8D%E7%BD%AE%E8%AE%B0%E5%BD%95.md)
6 | * [SSDB图形界面管理工具:phpssdbadmin安装部署](https://github.com/jhao104/memory-notes/blob/master/SSDB/SSDB%E5%9B%BE%E5%BD%A2%E7%95%8C%E9%9D%A2%E7%AE%A1%E7%90%86%E5%B7%A5%E5%85%B7%EF%BC%9Aphpssdbadmin%E5%AE%89%E8%A3%85%E9%83%A8%E7%BD%B2.md)
--------------------------------------------------------------------------------
/SSDB/SSDB图形界面管理工具:phpssdbadmin安装部署.md:
--------------------------------------------------------------------------------
1 | > 环境: 14.04.1-Ubuntu
2 |
3 | ## 1、安装Nginx
4 | ```shell
5 | apt-get install nginx
6 | ```
7 | ubantu安装完Nginx后,文件结构大致为:
8 |
9 | 所有的配置文件都在 `/etc/nginx`下;
10 |
11 | 启动程序文件在 `/usr/sbin/nginx`下;
12 |
13 | 日志文件在 `/var/log/nginx/`下,分别是access.log和error.log;
14 |
15 | 并且在 `/etc/init.d`下创建了nginx启动脚本
16 |
17 | 安装完成后可以尝试启动nginx:
18 | ```shell
19 | /etc/init.d/nginx start
20 | ```
21 | 然后能通过浏览器访问到 http://localhost/, 一切正常,如不能访问请检查原因。
22 |
23 | ## 2、安装PHP 和php-fpm
24 |
25 | ```shell
26 | sudo apt-get install php5-fpm
27 | sudo apt-get install php5-gd # Popular image manipulation library; used extensively by Wordpress and it's plugins.
28 | sudo apt-get install php5-cli # Makes the php5 command available to the terminal for php5 scripting
29 | sudo apt-get install php5-curl # Allows curl (file downloading tool) to be called from PHP5
30 | sudo apt-get install php5-mcrypt # Provides encryption algorithms to PHP scripts
31 | sudo apt-get install php5-mysql # Allows PHP5 scripts to talk to a MySQL Database
32 | sudo apt-get install php5-readline # Allows PHP5 scripts to use the readline function
33 | ```
34 |
35 | 查看php5运行进程:
36 |
37 | ```shell
38 | ps -waux | grep php5
39 | ```
40 |
41 | 启动关闭php5进程
42 |
43 | ```shell
44 | sudo service php5-fpm stop
45 | sudo service php5-fpm start
46 | sudo service php5-fpm restart
47 | sudo service php5-fpm status
48 | ```
49 |
50 |
51 | ## 3、配置php和nginx
52 |
53 | nginx的配置文件 `/etc/nginx/nginx.conf中include了/etc/nginx/sites-enabled/*`,因此可以去修改`/etc/nginx/sites-enabled`下的配置文件
54 |
55 | ```shell
56 | vi /etc/nginx/sites-available/default
57 | ```
58 |
59 | 做如下修改:
60 |
61 | ```
62 | location ~ \.php$ {
63 | # fastcgi_split_path_info ^(.+\.php)(/.+)$;
64 | # NOTE: You should have "cgi.fix_pathinfo = 0;" in php.ini
65 | # With php5-cgi alone:
66 | # fastcgi_pass 127.0.0.1:9000;
67 | # With php5-fpm:
68 | # try_files $uri =404;
69 | fastcgi_pass unix:/var/run/php5-fpm.sock;
70 | fastcgi_index index.php;
71 | include fastcgi_params;
72 | }
73 | ```
74 |
75 | 还需要在`/etc/nginx/fastcgi_params`添加如下两句:
76 | ```
77 | fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
78 | fastcgi_param PATH_INFO $fastcgi_script_name;
79 | ```
80 |
81 | 然后reload Nginx:
82 | ```shell
83 | sudo service nginx reload
84 | ```
85 |
86 | ## 4、验证php是否配置成功
87 |
88 | 新建phpinfo.php文件:
89 | ```shell
90 | sudo vim /usr/share/nginx/html/phpinfo.php
91 | ```
92 |
93 | 内容如下:
94 | ```
95 |
96 | ```
97 | 然后通过浏览器访问:http://localhost/phpinfo.php
98 | 能够看到php的详细信息则说明配置成功。
99 | 
100 |
101 | ## 5、下载phpssdbadmin
102 |
103 | 下载phpssdbadmin到`/usr/share/nginx/html`目录下:
104 |
105 | ```shell
106 | cd /usr/share/nginx/html
107 | git clone https://github.com/ssdb/phpssdbadmin.git
108 | ```
109 |
110 |
111 | ## 5、配置phpssdbadmin
112 |
113 | 修改phpssdbadmin的配置,修改`app/config/config.php`,将host和port改为ssdb配置的值:
114 | ```
115 | 'ssdb' => array(
116 | 'host' => '127.0.0.1',
117 | 'port' => '8888',
118 | ),
119 | # 如果使用新版的phpssdbadmin,还需要修改用户名和密码,因为原始密码太简单不允许登录:
120 | 'login' => array(
121 | 'name' => 'jinghao',
122 | 'password' => 'jinghao123', // at least 6 characters
123 | ),
124 | ```
125 |
126 |
127 | 修改nginx的配置文件:
128 | ```shell
129 | vim /etc/nginx/sites-enabled/default
130 | ```
131 | 添加:
132 | ```
133 | location /phpssdbadmin {
134 | try_files $uri $uri/ /phpssdbadmin/index.php?$args;
135 | index index.php;
136 | }
137 | ```
138 | 重启nginx,然后访问http://localhost/phpssdbadmin ,出现登录页面则配置成功。
139 |
140 | 
141 | 
142 |
143 |
--------------------------------------------------------------------------------
/SSDB/SSDB安装配置记录.md:
--------------------------------------------------------------------------------
1 | >SSDB的性能很突出,与Redis基本相当了,Redis是内存型,容量问题是弱项,并且内存成本太高,SSDB针对这个弱点,使用硬盘存储,使用Google高性能的存储引擎LevelDB,适合大数据量处理并把性能优化到Redis级别,具有Redis的数据结构、兼容Redis客户端,还给出了从Redis迁移到SSDB的方案。
2 |
3 | 本文是将我安装和测试的步骤记录下来,总结成文档,便于日后使用。
4 | ## 1、编译安装
5 |
6 | 照着官方的教程下载安装:
7 |
8 | ### 下载:
9 | ```
10 | wget --no-check-certificate https://github.com/ideawu/ssdb/archive/master.zip
11 | ```
12 | ### 解压:
13 | ```
14 | unzip master
15 | ```
16 | 一切顺利,进入解压后的目录执行:
17 | ```
18 | make
19 | ```
20 | 但是编译报错:
21 | ```
22 | ERROR! autoconf required! install autoconf first
23 | Makefile:4: build_config.mk: No such file or directory
24 | make: *** No rule to make target `build_config.mk'. Stop.
25 | ```
26 | 原来是没有autoconf不能实现自动编译,于是安装autoconf:
27 | ```
28 | sudo apt-get update
29 | sudo apt-get install autoconf
30 | ```
31 | 然后继续执行,又报错:
32 | ```
33 | make[1]: g++: Command not found
34 | make[1]: *** [db/builder.o] Error 127
35 | ```
36 | 原来是新买的vps没有安装gcc的编译器,于是又将其补上:
37 | ```
38 | sudo apt-get install build-essential
39 | ```
40 | 然后继续make编译,顺利完成。
41 | ### 安装:
42 | ```
43 | sudo make install
44 | ```
45 |
46 | ## 2、启动
47 | 默认配置是安装在 /usr/local/ssdb,进入该目录下:
48 | ```
49 | ./ssdb-server ssdb.conf
50 | # 此命令会阻塞命令行
51 |
52 | # 或者启动为后台进程(不阻塞命令行)
53 | ./ssdb-server -d ssdb.conf
54 | ```
55 |
56 | ## 3、停止
57 |
58 | ```
59 | ./ssdb-server ssdb.conf -s stop
60 | ```
61 |
62 | ## 参考
63 |
64 | [官方文档](http://ssdb.io/docs/zh_cn/install.html)
65 |
66 | [SSDB 安装部署及注意事项大全](http://www.izhangheng.com/ssdb/)
67 |
68 | [SSDB项目地址](https://github.com/ideawu/ssdb)
69 |
--------------------------------------------------------------------------------
/SSDB/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | -------------------------------------------------
4 | File Name: __init__.py.py
5 | Description :
6 | Author : JHao
7 | date: 2016/12/1
8 | -------------------------------------------------
9 | Change Activity:
10 | 2016/12/1:
11 | -------------------------------------------------
12 | """
--------------------------------------------------------------------------------
/ZooKeeper/Python操作zookeeper—kazoo模块.md:
--------------------------------------------------------------------------------
1 | ## 1、安装kazoo
2 |
3 | kazoo可以直接使用`pip`或者`easy_install`安装:
4 | ```shell
5 | pip install kazoo
6 | ```
7 |
8 | ## 2、基础使用
9 |
10 | ###2.1 连接
11 |
12 | 使用`KazooClient`对象建立连接:
13 | ```python
14 | from kazoo.client import KazooClient
15 |
16 | zk = KazooClient(hosts='10.10.20.127:4181',
17 | timeout=10.0,
18 | client_id=None,
19 | handler=None,
20 | default_acl=None,
21 | auth_data=None,
22 | read_only=None,
23 | randomize_hosts=True,
24 | connection_retry=None,
25 | command_retry=None,
26 | logger=None)
27 | zk.start()
28 | ```
29 | 一旦连接上,客户端会尽力保持连接,不管间歇性的连接丢失。如果要主动丢弃连接,可以使用```zk.stop()```,该方法会断开连接和关闭该连接的session,同时该连接创建的所有临时节点都会立即移除,并触发这些临时节点的DataWatch和这些临时节点的父节点的ChildrenWatch。
30 |
31 | * 参数说明:
32 |
33 | * `hosts`: 指定ZooKeeper的ip和端口,可以是以逗号分隔的多个ZooKeeper服务器IP和端口,客户端会随机选择一个来连接;
34 | * `timeout`: 会话超时时间,在连接断开后就开始计算,如果在此会话时间内重新连接上的话,该连接创建的临时节点就不会移除;
35 | * `client_id`: 传入一个可切片类型列表或者元组,[会话id, 密码],用于重新连接先前的会话;
36 | * `handler`: 传入一个~kazoo.interfaces.IHandler的类实例,用于回调操作;
37 | * `default_acl`: 创建节点时设置访问控制的模式,类似UNIX的文件访问权限;
38 | * `auth_data`: 验证证书;
39 | * `read_only`: 创建一个只读连接;
40 | * `randomize_hosts`: 随机从hosts中选择一个zk服务器连接;
41 | * `connection_retry`: 传入kazoo.retry.KazooRetry中的一个类实例,用于重试zk连接;
42 | * `logger`: 自定义的logger对象,用来替代原有的日志;
43 |
44 | ### 2.2 日志设置
45 |
46 | 如果代码你没有设置logging,运行时将会提醒你没有log handler:
47 | ```
48 | No handlers could be found for logger "kazoo.client"
49 | ```
50 | 除非你在代码中加入日志对象:
51 | ```python
52 | import logging
53 | logging.basicConfig()
54 | ```
55 |
56 | ### 2.3 zk类属性及方法
57 |
58 | * zk.client_state
59 |
60 | 返回客户端连接状态,状态一般有:`AUTH_FAILED`、`CONNECTED`、`CONNECTED_RO`、`CONNECTING`、`CLOSED`、`EXPIRED_SESSION`;
61 |
62 | * zk.connected
63 |
64 | 客户端是否已连接到zk服务器,已连接上返回True;
65 |
66 | * zk.add_listener(listener)
67 |
68 | 添加一个回调函数,当zk连接状态发生改变时会被调用;
69 |
70 | * zk.remove_listener(listener)
71 |
72 | 移出add_listener添加的function;
73 |
74 | * zk.start(timeout)
75 |
76 | 初始化到zookeeper服务器的连接,超过timeout时间没连接到zk服务器则会抛出timeout_exception异常,默认时间是15秒;
77 |
78 | * zk.stop()
79 |
80 | 关闭连接;
81 |
82 | * zk.restart()
83 |
84 | 重新连接zk,内部直接就是先后调用stop()和start();
85 |
86 | * zk.close()
87 |
88 | 释放客户端占用的资源,这个方法应该在stop()之前使用;
89 |
90 | * zk.command(self, cmd=b'ruok')
91 |
92 | 执行zk服务器的四字命令,传入二进制字符串;常见的命令如下:
93 |
94 | | 四字命令 | 功能描述
95 | |---|---|
96 | | conf |输出相关服务配置的详细信息。|
97 | |cons|列出所有连接到服务器的客户端的完全的连接/会话的详细信息。包括“接受/发送”的包数量、会话 id 、操作延迟、最后的操作执行等等信息。|
98 | |dump|列出未经处理的会话和临时节点。|
99 | |envi|输出关于服务环境的详细信息(区别于 conf 命令)。|
100 | |reqs|列出未经处理的请求|
101 | |ruok|测试服务是否处于正确状态。如果确实如此,那么服务返回“ imok ”,否则不做任何相应。|
102 | |stat|输出关于性能和连接的客户端的列表。|
103 | |wchs|列出服务器 watch 的详细信息。|
104 | |wchc|通过 session 列出服务器 watch 的详细信息,它的输出是一个与 watch 相关的会话的列表。|
105 | |wchp|通过路径列出服务器 watch 的详细信息。它输出一个与 session 相关的路径。|
106 |
107 | * zk.sync(path)
108 |
109 | 阻塞并等待指定节点同步到所有zk服务器,返回同步的节点;
110 |
111 | * zk.create(path, value=b"")
112 |
113 | 创建一个新的节点,节点数据为value;
114 |
115 | * zk.ensure_path(path)
116 |
117 | 如何这个节点的父节点不存在,自动创建父节点路径;
118 |
119 | * zk.exists(path,watch=None)
120 |
121 | 检查节点是否存在,存在返回节点的ZnodeStat信息,否则返回None。可传入回调方法watch,当节点create/delete或是set的时候该方法会被调用
122 |
123 | * zk.get(path)
124 |
125 | 获取节点值。
126 |
127 | * zk.get_children(path)
128 |
129 | 获取所有子节点,返回列表形式。
130 |
131 | * zk.set(path, value)
132 |
133 | 设置节点的值。
134 |
135 | * zk.delete(path recursive=False)
136 |
137 | 删除节点,recursive为True表示递归删除节点及其子节点,如果有子节点且recursive为False,则会产生NotEmptyError异常,表示该节点有子节点不能删除
138 |
139 |
140 | ### 2.4 监听连接事件
141 |
142 | 可用来知道ZooKeeper连接删除、恢复或者过期的消息。为了简化这个过程,Kazoo使用一个状态系统,并允许你注册监听函数,以便在状态改变时被调用。
143 | ```python
144 | from kazoo.client import KazooState
145 |
146 | def my_listener(state):
147 | if state == KazooState.LOST:
148 | # Register somewhere that the session was lost
149 | elif state == KazooState.SUSPENDED:
150 | # Handle being disconnected from Zookeeper
151 | else:
152 | # Handle being connected/reconnected to Zookeeper
153 |
154 | zk.add_listener(my_listener)
155 | ```
156 | 当使用`kazoo.recipe.lock.Lock`或创建临时节点时,最好添加一个状态监听器,以便在连接中断或Zookeeper会话丢失时做出应对动作。
157 |
158 | ### 2.5 Kazoo状态
159 |
160 | `KazooState`对象表示客户端链接的几个状态。客户端的当前状态总是可以通过查看state属性来确定。可能的状态有:
161 |
162 | * LOST
163 |
164 | * CONNECTED
165 |
166 | * SUSPENDED
167 |
168 | 首次创建KazooClient实例时,它处于LOST状态。建立连接后,它将转换到CONNECTED状态。如果出现连接问题或者需要连接到其他的Zookeeper集群节点,状态将转换为SUSPENDED,此时无法执行任何命令。如果Zookeeper节点不再是Quorum的一部分,连接也将丢失,状态置为SUSPENDED。
169 |
170 | 再重新建立连接时,如果会话已经过期,则客户端可以转换到LOST,或者如果会话仍然有效,则客户端可以转换为CONNECTED。
171 |
172 | > 注:在实际应用中最好使用前文提出的监听函数监视这些状态,以便客户端根据连接的状态正确运行。
173 |
174 | 当连接状态为SUSPENDED时,此时客户端应当暂停执行需要与其他系统协议的操作(例如分布式锁),当连接重新建立后,如果状态转换为CONNECTED才可以继续。当连接状态为LOST时,Zookeeper将删除已创建的任何临时节点。这会影响创建临时节点的所有recipes。
175 |
176 | #### 状态转换
177 |
178 | * LOST -> CONNECTED
179 |
180 | 建立新连接,或丢失的连接恢复。
181 |
182 | * CONNECTED -> SUSPENDED
183 |
184 | Connection丢失了服务端的连接。
185 |
186 | * CONNECTED -> LOST
187 |
188 | 仅在连接建立后提供无效的身份验证凭证时才会发生。
189 |
190 | * SUSPENDED -> LOST
191 |
192 | Connection服务端已恢复,但是会话已过期而丢失。
193 |
194 | * SUSPENDED -> CONNECTED
195 |
196 | 丢失的连接已恢复。
197 |
198 | ### 2.5 只读模式
199 |
200 | ZooKeeper3.4及以上版本支持[只读模式](https://wiki.apache.org/hadoop/ZooKeeper/GSoCReadOnlyMode)。只有ZooKeeper集群服务启用此模式,客户端才能使用它。只要将KazooClient的read_only设置为True便可以使客户端连接到只读的Zookeeper节点。
201 |
202 | ```python
203 | from kazoo.client import KazooClient
204 |
205 | zk = KazooClient(hosts='127.0.0.1:2181', read_only=True)
206 | zk.start()
207 | ```
208 |
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | # # -*- coding: utf-8 -*-
2 | # """
3 | # -------------------------------------------------
4 | # File Name: test.py
5 | # Description :
6 | # Author : JHao
7 | # date: 2017/2/7
8 | # -------------------------------------------------
9 | # Change Activity:
10 | # 2017/2/7:
11 | # -------------------------------------------------
12 | # """
13 | # __author__ = 'JHao'
14 | #
15 | # import re
16 | # # #
17 | # # # sql = ('SELECT count() FROM table '
18 | # # # 'WHERE id = "10" '
19 | # # # 'GROUP BY sex')
20 | # # #
21 | # # # print sql
22 | # #
23 | # # str = '123\nadf'
24 | # #
25 | # # print re.findall(r'.', str)
26 | #
27 | # import re
28 | #
29 | # a = 'a1b2c3'
30 | # print re.sub(r'\d+', '0', a)
31 | # print re.sub(r'\s+', '0', a)
32 | # !/usr/local/python/bin
33 | # coding=utf-8
34 |
35 | '''Implements a simple log library.
36 |
37 | This module is a simple encapsulation of logging module to provide a more
38 | convenient interface to write log. The log will both print to stdout and
39 | write to log file. It provides a more flexible way to set the log actions,
40 | and also very simple. See examples showed below:
41 |
42 | Example 1: Use default settings
43 |
44 | import log
45 |
46 | log.debug('hello, world')
47 | log.info('hello, world')
48 | log.error('hello, world')
49 | log.critical('hello, world')
50 |
51 | Result:
52 | Print all log messages to file, and only print log whose level is greater
53 | than ERROR to stdout. The log file is located in '/tmp/xxx.log' if the module
54 | name is xxx.py. The default log file handler is size-rotated, if the log
55 | file's size is greater than 20M, then it will be rotated.
56 |
57 | Example 2: Use set_logger to change settings
58 |
59 | # Change limit size in bytes of default rotating action
60 | log.set_logger(limit = 10240) # 10M
61 |
62 | # Use time-rotated file handler, each day has a different log file, see
63 | # logging.handlers.TimedRotatingFileHandler for more help about 'when'
64 | log.set_logger(when = 'D', limit = 1)
65 |
66 | # Use normal file handler (not rotated)
67 | log.set_logger(backup_count = 0)
68 |
69 | # File log level set to INFO, and stdout log level set to DEBUG
70 | log.set_logger(level = 'DEBUG:INFO')
71 |
72 | # Both log level set to INFO
73 | log.set_logger(level = 'INFO')
74 |
75 | # Change default log file name and log mode
76 | log.set_logger(filename = 'yyy.log', mode = 'w')
77 |
78 | # Change default log formatter
79 | log.set_logger(fmt = '[%(levelname)s] %(message)s'
80 | '''
81 |
82 | __author__ = "tuantuan.lv "
83 | __status__ = "Development"
84 |
85 | __all__ = ['set_logger', 'debug', 'info', 'warning', 'error',
86 | 'critical', 'exception']
87 |
88 | import os
89 | import sys
90 | import logging
91 | import logging.handlers
92 |
93 | # Color escape string
94 | COLOR_RED = '\033[1;31m'
95 | COLOR_GREEN = '\033[1;32m'
96 | COLOR_YELLOW = '\033[1;33m'
97 | COLOR_BLUE = '\033[1;34m'
98 | COLOR_PURPLE = '\033[1;35m'
99 | COLOR_CYAN = '\033[1;36m'
100 | COLOR_GRAY = '\033[1;37m'
101 | COLOR_WHITE = '\033[1;38m'
102 | COLOR_RESET = '\033[1;0m'
103 |
104 | # Define log color
105 | LOG_COLORS = {
106 | 'DEBUG': '%s',
107 | 'INFO': COLOR_GREEN + '%s' + COLOR_RESET,
108 | 'WARNING': COLOR_YELLOW + '%s' + COLOR_RESET,
109 | 'ERROR': COLOR_RED + '%s' + COLOR_RESET,
110 | 'CRITICAL': COLOR_RED + '%s' + COLOR_RESET,
111 | 'EXCEPTION': COLOR_RED + '%s' + COLOR_RESET,
112 | }
113 |
114 | # # Global logger
115 | # g_logger = None
116 | #
117 | #
118 | # class ColoredFormatter(logging.Formatter):
119 | # '''A colorful formatter.'''
120 | #
121 | # def __init__(self, fmt=None, datefmt=None):
122 | # logging.Formatter.__init__(self, fmt, datefmt)
123 | #
124 | # def format(self, record):
125 | # level_name = record.levelname
126 | # msg = logging.Formatter.format(self, record)
127 | #
128 | # return LOG_COLORS.get(level_name, '%s') % msg
129 | #
130 | #
131 | # def add_handler(cls, level, fmt, colorful, **kwargs):
132 | # '''Add a configured handler to the global logger.'''
133 | # global g_logger
134 | #
135 | # if isinstance(level, str):
136 | # level = getattr(logging, level.upper(), logging.DEBUG)
137 | #
138 | # handler = cls(**kwargs)
139 | # handler.setLevel(level)
140 | #
141 | # if colorful:
142 | # formatter = ColoredFormatter(fmt)
143 | # else:
144 | # formatter = logging.Formatter(fmt)
145 | #
146 | # handler.setFormatter(formatter)
147 | # g_logger.addHandler(handler)
148 | #
149 | # return handler
150 | #
151 | #
152 | # def add_streamhandler(level, fmt):
153 | # '''Add a stream handler to the global logger.'''
154 | # return add_handler(logging.StreamHandler, level, fmt, True)
155 | #
156 | #
157 | # def add_filehandler(level, fmt, filename, mode, backup_count, limit, when):
158 | # '''Add a file handler to the global logger.'''
159 | # kwargs = {}
160 | #
161 | # # If the filename is not set, use the default filename
162 | # if filename is None:
163 | # filename = getattr(sys.modules['__main__'], '__file__', 'log.py')
164 | # filename = os.path.basename(filename.replace('.py', '.log'))
165 | # filename = os.path.join('/tmp', filename)
166 | #
167 | # kwargs['filename'] = filename
168 | #
169 | # # Choose the filehandler based on the passed arguments
170 | # if backup_count == 0: # Use FileHandler
171 | # cls = logging.FileHandler
172 | # kwargs['mode'] = mode
173 | # elif when is None: # Use RotatingFileHandler
174 | # cls = logging.handlers.RotatingFileHandler
175 | # kwargs['maxBytes'] = limit
176 | # kwargs['backupCount'] = backup_count
177 | # kwargs['mode'] = mode
178 | # else: # Use TimedRotatingFileHandler
179 | # cls = logging.handlers.TimedRotatingFileHandler
180 | # kwargs['when'] = when
181 | # kwargs['interval'] = limit
182 | # kwargs['backupCount'] = backup_count
183 | #
184 | # return add_handler(cls, level, fmt, False, **kwargs)
185 | #
186 | #
187 | # def init_logger():
188 | # '''Reload the global logger.'''
189 | # global g_logger
190 | #
191 | # if g_logger is None:
192 | # g_logger = logging.getLogger()
193 | # else:
194 | # logging.shutdown()
195 | # g_logger.handlers = []
196 | #
197 | # g_logger.setLevel(logging.DEBUG)
198 | #
199 | #
200 | # def set_logger(filename=None, mode='a', level='ERROR:DEBUG',
201 | # fmt='[%(levelname)s] %(asctime)s %(message)s',
202 | # backup_count=5, limit=20480, when=None):
203 | # '''Configure the global logger.'''
204 | # level = level.split(':')
205 | #
206 | # if len(level) == 1: # Both set to the same level
207 | # s_level = f_level = level[0]
208 | # else:
209 | # s_level = level[0] # StreamHandler log level
210 | # f_level = level[1] # FileHandler log level
211 | #
212 | # init_logger()
213 | # add_streamhandler(s_level, fmt)
214 | # add_filehandler(f_level, fmt, filename, mode, backup_count, limit, when)
215 | #
216 | # # Import the common log functions for convenient
217 | # import_log_funcs()
218 | #
219 | #
220 | # def import_log_funcs():
221 | # '''Import the common log functions from the global logger to the module.'''
222 | # global g_logger
223 | #
224 | # curr_mod = sys.modules[__name__]
225 | # log_funcs = ['debug', 'info', 'warning', 'error', 'critical',
226 | # 'exception']
227 | #
228 | # for func_name in log_funcs:
229 | # func = getattr(g_logger, func_name)
230 | # setattr(curr_mod, func_name, func)
231 | #
232 | #
233 | # # Set a default logger
234 | # set_logger()
235 | #
236 | # g_logger.info('123')
237 |
238 |
239 | import sched, time
240 |
241 | s = sched.scheduler(time.time, time.sleep)
--------------------------------------------------------------------------------
/uwsgi.log:
--------------------------------------------------------------------------------
1 | *** Starting uWSGI 2.0.14 (64bit) on [Thu Nov 17 21:44:31 2016] ***
2 | compiled with version: 4.8.4 on 15 November 2016 21:28:00
3 | os: Linux-3.13.0-86-generic #131-Ubuntu SMP Thu May 12 23:33:13 UTC 2016
4 | nodename: VM-65-10-ubuntu
5 | machine: x86_64
6 | clock source: unix
7 | detected number of CPU cores: 1
8 | current working directory: /home/ubuntu/web_blog/blog
9 | detected binary path: /usr/local/bin/uwsgi
10 | !!! no internal routing support, rebuild with pcre support !!!
11 | uWSGI running as root, you can use --uid/--gid/--chroot options
12 | *** WARNING: you are running uWSGI as root !!! (use the --uid flag) ***
13 | chdir() to /home/ubuntu/web_blog
14 | your processes number limit is 7884
15 | your memory page size is 4096 bytes
16 | detected max file descriptor number: 1024
17 | lock engine: pthread robust mutexes
18 | thunder lock: disabled (you can enable it with --thunder-lock)
19 | uwsgi socket 0 bound to TCP address :8001 fd 3
20 | Python version: 2.7.6 (default, Jun 22 2015, 18:01:27) [GCC 4.8.2]
21 | *** Python threads support is disabled. You can enable it with --enable-threads ***
22 | Python main interpreter initialized at 0x803b50
23 | your server socket listen backlog is limited to 100 connections
24 | your mercy for graceful operations on workers is 60 seconds
25 | mapped 363800 bytes (355 KB) for 4 cores
26 | *** Operational MODE: preforking ***
27 | ImportError: No module named blog.wsgi
28 | unable to load app 0 (mountpoint='') (callable not found or import error)
29 | *** no app loaded. going in full dynamic mode ***
30 | *** uWSGI is running in multiple interpreter mode ***
31 | spawned uWSGI master process (pid: 11235)
32 | spawned uWSGI worker 1 (pid: 11236, cores: 1)
33 | spawned uWSGI worker 2 (pid: 11237, cores: 1)
34 | spawned uWSGI worker 3 (pid: 11238, cores: 1)
35 | spawned uWSGI worker 4 (pid: 11239, cores: 1)
36 | --- no python application found, check your startup logs for errors ---
37 | [pid: 11239|app: -1|req: -1/1] 117.139.250.49 () {42 vars in 695 bytes} [Thu Nov 17 21:44:43 2016] GET / => generated 21 bytes in 0 msecs (HTTP/1.1 500) 2 headers in 83 bytes (0 switches on core 0)
38 | --- no python application found, check your startup logs for errors ---
39 | [pid: 11238|app: -1|req: -1/2] 117.139.250.49 () {42 vars in 695 bytes} [Thu Nov 17 21:44:45 2016] GET / => generated 21 bytes in 0 msecs (HTTP/1.1 500) 2 headers in 83 bytes (0 switches on core 0)
40 | --- no python application found, check your startup logs for errors ---
41 | [pid: 11239|app: -1|req: -1/3] 117.139.250.49 () {42 vars in 695 bytes} [Thu Nov 17 21:44:46 2016] GET / => generated 21 bytes in 0 msecs (HTTP/1.1 500) 2 headers in 83 bytes (0 switches on core 0)
42 | --- no python application found, check your startup logs for errors ---
43 | [pid: 11238|app: -1|req: -1/4] 117.139.250.49 () {42 vars in 695 bytes} [Thu Nov 17 21:44:46 2016] GET / => generated 21 bytes in 0 msecs (HTTP/1.1 500) 2 headers in 83 bytes (0 switches on core 0)
44 | --- no python application found, check your startup logs for errors ---
45 | [pid: 11239|app: -1|req: -1/5] 117.139.250.49 () {40 vars in 615 bytes} [Thu Nov 17 21:44:51 2016] GET /favicon.ico => generated 21 bytes in 0 msecs (HTTP/1.1 500) 2 headers in 83 bytes (0 switches on core 0)
46 | --- no python application found, check your startup logs for errors ---
47 | [pid: 11239|app: -1|req: -1/6] 117.139.250.49 () {44 vars in 748 bytes} [Thu Nov 17 21:44:53 2016] GET / => generated 21 bytes in 0 msecs (HTTP/1.1 500) 2 headers in 83 bytes (0 switches on core 0)
48 | --- no python application found, check your startup logs for errors ---
49 | [pid: 11238|app: -1|req: -1/7] 117.139.250.49 () {44 vars in 668 bytes} [Thu Nov 17 21:44:54 2016] GET /favicon.ico => generated 21 bytes in 0 msecs (HTTP/1.1 500) 2 headers in 83 bytes (0 switches on core 0)
50 | --- no python application found, check your startup logs for errors ---
51 | [pid: 11238|app: -1|req: -1/8] 180.153.205.252 () {38 vars in 538 bytes} [Thu Nov 17 21:45:03 2016] GET / => generated 21 bytes in 0 msecs (HTTP/1.1 500) 2 headers in 83 bytes (0 switches on core 0)
52 | --- no python application found, check your startup logs for errors ---
53 | [pid: 11239|app: -1|req: -1/9] 101.226.33.203 () {38 vars in 576 bytes} [Thu Nov 17 21:45:14 2016] GET / => generated 21 bytes in 0 msecs (HTTP/1.1 500) 2 headers in 83 bytes (0 switches on core 0)
54 |
--------------------------------------------------------------------------------
/爬虫/Python Webdriver 重新使用已经打开的浏览器实例.md:
--------------------------------------------------------------------------------
1 | 因为Webdriver每次实例化都会新开一个全新的浏览器会话,在有些情况下需要复用之前打开未关闭的会话。比如爬虫,希望结束脚本时,让浏览器处于空闲状态。当脚本重新运行时,它将继续使用这个会话工作。还就是在做自动化测试时,前面做了一大推操作,但是由于程序出错,重启时不用再继续前面复杂的操作。
2 |
3 | 个人觉得这种功能非常有用,但是官方居然没有提供这种功能的API,苦苦搜搜,在网上找了两个java版的http://blog.csdn.net/wwwqjpcom/article/details/51232302 和 http://woxiangbo.iteye.com/blog/2372683
4 | 看了下源码其实java和python的驱动原理过程都非常相似。
5 |
6 | 打开一个Chrome会话:
7 | ```python
8 | from selenium import webdriver
9 | driver = webdriver.Chrome()
10 | ```
11 | 运行上面的脚本,它将启动浏览器并退出。因为没有调用`quit()`方法,所以浏览器会话仍会存在。但是代码里创建的`driver`对象已经不在了,理论上不能用脚本控制这个浏览器。它将变成一个僵尸浏览器,只能手动杀死它。
12 |
13 | 通过webdriver启动一个浏览器会话大概会有这样三个阶段:
14 |
15 | * 1、启动的浏览器驱动代理(hromedriver,Firefox的驱动程序,等等);
16 | * 2、创建一个命令执行器。用来向代理发送操作命令;
17 | * 3、使用代理建立一个新的浏览器会话,该代理将与浏览器进行通信。用`sessionId`来标识会话。
18 |
19 | 因此只要拿到阶段2中的执行器和阶段3中的`sessionID`就能恢复上次的会话。这两个有api可以直接获取:
20 | ```python
21 | from selenium import webdriver
22 |
23 | driver = webdriver.Chrome()
24 | executor_url = driver.command_executor._url
25 | session_id = driver.session_id
26 | print(session_id)
27 | print(executor_url)
28 | driver.get("http://www.spiderpy.cn/")
29 | ```
30 |
31 | 得到类似这样的输出(第一个是会话的sessionId,第二个就是命令执行器连接):
32 | ```shell
33 | 397d725f042a076f7d4a82f7d3fead13
34 | http://127.0.0.1:52869
35 | ```
36 |
37 | 一切就绪,下面就开始实现复用之前会话的功能,在[Stack Overflow](https://stackoverflow.com/questions/8344776/can-selenium-interact-with-an-existing-browser-session)上面讲的实现是这样的:
38 | ```python
39 | from selenium import webdriver
40 |
41 | driver = webdriver.Chrome()
42 | executor_url = driver.command_executor._url
43 | session_id = driver.session_id
44 | driver.get("http://www.spiderpy.cn/")
45 |
46 | print(session_id)
47 | print(executor_url)
48 |
49 | driver2 = webdriver.Remote(command_executor=executor_url, desired_capabilities={})
50 | driver2.session_id = session_id
51 | print(driver2.current_url)
52 | ```
53 | 可能是因为版本原因吧,反正在我环境中运行时,效果是实现了,能够重新连接到上一个会话,但是却打开了一个新的空白会话。看了下`Remote`类的源码,发现是因为每次实例化都会调用`start_session`这个方法新建一个会话。所以解决方法就是继承并重写这个类。自定义一个`ReuseChrome`这个类重写`start_session`方法使它不再新建session,使用传入的session_id:
54 | ```python
55 | from selenium.webdriver import Remote
56 | from selenium.webdriver.chrome import options
57 | from selenium.common.exceptions import InvalidArgumentException
58 |
59 |
60 | class ReuseChrome(Remote):
61 |
62 | def __init__(self, command_executor, session_id):
63 | self.r_session_id = session_id
64 | Remote.__init__(self, command_executor=command_executor, desired_capabilities={})
65 |
66 | def start_session(self, capabilities, browser_profile=None):
67 | """
68 | 重写start_session方法
69 | """
70 | if not isinstance(capabilities, dict):
71 | raise InvalidArgumentException("Capabilities must be a dictionary")
72 | if browser_profile:
73 | if "moz:firefoxOptions" in capabilities:
74 | capabilities["moz:firefoxOptions"]["profile"] = browser_profile.encoded
75 | else:
76 | capabilities.update({'firefox_profile': browser_profile.encoded})
77 |
78 | self.capabilities = options.Options().to_capabilities()
79 | self.session_id = self.r_session_id
80 | ```
81 |
82 | 然后在第二次连接是使用重写的`ReuseChrome`类:
83 | ```python
84 | from selenium import webdriver
85 |
86 | # 第一次使用Chrome() 新建浏览器会话
87 | driver = webdriver.Chrome()
88 |
89 | # 记录 executor_url 和 session_id 以便复用session
90 | executor_url = driver.command_executor._url
91 | session_id = driver.session_id
92 | # 访问百度
93 | driver.get("http://www.spiderpy.cn/")
94 |
95 | print(session_id)
96 | print(executor_url)
97 |
98 | # 假如driver对象不存在,但浏览器未关闭
99 | del driver
100 |
101 | # 使用ReuseChrome()复用上次的session
102 | driver2 = ReuseChrome(command_executor=executor_url, session_id=session_id)
103 |
104 | # 打印current_url为百度的地址,说明复用成功
105 | print(driver2.current_url)
106 | driver2.get("https://www.baidu.com")
107 | ```
108 |
109 | 这样就能顺利连接到上次没关闭的浏览器会话。
--------------------------------------------------------------------------------
/爬虫/Python检查xpath和csspath表达式是否合法.md:
--------------------------------------------------------------------------------
1 | > 在做一个可视化配置爬虫项目时,需要配置爬虫的用户自己输入xpath和csspath路径以提取数据或做浏览器操作。考虑到用户的有时会输入错误的xpath或csspath路径,后台需要对其做合法性校验。
2 |
3 | ## xpath有效性校验
4 |
5 | 对于xpath的有效性检验,使用第三方lxml模块中的etree.XPathEvalError进行校验。不得不说lxml是一个解析爬虫数据的利器,当etree.xpath()遇到不合法的xpath路径时会抛出XPathEvalError错误。
6 |
7 | 代码如下:
8 | ```
9 | from lxml import etree
10 | from StringIO import StringIO
11 |
12 | def _validXpathExpression(xpath):
13 | """
14 | 检查xpath合法性
15 | :param xpath:
16 | :return:
17 | """
18 | tree = etree.parse(StringIO(''))
19 | try:
20 | tree.xpath(xpath)
21 | return True
22 | except etree.XPathEvalError, e:
23 | return False
24 | ```
25 | 只有当输入的xpath路径合法时返回True。
26 | 验证:
27 | ```
28 | >>>print _validXpathExpression('./div[@class="name"]/a/text()')
29 | >>>True
30 | >>>
31 | >>>print _validXpathExpression('./div(@class="name")')
32 | >>>False
33 | ```
34 |
35 | ## csspath有效性检验
36 |
37 | 对于csspath检验的思路时,借助python标准库cssselect的css_to_xpath()方法。当输入的csspath不合法时会抛出SelectorError错误。
38 |
39 | 代码如下:
40 | ```
41 | from cssselect.parser import SelectorError
42 | from cssselect.xpath import HTMLTranslator
43 |
44 | def _validCssExpression(css):
45 | """
46 | 检查css合法性
47 | :param css:
48 | :return:
49 | """
50 | try:
51 | HTMLTranslator().css_to_xpath(css)
52 | return True
53 | except SelectorError, e:
54 | return False
55 | ```
56 | 只有当输入的csspath路径合法时返回True。
57 | 验证:
58 | ```
59 | >>>print _validCssExpression('.content>a')
60 | >>>True
61 | >>>
62 | >>>print _validCssExpression('.content>a[123]')
63 | >>>False
64 | ```
--------------------------------------------------------------------------------
/爬虫/Python爬虫代理IP池.md:
--------------------------------------------------------------------------------
1 |
2 | > 在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源出来。不过呢,闲暇时间手痒,所以就想利用一些免费的资源搞一个简单的代理池服务。
3 |
4 |
5 | ### 1、问题
6 |
7 | * 代理IP从何而来?
8 |
9 | 刚自学爬虫的时候没有代理IP就去西刺、快代理之类有免费代理的网站去爬,还是有个别代理能用。当然,如果你有更好的代理接口也可以自己接入。
10 | 免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
11 |
12 | * 如何保证代理质量?
13 |
14 | 可以肯定免费的代理IP大部分都是不能用的,不然别人为什么还提供付费的(不过事实是很多代理商的付费IP也不稳定,也有很多是不能用)。所以采集回来的代理IP不能直接使用,可以写检测程序不断的去用这些代理访问一个稳定的网站,看是否可以正常使用。这个过程可以使用多线程或异步的方式,因为检测代理是个很慢的过程。
15 |
16 | * 采集回来的代理如何存储?
17 |
18 | 这里不得不推荐一个高性能支持多种数据结构的NoSQL数据库[SSDB](http://ssdb.io/docs/zh_cn/),用于代理Redis。支持队列、hash、set、k-v对,支持T级别数据。是做分布式爬虫很好中间存储工具。
19 |
20 | * 如何让爬虫更简单的使用这些代理?
21 |
22 | 答案肯定是做成服务咯,python有这么多的web框架,随便拿一个来写个api供爬虫调用。这样有很多好处,比如:当爬虫发现代理不能使用可以主动通过api去delete代理IP,当爬虫发现代理池IP不够用时可以主动去refresh代理池。这样比检测程序更加靠谱。
23 |
24 | ### 2、代理池设计
25 |
26 | 代理池由四部分组成:
27 |
28 | * ProxyGetter:
29 |
30 | 代理获取接口,目前有5个免费代理源,每调用一次就会抓取这个5个网站的最新代理放入DB,可自行添加额外的代理获取接口;
31 |
32 | * DB:
33 |
34 | 用于存放代理IP,现在暂时只支持SSDB。至于为什么选择SSDB,大家可以参考这篇[文章](https://www.sdk.cn/news/2684),个人觉得SSDB是个不错的Redis替代方案,如果你没有用过SSDB,安装起来也很简单,可以参考[这里](https://github.com/jhao104/memory-notes/blob/master/SSDB/SSDB%E5%AE%89%E8%A3%85%E9%85%8D%E7%BD%AE%E8%AE%B0%E5%BD%95.md);
35 |
36 | * Schedule:
37 |
38 | 计划任务用户定时去检测DB中的代理可用性,删除不可用的代理。同时也会主动通过ProxyGetter去获取最新代理放入DB;
39 |
40 | * ProxyApi:
41 |
42 | 代理池的外部接口,由于现在这么代理池功能比较简单,花两个小时看了下[Flask](http://flask.pocoo.org/),愉快的决定用Flask搞定。功能是给爬虫提供get/delete/refresh等接口,方便爬虫直接使用。
43 |
44 | 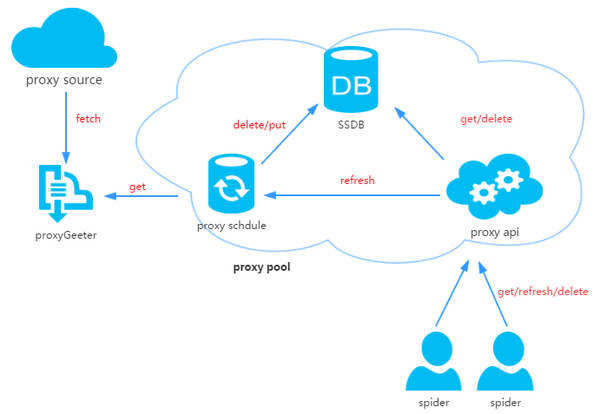
45 |
46 | ### 3、代码模块
47 |
48 | Python中高层次的数据结构,动态类型和动态绑定,使得它非常适合于快速应用开发,也适合于作为胶水语言连接已有的软件部件。用Python来搞这个代理IP池也很简单,代码分为6个模块:
49 |
50 | * Api:
51 |
52 | api接口相关代码,目前api是由Flask实现,代码也非常简单。客户端请求传给Flask,Flask调用ProxyManager中的实现,包括`get/delete/refresh/get_all`;
53 |
54 | * DB:
55 |
56 | 数据库相关代码,目前数据库是采用SSDB。代码用工厂模式实现,方便日后扩展其他类型数据库;
57 |
58 | * Manager:
59 |
60 | `get/delete/refresh/get_all`等接口的具体实现类,目前代理池只负责管理proxy,日后可能会有更多功能,比如代理和爬虫的绑定,代理和账号的绑定等等;
61 |
62 | * ProxyGetter:
63 |
64 | 代理获取的相关代码,目前抓取了[快代理](http://www.kuaidaili.com)、[代理66](http://www.66ip.cn/)、[有代理](http://www.youdaili.net/Daili/http/)、[西刺代理](http://api.xicidaili.com/free2016.txt)、[guobanjia](http://www.goubanjia.com/free/gngn/index.shtml)这个五个网站的免费代理,经测试这个5个网站每天更新的可用代理只有六七十个,当然也支持自己扩展代理接口;
65 |
66 | * Schedule:
67 |
68 | 定时任务相关代码,现在只是实现定时去刷新代码,并验证可用代理,采用多进程方式;
69 |
70 | * Util:
71 |
72 | 存放一些公共的模块方法或函数,包含`GetConfig`:读取配置文件config.ini的类,`ConfigParse`: 集成重写ConfigParser的类,使其对大小写敏感, `Singleton`:实现单例,`LazyProperty`:实现类属性惰性计算。等等;
73 |
74 | * 其他文件:
75 |
76 | 配置文件:Config.ini,数据库配置和代理获取接口配置,可以在GetFreeProxy中添加新的代理获取方法,并在Config.ini中注册即可使用;
77 |
78 | ### 4、安装
79 |
80 | 下载代码:
81 | ```
82 | git clone git@github.com:jhao104/proxy_pool.git
83 |
84 | 或者直接到https://github.com/jhao104/proxy_pool 下载zip文件
85 | ```
86 |
87 | 安装依赖:
88 | ```
89 | pip install -r requirements.txt
90 | ```
91 |
92 | 启动:
93 |
94 | ```
95 | 需要分别启动定时任务和api
96 | 到Config.ini中配置你的SSDB
97 |
98 | 到Schedule目录下:
99 | >>>python ProxyRefreshSchedule.py
100 |
101 | 到Api目录下:
102 | >>>python ProxyApi.py
103 | ```
104 |
105 | ### 5、使用
106 | 定时任务启动后,会通过代理获取方法fetch所有代理放入数据库并验证。此后默认每20分钟会重复执行一次。定时任务启动大概一两分钟后,便可在SSDB中看到刷新出来的可用的代理:
107 |
108 | 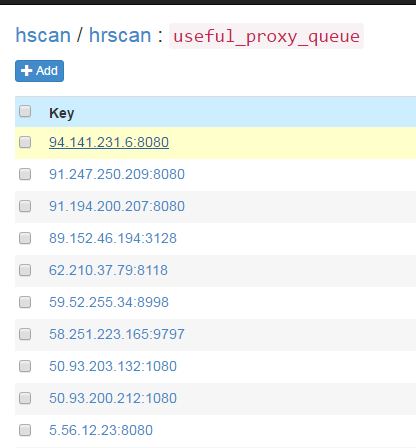
109 |
110 | 启动ProxyApi.py后即可在浏览器中使用接口获取代理,一下是浏览器中的截图:
111 |
112 | index页面:
113 |
114 | 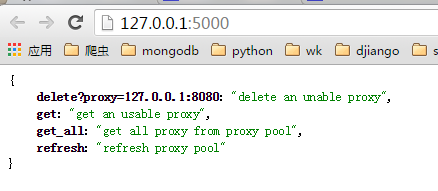
115 |
116 | get:
117 |
118 | 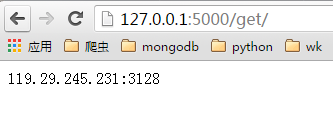
119 |
120 | get_all:
121 |
122 | 
123 |
124 |
125 | 爬虫中使用,如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
126 | ```python
127 | import requests
128 |
129 | def get_proxy():
130 | return requests.get("http://127.0.0.1:5000/get/").content
131 |
132 | def delete_proxy(proxy):
133 | requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
134 |
135 | # your spider code
136 |
137 | def spider():
138 | # ....
139 | requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
140 | # ....
141 |
142 | ```
143 |
144 | ### 6、最后
145 | 时间仓促,功能和代码都比较简陋,以后有时间再改进。喜欢的在github上给个star。感谢!
146 | 项目地址:https://github.com/jhao104/proxy_pool
147 |
--------------------------------------------------------------------------------
/爬虫/README.md:
--------------------------------------------------------------------------------
1 | [欢迎光临我的博客小站](http://www.spiderpy.cn/blog/)
2 |
3 | * 爬虫相关笔记
4 |
5 | * [Python Webdriver 重新使用已经打开的浏览器实例](https://github.com/jhao104/memory-notes/blob/master/%E7%88%AC%E8%99%AB/Python%20Webdriver%20%E9%87%8D%E6%96%B0%E4%BD%BF%E7%94%A8%E5%B7%B2%E7%BB%8F%E6%89%93%E5%BC%80%E7%9A%84%E6%B5%8F%E8%A7%88%E5%99%A8%E5%AE%9E%E4%BE%8B.md)
6 | * [Python检查xpath和csspath表达式是否合法](https://github.com/jhao104/memory-notes/blob/master/%E7%88%AC%E8%99%AB/Python%E6%A3%80%E6%9F%A5xpath%E5%92%8Ccsspath%E8%A1%A8%E8%BE%BE%E5%BC%8F%E6%98%AF%E5%90%A6%E5%90%88%E6%B3%95.md)
7 | * [Python爬虫—破解JS加密的Cookie](https://github.com/jhao104/memory-notes/blob/master/Python/Python%E7%88%AC%E8%99%AB%E2%80%94%E7%A0%B4%E8%A7%A3JS%E5%8A%A0%E5%AF%86%E7%9A%84Cookie.md)
8 | * [Python爬虫代理IP池](https://github.com/jhao104/memory-notes/blob/master/%E7%88%AC%E8%99%AB/Python%E7%88%AC%E8%99%AB%E4%BB%A3%E7%90%86IP%E6%B1%A0.md)
9 |
10 |
11 |
--------------------------------------------------------------------------------
/算法记录/README.md:
--------------------------------------------------------------------------------
1 | [欢迎光临我的博客小站](http://www.spiderpy.cn/blog/)
2 |
3 | * 算法记录
4 |
5 | * [曲线点抽稀算法-Python实现](https://github.com/jhao104/memory-notes/blob/master/%E7%AE%97%E6%B3%95%E8%AE%B0%E5%BD%95/%E6%9B%B2%E7%BA%BF%E7%82%B9%E6%8A%BD%E7%A8%80%E7%AE%97%E6%B3%95-Python%E5%AE%9E%E7%8E%B0.md)
6 |
7 | * [常用样本相似性和距离度量方法](https://github.com/jhao104/memory-notes/blob/master/算法记录/常用样本相似性和距度量方法.md)
8 |
--------------------------------------------------------------------------------
/算法记录/常用样本相似性和距离度量方法.md:
--------------------------------------------------------------------------------
1 |
2 | >数据挖掘中经常需要度量样本的相似度或距离,来评价样本间的相似性。特征数据不同,度量方法也不相同。
3 |
4 | ## 欧式距离
5 |
6 | **欧式距离**(Euclidean Distance)在数学上表示n维空间中两个点的直线距离。
7 |
8 | * 计算公式
9 |
10 | 空间中两个点 $x=(x_1,\ldots,x_n)$ 和 $y=(y_1, \ldots,y_n)$ 的欧式距离为:
11 |
12 | $$d(x,y)=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+\cdots+(x_n-y_n)^2}=\sqrt{\sum_{i=1}^n(x_i-y_i)^2}$$
13 |
14 | 例如二维平面上两点 $a(x_1,y_1),b(x_2,y_2)$ 的欧式距离为:
15 |
16 | $$d_{ab}=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2}$$
17 |
18 | ## 曼哈顿距离
19 |
20 | **曼哈顿距离**(Manhattan Distance)又称城市街区距离,用于表明两个坐标点在标准坐标系中的绝对轴距总和,也就是在欧几里德空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。例如[百度百科](https://baike.baidu.com/item/%E6%9B%BC%E5%93%88%E9%A1%BF%E8%B7%9D%E7%A6%BB)上的例子:
21 | 
22 |
23 | 图中红线代表曼哈顿距离,绿色代表欧氏距离,也就是直线距离,而蓝色和黄色代表等价的曼哈顿距离。
24 |
25 | * 计算公式
26 |
27 | $n$ 维空间两点 $a(x_{11},\ldots,x_{1k})$ 和 $b(y_{21},\ldots,y_{2k})$ 间的曼哈顿距离为:
28 |
29 | $$d_{ab}=\sum_{i=1}^k|x_{1i}-y_{2i}|$$
30 |
31 | 例如二维平面上两点 $a(x_1,y_1),b(x_2,y_2)$ 的曼哈顿距离为:
32 |
33 | $$d_{ab}=|x_1-x_2|+|y_1-y_2|$$
34 |
35 | ## 切比雪夫距离
36 |
37 | **切比雪夫距离**(Chebyshev Distance)在数学上,是 $L_{\infty}$ 度量,是向量空间中的一种度量,二个点之间的距离定义为其各座标数值差的最大值。
38 |
39 | * 计算公式
40 |
41 | $n$ 维空间两点 $a(x_{11},\ldots,x_{1k})$ 和 $b(y_{21},\ldots,y_{2k})$ 间的切比雪夫距离为:
42 |
43 | $$d_{ab}=max_i(|x_{1i}-y_{2i}|)$$
44 |
45 | 例如二维平面上两点 $a(x_1,y_1),b(x_2,y_2)$ 的切比雪夫距离为:
46 |
47 | $$d_{ab}=max(|x_{1}-y_{1}|,|x_{2}-y_{2}|)$$
48 |
49 | ## 闵式距离
50 |
51 | **闵式距离**(Minkowski Distance)又叫做闵可夫斯基距离,它不是一种距离,而是一组距离的定义。被看做是欧氏距离和曼哈顿距离的一种推广。
52 |
53 | * 定义
54 |
55 | 对于 $n$ 维空间两点 $a(x_{11},\ldots,x_{1n})$ 和 $b(y_{21},\ldots,y_{2n}) \in R^n$ 间的闵式距离定义为:
56 |
57 | $$d_{ab}=(\sum_{i=1}^n|x_{1i}-x_{2i}|^p)^{1 \over p}$$
58 |
59 | 其中 $p$ 是一个参数。
60 | 当 $p=1$ 时,就是曼哈顿距离;
61 | 当 $p=2$ 时,就是欧氏距离;
62 | 当 $p \rightarrow \infty$ 时,就是切比雪夫距离。
63 | 根据变参数的不同,闵氏距离可以表示一类的距离。
64 |
65 | ## 马氏距离
66 |
67 | **马氏距离**(Mahalanobis Distance)表示数据的**协方差距离**。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度。
68 |
69 | 马氏距离有很多优点,马氏距离不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关;由标准化数据和中心化数据(即原始数据与均值之差)计算出的二点之间的马氏距离相同。马氏距离还可以排除变量之间的相关性的干扰。它的缺点是夸大了变化微小的变量的作用。
70 |
71 | * 计算公式
72 |
73 | 有向量$(\mu_1,\mu_2,\mu_3,\ldots,\mu_p)^T$ 均值为 $\mu$ ,协方差矩阵为 $\Sigma$ 。样本向量 $x=(x_1,x_2,x_3,\ldots,x_p)^T$ 到 $\mu$ 的马氏距离科表示为:
74 | $$D(x)=\sqrt{(x-\mu)^T\Sigma^{-1}(x-\mu)}$$
75 |
76 | 向量 $X_i$ 与 $X_j$ 的马氏距离定义为:
77 | $$D(X_i,X_j)=\sqrt{(X_i-X_j)^T\Sigma^{-1}(X_i-X_j)}$$
78 |
79 | 若协方差矩阵是单位矩阵(各个样本向量之间独立同分布),则 $X_i$ 与 $X_j$ 之间的马氏距离等于他们的欧氏距离:
80 | $$D(X_i,X_j)=\sqrt{(X_i-X_j)^T(X_i-X_j)}$$
81 |
82 | 若协方差矩阵是对角矩阵,则就是标准化欧氏距离。
83 |
84 | ## 汉明距离
85 |
86 | **汉明距离**(Hamming Distance)在信息论中表示两个等长字符串之间对应位置的不同字符串个数。换而言之,就是将一个字符串变换成另一个等长字符串所需要的 *替换* 次数。
87 |
88 | **汉明重量**:是字符串相对于同样长度的零字符串的汉明距离,也就是说,它是字符串中非零的元素个数:对于二进制字符串来说,就是`1`的个数,所以`11101 `的汉明重量是4。因此,如果向量空间中的元素`a`和`b`之间的汉明距离等于它们汉明重量的差`a-b`。
89 |
90 | **编辑距离**,又称**Levenshtein距离**(也叫做`Edit Distance`),是汉明距离的一般化,指两个字串之间,由一个转成另一个所需的最少编辑操作次数,如果它们的距离越大,说明它们越是不同。许可的编辑操作包括替换、插入、删除。
91 |
92 | ## 杰卡德距离
93 |
94 | **杰卡德相似系数**(Jaccard similarity coefficient) 表示两个集合 $A$ 和 $B$ 的交集与并集的比值,是衡量两个集合相似度的一种指标。
95 | $$J(A,B)=\frac{|A \bigcap B|}{|A \bigcup B|}$$
96 |
97 | **杰卡德距离**(Jaccard Distance)是与杰卡德相似系数相反的概念。用来衡量两个集合差异性的一种指标。杰卡德距离可用如下公式表示:
98 | $$D_j(A,B)=1-J(A,B)=\frac{|A \bigcup B| - |A \bigcap B|}{|A \bigcup B|}$$
99 |
100 | ## 相关距离
101 |
102 | **皮尔森相关系数**(Pearson correlation coefficient),相关系数有很多种,这里以常用的P相关系数为例。P相关系数是衡量随机变量`X`与`Y`相关程度的一种方法,相关系数的取值范围是`[-1,1]`。相关系数的绝对值越大,则表明`X`与`Y`相关度越高。当`X`与`Y`线性相关时,相关系数取值为`1`(正线性相关)或`-1`(负线性相关)。
103 |
104 | * 定义
105 |
106 | $$\rho_{XY}=\frac{Cov(X,Y)}{\sqrt{D(X)}\sqrt{D(Y)}}=\frac{\sum_{i=1}^n(X_i-\overline{x})(y_i-\overline{y})}{\sqrt{\sum_{i=1}^n(X_i-\overline{x})^2\sqrt{\sum_{i=1}^n(y_i-\overline{y})^2}}}$$
107 |
108 | **相关距离**:
109 | $$D_{xy}=1-{\rho}_{xy}$$
110 |
111 | ## 余弦距离
112 |
113 | 几何中,夹角余弦可用来衡量两个向量方向的差异;通过测量两个向量的夹角的余弦值来度量它们之间的相似性。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为0到1之间。
114 |
115 | * 定义
116 |
117 | 给定两个向量 `A` 和 `B`, 其余弦相似性 $\theta$ 的计算公式如下:
118 | $$\cos(\theta)=\frac{A \cdot B}{\mid A\mid\mid B\mid}=\frac{\sum_{i=1}^nA_i \times B_i}{\sqrt{\sum_{i=1}^n(A_i)^2 \times \sqrt{\sum_{i=1}^n(B_i)^2}}}$$
119 |
120 | 例如,二维空间向量 $A(x_1,y_1)$ 和 $B(x_2,y_2)$ 的夹角余弦:
121 | $$\cos(\theta)=\frac{x_1x_2+y_1y_2}{\sqrt{x_1^2+y_1^2}\sqrt{x_2^2+y_2^2}}$$
122 |
123 |
124 | ## 信息熵
125 |
126 | **信息熵**(Information Entropy)描述的是整个系统内部样本之间的一个距离,或者称之为系统内样本分布的集中程度(一致程度)、分散程度、混乱程度(不一致程度)。系统内样本分布越分散(或者说分布越平均),信息熵就越大。分布越有序(或者说分布越集中),信息熵就越小。
127 |
128 | * 定义
129 |
130 | 计算给定的样本集 `X` 的信息熵的公式:
131 | $$Entropy(X)=-\sum_{i=1}^np_i \log_2p_i$$
132 |
133 | 参数含义:
134 | $n$:样本集 $X$ 的分类数;
135 | $p_i$: $X$ 中第 $i$ 类出现的概率。
136 |
137 | 信息熵越大表明样本集`X`的分布越分散(分布均衡),信息熵越小则表明样本集`X`的分布越集中(分布不均衡)。当`X`中`n`个分类出现的概率一样大时(都是`1/n`),信息熵取最大值`log2(n)`。当`X`只有一个分类时,信息熵取最小值`0`。
138 |
--------------------------------------------------------------------------------
/算法记录/曲线点抽稀算法-Python实现.md:
--------------------------------------------------------------------------------
1 | ## 何为抽稀
2 |
3 | >在处理矢量化数据时,记录中往往会有很多重复数据,对进一步数据处理带来诸多不便。多余的数据一方面浪费了较多的存储空间,另一方面造成所要表达的图形不光滑或不符合标准。因此要通过某种规则,在保证矢量曲线形状不变的情况下, 最大限度地减少数据点个数,这个过程称为抽稀。
4 |
5 | 通俗的讲就是对曲线进行采样简化,即在曲线上取有限个点,将其变为折线,并且能够在一定程度保持原有形状。比较常用的两种抽稀算法是:道格拉斯-普克(Douglas-Peuker)算法和垂距限值法。
6 |
7 | ## 道格拉斯-普克(Douglas-Peuker)算法
8 |
9 | Douglas-Peuker算法(DP算法)过程如下:
10 |
11 | * 1、连接曲线首尾两点A、B;
12 | * 2、依次计算曲线上所有点到A、B两点所在曲线的距离;
13 | * 3、计算最大距离D,如果D小于阈值threshold,则去掉曲线上出A、B外的所有点;如果D大于阈值threshold,则把曲线以最大距离分割成两段;
14 | * 4、对所有曲线分段重复1-3步骤,知道所有D均小于阈值。即完成抽稀。
15 |
16 | 这种算法的抽稀精度与阈值有很大关系,阈值越大,简化程度越大,点减少的越多;反之简化程度越低,点保留的越多,形状也越趋于原曲线。
17 |
18 | 下面是Python代码实现:
19 | ```python
20 | # -*- coding: utf-8 -*-
21 | """
22 | -------------------------------------------------
23 | File Name: DouglasPeuker
24 | Description : 道格拉斯-普克抽稀算法
25 | Author : J_hao
26 | date: 2017/8/16
27 | -------------------------------------------------
28 | Change Activity:
29 | 2017/8/16: 道格拉斯-普克抽稀算法
30 | -------------------------------------------------
31 | """
32 | from __future__ import division
33 |
34 | from math import sqrt, pow
35 |
36 | __author__ = 'J_hao'
37 |
38 | THRESHOLD = 0.0001 # 阈值
39 |
40 |
41 | def point2LineDistance(point_a, point_b, point_c):
42 | """
43 | 计算点a到点b c所在直线的距离
44 | :param point_a:
45 | :param point_b:
46 | :param point_c:
47 | :return:
48 | """
49 | # 首先计算b c 所在直线的斜率和截距
50 | if point_b[0] == point_c[0]:
51 | return 9999999
52 | slope = (point_b[1] - point_c[1]) / (point_b[0] - point_c[0])
53 | intercept = point_b[1] - slope * point_b[0]
54 |
55 | # 计算点a到b c所在直线的距离
56 | distance = abs(slope * point_a[0] - point_a[1] + intercept) / sqrt(1 + pow(slope, 2))
57 | return distance
58 |
59 |
60 | class DouglasPeuker(object):
61 | def __init__(self):
62 | self.threshold = THRESHOLD
63 | self.qualify_list = list()
64 | self.disqualify_list = list()
65 |
66 | def diluting(self, point_list):
67 | """
68 | 抽稀
69 | :param point_list:二维点列表
70 | :return:
71 | """
72 | if len(point_list) < 3:
73 | self.qualify_list.extend(point_list[::-1])
74 | else:
75 | # 找到与收尾两点连线距离最大的点
76 | max_distance_index, max_distance = 0, 0
77 | for index, point in enumerate(point_list):
78 | if index in [0, len(point_list) - 1]:
79 | continue
80 | distance = point2LineDistance(point, point_list[0], point_list[-1])
81 | if distance > max_distance:
82 | max_distance_index = index
83 | max_distance = distance
84 |
85 | # 若最大距离小于阈值,则去掉所有中间点。 反之,则将曲线按最大距离点分割
86 | if max_distance < self.threshold:
87 | self.qualify_list.append(point_list[-1])
88 | self.qualify_list.append(point_list[0])
89 | else:
90 | # 将曲线按最大距离的点分割成两段
91 | sequence_a = point_list[:max_distance_index]
92 | sequence_b = point_list[max_distance_index:]
93 |
94 | for sequence in [sequence_a, sequence_b]:
95 | if len(sequence) < 3 and sequence == sequence_b:
96 | self.qualify_list.extend(sequence[::-1])
97 | else:
98 | self.disqualify_list.append(sequence)
99 |
100 | def main(self, point_list):
101 | self.diluting(point_list)
102 | while len(self.disqualify_list) > 0:
103 | self.diluting(self.disqualify_list.pop())
104 | print self.qualify_list
105 | print len(self.qualify_list)
106 |
107 |
108 | if __name__ == '__main__':
109 | d = DouglasPeuker()
110 | d.main([[104.066228, 30.644527], [104.066279, 30.643528], [104.066296, 30.642528], [104.066314, 30.641529],
111 | [104.066332, 30.640529], [104.066383, 30.639530], [104.066400, 30.638530], [104.066451, 30.637531],
112 | [104.066468, 30.636532], [104.066518, 30.635533], [104.066535, 30.634533], [104.066586, 30.633534],
113 | [104.066636, 30.632536], [104.066686, 30.631537], [104.066735, 30.630538], [104.066785, 30.629539],
114 | [104.066802, 30.628539], [104.066820, 30.627540], [104.066871, 30.626541], [104.066888, 30.625541],
115 | [104.066906, 30.624541], [104.066924, 30.623541], [104.066942, 30.622542], [104.066960, 30.621542],
116 | [104.067011, 30.620543], [104.066122, 30.620086], [104.065124, 30.620021], [104.064124, 30.620022],
117 | [104.063124, 30.619990], [104.062125, 30.619958], [104.061125, 30.619926], [104.060126, 30.619894],
118 | [104.059126, 30.619895], [104.058127, 30.619928], [104.057518, 30.620722], [104.057625, 30.621716],
119 | [104.057735, 30.622710], [104.057878, 30.623700], [104.057984, 30.624694], [104.058094, 30.625688],
120 | [104.058204, 30.626682], [104.058315, 30.627676], [104.058425, 30.628670], [104.058502, 30.629667],
121 | [104.058518, 30.630667], [104.058503, 30.631667], [104.058521, 30.632666], [104.057664, 30.633182],
122 | [104.056664, 30.633174], [104.055664, 30.633166], [104.054672, 30.633289], [104.053758, 30.633694],
123 | [104.052852, 30.634118], [104.052623, 30.635091], [104.053145, 30.635945], [104.053675, 30.636793],
124 | [104.054200, 30.637643], [104.054756, 30.638475], [104.055295, 30.639317], [104.055843, 30.640153],
125 | [104.056387, 30.640993], [104.056933, 30.641830], [104.057478, 30.642669], [104.058023, 30.643507],
126 | [104.058595, 30.644327], [104.059152, 30.645158], [104.059663, 30.646018], [104.060171, 30.646879],
127 | [104.061170, 30.646855], [104.062168, 30.646781], [104.063167, 30.646823], [104.064167, 30.646814],
128 | [104.065163, 30.646725], [104.066157, 30.646618], [104.066231, 30.645620], [104.066247, 30.644621], ])
129 | ```
130 |
131 | ## 垂距限值法
132 |
133 | 垂距限值法其实和DP算法原理一样,但是垂距限值不是从整体角度考虑,而是依次扫描每一个点,检查是否符合要求。
134 |
135 | 算法过程如下:
136 |
137 | * 1、以第二个点开始,计算第二个点到前一个点和后一个点所在直线的距离d;
138 | * 2、如果d大于阈值,则保留第二个点,计算第三个点到第二个点和第四个点所在直线的距离d;若d小于阈值则舍弃第二个点,计算第三个点到第一个点和第四个点所在直线的距离d;
139 | * 3、依次类推,直线曲线上倒数第二个点。
140 |
141 | 下面是Python代码实现:
142 | ```python
143 | # -*- coding: utf-8 -*-
144 | """
145 | -------------------------------------------------
146 | File Name: LimitVerticalDistance
147 | Description : 垂距限值抽稀算法
148 | Author : J_hao
149 | date: 2017/8/17
150 | -------------------------------------------------
151 | Change Activity:
152 | 2017/8/17:
153 | -------------------------------------------------
154 | """
155 | from __future__ import division
156 |
157 | from math import sqrt, pow
158 |
159 | __author__ = 'J_hao'
160 |
161 | THRESHOLD = 0.0001 # 阈值
162 |
163 |
164 | def point2LineDistance(point_a, point_b, point_c):
165 | """
166 | 计算点a到点b c所在直线的距离
167 | :param point_a:
168 | :param point_b:
169 | :param point_c:
170 | :return:
171 | """
172 | # 首先计算b c 所在直线的斜率和截距
173 | if point_b[0] == point_c[0]:
174 | return 9999999
175 | slope = (point_b[1] - point_c[1]) / (point_b[0] - point_c[0])
176 | intercept = point_b[1] - slope * point_b[0]
177 |
178 | # 计算点a到b c所在直线的距离
179 | distance = abs(slope * point_a[0] - point_a[1] + intercept) / sqrt(1 + pow(slope, 2))
180 | return distance
181 |
182 |
183 | class LimitVerticalDistance(object):
184 | def __init__(self):
185 | self.threshold = THRESHOLD
186 | self.qualify_list = list()
187 |
188 | def diluting(self, point_list):
189 | """
190 | 抽稀
191 | :param point_list:二维点列表
192 | :return:
193 | """
194 | self.qualify_list.append(point_list[0])
195 | check_index = 1
196 | while check_index < len(point_list) - 1:
197 | distance = point2LineDistance(point_list[check_index],
198 | self.qualify_list[-1],
199 | point_list[check_index + 1])
200 |
201 | if distance < self.threshold:
202 | check_index += 1
203 | else:
204 | self.qualify_list.append(point_list[check_index])
205 | check_index += 1
206 | return self.qualify_list
207 |
208 |
209 | if __name__ == '__main__':
210 | l = LimitVerticalDistance()
211 | diluting = l.diluting([[104.066228, 30.644527], [104.066279, 30.643528], [104.066296, 30.642528], [104.066314, 30.641529],
212 | [104.066332, 30.640529], [104.066383, 30.639530], [104.066400, 30.638530], [104.066451, 30.637531],
213 | [104.066468, 30.636532], [104.066518, 30.635533], [104.066535, 30.634533], [104.066586, 30.633534],
214 | [104.066636, 30.632536], [104.066686, 30.631537], [104.066735, 30.630538], [104.066785, 30.629539],
215 | [104.066802, 30.628539], [104.066820, 30.627540], [104.066871, 30.626541], [104.066888, 30.625541],
216 | [104.066906, 30.624541], [104.066924, 30.623541], [104.066942, 30.622542], [104.066960, 30.621542],
217 | [104.067011, 30.620543], [104.066122, 30.620086], [104.065124, 30.620021], [104.064124, 30.620022],
218 | [104.063124, 30.619990], [104.062125, 30.619958], [104.061125, 30.619926], [104.060126, 30.619894],
219 | [104.059126, 30.619895], [104.058127, 30.619928], [104.057518, 30.620722], [104.057625, 30.621716],
220 | [104.057735, 30.622710], [104.057878, 30.623700], [104.057984, 30.624694], [104.058094, 30.625688],
221 | [104.058204, 30.626682], [104.058315, 30.627676], [104.058425, 30.628670], [104.058502, 30.629667],
222 | [104.058518, 30.630667], [104.058503, 30.631667], [104.058521, 30.632666], [104.057664, 30.633182],
223 | [104.056664, 30.633174], [104.055664, 30.633166], [104.054672, 30.633289], [104.053758, 30.633694],
224 | [104.052852, 30.634118], [104.052623, 30.635091], [104.053145, 30.635945], [104.053675, 30.636793],
225 | [104.054200, 30.637643], [104.054756, 30.638475], [104.055295, 30.639317], [104.055843, 30.640153],
226 | [104.056387, 30.640993], [104.056933, 30.641830], [104.057478, 30.642669], [104.058023, 30.643507],
227 | [104.058595, 30.644327], [104.059152, 30.645158], [104.059663, 30.646018], [104.060171, 30.646879],
228 | [104.061170, 30.646855], [104.062168, 30.646781], [104.063167, 30.646823], [104.064167, 30.646814],
229 | [104.065163, 30.646725], [104.066157, 30.646618], [104.066231, 30.645620], [104.066247, 30.644621], ])
230 | print len(diluting)
231 | print(diluting)
232 | ```
233 |
234 | ## 最后
235 |
236 | 其实DP算法和垂距限值法原理一样,DP算法是从整体上考虑一条完整的曲线,实现时较垂距限值法复杂,但垂距限值法可能会在某些情况下导致局部最优。另外在实际使用中发现采用点到另外两点所在直线距离的方法来判断偏离,在曲线弧度比较大的情况下比较准确。如果在曲线弧度比较小,弯曲程度不明显时,这种方法抽稀效果不是很理想,建议使用三点所围成的三角形面积作为判断标准。下面是抽稀效果:
237 |
238 | 
239 | 
240 |
241 |
--------------------------------------------------------------------------------
/算法记录/机器学习笔记—KNN算法.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 |
3 | **分类**(Classification)是数据挖掘领域中的一种重要技术,它从一组已分类的训练样本中发现分类模型,将这个分类模型应用到待分类的样本进行预测。
4 |
5 | 当前主流的分类算法有:朴素贝叶斯分类(Naive Bayes)、支持向量机(SVM)、KNN(K-Nearest Neighbors)、神经网络(NNet)、决策树(Decision Tree)等等。
6 |
7 | KNN算法是一个理论上比较成熟的方法,最初由Cover和Hart于1968年提出,思路非常简单直观,易于快速实现。
8 |
9 | ## 基本思想
10 |
11 | 如下图所示,假设有已知类型的三类训练样本 $ \omega_1、\omega_2、\omega_3$,现对样本 $ X_u $进行分类。根据**距离函数**依次计算待分类样本 $ X_u$ 和每个训练的距离,这个距离看做是**相似度**。选择与待分类样本距离最近的K个训练样本,如下图黑色箭头所指的5个样本。最后K个类别中所属类别最多的类别作为待分类样本的类别,如下图中 $ X_u $属于 $ \omega_1$ 类。
12 | 
13 |
14 | KNN可以说是一种最直接的用来分类未知数据的方法。简单来说,KNN可以看成:有那么一堆已经知道类别的数据,当有一个新数据进入时,依次计算这个数据和每个训练数据的距离,然后跳出离这个数据最近的K个点,看看这个K个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
15 |
16 | ## 算法实现
17 |
18 | ## 实现步骤
19 |
20 | * 1.构建训练数据集(数据标准化);
21 | * 2.计算训练数据集中的点与当前点的距离;
22 | * 3.按照距离递增排序;
23 | * 4.选取距离与当前距离最小的K个点;
24 | * 5.确定前K个点中所在类别的出现概率;
25 | * 6.返回前K个点中出现概率最高的类别作为当前点的分类。
26 |
27 | Python实现代码:
28 | ```python
29 | import numpy as np
30 | import operator
31 |
32 |
33 | def createDataSet():
34 | """
35 | 构造假的训练数据,产生四条训练样本,group为样本属性,labels为分类标签,即[1.0,1.1]属于A类
36 | :return:
37 | """
38 | group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
39 | labels = ['A', 'A', 'B', 'B']
40 | return group, labels
41 |
42 |
43 | def classify(inX, dataSet, labels, k):
44 | """
45 | 简单KNN分类
46 | :param inX: 待分类向量
47 | :param dataSet: 训练样本集
48 | :param labels: 训练样本标签
49 | :param k: K值
50 | :return:
51 | """
52 | dataSetSize = dataSet.shape[0] # 训练样本个数
53 | diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet # 计算训练样本和待分类样本的数值差值
54 | # 用于后面计算欧式距离,欧氏距离为各维度上数值差值的平方和再开方的结果
55 | sqDiffMat = diffMat ** 2 # 差值的平方
56 | sqDistances = sqDiffMat.sum(axis=1) # 平方和
57 | distances = sqDistances ** 0.5 # 平方和开方
58 | sortedDistIndicies = distances.argsort() # 返回升序排列后的索引
59 | classCount = {}
60 | # 统计前K个样本中各标签出现次数
61 | for i in range(k):
62 | voteIlabel = labels[sortedDistIndicies[i]]
63 | classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
64 | sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
65 | # 按标签次数排序,返回次数最多的标签
66 | return sortedClassCount[0][0]
67 |
68 | if __name__ == '__main__':
69 | group, labels = createDataSet()
70 | print(classify([0, 0], group, labels, 2))
71 | # 最终输出类别为B
72 | ```
73 |
74 | 上例代码中,样本距离计算采用的是**欧式距离**,距离方法的选择也会影响到分类结果,关于可选的距离度量以及计算公式,可以参考这篇文章 [常用样本相似性和距离度量方法](http://www.spiderpy.cn/blog/detail/33)。
75 |
76 | ## 优缺点
77 |
78 | * 优点
79 |
80 | - 1.KNN算法思想简单,非常容易实现;
81 | - 2.有新样本要加入训练集时,无需重新训练;
82 | - 3.时间和空间复杂度与训练集大小成线性相关;
83 |
84 |
85 | * 缺点
86 |
87 | - 1.分类速度慢;
88 |
89 | KNN算法的时间复杂度和储存空间会随着训练集规模和特征维数的增大而增加。因此每次分类新样本时,都要和所有的训练样本进行计算比较。整个算法的时间复杂度可以用 $O(m*n)$ 表示,其实 $m$ 和 $n$ 分别是特征维度和训练集样本个数。
90 |
91 | - 2.各属性权重相同,影响准确率;
92 |
93 | 当样分布不均匀时,如果某一个类的样本容量很大,而其他类样本容量很小。有可能在对新样本进行分类时,前K个最近的样本中样本容量大的类占了多数,而不是真正接近的类占了多数,这样会导致分类错误。
94 |
95 | - 3.样本依赖性很强;
96 | - 4.K值不好确定;
97 |
98 | K值设置过小时,得到的邻近数也会太小,这样会放大噪声数据的干扰,影响分类精度。K值设置过大时,就会使2中描述的错误概率增加。
99 |
100 | ## KNN改进
101 |
102 | ### 降低计算复杂度
103 |
104 | KNN的一个严重问题就是需要**储存全部训练样本**,以及繁重的**距离计算**量。下面是一些已知的改进方法:
105 |
106 | * 特征维度压缩
107 |
108 | 在KNN算法之前对样本属性进行**约简**,删除**对分类结果影响较小(不重要)**的属性。例如**粗糙集理论**在用于决策表的属性约简时,可在保持决策表中决策能力不变的前提下,删除其中不相关的冗余属性。
109 |
110 | * 缩小训练样本
111 |
112 | 就是在原样本中挑选出对分类计算**有效的样本**,使样本总数合理地减少,但又不会影响分类精度。常用的有**剪辑近邻法**和**压缩近邻法**。
113 |
114 | - **剪辑近邻法**
115 |
116 | 其基本思想是:利用现有样本集对自身进行剪辑,**将不同类别交界处的样本以适当方式筛选**,可以实现即减少样本数,又提高正确识别率的目的。过程如下:将样本集 $K^N$ 分成两个相互独立的子集: **test集** $K^T$ 和**reference集** $K^R$ 。首先对 $K^T$ 中每个样本 $X_i$ 在 $K^R$ 中找到其最近邻的样本 $Y_i(X_i)$ 。如果 $Y_i$ 和 $X_i$ 不属于同一类别, 则将 $X_i$ 从 $K^t$ 中删除,最后得到一个剪辑的样本集 $K^TE$ ,以取代原样本。
117 |
118 | - **压缩近邻法**
119 |
120 | 其基本思想是:利用现有样本集,逐渐生成一个新的样本集,使该样本在保留最少样本的条件下,仍能对原有样本的全部用最近邻法正确分类。过程如下:定义两个储存器,一个用来存放即将生成的样本集,称为**Store**;另一个储存器则存放原样本,称为**Grabbag**。算法过程: `过程1.初始化`,Store是空集,原样本存入Grabbag;从Grabbag中任意选择一样本放入Store中,作为新样本集的第一个样本。`过程2.样本集生成`,依次从Grabbag中取出第 $i$ 个样本,用Store中的样本集用最近邻发分类。若分类错误,则将该样本从Grabbag中转入Store,若分类正确,则将该样本放回Grabbag。`过程3.结束判断`,如果Grabbag中所有样本在执行过程2时没有发生转入Store现象,或者Grabbag已为空,则算法结束,否则转入过程2。
121 |
122 | * 预建立结构
123 |
124 | 常用的是基于树的快速查找,其基本思想是:将样本按邻近关系分解成组,给出每组的质心,已经组内样本至质心的最大距离。这些组又可以形成层次结构,即组又分子组,因而待识别样本可将**搜索近邻的范围从某一大组,逐渐深入到其中的子组**,直至树的叶节点所代表的组,确定其近邻关系。
125 |
126 | ### 提高分类准确度
127 |
128 | * 优化相似度量
129 |
130 | 前面已经计算样本间的相似度量有很多,[常用样本相似性和距离度量方法](http://www.spiderpy.cn/blog/detail/33)。基本上KNN算法都是基于**欧氏距离**来计算样本相似度,但这种方法认为各维度对分类贡献率是相同的,这回影响分类的准确度。因此也有人提出过**基于权重调整系数**的改进方法。改方法的思想是,在距离度量函数中对不同属性赋予不同权重,改进后的欧式距离公式为:
131 | $$d(x_i,y_j)=\sqrt{\sum_{k=1}^l\omega_l(x_{ki}-y_{kj})^2}$$
132 | 然后通过灵敏度法确定权重向量 $\omega_l$。
133 |
134 | - 首先统计出分类错误的样本数 $n$;
135 | - 依次去掉特征集中的属性,应用KNN分类,统计出分类错误的样本数量 $n_q$;
136 | - $n_q$与 $n$ 的比值 $n_q \over n$ 就是对于特征维度的权重系数。
137 |
138 | * 选取恰当K值
139 |
140 | 由于KNN算法中几乎所有的计算都发生在分类阶段,而且分类效果很大程度上依赖于L值的选择,而目前为止,比较好的选择K值的方法只能是通过反复试验调整。
--------------------------------------------------------------------------------