├── .idea
├── learning_to_rank.iml
├── misc.xml
├── modules.xml
├── vcs.xml
└── workspace.xml
├── README.md
├── data
├── __init__.py
├── dev
│ └── val.txt
├── model
│ └── model.mod
├── plot
│ ├── all_feature_importance_1.png
│ ├── all_feature_importance_2.png
│ ├── multi-dimension_feature_importance.png
│ ├── single_feature_importance.png
│ ├── tree_plot
│ ├── tree_plot.pdf
│ └── tree_plot.png
├── test
│ ├── leaf.txt
│ └── test.txt
└── train
│ ├── feats.txt
│ ├── group.txt
│ └── raw_train.txt
├── desktop.ini
└── src
├── __init__.py
├── trees
├── __init__.py
├── data.py
├── data_format_read.py
├── lgb_ltr.py
├── ndcg.py
└── xgb_ltr.py
└── utils
└── __init__.py
/.idea/learning_to_rank.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 | 1598364631292
103 |
104 |
105 | 1598364631292
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 | 1598370318750
119 |
120 |
121 |
122 | 1598370318750
123 |
124 |
125 | 1598452148942
126 |
127 |
128 |
129 | 1598452148942
130 |
131 |
132 | 1598452707123
133 |
134 |
135 |
136 | 1598452707123
137 |
138 |
139 | 1598539194342
140 |
141 |
142 |
143 | 1598539194342
144 |
145 |
146 | 1598539470076
147 |
148 |
149 |
150 | 1598539470076
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
208 |
209 |
210 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 利用lightgbm做learning to rank 排序,主要包括:
2 | - 数据预处理
3 | - 模型训练
4 | - 模型决策可视化
5 | - 预测
6 | - ndcg评估
7 | - 特征重要度
8 | - SHAP特征贡献度解释
9 | - 样本的叶结点输出
10 |
11 | (要求安装lightgbm、graphviz、shap等)
12 |
13 | ## 一.data format (raw data -> (feats.txt, group.txt))
14 |
15 | ###### python lgb_ltr.py -process
16 |
17 | ##### 1.raw_train.txt
18 |
19 | 0 qid:10002 1:0.007477 2:0.000000 ... 45:0.000000 46:0.007042 #docid = GX008-86-4444840 inc = 1 prob = 0.086622
20 |
21 | 0 qid:10002 1:0.603738 2:0.000000 ... 45:0.333333 46:1.000000 #docid = GX037-06-11625428 inc = 0.0031586555555558 prob = 0.0897452
22 | ...
23 |
24 | ##### 2.feats.txt:
25 |
26 | 0 1:0.007477 2:0.000000 ... 45:0.000000 46:0.007042
27 |
28 | 0 1:0.603738 2:0.000000 ... 45:0.333333 46:1.000000
29 | ...
30 |
31 | ##### 3.group.txt:
32 | 8
33 |
34 | 8
35 |
36 | 8
37 |
38 | 8
39 |
40 | 8
41 |
42 | 16
43 |
44 | 8
45 |
46 | 118
47 |
48 | 16
49 |
50 | 8
51 |
52 | ...
53 |
54 | ## 二.model train (feats.txt, group.txt) -> train -> model.mod
55 |
56 | ###### python lgb_ltr.py -train
57 |
58 |
59 |
60 | train params = {
61 | 'task': 'train', # 执行的任务类型
62 | 'boosting_type': 'gbrt', # 基学习器
63 | 'objective': 'lambdarank', # 排序任务(目标函数)
64 | 'metric': 'ndcg', # 度量的指标(评估函数)
65 | 'max_position': 10, # @NDCG 位置优化
66 | 'metric_freq': 1, # 每隔多少次输出一次度量结果
67 | 'train_metric': True, # 训练时就输出度量结果
68 | 'ndcg_at': [10],
69 | 'max_bin': 255, # 一个整数,表示最大的桶的数量。默认值为 255。lightgbm 会根据它来自动压缩内存。如max_bin=255 时,则lightgbm 将使用uint8 来表示特征的每一个值。
70 | 'num_iterations': 200, # 迭代次数,即生成的树的棵数
71 | 'learning_rate': 0.01, # 学习率
72 | 'num_leaves': 31, # 叶子数
73 | 'max_depth':6,
74 | 'tree_learner': 'serial', # 用于并行学习,‘serial’: 单台机器的tree learner
75 | 'min_data_in_leaf': 30, # 一个叶子节点上包含的最少样本数量
76 | 'verbose': 2 # 显示训练时的信息
77 | }
78 |
79 | - docs:7796
80 | - groups:380
81 | - consume time : 4 seconds
82 | - training's ndcg@10: 0.940891
83 |
84 | ##### 1.model.mod(model的格式在data/model/mode.mod)
85 | 训练时的输出:
86 | - [LightGBM] [Info] Total Bins 9171
87 | - [LightGBM] [Info] Number of data: 7796, number of used features: 40
88 | - [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
89 | - [1] training's ndcg@10: 0.791427
90 | - [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 12
91 | - [2] training's ndcg@10: 0.828608
92 | - [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
93 | - ...
94 | - ...
95 | - ...
96 | - [198] training's ndcg@10: 0.941018
97 | - [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
98 | - [199] training's ndcg@10: 0.941038
99 | - [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
100 | - [200] training's ndcg@10: 0.940891
101 | - consume time : 4 seconds
102 | ## 三.模型决策过程的可视化生成
103 | 可指定树的索引进行可视化生成,便于分析决策过程。
104 | ###### python lgb_ltr.py -plottree
105 |
106 | 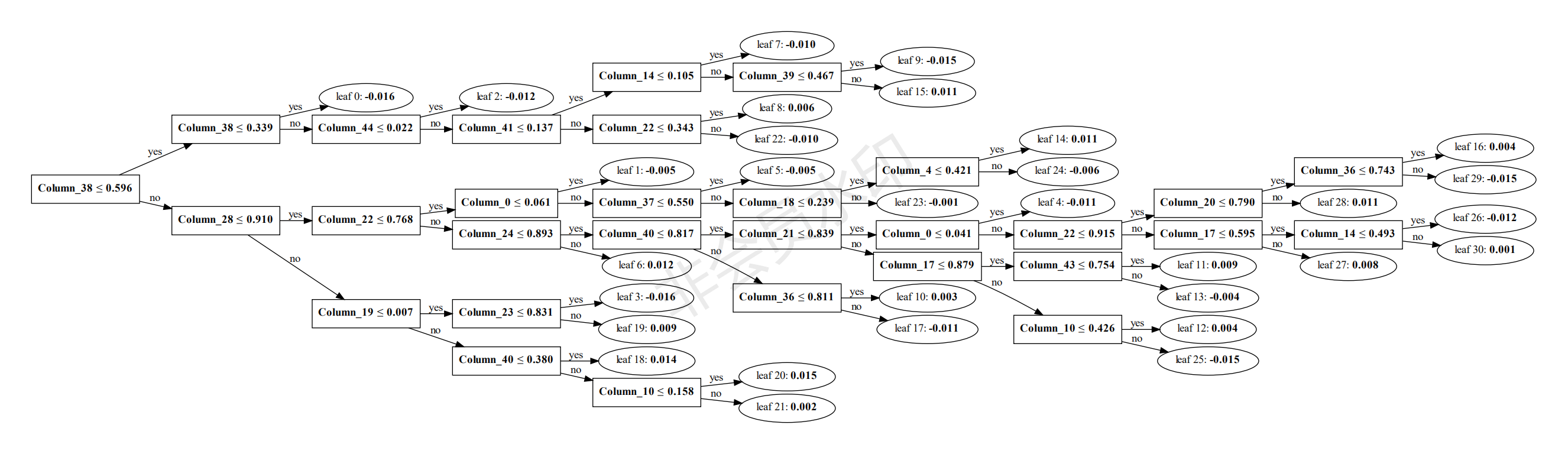
107 |
108 | ## 四.predict 数据格式如feats.txt,当然可以在每行后面加一个标识(如文档编号,商品编码等)作为排序的输出,这里我直接从test.txt中得到feats与comment作为predict
109 |
110 | ###### python lgb_ltr.py -predict
111 |
112 | ##### 1.predict results
113 |
114 | - ['docid = GX252-32-5579630 inc = 1 prob = 0.190849'
115 | - 'docid = GX108-43-5342284 inc = 0.188670948386237 prob = 0.103576'
116 | - 'docid = GX039-85-6430259 inc = 1 prob = 0.300191' ...,
117 | - 'docid = GX009-50-15026058 inc = 1 prob = 0.082903'
118 | - 'docid = GX065-08-0661325 inc = 0.012907717401617 prob = 0.0312699'
119 | - 'docid = GX012-13-5603768 inc = 1 prob = 0.0961297']
120 |
121 | ## 五.validate ndcg 数据来自test.txt(data from test.txt)
122 |
123 | ###### python lgb_ltr.py -ndcg
124 |
125 | all qids average ndcg: 0.761044123343
126 |
127 | ## 六.features 打印特征重要度(features importance)
128 |
129 | ###### python lgb_ltr.py -feature
130 |
131 | 模型中的特征是"Column_number",这里打印重要度时可以映射到真实的特征名,比如本测试用例是46个feature
132 |
133 | ##### 1.features importance
134 |
135 | - feat0name : 228 : 0.038
136 | - feat1name : 22 : 0.0036666666666666666
137 | - feat2name : 27 : 0.0045
138 | - feat3name : 11 : 0.0018333333333333333
139 | - feat4name : 198 : 0.033
140 | - feat10name : 160 : 0.02666666666666667
141 | - ...
142 | - ...
143 | - ...
144 | - feat37name : 188 : 0.03133333333333333
145 | - feat38name : 434 : 0.07233333333333333
146 | - feat39name : 286 : 0.04766666666666667
147 | - feat40name : 169 : 0.028166666666666666
148 | - feat41name : 348 : 0.058
149 | - feat43name : 304 : 0.050666666666666665
150 | - feat44name : 283 : 0.04716666666666667
151 | - feat45name : 220 : 0.03666666666666667
152 |
153 | ## 七.利用SHAP值解析模型中特征重要度
154 |
155 | ###### python lgb_ltr.py -shap
156 | 这里不同于六中特征重要度的计算,而是利用博弈论的方法--SHAP(SHapley Additive exPlanations)来解析模型。
157 | 利用SHAP可以进行特征总体分析、多维特征交叉分析以及单特征分析等。
158 |
159 | ##### 1.总体分析
160 |
161 | 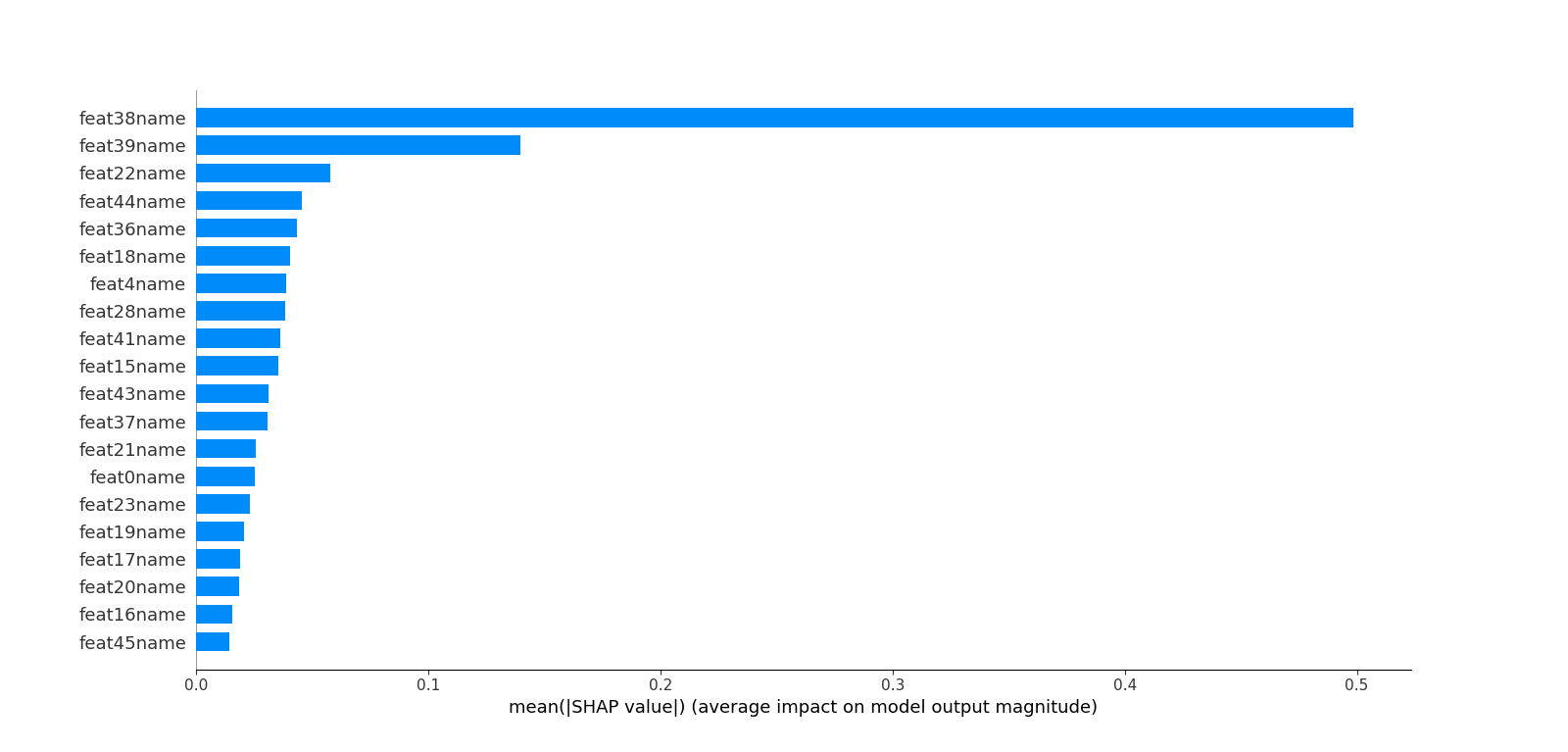
162 |
163 | 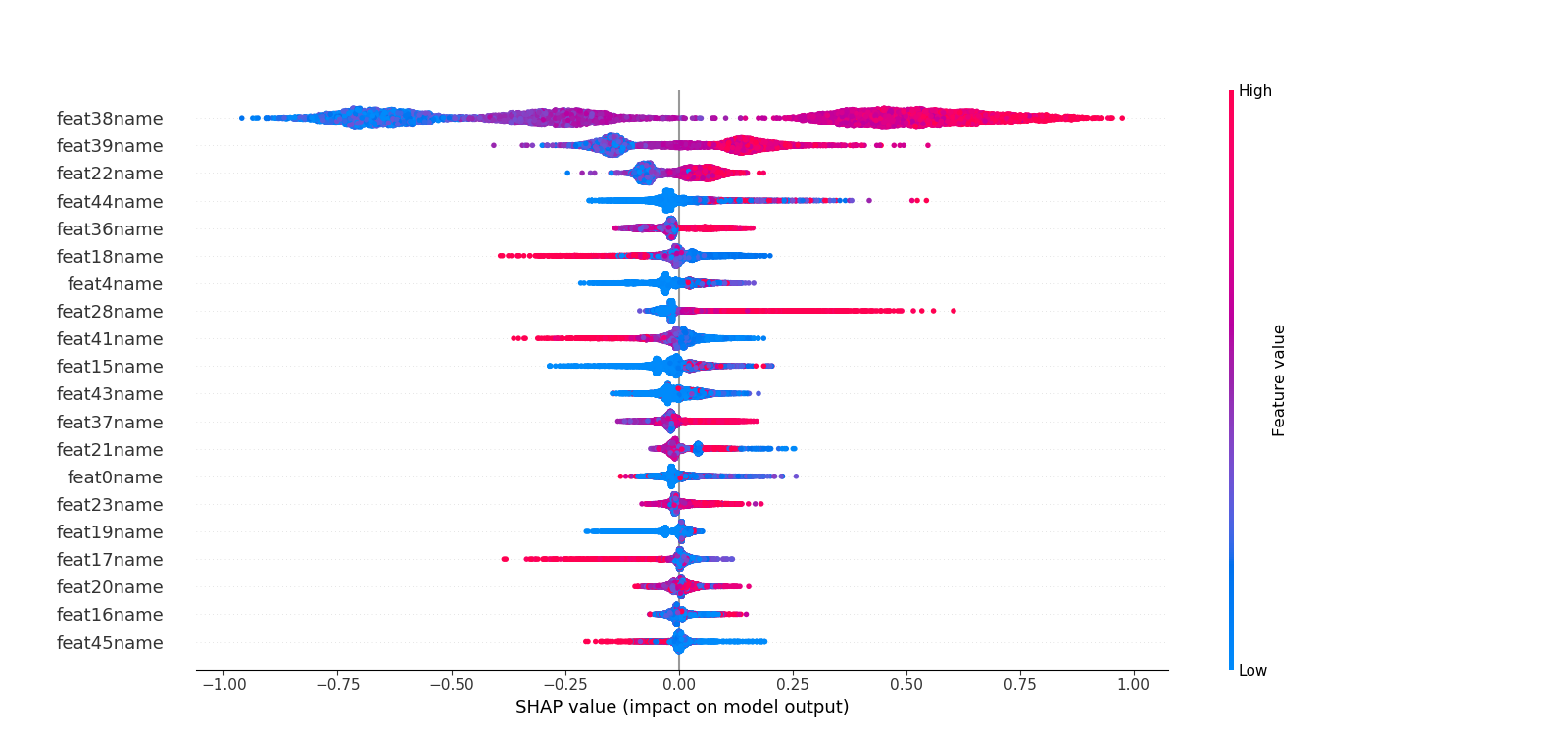
164 |
165 | ##### 2.多维特征交叉分析
166 |
167 | 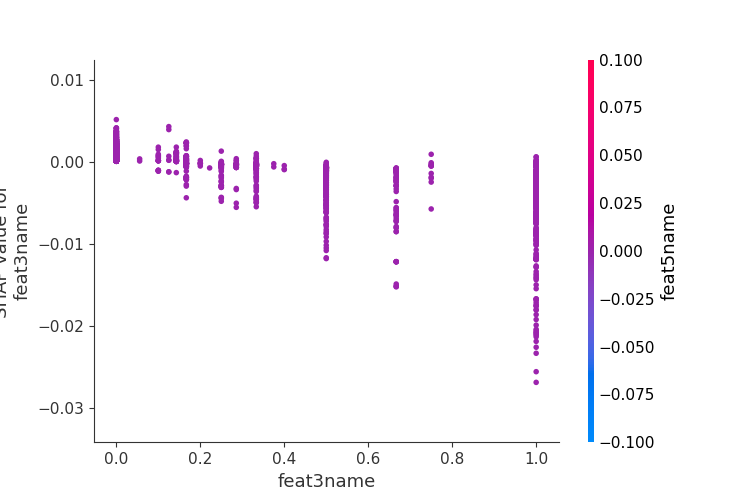
168 |
169 | ##### 3.单特征分析
170 |
171 | 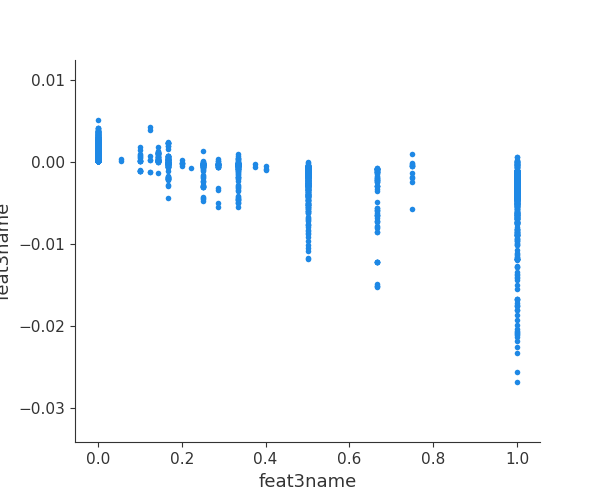
172 |
173 | ## 八.利用模型得到样本叶结点的one-hot表示,可以用于像gbdt+lr这种模型的训练
174 |
175 | ###### python lgb_ltr.py -leaf
176 |
177 | 这里测试用例是test/leaf.txt 5个样本
178 |
179 | [
180 | - [ 0. 1. 0. ..., 0. 0. 1.]
181 | - [ 1. 0. 0. ..., 0. 0. 0.]
182 | - [ 0. 0. 1. ..., 0. 0. 1.]
183 | - [ 0. 1. 0. ..., 0. 1. 0.]
184 | - [ 0. 0. 0. ..., 1. 0. 0.]
185 | ]
186 |
187 | ## 九.REFERENCES
188 |
189 | https://github.com/microsoft/LightGBM
190 |
191 | https://github.com/jma127/pyltr
192 |
193 | https://github.com/slundberg/shap
194 |
195 | ## contact
196 |
197 | 如有搜索、推荐、nlp以及大数据挖掘等问题或合作,可联系我:
198 |
199 | 1、我的github项目介绍:https://github.com/jiangnanboy
200 |
201 | 2、我的博客园技术博客:https://www.cnblogs.com/little-horse/
202 |
203 | 3、我的QQ号:2229029156
204 |
--------------------------------------------------------------------------------
/data/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiangnanboy/learning_to_rank/001c0c126266ee9a8dc723039b14442b67f2cc18/data/__init__.py
--------------------------------------------------------------------------------
/data/plot/all_feature_importance_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiangnanboy/learning_to_rank/001c0c126266ee9a8dc723039b14442b67f2cc18/data/plot/all_feature_importance_1.png
--------------------------------------------------------------------------------
/data/plot/all_feature_importance_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiangnanboy/learning_to_rank/001c0c126266ee9a8dc723039b14442b67f2cc18/data/plot/all_feature_importance_2.png
--------------------------------------------------------------------------------
/data/plot/multi-dimension_feature_importance.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiangnanboy/learning_to_rank/001c0c126266ee9a8dc723039b14442b67f2cc18/data/plot/multi-dimension_feature_importance.png
--------------------------------------------------------------------------------
/data/plot/single_feature_importance.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiangnanboy/learning_to_rank/001c0c126266ee9a8dc723039b14442b67f2cc18/data/plot/single_feature_importance.png
--------------------------------------------------------------------------------
/data/plot/tree_plot:
--------------------------------------------------------------------------------
1 | digraph tree2 {
2 | graph [nodesep=0.05 rankdir=LR ranksep=0.3]
3 | split0 [label=<Column_38 ≤ 0.596> fillcolor=white shape=rectangle style=""]
4 | split1 [label=<Column_38 ≤ 0.339> fillcolor=white shape=rectangle style=""]
5 | leaf0 [label=-0.016>]
6 | split1 -> leaf0 [label=yes]
7 | split6 [label=<Column_44 ≤ 0.022> fillcolor=white shape=rectangle style=""]
8 | leaf2 [label=-0.012>]
9 | split6 -> leaf2 [label=yes]
10 | split7 [label=<Column_41 ≤ 0.137> fillcolor=white shape=rectangle style=""]
11 | split8 [label=<Column_14 ≤ 0.105> fillcolor=white shape=rectangle style=""]
12 | leaf7 [label=-0.010>]
13 | split8 -> leaf7 [label=yes]
14 | split14 [label=<Column_39 ≤ 0.467> fillcolor=white shape=rectangle style=""]
15 | leaf9 [label=-0.015>]
16 | split14 -> leaf9 [label=yes]
17 | leaf15 [label=0.011>]
18 | split14 -> leaf15 [label=no]
19 | split8 -> split14 [label=no]
20 | split7 -> split8 [label=yes]
21 | split21 [label=<Column_22 ≤ 0.343> fillcolor=white shape=rectangle style=""]
22 | leaf8 [label=0.006>]
23 | split21 -> leaf8 [label=yes]
24 | leaf22 [label=-0.010>]
25 | split21 -> leaf22 [label=no]
26 | split7 -> split21 [label=no]
27 | split6 -> split7 [label=no]
28 | split1 -> split6 [label=no]
29 | split0 -> split1 [label=yes]
30 | split2 [label=<Column_28 ≤ 0.910> fillcolor=white shape=rectangle style=""]
31 | split3 [label=<Column_22 ≤ 0.768> fillcolor=white shape=rectangle style=""]
32 | split4 [label=<Column_0 ≤ 0.061> fillcolor=white shape=rectangle style=""]
33 | leaf1 [label=-0.005>]
34 | split4 -> leaf1 [label=yes]
35 | split13 [label=<Column_37 ≤ 0.550> fillcolor=white shape=rectangle style=""]
36 | leaf5 [label=-0.005>]
37 | split13 -> leaf5 [label=yes]
38 | split22 [label=<Column_18 ≤ 0.239> fillcolor=white shape=rectangle style=""]
39 | split23 [label=<Column_4 ≤ 0.421> fillcolor=white shape=rectangle style=""]
40 | leaf14 [label=0.011>]
41 | split23 -> leaf14 [label=yes]
42 | leaf24 [label=-0.006>]
43 | split23 -> leaf24 [label=no]
44 | split22 -> split23 [label=yes]
45 | leaf23 [label=-0.001>]
46 | split22 -> leaf23 [label=no]
47 | split13 -> split22 [label=no]
48 | split4 -> split13 [label=no]
49 | split3 -> split4 [label=yes]
50 | split5 [label=<Column_24 ≤ 0.893> fillcolor=white shape=rectangle style=""]
51 | split9 [label=<Column_40 ≤ 0.817> fillcolor=white shape=rectangle style=""]
52 | split10 [label=<Column_21 ≤ 0.839> fillcolor=white shape=rectangle style=""]
53 | split15 [label=<Column_0 ≤ 0.041> fillcolor=white shape=rectangle style=""]
54 | leaf4 [label=-0.011>]
55 | split15 -> leaf4 [label=yes]
56 | split25 [label=<Column_22 ≤ 0.915> fillcolor=white shape=rectangle style=""]
57 | split27 [label=<Column_20 ≤ 0.790> fillcolor=white shape=rectangle style=""]
58 | split28 [label=<Column_36 ≤ 0.743> fillcolor=white shape=rectangle style=""]
59 | leaf16 [label=0.004>]
60 | split28 -> leaf16 [label=yes]
61 | leaf29 [label=-0.015>]
62 | split28 -> leaf29 [label=no]
63 | split27 -> split28 [label=yes]
64 | leaf28 [label=0.011>]
65 | split27 -> leaf28 [label=no]
66 | split25 -> split27 [label=yes]
67 | split26 [label=<Column_17 ≤ 0.595> fillcolor=white shape=rectangle style=""]
68 | split29 [label=<Column_14 ≤ 0.493> fillcolor=white shape=rectangle style=""]
69 | leaf26 [label=-0.012>]
70 | split29 -> leaf26 [label=yes]
71 | leaf30 [label=0.001>]
72 | split29 -> leaf30 [label=no]
73 | split26 -> split29 [label=yes]
74 | leaf27 [label=0.008>]
75 | split26 -> leaf27 [label=no]
76 | split25 -> split26 [label=no]
77 | split15 -> split25 [label=no]
78 | split10 -> split15 [label=yes]
79 | split11 [label=<Column_17 ≤ 0.879> fillcolor=white shape=rectangle style=""]
80 | split12 [label=<Column_43 ≤ 0.754> fillcolor=white shape=rectangle style=""]
81 | leaf11 [label=0.009>]
82 | split12 -> leaf11 [label=yes]
83 | leaf13 [label=-0.004>]
84 | split12 -> leaf13 [label=no]
85 | split11 -> split12 [label=yes]
86 | split24 [label=<Column_10 ≤ 0.426> fillcolor=white shape=rectangle style=""]
87 | leaf12 [label=0.004>]
88 | split24 -> leaf12 [label=yes]
89 | leaf25 [label=-0.015>]
90 | split24 -> leaf25 [label=no]
91 | split11 -> split24 [label=no]
92 | split10 -> split11 [label=no]
93 | split9 -> split10 [label=yes]
94 | split16 [label=<Column_36 ≤ 0.811> fillcolor=white shape=rectangle style=""]
95 | leaf10 [label=0.003>]
96 | split16 -> leaf10 [label=yes]
97 | leaf17 [label=-0.011>]
98 | split16 -> leaf17 [label=no]
99 | split9 -> split16 [label=no]
100 | split5 -> split9 [label=yes]
101 | leaf6 [label=0.012>]
102 | split5 -> leaf6 [label=no]
103 | split3 -> split5 [label=no]
104 | split2 -> split3 [label=yes]
105 | split17 [label=<Column_19 ≤ 0.007> fillcolor=white shape=rectangle style=""]
106 | split18 [label=<Column_23 ≤ 0.831> fillcolor=white shape=rectangle style=""]
107 | leaf3 [label=-0.016>]
108 | split18 -> leaf3 [label=yes]
109 | leaf19 [label=0.009>]
110 | split18 -> leaf19 [label=no]
111 | split17 -> split18 [label=yes]
112 | split19 [label=<Column_40 ≤ 0.380> fillcolor=white shape=rectangle style=""]
113 | leaf18 [label=0.014>]
114 | split19 -> leaf18 [label=yes]
115 | split20 [label=<Column_10 ≤ 0.158> fillcolor=white shape=rectangle style=""]
116 | leaf20 [label=0.015>]
117 | split20 -> leaf20 [label=yes]
118 | leaf21 [label=0.002>]
119 | split20 -> leaf21 [label=no]
120 | split19 -> split20 [label=no]
121 | split17 -> split19 [label=no]
122 | split2 -> split17 [label=no]
123 | split0 -> split2 [label=no]
124 | }
125 |
--------------------------------------------------------------------------------
/data/plot/tree_plot.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiangnanboy/learning_to_rank/001c0c126266ee9a8dc723039b14442b67f2cc18/data/plot/tree_plot.pdf
--------------------------------------------------------------------------------
/data/plot/tree_plot.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiangnanboy/learning_to_rank/001c0c126266ee9a8dc723039b14442b67f2cc18/data/plot/tree_plot.png
--------------------------------------------------------------------------------
/data/test/leaf.txt:
--------------------------------------------------------------------------------
1 | 0 qid:18219 1:0.052893 2:1.000000 3:0.750000 4:1.000000 5:0.066225 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000 11:0.047634 12:1.000000 13:0.740506 14:1.000000 15:0.058539 16:0.003995 17:0.500000 18:0.400000 19:0.400000 20:0.004121 21:1.000000 22:1.000000 23:0.974510 24:1.000000 25:0.929240 26:1.000000 27:1.000000 28:0.829951 29:1.000000 30:1.000000 31:0.768123 32:1.000000 33:1.000000 34:1.000000 35:1.000000 36:1.000000 37:1.000000 38:1.000000 39:0.998377 40:1.000000 41:0.333333 42:0.434783 43:0.000000 44:0.396910 45:0.447368 46:0.966667 #docid = GX004-93-7097963 inc = 0.0428115405134536 prob = 0.860366
2 | 0 qid:18219 1:0.004959 2:0.000000 3:0.250000 4:0.500000 5:0.006623 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000 11:0.004971 12:0.000000 13:0.259494 14:0.521932 15:0.006639 16:0.000896 17:0.714286 18:0.700000 19:0.000000 20:0.001093 21:0.229604 22:0.237068 23:0.200021 24:0.063318 25:0.000000 26:0.000000 27:0.000000 28:0.000000 29:0.310838 30:0.033799 31:0.001398 32:0.025976 33:0.576917 34:0.036302 35:0.001129 36:0.022642 37:0.141223 38:0.212802 39:0.168053 40:0.069556 41:0.333333 42:0.000000 43:0.000000 44:0.019255 45:0.421053 46:0.000000 #docid = GX010-40-4497720 inc = 0.00110683825421716 prob = 0.089706
3 | 0 qid:18219 1:0.066116 2:0.750000 3:0.250000 4:1.000000 5:0.074503 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000 11:0.061487 12:0.716563 13:0.259494 14:1.000000 15:0.068044 16:0.004945 17:0.285714 18:0.300000 19:0.600000 20:0.005016 21:0.990081 22:0.973625 23:1.000000 24:0.973218 25:1.000000 26:0.878010 27:0.016022 28:1.000000 29:0.485677 30:0.147968 31:0.004197 32:0.113559 33:0.954513 34:0.946955 35:0.998874 36:0.966838 37:0.986045 38:0.963141 39:1.000000 40:0.962716 41:0.666667 42:0.826087 43:0.000000 44:0.045177 45:0.473684 46:1.000000 #docid = GX016-32-14546147 inc = 1 prob = 0.811482
4 | 1 qid:18219 1:0.026446 2:0.750000 3:0.750000 4:0.500000 5:0.036424 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000 11:0.024116 12:0.716563 13:0.702528 14:0.521932 15:0.031683 16:0.007919 17:1.000000 18:0.500000 19:0.200000 20:0.008170 21:0.780898 22:0.659859 23:0.722056 24:0.666725 25:0.428280 26:0.000000 27:0.000000 28:0.000000 29:0.876585 30:0.939544 31:0.664658 32:0.953860 33:0.548049 34:0.000000 35:0.000000 36:0.000000 37:0.843365 38:0.727569 39:0.786101 40:0.725966 41:0.000000 42:0.608696 43:0.000000 44:1.000000 45:1.000000 46:0.266667 #docid = GX020-25-8391882 inc = 1 prob = 0.115043
5 | 0 qid:18219 1:0.029752 2:0.000000 3:1.000000 4:1.000000 5:0.038079 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000 11:0.022643 12:0.000000 13:1.000000 14:1.000000 15:0.029721 16:0.007543 17:0.357143 18:1.000000 19:0.400000 20:0.007740 21:0.825886 22:0.735769 23:0.794308 24:0.735548 25:0.000000 26:0.000000 27:0.000000 28:0.000000 29:0.737766 30:0.830504 31:1.000000 32:0.852510 33:1.000000 34:1.000000 35:1.000000 36:1.000000 37:0.858094 38:0.761605 39:0.818017 40:0.759069 41:0.333333 42:0.956522 43:0.000000 44:0.013295 45:0.052632 46:0.100000 #docid = GX025-94-0531672 inc = 1 prob = 0.141903
6 |
--------------------------------------------------------------------------------
/data/train/group.txt:
--------------------------------------------------------------------------------
1 | 8
2 | 8
3 | 8
4 | 8
5 | 8
6 | 16
7 | 8
8 | 118
9 | 16
10 | 8
11 | 8
12 | 8
13 | 7
14 | 8
15 | 16
16 | 8
17 | 16
18 | 8
19 | 32
20 | 8
21 | 8
22 | 8
23 | 31
24 | 8
25 | 8
26 | 15
27 | 8
28 | 15
29 | 8
30 | 28
31 | 7
32 | 62
33 | 8
34 | 8
35 | 16
36 | 16
37 | 8
38 | 8
39 | 15
40 | 8
41 | 118
42 | 8
43 | 16
44 | 8
45 | 8
46 | 16
47 | 16
48 | 8
49 | 16
50 | 8
51 | 8
52 | 8
53 | 8
54 | 8
55 | 16
56 | 8
57 | 30
58 | 8
59 | 8
60 | 8
61 | 8
62 | 8
63 | 28
64 | 8
65 | 113
66 | 7
67 | 15
68 | 25
69 | 8
70 | 16
71 | 8
72 | 16
73 | 59
74 | 8
75 | 7
76 | 8
77 | 31
78 | 30
79 | 31
80 | 32
81 | 8
82 | 8
83 | 16
84 | 8
85 | 31
86 | 15
87 | 15
88 | 28
89 | 32
90 | 8
91 | 31
92 | 59
93 | 8
94 | 7
95 | 55
96 | 8
97 | 8
98 | 8
99 | 32
100 | 7
101 | 8
102 | 16
103 | 58
104 | 8
105 | 15
106 | 29
107 | 8
108 | 31
109 | 8
110 | 8
111 | 16
112 | 8
113 | 8
114 | 6
115 | 8
116 | 62
117 | 8
118 | 8
119 | 60
120 | 8
121 | 8
122 | 8
123 | 8
124 | 8
125 | 8
126 | 7
127 | 8
128 | 16
129 | 13
130 | 8
131 | 7
132 | 8
133 | 8
134 | 8
135 | 8
136 | 114
137 | 15
138 | 31
139 | 8
140 | 7
141 | 8
142 | 8
143 | 29
144 | 7
145 | 25
146 | 8
147 | 8
148 | 8
149 | 118
150 | 7
151 | 8
152 | 26
153 | 8
154 | 8
155 | 30
156 | 14
157 | 118
158 | 8
159 | 8
160 | 16
161 | 6
162 | 8
163 | 8
164 | 63
165 | 7
166 | 8
167 | 30
168 | 61
169 | 8
170 | 13
171 | 32
172 | 14
173 | 115
174 | 30
175 | 8
176 | 8
177 | 59
178 | 31
179 | 8
180 | 8
181 | 16
182 | 7
183 | 8
184 | 8
185 | 15
186 | 15
187 | 63
188 | 60
189 | 8
190 | 8
191 | 8
192 | 16
193 | 15
194 | 16
195 | 8
196 | 116
197 | 8
198 | 16
199 | 8
200 | 8
201 | 29
202 | 16
203 | 15
204 | 16
205 | 8
206 | 8
207 | 31
208 | 8
209 | 57
210 | 5
211 | 8
212 | 16
213 | 26
214 | 59
215 | 8
216 | 14
217 | 8
218 | 121
219 | 16
220 | 31
221 | 8
222 | 8
223 | 16
224 | 7
225 | 8
226 | 8
227 | 8
228 | 13
229 | 119
230 | 15
231 | 8
232 | 29
233 | 60
234 | 46
235 | 16
236 | 8
237 | 7
238 | 8
239 | 59
240 | 15
241 | 8
242 | 14
243 | 8
244 | 8
245 | 16
246 | 8
247 | 116
248 | 16
249 | 8
250 | 8
251 | 30
252 | 16
253 | 13
254 | 15
255 | 31
256 | 16
257 | 30
258 | 13
259 | 8
260 | 8
261 | 31
262 | 8
263 | 116
264 | 8
265 | 16
266 | 8
267 | 8
268 | 16
269 | 8
270 | 31
271 | 8
272 | 15
273 | 7
274 | 115
275 | 59
276 | 8
277 | 8
278 | 59
279 | 59
280 | 8
281 | 14
282 | 32
283 | 8
284 | 8
285 | 8
286 | 31
287 | 32
288 | 8
289 | 8
290 | 8
291 | 8
292 | 8
293 | 30
294 | 30
295 | 118
296 | 8
297 | 8
298 | 7
299 | 31
300 | 6
301 | 8
302 | 26
303 | 14
304 | 16
305 | 8
306 | 29
307 | 16
308 | 58
309 | 8
310 | 15
311 | 8
312 | 8
313 | 58
314 | 16
315 | 16
316 | 111
317 | 8
318 | 8
319 | 15
320 | 29
321 | 16
322 | 16
323 | 8
324 | 15
325 | 8
326 | 32
327 | 8
328 | 15
329 | 8
330 | 8
331 | 16
332 | 8
333 | 8
334 | 14
335 | 7
336 | 8
337 | 16
338 | 56
339 | 8
340 | 31
341 | 16
342 | 32
343 | 29
344 | 15
345 | 15
346 | 8
347 | 58
348 | 8
349 | 15
350 | 7
351 | 8
352 | 7
353 | 8
354 | 24
355 | 8
356 | 51
357 | 30
358 | 8
359 | 57
360 | 5
361 | 8
362 | 8
363 | 8
364 | 7
365 | 31
366 | 16
367 | 8
368 | 8
369 | 31
370 | 16
371 | 32
372 | 15
373 | 7
374 | 7
375 | 14
376 | 16
377 | 15
378 | 16
379 | 8
380 | 55
381 |
--------------------------------------------------------------------------------
/desktop.ini:
--------------------------------------------------------------------------------
1 | [ViewState]
2 | Mode=
3 | Vid=
4 | FolderType=Generic
5 |
--------------------------------------------------------------------------------
/src/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiangnanboy/learning_to_rank/001c0c126266ee9a8dc723039b14442b67f2cc18/src/__init__.py
--------------------------------------------------------------------------------
/src/trees/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiangnanboy/learning_to_rank/001c0c126266ee9a8dc723039b14442b67f2cc18/src/trees/__init__.py
--------------------------------------------------------------------------------
/src/trees/data.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import sklearn.externals.six
3 |
4 | def iter_lines(lines):
5 | for line in lines:
6 | toks = line.split()
7 | qid = toks[0]
8 | target = float(toks[4])
9 | pred = float(toks[5])
10 | yield (qid, target, pred)
11 |
12 | def read_dataset(source):
13 |
14 | if isinstance(source, sklearn.externals.six.string_types):
15 | source = source.splitlines(True)
16 |
17 | qids, targets, preds = [], [], []
18 | iter_content = iter_lines(source)
19 | for qid, target, pred in iter_content:
20 | qids.append(qid)
21 | targets.append(target)
22 | preds.append(pred)
23 |
24 | qids = np.array(qids)
25 | targets = np.array(targets)
26 | preds = np.array(preds)
27 |
28 | return (qids, targets, preds)
--------------------------------------------------------------------------------
/src/trees/data_format_read.py:
--------------------------------------------------------------------------------
1 | """
2 |
3 | Various utilities for converting data from/to Microsoft's LETOR format.
4 |
5 | """
6 |
7 | import numpy as np
8 | import sklearn.externals.six
9 |
10 | def iter_lines(lines, has_targets=True, one_indexed=True, missing=0.0):
11 | """Transforms an iterator of lines to an iterator of LETOR rows.
12 |
13 | Each row is represented by a (x, y, qid, comment) tuple.
14 |
15 | Parameters
16 | ----------
17 | lines : iterable of lines
18 | Lines to parse.
19 | has_targets : bool, optional
20 | Whether the file contains targets. If True, will expect the first token
21 | of every line to be a real representing the sample's target (i.e.
22 | score). If False, will use -1 as a placeholder for all targets.
23 | one_indexed : bool, optional 特征id从1开始的转为从0开始
24 | Whether feature ids are one-indexed. If True, will subtract 1 from each
25 | feature id.
26 | missing : float, optional
27 | Placeholder to use if a feature value is not provided for a sample.
28 |
29 | Yields
30 | ------
31 | x : array of floats
32 | Feature vector of the sample.
33 | y : float
34 | Target value (score) of the sample, or -1 if no target was parsed.
35 | qid : object
36 | Query id of the sample. This is currently guaranteed to be a string.
37 | comment : str
38 | Comment accompanying the sample.
39 |
40 | """
41 | for line in lines:
42 | data, _, comment = line.rstrip().partition('#')
43 | toks = data.strip().split()
44 | # toks = line.rstrip()
45 | # toks = re.split('\s+', toks.strip())
46 | # print("toks: ", toks)
47 | # comment = "no comment"
48 | num_features = 0 # 统计特征个数
49 | x = np.repeat(missing, 8)
50 | y = -1.0
51 | if has_targets:
52 | y = float(toks[0].strip()) # 相关度label
53 | toks = toks[1:]
54 | # qid:1 => 1
55 | qid = _parse_qid_tok(toks[0].strip())
56 |
57 | # feature(id:value)
58 | for tok in toks[1:]:
59 | # fid, _, val = tok.strip().partition(':') # fid,_,val => featureID,:,featureValue
60 | fid, val = tok.split(":") # featureID:featureValue
61 | fid = int(fid)
62 | val = float(val)
63 | if one_indexed:
64 | fid -= 1
65 | assert fid >= 0
66 | while len(x) <= fid:
67 | orig = len(x)
68 | # x=np.resize(x,(len(x) * 2))
69 | x.resize(len(x) * 2)
70 | x[orig:orig * 2] = missing
71 | x[fid] = val
72 | num_features = max(fid + 1, num_features)
73 |
74 | assert num_features > 0
75 | x.resize(num_features)
76 |
77 | yield (x, y, qid, comment)
78 |
79 |
80 | def read_dataset(source, has_targets=True, one_indexed=True, missing=0.0):
81 | """Parses a LETOR dataset from `source`.
82 |
83 | Parameters
84 | ----------
85 | source : string or iterable of lines
86 | String, file, or other file-like object to parse.
87 | has_targets : bool, optional
88 | See `iter_lines`.
89 | one_indexed : bool, optional
90 | See `iter_lines`.
91 | missing : float, optional
92 | See `iter_lines`.
93 |
94 | Returns
95 | -------
96 | X : array of arrays of floats
97 | Feature matrix (see `iter_lines`).
98 | y : array of floats
99 | Target vector (see `iter_lines`).
100 | qids : array of objects
101 | Query id vector (see `iter_lines`).
102 | comments : array of strs
103 | Comment vector (see `iter_lines`).
104 | """
105 | if isinstance(source, sklearn.externals.six.string_types):
106 | source = source.splitlines(True)
107 |
108 | max_width = 0 # 某行最多特征个数
109 | xs, ys, qids, comments = [], [], [], []
110 | iter_content = iter_lines(source, has_targets=has_targets,
111 | one_indexed=one_indexed, missing=missing)
112 | # x:特征向量; y:float 相关度值[0-4]; qid:string query id; comment: #后面内容
113 | for x, y, qid, comment in iter_content:
114 | xs.append(x)
115 | ys.append(y)
116 | qids.append(qid)
117 | comments.append(comment)
118 | max_width = max(max_width, len(x))
119 |
120 | assert max_width > 0
121 | # X.shape = [len(xs), max_width]
122 | X = np.ndarray((len(xs), max_width), dtype=np.float64)
123 | X.fill(missing)
124 | for i, x in enumerate(xs):
125 | X[i, :len(x)] = x
126 | ys = np.array(ys) if has_targets else None
127 | qids = np.array(qids)
128 | comments = np.array(comments)
129 |
130 | return (X, ys, qids, comments)
131 |
132 |
133 | def _parse_qid_tok(tok):
134 | assert tok.startswith('qid:')
135 | return tok[4:]
--------------------------------------------------------------------------------
/src/trees/lgb_ltr.py:
--------------------------------------------------------------------------------
1 | import os
2 | import lightgbm as lgb
3 | from sklearn import datasets as ds
4 | import pandas as pd
5 | import numpy as np
6 | from datetime import datetime
7 | import sys
8 | from sklearn.preprocessing import OneHotEncoder
9 | from data_format_read import read_dataset
10 | from ndcg import validate
11 | import shap
12 | import matplotlib.pyplot as plt
13 | import graphviz
14 |
15 | def split_data_from_keyword(data_read, data_group, data_feats):
16 | '''
17 | 利用pandas
18 | 转为lightgbm需要的格式进行保存
19 | :param data_read:
20 | :param data_group:
21 | :param data_feats:
22 | :return:
23 | '''
24 | with open(data_group, 'w', encoding='utf-8') as group_path:
25 | with open(data_feats, 'w', encoding='utf-8') as feats_path:
26 | dataframe = pd.read_csv(data_read,
27 | sep=' ',
28 | header=None,
29 | encoding="utf-8",
30 | engine='python')
31 | current_keyword = ''
32 | current_data = []
33 | group_size = 0
34 | for _, row in dataframe.iterrows():
35 | feats_line = [str(row[0])]
36 | for i in range(2, len(dataframe.columns) - 1):
37 | feats_line.append(str(row[i]))
38 | if current_keyword == '':
39 | current_keyword = row[1]
40 | if row[1] == current_keyword:
41 | current_data.append(feats_line)
42 | group_size += 1
43 | else:
44 | for line in current_data:
45 | feats_path.write(' '.join(line))
46 | feats_path.write('\n')
47 | group_path.write(str(group_size) + '\n')
48 |
49 | group_size = 1
50 | current_data = []
51 | current_keyword = row[1]
52 | current_data.append(feats_line)
53 |
54 | for line in current_data:
55 | feats_path.write(' '.join(line))
56 | feats_path.write('\n')
57 | group_path.write(str(group_size) + '\n')
58 |
59 | def save_data(group_data, output_feature, output_group):
60 | '''
61 | group与features分别进行保存
62 | :param group_data:
63 | :param output_feature:
64 | :param output_group:
65 | :return:
66 | '''
67 | if len(group_data) == 0:
68 | return
69 | output_group.write(str(len(group_data)) + '\n')
70 | for data in group_data:
71 | # 只包含非零特征
72 | # feats = [p for p in data[2:] if float(p.split(":")[1]) != 0.0]
73 | feats = [p for p in data[2:]]
74 | output_feature.write(data[0] + ' ' + ' '.join(feats) + '\n') # data[0] => level ; data[2:] => feats
75 |
76 | def process_data_format(test_path, test_feats, test_group):
77 | '''
78 | 转为lightgbm需要的格式进行保存
79 | :param test_path:
80 | :param test_feats:
81 | :param test_group:
82 | :return:
83 | '''
84 |
85 | with open(test_path, 'r', encoding='utf-8') as f_read:
86 | with open(test_feats, 'w', encoding='utf-8') as output_feature:
87 | with open(test_group, 'w', encoding='utf-8') as output_group:
88 | group_data = []
89 | group = ''
90 | for line in f_read:
91 | if '#' in line:
92 | line = line[:line.index('#')]
93 | splits = line.strip().split()
94 | if splits[1] != group: # qid => splits[1]
95 | save_data(group_data, output_feature, output_group)
96 | group_data = []
97 | group = splits[1]
98 | group_data.append(splits)
99 | save_data(group_data, output_feature, output_group)
100 |
101 | def load_data(feats, group):
102 | '''
103 | 加载数据
104 | 分别加载feature,label,query
105 | :param feats:
106 | :param group:
107 | :return:
108 | '''
109 |
110 | x_train, y_train = ds.load_svmlight_file(feats)
111 | q_train = np.loadtxt(group)
112 |
113 | return x_train, y_train, q_train
114 |
115 | def load_data_from_raw(raw_data):
116 | '''
117 | 加载原始数据
118 | :param raw_data:
119 | :return:
120 | '''
121 |
122 | with open(raw_data, 'r', encoding='utf-8') as testfile:
123 | test_X, test_y, test_qids, comments = read_dataset(testfile)
124 | return test_X, test_y, test_qids, comments
125 |
126 | def train(x_train, y_train, q_train, model_save_path):
127 | '''
128 | 模型的训练和保存
129 | :param x_train:
130 | :param y_train:
131 | :param q_train:
132 | :param model_save_path:
133 | :return:
134 | '''
135 |
136 | train_data = lgb.Dataset(x_train, label=y_train, group=q_train)
137 | params = {
138 | 'task': 'train', # 执行的任务类型
139 | 'boosting_type': 'gbrt', # 基学习器
140 | 'objective': 'lambdarank', # 排序任务(目标函数)
141 | 'metric': 'ndcg', # 度量的指标(评估函数)
142 | 'max_position': 10, # @NDCG 位置优化
143 | 'metric_freq': 1, # 每隔多少次输出一次度量结果
144 | 'train_metric': True, # 训练时就输出度量结果
145 | 'ndcg_at': [10],
146 | 'max_bin': 255, # 一个整数,表示最大的桶的数量。默认值为 255。lightgbm 会根据它来自动压缩内存。如max_bin=255 时,则lightgbm 将使用uint8 来表示特征的每一个值。
147 | 'num_iterations': 200, # 迭代次数,即生成的树的棵数
148 | 'learning_rate': 0.01, # 学习率
149 | 'num_leaves': 31, # 叶子数
150 | # 'max_depth':6,
151 | 'tree_learner': 'serial', # 用于并行学习,‘serial’: 单台机器的tree learner
152 | 'min_data_in_leaf': 30, # 一个叶子节点上包含的最少样本数量
153 | 'verbose': 2 # 显示训练时的信息
154 | }
155 | gbm = lgb.train(params, train_data, valid_sets=[train_data]) # 这里valid_sets可同时加入train_data,val_data
156 | gbm.save_model(model_save_path)
157 |
158 | def plot_tree(model_path, tree_index, save_plot_path):
159 | '''
160 | 对模型进行可视化
161 | :param model_path:
162 | :param tree_index:
163 | :param save_plot_path:
164 | :return:
165 | '''
166 | if not os.path.exists(model_path):
167 | print("file no exists! {}".format(model_path))
168 | sys.exit(0)
169 | gbm = lgb.Booster(model_file=model_path)
170 | graph = lgb.create_tree_digraph(gbm, tree_index=tree_index, name='tree' + str(tree_index))
171 | graph.render(filename=save_plot_path, view=True) #可视图保存到save_plot_path中
172 |
173 | def predict(x_test, comments, model_input_path):
174 | '''
175 | 预测得分并排序
176 | :param x_test:
177 | :param comments:
178 | :param model_input_path:
179 | :return:
180 | '''
181 |
182 | gbm = lgb.Booster(model_file=model_input_path) # 加载model
183 |
184 | ypred = gbm.predict(x_test)
185 |
186 | predicted_sorted_indexes = np.argsort(ypred)[::-1] # 返回从大到小的索引
187 |
188 | t_results = comments[predicted_sorted_indexes] # 返回对应的comments,从大到小的排序
189 |
190 | return t_results
191 |
192 | def test_data_ndcg(model_path, test_path):
193 | '''
194 | 评估测试数据的ndcg
195 | :param model_path:
196 | :param test_path:
197 | :return:
198 | '''
199 |
200 | with open(test_path, 'r', encoding='utf-8') as testfile:
201 | test_X, test_y, test_qids, comments = read_dataset(testfile)
202 |
203 | gbm = lgb.Booster(model_file=model_path)
204 | test_predict = gbm.predict(test_X)
205 |
206 | average_ndcg, _ = validate(test_qids, test_y, test_predict, 60)
207 | # 所有qid的平均ndcg
208 | print("all qid average ndcg: ", average_ndcg)
209 | print("job done!")
210 |
211 | def plot_print_feature_shap(model_path, data_feats, type):
212 | '''
213 | 利用shap打印特征重要度
214 | :param model_path:
215 | :param data_feats:
216 | :param type:
217 | :return:
218 | '''
219 |
220 | if not (os.path.exists(model_path) and os.path.exists(data_feats)):
221 | print("file no exists! {}, {}".format(model_path, data_feats))
222 | sys.exit(0)
223 | gbm = lgb.Booster(model_file=model_path)
224 | gbm.params["objective"] = "regression"
225 | #feature列名
226 | feats_col_name = []
227 | for feat_index in range(46):
228 | feats_col_name.append('feat' + str(feat_index) + 'name')
229 | X_train, _ = ds.load_svmlight_file(data_feats)
230 | #features
231 | feature_mat = X_train.todense()
232 | df_feature = pd.DataFrame(feature_mat)
233 | #增加表头
234 | df_feature.columns = feats_col_name
235 | explainer = shap.TreeExplainer(gbm)
236 | shap_values = explainer.shap_values(df_feature[feats_col_name])
237 |
238 | #特征总体分析,分别绘出散点图和条状图
239 | if type == 1:
240 | #把一个特征对目标变量影响程度的绝对值的均值作为这个特征的重要性(不同于feature_importance的计算方式)
241 | shap.summary_plot(shap_values, df_feature[feats_col_name], plot_type="bar")
242 | # 对特征总体分析
243 | shap.summary_plot(shap_values, df_feature[feats_col_name])
244 | #部分依赖图的功能,与传统的部分依赖图不同的是,这里纵坐标不是目标变量y的数值而是SHAP值
245 | if type == 2:
246 | shap.dependence_plot('feat3name', shap_values, df_feature[feats_col_name], interaction_index=None, show=True)
247 | # 两个变量交互下变量对目标值的影响
248 | if type == 3:
249 | shap.dependence_plot('feat3name', shap_values, df_feature[feats_col_name], interaction_index='feat5name', show=True)
250 | #多个变量的交互进行分析
251 | if type == 4:
252 | shap_interaction_values = explainer.shap_interaction_values(df_feature[feats_col_name])
253 | shap.summary_plot(shap_interaction_values, df_feature[feats_col_name], max_display=4, show=True)
254 |
255 | def plot_print_feature_importance(model_path):
256 | '''
257 | 打印特征的重要度
258 | :param model_path:
259 | :return:
260 | '''
261 |
262 | #模型中的特征是Column_数字,这里打印重要度时可以映射到真实的特征名
263 | # feats_dict = {
264 | # 'Column_0': '特征0名称',
265 | # 'Column_1': '特征1名称',
266 | # 'Column_2': '特征2名称',
267 | # 'Column_3': '特征3名称',
268 | # 'Column_4': '特征4名称',
269 | # 'Column_5': '特征5名称',
270 | # 'Column_6': '特征6名称',
271 | # 'Column_7': '特征7名称',
272 | # 'Column_8': '特征8名称',
273 | # 'Column_9': '特征9名称',
274 | # 'Column_10': '特征10名称',
275 | # }
276 | feats_dict = {}
277 | for feat_index in range(46):
278 | col = 'Column_' + str(feat_index)
279 | feats_dict[col] = 'feat' + str(feat_index) + 'name'
280 |
281 | if not os.path.exists(model_path):
282 | print("file no exists! {}".format(model_path))
283 | sys.exit(0)
284 |
285 | gbm = lgb.Booster(model_file=model_path)
286 |
287 | # 打印和保存特征重要度
288 | importances = gbm.feature_importance(importance_type='split')
289 | feature_names = gbm.feature_name()
290 |
291 | sum = 0.
292 | for value in importances:
293 | sum += value
294 |
295 | for feature_name, importance in zip(feature_names, importances):
296 | if importance != 0:
297 | feat_id = int(feature_name.split('_')[1]) + 1
298 | print('{} : {} : {} : {}'.format(feat_id, feats_dict[feature_name], importance, importance / sum))
299 |
300 | def get_leaf_index(data, model_path):
301 | '''
302 | 得到叶结点并进行one-hot编码
303 | :param data:
304 | :param model_path:
305 | :return:
306 | '''
307 |
308 | gbm = lgb.Booster(model_file=model_path)
309 | ypred = gbm.predict(data, pred_leaf=True)
310 |
311 | one_hot_encoder = OneHotEncoder()
312 | x_one_hot = one_hot_encoder.fit_transform(ypred)
313 | print(x_one_hot.shape)
314 | print(x_one_hot.toarray())
315 |
316 | if __name__ == '__main__':
317 |
318 | if len(sys.argv) != 2:
319 | print("Usage: python lgb_ltr.py [-process | -train | |-plot | -predict | -ndcg | -feature | -shap | -leaf]")
320 | sys.exit(0)
321 |
322 | base_path = os.path.abspath(os.path.join(os.getcwd(), "../.."))
323 |
324 | train_path = base_path + '/data/train/'
325 | raw_data_path = train_path + 'raw_train.txt'
326 | data_feats = train_path + 'feats.txt'
327 | data_group = train_path + 'group.txt'
328 |
329 | model_path = base_path + '/data/model/model.mod'
330 | save_plot_path = base_path + '/data/plot/tree_plot'
331 |
332 | if sys.argv[1] == '-process':
333 | # 训练样本的格式与ranklib中的训练样本是一样的,但是这里需要处理成lightgbm中排序所需的格式
334 | # lightgbm中是将样本特征feats和groups分开保存为txt的,什么意思呢,看下面解释
335 | '''
336 | 输入:
337 | 1 qid:0 1:0.2 2:0.4 ... #comment
338 | 2 qid:0 1:0.1 2:0.2 ... #comment
339 | 1 qid:1 1:0.2 2:0.1 ... #comment
340 | 3 qid:1 1:0.3 2:0.7 ... #comment
341 | 2 qid:1 1:0.5 2:0.5 ... #comment
342 | 1 qid:1 1:0.6 2:0.3 ... #comment
343 |
344 | 输出:
345 | feats:
346 | 1 1:0.2 2:0.4 ...
347 | 2 1:0.1 2:0.2 ...
348 | 1 1:0.2 2:0.1 ...
349 | 3 1:0.3 2:0.7 ...
350 | 2 1:0.5 2:0.5 ...
351 | 1 1:0.6 2:0.3 ...
352 | groups:
353 | 2
354 | 4
355 |
356 | 以上group中2表示前2个是一个qid,4表示后4个是一个qid
357 |
358 | '''
359 | process_data_format(raw_data_path, data_feats, data_group)
360 |
361 | elif sys.argv[1] == '-train':
362 | # train
363 | train_start = datetime.now()
364 | x_train, y_train, q_train = load_data(data_feats, data_group)
365 | train(x_train, y_train, q_train, model_path)
366 | train_end = datetime.now()
367 | consume_time = (train_end - train_start).seconds
368 | print("consume time : {}".format(consume_time))
369 |
370 | elif sys.argv[1] == '-plottree':
371 | #可视化树模型
372 | plot_tree(model_path, 2, save_plot_path)
373 |
374 | elif sys.argv[1] == '-predict':
375 | train_start = datetime.now()
376 | predict_data_path = base_path + '/data/test/test.txt'#格式如ranklib中的数据格式
377 | test_X, test_y, test_qids, comments = load_data_from_raw(predict_data_path)
378 | t_results = predict(test_X, comments, model_path)
379 | print(t_results)
380 | train_end = datetime.now()
381 | consume_time = (train_end - train_start).seconds
382 | print("consume time : {}".format(consume_time))
383 |
384 | elif sys.argv[1] == '-ndcg':
385 | # ndcg
386 | test_path = base_path + '/data/test/test.txt'#评估测试数据的平均ndcg
387 | test_data_ndcg(model_path, test_path)
388 |
389 | elif sys.argv[1] == '-feature':
390 | plot_print_feature_importance(model_path)
391 |
392 | elif sys.argv[1] == '-shap':
393 | plot_print_feature_shap(model_path, data_feats, 3)
394 |
395 | elif sys.argv[1] == '-leaf':
396 | #利用模型得到样本叶结点的one-hot表示
397 | raw_data = base_path + '/data/test/leaf.txt'
398 | with open(raw_data, 'r', encoding='utf-8') as testfile:
399 | test_X, test_y, test_qids, comments = read_dataset(testfile)
400 | get_leaf_index(test_X, model_path)
401 |
--------------------------------------------------------------------------------
/src/trees/ndcg.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import collections
3 |
4 | def validate(qids, targets, preds, k):
5 | """
6 | Predicts the scores for the test dataset and calculates the NDCG value.
7 | Parameters
8 | ----------
9 | data : Numpy array of documents
10 | Numpy array of documents with each document's format is [relevance score, query index, feature vector]
11 | k : int
12 | this is used to compute the NDCG@k
13 |
14 | Returns
15 | -------
16 | average_ndcg : float
17 | This is the average NDCG value of all the queries
18 | predicted_scores : Numpy array of scores
19 | This contains an array or the predicted scores for the documents.
20 | """
21 | query_groups = get_groups(qids) # (qid,from,to),一个元组,表示这个qid的样本从哪到哪
22 | all_ndcg = []
23 | every_qid_ndcg = collections.OrderedDict()
24 |
25 | for qid, a, b in query_groups:
26 | predicted_sorted_indexes = np.argsort(preds[a:b])[::-1] # 从大到小的索引
27 | t_results = targets[a:b] # 目标数据的相关度
28 | t_results = t_results[predicted_sorted_indexes] #是predicted_sorted_indexes排好序的在test_data中的相关度
29 |
30 | dcg_val = dcg_k(t_results, k)
31 | idcg_val = ideal_dcg_k(t_results, k)
32 | ndcg_val = (dcg_val / idcg_val)
33 | all_ndcg.append(ndcg_val)
34 | every_qid_ndcg.setdefault(qid, ndcg_val)
35 |
36 | average_ndcg = np.nanmean(all_ndcg)
37 | return average_ndcg, every_qid_ndcg
38 |
39 |
40 | '''
41 | for query in query_indexes:
42 | results = np.zeros(len(query_indexes[query]))
43 |
44 | for tree in self.trees:
45 | results += self.learning_rate * tree.predict(data[query_indexes[query], 2:])
46 | predicted_sorted_indexes = np.argsort(results)[::-1]
47 | t_results = data[query_indexes[query], 0] # 第0列的相关度
48 | t_results = t_results[predicted_sorted_indexes]
49 |
50 | dcg_val = dcg_k(t_results, k)
51 | idcg_val = ideal_dcg_k(t_results, k)
52 | ndcg_val = (dcg_val / idcg_val)
53 | average_ndcg.append(ndcg_val)
54 | average_ndcg = np.nanmean(average_ndcg)
55 | return average_ndcg
56 | '''
57 |
58 | def get_groups(qids):
59 | """Makes an iterator of query groups on the provided list of query ids.
60 |
61 | Parameters
62 | ----------
63 | qids : array_like of shape = [n_samples]
64 | List of query ids.
65 |
66 | Yields
67 | ------
68 | row : (qid, int, int)
69 | Tuple of query id, from, to.
70 | ``[i for i, q in enumerate(qids) if q == qid] == range(from, to)``
71 |
72 | """
73 | prev_qid = None
74 | prev_limit = 0
75 | total = 0
76 |
77 | for i, qid in enumerate(qids):
78 | total += 1
79 | if qid != prev_qid:
80 | if i != prev_limit:
81 | yield (prev_qid, prev_limit, i)
82 | prev_qid = qid
83 | prev_limit = i
84 |
85 | if prev_limit != total:
86 | yield (prev_qid, prev_limit, total)
87 |
88 | def group_queries(training_data, qid_index):
89 | """
90 | Returns a dictionary that groups the documents by their query ids.
91 | Parameters
92 | ----------
93 | training_data : Numpy array of lists
94 | Contains a list of document information. Each document's format is [relevance score, query index, feature vector]
95 | qid_index : int
96 | This is the index where the qid is located in the training data
97 |
98 | Returns
99 | -------
100 | query_indexes : dictionary
101 | The keys were the different query ids and teh values were the indexes in the training data that are associated of those keys.
102 | """
103 | query_indexes = {} # 每个qid对应的样本索引范围,比如qid=1020,那么此qid在training data中的训练样本从0到100的范围, { key=str,value=[] }
104 | index = 0
105 | for record in training_data:
106 | query_indexes.setdefault(record[qid_index], [])
107 | query_indexes[record[qid_index]].append(index)
108 | index += 1
109 | return query_indexes
110 |
111 |
112 | def dcg_k(scores, k):
113 | """
114 | Returns the DCG value of the list of scores and truncates to k values.
115 | Parameters
116 | ----------
117 | scores : list
118 | Contains labels in a certain ranked order
119 | k : int
120 | In the amount of values you want to only look at for computing DCG
121 |
122 | Returns
123 | -------
124 | DCG_val: int
125 | This is the value of the DCG on the given scores
126 | """
127 | return np.sum([
128 | (np.power(2, scores[i]) - 1) / np.log2(i + 2)
129 | for i in range(len(scores[:k]))
130 | ])
131 |
132 |
133 | def ideal_dcg_k(scores, k):
134 | """
135 | 前k个理想状态下的dcg
136 | Returns the Ideal DCG value of the list of scores and truncates to k values.
137 | Parameters
138 | ----------
139 | scores : list
140 | Contains labels in a certain ranked order
141 | k : int
142 | In the amount of values you want to only look at for computing DCG
143 |
144 | Returns
145 | -------
146 | Ideal_DCG_val: int
147 | This is the value of the Ideal DCG on the given scores
148 | """
149 | # 相关度降序排序
150 | scores = [score for score in sorted(scores)[::-1]]
151 | return dcg_k(scores, k)
--------------------------------------------------------------------------------
/src/trees/xgb_ltr.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiangnanboy/learning_to_rank/001c0c126266ee9a8dc723039b14442b67f2cc18/src/trees/xgb_ltr.py
--------------------------------------------------------------------------------
/src/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jiangnanboy/learning_to_rank/001c0c126266ee9a8dc723039b14442b67f2cc18/src/utils/__init__.py
--------------------------------------------------------------------------------