├── .idea
├── .gitignore
├── vcs.xml
├── misc.xml
├── inspectionProfiles
│ └── profiles_settings.xml
├── modules.xml
└── crawler_TOEFL.iml
├── README.md
└── crawler_toefl.py
/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # Default ignored files
2 | /shelf/
3 | /workspace.xml
4 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
6 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
--------------------------------------------------------------------------------
/.idea/inspectionProfiles/profiles_settings.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
6 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/crawler_TOEFL.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
8 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## NEEA托福考位爬虫 Getting Started with NEEA TOEFL Testseat Crawler
2 |
3 | 本文档简要介绍了NEEA托福考位本地爬虫的使用方法。
4 | This document provides a brief intro of the usage of NEEA TOEFL Test Seats Selenium Crawler.
5 |
6 | ### 动机 Motivation
7 | NEEA 托福考位网站正在提供着不便的服务。在寻找考位时,我们需要按每个日期,每个城市一个个地搜索考位,
8 | 这为那些想尽快找到测试座位的人带来了无法忍受的体验。
9 |
10 |
11 |
12 |
41 |
42 |
 12 |
12 | 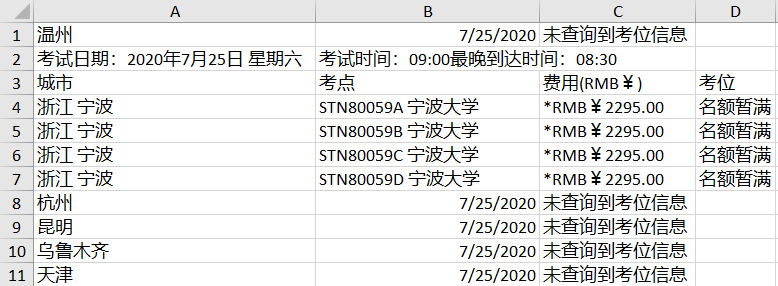 42 |
42 |