├── Java横向技术
├── 数据结构与算法面试题解析.md
├── Linux系统与运维面试题.md
├── MySQL索引面试题.md
├── MySQL锁面试题.md
├── 其他缓存面试题.md
├── 网络与web面试题.md
├── redis面试题.md
├── memcached面试题.md
├── MySQL进阶面试题.md
├── ibatisMybatis框架面试题.md
├── Spring框架面试题.md
└── 23种设计模式.md
├── README.md
└── Java基础技术
├── List与Set类面试题.md
├── 队列面试题.md
├── JDK基础面试题.md
├── 锁与并发面试题.md
├── JVM与垃圾回收机制.md
├── IO面试题.md
├── JVM进阶面试题.md
├── 线程和线程池面试题.md
├── 集合类进阶面试题.md
├── Java面向对象面试题.md
├── Map类面试题.md
├── Java进阶面试题.md
├── Java内存结构与类加载机制.md
└── Java并发进阶面试题.md
/Java横向技术/数据结构与算法面试题解析.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # imooc_java_interview_questions
2 | java interview questions for [高薪之路--Java面试题精选集](https://www.imooc.com/read/67)
3 |
--------------------------------------------------------------------------------
/Java基础技术/List与Set类面试题.md:
--------------------------------------------------------------------------------
1 | # List与Set类面试题
2 |
3 | ### 问:数组(Array)和列表(ArrayList)的差别是什么?
4 |
5 | **参考答案:**
6 |
7 | Array可以容纳基本类型和对象,而ArrayList只能容纳对象;
8 |
9 | Array 是静态的,一旦创建就无法更改它的大小,ArrayList 是Java集合框架类的一员,可以称它为一个动态数组。
10 |
11 | ###
12 |
13 | ### 问:ArrayList和Vector有何异同点?
14 |
15 | **参考答案:**
16 |
17 | - 相同点:
18 |
19 | (1)两者都是基于索引的,内部由一个数组支持。
20 |
21 | (2)两者维护插入的顺序,我们可以根据插入顺序来获取元素。
22 |
23 | (3)ArrayList和Vector的迭代器实现都是fail-fast的。
24 |
25 | (4)ArrayList和Vector两者允许null值,也可以使用索引值对元素进行随机访问。
26 |
27 | - 不同点:
28 |
29 | (1)Vector是同步的,而ArrayList不是。然而,如果你寻求在迭代的时候对列表进行改变,你应该使用CopyOnWriteArrayList。
30 |
31 | (2)ArrayList比Vector快,它因为有同步,不会过载。
32 |
33 | (3)ArrayList更加通用,因为我们可以使用Collections工具类轻易地获取同步列表和只读列表。
34 |
35 |
36 |
37 | ### 问:EnumSet是什么?
38 |
39 | **参考答案:**
40 |
41 | java.util.EnumSet是使用枚举类型的集合实现。当集合创建时,枚举集合中的所有元素必须来自单个指定的枚举类型,可以是显示的或隐示的。EnumSet是不同步的,不允许值为null的元素。
42 |
43 |
44 |
45 | ### 问:Java集合类中的Iterator和ListIterator的区别?
46 |
47 | **参考答案:**
48 |
49 | 1. iterator()方法在set和list接口中都有定义,但是ListIterator()仅存在于list接口中(或实现类中);
50 | 2. ListIterator有add()方法,可以向List中添加对象,而Iterator不能;
51 | 3. ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator就不可以;
52 | 4. ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现。Iterator没有此功能;
53 | 5. 都可实现删除对象,但是ListIterator可以实现对象的修改,set()方法可以实现。Iierator仅能遍历,不能修改;
54 |
55 |
56 |
--------------------------------------------------------------------------------
/Java基础技术/队列面试题.md:
--------------------------------------------------------------------------------
1 | # 队列面试题
2 | ### 问:LinkedHashMap和PriorityQueue的区别?
3 |
4 | **参考答案:**
5 |
6 | PriorityQueue 是一个优先级队列,保证最高或者最低优先级的的元素总是在队列头部,但是 LinkedHashMap 维持的顺序是元素插入的顺序。当遍历一个 PriorityQueue 时,没有任何顺序保证,但是 LinkedHashMap 课保证遍历顺序是元素插入的顺序。
7 |
8 |
9 |
10 | ### 问:BlockingQueue是什么?
11 |
12 | **参考答案:**
13 |
14 | Java.util.concurrent.BlockingQueue是一个队列,在进行检索或移除一个元素的时候,它会等待队列变为非空;当在添加一个元素时,它会等待队列中的可用空间。
15 |
16 | BlockingQueue接口是Java集合框架的一部分,主要用于实现生产者-消费者模式。我们不需要担心等待生产者有可用的空间,或消费者有可用的对象,因为它都在BlockingQueue的实现类中被处理了。
17 |
18 | Java提供了集中BlockingQueue的实现,比如ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue,、SynchronousQueue等。
19 |
20 |
21 |
22 | ### 问:队列和栈是什么,它们的区别是什么?
23 |
24 | **参考答案:**
25 |
26 | 栈又名堆栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。
27 |
28 | 队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
29 |
30 |
31 |
32 | ### 问:BlockingQueue有哪些实现类?ArrayBlockingQueue: 由数组组成的有界阻塞队列?
33 |
34 | **参考答案:**
35 |
36 | LinkedBlockingQueue: 由链表组成的有界阻塞队列(默认大小为 Integer.MAX_VALUE)
37 |
38 | PriorityBlockingQueue:支持优先级排序的无界阻塞队列
39 |
40 | DelayQueue:使用优先级队列实现的延迟无界阻塞队列
41 |
42 | SynchronousQueue: 不存储元素的阻塞队列,单个元素的队列,同步提交队列
43 |
44 | LinkedTransferQueue:链表组成的无界阻塞队列
45 |
46 | LinkedBlockingDeque:链表组成的双向阻塞队列
47 |
48 |
49 |
50 | ### 问:Queue中add/offer方法的区别?
51 |
52 | **参考答案:**
53 |
54 | add()和offer()都是向队列中添加一个元素。一些队列有大小限制,因此如果想在一个满的队列中加入一个新项,调用 add() 方法就会抛出IllegalStateException异常,而调用 offer() 方法会返回 false。
55 |
56 |
57 |
58 |
59 |
60 | ### 问:Queue中remove()/poll()方法的区别?
61 |
62 | **参考答案:**
63 |
64 | poll()/remove()方法都是从队列中删除第一个元素。如果队列元素为空,调用remove() 则会抛出NoSuchElementException,而poll() 方法在用空集合调用时只是返回 null。
65 |
66 |
67 |
68 |
69 |
70 | ### 问:Queue中element()/peek()方法的区别?
71 |
72 | **参考答案:**
73 |
74 | element() 和 peek() 用于在队列的头部查询元素。与 remove() 方法类似,在队列为空时, element() 抛出NoSuchElementException异常,而 peek() 返回 null。
75 |
--------------------------------------------------------------------------------
/Java基础技术/JDK基础面试题.md:
--------------------------------------------------------------------------------
1 | # JDK基础面试题
2 |
3 | #### 问:String是最基本的数据类型吗?
4 | **参考答案:**
不是,Java基本数据类型只有8种,byte、int、char、long、float、double、boolean和short。
5 |
6 | #### 问:Collection 和 Collections的区别?
7 | **参考答案:**
8 |
9 | Collection是集合类的上级接口,继承与他的接口主要有Set 和List.
10 | Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
11 |
12 |
13 | #### 问:String对象的intern()是指什么?
14 | **参考答案:**
intern()方法会首先从常量池中查找是否存在该常量值,如果常量池中不存在则现在常量池中创建,如果已经存在则直接返回. 比如 String s1="aa"; String s2=s1.intern(); System.out.print(s1==s2);//返回true
15 |
16 | #### 问:final、finally、finalize的区别是什么?
17 | **参考答案:**
final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
finally是异常处理语句结构的一部分,表示总是执行。
finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。
18 |
19 | #### 问:error和exception有什么区别?
20 | **参考答案:**
error通常表示恢复不是不可能但很困难的情况下的一种严重问题。比如说内存溢出、不可能指望程序能处理这样的情况;
exception通常表示一种设计或实现问题。也就是说,它表示如果程序运行正常,从不会发生的情况;
21 |
22 | #### 问:运行时异常与受检异常有何异同?
23 | **参考答案:**
运行时异常表示虚拟机的通常操作中可能遇到的异常,是一种常见运行错误,只要程序设计得没有问题通常就不会发生;
受检异常跟程序运行的上下文环境有关,即使程序设计无误,仍然可能因使用的问题而引发。Java编译器要求方法必须声明抛出可能发生的受检异常,但是并不要求必须声明抛出未被捕获的运行时异常。
24 |
25 |
26 |
27 | #### 问:列出一些你常见的运行时异常?
28 | **参考答案:**
29 |
30 | - ArithmeticException(算术异常)
31 |
32 | - ClassCastException (类转换异常)
33 |
34 | - IllegalArgumentException (非法参数异常)
35 |
36 | - IndexOutOfBoundsException (下标越界异常)
37 |
38 | - NullPointerException (空指针异常)
39 |
40 | - SecurityException (安全异常)
41 |
42 |
43 | #### 问:static都有哪些用法?
44 | **参考答案:**
45 |
46 | - 静态变量
47 | - 静态方法
48 | - 静态块,多用于初始化
49 | - 静态内部类.
50 | - 静态导向,即import static.import static是在JDK 1.5之后引入的新特性,可以用来指定导入某个类中的静态资源,并且不需要使用类名.资源名,可以直接使用资源名,比如:
51 |
52 | import static java.lang.Math.sin;
public class Test{
public static void main(String[] args){
//System.out.println(Math.sin(20));传统做法
System.out.println(sin(20)); // 静态导包
}
}
53 |
54 | #### 问:final有哪些用法
55 | **参考答案:**
56 |
57 | 1. 被final修饰的类不可以被继承
58 | 1. 被final修饰的方法不可以被重写
59 | 1. 被final修饰的变量不可以被改变.如果修饰引用,那么表示引用不可变,引用指向的内容可变.
60 | 1. 被final修饰的方法,JVM会尝试将其内联,以提高运行效率
61 | 1. 被final修饰的常量,在编译阶段会存入常量池中.
--------------------------------------------------------------------------------
/Java横向技术/Linux系统与运维面试题.md:
--------------------------------------------------------------------------------
1 | # Linux系统与运维面试题
2 | ### 问:什么是正向代理和反向代理?
3 |
4 | **参考答案:**
5 |
6 | - 正向代理,一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器)。然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端才能使用正向代理。**总结为一句话:代理端代理的是客户端;**
7 | - 反向代理是指以代理服务器来接受internet上的连接请求,然后将请求,发给内部网络上的服务器并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。**总结就一句话:代理端代理的是服务端。**
8 |
9 |
10 |
11 | ### 问:nginx是什么?有什么优点?
12 |
13 | **参考答案:**
14 |
15 | Nginx是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器。目前使用最广泛之一的web服务器或者代理服务器。
16 |
17 | ***优点:***
18 |
19 | - 跨平台、配置简单
20 | - 非阻塞、高并发连接:处理2-3万并发连接数,官方监测能支持5万并发
21 | - 内存消耗小:开启10个nginx才占150M内存 成本低廉:开源
22 | - 内置的健康检查功能:如果有一个服务器宕机,会做一个健康检查,再发送的请求就不会发送到宕机的服务器了。重新将请求提交到其他的节点上。
23 | - 节省宽带:支持GZIP压缩,可以添加浏览器本地缓存
24 | - 稳定性高:宕机的概率非常小
25 | - master/worker结构:一个master进程,生成一个或者多个worker进程
26 | - 接收用户请求是异步的:浏览器将请求发送到nginx服务器,它先将用户请求全部接收下来,再一次性发送给后端web服务器,极大减轻了web服务器的压力
27 | - 一边接收web服务器的返回数据,一边发送给浏览器客户端
28 | - 网络依赖性比较低,只要ping通就可以负载均衡
29 | - 可以有多台nginx服务器
30 | - 事件驱动:通信机制采用epoll模型
31 |
32 |
33 |
34 | ### 问:什么是机器负载?
35 |
36 | **参考答案:**
37 |
38 | 在UNIX系统中,系统负载是对当前CPU工作量的度量,被定义为特定时间间隔内运行队列中的平均线程数。load average 表示机器一段时间内的平均load。这个值越低越好。负载过高会导致机器无法处理其他请求及操作,甚至导致死机。
39 |
40 | Linux的负载高,主要是由于CPU使用、内存使用、IO消耗三部分构成。任意一项使用过多,都将导致服务器负载的急剧攀升。
41 |
42 |
43 |
44 | ### 问:怎么查看机器负载?
45 |
46 | **参考答案:**
47 |
48 | 在Linux机器上,有多个命令都可以查看机器的负载信息。其中包括uptime、top、w等。
49 |
50 | **(1)uptime命令**
51 |
52 | uptime命令能够打印系统总共运行了多长时间和系统的平均负载。uptime命令可以显示的信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。
53 |
54 | 
55 | 这行信息的后半部分,显示"load average",它的意思是"系统的平均负荷",里面有三个数字,我们可以从中判断系统负荷是大还是小。
56 |
57 | `0.00 0.03 0.04` 这三个数字的意思分别是1分钟、5分钟、15分钟内系统的平均负荷。我们一般表示为load1、load5、load15
58 |
59 | **(2)w命令**
60 |
61 | w命令的主要功能其实是显示目前登入系统的用户信息。但是与who不同的是,w命令功能更加强大,w命令还可以显示:当前时间,系统启动到现在的时间,登录用户的数目,系统在最近1分钟、5分钟和15分钟的平均负载。然后是每个用户的各项数据,项目显示顺序如下:登录帐号、终端名称、远 程主机名、登录时间、空闲时间、JCPU、PCPU、当前正在运行进程的命令行。
62 |
63 | 
64 | 从上面的`w`命令的结果可以看到,当前系统时间是21:57,系统启动到现在经历了7分钟,共有2个用户登录。系统在近1分钟、5分钟和15分钟的平均负载分别是`0.00 0.03 0.04`。这和uptime得到的结果相同。 下面还打印了一些登录的用户的各项数据,不详细介绍了。
65 |
66 | **(3)top命令**
67 |
68 | top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
69 | 
70 | 上面的输出结果中,load average: `0.00 0.03 0.04` 显示的就是负载信息。
71 |
72 |
73 |
74 |
--------------------------------------------------------------------------------
/Java横向技术/MySQL索引面试题.md:
--------------------------------------------------------------------------------
1 | # MySQL索引面试题
2 | ### **问:什么是索引?**
3 |
4 | **参考答案:**
5 |
6 | MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构,可以帮助我们快速的进行数据的查找。
7 |
8 |
9 |
10 | ### 问:索引是个什么样的数据结构呢?
11 |
12 | **参考答案:**
13 |
14 | 索引的数据结构和具体存储引擎的实现有关, 在MySQL中使用较多的索引有Hash索引,B+树索引等,而我们经常使用的InnoDB存储引擎的默认索引实现为:B+树索引。
15 |
16 |
17 |
18 | ### 问:MySQL支持哪些索引?
19 |
20 | **参考答案:**
21 |
22 | 因此MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等。
23 |
24 |
25 |
26 | ### 问:Hash索引和B+树所有有什么区别或者说优劣呢?
27 |
28 | **参考答案:**
29 |
30 | 首先要知道Hash索引和B+树索引的底层实现原理:
31 |
32 | hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据;B+树底层实现是多路平衡查找树,对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据.。
33 |
34 | 那么可以看出他们有以下的不同:
35 |
36 | 1、hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询.
37 |
38 | 因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询。而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范围。
39 |
40 | 2、hash索引不支持使用索引进行排序,原理同上;
41 |
42 | 3、hash索引不支持模糊查询以及多列索引的最左前缀匹配,原理也是因为hash函数的不可预测.**AAAA**和**AAAAB**的索引没有相关性;
43 |
44 | 4、hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询;
45 |
46 | 5、hash索引虽然在等值查询上较快,但是不稳定。性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差。而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低。
47 |
48 | 因此在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度,而不需要使用hash索引。
49 |
50 |
51 |
52 | ### 问:建立索引的原则有哪些?
53 |
54 | **参考答案:**
55 |
56 | 选择唯一性索引,为经常需要查询、排序、分组和联合操作的字段建立索引,限制索引的数目,最左前缀匹配原则(非常重要的原则),尽量选择区分度高的列作为索引,字段尽力设置不为null,索引列上不计算。
57 |
58 |
59 |
60 | ### 问:主键、外键和唯一索引的区别
61 |
62 | **参考答案:**
63 |
64 | 主键:唯一标识一条记录,不能有重复的,不允许为空
65 |
66 | 外键:表的外键是另一表的主键, 外键可以有重复的, 可以是空值
67 |
68 | 索引:该字段没有重复值,但可以有空值
69 |
70 |
71 |
72 | ###
73 |
74 |
75 |
76 |
77 |
78 | ### 问:什么是回表查询和覆盖索引?
79 |
80 | **参考答案:**
81 |
82 | 如果使用普通索引,则查询时间先查找到主键值,之后再通过主键值查找到自己想要的数据;需要扫码两遍所引树;这就是回表查询;
83 |
84 | 索引覆盖:只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表;
85 |
86 |
87 |
88 |
89 |
90 | ### 问: 非聚簇索引一定会回表查询吗?
91 |
92 | **参考答案:**
93 |
94 | 不一定。
95 |
96 |
97 |
98 |
99 |
100 | ### 问:使用索引查询一定能提高查询的性能吗?为什么
101 |
102 | **参考答案:**
103 |
104 | 通常,通过索引查询数据比全表扫描要快.但是我们也必须注意到它的代价.
105 |
106 | 索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时,索引本身也会被修改. 这意味着每条记录的INSERT,DELETE,UPDATE将为此多付出4,5 次的磁盘I/O. 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢.使用索引查询不一定能提高查询性能,索引范围查询(INDEX RANGE SCAN)适用于两种情况:
107 |
108 | - 基于一个范围的检索,一般查询返回结果集小于表中记录数的30%
109 | - 基于非唯一性索引的检索
110 |
--------------------------------------------------------------------------------
/Java横向技术/MySQL锁面试题.md:
--------------------------------------------------------------------------------
1 | # MySQL锁面试题
2 | ### 问:事务是什么?
3 |
4 | **参考答案:**
5 |
6 | 事务(Transaction)是并发控制的基本单位。所谓的事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。
7 |
8 |
9 |
10 | ### 问:事务有哪些特性?
11 |
12 | **参考答案:**
13 |
14 | **1、原子性(Atomicity)**:事务是一个不可分割的单位,事务中的所有SQL等操作要么都发生,要么都不发生。
15 |
16 | **2、一致性(Consistency)**:事务发生前和发生后,数据的完整性必须保持一致。
17 |
18 | **3、隔离性(Isolation)**:当并发访问数据库时,一个正在执行的事务在执行完毕前,对应其他的会话是不可见的,多个并发事务之间的数据是相互隔离的。备份的参数 --single-transaction
19 |
20 | **4、持久性(Durability)**:一个事务一旦被提交,它对数据库中的数据改变就是永久性的。如果出了错误,事务也不允许撤销,只能通过“补偿性事务”。
21 |
22 |
23 |
24 |
25 |
26 | ### 问:MySQL中InnoDB引擎的行锁是通过加在什么上完成(或称实现)的?为什么是这样子的?
27 |
28 | **参考答案:**
29 |
30 | InnoDB是基于索引来完成行锁。
31 |
32 | 例如在select * from tab_with_index where id = 1 for update中。for update 可以根据条件来完成行锁锁定,并且 id 是有索引键的列,如果 id 不是索引键那么InnoDB将完成表锁,并发将无从谈起。
33 |
34 |
35 |
36 | ### **问:并发事务带来哪些问题?**
37 |
38 | **参考答案:**
39 |
40 | 在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对统一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题:
41 |
42 | - **脏读(Dirty read):** 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
43 | - **丢****失修改(Lost to modify):** 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
44 | - **不可重复读(Unrepeatableread):** 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
45 | - **幻读(Phantom read):** 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
46 |
47 |
48 |
49 | **不可重复度和幻读区别:**
50 |
51 | 不可重复读的重点是修改,幻读的重点在于新增或者删除。
52 |
53 | 例1(同样的条件, 你读取过的数据, 再次读取出来发现值不一样了 ):事务1中的A先生读取自己的工资为 1000的操作还没完成,事务2中的B先生就修改了A的工资为2000,导 致A再读自己的工资时工资变为 2000;这就是不可重复读。
54 |
55 | 例2(同样的条件, 第1次和第2次读出来的记录数不一样 ):假某工资单表中工资大于3000的有4人,事务1读取了所有工资大于3000的人,共查到4条记录,这时事务2 又插入了一条工资大于3000的记录,事务1再次读取时查到的记录就变为了5条,这样就导致了幻读。
56 |
57 |
58 |
59 | ### 问:什么是基本表?什么是视图?
60 |
61 | **参考答案:**
62 |
63 | 基本表是本身独立存在的表,在 SQL 中一个关系就对应一个表。 视图是从一个或几个基本表导出的表。视图本身不独立存储在数据库中,是一个虚表。
64 |
65 |
66 |
67 | ### 问:试述视图的优点?
68 |
69 | **参考答案:**
70 |
71 | (1) 视图能够简化用户的操作 (2) 视图使用户能以多种角度看待同一数据; (3) 视图为数据库提供了一定程度的逻辑独立性; (4) 视图能够对机密数据提供安全保护。
72 |
73 |
74 |
75 | ### 问:请你介绍一下mysql的MVCC机制
76 | **参考答案:**
77 |
78 | MVCC是一种多版本并发控制机制,是MySQL的InnoDB存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。MVCC是通过保存数据在某个时间点的快照来实现该机制,其在每行记录后面保存两个隐藏的列,分别保存这个行的创建版本号和删除版本号,然后Innodb的MVCC使用到的快照存储在Undo日志中,该日志通过回滚指针把一个数据行所有快照连接起来。
79 |
80 | 可参见:
81 |
82 | - [【MySQL(5)| 五分钟搞清楚 MVCC 机制】](https://juejin.im/post/5c68a4056fb9a049e063e0ab)
83 | - [ 面试官:谈谈你对Mysql的MVCC的理解?](https://blog.csdn.net/belalds/article/details/98759840)
84 |
--------------------------------------------------------------------------------
/Java基础技术/锁与并发面试题.md:
--------------------------------------------------------------------------------
1 | # 锁与并发面试题
2 | ### 问:说说并发与并行的区别?
3 |
4 | **参考答案:**
5 |
6 | **并发(conurrent):**
7 |
8 | 在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。类似操作系统的时间片分时调度。打游戏和听音乐两件事情在同一个时间段内都是在同一台电脑上完成了从开始到结束的动作。那么,就可以说听音乐和打游戏是并发的。
9 |
10 | **并行(Parallel):**
11 |
12 | 当系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。所以,**并发是指在一段时间内宏观上多个程序同时运行。并行指的是同一个时刻,多个任务确实真的在同时运行。****并发,指的是多个事情,在同一时间段内同时发生了。****并行,指的是多个事情,在同一时间点上同时发生了。**并发的多个任务之间是互相抢占资源的。并行的多个任务之间是不互相抢占资源的、只有在多CPU的情况中,才会发生并行。否则,看似同时发生的事情,其实都是并发执行的。
13 |
14 | 这里面有一个很重要的点,那就是系统要有多个CPU才会出现并行。在有多个CPU的情况下,才会出现真正意义上的『同时进行』。
15 |
16 |
17 |
18 | ### 问:说说 sleep() 方法和 wait() 方法区别和共同点?
19 |
20 | **参考答案:**
21 |
22 | - 两者最主要的区别在于:**sleep()方法没有释放锁,而 wait()方法释放了锁**。
23 |
24 | - 两者都可以暂停线程的执行。
25 |
26 | - wait()通常被用于线程间交互/通信,sleep()通常被用于暂停执行。
27 |
28 | - wait()方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep()方法执行完成后,线程会自动苏醒。
29 |
30 |
31 |
32 | ### 问: 说说 JDK1.6 之后的synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗?
33 |
34 | **参考答案:**
35 |
36 | JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
37 |
38 | **1. 偏向锁**:无竞争条件下,消除整个同步互斥,连CAS都不操作。消除数据在无竞争情况下的同步原语,进一步提高程序的运行性能。即在无竞争的情况下,把 整个同步都消除掉。这个锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁 没有被其他的线程获取,则持有偏向锁的线程将永远不需要同步。
39 |
40 | **2.轻量级锁**:无竞争条件下,通过CAS消除同步互斥,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。
41 |
42 | **3.自旋锁**:为了减少线程状态改变带来的消耗,不停地执行当前线程;
43 |
44 | **4.自适应自旋锁**:自旋的时间不固定了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。 如果一个锁对象,自旋等待刚刚成功获得锁,并且持有锁的线程正在运行,那么虚拟机认 为这次自旋仍然可能成功,进而运行自旋等待更长的时间。 如果对于某个锁,自旋很少成功,那在以后要获取这个锁,可能省略掉自旋过程,以免浪费处理器资源。 有了自适应自旋,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测就会 越来越准确,虚拟机也会越来越聪明。
45 |
46 | **5.锁消除**:不可能存在共享数据竞争的锁进行消除;
47 |
48 | **6.锁粗化**:将连续的加锁,精简到只加一次锁。原则上,同步块的作用范围要尽量小。但是如果一系列的连续操作都对同一个对象反复加锁和 解锁,甚至加锁操作在循环体内,频繁地进行互斥同步操作也会导致不必要的性能损耗。 锁粗化就是增大锁的作用域;
49 |
50 | 其中,锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
51 | 
52 |
53 | ### 问:自旋锁解决什么问题?自旋锁的原理是什么?自旋的缺点?
54 |
55 | **参考答案:**
56 |
57 | **(1)自旋锁解决什么问题?**
58 |
59 | 互斥同步对性能最大的影响是阻塞的实现,**挂起线程**和**恢复线程**的操作都需要转入内核态中完 成,这些操作给系统的并发性带来很大压力。同时很多应用共享数据的锁定状态,只会持续很短的一段时间,为了这段时间去挂起和恢复线程并不值得。先不挂起线程,等一会儿。
60 |
61 | **(2)自旋锁的原理是什么?**
62 |
63 | 如果物理机器有一个以上的处理器,能让两个或以上的线程同时并行执行,让后面请求锁的线程稍等一会,但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放。为了让线程等待,我们只需让线程执行一个忙循环(自旋)。
64 |
65 | **(3)自旋的缺点?**
66 |
67 | 自旋等待本身虽然避免了线程切换的开销,但它要占用处理器时间。所以如果锁被占用的时间 很短,自旋等待的效果就非常好;如果时间很长,那么自旋的线程只会白白消耗处理器的资 源。所以自旋等待的时间要有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁, 那就应该使用传统的方式挂起线程了。
68 |
69 | ###
70 |
71 | ### 问:单机场景下常用的并发控制手段有哪些?
72 |
73 | **参考答案:**
74 |
75 | 最基础的:1.同步方法synchronized;2.同步块synchronized。
76 |
77 | 进阶的:重入锁ReentrantLock,Semaphore信号量
78 |
79 |
80 |
81 | ### 问:什么是公平锁?什么是非公平锁?
82 |
83 | **参考答案:**
84 |
85 | **公平锁**是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁大。
86 |
87 | **非公平锁**是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
88 |
89 | P.S:Java主流锁的分类
90 |
91 | 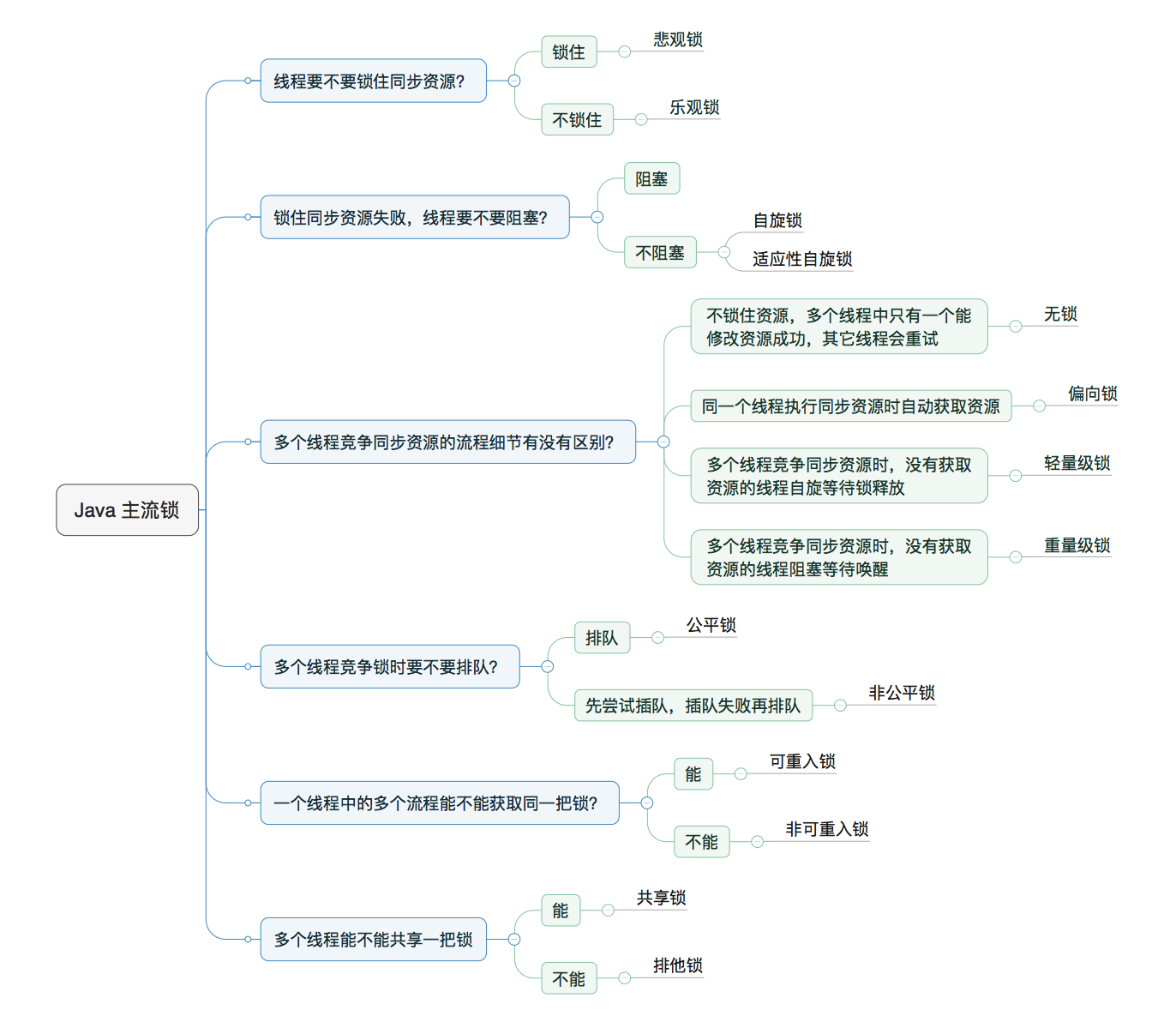
92 |
93 |
94 |
95 | ### 问:volatile的作用?
96 |
97 | **参考答案:**
98 |
99 | 关键字volatile是Java虚拟机提供的最轻量级的同步机制。当一个变量被定义成volatile之后, 具备两种特性:
100 |
101 | \1. 保证此变量对所有线程的可见性。当一条线程修改了这个变量的值,新值对于其他线程是 可以立即得知的。而普通变量做不到这一点。
102 |
103 | \2. 禁止指令重排序优化。普通变量仅仅能保证在该方法执行过程中,得到正确结果,但是不 保证程序代码的执行顺序。
104 |
105 | ### 问:为什么基于volatile变量的运算在并发下不一定是安全的?
106 |
107 | **参考答案:**
108 |
109 | volatile变量在各个线程的工作内存,不存在一致性问题(各个线程的工作内存中volatile变 量,每次使用前都要刷新到主内存)。但是Java里面的运算并非原子操作,导致volatile变量的运算在并发下一样是不安全的。
110 |
111 |
112 |
113 | ### 问:为什么使用volatile?
114 |
115 | **参考答案:**
116 |
117 | 在某些情况下,volatile同步机制的性能要优于锁(synchronized关键字),但是由于虚拟机 对锁实行的许多消除和优化,所以并不是很快。
118 |
119 | volatile变量读操作的性能消耗与普通变量几乎没有差别,但是写操作则可能慢一些,因为它 需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行。
120 |
--------------------------------------------------------------------------------
/Java横向技术/其他缓存面试题.md:
--------------------------------------------------------------------------------
1 | # 其他缓存面试题
2 | ### 问:用ConcurrentHashMap来实现LRU?
3 |
4 | **参考答案:**
5 |
6 | ```java
7 | import java.util.concurrent.ConcurrentHashMap;
8 | import java.util.concurrent.ConcurrentLinkedQueue;
9 | class LRU {
10 | private int size;
11 | private ConcurrentLinkedQueue linkedQueue;
12 | private ConcurrentHashMap hashMap;
13 | public LRU(final int size) {
14 | this.size = size;
15 | this.linkedQueue = new ConcurrentLinkedQueue();
16 | this.hashMap = new ConcurrentHashMap(size);
17 | }
18 |
19 | public Value get(Key key) {
20 | Value value = hashMap.get(key);
21 | if (value != null) {
22 | linkedQueue.remove(key);
23 | linkedQueue.add(key);
24 | }
25 | return value;
26 | }
27 |
28 | public synchronized void put(final Key key, final Value value) {
29 | if (hashMap.containsKey(key)) {
30 | linkedQueue.remove(key);
31 | }
32 | while (linkedQueue.size() >= size) {
33 | Key oldestKey = linkedQueue.poll();
34 | if (oldestKey != null) {
35 | hashMap.remove(oldestKey);
36 | }
37 | linkedQueue.add(key);
38 | hashMap.put(key, value);
39 | }
40 | }
41 | }
42 | ```
43 |
44 |
45 |
46 | ### 问:缓存与数据库双写不一致解决方案
47 |
48 | **参考答案:**
49 |
50 |
51 |
52 | 保证最终一致性的解决方案是缓存设置过期时间。
53 |
54 | **方案一:先更新缓存,再更新数据库**
55 |
56 | 不推荐。
57 |
58 | 先更新缓存若更新数据库失败,还需再更新缓存。
59 |
60 | **方案二:先更新数据库,再更新缓存**
61 |
62 | 不推荐。
63 |
64 | 同时有请求A和请求B进行更新操作,请求A与B在不同线程,可能会出现:
65 |
66 | 1. 请求A更新了数据库
67 | 2. 请求B更新了数据库
68 | 3. 请求B更新了缓存
69 | 4. 请求A更新了缓存
70 |
71 | 这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。
72 |
73 | **方案三:先删除缓存,再更新数据库**
74 |
75 | 有点问题。
76 |
77 | 有一个请求A进行更新操作,另一个请求B进行查询操作,可能会出现:
78 |
79 | *(1)、单个数据库*
80 |
81 | 1. 请求A进行写操作,删除缓存
82 | 2. 请求B查询发现缓存不存在
83 | 3. 请求B去数据库查询得到旧值
84 | 4. 请求B将旧值写入缓存
85 | 5. 请求A将新值写入数据库
86 |
87 | *(2)、读写分离架构*
88 |
89 | 1. 请求A进行写操作,删除缓存
90 | 2. 请求A将数据写入数据库了,
91 | 3. 请求B查询缓存发现,缓存没有值
92 | 4. 请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值
93 | 5. 请求B将旧值写入缓存
94 |
95 | 数据库完成主从同步,从库变为新值
96 |
97 | 上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。*
98 | *
99 |
100 | ***解决方案:延时双删策略***
101 |
102 | ```
103 | public void write(String key,Object data){
104 | redis.delKey(key);
105 | db.updateData(data);
106 | Thread.sleep(1000);
107 | redis.delKey(key);
108 | }
109 | ```
110 |
111 |
112 |
113 | 1. 先淘汰缓存
114 | 2. 再写数据库(这两步和原来一样)
115 | 3. 休眠1秒
116 | 4. 再次淘汰缓存
117 |
118 | 自行评估自己的项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上,加几百ms即可。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
119 |
120 | 对于MySQL读写分离架构,只是睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
121 |
122 | **方案四:先更新数据库,再删除缓存**
123 |
124 | 极端情况有问题。
125 |
126 | 有一个请求A进行更新操作,另一个请求B进行查询操作,可能会出现:
127 |
128 | 1. 请求A查询数据库得到一个旧值
129 | 2. 请求B将新值写入数据库
130 | 3. 请求B删除缓存
131 | 4. 请求A将查到的旧值写入缓存
132 |
133 |
134 |
135 | 步骤`2`的写数据库操作比步骤`1`的读数据库操作耗时更短,才有可能使得步骤`3`先于步骤`4`。可是,大家想想,数据库的读操作的速度远快于写操作的,因此步骤`2`耗时比步骤`1`更短,这一情形很难出现。
136 |
137 | ***解决方案:延时双删策略\***
138 |
139 | ```
140 | public void write(String key,Object data){
141 | db.updateData(data);
142 | redis.delKey(key);
143 | Thread.sleep(1000);
144 | redis.delKey(key);
145 | }
146 | ```
147 |
148 |
149 |
150 | 1. 先写数据库
151 | 2. 再淘汰缓存
152 | 3. 休眠1秒
153 | 4. 再次淘汰缓存
154 |
155 | ##
156 |
157 | **方案三与方案四还存在问题**
158 |
159 | 1. 同步双删导致并发降低
160 | 2. 比如一个写数据请求,然后写入数据库了,删缓存失败了,这会就出现不一致的情况。
161 |
162 | **问题1解决方案**
163 |
164 | 异步。
165 |
166 | **问题二解决方案**
167 |
168 | 提供一个保障的重试机制。
169 |
170 | ***方案一:消息队列方式\***
171 |
172 | 
173 |
174 | 1. 更新数据库数据
175 | 2. 缓存因为种种问题删除失败
176 | 3. 将需要删除的key发送至消息队列
177 | 4. 自己消费消息,获得需要删除的key
178 | 5. 继续重试删除操作,直到成功
179 |
180 | 业务线代码侵入较大。
181 |
182 | ***方案二:订阅binlong方式***
183 |
184 | 
185 |
186 | 1. 更新数据库数据
187 | 2. 数据库会将操作信息写入binlog日志当中
188 | 3. 订阅程序提取出所需要的数据以及key
189 | 4. 另起一段非业务代码,获得该信息
190 | 5. 尝试删除缓存操作,发现删除失败
191 | 6. 将这些信息发送至消息队列
192 | 7. 重新从消息队列中获得该数据,重试操作。
193 |
194 | 订阅binlog程序在MySQL中有阿里开源的中间件叫canal。
195 |
196 | 如果对一致性要求不是很高,直接在程序中另起一个线程,每隔一段时间去重试也可。
197 |
198 | **总结**
199 |
200 | 根据数据实时性要求,以及系统并发量考虑。
201 |
202 | 实时性不强,则可以选择设定缓存过期时间,先删缓存再更新数据库或先更新数据库再删缓存方案都可行。
203 |
204 | 实时性较强的,又有大并发量可以考虑延迟双删策略。
205 |
206 | 至于其他如请求串行化,放入同一个队列中依次执行的,复杂没必要。
207 |
--------------------------------------------------------------------------------
/Java基础技术/JVM与垃圾回收机制.md:
--------------------------------------------------------------------------------
1 | # JVM与垃圾回收机制
2 | ### 问:Java 虚拟机结束生命周期的几种场景?
3 |
4 | **参考答案:**
5 |
6 | - 执行了System.exit()方法;
7 | - 程序正常执行结束;
8 | - 程序在执行过程中遇到了异常或错误而异常终止;
9 | - 由于操作系统出现错误而导致 Java 虚拟机进程终止;
10 |
11 |
12 |
13 | ### 问:为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace)?
14 |
15 | **参考答案:**
16 |
17 | 整个永久代有一个 JVM 本身设置固定大小上线,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,并且永远不会得到 java.lang.OutOfMemoryError。你可以使用 -XX:MaxMetaspaceSize。 标志设置最大元空间大小,默认值为 unlimited,这意味着它只受系统内存的限制。 -XX:MetaspaceSize调整标志定义元空间的初始大小如果未指定此标志,则 Metaspace 将根据运行时的应用程序需求动态地重新调整大小。
18 |
19 |
20 |
21 | ### 问:JVM 中的 Class 只有满足什么条件被回收?
22 |
23 | **参考答案 :**
24 |
25 | - 该类所有的实例都已经被 GC,也就是 JVM 中不存在该 Class 的任何实例。
26 | - 加载该类的 ClassLoader 已经被 GC。
27 | - 该类的 java.lang.Class 对象没有在任何地方被引用,如不能在任何地方通过反射访问该类的方法
28 |
29 |
30 |
31 |
32 |
33 | ### 问:新生代、老年代、持久代都存储哪些东西?
34 |
35 | **参考答案:**
36 |
37 | - 新生代:方法中new一个对象,就会先进入新生代。
38 | - 老年代:
39 |
40 | - - 新生代中经历了N次垃圾回收仍然存活的对象就会被放到老年代中。
41 | - 大对象一般直接放入老年代。
42 | - 当Survivor空间不足。需要老年代担保一些空间,也会将对象放入老年代。
43 |
44 | - 永久代: 指的就是方法区。
45 |
46 |
47 |
48 |
49 |
50 | ### 问:什么时候进行**MinorGC**和FullGC
51 |
52 | **参考答案:**
53 |
54 | - MinorGC:当Eden区满时,触发Minor GC.
55 | - FullGC:
56 |
57 | - - 调用System.gc时,系统建议执行Full GC,但是不必然执行
58 | - 老年代空间不足
59 | - 方法区空间不足
60 | - 通过Minor GC后进入老年代的平均大小大于老年代的剩余空间
61 | - 堆中分配很大的对象,而老年代没有足够的空间
62 |
63 |
64 |
65 | ### 问:**MinorGC和FullGC的区别**
66 |
67 | **参考答案:**
68 |
69 | - Minor GC通常发生在新生代的Eden区,在这个区的对象生存期短,往往发生GC的频率较高,回收速度比较快,一般采用复制-回收算法
70 | - Full GC/Major GC 发生在老年代,一般情况下,触发老年代GC的时候不会触发Minor GC,所采用的是标记-清除算法
71 |
72 | ###
73 |
74 | ### 问:Java中的引用是如何分类的?
75 |
76 | **参考答案:**
77 |
78 | - 强引用:GC时不会被回收
79 | - 软引用:描述有用但不是必须的对象,在发生内存溢出异常之前被回收
80 | - 弱引用:描述有用但不是必须的对象,在下一次GC时被回收
81 | - 虚引用(幽灵引用/幻影引用):无法通过虚引用获得对象,用PhantomReference实现虚引用,虚引用用来在GC时返回一个通知。
82 |
83 |
84 |
85 | ### 问:空间分配担保是什么?
86 |
87 | **参考答案:**
88 |
89 | 在Minor GC之前,jvm会检查老年代最大可用连续空间是否大于新生代所有对象的空间。如果成立,则Minor GC是安全的。否则:
90 |
91 | 1、jvm设置不允许担保失败则立刻Full GC
92 |
93 | \2. jvm设置允许担保失败则检查老年代最大可用连续空间是否大于历次晋升到老年代对象的平均大小,如果大于则进行一次冒险的Minor GC 否则Full GC
94 |
95 | PS: Full GC 其实是为了让老年代腾出更多空间
96 |
97 |
98 |
99 | ### 问:堆内存不足的原因和解决方法
100 |
101 | **参考答案:**
102 |
103 | 这种场景最为常见,报错信息
104 |
105 | ```
106 | java.lang.OutOfMemoryError: Java heap space
107 | ```
108 |
109 | **原因:**
110 |
111 | 1、代码中可能存在大对象分配
112 |
113 | 2、可能存在内存泄露,导致在多次GC之后,还是无法找到一块足够大的内存容纳当前对象。
114 |
115 | **解决方法:**
116 |
117 | 1、检查是否存在大对象的分配,最有可能的是大数组分配
118 |
119 | 2、通过jmap命令,把堆内存dump下来,使用mat工具分析一下,检查是否存在内存泄露的问题
120 |
121 | 3、如果没有找到明显的内存泄露,使用 -Xmx 加大堆内存
122 |
123 | 4、还有一点容易被忽略,检查是否有大量的自定义的 Finalizable 对象,也有可能是框架内部提供的,考虑其存在的必要性
124 |
125 |
126 |
127 | ### 问:永久代/元空间溢出的原因和解决方法
128 |
129 | **参考答案:**
130 |
131 | 报错信息:
132 |
133 | ```
134 | java.lang.OutOfMemoryError: PermGen space
135 | java.lang.OutOfMemoryError: Metaspace
136 | ```
137 |
138 |
139 |
140 | **原因:**
141 |
142 | 永久代是 HotSot 虚拟机对方法区的具体实现,存放了被虚拟机加载的类信息、常量、静态变量、JIT编译后的代码等。
143 |
144 | JDK8后,元空间替换了永久代,元空间使用的是本地内存,还有其它细节变化:1、字符串常量由永久代转移到堆中;2、和永久代相关的JVM参数已移除;
145 |
146 | 出现永久代或元空间的溢出的原因可能有如下几种:
147 |
148 | 1、在Java7之前,频繁的错误使用String.intern方法;
149 |
150 | 2、生成了大量的代理类,导致方法区被撑爆,无法卸载;
151 |
152 | 3、应用长时间运行,没有重启。
153 |
154 | **解决方法:**
155 |
156 | 永久代/元空间 溢出的原因比较简单,解决方法有如下几种:
157 |
158 | 1、检查是否永久代空间或者元空间设置的过小;
159 |
160 | 2、检查代码中是否存在大量的反射操作;
161 |
162 | 3、dump之后通过mat检查是否存在大量由于反射生成的代理类;
163 |
164 | 4、放大招,重启JVM。
165 |
166 |
167 |
168 | ### 问:GC overhead limit exceeded的原因和解决方法
169 |
170 | **参考答案:**
171 |
172 | 这个异常比较的罕见,报错信息:
173 |
174 | ```
175 | java.lang.OutOfMemoryError:GC overhead limit exceeded
176 | ```
177 |
178 | **原因:**
179 |
180 | 这个是JDK6新加的错误类型,一般都是堆太小导致的。
181 |
182 | Sun 官方对此的定义:超过98%的时间用来做GC并且回收了不到2%的堆内存时会抛出此异常。
183 |
184 | **解决方法:**
185 |
186 | 1、检查项目中是否有大量的死循环或有使用大内存的代码,优化代码。
187 |
188 | 2、添加参数`-XX:-UseGCOverheadLimit`禁用这个检查,其实这个参数解决不了内存问题,只是把错误的信息延后,最终出现 java.lang.OutOfMemoryError: Java heap space。
189 |
190 | 3、dump内存,检查是否存在内存泄露,如果没有,加大内存。
191 |
192 | ##
193 |
194 | ### 问:方法栈溢出的原因和解决方法
195 |
196 | 报错信息:
197 |
198 |
199 |
200 | ```
201 | java.lang.OutOfMemoryError : unable to create new native Thread
202 | ```
203 |
204 | **原因:**
205 |
206 | 出现这种异常,基本上都是创建的了大量的线程导致的,以前碰到过一次,通过jstack出来一共8000多个线程。
207 |
208 |
209 |
210 | **解决方法:**
211 |
212 | 1、通过 *-Xss *降低的每个线程栈大小的容量
213 |
214 | 2、线程总数也受到系统空闲内存和操作系统的限制,检查是否该系统下有此限制:
215 |
216 | /proc/sys/kernel/pid_max
217 |
218 | /proc/sys/kernel/thread-max
219 |
220 | max_user_process(ulimit -u)
221 |
222 | /proc/sys/vm/max_map_count
223 |
--------------------------------------------------------------------------------
/Java基础技术/IO面试题.md:
--------------------------------------------------------------------------------
1 | # IO面试题
2 | ### 问:什么是流?作用是什么?
3 |
4 | **参考答案:**
5 |
6 | 流是一种有顺序的,有起点和终点的字节集合,是对数据传输的总成或抽象。即数据在两设备之间的传输称之为流,流的本质是数据传输,根据数据传输的特性讲流抽象为各种类,方便更直观的进行数据操作。
7 |
8 |
9 |
10 | ### 问:IO流的分类
11 |
12 | **参考答案:**
13 |
14 | 根据数据处理类的不同分为:字符流和字节流;
15 |
16 | 根据数据流向不同分为:输入流和输出流。
17 |
18 | ###
19 |
20 | ### 问:字符流和字节流的区别是区别是什么?
21 |
22 | **参考答案:**
23 |
24 | 字符流的由来:因为数据编码的不同,而有了对字符进行高效操作的流对象,其本质就是基于字节流读取时,去查了指定的码表。
25 |
26 | 字符流和字节流的区别:
27 |
28 | (1)读写单位不同:字节流一字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
29 |
30 | (2)处理对象不同:字节流能处理所有类型的数据(例如图片,avi),而字符流只能处理字符类型的数据。
31 |
32 | (3)字节流操作的时候本身是不会用到缓冲区的,是对文件本身的直接操作。而字符流在操作的时候是会用到缓冲区的,通过缓冲区来操作文件。
33 |
34 | 结论:优先使用字节流,首先因为在硬盘上所有的文件都是以字节的形式进行传输或保存的,包括图片等内容。但是字符流只是在内存中才会形成,所以在开发中字节流使用广泛。
35 |
36 |
37 |
38 | ### 问:什么是java序列化,如何实现java序列化?
39 |
40 | **参考答案:**
41 |
42 | Java对象的序列化指将一个java对象写入OI流中,与此对应的是,对象的反序列化则从IO流中恢复该java对象。 如果要让某个对象支持序列化机制,则必须让它的类是可序列化的,为了让某个类是可序列化的,该类必须实现Serializable接口或Externalizable接口
43 |
44 |
45 |
46 | ### 问:读写原始数据,采用什么流?
47 |
48 | **参考答案:**InputStream/OutputStream
49 |
50 |
51 |
52 | ### 问:为了提高读写性能,采用什么流?
53 |
54 | **参考答案:**BufferedInputStream/BufferedOutputStream
55 |
56 |
57 |
58 | ### 问:对各种基本数据类型和String类型的读写,采用什么流?
59 |
60 | **参考答案:**DataInputStream/DataOutputStream
61 |
62 |
63 |
64 | ### 问:指定字符编码,采用什么流?
65 |
66 | **参考答案:**InputStreamReader/OutputStreamWriterå
67 |
68 |
69 |
70 | ### 问:Linux常见IO模型有哪些?
71 |
72 | **参考答案:**linux下有五种常见的IO模型:
73 |
74 | 1、阻塞 I/O(blocking IO)
75 |
76 | 2、非阻塞 I/O(nonblocking IO)
77 |
78 | 3、I/O 多路复用( IO multiplexing)
79 |
80 | 4、信号驱动 I/O( signal driven IO)
81 |
82 | 5、异步 I/O(asynchronous IO)
83 |
84 | 只有5是异步模型,其余皆为同步模型。
85 |
86 | 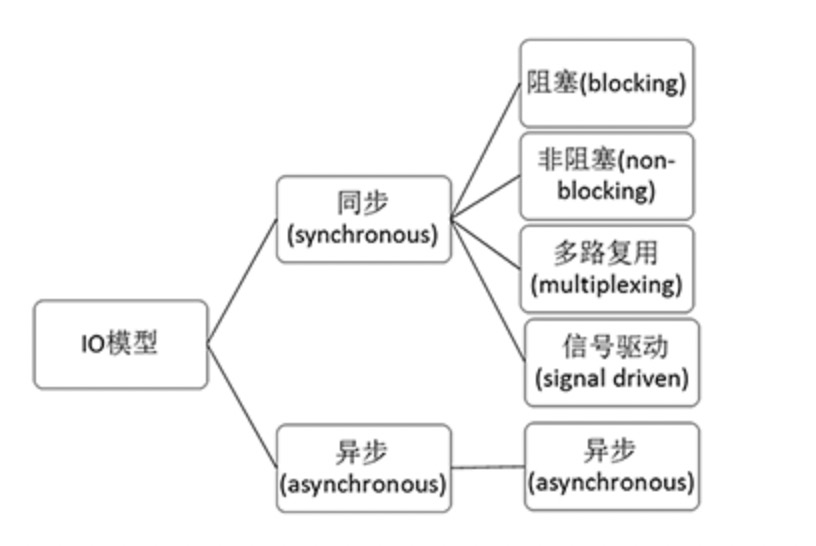
87 |
88 | ### 问:什么是阻塞IO模型?
89 |
90 | **参考答案:**
91 |
92 | 阻塞IO模型是最常见的IO模型了,对于所有的“慢速设备”(socket、pipe、fifo、terminal)的IO默认的方式都是阻塞的方式。阻塞就是进程放弃cpu,让给其他进程使用cpu。进程阻塞最显著的表现就是进程睡眠了。阻塞的时间通常取决于数据是否到来。 这种方式使用简单,但随之而来的问题就是会形成阻塞,需要独立线程配合,而这些线程在大多数时候都是没有进行运算的。Java的BIO使用这种方式,问题带来的问题很明显,一个Socket需要一个独立的线程,因此,会造成线程膨胀。
93 |
94 | 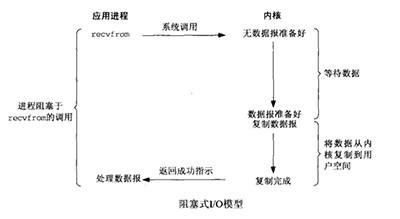
95 |
96 | ### 问:什么是非阻塞IO模型?
97 |
98 | **参考答案:**
99 |
100 | 非阻塞IO就是设置IO相关的系统调用为non-blocking,随后进行的IO操作无论有没有可用数据都会立即返回,并设置errno为EWOULDBLOCK或者EAGAIN。我们可以通过主动check的方式(polling,轮询)确保IO有效时,随之进行相关的IO操作。当然这种方式看起来就似乎不太靠谱,浪费了太多的CPU时间,用宝贵的CPU时间做轮询太不靠谱儿了。
101 |
102 | 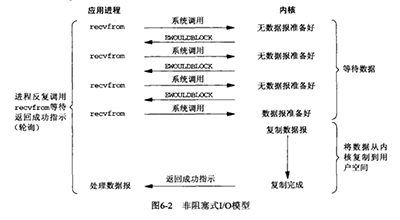
103 |
104 | ### 问:什么是多路复用IO模型?
105 |
106 | **参考答案:**
107 |
108 | 为了解决阻塞I/O的问题,就有了I/O多路复用模型,多路复用就是用单独的线程(是内核级的, 可以认为是高效的优化的) 来统一等待所有的socket上的数据, 一当某个socket上有数据后, 就启用用户线程(可能是从线程池中取出, 而不是重新生成), copy socket data, 并且处理message.因为网络延迟的原因, 同时在处理socket data的用户线程往往比实际的socket数量要少很多. 所以实际应用中, 大部分是用线程池, 池中thread数量可随socket的高峰和低谷 而动态调整.
109 |
110 | 多路复用I/O中内核中统一的wait socket data那部分可以理解成是非阻塞, 也可以理解成阻塞. 可以理解成非阻塞 是因为它不是等到socket数据全部到达再处理, 而是有了一部分数据就会调用用户线程来处理, 理解成阻塞, 是因为它和用户空间(Appliction)层的非阻塞socket的不同是: socket中没有数据时, 内核还是wait(阻塞)的, 而用户空间的非阻塞socket没有数据也会返回, 会造成CPU的浪费.
111 |
112 | Linux下的select和poll 就是多路复用模式,poll相对select,没有了句柄数的限制,但他们都是在内核层通过轮询socket句柄的方式来实现的, 没有利用更底层的notify机制. 但就算是这样,相对阻塞socket也已经进步了很多很多了! 毕竟用一个内核线程就解决了,阻塞socket中N多线程都在无谓地wait的局面.
113 |
114 | 多路复用I/O 还是让用户层来copy socket data. 这个过程是将内核中的socket buffer copy到用户空间的 buffer. 这有两个问题: 一是多了一次内核空间switch到用户空间的过程, 二是用户空间层不便暴露很低层但很高效的copy方式(比如DMA), 所以如果由内核层来做这个动作, 可以更好地提高效率!
115 |
116 | 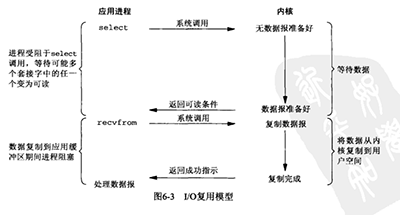
117 |
118 | ### 问:什么是信号驱动IO模型?
119 |
120 | **参考答案:**
121 |
122 | 所谓信号驱动,就是利用信号机制,安装信号SIGIO的处理函数(进行IO相关操作),通过监控文件描述符,当其就绪时,通知目标进程进行IO操作(signal handler)。
123 |
124 | 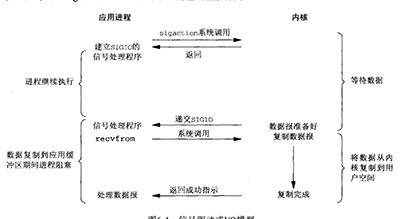
125 |
126 | ### 问:什么是异步IO模型?
127 |
128 | **参考答案:**
129 |
130 | 由于异步IO请求只是写入了缓存,从缓存到硬盘是否成功不可知,因此异步IO相当于把一个IO拆成了两部分,一是发起请求,二是获取处理结果。因此,对应用来说增加了复杂性。但是异步IO的性能是所有很好的,而且异步的思想贯穿了IT系统方方面面。
131 |
132 | 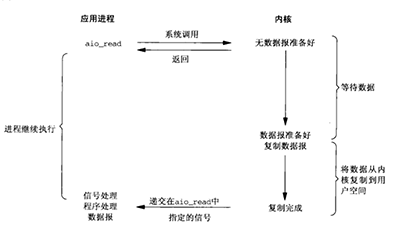
133 |
134 |
135 |
136 | ### 问:select、poll、epoll的区别是什么?
137 |
138 | **参考答案:**
139 |
140 | 1、支持一个进程所能打开的最大连接数
141 |
142 | - select 是 32位机默认是1024个,64位机默认是2048。
143 | - poll 本质上于select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的。
144 | - epoll 虽然有连接数上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的可以打开20万左右的连接。
145 |
146 | 2、fd剧增后带来的I/O效率问题
147 |
148 | - select 每次调用事都会对连接进行线性遍历,所以随着fd的增加会造成遍历速度慢,呈线性下降性能问题。
149 | - poll 同上
150 | - epoll epoll内核中实现是根据每个fd的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃的socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有的socket都很活跃的情况下,可能会有性能问题。
151 |
152 | 3、消息传递方式
153 |
154 | - select 内核需要将消息传递到用户空间,都需要内核拷贝动作
155 | - poll 同上
156 | - epoll 通过内核和用户空间共享一块内存来实现的。
157 |
--------------------------------------------------------------------------------
/Java基础技术/JVM进阶面试题.md:
--------------------------------------------------------------------------------
1 | # JVM进阶面试题
2 | ### 问:常用的调优命令有哪些
3 |
4 | **参考答案:**
5 |
6 | - jps,JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程;
7 | - jstat,JVM statistics Monitoring是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据;
8 | - jinfo,JVM Configuration info 这个命令作用是实时查看和调整虚拟机运行参数;
9 | - jmap,JVM Memory Map命令用于生成heap dump文件;
10 | - jstack,用于生成java虚拟机当前时刻的线程快照;
11 | - jhat,JVM Heap Analysis Tool命令是与jmap搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看。
12 |
13 | 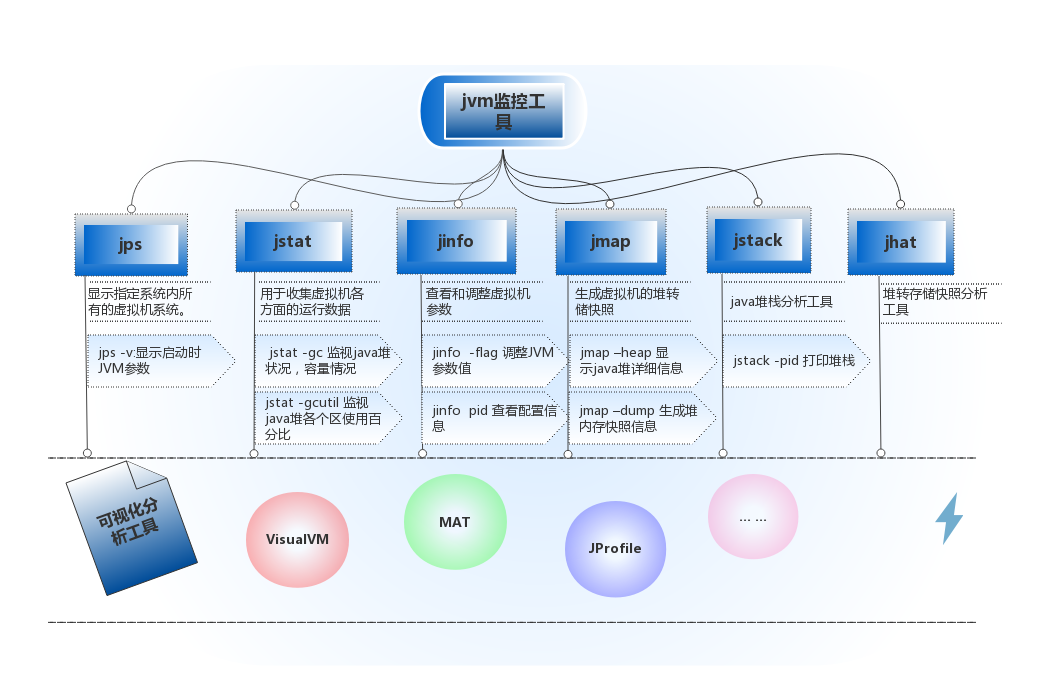
14 |
15 |
16 |
17 | ### 问:常用的调优工具有哪些?
18 |
19 | **参考答案:**
20 |
21 | 常用调优工具分为两类:**jdk自带监控工具:**jconsole、jvisualvm;**第三方**:MAT(Memory Analyzer Tool)、GChisto等。
22 |
23 | - jconsole,Java Monitoring and Management Console是从java5开始,在JDK中自带的java监控和管理控制台,用于对JVM中内存,线程和类等的监控
24 | - jvisualvm,jdk自带全能工具,可以分析内存快照、线程快照;监控内存变化、GC变化等。
25 | - MAT,Memory Analyzer Tool,一个基于Eclipse的内存分析工具,是一个快速、功能丰富的Java heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗
26 | - GChisto,一款专业分析gc日志的工具
27 |
28 |
29 |
30 | ### 问:什么是即时编译器?
31 |
32 | **参考答案:**
33 |
34 | Java程序最初是通过解释器进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频 繁,就会把这些代码认定为“热点代码”(Hot Spot Code)。
35 |
36 | 为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机 器码,并进行各种层次的优化,完成这个任务的编译器成为即时编译器(Just In Time Compiler,JIT编译器)。
37 |
38 |
39 |
40 |
41 |
42 | ### 问:热点代码有哪些?
43 |
44 | **参考答案:**
45 |
46 | - 被多次调用的方法;
47 | - 被多次执行的循环体;
48 |
49 |
50 |
51 | ### 问:如何判断一段代码是不是热点代码?
52 |
53 | **参考答案:**
54 |
55 |
56 |
57 | - **基于采样的热点探测**,虚拟机周期性检查各个线程的栈顶,如果发现某个方法经常出现在栈顶,那这个方法就是“热点方法”。实现简单高效,但是很难精确确认一个方法的热度。
58 | - **基于计数器的热点探测**,虚拟机会为每个方法建立计数器,统计方法的执行次数,如果执行次数超过一定的阈值,就认为它是热点方法。
59 |
60 | HotSpot虚拟机使用第二种,有两个计数器:**方法调用计数器**和**回边计数器(判断循环代码)**
61 |
62 | 方法调用计数器统计方法:统计的是一个相对的执行频率,即一段时间内方法被调用的次数。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器编译,那这个方法的调用计数器就会被减少一半,这个过程称为方法调用计数器的**热度衰减**,这个时间就被称为**半衰周期**。
63 |
64 |
65 |
66 |
67 |
68 | ### 问:什么是解释器和编译器?
69 |
70 | **参考答案:**
71 |
72 | 许多主流的商用虚拟机,都同时包含解释器和编译器。
73 |
74 | 当程序需要快速启动和执行时,**解释器**首先发挥作用,省去编译的时间,立即执行。 当程序运行后,随着时间的推移,**编译器**逐渐发挥作用,把越来越多的代码编译成本地代码,可以提高执行效率。 如果内存资源限制较大(部分嵌入式系统),可以使用解释执行节约内存,反之可以使用编译执行来提升效率。同时编译器的代码还能退回成解释器的代码。
75 |
76 |
77 |
78 | ### 问:Java的方法调用,有什么特殊之处?
79 |
80 | **参考答案:**
81 |
82 | Class文件的编译过程**不包含**传统编译的**连接步骤**,一切方法调用在Class文件里面存储的都只是**符号引用**,而不是方法在实际运行时内存布局中的入口地址。这使得Java有强大的动态扩展能力,但使Java方法的调用过程变得相对复杂,需要在类加载期间甚至到运行时才能确定目标方法的直接引用。
83 |
84 |
85 |
86 | ### 问:Java虚拟机调用字节码指令有哪些?
87 |
88 | **参考答案:**
89 |
90 | invokestatic:调用静态方法
91 |
92 | invokespecial:调用实例构造器方法、私有方法和父类方法
93 |
94 | invokevirtual:调用所有的虚方法
95 |
96 | invokeinterface:调用接口方法
97 |
98 |
99 |
100 | ### 问:虚拟机是如何执行方法里面的字节码指令的?
101 |
102 | **参考答案:**
103 |
104 | - **解释执行**(通过解释器执行)
105 | - **编译执行**(通过即时编译器产生本地代码)解释执行
106 |
107 | 当主流的虚拟机中都包含了即时编译器后,Class文件中的代码到底会被解释执行还是编译执行,只有虚拟机自己才能准确判断。
108 |
109 | Javac编译器完成了程序代码经过词法分析、语法分析到抽象语法树,再遍历语法树生成线性的字节码指令流的过程。因为这一动作是在Java虚拟机之外进行的,而解释器在虚拟机的内部,所以Java程序的编译是半独立的实现。
110 |
111 |
112 | # JVM进阶面试题
113 | ### 问:Java 是如何实现跨平台的?
114 |
115 | **参考答案:**
116 |
117 |
118 |
119 | Java 源码编译后会生成一种.class 文件,称为字节码文件。Java 虚拟机(JVM)就是负责将字节码文件翻译成特定平台下的机器码然后运行,也就是说,只要在不同平台上安装对应的JVM,就可以运行字节码文件,运行我们编写的Java 程序。
120 |
121 | 而这个过程,我们编写的Java 程序没有做任何改变,仅仅是通过JVM 这一 “中间层” ,就能在不同平台上运行,真正实现了 “一次编译,到处运行” 的目的。
122 |
123 | 
124 |
125 | **注意:跨平台的是Java 程序,而不是JVM。JVM是用C/C++ 开发的,是编译后的机器码,不能跨平台,不同平台下需要安装不同版本的JVM**
126 |
127 |
128 |
129 | ### 问:什么是内存屏障?
130 |
131 | **参考答案:** 内存屏障,又称内存栅栏,是一组处理器指令,用于实现对内存操作的顺序限制。
132 |
133 |
134 |
135 | ### 问:内存屏障为何重要?
136 |
137 | **参考答案:**
138 |
139 | 对主存的一次访问一般花费硬件的数百次时钟周期。处理器通过缓存(caching)能够从数量级上降低内存延迟的成本这些缓存为了性能重新排列待定内存操 作的顺序。也就是说,程序的读写操作不一定会按照它要求处理器的顺序执行。当数据是不可变的,同时/或者数据限制在线程范围内,这些优化是无害的。如果把 这些优化与对称多处理(symmetric multi-processing)和共享可变状态(shared mutable state)结合,那么就是一场噩梦。当基于共享可变状态的内存操作被重新排序时,程序可能行为不定。一个线程写入的数据可能被其他线程可见,原因是数据 写入的顺序不一致。适当的放置内存屏障通过强制处理器顺序执行待定的内存操作来避免这个问题。
140 |
141 |
142 |
143 | ### 问:对象的内存布局是怎样的?
144 |
145 | **参考答案:**
146 |
147 | 对象的内存布局包括三个部分:对象头,实例数据和对齐填充。
148 |
149 | **(1)、对象头:**
150 |
151 | 第一部分是与对象在运行时状态相关的信息,长度通过与操作系统的位数保持一致。包括对象的哈希值、GC分代年龄、锁状态以及偏向线程的ID等。由于对象头信息是与对象所定义的信息无关的数据,所以使用了非固定的数据结构,以便存储更多的信息,实现空间复用。因此对象在不同的状态下对象头的存储信息有所差别。
152 |
153 | 
154 |
155 | 另一部分是类型指针,即指向该对象所属类元数据的指针,虚拟机通常通过这个指针来确定该对象所属的类型(但并不是唯一方式)。
156 |
157 | 另外,如果对象是一个数组,在对象头中还应该有一块记录数组长度的数据,因为JVM可以通过对象的元数据确定对象的大小,但不能通过元数据确定数组的长度。
158 |
159 | **(2)、实例数据:**
160 |
161 | 实例数据存储的是真正的有效数据,即各个字段的值。无论是子类中定义的,还是从父类继承下来的都需要记录。这部分数据的存储顺序受到虚拟机的分配策略以及字段在类中的定义顺序的影响。
162 |
163 | **(3)、对齐补充:**
164 |
165 | 这部分数据不是必然存在的,因为对象的大小总是8字节的整数倍,该数据仅用于补齐实例数据部分不足整数倍的部分,充当占位符的作用。
166 |
167 |
168 |
169 | ### 问:能保证GC 执行吗?
170 |
171 | **参考答案:**
172 |
173 | 不能,虽然你可以调用System.gc() 或者Runtime.gc(),但是没有办法保证GC 的执行。
174 |
--------------------------------------------------------------------------------
/Java基础技术/线程和线程池面试题.md:
--------------------------------------------------------------------------------
1 | # 线程和线程池面试题
2 | ### 问:什么是进程?
3 |
4 | **参考答案:**
5 |
6 | 是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。
7 |
8 | ### 问:什么是线程?
9 |
10 | **参考答案:**
11 |
12 | 线程是操作系统能够进行运算调度的最小单位。
13 |
14 | 它被包含在进程之中,是进程中的实际运作单位。
15 |
16 | 一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
17 |
18 | ### 问:进程和线程的区别?
19 |
20 | **参考答案:**
21 |
22 | 进程和线程的主要差别在于它们是不同的操作系统资源管理方式。
23 |
24 | 进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响。
25 |
26 | 线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。
27 |
28 | 但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
29 |
30 | ### 问:多线程和单线程有什么区别?
31 |
32 | **参考答案:**
33 |
34 | 单线程程序:程序执行过程中只有一个有效操作的序列,不同操作之间都有明确的执行先后顺序,容易出现代码阻塞
35 |
36 | 多线程程序:有多个线程,线程间独立运行,能有效地避免代码阻塞,并且提高程序的运行性能
37 |
38 | ### 问:为什么要使用多线程?
39 |
40 | **参考答案:**
41 |
42 | 1、使用多线程可以减少程序的响应时间。 在单线程的情况下,如果某个程序很耗时或者陷入长时间等待(如等待网络响应),此时程序将不会相应鼠标和键盘等操作,使用多线程后,可以把这个耗时的线程分配到一个单独的线程去执行,从而是程序具备了更好的交互性。
43 |
44 | 2、与进程相比,线程的创建和切换开销更小。 由于启动一个新的线程必须给这个线程分配独立的地址空间,建立许多数据结构来维护线程代码段、数据段等信息,而运行于同一个进程内的线程共享代码段、数据段,线程的启动或切换的开销就比进程要少很多。同时多线程在数据共享方面效率非常高。
45 |
46 | 3、多CPU或多核心计算机本身就具有执行多线程的能力。 如果使用单个线程,将无法重复利用计算机资源,造成资源的巨大浪费。因此在多CPU计算机上使用多线程能提高CPU的利用率。
47 |
48 | 4、使用多线程能简化程序的结构,使用程序便于理解和维护。 一个非常复杂的进程可以分成多个线程来执行。
49 |
50 |
51 |
52 | ### 问:什么是线程安全?
53 |
54 | **参考答案:**
55 |
56 | 当多个线程访问同一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替运行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获取正确的结果,那这个对象是线程安全的。
57 |
58 | ### 问:为何要使用线程同步?
59 |
60 | **参考答案:**
61 |
62 | Java允许多线程并发控制,当多个线程同时操作一个可共享的资源变量时(如数据的增删改查),将会导致数据不准确,相互之间产生冲突。
63 |
64 | 因此加入同步锁以避免在该线程没有完成操作之前,被其他线程的调用,从而保证了该变量的唯一性和准确性。
65 |
66 | ### 问:如何确保线程安全?
67 |
68 |
69 | 1、对非安全的代码进行加锁控制;
70 |
71 | 2、使用线程安全的类;
72 |
73 | 3、多线程并发情况下,线程共享的变量改为方法级的局部变量
74 |
75 |
76 |
77 | ### 问:线程安全的级别?
78 |
79 | **参考答案:**
80 |
81 | 1、不可变。不可变的对象一定是线程安全的,并且永远也不需要额外的同步。
82 |
83 | > Java类库中大多数基本数值类如Integer、String和BigInteger都是不可变的。
84 |
85 |
86 | 2、无条件的线程安全。由类的规格说明所规定的约束在对象被多个线程访问时仍然有效,不管运行时环境如何排列,线程都不需要任何额外的同步。
87 |
88 | > 如 Random 、ConcurrentHashMap、Concurrent集合、atomic
89 |
90 | 3、有条件的线程安全。有条件的线程安全类对于单独的操作可以是线程安全的,但是某些操作序列可能需要外部同步。
91 |
92 | > 有条件线程安全的最常见的例子是遍历由 Hashtable 或者 Vector 或者返回的迭代器
93 |
94 | 4、非线程安全(线程兼容)。线程兼容类不是线程安全的,但是可以通过正确使用同步而在并发环境中安全地使用。
95 |
96 | > 如ArrayList HashMap
97 |
98 | 5、线程对立。线程对立是那些不管是否采用了同步措施,都不能在多线程环境中并发使用的代码。
99 |
100 | > 如如System.setOut()、System.runFinalizersOnExit()
101 |
102 |
103 |
104 | ### 问:为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
105 |
106 | **参考答案:**
107 |
108 | new 一个 Thread,线程进入了新建状态(NEW);调用 start() 方法,会启动一个线程并使线程进入了就绪状态(READY),当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。 而直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
109 |
110 | **总结: 调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。**
111 |
112 | ##
113 |
114 | ### 问:使用多线程可能带来什么问题?
115 |
116 | **参考答案:**
117 |
118 | 多线程的目的就是为了能提高程序的执行效率提高程序运行速度,但也可能会遇到很多问题:内存泄漏、上下文切换、死锁还有受限于硬件和软件的资源闲置问题。
119 |
120 |
121 |
122 | ### 问:线程池有哪些状态?
123 |
124 | **参考答案:**
125 |
126 | 线程池的5种状态:Running、ShutDown、Stop、Tidying、Terminated。
127 |
128 | 1. **RUNNING** :能接受新提交的任务,并且也能处理阻塞队列中的任务;
129 | 2. **SHUTDOWN**:关闭状态,不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务。在线程池处于 RUNNING 状态时,调用 shutdown()方法会使线程池进入到该状态。;
130 | 3. **STOP**:不能接受新任务,也不处理队列中的任务,会中断正在处理任务的线程。在线程池处于 RUNNING 或 SHUTDOWN 状态时,调用 shutdownNow() 方法会使线程池进入到该状态;
131 | 4. **TIDYING**:如果所有的任务都已终止了,workerCount (有效线程数) 为0,线程池进入该状态后会调用 terminated() 方法进入TERMINATED 状态。
132 | 5. **TERMINATED**:在terminated() 方法执行完后进入该状态,默认terminated()方法中什么也没有做。
133 |
134 | 线程流转如下:
135 | 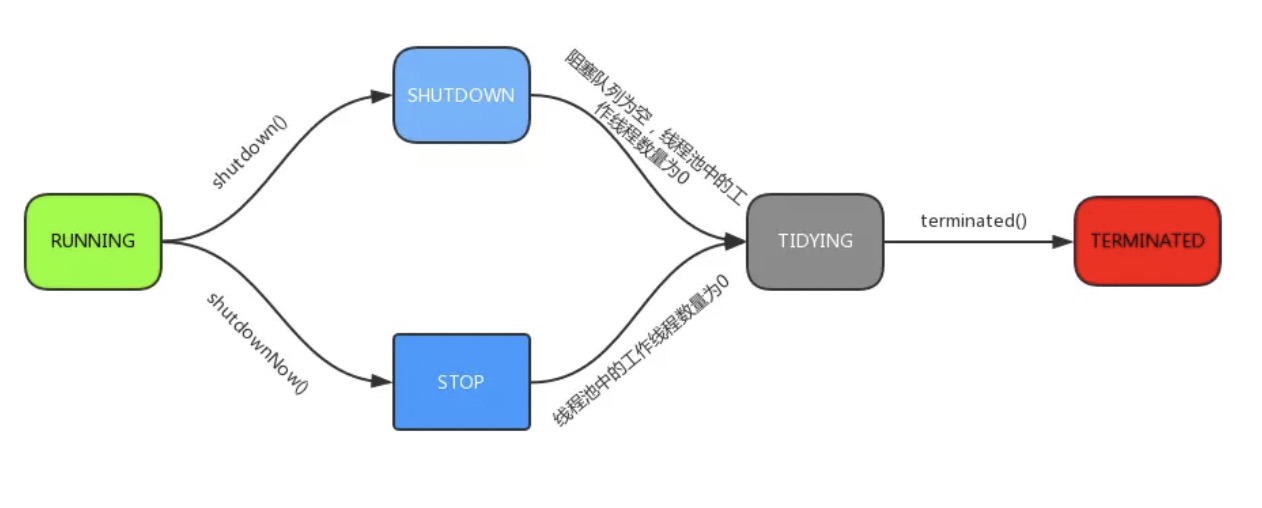
136 |
137 | **注意线程池的状态和线程的状态**
138 |
139 | ###
140 |
141 | ### 问:线程池中 execute()和submit()方法有什么区别?
142 |
143 | **参考答案:**
144 |
145 | 1、execute方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;
146 |
147 | 2、submit()方法用于提交需要返回值的任务。线程池会返回一个Future类型的对象,通过这个Future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
148 |
149 |
150 |
151 | ### 问:实现Runnable接口和Callable接口的区别?
152 |
153 | **参考答案:**
154 |
155 | 两者的区别在于 Runnable 接口不会返回结果但是 Callable 接口可以返回结果。
156 |
157 | 备注: 工具类Executors可以实现Runnable对象和Callable对象之间的相互转换。(Executors.callable(Runnable task)或Executors.callable(Runnable task,Object resule))。
158 |
159 |
160 |
161 | ###
162 |
163 | ### 问: 创建线程有哪些方式?
164 |
165 | **参考答案:**
166 |
167 | 1、继承 Thread 类创建线程类;
168 |
169 | 2、通过 Runnable 接口创建线程类。
170 |
171 | 3、通过 Callable 和 Future 创建线程。
172 |
173 | 4、线程池
174 |
175 |
176 |
177 | ### 问:线程池的拒绝策略有哪些?
178 |
179 | **参考答案:**
180 |
181 | 1、AbortPolicy:默认的拒绝策略,直接抛出 RejectedExecutionException 异常;
182 |
183 | 2、CallerRunsPolicy:既不会抛弃任务,也不会抛出异常,由调用线程处理该任务;
184 |
185 | 3、DiscardPolicy: 直接丢弃任务,不予处理也不抛出异常。如果允许任务丢失,是最好的处理策略。
186 |
187 | 4、DiscardOldestPolicy: 抛弃队列中等待最久的任务,然后把当前任务加入队列尝试再次提交(可能会再次失败,导致重复)。
188 |
--------------------------------------------------------------------------------
/Java基础技术/集合类进阶面试题.md:
--------------------------------------------------------------------------------
1 | # 集合类进阶面试题
2 |
3 | ### 问:Java集合框架是什么?说出一些集合框架的优点?
4 |
5 | **参考答案:**
6 |
7 | 每种编程语言中都有集合。集合框架的部分优点如下:
8 | (1)使用核心集合类降低开发成本,而非实现我们自己的集合类。
9 | (2)随着使用经过严格测试的集合框架类,代码质量会得到提高。
10 | (3)通过使用JDK附带的集合类,可以降低代码维护成本。
11 | (4)复用性和可操作性。
12 |
13 |
14 |
15 | ### 问:集合框架中的泛型有什么优点?
16 |
17 | **参考答案:**
18 |
19 | Java1.5引入了泛型,所有的集合接口和实现都大量地使用它。
20 |
21 | 泛型允许我们为集合提供一个可以容纳的对象类型,因此,如果你添加其它类型的任何元素,它会在编译时报错。这避免了在运行时出现ClassCastException,因为你将会在编译时得到报错信息。泛型也使得代码整洁,我们不需要使用显式转换和instanceOf操作符。它也给运行时带来好处,因为不会产生类型检查的字节码指令。
22 |
23 | ###
24 |
25 | ### 问:Java集合框架的基础接口有哪些?
26 |
27 | **参考答案:**
28 |
29 | Collection为集合层级的根接口。一个集合代表一组对象,这些对象即为它的元素。Java平台不提供这个接口任何直接的实现。
30 |
31 | Set是一个不能包含重复元素的集合。这个接口对数学集合抽象进行建模,被用来代表集合,就如一副牌。
32 |
33 | List是一个有序集合,可以包含重复元素。你可以通过它的索引来访问任何元素。List更像长度动态变换的数组。
34 |
35 | Map是一个将key映射到value的对象.一个Map不能包含重复的key:每个key最多只能映射一个value。
36 |
37 | 一些其它的接口有Queue、Dequeue、SortedSet、SortedMap和ListIterator。
38 |
39 |
40 |
41 | ### 问:为何Collection不从Cloneable和Serializable接口继承?
42 |
43 | **参考答案:**
44 |
45 | 克隆(cloning)或者是序列化(serialization)的语义和含义是跟具体的实现相关的。因此,应该由集合类的具体实现来决定如何被克隆或者是序列化。
46 |
47 |
48 |
49 | ### 问:Iterator是什么?
50 |
51 | **参考答案:**
52 |
53 | Iterator接口提供遍历任何Collection的接口。我们可以从一个Collection中使用迭代器方法来获取迭代器实例。迭代器取代了Java集合框架中的Enumeration。迭代器允许调用者在迭代过程中移除元素。
54 |
55 |
56 |
57 | ### 问:迭代器的优点
58 |
59 | **参考答案:**
60 |
61 | 如果用的是for循环,就用集合自带的remove(),而这样就改变了集合的Size()循环的时候会出错。但如果把集合放入迭代器,既iterator迭代可以遍历并选择集合中的每个对象而不改变集合的结构,而把集合放入迭代器,用迭代器的remove()就不会出现问题
62 |
63 |
64 |
65 | ### 问:Enumeration和Iterator接口的区别?
66 |
67 | **参考答案:**
68 |
69 | Enumeration速度是Iterator的2倍,同时占用更少的内存。但是,Iterator远远比Enumeration安全,因为其他线程不能够修改正在被iterator遍历的集合里面的对象。同时,Iterator允许调用者删除底层集合里面的元素,这对Enumeration来说是不可能的。
70 |
71 |
72 |
73 | ### 问:Iterater和ListIterator之间有什么区别?
74 |
75 | **参考答案:**
76 |
77 | (1)我们可以使用Iterator来遍历Set和List集合,而ListIterator只能遍历List。
78 |
79 | (2)Iterator只可以向前遍历,而LIstIterator可以双向遍历。
80 |
81 | (3)ListIterator从Iterator接口继承,然后添加了一些额外的功能,比如添加一个元素、替换一个元素、获取前面或后面元素的索引位置。
82 |
83 | ###
84 |
85 | ### 问:哪些集合类是线程安全的?
86 |
87 | **参考答案:**
88 |
89 | Vector、HashTable、Properties和Stack是同步类,所以它们是线程安全的,可以在多线程环境下使用。Java1.5并发API包括一些集合类,允许迭代时修改,因为它们都工作在集合的克隆上,所以它们在多线程环境中是安全的。
90 |
91 | ###
92 |
93 | ### 问:并发集合类是什么?
94 |
95 | **参考答案:**
96 |
97 | Java1.5并发包(java.util.concurrent)包含线程安全集合类,允许在迭代时修改集合。迭代器被设计为fail-fast的,会抛出ConcurrentModificationException。一部分类为:CopyOnWriteArrayList、 ConcurrentHashMap、CopyOnWriteArraySet。
98 |
99 |
100 |
101 | ### 问:Collections类是什么?
102 |
103 | **参考答案:**
104 |
105 | Java.util.Collections是一个工具类仅包含静态方法,它们操作或返回集合。它包含操作集合的多态算法,返回一个由指定集合支持的新集合和其它一些内容。这个类包含集合框架算法的方法,比如折半搜索、排序、混编和逆序等。
106 |
107 |
108 |
109 |
110 |
111 | ### 问:如何保证线程安全又效率高?
112 |
113 | **参考答案:**
114 |
115 | Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
116 |
117 | ConcurrentHashMap将整个Map分为N个segment(类似HashTable),可以提供相同的线程安全,但是效率提升N倍,默认N为16。
118 |
119 |
120 |
121 | ### 问:怎么确保一个集合不能被修改?
122 |
123 | **参考答案:**
124 |
125 | (1)Java中提供final关键字,对基本类型进行修饰,当第一次初始化后,该变量就不可被修改
126 | (2)Collections`工具类中的UnmodifiableList(不可修改的List、Map、Set等)
127 |
128 |
129 |
130 | ### 问:Comparator和Comparable的区别?
131 |
132 | **参考答案:**
133 |
134 | - **相同点**
135 |
136 | 都是用于比较两个对象“顺序”的接口
137 |
138 | 都可以使用Collections.sort()方法来对对象集合进行排序
139 |
140 | - **不同点**
141 |
142 | Comparable位于java.lang包下,而Comparator则位于java.util包下
143 |
144 | Comparable 是在集合内部定义的方法实现的排序,Comparator 是在集合外部实现的排序
145 |
146 | - **总结**
147 |
148 | 使用Comparable接口来实现对象之间的比较时,可以使这个类型(设为A)实现Comparable接口,并可以使用Collections.sort()方法来对A类型的List进行排序,之后可以通过a1.comparaTo(a2)来比较两个对象;
149 |
150 | 当使用Comparator接口来实现对象之间的比较时,只需要创建一个实现Comparator接口的比较器(设为AComparator),并将其传给Collections.sort()方法即可对A类型的List进行排序,之后也可以通过调用比较器AComparator.compare(a1, a2)来比较两个对象。
151 |
152 | 可以说一个是自己完成比较,一个是外部程序实现比较的差别而已。
153 |
154 | 用 Comparator 是策略模式(strategy design pattern),就是不改变对象自身,而用一个策略对象(strategy object)来改变它的行为。
155 |
156 | 比如:你想对整数采用绝对值大小来排序,Integer 是不符合要求的,你不需要去修改 Integer 类(实际上你也不能这么做)去改变它的排序行为,这时候只要(也只有)使用一个实现了 Comparator 接口的对象来实现控制它的排序就行了。
157 |
158 | 两种方式,各有各的特点:使用Comparable方式比较时,我们将比较的规则写入了比较的类型中,其特点是高内聚。但如果哪天这个规则需要修改,那么我们必须修改这个类型的源代码。如果使用Comparator方式比较,那么我们不需要修改比较的类,其特点是易维护,但需要自定义一个比较器,后续比较规则的修改,仅仅是改这个比较器中的代码即可。
159 |
160 |
161 |
162 | ### 问:为何Collection不从Cloneable和Serializable接口继承?
163 |
164 | **参考答案:**
165 |
166 | 克隆(cloning)或者是序列化(serialization)的语义和含义是跟具体的实现相关的。因此,应该由集合类的具体实现来决定如何被克隆或者是序列化。
167 |
168 |
169 |
170 | ### 问:哪些集合类提供对元素的随机访问?
171 |
172 | **参考答案:**
173 |
174 | ArrayList、HashMap、TreeMap和HashTable类提供对元素的随机访问。
175 |
176 |
177 |
178 | ### 问:与Java集合框架相关的有哪些最好的实践?
179 |
180 | **参考答案:**
181 |
182 | (1)根据需要选择正确的集合类型。比如,如果指定了大小,我们会选用Array而非ArrayList。如果我们想根据插入顺序遍历一个Map,我们需要使用LinkedHashMap。如果我们不想重复,我们应该使用Set。
183 |
184 | (2)一些集合类允许指定初始容量,所以如果我们能够估计到存储元素的数量,我们可以使用它,就避免了重新哈希或大小调整。
185 |
186 | (3)基于接口编程,而非基于实现编程,它允许我们后来轻易地改变实现。
187 |
188 | (4)总是使用类型安全的泛型,避免在运行时出现ClassCastException。
189 |
190 | (5)使用JDK提供的不可变类作为Map的key,可以避免自己实现hashCode()和equals()。
191 |
192 | (6)尽可能使用Collections工具类,或者获取只读、同步或空的集合,而非编写自己的实现。它将会提供代码重用性,它有着更好的稳定性和可维护性。
193 |
--------------------------------------------------------------------------------
/Java基础技术/Java面向对象面试题.md:
--------------------------------------------------------------------------------
1 | # Java面向对象面试题
2 |
3 |
4 | #### 问:抽象的(abstract)方法是否可同时是静态的(static),是否可同时是本地方法(native),是否可同时被synchronized修饰?为什么?
5 | **参考答案:**
都不能。
抽象方法需要子类重写,而静态的方法是无法被重写的,因此二者是矛盾的;
本地方法是由本地代码(如C代码)实现的方法,而抽象方法是没有实现的,也是矛盾的;
synchronized和方法的实现细节有关,抽象方法不涉及实现细节,因此也是相互矛盾的;
6 |
7 | #### 问:java.lang.Class类的newInstance方法和 java.lang.reflect.Constructor类的newInstance方法有什么区别?
8 | **参考答案:**
• Class类的newInstance只能触发无参数的构造方法创建对象,而构造器类的newInstance能触发有参数或者任意参数的构造方法来创建对象。
• Class类的newInstance需要其构造方法是public的或者对调用方法可见的,而构造器类的newInstance可以在特定环境下调用私有构造方法来创建对象。
• Class类的newInstance抛出类构造函数的异常,而构造器类的newInstance包装了一个InvocationTargetException异常。
说明:Class类本质上调用了反射包Constructor中无参数的newInstance方法,捕获了InvocationTargetException,将构造器本身的异常抛出
9 |
10 |
11 | #### 问:Java 中的final关键字有哪些用法?
12 | **参考答案:**
(1)修饰类:表示该类不能被继承;
(2)修饰方法:表示方法不能被重写;(3)修饰变量:表示变量只能一次赋值以后值不能被修改(常量)
13 |
14 |
15 | #### 问:关键字swtich 是否能作用在byte 上,是否能作用在long 上,是否能作用在String上?
16 | **参考答案:**
在Java 5以前,switch(expr)中,expr只能是byte、short、char、int。从Java 5开始,Java中引入了枚举类型,expr也可以是enum类型,从Java 7开始,expr还可以是字符串(String),但是长整型(long)在目前所有的版本中都是不可以的。
17 |
18 |
19 | #### 问:面向对象的特征有哪些?
20 | **参考答案:**
1.抽象:
抽象就是忽略一个主题中与当前目标无关的那些方面,以便更充分地注意与当前目标有关的方面。抽象并不打算了解全部问题,而只是选择其中的一部分,暂时不用部分细节。抽象包括两个方面,一是过程抽象,二是数据抽象。
2.继承:
继承是一种联结类的层次模型,并且允许和鼓励类的重用,它提供了一种明确表述共性的方法。对象的一个新类可以从现有的类中派生,这个过程称为类继承。新类继承了原始类的特性,新类称为原始类的派生类(子类),而原始类称为新类的基类(父类)。派生类可以从它的基类那里继承方法和实例变量,并且类可以修改或增加新的方法使之更适合特殊的需要。
3.封装:
封装是把过程和数据包围起来,对数据的访问只能通过已定义的界面。面向对象计算始于这个基本概念,即现实世界可以被描绘成一系列完全自治、封装的对象,这些对象通过一个受保护的接口访问其他对象。
4. 多态性:
多态性是指允许不同类的对象对同一消息作出响应。多态性包括参数化多态性和包含多态性。多态性语言具有灵活、抽象、行为共享、代码共享的优势,很好的解决了应用程序函数同名问题。
21 |
22 |
23 | #### 问:代码中如何实现多态?
24 | **参考答案:**
实现多态主要有以下三种方式:
25 |
26 | 1. 接口实现
27 | 1. 继承父类重写方法
28 | 1. 同一类中进行方法重载
29 |
30 |
31 | #### 问:overload和overide的区别?
32 | **参考答案:**
33 |
34 | - **Override** 可以翻译为覆盖,从字面就可以知道,它是覆盖了一个方法并且对其重写,以求达到不同的作用。对我们来说最熟悉的覆盖就是对接口方法的实现,在接口中一般只是 对方法进行了声明,而我们在实现时,就需要实现接口声明的所有方法。除了这个典型的用法以外,我们在继承中也可能会在子类覆盖父类中的方法。在覆盖要注意 以下的几点:
35 | 1. 覆盖的方法的标志必须要和被覆盖的方法的标志完全匹配,才能达到覆盖的效果;
36 | 1. 覆盖的方法的返回值必须和被覆盖的方法的返回值一致;
37 | 1. 覆盖的方法所抛出的异常必须和被覆盖方法的所抛出的异常一致,或者是其子类;
38 | 1. 被覆盖的方法不能为 private,否则在其子类中只是新定义了一个方法,并没有对其进行覆盖。
39 | - **Overload** 可以翻译为重载,它是指我们可以定义一些名称相同的方法,通过定义不同的输入参数来区分这些方法,然后再调用时,VM就会根据不同的参数样式,来选择合适的方法执行。在使用重载要注意以下的几点:
40 | 5. 在使用重载时只能通过不同的参数样式。例如,不同的参数类型,不同的参数个数,不同的参数顺序(当然,同一方法内的几个参数类型必须不一样,例如可以是 fun(int,float),但是不能为 fun(int,int));
41 | 5. 不能通过访问权限、返回类型、抛出的异常进行重载;
42 | 5. 方法的异常类型和数目不会对重载造成影响;
43 | 5. 对于继承来说,如果某一方法在父类中是访问权限是 private,那么就不能在子类对其进行重载,如果定义的话,也只是定义了一个新方法,而不会达到重载的效果。
44 |
45 | 总之,重写(Override) 是父类与子类之间多态性的一种表现,重载 (Overload) 是一个类中多态性的一种表现。很重要的一点就是,Overloaded 的方法是可以改变返回值的类型。
另外:在Java语言规范中,一个方法的特征仅包括方法的名字,参数的数目和种类,而不包括方法的返回类型,参数的名字以及所抛出来的异常。在Java编译 器检查方法的重载时,会根据这些条件判断两个方法是否是重载方法。但在Java编译器检查方法的置换时,则会进一步检查两个方法(分处超类型和子类型)的 返还类型和抛出的异常是否相同。
46 |
47 |
48 | #### 问:使用final关键字修饰一个变量时,是引用不能变,还是引用的对象不能变?
49 | **参考答案:**
使用 final 关键字修饰一个变量时,是指引用变量不能变,引用变量所指向的对象中的内容还是可以改
50 | 变的。例如,对于如下语句:
final StringBuffer a=new StringBuffer("immutable");
执行如下语句将报告编译期错误:
a=new StringBuffer("");
但是,执行如下语句则可以通过编译:
a.append(" broken!");
有人在定义方法的参数时,可能想采用如下形式来阻止方法内部修改传进来的参数对象:
public void method(final StringBuffer param){
}
实际上,这是办不到的,在该方法内部仍然可以增加如下代码来修改参数对象:
param.append("a");
51 |
52 | ####
53 |
54 | #### 问:静态变量和实例变量的区别?
55 | **参考答案:**
56 |
57 | - 在语法定义上的区别:静态变量前要加 static 关键字,而实例变量前则不加。
58 | - 在程序运行时的区别:实例变量属于某个对象的属性,必须创建了实例对象,其中的实例变量才会被分配空间,才能使用这个实例变量。静态变量不属于某个实例对象,而是属于类,所以也称为类变量,只要程序加载了类的字节码,不用创建任何实例对象,静态变量就会被分配空间,静态变量就可以被使用了。
59 | 总之,实例变量必须创建对象后才可以通过这个对象来使用,静态变量则可以直接使用类名来引用。
60 |
61 | 例如,对于下面的程序,无论创建多少个实例对象,永远都只分配了一个 staticVar 变量,并且每创建一个实例对象,这个 staticVar就会加1;但是,每创建一个实例对象,就会分配一个 instanceVar,即可能分配多个 instanceVar,并且每个 instanceVar 的值都只自加了 1 次。
62 | ```java
63 | public class VariantTest{
64 |
65 | public static int staticVar = 0;
66 |
67 | public int instanceVar = 0;
68 |
69 | public VariantTest(){
70 | staticVar++;
71 | instanceVar++;
72 | System.out.println("staticVar=" + staticVar + ",instanceVar=" + instanceVar);
73 | }
74 | }
75 | ```
76 |
77 |
78 |
79 | #### 问:&和&&的区别?
80 | **参考答案:**
&运算符有两种用法:(1)按位与;(2)逻辑与。
&&运算符是短路与运算。逻辑与跟短路与的差别是非常巨大的,虽然二者都要求运算符左右两端的布尔值都是true整个表达式的值才是true。&&之所以称为短路运算是因为,如果&&左边的表达式的值是false,右边的表达式会被直接短路掉,不会进行运算。很多时候我们可能都需要用&&而不是&,例如在验证用户登录时判定用户名不是null而且不是空字符串,应当写为:username != null &&!username.equals(""),二者的顺序不能交换,更不能用&运算符,因为第一个条件如果不成立,根本不能进行字符串的equals比较,否则会产生NullPointerException异常。注意:逻辑或运算符(|)和短路或运算符(||)的差别也是如此。
81 |
82 |
83 | #### 问:父类的静态方法能否被子类重写?
84 | **参考答案:**
不能。重写只适用于实例方法,不能用于静态方法,而子类当中含有和父类相同签名的静态方法,我们一般称之为隐藏,调用的方法为定义的类所有的静态方法。
85 |
86 |
87 | #### 问:什么是不可变对象?
88 | **参考答案:**
不可变对象指对象一旦被创建,状态就不能再改变。任何修改都会创建一个新的对象,如 String、Integer及其它包装类。
89 |
90 |
91 | #### 问:能否创建一个包含可变对象的不可变对象?
92 | **参考答案:**
可以,不过需要谨慎一点,不要共享可变对象的引用就可以了,如果需要变化时,就返回原对象的一个拷贝。
最常见的例子就是对象中包含一个String对象的引用.
93 |
94 |
95 |
96 |
97 |
--------------------------------------------------------------------------------
/Java基础技术/Map类面试题.md:
--------------------------------------------------------------------------------
1 | # **Map类面试题**
2 |
3 | - ### 问:说说List,Set,Map三者的区别?
4 |
5 | **参考答案:**
6 |
7 | List(对付顺序的好帮手):List接口存储一组不唯一(可以有多个元素引用相同的对象),有序的对象;
8 | Set(注重独一无二的性质):不允许重复的集合。不会有多个元素引用相同的对象;
9 | Map(用Key来搜索的专家):使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相同的对象,但Key不能重复,典型的Key是String类型,但也可以是任何对象。
10 |
11 |
12 |
13 |
14 |
15 | ### 问:poll()方法和remove()方法区别?
16 |
17 | **参考答案:**
18 |
19 | poll() 和 remove() 都是从队列中取出一个元素,但是 poll() 在获取元素失败的时候会返回空,但是 remove() 失败的时候会抛出异常。
20 |
21 |
22 |
23 | ### 问:为何Map接口不继承Collection接口?
24 |
25 | **参考答案:**
26 |
27 | 尽管Map接口和它的实现也是集合框架的一部分,但Map不是集合,集合也不是Map。因此,Map继承Collection毫无意义,反之亦然。
28 |
29 | 如果Map继承Collection接口,那么元素去哪儿?Map包含key-value对,它提供抽取key或value列表集合的方法,但是它不适合“一组对象”规范。
30 |
31 |
32 |
33 | ### 问:我们能否使用任何类作为Map的key?
34 |
35 | **参考答案:**
36 |
37 | 我们可以使用任何类作为Map的key,然而在使用它们之前,需要考虑以下几点:
38 |
39 | (1)如果类重写了equals()方法,它也应该重写hashCode()方法。
40 |
41 | (2)类的所有实例需要遵循与equals()和hashCode()相关的规则。请参考之前提到的这些规则。
42 |
43 | (3)如果一个类没有使用equals(),你不应该在hashCode()中使用它。
44 |
45 | (4)用户自定义key类的最佳实践是使之为不可变的,这样,hashCode()值可以被缓存起来,拥有更好的性能。不可变的类也可以确保hashCode()和equals()在未来不会改变,这样就会解决与可变相关的问题了。
46 |
47 | 比如,我有一个类MyKey,在HashMap中使用它。
48 |
49 | //传递给MyKey的name参数被用于equals()和hashCode()中 MyKey key = new MyKey('Pankaj'); //assume hashCode=1234 myHashMap.put(key, 'Value'); // 以下的代码会改变key的hashCode()和equals()值 key.setName('Amit'); //assume new hashCode=7890 //下面会返回null,因为HashMap会尝试查找存储同样索引的key,而key已被改变了,匹配失败,返回null myHashMap.get(new MyKey('Pankaj')); 那就是为何String和Integer被作为HashMap的key大量使用。
50 |
51 |
52 |
53 | ### 问:Map接口提供了哪些不同的集合视图?
54 |
55 | **参考答案:**
56 |
57 | Map接口提供三个集合视图:
58 |
59 | (1)Set keyset():返回map中包含的所有key的一个Set视图。集合是受map支持的,map的变化会在集合中反映出来,反之亦然。当一个迭代器正在遍历一个集合时,若map被修改了(除迭代器自身的移除操作以外),迭代器的结果会变为未定义。集合支持通过Iterator的Remove、Set.remove、removeAll、retainAll和clear操作进行元素移除,从map中移除对应的映射。它不支持add和addAll操作。
60 |
61 | (2)Collection values():返回一个map中包含的所有value的一个Collection视图。这个collection受map支持的,map的变化会在collection中反映出来,反之亦然。当一个迭代器正在遍历一个collection时,若map被修改了(除迭代器自身的移除操作以外),迭代器的结果会变为未定义。集合支持通过Iterator的Remove、Set.remove、removeAll、retainAll和clear操作进行元素移除,从map中移除对应的映射。它不支持add和addAll操作。
62 |
63 | (3)Set> entrySet():返回一个map钟包含的所有映射的一个集合视图。这个集合受map支持的,map的变化会在collection中反映出来,反之亦然。当一个迭代器正在遍历一个集合时,若map被修改了(除迭代器自身的移除操作,以及对迭代器返回的entry进行setValue外),迭代器的结果会变为未定义。集合支持通过Iterator的Remove、Set.remove、removeAll、retainAll和clear操作进行元素移除,从map中移除对应的映射。它不支持add和addAll操作。
64 |
65 |
66 |
67 | ### 问:如何决定选用HashMap还是TreeMap?
68 |
69 | **参考答案:**
70 |
71 | 对于在Map中插入、删除和定位元素这类操作,HashMap是最好的选择。然而,假如你需要对一个有序的key集合进行遍历,TreeMap是更好的选择。基于你的collection的大小,也许向HashMap中添加元素会更快,将map换为TreeMap进行有序key的遍历。
72 |
73 |
74 |
75 | ### 问:TreeMap和TreeSet在排序时如何比较元素?Collections工具类中的sort()方法如何比较元素?
76 |
77 | **参考答案:**
78 |
79 | TreeSet要求存放的对象所属的类必须实现Comparable接口,该接口提供了比较元素的compareTo()方法,当插入元素时会回调该方法比较元素的大小。TreeMap要求存放的键值对映射的键必须实现Comparable接口从而根据键对元素进行排序。Collections工具类的sort方法有两种重载的形式,第一种要求传入的待排序容器中存放的对象比较实现Comparable接口以实现元素的比较;第二种不强制性的要求容器中的元素必须可比较,但是要求传入第二个参数,参数是Comparator接口的子类型(需要重写compare方法实现元素的比较),相当于一个临时定义的排序规则,其实就是通过接口注入比较元素大小的算法,也是对回调模式的应用(Java中对函数式编程的支持)。
80 |
81 |
82 |
83 | ### 问:HashMap ,LinkedHashMap ,TreeMap,WeakHashMap,ConcurrentHashMap,IdentityHashMap的区别
84 |
85 | **参考答案:**
86 |
87 | - **HashMap**基于散列表来的实现,即使用hashCode()进行快速查询元素的位置,显著提高性能。插入和查询“键值对”的开销是固定的。可以通过设置容量和负载因子,以调整容器的性能。
88 | - **LinkedHashMap**, 类似于HashMap,但是迭代遍历它时,取得“键值对”的顺序是其**插入的次序**,只比HashMap慢一点。而在迭代访问时反而更快,**因为它使用链表维护内部次序**。
89 | - **TreeMap**, 是基于**红黑树**的实现。实现了SortedMap,SortedMap 可以确保键处于排序状态。所以查看“键”和“键值对”时,所有得到的结果都是经过排序的,次序由Comparable或Comparator决定。SortedMap拥有其他额外的功能,如:Comparator comparator()返回当前Map使用的Comparator或者null. T firstKey() 返回Map的第一个键,T lastKey() 返回最后一个键。SortedMap headMap(toKey),生成一个键小于toKey的Map子集。SortedMap tailMap(fromKey) 也是生成一个子集。TreeMap是唯一的带有subMap()方法的Map,它可以返回一个子树
90 | - **WeakHashMap**表示**弱键映射**,允许释放映射所指向的对象。这是为了解决某类特殊问题而设计的,如果映射之外没有引用指向某个“键”,则“键”可以被垃圾收集器回收。
91 | - **ConcurrentHashMap**一种线程安全的Map,它不涉及同步加锁。
92 | - **IdentityHashMap**使用==代替equals() 对“键”进行比较的散列映射。专为解决特殊问题而设计。
93 |
94 |
95 |
96 | ### 问:HashMap 和 HashSet区别是什么?
97 |
98 | **参考答案:**
99 |
100 | 如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了`clone()`、`writeObject()`、`readObject()`是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
101 |
102 | | HashMap | HashSet |
103 | | -------------------------------- | ------------------------------------------------------------ |
104 | | 实现了Map接口 | 实现Set接口 |
105 | | 存储键值对 | 仅存储对象 |
106 | | 调用 `put()`向map中添加元素 | 调用 `add()`方法向Set中添加元素 |
107 | | HashMap使用键(Key)计算Hashcode | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性, |
108 |
109 | ###
110 |
111 | ### 问:HashSet如何检查重复
112 |
113 | **参考答案:**
114 |
115 | 当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
116 |
117 |
118 |
119 | ### 问:WeakHashMap与HashMap的区别是什么?
120 |
121 | **参考答案:**
122 |
123 | WeakHashMap 的工作与正常的 HashMap 类似,但是使用弱引用作为 key,意思就是当 key 对象没有任何引用时,key/value 将会被回收。
124 |
--------------------------------------------------------------------------------
/Java基础技术/Java进阶面试题.md:
--------------------------------------------------------------------------------
1 | # Java进阶面试题
2 |
3 | ### 问:为什么反射的性能较差?有没有什么方法可以让他变快?
4 |
5 | **参考答案:**
6 | java反射要解析字节码,将内存中的对象进行解析,包括了一些动态类型,JVM难以优化,而且在调用时还需要拼接参数,执行步骤也更多。因此,反射操作的效率要更低
7 |
8 | 常用的改进性能方法主要有:
9 |
10 | - m.setAccessible(true);
11 |
12 | 由于JDK的安全检查耗时较多.所以通过setAccessible(true)的方式关闭安全检查就可以达到提升反射速度的目的;
13 |
14 | - 用缓存将反射得到的元数据保存起来;
15 | - 利用一些高性能的反射库,如ReflectASM ReflectASM 使用字节码生成的方式实现了更为高效的反射机制。执行时会生成一个存取类来 set/get 字段,访问方法或创建实例。一看到 ASM 就能领悟到 ReflectASM 会用字节码生成的方式,而不是依赖于 Java 本身的反射机制来实现的,所以它更快,并且避免了访问原始类型因自动装箱而产生的问题。
16 |
17 |
18 |
19 | ### 问:java当中的四种引用分别指什么?
20 |
21 | **参考答案:**
22 |
23 | 强引用,软引用,弱引用,虚引用。不同的引用类型主要体现在GC上:
24 |
25 | 强引用,如果一个对象具有强引用,它就不会被垃圾回收器回收。即使当前内存空间不足,JVM也不会回收它,而是抛出 OutOfMemoryError 错误,使程序异常终止。如果想中断强引用和某个对象之间的关联,可以显式地将引用赋值为null,这样一来的话,JVM在合适的时间就会回收该对象;
26 |
27 | 软引用,在使用软引用时,如果内存的空间足够,软引用就能继续被使用,而不会被垃圾回收器回收,只有在内存不足时,软引用才会被垃圾回收器回收;
28 |
29 | 弱引用,具有弱引用的对象拥有的生命周期更短暂。因为当 JVM 进行垃圾回收,一旦发现弱引用对象,无论当前内存空间是否充足,都会将弱引用回收。不过由于垃圾回收器是一个优先级较低的线程,所以并不一定能迅速发现弱引用对象;
30 |
31 | 虚引用,顾名思义,就是形同虚设,如果一个对象仅持有虚引用,那么它相当于没有引用,在任何时候都可能被垃圾回收器回收;
32 |
33 | ###
34 |
35 | ### 问:为什么要有不同的引用类型?
36 |
37 | **参考答案:**
38 |
39 | Java语言有时需要我们适当的控制对象被回收的时机,因此就诞生了不同的引用类型,可以说不同的引用类型实则是对GC回收时机不可控的妥协。比如说以下应用场景:
40 |
41 | 利用软引用和弱引用解决OOM问题:用一个HashMap来保存图片的路径和相应图片对象关联的软引用之间的映射关系,在内存不足时,JVM会自动回收这些缓存图片对象所占用的空间,从而有效地避免了OOM的问题;
42 |
43 |
44 |
45 | ### 问:虚拟机是如何实现多态的?
46 |
47 | **参考答案:**
48 |
49 | 动态绑定技术(dynamic binding),执行期间判断所引用对象的实际类型,根据实际类型调用对应的方法.
50 |
51 |
52 |
53 |
54 |
55 | ### 问:静态嵌套类(Static Nested Class)和内部类(Inner Class)的不同?
56 |
57 | **参考答案:**
58 |
59 | Static Nested Class是被声明为静态(static)的内部类,它可以不依赖于外部类实例被实例化。而通常的内部类需要在外部类实例化后才能实例化
60 |
61 |
62 |
63 | ### 问:内部类的作用
64 |
65 | **参考答案:**
66 |
67 | 内部类可以有多个实例,每个实例都有自己的状态信息,并且与其他外围对象的信息相互独立。在单个外围类当中,可以让多个内部类以不同的方式实现同一接口,或者继承同一个类.
68 |
69 | 创建内部类对象的时刻不依赖于外部类对象的创建.内部类并没有令人疑惑的”is-a”关系,它就像是一个独立的实体。内部类提供了更好的封装,除了该外围类,其他类都不能访问
70 |
71 |
72 |
73 | ### 问:3*0.1==0.3返回值是什么
74 |
75 | **参考答案:**
76 |
77 | false,因为有些浮点数不能完全精确的表示出来。
78 |
79 |
80 |
81 | ### 问:a=a+b与a+=b有什么区别吗?
82 |
83 | **参考答案:**
84 |
85 | +=操作符会进行隐式自动类型转换,此处a+=b隐式的将加操作的结果类型强制转换为持有结果的类型,而a=a+b则不会自动进行类型转换。
86 |
87 | 举个例子,如: byte a = 23; byte b = 22; b = a + b;//编译出错 而 b += a; // 编译OK
88 |
89 |
90 |
91 | ### 问:int 和Integer谁占用的内存更多?
92 |
93 | **参考答案:**
94 |
95 | Integer 对象会占用更多的内存。Integer是一个对象,需要存储对象的元数据。但是int是一个原始类型的数据,所以占用的空间更少;
96 |
97 |
98 |
99 | ### 问:JVM、JRE、JDK及 JIT 之间有什么不同
100 |
101 | **参考答案:**
102 |
103 | java 虚拟机 (JVM),是实现java语言平台独立性的基础,可以理解伪代码字节码,提供对多个平台的良好支持,在用户和操作系统之间建立了一层枢纽。
104 |
105 | java 运行时环境 (JRE),是JVM 的一个超集。JVM 对于一个平台或者操作系统是明确的,而 JRE 确实一个一般的概念,他代表了完整的运行时环境。在 jre 文件夹中的jar 文件和可执行文件都会变成运行时的一部分。事实上,运行时 JRE 变成了 JVM。所以对于一般情况时候使用 JRE,对于明确的操作系统来说使用 JVM。当你下载了 JRE 的时候,也就自动下载了 JVM。
106 |
107 | java 开发工具箱 (JDK),java 开发工具箱指的是编写一个 java 应用所需要的所有 jar 文件和可执行文件。事实上,JRE 是 JDK 的一部分。如果你下载了 JDK,你会看到一个名叫 JRE 的文件夹在里面。JDK 中要被牢记的 jar 文件就是 tools.jar,它包含了用于执行 java 文档的类还有用于类签名的 jar 包。
108 |
109 | 即时编译器 (JIT),即时编译器是种特殊的编译器,它通过有效的把字节码变成机器码来提高 JVM 的效率。JIT 这种功效很特殊,因为他把检测到的相似的字节码编译成单一运行的机器码,从而节省了 CPU 的使用。这和其他的字节码编译器不同,因为他是运行时编译(从字节码到机器码)而不是在程序运行之前。正是因为这些,动态编译这个词汇才和 JIT 有那么紧密的关系。
110 |
111 |
112 |
113 | ### 问:Java 泛型类在什么时候确定类型?
114 |
115 | **参考答案:**
116 |
117 | 在编译期间确定变量类型。类型擦除。
118 |
119 |
120 |
121 | ### 问:引用类型是占用几个字节?
122 |
123 | **参考答案:**
124 |
125 | hotspot在64位平台上,占8个字节,在32位平台上占4个字节。
126 |
127 |
128 |
129 | ### 问:JDK主流版本的差异
130 |
131 | **参考答案:**
132 |
133 | - Java 5(2004年发行),影响很大的一个版本;
134 |
135 | - - 1、**泛型**。
136 | - 2、**Metadata**,元数据,描述数据的数据。
137 | - 3、**自动装箱和拆箱**,也就是基本数据类型(如 int)和它的包装类型(如 Integer)自动帮你转换(其实背后是相关的方法帮你做了转换工作)。
138 | - 4、**枚举**。
139 | - 5、**可变参数**,一个函数可以传入数量不固定的参数值。
140 | - 6、**增强版的 for 循环**。
141 | - 7、**改进了 Java 的内存模型**,提供了 java.util.concurrent 并发包。
142 |
143 | - Java 6(2006年发行),这个版本的 Java 更多是对之前版本功能的优化,增强了用户的可用性和修复了一些漏洞,
144 |
145 | - - 1、提供**动态语言**支持。
146 | - 2、提供**编译 API**,即 Java 程序可以调用 Java 编译器的 API。
147 | - 3、**Swing 库的一些改进**。
148 | - 4、**JVM 的优化**。
149 | - 5、**微型 HTTP 服务器 API** ;
150 |
151 | - Java 7(2011年发行)
152 |
153 | - - 1、放宽 switch 的使用,可以在 switch 中使用字符串;
154 | - 2、try-resource-with 语句,帮助自动化管理资源,如打开文件,对文件操作结束后,JVM 可以自动帮我们关闭文件资源,当然前提是你要用 try-resource-with 语句。
155 | - 3、加入了类型推断功能,比如你之前版本使用泛型类型时这样写 ArrayList userList= new ArrayList();,这个版本只需要这样写 ArrayList userList= new ArrayList<>();,也即是后面一个尖括号内的类型,JVM 帮我们自动类型判断补全了。
156 | - 4、简化了可变参数的使用。
157 | - 5、支持二进制整数,在硬件开发中,二进制数更常用,方便人查看。
158 | - 6、支持带下划线的数值,如 int a = 100000000;,0 太多不便于人阅读,这个版本支持这样写 int a = 100_000_000,这样就对数值一目了然了吧。
159 | - 7、异常处理支持多个 catch 语句。
160 | - 8、NIO 库的一些改进,增加多重文件的支持、文件原始数据和符号链接。
161 |
162 | - Java 8(2014年发行)
163 |
164 | - - 1、**Lambda 表达式**,简化代码
165 | - 2、**注解功能的增强**。重复注解和注解扩展,现在几乎可以为任何东西添加注解:局部变量、泛型类、父类与接口的实现,就连方法的异常也能添加注解。
166 | - 3、**新的时间和日期 API**,在这之前 Java 的时间和日期库被投票为最难用的 API 之一,所以这个版本就改进了。
167 | - 4、**JavaFX**,一种用在桌面开发领域的技术(也是和其他公司竞争,这个让我们拭目以待吧)。
168 | - 5、**静态链接 JNI 程序库**(这个做安卓开发的同学应该熟悉)。
169 | - 6、接口默认方法和静态方法
170 | - 7、函数式接口
171 | - 8、方法引用
172 | - 9、java.util.stream
173 | - 10、HashMap的底层实现有变化
174 | - 11、JVM内存管理方面,由元空间代替了永久代。
175 |
176 | - Java 9 (2017年发行)
177 |
178 | - - 1、**模块化**(这点也是向其他语言学习的,如 JavaScript)。
179 | - 2、**Java Shell**(这点也是向其他语言学习的,如 Python),在这之前总有人说 Java 太麻烦,写个 Hello Word 都要新建个类,有时候测试个几行的代码都不方便,Java Shell 推出后,Java 开发者不用眼馋其他语言的 Shell 了;
180 | - 3、**即时编译功能的增强**。
181 | - 4、**XML Catalogs**,XML 文件自动校验。
182 |
183 | - Java 10(2018年发行)
184 |
185 | - - 1、局部变量的类型推断 var关键字
186 | - 2、GC改进和内存管理 并行全垃圾回收器 G1
187 | - 3、垃圾回收器接口
188 | - 4、线程-局部变量管控
189 | - 5、合并 JDK 多个代码仓库到一个单独的储存库中
190 |
191 | - Java 11(2018年发行)
192 |
193 | - - 1、本地变量类型推断
194 | - 2、字符串加强
195 | - 3、集合加强
196 | - 4、Stream 加强
197 | - Optional 加强
198 | - 5、InputStream 加强
199 | - 6、HTTP Client API
200 | - 7、化繁为简,一个命令编译运行源代码
201 |
--------------------------------------------------------------------------------
/Java横向技术/网络与web面试题.md:
--------------------------------------------------------------------------------
1 | # 网络与web面试题
2 |
3 |
4 | ### 问:说下TCP三次握手的过程?
5 |
6 | **参考答案:**
7 |
8 | 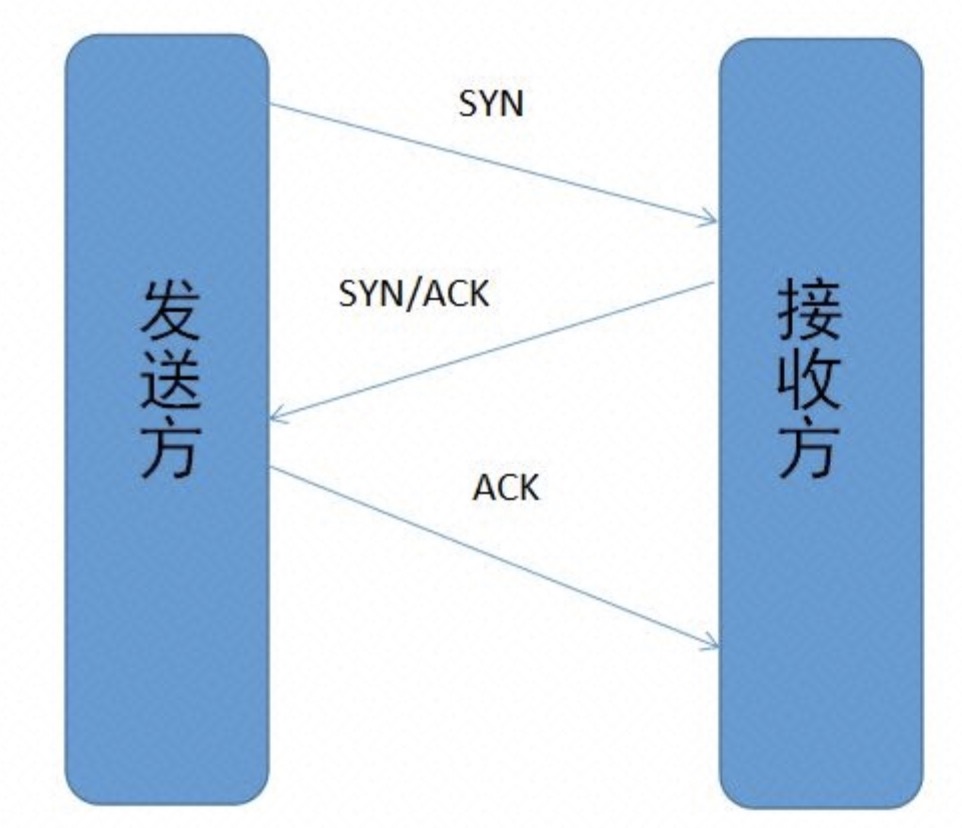
9 |
10 |
11 |
12 | 第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
13 |
14 | SYN:同步序列编号(Synchronize Sequence Numbers)
15 |
16 | 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
17 |
18 | 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
19 |
20 | 完成三次握手,客户端与服务器开始传送数据。
21 |
22 |
23 |
24 | ### 问:为什么要三次握手
25 |
26 | **参考答案:**
27 |
28 | 三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
29 |
30 | 第一次握手:Client 什么都不能确认;Server 确认了对方发送正常
31 |
32 | 第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己接收正常,对方发送正常
33 |
34 | 第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
35 |
36 | 所以三次握手就能确认双发收发功能都正常,缺一不可。
37 |
38 | ***为什么要传回 SYN?***
39 |
40 | 接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
41 |
42 | > SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的TCP连接,数据才可以在客户机和服务器之间传递。
43 |
44 | ***传了 SYN,为啥还要传 ACK?***
45 |
46 | 双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方到接收方的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
47 |
48 |
49 |
50 | ### 问:说下断开一个 TCP 连接的“四次挥手”
51 |
52 | **参考答案:**
53 |
54 | - 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
55 | - 服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加1 。和 SYN 一样,一个 FIN 将占用一个序号
56 | - 服务器-关闭与客户端的连接,发送一个FIN给客户端
57 | - 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1。
58 |
59 | ***为什么要四次挥手?***
60 |
61 | 任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。
62 |
63 | 举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
64 |
65 | 上面讲的比较概括,推荐一篇讲的比较细致的文章:https://blog.csdn.net/qzcsu/article/details/72861891
66 |
67 |
68 |
69 | ### 问:TCP,UDP 协议的区别?
70 |
71 | **参考答案:**
72 |
73 | 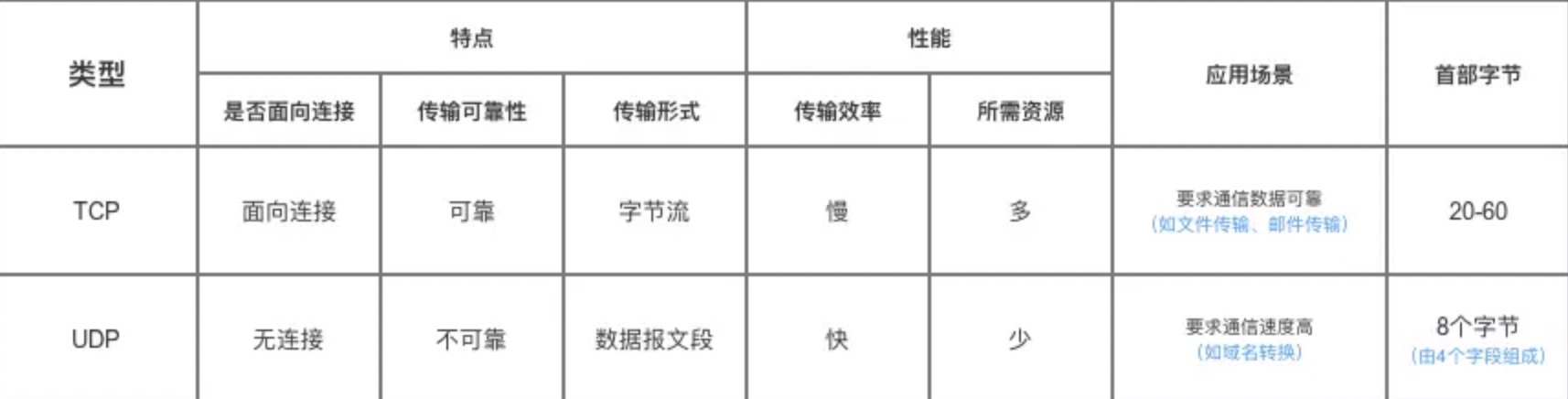
74 |
75 | UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等
76 |
77 | TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务(TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
78 |
79 |
80 |
81 | ### 问:TCP 协议如何保证可靠传输?
82 |
83 | **参考答案:**
84 |
85 | 1. 应用数据被分割成 TCP 认为最适合发送的数据块。
86 | 2. TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
87 | 3. **校验和:** TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
88 | 4. TCP 的接收端会丢弃重复的数据。
89 | 5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
90 | 6. **拥塞控制:** 当网络拥塞时,减少数据的发送。
91 | 7. **ARQ协议:** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
92 | 8. **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
93 |
94 |
95 |
96 |
97 |
98 | ### 问:说说HTTP长连接和短连接。
99 |
100 | **参考答案:**
101 |
102 | 在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
103 |
104 | 而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
105 |
106 | ```http
107 | Connection:keep-alive
108 | ```
109 |
110 | 在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
111 |
112 | **HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。**
113 |
114 | 其他可参考:[《HTTP长连接、短连接究竟是什么?》](https://www.cnblogs.com/gotodsp/p/6366163.html)
115 |
116 |
117 |
118 | ### 问:十一 HTTP 1.0和HTTP 1.1的主要区别是什么?
119 |
120 | **参考答案:**
121 |
122 | HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。 主要区别主要体现在:
123 |
124 | 1. **长连接** : **在HTTP/1.0中,默认使用的是短连接**,也就是说每次请求都要重新建立一次连接。HTTP 是基于TCP/IP协议的,每一次建立或者断开连接都需要三次握手四次挥手的开销,如果每次请求都要这样的话,开销会比较大。因此最好能维持一个长连接,可以用个长连接来发多个请求。**HTTP 1.1起,默认使用长连接** ,默认开启Connection: keep-alive。 **HTTP/1.1的持续连接有非流水线方式和流水线方式** 。流水线方式是客户在收到HTTP的响应报文之前就能接着发送新的请求报文。与之相对应的非流水线方式是客户在收到前一个响应后才能发送下一个请求。
125 | 2. **错误状态响应码** :在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
126 | 3. **缓存处理** :在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
127 | 4. **带宽优化及网络连接的使用** :HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
128 |
129 | 参考:https://mp.weixin.qq.com/s/GICbiyJpINrHZ41u_4zT-A?
130 |
131 |
132 |
133 | ### 问:URI和URL的区别是什么?
134 |
135 | **参考答案:**
136 |
137 | - URI(Uniform Resource Identifier) 是同一资源标志符,可以唯一标识一个资源。
138 | - URL(Uniform Resource Location) 是同一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
139 |
140 | URI的作用像身份证号一样,URL的作用更像家庭住址一样。URL是一种具体的URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
141 |
142 |
143 |
144 | ### 问:HTTP和HTTPS的区别?
145 |
146 | **参考答案:**
147 |
148 | 1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
149 |
150 | 2、https是具有安全性的ssl加密传输协议;而http是超文本传输协议,信息是明文传输。
151 |
152 | 3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
153 |
154 | 4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
155 |
156 |
157 |
158 |
159 |
160 | ### 问:Cookie和Session的区别是什么?
161 |
162 | **参考答案:**
163 |
164 | 1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
165 |
166 | 2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,考虑到安全应当使用session。
167 |
168 | 3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用COOKIE。
169 |
170 | 4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
171 |
172 | 总的来说,Cookie 和 Session都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
173 |
174 | **Cookie 一般用来保存用户信息** 比如①我们在 Cookie 中保存已经登录过得用户信息,下次访问网站的时候页面可以自动帮你登录的一些基本信息给填了;②一般的网站都会有保持登录也就是说下次你再访问网站的时候就不需要重新登录了,这是因为用户登录的时候我们可以存放了一个 Token 在 Cookie 中,下次登录的时候只需要根据 Token 值来查找用户即可(为了安全考虑,重新登录一般要将 Token 重写);③登录一次网站后访问网站其他页面不需要重新登录。**Session 的主要作用就是通过服务端记录用户的状态。** 典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了。
175 |
176 |
177 |
178 | ##
179 |
--------------------------------------------------------------------------------
/Java横向技术/redis面试题.md:
--------------------------------------------------------------------------------
1 | # redis面试题
2 |
3 | ### 问:使用 Redis 有哪些好处?
4 |
5 | **参考答案:**
6 |
7 | (1)速度快,因为数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是 O1)
8 |
9 | (2)支持丰富数据类型,支持 string,list,set,Zset,hash 等
10 |
11 | (3)支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
12 |
13 | (4)丰富的特性:可用于缓存,消息,按 key 设置过期时间,过期后将会自动删除
14 |
15 |
16 |
17 | ### 问:Redis 是单进程单线程的?
18 |
19 | **参考答案:**
20 |
21 | Redis 是单进程单线程的,redis 利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销。
22 |
23 | ### 问:一个字符串类型的值能存储最大容量是多少?
24 | **参考答案:** 512M
25 |
26 |
27 | ### 问:Redis 常见性能问题和解决方案有哪些?
28 |
29 | **参考答案:**
30 |
31 | (1)Master 最好不要写内存快照,如果 Master 写内存快照,save 命令调度 rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务;
32 |
33 | (2)如果数据比较重要,某个 Slave 开启 AOF 备份数据,策略设置为每秒同步一次;
34 |
35 | (3)为了主从复制的速度和连接的稳定性,Master 和 Slave 最好在同一个局域网;
36 |
37 | (4)尽量避免在压力很大的主库上增加从库;
38 |
39 | ###
40 |
41 | ### 问:为什么redis 需要把所有数据放到内存中?
42 |
43 | **参考答案:**
44 |
45 | Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以 redis 具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘 I/O 速度为严重影响 redis 的性能。在内存越来越便宜的今天,redis 将会越来越受欢迎。如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
46 |
47 |
48 |
49 | ### 问:Redis 支持的 Java 客户端都有哪些?官方推荐用哪个?
50 |
51 | **参考答案:**
52 |
53 | Redisson、Jedis、lettuce 等等,官方推荐使用 Redisson。
54 |
55 | ###
56 |
57 | ### 问:Jedis 与 Redisson 对比有什么优缺点?
58 |
59 | **参考答案:**
60 |
61 | Jedis 是 Redis 的 Java 实现的客户端,其 API 提供了比较全面的 Redis 命令的支持;Redisson 实现了分布式和可扩展的 Java 数据结构,和 Jedis 相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等 Redis 特性。
62 |
63 | Redisson 的宗旨是促进使用者对 Redis 的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
64 |
65 |
66 |
67 | ### 问:说说 Redis 哈希槽的概念?
68 |
69 | **参考答案:**
70 |
71 | Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
72 |
73 |
74 |
75 | ### 问:Redis 集群会有写操作丢失吗?为什么?
76 |
77 | **参考答案:**
78 |
79 | Redis 并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
80 |
81 |
82 |
83 | ### 问:Redis 集群之间是如何复制的?
84 |
85 | **参考答案**:异步复制
86 |
87 | ###
88 |
89 | ### 问:Redis 集群最大节点个数是多少?
90 |
91 | **参考答案**:16384 个。
92 |
93 |
94 |
95 | ### 问:Redis 事务相关的命令有哪几个?
96 |
97 | **参考答案**:MULTI、EXEC、DISCARD、WATCH
98 |
99 |
100 |
101 | ### 问:Redis key 的过期时间和永久有效分别怎么设置?
102 |
103 | **参考答案**:EXPIRE 和 PERSIST 命令。
104 |
105 |
106 |
107 | ### 问:Redis 如何做内存优化?
108 |
109 | **参考答案**:尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的 web 系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的 key,而是应该把这个用户的所有信息存储到一张散列表里面。
110 |
111 | ###
112 |
113 | ###
114 |
115 | ### 问:都有哪些办法可以降低 Redis 的内存使用情况呢?
116 |
117 | **参考答案**:如果你使用的是 32 位的 Redis 实例,可以好好利用 Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的 Key-Value 可以用更紧凑的方式存放到一起。
118 |
119 | ###
120 |
121 | ### 问:Redis 的内存用完了会发生什么?
122 |
123 | **参考答案**:如果达到设置的上限,Redis 的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以将 Redis 当缓存来使用配置淘汰机制,当 Redis 达到内存上限时会冲刷掉旧的内容。
124 |
125 | ###
126 |
127 | ### 问:一个 Redis 实例最多能存放多少的 keys?List、Set、Sorted Set 他们最多能存放多少元素?
128 |
129 | **参考答案**:理论上 Redis 可以处理多达 232 的 keys,每个实例至少存放了 2 亿 5 千万的 keys。任何 list、set、和 sorted set 都可以放 232 个元素。换句话说,Redis 的存储极限是系统中的可用内存值。
130 |
131 | ###
132 |
133 | ### 问:Redis 最适合的场景?
134 |
135 | **参考答案:**
136 |
137 | 1、会话缓存(Session Cache)
138 |
139 | 最常用的一种使用 Redis 的情景是会话缓存(session cache)。用 Redis 缓存会话比其他存储(如 Memcached)的优势在于:Redis 提供持久化。
140 |
141 | 2、全页缓存(FPC)
142 |
143 | 除基本的会话 token 之外,Redis 还提供很简便的 FPC 平台。回到一致性问题,即使重启了 Redis 实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似 PHP 本地 FPC。能帮助你以最快速度加载你曾浏览过的页面。
144 |
145 | 3、队列
146 |
147 | Reids 在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得 Redis能作为一个很好的消息队列平台来使用。Redis 作为队列使用的操作,就类似于本地程序语言(如 Python)对 list 的 push/pop 操作。
148 |
149 | 4,排行榜/计数器
150 |
151 | Redis 在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis 只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的 10个用户,我们只需要像下面一样执行即可: 当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行: ZRANGE user_scores 0 10 WITHSCORES。
152 |
153 | 5、发布/订阅
154 |
155 | 最后(但肯定不是最不重要的)是 Redis 的发布/订阅功能。发布/订阅的使用场景确实非常多。在社交网络中甚至可以用 Redis 的发布/订阅功能来建立聊天系统!
156 |
157 |
158 |
159 | ### 问:假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如果将它们全部找出来?
160 |
161 | **参考答案:**
162 |
163 | 使用 keys 指令可以扫出指定模式的 key 列表。
164 |
165 | *对方接着追问:如果这个 redis 正在给线上的业务提供服务,那使用 keys 指令会有什么问题?*
166 |
167 | 这个时候你要回答 redis 关键的一个特性:redis 的单线程的。keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令,scan 指令可以无阻塞的提取出指定模式的 key 列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长。
168 |
169 | ###
170 |
171 | ### 问:如果有大量的 key 需要设置同一时间过期,一般需要注意什么?
172 |
173 | **参考答案:**
174 |
175 | 如果大量的 key 过期时间设置的过于集中,到过期的那个时间点,redis 可能会出现短暂的卡顿现象。一般需要在时间上加一个随机值,使得过期时间分散一些。
176 |
177 | ###
178 |
179 | ### 问:使用过 Redis 做异步队列么,你是怎么用的?
180 |
181 | **参考答案:**
182 |
183 | 一般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有消息的时候,要适当 sleep 一会再重试。如果对方追问可不可以不用 sleep 呢?list 还有个指令叫 blpop,在没有消息的时候,它会阻塞住直到消息到来。
184 |
185 | *如果对方追问能不能生产一次消费多次呢?*
186 |
187 | 使用 pub/sub 主题订阅者模式,可以实现1:N 的消息队列。
188 |
189 | *如果对方追问 pub/sub 有什么缺点?*
190 |
191 | 在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如 RabbitMQ等。
192 |
193 | *如果对方追问 redis 如何实现延时队列?*
194 |
195 | 使用 sortedset,拿时间戳作为score,消息内容作为 key 调用 zadd 来生产消息,消费者用 zrangebyscore 指令获取 N 秒之前的数据轮询进行处理。
196 |
197 |
198 |
199 |
200 |
201 | ### 问:redis是单线程为啥那么快?
202 |
203 | **参考答案:**
204 |
205 | 1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
206 |
207 | 2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
208 |
209 | 3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
210 |
211 | 4、使用多路I/O复用模型,非阻塞IO;
212 |
213 | 5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
214 |
215 | ###
216 |
217 | ### 问:redis的支持哪些集群模式?
218 |
219 | **参考答案:**
220 |
221 | 1、Master-Slaver主从模式:
222 |
223 | 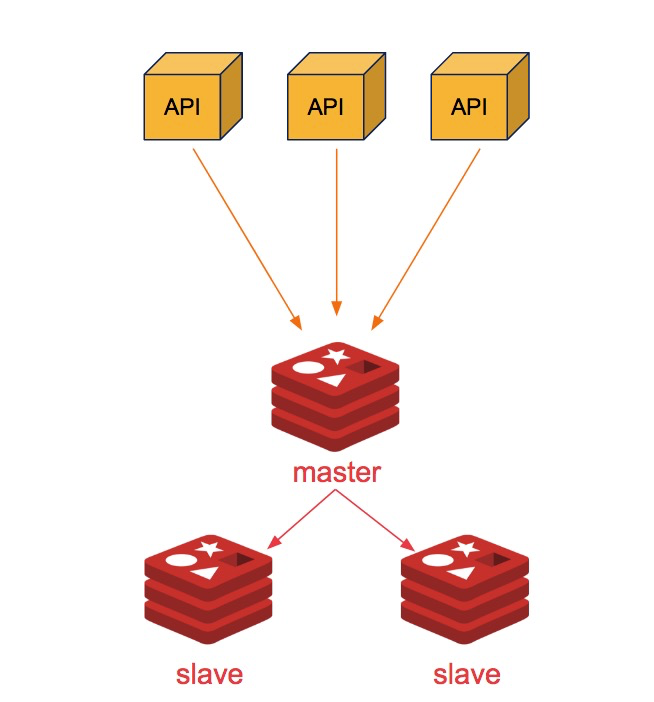
224 |
225 | 主从模式就是N个redis实例,可以是1主N从,也可以N主N从(N主N从则不是严格意义上的主从模式了,N主N从就是N+N个redis实例)
226 |
227 | 优点:1.备份数据,这样当一个节点损坏(指不可恢复的硬件损坏)时,数据因为有备份,可以方便恢复。
228 |
229 | 2.负载均衡,所有客户端都访问一个节点肯定会影响Redis工作效率,有了主从以后,查询操作就可以通过查询从节点来完成。
230 |
231 | 缺点:master节点挂了以后,redis就不能对外提供写服务了,因为剩下的slave不能成为master。
232 |
233 | 使用场景:读请求较多场景
234 |
235 |
236 |
237 | 2、Sentinel哨兵模式:
238 |
239 | 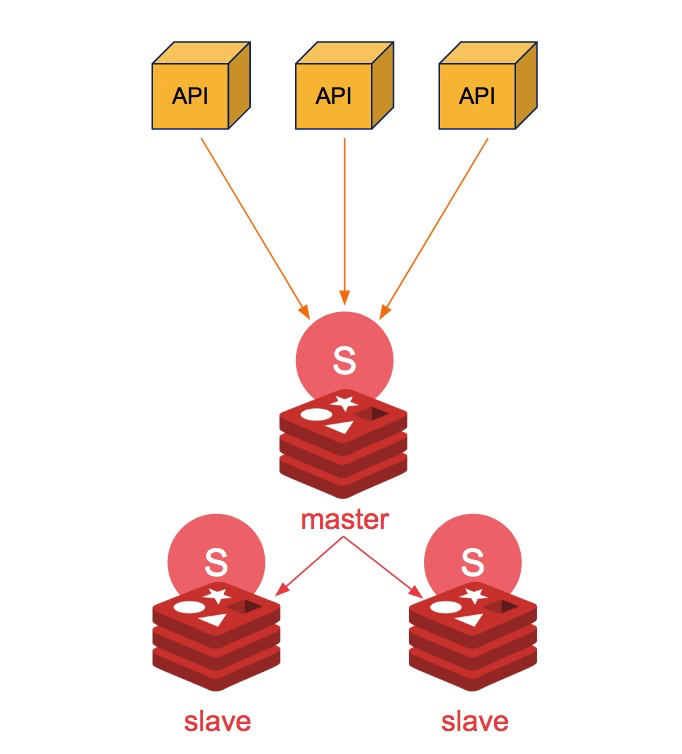
240 |
241 | 主从模式中slave节点不能主动选举一个master节点出来,那么就安排一个或多个sentinel来做这件事,当sentinel发现master节点挂了以后,sentinel就会从slave中重新选举一个master。
242 |
243 | 优点:解决了主从模式下master挂了无法提供写服务的情况
244 |
245 | 缺点:当数据量过大到一台服务器存放不下的情况(内存不够时),主从模式或sentinel模式就不能满足需求了
246 |
247 | 使用场景:存储量不大,单机可承受。
248 |
249 |
250 |
251 | 3、Cluster集群模式:
252 |
253 | 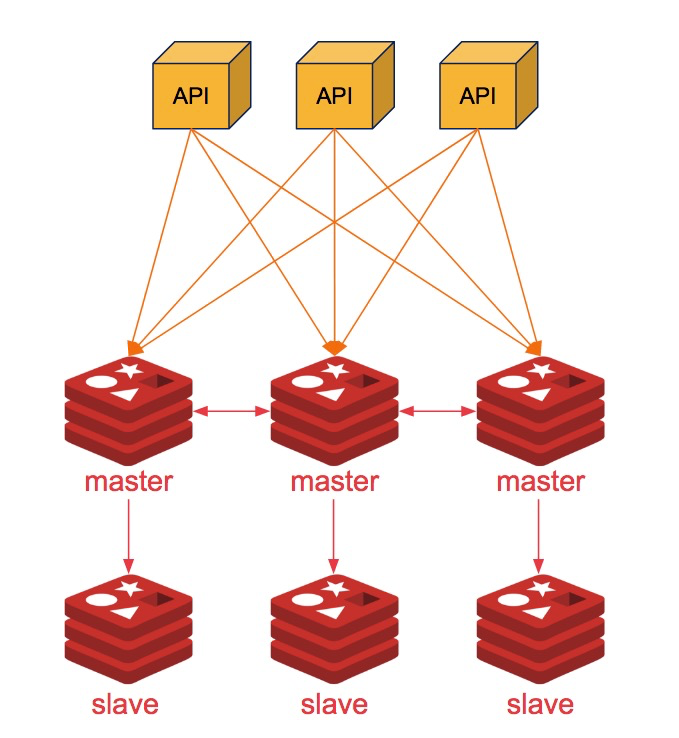
254 |
255 | cluster的出现是为了解决单机Redis容量有限的问题,将Redis的数据根据一定的规则分配到多台机器。一个 Redis 集群包含 16384 个哈希槽(hash slot),数据库中的每个键都属于这 16384 个哈希槽的其中一个,集群中的每个节点负责处理一部分哈希槽。
256 |
257 | 优点:解决了数据量较大,单机不够存储的情况,高并发高可用
258 |
259 | 使用场景:数据量大,高并发场景
260 |
261 |
262 |
263 |
264 |
265 | ### 问:Redis 集群方案什么情况下会导致整个集群不可用?
266 |
267 | **参考答案:**
268 |
269 | 有 A,B,C 三个节点的集群,在没有复制模型的情况下,如果节点 B 失败了,那么整个集群就会以为缺少 5501-11000 这个范围的槽而不可用。
270 |
--------------------------------------------------------------------------------
/Java基础技术/Java内存结构与类加载机制.md:
--------------------------------------------------------------------------------
1 | # Java内存结构与类加载机制
2 | ### 问:可以不可以自己写个String类?
3 |
4 | **参考答案:**
5 |
6 | 不可以,因为 根据类加载的双亲委派机制,会去加载父类,父类发现冲突了 String 就不再加载了;
7 |
8 |
9 |
10 | ### 问:什么是类加载器?
11 |
12 | **参考答案:**
13 |
14 | 负责读取 Java 字节代码,并转换成java.lang.Class类的一个实例。
15 |
16 |
17 |
18 | ### 问:程序计数器作用
19 |
20 | **参考答案:**
21 |
22 | 记录当前线程锁执行的字节码的行号。
23 |
24 | 1. 程序计数器是一块较小的内存空间。
25 | 2. 处于线程独占区。
26 | 3. 执行java方法时,它记录正在执行的虚拟机字节码指令地址。执行native方法,它的值为undefined
27 | 4. 该区域是唯一一个没有规定任何OutOfMemoryError的区域
28 |
29 |
30 |
31 | ### 问:如果判断两个类是否“相同”
32 |
33 | **参考答案:**
34 |
35 | 类加载器除了用于加载类外,还可用于确定类在Java虚拟机中的唯一性。即便是同样的字节代码,被不同的类加载器加载之后所得到的类,也是不同的。
36 |
37 | 通俗一点来讲,要判断两个类是否“相同”,前提是这两个类必须被同一个类加载器加载,否则这个两个类不“相同”。 这里指的“相同”,包括类的Class对象的equals()方法、isAssignableFrom()方法、isInstance()方法、instanceof关键字等判断出来的结果。
38 |
39 |
40 |
41 | ### 问:Java虚拟机如何结束生命周期
42 |
43 | **参考答案:**
44 |
45 | 1. 执行System.exit()方法;
46 | 2. 程序正常执行结束;
47 | 3. 程序执行遇到异常或Error终止;
48 | 4. 操作系统出错而导致java虚拟机运行终止。
49 |
50 |
51 |
52 | ### 问:何时触发初始化
53 |
54 | **参考答案:**
55 |
56 | 1. 为一个类型创建一个新的对象实例时(比如new、反射、序列化);
57 | 2. 调用一个类型的静态方法时(即在字节码中执行invokestatic指令);
58 | 3. 调用一个类型或接口的静态字段,或者对这些静态字段执行赋值操作时(即在字节码中,执行getstatic或者putstatic指令),不过用final修饰的静态字段除外,它被初始化为一个编译时常量表达式;
59 | 4. 调用JavaAPI中的反射方法时(比如调用java.lang.Class中的方法,或者java.lang.reflect包中其他类的方法);
60 | 5. 初始化一个类的派生类(子类)时(Java虚拟机规范明确要求初始化一个类时,它的超类必须提前完成初始化操作,接口例外);
61 | 6. JVM启动包含main方法的启动类时。
62 |
63 | **注意**:通过子类引用付了的静态字段,不会导致子类初始化
64 |
65 |
66 |
67 |
68 |
69 | ### 问:JAVA热部署实现
70 |
71 | **参考答案:**
72 |
73 | 首先谈一下何为**热部署**(hotswap),热部署是在不重启 Java 虚拟机的前提下,能自动侦测到 class 文件的变化,更新运行时 class 的行为。Java 类是通过 Java 虚拟机加载的,某个类的 class 文件在被 classloader 加载后,会生成对应的 Class 对象,之后就可以创建该类的实例。默认的虚拟机行为只会在启动时加载类,如果后期有一个类需要更新的话,单纯替换编译的 class 文件,Java 虚拟机是不会更新正在运行的 class。如果要实现热部署,最根本的方式是修改虚拟机的源代码,改变 classloader 的加载行为,使虚拟机能监听 class 文件的更新,重新加载 class 文件,这样的行为破坏性很大,为后续的 JVM 升级埋下了一个大坑。
74 |
75 | 另一种友好的方法是创建自己的 classloader 来加载需要监听的 class,这样就能控制类加载的时机,从而实现热部署。
76 |
77 |
78 |
79 | ### 问: String s1 = new String("abc");这句话创建了几个字符串对象?
80 |
81 | **参考答案:**
82 |
83 | 将创建 1 或 2 个字符串。如果池中已存在字符串文字“abc”,则池中只会创建一个字符串“s1”。如果池中没有字符串文字“abc”,那么它将首先在池中创建,然后在堆空间中创建,因此将创建总共 2 个字符串对象。
84 |
85 | **验证:**
86 |
87 | ```
88 | String s1 = new String("abc");// 堆内存的地址值
89 | String s2 = "abc";
90 | System.out.println(s1 == s2);// 输出 false,因为一个是堆内存,一个是常量池的内存,故两者是不同的。
91 | System.out.println(s1.equals(s2));// 输出 true
92 | ```
93 |
94 |
95 |
96 | **结果:**
97 |
98 | ```
99 | false
100 | true
101 | ```
102 |
103 |
104 |
105 |
106 |
107 | ### String 类和常量池
108 |
109 | **String 对象的两种创建方式:**
110 |
111 |
112 |
113 | ```
114 | String str1 = "abcd";//先检查字符串常量池中有没有"abcd",如果字符串常量池中没有,则创建一个,然后 str1 指向字符串常量池中的对象,如果有,则直接将 str1 指向"abcd"";
115 | String str2 = new String("abcd");//堆中创建一个新的对象
116 | String str3 = new String("abcd");//堆中创建一个新的对象
117 | System.out.println(str1==str2);//false
118 | System.out.println(str2==str3);//false
119 | ```
120 |
121 |
122 |
123 | 这两种不同的创建方法是有差别的。
124 |
125 | - 第一种方式是在常量池中拿对象;
126 | - 第二种方式是直接在堆内存空间创建一个新的对象。
127 |
128 | 记住一点:**只要使用 new 方法,便需要创建新的对象。**
129 |
130 | 再给大家一个图应该更容易理解:
131 |
132 | 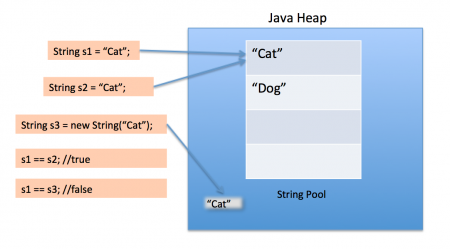
133 |
134 | **String 类型的常量池比较特殊。它的主要使用方法有两种:**
135 |
136 | - 直接使用双引号声明出来的 String 对象会直接存储在常量池中。
137 | - 如果不是用双引号声明的 String 对象,可以使用 String 提供的 intern 方法。String.intern() 是一个 Native 方法,它的作用是:如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;如果没有,则在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用。
138 |
139 | ```
140 | String s1 = new String("计算机");
141 | String s2 = s1.intern();
142 | String s3 = "计算机";
143 | System.out.println(s2);//计算机
144 | System.out.println(s1 == s2);//false,因为一个是堆内存中的 String 对象一个是常量池中的 String 对象,
145 | System.out.println(s3 == s2);//true,因为两个都是常量池中的 String 对象
146 | ```
147 |
148 |
149 |
150 | **字符串拼接:**
151 |
152 | ```
153 | String str1 = "str";
154 | String str2 = "ing";
155 |
156 | String str3 = "str" + "ing";//常量池中的对象
157 | String str4 = str1 + str2; //在堆上创建的新的对象
158 | String str5 = "string";//常量池中的对象
159 | System.out.println(str3 == str4);//false
160 | System.out.println(str3 == str5);//true
161 | System.out.println(str4 == str5);//false
162 | ```
163 |
164 |
165 | 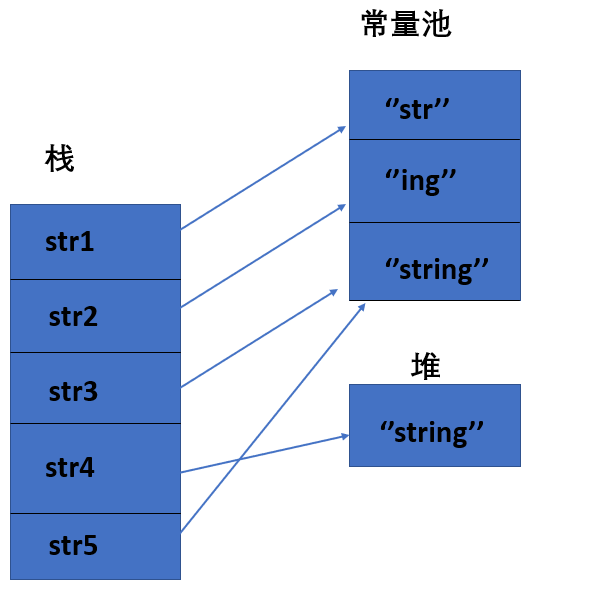
166 |
167 | 尽量避免多个字符串拼接,因为这样会重新创建对象。如果需要改变字符串的话,可以使用 StringBuilder 或者 StringBuffer。
168 |
169 |
170 |
171 | ### 问:说说Java对象创建过程
172 |
173 | **参考答案:**
174 |
175 | 
176 |
177 | Step1:类加载检查
178 |
179 | 虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
180 |
181 |
182 |
183 | Step2:分配内存
184 |
185 | 在**类加载检查**通过后,接下来虚拟机将为新生对象**分配内存**。对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。**分配方式**有 **“指针碰撞”**和 **“空闲列表”**两种,**选择那种分配方式由 Java 堆是否规整决定,而 Java 堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定**。
186 |
187 | **内存分配的两种方式:(补充内容,需要掌握)**
188 |
189 | 选择以上两种方式中的哪一种,取决于 Java 堆内存是否规整。而 Java 堆内存是否规整,取决于 GC 收集器的算法是"标记-清除",还是"标记-整理"(也称作"标记-压缩"),值得注意的是,复制算法内存也是规整的
190 |
191 | 
192 |
193 | **内存分配并发问题**
194 |
195 | 在创建对象的时候有一个很重要的问题,就是线程安全,因为在实际开发过程中,创建对象是很频繁的事情,作为虚拟机来说,必须要保证线程是安全的,通常来讲,虚拟机采用两种方式来保证线程安全:
196 |
197 | - **CAS+失败重试:**CAS 是乐观锁的一种实现方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。**虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。**
198 | - **TLAB:**为每一个线程预先在 Eden 区分配一块儿内存,JVM 在给线程中的对象分配内存时,首先在 TLAB 分配,当对象大于 TLAB 中的剩余内存或 TLAB 的内存已用尽时,再采用上述的 CAS 进行内存分配
199 |
200 | ####
201 |
202 | Step3:初始化零值
203 |
204 | 内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
205 |
206 | ####
207 |
208 | Step4:设置对象头
209 |
210 | 初始化零值完成之后,**虚拟机要对对象进行必要的设置**,例如这个对象是那个类的实例、如何才能找到类的元数据信息、对象的哈希吗、对象的 GC 分代年龄等信息。 **这些信息存放在对象头中。**另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
211 |
212 |
213 |
214 | Step5:执行 init 方法
215 |
216 | 在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,``方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行 ``方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
217 |
218 |
219 |
220 | ### 问:Java对象结构
221 |
222 | **参考答案:**
223 |
224 | Java对象由三个部分组成:对象头、实例数据、对齐填充。
225 |
226 | 对象头由两部分组成,第一部分存储对象自身的运行时数据:哈希码、GC分代年龄、锁标识状态、线程持有的锁、偏向线程ID(一般占32/64 bit)。第二部分是指针类型,指向对象的类元数据类型(即对象代表哪个类)。如果是数组对象,则对象头中还有一部分用来记录数组长度。
227 |
228 | 实例数据用来存储对象真正的有效信息(包括父类继承下来的和自己定义的)
229 |
230 | 对齐填充:JVM要求对象起始地址必须是8字节的整数倍(8字节对齐)
231 |
232 | ###
233 |
234 | ### 问:Java对象的定位方式
235 |
236 | **参考答案:**
237 |
238 | **句柄**和**直接指针**两种:
239 |
240 | 1. **句柄:**如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
241 | 2. **直接指针:**如果使用直接指针访问,那么 Java 堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,而 reference 中存储的直接就是对象的地址。
242 |
243 | 
244 |
245 | 这两种对象访问方式各有优势。使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。
246 |
247 |
248 |
249 | ### 问:**JDK8中MetaSpace代表什么?**
250 |
251 | **参考答案:**
252 |
253 | MetaqSpace是JDK8才诞生的名词,它是一种新的内存空间,中文译为:元空间;JDK8 HotSpot中移除了永久代(PermGen Space),使用MetaSpace来代替,MetaSpace是使用本地内存来存储类元数据信息。内存容量取决于操作系统虚拟内存大小,通过参数MaxMetaspaceSize来限制MetaSpace的大小。
254 |
--------------------------------------------------------------------------------
/Java横向技术/memcached面试题.md:
--------------------------------------------------------------------------------
1 | # memcached面试题
2 | ### **问:适用memcached的业务场景?**
3 |
4 | **参考答案:**
5 |
6 | 1)如果网站包含了访问量很大的动态网页,因而数据库的负载将会很高。由于大部分数据库请求都是读操作,那么memcached可以显著地减小数据库负载。
7 |
8 | 2)如果数据库服务器的负载比较低但CPU使用率很高,这时可以缓存计算好的结果( computed objects )和渲染后的网页模板(enderred templates)。
9 |
10 | 3)利用memcached可以缓存**session数据**、临时数据以减少对他们的数据库写操作。
11 |
12 | 4)缓存一些很小但是被频繁访问的文件。
13 |
14 | 5)缓存Web 'services'或RSS feeds的结果.。
15 |
16 |
17 |
18 | ### 问:不适用memcached的业务场景?
19 |
20 | **参考答案:**
21 |
22 | 1)缓存对象的大小大于1MB
23 |
24 | Memcached本身就不是为了处理庞大的多媒体(large media)和巨大的二进制块(streaming huge blobs)而设计的。
25 |
26 | 2)key的长度大于250字符
27 |
28 | 3)虚拟主机不让运行memcached服务
29 |
30 | 如果应用本身托管在低端的虚拟私有服务器上,像vmware, xen这类虚拟化技术并不适合运行memcached。Memcached需要接管和控制大块的内存,如果memcached管理的内存被OS或 hypervisor交换出去,memcached的性能将大打折扣。
31 |
32 | 4)应用运行在不安全的环境中
33 |
34 | Memcached为提供任何安全策略,仅仅通过telnet就可以访问到memcached。如果应用运行在共享的系统上,需要着重考虑安全问题。
35 |
36 | 5)业务本身需要的是持久化数据或者说需要的应该是database
37 |
38 |
39 |
40 | ### **问:能够遍历memcached中所有的item吗?**
41 |
42 | **参考答案:**
43 |
44 | 不能,这个操作的速度相对缓慢且阻塞其他的操作(这里的缓慢时相比memcached其他的命令)。memcached所有非调试(non-debug)命令,例如add, set, get, fulsh等无论memcached中存储了多少数据,它们的执行都只消耗常量时间。任何遍历所有item的命令执行所消耗的时间,将随着memcached中数据量的增加而增加。当其他命令因为等待(遍历所有item的命令执行完毕)而不能得到执行,因而阻塞将发生。
45 |
46 | ###
47 |
48 | ### **问:memcached和MySQL的query cache相比,有什么优缺点?**
49 |
50 | **参考答案:**
51 |
52 | *缺点:*
53 |
54 | 1)相比MySQL的query cache,把memcached引入应用中需要不少的工作量。MySQL的query cache,可以自动地缓存SQL查询的结果,被缓存的SQL查询可以被反复、快速的执行。
55 |
56 | *优点:*
57 |
58 | 1)当修改表时,MySQL的query cache会立刻被刷新(flush)。当写操作很频繁时,MySQL的query cache会经常让所有缓存数据都失效。
59 |
60 | 2)在多核CPU上,MySQL的query cache会遇到扩展问题(scalability issues)。在多核CPU上,query cache会增加一个全局锁(global lock), 由于需要刷新更多的缓存数据,速度会变得更慢。
61 |
62 | 3)在MySQL的query cache中,是不能存储任意的数据的(只能是SQL查询结果)。利用memcached,我们可以搭建出各种高效的缓存。比如,可以执行多个独立的查询,构建出一个用户对象(user object),然后将用户对象缓存到memcached中。而query cache是SQL语句级别的,不可能做到这一点。在小的网站中,query cache会有所帮助,但随着网站规模的增加,query cache的弊将大于利。
63 |
64 | 4)query cache能够利用的内存容量受到MySQL服务器空闲内存空间的限制。给数据库服务器增加更多的内存来缓存数据,固然是很好的。但是,有了memcached,只要您有空闲的内存,都可以用来增加memcached集群的规模,然后您就可以缓存更多的数据。
65 |
66 | ###
67 |
68 | ### **问:memcached和服务器的local cache(比如PHP的APC、mmap文件等)相比,有什么优缺点?**
69 |
70 | **参考答案:**
71 |
72 | 1)首先,local cache面临着严重的内存限制,能够利用的内存容量受到(单台)服务器空闲内存空间的限制。
73 |
74 | 2)local cache有一点比memcached和query cache都要好,那就是它不但可以存储任意的数据,而且没有网络存取的延迟。因此,local cache的数据查询更快。考虑把highly common的数据放在local cache中吧。如果每个页面都需要加载一些数量较少的数据,可以考虑把它们放在local cached。
75 |
76 | 3)local cache缺少集体失效(group invalidation)的特性。在memcached集群中,删除或更新一个key会让所有的观察者觉察到。但是在local cache中, 我们只能通知所有的服务器刷新cache(很慢,不具扩展性)或者仅仅依赖缓存超时失效机制。
77 |
78 | ###
79 |
80 | ### **问:memcached如何处理容错的?**
81 |
82 | **参考答案:**
83 |
84 | 在节点失效的情况下,集群没有必要做任何容错处理。如果发生了节点失效,应对的措施完全取决于用户。节点失效时,下面列出几种方案供您选择:
85 |
86 | 1)忽略它! 在失效节点被恢复或替换之前,还有很多其他节点可以应对节点失效带来的影响。
87 |
88 | 2)把失效的节点从节点列表中移除。做这个操作千万要小心!在默认情况下(余数式哈希算法),客户端添加或移除节点,会导致所有的缓存数据不可用!因为哈希参照的节点列表变化了,大部分key会因为哈希值的改变而被映射到(与原来)不同的节点上。
89 |
90 | 3)启动热备节点,接管失效节点所占用的IP。这样可以防止哈希紊乱(hashing chaos)。
91 |
92 | 4)如果希望添加和移除节点,而不影响原先的哈希结果,可以使用一致性哈希算法(consistent hashing)。
93 |
94 | 5)两次哈希(reshing)。当客户端存取数据时,如果发现一个节点down了,就再做一次哈希(哈希算法与前一次不同),重新选择另一个节点(需要注意的时,客户端并没有把down的节点从节点列表中移除,下次还是有可能先哈希到它)。如果某个节点时好时坏,两次哈希的方法就有风险了,好的节点和坏的节点上都可能存在脏数据(stale data)。
95 |
96 |
97 |
98 | ### **问:memcached是如何做身份验证的?**
99 |
100 | **参考答案:**
101 |
102 | 没有身份认证机制!memcached是运行在应用下层的软件(身份验证应该是应用上层的职责)。memcached的客户端和服务器端之所以是轻量级的,部分原因就是完全没有实现身份验证机制。这样,memcached可以很快地创建新连接,服务器端也无需任何配置。如果您希望限制访问,您可以使用防火墙,或者让memcached监听unix domain socket。
103 |
104 |
105 |
106 | ### **问:memcached能接受的key的最大长度是多少?**
107 |
108 | **参考答案:**
109 |
110 | memcached能接受的key的最大长度是250个字符。需要注意的是,250是memcached服务器端内部的限制。如果使用的Memcached客户端支持"key的前缀"或类似特性,那么key(前缀+原始key)的最大长度是可以超过250个字符的。推荐使用较短的key,这样可以节省内存和带宽。
111 |
112 |
113 |
114 | ### **问:memcached对item的过期时间有什么限制?**
115 |
116 | **参考答案:**
117 |
118 | item对象的过期时间最长可以达到30天。memcached把传入的过期时间(时间段)解释成时间点后,一旦到了这个时间点,memcached就把item置为失效状态。
119 |
120 | ###
121 |
122 | ### **问:memcached最大能存储多大的单个item?**
123 |
124 | **参考答案:**
125 |
126 | memcached最大能存储1MB的单个item。如果需要被缓存的数据大于1MB,可以考虑在客户端压缩或拆分到多个key中。
127 |
128 | ###
129 |
130 | ### **问:为什么单个item的大小被限制在1M byte之内?**
131 |
132 | **参考答案:**
133 |
134 | 简单的回答:因为内存分配器的算法就是这样的。
135 |
136 | 详细的回答:
137 |
138 | 1)Memcached的内存存储引擎,使用slabs来管理内存。内存被分成大小不等的slabs chunks(先分成大小相等的slabs,然后每个slab被分成大小相等chunks,不同slab的chunk大小是不相等的)。chunk的大小依次从一个最小数开始,按某个因子增长,直到达到最大的可能值。如果最小值为400B,最大值是1MB,因子是1.20,各个slab的chunk的大小依次是:slab1 - 400B;slab2 - 480B;slab3 - 576B ...slab中chunk越大,它和前面的slab之间的间隙就越大。因此,最大值越大,内存利用率越低。Memcached必须为每个slab预先分配内存,因此如果设置了较小的因子和较大的最大值,会需要为Memcached提供更多的内存。
139 |
140 | 2)不要尝试向memcached中存取很大的数据,例如把巨大的网页放到mencached中。因为将大数据load和unpack到内存中需要花费很长的时间,从而导致系统的性能反而不好。如果确实需要存储大于1MB的数据,可以修改slabs.c:POWER_BLOCK的值,然后重新编译memcached;或者使用低效的malloc/free。另外,可以使用数据库、MogileFS等方案代替Memcached系统。
141 |
142 | ###
143 |
144 | ### **问:memcached的内存分配器是如何工作的?为什么不适用malloc/free!?为何要使用slabs?**
145 |
146 | **参考答案:**
147 |
148 | 实际上,这是一个编译时选项。默认会使用内部的slab分配器,而且确实应该使用内建的slab分配器。最早的时候,memcached只使用malloc/free来管理内存。然而,这种方式不能与OS的内存管理以前很好地工作。反复地malloc/free造成了内存碎片,OS最终花费大量的时间去查找连续的内存块来满足malloc的请求,而不是运行memcached进程。slab分配器就是为了解决这个问题而生的。内存被分配并划分成chunks,一直被重复使用。因为内存被划分成大小不等的slabs,如果item的大小与被选择存放它的slab不是很合适的话,就会浪费一些内存。
149 |
150 | ### **问:memcached是原子的吗?**
151 |
152 | **参考答案:**
153 |
154 | 所有的被发送到memcached的单个命令是完全原子的。如果您针对同一份数据同时发送了一个set命令和一个get命令,它们不会影响对方。它们将被串行化、先后执行。即使在多线程模式,所有的命令都是原子的。然是,命令序列不是原子的。如果首先通过get命令获取了一个item,修改了它,然后再把它set回memcached,系统不保证这个item没有被其他进程(process,未必是操作系统中的进程)操作过。
155 |
156 | memcached 1.2.5以及更高版本,提供了gets和cas命令,它们可以解决上面的问题。如果使用gets命令查询某个key的item,memcached会返回该item当前值的唯一标识。如果客户端程序覆写了这个item并想把它写回到memcached中,可以通过cas命令把那个唯一标识一起发送给memcached。如果该item存放在memcached中的唯一标识与您提供的一致,写操作将会成功。如果另一个进程在这期间也修改了这个item,那么该item存放在memcached中的唯一标识将会改变,写操作就会失败。
157 |
158 |
159 |
160 | ### **问:什么时候失效的数据项会从缓存中删除?**
161 |
162 | **参考答案:**
163 |
164 | memcached 使用懒失效,当客户端请求数据项时, memcached 在返回数据前会检查失效时间来确定数据项是否已经失效。同样地,当添加一个新的数据项时,如果缓存已经满了, memcached 就会先替换失效的数据项,然后才是缓存中最少使用的数据项。
165 |
166 |
167 |
168 | ### **问:在设计应用时,可以通过Memcached缓存那些内容?**
169 |
170 | **参考答案:**
171 |
172 | **1)缓存简单的查询结果:**查询缓存存储了给定查询语句对应的整个结果集,最合适缓存那些**经常被用到,但不会改变的 SQL 语句对查询到的结果集,比如载入特定的过滤内容。**记住,如果查询语句对应的结果集改变,该结果集不会展现出来。这种方法不总是有用,但它确实让工作变得比较快。
173 |
174 | **2)缓存简单的基于行的查询结果:**基于行的缓存会检查缓存数据key的列表,那些在缓存中的行可以直接被取出,不在缓存中的行将会从数据库中取出并以唯一的键为标识缓存起来,最后加入到最终的数据集中返回。随着时间的推移,大多数数据都会被缓存,这也意味着相比与数据库,查询语句会更多地从 memcached 中得到数据行。如果数据是相当静态的,我们可以设置一个较长的缓存时间。
175 |
176 | **基于行的缓存模式对下面这种搜索情况特别有用**:数据集本身很大或是数据集是从多张表中得到,而数据集取决于查询的输入参数但是查询的结果集之间的有重复部分。
177 |
178 | 比如,如果你有用户 A , B , C , D , E 的数据集。你去点击一张显示用户 A , B , E 信息的页面。首先, memcached 得到 3 个不同的键,每个对应一个用户去缓存中查找,全部未命中。然后就到数据库中用 SQL 查询得到 3 个用户的数据行,并缓存他们。现在,你又去点击另一张显示显示 C , D , E 信息的页面。当你去查找 memcached 时, C , D 的数据并没有被命中,但我们命中了 E 的数据。然后从数据库得到 C , D 的行数据,缓存在 memcached 中。至此以后,无论这些用户信息怎样地排列组合,任何关于 A , B , C , D , E 信息的页面都可以从 memcached 得到数据了。
179 |
180 | **3)缓存的不只是 SQL 数据,可以缓存最终完成的部分显示页面,以节省CPU计算时间**
181 |
182 | 例如正在制作一张显示用户信息的页面,你可能得到一段关于用户的信息(姓名,生日,家庭住址,简介),然后你可能会将 XML 格式的简介信息转化为 HTML 格式或做其他的一些工作。相比单独存储这些属性,你可能更愿意**存储经过渲染的数据块**。那时你就可以简单地取出被预处理后的 HTML 直接填充在页面中,这样节省了宝贵的 CPU 时间。
183 |
--------------------------------------------------------------------------------
/Java横向技术/MySQL进阶面试题.md:
--------------------------------------------------------------------------------
1 | # MySQL进阶面试题
2 | ### 问:简单说一说drop、delete与truncate的区别?
3 |
4 | **参考答案:**
5 |
6 | delete和truncate只删除表的数据不删除表的结构
7 |
8 | 速度:drop> truncate >delete
9 |
10 | delete语句是dml,这个操作会放到rollback segement中,事务提交之后才生效;如果有相应的trigger,执行的时候将被触发。 truncate,drop是ddl,操作立即生效,原数据不放到rollback segment中,不能回滚。操作不触发trigger。
11 |
12 |
13 |
14 | ### 问:谈谈三大范式,什么时候使用反范式设计
15 |
16 | **参考答案:**
17 |
18 | 第一范式(1NF):确保每列保持原子性即列不可分,即数据库表中的字段都是单一属性的。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。
19 |
20 | 第二范式(2NF):属性完全依赖于主键,也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
21 |
22 | 第三范式(3NF):在第二范式的基础上,属性和主键不能间接相关(减少数据冗余,这样就可以通过主外键进行表之间连接)。比如我们表比较多,需要关联时,但我们的A表只需要关联B表的一个字段,而且每次都需要关联查询你,这时我们可以采用A表放置一个冗余字段来存B表的那个字段。这个操作其实就是一个反范式的。
23 |
24 | ###
25 |
26 | ### 问:说几个mysql中你常用的函数
27 |
28 | **参考答案:**
29 |
30 | sum、count 、avg、min、max
31 |
32 |
33 |
34 | ### 问:redo log和binlog的区别是什么?
35 |
36 | **参考答案:**
37 |
38 | 1. redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
39 | 2. redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
40 | 3. redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
41 | 4. redo log用于保证crash-safe能力。innodb_flush_log_at_trx_commit =1表示每次事务的redo log 都持久化到磁盘,保证mysql异常重启之后数据不丢失。Sync_binlog=1参数设置为1,表示每次事务的binlog都持久化到磁盘,保证mysql异常重启之后binlog不丢失。
42 |
43 |
44 |
45 |
46 |
47 | ### 问:说一说mysql主从复制。
48 |
49 | **参考答案:**
50 |
51 | 在MySQL主从复制架构中,读操作可以在所有的服务器上面进行,而写操作只能在主服务器上面进行。主从复制架构虽然给读操作提供了扩展,可如果写操作也比较多的话(多台从服务器还要从主服务器上面同步数据),单主模型的复制中主服务器势必会成为性能瓶颈。
52 |
53 | 1. 基于记录的复制:主服务器上面执行的语句在从服务器上面再执行一遍,在MySQL-3.23版本以后支持。
54 | 存在的问题:时间上可能不完全同步造成偏差,执行语句的用户也可能是不同一个用户
55 | 2. 基于语句的复制:把主服务器上面改编后的内容直接复制过去,而不关心到底改变该内容是由哪条语句引发的,在MySQL-5.0版本以后引入。
56 | 存在的问题:比如一个工资表中有一万个用户,我们把每个用户的工资+1000,那么基于行的复制则要复制一万行的内容,由此造成的开销比较大,而基于语句的复制仅仅一条语句就可以了。
57 |
58 | **复制过程:**
59 |
60 | 1. 在每个事务更新数据完成之前,master在二进制日志记录这些改变。写入二进制日志完成后,master通知存储引擎提交事务。
61 | 2. Slave将master的binary log复制到其中继日志。首先slave开始一个工作线程(I/O),I/O线程在master上打开一个普通的连接,然后开始binlog dump process。binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件,I/O线程将这些事件写入中继日志。
62 | 3. Sql slave thread(sql从线程)处理该过程的最后一步,sql线程从中继日志读取事件,并重放其中的事件而更新slave数据,使其与master中的数据一致,只要该线程与I/O线程保持一致,中继日志通常会位于os缓存中,所以中继日志的开销很小。
63 |
64 |
65 |
66 | ### 问:如何开启慢日志查询?
67 |
68 | **参考答案:**
69 |
70 | 有2种方式,一是修改mysql的配置文件,二是通过set global语句来实现。slow_query_log = ON,打开日志,long_query_time = 2,设置时间,2秒就算是慢查询,然后重启mysql服务即可,进入mysql控制台,输入SET GLOBAL slow_query_log = 'ON';SET GLOBAL long_query_time = X;不需要重启服务就可以得到慢查询日志。
71 |
72 |
73 |
74 | ### 问:如何生成UUID,以及UUID的缺点?
75 |
76 | **参考答案:**
77 |
78 | ```java
79 | UUID uuid = UUID.randomUUID();
80 | System.out.println(uuid);
81 | String dxmbid = uuid.toString().replace("-", ""); System.out.println(dxmbid);
82 | System.out.println(dxmbid.length());
83 | ```
84 |
85 | - 缺点:
86 |
87 | 1. 占空间太大
88 | 2. 索引效率低
89 | 3. UUID是唯一随机的,不适合人读
90 | 4. 无法排序
91 |
92 |
93 |
94 | ### 问:mysql中varchar与char的区别以及varchar(50)中的50代表的含义?
95 |
96 | **参考答案:**
97 |
98 | (1) varchar与char的区别
99 |
100 | 变长和固定长度
101 |
102 | (2)varchar(50)中50的涵义
103 |
104 | 字符最大长度50,所代表的字节数与字符集有关,比如是utf8占3个字节,那么varchar(50)字段在表中最大取到150个字节。
105 |
106 | varchar(50)和(200)存储hello所占空间一样,但后者在排序时会消耗更多内存,因为order by col采用fixed_length计算col长度(memory引擎也一样)。
107 |
108 | (3) int(20)中20的涵义
109 |
110 | 是指显示字符的长度不影响内部存储,只是影响带 zerofill 定义的 int 时,前面补多少个 0,易于报表展示
111 |
112 | (4) varchar(20)和int(20)中的20含义一样吗?
113 |
114 | int(M) M表示的不是数据的最大长度,只是数据宽度,并不影响存储多少位长度的数据;varchar(M) M表示的是varchar类型数据在数据库中存储的最大长度,超过则不存;
115 |
116 |
117 |
118 |
119 |
120 | ### 问:FLOAT和DOUBLE的区别是什么?
121 |
122 | **参考答案:**
123 |
124 | - 浮点数以8位精度存储在FLOAT中,有四个字节。
125 | - 浮点数以18位精度存储在DOUBLE中,有八个字节。
126 |
127 |
128 |
129 | ### 问:CHAR_LENGTH和LENGTH的区别是什么?
130 |
131 | **参考答案:**
132 |
133 | CHAR_LENGTH是字符数,而LENGTH是字节数。Latin字符的这两个数据是相同的,但是对于Unicode和其他编码,它们是不同的。
134 |
135 |
136 |
137 | ### 问:CHAR和VARCHAR的区别是什么?
138 |
139 | **参考答案:**
140 |
141 | CHAR和VARCHAR类型在存储和检索方面有所不同
142 |
143 | - CHAR列长度固定为创建表时声明的长度,长度值范围是1到255;
144 | - 当CHAR值被存储时,它们被用空格填充到特定长度,检索CHAR值时需删除尾随空格。
145 |
146 |
147 |
148 | ### 问:列的字符串类型可以是什么??
149 |
150 | **参考答案:**
151 |
152 | SET、BLOB、ENUM、CHAR、TEXT、VARCHAR
153 |
154 |
155 |
156 | ### 问: myisamchk是用来做什么的?
157 |
158 | **参考答案:**
159 |
160 | 它用来压缩MyISAM表,这减少了磁盘或内存使用。
161 |
162 |
163 |
164 | ### 问: 怎样才能找出最后一次插入时分配了哪个自动增量?
165 |
166 | **参考答案:**
167 |
168 | LAST_INSERT_ID将返回由Auto_increment分配的最后一个值,并且不需要指定表名称。
169 |
170 | ###
171 |
172 | ### 问: 你怎么看到为表格定义的所有索引?
173 |
174 | **参考答案:**
175 |
176 | 索引是通过以下方式为表格定义的:SHOW INDEX FROM;
177 |
178 | ###
179 |
180 | ### 问: LIKE声明中的%和_是什么意思?
181 |
182 | **参考答案:**
183 |
184 | %对应于0个或更多字符,_只是LIKE语句中的一个字符。
185 |
186 |
187 |
188 | ### 问:事务是如何通过日志来实现的,说得越深入越好
189 |
190 | **参考答案:**
191 |
192 | 基本流程如下:
193 |
194 | 因为事务在修改页时,要先记 undo,在记 undo之前要记 undo 的 redo, 然后修改数据页,再记数据页修改的 redo。redo(里面包括 undo 的修改) 一定要比数据页先持久化到磁盘。当事务需要回滚时,因为有 undo,可以把数据页回滚到前镜像的状态;崩溃恢复时,如果 redo log 中事务没有对应的 commit 记录,那么需要用 undo把该事务的修改回滚到事务开始之前。如果有 commit 记录,就用 redo 前滚到该事务完成时并提交掉。
195 |
196 |
197 |
198 | ### 问:BLOB和TEXT有什么区别?
199 |
200 | **参考答案:**
201 |
202 | BLOB是一个二进制对象,可以容纳可变数量的数据。有四种类型:TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB,它们只是在所能容纳价值的最大长度上有所不同。
203 |
204 | TEXT是一个不区分大小写的BLOB。有四种类型:TINYTEXT、TEXT、MEDIUMTEXT和
205 |
206 | LONGTEXT。它们对应于四种BLOB类型,并具有相同的最大长度和存储要求。
207 |
208 | BLOB和TEXT类型之间的唯一区别在于对BLOB值进行排序和比较时区分大小写,对TEXT值不区分大小写。
209 |
210 |
211 |
212 | ### 问:MySQL数据库cpu飙升到500%的话他怎么处理?
213 |
214 | **参考答案:**
215 |
216 | 当 cpu 飙升到 500%时,先用操作系统命令 top 命令观察是不是 mysqld 占用导致的,如果不是,找出占用高的进程,并进行相关处理。如果是 mysqld 造成的, show processlist,看看里面跑的 session 情况,是不是有消耗资源的 sql 在运行。找出消耗高的 sql,看看执行计划是否准确, index 是否缺失,或者实在是数据量太大造成。一般来说,肯定要 kill 掉这些线程(同时观察 cpu 使用率是否下降),等进行相应的调整(比如说加索引、改 sql、改内存参数)之后,再重新跑这些 SQL。也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等
217 |
218 | ###
219 |
220 | ### 问:SELECT * 和 SELECT 全部字段两种写法有何优缺点?
221 |
222 | **参考答案:**
223 |
224 | 1. 前者要解析数据字典,后者不需要;
225 | 2. 结果输出顺序,前者与建表列顺序相同,后者按指定字段顺序;
226 | 3. 表字段改名,前者不需要修改,后者需要改;
227 | 4. 后者可以建立索引进行优化,前者无法优化;
228 | 5. 后者的可读性比前者要高。
229 |
230 | ###
231 |
232 | ### 问:**HAVNG 子句 和 WHERE 的异同点?**
233 |
234 | **参考答案:**
235 |
236 | 1. 语法上:where 用表中列名,having 用 select 结果别名;
237 | 2. 影响结果范围:where 从表读出数据的行数,having 返回客户端的行数
238 | 3. 索引:where 可以使用索引,having 不能使用索引,只能在临时结果集操作
239 | 4. where 后面不能使用聚集函数,having 是专门使用聚集函数的。
240 |
241 |
242 |
243 | ### 问:Explain各个字段的含义
244 |
245 | **参考答案:**
246 |
247 | **(1)、explain出来的各种item的意义**
248 |
249 | id:每个被独立执行的操作的标志,表示对象被操作的顺序。一般来说, id 值大,先被执行;如果 id 值相同,则顺序从上到下。
250 |
251 | select_type:查询中每个 select 子句的类型。
252 |
253 | table:名字,被操作的对象名称,通常的表名(或者别名),但是也有其他格式。
254 |
255 | partitions:匹配的分区信息。
256 |
257 | type:join 类型。
258 |
259 | possible_keys:列出可能会用到的索引。
260 |
261 | key:实际用到的索引。
262 |
263 | key_len:用到的索引键的平均长度,单位为字节。
264 |
265 | ref:表示本行被操作的对象的参照对象,可能是一个常量用 const 表示,也可能是其他表的
266 |
267 | key:指向的对象,比如说驱动表的连接列。
268 |
269 | rows:估计每次需要扫描的行数,数值越大越不好,说明没有用好索引
270 |
271 | filtered:rows*filtered/100 表示该步骤最后得到的行数(估计值)。
272 |
273 | extra:重要的补充信息。
274 |
275 | **(2)、explain 中的索引问题**
276 |
277 | Explain 结果中,一般来说,要看到尽量用 index(type 为 const、 ref 等, key 列有值),避免使用全表扫描(type 显式为 ALL)。比如说有 where 条件且选择性不错的列,需要建立索引。
278 |
279 | 被驱动表的连接列,也需要建立索引。被驱动表的连接列也可能会跟 where 条件列一起建立联合索引。当有排序或者 group by 的需求时,也可以考虑建立索引来达到直接排序和汇总的需求
280 |
--------------------------------------------------------------------------------
/Java基础技术/Java并发进阶面试题.md:
--------------------------------------------------------------------------------
1 | ### 问:synchronized关键字的作用?
2 |
3 | **参考答案:**
4 |
5 | synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。
6 |
7 | 另外,在 Java 早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的 synchronized 效率低的原因。庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
8 |
9 |
10 |
11 | ### 问:synchronized关键字如何使用?
12 |
13 | **参考答案:**
14 |
15 | **1、修饰实例方法:** 作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁
16 |
17 | **2、修饰静态方法:** :也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份)。所以如果一个线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,**因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁**。
18 |
19 | **3、修饰代码块:** 指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
20 |
21 | synchronized 关键字加到 static 静态方法和 synchronized(class)代码块上都是是给 Class 类上锁。synchronized 关键字加到静态方法上是给对象实例上锁。尽量不要使用 synchronized(String a) 因为JVM中,字符串常量池具有缓存功能!
22 |
23 | ###
24 |
25 | ### 问:synchronized 关键字的底层原理是什么?
26 |
27 | **参考答案:**
28 |
29 | synchronized 关键字底层原理属于 JVM 层面。
30 |
31 | **1、synchronized 同步语句块的情况。** synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。 当执行 monitorenter 指令时,线程试图获取锁也就是获取 monitor(monitor对象存在于每个Java对象的对象头中,synchronized 锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因) 的持有权。当计数器为0则可以成功获取,获取后将锁计数器设为1也就是加1。相应的在执行 monitorexit 指令后,将锁计数器设为0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
32 |
33 | **2、synchronized 修饰方法的的情况。** synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法,JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
34 |
35 |
36 |
37 | ### 问:说说 synchronized 关键字和 volatile 关键字的区别
38 |
39 | **参考答案:**
40 |
41 | 1、volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块。synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,实际开发中使用 synchronized 关键字的场景还是更多一些;
42 |
43 | 2、多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞;
44 |
45 | 3、volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证; 4、volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性。
46 |
47 |
48 |
49 | ### 问:通过N个线程顺序循环打印从0至100,如给定N=3则输出:
50 |
51 |
52 |
53 | ```
54 | thread0: 0
55 | thread1: 1
56 | thread2: 2
57 | thread0: 3
58 | thread1: 4
59 | ```
60 |
61 |
62 |
63 |
64 |
65 | **参考答案:**
66 |
67 |
68 |
69 | ```
70 | static int result = 0;
71 |
72 | public static void main(String[] args) throws InterruptedException {
73 | int N = 3;
74 | Thread[] threads = new Thread[N];
75 | final Semaphore[] syncObjects = new Semaphore[N];
76 | for (int i = 0; i < N; i++) {
77 | syncObjects[i] = new Semaphore(1);
78 | if (i != N-1){
79 | syncObjects[i].acquire();
80 | }
81 | }
82 | for (int i = 0; i < N; i++) {
83 | final Semaphore lastSemphore = i == 0 ? syncObjects[N - 1] : syncObjects[i - 1];
84 | final Semaphore curSemphore = syncObjects[i];
85 | final int index = i;
86 | threads[i] = new Thread(new Runnable() {
87 |
88 | public void run() {
89 | try {
90 | while (true) {
91 | lastSemphore.acquire();
92 | System.out.println("thread" + index + ": " + result++);
93 | if (result > 100){
94 | System.exit(0);
95 | }
96 | curSemphore.release();
97 | }
98 | } catch (Exception e) {
99 | e.printStackTrace();
100 | }
101 |
102 | }
103 | });
104 | threads[i].start();
105 | }
106 | }
107 | ```
108 |
109 |
110 |
111 | ### 问:介绍一下AtomicInteger 类的原理
112 |
113 | **参考答案:**
114 |
115 | AtomicInteger 类的部分源码:
116 |
117 |
118 |
119 | ```
120 | // setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
121 | private static final Unsafe unsafe = Unsafe.getUnsafe();
122 | private static final long valueOffset;
123 | static {
124 | try {
125 | valueOffset = unsafe.objectFieldOffset
126 | (AtomicInteger.class.getDeclaredField("value"));
127 | } catch (Exception ex) { throw new Error(ex); }
128 | }
129 | private volatile int value;
130 | ```
131 |
132 | AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
133 |
134 | CAS的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个volatile变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
135 |
136 | 备注:JUC 包中的四种原子类。
137 |
138 | **1、基本类型,** 使用原子的方式更新基本类型
139 |
140 | (1)、AtomicInteger:整形原子类;
141 |
142 | (2)、AtomicLong:长整型原子类;
143 |
144 | (3)、AtomicBoolean:布尔型原子类
145 |
146 | **2、数组类型,** 使用原子的方式更新数组里的某个元素
147 |
148 | (1)、AtomicIntegerArray:整形数组原子类
149 |
150 | (2)、AtomicLongArray:长整形数组原子类
151 |
152 | (3)、AtomicReferenceArray:引用类型数组原子类
153 |
154 | **3、引用类型**
155 |
156 | (1)、AtomicReference:引用类型原子类
157 |
158 | (2)、AtomicStampedReference:原子更新引用类型里的字段原子类
159 |
160 | (3)、AtomicMarkableReference :原子更新带有标记位的引用类型
161 |
162 | **4、对象的属性修改类型**
163 |
164 | (1)、AtomicIntegerFieldUpdater:原子更新整形字段的更新器
165 |
166 | (2)、AtomicLongFieldUpdater:原子更新长整形字段的更新器
167 |
168 | (3)、AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
169 |
170 |
171 |
172 | ### 问:什么是线程调度器(Thread Scheduler)和时间分片(Time Slicing)?
173 |
174 | **参考答案:**
175 |
176 | 线程调度器是一个操作系统服务,它负责为Runnable状态的线程分配CPU时间。一旦创建一个线程并启动它,它的执行便依赖于线程调度器的实现。
177 |
178 | 时间分片是指将可用的CPU时间分配给可用的Runnable线程的过程。分配CPU时间可以基于线程优先级或者线程等待的时间。
179 |
180 | 线程调度并不受到Java虚拟机控制,所以由应用程序来控制它是更好的选择。
181 |
182 |
183 |
184 | ### 问:什么是竞态条件?你怎样发现和解决竞争?
185 |
186 | **参考答案:**
187 |
188 | 当两个线程竞争同一资源时,如果对资源的访问顺序敏感,就称存在竞态条件。在临界区中使用适当的同步就可以避免竞态条件,实现方法有两种,一种是用synchronized,一种是用Lock显式锁实现。
189 |
190 |
191 |
192 | ### 问:你对线程优先级的理解是什么?
193 |
194 | **参考答案:**
195 |
196 | 每一个线程都是有优先级的,一般来说,高优先级的线程在运行时会具有优先权,但这依赖于线程调度的实现,这个实现是和操作系统相关的(OSdependent)。
197 |
198 | 可以定义线程的优先级,但是这并不能保证高优先级的线程会在低优先级的线程前执行。线程优先级是一个int变量(从1-10),1代表最低优先级,10代表最高优先级。
199 |
200 |
201 |
202 | ### 问:在多线程中,什么是上下文切换(context-switching)?
203 |
204 | **参考答案:**
205 |
206 | 单核CPU也支持多线程执行代码,CPU通过给每个线程分配CPU时间片来实现这个机制。时间片是CPU分配给各个线程的时间,因为时间片非常短,所以CPU通过不停地切换线程执行,让我们感觉多个线程时同时执行的,时间片一般是几十毫秒(ms)。
207 |
208 | 操作系统中,CPU时间分片切换到另一个就绪的线程,则需要保存当前线程的运行的位置,同时需要加载需要恢复线程的环境信息。
209 |
210 |
211 |
212 | ### 问:用户线程和守护线程有什么区别?
213 |
214 | **参考答案:**
215 |
216 | 守护线程都是为JVM中所有非守护线程的运行提供便利服务: 只要当前JVM实例中尚存在任何一个非守护线程没有结束,守护线程就全部工作;只有当最后一个非守护线程结束时,守护线程随着JVM一同结束工作。
217 |
218 | 两者几乎没有区别,唯一的不同之处就在于虚拟机的离开:如果用户线程已经全部退出运行了,只剩下守护线程存在了,虚拟机也就退出了。
219 |
220 | 因为没有了被守护者,守护线程也就没有工作可做了,也就没有继续运行程序的必要了。
221 |
222 | ### 问:如何创建守护线程?以及在什么场合来使用它?
223 |
224 | **参考答案:**
225 |
226 | 任何线程都可以设置为守护线程和用户线程,通过方法Thread.setDaemon(bool on);true则把该线程设置为守护线程,反之则为用户线程。Thread.setDaemon()必须在Thread.start()之前调用,否则运行时会抛出异常。
227 |
228 | 守护线程相当于后台管理者 比如 : 进行内存回收,垃圾清理等工作
229 |
230 |
231 |
232 | ### 问:线程中断是否能直接调用stop,为什么?
233 |
234 | **参考答案:**
235 |
236 | Java提供的终止方法只有一个stop,但是不建议使用此方法,因为它有以下三个问题:
237 |
238 | 1、stop方法是过时的 从Java编码规则来说,已经过时的方式不建议采用;
239 |
240 | 2、stop方法会导致代码逻辑不完整,stop方法是一种"恶意"的中断,一旦执行stop方法,即终止当前正在运行的线程,不管线程逻辑是否完整,这是非常危险的.
241 |
242 | 3、stop方法会破坏原子逻辑。多线程为了解决共享资源抢占的问题,使用了锁概念,避免资源不同步,但是正因此原因,stop方法却会带来更大的麻烦:它会丢弃所有的锁,导致原子逻辑受损。
243 |
--------------------------------------------------------------------------------
/Java横向技术/ibatisMybatis框架面试题.md:
--------------------------------------------------------------------------------
1 | # ibatis/MyBatis面试题
2 |
3 | ## 问:介绍一下Mybatis和主要的工作过程?
4 |
5 | **参考答案:**
6 |
7 | 每一个Mybatis的应用程序都以一个SqlSessionFactory对象的实例为核心。首先用字节流通过Resource将配置文件读入,然后通过SqlSessionFactoryBuilder().build方法创建SqlSessionFactory,然后再通过SqlSessionFactory.openSession()方法创建一个SqlSession为每一个数据库事务服务。
8 |
9 | 经历了Mybatis初始化 –>创建SqlSession –>运行SQL语句,返回结果三个过程。
10 |
11 | ##
12 |
13 | ## 问:MyBatis编程步骤是什么样的?
14 |
15 | **参考答案:**
16 |
17 | 1、创建SqlSessionFactory
18 |
19 | 2、通过SqlSessionFactory创建SqlSession
20 |
21 | 3、通过sqlsession执行数据库操作
22 |
23 | 4、调用session.commit()提交事务
24 |
25 | 5、调用session.close()关闭会话
26 |
27 |
28 |
29 | ## 问:什么是Mybatis的动态SQL?都有哪些标签?能简述一下动态sql的执行原理不?
30 |
31 | **参考答案:**
32 |
33 | Mybatis 动态 SQL ,可以让我们在 XML 映射文件内,以 XML 标签的形式编写动态 SQL ,完成逻辑判断和动态拼接 SQL 的功能。
34 |
35 | Mybatis 提供了 9 种动态 SQL 标签:if、choose 、when 、otherwise 、trim 、where 、set 、foreach、bind
36 |
37 | 执行原理为,使用OGNL从sql参数对象中计算表达式的值,**根据表达式的值动态拼接sql,以此来完成动态sql的功能**。
38 |
39 | ##
40 |
41 | ## 问:MyBatis 的一级缓存和二级缓存的概念和实现原理?
42 |
43 | **参考答案:**
44 |
45 | MyBatis的缓存分为一级缓存和二级缓存,一级缓存放在session里面,默认就有;二级缓存放在它的命名空间里,默认是不打开的,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置。
46 |
47 | 具体来说:
48 |
49 | 1、一级缓存是指SQLSession,一级缓存的作用域是SQlSession, Mabits默认开启一级缓存。 在同一个SqlSession中,执行相同的SQL查询时;第一次会去查询数据库,并写在缓存中,第二次会直接从缓存中取。 当执行SQL时候两次查询中间发生了增删改的操作,则SQLSession的缓存会被清空。 每次查询会先去缓存中找,如果找不到,再去数据库查询,然后把结果写到缓存中。 Mybatis的内部缓存使用一个HashMap,key为hashcode+statementId+sql语句。Value为查询出来的结果集映射成的java对象。 SqlSession执行insert、update、delete等操作commit后会清空该SQLSession缓存。**
50 | **
51 |
52 | 2、二级缓存是mapper级别的,Mybatis默认是没有开启二级缓存的(**可通过配置文件****cacheEnabled=true开启)**。 第一次调用mapper下的SQL去查询用户的信息,查询到的信息会存放代该mapper对应的二级缓存区域。 第二次调用namespace下的mapper映射文件中,相同的sql去查询用户信息,会去对应的二级缓存内取结果。
53 |
54 | 二级缓存缺点:二级缓存是建立在同一个namespace下的,如果对表的操作查询可能有多个namespace,那么得到的数据就是错误的。
55 |
56 | 举个简单的例子:
57 |
58 | 订单和订单详情,orderMapper、orderDetailMapper。在查询订单详情时我们需要把订单信息也查询出来,那么这个订单详情的信息被二级缓存在orderDetailMapper的namespace中,这个时候有人要修改订单的基本信息,那就是在orderMapper的namespace下修改,他是不会影响到orderDetailMapper的缓存的,那么你再次查找订单详情时,拿到的是缓存的数据,这个数据其实已经是过时的。
59 |
60 | 当开启缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -> 数据库。
61 |
62 |
63 |
64 | ## 问:Mybatis 是如何进行分页的?分页插件的原理是什么?
65 |
66 | **参考答案:**
67 |
68 | Mybatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内存分页,而非数据库分页。所以,实际场景下,不适合直接使用 MyBatis 原有的 RowBounds 对象进行分页。而是使用如下两种方案:
69 |
70 | 1、在 SQL 内直接书写带有数据库分页的参数来完成数据库分页功能;
71 |
72 | 2、使用分页插件来完成数据库分页。
73 |
74 | 这两者都是基于数据库分页,差别在于前者是工程师手动编写分页条件,后者是插件自动添加分页条件。分页插件的基本原理是使用 Mybatis 提供的插件接口,实现自定义分页插件。在插件的拦截方法内,拦截待执行的 SQL ,然后重写 SQL ,根据dialect 方言,添加对应的物理分页语句和物理分页参数。比如说`select * from student,拦截sql后重写为:select t.* from (select * from student)t limit 0,10`
75 |
76 | ##
77 |
78 | ## 问: 通常一个Xml映射文件,都会写一个Mapper接口与之对应,请问,这个Mapper接口的工作原理是什么?Mapper接口里的方法,参数不同时,方法能重载吗?
79 |
80 | **参考答案:**
81 |
82 | Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。
83 |
84 | Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement,Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
85 |
86 | Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
87 |
88 | ##
89 |
90 | ## 问:Mybatis中的Dao接口和XML文件里的SQL是如何建立关系的?
91 |
92 | **参考答案:**
93 |
94 | 1、解析XML: 初始化SqlSessionFactoryBean会将mapperLocations路径下所有的XML文件进行解析:
95 |
96 | ①、创建SqlSource: Mybatis会把每个SQL标签封装成SqlSource对象,可以为动态SQL和静态SQL
97 |
98 | ②、创建MappedStatement: XML文件中的每一个SQL标签就对应一个MappedStatement对象 ,并由 Configuration解析XML
99 |
100 | 2、Dao接口代理: Spring中的FactoryBean 和 JDK动态代理返回了可以注入的一个Dao接口的代理对象
101 |
102 | 3、执行: 通过statement全限定类型+方法名拿到MappedStatement 对象,然后通过执行器Executor去执行具体SQL并返回。
103 |
104 |
105 |
106 |
107 |
108 | ## 问:当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
109 |
110 | **参考答案:**
111 |
112 | 1、 通过在查询的sql语句中**定义字段名的别名,让字段名的别名和实体类的属性名一致**
113 |
114 | ```xml
115 |
118 | ```
119 |
120 | 2、 通过resultMap来映射字段名和实体类属性名的一一对应的关系
121 |
122 | ```xml
123 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 | ```
134 |
135 |
136 |
137 | ## 问:JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
138 |
139 | **参考答案:**
140 |
141 | 数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。 解决:在SqlMapConfig.xml中配置数据链接池,使用连接池管理数据库链接。
142 |
143 | Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。 解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
144 |
145 | 向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。 解决: Mybatis自动将java对象映射至sql语句。
146 |
147 | 对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。 解决:Mybatis自动将sql执行结果映射至java对象。
148 |
149 | ##
150 |
151 |
152 |
153 | ## 问:使用MyBatis的mapper接口调用时有哪些要求?
154 |
155 | **参考答案:**
156 |
157 | 1、Mapper接口方法名和mapper.xml中定义的每个sql的id相同
158 |
159 | 2、Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
160 |
161 | 3、Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
162 |
163 | 4、Mapper.xml文件中的namespace即是mapper接口的类路径。
164 |
165 |
166 |
167 | ## 问:SqlMapConfig.xml中配置有哪些内容?
168 |
169 | **参考答案:**
170 |
171 | properties(属性) settings(配置) typeAliases(类型别名) typeHandlers(类型处理器) objectFactory(对象工厂) plugins(插件) environments(环境集合属性对象) environment(环境子属性对象) transactionManager(事务管理) dataSource(数据源) mappers(映射器)
172 |
173 |
174 |
175 | ## 问:Mapper编写有哪几种方式?
176 |
177 | **参考答案:**
178 |
179 | 1、接口实现类继承SqlSessionDaoSupport 使用此种方法需要编写mapper接口,mapper接口实现类、mapper.xml文件
180 |
181 | ①、在sqlMapConfig.xml中配置mapper.xml的位置
182 |
183 | ```xml
184 |
185 |
186 |
187 |
188 | ```
189 |
190 | ② 、定义mapper接口
191 |
192 | ③ 、实现类集成SqlSessionDaoSupport。mapper方法中可以this.getSqlSession()进行数据增删改查。
193 |
194 | ④、spring 配置
195 |
196 | ```xml
197 |
198 |
199 |
200 | ```
201 |
202 | 2、使用org.mybatis.spring.mapper.MapperFactoryBean
203 |
204 | ①、在sqlMapConfig.xml中配置mapper.xml的位置。如果mapper.xml和mappre接口的名称相同且在同一个目录,这里可以不用配置
205 |
206 | ```xml
207 |
208 |
209 |
210 |
211 | ```
212 |
213 | ②、定义mapper接口
214 |
215 | 注意
216 |
217 | (1)、mapper.xml中的namespace为mapper接口的地址
218 |
219 | (2)、mapper接口中的方法名和mapper.xml中的定义的statement的id保持一致
220 |
221 | (3)、 Spring中定义
222 |
223 | ```xml
224 |
225 |
226 |
227 |
228 | ```
229 |
230 | 3、使用mapper扫描器
231 |
232 | ①、mapper.xml文件编写
233 |
234 | > 注意: mapper.xml中的namespace为mapper接口的地址 mapper接口中的方法名和mapper.xml中的定义的statement的id保持一致 如果将mapper.xml和mapper接口的名称保持一致则不用在sqlMapConfig.xml中进行配置
235 |
236 | ②、定义mapper接口
237 |
238 | > 注意mapper.xml的文件名和mapper的接口名称保持一致,且放在同一个目录
239 |
240 | ③、配置mapper扫描器
241 |
242 | ```xml
243 |
244 |
245 |
246 |
247 | ```
248 |
249 | ④、使用扫描器后从spring容器中获取mapper的实现对象扫描器将接口通过代理方法生成实现对象,要spring容器中自动注册,名称为mapper 接口的名称。
250 |
251 |
252 |
253 | ## 问:在mapper中如何传递多个参数?
254 |
255 | **参考答案:**
256 |
257 | **1、使用占位符的思想**
258 |
259 | ① 在映射文件中使用#{0},#{1}代表传递进来的第几个参数
260 |
261 | ```xml
262 | //对应的xml,#{0}代表接收的是dao层中的第一个参数,#{1}代表dao层中第二参数,更多参数一致往后加即可。
263 |
266 | 复制代码
267 | ```
268 |
269 | ② 使用@param注解:来命名参数
270 |
271 | ```xml
272 | public interface usermapper {
273 | user selectuser(@param(“username”) string username,
274 | @param(“hashedpassword”) string hashedpassword);
275 | }
276 | 复制代码
277 |
283 | 复制代码
284 | ```
285 |
286 | **第二种:使用Map集合作为参数来装载**
287 |
288 | ```xml
289 | try{
290 | //映射文件的命名空间.SQL片段的ID,就可以调用对应的映射文件中的SQL
291 | /**
292 | * 由于我们的参数超过了两个,而方法中只有一个Object参数收集
293 | * 因此我们使用Map集合来装载我们的参数
294 | */
295 | Map map = new HashMap();
296 | map.put("start", start);
297 | map.put("end", end);
298 | return sqlSession.selectList("StudentID.pagination", map);
299 | }catch(Exception e){
300 | e.printStackTrace();
301 | sqlSession.rollback();
302 | throw e;
303 | }finally{
304 | MybatisUtil.closeSqlSession();
305 | }
306 | 复制代码
307 |
308 |
312 | 复制代码
313 | ```
314 |
315 | ##
316 |
317 |
318 |
319 | ## 问:Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
320 |
321 | **参考答案:**
322 |
323 | 如果配置了namespace那么当然是可以重复的,因为我们的Statement实际上就是namespace+id
324 |
325 | 如果没有配置namespace的话,那么相同的id就会导致覆盖了。
326 |
327 | ##
328 |
329 |
330 |
331 | ## 问:Mybatis比IBatis比较大的几个改进是什么
332 |
333 | **参考答案:**
334 |
335 | 1、有接口绑定,包括注解绑定sql和xml绑定Sql ;
336 |
337 | 2、动态sql由原来的节点配置变成OGNL表达式;
338 |
339 | 3、在一对一,一对多的时候引进了association,在一对多的时候引入了collection节点,不过都是在resultMap里面配置。
340 |
341 | ##
342 |
343 | ## 问:接口绑定有几种实现方式,分别是怎么实现的?
344 |
345 | **参考答案:**
346 |
347 | 两种实现方式:
348 |
349 | 1、通过注解绑定,就是在接口的方法上面加上@Select@Update等注解里面包含Sql语句来绑定;
350 |
351 | 2、通过xml里面写SQL来绑定,在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名.
352 |
353 |
354 |
355 |
356 |
357 | ## 问:简述Mybatis的插件运行原理,以及如何编写一个插件
358 |
359 | **参考答案:**
360 |
361 | Mybatis仅可以编写针对ParameterHandler、ResultSetHandler、StatementHandler、Executor这4种接口的插件,Mybatis使用JDK的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这4种接口对象的方法时,就会进入拦截方法,具体就是InvocationHandler的invoke()方法,当然,只会拦截那些你指定需要拦截的方法。
362 |
363 | 实现Mybatis的Interceptor接口并复写intercept()方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
364 |
365 | ##
366 |
367 | ## 问:Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
368 |
369 | **参考答案:**
370 |
371 | Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,**可以配置是否启用延迟加载**
372 |
373 | ```
374 | lazyLoadingEnabled=true|false。
375 | ```
376 |
377 | 它的原理是,**使用CGLIB创建目标对象的代理对象**,当调用目标方法时,**进入拦截器方法**,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
378 |
379 | 当然了,不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。
380 |
381 |
382 |
383 |
384 |
385 | ## 问:Mybatis都有哪些Executor执行器?它们之间的区别是什么?
386 |
387 | **参考答案:**
388 |
389 | Mybatis有三种基本的Executor执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。
390 |
391 | 1、SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
392 |
393 | 2、ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map内,供下一次使用。简言之,就是重复使用Statement对象。
394 |
395 | 3、BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
396 |
397 | Executor的这些特点,都严格限制在SqlSession生命周期范围内。
398 |
399 | ##
400 |
--------------------------------------------------------------------------------
/Java横向技术/Spring框架面试题.md:
--------------------------------------------------------------------------------
1 | # Spring框架面试题
2 |
3 | ## 问:说说你理解的Spring?
4 |
5 | **参考答案:**
6 |
7 | Spring是一个开源框架,它由Rod Johnson创建,是为解决企业应用开发的复杂性而创建的。Spring使用基本的JavaBean来完成以前只可能由EJB完成的事情。然而,Spring的用途不仅限于服务器端的开发。从简单性、可测试性和松耦合的角度而言,任何Java应用都可以从Spring中受益。
8 |
9 | **(1)、 目的**:解决企业应用开发的复杂性;
10 |
11 | **(2)、功能**:使用基本的JavaBean代替EJB,并提供了更多的企业应用功能;
12 |
13 | **(3)、范围**:任何Java应用;
14 |
15 | (4)、简单来说,Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架;
16 |
17 | **(5)、轻量:** 从大小与开销两方面而言Spring都是轻量的。完整的Spring框架可以在一个大小只有1MB多的JAR文件里发布。并且Spring所需的处理开销也是微不足道的。此外,Spring是非侵入式的:典型地,Spring应用中的对象不依赖于Spring的特定类。
18 |
19 | (**6)、控制反转:** Spring通过一种称作控制反转(IoC)的技术促进了松耦合。当应用了IoC,一个对象依赖的其它对象会通过被动的方式传递进来,而不是这个对象自己创建或者查找依赖对象。你可以认为IoC与JNDI相反——不是对象从容器中查找依赖,而是容器在对象初始化时不等对象请求就主动将依赖传递给它。
20 |
21 | **(7)、面向切面:** Spring提供了面向切面编程的丰富支持,允许通过分离应用的业务逻辑与系统级服务(例如审计(auditing)和事务()管理)进行内聚性的开发。应用对象只实现它们应该做的——完成业务逻辑——仅此而已。它们并不负责(甚至是意识)其它的系统级关注点,例如日志或事务支持。
22 |
23 | **(8)、容器:** Spring包含并管理应用对象的配置和生命周期,在这个意义上它是一种容器,你可以配置你的每个bean如何被创建——基于一个可配置原型(prototype),你的bean可以创建一个单独的实例或者每次需要时都生成一个新的实例——以及它们是如何相互关联的。然而,Spring不应该被混同于传统的重量级的EJB容器,它们经常是庞大与笨重的,难以使用。
24 |
25 | **(9)、框架:** Spring可以将简单的组件配置、组合成为复杂的应用。在Spring中,应用对象被声明式地组合,典型地是在一个XML文件里。Spring也提供了很多基础功能(事务管理、持久化框架集成等等),将应用逻辑的开发留给了你。
26 |
27 | 所有Spring的这些特征使你能够编写更干净、更可管理、并且更易于测试的代码。它们也为Spring中的各种模块提供了基础支持。
28 |
29 |
30 |
31 | ## 问:**选择使用Spring框架的原因(Spring框架为企业级开发带来的好处有哪些)?**
32 |
33 | **参考答案:**
34 |
35 | 可以从以下几个方面作答:
36 |
37 | **(1)、非侵入式**:支持基于POJO的编程模式,不强制性的要求实现Spring框架中的接口或继承Spring框架中的类。
38 |
39 | **(2)、** **IoC容器**:IoC容器帮助应用程序管理对象以及对象之间的依赖关系,对象之间的依赖关系如果发生了改变只需要修改配置文件而不是修改代码,因为代码的修改可能意味着项目的重新构建和完整的回归测试。有了IoC容器,程序员再也不需要自己编写工厂、单例,这一点特别符合Spring的精神"不要重复的发明轮子"。
40 |
41 | **(3)、AOP(面向切面编程)**:将所有的横切关注功能封装到切面(aspect)中,通过配置的方式将横切关注功能动态添加到目标代码上,进一步实现了业务逻辑和系统服务之间的分离。另一方面,有了AOP程序员可以省去很多自己写代理类的工作。
42 |
43 | **(4)、 MVC**:Spring的MVC框架是非常优秀的,为Web表示层提供了更好的解决方案;
44 |
45 | **(5)、事务管理**:Spring以宽广的胸怀接纳多种持久层技术,并且为其提供了声明式的事务管理,在不需要任何一行代码的情况下就能够完成事务管理。
46 |
47 | **(6)、其他**:选择Spring框架的原因还远不止于此,Spring为Java企业级开发提供了一站式选择,你可以在需要的时候使用它的部分和全部,更重要的是,你甚至可以在感觉不到Spring存在的情况下,在你的项目中使用Spring提供的各种优秀的功能。
48 |
49 |
50 |
51 | ## 问:为什么使用Spring?
52 |
53 | **参考答案:**
54 |
55 | **(1)、方便解耦,简化开发**
56 |
57 | 通过Spring提供的IoC容器,我们可以将对象之间的依赖关系交由Spring进行控制,避免硬编码所造成的过度程序耦合。有了Spring,用户不必再为单实例模式类、属性文件解析等这些很底层的需求编写代码,可以更专注于上层的应用。
58 |
59 | **(2)、AOP编程的支持**
60 |
61 | 通过Spring提供的AOP功能,方便进行面向切面的编程,许多不容易用传统OOP实现的功能可以通过AOP轻松应付。
62 |
63 | **(3)、声明事物的支持**
64 |
65 | 在Spring中,我们可以从单调烦闷的事务管理代码中解脱出来,通过声明式方式灵活地进行事务的管理,提高开发效率和质量。
66 |
67 | **(4)、方便程序的测试**
68 |
69 | 可以用非容器依赖的编程方式进行几乎所有的测试工作,在Spring里,测试不再是昂贵的操作,而是随手可做的事情。例如:Spring对Junit4支持,可以通过注解方便的测试Spring程序。
70 |
71 | **(5)、方便集成各种优秀框架**
72 |
73 | Spring不排斥各种优秀的开源框架,相反,Spring可以降低各种框架的使用难度,Spring提供了对各种优秀框架(如Struts,Hibernate、Hessian、Quartz)等的直接支持。
74 |
75 | **(6)、降低Java EE API的使用难度**
76 |
77 | Spring对很多难用的Java EE API(如JDBC,JavaMail,远程调用等)提供了一个薄薄的封装层,通过Spring的简易封装,这些Java EE API的使用难度大为降低。
78 |
79 | **(7)、Java 源码是经典学习范例**
80 |
81 | Spring的源码设计精妙、结构清晰、匠心独用,处处体现着大师对Java设计模式灵活运用以及对Java技术的高深造诣。Spring框架源码无疑是Java技术的最佳实践范例。如果想在短时间内迅速提高自己的Java技术水平和应用开发水平,学习和研究Spring源码将会使你收到意想不到的效果。
82 |
83 |
84 |
85 | ## 问:Spring能做什么?
86 |
87 | **参考答案:**
88 |
89 | **(1)、Spring提供许多功能,在此我将快速地依次展示其各个主要方面。**
90 |
91 | 首先,让我们明确Spring范围。尽管Spring覆盖了许多方面,但我们已经有清楚的概念,它什么应该涉及和什么不应该涉及。
92 |
93 | **(2)、Spring的主要目的是使J2EE易用和促进好编程习惯。**
94 |
95 | Spring不重新开发已有的东西。因此,在Spring中你将发现没有日志记录的包,没有连接池,没有分布事务调度。这些 均有开源项目提供(例如Commons Logging 用来做所有的日志输出,或Commons DBCP用来作数据连接池),或由你的应用程序服务器提供。因为同样的的原因,我们没有提供O/R mapping层,对此,已有有好的解决办法如Hibernate和JDO。
96 |
97 | **(3)、Spring的目标是使已存在的技术更加易用。**
98 |
99 | 例如,尽管我们没有底层事务协调处理,但我们提供了一个抽象层覆盖了JTA或任何其他的事务策略。
100 |
101 | Spring没有直接和其他的开源项目竞争,除非我们感到我们能提供新的一些东西。例如,象许多开发人员,我们从来没有为Struts高兴过,并且感到在MVC web framework中还有改进的余地。在某些领域,例如轻量级的IoC容器和AOP框架,Spring有直接的竞争,但是在这些领域还没有已经较为流行的解决方案。(Spring在这些区域是开路先锋。)
102 |
103 | **(4)、Spring也得益于内在的一致性。**
104 |
105 | 所有的开发者都在唱同样的的赞歌,基础想法依然是Expert One-on-One J2EE设计与开发的那些。并且我们已经能够使用一些主要的概念,例如倒置控制,来处理多个领域。
106 |
107 | **(5)、Spring在应用服务器之间是可移植的。**
108 |
109 | 当然保证可移植性总是一次挑战,但是我们避免任何特定平台或非标准化,并且支持在WebLogic,Tomcat,Resin,JBoss,WebSphere和其他的应用服务器上的用户。
110 |
111 |
112 |
113 | ## 问:Spring有哪些常用的 Context?
114 |
115 | **参考答案:**
116 |
117 | 最常被使用的 ApplicationContext 接口实现:
118 |
119 | (1)、FileSystemXmlApplicationContext:该容器从 XML 文件中加载已被定义的 bean。在这里,你需要提供给构造器 XML 文件的完整路径;
120 |
121 | (2)、ClassPathXmlApplicationContext:该容器从 XML 文件中加载已被定义的 bean。在这里,你不需要提供 XML 文件的完整路径,只需正确配置 CLASSPATH 环境变量即可,因为,容器会从 CLASSPATH 中搜索 bean 配置文件。
122 |
123 | (3)、WebXmlApplicationContext:该容器会在一个 web 应用程序的范围内加载在 XML 文件中已被定义的bean。
124 |
125 |
126 |
127 | ## 问:**Spring中自动装配的方式有哪些?**
128 |
129 | **参考答案:**
130 |
131 | (1)no:不进行自动装配,手动设置Bean的依赖关系;
132 |
133 | (2)byName:根据Bean的名字进行自动装配。
134 |
135 | (3)byType:根据Bean的类型进行自动装配。
136 |
137 | (4)constructor:类似于byType,不过是应用于构造器的参数,如果正好有一个Bean与构造器的参数类型相同则可以自动装配,否则会导致错误。
138 |
139 | (5)autodetect:如果有默认的构造器,则通过constructor的方式进行自动装配,否则使用byType的方式进行自动装配。
140 |
141 | > **说明:** 自动装配没有自定义装配方式那么精确,而且不能自动装配简单属性(基本类型、字符串等),在使用时应注意。
142 |
143 |
144 |
145 | ## 问:**Spring中如何使用注解来配置Bean?有哪些相关的注解?**
146 |
147 | **参考答案:** 首先需要在Spring配置文件中增加如下配置:
148 |
149 | ```xml
150 |
151 | ```
152 |
153 | 然后可以用@Component、@Controller、@Service、@Repository注解来标注需要由Spring IoC容器进行对象托管的类。这几个注解没有本质区别,只不过@Controller通常用于控制器,@Service通常用于业务逻辑类,@Repository通常用于仓储类(例如我们的DAO实现类),普通的类用@Component来标注。
154 |
155 | ## 问:Spring的事务底层原理?
156 |
157 | **参考答案:**
158 |
159 | (1)、划分处理单元——IOC
160 |
161 | 由于spring解决的问题是对单个数据库进行局部事务处理的,具体的实现首相用spring中的IOC划分了事务处理单元。并且将对事务的各种配置放到了IOC容器中(设置事务管理器,设置事务的传播特性及隔离机制)。
162 |
163 | (2)、AOP拦截需要进行事务处理的类
164 |
165 | Spring事务处理模块是通过AOP功能来实现声明式事务处理的,具体操作(比如事务实行的配置和读取,事务对象的抽象),用TransactionProxyFactoryBean接口来使用AOP功能,生成proxy代理对象,通过TransactionInterceptor完成对代理方法的拦截,将事务处理的功能编织到拦截的方法中。读取ioc容器事务配置属性,转化为spring事务处理需要的内部数据结构(TransactionAttributeSourceAdvisor),转化为TransactionAttribute表示的数据对象。
166 |
167 | (3)、对事物处理实现(事务的生成、提交、回滚、挂起)
168 |
169 | spring委托给具体的事务处理器实现。实现了一个抽象和适配。适配的具体事务处理器:DataSource数据源支持、hibernate数据源事务处理支持、JDO数据源事务处理支持,JPA、JTA数据源事务处理支持。这些支持都是通过设计PlatformTransactionManager、AbstractPlatforTransaction一系列事务处理的支持。 为常用数据源支持提供了一系列的TransactionManager。
170 |
171 | (4)、结合
172 |
173 | PlatformTransactionManager实现了TransactionInterception接口,让其与TransactionProxyFactoryBean结合起来,形成一个Spring声明式事务处理的设计体系。
174 |
175 |
176 |
177 | ## 问: Spring 中的事务传播行为了解吗?TransactionDefinition 接口中哪五个表示隔离级别的常量?
178 |
179 | **参考答案:**
180 |
181 | 事务传播行为(为了解决业务层方法之间互相调用的事务问题): 当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。在TransactionDefinition定义中包括了如下几个表示传播行为的常量:
182 |
183 | **支持当前事务的情况:**
184 |
185 | - TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
186 | - TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
187 | - TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
188 |
189 | **不支持当前事务的情况:**
190 |
191 | - TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起(新事务回滚不会影响当前事务)。
192 | - TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
193 | - TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
194 |
195 | **其他情况:**
196 |
197 | - TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED(创建一个新事务)。
198 |
199 | #### 隔离级别
200 |
201 | TransactionDefinition 接口中定义了五个表示隔离级别的常量:
202 |
203 | - **TransactionDefinition.ISOLATION_DEFAULT:** 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别.
204 | - **TransactionDefinition.ISOLATION_READ_UNCOMMITTED:** 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
205 | - **TransactionDefinition.ISOLATION_READ_COMMITTED:** 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
206 | - **TransactionDefinition.ISOLATION_REPEATABLE_READ:** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
207 | - **TransactionDefinition.ISOLATION_SERIALIZABLE:** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
208 |
209 |
210 |
211 | ## 问:@Transactional 失效?
212 |
213 | **参考答案:**
214 |
215 | @Transactional 注解应该只被应用到 public 方法上,这是由 Spring AOP 的本质决定的。如果你在 protected、private 或者默认可见性的方法上使用 @Transactional 注解,这将被忽略,也不会抛出任何异常。
216 |
217 | 默认情况下,只有来自外部的方法调用才会被AOP代理捕获,也就是,类内部方法调用本类内部的其他方法并不会引起事务行为,即使被调用方法使用@Transactional注解进行修饰。
218 |
219 |
220 |
221 | ## 问:Spring MVC的工作原理是怎样的?/请简介下SpringMVC处理一个请求的流程?
222 |
223 | **参考答案:**
224 |
225 | Spring MVC的工作原理如下图所示:
226 |
227 | 
228 |
229 | (1)、客户端的所有请求都交给前端控制器DispatcherServlet来处理,它会负责调用系统的其他模块来真正处理用户的请求。
230 |
231 | (2)、DispatcherServlet收到请求后,将根据请求的信息(包括URL、HTTP协议方法、请求头、请求参数、Cookie等)以及HandlerMapping的配置找到处理该请求的Handler(任何一个对象都可以作为请求的Handler)。
232 |
233 | (3)、在这个地方Spring会通过HandlerAdapter对该处理器进行封装。
234 |
235 | (4)、HandlerAdapter是一个适配器,它用统一的接口对各种Handler中的方法进行调用。
236 |
237 | (5)、Handler完成对用户请求的处理后,会返回一个ModelAndView对象给DispatcherServlet,ModelAndView顾名思义,包含了数据模型以及相应的视图的信息。
238 |
239 | (6)、ModelAndView的视图是逻辑视图,DispatcherServlet还要借助ViewResolver完成从逻辑视图到真实视图对象的解析工作。
240 |
241 | (7)、 当得到真正的视图对象后,DispatcherServlet会利用视图对象对模型数据进行渲染。
242 |
243 | (8)、客户端得到响应,可能是一个普通的HTML页面,也可以是XML或JSON字符串,还可以是一张图片或者一个PDF文件。
244 |
245 |
246 |
247 | ## 问:Spring框架由哪些模块组成?
248 |
249 | **参考答案:**
250 |
251 | - Core module
252 | - Bean module
253 | - Context module
254 | - Expression Language module
255 | - JDBC module
256 | - ORM module
257 | - OXM module
258 | - beJava Messaging Service(JMS) module
259 | - Transaction module
260 | - Web module
261 | - Web-Servlet module
262 | - Web-Struts module
263 | - Web-Portlet module
264 |
265 |
266 |
267 | ## 问: Spring支持的几种bean的作用域?
268 |
269 | **参考答案:**
270 |
271 | (1)、singleton : bean在每个Spring ioc 容器中只有一个实例。默认的缺省。
272 |
273 | (2)、prototype:一个bean的定义可以有多个实例。
274 |
275 | (3)、request:每次http请求都会创建一个bean,该作用域仅在基于web的Spring ApplicationContext情形下有效。
276 |
277 | (4)、session:在一个HTTP Session中,一个bean定义对应一个实例。该作用域仅在基于web的Spring
278 |
279 | (5)、global-session:在一个全局的HTTP Session中,一个bean定义对应一个实例。该作用域仅在基于web的Spring ApplicationContext情形下有效。
280 |
281 | 默认的Spring bean 的作用域是Singleton.
282 |
283 |
284 |
285 | ## 问:Spring框架中的单例bean是线程安全的吗?
286 |
287 | **参考答案:**
288 |
289 | 不,Spring框架中的单例bean不是线程安全的。
290 |
291 |
292 |
293 | ## 问:**Spring IoC容器配置Bean的方式?**
294 |
295 | **参考答案:**
296 |
297 | (1)、基于XML文件进行配置;
298 |
299 | (2)、基于注解进行配置;
300 |
301 | (3)、基于Java程序进行配置(Spring 3+)
302 |
303 |
304 |
305 | ## 问: Spring IoC的实现原理?
306 |
307 | **参考答案:**
308 |
309 | 工厂模式+反射机制
310 |
311 | (1)、 加载配置文件,解析成 BeanDefinition 放在 Map 里;
312 |
313 | (2)、调用 getBean 的时候,从 BeanDefinition 所属的 Map 里,拿出 Class 对象进行实例化,同时,如果有依赖关系,将递归调用 getBean 方法 —— 完成依赖注入。
314 |
315 |
316 |
317 | ## 问: BeanFactory 和 ApplicationContext 有什么区别?
318 |
319 | **参考答案:**
320 |
321 | BeanFactory和ApplicationContext是Spring的两大核心接口,都可以当做Spring的容器。其中ApplicationContext是BeanFactory的子接口。
322 |
323 | (1)BeanFactory:是Spring里面最底层的接口,包含了各种Bean的定义,读取bean配置文档,管理bean的加载、实例化,控制bean的生命周期,维护bean之间的依赖关系。ApplicationContext接口作为BeanFactory的派生,除了提供BeanFactory所具有的功能外,还提供了更完整的框架功能:
324 | ①继承MessageSource,因此支持国际化。
325 |
326 | ②统一的资源文件访问方式。
327 |
328 | ③提供在监听器中注册bean的事件。
329 |
330 | ④同时加载多个配置文件。
331 |
332 | ⑤载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层。
333 |
334 | (2)创建Bean的时机不一样:
335 |
336 | ①BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。这样,我们就不能发现一些存在的Spring的配置问题。如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常。
337 |
338 | ②ApplicationContext,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。 ApplicationContext启动后预载入所有的单实例Bean,通过预载入单实例bean ,确保当你需要的时候,你就不用等待,因为它们已经创建好了。
339 |
340 | ③相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
341 |
342 | (3)BeanFactory通常以编程的方式被创建,ApplicationContext还能以声明的方式创建,如使用ContextLoader。
343 |
344 | (4)BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。
345 |
346 |
347 |
348 | ## 问:你如何理解AOP中的连接点(Joinpoint)、切入点(Pointcut)、增强(Advice)、引介(Introduction)、织入(Weaving)、切面(Aspect)、目标对象(Target)、代理对象(Proxy)这些概念?
349 |
350 | **参考答案:**
351 |
352 | **连接点(Joinpoint)**:就是程序在运行过程中能够插入切面的地点。例如,方法调用、异常抛出或字段修改等,但Spring只支持方法级的连接点。
353 |
354 | **切入点(Pointcut)**:如果连接点相当于数据中的记录,那么切入点相当于查询条件,一个切入点可以匹配多个连接点。Spring AOP的规则解析引擎负责解析切点所设定的查询条件,找到对应的连接点。
355 |
356 | **增强(Advice)**:是切面的具体实现。以目标方法为参照点,根据放置的地方不同,可分为前置增加(Before)、后置增加(After Returning)、异常增加(After Throwing)、最终增加(After)与环绕增加(Around)5种。在实际应用中通常是切面类中的一个方法,具体属于哪类增加,同样是在配置中指定的。
357 |
358 | > **说明:** Advice在国内的很多书面资料中都被翻译成"通知",但是很显然这个翻译无法表达其本质,有少量的读物上将这个词翻译为"增强",这个翻译是对Advice较为准确的诠释,我们通过AOP将横切关注功能加到原有的业务逻辑上,这就是对原有业务逻辑的一种增强。
359 |
360 | **引介(Introduction)**:引介是一种特殊的**增强**,它为类添加一些属性和方法。这样,即使一个业务类原本没有实现某个接口,通过引介功能,可以动态的未该业务类添加接口的实现逻辑,让业务类成为这个接口的实现类。
361 |
362 | **织入(Weaving)**:织入是将**增强**添加到**目标类**具体**连接点上**的过程,AOP有三种织入方式:①编译期织入:需要特殊的Java编译期(例如AspectJ的ajc);②装载期织入:要求使用特殊的类加载器,在装载类的时候对类进行增强;③运行时织入:在运行时为目标类生成代理实现增强。Spring采用了动态代理的方式实现了运行时织入,而AspectJ采用了编译期织入和装载期织入的方式。
363 |
364 | **切面(Aspect)**:其实就是共有功能的实现。如日志切面、权限切面、事务切面等。在实际应用中通常是一个存放共有功能实现的普通Java类,之所以能被AOP容器识别成切面,是在配置中指定的。
365 |
366 | **目标对象(Target)**:就是那些即将切入切面的对象,也就是那些被通知的对象。这些对象中已经只剩下干干净净的核心业务逻辑代码了,所有的共有功能代码等待AOP容器的切入。
367 |
368 | **代理对象(Proxy)**:将通知应用到目标对象之后被动态创建的对象。可以简单地理解为,代理对象的功能等于目标对象的核心业务逻辑功能加上共有功能。代理对象对于使用者而言是透明的,是程序运行过程中的产物。
369 |
370 |
371 |
372 | ## 问:将一个请求url指向一个类的方法的注解是?
373 |
374 | **参考答案:**
375 |
376 | @RequestMapping
377 |
378 |
379 |
380 | ## 问:将前台的form中input控件的name属性绑定到控制器类中的方法参数的注解是?
381 |
382 | **参考答案:**
383 |
384 | @RequestParam
385 |
386 |
387 |
388 | ## 问:SpringMVC的控制器是单例的吗?为什么?
389 |
390 | **参考答案:**
391 |
392 | **默认是单例。** 主要原因是为了提高程序的性能和以后程序的维护只针对业务的维护就行(也不需要多例,因为一般不会在控制器中定义成员变量,如果非要定义一个非静态成员变量时候,则通过注解@Scope(“prototype”),将其设置为多例模式)
393 |
394 | 参考:https://www.javazhiyin.com/59594.html
395 |
396 |
397 |
398 | - 其他常见的Spring面试题还可以参见:http://ifeve.com/spring-interview-questions-and-answers/
399 |
400 | ####
401 |
402 | ####
403 |
404 | ####
405 |
--------------------------------------------------------------------------------
/Java横向技术/23种设计模式.md:
--------------------------------------------------------------------------------
1 | # 23种设计模式
2 |
3 | ## 问:说一说工厂模式?
4 |
5 | **参考答案:**
6 |
7 | 工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
8 |
9 | 在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
10 |
11 | **意图:** 定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。
12 |
13 | **主要解决:** 主要解决接口选择的问题。
14 |
15 | **何时使用:** 我们明确地计划不同条件下创建不同实例时。
16 |
17 | **如何解决:** 让其子类实现工厂接口,返回的也是一个抽象的产品。
18 |
19 | **关键代码:** 创建过程在其子类执行。
20 |
21 | **应用实例:**
22 |
23 | 1、您需要一辆汽车,可以直接从工厂里面提货,而不用去管这辆汽车是怎么做出来的,以及这个汽车里面的具体实现。
24 |
25 | 2、Hibernate 换数据库只需换方言和驱动就可以。
26 |
27 | **优点:**
28 |
29 | 1、一个调用者想创建一个对象,只要知道其名称就可以了。
30 |
31 | 2、扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
32 |
33 | 3、屏蔽产品的具体实现,调用者只关心产品的接口。
34 |
35 | **缺点:** 每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。这并不是什么好事。
36 |
37 | **使用场景:**
38 |
39 | 1、日志记录器:记录可能记录到本地硬盘、系统事件、远程服务器等,用户可以选择记录日志到什么地方。
40 | 2、数据库访问,当用户不知道最后系统采用哪一类数据库,以及数据库可能有变化时。
41 | 3、设计一个连接服务器的框架,需要三个协议,"POP3"、"IMAP"、"HTTP",可以把这三个作为产品类,共同实现一个接口。
42 |
43 | **注意事项:** 作为一种创建类模式,在任何需要生成复杂对象的地方,都可以使用工厂方法模式。有一点需要注意的地方就是复杂对象适合使用工厂模式,而简单对象,特别是只需要通过 new 就可以完成创建的对象,无需使用工厂模式。如果使用工厂模式,就需要引入一个工厂类,会增加系统的复杂度。
44 |
45 |
46 |
47 | ## 问:说一说抽象工厂模式?
48 |
49 | **参考答案:**
50 |
51 | 抽象工厂模式(Abstract Factory Pattern)是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
52 |
53 | 在抽象工厂模式中,接口是负责创建一个相关对象的工厂,不需要显式指定它们的类。每个生成的工厂都能按照工厂模式提供对象。
54 |
55 | **意图:** 提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
56 |
57 | **主要解决:** 主要解决接口选择的问题。
58 |
59 | **何时使用:** 系统的产品有多于一个的产品族,而系统只消费其中某一族的产品。
60 |
61 | **如何解决:** 在一个产品族里面,定义多个产品。
62 |
63 | **关键代码:** 在一个工厂里聚合多个同类产品。
64 |
65 | **应用实例:**
66 |
67 | 工作了,为了参加一些聚会,肯定有两套或多套衣服吧,比如说有商务装(成套,一系列具体产品)、时尚装(成套,一系列具体产品),甚至对于一个家庭来说,可能有商务女装、商务男装、时尚女装、时尚男装,这些也都是成套的,即一系列具体产品。假设一种情况(现实中是不存在的,要不然,没法进入共产主义了,但有利于说明抽象工厂模式),在您的家中,某一个衣柜(具体工厂)只能存放某一种这样的衣服(成套,一系列具体产品),每次拿这种成套的衣服时也自然要从这个衣柜中取出了。用 OOP 的思想去理解,所有的衣柜(具体工厂)都是衣柜类的(抽象工厂)某一个,而每一件成套的衣服又包括具体的上衣(某一具体产品),裤子(某一具体产品),这些具体的上衣其实也都是上衣(抽象产品),具体的裤子也都是裤子(另一个抽象产品)。
68 |
69 | **优点:** 当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象。
70 |
71 | **缺点:** 产品族扩展非常困难,要增加一个系列的某一产品,既要在抽象的 Creator 里加代码,又要在具体的里面加代码。
72 |
73 | **使用场景:**
74 |
75 | 1、QQ 换皮肤,一整套一起换。
76 |
77 | 2、生成不同操作系统的程序。
78 |
79 | **注意事项:** 产品族难扩展,产品等级易扩展。
80 |
81 |
82 |
83 | ## 问:说一说单例模式?
84 |
85 | **参考答案:**
86 |
87 | 单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
88 |
89 | 这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
90 |
91 | **注意:**
92 |
93 | 1、单例类只能有一个实例。
94 |
95 | 2、单例类必须自己创建自己的唯一实例。
96 |
97 | 3、单例类必须给所有其他对象提供这一实例。
98 |
99 | **意图:** 保证一个类仅有一个实例,并提供一个访问它的全局访问点。
100 |
101 | **主要解决:** 主要解决接口选择的问题。一个全局使用的类频繁地创建与销毁。
102 |
103 | **何时使用:** 当您想控制实例数目,节省系统资源的时候。
104 |
105 | **如何解决:** 判断系统是否已经有这个单例,如果有则返回,如果没有则创建。
106 |
107 | **关键代码:** 构造函数是私有的。
108 |
109 | **应用实例:**
110 |
111 | 1、一个班级只有一个班主任。
112 |
113 | 2、Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。
114 |
115 | 3、一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件。
116 |
117 | **优点:**
118 |
119 | 1、在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。
120 |
121 | 2、避免对资源的多重占用(比如写文件操作)。
122 |
123 | **缺点:** 没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
124 |
125 | **使用场景:**
126 |
127 | 1、要求生产唯一序列号。
128 |
129 | 2、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
130 |
131 | 3、创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
132 |
133 | **注意事项:** getInstance() 方法中需要使用同步锁 synchronized (Singleton.class) 防止多线程同时进入造成 instance 被多次实例化。
134 |
135 |
136 |
137 | ## 问:说一说建造者模式?
138 |
139 | **参考答案:**
140 |
141 | 建造者模式(Builder Pattern)使用多个简单的对象一步一步构建成一个复杂的对象。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
142 |
143 | 一个 Builder 类会一步一步构造最终的对象。该 Builder 类是独立于其他对象的。
144 |
145 | **意图:** 将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。
146 |
147 | **主要解决:** 主要解决在软件系统中,有时候面临着"一个复杂对象"的创建工作,其通常由各个部分的子对象用一定的算法构成;由于需求的变化,这个复杂对象的各个部分经常面临着剧烈的变化,但是将它们组合在一起的算法却相对稳定。
148 |
149 | **何时使用:** 一些基本部件不会变,而其组合经常变化的时候。
150 |
151 | **如何解决:** 将变与不变分离开。
152 |
153 | **关键代码:** 建造者:创建和提供实例,导演:管理建造出来的实例的依赖关系。
154 |
155 | **应用实例:**
156 |
157 | 1、去肯德基,汉堡、可乐、薯条、炸鸡翅等是不变的,而其组合是经常变化的,生成出所谓的"套餐"。
158 |
159 | 2、JAVA 中的 StringBuilder。
160 |
161 | **优点:**
162 |
163 | 1、建造者独立,易扩展。
164 |
165 | 2、便于控制细节风险。
166 |
167 | **缺点:**
168 |
169 | 1、产品必须有共同点,范围有限制。
170 |
171 | 2、如内部变化复杂,会有很多的建造类。
172 |
173 | **使用场景:**
174 |
175 | 1、需要生成的对象具有复杂的内部结构。
176 |
177 | 2、需要生成的对象内部属性本身相互依赖。
178 |
179 | **注意事项:** 与工厂模式的区别是:建造者模式更加关注与零件装配的顺序。
180 |
181 |
182 |
183 | ## 问:说一说原型模式?
184 |
185 | **参考答案:**
186 |
187 | 原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
188 |
189 | 这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直接创建对象的代价比较大时,则采用这种模式。例如,一个对象需要在一个高代价的数据库操作之后被创建。我们可以缓存该对象,在下一个请求时返回它的克隆,在需要的时候更新数据库,以此来减少数据库调用。
190 |
191 | **意图:** 用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
192 |
193 | **主要解决:** 在运行期建立和删除原型。
194 |
195 | **何时使用:**
196 |
197 | 1、当一个系统应该独立于它的产品创建,构成和表示时。
198 |
199 | 2、当要实例化的类是在运行时刻指定时,例如,通过动态装载。
200 |
201 | 3、为了避免创建一个与产品类层次平行的工厂类层次时。
202 |
203 | 4、当一个类的实例只能有几个不同状态组合中的一种时。建立相应数目的原型并克隆它们可能比每次用合适的状态手工实例化该类更方便一些。
204 |
205 | **如何解决:** 利用已有的一个原型对象,快速地生成和原型对象一样的实例。
206 |
207 | **关键代码:**
208 |
209 | 1、实现克隆操作,在 JAVA 继承 Cloneable,重写 clone(),在 .NET 中可以使用 Object 类的 MemberwiseClone() 方法来实现对象的浅拷贝或通过序列化的方式来实现深拷贝。
210 |
211 | 2、原型模式同样用于隔离类对象的使用者和具体类型(易变类)之间的耦合关系,它同样要求这些"易变类"拥有稳定的接口。
212 |
213 | **应用实例:**
214 |
215 | 1、细胞分裂。
216 |
217 | 2、JAVA 中的 Object clone() 方法。
218 |
219 | **优点:**
220 |
221 | 1、性能提高。
222 |
223 | 2、逃避构造函数的约束。
224 |
225 | **缺点:**
226 |
227 | 1、配备克隆方法需要对类的功能进行通盘考虑,这对于全新的类不是很难,但对于已有的类不一定很容易,特别当一个类引用不支持串行化的间接对象,或者引用含有循环结构的时候。
228 |
229 | 2、必须实现 Cloneable 接口。
230 |
231 | **使用场景:**
232 |
233 | 1、资源优化场景。
234 |
235 | 2、类初始化需要消化非常多的资源,这个资源包括数据、硬件资源等。
236 |
237 | 3、性能和安全要求的场景。
238 |
239 | 4、通过 new 产生一个对象需要非常繁琐的数据准备或访问权限,则可以使用原型模式。
240 |
241 | 5、一个对象多个修改者的场景。
242 |
243 | 6、一个对象需要提供给其他对象访问,而且各个调用者可能都需要修改其值时,可以考虑使用原型模式拷贝多个对象供调用者使用。
244 |
245 | 7、在实际项目中,原型模式很少单独出现,一般是和工厂方法模式一起出现,通过 clone 的方法创建一个对象,然后由工厂方法提供给调用者。原型模式已经与 Java 融为浑然一体,大家可以随手拿来使用。
246 |
247 | **注意事项:** 与通过对一个类进行实例化来构造新对象不同的是,原型模式是通过拷贝一个现有对象生成新对象的。浅拷贝实现 Cloneable,重写,深拷贝是通过实现 Serializable 读取二进制流。
248 |
249 |
250 |
251 | ## 问:说一说适配器模式?
252 |
253 | **参考答案:**
254 |
255 | 适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁。这种类型的设计模式属于结构型模式,它结合了两个独立接口的功能。
256 |
257 | 这种模式涉及到一个单一的类,该类负责加入独立的或不兼容的接口功能。举个真实的例子,读卡器是作为内存卡和笔记本之间的适配器。您将内存卡插入读卡器,再将读卡器插入笔记本,这样就可以通过笔记本来读取内存卡。
258 |
259 | 我们通过下面的实例来演示适配器模式的使用。其中,音频播放器设备只能播放 mp3 文件,通过使用一个更高级的音频播放器来播放 vlc 和 mp4 文件。
260 |
261 | **意图:** 将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
262 |
263 | **主要解决:** 主要解决在软件系统中,常常要将一些"现存的对象"放到新的环境中,而新环境要求的接口是现对象不能满足的。
264 |
265 | **何时使用:**
266 |
267 | 1、系统需要使用现有的类,而此类的接口不符合系统的需要。
268 |
269 | 2、想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作,这些源类不一定有一致的接口。
270 |
271 | 3、通过接口转换,将一个类插入另一个类系中。(比如老虎和飞禽,现在多了一个飞虎,在不增加实体的需求下,增加一个适配器,在里面包容一个虎对象,实现飞的接口。)
272 |
273 | **如何解决:** 继承或依赖(推荐)。
274 |
275 | **关键代码:** 适配器继承或依赖已有的对象,实现想要的目标接口。
276 |
277 | **应用实例:**
278 |
279 | 1、美国电器 110V,中国 220V,就要有一个适配器将 110V 转化为 220V。
280 |
281 | 2、JAVA JDK 1.1 提供了 Enumeration 接口,而在 1.2 中提供了 Iterator 接口,想要使用 1.2 的 JDK,则要将以前系统的 Enumeration 接口转化为 Iterator 接口,这时就需要适配器模式。
282 |
283 | 3、在 LINUX 上运行 WINDOWS 程序。
284 |
285 | 4、JAVA 中的 jdbc。
286 |
287 | **优点:**
288 |
289 | 1、可以让任何两个没有关联的类一起运行。
290 |
291 | 2、提高了类的复用。
292 |
293 | 3、增加了类的透明度。
294 |
295 | 4、灵活性好。
296 |
297 | **缺点:**
298 |
299 | 1、过多地使用适配器,会让系统非常零乱,不易整体进行把握。比如,明明看到调用的是 A 接口,其实内部被适配成了 B 接口的实现,一个系统如果太多出现这种情况,无异于一场灾难。因此如果不是很有必要,可以不使用适配器,而是直接对系统进行重构。
300 |
301 | 2.由于 JAVA 至多继承一个类,所以至多只能适配一个适配者类,而且目标类必须是抽象类。
302 |
303 | **使用场景:** 有动机地修改一个正常运行的系统的接口,这时应该考虑使用适配器模式。
304 |
305 | **注意事项:** 适配器不是在详细设计时添加的,而是解决正在服役的项目的问题。
306 |
307 |
308 |
309 | ## 问:说一说装饰器模式?
310 |
311 | **参考答案:**
312 |
313 | 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构。这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装。
314 |
315 | 这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能。
316 |
317 | 我们通过下面的实例来演示装饰器模式的用法。其中,我们将把一个形状装饰上不同的颜色,同时又不改变形状类。
318 |
319 | **意图:** 动态地给一个对象添加一些额外的职责。就增加功能来说,装饰器模式相比生成子类更为灵活。
320 |
321 | **主要解决:** 一般的,我们为了扩展一个类经常使用继承方式实现,由于继承为类引入静态特征,并且随着扩展功能的增多,子类会很膨胀。
322 |
323 | **何时使用:** 在不想增加很多子类的情况下扩展类。
324 |
325 | **如何解决:** 将具体功能职责划分,同时继承装饰者模式。
326 |
327 | **关键代码:**
328 |
329 | 1、Component 类充当抽象角色,不应该具体实现。
330 |
331 | 2、修饰类引用和继承 Component 类,具体扩展类重写父类方法。
332 |
333 | **应用实例:**
334 |
335 | 1、孙悟空有 72 变,当他变成"庙宇"后,他的根本还是一只猴子,但是他又有了庙宇的功能。
336 |
337 | 2、不论一幅画有没有画框都可以挂在墙上,但是通常都是有画框的,并且实际上是画框被挂在墙上。在挂在墙上之前,画可以被蒙上玻璃,装到框子里;这时画、玻璃和画框形成了一个物体。
338 |
339 | **优点:** 装饰类和被装饰类可以独立发展,不会相互耦合,装饰模式是继承的一个替代模式,装饰模式可以动态扩展一个实现类的功能。
340 |
341 | **缺点:** 多层装饰比较复杂。
342 |
343 | **使用场景:**
344 |
345 | 1、扩展一个类的功能。
346 |
347 | 2、动态增加功能,动态撤销。
348 |
349 | **注意事项:** 可代替继承。
350 |
351 |
352 |
353 | ## 问:说一说代理模式?
354 |
355 | **参考答案:**
356 |
357 | 在代理模式(Proxy Pattern)中,一个类代表另一个类的功能。这种类型的设计模式属于结构型模式。
358 |
359 | 在代理模式中,我们创建具有现有对象的对象,以便向外界提供功能接口。
360 |
361 | **意图:** 为其他对象提供一种代理以控制对这个对象的访问。
362 |
363 | **主要解决:** 在直接访问对象时带来的问题,比如说:要访问的对象在远程的机器上。在面向对象系统中,有些对象由于某些原因(比如对象创建开销很大,或者某些操作需要安全控制,或者需要进程外的访问),直接访问会给使用者或者系统结构带来很多麻烦,我们可以在访问此对象时加上一个对此对象的访问层。
364 |
365 | **何时使用:** 想在访问一个类时做一些控制。
366 |
367 | **如何解决:** 增加中间层。
368 |
369 | **关键代码:** 实现与被代理类组合。
370 |
371 | **应用实例:**
372 |
373 | 1、Windows 里面的快捷方式。
374 |
375 | 2、猪八戒去找高翠兰结果是孙悟空变的,可以这样理解:把高翠兰的外貌抽象出来,高翠兰本人和孙悟空都实现了这个接口,猪八戒访问高翠兰的时候看不出来这个是孙悟空,所以说孙悟空是高翠兰代理类。
376 |
377 | 3、买火车票不一定在火车站买,也可以去代售点。
378 |
379 | 4、一张支票或银行存单是账户中资金的代理。支票在市场交易中用来代替现金,并提供对签发人账号上资金的控制。
380 |
381 | 5、spring aop。
382 |
383 | **优点:** 1、职责清晰。 2、高扩展性。 3、智能化。
384 |
385 | **缺点:**
386 |
387 | 1、由于在客户端和真实主题之间增加了代理对象,因此有些类型的代理模式可能会造成请求的处理速度变慢。
388 |
389 | 2、实现代理模式需要额外的工作,有些代理模式的实现非常复杂。
390 |
391 | **使用场景:** 按职责来划分,通常有以下使用场景: 1、远程代理。 2、虚拟代理。 3、Copy-on-Write 代理。 4、保护(Protect or Access)代理。 5、Cache代理。 6、防火墙(Firewall)代理。 7、同步化(Synchronization)代理。 8、智能引用(Smart Reference)代理。
392 |
393 | **注意事项:**
394 |
395 | 1、和适配器模式的区别:适配器模式主要改变所考虑对象的接口,而代理模式不能改变所代理类的接口。
396 |
397 | 2、和装饰器模式的区别:装饰器模式为了增强功能,而代理模式是为了加以控制。
398 |
399 |
400 |
401 | ## 问:说一说外观模式?
402 |
403 | **参考答案:**
404 |
405 | 外观模式(Facade Pattern)隐藏系统的复杂性,并向客户端提供了一个客户端可以访问系统的接口。这种类型的设计模式属于结构型模式,它向现有的系统添加一个接口,来隐藏系统的复杂性。
406 |
407 | 这种模式涉及到一个单一的类,该类提供了客户端请求的简化方法和对现有系统类方法的委托调用。
408 | **意图:** 为子系统中的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
409 |
410 | **主要解决:** 降低访问复杂系统的内部子系统时的复杂度,简化客户端与之的接口。
411 |
412 | **何时使用:**
413 |
414 | 1、客户端不需要知道系统内部的复杂联系,整个系统只需提供一个"接待员"即可。
415 |
416 | 2、定义系统的入口。
417 |
418 | **如何解决:** 客户端不与系统耦合,外观类与系统耦合。
419 |
420 | **关键代码:** 在客户端和复杂系统之间再加一层,这一层将调用顺序、依赖关系等处理好。
421 |
422 | **应用实例:**
423 |
424 | 1、去医院看病,可能要去挂号、门诊、划价、取药,让患者或患者家属觉得很复杂,如果有提供接待人员,只让接待人员来处理,就很方便。
425 |
426 | 2、JAVA 的三层开发模式。
427 |
428 | **优点:**
429 |
430 | 1、减少系统相互依赖。 2、提高灵活性。 3、提高了安全性。
431 |
432 | **缺点:** 不符合开闭原则,如果要改东西很麻烦,继承重写都不合适。
433 |
434 | **使用场景:**
435 |
436 | 1、为复杂的模块或子系统提供外界访问的模块。
437 |
438 | 2、子系统相对独立。
439 |
440 | 3、预防低水平人员带来的风险。
441 |
442 | **注意事项:** 在层次化结构中,可以使用外观模式定义系统中每一层的入口。
443 |
444 |
445 |
446 | ## 问:说一说桥接模式?
447 |
448 | **参考答案:**
449 |
450 | 桥接(Bridge)是用于把抽象化与实现化解耦,使得二者可以独立变化。这种类型的设计模式属于结构型模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。
451 |
452 | 这种模式涉及到一个作为桥接的接口,使得实体类的功能独立于接口实现类。这两种类型的类可被结构化改变而互不影响。
453 | **意图:** 将抽象部分与实现部分分离,使它们都可以独立的变化。
454 |
455 | **主要解决:** 在有多种可能会变化的情况下,用继承会造成类爆炸问题,扩展起来不灵活。
456 |
457 | **何时使用:** 实现系统可能有多个角度分类,每一种角度都可能变化。
458 |
459 | **如何解决:** 把这种多角度分类分离出来,让它们独立变化,减少它们之间耦合。
460 |
461 | **关键代码:** 抽象类依赖实现类。
462 |
463 | **应用实例:**
464 |
465 | 1、猪八戒从天蓬元帅转世投胎到猪,转世投胎的机制将尘世划分为两个等级,即:灵魂和肉体,前者相当于抽象化,后者相当于实现化。生灵通过功能的委派,调用肉体对象的功能,使得生灵可以动态地选择。
466 |
467 | 2、墙上的开关,可以看到的开关是抽象的,不用管里面具体怎么实现的。
468 |
469 | **优点:**
470 |
471 | 1、抽象和实现的分离。 2、优秀的扩展能力。 3、实现细节对客户透明。
472 |
473 | **缺点:** 桥接模式的引入会增加系统的理解与设计难度,由于聚合关联关系建立在抽象层,要求开发者针对抽象进行设计与编程。
474 |
475 | **使用场景:**
476 |
477 | 1、如果一个系统需要在构件的抽象化角色和具体化角色之间增加更多的灵活性,避免在两个层次之间建立静态的继承联系,通过桥接模式可以使它们在抽象层建立一个关联关系。
478 |
479 | 2、对于那些不希望使用继承或因为多层次继承导致系统类的个数急剧增加的系统,桥接模式尤为适用。
480 |
481 | 3、一个类存在两个独立变化的维度,且这两个维度都需要进行扩展。
482 |
483 | **注意事项:** 对于两个独立变化的维度,使用桥接模式再适合不过了。
484 |
485 |
486 |
487 | ## 问:说一说组合模式?
488 |
489 | **参考答案:**
490 |
491 | 组合模式(Composite Pattern),又叫部分整体模式,是用于把一组相似的对象当作一个单一的对象。组合模式依据树形结构来组合对象,用来表示部分以及整体层次。这种类型的设计模式属于结构型模式,它创建了对象组的树形结构。
492 |
493 | 这种模式创建了一个包含自己对象组的类。该类提供了修改相同对象组的方式。
494 |
495 | **意图:** 将对象组合成树形结构以表示"部分-整体"的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
496 |
497 | **主要解决:** 它在我们树型结构的问题中,模糊了简单元素和复杂元素的概念,客户程序可以像处理简单元素一样来处理复杂元素,从而使得客户程序与复杂元素的内部结构解耦。
498 |
499 | **何时使用:**
500 |
501 | 1、您想表示对象的部分-整体层次结构(树形结构)。
502 |
503 | 2、您希望用户忽略组合对象与单个对象的不同,用户将统一地使用组合结构中的所有对象。
504 |
505 | **如何解决:** 树枝和叶子实现统一接口,树枝内部组合该接口。
506 |
507 | **关键代码:** 树枝内部组合该接口,并且含有内部属性 List,里面放 Component。
508 |
509 | **应用实例:**
510 |
511 | 1、算术表达式包括操作数、操作符和另一个操作数,其中,另一个操作符也可以是操作数、操作符和另一个操作数。
512 |
513 | 2、在 JAVA AWT 和 SWING 中,对于 Button 和 Checkbox 是树叶,Container 是树枝。
514 |
515 | **优点:**
516 |
517 | 1、高层模块调用简单。 2、节点自由增加。
518 |
519 | **缺点:** 在使用组合模式时,其叶子和树枝的声明都是实现类,而不是接口,违反了依赖倒置原则。
520 |
521 | **使用场景:** 部分、整体场景,如树形菜单,文件、文件夹的管理。
522 |
523 | **注意事项:** 定义时为具体类。
524 |
525 |
526 |
527 | ## 问:说一说享元模式?
528 |
529 | **参考答案:**
530 |
531 | 享元模式(Flyweight Pattern)主要用于减少创建对象的数量,以减少内存占用和提高性能。这种类型的设计模式属于结构型模式,它提供了减少对象数量从而改善应用所需的对象结构的方式。
532 |
533 | 享元模式尝试重用现有的同类对象,如果未找到匹配的对象,则创建新对象。
534 |
535 | **意图:** 运用共享技术有效地支持大量细粒度的对象。
536 |
537 | **主要解决:** 在有大量对象时,有可能会造成内存溢出,我们把其中共同的部分抽象出来,如果有相同的业务请求,直接返回在内存中已有的对象,避免重新创建。
538 |
539 | **何时使用:**
540 |
541 | 1、系统中有大量对象。
542 |
543 | 2、这些对象消耗大量内存。
544 |
545 | 3、这些对象的状态大部分可以外部化。
546 |
547 | 4、这些对象可以按照内蕴状态分为很多组,当把外蕴对象从对象中剔除出来时,每一组对象都可以用一个对象来代替。
548 |
549 | 5、系统不依赖于这些对象身份,这些对象是不可分辨的。
550 |
551 | **如何解决:** 用唯一标识码判断,如果在内存中有,则返回这个唯一标识码所标识的对象。
552 |
553 | **关键代码:** 用 HashMap 存储这些对象。
554 |
555 | **应用实例:** 1、JAVA 中的 String,如果有则返回,如果没有则创建一个字符串保存在字符串缓存池里面。 2、数据库的数据池。
556 |
557 | **优点:** 大大减少对象的创建,降低系统的内存,使效率提高。
558 |
559 | **缺点:** 提高了系统的复杂度,需要分离出外部状态和内部状态,而且外部状态具有固有化的性质,不应该随着内部状态的变化而变化,否则会造成系统的混乱。
560 |
561 | **使用场景:** 1、系统有大量相似对象。 2、需要缓冲池的场景。
562 |
563 | **注意事项:** 1、注意划分外部状态和内部状态,否则可能会引起线程安全问题。 2、这些类必须有一个工厂对象加以控制。
564 |
565 |
566 |
567 | ## 问:说一说策略模式?
568 |
569 | **参考答案:**
570 |
571 | 在策略模式(Strategy Pattern)中,一个类的行为或其算法可以在运行时更改。这种类型的设计模式属于行为型模式。
572 |
573 | 在策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 context 对象的执行算法。
574 |
575 | **意图:** 定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。
576 |
577 | **主要解决:** 在有多种算法相似的情况下,使用 if...else 所带来的复杂和难以维护。
578 |
579 | **何时使用:** 一个系统有许多许多类,而区分它们的只是他们直接的行为。
580 |
581 | **如何解决:** 将这些算法封装成一个一个的类,任意地替换。
582 |
583 | **关键代码:** 实现同一个接口。
584 |
585 | **应用实例:**
586 |
587 | 1、诸葛亮的锦囊妙计,每一个锦囊就是一个策略。
588 |
589 | 2、旅行的出游方式,选择骑自行车、坐汽车,每一种旅行方式都是一个策略。
590 |
591 | 3、JAVA AWT 中的 LayoutManager。
592 |
593 | **优点:**
594 |
595 | 1、算法可以自由切换。 2、避免使用多重条件判断。 3、扩展性良好。
596 |
597 | **缺点:**
598 |
599 | 1、策略类会增多。 2、所有策略类都需要对外暴露。
600 |
601 | **使用场景:**
602 |
603 | 1、如果在一个系统里面有许多类,它们之间的区别仅在于它们的行为,那么使用策略模式可以动态地让一个对象在许多行为中选择一种行为。
604 |
605 | 2、一个系统需要动态地在几种算法中选择一种。
606 |
607 | 3、如果一个对象有很多的行为,如果不用恰当的模式,这些行为就只好使用多重的条件选择语句来实现。
608 |
609 | **注意事项:** 如果一个系统的策略多于四个,就需要考虑使用混合模式,解决策略类膨胀的问题。
610 |
611 |
612 |
613 | ## 问:说一说模板方法模式?
614 |
615 | **参考答案:**
616 |
617 | 在模板模式(Template Method Pattern)中,一个抽象类公开定义了执行它的方法的方式/模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行。这种类型的设计模式属于行为型模式。
618 |
619 | **意图:** 定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
620 |
621 | **主要解决:** 一些方法通用,却在每一个子类都重新写了这一方法。
622 |
623 | **何时使用:** 有一些通用的方法。
624 |
625 | **如何解决:** 将这些通用算法抽象出来。
626 |
627 | **关键代码:** 在抽象类实现,其他步骤在子类实现。
628 |
629 | **应用实例:**
630 |
631 | 1、在造房子的时候,地基、走线、水管都一样,只有在建筑的后期才有加壁橱加栅栏等差异。
632 |
633 | 2、spring 中对 Hibernate 的支持,将一些已经定好的方法封装起来,比如开启事务、获取 Session、关闭 Session 等,程序员不重复写那些已经规范好的代码,直接丢一个实体就可以保存。
634 |
635 | **优点:**
636 |
637 | 1、封装不变部分,扩展可变部分。 2、提取公共代码,便于维护。 3、行为由父类控制,子类实现。
638 |
639 | **缺点:** 每一个不同的实现都需要一个子类来实现,导致类的个数增加,使得系统更加庞大。
640 |
641 | **使用场景:**
642 |
643 | 1、有多个子类共有的方法,且逻辑相同。 2、重要的、复杂的方法,可以考虑作为模板方法。
644 |
645 | **注意事项:** 为防止恶意操作,一般模板方法都加上 final 关键词。
646 |
647 |
648 |
649 | ## 问:说一说观察者模式?
650 |
651 | **参考答案:**
652 |
653 | 当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知它的依赖对象。观察者模式属于行为型模式。
654 |
655 | **意图:** 定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
656 |
657 | **主要解决:** 一个对象状态改变给其他对象通知的问题,而且要考虑到易用和低耦合,保证高度的协作。
658 |
659 | **何时使用:** 一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知,进行广播通知。
660 |
661 | **如何解决:** 使用面向对象技术,可以将这种依赖关系弱化。
662 |
663 | **关键代码:** 在抽象类里有一个 ArrayList 存放观察者们。
664 |
665 | **应用实例:**
666 |
667 | 1、拍卖的时候,拍卖师观察最高标价,然后通知给其他竞价者竞价。
668 |
669 | 2、西游记里面悟空请求菩萨降服红孩儿,菩萨洒了一地水招来一个老乌龟,这个乌龟就是观察者,他观察菩萨洒水这个动作。
670 |
671 | **优点:**
672 |
673 | 1、观察者和被观察者是抽象耦合的。 2、建立一套触发机制。
674 |
675 | **缺点:**
676 |
677 | 1、如果一个被观察者对象有很多的直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。
678 |
679 | 2、如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。
680 |
681 | 3、观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
682 |
683 | **使用场景:**
684 |
685 | 1、一个抽象模型有两个方面,其中一个方面依赖于另一个方面。将这些方面封装在独立的对象中使它们可以各自独立地改变和复用。
686 |
687 | 2、一个对象的改变将导致其他一个或多个对象也发生改变,而不知道具体有多少对象将发生改变,可以降低对象之间的耦合度。
688 |
689 | 3、一个对象必须通知其他对象,而并不知道这些对象是谁。
690 |
691 | 4、需要在系统中创建一个触发链,A对象的行为将影响B对象,B对象的行为将影响C对象……,可以使用观察者模式创建一种链式触发机制。
692 |
693 | **注意事项:**
694 |
695 | 1、JAVA 中已经有了对观察者模式的支持类。
696 |
697 | 2、避免循环引用。
698 |
699 | 3、如果顺序执行,某一观察者错误会导致系统卡壳,一般采用异步方式。
700 |
701 |
702 |
703 | ## 问:说一说迭代器模式?
704 |
705 | **参考答案:**
706 |
707 | 迭代器模式(Iterator Pattern)是 Java 和 .Net 编程环境中非常常用的设计模式。这种模式用于顺序访问集合对象的元素,不需要知道集合对象的底层表示。
708 |
709 | **意图:** 提供一种方法顺序访问一个聚合对象中各个元素, 而又无须暴露该对象的内部表示。
710 |
711 | **主要解决:** 不同的方式来遍历整个整合对象。
712 |
713 | **何时使用:** 遍历一个聚合对象。
714 |
715 | **如何解决:** 把在元素之间游走的责任交给迭代器,而不是聚合对象。
716 |
717 | **关键代码:** 定义接口:hasNext, next。
718 |
719 | **应用实例:** JAVA 中的 iterator。
720 |
721 | **优点:**
722 |
723 | 1、它支持以不同的方式遍历一个聚合对象。
724 |
725 | 2、迭代器简化了聚合类。
726 |
727 | 3、在同一个聚合上可以有多个遍历。
728 |
729 | 4、在迭代器模式中,增加新的聚合类和迭代器类都很方便,无须修改原有代码。
730 |
731 | **缺点:** 由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
732 |
733 | **使用场景:**
734 |
735 | 1、访问一个聚合对象的内容而无须暴露它的内部表示。
736 |
737 | 2、需要为聚合对象提供多种遍历方式。 3、为遍历不同的聚合结构提供一个统一的接口。
738 |
739 | **注意事项:** 迭代器模式就是分离了集合对象的遍历行为,抽象出一个迭代器类来负责,这样既可以做到不暴露集合的内部结构,又可让外部代码透明地访问集合内部的数据。
740 |
741 |
742 |
743 | ## 问:说一说责任链模式?
744 |
745 | **参考答案:**
746 |
747 | 顾名思义,责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。
748 |
749 | 在这种模式中,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推。
750 |
751 | **意图:** 避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。
752 |
753 | **主要解决:** 职责链上的处理者负责处理请求,客户只需要将请求发送到职责链上即可,无须关心请求的处理细节和请求的传递,所以职责链将请求的发送者和请求的处理者解耦了。
754 |
755 | **何时使用:** 在处理消息的时候以过滤很多道。
756 |
757 | **如何解决:** 拦截的类都实现统一接口。
758 |
759 | **关键代码:** Handler 里面聚合它自己,在 HandlerRequest 里判断是否合适,如果没达到条件则向下传递,向谁传递之前 set 进去。
760 |
761 | **应用实例:**
762 |
763 | 1、红楼梦中的"击鼓传花"。
764 |
765 | 2、JS 中的事件冒泡。
766 |
767 | 3、JAVA WEB 中 Apache Tomcat 对 Encoding 的处理,Struts2 的拦截器,jsp servlet 的 Filter。
768 |
769 | **优点:**
770 |
771 | 1、降低耦合度。它将请求的发送者和接收者解耦。
772 |
773 | 2、简化了对象。使得对象不需要知道链的结构。
774 |
775 | 3、增强给对象指派职责的灵活性。通过改变链内的成员或者调动它们的次序,允许动态地新增或者删除责任。
776 |
777 | 4、增加新的请求处理类很方便。
778 |
779 | **缺点:**
780 |
781 | 1、不能保证请求一定被接收。
782 |
783 | 2、系统性能将受到一定影响,而且在进行代码调试时不太方便,可能会造成循环调用。
784 |
785 | 3、可能不容易观察运行时的特征,有碍于除错。
786 |
787 | **使用场景:**
788 |
789 | 1、有多个对象可以处理同一个请求,具体哪个对象处理该请求由运行时刻自动确定。
790 |
791 | 2、在不明确指定接收者的情况下,向多个对象中的一个提交一个请求。
792 |
793 | 3、可动态指定一组对象处理请求。
794 |
795 | ## 问:说一说命令模式?
796 |
797 | **参考答案:**
798 |
799 | 命令模式(Command Pattern)是一种数据驱动的设计模式,它属于行为型模式。请求以命令的形式包裹在对象中,并传给调用对象。调用对象寻找可以处理该命令的合适的对象,并把该命令传给相应的对象,该对象执行命令。
800 |
801 | **意图:** 将一个请求封装成一个对象,从而使您可以用不同的请求对客户进行参数化。
802 |
803 | **主要解决:** 在软件系统中,行为请求者与行为实现者通常是一种紧耦合的关系,但某些场合,比如需要对行为进行记录、撤销或重做、事务等处理时,这种无法抵御变化的紧耦合的设计就不太合适。
804 |
805 | **何时使用:** 在某些场合,比如要对行为进行"记录、撤销/重做、事务"等处理,这种无法抵御变化的紧耦合是不合适的。在这种情况下,如何将"行为请求者"与"行为实现者"解耦?将一组行为抽象为对象,可以实现二者之间的松耦合。
806 |
807 | **如何解决:** 通过调用者调用接受者执行命令,顺序:调用者→接受者→命令。
808 |
809 | **关键代码:** 定义三个角色:1、received 真正的命令执行对象 2、Command 3、invoker 使用命令对象的入口
810 |
811 | **应用实例:** struts 1 中的 action 核心控制器 ActionServlet 只有一个,相当于 Invoker,而模型层的类会随着不同的应用有不同的模型类,相当于具体的 Command。
812 |
813 | **优点:**
814 |
815 | 1、降低了系统耦合度。 2、新的命令可以很容易添加到系统中去。
816 |
817 | **缺点:** 使用命令模式可能会导致某些系统有过多的具体命令类。
818 |
819 | **使用场景:**
820 |
821 | 认为是命令的地方都可以使用命令模式,比如: 1、GUI 中每一个按钮都是一条命令。 2、模拟 CMD。
822 |
823 | **注意事项:** 系统需要支持命令的撤销(Undo)操作和恢复(Redo)操作,也可以考虑使用命令模式。
824 |
825 |
826 |
827 | ##问:说一说备忘录模式?
828 |
829 | **参考答案:**
830 |
831 | 备忘录模式(Memento Pattern)保存一个对象的某个状态,以便在适当的时候恢复对象。
832 |
833 | **意图:** 在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。
834 |
835 | **主要解决:** 所谓备忘录模式就是在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样可以在以后将对象恢复到原先保存的状态。
836 |
837 | **何时使用:** 很多时候我们总是需要记录一个对象的内部状态,这样做的目的就是为了允许用户取消不确定或者错误的操作,能够恢复到他原先的状态,使得他有"后悔药"可吃。
838 |
839 | **如何解决:** 通过一个备忘录类专门存储对象状态。
840 |
841 | **关键代码:** 客户不与备忘录类耦合,与备忘录管理类耦合。
842 |
843 | **应用实例:**
844 |
845 | 1、后悔药。 2、打游戏时的存档。 3、Windows 里的 ctri + z。 4、IE 中的后退。 4、数据库的事务管理。
846 |
847 | **优点:**
848 |
849 | 1、给用户提供了一种可以恢复状态的机制,可以使用户能够比较方便地回到某个历史的状态。
850 |
851 | 2、实现了信息的封装,使得用户不需要关心状态的保存细节。
852 |
853 | **缺点:** 消耗资源。如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存。
854 |
855 | **使用场景:**
856 |
857 | 1、需要保存/恢复数据的相关状态场景。 2、提供一个可回滚的操作。
858 |
859 | **注意事项:**
860 |
861 | 1、为了符合迪米特原则,还要增加一个管理备忘录的类。
862 |
863 | 2、为了节约内存,可使用原型模式+备忘录模式。
864 |
865 |
866 |
867 | ## 问:说一说状态模式?
868 |
869 | **参考答案:**
870 |
871 | 在状态模式(State Pattern)中,类的行为是基于它的状态改变的。这种类型的设计模式属于行为型模式。
872 |
873 | 在状态模式中,我们创建表示各种状态的对象和一个行为随着状态对象改变而改变的 context 对象。
874 |
875 | **意图:** 允许对象在内部状态发生改变时改变它的行为,对象看起来好像修改了它的类。
876 |
877 | **主要解决:** 对象的行为依赖于它的状态(属性),并且可以根据它的状态改变而改变它的相关行为。
878 |
879 | **何时使用:** 代码中包含大量与对象状态有关的条件语句。
880 |
881 | **如何解决:** 将各种具体的状态类抽象出来。
882 |
883 | **关键代码:**
884 |
885 | 通常命令模式的接口中只有一个方法。而状态模式的接口中有一个或者多个方法。而且,状态模式的实现类的方法,一般返回值,或者是改变实例变量的值。也就是说,状态模式一般和对象的状态有关。实现类的方法有不同的功能,覆盖接口中的方法。状态模式和命令模式一样,也可以用于消除 if...else 等条件选择语句。
886 |
887 | **应用实例:**
888 |
889 | 1、打篮球的时候运动员可以有正常状态、不正常状态和超常状态。
890 |
891 | 2、曾侯乙编钟中,'钟是抽象接口','钟A'等是具体状态,'曾侯乙编钟'是具体环境(Context)。
892 |
893 | **优点:**
894 |
895 | 1、封装了转换规则。
896 |
897 | 2、枚举可能的状态,在枚举状态之前需要确定状态种类。
898 |
899 | 3、将所有与某个状态有关的行为放到一个类中,并且可以方便地增加新的状态,只需要改变对象状态即可改变对象的行为。
900 |
901 | 4、允许状态转换逻辑与状态对象合成一体,而不是某一个巨大的条件语句块。
902 |
903 | 5、可以让多个环境对象共享一个状态对象,从而减少系统中对象的个数。
904 |
905 | **缺点:**
906 |
907 | 1、状态模式的使用必然会增加系统类和对象的个数。
908 |
909 | 2、状态模式的结构与实现都较为复杂,如果使用不当将导致程序结构和代码的混乱。
910 |
911 | 3、状态模式对"开闭原则"的支持并不太好,对于可以切换状态的状态模式,增加新的状态类需要修改那些负责状态转换的源代码,否则无法切换到新增状态,而且修改某个状态类的行为也需修改对应类的源代码。
912 |
913 | **使用场景:**
914 |
915 | 1、行为随状态改变而改变的场景。 2、条件、分支语句的代替者。
916 |
917 | **注意事项:** 在行为受状态约束的时候使用状态模式,而且状态不超过 5 个。
918 |
919 |
920 |
921 | ## 问:说一说访问者模式?
922 |
923 | **参考答案:**
924 |
925 | 在访问者模式(Visitor Pattern)中,我们使用了一个访问者类,它改变了元素类的执行算法。通过这种方式,元素的执行算法可以随着访问者改变而改变。这种类型的设计模式属于行为型模式。根据模式,元素对象已接受访问者对象,这样访问者对象就可以处理元素对象上的操作。
926 |
927 | **意图:** 主要将数据结构与数据操作分离。
928 |
929 | **主要解决:** 稳定的数据结构和易变的操作耦合问题。
930 |
931 | **何时使用:** 需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作"污染"这些对象的类,使用访问者模式将这些封装到类中。
932 |
933 | **如何解决:** 在被访问的类里面加一个对外提供接待访问者的接口。
934 |
935 | **关键代码:** 在数据基础类里面有一个方法接受访问者,将自身引用传入访问者。
936 |
937 | **应用实例:** 您在朋友家做客,您是访问者,朋友接受您的访问,您通过朋友的描述,然后对朋友的描述做出一个判断,这就是访问者模式。
938 |
939 | **优点:**
940 |
941 | 1、符合单一职责原则。 2、优秀的扩展性。 3、灵活性。
942 |
943 | **缺点:**
944 |
945 | 1、具体元素对访问者公布细节,违反了迪米特原则。
946 |
947 | 2、具体元素变更比较困难。
948 |
949 | 3、违反了依赖倒置原则,依赖了具体类,没有依赖抽象。
950 |
951 | **使用场景:**
952 |
953 | 1、对象结构中对象对应的类很少改变,但经常需要在此对象结构上定义新的操作。
954 |
955 | 2、需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作"污染"这些对象的类,也不希望在增加新操作时修改这些类。
956 |
957 | **注意事项:** 访问者可以对功能进行统一,可以做报表、UI、拦截器与过滤器。
958 |
959 |
960 |
961 | ## 问:说一说中介者模式?
962 |
963 | **参考答案:**
964 |
965 | 中介者模式(Mediator Pattern)是用来降低多个对象和类之间的通信复杂性。这种模式提供了一个中介类,该类通常处理不同类之间的通信,并支持松耦合,使代码易于维护。中介者模式属于行为型模式。
966 |
967 | **意图:** 用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
968 |
969 | **主要解决:** 对象与对象之间存在大量的关联关系,这样势必会导致系统的结构变得很复杂,同时若一个对象发生改变,我们也需要跟踪与之相关联的对象,同时做出相应的处理。
970 |
971 | **何时使用:** 多个类相互耦合,形成了网状结构。
972 |
973 | **如何解决:** 将上述网状结构分离为星型结构。
974 |
975 | **关键代码:** 对象 Colleague 之间的通信封装到一个类中单独处理。
976 |
977 | **应用实例:**
978 |
979 | 1、中国加入 WTO 之前是各个国家相互贸易,结构复杂,现在是各个国家通过 WTO 来互相贸易。
980 |
981 | 2、机场调度系统。
982 |
983 | 3、MVC 框架,其中C(控制器)就是 M(模型)和 V(视图)的中介者。
984 |
985 | **优点:**
986 |
987 | 1、降低了类的复杂度,将一对多转化成了一对一。 2、各个类之间的解耦。 3、符合迪米特原则。
988 |
989 | **缺点:** 中介者会庞大,变得复杂难以维护。
990 |
991 | **使用场景:**
992 |
993 | 1、系统中对象之间存在比较复杂的引用关系,导致它们之间的依赖关系结构混乱而且难以复用该对象。
994 |
995 | 2、想通过一个中间类来封装多个类中的行为,而又不想生成太多的子类。
996 |
997 | **注意事项:** 不应当在职责混乱的时候使用。
998 |
999 |
1000 |
1001 | ## 问:说一说解释器模式?
1002 |
1003 | **参考答案:**
1004 |
1005 | 解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在 SQL 解析、符号处理引擎等。
1006 |
1007 | **意图:** 给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子。
1008 |
1009 | **主要解决:** 对于一些固定文法构建一个解释句子的解释器。
1010 |
1011 | **何时使用:** 如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。
1012 |
1013 | **如何解决:** 构建语法树,定义终结符与非终结符。
1014 |
1015 | **关键代码:** 构建环境类,包含解释器之外的一些全局信息,一般是 HashMap。
1016 |
1017 | **应用实例:** 编译器、运算表达式计算。
1018 |
1019 | **优点:**
1020 |
1021 | 1、可扩展性比较好,灵活。 2、增加了新的解释表达式的方式。 3、易于实现简单文法。
1022 |
1023 | **缺点:**
1024 |
1025 | 1、可利用场景比较少。 2、对于复杂的文法比较难维护。 3、解释器模式会引起类膨胀。 4、解释器模式采用递归调用方法。
1026 |
1027 | **使用场景:**
1028 |
1029 | 1、可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。
1030 |
1031 | 2、一些重复出现的问题可以用一种简单的语言来进行表达。
1032 |
1033 | 3、一个简单语法需要解释的场景。
1034 |
--------------------------------------------------------------------------------