├── OperatingSystem
├── img
│ ├── d
│ ├── PCB.png
│ ├── Thread.jpg
│ ├── External.png
│ ├── Generics.png
│ ├── Internal.png
│ ├── Swapping.png
│ ├── Swapping2.png
│ ├── Switching.jpg
│ └── ThreadLevel.png
├── README.md
├── Part2.md
├── Part3.md
└── Part1.md
├── Java
├── img
│ ├── JVM.png
│ ├── Blocking.jpg
│ ├── Equals.png
│ ├── Generics.png
│ ├── Runtime.png
│ ├── Interface.png
│ ├── Collections.png
│ └── NonBlocking.jpg
├── README.md
├── Part1.md
├── Part2.md
├── Part3.md
└── Part4.md
├── Network
├── img
│ ├── CORS.png
│ ├── CORS2.png
│ ├── Cookie.png
│ ├── GetPost.png
│ └── HTTP_HTTPS.jpg
├── Part3.md
├── Part1.md
└── Part2.md
├── DataStructure
├── README.md
└── structure.md
├── ETC
└── README.md
├── Algorithm
└── README.md
├── Database
└── README.md
├── Security
└── README.md
├── DesignPattern
└── README.md
├── Javascript
└── README.md
├── README.md
├── Web
└── Web.md
└── Spring
└── README.md
/OperatingSystem/img/d:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/Java/img/JVM.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Java/img/JVM.png
--------------------------------------------------------------------------------
/Java/img/Blocking.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Java/img/Blocking.jpg
--------------------------------------------------------------------------------
/Java/img/Equals.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Java/img/Equals.png
--------------------------------------------------------------------------------
/Java/img/Generics.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Java/img/Generics.png
--------------------------------------------------------------------------------
/Java/img/Runtime.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Java/img/Runtime.png
--------------------------------------------------------------------------------
/Network/img/CORS.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Network/img/CORS.png
--------------------------------------------------------------------------------
/Network/img/CORS2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Network/img/CORS2.png
--------------------------------------------------------------------------------
/Java/img/Interface.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Java/img/Interface.png
--------------------------------------------------------------------------------
/Network/img/Cookie.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Network/img/Cookie.png
--------------------------------------------------------------------------------
/Network/img/GetPost.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Network/img/GetPost.png
--------------------------------------------------------------------------------
/Java/img/Collections.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Java/img/Collections.png
--------------------------------------------------------------------------------
/Java/img/NonBlocking.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Java/img/NonBlocking.jpg
--------------------------------------------------------------------------------
/Network/img/HTTP_HTTPS.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/Network/img/HTTP_HTTPS.jpg
--------------------------------------------------------------------------------
/OperatingSystem/img/PCB.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/OperatingSystem/img/PCB.png
--------------------------------------------------------------------------------
/OperatingSystem/img/Thread.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/OperatingSystem/img/Thread.jpg
--------------------------------------------------------------------------------
/OperatingSystem/img/External.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/OperatingSystem/img/External.png
--------------------------------------------------------------------------------
/OperatingSystem/img/Generics.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/OperatingSystem/img/Generics.png
--------------------------------------------------------------------------------
/OperatingSystem/img/Internal.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/OperatingSystem/img/Internal.png
--------------------------------------------------------------------------------
/OperatingSystem/img/Swapping.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/OperatingSystem/img/Swapping.png
--------------------------------------------------------------------------------
/OperatingSystem/img/Swapping2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/OperatingSystem/img/Swapping2.png
--------------------------------------------------------------------------------
/OperatingSystem/img/Switching.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/OperatingSystem/img/Switching.jpg
--------------------------------------------------------------------------------
/OperatingSystem/img/ThreadLevel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jihyuno301/tech-interview/HEAD/OperatingSystem/img/ThreadLevel.png
--------------------------------------------------------------------------------
/DataStructure/README.md:
--------------------------------------------------------------------------------
1 | # tech-interview
2 | 👨👨👧👧 개발자 전공 지식 & 기술 면접 대비
3 |
4 | #### 기술 면접 대비 전공 지식을 공부하는 Repository입니다.
5 |
6 | #### Collaborator
7 |
8 |
9 |
10 | ## 📌DataStructure
11 |
12 | * [Array]()
13 | * [LinkedList]()
14 | * [HashTable]()
15 | * [Stack]()
16 | * [Queue]()
17 | * [Graph]()
18 | * [Tree]()
19 | * [그래프(Graph)와 트리(Tree)의 차이점]()
20 | * [Binary Heap]()
21 | * [Red-Black Tree]()
22 | * [B+ Tree]()
23 |
--------------------------------------------------------------------------------
/OperatingSystem/README.md:
--------------------------------------------------------------------------------
1 | # tech-interview
2 | 👨👨👧👧 개발자 전공 지식 & 기술 면접 대비
3 |
4 | #### 기술 면접 대비 전공 지식을 공부하는 Repository입니다.
5 |
6 | #### Collaborator
7 |
8 |
9 |
10 | ## 📌Operating System
11 |
12 | * [프로세스와 스레드의 차이(Process vs Thread)]()
13 | * [멀티 프로세스 대신 멀티 스레드를 사용하는 이유]()
14 | * [Thread-safe]()
15 | * [동기화 객체의 종류]()
16 | * [뮤텍스와 세마포어의 차이]()
17 | * [CPU 스케줄링]()
18 | * [동기와 비동기]()
19 | * [프로세스 동기화]()
20 | * [메모리 관리 전략]()
21 | * [가상 메모리]()
22 | * [캐시의 지역성]()
23 | * [교착상태(데드락, Deadlock)의 개념과 조건]()
24 | * [사용자 수준 스레드와 커널 수준 스레드]()
25 | * [외부 단편화와 내부 단편화]()
26 | * [Context Switching]()
27 | * [Swapping]()
28 |
--------------------------------------------------------------------------------
/ETC/README.md:
--------------------------------------------------------------------------------
1 | # tech-interview
2 | 👨👨👧👧 개발자 전공 지식 & 기술 면접 대비
3 |
4 | #### 기술 면접 대비 전공 지식을 공부하는 Repository입니다.
5 |
6 | #### Collaborator
7 |
8 |
9 |
10 | ## 📌Network
11 |
12 | * [OSI 7계층]()
13 | * [TCP/IP의 개념]()
14 | * [TCP와 UDP]()
15 | * [TCP와 UDP의 헤더 분석]()
16 | * [TCP의 3-way-handshake와 4-way-handshake]()
17 | * [Q. TCP의 연결 설정 과정(3단계)과 연결 종료 과정(4단계)이 단계가 차이나는 이유?]()
18 | * [Q. 만약 Server에서 FIN 플래그를 전송하기 전에 전송한 패킷이 Routing 지연이나 패킷 유실로 인한 재전송 등으로 인해 FIN 패킷보다 늦게 도착하는 상황이 발생하면 어떻게 될까?]()
19 | * [Q. 초기 Sequence Number인 ISN을 0부터 시작하지 않고 난수를 생성해서 설정하는 이유?]()
20 | * [HTTP와 HTTPS]()
21 | * [HTTP 요청/응답 헤더]()
22 | * [CORS란]()
23 | * [GET 메서드와 POST 메서드]()
24 | * [쿠키(Cookie)와 세션(Session)]()
25 | * [DNS]()
26 | * [REST와 RESTful의 개념]()
27 | * [소켓(Socket)이란]()
28 | * [Socket.io와 WebSocket의 차이]()
29 | * [Frame, Packet, Segment, Datagram]()
30 |
--------------------------------------------------------------------------------
/Algorithm/README.md:
--------------------------------------------------------------------------------
1 | # tech-interview
2 | 👨👨👧👧 개발자 전공 지식 & 기술 면접 대비
3 |
4 | #### 기술 면접 대비 전공 지식을 공부하는 Repository입니다.
5 |
6 | #### Collaborator
7 |
8 |
9 |
10 | ## 📌Network
11 |
12 | * [OSI 7계층]()
13 | * [TCP/IP의 개념]()
14 | * [TCP와 UDP]()
15 | * [TCP와 UDP의 헤더 분석]()
16 | * [TCP의 3-way-handshake와 4-way-handshake]()
17 | * [Q. TCP의 연결 설정 과정(3단계)과 연결 종료 과정(4단계)이 단계가 차이나는 이유?]()
18 | * [Q. 만약 Server에서 FIN 플래그를 전송하기 전에 전송한 패킷이 Routing 지연이나 패킷 유실로 인한 재전송 등으로 인해 FIN 패킷보다 늦게 도착하는 상황이 발생하면 어떻게 될까?]()
19 | * [Q. 초기 Sequence Number인 ISN을 0부터 시작하지 않고 난수를 생성해서 설정하는 이유?]()
20 | * [HTTP와 HTTPS]()
21 | * [HTTP 요청/응답 헤더]()
22 | * [CORS란]()
23 | * [GET 메서드와 POST 메서드]()
24 | * [쿠키(Cookie)와 세션(Session)]()
25 | * [DNS]()
26 | * [REST와 RESTful의 개념]()
27 | * [소켓(Socket)이란]()
28 | * [Socket.io와 WebSocket의 차이]()
29 | * [Frame, Packet, Segment, Datagram]()
30 |
--------------------------------------------------------------------------------
/Database/README.md:
--------------------------------------------------------------------------------
1 | # tech-interview
2 | 👨👨👧👧 개발자 전공 지식 & 기술 면접 대비
3 |
4 | #### 기술 면접 대비 전공 지식을 공부하는 Repository입니다.
5 |
6 | #### Collaborator
7 |
8 |
9 |
10 | ## 📌Network
11 |
12 | * [OSI 7계층]()
13 | * [TCP/IP의 개념]()
14 | * [TCP와 UDP]()
15 | * [TCP와 UDP의 헤더 분석]()
16 | * [TCP의 3-way-handshake와 4-way-handshake]()
17 | * [Q. TCP의 연결 설정 과정(3단계)과 연결 종료 과정(4단계)이 단계가 차이나는 이유?]()
18 | * [Q. 만약 Server에서 FIN 플래그를 전송하기 전에 전송한 패킷이 Routing 지연이나 패킷 유실로 인한 재전송 등으로 인해 FIN 패킷보다 늦게 도착하는 상황이 발생하면 어떻게 될까?]()
19 | * [Q. 초기 Sequence Number인 ISN을 0부터 시작하지 않고 난수를 생성해서 설정하는 이유?]()
20 | * [HTTP와 HTTPS]()
21 | * [HTTP 요청/응답 헤더]()
22 | * [CORS란]()
23 | * [GET 메서드와 POST 메서드]()
24 | * [쿠키(Cookie)와 세션(Session)]()
25 | * [DNS]()
26 | * [REST와 RESTful의 개념]()
27 | * [소켓(Socket)이란]()
28 | * [Socket.io와 WebSocket의 차이]()
29 | * [Frame, Packet, Segment, Datagram]()
30 |
--------------------------------------------------------------------------------
/Security/README.md:
--------------------------------------------------------------------------------
1 | # tech-interview
2 | 👨👨👧👧 개발자 전공 지식 & 기술 면접 대비
3 |
4 | #### 기술 면접 대비 전공 지식을 공부하는 Repository입니다.
5 |
6 | #### Collaborator
7 |
8 |
9 |
10 | ## 📌Network
11 |
12 | * [OSI 7계층]()
13 | * [TCP/IP의 개념]()
14 | * [TCP와 UDP]()
15 | * [TCP와 UDP의 헤더 분석]()
16 | * [TCP의 3-way-handshake와 4-way-handshake]()
17 | * [Q. TCP의 연결 설정 과정(3단계)과 연결 종료 과정(4단계)이 단계가 차이나는 이유?]()
18 | * [Q. 만약 Server에서 FIN 플래그를 전송하기 전에 전송한 패킷이 Routing 지연이나 패킷 유실로 인한 재전송 등으로 인해 FIN 패킷보다 늦게 도착하는 상황이 발생하면 어떻게 될까?]()
19 | * [Q. 초기 Sequence Number인 ISN을 0부터 시작하지 않고 난수를 생성해서 설정하는 이유?]()
20 | * [HTTP와 HTTPS]()
21 | * [HTTP 요청/응답 헤더]()
22 | * [CORS란]()
23 | * [GET 메서드와 POST 메서드]()
24 | * [쿠키(Cookie)와 세션(Session)]()
25 | * [DNS]()
26 | * [REST와 RESTful의 개념]()
27 | * [소켓(Socket)이란]()
28 | * [Socket.io와 WebSocket의 차이]()
29 | * [Frame, Packet, Segment, Datagram]()
30 |
--------------------------------------------------------------------------------
/DesignPattern/README.md:
--------------------------------------------------------------------------------
1 | # tech-interview
2 | 👨👨👧👧 개발자 전공 지식 & 기술 면접 대비
3 |
4 | #### 기술 면접 대비 전공 지식을 공부하는 Repository입니다.
5 |
6 | #### Collaborator
7 |
8 |
9 |
10 | ## 📌Network
11 |
12 | * [OSI 7계층]()
13 | * [TCP/IP의 개념]()
14 | * [TCP와 UDP]()
15 | * [TCP와 UDP의 헤더 분석]()
16 | * [TCP의 3-way-handshake와 4-way-handshake]()
17 | * [Q. TCP의 연결 설정 과정(3단계)과 연결 종료 과정(4단계)이 단계가 차이나는 이유?]()
18 | * [Q. 만약 Server에서 FIN 플래그를 전송하기 전에 전송한 패킷이 Routing 지연이나 패킷 유실로 인한 재전송 등으로 인해 FIN 패킷보다 늦게 도착하는 상황이 발생하면 어떻게 될까?]()
19 | * [Q. 초기 Sequence Number인 ISN을 0부터 시작하지 않고 난수를 생성해서 설정하는 이유?]()
20 | * [HTTP와 HTTPS]()
21 | * [HTTP 요청/응답 헤더]()
22 | * [CORS란]()
23 | * [GET 메서드와 POST 메서드]()
24 | * [쿠키(Cookie)와 세션(Session)]()
25 | * [DNS]()
26 | * [REST와 RESTful의 개념]()
27 | * [소켓(Socket)이란]()
28 | * [Socket.io와 WebSocket의 차이]()
29 | * [Frame, Packet, Segment, Datagram]()
30 |
--------------------------------------------------------------------------------
/Javascript/README.md:
--------------------------------------------------------------------------------
1 | # tech-interview
2 | 👨👨👧👧 개발자 전공 지식 & 기술 면접 대비
3 |
4 | #### 기술 면접 대비 전공 지식을 공부하는 Repository입니다.
5 |
6 | #### Collaborator
7 |
8 |
9 |
10 | ## 📌Network
11 |
12 | * [OSI 7계층]()
13 | * [TCP/IP의 개념]()
14 | * [TCP와 UDP]()
15 | * [TCP와 UDP의 헤더 분석]()
16 | * [TCP의 3-way-handshake와 4-way-handshake]()
17 | * [Q. TCP의 연결 설정 과정(3단계)과 연결 종료 과정(4단계)이 단계가 차이나는 이유?]()
18 | * [Q. 만약 Server에서 FIN 플래그를 전송하기 전에 전송한 패킷이 Routing 지연이나 패킷 유실로 인한 재전송 등으로 인해 FIN 패킷보다 늦게 도착하는 상황이 발생하면 어떻게 될까?]()
19 | * [Q. 초기 Sequence Number인 ISN을 0부터 시작하지 않고 난수를 생성해서 설정하는 이유?]()
20 | * [HTTP와 HTTPS]()
21 | * [HTTP 요청/응답 헤더]()
22 | * [CORS란]()
23 | * [GET 메서드와 POST 메서드]()
24 | * [쿠키(Cookie)와 세션(Session)]()
25 | * [DNS]()
26 | * [REST와 RESTful의 개념]()
27 | * [소켓(Socket)이란]()
28 | * [Socket.io와 WebSocket의 차이]()
29 | * [Frame, Packet, Segment, Datagram]()
30 |
--------------------------------------------------------------------------------
/Java/README.md:
--------------------------------------------------------------------------------
1 | # tech-interview
2 | 👨👨👧👧 개발자 전공 지식 & 기술 면접 대비
3 |
4 | #### 기술 면접 대비 전공 지식을 공부하는 Repository입니다.
5 |
6 | #### Collaborator
7 |
8 |
9 |
10 | ## 📌Java
11 |
12 | * [java 프로그래밍이란](#java-프로그래밍이란)
13 | * [Java SE와 Java EE 애플리케이션 차이](#java-se와-java-ee-애플리케이션-차이)
14 | * [java와 c/c++의 차이점](#java와-c/c++의-차이점)
15 | * [java 언어의 장단점](#java-언어의-장단점)
16 | * [java의 접근 제어자의 종류와 특징](#java의-접근-제어자의-종류와-특징)
17 | * [java의 데이터 타입](#java의-데이터-타입)
18 | * [Wrapper class](#wrapper-class)
19 | * [OOP의 4가지 특징](#oop의-4가지-특징)
20 | * [OOP의 5대 원칙 (SOLID)](#oop의-5대-원칙)
21 | * [객체지향 프로그래밍과 절차지향 프로그래밍의 차이](#객체지향-프로그래밍과-절차지향-프로그래밍의-차이)
22 | * [객체지향(Object-Oriented)이란](#객체지향이란)
23 | * [java의 non-static 멤버와 static 멤버의 차이](#java의-non-static-멤버와-static-멤버의-차이)
24 | * [Q. java의 main 메서드가 static인 이유](#java의-main-메서드가-static인-이유)
25 | * [java의 final 키워드 (final/finally/finalize)](#java의-final-키워드)
26 | * [java의 제네릭(Generic)과 c++의 템플릿(Template)의 차이](#java의-제네릭과-c++의-템플릿의-차이)
27 | * [java의 가비지 컬렉션(Garbage Collection) 처리 방법](#java의-가비지-컬렉션-처리-방법)
28 | * [java 직렬화(Serialization)와 역직렬화(Deserialization)란 무엇인가](#java-직렬화와-역직렬화란-무엇인가)
29 | * [클래스, 객체, 인스턴스의 차이](#클래스-객체-인스턴스의-차이)
30 | * [객체(Object)란 무엇인가](#객체란-무엇인가)
31 | * [오버로딩과 오버라이딩의 차이(Overloading vs Overriding)](#오버로딩과-오버라이딩의-차이)
32 | * [Call by Reference와 Call by Value의 차이](#call-by-reference와-call-by-value의-차이)
33 | * [인터페이스와 추상 클래스의 차이(Interface vs Abstract Class)](#인터페이스와-추상-클래스의-차이)
34 | * [JVM 구조](#jvm-구조)
35 | * [Java Collections Framework](#java-collections-framework)
36 | * [java Map 인터페이스 구현체의 종류](#java-map-인터페이스-구현체의-종류)
37 | * [java Set 인터페이스 구현체의 종류](#java-set-인터페이스-구현체의-종류)
38 | * [java List 인터페이스 구현체의 종류](#java-list-인터페이스-구현체의-종류)
39 | * [Annotation](#annotation)
40 | * [String, StringBuilder, StringBuffer](#string-stringbuilder-stringbuffer)
41 | * [동기화와 비동기화의 차이(Syncronous vs Asyncronous)](#동기화와-비동기화의-차이)
42 | * [java에서 '=='와 'equals()'의 차이](#java에서-==와-equals의-차이)
43 | * [java의 리플렉션(Reflection) 이란](#java의-리플렉션-이란)
44 |
45 |
46 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # tech-interview
2 | 👨👨👧👧 개발자 전공 지식 & 기술 면접 대비
3 |
4 | #### 기술 면접 대비 전공 지식을 공부하는 Repository입니다.
5 |
6 | #### Collaborator
7 |
8 |
9 |
10 | ## 📌Network
11 |
12 | * [OSI 7계층](./Network/Part1.md#OSI-7계층)
13 | * [TCP/IP의 개념](./Network/Part1.md#TCPIP의-개념)
14 | * [TCP와 UDP](./Network/Part1.md#TCP와-UDP)
15 | * [TCP(흐름제어/혼잡제어)](./Network/Part1.md#TCP흐름제어-혼잡제어)
16 | * [TCP와 UDP의 헤더 분석](./Network/Part1.md#TCP와-UDP의-헤더-분석)
17 | * [TCP의 3-way-handshake와 4-way-handshake](./Network/Part1.md#TCP의-3-way-handshake와-4-way-handshake)
18 | * [Q. TCP의 연결 설정 과정(3단계)과 연결 종료 과정(4단계)이 단계가 차이나는 이유?]()
19 | * [Q. 만약 Server에서 FIN 플래그를 전송하기 전에 전송한 패킷이 Routing 지연이나 패킷 유실로 인한 재전송 등으로 인해 FIN 패킷보다 늦게 도착하는 상황이 발생하면 어떻게 될까?]()
20 | * [Q. 초기 Sequence Number인 ISN을 0부터 시작하지 않고 난수를 생성해서 설정하는 이유?]()
21 | * [HTTP와 HTTPS](./Network/Part2.md#http와-https)
22 | * [HTTP 요청/응답 헤더](./Network/Part2.md#http-요청-응답-헤더)
23 | * [CORS란](./Network/Part2.md#cors란)
24 | * [GET 메서드와 POST 메서드](./Network/Part2.md#get-메서드와-post-메서드)
25 | * [쿠키(Cookie)와 세션(Session)](./Network/Part2.md#쿠키와-세션)
26 | * [DNS](./Network/Part3.md#DNS란)
27 | * [REST와 RESTful의 개념](./Network/Part3.md#REST와-RESTful)
28 | * [소켓(Socket)이란](./Network/Part3.md#Socket이란)
29 | * [Socket.io와 WebSocket의 차이](./Network/Part3.md#양방향-통신)
30 | * [Frame, Packet, Segment, Datagram](./Network/Part3.md#Frame-Packet-Segment-Datagram)
31 |
32 |
33 |
34 | ## 📌Java
35 |
36 | * [java 프로그래밍이란](./Java/Part1.md#java-프로그래밍이란)
37 | * [Java SE와 Java EE 애플리케이션 차이](./Java/Part1.md#java-se와-java-ee-애플리케이션-차이)
38 | * [java와 c/c++의 차이점](./Java/Part1.md/#java와-c-c쁠쁠의-차이점)
39 | * [java 언어의 장단점](./Java/Part1.md/#java-언어의-장단점)
40 | * [java의 접근 제어자의 종류와 특징](./Java/Part1.md#java의-접근-제어자의-종류와-특징)
41 | * [java의 데이터 타입](./Java/Part1.md#java의-데이터-타입)
42 | * [Wrapper class](./Java/Part1.md#wrapper-class)
43 | * [OOP의 4가지 특징](./Java/Part2.md#oop의-4가지-특징)
44 | * [OOP의 5대 원칙 (SOLID)](./Java/Part2.md#oop의-5대-원칙)
45 | * [객체지향 프로그래밍과 절차지향 프로그래밍의 차이](#객체지향-프로그래밍과-절차지향-프로그래밍의-차이)
46 | * [객체지향(Object-Oriented)이란](#객체지향이란)
47 | * [java의 non-static 멤버와 static 멤버의 차이](#java의-non-static-멤버와-static-멤버의-차이)
48 | * [Q. java의 main 메서드가 static인 이유](#java의-main-메서드가-static인-이유)
49 | * [java의 final 키워드 (final/finally/finalize)](./Java/Part3.md#java의-final-키워드)
50 | * [java의 제네릭(Generic)과 c++의 템플릿(Template)의 차이](./Java/Part3.md#java의-제네릭과-c++의-템플릿의-차이)
51 | * [java의 가비지 컬렉션(Garbage Collection) 처리 방법](#java의-가비지-컬렉션-처리-방법)
52 | * [java 직렬화(Serialization)와 역직렬화(Deserialization)란 무엇인가](#java-직렬화와-역직렬화란-무엇인가)
53 | * [클래스, 객체, 인스턴스의 차이](#클래스-객체-인스턴스의-차이)
54 | * [객체(Object)란 무엇인가](#객체란-무엇인가)
55 | * [오버로딩과 오버라이딩의 차이(Overloading vs Overriding)](#오버로딩과-오버라이딩의-차이)
56 | * [Call by Reference와 Call by Value의 차이](#call-by-reference와-call-by-value의-차이)
57 | * [인터페이스와 추상 클래스의 차이(Interface vs Abstract Class)](#인터페이스와-추상-클래스의-차이)
58 | * [JVM 구조](./Java/Part4.md#jvm-구조)
59 | * [Java Collections Framework](./Java/Part4.md#java-collections-framework)
60 | * [java Map 인터페이스 구현체의 종류](./Java/Part4.md#java-map-인터페이스-구현체의-종류)
61 | * [java Set 인터페이스 구현체의 종류](./Java/Part4.md#java-set-인터페이스-구현체의-종류)
62 | * [java List 인터페이스 구현체의 종류](./Java/Part4.md#java-list-인터페이스-구현체의-종류)
63 | * [Annotation](./Java/Part4.md#annotation)
64 | * [String, StringBuilder, StringBuffer](./Java/Part4.md#string-stringbuilder-stringbuffer)
65 | * [동기화와 비동기화의 차이(Syncronous vs Asyncronous)](./Java/Part4.md#동기화와-비동기화의-차이)
66 | * [java에서 '=='와 'equals()'의 차이](./Java/Part4.md#java에서-==와-equals()의-차이)
67 | * [java의 리플렉션(Reflection) 이란](./Java/Part4.md#java의-리플렉션-이란)
68 |
69 |
70 |
71 | ## 📌Operating System
72 |
73 | * [프로세스와 스레드의 차이(Process vs Thread)](./OperatingSystem/Part1.md#프로세스와-스레드의-차이)
74 | * [멀티 프로세스 대신 멀티 스레드를 사용하는 이유](./OperatingSystem/Part1.md#멀티-프로세스-대신-멀티-스레드를-사용하는-이유)
75 | * [Thread-safe](./OperatingSystem/Part1.md#Thread-safe)
76 | * [동기화 객체의 종류](./OperatingSystem/Part1.md#동기화-객체의-종류)
77 | * [뮤텍스와 세마포어의 차이](./OperatingSystem/Part1.md#뮤텍스와-세마포어의-차이)
78 | * [CPU 스케줄링](./OperatingSystem/Part1.md#CPU-스케줄링)
79 | * [동기와 비동기]()
80 | * [프로세스 동기화]()
81 | * [메모리 관리 전략]()
82 | * [가상 메모리]()
83 | * [캐시의 지역성]()
84 | * [교착상태(데드락, Deadlock)의 개념과 조건](./OperatingSystem/Part3.md#교착상태의-개념과-조건)
85 | * [사용자 수준 스레드와 커널 수준 스레드](./OperatingSystem/Part3.md#사용자-수준-스레드,-커널-수준-스레드)
86 | * [외부 단편화와 내부 단편화](./OperatingSystem/Part3.md#외부-단편화와-내부-단편화)
87 | * [Context Switching](./OperatingSystem/Part3.md#context-switching)
88 | * [Swapping](./OperatingSystem/Part3.md#swapping)
89 |
90 |
91 |
92 | ## 📌Spring
93 |
94 | * [스프링 프레임워크란](./Spring/READMe.md#스프링-프레임워크란)
95 | * [Spring과 Spring Boot의 차이](./Spring/READMe.md#spring과-spring-boot의-차이)
96 | * [Container란](./Spring/READMe.md#container란)
97 | * [IOC(Inversion of Control, 제어의 역전)란](./Spring/READMe.md#ioc란)
98 | * [Bean이란](./Spring/READMe.md#bean이란)
99 | * [MVC 패턴이란](./Spring/READMe.md#mvc-패턴이란)
100 | * [MVC1과 MVC2 패턴차이](./Spring/READMe.md#MVC1과-MVC2-패턴차이)
101 | * [JSP와 서블릿 비교](./Spring/READMe.md#JSP와-서블릿-비교)
102 | * [Dispatcher Servlet](./Spring/READMe.md#Dispatcher-Servlet)
103 | * [Spring MVC 구조 흐름](./Spring/READMe.md#Spring-MVC-구조-흐름)
104 | * [DI(Dependency Injection, 의존성 주입)란](./Spring/READMe.md#di란)
105 | * [AOP(Aspect Oriented Programming)란](./Spring/READMe.md#aop란)
106 | * [POJO](./Spring/READMe.md#pojo)
107 | * [DAO와 DTO의 차이](./Spring/READMe.md#dao와-dto의-차이)
108 | * [Spring JDBC를 이용한 데이터 접근](./Spring/READMe.md#spring-jdbc를-이용한-데이터-접근)
109 | * [Annotation이란](./Spring/READMe.md#Annotation이란)
110 | * [Filter와 Interceptor 차이](./Spring/READMe.md#filter와-interceptor-차이)
111 |
112 |
113 |
--------------------------------------------------------------------------------
/Web/Web.md:
--------------------------------------------------------------------------------
1 | # Web
2 | **:book: Contents**
3 | * [Ajax란](#Ajax란)
4 | * [JSON과 XML차이](#JSON과-XML차이)
5 | * [REST API](#REST-API)
6 | * [쿠키와 세션](#쿠키와-세션)
7 | * [JWT](#JWT)
8 | * [쿠키와 세션과 JWT 차이](#쿠키와-세션과-JWT-차이)
9 | ---
10 |
11 | ### Ajax란
12 |
13 | * 기본적으로 HTTP 프로토콜은 클라이언트쪽에서 서버에 Request를 보내고 서버쪽에서 Response를 받으면 이어졌던 연결이 끊기게 된다.
14 | * 그래서 화면의 내용을 갱신하기 위해서는 다시 Request를 하고 Response를 하면서 **페이지 전체**를 갱신하게 된다.
15 | * 하지만 페이지의 일부분만 갱신할 경우에는 페이지 전체를 다시 다시 로드해야하기 때문에 엄청난 자원낭비와 시간낭비를 초래할 수 있다.
16 | * 이에 따라 Ajax 기술을 활용하여 HTML 페이지 전체가 아닌 일부분만 갱신할 수 있도록 XMLHTTPRequest 객체를 통해 서버에 Request 한다.
17 | * 이 경우에는 JSON이나 XML 형태로 필요한 데이터만 받아 갱신하기 때문에 그만큼의 자원과 시간을 아낄 수 있다.
18 |
19 | * 장점
20 | * 웹 페이지 속도 향상
21 | * 서버의 처리가 완료될 때까지 기다리지 않고 처리 가능하다.
22 | * 서버에서 데이터만 전송해오면 되기 때문에 전체적이 코딩의 양이 줄어든다.
23 | * 사진의 제목이나 태그를 페이지 리로드 없이 수정할 수 있다.
24 | * 단점
25 | * 히스토리 관리가 안된다(보안에 좀 더 신경을 써야한다)
26 | * 연속으로 데이터를 요청하면 서버부하가 증가할 수 있다
27 | * XML HttpRequest를 통해 통신을 하는 경우 사용자에게 아무런 진행 정보가 주어지지 않는다. 그래서 아직 요청이 완료되지 않았는데
28 | 사용자가 페이지를 떠나거나 오작동할 우려가 발생하게 된다.
29 |
30 |
31 | ### JSON과 XML차이
32 | 1. JSON이란
33 | * JavaScript Object Notation의 약자
34 | * JSON은 XML의 대안으로서 좀 더 쉽게 데이터를 교환하고 저장하기 위하여 만들어진 **텍스트 기반의 데이터 교환 표준**이다.
35 | * 텍스트 기반이기 때문에 어떠한 프로그래밍 언어에서도 JSON 데이터를 읽고 사용할 수 있다.
36 | * 사람과 기계 모두 읽기 편하도록 고안되었다. 그로 인해 브라우저 영역에서도 쉽고 빠르게 그 의미를 해석할 수 있다.
37 | 2. XML이란
38 | * XML은 HTML과 매우 비슷한 문자 기반의 마크업 언어(text-based markup language)이다.
39 | * 이 언어는 사람과 기계가 동시에 읽기 편한 구조로 되어 있다.
40 | * HTML처럼 데이터를 보여주는 보여주는 목적이 아닌, 데이터를 저장하고 전달할 목적으로만 만들어졌다.
41 |
42 | 3. 공통점
43 | * 둘 다 데이터를 저장하고 전달하기 위해 고안되었다.
44 | * 둘 다 기계뿐만 아니라 사람도 쉽게 읽을 수 있다.
45 | * 계층적인 구조를 가진다.
46 | * 다양한 프로그래밍 언어에 의해 파싱될 수 있다.
47 | * XMLHttpRequest 객체를 이용하여 서버로부터 데이터를 전송받을 수 있다.
48 | 4. 차이점
49 | * JSON의 구문이 XML 구문보다 더 짧다
50 | * JSON 데이터가 XML 데이터보다 더 빨리 읽고 쓸 수 있다.
51 | * XML은 배열을 사용할 수 없지만, JSON은 배열을 사용할 수 있다.
52 | * **But** JSON은 전송받은 **데이터의 무결성**을 사용자가 직접 검증해야 한다. 따라서 데이터의 검증이 필요한 곳에서는 스키마를 사용하여
53 | 데이터의 무결성을 검증할 수 있는 XML이 아직도 많이 사용되고 있다.
54 |
55 | > - [http://www.tcpschool.com/json/json_intro_xml](http://www.tcpschool.com/json/json_intro_xml)
56 |
57 |
58 | ### REST API
59 |
60 | 1. REST의 Method : POST(CREATE), GET(SELECT), PUT(UPDATE), DELETE(DELETE)
61 | 2. 리소스
62 | * http://myweb/users와 같은 URI
63 | * 모든 것을 Resource로 식별하고, 세부 Resource에는 id를 붙인다.
64 | 3. 메시지
65 | * JSON, XML과 같은 형태가 있다.
66 | 4. REST의 특징
67 | * HTTP 표준만 맞는다면, 어떠 기술도 가능한 Interface 스타일이다.
68 | * API 메시지만 보고, API를 이해할 수 있는 구조이다. (Resource, Method를 이용해 무슨 행위를 하는지 직관적으로 이해할 수 있다)
69 | * HTTP Session과 같은 컨텍스트 저장소에 상태 정보 저장 안함 => REST API 실행중 실패가 발생한 경우, Transaction 복구를 위해 기존의 상태를 저장할 필요가 있다. (POST Method 제외)
70 | > - [https://gyoogle.dev/blog/web-knowledge/REST%20API.html](https://gyoogle.dev/blog/web-knowledge/REST%20API.html)
71 |
72 | ### 쿠키와 세션
73 | 1. 인증 방식 순서
74 | 1. 사용자가 로그인을 한다.
75 | 2. 서버에서는 계정정보를 읽어 사용자를 확인한 후, 사용자의 고유한 ID값을 부여하여 세션 저장소에 저장한 후, 이와 연결되는 세션ID를 발행합니다.
76 | 3 사용자는 서버에서 해당 세션ID를 받아 쿠키에 저장을 한 후, 인증이 필요한 요청마다 쿠키를 헤더에 실어 보냅니다.
77 | 4. 서버에서는 쿠키를 받아 세션 저장소에서 대조를 한 후 대응되는 정보를 가져옵니다.
78 | 5. 인증이 완료되고 서버는 사용자에 맞는 데이터를 보내줍니다.
79 | 세션 쿠키 방식의 인증은 기본적으로 세션 저장소를 필요로 한다. 세션 저장소는 로그인을 했을 때 사용자의 정보를 저장하고 열쇠가 되는 세션 ID값을 만든다. 그리고 HTTP 헤더에 실어 사용자에게 돌려보낸다. 그러면 사용자는 쿠키로 보관하고 있다가 인증이 필요한 요청에 쿠키(세션ID)를 넣어 보낸다.
80 | * 세션ID를 쿠키라고 봐도 동일, 쿠키가 사용자 개념에서 더 큰 범주. 세션ID를 쿠키로 저장.
81 |
82 |
83 | 2. 장점
84 | * 세션/쿠키 방식은 기본적으로 쿠키를 매개로 인증을 거칩니다. 여기서 쿠키는 세션 저장소에 담긴 유저 정보를 얻기 위한 열쇠라고 보시면 됩니다.
85 | * 따라서 쿠키가 담긴 HTTP 요청이 도중에 노출되더라도 쿠키 자체(세션 ID)는 유의미한 값을 갖고있지 않습니다(중요 정보는 서버 세션에) 이는 위의 계정정보를 담아 인증을 거치는 것보단 안전해 보입니다.
86 |
87 | - 쿠키에 담긴 HTTP 요청이 도중에 노출이 되더라도 쿠키 자체(세션 ID)는 유의미한 값을 갖고 있지 않기 때문에 안전합니다.
88 | - 일일이 회원정보를 확인할 필요가 없어 바로 어떤 회원인지를 확인할 수 있어서 서버의 자원에 접근하기 용이합니다.
89 |
90 |
91 | 3. 단점
92 | * 쿠키 탈취 자체는 안전하지만, 만약에 HTTP 요청을 해커가 가로챈다면 그 안에 있는 쿠키를 가로채서 HTTP 요청을 보낼 수 있습니다.
93 | * (세션 하이재킹 공격) => HTTPS 사용, 세션에 유효기간을 넣어주기.
94 | * 서버에서 세션 저장소를 사용한다고 하기에 추가적인 저장공간을 필요로 하게되고 자연스럽게 부하도 높아질 것이다.
95 |
96 | ### JWT
97 |
98 | * 인증에 필요한 정보들을 암호화시킨 토큰을 말한다. Access Token을 HTTP 헤더에 실어 서버로 보내게 된다.
99 | * JWT 구성요소
100 | 1. Header : 위 3가지 정보를 암호화할 방식(alg), 타입(type) 등이 들어갑니다. (agl:HS256, type:jwt)
101 | 2. payload : 서버에 보내질 데이터. 유저 아이디, 유효기간 등이 들어갑니다.
102 | 3. Verify Signature : Base64로 인코딩한 Header와 Payload, SECRET KEY
103 |
104 | * 장점
105 | 1. 간편합니다. 세션/쿠키는 별도의 저장소의 관리가 필요합니다. 그러나 JWT는 발급한 후 검증만 하면 되기 때문에 추가 저장소가 필요 없습니다.
106 | 이는 Stateless 한 서버를 만드는 입장에서는 큰 강점입니다. 여기서 Stateless는 어떠한 별도의 저장소도 사용하지 않는, 즉 상태를 저장하지 않는 것을 의미합니다.
107 | 이는 서버를 확장하거나 유지,보수하는데 유리합니다.
108 |
109 | 2. 확장성이 뛰어납니다. 토큰 기반으로 하는 다른 인증 시스템에 접근이 가능합니다. 예를 들어 Facebook 로그인, Google 로그인 등은 모두 토큰을 기반으로 인증을 합니다.
110 | 이에 선택적으로 이름이나 이메일 등을 받을 수 있는 권한도 받을 수 있습니다.
111 |
112 | * 단점
113 | 1. 이미 발급된 JWT에 대해서는 돌이킬 수 없습니다. 세션/쿠키의 경우 만일 쿠키가 악의적으로 이용된다면, 해당하는 세션을 지워버리면 됩니다. 하지만 JWT는 한 번 발급되면 유효기간이 완료될 때 까지는 계속 사용이 가능합니다. 따라서 악의적인 사용자는 유효기간이 지나기 전까지 정보 탈취가 가능합니다.
114 | -> 해결책 : 기존의 Access Token의 유효기간을 짧게 하고 Refresh Token이라는 새로운 토큰을 발급합니다. 그렇게 되면 Access Token을 탈취당해도 상대적으로 피해를 줄일 수 있습니다.
115 |
116 | 2. Payload 정보가 제한적입니다. 위에서 언급했다시피 Payload는 따로 암호화되지 않기 때문에 디코딩하면 누구나 정보를 확인할 수 있습니다. (세션/쿠키 방식에서는 유저의 정보가 전부 서버의 저장소에 안전하게 보관됩니다) 따라서 유저의 중요한 정보들은 Payload에 넣을 수 없습니다.
117 | 3. JWT의 길이입니다. 세션/쿠키 방식에 비해 JWT의 길이는 깁니다. 따라서 인증이 필요한 요청이 많아질 수록 서버의 자원낭비가 발생하게 됩니다.
118 |
119 |
120 | ### 쿠키와 세션과 JWT 차이
121 |
122 | 세션/쿠키 방식과 가장 큰 차이점은 세션/쿠키는 세션 저장소에 유저의 정보를 넣는 반면, JWT는 토큰 안에 유저의 정보들이 넣는다는 점입니다. 물론 클라이언트 입장에서는 HTTP 헤더에 세션ID나 토큰을 실어서 보내준다는 점에서는 동일하나, 서버 측에서는 인증을 위해 암호화를 하냐, 별도의 저장소를 이용하냐는 차이가 발생합니다.
123 |
124 | > -[https://tansfil.tistory.com/58](https://tansfil.tistory.com/58)
125 |
--------------------------------------------------------------------------------
/DataStructure/structure.md:
--------------------------------------------------------------------------------
1 | # 5. DataStructure
2 | **:book: Contents**
3 | * [Array VS LinkedList]()
4 | * [Stack and Queue]()
5 | * [Tree]()
6 | * [Binary Tree]()
7 | * [Full Binary Tree]()
8 | * [Complete Binary Tree]()
9 | * [BST (Binary Search Tree)]()
10 | * [Binary Heap]()
11 | * [Red-Black Tree]()
12 | * [HashTable]()
13 | * [Graph]()
14 | * [그래프(Graph)와 트리(Tree)의 차이점]()
15 | * [B+ Tree]()
16 |
17 |
18 | ---
19 |
20 | ## Array
21 |
22 | 1. 장점
23 | - 가장 기본적인 자료구조로, 논리적 저장 순서와 물리적 저장 순서가 일치
24 | - 따라서, 인덱스(Index)로 해당 원소에 접근을 할 수 있음 (a[0] ...)
25 | - 그렇기 때문에 찾고자 하는 원소의 인덱스 값을 알고 있으면 Big-O(1)에 해당 원소로 접근이 가능
26 | 즉, random access가 가능하다는 장점이 있음
27 | 2. 단점
28 | - 삭제 또는 삽입의 과정에서는 해당 원소에 접근하여 작업을 완료한 뒤 (O(1)), 또 한가지의 작업을 추가적으로 해줘야 하기 때문에, 시간이 더 걸림
29 | - 만약, 배열의 원소 중 어느 원소를 삭제했다고 했을 때, 배열의 연속적인 특징이 깨지게 된다.
30 | - 따라서 삭제한 원소보다 큰 인덱스를 갖는 원소들을 shift 해줘야 하는 비용(cost)이 발생하고 이 경우의 시간 복잡도는 O(n)가 된다.
31 | - 그렇기 때문에 Array 자료구조에서 삭제 기능에 대한 시간 복잡도의 최악의 경우는 O(n)이 된다.
32 | - 삽입의 경우도 역시, 첫번째 자리에 새로운 원소를 추가하고자 한다면 모든 원소들의 인덱스를 1씩 shift 해줘야 하므로 이 경우도 O(n)의 시간을 요구하게 됨
33 |
34 | ## Linked List
35 |
36 | 1. 개념 및 장점
37 | - Array의 삽입, 삭제에서 발생하는 문제를 해결하기 위해 고안된 자료구조로 각각의 원소들은 자기 자신 다음에 어떤 원소가 있는지만을 기억하고 있다.
38 | - 따라서 이 부분만 다른 값으로 바꿔주면 삭제와 삽입을 O(1) 만에 해결할 수 있음
39 |
40 | 2. 단점
41 | - 원하는 위치에 삽입을 하고자하면 원하는 위치를 Search 과정에 있어서 첫번째 원소부터 다 확인해봐야 함 (Array와 달리 논리적 저장 순서와 물리적 저장 순서가 일치하지 않기 때문에)
42 | - 어떠한 원소를 삭제 또는 추가하고자 했을 때, 그 원소를 찾기 위해서 O(n)의 시간이 추가적으로 발생
43 | - 결국 LinkedList 자료구조는 search에도 O(n)의 시간 복잡도를 갖고, 삽입, 삭제에 대해서도 O(n)의 시간 복잡도를 갖는다.
44 | - 하지만, Tree 구조의 근간이 되는 자료구조로써, Tree에서 사용되었을 때 그 유용성이 드러남
45 |
46 | ## Stack and Queue
47 |
48 | ### Stack
49 | - 선형 자료구조의 일종으로 Last In First Out (LIFO). 즉, 나중에 들어간 원소가 먼저 나온다. 이것이 Stack의 가장 큰 특징
50 | - 차곡차곡 쌓이는 구조로 먼저 Stack에 들어가게 된 원소는 맨 바닥에 깔리게 된다.
51 | - 그렇기 때문에 늦게 들어간 녀석들은 그 위에 쌓이게 되고 호출 시 가장 위에 있는 녀석이 호출되는 구조
52 |
53 | ### Queue
54 | - 선형 자료구조의 일종으로 First In First Qut (FIFO). 즉, 먼저 들어간 놈이 먼저 나온다.
55 | - Stack과는 반대로 먼저 들어간 놈이 맨 앞에서 대기하고 있다가 먼저 나오게 되는 구조이다.
56 |
57 | ## Tree
58 |
59 | - 비선형 자료구조로 계층적 관계를 표현하는 자료구조로 무엇인가를 저장하고 꺼낸다는 사고보다는 자료구조의 표현에 집중한다.
60 | - 트리를 구성하고 있는 구성 요소들 (용어)
61 | - Node(노드) : 트리를 구성하고 있는 각각의 요소를 의미
62 | - Edge(간선) : 트리를 구성하기 위해 노드와 노드를 연결하는 선
63 | - Root Node(루트 노드) : 트리 구조에서 최상위에 있는 노드를 의미
64 | - Terminal Node(=leaf Node, 단말 노드) : 하위에 다른 노드가 연결되어 있지 않은 노드를 의미
65 | - Internal Node (내부노드, 비단말 노드) : 단말 노드를 제외한 모든 노드로 루트 노드를 포함
66 |
67 | ## Binary Tree (이진 트리)
68 |
69 | - 루트 노드를 중심으로 두 개의 서브 트리로 나눠짐 또한, 나눠진 두 서브 트리도 모두 이진 트리이어야 한다.
70 | - 트리에서는 각 층별로 숫자를 매겨서 이를 트리의 Level이라고 한다. 레벨의 값은 0부터 시작하고 따라서 루트 노드의 레벨은 0이다. 그리고 트리의 최고 레벨을 가리켜 해당 트리의 height(높이)라고 한다.
71 |
72 | ### Complete Binary Tree (완전 이진 트리)
73 |
74 | - 모든 레벨이 꽉 찬 이진 트리 (포화 이진 트리)
75 | - 모든 노드가 0개 혹은 2개의 자식 노드만을 갖는 이진 트리
76 | - 배열로 구성된 Binary Tree는 노드의 개수가 n개이고 root가 0이 아닌 1에서 시작할 때, i번째 노드에 대해서 parent(i) = i/2, left_child(i) = 2i, right_child(i) = 2i + 1의 index 값을 갖는다.
77 |
78 | ### BST (Binary Search Tree)
79 |
80 | 1. 규칙 (특정 데이터의 위치를 찾는데 사용)
81 | - 이진 탐색 트리의 노드에 저장된 키는 유일하다.
82 | - 부모의 키가 왼쪽 자식 노드의 키보다 크다.
83 | - 부모의 키가 오른쪽 자식 노드의 키보다 작다.
84 | - 왼쪽과 오른쪽 서브트리도 이진 탐색 트리이다.
85 | 2. 시간 복잡도
86 | - 탐색 연산 : O(log n) == O(h)
87 | - 트리의 높이를 하나씩 더해갈수록 추가할 수 있는 노드의 수가 두 배씩 증가하기 때문
88 | - 하지만, 이러한 이진 탐색 트리는 편항 트리가 될 수 있다. 저장 순서에 따라 계속 한 쪽으로만 노드가 추가되는 경우가 발생하기 때문
89 | - 이럴 경우 성능에 영향을 미치게 되며, 탐색의 Worst Case가 되고 시간 복잡도는 O(n)
90 | - 배열보다 많은 메모리를 사용하며 데이터를 저장했지만, 탐색에 필요한 시간 복잡도가 같게 되는 비효율적인 상황이 발생 이를 해결하기 위해 Rebalancing 기법이 등장
91 | - Rebalancing : 균형을 잡기 위한 트리 구조의 재조정 (이 기법을 구현한 트리에는 여러 종류가 존재하는데 그 중에서 하나가 Red-Black Tree!)
92 |
93 | ## Binary Heap
94 |
95 | 1. 특징
96 | - 자료구조의 일종으로 Tree의 형식을 하고 있으며, Tree 중에서도 배열에 기반한 Complete Binary Tree
97 | - 배열에 트리의 값들을 넣어줄 때, 0번째는 건너뛰고 1번 index부터 루트노트가 시작된다.
98 | - 이는 노드의 고유번호값과 배열의 index를 일치시켜 혼동을 줄이기 위함
99 | - Heap에는 최대 힙 (max heap), 최소 힙 (min heap) 두 종류가 존재
100 | - Max Heap : 각 노드의 값이 해당 children의 값보다 크거나 같은 complete binary tree (Min Heap은 그 반대!)
101 | 2. 시간 복잡도
102 | - 최대값을 찾는데 소요되는 시간 : O(1) ⇒ 루트 노드에 있는 값이 제일 크므로
103 | - 완전 이진 트리이기 때문에 배열을 사용해 효율적인 관리가 가능 (Random access가 가능)
104 | - 하지만, heap의 구조를 계속 유지하기 위해서는 제거된 루트 노드를 대체할 다른 노드가 필요 ⇒ 여기서 heap은 맨 마지막 노드를 루트 노드로 대체시킨 후, 다시 heapify 과정을 거쳐 heap 구조를 유지
105 | - 이런 경우에는 결국 O(log n)의 시간 복잡도로 최대값 또는 최소값에 접근할 수 있게 된다.
106 |
107 | ## Red Black Tree
108 |
109 | - BST를 기반으로하는 트리 형식의 자료구조
110 | - Red-Black Tree에 데이터를 저장하게 되면 search, insert, delete에 O(log n)의 시간 복잡도가 소요
111 | - 동일한 노드의 개수일 때, depth를 최소화하여 시간 복잡도를 줄이는 것이 핵심 아이디어
112 | - 동일한 노드의 개수일 때, depth가 최소가 되는 경우는 tree가 완전 이진 트리인 경우이다.
113 |
114 | ### Red-Black Tree의 정의
115 |
116 | Red-black Tree는 다음의 성질들을 만족하는 BST이다.
117 |
118 | 1. 각 노드는 Red or Black이라는 색깔을 갖는다.
119 | 2. Root node의 색깔은 black이다.
120 | 3. 각 leaf node는 black이다.
121 | 4. 어떤 노드의 색깔이 red라면 두 개의 children의 색깔은 모두 black이다.
122 | 5. 각 노드에 대해서 노드로부터 descendant leaves까지의 단순 경로는 모두 같은 수의 black nodes들을 포함하고 있다. 이를 해당 노드의 black-height라고 한다.
123 | (Black-Height : 노드 x로부터 노드 x를 포함하지 않은 leaf node까지의 simple path 상에 있는 black nodes들의 개수
124 |
125 | ### Red-Black Tree의 특징
126 |
127 | 1. 이진 탐색 트리이므로 BST의 특징을 모두 갖는다.
128 | 2. Root node부터 leaf node까지의 모든 경로 중 최소 경로와 최대 경로의 크기 비율은 2보다 크지 않다. 이러한 상태를 balanced 상태라고 한다.
129 | 3. 노드의 child가 없을 경우 child를 가리키는 포인터는 NIL 값을 저장한다. 이러한 NIL들을 leaf node로 간주한다.
130 |
131 | *cf) RBT는 BST의 삽입, 삭제 연산 과정에서 발생할 수 있는 문제점을 해결하기 위해 만들어진 자료구조이다. 이를 어떻게 해결한 것인가?*
132 |
133 | ### 삽입
134 |
135 | 우선 BST의 특성을 유지하면서 노드를 삽입한다. 그리고 삽입된 노드의 색깔을 RED로 지정한다. Red로 지정하는 이유는 Black-Height 변경을 최소화하기 위함이다.
136 | 삽입 결과 RBT의 특성 위배(violation)시 노드의 색깔을 조정하고, Black-Height가 위배되었다면 rotation을 통해 height를 조정한다.
137 |
138 | 이러한 과정을 통해 RBT의 동일한 height에 존재하는 internal node들의 Black-height가 같아지게 되고 최소 경로와 최대 경로의 크기 비율이 2미만으로 유지된다.
139 |
140 | ### 삭제
141 |
142 | 삭제될 노드의 child의 개수에 따라 rotation 방법이 달라지게된다.
143 |
144 |
--------------------------------------------------------------------------------
/Java/Part1.md:
--------------------------------------------------------------------------------
1 | # 2. Java - Part1
2 | ### :book: Contents
3 | * [java 프로그래밍이란](#java-프로그래밍이란)
4 | * [Java SE와 Java EE 애플리케이션 차이](#java-se와-java-ee-애플리케이션-차이)
5 | * [java와 c/c++의 차이점](#java와-C-C쁠쁠의-차이점)
6 | * [java 언어의 장단점](#java-언어의-장단점)
7 | * [java의 접근 제어자의 종류와 특징](#java의-접근-제어자의-종류와-특징)
8 | * [java의 데이터 타입](#java의-데이터-타입)
9 | * [Wrapper class](#wrapper-class)
10 |
11 | ---
12 |
13 | ### java 프로그래밍이란
14 | * 자바란?
15 |
16 | * 1995년 제임스 고슬링(James Gosling)에 의해서 탄생
17 | * 썬 마이크로시스템즈(Sun Micrsystems)에서 발표
18 | * 오크(Oak)언어에서 시작해서 Java 언어로 발전
19 | * 가전제품에서 탑재할 수 있는 프로그램을 개발하기 위한 목적으로 탄생
20 | * 자바 언어 등장 당시에는 C언어에 비해 효율성이 떨어진다는 지적이 있었으나 메모리 및 CPU의 발전으로 해결되었다.
21 |
22 | * 자바의 특징
23 | * 이식성이 높다 : 자바 언어로 개발된 프로그램은 자바실행환경(JRE: Java Runtime Environment)이 설치된 모든 운영체제에서 실행 가능
24 | * 객체 지향 언어 : OOP(Object Oriented Programming), 캡슐화, 상속, 다형성
25 | * 함수적 스타일 코딩 지원 : 대용량 데이터의 병렬처리, 람다식 지원(자바1.8)으로 컬렉션의 요소를 필터링, 매핑, 집계하기 쉬워지고 코드
26 | 자체도 간결해짐
27 | * 메모리 자동으로 관리 : Garbage Collector
28 | * 웹, 모바일 등의 다양한 애플리케이션 개발 가능
29 |
30 | ### Java SE와 Java EE 애플리케이션 차이
31 |
32 | 자바 프로그래밍 언어의 플랫폼은 **4가지**가 존재(Java SE, Java EE, Java ME, JavaFX)
33 |
34 | * Java SE (Standard Edition)
35 | * 대부분의 사람들이 자바 프로그래밍 언어를 떠올릴때 플랫폼
36 | * Java SE의 API는 자바 프로그래밍 언어의 핵심 기능들을 제공
37 | * 기초적인 타입부터 네트워킹, 보안, 데이터베이스 처리, GUI 개발은 물론 XML 파싱에 이르는 고수준의 클래스들을
38 | 모두 다룰 수 있다.
39 | * 가상 머신, 개발 도구, 배포 기술 그리고 자바 기술을 사용하는 어플리케이션에서 일반적으로 사용되는 부가적인 클래스
40 | 라이브러리들과 툴킷까지 제공하고 있다.
41 | * Java EE (Enterprise Edition)
42 | * Java SE 플랫폼을 기반으로 그 위에 탑재된다.
43 | * 대규모, 다계층, 확장성, 신뢰성, 그리고 보안 네트워킹 어플리케이션의 개발 과 실행을 위한 API 및 환경을 제공하고 있다.
44 |
45 |
46 | > https://www.ibm.com/support/knowledgecenter/ko/SSQP76_8.9.1/com.ibm.odm.dserver.rules.res.managing/topics/con_javase_javaee_applis.html
47 |
48 |
49 | ### java와 c c쁠쁠의 차이점
50 | 1. **메모리관리**
51 | - C/C++은 메모리 관리를 직접한다. 코드로 하드웨어를 제어 가능
52 | - JAVA는 GarbageCollector라는 별도 프로그램이 돌면서 메모리관리를 함
53 |
54 | 2. **속도차이 because 실행환경**
55 | - C언어가 JAVA보다 상대적으로 처리속도가 빠름.
56 | - Why?
57 | - C코드는 컴파일 된 프로세스를 수행 함. 컴파일 과정이 오래걸릴 뿐 수행시간은 빠름.
58 | - Java코드는 실행하면서 JVM인터프리터에의해 바이트코드를 기계코드로 변환 함.
59 | - 또, 자바의 자동 메모리 관리는 대부분의 환경에서 유용하지만 제한된 메모리 리소스를 최적으로 사용해야 하는 프로그램에는 C가 더 좋음.
60 |
61 | 3. **객체지향과 절차지향** ( C와 JAVA의 차이점 )
62 | - 절차지향은 대부분 코드가 main메소드에 한방에 정의 됨.
63 | - 흐름을 읽기는 좋지만 부분수정할때도 전체코드를 컴파일 해야 됨.
64 | - 객체지향은 여러 Class로 나누어 개발이 가능 함.
65 | - 필요한 Class만 수정해서 컴파일 할 수 있어 유지보수 측면에서 유리 함.
66 |
67 | 4. C/C++과 Java의 **컴파일 과정 차이점**
68 | - C코드는 [ Editor -> Source File --(컴파일)--> Object File --(링크)--> 실행 File -> 프로그램 실행 ] 순서로 진행
69 | * 컴파일 : 프로그래밍언어로 작성한 원시코드파일을 기계어로 번역하여 목적코드파일에 저장
70 | * 링크 : 목적코드 파일과 라이브러리 파일을 하나로 합처 실행파일 생성
71 | - Java코드는 링크과정이 없음.
72 | - 컴파일러가 바로 바이트코드를 생성.
73 |
74 |
75 | ### java 언어의 장단점
76 | - 장점
77 | - **운영체제에 독립적이다.**
78 | - JVM에서 동작하기 때문에, 특정 운영체제에 종속되지 않는다.
79 | - **객체지향 언어이다.**
80 | - 객체지향적으로 프로그래밍 하기 위해 여러 언어적 지원을 하고있다. (캡슐화, 상속, 추상화, 다형성 등)
81 | - 객체지향 패러다임의 특성상 비교적 이해하고 배우기 쉽다.
82 | - **자동으로 메모리 관리를 해준다.**
83 | - JVM에서 Garbage Collector라고 불리는 데몬 쓰레드에 의해 GC(Garbage Collection)가 일어난다. GC로 인해 별도의 메모리 관리가 필요 없으며 비지니스 로직에 집중할 수 있다. [(참고)](http://www.jpstory.net/2013/12/15/garbage-collection-in-java/)
84 | - **오픈소스이다.**
85 | - *정확히 말하면 OpenJDK가 오픈소스이다. OracleJDK는 사용 목적에 따라서 유료가 될 수 있다.*
86 | - OracleJDK의 유료화 이슈는 다음을 참고. [(참고)](https://okky.kr/article/490213)
87 | - 많은 Java 개발자가 존재하고 생태계가 잘 구축되어있다. 덕분에 오픈소스 라이브러리가 풍부하며 잘 활용한다면 짧은 개발 시간 내에 안정적인 애플리케이션을 쉽게 구현할 수 있다.
88 | - **멀티스레드를 쉽게 구현할 수 있다.**
89 | - 자바는 스레드 생성 및 제어와 관련된 라이브러리 API를 제공하고 있기 때문에 실행되는 운영체제에 상관없이 멀티 스레드를 쉽게 구현할 수 있다.
90 | - **동적 로딩(Dynamic Loading)을 지원한다**
91 | - 애플리케이션이 실행될 때 모든 객체가 생성되지 않고, 각 객체가 필요한 시점에 클래스를 동적 로딩해서 생성한다. 또한 유지보수 시 해당 클래스만 수정하면 되기 때문에 전체 애플리케이션을 다시 컴파일할 필요가 없다. 따라서 유지보수가 쉽고 빠르다.
92 | - 단점
93 | - **비교적 속도가 느리다.**
94 | - 자바는 한 번의 컴파일링으로 실행 가능한 기계어가 만들어지지 않고 JVM에 의해 기계어로 번역되고 실행하는 과정을 거치기 때문에 C나 C++의 컴파일 단계에서 만들어지는 완전한 기계어보다는 속도가 느리다. 그러나 하드웨어의 성능 향상과 바이트 코드를 기계어로 변환해주는 JIT 컴파일러 같은 기술 적용으로 JVM의 기능이 향상되어 속도의 격차가 많이 줄어들었다.
95 | - **예외처리가 불편하다.**
96 | - 프로그래머 검사가 필요한 예외가 등장한다면 무조건 프로그래머가 선언을 해줘야 한다.
97 |
98 | > - [http://yolojeb.tistory.com/17](http://yolojeb.tistory.com/17)
99 | > - [http://huhghiza.tistory.com/7](http://huhghiza.tistory.com/7)
100 |
101 | ### java의 접근 제어자의 종류와 특징
102 |
103 | **접근 제어자(access modifier)**
104 |
105 | >객체 지향에서 정보 은닉(data hiding)이란 사용자가 굳이 알 필요가 없는 정보는 사용자로부터 숨겨야 한다는 개념이다.
106 | >그렇게 함으로써 사용자는 언제나 최소한의 정보만으로 프로그램을 손쉽게 사용할 수있게 된다.
107 | >자바에서는 이러한 정보 은닉을 위해 접근 제어자(access modifier)라는 기능을 제공하고 있다.
108 | >접근 제어자를 사용하면 클래스 외부에서의 직접적인 접근을 허용하지 않는 멤버를 설정하여 정보 은닉을 구체화할 수 있다.
109 |
110 | * private
111 | * private 접근 제어자를 사용하여 선언된 클래스 멤버는 외부에 공개되지 않으며, 외부에서는 직접 접근할 수 없다.
112 | * 즉, 자바 프로그램은 private 멤버에 직접 접근할 수 없으며, 해당 객체의 public 메소드를 통해서만 접근할 수 있다.
113 | * 따라서 private 멤버는 public 인터페이스를 직접 구성하지 않고, 클래스 내부의 세부적인 동작을 구현하는 데 사용된다.
114 | * public
115 | * public 접근 제어자를 사용하여 선언된 클래스 멤버는 외부로 공개되며, 해당 객체를 사용하는 프로그램 어디에서나 직접 접근할 수 있다.
116 | * 자바 프로그램은 public 메소드를 통해서만 해당 객체의 private 멤버에 접근할 수 있다.
117 | * 따라서 public 메소드는 private 멤버와 프로그램 사이의 인터페이스(interface) 역할을 수행한다고 할 수 있다.
118 | * default
119 | * 자바에서는 클래스 및 클래스 멤버의 접근 제어의 기본값으로 default 접근 제어를 별도로 명시하고 있다.
120 | * 이러한 default를 위한 접근 제어자는 따로 존재하지 않으며, 접근 제어자가 지정되지 않으면 자동적으로 default 접근 제어를 가지게 된다.
121 | * default 접근 제어를 가지는 멤버는 같은 클래스의 멤버와 같은 패키지에 속하는 멤버에서만 접근할 수 있다.
122 | * protected
123 | * 자바 클래스는 private 멤버로 정보를 은닉하고, public 멤버로 사용자나 프로그램과의 인터페이스를 구축한다.
124 | * 여기에 부모 클래스(parent class)와 관련된 접근 제어자가 하나 더 존재한다.
125 | * protected 멤버는 부모 클래스에 대해서는 public 멤버처럼 취급되며, 외부에서는 private 멤버처럼 취급됩니다.
126 | * 클래스의 protected 멤버에 접근할 수 있는 영역은 다음과 같다.
127 | 1. 이 멤버를 선언한 클래스의 멤버
128 | 2. 이 멤버를 선언한 클래스가 속한 패키지의 멤버
129 | 3. 이 멤버를 선언한 클래스를 상속받은 자식 클래스(child class)의 멤버
130 |
131 | 
132 |
133 |
134 | ### java의 데이터 타입
135 | 1. 기본 데이터 타입(Primitive Data Type)
136 | * 기본 타입의 종류는 byte, short, char, int, float, double, boolean이 있다.
137 | * 정수형 : byte, short, int, long
138 | * 실수형 : float, double
139 | * 논리형 : boolean(true/false)
140 | * 문자형 : char
141 | * 기본 타입의 크기가 작고 고정적이기 때문에 메모리의 **Stack** 영역에 저장된다.
142 | 2. 참조 타입(Reference Data Type)
143 | * 참조 타입의 종류는 class, array, interface, Enumeration이 있다.
144 | * 기본형을 제외하고는 모두 참조형이다.
145 | * new 키워드를 이용하여 객체를 생성하여 데이터가 생성된 주소를 참조하는 타입이다.
146 | * String, StringBuffer, List, 개인이 만든 클래스 등
147 | * String과 배열은 참조 타입과 달리 new 없이 생성이 가능하지만 기본 타입이 아닌 참조 타입이다.
148 | * 참조 타입의 데이터의 크기가 가변적, 동적이기 때문에 동적으로 관리되는 **Heap** 영역에 저장된다.
149 | * 더 이상 참조하는 변수가 없을 때 가비지 컬렉션에 의해 파괴된다.
150 | * 참조 타입은 값이 저장된 곳의 주소를 저장하는 공간으로 객체의 주소를 저장한다. (Call-By-Value)
151 | > - [http://robyncloud.tistory.com/entry/](http://robyncloud.tistory.com/entry/%EC%9E%90%EB%B0%94%EC%97%90%EC%84%9C-%EA%BC%AD-%EC%9D%B4%ED%95%B4%ED%95%B4%EC%95%BC-%EB%90%98%EB%8A%94%EA%B0%9C%EB%85%90-1%EB%A9%94%EB%AA%A8%EB%A6%AC-%EA%B0%9D%EC%B2%B4-%EC%B0%B8%EC%A1%B0%EB%B3%80%EC%88%98)
152 | > - [https://m.blog.naver.com/PostView.nhn?blogId=roropoly1&logNo=220649338545&proxyReferer=https%3A%2F%2Fwww.google.co.kr%2F](https://m.blog.naver.com/PostView.nhn?blogId=roropoly1&logNo=220649338545&proxyReferer=https%3A%2F%2Fwww.google.co.kr%2F)
153 |
154 | ### Wrapper class
155 | 1. 래퍼 클래스(Wrapper Class)
156 | * 프로그램에 따라 기본 타입의 데이터를 객체로 취급해야 하는 경우가 있다.
157 | * 예를 들어, 메소드의 인수로 객체 타입만이 요구되면, 기본 타입의 데이터를 그대로 사용할 수 없다.
158 | * 이때에는 기본 타입의 데이터를 먼저 객체로 변환한 후 작업을 수행해야 한다
159 | * 이렇게 8개의 기본 타입(byte, short, int, long, float, double, char, boolean)에 해당하는 데이터를 객체로 포장해주는
160 | 클래스를 래퍼클래스(Wrapper Class)라고 한다.
161 | * 래퍼 클래스는 모두 java.lang 패키지에 포함되어 제공된다.
162 |
163 | 2. 박싱(Boxing)과 언박싱(UnBoxing)
164 | * Boxing : 기본 타입의 데이터를 래퍼 클래스의 인스턴스로 변환하는 과정
165 | * UnBoxing : 래퍼 클래스의 인스턴스에 저장된 값을 다시 기본 타입의 데이터로 꺼내는 과정
166 | 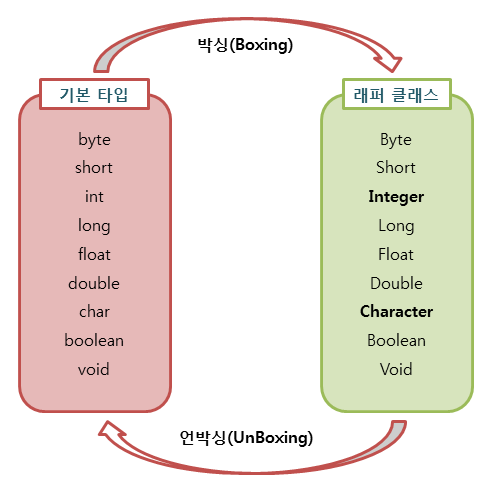
167 | 3. 오토 박싱(AutoBoxing)과 오토 언박싱(Auto UnBoxing)
168 | * JDK 1.5부터는 박싱과 언박싱이 필요한 상황에서 자바 컴파일러가 이를 자동으로 처리해준다. [참고](http://tcpschool.com/java/java_api_wrapper)
169 |
170 |
171 | > - [Wrapper Class](http://tcpschool.com/java/java_api_wrapper)
172 |
--------------------------------------------------------------------------------
/OperatingSystem/Part2.md:
--------------------------------------------------------------------------------
1 | # 3. Operating System - Part2
2 | ### :book: Contents
3 | - [동기와 비동기](#동기와-비동기)
4 | - [프로세스 동기화](#프로세스-동기화)
5 | - [메모리 관리 전략](#메모리-관리-전략)
6 | - [가상 메모리](#가상-메모리)
7 | - [캐시의 지역성](#캐시의-지역성)
8 |
9 |
10 | ---
11 |
12 |
13 |
14 | ### 동기와-비동기
15 | - **동기(synchronous: 동시에 일어나는)**
16 | - 말 그대로 동시에 일어난다는 뜻이다. 요청과 그 결과가 동시에 일어난다는 약속이다.
17 | - 바로 요청을 하면 시간이 얼마나 걸리던지 요청한 자리에서 결과가 주어져야 한다.
18 | - \* 요청과 결과가 한 자리에서 일어남
19 | \* A노드와 B노드 사이의 작업 처리 단위(Transaction)를 동시에 맞추겠다
20 | 
21 | 1. A의 계좌는 10,000원을 뺄 생각을 하고 있다.
22 | 2. A의 계좌가 B의 계좌에 10,000원을 송금한다.
23 | 3. B의 계좌는 10,000원을 받았다는 걸 인지하고, A의 계좌에 10,000원을 받았다고 전송한다.
24 | 4. A, B 계좌 각 각 차감과 증거가 동시에 발생하였다.
25 |
26 | A의 계좌와 B의 계좌는 서로 요청과 응답(1~3 과정)을 확인한 수 같은 일을 동시에 진행하였다. (4번 과정)
27 |
28 |
29 |
30 | - **비동기(Asynchronous: 동시에 일어나지 않는)**
31 | - 비동기는 동시에 일어나지 않는다를 의미한다. 요청과 결과가 동시에 일어나지 않을 거라는 약속이다.
32 | - \* 요청한 그 자리에서 결과가 주어지지 않음
33 | \* 노드 사이의 작업 처리 단위를 동시에 맞추지 않아도 된다.
34 |
35 | 
36 | 1. 학생은 시험문제를 푼다
37 | 2. 시험문제를 모두 푼 학생은 선생님에게 전송한다.
38 | 3. 선생은 학생의 시험지를 채점한다.
39 | 4. 채점이 다 된 시험지를 학생에게 전송한다.
40 | 5. 학생은 선생이 전송한 시험지를 받아 결과를 확인한다.
41 |
42 | > 학생과 선생은 시험지라는 연결고리가 있지만 시험지에 행하는 행위(목적)는 서로 다르다.
43 | 학생은 시험지를 푸는 역할을 하고 선생은 시험지를 채점하는 역할을 한다. 서로의 행위(목적)가 다르기때문에
44 | 둘의 작업 처리 시간은 일치하지 않고, 일치하지 않아도 된다.
45 |
46 |
47 |
48 | - **블록과 논블록의 차이**
49 | - 블록 상태 : 학생이 시험지를 선생에게 건넨 후 가만히 앉아 채점이 끝나서 시험지를 돌려받기만을 기다리는 것
50 | - 논블록 상태 : 학생이 시험지를 건넨 후 선생에게 채점이 완료되었다는 전송을 받기 전까지 다른 일을 할 수 있는 것
51 |
52 | >-[https://byeongmoo.tistory.com/5](https://byeongmoo.tistory.com/5)
53 |
54 |
55 | ### 프로세스-동기화
56 | - 프로세스 동기화(Process Synchronization)란?
57 | - 협력하는 프로레스들 사이의 실행 순서의 규칙을 보장하며 공유되는 데이터의 일관성을 보장한다.
58 |
59 |
60 |
61 | **동기화 작업이 요구되는 상황?**
62 | - 병행 프로세스 : 스케줄링을 통해서 CPU에서 프로세스들을 교체해나가며 여러 개의 프로세스를 동시에 실행하는 것처럼 보이게 하는 것
63 | - 종류
64 | 1. 독립적 프로세스 (Independent process)
65 | - 단일 처리 시스템 (cpu 1개) 에서 각각 독립적으로 여러 프로세스들이 병행 수행되는 것
66 | - 실행중인 다른 프로세스들에게 영향을 주지도, 받지도 않고, 데이터를 공유하지 않음
67 | 2. 협력 프로세스 (cooperaitng process)
68 | - 다중 처리 시스템에서 모든 입출력 장치와 메모리에 참조가 가능하기 때문에 다른 프로세스의 실행에 영향을 주거나 받는다.
69 | - 주로 스레드와 같이 논리 주소 공간을 통해 공유하거나 공유 변수, 공유 파일을 통해 데이터를 공유한다.
70 |
71 | - 비동기적 수행 방식과 동기적 수행 방식
72 | - 비동기적 수행 방식 : 프로세스들 간에 어떤 정교한 협력을 통해서만 기능을 수행
73 | - 동기적 수행 방식 : 프로세스 동기화가 필요한 방식
74 |
75 | > 즉, **프로세스 동기화**란 I/O 장치나 메모리와 같은 자원을
76 | 한번에 하나의 프로세스만 이용하도록 제어해 데이터의 일관성을 보장해주는 것이다.
77 |
78 |
79 |
80 | - **경쟁 조건 (Race Condition)**
81 | - 공유된 자원의 둘 이상의 입력 또는 조작의 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태
82 | 1. 여러 프로세스가 공유 데이터를 동시에 조작할 때, 실행의 특정 순서에 따라 결과가 달라지는 상황
83 | 2. 공유 데이터 조작을 원자적 연산으로 처리하면 경쟁 조건은 발생하지 않는다.
84 | > 원자적 연산 : 어떤 연산의 결과가 외부의 간섭에 관계없이 전체가 완료되든지 전혀 실행되지 않는 상태로만 나타남
85 |
86 |
87 |
88 | - **임계 영역 (Critical Section)**
89 | - 동일한 자원을 동시에 접근하는 작업을 실행하는 코드 영역
90 | - 경쟁 조건이 발생할 수 있는 프로그램 코드 부분
91 | - 다른 프로세스와 공유하는 변수나 파일을 변경
92 | - 임계 영역 문제의 해결 방법
93 | - 한 번에 하나의 프로세스만 임계 영역을 실행하도록 보장 (Lock)
94 | - 적절한 동기화 기법을 설계
95 | - 임계 영역 전체를 원자적으로 처리하는 효과
96 |
97 |
98 |
99 | - **임계 영역 문제 해결을 위한 기본 조건**
100 | - 3가지 조건을 모두 만족해야지 안전한 동기화가 가능하다 (=임계 영역 문제를 해결)
101 | 1. **상호 배제 (Mutual Exclusion)**
102 | - 어떤 프로세스가 자신의 임계 영역 내에서 실행 중일 때 다른 프로세스는 각자의 임계 영역으로 진입할 수 없다.
103 | 2. **진행 (Progress)**
104 | - 임계 영역에서 실행 중인 프로세스가 없다면, 임계 영역으로 진입하려는 프로세스들 중 하나는 유한한 시간 내에 진입할 수 있어야 한다.
105 | 3. **한정된 대기 (Bounded waiting)**
106 | - 한 프로세스가 임계 영역에 대한 진입을 요청한 후에는 다른 프로세스의 임계 영역 진입이 유한한 횟수로 제한되어야 한다.
107 | 즉, 임계 영역에 대한 진입 요청 후 무한히 기다리지 않는다.
108 |
109 | >[https://jungwoon.github.io/os/2019/07/31/Process-Synchronization/](https://jungwoon.github.io/os/2019/07/31/Process-Synchronization/)
110 |
111 | ### 메모리-관리-전략
112 | - 메모리 관리 전략(Memory Managing Strategy)이란?
113 | - 메모리 용량이 증가함에 따라 프로그램의 크기 또한 계속 증가하고 있기 떄문에 메모리는 언제나 부족
114 | - 제한된 물리 메모리의 효율적인 사용과 메모리 참조 방식을 제공하기 위한 전략
115 |
116 | - 효과적인 메모리 사용
117 | 1. 동적 적재(Dynamic Loading)
118 | - 프로그램 실행에 반드시 필요한 루틴과 데이터만 적재하는 기법
119 | - 모든 루틴(ex. 오류처리)과 데이터(ex. 배열)는 항상 사용하지 않고, 실행 시 필요하다면 그때 해당 부분을 메모리에 적재
120 | 2. 동적 연결(Dynamic Linking)
121 | - 라이브러리 루틴연결을 컴파일 시점에 하는 것이 아닌 실행 시점까지 미루는 기법
122 | 3. 스와핑(Swapping)
123 | - CPU에서 실행중이지 않는 프로세스는 저장장치의 Swap 영역으로 이동(Swap in/Swap out)해 메모리를 확보
124 | - 문맥 교환으로 인한 오버헤드가 발생할 수 있고 속도가 느려지지만, 메모리 공간 확보에는 효율적
125 |
126 |
127 |
128 | - 메모리 관리 전략의 종류
129 | 1. 연속 메모리 할당
130 | - 프로세스를 메모리에 연속적으로 할당하는 기법
131 | - 할당과 제거를 반복하다보면 Scattered Holes가 생겨나고 이로 인한 외부 단편화가 발생
132 |
133 | (1) 연속 메모리 할당에서 외부 단편화를 줄이기 위한 할당 방식
134 | a. 최초 적합(First fit)
135 | - 가장 처음 만나는 빈 메모리 공간에 프로세스를 할당
136 | - 빠름
137 |
138 | b. 최적 적합(Best fit)
139 | - 빈 메모리 공간의 크기와 프로세스의 크기 차이가 가장 적은 곳에 프로세스를 할당
140 |
141 | c. 최악 적합(Worst fit)
142 | - 빈 메모리 공간의 크기와 프로세스의 크기 차이가 가장 큰 곳에 프로세스를 할당
143 | - 이렇게 생긴 빈 메모리 공간에 또 다른 프로세스를 할당할 수 있을 거라는 가정에 기인
144 |
145 | 2) 페이징(Paging)
146 | - 메모리 공간이 연속적으로 할당되어야 한다는 제약조건을 없애는 메모리 관리 전략
147 | - 논리 메모리는 고정크기의 페이지, 물리메모리는 고정크기의 프레임 블록으로 나누어 관리
148 | - 프로세스가 사용하는 공간을 논리 메모리에서 여러 개의 페이지로 나누어 관리하고, 개별 페이지는 순서에 상관없이 물리 메모리에 있는 프레임에 매핑되어 저장
149 | - MMU(Memory Management Unit)의 재배치 레지스터 방식을 활용해 CPU가 마치 프로세스가 연속된 메모리에 할당된 것처럼 인식하도록 함
150 | - 내부 단편화 발생
151 |
152 | 3) 세그멘테이션(Segmentation)
153 | - 페이징 기법과 반대로 논리 메모리와 물리 메모리를 같은 크기의 블록이 아닌, 서로 다른 크기의 논리적 단위인 세그먼트로 분할
154 | - 외부 단편화 발생
155 |
156 | 4) 세그멘테이션 페이징 혼용 기법
157 | - 페이징과 세그멘테이션도 각각 내부 단편화와 외부 단편화가 발생
158 | - 페이징과 세그멘테이션을 혼용해 이러한 단편화를 최대한 줄이는 전략
159 | - 프로세스를 세그먼트(논리적 기능 단위)로 나눈 다음 세그먼트를 다시 페이지 단위로 나누어 관리
160 | - 매핑 테이블을 두 번 거쳐야하므로 속도가 느려짐
161 |
162 | >[https://dheldh77.tistory.com/entry/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C%EB%A9%94%EB%AA%A8%EB%A6%AC-%EA%B4%80%EB%A6%AC-%EC%A0%84%EB%9E%B5Memory-Management-Strategy](https://dheldh77.tistory.com/entry/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C%EB%A9%94%EB%AA%A8%EB%A6%AC-%EA%B4%80%EB%A6%AC-%EC%A0%84%EB%9E%B5Memory-Management-Strategy)
163 |
164 | ### 가상-메모리
165 | - **가상 메모리(Virtual Memory)란?**
166 | - 실제 사용하는 메모리는 작다는 점에 착안해서 고안된 기술로 실제 메모리보다 많이 보이게 하는 기술이다.
167 | - 프로세스는 가상 주소를 사용하고, 실제 해당 주소에서 데이터를 읽고/쓸 때만 물리 주소로 바꿔주면 된다.
168 | - virtual address(가상주소) : 프로세스가 참조하는 주소
169 | - physical address : 실제 메모리 주소
170 | - 프로세스간 공간 분리로, 프로세스 이슈가 전체 시스템에 영향을 주지 않을 수 있다.
171 |
172 | - **가상 메모리가 필요한 이유?**
173 | - 메모리 용량 부족 이슈
174 | - 프로세스 메모리 영역 간에 침범 이슈
175 |
176 | - **페이징(paging)**
177 | - 가상 메모리상의 주소 공간을 일정한 크기의 페이지로 분할하고 실제 메모리 또한 가상메모리와 같은 크기로 분할한다.
178 | - 페이지의 크기는 대부분 4Kbyte를 사용한다.
179 | - 크기가 동일한 페이지로 가상 주소 공간과 이에 매칭하는 물리 주소 공간을 관리한다.
180 |
181 | - **페이지 테이블**
182 | - 가상 메모리의 페이지와 실제 메모리의 페이지를 연결시켜주기 위한 매핑 테이블
183 | - 가상 메모리의 페이지 넘버와 실제 메모리의 페이지 프레임을 하나의 순서쌍으로 정의하고 있는 도표
184 | - 이러한 페이지 테이블이 존재하면, 성능은 하락한다. 따라서 MMU라는 H/W를 통해 매핑 시킨다. (이를 통해 메모리 접근 횟수 감소)
185 | > CPU는 가상 주소 접근시 mmu 하드웨어 장치를 통해 물리 메모리에 접근한다.
186 |
187 | - **페이징 시스템**
188 | - 프로세스(4GB)의 PCB에 Page Table 구조체를 가르키는 주소가 들어있다.
189 | - Page Table에는 가상 주소와 물리 주소간 매핑 정보가 들어 있다.
190 |
191 | - **페이징 시스템 구조**
192 | - 물리 주소에 있는 페이지 번호와 해당 페이지의 첫 물리 주소 정보를 매핑한 표
193 | - 가상주소 v = (p,d)라면
194 | - p : 페이지 번호
195 | - d : 페이지 처음부터 얼마 떨어진 위치인지
196 | - paging system 동작
197 | - 해당 프로세스에서 특정 가상 주소 액세스를 하려면?
198 | - 해당 프로세스의 page table에 해당 가상 주소가 포함된 page번호가 있는지 확인
199 | - page 번호가 있으면 이 page가 맵핑된 첫 물리 주소를 알아내고(p')
200 | - p' + d가 실제 물리 주소가 된다.
201 |
202 | > [https://velog.io/@pa324/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-%EA%B0%80%EC%83%81-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EA%B0%9C%EB%85%90-4dk2q3ivff](https://velog.io/@pa324/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-%EA%B0%80%EC%83%81-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EA%B0%9C%EB%85%90-4dk2q3ivff)
203 |
204 | ### 캐시의-지역성
205 | - 캐시 메모리
206 | - 속도가 빠른 장치와 느린 장치간의 속도차에 따른 병목 현상을 줄이기 위한 범용 메모리
207 | - 이러한 역할을 수행하기 위해서는 CPU 가 어떤 데이터를 원할 것인가를 어느 정도 예측할 수 있어야 함
208 | - 캐시의 성능은 작은 용량의 캐시 메모리에 CPU 가 이후에 참조할, 쓸모 있는 정보가 어느 정도 들어있느냐에 따라 좌우됨
209 |
210 | - 지역성(Locality)의 원리
211 | - 캐시 메모리의 적중율(Hit rate)을 극대화 시키기 위한 원리
212 | - 전제조건 : 프로그램은 모든 코드나 데이터를 균등하게 Access 하지 않는다는 특성을 기본으로 한다
213 | - 기억 장치 내의 정보를 균일하게 Access 하는 것이 아닌 어느 한 순간에 특정 부분을 집중적으로 참조하는 특성
214 | - 종류
215 | - 시간 지역성 : 최근에 참조된 주소의 내용은 곧 다음에 다시 참조되는 특성.
216 | - 공간 지역성 : 대부분의 실제 프로그램이 참조된 주소와 인접한 주소의 내용이 다시 참조되는 특성
217 |
218 | > [https://k39335.tistory.com/38](https://k39335.tistory.com/38)
219 |
--------------------------------------------------------------------------------
/OperatingSystem/Part3.md:
--------------------------------------------------------------------------------
1 | # 3. Operating System
2 | **:book: Contents**
3 | * [교착상태(데드락, Deadlock)의 개념과 조건](#교착상태의-개념과-조건)
4 | * [사용자 수준 스레드와 커널 수준 스레드](#사용자-수준-스레드,-커널-수준-스레드)
5 | * [외부 단편화와 내부 단편화](#외부-단편화와-내부-단편화)
6 | * [Context Switching](#context-switching)
7 | * [Swapping](#swapping)
8 |
9 | ---
10 |
11 | ### 교착상태의 개념과 조건
12 | * 교착상태(데드락, Deadlock) 란
13 | * 첫 번째 스레드는 두 번째 스레드가 들고 있는 객체의 락이 풀리기를 기다리고 있고, 두 번째 스레드 역시 첫 번째 스레드가 들고 있는 객체의 락이 풀리기를 기다리는 상황을 일컷는다.
14 | * 모든 스레드가 락이 풀리기를 기다리고 있기 때문에, 무한 대기 상태에 빠지게 된다. 이런 스레드를 교착상태에 빠졌다고 한다.
15 | * 교착상태의 4가지 조건
16 | 1. 상호 배제(mutual exclusion)
17 | * 한 번에 한 프로세스만 공유 자원을 사용할 수 있다.
18 | * 좀 더 정확하게는, 공유 자원에 대한 접근 권한이 제한된다. 자원의 양이 제한되어 있더라도 교착상태는 발생할 수 있다.
19 | 2. 들고 기다리기(hold and wait) = **점유대기**
20 | * 공유 자원에 대한 접근 권한을 갖고 있는 프로세스가, 그 접근 권한을 양보하지 않은 상태에서 다른 자원에 대한 접근 권한을 요구할 수 있다.
21 | 3. 선취(preemption) 불가능 = **비선점**
22 | * 한 프로세스가 다른 프로세스의 자원 접근 권한을 강제로 취소할 수 없다.
23 | 4. 대기 상태의 사이클(circular wait) = **순환대기**
24 | * 두 개 이상의 프로세스가 자원 접근을 기다리는데, 그 관계에 사이클이 존재한다.
25 | * 교착상태 방지
26 | * 4가지 조건들 가운데 하나를 제거하면 된다.
27 | * 상호 배제(Mutual Exclusion)부정 : 한번에 여러개의 프로세스가 공유 자원을 사용할 수 있도록 한다.
28 | * 점유 및 대기(Hold and Wait) 부정 : 프로세스가 실행되기 전 필요한 모든 자원을 할당하여 프로세스 대기를 없애거나 자원이 점유되지 않은 상태에서만 자원을 요구하도록 한다.
29 | * 비선점(Non-preemption)부정 : 자원을 점유하고 있는 프로세스가 다른 자원을 요구할 때 점유하고 있는 자원을 반납하고, 요구한 자원을 사용하기 위해 기다리게 한다.
30 | * 환형 대기(Circular Wait)부정 : 자원을 선형 순서로 분류하여 고유 번호를 할당하고, 각 프로세스는 현재 점유한 자원의 고유 번호보다 앞이나 뒤 어느 한쪽 방향으로만 자원을 요구하도록 한다.
31 |
32 | > :arrow_double_up:[Top](#3-operating-system) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
33 | > - [코딩 인터뷰 완전 분석, 프로그래밍인사이트](https://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&barcode=9788966263080&OV_REFFER=http://click.linkprice.com/click.php?m=kbbook&a=A100532541&l=9999&l_cd1=0&u_id=jm0gctc7ca029ofs02yqe&l_cd2=0&tu=https%3A%2F%2Fwww.kyobobook.co.kr%2Fproduct%2FdetailViewKor.laf%3FmallGb%3DKOR%26ejkGb%3DKOR%26barcode%3D9788966263080)
34 | > - [https://coding-factory.tistory.com/311](https://coding-factory.tistory.com/311)
35 |
36 | ---
37 |
38 |
39 | ### 사용자 수준 스레드와 커널 수준 스레드
40 |
41 |  42 |
43 | * 쓰레드(Thread)
44 | * 쓰레드(Thread)란 간단히 말해 프로세스 내에서 실행되는 실행 단위이다.
45 | * 프로세스는 이러한 쓰레드를 한 개 이상으로 나눌 수 있다.
46 | * 쓰레드는 프로그램 카운터와 스택 포인터 등을 비롯한 쓰레드 실행 환경 정보(Context 정보), 지역 데이터, 스택을 독립적으로 가지면서 코드, 전역 데이터, 힙을 다른 쓰레드와 공유한다.
47 |
48 |
42 |
43 | * 쓰레드(Thread)
44 | * 쓰레드(Thread)란 간단히 말해 프로세스 내에서 실행되는 실행 단위이다.
45 | * 프로세스는 이러한 쓰레드를 한 개 이상으로 나눌 수 있다.
46 | * 쓰레드는 프로그램 카운터와 스택 포인터 등을 비롯한 쓰레드 실행 환경 정보(Context 정보), 지역 데이터, 스택을 독립적으로 가지면서 코드, 전역 데이터, 힙을 다른 쓰레드와 공유한다.
47 |
48 |  49 |
50 | * 쓰레드의 구현
51 | * 쓰레드는 운영체제에 따라 다양하게 구현할 수 있는데, 대부분 다음 세 가지 형태로 구현한다.
52 | * 사용자 수준 쓰레드는 쓰레드 라이브러리를 이용하여 작동하는 형태이고, 커널 수준 쓰레드는 커널(운영체제)에서 지원하는 형태이다. 그리고 이 둘을 혼합한 형태가 혼합형 쓰레드이다.
53 | * 사용자 수준 쓰레드 - 다대일 매핑
54 | * 커널 수준 쓰레드 - 일대일 매핑
55 | * 혼합형 쓰레드 - 다대다 매핑
56 |
57 | * 사용자 수준 쓰레드
58 | * 사용자 수준 쓰레드는 사용자 영역의 쓰레드 라이브러리로 구현하고, 쓰레드와 관련된 모든 행위를 사용자 영역에서 하므로 커널이 쓰레드의 존재를 알지 못한다.
59 | * 여기서 쓰레드 라이브러리는 쓰레드의 생성과 종료, 쓰레드 간의 메시지 전달, 쓰레드의 스케줄링과 컨텍스트 등 정보를 보관한다.
60 | * 사용자 수준 쓰레드에서는 쓰레드 교환에 커널이 개입하지 않아 커널에서 사용자 영역으로 전환할 필요가 없다.
61 | * 그리고 커널은 쓰레드가 아닌 프로세스를 한 단위로 인식하고 프로세서를 할당한다.
62 | * 다수의 사용자 수준 쓰레드가 커널 수준 쓰레드 한 개에 매핑되므로 다대일 쓰레드 매핑이라고 한다.
63 |
64 | * 커널 수준 쓰레드
65 | * 커널 수준 쓰레드는 사용자 수준 쓰레드의 한계를 극복하는 방법으로, 커널이 쓰레드와 관련된 모든 작업을 관리한다.
66 | * 한 프로세스에서 다수의 쓰레드가 프로세서를 할당받아 병행으로 수행하고, 쓰레드 한 개가 대기 상태가 되면 동일한 프로세스에 속한 다른 쓰레드로 교환이 가능하다.
67 | * 이때도 커널이 개입하므로 사용자 영역에서 커널 영역으로 전환이 필요하다. 커널 수준 쓰레드는 사용자 수준 쓰레드와 커널 수준 쓰레드가 일대일로 매핑된다.
68 | * 따라서 사용자 수준 쓰레드를 생성하면 이에 대응하는 커널 쓰레드를 자동으로 생성한다.
69 |
70 | * 혼합형 쓰레드
71 | * 혼합형 쓰레드는 사용자 수준 쓰레드와 커널 수준 쓰레드를 혼합한 구조이다.
72 | * 이는 시스템 호출을 할 때 다른 쓰레드를 중단하는 다대일 매핑의 사용자 수준 쓰레드와 쓰레드 수를 제한하는 일대일 매핑의 커널 수준 쓰레드 문제를 극복하는 방법이다.
73 | * 즉, 사용자 수준 쓰레드는 커널 수준 쓰레드와 비슷한 경량 프로세스에 다대다로 매핑되고, 경량 프로세스는 커널 수준 쓰레드와 일대일로 매핑된다.
74 | * 결국 다수의 사용자 수준 쓰레드에 다수의 커널 쓰레드가 다대다로 매핑된다.
75 |
76 | > :arrow_double_up:[Top](#3-operating-system) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
77 | > - [https://coding-start.tistory.com/199](https://coding-start.tistory.com/199)
78 |
79 | ---
80 |
81 | ### 외부 단편화와 내부 단편화
82 |
83 | * 메모리 단편화
84 | * RAM에서 메모리의 공간이 작은 조각으로 나뉘어져 사용가능한 메모리가 충분히 존재하지만 할당(사용)이 불가능한 상태를 보고 메모리 단편화가 발생했다고 한다.
85 | * 메모리 단편화는 내부 단편화와 외부 단편화로 구분 가능하다.
86 |
87 |
88 | * 내부 단편화(Internal Fragmentation)
89 | * 메모리를 할당할 때 프로세스가 필요한 양보다 더 큰 메모리가 할당되어서 프로세스에서 사용하는 메모리 공간이 낭비 되는 상황
90 | * 예를 들어 블록의 크기가 10K인데, 7K 프로세스를 할당하면 3K의 공간이 낭비된다.
91 |
92 |
49 |
50 | * 쓰레드의 구현
51 | * 쓰레드는 운영체제에 따라 다양하게 구현할 수 있는데, 대부분 다음 세 가지 형태로 구현한다.
52 | * 사용자 수준 쓰레드는 쓰레드 라이브러리를 이용하여 작동하는 형태이고, 커널 수준 쓰레드는 커널(운영체제)에서 지원하는 형태이다. 그리고 이 둘을 혼합한 형태가 혼합형 쓰레드이다.
53 | * 사용자 수준 쓰레드 - 다대일 매핑
54 | * 커널 수준 쓰레드 - 일대일 매핑
55 | * 혼합형 쓰레드 - 다대다 매핑
56 |
57 | * 사용자 수준 쓰레드
58 | * 사용자 수준 쓰레드는 사용자 영역의 쓰레드 라이브러리로 구현하고, 쓰레드와 관련된 모든 행위를 사용자 영역에서 하므로 커널이 쓰레드의 존재를 알지 못한다.
59 | * 여기서 쓰레드 라이브러리는 쓰레드의 생성과 종료, 쓰레드 간의 메시지 전달, 쓰레드의 스케줄링과 컨텍스트 등 정보를 보관한다.
60 | * 사용자 수준 쓰레드에서는 쓰레드 교환에 커널이 개입하지 않아 커널에서 사용자 영역으로 전환할 필요가 없다.
61 | * 그리고 커널은 쓰레드가 아닌 프로세스를 한 단위로 인식하고 프로세서를 할당한다.
62 | * 다수의 사용자 수준 쓰레드가 커널 수준 쓰레드 한 개에 매핑되므로 다대일 쓰레드 매핑이라고 한다.
63 |
64 | * 커널 수준 쓰레드
65 | * 커널 수준 쓰레드는 사용자 수준 쓰레드의 한계를 극복하는 방법으로, 커널이 쓰레드와 관련된 모든 작업을 관리한다.
66 | * 한 프로세스에서 다수의 쓰레드가 프로세서를 할당받아 병행으로 수행하고, 쓰레드 한 개가 대기 상태가 되면 동일한 프로세스에 속한 다른 쓰레드로 교환이 가능하다.
67 | * 이때도 커널이 개입하므로 사용자 영역에서 커널 영역으로 전환이 필요하다. 커널 수준 쓰레드는 사용자 수준 쓰레드와 커널 수준 쓰레드가 일대일로 매핑된다.
68 | * 따라서 사용자 수준 쓰레드를 생성하면 이에 대응하는 커널 쓰레드를 자동으로 생성한다.
69 |
70 | * 혼합형 쓰레드
71 | * 혼합형 쓰레드는 사용자 수준 쓰레드와 커널 수준 쓰레드를 혼합한 구조이다.
72 | * 이는 시스템 호출을 할 때 다른 쓰레드를 중단하는 다대일 매핑의 사용자 수준 쓰레드와 쓰레드 수를 제한하는 일대일 매핑의 커널 수준 쓰레드 문제를 극복하는 방법이다.
73 | * 즉, 사용자 수준 쓰레드는 커널 수준 쓰레드와 비슷한 경량 프로세스에 다대다로 매핑되고, 경량 프로세스는 커널 수준 쓰레드와 일대일로 매핑된다.
74 | * 결국 다수의 사용자 수준 쓰레드에 다수의 커널 쓰레드가 다대다로 매핑된다.
75 |
76 | > :arrow_double_up:[Top](#3-operating-system) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
77 | > - [https://coding-start.tistory.com/199](https://coding-start.tistory.com/199)
78 |
79 | ---
80 |
81 | ### 외부 단편화와 내부 단편화
82 |
83 | * 메모리 단편화
84 | * RAM에서 메모리의 공간이 작은 조각으로 나뉘어져 사용가능한 메모리가 충분히 존재하지만 할당(사용)이 불가능한 상태를 보고 메모리 단편화가 발생했다고 한다.
85 | * 메모리 단편화는 내부 단편화와 외부 단편화로 구분 가능하다.
86 |
87 |
88 | * 내부 단편화(Internal Fragmentation)
89 | * 메모리를 할당할 때 프로세스가 필요한 양보다 더 큰 메모리가 할당되어서 프로세스에서 사용하는 메모리 공간이 낭비 되는 상황
90 | * 예를 들어 블록의 크기가 10K인데, 7K 프로세스를 할당하면 3K의 공간이 낭비된다.
91 |
92 |  93 |
94 | * 외부 단편화(External Fragmentation)
95 | * 메모리가 할당되고 해제되는 작업이 반복될 때 작은 메모리가 중간중간 존재하게 된다.
96 | * 이 때 중간중간에 생긴 사용하지 않는 메모리가 많이 존재해서 총 메모리 공간은 충분하지만 실제로 할당할 수 없는 상황
97 | * 예를 들어 메모리에 3K, 1K, 5K의 여유 공간이 있지만 7K의 프로세스를 할당할 수 없다.
98 |
99 |
93 |
94 | * 외부 단편화(External Fragmentation)
95 | * 메모리가 할당되고 해제되는 작업이 반복될 때 작은 메모리가 중간중간 존재하게 된다.
96 | * 이 때 중간중간에 생긴 사용하지 않는 메모리가 많이 존재해서 총 메모리 공간은 충분하지만 실제로 할당할 수 없는 상황
97 | * 예를 들어 메모리에 3K, 1K, 5K의 여유 공간이 있지만 7K의 프로세스를 할당할 수 없다.
98 |
99 |  100 |
101 | * 메모리 파편화 문제 해결 방법
102 | * (1) 페이징(Paging)기법 - 가상메모리사용, 외부 단편화 해결, 내부 단편화 존재
103 | * 보조기억장치를 이용한 가상메모리를 같은 크기의 블록으로 나눈 것을 페이지라고 하고 RAM을 페이지와 같은 크기로 나눈 것을 프레임이라고 할 때,
104 | * 페이징 기법이란 사용하지 않는 프레임을 페이지에 옮기고, 필요한 메모리를 페이지 단위로 프레임에 옮기는 기법.
105 | * 페이지와 프레임을 대응시키기 위해 page mapping과정이 필요해서 paging table을 만든다.
106 | * 페이징 기법을 사용하면 연속적이지 않은 공간도 활용할 수 있기 때문에 외부 단편화 문제를 해결할 수 있다.
107 | * 대신 페이지 단위에 알맞게 꽉채워 쓰는게 아니므로 내부 단편화 문제는 여전히 있다.
108 | * 페이지 단위를 작게하면 내부 단편화 문제도 해결할 수 있겠지만 대신 page mapping 과정이 많아지므로 오히려 효율이 떨어질 수 있다.
109 |
110 | * (2) 세그멘테이션(Segmentation)기법 - 가상메모리사용, 내부 단편화 해결, 외부 단편화 존재
111 | * 페이징기법에서 가상메모리를 같은 크기의 단위로 분할했지만 세그멘테이션기법에서는 가상메모리를 서로 크기가 다른 논리적 단위인 세그먼트로 분할해서 메모리를 할당하여 실제 메모리 주소로 변환을 하게 된다.
112 | * 각 세그먼트는 연속적인 공간에 저장되어 있다.
113 | * 세그먼트들의 크기가 다르기 때문에 미리 분할해 둘 수 없고 메모리에 적재될 때 빈 공간을 찾아 할당하는 기법이다.
114 | * 마찬가지로 mapping을 위해 세그먼트 테이블이 필요하다.
115 | * (각 세그먼트 항목별 세그먼트 시작주소와 세그먼트의 길이 정보를 가지고 있음)
116 | * 프로세스가 필요한 메모리 만큼 할당해주기 때문에 내부단편화는 일어나지 않으나 여전히 중간에 프로세스가 메모리를 해제하면 생기는 구멍, 즉 외부 단편화 문제는 여전히 존재한다.
117 |
118 | * (3) 메모리 풀(Memory Pool)
119 | * 필요한 메모리 공간을 필요한 크기, 개수 만큼 사용자가 직접 지정하여 미리 할당받아 놓고 필요할 때마다 사용하고 반납하는 기법
120 | * 메모리 풀 없이 동적할당과 해제를 반복하면 메모리의 랜덤한(실제로는 알고리즘에 의한) 위치에 할당과 해제가 반복되면서 단편화를 일으킬 수 있겠지만 미리 공간을 할당해놓고 가져다 쓰고 반납하기 때문에 할당과 해제로 인한 외부 단편화가 발생하지 않는다.
121 | * 또한 필요한 크기만큼 할당을 해놓기 때문에 내부 단편화 또한 생기지 않는다.
122 | * 하지만 메모리 단편화로 인한 메모리 낭비량보다 메모리 풀을 만들었지만 쓰지 않았을 때 메모리 양이 커질 경우 사용하지 않아야 한다.
123 | * 메모리의 할당, 해제가 잦은 경우에 메모리 풀을 쓰면 효과적이다.
124 | * 미리 할당해놓고 사용하지 않는 순간에도 계속 할당해놓으므로 메모리 누수가 있는 방식이다.
125 |
126 |
127 | > :arrow_double_up:[Top](#3-operating-system) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
128 | > - [기본기를 쌓는 정아마추어 코딩블로그](https://jeong-pro.tistory.com/91)
129 |
130 | ---
131 |
132 | ### Context Switching
133 |
134 | * 프로세스와 PCB
135 | * 먼저 프로세스란 실행중인 프로그램 또는 작업이라고 할 수 있다.
136 | * CPU가 프로세스를 실행하기 위해서는 프로세스에 대한 정보가 필요한데, 이를 Context라고 한다.
137 | * 각 프로세스의 Context를 저장한 공간을 PCB라고 한다.
138 |
139 | * PCB (Process Control Block)
140 | * PCB는 운영체제의 커널 내부에 존재한다.
141 | * 또한, 각 프로세스의 생성과 동시에 생성되며, 프로세스 종료 시 함께 사라진다.
142 |
143 |
100 |
101 | * 메모리 파편화 문제 해결 방법
102 | * (1) 페이징(Paging)기법 - 가상메모리사용, 외부 단편화 해결, 내부 단편화 존재
103 | * 보조기억장치를 이용한 가상메모리를 같은 크기의 블록으로 나눈 것을 페이지라고 하고 RAM을 페이지와 같은 크기로 나눈 것을 프레임이라고 할 때,
104 | * 페이징 기법이란 사용하지 않는 프레임을 페이지에 옮기고, 필요한 메모리를 페이지 단위로 프레임에 옮기는 기법.
105 | * 페이지와 프레임을 대응시키기 위해 page mapping과정이 필요해서 paging table을 만든다.
106 | * 페이징 기법을 사용하면 연속적이지 않은 공간도 활용할 수 있기 때문에 외부 단편화 문제를 해결할 수 있다.
107 | * 대신 페이지 단위에 알맞게 꽉채워 쓰는게 아니므로 내부 단편화 문제는 여전히 있다.
108 | * 페이지 단위를 작게하면 내부 단편화 문제도 해결할 수 있겠지만 대신 page mapping 과정이 많아지므로 오히려 효율이 떨어질 수 있다.
109 |
110 | * (2) 세그멘테이션(Segmentation)기법 - 가상메모리사용, 내부 단편화 해결, 외부 단편화 존재
111 | * 페이징기법에서 가상메모리를 같은 크기의 단위로 분할했지만 세그멘테이션기법에서는 가상메모리를 서로 크기가 다른 논리적 단위인 세그먼트로 분할해서 메모리를 할당하여 실제 메모리 주소로 변환을 하게 된다.
112 | * 각 세그먼트는 연속적인 공간에 저장되어 있다.
113 | * 세그먼트들의 크기가 다르기 때문에 미리 분할해 둘 수 없고 메모리에 적재될 때 빈 공간을 찾아 할당하는 기법이다.
114 | * 마찬가지로 mapping을 위해 세그먼트 테이블이 필요하다.
115 | * (각 세그먼트 항목별 세그먼트 시작주소와 세그먼트의 길이 정보를 가지고 있음)
116 | * 프로세스가 필요한 메모리 만큼 할당해주기 때문에 내부단편화는 일어나지 않으나 여전히 중간에 프로세스가 메모리를 해제하면 생기는 구멍, 즉 외부 단편화 문제는 여전히 존재한다.
117 |
118 | * (3) 메모리 풀(Memory Pool)
119 | * 필요한 메모리 공간을 필요한 크기, 개수 만큼 사용자가 직접 지정하여 미리 할당받아 놓고 필요할 때마다 사용하고 반납하는 기법
120 | * 메모리 풀 없이 동적할당과 해제를 반복하면 메모리의 랜덤한(실제로는 알고리즘에 의한) 위치에 할당과 해제가 반복되면서 단편화를 일으킬 수 있겠지만 미리 공간을 할당해놓고 가져다 쓰고 반납하기 때문에 할당과 해제로 인한 외부 단편화가 발생하지 않는다.
121 | * 또한 필요한 크기만큼 할당을 해놓기 때문에 내부 단편화 또한 생기지 않는다.
122 | * 하지만 메모리 단편화로 인한 메모리 낭비량보다 메모리 풀을 만들었지만 쓰지 않았을 때 메모리 양이 커질 경우 사용하지 않아야 한다.
123 | * 메모리의 할당, 해제가 잦은 경우에 메모리 풀을 쓰면 효과적이다.
124 | * 미리 할당해놓고 사용하지 않는 순간에도 계속 할당해놓으므로 메모리 누수가 있는 방식이다.
125 |
126 |
127 | > :arrow_double_up:[Top](#3-operating-system) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
128 | > - [기본기를 쌓는 정아마추어 코딩블로그](https://jeong-pro.tistory.com/91)
129 |
130 | ---
131 |
132 | ### Context Switching
133 |
134 | * 프로세스와 PCB
135 | * 먼저 프로세스란 실행중인 프로그램 또는 작업이라고 할 수 있다.
136 | * CPU가 프로세스를 실행하기 위해서는 프로세스에 대한 정보가 필요한데, 이를 Context라고 한다.
137 | * 각 프로세스의 Context를 저장한 공간을 PCB라고 한다.
138 |
139 | * PCB (Process Control Block)
140 | * PCB는 운영체제의 커널 내부에 존재한다.
141 | * 또한, 각 프로세스의 생성과 동시에 생성되며, 프로세스 종료 시 함께 사라진다.
142 |
143 |  144 |
145 | * PCB 정보
146 | 1) 프로세스 식별자(Process ID)
147 | 2) 프로세스 상태(Process State) : 생성(create), 준비(ready), 실행 (running), 대기(waiting), 완료(terminated)
148 | 3) 프로그램 계수기(Program Counter) : 이 프로세스가 다음에 실행할 명령어의 주소
149 | 4) 사용 중인 레지스터 정보
150 | 5) CPU 스케줄링 정보 : 우선 순위, 최종 실행시각, CPU 점유시간 등
151 | 6) 메모리 관리 정보(Memory limits) : 사용 가능한 메모리 공간 정보
152 | 7) 입출력 상태 정보 : 프로세스에 할당된 입출력장치 목록, 사용 파일 목록 등
153 | 8) 포인터 : 부모 프로세스에 대한 포인터, 자식 프로세스에 대한 포인터, 프로세스가 위치한 메모리 주소에 대한 포인터, 할당된 자원에 대한 포인터 정보
154 |
155 |
144 |
145 | * PCB 정보
146 | 1) 프로세스 식별자(Process ID)
147 | 2) 프로세스 상태(Process State) : 생성(create), 준비(ready), 실행 (running), 대기(waiting), 완료(terminated)
148 | 3) 프로그램 계수기(Program Counter) : 이 프로세스가 다음에 실행할 명령어의 주소
149 | 4) 사용 중인 레지스터 정보
150 | 5) CPU 스케줄링 정보 : 우선 순위, 최종 실행시각, CPU 점유시간 등
151 | 6) 메모리 관리 정보(Memory limits) : 사용 가능한 메모리 공간 정보
152 | 7) 입출력 상태 정보 : 프로세스에 할당된 입출력장치 목록, 사용 파일 목록 등
153 | 8) 포인터 : 부모 프로세스에 대한 포인터, 자식 프로세스에 대한 포인터, 프로세스가 위치한 메모리 주소에 대한 포인터, 할당된 자원에 대한 포인터 정보
154 |
155 |  156 |
157 | * 컨택스트 스위칭(Context Switching)이란?
158 | * 프로세스 P0와 P1이 존재할 때, P0가 CPU를 점유중(excuting)이었고 P1이 대기중(idle)이었는 상태이다가 얼마후에는 P1이 실행이 되고 P0가 대기가 되는 상태가 찾아온다.
159 | * 이때 P0가 실행중에서 대기로 변하게 될 때는 지금까지 작업해오던 내용을 모두 어딘가에 저장해야하는데 그것이 PCB라는 곳이다.
160 | * 즉, P0는 PCB에 저장해야하고 P1이 가지고 있던 데이터는 PCB에서 가져와야한다.
161 | * 이러한 과정 즉, P0와 P1이 서로 대기<->실행을 번갈아가며 하는 것을 컨텍스트 스위칭이라고 한다.
162 |
163 | * 컨텍스트 스위칭(Context Switching)을 정리하자면
164 | * CPU가 어떤 프로세스를 실행하고 있는 상태에서 인터럽트에 의해 다음 우선 순위를 가진 프로세스가 실행되어야 할 때 기존의 프로세스 정보들은 PCB에 저장하고 다음 프로세스의 정보를 PCB에서 가져와 교체하는 작업을 컨텍스트 스위칭이라 한다.
165 | * 이러한 컨텍스트 스위칭을 통해 우리는 멀티 프로세싱, 멀티 스레딩 운영이 가능하다.
166 |
167 |
168 |
169 |
170 | > :arrow_double_up:[Top](#3-operating-system) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
171 |
172 | > - [Context Switching이란?](https://nesoy.github.io/articles/2018-11/Context-Switching)
173 | > - [Crocus](https://www.crocus.co.kr/1364)
174 | > - [https://velog.io/@sohi_5/](https://velog.io/@sohi_5/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-Context-Switching-suaduxev)
175 |
176 | ---
177 |
178 | ### Swapping
179 |
180 | * 메모리 스와핑(Swapping)
181 | * 프로세스가 실행되기 위해서는 메모리에 있어야 하지만 필요한 경우 프로세스는 실행도중에 임시로 보조 메모리로 보내어졌다가다시 메모리로 되돌아 올 수 있다.
182 | * 라운드로빈 스케줄링을 하는 경우 다중 프로그램 환경에서 한 프로세스가 CPU 할당 시간이 끝나면 메모리 관리기(MMU)가 이 프로세스를 보조 메모리로 보내고 다른 프로세스를 메모리로 불러올 수 있다.
183 |
184 |
156 |
157 | * 컨택스트 스위칭(Context Switching)이란?
158 | * 프로세스 P0와 P1이 존재할 때, P0가 CPU를 점유중(excuting)이었고 P1이 대기중(idle)이었는 상태이다가 얼마후에는 P1이 실행이 되고 P0가 대기가 되는 상태가 찾아온다.
159 | * 이때 P0가 실행중에서 대기로 변하게 될 때는 지금까지 작업해오던 내용을 모두 어딘가에 저장해야하는데 그것이 PCB라는 곳이다.
160 | * 즉, P0는 PCB에 저장해야하고 P1이 가지고 있던 데이터는 PCB에서 가져와야한다.
161 | * 이러한 과정 즉, P0와 P1이 서로 대기<->실행을 번갈아가며 하는 것을 컨텍스트 스위칭이라고 한다.
162 |
163 | * 컨텍스트 스위칭(Context Switching)을 정리하자면
164 | * CPU가 어떤 프로세스를 실행하고 있는 상태에서 인터럽트에 의해 다음 우선 순위를 가진 프로세스가 실행되어야 할 때 기존의 프로세스 정보들은 PCB에 저장하고 다음 프로세스의 정보를 PCB에서 가져와 교체하는 작업을 컨텍스트 스위칭이라 한다.
165 | * 이러한 컨텍스트 스위칭을 통해 우리는 멀티 프로세싱, 멀티 스레딩 운영이 가능하다.
166 |
167 |
168 |
169 |
170 | > :arrow_double_up:[Top](#3-operating-system) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
171 |
172 | > - [Context Switching이란?](https://nesoy.github.io/articles/2018-11/Context-Switching)
173 | > - [Crocus](https://www.crocus.co.kr/1364)
174 | > - [https://velog.io/@sohi_5/](https://velog.io/@sohi_5/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-Context-Switching-suaduxev)
175 |
176 | ---
177 |
178 | ### Swapping
179 |
180 | * 메모리 스와핑(Swapping)
181 | * 프로세스가 실행되기 위해서는 메모리에 있어야 하지만 필요한 경우 프로세스는 실행도중에 임시로 보조 메모리로 보내어졌다가다시 메모리로 되돌아 올 수 있다.
182 | * 라운드로빈 스케줄링을 하는 경우 다중 프로그램 환경에서 한 프로세스가 CPU 할당 시간이 끝나면 메모리 관리기(MMU)가 이 프로세스를 보조 메모리로 보내고 다른 프로세스를 메모리로 불러올 수 있다.
183 |
184 |  185 |
186 | * CPU 스케줄러는 메모리 내의 다른 프로세스에게도 시간 할당량(time quantum)을 정해 놓고 그 할당량을 모두 소비했을 때 그 프로세스도 스왑시킬 수 있다.
187 | * CPU 스케줄러는 할아 시간이 만료 되어 CPU를 새로 스케줄 할때마다 메모리 관리기가 메모리 내에 준비시켜 놓은 여러 프로세스들 중 하나를 고르기만 하면 된다.
188 | * 시간 할당량은 스왑 작업을 고려하여 원활한 작업 처리가 이루어 질 수 있도록 충분히 길어야 한다.
189 | * 스와핑 정책은 시간 할당 외에도 우선순위 방식으로 바꿀 수도 있다. 이러한스와핑의 변형을 롤인(roll-in), 롤 아웃(roll_out)이라고한다.
190 |
191 |
185 |
186 | * CPU 스케줄러는 메모리 내의 다른 프로세스에게도 시간 할당량(time quantum)을 정해 놓고 그 할당량을 모두 소비했을 때 그 프로세스도 스왑시킬 수 있다.
187 | * CPU 스케줄러는 할아 시간이 만료 되어 CPU를 새로 스케줄 할때마다 메모리 관리기가 메모리 내에 준비시켜 놓은 여러 프로세스들 중 하나를 고르기만 하면 된다.
188 | * 시간 할당량은 스왑 작업을 고려하여 원활한 작업 처리가 이루어 질 수 있도록 충분히 길어야 한다.
189 | * 스와핑 정책은 시간 할당 외에도 우선순위 방식으로 바꿀 수도 있다. 이러한스와핑의 변형을 롤인(roll-in), 롤 아웃(roll_out)이라고한다.
190 |
191 |  192 |
193 | * 스와핑은 보조 메모리를 필요로 하며 보통 디스크를 사용한다.
194 | * 시스템은 실행 준비가 된 모든 프로세스를 모아 준비 완료 큐(Ready queue)에 가지고 있어야 한다.
195 | * CPU가 스케줄을 고를 때 디스패처(dispatcher)를 호출하고디스패처는 준비 완료 큐(Ready queue)에 있는 다음 프로세스가 메모리에 올라와 있는지 확인하여 메모리에 없다면 디스크로부터 읽어 들인다. 그런데 메모리에 이 프로세스에 대한 공간이 없다면 공간을만들기 위해 현재 메모리에 올라와 있는 프로세스를 내보내고(swap out) 원하는 프로세스를 불러들인다.
196 | * 그리고 나서 CPU의 모든 레지스터를 실행해야 할 프로세스의 것으로다시 적재하고 제어권을 그 프로세스에게 넘긴다.
197 |
198 | * [문맥교환 시간]
199 | * 사용자 프로세스크기 10MB
200 | * 보조 메모리의전송률 : 초당 40MB
201 | * 10MB의 프로세스를 전송하는데 걸리는 시간 10,000KB / 40,000 kb = 1/4초 = 250ms
202 | * 헤드 탐색 시간이 없다고 가정하고 평균 8 밀리초의 회전 지연시간을가정 했을 때 스왑시간은 258ms가 된다. 스왑 시간의대부분은 디스크 전송 시간이다.
203 | * 한 프로세스를 스왑 아웃하고 다른 프로세스를 스왑인 해야 하므로 총 스왑시간은516ms 가 필요하다.
204 | * 효과적인 CPU 사용을위해서 각 프로세스의 실행 시간은 스왑 시간보다 충분히 길어야 한다.
205 | * 라운드 로빈 스케줄링의 경우 최소 0.516초보다 커야 한다.
206 |
207 |
208 |
209 | > :arrow_double_up:[Top](#3-operating-system) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
210 | > - [https://m.blog.naver.com/PostView.nhn?blogId=jevida](https://m.blog.naver.com/PostView.nhn?blogId=jevida&logNo=140191090013&proxyReferer=https:%2F%2Fwww.google.com%2F)
211 |
212 | ---
213 |
214 | ## Reference
215 | > - []()
216 |
217 |
218 | ## :house: [Home](https://github.com/WeareSoft/tech-interview)
219 |
--------------------------------------------------------------------------------
/OperatingSystem/Part1.md:
--------------------------------------------------------------------------------
1 | # 3. Operating System - Part1
2 | ### :book: Contents
3 | * [프로세스와 스레드의 차이(Process vs Thread)](#프로세스와-스레드의-차이)
4 | * [멀티 프로세스 대신 멀티 스레드를 사용하는 이유](#멀티-프로세스-대신-멀티-스레드를-사용하는-이유)
5 | * [Thread-safe](#thread-safe)
6 | * [동기화 객체의 종류](#동기화-객체의-종류)
7 | * [뮤텍스와 세마포어의 차이](#뮤텍스와-세마포어의-차이)
8 | * [CPU 스케줄링](#CPU-스케줄링)
9 |
10 |
11 | ---
12 | ### 프로세스와 스레드의 차이
13 | * 프로그램(Program) 이란
14 | * 사전적 의미: 어떤 작업을 위해 실행할 수 있는 파일
15 | * 프로세스(Process) 란
16 | * 메모리에 올라와 **실행되고 있는 프로그램의 인스턴스(독립적인 개체)**
17 | * 운영체제로부터 시스템 자원을 할당받는 작업의 단위
18 | * 즉, 동적인 개념으로는 실행중인 프로그램을 의미한다.
19 | * 할당받는 시스템 자원의 예
20 | * CPU 시간
21 | * 운영되기 위해 필요한 주소 공간
22 | * Code, Data, Stack, Heap의 구조로 되어 있는 독립된 메모리 영역
23 | * 특징
24 | * 
25 | * 프로세스는 각각 독립된 메모리 영역(Code, Data, Stack, Heap의 구조)을 할당받는다.
26 | * Code : 코드 자체를 구성하는 메모리 영역(프로그램 명령)
27 | * Data : 전역변수, 정적변수, 배열 등 (초기화된 데이터)
28 | * Heap : 동적 할당 시 사용 (new(), mallock() 등)
29 | * Stack : 지역변수, 매개변수, 리턴 값 (임시 메모리 영역)
30 | * 기본적으로 프로세스당 최소 1개의 스레드(메인 스레드)를 가지고 있다.
31 | * 각 프로세스는 별도의 주소 공간에서 실행되며, 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수 없다.
32 | * 한 프로세스가 다른 프로세스의 자원에 접근하려면 프로세스 간의 통신(IPC, inter-process communication)을 사용해야 한다. (Ex. 파이프, 파일, 소켓 등을 이용한 통신 방법 이용)
33 | * 스레드(Thread) 란
34 | * 프로세스 안에서 실행되는 여러 흐름의 단위
35 | * **프로세스의 특정한 수행 경로**
36 | * 프로세스가 할당받은 자원을 이용하는 실행의 단위
37 | * 특징
38 | * 
39 | * 스레드는 프로세스 내에서 각각 Stack만 따로 할당받고 Code, Data, Heap 영역은 공유한다.
40 | * 스레드는 한 프로세스 내에서 동작되는 여러 실행의 흐름으로, 프로세스 내의 주소 공간이나 자원들(힙 공간 등)을 같은 프로세스 내에 스레드끼리 공유하면서 실행된다.
41 | * 같은 프로세스 안에 있는 여러 스레드들은 같은 힙 공간을 공유한다. 반면에 프로세스는 다른 프로세스의 메모리에 직접 접근할 수 없다.
42 | * 각각의 스레드는 별도의 레지스터와 스택을 갖고 있지만, 힙 메모리는 서로 읽고 쓸 수 있다.
43 | * 한 스레드가 프로세스 자원을 변경하면, 다른 이웃 스레드(sibling thread)도 그 변경 결과를 즉시 볼 수 있다.
44 | * 자바 스레드(Java Thread) 란
45 | * 일반 스레드와 거의 차이가 없으며, JVM가 운영체제의 역할을 한다.
46 | * 자바에는 프로세스가 존재하지 않고 스레드만 존재하며, 자바 스레드는 JVM에 의해 스케줄되는 실행 단위 코드 블록이다.
47 | * 자바에서 스레드 스케줄링은 전적으로 JVM에 의해 이루어진다.
48 | * 아래와 같은 스레드와 관련된 많은 정보들도 JVM이 관리한다.
49 | * 스레드가 몇 개 존재하는지
50 | * 스레드로 실행되는 프로그램 코드의 메모리 위치는 어디인지
51 | * 스레드의 상태는 무엇인지
52 | * 스레드 우선순위는 얼마인지
53 | * 즉, 개발자는 자바 스레드로 작동할 스레드 코드를 작성하고, 스레드 코드가 생명을 가지고 실행을 시작하도록 JVM에 요청하는 일 뿐이다.
54 |
55 | **💡 프로세스는 자신만의 고유 공간과 자원을 할당받아 사용하는데 반해, 스레드는 다른 스레드와 공간, 자원을 공유하면서 사용하는 차이가 존재함**
56 |
57 |
58 | > - [https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html](https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html)
59 | > - [https://brunch.co.kr/@kd4/3](https://brunch.co.kr/@kd4/3)
60 | > - [https://magi82.github.io/process-thread/](https://magi82.github.io/process-thread/)
61 | > - [https://jaybdev.net/2017/06/05/Java-3/](https://jaybdev.net/2017/06/05/Java-3/)
62 | > - [http://includestdio.tistory.com/6](http://includestdio.tistory.com/6)
63 | > - [https://lalwr.blogspot.com/2016/02/process-thread.html](https://lalwr.blogspot.com/2016/02/process-thread.html)
64 |
65 | ### 멀티 프로세스 대신 멀티 스레드를 사용하는 이유
66 |
67 | * **멀티 프로세스**
68 | > 하나의 컴퓨터에 여러 CPU 장착 → 하나 이상의 프로세스들을 동시에 처리(병렬)
69 | * 장점 : 안전성 (메모리 침범 문제를 OS 차원에서 해결)
70 | * 단점 : 각각 독립된 메모리 영역을 갖고 있어, 작업량 많을 수록 오버헤드 발생. Context Switching으로 인한 성능 저하
71 | * Context Switching
72 | * 프로세스의 상태 정보를 저장하고 복원하는 일련의 과정
73 | * 즉, 동작 중인 프로세스가 대기하면서 해당 프로세스의 상태를 보관하고, 대기하고 있던 다음 순번의 프로세스가 동작하면서 이전에 보관했던 프로세스 상태를 복구하는 과정을 말함
74 | * 프로세스는 각 독립된 메모리 영역을 할당받아 사용되므로, 캐시 메모리 초기화와 같은 무거운 작업이 진행되었을 때 오버헤드가 발생할 문제가 존재함
75 | * 오버헤드(overhead) : 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간/메모리 등을 말한다.
76 | * 예) A를 단순하게 처리하면 10초 걸리는데, 안전성을 고려하고 부가적인 B를 처리한 결과 처리시간이 15초 걸렸다면 오버헤드는 5초가 된다. 만약 B를 처리하는 것을 개선해 12초가
77 | 걸렸다면 오버헤드가 3초 단축되었다고 한다.
78 | * **멀티 스레드**
79 | > 하나의 응용 프로그램에서 여러 스레드를 구성해 각 스레드가 하나의 작업을 처리하는 것
80 | > 스레드들이 공유 메모리를 통해 다수의 작업을 동시에 처리하도록 해줌
81 |
82 | * 장점 : 독립적인 프로세스에 비해 공유 메모리만큼의 시간, 자원 손실이 감소. 전역 변수와 정적 변수에 대한 자료 공유 가능
83 | * 단점 : 안전성 문제. 하나의 스레드의 데이터 공간이 망가지면, 모든 스레드가 작동 불능 상태가 된다. (공유 메모리를 갖기 때문)
84 | * 안전성에 대한 단점은 Critical Section 기법을 통해 대비함
85 | * 하나의 스레드가 공유 데이터 값을 변경하는 시점에 다른 스레드가 그 값을 읽으려할 때 발생하는 문제를 해결하기 위한 **동기화**과정
86 | * 단, 상호 배제, 진행, 한정된 대기를 충족해야 함.
87 |
192 |
193 | * 스와핑은 보조 메모리를 필요로 하며 보통 디스크를 사용한다.
194 | * 시스템은 실행 준비가 된 모든 프로세스를 모아 준비 완료 큐(Ready queue)에 가지고 있어야 한다.
195 | * CPU가 스케줄을 고를 때 디스패처(dispatcher)를 호출하고디스패처는 준비 완료 큐(Ready queue)에 있는 다음 프로세스가 메모리에 올라와 있는지 확인하여 메모리에 없다면 디스크로부터 읽어 들인다. 그런데 메모리에 이 프로세스에 대한 공간이 없다면 공간을만들기 위해 현재 메모리에 올라와 있는 프로세스를 내보내고(swap out) 원하는 프로세스를 불러들인다.
196 | * 그리고 나서 CPU의 모든 레지스터를 실행해야 할 프로세스의 것으로다시 적재하고 제어권을 그 프로세스에게 넘긴다.
197 |
198 | * [문맥교환 시간]
199 | * 사용자 프로세스크기 10MB
200 | * 보조 메모리의전송률 : 초당 40MB
201 | * 10MB의 프로세스를 전송하는데 걸리는 시간 10,000KB / 40,000 kb = 1/4초 = 250ms
202 | * 헤드 탐색 시간이 없다고 가정하고 평균 8 밀리초의 회전 지연시간을가정 했을 때 스왑시간은 258ms가 된다. 스왑 시간의대부분은 디스크 전송 시간이다.
203 | * 한 프로세스를 스왑 아웃하고 다른 프로세스를 스왑인 해야 하므로 총 스왑시간은516ms 가 필요하다.
204 | * 효과적인 CPU 사용을위해서 각 프로세스의 실행 시간은 스왑 시간보다 충분히 길어야 한다.
205 | * 라운드 로빈 스케줄링의 경우 최소 0.516초보다 커야 한다.
206 |
207 |
208 |
209 | > :arrow_double_up:[Top](#3-operating-system) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
210 | > - [https://m.blog.naver.com/PostView.nhn?blogId=jevida](https://m.blog.naver.com/PostView.nhn?blogId=jevida&logNo=140191090013&proxyReferer=https:%2F%2Fwww.google.com%2F)
211 |
212 | ---
213 |
214 | ## Reference
215 | > - []()
216 |
217 |
218 | ## :house: [Home](https://github.com/WeareSoft/tech-interview)
219 |
--------------------------------------------------------------------------------
/OperatingSystem/Part1.md:
--------------------------------------------------------------------------------
1 | # 3. Operating System - Part1
2 | ### :book: Contents
3 | * [프로세스와 스레드의 차이(Process vs Thread)](#프로세스와-스레드의-차이)
4 | * [멀티 프로세스 대신 멀티 스레드를 사용하는 이유](#멀티-프로세스-대신-멀티-스레드를-사용하는-이유)
5 | * [Thread-safe](#thread-safe)
6 | * [동기화 객체의 종류](#동기화-객체의-종류)
7 | * [뮤텍스와 세마포어의 차이](#뮤텍스와-세마포어의-차이)
8 | * [CPU 스케줄링](#CPU-스케줄링)
9 |
10 |
11 | ---
12 | ### 프로세스와 스레드의 차이
13 | * 프로그램(Program) 이란
14 | * 사전적 의미: 어떤 작업을 위해 실행할 수 있는 파일
15 | * 프로세스(Process) 란
16 | * 메모리에 올라와 **실행되고 있는 프로그램의 인스턴스(독립적인 개체)**
17 | * 운영체제로부터 시스템 자원을 할당받는 작업의 단위
18 | * 즉, 동적인 개념으로는 실행중인 프로그램을 의미한다.
19 | * 할당받는 시스템 자원의 예
20 | * CPU 시간
21 | * 운영되기 위해 필요한 주소 공간
22 | * Code, Data, Stack, Heap의 구조로 되어 있는 독립된 메모리 영역
23 | * 특징
24 | * 
25 | * 프로세스는 각각 독립된 메모리 영역(Code, Data, Stack, Heap의 구조)을 할당받는다.
26 | * Code : 코드 자체를 구성하는 메모리 영역(프로그램 명령)
27 | * Data : 전역변수, 정적변수, 배열 등 (초기화된 데이터)
28 | * Heap : 동적 할당 시 사용 (new(), mallock() 등)
29 | * Stack : 지역변수, 매개변수, 리턴 값 (임시 메모리 영역)
30 | * 기본적으로 프로세스당 최소 1개의 스레드(메인 스레드)를 가지고 있다.
31 | * 각 프로세스는 별도의 주소 공간에서 실행되며, 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수 없다.
32 | * 한 프로세스가 다른 프로세스의 자원에 접근하려면 프로세스 간의 통신(IPC, inter-process communication)을 사용해야 한다. (Ex. 파이프, 파일, 소켓 등을 이용한 통신 방법 이용)
33 | * 스레드(Thread) 란
34 | * 프로세스 안에서 실행되는 여러 흐름의 단위
35 | * **프로세스의 특정한 수행 경로**
36 | * 프로세스가 할당받은 자원을 이용하는 실행의 단위
37 | * 특징
38 | * 
39 | * 스레드는 프로세스 내에서 각각 Stack만 따로 할당받고 Code, Data, Heap 영역은 공유한다.
40 | * 스레드는 한 프로세스 내에서 동작되는 여러 실행의 흐름으로, 프로세스 내의 주소 공간이나 자원들(힙 공간 등)을 같은 프로세스 내에 스레드끼리 공유하면서 실행된다.
41 | * 같은 프로세스 안에 있는 여러 스레드들은 같은 힙 공간을 공유한다. 반면에 프로세스는 다른 프로세스의 메모리에 직접 접근할 수 없다.
42 | * 각각의 스레드는 별도의 레지스터와 스택을 갖고 있지만, 힙 메모리는 서로 읽고 쓸 수 있다.
43 | * 한 스레드가 프로세스 자원을 변경하면, 다른 이웃 스레드(sibling thread)도 그 변경 결과를 즉시 볼 수 있다.
44 | * 자바 스레드(Java Thread) 란
45 | * 일반 스레드와 거의 차이가 없으며, JVM가 운영체제의 역할을 한다.
46 | * 자바에는 프로세스가 존재하지 않고 스레드만 존재하며, 자바 스레드는 JVM에 의해 스케줄되는 실행 단위 코드 블록이다.
47 | * 자바에서 스레드 스케줄링은 전적으로 JVM에 의해 이루어진다.
48 | * 아래와 같은 스레드와 관련된 많은 정보들도 JVM이 관리한다.
49 | * 스레드가 몇 개 존재하는지
50 | * 스레드로 실행되는 프로그램 코드의 메모리 위치는 어디인지
51 | * 스레드의 상태는 무엇인지
52 | * 스레드 우선순위는 얼마인지
53 | * 즉, 개발자는 자바 스레드로 작동할 스레드 코드를 작성하고, 스레드 코드가 생명을 가지고 실행을 시작하도록 JVM에 요청하는 일 뿐이다.
54 |
55 | **💡 프로세스는 자신만의 고유 공간과 자원을 할당받아 사용하는데 반해, 스레드는 다른 스레드와 공간, 자원을 공유하면서 사용하는 차이가 존재함**
56 |
57 |
58 | > - [https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html](https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html)
59 | > - [https://brunch.co.kr/@kd4/3](https://brunch.co.kr/@kd4/3)
60 | > - [https://magi82.github.io/process-thread/](https://magi82.github.io/process-thread/)
61 | > - [https://jaybdev.net/2017/06/05/Java-3/](https://jaybdev.net/2017/06/05/Java-3/)
62 | > - [http://includestdio.tistory.com/6](http://includestdio.tistory.com/6)
63 | > - [https://lalwr.blogspot.com/2016/02/process-thread.html](https://lalwr.blogspot.com/2016/02/process-thread.html)
64 |
65 | ### 멀티 프로세스 대신 멀티 스레드를 사용하는 이유
66 |
67 | * **멀티 프로세스**
68 | > 하나의 컴퓨터에 여러 CPU 장착 → 하나 이상의 프로세스들을 동시에 처리(병렬)
69 | * 장점 : 안전성 (메모리 침범 문제를 OS 차원에서 해결)
70 | * 단점 : 각각 독립된 메모리 영역을 갖고 있어, 작업량 많을 수록 오버헤드 발생. Context Switching으로 인한 성능 저하
71 | * Context Switching
72 | * 프로세스의 상태 정보를 저장하고 복원하는 일련의 과정
73 | * 즉, 동작 중인 프로세스가 대기하면서 해당 프로세스의 상태를 보관하고, 대기하고 있던 다음 순번의 프로세스가 동작하면서 이전에 보관했던 프로세스 상태를 복구하는 과정을 말함
74 | * 프로세스는 각 독립된 메모리 영역을 할당받아 사용되므로, 캐시 메모리 초기화와 같은 무거운 작업이 진행되었을 때 오버헤드가 발생할 문제가 존재함
75 | * 오버헤드(overhead) : 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간/메모리 등을 말한다.
76 | * 예) A를 단순하게 처리하면 10초 걸리는데, 안전성을 고려하고 부가적인 B를 처리한 결과 처리시간이 15초 걸렸다면 오버헤드는 5초가 된다. 만약 B를 처리하는 것을 개선해 12초가
77 | 걸렸다면 오버헤드가 3초 단축되었다고 한다.
78 | * **멀티 스레드**
79 | > 하나의 응용 프로그램에서 여러 스레드를 구성해 각 스레드가 하나의 작업을 처리하는 것
80 | > 스레드들이 공유 메모리를 통해 다수의 작업을 동시에 처리하도록 해줌
81 |
82 | * 장점 : 독립적인 프로세스에 비해 공유 메모리만큼의 시간, 자원 손실이 감소. 전역 변수와 정적 변수에 대한 자료 공유 가능
83 | * 단점 : 안전성 문제. 하나의 스레드의 데이터 공간이 망가지면, 모든 스레드가 작동 불능 상태가 된다. (공유 메모리를 갖기 때문)
84 | * 안전성에 대한 단점은 Critical Section 기법을 통해 대비함
85 | * 하나의 스레드가 공유 데이터 값을 변경하는 시점에 다른 스레드가 그 값을 읽으려할 때 발생하는 문제를 해결하기 위한 **동기화**과정
86 | * 단, 상호 배제, 진행, 한정된 대기를 충족해야 함.
87 |
88 |
89 | 💡 **멀티 프로세스 대신 멀티 스레드를 사용하는 이유**
90 |
91 | 프로그램을 여러 개 키는 것보다 하나의 프로그램 안에서 여러 작업을 해결하는 것이 더 낫기 때문이다.
92 |
93 | * 
94 |
95 | 1. 자원의 효율성 증대
96 | * 멀티 프로세스로 실행되는 작업을 멀티 스레드로 실행할 경우, **프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어** 자원을 효율적으로 관리할 수 있다.
97 | * 프로세스 간의 Context Switching시 단순히 CPU 레지스터 교체 뿐만 아니라 RAM과 CPU 사이의 캐시 메모리에 대한 데이터까지 초기화되므로 오버헤드가 크기 때문
98 | * 스레드는 프로세스 내의 메모리를 공유하기 때문에 독립적인 프로세스와 달리 스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어들게 된다.
99 | 2. 처리 비용 감소 및 응답 시간 단축
100 | * 또한 프로세스 간의 통신(IPC)보다 스레드 간의 통신의 비용이 적으므로 작업들 간의 통신의 부담이 줄어든다.
101 | * 스레드는 Stack 영역을 제외한 모든 메모리를 공유하기 때문
102 | * 프로세스 간의 전환 속도보다 스레드 간의 전환 속도가 빠르다.
103 | * Context Switching시 스레드는 Stack 영역만 처리하기 때문
104 |
105 | * ***주의할 점!***
106 | * **동기화 문제**
107 | * 스레드 간의 자원 공유는 전역 변수(데이터 세그먼트)를 이용하므로 함께 상용할 때 충돌이 발생할 수 있다.
108 |
109 | > [http://you9010.tistory.com/136](http://you9010.tistory.com/136)
110 |
111 |
112 | ### Thread-safe
113 | - **Thread-safe란?**
114 | - 멀티스레드 환경에서 **여러 스레드**가 동시에 하나의 객체 및 변수(공유 자원)에 접근할 때, 의도한 대로 동작하는 것을 말한다.
115 | - 이러한 상황을 "Thead-safe하다" 라고 표현한다.
116 | - **Thread-safe하게 구현하기**
117 | - Thread-safe하기 위해서는 공유 자원에 접근하는 임계영역(critical section)을 동기화 기법으로 제어해줘야 한다.
118 | - 이를 '상호배제'라고 한다.
119 | - 동기화 기법으로는 Mutex나 Semaphore 등이 있다.
120 | - **Reentrant**
121 | - Reentrant는 **재진입성**이라는 의미로, 어떤 함수가 Reentrant하다는 것은 여러 스레드가 동시에 접근해도 언제나 같은 실행 결과를 보장한다는 의미이다.
122 | - 이를 만족하기 위해서 해당 서브루틴에서는 공유자원을 사용하지 않으면 된다.
123 | - 예를들어 정적(전역) 변수를 사용하거나 반환하면 안 되고 호출 시 제공된 매개변수만으로 동작해야한다.
124 | - 따라서, Reentrant하다면 Thread-safe하지만 그 역은 성립하지 않는다.
125 |
126 | > - [위키백과 - 재진입성](https://ko.wikipedia.org/wiki/%EC%9E%AC%EC%A7%84%EC%9E%85%EC%84%B1)
127 | > - [[OS] Thread Safe란? - 곰팡](gompangs.tistory.com/7)
128 | > - [스레드-안전(Thread-safe)과 재진입가능(Reentrant)의 차이 - 커피한잔의 여유와 코딩](sjava.net/tag/thread-safe/)
129 |
130 | ### 동기화 객체의 종류
131 | * 스레드 동기화 방법
132 | 1. 실행 순서의 동기화
133 | * 스레드의 실행순서를 정의하고, 이 순서에 반드시 따르도록 하는 것
134 | 2. 메모리 접근에 대한 동기화
135 | * 메모리 접근에 있어서 동시접근을 막는 것
136 | * 실행의 순서가 중요한 상황이 아니고, 한 순간에 하나의 스레드만 접근하면 되는 상황을 의미
137 | * 동기화 기법의 종류
138 | 1. 유저 모드 동기화
139 | * 커널의 힘을 빌리지 않는(커널 코드가 실행되지 않는) 동기화 기법
140 | * 성능상 이점, 기능상의 제한(라이브러리를 이용)
141 | * **Ex) 크리티컬 섹션 기반의 동기화, 인터락 함수 기반의 동기화**
142 | 2. 커널 모드 동기화
143 | * 커널에서 제공하는 동기화 기능을 활용하는 방법
144 | * 기능상 우수, 속도 떨어짐. 각 프로세스들 안에 있는 쓰레드끼리의 동기화도 가능하다.(근데 잘 안 쓸 수도 있다)
145 | * 커널 모드로의 변경이 필요하고 이는 성능 저하로 이어짐, 다양한 기능 활용 가능
146 | * **Ex) 뮤텍스 기반의 동기화, 세마포어 기반의 동기화, 이름있는 뮤텍스 기반의 프로세스 동기화, 이벤트 기반의 동기화**
147 |
148 | > - [http://christin2.tistory.com/entry/Chapter-13-%EC%93%B0%EB%A0%88%EB%93%9C-%EB%8F%99%EA%B8%B0%ED%99%94-%EA%B8%B0%EB%B2%95-1](http://christin2.tistory.com/entry/Chapter-13-%EC%93%B0%EB%A0%88%EB%93%9C-%EB%8F%99%EA%B8%B0%ED%99%94-%EA%B8%B0%EB%B2%95-1)
149 | > - [https://m.blog.naver.com/PostView.nhn?blogId=smuoon4680&logNo=50127179815&proxyReferer=https%3A%2F%2Fwww.google.co.kr%2F](https://m.blog.naver.com/PostView.nhn?blogId=smuoon4680&logNo=50127179815&proxyReferer=https%3A%2F%2Fwww.google.co.kr%2F)
150 |
151 |
152 | ### 뮤텍스와 세마포어의 차이
153 |
154 | * 프로세스 간 메시지를 전송하거나, 공유메모리를 통해 특정 데이터를 공유하게 되는 경우 문제가 발생할 수 있다. 즉, 공유된 자원에 여러개의 프로세스가 동시에 접근하면서 문제가 발생하는 것으로써 공유된 자원 속 하나의 데이터는 한 번에 하나의 프로세스만 접근할 수 있도록 제한해 두어야 한다.
155 |
156 | * 이를 위하여 고안된 것이 바로 **Semaphore 세마포어**다.
157 |
158 | * **세마포어** : 멀티프로그래밍 환경에서 공유 자원에 대한 접근을 제한하는 방법
159 |
160 | * **임계 구역(Critical Section)**
161 | * 여러 프로세스가 데이터를 공유하며 수행될 때, 각 프로세스에서 공유 데이터를 접근하는 프로그램 코드 부분. 공유 데이터를 여러 프로세스가 동시에 접근할 때 잘못된 결과를 만들 수 있기 때문에, 한 프로세스가 임계 구역을 수행할 때는 다른 프로세스가 접근하지 못하도록 해야 한다.
162 |
163 | * 뮤텍스(Mutex)
164 | * 공유된 자원의 데이터를 **여러 스레드가** 접근하는 것을 막는 것
165 | * 상호배제라고도 하며, Critical Section(=임계구역)을 가진 스레드의 Running time이 서로 겹치지 않도록 각각 단독으로 실행하게 하는 기술이다.
166 | * 해당 접근을 조율하기 위해 lock과 unlock을 사용한다.
167 | * lock : 현재 임계구역에 들어갈 권한을 얻어옴(만약 다른 프로세스/스레드가 임계 구역 수행 중이면 종료할 때까지 대기)
168 | * unlock : 현재 임계 구역을 모두 사용했음을 알림. (대기 중인 다른 프로세스/스레드가 임계 구역에 진입할 수 있음)
169 | * 뮤텍스는 상태가 0, 1로 **이진 세마포어**로 부르기도 한다.
170 | * 세마포어(Semaphore)
171 | * 공유된 자원의 데이터를 **여러 프로세스가** 접근하는 것을 막는 것
172 | * 리소스 상태를 나타내는 간단한 **카운터**로 생각할 수 있다.
173 | * 운영체제 또는 커널의 한 지정된 저장장치 내의 값이다.
174 | * 일반적으로 비교적 긴 시간을 확보하는 리소스에 대해 이용한다.
175 | * 유닉스 시스템 프로그래밍에서 세마포어는 운영체제의 리소스를 경쟁적으로 사용하는 다중 프로세스에서 행동을 조정하거나 또는 동기화 시키는 기술이다.
176 | * 공유 리소스에 접근할 수 있는 프로세스의 최대 허용치만큼 동시에 사용자가 접근하여 사용할 수 있다.
177 | * 각 프로세스는 세마포어 값을 확인하고 변경할 수 있다.
178 | * 사용 중이지 않는 자원의 경우 그 프로세스가 즉시 자원을 사용할 수 있다.
179 | * 이미 다른 프로세스에 의해 사용 중이라는 사실을 알게 되면 재시도하기 전에 일정 시간을 기다려야 한다.
180 | * 세마포어를 사용하는 프로세스는 그 값을 확인하고, 자원을 사용하는 동안에는 그 값을 변경함으로써 다른 세마포어 사용자들이 기다리도록 해야한다.
181 | * 세마포어는 이진수 (0 또는 1)를 사용하거나, 또는 **추가적인 값을 가질 수도 있다.**
182 | * 차이
183 | 1. 가장 큰 차이점은 관리하는 **동기화 대상의 개수**
184 | * Mutex는 동기화 대상이 오직 하나뿐일 때, Semaphore는 동기화 대상이 하나 이상일 때 사용한다.
185 | 2. Semaphore는 Mutex가 될 수 있지만 Mutex는 Semaphore가 될 수 없다.
186 | * Mutex는 상태가 0, 1 두 개 뿐인 binary Semaphore
187 | * Semaphore는 이진수 (0 또는 1)를 사용하거나, 또는 추가적인 값을 가질 수도 있다.
188 | 3. Semaphore는 소유할 수 없는 반면, Mutex는 소유가 가능하며 소유주가 이에 대한 책임을 가진다.
189 | * Mutex 의 경우 상태가 두개 뿐인 lock 이므로 lock 을 가질 수 있다.
190 | 4. Mutex의 경우 Mutex를 소유하고 있는 스레드가 이 Mutex를 해제할 수 있다. 하지만 Semaphore의 경우 이러한 Semaphore를 소유하지 않는 스레드가 Semaphore를 해제할 수 있다.
191 | 5. Semaphore는 시스템 범위에 걸쳐있고 파일시스템상의 파일 형태로 존재하는 반면 Mutex는 프로세스 범위를 가지며 프로세스가 종료될 때 자동으로 Clean up 된다.
192 |
193 | > [http://jwprogramming.tistory.com/13](http://jwprogramming.tistory.com/13)
194 |
195 | ### CPU 스케줄링
196 |
197 | * CPU가 하나의 프로세스 작업이 끝나면 다음 프로세스 작업을 수행해야 한다. 이때 어떤 프로세스를 다음에 처리할 지 선택하는 알고리즘을 CPU Scheduling 알고리즘이라고 한다. 따라서 상황에 맞게 CPU를 어떤 프로세스에 배정하여 효율적으로 처리하는가가 관건이다.
198 |
199 | * 선점 vs 비선점
200 | * Preemptive(선점)
201 | * 프로세스가 CPU를 점유하고 있는 동안 I/O나 인터럽트가 발생하지 않았음에도 다른 프로세스가 해당 CPU를 강제로 점유할 수 있다.
202 | * 즉, 프로세스가 정상적으로 수행중인 동안 다른 프로세스가 CPU를 강제로 점유하여 실행할 수 있다.
203 | * Non-Preemptive(비선점)
204 | * 한 프로세스가 CPU를 점유했다면 I/O나 인터럽트 발생 또는 프로세스가 종료될 때까지 다른 프로세스가 CPU를 점유하지 못하는 것이다.
205 | * CPU 스케줄링의 종류
206 | * 선점형 스케줄링
207 | * Priority Scheduling
208 | - 정적/동적으로 우선순위를 부여하여 우선순위가 높은 순서대로 처리
209 | - 우선 순위가 낮은 프로세스가 무한정 기다리는 Starvation 이 생길 수 있음
210 | - Aging 방법으로 Starvation 문제 해결 가능
211 | * SRT(Shortest Remaining Time) 스케줄링
212 | - 짧은 시간 순서대로 프로세스를 수행한다.
213 | - 현재 CPU에서 실행 중인 프로세스의 남은 CPU 버스트 시간보다 더 짧은 CPU 버스트 시간을 가지는 프로세스가 도착하면 CPU가 선점된다.
214 | * Round Robin 스케줄링
215 | - 시분할 시스템의 성질을 활용한 방법
216 | - 일정 시간을 정하여 하나의 프로세스가 이 시간동안 수행하고 다시 대기 상태로 돌아간다.
217 | - 그리고 다음 프로세스 역시 같은 시간동안 수행한 후, 대기한다. 이러한 작업을 모든 프로세스가 돌아가면서 진행하며, 마지막 프로세스가 끝나면 다시 처음 프로세스로 돌아와서 작업을 반복한다.
218 | - 일정 시간을 Time Quantum(Time Slice)라고 부른다. 일반적으로 10 ~ 100msec 사이의 범위를 갖는다.
219 | - 한 프로세스가 종료되기 전에 time quantum이 끝나면 다른 프로세스에게 CPU를 넘겨주기 때문에 선점형 스케줄링의 대표적인 예시다.
220 | * Multi-level Queue 스케줄링
221 | - 프로세스를 그룹으로 나누어, 각 그룹에 따라 Ready Queue(준비 큐)를 여러 개 두며, 각 큐마다 다른 규칙을 지정할 수도 있다.(ex. 우선순위, CPU 시간 등)
222 | - 즉, 준비 큐를 여러 개로 분할해 관리하는 스케줄링 방법이다.
223 | - 프로세스들이 CPU를 기다리기 위해 한 줄로 서는 게 아니라 여러 줄로 선다.
224 | - 
225 |
226 | * Multi-level feedback Queue 스케줄링
227 | - 기본 개념은 Multi-level Queue와 동일하나, 프로세스가 하나의 큐에서 다른 큐로 이동 가능하다는 점이 다르다.
228 | - 모든 프로세스는 가장 위의 큐에서 CPU의 점유를 대기한다. 이 상태로 진행하다가 이 큐에서 기다리는 시간이 너무 오래 걸린다면 **아래의 큐로 프로세스를 옮긴다.** 이와 같은 방식으로 대기 시간을 조정할 수 있다.
229 | - 만약, 우선순위 순으로 큐를 사용하는 상황에서 우선순위가 낮은 아래의 큐에 있는 프로세스에서 starvation 상태가 발생하면 이를 우선순위가 높은 위의 큐로 옮길 수도 있다.
230 | - 대부분의 상용 운영체제는 여러 개의 큐를 사용하고 각 큐마다 다른 스케줄링 방식을 사용한다. 프로세스의 성격에 맞는 스케줄링 방식을 사용하여 최대한 효율을 높일 수 있는 방법을 선택한다.
231 | -
232 |
233 | * 비선점형 스케줄링
234 | 1. FCFS (First Come First Served)
235 | - 큐에 도착한 순서대로 CPU 할당
236 | * Convoy Effect 발생 : 소요 시간이 긴 프로세스가 짧은 프로세스보다 먼저 도착해서 뒤에 프로세스들이 오래 기다려야 하는 현상
237 | - 실행 시간이 짧은 게 뒤로 가면 평균 대기 시간이 길어짐
238 | 2. SJF (Shortest Job First)
239 | - 수행시간이 가장 짧다고 판단되는 작업을 먼저 수행
240 | - FCFS 보다 평균 대기 시간 감소, 짧은 작업에 유리
241 |
242 | * CPU 스케줄링 척도
243 | * Response Time
244 | - 작업이 처음 실행되기까지 걸린 시간
245 | * Turnaround Time
246 | - 실행 시간과 대기 시간을 모두 합한 시간으로 작업이 완료될 때 까지 걸린 시간
247 |
248 | > - [운영체제(OS) 6. CPU 스케줄링](https://velog.io/@codemcd/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9COS-6.-CPU-%EC%8A%A4%EC%BC%80%EC%A4%84%EB%A7%81)
249 | > - [https://github.com/WooVictory/Ready-For-Tech-Interview](https://github.com/WooVictory/Ready-For-Tech-Interview)
250 |
--------------------------------------------------------------------------------
/Network/Part3.md:
--------------------------------------------------------------------------------
1 | # 2. Network - Part3
2 |
3 |
4 |
5 | ### :book: Contents
6 | - [DNS](#DNS란)
7 | - [REST와 RESTful의 개념](#REST와-RESTful)
8 | - [소켓(Socket)이란](#Socket이란)
9 | - [Socket.io와 WebSocket의 차이](#양방향-통신)
10 | - [Frame, Packet, Segment, Datagram](#Frame-Packet-Segment-Datagram)
11 |
12 |
13 |
14 | ---
15 |
16 |
17 |
18 | ### DNS란
19 |  20 | - **DNS의 등장 배경**
21 | - TCP/IP 프로토콜을 사용하는 네트워크 안에서는 IP주소를 알고 있어야 상대방 장비와 연결이 가능하다.
22 | - 즉, 네트워크에서 도메인이나 호스트 이름을 숫자로 된 IP 주소로 해석해 주기 위해 TCP/IP Network Service인 DNS 등장
23 | - **DNS의 개념 (Domain Name System)**
24 | - 숫자로 구성된 네트워크 주소인 IP주소를 사람이 이해하기 쉬운 명칭인 도메인 이름으로 상호 매칭시켜주는 시스템
25 | - 도메인에 해당하는 IP주소를 알려주거나 반대로 IP주소에 해당하는 도메인을 알려주는 서비스
26 | - UDP와 TCP **포트 53번**을 사용한다.
27 | - UDP : 일반적인 DNS 조회를 할 경우에 사용
28 | - TCP : Zone Transfer(영역 전송)와 512Byte를 초과하는 DNS 패킷을 전송해야 할 경우
29 | - 분산된 DB를 이용해 각 조직들은 자신들의 도메인 정보를 관리하는 DNS 서버를 자체적으로 운영
30 | - 이 수 많은 도메인의 **DNS 서버들이 상호 연동되어 있는 Domain Name Space를 구성**하게 된다.
31 |
20 | - **DNS의 등장 배경**
21 | - TCP/IP 프로토콜을 사용하는 네트워크 안에서는 IP주소를 알고 있어야 상대방 장비와 연결이 가능하다.
22 | - 즉, 네트워크에서 도메인이나 호스트 이름을 숫자로 된 IP 주소로 해석해 주기 위해 TCP/IP Network Service인 DNS 등장
23 | - **DNS의 개념 (Domain Name System)**
24 | - 숫자로 구성된 네트워크 주소인 IP주소를 사람이 이해하기 쉬운 명칭인 도메인 이름으로 상호 매칭시켜주는 시스템
25 | - 도메인에 해당하는 IP주소를 알려주거나 반대로 IP주소에 해당하는 도메인을 알려주는 서비스
26 | - UDP와 TCP **포트 53번**을 사용한다.
27 | - UDP : 일반적인 DNS 조회를 할 경우에 사용
28 | - TCP : Zone Transfer(영역 전송)와 512Byte를 초과하는 DNS 패킷을 전송해야 할 경우
29 | - 분산된 DB를 이용해 각 조직들은 자신들의 도메인 정보를 관리하는 DNS 서버를 자체적으로 운영
30 | - 이 수 많은 도메인의 **DNS 서버들이 상호 연동되어 있는 Domain Name Space를 구성**하게 된다.
31 |
32 | - **DNS의 동작 원리**
33 | 
34 | 1. 웹브라우저에 `www.naver.com`을 입력하면 먼저 `Local DNS`에게
35 | `www.naver.com`이라는 hostname에 대한 IP 주소를 질의하여 Local DNS에 없으면
36 | 다른 DNS name 서버 정보를 받는다. `(Root DNS 정보)`
37 | 2. `Root DNS` 서버에 `www.naver.com` 질의
38 | 3. Root DNS 서버로부터 `com 도메인`을 관리하는 `TLD(Top-Level Domina)` 서버 정보를 전달 받는다.
39 | 4. `TLD` 서버에 `www.naver.com` 질의
40 | 5. TLD에서 `www.naver.com`을 관리하는 DNS 정보를 전달한다.
41 | 6. `"www.naver.com"` 도메인을 관리하는 DNS 서버에 `"www.naver.com"` 호스트 네임에 대한 IP 주소 질의
42 | 7. `Local DNS` 서버에게 `www.naver.com`에 대한 IP 주소는 `222.122.195.6이라고 응답`
43 | 8. Local DNS는 `www.naver.com`에 대한 IP 주소를 캐싱하고 IP 주소 정보를 전달
44 |
45 | - **DNS의 구성 요소**
46 | 
47 | 1. 도메인 네임 스페이스 (Domain Name Space) : DNS가 저장, 관리하는 계층적 구조
48 | - 최상위에 루트 DNS 서버가 존재하고, 그 하위로 인터넷에 연결된 모든 노드가 연속해서 이어진 계층 구조로 구성
49 | - 각 레벨의 도메인은 그 하위 도메인에 관한 정보를 관리하는 구조 (계층적 구조)
50 | - 도메인(Domain) : 도메인 네임 스페이스의 서브 트리
51 | 2. 네임 서버 (Name Sever) : 도메인 네임 스페이스의 트리 구조에 대한 정보를 가지고 있는 서버
52 | - 네임 서비스 : 도메인 이름을 IP 주소로 변환하는 것
53 | - 리졸버로부터 요청 받은 도메인 이름에 대한 IP주소를 다시 리졸버로 전달해주는 역할을 수행
54 | - 해당 도메인을 관리하는 주 네임 서버인 Primary Name Server와 보조 Secondary Name Server로 구성
55 | 3. 리졸버 (Resolver)
56 | - client의 요청을 네임 서버로 전달하고 네임 서버로부터 정보를 받아 client에게 제공하는 기능 수행
57 | 4. 스티브 리졸버(Stub Resolver)
58 | - 질의를 네임 서버로 전달하고 응답을 웹 브라우저로 전달하는 인터페이스 기능만을 수행
59 |
60 | - **DNS의 질의/응답 과정**
61 | 1. **재귀적 질의 (Recursive Queries)**
62 | - **가장 간단한 유형의 DNS 쿼리**로, Client가 원하는 정보를 전달해 주거나, 정보가 없다면 에러 메시지를 전달
63 | - www.naver.com에 대한 변환 요청 과정
64 | 
65 | 2. **반복적 질의 (Iterative Queries)**
66 | - 질의를 요청한 client 또는 server가 최종적인 응답을 받을 때까지 요청과 응답을 반복적으로 진행
67 | - 질의를 날릴 때 마다 서버는 질의에 응답이 가능한 NS 목록으로 응답한다.
68 | - www.naver.com에 대한 변환 요청 과정
69 | 
70 |
71 | - **DNS의 역할**
72 | 1. 호스트 에일리어싱(Host Aliasing) : 복잡한 호스트 네임을 가진 호스트는 하나 이상의 별명을 가질 수 있다.
73 | - ex) www.naver.com == naver.com 따라서 정식 호스트 네임을 얻기 위해 사용한다.
74 | 2. 메일 서버 에일리어싱(Mail Server Aliasing)
75 | - 위와 마찬가지로 메일주소의 별명을 가질 수 있고 DNS는 정식 호스트 네임을 알려주는 역할
76 | 3. 도메인 네임을 IP주소로 변환해주는 역할을 한다.
77 |
78 | > - [https://security-nanglam.tistory.com/24?category=800892](https://security-nanglam.tistory.com/24?category=800892)
79 | > - [https://peemangit.tistory.com/52](https://peemangit.tistory.com/52)
80 |
81 |
82 |
83 | ### REST와-RESTful
84 | [REST](./img/rest.png)
85 |
86 | - **REST이란?**
87 | - 분산 시스템 설계를 위한 **아키텍처 스타일** (아키텍처 = **제약 조건의 집합**)
88 | - **RESTfUL이란?**
89 | - 제약 조건의 집합(아키텍처 스타일, 아키텍처 원칙)을 **모두 만족하는 것**
90 | - RESTful API는 REST 아키텍처 원칙을 모두 만족하는 API라는 뜻
91 | - RESTful API를 이용해서 하나의 큰 서비스 앱을 여러 모듈화된 마이크로 서비스들로 나눌 수 있게 됨
92 | - **REST가 필요한 이유**
93 | 1. 분산 시스템의 도입
94 | - 거대한 애플리케이션을 모듈, 기능별로 분리하기 쉬워졌다.
95 | - RESTful API를 서비스하기만 하면 다른 module 또는 Application들이라도 RESTful API를 통해 상호 간에 통신 가능
96 | 2. 멀티 플랫폼 클라이언트 지원
97 | - WEB을 위한 HTML 및 이미지 등을 보내던 것과 달리 데이터만 보내면 여러 클라이언트에서 데이터를 적절히 보여줘야 한다.
98 | - RESTful API를 사용하면서 데이터만 주고 받기 때문에 여러 클라이언트가 자유롭고 부담없이 데이터 이용 가능
99 | - 서버도 요청한 데이터만 깔끔하게 보내주면되기 때문에 가벼워지고 유지보수성도 좋아졌다.
100 | - **REST의 구성 요소**
101 | 1. HTTP URI = 자원 (Resource)
102 | 2. HTTP Method = 행위
103 | 3. MIME Type = 표현 방식
104 | ``` javascript
105 | GET /100 HTTP/1.1
106 | Host : www.naver.com
107 | ```
108 | - **요청 메시지의 예시 (REST 방식을 이용한 Request 예제)**
109 | - 위와 같은 Request 메시지가 있으면 URI 자원은 "/100"이고, HTTP Method는 "GET"이다.
110 | - MIME 타입은 보통 Response HTTP header 메시지에 Content-type으로 쓰인다.
111 | - 즉, www.naver.com 서버에 /100 이라는 자원을 GET(조회)하고 싶다는 요청으로 해성 가능하다.
112 | ``` javascript
113 | HTTP/1.1 200 OK
114 | Content-Type : application/json-patch+json
115 |
116 | [{"title" : "helloworld"}]
117 | ```
118 | - **응답 메시지의 예시**
119 | - 이런 Response가 왔다고 가정했을 때
120 | - Content-Type을 보고 클라이언트는 IANA라는 타입들의 명세를 모아놓은 사이트에 방문해
121 | - application/json-patch+json 이라는 타입의 명세를 확인하고 아래 Body의 내용이 json타입임을 알 수 있는 것
122 | - **제약 조건의 의미**
123 | 1. Client/Server 방식
124 | 2. Stateless : 각 요청에 클라이언트의 context가 서버에 저장되어서는 안된다.
125 | - 즉, HTTP Sesstion과 같은 컨텍스트 저장소에 상태 정보를 저장하지 않는다.
126 | - 상태 정보를 저장하지 않으면 각 API 서버는 들어오는 요청만을 들어오는 메시지로만 처리
127 | - 세션과 같은 컨텍스트 정보를 신경쓸 필요가 없기 때문에 구현이 단순해진다.
128 | 3. Cacheable : 클라이언트는 응답을 캐싱할 수 있어야 한다.
129 | 4. Layered System : 클라이언트는 서버에 직접 연결되었는지 미들웨어에 연결되었는지 알 필요가 없어야 한다.
130 | 5. Code on demand (option) : 서버는 코드를 클라이언트에게 보내서 실행하게 할 수 있어야 한다.
131 | 6. **Uniform Interface** : RESTful 하기 위해서 가장 잘 지켜져야 하는 요소
132 | - 자원은 유일하게 식별가능해야 한다.
133 | - HTTP Method로 표현을 담아야 한다.
134 | - 메시지는 스스로 설명(self-descrptive)해야 한다.
135 | - 하이퍼링크를 통해서 애플리케이션의 상태가 전이(HATEOAS)되어야 한다.
136 | - HATEOAS : Link라는 HTTP 헤더에 다른 리소스를 가리켜 주는 값을 넣는 방법으로 해결
137 | - Spring에는 spring-data-rest, spring hateoas, spring-rest-doc으로
138 | - 두 제약을 지키기위해 사용할 수 있는 라이브러리가 존재
139 | ``` javascript
140 | HTTP/1.1 200 OK
141 | Content-Type : application/json
142 | Link : ; rel="previous"
143 |
144 | [{"title" : "helloworld"}]
145 | ```
146 | - **HATEOAS의 예시**
147 | - 위와 같이 해당 정보에서 다른 정보로 넘어갈 수 있는 하이퍼링크를 명시해주면 된다.
148 | - **REST API의 장단점**
149 | - **장점**
150 | - 메시지를 단순하게 표현할 수 있고 WEB의 원칙인 확장에 유연하다. (멀티플랫폼)
151 | - 별도의 장비나 프로토콜이 필요없이 기존의 HTTP 인프라를 이용할 수 있다. (사용이 용이함)
152 | - Server, Client를 완전히 독립적으로 구현할 수 있다.
153 | - **단점**
154 | - 표준, 스키마가 없다. 결국 API 문서가 만들어지는 이유이다.
155 | - 행위에 대한 메소드가 제한적이다. (GET, POST, PUT, DELETE, HEAD, ... )
156 | - **URI와 URL의 차이점**
157 | - **URI : Uniform Resource Identifier**
158 | - REST에서는 모든 것을 리소스로 표현한다. 그리고 그 자원은 유일한 것을 나타낸다. (Identifier, 식별자)
159 | - 파일 뿐만 아니라 여러 자원들 까지도 포함하는 개념
160 | - **URL : Uniform Resource Locator**
161 | - 반면에 과거의 웹에서는 html같은 파일들을 주고 받았기 때문에 Identifier의 개념이 따로 필요없었다.
162 | - 파일의 위치를 가리키는 Locator를 썼다.
163 |
164 | > - [https://jeong-pro.tistory.com/180](https://jeong-pro.tistory.com/180)
165 |
166 |
167 |
168 | ### Socket이란
169 | - **소켓(Socket)의 개념**
170 | - 네트워크상에서 동작하는 프로그램 간 통신의 종착점(Endpoint)
171 | - 두 프로그램이 네트워크를 통해 서로 통신을 할 수 있도록 양쪽에 생성되는 링크의 단자
172 | = 서로 다른 프로세스끼리 데이터 전달이 가능
173 | - **소켓(Socket)과 포트(Port)의 차이**
174 | - 포트(Port) : 네트워크를 통해 데이터를 주고 받는 프로세스를 식별하기 위해 호스트 내부적으로 프로세스가 할당받는 고유한 값
175 | - 소켓(Socket) : 프로세스가 네트워크를 통해서 데이터를 주고 받으려면 반드시 열어야 하는 창구
176 | * 보내는 쪽도 받는 쪽도 동일하게 소켓을 열어야 한다.
177 | - **소켓 통신의 Workflow**
178 | 
179 | - **서버 (Server)**
180 | 1. **socket()** 함수를 이용하여 소켓을 생성
181 | 2. **bind()** 함수로 ip와 port 번호를 설정
182 | 3. **listen()** 함수로 클라이언트의 접근 요청에 수신 대기열을 만들어 몇 개의 클라이언트를 대기 시킬지 결정
183 | 4. **accept()** 함수를 사용하여 클라이언트와의 연결을 기다림
184 | - **클라이언트 (Client)**
185 | 1. **socket()** 함수로 가장 먼저 소켓을 엶.
186 | 2. **connect()** 함수를 이용하여 통신 할 서버의 설정된 ip와 port 번호에 통신을 시도
187 | 3. 통신을 시도 시, 서버가 **accept()** 함수를 이용하여 클라이언트의 socket descriptor를 반환
188 | 4. 이를 통해 클라이언트와 서버가 서로 **read(), write()**를 하며 통신 (이 과정이 반복)
189 |
190 | > - [https://song-yoshiii.tistory.com/3](https://song-yoshiii.tistory.com/3)
191 |
192 |
193 |
194 | ### 양방향-통신
195 | - **웹 브라우저에서 양방향 통신 (Socket.io와 WebSocket)**
196 | > http 프로토콜은 요청/응답 패러다임이기에 클라이언트에서 요청을 보내야만 그에 대한 응답을 받는다.
197 | 그러나, 클라이언트가 요청을 보내지 않아도 서버에서 클라이언트쪽으로 데이터를 보내야 하는 경우가 생기게 된다.
198 | http 프로토콜로 통신하는 경우 연결이 유지되지 않기 때문에 먼저 요청을 보내는 것이 불가능하기 떄문에
199 | 이러한 문제를 해결하기 위해 양방향 통신의 개념이 고안이 되었다.
200 |
201 | - **Websocket의 개념**
202 | 
203 | - TCP 프로토콜에서 양방향 커뮤니케이션을 가능하게 하는 통신 프로토콜
204 | - HTTP의 프록시를 지원할 수 있게 하기 위해서 HTTP 포트 80, 443에서 동작하도록 설계 때문에 HTTP와 호환 가능
205 | - 웹 소켓을 사용하기 위해서는 HTTP Upgrade header를 사용해
206 | HTTP 프로토콜에서 웹 소켓 프로토콜로 전환 ( = 웹 소켓 핸드 쉐이크)
207 |
208 | - **Websocket의 특징**
209 | - 양방향으로 원할 때 요청을 보낼 수 있으며 stateless한 HTTP에 비해 오버헤드가 적어서 유용
210 | - 클라이언트가 먼저 서버에게 요청하지 않고, 서버가 클라이언트에게 contents를 보내고 이 연결이 계속 열린채로 유지됨
211 | - **Websocket의 간단한 예제**
212 | ```JAVA
213 | if ('WebSocket' in window) {
214 | var oSocket = new WebSocket(“ws://localhost:80”);
215 |
216 | oSocket.onmessage = function (e) {
217 | console.log(e.data);
218 | };
219 |
220 | oSocket.onopen = function (e) {
221 | console.log(“open”);
222 | };
223 |
224 | oSocket.onclose = function (e) {
225 | console.log(“close”);
226 | };
227 |
228 | oSocket.send(“message”);
229 | oSocket.close();
230 | }
231 | ```
232 | 1. ws:// : WebSocket 프로토콜을 나타내며 URI 스키마를 사용한다. 암호화 소켓은 https:// 처럼 wss://를 사용
233 | 2. 먼저 new WebSocket() 메서드로 웹서버와 연결한다.
234 | 3. 생성된 WebSocket 인스턴스를 이용하여 소켓에 연결할 때(onopen), 소켓 연결을 종료할 때(onclose),
235 | 메시지를 받았을 때(onmessage) 등의 이벤트를 각각 정의할 수 있다.
236 | 4. 서버에 메시지를 보내고 싶을 때에는 send() 메서드를 이용한다.
237 |
238 | - **Socket.io의 개념**
239 | - JavaScript를 이용하여 브라우저 종류에 상관없이 실시간 웹을 구현할 수 있도록 한 기술
240 | - 브라우저와 웹 서버의 종류와 버전을 파악해 가장 적합한 기술을 선택해 실시간 웹을 구현할 수 있도록 해주는 기술
241 | - 예를 들어 브라우저에 Flash Socket을 지언하는 Flash Plugin v10.0.0 이상이 있으면
242 | FlashSocket을 이용 없으면 Ajax Long Polling 방식을 이용
243 | - Web socket과 달리 node.js의 모듈이다.
244 | - **Socket.io를 활용한 다양한 예제**
245 | - https://socket.io/
246 |
247 |
248 | > - [https://velog.io/@imacoolgirlyo/web-socket과-socket.io](https://velog.io/@imacoolgirlyo/web-socket과-socket.io)
249 | > - [https://d2.naver.com/helloworld/1336](https://d2.naver.com/helloworld/1336)
250 |
251 |
252 |
253 | ### Frame-Packet-Segment-Datagram
254 | - **프로토콜 데이터 단위 (PDU / Protocol Data Unit)**
255 | - 데이터 통신에서 상위 계층이 전달한 데이터에 붙이는 제어정보
256 | - 모든 계층에서 우리가 전송하는 데이터 자체는 동일하지만
257 | 각 레이어를 거치면서 헤더 정보가 추가되며 이름이 달라진다.
258 | - 동일 레이어 내에서 데이터 단위를 부르는 이름
259 | - **서비스 데이터 단위 (SDU / Service Data Unit)**
260 | - 상향 / 하향 통신 레이어 간에 전달되는 실제 정보
261 | - 즉, PDU = PCI(프로토콜 통신 유닛의 줄인말로 쉽게 말하면 헤더 정보) + SDU
262 | 
263 |
264 | > 쉽게 생각하면 사용자는 Data라 부르고,
265 | TCP는 Segment라고 부르고, IP는 Packet이라고 부르고,
266 | 데이터 링크는 Frame, 컴퓨터 하드웨어는 그것을 Bit로 연산하고 다루게 되는 것
267 |
268 | 1. **데이터 그램**
269 | - 사용자의 순수한 message를 다르게 부르는 말
270 |
271 | 2. **세그먼트 (전송 계층)**
272 | - 상위 계층에서 데이터를 전달받은 전송계층에서는 아래의 정보들을 추가해 그룹화 한다. 이때부터는 데이터가 아닌 세그먼트라 불림
273 | - 발신지 포트 : 발싱하는 application의 포트
274 | - 목적지 포트 : 수신해야 할 application의 포트
275 | - 순서 번호 : 순차적 전송할 경우 순서를 붙이며, 순서가 어긋나면 목적지 프로토콜이 이를 바로 잡는다.
276 | - 오류검출코드 : 발신지와 목적지 프로토콜은 세그먼트를 연산하여 오류 검출 코드를 각각 만든다.
277 | > 만약 발신지에서 전송한 세그먼트에 포함된 오류 검출 코드와 목적지에서 만든 오류 검출 코드가 다르다면
278 | 전송되는 과정에서 오류가 발생한 것이다. 이 경우, 수신측은 그 세그먼트를 폐기하고 복구 절차를 밟는다.
279 | 오류검출코드는 체크섬, 프레임 체크 시퀀스라고도 부른다.
280 |
281 | 3. **패킷 (네트워크 계층)**
282 | - 전송 계층으로부터 전달받은 세그먼트는 네트워크 계층의 정보를 포함해 패킷이라고 불리게 된다.
283 | - 발신지 컴퓨터 주소(Destination IP) : 패킷의 발신자 주소
284 | - 목적지 컴퓨터 주소(Source IP) : 패킷의 수신자 주소
285 | - 서비스 요청 : 네트워크 접속 프로토콜은 우선 순위와 같은 서브 네트워크의 사용을 요청할 수 있다.
286 |
287 | > **전반적인 네트워킹에서의 packet의 의미**
288 | Circuit switching vs Packet switching의 개념으로 회선 교환에 대비되는 모든 데이터 교환을 일컬어 packet switching이라고 한다.
289 | ATM cell ATM cell switching은 물론이고, Ethernet frame switching, Frame Relay frame switching, 등등
290 | 회선교환이 아닌 모든 데이터 단위가 packet의 범주에 들어간다.
291 |
292 | 4. **프레임 (데이터 링크 계층)**
293 | - 최종적으로 데이터 전송을 하기 전 패킷헤더에 Mac Address와 CRC를 위한
294 | Trailer(데이터가 정확하게 수신 할 수 있는가에 대한 무결성을 검증하기 위한 FCS)를 붙인 단위
295 | - CRC : 순환 중복 검사 (데이터를 전송할 때 전송된 데이터에 오류가 있는지 확인하기 위한 체크값을 결정하는 방식)
296 | - FCS : 프레임 검사 시퀀스 (Frame Check Sequence)
297 |
298 |
299 | > - [https://velog.io/@hidaehyunlee/%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%84%B8%EA%B7%B8%EB%A8%BC%ED%8A%B8-%ED%8C%A8%ED%82%B7-%ED%97%B7%EA%B0%88%EB%A6%B4-%EB%95%90-PDU%EB%A5%BC-%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90](https://velog.io/@imacoolgirlyo/web-socket과-socket.io)
300 |
301 |
302 |
--------------------------------------------------------------------------------
/Java/Part2.md:
--------------------------------------------------------------------------------
1 | # 2. Java - Part2
2 | ### :book: Contents
3 | * [OOP의 4가지 특징](#OOP의-4가지-특징)
4 | * [OOP의 5대 원칙 (SOLID)](#OOP의-5대-원칙)
5 | * [객체지향 프로그래밍과 절차지향 프로그래밍의 차이](#객체지향-프로그래밍과-절차지향-프로그래밍의-차이)
6 | * [객체지향(Object-Oriented)이란](#객체지향(Object-Oriented)이란)
7 | * [java의 non-static 멤버와 static 멤버의 차이](#java의-non-static-멤버와-static-멤버의-차이)
8 | * [Q. java의 main 메서드가 static인 이유](#java의-main-메서드가-static인-이유)
9 | * [java의 final 키워드 (final/finally/finalize)](#java의-final-키워드)
10 | * [java의 제네릭(Generic)과 c++의 템플릿(Template)의 차이](#java의-제네릭과-c++의-템플릿의-차이)
11 |
12 | ---
13 |
14 | ### OOP의 4가지 특징
15 | 1. 추상화(Abstraction)
16 | * 구체적인 사물들의 공통적인 특징을 파악해서 이를 하나의 개념(집합)으로 다루는 것
17 | * 각 객체의 구체적인 개념에 의존하지 말고 추상적 개념에 의존해야 설계를 유연하게 변경할 수 있다.
18 | * 
19 | 2. 캡슐화(Encapsulation)
20 | * **참고** SW 공학에서 요구사항 변경에 대처하는 고전적인 설계 원리
21 | * 높은 응집도와 낮은 결합도를 유지할 수 있도록 설계해야 요구사항을 변경할 때 유연하게 대처할 수 있다.
22 | 1. 응집도(Cohesion)
23 | * 클래스나 모듈 안의 요소들이 얼마나 밀접하게 관련되어 있는지를 나타낸다.
24 | 2. 결합도(Coupling)
25 | * 어떤 기능을 실행하는 데 다른 클래스나 모듈들에 얼마나 의존적인지를 나타낸다.
26 | * 캡슐화는 **정보 은닉**을 통해 **높은 응집도와 낮은 결합도**를 갖도록 한다.
27 | * 정보 은닉(information hiding)
28 | * 필요가 없는 정보는 외부에서 접근하지 못하도록 제한하는 것
29 | * private 키워드
30 | * 정보 은닉이 왜 필요할까?
31 | * SW는 결합이 많을수록 문제가 많이 발생한다.
32 | * 한 클래스가 변경이 발생하면 변경된 클래스의 비밀에 의존하는 다른 클래스들도 변경해야 할 가능성이 커진다는 뜻이다.
33 | 3. 상속(Inheritance)
34 | * 기존의 클래스를 재사용하여 새로운 클래스를 작성하는 것이다.
35 | * 보다 적은 코드로 새로운 클래스를 작성할 수 있고, 코드를 공통적으로 관리할 수 있기 대문에 코드의 추가 및 변경이 매우 용이하다.
36 | * 이러한 특징은 코드의 재사용성을 높이고 코드의 중복을 제거하여 프로그램의 생산성과 유지보수에 크게 기여한다.
37 | 4. 다형성(Polymorphism)
38 | * 서로 다른 클래스의 객체가 같은 메시지를 받았을 때 각자의 방식으로 동작하는 능력
39 | * 같은 이름의 메소드를 여러개 정의(오버로딩)
40 | * **오버로딩**의 장점 : 하나의 이름을 정의함으로써 하나의 이름만 기억하면 되므로 기억하기도 쉽고 같은 기능을 한다는 것을 쉽게 예측할 수 있다.
41 | > [https://gmlwjd9405.github.io/2018/07/05/oop-features.html](https://gmlwjd9405.github.io/2018/07/05/oop-features.html)
42 |
43 | ### OOP의 5대 원칙
44 | "**SOLID**" 원칙
45 | * **S**: 단일 책임 원칙(SRP, Single Responsibility Principle)
46 | * 객체는 단 하나의 책임만 가져야 한다.
47 | * **O**: 개방-폐쇄 원칙(OCP, Open Closed Principle)
48 | * 기존의 코드를 변경하지 않으면서 기능을 추가할 수 있도록 설계가 되어야 한다.
49 | * **L**: 리스코프 치환 원칙(LSP, Liskov Substitution Principle)
50 | * 일반화 관계에 대한 이야기며, 자식 클래스는 최소한 자신의 부모 클래스에서 가능한 행위는 수행할 수 있어야 한다.
51 | * **I**: 인터페이스 분리 원칙(ISP, Interface Segregation Principle)
52 | * 인터페이스를 클라이언트에 특화되도록 분리시키라는 설계 원칙이다.
53 | * **D**: 의존 역전 원칙(DIP, Dependency Inversion Principle)
54 | * 의존 관계를 맺을 때 변화하기 쉬운 것 또는 자주 변화하는 것보다는 변화하기 어려운 것, 거의 변화가 없는 것에 의존하라는 것이다.
55 | > [https://gmlwjd9405.github.io/2018/07/05/oop-solid.html](https://gmlwjd9405.github.io/2018/07/05/oop-solid.html)
56 |
57 | ### 객체지향-프로그래밍과-절차지향-프로그래밍의-차이
58 | - **절차지향(Procedural Programming)이란?**
59 | * **개념** : 물이 위에서 아래로 흐르는 것처럼 순차적인 처리가 중요시 되며 프로그램 전체가 유기적으로 연결되도록 만드는 프로그래밍 기법
60 | * **대표적인 절차지향 언어** : C언어
61 | * 컴퓨터의 작업 처리 방식과 유사하기 때문에 객체 지향 언어를 사용하는 것에 비해 더 빨리 처리되어 **시간적으로 유리**하다.
62 | * **장점**
63 | * 컴퓨터의 처리 구조와 유사해 실행 속도가 빠름
64 | * **단점**
65 | * 유지 보수가 어렵다
66 | * 실행 순서가 정해져 있으므로 코드의 순서가 바뀌면 동일한 결과를 보장하기 어렵다
67 | * 디버깅이 어렵다.
68 |
69 | * **객체지향 언어가 등장하게 되는 계기**
70 | * 옛날엔 H/W와 S/W의 개발 속도차이가 크지 않았지만, S/W언어의 발달과 컴파일러의 발달로 **H/W가 S/W의 발달을 처리하지 못하는 상황이 발생**
71 | * 객체지향 프로그래밍은 개발하려는 것을 **기능별로 묶어 모듈화**를 함으로써 H/W가 같은 기능을 중복으로 연산하지 않도록 하고 모듈을 재활용하기 때문에 **H/W의 처리양을 획기적으로 줄여줌**
72 |
73 | * **객체지향(Object Oriented Programming)이란?**
74 | * **객체지향의 정의** : 실제 세게를 모델링하여 S/W를 개발하는 방법
75 | * **데이터와 절차를 하나의 덩어리로 묶어서 생각하는 기법**으로 마치 컴퓨터 부품을 하나씩 사다가 컴퓨터를 조립하는 것과 같은 방법
76 | * **객체 지향의 3대 특성** : 캡슐화, 상속, 다형성
77 | * **장점**
78 | 1. 신뢰성 있는 소프트웨어를 쉽게 작성할 수 있다. (개발자가 만든 데이터를 사용하기에 신뢰할 수 있다.)
79 | 2. 코드를 재사용하기 쉽다. (코드의 재활용성이 높다)
80 | 3. 업그레이드가 쉽다.
81 | 4. 디버깅이 쉽다.
82 | * **단점**
83 | 1. 처리속도가 절차지향보다 느리다.
84 | 2. 설계에 많은 시간 소요가 들어간다.
85 |
86 | * **객체지향과 절차지향의 차이점**
87 | * 절차지향 : 순차적인 실행에 초점 (데이터를 중심으로 함수를 구현)
88 | * 객체지향 : 객체 간의 관계/조직에 초점을 두고 있다. (기능을 중심으로 메소드를 구현)
89 | * But. 객체지향의 반대는 절차지향이 아니고 절차지향의 반대는 객체지향이 아니다.
90 | 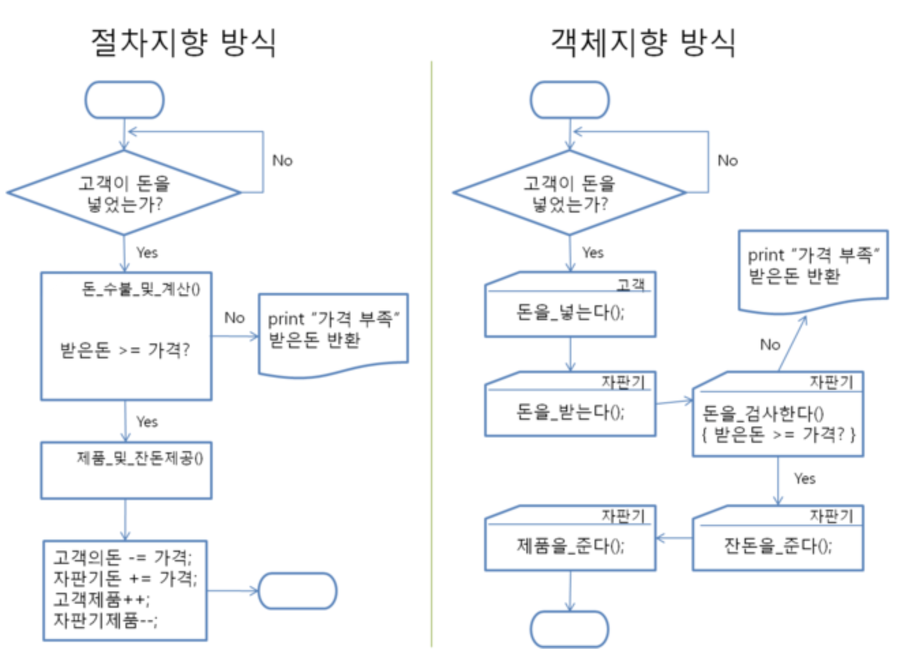
91 |
92 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
93 | > - [절자치향 VS 객체지향 :: 개인적인공간](https://brownbears.tistory.com/407)
94 |
95 | ### 객체지향(Object-Oriented)이란
96 |
97 | - **객체 지향 프로그래밍(OOP)이란?**
98 | - 개념 : 컴퓨터 프로그래밍 패러다임 중 하나로, 프로그래밍에서 필요한 데이터를 추상화시켜 상태와 행위를 가진 객체를 만들고 그 객체들 간의 유기적인 상호작용을 통해 로직을 구성하는 프로그래밍 방법
99 | - 이 때, 객체는 목적을 달성하기 위해 협력하는 존재로 자신만의 상태를 가지고 협력 여부를 판단하고 협력할 때는 객체의 방식대로 처리
100 | 협력의 과정에서 역할을 부여받고 그 역할에 따라 행동하는 존재
101 |
102 | > - **프로그래밍 패러다임**
103 | 프로그래밍의 원칙, 어떤 것을 기준으로 세워두고 프로그래밍 하는 것을 말한다.
104 | > - **객체**
105 | 프로그래밍 기능 구성을 위해 존재하는 것 그리고 다른 객체와 구별되는 것
106 | > - 즉, 어떤 기능을 만듦에 있어서 1단계 무엇 2단계 무엇 이렇게 프로그래밍을 하는 것이 아니라 그러한 기능을 만듦에 있어서 객체들의 협력 관점으로 만들겠다는 것
107 | (어떤 객체는 이 일을 하고, 어떤 객체는 저 일을 하고 분업화 하겠다는 것)
108 |
109 | - **객체 지향 프로그래밍의 장.단점**
110 | - **장점**
111 | 1. 코드 재사용이 용이
112 | * 남이 만든 클래스를 가져와서 이용할 수 있고 상속을 통해 확장해서 사용할 수 있다.
113 | 2. 유지 보수가 쉽다.
114 | * 절차 지향 프로그래밍에서는 코드를 수정해야 할 때 일일이 찾아 수정해야하는 반면 객체 지향 프로그래밍에서는 수정해야 할 부분이 클래스 내부에 멤버 변수 혹은 메소드로 있기 때문에 해당 부분만 수정하면 된다.
115 | 3. 대형 프로젝트에 적합하다.
116 | * 클래스 단위로 모듈화시켜서 개발할 수 있으므로 대형 프로젝트처럼 여러명, 여러 회사에서 개발이 필요할 시 업무 분담이 쉽다.
117 | * **단점**
118 | 1. 처리 속도가 상대적으로 느리다.
119 | 2. 객체가 많으면 용량이 커질 수 있다.
120 | 3. 설계시 많은 시간과 노력이 필요하다.
121 |
122 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
123 | > - [객체 지향 프로그래밍이 뭔가요? (꼬리에 꼬리를 무는 질문 1순위, 그놈의 OOP)](https://jeong-pro.tistory.com/95)
124 | > - [[Java] 개념은 제대로 알고가자 - 객체지향 무엇인가](https://jinbroing.tistory.com/207)
125 |
126 | ### java의-non-static-멤버와-static-멤버의-차이
127 | * non-static 멤버
128 | 1. 공간적 특성
129 | - 멤버는 객체마다 별도 존재
130 | - 인스턴스 멤버라고 부름
131 | 2. 시간적 특성
132 | - 객체 생성시에 멤버 생성됨
133 | - 객체가 생길 때 멤버도 생성
134 | - 객체 생성 후 멤버 사용 가능
135 | - 객체가 사라지면 멤버도 사라짐
136 | 3. 공유의 특성
137 | - 공유되지 않음
138 | - 멤버는 객체 내에 각각 공간 유지
139 | * static 멤버
140 | 1. 공간적 특성
141 | - 멤버는 클래스 당 하나 생성
142 | - 멤버는 객체 내부가 아닌 별도의 공간(클래스 코드가 적재되는 메모리)에 생성
143 | - 클래스 멤버라고 부름
144 | 2. 시간적 특성
145 | - 클래스 로딩 시에 멤버 생성
146 | - 객체가 생기기 전에 이미 생성
147 | - 객체가 생기기 전에도 사용 가능
148 | - 객체가 사라져도 멤버는 사라지지 않음
149 | - 멤버는 프로그램이 종료될 때 사라짐
150 | 3. 공유의 특성
151 | - 동일한 클래스의 모든 객체들에 의해 공유됨
152 |
153 | * static의 활용
154 | - 전역 변수와 전역 함수를 만들 때 사용
155 | - 자바에서는 C++과 달리 어떤 변수나 함수도 클래스 바깥에 존재할 수 없으며 클래스 멤버로 존재해야함
156 | => 자바의 캡슐화 특징 때문에
157 | - static은 모든 클래스에서 공유하는 전역 변수나 모든 클래스에서 호출할 수 있는 전역 함수가 필요한 경우가 있음
158 | => static으로 활용
159 | - 공유 멤버를 만들고자 할 때 사용
160 | - static으로 선언된 필드나 메소드는 하나만 생성되어 클래스의 객체들 사이에서 공유됨
161 |
162 | * static 메소드의 제약 조건
163 | - static 메소드는 static 멤버만 접근할 수 있다.
164 | - 객체 없이 존재하기 때문에 non-static 멤버를 사용할 수 없고 static 멤버만 사용 가능
165 | 반면 non-static 메소드는 static 멤버들을 사용할 수 있다.
166 | - static 메소드는 this를 사용할 수 없다.
167 | - static 메소드는 객체 없이도 존재하기 때문에 this를 사용할 수 없다.
168 |
169 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
170 | > - [[JAVA] static 멤버, static 메소드](https://transferhwang.tistory.com/146)
171 |
172 | ### java의 main 메서드가 static인 이유
173 | - **static 키워드의 의미**
174 | - static은 java 프로그램이 실행되기 전에 static 함수나 static 변수를 첫 단계로 메모리에 올려 프로그램을 실행시킨다.
175 | (static은 실행시 1순위) 또한, 프로그램이 종료될 때 까지 사라지지 않는다.
176 |
177 | - **main에 static을 사용하는 이유?**
178 | - main 함수가 실행되기 위해서는 메모리에 미리 올라가야 한다.
179 | - 메모리에 올라가 있지 않으면, 시작점인 main() 메소드를 호출하려고 하는데 메모리에는 main이 없기 때문에 실행이 불가능
180 | - main 메소드도 호출되기 전에는 메모리에 올라가지 않는다. 때문에 main을 호출하기 위해서는 메모리에 main 메소드 내용이 있어야 하는데
181 | 이 main 메소드는 누군가 호출하기 전에 미리 메모리에 있어야 하기 때문에 static을 붙이는 것이다.
182 | - 그렇게함으로써 프로그램의 시작점으로 main이 실행되는 것이다.
183 |
184 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
185 | > - [main에 static 사용하는 이유 :: pu.. : 네이버블로그](https://blog.naver.com/blogpyh/220041002621)
186 |
187 | ### java의 final 키워드
188 | * **final 키워드**
189 | * 개념: 변수나 메서드 또는 클래스가 '변경 불가능'하도록 만든다.
190 | * 원시(Primitive) 변수에 적용 시
191 | * 해당 변수의 값은 변경이 불가능하다.
192 | * 참조(Reference) 변수에 적용 시
193 | * 참조 변수가 힙(heap) 내의 다른 객체를 가리키도록 변경할 수 없다.
194 | * 메서드에 적용 시
195 | * 해당 메서드를 오버라이드할 수 없다.
196 | * 클래스에 적용 시
197 | * 해당 클래스의 하위 클래스를 정의할 수 없다.
198 | * **finally 키워드**
199 | * 개념: try/catch 블록이 종료될 때 항상 실행될 코드 블록을 정의하기 위해 사용한다.
200 | * finally는 선택적으로 try 혹은 catch 블록 뒤에 정의할 때 사용한다.
201 | * finally 블록은 예외가 발생하더라도 항상 실행된다.
202 | * 단, JVM이 try 블록 실행 중에 종료되는 경우는 제외한다.
203 | * finally 블록은 종종 뒷마무리 코드를 작성하는 데 사용된다.
204 | * finally 블록은 try와 catch 블록 다음과, 통제권이 이전으로 다시 돌아가기 전 사이에 실행된다.
205 | * **finalize() 메서드**
206 | * 개념: 쓰레기 수집기(GC, Garbage Collector)가 더 이상의 참조가 존재하지 않는 객체를 메모리에서 삭제하겠다고 결정하는 순간 호출된다.
207 | * Object 클래스의 finalize() 메서드를 오버라이드해서 맞춤별 GC를 정의할 수 있다.
208 | * `protected void finalize() throws Throwable { // 파일 닫기, 자원 반환 등등 }`
209 |
210 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
211 | > - [https://gmlwjd9405.github.io/2018/08/06/java-final.html](https://gmlwjd9405.github.io/2018/08/06/java-final.html)
212 |
213 | ### java의 제네릭과 c++의 템플릿의 차이
214 | * java의 제네릭(Generic)
215 | * 개념: 모든 종류의 타입을 다룰 수 있도록 일반화된 타입 매개 변수(generic type)로 클래스나 메서드를 선언하는 기법
216 | *  217 | * 처리 방법: 타입 제거(type erasure)라는 개념에 근거한다.
218 | * 소스 코드를 JVM이 인식하는 바이트 코드로 변환할 때 인자로 주어진 타입을 제거하는 기술이다.
219 | * 제네릭이 있다고 해서 크게 달라지는 것은 없다. 단지 코드를 좀 더 예쁘게 할 뿐이다.
220 | * 그래서 java의 제네릭(Generic)은 때로는 **문법적 양념(syntactic sugar)** 이라고 부른다.
221 | ~~~java
222 | Vector vector = new Vector();
223 | vector.add(new String("hello"));
224 | String str = vector.get(0);
225 |
226 | // 컴파일러가 아래와 같이 변환
227 | Vector vector = new Vector();
228 | vector.add(new String("hello"));
229 | String str = (String) vector.get(0);
230 | ~~~
231 | * c++의 템플릿(Template)
232 | * 개념: 템플릿은 하나의 클래스를 서로 다른 여러 타입에 재사용할 수 있도록 하는 방법
233 | * 예를 들어 여러 타입의 객체를 저장할 수 있는 연결리스트와 같은 자료구조를 만들 수 있다.
234 | * 처리 방법: 컴파일러는 인자로 주어진 각각의 타입에 대해 별도의 템플릿 코드를 생성한다.
235 | * 예를 들어 MyClass가 MyClass와 정적 변수(static variable)를 공유하지 않는다.
236 | * 하지만 java에서 정적 변수는 제네릭(Generic) 인자로 어떤 타입을 주었는지에 관계없이 MyClass로 만든 모든 객체가 공유한다.
237 | * 즉, 템플릿은 좀 더 **우아한 형태의 매크로** 다.
238 | ~~~c
239 | /** MyClass.h **/
240 | template class MyClass {
241 | public:
242 | static int val;
243 | MyClass(int v) { val = v; }
244 | };
245 |
246 | /** MyClass.cpp **/
247 | template
248 | int MyClass::bar;
249 | template class MyClass;
250 | template class MyClass;
251 |
252 | /** main.cpp **/
253 | MyClass * foo1 = new MyClass(10);
254 | MyClass * foo2 = new MyClass(15);
255 | MyClass * bar1 = new MyClass(20);
256 | MyClass * bar2 = new MyClass(35);
257 | int f1 = foo1->val; // 15
258 | int f2 = foo2->val; // 15
259 | int b1 = bar1->val; // 35
260 | int b2 = bar2->val; // 35
261 | ~~~
262 |
263 | * java의 제네릭과 c++의 템플릿의 차이
264 | 1. List처럼 코드를 작성할 수 있다는 이유에서 동등한 개념으로 착각하기 쉽지만 두 언어가 이를 처리하는 방법은 아주 많이 다르다.
265 | 2. c++의 Template에는 int와 같은 기본 타입을 인자로 넘길 수 있지만, java의 Generic에서는 Integer을 대신 사용해야 한다.
266 | 3. c++의 Template은 인자로 주어진 타입으로부터 객체를 만들어 낼 수 있지만, java에서는 불가능하다.
267 | 4. java에서 MyClass로 만든 모든 객체는 Generic 타입 인자가 무엇이냐에 관계없이 전부 동등한 타입이다.(실행 시간에 타입 인자 정보는 삭제된다.)
268 | * c++에서는 다른 Template 타입 인자를 사용해 만든 객체는 서로 다른 타입의 객체이다.
269 | 5. java의 경우 Generic 타입 인자를 특정한 타입이 되도록 제한할 수 있다.
270 | * 예를 들어 CardDeck을 Generic 클래스로 정의할 때 CardGame의 하위 클래스만 사용되도록 제한할 수 있다.
271 | 6. java에서 Generic 타입의 인자는 정적 메서드나 변수를 선언하는 데 사용될 수 없다.
272 | * 왜냐하면 MyClass나 MyClass가 이 메서드와 변수를 공유하기 때문이다.
273 | * c++ Template은 이 두 클래스를 다른 클래스로 처리하므로 Template 타입 인자를 정적 메서드나 변수를 선언하는 데 사용할 수 있다.
274 |
275 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
276 | > - [코딩 인터뷰 완전 분석, 프로그래밍인사이트](https://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&barcode=9788966263080&OV_REFFER=http://click.linkprice.com/click.php?m=kbbook&a=A100532541&l=9999&l_cd1=0&u_id=jm0gctc7ca029ofs02yqe&l_cd2=0&tu=https%3A%2F%2Fwww.kyobobook.co.kr%2Fproduct%2FdetailViewKor.laf%3FmallGb%3DKOR%26ejkGb%3DKOR%26barcode%3D9788966263080)
277 |
--------------------------------------------------------------------------------
/Java/Part3.md:
--------------------------------------------------------------------------------
1 | # 2. Java - Part3
2 | ### :book: Contents
3 | - [java의 가비지 컬렉션(Garbage Collection) 처리 방법](#java의-가비지-컬렉션-처리-방법)
4 | - [java 직렬화(Serialization)와 역직렬화(Deserialization)란 무엇인가](#직렬화와-역직렬화)
5 | - [클래스, 객체, 인스턴스의 차이](#클래스-객체-인스턴스의-차이)
6 | - [객체(Object)란 무엇인가](#객체란-무엇인가)
7 | - [오버로딩과 오버라이딩의 차이(Overloading vs Overriding)](#오버로딩과-오버라이딩의-차이)
8 | - [Call by Reference와 Call by Value의 차이](#Call-by-Reference와-Call-by-Value의-차이)
9 | - [인터페이스와 추상 클래스의 차이(Interface vs Abstract Class)](#인터페이스와-추상-클래스의-차이)
10 |
11 |
217 | * 처리 방법: 타입 제거(type erasure)라는 개념에 근거한다.
218 | * 소스 코드를 JVM이 인식하는 바이트 코드로 변환할 때 인자로 주어진 타입을 제거하는 기술이다.
219 | * 제네릭이 있다고 해서 크게 달라지는 것은 없다. 단지 코드를 좀 더 예쁘게 할 뿐이다.
220 | * 그래서 java의 제네릭(Generic)은 때로는 **문법적 양념(syntactic sugar)** 이라고 부른다.
221 | ~~~java
222 | Vector vector = new Vector();
223 | vector.add(new String("hello"));
224 | String str = vector.get(0);
225 |
226 | // 컴파일러가 아래와 같이 변환
227 | Vector vector = new Vector();
228 | vector.add(new String("hello"));
229 | String str = (String) vector.get(0);
230 | ~~~
231 | * c++의 템플릿(Template)
232 | * 개념: 템플릿은 하나의 클래스를 서로 다른 여러 타입에 재사용할 수 있도록 하는 방법
233 | * 예를 들어 여러 타입의 객체를 저장할 수 있는 연결리스트와 같은 자료구조를 만들 수 있다.
234 | * 처리 방법: 컴파일러는 인자로 주어진 각각의 타입에 대해 별도의 템플릿 코드를 생성한다.
235 | * 예를 들어 MyClass가 MyClass와 정적 변수(static variable)를 공유하지 않는다.
236 | * 하지만 java에서 정적 변수는 제네릭(Generic) 인자로 어떤 타입을 주었는지에 관계없이 MyClass로 만든 모든 객체가 공유한다.
237 | * 즉, 템플릿은 좀 더 **우아한 형태의 매크로** 다.
238 | ~~~c
239 | /** MyClass.h **/
240 | template class MyClass {
241 | public:
242 | static int val;
243 | MyClass(int v) { val = v; }
244 | };
245 |
246 | /** MyClass.cpp **/
247 | template
248 | int MyClass::bar;
249 | template class MyClass;
250 | template class MyClass;
251 |
252 | /** main.cpp **/
253 | MyClass * foo1 = new MyClass(10);
254 | MyClass * foo2 = new MyClass(15);
255 | MyClass * bar1 = new MyClass(20);
256 | MyClass * bar2 = new MyClass(35);
257 | int f1 = foo1->val; // 15
258 | int f2 = foo2->val; // 15
259 | int b1 = bar1->val; // 35
260 | int b2 = bar2->val; // 35
261 | ~~~
262 |
263 | * java의 제네릭과 c++의 템플릿의 차이
264 | 1. List처럼 코드를 작성할 수 있다는 이유에서 동등한 개념으로 착각하기 쉽지만 두 언어가 이를 처리하는 방법은 아주 많이 다르다.
265 | 2. c++의 Template에는 int와 같은 기본 타입을 인자로 넘길 수 있지만, java의 Generic에서는 Integer을 대신 사용해야 한다.
266 | 3. c++의 Template은 인자로 주어진 타입으로부터 객체를 만들어 낼 수 있지만, java에서는 불가능하다.
267 | 4. java에서 MyClass로 만든 모든 객체는 Generic 타입 인자가 무엇이냐에 관계없이 전부 동등한 타입이다.(실행 시간에 타입 인자 정보는 삭제된다.)
268 | * c++에서는 다른 Template 타입 인자를 사용해 만든 객체는 서로 다른 타입의 객체이다.
269 | 5. java의 경우 Generic 타입 인자를 특정한 타입이 되도록 제한할 수 있다.
270 | * 예를 들어 CardDeck을 Generic 클래스로 정의할 때 CardGame의 하위 클래스만 사용되도록 제한할 수 있다.
271 | 6. java에서 Generic 타입의 인자는 정적 메서드나 변수를 선언하는 데 사용될 수 없다.
272 | * 왜냐하면 MyClass나 MyClass가 이 메서드와 변수를 공유하기 때문이다.
273 | * c++ Template은 이 두 클래스를 다른 클래스로 처리하므로 Template 타입 인자를 정적 메서드나 변수를 선언하는 데 사용할 수 있다.
274 |
275 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
276 | > - [코딩 인터뷰 완전 분석, 프로그래밍인사이트](https://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&barcode=9788966263080&OV_REFFER=http://click.linkprice.com/click.php?m=kbbook&a=A100532541&l=9999&l_cd1=0&u_id=jm0gctc7ca029ofs02yqe&l_cd2=0&tu=https%3A%2F%2Fwww.kyobobook.co.kr%2Fproduct%2FdetailViewKor.laf%3FmallGb%3DKOR%26ejkGb%3DKOR%26barcode%3D9788966263080)
277 |
--------------------------------------------------------------------------------
/Java/Part3.md:
--------------------------------------------------------------------------------
1 | # 2. Java - Part3
2 | ### :book: Contents
3 | - [java의 가비지 컬렉션(Garbage Collection) 처리 방법](#java의-가비지-컬렉션-처리-방법)
4 | - [java 직렬화(Serialization)와 역직렬화(Deserialization)란 무엇인가](#직렬화와-역직렬화)
5 | - [클래스, 객체, 인스턴스의 차이](#클래스-객체-인스턴스의-차이)
6 | - [객체(Object)란 무엇인가](#객체란-무엇인가)
7 | - [오버로딩과 오버라이딩의 차이(Overloading vs Overriding)](#오버로딩과-오버라이딩의-차이)
8 | - [Call by Reference와 Call by Value의 차이](#Call-by-Reference와-Call-by-Value의-차이)
9 | - [인터페이스와 추상 클래스의 차이(Interface vs Abstract Class)](#인터페이스와-추상-클래스의-차이)
10 |
11 |
12 |
13 | ---
14 |
15 |
16 |
17 | ### java의-가비지-컬렉션-처리-방법
18 | 
19 | - **가비지 콜렉터(Garbage Collector)란?**
20 | > 가비지 : '정리되지 않은 메모리', '유효하지 않은 메모리 주소'
21 | = 주소를 잃어버려서 사용할 수 없는 메모리 혹은 앞으로 사용하지 않고 메모리를 가지고 있는 객체
22 |
23 | \- 메모리가 부족할 때 이런 가비지들을 메모리에서 해제 시켜 다른 용도로 사용할 수 있게 해주는 프로그램이 가비지 콜렉터
24 | \- C++와 같은 다른 언어에서는 사용하지 않을 객체의 메모리를 직접 해제해주어야 함
25 | > Stop-the-world : GC를 실행하기 위해 **JVM이 애플리케이션 실행을 멈추는 것**으로
26 | stop-the-world가 발생하면 GC를 실행하는 쓰레드를 제외한 나머지 쓰레드는 모두 작업을 멈춤
27 | GC 작업을 완료한 이후에야 중단했던 작업을 다시 시작한다. (어떤 GC알고리즘을 사용해도 발생!)
28 |
29 | - **가비지 컬렉터의 역할**
30 | 1. 힙(Heap) 내의 객체 중에서 가비지(Garbage)를 찾아낸다.
31 | 2. 찾아낸 가비지를 처리해서 힙의 메모리를 회수한다.
32 |
33 | - **가비지 컬렉터의 과정 (Mark and Sweep)**
34 | 1. Mark
35 | - GC가 스택의 모든 변수 또는 Reachable 객체를 스캔하면서 어떤 객체를 참조하고 있는지 찾는 과정
36 | - 이 과정에서 Stop and world가 발생!
37 | 2. Sweep
38 | - 이후 Mark 되어 있지 않은 객체들을 힙에서 제거하는 과정
39 |
40 | - **Minor GC와 Major GC**
41 | > JVM의 **Heap은 Young, Old, Perm 세 영역**으로 나뉜다.
42 | **Young 영역에서 발생한 GC를 Minor GC**, **나머지 두 영역에서 발생한 GC를 Major GC(Full GC)**라고 한다.
43 | 1. **Young 영역**
44 | : 새롭게 생성한 객체가 위치,
45 | 대부분의 객체가 금방 unreachable 상태가 되기 떄문에 많은 객체가 Young 영역에 생성되었다 사라짐
46 | 2. **Old 영역**
47 | : Young 영역에서 reachable 상태를 유지해 살아남은객체가 여기로 복사된다.
48 | 대부분 Young 영역보다 크게 할당하며, 크기가 큰 만큼 Young 영역보다 GC는 적게 발생한다.
49 | 3. **Perm 영역**
50 | : Method Area라고도 한다. 클래스와 메소드 정보와 같이 자바 언어 레벨에서는 거의 사용되지 않는다.
51 |
52 | - **Reachability**
53 | > **Java의 GC가 가비지 객체를 판별하기 위해 도입한 개념**
54 | 어떤 객체에 유효한 참조가 있으면 'reachable', 없으면 'unreachable'로 구별하고 이것을 가비지로 간주한다.
55 | 즉, 객체에 대한 Reachability을 제어할 수 있다면 코드를 통해 Java GC에 일부 관여하는 것이 가능하다.
56 | - java에서는 이를 위해 java.lang.ref 패키지에 SoftReference, WeakReference 등을 제공
57 |
58 | - **Strong Reference**
59 | - 기본적으로 new로 할당되는 메모리들은 모두 Strong Reference를 가지기 때문에, 캐시와 같은 것을 만든다고 할 때 메모리 누수에 조심해야 함
60 | - 캐시의 키가 원래 데이터에서 삭제가 된다면 캐시 내부의 키와 값은 더 이상 의미가 없는 데이터, 즉 가비지가 된다.
61 | - 그럼에도 GC는 삭제된 캐시의 키를 가비지로 인식하지 못함.
62 | - 이는 캐시에 넣어준 데이터가 Strong Reference로 독자적인 Reachability를 가지기 때문이다.
63 | - 따라서 캐시에 데이터를 넣어 줄 때, 원래 데이터에 Weak Reference를 넣어준다면 이러한 문제를 방지할 수 있다.
64 |
65 | - **Weak Reference**
66 | - new로 할당된 객체의 유효 참조를 인위적으로 설정할 수 있게 해준다.
67 | - 원래의 데이터가 삭제되면 이 객체에 Weak Reference가 걸려있는 객체들은 모두 가비지로 인식된다.
68 | - 위와 같은 이유로 캐시를 만들 때 WeakHashMap을 사용하는 것을 권장
69 |
70 | > - [https://velog.io/@litien/%EA%B0%80%EB%B9%84%EC%A7%80-%EC%BB%AC%EB%A0%89%ED%84%B0GC](https://velog.io/@litien/%EA%B0%80%EB%B9%84%EC%A7%80-%EC%BB%AC%EB%A0%89%ED%84%B0GC)
71 | > - [https://d2.naver.com/helloworld/1329](https://d2.naver.com/helloworld/1329)
72 |
73 |
74 |
75 | ### 직렬화와-역직렬화
76 | 
77 | - **직렬화(Serialize)란?**
78 | - 자바 내부에서 사용되는 Object, Data를 외부 자바 시스템에서도 사용할 수 있도록 **byte 형태로 데이터를 변환**하는 기술
79 | - JVM의 메모리에 상주되어 있는 객체 데이터를 바이트 형태로 변환하는 기술
80 | - **역직렬화(Deserialize)란?**
81 | - byte로 변환된 Data를 원래대로 Object나 Data로 변환하는 기술
82 | - 직렬화된 바이트 형태의 데이터를 객체로 변환해서 JVM으로 상주시키는 형태
83 | - 자바 직렬화 조건
84 | 1. **자바 기본(Primiptive) 타입**
85 | 2. **java.io.Serializable 인터페이스를 상속받은 객체**는 직렬화 할 수 있는 기본 조건을 가짐
86 | - 직렬화 방법
87 | 자바 직렬화 방법은 java.io.ObjectOutputStream 객체를 이용한다.
88 | ```JAVA
89 | Member member = new Member("김배민", "deliverykim@baemin.com", 25);
90 | byte[] serializedMember;
91 | try (ByteArrayOutputStream baos = new ByteArrayOutputStream()) {
92 | try (ObjectOutputStream oos = new ObjectOutputStream(baos)) {
93 | oos.writeObject(member);
94 | // serializedMember -> 직렬화된 member 객체
95 | serializedMember = baos.toByteArray();
96 | }
97 | }
98 | // 바이트 배열로 생성된 직렬화 데이터를 base64로 변환
99 | System.out.println(Base64.getEncoder().encodeToString(serializedMember));
100 | }
101 | ```
102 | - 역직렬화 조건
103 | 1. 직렬화 대상이 된 객체의 클래스가 클래스 패스에 존재해야 하며 import 되어 있어야 함
104 | - 직렬화와 역직렬화를 진행하는 시스템이 서로 다를 수 있다.
105 | (같은 시스템 내부이라도 소스 버전이 다를 수 있다.)
106 | 2. 자바 직렬화 대상 객체는 동일한 serialVersionUID 를 가지고 있어야 한다.
107 | - 모델의 버젼간의 호환성을 유지하기 위해서 SUID(serialVersionUID)를 정의한다.
108 |
109 | - 역직렬화 예제
110 | ```JAVA
111 | // 직렬화 예제에서 생성된 base64 데이터
112 | String base64Member = "...생략";
113 | byte[] serializedMember = Base64.getDecoder().decode(base64Member);
114 | try (ByteArrayInputStream bais = new ByteArrayInputStream(serializedMember)) {
115 | try (ObjectInputStream ois = new ObjectInputStream(bais)) {
116 | // 역직렬화된 Member 객체를 읽어온다.
117 | Object objectMember = ois.readObject();
118 | Member member = (Member) objectMember;
119 | System.out.println(member);
120 | }
121 | }
122 | ```
123 |
124 | - 자바 직렬화가 사용되는 이유
125 | 1. 데이터 타입이 자동으로 맞춰진다.
126 | - 자바 시스템 개발에 최적화되어 있기 때문에 복잡한 데이터 구조의 클래스의 객체라도
127 | 직렬화 기본 조건을 지키면 큰 작업없이 바로 직렬화가 가능하다.
128 | 2. JVM의 메모리에서만 상주되어있는 객체 데이터를 그대로 영속화(Persistence)가 필요할 때 사용된다.
129 | 3. 주로 서블릿 세션, 캐시, 자바 RMI(Remote Method Invocation)에 사용된다.
130 |
131 | - 주의할 점 **(자바의 직렬화는 타입에 엄격하다!)**
132 | - 외부 저장소로 저장되는 데이터는 짧은 만료시간의 데이터를 제외하고 자바 직렬화의 사용을 지양한다.
133 | - 역직렬화시 반드시 예외가 생긴다는 것을 생각하고 개발한다.
134 | - 자주 변경되는 비즈니스적인 데이터를 자바 직렬화을 사용하지 않는다.
135 | - 긴 만료 시간을 가지는 데이터는 JSON 등 다른 포맷을 사용하여 저장한다.
136 |
137 | > - [https://nesoy.github.io/articles/2018-04/Java-Serialize](https://nesoy.github.io/articles/2018-04/Java-Serialize)
138 | > - [https://woowabros.github.io/experience/2017/10/17/java-serialize.html](https://woowabros.github.io/experience/2017/10/17/java-serialize.html)
139 |
140 |
141 |
142 | ### 클래스-객체-인스턴스의-차이
143 | 1. **Class란?**
144 | - 개념
145 | - **Object를 만들어 내기 위한 설계도 혹은 틀**
146 | - 연관되어 있는 Variable과 Method의 집합
147 | 2. **Object란?**
148 | - 개념
149 | - 소프트웨어 세계에 구현할 대상
150 | - **Class에 선언 된 모양 그대로 생성된 실체**
151 | - 특징
152 | - 'Class의 Instance'라고도 부른다.
153 | - Object는 모든 Instance를 대표하는 포괄적인 의미를 갖는다.
154 | - OOP의 관점에서 **Class의 타입으로 선언되었을 때 'Object'**라고 부른다.
155 | 3. **Instance란?**
156 | - 개념
157 | - 설계도를 바탕으로 **소프트웨어 세계에 구현된 구체적인 실체**
158 | - 즉, 객체를 소프트웨어에 실체화 하면 그것을 'Instance'라고 부른다.
159 | - 실체화된 Instance는 메모리에 할당된다.
160 | - 특징
161 | - Instance는 Object에 포함된다고 볼 수 있다.
162 | - OOP의 관점에서 **Object가 메모리에 할당되어 실제 사용될 때 'instance'**라고 부른다.
163 | - 추상적인 개념(또는 명세)과 구체적인 Object 사이의 관계에 초점을 맞출 경우에 사용한다.
164 | - '~의 instance'의 형태로 사용된다.
165 | - Object는 Class의 Instance이다.
166 | - Object 간의 링크는 Class 간의 연관 관계의 Instance이다.
167 | - 실행 프로세스는 프로그램의 Instance이다.
168 | - 즉, Instance라는 용어는 반드시 Class와 Object 사이의 관계로 한정지어 사용할 필요는 없다.
169 | - 인스턴스는 어떤 원본(추상적인 개념)으로부터 '생성된 복제본'을 의미한다.
170 | ```java
171 | /* Animal Class */
172 | public class Animal {
173 | ...
174 | }
175 | /* Object와 Instance */
176 | public class Main {
177 | public static void main(String[] args) {
178 | Animal cat, dog; // 'Object'
179 | // Instance화
180 | cat = new Animal(); // cat은 Animal Class의 'Instance'(Object를 메모리에 할당)
181 | dog = new Animal(); // dog은 Animal Class의 'Instance'(Object를 메모리에 할당)
182 | }
183 | }
184 | ```
185 | 4. Class, Object, Instance의 차이
186 | - Class VS Object
187 | - **Class는 설계도, Object는 설계도로 구현한 모든 대상**을 의미한다.
188 | - Object VS Instance
189 | - **Class의 타입으로 선언될 때, Object**라 부르고, 그 **Object가 메모리에 할당되어 실제 사용될 때 Instance**라고 부름
190 | - Object는 현실 세계에 가깝고, Instance는 소프트웨어 세계에 가깝다.
191 | - Object는 실체, Instance는 관계에 초점을 둔다. (= Object를 Class의 Instance라고도 부른다.)
192 | - **Instance화하여 레퍼런스를 할당한 Object를 Instance**라고 말하지만,
193 | 이는 원본(추상적인 개념)으로부터 생성되었다는 것에 의미를 부여하는 것일 뿐 둘을 엄격하게 구분하긴 어렵다.
194 |
195 | > - [https://geonlee.tistory.com/11](https://geonlee.tistory.com/11)
196 |
197 |
198 |
199 | ### 객체란-무엇인가
200 | - **객체(Object)란?**
201 | - 물리적으로 존재하거나 추상적으로 생각할 수 있는 것 중에서 자신의 속성을 가지고 있고 다른 것과 식별 가능한 것
202 | - 속성과 동작으로 구성되어 있으며 자바에서는 이를 각각 **필드(Field)와 메소드(Method)**라고 부른다.
203 | - **객체 모델링(Object Modeling)**
204 | - **현실세계의 객체를 소프트웨어 객체로 설계하는 것**
205 | - 현실 객체의 속성과 동작을 추려내서 소프트웨어 객체의 필드와 메소드로 정의하는 과정
206 |
207 | - 객체 지향 프로그래밍의 특징
208 | 1. **캡슐화 (Encapsultaion)**
209 | - 객체의 필드, 메소드를 하나로 묶고, 실제 구현 내용을 감추는 것
210 | - 외부 객체는 객체내부의 구조를 알지 못하며 객체가 노출해서 제공하는 필드와 메소드만 이용할 수 있다.
211 | > cf.) 캡슐화를 하는 이유?
212 | 외부의 잘못된 사용으로 인해 객체가 속상되지 않도록 하기 위함
213 | 자바는 캡슐화된 멤버를 노출시킬지, 숨길지 결정하기 위해 접근 제한자를 사용. 이를 통해 필드, 메소드의 사용범위를 제한한다.
214 | 2. **상속 (Inheritance)**
215 | - OOP에서 부모 역할의 상위 객체가 자기가 가지고 있는 필드와 메소드를
216 | 자식 역할의 하위 객체에게 물려주어 하위 객체가 사용할 수 있도록 해주는 것
217 | - 상위 객체를 재사용함으로써 하위 객체를 쉽고 빨리 설계할 수 있도록 도와줌
218 | - 이미 잘 개발된 객체를 재사용해서 새로운 객체를 만들기 때문에 반복된 코드의 중복을 줄여준다.
219 | 3. **다형성 (Polymorphism)**
220 | - 같은 타입이지만 실행결과가 다양한 객체를 이용할 수 있는 성질
221 | - 하나의 타입에 여러 객체를 대입함으로써 다양한 기능을 이용할 수 있게 도와준다.
222 |
223 | > - [https://jwprogramming.tistory.com/121](https://jwprogramming.tistory.com/121)
224 |
225 |
226 |
227 | ### 오버로딩과-오버라이딩의-차이
228 | 1. **오버로딩(Overloading)**
229 | - 두 메소드가 같은 이름을 갖고 있으나 **인자의 수나 자료형**이 다른 경우
230 |
231 | 1-1. **오버로딩의 특징**
232 | 1) 메소드의 이름이 같아야 한다.
233 | 2) 리턴형이 같아도 되고 달라도 된다.
234 | 3) 파라미터 개수가 달라야 한다.
235 | 4) 파라미터 개수가 같을 경우, 데이터 타입이 달라야 한다.
236 | \* 리턴타입은 시그니처에 포함되지 않기 때문에 주의해야 한다. 컴파일 에러가 발생함
237 | - 예시
238 | ``` java
239 | public double computeArea(Circle c) { ... }
240 | public double computeArea(Circle c1, Circle c2) { ... }
241 | public double computeArea(Square c) { ... }
242 | ```
243 |
244 | 1-2. **오버로딩의 장점**
245 | - 한 클래스 내에, 여러 개의 같은 이름의 메소드를 정의함으로써 프로그램의 가독성을 증가시킬 수 있다.
246 |
247 | 2. **오버라이딩(Overriding)**
248 | - **상위 클래스의 메소드와 이름과 시그니처(인자의 수, 자료형)가 같은 함수를 하위 클래스에 재정의하는 것**을 말한다.
249 | - 즉, 상속 관계에 있는 클래스 간에 **같은 이름의 메소드를 재정의**하는 것을 말한다.
250 | - 오버라이딩을 할 때 개발자의 실수를 방지하기 위해 메소드 위에 관례적으로 @Override를 기입한다.
251 |
252 | 2-1. **오버라이딩의 특징**
253 | 1) 오버라이드 하고자 하는 메소드가 **상위 클래스에 존재**해야 한다.
254 | 2) 메소드 이름이 같아야 한다.
255 | 3) 메소드 파라미터 개수, 파라미터의 자료형이 같아야 한다.
256 | 4) 메소드 리턴형이 같아야 한다.
257 | 5) 상위 메소드와 동일하거나 내용이 추가되어야 한다.
258 | - 예시
259 | ``` java
260 | public class Circle extends Shape {
261 | private double rad = 5;
262 | @Override // 개발자의 실수를 방지하기 위해 @Override(annotation) 쓰는 것을 권장
263 | public void printMe() { System.out.println("Circle"); }
264 | public double computeArea() { return rad * rad * 3.15; }
265 | }
266 | ```
267 |
268 | 2-2. **오버라이딩의 장점**
269 | - 부모로부터 받은 메소드의 로직(내부)을 입맛에 맞게 변경함으로써 객체 지향 언어의 특징인 다형성을 살려 프로그래밍을 할 수 있다.
270 |
271 |
272 | > - [https://brunch.co.kr/@kimkm4726/2](https://brunch.co.kr/@kimkm4726/2)
273 |
274 |
275 |
276 | ### Call-by-Reference와-Call-by-Value의-차이
277 | > **메소드(함수) 호출 방식**
278 | 프로그래밍 언어에서는 변수를 다른 함수의 인자로 넘겨줄 수 있다.
279 | 이 때 이 변수의 '값'을 넘겨 주는 호출 방식을 Call by Value,
280 | 이 변수의 '참조값' (혹은 주소, 포인터)를 넘겨주는 방식을 Call by Reference라고 한다.
281 | 자바는 Call by Value 방식으로 동작하게 된다.
282 |
283 | - **자바의 메소드 호출 방식** ( = call by value)
284 | ``` java
285 | public static void main(String[] args) {
286 | int a = 1;
287 | int b = 2;
288 | swap(a, b);
289 |
290 | System.out.println(a); //출력결과 1
291 | System.out.println(b); //출력결과 2
292 | }
293 |
294 | static void swap(int a, int b) {
295 | int tmp = a;
296 | a = b;
297 | b = tmp;
298 | }
299 | ```
300 |
301 | > **자바의 함수 호출 방식이 Call by Value**이기 때문에 인자로 넘겨주었던 변수들의 값이 변경 되지 않고, 그대로 출력된다.
302 |
303 | 1. **Call-by-Value의 개념**
304 | - **값에 의한 호출**
305 | - 메소드 호출 시에 사용되는 인자의 **메모리에 저장되어 있는 값(Value)를 복사하여 보낸다.**
306 | - 앞선 예시와 동일한 방식으로 swap() 메소드 호출 시에 사용한 인자 a,b와
307 | swap() 메소드 내의 매개변수 x,y가 서로 다르기 때문에 둘의 값이 변경되지 않는다.
308 | 
309 |
310 |
311 |
312 | 2. **Call-by-Reference의 개념**
313 | - **참조에 의한 호출**
314 | - 인자를 값이 아닌 주소(Address)로 넘겨줌으로써, 주소를 참조하여 데이터를 변경할 수 있다.
315 | - 메소드 호출시 사용되는 인자 값의 **메모리에 저장되어 있는 주소(Address)를 복사하여 보낸다.**
316 |
317 | 2-1. **Call-by-Reference의 예시**
318 | ``` java
319 | Class CallByReference{
320 | int value;
321 |
322 | CallByReference(int value) {
323 | this.value = value;
324 | }
325 |
326 | public static void swap(CallByReference x, CallByReference y) {
327 | int temp = x.value;
328 | x.value = y.value;
329 | y.value = temp;
330 | }
331 |
332 | public static void main(String[] args) {
333 | CallByReference a = new CallByReference(10);
334 | CallByReference b = new CallByReference(20);
335 |
336 | System.out.println("swap() 호출 전 : a = " + a.value + ", b = " + b.value);
337 |
338 | swap(a, b);
339 |
340 | System.out.println("swap() 호출 전 : a = " + a.value + ", b = " + b.value);
341 | }
342 | }
343 | ```
344 |
345 | > 원하는 대로 a와 b의 값이 잘 바뀌어서 출력이 된다. (호출 후 : a = 20, b = 10)
346 |
347 | 
348 |
349 |
350 | > - [https://re-build.tistory.com/3](https://re-build.tistory.com/3)
351 |
352 |
353 |
354 | ### 인터페이스와-추상-클래스의-차이
355 | 1. **추상 클래스(Abstract Class)의 개념**
356 | - 클래스 구현부 내부에 **추상 메소드가 하나 이상 포함되거나 abstract로 정의**된 경우를 말한다.
357 | - **동일한 부모를 가지는 클래스를 묶는 개념으로 상속을 받아서 기능을 확장시키는 것이 목적**이다.
358 |
359 | 1-1. **추상 클래스(Abstract Class)의 특징**
360 | - 추상 클래스는 **new 연산자를 사용하여 객체를 생성할 수 없다.**
361 | - 추상 클래스(부모)와 일반 클래스(자식)는 상속의 관계에 놓여있다.
362 | - 추상 클래스는 **새로운 일반 클래스를 위한 부모 클래스의 용도**로만 사용된다.
363 | - 일반 클래스들의 **필드와 메소드를 통일**하여 일반 클래스 작성 시 시간을 절약할 수 있다.
364 | - 추상 클래스는 단일 상속만 가능하며 일반 변수를 가질 수 있다.
365 |
366 |
367 |
368 | 2. **인터페이스(Interface)의 개념**
369 | - 모든 메소드가 추상 메소드인 경우
370 | - 추상 클래스보다 한 단계 더 추상화된 클래스
371 | - 구현 객체가 같은 동작을 한다는 걸 보장하는 것이 목적이다.
372 |
373 | 2-1. **인터페이스(Interface)의 특징**
374 | - 인터페이스에 적는 모든 메서드들은 추상 메서드로 간주되기 때문에 abstract를 적지 않는다.
375 | - default 예약어를 통해 일반 메소드 구현이 가능하다.
376 | - static final 필드만 가질 수 있다. (public static final이 생략되어있다고 생각)
377 | - new 연산자를 사용해 객체를 생성할 수 없다.
378 | - 다중 상속이 가능하다.
379 |
380 | > cf.) public static final을 사용하는 이유?
381 | 구현 객체의 같은 동작을 보장하기 위한 목적으로 인터페이스의 변수는 스스로 초기화 될 권한이 없어서
382 | 아무 인스턴스도 존재하지 않는 시점이기 때문이다.
383 |
384 |
385 |
386 | 3. **클래스와 인터페이스 사이 관계 이해하기**
387 | 
388 | - 클래스끼리, 인터페이스끼리 상속을 할 때는 extends, 클래스가 인터페이스를 상속받을 때는 implements 키워드를 사용
389 |
390 | 4. **추상 클래스와 인터페이스의 공통점과 차이점**
391 | - 공통점
392 | - 선언만 있고 구현 내용은 없는 클래스이다.
393 | - 인터페이스화(객체를 생성) 할 수 없다.
394 | - 추상 클래스를 extends로 상속받은 자식들과 인터페이스를 implements하고 구현한 자식들만 객체를 생성할 수 있다.
395 | - 차이점
396 | - 추상 클래스 (단일 상속) / 인터페이스 (다중 상속)
397 | - 추상 클래스의 목적은 상속을 받아서 기능을 확장시키는 것 (부모의 유전자를 물려받는다.)
398 | - 인터페이스의 목적은 구현하는 모든 클래스에 대해 특정한 메소드가 반드시 존재하도록 강제하는 역할
399 | (유전자를 물려받는 것이 아니라 사교적으로 필요에 따라 결합하는 관계)
400 | 즉, 구현 객체가 같은 동작을 한다는 것을 보장하기 위함이다.
401 |
402 |
403 | > - [https://cbw1030.tistory.com/47](https://cbw1030.tistory.com/47)
404 |
405 |
406 |
--------------------------------------------------------------------------------
/Network/Part1.md:
--------------------------------------------------------------------------------
1 | # 2. Network
2 | **:book: Contents**
3 | * [OSI 7계층](#OSI-7계층)
4 | * [TCP/IP의 개념](#TCPIP의-개념)
5 | * [TCP와 UDP](#TCP와-UDP)
6 | * [TCP(흐름제어/혼잡제어)](#TCP흐름제어-혼잡제어)
7 | * [TCP와 UDP의 헤더 분석](#TCP와-UDP의-헤더-분석)
8 | * [TCP의 3-way-handshake와 4-way-handshake](#TCP의-3-way-handshake와-4-way-handshake)
9 |
10 |
11 | ---
12 |
13 | ### OSI 7계층
14 |
15 | **OSI(Open Systems Interconnection Reference Model)란**
16 |
17 | 
18 |
19 | * 국제표준화기구(ISO)에서 개발한 모델로, **컴퓨터 네트워크 프로토콜 디자인과 통신을 계층으로 나누어 설명**한 것이다.
20 | * 이 모델은 프로토콜을 기능별로 나눈 것이다.
21 | * 각 계층은 하위 계층의 기능만을 이용하고, 상위 계층에게 기능을 제공한다.
22 | * 일반적으로 하위 계층들은 하드웨어로, 상위 계층들은 소프트웨어로 구현된다.
23 |
24 | **7계층은 왜 나눌까?**
25 |
26 | 통신이 일어나는 과정을 단계별로 알 수 있고, 특정한 곳에 이상이 생기면 그 단계만 수정할 수 있기 때문이다.
27 |
28 | **데이터의 계층별 이름(PDU, 데이터의 전송 단위)**
29 | * Application / Presentation / Session : Data
30 | * Transport : Segment
31 | * Network : Packet
32 | * Data Linke : Frame
33 | * Physical : Bit
34 |
35 | **1) 물리(Physical)**
36 |
37 | > 리피터, 케이블, 허브 등
38 | 단지 데이터 전기적인 신호로 변환해서 주고받는 기능을 진행하는 공간
39 |
40 | 즉, 데이터를 전송하는 역할만 진행한다.
41 |
42 |
43 |
44 | **2) 데이터 링크(Data Link)**
45 |
46 | > 브릿지, 스위치 등
47 | 물리 계층으로 송수신되는 정보를 관리하여 안전하게 전달되도록 도와주는 역할
48 |
49 | Mac 주소를 통해 통신한다. 프레임에 Mac 주소를 부여하고 에러검출, 재전송, 흐름제어를 진행한다.
50 |
51 |
52 | **3) 네트워크(Network)**
53 |
54 | > 라우터, IP
55 | 데이터를 목적지까지 가장 안전하고 빠르게 전달하는 기능을 담당한다.
56 |
57 | 라우터를 통해 이동할 경로를 선택하여 IP 주소를 지정하고, 해당 경로에 따라 패킷을 전달해준다.
58 |
59 | 라우팅, 흐름 제어, 오류 제어, 세그먼테이션 등을 수행한다.
60 |
61 |
62 | **4) 전송(Transport)**
63 |
64 |
65 | > TCP, UDP
66 | TCP와 UDP 프로토콜을 통해 통신을 활성화한다. 포트를 열어두고, 프로그램들이 전송을 할 수 있도록 제공해준다.
67 |
68 | TCP : 신뢰성, 연결지향적
69 |
70 | UDP : 비신뢰성, 비연결성, 실시간
71 |
72 |
73 | **5) 세션(Session)**
74 |
75 | > API, Socket
76 | 데이터가 통신하기 위한 논리적 연결을 담당한다. TCP/IP 세션을 만들고 없애는 책임을 지니고 있다.
77 |
78 |
79 | **6) 표현(Presentation)**
80 |
81 | > JPEG, MPEG 등
82 | 데이터 표현에 대한 독립성을 제공하고 암호화하는 역할을 담당한다.
83 |
84 | 파일 인코딩, 명령어를 포장, 압축, 암호화한다.
85 |
86 |
87 | **7) 응용(Application)**
88 |
89 | > HTTP, FTP, DNS 등
90 | 최종 목적지로, 응용 프로세스와 직접 관계하여 일반적인 응용 서비스를 수행한다.
91 |
92 | 사용자 인터페이스, 전자우편, 데이터베이스 관리 등의 서비스를 제공한다.
93 |
94 |
95 |
96 | ### TCP/IP의 개념
97 |
98 | - 프로토콜
99 | 컴퓨터 간의 주고받는 메시지를 전송할 때 데이터 통신을 원활하게 하기 위해 필요한 통신 규약
100 |
101 | - TCP/IP 프로토콜
102 | - 개방형 프로토콜의 표준. 특정 하드웨어나 OS에 독립적으로 사용하는 것이 가능.
103 | - 인터넷에서 서로 다른 시스템을 가진 컴퓨터들을 서로 연결하고, 데이터를 전송하는데 사용하는 통신 프로토콜로 근거리 및 원거리 모두에 사용할 수 있음
104 | - 인터넷 프로토콜 중 가장 중요한 역할을 하는 TCP와 IP의 합성어
105 | - 인터넷 동작의 중심이 되는 통신규약
106 | - 데이터의 흐름 관리, 데이터의 정확성 확인(TCP의 역할), 패킷을 목적지까지 전송하는 역할(IP역할)을 담당
107 | - TCP : 전체 데이터가 잘 전송될 수 있도록 데이터의 흐름을 조절하고 성공적으로 상대편 컴퓨터에 도착할 수 있도록
108 | 보장하는 역할
109 | - IP : 데이터를 한 장소에서 다른 장소로 정확하게 옮겨주는 역할
110 | - TCP/IP 4계층
111 |
112 | 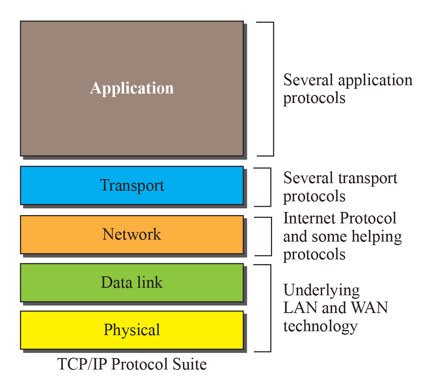
113 | - 응용 계층(Application Layer)
114 | - 사용자 응용 프로그램으로부터 요청을 받아서 이를 적절한 메시지로 변환하고 하위계층으로 전달하는 역할
115 | - TCP/UDP 기반의 응용 프로그램을 구현할 때 사용
116 | > 프로토콜 : FTP, HTTP, SSH
117 | - 전송 계층(Transport Layer)
118 | - IP에 의해 전달되는 패킷의 오류를 검사하고 재전송을 요구하는 등의 제어를 담당하는 계층
119 | - 통신 노드 간의 연결을 제어하고, 신뢰성 있는 데이터 전송을 담당
120 | > 프로토콜 : TCP, UDP
121 | - 인터넷 계층(Internet Layer)
122 | - 통신 노드 간의 IP패킷을 전송하는 기능과 라우팅 기능을 담당
123 | - 라우팅 : 어떤 네트워크 안에서 통신 데이터를 보낼 때 최적의 경로를 선택하는 과정
124 | - 전송 계층에서 받은 패킷을 목적지까지 효율적으로 전달하는 것만 고려.
125 | > 프로토콜 : IP, ARP, RARP
126 | - 네트워크 인터페이스 계층(Network Interface Layer)
127 | - OSI 7계층의 물리계층과 데이터 링크 계층에 해당
128 | - 물리적인 주소로 MAC을 사용
129 | - 특정 프로토콜을 규정하지 않고, 모든 표준과 기술적인 프로토콜을 지원하는 계층으로서 **프레임**을 물리적인 회선에 올리거나 내려받는 역할을 담당
130 | - LAN, 패킷망 등에 사용된다.
131 |
132 |
133 | ### TCP와 UDP
134 |
135 | * 네트워크 계층 중 **전송 계층에서 사용하는 프로토콜**
136 | * TCP(Transmission Control Protocol)
137 | 
138 | * 인터넷 상에서 데이터를 메세지의 형태(**세그먼트** 라는 블록 단위)로 보내기 위해 IP와 함께 사용하는 프로토콜이다.
139 | * TCP와 IP를 함께 사용하는데, IP가 데이터의 배달을 처리한다면 TCP는 패킷을 추적 및 관리한다.
140 | * **연결형 서비스로** 가상 회선 패킷 교환 방식을 제공한다.
141 | * 가상회선 : 데이터를 전송하기 전에 논리적 연결이 설정(연결 지향형)
142 | * 패킷에는 가상회선 식별 번호(VCI)가 포함되고, 모든 패킷을 전송하면 가상회선이 해제되고
143 | 패킷은 전송된 순서대로 도착한다.
144 | * 3-way handshaking과정을 통해 연결을 설정하고, 4-way handshaking을 통해 연결을 해제한다.
145 | * 흐름제어 및 혼잡제어를 제공한다.
146 | * 흐름제어
147 | * 데이터를 송신하는 곳과 수신하는 곳의 데이터 처리 속도를 조절하여 수신자의 버퍼 오버플로우를 방지하는 것
148 | * 송신하는 곳에서 감당이 안되게 많은 데이터를 빠르게 보내 수신하는 곳에서 문제가 일어나는 것을 막는다.
149 | * 혼잡제어
150 | * 네트워크 내의 패킷 수가 넘치게 증가하지 않도록 방지하는 것
151 | * 정보의 소통량이 과다하면 패킷을 조금만 전송하여 혼잡 붕괴 현상이 일어나는 것을 막는다.
152 | * 높은 신뢰성을 보장한다.
153 | * UDP보다 속도가 느리다.
154 | * 전이중(Full-Duplex), 점대점(Point to Point) 방식이다.
155 | * 전이중
156 | * 전송이 양방향으로 동시에 일어날 수 있다.
157 | * 점대점
158 | * 각 연결이 정확히 2개의 종단점을 가지고 있다.
159 | * 멀티캐스팅이나 브로드캐스팅을 지원하지 않는다.
160 | * 브로드캐스팅 : 불특정 다수를 대상을 데이터를 전송
161 | * 멀티캐스팅 : 수신 대상이 정해져 있음
162 | * 공통점 : 동시에 많은 사람들에게 똑같은 데이터를 전송
163 | * 차이점 : 특정 다수, 불특정 다수의 차이
164 | * 연속성보다 신뢰성있는 전송이 중요할 때에 사용된다.
165 | * UDP(User Datagram Protocol)
166 | 
167 | * 데이터를 **데이터그램** 단위로 처리하는 프로토콜이다.
168 | * **비연결형 서비스로** 데이터그램 방식을 제공한다.
169 | * 연결을 위해 할당되는 논리적인 경로가 없다.
170 | * 그렇기 때문에 각각의 패킷은 다른 경로로 전송되고, 각각의 패킷은 독립적인 관계를 지니게 된다.
171 | * 이렇게 데이터를 서로 다른 경로로 독립적으로 처리한다.
172 | * 송신 측에서 전송한 순서와 수신 측에서 도착한 순서가 다를 수 있다.
173 | * 정보를 주고 받을 때 정보를 보내거나 받는다는 신호절차를 거치지 않는다.
174 | * UDP헤더의 CheckSum 필드를 통해 최소한의 오류만 검출한다.
175 | * 신뢰성이 낮다.
176 | * TCP보다 속도가 빠르다.
177 | * 신뢰성보다는 연속성이 중요한 서비스, 예를 들면 실시간 서비스(streaming)에 사용된다.
178 | * 참고
179 | * UDP와 TCP는 각각 별도의 포트 주소 공간을 관리하므로 같은 포트 번호를 사용해도 무방하다. 즉, 두 프로토콜에서 동일한 포트 번호를 할당해도 서로 다른 포트로 간주한다.
180 | * 또한 같은 모듈(UDP or TCP) 내에서도 클라이언트 프로그램에서 동시에 여러 커넥션을 확립한 경우에는 서로 다른 포트 번호를 동적으로 할당한다. (동적할당에 사용되는 포트번호는 49,152~65,535이다.)
181 | * 가상회선 방식 vs 데이터그램 방식
182 | * 정해진 시간 안이나 다량의 데이터를 **연속**으로 보낼 때는 가상회선 방식이 적합하다.
183 | * 짧은 메시지의 일시적인 전송에는 데이터그램 방식이 적합하다
184 | * 네트워크 내의 한 노드가 다운되면 데이터그램 방식은 다른 경로를 새로 설정하지만,
185 | * 가상회선 방식은 그 노드를 지나는 모든 가상회선을 잃게 된다.
186 | * Ref
187 | * [데이터그램 패킷 교환 vs 가상회선 패킷 교환](https://gotwo.tistory.com/107)
188 | * [데이터그램 & 가상회선(Virtual Circuit)](https://security-nanglam.tistory.com/179)
189 |
190 | ### TCP흐름제어 혼잡제어
191 | - TCP 통신이란?
192 | - 네트워크 통신에서 신뢰적인 연결방식
193 | - TCP는 기본적으로 unreliable network에서, reliable network를 보장할 수 있도록 하는 프로토콜
194 | - TCP는 network congestion avoidance algorithm을 사용
195 | - reliable network를 보장한다는 것은 4가지 문제점 존재
196 | - 손실 : packet이 손실될 수 있는 문제
197 | - 순서 바뀜 : packet의 순서가 바뀌는 문제
198 | - Congestion : 네트워크가 혼잡한 문제
199 | - Overload : receiver가 overload 되는 문제
200 | - 흐름제어/혼잡제어란?
201 | - 흐름제어 (endsystem 대 endsystem)
202 | - 송신측과 수신측의 데이터 처리 속도 차이를 해결하기 위한 기법
203 | - Flow Control은 receiver가 packet을 지나치게 많이 받지 않도록 조절하는 것
204 | - 기본 개념은 receiver가 sender에게 현재 자신의 상태를 feedback 한다는 점
205 | - 혼잡제어 : 송신측의 데이터 전달과 네트워크의 데이터 처리 속도 차이를 해결하기 위한 기법
206 | - 전송의 전체 과정
207 | - Application layer : sender application layer가 socket에 data를 씀.
208 | - Transport layer : data를 segment에 감싼다. 그리고 network layer에 넘겨줌.
209 | - 그러면 아랫단에서 어쨋든 receiving node로 전송이 됨. 이 때, sender의 send buffer에 data를 저장하고, receiver는 receive buffer에 data를 저장함.
210 | - application에서 준비가 되면 이 buffer에 있는 것을 읽기 시작함.
211 | - 따라서 flow control의 핵심은 이 receiver buffer가 넘치지 않게 하는 것임.
212 | - 따라서 receiver는 RWND(Receive WiNDow) : receive buffer의 남은 공간을 홍보함
213 |
214 | #### 1. 흐름제어 (Flow Control)
215 |
216 | - 수신측이 송신측보다 데이터 처리 속도가 빠르면 문제없지만, 송신측의 속도가 빠를 경우 문제가 생긴다.
217 |
218 | - 수신측에서 제한된 저장 용량을 초과한 이후에 도착하는 데이터는 손실 될 수 있으며, 만약 손실 된다면 불필요하게 응답과 데이터 전송이 송/수신 측 간에 빈번히 발생한다.
219 |
220 | - 이러한 위험을 줄이기 위해 송신 측의 데이터 전송량을 수신측에 따라 조절해야한다.
221 |
222 | - 해결방법
223 |
224 | - Stop and Wait : 매번 전송한 패킷에 대해 확인 응답을 받아야만 그 다음 패킷을 전송하는 방법
225 |
226 | -  227 |
228 | - Sliding Window (Go Back N ARQ)
229 |
230 | - 수신측에서 설정한 윈도우 크기만큼 송신측에서 확인응답없이 세그먼트를 전송할 수 있게 하여 데이터 흐름을 동적으로 조절하는 제어기법
231 |
232 | - 목적 : 전송은 되었지만, acked를 받지 못한 byte의 숫자를 파악하기 위해 사용하는 protocol
233 |
234 | LastByteSent - LastByteAcked <= ReceivecWindowAdvertised
235 |
236 | (마지막에 보내진 바이트 - 마지막에 확인된 바이트 <= 남아있는 공간) ==
237 |
238 | (현재 공중에 떠있는 패킷 수 <= sliding window)
239 |
240 | - 동작방식 : 먼저 윈도우에 포함되는 모든 패킷을 전송하고, 그 패킷들의 전달이 확인되는대로 이 윈도우를 옆으로 옮김으로써 그 다음 패킷들을 전송
241 |
242 | -
227 |
228 | - Sliding Window (Go Back N ARQ)
229 |
230 | - 수신측에서 설정한 윈도우 크기만큼 송신측에서 확인응답없이 세그먼트를 전송할 수 있게 하여 데이터 흐름을 동적으로 조절하는 제어기법
231 |
232 | - 목적 : 전송은 되었지만, acked를 받지 못한 byte의 숫자를 파악하기 위해 사용하는 protocol
233 |
234 | LastByteSent - LastByteAcked <= ReceivecWindowAdvertised
235 |
236 | (마지막에 보내진 바이트 - 마지막에 확인된 바이트 <= 남아있는 공간) ==
237 |
238 | (현재 공중에 떠있는 패킷 수 <= sliding window)
239 |
240 | - 동작방식 : 먼저 윈도우에 포함되는 모든 패킷을 전송하고, 그 패킷들의 전달이 확인되는대로 이 윈도우를 옆으로 옮김으로써 그 다음 패킷들을 전송
241 |
242 | -  243 |
244 | - Window : TCP/IP를 사용하는 모든 호스트들은 송신하기 위한 것과 수신하기 위한 2개의 Window를 가지고 있다. 호스트들은 실제 데이터를 보내기 전에 '3 way handshaking'을 통해 수신 호스트의 receive window size에 자신의 send window size를 맞추게 된다.
245 |
246 | - 세부구조
247 |
248 | 1. 송신 버퍼
249 | -
243 |
244 | - Window : TCP/IP를 사용하는 모든 호스트들은 송신하기 위한 것과 수신하기 위한 2개의 Window를 가지고 있다. 호스트들은 실제 데이터를 보내기 전에 '3 way handshaking'을 통해 수신 호스트의 receive window size에 자신의 send window size를 맞추게 된다.
245 |
246 | - 세부구조
247 |
248 | 1. 송신 버퍼
249 | -  -
250 | - 200 이전의 바이트는 이미 전송되었고, 확인응답을 받은 상태
251 | - 200 ~ 202 바이트는 전송되었으나 확인응답을 받지 못한 상태
252 | - 203 ~ 211 바이트는 아직 전송이 되지 않은 상태
253 | 2. 수신 윈도우
254 | -
-
250 | - 200 이전의 바이트는 이미 전송되었고, 확인응답을 받은 상태
251 | - 200 ~ 202 바이트는 전송되었으나 확인응답을 받지 못한 상태
252 | - 203 ~ 211 바이트는 아직 전송이 되지 않은 상태
253 | 2. 수신 윈도우
254 | -  255 | 3. 송신 윈도우
256 | -
255 | 3. 송신 윈도우
256 | -  257 | - 수신 윈도우보다 작거나 같은 크기로 송신 윈도우를 지정하게되면 흐름제어가 가능하다.
258 | 4. 송신 윈도우 이동
259 | -
257 | - 수신 윈도우보다 작거나 같은 크기로 송신 윈도우를 지정하게되면 흐름제어가 가능하다.
258 | 4. 송신 윈도우 이동
259 | -  260 | - Before : 203 ~ 204를 전송하면 수신측에서는 확인 응답 203을 보내고, 송신측은 이를 받아 after 상태와 같이 수신 윈도우를 203 ~ 209 범위로 이동
261 | - after : 205 ~ 209가 전송 가능한 상태
262 | 5. Selected Repeat
263 |
264 |
260 | - Before : 203 ~ 204를 전송하면 수신측에서는 확인 응답 203을 보내고, 송신측은 이를 받아 after 상태와 같이 수신 윈도우를 203 ~ 209 범위로 이동
261 | - after : 205 ~ 209가 전송 가능한 상태
262 | 5. Selected Repeat
263 |
264 |
265 |
266 | #### 2. 혼잡제어 (Congestion Control)
267 |
268 | - 송신측의 데이터는 지역망이나 인터넷으로 연결된 대형 네트워크를 통해 전달된다. 만약 한 라우터에 데이터가 몰릴 경우, 자신에게 온 데이터를 모두 처리할 수 없게 된다. 이런 경우 호스트들은 또 다시 재전송을 하게되고 결국 혼잡만 가중시켜 오버플로우나 데이터 손실을 발생시키게 된다. 따라서 이러한 네트워크의 혼잡을 피하기 위해 송신측에서 보내는 데이터의 전송속도를 강제로 줄이게 되는데, 이러한 작업을 혼잡제어라고 한다.
269 | - 또한 네트워크 내에 패킷의 수가 과도하게 증가하는 현상을 혼잡이라 하며, 혼잡 현상을 방지하거나 제거하는 기능을 혼잡제어라고 한다.
270 | - 흐름제어가 송신측과 수신측 사이의 전송속도를 다루는데 반해, 혼잡제어는 호스트와 라우터를 포함한 보다 넓은 관점에서 전송 문제를 다루게 된다.
271 | - 해결 방법
272 | -  273 | - AIMD(Additive Increase / Multicative Decrease)
274 | - 처음에 패킷을 하나씩 보내고 이것이 문제없이 도착하면 window 크기(단위 시간 내에 보내는 패킷의 수)를 1씩 증가시켜가며 전송하는 방법
275 | - 패킷 전송에 실패하거나 일정 시간을 넘으면 패킷의 보내는 속도를 절반으로 줄인다.
276 | - 공평한 방식으로, 여러 호스트가 한 네트워크를 공유하고 있으면 나중에 진입하는 쪽이 처음에는 불리하지만, 시간이 흐르면 평형상태로 수렴하게 되는 특징이 있다.
277 | - 문제점은 초기에 네트워크의 높은 대역폭을 사용하지 못하여 오랜 시간이 걸리게 되고, 네트워크가 혼잡해지는 상황을 미리 감지하지 못한다. 즉, 네트워크가 혼잡해지고 나서야 대역폭을 줄이는 방식이다.
278 | - Slow Start (느린 시작)
279 | - AIMD 방식이 네트워크의 수용량 주변에서는 효율적으로 작동하지만, 처음에 전송 속도를 올리는데 시간이 오래 걸리는 단점이 존재했다.
280 | - Slow Start 방식은 AIMD와 마찬가지로 패킷을 하나씩 보내면서 시작하고, 패킷이 문제없이 도착하면 각각의 ACK 패킷마다 window size를 1씩 늘려준다. 즉, 한 주기가 지나면 window size가 2배로 된다.
281 | - 전송속도는 AIMD에 반해 지수 함수 꼴로 증가한다. 대신에 혼잡 현상이 발생하면 window size를 1로 떨어뜨리게 된다.
282 | - 처음에는 네트워크의 수용량을 예상할 수 있는 정보가 없지만, 한번 혼잡 현상이 발생하고 나면 네트워크의 수용량을 어느 정도 예상할 수 있다.
283 | - 그러므로 혼잡 현상이 발생하였던 window size의 절반까지는 이전처럼 지수 함수 꼴로 창 크기를 증가시키고 그 이후부터는 완만하게 1씩 증가시킨다.
284 | - Fast Retransmit (빠른 재전송)
285 | - 빠른 재전송은 TCP의 혼잡 조절에 추가된 정책이다.
286 | - 패킷을 받는 쪽에서 먼저 도착해야할 패킷이 도착하지 않고 다음 패킷이 도착한 경우에도 ACK 패킷을 보내게 된다.
287 | - 단, 순서대로 잘 도착한 마지막 패킷의 다음 패킷의 순번을 ACK 패킷에 실어서 보내게 되므로, 중간에 하나가 손실되게 되면 송신 측에서는 순번이 중복된 ACK 패킷을 받게 된다. 이것을 감지하는 순간 문제가 되는 순번의 패킷을 재전송 해줄 수 있다.
288 | - 중복된 순번의 패킷을 3개 받으면 재전송을 하게 된다. 약간 혼잡한 상황이 일어난 것이므로 혼잡을 감지하고 window size를 줄이게 된다.
289 | - Fast Recovery (빠른 회복)
290 | - 혼잡한 상태가 되면 window size를 1로 줄이지 않고 반으로 줄이고 선형증가시키는 방법이다. 이 정책까지 적용하면 혼잡 상황을 한번 겪고 나서부터는 순수한 AIMD 방식으로 동작하게 된다.
291 |
292 |
273 | - AIMD(Additive Increase / Multicative Decrease)
274 | - 처음에 패킷을 하나씩 보내고 이것이 문제없이 도착하면 window 크기(단위 시간 내에 보내는 패킷의 수)를 1씩 증가시켜가며 전송하는 방법
275 | - 패킷 전송에 실패하거나 일정 시간을 넘으면 패킷의 보내는 속도를 절반으로 줄인다.
276 | - 공평한 방식으로, 여러 호스트가 한 네트워크를 공유하고 있으면 나중에 진입하는 쪽이 처음에는 불리하지만, 시간이 흐르면 평형상태로 수렴하게 되는 특징이 있다.
277 | - 문제점은 초기에 네트워크의 높은 대역폭을 사용하지 못하여 오랜 시간이 걸리게 되고, 네트워크가 혼잡해지는 상황을 미리 감지하지 못한다. 즉, 네트워크가 혼잡해지고 나서야 대역폭을 줄이는 방식이다.
278 | - Slow Start (느린 시작)
279 | - AIMD 방식이 네트워크의 수용량 주변에서는 효율적으로 작동하지만, 처음에 전송 속도를 올리는데 시간이 오래 걸리는 단점이 존재했다.
280 | - Slow Start 방식은 AIMD와 마찬가지로 패킷을 하나씩 보내면서 시작하고, 패킷이 문제없이 도착하면 각각의 ACK 패킷마다 window size를 1씩 늘려준다. 즉, 한 주기가 지나면 window size가 2배로 된다.
281 | - 전송속도는 AIMD에 반해 지수 함수 꼴로 증가한다. 대신에 혼잡 현상이 발생하면 window size를 1로 떨어뜨리게 된다.
282 | - 처음에는 네트워크의 수용량을 예상할 수 있는 정보가 없지만, 한번 혼잡 현상이 발생하고 나면 네트워크의 수용량을 어느 정도 예상할 수 있다.
283 | - 그러므로 혼잡 현상이 발생하였던 window size의 절반까지는 이전처럼 지수 함수 꼴로 창 크기를 증가시키고 그 이후부터는 완만하게 1씩 증가시킨다.
284 | - Fast Retransmit (빠른 재전송)
285 | - 빠른 재전송은 TCP의 혼잡 조절에 추가된 정책이다.
286 | - 패킷을 받는 쪽에서 먼저 도착해야할 패킷이 도착하지 않고 다음 패킷이 도착한 경우에도 ACK 패킷을 보내게 된다.
287 | - 단, 순서대로 잘 도착한 마지막 패킷의 다음 패킷의 순번을 ACK 패킷에 실어서 보내게 되므로, 중간에 하나가 손실되게 되면 송신 측에서는 순번이 중복된 ACK 패킷을 받게 된다. 이것을 감지하는 순간 문제가 되는 순번의 패킷을 재전송 해줄 수 있다.
288 | - 중복된 순번의 패킷을 3개 받으면 재전송을 하게 된다. 약간 혼잡한 상황이 일어난 것이므로 혼잡을 감지하고 window size를 줄이게 된다.
289 | - Fast Recovery (빠른 회복)
290 | - 혼잡한 상태가 되면 window size를 1로 줄이지 않고 반으로 줄이고 선형증가시키는 방법이다. 이 정책까지 적용하면 혼잡 상황을 한번 겪고 나서부터는 순수한 AIMD 방식으로 동작하게 된다.
291 |
292 |
293 |
294 | [ref]
295 |
296 | -
297 | -
298 |
299 | ### TCP와 UDP의 헤더 분석
300 |
301 | * TCP 헤더 구조(TCP는 양방향성)
302 | * 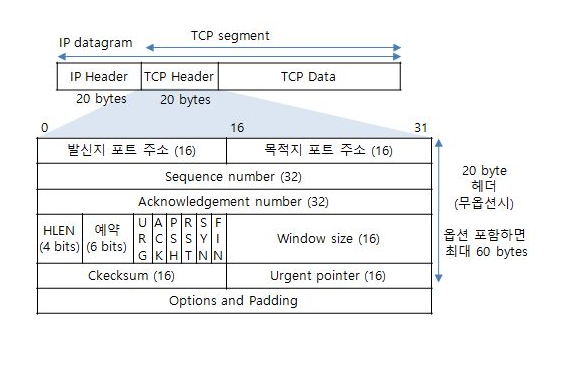
303 |
304 | * UDP 헤더 구조
305 | * 
306 |
307 | > - [https://idchowto.com/?p=18352](https://idchowto.com/?p=18352)
308 | > - [https://m.blog.naver.com/PostView.nhn?blogId=koromoon&logNo=120162515270&proxyReferer=https%3A%2F%2Fwww.google.co.kr%2F](https://m.blog.naver.com/PostView.nhn?blogId=koromoon&logNo=120162515270&proxyReferer=https%3A%2F%2Fwww.google.co.kr%2F)
309 |
310 | ### TCP의 3 way handshake와 4 way handshake
311 | * TCP는 장치들 사이에 논리적인 접속을 성립(establish)하기 위하여 연결을 설정하여 **신뢰성을 보장하는 연결형 서비스** 이다.
312 | * 3-way handshake 란
313 | * TCP 통신을 이용하여 데이터를 전송하기 위해 네트워크 **연결을 설정(Connection Establish)** 하는 과정
314 | * 양쪽 모두 데이터를 전송할 준비가 되었다는 것을 보장하고, 실제로 데이터 전달이 시작하기 전에 한 쪽이 다른 쪽이 준비되었다는 것을 알 수 있도록 한다.
315 | * 즉, TCP/IP 프로토콜을 이용해서 통신을 하는 응용 프로그램이 데이터를 전송하기 전에 먼저 정확한 전송을 보장하기 위해 상대방 컴퓨터와 사전에 세션을 수립하는 과정을 의미한다.
316 | * A 프로세스(Client)가 B 프로세스(Server)에 연결을 요청
317 | 
318 | 먼저 Server에서 열려있는 포트는 LISTEN 상태이고 Client에서는 Closed 상태이다.
319 | 1. Client에서 Server에 연결 요청을 하기위해 SYN 데이터를 보낸다.
320 | 2. Server에서 해당 포트는 LISTEN 상태에서 SYN 데이터를 받고 SYN_RCV로 상태가 변경된다.
321 | 그리고 요청을 정상적으로 받았다는 대답(ACK)와 Client도 포트를 열어달라는 SYN 을 같이 보낸다.
322 | 3. Client에서는 SYN+ACK 를 받고 ESTABLISHED로 상태를 변경하고 서버에 요청을 잘 받았다는 ACK 를 전송한다.
323 | ACK를 받은 서버는 상태가 ESTABLSHED로 변경된다.
324 |
325 | 위와 같이 3번의 통신이 정상적으로 이루어지면, 서로의 서로의 포트가 ESTABLISHED 되면서 연결이 되게 된다.
326 |
327 | * Status
328 | * Closed : 닫힌 상태
329 | * LISTEN : 포트가 열린 상태로 연결 요청 대기 중
330 | * SYN_RCV : SYNC 요청을 받고 상대방의 응답을 기다리는 중
331 | * ESTABLISHED : 포트 연결 상태
332 |
333 |
334 | * 4-way handshake 란
335 | * TCP의 **연결을 해제(Connection Termination)** 하는 과정
336 | * TCP 연결을 위해 3 Way handshake를 통해 ESTBLISHED 하는 것과 달리 프로세스 간 연결을 종료할 때는 4 Way
337 | handshake를 수행한다.
338 | * 아무래도 새로 연결하는 것보다, 연결되어 있는 상황에서 종료할 때 예기치 못한 상황이 많기 때문에, 확인 과정이 더 까다롭다.
339 | 
340 | * 최초에는 서로 통신 상태이기 때문에 양쪽이 ESTABLISHED 상태이다.
341 | 1. 통신을 종료하고자 하는 Client가 서버에게 FIN 패킷을 보내고 자신은 FIN_WAIT_1 상태로 대기한다.
342 | 2. FIN 패킷을 받은 서버는 해당 포트를 CLOSE_WAIT으로 바꾸고 잘 받았다는 ACK 를 Client에게 전하고 ACK를 받은 Client는 상태를 FIN_WAIT_2로 변경한다.
343 | 그와 동시에 Server에서는 해당 포트에 연결되어 있는 Application에게 Close()를 요청한다.
344 | 3. Close() 요청을 받은 Application은 종료 프로세스를 진행시켜 최종적으로 close()가 되고 server는 FIN 패킷을 Client에게 전송 후 자신은 LAST_ACK 로 상태를 바꾼다.
345 | 4. FIN_WAIT_2 에서 Server가 연결을 종료했다는 신호를 기다리다가 FIN 을 받으면 받았다는 ACK를 Server에 전송하고 자신은 TIME_WAIT 으로 상태를 바꾼다. (TIME_WAIT 에서 일정 시간이 지나면 CLOSED 되게 된다.)
346 | 최종 ACK를 받은 서버는 자신의 포트도 CLOSED로 닫게 된다.
347 |
348 | TCP 연결 종료는 연결보다 더 복잡하고 예기치 못한 상황들이 많이 일어난다.
349 | * 비정상 종료 상황
350 | 다양한 상황에 따른 연결의 종료를 적절하게 처리하지 못하면, FIN_WAIT_1, FIN_WAIT_2, CLOSE_WAIT 상태로 남아 계속 기다리는 상황이 올 수 있다.
351 | - CLOSE_WAIT 상태 : 어플리케이션에서 close()를 적절하게 처리해주지 못하면, TCP 포트는 CLOSE_WAIT 상태로 계속 기다리게 된다. 이렇게 CLOSE_WAIT 상태가 statement에 많아지게 되면, Hang 이 걸려 더이상 연결을 하지 못하는 경우가 생기기도 한다. 따라서 어플리케이션 개발시 여러 상황에 따라 close() 처리를 잘 해줘야 한다.
352 | - FIN_WAIT_1 상태 : FIN_WAIT_1 상태라는 것은 상대방측에 커넥션 종료 요청을 했는데, ACK를 받지 못한 상태로 기다리고 있는 것이다. 이것은 아마 서버를 찾을 수 없는 것으로, 네트워크 및 방화벽의 문제일 수 있다.
353 | (FIN_WAIT_1 의 상태는 일정 시간이 지나 Time Out이 되면 자동으로 닫는다.)
354 | - FIN_WAIT_2 상태 : FIN_WAIT_2 상태는 클라이언트가 서버에 종료를 요청한 후 서버에서 요청을 접수했다고 ACK를 받았지만, 서버에서 종료를 완료했다는 FIN 을 받지 못하고 기다리고 있는 상태이다. 이상태는 양방의 두번의 통신이 이루어졌기 때문에 네트워크의 문제는 아닌 것으로 판단되며,(FIN 을 보내는 순간에 순단이 있어 못받은 것일 수도 있다.) 서버측에서 CLOSE를 처리하지 못하는 경우일 수도 있다. FIN_WAIT_2 역시 일정시간 후 Time Out이 되면 스스로 Closed 하게 된다.
355 | - 어떠한 이유에서 FIN_WAIT_1과 FIN_WAIT_2 상태인 연결이 많이 남아있다면, 문제가 발생할 수 있다. 물론 일정 시간이 지나 Time Out이 되면 연결이 자동으로 종료되긴 하지만, 이 Time Out이 길어서 많은 수의 소켓이 늘어만 난다면, 메모리 부족으로 더 이상 소켓을 오픈하지 못하는 경우가 발생한다.
356 | (이 경우는 네트워크나 방화벽 또는 어플리케이션에서 close() 처리 등에 대한 문제등으로 발생할 수 있으며, 원인을 찾기가 쉽지 않다.)
357 | - 이러한 문제 해결을 위해서 FIN_WAIT_1과 FIN_WAIT_2 의 Time Out 시간을 적절히 조절할 필요가 있다.
358 |
359 | * 참고 - ***플래그 정보***
360 | * TCP Header에는 CONTROL BIT(플래그 비트, 6bit)가 존재하며, 각각의 bit는 "URG-ACK-PSH-RST-SYN-FIN"의 의미를 가진다.
361 | * 즉, 해당 위치의 bit가 1이면 해당 패킷이 어떠한 내용을 담고 있는 패킷인지를 나타낸다.
362 | * SYN(Synchronize Sequence Number) / 000010
363 | * 연결 설정. Sequence Number를 랜덤으로 설정하여 세션을 연결하는 데 사용하며, 초기에 Sequence Number를 전송한다.
364 | * ACK(Acknowledgement) / 010000
365 | * 응답 확인. 패킷을 받았다는 것을 의미한다.
366 | * Acknowledgement Number 필드가 유효한지를 나타낸다.
367 | * 양단 프로세스가 쉬지 않고 데이터를 전송한다고 가정하면 최초 연결 설정 과정에서 전송되는 첫 번째 세그먼트를 제외한 모든 세그먼트의 ACK 비트는 1로 지정된다고 생각할 수 있다.
368 | * FIN(Finish) / 000001
369 | * 연결 해제. 세션 연결을 종료시킬 때 사용되며, 더 이상 전송할 데이터가 없음을 의미한다.
370 | * Ref : [4-way-handshake](https://hyeonstorage.tistory.com/287?category=583737)
371 |
372 | #### :question:TCP 관련 질문 1
373 | * Q. TCP의 연결 설정 과정(3단계)과 연결 종료 과정(4단계)이 단계가 차이나는 이유?
374 | * A. Client가 데이터 전송을 마쳤다고 하더라도 Server는 아직 보낼 데이터가 남아있을 수 있기 때문에 일단 FIN에 대한 ACK만 보내고, 데이터를 모두 전송한 후에 자신도 FIN 메시지를 보내기 때문이다.
375 | * [관련 Reference](http://ddooooki.tistory.com/21)
376 |
377 | #### :question:TCP 관련 질문 2
378 | * Q. 만약 Server에서 FIN 플래그를 전송하기 전에 전송한 패킷이 Routing 지연이나 패킷 유실로 인한 재전송 등으로 인해 FIN 패킷보다 늦게 도착하는 상황이 발생하면 어떻게 될까?
379 | * A. 이러한 현상에 대비하여 Client는 Server로부터 FIN 플래그를 수신하더라도 일정시간(Default: 240sec)동안 세션을 남겨 놓고 잉여 패킷을 기다리는 과정을 거친다. (TIME_WAIT 과정)
380 | * [관련 Reference](http://mindnet.tistory.com/entry/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-22%ED%8E%B8-TCP-3-WayHandshake-4-WayHandshake)
381 |
382 | #### :question:TCP 관련 질문 3
383 | * Q. 초기 Sequence Number인 ISN을 0부터 시작하지 않고 난수를 생성해서 설정하는 이유?
384 | * A. Connection을 맺을 때 사용하는 포트(Port)는 유한 범위 내에서 사용하고 시간이 지남에 따라 재사용된다. 따라서 두 통신 호스트가 과거에 사용된 포트 번호 쌍을 사용하는 가능성이 존재한다. 서버 측에서는 패킷의 SYN을 보고 패킷을 구분하게 되는데 난수가 아닌 순처적인 Number가 전송된다면 이전의 Connection으로부터 오는 패킷으로 인식할 수 있다. 이런 문제가 발생할 가능성을 줄이기 위해서 난수로 ISN을 설정한다.
385 | * [관련 Reference](http://asfirstalways.tistory.com/356)
386 |
--------------------------------------------------------------------------------
/Java/Part4.md:
--------------------------------------------------------------------------------
1 | # 7. Java
2 | **:book: Contents**
3 | * [JVM 구조](#jvm-구조)
4 | * [Java Collections Framework](#java-collections-framework)
5 | * [java Map 인터페이스 구현체의 종류](#java-map-인터페이스-구현체의-종류)
6 | * [java Set 인터페이스 구현체의 종류](#java-set-인터페이스-구현체의-종류)
7 | * [java List 인터페이스 구현체의 종류](#java-list-인터페이스-구현체의-종류)
8 | * [Annotation](#annotation)
9 | * [String, StringBuilder, StringBuffer](#string-stringbuilder-stringbuffer)
10 | * [동기화와 비동기화의 차이(Syncronous vs Asyncronous)](#동기화와-비동기화의-차이)
11 | * [java에서 '=='와 'equals()'의 차이](#java에서-==와-equals()의-차이)
12 | * [java의 리플렉션(Reflection) 이란](#java의-리플렉션-이란)
13 |
14 | ---
15 |
16 | ### JVM 구조
17 |
18 |  19 |
20 | - JVM(Java Virtual Machine)
21 | - 자바 가상 머신으로 자바 바이트 코드를 실행할 수 있는 주체다.
22 | - CPU나 운영체제(플랫폼)의 종류와 무관하게 실행이 가능하다.
23 | - 즉, 운영체제 위에서 동작하는 프로세스로 자바 코드를 컴파일해서 얻은 바이트 코드를 해당 운영체제가 이해할 수 있는 기계어로 바꿔 실행시켜주는 역할을 한다.
24 | - JVM의 구성을 살펴보면 크게 4가지(Class Loader, Execution Engine, Garbage Collector, Runtime Data Area)로 나뉜다.
25 |
26 | 1. Class Loader
27 | - 자바에서 소스를 작성하면 Person.java 처럼 .java파일이 생성된다.
28 | - .java 소스를 자바컴파일러가 컴파일하면 Person.class 같은 .class파일(바이트코드)이 생성된다.
29 | - 이렇게 생성된 클래스파일들을 엮어서 JVM이 운영체제로부터 할당받은 메모리영역인 Runtime Data Area로 적재하는 역할을 Class Loader가 한다. (자바 애플리케이션이 실행중일 때 이런 작업이 수행된다.)
30 |
31 | 2. Execution Engine
32 | - Class Loader에 의해 메모리에 적재된 클래스(바이트 코드)들을 기계어로 변경해 명령어 단위로 실행하는 역할을 한다.
33 | - 명령어를 하나 하나 실행하는 인터프리터(Interpreter)방식이 있고 JIT(Just-In-Time) 컴파일러를 이용하는 방식이 있다.
34 | - JIT 컴파일러는 적절한 시간에 전체 바이트 코드를 네이티브 코드로 변경해서 Execution Engine이 네이티브로 컴파일된 코드를 실행하는 것으로 성능을 높이는 방식이다.
35 |
36 | 3. Garbage Collector
37 | - Garbage Collector(GC)는 Heap 메모리 영역에 생성(적재)된 객체들 중에 참조되지 않는 객체들을 탐색 후 제거하는 역할을 한다.
38 | - GC가 역할을 하는 시간은 정확히 언제인지를 알 수 없다. (참조가 없어지자마자 해제되는 것을 보장하지 않음)
39 | - 또 다른 특징은 GC가 수행되는 동안 GC를 수행하는 쓰레드가 아닌 다른 모든 쓰레드가 일시정지된다.
40 | - 특히 Full GC가 일어나서 수 초간 모든 쓰레드가 정지한다면 장애로 이어지는 치명적인 문제가 생길 수 있는 것이다. (GC와 관련된 내용은 아래 Heap영역 메모리를 설명할 때 더 자세히 알아본다.)
41 |
42 | 4. Runtime Data Area
43 | - JVM의 메모리 영역으로 자바 애플리케이션을 실행할 때 사용되는 데이터들을 적재하는 영역이다.
44 | - 이 영역은 크게 Method Area, Heap Area, Stack Area, PC Register, Native Method Stack로 나눌 수 있다.
45 |
46 |
19 |
20 | - JVM(Java Virtual Machine)
21 | - 자바 가상 머신으로 자바 바이트 코드를 실행할 수 있는 주체다.
22 | - CPU나 운영체제(플랫폼)의 종류와 무관하게 실행이 가능하다.
23 | - 즉, 운영체제 위에서 동작하는 프로세스로 자바 코드를 컴파일해서 얻은 바이트 코드를 해당 운영체제가 이해할 수 있는 기계어로 바꿔 실행시켜주는 역할을 한다.
24 | - JVM의 구성을 살펴보면 크게 4가지(Class Loader, Execution Engine, Garbage Collector, Runtime Data Area)로 나뉜다.
25 |
26 | 1. Class Loader
27 | - 자바에서 소스를 작성하면 Person.java 처럼 .java파일이 생성된다.
28 | - .java 소스를 자바컴파일러가 컴파일하면 Person.class 같은 .class파일(바이트코드)이 생성된다.
29 | - 이렇게 생성된 클래스파일들을 엮어서 JVM이 운영체제로부터 할당받은 메모리영역인 Runtime Data Area로 적재하는 역할을 Class Loader가 한다. (자바 애플리케이션이 실행중일 때 이런 작업이 수행된다.)
30 |
31 | 2. Execution Engine
32 | - Class Loader에 의해 메모리에 적재된 클래스(바이트 코드)들을 기계어로 변경해 명령어 단위로 실행하는 역할을 한다.
33 | - 명령어를 하나 하나 실행하는 인터프리터(Interpreter)방식이 있고 JIT(Just-In-Time) 컴파일러를 이용하는 방식이 있다.
34 | - JIT 컴파일러는 적절한 시간에 전체 바이트 코드를 네이티브 코드로 변경해서 Execution Engine이 네이티브로 컴파일된 코드를 실행하는 것으로 성능을 높이는 방식이다.
35 |
36 | 3. Garbage Collector
37 | - Garbage Collector(GC)는 Heap 메모리 영역에 생성(적재)된 객체들 중에 참조되지 않는 객체들을 탐색 후 제거하는 역할을 한다.
38 | - GC가 역할을 하는 시간은 정확히 언제인지를 알 수 없다. (참조가 없어지자마자 해제되는 것을 보장하지 않음)
39 | - 또 다른 특징은 GC가 수행되는 동안 GC를 수행하는 쓰레드가 아닌 다른 모든 쓰레드가 일시정지된다.
40 | - 특히 Full GC가 일어나서 수 초간 모든 쓰레드가 정지한다면 장애로 이어지는 치명적인 문제가 생길 수 있는 것이다. (GC와 관련된 내용은 아래 Heap영역 메모리를 설명할 때 더 자세히 알아본다.)
41 |
42 | 4. Runtime Data Area
43 | - JVM의 메모리 영역으로 자바 애플리케이션을 실행할 때 사용되는 데이터들을 적재하는 영역이다.
44 | - 이 영역은 크게 Method Area, Heap Area, Stack Area, PC Register, Native Method Stack로 나눌 수 있다.
45 |
46 |  47 |
48 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
49 | > - [https://jeong-pro.tistory.com/148](https://jeong-pro.tistory.com/148)
50 | > - [http://www.itworld.co.kr/news/110837](http://www.itworld.co.kr/news/110837)
51 | > - [http://hoonmaro.tistory.com/19](http://hoonmaro.tistory.com/19)
52 |
53 | ---
54 | ### Java Collections Framework
55 |
56 |
47 |
48 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
49 | > - [https://jeong-pro.tistory.com/148](https://jeong-pro.tistory.com/148)
50 | > - [http://www.itworld.co.kr/news/110837](http://www.itworld.co.kr/news/110837)
51 | > - [http://hoonmaro.tistory.com/19](http://hoonmaro.tistory.com/19)
52 |
53 | ---
54 | ### Java Collections Framework
55 |
56 |  57 |
58 | - 컬렉션 프레임워크(collection framework)란?
59 | - 자바에서 컬렉션 프레임워크(collection framework)란 다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스의 집합을 의미한다.
60 | - 즉, 데이터를 저장하는 자료 구조와 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현해 놓은 것이다.
61 | - 이러한 컬렉션 프레임워크는 자바의 인터페이스(interface)를 사용하여 구현된다.
62 |
63 | * Map
64 | * 검색할 수 있는 인터페이스
65 | * 데이터를 삽입할 때 Key와 Value의 형태로 삽입되며, Key를 이용해서 Value를 얻을 수 있다.
66 | * Collection
67 | * List
68 | * 순서가 있는 Collection
69 | * 데이터를 중복해서 포함할 수 있다.
70 | * Set
71 | * 집합적인 개념의 Collection
72 | * 순서의 의미가 없다.
73 | * 데이터를 중복해서 포함할 수 없다.
74 | * Collections Framework 선택 과정
75 | - 1. Map과 Collection 인터페이스 중 선택
76 | - 1-1. Collection 선택 시 사용 목적에 따라 List와 Set중 선택
77 | - 2. 사용 목적에 따라 Map, List, Set 각각의 하위 구현체를 선택
78 | - 2-1. Map: HashMap, LinkedHashMap, HashTable, TreeMap
79 | - 2-2. List: LinkedList, ArrayList
80 | - 2-3. Set: TreeSet, HashSet
81 |
82 | * Collections Framework 동기화
83 | * [https://madplay.github.io/post/java-collection-synchronize](https://madplay.github.io/post/java-collection-synchronize)
84 |
85 | - Collection 인터페이스
86 | - List와 Set 인터페이스의 많은 공통된 부분을 Collection 인터페이스에서 정의하고, 두 인터페이스는 그것을 상속받는다.
87 | - 따라서 Collection 인터페이스는 컬렉션을 다루는데 가장 기본적인 동작들을 정의하고, 그것을 메소드로 제공하고 있다.
88 |
89 |
57 |
58 | - 컬렉션 프레임워크(collection framework)란?
59 | - 자바에서 컬렉션 프레임워크(collection framework)란 다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스의 집합을 의미한다.
60 | - 즉, 데이터를 저장하는 자료 구조와 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현해 놓은 것이다.
61 | - 이러한 컬렉션 프레임워크는 자바의 인터페이스(interface)를 사용하여 구현된다.
62 |
63 | * Map
64 | * 검색할 수 있는 인터페이스
65 | * 데이터를 삽입할 때 Key와 Value의 형태로 삽입되며, Key를 이용해서 Value를 얻을 수 있다.
66 | * Collection
67 | * List
68 | * 순서가 있는 Collection
69 | * 데이터를 중복해서 포함할 수 있다.
70 | * Set
71 | * 집합적인 개념의 Collection
72 | * 순서의 의미가 없다.
73 | * 데이터를 중복해서 포함할 수 없다.
74 | * Collections Framework 선택 과정
75 | - 1. Map과 Collection 인터페이스 중 선택
76 | - 1-1. Collection 선택 시 사용 목적에 따라 List와 Set중 선택
77 | - 2. 사용 목적에 따라 Map, List, Set 각각의 하위 구현체를 선택
78 | - 2-1. Map: HashMap, LinkedHashMap, HashTable, TreeMap
79 | - 2-2. List: LinkedList, ArrayList
80 | - 2-3. Set: TreeSet, HashSet
81 |
82 | * Collections Framework 동기화
83 | * [https://madplay.github.io/post/java-collection-synchronize](https://madplay.github.io/post/java-collection-synchronize)
84 |
85 | - Collection 인터페이스
86 | - List와 Set 인터페이스의 많은 공통된 부분을 Collection 인터페이스에서 정의하고, 두 인터페이스는 그것을 상속받는다.
87 | - 따라서 Collection 인터페이스는 컬렉션을 다루는데 가장 기본적인 동작들을 정의하고, 그것을 메소드로 제공하고 있다.
88 |
89 |  90 |
91 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
92 | > - [http://tcpschool.com/java/java_collectionFramework_concept](http://tcpschool.com/java/java_collectionFramework_concept)
93 | > - [https://postitforhooney.tistory.com](https://postitforhooney.tistory.com/entry/JavaCollection-Java-Collection-Framework%EC%97%90-%EB%8C%80%ED%95%9C-%EC%9D%B4%ED%95%B4%EB%A5%BC-%ED%86%B5%ED%95%B4-Data-Structure-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0)
94 |
95 | ---
96 | ### java Map 인터페이스 구현체의 종류
97 | * Map
98 | * Key와 Value를 저장하며, Key는 중복될 수 없다. 키와 값은 모두 객체이다.
99 | * 만약, 기존에 저장된 키와 동일한 키로 값을 저장하면 기존 값은 없어지고 새로운 값으로 대체 된다.
100 | * HashMap
101 | * Entry의 배열로 저장되며, 배열의 index는 내부 해쉬 함수를 통해 계산된다.
102 | * 내부 hash값에 따라서 키순서가 정해지므로 특정 규칙없이 출력된다.
103 | * key와 value에 null값을 허용한다.
104 | * 비동기 처리
105 | * 시간복잡도: O(1)
106 | * LinkedHashMap
107 | * HaspMap을 상속받으며, Linked List로 저장된다.
108 | * 입력 순서대로 출력된다.
109 | * 비동기 처리
110 | * 시간복잡도: O(n)
111 | * TreeMap
112 | * 내부적으로 레드-블랙 트리(Red-Black tree)로 저장된다.
113 | * 키값이 기본적으로 오름차순 정렬되어 출력된다.
114 | * 키값에 대한 Compartor 구현으로 정렬 방법을 지정할 수 있다.
115 | * 시간복잡도: O(logn)
116 | * ConCurrentHashMap
117 | * multiple lock
118 | * update할 때만 동기 처리
119 | * key와 value에 null값을 허용하지 않는다.
120 | * HashTable
121 | * single lock
122 | * 모든 메서드에 대해 동기 처리
123 | * key와 value에 null값을 허용하지 않는다.
124 |
125 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
126 |
127 | ---
128 | ### java Set 인터페이스 구현체의 종류
129 | * Set
130 | * Set Collection은 List처럼 Index로 저장 순서를 유지하지 않는다.
131 | * 객체를 중복 저장할 수 없으며, 하나의 Null만 존재한다.
132 |
133 | * HashSet
134 | * 저장 순서를 유지하지 않는 데이터의 집합이다.
135 | * 해시 알고리즘(hash algorithm)을 사용하여 검색 속도가 매우 빠르다.
136 | * 내부적으로 HashMap 인스턴스를 이용하여 요소를 저장한다.
137 | * LinkedHashSet
138 | * 저장 순서를 유지하는 HashSet
139 | * TreeSet
140 | * 데이터가 정렬된 상태로 저장되는 이진 탐색 트리(binary search tree)의 형태로 요소를 저장한다.
141 | * 이진 탐색 트리 중에 성능을 향상시킨 레드-블랙 트리(Red-Black tree)로 구현되어 있다.
142 | * Compartor 구현으로 정렬 방법을 지정할 수 있다.
143 |
144 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
145 |
146 | ---
147 | ### java List 인터페이스 구현체의 종류
148 | * List
149 | * 객체를 인덱스로 관리하기 때문에 객체를 저장하면 자동 인덱스가 부여되고 인덱스로 객체를 검색, 삭제할 수 있는 기능을 제공한다.
150 | * List는 객체 자체를 저장하는 것이 아니라, 해당하는 인덱스에 객체의 주소를 참조하여 저장한다.
151 |
152 | * ArrayList
153 | * 단방향 포인터 구조로 각 데이터에 대한 인덱스를 가지고 있어 데이터 검색에 적합하다.
154 | * 데이터의 삽입, 삭제 시 해당 데이터 이후 모든 데이터가 복사되므로 삽입, 삭제가 빈번한 데이터에는 부적합하다.
155 | * LinkedList
156 | * 양방향 포인터 구조로 데이터의 삽입, 삭제 시 해당 노드의 주소지만 바꾸면 되므로 삽입, 삭제가 빈번한 데이터에 적합하다.
157 | * 데이터의 검색 시 처음부터 노드를 순회하므로 검색에는 부적합하다.
158 | * 스택, 큐, 양방향 큐 등을 만들기 위한 용도로 쓰인다.
159 | * Vector
160 | * 내부에서 자동으로 동기화 처리가 일어난다.
161 | * 성능이 좋지 않고 무거워 잘 쓰이지 않는다.
162 |
163 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
164 |
165 | ---
166 | ### Annotation
167 |
168 | * Java에서 어노테이션(Annotation) 이란?
169 | * 어노테이션은 JEE5(Java Platform, Enterprise Edition 5)부터 새롭게 추가된 요소이다.
170 | * 이 어노테이션으로 인해 데이터의 유효성 검사 등을 쉽게 알 수 있고, 이와 관련한 코드가 깔끔해지게 되었다.
171 | * 어노테이션의 용도는 다양한 목적이 있지만 메타 데이터의 비중이 가장 크다 할 수 있다.
172 | * 메타-테이터(Meta-Data) : 데이터를 위한 데이터를 의미하며, 풀어 이야기하면 한 데이터에 대한 설명을 의미하는 데이터. (자신의 정보를 담고 있는 데이터)
173 |
174 | * Java에서 기본적으로 제공하는 어노테이션 종류
175 | * @Override
176 | * 선언한 메서드가 오버라이드 되었다는 것을 나타낸다.
177 | * 만약 상위(부모) 클래스(또는 인터페이스)에서 해당 메서드를 찾을 수 없다면 컴파일 에러를 발생 시킨다.
178 | * @Deprecated
179 | * 해당 메서드가 더 이상 사용되지 않음을 표시한다.
180 | * 만약 사용할 경우 컴파일 경고를 발생시킨다.
181 | * @SuppressWarnings
182 | * 선언한 곳의 컴파일 경고를 무시하도록 한다.
183 | * @SafeVarargs
184 | * Java7 부터 지원하며, 제너릭 같은 가변인자의 매개변수를 사용할 때의 경고를 무시한다.
185 | * @FunctionalInterface
186 | * Java8 부터 지원하며, 함수형 인터페이스를 지정하는 어노테이션이다.
187 | * 만약 메서드가 존재하지 않거나, 1개 이상의 메서드(default 메서드 제외)가 존재할 경우 컴파일 오류를 발생시킨다.
188 |
189 | * 메타 어노테이션의 종류
190 | * @Retention
191 | * 자바 컴파일러가 어노테이션을 다루는 방법을 기술하며, 특정 시점까지 영향을 미치는지를 결정한다.
192 | * RetentionPolicy.SOURCE : 컴파일 전까지만 유효. (컴파일 이후에는 사라짐)
193 | * RetentionPolicy.CLASS : 컴파일러가 클래스를 참조할 때까지 유효.
194 | * RetentionPolicy.RUNTIME : 컴파일 이후에도 JVM에 의해 계속 참조가 가능. (리플렉션 사용)
195 | * @Target
196 | * 어노테이션이 적용할 위치를 선택한다.
197 | * ElementType.PACKAGE : 패키지 선언
198 | * ElementType.TYPE : 타입 선언
199 | * ElementType.ANNOTATION_TYPE : 어노테이션 타입 선언
200 | * ElementType.CONSTRUCTOR : 생성자 선언
201 | * ElementType.FIELD : 멤버 변수 선언
202 | * ElementType.LOCAL_VARIABLE : 지역 변수 선언
203 | * ElementType.METHOD : 메서드 선언
204 | * ElementType.PARAMETER : 전달인자 선언
205 | * ElementType.TYPE_PARAMETER : 전달인자 타입 선언
206 | * ElementType.TYPE_USE : 타입 선언
207 | * @Documented
208 | * 해당 어노테이션을 Javadoc에 포함시킨다.
209 | * @Inherited
210 | * 어노테이션의 상속을 가능하게 한다.
211 | * @Repeatable
212 | * Java8 부터 지원하며, 연속적으로 어노테이션을 선언할 수 있게 해준다.
213 |
214 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
215 |
216 | > - [https://elfinlas.github.io/2017/12/14/java-annotation/](https://elfinlas.github.io/2017/12/14/java-annotation/)
217 |
218 | ---
219 | ### String StringBuilder StringBuffer
220 | * String
221 | * 새로운 값을 할당할 때마다 새로 클래스에 대한 객체가 생성된다.
222 | * String에서 저장되는 문자열은 private final char[]의 형태이기 때문에 String 값은 바꿀수 없다.
223 | * private: 외부에서 접근 불가
224 | * final: 초기값 변경 불가
225 | * String + String + String...
226 | * 각각의 String 주솟값이 Stack에 쌓이고, Garbage Collector가 호출되기 전까지 생성된 String 객체들은 Heap에 쌓이기 때문에 메모리 관리에 치명적이다.
227 | * String을 직접 더하는 것보다는 StringBuffer나 StringBuilder를 사용하는 것이 좋다.
228 | * StringBuilder, StringBuffer
229 | * memory에 append하는 방식으로, 클래스에 대한 객체를 직접 생성하지 않는다.
230 | * StringBuilder
231 | * 변경가능한 문자열
232 | * 비동기 처리
233 | * StringBuffer
234 | * 변경가능한 문자열
235 | * 동기 처리
236 | * multiple thread 환경에서 안전한 클래스(thread safe)
237 | * Java 버전별 String Class 변경 사항
238 | * JDK 1.5 버전 이전에서는 문자열 연산(+, concat)을 할 때 조합된 문자열을 새로운 메모리에 할당하여 참조해 성능상의 이슈 존재
239 | * JDK 1.5 버전 이후에는 컴파일 단계에서 String 객체를 StringBuilder로 컴파일 되도록 변경됨
240 | * 그래서 JDK 1.5 이후 버전에서는 String 클래스를 사용해도 StringBuilder와 성능 차이가 없어짐
241 | * 하지만 반복 루프를 사용해서 문자열을 더할 때에는 객체를 계속 새로운 메모리에 할당함
242 | * String 클래스를 사용하는 것 보다는 스레드와 관련이 있으면 StringBuffer, 스레드 안전 여부와 상관이 없으면 StringBuilder를 사용하는 것을 권장
243 |
244 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
245 | > - [https://12bme.tistory.com/42](https://12bme.tistory.com/42)
246 |
247 | ---
248 | ### 동기화와 비동기화의 차이
249 |
250 | - 동기화와 비동기화
251 | - 동기화 방식은 한 자원에 대해 동시에 접근하는 것을 제한하는 방식이다.
252 | - 다시말해서, 순서를 지키겠다는 말이다.
253 | - 비동기화 방식은 한 자원에 대해 동시에 접근이 가능하다
254 |
255 |
90 |
91 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
92 | > - [http://tcpschool.com/java/java_collectionFramework_concept](http://tcpschool.com/java/java_collectionFramework_concept)
93 | > - [https://postitforhooney.tistory.com](https://postitforhooney.tistory.com/entry/JavaCollection-Java-Collection-Framework%EC%97%90-%EB%8C%80%ED%95%9C-%EC%9D%B4%ED%95%B4%EB%A5%BC-%ED%86%B5%ED%95%B4-Data-Structure-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0)
94 |
95 | ---
96 | ### java Map 인터페이스 구현체의 종류
97 | * Map
98 | * Key와 Value를 저장하며, Key는 중복될 수 없다. 키와 값은 모두 객체이다.
99 | * 만약, 기존에 저장된 키와 동일한 키로 값을 저장하면 기존 값은 없어지고 새로운 값으로 대체 된다.
100 | * HashMap
101 | * Entry의 배열로 저장되며, 배열의 index는 내부 해쉬 함수를 통해 계산된다.
102 | * 내부 hash값에 따라서 키순서가 정해지므로 특정 규칙없이 출력된다.
103 | * key와 value에 null값을 허용한다.
104 | * 비동기 처리
105 | * 시간복잡도: O(1)
106 | * LinkedHashMap
107 | * HaspMap을 상속받으며, Linked List로 저장된다.
108 | * 입력 순서대로 출력된다.
109 | * 비동기 처리
110 | * 시간복잡도: O(n)
111 | * TreeMap
112 | * 내부적으로 레드-블랙 트리(Red-Black tree)로 저장된다.
113 | * 키값이 기본적으로 오름차순 정렬되어 출력된다.
114 | * 키값에 대한 Compartor 구현으로 정렬 방법을 지정할 수 있다.
115 | * 시간복잡도: O(logn)
116 | * ConCurrentHashMap
117 | * multiple lock
118 | * update할 때만 동기 처리
119 | * key와 value에 null값을 허용하지 않는다.
120 | * HashTable
121 | * single lock
122 | * 모든 메서드에 대해 동기 처리
123 | * key와 value에 null값을 허용하지 않는다.
124 |
125 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
126 |
127 | ---
128 | ### java Set 인터페이스 구현체의 종류
129 | * Set
130 | * Set Collection은 List처럼 Index로 저장 순서를 유지하지 않는다.
131 | * 객체를 중복 저장할 수 없으며, 하나의 Null만 존재한다.
132 |
133 | * HashSet
134 | * 저장 순서를 유지하지 않는 데이터의 집합이다.
135 | * 해시 알고리즘(hash algorithm)을 사용하여 검색 속도가 매우 빠르다.
136 | * 내부적으로 HashMap 인스턴스를 이용하여 요소를 저장한다.
137 | * LinkedHashSet
138 | * 저장 순서를 유지하는 HashSet
139 | * TreeSet
140 | * 데이터가 정렬된 상태로 저장되는 이진 탐색 트리(binary search tree)의 형태로 요소를 저장한다.
141 | * 이진 탐색 트리 중에 성능을 향상시킨 레드-블랙 트리(Red-Black tree)로 구현되어 있다.
142 | * Compartor 구현으로 정렬 방법을 지정할 수 있다.
143 |
144 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
145 |
146 | ---
147 | ### java List 인터페이스 구현체의 종류
148 | * List
149 | * 객체를 인덱스로 관리하기 때문에 객체를 저장하면 자동 인덱스가 부여되고 인덱스로 객체를 검색, 삭제할 수 있는 기능을 제공한다.
150 | * List는 객체 자체를 저장하는 것이 아니라, 해당하는 인덱스에 객체의 주소를 참조하여 저장한다.
151 |
152 | * ArrayList
153 | * 단방향 포인터 구조로 각 데이터에 대한 인덱스를 가지고 있어 데이터 검색에 적합하다.
154 | * 데이터의 삽입, 삭제 시 해당 데이터 이후 모든 데이터가 복사되므로 삽입, 삭제가 빈번한 데이터에는 부적합하다.
155 | * LinkedList
156 | * 양방향 포인터 구조로 데이터의 삽입, 삭제 시 해당 노드의 주소지만 바꾸면 되므로 삽입, 삭제가 빈번한 데이터에 적합하다.
157 | * 데이터의 검색 시 처음부터 노드를 순회하므로 검색에는 부적합하다.
158 | * 스택, 큐, 양방향 큐 등을 만들기 위한 용도로 쓰인다.
159 | * Vector
160 | * 내부에서 자동으로 동기화 처리가 일어난다.
161 | * 성능이 좋지 않고 무거워 잘 쓰이지 않는다.
162 |
163 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
164 |
165 | ---
166 | ### Annotation
167 |
168 | * Java에서 어노테이션(Annotation) 이란?
169 | * 어노테이션은 JEE5(Java Platform, Enterprise Edition 5)부터 새롭게 추가된 요소이다.
170 | * 이 어노테이션으로 인해 데이터의 유효성 검사 등을 쉽게 알 수 있고, 이와 관련한 코드가 깔끔해지게 되었다.
171 | * 어노테이션의 용도는 다양한 목적이 있지만 메타 데이터의 비중이 가장 크다 할 수 있다.
172 | * 메타-테이터(Meta-Data) : 데이터를 위한 데이터를 의미하며, 풀어 이야기하면 한 데이터에 대한 설명을 의미하는 데이터. (자신의 정보를 담고 있는 데이터)
173 |
174 | * Java에서 기본적으로 제공하는 어노테이션 종류
175 | * @Override
176 | * 선언한 메서드가 오버라이드 되었다는 것을 나타낸다.
177 | * 만약 상위(부모) 클래스(또는 인터페이스)에서 해당 메서드를 찾을 수 없다면 컴파일 에러를 발생 시킨다.
178 | * @Deprecated
179 | * 해당 메서드가 더 이상 사용되지 않음을 표시한다.
180 | * 만약 사용할 경우 컴파일 경고를 발생시킨다.
181 | * @SuppressWarnings
182 | * 선언한 곳의 컴파일 경고를 무시하도록 한다.
183 | * @SafeVarargs
184 | * Java7 부터 지원하며, 제너릭 같은 가변인자의 매개변수를 사용할 때의 경고를 무시한다.
185 | * @FunctionalInterface
186 | * Java8 부터 지원하며, 함수형 인터페이스를 지정하는 어노테이션이다.
187 | * 만약 메서드가 존재하지 않거나, 1개 이상의 메서드(default 메서드 제외)가 존재할 경우 컴파일 오류를 발생시킨다.
188 |
189 | * 메타 어노테이션의 종류
190 | * @Retention
191 | * 자바 컴파일러가 어노테이션을 다루는 방법을 기술하며, 특정 시점까지 영향을 미치는지를 결정한다.
192 | * RetentionPolicy.SOURCE : 컴파일 전까지만 유효. (컴파일 이후에는 사라짐)
193 | * RetentionPolicy.CLASS : 컴파일러가 클래스를 참조할 때까지 유효.
194 | * RetentionPolicy.RUNTIME : 컴파일 이후에도 JVM에 의해 계속 참조가 가능. (리플렉션 사용)
195 | * @Target
196 | * 어노테이션이 적용할 위치를 선택한다.
197 | * ElementType.PACKAGE : 패키지 선언
198 | * ElementType.TYPE : 타입 선언
199 | * ElementType.ANNOTATION_TYPE : 어노테이션 타입 선언
200 | * ElementType.CONSTRUCTOR : 생성자 선언
201 | * ElementType.FIELD : 멤버 변수 선언
202 | * ElementType.LOCAL_VARIABLE : 지역 변수 선언
203 | * ElementType.METHOD : 메서드 선언
204 | * ElementType.PARAMETER : 전달인자 선언
205 | * ElementType.TYPE_PARAMETER : 전달인자 타입 선언
206 | * ElementType.TYPE_USE : 타입 선언
207 | * @Documented
208 | * 해당 어노테이션을 Javadoc에 포함시킨다.
209 | * @Inherited
210 | * 어노테이션의 상속을 가능하게 한다.
211 | * @Repeatable
212 | * Java8 부터 지원하며, 연속적으로 어노테이션을 선언할 수 있게 해준다.
213 |
214 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
215 |
216 | > - [https://elfinlas.github.io/2017/12/14/java-annotation/](https://elfinlas.github.io/2017/12/14/java-annotation/)
217 |
218 | ---
219 | ### String StringBuilder StringBuffer
220 | * String
221 | * 새로운 값을 할당할 때마다 새로 클래스에 대한 객체가 생성된다.
222 | * String에서 저장되는 문자열은 private final char[]의 형태이기 때문에 String 값은 바꿀수 없다.
223 | * private: 외부에서 접근 불가
224 | * final: 초기값 변경 불가
225 | * String + String + String...
226 | * 각각의 String 주솟값이 Stack에 쌓이고, Garbage Collector가 호출되기 전까지 생성된 String 객체들은 Heap에 쌓이기 때문에 메모리 관리에 치명적이다.
227 | * String을 직접 더하는 것보다는 StringBuffer나 StringBuilder를 사용하는 것이 좋다.
228 | * StringBuilder, StringBuffer
229 | * memory에 append하는 방식으로, 클래스에 대한 객체를 직접 생성하지 않는다.
230 | * StringBuilder
231 | * 변경가능한 문자열
232 | * 비동기 처리
233 | * StringBuffer
234 | * 변경가능한 문자열
235 | * 동기 처리
236 | * multiple thread 환경에서 안전한 클래스(thread safe)
237 | * Java 버전별 String Class 변경 사항
238 | * JDK 1.5 버전 이전에서는 문자열 연산(+, concat)을 할 때 조합된 문자열을 새로운 메모리에 할당하여 참조해 성능상의 이슈 존재
239 | * JDK 1.5 버전 이후에는 컴파일 단계에서 String 객체를 StringBuilder로 컴파일 되도록 변경됨
240 | * 그래서 JDK 1.5 이후 버전에서는 String 클래스를 사용해도 StringBuilder와 성능 차이가 없어짐
241 | * 하지만 반복 루프를 사용해서 문자열을 더할 때에는 객체를 계속 새로운 메모리에 할당함
242 | * String 클래스를 사용하는 것 보다는 스레드와 관련이 있으면 StringBuffer, 스레드 안전 여부와 상관이 없으면 StringBuilder를 사용하는 것을 권장
243 |
244 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
245 | > - [https://12bme.tistory.com/42](https://12bme.tistory.com/42)
246 |
247 | ---
248 | ### 동기화와 비동기화의 차이
249 |
250 | - 동기화와 비동기화
251 | - 동기화 방식은 한 자원에 대해 동시에 접근하는 것을 제한하는 방식이다.
252 | - 다시말해서, 순서를 지키겠다는 말이다.
253 | - 비동기화 방식은 한 자원에 대해 동시에 접근이 가능하다
254 |
255 |  256 |
257 | * 동기화(Syncronous)
258 | - System Call이 끝날 때까지 다른 쓰레드의 접근을 막아버리는 것이다.
259 | - 한마디로, nextLine()에서 입력을 받을 때까지 대기하는 것과 같다.
260 |
261 |
256 |
257 | * 동기화(Syncronous)
258 | - System Call이 끝날 때까지 다른 쓰레드의 접근을 막아버리는 것이다.
259 | - 한마디로, nextLine()에서 입력을 받을 때까지 대기하는 것과 같다.
260 |
261 |  262 |
263 | * 비동기화(Asyncronous)
264 | - System Call이 왔든 말든 상관없이 계속 호출할 수 있다.
265 | - Call Back 함수를 통해 결과를 가져온다!
266 | * 동기화의 차이?
267 | - 결과물을 가져오는 시점이 달라진다!
268 |
269 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
270 | > - [https://huisam.tistory.com/entry/Synchronized-Asynchronized](https://huisam.tistory.com/entry/Synchronized-Asynchronized)
271 |
272 | ---
273 | ### java에서 ==와 equals()의 차이
274 | * "=="
275 | * 항등 **연산자(Operator)** 이다.
276 | * <--> !=
277 | * **참조 비교(Reference Comparison)** ; (주소 비교, Address Comparison)
278 | * 두 객체가 같은 메모리 공간을 가리키는지 확인한다.
279 | * 반환 형태: boolean type
280 | * 같은 주소면 return true, 다른 주소면 return false
281 | * 모든 기본 유형(Primitive Types)에 대해 적용할 수 있다.
282 | * byte, short, char, int, float, double, boolean
283 | * "equals()"
284 | * 객체 비교 **메서드(Method)** 이다.
285 | * <--> !(s1.equals(s2));
286 | * **내용 비교(Content Comparison)**
287 | * 두 객체의 값이 같은지 확인한다.
288 | * 즉, 문자열의 데이터/내용을 기반으로 비교한다.
289 | * 기본 유형(Primitive Types)에 대해서는 적용할 수 없다.
290 | * 반환 형태: boolean type
291 | * 같은 내용이면 return true, 다른 내용이면 return false
292 | * "==" VS "equals()" 예시
293 |
262 |
263 | * 비동기화(Asyncronous)
264 | - System Call이 왔든 말든 상관없이 계속 호출할 수 있다.
265 | - Call Back 함수를 통해 결과를 가져온다!
266 | * 동기화의 차이?
267 | - 결과물을 가져오는 시점이 달라진다!
268 |
269 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
270 | > - [https://huisam.tistory.com/entry/Synchronized-Asynchronized](https://huisam.tistory.com/entry/Synchronized-Asynchronized)
271 |
272 | ---
273 | ### java에서 ==와 equals()의 차이
274 | * "=="
275 | * 항등 **연산자(Operator)** 이다.
276 | * <--> !=
277 | * **참조 비교(Reference Comparison)** ; (주소 비교, Address Comparison)
278 | * 두 객체가 같은 메모리 공간을 가리키는지 확인한다.
279 | * 반환 형태: boolean type
280 | * 같은 주소면 return true, 다른 주소면 return false
281 | * 모든 기본 유형(Primitive Types)에 대해 적용할 수 있다.
282 | * byte, short, char, int, float, double, boolean
283 | * "equals()"
284 | * 객체 비교 **메서드(Method)** 이다.
285 | * <--> !(s1.equals(s2));
286 | * **내용 비교(Content Comparison)**
287 | * 두 객체의 값이 같은지 확인한다.
288 | * 즉, 문자열의 데이터/내용을 기반으로 비교한다.
289 | * 기본 유형(Primitive Types)에 대해서는 적용할 수 없다.
290 | * 반환 형태: boolean type
291 | * 같은 내용이면 return true, 다른 내용이면 return false
292 | * "==" VS "equals()" 예시
293 |  294 |
295 | ~~~java
296 | public class Test {
297 | public static void main(String[] args) {
298 | // Thread 객체
299 | Thread t1 = new Thread();
300 | Thread t2 = new Thread(); // 새로운 객체 생성. 즉, s1과 다른 객체.
301 | Thread t3 = t1; // 같은 대상을 가리킨다.
302 | // String 객체
303 | String s1 = new String("WORLD");
304 | String s2 = new String("WORLD");
305 | /* --print-- */
306 | System.out.println(t1 == t3); // true
307 | System.out.println(t1 == t2); // false(서로 다른 객체이므로 별도의 주소를 갖는다.)
308 | System.out.println(t1.equals(t2)); // false
309 | System.out.println(s1.equals(s2)); // true(모두 "WORLD"라는 동일한 내용을 갖는다.)
310 | }
311 | }
312 | ~~~
313 |
314 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
315 | > - [https://gmlwjd9405.github.io/2018/10/06/java-==-and-equals.html](https://gmlwjd9405.github.io/2018/10/06/java-==-and-equals.html)
316 |
317 | ---
318 | ### java의 리플렉션 이란
319 | * 리플렉션(Reflection) 이란?
320 | * 자바에서 이미 로딩이 완료된 클래스에서 또 다른 클래스를 동적으로 로딩(Dynamic Loading)하여 생성자(Constructor), 멤버 필드(Member Variables) 그리고 멤버 메서드(Member Method) 등을 사용할 수 있는 기법이다.
321 | * 클래스의 패키지 정보, 접근 지정자, 수퍼 클래스, 어노테이션(Annotation) 등을 얻을 수 있다.
322 | * 컴파일 시간(Compile Time)이 아니라 실행 시간(Run Time)에 동적으로 특정 클래스의 정보를 객체화를 통해 분석 및 추출해낼 수 있는 프로그래밍 기법이다.
323 | * 사용 방법
324 | * `Class.forName("클래스이름")`
325 | * 클래스의 이름으로부터 인스턴스를 생성할 수 있고, 이를 이용하여 클래스의 정보를 가져올 수 있다.
326 | ~~~java
327 | public class DoHee {
328 | public String name;
329 | public int number;
330 | public void setDoHee (String name, int number) {
331 | this.name = name;
332 | this.number = number;
333 | }
334 | public void setNumber(int number) {
335 | this.number = number;
336 | }
337 | public void sayHello(String name) {
338 | System.out.println("Hello, " + name);
339 | }
340 | }
341 | ~~~
342 | ~~~java
343 | import java.lang.reflect.Method;
344 | import java.lang.reflect.Field;
345 |
346 | public class ReflectionTest {
347 | public void reflectionTest() {
348 | try {
349 | Class myClass = Class.forName("DoHee");
350 | Method[] methods = myClass.getDeclaredMethods();
351 |
352 | /* 클래스 내 선언된 메서드의 목록 출력 */
353 | /* 출력 : public void DoHee.setDoHee(java.lang.String,int)
354 | public void DoHee.setNumber(int)
355 | public void DoHee.sayHello(java.lang.String) */
356 | for (Method method : methods) {
357 | System.out.println(method.toString());
358 | }
359 |
360 | /* 메서드의 매개변수와 반환 타입 확인 */
361 | /* 출력 : Class Name : class DoHee
362 | Method Name : setDoHee
363 | Return Type : void */
364 | Method method = methods[0];
365 | System.out.println("Class Name : " + method.getDeclaringClass());
366 | System.out.println("Method Name : " + method.getName());
367 | System.out.println("Return Type : " + method.getReturnType());
368 |
369 | /* 출력 : Param Type : class java.lang.String
370 | Param Type : int */
371 | Class[] paramTypes = method.getParameterTypes();
372 | for(Class paramType : paramTypes) {
373 | System.out.println("Param Type : " + paramType);
374 | }
375 |
376 | /* 메서드 이름으로 호출 */
377 | Method sayHelloMethod = myClass.getMethod("sayHello", String.class);
378 | sayHelloMethod.invoke(myClass.newInstance(), new String("DoHee")); // 출력 : Hello, DoHee
379 |
380 | /* 다른 클래스의 멤버 필드의 값 수정 */
381 | Field field = myClass.getField("number");
382 | DoHee obj = (DoHee) myClass.newInstance();
383 | obj.setNumber(5);
384 | System.out.println("Before Number : " + field.get(obj)); // 출력 : Before Number : 5
385 | field.set(obj, 10);
386 | System.out.println("After Number : " + field.get(obj)); // 출력 : After Number : 10
387 | } catch (Exception e) {
388 | // Exception Handling
389 | }
390 | }
391 |
392 | public static void main(String[] args) {
393 | new ReflectionTest().reflectionTest();
394 | }
395 | }
396 | ~~~
397 | * 왜 사용할까?
398 | * 실행 시간에 다른 클래스를 동적으로 로딩하여 접근할 때
399 | * 클래스와 멤버 필드 그리고 메서드 등에 관한 정보를 얻어야할 때
400 | * 리플렉션 없이도 완성도 높은 코드를 구현할 수 있지만 사용한다면 조금 더 유연한 코드를 만들 수 있다.
401 | * 주의할 점
402 | * 외부에 공개되지 않는 private 멤버도 `Field.setAccessible()` 메서드를 true로 지정하면 접근과 조작이 가능하기 때문에 주의해야 한다.
403 |
404 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/WeareSoft/tech-interview#7-java) :information_source:[Home](https://github.com/WeareSoft/tech-interview#tech-interview)
405 | > - [https://madplay.github.io/post/java-reflection](https://madplay.github.io/post/java-reflection)
406 |
407 | ---
408 |
409 |
410 | ## :house: [Home](https://github.com/jihyuno301/tech-interview)
411 |
--------------------------------------------------------------------------------
/Spring/README.md:
--------------------------------------------------------------------------------
1 | # Spring
2 | **:book: Contents**
3 | * [스프링 프레임워크란](#스프링-프레임워크란)
4 | * [Spring과 Spring Boot의 차이](#spring과-spring-boot의-차이)
5 | * [Container란](#container란)
6 | * [IOC(Inversion of Control, 제어의 역전)란](#ioc란)
7 | * [Bean이란](#bean이란)
8 | * [MVC 패턴이란](#mvc-패턴이란)
9 | * [MVC1과 MVC2 패턴차이](#MVC1과-MVC2-패턴차이)
10 | * [JSP와 서블릿 비교](#JSP와-서블릿-비교)
11 | * [Dispatcher Servlet](#Dispatcher-Servlet)
12 | * [Spring MVC 구조 흐름](#Spring-MVC-구조-흐름)
13 | * [DI(Dependency Injection, 의존성 주입)란](#di란)
14 | * [AOP(Aspect Oriented Programming)란](#aop란)
15 | * [POJO](#pojo)
16 | * [DAO와 DTO의 차이](#dao와-dto의-차이)
17 | * [Spring JDBC를 이용한 데이터 접근](#spring-jdbc를-이용한-데이터-접근)
18 | * [Annotation이란](#Annotation이란)
19 | * [Filter와 Interceptor 차이](#filter와-interceptor-차이)
20 | * [Mybatis](#mybatis)
21 |
22 | ---
23 |
24 | ### 스프링 프레임워크란
25 | * 스프링은 자바 플랫폼을 위한 오픈소스 애플리케이션 프레임워크이다.
26 | * Java SE로 된 자바 객체 POJO를 자바 EE에 의존적이지 않게 연결해주는 역할을 한다.
27 | * 스프링의 특징으로는 크기와 부하 측면에서 경량시킨 것과 IOC 기술로 애플리케이션의 느슨한 결합을 도모시킨 것이 있다.
28 | * 대한민국 공공기관의 웹 서비스 개발 시 사용을 권장하고 있는 전자 정부 표준 프레임워크의 기반 기술이다.
29 |
30 | ### Spring과 Spring Boot의 차이
31 | 스프링 부트는 스프링에서 사용하는 프로젝트를 간편하게 셋업할 수 있는 서브 프로젝트이다. 독립 컨테이너에서 동작할 수 있기 때문에 임베디드 톰갯이 자동으로 실행되고, 임베디드 컨테이너에서 애플리케이션을 실행시키기에는 다소 불안전해서 큰 프로젝트로는 사용하지 않는다.
32 |
33 | ### Container란
34 | - 컨테이너(Container)는 보통 **인스턴스의 생명주기를 관리**하며, 생성된 인스턴스들에게 추가적인 기능을 제공하도록하는 것이라 할 수 있다. 다시말해, 컨테이너란 당신이 작성한 코드의 처리과정을 위임받은 독립적인 존재라고 생각하면 된다. 컨테이너는 적절한 설정만 되어있다면 누구의 도움없이도 프로그래머가 작성한 코드를 스스로 참조한 뒤 알아서 객체의 생성과 소멸을 컨트롤해준다.
35 |
36 | - Spring 프레임워크는 다른 프레임워크들과 달리 컨테이너 기능을 제공하고 있다. 이와 같은 컨테이너 기능을 제공하는 것이 가능하도록 하는 것이 IoC 패턴이다.
37 |
38 | > - [http://limmmee.tistory.com/13](http://limmmee.tistory.com/13)
39 | > - [http://wiki.javajigi.net/pages/viewpage.action?pageId=281](http://wiki.javajigi.net/pages/viewpage.action?pageId=281)
40 |
41 | ### IoC란
42 | - 한줄 요약 : IOC란, 인스턴스의 생성부터 소멸까지 개발자가 아닌 컨테이너가 대신 관리해준느 것을 말한다. 인스턴스 생성의 제어를 서블릿과 같은 bean을 관리해주는 컨테이너가 관리합니다.
43 | - IoC(Inversion of Control, 제어의 역전)란
44 | - 객체의 생성에서부터 생명주기의 관리까지 모든 객체에 대한 제어권이 바뀐 것을 의미, 또는 제어 권한을 자신이 아닌 다른 대상에게 위임하는 것이다.
45 | - 이 방식은 대부분의 프레임워크에서 사용하는 방법으로, 개발자는 필요한 부분을 개발해서 끼워 넣기의 형태로 개발하고 실행하게 된다. 프레임워크가 이러한 구조를 가지기 때문에 개발자는 프레임워크에 필요한 부품을 개발하고 조립하는 방식의 개발을 하게 된다.
46 | - 이렇게 조립된 코드의 최종 호출은 개발자에 의해서 제어되는 것이 아니라 프레임워크의 내부에서 결정된 대로 이뤄지게 되는데, 이러한 현상을 "제어의 역전"이라고 표현한다.
47 | - Spring에서의 IoC
48 | - Spring 프레임워크에서 지원하는 Ioc Container는 우리들이 흔히 개발하고 사용해왔던 일반 POJO(Plain Old Java Object)의 생명주기를 관리하며, 생성된 인스턴스들에게 추가적인 기능들을 제공한다.
49 | - 라이브러리와 프레임워크의 차이
50 | - IoC의 개념이 적용되었나의 차이
51 | - 라이브러리를 사용하는 애플리케이션 코드는 애플리케이션 흐름을 직접 제어한다. 단지 동작히는 중에 필요한 기능이 있을 때 능동적으로 라이브러리를 시용할 뿐이다.
52 | - 반면에 프레임워크는 거꾸로 애플리케이션 코드가 프레임워크에 의해 사용된다. 보통 프레임워크 위에 개발한 클래스를 등록해두고, 프레임워크가 흐름을 주도히는 중에 개발자가 만든 애플리케이션 코드를 시용하도록 만드는 방식이다.
53 |
54 | > - [http://wiki.javajigi.net/pages/viewpage.action?pageId=3664](http://wiki.javajigi.net/pages/viewpage.action?pageId=3664)
55 | > - [http://limmmee.tistory.com/13](http://limmmee.tistory.com/13)
56 | > - [http://wiki.javajigi.net/pages/viewpage.action?pageId=281](http://wiki.javajigi.net/pages/viewpage.action?pageId=281)
57 | > - [https://gyoogle.dev/blog/interview/%EC%9B%B9.html](https://gyoogle.dev/blog/interview/%EC%9B%B9.html)
58 |
59 | ### Bean이란
60 | * 컨테이너 안에 들어있는 객체
61 | * 컨테이너에 담겨있으며, 필요할 때 컨테이너에서 가져와서 사용
62 | * @Bean 을 사용하거나 xml 설정을 통해 일반 객체를 Bean으로 등록할 수 있고, Bean으로 등록된 객체는 쉽게 주입하여 사용 가능
63 |
64 | #### Bean 생명주기
65 | - 객체 생성 -> 의존 설정 -> 초기화 -> 사용 -> 소멸
66 | - 스프링 컨테이너에 의해 생명주기 관리
67 | - 스프링 컨테이너 초기화 시 빈 객체 생성, 의존 객체 주입 및 초기화
68 | - 스프링 컨테이너 종료 시 빈 객체 소멸
69 |
70 | #### Bean 초기화 방법 3가지
71 | 1. 빈 초기화 메소드에 ```@PostConstruct``` 사용
72 | - 빈 정의 xml에 `````` 추가
73 | 2. ```InitializingBean``` 인터페이스의 ```afterPropertiesSet()``` 메소드 오버라이드
74 | 3. 커스텀 init() 메소드 정의
75 | - 빈 정의 xml에 ```init-method``` 속성으로 메소드 이름 지정
76 | - 또는 빈 초기화 메소드에 ```@Bean(init-method="init")``` 지정
77 |
78 | #### Bean 소멸 방법 3가지
79 | 1. 빈 소멸 메소드에 ```@PreDestroy``` 사용
80 | - 빈 정의 xml에 `````` 추가
81 | 2. ```DisposableBean``` 인터페이스의 ```destroy()``` 메소드 오버라이드
82 | 3. 커스텀 destroy() 메소드 정의
83 | - 빈 정의 xml에 ```destroy-method``` 속성으로 메소드 이름 지정
84 |
85 | ##### 권장하는 방법
86 | - 1번 방법 (권장)
87 | - 사용 방법이 간결하며 코드에서 초기화 메소드가 존재함을 쉽게 파악 가능하여 xml 설정 방법보다 직관적
88 | - 2번 방법 (지양)
89 | - 빈 코드에 스프링 인터페이스가 노출되어 권장하지 않으며 간결하지 않은 방법
90 | - 3번 방법
91 | - 빈 코드에 스프링 인터페이스는 노출되지 않지만, 코드만으로 초기화 메소드 호출 여부를 알 수 없는 단점
92 |
93 | #### Bean Scope
94 | * **singleton (default)**
95 | * 애플리케이션에서 Bean 등록 시 singleton scope로 등록
96 | * Spring IoC 컨테이너 당 한 개의 인스턴스만 생성
97 | * 컨테이너가 Bean 가져다 주입할 때 항상 같은 객체 사용
98 | * 메모리나 성능 최적화에 유리
99 | * **prototype**
100 | * 컨테이너에서 Bean 가져다 쓸 때 항상 다른 인스턴스 사용
101 | * 모든 요청에서 새로운 객체 생성
102 | * gc에 의해 Bean 제거
103 | * request
104 | * Bean 등록 시 하나의 HTTP request 생명주기 안에 단 하나의 Bean만 존재
105 | * 각각의 HTTP 요청은 고유 Bean 객체 보유
106 | * Spring MVC Web Application에서 사용
107 | * session
108 | * 하나의 HTTP Session 생명주기 안에 단 하나의 Bean만 존재
109 | * Spring MVC Web Application에서 사용
110 | * global session
111 | * 하나의 global HTTP Session 생명주기 안에 한 개의 Bean 지정
112 | * Spring MVC Web Application에서 사용
113 | * application
114 | * ServletContext 생명주기 안에 한 개의 Bean 지정
115 | * Spring MVC Web Application에서 사용
116 |
117 | > - [[Spring] IOC(Inversion Of Control): 제어 역전](https://velog.io/@max9106/Spring-IOC%EB%AF%B8%EC%99%84)
118 | > - [[Spring] Spring Bean의 개념과 Bean Scope 종류](https://gmlwjd9405.github.io/2018/11/10/spring-beans.html)
119 | > - [Spring 빈/컨테이너 생명주기 (Lifecycle)](https://flowarc.tistory.com/entry/Spring-%EB%B9%88%EC%BB%A8%ED%85%8C%EC%9D%B4%EB%84%88-%EC%83%9D%EB%AA%85%EC%A3%BC%EA%B8%B0-Lifecycle)
120 | > - [SpringMVC :: 스프링 컨테이너의 생명주기, 빈의 생명주기 (Life cycle), InitialzingBean, DisposableBean, @PreDestroy, @PostConstruct](https://hongku.tistory.com/106)
121 | > - [[Spring] 빈(bean)생명주기 메소드](https://cornswrold.tistory.com/100)
122 |
123 |
124 |
125 | ### MVC 패턴이란
126 | - MVC 패턴은 코드의 재사용에 유용하며, 사용자 인터페이스와 응용 프로그램 개발에 소요되는 시간을 줄여주는 효과적인 설계 방식을 말한다.
127 | - 구성요소로는 Model, View, Controller가 있다. Model은 핵심적인 비즈니스 로직을 담당하여 데이터베이스를 관리하는 부분이고, View는 사용자에게 보여주는 화면, Controller는 모델과 뷰 사이에서 정보 교환을 할 수 있도록 연결해주는 역할을 한다.
128 |
129 | > - [https://gyoogle.dev/blog/interview/%EC%9B%B9.html](https://gyoogle.dev/blog/interview/%EC%9B%B9.html)
130 |
131 | ### MVC1과 MVC2 패턴차이
132 |
133 | 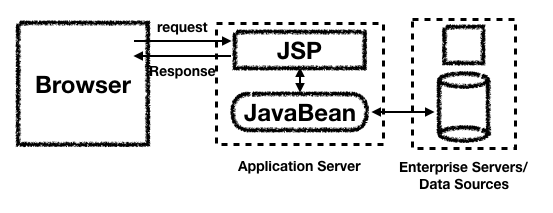
134 |
135 | - MVC1 패턴의 경우 View와 Controller를 모두 JSP가 담당하는 형태를 가진다. JSP 페이지 안에서 로직 처리를 위해 자바 코드와 함께 사용이 되고, 브라우저에서 JSP에 요청이 오면 직접 자바빈이나 클래스를 이용해 작업을 처리하고, 이를 클라이언트에 출력해준다. 단순한 프로젝트에서는 괜찮지만 큰 프로젝트에서는 조금 사용하기 어려운 패턴이다. JSP 하나에서 MVC가 모두 이루어지다보니 재사용성도 매우 떨어지고, 코드 가독성도 떨어진다. 또한 유지보수가 어렵다.
136 |
137 | 
138 |
139 | - MVC2 패턴은 이와는 다르게 모든 처리를 JSP에서만 담당하는 것이 아니라 서블릿을 만들어 역할 분담을 하는 패턴이다. 요청 결과를 출력해주는 뷰만 JSP가 담당하고, 흐름을 제어해주고 비즈니스 로직에 해당하는 컨트롤러 역할을 서블릿이 담당하게 된다. 이처럼 역할을 분담하면서 유지보수가 용이해지는 장점이 있지만 습득하기 힘들고 구조가 복잡해지는 단점도 있다.
140 | - 스프링 프레임워크가 MVC2 패턴
141 |
142 | > - [https://velog.io/@aquarius1997/MVC-%ED%8C%A8%ED%84%B4](https://velog.io/@aquarius1997/MVC-%ED%8C%A8%ED%84%B4)
143 |
144 | ### JSP와 서블릿 비교
145 | 1. 서블릿(Servlet)
146 | - 서버에서 웹페이지 등을 동적으로 생성하거나 데이터 처리를 수행하기 위해 자바로 작성된 프로그램이다.
147 | - 서블릿은 자바코드 안에 HTML태그가 삽입되며 자바언어로 되어있다. .java가 확장자이다.
148 | - 클라이언트 요청을 처리하고 그 결과를 다시 클라이언트에게 전송하는 서블릿 클래스의 구현 규칙을 지킨 자바 프로그램이다.
149 | - Data Processing(Controller)에 좋다.
150 | - 즉, DB와의 통신, 비즈니스 로직 호출, 데이터를 읽고 확인하는 작업 등에 유용하다.
151 | - 서블릿이 수정된 경우 Java 코드를 컴파일(.class 파일 생성)한 후 동적인 페이지를 처리하기 때문에 전체 코드를 업데이트하고 다시 컴파일한 후 재배포하는 작업이 필요하다.(개발 생산성 저하)
152 |
153 | 2. JSP
154 | - HTML을 코딩하기가 너무 어렵고 불편해서 HTML 내부에 Java 코드를 삽입하는 형식이다. 서블릿의 단점을 보완하고자 만든 서블릿 기반의 스크립트 기술이다.
155 | - 서블릿을 사용하게 되면 웹프로그래밍을 할 수 있지만 자바에 대한 지식이 필요하며 화면 인터페이스 구현에 너무 많은 코드를 필요로 하는 등 비효율적인 측면이 있다.
156 | - 때문에 서블릿을 작성하지 않고도 간편하게 웹 프로그래밍을 구현하게 만든 기술이 JSP(Java Server Pages)이다.
157 | - 서블릿 기바의 '서버 스크립트 기술'이다.
158 | - 스크립트 기술 : ASP, PHP 처럼 미리 약속된 규정에 따라 **간단한 키워드**를 조합하여 입력하면, 실행 시점에 각각의 키워드에 매핑이 되어 있는 어떤 코드로 변환 후에 실행되는 형태
159 |
160 | 3. 서블릿과 JSP의 역할
161 | - 웹 기반의 동적인 처리를 하는 것은 둘 다 같다. 하지만 주로하는 역할의 차이가 있다.
162 | - JSP는 JSP 기술의 장점을 최대한 활용할 수 있는 웹애플리케이션 구조에서 사용자에게 결과를 보여주는 프레젠테이션 층을 담당
163 | - Servlet은 Servlet 기술의 장점을 최대한 활용할 수 있는 사용자의 요청을 받아 분석하고 비즈니스 층과 통신하여 처리하고 처리한 결과를 다시 사용자에게 응답하는 Controller 층을 담당한다.
164 |
165 | > - [https://m.blog.naver.com/acornedu/221128616501](https://m.blog.naver.com/acornedu/221128616501)
166 | > - [https://gmlwjd9405.github.io/2018/11/04/servlet-vs-jsp.html](https://gmlwjd9405.github.io/2018/11/04/servlet-vs-jsp.html)
167 |
168 | ### Dispatcher Servlet
169 | - 서블릿 컨테이너에서 HTTP 프로토콜을 통해 들어오는 모든 요청을 제일 앞에서 처리해주는 프론트 컨트롤러를 말한다.
170 | - 따라서 서버가 받기 전에, 공통처리 작업을 디스패치 서블릿이 처리해주고 적절한 세부 컨트롤러 작업을 위임해준다.
171 | - 디스패치 서블릿이 처리하는 URL 패턴을 지정해줘야 하는데, 일반적으로는 .mvc와 같은 패턴으로 처리하라고 미리 지정해준다.
172 | - 디스패치 서블릿으로 인해 web.xml이 가진 역할이 상당히 축소되었다. 기존에는 모든 서블릿을 URL 매핑 활용을 위해 모두 web.xml에 등록해 주었지만, 디스패치 서블릿은 그 전에 모든 요청을 핸들링해주면서 작업을 편리하게 할 수 있도록 도와준다. 또한 이 서블릿을 통해 MVC를 사용할 수 있기 때문에 웹 개발 시 큰 장점을 가져다 준다.
173 | - web.xml
174 | - Deploy할 때 Servlet의 정보를 설정해준다.
175 | - 브라우저가 Java Servlet에 접근하기 위해서는 WAS(Ex. Tomcat)에 필요한 정보를 알려줘야 해당하는 Servlet을 호출할 수 있다.
176 | - 정보 1) 배포할 Servlet이 무엇인지
177 | - 정보 2) 해당 Servlet이 어떤 URL에 매핑되는지
178 |
179 | > - [https://gmlwjd9405.github.io/2018/10/29/web-application-structure.html](https://gmlwjd9405.github.io/2018/10/29/web-application-structure.html)
180 |
181 | ### Spring MVC 구조 흐름
182 |
183 | - 우선, 디스패치 서블릿이 클라이언트로부터 요청을 받으면, 이를 요청할 핸들러 이름을 알기 위해 핸들러맵핑에게 물어본다.
184 | - 핸들러맵핑은 요청 URL을 보고 핸들러 이름을 디스패치 서블릿에게 알려준다. 이때 핸들러를 실행하기 전/후에 처리할 것들을 **인터셉터**로 만들어 준다.
185 | - 디스패처 서블릿은 해당 핸들러에게 제어권을 넘겨주고, 이 핸들러는 응답에 필요한 서비스를 호출하고 렌더링해야 하는 뷰 이름을 판단하여 디스패처 서블릿에게 전송해줍니다.
186 | - 디스패처 서블릿은 받은 뷰 이름을 뷰 리졸버에게 전달해 응답에 필요한 뷰를 만들라고 명령합니다.
187 | - 이때 해당하는 뷰는 디스패처 서블릿에게 받은 모델과 컨트롤러를 활용해 원하는 응답을 생성해서 다시 보내줍니다.
188 | - 디스패처 서블릿은 뷰로부터 받은 것을 클라이언트에게 응답해줍니다.
189 |
190 |
191 | ### DI란
192 | - DI?
193 | - Dependency Injection, 의존성 주입
194 | - Dependency Injection은 Spring 프레임워크에서 지원하는 IoC의 형태이다.
195 | - DI는 클래스 사이의 의존관계를 빈 설정 정보를 바탕으로 컨테이너가 자동적으로 연결해주는 것을 말한다. 개발자들은 제어를 담당할 필요없이 빈 설정 파일에 의존관계가 필요하다는 정보만 추가해주면 된다.
196 | - 컨테이너가 실행 흐름의 주체가 되어 애플리케이션 코드에 의존관계를 주입해주는 것.
197 | - 객체는 직접 의존하고 있는 객체를 생성하거나 검색할 필요가 없으므로 코드 관리가 쉬워지는 장점이 있다.
198 |
199 | - 의존성(Dependency)
200 | - 현재 객체가 다른 객체와 상호작용(참조)하고 있다면 다른 객체들을 현재 객체의 의존이라 한다.
201 | - 의존성이 위험한 이유
202 | - 하나의 모듈이 바뀌면 의존한 다른 모듈까지 변경되야 한다.
203 | - 테스트 가능한 어플을 만들 때 의존성이 있으면 유닛테스트 작성이 어렵다.
204 | - 유닛테스트의 목적 자체가 다른 모듈로부터 독립적으로 테스트하는 것을 요구한다.
205 | - DI의 특징
206 | - ‘new’를 사용해 모듈 내에서 다른 모듈을 초기화하지 않으려면 객체 생성은 다른 곳에서 하고, 생성된 객체를 참조하면 된다.
207 | - 의존성 주입은 Inversion of Control 개념을 바탕으로 한다. 클래스가 외부로부터 의존성을 가져야한다.
208 | - DI가 필요한 이유(DI의 장점)
209 | - 클래스를 재사용 할 가능성을 높이고, 다른 클래스와 독립적으로 클래스를 테스트 할 수 있다.
210 | - 비즈니스 로직의 특정 구현이 아닌 클래스를 생성하는데 매우 효과적
211 | - DI의 세가지 방법
212 | - Contructor Injection : 생성자 삽입
213 | - Method(Setter) Injection : 메소드 매개 변수 삽입
214 | - Field Injection : 멤버 변수 삽입
215 |
216 | > - [http://www.nextree.co.kr/p11247/](http://www.nextree.co.kr/p11247/)
217 | > - [http://wiki.javajigi.net/pages/viewpage.action?pageId=281](http://wiki.javajigi.net/pages/viewpage.action?pageId=281)
218 | > - [http://tony-programming.tistory.com/entry/Dependency-의존성-이란](http://tony-programming.tistory.com/entry/Dependency-의존성-이란)
219 |
220 | ### AOP란
221 | * AOP(Aspect Oriented Programming)란
222 | - Aspect Oriented Programming, 관점 지향 프로그래밍
223 | - 어떤 로직을 기준으로 핵심 관점과 부가 관점을 나누고, 관점을 기준으로 모듈화하는 것
224 | - 핵심 관점은 주로 핵심 비즈니스 로직
225 | - 부가 관점은 핵심 로직을 실행하기 위한 데이터베이스 연결, 로깅, 파일 입출력 등
226 |
227 | * AOP 목적
228 | - 소스 코드에서 여러 번 반복해서 쓰는 코드(= 흩어진 관심사, Concern)를 Aspect로 모듈화하여 핵심 로직에서 분리 및 재사용
229 | - 개발자가 핵심 로직에 집중할 수 있게 하기 위함
230 | - 주로 부가 기능을 모듈화
231 |
232 | * AOP 주요 용어
233 | - **Aspect**
234 | - 흩어진 관심사를 모듈화 한 것
235 | - Advice + PointCut
236 | - **Target**
237 | - Aspect를 적용하는 곳(클래스, 메소드 등)
238 | - **Advice**
239 | - 실질적으로 수행해야 하는 기능을 담은 구현체
240 | - **JoinPoint**
241 | - Advice가 적용될 위치
242 | - 끼어들 수 있는 지점
243 | - ex. 메소드 진입 시, 생성자 호출 시, 필드에서 값 꺼낼 때 등
244 | - **PointCut**
245 | - JoinPoint의 상세 스펙 정의
246 | - 더욱 구체적으로 Advice가 실행될 지점 지정
247 | - **Weaving**
248 | - PointCut에 의해 결정된 Target의 JoinPoint에 Advice를 삽입하는 과정
249 |
250 | * AOP 적용 방법
251 | 1. 컴파일 시 적용
252 | - AspectJ가 사용하는 방법
253 | - 자바 파일을 클래스 파일로 만들 때 Advice 소스가 추가되어 조작된 바이트 코드 생성하는 방법
254 | 2. 로드 시 적용
255 | - AspectJ가 사용하는 방법
256 | - 컴파일 후 컴파일 된 클래스를 로딩하는 시점에 Advice 소스를 끼워넣는 방법
257 | 3. 런타임 시 적용
258 | - **Spring AOP**가 사용하는 방법
259 | - 스프링은 런타임 시 Bean 생성
260 | - A라는 Bean 만들 때 A라는 타입의 프록시 Bean도 생성하고, 프록시 Bean이 A의 메소드 호출 직전에 Advice 소스를 호출한 후 A의 메소드 호출
261 |
262 | * Spring AOP 특징
263 | - [프록시 패턴](https://velog.io/@max9106/Spring-%ED%94%84%EB%A1%9D%EC%8B%9C-AOP-xwk5zy57ee) 기반의 AOP 구현체
264 | - 프록시 객체는 원래 객체를 감싸고 있는 객체이다. 원래 객체와 타입은 동일하다. 프록시 객체가 원래 객체를 감싸서 client의 요청을 처리하게 하는 패턴이다. 프록시 패턴을 쓰는 이유는 접근을 제어하고 싶거나, 부가 기능을 추가하고 싶을 때 사용한다.
265 | - Target 객체에 대한 프록시를 만들어 제공
266 | - Target을 감싸는 프록시는 런타임 시 생성
267 | - 접근 제어 및 부가 기능 추가를 위해 프록시 객체 사용
268 | - 프록시가 Target 객체의 호출을 가로채 Advice 수행 전/후 핵심 로직 호출
269 | - 스프링 Bean에만 AOP 적용 가능
270 | - 메소드 조인 포인트만 지원하여 메소드가 호출되는 런타임 시점에만 Advice 적용 가능
271 | - 모든 AOP기능을 제공하지는 않으며 스프링 IoC와 연동하여 엔터프라이즈 애플리케이션의 각종 문제(중복 코드, 프록시 클래스 작성의 번거로움, 객체 간 관계 복잡도 증가)에 대한 해결책 지원 목적
272 |
273 | > - [[Spring] 스프링 AOP (Spring AOP) 총정리 : 개념, 프록시 기반 AOP, @AOP](https://engkimbs.tistory.com/746)
274 | > - [[Spring] AOP란?](https://velog.io/@max9106/Spring-AOP%EB%9E%80-93k5zjsm95)
275 | > - [Spring AOP, Aspect 개념 특징, AOP 용어 정리](https://shlee0882.tistory.com/206)
276 |
277 | ### POJO
278 |
279 | Plain Old Java Objet(평범한 구식 자바 객체)
280 |
281 | - POJO란 단어가 생긴 배경 설명
282 | - EJB(Enterprise JavaBean)와 엔터프라이즈 서비스
283 | - 기업업무처리의 IT 시스템에 대한 의존도가 높아지면서 시스템이 다뤄야 하는 비즈니스 로직 자체가 점차 복잡해졌다.
284 | - 애플리케이션 로직의 복잡도와 상세 기술의 복작함을 개발자들이 한 번에 다룬다는 것은 쉬운 일이 아니다. 예를 들어, 한 개발자가 보험업무와 관련된 계산 로직을 자바로 어떻게 구현해야 하는지에 집중하면서 동시에 시스템 레벨에서 멀티DB로 확장 가능한 트랜잭션 처리와 보안 기능을 멀티쓰레드에 세이프하게 만드는 것에 신경쓰는 것은 부담이 매우 크다
285 | - 많은 사용자의 처리요구를 빠르게 안정적이면서 확장 가능한 형태로 유지하기 위해 필요한 **Low Level의 기술적인(트랜잭션 처리, 상태관리, 멀티쓰레딩, 리소스풀링, 보안 등) 처리**가 요구됐다.
286 | - 이에 EJB가 등장, 애플리케이션 개발자는 Low Level의 기술들에 관심을 가질 필요가 없다. **BUT** 결론적으로 불필요한만큼 **과도한 엔지니어링**으로 실패한 대표적인 케이스가 되었다.
287 | - 마틴 파울러는 **EJB와 같은 잘못 설계된 과도한 기술을 피하고, 객체지향 원리에 따라 만들어진 자바 언어의 기본에 충실하게 비즈니스 로직을 구현하는 일명 POJO 방식으로 돌아서야 한다**고 지적했다.
288 |
289 | - 특징
290 | - Java에서 제공하는 API 외에 종속되지 않음
291 | - 특정 규약, 환경에 종속되지 않음
292 | - 환경에 종속되지 않는 것의 장점
293 | - 코드의 간결함 (비즈니스 로직과 특정 환경/low 레벨 종속적인 코드를 분리하므로 단순)
294 | - 비즈니스 로직과 특정 환경이 분리되므로 단순함
295 | - 자동화 테스트에 유리 (환경 종속적인 코드는 자동화 테스트가 어렵지만, POJO는 테스트가 매우 유연)
296 | - 객체지향 설계의 자유로운 사용
297 | > - [http://limmmee.tistory.com/8?category=654011](http://limmmee.tistory.com/8?category=654011)
298 |
299 | ### DAO와 DTO의 차이
300 | - **DAO(Data Access Object)**
301 | - DB의 데이터를 조회하거나 조작하는 기능을 전담하도록 만든 객체를 말한다.
302 | - DB에 접근을 하기위한 로직과 비즈니스 로직을 분리하기 위해서 사용 한다.
303 | - **DTO(Data Transfer Object)**
304 | - 계층간 데이터 교환을 위한 자바빈즈를 말한다.
305 | - 여기서 말하는 계층은 Controller, View, Business Layer, Persistent Layer 이다.
306 | - 일반적인 DTO는 **로직을 갖고 있지 않는 순수한 데이터 객체**이며, 속성과 그 속성에 접근하기 위한 getter, setter 메소드만 가진 클래스이다.
307 | - VO(Value Object) 라고도 불린다.
308 | - DTO와 동일한 개념이지만 read only 속성을 가진다.
309 | - 프로퍼티(Property)
310 | - setter/getter에서 set과 get이후에 나오는 단어가 property라고 약속한다.
311 | - setAge의 프로퍼티는 age, getName에서의 프로퍼티는 name
312 | - 중요한 점은 프로퍼티는 멤버변수 name, age로 결정되는 것이 아니라 getter/setter에서의 name과 age임을 명심해야 한다.
313 | - 자바는 다양한 프레임워크에서 **데이터 자동화 처리**를 위해 리플렉션 기법을 사용한다. 데이터 자동화 처리에서 제일 중요한 것은 **표준규격**이다.
314 | - 우리가 setter 요청을 하면 프레임워크단에서 setter가 실행된다. 그로 인하여, Layer(서버코딩->view코딩)에 데이터를 넘길 때 DTO를 쓰면 편하다.
315 | - 데이터가 자동적으로 클래스화 된다는 것이다. 데이터 자동화 처리된 DTO로 변환되어 우리는 손쉽게 데이터가 셋팅된 오브젝트를 받을 수 있다.
316 | - 프로퍼티 규격만 잘 지킨다면, 얼마든지 편하게 DTO로 받을 수 있다.
317 |
318 | > - [https://jungwoon.github.io/common%20sense/2017/11/16/DAO-VO-DTO/](https://jungwoon.github.io/common%20sense/2017/11/16/DAO-VO-DTO/)
319 |
320 | ### Spring JDBC를 이용한 데이터 접근
321 |
322 | - 데이터베이스 테이블과, 자바 객체 사이의 단순한 매핑을 간단한 설정을 통해 처리하는 것
323 | - 기존의 JDBC에서는 구현하고 싶은 로직마다 필요한 SQL문이 모두 달랐고, 이에 필요한 Connection, PrepareStatement, ResultSet 등을 생성하고 Exception 처리도 모두 해야하는 번거러움이 존재했습니다.
324 | - Spring에서는 JDBC와 ORM 프레임워크를 직접 지원하기 때문에 따로 작성하지 않아도 모두 다 처리해주는 장점이 있습니다.
325 |
326 | ### Annotation이란
327 |
328 | - 소스코드에 @어노테이션의 형태로 표현하며 클래스, 필드, 메소드의 선언부에 적용할 수 있는 특정기능이 부여된 표현법을 말합니다.
329 | - 애플리케이션 규모가 커질수록, xml 환경설정이 매우 복잡해지는데 이러한 어려움을 개선시키기 위해 자바 파일에 어노테이션을 적용해서 개발자가 설정 파일 작업을 할 때 발생시키는 오류를 최소화해주는 역할을 합니다.
330 | - 어노테이션 사용으로 소스 코드에 메타데이터를 보관할 수 있고, 컴파일 타임의 체크뿐 아니라 어노테이션 API를 사용해 코드 가독성도 높여줍니다.
331 | - @Controller : dispatcher-servlet.xml에서 bean 태그로 정의하는 것과 같음.
332 | - @RequestMapping : 특정 메소드에서 요청되는 URL과 매칭시키는 어노테이션
333 | - @Autowired : 자동으로 의존성 주입하기 위한 어노테이션
334 | - @Service : 비즈니스 로직 처리하는 서비스 클래스에 등록
335 | - @Repository : DAO에 등록
336 |
337 | ### Filter와 Interceptor 차이
338 |
339 | #### Filter, Interceptor
340 | * 애플리케이션에서 자주 사용되는 기능(공통 부분)을 분리하여 관리할 수 있도록 Spring이 제공하는 기능
341 |
342 | #### Filter, Interceptor 흐름
343 |
344 | 
345 | 1. 서버 실행 시 Servlet이 올라오는 동안 init 후 doFilter 실행
346 | 2. Dispatcher Servlet을 지나쳐 Interceptor의 preHandler 실행
347 | 3. 컨트롤러를 거쳐 내부 로직 수행 후, Interceptor의 postHandler 실행
348 | 4. doFilter 실행
349 | 5. Servlet 종료 시 destroy
350 |
351 | #### Filter 특징
352 | * Dispatcher Servlet 이전에 수행되고, 응답 처리에 대해서도 변경 및 조작 수행 가능
353 | * WAS 내의 ApplicationContext에서 등록된 필터가 실행
354 | * WAS 구동 시 FilterMap이라는 배열에 등록되고, 실행 시 Filter chain을 구성하여 순차적으로 실행
355 | * Spring Context 외부에 존재하여 Spring과 무관한 자원에 대해 동작
356 | * 일반적으로 web.xml에 설정
357 | * 예외 발생 시 Web Application에서 예외 처리
358 | * ex. 인코딩 변환, XSS 방어 등
359 | * 실행 메소드
360 | * init() : 필터 인스턴스 초기화
361 | * doFilter() : 실제 처리 로직
362 | * destroy() : 필터 인스턴스 종료
363 |
364 | #### Interceptor 특징
365 | * Dispatcher Servlet 이후 Controller 호출 전, 후에 끼어들어 기능 수행
366 | * Spring Context 내부에서 Controller의 요청과 응답에 관여하며 모든 Bean에 접근 가능
367 | * 일반적으로 servlet-context.xml에 설정
368 | * 예외 발생 시 @ControllerAdvice에서 @ExceptionHandler를 사용해 예외 처리
369 | * ex. 로그인 체크, 권한 체크, 로그 확인 등
370 | * 실행 메소드
371 | * preHandler() : Controller 실행 전
372 | * postHandler() : Controller 실행 후
373 | * afterCompletion() : view Rendering 후
374 |
375 | ##### Filter, Interceptor 차이점 요약
376 | * 필터와 인터셉터는 실행되는 시점에서 차이가 있다. 필터는 웹 애플리케이션에 등록을 하고, 인터셉터는 스프링의 context에 등록을 한다. 따라서 컨트롤러에 들어가기 전 작업을 처리하기 위해 사용하는 공통점이 있지만, 호출되는 시점에서 차이가 존재한다.
377 | * Filter는 WAS단에 설정되어 Spring과 무관한 자원에 대해 동작하고, Interceptor는 Spring Context 내부에 설정되어 컨트롤러 접근 전, 후에 가로채서 기능 동작
378 | * Filter는 doFilter() 메소드만 있지만, Interceptor는 pre와 post로 명확하게 분리
379 | * Interceptor의 경우 AOP 흉내 가능
380 | * handlerMethod(@RequestMapping을 사용해 매핑 된 @Controller의 메소드)를 파라미터로 제공하여 메소드 시그니처 등 추가 정보를 파악해 로직 실행 여부 판단 가능
381 |
382 | > - [[Spring] Filter, Interceptor, AOP 차이 및 정리](https://goddaehee.tistory.com/154)
383 | > - [[Spring] Filter, Interceptor, AOP 차이](https://velog.io/@sa833591/Spring-Filter-Interceptor-AOP-%EC%B0%A8%EC%9D%B4-yvmv4k96)
384 | > - [Spring Filter와 Interceptor](https://jaehun2841.github.io/2018/08/25/2018-08-18-spring-filter-interceptor/#spring-request-flow)
385 | > - [(Spring)Filter와 Interceptor의 차이](https://supawer0728.github.io/2018/04/04/spring-filter-interceptor/)
386 |
387 |
388 | ### ORM
389 |
390 | - RDBS에서 조회한 데이터를 Java 객체로 변환하여 리턴해 주고, Java 객체를 RDBMS에 저장해주는 라이브러리 혹은 기술을 말한다.
391 | - Java ORM 기술로 유명한 것은 mybatis, Hibernate, JPA 이다.
392 | - Mybatis와 Hibernate는 오픈소스 프로젝트이고 jar 라이브러리 형태로 제공된다.
393 | - JPA(Java persistence API)는 API 표준의 이름이다. JPA 표준 규격대로 만들어진 제품 중에서 유명한 것이 Hibernate 오픈소스 라이브러리이다.
394 | - 우리가 사용하는 Spring JPA에 Hibernate 라이브러리가 포함되어 있다.
395 | - 우리나라의 전자 정보 표준 프레임워크에서 Spring Mybatis를 채택하고 있기 때문에, 우리나라 공공 프로젝트에서 Mybatis를 사용하는 경우가 많다. 그렇지만 JPA가 좀 더
396 | 미래지향적인 기술이기 때문에 점점 JPA를 사용하는 경우가 늘어나고 있다.
397 |
398 | > :arrow_double_up:[Top](#Spring)
399 |
400 | ### Mybatis
401 |
402 | - 객체, 데이터베이스, Mapper 자체를 독립적으로 작성하고, DTO에 해당하는 부분과 SQL 실행결과를 매핑해서 사용할 수 있도록 지원한다.
403 | - 기존에는 DAO에 모든 SQL문이 자바 소스상에 위치했으나, MyBatis를 통해 SQL은 XML 설정 파일로 관리한다.
404 | - 설정파일로 분리하면, 수정할 때 설정파일만 건드리면 되므로 유지보수에 매우 좋고, 또한 매개변수나 리턴 타입으로 매핑되는 모든 DTO에 관련된 부분도 모두 설정파일에서 작업할 수 있는 장점이 있습니다.
405 |
406 | * 장점
407 | * 익숙한 SQL 명령으로 구현할 수 있다.
408 | * DB 조회 결과를 복잡한 객체 구조로 변환해야 할 때 mybatis 기능이 좋다.
409 | * mybatis의 resultMap 기능이 바로 그것이다.
410 | * 단점
411 | * 구현할 소스코드의 양이 상대적으로 많다.
412 | * RDBMS에만 적용할 수 있다.
413 | * DBMS 제품을 교체하면 SQL 소스코드를 수정해야 한다. SQL문을 사용하지 않는 Hibernate, JPA에는 이런 문제가 없다.
414 |
415 | > :arrow_double_up:[Top](#Spring)
416 |
417 |
418 |
419 | ---
420 |
421 | ## Reference
422 | > - []()
423 |
424 |
--------------------------------------------------------------------------------
/Network/Part2.md:
--------------------------------------------------------------------------------
1 | # 2. Network
2 | **:book: Contents**
3 | * [HTTP와 HTTPS](#http와-https)
4 | * [HTTP 요청/응답 헤더](#http-요청-응답-헤더)
5 | * [CORS란](#cors란)
6 | * [GET 메서드와 POST 메서드](#get-메서드와-post-메서드)
7 | * [쿠키(Cookie)와 세션(Session)](#쿠키와-세션)
8 |
9 |
10 | ---
11 |
12 | ### HTTP와 HTTPS
13 |
294 |
295 | ~~~java
296 | public class Test {
297 | public static void main(String[] args) {
298 | // Thread 객체
299 | Thread t1 = new Thread();
300 | Thread t2 = new Thread(); // 새로운 객체 생성. 즉, s1과 다른 객체.
301 | Thread t3 = t1; // 같은 대상을 가리킨다.
302 | // String 객체
303 | String s1 = new String("WORLD");
304 | String s2 = new String("WORLD");
305 | /* --print-- */
306 | System.out.println(t1 == t3); // true
307 | System.out.println(t1 == t2); // false(서로 다른 객체이므로 별도의 주소를 갖는다.)
308 | System.out.println(t1.equals(t2)); // false
309 | System.out.println(s1.equals(s2)); // true(모두 "WORLD"라는 동일한 내용을 갖는다.)
310 | }
311 | }
312 | ~~~
313 |
314 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
315 | > - [https://gmlwjd9405.github.io/2018/10/06/java-==-and-equals.html](https://gmlwjd9405.github.io/2018/10/06/java-==-and-equals.html)
316 |
317 | ---
318 | ### java의 리플렉션 이란
319 | * 리플렉션(Reflection) 이란?
320 | * 자바에서 이미 로딩이 완료된 클래스에서 또 다른 클래스를 동적으로 로딩(Dynamic Loading)하여 생성자(Constructor), 멤버 필드(Member Variables) 그리고 멤버 메서드(Member Method) 등을 사용할 수 있는 기법이다.
321 | * 클래스의 패키지 정보, 접근 지정자, 수퍼 클래스, 어노테이션(Annotation) 등을 얻을 수 있다.
322 | * 컴파일 시간(Compile Time)이 아니라 실행 시간(Run Time)에 동적으로 특정 클래스의 정보를 객체화를 통해 분석 및 추출해낼 수 있는 프로그래밍 기법이다.
323 | * 사용 방법
324 | * `Class.forName("클래스이름")`
325 | * 클래스의 이름으로부터 인스턴스를 생성할 수 있고, 이를 이용하여 클래스의 정보를 가져올 수 있다.
326 | ~~~java
327 | public class DoHee {
328 | public String name;
329 | public int number;
330 | public void setDoHee (String name, int number) {
331 | this.name = name;
332 | this.number = number;
333 | }
334 | public void setNumber(int number) {
335 | this.number = number;
336 | }
337 | public void sayHello(String name) {
338 | System.out.println("Hello, " + name);
339 | }
340 | }
341 | ~~~
342 | ~~~java
343 | import java.lang.reflect.Method;
344 | import java.lang.reflect.Field;
345 |
346 | public class ReflectionTest {
347 | public void reflectionTest() {
348 | try {
349 | Class myClass = Class.forName("DoHee");
350 | Method[] methods = myClass.getDeclaredMethods();
351 |
352 | /* 클래스 내 선언된 메서드의 목록 출력 */
353 | /* 출력 : public void DoHee.setDoHee(java.lang.String,int)
354 | public void DoHee.setNumber(int)
355 | public void DoHee.sayHello(java.lang.String) */
356 | for (Method method : methods) {
357 | System.out.println(method.toString());
358 | }
359 |
360 | /* 메서드의 매개변수와 반환 타입 확인 */
361 | /* 출력 : Class Name : class DoHee
362 | Method Name : setDoHee
363 | Return Type : void */
364 | Method method = methods[0];
365 | System.out.println("Class Name : " + method.getDeclaringClass());
366 | System.out.println("Method Name : " + method.getName());
367 | System.out.println("Return Type : " + method.getReturnType());
368 |
369 | /* 출력 : Param Type : class java.lang.String
370 | Param Type : int */
371 | Class[] paramTypes = method.getParameterTypes();
372 | for(Class paramType : paramTypes) {
373 | System.out.println("Param Type : " + paramType);
374 | }
375 |
376 | /* 메서드 이름으로 호출 */
377 | Method sayHelloMethod = myClass.getMethod("sayHello", String.class);
378 | sayHelloMethod.invoke(myClass.newInstance(), new String("DoHee")); // 출력 : Hello, DoHee
379 |
380 | /* 다른 클래스의 멤버 필드의 값 수정 */
381 | Field field = myClass.getField("number");
382 | DoHee obj = (DoHee) myClass.newInstance();
383 | obj.setNumber(5);
384 | System.out.println("Before Number : " + field.get(obj)); // 출력 : Before Number : 5
385 | field.set(obj, 10);
386 | System.out.println("After Number : " + field.get(obj)); // 출력 : After Number : 10
387 | } catch (Exception e) {
388 | // Exception Handling
389 | }
390 | }
391 |
392 | public static void main(String[] args) {
393 | new ReflectionTest().reflectionTest();
394 | }
395 | }
396 | ~~~
397 | * 왜 사용할까?
398 | * 실행 시간에 다른 클래스를 동적으로 로딩하여 접근할 때
399 | * 클래스와 멤버 필드 그리고 메서드 등에 관한 정보를 얻어야할 때
400 | * 리플렉션 없이도 완성도 높은 코드를 구현할 수 있지만 사용한다면 조금 더 유연한 코드를 만들 수 있다.
401 | * 주의할 점
402 | * 외부에 공개되지 않는 private 멤버도 `Field.setAccessible()` 메서드를 true로 지정하면 접근과 조작이 가능하기 때문에 주의해야 한다.
403 |
404 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/WeareSoft/tech-interview#7-java) :information_source:[Home](https://github.com/WeareSoft/tech-interview#tech-interview)
405 | > - [https://madplay.github.io/post/java-reflection](https://madplay.github.io/post/java-reflection)
406 |
407 | ---
408 |
409 |
410 | ## :house: [Home](https://github.com/jihyuno301/tech-interview)
411 |
--------------------------------------------------------------------------------
/Spring/README.md:
--------------------------------------------------------------------------------
1 | # Spring
2 | **:book: Contents**
3 | * [스프링 프레임워크란](#스프링-프레임워크란)
4 | * [Spring과 Spring Boot의 차이](#spring과-spring-boot의-차이)
5 | * [Container란](#container란)
6 | * [IOC(Inversion of Control, 제어의 역전)란](#ioc란)
7 | * [Bean이란](#bean이란)
8 | * [MVC 패턴이란](#mvc-패턴이란)
9 | * [MVC1과 MVC2 패턴차이](#MVC1과-MVC2-패턴차이)
10 | * [JSP와 서블릿 비교](#JSP와-서블릿-비교)
11 | * [Dispatcher Servlet](#Dispatcher-Servlet)
12 | * [Spring MVC 구조 흐름](#Spring-MVC-구조-흐름)
13 | * [DI(Dependency Injection, 의존성 주입)란](#di란)
14 | * [AOP(Aspect Oriented Programming)란](#aop란)
15 | * [POJO](#pojo)
16 | * [DAO와 DTO의 차이](#dao와-dto의-차이)
17 | * [Spring JDBC를 이용한 데이터 접근](#spring-jdbc를-이용한-데이터-접근)
18 | * [Annotation이란](#Annotation이란)
19 | * [Filter와 Interceptor 차이](#filter와-interceptor-차이)
20 | * [Mybatis](#mybatis)
21 |
22 | ---
23 |
24 | ### 스프링 프레임워크란
25 | * 스프링은 자바 플랫폼을 위한 오픈소스 애플리케이션 프레임워크이다.
26 | * Java SE로 된 자바 객체 POJO를 자바 EE에 의존적이지 않게 연결해주는 역할을 한다.
27 | * 스프링의 특징으로는 크기와 부하 측면에서 경량시킨 것과 IOC 기술로 애플리케이션의 느슨한 결합을 도모시킨 것이 있다.
28 | * 대한민국 공공기관의 웹 서비스 개발 시 사용을 권장하고 있는 전자 정부 표준 프레임워크의 기반 기술이다.
29 |
30 | ### Spring과 Spring Boot의 차이
31 | 스프링 부트는 스프링에서 사용하는 프로젝트를 간편하게 셋업할 수 있는 서브 프로젝트이다. 독립 컨테이너에서 동작할 수 있기 때문에 임베디드 톰갯이 자동으로 실행되고, 임베디드 컨테이너에서 애플리케이션을 실행시키기에는 다소 불안전해서 큰 프로젝트로는 사용하지 않는다.
32 |
33 | ### Container란
34 | - 컨테이너(Container)는 보통 **인스턴스의 생명주기를 관리**하며, 생성된 인스턴스들에게 추가적인 기능을 제공하도록하는 것이라 할 수 있다. 다시말해, 컨테이너란 당신이 작성한 코드의 처리과정을 위임받은 독립적인 존재라고 생각하면 된다. 컨테이너는 적절한 설정만 되어있다면 누구의 도움없이도 프로그래머가 작성한 코드를 스스로 참조한 뒤 알아서 객체의 생성과 소멸을 컨트롤해준다.
35 |
36 | - Spring 프레임워크는 다른 프레임워크들과 달리 컨테이너 기능을 제공하고 있다. 이와 같은 컨테이너 기능을 제공하는 것이 가능하도록 하는 것이 IoC 패턴이다.
37 |
38 | > - [http://limmmee.tistory.com/13](http://limmmee.tistory.com/13)
39 | > - [http://wiki.javajigi.net/pages/viewpage.action?pageId=281](http://wiki.javajigi.net/pages/viewpage.action?pageId=281)
40 |
41 | ### IoC란
42 | - 한줄 요약 : IOC란, 인스턴스의 생성부터 소멸까지 개발자가 아닌 컨테이너가 대신 관리해준느 것을 말한다. 인스턴스 생성의 제어를 서블릿과 같은 bean을 관리해주는 컨테이너가 관리합니다.
43 | - IoC(Inversion of Control, 제어의 역전)란
44 | - 객체의 생성에서부터 생명주기의 관리까지 모든 객체에 대한 제어권이 바뀐 것을 의미, 또는 제어 권한을 자신이 아닌 다른 대상에게 위임하는 것이다.
45 | - 이 방식은 대부분의 프레임워크에서 사용하는 방법으로, 개발자는 필요한 부분을 개발해서 끼워 넣기의 형태로 개발하고 실행하게 된다. 프레임워크가 이러한 구조를 가지기 때문에 개발자는 프레임워크에 필요한 부품을 개발하고 조립하는 방식의 개발을 하게 된다.
46 | - 이렇게 조립된 코드의 최종 호출은 개발자에 의해서 제어되는 것이 아니라 프레임워크의 내부에서 결정된 대로 이뤄지게 되는데, 이러한 현상을 "제어의 역전"이라고 표현한다.
47 | - Spring에서의 IoC
48 | - Spring 프레임워크에서 지원하는 Ioc Container는 우리들이 흔히 개발하고 사용해왔던 일반 POJO(Plain Old Java Object)의 생명주기를 관리하며, 생성된 인스턴스들에게 추가적인 기능들을 제공한다.
49 | - 라이브러리와 프레임워크의 차이
50 | - IoC의 개념이 적용되었나의 차이
51 | - 라이브러리를 사용하는 애플리케이션 코드는 애플리케이션 흐름을 직접 제어한다. 단지 동작히는 중에 필요한 기능이 있을 때 능동적으로 라이브러리를 시용할 뿐이다.
52 | - 반면에 프레임워크는 거꾸로 애플리케이션 코드가 프레임워크에 의해 사용된다. 보통 프레임워크 위에 개발한 클래스를 등록해두고, 프레임워크가 흐름을 주도히는 중에 개발자가 만든 애플리케이션 코드를 시용하도록 만드는 방식이다.
53 |
54 | > - [http://wiki.javajigi.net/pages/viewpage.action?pageId=3664](http://wiki.javajigi.net/pages/viewpage.action?pageId=3664)
55 | > - [http://limmmee.tistory.com/13](http://limmmee.tistory.com/13)
56 | > - [http://wiki.javajigi.net/pages/viewpage.action?pageId=281](http://wiki.javajigi.net/pages/viewpage.action?pageId=281)
57 | > - [https://gyoogle.dev/blog/interview/%EC%9B%B9.html](https://gyoogle.dev/blog/interview/%EC%9B%B9.html)
58 |
59 | ### Bean이란
60 | * 컨테이너 안에 들어있는 객체
61 | * 컨테이너에 담겨있으며, 필요할 때 컨테이너에서 가져와서 사용
62 | * @Bean 을 사용하거나 xml 설정을 통해 일반 객체를 Bean으로 등록할 수 있고, Bean으로 등록된 객체는 쉽게 주입하여 사용 가능
63 |
64 | #### Bean 생명주기
65 | - 객체 생성 -> 의존 설정 -> 초기화 -> 사용 -> 소멸
66 | - 스프링 컨테이너에 의해 생명주기 관리
67 | - 스프링 컨테이너 초기화 시 빈 객체 생성, 의존 객체 주입 및 초기화
68 | - 스프링 컨테이너 종료 시 빈 객체 소멸
69 |
70 | #### Bean 초기화 방법 3가지
71 | 1. 빈 초기화 메소드에 ```@PostConstruct``` 사용
72 | - 빈 정의 xml에 `````` 추가
73 | 2. ```InitializingBean``` 인터페이스의 ```afterPropertiesSet()``` 메소드 오버라이드
74 | 3. 커스텀 init() 메소드 정의
75 | - 빈 정의 xml에 ```init-method``` 속성으로 메소드 이름 지정
76 | - 또는 빈 초기화 메소드에 ```@Bean(init-method="init")``` 지정
77 |
78 | #### Bean 소멸 방법 3가지
79 | 1. 빈 소멸 메소드에 ```@PreDestroy``` 사용
80 | - 빈 정의 xml에 `````` 추가
81 | 2. ```DisposableBean``` 인터페이스의 ```destroy()``` 메소드 오버라이드
82 | 3. 커스텀 destroy() 메소드 정의
83 | - 빈 정의 xml에 ```destroy-method``` 속성으로 메소드 이름 지정
84 |
85 | ##### 권장하는 방법
86 | - 1번 방법 (권장)
87 | - 사용 방법이 간결하며 코드에서 초기화 메소드가 존재함을 쉽게 파악 가능하여 xml 설정 방법보다 직관적
88 | - 2번 방법 (지양)
89 | - 빈 코드에 스프링 인터페이스가 노출되어 권장하지 않으며 간결하지 않은 방법
90 | - 3번 방법
91 | - 빈 코드에 스프링 인터페이스는 노출되지 않지만, 코드만으로 초기화 메소드 호출 여부를 알 수 없는 단점
92 |
93 | #### Bean Scope
94 | * **singleton (default)**
95 | * 애플리케이션에서 Bean 등록 시 singleton scope로 등록
96 | * Spring IoC 컨테이너 당 한 개의 인스턴스만 생성
97 | * 컨테이너가 Bean 가져다 주입할 때 항상 같은 객체 사용
98 | * 메모리나 성능 최적화에 유리
99 | * **prototype**
100 | * 컨테이너에서 Bean 가져다 쓸 때 항상 다른 인스턴스 사용
101 | * 모든 요청에서 새로운 객체 생성
102 | * gc에 의해 Bean 제거
103 | * request
104 | * Bean 등록 시 하나의 HTTP request 생명주기 안에 단 하나의 Bean만 존재
105 | * 각각의 HTTP 요청은 고유 Bean 객체 보유
106 | * Spring MVC Web Application에서 사용
107 | * session
108 | * 하나의 HTTP Session 생명주기 안에 단 하나의 Bean만 존재
109 | * Spring MVC Web Application에서 사용
110 | * global session
111 | * 하나의 global HTTP Session 생명주기 안에 한 개의 Bean 지정
112 | * Spring MVC Web Application에서 사용
113 | * application
114 | * ServletContext 생명주기 안에 한 개의 Bean 지정
115 | * Spring MVC Web Application에서 사용
116 |
117 | > - [[Spring] IOC(Inversion Of Control): 제어 역전](https://velog.io/@max9106/Spring-IOC%EB%AF%B8%EC%99%84)
118 | > - [[Spring] Spring Bean의 개념과 Bean Scope 종류](https://gmlwjd9405.github.io/2018/11/10/spring-beans.html)
119 | > - [Spring 빈/컨테이너 생명주기 (Lifecycle)](https://flowarc.tistory.com/entry/Spring-%EB%B9%88%EC%BB%A8%ED%85%8C%EC%9D%B4%EB%84%88-%EC%83%9D%EB%AA%85%EC%A3%BC%EA%B8%B0-Lifecycle)
120 | > - [SpringMVC :: 스프링 컨테이너의 생명주기, 빈의 생명주기 (Life cycle), InitialzingBean, DisposableBean, @PreDestroy, @PostConstruct](https://hongku.tistory.com/106)
121 | > - [[Spring] 빈(bean)생명주기 메소드](https://cornswrold.tistory.com/100)
122 |
123 |
124 |
125 | ### MVC 패턴이란
126 | - MVC 패턴은 코드의 재사용에 유용하며, 사용자 인터페이스와 응용 프로그램 개발에 소요되는 시간을 줄여주는 효과적인 설계 방식을 말한다.
127 | - 구성요소로는 Model, View, Controller가 있다. Model은 핵심적인 비즈니스 로직을 담당하여 데이터베이스를 관리하는 부분이고, View는 사용자에게 보여주는 화면, Controller는 모델과 뷰 사이에서 정보 교환을 할 수 있도록 연결해주는 역할을 한다.
128 |
129 | > - [https://gyoogle.dev/blog/interview/%EC%9B%B9.html](https://gyoogle.dev/blog/interview/%EC%9B%B9.html)
130 |
131 | ### MVC1과 MVC2 패턴차이
132 |
133 | 
134 |
135 | - MVC1 패턴의 경우 View와 Controller를 모두 JSP가 담당하는 형태를 가진다. JSP 페이지 안에서 로직 처리를 위해 자바 코드와 함께 사용이 되고, 브라우저에서 JSP에 요청이 오면 직접 자바빈이나 클래스를 이용해 작업을 처리하고, 이를 클라이언트에 출력해준다. 단순한 프로젝트에서는 괜찮지만 큰 프로젝트에서는 조금 사용하기 어려운 패턴이다. JSP 하나에서 MVC가 모두 이루어지다보니 재사용성도 매우 떨어지고, 코드 가독성도 떨어진다. 또한 유지보수가 어렵다.
136 |
137 | 
138 |
139 | - MVC2 패턴은 이와는 다르게 모든 처리를 JSP에서만 담당하는 것이 아니라 서블릿을 만들어 역할 분담을 하는 패턴이다. 요청 결과를 출력해주는 뷰만 JSP가 담당하고, 흐름을 제어해주고 비즈니스 로직에 해당하는 컨트롤러 역할을 서블릿이 담당하게 된다. 이처럼 역할을 분담하면서 유지보수가 용이해지는 장점이 있지만 습득하기 힘들고 구조가 복잡해지는 단점도 있다.
140 | - 스프링 프레임워크가 MVC2 패턴
141 |
142 | > - [https://velog.io/@aquarius1997/MVC-%ED%8C%A8%ED%84%B4](https://velog.io/@aquarius1997/MVC-%ED%8C%A8%ED%84%B4)
143 |
144 | ### JSP와 서블릿 비교
145 | 1. 서블릿(Servlet)
146 | - 서버에서 웹페이지 등을 동적으로 생성하거나 데이터 처리를 수행하기 위해 자바로 작성된 프로그램이다.
147 | - 서블릿은 자바코드 안에 HTML태그가 삽입되며 자바언어로 되어있다. .java가 확장자이다.
148 | - 클라이언트 요청을 처리하고 그 결과를 다시 클라이언트에게 전송하는 서블릿 클래스의 구현 규칙을 지킨 자바 프로그램이다.
149 | - Data Processing(Controller)에 좋다.
150 | - 즉, DB와의 통신, 비즈니스 로직 호출, 데이터를 읽고 확인하는 작업 등에 유용하다.
151 | - 서블릿이 수정된 경우 Java 코드를 컴파일(.class 파일 생성)한 후 동적인 페이지를 처리하기 때문에 전체 코드를 업데이트하고 다시 컴파일한 후 재배포하는 작업이 필요하다.(개발 생산성 저하)
152 |
153 | 2. JSP
154 | - HTML을 코딩하기가 너무 어렵고 불편해서 HTML 내부에 Java 코드를 삽입하는 형식이다. 서블릿의 단점을 보완하고자 만든 서블릿 기반의 스크립트 기술이다.
155 | - 서블릿을 사용하게 되면 웹프로그래밍을 할 수 있지만 자바에 대한 지식이 필요하며 화면 인터페이스 구현에 너무 많은 코드를 필요로 하는 등 비효율적인 측면이 있다.
156 | - 때문에 서블릿을 작성하지 않고도 간편하게 웹 프로그래밍을 구현하게 만든 기술이 JSP(Java Server Pages)이다.
157 | - 서블릿 기바의 '서버 스크립트 기술'이다.
158 | - 스크립트 기술 : ASP, PHP 처럼 미리 약속된 규정에 따라 **간단한 키워드**를 조합하여 입력하면, 실행 시점에 각각의 키워드에 매핑이 되어 있는 어떤 코드로 변환 후에 실행되는 형태
159 |
160 | 3. 서블릿과 JSP의 역할
161 | - 웹 기반의 동적인 처리를 하는 것은 둘 다 같다. 하지만 주로하는 역할의 차이가 있다.
162 | - JSP는 JSP 기술의 장점을 최대한 활용할 수 있는 웹애플리케이션 구조에서 사용자에게 결과를 보여주는 프레젠테이션 층을 담당
163 | - Servlet은 Servlet 기술의 장점을 최대한 활용할 수 있는 사용자의 요청을 받아 분석하고 비즈니스 층과 통신하여 처리하고 처리한 결과를 다시 사용자에게 응답하는 Controller 층을 담당한다.
164 |
165 | > - [https://m.blog.naver.com/acornedu/221128616501](https://m.blog.naver.com/acornedu/221128616501)
166 | > - [https://gmlwjd9405.github.io/2018/11/04/servlet-vs-jsp.html](https://gmlwjd9405.github.io/2018/11/04/servlet-vs-jsp.html)
167 |
168 | ### Dispatcher Servlet
169 | - 서블릿 컨테이너에서 HTTP 프로토콜을 통해 들어오는 모든 요청을 제일 앞에서 처리해주는 프론트 컨트롤러를 말한다.
170 | - 따라서 서버가 받기 전에, 공통처리 작업을 디스패치 서블릿이 처리해주고 적절한 세부 컨트롤러 작업을 위임해준다.
171 | - 디스패치 서블릿이 처리하는 URL 패턴을 지정해줘야 하는데, 일반적으로는 .mvc와 같은 패턴으로 처리하라고 미리 지정해준다.
172 | - 디스패치 서블릿으로 인해 web.xml이 가진 역할이 상당히 축소되었다. 기존에는 모든 서블릿을 URL 매핑 활용을 위해 모두 web.xml에 등록해 주었지만, 디스패치 서블릿은 그 전에 모든 요청을 핸들링해주면서 작업을 편리하게 할 수 있도록 도와준다. 또한 이 서블릿을 통해 MVC를 사용할 수 있기 때문에 웹 개발 시 큰 장점을 가져다 준다.
173 | - web.xml
174 | - Deploy할 때 Servlet의 정보를 설정해준다.
175 | - 브라우저가 Java Servlet에 접근하기 위해서는 WAS(Ex. Tomcat)에 필요한 정보를 알려줘야 해당하는 Servlet을 호출할 수 있다.
176 | - 정보 1) 배포할 Servlet이 무엇인지
177 | - 정보 2) 해당 Servlet이 어떤 URL에 매핑되는지
178 |
179 | > - [https://gmlwjd9405.github.io/2018/10/29/web-application-structure.html](https://gmlwjd9405.github.io/2018/10/29/web-application-structure.html)
180 |
181 | ### Spring MVC 구조 흐름
182 |
183 | - 우선, 디스패치 서블릿이 클라이언트로부터 요청을 받으면, 이를 요청할 핸들러 이름을 알기 위해 핸들러맵핑에게 물어본다.
184 | - 핸들러맵핑은 요청 URL을 보고 핸들러 이름을 디스패치 서블릿에게 알려준다. 이때 핸들러를 실행하기 전/후에 처리할 것들을 **인터셉터**로 만들어 준다.
185 | - 디스패처 서블릿은 해당 핸들러에게 제어권을 넘겨주고, 이 핸들러는 응답에 필요한 서비스를 호출하고 렌더링해야 하는 뷰 이름을 판단하여 디스패처 서블릿에게 전송해줍니다.
186 | - 디스패처 서블릿은 받은 뷰 이름을 뷰 리졸버에게 전달해 응답에 필요한 뷰를 만들라고 명령합니다.
187 | - 이때 해당하는 뷰는 디스패처 서블릿에게 받은 모델과 컨트롤러를 활용해 원하는 응답을 생성해서 다시 보내줍니다.
188 | - 디스패처 서블릿은 뷰로부터 받은 것을 클라이언트에게 응답해줍니다.
189 |
190 |
191 | ### DI란
192 | - DI?
193 | - Dependency Injection, 의존성 주입
194 | - Dependency Injection은 Spring 프레임워크에서 지원하는 IoC의 형태이다.
195 | - DI는 클래스 사이의 의존관계를 빈 설정 정보를 바탕으로 컨테이너가 자동적으로 연결해주는 것을 말한다. 개발자들은 제어를 담당할 필요없이 빈 설정 파일에 의존관계가 필요하다는 정보만 추가해주면 된다.
196 | - 컨테이너가 실행 흐름의 주체가 되어 애플리케이션 코드에 의존관계를 주입해주는 것.
197 | - 객체는 직접 의존하고 있는 객체를 생성하거나 검색할 필요가 없으므로 코드 관리가 쉬워지는 장점이 있다.
198 |
199 | - 의존성(Dependency)
200 | - 현재 객체가 다른 객체와 상호작용(참조)하고 있다면 다른 객체들을 현재 객체의 의존이라 한다.
201 | - 의존성이 위험한 이유
202 | - 하나의 모듈이 바뀌면 의존한 다른 모듈까지 변경되야 한다.
203 | - 테스트 가능한 어플을 만들 때 의존성이 있으면 유닛테스트 작성이 어렵다.
204 | - 유닛테스트의 목적 자체가 다른 모듈로부터 독립적으로 테스트하는 것을 요구한다.
205 | - DI의 특징
206 | - ‘new’를 사용해 모듈 내에서 다른 모듈을 초기화하지 않으려면 객체 생성은 다른 곳에서 하고, 생성된 객체를 참조하면 된다.
207 | - 의존성 주입은 Inversion of Control 개념을 바탕으로 한다. 클래스가 외부로부터 의존성을 가져야한다.
208 | - DI가 필요한 이유(DI의 장점)
209 | - 클래스를 재사용 할 가능성을 높이고, 다른 클래스와 독립적으로 클래스를 테스트 할 수 있다.
210 | - 비즈니스 로직의 특정 구현이 아닌 클래스를 생성하는데 매우 효과적
211 | - DI의 세가지 방법
212 | - Contructor Injection : 생성자 삽입
213 | - Method(Setter) Injection : 메소드 매개 변수 삽입
214 | - Field Injection : 멤버 변수 삽입
215 |
216 | > - [http://www.nextree.co.kr/p11247/](http://www.nextree.co.kr/p11247/)
217 | > - [http://wiki.javajigi.net/pages/viewpage.action?pageId=281](http://wiki.javajigi.net/pages/viewpage.action?pageId=281)
218 | > - [http://tony-programming.tistory.com/entry/Dependency-의존성-이란](http://tony-programming.tistory.com/entry/Dependency-의존성-이란)
219 |
220 | ### AOP란
221 | * AOP(Aspect Oriented Programming)란
222 | - Aspect Oriented Programming, 관점 지향 프로그래밍
223 | - 어떤 로직을 기준으로 핵심 관점과 부가 관점을 나누고, 관점을 기준으로 모듈화하는 것
224 | - 핵심 관점은 주로 핵심 비즈니스 로직
225 | - 부가 관점은 핵심 로직을 실행하기 위한 데이터베이스 연결, 로깅, 파일 입출력 등
226 |
227 | * AOP 목적
228 | - 소스 코드에서 여러 번 반복해서 쓰는 코드(= 흩어진 관심사, Concern)를 Aspect로 모듈화하여 핵심 로직에서 분리 및 재사용
229 | - 개발자가 핵심 로직에 집중할 수 있게 하기 위함
230 | - 주로 부가 기능을 모듈화
231 |
232 | * AOP 주요 용어
233 | - **Aspect**
234 | - 흩어진 관심사를 모듈화 한 것
235 | - Advice + PointCut
236 | - **Target**
237 | - Aspect를 적용하는 곳(클래스, 메소드 등)
238 | - **Advice**
239 | - 실질적으로 수행해야 하는 기능을 담은 구현체
240 | - **JoinPoint**
241 | - Advice가 적용될 위치
242 | - 끼어들 수 있는 지점
243 | - ex. 메소드 진입 시, 생성자 호출 시, 필드에서 값 꺼낼 때 등
244 | - **PointCut**
245 | - JoinPoint의 상세 스펙 정의
246 | - 더욱 구체적으로 Advice가 실행될 지점 지정
247 | - **Weaving**
248 | - PointCut에 의해 결정된 Target의 JoinPoint에 Advice를 삽입하는 과정
249 |
250 | * AOP 적용 방법
251 | 1. 컴파일 시 적용
252 | - AspectJ가 사용하는 방법
253 | - 자바 파일을 클래스 파일로 만들 때 Advice 소스가 추가되어 조작된 바이트 코드 생성하는 방법
254 | 2. 로드 시 적용
255 | - AspectJ가 사용하는 방법
256 | - 컴파일 후 컴파일 된 클래스를 로딩하는 시점에 Advice 소스를 끼워넣는 방법
257 | 3. 런타임 시 적용
258 | - **Spring AOP**가 사용하는 방법
259 | - 스프링은 런타임 시 Bean 생성
260 | - A라는 Bean 만들 때 A라는 타입의 프록시 Bean도 생성하고, 프록시 Bean이 A의 메소드 호출 직전에 Advice 소스를 호출한 후 A의 메소드 호출
261 |
262 | * Spring AOP 특징
263 | - [프록시 패턴](https://velog.io/@max9106/Spring-%ED%94%84%EB%A1%9D%EC%8B%9C-AOP-xwk5zy57ee) 기반의 AOP 구현체
264 | - 프록시 객체는 원래 객체를 감싸고 있는 객체이다. 원래 객체와 타입은 동일하다. 프록시 객체가 원래 객체를 감싸서 client의 요청을 처리하게 하는 패턴이다. 프록시 패턴을 쓰는 이유는 접근을 제어하고 싶거나, 부가 기능을 추가하고 싶을 때 사용한다.
265 | - Target 객체에 대한 프록시를 만들어 제공
266 | - Target을 감싸는 프록시는 런타임 시 생성
267 | - 접근 제어 및 부가 기능 추가를 위해 프록시 객체 사용
268 | - 프록시가 Target 객체의 호출을 가로채 Advice 수행 전/후 핵심 로직 호출
269 | - 스프링 Bean에만 AOP 적용 가능
270 | - 메소드 조인 포인트만 지원하여 메소드가 호출되는 런타임 시점에만 Advice 적용 가능
271 | - 모든 AOP기능을 제공하지는 않으며 스프링 IoC와 연동하여 엔터프라이즈 애플리케이션의 각종 문제(중복 코드, 프록시 클래스 작성의 번거로움, 객체 간 관계 복잡도 증가)에 대한 해결책 지원 목적
272 |
273 | > - [[Spring] 스프링 AOP (Spring AOP) 총정리 : 개념, 프록시 기반 AOP, @AOP](https://engkimbs.tistory.com/746)
274 | > - [[Spring] AOP란?](https://velog.io/@max9106/Spring-AOP%EB%9E%80-93k5zjsm95)
275 | > - [Spring AOP, Aspect 개념 특징, AOP 용어 정리](https://shlee0882.tistory.com/206)
276 |
277 | ### POJO
278 |
279 | Plain Old Java Objet(평범한 구식 자바 객체)
280 |
281 | - POJO란 단어가 생긴 배경 설명
282 | - EJB(Enterprise JavaBean)와 엔터프라이즈 서비스
283 | - 기업업무처리의 IT 시스템에 대한 의존도가 높아지면서 시스템이 다뤄야 하는 비즈니스 로직 자체가 점차 복잡해졌다.
284 | - 애플리케이션 로직의 복잡도와 상세 기술의 복작함을 개발자들이 한 번에 다룬다는 것은 쉬운 일이 아니다. 예를 들어, 한 개발자가 보험업무와 관련된 계산 로직을 자바로 어떻게 구현해야 하는지에 집중하면서 동시에 시스템 레벨에서 멀티DB로 확장 가능한 트랜잭션 처리와 보안 기능을 멀티쓰레드에 세이프하게 만드는 것에 신경쓰는 것은 부담이 매우 크다
285 | - 많은 사용자의 처리요구를 빠르게 안정적이면서 확장 가능한 형태로 유지하기 위해 필요한 **Low Level의 기술적인(트랜잭션 처리, 상태관리, 멀티쓰레딩, 리소스풀링, 보안 등) 처리**가 요구됐다.
286 | - 이에 EJB가 등장, 애플리케이션 개발자는 Low Level의 기술들에 관심을 가질 필요가 없다. **BUT** 결론적으로 불필요한만큼 **과도한 엔지니어링**으로 실패한 대표적인 케이스가 되었다.
287 | - 마틴 파울러는 **EJB와 같은 잘못 설계된 과도한 기술을 피하고, 객체지향 원리에 따라 만들어진 자바 언어의 기본에 충실하게 비즈니스 로직을 구현하는 일명 POJO 방식으로 돌아서야 한다**고 지적했다.
288 |
289 | - 특징
290 | - Java에서 제공하는 API 외에 종속되지 않음
291 | - 특정 규약, 환경에 종속되지 않음
292 | - 환경에 종속되지 않는 것의 장점
293 | - 코드의 간결함 (비즈니스 로직과 특정 환경/low 레벨 종속적인 코드를 분리하므로 단순)
294 | - 비즈니스 로직과 특정 환경이 분리되므로 단순함
295 | - 자동화 테스트에 유리 (환경 종속적인 코드는 자동화 테스트가 어렵지만, POJO는 테스트가 매우 유연)
296 | - 객체지향 설계의 자유로운 사용
297 | > - [http://limmmee.tistory.com/8?category=654011](http://limmmee.tistory.com/8?category=654011)
298 |
299 | ### DAO와 DTO의 차이
300 | - **DAO(Data Access Object)**
301 | - DB의 데이터를 조회하거나 조작하는 기능을 전담하도록 만든 객체를 말한다.
302 | - DB에 접근을 하기위한 로직과 비즈니스 로직을 분리하기 위해서 사용 한다.
303 | - **DTO(Data Transfer Object)**
304 | - 계층간 데이터 교환을 위한 자바빈즈를 말한다.
305 | - 여기서 말하는 계층은 Controller, View, Business Layer, Persistent Layer 이다.
306 | - 일반적인 DTO는 **로직을 갖고 있지 않는 순수한 데이터 객체**이며, 속성과 그 속성에 접근하기 위한 getter, setter 메소드만 가진 클래스이다.
307 | - VO(Value Object) 라고도 불린다.
308 | - DTO와 동일한 개념이지만 read only 속성을 가진다.
309 | - 프로퍼티(Property)
310 | - setter/getter에서 set과 get이후에 나오는 단어가 property라고 약속한다.
311 | - setAge의 프로퍼티는 age, getName에서의 프로퍼티는 name
312 | - 중요한 점은 프로퍼티는 멤버변수 name, age로 결정되는 것이 아니라 getter/setter에서의 name과 age임을 명심해야 한다.
313 | - 자바는 다양한 프레임워크에서 **데이터 자동화 처리**를 위해 리플렉션 기법을 사용한다. 데이터 자동화 처리에서 제일 중요한 것은 **표준규격**이다.
314 | - 우리가 setter 요청을 하면 프레임워크단에서 setter가 실행된다. 그로 인하여, Layer(서버코딩->view코딩)에 데이터를 넘길 때 DTO를 쓰면 편하다.
315 | - 데이터가 자동적으로 클래스화 된다는 것이다. 데이터 자동화 처리된 DTO로 변환되어 우리는 손쉽게 데이터가 셋팅된 오브젝트를 받을 수 있다.
316 | - 프로퍼티 규격만 잘 지킨다면, 얼마든지 편하게 DTO로 받을 수 있다.
317 |
318 | > - [https://jungwoon.github.io/common%20sense/2017/11/16/DAO-VO-DTO/](https://jungwoon.github.io/common%20sense/2017/11/16/DAO-VO-DTO/)
319 |
320 | ### Spring JDBC를 이용한 데이터 접근
321 |
322 | - 데이터베이스 테이블과, 자바 객체 사이의 단순한 매핑을 간단한 설정을 통해 처리하는 것
323 | - 기존의 JDBC에서는 구현하고 싶은 로직마다 필요한 SQL문이 모두 달랐고, 이에 필요한 Connection, PrepareStatement, ResultSet 등을 생성하고 Exception 처리도 모두 해야하는 번거러움이 존재했습니다.
324 | - Spring에서는 JDBC와 ORM 프레임워크를 직접 지원하기 때문에 따로 작성하지 않아도 모두 다 처리해주는 장점이 있습니다.
325 |
326 | ### Annotation이란
327 |
328 | - 소스코드에 @어노테이션의 형태로 표현하며 클래스, 필드, 메소드의 선언부에 적용할 수 있는 특정기능이 부여된 표현법을 말합니다.
329 | - 애플리케이션 규모가 커질수록, xml 환경설정이 매우 복잡해지는데 이러한 어려움을 개선시키기 위해 자바 파일에 어노테이션을 적용해서 개발자가 설정 파일 작업을 할 때 발생시키는 오류를 최소화해주는 역할을 합니다.
330 | - 어노테이션 사용으로 소스 코드에 메타데이터를 보관할 수 있고, 컴파일 타임의 체크뿐 아니라 어노테이션 API를 사용해 코드 가독성도 높여줍니다.
331 | - @Controller : dispatcher-servlet.xml에서 bean 태그로 정의하는 것과 같음.
332 | - @RequestMapping : 특정 메소드에서 요청되는 URL과 매칭시키는 어노테이션
333 | - @Autowired : 자동으로 의존성 주입하기 위한 어노테이션
334 | - @Service : 비즈니스 로직 처리하는 서비스 클래스에 등록
335 | - @Repository : DAO에 등록
336 |
337 | ### Filter와 Interceptor 차이
338 |
339 | #### Filter, Interceptor
340 | * 애플리케이션에서 자주 사용되는 기능(공통 부분)을 분리하여 관리할 수 있도록 Spring이 제공하는 기능
341 |
342 | #### Filter, Interceptor 흐름
343 |
344 | 
345 | 1. 서버 실행 시 Servlet이 올라오는 동안 init 후 doFilter 실행
346 | 2. Dispatcher Servlet을 지나쳐 Interceptor의 preHandler 실행
347 | 3. 컨트롤러를 거쳐 내부 로직 수행 후, Interceptor의 postHandler 실행
348 | 4. doFilter 실행
349 | 5. Servlet 종료 시 destroy
350 |
351 | #### Filter 특징
352 | * Dispatcher Servlet 이전에 수행되고, 응답 처리에 대해서도 변경 및 조작 수행 가능
353 | * WAS 내의 ApplicationContext에서 등록된 필터가 실행
354 | * WAS 구동 시 FilterMap이라는 배열에 등록되고, 실행 시 Filter chain을 구성하여 순차적으로 실행
355 | * Spring Context 외부에 존재하여 Spring과 무관한 자원에 대해 동작
356 | * 일반적으로 web.xml에 설정
357 | * 예외 발생 시 Web Application에서 예외 처리
358 | * ex. 인코딩 변환, XSS 방어 등
359 | * 실행 메소드
360 | * init() : 필터 인스턴스 초기화
361 | * doFilter() : 실제 처리 로직
362 | * destroy() : 필터 인스턴스 종료
363 |
364 | #### Interceptor 특징
365 | * Dispatcher Servlet 이후 Controller 호출 전, 후에 끼어들어 기능 수행
366 | * Spring Context 내부에서 Controller의 요청과 응답에 관여하며 모든 Bean에 접근 가능
367 | * 일반적으로 servlet-context.xml에 설정
368 | * 예외 발생 시 @ControllerAdvice에서 @ExceptionHandler를 사용해 예외 처리
369 | * ex. 로그인 체크, 권한 체크, 로그 확인 등
370 | * 실행 메소드
371 | * preHandler() : Controller 실행 전
372 | * postHandler() : Controller 실행 후
373 | * afterCompletion() : view Rendering 후
374 |
375 | ##### Filter, Interceptor 차이점 요약
376 | * 필터와 인터셉터는 실행되는 시점에서 차이가 있다. 필터는 웹 애플리케이션에 등록을 하고, 인터셉터는 스프링의 context에 등록을 한다. 따라서 컨트롤러에 들어가기 전 작업을 처리하기 위해 사용하는 공통점이 있지만, 호출되는 시점에서 차이가 존재한다.
377 | * Filter는 WAS단에 설정되어 Spring과 무관한 자원에 대해 동작하고, Interceptor는 Spring Context 내부에 설정되어 컨트롤러 접근 전, 후에 가로채서 기능 동작
378 | * Filter는 doFilter() 메소드만 있지만, Interceptor는 pre와 post로 명확하게 분리
379 | * Interceptor의 경우 AOP 흉내 가능
380 | * handlerMethod(@RequestMapping을 사용해 매핑 된 @Controller의 메소드)를 파라미터로 제공하여 메소드 시그니처 등 추가 정보를 파악해 로직 실행 여부 판단 가능
381 |
382 | > - [[Spring] Filter, Interceptor, AOP 차이 및 정리](https://goddaehee.tistory.com/154)
383 | > - [[Spring] Filter, Interceptor, AOP 차이](https://velog.io/@sa833591/Spring-Filter-Interceptor-AOP-%EC%B0%A8%EC%9D%B4-yvmv4k96)
384 | > - [Spring Filter와 Interceptor](https://jaehun2841.github.io/2018/08/25/2018-08-18-spring-filter-interceptor/#spring-request-flow)
385 | > - [(Spring)Filter와 Interceptor의 차이](https://supawer0728.github.io/2018/04/04/spring-filter-interceptor/)
386 |
387 |
388 | ### ORM
389 |
390 | - RDBS에서 조회한 데이터를 Java 객체로 변환하여 리턴해 주고, Java 객체를 RDBMS에 저장해주는 라이브러리 혹은 기술을 말한다.
391 | - Java ORM 기술로 유명한 것은 mybatis, Hibernate, JPA 이다.
392 | - Mybatis와 Hibernate는 오픈소스 프로젝트이고 jar 라이브러리 형태로 제공된다.
393 | - JPA(Java persistence API)는 API 표준의 이름이다. JPA 표준 규격대로 만들어진 제품 중에서 유명한 것이 Hibernate 오픈소스 라이브러리이다.
394 | - 우리가 사용하는 Spring JPA에 Hibernate 라이브러리가 포함되어 있다.
395 | - 우리나라의 전자 정보 표준 프레임워크에서 Spring Mybatis를 채택하고 있기 때문에, 우리나라 공공 프로젝트에서 Mybatis를 사용하는 경우가 많다. 그렇지만 JPA가 좀 더
396 | 미래지향적인 기술이기 때문에 점점 JPA를 사용하는 경우가 늘어나고 있다.
397 |
398 | > :arrow_double_up:[Top](#Spring)
399 |
400 | ### Mybatis
401 |
402 | - 객체, 데이터베이스, Mapper 자체를 독립적으로 작성하고, DTO에 해당하는 부분과 SQL 실행결과를 매핑해서 사용할 수 있도록 지원한다.
403 | - 기존에는 DAO에 모든 SQL문이 자바 소스상에 위치했으나, MyBatis를 통해 SQL은 XML 설정 파일로 관리한다.
404 | - 설정파일로 분리하면, 수정할 때 설정파일만 건드리면 되므로 유지보수에 매우 좋고, 또한 매개변수나 리턴 타입으로 매핑되는 모든 DTO에 관련된 부분도 모두 설정파일에서 작업할 수 있는 장점이 있습니다.
405 |
406 | * 장점
407 | * 익숙한 SQL 명령으로 구현할 수 있다.
408 | * DB 조회 결과를 복잡한 객체 구조로 변환해야 할 때 mybatis 기능이 좋다.
409 | * mybatis의 resultMap 기능이 바로 그것이다.
410 | * 단점
411 | * 구현할 소스코드의 양이 상대적으로 많다.
412 | * RDBMS에만 적용할 수 있다.
413 | * DBMS 제품을 교체하면 SQL 소스코드를 수정해야 한다. SQL문을 사용하지 않는 Hibernate, JPA에는 이런 문제가 없다.
414 |
415 | > :arrow_double_up:[Top](#Spring)
416 |
417 |
418 |
419 | ---
420 |
421 | ## Reference
422 | > - []()
423 |
424 |
--------------------------------------------------------------------------------
/Network/Part2.md:
--------------------------------------------------------------------------------
1 | # 2. Network
2 | **:book: Contents**
3 | * [HTTP와 HTTPS](#http와-https)
4 | * [HTTP 요청/응답 헤더](#http-요청-응답-헤더)
5 | * [CORS란](#cors란)
6 | * [GET 메서드와 POST 메서드](#get-메서드와-post-메서드)
7 | * [쿠키(Cookie)와 세션(Session)](#쿠키와-세션)
8 |
9 |
10 | ---
11 |
12 | ### HTTP와 HTTPS
13 |  14 |
15 | - HTTP 프로토콜
16 | - 개념
17 | - HyperText Transfer Protocol(하이퍼텍스트 전송 프로토콜)
18 | - 웹 상에서 클라이언트와 서버 간에 요청/응답(request/response)으로 정보를 주고 받을 수 있는 프로토콜
19 | - 서로 다른 시스템들 사이에서 통신을 주고받게 해주는 가장 기초적인 프로토콜
20 | - ISO 모형의 응용계층(L7), TCP/IP 의 응용계층(L4) 이다.
21 | - 특징
22 | - 주로 HTML 문서를 주고받는 데에 쓰인다.
23 | - TCP와 UDP를 사용하며, **80번 포트**를 사용한다.
24 | - 1) 비연결(Connectionless)
25 | - 클라이언트가 요청을 서버에 보내고 서버가 적절한 응답을 클라이언트에 보내면 바로 연결이 끊긴다.
26 | - 2) 무상태(Stateless)
27 | - 연결을 끊는 순간 클라이언트와 서버의 통신은 끝나며 상태 정보를 유지하지 않는다.
28 |
29 | - HTTPS 프로토콜
30 | - 개념
31 | - HyperText Transfer Protocol over Secure Socket Layer
32 | - 또는 HTTP over TLS, HTTP over SSL, HTTP Secure
33 | - 웹 통신 프로토콜인 HTTP의 보안이 강화된 버전의 프로토콜
34 | - 특징
35 | - SSL은 서버와 브라우저 사이에 안전하게 암호화된 연결을 만들 수 있게 도와주고, 서버 브라우저가 민감한 정보를 주고받을 때 이것이 도난당하는 것을 막아준다.
36 | - HTTPS의 기본 TCP/IP 포트로 **443번 포트**를 사용한다.
37 | - HTTPS는 소켓 통신에서 일반 텍스트를 이용하는 대신에, 웹 상에서 정보를 암호화하는 SSL이나 TLS 프로토콜을 통해 세션 데이터를 암호화한다.
38 | - TLS(Transport Layer Security) 프로토콜은 SSL(Secure Socket Layer) 프로토콜에서 발전한 것이다.
39 | - SSL은 넷스케이프가 개발한 프로토콜인 반면 TLS는 IETF 표준이다.
40 | - 두 프로토콜의 주요 목표는 기밀성(사생활 보호), 데이터 무결성, ID 및 디지털 인증서를 사용한 인증을 제공하는 것이다.
41 | - 따라서 데이터의 적절한 보호를 보장한다.
42 | - 보호의 수준은 웹 브라우저에서의 구현 정확도와 서버 소프트웨어, 지원하는 암호화 알고리즘에 달려있다.
43 | - 금융 정보나 메일 등 중요한 정보를 주고받는 것은 HTTPS를, 아무나 봐도 상관 없는 페이지는 HTTP를 사용한다.
44 | - HTTPS가 필요한 이유?
45 | - 클라이언트인 웹브라우저가 서버에 HTTP를 통해 웹 페이지나 이미지 정보를 요청하면 서버는 이 요청에 응답하여 요구하는 정보를 제공하게 된다.
46 | - 웹 페이지(HTML)는 텍스트이고, HTTP를 통해 이런 텍스트 정보를 교환하는 것이다.
47 | - 이때 주고받는 텍스트 정보에 주민등록번호나 비밀번호와 같이 민감한 정보가 포함된 상태에서 네트워크 상에서 중간에 제3자가 정보를 가로챈다면 보안상 큰 문제가 발생한다.
48 | - 즉, 중간에서 정보를 볼 수 없도록 주고받는 정보를 암호화하는 방법인 HTTPS를 사용하는 것이다.
49 | - HTTPS의 원리
50 | - 공개키 알고리즘 방식
51 | - 암호화, 복호화시킬 수 있는 서로 다른 키(공개키, 개인키)를 이용한 암호화 방법
52 | - 공개키: 모두에게 공개. 공캐키 저장소에 등록
53 | - 개인키(비공개키): 개인에게만 공개. 클라이언트-서버 구조에서는 서버가 가지고 있는 비공개키
54 | - 클라이언트 -> 서버
55 | - 사용자의 데이터를 **공개키로 암호화** (공개키를 얻은 인증된 사용자)
56 | - 서버로 전송 (데이터를 가로채도 개인키가 없으므로 **복호화할 수 없음**)
57 | - 서버의 **개인키를 통해 복호화**하여 요청 처리
58 | - HTTPS의 장단점
59 | - 장점
60 | - 네트워크 상에서 열람, 수정이 불가능하므로 안전하다.
61 | - 사용자들이 안전하다고 생각하여 많이 방문되어, 검색엔진 최적화(SEO)에서 혜택을 받는다.
62 | - 가속화된 모바일 페이지(AMP, Accelerated Mobile Pages)를 만들기에 적합하다.
63 | - 단점
64 | - 암호화를 하는 과정이 웹 서버에 부하를 준다.
65 | - HTTPS는 설치 및 인증서를 유지하는데 추가 비용이 발생한다.
66 | - HTTP에 비해 느리다.
67 | - 인터넷 연결이 끊긴 경우 재인증 시간이 소요된다.
68 | - HTTP는 비연결형으로 웹 페이지를 보는 중 인터넷 연결이 끊겼다가 다시 연결되어도 페이지를 계속 볼 수 있다.
69 | - 그러나 HTTPS의 경우에는 소켓(데이터를 주고 받는 경로) 자체에서 인증을 하기 때문에 인터넷 연결이 끊기면 소켓도 끊어져서 다시 HTTPS 인증이 필요하다.
70 |
71 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
72 | > - [https://ko.wikipedia.org/wiki/HTTPS](https://ko.wikipedia.org/wiki/HTTPS)
73 | > - [https://coding-start.tistory.com/208](https://coding-start.tistory.com/208)
74 | > - [https://jeong-pro.tistory.com/89](https://jeong-pro.tistory.com/89)
75 | > - [https://m.blog.naver.com/reviewer__/221294104297](https://m.blog.naver.com/reviewer__/221294104297)
76 | > - [https://www.ibm.com/support/knowledgecenter/ko/SSFKSJ_7.1.0/com.ibm.mq.doc/sy10630_.htm](https://www.ibm.com/support/knowledgecenter/ko/SSFKSJ_7.1.0/com.ibm.mq.doc/sy10630_.htm)
77 |
78 |
79 | ---
80 |
81 | ### HTTP 요청 응답 헤더
82 | - HTTP 헤더 항목(컨텍스트에 따른 그룹핑)
83 | - General header: 요청과 응답 모두에 적용되지만 바디에서 최종적으로 전송되는 데이터와는 관련이 없는 헤더.
84 | - Entity header: 컨텐츠 길이나 MIME 타입과 같이 엔티티 바디에 대한 자세한 정보를 포함하는 헤더.
85 | - Request header: 페치될 리소스나 클라이언트 자체에 대한 자세한 정보를 포함하는 헤더.
86 | - Response header: 위치 또는 서버 자체에 대한 정보(이름, 버전 등)와 같이 응답에 대한 부가적인 정보를 갖는 헤더.
87 | - HTTP 헤더 내 일반 헤더(General Header) 항목
88 | - 요청 및 응답 메시지 모두에서 사용 가능한 일반 목적의(기본적인) 헤더 항목
89 | - 주요 항목들
90 | - **Date**: HTTP 메시지가 만들어진 시각. 자동으로 만들어진다. (RFC 1123에서 규정)
91 | - `Date: Sat, 2 Oct 2018 02:00:12 GMT`
92 | - **Connection**: 클라이언트와 서버 간 연결에 대한 옵션 설정(다소 모호한 복잡성 있음)
93 | - 일반적으로 HTTP/1.1을 사용하며 Connection은 기본적으로 keep-alive로 되어있다.
94 | - `Connection: close` => 현재 HTTP 메시지 직후에 TCP 접속을 끊는다는 것을 알림
95 | - `Connection: Keep-Alive` => 현재 TCP 커넥션을 유지
96 | - **Content-Length**
97 | - 요청과 응답 메시지의 본문 크기를 바이트 단위로 표시해준다. 메시지 크기에 따라 자동으로 만들어진다.
98 | - `Content-Length: 88052`
99 | - **Cache-Control**
100 | - 각 리소스는 Cache-Control HTTP 헤더를 통해 캐싱 정책을 정의할 수 있다.
101 | - Cache-Control 지시문은 응답을 캐시할 수 있는 사용자, 해당 조건 및 기간을 제어한다.
102 | - `Cache-Control: public, max-age=3600`
103 | - **Pragma**
104 | - 요청-응답 체인에 다양한 영향을 줄 수 있는 구현관련 헤더이다.
105 | - **Trailer**
106 | - HTTP 헤더 내 엔티티/개체 헤더 (Entity Header) 항목
107 | - 요청 및 응답 메시지 모두에서 사용 가능한 Entity(콘텐츠, 본문, 리소스 등)에 대한 설명 헤더
108 | - 주요 항목들
109 | - **Content-Type**: 해당 개체에 포함되는 미디어 타입 정보
110 | - 컨텐츠의 타입(MIME 미디어 타입) 및 문자 인코딩 방식(EUC-KR,UTF-8 등)을 지정
111 | - 타입 및 서브타입(type/subtype)으로 구성
112 | - `Content-Type: text/html; charset-latin-1` => 해당 개체가 html으로 표현된 텍스트 문서이고, iso-latin-1 문자 인코딩 방식으로 표현됨
113 | - **Content-Language**: 해당 개체와 가장 잘 어울리는 사용자 언어(자연언어)
114 | - **Content-Encoding**: 해당 개체 데이터의 압축 방식
115 | - `Content-Encoding: gzip, deflate`
116 | - 만일 압축이 시행되었다면, Content-Encoding 및 Content-Length 2개 항목을 토대로 압축 해제 가능
117 | - **Content-Length**: 전달되는 해당 개체의 바이트 길이 또는 크기(10진수)
118 | - 응답 메시지 Body의 길이를 지정하거나, 특정 지정된 개체의 길이를 지정함
119 | - **Content-Location**: 해당 개체가 실제 어디에 위치하는가를 알려줌
120 | - **Content-Disposition**: 응답 Body를 브라우저가 어떻게 표시해야 할지 알려주는 헤더
121 | - inline인 경우 웹페이지 화면에 표시되고, attachment인 경우 다운로드
122 | - `Content-Disposition: inline`
123 | - `Content-Disposition: attachment; filename='filename.csv'`
124 | - 다운로드되길 원하는 파일은 attachment로 값을 설정하고, filename 옵션으로 파일명까지 지정해줄 수 있다.
125 | - 파일용 서버인 경우 이 태그를 자주 사용
126 | - **Content-Security-Policy**: 다른 외부 파일들을 불러오는 경우, 차단할 소스와 불러올 소스를 명시
127 | - *XSS 공격*에 대한 방어 가능 (허용한 외부 소스만 지정 가능)
128 | - `Content-Security-Policy: default-src https:` => https를 통해서만 파일을 가져옴
129 | - `Content-Security-Policy: default-src 'self'` => 자신의 도메인의 파일들만 가져옴
130 | - `Content-Security-Policy: default-src 'none'` => 파일을 가져올 수 없음
131 | - **Location**: 리소스가 리다이렉트(redirect)된 때에 이동된 주소, 또는 새로 생성된 리소스 주소
132 | - 300번대 응답이나 201 Created 응답일 때 어느 페이지로 이동할지를 알려주는 헤더
133 | - 새로 생성된 경우에 HTTP 상태 코드 `201 Created`가 반환됨
134 | - `HTTP/1.1 302 Found Location: /`
135 | - 이런 응답이 왔다면 브라우저는 / 주소로 redirect한다.
136 | - **Last-Modified**: 리소스를 마지막으로 갱신한 일시
137 | - HTTP 헤더 내 요청 헤더 (Request Header) 항목
138 | - 요청 헤더는 HTTP 요청 메시지 내에서만 나타나며 가장 방대하다.
139 | - 주요 항목들
140 | - **Host**: 요청하는 호스트에 대한 호스트명 및 포트번호 (***필수***)
141 | - 서버의 도메인 네임. Host 헤더는 반드시 하나가 존재해야 한다.
142 | - Host 필드에 도메인명 및 호스트명 모두를 포함한 전체 URI(FQDN) 지정 필요
143 | - 이에 따라 동일 IP 주소를 갖는 단일 서버에 여러 사이트가 구축 가능
144 | - **User-Agent**: 클라이언트 소프트웨어(브라우저, OS) 명칭 및 버전 정보
145 | - 현재 사용자가 어떤 클라이언트(운영체제, 앱, 브라우저 등)를 통해 요청을 보냈는지 알 수 있다.
146 | - `User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36`
147 | - **From**: 클라이언트 사용자 메일 주소
148 | - 주로 검색엔진 웹 로봇의 연락처 메일 주소를 나타냄
149 | - 때로는, 이 연락처 메일 주소를 User-Agent 항목에 두는 경우도 있음
150 | - **Cookie**: 서버에 의해 Set-Cookie로 클라이언트에게 설정된 쿠키 정보
151 | - 웹서버가 클라이언트에 쿠키를 저장해 놓았다면 해당 쿠키의 정보를 이름-값 쌍으로 웹서버에 전송한다.
152 | - **Referer**: 바로 직전에 머물었던 웹 링크 주소
153 | - **If-Modified-Since**: 제시한 일시 이후로만 변경된 리소스를 취득 요청
154 | - 만일 요청한 파일이 이 필드에 지정된 시간 이후로 변경되지 않았다면, 서버로부터 데이터를 전송받지 않는다.
155 | - **Authorization**: 인증 토큰(JWT/Bearer 토큰)을 서버로 보낼 때 사용하는 헤더
156 | - 토큰의 종류(Basic, Bearer 등) + 실제 토큰 문자를 전송
157 | - **Origin**
158 | - 서버로 POST 요청을 보낼 때, 요청이 어느 주소에서 시작되었는지 나타냄
159 | - 여기서 요청을 보낸 주소와 받는 주소가 다르면 *CORS 에러*가 발생
160 | - 응답 헤더의 **Access-Control-Allow-Origin**와 관련
161 | - 다음 4개는 주로 HTTP 메세지 Body의 속성 또는 내용 협상용 항목들
162 | - **Accept**: 클라이언트 자신이 원하는 미디어 타입 및 우선순위를 알림
163 | - `Accept: */*` => 어떤 미디어 타입도 가능
164 | - `Accept: image/*` => 모든 이미지 유형
165 | - **Accept-Charset**: 클라이언트 자신이 원하는 문자 집합
166 | - **Accept-Encoding**: 클라이언트 자신이 원하는 문자 인코딩 방식
167 | - **Accept-Language**: 클라이언트 자신이 원하는 가능한 언어
168 | - 각각이 HTTP Entity Header 항목 중에 `Content-Type, Content-Type charset-xxx, Content-Encoding, Content-Language`과 일대일로 대응됨
169 | - HTTP 헤더 내 응답 헤더 (Response Header) 항목
170 | - 특정 유형의 HTTP 요청이나 특정 HTTP 헤더를 수신했을 때, 이에 응답한다.
171 | - 주요 항목들
172 | - **Server**: 서버 소프트웨어 정보
173 | - **Accept-Range**
174 | - **Set-Cookie**: 서버측에서 클라이언트에게 세션 쿠키 정보를 설정 (RFC 2965에서 규정)
175 | - **Expires**: 리소스가 지정된 일시까지 캐시로써 유효함
176 | - **Age**: 캐시 응답. max-age 시간 내에서 얼마나 흘렀는지 알려줌(초 단위)
177 | - **ETag**: HTTP 컨텐츠가 바뀌었는지를 검사할 수 있는 태그
178 | - **Proxy-authenticate**
179 | - **Allow**: 해당 엔터티에 대해 서버 측에서 지원 가능한 HTTP 메소드의 리스트를 나타냄
180 | - 때론, HTTP 요청 메세지의 HTTP 메소드 OPTIONS에 대한 응답용 항목
181 | - OPTIONS: 웹서버측 제공 HTTP 메소드에 대한 질의
182 | - `Allow: GET,HEAD` => 웹 서버측이 제공 가능한 HTTP 메서드는 GET,HEAD 뿐임을 알림 (405 Method Not Allowed 에러와 함께)
183 | - **Access-Control-Allow-Origin**: 요청을 보내는 프론트 주소와 받는 백엔드 주소가 다르면 *CORS 에러*가 발생
184 | * 서버에서 이 헤더에 프론트 주소를 적어주어야 에러가 나지 않는다.
185 | * `Access-Control-Allow-Origin: www.zerocho.com`
186 | * 프로토콜, 서브도메인, 도메인, 포트 중 하나만 달라도 CORS 에러가 난다.
187 | * `Access-Control-Allow-Origin: *`
188 | * 만약 주소를 일일이 지정하기 싫다면 *으로 모든 주소에 CORS 요청을 허용되지만 그만큼 보안이 취약해진다.
189 | * 유사한 헤더로 `Access-Control-Request-Method, Access-Control-Request-Headers, Access-Control-Allow-Methods, Access-Control-Allow-Headers` 등이 있다.
190 |
191 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
192 | > - [http://www.ktword.co.kr/abbr_view.php?nav=&m_temp1=5905&id=902](http://www.ktword.co.kr/abbr_view.php?nav=&m_temp1=5905&id=902)
193 | > - [https://gmlwjd9405.github.io/2019/01/28/http-header-types.html](https://gmlwjd9405.github.io/2019/01/28/http-header-types.html)
194 | > - [https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers)
195 | > - [https://goddaehee.tistory.com/169](https://goddaehee.tistory.com/169)
196 |
197 | ---
198 |
199 | ### CORS란
200 |
14 |
15 | - HTTP 프로토콜
16 | - 개념
17 | - HyperText Transfer Protocol(하이퍼텍스트 전송 프로토콜)
18 | - 웹 상에서 클라이언트와 서버 간에 요청/응답(request/response)으로 정보를 주고 받을 수 있는 프로토콜
19 | - 서로 다른 시스템들 사이에서 통신을 주고받게 해주는 가장 기초적인 프로토콜
20 | - ISO 모형의 응용계층(L7), TCP/IP 의 응용계층(L4) 이다.
21 | - 특징
22 | - 주로 HTML 문서를 주고받는 데에 쓰인다.
23 | - TCP와 UDP를 사용하며, **80번 포트**를 사용한다.
24 | - 1) 비연결(Connectionless)
25 | - 클라이언트가 요청을 서버에 보내고 서버가 적절한 응답을 클라이언트에 보내면 바로 연결이 끊긴다.
26 | - 2) 무상태(Stateless)
27 | - 연결을 끊는 순간 클라이언트와 서버의 통신은 끝나며 상태 정보를 유지하지 않는다.
28 |
29 | - HTTPS 프로토콜
30 | - 개념
31 | - HyperText Transfer Protocol over Secure Socket Layer
32 | - 또는 HTTP over TLS, HTTP over SSL, HTTP Secure
33 | - 웹 통신 프로토콜인 HTTP의 보안이 강화된 버전의 프로토콜
34 | - 특징
35 | - SSL은 서버와 브라우저 사이에 안전하게 암호화된 연결을 만들 수 있게 도와주고, 서버 브라우저가 민감한 정보를 주고받을 때 이것이 도난당하는 것을 막아준다.
36 | - HTTPS의 기본 TCP/IP 포트로 **443번 포트**를 사용한다.
37 | - HTTPS는 소켓 통신에서 일반 텍스트를 이용하는 대신에, 웹 상에서 정보를 암호화하는 SSL이나 TLS 프로토콜을 통해 세션 데이터를 암호화한다.
38 | - TLS(Transport Layer Security) 프로토콜은 SSL(Secure Socket Layer) 프로토콜에서 발전한 것이다.
39 | - SSL은 넷스케이프가 개발한 프로토콜인 반면 TLS는 IETF 표준이다.
40 | - 두 프로토콜의 주요 목표는 기밀성(사생활 보호), 데이터 무결성, ID 및 디지털 인증서를 사용한 인증을 제공하는 것이다.
41 | - 따라서 데이터의 적절한 보호를 보장한다.
42 | - 보호의 수준은 웹 브라우저에서의 구현 정확도와 서버 소프트웨어, 지원하는 암호화 알고리즘에 달려있다.
43 | - 금융 정보나 메일 등 중요한 정보를 주고받는 것은 HTTPS를, 아무나 봐도 상관 없는 페이지는 HTTP를 사용한다.
44 | - HTTPS가 필요한 이유?
45 | - 클라이언트인 웹브라우저가 서버에 HTTP를 통해 웹 페이지나 이미지 정보를 요청하면 서버는 이 요청에 응답하여 요구하는 정보를 제공하게 된다.
46 | - 웹 페이지(HTML)는 텍스트이고, HTTP를 통해 이런 텍스트 정보를 교환하는 것이다.
47 | - 이때 주고받는 텍스트 정보에 주민등록번호나 비밀번호와 같이 민감한 정보가 포함된 상태에서 네트워크 상에서 중간에 제3자가 정보를 가로챈다면 보안상 큰 문제가 발생한다.
48 | - 즉, 중간에서 정보를 볼 수 없도록 주고받는 정보를 암호화하는 방법인 HTTPS를 사용하는 것이다.
49 | - HTTPS의 원리
50 | - 공개키 알고리즘 방식
51 | - 암호화, 복호화시킬 수 있는 서로 다른 키(공개키, 개인키)를 이용한 암호화 방법
52 | - 공개키: 모두에게 공개. 공캐키 저장소에 등록
53 | - 개인키(비공개키): 개인에게만 공개. 클라이언트-서버 구조에서는 서버가 가지고 있는 비공개키
54 | - 클라이언트 -> 서버
55 | - 사용자의 데이터를 **공개키로 암호화** (공개키를 얻은 인증된 사용자)
56 | - 서버로 전송 (데이터를 가로채도 개인키가 없으므로 **복호화할 수 없음**)
57 | - 서버의 **개인키를 통해 복호화**하여 요청 처리
58 | - HTTPS의 장단점
59 | - 장점
60 | - 네트워크 상에서 열람, 수정이 불가능하므로 안전하다.
61 | - 사용자들이 안전하다고 생각하여 많이 방문되어, 검색엔진 최적화(SEO)에서 혜택을 받는다.
62 | - 가속화된 모바일 페이지(AMP, Accelerated Mobile Pages)를 만들기에 적합하다.
63 | - 단점
64 | - 암호화를 하는 과정이 웹 서버에 부하를 준다.
65 | - HTTPS는 설치 및 인증서를 유지하는데 추가 비용이 발생한다.
66 | - HTTP에 비해 느리다.
67 | - 인터넷 연결이 끊긴 경우 재인증 시간이 소요된다.
68 | - HTTP는 비연결형으로 웹 페이지를 보는 중 인터넷 연결이 끊겼다가 다시 연결되어도 페이지를 계속 볼 수 있다.
69 | - 그러나 HTTPS의 경우에는 소켓(데이터를 주고 받는 경로) 자체에서 인증을 하기 때문에 인터넷 연결이 끊기면 소켓도 끊어져서 다시 HTTPS 인증이 필요하다.
70 |
71 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
72 | > - [https://ko.wikipedia.org/wiki/HTTPS](https://ko.wikipedia.org/wiki/HTTPS)
73 | > - [https://coding-start.tistory.com/208](https://coding-start.tistory.com/208)
74 | > - [https://jeong-pro.tistory.com/89](https://jeong-pro.tistory.com/89)
75 | > - [https://m.blog.naver.com/reviewer__/221294104297](https://m.blog.naver.com/reviewer__/221294104297)
76 | > - [https://www.ibm.com/support/knowledgecenter/ko/SSFKSJ_7.1.0/com.ibm.mq.doc/sy10630_.htm](https://www.ibm.com/support/knowledgecenter/ko/SSFKSJ_7.1.0/com.ibm.mq.doc/sy10630_.htm)
77 |
78 |
79 | ---
80 |
81 | ### HTTP 요청 응답 헤더
82 | - HTTP 헤더 항목(컨텍스트에 따른 그룹핑)
83 | - General header: 요청과 응답 모두에 적용되지만 바디에서 최종적으로 전송되는 데이터와는 관련이 없는 헤더.
84 | - Entity header: 컨텐츠 길이나 MIME 타입과 같이 엔티티 바디에 대한 자세한 정보를 포함하는 헤더.
85 | - Request header: 페치될 리소스나 클라이언트 자체에 대한 자세한 정보를 포함하는 헤더.
86 | - Response header: 위치 또는 서버 자체에 대한 정보(이름, 버전 등)와 같이 응답에 대한 부가적인 정보를 갖는 헤더.
87 | - HTTP 헤더 내 일반 헤더(General Header) 항목
88 | - 요청 및 응답 메시지 모두에서 사용 가능한 일반 목적의(기본적인) 헤더 항목
89 | - 주요 항목들
90 | - **Date**: HTTP 메시지가 만들어진 시각. 자동으로 만들어진다. (RFC 1123에서 규정)
91 | - `Date: Sat, 2 Oct 2018 02:00:12 GMT`
92 | - **Connection**: 클라이언트와 서버 간 연결에 대한 옵션 설정(다소 모호한 복잡성 있음)
93 | - 일반적으로 HTTP/1.1을 사용하며 Connection은 기본적으로 keep-alive로 되어있다.
94 | - `Connection: close` => 현재 HTTP 메시지 직후에 TCP 접속을 끊는다는 것을 알림
95 | - `Connection: Keep-Alive` => 현재 TCP 커넥션을 유지
96 | - **Content-Length**
97 | - 요청과 응답 메시지의 본문 크기를 바이트 단위로 표시해준다. 메시지 크기에 따라 자동으로 만들어진다.
98 | - `Content-Length: 88052`
99 | - **Cache-Control**
100 | - 각 리소스는 Cache-Control HTTP 헤더를 통해 캐싱 정책을 정의할 수 있다.
101 | - Cache-Control 지시문은 응답을 캐시할 수 있는 사용자, 해당 조건 및 기간을 제어한다.
102 | - `Cache-Control: public, max-age=3600`
103 | - **Pragma**
104 | - 요청-응답 체인에 다양한 영향을 줄 수 있는 구현관련 헤더이다.
105 | - **Trailer**
106 | - HTTP 헤더 내 엔티티/개체 헤더 (Entity Header) 항목
107 | - 요청 및 응답 메시지 모두에서 사용 가능한 Entity(콘텐츠, 본문, 리소스 등)에 대한 설명 헤더
108 | - 주요 항목들
109 | - **Content-Type**: 해당 개체에 포함되는 미디어 타입 정보
110 | - 컨텐츠의 타입(MIME 미디어 타입) 및 문자 인코딩 방식(EUC-KR,UTF-8 등)을 지정
111 | - 타입 및 서브타입(type/subtype)으로 구성
112 | - `Content-Type: text/html; charset-latin-1` => 해당 개체가 html으로 표현된 텍스트 문서이고, iso-latin-1 문자 인코딩 방식으로 표현됨
113 | - **Content-Language**: 해당 개체와 가장 잘 어울리는 사용자 언어(자연언어)
114 | - **Content-Encoding**: 해당 개체 데이터의 압축 방식
115 | - `Content-Encoding: gzip, deflate`
116 | - 만일 압축이 시행되었다면, Content-Encoding 및 Content-Length 2개 항목을 토대로 압축 해제 가능
117 | - **Content-Length**: 전달되는 해당 개체의 바이트 길이 또는 크기(10진수)
118 | - 응답 메시지 Body의 길이를 지정하거나, 특정 지정된 개체의 길이를 지정함
119 | - **Content-Location**: 해당 개체가 실제 어디에 위치하는가를 알려줌
120 | - **Content-Disposition**: 응답 Body를 브라우저가 어떻게 표시해야 할지 알려주는 헤더
121 | - inline인 경우 웹페이지 화면에 표시되고, attachment인 경우 다운로드
122 | - `Content-Disposition: inline`
123 | - `Content-Disposition: attachment; filename='filename.csv'`
124 | - 다운로드되길 원하는 파일은 attachment로 값을 설정하고, filename 옵션으로 파일명까지 지정해줄 수 있다.
125 | - 파일용 서버인 경우 이 태그를 자주 사용
126 | - **Content-Security-Policy**: 다른 외부 파일들을 불러오는 경우, 차단할 소스와 불러올 소스를 명시
127 | - *XSS 공격*에 대한 방어 가능 (허용한 외부 소스만 지정 가능)
128 | - `Content-Security-Policy: default-src https:` => https를 통해서만 파일을 가져옴
129 | - `Content-Security-Policy: default-src 'self'` => 자신의 도메인의 파일들만 가져옴
130 | - `Content-Security-Policy: default-src 'none'` => 파일을 가져올 수 없음
131 | - **Location**: 리소스가 리다이렉트(redirect)된 때에 이동된 주소, 또는 새로 생성된 리소스 주소
132 | - 300번대 응답이나 201 Created 응답일 때 어느 페이지로 이동할지를 알려주는 헤더
133 | - 새로 생성된 경우에 HTTP 상태 코드 `201 Created`가 반환됨
134 | - `HTTP/1.1 302 Found Location: /`
135 | - 이런 응답이 왔다면 브라우저는 / 주소로 redirect한다.
136 | - **Last-Modified**: 리소스를 마지막으로 갱신한 일시
137 | - HTTP 헤더 내 요청 헤더 (Request Header) 항목
138 | - 요청 헤더는 HTTP 요청 메시지 내에서만 나타나며 가장 방대하다.
139 | - 주요 항목들
140 | - **Host**: 요청하는 호스트에 대한 호스트명 및 포트번호 (***필수***)
141 | - 서버의 도메인 네임. Host 헤더는 반드시 하나가 존재해야 한다.
142 | - Host 필드에 도메인명 및 호스트명 모두를 포함한 전체 URI(FQDN) 지정 필요
143 | - 이에 따라 동일 IP 주소를 갖는 단일 서버에 여러 사이트가 구축 가능
144 | - **User-Agent**: 클라이언트 소프트웨어(브라우저, OS) 명칭 및 버전 정보
145 | - 현재 사용자가 어떤 클라이언트(운영체제, 앱, 브라우저 등)를 통해 요청을 보냈는지 알 수 있다.
146 | - `User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36`
147 | - **From**: 클라이언트 사용자 메일 주소
148 | - 주로 검색엔진 웹 로봇의 연락처 메일 주소를 나타냄
149 | - 때로는, 이 연락처 메일 주소를 User-Agent 항목에 두는 경우도 있음
150 | - **Cookie**: 서버에 의해 Set-Cookie로 클라이언트에게 설정된 쿠키 정보
151 | - 웹서버가 클라이언트에 쿠키를 저장해 놓았다면 해당 쿠키의 정보를 이름-값 쌍으로 웹서버에 전송한다.
152 | - **Referer**: 바로 직전에 머물었던 웹 링크 주소
153 | - **If-Modified-Since**: 제시한 일시 이후로만 변경된 리소스를 취득 요청
154 | - 만일 요청한 파일이 이 필드에 지정된 시간 이후로 변경되지 않았다면, 서버로부터 데이터를 전송받지 않는다.
155 | - **Authorization**: 인증 토큰(JWT/Bearer 토큰)을 서버로 보낼 때 사용하는 헤더
156 | - 토큰의 종류(Basic, Bearer 등) + 실제 토큰 문자를 전송
157 | - **Origin**
158 | - 서버로 POST 요청을 보낼 때, 요청이 어느 주소에서 시작되었는지 나타냄
159 | - 여기서 요청을 보낸 주소와 받는 주소가 다르면 *CORS 에러*가 발생
160 | - 응답 헤더의 **Access-Control-Allow-Origin**와 관련
161 | - 다음 4개는 주로 HTTP 메세지 Body의 속성 또는 내용 협상용 항목들
162 | - **Accept**: 클라이언트 자신이 원하는 미디어 타입 및 우선순위를 알림
163 | - `Accept: */*` => 어떤 미디어 타입도 가능
164 | - `Accept: image/*` => 모든 이미지 유형
165 | - **Accept-Charset**: 클라이언트 자신이 원하는 문자 집합
166 | - **Accept-Encoding**: 클라이언트 자신이 원하는 문자 인코딩 방식
167 | - **Accept-Language**: 클라이언트 자신이 원하는 가능한 언어
168 | - 각각이 HTTP Entity Header 항목 중에 `Content-Type, Content-Type charset-xxx, Content-Encoding, Content-Language`과 일대일로 대응됨
169 | - HTTP 헤더 내 응답 헤더 (Response Header) 항목
170 | - 특정 유형의 HTTP 요청이나 특정 HTTP 헤더를 수신했을 때, 이에 응답한다.
171 | - 주요 항목들
172 | - **Server**: 서버 소프트웨어 정보
173 | - **Accept-Range**
174 | - **Set-Cookie**: 서버측에서 클라이언트에게 세션 쿠키 정보를 설정 (RFC 2965에서 규정)
175 | - **Expires**: 리소스가 지정된 일시까지 캐시로써 유효함
176 | - **Age**: 캐시 응답. max-age 시간 내에서 얼마나 흘렀는지 알려줌(초 단위)
177 | - **ETag**: HTTP 컨텐츠가 바뀌었는지를 검사할 수 있는 태그
178 | - **Proxy-authenticate**
179 | - **Allow**: 해당 엔터티에 대해 서버 측에서 지원 가능한 HTTP 메소드의 리스트를 나타냄
180 | - 때론, HTTP 요청 메세지의 HTTP 메소드 OPTIONS에 대한 응답용 항목
181 | - OPTIONS: 웹서버측 제공 HTTP 메소드에 대한 질의
182 | - `Allow: GET,HEAD` => 웹 서버측이 제공 가능한 HTTP 메서드는 GET,HEAD 뿐임을 알림 (405 Method Not Allowed 에러와 함께)
183 | - **Access-Control-Allow-Origin**: 요청을 보내는 프론트 주소와 받는 백엔드 주소가 다르면 *CORS 에러*가 발생
184 | * 서버에서 이 헤더에 프론트 주소를 적어주어야 에러가 나지 않는다.
185 | * `Access-Control-Allow-Origin: www.zerocho.com`
186 | * 프로토콜, 서브도메인, 도메인, 포트 중 하나만 달라도 CORS 에러가 난다.
187 | * `Access-Control-Allow-Origin: *`
188 | * 만약 주소를 일일이 지정하기 싫다면 *으로 모든 주소에 CORS 요청을 허용되지만 그만큼 보안이 취약해진다.
189 | * 유사한 헤더로 `Access-Control-Request-Method, Access-Control-Request-Headers, Access-Control-Allow-Methods, Access-Control-Allow-Headers` 등이 있다.
190 |
191 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
192 | > - [http://www.ktword.co.kr/abbr_view.php?nav=&m_temp1=5905&id=902](http://www.ktword.co.kr/abbr_view.php?nav=&m_temp1=5905&id=902)
193 | > - [https://gmlwjd9405.github.io/2019/01/28/http-header-types.html](https://gmlwjd9405.github.io/2019/01/28/http-header-types.html)
194 | > - [https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers)
195 | > - [https://goddaehee.tistory.com/169](https://goddaehee.tistory.com/169)
196 |
197 | ---
198 |
199 | ### CORS란
200 |  201 |
202 | - CORS(Cross Origin Resource Sharing)란
203 | - 추가 HTTP 헤더를 사용하여 브라우저가 실행 중인 웹 애플리케이션에 선택된 액세스 권한을 부여하도록 하는 메커니즘
204 | - 다른 출처(도메인, 프로토콜 또는 포트)의 자원 및 리소스를 요청할 때 cross-origin HTTP 요청을 실행한다.
205 | - 배경
206 | - 과거에 보안 상의 이유로, 브라우저들은 스크립트 내에서 cross-origin HTTP 요청을 제한했다.
207 | - 예를 들어, XMLHttpRequest and the Fetch API는 same-origin 정책을 따랐다.
208 | - 다른 API의 응답에 올바른 CORS 헤더가 포함되어 있지 않으면 해당 API를 사용하는 웹 응용 프로그램은 동일한 출처의 리소스(같은 도메인, 같은 포트)만 요청할 수 있다.
209 | - 서버의 기본 설정(프레임워크 및 언어다마 다를 수 있다.)에서 CORS_ORIGIN_ALLOW_ALL를 활성화했을 경우 CORS의 요청을 허용하여 응답한다.
210 | - CORS의 최종 주체는 서버이다. 브라우저에서는 언제든지 CORS를 허용을 할 수 있다.
211 | - 브라우저의 옵션(크롬의 경우 chrome://flags/), CORS 확장프로그램은 해당 옵션을 수정 및 요청 시 헤더에 "Access-Control-Allow-Origin"을 추가하는 역할을 한다.
212 | - 서버에서 CORS의 설정을 허용하지 않았다면 JSONP와 같은 우회를 사용하기도 했다.(단 GET통신만 가능)
213 |
214 |
201 |
202 | - CORS(Cross Origin Resource Sharing)란
203 | - 추가 HTTP 헤더를 사용하여 브라우저가 실행 중인 웹 애플리케이션에 선택된 액세스 권한을 부여하도록 하는 메커니즘
204 | - 다른 출처(도메인, 프로토콜 또는 포트)의 자원 및 리소스를 요청할 때 cross-origin HTTP 요청을 실행한다.
205 | - 배경
206 | - 과거에 보안 상의 이유로, 브라우저들은 스크립트 내에서 cross-origin HTTP 요청을 제한했다.
207 | - 예를 들어, XMLHttpRequest and the Fetch API는 same-origin 정책을 따랐다.
208 | - 다른 API의 응답에 올바른 CORS 헤더가 포함되어 있지 않으면 해당 API를 사용하는 웹 응용 프로그램은 동일한 출처의 리소스(같은 도메인, 같은 포트)만 요청할 수 있다.
209 | - 서버의 기본 설정(프레임워크 및 언어다마 다를 수 있다.)에서 CORS_ORIGIN_ALLOW_ALL를 활성화했을 경우 CORS의 요청을 허용하여 응답한다.
210 | - CORS의 최종 주체는 서버이다. 브라우저에서는 언제든지 CORS를 허용을 할 수 있다.
211 | - 브라우저의 옵션(크롬의 경우 chrome://flags/), CORS 확장프로그램은 해당 옵션을 수정 및 요청 시 헤더에 "Access-Control-Allow-Origin"을 추가하는 역할을 한다.
212 | - 서버에서 CORS의 설정을 허용하지 않았다면 JSONP와 같은 우회를 사용하기도 했다.(단 GET통신만 가능)
213 |
214 |  215 |
216 | - 동작 방법
217 | - CORS 메커니즘은 브라우저와 서버 간의 안전한 교차 출처 요청 및 데이터 전송을 지원한다.
218 | - HTTP OPTIONS 요청 메서드를 이용해 서버로부터 지원 중인 메서드들을 내려 받은 뒤, 서버에서 "approval"(승인) 시에 실제 HTTP 요청 메서드를 이용해 실제 요청을 전송하는 것을 말한다.
219 | - 서버들은 또한 클라이언트에게 (Cookie와 HTTP Authentication 데이터를 포함하는) "credentials"가 요청과 함께 전송되어야 하는지를 알려줄 수도 있다.
220 |
221 | 1. 브라우저에서 다른 도메인의 서버로 options 메서드로 전송한다.
222 | 2. 서버의 설정이 access-control-allow-origin이 허용일 경우 OK를 리턴한다.
223 | 3. OK이며, 사용 가능한 http 메소드 라면, 요청하려는 API를 서버 측에 호출한다.
224 | 4. 서버에서 응답한다.
225 | - 이렇게 2번의 통신이 클라이언트와 서버에서 일어나게 된다.
226 | - options으로 확인하는 것은 http 메소드 중 멱등성이 없는 메소드로 확인 및 리턴으로 해당 API로 사용할 수 있는 메서드를 리턴하여 요청을 수행할 수 있는지를 확인하기 위함이다.
227 |
228 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/Do-Hee/tech-interview#2-network) :information_source:[Home](https://github.com/Do-Hee/tech-interview#tech-interview)
229 |
230 | > - [https://uiandwe.tistory.com/1244](https://uiandwe.tistory.com/1244)
231 | > - [https://zamezzz.tistory.com/137](https://zamezzz.tistory.com/137)
232 | > - [https://developer.mozilla.org/ko/docs/Web/HTTP/Access_control_CORS](https://developer.mozilla.org/ko/docs/Web/HTTP/Access_control_CORS)
233 |
234 | ---
235 |
236 | ### GET 메서드와 POST 메서드
237 |
238 |
215 |
216 | - 동작 방법
217 | - CORS 메커니즘은 브라우저와 서버 간의 안전한 교차 출처 요청 및 데이터 전송을 지원한다.
218 | - HTTP OPTIONS 요청 메서드를 이용해 서버로부터 지원 중인 메서드들을 내려 받은 뒤, 서버에서 "approval"(승인) 시에 실제 HTTP 요청 메서드를 이용해 실제 요청을 전송하는 것을 말한다.
219 | - 서버들은 또한 클라이언트에게 (Cookie와 HTTP Authentication 데이터를 포함하는) "credentials"가 요청과 함께 전송되어야 하는지를 알려줄 수도 있다.
220 |
221 | 1. 브라우저에서 다른 도메인의 서버로 options 메서드로 전송한다.
222 | 2. 서버의 설정이 access-control-allow-origin이 허용일 경우 OK를 리턴한다.
223 | 3. OK이며, 사용 가능한 http 메소드 라면, 요청하려는 API를 서버 측에 호출한다.
224 | 4. 서버에서 응답한다.
225 | - 이렇게 2번의 통신이 클라이언트와 서버에서 일어나게 된다.
226 | - options으로 확인하는 것은 http 메소드 중 멱등성이 없는 메소드로 확인 및 리턴으로 해당 API로 사용할 수 있는 메서드를 리턴하여 요청을 수행할 수 있는지를 확인하기 위함이다.
227 |
228 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/Do-Hee/tech-interview#2-network) :information_source:[Home](https://github.com/Do-Hee/tech-interview#tech-interview)
229 |
230 | > - [https://uiandwe.tistory.com/1244](https://uiandwe.tistory.com/1244)
231 | > - [https://zamezzz.tistory.com/137](https://zamezzz.tistory.com/137)
232 | > - [https://developer.mozilla.org/ko/docs/Web/HTTP/Access_control_CORS](https://developer.mozilla.org/ko/docs/Web/HTTP/Access_control_CORS)
233 |
234 | ---
235 |
236 | ### GET 메서드와 POST 메서드
237 |
238 |  239 |
240 | * HTTP 프로토콜을 이용해서 서버에 데이터(요청 정보)를 전달할 때 사용하는 방식
241 | * GET 메서드 방식
242 | * 개념
243 | * 정보를 조회하기 위한 메서드
244 | * 서버에서 어떤 데이터를 가져와서 보여주기 위한 용도의 메서드
245 | * **가져오는 것(Select)**
246 | * 사용 방법
247 | * URL의 끝에 '?'가 붙고, 요청 정보가 (key=value)형태의 쌍을 이루어 ?뒤에 이어서 붙어 서버로 전송한다.
248 | * 요청 정보가 여러 개일 경우에는 '&'로 구분한다.
249 | * Ex) `www.urladdress.xyz?name1=value1&name2=value2`
250 | * 특징
251 | * URL에 요청 정보를 붙여서 전송한다.
252 | * URL에 요청 정보가 이어붙기 때문에 길이 제한이 있어서 대용량의 데이터를 전송하기 어렵다.
253 | * 한 번 요청 시 전송 데이터(주솟값 + 파라미터)의 양은 255자로 제한된다.(HTTP/1.1은 2048자)
254 | * 요청 정보를 사용자가 쉽게 눈으로 확인할 수 있다.
255 | * POST 방식보다 보안상 취약하다.
256 | * HTTP 패킷의 Body는 비어 있는 상태로 전송한다.
257 | * 즉, Body의 데이터 타입을 표현하는 'Content-Type' 필드도 HTTP Request Header에 들어가지 않는다.
258 | * POST 방식보다 빠르다.
259 | * GET 방식은 캐싱을 사용할 수 있어, GET 요청과 그에 대한 응답이 브라우저에 의해 캐쉬된다.
260 | * POST 메서드 방식
261 | * 개념
262 | * 서버의 값이나 상태를 바꾸기 위한 용도의 메서드
263 | * **수행하는 것(Insert, Update, Delete)**
264 | * 사용 방법
265 | * 요청 정보를 HTTP 패킷의 Body 안에 숨겨서 서버로 전송한다.
266 |
267 | * Request Header의 Content-Type에 해당 데이터 타입이 표현되며, 전송하고자 하는 데이터 타입을 적어주어야 한다.
268 | * Default: application/octet-stream
269 | * 단순 txt의 경우: text/plain
270 | * 파일의 경우: multipart/form-date
271 | * 특징
272 | * Body 안에 숨겨서 요청 정보를 전송하기 때문에 대용량의 데이터를 전송하기에 적합하다.
273 | * 클라이언트 쪽에서 데이터를 인코딩하여 서버로 전송하고, 이를 받은 서버 쪽이 해당 데이터를 디코딩한다.
274 | * GET 방식보다 보안상 안전하다.
275 |
276 | * GET과 POST의 차이
277 | * GET은 Idempotent, POST는 Non-idempotent하게 설계되었다.
278 | * GET으로 서버에게 동일한 요청을 여러 번 전송하더라도 동일한 응답이 돌아와야 한다.
279 | * POST로 서버에게 동일한 요청을 여러 번 전송해도 응답은 항상 다를 수 있다.
280 | * 웹페이지를 조회할 때, 링크를 통해 특정 페이지로 바로 이동하려면 해당 링크와 관련된 정보가 필요한데 POST는 요청 데이터가 Body에 담겨 있기 때문에 링크 정보를 가져올 수 없다. 반면, GET은 URL에 요청 파라미터를 가지고 있기 때문에 링크를 걸 때, URL에 파라미터를 사용해 더 디테일하게 페이지를 링크할 수 있다.
281 |
282 | * Q. 조회하기 위한 용도 POST가 아닌 GET 방식을 사용하는 이유?
283 | 1. 설계 원칙에 따라 GET 방식은 서버에게 여러 번 요청을 하더라도 동일한 응답이 돌아와야 한다. (Idempotent, 멱등)
284 | * GET 방식은 **가져오는 것(Select)** 으로, 서버의 데이터나 상태를 변경시키지 않아야 한다.
285 | * Ex) 게시판의 리스트, 게시글 보기 기능
286 | * 예외) 방문자의 로그 남기기, 글을 읽은 횟수 증가 기능
287 | * POST 방식은 **수행하는 것** 으로, 서버의 값이나 상태를 바꾸기 위한 용도이다.
288 | * Ex) 게시판에 글쓰기 기능
289 | 2. 웹에서 모든 리소스는 Link할 수 있는 URL을 가지고 있어야 한다.
290 | * 어떤 웹페이지를 보고 있을 때 다른 사람한테 그 주소를 주기 위해서 주소창의 URL을 복사해서 줄 수 있어야 한다.
291 | * 즉, 어떤 웹페이지를 조회할 때 원하는 페이지로 바로 이동하거나 이동시키기 위해서는 해당 링크의 정보가 필요하다.
292 | * 이때 POST 방식을 사용할 경우에 값(링크의 정보)이 Body에 있기 때문에 URL만 전달할 수 없으므로 GET 방식을 사용해야한다. 그러나 글을 저장하는 경우에는 URL을 제공할 필요가 없기 때문에 POST 방식을 사용한다.
293 |
294 |
295 |
296 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
297 | > - [https://blog.outsider.ne.kr/312](https://blog.outsider.ne.kr/312)
298 | > - [https://hongsii.github.io/2017/08/02/what-is-the-difference-get-and-post/](https://hongsii.github.io/2017/08/02/what-is-the-difference-get-and-post/)
299 | > - [https://www.w3schools.com/tags/ref_httpmethods.asp](https://www.w3schools.com/tags/ref_httpmethods.asp)
300 |
301 | ---
302 |
303 | ### 쿠키와 세션
304 |
239 |
240 | * HTTP 프로토콜을 이용해서 서버에 데이터(요청 정보)를 전달할 때 사용하는 방식
241 | * GET 메서드 방식
242 | * 개념
243 | * 정보를 조회하기 위한 메서드
244 | * 서버에서 어떤 데이터를 가져와서 보여주기 위한 용도의 메서드
245 | * **가져오는 것(Select)**
246 | * 사용 방법
247 | * URL의 끝에 '?'가 붙고, 요청 정보가 (key=value)형태의 쌍을 이루어 ?뒤에 이어서 붙어 서버로 전송한다.
248 | * 요청 정보가 여러 개일 경우에는 '&'로 구분한다.
249 | * Ex) `www.urladdress.xyz?name1=value1&name2=value2`
250 | * 특징
251 | * URL에 요청 정보를 붙여서 전송한다.
252 | * URL에 요청 정보가 이어붙기 때문에 길이 제한이 있어서 대용량의 데이터를 전송하기 어렵다.
253 | * 한 번 요청 시 전송 데이터(주솟값 + 파라미터)의 양은 255자로 제한된다.(HTTP/1.1은 2048자)
254 | * 요청 정보를 사용자가 쉽게 눈으로 확인할 수 있다.
255 | * POST 방식보다 보안상 취약하다.
256 | * HTTP 패킷의 Body는 비어 있는 상태로 전송한다.
257 | * 즉, Body의 데이터 타입을 표현하는 'Content-Type' 필드도 HTTP Request Header에 들어가지 않는다.
258 | * POST 방식보다 빠르다.
259 | * GET 방식은 캐싱을 사용할 수 있어, GET 요청과 그에 대한 응답이 브라우저에 의해 캐쉬된다.
260 | * POST 메서드 방식
261 | * 개념
262 | * 서버의 값이나 상태를 바꾸기 위한 용도의 메서드
263 | * **수행하는 것(Insert, Update, Delete)**
264 | * 사용 방법
265 | * 요청 정보를 HTTP 패킷의 Body 안에 숨겨서 서버로 전송한다.
266 |
267 | * Request Header의 Content-Type에 해당 데이터 타입이 표현되며, 전송하고자 하는 데이터 타입을 적어주어야 한다.
268 | * Default: application/octet-stream
269 | * 단순 txt의 경우: text/plain
270 | * 파일의 경우: multipart/form-date
271 | * 특징
272 | * Body 안에 숨겨서 요청 정보를 전송하기 때문에 대용량의 데이터를 전송하기에 적합하다.
273 | * 클라이언트 쪽에서 데이터를 인코딩하여 서버로 전송하고, 이를 받은 서버 쪽이 해당 데이터를 디코딩한다.
274 | * GET 방식보다 보안상 안전하다.
275 |
276 | * GET과 POST의 차이
277 | * GET은 Idempotent, POST는 Non-idempotent하게 설계되었다.
278 | * GET으로 서버에게 동일한 요청을 여러 번 전송하더라도 동일한 응답이 돌아와야 한다.
279 | * POST로 서버에게 동일한 요청을 여러 번 전송해도 응답은 항상 다를 수 있다.
280 | * 웹페이지를 조회할 때, 링크를 통해 특정 페이지로 바로 이동하려면 해당 링크와 관련된 정보가 필요한데 POST는 요청 데이터가 Body에 담겨 있기 때문에 링크 정보를 가져올 수 없다. 반면, GET은 URL에 요청 파라미터를 가지고 있기 때문에 링크를 걸 때, URL에 파라미터를 사용해 더 디테일하게 페이지를 링크할 수 있다.
281 |
282 | * Q. 조회하기 위한 용도 POST가 아닌 GET 방식을 사용하는 이유?
283 | 1. 설계 원칙에 따라 GET 방식은 서버에게 여러 번 요청을 하더라도 동일한 응답이 돌아와야 한다. (Idempotent, 멱등)
284 | * GET 방식은 **가져오는 것(Select)** 으로, 서버의 데이터나 상태를 변경시키지 않아야 한다.
285 | * Ex) 게시판의 리스트, 게시글 보기 기능
286 | * 예외) 방문자의 로그 남기기, 글을 읽은 횟수 증가 기능
287 | * POST 방식은 **수행하는 것** 으로, 서버의 값이나 상태를 바꾸기 위한 용도이다.
288 | * Ex) 게시판에 글쓰기 기능
289 | 2. 웹에서 모든 리소스는 Link할 수 있는 URL을 가지고 있어야 한다.
290 | * 어떤 웹페이지를 보고 있을 때 다른 사람한테 그 주소를 주기 위해서 주소창의 URL을 복사해서 줄 수 있어야 한다.
291 | * 즉, 어떤 웹페이지를 조회할 때 원하는 페이지로 바로 이동하거나 이동시키기 위해서는 해당 링크의 정보가 필요하다.
292 | * 이때 POST 방식을 사용할 경우에 값(링크의 정보)이 Body에 있기 때문에 URL만 전달할 수 없으므로 GET 방식을 사용해야한다. 그러나 글을 저장하는 경우에는 URL을 제공할 필요가 없기 때문에 POST 방식을 사용한다.
293 |
294 |
295 |
296 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
297 | > - [https://blog.outsider.ne.kr/312](https://blog.outsider.ne.kr/312)
298 | > - [https://hongsii.github.io/2017/08/02/what-is-the-difference-get-and-post/](https://hongsii.github.io/2017/08/02/what-is-the-difference-get-and-post/)
299 | > - [https://www.w3schools.com/tags/ref_httpmethods.asp](https://www.w3schools.com/tags/ref_httpmethods.asp)
300 |
301 | ---
302 |
303 | ### 쿠키와 세션
304 |  305 |
306 | * HTTP의 특징과 쿠키와 세션을 사용하는 이유
307 | * HTTP 프로토콜의 특징이자 약점을 보완하기 위해서 사용한다.
308 | * HTTP 프로토콜 환경에서 서버는 클라이언트가 누구인지 확인해야한다. 그 이유는 HTTP 프로토콜이 connectionless, stateless한 특성이 있기 때문이다.
309 | * 비연결 지향(Connectionless)
310 | * 클라이언트가 요청을 한 후 응답을 받으면 그 연결을 끊어 버리는 특징
311 | * HTTP는 먼저 클라이언트가 request를 서버에 보내면, 서버는 클라이언트에게 요청에 맞는 response를 보내고 접속을 끊는 특성이 있다.
312 | * 헤더에 keep-alive라는 값을 줘서 커넥션을 재활용하는데 HTTP1.1에서는 이것이 디폴트다.
313 | * HTTP가 tcp위에서 구현되었기 때문에 (tcp는 연결지향,udp는 비연결지향) 네트워크 관점에서 keep-alive는 옵션으로 connectionless의 연결비용을 줄이는 것을 장점으로 비연결지향이라 한다.
314 | * 상태정보 유지 안 함(Stateless)
315 | * 통신이 끝나면 상태를 유지하지 않는 특징
316 | * 연결을 끊는 순간 클라이언트와 서버의 통신이 끝나며 상태 정보는 유지하지 않는 특성이 있다.
317 | * 쿠키와 세션은 위의 두 가지 특징을 해결하기 위해 사용한다.
318 | * 예를 들어, 쿠키와 세션을 사용하지 않으면 쇼핑몰에서 옷을 구매하려고 로그인을 했음에도, 페이지를 이동할 때 마다 계속 로그인을 해야 한다.
319 | * 쿠키와 세션을 사용했을 경우, 한 번 로그인을 하면 어떠한 방식에 의해서 그 사용자에 대한 인증을 유지하게 된다.
320 |
321 | * 쿠키 ( Cookie )
322 | * 쿠키란?
323 | * 쿠키는 클라이언트(브라우저) 로컬에 저장되는 키와 값이 들어있는 작은 데이터 파일이다.
324 | * 사용자 인증이 유효한 시간을 명시할 수 있으며, 유효 시간이 정해지면 브라우저가 종료되어도 인증이 유지된다는 특징이 있다.
325 | * 쿠키는 클라이언트의 상태 정보를 로컬에 저장했다가 참조한다.
326 | * 클라이언트에 300개까지 쿠키저장 가능, 하나의 도메인당 20개의 값만 가질 수 있음, 하나의 쿠키값은 4KB까지 저장한다.
327 | * Response Header에 Set-Cookie 속성을 사용하면 클라이언트에 쿠키를 만들 수 있다.
328 | * 쿠키는 사용자가 따로 요청하지 않아도 브라우저가 Request시에 Request Header를 넣어서 자동으로 서버에 전송한다.
329 | * 쿠키의 구성 요소
330 | * 이름 : 각각의 쿠키를 구별하는 데 사용되는 이름
331 | * 값 : 쿠키의 이름과 관련된 값
332 | * 유효시간 : 쿠키의 유지시간
333 | * 도메인 : 쿠키를 전송할 도메인
334 | * 경로 : 쿠키를 전송할 요청 경로
335 | * 쿠키의 동작 방식
336 | * 클라이언트가 페이지를 요청
337 | * 서버에서 쿠키를 생성
338 | * HTTP 헤더에 쿠키를 포함 시켜 응답
339 | * 브라우저가 종료되어도 쿠키 만료 기간이 있다면 클라이언트에서 보관하고 있음
340 | * 같은 요청을 할 경우 HTTP 헤더에 쿠키를 함께 보냄
341 | * 서버에서 쿠키를 읽어 이전 상태 정보를 변경 할 필요가 있을 때 쿠키를 업데이트 하여 변경된 쿠키를 HTTP 헤더에 포함시켜 응답
342 | * 쿠키의 사용 예
343 | * 방문 사이트에서 로그인 시, "아이디와 비밀번호를 저장하시겠습니까?"
344 | * 쇼핑몰의 장바구니 기능
345 | * 자동로그인, 팝업에서 "오늘 더 이상 이 창을 보지 않음" 체크, 쇼핑몰의 장바구니
346 |
347 | * 세션 ( Session )
348 | * 세션이란?
349 | * 세션은 쿠키를 기반하고 있지만, 사용자 정보 파일을 브라우저에 저장하는 쿠키와 달리 세션은 서버 측에서 관리한다.
350 | * 서버에서는 클라이언트를 구분하기 위해 세션 ID를 부여하며 웹 브라우저가 서버에 접속해서 브라우저를 종료할 때까지 인증상태를 유지한다.
351 | * 물론 접속 시간에 제한을 두어 일정 시간 응답이 없다면 정보가 유지되지 않게 설정이 가능하다.
352 | * 사용자에 대한 정보를 서버에 두기 때문에 쿠키보다 보안에 좋지만, 사용자가 많아질수록 서버 메모리를 많이 차지하게 된다.
353 | * 즉 동접자 수가 많은 웹 사이트인 경우 서버에 과부하를 주게 되므로 성능 저하의 요인이 된다.
354 | * 클라이언트가 Request를 보내면, 해당 서버의 엔진이 클라이언트에게 유일한 ID를 부여하는데 이것이 세션ID다.
355 | * 세션의 동작 방식
356 | * 클라이언트가 서버에 접속 시 세션 ID를 발급받는다.
357 | * 클라이언트는 세션 ID에 대해 쿠키를 사용해서 저장하고 가지고 있다.
358 | * 클라리언트는 서버에 요청할 때, 이 쿠키의 세션 ID를 서버에 전달해서 사용한다.
359 | * 서버는 세션 ID를 전달 받아서 별다른 작업없이 세션 ID로 세션에 있는 클라언트 정보를 가져온다.
360 | * 클라이언트 정보를 가지고 서버 요청을 처리하여 클라이언트에게 응답한다.
361 | * 세션의 특징
362 | * 각 클라이언트에게 고유 ID를 부여
363 | * 세션 ID로 클라이언트를 구분해서 클라이언트의 요구에 맞는 서비스를 제공
364 | * 보안 면에서 쿠키보다 우수
365 | * 사용자가 많아질수록 서버 메모리를 많이 차지하게 됨
366 | * 세션의 사용 예
367 | * 로그인 같이 보안상 중요한 작업을 수행할 때 사용
368 |
369 | * 쿠키와 세션의 차이
370 | * 쿠키와 세션은 비슷한 역할을 하며, 동작원리도 비슷하다. 그 이유는 세션도 결국 쿠키를 사용하기 때문이다.
371 | * 가장 큰 차이점은 사용자의 정보가 저장되는 위치이다. 때문에 쿠키는 서버의 자원을 전혀 사용하지 않으며, 세션은 서버의 자원을 사용한다.
372 | * 보안 면에서 세션이 더 우수하며, 요청 속도는 쿠키가 세션보다 더 빠르다. 그 이유는 세션은 서버의 처리가 필요하기 때문이다.
373 | * 보안, 쿠키는 클라이언트 로컬에 저장되기 때문에 변질되거나 request에서 스니핑 당할 우려가 있어서 보안에 취약하지만 세션은 쿠키를 이용해서 sessionid 만 저장하고 그것으로 구분해서 서버에서 처리하기 때문에 비교적 보안성이 좋다.
374 | * 라이프 사이클, 쿠키도 만료시간이 있지만 파일로 저장되기 때문에 브라우저를 종료해도 계속해서 정보가 남아 있을 수 있다. 또한 만료기간을 넉넉하게 잡아두면 쿠키삭제를 할 때 까지 유지될 수도 있다.
375 | * 반면에 세션도 만료시간을 정할 수 있지만 브라우저가 종료되면 만료시간에 상관없이 삭제된다.
376 | * 속도, 쿠키에 정보가 있기 때문에 서버에 요청시 속도가 빠르고 세션은 정보가 서버에 있기 때문에 처리가 요구되어 비교적 느린 속도를 낸다.
377 | * 세션을 사용하면 좋은데 왜 쿠키를 사용할까?
378 | * 세션은 서버의 자원을 사용하기때문에 무분별하게 만들다보면 서버의 메모리가 감당할 수 없어질 수가 있고 속도가 느려질 수 있기 때문이다.
379 |
380 | * 쿠키/세션은 캐시와 엄연히 다르다!
381 | * 캐시는 이미지나 css, js파일 등을 브라우저나 서버 앞 단에 저장해놓고 사용하는 것이다.
382 | * 한번 캐시에 저장되면 브라우저를 참고하기 때문에 서버에서 변경이 되어도 사용자는 변경되지 않게 보일 수 있는데 이런 부분을 캐시를 지워주거나 서버에서 클라이언트로 응답을 보낼 때 header에 캐시 만료시간을 명시하는 방법등을 이용할 수 있다.
383 | * 보통 쿠키와 세션의 차이를 물어볼 때 저장위치와 보안에 대해서는 잘 말하는데 사실 중요한 것은 라이프사이클을 얘기하는 것이다.
384 |
385 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
386 | > - [https://interconnection.tistory.com/74](https://interconnection.tistory.com/74)
387 | > - [https://doooyeon.github.io/2018/09/10/cookie-and-session.html](https://doooyeon.github.io/2018/09/10/cookie-and-session.html)
388 |
--------------------------------------------------------------------------------
305 |
306 | * HTTP의 특징과 쿠키와 세션을 사용하는 이유
307 | * HTTP 프로토콜의 특징이자 약점을 보완하기 위해서 사용한다.
308 | * HTTP 프로토콜 환경에서 서버는 클라이언트가 누구인지 확인해야한다. 그 이유는 HTTP 프로토콜이 connectionless, stateless한 특성이 있기 때문이다.
309 | * 비연결 지향(Connectionless)
310 | * 클라이언트가 요청을 한 후 응답을 받으면 그 연결을 끊어 버리는 특징
311 | * HTTP는 먼저 클라이언트가 request를 서버에 보내면, 서버는 클라이언트에게 요청에 맞는 response를 보내고 접속을 끊는 특성이 있다.
312 | * 헤더에 keep-alive라는 값을 줘서 커넥션을 재활용하는데 HTTP1.1에서는 이것이 디폴트다.
313 | * HTTP가 tcp위에서 구현되었기 때문에 (tcp는 연결지향,udp는 비연결지향) 네트워크 관점에서 keep-alive는 옵션으로 connectionless의 연결비용을 줄이는 것을 장점으로 비연결지향이라 한다.
314 | * 상태정보 유지 안 함(Stateless)
315 | * 통신이 끝나면 상태를 유지하지 않는 특징
316 | * 연결을 끊는 순간 클라이언트와 서버의 통신이 끝나며 상태 정보는 유지하지 않는 특성이 있다.
317 | * 쿠키와 세션은 위의 두 가지 특징을 해결하기 위해 사용한다.
318 | * 예를 들어, 쿠키와 세션을 사용하지 않으면 쇼핑몰에서 옷을 구매하려고 로그인을 했음에도, 페이지를 이동할 때 마다 계속 로그인을 해야 한다.
319 | * 쿠키와 세션을 사용했을 경우, 한 번 로그인을 하면 어떠한 방식에 의해서 그 사용자에 대한 인증을 유지하게 된다.
320 |
321 | * 쿠키 ( Cookie )
322 | * 쿠키란?
323 | * 쿠키는 클라이언트(브라우저) 로컬에 저장되는 키와 값이 들어있는 작은 데이터 파일이다.
324 | * 사용자 인증이 유효한 시간을 명시할 수 있으며, 유효 시간이 정해지면 브라우저가 종료되어도 인증이 유지된다는 특징이 있다.
325 | * 쿠키는 클라이언트의 상태 정보를 로컬에 저장했다가 참조한다.
326 | * 클라이언트에 300개까지 쿠키저장 가능, 하나의 도메인당 20개의 값만 가질 수 있음, 하나의 쿠키값은 4KB까지 저장한다.
327 | * Response Header에 Set-Cookie 속성을 사용하면 클라이언트에 쿠키를 만들 수 있다.
328 | * 쿠키는 사용자가 따로 요청하지 않아도 브라우저가 Request시에 Request Header를 넣어서 자동으로 서버에 전송한다.
329 | * 쿠키의 구성 요소
330 | * 이름 : 각각의 쿠키를 구별하는 데 사용되는 이름
331 | * 값 : 쿠키의 이름과 관련된 값
332 | * 유효시간 : 쿠키의 유지시간
333 | * 도메인 : 쿠키를 전송할 도메인
334 | * 경로 : 쿠키를 전송할 요청 경로
335 | * 쿠키의 동작 방식
336 | * 클라이언트가 페이지를 요청
337 | * 서버에서 쿠키를 생성
338 | * HTTP 헤더에 쿠키를 포함 시켜 응답
339 | * 브라우저가 종료되어도 쿠키 만료 기간이 있다면 클라이언트에서 보관하고 있음
340 | * 같은 요청을 할 경우 HTTP 헤더에 쿠키를 함께 보냄
341 | * 서버에서 쿠키를 읽어 이전 상태 정보를 변경 할 필요가 있을 때 쿠키를 업데이트 하여 변경된 쿠키를 HTTP 헤더에 포함시켜 응답
342 | * 쿠키의 사용 예
343 | * 방문 사이트에서 로그인 시, "아이디와 비밀번호를 저장하시겠습니까?"
344 | * 쇼핑몰의 장바구니 기능
345 | * 자동로그인, 팝업에서 "오늘 더 이상 이 창을 보지 않음" 체크, 쇼핑몰의 장바구니
346 |
347 | * 세션 ( Session )
348 | * 세션이란?
349 | * 세션은 쿠키를 기반하고 있지만, 사용자 정보 파일을 브라우저에 저장하는 쿠키와 달리 세션은 서버 측에서 관리한다.
350 | * 서버에서는 클라이언트를 구분하기 위해 세션 ID를 부여하며 웹 브라우저가 서버에 접속해서 브라우저를 종료할 때까지 인증상태를 유지한다.
351 | * 물론 접속 시간에 제한을 두어 일정 시간 응답이 없다면 정보가 유지되지 않게 설정이 가능하다.
352 | * 사용자에 대한 정보를 서버에 두기 때문에 쿠키보다 보안에 좋지만, 사용자가 많아질수록 서버 메모리를 많이 차지하게 된다.
353 | * 즉 동접자 수가 많은 웹 사이트인 경우 서버에 과부하를 주게 되므로 성능 저하의 요인이 된다.
354 | * 클라이언트가 Request를 보내면, 해당 서버의 엔진이 클라이언트에게 유일한 ID를 부여하는데 이것이 세션ID다.
355 | * 세션의 동작 방식
356 | * 클라이언트가 서버에 접속 시 세션 ID를 발급받는다.
357 | * 클라이언트는 세션 ID에 대해 쿠키를 사용해서 저장하고 가지고 있다.
358 | * 클라리언트는 서버에 요청할 때, 이 쿠키의 세션 ID를 서버에 전달해서 사용한다.
359 | * 서버는 세션 ID를 전달 받아서 별다른 작업없이 세션 ID로 세션에 있는 클라언트 정보를 가져온다.
360 | * 클라이언트 정보를 가지고 서버 요청을 처리하여 클라이언트에게 응답한다.
361 | * 세션의 특징
362 | * 각 클라이언트에게 고유 ID를 부여
363 | * 세션 ID로 클라이언트를 구분해서 클라이언트의 요구에 맞는 서비스를 제공
364 | * 보안 면에서 쿠키보다 우수
365 | * 사용자가 많아질수록 서버 메모리를 많이 차지하게 됨
366 | * 세션의 사용 예
367 | * 로그인 같이 보안상 중요한 작업을 수행할 때 사용
368 |
369 | * 쿠키와 세션의 차이
370 | * 쿠키와 세션은 비슷한 역할을 하며, 동작원리도 비슷하다. 그 이유는 세션도 결국 쿠키를 사용하기 때문이다.
371 | * 가장 큰 차이점은 사용자의 정보가 저장되는 위치이다. 때문에 쿠키는 서버의 자원을 전혀 사용하지 않으며, 세션은 서버의 자원을 사용한다.
372 | * 보안 면에서 세션이 더 우수하며, 요청 속도는 쿠키가 세션보다 더 빠르다. 그 이유는 세션은 서버의 처리가 필요하기 때문이다.
373 | * 보안, 쿠키는 클라이언트 로컬에 저장되기 때문에 변질되거나 request에서 스니핑 당할 우려가 있어서 보안에 취약하지만 세션은 쿠키를 이용해서 sessionid 만 저장하고 그것으로 구분해서 서버에서 처리하기 때문에 비교적 보안성이 좋다.
374 | * 라이프 사이클, 쿠키도 만료시간이 있지만 파일로 저장되기 때문에 브라우저를 종료해도 계속해서 정보가 남아 있을 수 있다. 또한 만료기간을 넉넉하게 잡아두면 쿠키삭제를 할 때 까지 유지될 수도 있다.
375 | * 반면에 세션도 만료시간을 정할 수 있지만 브라우저가 종료되면 만료시간에 상관없이 삭제된다.
376 | * 속도, 쿠키에 정보가 있기 때문에 서버에 요청시 속도가 빠르고 세션은 정보가 서버에 있기 때문에 처리가 요구되어 비교적 느린 속도를 낸다.
377 | * 세션을 사용하면 좋은데 왜 쿠키를 사용할까?
378 | * 세션은 서버의 자원을 사용하기때문에 무분별하게 만들다보면 서버의 메모리가 감당할 수 없어질 수가 있고 속도가 느려질 수 있기 때문이다.
379 |
380 | * 쿠키/세션은 캐시와 엄연히 다르다!
381 | * 캐시는 이미지나 css, js파일 등을 브라우저나 서버 앞 단에 저장해놓고 사용하는 것이다.
382 | * 한번 캐시에 저장되면 브라우저를 참고하기 때문에 서버에서 변경이 되어도 사용자는 변경되지 않게 보일 수 있는데 이런 부분을 캐시를 지워주거나 서버에서 클라이언트로 응답을 보낼 때 header에 캐시 만료시간을 명시하는 방법등을 이용할 수 있다.
383 | * 보통 쿠키와 세션의 차이를 물어볼 때 저장위치와 보안에 대해서는 잘 말하는데 사실 중요한 것은 라이프사이클을 얘기하는 것이다.
384 |
385 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/jihyuno301/tech-interview/blob/master/README.md) :information_source:[Home](https://github.com/jihyuno301/tech-interview)
386 | > - [https://interconnection.tistory.com/74](https://interconnection.tistory.com/74)
387 | > - [https://doooyeon.github.io/2018/09/10/cookie-and-session.html](https://doooyeon.github.io/2018/09/10/cookie-and-session.html)
388 |
--------------------------------------------------------------------------------