├── LICENCE
├── README.md
├── RL_cover.jpg
├── contents
├── 10_A3C
│ ├── A3C_RNN.py
│ ├── A3C_continuous_action.py
│ ├── A3C_discrete_action.py
│ └── A3C_distributed_tf.py
├── 11_Dyna_Q
│ ├── RL_brain.py
│ ├── maze_env.py
│ └── run_this.py
├── 12_Proximal_Policy_Optimization
│ ├── DPPO.py
│ └── simply_PPO.py
├── 1_command_line_reinforcement_learning
│ └── treasure_on_right.py
├── 2_Q_Learning_maze
│ ├── RL_brain.py
│ ├── maze_env.py
│ └── run_this.py
├── 3_Sarsa_maze
│ ├── RL_brain.py
│ ├── maze_env.py
│ └── run_this.py
├── 4_Sarsa_lambda_maze
│ ├── RL_brain.py
│ ├── maze_env.py
│ └── run_this.py
├── 5.1_Double_DQN
│ ├── RL_brain.py
│ └── run_Pendulum.py
├── 5.2_Prioritized_Replay_DQN
│ ├── RL_brain.py
│ └── run_MountainCar.py
├── 5.3_Dueling_DQN
│ ├── RL_brain.py
│ └── run_Pendulum.py
├── 5_Deep_Q_Network
│ ├── DQN_modified.py
│ ├── RL_brain.py
│ ├── maze_env.py
│ └── run_this.py
├── 6_OpenAI_gym
│ ├── RL_brain.py
│ ├── run_CartPole.py
│ └── run_MountainCar.py
├── 7_Policy_gradient_softmax
│ ├── RL_brain.py
│ ├── run_CartPole.py
│ └── run_MountainCar.py
├── 8_Actor_Critic_Advantage
│ ├── AC_CartPole.py
│ └── AC_continue_Pendulum.py
└── 9_Deep_Deterministic_Policy_Gradient_DDPG
│ ├── DDPG.py
│ ├── DDPG_update.py
│ └── DDPG_update2.py
└── experiments
├── 2D_car
├── DDPG.py
├── car_env.py
└── collision.py
├── Robot_arm
├── A3C.py
├── DDPG.py
├── DPPO.py
└── arm_env.py
├── Solve_BipedalWalker
├── A3C.py
├── A3C_rnn.py
├── DDPG.py
└── log
│ └── events.out.tfevents.1490801027.Morvan
└── Solve_LunarLander
├── A3C.py
├── DuelingDQNPrioritizedReplay.py
└── run_LunarLander.py
/LICENCE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2017
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |  4 |
5 |
4 |
5 |
6 |
7 |
8 |
9 |
10 | # Reinforcement Learning Methods and Tutorials
11 |
12 | In these tutorials for reinforcement learning, it covers from the basic RL algorithms to advanced algorithms developed recent years.
13 |
14 | **If you speak Chinese, visit [莫烦 Python](https://morvanzhou.github.io/tutorials/) or my [Youtube channel](https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg) for more.**
15 |
16 | **As many requests about making these tutorials available in English, please find them in this playlist:** ([https://www.youtube.com/playlist?list=PLXO45tsB95cIplu-fLMpUEEZTwrDNh6Ba](https://www.youtube.com/playlist?list=PLXO45tsB95cIplu-fLMpUEEZTwrDNh6Ba))
17 |
18 | # Table of Contents
19 |
20 | * Tutorials
21 | * [Simple entry example](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/1_command_line_reinforcement_learning)
22 | * [Q-learning](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/2_Q_Learning_maze)
23 | * [Sarsa](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/3_Sarsa_maze)
24 | * [Sarsa(lambda)](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/4_Sarsa_lambda_maze)
25 | * [Deep Q Network](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/5_Deep_Q_Network)
26 | * [Using OpenAI Gym](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/6_OpenAI_gym)
27 | * [Double DQN](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/5.1_Double_DQN)
28 | * [DQN with Prioitized Experience Replay](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/5.2_Prioritized_Replay_DQN)
29 | * [Dueling DQN](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/5.3_Dueling_DQN)
30 | * [Policy Gradients](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/7_Policy_gradient_softmax)
31 | * [Actor Critic](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/8_Actor_Critic_Advantage)
32 | * [Deep Deterministic Policy Gradient](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/9_Deep_Deterministic_Policy_Gradient_DDPG)
33 | * [A3C](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/10_A3C)
34 | * [Dyna-Q](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/11_Dyna_Q)
35 | * [Proximal Policy Optimization (PPO)](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/12_Proximal_Policy_Optimization)
36 | * [Some of my experiments](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/experiments)
37 | * [2D Car](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/experiments/2D_car)
38 | * [Robot arm](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/experiments/Robot_arm)
39 | * [BipedalWalker](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/experiments/Solve_BipedalWalker)
40 | * [LunarLander](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/experiments/Solve_LunarLander)
41 |
42 | # Some RL Networks
43 | ### [Deep Q Network](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/5_Deep_Q_Network)
44 |
45 |
46 | 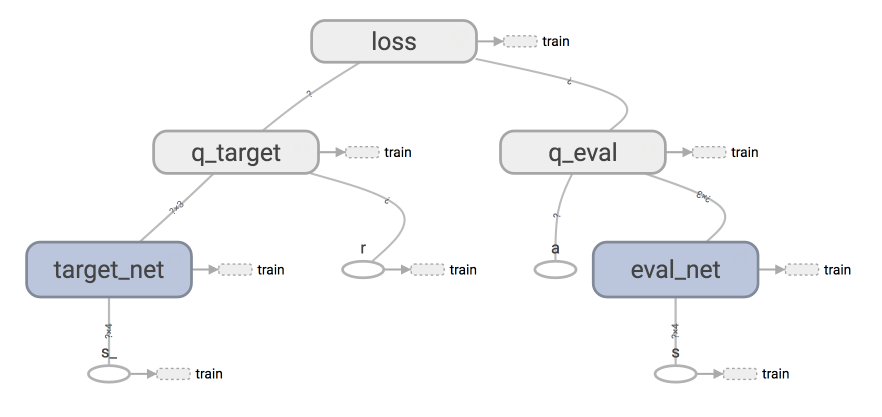 47 |
48 |
49 | ### [Double DQN](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/5.1_Double_DQN)
50 |
51 |
52 |
47 |
48 |
49 | ### [Double DQN](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/5.1_Double_DQN)
50 |
51 |
52 | 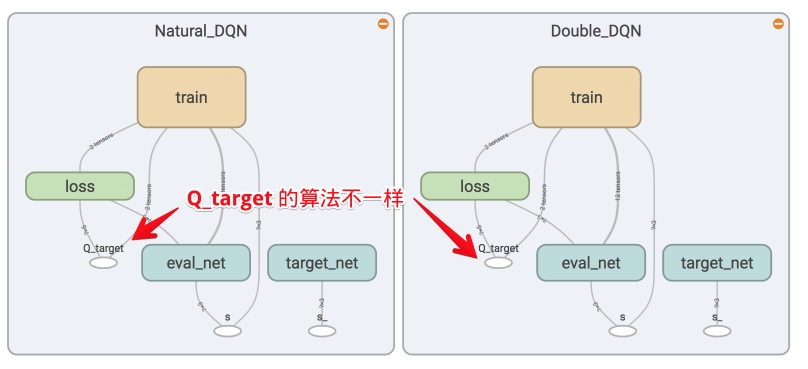 53 |
54 |
55 | ### [Dueling DQN](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/5.3_Dueling_DQN)
56 |
57 |
58 |
53 |
54 |
55 | ### [Dueling DQN](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/5.3_Dueling_DQN)
56 |
57 |
58 | 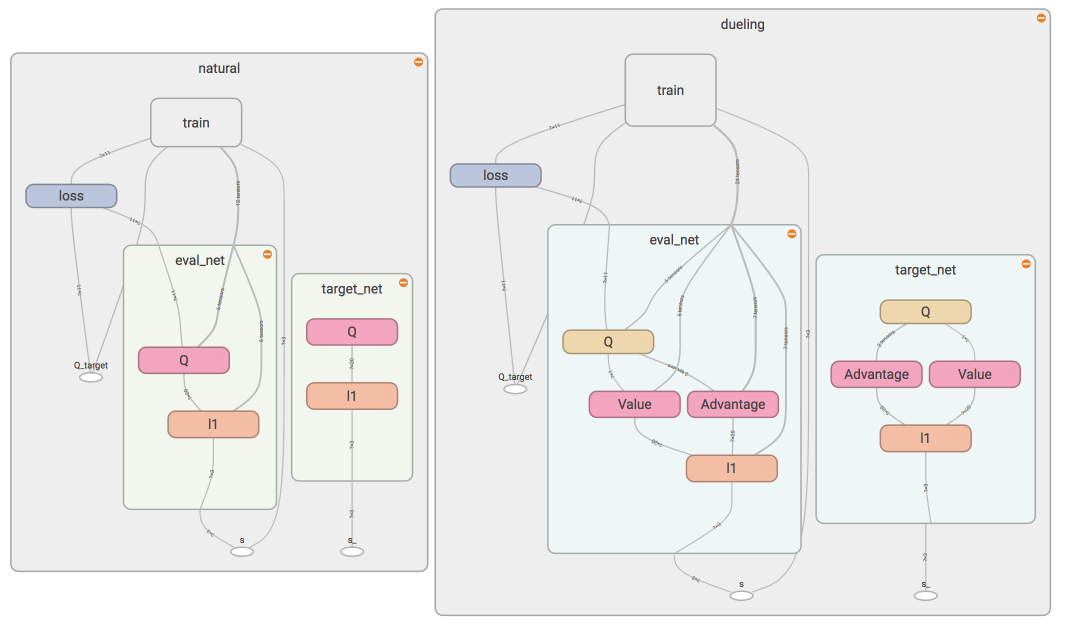 59 |
60 |
61 | ### [Actor Critic](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/8_Actor_Critic_Advantage)
62 |
63 |
64 |
59 |
60 |
61 | ### [Actor Critic](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/8_Actor_Critic_Advantage)
62 |
63 |
64 | 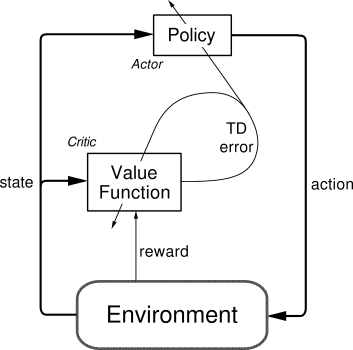 65 |
66 |
67 | ### [Deep Deterministic Policy Gradient](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/9_Deep_Deterministic_Policy_Gradient_DDPG)
68 |
69 |
70 |
65 |
66 |
67 | ### [Deep Deterministic Policy Gradient](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/9_Deep_Deterministic_Policy_Gradient_DDPG)
68 |
69 |
70 | 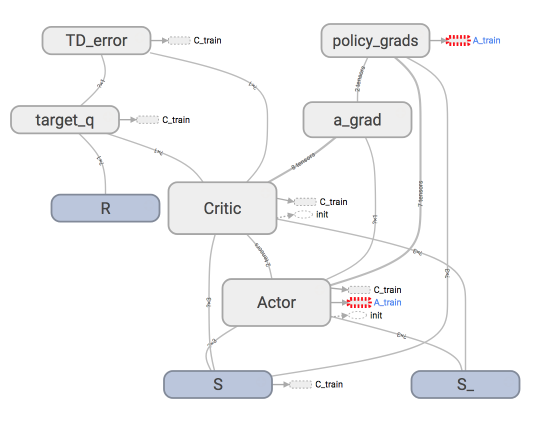 71 |
72 |
73 | ### [A3C](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/10_A3C)
74 |
75 |
76 |
71 |
72 |
73 | ### [A3C](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/10_A3C)
74 |
75 |
76 | 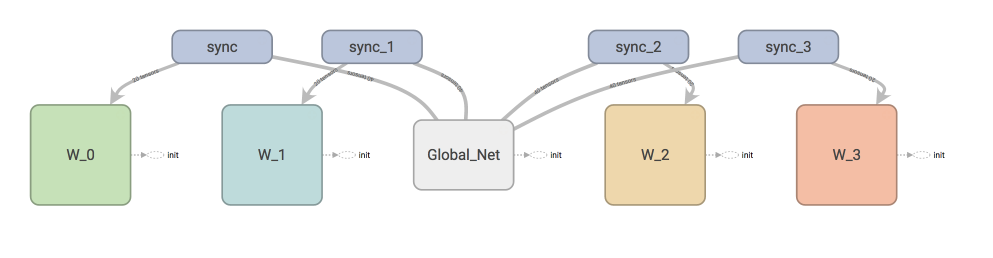 77 |
78 |
79 | ### [Proximal Policy Optimization (PPO)](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/12_Proximal_Policy_Optimization)
80 |
81 |
82 |
77 |
78 |
79 | ### [Proximal Policy Optimization (PPO)](https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/12_Proximal_Policy_Optimization)
80 |
81 |
82 | 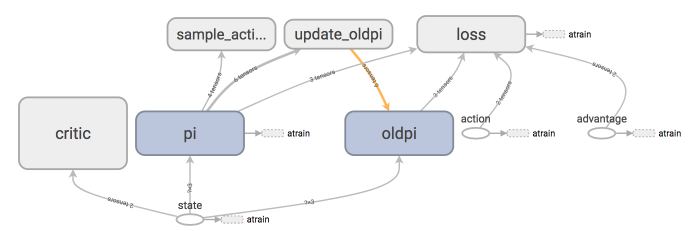 83 |
84 |
85 | # Donation
86 |
87 | *If this does help you, please consider donating to support me for better tutorials. Any contribution is greatly appreciated!*
88 |
89 |
96 |
97 |
103 |
--------------------------------------------------------------------------------
/RL_cover.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiajunhua/MorvanZhou-Reinforcement-learning-with-tensorflow/b484df7fc7dadab61e73e04aa40416bf6db68321/RL_cover.jpg
--------------------------------------------------------------------------------
/contents/10_A3C/A3C_continuous_action.py:
--------------------------------------------------------------------------------
1 | """
2 | Asynchronous Advantage Actor Critic (A3C) with continuous action space, Reinforcement Learning.
3 |
4 | The Pendulum example.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | tensorflow r1.3
10 | gym 0.8.0
11 | """
12 |
13 | import multiprocessing
14 | import threading
15 | import tensorflow as tf
16 | import numpy as np
17 | import gym
18 | import os
19 | import shutil
20 | import matplotlib.pyplot as plt
21 |
22 | GAME = 'Pendulum-v0'
23 | OUTPUT_GRAPH = True
24 | LOG_DIR = './log'
25 | N_WORKERS = multiprocessing.cpu_count()
26 | MAX_EP_STEP = 200
27 | MAX_GLOBAL_EP = 2000
28 | GLOBAL_NET_SCOPE = 'Global_Net'
29 | UPDATE_GLOBAL_ITER = 10
30 | GAMMA = 0.9
31 | ENTROPY_BETA = 0.01
32 | LR_A = 0.0001 # learning rate for actor
33 | LR_C = 0.001 # learning rate for critic
34 | GLOBAL_RUNNING_R = []
35 | GLOBAL_EP = 0
36 |
37 | env = gym.make(GAME)
38 |
39 | N_S = env.observation_space.shape[0]
40 | N_A = env.action_space.shape[0]
41 | A_BOUND = [env.action_space.low, env.action_space.high]
42 |
43 |
44 | class ACNet(object):
45 | def __init__(self, scope, globalAC=None):
46 |
47 | if scope == GLOBAL_NET_SCOPE: # get global network
48 | with tf.variable_scope(scope):
49 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
50 | self.a_params, self.c_params = self._build_net(scope)[-2:]
51 | else: # local net, calculate losses
52 | with tf.variable_scope(scope):
53 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
54 | self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
55 | self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
56 |
57 | mu, sigma, self.v, self.a_params, self.c_params = self._build_net(scope)
58 |
59 | td = tf.subtract(self.v_target, self.v, name='TD_error')
60 | with tf.name_scope('c_loss'):
61 | self.c_loss = tf.reduce_mean(tf.square(td))
62 |
63 | with tf.name_scope('wrap_a_out'):
64 | mu, sigma = mu * A_BOUND[1], sigma + 1e-4
65 |
66 | normal_dist = tf.distributions.Normal(mu, sigma)
67 |
68 | with tf.name_scope('a_loss'):
69 | log_prob = normal_dist.log_prob(self.a_his)
70 | exp_v = log_prob * tf.stop_gradient(td)
71 | entropy = normal_dist.entropy() # encourage exploration
72 | self.exp_v = ENTROPY_BETA * entropy + exp_v
73 | self.a_loss = tf.reduce_mean(-self.exp_v)
74 |
75 | with tf.name_scope('choose_a'): # use local params to choose action
76 | self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=0), A_BOUND[0], A_BOUND[1])
77 | with tf.name_scope('local_grad'):
78 | self.a_grads = tf.gradients(self.a_loss, self.a_params)
79 | self.c_grads = tf.gradients(self.c_loss, self.c_params)
80 |
81 | with tf.name_scope('sync'):
82 | with tf.name_scope('pull'):
83 | self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
84 | self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
85 | with tf.name_scope('push'):
86 | self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
87 | self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
88 |
89 | def _build_net(self, scope):
90 | w_init = tf.random_normal_initializer(0., .1)
91 | with tf.variable_scope('actor'):
92 | l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
93 | mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
94 | sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
95 | with tf.variable_scope('critic'):
96 | l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
97 | v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
98 | a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
99 | c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
100 | return mu, sigma, v, a_params, c_params
101 |
102 | def update_global(self, feed_dict): # run by a local
103 | SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
104 |
105 | def pull_global(self): # run by a local
106 | SESS.run([self.pull_a_params_op, self.pull_c_params_op])
107 |
108 | def choose_action(self, s): # run by a local
109 | s = s[np.newaxis, :]
110 | return SESS.run(self.A, {self.s: s})[0]
111 |
112 |
113 | class Worker(object):
114 | def __init__(self, name, globalAC):
115 | self.env = gym.make(GAME).unwrapped
116 | self.name = name
117 | self.AC = ACNet(name, globalAC)
118 |
119 | def work(self):
120 | global GLOBAL_RUNNING_R, GLOBAL_EP
121 | total_step = 1
122 | buffer_s, buffer_a, buffer_r = [], [], []
123 | while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
124 | s = self.env.reset()
125 | ep_r = 0
126 | for ep_t in range(MAX_EP_STEP):
127 | # if self.name == 'W_0':
128 | # self.env.render()
129 | a = self.AC.choose_action(s)
130 | s_, r, done, info = self.env.step(a)
131 | done = True if ep_t == MAX_EP_STEP - 1 else False
132 |
133 | ep_r += r
134 | buffer_s.append(s)
135 | buffer_a.append(a)
136 | buffer_r.append((r+8)/8) # normalize
137 |
138 | if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
139 | if done:
140 | v_s_ = 0 # terminal
141 | else:
142 | v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
143 | buffer_v_target = []
144 | for r in buffer_r[::-1]: # reverse buffer r
145 | v_s_ = r + GAMMA * v_s_
146 | buffer_v_target.append(v_s_)
147 | buffer_v_target.reverse()
148 |
149 | buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
150 | feed_dict = {
151 | self.AC.s: buffer_s,
152 | self.AC.a_his: buffer_a,
153 | self.AC.v_target: buffer_v_target,
154 | }
155 | self.AC.update_global(feed_dict)
156 | buffer_s, buffer_a, buffer_r = [], [], []
157 | self.AC.pull_global()
158 |
159 | s = s_
160 | total_step += 1
161 | if done:
162 | if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
163 | GLOBAL_RUNNING_R.append(ep_r)
164 | else:
165 | GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r)
166 | print(
167 | self.name,
168 | "Ep:", GLOBAL_EP,
169 | "| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
170 | )
171 | GLOBAL_EP += 1
172 | break
173 |
174 | if __name__ == "__main__":
175 | SESS = tf.Session()
176 |
177 | with tf.device("/cpu:0"):
178 | OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
179 | OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
180 | GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
181 | workers = []
182 | # Create worker
183 | for i in range(N_WORKERS):
184 | i_name = 'W_%i' % i # worker name
185 | workers.append(Worker(i_name, GLOBAL_AC))
186 |
187 | COORD = tf.train.Coordinator()
188 | SESS.run(tf.global_variables_initializer())
189 |
190 | if OUTPUT_GRAPH:
191 | if os.path.exists(LOG_DIR):
192 | shutil.rmtree(LOG_DIR)
193 | tf.summary.FileWriter(LOG_DIR, SESS.graph)
194 |
195 | worker_threads = []
196 | for worker in workers:
197 | job = lambda: worker.work()
198 | t = threading.Thread(target=job)
199 | t.start()
200 | worker_threads.append(t)
201 | COORD.join(worker_threads)
202 |
203 | plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
204 | plt.xlabel('step')
205 | plt.ylabel('Total moving reward')
206 | plt.show()
207 |
208 |
--------------------------------------------------------------------------------
/contents/10_A3C/A3C_discrete_action.py:
--------------------------------------------------------------------------------
1 | """
2 | Asynchronous Advantage Actor Critic (A3C) with discrete action space, Reinforcement Learning.
3 |
4 | The Cartpole example.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | tensorflow 1.0
10 | gym 0.8.0
11 | """
12 |
13 | import multiprocessing
14 | import threading
15 | import tensorflow as tf
16 | import numpy as np
17 | import gym
18 | import os
19 | import shutil
20 | import matplotlib.pyplot as plt
21 |
22 |
23 | GAME = 'CartPole-v0'
24 | OUTPUT_GRAPH = True
25 | LOG_DIR = './log'
26 | N_WORKERS = multiprocessing.cpu_count()
27 | MAX_GLOBAL_EP = 1000
28 | GLOBAL_NET_SCOPE = 'Global_Net'
29 | UPDATE_GLOBAL_ITER = 10
30 | GAMMA = 0.9
31 | ENTROPY_BETA = 0.001
32 | LR_A = 0.001 # learning rate for actor
33 | LR_C = 0.001 # learning rate for critic
34 | GLOBAL_RUNNING_R = []
35 | GLOBAL_EP = 0
36 |
37 | env = gym.make(GAME)
38 | N_S = env.observation_space.shape[0]
39 | N_A = env.action_space.n
40 |
41 |
42 | class ACNet(object):
43 | def __init__(self, scope, globalAC=None):
44 |
45 | if scope == GLOBAL_NET_SCOPE: # get global network
46 | with tf.variable_scope(scope):
47 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
48 | self.a_params, self.c_params = self._build_net(scope)[-2:]
49 | else: # local net, calculate losses
50 | with tf.variable_scope(scope):
51 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
52 | self.a_his = tf.placeholder(tf.int32, [None, ], 'A')
53 | self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
54 |
55 | self.a_prob, self.v, self.a_params, self.c_params = self._build_net(scope)
56 |
57 | td = tf.subtract(self.v_target, self.v, name='TD_error')
58 | with tf.name_scope('c_loss'):
59 | self.c_loss = tf.reduce_mean(tf.square(td))
60 |
61 | with tf.name_scope('a_loss'):
62 | log_prob = tf.reduce_sum(tf.log(self.a_prob) * tf.one_hot(self.a_his, N_A, dtype=tf.float32), axis=1, keep_dims=True)
63 | exp_v = log_prob * tf.stop_gradient(td)
64 | entropy = -tf.reduce_sum(self.a_prob * tf.log(self.a_prob + 1e-5),
65 | axis=1, keep_dims=True) # encourage exploration
66 | self.exp_v = ENTROPY_BETA * entropy + exp_v
67 | self.a_loss = tf.reduce_mean(-self.exp_v)
68 |
69 | with tf.name_scope('local_grad'):
70 | self.a_grads = tf.gradients(self.a_loss, self.a_params)
71 | self.c_grads = tf.gradients(self.c_loss, self.c_params)
72 |
73 | with tf.name_scope('sync'):
74 | with tf.name_scope('pull'):
75 | self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
76 | self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
77 | with tf.name_scope('push'):
78 | self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
79 | self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
80 |
81 | def _build_net(self, scope):
82 | w_init = tf.random_normal_initializer(0., .1)
83 | with tf.variable_scope('actor'):
84 | l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
85 | a_prob = tf.layers.dense(l_a, N_A, tf.nn.softmax, kernel_initializer=w_init, name='ap')
86 | with tf.variable_scope('critic'):
87 | l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
88 | v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
89 | a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
90 | c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
91 | return a_prob, v, a_params, c_params
92 |
93 | def update_global(self, feed_dict): # run by a local
94 | SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
95 |
96 | def pull_global(self): # run by a local
97 | SESS.run([self.pull_a_params_op, self.pull_c_params_op])
98 |
99 | def choose_action(self, s): # run by a local
100 | prob_weights = SESS.run(self.a_prob, feed_dict={self.s: s[np.newaxis, :]})
101 | action = np.random.choice(range(prob_weights.shape[1]),
102 | p=prob_weights.ravel()) # select action w.r.t the actions prob
103 | return action
104 |
105 |
106 | class Worker(object):
107 | def __init__(self, name, globalAC):
108 | self.env = gym.make(GAME).unwrapped
109 | self.name = name
110 | self.AC = ACNet(name, globalAC)
111 |
112 | def work(self):
113 | global GLOBAL_RUNNING_R, GLOBAL_EP
114 | total_step = 1
115 | buffer_s, buffer_a, buffer_r = [], [], []
116 | while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
117 | s = self.env.reset()
118 | ep_r = 0
119 | while True:
120 | # if self.name == 'W_0':
121 | # self.env.render()
122 | a = self.AC.choose_action(s)
123 | s_, r, done, info = self.env.step(a)
124 | if done: r = -5
125 | ep_r += r
126 | buffer_s.append(s)
127 | buffer_a.append(a)
128 | buffer_r.append(r)
129 |
130 | if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
131 | if done:
132 | v_s_ = 0 # terminal
133 | else:
134 | v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
135 | buffer_v_target = []
136 | for r in buffer_r[::-1]: # reverse buffer r
137 | v_s_ = r + GAMMA * v_s_
138 | buffer_v_target.append(v_s_)
139 | buffer_v_target.reverse()
140 |
141 | buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.array(buffer_a), np.vstack(buffer_v_target)
142 | feed_dict = {
143 | self.AC.s: buffer_s,
144 | self.AC.a_his: buffer_a,
145 | self.AC.v_target: buffer_v_target,
146 | }
147 | self.AC.update_global(feed_dict)
148 |
149 | buffer_s, buffer_a, buffer_r = [], [], []
150 | self.AC.pull_global()
151 |
152 | s = s_
153 | total_step += 1
154 | if done:
155 | if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
156 | GLOBAL_RUNNING_R.append(ep_r)
157 | else:
158 | GLOBAL_RUNNING_R.append(0.99 * GLOBAL_RUNNING_R[-1] + 0.01 * ep_r)
159 | print(
160 | self.name,
161 | "Ep:", GLOBAL_EP,
162 | "| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
163 | )
164 | GLOBAL_EP += 1
165 | break
166 |
167 | if __name__ == "__main__":
168 | SESS = tf.Session()
169 |
170 | with tf.device("/cpu:0"):
171 | OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
172 | OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
173 | GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
174 | workers = []
175 | # Create worker
176 | for i in range(N_WORKERS):
177 | i_name = 'W_%i' % i # worker name
178 | workers.append(Worker(i_name, GLOBAL_AC))
179 |
180 | COORD = tf.train.Coordinator()
181 | SESS.run(tf.global_variables_initializer())
182 |
183 | if OUTPUT_GRAPH:
184 | if os.path.exists(LOG_DIR):
185 | shutil.rmtree(LOG_DIR)
186 | tf.summary.FileWriter(LOG_DIR, SESS.graph)
187 |
188 | worker_threads = []
189 | for worker in workers:
190 | job = lambda: worker.work()
191 | t = threading.Thread(target=job)
192 | t.start()
193 | worker_threads.append(t)
194 | COORD.join(worker_threads)
195 |
196 | plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
197 | plt.xlabel('step')
198 | plt.ylabel('Total moving reward')
199 | plt.show()
200 |
--------------------------------------------------------------------------------
/contents/11_Dyna_Q/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the Dyna-Q learning brain, which is a brain of the agent.
3 | All decisions and learning processes are made in here.
4 |
5 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
6 | """
7 |
8 | import numpy as np
9 | import pandas as pd
10 |
11 |
12 | class QLearningTable:
13 | def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
14 | self.actions = actions # a list
15 | self.lr = learning_rate
16 | self.gamma = reward_decay
17 | self.epsilon = e_greedy
18 | self.q_table = pd.DataFrame(columns=self.actions)
19 |
20 | def choose_action(self, observation):
21 | self.check_state_exist(observation)
22 | # action selection
23 | if np.random.uniform() < self.epsilon:
24 | # choose best action
25 | state_action = self.q_table.ix[observation, :]
26 | state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
27 | action = state_action.argmax()
28 | else:
29 | # choose random action
30 | action = np.random.choice(self.actions)
31 | return action
32 |
33 | def learn(self, s, a, r, s_):
34 | self.check_state_exist(s_)
35 | q_predict = self.q_table.ix[s, a]
36 | if s_ != 'terminal':
37 | q_target = r + self.gamma * self.q_table.ix[s_, :].max() # next state is not terminal
38 | else:
39 | q_target = r # next state is terminal
40 | self.q_table.ix[s, a] += self.lr * (q_target - q_predict) # update
41 |
42 | def check_state_exist(self, state):
43 | if state not in self.q_table.index:
44 | # append new state to q table
45 | self.q_table = self.q_table.append(
46 | pd.Series(
47 | [0]*len(self.actions),
48 | index=self.q_table.columns,
49 | name=state,
50 | )
51 | )
52 |
53 |
54 | class EnvModel:
55 | """Similar to the memory buffer in DQN, you can store past experiences in here.
56 | Alternatively, the model can generate next state and reward signal accurately."""
57 | def __init__(self, actions):
58 | # the simplest case is to think about the model is a memory which has all past transition information
59 | self.actions = actions
60 | self.database = pd.DataFrame(columns=actions, dtype=np.object)
61 |
62 | def store_transition(self, s, a, r, s_):
63 | if s not in self.database.index:
64 | self.database = self.database.append(
65 | pd.Series(
66 | [None] * len(self.actions),
67 | index=self.database.columns,
68 | name=s,
69 | ))
70 | self.database.set_value(s, a, (r, s_))
71 |
72 | def sample_s_a(self):
73 | s = np.random.choice(self.database.index)
74 | a = np.random.choice(self.database.ix[s].dropna().index) # filter out the None value
75 | return s, a
76 |
77 | def get_r_s_(self, s, a):
78 | r, s_ = self.database.ix[s, a]
79 | return r, s_
80 |
--------------------------------------------------------------------------------
/contents/11_Dyna_Q/maze_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the environment part of this example. The RL is in RL_brain.py.
10 |
11 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
12 | """
13 |
14 |
15 | import numpy as np
16 | np.random.seed(1)
17 | import tkinter as tk
18 | import time
19 |
20 |
21 | UNIT = 40 # pixels
22 | MAZE_H = 4 # grid height
23 | MAZE_W = 4 # grid width
24 |
25 |
26 | class Maze(tk.Tk, object):
27 | def __init__(self):
28 | super(Maze, self).__init__()
29 | self.action_space = ['u', 'd', 'l', 'r']
30 | self.n_actions = len(self.action_space)
31 | self.title('maze')
32 | self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
33 | self._build_maze()
34 |
35 | def _build_maze(self):
36 | self.canvas = tk.Canvas(self, bg='white',
37 | height=MAZE_H * UNIT,
38 | width=MAZE_W * UNIT)
39 |
40 | # create grids
41 | for c in range(0, MAZE_W * UNIT, UNIT):
42 | x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
43 | self.canvas.create_line(x0, y0, x1, y1)
44 | for r in range(0, MAZE_H * UNIT, UNIT):
45 | x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
46 | self.canvas.create_line(x0, y0, x1, y1)
47 |
48 | # create origin
49 | origin = np.array([20, 20])
50 |
51 | # hell
52 | hell1_center = origin + np.array([UNIT * 2, UNIT])
53 | self.hell1 = self.canvas.create_rectangle(
54 | hell1_center[0] - 15, hell1_center[1] - 15,
55 | hell1_center[0] + 15, hell1_center[1] + 15,
56 | fill='black')
57 | # hell
58 | hell2_center = origin + np.array([UNIT, UNIT * 2])
59 | self.hell2 = self.canvas.create_rectangle(
60 | hell2_center[0] - 15, hell2_center[1] - 15,
61 | hell2_center[0] + 15, hell2_center[1] + 15,
62 | fill='black')
63 |
64 | # create oval
65 | oval_center = origin + UNIT * 2
66 | self.oval = self.canvas.create_oval(
67 | oval_center[0] - 15, oval_center[1] - 15,
68 | oval_center[0] + 15, oval_center[1] + 15,
69 | fill='yellow')
70 |
71 | # create red rect
72 | self.rect = self.canvas.create_rectangle(
73 | origin[0] - 15, origin[1] - 15,
74 | origin[0] + 15, origin[1] + 15,
75 | fill='red')
76 |
77 | # pack all
78 | self.canvas.pack()
79 |
80 | def reset(self):
81 | self.update()
82 | time.sleep(0.5)
83 | self.canvas.delete(self.rect)
84 | origin = np.array([20, 20])
85 | self.rect = self.canvas.create_rectangle(
86 | origin[0] - 15, origin[1] - 15,
87 | origin[0] + 15, origin[1] + 15,
88 | fill='red')
89 | # return observation
90 | return self.canvas.coords(self.rect)
91 |
92 | def step(self, action):
93 | s = self.canvas.coords(self.rect)
94 | base_action = np.array([0, 0])
95 | if action == 0: # up
96 | if s[1] > UNIT:
97 | base_action[1] -= UNIT
98 | elif action == 1: # down
99 | if s[1] < (MAZE_H - 1) * UNIT:
100 | base_action[1] += UNIT
101 | elif action == 2: # right
102 | if s[0] < (MAZE_W - 1) * UNIT:
103 | base_action[0] += UNIT
104 | elif action == 3: # left
105 | if s[0] > UNIT:
106 | base_action[0] -= UNIT
107 |
108 | self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
109 |
110 | s_ = self.canvas.coords(self.rect) # next state
111 |
112 | # reward function
113 | if s_ == self.canvas.coords(self.oval):
114 | reward = 1
115 | done = True
116 | elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
117 | reward = -1
118 | done = True
119 | else:
120 | reward = 0
121 | done = False
122 |
123 | return s_, reward, done
124 |
125 | def render(self):
126 | # time.sleep(0.1)
127 | self.update()
128 |
129 |
130 |
--------------------------------------------------------------------------------
/contents/11_Dyna_Q/run_this.py:
--------------------------------------------------------------------------------
1 | """
2 | Simplest model-based RL, Dyna-Q.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the main part which controls the update method of this example.
10 | The RL is in RL_brain.py.
11 |
12 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
13 | """
14 |
15 | from maze_env import Maze
16 | from RL_brain import QLearningTable, EnvModel
17 |
18 |
19 | def update():
20 | for episode in range(40):
21 | s = env.reset()
22 | while True:
23 | env.render()
24 | a = RL.choose_action(str(s))
25 | s_, r, done = env.step(a)
26 | RL.learn(str(s), a, r, str(s_))
27 |
28 | # use a model to output (r, s_) by inputting (s, a)
29 | # the model in dyna Q version is just like a memory replay buffer
30 | env_model.store_transition(str(s), a, r, s_)
31 | for n in range(10): # learn 10 more times using the env_model
32 | ms, ma = env_model.sample_s_a() # ms in here is a str
33 | mr, ms_ = env_model.get_r_s_(ms, ma)
34 | RL.learn(ms, ma, mr, str(ms_))
35 |
36 | s = s_
37 | if done:
38 | break
39 |
40 | # end of game
41 | print('game over')
42 | env.destroy()
43 |
44 |
45 | if __name__ == "__main__":
46 | env = Maze()
47 | RL = QLearningTable(actions=list(range(env.n_actions)))
48 | env_model = EnvModel(actions=list(range(env.n_actions)))
49 |
50 | env.after(0, update)
51 | env.mainloop()
--------------------------------------------------------------------------------
/contents/12_Proximal_Policy_Optimization/DPPO.py:
--------------------------------------------------------------------------------
1 | """
2 | A simple version of OpenAI's Proximal Policy Optimization (PPO). [https://arxiv.org/abs/1707.06347]
3 |
4 | Distributing workers in parallel to collect data, then stop worker's roll-out and train PPO on collected data.
5 | Restart workers once PPO is updated.
6 |
7 | The global PPO updating rule is adopted from DeepMind's paper (DPPO):
8 | Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [https://arxiv.org/abs/1707.02286]
9 |
10 | View more on my tutorial website: https://morvanzhou.github.io/tutorials
11 |
12 | Dependencies:
13 | tensorflow r1.3
14 | gym 0.9.2
15 | """
16 |
17 | import tensorflow as tf
18 | import numpy as np
19 | import matplotlib.pyplot as plt
20 | import gym, threading, queue
21 |
22 | EP_MAX = 1000
23 | EP_LEN = 200
24 | N_WORKER = 4 # parallel workers
25 | GAMMA = 0.9 # reward discount factor
26 | A_LR = 0.0001 # learning rate for actor
27 | C_LR = 0.0002 # learning rate for critic
28 | MIN_BATCH_SIZE = 64 # minimum batch size for updating PPO
29 | UPDATE_STEP = 10 # loop update operation n-steps
30 | EPSILON = 0.2 # for clipping surrogate objective
31 | GAME = 'Pendulum-v0'
32 | S_DIM, A_DIM = 3, 1 # state and action dimension
33 |
34 |
35 | class PPO(object):
36 | def __init__(self):
37 | self.sess = tf.Session()
38 | self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
39 |
40 | # critic
41 | l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
42 | self.v = tf.layers.dense(l1, 1)
43 | self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
44 | self.advantage = self.tfdc_r - self.v
45 | self.closs = tf.reduce_mean(tf.square(self.advantage))
46 | self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
47 |
48 | # actor
49 | pi, pi_params = self._build_anet('pi', trainable=True)
50 | oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
51 | self.sample_op = tf.squeeze(pi.sample(1), axis=0) # operation of choosing action
52 | self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
53 |
54 | self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
55 | self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
56 | # ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
57 | ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
58 | surr = ratio * self.tfadv # surrogate loss
59 |
60 | self.aloss = -tf.reduce_mean(tf.minimum( # clipped surrogate objective
61 | surr,
62 | tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
63 |
64 | self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
65 | self.sess.run(tf.global_variables_initializer())
66 |
67 | def update(self):
68 | global GLOBAL_UPDATE_COUNTER
69 | while not COORD.should_stop():
70 | if GLOBAL_EP < EP_MAX:
71 | UPDATE_EVENT.wait() # wait until get batch of data
72 | self.sess.run(self.update_oldpi_op) # copy pi to old pi
73 | data = [QUEUE.get() for _ in range(QUEUE.qsize())] # collect data from all workers
74 | data = np.vstack(data)
75 | s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + A_DIM], data[:, -1:]
76 | adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
77 | # update actor and critic in a update loop
78 | [self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
79 | [self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
80 | UPDATE_EVENT.clear() # updating finished
81 | GLOBAL_UPDATE_COUNTER = 0 # reset counter
82 | ROLLING_EVENT.set() # set roll-out available
83 |
84 | def _build_anet(self, name, trainable):
85 | with tf.variable_scope(name):
86 | l1 = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
87 | mu = 2 * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
88 | sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
89 | norm_dist = tf.distributions.Normal(loc=mu, scale=sigma)
90 | params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
91 | return norm_dist, params
92 |
93 | def choose_action(self, s):
94 | s = s[np.newaxis, :]
95 | a = self.sess.run(self.sample_op, {self.tfs: s})[0]
96 | return np.clip(a, -2, 2)
97 |
98 | def get_v(self, s):
99 | if s.ndim < 2: s = s[np.newaxis, :]
100 | return self.sess.run(self.v, {self.tfs: s})[0, 0]
101 |
102 |
103 | class Worker(object):
104 | def __init__(self, wid):
105 | self.wid = wid
106 | self.env = gym.make(GAME).unwrapped
107 | self.ppo = GLOBAL_PPO
108 |
109 | def work(self):
110 | global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
111 | while not COORD.should_stop():
112 | s = self.env.reset()
113 | ep_r = 0
114 | buffer_s, buffer_a, buffer_r = [], [], []
115 | for t in range(EP_LEN):
116 | if not ROLLING_EVENT.is_set(): # while global PPO is updating
117 | ROLLING_EVENT.wait() # wait until PPO is updated
118 | buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer, use new policy to collect data
119 | a = self.ppo.choose_action(s)
120 | s_, r, done, _ = self.env.step(a)
121 | buffer_s.append(s)
122 | buffer_a.append(a)
123 | buffer_r.append((r + 8) / 8) # normalize reward, find to be useful
124 | s = s_
125 | ep_r += r
126 |
127 | GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size, no need to wait other workers
128 | if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
129 | v_s_ = self.ppo.get_v(s_)
130 | discounted_r = [] # compute discounted reward
131 | for r in buffer_r[::-1]:
132 | v_s_ = r + GAMMA * v_s_
133 | discounted_r.append(v_s_)
134 | discounted_r.reverse()
135 |
136 | bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
137 | buffer_s, buffer_a, buffer_r = [], [], []
138 | QUEUE.put(np.hstack((bs, ba, br))) # put data in the queue
139 | if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
140 | ROLLING_EVENT.clear() # stop collecting data
141 | UPDATE_EVENT.set() # globalPPO update
142 |
143 | if GLOBAL_EP >= EP_MAX: # stop training
144 | COORD.request_stop()
145 | break
146 |
147 | # record reward changes, plot later
148 | if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
149 | else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
150 | GLOBAL_EP += 1
151 | print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
152 |
153 |
154 | if __name__ == '__main__':
155 | GLOBAL_PPO = PPO()
156 | UPDATE_EVENT, ROLLING_EVENT = threading.Event(), threading.Event()
157 | UPDATE_EVENT.clear() # not update now
158 | ROLLING_EVENT.set() # start to roll out
159 | workers = [Worker(wid=i) for i in range(N_WORKER)]
160 |
161 | GLOBAL_UPDATE_COUNTER, GLOBAL_EP = 0, 0
162 | GLOBAL_RUNNING_R = []
163 | COORD = tf.train.Coordinator()
164 | QUEUE = queue.Queue() # workers putting data in this queue
165 | threads = []
166 | for worker in workers: # worker threads
167 | t = threading.Thread(target=worker.work, args=())
168 | t.start() # training
169 | threads.append(t)
170 | # add a PPO updating thread
171 | threads.append(threading.Thread(target=GLOBAL_PPO.update,))
172 | threads[-1].start()
173 | COORD.join(threads)
174 |
175 | # plot reward change and test
176 | plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
177 | plt.xlabel('Episode'); plt.ylabel('Moving reward'); plt.ion(); plt.show()
178 | env = gym.make('Pendulum-v0')
179 | while True:
180 | s = env.reset()
181 | for t in range(300):
182 | env.render()
183 | s = env.step(GLOBAL_PPO.choose_action(s))[0]
--------------------------------------------------------------------------------
/contents/12_Proximal_Policy_Optimization/simply_PPO.py:
--------------------------------------------------------------------------------
1 | """
2 | A simple version of Proximal Policy Optimization (PPO) using single thread.
3 |
4 | Based on:
5 | 1. Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [https://arxiv.org/abs/1707.02286]
6 | 2. Proximal Policy Optimization Algorithms (OpenAI): [https://arxiv.org/abs/1707.06347]
7 |
8 | View more on my tutorial website: https://morvanzhou.github.io/tutorials
9 |
10 | Dependencies:
11 | tensorflow r1.2
12 | gym 0.9.2
13 | """
14 |
15 | import tensorflow as tf
16 | import numpy as np
17 | import matplotlib.pyplot as plt
18 | import gym
19 |
20 | EP_MAX = 1000
21 | EP_LEN = 200
22 | GAMMA = 0.9
23 | A_LR = 0.0001
24 | C_LR = 0.0002
25 | BATCH = 32
26 | A_UPDATE_STEPS = 10
27 | C_UPDATE_STEPS = 10
28 | S_DIM, A_DIM = 3, 1
29 | METHOD = [
30 | dict(name='kl_pen', kl_target=0.01, lam=0.5), # KL penalty
31 | dict(name='clip', epsilon=0.2), # Clipped surrogate objective, find this is better
32 | ][1] # choose the method for optimization
33 |
34 |
35 | class PPO(object):
36 |
37 | def __init__(self):
38 | self.sess = tf.Session()
39 | self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
40 |
41 | # critic
42 | with tf.variable_scope('critic'):
43 | l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
44 | self.v = tf.layers.dense(l1, 1)
45 | self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
46 | self.advantage = self.tfdc_r - self.v
47 | self.closs = tf.reduce_mean(tf.square(self.advantage))
48 | self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
49 |
50 | # actor
51 | pi, pi_params = self._build_anet('pi', trainable=True)
52 | oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
53 | with tf.variable_scope('sample_action'):
54 | self.sample_op = tf.squeeze(pi.sample(1), axis=0) # choosing action
55 | with tf.variable_scope('update_oldpi'):
56 | self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
57 |
58 | self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
59 | self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
60 | with tf.variable_scope('loss'):
61 | with tf.variable_scope('surrogate'):
62 | # ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
63 | ratio = pi.prob(self.tfa) / oldpi.prob(self.tfa)
64 | surr = ratio * self.tfadv
65 | if METHOD['name'] == 'kl_pen':
66 | self.tflam = tf.placeholder(tf.float32, None, 'lambda')
67 | kl = tf.distributions.kl_divergence(oldpi, pi)
68 | self.kl_mean = tf.reduce_mean(kl)
69 | self.aloss = -(tf.reduce_mean(surr - self.tflam * kl))
70 | else: # clipping method, find this is better
71 | self.aloss = -tf.reduce_mean(tf.minimum(
72 | surr,
73 | tf.clip_by_value(ratio, 1.-METHOD['epsilon'], 1.+METHOD['epsilon'])*self.tfadv))
74 |
75 | with tf.variable_scope('atrain'):
76 | self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
77 |
78 | tf.summary.FileWriter("log/", self.sess.graph)
79 |
80 | self.sess.run(tf.global_variables_initializer())
81 |
82 | def update(self, s, a, r):
83 | self.sess.run(self.update_oldpi_op)
84 | adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
85 | # adv = (adv - adv.mean())/(adv.std()+1e-6) # sometimes helpful
86 |
87 | # update actor
88 | if METHOD['name'] == 'kl_pen':
89 | for _ in range(A_UPDATE_STEPS):
90 | _, kl = self.sess.run(
91 | [self.atrain_op, self.kl_mean],
92 | {self.tfs: s, self.tfa: a, self.tfadv: adv, self.tflam: METHOD['lam']})
93 | if kl > 4*METHOD['kl_target']: # this in in google's paper
94 | break
95 | if kl < METHOD['kl_target'] / 1.5: # adaptive lambda, this is in OpenAI's paper
96 | METHOD['lam'] /= 2
97 | elif kl > METHOD['kl_target'] * 1.5:
98 | METHOD['lam'] *= 2
99 | METHOD['lam'] = np.clip(METHOD['lam'], 1e-4, 10) # sometimes explode, this clipping is my solution
100 | else: # clipping method, find this is better (OpenAI's paper)
101 | [self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(A_UPDATE_STEPS)]
102 |
103 | # update critic
104 | [self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(C_UPDATE_STEPS)]
105 |
106 | def _build_anet(self, name, trainable):
107 | with tf.variable_scope(name):
108 | l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu, trainable=trainable)
109 | mu = 2 * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
110 | sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
111 | norm_dist = tf.distributions.Normal(loc=mu, scale=sigma)
112 | params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
113 | return norm_dist, params
114 |
115 | def choose_action(self, s):
116 | s = s[np.newaxis, :]
117 | a = self.sess.run(self.sample_op, {self.tfs: s})[0]
118 | return np.clip(a, -2, 2)
119 |
120 | def get_v(self, s):
121 | if s.ndim < 2: s = s[np.newaxis, :]
122 | return self.sess.run(self.v, {self.tfs: s})[0, 0]
123 |
124 | env = gym.make('Pendulum-v0').unwrapped
125 | ppo = PPO()
126 | all_ep_r = []
127 |
128 | for ep in range(EP_MAX):
129 | s = env.reset()
130 | buffer_s, buffer_a, buffer_r = [], [], []
131 | ep_r = 0
132 | for t in range(EP_LEN): # in one episode
133 | env.render()
134 | a = ppo.choose_action(s)
135 | s_, r, done, _ = env.step(a)
136 | buffer_s.append(s)
137 | buffer_a.append(a)
138 | buffer_r.append((r+8)/8) # normalize reward, find to be useful
139 | s = s_
140 | ep_r += r
141 |
142 | # update ppo
143 | if (t+1) % BATCH == 0 or t == EP_LEN-1:
144 | v_s_ = ppo.get_v(s_)
145 | discounted_r = []
146 | for r in buffer_r[::-1]:
147 | v_s_ = r + GAMMA * v_s_
148 | discounted_r.append(v_s_)
149 | discounted_r.reverse()
150 |
151 | bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
152 | buffer_s, buffer_a, buffer_r = [], [], []
153 | ppo.update(bs, ba, br)
154 | if ep == 0: all_ep_r.append(ep_r)
155 | else: all_ep_r.append(all_ep_r[-1]*0.9 + ep_r*0.1)
156 | print(
157 | 'Ep: %i' % ep,
158 | "|Ep_r: %i" % ep_r,
159 | ("|Lam: %.4f" % METHOD['lam']) if METHOD['name'] == 'kl_pen' else '',
160 | )
161 |
162 | plt.plot(np.arange(len(all_ep_r)), all_ep_r)
163 | plt.xlabel('Episode');plt.ylabel('Moving averaged episode reward');plt.show()
--------------------------------------------------------------------------------
/contents/1_command_line_reinforcement_learning/treasure_on_right.py:
--------------------------------------------------------------------------------
1 | """
2 | A simple example for Reinforcement Learning using table lookup Q-learning method.
3 | An agent "o" is on the left of a 1 dimensional world, the treasure is on the rightmost location.
4 | Run this program and to see how the agent will improve its strategy of finding the treasure.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 | """
8 |
9 | import numpy as np
10 | import pandas as pd
11 | import time
12 |
13 | np.random.seed(2) # reproducible
14 |
15 |
16 | N_STATES = 6 # the length of the 1 dimensional world
17 | ACTIONS = ['left', 'right'] # available actions
18 | EPSILON = 0.9 # greedy police
19 | ALPHA = 0.1 # learning rate
20 | GAMMA = 0.9 # discount factor
21 | MAX_EPISODES = 13 # maximum episodes
22 | FRESH_TIME = 0.3 # fresh time for one move
23 |
24 |
25 | def build_q_table(n_states, actions):
26 | table = pd.DataFrame(
27 | np.zeros((n_states, len(actions))), # q_table initial values
28 | columns=actions, # actions's name
29 | )
30 | # print(table) # show table
31 | return table
32 |
33 |
34 | def choose_action(state, q_table):
35 | # This is how to choose an action
36 | state_actions = q_table.iloc[state, :]
37 | if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have no value
38 | action_name = np.random.choice(ACTIONS)
39 | else: # act greedy
40 | action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
41 | return action_name
42 |
43 |
44 | def get_env_feedback(S, A):
45 | # This is how agent will interact with the environment
46 | if A == 'right': # move right
47 | if S == N_STATES - 2: # terminate
48 | S_ = 'terminal'
49 | R = 1
50 | else:
51 | S_ = S + 1
52 | R = 0
53 | else: # move left
54 | R = 0
55 | if S == 0:
56 | S_ = S # reach the wall
57 | else:
58 | S_ = S - 1
59 | return S_, R
60 |
61 |
62 | def update_env(S, episode, step_counter):
63 | # This is how environment be updated
64 | env_list = ['-']*(N_STATES-1) + ['T'] # '---------T' our environment
65 | if S == 'terminal':
66 | interaction = 'Episode %s: total_steps = %s' % (episode+1, step_counter)
67 | print('\r{}'.format(interaction), end='')
68 | time.sleep(2)
69 | print('\r ', end='')
70 | else:
71 | env_list[S] = 'o'
72 | interaction = ''.join(env_list)
73 | print('\r{}'.format(interaction), end='')
74 | time.sleep(FRESH_TIME)
75 |
76 |
77 | def rl():
78 | # main part of RL loop
79 | q_table = build_q_table(N_STATES, ACTIONS)
80 | for episode in range(MAX_EPISODES):
81 | step_counter = 0
82 | S = 0
83 | is_terminated = False
84 | update_env(S, episode, step_counter)
85 | while not is_terminated:
86 |
87 | A = choose_action(S, q_table)
88 | S_, R = get_env_feedback(S, A) # take action & get next state and reward
89 | q_predict = q_table.loc[S, A]
90 | if S_ != 'terminal':
91 | q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
92 | else:
93 | q_target = R # next state is terminal
94 | is_terminated = True # terminate this episode
95 |
96 | q_table.loc[S, A] += ALPHA * (q_target - q_predict) # update
97 | S = S_ # move to next state
98 |
99 | update_env(S, episode, step_counter+1)
100 | step_counter += 1
101 | return q_table
102 |
103 |
104 | if __name__ == "__main__":
105 | q_table = rl()
106 | print('\r\nQ-table:\n')
107 | print(q_table)
108 |
--------------------------------------------------------------------------------
/contents/2_Q_Learning_maze/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the Q learning brain, which is a brain of the agent.
3 | All decisions are made in here.
4 |
5 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
6 | """
7 |
8 | import numpy as np
9 | import pandas as pd
10 |
11 |
12 | class QLearningTable:
13 | def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
14 | self.actions = actions # a list
15 | self.lr = learning_rate
16 | self.gamma = reward_decay
17 | self.epsilon = e_greedy
18 | self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
19 |
20 | def choose_action(self, observation):
21 | self.check_state_exist(observation)
22 | # action selection
23 | if np.random.uniform() < self.epsilon:
24 | # choose best action
25 | state_action = self.q_table.loc[observation, :]
26 | state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
27 | action = state_action.idxmax()
28 | else:
29 | # choose random action
30 | action = np.random.choice(self.actions)
31 | return action
32 |
33 | def learn(self, s, a, r, s_):
34 | self.check_state_exist(s_)
35 | q_predict = self.q_table.loc[s, a]
36 | if s_ != 'terminal':
37 | q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
38 | else:
39 | q_target = r # next state is terminal
40 | self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
41 |
42 | def check_state_exist(self, state):
43 | if state not in self.q_table.index:
44 | # append new state to q table
45 | self.q_table = self.q_table.append(
46 | pd.Series(
47 | [0]*len(self.actions),
48 | index=self.q_table.columns,
49 | name=state,
50 | )
51 | )
--------------------------------------------------------------------------------
/contents/2_Q_Learning_maze/maze_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the environment part of this example. The RL is in RL_brain.py.
10 |
11 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
12 | """
13 |
14 |
15 | import numpy as np
16 | import time
17 | import sys
18 | if sys.version_info.major == 2:
19 | import Tkinter as tk
20 | else:
21 | import tkinter as tk
22 |
23 |
24 | UNIT = 40 # pixels
25 | MAZE_H = 4 # grid height
26 | MAZE_W = 4 # grid width
27 |
28 |
29 | class Maze(tk.Tk, object):
30 | def __init__(self):
31 | super(Maze, self).__init__()
32 | self.action_space = ['u', 'd', 'l', 'r']
33 | self.n_actions = len(self.action_space)
34 | self.title('maze')
35 | self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
36 | self._build_maze()
37 |
38 | def _build_maze(self):
39 | self.canvas = tk.Canvas(self, bg='white',
40 | height=MAZE_H * UNIT,
41 | width=MAZE_W * UNIT)
42 |
43 | # create grids
44 | for c in range(0, MAZE_W * UNIT, UNIT):
45 | x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
46 | self.canvas.create_line(x0, y0, x1, y1)
47 | for r in range(0, MAZE_H * UNIT, UNIT):
48 | x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
49 | self.canvas.create_line(x0, y0, x1, y1)
50 |
51 | # create origin
52 | origin = np.array([20, 20])
53 |
54 | # hell
55 | hell1_center = origin + np.array([UNIT * 2, UNIT])
56 | self.hell1 = self.canvas.create_rectangle(
57 | hell1_center[0] - 15, hell1_center[1] - 15,
58 | hell1_center[0] + 15, hell1_center[1] + 15,
59 | fill='black')
60 | # hell
61 | hell2_center = origin + np.array([UNIT, UNIT * 2])
62 | self.hell2 = self.canvas.create_rectangle(
63 | hell2_center[0] - 15, hell2_center[1] - 15,
64 | hell2_center[0] + 15, hell2_center[1] + 15,
65 | fill='black')
66 |
67 | # create oval
68 | oval_center = origin + UNIT * 2
69 | self.oval = self.canvas.create_oval(
70 | oval_center[0] - 15, oval_center[1] - 15,
71 | oval_center[0] + 15, oval_center[1] + 15,
72 | fill='yellow')
73 |
74 | # create red rect
75 | self.rect = self.canvas.create_rectangle(
76 | origin[0] - 15, origin[1] - 15,
77 | origin[0] + 15, origin[1] + 15,
78 | fill='red')
79 |
80 | # pack all
81 | self.canvas.pack()
82 |
83 | def reset(self):
84 | self.update()
85 | time.sleep(0.5)
86 | self.canvas.delete(self.rect)
87 | origin = np.array([20, 20])
88 | self.rect = self.canvas.create_rectangle(
89 | origin[0] - 15, origin[1] - 15,
90 | origin[0] + 15, origin[1] + 15,
91 | fill='red')
92 | # return observation
93 | return self.canvas.coords(self.rect)
94 |
95 | def step(self, action):
96 | s = self.canvas.coords(self.rect)
97 | base_action = np.array([0, 0])
98 | if action == 0: # up
99 | if s[1] > UNIT:
100 | base_action[1] -= UNIT
101 | elif action == 1: # down
102 | if s[1] < (MAZE_H - 1) * UNIT:
103 | base_action[1] += UNIT
104 | elif action == 2: # right
105 | if s[0] < (MAZE_W - 1) * UNIT:
106 | base_action[0] += UNIT
107 | elif action == 3: # left
108 | if s[0] > UNIT:
109 | base_action[0] -= UNIT
110 |
111 | self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
112 |
113 | s_ = self.canvas.coords(self.rect) # next state
114 |
115 | # reward function
116 | if s_ == self.canvas.coords(self.oval):
117 | reward = 1
118 | done = True
119 | s_ = 'terminal'
120 | elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
121 | reward = -1
122 | done = True
123 | s_ = 'terminal'
124 | else:
125 | reward = 0
126 | done = False
127 |
128 | return s_, reward, done
129 |
130 | def render(self):
131 | time.sleep(0.1)
132 | self.update()
133 |
134 |
135 | def update():
136 | for t in range(10):
137 | s = env.reset()
138 | while True:
139 | env.render()
140 | a = 1
141 | s, r, done = env.step(a)
142 | if done:
143 | break
144 |
145 | if __name__ == '__main__':
146 | env = Maze()
147 | env.after(100, update)
148 | env.mainloop()
--------------------------------------------------------------------------------
/contents/2_Q_Learning_maze/run_this.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the main part which controls the update method of this example.
10 | The RL is in RL_brain.py.
11 |
12 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
13 | """
14 |
15 | from maze_env import Maze
16 | from RL_brain import QLearningTable
17 |
18 |
19 | def update():
20 | for episode in range(100):
21 | # initial observation
22 | observation = env.reset()
23 |
24 | while True:
25 | # fresh env
26 | env.render()
27 |
28 | # RL choose action based on observation
29 | action = RL.choose_action(str(observation))
30 |
31 | # RL take action and get next observation and reward
32 | observation_, reward, done = env.step(action)
33 |
34 | # RL learn from this transition
35 | RL.learn(str(observation), action, reward, str(observation_))
36 |
37 | # swap observation
38 | observation = observation_
39 |
40 | # break while loop when end of this episode
41 | if done:
42 | break
43 |
44 | # end of game
45 | print('game over')
46 | env.destroy()
47 |
48 | if __name__ == "__main__":
49 | env = Maze()
50 | RL = QLearningTable(actions=list(range(env.n_actions)))
51 |
52 | env.after(100, update)
53 | env.mainloop()
--------------------------------------------------------------------------------
/contents/3_Sarsa_maze/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the Q learning brain, which is a brain of the agent.
3 | All decisions are made in here.
4 |
5 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
6 | """
7 |
8 | import numpy as np
9 | import pandas as pd
10 |
11 |
12 | class RL(object):
13 | def __init__(self, action_space, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
14 | self.actions = action_space # a list
15 | self.lr = learning_rate
16 | self.gamma = reward_decay
17 | self.epsilon = e_greedy
18 |
19 | self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
20 |
21 | def check_state_exist(self, state):
22 | if state not in self.q_table.index:
23 | # append new state to q table
24 | self.q_table = self.q_table.append(
25 | pd.Series(
26 | [0]*len(self.actions),
27 | index=self.q_table.columns,
28 | name=state,
29 | )
30 | )
31 |
32 | def choose_action(self, observation):
33 | self.check_state_exist(observation)
34 | # action selection
35 | if np.random.rand() < self.epsilon:
36 | # choose best action
37 | state_action = self.q_table.loc[observation, :]
38 | state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
39 | action = state_action.idxmax()
40 | else:
41 | # choose random action
42 | action = np.random.choice(self.actions)
43 | return action
44 |
45 | def learn(self, *args):
46 | pass
47 |
48 |
49 | # off-policy
50 | class QLearningTable(RL):
51 | def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
52 | super(QLearningTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
53 |
54 | def learn(self, s, a, r, s_):
55 | self.check_state_exist(s_)
56 | q_predict = self.q_table.loc[s, a]
57 | if s_ != 'terminal':
58 | q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
59 | else:
60 | q_target = r # next state is terminal
61 | self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
62 |
63 |
64 | # on-policy
65 | class SarsaTable(RL):
66 |
67 | def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
68 | super(SarsaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
69 |
70 | def learn(self, s, a, r, s_, a_):
71 | self.check_state_exist(s_)
72 | q_predict = self.q_table.loc[s, a]
73 | if s_ != 'terminal':
74 | q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminal
75 | else:
76 | q_target = r # next state is terminal
77 | self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
78 |
--------------------------------------------------------------------------------
/contents/3_Sarsa_maze/maze_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the environment part of this example.
10 | The RL is in RL_brain.py.
11 |
12 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
13 | """
14 |
15 |
16 | import numpy as np
17 | import time
18 | import sys
19 | if sys.version_info.major == 2:
20 | import Tkinter as tk
21 | else:
22 | import tkinter as tk
23 |
24 |
25 | UNIT = 40 # pixels
26 | MAZE_H = 4 # grid height
27 | MAZE_W = 4 # grid width
28 |
29 |
30 | class Maze(tk.Tk, object):
31 | def __init__(self):
32 | super(Maze, self).__init__()
33 | self.action_space = ['u', 'd', 'l', 'r']
34 | self.n_actions = len(self.action_space)
35 | self.title('maze')
36 | self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
37 | self._build_maze()
38 |
39 | def _build_maze(self):
40 | self.canvas = tk.Canvas(self, bg='white',
41 | height=MAZE_H * UNIT,
42 | width=MAZE_W * UNIT)
43 |
44 | # create grids
45 | for c in range(0, MAZE_W * UNIT, UNIT):
46 | x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
47 | self.canvas.create_line(x0, y0, x1, y1)
48 | for r in range(0, MAZE_H * UNIT, UNIT):
49 | x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
50 | self.canvas.create_line(x0, y0, x1, y1)
51 |
52 | # create origin
53 | origin = np.array([20, 20])
54 |
55 | # hell
56 | hell1_center = origin + np.array([UNIT * 2, UNIT])
57 | self.hell1 = self.canvas.create_rectangle(
58 | hell1_center[0] - 15, hell1_center[1] - 15,
59 | hell1_center[0] + 15, hell1_center[1] + 15,
60 | fill='black')
61 | # hell
62 | hell2_center = origin + np.array([UNIT, UNIT * 2])
63 | self.hell2 = self.canvas.create_rectangle(
64 | hell2_center[0] - 15, hell2_center[1] - 15,
65 | hell2_center[0] + 15, hell2_center[1] + 15,
66 | fill='black')
67 |
68 | # create oval
69 | oval_center = origin + UNIT * 2
70 | self.oval = self.canvas.create_oval(
71 | oval_center[0] - 15, oval_center[1] - 15,
72 | oval_center[0] + 15, oval_center[1] + 15,
73 | fill='yellow')
74 |
75 | # create red rect
76 | self.rect = self.canvas.create_rectangle(
77 | origin[0] - 15, origin[1] - 15,
78 | origin[0] + 15, origin[1] + 15,
79 | fill='red')
80 |
81 | # pack all
82 | self.canvas.pack()
83 |
84 | def reset(self):
85 | self.update()
86 | time.sleep(0.5)
87 | self.canvas.delete(self.rect)
88 | origin = np.array([20, 20])
89 | self.rect = self.canvas.create_rectangle(
90 | origin[0] - 15, origin[1] - 15,
91 | origin[0] + 15, origin[1] + 15,
92 | fill='red')
93 | # return observation
94 | return self.canvas.coords(self.rect)
95 |
96 | def step(self, action):
97 | s = self.canvas.coords(self.rect)
98 | base_action = np.array([0, 0])
99 | if action == 0: # up
100 | if s[1] > UNIT:
101 | base_action[1] -= UNIT
102 | elif action == 1: # down
103 | if s[1] < (MAZE_H - 1) * UNIT:
104 | base_action[1] += UNIT
105 | elif action == 2: # right
106 | if s[0] < (MAZE_W - 1) * UNIT:
107 | base_action[0] += UNIT
108 | elif action == 3: # left
109 | if s[0] > UNIT:
110 | base_action[0] -= UNIT
111 |
112 | self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
113 |
114 | s_ = self.canvas.coords(self.rect) # next state
115 |
116 | # reward function
117 | if s_ == self.canvas.coords(self.oval):
118 | reward = 1
119 | done = True
120 | s_ = 'terminal'
121 | elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
122 | reward = -1
123 | done = True
124 | s_ = 'terminal'
125 | else:
126 | reward = 0
127 | done = False
128 |
129 | return s_, reward, done
130 |
131 | def render(self):
132 | time.sleep(0.1)
133 | self.update()
134 |
135 |
136 |
--------------------------------------------------------------------------------
/contents/3_Sarsa_maze/run_this.py:
--------------------------------------------------------------------------------
1 | """
2 | Sarsa is a online updating method for Reinforcement learning.
3 |
4 | Unlike Q learning which is a offline updating method, Sarsa is updating while in the current trajectory.
5 |
6 | You will see the sarsa is more coward when punishment is close because it cares about all behaviours,
7 | while q learning is more brave because it only cares about maximum behaviour.
8 | """
9 |
10 | from maze_env import Maze
11 | from RL_brain import SarsaTable
12 |
13 |
14 | def update():
15 | for episode in range(100):
16 | # initial observation
17 | observation = env.reset()
18 |
19 | # RL choose action based on observation
20 | action = RL.choose_action(str(observation))
21 |
22 | while True:
23 | # fresh env
24 | env.render()
25 |
26 | # RL take action and get next observation and reward
27 | observation_, reward, done = env.step(action)
28 |
29 | # RL choose action based on next observation
30 | action_ = RL.choose_action(str(observation_))
31 |
32 | # RL learn from this transition (s, a, r, s, a) ==> Sarsa
33 | RL.learn(str(observation), action, reward, str(observation_), action_)
34 |
35 | # swap observation and action
36 | observation = observation_
37 | action = action_
38 |
39 | # break while loop when end of this episode
40 | if done:
41 | break
42 |
43 | # end of game
44 | print('game over')
45 | env.destroy()
46 |
47 | if __name__ == "__main__":
48 | env = Maze()
49 | RL = SarsaTable(actions=list(range(env.n_actions)))
50 |
51 | env.after(100, update)
52 | env.mainloop()
--------------------------------------------------------------------------------
/contents/4_Sarsa_lambda_maze/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the Q learning brain, which is a brain of the agent.
3 | All decisions are made in here.
4 |
5 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
6 | """
7 |
8 | import numpy as np
9 | import pandas as pd
10 |
11 |
12 | class RL(object):
13 | def __init__(self, action_space, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
14 | self.actions = action_space # a list
15 | self.lr = learning_rate
16 | self.gamma = reward_decay
17 | self.epsilon = e_greedy
18 |
19 | self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
20 |
21 | def check_state_exist(self, state):
22 | if state not in self.q_table.index:
23 | # append new state to q table
24 | self.q_table = self.q_table.append(
25 | pd.Series(
26 | [0]*len(self.actions),
27 | index=self.q_table.columns,
28 | name=state,
29 | )
30 | )
31 |
32 | def choose_action(self, observation):
33 | self.check_state_exist(observation)
34 | # action selection
35 | if np.random.rand() < self.epsilon:
36 | # choose best action
37 | state_action = self.q_table.loc[observation, :]
38 | state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
39 | action = state_action.idxmax()
40 | else:
41 | # choose random action
42 | action = np.random.choice(self.actions)
43 | return action
44 |
45 | def learn(self, *args):
46 | pass
47 |
48 |
49 | # backward eligibility traces
50 | class SarsaLambdaTable(RL):
51 | def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9, trace_decay=0.9):
52 | super(SarsaLambdaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
53 |
54 | # backward view, eligibility trace.
55 | self.lambda_ = trace_decay
56 | self.eligibility_trace = self.q_table.copy()
57 |
58 | def check_state_exist(self, state):
59 | if state not in self.q_table.index:
60 | # append new state to q table
61 | to_be_append = pd.Series(
62 | [0] * len(self.actions),
63 | index=self.q_table.columns,
64 | name=state,
65 | )
66 | self.q_table = self.q_table.append(to_be_append)
67 |
68 | # also update eligibility trace
69 | self.eligibility_trace = self.eligibility_trace.append(to_be_append)
70 |
71 | def learn(self, s, a, r, s_, a_):
72 | self.check_state_exist(s_)
73 | q_predict = self.q_table.loc[s, a]
74 | if s_ != 'terminal':
75 | q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminal
76 | else:
77 | q_target = r # next state is terminal
78 | error = q_target - q_predict
79 |
80 | # increase trace amount for visited state-action pair
81 |
82 | # Method 1:
83 | # self.eligibility_trace.loc[s, a] += 1
84 |
85 | # Method 2:
86 | self.eligibility_trace.loc[s, :] *= 0
87 | self.eligibility_trace.loc[s, a] = 1
88 |
89 | # Q update
90 | self.q_table += self.lr * error * self.eligibility_trace
91 |
92 | # decay eligibility trace after update
93 | self.eligibility_trace *= self.gamma*self.lambda_
94 |
--------------------------------------------------------------------------------
/contents/4_Sarsa_lambda_maze/maze_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the environment part of this example.
10 | The RL is in RL_brain.py.
11 |
12 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
13 | """
14 |
15 |
16 | import numpy as np
17 | import time
18 | import sys
19 | if sys.version_info.major == 2:
20 | import Tkinter as tk
21 | else:
22 | import tkinter as tk
23 |
24 |
25 | UNIT = 40 # pixels
26 | MAZE_H = 4 # grid height
27 | MAZE_W = 4 # grid width
28 |
29 |
30 | class Maze(tk.Tk, object):
31 | def __init__(self):
32 | super(Maze, self).__init__()
33 | self.action_space = ['u', 'd', 'l', 'r']
34 | self.n_actions = len(self.action_space)
35 | self.title('maze')
36 | self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
37 | self._build_maze()
38 |
39 | def _build_maze(self):
40 | self.canvas = tk.Canvas(self, bg='white',
41 | height=MAZE_H * UNIT,
42 | width=MAZE_W * UNIT)
43 |
44 | # create grids
45 | for c in range(0, MAZE_W * UNIT, UNIT):
46 | x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
47 | self.canvas.create_line(x0, y0, x1, y1)
48 | for r in range(0, MAZE_H * UNIT, UNIT):
49 | x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
50 | self.canvas.create_line(x0, y0, x1, y1)
51 |
52 | # create origin
53 | origin = np.array([20, 20])
54 |
55 | # hell
56 | hell1_center = origin + np.array([UNIT * 2, UNIT])
57 | self.hell1 = self.canvas.create_rectangle(
58 | hell1_center[0] - 15, hell1_center[1] - 15,
59 | hell1_center[0] + 15, hell1_center[1] + 15,
60 | fill='black')
61 | # hell
62 | hell2_center = origin + np.array([UNIT, UNIT * 2])
63 | self.hell2 = self.canvas.create_rectangle(
64 | hell2_center[0] - 15, hell2_center[1] - 15,
65 | hell2_center[0] + 15, hell2_center[1] + 15,
66 | fill='black')
67 |
68 | # create oval
69 | oval_center = origin + UNIT * 2
70 | self.oval = self.canvas.create_oval(
71 | oval_center[0] - 15, oval_center[1] - 15,
72 | oval_center[0] + 15, oval_center[1] + 15,
73 | fill='yellow')
74 |
75 | # create red rect
76 | self.rect = self.canvas.create_rectangle(
77 | origin[0] - 15, origin[1] - 15,
78 | origin[0] + 15, origin[1] + 15,
79 | fill='red')
80 |
81 | # pack all
82 | self.canvas.pack()
83 |
84 | def reset(self):
85 | self.update()
86 | time.sleep(0.5)
87 | self.canvas.delete(self.rect)
88 | origin = np.array([20, 20])
89 | self.rect = self.canvas.create_rectangle(
90 | origin[0] - 15, origin[1] - 15,
91 | origin[0] + 15, origin[1] + 15,
92 | fill='red')
93 | # return observation
94 | return self.canvas.coords(self.rect)
95 |
96 | def step(self, action):
97 | s = self.canvas.coords(self.rect)
98 | base_action = np.array([0, 0])
99 | if action == 0: # up
100 | if s[1] > UNIT:
101 | base_action[1] -= UNIT
102 | elif action == 1: # down
103 | if s[1] < (MAZE_H - 1) * UNIT:
104 | base_action[1] += UNIT
105 | elif action == 2: # right
106 | if s[0] < (MAZE_W - 1) * UNIT:
107 | base_action[0] += UNIT
108 | elif action == 3: # left
109 | if s[0] > UNIT:
110 | base_action[0] -= UNIT
111 |
112 | self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
113 |
114 | s_ = self.canvas.coords(self.rect) # next state
115 |
116 | # reward function
117 | if s_ == self.canvas.coords(self.oval):
118 | reward = 1
119 | done = True
120 | s_ = 'terminal'
121 | elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
122 | reward = -1
123 | done = True
124 | s_ = 'terminal'
125 | else:
126 | reward = 0
127 | done = False
128 |
129 | return s_, reward, done
130 |
131 | def render(self):
132 | time.sleep(0.05)
133 | self.update()
134 |
135 |
136 |
--------------------------------------------------------------------------------
/contents/4_Sarsa_lambda_maze/run_this.py:
--------------------------------------------------------------------------------
1 | """
2 | Sarsa is a online updating method for Reinforcement learning.
3 |
4 | Unlike Q learning which is a offline updating method, Sarsa is updating while in the current trajectory.
5 |
6 | You will see the sarsa is more coward when punishment is close because it cares about all behaviours,
7 | while q learning is more brave because it only cares about maximum behaviour.
8 | """
9 |
10 | from maze_env import Maze
11 | from RL_brain import SarsaLambdaTable
12 |
13 |
14 | def update():
15 | for episode in range(100):
16 | # initial observation
17 | observation = env.reset()
18 |
19 | # RL choose action based on observation
20 | action = RL.choose_action(str(observation))
21 |
22 | # initial all zero eligibility trace
23 | RL.eligibility_trace *= 0
24 |
25 | while True:
26 | # fresh env
27 | env.render()
28 |
29 | # RL take action and get next observation and reward
30 | observation_, reward, done = env.step(action)
31 |
32 | # RL choose action based on next observation
33 | action_ = RL.choose_action(str(observation_))
34 |
35 | # RL learn from this transition (s, a, r, s, a) ==> Sarsa
36 | RL.learn(str(observation), action, reward, str(observation_), action_)
37 |
38 | # swap observation and action
39 | observation = observation_
40 | action = action_
41 |
42 | # break while loop when end of this episode
43 | if done:
44 | break
45 |
46 | # end of game
47 | print('game over')
48 | env.destroy()
49 |
50 | if __name__ == "__main__":
51 | env = Maze()
52 | RL = SarsaLambdaTable(actions=list(range(env.n_actions)))
53 |
54 | env.after(100, update)
55 | env.mainloop()
--------------------------------------------------------------------------------
/contents/5.1_Double_DQN/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | The double DQN based on this paper: https://arxiv.org/abs/1509.06461
3 |
4 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
5 |
6 | Using:
7 | Tensorflow: 1.0
8 | gym: 0.8.0
9 | """
10 |
11 | import numpy as np
12 | import tensorflow as tf
13 |
14 | np.random.seed(1)
15 | tf.set_random_seed(1)
16 |
17 |
18 | class DoubleDQN:
19 | def __init__(
20 | self,
21 | n_actions,
22 | n_features,
23 | learning_rate=0.005,
24 | reward_decay=0.9,
25 | e_greedy=0.9,
26 | replace_target_iter=200,
27 | memory_size=3000,
28 | batch_size=32,
29 | e_greedy_increment=None,
30 | output_graph=False,
31 | double_q=True,
32 | sess=None,
33 | ):
34 | self.n_actions = n_actions
35 | self.n_features = n_features
36 | self.lr = learning_rate
37 | self.gamma = reward_decay
38 | self.epsilon_max = e_greedy
39 | self.replace_target_iter = replace_target_iter
40 | self.memory_size = memory_size
41 | self.batch_size = batch_size
42 | self.epsilon_increment = e_greedy_increment
43 | self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
44 |
45 | self.double_q = double_q # decide to use double q or not
46 |
47 | self.learn_step_counter = 0
48 | self.memory = np.zeros((self.memory_size, n_features*2+2))
49 | self._build_net()
50 | t_params = tf.get_collection('target_net_params')
51 | e_params = tf.get_collection('eval_net_params')
52 | self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
53 |
54 | if sess is None:
55 | self.sess = tf.Session()
56 | self.sess.run(tf.global_variables_initializer())
57 | else:
58 | self.sess = sess
59 | if output_graph:
60 | tf.summary.FileWriter("logs/", self.sess.graph)
61 | self.cost_his = []
62 |
63 | def _build_net(self):
64 | def build_layers(s, c_names, n_l1, w_initializer, b_initializer):
65 | with tf.variable_scope('l1'):
66 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
67 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
68 | l1 = tf.nn.relu(tf.matmul(s, w1) + b1)
69 |
70 | with tf.variable_scope('l2'):
71 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
72 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
73 | out = tf.matmul(l1, w2) + b2
74 | return out
75 | # ------------------ build evaluate_net ------------------
76 | self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
77 | self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
78 |
79 | with tf.variable_scope('eval_net'):
80 | c_names, n_l1, w_initializer, b_initializer = \
81 | ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 20, \
82 | tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
83 |
84 | self.q_eval = build_layers(self.s, c_names, n_l1, w_initializer, b_initializer)
85 |
86 | with tf.variable_scope('loss'):
87 | self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
88 | with tf.variable_scope('train'):
89 | self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
90 |
91 | # ------------------ build target_net ------------------
92 | self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
93 | with tf.variable_scope('target_net'):
94 | c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
95 |
96 | self.q_next = build_layers(self.s_, c_names, n_l1, w_initializer, b_initializer)
97 |
98 | def store_transition(self, s, a, r, s_):
99 | if not hasattr(self, 'memory_counter'):
100 | self.memory_counter = 0
101 | transition = np.hstack((s, [a, r], s_))
102 | index = self.memory_counter % self.memory_size
103 | self.memory[index, :] = transition
104 | self.memory_counter += 1
105 |
106 | def choose_action(self, observation):
107 | observation = observation[np.newaxis, :]
108 | actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
109 | action = np.argmax(actions_value)
110 |
111 | if not hasattr(self, 'q'): # record action value it gets
112 | self.q = []
113 | self.running_q = 0
114 | self.running_q = self.running_q*0.99 + 0.01 * np.max(actions_value)
115 | self.q.append(self.running_q)
116 |
117 | if np.random.uniform() > self.epsilon: # choosing action
118 | action = np.random.randint(0, self.n_actions)
119 | return action
120 |
121 | def learn(self):
122 | if self.learn_step_counter % self.replace_target_iter == 0:
123 | self.sess.run(self.replace_target_op)
124 | print('\ntarget_params_replaced\n')
125 |
126 | if self.memory_counter > self.memory_size:
127 | sample_index = np.random.choice(self.memory_size, size=self.batch_size)
128 | else:
129 | sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
130 | batch_memory = self.memory[sample_index, :]
131 |
132 | q_next, q_eval4next = self.sess.run(
133 | [self.q_next, self.q_eval],
134 | feed_dict={self.s_: batch_memory[:, -self.n_features:], # next observation
135 | self.s: batch_memory[:, -self.n_features:]}) # next observation
136 | q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
137 |
138 | q_target = q_eval.copy()
139 |
140 | batch_index = np.arange(self.batch_size, dtype=np.int32)
141 | eval_act_index = batch_memory[:, self.n_features].astype(int)
142 | reward = batch_memory[:, self.n_features + 1]
143 |
144 | if self.double_q:
145 | max_act4next = np.argmax(q_eval4next, axis=1) # the action that brings the highest value is evaluated by q_eval
146 | selected_q_next = q_next[batch_index, max_act4next] # Double DQN, select q_next depending on above actions
147 | else:
148 | selected_q_next = np.max(q_next, axis=1) # the natural DQN
149 |
150 | q_target[batch_index, eval_act_index] = reward + self.gamma * selected_q_next
151 |
152 | _, self.cost = self.sess.run([self._train_op, self.loss],
153 | feed_dict={self.s: batch_memory[:, :self.n_features],
154 | self.q_target: q_target})
155 | self.cost_his.append(self.cost)
156 |
157 | self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
158 | self.learn_step_counter += 1
159 |
160 |
161 |
162 |
163 |
--------------------------------------------------------------------------------
/contents/5.1_Double_DQN/run_Pendulum.py:
--------------------------------------------------------------------------------
1 | """
2 | Double DQN & Natural DQN comparison,
3 | The Pendulum example.
4 |
5 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
6 |
7 | Using:
8 | Tensorflow: 1.0
9 | gym: 0.8.0
10 | """
11 |
12 |
13 | import gym
14 | from RL_brain import DoubleDQN
15 | import numpy as np
16 | import matplotlib.pyplot as plt
17 | import tensorflow as tf
18 |
19 |
20 | env = gym.make('Pendulum-v0')
21 | env = env.unwrapped
22 | env.seed(1)
23 | MEMORY_SIZE = 3000
24 | ACTION_SPACE = 11
25 |
26 | sess = tf.Session()
27 | with tf.variable_scope('Natural_DQN'):
28 | natural_DQN = DoubleDQN(
29 | n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
30 | e_greedy_increment=0.001, double_q=False, sess=sess
31 | )
32 |
33 | with tf.variable_scope('Double_DQN'):
34 | double_DQN = DoubleDQN(
35 | n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
36 | e_greedy_increment=0.001, double_q=True, sess=sess, output_graph=True)
37 |
38 | sess.run(tf.global_variables_initializer())
39 |
40 |
41 | def train(RL):
42 | total_steps = 0
43 | observation = env.reset()
44 | while True:
45 | # if total_steps - MEMORY_SIZE > 8000: env.render()
46 |
47 | action = RL.choose_action(observation)
48 |
49 | f_action = (action-(ACTION_SPACE-1)/2)/((ACTION_SPACE-1)/4) # convert to [-2 ~ 2] float actions
50 | observation_, reward, done, info = env.step(np.array([f_action]))
51 |
52 | reward /= 10 # normalize to a range of (-1, 0). r = 0 when get upright
53 | # the Q target at upright state will be 0, because Q_target = r + gamma * Qmax(s', a') = 0 + gamma * 0
54 | # so when Q at this state is greater than 0, the agent overestimates the Q. Please refer to the final result.
55 |
56 | RL.store_transition(observation, action, reward, observation_)
57 |
58 | if total_steps > MEMORY_SIZE: # learning
59 | RL.learn()
60 |
61 | if total_steps - MEMORY_SIZE > 20000: # stop game
62 | break
63 |
64 | observation = observation_
65 | total_steps += 1
66 | return RL.q
67 |
68 | q_natural = train(natural_DQN)
69 | q_double = train(double_DQN)
70 |
71 | plt.plot(np.array(q_natural), c='r', label='natural')
72 | plt.plot(np.array(q_double), c='b', label='double')
73 | plt.legend(loc='best')
74 | plt.ylabel('Q eval')
75 | plt.xlabel('training steps')
76 | plt.grid()
77 | plt.show()
78 |
--------------------------------------------------------------------------------
/contents/5.2_Prioritized_Replay_DQN/run_MountainCar.py:
--------------------------------------------------------------------------------
1 | """
2 | The DQN improvement: Prioritized Experience Replay (based on https://arxiv.org/abs/1511.05952)
3 |
4 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
5 |
6 | Using:
7 | Tensorflow: 1.0
8 | gym: 0.8.0
9 | """
10 |
11 |
12 | import gym
13 | from RL_brain import DQNPrioritizedReplay
14 | import matplotlib.pyplot as plt
15 | import tensorflow as tf
16 | import numpy as np
17 |
18 | env = gym.make('MountainCar-v0')
19 | env = env.unwrapped
20 | env.seed(21)
21 | MEMORY_SIZE = 10000
22 |
23 | sess = tf.Session()
24 | with tf.variable_scope('natural_DQN'):
25 | RL_natural = DQNPrioritizedReplay(
26 | n_actions=3, n_features=2, memory_size=MEMORY_SIZE,
27 | e_greedy_increment=0.00005, sess=sess, prioritized=False,
28 | )
29 |
30 | with tf.variable_scope('DQN_with_prioritized_replay'):
31 | RL_prio = DQNPrioritizedReplay(
32 | n_actions=3, n_features=2, memory_size=MEMORY_SIZE,
33 | e_greedy_increment=0.00005, sess=sess, prioritized=True, output_graph=True,
34 | )
35 | sess.run(tf.global_variables_initializer())
36 |
37 |
38 | def train(RL):
39 | total_steps = 0
40 | steps = []
41 | episodes = []
42 | for i_episode in range(20):
43 | observation = env.reset()
44 | while True:
45 | # env.render()
46 |
47 | action = RL.choose_action(observation)
48 |
49 | observation_, reward, done, info = env.step(action)
50 |
51 | if done: reward = 10
52 |
53 | RL.store_transition(observation, action, reward, observation_)
54 |
55 | if total_steps > MEMORY_SIZE:
56 | RL.learn()
57 |
58 | if done:
59 | print('episode ', i_episode, ' finished')
60 | steps.append(total_steps)
61 | episodes.append(i_episode)
62 | break
63 |
64 | observation = observation_
65 | total_steps += 1
66 | return np.vstack((episodes, steps))
67 |
68 | his_natural = train(RL_natural)
69 | his_prio = train(RL_prio)
70 |
71 | # compare based on first success
72 | plt.plot(his_natural[0, :], his_natural[1, :] - his_natural[1, 0], c='b', label='natural DQN')
73 | plt.plot(his_prio[0, :], his_prio[1, :] - his_prio[1, 0], c='r', label='DQN with prioritized replay')
74 | plt.legend(loc='best')
75 | plt.ylabel('total training time')
76 | plt.xlabel('episode')
77 | plt.grid()
78 | plt.show()
79 |
80 |
81 |
--------------------------------------------------------------------------------
/contents/5.3_Dueling_DQN/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | The Dueling DQN based on this paper: https://arxiv.org/abs/1511.06581
3 |
4 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
5 |
6 | Using:
7 | Tensorflow: 1.0
8 | gym: 0.8.0
9 | """
10 |
11 | import numpy as np
12 | import tensorflow as tf
13 |
14 | np.random.seed(1)
15 | tf.set_random_seed(1)
16 |
17 |
18 | class DuelingDQN:
19 | def __init__(
20 | self,
21 | n_actions,
22 | n_features,
23 | learning_rate=0.001,
24 | reward_decay=0.9,
25 | e_greedy=0.9,
26 | replace_target_iter=200,
27 | memory_size=500,
28 | batch_size=32,
29 | e_greedy_increment=None,
30 | output_graph=False,
31 | dueling=True,
32 | sess=None,
33 | ):
34 | self.n_actions = n_actions
35 | self.n_features = n_features
36 | self.lr = learning_rate
37 | self.gamma = reward_decay
38 | self.epsilon_max = e_greedy
39 | self.replace_target_iter = replace_target_iter
40 | self.memory_size = memory_size
41 | self.batch_size = batch_size
42 | self.epsilon_increment = e_greedy_increment
43 | self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
44 |
45 | self.dueling = dueling # decide to use dueling DQN or not
46 |
47 | self.learn_step_counter = 0
48 | self.memory = np.zeros((self.memory_size, n_features*2+2))
49 | self._build_net()
50 | t_params = tf.get_collection('target_net_params')
51 | e_params = tf.get_collection('eval_net_params')
52 | self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
53 |
54 | if sess is None:
55 | self.sess = tf.Session()
56 | self.sess.run(tf.global_variables_initializer())
57 | else:
58 | self.sess = sess
59 | if output_graph:
60 | tf.summary.FileWriter("logs/", self.sess.graph)
61 | self.cost_his = []
62 |
63 | def _build_net(self):
64 | def build_layers(s, c_names, n_l1, w_initializer, b_initializer):
65 | with tf.variable_scope('l1'):
66 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
67 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
68 | l1 = tf.nn.relu(tf.matmul(s, w1) + b1)
69 |
70 | if self.dueling:
71 | # Dueling DQN
72 | with tf.variable_scope('Value'):
73 | w2 = tf.get_variable('w2', [n_l1, 1], initializer=w_initializer, collections=c_names)
74 | b2 = tf.get_variable('b2', [1, 1], initializer=b_initializer, collections=c_names)
75 | self.V = tf.matmul(l1, w2) + b2
76 |
77 | with tf.variable_scope('Advantage'):
78 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
79 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
80 | self.A = tf.matmul(l1, w2) + b2
81 |
82 | with tf.variable_scope('Q'):
83 | out = self.V + (self.A - tf.reduce_mean(self.A, axis=1, keep_dims=True)) # Q = V(s) + A(s,a)
84 | else:
85 | with tf.variable_scope('Q'):
86 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
87 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
88 | out = tf.matmul(l1, w2) + b2
89 |
90 | return out
91 |
92 | # ------------------ build evaluate_net ------------------
93 | self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
94 | self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
95 | with tf.variable_scope('eval_net'):
96 | c_names, n_l1, w_initializer, b_initializer = \
97 | ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 20, \
98 | tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
99 |
100 | self.q_eval = build_layers(self.s, c_names, n_l1, w_initializer, b_initializer)
101 |
102 | with tf.variable_scope('loss'):
103 | self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
104 | with tf.variable_scope('train'):
105 | self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
106 |
107 | # ------------------ build target_net ------------------
108 | self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
109 | with tf.variable_scope('target_net'):
110 | c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
111 |
112 | self.q_next = build_layers(self.s_, c_names, n_l1, w_initializer, b_initializer)
113 |
114 | def store_transition(self, s, a, r, s_):
115 | if not hasattr(self, 'memory_counter'):
116 | self.memory_counter = 0
117 | transition = np.hstack((s, [a, r], s_))
118 | index = self.memory_counter % self.memory_size
119 | self.memory[index, :] = transition
120 | self.memory_counter += 1
121 |
122 | def choose_action(self, observation):
123 | observation = observation[np.newaxis, :]
124 | if np.random.uniform() < self.epsilon: # choosing action
125 | actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
126 | action = np.argmax(actions_value)
127 | else:
128 | action = np.random.randint(0, self.n_actions)
129 | return action
130 |
131 | def learn(self):
132 | if self.learn_step_counter % self.replace_target_iter == 0:
133 | self.sess.run(self.replace_target_op)
134 | print('\ntarget_params_replaced\n')
135 |
136 | sample_index = np.random.choice(self.memory_size, size=self.batch_size)
137 | batch_memory = self.memory[sample_index, :]
138 |
139 | q_next = self.sess.run(self.q_next, feed_dict={self.s_: batch_memory[:, -self.n_features:]}) # next observation
140 | q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
141 |
142 | q_target = q_eval.copy()
143 |
144 | batch_index = np.arange(self.batch_size, dtype=np.int32)
145 | eval_act_index = batch_memory[:, self.n_features].astype(int)
146 | reward = batch_memory[:, self.n_features + 1]
147 |
148 | q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
149 |
150 | _, self.cost = self.sess.run([self._train_op, self.loss],
151 | feed_dict={self.s: batch_memory[:, :self.n_features],
152 | self.q_target: q_target})
153 | self.cost_his.append(self.cost)
154 |
155 | self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
156 | self.learn_step_counter += 1
157 |
158 |
159 |
160 |
161 |
162 |
--------------------------------------------------------------------------------
/contents/5.3_Dueling_DQN/run_Pendulum.py:
--------------------------------------------------------------------------------
1 | """
2 | Dueling DQN & Natural DQN comparison
3 |
4 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
5 |
6 | Using:
7 | Tensorflow: 1.0
8 | gym: 0.8.0
9 | """
10 |
11 |
12 | import gym
13 | from RL_brain import DuelingDQN
14 | import numpy as np
15 | import matplotlib.pyplot as plt
16 | import tensorflow as tf
17 |
18 |
19 | env = gym.make('Pendulum-v0')
20 | env = env.unwrapped
21 | env.seed(1)
22 | MEMORY_SIZE = 3000
23 | ACTION_SPACE = 25
24 |
25 | sess = tf.Session()
26 | with tf.variable_scope('natural'):
27 | natural_DQN = DuelingDQN(
28 | n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
29 | e_greedy_increment=0.001, sess=sess, dueling=False)
30 |
31 | with tf.variable_scope('dueling'):
32 | dueling_DQN = DuelingDQN(
33 | n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
34 | e_greedy_increment=0.001, sess=sess, dueling=True, output_graph=True)
35 |
36 | sess.run(tf.global_variables_initializer())
37 |
38 |
39 | def train(RL):
40 | acc_r = [0]
41 | total_steps = 0
42 | observation = env.reset()
43 | while True:
44 | # if total_steps-MEMORY_SIZE > 9000: env.render()
45 |
46 | action = RL.choose_action(observation)
47 |
48 | f_action = (action-(ACTION_SPACE-1)/2)/((ACTION_SPACE-1)/4) # [-2 ~ 2] float actions
49 | observation_, reward, done, info = env.step(np.array([f_action]))
50 |
51 | reward /= 10 # normalize to a range of (-1, 0)
52 | acc_r.append(reward + acc_r[-1]) # accumulated reward
53 |
54 | RL.store_transition(observation, action, reward, observation_)
55 |
56 | if total_steps > MEMORY_SIZE:
57 | RL.learn()
58 |
59 | if total_steps-MEMORY_SIZE > 15000:
60 | break
61 |
62 | observation = observation_
63 | total_steps += 1
64 | return RL.cost_his, acc_r
65 |
66 | c_natural, r_natural = train(natural_DQN)
67 | c_dueling, r_dueling = train(dueling_DQN)
68 |
69 | plt.figure(1)
70 | plt.plot(np.array(c_natural), c='r', label='natural')
71 | plt.plot(np.array(c_dueling), c='b', label='dueling')
72 | plt.legend(loc='best')
73 | plt.ylabel('cost')
74 | plt.xlabel('training steps')
75 | plt.grid()
76 |
77 | plt.figure(2)
78 | plt.plot(np.array(r_natural), c='r', label='natural')
79 | plt.plot(np.array(r_dueling), c='b', label='dueling')
80 | plt.legend(loc='best')
81 | plt.ylabel('accumulated reward')
82 | plt.xlabel('training steps')
83 | plt.grid()
84 |
85 | plt.show()
86 |
87 |
--------------------------------------------------------------------------------
/contents/5_Deep_Q_Network/DQN_modified.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the Deep Q Network (DQN) brain.
3 |
4 | view the tensorboard picture about this DQN structure on: https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/4-3-DQN3/#modification
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | Tensorflow: r1.2
10 | """
11 |
12 | import numpy as np
13 | import tensorflow as tf
14 |
15 | np.random.seed(1)
16 | tf.set_random_seed(1)
17 |
18 |
19 | # Deep Q Network off-policy
20 | class DeepQNetwork:
21 | def __init__(
22 | self,
23 | n_actions,
24 | n_features,
25 | learning_rate=0.01,
26 | reward_decay=0.9,
27 | e_greedy=0.9,
28 | replace_target_iter=300,
29 | memory_size=500,
30 | batch_size=32,
31 | e_greedy_increment=None,
32 | output_graph=False,
33 | ):
34 | self.n_actions = n_actions
35 | self.n_features = n_features
36 | self.lr = learning_rate
37 | self.gamma = reward_decay
38 | self.epsilon_max = e_greedy
39 | self.replace_target_iter = replace_target_iter
40 | self.memory_size = memory_size
41 | self.batch_size = batch_size
42 | self.epsilon_increment = e_greedy_increment
43 | self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
44 |
45 | # total learning step
46 | self.learn_step_counter = 0
47 |
48 | # initialize zero memory [s, a, r, s_]
49 | self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
50 |
51 | # consist of [target_net, evaluate_net]
52 | self._build_net()
53 |
54 | t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
55 | e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
56 |
57 | with tf.variable_scope('soft_replacement'):
58 | self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
59 |
60 | self.sess = tf.Session()
61 |
62 | if output_graph:
63 | # $ tensorboard --logdir=logs
64 | tf.summary.FileWriter("logs/", self.sess.graph)
65 |
66 | self.sess.run(tf.global_variables_initializer())
67 | self.cost_his = []
68 |
69 | def _build_net(self):
70 | # ------------------ all inputs ------------------------
71 | self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input State
72 | self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input Next State
73 | self.r = tf.placeholder(tf.float32, [None, ], name='r') # input Reward
74 | self.a = tf.placeholder(tf.int32, [None, ], name='a') # input Action
75 |
76 | w_initializer, b_initializer = tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1)
77 |
78 | # ------------------ build evaluate_net ------------------
79 | with tf.variable_scope('eval_net'):
80 | e1 = tf.layers.dense(self.s, 20, tf.nn.relu, kernel_initializer=w_initializer,
81 | bias_initializer=b_initializer, name='e1')
82 | self.q_eval = tf.layers.dense(e1, self.n_actions, kernel_initializer=w_initializer,
83 | bias_initializer=b_initializer, name='q')
84 |
85 | # ------------------ build target_net ------------------
86 | with tf.variable_scope('target_net'):
87 | t1 = tf.layers.dense(self.s_, 20, tf.nn.relu, kernel_initializer=w_initializer,
88 | bias_initializer=b_initializer, name='t1')
89 | self.q_next = tf.layers.dense(t1, self.n_actions, kernel_initializer=w_initializer,
90 | bias_initializer=b_initializer, name='t2')
91 |
92 | with tf.variable_scope('q_target'):
93 | q_target = self.r + self.gamma * tf.reduce_max(self.q_next, axis=1, name='Qmax_s_') # shape=(None, )
94 | self.q_target = tf.stop_gradient(q_target)
95 | with tf.variable_scope('q_eval'):
96 | a_indices = tf.stack([tf.range(tf.shape(self.a)[0], dtype=tf.int32), self.a], axis=1)
97 | self.q_eval_wrt_a = tf.gather_nd(params=self.q_eval, indices=a_indices) # shape=(None, )
98 | with tf.variable_scope('loss'):
99 | self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval_wrt_a, name='TD_error'))
100 | with tf.variable_scope('train'):
101 | self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
102 |
103 | def store_transition(self, s, a, r, s_):
104 | if not hasattr(self, 'memory_counter'):
105 | self.memory_counter = 0
106 | transition = np.hstack((s, [a, r], s_))
107 | # replace the old memory with new memory
108 | index = self.memory_counter % self.memory_size
109 | self.memory[index, :] = transition
110 | self.memory_counter += 1
111 |
112 | def choose_action(self, observation):
113 | # to have batch dimension when feed into tf placeholder
114 | observation = observation[np.newaxis, :]
115 |
116 | if np.random.uniform() < self.epsilon:
117 | # forward feed the observation and get q value for every actions
118 | actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
119 | action = np.argmax(actions_value)
120 | else:
121 | action = np.random.randint(0, self.n_actions)
122 | return action
123 |
124 | def learn(self):
125 | # check to replace target parameters
126 | if self.learn_step_counter % self.replace_target_iter == 0:
127 | self.sess.run(self.target_replace_op)
128 | print('\ntarget_params_replaced\n')
129 |
130 | # sample batch memory from all memory
131 | if self.memory_counter > self.memory_size:
132 | sample_index = np.random.choice(self.memory_size, size=self.batch_size)
133 | else:
134 | sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
135 | batch_memory = self.memory[sample_index, :]
136 |
137 | _, cost = self.sess.run(
138 | [self._train_op, self.loss],
139 | feed_dict={
140 | self.s: batch_memory[:, :self.n_features],
141 | self.a: batch_memory[:, self.n_features],
142 | self.r: batch_memory[:, self.n_features + 1],
143 | self.s_: batch_memory[:, -self.n_features:],
144 | })
145 |
146 | self.cost_his.append(cost)
147 |
148 | # increasing epsilon
149 | self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
150 | self.learn_step_counter += 1
151 |
152 | def plot_cost(self):
153 | import matplotlib.pyplot as plt
154 | plt.plot(np.arange(len(self.cost_his)), self.cost_his)
155 | plt.ylabel('Cost')
156 | plt.xlabel('training steps')
157 | plt.show()
158 |
159 | if __name__ == '__main__':
160 | DQN = DeepQNetwork(3,4, output_graph=True)
--------------------------------------------------------------------------------
/contents/5_Deep_Q_Network/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the DQN brain, which is a brain of the agent.
3 | All decisions are made in here.
4 | Using Tensorflow to build the neural network.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | Tensorflow: 1.0
10 | gym: 0.7.3
11 | """
12 |
13 | import numpy as np
14 | import pandas as pd
15 | import tensorflow as tf
16 |
17 | np.random.seed(1)
18 | tf.set_random_seed(1)
19 |
20 |
21 | # Deep Q Network off-policy
22 | class DeepQNetwork:
23 | def __init__(
24 | self,
25 | n_actions,
26 | n_features,
27 | learning_rate=0.01,
28 | reward_decay=0.9,
29 | e_greedy=0.9,
30 | replace_target_iter=300,
31 | memory_size=500,
32 | batch_size=32,
33 | e_greedy_increment=None,
34 | output_graph=False,
35 | ):
36 | self.n_actions = n_actions
37 | self.n_features = n_features
38 | self.lr = learning_rate
39 | self.gamma = reward_decay
40 | self.epsilon_max = e_greedy
41 | self.replace_target_iter = replace_target_iter
42 | self.memory_size = memory_size
43 | self.batch_size = batch_size
44 | self.epsilon_increment = e_greedy_increment
45 | self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
46 |
47 | # total learning step
48 | self.learn_step_counter = 0
49 |
50 | # initialize zero memory [s, a, r, s_]
51 | self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
52 |
53 | # consist of [target_net, evaluate_net]
54 | self._build_net()
55 | t_params = tf.get_collection('target_net_params')
56 | e_params = tf.get_collection('eval_net_params')
57 | self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
58 |
59 | self.sess = tf.Session()
60 |
61 | if output_graph:
62 | # $ tensorboard --logdir=logs
63 | # tf.train.SummaryWriter soon be deprecated, use following
64 | tf.summary.FileWriter("logs/", self.sess.graph)
65 |
66 | self.sess.run(tf.global_variables_initializer())
67 | self.cost_his = []
68 |
69 | def _build_net(self):
70 | # ------------------ build evaluate_net ------------------
71 | self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
72 | self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
73 | with tf.variable_scope('eval_net'):
74 | # c_names(collections_names) are the collections to store variables
75 | c_names, n_l1, w_initializer, b_initializer = \
76 | ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, \
77 | tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
78 |
79 | # first layer. collections is used later when assign to target net
80 | with tf.variable_scope('l1'):
81 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
82 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
83 | l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
84 |
85 | # second layer. collections is used later when assign to target net
86 | with tf.variable_scope('l2'):
87 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
88 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
89 | self.q_eval = tf.matmul(l1, w2) + b2
90 |
91 | with tf.variable_scope('loss'):
92 | self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
93 | with tf.variable_scope('train'):
94 | self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
95 |
96 | # ------------------ build target_net ------------------
97 | self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
98 | with tf.variable_scope('target_net'):
99 | # c_names(collections_names) are the collections to store variables
100 | c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
101 |
102 | # first layer. collections is used later when assign to target net
103 | with tf.variable_scope('l1'):
104 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
105 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
106 | l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
107 |
108 | # second layer. collections is used later when assign to target net
109 | with tf.variable_scope('l2'):
110 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
111 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
112 | self.q_next = tf.matmul(l1, w2) + b2
113 |
114 | def store_transition(self, s, a, r, s_):
115 | if not hasattr(self, 'memory_counter'):
116 | self.memory_counter = 0
117 |
118 | transition = np.hstack((s, [a, r], s_))
119 |
120 | # replace the old memory with new memory
121 | index = self.memory_counter % self.memory_size
122 | self.memory[index, :] = transition
123 |
124 | self.memory_counter += 1
125 |
126 | def choose_action(self, observation):
127 | # to have batch dimension when feed into tf placeholder
128 | observation = observation[np.newaxis, :]
129 |
130 | if np.random.uniform() < self.epsilon:
131 | # forward feed the observation and get q value for every actions
132 | actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
133 | action = np.argmax(actions_value)
134 | else:
135 | action = np.random.randint(0, self.n_actions)
136 | return action
137 |
138 | def learn(self):
139 | # check to replace target parameters
140 | if self.learn_step_counter % self.replace_target_iter == 0:
141 | self.sess.run(self.replace_target_op)
142 | print('\ntarget_params_replaced\n')
143 |
144 | # sample batch memory from all memory
145 | if self.memory_counter > self.memory_size:
146 | sample_index = np.random.choice(self.memory_size, size=self.batch_size)
147 | else:
148 | sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
149 | batch_memory = self.memory[sample_index, :]
150 |
151 | q_next, q_eval = self.sess.run(
152 | [self.q_next, self.q_eval],
153 | feed_dict={
154 | self.s_: batch_memory[:, -self.n_features:], # fixed params
155 | self.s: batch_memory[:, :self.n_features], # newest params
156 | })
157 |
158 | # change q_target w.r.t q_eval's action
159 | q_target = q_eval.copy()
160 |
161 | batch_index = np.arange(self.batch_size, dtype=np.int32)
162 | eval_act_index = batch_memory[:, self.n_features].astype(int)
163 | reward = batch_memory[:, self.n_features + 1]
164 |
165 | q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
166 |
167 | """
168 | For example in this batch I have 2 samples and 3 actions:
169 | q_eval =
170 | [[1, 2, 3],
171 | [4, 5, 6]]
172 |
173 | q_target = q_eval =
174 | [[1, 2, 3],
175 | [4, 5, 6]]
176 |
177 | Then change q_target with the real q_target value w.r.t the q_eval's action.
178 | For example in:
179 | sample 0, I took action 0, and the max q_target value is -1;
180 | sample 1, I took action 2, and the max q_target value is -2:
181 | q_target =
182 | [[-1, 2, 3],
183 | [4, 5, -2]]
184 |
185 | So the (q_target - q_eval) becomes:
186 | [[(-1)-(1), 0, 0],
187 | [0, 0, (-2)-(6)]]
188 |
189 | We then backpropagate this error w.r.t the corresponding action to network,
190 | leave other action as error=0 cause we didn't choose it.
191 | """
192 |
193 | # train eval network
194 | _, self.cost = self.sess.run([self._train_op, self.loss],
195 | feed_dict={self.s: batch_memory[:, :self.n_features],
196 | self.q_target: q_target})
197 | self.cost_his.append(self.cost)
198 |
199 | # increasing epsilon
200 | self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
201 | self.learn_step_counter += 1
202 |
203 | def plot_cost(self):
204 | import matplotlib.pyplot as plt
205 | plt.plot(np.arange(len(self.cost_his)), self.cost_his)
206 | plt.ylabel('Cost')
207 | plt.xlabel('training steps')
208 | plt.show()
209 |
210 |
211 |
212 |
--------------------------------------------------------------------------------
/contents/5_Deep_Q_Network/maze_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the environment part of this example.
10 | The RL is in RL_brain.py.
11 |
12 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
13 | """
14 | import numpy as np
15 | import time
16 | import sys
17 | if sys.version_info.major == 2:
18 | import Tkinter as tk
19 | else:
20 | import tkinter as tk
21 |
22 | UNIT = 40 # pixels
23 | MAZE_H = 4 # grid height
24 | MAZE_W = 4 # grid width
25 |
26 |
27 | class Maze(tk.Tk, object):
28 | def __init__(self):
29 | super(Maze, self).__init__()
30 | self.action_space = ['u', 'd', 'l', 'r']
31 | self.n_actions = len(self.action_space)
32 | self.n_features = 2
33 | self.title('maze')
34 | self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
35 | self._build_maze()
36 |
37 | def _build_maze(self):
38 | self.canvas = tk.Canvas(self, bg='white',
39 | height=MAZE_H * UNIT,
40 | width=MAZE_W * UNIT)
41 |
42 | # create grids
43 | for c in range(0, MAZE_W * UNIT, UNIT):
44 | x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
45 | self.canvas.create_line(x0, y0, x1, y1)
46 | for r in range(0, MAZE_H * UNIT, UNIT):
47 | x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
48 | self.canvas.create_line(x0, y0, x1, y1)
49 |
50 | # create origin
51 | origin = np.array([20, 20])
52 |
53 | # hell
54 | hell1_center = origin + np.array([UNIT * 2, UNIT])
55 | self.hell1 = self.canvas.create_rectangle(
56 | hell1_center[0] - 15, hell1_center[1] - 15,
57 | hell1_center[0] + 15, hell1_center[1] + 15,
58 | fill='black')
59 | # hell
60 | # hell2_center = origin + np.array([UNIT, UNIT * 2])
61 | # self.hell2 = self.canvas.create_rectangle(
62 | # hell2_center[0] - 15, hell2_center[1] - 15,
63 | # hell2_center[0] + 15, hell2_center[1] + 15,
64 | # fill='black')
65 |
66 | # create oval
67 | oval_center = origin + UNIT * 2
68 | self.oval = self.canvas.create_oval(
69 | oval_center[0] - 15, oval_center[1] - 15,
70 | oval_center[0] + 15, oval_center[1] + 15,
71 | fill='yellow')
72 |
73 | # create red rect
74 | self.rect = self.canvas.create_rectangle(
75 | origin[0] - 15, origin[1] - 15,
76 | origin[0] + 15, origin[1] + 15,
77 | fill='red')
78 |
79 | # pack all
80 | self.canvas.pack()
81 |
82 | def reset(self):
83 | self.update()
84 | time.sleep(0.1)
85 | self.canvas.delete(self.rect)
86 | origin = np.array([20, 20])
87 | self.rect = self.canvas.create_rectangle(
88 | origin[0] - 15, origin[1] - 15,
89 | origin[0] + 15, origin[1] + 15,
90 | fill='red')
91 | # return observation
92 | return (np.array(self.canvas.coords(self.rect)[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
93 |
94 | def step(self, action):
95 | s = self.canvas.coords(self.rect)
96 | base_action = np.array([0, 0])
97 | if action == 0: # up
98 | if s[1] > UNIT:
99 | base_action[1] -= UNIT
100 | elif action == 1: # down
101 | if s[1] < (MAZE_H - 1) * UNIT:
102 | base_action[1] += UNIT
103 | elif action == 2: # right
104 | if s[0] < (MAZE_W - 1) * UNIT:
105 | base_action[0] += UNIT
106 | elif action == 3: # left
107 | if s[0] > UNIT:
108 | base_action[0] -= UNIT
109 |
110 | self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
111 |
112 | next_coords = self.canvas.coords(self.rect) # next state
113 |
114 | # reward function
115 | if next_coords == self.canvas.coords(self.oval):
116 | reward = 1
117 | done = True
118 | elif next_coords in [self.canvas.coords(self.hell1)]:
119 | reward = -1
120 | done = True
121 | else:
122 | reward = 0
123 | done = False
124 | s_ = (np.array(next_coords[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
125 | return s_, reward, done
126 |
127 | def render(self):
128 | # time.sleep(0.01)
129 | self.update()
130 |
131 |
132 |
--------------------------------------------------------------------------------
/contents/5_Deep_Q_Network/run_this.py:
--------------------------------------------------------------------------------
1 | from maze_env import Maze
2 | from RL_brain import DeepQNetwork
3 |
4 |
5 | def run_maze():
6 | step = 0
7 | for episode in range(300):
8 | # initial observation
9 | observation = env.reset()
10 |
11 | while True:
12 | # fresh env
13 | env.render()
14 |
15 | # RL choose action based on observation
16 | action = RL.choose_action(observation)
17 |
18 | # RL take action and get next observation and reward
19 | observation_, reward, done = env.step(action)
20 |
21 | RL.store_transition(observation, action, reward, observation_)
22 |
23 | if (step > 200) and (step % 5 == 0):
24 | RL.learn()
25 |
26 | # swap observation
27 | observation = observation_
28 |
29 | # break while loop when end of this episode
30 | if done:
31 | break
32 | step += 1
33 |
34 | # end of game
35 | print('game over')
36 | env.destroy()
37 |
38 |
39 | if __name__ == "__main__":
40 | # maze game
41 | env = Maze()
42 | RL = DeepQNetwork(env.n_actions, env.n_features,
43 | learning_rate=0.01,
44 | reward_decay=0.9,
45 | e_greedy=0.9,
46 | replace_target_iter=200,
47 | memory_size=2000,
48 | # output_graph=True
49 | )
50 | env.after(100, run_maze)
51 | env.mainloop()
52 | RL.plot_cost()
--------------------------------------------------------------------------------
/contents/6_OpenAI_gym/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the DQN brain, which is a brain of the agent.
3 | All decisions are made in here.
4 | Using Tensorflow to build the neural network.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | Tensorflow: 1.0
10 | gym: 0.8.0
11 | """
12 |
13 | import numpy as np
14 | import pandas as pd
15 | import tensorflow as tf
16 |
17 |
18 | # Deep Q Network off-policy
19 | class DeepQNetwork:
20 | def __init__(
21 | self,
22 | n_actions,
23 | n_features,
24 | learning_rate=0.01,
25 | reward_decay=0.9,
26 | e_greedy=0.9,
27 | replace_target_iter=300,
28 | memory_size=500,
29 | batch_size=32,
30 | e_greedy_increment=None,
31 | output_graph=False,
32 | ):
33 | self.n_actions = n_actions
34 | self.n_features = n_features
35 | self.lr = learning_rate
36 | self.gamma = reward_decay
37 | self.epsilon_max = e_greedy
38 | self.replace_target_iter = replace_target_iter
39 | self.memory_size = memory_size
40 | self.batch_size = batch_size
41 | self.epsilon_increment = e_greedy_increment
42 | self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
43 |
44 | # total learning step
45 | self.learn_step_counter = 0
46 |
47 | # initialize zero memory [s, a, r, s_]
48 | self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
49 |
50 | # consist of [target_net, evaluate_net]
51 | self._build_net()
52 | t_params = tf.get_collection('target_net_params')
53 | e_params = tf.get_collection('eval_net_params')
54 | self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
55 |
56 | self.sess = tf.Session()
57 |
58 | if output_graph:
59 | # $ tensorboard --logdir=logs
60 | # tf.train.SummaryWriter soon be deprecated, use following
61 | tf.summary.FileWriter("logs/", self.sess.graph)
62 |
63 | self.sess.run(tf.global_variables_initializer())
64 | self.cost_his = []
65 |
66 | def _build_net(self):
67 | # ------------------ build evaluate_net ------------------
68 | self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
69 | self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
70 | with tf.variable_scope('eval_net'):
71 | # c_names(collections_names) are the collections to store variables
72 | c_names, n_l1, w_initializer, b_initializer = \
73 | ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, \
74 | tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
75 |
76 | # first layer. collections is used later when assign to target net
77 | with tf.variable_scope('l1'):
78 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
79 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
80 | l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
81 |
82 | # second layer. collections is used later when assign to target net
83 | with tf.variable_scope('l2'):
84 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
85 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
86 | self.q_eval = tf.matmul(l1, w2) + b2
87 |
88 | with tf.variable_scope('loss'):
89 | self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
90 | with tf.variable_scope('train'):
91 | self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
92 |
93 | # ------------------ build target_net ------------------
94 | self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
95 | with tf.variable_scope('target_net'):
96 | # c_names(collections_names) are the collections to store variables
97 | c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
98 |
99 | # first layer. collections is used later when assign to target net
100 | with tf.variable_scope('l1'):
101 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
102 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
103 | l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
104 |
105 | # second layer. collections is used later when assign to target net
106 | with tf.variable_scope('l2'):
107 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
108 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
109 | self.q_next = tf.matmul(l1, w2) + b2
110 |
111 | def store_transition(self, s, a, r, s_):
112 | if not hasattr(self, 'memory_counter'):
113 | self.memory_counter = 0
114 |
115 | transition = np.hstack((s, [a, r], s_))
116 |
117 | # replace the old memory with new memory
118 | index = self.memory_counter % self.memory_size
119 | self.memory[index, :] = transition
120 |
121 | self.memory_counter += 1
122 |
123 | def choose_action(self, observation):
124 | # to have batch dimension when feed into tf placeholder
125 | observation = observation[np.newaxis, :]
126 |
127 | if np.random.uniform() < self.epsilon:
128 | # forward feed the observation and get q value for every actions
129 | actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
130 | action = np.argmax(actions_value)
131 | else:
132 | action = np.random.randint(0, self.n_actions)
133 | return action
134 |
135 | def learn(self):
136 | # check to replace target parameters
137 | if self.learn_step_counter % self.replace_target_iter == 0:
138 | self.sess.run(self.replace_target_op)
139 | print('\ntarget_params_replaced\n')
140 |
141 | # sample batch memory from all memory
142 | if self.memory_counter > self.memory_size:
143 | sample_index = np.random.choice(self.memory_size, size=self.batch_size)
144 | else:
145 | sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
146 | batch_memory = self.memory[sample_index, :]
147 |
148 | q_next, q_eval = self.sess.run(
149 | [self.q_next, self.q_eval],
150 | feed_dict={
151 | self.s_: batch_memory[:, -self.n_features:], # fixed params
152 | self.s: batch_memory[:, :self.n_features], # newest params
153 | })
154 |
155 | # change q_target w.r.t q_eval's action
156 | q_target = q_eval.copy()
157 |
158 | batch_index = np.arange(self.batch_size, dtype=np.int32)
159 | eval_act_index = batch_memory[:, self.n_features].astype(int)
160 | reward = batch_memory[:, self.n_features + 1]
161 |
162 | q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
163 |
164 | """
165 | For example in this batch I have 2 samples and 3 actions:
166 | q_eval =
167 | [[1, 2, 3],
168 | [4, 5, 6]]
169 |
170 | q_target = q_eval =
171 | [[1, 2, 3],
172 | [4, 5, 6]]
173 |
174 | Then change q_target with the real q_target value w.r.t the q_eval's action.
175 | For example in:
176 | sample 0, I took action 0, and the max q_target value is -1;
177 | sample 1, I took action 2, and the max q_target value is -2:
178 | q_target =
179 | [[-1, 2, 3],
180 | [4, 5, -2]]
181 |
182 | So the (q_target - q_eval) becomes:
183 | [[(-1)-(1), 0, 0],
184 | [0, 0, (-2)-(6)]]
185 |
186 | We then backpropagate this error w.r.t the corresponding action to network,
187 | leave other action as error=0 cause we didn't choose it.
188 | """
189 |
190 | # train eval network
191 | _, self.cost = self.sess.run([self._train_op, self.loss],
192 | feed_dict={self.s: batch_memory[:, :self.n_features],
193 | self.q_target: q_target})
194 | self.cost_his.append(self.cost)
195 |
196 | # increasing epsilon
197 | self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
198 | self.learn_step_counter += 1
199 |
200 | def plot_cost(self):
201 | import matplotlib.pyplot as plt
202 | plt.plot(np.arange(len(self.cost_his)), self.cost_his)
203 | plt.ylabel('Cost')
204 | plt.xlabel('training steps')
205 | plt.show()
206 |
207 |
208 |
209 |
--------------------------------------------------------------------------------
/contents/6_OpenAI_gym/run_CartPole.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Q network,
3 |
4 | Using:
5 | Tensorflow: 1.0
6 | gym: 0.7.3
7 | """
8 |
9 |
10 | import gym
11 | from RL_brain import DeepQNetwork
12 |
13 | env = gym.make('CartPole-v0')
14 | env = env.unwrapped
15 |
16 | print(env.action_space)
17 | print(env.observation_space)
18 | print(env.observation_space.high)
19 | print(env.observation_space.low)
20 |
21 | RL = DeepQNetwork(n_actions=env.action_space.n,
22 | n_features=env.observation_space.shape[0],
23 | learning_rate=0.01, e_greedy=0.9,
24 | replace_target_iter=100, memory_size=2000,
25 | e_greedy_increment=0.001,)
26 |
27 | total_steps = 0
28 |
29 |
30 | for i_episode in range(100):
31 |
32 | observation = env.reset()
33 | ep_r = 0
34 | while True:
35 | env.render()
36 |
37 | action = RL.choose_action(observation)
38 |
39 | observation_, reward, done, info = env.step(action)
40 |
41 | # the smaller theta and closer to center the better
42 | x, x_dot, theta, theta_dot = observation_
43 | r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8
44 | r2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians - 0.5
45 | reward = r1 + r2
46 |
47 | RL.store_transition(observation, action, reward, observation_)
48 |
49 | ep_r += reward
50 | if total_steps > 1000:
51 | RL.learn()
52 |
53 | if done:
54 | print('episode: ', i_episode,
55 | 'ep_r: ', round(ep_r, 2),
56 | ' epsilon: ', round(RL.epsilon, 2))
57 | break
58 |
59 | observation = observation_
60 | total_steps += 1
61 |
62 | RL.plot_cost()
63 |
--------------------------------------------------------------------------------
/contents/6_OpenAI_gym/run_MountainCar.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Q network,
3 |
4 | Using:
5 | Tensorflow: 1.0
6 | gym: 0.8.0
7 | """
8 |
9 |
10 | import gym
11 | from RL_brain import DeepQNetwork
12 |
13 | env = gym.make('MountainCar-v0')
14 | env = env.unwrapped
15 |
16 | print(env.action_space)
17 | print(env.observation_space)
18 | print(env.observation_space.high)
19 | print(env.observation_space.low)
20 |
21 | RL = DeepQNetwork(n_actions=3, n_features=2, learning_rate=0.001, e_greedy=0.9,
22 | replace_target_iter=300, memory_size=3000,
23 | e_greedy_increment=0.0002,)
24 |
25 | total_steps = 0
26 |
27 |
28 | for i_episode in range(10):
29 |
30 | observation = env.reset()
31 | ep_r = 0
32 | while True:
33 | env.render()
34 |
35 | action = RL.choose_action(observation)
36 |
37 | observation_, reward, done, info = env.step(action)
38 |
39 | position, velocity = observation_
40 |
41 | # the higher the better
42 | reward = abs(position - (-0.5)) # r in [0, 1]
43 |
44 | RL.store_transition(observation, action, reward, observation_)
45 |
46 | if total_steps > 1000:
47 | RL.learn()
48 |
49 | ep_r += reward
50 | if done:
51 | get = '| Get' if observation_[0] >= env.unwrapped.goal_position else '| ----'
52 | print('Epi: ', i_episode,
53 | get,
54 | '| Ep_r: ', round(ep_r, 4),
55 | '| Epsilon: ', round(RL.epsilon, 2))
56 | break
57 |
58 | observation = observation_
59 | total_steps += 1
60 |
61 | RL.plot_cost()
62 |
--------------------------------------------------------------------------------
/contents/7_Policy_gradient_softmax/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the reinforcement learning brain, which is a brain of the agent.
3 | All decisions are made in here.
4 |
5 | Policy Gradient, Reinforcement Learning.
6 |
7 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
8 |
9 | Using:
10 | Tensorflow: 1.0
11 | gym: 0.8.0
12 | """
13 |
14 | import numpy as np
15 | import tensorflow as tf
16 |
17 | # reproducible
18 | np.random.seed(1)
19 | tf.set_random_seed(1)
20 |
21 |
22 | class PolicyGradient:
23 | def __init__(
24 | self,
25 | n_actions,
26 | n_features,
27 | learning_rate=0.01,
28 | reward_decay=0.95,
29 | output_graph=False,
30 | ):
31 | self.n_actions = n_actions
32 | self.n_features = n_features
33 | self.lr = learning_rate
34 | self.gamma = reward_decay
35 |
36 | self.ep_obs, self.ep_as, self.ep_rs = [], [], []
37 |
38 | self._build_net()
39 |
40 | self.sess = tf.Session()
41 |
42 | if output_graph:
43 | # $ tensorboard --logdir=logs
44 | # http://0.0.0.0:6006/
45 | # tf.train.SummaryWriter soon be deprecated, use following
46 | tf.summary.FileWriter("logs/", self.sess.graph)
47 |
48 | self.sess.run(tf.global_variables_initializer())
49 |
50 | def _build_net(self):
51 | with tf.name_scope('inputs'):
52 | self.tf_obs = tf.placeholder(tf.float32, [None, self.n_features], name="observations")
53 | self.tf_acts = tf.placeholder(tf.int32, [None, ], name="actions_num")
54 | self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value")
55 | # fc1
56 | layer = tf.layers.dense(
57 | inputs=self.tf_obs,
58 | units=10,
59 | activation=tf.nn.tanh, # tanh activation
60 | kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
61 | bias_initializer=tf.constant_initializer(0.1),
62 | name='fc1'
63 | )
64 | # fc2
65 | all_act = tf.layers.dense(
66 | inputs=layer,
67 | units=self.n_actions,
68 | activation=None,
69 | kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
70 | bias_initializer=tf.constant_initializer(0.1),
71 | name='fc2'
72 | )
73 |
74 | self.all_act_prob = tf.nn.softmax(all_act, name='act_prob') # use softmax to convert to probability
75 |
76 | with tf.name_scope('loss'):
77 | # to maximize total reward (log_p * R) is to minimize -(log_p * R), and the tf only have minimize(loss)
78 | neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=all_act, labels=self.tf_acts) # this is negative log of chosen action
79 | # or in this way:
80 | # neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions), axis=1)
81 | loss = tf.reduce_mean(neg_log_prob * self.tf_vt) # reward guided loss
82 |
83 | with tf.name_scope('train'):
84 | self.train_op = tf.train.AdamOptimizer(self.lr).minimize(loss)
85 |
86 | def choose_action(self, observation):
87 | prob_weights = self.sess.run(self.all_act_prob, feed_dict={self.tf_obs: observation[np.newaxis, :]})
88 | action = np.random.choice(range(prob_weights.shape[1]), p=prob_weights.ravel()) # select action w.r.t the actions prob
89 | return action
90 |
91 | def store_transition(self, s, a, r):
92 | self.ep_obs.append(s)
93 | self.ep_as.append(a)
94 | self.ep_rs.append(r)
95 |
96 | def learn(self):
97 | # discount and normalize episode reward
98 | discounted_ep_rs_norm = self._discount_and_norm_rewards()
99 |
100 | # train on episode
101 | self.sess.run(self.train_op, feed_dict={
102 | self.tf_obs: np.vstack(self.ep_obs), # shape=[None, n_obs]
103 | self.tf_acts: np.array(self.ep_as), # shape=[None, ]
104 | self.tf_vt: discounted_ep_rs_norm, # shape=[None, ]
105 | })
106 |
107 | self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data
108 | return discounted_ep_rs_norm
109 |
110 | def _discount_and_norm_rewards(self):
111 | # discount episode rewards
112 | discounted_ep_rs = np.zeros_like(self.ep_rs)
113 | running_add = 0
114 | for t in reversed(range(0, len(self.ep_rs))):
115 | running_add = running_add * self.gamma + self.ep_rs[t]
116 | discounted_ep_rs[t] = running_add
117 |
118 | # normalize episode rewards
119 | discounted_ep_rs -= np.mean(discounted_ep_rs)
120 | discounted_ep_rs /= np.std(discounted_ep_rs)
121 | return discounted_ep_rs
122 |
123 |
124 |
125 |
--------------------------------------------------------------------------------
/contents/7_Policy_gradient_softmax/run_CartPole.py:
--------------------------------------------------------------------------------
1 | """
2 | Policy Gradient, Reinforcement Learning.
3 |
4 | The cart pole example
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | Tensorflow: 1.0
10 | gym: 0.8.0
11 | """
12 |
13 | import gym
14 | from RL_brain import PolicyGradient
15 | import matplotlib.pyplot as plt
16 |
17 | DISPLAY_REWARD_THRESHOLD = 400 # renders environment if total episode reward is greater then this threshold
18 | RENDER = False # rendering wastes time
19 |
20 | env = gym.make('CartPole-v0')
21 | env.seed(1) # reproducible, general Policy gradient has high variance
22 | env = env.unwrapped
23 |
24 | print(env.action_space)
25 | print(env.observation_space)
26 | print(env.observation_space.high)
27 | print(env.observation_space.low)
28 |
29 | RL = PolicyGradient(
30 | n_actions=env.action_space.n,
31 | n_features=env.observation_space.shape[0],
32 | learning_rate=0.02,
33 | reward_decay=0.99,
34 | # output_graph=True,
35 | )
36 |
37 | for i_episode in range(3000):
38 |
39 | observation = env.reset()
40 |
41 | while True:
42 | if RENDER: env.render()
43 |
44 | action = RL.choose_action(observation)
45 |
46 | observation_, reward, done, info = env.step(action)
47 |
48 | RL.store_transition(observation, action, reward)
49 |
50 | if done:
51 | ep_rs_sum = sum(RL.ep_rs)
52 |
53 | if 'running_reward' not in globals():
54 | running_reward = ep_rs_sum
55 | else:
56 | running_reward = running_reward * 0.99 + ep_rs_sum * 0.01
57 | if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
58 | print("episode:", i_episode, " reward:", int(running_reward))
59 |
60 | vt = RL.learn()
61 |
62 | if i_episode == 0:
63 | plt.plot(vt) # plot the episode vt
64 | plt.xlabel('episode steps')
65 | plt.ylabel('normalized state-action value')
66 | plt.show()
67 | break
68 |
69 | observation = observation_
70 |
--------------------------------------------------------------------------------
/contents/7_Policy_gradient_softmax/run_MountainCar.py:
--------------------------------------------------------------------------------
1 | """
2 | Policy Gradient, Reinforcement Learning.
3 |
4 | The cart pole example
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | Tensorflow: 1.0
10 | gym: 0.8.0
11 | """
12 |
13 | import gym
14 | from RL_brain import PolicyGradient
15 | import matplotlib.pyplot as plt
16 |
17 | DISPLAY_REWARD_THRESHOLD = -2000 # renders environment if total episode reward is greater then this threshold
18 | # episode: 154 reward: -10667
19 | # episode: 387 reward: -2009
20 | # episode: 489 reward: -1006
21 | # episode: 628 reward: -502
22 |
23 | RENDER = False # rendering wastes time
24 |
25 | env = gym.make('MountainCar-v0')
26 | env.seed(1) # reproducible, general Policy gradient has high variance
27 | env = env.unwrapped
28 |
29 | print(env.action_space)
30 | print(env.observation_space)
31 | print(env.observation_space.high)
32 | print(env.observation_space.low)
33 |
34 | RL = PolicyGradient(
35 | n_actions=env.action_space.n,
36 | n_features=env.observation_space.shape[0],
37 | learning_rate=0.02,
38 | reward_decay=0.995,
39 | # output_graph=True,
40 | )
41 |
42 | for i_episode in range(1000):
43 |
44 | observation = env.reset()
45 |
46 | while True:
47 | if RENDER: env.render()
48 |
49 | action = RL.choose_action(observation)
50 |
51 | observation_, reward, done, info = env.step(action) # reward = -1 in all cases
52 |
53 | RL.store_transition(observation, action, reward)
54 |
55 | if done:
56 | # calculate running reward
57 | ep_rs_sum = sum(RL.ep_rs)
58 | if 'running_reward' not in globals():
59 | running_reward = ep_rs_sum
60 | else:
61 | running_reward = running_reward * 0.99 + ep_rs_sum * 0.01
62 | if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
63 |
64 | print("episode:", i_episode, " reward:", int(running_reward))
65 |
66 | vt = RL.learn() # train
67 |
68 | if i_episode == 30:
69 | plt.plot(vt) # plot the episode vt
70 | plt.xlabel('episode steps')
71 | plt.ylabel('normalized state-action value')
72 | plt.show()
73 |
74 | break
75 |
76 | observation = observation_
77 |
--------------------------------------------------------------------------------
/contents/8_Actor_Critic_Advantage/AC_CartPole.py:
--------------------------------------------------------------------------------
1 | """
2 | Actor-Critic using TD-error as the Advantage, Reinforcement Learning.
3 |
4 | The cart pole example. Policy is oscillated.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | tensorflow 1.0
10 | gym 0.8.0
11 | """
12 |
13 | import numpy as np
14 | import tensorflow as tf
15 | import gym
16 |
17 | np.random.seed(2)
18 | tf.set_random_seed(2) # reproducible
19 |
20 | # Superparameters
21 | OUTPUT_GRAPH = False
22 | MAX_EPISODE = 3000
23 | DISPLAY_REWARD_THRESHOLD = 200 # renders environment if total episode reward is greater then this threshold
24 | MAX_EP_STEPS = 1000 # maximum time step in one episode
25 | RENDER = False # rendering wastes time
26 | GAMMA = 0.9 # reward discount in TD error
27 | LR_A = 0.001 # learning rate for actor
28 | LR_C = 0.01 # learning rate for critic
29 |
30 | env = gym.make('CartPole-v0')
31 | env.seed(1) # reproducible
32 | env = env.unwrapped
33 |
34 | N_F = env.observation_space.shape[0]
35 | N_A = env.action_space.n
36 |
37 |
38 | class Actor(object):
39 | def __init__(self, sess, n_features, n_actions, lr=0.001):
40 | self.sess = sess
41 |
42 | self.s = tf.placeholder(tf.float32, [1, n_features], "state")
43 | self.a = tf.placeholder(tf.int32, None, "act")
44 | self.td_error = tf.placeholder(tf.float32, None, "td_error") # TD_error
45 |
46 | with tf.variable_scope('Actor'):
47 | l1 = tf.layers.dense(
48 | inputs=self.s,
49 | units=20, # number of hidden units
50 | activation=tf.nn.relu,
51 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
52 | bias_initializer=tf.constant_initializer(0.1), # biases
53 | name='l1'
54 | )
55 |
56 | self.acts_prob = tf.layers.dense(
57 | inputs=l1,
58 | units=n_actions, # output units
59 | activation=tf.nn.softmax, # get action probabilities
60 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
61 | bias_initializer=tf.constant_initializer(0.1), # biases
62 | name='acts_prob'
63 | )
64 |
65 | with tf.variable_scope('exp_v'):
66 | log_prob = tf.log(self.acts_prob[0, self.a])
67 | self.exp_v = tf.reduce_mean(log_prob * self.td_error) # advantage (TD_error) guided loss
68 |
69 | with tf.variable_scope('train'):
70 | self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v) # minimize(-exp_v) = maximize(exp_v)
71 |
72 | def learn(self, s, a, td):
73 | s = s[np.newaxis, :]
74 | feed_dict = {self.s: s, self.a: a, self.td_error: td}
75 | _, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
76 | return exp_v
77 |
78 | def choose_action(self, s):
79 | s = s[np.newaxis, :]
80 | probs = self.sess.run(self.acts_prob, {self.s: s}) # get probabilities for all actions
81 | return np.random.choice(np.arange(probs.shape[1]), p=probs.ravel()) # return a int
82 |
83 |
84 | class Critic(object):
85 | def __init__(self, sess, n_features, lr=0.01):
86 | self.sess = sess
87 |
88 | self.s = tf.placeholder(tf.float32, [1, n_features], "state")
89 | self.v_ = tf.placeholder(tf.float32, [1, 1], "v_next")
90 | self.r = tf.placeholder(tf.float32, None, 'r')
91 |
92 | with tf.variable_scope('Critic'):
93 | l1 = tf.layers.dense(
94 | inputs=self.s,
95 | units=20, # number of hidden units
96 | activation=tf.nn.relu, # None
97 | # have to be linear to make sure the convergence of actor.
98 | # But linear approximator seems hardly learns the correct Q.
99 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
100 | bias_initializer=tf.constant_initializer(0.1), # biases
101 | name='l1'
102 | )
103 |
104 | self.v = tf.layers.dense(
105 | inputs=l1,
106 | units=1, # output units
107 | activation=None,
108 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
109 | bias_initializer=tf.constant_initializer(0.1), # biases
110 | name='V'
111 | )
112 |
113 | with tf.variable_scope('squared_TD_error'):
114 | self.td_error = self.r + GAMMA * self.v_ - self.v
115 | self.loss = tf.square(self.td_error) # TD_error = (r+gamma*V_next) - V_eval
116 | with tf.variable_scope('train'):
117 | self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
118 |
119 | def learn(self, s, r, s_):
120 | s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
121 |
122 | v_ = self.sess.run(self.v, {self.s: s_})
123 | td_error, _ = self.sess.run([self.td_error, self.train_op],
124 | {self.s: s, self.v_: v_, self.r: r})
125 | return td_error
126 |
127 |
128 | sess = tf.Session()
129 |
130 | actor = Actor(sess, n_features=N_F, n_actions=N_A, lr=LR_A)
131 | critic = Critic(sess, n_features=N_F, lr=LR_C) # we need a good teacher, so the teacher should learn faster than the actor
132 |
133 | sess.run(tf.global_variables_initializer())
134 |
135 | if OUTPUT_GRAPH:
136 | tf.summary.FileWriter("logs/", sess.graph)
137 |
138 | for i_episode in range(MAX_EPISODE):
139 | s = env.reset()
140 | t = 0
141 | track_r = []
142 | while True:
143 | if RENDER: env.render()
144 |
145 | a = actor.choose_action(s)
146 |
147 | s_, r, done, info = env.step(a)
148 |
149 | if done: r = -20
150 |
151 | track_r.append(r)
152 |
153 | td_error = critic.learn(s, r, s_) # gradient = grad[r + gamma * V(s_) - V(s)]
154 | actor.learn(s, a, td_error) # true_gradient = grad[logPi(s,a) * td_error]
155 |
156 | s = s_
157 | t += 1
158 |
159 | if done or t >= MAX_EP_STEPS:
160 | ep_rs_sum = sum(track_r)
161 |
162 | if 'running_reward' not in globals():
163 | running_reward = ep_rs_sum
164 | else:
165 | running_reward = running_reward * 0.95 + ep_rs_sum * 0.05
166 | if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
167 | print("episode:", i_episode, " reward:", int(running_reward))
168 | break
169 |
170 |
--------------------------------------------------------------------------------
/contents/8_Actor_Critic_Advantage/AC_continue_Pendulum.py:
--------------------------------------------------------------------------------
1 | """
2 | Actor-Critic with continuous action using TD-error as the Advantage, Reinforcement Learning.
3 |
4 | The Pendulum example (based on https://github.com/dennybritz/reinforcement-learning/blob/master/PolicyGradient/Continuous%20MountainCar%20Actor%20Critic%20Solution.ipynb)
5 |
6 | Cannot converge!!! oscillate!!!
7 |
8 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
9 |
10 | Using:
11 | tensorflow r1.3
12 | gym 0.8.0
13 | """
14 |
15 | import tensorflow as tf
16 | import numpy as np
17 | import gym
18 |
19 | np.random.seed(2)
20 | tf.set_random_seed(2) # reproducible
21 |
22 |
23 | class Actor(object):
24 | def __init__(self, sess, n_features, action_bound, lr=0.0001):
25 | self.sess = sess
26 |
27 | self.s = tf.placeholder(tf.float32, [1, n_features], "state")
28 | self.a = tf.placeholder(tf.float32, None, name="act")
29 | self.td_error = tf.placeholder(tf.float32, None, name="td_error") # TD_error
30 |
31 | l1 = tf.layers.dense(
32 | inputs=self.s,
33 | units=30, # number of hidden units
34 | activation=tf.nn.relu,
35 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
36 | bias_initializer=tf.constant_initializer(0.1), # biases
37 | name='l1'
38 | )
39 |
40 | mu = tf.layers.dense(
41 | inputs=l1,
42 | units=1, # number of hidden units
43 | activation=tf.nn.tanh,
44 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
45 | bias_initializer=tf.constant_initializer(0.1), # biases
46 | name='mu'
47 | )
48 |
49 | sigma = tf.layers.dense(
50 | inputs=l1,
51 | units=1, # output units
52 | activation=tf.nn.softplus, # get action probabilities
53 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
54 | bias_initializer=tf.constant_initializer(1.), # biases
55 | name='sigma'
56 | )
57 | global_step = tf.Variable(0, trainable=False)
58 | # self.e = epsilon = tf.train.exponential_decay(2., global_step, 1000, 0.9)
59 | self.mu, self.sigma = tf.squeeze(mu*2), tf.squeeze(sigma+0.1)
60 | self.normal_dist = tf.distributions.Normal(self.mu, self.sigma)
61 |
62 | self.action = tf.clip_by_value(self.normal_dist.sample(1), action_bound[0], action_bound[1])
63 |
64 | with tf.name_scope('exp_v'):
65 | log_prob = self.normal_dist.log_prob(self.a) # loss without advantage
66 | self.exp_v = log_prob * self.td_error # advantage (TD_error) guided loss
67 | # Add cross entropy cost to encourage exploration
68 | self.exp_v += 0.01*self.normal_dist.entropy()
69 |
70 | with tf.name_scope('train'):
71 | self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v, global_step) # min(v) = max(-v)
72 |
73 | def learn(self, s, a, td):
74 | s = s[np.newaxis, :]
75 | feed_dict = {self.s: s, self.a: a, self.td_error: td}
76 | _, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
77 | return exp_v
78 |
79 | def choose_action(self, s):
80 | s = s[np.newaxis, :]
81 | return self.sess.run(self.action, {self.s: s}) # get probabilities for all actions
82 |
83 |
84 | class Critic(object):
85 | def __init__(self, sess, n_features, lr=0.01):
86 | self.sess = sess
87 | with tf.name_scope('inputs'):
88 | self.s = tf.placeholder(tf.float32, [1, n_features], "state")
89 | self.v_ = tf.placeholder(tf.float32, [1, 1], name="v_next")
90 | self.r = tf.placeholder(tf.float32, name='r')
91 |
92 | with tf.variable_scope('Critic'):
93 | l1 = tf.layers.dense(
94 | inputs=self.s,
95 | units=30, # number of hidden units
96 | activation=tf.nn.relu,
97 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
98 | bias_initializer=tf.constant_initializer(0.1), # biases
99 | name='l1'
100 | )
101 |
102 | self.v = tf.layers.dense(
103 | inputs=l1,
104 | units=1, # output units
105 | activation=None,
106 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
107 | bias_initializer=tf.constant_initializer(0.1), # biases
108 | name='V'
109 | )
110 |
111 | with tf.variable_scope('squared_TD_error'):
112 | self.td_error = tf.reduce_mean(self.r + GAMMA * self.v_ - self.v)
113 | self.loss = tf.square(self.td_error) # TD_error = (r+gamma*V_next) - V_eval
114 | with tf.variable_scope('train'):
115 | self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
116 |
117 | def learn(self, s, r, s_):
118 | s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
119 |
120 | v_ = self.sess.run(self.v, {self.s: s_})
121 | td_error, _ = self.sess.run([self.td_error, self.train_op],
122 | {self.s: s, self.v_: v_, self.r: r})
123 | return td_error
124 |
125 |
126 | OUTPUT_GRAPH = False
127 | MAX_EPISODE = 1000
128 | MAX_EP_STEPS = 200
129 | DISPLAY_REWARD_THRESHOLD = -100 # renders environment if total episode reward is greater then this threshold
130 | RENDER = False # rendering wastes time
131 | GAMMA = 0.9
132 | LR_A = 0.001 # learning rate for actor
133 | LR_C = 0.01 # learning rate for critic
134 |
135 | env = gym.make('Pendulum-v0')
136 | env.seed(1) # reproducible
137 | env = env.unwrapped
138 |
139 | N_S = env.observation_space.shape[0]
140 | A_BOUND = env.action_space.high
141 |
142 | sess = tf.Session()
143 |
144 | actor = Actor(sess, n_features=N_S, lr=LR_A, action_bound=[-A_BOUND, A_BOUND])
145 | critic = Critic(sess, n_features=N_S, lr=LR_C)
146 |
147 | sess.run(tf.global_variables_initializer())
148 |
149 | if OUTPUT_GRAPH:
150 | tf.summary.FileWriter("logs/", sess.graph)
151 |
152 | for i_episode in range(MAX_EPISODE):
153 | s = env.reset()
154 | t = 0
155 | ep_rs = []
156 | while True:
157 | # if RENDER:
158 | env.render()
159 | a = actor.choose_action(s)
160 |
161 | s_, r, done, info = env.step(a)
162 | r /= 10
163 |
164 | td_error = critic.learn(s, r, s_) # gradient = grad[r + gamma * V(s_) - V(s)]
165 | actor.learn(s, a, td_error) # true_gradient = grad[logPi(s,a) * td_error]
166 |
167 | s = s_
168 | t += 1
169 | ep_rs.append(r)
170 | if t > MAX_EP_STEPS:
171 | ep_rs_sum = sum(ep_rs)
172 | if 'running_reward' not in globals():
173 | running_reward = ep_rs_sum
174 | else:
175 | running_reward = running_reward * 0.9 + ep_rs_sum * 0.1
176 | if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
177 | print("episode:", i_episode, " reward:", int(running_reward))
178 | break
179 |
180 |
--------------------------------------------------------------------------------
/contents/9_Deep_Deterministic_Policy_Gradient_DDPG/DDPG_update.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Deterministic Policy Gradient (DDPG), Reinforcement Learning.
3 | DDPG is Actor Critic based algorithm.
4 | Pendulum example.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | tensorflow 1.0
10 | gym 0.8.0
11 | """
12 |
13 | import tensorflow as tf
14 | import numpy as np
15 | import gym
16 | import time
17 |
18 |
19 | ##################### hyper parameters ####################
20 |
21 | MAX_EPISODES = 200
22 | MAX_EP_STEPS = 200
23 | LR_A = 0.001 # learning rate for actor
24 | LR_C = 0.002 # learning rate for critic
25 | GAMMA = 0.9 # reward discount
26 | TAU = 0.01 # soft replacement
27 | MEMORY_CAPACITY = 10000
28 | BATCH_SIZE = 32
29 |
30 | RENDER = False
31 | ENV_NAME = 'Pendulum-v0'
32 |
33 | ############################### DDPG ####################################
34 |
35 | class DDPG(object):
36 | def __init__(self, a_dim, s_dim, a_bound,):
37 | self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
38 | self.pointer = 0
39 | self.sess = tf.Session()
40 |
41 | self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
42 | self.S = tf.placeholder(tf.float32, [None, s_dim], 's')
43 | self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
44 | self.R = tf.placeholder(tf.float32, [None, 1], 'r')
45 |
46 | with tf.variable_scope('Actor'):
47 | self.a = self._build_a(self.S, scope='eval', trainable=True)
48 | a_ = self._build_a(self.S_, scope='target', trainable=False)
49 | with tf.variable_scope('Critic'):
50 | # assign self.a = a in memory when calculating q for td_error,
51 | # otherwise the self.a is from Actor when updating Actor
52 | q = self._build_c(self.S, self.a, scope='eval', trainable=True)
53 | q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
54 |
55 | # networks parameters
56 | self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
57 | self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
58 | self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
59 | self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
60 |
61 | # target net replacement
62 | self.soft_replace = [[tf.assign(ta, (1 - TAU) * ta + TAU * ea), tf.assign(tc, (1 - TAU) * tc + TAU * ec)]
63 | for ta, ea, tc, ec in zip(self.at_params, self.ae_params, self.ct_params, self.ce_params)]
64 |
65 | q_target = self.R + GAMMA * q_
66 | # in the feed_dic for the td_error, the self.a should change to actions in memory
67 | td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
68 | self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
69 |
70 | a_loss = - tf.reduce_mean(q) # maximize the q
71 | self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
72 |
73 | self.sess.run(tf.global_variables_initializer())
74 |
75 | def choose_action(self, s):
76 | return self.sess.run(self.a, {self.S: s[np.newaxis, :]})[0]
77 |
78 | def learn(self):
79 | # soft target replacement
80 | self.sess.run(self.soft_replace)
81 |
82 | indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
83 | bt = self.memory[indices, :]
84 | bs = bt[:, :self.s_dim]
85 | ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
86 | br = bt[:, -self.s_dim - 1: -self.s_dim]
87 | bs_ = bt[:, -self.s_dim:]
88 |
89 | self.sess.run(self.atrain, {self.S: bs})
90 | self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
91 |
92 | def store_transition(self, s, a, r, s_):
93 | transition = np.hstack((s, a, [r], s_))
94 | index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
95 | self.memory[index, :] = transition
96 | self.pointer += 1
97 |
98 | def _build_a(self, s, scope, trainable):
99 | with tf.variable_scope(scope):
100 | net = tf.layers.dense(s, 30, activation=tf.nn.relu, name='l1', trainable=trainable)
101 | a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
102 | return tf.multiply(a, self.a_bound, name='scaled_a')
103 |
104 | def _build_c(self, s, a, scope, trainable):
105 | with tf.variable_scope(scope):
106 | n_l1 = 30
107 | w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
108 | w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
109 | b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
110 | net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
111 | return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
112 |
113 | ############################### training ####################################
114 |
115 | env = gym.make(ENV_NAME)
116 | env = env.unwrapped
117 | env.seed(1)
118 |
119 | s_dim = env.observation_space.shape[0]
120 | a_dim = env.action_space.shape[0]
121 | a_bound = env.action_space.high
122 |
123 | ddpg = DDPG(a_dim, s_dim, a_bound)
124 |
125 | var = 3 # control exploration
126 | t1 = time.time()
127 | for i in range(MAX_EPISODES):
128 | s = env.reset()
129 | ep_reward = 0
130 | for j in range(MAX_EP_STEPS):
131 | if RENDER:
132 | env.render()
133 |
134 | # Add exploration noise
135 | a = ddpg.choose_action(s)
136 | a = np.clip(np.random.normal(a, var), -2, 2) # add randomness to action selection for exploration
137 | s_, r, done, info = env.step(a)
138 |
139 | ddpg.store_transition(s, a, r / 10, s_)
140 |
141 | if ddpg.pointer > MEMORY_CAPACITY:
142 | var *= .9995 # decay the action randomness
143 | ddpg.learn()
144 |
145 | s = s_
146 | ep_reward += r
147 | if j == MAX_EP_STEPS-1:
148 | print('Episode:', i, ' Reward: %i' % int(ep_reward), 'Explore: %.2f' % var, )
149 | # if ep_reward > -300:RENDER = True
150 | break
151 | print('Running time: ', time.time() - t1)
--------------------------------------------------------------------------------
/contents/9_Deep_Deterministic_Policy_Gradient_DDPG/DDPG_update2.py:
--------------------------------------------------------------------------------
1 | """
2 | Note: This is a updated version from my previous code,
3 | for the target network, I use moving average to soft replace target parameters instead using assign function.
4 | By doing this, it has 20% speed up on my machine (CPU).
5 |
6 | Deep Deterministic Policy Gradient (DDPG), Reinforcement Learning.
7 | DDPG is Actor Critic based algorithm.
8 | Pendulum example.
9 |
10 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
11 |
12 | Using:
13 | tensorflow 1.0
14 | gym 0.8.0
15 | """
16 |
17 | import tensorflow as tf
18 | import numpy as np
19 | import gym
20 | import time
21 |
22 |
23 | ##################### hyper parameters ####################
24 |
25 | MAX_EPISODES = 200
26 | MAX_EP_STEPS = 200
27 | LR_A = 0.001 # learning rate for actor
28 | LR_C = 0.002 # learning rate for critic
29 | GAMMA = 0.9 # reward discount
30 | TAU = 0.01 # soft replacement
31 | MEMORY_CAPACITY = 10000
32 | BATCH_SIZE = 32
33 |
34 | RENDER = False
35 | ENV_NAME = 'Pendulum-v0'
36 |
37 |
38 | ############################### DDPG ####################################
39 |
40 |
41 | class DDPG(object):
42 | def __init__(self, a_dim, s_dim, a_bound,):
43 | self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
44 | self.pointer = 0
45 | self.sess = tf.Session()
46 |
47 | self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
48 | self.S = tf.placeholder(tf.float32, [None, s_dim], 's')
49 | self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
50 | self.R = tf.placeholder(tf.float32, [None, 1], 'r')
51 |
52 | self.a = self._build_a(self.S,)
53 | q = self._build_c(self.S, self.a, )
54 | a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Actor')
55 | c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Critic')
56 | ema = tf.train.ExponentialMovingAverage(decay=1 - TAU) # soft replacement
57 |
58 | def ema_getter(getter, name, *args, **kwargs):
59 | return ema.average(getter(name, *args, **kwargs))
60 |
61 | target_update = [ema.apply(a_params), ema.apply(c_params)] # soft update operation
62 | a_ = self._build_a(self.S_, reuse=True, custom_getter=ema_getter) # replaced target parameters
63 | q_ = self._build_c(self.S_, a_, reuse=True, custom_getter=ema_getter)
64 |
65 | a_loss = - tf.reduce_mean(q) # maximize the q
66 | self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=a_params)
67 |
68 | with tf.control_dependencies(target_update): # soft replacement happened at here
69 | q_target = self.R + GAMMA * q_
70 | td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
71 | self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=c_params)
72 |
73 | self.sess.run(tf.global_variables_initializer())
74 |
75 | def choose_action(self, s):
76 | return self.sess.run(self.a, {self.S: s[np.newaxis, :]})[0]
77 |
78 | def learn(self):
79 | indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
80 | bt = self.memory[indices, :]
81 | bs = bt[:, :self.s_dim]
82 | ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
83 | br = bt[:, -self.s_dim - 1: -self.s_dim]
84 | bs_ = bt[:, -self.s_dim:]
85 |
86 | self.sess.run(self.atrain, {self.S: bs})
87 | self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
88 |
89 | def store_transition(self, s, a, r, s_):
90 | transition = np.hstack((s, a, [r], s_))
91 | index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
92 | self.memory[index, :] = transition
93 | self.pointer += 1
94 |
95 | def _build_a(self, s, reuse=None, custom_getter=None):
96 | trainable = True if reuse is None else False
97 | with tf.variable_scope('Actor', reuse=reuse, custom_getter=custom_getter):
98 | net = tf.layers.dense(s, 30, activation=tf.nn.relu, name='l1', trainable=trainable)
99 | a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
100 | return tf.multiply(a, self.a_bound, name='scaled_a')
101 |
102 | def _build_c(self, s, a, reuse=None, custom_getter=None):
103 | trainable = True if reuse is None else False
104 | with tf.variable_scope('Critic', reuse=reuse, custom_getter=custom_getter):
105 | n_l1 = 30
106 | w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
107 | w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
108 | b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
109 | net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
110 | return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
111 |
112 |
113 | ############################### training ####################################
114 |
115 | env = gym.make(ENV_NAME)
116 | env = env.unwrapped
117 | env.seed(1)
118 |
119 | s_dim = env.observation_space.shape[0]
120 | a_dim = env.action_space.shape[0]
121 | a_bound = env.action_space.high
122 |
123 | ddpg = DDPG(a_dim, s_dim, a_bound)
124 |
125 | var = 3 # control exploration
126 | t1 = time.time()
127 | for i in range(MAX_EPISODES):
128 | s = env.reset()
129 | ep_reward = 0
130 | for j in range(MAX_EP_STEPS):
131 | if RENDER:
132 | env.render()
133 |
134 | # Add exploration noise
135 | a = ddpg.choose_action(s)
136 | a = np.clip(np.random.normal(a, var), -2, 2) # add randomness to action selection for exploration
137 | s_, r, done, info = env.step(a)
138 |
139 | ddpg.store_transition(s, a, r / 10, s_)
140 |
141 | if ddpg.pointer > MEMORY_CAPACITY:
142 | var *= .9995 # decay the action randomness
143 | ddpg.learn()
144 |
145 | s = s_
146 | ep_reward += r
147 | if j == MAX_EP_STEPS-1:
148 | print('Episode:', i, ' Reward: %i' % int(ep_reward), 'Explore: %.2f' % var, )
149 | # if ep_reward > -300:RENDER = True
150 | break
151 |
152 | print('Running time: ', time.time() - t1)
--------------------------------------------------------------------------------
/experiments/2D_car/car_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Environment for 2D car driving.
3 | You can customize this script in a way you want.
4 |
5 | View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
6 |
7 |
8 | Requirement:
9 | pyglet >= 1.2.4
10 | numpy >= 1.12.1
11 | """
12 | import numpy as np
13 | import pyglet
14 |
15 |
16 | pyglet.clock.set_fps_limit(10000)
17 |
18 |
19 | class CarEnv(object):
20 | n_sensor = 5
21 | action_dim = 1
22 | state_dim = n_sensor
23 | viewer = None
24 | viewer_xy = (500, 500)
25 | sensor_max = 150.
26 | start_point = [450, 300]
27 | speed = 50.
28 | dt = 0.1
29 |
30 | def __init__(self, discrete_action=False):
31 | self.is_discrete_action = discrete_action
32 | if discrete_action:
33 | self.actions = [-1, 0, 1]
34 | else:
35 | self.action_bound = [-1, 1]
36 |
37 | self.terminal = False
38 | # node1 (x, y, r, w, l),
39 | self.car_info = np.array([0, 0, 0, 20, 40], dtype=np.float64) # car coordination
40 | self.obstacle_coords = np.array([
41 | [120, 120],
42 | [380, 120],
43 | [380, 380],
44 | [120, 380],
45 | ])
46 | self.sensor_info = self.sensor_max + np.zeros((self.n_sensor, 3)) # n sensors, (distance, end_x, end_y)
47 |
48 | def step(self, action):
49 | if self.is_discrete_action:
50 | action = self.actions[action]
51 | else:
52 | action = np.clip(action, *self.action_bound)[0]
53 | self.car_info[2] += action * np.pi/30 # max r = 6 degree
54 | self.car_info[:2] = self.car_info[:2] + \
55 | self.speed * self.dt * np.array([np.cos(self.car_info[2]), np.sin(self.car_info[2])])
56 |
57 | self._update_sensor()
58 | s = self._get_state()
59 | r = -1 if self.terminal else 0
60 | return s, r, self.terminal
61 |
62 | def reset(self):
63 | self.terminal = False
64 | self.car_info[:3] = np.array([*self.start_point, -np.pi/2])
65 | self._update_sensor()
66 | return self._get_state()
67 |
68 | def render(self):
69 | if self.viewer is None:
70 | self.viewer = Viewer(*self.viewer_xy, self.car_info, self.sensor_info, self.obstacle_coords)
71 | self.viewer.render()
72 |
73 | def sample_action(self):
74 | if self.is_discrete_action:
75 | a = np.random.choice(list(range(3)))
76 | else:
77 | a = np.random.uniform(*self.action_bound, size=self.action_dim)
78 | return a
79 |
80 | def set_fps(self, fps=30):
81 | pyglet.clock.set_fps_limit(fps)
82 |
83 | def _get_state(self):
84 | s = self.sensor_info[:, 0].flatten()/self.sensor_max
85 | return s
86 |
87 | def _update_sensor(self):
88 | cx, cy, rotation = self.car_info[:3]
89 |
90 | n_sensors = len(self.sensor_info)
91 | sensor_theta = np.linspace(-np.pi / 2, np.pi / 2, n_sensors)
92 | xs = cx + (np.zeros((n_sensors, ))+self.sensor_max) * np.cos(sensor_theta)
93 | ys = cy + (np.zeros((n_sensors, ))+self.sensor_max) * np.sin(sensor_theta)
94 | xys = np.array([[x, y] for x, y in zip(xs, ys)]) # shape (5 sensors, 2)
95 |
96 | # sensors
97 | tmp_x = xys[:, 0] - cx
98 | tmp_y = xys[:, 1] - cy
99 | # apply rotation
100 | rotated_x = tmp_x * np.cos(rotation) - tmp_y * np.sin(rotation)
101 | rotated_y = tmp_x * np.sin(rotation) + tmp_y * np.cos(rotation)
102 | # rotated x y
103 | self.sensor_info[:, -2:] = np.vstack([rotated_x+cx, rotated_y+cy]).T
104 |
105 | q = np.array([cx, cy])
106 | for si in range(len(self.sensor_info)):
107 | s = self.sensor_info[si, -2:] - q
108 | possible_sensor_distance = [self.sensor_max]
109 | possible_intersections = [self.sensor_info[si, -2:]]
110 |
111 | # obstacle collision
112 | for oi in range(len(self.obstacle_coords)):
113 | p = self.obstacle_coords[oi]
114 | r = self.obstacle_coords[(oi + 1) % len(self.obstacle_coords)] - self.obstacle_coords[oi]
115 | if np.cross(r, s) != 0: # may collision
116 | t = np.cross((q - p), s) / np.cross(r, s)
117 | u = np.cross((q - p), r) / np.cross(r, s)
118 | if 0 <= t <= 1 and 0 <= u <= 1:
119 | intersection = q + u * s
120 | possible_intersections.append(intersection)
121 | possible_sensor_distance.append(np.linalg.norm(u*s))
122 |
123 | # window collision
124 | win_coord = np.array([
125 | [0, 0],
126 | [self.viewer_xy[0], 0],
127 | [*self.viewer_xy],
128 | [0, self.viewer_xy[1]],
129 | [0, 0],
130 | ])
131 | for oi in range(4):
132 | p = win_coord[oi]
133 | r = win_coord[(oi + 1) % len(win_coord)] - win_coord[oi]
134 | if np.cross(r, s) != 0: # may collision
135 | t = np.cross((q - p), s) / np.cross(r, s)
136 | u = np.cross((q - p), r) / np.cross(r, s)
137 | if 0 <= t <= 1 and 0 <= u <= 1:
138 | intersection = p + t * r
139 | possible_intersections.append(intersection)
140 | possible_sensor_distance.append(np.linalg.norm(intersection - q))
141 |
142 | distance = np.min(possible_sensor_distance)
143 | distance_index = np.argmin(possible_sensor_distance)
144 | self.sensor_info[si, 0] = distance
145 | self.sensor_info[si, -2:] = possible_intersections[distance_index]
146 | if distance < self.car_info[-1]/2:
147 | self.terminal = True
148 |
149 |
150 | class Viewer(pyglet.window.Window):
151 | color = {
152 | 'background': [1]*3 + [1]
153 | }
154 | fps_display = pyglet.clock.ClockDisplay()
155 | bar_thc = 5
156 |
157 | def __init__(self, width, height, car_info, sensor_info, obstacle_coords):
158 | super(Viewer, self).__init__(width, height, resizable=False, caption='2D car', vsync=False) # vsync=False to not use the monitor FPS
159 | self.set_location(x=80, y=10)
160 | pyglet.gl.glClearColor(*self.color['background'])
161 |
162 | self.car_info = car_info
163 | self.sensor_info = sensor_info
164 |
165 | self.batch = pyglet.graphics.Batch()
166 | background = pyglet.graphics.OrderedGroup(0)
167 | foreground = pyglet.graphics.OrderedGroup(1)
168 |
169 | self.sensors = []
170 | line_coord = [0, 0] * 2
171 | c = (73, 73, 73) * 2
172 | for i in range(len(self.sensor_info)):
173 | self.sensors.append(self.batch.add(2, pyglet.gl.GL_LINES, foreground, ('v2f', line_coord), ('c3B', c)))
174 |
175 | car_box = [0, 0] * 4
176 | c = (249, 86, 86) * 4
177 | self.car = self.batch.add(4, pyglet.gl.GL_QUADS, foreground, ('v2f', car_box), ('c3B', c))
178 |
179 | c = (134, 181, 244) * 4
180 | self.obstacle = self.batch.add(4, pyglet.gl.GL_QUADS, background, ('v2f', obstacle_coords.flatten()), ('c3B', c))
181 |
182 | def render(self):
183 | pyglet.clock.tick()
184 | self._update()
185 | self.switch_to()
186 | self.dispatch_events()
187 | self.dispatch_event('on_draw')
188 | self.flip()
189 |
190 | def on_draw(self):
191 | self.clear()
192 | self.batch.draw()
193 | # self.fps_display.draw()
194 |
195 | def _update(self):
196 | cx, cy, r, w, l = self.car_info
197 |
198 | # sensors
199 | for i, sensor in enumerate(self.sensors):
200 | sensor.vertices = [cx, cy, *self.sensor_info[i, -2:]]
201 |
202 | # car
203 | xys = [
204 | [cx + l / 2, cy + w / 2],
205 | [cx - l / 2, cy + w / 2],
206 | [cx - l / 2, cy - w / 2],
207 | [cx + l / 2, cy - w / 2],
208 | ]
209 | r_xys = []
210 | for x, y in xys:
211 | tempX = x - cx
212 | tempY = y - cy
213 | # apply rotation
214 | rotatedX = tempX * np.cos(r) - tempY * np.sin(r)
215 | rotatedY = tempX * np.sin(r) + tempY * np.cos(r)
216 | # rotated x y
217 | x = rotatedX + cx
218 | y = rotatedY + cy
219 | r_xys += [x, y]
220 | self.car.vertices = r_xys
221 |
222 |
223 | if __name__ == '__main__':
224 | np.random.seed(1)
225 | env = CarEnv()
226 | env.set_fps(30)
227 | for ep in range(20):
228 | s = env.reset()
229 | # for t in range(100):
230 | while True:
231 | env.render()
232 | s, r, done = env.step(env.sample_action())
233 | if done:
234 | break
--------------------------------------------------------------------------------
/experiments/2D_car/collision.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | def intersection():
4 | p = np.array([0, 0])
5 | r = np.array([1, 1])
6 | q = np.array([0.1, 0.1])
7 | s = np.array([.1, .1])
8 |
9 | if np.cross(r, s) == 0 and np.cross((q-p), r) == 0: # collinear
10 | # t0 = (q − p) · r / (r · r)
11 | # t1 = (q + s − p) · r / (r · r) = t0 + s · r / (r · r)
12 | t0 = np.dot(q-p, r)/np.dot(r, r)
13 | t1 = t0 + np.dot(s, r)/np.dot(r, r)
14 | print(t1, t0)
15 | if ((np.dot(s, r) > 0) and (0 <= t1 - t0 <= 1)) or ((np.dot(s, r) <= 0) and (0 <= t0 - t1 <= 1)):
16 | print('collinear and overlapping, q_s in p_r')
17 | else:
18 | print('collinear and disjoint')
19 | elif np.cross(r, s) == 0 and np.cross((q-p), r) != 0: # parallel r × s = 0 and (q − p) × r ≠ 0,
20 | print('parallel')
21 | else:
22 | t = np.cross((q - p), s) / np.cross(r, s)
23 | u = np.cross((q - p), r) / np.cross(r, s)
24 | if 0 <= t <= 1 and 0 <= u <= 1:
25 | # If r × s ≠ 0 and 0 ≤ t ≤ 1 and 0 ≤ u ≤ 1, the two line segments meet at the point p + t r = q + u s
26 | print('intersection: ', p + t*r)
27 | else:
28 | print('not parallel and not intersect')
29 |
30 |
31 | def point2segment():
32 | p = np.array([-1, 1]) # coordination of point
33 | a = np.array([0, 1]) # coordination of line segment end 1
34 | b = np.array([1, 0]) # coordination of line segment end 2
35 | ab = b-a # line ab
36 | ap = p-a
37 | distance = np.abs(np.cross(ab, ap)/np.linalg.norm(ab)) # d = (AB x AC)/|AB|
38 | print(distance)
39 |
40 | # angle Cos(θ) = A dot B /(|A||B|)
41 | bp = p-b
42 | cosTheta1 = np.dot(ap, ab) / (np.linalg.norm(ap) * np.linalg.norm(ab))
43 | theta1 = np.arccos(cosTheta1)
44 | cosTheta2 = np.dot(bp, ab) / (np.linalg.norm(bp) * np.linalg.norm(ab))
45 | theta2 = np.arccos(cosTheta2)
46 | if np.pi/2 <= (theta1 % (np.pi*2)) <= 3/2 * np.pi:
47 | print('out of a')
48 | elif -np.pi/2 <= (theta2 % (np.pi*2)) <= np.pi/2:
49 | print('out of b')
50 | else:
51 | print('between a and b')
52 |
53 |
54 |
55 | if __name__ == '__main__':
56 | point2segment()
57 | # intersection()
58 |
--------------------------------------------------------------------------------
/experiments/Robot_arm/A3C.py:
--------------------------------------------------------------------------------
1 | """
2 | Environment is a Robot Arm. The arm tries to get to the blue point.
3 | The environment will return a geographic (distance) information for the arm to learn.
4 |
5 | The far away from blue point the less reward; touch blue r+=1; stop at blue for a while then get r=+10.
6 |
7 | You can train this RL by using LOAD = False, after training, this model will be store in the a local folder.
8 | Using LOAD = True to reload the trained model for playing.
9 |
10 | You can customize this script in a way you want.
11 |
12 | View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
13 |
14 |
15 | Requirement:
16 | pyglet >= 1.2.4
17 | numpy >= 1.12.1
18 | tensorflow >= 1.0.1
19 | """
20 |
21 | import multiprocessing
22 | import threading
23 | import tensorflow as tf
24 | import numpy as np
25 | from arm_env import ArmEnv
26 |
27 |
28 | # np.random.seed(1)
29 | # tf.set_random_seed(1)
30 |
31 | MAX_GLOBAL_EP = 2000
32 | MAX_EP_STEP = 300
33 | UPDATE_GLOBAL_ITER = 5
34 | N_WORKERS = multiprocessing.cpu_count()
35 | LR_A = 1e-4 # learning rate for actor
36 | LR_C = 2e-4 # learning rate for critic
37 | GAMMA = 0.9 # reward discount
38 | MODE = ['easy', 'hard']
39 | n_model = 1
40 | GLOBAL_NET_SCOPE = 'Global_Net'
41 | ENTROPY_BETA = 0.01
42 | GLOBAL_RUNNING_R = []
43 | GLOBAL_EP = 0
44 |
45 |
46 | env = ArmEnv(mode=MODE[n_model])
47 | N_S = env.state_dim
48 | N_A = env.action_dim
49 | A_BOUND = env.action_bound
50 | del env
51 |
52 |
53 | class ACNet(object):
54 | def __init__(self, scope, globalAC=None):
55 |
56 | if scope == GLOBAL_NET_SCOPE: # get global network
57 | with tf.variable_scope(scope):
58 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
59 | self._build_net()
60 | self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
61 | self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
62 | else: # local net, calculate losses
63 | with tf.variable_scope(scope):
64 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
65 | self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
66 | self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
67 |
68 | mu, sigma, self.v = self._build_net()
69 |
70 | td = tf.subtract(self.v_target, self.v, name='TD_error')
71 | with tf.name_scope('c_loss'):
72 | self.c_loss = tf.reduce_mean(tf.square(td))
73 |
74 | with tf.name_scope('wrap_a_out'):
75 | self.test = sigma[0]
76 | mu, sigma = mu * A_BOUND[1], sigma + 1e-5
77 |
78 | normal_dist = tf.contrib.distributions.Normal(mu, sigma)
79 |
80 | with tf.name_scope('a_loss'):
81 | log_prob = normal_dist.log_prob(self.a_his)
82 | exp_v = log_prob * td
83 | entropy = normal_dist.entropy() # encourage exploration
84 | self.exp_v = ENTROPY_BETA * entropy + exp_v
85 | self.a_loss = tf.reduce_mean(-self.exp_v)
86 |
87 | with tf.name_scope('choose_a'): # use local params to choose action
88 | self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=0), *A_BOUND)
89 | with tf.name_scope('local_grad'):
90 | self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
91 | self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
92 | self.a_grads = tf.gradients(self.a_loss, self.a_params)
93 | self.c_grads = tf.gradients(self.c_loss, self.c_params)
94 |
95 | with tf.name_scope('sync'):
96 | with tf.name_scope('pull'):
97 | self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
98 | self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
99 | with tf.name_scope('push'):
100 | self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
101 | self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
102 |
103 | def _build_net(self):
104 | w_init = tf.contrib.layers.xavier_initializer()
105 | with tf.variable_scope('actor'):
106 | l_a = tf.layers.dense(self.s, 400, tf.nn.relu6, kernel_initializer=w_init, name='la')
107 | l_a = tf.layers.dense(l_a, 300, tf.nn.relu6, kernel_initializer=w_init, name='la2')
108 | mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
109 | sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
110 | with tf.variable_scope('critic'):
111 | l_c = tf.layers.dense(self.s, 400, tf.nn.relu6, kernel_initializer=w_init, name='lc')
112 | l_c = tf.layers.dense(l_c, 200, tf.nn.relu6, kernel_initializer=w_init, name='lc2')
113 | v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
114 | return mu, sigma, v
115 |
116 | def update_global(self, feed_dict): # run by a local
117 | _, _, t = SESS.run([self.update_a_op, self.update_c_op, self.test], feed_dict) # local grads applies to global net
118 | return t
119 |
120 | def pull_global(self): # run by a local
121 | SESS.run([self.pull_a_params_op, self.pull_c_params_op])
122 |
123 | def choose_action(self, s): # run by a local
124 | s = s[np.newaxis, :]
125 | return SESS.run(self.A, {self.s: s})[0]
126 |
127 |
128 | class Worker(object):
129 | def __init__(self, name, globalAC):
130 | self.env = ArmEnv(mode=MODE[n_model])
131 | self.name = name
132 | self.AC = ACNet(name, globalAC)
133 |
134 | def work(self):
135 | global GLOBAL_RUNNING_R, GLOBAL_EP
136 | total_step = 1
137 | buffer_s, buffer_a, buffer_r = [], [], []
138 | while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
139 | s = self.env.reset()
140 | ep_r = 0
141 | for ep_t in range(MAX_EP_STEP):
142 | if self.name == 'W_0':
143 | self.env.render()
144 | a = self.AC.choose_action(s)
145 | s_, r, done = self.env.step(a)
146 | if ep_t == MAX_EP_STEP - 1: done = True
147 | ep_r += r
148 | buffer_s.append(s)
149 | buffer_a.append(a)
150 | buffer_r.append(r)
151 |
152 | if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
153 | if done:
154 | v_s_ = 0 # terminal
155 | else:
156 | v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
157 | buffer_v_target = []
158 | for r in buffer_r[::-1]: # reverse buffer r
159 | v_s_ = r + GAMMA * v_s_
160 | buffer_v_target.append(v_s_)
161 | buffer_v_target.reverse()
162 |
163 | buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
164 | feed_dict = {
165 | self.AC.s: buffer_s,
166 | self.AC.a_his: buffer_a,
167 | self.AC.v_target: buffer_v_target,
168 | }
169 | test = self.AC.update_global(feed_dict)
170 | buffer_s, buffer_a, buffer_r = [], [], []
171 | self.AC.pull_global()
172 |
173 | s = s_
174 | total_step += 1
175 | if done:
176 | if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
177 | GLOBAL_RUNNING_R.append(ep_r)
178 | else:
179 | GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r)
180 | print(
181 | self.name,
182 | "Ep:", GLOBAL_EP,
183 | "| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
184 | '| Var:', test,
185 |
186 | )
187 | GLOBAL_EP += 1
188 | break
189 |
190 | if __name__ == "__main__":
191 | SESS = tf.Session()
192 |
193 | with tf.device("/cpu:0"):
194 | OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
195 | OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
196 | GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
197 | workers = []
198 | # Create worker
199 | for i in range(N_WORKERS):
200 | i_name = 'W_%i' % i # worker name
201 | workers.append(Worker(i_name, GLOBAL_AC))
202 |
203 | COORD = tf.train.Coordinator()
204 | SESS.run(tf.global_variables_initializer())
205 |
206 | worker_threads = []
207 | for worker in workers:
208 | job = lambda: worker.work()
209 | t = threading.Thread(target=job)
210 | t.start()
211 | worker_threads.append(t)
212 | COORD.join(worker_threads)
213 |
214 |
215 |
--------------------------------------------------------------------------------
/experiments/Robot_arm/DPPO.py:
--------------------------------------------------------------------------------
1 | """
2 | A simple version of OpenAI's Proximal Policy Optimization (PPO). [http://adsabs.harvard.edu/abs/2017arXiv170706347S]
3 |
4 | Distributing workers in parallel to collect data, then stop worker's roll-out and train PPO on collected data.
5 | Restart workers once PPO is updated.
6 |
7 | The global PPO updating rule is adopted from DeepMind's paper (DPPO):
8 | Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [http://adsabs.harvard.edu/abs/2017arXiv170702286H]
9 |
10 | View more on my tutorial website: https://morvanzhou.github.io/tutorials
11 |
12 | Dependencies:
13 | tensorflow r1.2
14 | gym 0.9.2
15 | """
16 |
17 | import tensorflow as tf
18 | from tensorflow.contrib.distributions import Normal
19 | import numpy as np
20 | import matplotlib.pyplot as plt
21 | import threading, queue
22 | from arm_env import ArmEnv
23 |
24 |
25 | EP_MAX = 2000
26 | EP_LEN = 300
27 | N_WORKER = 4 # parallel workers
28 | GAMMA = 0.9 # reward discount factor
29 | A_LR = 0.0001 # learning rate for actor
30 | C_LR = 0.0005 # learning rate for critic
31 | MIN_BATCH_SIZE = 64 # minimum batch size for updating PPO
32 | UPDATE_STEP = 5 # loop update operation n-steps
33 | EPSILON = 0.2 # Clipped surrogate objective
34 | MODE = ['easy', 'hard']
35 | n_model = 1
36 |
37 | env = ArmEnv(mode=MODE[n_model])
38 | S_DIM = env.state_dim
39 | A_DIM = env.action_dim
40 | A_BOUND = env.action_bound[1]
41 |
42 |
43 | class PPO(object):
44 | def __init__(self):
45 | self.sess = tf.Session()
46 |
47 | self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
48 |
49 | # critic
50 | l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
51 | self.v = tf.layers.dense(l1, 1)
52 | self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
53 | self.advantage = self.tfdc_r - self.v
54 | self.closs = tf.reduce_mean(tf.square(self.advantage))
55 | self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
56 |
57 | # actor
58 | pi, pi_params = self._build_anet('pi', trainable=True)
59 | oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
60 | self.sample_op = tf.squeeze(pi.sample(1), axis=0) # choosing action
61 | self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
62 |
63 | self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
64 | self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
65 | # ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
66 | ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
67 | surr = ratio * self.tfadv # surrogate loss
68 |
69 | self.aloss = -tf.reduce_mean(tf.minimum(
70 | surr,
71 | tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
72 |
73 | self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
74 | self.sess.run(tf.global_variables_initializer())
75 |
76 | def update(self):
77 | global GLOBAL_UPDATE_COUNTER
78 | while not COORD.should_stop():
79 | if GLOBAL_EP < EP_MAX:
80 | UPDATE_EVENT.wait() # wait until get batch of data
81 | self.sess.run(self.update_oldpi_op) # old pi to pi
82 | data = [QUEUE.get() for _ in range(QUEUE.qsize())]
83 | data = np.vstack(data)
84 | s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + A_DIM], data[:, -1:]
85 | adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
86 | [self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
87 | [self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
88 | UPDATE_EVENT.clear() # updating finished
89 | GLOBAL_UPDATE_COUNTER = 0 # reset counter
90 | ROLLING_EVENT.set() # set roll-out available
91 |
92 | def _build_anet(self, name, trainable):
93 | with tf.variable_scope(name):
94 | l1 = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
95 | mu = A_BOUND * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
96 | sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
97 | norm_dist = Normal(loc=mu, scale=sigma)
98 | params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
99 | return norm_dist, params
100 |
101 | def choose_action(self, s):
102 | s = s[np.newaxis, :]
103 | a = self.sess.run(self.sample_op, {self.tfs: s})[0]
104 | return np.clip(a, -2, 2)
105 |
106 | def get_v(self, s):
107 | if s.ndim < 2: s = s[np.newaxis, :]
108 | return self.sess.run(self.v, {self.tfs: s})[0, 0]
109 |
110 |
111 | class Worker(object):
112 | def __init__(self, wid):
113 | self.wid = wid
114 | self.env = ArmEnv(mode=MODE[n_model])
115 | self.ppo = GLOBAL_PPO
116 |
117 | def work(self):
118 | global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
119 | while not COORD.should_stop():
120 | s = self.env.reset()
121 | ep_r = 0
122 | buffer_s, buffer_a, buffer_r = [], [], []
123 | for t in range(EP_LEN):
124 | if not ROLLING_EVENT.is_set(): # while global PPO is updating
125 | ROLLING_EVENT.wait() # wait until PPO is updated
126 | buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer
127 | a = self.ppo.choose_action(s)
128 | s_, r, done = self.env.step(a)
129 | buffer_s.append(s)
130 | buffer_a.append(a)
131 | buffer_r.append(r) # normalize reward, find to be useful
132 | s = s_
133 | ep_r += r
134 |
135 | GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size
136 | if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
137 | v_s_ = self.ppo.get_v(s_)
138 | discounted_r = [] # compute discounted reward
139 | for r in buffer_r[::-1]:
140 | v_s_ = r + GAMMA * v_s_
141 | discounted_r.append(v_s_)
142 | discounted_r.reverse()
143 |
144 | bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
145 | buffer_s, buffer_a, buffer_r = [], [], []
146 | QUEUE.put(np.hstack((bs, ba, br)))
147 | if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
148 | ROLLING_EVENT.clear() # stop collecting data
149 | UPDATE_EVENT.set() # globalPPO update
150 |
151 | if GLOBAL_EP >= EP_MAX: # stop training
152 | COORD.request_stop()
153 | break
154 |
155 | # record reward changes, plot later
156 | if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
157 | else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
158 | GLOBAL_EP += 1
159 | print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
160 |
161 |
162 | if __name__ == '__main__':
163 | GLOBAL_PPO = PPO()
164 | UPDATE_EVENT, ROLLING_EVENT = threading.Event(), threading.Event()
165 | UPDATE_EVENT.clear() # no update now
166 | ROLLING_EVENT.set() # start to roll out
167 | workers = [Worker(wid=i) for i in range(N_WORKER)]
168 |
169 | GLOBAL_UPDATE_COUNTER, GLOBAL_EP = 0, 0
170 | GLOBAL_RUNNING_R = []
171 | COORD = tf.train.Coordinator()
172 | QUEUE = queue.Queue()
173 | threads = []
174 | for worker in workers: # worker threads
175 | t = threading.Thread(target=worker.work, args=())
176 | t.start()
177 | threads.append(t)
178 | # add a PPO updating thread
179 | threads.append(threading.Thread(target=GLOBAL_PPO.update,))
180 | threads[-1].start()
181 | COORD.join(threads)
182 |
183 | # plot reward change and testing
184 | plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
185 | plt.xlabel('Episode'); plt.ylabel('Moving reward'); plt.ion(); plt.show()
186 | env.set_fps(30)
187 | while True:
188 | s = env.reset()
189 | for t in range(400):
190 | env.render()
191 | s = env.step(GLOBAL_PPO.choose_action(s))[0]
--------------------------------------------------------------------------------
/experiments/Robot_arm/arm_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Environment for Robot Arm.
3 | You can customize this script in a way you want.
4 |
5 | View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
6 |
7 |
8 | Requirement:
9 | pyglet >= 1.2.4
10 | numpy >= 1.12.1
11 | """
12 | import numpy as np
13 | import pyglet
14 |
15 |
16 | pyglet.clock.set_fps_limit(10000)
17 |
18 |
19 | class ArmEnv(object):
20 | action_bound = [-1, 1]
21 | action_dim = 2
22 | state_dim = 7
23 | dt = .1 # refresh rate
24 | arm1l = 100
25 | arm2l = 100
26 | viewer = None
27 | viewer_xy = (400, 400)
28 | get_point = False
29 | mouse_in = np.array([False])
30 | point_l = 15
31 | grab_counter = 0
32 |
33 | def __init__(self, mode='easy'):
34 | # node1 (l, d_rad, x, y),
35 | # node2 (l, d_rad, x, y)
36 | self.mode = mode
37 | self.arm_info = np.zeros((2, 4))
38 | self.arm_info[0, 0] = self.arm1l
39 | self.arm_info[1, 0] = self.arm2l
40 | self.point_info = np.array([250, 303])
41 | self.point_info_init = self.point_info.copy()
42 | self.center_coord = np.array(self.viewer_xy)/2
43 |
44 | def step(self, action):
45 | # action = (node1 angular v, node2 angular v)
46 | action = np.clip(action, *self.action_bound)
47 | self.arm_info[:, 1] += action * self.dt
48 | self.arm_info[:, 1] %= np.pi * 2
49 |
50 | arm1rad = self.arm_info[0, 1]
51 | arm2rad = self.arm_info[1, 1]
52 | arm1dx_dy = np.array([self.arm_info[0, 0] * np.cos(arm1rad), self.arm_info[0, 0] * np.sin(arm1rad)])
53 | arm2dx_dy = np.array([self.arm_info[1, 0] * np.cos(arm2rad), self.arm_info[1, 0] * np.sin(arm2rad)])
54 | self.arm_info[0, 2:4] = self.center_coord + arm1dx_dy # (x1, y1)
55 | self.arm_info[1, 2:4] = self.arm_info[0, 2:4] + arm2dx_dy # (x2, y2)
56 |
57 | s, arm2_distance = self._get_state()
58 | r = self._r_func(arm2_distance)
59 |
60 | return s, r, self.get_point
61 |
62 | def reset(self):
63 | self.get_point = False
64 | self.grab_counter = 0
65 |
66 | if self.mode == 'hard':
67 | pxy = np.clip(np.random.rand(2) * self.viewer_xy[0], 100, 300)
68 | self.point_info[:] = pxy
69 | else:
70 | arm1rad, arm2rad = np.random.rand(2) * np.pi * 2
71 | self.arm_info[0, 1] = arm1rad
72 | self.arm_info[1, 1] = arm2rad
73 | arm1dx_dy = np.array([self.arm_info[0, 0] * np.cos(arm1rad), self.arm_info[0, 0] * np.sin(arm1rad)])
74 | arm2dx_dy = np.array([self.arm_info[1, 0] * np.cos(arm2rad), self.arm_info[1, 0] * np.sin(arm2rad)])
75 | self.arm_info[0, 2:4] = self.center_coord + arm1dx_dy # (x1, y1)
76 | self.arm_info[1, 2:4] = self.arm_info[0, 2:4] + arm2dx_dy # (x2, y2)
77 |
78 | self.point_info[:] = self.point_info_init
79 | return self._get_state()[0]
80 |
81 | def render(self):
82 | if self.viewer is None:
83 | self.viewer = Viewer(*self.viewer_xy, self.arm_info, self.point_info, self.point_l, self.mouse_in)
84 | self.viewer.render()
85 |
86 | def sample_action(self):
87 | return np.random.uniform(*self.action_bound, size=self.action_dim)
88 |
89 | def set_fps(self, fps=30):
90 | pyglet.clock.set_fps_limit(fps)
91 |
92 | def _get_state(self):
93 | # return the distance (dx, dy) between arm finger point with blue point
94 | arm_end = self.arm_info[:, 2:4]
95 | t_arms = np.ravel(arm_end - self.point_info)
96 | center_dis = (self.center_coord - self.point_info)/200
97 | in_point = 1 if self.grab_counter > 0 else 0
98 | return np.hstack([in_point, t_arms/200, center_dis,
99 | # arm1_distance_p, arm1_distance_b,
100 | ]), t_arms[-2:]
101 |
102 | def _r_func(self, distance):
103 | t = 50
104 | abs_distance = np.sqrt(np.sum(np.square(distance)))
105 | r = -abs_distance/200
106 | if abs_distance < self.point_l and (not self.get_point):
107 | r += 1.
108 | self.grab_counter += 1
109 | if self.grab_counter > t:
110 | r += 10.
111 | self.get_point = True
112 | elif abs_distance > self.point_l:
113 | self.grab_counter = 0
114 | self.get_point = False
115 | return r
116 |
117 |
118 | class Viewer(pyglet.window.Window):
119 | color = {
120 | 'background': [1]*3 + [1]
121 | }
122 | fps_display = pyglet.clock.ClockDisplay()
123 | bar_thc = 5
124 |
125 | def __init__(self, width, height, arm_info, point_info, point_l, mouse_in):
126 | super(Viewer, self).__init__(width, height, resizable=False, caption='Arm', vsync=False) # vsync=False to not use the monitor FPS
127 | self.set_location(x=80, y=10)
128 | pyglet.gl.glClearColor(*self.color['background'])
129 |
130 | self.arm_info = arm_info
131 | self.point_info = point_info
132 | self.mouse_in = mouse_in
133 | self.point_l = point_l
134 |
135 | self.center_coord = np.array((min(width, height)/2, ) * 2)
136 | self.batch = pyglet.graphics.Batch()
137 |
138 | arm1_box, arm2_box, point_box = [0]*8, [0]*8, [0]*8
139 | c1, c2, c3 = (249, 86, 86)*4, (86, 109, 249)*4, (249, 39, 65)*4
140 | self.point = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', point_box), ('c3B', c2))
141 | self.arm1 = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', arm1_box), ('c3B', c1))
142 | self.arm2 = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', arm2_box), ('c3B', c1))
143 |
144 | def render(self):
145 | pyglet.clock.tick()
146 | self._update_arm()
147 | self.switch_to()
148 | self.dispatch_events()
149 | self.dispatch_event('on_draw')
150 | self.flip()
151 |
152 | def on_draw(self):
153 | self.clear()
154 | self.batch.draw()
155 | # self.fps_display.draw()
156 |
157 | def _update_arm(self):
158 | point_l = self.point_l
159 | point_box = (self.point_info[0] - point_l, self.point_info[1] - point_l,
160 | self.point_info[0] + point_l, self.point_info[1] - point_l,
161 | self.point_info[0] + point_l, self.point_info[1] + point_l,
162 | self.point_info[0] - point_l, self.point_info[1] + point_l)
163 | self.point.vertices = point_box
164 |
165 | arm1_coord = (*self.center_coord, *(self.arm_info[0, 2:4])) # (x0, y0, x1, y1)
166 | arm2_coord = (*(self.arm_info[0, 2:4]), *(self.arm_info[1, 2:4])) # (x1, y1, x2, y2)
167 | arm1_thick_rad = np.pi / 2 - self.arm_info[0, 1]
168 | x01, y01 = arm1_coord[0] - np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[1] + np.sin(
169 | arm1_thick_rad) * self.bar_thc
170 | x02, y02 = arm1_coord[0] + np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[1] - np.sin(
171 | arm1_thick_rad) * self.bar_thc
172 | x11, y11 = arm1_coord[2] + np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[3] - np.sin(
173 | arm1_thick_rad) * self.bar_thc
174 | x12, y12 = arm1_coord[2] - np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[3] + np.sin(
175 | arm1_thick_rad) * self.bar_thc
176 | arm1_box = (x01, y01, x02, y02, x11, y11, x12, y12)
177 | arm2_thick_rad = np.pi / 2 - self.arm_info[1, 1]
178 | x11_, y11_ = arm2_coord[0] + np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[1] - np.sin(
179 | arm2_thick_rad) * self.bar_thc
180 | x12_, y12_ = arm2_coord[0] - np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[1] + np.sin(
181 | arm2_thick_rad) * self.bar_thc
182 | x21, y21 = arm2_coord[2] - np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[3] + np.sin(
183 | arm2_thick_rad) * self.bar_thc
184 | x22, y22 = arm2_coord[2] + np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[3] - np.sin(
185 | arm2_thick_rad) * self.bar_thc
186 | arm2_box = (x11_, y11_, x12_, y12_, x21, y21, x22, y22)
187 | self.arm1.vertices = arm1_box
188 | self.arm2.vertices = arm2_box
189 |
190 | def on_key_press(self, symbol, modifiers):
191 | if symbol == pyglet.window.key.UP:
192 | self.arm_info[0, 1] += .1
193 | print(self.arm_info[:, 2:4] - self.point_info)
194 | elif symbol == pyglet.window.key.DOWN:
195 | self.arm_info[0, 1] -= .1
196 | print(self.arm_info[:, 2:4] - self.point_info)
197 | elif symbol == pyglet.window.key.LEFT:
198 | self.arm_info[1, 1] += .1
199 | print(self.arm_info[:, 2:4] - self.point_info)
200 | elif symbol == pyglet.window.key.RIGHT:
201 | self.arm_info[1, 1] -= .1
202 | print(self.arm_info[:, 2:4] - self.point_info)
203 | elif symbol == pyglet.window.key.Q:
204 | pyglet.clock.set_fps_limit(1000)
205 | elif symbol == pyglet.window.key.A:
206 | pyglet.clock.set_fps_limit(30)
207 |
208 | def on_mouse_motion(self, x, y, dx, dy):
209 | self.point_info[:] = [x, y]
210 |
211 | def on_mouse_enter(self, x, y):
212 | self.mouse_in[0] = True
213 |
214 | def on_mouse_leave(self, x, y):
215 | self.mouse_in[0] = False
216 |
217 |
218 |
219 |
--------------------------------------------------------------------------------
/experiments/Solve_BipedalWalker/A3C.py:
--------------------------------------------------------------------------------
1 | """
2 | Asynchronous Advantage Actor Critic (A3C), Reinforcement Learning.
3 |
4 | The BipedalWalker example.
5 |
6 | View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | tensorflow 1.0
10 | gym 0.8.0
11 | """
12 |
13 | import multiprocessing
14 | import threading
15 | import tensorflow as tf
16 | import numpy as np
17 | import gym
18 | import os
19 | import shutil
20 |
21 |
22 | GAME = 'BipedalWalker-v2'
23 | OUTPUT_GRAPH = False
24 | LOG_DIR = './log'
25 | N_WORKERS = multiprocessing.cpu_count()
26 | MAX_GLOBAL_EP = 8000
27 | GLOBAL_NET_SCOPE = 'Global_Net'
28 | UPDATE_GLOBAL_ITER = 10
29 | GAMMA = 0.999
30 | ENTROPY_BETA = 0.005
31 | LR_A = 0.00002 # learning rate for actor
32 | LR_C = 0.0001 # learning rate for critic
33 | GLOBAL_RUNNING_R = []
34 | GLOBAL_EP = 0
35 |
36 | env = gym.make(GAME)
37 |
38 | N_S = env.observation_space.shape[0]
39 | N_A = env.action_space.shape[0]
40 | A_BOUND = [env.action_space.low, env.action_space.high]
41 | del env
42 |
43 |
44 | class ACNet(object):
45 | def __init__(self, scope, globalAC=None):
46 |
47 | if scope == GLOBAL_NET_SCOPE: # get global network
48 | with tf.variable_scope(scope):
49 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
50 | self._build_net()
51 | self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
52 | self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
53 | else: # local net, calculate losses
54 | with tf.variable_scope(scope):
55 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
56 | self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
57 | self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
58 |
59 | mu, sigma, self.v = self._build_net()
60 |
61 | td = tf.subtract(self.v_target, self.v, name='TD_error')
62 | with tf.name_scope('c_loss'):
63 | self.c_loss = tf.reduce_mean(tf.square(td))
64 |
65 | with tf.name_scope('wrap_a_out'):
66 | self.test = sigma[0]
67 | mu, sigma = mu * A_BOUND[1], sigma + 1e-5
68 |
69 | normal_dist = tf.contrib.distributions.Normal(mu, sigma)
70 |
71 | with tf.name_scope('a_loss'):
72 | log_prob = normal_dist.log_prob(self.a_his)
73 | exp_v = log_prob * td
74 | entropy = normal_dist.entropy() # encourage exploration
75 | self.exp_v = ENTROPY_BETA * entropy + exp_v
76 | self.a_loss = tf.reduce_mean(-self.exp_v)
77 |
78 | with tf.name_scope('choose_a'): # use local params to choose action
79 | self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=0), *A_BOUND)
80 | with tf.name_scope('local_grad'):
81 | self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
82 | self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
83 | self.a_grads = tf.gradients(self.a_loss, self.a_params)
84 | self.c_grads = tf.gradients(self.c_loss, self.c_params)
85 |
86 | with tf.name_scope('sync'):
87 | with tf.name_scope('pull'):
88 | self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
89 | self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
90 | with tf.name_scope('push'):
91 | self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
92 | self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
93 |
94 | def _build_net(self):
95 | w_init = tf.contrib.layers.xavier_initializer()
96 | with tf.variable_scope('actor'):
97 | l_a = tf.layers.dense(self.s, 500, tf.nn.relu6, kernel_initializer=w_init, name='la')
98 | l_a = tf.layers.dense(l_a, 300, tf.nn.relu6, kernel_initializer=w_init, name='la2')
99 | mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
100 | sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
101 | with tf.variable_scope('critic'):
102 | l_c = tf.layers.dense(self.s, 500, tf.nn.relu6, kernel_initializer=w_init, name='lc')
103 | l_c = tf.layers.dense(l_c, 200, tf.nn.relu6, kernel_initializer=w_init, name='lc2')
104 | v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
105 | return mu, sigma, v
106 |
107 | def update_global(self, feed_dict): # run by a local
108 | _, _, t = SESS.run([self.update_a_op, self.update_c_op, self.test], feed_dict) # local grads applies to global net
109 | return t
110 |
111 | def pull_global(self): # run by a local
112 | SESS.run([self.pull_a_params_op, self.pull_c_params_op])
113 |
114 | def choose_action(self, s): # run by a local
115 | s = s[np.newaxis, :]
116 | return SESS.run(self.A, {self.s: s})[0]
117 |
118 |
119 | class Worker(object):
120 | def __init__(self, name, globalAC):
121 | self.env = gym.make(GAME)
122 | self.name = name
123 | self.AC = ACNet(name, globalAC)
124 |
125 | def work(self):
126 | global GLOBAL_RUNNING_R, GLOBAL_EP
127 | total_step = 1
128 | buffer_s, buffer_a, buffer_r = [], [], []
129 | while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
130 | s = self.env.reset()
131 | ep_r = 0
132 | while True:
133 | if self.name == 'W_0' and total_step % 30 == 0:
134 | self.env.render()
135 | a = self.AC.choose_action(s)
136 | s_, r, done, info = self.env.step(a)
137 | if r == -100: r = -2
138 |
139 | ep_r += r
140 | buffer_s.append(s)
141 | buffer_a.append(a)
142 | buffer_r.append(r)
143 |
144 | if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
145 | if done:
146 | v_s_ = 0 # terminal
147 | else:
148 | v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
149 | buffer_v_target = []
150 | for r in buffer_r[::-1]: # reverse buffer r
151 | v_s_ = r + GAMMA * v_s_
152 | buffer_v_target.append(v_s_)
153 | buffer_v_target.reverse()
154 |
155 | buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
156 | feed_dict = {
157 | self.AC.s: buffer_s,
158 | self.AC.a_his: buffer_a,
159 | self.AC.v_target: buffer_v_target,
160 | }
161 | test = self.AC.update_global(feed_dict)
162 | buffer_s, buffer_a, buffer_r = [], [], []
163 | self.AC.pull_global()
164 |
165 | s = s_
166 | total_step += 1
167 | if done:
168 | achieve = '| Achieve' if self.env.unwrapped.hull.position[0] >= 88 else '| -------'
169 | if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
170 | GLOBAL_RUNNING_R.append(ep_r)
171 | else:
172 | GLOBAL_RUNNING_R.append(0.95 * GLOBAL_RUNNING_R[-1] + 0.05 * ep_r)
173 | print(
174 | self.name,
175 | "Ep:", GLOBAL_EP,
176 | achieve,
177 | "| Pos: %i" % self.env.unwrapped.hull.position[0],
178 | "| RR: %.1f" % GLOBAL_RUNNING_R[-1],
179 | '| EpR: %.1f' % ep_r,
180 | '| var:', test,
181 | )
182 | GLOBAL_EP += 1
183 | break
184 |
185 | if __name__ == "__main__":
186 | SESS = tf.Session()
187 |
188 | with tf.device("/cpu:0"):
189 | OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
190 | OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
191 | GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
192 | workers = []
193 | # Create worker
194 | for i in range(N_WORKERS):
195 | i_name = 'W_%i' % i # worker name
196 | workers.append(Worker(i_name, GLOBAL_AC))
197 |
198 | COORD = tf.train.Coordinator()
199 | SESS.run(tf.global_variables_initializer())
200 |
201 | worker_threads = []
202 | for worker in workers:
203 | job = lambda: worker.work()
204 | t = threading.Thread(target=job)
205 | t.start()
206 | worker_threads.append(t)
207 | COORD.join(worker_threads)
208 |
209 |
210 |
--------------------------------------------------------------------------------
/experiments/Solve_BipedalWalker/log/events.out.tfevents.1490801027.Morvan:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiajunhua/MorvanZhou-Reinforcement-learning-with-tensorflow/b484df7fc7dadab61e73e04aa40416bf6db68321/experiments/Solve_BipedalWalker/log/events.out.tfevents.1490801027.Morvan
--------------------------------------------------------------------------------
/experiments/Solve_LunarLander/run_LunarLander.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Q network,
3 |
4 | LunarLander-v2 example
5 |
6 | Using:
7 | Tensorflow: 1.0
8 | gym: 0.8.0
9 | """
10 |
11 |
12 | import gym
13 | from gym import wrappers
14 | from DuelingDQNPrioritizedReplay import DuelingDQNPrioritizedReplay
15 |
16 | env = gym.make('LunarLander-v2')
17 | # env = env.unwrapped
18 | env.seed(1)
19 |
20 | N_A = env.action_space.n
21 | N_S = env.observation_space.shape[0]
22 | MEMORY_CAPACITY = 50000
23 | TARGET_REP_ITER = 2000
24 | MAX_EPISODES = 900
25 | E_GREEDY = 0.95
26 | E_INCREMENT = 0.00001
27 | GAMMA = 0.99
28 | LR = 0.0001
29 | BATCH_SIZE = 32
30 | HIDDEN = [400, 400]
31 | RENDER = True
32 |
33 | RL = DuelingDQNPrioritizedReplay(
34 | n_actions=N_A, n_features=N_S, learning_rate=LR, e_greedy=E_GREEDY, reward_decay=GAMMA,
35 | hidden=HIDDEN, batch_size=BATCH_SIZE, replace_target_iter=TARGET_REP_ITER,
36 | memory_size=MEMORY_CAPACITY, e_greedy_increment=E_INCREMENT,)
37 |
38 |
39 | total_steps = 0
40 | running_r = 0
41 | r_scale = 100
42 | for i_episode in range(MAX_EPISODES):
43 | s = env.reset() # (coord_x, coord_y, vel_x, vel_y, angle, angular_vel, l_leg_on_ground, r_leg_on_ground)
44 | ep_r = 0
45 | while True:
46 | if total_steps > MEMORY_CAPACITY: env.render()
47 | a = RL.choose_action(s)
48 | s_, r, done, _ = env.step(a)
49 | if r == -100: r = -30
50 | r /= r_scale
51 |
52 | ep_r += r
53 | RL.store_transition(s, a, r, s_)
54 | if total_steps > MEMORY_CAPACITY:
55 | RL.learn()
56 | if done:
57 | land = '| Landed' if r == 100/r_scale else '| ------'
58 | running_r = 0.99 * running_r + 0.01 * ep_r
59 | print('Epi: ', i_episode,
60 | land,
61 | '| Epi_R: ', round(ep_r, 2),
62 | '| Running_R: ', round(running_r, 2),
63 | '| Epsilon: ', round(RL.epsilon, 3))
64 | break
65 |
66 | s = s_
67 | total_steps += 1
68 |
69 |
--------------------------------------------------------------------------------
83 |
84 |
85 | # Donation
86 |
87 | *If this does help you, please consider donating to support me for better tutorials. Any contribution is greatly appreciated!*
88 |
89 |
96 |
97 |
103 |
--------------------------------------------------------------------------------
/RL_cover.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiajunhua/MorvanZhou-Reinforcement-learning-with-tensorflow/b484df7fc7dadab61e73e04aa40416bf6db68321/RL_cover.jpg
--------------------------------------------------------------------------------
/contents/10_A3C/A3C_continuous_action.py:
--------------------------------------------------------------------------------
1 | """
2 | Asynchronous Advantage Actor Critic (A3C) with continuous action space, Reinforcement Learning.
3 |
4 | The Pendulum example.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | tensorflow r1.3
10 | gym 0.8.0
11 | """
12 |
13 | import multiprocessing
14 | import threading
15 | import tensorflow as tf
16 | import numpy as np
17 | import gym
18 | import os
19 | import shutil
20 | import matplotlib.pyplot as plt
21 |
22 | GAME = 'Pendulum-v0'
23 | OUTPUT_GRAPH = True
24 | LOG_DIR = './log'
25 | N_WORKERS = multiprocessing.cpu_count()
26 | MAX_EP_STEP = 200
27 | MAX_GLOBAL_EP = 2000
28 | GLOBAL_NET_SCOPE = 'Global_Net'
29 | UPDATE_GLOBAL_ITER = 10
30 | GAMMA = 0.9
31 | ENTROPY_BETA = 0.01
32 | LR_A = 0.0001 # learning rate for actor
33 | LR_C = 0.001 # learning rate for critic
34 | GLOBAL_RUNNING_R = []
35 | GLOBAL_EP = 0
36 |
37 | env = gym.make(GAME)
38 |
39 | N_S = env.observation_space.shape[0]
40 | N_A = env.action_space.shape[0]
41 | A_BOUND = [env.action_space.low, env.action_space.high]
42 |
43 |
44 | class ACNet(object):
45 | def __init__(self, scope, globalAC=None):
46 |
47 | if scope == GLOBAL_NET_SCOPE: # get global network
48 | with tf.variable_scope(scope):
49 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
50 | self.a_params, self.c_params = self._build_net(scope)[-2:]
51 | else: # local net, calculate losses
52 | with tf.variable_scope(scope):
53 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
54 | self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
55 | self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
56 |
57 | mu, sigma, self.v, self.a_params, self.c_params = self._build_net(scope)
58 |
59 | td = tf.subtract(self.v_target, self.v, name='TD_error')
60 | with tf.name_scope('c_loss'):
61 | self.c_loss = tf.reduce_mean(tf.square(td))
62 |
63 | with tf.name_scope('wrap_a_out'):
64 | mu, sigma = mu * A_BOUND[1], sigma + 1e-4
65 |
66 | normal_dist = tf.distributions.Normal(mu, sigma)
67 |
68 | with tf.name_scope('a_loss'):
69 | log_prob = normal_dist.log_prob(self.a_his)
70 | exp_v = log_prob * tf.stop_gradient(td)
71 | entropy = normal_dist.entropy() # encourage exploration
72 | self.exp_v = ENTROPY_BETA * entropy + exp_v
73 | self.a_loss = tf.reduce_mean(-self.exp_v)
74 |
75 | with tf.name_scope('choose_a'): # use local params to choose action
76 | self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=0), A_BOUND[0], A_BOUND[1])
77 | with tf.name_scope('local_grad'):
78 | self.a_grads = tf.gradients(self.a_loss, self.a_params)
79 | self.c_grads = tf.gradients(self.c_loss, self.c_params)
80 |
81 | with tf.name_scope('sync'):
82 | with tf.name_scope('pull'):
83 | self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
84 | self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
85 | with tf.name_scope('push'):
86 | self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
87 | self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
88 |
89 | def _build_net(self, scope):
90 | w_init = tf.random_normal_initializer(0., .1)
91 | with tf.variable_scope('actor'):
92 | l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
93 | mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
94 | sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
95 | with tf.variable_scope('critic'):
96 | l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
97 | v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
98 | a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
99 | c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
100 | return mu, sigma, v, a_params, c_params
101 |
102 | def update_global(self, feed_dict): # run by a local
103 | SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
104 |
105 | def pull_global(self): # run by a local
106 | SESS.run([self.pull_a_params_op, self.pull_c_params_op])
107 |
108 | def choose_action(self, s): # run by a local
109 | s = s[np.newaxis, :]
110 | return SESS.run(self.A, {self.s: s})[0]
111 |
112 |
113 | class Worker(object):
114 | def __init__(self, name, globalAC):
115 | self.env = gym.make(GAME).unwrapped
116 | self.name = name
117 | self.AC = ACNet(name, globalAC)
118 |
119 | def work(self):
120 | global GLOBAL_RUNNING_R, GLOBAL_EP
121 | total_step = 1
122 | buffer_s, buffer_a, buffer_r = [], [], []
123 | while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
124 | s = self.env.reset()
125 | ep_r = 0
126 | for ep_t in range(MAX_EP_STEP):
127 | # if self.name == 'W_0':
128 | # self.env.render()
129 | a = self.AC.choose_action(s)
130 | s_, r, done, info = self.env.step(a)
131 | done = True if ep_t == MAX_EP_STEP - 1 else False
132 |
133 | ep_r += r
134 | buffer_s.append(s)
135 | buffer_a.append(a)
136 | buffer_r.append((r+8)/8) # normalize
137 |
138 | if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
139 | if done:
140 | v_s_ = 0 # terminal
141 | else:
142 | v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
143 | buffer_v_target = []
144 | for r in buffer_r[::-1]: # reverse buffer r
145 | v_s_ = r + GAMMA * v_s_
146 | buffer_v_target.append(v_s_)
147 | buffer_v_target.reverse()
148 |
149 | buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
150 | feed_dict = {
151 | self.AC.s: buffer_s,
152 | self.AC.a_his: buffer_a,
153 | self.AC.v_target: buffer_v_target,
154 | }
155 | self.AC.update_global(feed_dict)
156 | buffer_s, buffer_a, buffer_r = [], [], []
157 | self.AC.pull_global()
158 |
159 | s = s_
160 | total_step += 1
161 | if done:
162 | if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
163 | GLOBAL_RUNNING_R.append(ep_r)
164 | else:
165 | GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r)
166 | print(
167 | self.name,
168 | "Ep:", GLOBAL_EP,
169 | "| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
170 | )
171 | GLOBAL_EP += 1
172 | break
173 |
174 | if __name__ == "__main__":
175 | SESS = tf.Session()
176 |
177 | with tf.device("/cpu:0"):
178 | OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
179 | OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
180 | GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
181 | workers = []
182 | # Create worker
183 | for i in range(N_WORKERS):
184 | i_name = 'W_%i' % i # worker name
185 | workers.append(Worker(i_name, GLOBAL_AC))
186 |
187 | COORD = tf.train.Coordinator()
188 | SESS.run(tf.global_variables_initializer())
189 |
190 | if OUTPUT_GRAPH:
191 | if os.path.exists(LOG_DIR):
192 | shutil.rmtree(LOG_DIR)
193 | tf.summary.FileWriter(LOG_DIR, SESS.graph)
194 |
195 | worker_threads = []
196 | for worker in workers:
197 | job = lambda: worker.work()
198 | t = threading.Thread(target=job)
199 | t.start()
200 | worker_threads.append(t)
201 | COORD.join(worker_threads)
202 |
203 | plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
204 | plt.xlabel('step')
205 | plt.ylabel('Total moving reward')
206 | plt.show()
207 |
208 |
--------------------------------------------------------------------------------
/contents/10_A3C/A3C_discrete_action.py:
--------------------------------------------------------------------------------
1 | """
2 | Asynchronous Advantage Actor Critic (A3C) with discrete action space, Reinforcement Learning.
3 |
4 | The Cartpole example.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | tensorflow 1.0
10 | gym 0.8.0
11 | """
12 |
13 | import multiprocessing
14 | import threading
15 | import tensorflow as tf
16 | import numpy as np
17 | import gym
18 | import os
19 | import shutil
20 | import matplotlib.pyplot as plt
21 |
22 |
23 | GAME = 'CartPole-v0'
24 | OUTPUT_GRAPH = True
25 | LOG_DIR = './log'
26 | N_WORKERS = multiprocessing.cpu_count()
27 | MAX_GLOBAL_EP = 1000
28 | GLOBAL_NET_SCOPE = 'Global_Net'
29 | UPDATE_GLOBAL_ITER = 10
30 | GAMMA = 0.9
31 | ENTROPY_BETA = 0.001
32 | LR_A = 0.001 # learning rate for actor
33 | LR_C = 0.001 # learning rate for critic
34 | GLOBAL_RUNNING_R = []
35 | GLOBAL_EP = 0
36 |
37 | env = gym.make(GAME)
38 | N_S = env.observation_space.shape[0]
39 | N_A = env.action_space.n
40 |
41 |
42 | class ACNet(object):
43 | def __init__(self, scope, globalAC=None):
44 |
45 | if scope == GLOBAL_NET_SCOPE: # get global network
46 | with tf.variable_scope(scope):
47 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
48 | self.a_params, self.c_params = self._build_net(scope)[-2:]
49 | else: # local net, calculate losses
50 | with tf.variable_scope(scope):
51 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
52 | self.a_his = tf.placeholder(tf.int32, [None, ], 'A')
53 | self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
54 |
55 | self.a_prob, self.v, self.a_params, self.c_params = self._build_net(scope)
56 |
57 | td = tf.subtract(self.v_target, self.v, name='TD_error')
58 | with tf.name_scope('c_loss'):
59 | self.c_loss = tf.reduce_mean(tf.square(td))
60 |
61 | with tf.name_scope('a_loss'):
62 | log_prob = tf.reduce_sum(tf.log(self.a_prob) * tf.one_hot(self.a_his, N_A, dtype=tf.float32), axis=1, keep_dims=True)
63 | exp_v = log_prob * tf.stop_gradient(td)
64 | entropy = -tf.reduce_sum(self.a_prob * tf.log(self.a_prob + 1e-5),
65 | axis=1, keep_dims=True) # encourage exploration
66 | self.exp_v = ENTROPY_BETA * entropy + exp_v
67 | self.a_loss = tf.reduce_mean(-self.exp_v)
68 |
69 | with tf.name_scope('local_grad'):
70 | self.a_grads = tf.gradients(self.a_loss, self.a_params)
71 | self.c_grads = tf.gradients(self.c_loss, self.c_params)
72 |
73 | with tf.name_scope('sync'):
74 | with tf.name_scope('pull'):
75 | self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
76 | self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
77 | with tf.name_scope('push'):
78 | self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
79 | self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
80 |
81 | def _build_net(self, scope):
82 | w_init = tf.random_normal_initializer(0., .1)
83 | with tf.variable_scope('actor'):
84 | l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
85 | a_prob = tf.layers.dense(l_a, N_A, tf.nn.softmax, kernel_initializer=w_init, name='ap')
86 | with tf.variable_scope('critic'):
87 | l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
88 | v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
89 | a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
90 | c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
91 | return a_prob, v, a_params, c_params
92 |
93 | def update_global(self, feed_dict): # run by a local
94 | SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
95 |
96 | def pull_global(self): # run by a local
97 | SESS.run([self.pull_a_params_op, self.pull_c_params_op])
98 |
99 | def choose_action(self, s): # run by a local
100 | prob_weights = SESS.run(self.a_prob, feed_dict={self.s: s[np.newaxis, :]})
101 | action = np.random.choice(range(prob_weights.shape[1]),
102 | p=prob_weights.ravel()) # select action w.r.t the actions prob
103 | return action
104 |
105 |
106 | class Worker(object):
107 | def __init__(self, name, globalAC):
108 | self.env = gym.make(GAME).unwrapped
109 | self.name = name
110 | self.AC = ACNet(name, globalAC)
111 |
112 | def work(self):
113 | global GLOBAL_RUNNING_R, GLOBAL_EP
114 | total_step = 1
115 | buffer_s, buffer_a, buffer_r = [], [], []
116 | while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
117 | s = self.env.reset()
118 | ep_r = 0
119 | while True:
120 | # if self.name == 'W_0':
121 | # self.env.render()
122 | a = self.AC.choose_action(s)
123 | s_, r, done, info = self.env.step(a)
124 | if done: r = -5
125 | ep_r += r
126 | buffer_s.append(s)
127 | buffer_a.append(a)
128 | buffer_r.append(r)
129 |
130 | if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
131 | if done:
132 | v_s_ = 0 # terminal
133 | else:
134 | v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
135 | buffer_v_target = []
136 | for r in buffer_r[::-1]: # reverse buffer r
137 | v_s_ = r + GAMMA * v_s_
138 | buffer_v_target.append(v_s_)
139 | buffer_v_target.reverse()
140 |
141 | buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.array(buffer_a), np.vstack(buffer_v_target)
142 | feed_dict = {
143 | self.AC.s: buffer_s,
144 | self.AC.a_his: buffer_a,
145 | self.AC.v_target: buffer_v_target,
146 | }
147 | self.AC.update_global(feed_dict)
148 |
149 | buffer_s, buffer_a, buffer_r = [], [], []
150 | self.AC.pull_global()
151 |
152 | s = s_
153 | total_step += 1
154 | if done:
155 | if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
156 | GLOBAL_RUNNING_R.append(ep_r)
157 | else:
158 | GLOBAL_RUNNING_R.append(0.99 * GLOBAL_RUNNING_R[-1] + 0.01 * ep_r)
159 | print(
160 | self.name,
161 | "Ep:", GLOBAL_EP,
162 | "| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
163 | )
164 | GLOBAL_EP += 1
165 | break
166 |
167 | if __name__ == "__main__":
168 | SESS = tf.Session()
169 |
170 | with tf.device("/cpu:0"):
171 | OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
172 | OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
173 | GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
174 | workers = []
175 | # Create worker
176 | for i in range(N_WORKERS):
177 | i_name = 'W_%i' % i # worker name
178 | workers.append(Worker(i_name, GLOBAL_AC))
179 |
180 | COORD = tf.train.Coordinator()
181 | SESS.run(tf.global_variables_initializer())
182 |
183 | if OUTPUT_GRAPH:
184 | if os.path.exists(LOG_DIR):
185 | shutil.rmtree(LOG_DIR)
186 | tf.summary.FileWriter(LOG_DIR, SESS.graph)
187 |
188 | worker_threads = []
189 | for worker in workers:
190 | job = lambda: worker.work()
191 | t = threading.Thread(target=job)
192 | t.start()
193 | worker_threads.append(t)
194 | COORD.join(worker_threads)
195 |
196 | plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
197 | plt.xlabel('step')
198 | plt.ylabel('Total moving reward')
199 | plt.show()
200 |
--------------------------------------------------------------------------------
/contents/11_Dyna_Q/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the Dyna-Q learning brain, which is a brain of the agent.
3 | All decisions and learning processes are made in here.
4 |
5 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
6 | """
7 |
8 | import numpy as np
9 | import pandas as pd
10 |
11 |
12 | class QLearningTable:
13 | def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
14 | self.actions = actions # a list
15 | self.lr = learning_rate
16 | self.gamma = reward_decay
17 | self.epsilon = e_greedy
18 | self.q_table = pd.DataFrame(columns=self.actions)
19 |
20 | def choose_action(self, observation):
21 | self.check_state_exist(observation)
22 | # action selection
23 | if np.random.uniform() < self.epsilon:
24 | # choose best action
25 | state_action = self.q_table.ix[observation, :]
26 | state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
27 | action = state_action.argmax()
28 | else:
29 | # choose random action
30 | action = np.random.choice(self.actions)
31 | return action
32 |
33 | def learn(self, s, a, r, s_):
34 | self.check_state_exist(s_)
35 | q_predict = self.q_table.ix[s, a]
36 | if s_ != 'terminal':
37 | q_target = r + self.gamma * self.q_table.ix[s_, :].max() # next state is not terminal
38 | else:
39 | q_target = r # next state is terminal
40 | self.q_table.ix[s, a] += self.lr * (q_target - q_predict) # update
41 |
42 | def check_state_exist(self, state):
43 | if state not in self.q_table.index:
44 | # append new state to q table
45 | self.q_table = self.q_table.append(
46 | pd.Series(
47 | [0]*len(self.actions),
48 | index=self.q_table.columns,
49 | name=state,
50 | )
51 | )
52 |
53 |
54 | class EnvModel:
55 | """Similar to the memory buffer in DQN, you can store past experiences in here.
56 | Alternatively, the model can generate next state and reward signal accurately."""
57 | def __init__(self, actions):
58 | # the simplest case is to think about the model is a memory which has all past transition information
59 | self.actions = actions
60 | self.database = pd.DataFrame(columns=actions, dtype=np.object)
61 |
62 | def store_transition(self, s, a, r, s_):
63 | if s not in self.database.index:
64 | self.database = self.database.append(
65 | pd.Series(
66 | [None] * len(self.actions),
67 | index=self.database.columns,
68 | name=s,
69 | ))
70 | self.database.set_value(s, a, (r, s_))
71 |
72 | def sample_s_a(self):
73 | s = np.random.choice(self.database.index)
74 | a = np.random.choice(self.database.ix[s].dropna().index) # filter out the None value
75 | return s, a
76 |
77 | def get_r_s_(self, s, a):
78 | r, s_ = self.database.ix[s, a]
79 | return r, s_
80 |
--------------------------------------------------------------------------------
/contents/11_Dyna_Q/maze_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the environment part of this example. The RL is in RL_brain.py.
10 |
11 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
12 | """
13 |
14 |
15 | import numpy as np
16 | np.random.seed(1)
17 | import tkinter as tk
18 | import time
19 |
20 |
21 | UNIT = 40 # pixels
22 | MAZE_H = 4 # grid height
23 | MAZE_W = 4 # grid width
24 |
25 |
26 | class Maze(tk.Tk, object):
27 | def __init__(self):
28 | super(Maze, self).__init__()
29 | self.action_space = ['u', 'd', 'l', 'r']
30 | self.n_actions = len(self.action_space)
31 | self.title('maze')
32 | self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
33 | self._build_maze()
34 |
35 | def _build_maze(self):
36 | self.canvas = tk.Canvas(self, bg='white',
37 | height=MAZE_H * UNIT,
38 | width=MAZE_W * UNIT)
39 |
40 | # create grids
41 | for c in range(0, MAZE_W * UNIT, UNIT):
42 | x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
43 | self.canvas.create_line(x0, y0, x1, y1)
44 | for r in range(0, MAZE_H * UNIT, UNIT):
45 | x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
46 | self.canvas.create_line(x0, y0, x1, y1)
47 |
48 | # create origin
49 | origin = np.array([20, 20])
50 |
51 | # hell
52 | hell1_center = origin + np.array([UNIT * 2, UNIT])
53 | self.hell1 = self.canvas.create_rectangle(
54 | hell1_center[0] - 15, hell1_center[1] - 15,
55 | hell1_center[0] + 15, hell1_center[1] + 15,
56 | fill='black')
57 | # hell
58 | hell2_center = origin + np.array([UNIT, UNIT * 2])
59 | self.hell2 = self.canvas.create_rectangle(
60 | hell2_center[0] - 15, hell2_center[1] - 15,
61 | hell2_center[0] + 15, hell2_center[1] + 15,
62 | fill='black')
63 |
64 | # create oval
65 | oval_center = origin + UNIT * 2
66 | self.oval = self.canvas.create_oval(
67 | oval_center[0] - 15, oval_center[1] - 15,
68 | oval_center[0] + 15, oval_center[1] + 15,
69 | fill='yellow')
70 |
71 | # create red rect
72 | self.rect = self.canvas.create_rectangle(
73 | origin[0] - 15, origin[1] - 15,
74 | origin[0] + 15, origin[1] + 15,
75 | fill='red')
76 |
77 | # pack all
78 | self.canvas.pack()
79 |
80 | def reset(self):
81 | self.update()
82 | time.sleep(0.5)
83 | self.canvas.delete(self.rect)
84 | origin = np.array([20, 20])
85 | self.rect = self.canvas.create_rectangle(
86 | origin[0] - 15, origin[1] - 15,
87 | origin[0] + 15, origin[1] + 15,
88 | fill='red')
89 | # return observation
90 | return self.canvas.coords(self.rect)
91 |
92 | def step(self, action):
93 | s = self.canvas.coords(self.rect)
94 | base_action = np.array([0, 0])
95 | if action == 0: # up
96 | if s[1] > UNIT:
97 | base_action[1] -= UNIT
98 | elif action == 1: # down
99 | if s[1] < (MAZE_H - 1) * UNIT:
100 | base_action[1] += UNIT
101 | elif action == 2: # right
102 | if s[0] < (MAZE_W - 1) * UNIT:
103 | base_action[0] += UNIT
104 | elif action == 3: # left
105 | if s[0] > UNIT:
106 | base_action[0] -= UNIT
107 |
108 | self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
109 |
110 | s_ = self.canvas.coords(self.rect) # next state
111 |
112 | # reward function
113 | if s_ == self.canvas.coords(self.oval):
114 | reward = 1
115 | done = True
116 | elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
117 | reward = -1
118 | done = True
119 | else:
120 | reward = 0
121 | done = False
122 |
123 | return s_, reward, done
124 |
125 | def render(self):
126 | # time.sleep(0.1)
127 | self.update()
128 |
129 |
130 |
--------------------------------------------------------------------------------
/contents/11_Dyna_Q/run_this.py:
--------------------------------------------------------------------------------
1 | """
2 | Simplest model-based RL, Dyna-Q.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the main part which controls the update method of this example.
10 | The RL is in RL_brain.py.
11 |
12 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
13 | """
14 |
15 | from maze_env import Maze
16 | from RL_brain import QLearningTable, EnvModel
17 |
18 |
19 | def update():
20 | for episode in range(40):
21 | s = env.reset()
22 | while True:
23 | env.render()
24 | a = RL.choose_action(str(s))
25 | s_, r, done = env.step(a)
26 | RL.learn(str(s), a, r, str(s_))
27 |
28 | # use a model to output (r, s_) by inputting (s, a)
29 | # the model in dyna Q version is just like a memory replay buffer
30 | env_model.store_transition(str(s), a, r, s_)
31 | for n in range(10): # learn 10 more times using the env_model
32 | ms, ma = env_model.sample_s_a() # ms in here is a str
33 | mr, ms_ = env_model.get_r_s_(ms, ma)
34 | RL.learn(ms, ma, mr, str(ms_))
35 |
36 | s = s_
37 | if done:
38 | break
39 |
40 | # end of game
41 | print('game over')
42 | env.destroy()
43 |
44 |
45 | if __name__ == "__main__":
46 | env = Maze()
47 | RL = QLearningTable(actions=list(range(env.n_actions)))
48 | env_model = EnvModel(actions=list(range(env.n_actions)))
49 |
50 | env.after(0, update)
51 | env.mainloop()
--------------------------------------------------------------------------------
/contents/12_Proximal_Policy_Optimization/DPPO.py:
--------------------------------------------------------------------------------
1 | """
2 | A simple version of OpenAI's Proximal Policy Optimization (PPO). [https://arxiv.org/abs/1707.06347]
3 |
4 | Distributing workers in parallel to collect data, then stop worker's roll-out and train PPO on collected data.
5 | Restart workers once PPO is updated.
6 |
7 | The global PPO updating rule is adopted from DeepMind's paper (DPPO):
8 | Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [https://arxiv.org/abs/1707.02286]
9 |
10 | View more on my tutorial website: https://morvanzhou.github.io/tutorials
11 |
12 | Dependencies:
13 | tensorflow r1.3
14 | gym 0.9.2
15 | """
16 |
17 | import tensorflow as tf
18 | import numpy as np
19 | import matplotlib.pyplot as plt
20 | import gym, threading, queue
21 |
22 | EP_MAX = 1000
23 | EP_LEN = 200
24 | N_WORKER = 4 # parallel workers
25 | GAMMA = 0.9 # reward discount factor
26 | A_LR = 0.0001 # learning rate for actor
27 | C_LR = 0.0002 # learning rate for critic
28 | MIN_BATCH_SIZE = 64 # minimum batch size for updating PPO
29 | UPDATE_STEP = 10 # loop update operation n-steps
30 | EPSILON = 0.2 # for clipping surrogate objective
31 | GAME = 'Pendulum-v0'
32 | S_DIM, A_DIM = 3, 1 # state and action dimension
33 |
34 |
35 | class PPO(object):
36 | def __init__(self):
37 | self.sess = tf.Session()
38 | self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
39 |
40 | # critic
41 | l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
42 | self.v = tf.layers.dense(l1, 1)
43 | self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
44 | self.advantage = self.tfdc_r - self.v
45 | self.closs = tf.reduce_mean(tf.square(self.advantage))
46 | self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
47 |
48 | # actor
49 | pi, pi_params = self._build_anet('pi', trainable=True)
50 | oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
51 | self.sample_op = tf.squeeze(pi.sample(1), axis=0) # operation of choosing action
52 | self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
53 |
54 | self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
55 | self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
56 | # ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
57 | ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
58 | surr = ratio * self.tfadv # surrogate loss
59 |
60 | self.aloss = -tf.reduce_mean(tf.minimum( # clipped surrogate objective
61 | surr,
62 | tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
63 |
64 | self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
65 | self.sess.run(tf.global_variables_initializer())
66 |
67 | def update(self):
68 | global GLOBAL_UPDATE_COUNTER
69 | while not COORD.should_stop():
70 | if GLOBAL_EP < EP_MAX:
71 | UPDATE_EVENT.wait() # wait until get batch of data
72 | self.sess.run(self.update_oldpi_op) # copy pi to old pi
73 | data = [QUEUE.get() for _ in range(QUEUE.qsize())] # collect data from all workers
74 | data = np.vstack(data)
75 | s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + A_DIM], data[:, -1:]
76 | adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
77 | # update actor and critic in a update loop
78 | [self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
79 | [self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
80 | UPDATE_EVENT.clear() # updating finished
81 | GLOBAL_UPDATE_COUNTER = 0 # reset counter
82 | ROLLING_EVENT.set() # set roll-out available
83 |
84 | def _build_anet(self, name, trainable):
85 | with tf.variable_scope(name):
86 | l1 = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
87 | mu = 2 * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
88 | sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
89 | norm_dist = tf.distributions.Normal(loc=mu, scale=sigma)
90 | params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
91 | return norm_dist, params
92 |
93 | def choose_action(self, s):
94 | s = s[np.newaxis, :]
95 | a = self.sess.run(self.sample_op, {self.tfs: s})[0]
96 | return np.clip(a, -2, 2)
97 |
98 | def get_v(self, s):
99 | if s.ndim < 2: s = s[np.newaxis, :]
100 | return self.sess.run(self.v, {self.tfs: s})[0, 0]
101 |
102 |
103 | class Worker(object):
104 | def __init__(self, wid):
105 | self.wid = wid
106 | self.env = gym.make(GAME).unwrapped
107 | self.ppo = GLOBAL_PPO
108 |
109 | def work(self):
110 | global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
111 | while not COORD.should_stop():
112 | s = self.env.reset()
113 | ep_r = 0
114 | buffer_s, buffer_a, buffer_r = [], [], []
115 | for t in range(EP_LEN):
116 | if not ROLLING_EVENT.is_set(): # while global PPO is updating
117 | ROLLING_EVENT.wait() # wait until PPO is updated
118 | buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer, use new policy to collect data
119 | a = self.ppo.choose_action(s)
120 | s_, r, done, _ = self.env.step(a)
121 | buffer_s.append(s)
122 | buffer_a.append(a)
123 | buffer_r.append((r + 8) / 8) # normalize reward, find to be useful
124 | s = s_
125 | ep_r += r
126 |
127 | GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size, no need to wait other workers
128 | if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
129 | v_s_ = self.ppo.get_v(s_)
130 | discounted_r = [] # compute discounted reward
131 | for r in buffer_r[::-1]:
132 | v_s_ = r + GAMMA * v_s_
133 | discounted_r.append(v_s_)
134 | discounted_r.reverse()
135 |
136 | bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
137 | buffer_s, buffer_a, buffer_r = [], [], []
138 | QUEUE.put(np.hstack((bs, ba, br))) # put data in the queue
139 | if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
140 | ROLLING_EVENT.clear() # stop collecting data
141 | UPDATE_EVENT.set() # globalPPO update
142 |
143 | if GLOBAL_EP >= EP_MAX: # stop training
144 | COORD.request_stop()
145 | break
146 |
147 | # record reward changes, plot later
148 | if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
149 | else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
150 | GLOBAL_EP += 1
151 | print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
152 |
153 |
154 | if __name__ == '__main__':
155 | GLOBAL_PPO = PPO()
156 | UPDATE_EVENT, ROLLING_EVENT = threading.Event(), threading.Event()
157 | UPDATE_EVENT.clear() # not update now
158 | ROLLING_EVENT.set() # start to roll out
159 | workers = [Worker(wid=i) for i in range(N_WORKER)]
160 |
161 | GLOBAL_UPDATE_COUNTER, GLOBAL_EP = 0, 0
162 | GLOBAL_RUNNING_R = []
163 | COORD = tf.train.Coordinator()
164 | QUEUE = queue.Queue() # workers putting data in this queue
165 | threads = []
166 | for worker in workers: # worker threads
167 | t = threading.Thread(target=worker.work, args=())
168 | t.start() # training
169 | threads.append(t)
170 | # add a PPO updating thread
171 | threads.append(threading.Thread(target=GLOBAL_PPO.update,))
172 | threads[-1].start()
173 | COORD.join(threads)
174 |
175 | # plot reward change and test
176 | plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
177 | plt.xlabel('Episode'); plt.ylabel('Moving reward'); plt.ion(); plt.show()
178 | env = gym.make('Pendulum-v0')
179 | while True:
180 | s = env.reset()
181 | for t in range(300):
182 | env.render()
183 | s = env.step(GLOBAL_PPO.choose_action(s))[0]
--------------------------------------------------------------------------------
/contents/12_Proximal_Policy_Optimization/simply_PPO.py:
--------------------------------------------------------------------------------
1 | """
2 | A simple version of Proximal Policy Optimization (PPO) using single thread.
3 |
4 | Based on:
5 | 1. Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [https://arxiv.org/abs/1707.02286]
6 | 2. Proximal Policy Optimization Algorithms (OpenAI): [https://arxiv.org/abs/1707.06347]
7 |
8 | View more on my tutorial website: https://morvanzhou.github.io/tutorials
9 |
10 | Dependencies:
11 | tensorflow r1.2
12 | gym 0.9.2
13 | """
14 |
15 | import tensorflow as tf
16 | import numpy as np
17 | import matplotlib.pyplot as plt
18 | import gym
19 |
20 | EP_MAX = 1000
21 | EP_LEN = 200
22 | GAMMA = 0.9
23 | A_LR = 0.0001
24 | C_LR = 0.0002
25 | BATCH = 32
26 | A_UPDATE_STEPS = 10
27 | C_UPDATE_STEPS = 10
28 | S_DIM, A_DIM = 3, 1
29 | METHOD = [
30 | dict(name='kl_pen', kl_target=0.01, lam=0.5), # KL penalty
31 | dict(name='clip', epsilon=0.2), # Clipped surrogate objective, find this is better
32 | ][1] # choose the method for optimization
33 |
34 |
35 | class PPO(object):
36 |
37 | def __init__(self):
38 | self.sess = tf.Session()
39 | self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
40 |
41 | # critic
42 | with tf.variable_scope('critic'):
43 | l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
44 | self.v = tf.layers.dense(l1, 1)
45 | self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
46 | self.advantage = self.tfdc_r - self.v
47 | self.closs = tf.reduce_mean(tf.square(self.advantage))
48 | self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
49 |
50 | # actor
51 | pi, pi_params = self._build_anet('pi', trainable=True)
52 | oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
53 | with tf.variable_scope('sample_action'):
54 | self.sample_op = tf.squeeze(pi.sample(1), axis=0) # choosing action
55 | with tf.variable_scope('update_oldpi'):
56 | self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
57 |
58 | self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
59 | self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
60 | with tf.variable_scope('loss'):
61 | with tf.variable_scope('surrogate'):
62 | # ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
63 | ratio = pi.prob(self.tfa) / oldpi.prob(self.tfa)
64 | surr = ratio * self.tfadv
65 | if METHOD['name'] == 'kl_pen':
66 | self.tflam = tf.placeholder(tf.float32, None, 'lambda')
67 | kl = tf.distributions.kl_divergence(oldpi, pi)
68 | self.kl_mean = tf.reduce_mean(kl)
69 | self.aloss = -(tf.reduce_mean(surr - self.tflam * kl))
70 | else: # clipping method, find this is better
71 | self.aloss = -tf.reduce_mean(tf.minimum(
72 | surr,
73 | tf.clip_by_value(ratio, 1.-METHOD['epsilon'], 1.+METHOD['epsilon'])*self.tfadv))
74 |
75 | with tf.variable_scope('atrain'):
76 | self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
77 |
78 | tf.summary.FileWriter("log/", self.sess.graph)
79 |
80 | self.sess.run(tf.global_variables_initializer())
81 |
82 | def update(self, s, a, r):
83 | self.sess.run(self.update_oldpi_op)
84 | adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
85 | # adv = (adv - adv.mean())/(adv.std()+1e-6) # sometimes helpful
86 |
87 | # update actor
88 | if METHOD['name'] == 'kl_pen':
89 | for _ in range(A_UPDATE_STEPS):
90 | _, kl = self.sess.run(
91 | [self.atrain_op, self.kl_mean],
92 | {self.tfs: s, self.tfa: a, self.tfadv: adv, self.tflam: METHOD['lam']})
93 | if kl > 4*METHOD['kl_target']: # this in in google's paper
94 | break
95 | if kl < METHOD['kl_target'] / 1.5: # adaptive lambda, this is in OpenAI's paper
96 | METHOD['lam'] /= 2
97 | elif kl > METHOD['kl_target'] * 1.5:
98 | METHOD['lam'] *= 2
99 | METHOD['lam'] = np.clip(METHOD['lam'], 1e-4, 10) # sometimes explode, this clipping is my solution
100 | else: # clipping method, find this is better (OpenAI's paper)
101 | [self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(A_UPDATE_STEPS)]
102 |
103 | # update critic
104 | [self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(C_UPDATE_STEPS)]
105 |
106 | def _build_anet(self, name, trainable):
107 | with tf.variable_scope(name):
108 | l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu, trainable=trainable)
109 | mu = 2 * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
110 | sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
111 | norm_dist = tf.distributions.Normal(loc=mu, scale=sigma)
112 | params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
113 | return norm_dist, params
114 |
115 | def choose_action(self, s):
116 | s = s[np.newaxis, :]
117 | a = self.sess.run(self.sample_op, {self.tfs: s})[0]
118 | return np.clip(a, -2, 2)
119 |
120 | def get_v(self, s):
121 | if s.ndim < 2: s = s[np.newaxis, :]
122 | return self.sess.run(self.v, {self.tfs: s})[0, 0]
123 |
124 | env = gym.make('Pendulum-v0').unwrapped
125 | ppo = PPO()
126 | all_ep_r = []
127 |
128 | for ep in range(EP_MAX):
129 | s = env.reset()
130 | buffer_s, buffer_a, buffer_r = [], [], []
131 | ep_r = 0
132 | for t in range(EP_LEN): # in one episode
133 | env.render()
134 | a = ppo.choose_action(s)
135 | s_, r, done, _ = env.step(a)
136 | buffer_s.append(s)
137 | buffer_a.append(a)
138 | buffer_r.append((r+8)/8) # normalize reward, find to be useful
139 | s = s_
140 | ep_r += r
141 |
142 | # update ppo
143 | if (t+1) % BATCH == 0 or t == EP_LEN-1:
144 | v_s_ = ppo.get_v(s_)
145 | discounted_r = []
146 | for r in buffer_r[::-1]:
147 | v_s_ = r + GAMMA * v_s_
148 | discounted_r.append(v_s_)
149 | discounted_r.reverse()
150 |
151 | bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
152 | buffer_s, buffer_a, buffer_r = [], [], []
153 | ppo.update(bs, ba, br)
154 | if ep == 0: all_ep_r.append(ep_r)
155 | else: all_ep_r.append(all_ep_r[-1]*0.9 + ep_r*0.1)
156 | print(
157 | 'Ep: %i' % ep,
158 | "|Ep_r: %i" % ep_r,
159 | ("|Lam: %.4f" % METHOD['lam']) if METHOD['name'] == 'kl_pen' else '',
160 | )
161 |
162 | plt.plot(np.arange(len(all_ep_r)), all_ep_r)
163 | plt.xlabel('Episode');plt.ylabel('Moving averaged episode reward');plt.show()
--------------------------------------------------------------------------------
/contents/1_command_line_reinforcement_learning/treasure_on_right.py:
--------------------------------------------------------------------------------
1 | """
2 | A simple example for Reinforcement Learning using table lookup Q-learning method.
3 | An agent "o" is on the left of a 1 dimensional world, the treasure is on the rightmost location.
4 | Run this program and to see how the agent will improve its strategy of finding the treasure.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 | """
8 |
9 | import numpy as np
10 | import pandas as pd
11 | import time
12 |
13 | np.random.seed(2) # reproducible
14 |
15 |
16 | N_STATES = 6 # the length of the 1 dimensional world
17 | ACTIONS = ['left', 'right'] # available actions
18 | EPSILON = 0.9 # greedy police
19 | ALPHA = 0.1 # learning rate
20 | GAMMA = 0.9 # discount factor
21 | MAX_EPISODES = 13 # maximum episodes
22 | FRESH_TIME = 0.3 # fresh time for one move
23 |
24 |
25 | def build_q_table(n_states, actions):
26 | table = pd.DataFrame(
27 | np.zeros((n_states, len(actions))), # q_table initial values
28 | columns=actions, # actions's name
29 | )
30 | # print(table) # show table
31 | return table
32 |
33 |
34 | def choose_action(state, q_table):
35 | # This is how to choose an action
36 | state_actions = q_table.iloc[state, :]
37 | if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have no value
38 | action_name = np.random.choice(ACTIONS)
39 | else: # act greedy
40 | action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
41 | return action_name
42 |
43 |
44 | def get_env_feedback(S, A):
45 | # This is how agent will interact with the environment
46 | if A == 'right': # move right
47 | if S == N_STATES - 2: # terminate
48 | S_ = 'terminal'
49 | R = 1
50 | else:
51 | S_ = S + 1
52 | R = 0
53 | else: # move left
54 | R = 0
55 | if S == 0:
56 | S_ = S # reach the wall
57 | else:
58 | S_ = S - 1
59 | return S_, R
60 |
61 |
62 | def update_env(S, episode, step_counter):
63 | # This is how environment be updated
64 | env_list = ['-']*(N_STATES-1) + ['T'] # '---------T' our environment
65 | if S == 'terminal':
66 | interaction = 'Episode %s: total_steps = %s' % (episode+1, step_counter)
67 | print('\r{}'.format(interaction), end='')
68 | time.sleep(2)
69 | print('\r ', end='')
70 | else:
71 | env_list[S] = 'o'
72 | interaction = ''.join(env_list)
73 | print('\r{}'.format(interaction), end='')
74 | time.sleep(FRESH_TIME)
75 |
76 |
77 | def rl():
78 | # main part of RL loop
79 | q_table = build_q_table(N_STATES, ACTIONS)
80 | for episode in range(MAX_EPISODES):
81 | step_counter = 0
82 | S = 0
83 | is_terminated = False
84 | update_env(S, episode, step_counter)
85 | while not is_terminated:
86 |
87 | A = choose_action(S, q_table)
88 | S_, R = get_env_feedback(S, A) # take action & get next state and reward
89 | q_predict = q_table.loc[S, A]
90 | if S_ != 'terminal':
91 | q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
92 | else:
93 | q_target = R # next state is terminal
94 | is_terminated = True # terminate this episode
95 |
96 | q_table.loc[S, A] += ALPHA * (q_target - q_predict) # update
97 | S = S_ # move to next state
98 |
99 | update_env(S, episode, step_counter+1)
100 | step_counter += 1
101 | return q_table
102 |
103 |
104 | if __name__ == "__main__":
105 | q_table = rl()
106 | print('\r\nQ-table:\n')
107 | print(q_table)
108 |
--------------------------------------------------------------------------------
/contents/2_Q_Learning_maze/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the Q learning brain, which is a brain of the agent.
3 | All decisions are made in here.
4 |
5 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
6 | """
7 |
8 | import numpy as np
9 | import pandas as pd
10 |
11 |
12 | class QLearningTable:
13 | def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
14 | self.actions = actions # a list
15 | self.lr = learning_rate
16 | self.gamma = reward_decay
17 | self.epsilon = e_greedy
18 | self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
19 |
20 | def choose_action(self, observation):
21 | self.check_state_exist(observation)
22 | # action selection
23 | if np.random.uniform() < self.epsilon:
24 | # choose best action
25 | state_action = self.q_table.loc[observation, :]
26 | state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
27 | action = state_action.idxmax()
28 | else:
29 | # choose random action
30 | action = np.random.choice(self.actions)
31 | return action
32 |
33 | def learn(self, s, a, r, s_):
34 | self.check_state_exist(s_)
35 | q_predict = self.q_table.loc[s, a]
36 | if s_ != 'terminal':
37 | q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
38 | else:
39 | q_target = r # next state is terminal
40 | self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
41 |
42 | def check_state_exist(self, state):
43 | if state not in self.q_table.index:
44 | # append new state to q table
45 | self.q_table = self.q_table.append(
46 | pd.Series(
47 | [0]*len(self.actions),
48 | index=self.q_table.columns,
49 | name=state,
50 | )
51 | )
--------------------------------------------------------------------------------
/contents/2_Q_Learning_maze/maze_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the environment part of this example. The RL is in RL_brain.py.
10 |
11 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
12 | """
13 |
14 |
15 | import numpy as np
16 | import time
17 | import sys
18 | if sys.version_info.major == 2:
19 | import Tkinter as tk
20 | else:
21 | import tkinter as tk
22 |
23 |
24 | UNIT = 40 # pixels
25 | MAZE_H = 4 # grid height
26 | MAZE_W = 4 # grid width
27 |
28 |
29 | class Maze(tk.Tk, object):
30 | def __init__(self):
31 | super(Maze, self).__init__()
32 | self.action_space = ['u', 'd', 'l', 'r']
33 | self.n_actions = len(self.action_space)
34 | self.title('maze')
35 | self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
36 | self._build_maze()
37 |
38 | def _build_maze(self):
39 | self.canvas = tk.Canvas(self, bg='white',
40 | height=MAZE_H * UNIT,
41 | width=MAZE_W * UNIT)
42 |
43 | # create grids
44 | for c in range(0, MAZE_W * UNIT, UNIT):
45 | x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
46 | self.canvas.create_line(x0, y0, x1, y1)
47 | for r in range(0, MAZE_H * UNIT, UNIT):
48 | x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
49 | self.canvas.create_line(x0, y0, x1, y1)
50 |
51 | # create origin
52 | origin = np.array([20, 20])
53 |
54 | # hell
55 | hell1_center = origin + np.array([UNIT * 2, UNIT])
56 | self.hell1 = self.canvas.create_rectangle(
57 | hell1_center[0] - 15, hell1_center[1] - 15,
58 | hell1_center[0] + 15, hell1_center[1] + 15,
59 | fill='black')
60 | # hell
61 | hell2_center = origin + np.array([UNIT, UNIT * 2])
62 | self.hell2 = self.canvas.create_rectangle(
63 | hell2_center[0] - 15, hell2_center[1] - 15,
64 | hell2_center[0] + 15, hell2_center[1] + 15,
65 | fill='black')
66 |
67 | # create oval
68 | oval_center = origin + UNIT * 2
69 | self.oval = self.canvas.create_oval(
70 | oval_center[0] - 15, oval_center[1] - 15,
71 | oval_center[0] + 15, oval_center[1] + 15,
72 | fill='yellow')
73 |
74 | # create red rect
75 | self.rect = self.canvas.create_rectangle(
76 | origin[0] - 15, origin[1] - 15,
77 | origin[0] + 15, origin[1] + 15,
78 | fill='red')
79 |
80 | # pack all
81 | self.canvas.pack()
82 |
83 | def reset(self):
84 | self.update()
85 | time.sleep(0.5)
86 | self.canvas.delete(self.rect)
87 | origin = np.array([20, 20])
88 | self.rect = self.canvas.create_rectangle(
89 | origin[0] - 15, origin[1] - 15,
90 | origin[0] + 15, origin[1] + 15,
91 | fill='red')
92 | # return observation
93 | return self.canvas.coords(self.rect)
94 |
95 | def step(self, action):
96 | s = self.canvas.coords(self.rect)
97 | base_action = np.array([0, 0])
98 | if action == 0: # up
99 | if s[1] > UNIT:
100 | base_action[1] -= UNIT
101 | elif action == 1: # down
102 | if s[1] < (MAZE_H - 1) * UNIT:
103 | base_action[1] += UNIT
104 | elif action == 2: # right
105 | if s[0] < (MAZE_W - 1) * UNIT:
106 | base_action[0] += UNIT
107 | elif action == 3: # left
108 | if s[0] > UNIT:
109 | base_action[0] -= UNIT
110 |
111 | self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
112 |
113 | s_ = self.canvas.coords(self.rect) # next state
114 |
115 | # reward function
116 | if s_ == self.canvas.coords(self.oval):
117 | reward = 1
118 | done = True
119 | s_ = 'terminal'
120 | elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
121 | reward = -1
122 | done = True
123 | s_ = 'terminal'
124 | else:
125 | reward = 0
126 | done = False
127 |
128 | return s_, reward, done
129 |
130 | def render(self):
131 | time.sleep(0.1)
132 | self.update()
133 |
134 |
135 | def update():
136 | for t in range(10):
137 | s = env.reset()
138 | while True:
139 | env.render()
140 | a = 1
141 | s, r, done = env.step(a)
142 | if done:
143 | break
144 |
145 | if __name__ == '__main__':
146 | env = Maze()
147 | env.after(100, update)
148 | env.mainloop()
--------------------------------------------------------------------------------
/contents/2_Q_Learning_maze/run_this.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the main part which controls the update method of this example.
10 | The RL is in RL_brain.py.
11 |
12 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
13 | """
14 |
15 | from maze_env import Maze
16 | from RL_brain import QLearningTable
17 |
18 |
19 | def update():
20 | for episode in range(100):
21 | # initial observation
22 | observation = env.reset()
23 |
24 | while True:
25 | # fresh env
26 | env.render()
27 |
28 | # RL choose action based on observation
29 | action = RL.choose_action(str(observation))
30 |
31 | # RL take action and get next observation and reward
32 | observation_, reward, done = env.step(action)
33 |
34 | # RL learn from this transition
35 | RL.learn(str(observation), action, reward, str(observation_))
36 |
37 | # swap observation
38 | observation = observation_
39 |
40 | # break while loop when end of this episode
41 | if done:
42 | break
43 |
44 | # end of game
45 | print('game over')
46 | env.destroy()
47 |
48 | if __name__ == "__main__":
49 | env = Maze()
50 | RL = QLearningTable(actions=list(range(env.n_actions)))
51 |
52 | env.after(100, update)
53 | env.mainloop()
--------------------------------------------------------------------------------
/contents/3_Sarsa_maze/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the Q learning brain, which is a brain of the agent.
3 | All decisions are made in here.
4 |
5 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
6 | """
7 |
8 | import numpy as np
9 | import pandas as pd
10 |
11 |
12 | class RL(object):
13 | def __init__(self, action_space, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
14 | self.actions = action_space # a list
15 | self.lr = learning_rate
16 | self.gamma = reward_decay
17 | self.epsilon = e_greedy
18 |
19 | self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
20 |
21 | def check_state_exist(self, state):
22 | if state not in self.q_table.index:
23 | # append new state to q table
24 | self.q_table = self.q_table.append(
25 | pd.Series(
26 | [0]*len(self.actions),
27 | index=self.q_table.columns,
28 | name=state,
29 | )
30 | )
31 |
32 | def choose_action(self, observation):
33 | self.check_state_exist(observation)
34 | # action selection
35 | if np.random.rand() < self.epsilon:
36 | # choose best action
37 | state_action = self.q_table.loc[observation, :]
38 | state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
39 | action = state_action.idxmax()
40 | else:
41 | # choose random action
42 | action = np.random.choice(self.actions)
43 | return action
44 |
45 | def learn(self, *args):
46 | pass
47 |
48 |
49 | # off-policy
50 | class QLearningTable(RL):
51 | def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
52 | super(QLearningTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
53 |
54 | def learn(self, s, a, r, s_):
55 | self.check_state_exist(s_)
56 | q_predict = self.q_table.loc[s, a]
57 | if s_ != 'terminal':
58 | q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
59 | else:
60 | q_target = r # next state is terminal
61 | self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
62 |
63 |
64 | # on-policy
65 | class SarsaTable(RL):
66 |
67 | def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
68 | super(SarsaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
69 |
70 | def learn(self, s, a, r, s_, a_):
71 | self.check_state_exist(s_)
72 | q_predict = self.q_table.loc[s, a]
73 | if s_ != 'terminal':
74 | q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminal
75 | else:
76 | q_target = r # next state is terminal
77 | self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
78 |
--------------------------------------------------------------------------------
/contents/3_Sarsa_maze/maze_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the environment part of this example.
10 | The RL is in RL_brain.py.
11 |
12 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
13 | """
14 |
15 |
16 | import numpy as np
17 | import time
18 | import sys
19 | if sys.version_info.major == 2:
20 | import Tkinter as tk
21 | else:
22 | import tkinter as tk
23 |
24 |
25 | UNIT = 40 # pixels
26 | MAZE_H = 4 # grid height
27 | MAZE_W = 4 # grid width
28 |
29 |
30 | class Maze(tk.Tk, object):
31 | def __init__(self):
32 | super(Maze, self).__init__()
33 | self.action_space = ['u', 'd', 'l', 'r']
34 | self.n_actions = len(self.action_space)
35 | self.title('maze')
36 | self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
37 | self._build_maze()
38 |
39 | def _build_maze(self):
40 | self.canvas = tk.Canvas(self, bg='white',
41 | height=MAZE_H * UNIT,
42 | width=MAZE_W * UNIT)
43 |
44 | # create grids
45 | for c in range(0, MAZE_W * UNIT, UNIT):
46 | x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
47 | self.canvas.create_line(x0, y0, x1, y1)
48 | for r in range(0, MAZE_H * UNIT, UNIT):
49 | x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
50 | self.canvas.create_line(x0, y0, x1, y1)
51 |
52 | # create origin
53 | origin = np.array([20, 20])
54 |
55 | # hell
56 | hell1_center = origin + np.array([UNIT * 2, UNIT])
57 | self.hell1 = self.canvas.create_rectangle(
58 | hell1_center[0] - 15, hell1_center[1] - 15,
59 | hell1_center[0] + 15, hell1_center[1] + 15,
60 | fill='black')
61 | # hell
62 | hell2_center = origin + np.array([UNIT, UNIT * 2])
63 | self.hell2 = self.canvas.create_rectangle(
64 | hell2_center[0] - 15, hell2_center[1] - 15,
65 | hell2_center[0] + 15, hell2_center[1] + 15,
66 | fill='black')
67 |
68 | # create oval
69 | oval_center = origin + UNIT * 2
70 | self.oval = self.canvas.create_oval(
71 | oval_center[0] - 15, oval_center[1] - 15,
72 | oval_center[0] + 15, oval_center[1] + 15,
73 | fill='yellow')
74 |
75 | # create red rect
76 | self.rect = self.canvas.create_rectangle(
77 | origin[0] - 15, origin[1] - 15,
78 | origin[0] + 15, origin[1] + 15,
79 | fill='red')
80 |
81 | # pack all
82 | self.canvas.pack()
83 |
84 | def reset(self):
85 | self.update()
86 | time.sleep(0.5)
87 | self.canvas.delete(self.rect)
88 | origin = np.array([20, 20])
89 | self.rect = self.canvas.create_rectangle(
90 | origin[0] - 15, origin[1] - 15,
91 | origin[0] + 15, origin[1] + 15,
92 | fill='red')
93 | # return observation
94 | return self.canvas.coords(self.rect)
95 |
96 | def step(self, action):
97 | s = self.canvas.coords(self.rect)
98 | base_action = np.array([0, 0])
99 | if action == 0: # up
100 | if s[1] > UNIT:
101 | base_action[1] -= UNIT
102 | elif action == 1: # down
103 | if s[1] < (MAZE_H - 1) * UNIT:
104 | base_action[1] += UNIT
105 | elif action == 2: # right
106 | if s[0] < (MAZE_W - 1) * UNIT:
107 | base_action[0] += UNIT
108 | elif action == 3: # left
109 | if s[0] > UNIT:
110 | base_action[0] -= UNIT
111 |
112 | self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
113 |
114 | s_ = self.canvas.coords(self.rect) # next state
115 |
116 | # reward function
117 | if s_ == self.canvas.coords(self.oval):
118 | reward = 1
119 | done = True
120 | s_ = 'terminal'
121 | elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
122 | reward = -1
123 | done = True
124 | s_ = 'terminal'
125 | else:
126 | reward = 0
127 | done = False
128 |
129 | return s_, reward, done
130 |
131 | def render(self):
132 | time.sleep(0.1)
133 | self.update()
134 |
135 |
136 |
--------------------------------------------------------------------------------
/contents/3_Sarsa_maze/run_this.py:
--------------------------------------------------------------------------------
1 | """
2 | Sarsa is a online updating method for Reinforcement learning.
3 |
4 | Unlike Q learning which is a offline updating method, Sarsa is updating while in the current trajectory.
5 |
6 | You will see the sarsa is more coward when punishment is close because it cares about all behaviours,
7 | while q learning is more brave because it only cares about maximum behaviour.
8 | """
9 |
10 | from maze_env import Maze
11 | from RL_brain import SarsaTable
12 |
13 |
14 | def update():
15 | for episode in range(100):
16 | # initial observation
17 | observation = env.reset()
18 |
19 | # RL choose action based on observation
20 | action = RL.choose_action(str(observation))
21 |
22 | while True:
23 | # fresh env
24 | env.render()
25 |
26 | # RL take action and get next observation and reward
27 | observation_, reward, done = env.step(action)
28 |
29 | # RL choose action based on next observation
30 | action_ = RL.choose_action(str(observation_))
31 |
32 | # RL learn from this transition (s, a, r, s, a) ==> Sarsa
33 | RL.learn(str(observation), action, reward, str(observation_), action_)
34 |
35 | # swap observation and action
36 | observation = observation_
37 | action = action_
38 |
39 | # break while loop when end of this episode
40 | if done:
41 | break
42 |
43 | # end of game
44 | print('game over')
45 | env.destroy()
46 |
47 | if __name__ == "__main__":
48 | env = Maze()
49 | RL = SarsaTable(actions=list(range(env.n_actions)))
50 |
51 | env.after(100, update)
52 | env.mainloop()
--------------------------------------------------------------------------------
/contents/4_Sarsa_lambda_maze/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the Q learning brain, which is a brain of the agent.
3 | All decisions are made in here.
4 |
5 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
6 | """
7 |
8 | import numpy as np
9 | import pandas as pd
10 |
11 |
12 | class RL(object):
13 | def __init__(self, action_space, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
14 | self.actions = action_space # a list
15 | self.lr = learning_rate
16 | self.gamma = reward_decay
17 | self.epsilon = e_greedy
18 |
19 | self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
20 |
21 | def check_state_exist(self, state):
22 | if state not in self.q_table.index:
23 | # append new state to q table
24 | self.q_table = self.q_table.append(
25 | pd.Series(
26 | [0]*len(self.actions),
27 | index=self.q_table.columns,
28 | name=state,
29 | )
30 | )
31 |
32 | def choose_action(self, observation):
33 | self.check_state_exist(observation)
34 | # action selection
35 | if np.random.rand() < self.epsilon:
36 | # choose best action
37 | state_action = self.q_table.loc[observation, :]
38 | state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
39 | action = state_action.idxmax()
40 | else:
41 | # choose random action
42 | action = np.random.choice(self.actions)
43 | return action
44 |
45 | def learn(self, *args):
46 | pass
47 |
48 |
49 | # backward eligibility traces
50 | class SarsaLambdaTable(RL):
51 | def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9, trace_decay=0.9):
52 | super(SarsaLambdaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
53 |
54 | # backward view, eligibility trace.
55 | self.lambda_ = trace_decay
56 | self.eligibility_trace = self.q_table.copy()
57 |
58 | def check_state_exist(self, state):
59 | if state not in self.q_table.index:
60 | # append new state to q table
61 | to_be_append = pd.Series(
62 | [0] * len(self.actions),
63 | index=self.q_table.columns,
64 | name=state,
65 | )
66 | self.q_table = self.q_table.append(to_be_append)
67 |
68 | # also update eligibility trace
69 | self.eligibility_trace = self.eligibility_trace.append(to_be_append)
70 |
71 | def learn(self, s, a, r, s_, a_):
72 | self.check_state_exist(s_)
73 | q_predict = self.q_table.loc[s, a]
74 | if s_ != 'terminal':
75 | q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminal
76 | else:
77 | q_target = r # next state is terminal
78 | error = q_target - q_predict
79 |
80 | # increase trace amount for visited state-action pair
81 |
82 | # Method 1:
83 | # self.eligibility_trace.loc[s, a] += 1
84 |
85 | # Method 2:
86 | self.eligibility_trace.loc[s, :] *= 0
87 | self.eligibility_trace.loc[s, a] = 1
88 |
89 | # Q update
90 | self.q_table += self.lr * error * self.eligibility_trace
91 |
92 | # decay eligibility trace after update
93 | self.eligibility_trace *= self.gamma*self.lambda_
94 |
--------------------------------------------------------------------------------
/contents/4_Sarsa_lambda_maze/maze_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the environment part of this example.
10 | The RL is in RL_brain.py.
11 |
12 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
13 | """
14 |
15 |
16 | import numpy as np
17 | import time
18 | import sys
19 | if sys.version_info.major == 2:
20 | import Tkinter as tk
21 | else:
22 | import tkinter as tk
23 |
24 |
25 | UNIT = 40 # pixels
26 | MAZE_H = 4 # grid height
27 | MAZE_W = 4 # grid width
28 |
29 |
30 | class Maze(tk.Tk, object):
31 | def __init__(self):
32 | super(Maze, self).__init__()
33 | self.action_space = ['u', 'd', 'l', 'r']
34 | self.n_actions = len(self.action_space)
35 | self.title('maze')
36 | self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
37 | self._build_maze()
38 |
39 | def _build_maze(self):
40 | self.canvas = tk.Canvas(self, bg='white',
41 | height=MAZE_H * UNIT,
42 | width=MAZE_W * UNIT)
43 |
44 | # create grids
45 | for c in range(0, MAZE_W * UNIT, UNIT):
46 | x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
47 | self.canvas.create_line(x0, y0, x1, y1)
48 | for r in range(0, MAZE_H * UNIT, UNIT):
49 | x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
50 | self.canvas.create_line(x0, y0, x1, y1)
51 |
52 | # create origin
53 | origin = np.array([20, 20])
54 |
55 | # hell
56 | hell1_center = origin + np.array([UNIT * 2, UNIT])
57 | self.hell1 = self.canvas.create_rectangle(
58 | hell1_center[0] - 15, hell1_center[1] - 15,
59 | hell1_center[0] + 15, hell1_center[1] + 15,
60 | fill='black')
61 | # hell
62 | hell2_center = origin + np.array([UNIT, UNIT * 2])
63 | self.hell2 = self.canvas.create_rectangle(
64 | hell2_center[0] - 15, hell2_center[1] - 15,
65 | hell2_center[0] + 15, hell2_center[1] + 15,
66 | fill='black')
67 |
68 | # create oval
69 | oval_center = origin + UNIT * 2
70 | self.oval = self.canvas.create_oval(
71 | oval_center[0] - 15, oval_center[1] - 15,
72 | oval_center[0] + 15, oval_center[1] + 15,
73 | fill='yellow')
74 |
75 | # create red rect
76 | self.rect = self.canvas.create_rectangle(
77 | origin[0] - 15, origin[1] - 15,
78 | origin[0] + 15, origin[1] + 15,
79 | fill='red')
80 |
81 | # pack all
82 | self.canvas.pack()
83 |
84 | def reset(self):
85 | self.update()
86 | time.sleep(0.5)
87 | self.canvas.delete(self.rect)
88 | origin = np.array([20, 20])
89 | self.rect = self.canvas.create_rectangle(
90 | origin[0] - 15, origin[1] - 15,
91 | origin[0] + 15, origin[1] + 15,
92 | fill='red')
93 | # return observation
94 | return self.canvas.coords(self.rect)
95 |
96 | def step(self, action):
97 | s = self.canvas.coords(self.rect)
98 | base_action = np.array([0, 0])
99 | if action == 0: # up
100 | if s[1] > UNIT:
101 | base_action[1] -= UNIT
102 | elif action == 1: # down
103 | if s[1] < (MAZE_H - 1) * UNIT:
104 | base_action[1] += UNIT
105 | elif action == 2: # right
106 | if s[0] < (MAZE_W - 1) * UNIT:
107 | base_action[0] += UNIT
108 | elif action == 3: # left
109 | if s[0] > UNIT:
110 | base_action[0] -= UNIT
111 |
112 | self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
113 |
114 | s_ = self.canvas.coords(self.rect) # next state
115 |
116 | # reward function
117 | if s_ == self.canvas.coords(self.oval):
118 | reward = 1
119 | done = True
120 | s_ = 'terminal'
121 | elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
122 | reward = -1
123 | done = True
124 | s_ = 'terminal'
125 | else:
126 | reward = 0
127 | done = False
128 |
129 | return s_, reward, done
130 |
131 | def render(self):
132 | time.sleep(0.05)
133 | self.update()
134 |
135 |
136 |
--------------------------------------------------------------------------------
/contents/4_Sarsa_lambda_maze/run_this.py:
--------------------------------------------------------------------------------
1 | """
2 | Sarsa is a online updating method for Reinforcement learning.
3 |
4 | Unlike Q learning which is a offline updating method, Sarsa is updating while in the current trajectory.
5 |
6 | You will see the sarsa is more coward when punishment is close because it cares about all behaviours,
7 | while q learning is more brave because it only cares about maximum behaviour.
8 | """
9 |
10 | from maze_env import Maze
11 | from RL_brain import SarsaLambdaTable
12 |
13 |
14 | def update():
15 | for episode in range(100):
16 | # initial observation
17 | observation = env.reset()
18 |
19 | # RL choose action based on observation
20 | action = RL.choose_action(str(observation))
21 |
22 | # initial all zero eligibility trace
23 | RL.eligibility_trace *= 0
24 |
25 | while True:
26 | # fresh env
27 | env.render()
28 |
29 | # RL take action and get next observation and reward
30 | observation_, reward, done = env.step(action)
31 |
32 | # RL choose action based on next observation
33 | action_ = RL.choose_action(str(observation_))
34 |
35 | # RL learn from this transition (s, a, r, s, a) ==> Sarsa
36 | RL.learn(str(observation), action, reward, str(observation_), action_)
37 |
38 | # swap observation and action
39 | observation = observation_
40 | action = action_
41 |
42 | # break while loop when end of this episode
43 | if done:
44 | break
45 |
46 | # end of game
47 | print('game over')
48 | env.destroy()
49 |
50 | if __name__ == "__main__":
51 | env = Maze()
52 | RL = SarsaLambdaTable(actions=list(range(env.n_actions)))
53 |
54 | env.after(100, update)
55 | env.mainloop()
--------------------------------------------------------------------------------
/contents/5.1_Double_DQN/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | The double DQN based on this paper: https://arxiv.org/abs/1509.06461
3 |
4 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
5 |
6 | Using:
7 | Tensorflow: 1.0
8 | gym: 0.8.0
9 | """
10 |
11 | import numpy as np
12 | import tensorflow as tf
13 |
14 | np.random.seed(1)
15 | tf.set_random_seed(1)
16 |
17 |
18 | class DoubleDQN:
19 | def __init__(
20 | self,
21 | n_actions,
22 | n_features,
23 | learning_rate=0.005,
24 | reward_decay=0.9,
25 | e_greedy=0.9,
26 | replace_target_iter=200,
27 | memory_size=3000,
28 | batch_size=32,
29 | e_greedy_increment=None,
30 | output_graph=False,
31 | double_q=True,
32 | sess=None,
33 | ):
34 | self.n_actions = n_actions
35 | self.n_features = n_features
36 | self.lr = learning_rate
37 | self.gamma = reward_decay
38 | self.epsilon_max = e_greedy
39 | self.replace_target_iter = replace_target_iter
40 | self.memory_size = memory_size
41 | self.batch_size = batch_size
42 | self.epsilon_increment = e_greedy_increment
43 | self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
44 |
45 | self.double_q = double_q # decide to use double q or not
46 |
47 | self.learn_step_counter = 0
48 | self.memory = np.zeros((self.memory_size, n_features*2+2))
49 | self._build_net()
50 | t_params = tf.get_collection('target_net_params')
51 | e_params = tf.get_collection('eval_net_params')
52 | self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
53 |
54 | if sess is None:
55 | self.sess = tf.Session()
56 | self.sess.run(tf.global_variables_initializer())
57 | else:
58 | self.sess = sess
59 | if output_graph:
60 | tf.summary.FileWriter("logs/", self.sess.graph)
61 | self.cost_his = []
62 |
63 | def _build_net(self):
64 | def build_layers(s, c_names, n_l1, w_initializer, b_initializer):
65 | with tf.variable_scope('l1'):
66 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
67 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
68 | l1 = tf.nn.relu(tf.matmul(s, w1) + b1)
69 |
70 | with tf.variable_scope('l2'):
71 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
72 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
73 | out = tf.matmul(l1, w2) + b2
74 | return out
75 | # ------------------ build evaluate_net ------------------
76 | self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
77 | self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
78 |
79 | with tf.variable_scope('eval_net'):
80 | c_names, n_l1, w_initializer, b_initializer = \
81 | ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 20, \
82 | tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
83 |
84 | self.q_eval = build_layers(self.s, c_names, n_l1, w_initializer, b_initializer)
85 |
86 | with tf.variable_scope('loss'):
87 | self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
88 | with tf.variable_scope('train'):
89 | self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
90 |
91 | # ------------------ build target_net ------------------
92 | self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
93 | with tf.variable_scope('target_net'):
94 | c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
95 |
96 | self.q_next = build_layers(self.s_, c_names, n_l1, w_initializer, b_initializer)
97 |
98 | def store_transition(self, s, a, r, s_):
99 | if not hasattr(self, 'memory_counter'):
100 | self.memory_counter = 0
101 | transition = np.hstack((s, [a, r], s_))
102 | index = self.memory_counter % self.memory_size
103 | self.memory[index, :] = transition
104 | self.memory_counter += 1
105 |
106 | def choose_action(self, observation):
107 | observation = observation[np.newaxis, :]
108 | actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
109 | action = np.argmax(actions_value)
110 |
111 | if not hasattr(self, 'q'): # record action value it gets
112 | self.q = []
113 | self.running_q = 0
114 | self.running_q = self.running_q*0.99 + 0.01 * np.max(actions_value)
115 | self.q.append(self.running_q)
116 |
117 | if np.random.uniform() > self.epsilon: # choosing action
118 | action = np.random.randint(0, self.n_actions)
119 | return action
120 |
121 | def learn(self):
122 | if self.learn_step_counter % self.replace_target_iter == 0:
123 | self.sess.run(self.replace_target_op)
124 | print('\ntarget_params_replaced\n')
125 |
126 | if self.memory_counter > self.memory_size:
127 | sample_index = np.random.choice(self.memory_size, size=self.batch_size)
128 | else:
129 | sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
130 | batch_memory = self.memory[sample_index, :]
131 |
132 | q_next, q_eval4next = self.sess.run(
133 | [self.q_next, self.q_eval],
134 | feed_dict={self.s_: batch_memory[:, -self.n_features:], # next observation
135 | self.s: batch_memory[:, -self.n_features:]}) # next observation
136 | q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
137 |
138 | q_target = q_eval.copy()
139 |
140 | batch_index = np.arange(self.batch_size, dtype=np.int32)
141 | eval_act_index = batch_memory[:, self.n_features].astype(int)
142 | reward = batch_memory[:, self.n_features + 1]
143 |
144 | if self.double_q:
145 | max_act4next = np.argmax(q_eval4next, axis=1) # the action that brings the highest value is evaluated by q_eval
146 | selected_q_next = q_next[batch_index, max_act4next] # Double DQN, select q_next depending on above actions
147 | else:
148 | selected_q_next = np.max(q_next, axis=1) # the natural DQN
149 |
150 | q_target[batch_index, eval_act_index] = reward + self.gamma * selected_q_next
151 |
152 | _, self.cost = self.sess.run([self._train_op, self.loss],
153 | feed_dict={self.s: batch_memory[:, :self.n_features],
154 | self.q_target: q_target})
155 | self.cost_his.append(self.cost)
156 |
157 | self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
158 | self.learn_step_counter += 1
159 |
160 |
161 |
162 |
163 |
--------------------------------------------------------------------------------
/contents/5.1_Double_DQN/run_Pendulum.py:
--------------------------------------------------------------------------------
1 | """
2 | Double DQN & Natural DQN comparison,
3 | The Pendulum example.
4 |
5 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
6 |
7 | Using:
8 | Tensorflow: 1.0
9 | gym: 0.8.0
10 | """
11 |
12 |
13 | import gym
14 | from RL_brain import DoubleDQN
15 | import numpy as np
16 | import matplotlib.pyplot as plt
17 | import tensorflow as tf
18 |
19 |
20 | env = gym.make('Pendulum-v0')
21 | env = env.unwrapped
22 | env.seed(1)
23 | MEMORY_SIZE = 3000
24 | ACTION_SPACE = 11
25 |
26 | sess = tf.Session()
27 | with tf.variable_scope('Natural_DQN'):
28 | natural_DQN = DoubleDQN(
29 | n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
30 | e_greedy_increment=0.001, double_q=False, sess=sess
31 | )
32 |
33 | with tf.variable_scope('Double_DQN'):
34 | double_DQN = DoubleDQN(
35 | n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
36 | e_greedy_increment=0.001, double_q=True, sess=sess, output_graph=True)
37 |
38 | sess.run(tf.global_variables_initializer())
39 |
40 |
41 | def train(RL):
42 | total_steps = 0
43 | observation = env.reset()
44 | while True:
45 | # if total_steps - MEMORY_SIZE > 8000: env.render()
46 |
47 | action = RL.choose_action(observation)
48 |
49 | f_action = (action-(ACTION_SPACE-1)/2)/((ACTION_SPACE-1)/4) # convert to [-2 ~ 2] float actions
50 | observation_, reward, done, info = env.step(np.array([f_action]))
51 |
52 | reward /= 10 # normalize to a range of (-1, 0). r = 0 when get upright
53 | # the Q target at upright state will be 0, because Q_target = r + gamma * Qmax(s', a') = 0 + gamma * 0
54 | # so when Q at this state is greater than 0, the agent overestimates the Q. Please refer to the final result.
55 |
56 | RL.store_transition(observation, action, reward, observation_)
57 |
58 | if total_steps > MEMORY_SIZE: # learning
59 | RL.learn()
60 |
61 | if total_steps - MEMORY_SIZE > 20000: # stop game
62 | break
63 |
64 | observation = observation_
65 | total_steps += 1
66 | return RL.q
67 |
68 | q_natural = train(natural_DQN)
69 | q_double = train(double_DQN)
70 |
71 | plt.plot(np.array(q_natural), c='r', label='natural')
72 | plt.plot(np.array(q_double), c='b', label='double')
73 | plt.legend(loc='best')
74 | plt.ylabel('Q eval')
75 | plt.xlabel('training steps')
76 | plt.grid()
77 | plt.show()
78 |
--------------------------------------------------------------------------------
/contents/5.2_Prioritized_Replay_DQN/run_MountainCar.py:
--------------------------------------------------------------------------------
1 | """
2 | The DQN improvement: Prioritized Experience Replay (based on https://arxiv.org/abs/1511.05952)
3 |
4 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
5 |
6 | Using:
7 | Tensorflow: 1.0
8 | gym: 0.8.0
9 | """
10 |
11 |
12 | import gym
13 | from RL_brain import DQNPrioritizedReplay
14 | import matplotlib.pyplot as plt
15 | import tensorflow as tf
16 | import numpy as np
17 |
18 | env = gym.make('MountainCar-v0')
19 | env = env.unwrapped
20 | env.seed(21)
21 | MEMORY_SIZE = 10000
22 |
23 | sess = tf.Session()
24 | with tf.variable_scope('natural_DQN'):
25 | RL_natural = DQNPrioritizedReplay(
26 | n_actions=3, n_features=2, memory_size=MEMORY_SIZE,
27 | e_greedy_increment=0.00005, sess=sess, prioritized=False,
28 | )
29 |
30 | with tf.variable_scope('DQN_with_prioritized_replay'):
31 | RL_prio = DQNPrioritizedReplay(
32 | n_actions=3, n_features=2, memory_size=MEMORY_SIZE,
33 | e_greedy_increment=0.00005, sess=sess, prioritized=True, output_graph=True,
34 | )
35 | sess.run(tf.global_variables_initializer())
36 |
37 |
38 | def train(RL):
39 | total_steps = 0
40 | steps = []
41 | episodes = []
42 | for i_episode in range(20):
43 | observation = env.reset()
44 | while True:
45 | # env.render()
46 |
47 | action = RL.choose_action(observation)
48 |
49 | observation_, reward, done, info = env.step(action)
50 |
51 | if done: reward = 10
52 |
53 | RL.store_transition(observation, action, reward, observation_)
54 |
55 | if total_steps > MEMORY_SIZE:
56 | RL.learn()
57 |
58 | if done:
59 | print('episode ', i_episode, ' finished')
60 | steps.append(total_steps)
61 | episodes.append(i_episode)
62 | break
63 |
64 | observation = observation_
65 | total_steps += 1
66 | return np.vstack((episodes, steps))
67 |
68 | his_natural = train(RL_natural)
69 | his_prio = train(RL_prio)
70 |
71 | # compare based on first success
72 | plt.plot(his_natural[0, :], his_natural[1, :] - his_natural[1, 0], c='b', label='natural DQN')
73 | plt.plot(his_prio[0, :], his_prio[1, :] - his_prio[1, 0], c='r', label='DQN with prioritized replay')
74 | plt.legend(loc='best')
75 | plt.ylabel('total training time')
76 | plt.xlabel('episode')
77 | plt.grid()
78 | plt.show()
79 |
80 |
81 |
--------------------------------------------------------------------------------
/contents/5.3_Dueling_DQN/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | The Dueling DQN based on this paper: https://arxiv.org/abs/1511.06581
3 |
4 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
5 |
6 | Using:
7 | Tensorflow: 1.0
8 | gym: 0.8.0
9 | """
10 |
11 | import numpy as np
12 | import tensorflow as tf
13 |
14 | np.random.seed(1)
15 | tf.set_random_seed(1)
16 |
17 |
18 | class DuelingDQN:
19 | def __init__(
20 | self,
21 | n_actions,
22 | n_features,
23 | learning_rate=0.001,
24 | reward_decay=0.9,
25 | e_greedy=0.9,
26 | replace_target_iter=200,
27 | memory_size=500,
28 | batch_size=32,
29 | e_greedy_increment=None,
30 | output_graph=False,
31 | dueling=True,
32 | sess=None,
33 | ):
34 | self.n_actions = n_actions
35 | self.n_features = n_features
36 | self.lr = learning_rate
37 | self.gamma = reward_decay
38 | self.epsilon_max = e_greedy
39 | self.replace_target_iter = replace_target_iter
40 | self.memory_size = memory_size
41 | self.batch_size = batch_size
42 | self.epsilon_increment = e_greedy_increment
43 | self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
44 |
45 | self.dueling = dueling # decide to use dueling DQN or not
46 |
47 | self.learn_step_counter = 0
48 | self.memory = np.zeros((self.memory_size, n_features*2+2))
49 | self._build_net()
50 | t_params = tf.get_collection('target_net_params')
51 | e_params = tf.get_collection('eval_net_params')
52 | self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
53 |
54 | if sess is None:
55 | self.sess = tf.Session()
56 | self.sess.run(tf.global_variables_initializer())
57 | else:
58 | self.sess = sess
59 | if output_graph:
60 | tf.summary.FileWriter("logs/", self.sess.graph)
61 | self.cost_his = []
62 |
63 | def _build_net(self):
64 | def build_layers(s, c_names, n_l1, w_initializer, b_initializer):
65 | with tf.variable_scope('l1'):
66 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
67 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
68 | l1 = tf.nn.relu(tf.matmul(s, w1) + b1)
69 |
70 | if self.dueling:
71 | # Dueling DQN
72 | with tf.variable_scope('Value'):
73 | w2 = tf.get_variable('w2', [n_l1, 1], initializer=w_initializer, collections=c_names)
74 | b2 = tf.get_variable('b2', [1, 1], initializer=b_initializer, collections=c_names)
75 | self.V = tf.matmul(l1, w2) + b2
76 |
77 | with tf.variable_scope('Advantage'):
78 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
79 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
80 | self.A = tf.matmul(l1, w2) + b2
81 |
82 | with tf.variable_scope('Q'):
83 | out = self.V + (self.A - tf.reduce_mean(self.A, axis=1, keep_dims=True)) # Q = V(s) + A(s,a)
84 | else:
85 | with tf.variable_scope('Q'):
86 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
87 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
88 | out = tf.matmul(l1, w2) + b2
89 |
90 | return out
91 |
92 | # ------------------ build evaluate_net ------------------
93 | self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
94 | self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
95 | with tf.variable_scope('eval_net'):
96 | c_names, n_l1, w_initializer, b_initializer = \
97 | ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 20, \
98 | tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
99 |
100 | self.q_eval = build_layers(self.s, c_names, n_l1, w_initializer, b_initializer)
101 |
102 | with tf.variable_scope('loss'):
103 | self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
104 | with tf.variable_scope('train'):
105 | self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
106 |
107 | # ------------------ build target_net ------------------
108 | self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
109 | with tf.variable_scope('target_net'):
110 | c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
111 |
112 | self.q_next = build_layers(self.s_, c_names, n_l1, w_initializer, b_initializer)
113 |
114 | def store_transition(self, s, a, r, s_):
115 | if not hasattr(self, 'memory_counter'):
116 | self.memory_counter = 0
117 | transition = np.hstack((s, [a, r], s_))
118 | index = self.memory_counter % self.memory_size
119 | self.memory[index, :] = transition
120 | self.memory_counter += 1
121 |
122 | def choose_action(self, observation):
123 | observation = observation[np.newaxis, :]
124 | if np.random.uniform() < self.epsilon: # choosing action
125 | actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
126 | action = np.argmax(actions_value)
127 | else:
128 | action = np.random.randint(0, self.n_actions)
129 | return action
130 |
131 | def learn(self):
132 | if self.learn_step_counter % self.replace_target_iter == 0:
133 | self.sess.run(self.replace_target_op)
134 | print('\ntarget_params_replaced\n')
135 |
136 | sample_index = np.random.choice(self.memory_size, size=self.batch_size)
137 | batch_memory = self.memory[sample_index, :]
138 |
139 | q_next = self.sess.run(self.q_next, feed_dict={self.s_: batch_memory[:, -self.n_features:]}) # next observation
140 | q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
141 |
142 | q_target = q_eval.copy()
143 |
144 | batch_index = np.arange(self.batch_size, dtype=np.int32)
145 | eval_act_index = batch_memory[:, self.n_features].astype(int)
146 | reward = batch_memory[:, self.n_features + 1]
147 |
148 | q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
149 |
150 | _, self.cost = self.sess.run([self._train_op, self.loss],
151 | feed_dict={self.s: batch_memory[:, :self.n_features],
152 | self.q_target: q_target})
153 | self.cost_his.append(self.cost)
154 |
155 | self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
156 | self.learn_step_counter += 1
157 |
158 |
159 |
160 |
161 |
162 |
--------------------------------------------------------------------------------
/contents/5.3_Dueling_DQN/run_Pendulum.py:
--------------------------------------------------------------------------------
1 | """
2 | Dueling DQN & Natural DQN comparison
3 |
4 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
5 |
6 | Using:
7 | Tensorflow: 1.0
8 | gym: 0.8.0
9 | """
10 |
11 |
12 | import gym
13 | from RL_brain import DuelingDQN
14 | import numpy as np
15 | import matplotlib.pyplot as plt
16 | import tensorflow as tf
17 |
18 |
19 | env = gym.make('Pendulum-v0')
20 | env = env.unwrapped
21 | env.seed(1)
22 | MEMORY_SIZE = 3000
23 | ACTION_SPACE = 25
24 |
25 | sess = tf.Session()
26 | with tf.variable_scope('natural'):
27 | natural_DQN = DuelingDQN(
28 | n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
29 | e_greedy_increment=0.001, sess=sess, dueling=False)
30 |
31 | with tf.variable_scope('dueling'):
32 | dueling_DQN = DuelingDQN(
33 | n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
34 | e_greedy_increment=0.001, sess=sess, dueling=True, output_graph=True)
35 |
36 | sess.run(tf.global_variables_initializer())
37 |
38 |
39 | def train(RL):
40 | acc_r = [0]
41 | total_steps = 0
42 | observation = env.reset()
43 | while True:
44 | # if total_steps-MEMORY_SIZE > 9000: env.render()
45 |
46 | action = RL.choose_action(observation)
47 |
48 | f_action = (action-(ACTION_SPACE-1)/2)/((ACTION_SPACE-1)/4) # [-2 ~ 2] float actions
49 | observation_, reward, done, info = env.step(np.array([f_action]))
50 |
51 | reward /= 10 # normalize to a range of (-1, 0)
52 | acc_r.append(reward + acc_r[-1]) # accumulated reward
53 |
54 | RL.store_transition(observation, action, reward, observation_)
55 |
56 | if total_steps > MEMORY_SIZE:
57 | RL.learn()
58 |
59 | if total_steps-MEMORY_SIZE > 15000:
60 | break
61 |
62 | observation = observation_
63 | total_steps += 1
64 | return RL.cost_his, acc_r
65 |
66 | c_natural, r_natural = train(natural_DQN)
67 | c_dueling, r_dueling = train(dueling_DQN)
68 |
69 | plt.figure(1)
70 | plt.plot(np.array(c_natural), c='r', label='natural')
71 | plt.plot(np.array(c_dueling), c='b', label='dueling')
72 | plt.legend(loc='best')
73 | plt.ylabel('cost')
74 | plt.xlabel('training steps')
75 | plt.grid()
76 |
77 | plt.figure(2)
78 | plt.plot(np.array(r_natural), c='r', label='natural')
79 | plt.plot(np.array(r_dueling), c='b', label='dueling')
80 | plt.legend(loc='best')
81 | plt.ylabel('accumulated reward')
82 | plt.xlabel('training steps')
83 | plt.grid()
84 |
85 | plt.show()
86 |
87 |
--------------------------------------------------------------------------------
/contents/5_Deep_Q_Network/DQN_modified.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the Deep Q Network (DQN) brain.
3 |
4 | view the tensorboard picture about this DQN structure on: https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/4-3-DQN3/#modification
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | Tensorflow: r1.2
10 | """
11 |
12 | import numpy as np
13 | import tensorflow as tf
14 |
15 | np.random.seed(1)
16 | tf.set_random_seed(1)
17 |
18 |
19 | # Deep Q Network off-policy
20 | class DeepQNetwork:
21 | def __init__(
22 | self,
23 | n_actions,
24 | n_features,
25 | learning_rate=0.01,
26 | reward_decay=0.9,
27 | e_greedy=0.9,
28 | replace_target_iter=300,
29 | memory_size=500,
30 | batch_size=32,
31 | e_greedy_increment=None,
32 | output_graph=False,
33 | ):
34 | self.n_actions = n_actions
35 | self.n_features = n_features
36 | self.lr = learning_rate
37 | self.gamma = reward_decay
38 | self.epsilon_max = e_greedy
39 | self.replace_target_iter = replace_target_iter
40 | self.memory_size = memory_size
41 | self.batch_size = batch_size
42 | self.epsilon_increment = e_greedy_increment
43 | self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
44 |
45 | # total learning step
46 | self.learn_step_counter = 0
47 |
48 | # initialize zero memory [s, a, r, s_]
49 | self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
50 |
51 | # consist of [target_net, evaluate_net]
52 | self._build_net()
53 |
54 | t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
55 | e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
56 |
57 | with tf.variable_scope('soft_replacement'):
58 | self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
59 |
60 | self.sess = tf.Session()
61 |
62 | if output_graph:
63 | # $ tensorboard --logdir=logs
64 | tf.summary.FileWriter("logs/", self.sess.graph)
65 |
66 | self.sess.run(tf.global_variables_initializer())
67 | self.cost_his = []
68 |
69 | def _build_net(self):
70 | # ------------------ all inputs ------------------------
71 | self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input State
72 | self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input Next State
73 | self.r = tf.placeholder(tf.float32, [None, ], name='r') # input Reward
74 | self.a = tf.placeholder(tf.int32, [None, ], name='a') # input Action
75 |
76 | w_initializer, b_initializer = tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1)
77 |
78 | # ------------------ build evaluate_net ------------------
79 | with tf.variable_scope('eval_net'):
80 | e1 = tf.layers.dense(self.s, 20, tf.nn.relu, kernel_initializer=w_initializer,
81 | bias_initializer=b_initializer, name='e1')
82 | self.q_eval = tf.layers.dense(e1, self.n_actions, kernel_initializer=w_initializer,
83 | bias_initializer=b_initializer, name='q')
84 |
85 | # ------------------ build target_net ------------------
86 | with tf.variable_scope('target_net'):
87 | t1 = tf.layers.dense(self.s_, 20, tf.nn.relu, kernel_initializer=w_initializer,
88 | bias_initializer=b_initializer, name='t1')
89 | self.q_next = tf.layers.dense(t1, self.n_actions, kernel_initializer=w_initializer,
90 | bias_initializer=b_initializer, name='t2')
91 |
92 | with tf.variable_scope('q_target'):
93 | q_target = self.r + self.gamma * tf.reduce_max(self.q_next, axis=1, name='Qmax_s_') # shape=(None, )
94 | self.q_target = tf.stop_gradient(q_target)
95 | with tf.variable_scope('q_eval'):
96 | a_indices = tf.stack([tf.range(tf.shape(self.a)[0], dtype=tf.int32), self.a], axis=1)
97 | self.q_eval_wrt_a = tf.gather_nd(params=self.q_eval, indices=a_indices) # shape=(None, )
98 | with tf.variable_scope('loss'):
99 | self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval_wrt_a, name='TD_error'))
100 | with tf.variable_scope('train'):
101 | self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
102 |
103 | def store_transition(self, s, a, r, s_):
104 | if not hasattr(self, 'memory_counter'):
105 | self.memory_counter = 0
106 | transition = np.hstack((s, [a, r], s_))
107 | # replace the old memory with new memory
108 | index = self.memory_counter % self.memory_size
109 | self.memory[index, :] = transition
110 | self.memory_counter += 1
111 |
112 | def choose_action(self, observation):
113 | # to have batch dimension when feed into tf placeholder
114 | observation = observation[np.newaxis, :]
115 |
116 | if np.random.uniform() < self.epsilon:
117 | # forward feed the observation and get q value for every actions
118 | actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
119 | action = np.argmax(actions_value)
120 | else:
121 | action = np.random.randint(0, self.n_actions)
122 | return action
123 |
124 | def learn(self):
125 | # check to replace target parameters
126 | if self.learn_step_counter % self.replace_target_iter == 0:
127 | self.sess.run(self.target_replace_op)
128 | print('\ntarget_params_replaced\n')
129 |
130 | # sample batch memory from all memory
131 | if self.memory_counter > self.memory_size:
132 | sample_index = np.random.choice(self.memory_size, size=self.batch_size)
133 | else:
134 | sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
135 | batch_memory = self.memory[sample_index, :]
136 |
137 | _, cost = self.sess.run(
138 | [self._train_op, self.loss],
139 | feed_dict={
140 | self.s: batch_memory[:, :self.n_features],
141 | self.a: batch_memory[:, self.n_features],
142 | self.r: batch_memory[:, self.n_features + 1],
143 | self.s_: batch_memory[:, -self.n_features:],
144 | })
145 |
146 | self.cost_his.append(cost)
147 |
148 | # increasing epsilon
149 | self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
150 | self.learn_step_counter += 1
151 |
152 | def plot_cost(self):
153 | import matplotlib.pyplot as plt
154 | plt.plot(np.arange(len(self.cost_his)), self.cost_his)
155 | plt.ylabel('Cost')
156 | plt.xlabel('training steps')
157 | plt.show()
158 |
159 | if __name__ == '__main__':
160 | DQN = DeepQNetwork(3,4, output_graph=True)
--------------------------------------------------------------------------------
/contents/5_Deep_Q_Network/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the DQN brain, which is a brain of the agent.
3 | All decisions are made in here.
4 | Using Tensorflow to build the neural network.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | Tensorflow: 1.0
10 | gym: 0.7.3
11 | """
12 |
13 | import numpy as np
14 | import pandas as pd
15 | import tensorflow as tf
16 |
17 | np.random.seed(1)
18 | tf.set_random_seed(1)
19 |
20 |
21 | # Deep Q Network off-policy
22 | class DeepQNetwork:
23 | def __init__(
24 | self,
25 | n_actions,
26 | n_features,
27 | learning_rate=0.01,
28 | reward_decay=0.9,
29 | e_greedy=0.9,
30 | replace_target_iter=300,
31 | memory_size=500,
32 | batch_size=32,
33 | e_greedy_increment=None,
34 | output_graph=False,
35 | ):
36 | self.n_actions = n_actions
37 | self.n_features = n_features
38 | self.lr = learning_rate
39 | self.gamma = reward_decay
40 | self.epsilon_max = e_greedy
41 | self.replace_target_iter = replace_target_iter
42 | self.memory_size = memory_size
43 | self.batch_size = batch_size
44 | self.epsilon_increment = e_greedy_increment
45 | self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
46 |
47 | # total learning step
48 | self.learn_step_counter = 0
49 |
50 | # initialize zero memory [s, a, r, s_]
51 | self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
52 |
53 | # consist of [target_net, evaluate_net]
54 | self._build_net()
55 | t_params = tf.get_collection('target_net_params')
56 | e_params = tf.get_collection('eval_net_params')
57 | self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
58 |
59 | self.sess = tf.Session()
60 |
61 | if output_graph:
62 | # $ tensorboard --logdir=logs
63 | # tf.train.SummaryWriter soon be deprecated, use following
64 | tf.summary.FileWriter("logs/", self.sess.graph)
65 |
66 | self.sess.run(tf.global_variables_initializer())
67 | self.cost_his = []
68 |
69 | def _build_net(self):
70 | # ------------------ build evaluate_net ------------------
71 | self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
72 | self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
73 | with tf.variable_scope('eval_net'):
74 | # c_names(collections_names) are the collections to store variables
75 | c_names, n_l1, w_initializer, b_initializer = \
76 | ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, \
77 | tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
78 |
79 | # first layer. collections is used later when assign to target net
80 | with tf.variable_scope('l1'):
81 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
82 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
83 | l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
84 |
85 | # second layer. collections is used later when assign to target net
86 | with tf.variable_scope('l2'):
87 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
88 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
89 | self.q_eval = tf.matmul(l1, w2) + b2
90 |
91 | with tf.variable_scope('loss'):
92 | self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
93 | with tf.variable_scope('train'):
94 | self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
95 |
96 | # ------------------ build target_net ------------------
97 | self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
98 | with tf.variable_scope('target_net'):
99 | # c_names(collections_names) are the collections to store variables
100 | c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
101 |
102 | # first layer. collections is used later when assign to target net
103 | with tf.variable_scope('l1'):
104 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
105 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
106 | l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
107 |
108 | # second layer. collections is used later when assign to target net
109 | with tf.variable_scope('l2'):
110 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
111 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
112 | self.q_next = tf.matmul(l1, w2) + b2
113 |
114 | def store_transition(self, s, a, r, s_):
115 | if not hasattr(self, 'memory_counter'):
116 | self.memory_counter = 0
117 |
118 | transition = np.hstack((s, [a, r], s_))
119 |
120 | # replace the old memory with new memory
121 | index = self.memory_counter % self.memory_size
122 | self.memory[index, :] = transition
123 |
124 | self.memory_counter += 1
125 |
126 | def choose_action(self, observation):
127 | # to have batch dimension when feed into tf placeholder
128 | observation = observation[np.newaxis, :]
129 |
130 | if np.random.uniform() < self.epsilon:
131 | # forward feed the observation and get q value for every actions
132 | actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
133 | action = np.argmax(actions_value)
134 | else:
135 | action = np.random.randint(0, self.n_actions)
136 | return action
137 |
138 | def learn(self):
139 | # check to replace target parameters
140 | if self.learn_step_counter % self.replace_target_iter == 0:
141 | self.sess.run(self.replace_target_op)
142 | print('\ntarget_params_replaced\n')
143 |
144 | # sample batch memory from all memory
145 | if self.memory_counter > self.memory_size:
146 | sample_index = np.random.choice(self.memory_size, size=self.batch_size)
147 | else:
148 | sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
149 | batch_memory = self.memory[sample_index, :]
150 |
151 | q_next, q_eval = self.sess.run(
152 | [self.q_next, self.q_eval],
153 | feed_dict={
154 | self.s_: batch_memory[:, -self.n_features:], # fixed params
155 | self.s: batch_memory[:, :self.n_features], # newest params
156 | })
157 |
158 | # change q_target w.r.t q_eval's action
159 | q_target = q_eval.copy()
160 |
161 | batch_index = np.arange(self.batch_size, dtype=np.int32)
162 | eval_act_index = batch_memory[:, self.n_features].astype(int)
163 | reward = batch_memory[:, self.n_features + 1]
164 |
165 | q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
166 |
167 | """
168 | For example in this batch I have 2 samples and 3 actions:
169 | q_eval =
170 | [[1, 2, 3],
171 | [4, 5, 6]]
172 |
173 | q_target = q_eval =
174 | [[1, 2, 3],
175 | [4, 5, 6]]
176 |
177 | Then change q_target with the real q_target value w.r.t the q_eval's action.
178 | For example in:
179 | sample 0, I took action 0, and the max q_target value is -1;
180 | sample 1, I took action 2, and the max q_target value is -2:
181 | q_target =
182 | [[-1, 2, 3],
183 | [4, 5, -2]]
184 |
185 | So the (q_target - q_eval) becomes:
186 | [[(-1)-(1), 0, 0],
187 | [0, 0, (-2)-(6)]]
188 |
189 | We then backpropagate this error w.r.t the corresponding action to network,
190 | leave other action as error=0 cause we didn't choose it.
191 | """
192 |
193 | # train eval network
194 | _, self.cost = self.sess.run([self._train_op, self.loss],
195 | feed_dict={self.s: batch_memory[:, :self.n_features],
196 | self.q_target: q_target})
197 | self.cost_his.append(self.cost)
198 |
199 | # increasing epsilon
200 | self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
201 | self.learn_step_counter += 1
202 |
203 | def plot_cost(self):
204 | import matplotlib.pyplot as plt
205 | plt.plot(np.arange(len(self.cost_his)), self.cost_his)
206 | plt.ylabel('Cost')
207 | plt.xlabel('training steps')
208 | plt.show()
209 |
210 |
211 |
212 |
--------------------------------------------------------------------------------
/contents/5_Deep_Q_Network/maze_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Reinforcement learning maze example.
3 |
4 | Red rectangle: explorer.
5 | Black rectangles: hells [reward = -1].
6 | Yellow bin circle: paradise [reward = +1].
7 | All other states: ground [reward = 0].
8 |
9 | This script is the environment part of this example.
10 | The RL is in RL_brain.py.
11 |
12 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
13 | """
14 | import numpy as np
15 | import time
16 | import sys
17 | if sys.version_info.major == 2:
18 | import Tkinter as tk
19 | else:
20 | import tkinter as tk
21 |
22 | UNIT = 40 # pixels
23 | MAZE_H = 4 # grid height
24 | MAZE_W = 4 # grid width
25 |
26 |
27 | class Maze(tk.Tk, object):
28 | def __init__(self):
29 | super(Maze, self).__init__()
30 | self.action_space = ['u', 'd', 'l', 'r']
31 | self.n_actions = len(self.action_space)
32 | self.n_features = 2
33 | self.title('maze')
34 | self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
35 | self._build_maze()
36 |
37 | def _build_maze(self):
38 | self.canvas = tk.Canvas(self, bg='white',
39 | height=MAZE_H * UNIT,
40 | width=MAZE_W * UNIT)
41 |
42 | # create grids
43 | for c in range(0, MAZE_W * UNIT, UNIT):
44 | x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
45 | self.canvas.create_line(x0, y0, x1, y1)
46 | for r in range(0, MAZE_H * UNIT, UNIT):
47 | x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
48 | self.canvas.create_line(x0, y0, x1, y1)
49 |
50 | # create origin
51 | origin = np.array([20, 20])
52 |
53 | # hell
54 | hell1_center = origin + np.array([UNIT * 2, UNIT])
55 | self.hell1 = self.canvas.create_rectangle(
56 | hell1_center[0] - 15, hell1_center[1] - 15,
57 | hell1_center[0] + 15, hell1_center[1] + 15,
58 | fill='black')
59 | # hell
60 | # hell2_center = origin + np.array([UNIT, UNIT * 2])
61 | # self.hell2 = self.canvas.create_rectangle(
62 | # hell2_center[0] - 15, hell2_center[1] - 15,
63 | # hell2_center[0] + 15, hell2_center[1] + 15,
64 | # fill='black')
65 |
66 | # create oval
67 | oval_center = origin + UNIT * 2
68 | self.oval = self.canvas.create_oval(
69 | oval_center[0] - 15, oval_center[1] - 15,
70 | oval_center[0] + 15, oval_center[1] + 15,
71 | fill='yellow')
72 |
73 | # create red rect
74 | self.rect = self.canvas.create_rectangle(
75 | origin[0] - 15, origin[1] - 15,
76 | origin[0] + 15, origin[1] + 15,
77 | fill='red')
78 |
79 | # pack all
80 | self.canvas.pack()
81 |
82 | def reset(self):
83 | self.update()
84 | time.sleep(0.1)
85 | self.canvas.delete(self.rect)
86 | origin = np.array([20, 20])
87 | self.rect = self.canvas.create_rectangle(
88 | origin[0] - 15, origin[1] - 15,
89 | origin[0] + 15, origin[1] + 15,
90 | fill='red')
91 | # return observation
92 | return (np.array(self.canvas.coords(self.rect)[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
93 |
94 | def step(self, action):
95 | s = self.canvas.coords(self.rect)
96 | base_action = np.array([0, 0])
97 | if action == 0: # up
98 | if s[1] > UNIT:
99 | base_action[1] -= UNIT
100 | elif action == 1: # down
101 | if s[1] < (MAZE_H - 1) * UNIT:
102 | base_action[1] += UNIT
103 | elif action == 2: # right
104 | if s[0] < (MAZE_W - 1) * UNIT:
105 | base_action[0] += UNIT
106 | elif action == 3: # left
107 | if s[0] > UNIT:
108 | base_action[0] -= UNIT
109 |
110 | self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
111 |
112 | next_coords = self.canvas.coords(self.rect) # next state
113 |
114 | # reward function
115 | if next_coords == self.canvas.coords(self.oval):
116 | reward = 1
117 | done = True
118 | elif next_coords in [self.canvas.coords(self.hell1)]:
119 | reward = -1
120 | done = True
121 | else:
122 | reward = 0
123 | done = False
124 | s_ = (np.array(next_coords[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
125 | return s_, reward, done
126 |
127 | def render(self):
128 | # time.sleep(0.01)
129 | self.update()
130 |
131 |
132 |
--------------------------------------------------------------------------------
/contents/5_Deep_Q_Network/run_this.py:
--------------------------------------------------------------------------------
1 | from maze_env import Maze
2 | from RL_brain import DeepQNetwork
3 |
4 |
5 | def run_maze():
6 | step = 0
7 | for episode in range(300):
8 | # initial observation
9 | observation = env.reset()
10 |
11 | while True:
12 | # fresh env
13 | env.render()
14 |
15 | # RL choose action based on observation
16 | action = RL.choose_action(observation)
17 |
18 | # RL take action and get next observation and reward
19 | observation_, reward, done = env.step(action)
20 |
21 | RL.store_transition(observation, action, reward, observation_)
22 |
23 | if (step > 200) and (step % 5 == 0):
24 | RL.learn()
25 |
26 | # swap observation
27 | observation = observation_
28 |
29 | # break while loop when end of this episode
30 | if done:
31 | break
32 | step += 1
33 |
34 | # end of game
35 | print('game over')
36 | env.destroy()
37 |
38 |
39 | if __name__ == "__main__":
40 | # maze game
41 | env = Maze()
42 | RL = DeepQNetwork(env.n_actions, env.n_features,
43 | learning_rate=0.01,
44 | reward_decay=0.9,
45 | e_greedy=0.9,
46 | replace_target_iter=200,
47 | memory_size=2000,
48 | # output_graph=True
49 | )
50 | env.after(100, run_maze)
51 | env.mainloop()
52 | RL.plot_cost()
--------------------------------------------------------------------------------
/contents/6_OpenAI_gym/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the DQN brain, which is a brain of the agent.
3 | All decisions are made in here.
4 | Using Tensorflow to build the neural network.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | Tensorflow: 1.0
10 | gym: 0.8.0
11 | """
12 |
13 | import numpy as np
14 | import pandas as pd
15 | import tensorflow as tf
16 |
17 |
18 | # Deep Q Network off-policy
19 | class DeepQNetwork:
20 | def __init__(
21 | self,
22 | n_actions,
23 | n_features,
24 | learning_rate=0.01,
25 | reward_decay=0.9,
26 | e_greedy=0.9,
27 | replace_target_iter=300,
28 | memory_size=500,
29 | batch_size=32,
30 | e_greedy_increment=None,
31 | output_graph=False,
32 | ):
33 | self.n_actions = n_actions
34 | self.n_features = n_features
35 | self.lr = learning_rate
36 | self.gamma = reward_decay
37 | self.epsilon_max = e_greedy
38 | self.replace_target_iter = replace_target_iter
39 | self.memory_size = memory_size
40 | self.batch_size = batch_size
41 | self.epsilon_increment = e_greedy_increment
42 | self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
43 |
44 | # total learning step
45 | self.learn_step_counter = 0
46 |
47 | # initialize zero memory [s, a, r, s_]
48 | self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
49 |
50 | # consist of [target_net, evaluate_net]
51 | self._build_net()
52 | t_params = tf.get_collection('target_net_params')
53 | e_params = tf.get_collection('eval_net_params')
54 | self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
55 |
56 | self.sess = tf.Session()
57 |
58 | if output_graph:
59 | # $ tensorboard --logdir=logs
60 | # tf.train.SummaryWriter soon be deprecated, use following
61 | tf.summary.FileWriter("logs/", self.sess.graph)
62 |
63 | self.sess.run(tf.global_variables_initializer())
64 | self.cost_his = []
65 |
66 | def _build_net(self):
67 | # ------------------ build evaluate_net ------------------
68 | self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
69 | self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
70 | with tf.variable_scope('eval_net'):
71 | # c_names(collections_names) are the collections to store variables
72 | c_names, n_l1, w_initializer, b_initializer = \
73 | ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, \
74 | tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
75 |
76 | # first layer. collections is used later when assign to target net
77 | with tf.variable_scope('l1'):
78 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
79 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
80 | l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
81 |
82 | # second layer. collections is used later when assign to target net
83 | with tf.variable_scope('l2'):
84 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
85 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
86 | self.q_eval = tf.matmul(l1, w2) + b2
87 |
88 | with tf.variable_scope('loss'):
89 | self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
90 | with tf.variable_scope('train'):
91 | self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
92 |
93 | # ------------------ build target_net ------------------
94 | self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
95 | with tf.variable_scope('target_net'):
96 | # c_names(collections_names) are the collections to store variables
97 | c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
98 |
99 | # first layer. collections is used later when assign to target net
100 | with tf.variable_scope('l1'):
101 | w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
102 | b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
103 | l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
104 |
105 | # second layer. collections is used later when assign to target net
106 | with tf.variable_scope('l2'):
107 | w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
108 | b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
109 | self.q_next = tf.matmul(l1, w2) + b2
110 |
111 | def store_transition(self, s, a, r, s_):
112 | if not hasattr(self, 'memory_counter'):
113 | self.memory_counter = 0
114 |
115 | transition = np.hstack((s, [a, r], s_))
116 |
117 | # replace the old memory with new memory
118 | index = self.memory_counter % self.memory_size
119 | self.memory[index, :] = transition
120 |
121 | self.memory_counter += 1
122 |
123 | def choose_action(self, observation):
124 | # to have batch dimension when feed into tf placeholder
125 | observation = observation[np.newaxis, :]
126 |
127 | if np.random.uniform() < self.epsilon:
128 | # forward feed the observation and get q value for every actions
129 | actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
130 | action = np.argmax(actions_value)
131 | else:
132 | action = np.random.randint(0, self.n_actions)
133 | return action
134 |
135 | def learn(self):
136 | # check to replace target parameters
137 | if self.learn_step_counter % self.replace_target_iter == 0:
138 | self.sess.run(self.replace_target_op)
139 | print('\ntarget_params_replaced\n')
140 |
141 | # sample batch memory from all memory
142 | if self.memory_counter > self.memory_size:
143 | sample_index = np.random.choice(self.memory_size, size=self.batch_size)
144 | else:
145 | sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
146 | batch_memory = self.memory[sample_index, :]
147 |
148 | q_next, q_eval = self.sess.run(
149 | [self.q_next, self.q_eval],
150 | feed_dict={
151 | self.s_: batch_memory[:, -self.n_features:], # fixed params
152 | self.s: batch_memory[:, :self.n_features], # newest params
153 | })
154 |
155 | # change q_target w.r.t q_eval's action
156 | q_target = q_eval.copy()
157 |
158 | batch_index = np.arange(self.batch_size, dtype=np.int32)
159 | eval_act_index = batch_memory[:, self.n_features].astype(int)
160 | reward = batch_memory[:, self.n_features + 1]
161 |
162 | q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
163 |
164 | """
165 | For example in this batch I have 2 samples and 3 actions:
166 | q_eval =
167 | [[1, 2, 3],
168 | [4, 5, 6]]
169 |
170 | q_target = q_eval =
171 | [[1, 2, 3],
172 | [4, 5, 6]]
173 |
174 | Then change q_target with the real q_target value w.r.t the q_eval's action.
175 | For example in:
176 | sample 0, I took action 0, and the max q_target value is -1;
177 | sample 1, I took action 2, and the max q_target value is -2:
178 | q_target =
179 | [[-1, 2, 3],
180 | [4, 5, -2]]
181 |
182 | So the (q_target - q_eval) becomes:
183 | [[(-1)-(1), 0, 0],
184 | [0, 0, (-2)-(6)]]
185 |
186 | We then backpropagate this error w.r.t the corresponding action to network,
187 | leave other action as error=0 cause we didn't choose it.
188 | """
189 |
190 | # train eval network
191 | _, self.cost = self.sess.run([self._train_op, self.loss],
192 | feed_dict={self.s: batch_memory[:, :self.n_features],
193 | self.q_target: q_target})
194 | self.cost_his.append(self.cost)
195 |
196 | # increasing epsilon
197 | self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
198 | self.learn_step_counter += 1
199 |
200 | def plot_cost(self):
201 | import matplotlib.pyplot as plt
202 | plt.plot(np.arange(len(self.cost_his)), self.cost_his)
203 | plt.ylabel('Cost')
204 | plt.xlabel('training steps')
205 | plt.show()
206 |
207 |
208 |
209 |
--------------------------------------------------------------------------------
/contents/6_OpenAI_gym/run_CartPole.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Q network,
3 |
4 | Using:
5 | Tensorflow: 1.0
6 | gym: 0.7.3
7 | """
8 |
9 |
10 | import gym
11 | from RL_brain import DeepQNetwork
12 |
13 | env = gym.make('CartPole-v0')
14 | env = env.unwrapped
15 |
16 | print(env.action_space)
17 | print(env.observation_space)
18 | print(env.observation_space.high)
19 | print(env.observation_space.low)
20 |
21 | RL = DeepQNetwork(n_actions=env.action_space.n,
22 | n_features=env.observation_space.shape[0],
23 | learning_rate=0.01, e_greedy=0.9,
24 | replace_target_iter=100, memory_size=2000,
25 | e_greedy_increment=0.001,)
26 |
27 | total_steps = 0
28 |
29 |
30 | for i_episode in range(100):
31 |
32 | observation = env.reset()
33 | ep_r = 0
34 | while True:
35 | env.render()
36 |
37 | action = RL.choose_action(observation)
38 |
39 | observation_, reward, done, info = env.step(action)
40 |
41 | # the smaller theta and closer to center the better
42 | x, x_dot, theta, theta_dot = observation_
43 | r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8
44 | r2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians - 0.5
45 | reward = r1 + r2
46 |
47 | RL.store_transition(observation, action, reward, observation_)
48 |
49 | ep_r += reward
50 | if total_steps > 1000:
51 | RL.learn()
52 |
53 | if done:
54 | print('episode: ', i_episode,
55 | 'ep_r: ', round(ep_r, 2),
56 | ' epsilon: ', round(RL.epsilon, 2))
57 | break
58 |
59 | observation = observation_
60 | total_steps += 1
61 |
62 | RL.plot_cost()
63 |
--------------------------------------------------------------------------------
/contents/6_OpenAI_gym/run_MountainCar.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Q network,
3 |
4 | Using:
5 | Tensorflow: 1.0
6 | gym: 0.8.0
7 | """
8 |
9 |
10 | import gym
11 | from RL_brain import DeepQNetwork
12 |
13 | env = gym.make('MountainCar-v0')
14 | env = env.unwrapped
15 |
16 | print(env.action_space)
17 | print(env.observation_space)
18 | print(env.observation_space.high)
19 | print(env.observation_space.low)
20 |
21 | RL = DeepQNetwork(n_actions=3, n_features=2, learning_rate=0.001, e_greedy=0.9,
22 | replace_target_iter=300, memory_size=3000,
23 | e_greedy_increment=0.0002,)
24 |
25 | total_steps = 0
26 |
27 |
28 | for i_episode in range(10):
29 |
30 | observation = env.reset()
31 | ep_r = 0
32 | while True:
33 | env.render()
34 |
35 | action = RL.choose_action(observation)
36 |
37 | observation_, reward, done, info = env.step(action)
38 |
39 | position, velocity = observation_
40 |
41 | # the higher the better
42 | reward = abs(position - (-0.5)) # r in [0, 1]
43 |
44 | RL.store_transition(observation, action, reward, observation_)
45 |
46 | if total_steps > 1000:
47 | RL.learn()
48 |
49 | ep_r += reward
50 | if done:
51 | get = '| Get' if observation_[0] >= env.unwrapped.goal_position else '| ----'
52 | print('Epi: ', i_episode,
53 | get,
54 | '| Ep_r: ', round(ep_r, 4),
55 | '| Epsilon: ', round(RL.epsilon, 2))
56 | break
57 |
58 | observation = observation_
59 | total_steps += 1
60 |
61 | RL.plot_cost()
62 |
--------------------------------------------------------------------------------
/contents/7_Policy_gradient_softmax/RL_brain.py:
--------------------------------------------------------------------------------
1 | """
2 | This part of code is the reinforcement learning brain, which is a brain of the agent.
3 | All decisions are made in here.
4 |
5 | Policy Gradient, Reinforcement Learning.
6 |
7 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
8 |
9 | Using:
10 | Tensorflow: 1.0
11 | gym: 0.8.0
12 | """
13 |
14 | import numpy as np
15 | import tensorflow as tf
16 |
17 | # reproducible
18 | np.random.seed(1)
19 | tf.set_random_seed(1)
20 |
21 |
22 | class PolicyGradient:
23 | def __init__(
24 | self,
25 | n_actions,
26 | n_features,
27 | learning_rate=0.01,
28 | reward_decay=0.95,
29 | output_graph=False,
30 | ):
31 | self.n_actions = n_actions
32 | self.n_features = n_features
33 | self.lr = learning_rate
34 | self.gamma = reward_decay
35 |
36 | self.ep_obs, self.ep_as, self.ep_rs = [], [], []
37 |
38 | self._build_net()
39 |
40 | self.sess = tf.Session()
41 |
42 | if output_graph:
43 | # $ tensorboard --logdir=logs
44 | # http://0.0.0.0:6006/
45 | # tf.train.SummaryWriter soon be deprecated, use following
46 | tf.summary.FileWriter("logs/", self.sess.graph)
47 |
48 | self.sess.run(tf.global_variables_initializer())
49 |
50 | def _build_net(self):
51 | with tf.name_scope('inputs'):
52 | self.tf_obs = tf.placeholder(tf.float32, [None, self.n_features], name="observations")
53 | self.tf_acts = tf.placeholder(tf.int32, [None, ], name="actions_num")
54 | self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value")
55 | # fc1
56 | layer = tf.layers.dense(
57 | inputs=self.tf_obs,
58 | units=10,
59 | activation=tf.nn.tanh, # tanh activation
60 | kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
61 | bias_initializer=tf.constant_initializer(0.1),
62 | name='fc1'
63 | )
64 | # fc2
65 | all_act = tf.layers.dense(
66 | inputs=layer,
67 | units=self.n_actions,
68 | activation=None,
69 | kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
70 | bias_initializer=tf.constant_initializer(0.1),
71 | name='fc2'
72 | )
73 |
74 | self.all_act_prob = tf.nn.softmax(all_act, name='act_prob') # use softmax to convert to probability
75 |
76 | with tf.name_scope('loss'):
77 | # to maximize total reward (log_p * R) is to minimize -(log_p * R), and the tf only have minimize(loss)
78 | neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=all_act, labels=self.tf_acts) # this is negative log of chosen action
79 | # or in this way:
80 | # neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions), axis=1)
81 | loss = tf.reduce_mean(neg_log_prob * self.tf_vt) # reward guided loss
82 |
83 | with tf.name_scope('train'):
84 | self.train_op = tf.train.AdamOptimizer(self.lr).minimize(loss)
85 |
86 | def choose_action(self, observation):
87 | prob_weights = self.sess.run(self.all_act_prob, feed_dict={self.tf_obs: observation[np.newaxis, :]})
88 | action = np.random.choice(range(prob_weights.shape[1]), p=prob_weights.ravel()) # select action w.r.t the actions prob
89 | return action
90 |
91 | def store_transition(self, s, a, r):
92 | self.ep_obs.append(s)
93 | self.ep_as.append(a)
94 | self.ep_rs.append(r)
95 |
96 | def learn(self):
97 | # discount and normalize episode reward
98 | discounted_ep_rs_norm = self._discount_and_norm_rewards()
99 |
100 | # train on episode
101 | self.sess.run(self.train_op, feed_dict={
102 | self.tf_obs: np.vstack(self.ep_obs), # shape=[None, n_obs]
103 | self.tf_acts: np.array(self.ep_as), # shape=[None, ]
104 | self.tf_vt: discounted_ep_rs_norm, # shape=[None, ]
105 | })
106 |
107 | self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data
108 | return discounted_ep_rs_norm
109 |
110 | def _discount_and_norm_rewards(self):
111 | # discount episode rewards
112 | discounted_ep_rs = np.zeros_like(self.ep_rs)
113 | running_add = 0
114 | for t in reversed(range(0, len(self.ep_rs))):
115 | running_add = running_add * self.gamma + self.ep_rs[t]
116 | discounted_ep_rs[t] = running_add
117 |
118 | # normalize episode rewards
119 | discounted_ep_rs -= np.mean(discounted_ep_rs)
120 | discounted_ep_rs /= np.std(discounted_ep_rs)
121 | return discounted_ep_rs
122 |
123 |
124 |
125 |
--------------------------------------------------------------------------------
/contents/7_Policy_gradient_softmax/run_CartPole.py:
--------------------------------------------------------------------------------
1 | """
2 | Policy Gradient, Reinforcement Learning.
3 |
4 | The cart pole example
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | Tensorflow: 1.0
10 | gym: 0.8.0
11 | """
12 |
13 | import gym
14 | from RL_brain import PolicyGradient
15 | import matplotlib.pyplot as plt
16 |
17 | DISPLAY_REWARD_THRESHOLD = 400 # renders environment if total episode reward is greater then this threshold
18 | RENDER = False # rendering wastes time
19 |
20 | env = gym.make('CartPole-v0')
21 | env.seed(1) # reproducible, general Policy gradient has high variance
22 | env = env.unwrapped
23 |
24 | print(env.action_space)
25 | print(env.observation_space)
26 | print(env.observation_space.high)
27 | print(env.observation_space.low)
28 |
29 | RL = PolicyGradient(
30 | n_actions=env.action_space.n,
31 | n_features=env.observation_space.shape[0],
32 | learning_rate=0.02,
33 | reward_decay=0.99,
34 | # output_graph=True,
35 | )
36 |
37 | for i_episode in range(3000):
38 |
39 | observation = env.reset()
40 |
41 | while True:
42 | if RENDER: env.render()
43 |
44 | action = RL.choose_action(observation)
45 |
46 | observation_, reward, done, info = env.step(action)
47 |
48 | RL.store_transition(observation, action, reward)
49 |
50 | if done:
51 | ep_rs_sum = sum(RL.ep_rs)
52 |
53 | if 'running_reward' not in globals():
54 | running_reward = ep_rs_sum
55 | else:
56 | running_reward = running_reward * 0.99 + ep_rs_sum * 0.01
57 | if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
58 | print("episode:", i_episode, " reward:", int(running_reward))
59 |
60 | vt = RL.learn()
61 |
62 | if i_episode == 0:
63 | plt.plot(vt) # plot the episode vt
64 | plt.xlabel('episode steps')
65 | plt.ylabel('normalized state-action value')
66 | plt.show()
67 | break
68 |
69 | observation = observation_
70 |
--------------------------------------------------------------------------------
/contents/7_Policy_gradient_softmax/run_MountainCar.py:
--------------------------------------------------------------------------------
1 | """
2 | Policy Gradient, Reinforcement Learning.
3 |
4 | The cart pole example
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | Tensorflow: 1.0
10 | gym: 0.8.0
11 | """
12 |
13 | import gym
14 | from RL_brain import PolicyGradient
15 | import matplotlib.pyplot as plt
16 |
17 | DISPLAY_REWARD_THRESHOLD = -2000 # renders environment if total episode reward is greater then this threshold
18 | # episode: 154 reward: -10667
19 | # episode: 387 reward: -2009
20 | # episode: 489 reward: -1006
21 | # episode: 628 reward: -502
22 |
23 | RENDER = False # rendering wastes time
24 |
25 | env = gym.make('MountainCar-v0')
26 | env.seed(1) # reproducible, general Policy gradient has high variance
27 | env = env.unwrapped
28 |
29 | print(env.action_space)
30 | print(env.observation_space)
31 | print(env.observation_space.high)
32 | print(env.observation_space.low)
33 |
34 | RL = PolicyGradient(
35 | n_actions=env.action_space.n,
36 | n_features=env.observation_space.shape[0],
37 | learning_rate=0.02,
38 | reward_decay=0.995,
39 | # output_graph=True,
40 | )
41 |
42 | for i_episode in range(1000):
43 |
44 | observation = env.reset()
45 |
46 | while True:
47 | if RENDER: env.render()
48 |
49 | action = RL.choose_action(observation)
50 |
51 | observation_, reward, done, info = env.step(action) # reward = -1 in all cases
52 |
53 | RL.store_transition(observation, action, reward)
54 |
55 | if done:
56 | # calculate running reward
57 | ep_rs_sum = sum(RL.ep_rs)
58 | if 'running_reward' not in globals():
59 | running_reward = ep_rs_sum
60 | else:
61 | running_reward = running_reward * 0.99 + ep_rs_sum * 0.01
62 | if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
63 |
64 | print("episode:", i_episode, " reward:", int(running_reward))
65 |
66 | vt = RL.learn() # train
67 |
68 | if i_episode == 30:
69 | plt.plot(vt) # plot the episode vt
70 | plt.xlabel('episode steps')
71 | plt.ylabel('normalized state-action value')
72 | plt.show()
73 |
74 | break
75 |
76 | observation = observation_
77 |
--------------------------------------------------------------------------------
/contents/8_Actor_Critic_Advantage/AC_CartPole.py:
--------------------------------------------------------------------------------
1 | """
2 | Actor-Critic using TD-error as the Advantage, Reinforcement Learning.
3 |
4 | The cart pole example. Policy is oscillated.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | tensorflow 1.0
10 | gym 0.8.0
11 | """
12 |
13 | import numpy as np
14 | import tensorflow as tf
15 | import gym
16 |
17 | np.random.seed(2)
18 | tf.set_random_seed(2) # reproducible
19 |
20 | # Superparameters
21 | OUTPUT_GRAPH = False
22 | MAX_EPISODE = 3000
23 | DISPLAY_REWARD_THRESHOLD = 200 # renders environment if total episode reward is greater then this threshold
24 | MAX_EP_STEPS = 1000 # maximum time step in one episode
25 | RENDER = False # rendering wastes time
26 | GAMMA = 0.9 # reward discount in TD error
27 | LR_A = 0.001 # learning rate for actor
28 | LR_C = 0.01 # learning rate for critic
29 |
30 | env = gym.make('CartPole-v0')
31 | env.seed(1) # reproducible
32 | env = env.unwrapped
33 |
34 | N_F = env.observation_space.shape[0]
35 | N_A = env.action_space.n
36 |
37 |
38 | class Actor(object):
39 | def __init__(self, sess, n_features, n_actions, lr=0.001):
40 | self.sess = sess
41 |
42 | self.s = tf.placeholder(tf.float32, [1, n_features], "state")
43 | self.a = tf.placeholder(tf.int32, None, "act")
44 | self.td_error = tf.placeholder(tf.float32, None, "td_error") # TD_error
45 |
46 | with tf.variable_scope('Actor'):
47 | l1 = tf.layers.dense(
48 | inputs=self.s,
49 | units=20, # number of hidden units
50 | activation=tf.nn.relu,
51 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
52 | bias_initializer=tf.constant_initializer(0.1), # biases
53 | name='l1'
54 | )
55 |
56 | self.acts_prob = tf.layers.dense(
57 | inputs=l1,
58 | units=n_actions, # output units
59 | activation=tf.nn.softmax, # get action probabilities
60 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
61 | bias_initializer=tf.constant_initializer(0.1), # biases
62 | name='acts_prob'
63 | )
64 |
65 | with tf.variable_scope('exp_v'):
66 | log_prob = tf.log(self.acts_prob[0, self.a])
67 | self.exp_v = tf.reduce_mean(log_prob * self.td_error) # advantage (TD_error) guided loss
68 |
69 | with tf.variable_scope('train'):
70 | self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v) # minimize(-exp_v) = maximize(exp_v)
71 |
72 | def learn(self, s, a, td):
73 | s = s[np.newaxis, :]
74 | feed_dict = {self.s: s, self.a: a, self.td_error: td}
75 | _, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
76 | return exp_v
77 |
78 | def choose_action(self, s):
79 | s = s[np.newaxis, :]
80 | probs = self.sess.run(self.acts_prob, {self.s: s}) # get probabilities for all actions
81 | return np.random.choice(np.arange(probs.shape[1]), p=probs.ravel()) # return a int
82 |
83 |
84 | class Critic(object):
85 | def __init__(self, sess, n_features, lr=0.01):
86 | self.sess = sess
87 |
88 | self.s = tf.placeholder(tf.float32, [1, n_features], "state")
89 | self.v_ = tf.placeholder(tf.float32, [1, 1], "v_next")
90 | self.r = tf.placeholder(tf.float32, None, 'r')
91 |
92 | with tf.variable_scope('Critic'):
93 | l1 = tf.layers.dense(
94 | inputs=self.s,
95 | units=20, # number of hidden units
96 | activation=tf.nn.relu, # None
97 | # have to be linear to make sure the convergence of actor.
98 | # But linear approximator seems hardly learns the correct Q.
99 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
100 | bias_initializer=tf.constant_initializer(0.1), # biases
101 | name='l1'
102 | )
103 |
104 | self.v = tf.layers.dense(
105 | inputs=l1,
106 | units=1, # output units
107 | activation=None,
108 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
109 | bias_initializer=tf.constant_initializer(0.1), # biases
110 | name='V'
111 | )
112 |
113 | with tf.variable_scope('squared_TD_error'):
114 | self.td_error = self.r + GAMMA * self.v_ - self.v
115 | self.loss = tf.square(self.td_error) # TD_error = (r+gamma*V_next) - V_eval
116 | with tf.variable_scope('train'):
117 | self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
118 |
119 | def learn(self, s, r, s_):
120 | s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
121 |
122 | v_ = self.sess.run(self.v, {self.s: s_})
123 | td_error, _ = self.sess.run([self.td_error, self.train_op],
124 | {self.s: s, self.v_: v_, self.r: r})
125 | return td_error
126 |
127 |
128 | sess = tf.Session()
129 |
130 | actor = Actor(sess, n_features=N_F, n_actions=N_A, lr=LR_A)
131 | critic = Critic(sess, n_features=N_F, lr=LR_C) # we need a good teacher, so the teacher should learn faster than the actor
132 |
133 | sess.run(tf.global_variables_initializer())
134 |
135 | if OUTPUT_GRAPH:
136 | tf.summary.FileWriter("logs/", sess.graph)
137 |
138 | for i_episode in range(MAX_EPISODE):
139 | s = env.reset()
140 | t = 0
141 | track_r = []
142 | while True:
143 | if RENDER: env.render()
144 |
145 | a = actor.choose_action(s)
146 |
147 | s_, r, done, info = env.step(a)
148 |
149 | if done: r = -20
150 |
151 | track_r.append(r)
152 |
153 | td_error = critic.learn(s, r, s_) # gradient = grad[r + gamma * V(s_) - V(s)]
154 | actor.learn(s, a, td_error) # true_gradient = grad[logPi(s,a) * td_error]
155 |
156 | s = s_
157 | t += 1
158 |
159 | if done or t >= MAX_EP_STEPS:
160 | ep_rs_sum = sum(track_r)
161 |
162 | if 'running_reward' not in globals():
163 | running_reward = ep_rs_sum
164 | else:
165 | running_reward = running_reward * 0.95 + ep_rs_sum * 0.05
166 | if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
167 | print("episode:", i_episode, " reward:", int(running_reward))
168 | break
169 |
170 |
--------------------------------------------------------------------------------
/contents/8_Actor_Critic_Advantage/AC_continue_Pendulum.py:
--------------------------------------------------------------------------------
1 | """
2 | Actor-Critic with continuous action using TD-error as the Advantage, Reinforcement Learning.
3 |
4 | The Pendulum example (based on https://github.com/dennybritz/reinforcement-learning/blob/master/PolicyGradient/Continuous%20MountainCar%20Actor%20Critic%20Solution.ipynb)
5 |
6 | Cannot converge!!! oscillate!!!
7 |
8 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
9 |
10 | Using:
11 | tensorflow r1.3
12 | gym 0.8.0
13 | """
14 |
15 | import tensorflow as tf
16 | import numpy as np
17 | import gym
18 |
19 | np.random.seed(2)
20 | tf.set_random_seed(2) # reproducible
21 |
22 |
23 | class Actor(object):
24 | def __init__(self, sess, n_features, action_bound, lr=0.0001):
25 | self.sess = sess
26 |
27 | self.s = tf.placeholder(tf.float32, [1, n_features], "state")
28 | self.a = tf.placeholder(tf.float32, None, name="act")
29 | self.td_error = tf.placeholder(tf.float32, None, name="td_error") # TD_error
30 |
31 | l1 = tf.layers.dense(
32 | inputs=self.s,
33 | units=30, # number of hidden units
34 | activation=tf.nn.relu,
35 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
36 | bias_initializer=tf.constant_initializer(0.1), # biases
37 | name='l1'
38 | )
39 |
40 | mu = tf.layers.dense(
41 | inputs=l1,
42 | units=1, # number of hidden units
43 | activation=tf.nn.tanh,
44 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
45 | bias_initializer=tf.constant_initializer(0.1), # biases
46 | name='mu'
47 | )
48 |
49 | sigma = tf.layers.dense(
50 | inputs=l1,
51 | units=1, # output units
52 | activation=tf.nn.softplus, # get action probabilities
53 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
54 | bias_initializer=tf.constant_initializer(1.), # biases
55 | name='sigma'
56 | )
57 | global_step = tf.Variable(0, trainable=False)
58 | # self.e = epsilon = tf.train.exponential_decay(2., global_step, 1000, 0.9)
59 | self.mu, self.sigma = tf.squeeze(mu*2), tf.squeeze(sigma+0.1)
60 | self.normal_dist = tf.distributions.Normal(self.mu, self.sigma)
61 |
62 | self.action = tf.clip_by_value(self.normal_dist.sample(1), action_bound[0], action_bound[1])
63 |
64 | with tf.name_scope('exp_v'):
65 | log_prob = self.normal_dist.log_prob(self.a) # loss without advantage
66 | self.exp_v = log_prob * self.td_error # advantage (TD_error) guided loss
67 | # Add cross entropy cost to encourage exploration
68 | self.exp_v += 0.01*self.normal_dist.entropy()
69 |
70 | with tf.name_scope('train'):
71 | self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v, global_step) # min(v) = max(-v)
72 |
73 | def learn(self, s, a, td):
74 | s = s[np.newaxis, :]
75 | feed_dict = {self.s: s, self.a: a, self.td_error: td}
76 | _, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
77 | return exp_v
78 |
79 | def choose_action(self, s):
80 | s = s[np.newaxis, :]
81 | return self.sess.run(self.action, {self.s: s}) # get probabilities for all actions
82 |
83 |
84 | class Critic(object):
85 | def __init__(self, sess, n_features, lr=0.01):
86 | self.sess = sess
87 | with tf.name_scope('inputs'):
88 | self.s = tf.placeholder(tf.float32, [1, n_features], "state")
89 | self.v_ = tf.placeholder(tf.float32, [1, 1], name="v_next")
90 | self.r = tf.placeholder(tf.float32, name='r')
91 |
92 | with tf.variable_scope('Critic'):
93 | l1 = tf.layers.dense(
94 | inputs=self.s,
95 | units=30, # number of hidden units
96 | activation=tf.nn.relu,
97 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
98 | bias_initializer=tf.constant_initializer(0.1), # biases
99 | name='l1'
100 | )
101 |
102 | self.v = tf.layers.dense(
103 | inputs=l1,
104 | units=1, # output units
105 | activation=None,
106 | kernel_initializer=tf.random_normal_initializer(0., .1), # weights
107 | bias_initializer=tf.constant_initializer(0.1), # biases
108 | name='V'
109 | )
110 |
111 | with tf.variable_scope('squared_TD_error'):
112 | self.td_error = tf.reduce_mean(self.r + GAMMA * self.v_ - self.v)
113 | self.loss = tf.square(self.td_error) # TD_error = (r+gamma*V_next) - V_eval
114 | with tf.variable_scope('train'):
115 | self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
116 |
117 | def learn(self, s, r, s_):
118 | s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
119 |
120 | v_ = self.sess.run(self.v, {self.s: s_})
121 | td_error, _ = self.sess.run([self.td_error, self.train_op],
122 | {self.s: s, self.v_: v_, self.r: r})
123 | return td_error
124 |
125 |
126 | OUTPUT_GRAPH = False
127 | MAX_EPISODE = 1000
128 | MAX_EP_STEPS = 200
129 | DISPLAY_REWARD_THRESHOLD = -100 # renders environment if total episode reward is greater then this threshold
130 | RENDER = False # rendering wastes time
131 | GAMMA = 0.9
132 | LR_A = 0.001 # learning rate for actor
133 | LR_C = 0.01 # learning rate for critic
134 |
135 | env = gym.make('Pendulum-v0')
136 | env.seed(1) # reproducible
137 | env = env.unwrapped
138 |
139 | N_S = env.observation_space.shape[0]
140 | A_BOUND = env.action_space.high
141 |
142 | sess = tf.Session()
143 |
144 | actor = Actor(sess, n_features=N_S, lr=LR_A, action_bound=[-A_BOUND, A_BOUND])
145 | critic = Critic(sess, n_features=N_S, lr=LR_C)
146 |
147 | sess.run(tf.global_variables_initializer())
148 |
149 | if OUTPUT_GRAPH:
150 | tf.summary.FileWriter("logs/", sess.graph)
151 |
152 | for i_episode in range(MAX_EPISODE):
153 | s = env.reset()
154 | t = 0
155 | ep_rs = []
156 | while True:
157 | # if RENDER:
158 | env.render()
159 | a = actor.choose_action(s)
160 |
161 | s_, r, done, info = env.step(a)
162 | r /= 10
163 |
164 | td_error = critic.learn(s, r, s_) # gradient = grad[r + gamma * V(s_) - V(s)]
165 | actor.learn(s, a, td_error) # true_gradient = grad[logPi(s,a) * td_error]
166 |
167 | s = s_
168 | t += 1
169 | ep_rs.append(r)
170 | if t > MAX_EP_STEPS:
171 | ep_rs_sum = sum(ep_rs)
172 | if 'running_reward' not in globals():
173 | running_reward = ep_rs_sum
174 | else:
175 | running_reward = running_reward * 0.9 + ep_rs_sum * 0.1
176 | if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
177 | print("episode:", i_episode, " reward:", int(running_reward))
178 | break
179 |
180 |
--------------------------------------------------------------------------------
/contents/9_Deep_Deterministic_Policy_Gradient_DDPG/DDPG_update.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Deterministic Policy Gradient (DDPG), Reinforcement Learning.
3 | DDPG is Actor Critic based algorithm.
4 | Pendulum example.
5 |
6 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | tensorflow 1.0
10 | gym 0.8.0
11 | """
12 |
13 | import tensorflow as tf
14 | import numpy as np
15 | import gym
16 | import time
17 |
18 |
19 | ##################### hyper parameters ####################
20 |
21 | MAX_EPISODES = 200
22 | MAX_EP_STEPS = 200
23 | LR_A = 0.001 # learning rate for actor
24 | LR_C = 0.002 # learning rate for critic
25 | GAMMA = 0.9 # reward discount
26 | TAU = 0.01 # soft replacement
27 | MEMORY_CAPACITY = 10000
28 | BATCH_SIZE = 32
29 |
30 | RENDER = False
31 | ENV_NAME = 'Pendulum-v0'
32 |
33 | ############################### DDPG ####################################
34 |
35 | class DDPG(object):
36 | def __init__(self, a_dim, s_dim, a_bound,):
37 | self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
38 | self.pointer = 0
39 | self.sess = tf.Session()
40 |
41 | self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
42 | self.S = tf.placeholder(tf.float32, [None, s_dim], 's')
43 | self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
44 | self.R = tf.placeholder(tf.float32, [None, 1], 'r')
45 |
46 | with tf.variable_scope('Actor'):
47 | self.a = self._build_a(self.S, scope='eval', trainable=True)
48 | a_ = self._build_a(self.S_, scope='target', trainable=False)
49 | with tf.variable_scope('Critic'):
50 | # assign self.a = a in memory when calculating q for td_error,
51 | # otherwise the self.a is from Actor when updating Actor
52 | q = self._build_c(self.S, self.a, scope='eval', trainable=True)
53 | q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
54 |
55 | # networks parameters
56 | self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
57 | self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
58 | self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
59 | self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
60 |
61 | # target net replacement
62 | self.soft_replace = [[tf.assign(ta, (1 - TAU) * ta + TAU * ea), tf.assign(tc, (1 - TAU) * tc + TAU * ec)]
63 | for ta, ea, tc, ec in zip(self.at_params, self.ae_params, self.ct_params, self.ce_params)]
64 |
65 | q_target = self.R + GAMMA * q_
66 | # in the feed_dic for the td_error, the self.a should change to actions in memory
67 | td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
68 | self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
69 |
70 | a_loss = - tf.reduce_mean(q) # maximize the q
71 | self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
72 |
73 | self.sess.run(tf.global_variables_initializer())
74 |
75 | def choose_action(self, s):
76 | return self.sess.run(self.a, {self.S: s[np.newaxis, :]})[0]
77 |
78 | def learn(self):
79 | # soft target replacement
80 | self.sess.run(self.soft_replace)
81 |
82 | indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
83 | bt = self.memory[indices, :]
84 | bs = bt[:, :self.s_dim]
85 | ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
86 | br = bt[:, -self.s_dim - 1: -self.s_dim]
87 | bs_ = bt[:, -self.s_dim:]
88 |
89 | self.sess.run(self.atrain, {self.S: bs})
90 | self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
91 |
92 | def store_transition(self, s, a, r, s_):
93 | transition = np.hstack((s, a, [r], s_))
94 | index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
95 | self.memory[index, :] = transition
96 | self.pointer += 1
97 |
98 | def _build_a(self, s, scope, trainable):
99 | with tf.variable_scope(scope):
100 | net = tf.layers.dense(s, 30, activation=tf.nn.relu, name='l1', trainable=trainable)
101 | a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
102 | return tf.multiply(a, self.a_bound, name='scaled_a')
103 |
104 | def _build_c(self, s, a, scope, trainable):
105 | with tf.variable_scope(scope):
106 | n_l1 = 30
107 | w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
108 | w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
109 | b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
110 | net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
111 | return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
112 |
113 | ############################### training ####################################
114 |
115 | env = gym.make(ENV_NAME)
116 | env = env.unwrapped
117 | env.seed(1)
118 |
119 | s_dim = env.observation_space.shape[0]
120 | a_dim = env.action_space.shape[0]
121 | a_bound = env.action_space.high
122 |
123 | ddpg = DDPG(a_dim, s_dim, a_bound)
124 |
125 | var = 3 # control exploration
126 | t1 = time.time()
127 | for i in range(MAX_EPISODES):
128 | s = env.reset()
129 | ep_reward = 0
130 | for j in range(MAX_EP_STEPS):
131 | if RENDER:
132 | env.render()
133 |
134 | # Add exploration noise
135 | a = ddpg.choose_action(s)
136 | a = np.clip(np.random.normal(a, var), -2, 2) # add randomness to action selection for exploration
137 | s_, r, done, info = env.step(a)
138 |
139 | ddpg.store_transition(s, a, r / 10, s_)
140 |
141 | if ddpg.pointer > MEMORY_CAPACITY:
142 | var *= .9995 # decay the action randomness
143 | ddpg.learn()
144 |
145 | s = s_
146 | ep_reward += r
147 | if j == MAX_EP_STEPS-1:
148 | print('Episode:', i, ' Reward: %i' % int(ep_reward), 'Explore: %.2f' % var, )
149 | # if ep_reward > -300:RENDER = True
150 | break
151 | print('Running time: ', time.time() - t1)
--------------------------------------------------------------------------------
/contents/9_Deep_Deterministic_Policy_Gradient_DDPG/DDPG_update2.py:
--------------------------------------------------------------------------------
1 | """
2 | Note: This is a updated version from my previous code,
3 | for the target network, I use moving average to soft replace target parameters instead using assign function.
4 | By doing this, it has 20% speed up on my machine (CPU).
5 |
6 | Deep Deterministic Policy Gradient (DDPG), Reinforcement Learning.
7 | DDPG is Actor Critic based algorithm.
8 | Pendulum example.
9 |
10 | View more on my tutorial page: https://morvanzhou.github.io/tutorials/
11 |
12 | Using:
13 | tensorflow 1.0
14 | gym 0.8.0
15 | """
16 |
17 | import tensorflow as tf
18 | import numpy as np
19 | import gym
20 | import time
21 |
22 |
23 | ##################### hyper parameters ####################
24 |
25 | MAX_EPISODES = 200
26 | MAX_EP_STEPS = 200
27 | LR_A = 0.001 # learning rate for actor
28 | LR_C = 0.002 # learning rate for critic
29 | GAMMA = 0.9 # reward discount
30 | TAU = 0.01 # soft replacement
31 | MEMORY_CAPACITY = 10000
32 | BATCH_SIZE = 32
33 |
34 | RENDER = False
35 | ENV_NAME = 'Pendulum-v0'
36 |
37 |
38 | ############################### DDPG ####################################
39 |
40 |
41 | class DDPG(object):
42 | def __init__(self, a_dim, s_dim, a_bound,):
43 | self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
44 | self.pointer = 0
45 | self.sess = tf.Session()
46 |
47 | self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
48 | self.S = tf.placeholder(tf.float32, [None, s_dim], 's')
49 | self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
50 | self.R = tf.placeholder(tf.float32, [None, 1], 'r')
51 |
52 | self.a = self._build_a(self.S,)
53 | q = self._build_c(self.S, self.a, )
54 | a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Actor')
55 | c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Critic')
56 | ema = tf.train.ExponentialMovingAverage(decay=1 - TAU) # soft replacement
57 |
58 | def ema_getter(getter, name, *args, **kwargs):
59 | return ema.average(getter(name, *args, **kwargs))
60 |
61 | target_update = [ema.apply(a_params), ema.apply(c_params)] # soft update operation
62 | a_ = self._build_a(self.S_, reuse=True, custom_getter=ema_getter) # replaced target parameters
63 | q_ = self._build_c(self.S_, a_, reuse=True, custom_getter=ema_getter)
64 |
65 | a_loss = - tf.reduce_mean(q) # maximize the q
66 | self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=a_params)
67 |
68 | with tf.control_dependencies(target_update): # soft replacement happened at here
69 | q_target = self.R + GAMMA * q_
70 | td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
71 | self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=c_params)
72 |
73 | self.sess.run(tf.global_variables_initializer())
74 |
75 | def choose_action(self, s):
76 | return self.sess.run(self.a, {self.S: s[np.newaxis, :]})[0]
77 |
78 | def learn(self):
79 | indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
80 | bt = self.memory[indices, :]
81 | bs = bt[:, :self.s_dim]
82 | ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
83 | br = bt[:, -self.s_dim - 1: -self.s_dim]
84 | bs_ = bt[:, -self.s_dim:]
85 |
86 | self.sess.run(self.atrain, {self.S: bs})
87 | self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
88 |
89 | def store_transition(self, s, a, r, s_):
90 | transition = np.hstack((s, a, [r], s_))
91 | index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
92 | self.memory[index, :] = transition
93 | self.pointer += 1
94 |
95 | def _build_a(self, s, reuse=None, custom_getter=None):
96 | trainable = True if reuse is None else False
97 | with tf.variable_scope('Actor', reuse=reuse, custom_getter=custom_getter):
98 | net = tf.layers.dense(s, 30, activation=tf.nn.relu, name='l1', trainable=trainable)
99 | a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
100 | return tf.multiply(a, self.a_bound, name='scaled_a')
101 |
102 | def _build_c(self, s, a, reuse=None, custom_getter=None):
103 | trainable = True if reuse is None else False
104 | with tf.variable_scope('Critic', reuse=reuse, custom_getter=custom_getter):
105 | n_l1 = 30
106 | w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
107 | w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
108 | b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
109 | net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
110 | return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
111 |
112 |
113 | ############################### training ####################################
114 |
115 | env = gym.make(ENV_NAME)
116 | env = env.unwrapped
117 | env.seed(1)
118 |
119 | s_dim = env.observation_space.shape[0]
120 | a_dim = env.action_space.shape[0]
121 | a_bound = env.action_space.high
122 |
123 | ddpg = DDPG(a_dim, s_dim, a_bound)
124 |
125 | var = 3 # control exploration
126 | t1 = time.time()
127 | for i in range(MAX_EPISODES):
128 | s = env.reset()
129 | ep_reward = 0
130 | for j in range(MAX_EP_STEPS):
131 | if RENDER:
132 | env.render()
133 |
134 | # Add exploration noise
135 | a = ddpg.choose_action(s)
136 | a = np.clip(np.random.normal(a, var), -2, 2) # add randomness to action selection for exploration
137 | s_, r, done, info = env.step(a)
138 |
139 | ddpg.store_transition(s, a, r / 10, s_)
140 |
141 | if ddpg.pointer > MEMORY_CAPACITY:
142 | var *= .9995 # decay the action randomness
143 | ddpg.learn()
144 |
145 | s = s_
146 | ep_reward += r
147 | if j == MAX_EP_STEPS-1:
148 | print('Episode:', i, ' Reward: %i' % int(ep_reward), 'Explore: %.2f' % var, )
149 | # if ep_reward > -300:RENDER = True
150 | break
151 |
152 | print('Running time: ', time.time() - t1)
--------------------------------------------------------------------------------
/experiments/2D_car/car_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Environment for 2D car driving.
3 | You can customize this script in a way you want.
4 |
5 | View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
6 |
7 |
8 | Requirement:
9 | pyglet >= 1.2.4
10 | numpy >= 1.12.1
11 | """
12 | import numpy as np
13 | import pyglet
14 |
15 |
16 | pyglet.clock.set_fps_limit(10000)
17 |
18 |
19 | class CarEnv(object):
20 | n_sensor = 5
21 | action_dim = 1
22 | state_dim = n_sensor
23 | viewer = None
24 | viewer_xy = (500, 500)
25 | sensor_max = 150.
26 | start_point = [450, 300]
27 | speed = 50.
28 | dt = 0.1
29 |
30 | def __init__(self, discrete_action=False):
31 | self.is_discrete_action = discrete_action
32 | if discrete_action:
33 | self.actions = [-1, 0, 1]
34 | else:
35 | self.action_bound = [-1, 1]
36 |
37 | self.terminal = False
38 | # node1 (x, y, r, w, l),
39 | self.car_info = np.array([0, 0, 0, 20, 40], dtype=np.float64) # car coordination
40 | self.obstacle_coords = np.array([
41 | [120, 120],
42 | [380, 120],
43 | [380, 380],
44 | [120, 380],
45 | ])
46 | self.sensor_info = self.sensor_max + np.zeros((self.n_sensor, 3)) # n sensors, (distance, end_x, end_y)
47 |
48 | def step(self, action):
49 | if self.is_discrete_action:
50 | action = self.actions[action]
51 | else:
52 | action = np.clip(action, *self.action_bound)[0]
53 | self.car_info[2] += action * np.pi/30 # max r = 6 degree
54 | self.car_info[:2] = self.car_info[:2] + \
55 | self.speed * self.dt * np.array([np.cos(self.car_info[2]), np.sin(self.car_info[2])])
56 |
57 | self._update_sensor()
58 | s = self._get_state()
59 | r = -1 if self.terminal else 0
60 | return s, r, self.terminal
61 |
62 | def reset(self):
63 | self.terminal = False
64 | self.car_info[:3] = np.array([*self.start_point, -np.pi/2])
65 | self._update_sensor()
66 | return self._get_state()
67 |
68 | def render(self):
69 | if self.viewer is None:
70 | self.viewer = Viewer(*self.viewer_xy, self.car_info, self.sensor_info, self.obstacle_coords)
71 | self.viewer.render()
72 |
73 | def sample_action(self):
74 | if self.is_discrete_action:
75 | a = np.random.choice(list(range(3)))
76 | else:
77 | a = np.random.uniform(*self.action_bound, size=self.action_dim)
78 | return a
79 |
80 | def set_fps(self, fps=30):
81 | pyglet.clock.set_fps_limit(fps)
82 |
83 | def _get_state(self):
84 | s = self.sensor_info[:, 0].flatten()/self.sensor_max
85 | return s
86 |
87 | def _update_sensor(self):
88 | cx, cy, rotation = self.car_info[:3]
89 |
90 | n_sensors = len(self.sensor_info)
91 | sensor_theta = np.linspace(-np.pi / 2, np.pi / 2, n_sensors)
92 | xs = cx + (np.zeros((n_sensors, ))+self.sensor_max) * np.cos(sensor_theta)
93 | ys = cy + (np.zeros((n_sensors, ))+self.sensor_max) * np.sin(sensor_theta)
94 | xys = np.array([[x, y] for x, y in zip(xs, ys)]) # shape (5 sensors, 2)
95 |
96 | # sensors
97 | tmp_x = xys[:, 0] - cx
98 | tmp_y = xys[:, 1] - cy
99 | # apply rotation
100 | rotated_x = tmp_x * np.cos(rotation) - tmp_y * np.sin(rotation)
101 | rotated_y = tmp_x * np.sin(rotation) + tmp_y * np.cos(rotation)
102 | # rotated x y
103 | self.sensor_info[:, -2:] = np.vstack([rotated_x+cx, rotated_y+cy]).T
104 |
105 | q = np.array([cx, cy])
106 | for si in range(len(self.sensor_info)):
107 | s = self.sensor_info[si, -2:] - q
108 | possible_sensor_distance = [self.sensor_max]
109 | possible_intersections = [self.sensor_info[si, -2:]]
110 |
111 | # obstacle collision
112 | for oi in range(len(self.obstacle_coords)):
113 | p = self.obstacle_coords[oi]
114 | r = self.obstacle_coords[(oi + 1) % len(self.obstacle_coords)] - self.obstacle_coords[oi]
115 | if np.cross(r, s) != 0: # may collision
116 | t = np.cross((q - p), s) / np.cross(r, s)
117 | u = np.cross((q - p), r) / np.cross(r, s)
118 | if 0 <= t <= 1 and 0 <= u <= 1:
119 | intersection = q + u * s
120 | possible_intersections.append(intersection)
121 | possible_sensor_distance.append(np.linalg.norm(u*s))
122 |
123 | # window collision
124 | win_coord = np.array([
125 | [0, 0],
126 | [self.viewer_xy[0], 0],
127 | [*self.viewer_xy],
128 | [0, self.viewer_xy[1]],
129 | [0, 0],
130 | ])
131 | for oi in range(4):
132 | p = win_coord[oi]
133 | r = win_coord[(oi + 1) % len(win_coord)] - win_coord[oi]
134 | if np.cross(r, s) != 0: # may collision
135 | t = np.cross((q - p), s) / np.cross(r, s)
136 | u = np.cross((q - p), r) / np.cross(r, s)
137 | if 0 <= t <= 1 and 0 <= u <= 1:
138 | intersection = p + t * r
139 | possible_intersections.append(intersection)
140 | possible_sensor_distance.append(np.linalg.norm(intersection - q))
141 |
142 | distance = np.min(possible_sensor_distance)
143 | distance_index = np.argmin(possible_sensor_distance)
144 | self.sensor_info[si, 0] = distance
145 | self.sensor_info[si, -2:] = possible_intersections[distance_index]
146 | if distance < self.car_info[-1]/2:
147 | self.terminal = True
148 |
149 |
150 | class Viewer(pyglet.window.Window):
151 | color = {
152 | 'background': [1]*3 + [1]
153 | }
154 | fps_display = pyglet.clock.ClockDisplay()
155 | bar_thc = 5
156 |
157 | def __init__(self, width, height, car_info, sensor_info, obstacle_coords):
158 | super(Viewer, self).__init__(width, height, resizable=False, caption='2D car', vsync=False) # vsync=False to not use the monitor FPS
159 | self.set_location(x=80, y=10)
160 | pyglet.gl.glClearColor(*self.color['background'])
161 |
162 | self.car_info = car_info
163 | self.sensor_info = sensor_info
164 |
165 | self.batch = pyglet.graphics.Batch()
166 | background = pyglet.graphics.OrderedGroup(0)
167 | foreground = pyglet.graphics.OrderedGroup(1)
168 |
169 | self.sensors = []
170 | line_coord = [0, 0] * 2
171 | c = (73, 73, 73) * 2
172 | for i in range(len(self.sensor_info)):
173 | self.sensors.append(self.batch.add(2, pyglet.gl.GL_LINES, foreground, ('v2f', line_coord), ('c3B', c)))
174 |
175 | car_box = [0, 0] * 4
176 | c = (249, 86, 86) * 4
177 | self.car = self.batch.add(4, pyglet.gl.GL_QUADS, foreground, ('v2f', car_box), ('c3B', c))
178 |
179 | c = (134, 181, 244) * 4
180 | self.obstacle = self.batch.add(4, pyglet.gl.GL_QUADS, background, ('v2f', obstacle_coords.flatten()), ('c3B', c))
181 |
182 | def render(self):
183 | pyglet.clock.tick()
184 | self._update()
185 | self.switch_to()
186 | self.dispatch_events()
187 | self.dispatch_event('on_draw')
188 | self.flip()
189 |
190 | def on_draw(self):
191 | self.clear()
192 | self.batch.draw()
193 | # self.fps_display.draw()
194 |
195 | def _update(self):
196 | cx, cy, r, w, l = self.car_info
197 |
198 | # sensors
199 | for i, sensor in enumerate(self.sensors):
200 | sensor.vertices = [cx, cy, *self.sensor_info[i, -2:]]
201 |
202 | # car
203 | xys = [
204 | [cx + l / 2, cy + w / 2],
205 | [cx - l / 2, cy + w / 2],
206 | [cx - l / 2, cy - w / 2],
207 | [cx + l / 2, cy - w / 2],
208 | ]
209 | r_xys = []
210 | for x, y in xys:
211 | tempX = x - cx
212 | tempY = y - cy
213 | # apply rotation
214 | rotatedX = tempX * np.cos(r) - tempY * np.sin(r)
215 | rotatedY = tempX * np.sin(r) + tempY * np.cos(r)
216 | # rotated x y
217 | x = rotatedX + cx
218 | y = rotatedY + cy
219 | r_xys += [x, y]
220 | self.car.vertices = r_xys
221 |
222 |
223 | if __name__ == '__main__':
224 | np.random.seed(1)
225 | env = CarEnv()
226 | env.set_fps(30)
227 | for ep in range(20):
228 | s = env.reset()
229 | # for t in range(100):
230 | while True:
231 | env.render()
232 | s, r, done = env.step(env.sample_action())
233 | if done:
234 | break
--------------------------------------------------------------------------------
/experiments/2D_car/collision.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | def intersection():
4 | p = np.array([0, 0])
5 | r = np.array([1, 1])
6 | q = np.array([0.1, 0.1])
7 | s = np.array([.1, .1])
8 |
9 | if np.cross(r, s) == 0 and np.cross((q-p), r) == 0: # collinear
10 | # t0 = (q − p) · r / (r · r)
11 | # t1 = (q + s − p) · r / (r · r) = t0 + s · r / (r · r)
12 | t0 = np.dot(q-p, r)/np.dot(r, r)
13 | t1 = t0 + np.dot(s, r)/np.dot(r, r)
14 | print(t1, t0)
15 | if ((np.dot(s, r) > 0) and (0 <= t1 - t0 <= 1)) or ((np.dot(s, r) <= 0) and (0 <= t0 - t1 <= 1)):
16 | print('collinear and overlapping, q_s in p_r')
17 | else:
18 | print('collinear and disjoint')
19 | elif np.cross(r, s) == 0 and np.cross((q-p), r) != 0: # parallel r × s = 0 and (q − p) × r ≠ 0,
20 | print('parallel')
21 | else:
22 | t = np.cross((q - p), s) / np.cross(r, s)
23 | u = np.cross((q - p), r) / np.cross(r, s)
24 | if 0 <= t <= 1 and 0 <= u <= 1:
25 | # If r × s ≠ 0 and 0 ≤ t ≤ 1 and 0 ≤ u ≤ 1, the two line segments meet at the point p + t r = q + u s
26 | print('intersection: ', p + t*r)
27 | else:
28 | print('not parallel and not intersect')
29 |
30 |
31 | def point2segment():
32 | p = np.array([-1, 1]) # coordination of point
33 | a = np.array([0, 1]) # coordination of line segment end 1
34 | b = np.array([1, 0]) # coordination of line segment end 2
35 | ab = b-a # line ab
36 | ap = p-a
37 | distance = np.abs(np.cross(ab, ap)/np.linalg.norm(ab)) # d = (AB x AC)/|AB|
38 | print(distance)
39 |
40 | # angle Cos(θ) = A dot B /(|A||B|)
41 | bp = p-b
42 | cosTheta1 = np.dot(ap, ab) / (np.linalg.norm(ap) * np.linalg.norm(ab))
43 | theta1 = np.arccos(cosTheta1)
44 | cosTheta2 = np.dot(bp, ab) / (np.linalg.norm(bp) * np.linalg.norm(ab))
45 | theta2 = np.arccos(cosTheta2)
46 | if np.pi/2 <= (theta1 % (np.pi*2)) <= 3/2 * np.pi:
47 | print('out of a')
48 | elif -np.pi/2 <= (theta2 % (np.pi*2)) <= np.pi/2:
49 | print('out of b')
50 | else:
51 | print('between a and b')
52 |
53 |
54 |
55 | if __name__ == '__main__':
56 | point2segment()
57 | # intersection()
58 |
--------------------------------------------------------------------------------
/experiments/Robot_arm/A3C.py:
--------------------------------------------------------------------------------
1 | """
2 | Environment is a Robot Arm. The arm tries to get to the blue point.
3 | The environment will return a geographic (distance) information for the arm to learn.
4 |
5 | The far away from blue point the less reward; touch blue r+=1; stop at blue for a while then get r=+10.
6 |
7 | You can train this RL by using LOAD = False, after training, this model will be store in the a local folder.
8 | Using LOAD = True to reload the trained model for playing.
9 |
10 | You can customize this script in a way you want.
11 |
12 | View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
13 |
14 |
15 | Requirement:
16 | pyglet >= 1.2.4
17 | numpy >= 1.12.1
18 | tensorflow >= 1.0.1
19 | """
20 |
21 | import multiprocessing
22 | import threading
23 | import tensorflow as tf
24 | import numpy as np
25 | from arm_env import ArmEnv
26 |
27 |
28 | # np.random.seed(1)
29 | # tf.set_random_seed(1)
30 |
31 | MAX_GLOBAL_EP = 2000
32 | MAX_EP_STEP = 300
33 | UPDATE_GLOBAL_ITER = 5
34 | N_WORKERS = multiprocessing.cpu_count()
35 | LR_A = 1e-4 # learning rate for actor
36 | LR_C = 2e-4 # learning rate for critic
37 | GAMMA = 0.9 # reward discount
38 | MODE = ['easy', 'hard']
39 | n_model = 1
40 | GLOBAL_NET_SCOPE = 'Global_Net'
41 | ENTROPY_BETA = 0.01
42 | GLOBAL_RUNNING_R = []
43 | GLOBAL_EP = 0
44 |
45 |
46 | env = ArmEnv(mode=MODE[n_model])
47 | N_S = env.state_dim
48 | N_A = env.action_dim
49 | A_BOUND = env.action_bound
50 | del env
51 |
52 |
53 | class ACNet(object):
54 | def __init__(self, scope, globalAC=None):
55 |
56 | if scope == GLOBAL_NET_SCOPE: # get global network
57 | with tf.variable_scope(scope):
58 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
59 | self._build_net()
60 | self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
61 | self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
62 | else: # local net, calculate losses
63 | with tf.variable_scope(scope):
64 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
65 | self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
66 | self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
67 |
68 | mu, sigma, self.v = self._build_net()
69 |
70 | td = tf.subtract(self.v_target, self.v, name='TD_error')
71 | with tf.name_scope('c_loss'):
72 | self.c_loss = tf.reduce_mean(tf.square(td))
73 |
74 | with tf.name_scope('wrap_a_out'):
75 | self.test = sigma[0]
76 | mu, sigma = mu * A_BOUND[1], sigma + 1e-5
77 |
78 | normal_dist = tf.contrib.distributions.Normal(mu, sigma)
79 |
80 | with tf.name_scope('a_loss'):
81 | log_prob = normal_dist.log_prob(self.a_his)
82 | exp_v = log_prob * td
83 | entropy = normal_dist.entropy() # encourage exploration
84 | self.exp_v = ENTROPY_BETA * entropy + exp_v
85 | self.a_loss = tf.reduce_mean(-self.exp_v)
86 |
87 | with tf.name_scope('choose_a'): # use local params to choose action
88 | self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=0), *A_BOUND)
89 | with tf.name_scope('local_grad'):
90 | self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
91 | self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
92 | self.a_grads = tf.gradients(self.a_loss, self.a_params)
93 | self.c_grads = tf.gradients(self.c_loss, self.c_params)
94 |
95 | with tf.name_scope('sync'):
96 | with tf.name_scope('pull'):
97 | self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
98 | self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
99 | with tf.name_scope('push'):
100 | self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
101 | self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
102 |
103 | def _build_net(self):
104 | w_init = tf.contrib.layers.xavier_initializer()
105 | with tf.variable_scope('actor'):
106 | l_a = tf.layers.dense(self.s, 400, tf.nn.relu6, kernel_initializer=w_init, name='la')
107 | l_a = tf.layers.dense(l_a, 300, tf.nn.relu6, kernel_initializer=w_init, name='la2')
108 | mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
109 | sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
110 | with tf.variable_scope('critic'):
111 | l_c = tf.layers.dense(self.s, 400, tf.nn.relu6, kernel_initializer=w_init, name='lc')
112 | l_c = tf.layers.dense(l_c, 200, tf.nn.relu6, kernel_initializer=w_init, name='lc2')
113 | v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
114 | return mu, sigma, v
115 |
116 | def update_global(self, feed_dict): # run by a local
117 | _, _, t = SESS.run([self.update_a_op, self.update_c_op, self.test], feed_dict) # local grads applies to global net
118 | return t
119 |
120 | def pull_global(self): # run by a local
121 | SESS.run([self.pull_a_params_op, self.pull_c_params_op])
122 |
123 | def choose_action(self, s): # run by a local
124 | s = s[np.newaxis, :]
125 | return SESS.run(self.A, {self.s: s})[0]
126 |
127 |
128 | class Worker(object):
129 | def __init__(self, name, globalAC):
130 | self.env = ArmEnv(mode=MODE[n_model])
131 | self.name = name
132 | self.AC = ACNet(name, globalAC)
133 |
134 | def work(self):
135 | global GLOBAL_RUNNING_R, GLOBAL_EP
136 | total_step = 1
137 | buffer_s, buffer_a, buffer_r = [], [], []
138 | while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
139 | s = self.env.reset()
140 | ep_r = 0
141 | for ep_t in range(MAX_EP_STEP):
142 | if self.name == 'W_0':
143 | self.env.render()
144 | a = self.AC.choose_action(s)
145 | s_, r, done = self.env.step(a)
146 | if ep_t == MAX_EP_STEP - 1: done = True
147 | ep_r += r
148 | buffer_s.append(s)
149 | buffer_a.append(a)
150 | buffer_r.append(r)
151 |
152 | if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
153 | if done:
154 | v_s_ = 0 # terminal
155 | else:
156 | v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
157 | buffer_v_target = []
158 | for r in buffer_r[::-1]: # reverse buffer r
159 | v_s_ = r + GAMMA * v_s_
160 | buffer_v_target.append(v_s_)
161 | buffer_v_target.reverse()
162 |
163 | buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
164 | feed_dict = {
165 | self.AC.s: buffer_s,
166 | self.AC.a_his: buffer_a,
167 | self.AC.v_target: buffer_v_target,
168 | }
169 | test = self.AC.update_global(feed_dict)
170 | buffer_s, buffer_a, buffer_r = [], [], []
171 | self.AC.pull_global()
172 |
173 | s = s_
174 | total_step += 1
175 | if done:
176 | if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
177 | GLOBAL_RUNNING_R.append(ep_r)
178 | else:
179 | GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r)
180 | print(
181 | self.name,
182 | "Ep:", GLOBAL_EP,
183 | "| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
184 | '| Var:', test,
185 |
186 | )
187 | GLOBAL_EP += 1
188 | break
189 |
190 | if __name__ == "__main__":
191 | SESS = tf.Session()
192 |
193 | with tf.device("/cpu:0"):
194 | OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
195 | OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
196 | GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
197 | workers = []
198 | # Create worker
199 | for i in range(N_WORKERS):
200 | i_name = 'W_%i' % i # worker name
201 | workers.append(Worker(i_name, GLOBAL_AC))
202 |
203 | COORD = tf.train.Coordinator()
204 | SESS.run(tf.global_variables_initializer())
205 |
206 | worker_threads = []
207 | for worker in workers:
208 | job = lambda: worker.work()
209 | t = threading.Thread(target=job)
210 | t.start()
211 | worker_threads.append(t)
212 | COORD.join(worker_threads)
213 |
214 |
215 |
--------------------------------------------------------------------------------
/experiments/Robot_arm/DPPO.py:
--------------------------------------------------------------------------------
1 | """
2 | A simple version of OpenAI's Proximal Policy Optimization (PPO). [http://adsabs.harvard.edu/abs/2017arXiv170706347S]
3 |
4 | Distributing workers in parallel to collect data, then stop worker's roll-out and train PPO on collected data.
5 | Restart workers once PPO is updated.
6 |
7 | The global PPO updating rule is adopted from DeepMind's paper (DPPO):
8 | Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [http://adsabs.harvard.edu/abs/2017arXiv170702286H]
9 |
10 | View more on my tutorial website: https://morvanzhou.github.io/tutorials
11 |
12 | Dependencies:
13 | tensorflow r1.2
14 | gym 0.9.2
15 | """
16 |
17 | import tensorflow as tf
18 | from tensorflow.contrib.distributions import Normal
19 | import numpy as np
20 | import matplotlib.pyplot as plt
21 | import threading, queue
22 | from arm_env import ArmEnv
23 |
24 |
25 | EP_MAX = 2000
26 | EP_LEN = 300
27 | N_WORKER = 4 # parallel workers
28 | GAMMA = 0.9 # reward discount factor
29 | A_LR = 0.0001 # learning rate for actor
30 | C_LR = 0.0005 # learning rate for critic
31 | MIN_BATCH_SIZE = 64 # minimum batch size for updating PPO
32 | UPDATE_STEP = 5 # loop update operation n-steps
33 | EPSILON = 0.2 # Clipped surrogate objective
34 | MODE = ['easy', 'hard']
35 | n_model = 1
36 |
37 | env = ArmEnv(mode=MODE[n_model])
38 | S_DIM = env.state_dim
39 | A_DIM = env.action_dim
40 | A_BOUND = env.action_bound[1]
41 |
42 |
43 | class PPO(object):
44 | def __init__(self):
45 | self.sess = tf.Session()
46 |
47 | self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
48 |
49 | # critic
50 | l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
51 | self.v = tf.layers.dense(l1, 1)
52 | self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
53 | self.advantage = self.tfdc_r - self.v
54 | self.closs = tf.reduce_mean(tf.square(self.advantage))
55 | self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
56 |
57 | # actor
58 | pi, pi_params = self._build_anet('pi', trainable=True)
59 | oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
60 | self.sample_op = tf.squeeze(pi.sample(1), axis=0) # choosing action
61 | self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
62 |
63 | self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
64 | self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
65 | # ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
66 | ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
67 | surr = ratio * self.tfadv # surrogate loss
68 |
69 | self.aloss = -tf.reduce_mean(tf.minimum(
70 | surr,
71 | tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
72 |
73 | self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
74 | self.sess.run(tf.global_variables_initializer())
75 |
76 | def update(self):
77 | global GLOBAL_UPDATE_COUNTER
78 | while not COORD.should_stop():
79 | if GLOBAL_EP < EP_MAX:
80 | UPDATE_EVENT.wait() # wait until get batch of data
81 | self.sess.run(self.update_oldpi_op) # old pi to pi
82 | data = [QUEUE.get() for _ in range(QUEUE.qsize())]
83 | data = np.vstack(data)
84 | s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + A_DIM], data[:, -1:]
85 | adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
86 | [self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
87 | [self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
88 | UPDATE_EVENT.clear() # updating finished
89 | GLOBAL_UPDATE_COUNTER = 0 # reset counter
90 | ROLLING_EVENT.set() # set roll-out available
91 |
92 | def _build_anet(self, name, trainable):
93 | with tf.variable_scope(name):
94 | l1 = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
95 | mu = A_BOUND * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
96 | sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
97 | norm_dist = Normal(loc=mu, scale=sigma)
98 | params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
99 | return norm_dist, params
100 |
101 | def choose_action(self, s):
102 | s = s[np.newaxis, :]
103 | a = self.sess.run(self.sample_op, {self.tfs: s})[0]
104 | return np.clip(a, -2, 2)
105 |
106 | def get_v(self, s):
107 | if s.ndim < 2: s = s[np.newaxis, :]
108 | return self.sess.run(self.v, {self.tfs: s})[0, 0]
109 |
110 |
111 | class Worker(object):
112 | def __init__(self, wid):
113 | self.wid = wid
114 | self.env = ArmEnv(mode=MODE[n_model])
115 | self.ppo = GLOBAL_PPO
116 |
117 | def work(self):
118 | global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
119 | while not COORD.should_stop():
120 | s = self.env.reset()
121 | ep_r = 0
122 | buffer_s, buffer_a, buffer_r = [], [], []
123 | for t in range(EP_LEN):
124 | if not ROLLING_EVENT.is_set(): # while global PPO is updating
125 | ROLLING_EVENT.wait() # wait until PPO is updated
126 | buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer
127 | a = self.ppo.choose_action(s)
128 | s_, r, done = self.env.step(a)
129 | buffer_s.append(s)
130 | buffer_a.append(a)
131 | buffer_r.append(r) # normalize reward, find to be useful
132 | s = s_
133 | ep_r += r
134 |
135 | GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size
136 | if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
137 | v_s_ = self.ppo.get_v(s_)
138 | discounted_r = [] # compute discounted reward
139 | for r in buffer_r[::-1]:
140 | v_s_ = r + GAMMA * v_s_
141 | discounted_r.append(v_s_)
142 | discounted_r.reverse()
143 |
144 | bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
145 | buffer_s, buffer_a, buffer_r = [], [], []
146 | QUEUE.put(np.hstack((bs, ba, br)))
147 | if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
148 | ROLLING_EVENT.clear() # stop collecting data
149 | UPDATE_EVENT.set() # globalPPO update
150 |
151 | if GLOBAL_EP >= EP_MAX: # stop training
152 | COORD.request_stop()
153 | break
154 |
155 | # record reward changes, plot later
156 | if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
157 | else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
158 | GLOBAL_EP += 1
159 | print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
160 |
161 |
162 | if __name__ == '__main__':
163 | GLOBAL_PPO = PPO()
164 | UPDATE_EVENT, ROLLING_EVENT = threading.Event(), threading.Event()
165 | UPDATE_EVENT.clear() # no update now
166 | ROLLING_EVENT.set() # start to roll out
167 | workers = [Worker(wid=i) for i in range(N_WORKER)]
168 |
169 | GLOBAL_UPDATE_COUNTER, GLOBAL_EP = 0, 0
170 | GLOBAL_RUNNING_R = []
171 | COORD = tf.train.Coordinator()
172 | QUEUE = queue.Queue()
173 | threads = []
174 | for worker in workers: # worker threads
175 | t = threading.Thread(target=worker.work, args=())
176 | t.start()
177 | threads.append(t)
178 | # add a PPO updating thread
179 | threads.append(threading.Thread(target=GLOBAL_PPO.update,))
180 | threads[-1].start()
181 | COORD.join(threads)
182 |
183 | # plot reward change and testing
184 | plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
185 | plt.xlabel('Episode'); plt.ylabel('Moving reward'); plt.ion(); plt.show()
186 | env.set_fps(30)
187 | while True:
188 | s = env.reset()
189 | for t in range(400):
190 | env.render()
191 | s = env.step(GLOBAL_PPO.choose_action(s))[0]
--------------------------------------------------------------------------------
/experiments/Robot_arm/arm_env.py:
--------------------------------------------------------------------------------
1 | """
2 | Environment for Robot Arm.
3 | You can customize this script in a way you want.
4 |
5 | View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
6 |
7 |
8 | Requirement:
9 | pyglet >= 1.2.4
10 | numpy >= 1.12.1
11 | """
12 | import numpy as np
13 | import pyglet
14 |
15 |
16 | pyglet.clock.set_fps_limit(10000)
17 |
18 |
19 | class ArmEnv(object):
20 | action_bound = [-1, 1]
21 | action_dim = 2
22 | state_dim = 7
23 | dt = .1 # refresh rate
24 | arm1l = 100
25 | arm2l = 100
26 | viewer = None
27 | viewer_xy = (400, 400)
28 | get_point = False
29 | mouse_in = np.array([False])
30 | point_l = 15
31 | grab_counter = 0
32 |
33 | def __init__(self, mode='easy'):
34 | # node1 (l, d_rad, x, y),
35 | # node2 (l, d_rad, x, y)
36 | self.mode = mode
37 | self.arm_info = np.zeros((2, 4))
38 | self.arm_info[0, 0] = self.arm1l
39 | self.arm_info[1, 0] = self.arm2l
40 | self.point_info = np.array([250, 303])
41 | self.point_info_init = self.point_info.copy()
42 | self.center_coord = np.array(self.viewer_xy)/2
43 |
44 | def step(self, action):
45 | # action = (node1 angular v, node2 angular v)
46 | action = np.clip(action, *self.action_bound)
47 | self.arm_info[:, 1] += action * self.dt
48 | self.arm_info[:, 1] %= np.pi * 2
49 |
50 | arm1rad = self.arm_info[0, 1]
51 | arm2rad = self.arm_info[1, 1]
52 | arm1dx_dy = np.array([self.arm_info[0, 0] * np.cos(arm1rad), self.arm_info[0, 0] * np.sin(arm1rad)])
53 | arm2dx_dy = np.array([self.arm_info[1, 0] * np.cos(arm2rad), self.arm_info[1, 0] * np.sin(arm2rad)])
54 | self.arm_info[0, 2:4] = self.center_coord + arm1dx_dy # (x1, y1)
55 | self.arm_info[1, 2:4] = self.arm_info[0, 2:4] + arm2dx_dy # (x2, y2)
56 |
57 | s, arm2_distance = self._get_state()
58 | r = self._r_func(arm2_distance)
59 |
60 | return s, r, self.get_point
61 |
62 | def reset(self):
63 | self.get_point = False
64 | self.grab_counter = 0
65 |
66 | if self.mode == 'hard':
67 | pxy = np.clip(np.random.rand(2) * self.viewer_xy[0], 100, 300)
68 | self.point_info[:] = pxy
69 | else:
70 | arm1rad, arm2rad = np.random.rand(2) * np.pi * 2
71 | self.arm_info[0, 1] = arm1rad
72 | self.arm_info[1, 1] = arm2rad
73 | arm1dx_dy = np.array([self.arm_info[0, 0] * np.cos(arm1rad), self.arm_info[0, 0] * np.sin(arm1rad)])
74 | arm2dx_dy = np.array([self.arm_info[1, 0] * np.cos(arm2rad), self.arm_info[1, 0] * np.sin(arm2rad)])
75 | self.arm_info[0, 2:4] = self.center_coord + arm1dx_dy # (x1, y1)
76 | self.arm_info[1, 2:4] = self.arm_info[0, 2:4] + arm2dx_dy # (x2, y2)
77 |
78 | self.point_info[:] = self.point_info_init
79 | return self._get_state()[0]
80 |
81 | def render(self):
82 | if self.viewer is None:
83 | self.viewer = Viewer(*self.viewer_xy, self.arm_info, self.point_info, self.point_l, self.mouse_in)
84 | self.viewer.render()
85 |
86 | def sample_action(self):
87 | return np.random.uniform(*self.action_bound, size=self.action_dim)
88 |
89 | def set_fps(self, fps=30):
90 | pyglet.clock.set_fps_limit(fps)
91 |
92 | def _get_state(self):
93 | # return the distance (dx, dy) between arm finger point with blue point
94 | arm_end = self.arm_info[:, 2:4]
95 | t_arms = np.ravel(arm_end - self.point_info)
96 | center_dis = (self.center_coord - self.point_info)/200
97 | in_point = 1 if self.grab_counter > 0 else 0
98 | return np.hstack([in_point, t_arms/200, center_dis,
99 | # arm1_distance_p, arm1_distance_b,
100 | ]), t_arms[-2:]
101 |
102 | def _r_func(self, distance):
103 | t = 50
104 | abs_distance = np.sqrt(np.sum(np.square(distance)))
105 | r = -abs_distance/200
106 | if abs_distance < self.point_l and (not self.get_point):
107 | r += 1.
108 | self.grab_counter += 1
109 | if self.grab_counter > t:
110 | r += 10.
111 | self.get_point = True
112 | elif abs_distance > self.point_l:
113 | self.grab_counter = 0
114 | self.get_point = False
115 | return r
116 |
117 |
118 | class Viewer(pyglet.window.Window):
119 | color = {
120 | 'background': [1]*3 + [1]
121 | }
122 | fps_display = pyglet.clock.ClockDisplay()
123 | bar_thc = 5
124 |
125 | def __init__(self, width, height, arm_info, point_info, point_l, mouse_in):
126 | super(Viewer, self).__init__(width, height, resizable=False, caption='Arm', vsync=False) # vsync=False to not use the monitor FPS
127 | self.set_location(x=80, y=10)
128 | pyglet.gl.glClearColor(*self.color['background'])
129 |
130 | self.arm_info = arm_info
131 | self.point_info = point_info
132 | self.mouse_in = mouse_in
133 | self.point_l = point_l
134 |
135 | self.center_coord = np.array((min(width, height)/2, ) * 2)
136 | self.batch = pyglet.graphics.Batch()
137 |
138 | arm1_box, arm2_box, point_box = [0]*8, [0]*8, [0]*8
139 | c1, c2, c3 = (249, 86, 86)*4, (86, 109, 249)*4, (249, 39, 65)*4
140 | self.point = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', point_box), ('c3B', c2))
141 | self.arm1 = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', arm1_box), ('c3B', c1))
142 | self.arm2 = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', arm2_box), ('c3B', c1))
143 |
144 | def render(self):
145 | pyglet.clock.tick()
146 | self._update_arm()
147 | self.switch_to()
148 | self.dispatch_events()
149 | self.dispatch_event('on_draw')
150 | self.flip()
151 |
152 | def on_draw(self):
153 | self.clear()
154 | self.batch.draw()
155 | # self.fps_display.draw()
156 |
157 | def _update_arm(self):
158 | point_l = self.point_l
159 | point_box = (self.point_info[0] - point_l, self.point_info[1] - point_l,
160 | self.point_info[0] + point_l, self.point_info[1] - point_l,
161 | self.point_info[0] + point_l, self.point_info[1] + point_l,
162 | self.point_info[0] - point_l, self.point_info[1] + point_l)
163 | self.point.vertices = point_box
164 |
165 | arm1_coord = (*self.center_coord, *(self.arm_info[0, 2:4])) # (x0, y0, x1, y1)
166 | arm2_coord = (*(self.arm_info[0, 2:4]), *(self.arm_info[1, 2:4])) # (x1, y1, x2, y2)
167 | arm1_thick_rad = np.pi / 2 - self.arm_info[0, 1]
168 | x01, y01 = arm1_coord[0] - np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[1] + np.sin(
169 | arm1_thick_rad) * self.bar_thc
170 | x02, y02 = arm1_coord[0] + np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[1] - np.sin(
171 | arm1_thick_rad) * self.bar_thc
172 | x11, y11 = arm1_coord[2] + np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[3] - np.sin(
173 | arm1_thick_rad) * self.bar_thc
174 | x12, y12 = arm1_coord[2] - np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[3] + np.sin(
175 | arm1_thick_rad) * self.bar_thc
176 | arm1_box = (x01, y01, x02, y02, x11, y11, x12, y12)
177 | arm2_thick_rad = np.pi / 2 - self.arm_info[1, 1]
178 | x11_, y11_ = arm2_coord[0] + np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[1] - np.sin(
179 | arm2_thick_rad) * self.bar_thc
180 | x12_, y12_ = arm2_coord[0] - np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[1] + np.sin(
181 | arm2_thick_rad) * self.bar_thc
182 | x21, y21 = arm2_coord[2] - np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[3] + np.sin(
183 | arm2_thick_rad) * self.bar_thc
184 | x22, y22 = arm2_coord[2] + np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[3] - np.sin(
185 | arm2_thick_rad) * self.bar_thc
186 | arm2_box = (x11_, y11_, x12_, y12_, x21, y21, x22, y22)
187 | self.arm1.vertices = arm1_box
188 | self.arm2.vertices = arm2_box
189 |
190 | def on_key_press(self, symbol, modifiers):
191 | if symbol == pyglet.window.key.UP:
192 | self.arm_info[0, 1] += .1
193 | print(self.arm_info[:, 2:4] - self.point_info)
194 | elif symbol == pyglet.window.key.DOWN:
195 | self.arm_info[0, 1] -= .1
196 | print(self.arm_info[:, 2:4] - self.point_info)
197 | elif symbol == pyglet.window.key.LEFT:
198 | self.arm_info[1, 1] += .1
199 | print(self.arm_info[:, 2:4] - self.point_info)
200 | elif symbol == pyglet.window.key.RIGHT:
201 | self.arm_info[1, 1] -= .1
202 | print(self.arm_info[:, 2:4] - self.point_info)
203 | elif symbol == pyglet.window.key.Q:
204 | pyglet.clock.set_fps_limit(1000)
205 | elif symbol == pyglet.window.key.A:
206 | pyglet.clock.set_fps_limit(30)
207 |
208 | def on_mouse_motion(self, x, y, dx, dy):
209 | self.point_info[:] = [x, y]
210 |
211 | def on_mouse_enter(self, x, y):
212 | self.mouse_in[0] = True
213 |
214 | def on_mouse_leave(self, x, y):
215 | self.mouse_in[0] = False
216 |
217 |
218 |
219 |
--------------------------------------------------------------------------------
/experiments/Solve_BipedalWalker/A3C.py:
--------------------------------------------------------------------------------
1 | """
2 | Asynchronous Advantage Actor Critic (A3C), Reinforcement Learning.
3 |
4 | The BipedalWalker example.
5 |
6 | View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
7 |
8 | Using:
9 | tensorflow 1.0
10 | gym 0.8.0
11 | """
12 |
13 | import multiprocessing
14 | import threading
15 | import tensorflow as tf
16 | import numpy as np
17 | import gym
18 | import os
19 | import shutil
20 |
21 |
22 | GAME = 'BipedalWalker-v2'
23 | OUTPUT_GRAPH = False
24 | LOG_DIR = './log'
25 | N_WORKERS = multiprocessing.cpu_count()
26 | MAX_GLOBAL_EP = 8000
27 | GLOBAL_NET_SCOPE = 'Global_Net'
28 | UPDATE_GLOBAL_ITER = 10
29 | GAMMA = 0.999
30 | ENTROPY_BETA = 0.005
31 | LR_A = 0.00002 # learning rate for actor
32 | LR_C = 0.0001 # learning rate for critic
33 | GLOBAL_RUNNING_R = []
34 | GLOBAL_EP = 0
35 |
36 | env = gym.make(GAME)
37 |
38 | N_S = env.observation_space.shape[0]
39 | N_A = env.action_space.shape[0]
40 | A_BOUND = [env.action_space.low, env.action_space.high]
41 | del env
42 |
43 |
44 | class ACNet(object):
45 | def __init__(self, scope, globalAC=None):
46 |
47 | if scope == GLOBAL_NET_SCOPE: # get global network
48 | with tf.variable_scope(scope):
49 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
50 | self._build_net()
51 | self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
52 | self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
53 | else: # local net, calculate losses
54 | with tf.variable_scope(scope):
55 | self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
56 | self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
57 | self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
58 |
59 | mu, sigma, self.v = self._build_net()
60 |
61 | td = tf.subtract(self.v_target, self.v, name='TD_error')
62 | with tf.name_scope('c_loss'):
63 | self.c_loss = tf.reduce_mean(tf.square(td))
64 |
65 | with tf.name_scope('wrap_a_out'):
66 | self.test = sigma[0]
67 | mu, sigma = mu * A_BOUND[1], sigma + 1e-5
68 |
69 | normal_dist = tf.contrib.distributions.Normal(mu, sigma)
70 |
71 | with tf.name_scope('a_loss'):
72 | log_prob = normal_dist.log_prob(self.a_his)
73 | exp_v = log_prob * td
74 | entropy = normal_dist.entropy() # encourage exploration
75 | self.exp_v = ENTROPY_BETA * entropy + exp_v
76 | self.a_loss = tf.reduce_mean(-self.exp_v)
77 |
78 | with tf.name_scope('choose_a'): # use local params to choose action
79 | self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=0), *A_BOUND)
80 | with tf.name_scope('local_grad'):
81 | self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
82 | self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
83 | self.a_grads = tf.gradients(self.a_loss, self.a_params)
84 | self.c_grads = tf.gradients(self.c_loss, self.c_params)
85 |
86 | with tf.name_scope('sync'):
87 | with tf.name_scope('pull'):
88 | self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
89 | self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
90 | with tf.name_scope('push'):
91 | self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
92 | self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
93 |
94 | def _build_net(self):
95 | w_init = tf.contrib.layers.xavier_initializer()
96 | with tf.variable_scope('actor'):
97 | l_a = tf.layers.dense(self.s, 500, tf.nn.relu6, kernel_initializer=w_init, name='la')
98 | l_a = tf.layers.dense(l_a, 300, tf.nn.relu6, kernel_initializer=w_init, name='la2')
99 | mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
100 | sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
101 | with tf.variable_scope('critic'):
102 | l_c = tf.layers.dense(self.s, 500, tf.nn.relu6, kernel_initializer=w_init, name='lc')
103 | l_c = tf.layers.dense(l_c, 200, tf.nn.relu6, kernel_initializer=w_init, name='lc2')
104 | v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
105 | return mu, sigma, v
106 |
107 | def update_global(self, feed_dict): # run by a local
108 | _, _, t = SESS.run([self.update_a_op, self.update_c_op, self.test], feed_dict) # local grads applies to global net
109 | return t
110 |
111 | def pull_global(self): # run by a local
112 | SESS.run([self.pull_a_params_op, self.pull_c_params_op])
113 |
114 | def choose_action(self, s): # run by a local
115 | s = s[np.newaxis, :]
116 | return SESS.run(self.A, {self.s: s})[0]
117 |
118 |
119 | class Worker(object):
120 | def __init__(self, name, globalAC):
121 | self.env = gym.make(GAME)
122 | self.name = name
123 | self.AC = ACNet(name, globalAC)
124 |
125 | def work(self):
126 | global GLOBAL_RUNNING_R, GLOBAL_EP
127 | total_step = 1
128 | buffer_s, buffer_a, buffer_r = [], [], []
129 | while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
130 | s = self.env.reset()
131 | ep_r = 0
132 | while True:
133 | if self.name == 'W_0' and total_step % 30 == 0:
134 | self.env.render()
135 | a = self.AC.choose_action(s)
136 | s_, r, done, info = self.env.step(a)
137 | if r == -100: r = -2
138 |
139 | ep_r += r
140 | buffer_s.append(s)
141 | buffer_a.append(a)
142 | buffer_r.append(r)
143 |
144 | if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
145 | if done:
146 | v_s_ = 0 # terminal
147 | else:
148 | v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
149 | buffer_v_target = []
150 | for r in buffer_r[::-1]: # reverse buffer r
151 | v_s_ = r + GAMMA * v_s_
152 | buffer_v_target.append(v_s_)
153 | buffer_v_target.reverse()
154 |
155 | buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
156 | feed_dict = {
157 | self.AC.s: buffer_s,
158 | self.AC.a_his: buffer_a,
159 | self.AC.v_target: buffer_v_target,
160 | }
161 | test = self.AC.update_global(feed_dict)
162 | buffer_s, buffer_a, buffer_r = [], [], []
163 | self.AC.pull_global()
164 |
165 | s = s_
166 | total_step += 1
167 | if done:
168 | achieve = '| Achieve' if self.env.unwrapped.hull.position[0] >= 88 else '| -------'
169 | if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
170 | GLOBAL_RUNNING_R.append(ep_r)
171 | else:
172 | GLOBAL_RUNNING_R.append(0.95 * GLOBAL_RUNNING_R[-1] + 0.05 * ep_r)
173 | print(
174 | self.name,
175 | "Ep:", GLOBAL_EP,
176 | achieve,
177 | "| Pos: %i" % self.env.unwrapped.hull.position[0],
178 | "| RR: %.1f" % GLOBAL_RUNNING_R[-1],
179 | '| EpR: %.1f' % ep_r,
180 | '| var:', test,
181 | )
182 | GLOBAL_EP += 1
183 | break
184 |
185 | if __name__ == "__main__":
186 | SESS = tf.Session()
187 |
188 | with tf.device("/cpu:0"):
189 | OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
190 | OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
191 | GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
192 | workers = []
193 | # Create worker
194 | for i in range(N_WORKERS):
195 | i_name = 'W_%i' % i # worker name
196 | workers.append(Worker(i_name, GLOBAL_AC))
197 |
198 | COORD = tf.train.Coordinator()
199 | SESS.run(tf.global_variables_initializer())
200 |
201 | worker_threads = []
202 | for worker in workers:
203 | job = lambda: worker.work()
204 | t = threading.Thread(target=job)
205 | t.start()
206 | worker_threads.append(t)
207 | COORD.join(worker_threads)
208 |
209 |
210 |
--------------------------------------------------------------------------------
/experiments/Solve_BipedalWalker/log/events.out.tfevents.1490801027.Morvan:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiajunhua/MorvanZhou-Reinforcement-learning-with-tensorflow/b484df7fc7dadab61e73e04aa40416bf6db68321/experiments/Solve_BipedalWalker/log/events.out.tfevents.1490801027.Morvan
--------------------------------------------------------------------------------
/experiments/Solve_LunarLander/run_LunarLander.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Q network,
3 |
4 | LunarLander-v2 example
5 |
6 | Using:
7 | Tensorflow: 1.0
8 | gym: 0.8.0
9 | """
10 |
11 |
12 | import gym
13 | from gym import wrappers
14 | from DuelingDQNPrioritizedReplay import DuelingDQNPrioritizedReplay
15 |
16 | env = gym.make('LunarLander-v2')
17 | # env = env.unwrapped
18 | env.seed(1)
19 |
20 | N_A = env.action_space.n
21 | N_S = env.observation_space.shape[0]
22 | MEMORY_CAPACITY = 50000
23 | TARGET_REP_ITER = 2000
24 | MAX_EPISODES = 900
25 | E_GREEDY = 0.95
26 | E_INCREMENT = 0.00001
27 | GAMMA = 0.99
28 | LR = 0.0001
29 | BATCH_SIZE = 32
30 | HIDDEN = [400, 400]
31 | RENDER = True
32 |
33 | RL = DuelingDQNPrioritizedReplay(
34 | n_actions=N_A, n_features=N_S, learning_rate=LR, e_greedy=E_GREEDY, reward_decay=GAMMA,
35 | hidden=HIDDEN, batch_size=BATCH_SIZE, replace_target_iter=TARGET_REP_ITER,
36 | memory_size=MEMORY_CAPACITY, e_greedy_increment=E_INCREMENT,)
37 |
38 |
39 | total_steps = 0
40 | running_r = 0
41 | r_scale = 100
42 | for i_episode in range(MAX_EPISODES):
43 | s = env.reset() # (coord_x, coord_y, vel_x, vel_y, angle, angular_vel, l_leg_on_ground, r_leg_on_ground)
44 | ep_r = 0
45 | while True:
46 | if total_steps > MEMORY_CAPACITY: env.render()
47 | a = RL.choose_action(s)
48 | s_, r, done, _ = env.step(a)
49 | if r == -100: r = -30
50 | r /= r_scale
51 |
52 | ep_r += r
53 | RL.store_transition(s, a, r, s_)
54 | if total_steps > MEMORY_CAPACITY:
55 | RL.learn()
56 | if done:
57 | land = '| Landed' if r == 100/r_scale else '| ------'
58 | running_r = 0.99 * running_r + 0.01 * ep_r
59 | print('Epi: ', i_episode,
60 | land,
61 | '| Epi_R: ', round(ep_r, 2),
62 | '| Running_R: ', round(running_r, 2),
63 | '| Epsilon: ', round(RL.epsilon, 3))
64 | break
65 |
66 | s = s_
67 | total_steps += 1
68 |
69 |
--------------------------------------------------------------------------------
 95 |
95 |  102 |
102 |