├── .gitignore
├── README.md
├── SUMMARY.md
├── _config.yml
├── docs
├── assets
│ ├── css
│ │ └── main.css
│ └── js
│ │ └── jquery.min.js
└── index.html
├── markdown
├── chap01
│ ├── chap01_introduction.md
│ ├── chap01_negativetransfer.md
│ ├── chap01_tlvsml.md
│ └── chap01_whytransfer.md
├── chap02
│ └── chap02_research_area.md
├── chap03
│ └── chap03_application.md
├── chap04
│ ├── chap04_basic.md
│ ├── chap04_formulation.md
│ ├── chap04_metric.md
│ ├── chap04_overview.md
│ └── chap04_theory.md
├── chap05
│ └── chap05_method.md
├── chap06
│ ├── chap06_conditional.md
│ ├── chap06_distribution.md
│ ├── chap06_dynamic.md
│ ├── chap06_joint.md
│ └── chap06_marginal.md
├── chap07
│ └── chap07_featureselect.md
├── chap08
│ ├── chap08_manifold.md
│ ├── chap08_statistics.md
│ └── chap08_subspace.md
├── chap09
│ ├── chap09_adversarial.md
│ ├── chap09_deep.md
│ ├── chap09_deepmethod.md
│ ├── chap09_deeptransfer.md
│ └── chap09_finetune.md
├── chap10
│ ├── chap10_adversarial.md
│ ├── chap10_deep.md
│ ├── chap10_finetune.md
│ ├── chap10_practice.md
│ ├── chap10_tcamatlab.md
│ └── chap10_tcapython.md
├── chap11
│ └── chap11_future.md
├── chap12
│ └── chap12_conclusion.md
├── chap13
│ ├── chap13_appendix.md
│ └── chap13_data.md
└── index.md
├── shou-ce-shuo-ming.md
├── src
├── chaps
│ ├── ch00_prefix.tex
│ ├── ch01_introduction.tex
│ ├── ch02_research_area.tex
│ ├── ch03_application.tex
│ ├── ch04_basic.tex
│ ├── ch05_method.tex
│ ├── ch06_distributionadapt.tex
│ ├── ch07_featureselect.tex
│ ├── ch08_subspacelearn.tex
│ ├── ch09_deep.tex
│ ├── ch10_practice.tex
│ ├── ch11_future.tex
│ ├── ch12_conclusion.tex
│ ├── ch13_appendix.tex
│ └── combine.tex
├── figures
│ ├── fig-8_1.pdf
│ ├── fig-8_2.pdf
│ ├── fig-8_3.pdf
│ ├── fig-app-all.pdf
│ ├── fig-app-cv.pdf
│ ├── fig-app-location.pdf
│ ├── fig-app-text.pdf
│ ├── fig-app-time.pdf
│ ├── fig-area.pdf
│ ├── fig-deep-84.pdf
│ ├── fig-deep-adabn.pdf
│ ├── fig-deep-compare.pdf
│ ├── fig-deep-dan.pdf
│ ├── fig-deep-ddc.pdf
│ ├── fig-deep-dsn.pdf
│ ├── fig-deep-finetune.pdf
│ ├── fig-deep-jan.pdf
│ ├── fig-deep-partial.pdf
│ ├── fig-deep-softlabel.pdf
│ ├── fig-deep-tzeng2015.pdf
│ ├── fig-distribution-bdammd.pdf
│ ├── fig-distribution-daan.png
│ ├── fig-distribution-deep.pdf
│ ├── fig-distribution-mu.pdf
│ ├── fig-distribution-source.pdf
│ ├── fig-distribution-stl.pdf
│ ├── fig-distribution-target1.pdf
│ ├── fig-distribution-target2.pdf
│ ├── fig-distribution-tca.pdf
│ ├── fig-feature-pivot.pdf
│ ├── fig-feature.pdf
│ ├── fig-future-ddtl.pdf
│ ├── fig-future-l2t.pdf
│ ├── fig-future-labelfree.pdf
│ ├── fig-introduction-bigdata.pdf
│ ├── fig-introduction-coldstart.pdf
│ ├── fig-introduction-data.pdf
│ ├── fig-introduction-example.pdf
│ ├── fig-introduction-model.pdf
│ ├── fig-introduction-negativetransfer.pdf
│ ├── fig-introduction-transfer.pdf
│ ├── fig-method-feature.pdf
│ ├── fig-method-instance.pdf
│ ├── fig-method-model.pdf
│ ├── fig-method-relation.pdf
│ ├── fig-method-relation2.pdf
│ ├── fig-subspace-deepcoral.pdf
│ ├── fig-subspace-earth.pdf
│ ├── fig-subspace-gfk.pdf
│ ├── fig-subspace-sda.pdf
│ ├── fig-subspace-sgf.pdf
│ ├── fig-whydeep.pdf
│ ├── l1sys.pdf
│ └── png
│ │ ├── fig-8_1.png
│ │ ├── fig-8_2.png
│ │ ├── fig-8_3.png
│ │ ├── fig-app-all.png
│ │ ├── fig-app-cv.png
│ │ ├── fig-app-location.png
│ │ ├── fig-app-text.png
│ │ ├── fig-app-time.png
│ │ ├── fig-area.png
│ │ ├── fig-dda.png
│ │ ├── fig-deep-84.png
│ │ ├── fig-deep-adabn.png
│ │ ├── fig-deep-compare.png
│ │ ├── fig-deep-dan.png
│ │ ├── fig-deep-ddc.png
│ │ ├── fig-deep-dsn.png
│ │ ├── fig-deep-finetune.png
│ │ ├── fig-deep-jan.png
│ │ ├── fig-deep-partial.png
│ │ ├── fig-deep-softlabel.png
│ │ ├── fig-deep-tzeng2015.png
│ │ ├── fig-distribution-bdammd.png
│ │ ├── fig-distribution-deep.png
│ │ ├── fig-distribution-mu.png
│ │ ├── fig-distribution-overview.jpg
│ │ ├── fig-distribution-source.png
│ │ ├── fig-distribution-stl.png
│ │ ├── fig-distribution-target1.png
│ │ ├── fig-distribution-target2.png
│ │ ├── fig-distribution-tca.png
│ │ ├── fig-feature-pivot.png
│ │ ├── fig-feature.png
│ │ ├── fig-future-ddtl.png
│ │ ├── fig-future-l2t.png
│ │ ├── fig-future-labelfree.png
│ │ ├── fig-introduction-bigdata.png
│ │ ├── fig-introduction-coldstart.png
│ │ ├── fig-introduction-data.png
│ │ ├── fig-introduction-example.png
│ │ ├── fig-introduction-model.png
│ │ ├── fig-introduction-negativetransfer.png
│ │ ├── fig-introduction-transfer.png
│ │ ├── fig-method-feature.png
│ │ ├── fig-method-instance.png
│ │ ├── fig-method-model.png
│ │ ├── fig-method-relation.png
│ │ ├── fig-method-relation2.png
│ │ ├── fig-subspace-deepcoral.png
│ │ ├── fig-subspace-earth.png
│ │ ├── fig-subspace-gfk.png
│ │ ├── fig-subspace-sda.png
│ │ ├── fig-subspace-sgf.png
│ │ ├── fig-whydeep.png
│ │ ├── gitbook_first.png
│ │ └── l1sys.png
├── main.tex
├── main.toc
├── makepdf_mac.sh
├── pdf2img.py
└── refs.bib
├── web
├── assets
│ ├── css
│ │ └── main.css
│ └── js
│ │ └── jquery.min.js
└── transfer_tutorial.html
├── xie-zai-qian-mian.md
└── zhi-xie.md
/.gitignore:
--------------------------------------------------------------------------------
1 | ## Core latex/pdflatex auxiliary files:
2 | *.aux
3 | *.lof
4 | *.log
5 | *.lot
6 | *.fls
7 | *.out
8 | *.toc
9 | *.fmt
10 | *.fot
11 | *.cb
12 | *.cb2
13 | *.xdv
14 |
15 | ## Bibliography auxiliary files (bibtex/biblatex/biber):
16 | *.bbl
17 | *.bcf
18 | *.blg
19 | *-blx.aux
20 | *-blx.bib
21 | *.run.xml
22 |
23 | ## Build tool auxiliary files:
24 | *.fdb_latexmk
25 | *.synctex
26 | *.synctex(busy)
27 | *.synctex.gz
28 | *.synctex.gz(busy)
29 | *.pdfsync
30 |
31 | # auto folder when using emacs and auctex
32 | ./auto/*
33 | *.el
34 |
35 | # PDF
36 | *.pdf
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 《迁移学习简明手册》
2 |
3 | [](https://opensource.org/licenses/MIT) [](https://github.com/jindongwang/transferlearning-tutorial) [](https://github.com/jindongwang/transferlearning-tutorial/issues) 
4 |
5 | 这是《迁移学习简明手册》的LaTex源码。欢迎有兴趣的学者一起来贡献维护。
6 |
7 | ## News
8 |
9 | This repo is not maintained anymore since our latest efforts have been organized into a book called Introduction to Transfer learning, both has [English](https://link.springer.com/book/9789811975837) version and [Chinese](https://zhuanlan.zhihu.com/p/374927278) version. The homepage for the book is: https://jd92.wang/tlbook/.
10 |
11 | 
12 |
13 | This open-source version will be here forever. But this is significantly different from the book. So if you like it, you can buy the book.
14 |
15 |
16 | ## The following are deprecated.
17 |
18 | ### 意见与建议
19 |
20 | 对于不足和错误之处,以及新的意见,欢迎到[这里](https://github.com/jindongwang/transferlearning-tutorial/issues/6)留言!
21 |
22 | #### 引用
23 |
24 | 可以按如下方式进行引用:
25 |
26 | Jindong Wang et al. Transfer Learning Tutorial. 2018.
27 |
28 | 王晋东等. 迁移学习简明手册. 2018.
29 |
30 | **BibTeX**
31 |
32 | ```text
33 | @misc{WangTLTutorial2018,
34 | Author = {Jindon Wang et al.},
35 | Title = {Transfer Learning Tutorial},
36 | Url = {https://github.com/jindongwang/transferlearning-tutorial},
37 | Year = {2018},
38 | }
39 |
40 | @misc{WangTLTutorial2018cn,
41 | Author = {王晋东等},
42 | Title = {迁移学习简明手册},
43 | Url = {https://github.com/jindongwang/transferlearning-tutorial},
44 | Year = {2018},
45 | }
46 | ```
47 |
48 | ### 参与贡献方式
49 |
50 | 以下部分为参与贡献的详细说明。
51 |
52 | #### 在线编译 \(推荐\)
53 |
54 | 直接通过pull request的方式在`markdown`文件夹中修改。修改通过后,GitBook会自动更新。
55 |
56 | #### 本地编译方式
57 |
58 | * 在任何装有较新版TexLive的电脑上,首先选择`xelatex`引擎进行第一次编译
59 | * 再选择`BibTeX`编译一次生成参考文献
60 | * 最后选择`xelatex`引擎进行第三次编译即可生成带书签的PDF文档
61 |
62 | #### 主要文件介绍
63 |
64 | 以下是本手册的主要文件与其内容介绍:
65 |
66 | | 章节 | 名称 | 文件名 | 内容 | 状态 |
67 | | :---: | :---: | :---: | :---: | :---: |
68 | | 主文件 | .. | main.tex | 题目、摘要、推荐语、目录、文件组织 | V1.0 |
69 | | 写在前面等 | .. | prefix.tex | 写在前面、致谢、说明 | V1.0 |
70 | | 第1章 | 迁移学习基本概念 | introduction.tex | 迁移学习基本介绍 | V1.0 |
71 | | 第2章 | 迁移学习的研究领域 | research\_area.tex | 研究领域 | V1.0 |
72 | | 第3章 | 迁移学习的应用 | application.tex | 应用 | V1.0 |
73 | | 第4章 | 基础知识 | basic.tex | 基础知识 | V1.0 |
74 | | 第5章 | 迁移学习的基本方法 | method.tex | 四类基本方法 | V1.0 |
75 | | 第6章 | 第一类方法:数据分布自适应 | distributionadapt.tex | 数据分布自适应 | V1.0 |
76 | | 第7章 | 第二类方法:特征选择 | featureselect.tex | 特征选择 | V1.0 |
77 | | 第8章 | 第三类方法:子空间学习 | subspacelearn.tex | 子空间学习法 | V1.0 |
78 | | 第9章 | 深度迁移学习 | deep.tex | 深度和对抗迁移方法 | V1.0 |
79 | | 第10章 | 上手实践 | practice.tex | 实践教程 | V1.0 |
80 | | 第11章 | 迁移学习前沿 | future.tex | 展望 | V1.0 |
81 | | 第12章 | 总结语 | conclusion | 总结 | V1.0 |
82 | | 第13章 | 附录 | appendix.tex | 附录 | V1.0 |
83 |
84 | 所有的源码均在`src`目录下。其中,除去主文件`main.tex`外,所有章节都在`chaps/`文件夹下。
85 |
86 | 所有的图片都在`figures/`文件夹下。推荐实用eps或pdf格式高清文件。
87 |
88 | 参考文献采用`bibtex`方式,见`refs.bib`文件。
89 |
90 | #### 未来计划
91 |
92 | * [ ] 丰富和完善现有的V1.0
93 | * [ ] 单独写一章介绍基于实例的迁移学习方法\(instance-based\),以及相关的instance selection method,如比较经典的tradaboost等
94 | * [ ] 深度和对抗迁移学习方法分成两章,再结合有关文献进行补充
95 | * [ ] 上手实践部分增加对深度方法的说明
96 | * [ ] ……
97 |
98 | #### 参与方式
99 |
100 | 欢迎有兴趣的学者一起加入,让手册更完善!现阶段有2个branch:master用于开发和完善,V1.0是稳定的1.0版本。后续可根据进度增加更多的branch。
101 |
102 | 具体参与方式:
103 |
104 | * 在[这个issue](https://github.com/jindongwang/transferlearning-tutorial/issues/1)下留言你的Github账号和邮箱,我将你添加到协作者中
105 | * 直接fork,然后将你的修改提交pull request
106 | * 如果不熟悉git,可直接下载本目录,然后将你修改的部分发给我\(jindongwang@outlook.com\)
107 | * 有任何问题,均可以提交issue
108 |
109 | 贡献之后:
110 |
111 | * 在下面的贡献者信息中加入自己的信息。
112 | * 如果是对错误的更正,在`web/transfer_tutorial.html`中的"勘误表"部分加入勘误信息。
113 |
114 | #### 如何提交 Pull Request
115 |
116 | **准备工作**
117 |
118 | 1. 在原始代码库上点 Fork ,在自己的账户下开一个分支代码库
119 | 2. 将自己的分支克隆到本地
120 | * `git clone https://github.com/(YOUR_GIT_NAME)/transferlearning-tutorial.git`
121 | 3. 将本机自己的 fork 的代码库和 GitHub 上原始作者的代码库 ,即上游( upstream )连接起来
122 | * `git remote add upstream https://github.com/jindongwang/transferlearning-tutorial.git`
123 |
124 | **提交代码**
125 |
126 | 1. 每次修改之前,先将自己的本地分支同步到上游分支的最新状态
127 | * `git pull upstream master`
128 | 2. 作出修改后 push 到自己名下的代码库
129 | 3. 在 GitHub 网页端自己的账户下看到最新修改后点击 New pull request 即可
130 |
131 | #### 贡献者信息
132 |
133 | * [@jindongwang](https://github.com/jindongwang) 王晋东,中国科学院计算技术研究所
134 | * [@Godblesswz](https://github.com/Godblesswz) 万震,重庆大学
135 |
136 |
--------------------------------------------------------------------------------
/SUMMARY.md:
--------------------------------------------------------------------------------
1 | # Table of contents
2 |
3 | * [迁移学习简明手册](markdown/index.md)
4 | * [写在前面](xie-zai-qian-mian.md)
5 | * [致谢](zhi-xie.md)
6 | * [手册说明](shou-ce-shuo-ming.md)
7 |
8 | ## 第1章 迁移学习基本概念
9 |
10 | * [基本概念](markdown/chap01/chap01_introduction.md)
11 | * [为什么需要迁移学习](markdown/chap01/chap01_whytransfer.md)
12 | * [与已有概念的区别和联系](markdown/chap01/chap01_tlvsml.md)
13 | * [负迁移](markdown/chap01/chap01_negativetransfer.md)
14 |
15 | ## 第2章 迁移学习研究领域
16 | * [研究领域](markdown/chap02/chap02_research_area.md)
17 |
18 | ## 第3章 迁移学习的应用
19 | * [迁移学习的应用](markdown/chap03/chap03_application.md)
20 |
21 | ## 第4章 基础知识
22 | * [基础知识](markdown/chap04/chap04_basic.md)
23 | * [迁移学习问题形式化](markdown/chap04/chap04_formulation.md)
24 | * [总体思路](markdown/chap04/chap04_overview.md)
25 | * [度量准则](markdown/chap04/chap04_metric.md)
26 | * [理论知识](markdown/chap04/chap04_theory.md)
27 |
28 | ## 第5章 迁移学习基本方法
29 | * [迁移学习基本方法](markdown/chap05/chap05_method.md)
30 |
31 | ## 第6章 数据分布自适应方法
32 | * [总体思路](markdown/chap06/chap06_distribution.md)
33 | * [边缘分布自适应](markdown/chap06/chap06_marginal.md)
34 | * [条件分布自适应](markdown/chap06/chap06_conditional.md)
35 | * [联合分布自适应](markdown/chap06/chap06_joint.md)
36 | * [动态分布自适应](markdown/chap06/chap06_dynamic.md)
37 |
38 | ## 第7章 特征选择法
39 | * [特征选择法](markdown/chap07/chap07_featureselect.md)
40 |
41 | ## 第8章 子空间学习法
42 | * [子空间学习法](markdown/chap08/chap08_subspace.md)
43 | * [统计特征对齐](markdown/chap08/chap08_statistics.md)
44 | * [流形学习](markdown/chap08/chap08_manifold.md)
45 |
46 | ## 第9章 深度迁移学习
47 | * [深度迁移学习](markdown/chap09/chap09_deep.md)
48 | * [深度网络的可迁移性](markdown/chap09/chap09_deeptransfer.md)
49 | * [最简单的深度迁移:预训练与微调](markdown/chap09/chap08_finetune.md)
50 | * [深度迁移学习方法](markdown/chap09/chap09_deepmethod.md)
51 | * [深度对抗迁移方法](markdown/chap09/chap09_adversarial.md)
52 |
53 | ## 第10章 上手实践
54 | * [上手实践](markdown/chap10/chap10_practice.md)
55 | * [TCA方法Matlab实现](markdown/chap10/chap10_tcamatlab.md)
56 | * [TCA方法Python实现](markdown/chap10/chap10_tcapython.md)
57 | * [预训练finetune实现](markdown/chap10/chap10_finetune.md)
58 | * [深度迁移学习实现](markdown/chap10/chap10_deep.md)
59 | * [对抗迁移学习实现](markdown/chap10/chap10_adversarial.md)
60 |
61 | ## 第11章 迁移学习前沿
62 | * [迁移学习前沿](markdown/chap11/chap11_future.md)
63 |
64 | ## 第12章 总结
65 | * [总结](markdown/chap12/chap12_conclusion.md)
66 |
67 | ## 第13章 附录
68 | * [附录](markdown/chap13/chap13_appendix.md)
69 | * [迁移学习著名学者](https://github.com/jindongwang/transferlearning/blob/master/doc/scholar_TL.md)
70 | * [迁移学习常用数据集和算法](markdown/chap13/chap13_data.md)
--------------------------------------------------------------------------------
/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-cayman
--------------------------------------------------------------------------------
/docs/assets/css/main.css:
--------------------------------------------------------------------------------
1 | body {
2 | line-height: 1.5;
3 | margin: 2% 10% 2% 10%;
4 | font-family: Arial;
5 | }
6 |
7 | .header {
8 | text-align: center;
9 | font-size: 22px;
10 | }
11 |
12 | .myicon {
13 | width: 100;
14 | float:left;
15 | margin-right: 15px;
16 | }
17 |
18 | .sectiontitle {
19 | font-size: 18px;
20 | font-weight: bold;
21 | }
22 |
23 | .sectioncontent {
24 | font-size: 16px;
25 | font-weight: normal;
26 |
27 | }
28 |
29 | .date {
30 | font-size: 14px;
31 | font-style: italic;
32 | }
33 |
34 | .email {
35 | font-size: 12px;
36 | }
37 |
38 | .appicon {
39 | width: 25;
40 | }
41 |
42 | .new{
43 | height: 20px;
44 | widows: 40px;
45 | }
46 |
47 | .author{
48 | color:#080808;
49 | }
50 |
51 | .venue{
52 | color:#080808;
53 | font-style: italic;
54 | }
55 |
56 | .article{
57 | color:#000000;
58 | font-weight: bold;
59 | }
60 |
61 | .image{
62 | height: 30px;
63 | width:30px;
64 | }
65 |
66 | a:link {
67 | color:#337ab7;
68 | text-decoration:none;
69 | }
70 |
71 | a:hover {
72 | color:#337adf;
73 | text-decoration:underline;
74 | }
75 |
76 | a:visited {
77 | color:#337ab7;
78 | text-decoration:none;
79 | }
80 |
81 | .category{
82 | color:#000000;
83 | font-weight: bold;
84 | font-size: 17px;
85 | }
--------------------------------------------------------------------------------
/docs/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 | 迁移学习导论
4 |
5 |
6 |
7 |
8 |
17 |
18 |
19 |
20 | 迁移学习导论
21 |  22 |
23 | 知乎介绍
24 |
25 | 购买链接
22 |
23 | 知乎介绍
24 |
25 | 购买链接
26 |
27 | 之前开源的手册:
28 |
29 | 迁移学习简明手册
30 |
31 |
32 |
33 |
34 |
35 | 摘要
36 |
37 |
38 | 迁移学习作为机器学习的一大分支,已经取得了长足的进步。本手册简明地介绍迁移学习的概念与基本方法,并对其中的领域自适应问题中的若干代表性方法进行讲述。最后简要探讨迁移学习未来可能的方向。本手册编写的目的是帮助迁移学习领域的初学者快速入门并掌握基本方法,为自己的研究和应用工作打下良好基础。
39 | 本手册的编写逻辑很简单:是什么——介绍迁移学习;为什么——为什么要用迁移学习、为什么能用;怎么办——如何进行迁移 (迁移学习方法)。其中,是什么和为什么解决概念问题,这是一切的前提;怎么办是我们的重点,也占据了最多的篇幅。为了最大限度地方便初学者,我们还特别编写了一章上手实践,直接分享实现代码和心得体会。
40 |
41 |
43 |
44 |
45 | 写在前面
46 |
47 |
48 | 一直以来都有这样的愿望:无论学习什么知识,总是希望可以快速准确地找到对应的有价值资源进行学习。我相信我们每个人都梦寐以求。然而,越来越多的学科,尤其是我目前从事的计算机科学、人工智能领域,当下正在飞速地发展着。太多的新知识都难以事半功倍地找到快速入手的教程。庄子曰: “吾生也有涯,而知也无涯。以有涯随无涯,殆已。”
49 |
50 | 我只是迁移学习领域一个很普通的博士生,也同样经历了由“一问三不知”到“稍稍理解”的艰难过程。我在 2016 年初入门迁移学习之时,迁移学习这个概念还未曾像今天一样炙手可热。当时所能找到的学习资源只有两种:别人已发表的论文和已做过的演讲。这些还是不够简单、不够直观。我需要从如此众多的材料中不断归纳,才能站在博士研究的那个圈子的边缘,以便将来可以做出一点点贡献,往圆圈外突破一点点。
51 |
52 | 相信不只是我,任何一个刚刚入门的学习者都会经历此过程。
53 |
54 | “沉舟侧畔千帆过,病树前头万木春。”
55 |
56 | 已所不欲,勿施于人。正是因为我在初学之时也经历过如此沮丧的时期,我才在 Github上对迁移学习进行了整理归纳,在知乎网上以“王晋东不在家”为名分享自己对于迁移学习和机器学习的理解和教训、在线上线下与大家讨论相关的问题。很欣慰的是,这些免费开放的资源或多或少地,帮助到了一些初学者,使他们更快速地步入迁移学习之门。
57 |
58 | 但这些还是不太够。 Github 上的资源模式已经固定,目前主要是进行日常更新,不断加入新的论文和代码。目前还是缺乏一个人人都能上手的初学者教程。也不只一次,有读者提问有没有相关的入门教程,能真正从0到1帮助初学者进行入门。
59 |
60 | 最近,南京大学博士(现任旷视科技南京研究院负责人)魏秀参学长写了一本《解析卷积神经网络—深度学习实践手册》,给很多深度学习的初学者提供了帮助。受他的启发,我也决定将自己在迁移学习领域的一些学习心得体会整理成一本手册,免费进行分享。希望能借此方式,帮助更多的初学者。 我们不谈风月,只谈干货。
61 |
62 | 我不是大佬,我也是迁移学习路上的一名小学生。迁移学习领域比我做的好的同龄人太多了。因此,不敢谈什么指导。所有的目的都仅为分享。
63 |
64 | 本手册在互联网上免费开放。随着作者理解的深入 (以及其他有意者的增补),本手册肯定会不断修改、越来越好。因此,我打算效仿软件的开发、采取版本更新的方式进行管理。
65 |
66 | 希望未来可以有更多的有志之士加入,让我们的教程日渐丰富。
67 |
68 |
70 |
71 |
80 |
81 |
82 |
83 | 勘误表
84 |
85 |
86 |
87 | -
88 | 4.1.1节最后一段最后一句话:“... 却并给出(也难以给出)P 的具体形式。” 应为: “... 却并未给出(也难以给出)P的具体形式。”
89 |
90 | -
91 | TCA的介绍中“TCA假设存在一个特征映射$\phi$,使得映射后数据的分布$P(\phi(\mathbf{x}_s)) \approx P(\phi(\mathbf{x}_s))$” 这里的公式应改为 “$P(\phi(\mathbf{x}_s)) \approx P(\phi(\mathbf{x}_t))$”
92 |
93 |
94 | -
95 | 图27名称应为”DeepCORAL方法示意图“
96 |
97 |
98 | -
99 | 公式6.18(JDA)的统一优化目标的分子项应该和6.17一样,原版本印刷错误
100 |
101 |
102 | -
103 | 人脸识别图像数据集这一小节中 “...按照不同的关照和曝光条件随机选出。“ 改为 “...光照和曝光条件...”
104 |
105 | -
106 | 9.3.3小节中“其核心在于,找到网络需要进行自适应层,并且对这些导加上自适应的损失度量” 改为 “其核心在于,找到网络需要进行自适应层,并且对这些层加上自适应的损失度量”
107 |
108 |
109 | -
110 | 公式4.19第二个指示函数中是否应该是η(xi)=1而不是η(xi)=0
111 |
112 |
113 | -
114 | 删除第14页余弦相似度引用文章。
115 |
116 |
117 | -
118 | 第11章终身迁移学习中,试验2000种灯泡材料,不是爱因斯坦说的,是爱迪生说的。
119 |
120 |
121 | -
122 | 第14页,公式4.3。闵可夫斯基距离公式应是范数||·||表示才对。
123 |
124 |
125 |
126 |
128 |
129 |
136 |
137 |
138 |
--------------------------------------------------------------------------------
/markdown/chap01/chap01_introduction.md:
--------------------------------------------------------------------------------
1 | # 第1章 迁移学习基本概念
2 |
3 | ## 引子
4 |
5 | 冬末春初,北京的天气渐渐暖了起来。这是一句再平常不过的气候描述。对于我们在北半球生活的人来说,这似乎是一个司空见惯的现象。北京如此,纽约如此,东京如此,巴黎也如此。
6 |
7 | 然而此刻,假如我问你,阿根廷的首都布宜诺斯艾利斯,天气如何?稍稍有点地理常识的人就该知道,阿根廷位于南半球,天气恰恰相反:正是夏末秋初的时候,天气渐渐凉了起来。
8 |
9 | 我们何以根据北京的天气来推测出纽约、东京和巴黎的天气?我们又何以不能用相同的方式来推测阿根廷的天气?
10 |
11 | 答案显而易见:因为它们的地理位置不同。除去阿根廷在南半球之外,其他几个城市均位于北半球,故而天气变化相似。
12 |
13 | 我们可以利用这些**地点和地理位置的相似性和差异性**,很容易地推测出其他地点的天气。
14 |
15 | 这样一个简单的事实,就引出了我们要介绍的主题:**迁移学习**。
16 |
17 | ## 迁移学习
18 |
19 | 迁移学习,顾名思义,就是要进行迁移。放到我们人工智能和机器学习的学科里讲,迁移学习是一种学习的思想和模式。
20 |
21 | 我们都对机器学习有了基本的了解。机器学习是人工智能的一大类重要方法,也是目前发展最迅速、效果最显著的方法。机器学习解决的是让机器自主地从数据中获取知识,从而应用于新的问题中。迁移学习作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。
22 |
23 | 迁移学习的核心问题是,找到新问题和原问题之间的相似性,才可以顺利地实现知识的迁移。比如在我们一开始说的天气问题中,那些北半球的天气之所以相似,是因为它们的地理位置相似;而南北半球的天气之所以有差异,也是因为地理位置有根本不同。
24 |
25 | 其实我们人类对于迁移学习这种能力,是与生俱来的。比如,我们如果已经会打乒乓球,就可以类比着学习打网球。再比如,我们如果已经会下中国象棋,就可以类比着下国际象棋。因为这些活动之间,往往有着极高的相似性。生活中常用的“**举一反三**”、“**照猫画虎**”就很好地体现了迁移学习的思想。
26 |
27 | 回到我们的问题中来。我们用更加学术更加机器学习的语言来对迁移学习下一个定义。迁移学习,是指利用数据、任务、或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。
28 |
29 | 迁移学习最权威的综述文章是香港科技大学杨强教授团队的[A survey on transfer learning](https://ieeexplore.ieee.org/abstract/document/5288526/)。
30 |
31 | 下图简要表示了一个迁移学习过程。
32 |
33 | 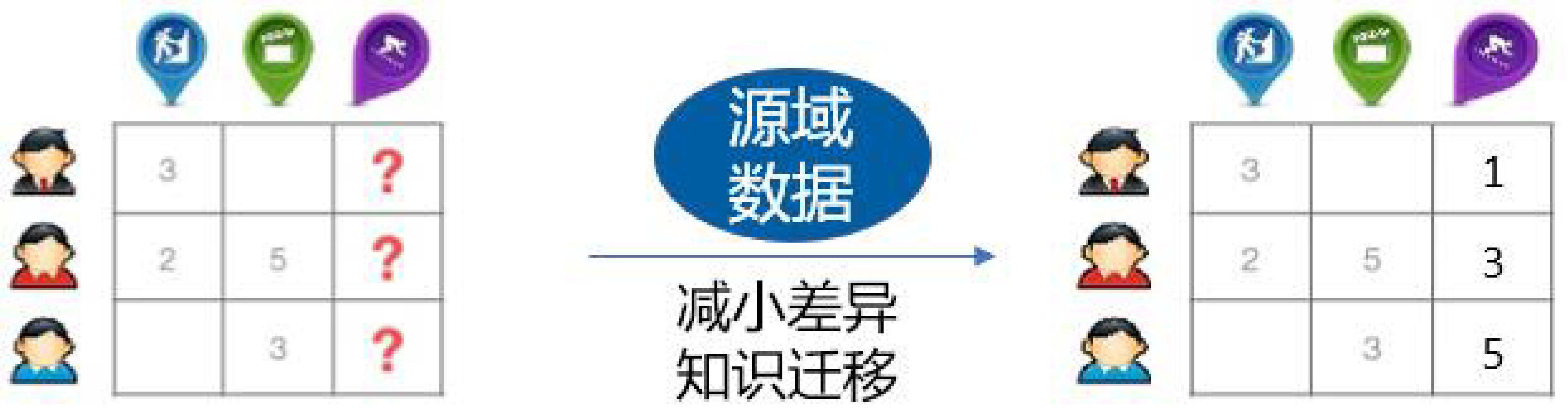
34 |
35 | 下图展示了生活中常见的迁移学习的例子。
36 |
37 | 
38 |
39 | 值得一提的是,[新华社报道](https://mp.weixin.qq.com/s?__biz=MjM5ODYzNzAyMQ==&mid=2651933920&idx=1\&sn=ae2866bd12000f1644eae1094497837e)指出,迁移学习是中国领先于世界的少数几个人工智能领域之一。中国的人工智能赶超的机会来了!
40 |
41 |
--------------------------------------------------------------------------------
/markdown/chap01/chap01_negativetransfer.md:
--------------------------------------------------------------------------------
1 | # 负迁移
2 |
3 | 我们都希望迁移学习能够比较顺利地进行,我们得到的结果也是满足我们要求的,皆大欢喜。然而,事情却并不总是那么顺利。这就引入了迁移学习中的一个负面现象,也就是所谓的**负迁移**。
4 |
5 | 用我们熟悉的成语来描述:如果说成功的迁移学习是“举一反三”、“照猫画虎”,那么负迁移则是“**东施效颦**”。东施已经模仿西施捂着胸口皱着眉头,为什么她还是那么丑?
6 |
7 | 要理解负迁移,首先要理解什么是迁移学习。迁移学习指的是,利用数据和领域之间存在的相似性关系,把之前学习到的知识,应用于新的未知领域。迁移学习的核心问题是,找到两个领域的相似性。找到了这个相似性,就可以合理地利用,从而很好地完成迁移学习任务。比如,之前会骑自行车,要学习骑摩托车,这种相似性指的就是自行车和摩托车之间的相似性以及骑车体验的相似性。这种相似性在我们人类看来是可以接受的。
8 |
9 | 所以,如果这个相似性找的不合理,也就是说,两个领域之间不存在相似性,或者基本不相似,那么,就会大大损害迁移学习的效果。还是拿骑自行车来说,你要拿骑自行车的经验来学习开汽车,这显然是不太可能的。因为自行车和汽车之间基本不存在什么相似性。所以,这个任务基本上完不成。这时候,我们可以说出现了**负迁移\(Negative Transfer\)**。
10 |
11 | 所以,为什么东施和西施做了一样的动作,反而变得更丑了?**因为东施和西施之间压根就不存在相似性。**
12 |
13 | 迁移学习领域权威学者、香港科技大学杨强教授发表的迁移学习的综述文章A survey on transfer learning给出了负迁移的一个定义:
14 |
15 | > 负迁移指的是,在源域上学习到的知识,对于目标域上的学习产生负面作用。
16 |
17 | 文章也引用了一些经典的解决负迁移问题的文献。但是普遍较老,这里就不说了。
18 |
19 | 所以,产生负迁移的原因主要有:
20 |
21 | * 数据问题:源域和目标域压根不相似,谈何迁移?
22 | * 方法问题:源域和目标域是相似的,但是,迁移学习方法不够好,没找到可迁移的成分。
23 |
24 | 负迁移给迁移学习的研究和应用带来了负面影响。在实际应用中,找到合理的相似性,并且选择或开发合理的迁移学习方法,能够避免负迁移现象。
25 |
26 | ## 最新的研究成果
27 |
28 | 随着研究的深入,已经有新的研究成果在逐渐克服负迁移的影响。杨强教授团队2015在数据挖掘领域顶级会议KDD上发表了传递迁移学习文章Transitive transfer learning,提出了传递迁移学习的思想。传统迁移学习就好比是**踩着一块石头过河**,传递迁移学习就好比是**踩着连续的两块石头**。
29 |
30 | 更进一步,杨强教授团队在2017年人工智能领域顶级会议AAAI上发表了远领域迁移学习的文章Distant domain transfer learning,可以用人脸来识别飞机!这就好比是**踩着一连串石头过河**。
31 |
32 | 这些研究的意义在于,传统迁移学习只有两个领域足够相似才可以完成,而当两个领域不相似时,传递迁移学习却可以利用处于这两个领域之间的若干领域,将知识传递式的完成迁移。这个是很有意义的工作,可以视为解决负迁移的有效思想和方法。可以预见在未来会有更多的应用前景。
33 |
34 | 下图对传递迁移学习给出了简明的示意。
35 |
36 | 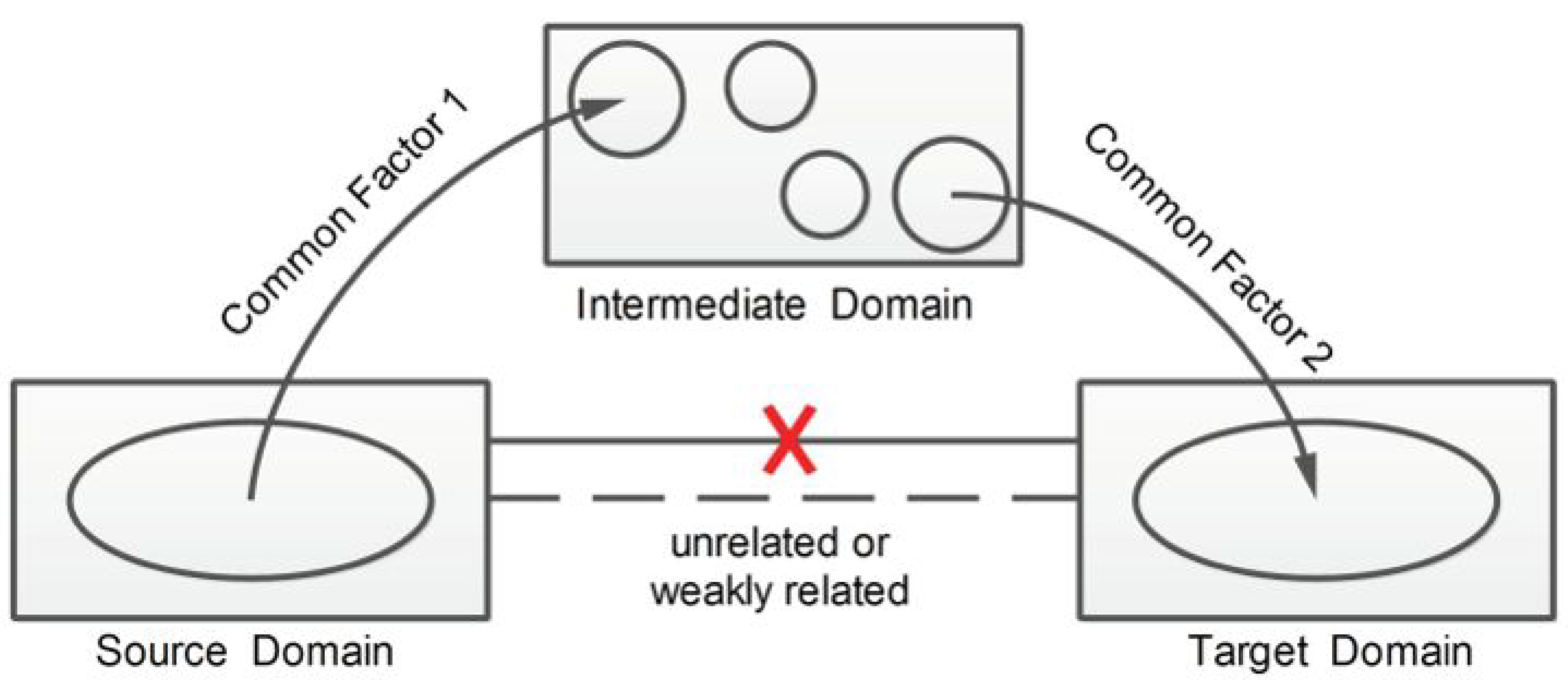
37 |
38 |
--------------------------------------------------------------------------------
/markdown/chap01/chap01_tlvsml.md:
--------------------------------------------------------------------------------
1 | # 与已有概念的区别和联系
2 |
3 | 迁移学习并不是一个横空出世的概念,它与许多已有的概念都有些联系,但是也有着一些区别。我们在这里汇总一些与迁移学习非常接近的概念,并简述迁移学习与它们的区别和联系。
4 |
5 | ## 1. 迁移学习 VS 传统机器学习
6 |
7 | 迁移学习属于机器学习的一类,但它在如下几个方面有别于传统的机器学习:
8 |
9 | | 比较项目 | 传统机器学习 | 迁移学习 |
10 | | :---: | :---: | :---: |
11 | | 数据分布 | 训练和测试数据服从相同的分布 | 训练和测试数据服从不同的分布 |
12 | | 数据标注 | 需要足够的数据标注来训练模型 | 不需要足够的数据标注 |
13 | | 模型 | 每个任务分别建模 | 模型可以在不同任务之间迁移 |
14 |
15 | ## 2. 迁移学习 VS 多任务学习
16 |
17 | 多任务学习指多个相关的任务一起协同学习;迁移学习则强调知识由一个领域迁移到另一个领域的过程。迁移是思想,多任务是其中的一个具体形式。
18 |
19 | ## 3. 迁移学习 VS 终身学习
20 |
21 | 终身学习可以认为是序列化的多任务学习,在已经学习好若干个任务之后,面对新的任务可以继续学习而不遗忘之前学习的任务。迁移学习则侧重于模型的迁移和共同学习。
22 |
23 | ## 4. 迁移学习 VS 领域自适应
24 |
25 | 领域自适应问题是迁移学习的研究内容之一,它侧重于解决特征空间一致、类别空间一致,仅特征分布不一致的问题。而迁移学习也可以解决上述内容不一致的情况。
26 |
27 | ## 5. 迁移学习 VS 增量学习
28 |
29 | 增量学习侧重解决数据不断到来,模型不断更新的问题。迁移学习显然和其有着不同之处。
30 |
31 | ## 6. 迁移学习 VS 自我学习
32 |
33 | 自我学习指的是模型不断地从自身处进行更新,而迁移学习强调知识在不同的领域间进行迁移。
34 |
35 | ## 7. 迁移学习 VS 协方差漂移
36 |
37 | 协方差漂移指数据的边缘概率分布发生变化。领域自适应研究问题解决的就是协方差漂移现象。
38 |
39 |
--------------------------------------------------------------------------------
/markdown/chap01/chap01_whytransfer.md:
--------------------------------------------------------------------------------
1 | # 为什么需要迁移学习
2 |
3 | 了解了迁移学习的概念之后,紧接着还有一个非常重要的问题:迁移学习的目的是什么? 或者说,**为什么要用迁移学习**?
4 |
5 | 我们把原因概括为以下四个方面:
6 |
7 | ## 1. 大数据与少标注之间的矛盾
8 |
9 | 我们正处在一个大数据时代,每天每时,社交网络、智能交通、视频监控、行业物流等,都产生着海量的图像、文本、语音等各类数据。数据的增多,使得机器学习和深度学习模型可以依赖于如此\textit{海量的数据},持续不断地训练和更新相应的模型,使得模型的性能越来越好,越来越适合特定场景的应用。然而,这些大数据带来了严重的问题:总是缺乏完善的\textit{数据标注}。
10 |
11 | 
12 |
13 | 众所周知,机器学习模型的训练和更新,均依赖于数据的标注。然而,尽管我们可以获取到海量的数据,这些数据往往是很初级的原始形态,很少有数据被加以正确的人工标注。数据的标注是一个耗时且昂贵的操作,目前为止,尚未有行之有效的方式来解决这一问题。这给机器学习和深度学习的模型训练和更新带来了挑战。反过来说,特定的领域,因为没有足够的标定数据用来学习,使得这些领域一直不能很好的发展。
14 |
15 | ## 2. 大数据与弱计算之间的矛盾
16 |
17 | 大数据,就需要大设备、强计算能力的设备来进行存储和计算。然而,大数据的大计算能力,是"有钱人"才能玩得起的游戏。比如Google,Facebook,Microsoft,这些巨无霸公司有着雄厚的计算能力去利用这些数据训练模型。例如,ResNet需要很长的时间进行训练。Google TPU也都是有钱人的才可以用得起的。
18 |
19 | 绝大多数普通用户是不可能具有这些强计算能力的。这就引发了大数据和弱计算之间的矛盾。在这种情况下,普通人想要利用这些海量的大数据去训练模型完成自己的任务,基本上不太可能。那么如何让普通人也能利用这些数据和模型?
20 |
21 | 
22 |
23 | ## 3. 普适化模型与个性化需求之间的矛盾
24 |
25 | 机器学习的目标是构建一个尽可能通用的模型,使得这个模型对于不同用户、不同设备、不同环境、不同需求,都可以很好地进行满足。这是我们的美好愿景。这就是要尽可能地提高机器学习模型的**泛化能力**,使之适应不同的数据情形。基于这样的愿望,我们构建了多种多样的普适化模型,来服务于现实应用。然而,这只能是我们竭尽全力想要做的,目前却始终无法彻底解决的问题。
26 |
27 | 人们的个性化需求五花八门,短期内根本无法用一个通用的模型去满足。比如导航模型,可以定位及导航所有的路线。但是不同的人有不同的需求。比如有的人喜欢走高速,有的人喜欢走偏僻小路,这就是个性化需求。并且,不同的用户,通常都有不同的**隐私需求**。这也是构建应用需要着重考虑的。
28 |
29 | 
30 |
31 | 所以目前的情况是,我们对于每一个通用的任务都构建了一个通用的模型。这个模型可以解决绝大多数的公共问题。但是具体到每个个体、每个需求,都存在其唯一性和特异性,一个普适化的通用模型根本无法满足。
32 |
33 | 那么,能否将这个通用的模型加以改造和适配,使其更好地服务于人们的个性化需求?
34 |
35 | ## 4. 特定应用的需求
36 |
37 | 机器学习已经被广泛应用于现实生活中。在这些应用中,也存在着一些特定的应用,它们面临着一些现实存在的问题。比如推荐系统的**冷启动**问题。一个新的推荐系统,没有足够的用户数据,如何进行精准的推荐? 一个崭新的图片标注系统,没有足够的标签,如何进行精准的服务?现实世界中的应用驱动着我们去开发更加便捷更加高效的机器学习方法来加以解决。
38 |
39 | 
40 |
41 | 上述存在的几个重要问题,使得传统的机器学习方法疲于应对。迁移学习则可以很好地进行解决。那么,迁移学习是如何进行解决的呢?
42 |
43 | - 大数据与少标注:迁移数据标注
44 |
45 | 单纯地凭借少量的标注数据,无法准确地训练高可用度的模型。为了解决这个问题,我们直观的想法是:多增加一些标注数据不就行了?但是不依赖于人工,如何增加标注数据?
46 |
47 | 利用迁移学习的思想,我们可以寻找一些与目标数据相近的有标注的数据,从而利用这些数据来构建模型,增加我们目标数据的标注。
48 |
49 | - 大数据与弱计算:模型迁移
50 |
51 | 不可能所有人都有能力利用大数据快速进行模型的训练。利用迁移学习的思想,我们可以将那些大公司在大数据上训练好的模型,迁移到我们的任务中。针对于我们的任务进行微调,从而我们也可以拥有在大数据上训练好的模型。更进一步,我们可以将这些模型针对我们的任务进行自适应更新,从而取得更好的效果。
52 |
53 | - 普适化模型与个性化需求:自适应学习
54 |
55 | 为了解决个性化需求的挑战,我们利用迁移学习的思想,进行自适应的学习。考虑到不同用户之间的相似性和差异性,我们对普适化模型进行灵活的调整,以便完成我们的任务。
56 |
57 | - 特定应用的需求:相似领域知识迁移
58 |
59 | 为了满足特定领域应用的需求,我们可以利用上述介绍过的手段,从数据和模型方法上进行迁移学习。
60 |
61 | 下表概括地描述了迁移学习的必要性。
62 |
63 | | 矛盾 | 传统机器学习 | 迁移学习 |
64 | | :---: | :---: | :---: |
65 | | 大数据与少标注 | 增加人工标注,但是昂贵且耗时 | 数据的迁移标注 |
66 | | 大数据与弱计算 | 只能依赖强大计算能力,但是受众少 | 模型迁移 |
67 | | 普适化模型与个性化需求 | 通用模型无法满足个性化需求 | 模型自适应调整 |
68 | | 特定应用 | 冷启动问题无法解决 | 数据迁移 |
69 |
70 |
--------------------------------------------------------------------------------
/markdown/chap02/chap02_research_area.md:
--------------------------------------------------------------------------------
1 | # 第2章 迁移学习的研究领域
2 |
3 | 依据目前较流行的机器学习分类方法,机器学习主要可以分为有监督、半监督和无监督机器学习三大类。同理,迁移学习也可以进行这样的分类。需要注意的是,依据的分类准则不同,分类结果也不同。在这一点上,并没有一个统一的说法。我们在这里仅根据目前较流行的方法,对迁移学习的研究领域进行一个大致的划分。
4 |
5 | 下图给出了迁移学习的常用分类方法总结。
6 |
7 | 
8 |
9 | 大体上讲,迁移学习的分类可以按照四个准则进行:按目标域有无标签分、按学习方法分、按特征分、按离线与在线形式分。不同的分类方式对应着不同的专业名词。当然,即使是一个分类下的研究领域,也可能同时处于另一个分类下。下面我们对这些分类方法及相应的领域作简单描述。
10 |
11 | ## 按目标域标签分
12 |
13 | 这种分类方式最为直观。类比机器学习,按照目标领域有无标签,迁移学习可以分为以下三个大类:
14 |
15 | - 监督迁移学习 (Supervised Transfer Learning)
16 | - 半监督迁移学习 (Semi-Supervised Transfer Learning)
17 | - 无监督迁移学习 (Unsupervised Transfer Learning)
18 |
19 | 显然,少标签或无标签的问题(半监督和无监督迁移学习),是研究的热点和难点。这也是本手册重点关注的领域。
20 |
21 | ## 按学习方法分类
22 |
23 | 按学习方法的分类形式,最早在迁移学习领域的权威综述文章给出定义。它将迁移学习方法分为以下四个大类:
24 |
25 | - 基于样本的迁移学习方法 (Instance based Transfer Learning)
26 | - 基于特征的迁移学习方法 (Feature based Transfer Learning)
27 | - 基于模型的迁移学习方法 (Model based Transfer Learning)
28 | - 基于关系的迁移学习方法 (Relation based Transfer Learning)
29 |
30 | 这是一个很直观的分类方式,按照数据、特征、模型的机器学习逻辑进行区分,再加上不属于这三者中的关系模式。
31 |
32 | 基于实例的迁移,简单来说就是通过权重重用,对源域和目标域的样例进行迁移。就是说直接对不同的样本赋予不同权重,比如说相似的样本,我就给它高权重,这样我就完成了迁移,非常简单非常非常直接。
33 |
34 | 基于特征的迁移,就是更进一步对特征进行变换。意思是说,假设源域和目标域的特征原来不在一个空间,或者说它们在原来那个空间上不相似,那我们就想办法把它们变换到一个空间里面,那这些特征不就相似了?这个思路也非常直接。这个方法是用得非常多的,一直在研究,目前是感觉是研究最热的。
35 |
36 | 基于模型的迁移,就是说构建参数共享的模型。这个主要就是在神经网络里面用的特别多,因为神经网络的结构可以直接进行迁移。比如说神经网络最经典的finetune就是模型参数迁移的很好的体现。
37 |
38 | 基于关系的迁移,这个方法用的比较少,这个主要就是说挖掘和利用关系进行类比迁移。比如老师上课、学生听课就可以类比为公司开会的场景。这个就是一种关系的迁移。
39 |
40 | 目前最热的就是基于特征还有模型的迁移,然后基于实例的迁移方法和他们结合起来使用。
41 |
42 | 迁移学习方法是本手册的重点。我们在后续的篇幅中介绍。
43 |
44 | ## 按特征分类
45 |
46 | 按照特征的属性进行分类,也是一种常用的分类方法。这在最近的迁移学习综述~\cite{weiss2016survey}中给出。按照特征属性,迁移学习可以分为两个大类:
47 |
48 | - 同构迁移学习 (Homogeneous Transfer Learning)
49 | - 异构迁移学习 (Heterogeneous Transfer Learning)
50 |
51 | 这也是一种很直观的方式:如果特征语义和维度都相同,那么就是同构;反之,如果特征完全不相同,那么就是异构。举个例子来说,不同图片的迁移,就可以认为是同构;而图片到文本的迁移,则是异构的。
52 |
53 | ## 按离线与在线形式分
54 |
55 | 按照离线学习与在线学习的方式,迁移学习还可以被分为:
56 |
57 | - 离线迁移学习 (Offline Transfer Learning)
58 | - 在线迁移学习 (Online Transfer Learning)
59 |
60 | 目前,绝大多数的迁移学习方法,都采用了离线方式。即,源域和目标域均是给定的,迁移一次即可。这种方式的缺点是显而易见的:算法无法对新加入的数据进行学习,模型也无法得到更新。与之相对的,是在线的方式。即随着数据的动态加入,迁移学习算法也可以不断地更新。
--------------------------------------------------------------------------------
/markdown/chap03/chap03_application.md:
--------------------------------------------------------------------------------
1 | # 第3章 迁移学习的应用
2 |
3 | 迁移学习是机器学习领域的一个重要分支。因此,其应用并不局限于特定的领域。凡是满足迁移学习问题情景的应用,迁移学习都可以发挥作用。这些领域包括但不限于计算机视觉、文本分类、行为识别、自然语言处理、室内定位、视频监控、舆情分析、人机交互等。下展示了迁移学习可能的应用领域。
4 |
5 | 
6 |
7 | 下面我们选择几个研究热点,对迁移学习在这些领域的应用场景作一简单介绍。
8 |
9 | ## 计算机视觉
10 |
11 | 迁移学习已被广泛地应用于计算机视觉的研究中。特别地,在计算机视觉中,迁移学习方法被称为Domain Adaptation。Domain adaptation的应用场景有很多,比如图片分类、图片哈希等。
12 |
13 | 下图展示了不同的迁移学习图片分类任务示意。同一类图片,不同的拍摄角度、不同光照、不同背景,都会造成特征分布发生改变。因此,使用迁移学习构建跨领域的鲁棒分类器是十分重要的。
14 |
15 | 
16 |
17 | 计算机视觉三大顶会(CVPR、ICCV、ECCV)每年都会发表大量的文章对迁移学习在视觉领域的应用进行介绍。
18 |
19 | ## 文本分类
20 |
21 | 由于文本数据有其领域特殊性,因此,在一个领域上训练的分类器,不能直接拿来作用到另一个领域上。这就需要用到迁移学习。例如,在电影评论文本数据集上训练好的分类器,不能直接用于图书评论的预测。这就需要进行迁移学习。下图是一个由电子产品评论迁移到DVD评论的迁移学习任务。
22 |
23 | 
24 |
25 | 文本和网络领域顶级会议WWW和CIKM每年有大量的文章对迁移学习在文本领域的应用作介绍。
26 |
27 | ## 时间序列
28 |
29 | **行为识别 (Activity Recognition)**主要通过佩戴在用户身体上的传感器,研究用户的行为。行为数据是一种时间序列数据。不同用户、不同环境、不同位置、不同设备,都会导致时间序列数据的分布发生变化。此时,也需要进行迁移学习。下图展示了同一用户不同位置的信号差异性。在这个领域,华盛顿州立大学的Diane Cook等人在2013年发表的关于迁移学习在行为识别领域的综述文章"[Transfer learning for activity recognition: a survey](https://link.springer.com/article/10.1007/s10115-013-0665-3)"是很好的参考资料。
30 |
31 | 
32 |
33 | **室内定位 (Indoor Location)**与传统的室外用GPS定位不同,它通过WiFi、蓝牙等设备研究人在室内的位置。不同用户、不同环境、不同时刻也会使得采集的信号分布发生变化。下图展示了不同时间、不同设备的WiFi信号变化。
34 |
35 | 
36 |
37 | ## 医疗健康
38 |
39 | 医疗健康领域的研究正变得越来越重要。不同于其他领域,医疗领域研究的难点问题是,无法获取足够有效的医疗数据。在这一领域,迁移学习同样也变得越来越重要。
40 |
41 | 最近,顶级生物期刊细胞杂志报道了由张康教授领导的广州妇女儿童医疗中心和加州大学圣迭戈分校团队的重磅研究成果:基于深度学习开发出一个能诊断眼病和肺炎两大类疾病的[AI系统](https://www.sciencedirect.com/science/article/pii/S0092867418301545),准确性匹敌顶尖医生。这不仅是中国研究团队首次在顶级生物医学杂志发表有关医学人工智能的研究成果;也是世界范围内首次使用如此庞大的标注好的高质量数据进行迁移学习,并取得高度精确的诊断结果,达到匹敌甚至超越人类医生的准确性;还是全世界首次实现用AI精确推荐治疗手段。细胞杂志封面报道了该研究成果。
42 |
43 | 我们可以预见到的是,迁移学习对于那些不易获取标注数据的领域,将会发挥越来越重要的作用。
--------------------------------------------------------------------------------
/markdown/chap04/chap04_basic.md:
--------------------------------------------------------------------------------
1 | # 第4章 基础知识
2 |
3 | 本部分介绍迁移学习领域的一些基本知识。我们对迁移学习的问题进行简单的形式化,给出迁移学习的总体思路,并且介绍目前常用的一些度量准则。本部分中出现的所有符号和表示形式,是以后章节的基础。已有相关知识的读者可以直接跳过。
--------------------------------------------------------------------------------
/markdown/chap04/chap04_formulation.md:
--------------------------------------------------------------------------------
1 | # 迁移学习的问题形式化
2 |
3 | 迁移学习的问题形式化,是进行一切研究的前提。在迁移学习中,有两个基本的概念:**领域(Domain)**和**任务(Task)**。它们是最基础的概念。定义如下:
4 |
5 | ## 领域 Domain
6 |
7 | **领域(Domain):** 是进行学习的主体。领域主要由两部分构成:**数据**和生成这些数据的**概率分布**。通常我们用花体$$\mathcal{D}$$来表示一个domain,用大写斜体$$P$$来表示一个概率分布。
8 |
9 | 特别地,因为涉及到迁移,所以对应于两个基本的领域:**源领域(Source Domain)**和**目标领域(Target Domain)**。这两个概念很好理解。源领域就是有知识、有大量数据标注的领域,是我们要迁移的对象;目标领域就是我们最终要赋予知识、赋予标注的对象。知识从源领域传递到目标领域,就完成了迁移。
10 |
11 | 领域上的数据,我们通常用小写粗体$$\mathbf{x}$$来表示,它也是向量的表示形式。例如,$$\mathbf{x}_i$$就表示第$$i$$个样本或特征。用大写的黑体$$\mathbf{X}$$表示一个领域的数据,这是一种矩阵形式。我们用大写花体$$\mathcal{X}$$来表示数据的特征空间。
12 |
13 | 通常我们用小写下标$$s$$和$$t$$来分别指代两个领域。结合领域的表示方式,则:$$\mathcal{D}_s$$表示源领域,$$\mathcal{D}_t$$表示目标领域。
14 |
15 | 值得注意的是,概率分布$$P$$通常只是一个逻辑上的概念,即我们认为不同领域有不同的概率分布,却一般不给出(也难以给出)$$P$$的具体形式。
16 |
17 | ## 任务 Task
18 |
19 | **任务(Task):** 是学习的目标。任务主要由两部分组成:**标签**和**标签对应的函数**。通常我们用花体$$\mathcal{Y}$$来表示一个标签空间,用$$f(\cdot)$$来表示一个学习函数。
20 |
21 | 相应地,源领域和目标领域的类别空间就可以分别表示为$$\mathcal{Y}_s$$和$$\mathcal{Y}_t$$。我们用小写$$y_s$$和$$y_t$$分别表示源领域和目标领域的实际类别。
22 |
23 | ## 迁移学习
24 |
25 | 有了上面领域和任务的定义,我们就可以对迁移学习进行形式化。
26 |
27 | **迁移学习(Transfer Learning):** 给定一个有标记的源域$$\mathcal{D}_s=\{\mathbf{x}_{i},y_{i}\}^n_{i=1}$$和一个无标记的目标域$$\mathcal{D}_t=\{\mathbf{x}_{j}\}^{n+m}_{j=n+1}$$。这两个领域的数据分布$$P(\mathbf{x}_s)$$和P($$\mathbf{x}_t)$$不同,即$$P(\mathbf{x}_s) \ne P(\mathbf{x}_t)$$。迁移学习的目的就是要借助$$\mathcal{D}_s$$的知识,来学习目标域$$\mathcal{D}_t$$的知识(标签)。
28 |
29 | 更进一步,结合我们前面说过的迁移学习研究领域,迁移学习的定义需要进行如下的考虑:
30 |
31 | (1) 特征空间的异同,即$$\mathcal{X}_s$$和$$\mathcal{X}_t$$是否相等。
32 |
33 | (2) 类别空间的异同:即$$\mathcal{Y}_s$$和$$\mathcal{Y}_t$$是否相等。
34 |
35 | (3) 条件概率分布的异同:即$$Q_s(y_s|\mathbf{x}_s)$$和$$Q_t(y_t|\mathbf{x}_t)$$是否相等。
36 |
37 | 结合上述形式化,我们给出**领域自适应(Domain Adaptation)}这一热门研究方向的定义:
38 |
39 | **领域自适应(Domain Adaptation):** 给定一个有标记的源域$$\mathcal{D}_s=\{\mathbf{x}_{i},y_{i}\}^n_{i=1}$$和一个无标记的目标域$$\mathcal{D}_t=\{\mathbf{x}_{j}\}^{n+m}_{j=n+1}$$,假定它们的特征空间相同,即$$\mathcal{X}_s = \mathcal{X}_t$$,并且它们的类别空间也相同,即$$\mathcal{Y}_s = \mathcal{Y}_t$$以及条件概率分布也相同,即$$Q_s(y_s|\mathbf{x}_s) = Q_t(y_t|\mathbf{x}_t)$$。但是这两个域的边缘分布不同,即$$P_s(\mathbf{x}_s) \ne P_t(\mathbf{x}_t)$$。迁移学习的目标就是,利用有标记的数据$$\mathcal{D}_s$$去学习一个分类器$$f:\mathbf{x}_t \mapsto \mathbf{y}_t$$来预测目标域$$\mathcal{D}_t$$的标签$$\mathbf{y}_t \in \mathcal{Y}_t$$.
40 |
41 | 在实际的研究和应用中,读者可以针对自己的不同任务,结合上述表述,灵活地给出相关的形式化定义。
42 |
43 | **符号小结**
44 |
45 | 我们已经基本介绍了迁移学习中常用的符号。下表是一个符号表:
46 |
47 | | 符号 | 含义 |
48 | |:-----------------------------------------------------------------------:|:-------------------------------:|
49 | | 下标$$s$$ / $$t$$ | 指示源域 / 目标域 |
50 | | $$\mathcal{D}_s$$ / $$\mathcal{D}_t$$ | 源域数据 / 目标域数据 |
51 | | $$\mathbf{x}$$ / $$\mathbf{X}$$ / $$\mathcal{X}$$ | 向量 / 矩阵 / 特征空间 |
52 | | $$\mathbf{y}$$ / $$\mathcal{Y}$$ | 类别向量 / 类别空间 |
53 | | $$(n,m)$$ [或 $$(n_1,n_2)$$ 或 $$(n_s,n_t)$$] | (源域样本数,目标域样本数) |
54 | | $$P(\mathbf{x}_s)$$ / $$P(\mathbf{x}_t)$$ | 源域数据 / 目标域数据的边缘分布 |
55 | | $$Q(\mathbf{y}_s$$ , $$\mathbf{x}_s)$$ / $$Q(\mathbf{y}_t$$ , $$\mathbf{x}_t)$$ | 源域数据 / 目标域数据的条件分布 |
56 | | $$f(\cdot)$$ | 要学习的目标函数 |
57 |
--------------------------------------------------------------------------------
/markdown/chap04/chap04_metric.md:
--------------------------------------------------------------------------------
1 | # 度量准则
2 |
3 | 度量不仅是机器学习和统计学等学科中使用的基础手段,也是迁移学习中的重要工具。它的核心就是衡量两个数据域的差异。计算两个向量(点、矩阵)的距离和相似度是许多机器学习算法的基础,有时候一个好的距离度量就能决定算法最后的结果好坏。比如KNN分类算法就对距离非常敏感。本质上就是找一个变换使得源域和目标域的距离最小(相似度最大)。所以,相似度和距离度量在机器学习中非常重要。
4 |
5 | 这里给出常用的度量手段,它们都是迁移学习研究中非常常见的度量准则。对这些准则有很好的理解,可以帮助我们设计出更加好用的算法。用一个简单的式子来表示,度量就是描述源域和目标域这两个领域的距离:
6 |
7 | $$
8 | DISTANCE(\mathcal{D}_s,\mathcal{D}_t) = \mathrm{DistanceMeasure}(\cdot,\cdot)
9 | $$
10 |
11 | 下面我们从距离和相似度度量准则几个方面进行简要介绍。
12 |
13 | ## 常见的几种距离
14 |
15 | ### 1. 欧氏距离
16 |
17 | 定义在两个向量(空间中的两个点)上:点$$\mathbf{x}$$和点$$\mathbf{y}$$的欧氏距离为:
18 |
19 | $$
20 | d_{Euclidean}=\sqrt{(\mathbf{x}-\mathbf{y})^\top (\mathbf{x}-\mathbf{y})}
21 | $$
22 |
23 | ### 2. 闵可夫斯基距离
24 |
25 | Minkowski distance, 两个向量(点)的$$p$$阶距离:
26 |
27 | $$
28 | d_{Minkowski}=(||\mathbf{x}-\mathbf{y}||^p)^{1/p}
29 | $$
30 |
31 | 当$$p=1$$时就是曼哈顿距离,当$$p=2$$时就是欧氏距离。
32 |
33 | ### 3. 马氏距离
34 |
35 | 定义在两个向量(两个点)上,这两个数据在同一个分布里。点$$\mathbf{x}$$和点$$\mathbf{y}$$的马氏距离为:
36 |
37 | $$
38 | d_{Mahalanobis}=\sqrt{(\mathbf{x}-\mathbf{y})^\top \Sigma^{-1} (\mathbf{x}-\mathbf{y})}
39 | $$
40 |
41 | 其中,$$\Sigma$$是这个分布的协方差。
42 |
43 | 当$$\Sigma=\mathbf{I}$$时,马氏距离退化为欧氏距离。
44 |
45 | ## 相似度
46 |
47 | ### 1. 余弦相似度
48 |
49 | 衡量两个向量的相关性(夹角的余弦)。向量$$\mathbf{x},\mathbf{y}$$的余弦相似度为:
50 |
51 | $$
52 | \cos (\mathbf{x},\mathbf{y}) = \frac{\mathbf{x} \cdot \mathbf{y}}{|\mathbf{x}|\cdot |\mathbf{y}|}
53 | $$
54 |
55 | ### 2. 互信息
56 |
57 | 定义在两个概率分布$$X,Y$$上,$$x \in X, y \in Y$$。它们的互信息为:
58 |
59 | $$
60 | I(X;Y)=\sum_{x \in X} \sum_{y \in Y} p(x,y) \log \frac{p(x,y)}{p(x)p(y)}
61 | $$
62 |
63 | ### 3. 皮尔逊相关系数
64 |
65 | 衡量两个随机变量的相关性。随机变量$$X,Y$$的Pearson相关系数为:
66 |
67 | $$
68 | \rho_{X,Y}=\frac{Cov(X,Y)}{\sigma_X \sigma_Y}
69 | $$
70 |
71 | 理解:协方差矩阵除以标准差之积。
72 |
73 | 范围:$$[-1,1]$$,绝对值越大表示(正/负)相关性越大。
74 |
75 | ### 4. Jaccard相关系数
76 |
77 | 对两个集合$$X,Y$$,判断他们的相关性,借用集合的手段:
78 |
79 | $$
80 | J=\frac{X \cap Y}{X \cup Y}
81 | $$
82 |
83 | 理解:两个集合的交集除以并集。
84 |
85 | 扩展:Jaccard距离=$$1-J$$。
86 |
87 | ### KL散度与JS距离
88 |
89 | KL散度和JS距离是迁移学习中被广泛应用的度量手段。
90 |
91 | - KL散度
92 |
93 | Kullback–Leibler divergence,又叫做**相对熵**,衡量两个概率分布$$P(x),Q(x)$$的距离:
94 |
95 | $$
96 | D_{KL}(P||Q)=\sum_{i=1} P(x) \log \frac{P(x)}{Q(x)}
97 | $$
98 |
99 | 这是一个非对称距离:$$D_{KL}(P||Q) \ne D_{KL}(Q||P)$$.
100 |
101 | - JS距离
102 |
103 | Jensen–Shannon divergence,基于KL散度发展而来,是对称度量:
104 |
105 | $$
106 | JSD(P||Q)= \frac{1}{2} D_{KL}(P||M) + \frac{1}{2} D_{KL}(Q||M)
107 | $$
108 |
109 | 其中$$M=\frac{1}{2}(P+Q)$$。
110 |
111 | ### 最大均值差异MMD
112 |
113 | 最大均值差异是迁移学习中使用频率最高的度量。Maximum mean discrepancy,它度量在再生希尔伯特空间中两个分布的距离,是一种核学习方法。两个随机变量的MMD平方距离为
114 |
115 | $$
116 | MMD^2(X,Y)=\left \Vert \sum_{i=1}^{n_1}\phi(\mathbf{x}_i)- \sum_{j=1}^{n_2}\phi(\mathbf{y}_j) \right \Vert^2_\mathcal{H}
117 | $$
118 |
119 | 其中$$\phi(\cdot)$$是映射,用于把原变量映射到**再生核希尔伯特空间 (Reproducing Kernel Hilbert Space, RKHS)**中。什么是RKHS?形式化定义太复杂,简单来说希尔伯特空间是对于函数的内积完备的,而再生核希尔伯特空间是具有再生性$$\langle K(x,\cdot),K(y,\cdot)\rangle_\mathcal{H}=K(x,y)$$的希尔伯特空间。就是比欧几里得空间更高端的。将平方展开后,RKHS空间中的内积就可以转换成核函数,所以最终MMD可以直接通过核函数进行计算。
120 |
121 | 理解:就是求两堆数据在RKHS中的**均值**的距离。
122 |
123 | **Multiple-kernel MMD**:多核的MMD,简称MK-MMD。现有的MMD方法是基于单一核变换的,多核的MMD假设最优的核可以由多个核线性组合得到。多核MMD的提出和计算方法在文献~\cite{gretton2012optimal}中形式化给出。MK-MMD在许多后来的方法中被大量使用,例如DAN~\cite{long2015learning}。我们将在后续单独介绍此工作。
124 |
125 | ### Principal Angle
126 |
127 | 也是将两个分布映射到高维空间(格拉斯曼流形)中,在流形中两堆数据就可以看成两个点。Principal angle是求这两堆数据的对应维度的夹角之和。
128 |
129 | 对于两个矩阵$$\mathbf{X},\mathbf{Y}$$,计算方法:首先正交化(用PCA)两个矩阵,然后:
130 |
131 | $$
132 | PA(\mathbf{X},\mathbf{Y})=\sum_{i=1}^{\min(m,n)} \sin \theta_i
133 | $$
134 |
135 | 其中$$m,n$$分别是两个矩阵的维度,$$\theta_i$$是两个矩阵第$$i$$个维度的夹角,$$\Theta=\{\theta_1,\theta_2,\cdots,\theta_t\}$$是两个矩阵SVD后的角度:
136 |
137 | $$
138 | \mathbf{X}^\top\mathbf{Y}=\mathbf{U} (\cos \Theta) \mathbf{V}^\top
139 | $$
140 |
141 | ### A-distance
142 |
143 | A-distance是一个很简单却很有用的度量。文献\cite{ben2007analysis}介绍了此距离,它可以用来估计不同分布之间的差异性。$$\mathcal{A}$$-distance被定义为建立一个线性分类器来区分两个数据领域的hinge损失(也就是进行二类分类的hinge损失)。它的计算方式是,我们首先在源域和目标域上训练一个二分类器$$h$$,使得这个分类器可以区分样本是来自于哪一个领域。我们用$$err(h)$$来表示分类器的损失,则$$\mathcal{A}$$-distance定义为:
144 |
145 | $$
146 | \mathcal{A}(\mathcal{D}_s,\mathcal{D}_t) = 2(1 - 2 err(h))
147 | $$
148 |
149 | A-distance通常被用来计算两个领域数据的相似性程度,以便与实验结果进行验证对比。
150 |
151 | ### Hilbert-Schmidt Independence Criterion
152 |
153 | 希尔伯特-施密特独立性系数,Hilbert-Schmidt Independence Criterion,用来检验两组数据的独立性:
154 |
155 | $$
156 | HSIC(X,Y) = trace(HXHY)
157 | $$
158 | 其中$$X,Y$$是两堆数据的kernel形式。
159 |
160 | ### Wasserstein Distance
161 |
162 | Wasserstein Distance是一套用来衡量两个概率分布之间距离的度量方法。该距离在一个度量空间$$(M,\rho)$$上定义,其中$$\rho(x,y)$$表示集合$$M$$中两个实例$$x$$和$$y$$的距离函数,比如欧几里得距离。两个概率分布$$\mathbb{P}$$和$$\mathbb{Q}$$之间的$$p{\text{-th}}$$ Wasserstein distance可以被定义为
163 |
164 | $$
165 | W_p(\mathbb{P}, \mathbb{Q}) = \Big(\inf_{\mu \in \Gamma(\mathbb{P}, \mathbb{Q}) } \int \rho(x,y)^p d\mu(x,y) \Big)^{1/p},
166 | $$
167 |
168 | 其中$$\Gamma(\mathbb{P}, \mathbb{Q})$$是在集合$$M\times M$$内所有的以$$\mathbb{P}$$和$$\mathbb{Q}$$为边缘分布的联合分布。著名的Kantorovich-Rubinstein定理表示当$$M$$是可分离的时候,第一Wasserstein distance可以等价地表示成一个积分概率度量(integral probability metric)的形式
169 |
170 | $$
171 | W_1(\mathbb{P},\mathbb{Q})= \sup_{\left \| f \right \|_L \leq 1} \mathbb{E}_{x \sim \mathbb{P}}[f(x)] - \mathbb{E}_{x \sim \mathbb{Q}}[f(x)],
172 | $$
173 |
174 | 其中$$\left \| f \right \|_L = \sup{|f(x) - f(y)|} / \rho(x,y)$$并且$$\left \| f \right \|_L \leq 1$$称为$$1-$$利普希茨条件。
175 |
--------------------------------------------------------------------------------
/markdown/chap04/chap04_overview.md:
--------------------------------------------------------------------------------
1 | # 总体思路
2 |
3 | 形式化之后,我们可以进行迁移学习的研究。迁移学习的总体思路可以概括为
4 |
5 | > 开发算法来最大限度地利用有标注的领域的知识,来辅助目标领域的知识获取和学习。
6 |
7 | 迁移学习的核心是,找到源领域和目标领域之间的**相似性**,并加以合理利用。这种相似性非常普遍。比如,不同人的身体构造是相似的;自行车和摩托车的骑行方式是相似的;国际象棋和中国象棋是相似的;羽毛球和网球的打球方式是相似的。这种相似性也可以理解为**不变量**。以不变应万变,才能立于不败之地。
8 |
9 | 举一个杨强教授经常举的例子来说明:我们都知道在中国大陆开车时,驾驶员坐在左边,靠马路右侧行驶。这是基本的规则。然而,如果在英国、香港等地区开车,驾驶员是坐在右边,需要靠马路左侧行驶。那么,如果我们从中国大陆到了香港,应该如何快速地适应他们的开车方式呢?诀窍就是找到这里的不变量:**不论在哪个地区,驾驶员都是紧靠马路中间。**这就是我们这个开车问题中的不变量。
10 |
11 | 找到相似性(不变量),是进行迁移学习的核心。
12 |
13 | 有了这种相似性后,下一步工作就是,**如何度量和利用这种相似性**。度量工作的目标有两点:一是很好地度量两个领域的相似性,不仅定性地告诉我们它们是否相似,更**定量**地给出相似程度。二是以度量为准则,通过我们所要采用的学习手段,增大两个领域之间的相似性,从而完成迁移学习。
14 |
15 | 一句话总结:
16 |
17 | > 相似性是核心,度量准则是重要手段。
--------------------------------------------------------------------------------
/markdown/chap04/chap04_theory.md:
--------------------------------------------------------------------------------
1 | # 迁移学习的理论保证*
2 |
3 |
4 | 本部分的标题中带有*号,有一些难度,为可看可不看的内容。此部分最常见的形式是当自己提出的算法需要理论证明时,可以借鉴。
5 |
6 | 在第一章里我们介绍了两个重要的概念:迁移学习是什么,以及为什么需要迁移学习。但是,还有一个重要的问题没有得到解答:*为什么可以进行迁移*?也就是说,迁移学习的可行性还没有探讨。
7 |
8 | 值得注意的是,就目前的研究成果来说,迁移学习领域的理论工作非常匮乏。我们在这里仅回答一个问题:为什么数据分布不同的两个领域之间,知识可以进行迁移?或者说,到底达到什么样的误差范围,我们才认为知识可以进行迁移?
9 |
10 | 加拿大滑铁卢大学的Ben-David等人从2007年开始,连续地对迁移学习的理论进行探讨。具体的一些文章可以见[这里](https://github.com/jindongwang/transferlearning#3theory-and-survey-%E7%90%86%E8%AE%BA%E4%B8%8E%E7%BB%BC%E8%BF%B0)在文中,作者将此称之为“Learning from different domains”。在三篇文章也成为了迁移学习理论方面的经典文章。文章主要回答的问题就是:在怎样的误差范围内,从不同领域进行学习是可行的?
11 |
12 | **学习误差:** 给定两个领域$$\mathcal{D}_s,\mathcal{D}_t$$,$$X$$是定义在它们之上的数据,一个假设类$$\mathcal{H}$$。则两个领域$$\mathcal{D}_s,\mathcal{D}_t$$之间的$$\mathcal{H}$$-divergence被定义为
13 |
14 | $$
15 | \hat{d}_{\mathcal{H}}(\mathcal{D}_s,\mathcal{D}_t) = 2 \sup_{\eta \in \mathcal{H}} \left|\underset{\mathbf{x} \in \mathcal{D}_s}{P}[\eta(\mathbf{x}) = 1] - \underset{\mathbf{x} \in \mathcal{D}_t}{P}[\eta(\mathbf{x}) = 1] \right|
16 | $$
17 |
18 | 因此,这个$$\mathcal{H}$$-divergence依赖于假设$$\mathcal{H}$$来判别数据是来自于$$\mathcal{D}_s$$还是$$\mathcal{D}_t$$。作者证明了,对于一个对称的$$\mathcal{H}$$,我们可以通过如下的方式进行计算
19 |
20 | $$
21 | d_\mathcal{H} (\mathcal{D}_s,\mathcal{D}_t) = 2 \left(1 - \min_{\eta \in \mathcal{H}} \left[\frac{1}{n_1} \sum_{i=1}^{n_1} I[\eta(\mathbf{x}_i)=0] + \frac{1}{n_2} \sum_{i=1}^{n_2} I[\eta(\mathbf{x}_i)=1]\right] \right)
22 | $$
23 | 其中$$I[a]$$为指示函数:当$$a$$成立时其值为1,否则其值为0。
24 |
25 | **在目标领域的泛化界(Bound):**
26 |
27 | 假设$$\mathcal{H}$$为一个具有$$d$$个VC维的假设类,则对于任意的$$\eta \in \mathcal{H}$$,下面的不等式有$$1 - \delta$$的概率成立:
28 |
29 | $$
30 | R_{\mathcal{D}_t}(\eta) \le R_s(\eta) + \sqrt{\frac{4}{n}(d \log \frac{2en}{d} + \log \frac{4}{\delta})} + \hat{d}_{\mathcal{H}}(\mathcal{D}_s,\mathcal{D}_t) + 4 \sqrt{\frac{4}{n}(d \log \frac{2n}{d} + \log \frac{4}{\delta})} + \beta
31 | $$
32 | 其中
33 | $$
34 | \beta \ge \inf_{\eta^\star \in \mathcal{H}} [R_{\mathcal{D}_s}(\eta^\star) + R_{\mathcal{D}_t}(\eta^\star)]
35 | $$
36 | 并且
37 | $$
38 | R_{s}(\eta) = \frac{1}{n} \sum_{i=1}^{m} I[\eta(\mathbf{x}_i) \ne y_i]
39 | $$
40 |
41 | 具体的理论证明细节,请参照上述提到的三篇文章。
42 |
43 | 在自己的研究中,如果需要进行相关的证明,可以参考一些已经发表的文章的写法,例如[Adaptation regularization: a general framework for transfer learning](https://ieeexplore.ieee.org/abstract/document/6550016/)等。
44 |
45 | 另外,英国的Gretton等人也在进行一些学习理论方面的研究,有兴趣的读者可以关注他的个人主页:http://www.gatsby.ucl.ac.uk/~gretton/。
--------------------------------------------------------------------------------
/markdown/chap05/chap05_method.md:
--------------------------------------------------------------------------------
1 | # 第5章 迁移学习的基本方法
2 |
3 | 按照迁移学习领域权威综述文章A survey on transfer learning,迁移学习的基本方法可以分为四种。这四种基本的方法分别是:**基于样本的迁移**,**基于模型的迁移**,**基于特征的迁移**,及**基于关系的迁移**。
4 |
5 | 本部分简要叙述各种方法的基本原理和代表性相关工作。基于特征和模型的迁移方法是我们的重点。因此,在后续的章节中,将会更加深入地讨论和分析。
6 |
7 | # 基于样本迁移
8 |
9 | 基于样本的迁移学习方法(Instance based Transfer Learning)根据一定的权重生成规则,对数据样本进行重用,来进行迁移学习。下图形象地表示了基于样本迁移方法的思想。源域中存在不同种类的动物,如狗、鸟、猫等,目标域只有狗这一种类别。在迁移时,为了最大限度地和目标域相似,我们可以人为地**提高**源域中属于狗这个类别的样本权重。
10 |
11 | 
12 |
13 | 在迁移学习中,对于源域$$\mathcal{D}_s$$和目标域$$\mathcal{D}_t$$,通常假定产生它们的概率分布是不同且未知的($$P(\mathbf{x}_s) \ne P(\mathbf{x}_t)$$)。另外,由于实例的维度和数量通常都非常大,因此,直接对$$P(\mathbf{x}_s)$$和$$P(\mathbf{x}_t)$$进行估计是不可行的。因而,大量的研究工作[khan2016adapting](https://ieeexplore.ieee.org/abstract/document/7899859), [zadrozny2004learning](https://dl.acm.org/citation.cfm?id=1015425), [cortes2008sample](https://link.springer.com/chapter/10.1007/978-3-540-87987-9_8), [dai2007boosting](https://dl.acm.org/citation.cfm?id=1273521), [tan2015transitive](https://dl.acm.org/citation.cfm?id=2783295), [tan2017distant](https://www.aaai.org/ocs/index.php/AAAI/AAAI17/paper/viewPaper/14446)着眼于对源域和目标域的分布比值进行估计($$P(\mathbf{x}_t)/P(\mathbf{x}_s)$$)。所估计得到的比值即为样本的权重。这些方法通常都假设$$\frac{P(\mathbf{x}_t)}{P(\mathbf{x}_s)}<\infty$$并且源域和目标域的条件概率分布相同($$P(y|\mathbf{x}_s)=P(y|\mathbf{x}_t)$$)。
14 |
15 | 特别地,上海交通大学Dai等人提出了TrAdaboost方法,将AdaBoost的思想应用于迁移学习中,提高有利于目标分类任务的实例权重、降低
16 | 不利于目标分类任务的实例权重,并基于PAC理论推导了模型的泛化误差上界。TrAdaBoost方法是此方面的经典研究之一。文献[huang2007correcting](http://papers.nips.cc/paper/3075-correcting-sample-selection-bias-by-unlabeled-data.pdf)提出核均值匹配方法(Kernel Mean Matching, KMM)对于概率分布进行估计,目标是使得加权后的源域和目标域的概率分布尽可能相近。
17 |
18 | 在最新的研究成果中,香港科技大学的Tan等人扩展了实例迁移学习方法的应用场景,提出了传递迁移学习方法(Transitive Transfer Learning, TTL, [tan2015transitive](https://dl.acm.org/citation.cfm?id=2783295))和远域迁移学习(Distant Domain Transfer Learning, DDTL) [tan2017distant](https://www.aaai.org/ocs/index.php/AAAI/AAAI17/paper/viewPaper/14446),利用联合矩阵分解和深度神经网络,将迁移学习应用于多个不相似的领域之间的知识共享,取得了良好的效果。
19 |
20 | 虽然实例权重法具有较好的理论支撑、容易推导泛化误差上界,但这类方法通常只在领域间分布差异较小时有效,因此对自然语言处理、计算机视觉等任务效果并不理想。而基于特征表示的迁移学习方法效果更好,是我们研究的重点。
21 |
22 | # 基于特征迁移
23 |
24 | 基于特征的迁移方法(Feature based Transfer Learning)是指将通过特征变换的方式互相迁移,例如[liu2011cross](https://ieeexplore.ieee.org/abstract/document/5995729), [zheng2008transferring](https://www.aaai.org/Papers/AAAI/2008/AAAI08-226.pdf), [hu2011transfer](https://www.aaai.org/ocs/index.php/IJCAI/IJCAI11/paper/viewPaper/3275)等,来减少源域和目标域之间的差距;或者将源域和目标域的数据特征变换到统一特征空间中,例如[pan2011domain](https://ieeexplore.ieee.org/abstract/document/5640675), [duan2012domain](https://ieeexplore.ieee.org/abstract/document/6136518),[wang2017balanced](https://ieeexplore.ieee.org/abstract/document/8215613)等,然后利用传统的机器学习方法进行分类识别。根据特征的同构和异构性,又可以分为同构和异构迁移学习。
25 |
26 | 下图很形象地表示了两种基于特征的迁移学习方法。
27 |
28 | 
29 |
30 | 基于特征的迁移学习方法是迁移学习领域中**最热门**的研究方法,这类方法通常假设源域和目标域间有一些交叉的特征。香港科技大学的Pan等人[pan2011domain](https://ieeexplore.ieee.org/abstract/document/5640675)提出的迁移成分分析方法(Transfer Component Analysis, TCA)是其中较为典型的一个方法。该方法的核心内容是以[最大均值差异(Maximum Mean Discrepancy, MMD)](https://academic.oup.com/bioinformatics/article-abstract/22/14/e49/228383)作为度量准则,将不同数据领域中的分布差异最小化。加州大学伯克利分校的[Blitzer等人](https://dl.acm.org/citation.cfm?id=1610094)提出了一种基于结构对应的学习方法(Structural Corresponding Learning, SCL),该算法可以通过映射将一个空间中独有的一些特征变换到其他所有空间中的轴特征上,然后在该特征上使用机器学习的算法进行分类预测。
31 |
32 | 清华大学[龙明盛等人](https://www.cv-foundation.org/openaccess/content_cvpr_2014/html/Long_Transfer_Joint_Matching_2014_CVPR_paper.html)提出在最小化分布距离的同时,加入实例选择的迁移联合匹配(Tranfer Joint Matching, TJM)方法,将实例和特征迁移学习方法进行了有机的结合。澳大利亚卧龙岗大学的[Jing Zhang等人](http://openaccess.thecvf.com/content_cvpr_2017/html/Zhang_Joint_Geometrical_and_CVPR_2017_paper.html)提出对于源域和目标域各自训练不同的变换矩阵,从而达到迁移学习的目标。
33 |
34 | 近年来,基于特征的迁移学习方法大多与神经网络进行结合,如[long2015learning](http://www.jmlr.org/proceedings/papers/v37/long15.pdf),[sener2016learning](http://papers.nips.cc/paper/6360-learning-transferrable-representations-for-unsupervised-domain-adaptation),[wang2019transfer](https://arxiv.org/abs/1909.08531v1)等。这些方法在神经网络的训练中进行学习特征和模型的迁移。
35 |
36 | 由于本文的研究重点即是基于特征的迁移学习方法,因此,我们在本小节对这类方法不作过多介绍。在下一小节中,我们将从不同的研究层面,系统地介绍这类工作。
37 |
38 | # 基于模型迁移
39 |
40 | 基于模型的迁移方法(Parameter/Model based Transfer Learning)是指从源域和目标域中找到他们之间共享的参数信息,以实现迁移的方法。这种迁移方式要求的假设条件是:**源域中的数据与目标域中的数据可以共享一些模型的参数**。其中的代表性工作主要有[zhao2010cross](https://dl.acm.org/citation.cfm?id=2505603), [zhao2011cross](https://www.aaai.org/ocs/index.php/IJCAI/IJCAI11/paper/viewPaper/2983), [pan2008transferring](https://www.aaai.org/Papers/AAAI/2008/AAAI08-219.pdf), [pan2008transfer](http://new.aaai.org/Papers/AAAI/2008/AAAI08-108.pdf)。
41 |
42 | 下图形象地表示了基于模型的迁移学习方法的基本思想。
43 |
44 | 
45 |
46 | 其中,中科院计算所的Zhao等人([zhao2010cross](https://dl.acm.org/citation.cfm?id=2505603))提出了TransEMDT方法。该方法首先针对已有标记的数据,利用决策树构建鲁棒性的行为识别模型,然后针对无标定数据,利用K-Means聚类方法寻找最优化的标定参数。西安邮电大学的Deng等人([deng2014cross](https://www.sciencedirect.com/science/article/abs/pii/S0893608014000203))也用超限学习机做了类似的工作。香港科技大学的Pan等人([pan2008transfer](http://new.aaai.org/Papers/AAAI/2008/AAAI08-108.pdf))利用HMM,针对Wifi室内定位在不同设备、不同时间和不同空间下动态变化的特点,进行不同分布下的室内定位研究。
47 |
48 | 另一部分研究人员对支持向量机SVM进行了改进研究([nater2011transferring](https://ieeexplore.ieee.org/abstract/document/6130459),[li2012cross](https://www.sciencedirect.com/science/article/pii/S0957417412006513))。这些方法假定SVM中的权重向量$$\mathbf{w}$$可以分成两个部分:$$\mathbf{w}=\mathbf{w_o}+\mathbf{v}$$,其中$$\mathbf{w}_0$$代表源域和目标域的共享部分,$$\mathbf{v}$$代表了对于不同领域的特定处理。在最新的研究成果中,香港科技大学的Wei等人([wei2016instilling](https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/viewPaper/12308))将社交信息加入迁移学习方法的正则项中,对方法进行了改进。清华大学龙明盛等人([long2015learning](http://www.jmlr.org/proceedings/papers/v37/long15.pdf))改进了深度网络结构,通过在网络中加入概率分布适配层,进一步提高了深度迁移学习网络对于大数据的泛化能力。
49 |
50 | 通过对现有工作的调研可以发现,目前绝大多数基于模型的迁移学习方法都与深度神经网络进行结合([long2015learning](http://www.jmlr.org/proceedings/papers/v37/long15.pdf), [sener2016learning](http://papers.nips.cc/paper/6360-learning-transferrable-representations-for-unsupervised-domain-adaptation),[wang2019transfer](https://arxiv.org/abs/1909.08531v1))。这些方法对现有的一些神经网络结构进行修改,在网络中加入领域适配层,然后联合进行训练。因此,这些方法也可以看作是基于模型、特征的方法的结合。
51 |
52 | # 基于关系迁移
53 |
54 | 基于关系的迁移学习方法(Relation Based Transfer Learning)与上述三种方法具有截然不同的思路。这种方法比较关注源域和目标域的样本之间的关系。下图形象地表示了不同领域之间相似的关系。
55 |
56 | 
57 |
58 | 就目前来说,基于关系的迁移学习方法的相关研究工作非常少,仅有几篇连贯式的文章讨论:[mihalkova2007mapping](http://new.aaai.org/Papers/AAAI/2007/AAAI07-096.pdf), [mihalkova2008transfer](https://www.aaai.org/Papers/Workshops/2008/WS-08-13/WS08-13-006.pdf), [davis2009deep](https://dl.acm.org/citation.cfm?id=1553402)。这些文章都借助于马尔科夫逻辑网络(Markov Logic Net)来挖掘不同领域之间的关系相似性。
59 |
60 | 
61 |
62 | 我们将重点讨论基于特征和基于模型的迁移学习方法,这也是目前绝大多数研究工作的热点。
--------------------------------------------------------------------------------
/markdown/chap06/chap06_conditional.md:
--------------------------------------------------------------------------------
1 | # 条件分布自适应
2 |
3 | 条件分布自适应方法(Conditional Distribution Adaptation)的目标是减小源域和目标域的条件概率分布的距离,从而完成迁移学习。从形式上来说,条件分布自适应方法是用$$P(y_s|\mathbf{x}_s)$$和$$P(y_t|\mathbf{x}_t)$$之间的距离来近似两个领域之间的差异。即:
4 |
5 | $$
6 | DISTANCE(\mathcal{D}_s,\mathcal{D}_t) \approx ||P(y_s|\mathbf{x}_s) - P(y_t|\mathbf{x}_t)||
7 | $$
8 |
9 | 条件分布自适应对应于上一页图中由source迁移到第二类target的情形。
10 |
11 | 目前单独利用条件分布自适应的工作较少。最近,中科院计算所的Wang等人提出了[STL方法(Stratified Transfer Learning)](https://ieeexplore.ieee.org/abstract/document/8444572/)。作者提出了**类内迁移(Intra-class Transfer)**的思想。指出现有的绝大多数方法都只是学习一个全局的特征变换(Global Domain Shift),而忽略了类内的相似性。类内迁移可以利用类内特征,实现更好的迁移效果。
12 |
13 | STL方法的基本思路如下图所示。首先利用大多数投票的思想,对无标定的位置行为生成伪标签;然后在再生核希尔伯特空间中,利用类内相关性进行自适应地空间降维,使得不同情境中的行为数据之间的相关性增大;最后,通过二次标定,实现对未知标定数据的精准标定。
14 |
15 | 
16 |
17 | 为了实现类内迁移,我们需要计算每一类别的MMD距离。由于目标域没有标记,作者使用来自大多数投票结果中的伪标记。更加准确地说,用$$c \in \{1, 2, \cdots, C\}$$来表示类别标记,则类内迁移可以按如下方式计算:
18 |
19 | $$
20 | D(\mathcal{D}_{s},\mathcal{D}_{t})
21 | =\sum_{c=1}^{C}\left \Vert \frac{1}{n^{(c)}_1} \sum_{\mathbf{x}_i \in \mathcal{D}^{(c)}_s} \phi(\mathbf{x}_i) - \frac{1}{n^{(c)}_2} \sum_{\mathbf{x}_j \in \mathcal{D}^{(c)}_t} \phi(\mathbf{x}_j) \right \Vert ^2_\mathcal{H}
22 | $$
23 |
24 | 其中,$$\mathcal{D}^{(c)}_s$$和$$\mathcal{D}^{(c)}_t$$分别表示源域和目标域中属于类别$$c$$的样本。$$n^{(c)}_1=|\mathcal{D}^{(c)}_s|$$,且$$n^{(c)}_2=|\mathcal{D}_t|$$。
25 |
26 | 接下来的步骤请参照STL方法原文进行理解。
27 |
28 | STL方法在大量行为识别数据中进行了跨位置行为识别的实验。实验结果表明,该方法可以很好地实现跨领域的行为识别任务,取得了当前最好的效果。
29 |
30 | STL提出之后,最近有一些方法沿袭了相应的思路,分别将其应用于深度网络语义匹配([MSTN](http://proceedings.mlr.press/v80/xie18c.html))、类间对抗迁移([MADA](https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/viewPaper/17067))等,大大提高了迁移学习方法的效果和精度。
--------------------------------------------------------------------------------
/markdown/chap06/chap06_distribution.md:
--------------------------------------------------------------------------------
1 | 第6章 数据分布自适应方法
2 |
3 | 数据分布自适应(Distribution Adaptation)是一类最常用的迁移学习方法。这种方法的基本思想是,由于源域和目标域的数据概率分布不同,那么最直接的方式就是通过一些变换,将不同的数据分布的距离拉近。
4 |
5 | 下图形象地表示了几种数据分布的情况。(图源:[yu2019transfer](http://jd92.wang/assets/files/a16_icdm19.pdf))
6 |
7 | > 简单来说,数据的边缘分布不同,就是数据整体不相似。数据的条件分布不同,就是数据整体相似,但是具体到每个类里,都不太相似。
8 |
9 | 
10 |
11 | 根据数据分布的性质,这类方法又可以分为**边缘分布自适应**、**条件分布自适应**、以及**联合分布自适应**。最近的研究成果又提出了**动态分布自适应**。下面我们分别介绍每类方法的基本原理和代表性研究工作。介绍每类研究工作时,我们首先给出基本思路,然后介绍该类方法的核心,最后结合最近的相关工作介绍该类方法的扩展。
12 |
13 | 总的来说,四种概率分布适配方法的比较如下:
14 |
15 | - 精度比较:DDA > JDA > TCA > 条件分布自适应。
16 | - 将不同的概率分布自适应方法用于神经网络,是一个发展趋势。将概率分布适配加入深度网络中,往往会取得比非深度方法更好的结果。
--------------------------------------------------------------------------------
/markdown/chap06/chap06_dynamic.md:
--------------------------------------------------------------------------------
1 | # 动态分布自适应
2 |
3 | ## 平衡分布自适应BDA
4 |
5 | 在最近的研究中,来自中科院计算所的Wang等人注意到了JDA的不足:**边缘分布自适应和条件分布自适应并不是同等重要**。回到下图表示的两种分布的问题上来。显然,当目标域是Source迁移到Target I所示的情况时,边缘分布应该被优先考虑;而当目标域是Source迁移到Target II所示的情况时,条件分布应该被优先考虑。JDA以及后来的扩展工作均忽视了这一问题。
6 |
7 | 
8 |
9 | 作者提出了[BDA方法(Balanced Distribution Adaptation)](https://ieeexplore.ieee.org/abstract/document/8215613/)来解决这一问题。该方法能够根据特定的数据领域,自适应地调整分布适配过程中边缘分布和条件分布的重要性。准确而言,BDA通过采用一种**平衡因子**$$\mu$$来动态调整两个分布之间的距离
10 | $$
11 | DISTANCE(\mathcal{D}_s,\mathcal{D}_t) \approx (1 - \mu)DISTANCE(P(\mathbf{x}_s),P(\mathbf{x}_t)) + \mu DISTANCE(P(y_s|\mathbf{x}_s),P(y_t|\mathbf{x}_t))
12 | $$
13 |
14 | 其中$$\mu \in [0,1]$$表示平衡因子。当$$\mu \rightarrow 0$$,这表示源域和目标域数据本身存在较大的差异性,因此,边缘分布适配更重要;当$$\mu \rightarrow 1$$时,这表示源域和目标域数据集有较高的相似性,因此,条件概率分布适配更加重要。综合上面的分析可知,平衡因子可以根据实际数据分布的情况,动态地调节每个分布的重要性,并取得良好的分布适配效果。
15 |
16 | 其中的平衡因子$$\mu$$可以通过分别计算两个领域数据的整体和局部的$$\mathcal{A}$$-distance近似给出。特别地,当$$\mu = 0$$时,方法退化为TCA;当$$\mu = 0.5$$时,方法退化为JDA。
17 |
18 | 我们采用BDA文章中的图来具体地展示出$$\mu$$的作用。下图的结果清晰地显示出,平衡因子可以取得比JDA、TCA更小的MMD距离、更高的精度。
19 |
20 | 
21 |
22 | 
23 |
24 | ## 动态分布自适应
25 |
26 | BDA方法是首次给出边缘分布和条件分布的定量估计。然而,其并未解决平衡因子$$\mu$$的精确计算问题。最近,作者扩展了BDA方法,提出了一个更具普适性的动态迁移框架[DDA(Dynamic Distribution Adaptation)](https://dl.acm.org/citation.cfm?id=3240512)来解决$$\mu$$值的精确估计问题。
27 |
28 | 注意到,可以简单地将$$\mu$$视为一个迁移过程中的参数,通过交叉验证 (cross-validation)来确定其最优的取值$$\mu_{opt}$$。然而,在本章的无监督迁移学习问题定义中,目标域完全没有标记,故此方式不可行。有另外两种非直接的方式可以对$$\mu$$值进行估计:随机猜测和最大最小平均法。随机猜测从神经网络随机调参中得到启发,指的是任意从$$[0,1]$$区间内选择一个$$\mu$$的值,然后进行动态迁移,其并不算是一种技术严密型的方案。如果重复此过程$$t$$次,记第$$t$$次的迁移学习结果为$$r_t$$,则随机猜测法最终的迁移结果为$$r_{rand} = \frac{1}{t} \sum_{i=1}^{t} r_t$$。最大最小平均法与随机猜测法相似,可以在$$[0,1]$$区间内从0开始取$$\mu$$的值,每次增加0.1,得到一个集合$$[0,0.1,\cdots,0.9,1.0]$$,然后,与随机猜测法相似,也可以得到其最终迁移结果$$r_{maxmin}=\frac{1}{11} \sum_{i=1}^{11} r_i$$。
29 |
30 | 然而,尽管上述两种估计方案有一定的可行性,它们均需要大量的重复计算,给普适计算设备带来了严峻的挑战。另外,上述结果并不具有可解释性,其正确性也无法得到保证。
31 |
32 | 作者提出的动态迁移方法是首次对$$\mu$$值进行精确的定量估计方法。该方法利用领域的整体和局部性质来定量计算$$\mu$$(计算出的值用$$\hat{\mu}$$来表示)。采用$$\mathcal{A}-distance$$作为基本的度量方式。$$\mathcal{A}-distance$$被定义为建立一个二分类器进行两个不同领域的分类得出的误差。从形式化来看,定义$$\epsilon(h)$$作为线性分类器$$h$$区分两个领域$$\Omega_s$$和$$\Omega_t$$的误差。则,$$\mathcal{A}-distance$$可以被定义为:
33 | $$
34 | d_A(\Omega_s,\Omega_t) = 2(1 - 2 \epsilon(h)).
35 | $$
36 |
37 | 直接根据上式计算边缘分布的$$\mathcal{A}-distance$$,将其用$$d_M$$来表示。对于条件分布之间的$$\mathcal{A}-distance$$,用$$d_c$$来表示对应于类别$$c$$的条件分布距离。它可以由式$$d_c = d_A(\Omega^{(c)}_s,\Omega^{(c)}_t)$$进行计算,其中$$\Omega^{(c)}_s$$和$$\Omega^{(c)}_t$$分别表示来自源域和目标域的第$$c$$个类的样本。最终,$$\mu$$可以由下式进行计算:
38 | $$
39 | \hat{\mu} = 1 - \frac{d_M}{d_M + \sum_{c=1}^{C} d_c}.
40 | $$
41 |
42 | 由于特征的动态和渐近变化性,此估计需要在每一轮迭代中给出。值得注意的是,这是**首次**给出边缘分布和条件分布的定量估计,对于迁移学习研究具有很大的意义。
43 |
44 | 具体而言,作者将机器学习问题规约成一个统计机器学习问题,可以用统计机器学习中的结构风险最小化的原则(Structural Risk Minimization, SRM)~\cite{belkin2006manifold,vapnik1998statistical}进行表示学习。在SRM中,分类器$$f$$可以被表示为:
45 | $$
46 | f = \mathop{\arg\min}_{f \in \mathcal{H}_{K}, (\mathbf{x},y) \sim \Omega_l} J(f(\mathbf{x}),y) + R(f),
47 | $$
48 | 其中第一项表示$$f$$在有标记数据上的损失,第二项为正则项,$$\mathcal{H}_{K}$$表示核函数$$K(\cdot,\cdot)$$构造的希尔伯特空间 (Hilbert space)。符号$$\Omega_l$$表示有标记的数据领域。在本章的问题中,$$\Omega_l = \Omega_s$$,即只有源域数据有标记。特别地,由于在迁移学习问题中,源域和目标域数据有着不同的数据分布,为了表示此分布距离,可以进一步将正则项表示成如下的形式:
49 | $$
50 | R(f) = \lambda \overline{D_f}(\Omega_s,\Omega_t) + R_f(\Omega_s,\Omega_t),
51 | $$
52 | 其中$$\overline{D_f}(\cdot, \cdot)$$表示$$\Omega_s$$和$$\Omega_t$$的分布距离,$$\lambda$$为平衡系数,$$R_f(\cdot, \cdot)$$则为其他形式的正则项。根据公式~(\ref{eq-meda-srm})中的结构风险最小化公式,如果用$$g(\cdot)$$来表示特征学习过程,则$$f$$可以被表示为:
53 | $$
54 | f = \mathop{\arg\min}_{f \in \sum_{i=1}^{n} \mathcal{H}_{K}} J(f(g(\mathbf{x}_i)),y_i) + \eta ||f||^2_K + \lambda \overline{D_f}(\Omega_s,\Omega_t) + \rho R_f(\Omega_s,\Omega_t),
55 | $$
56 | 其中$$||f||^2_K$$是$$f$$的平方标准形式。$$\overline{D_f}(\cdot,\cdot)$$这一项表示本章提出的动态迁移学习。引入拉普拉斯约束作为$$f$$的额外正则项[belkin2006manifold](http://www.jmlr.org/papers/v7/belkin06a.html)。$$\eta,\lambda$$,和$$\rho$$是对应的正则项系数。
57 |
58 | 上式则为通用的一个迁移学习框架,可以适用于任何问题。为了对此框架进行学习,作者分别提出了[基于流形学习的动态迁移方法MEDA (Manifold Embedded Distribution Alignment)](https://dl.acm.org/citation.cfm?id=3240512)和[基于深度学习的动态迁移方法DDAN (Deep Dynamic Adaptation Network)](https://arxiv.org/abs/1909.08184)来进行学习。这两种方法分别如下图所示。
59 |
60 | 
61 |
62 | 最近,作者在[yu2019transfer](http://jd92.wang/assets/files/a16_icdm19.pdf)中将DDA的概念进一步扩展到了对抗网络中,证明了对抗网络中同样存在边缘分布和条件分布不匹配的问题。作者提出一个动态对抗适配网络DAAN (Dynamic Adversarial Adaptation Networks)来解决对抗网络中的动态分布适配问题,取得了当前的最好效果。下图展示了DAAN的架构。
63 |
64 | 
--------------------------------------------------------------------------------
/markdown/chap06/chap06_joint.md:
--------------------------------------------------------------------------------
1 | # 联合分布自适应
2 |
3 | ## 基本思路
4 |
5 | 联合分布自适应方法(Joint Distribution Adaptation)的目标是减小源域和目标域的联合概率分布的距离,从而完成迁移学习。从形式上来说,联合分布自适应方法是用$$P(\mathbf{x}_s)$$和$$P(\mathbf{x}_t)$$之间的距离、以及$$P(y_s|\mathbf{x}_s)$$和$$P(y_t|\mathbf{x}_t)$$之间的距离来近似两个领域之间的差异。即:
6 |
7 | $$
8 | DISTANCE(\mathcal{D}_s,\mathcal{D}_t) \approx ||P(\mathbf{x}_s) - P(\mathbf{x}_t)|| + ||P(y_s|\mathbf{x}_s) - P(y_t|\mathbf{x}_t)||
9 | $$
10 |
11 | ## 核心方法
12 |
13 | 联合分布适配的[JDA方法](http://openaccess.thecvf.com/content_iccv_2013/html/Long_Transfer_Feature_Learning_2013_ICCV_paper.html)首次发表于2013年的ICCV(计算机视觉领域顶会,与CVPR类似)。
14 |
15 | 假设是最基本的出发点。那么JDA这个方法的假设是什么呢?就是假设两点:1)源域和目标域边缘分布不同,2)源域和目标域条件分布不同。既然有了目标,同时适配两个分布不就可以了吗?于是作者很自然地提出了联合分布适配方法:适配联合概率。
16 |
17 | 不过这里我感觉有一些争议:边缘分布和条件分布不同,与联合分布不同并不等价。所以这里的“联合”二字实在是会引起歧义。我的理解是,同时适配两个分布,也可以叫联合,而不是概率上的“联合”。尽管作者在文章里第一个公式就写的是适配联合概率,但是这里感觉是有一些问题的。我们抛开它这个有歧义的,把“联合”理解成同时适配两个分布。
18 |
19 | 那么,JDA方法的目标就是,寻找一个变换$$\mathbf{A}$$,使得经过变换后的$$P(\mathbf{A}^\top \mathbf{x}_s)$$和$$P(\mathbf{A}^\top \mathbf{x}_t)$$的距离能够尽可能地接近,同时,$$P(y_s|\mathbf{A}^\top \mathbf{x}_s)$$和$$P(y_t|\mathbf{A}^\top \mathbf{x}_t)$$的距离也要小。很自然地,这个方法也就分成了两个步骤。
20 |
21 | ### 边缘分布适配
22 |
23 | 首先来适配边缘分布,也就是$$P(\mathbf{A}^\top \mathbf{x}_s)$$和$$P(\mathbf{A}^\top \mathbf{x}_t)$$的距离能够尽可能地接近。其实这个操作就是迁移成分分析(TCA)。我们仍然使用MMD距离来最小化源域和目标域的最大均值差异。MMD距离是
24 |
25 | $$
26 | \left \Vert \frac{1}{n} \sum_{i=1}^{n} \mathbf{A}^\top \mathbf{x}_{i} - \frac{1}{m} \sum_{j=1}^{m} \mathbf{A}^\top \mathbf{x}_{j} \right \Vert ^2_\mathcal{H}
27 | $$
28 |
29 | 这个式子实在不好求解。我们引入核方法,化简这个式子,它就变成了
30 |
31 | $$
32 | D(\mathcal{D}_s,\mathcal{D}_t)=tr(\mathbf{A}^\top \mathbf{X} \mathbf{M}_0 \mathbf{X}^\top \mathbf{A})
33 | $$
34 |
35 | 其中$$\mathbf{A}$$就是变换矩阵,我们把它加黑加粗,$$\mathbf{X}$$是源域和目标域合并起来的数据。$$\mathbf{M}_0$$是一个MMD矩阵:
36 |
37 | $$
38 | (\mathbf{M}_0)_{ij}=\begin{cases} \frac{1}{n^2}, & \mathbf{x}_i,\mathbf{x}_j \in \mathcal{D}_s\\ \frac{1}{m^2}, & \mathbf{x}_i,\mathbf{x}_j \in \mathcal{D}_t\\ -\frac{1}{mn}, & \text{otherwise} \end{cases}
39 | $$
40 |
41 | $$n,m$$分别是源域和目标域样本的个数。
42 |
43 | 到此为止没有什么创新点,因为这就是一个TCA。
44 |
45 | ### 条件分布适配
46 |
47 | 这是我们要做的第二个目标,适配源域和目标域的条件概率分布。也就是说,还是要找一个变换$$\mathbf{A}$$,使得$$P(y_s|\mathbf{A}^\top \mathbf{x}_s)$$和$$P(y_t|\mathbf{A}^\top \mathbf{x}_t)$$的距离也要小。那么简单了,我们再用一遍MMD啊。可是问题来了:我们的目标域里,没有$$y_t$$,没法求目标域的条件分布!
48 |
49 | 这条路看来是走不通了。也就是说,直接建模$$P(y_t|\mathbf{x}_t)$$不行。那么,能不能有别的办法可以逼近这个条件概率?我们可以换个角度,利用类条件概率$$P(\mathbf{x}_t|y_t)$$。根据贝叶斯公式$$P(y_t|\mathbf{x}_t)=p(y_t)p(\mathbf{x}_t|y_t)$$,我们如果忽略$$P(\mathbf{x}_t)$$,那么岂不是就可以用$$P(\mathbf{x}_t|y_t)$$来近似$$P(y_t|\mathbf{x}_t)$$?
50 |
51 | 而这样的近似也不是空穴来风。在统计学上,有一个概念叫做**充分统计量**,它是什么意思呢?大概意思就是说,如果样本里有太多的东西未知,样本足够好,我们就能够从中选择一些统计量,近似地代替我们要估计的分布。好了,我们为近似找到了理论依据。
52 |
53 | 实际怎么做呢?我们依然没有$$y_t$$。采用的方法是,用$$(\mathbf{x}_s,y_s)$$来训练一个简单的分类器(比如knn、逻辑斯特回归),到$$\mathbf{x}_t$$上直接进行预测。总能够得到一些伪标签$$\hat{y}_t$$。我们根据伪标签来计算,这个问题就可解了。
54 |
55 | 类与类之间的MMD距离表示为
56 |
57 | $$
58 | \sum_{c=1}^{C}\left \Vert \frac{1}{n_c} \sum_{\mathbf{x}_{i} \in \mathcal{D}^{(c)}_s} \mathbf{A}^\top \mathbf{x}_{i} - \frac{1}{m_c} \sum_{\mathbf{x}_{i} \in \mathcal{D}^{(c)}_t} \mathbf{A}^\top \mathbf{x}_{i} \right \Vert ^2_\mathcal{H}
59 | $$
60 |
61 | 其中,$$n_c,m_c$$分别标识源域和目标域中来自第$$c$$类的样本个数。同样地我们用核方法,得到了下面的式子
62 |
63 | $$
64 | \sum_{c=1}^{C}tr(\mathbf{A}^\top \mathbf{X} \mathbf{M}_c \mathbf{X}^\top \mathbf{A})
65 | $$
66 |
67 | 其中$$\mathbf{M}_c$$为
68 |
69 | $$
70 | (\mathbf{M}_c)_{ij}=\begin{cases} \frac{1}{n^2_c}, & \mathbf{x}_i,\mathbf{x}_j \in \mathcal{D}^{(c)}_s\\ \frac{1}{m^2_c}, & \mathbf{x}_i,\mathbf{x}_j \in \mathcal{D}^{(c)}_t\\ -\frac{1}{m_c n_c}, & \begin{cases} \mathbf{x}_i \in \mathcal{D}^{(c)}_s ,\mathbf{x}_j \in \mathcal{D}^{(c)}_t \\ \mathbf{x}_i \in \mathcal{D}^{(c)}_t ,\mathbf{x}_j \in \mathcal{D}^{(c)}_s \end{cases}\\ 0, & \text{otherwise}\end{cases}
71 | $$
72 |
73 | ### 总优化目标
74 |
75 | 现在我们把两个距离结合起来,得到了一个总的优化目标:
76 |
77 | $$
78 | \min \sum_{c=0}^{C}tr(\mathbf{A}^\top \mathbf{X} \mathbf{M}_c \mathbf{X}^\top \mathbf{A}) + \lambda \Vert \mathbf{A} \Vert ^2_F
79 | $$
80 |
81 | 看到没,通过$$c=0 \cdots C$$就把两个距离统一起来了!其中的$$\lambda \Vert \mathbf{A} \Vert ^2_F$$是正则项,使得模型是**良好定义(Well-defined)**的。
82 |
83 | 我们还缺一个限制条件,不然这个问题无法解。限制条件是什么呢?和TCA一样,变换前后数据的方差要维持不变。怎么求数据的方差呢,还和TCA一样:$$\mathbf{A}^\top \mathbf{X} \mathbf{H} \mathbf{X}^\top \mathbf{A} = \mathbf{I}$$,其中的$$\mathbf{H}$$也是中心矩阵,$$\mathbf{I}$$是单位矩阵。也就是说,我们又添加了一个优化目标是要$$\max \mathbf{A}^\top \mathbf{X} \mathbf{H} \mathbf{X}^\top \mathbf{A}$$(这一个步骤等价于PCA了)。和原来的优化目标合并,优化目标统一为:
84 |
85 | $$
86 | \min \frac{\sum_{c=0}^{C}tr(\mathbf{A}^\top \mathbf{X} \mathbf{M}_c \mathbf{X}^\top \mathbf{A}) + \lambda \Vert \mathbf{A}\Vert^2_F}{ \mathbf{A}^\top \mathbf{X} \mathbf{H} \mathbf{X}^\top \mathbf{A}}
87 | $$
88 |
89 | 这个式子实在不好求解。但是,有个东西叫做[Rayleigh quotient](https://www.wikiwand.com/en/Rayleigh_quotient),上面两个一样的这种形式。因为$$\mathbf{A}$$是可以进行拉伸而不改变最终结果的,而如果下面为0的话,整个式子就求不出来值了。所以,我们直接就可以让下面不变,只求上面。所以我们最终的优化问题形式搞成了
90 |
91 | $$
92 | \min \quad \sum_{c=0}^{C}tr(\mathbf{A}^\top \mathbf{X} \mathbf{M}_c \mathbf{X}^\top \mathbf{A}) + \lambda \Vert \mathbf{A} \Vert ^2_F \quad \text{s.t.} \quad \mathbf{A}^\top \mathbf{X} \mathbf{H} \mathbf{X}^\top \mathbf{A} = \mathbf{I}
93 | $$
94 |
95 | 怎么解?太简单了,可以用拉格朗日法。最后变成了
96 |
97 | $$
98 | \left(\mathbf{X} \sum_{c=0}^{C} \mathbf{M}_c \mathbf{X}^\top + \lambda \mathbf{I}\right) \mathbf{A} =\mathbf{X} \mathbf{H} \mathbf{X}^\top \mathbf{A} \Phi
99 | $$
100 |
101 | 其中的$$\Phi$$是拉格朗日乘子。别看这个东西复杂,又有要求解的$$\mathbf{A}$$,又有一个新加入的$$\Phi$$ 。但是它在Matlab里是可以直接解的(用$$\mathrm{eigs}$$函数即可)。这样我们就得到了变换$$\mathbf{A}$$,问题解决了。
102 |
103 | 可是伪标签终究是伪标签啊,肯定精度不高,怎么办?有个东西叫做\textit{迭代},一次不行,我们再做一次。后一次做的时候,我们用上一轮得到的标签来作伪标签。这样的目的是得到越来越好的伪标签,而参与迁移的数据是不会变的。这样往返多次,结果就自然而然好了。
104 |
105 | ## 扩展
106 |
107 | JDA方法是十分经典的迁移学习方法。后续的相关工作通过在JDA的基础上加入额外的损失项,使得迁移学习的效果得到了很大提升。我们在这里简要介绍一些基于JDA的相关工作。
108 |
109 | - [ARTL (Adaptation Regularization)](https://ieeexplore.ieee.org/abstract/document/6550016/): 将JDA嵌入一个结构风险最小化框架中,用表示定理直接学习分类器
110 | - [VDA](https://link.springer.com/article/10.1007/s10115-016-0944-x): 在JDA的优化目标中加入了类内距和类间距的计算
111 | - [hsiao2016learning](https://ieeexplore.ieee.org/abstract/document/7478127/): 在JDA的基础上加入结构不变性控制
112 | - [hou2015unsupervised](https://ieeexplore.ieee.org/abstract/document/7301758/): 在JDA的基础上加入目标域的选择
113 | - [JGSA (Joint Geometrical and Statistical Alignment)](http://openaccess.thecvf.com/content_cvpr_2017/html/Zhang_Joint_Geometrical_and_CVPR_2017_paper.html): 在JDA的基础上加入类内距、类间距、标签持久化
114 | - [JAN~(Joint Adaptation Network)(https://dl.acm.org/citation.cfm?id=3305909)]: 提出了联合分布度量JMMD,在深度网络中进行联合分布的优化
115 |
116 | JDA的代码可以在这里被找到:https://github.com/jindongwang/transferlearning/tree/master/code/traditional/JDA。
--------------------------------------------------------------------------------
/markdown/chap06/chap06_marginal.md:
--------------------------------------------------------------------------------
1 | # 边缘分布自适应
2 |
3 | ## 基本思路
4 |
5 | 边缘分布自适应方法(Marginal Distribution Adaptation)的目标是减小源域和目标域的边缘概率分布的距离,从而完成迁移学习。从形式上来说,边缘分布自适应方法是用$$P(\mathbf{x}_s)$$和$$P(\mathbf{x}_t)$$之间的距离来近似两个领域之间的差异。即:
6 | $$
7 | DISTANCE(\mathcal{D}_s,\mathcal{D}_t) \approx ||P(\mathbf{x}_s) - P(\mathbf{x}_t)||
8 | $$
9 |
10 | 边缘分布自适应对应于前页中由source迁移到第一类target的情形。
11 |
12 | ## 核心方法
13 |
14 | 边缘分布自适应的方法最早由香港科技大学杨强教授团队提出,方法名称为[迁移成分分析(Transfer Component Analysis)](https://ieeexplore.ieee.org/abstract/document/5640675)。由于$$P(\mathbf{x}_s) \ne P(\mathbf{x}_t)$$,因此,直接减小二者之间的距离是不可行的。TCA假设存在一个特征映射$$\phi$$,使得映射后数据的分布$$P(\phi(\mathbf{x}_s)) \approx P(\phi(\mathbf{x}_t))$$。TCA假设如果边缘分布接近,那么两个领域的条件分布也会接近,即条件分布$$P(y_s | \phi(\mathbf{x}_s))) \approx P(y_t | \phi(\mathbf{x}_t)))$$。这就是TCA的全部思想。因此,我们现在的目标是,找到这个合适的$$\phi$$。
15 |
16 | 但是世界上有无穷个这样的$$\phi$$,也许终我们一生也无法找到合适的那一个。庄子说过,吾生也有涯,而知也无涯,以有涯随无涯,殆已!我们肯定不能通过穷举的方法来找$$\phi$$的。那么怎么办呢?
17 |
18 | 回到迁移学习的本质上来:最小化源域和目标域的距离。好了,我们能不能先假设这个$$\phi$$是已知的,然后去求距离,看看能推出什么呢?
19 |
20 | 更进一步,这个距离怎么算?机器学习中有很多种形式的距离,从欧氏距离到马氏距离,从曼哈顿距离到余弦相似度,我们需要什么距离呢?TCA利用了一个经典的也算是比较“高端”的距离叫做最大均值差异(MMD,maximum mean discrepancy)。我们令$$n_1,n_2$$分别表示源域和目标域的样本个数,那么它们之间的MMD距离可以计算为:
21 |
22 | $$
23 | DISTANCE(\mathbf{x}_{s},\mathbf{x}_{t})= \begin{Vmatrix} \frac{1}{n_1} \sum \limits_{i=1}^{n_1} \phi(\mathbf{x}_{i}) - \frac{1}{n_2}\sum \limits _{j=1}^{n_2} \phi(\mathbf{x}_{j}) \end{Vmatrix}_{\mathcal{H}}
24 | $$
25 |
26 | MMD是做了一件什么事呢?简单,就是求映射后源域和目标域的**均值**之差。
27 |
28 | 事情到这里似乎也没什么进展:我们想求的$$\phi$$仍然没法求。
29 |
30 | TCA是怎么做的呢,这里就要感谢矩阵了!我们发现,上面这个MMD距离平方展开后,有二次项乘积的部分!那么,联系在SVM中学过的核函数,把一个难求的映射以核函数的形式来求,不就可以了?于是,TCA引入了一个核矩阵$$\mathbf{K}$$:
31 |
32 | $$
33 | \mathbf{K}=\begin{bmatrix}\mathbf{K}_{s,s} & \mathbf{K}_{s,t}\\\mathbf{K}_{t,s} & \mathbf{K}_{t,t}\end{bmatrix}
34 | $$
35 |
36 | 以及一个MMD矩阵$$\mathbf{L}$$,它的每个元素的计算方式为:
37 |
38 | $$
39 | l_{ij}=\begin{cases} \frac{1}{{n_1}^2} & \mathbf{x}_i,\mathbf{x}_j \in \mathcal{D}_s,\\ \frac{1}{{n_2}^2} & \mathbf{x}_i,\mathbf{x}_j \in \mathcal{D}_t,\\ -\frac{1}{n_1 n_2} & \text{otherwise} \end{cases}
40 | $$
41 |
42 | 这样的好处是,直接把那个难求的距离,变换成了下面的形式:
43 |
44 | $$
45 | \mathrm{tr}(\mathbf{KL})-\lambda \mathrm{tr}(\mathbf{K})
46 | $$
47 |
48 | 其中,$$\mathrm{tr}(\cdot)$$操作表示求矩阵的迹,用人话来说就是一个矩阵对角线元素的和。这样是不是感觉离目标又进了一步呢?
49 |
50 | 其实这个问题到这里就已经是可解的了,也就是说,属于计算机的部分已经做完了。只不过它是一个数学中的半定规划(SDP,semi-definite programming)的问题,解决起来非常耗费时间。由于TCA的第一作者Sinno Jialin Pan以前是中山大学的数学硕士,他想用更简单的方法来解决。他是怎么做的呢?
51 |
52 | 他想出了用降维的方法去构造结果。用一个更低维度的矩阵$$\mathbf{W}$$:
53 |
54 | $$
55 | \widetilde{\mathbf{K}}=({\mathbf{K}}{\mathbf{K}}^{-1/2}\widetilde{\mathbf{W}})(\widetilde{\mathbf{W}}^{\top}{\mathbf{K}}^{-1/2}{\mathbf{K}})={\mathbf{K}}\mathbf{W} \mathbf{W}^{\top}{\mathbf{K}}
56 | $$
57 |
58 | 这里的$$\mathbf{W}$$矩阵是比$$\mathbf{K}$$更低维度的矩阵。最后的$$\mathbf{W}$$就是问题的解答了!
59 |
60 | 好了,问题到这里,整理一下,TCA最后的优化目标是:
61 |
62 | $$
63 | \begin{split} \min_\mathbf{W} \quad& \mathrm{tr}(\mathbf{W}^\top \mathbf{K} \mathbf{L} \mathbf{K} \mathbf{W}) + \mu \mathrm{tr}(\mathbf{W}^\top \mathbf{W})\\ \text{s.t.} \quad & \mathbf{W}^\top \mathbf{K} \mathbf{H} \mathbf{K} \mathbf{W} = \mathbf{I}_m \end{split}
64 | $$
65 |
66 | 这里的$$\mathbf{H}$$是一个中心矩阵,$$\mathbf{H} = \mathbf{I}_{n_1 + n_2} - 1/(n_1 + n_2)\mathbf{11}^\top$$.
67 |
68 | 这个式子下面的条件是什么意思呢?那个$$\min$$的目标我们大概理解,就是要最小化源域和目标域的距离,加上$$\mathbf{W}$$的约束让它不能太复杂。那么下面的条件是什么呢?下面的条件就是要实现第二个目标:维持各自的数据特征。
69 |
70 | TCA要维持的是什么特征呢?文章中说是variance,但是实际是scatter matrix,就是数据的散度。就是说,一个矩阵散度怎么计算?对于一个矩阵$$\mathbf{A}$$,它的scatter matrix就是$$\mathbf{A} \mathbf{H} \mathbf{A}^\top$$。这个$$\mathbf{H}$$就是上面的中心矩阵啦。
71 |
72 | 解决上面的优化问题时,作者又求了它的拉格朗日对偶。最后得出结论,$$\mathbf{W}$$的解就是它的前$$m$$个特征值!简单不?数学美不美?
73 |
74 | 好了,我们现在总结一下TCA方法的步骤。输入是两个特征矩阵,我们首先计算$$\mathbf{L}$$和$$\mathbf{H}$$矩阵,然后选择一些常用的核函数进行映射(比如线性核、高斯核)计算$$\mathbf{K}$$,接着求$$({\mathbf{K}} \mathbf{L} {\mathbf{K}}+\mu \mathbf{I})^{-1}{\mathbf{K}} \mathbf{H}{\mathbf{K}}$$的前$$m$$个特征值。仅此而已。然后,得到的就是源域和目标域的降维后的数据,我们就可以在上面用传统机器学习方法了。
75 |
76 | 为了形象地展示TCA方法的优势,我们借用TCA的paper中提供的可视化效果,在图中展示了对于源域和目标域数据(红色和蓝色),分别由PCA(主成分分析)和TCA得到的分布结果。从下中可以很明显地看出,对于概率分布不同的两部分数据,在经过TCA处理后,概率分布更加接近。这说明了TCA在拉近数据分布距离上的优势。
77 |
78 | 
79 |
80 | ## 扩展
81 |
82 | TCA方法是迁移学习领域一个经典的方法,之后的许多研究工作都以TCA为基础。我们列举部分如下:
83 |
84 | - [ACA (Adapting Component Analysis)](https://ieeexplore.ieee.org/abstract/document/6413843/): 在TCA中加入HSIC
85 | - [DTMKL (Domain Transfer Multiple Kernel Learning)](https://ieeexplore.ieee.org/abstract/document/6136518/): 在TCA中加入了MK-MMD,用了新的求解方式
86 | - [TJM (Transfer Joint Matching)](https://www.cv-foundation.org/openaccess/content_cvpr_2014/html/Long_Transfer_Joint_Matching_2014_CVPR_paper.html): 在优化目标中同时进行边缘分布自适应和源域样本选择
87 | - [DDC (Deep Domain Confusion)](https://arxiv.org/abs/1412.3474): 将MMD度量加入了深度网络特征层的loss中(我们将会在深度迁移学习中介绍此工作)
88 | - [DAN (Deep Adaptation Network)](http://www.jmlr.org/proceedings/papers/v37/long15.pdf): 扩展了DDC的工作,将MMD换成了MK-MMD,并且进行多层loss计算(我们将会在深度迁移学习中介绍此工作)
89 | - [DME (Distribution Matching Embedding)](http://www.jmlr.org/papers/volume17/15-207/15-207.pdf): 先计算变换矩阵,再进行特征映射(与TCA顺序相反)
90 | - [CMD (Central Moment Matching)](https://arxiv.org/abs/1702.08811): MMD着眼于一阶,此工作将MMD推广到了多阶
91 |
92 | ## 附加信息
93 |
94 | 想了解TCA完整推导过程的,可以见这里:https://zhuanlan.zhihu.com/p/63026435。
95 |
96 | TCA的Matlab和Python代码可以在这里被找到:https://github.com/jindongwang/transferlearning/tree/master/code/traditional/TCA。
--------------------------------------------------------------------------------
/markdown/chap07/chap07_featureselect.md:
--------------------------------------------------------------------------------
1 | # 特征选择法
2 |
3 | 特征选择法的基本假设是:源域和目标域中均含有一部分公共的特征,在这部分公共的特征上,源领域和目标领域的数据分布是一致的。因此,此类方法的目标就是,通过机器学习方法,选择出这部分共享的特征,即可依据这些特征构建模型。
4 |
5 | 下图形象地表示了特征选择法的主要思路。
6 |
7 | 
8 |
9 | ## 核心方法
10 |
11 | 这这个领域比较经典的一个方法是发表在2006年的ECML-PKDD会议上,作者提出了一个叫做[SCL的方法(Structural Correspondence Learning)](https://dl.acm.org/citation.cfm?id=1610094)。这个方法的目标就是我们说的,找到两个领域公共的那些特征。作者将这些公共的特征叫做Pivot feature。找出来这些Pivot feature,就完成了迁移学习的任务。
12 |
13 | 
14 |
15 | 上图形象地展示了Pivot feature的含义。Pivot feature指的是在文本分类中,在不同领域中出现频次较高的那些词。
16 |
17 | ## 扩展
18 |
19 | SCL方法是特征选择方面的经典研究工作。基于SCL,也出现了一些扩展工作。
20 |
21 | - [Joint feature selection and subspace learning](https://www.aaai.org/ocs/index.php/IJCAI/IJCAI11/paper/viewPaper/2910):特征选择+子空间学习
22 | - [TJM (Transfer Joint Matching)](https://www.cv-foundation.org/openaccess/content_cvpr_2014/html/Long_Transfer_Joint_Matching_2014_CVPR_paper.html): 在优化目标中同时进行边缘分布自适应和源域样本选择
23 | - [FSSL (Feature Selection and Structure Preservation)](https://www.ijcai.org/Proceedings/16/Papers/243.pdf): 特征选择+信息不变性
24 |
25 | ## 小结
26 |
27 | - 特征选择法从源域和目标域中选择提取共享的特征,建立统一模型
28 | - 通常与分布自适应方法进行结合
29 | - 通常采用稀疏表示$||\mathbf{A}||_{2,1}$实现特征选择
--------------------------------------------------------------------------------
/markdown/chap08/chap08_manifold.md:
--------------------------------------------------------------------------------
1 | # 流形学习法
2 |
3 | 流形学习自从2000年在Science上被提出来以后,就成为了机器学习和数据挖掘领域的热门问题。它的基本假设是,现有的数据是从一个**高维空间**中采样出来的,所以,它具有高维空间中的低维流形结构。流形就是一种几何对象(就是我们能想像能观测到的)。通俗点说,我们无法从原始的数据表达形式明显看出数据所具有的结构特征,那我把它想像成是处在一个高维空间,在这个高维空间里它是有个形状的。一个很好的例子就是星座。满天星星怎么描述?我们想像它们在一个更高维的宇宙空间里是有形状的,这就有了各自星座,比如织女座、猎户座。流形学习的经典方法有Isomap、locally linear embedding、laplacian eigenmap等。
4 |
5 | 流形空间中的距离度量:两点之间什么最短?在二维上是直线(线段),可在三维呢?地球上的两个点的最短距离可不是直线,它是把地球展开成二维平面后画的那条直线。那条线在三维的地球上就是一条曲线。这条曲线就表示了两个点之间的最短距离,我们叫它**测地线**。更通俗一点,两点之间,测地线最短。在流形学习中,我们遇到测量距离的时候,更多的时候用的就是这个测地线。在我们要介绍的GFK方法中,也是利用了这个测地线距离。比如在下面的图中,从A到C最短的距离在就是展开后的线段,但是在三维球体上看,它却是一条曲线。
6 |
7 | 
8 |
9 | 由于在流形空间中的特征通常都有着很好的几何性质,可以避免特征扭曲,因此我们首先将原始空间下的特征变换到流形空间中。在众多已知的流形中,Grassmann流形$$\mathbb{G}(d)$$可以通过将原始的$$d$$维子空间(特征向量)看作它基础的元素,从而可以帮助学习分类器。在Grassmann流形中,特征变换和分布适配通常都有着有效的数值形式,因此在迁移学习问题中可以被很高效地表示和求解[~\cite{]hamm2008grassmann](https://dl.acm.org/citation.cfm?id=1390204)。因此,利用Grassmann流形空间中来进行迁移学习是可行的。现存有很多方法可以将原始特征变换到流形空间中([gopalan2011domain](https://ieeexplore.ieee.org/abstract/document/6126344/), [baktashmotlagh2014domain](https://www.cv-foundation.org/openaccess/content_cvpr_2014/html/Baktashmotlagh_Domain_Adaptation_on_2014_CVPR_paper.html))。
10 |
11 | ## GFK方法
12 |
13 | 在众多的基于流形变换的迁移学习方法中,[GFK(Geodesic Flow Kernel)方法](https://ieeexplore.ieee.org/abstract/document/6247911/)是最为代表性的一个。GFK是在2011年发表在ICCV上的SGF方法[gopalan2011domain](https://ieeexplore.ieee.org/abstract/document/6126344/)发展起来的。我们首先介绍SGF方法。
14 |
15 | SGF方法从**增量学习**中得到启发:人类从一个点想到达另一个点,需要从这个点一步一步走到那一个点。那么,如果我们把源域和目标域都分别看成是高维空间中的两个点,由源域变换到目标域的过程不就完成了迁移学习吗?也就是说,**路是一步一步走出来的**。
16 |
17 | 于是SGF就做了这个事情。它是怎么做的呢?把源域和目标域分别看成高维空间(即Grassmann流形)中的两个点,在这两个点的测地线距离上取$$d$$个中间点,然后依次连接起来。这样,源域和目标域就构成了一条测地线的路径。我们只需要找到合适的每一步的变换,就能从源域变换到目标域了。下图是SGF方法的示意图。
18 |
19 | 
20 |
21 | SGF方法的主要贡献在于:提出了这种变换的计算及实现了相应的算法。但是它有很明显的缺点:到底需要找几个中间点?SGF也没能给出答案,就是说这个参数$$d$$是没法估计的,没有一个好的方法。这个问题在GFK中被回答了。
22 |
23 | GFK方法首先解决SGF的问题:如何确定中间点的个数$$d$$。它通过提出一种核学习的方法,利用路径上的无穷个点的**积分**,把这个问题解决了。这是第一个贡献。然后,它又解决了第二个问题:当有多个源域的时候,我们如何决定使用哪个源域跟目标域进行迁移?GFK通过提出Rank of Domain度量,度量出跟目标域最近的源域,来解决这个问题。下图是GFK方法的示意图。
24 |
25 | 
26 |
27 | 用$$\mathcal{S}_s$$和$$\mathcal{S}_t$$分别表示源域和目标域经过主成分分析(PCA)之后的子空间,则G可以视为所有的d维子空间的集合。每一个$$d$$维的原始子空间都可以被看作$$\mathbb{G}$$上的一个点。因此,在两点之间的测地线$$\{\Phi(t):0 \leq t \leq 1\}$$可以在两个子空间之间构成一条路径。如果我们令$$\mathcal{S}_s=\Phi(0)$$,$$\mathcal{S}_t=\Phi(1)$$,则寻找一条从$$\Phi\left(0\right)$$到$$\Phi\left(1\right)$$的测地线就等同于将原始的特征变换到一个无穷维度的空间中,最终减小域之间的漂移现象。这种方法可以被看作是一种从$$\Phi\left(0\right)$$到$$\Phi\left(1\right)$$的增量式“行走”方法。
28 |
29 | 特别地,流形空间中的特征可以被表示为$$\mathbf{z}=\Phi\left(t\right)^\top \mathbf{x}$$。变换后的特征$$\mathbf{z}_i$$和$$\mathbf{z}_j$$的内积定义了一个半正定(positive semidefinite)的测地线流式核
30 | $$
31 | \langle\mathbf{z}_i,\mathbf{z}_j\rangle= \int_{0}^{1} (\Phi(t)^T \mathbf{x}_i)^T (\Phi(t)^T \mathbf{x}_j) \, dt = \mathbf{x}^T_i \mathbf{G} \mathbf{x}_j
32 | $$
33 |
34 | GFK方法详细的计算过程可以参考原始的文章,我们在这里不再赘述。
35 |
36 | GFK的代码可以在这里被找到:https://github.com/jindongwang/transferlearning/tree/master/code/traditional/GFK。
37 |
38 | ## 扩展与小结
39 |
40 | 子空间学习方法和概率分布自适应方法可以有机地进行组合,克服各自的缺点。下面是一些相关工作。
41 |
42 | - [DIP (Domain-Invariant Projection)](https://www.cv-foundation.org/openaccess/content_iccv_2013/html/Baktashmotlagh_Unsupervised_Domain_Adaptation_2013_ICCV_paper.html): 边缘分布自适应+流形变换
43 | - [baktashmotlagh2014domain](https://www.cv-foundation.org/openaccess/content_cvpr_2014/html/Baktashmotlagh_Domain_Adaptation_on_2014_CVPR_paper.html): 统计流形法,在黎曼流形上进行距离度量。
44 | - [MEDA (Manifold Embedded Distribution Alignment)](http://jd92.wang/assets/files/a11_mm18.pdf): 将GFK流形学习与概率分布适配进行有机结合,达到了很好的效果。
--------------------------------------------------------------------------------
/markdown/chap08/chap08_statistics.md:
--------------------------------------------------------------------------------
1 | # 统计特征对齐
2 |
3 | 统计特征对齐方法主要将数据的统计特征进行变换对齐。对齐后的数据,可以利用传统机器学习方法构建分类器进行学习。
4 |
5 | ## SA方法
6 |
7 | SA方法(Subspace Alignment,子空间对齐)([fernando2013unsupervised](http://openaccess.thecvf.com/content_iccv_2013/html/Fernando_Unsupervised_Visual_Domain_2013_ICCV_paper.html))是其中的代表性成果。SA方法直接寻求一个线性变换$$\mathbf{M}$$,将不同的数据实现变换对齐。
8 |
9 | SA方法的优化目标如下:
10 |
11 | $$
12 | F(\mathbf{M}) = ||\mathbf{X}_s \mathbf{M} - \mathbf{X}_t||^2_F
13 | $$
14 |
15 | 则变换$$\mathbf{M}$$的值为:
16 |
17 | $$
18 | \mathbf{M}^\star = \arg \min_\mathbf{M} (F(\mathbf{M}))
19 | $$
20 |
21 | 可以直接获得上述优化问题的闭式解:
22 |
23 | $$
24 | F(\mathbf{M}) = ||\mathbf{X}^\top_s \mathbf{X}_s \mathbf{M} - \mathbf{X}^\top_s \mathbf{X}_t||^2_F = ||\mathbf{M} - \mathbf{X}^\top_s \mathbf{X}_t||^2_F
25 | $$
26 |
27 | SA方法实现简单,计算过程高效,是子空间学习的代表性方法。
28 |
29 | ## SDA方法
30 |
31 | 基于SA方法,Sun等人在2015年提出了SDA方法(Subspace Distribution Alignment)([sun2015subspace](http://www.bmva.org/bmvc/2015/papers/paper024/paper024.pdf))。该方法在SA的基础上,加入了概率分布自适应。下图示意了该方法的简单流程。
32 |
33 | 
34 |
35 | SDA方法提出,除了子空间变换矩阵$$\mathbf{T}$$之外,还应当增加一个概率分布自适应变换$$\mathbf{A}$$。SDA方法的优化目标如下:
36 |
37 | $$
38 | \mathbf{M} = \mathbf{X}_s \mathbf{T} \mathbf{A} \mathbf{X}^\top_t
39 | $$
40 |
41 | ## CORAL方法
42 |
43 | 有别于SA和SDA方法只进行源域和目标域的一阶特征对齐,Sun等人提出了[CORAL方法(CORrelation ALignment)](https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/viewPaper/12443),对两个领域进行二阶特征对齐。假设$$\mathbf{C}_s$$和$$\mathbf{C}_t$$分别是源领域和目标领域的协方差矩阵,则CORAL方法学习一个二阶特征变换$$\mathbf{A}$$,使得源域和目标域的特征距离最小:
44 |
45 | $$
46 | \min_\mathbf{A} ||\mathbf{A}^\top \mathbf{C}_s \mathbf{A} - \mathbf{C}_t||^2_F
47 | $$
48 |
49 | CORAL方法的求解同样非常简单且高效。CORAL方法被应用到神经网络中,提出了[DeepCORAL方法](https://link.springer.com/chapter/10.1007/978-3-319-49409-8_35)。作者将CORAL度量作为一个神经网络的损失进行计算。下图展示了DeepCORAL方法的网络结构。
50 |
51 | 
52 |
53 | CORAL损失被定义为源域和目标域的二阶统计特征距离:
54 |
55 | $$
56 | \ell_{CORAL} = \frac{1}{4d^2} ||\mathbf{C}_s - \mathbf{C}_t||^2_F
57 | $$
--------------------------------------------------------------------------------
/markdown/chap08/chap08_subspace.md:
--------------------------------------------------------------------------------
1 | # 子空间学习
2 |
3 | 子空间学习法通常假设源域和目标域数据在变换后的子空间中会有着相似的分布。我们按照特征变换的形式,将子空间学习法分为两种:**基于统计特征变换的统计特征对齐方法**,以及**基于流形变换的流形学习方法**。下面我们分别介绍这两种方法的基本思路和代表性研究成果。
--------------------------------------------------------------------------------
/markdown/chap09/chap09_adversarial.md:
--------------------------------------------------------------------------------
1 | # 深度对抗迁移学习
2 |
3 | 生成对抗网络GAN(Generative Adversarial Nets)([goodfellow2014generative](http://papers.nips.cc/paper/5423-generative-adversarial-nets))是目前人工智能领域最炙手可热的概念之一。其也被深度学习领军人物Yann Lecun评为近年来最令人欣喜的成就。由此发展而来的对抗网络,也成为了提升网络性能的利器。本小节介绍深度对抗网络用于解决迁移学习问题方面的基本思路以及代表性研究成果。
4 |
5 | ## 基本思路
6 |
7 | GAN受到自博弈论中的二人零和博弈(two-player game)思想的启发而提出。它一共包括两个部分:一部分为生成网络(Generative Network),此部分负责生成尽可能地以假乱真的样本,这部分被成为**生成器 (Generator)**;另一部分为判别网络(Discriminative Network),此部分负责判断样本是真实的,还是由生成器生成的,这部分被成为**判别器 (Discriminator)**。生成器和判别器的互相博弈,就完成了对抗训练。
8 |
9 | GAN的目标很明确:生成训练样本。这似乎与迁移学习的大目标有些许出入。然而,由于在迁移学习中,天然地存在一个源领域,一个目标领域,因此,我们可以免去生成样本的过程,而直接将其中一个领域的数据(通常是目标域)当作是生成的样本。此时,生成器的职能发生变化,不再生成新样本,而是扮演了特征提取的功能:不断学习领域数据的特征,使得判别器无法对两个领域进行分辨。这样,原来的生成器也可以称为特征提取器(Feature Extractor)。
10 |
11 | 通常用$$G_f$$来表示特征提取器,用$$G_d$$来表示判别器。
12 |
13 | 正是基于这样的领域对抗的思想,深度对抗网络可以被很好地运用于迁移学习问题中。
14 |
15 | 与深度网络自适应迁移方法类似,深度对抗网络的损失也由两部分构成:网络训练的损失$$\ell_c$$和领域判别损失$$\ell_d$$:
16 |
17 | $$
18 | \ell = \ell_c(\mathcal{D}_s,\mathbf{y}_s) + \lambda \ell_d(\mathcal{D}_s,\mathcal{D}_t)
19 | $$
20 |
21 | ## DANN
22 |
23 | Yaroslav Ganin等人首先在神经网络的训练中加入了对抗机制,作者将他们的网络称之为[DANN(Domain-Adversarial Neural Network)](https://arxiv.org/abs/1409.7495)。在此研究中,网络的学习目标是:生成的特征尽可能帮助区分两个领域的特征,同时使得判别器无法对两个领域的差异进行判别。该方法的领域对抗损失函数表示为:
24 |
25 | $$
26 | \ell_d = \max \left[-\frac{1}{n} \sum_{i=1}^{n} \mathcal{L}^i_d(\mathbf{W},\mathbf{b},\mathbf{u},z) - \frac{1}{n'} \sum_{i=n+1}^{N} \mathcal{L}^i_d(\mathbf{W},\mathbf{b},\mathbf{u},z)\right]
27 | $$
28 |
29 | 其中的$$\mathcal{L}_d$$表示为
30 |
31 | $$
32 | \mathcal{L}_d(G_d(G_f(\mathbf{x}_i)),d_i) = d_i \log \frac{1}{G_d(G_f(\mathbf{x}_i))} + (1 - d_i) \log \frac{1}{G_d(G_f(\mathbf{x}_i))}
33 | $$
34 |
35 | ## DSN
36 |
37 | 来自Google Brain的Bousmalis等人通过提出[DSN网络(Domain Separation Networks)](http://papers.nips.cc/paper/6254-domain-separation-networks)对DANN进行了扩展。DSN认为,源域和目标域都由两部分构成:公共部分和私有部分。公共部分可以学习公共的特征,私有部分用来保持各个领域独立的特性。DSN进一步对损失函数进行了定义:
38 |
39 | $$
40 | \ell = \ell_{task} + \alpha \ell_{recon} + \beta \ell_{difference} + \gamma \ell_{similarity}
41 | $$
42 |
43 | 除去网络的常规训练损失$$\ell_{task}$$外,其他损失的含义如下:
44 |
45 | - $$\ell_{recon}$$: 重构损失,确保私有部分仍然对学习目标有作用
46 | - $$\ell_{difference}$$: 公共部分与私有部分的差异损失
47 | - $$\ell_{similarity}$$: 源域和目标域公共部分的相似性损失
48 |
49 | 下图是DSN方法的示意图。
50 |
51 | 
52 |
53 | DDC方法的作者、加州大学伯克利分校的Tzeng等人在2017年发表于计算机视觉顶级会议CVPR上的文章提出了[ADDA方法(Adversarial Discriminative Domain Adaptation)](http://openaccess.thecvf.com/content_cvpr_2017/html/Tzeng_Adversarial_Discriminative_Domain_CVPR_2017_paper.html)。ADDA是一个通用的框架,现有的很多方法都可被看作是ADDA的特例。上海交通大学的研究者们用Wasserstein GAN进行迁移学习([WDGRL](https://arxiv.org/abs/1707.01217)),Liu等人提出了Coupled GAN用于迁移学习([liu2016coupled](http://papers.nips.cc/paper/6544-coupled-generative-adversarial-networks))。这些工作都大体上按照之前思路进行。
54 |
55 | ## SAN
56 |
57 | 清华大学龙明盛团队2018年发表在计算机视觉顶级会议CVPR上的文章提出了一个选择性迁移网络[(Partial Transfer Learning)](http://openaccess.thecvf.com/content_cvpr_2018/html/Cao_Partial_Transfer_Learning_CVPR_2018_paper.html)。作者认为,在大数据时代,通常我们会有大量的源域数据。这些源域数据比目标域数据,在类别上通常都是丰富的。比如基于ImageNet训练的图像分类器,必然是针对几千个类别进行的分类。我们实际用的时候,目标域往往只是其中的一部分类别。这样就会带来一个问题:那些只存在于源域中的类别在迁移时,会对迁移结果产生负迁移影响。
58 |
59 | 这种情况通常来说是非常普遍的。因此,就要求相应的迁移学习方法能够对目标域,选择相似的源域样本(类别),同时也要避免负迁移。但是目标域通常是没有标签的,不知道和源域中哪个类别更相似。作者指出这个问题叫做partial transfer learning。这个partial,就是只迁移源域中那部分和目标域相关的样本。下图展示了部分迁移学习的思想。
60 |
61 | 
62 |
63 | 作者提出了一个叫做Selective Adversarial Networks (SAN)的方法来处理partial transfer问题。在partial问题中,传统的对抗网络不再适用。所以就需要对进行一些修改,使得它能够适用于partial问题。
64 |
65 | 因为不知道目标域的标签,也就没办法知道到底是源域中哪些类是目标域的。为了达到这个目的,作者对目标域按照类别分组,把原来的一整个判别器分成了$$|\mathcal{C}_s|$$个:$$G^k_d$$,每一个子判别器都对它所在的第$$k$$个类进行判别。作者观察到了这样的事实:对于每个数据点$$\mathbf{x}_i$$来说,分类器的预测结果 $$\hat{\mathbf{y}}_i$$ 其实是对于整个类别空间的一个\textit{概率分布}。因此,在进行对抗时,需要考虑每个样本属于每个类别的影响。这个影响就是由概率来刻画。所以作者提出了一个概率权重的判别器:
66 |
67 | $$
68 | L'_d=\frac{1}{n_s+n_t} \sum_{k=1}^{|\mathcal{C}_s|} \sum_{\mathbf{x}_i \in \mathcal{D}_s + \mathcal{D}_t}^{} \hat{y}^k_i L^k_d(G^k_d(G_f(\mathbf{x}_i)),d_i)
69 | $$
70 |
71 | 上面这个式子能很好地在partial transfer情景下,避免负迁移。这种约束是样本级别的,就是可以控制尽可能让更相似的样本参与迁移。除此之外,作者还介绍了一个类别级别的约束,可以很好地避免不在目标域中的那些类别不参与迁移。于是,进一步地,变成了下面的约束
72 |
73 | $$
74 | L'_d=\frac{1}{n_s+n_t} \sum_{k=1}^{|\mathcal{C}_s|} \sum_{\mathbf{x}_i \in \mathcal{D}_s + \mathcal{D}_t}^{} (\frac{1}{n_t} \sum_{\mathbf{x}_i^{} \in \mathcal{D}_t}\hat{y}^k_i) L^k_d(G^k_d(G_f(\mathbf{x}_i)),d_i)
75 | $$
76 |
77 | 上面这个式子比较依赖于之前说的每个样本的预测概率。为了消除这个影响,作者又在目标域上加了一项熵最小化
78 |
79 | $$
80 | E=\frac{1}{n_t} \sum_{\mathbf{x}_i \in \mathcal{D}_t} H(G_y(G_f(\mathbf{x}_i)))
81 | $$
82 |
83 | ## DAAN
84 |
85 | 最近,Yu等人将动态分布适配的概念进一步扩展到了对抗网络中,证明了对抗网络中同样存在边缘分布和条件分布不匹配的问题。作者提出一个动态对抗适配网络[DAAN (Dynamic Adversarial Adaptation Networks)](http://jd92.wang/assets/files/a16_icdm19.pdf)来解决对抗网络中的动态分布适配问题,取得了当前的最好效果。下图展示了DAAN的架构。
86 |
87 | 
88 |
89 | ## 小结
90 |
91 | 使用对抗网络进行迁移学习是近年来的研究热点。我们期待在这个领域会有越来越多的工作发表。
--------------------------------------------------------------------------------
/markdown/chap09/chap09_deep.md:
--------------------------------------------------------------------------------
1 | # 第9章深度迁移学习
2 |
3 | 随着深度学习方法的大行其道,越来越多的研究人员使用深度神经网络进行迁移学习。对比传统的非深度迁移学习方法,深度迁移学习直接提升了在不同任务上的学习效果。并且,由于深度学习直接对原始数据进行学习,所以其对比非深度方法还有两个优势:**自动化地提取更具表现力的特征**,以及**满足了实际应用中的端到端(End-to-End)需求**。
4 |
5 | 近年来,以生成对抗网络(Generative Adversarial Nets, GAN)([goodfellow2014generative](http://papers.nips.cc/paper/5423-generative-adversarial-nets))为代表的对抗学习也吸引了很多研究者的目光。基于GAN的各种变体网络不断涌现。对抗学习网络对比传统的深度神经网络,极大地提升了学习效果。因此,基于对抗网络的迁移学习,也是一个热门的研究点。
6 |
7 | 下图展示了近几年的一些代表性方法在相同数据集上的表现。从图中的结果我们可以看出,深度迁移学习方法(BA、DDC、DAN)对比传统迁移学习方法(TCA、GFK等),在精度上具有无可匹敌的优势。
8 |
9 | 
10 |
11 | 本部分重点介绍深度迁移学习的基本思路。首先我们回答一个最基本的问题:**为什么深度网络是可迁移的?**然后,我们介绍最简单的深度网络迁移形式:finetune。接着分别介绍使用深度网络和深度对抗网络进行迁移学习的基本思路和核心方法。值得注意的是,由于深度迁移学习方面的研究工作层出不穷,我们不可能覆盖到所有最新的方法。但是基本上这些方法的原理都大同小异。因此,我们的介绍是具有普适性的。
--------------------------------------------------------------------------------
/markdown/chap09/chap09_deepmethod.md:
--------------------------------------------------------------------------------
1 | # 深度迁移方法
2 |
3 | ## 基本思路
4 |
5 | 深度网络的finetune可以帮助我们节省训练时间,提高学习精度。但是finetune有它的先天不足:它无法处理训练数据和测试数据分布不同的情况。而这一现象在实际应用中比比皆是。因为finetune的基本假设也是训练数据和测试数据服从相同的数据分布。这在迁移学习中也是不成立的。因此,我们需要更进一步,针对深度网络开发出更好的方法使之更好地完成迁移学习任务。
6 |
7 | 以我们之前介绍过的数据分布自适应方法为参考,许多深度学习方法([tzeng2014deep](https://arxiv.org/abs/1412.3474))都开发出了**自适应层(Adaptation Layer)**来完成源域和目标域数据的自适应。自适应能够使得源域和目标域的数据分布更加接近,从而使得网络的效果更好。
8 |
9 | 从上述的分析我们可以得出,深度网络的自适应主要完成两部分的工作:
10 |
11 | 一是哪些层可以自适应,这决定了网络的学习程度;
12 |
13 | 二是采用什么样的自适应方法(度量准则),这决定了网络的泛化能力。
14 |
15 | 深度网络中最重要的是网络损失的定义。绝大多数深度迁移学习方法都采用了以下的损失定义方式:
16 |
17 | $$
18 | \ell = \ell_c(\mathcal{D}_s,\mathbf{y}_s) + \lambda \ell_A(\mathcal{D}_s,\mathcal{D}_t)
19 | $$
20 |
21 | 其中,$$\ell$$表示网络的最终损失,$$\ell_c(\mathcal{D}_s,\mathbf{y}_s)$$表示网络在有标注的数据(大部分是源域)上的常规分类损失(这与普通的深度网络完全一致),$$\ell_A(\mathcal{D}_s,\mathcal{D}_t)$$表示网络的自适应损失。最后一部分是传统的深度网络所不具有的、迁移学习所独有的。此部分的表达与我们先前讨论过的源域和目标域的分布差异,在道理上是相同的。式中的$$\lambda$$是权衡两部分的权重参数。
22 |
23 | 上述的分析指导我们设计深度迁移网络的基本准则:决定自适应层,然后在这些层加入自适应度量,最后对网络进行finetune。
24 |
25 | ## 经典方法
26 |
27 | 前期的研究者在2014年环太平洋人工智能大会(PRICAI)上提出了一个叫做DaNN(Domain Adaptive Neural Network)的神经网络([ghifary2014domain](https://link.springer.com/chapter/10.1007/978-3-319-13560-1_76))。DaNN的结构异常简单,它仅由两层神经元组成:特征层和分类器层。作者的创新工作在于,在特征层后加入了一项MMD适配层,用来计算源域和目标域的距离,并将其加入网络的损失中进行训练。
28 |
29 | 但是,由于网络太浅,表征能力有限,故无法很有效地解决domain adaptation问题。因此,后续的研究者大多数都基于其思想进行扩充,如将浅层网络改为更深层的AlexNet、ResNet、VGG等;如将MMD换为多核的MMD等。
30 |
31 | ## DDC方法
32 |
33 | 加州大学伯克利分校的Tzeng等人~\cite{tzeng2014deep}首先提出了一个DDC方法(Deep Domain Confusion)解决深度网络的自适应问题([tzeng2014deep](https://arxiv.org/abs/1412.3474))。DDC遵循了我们上述讨论过的基本思路,采用了在ImageNet数据集上训练好的[AlexNet网络](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networ)进行自适应学习。
34 |
35 | 下图是DDC方法的示意。DDC固定了AlexNet的前7层,在第8层(分类器前一层)上加入了自适应的度量。自适应度量方法采用了被广泛使用的MMD准则。
36 |
37 | 
38 |
39 | DDC方法的损失函数表示为:
40 |
41 | $$
42 | \ell = \ell_c(\mathcal{D}_s,\mathbf{y}_s) + \lambda MMD^2(\mathcal{D}_s,\mathcal{D}_t)
43 | $$
44 |
45 | 为什么选择了倒数第二层? DDC方法的作者在文章中提到,他们经过了多次实验,在不同的层进行了尝试,最终得出结论,在分类器前一层加入自适应可以达到最好的效果。
46 |
47 | 这也是与我们的认知相符合的。通常来说,分类器前一层即特征,在特征上加入自适应,也正是迁移学习要完成的工作。
48 |
49 | 自动选择迁移层的工作在最近的ICML 2019上被提出:https://zhuanlan.zhihu.com/p/66130006=。
50 |
51 | ## DAN方法
52 |
53 | 来自清华大学的龙明盛等人在2015年发表在机器学习顶级会议ICML上的DAN方法(Deep Adaptation Networks)([long2015learning](http://www.jmlr.org/proceedings/papers/v37/long15.pdf))对DDC方法进行了几个方面的扩展。首先,有别于DDC方法只加入一个自适应层,DAN方法同时加入了三个自适应层(分类器前三层)。其次,DAN方法采用了表征能力更好的**[多核MMD度量(MK-MMD)](http://papers.nips.cc/paper/4727-optimal-kernel-choice-for-large-scale-two-sample-tests)**代替了DDC方法中的单一核MMD。然后,DAN方法将多核MMD的参数学习融入到深度网络的训练中,不增加网络的额外训练时间。DAN方法在多个任务上都取得了比DDC更好的分类效果。
54 |
55 | 为什么是适配3层?原来的DDC方法只是适配了一层,现在DAN也基于AlexNet网络,适配最后三层(第6第7第8层)。为什么是这三层?因为在Jason的文章[yosinski2014transferable](http://papers.nips.cc/paper/5347-how-transferable-are-features-in-deep-n%E2%80%A6)中已经说了,网络的迁移能力在这三层开始就会特别地task-specific,所以要着重适配这三层。至于别的网络(比如GoogLeNet、VGG)等是不是这三层就需要通过自己的实验来推测。DAN只关注使用AlexNet。
56 |
57 | MK-MMD的多核表示形式为
58 |
59 | $$
60 | \mathcal{K} \triangleq \left\{k= \sum_{u=1}^{m}\beta_u k_u : \beta_u \ge 0, \forall u \right\}
61 | $$
62 |
63 | DAN的优化目标也由两部分组成:损失函数和自适应损失。损失函数这个好理解,基本上所有的机器学习方法都会定义一个损失函数,它来度量预测值和真实值的差异。分布距离就是我们上面提到的MK-MMD距离。于是,DAN的优化目标就是
64 |
65 | $$
66 | \label{eq-deep-dan}
67 | \min_\Theta \frac{1}{n_a} \sum_{i=1}^{n_a} J(\theta(\mathbf{x}^a_i),y^a_i) + \lambda \sum_{l=l_1}^{l_2}d^2_k(\mathcal{D}^l_s,\mathcal{D}^l_t)
68 | $$
69 |
70 | 这个式子中,$$\Theta$$表示网络的所有权重和bias参数,是用来学习的目标。其中$$l_1,l_2$$分别是6和8,表示网络适配是从第6层到第8层,前面的不进行适配。$$\mathbf{x}_a,n_a$$表示源域和目标域中所有有标注的数据的集合。$$J(\cdot)$$就定义了一个损失函数,在深度网络中一般都是cross-entropy。DAN的网络结构如下图所示。
71 |
72 | 
73 |
74 | DAN的学习一共分为两大类参数:学习网络参数$$\Theta$$和MMD的$$\beta$$。
75 |
76 | 对$$\Theta$$的学习依赖于MK-MMD距离的计算。通过kernel trick(类比以前的MMD变换)我们总是可以把MK-MMD展开成一堆内积的形式。然而,数据之间两两计算内积是非常复杂的,时间复杂度为$$O(n^2)$$,这个在深度学习中的开销非常之大。怎么办?作者在这里采用了Gretton在文章~\cite{gretton2012optimal}提出的对MK-MMD的无偏估计:$$d^2_k(p,q)=\frac{2}{n_s}\sum_{i=1}^{n_s/2}g_k(\mathbf{z}_i)$$,其中的$$\mathbf{z}_i$$是一个四元组:$$\mathbf{z}_i \triangleq (\mathbf{x}^s_{2i-1},\mathbf{x}^s_{2i},\mathbf{x}^t_{2i-1},\mathbf{x}^t_{2i})$$。将kernel作用到$$\mathbf{z}_i$$上以后,变成$$g_k(\mathbf{z}_i) \triangleq k(\mathbf{x}^s_{2i-1},\mathbf{x}^s_{2i})+k(\mathbf{x}^t_{2i-1},\mathbf{x}^t_{2i})-k(\mathbf{x}^s_{2i-1},\mathbf{x}^t_{2i})-k(\mathbf{x}^s_{2i},\mathbf{x}^t_{2i-1})$$。
77 |
78 | 上面这些变换看着很复杂。简单来说,它就是只计算了连续的一对数据的距离,再乘以2.这样就可以把时间复杂度降低到$$O(n)$$!至于具体的理论,可以去参考Gretton的论文,这里就不说了。
79 |
80 | 在具体进行SGD的时候,我们需要对所有的参数求导:对$$\Theta$$求导。在实际用multiple-kernel的时候,作者用的是多个高斯核。
81 |
82 | 学习$$\beta$$主要是为了确定多个kernel的权重。学习的时候,目标是:确保每个kernel生成的MMD距离的方差最小。也就是
83 |
84 | $$
85 | \max_{k \in \mathcal{K}} d^2_k(\mathcal{D}^l_s,\mathcal{D}^l_t) \sigma^{-2}_k
86 | $$
87 |
88 | 这里的$$\sigma^{-2}_k=E[g^2_k(\mathbf{z})]-[E(g_k(\mathbf{z}))]^2$$是估计方差。实际求解的时候问题可以被规约成一个二次规划问题求解,具体可以参照文章。
89 |
90 | ## 同时迁移领域和任务
91 |
92 | DDC的作者Tzeng在2015年扩展了DDC方法,提出了领域和任务同时迁移的方法[tzeng2015simultaneous](http://openaccess.thecvf.com/content_iccv_2015/html/Tzeng_Simultaneous_Deep_Transfer_ICCV_2015_paper.html)。作者提出网络要进行两部分的迁移:
93 |
94 | 一是domain transfer,就是适配分布,特别地是指适配marginal distribution,但是没有考虑类别信息。如何做domain transfer:在传统深度网路的loss上,再加另一个confusion loss,作为classifier能否将两个domain进行分开的loss。两个loss一起计算,就是domain transfer。
95 |
96 | 二是task transfer,就是利用class之间的相似度,其实特指的是conditional distribution。类别之间有相似度,要利用上。类别之间的相似度:比如一个杯子与瓶子更相似,而与键盘不相似。文章的原话:it does not necessarily align the classes in the target with those in the source. Thus, we also explicity transfer the similarity structure amongst categories.
97 |
98 | 现有的深度迁移学习方法通常都只是考虑domain transfer,\textit{而没有考虑到类别之间的信息}。如何把domain和task transfer结合起来,是一个问题。
99 |
100 | 文章针对的情况是:target的部分class有少量label,剩下的class无label。
101 |
102 | 作者提出的方法名字叫做joint CNN architecture for domain and task transfer。最大的创新点是:现有的方法都是domain classifier加上一个domain confusion,就是适配。作者提出这些是不够的,因为忽略了类别之间的联系,所以提出了还要再加一个soft label loss。意思就是在source和target进行适配的时候,也要根据source的类别分布情况来进行调整target的。其实本意和JDA差不多。
103 |
104 | 相应地,文章的方法就是把这两个loss结合到一个新的CNN网络上,这个CNN是用AlexNet的结构修改成的。总的loss可以表示成几部分的和:
105 |
106 | $$
107 | L(x_S,y_S,x_T,y_T,\theta_D;\theta_{repr},\theta_C)=L_C(x_S,y_S,x_T,y_T;\theta_{repr},\theta_C) + \lambda L_{conf}(x_S,x_T,\theta_D;\theta_{repr})+v L_{soft}(x_T,y_T;\theta_{repr},\theta_C)
108 | $$
109 |
110 | Loss由三部分组成:第一部分是普通训练的loss,对应于经验风险最小化,所以作用到了所有有label的数据 $$x_S,y_S,x_T,y_T$$上;第二部分是现有方法也都做过的,就是domain adaptation,所以作用于 $$x_S,x_T$$上;第三部分是作者的贡献:新加的soft label的loss,只作用于target上。
111 |
112 | 网络结构如下图所示。网络由AlexNet修改而来,前面的几层都一样,区别只是在第fc7层后面加入了一个domain classifier,也就是进行domain adaptation的一层;在fc8后计算网络的loss和soft label的loss。
113 |
114 | 
115 |
116 | Domain confusion就不用多说,和现有的一些比如DAN和JAN一样,直接对source和target的margina distribution进行估计即可。
117 |
118 | 什么是soft label loss?这和作者的motivation有关。不仅仅要适配两个domain的marginal distribution,也要把类别信息考虑进去。而target中有大量数据没有label,怎么办呢?可以利用source中的label信息。具体做法是:在网络对source进行训练的时候,把source的每一个样本处于每一个类的概率都记下来,然后,对于所有样本,属于每一个类的概率就可以通过求和再平均得到。如下图所示。这样的目的是:根据source中的类别分布关系,来对target做相应的约束。比如,source中和bike最相似的class,肯定是motorbike,而不是truck。这样有一定的道理。
119 |
120 | 但是在我看来,这就是深度网络版的conditional distribution adaptation。因为也对应于得到了每个类的proportion。只不过作者在这里取了个“soft label loss”这个好听的名字,再冠以“task transfer”这样高大上的名字。下图是soft label的示意。
121 |
122 | 
123 |
124 | ## AdaBN
125 |
126 | 与上述工作选择在已有网络层中增加适配层不同的是,北京大学的Haoyang Li和图森科技的Naiyan Wang等人提出了([AdaBN(Adaptive Batch Normalization)](https://arxiv.org/abs/1603.04779)),通过在归一化层加入统计特征的适配,从而完成迁移。
127 |
128 | 
129 |
130 | AdaBN对比其他方法,实现相当简单。并且,方法本身不带有任何额外的参数。在许多公开数据集上都取得了很好的效果。
131 |
132 | ## 小结
133 |
134 | 基于深度网络进行迁移学习,其核心在于,找到网络需要进行自适应的层,并且对这些层加上自适应的损失度量。越来越多的研究者开始使用深度网络进行迁移学习([long2016deep](http://papers.nips.cc/paper/6110-unsupervised-domain-adaptation-with-residual-transfer-networks), [zhuang2015supervised](https://www.aaai.org/ocs/index.php/IJCAI/IJCAI15/paper/viewPaper/10724), [sun2016deep](https://arxiv.org/abs/1607.01719), [luo2017label](http://papers.nips.cc/paper/6621-label-efficient-learning-of-transferable-representations-acrosss-domains-and-tasks))。在这其中,几乎绝大多数方法都采用了卷积神经网络,在已训练好的模型(如AlexNet、Inception、GoogLeNet、Resnet等)上进行迁移。
135 |
136 | 特别地,最近意大利的学者Carlucci等人在2017年计算机视觉领域顶级会议ICCV上提出了[自动深度网络自适应层(AutoDIAL, Automatic DomaIn Alignment Layers)](https://ieeexplore.ieee.org/abstract/document/8237804/)。该方法可以很简单地被加入现有的深度网络中,实现自动的自适应学习,使得深度网络的迁移更便捷。
137 |
138 | 由于篇幅和时间所限,我们未对所有新出现的研究工作给予介绍,仅在这里介绍了其中最具代表性的几种方法。但是绝大多数方法的原理都和我们已介绍过的大同小异。请读者持续关注最新发表的研究成果。
--------------------------------------------------------------------------------
/markdown/chap09/chap09_deeptransfer.md:
--------------------------------------------------------------------------------
1 | ## 深度网络的可迁移性
2 |
3 | 随着[AlexNet](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networ)在2012年的ImageNet大赛上获得冠军,深度学习开始在机器学习的研究和应用领域大放异彩。尽管取得了很好的结果,但是神经网络本身就像一个黑箱子,看得见,摸不着,解释性不好。由于神经网络具有良好的层次结构,很自然地就有人开始关注,能否通过这些层次结构来很好地解释网络?于是,有了我们熟知的例子:假设一个网络要识别一只猫,那么一开始它只能检测到一些边边角角的东西,和猫根本没有关系;然后可能会检测到一些线条和圆形;慢慢地,可以检测到有猫的区域;接着是猫腿、猫脸等等。下图是一个简单的示例。
4 |
5 | 
6 |
7 | 这表达了一个什么事实呢?概括来说就是:前面几层都学习到的是通用的特征(general feature);随着网络层次的加深,后面的网络更偏重于学习任务特定的特征(specific feature)。这非常好理解,我们也都很好接受。那么问题来了:如何得知哪些层能够学习到general feature,哪些层能够学习到specific feature。更进一步:**如果应用于迁移学习,如何决定该迁移哪些层、固定哪些层?**
8 |
9 | 这个问题对于理解神经网络以及深度迁移学习都有着非常重要的意义。
10 |
11 | 来自康奈尔大学的Jason Yosinski等人([yosinski2014transferable](http://papers.nips.cc/paper/5347-how-transferable-are-features-in-deep-n%E2%80%A6))率先进行了深度神经网络可迁移性的研究,将成果发表在2014年机器学习领域顶级会议NIPS上并做了口头汇报。该论文是一篇实验性质的文章(通篇没有一个公式)。其目的就是要探究上面我们提到的几个关键性问题。因此,文章的全部贡献都来自于实验及其结果。
12 |
13 | 在ImageNet的1000类上,作者把1000类分成两份(A和B),每份500个类别。然后,分别对A和B基于Caffe训练了一个AlexNet网络。一个AlexNet网络一共有8层,除去第8层是类别相关的网络无法迁移以外,作者在1到7这7层上逐层进行finetune实验,探索网络的可迁移性。
14 |
15 | 为了更好地说明finetune的结果,作者提出了有趣的概念:AnB和BnB。
16 |
17 | 迁移A网络的前$$n$$层到B(AnB) vs 固定B网络的前$$n$$层(BnB)
18 |
19 | 简单说一下什么叫AnB:(所有实验都是针对数据B来说的)将A网络的前$$n$$层拿来并将它frozen,剩下的$$8-n$$层随机初始化,然后对B进行分类。
20 |
21 | 相应地,有BnB:把训练好的B网络的前$$n$$层拿来并将它frozen,剩下的$$8-n$$层随机初始化,然后对B进行分类。
22 |
23 | 实验结果如下图所示:
24 |
25 | 
26 |
27 | 这个图说明了什么呢?我们先看蓝色的BnB和BnB+(就是BnB加上finetune)。对BnB而言,原训练好的B模型的前3层直接拿来就可以用而不会对模型精度有什么损失。到了第4和第5层,精度略有下降,不过还是可以接受。然而到了第6第第7层,精度居然奇迹般地回升了!这是为什么?原因如下:对于一开始精度下降的第4第5层来说,确实是到了这一步,feature变得越来越specific,所以下降了。那对于第6第7层为什么精度又不变了?那是因为,整个网络就8层,我们固定了第6第7层,这个网络还能学什么呢?所以很自然地,精度和原来的B网络几乎一致!
28 |
29 | 对BnB+来说,结果基本上都保持不变。说明finetune对模型结果有着很好的促进作用!
30 |
31 | 我们重点关注AnB和AnB+。对AnB来说,直接将A网络的前3层迁移到B,貌似不会有什么影响,再一次说明,网络的前3层学到的几乎都是general feature!往后,到了第4第5层的时候,精度开始下降,我们直接说:一定是feature不general了!然而,到了第6第7层,精度出现了小小的提升后又下降,这又是为什么?作者在这里提出两点:co-adaptation和feature representation。就是说,第4第5层精度下降的时候,主要是由于A和B两个数据集的差异比较大,所以会下降;到了第6第7层,由于网络几乎不迭代了,学习能力太差,此时feature学不到,所以精度下降得更厉害。
32 |
33 | 再看AnB+。加入了finetune以后,AnB+的表现对于所有的$$n$$几乎都非常好,甚至比baseB(最初的B)还要好一些!这说明:finetune对于深度迁移有着非常好的促进作用!
34 |
35 | 把上面的结果合并就得到了下面一张图:
36 |
37 | 
38 |
39 | 至此,AnB和BnB基本完成。作者又想,是不是我分A和B数据的时候,里面存在一些比较相似的类使结果好了?比如说A里有猫,B里有狮子,所以结果会好?为了排除这些影响,作者又分了一下数据集,这次使得A和B里几乎没有相似的类别。在这个条件下再做AnB,与原来精度比较(0\%为基准)得到了下图:
40 |
41 | 
42 |
43 | 这个图说明了什么呢?简单:随着可迁移层数的增加,模型性能下降。但是,前3层仍然还是可以迁移的!同时,与随机初始化所有权重比较,迁移学习的精度是很高的!
44 |
45 | ## 结论
46 |
47 | 虽然该论文并没有提出一个创新方法,但是通过实验得到了以下几个结论,对以后的深度学习和深度迁移学习都有着非常高的指导意义:
48 |
49 | - 神经网络的前3层基本都是general feature,进行迁移的效果会比较好;
50 | - 深度迁移网络中加入fine-tune,效果会提升比较大,可能会比原网络效果还好;
51 | - Fine-tune可以比较好地克服数据之间的差异性;
52 | - 深度迁移网络要比随机初始化权重效果好;
53 | - 网络层数的迁移可以加速网络的学习和优化。
--------------------------------------------------------------------------------
/markdown/chap09/chap09_finetune.md:
--------------------------------------------------------------------------------
1 | # 最简单的深度迁移:预训练与微调
2 |
3 | 深度网络的预训练-微调也许是最简单的深度网络迁移方法。Pretraining-finetune,也叫微调、finetuning,是深度学习中的一个重要概念。简而言之,finetune就是利用别人已经训练好的网络,针对自己的任务再进行调整。从这个意思上看,我们不难理解finetune是迁移学习的一部分。
4 |
5 | ## 为什么需要已经训练好的网络?
6 |
7 | 在实际的应用中,我们通常不会针对一个新任务,就去从头开始训练一个神经网络。这样的操作显然是非常耗时的。尤其是,我们的训练数据不可能像ImageNet那么大,可以训练出泛化能力足够强的深度神经网络。即使有如此之多的训练数据,我们从头开始训练,其代价也是不可承受的。
8 |
9 | 那么怎么办呢?迁移学习告诉我们,利用之前已经训练好的模型,将它很好地迁移到自己的任务上即可。
10 |
11 | ## 为什么需要finetune?
12 |
13 | 因为别人训练好的模型,可能并不是完全适用于我们自己的任务。可能别人的训练数据和我们的数据之间不服从同一个分布;可能别人的网络能做比我们的任务更多的事情;可能别人的网络比较复杂,我们的任务比较简单。
14 |
15 | 举一个例子来说,假如我们想训练一个猫狗图像二分类的神经网络,那么很有参考价值的就是在CIFAR-100上训练好的神经网络。但是CIFAR-100有100个类别,我们只需要2个类别。此时,就需要针对我们自己的任务,固定原始网络的相关层,修改网络的输出层,以使结果更符合我们的需要。
16 |
17 | 下图展示了一个简单的finetune过程。从图中我们可以看到,我们采用的预训练好的网络非常复杂,如果直接拿来从头开始训练,则时间成本会非常高昂。我们可以将此网络进行改造,固定前面若干层的参数,只针对我们的任务,微调后面若干层。这样,网络训练速度会极大地加快,而且对提高我们任务的表现也具有很大的促进作用。
18 |
19 | 
20 |
21 | ## 预训练-微调的优势
22 |
23 | Finetune的优势是显然的,包括:
24 |
25 | - 不需要针对新任务从头开始训练网络,节省了时间成本;
26 | - 预训练好的模型通常都是在大数据集上进行的,无形中扩充了我们的训练数据,使得模型更鲁棒、泛化能力更好;
27 | - Finetune实现简单,使得我们只关注自己的任务即可。
28 |
29 | ## Finetune的应用与扩展
30 |
31 | 在实际应用中,通常几乎没有人会针对自己的新任务从头开始训练一个神经网络。Finetune是一个理想的选择。
32 |
33 | Finetune并不只是针对深度神经网络有促进作用,对传统的非深度学习也有很好的效果。例如,finetune对传统的人工提取特征方法就进行了很好的替代。我们可以使用深度网络对原始数据进行训练,依赖网络提取出更丰富更有表现力的特征。然后,将这些特征作为传统机器学习方法的输入。这样的好处是显然的:既避免了繁复的手工特征提取,又能自动地提取出更有表现力的特征。
34 |
35 | 比如,图像领域的研究,一直是以SIFT、SURF等传统特征为依据的,直到2014年,伯克利的研究人员提出了DeCAF特征提取方法([donahue2014decaf](http://www.jmlr.org/proceedings/papers/v32/donahue14.pdf)),直接使用深度卷积神经网络进行特征提取。实验结果表明,该特征提取方法对比传统的图像特征,在精度上有着无可匹敌的优势。另外,也有研究人员用卷积神经网络提取的特征作为SVM分类器的输入([razavian2014cnn](https://www.cv-foundation.org/openaccess/content_cvpr_workshops_2014/W15/html/Razavian_CNN_Features_Off-the-Shelf_2014_CVPR_paper.html)),显著提升了图像分类的精度。
36 |
37 | 在NLP领域,2018年Google提出的[BERT模型](https://arxiv.org/abs/1810.04805),几乎成为所有NLP任务进行预训练的起点。基于BERT,产生了大量的应用,这表明预训练已经在NLP领域大放异彩。
--------------------------------------------------------------------------------
/markdown/chap10/chap10_adversarial.md:
--------------------------------------------------------------------------------
1 | # 对抗迁移实现
2 |
3 | 对抗迁移的实现代码可以在[这里](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DANN(RevGrad))找到。
--------------------------------------------------------------------------------
/markdown/chap10/chap10_deep.md:
--------------------------------------------------------------------------------
1 | # 深度网络自适应代码
2 |
3 | 我们仍然以Pytorch为例,实现深度网络的自适应。具体地说,实现经典的[DDC (Deep Domain Confusion)](https://arxiv.org/abs/1412.3474)方法和与其类似的[DCORAL (Deep CORAL)](https://link.springer.com/chapter/10.1007/978-3-319-49409-8_35)方法。
4 |
5 | 此网络实现的核心是:如何正确计算DDC中的MMD损失、以及DCORAL中的CORAL损失,并且与神经网络进行集成。此部分对于初学者难免有一些困惑。如何输入源域和目标域、如何进行判断?因此,我们认为此部分应该是深度迁移学习的基础代码,读者应该努力地进行学习和理解。
6 |
7 | ## 网络结构
8 |
9 | 首先我们要定义好网络的架构,其应该是来自于已有的网络结构,如Alexnet和Resnet。但不同的是,由于要进行深度迁移适配,因此,输出层要和finetune一样,和目标的类别数相同。其二,由于要进行距离的计算,我们需要加一个叫做bottleneck的层,用来将最高维的特征进行降维,然后进行距离计算。当然,bottleneck层不加尚可。
10 |
11 | 我们的网络结构如下所示:
12 |
13 | ```
14 | import torch.nn as nn
15 | import torchvision
16 | from Coral import CORAL
17 | import mmd
18 | import backbone
19 |
20 |
21 | class Transfer_Net(nn.Module):
22 | def __init__(self, num_class, base_net='resnet50', transfer_loss='mmd', use_bottleneck=True, bottleneck_width=256, width=1024):
23 | super(Transfer_Net, self).__init__()
24 | self.base_network = backbone.network_dict[base_net]()
25 | self.use_bottleneck = use_bottleneck
26 | self.transfer_loss = transfer_loss
27 | bottleneck_list = [nn.Linear(self.base_network.output_num(
28 | ), bottleneck_width), nn.BatchNorm1d(bottleneck_width), nn.ReLU(), nn.Dropout(0.5)]
29 | self.bottleneck_layer = nn.Sequential(*bottleneck_list)
30 | classifier_layer_list = [nn.Linear(self.base_network.output_num(), width), nn.ReLU(), nn.Dropout(0.5),
31 | nn.Linear(width, num_class)]
32 | self.classifier_layer = nn.Sequential(*classifier_layer_list)
33 |
34 | self.bottleneck_layer[0].weight.data.normal_(0, 0.005)
35 | self.bottleneck_layer[0].bias.data.fill_(0.1)
36 | for i in range(2):
37 | self.classifier_layer[i * 3].weight.data.normal_(0, 0.01)
38 | self.classifier_layer[i * 3].bias.data.fill_(0.0)
39 |
40 | def forward(self, source, target):
41 | source = self.base_network(source)
42 | target = self.base_network(target)
43 | source_clf = self.classifier_layer(source)
44 | if self.use_bottleneck:
45 | source = self.bottleneck_layer(source)
46 | target = self.bottleneck_layer(target)
47 | transfer_loss = self.adapt_loss(source, target, self.transfer_loss)
48 | return source_clf, transfer_loss
49 |
50 | def predict(self, x):
51 | features = self.base_network(x)
52 | clf = self.classifier_layer(features)
53 | return clf
54 | ```
55 |
56 | 其中Transfer Net是整个网络的模型定义。它接受参数有:
57 |
58 |
59 | - num class: 目标域类别数
60 | - base net: 主干网络,例如Resnet等,也可以是自己定义的网络结构
61 | - Transfer loss: 迁移的损失,比如MMD和CORAL,也可以是自己定义的损失
62 | - use bottleneck: 是否使用bottleneck
63 | - bottleneck width: bottleneck的宽度
64 | - width: 分类器层的width
65 |
66 | ## 迁移损失定义
67 |
68 | 迁移损失是核心。其定义如下:
69 |
70 | ```
71 | def adapt_loss(self, X, Y, adapt_loss):
72 | """Compute adaptation loss, currently we support mmd and coral
73 | Arguments:
74 | X {tensor} -- source matrix
75 | Y {tensor} -- target matrix
76 | adapt_loss {string} -- loss type, 'mmd' or 'coral'. You can add your own loss
77 | Returns:
78 | [tensor] -- adaptation loss tensor
79 | """
80 | if adapt_loss == 'mmd':
81 | mmd_loss = mmd.MMD_loss()
82 | loss = mmd_loss(X, Y)
83 | elif adapt_loss == 'coral':
84 | loss = CORAL(X, Y)
85 | else:
86 | loss = 0
87 | return loss
88 | ```
89 |
90 | 其中的MMD和CORAL是自己实现的两个loss,MMD对应DDC方法,CORAL对应DCORAL方法。其代码在上述github中可以找到,我们不再赘述。
91 |
92 | ## 训练
93 |
94 | 训练时,我们一次输入一个batch的源域和目标域数据。为了方便,我们使用pytorch自带的dataloader。
95 |
96 | ```
97 | def train(source_loader, target_train_loader, target_test_loader, model, optimizer, CFG):
98 | len_source_loader = len(source_loader)
99 | len_target_loader = len(target_train_loader)
100 | train_loss_clf = utils.AverageMeter()
101 | train_loss_transfer = utils.AverageMeter()
102 | train_loss_total = utils.AverageMeter()
103 | for e in range(CFG['epoch']):
104 | model.train()
105 | iter_source, iter_target = iter(
106 | source_loader), iter(target_train_loader)
107 | n_batch = min(len_source_loader, len_target_loader)
108 | criterion = torch.nn.CrossEntropyLoss()
109 | for i in range(n_batch):
110 | data_source, label_source = iter_source.next()
111 | data_target, _ = iter_target.next()
112 | data_source, label_source = data_source.to(
113 | DEVICE), label_source.to(DEVICE)
114 | data_target = data_target.to(DEVICE)
115 |
116 | optimizer.zero_grad()
117 | label_source_pred, transfer_loss = model(data_source, data_target)
118 | clf_loss = criterion(label_source_pred, label_source)
119 | loss = clf_loss + CFG['lambda'] * transfer_loss
120 | loss.backward()
121 | optimizer.step()
122 | train_loss_clf.update(clf_loss.item())
123 | train_loss_transfer.update(transfer_loss.item())
124 | train_loss_total.update(loss.item())
125 | if i % CFG['log_interval'] == 0:
126 | print('Train Epoch: [{}/{} ({:02d}%)], cls_Loss: {:.6f}, transfer_loss: {:.6f}, total_Loss: {:.6f}'.format(
127 | e + 1,
128 | CFG['epoch'],
129 | int(100. * i / n_batch), train_loss_clf.avg, train_loss_transfer.avg, train_loss_total.avg))
130 |
131 | # Test
132 | test(model, target_test_loader)
133 | ```
134 |
135 | 完整代码可以在[这里](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DDC_DeepCoral)找到。
--------------------------------------------------------------------------------
/markdown/chap10/chap10_finetune.md:
--------------------------------------------------------------------------------
1 | # 深度网络的finetune实现
2 |
3 | 本小节我们用Pytorch实现一个深度网络的finetune。Pytorch是一个较为流行的深度学习工具包,由Facebook进行开发,在[Github](https://github.com/pytorch/pytorch)上也进行了开源。
4 |
5 | Finetune指的是训练好的深度网络,拿来在新的目标域上进行微调。因此,我们假定读者具有基本的Pytorch知识,直接给出finetune的代码。完整的代码可以在[这里](https://github.com/jindongwang/transferlearning/tree/master/code/deep/finetune_AlexNet_ResNet)找到。
6 |
7 | 我们定义一个叫做finetune的函数,它接受输入的一个已有模型,从目标数据中进行微调,输出最好的模型其结果。其代码如下:
8 |
9 | ```
10 | def finetune(model, dataloaders, optimizer):
11 | since = time.time()
12 | best_acc = 0.0
13 | acc_hist = []
14 | criterion = nn.CrossEntropyLoss()
15 | for epoch in range(1, N_EPOCH + 1):
16 | # lr_schedule(optimizer, epoch)
17 | print('Learning rate: {:.8f}'.format(optimizer.param_groups[0]['lr']))
18 | print('Learning rate: {:.8f}'.format(optimizer.param_groups[-1]['lr']))
19 | for phase in ['src', 'val', 'tar']:
20 | if phase == 'src':
21 | model.train()
22 | else:
23 | model.eval()
24 | total_loss, correct = 0, 0
25 | for inputs, labels in dataloaders[phase]:
26 | inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
27 | optimizer.zero_grad()
28 | with torch.set_grad_enabled(phase == 'src'):
29 | outputs = model(inputs)
30 | loss = criterion(outputs, labels)
31 | preds = torch.max(outputs, 1)[1]
32 | if phase == 'src':
33 | loss.backward()
34 | optimizer.step()
35 | total_loss += loss.item() * inputs.size(0)
36 | correct += torch.sum(preds == labels.data)
37 | epoch_loss = total_loss / len(dataloaders[phase].dataset)
38 | epoch_acc = correct.double() / len(dataloaders[phase].dataset)
39 | acc_hist.append([epoch_loss, epoch_acc])
40 | print('Epoch: [{:02d}/{:02d}]---{}, loss: {:.6f}, acc: {:.4f}'.format(epoch, N_EPOCH, phase, epoch_loss,
41 | epoch_acc))
42 | if phase == 'tar' and epoch_acc > best_acc:
43 | best_acc = epoch_acc
44 | print()
45 | fname = 'finetune_result' + model_name + \
46 | str(LEARNING_RATE) + str(args.source) + \
47 | '-' + str(args.target) + '.csv'
48 | np.savetxt(fname, np.asarray(a=acc_hist, dtype=float), delimiter=',',
49 | fmt='%.4f')
50 | time_pass = time.time() - since
51 | print('Training complete in {:.0f}m {:.0f}s'.format(
52 | time_pass // 60, time_pass % 60))
53 |
54 | return model, best_acc, acc_hist
55 | ```
56 |
57 | 其中,model可以是由任意深度网络训练好的模型,如Alexnet、Resnet等。
58 |
59 | 另外,有很多任务也需要用到深度网络来提取深度特征以便进一步处理。我们也进行了实现,代码在https://github.com/jindongwang/transferlearning/blob/master/code/feature_extractor中。
--------------------------------------------------------------------------------
/markdown/chap10/chap10_practice.md:
--------------------------------------------------------------------------------
1 | # 第10章 上手实践
2 |
3 | 以上对迁移学习基本方法的介绍还只是停留在算法的阶段。对于初学者来说,不仅需要掌握基础的算法知识,更重要的是,需要在实验中发现问题。本章的目的是为初学者提供一个迁移学习上手实践的介绍。通过一步步编写代码、下载数据,完成迁移学习任务。在本部分,我们以迁移学习中最为流行的图像分类为实验对象,在流行的Office+Caltech10数据集上完成。
4 |
5 | 迁移学习方法主要包括:传统的非深度迁移、深度网络的finetune、深度网络自适应、以及深度对抗网络的迁移。教程的目的是抛砖引玉,帮助初学者快速入门。由于网络上已有成型的深度网络的finetune、深度网络自适应、以及深度对抗网络的迁移教程,因此我们不再叙述这些方法,只在这里介绍非深度方法的教程。其他三种方法的地址分别是:
6 |
7 | - 深度网络的finetune:
8 | - [用Pytorch对Alexnet和Resnet进行微调](https://github.com/jindongwang/transferlearning/tree/master/code/deep/finetune_AlexNet_ResNet)
9 | - [使用PyTorch进行finetune](https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html)
10 | - 深度网络的自适应:[DDC/DCORAL方法的Pytorch代码](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DDC_DeepCoral)
11 | - 深度对抗网络迁移:[DANN方法](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DANN(RevGrad))
12 |
13 | 更多深度迁移方法的代码,请见[这里](https://github.com/jindongwang/transferlearning/tree/master/code/deep)。
14 |
15 | 在众多的非深度迁移学习方法中,我们选择最经典的迁移方法之一、发表于IEEE TNN 2011的[TCA (Transfer Component Analysis)](https://ieeexplore.ieee.org/abstract/document/5640675/)方法进行实践。为了便于学习,我们同时用Matlab和Python实现了此代码。代码的链接在[这里](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/TCA)。下面我们对代码进行简单讲解。
--------------------------------------------------------------------------------
/markdown/chap10/chap10_tcamatlab.md:
--------------------------------------------------------------------------------
1 | # TCA方法的Matlab实现
2 |
3 | ## 数据获取
4 |
5 | 由于我们要测试非深度方法,因此,选择SURF特征文件作为算法的输入。SURF特征文件可以从[网络上](https://pan.baidu.com/s/1bp4g7Av)下载。下载到的文件主要包含4个.mat文件:Caltech.mat, amazon.mat, webcam.mat, dslr.mat。它们恰巧对应4个不同的领域。彼此之间两两一组,就是一个迁移学习任务。每个数据文件包含两个部分:fts为800维的特征,labels为对应的标注。在测试中,我们选择由Caltech.mat作为源域,由amazon.mat作为目标域。Office+Caltech10数据集的介绍可以在本手册的附录部分找到。
6 |
7 | 我们对数据进行加载并做简单的归一化,将最后的数据存入$$X_s,Y_s,X_t,Y_t$$这四个变量中。这四个变量分别对应源域的特征和标注、以及目标域的特征和标注。代码如下:
8 |
9 | ```
10 | load('Caltech.mat'); % source domain
11 | fts = fts ./ repmat(sum(fts,2),1,size(fts,2));
12 | Xs = zscore(fts,1); clear fts
13 | Ys = labels; clear labels
14 |
15 | load('amazon.mat'); % target domain
16 | fts = fts ./ repmat(sum(fts,2),1,size(fts,2));
17 | Xt = zscore(fts,1); clear fts
18 | Yt = labels; clear labels
19 | ```
20 |
21 | ## 算法精炼
22 |
23 | TCA主要进行边缘分布自适应。通过整理化简,TCA最终的求解目标是:
24 | $$
25 | \left(\mathbf{X} \mathbf{M} \mathbf{X}^\top + \lambda \mathbf{I}\right) \mathbf{A} =\mathbf{X} \mathbf{H} \mathbf{X}^\top \mathbf{A} \Phi
26 | $$
27 |
28 | 上述表达式可以通过Matlab自带的`eigs()`函数直接求解。$$\mathbf{A}$$就是我们要求解的变换矩阵。下面我们需要明确各个变量所指代的含义:
29 |
30 | - $$\mathbf{X}$$: 由源域和目标域数据共同构成的数据矩阵
31 | - $$C$$: 总的类别个数。在我们的数据集中,$$C=10$$
32 | - $$\mathbf{M}_c$$: MMD矩阵。当$$c=0$$时为全MMD矩阵;当$$c>1$$时对应为每个类别- 的矩阵。
33 | - $$\mathbf{I}$$:单位矩阵
34 | - $$\lambda$$:平衡参数,直接给出
35 | - $$\mathbf{H}$$: 中心矩阵,直接计算得出
36 | - $$\Phi$$: 拉格朗日因子,不用理会,求解用不到
37 |
38 | ## 编写代码
39 |
40 | 我们直接给出精炼后的源码:
41 |
42 | ```
43 | function [X_src_new,X_tar_new,A] = TCA(X_src,X_tar,options)
44 | % The is the implementation of Transfer Component Analysis.
45 | % Reference: Sinno Pan et al. Domain Adaptation via Transfer Component Analysis. TNN 2011.
46 |
47 | % Inputs:
48 | %%% X_src : source feature matrix, ns * n_feature
49 | %%% X_tar : target feature matrix, nt * n_feature
50 | %%% options : option struct
51 | %%%%% lambda : regularization parameter
52 | %%%%% dim : dimensionality after adaptation (dim <= n_feature)
53 | %%%%% kernel_tpye : kernel name, choose from 'primal' | 'linear' | 'rbf'
54 | %%%%% gamma : bandwidth for rbf kernel, can be missed for other kernels
55 |
56 | % Outputs:
57 | %%% X_src_new : transformed source feature matrix, ns * dim
58 | %%% X_tar_new : transformed target feature matrix, nt * dim
59 | %%% A : adaptation matrix, (ns + nt) * (ns + nt)
60 |
61 | %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
62 |
63 | %% Set options
64 | lambda = options.lambda;
65 | dim = options.dim;
66 | kernel_type = options.kernel_type;
67 | gamma = options.gamma;
68 |
69 | %% Calculate
70 | X = [X_src',X_tar'];
71 | X = X*diag(sparse(1./sqrt(sum(X.^2))));
72 | [m,n] = size(X);
73 | ns = size(X_src,1);
74 | nt = size(X_tar,1);
75 | e = [1/ns*ones(ns,1);-1/nt*ones(nt,1)];
76 | M = e * e';
77 | M = M / norm(M,'fro');
78 | H = eye(n)-1/(n)*ones(n,n);
79 | if strcmp(kernel_type,'primal')
80 | [A,~] = eigs(X*M*X'+lambda*eye(m),X*H*X',dim,'SM');
81 | Z = A' * X;
82 | Z = Z * diag(sparse(1./sqrt(sum(Z.^2))));
83 | X_src_new = Z(:,1:ns)';
84 | X_tar_new = Z(:,ns+1:end)';
85 | else
86 | K = TCA_kernel(kernel_type,X,[],gamma);
87 | [A,~] = eigs(K*M*K'+lambda*eye(n),K*H*K',dim,'SM');
88 | Z = A' * K;
89 | Z = Z*diag(sparse(1./sqrt(sum(Z.^2))));
90 | X_src_new = Z(:,1:ns)';
91 | X_tar_new = Z(:,ns+1:end)';
92 | end
93 | end
94 |
95 | % With Fast Computation of the RBF kernel matrix
96 | % To speed up the computation, we exploit a decomposition of the Euclidean distance (norm)
97 | %
98 | % Inputs:
99 | % ker: 'linear','rbf','sam'
100 | % X: data matrix (features * samples)
101 | % gamma: bandwidth of the RBF/SAM kernel
102 | % Output:
103 | % K: kernel matrix
104 | %
105 | % Gustavo Camps-Valls
106 | % 2006(c)
107 | % Jordi (jordi@uv.es), 2007
108 | % 2007-11: if/then -> switch, and fixed RBF kernel
109 | % Modified by Mingsheng Long
110 | % 2013(c)
111 | % Mingsheng Long (longmingsheng@gmail.com), 2013
112 | function K = TCA_kernel(ker,X,X2,gamma)
113 |
114 | switch ker
115 | case 'linear'
116 |
117 | if isempty(X2)
118 | K = X'*X;
119 | else
120 | K = X'*X2;
121 | end
122 |
123 | case 'rbf'
124 |
125 | n1sq = sum(X.^2,1);
126 | n1 = size(X,2);
127 |
128 | if isempty(X2)
129 | D = (ones(n1,1)*n1sq)' + ones(n1,1)*n1sq -2*X'*X;
130 | else
131 | n2sq = sum(X2.^2,1);
132 | n2 = size(X2,2);
133 | D = (ones(n2,1)*n1sq)' + ones(n1,1)*n2sq -2*X'*X2;
134 | end
135 | K = exp(-gamma*D);
136 |
137 | case 'sam'
138 |
139 | if isempty(X2)
140 | D = X'*X;
141 | else
142 | D = X'*X2;
143 | end
144 | K = exp(-gamma*acos(D).^2);
145 |
146 | otherwise
147 | error(['Unsupported kernel ' ker])
148 | end
149 | end
150 | ```
151 |
152 | 我们将TCA方法包装成函数`TCA}`。注意到TCA是一个无监督迁移方法,不需要接受label作为参数。因此,函数共接受3个输入参数:
153 |
154 | - $$\mathrm{X_{src}}$$: 源域的特征,大小为$$n_s \times m$$
155 | - $$\mathrm{X_{tar}}$$: 目标域的特征,大小为$$n_t \times m$$
156 | - $$\mathrm{options}$$: 参数结构体,它包含:
157 | - $$\lambda$$: 平衡参数,可以自由给出
158 | - $$dim$$: 算法最终选择将数据将到多少维
159 | - $$kernel type$$: 选择的核类型,可以选择RBF、线性、或无核
160 | - $$\gamma$$: 如果选择RBF核,那么它的宽度为$$\gamma$
161 |
162 | 函数的输出包含3项:
163 |
164 | - $$X_{srcnew}$$: TCA后的源域
165 | - $$X_{tarnew}$$: TCA后的目标域
166 | - $$A$$: 最终的变换矩阵
167 |
168 | ## 测试算法
169 |
170 | 我们使用如下的代码对TCA算法进行测试:
171 |
172 | ```
173 | options.gamma = 2; % the parameter for kernel
174 | options.kernel_type = 'linear';
175 | options.lambda = 1.0;
176 | options.dim = 20;
177 | [X_src_new,X_tar_new,A] = TCA(Xs,Xt,options);
178 |
179 | % Use knn to predict the target label
180 | knn_model = fitcknn(X_src_new,Y_src,'NumNeighbors',1);
181 | Y_tar_pseudo = knn_model.predict(X_tar_new);
182 | acc = length(find(Y_tar_pseudo==Y_tar))/length(Y_tar);
183 | fprintf('Acc=%0.4f\n',acc);
184 | ```
185 |
186 | 结果显示如下:
187 |
188 | ```
189 | Acc=0.4499
190 | ```
191 |
192 | 至此,Matlab版TCA实现完成。完整代码可以在[Github](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/TCA)上找到。
--------------------------------------------------------------------------------
/markdown/chap10/chap10_tcapython.md:
--------------------------------------------------------------------------------
1 | # TCA方法的Matlab实现
2 |
3 | 与Matlab代码类似,我们也可以用Python对TCA进行实现,其主要依赖于Numpy和Scipy两个强大的科学计算库。Python版本的TCA代码如下:
4 |
5 | ```
6 | import numpy as np
7 | import scipy.io
8 | import scipy.linalg
9 | import sklearn.metrics
10 | from sklearn.neighbors import KNeighborsClassifier
11 |
12 |
13 | def kernel(ker, X1, X2, gamma):
14 | K = None
15 | if not ker or ker == 'primal':
16 | K = X1
17 | elif ker == 'linear':
18 | if X2 is not None:
19 | K = sklearn.metrics.pairwise.linear_kernel(np.asarray(X1).T, np.asarray(X2).T)
20 | else:
21 | K = sklearn.metrics.pairwise.linear_kernel(np.asarray(X1).T)
22 | elif ker == 'rbf':
23 | if X2 is not None:
24 | K = sklearn.metrics.pairwise.rbf_kernel(np.asarray(X1).T, np.asarray(X2).T, gamma)
25 | else:
26 | K = sklearn.metrics.pairwise.rbf_kernel(np.asarray(X1).T, None, gamma)
27 | return K
28 |
29 |
30 | class TCA:
31 | def __init__(self, kernel_type='primal', dim=30, lamb=1, gamma=1):
32 | '''
33 | Init func
34 | :param kernel_type: kernel, values: 'primal' | 'linear' | 'rbf'
35 | :param dim: dimension after transfer
36 | :param lamb: lambda value in equation
37 | :param gamma: kernel bandwidth for rbf kernel
38 | '''
39 | self.kernel_type = kernel_type
40 | self.dim = dim
41 | self.lamb = lamb
42 | self.gamma = gamma
43 |
44 | def fit(self, Xs, Xt):
45 | '''
46 | Transform Xs and Xt
47 | :param Xs: ns * n_feature, source feature
48 | :param Xt: nt * n_feature, target feature
49 | :return: Xs_new and Xt_new after TCA
50 | '''
51 | X = np.hstack((Xs.T, Xt.T))
52 | X /= np.linalg.norm(X, axis=0)
53 | m, n = X.shape
54 | ns, nt = len(Xs), len(Xt)
55 | e = np.vstack((1 / ns * np.ones((ns, 1)), -1 / nt * np.ones((nt, 1))))
56 | M = e * e.T
57 | M = M / np.linalg.norm(M, 'fro')
58 | H = np.eye(n) - 1 / n * np.ones((n, n))
59 | K = kernel(self.kernel_type, X, None, gamma=self.gamma)
60 | n_eye = m if self.kernel_type == 'primal' else n
61 | a, b = np.linalg.multi_dot([K, M, K.T]) + self.lamb * np.eye(n_eye), np.linalg.multi_dot([K, H, K.T])
62 | w, V = scipy.linalg.eig(a, b)
63 | ind = np.argsort(w)
64 | A = V[:, ind[:self.dim]]
65 | Z = np.dot(A.T, K)
66 | Z /= np.linalg.norm(Z, axis=0)
67 | Xs_new, Xt_new = Z[:, :ns].T, Z[:, ns:].T
68 | return Xs_new, Xt_new
69 |
70 | def fit_predict(self, Xs, Ys, Xt, Yt):
71 | '''
72 | Transform Xs and Xt, then make predictions on target using 1NN
73 | :param Xs: ns * n_feature, source feature
74 | :param Ys: ns * 1, source label
75 | :param Xt: nt * n_feature, target feature
76 | :param Yt: nt * 1, target label
77 | :return: Accuracy and predicted_labels on the target domain
78 | '''
79 | Xs_new, Xt_new = self.fit(Xs, Xt)
80 | clf = KNeighborsClassifier(n_neighbors=1)
81 | clf.fit(Xs_new, Ys.ravel())
82 | y_pred = clf.predict(Xt_new)
83 | acc = sklearn.metrics.accuracy_score(Yt, y_pred)
84 | return acc, y_pred
85 |
86 |
87 | if __name__ == '__main__':
88 | domains = ['caltech.mat', 'amazon.mat', 'webcam.mat', 'dslr.mat']
89 | for i in [2]:
90 | for j in [3]:
91 | if i != j:
92 | src, tar = 'data/' + domains[i], 'data/' + domains[j]
93 | src_domain, tar_domain = scipy.io.loadmat(src), scipy.io.loadmat(tar)
94 | Xs, Ys, Xt, Yt = src_domain['feas'], src_domain['label'], tar_domain['feas'], tar_domain['label']
95 | tca = TCA(kernel_type='linear', dim=30, lamb=1, gamma=1)
96 | acc, ypre = tca.fit_predict(Xs, Ys, Xt, Yt)
97 | print(acc)
98 | ```
99 |
100 | 通过以上过程,我们分别使用Matlab代码和Python代码对经典的TCA方法进行了实验,完成了一个迁移学习任务。其他的非深度迁移学习方法,均可以参考上面的过程。值得庆幸的是,许多论文的作者都公布了他们的文章代码,以方便我们进行接下来的研究。读者可以从[Github](https://github.com/jindongwang/transferlearning/tree/master/code)或者相关作者的网站上获取其他许多方法的代码。
--------------------------------------------------------------------------------
/markdown/chap11/chap11_future.md:
--------------------------------------------------------------------------------
1 | # 迁移学习前沿
2 |
3 | 从我们上述介绍的多种迁移学习方法来看,领域自适应(Domain Adaptation)作为迁移学习的重要分类,在近年来已经取得了大量的研究成果。但是,迁移学习仍然是一个活跃的领域,仍然有大量的问题没有被很好地解决。
4 |
5 | 本节我们简要介绍一些迁移学习领域较新的研究成果。并且,管中窥豹,展望迁移学习未来可能的研究方向。
6 |
7 | # 机器智能与人类经验结合迁移
8 |
9 | 机器学习的目的是让机器从众多的数据中发掘知识,从而可以指导人的行为。这样看来,似乎“全自动”是我们的终极目标。我们理想中的机器学习系统,似乎就应该完全不依赖于人的干预,靠算法和数据就能完成所有的任务。Google Deepmind公司最新发布的[AlphaZero](https://www.nature.com/articles/nature24270?sf123103138=1)就实现了这样的愿景:算法完全不依赖于人提供知识,从零开始掌握围棋知识,最终打败人类围棋冠军。随着机器学习的发展,似乎人的角色也会越来越不重要。
10 |
11 | 然而,在目前看来,机器想完全不依赖于人的经验,就必须付出巨大的时间和计算代价。普通人也许根本无法掌握这样的能力。那么,如果在机器智能中,特别是迁移学习的机器智能中,加入人的经验,可以大幅度提高算法的训练水平,这岂不是我们喜闻乐见的?
12 |
13 | 来自斯坦福大学的研究人员2017年发表在人工智能顶级会议AAAI上的研究成果就率先实践了这一想法([stewart2017label](https://www.aaai.org/ocs/index.php/AAAI/AAAI17/paper/viewPaper/14967))。研究人员提出了一种无需人工标注的神经网络,对视频数据进行分析预测。在该成果中,研究人员的目标是用神经网络预测扔出的枕头的下落轨迹。不同于传统的神经网络需要大量标注,该方法完全不使用人工标注。取而代之的是,将人类的知识赋予神经网络。
14 |
15 | 我们都知道,抛出的物体往往会沿着抛物线的轨迹进行运动。这就是研究人员所利用的核心知识。计算机对于这一点并不知情。因此,在网络中,如果加入抛物线这一基本的先验知识,则会极大地促进网络的训练。并且,最终会取得比单纯依赖算法本身更好的效果。
16 |
17 | 我们认为将机器智能与人类经验结合起来的迁移学习应该是未来的发展方向之一。期待这方面有更多的研究成果发表。
18 |
19 | ## 传递式迁移学习
20 |
21 | 迁移学习的核心是找到两个领域的相似性。这是成功进行迁移的保证。但是,假如我们的领域数据本身就不存在相似性,或者相似性极小,这时候就很容易出现负迁移。负迁移是迁移学习研究中极力需要避免的。
22 |
23 | 我们由两个领域的相似性推广开来,其实世间万事万物都有一定的联系。表面上看似无关的两个领域,它们也可以由中间的领域构成联系。也就是一种传递式的相似性。例如,领域A和领域B从表面上看,完全不相似。那么,是否可以找到中间的一个领域C,领域C与A和B都有一定的相似性?这样,知识原来不能直接从领域A迁移到领域B,加入C以后,就可以先从A迁移到C,再从C迁移到B。这就是传递迁移学习。
24 |
25 | 香港科技大学杨强教授的团队率先在2015年数据挖掘顶级会议KDD上提出了这一概念:[Transitive transfer learning](https://dl.acm.org/citation.cfm?id=2783295)。随后,作者又进行了进一步的扩展,将三个领域的迁移,扩展到多个领域。这也是符合我们认知的:原先完全不相似的两个领域,如果它们中间存在若干领域都与这两个领域相似,那么就可以构成一条相似性链条,知识就可以进行链式的迁移。作者提出了远领域的迁移学习[(Distant Domain Transfer Learning)](https://www.aaai.org/ocs/index.php/AAAI/AAAI17/paper/viewPaper/14446),用卷积神经网络解决了这一问题。
26 |
27 | 在远领域迁移学习中,作者做出了看起来并不符合常人认知的实验:由人脸图片训练好的分类器,迁移识别飞机图像。研究人员采用了人脸和飞机中间的一系列类别,例如头像、头盔、水壶、交通工具等。在实验中,算法自动地选择相似的领域进行迁移。结果表明,在初始迁移阶段,算法选择的大多是与源领域较为相似的类别;随着迁移的进行,算法会越来越倾向于选择与目标领域相似的类别。这也是符合我们的基本认知的。最终的对比实验表明,这种远领域的迁移学习比直接训练分类器的精度会有极大的提升。下图展示了知识迁移的过程。
28 |
29 | 
30 |
31 | 传递迁移学习目前的研究成果还十分稀少。我们期待这一领域会有更多好的成果出现。
32 |
33 | ## 终身迁移学习
34 |
35 | 我们在进行迁移学习时,往往不知道应该选择怎么样的算法。通常都通过人为地不断尝试来确定要用的方法。这个过程无疑是浪费时间,而且充满了不确定性。已有的迁移学习方法,基本都是这样。我们在拿到一个新问题时,如何选择迁移学习算法达到最好的效果?从人的学习过程中来说,人总是可以从以前的经验中学习知识。那么,既然我们已经实验了很多次迁移学习算法,我们能不能让机器也可以从我们这些实验中选择知识?这是符合我们人类认知的:不可能每遇到一个新问题,我们就从头开始做吧?
36 |
37 | 同样是来自香港科技大学杨强教授团队就开始了这一方面的研究工作。他们提出一种学习迁移(L2T, Learning to Transfer)的框架([wei2017learning](http://proceedings.mlr.press/v80/wei18a.html)),解决\textit{何时迁移、要迁移什么、怎么迁移}的问题。方法分为两个部分:从已有的迁移学习方法和结果中学习迁移的经验,然后再把这些学习到的经验应用到新来的数据。
38 |
39 | 首先要明确学习目标。跟以前的迁移学习方法都有所不同,以往的方法都是要学习最好的迁移函数,而这个问题的目标是要使得方法尽可能地具有泛化能力。因此,它的学习目标是:\textbf{以往的经验}!对的,就是经验。这也是符合我们人类认知的。我们一般都是知道的越多,这个人越厉害(当然,《权利的游戏》里的Jon Snow除外,因为他什么也不知道)。因此,这个方法的目标就是要尽可能多地从以往的迁移知识中学习经验,使之对于后来的问题具有最好的泛化能力。
40 |
41 | 那么\textit{什么是迁移的经验}?这个在文中叫做transfer learning experience。作者这样定义:$$Ee=(S_e,T_e,a_e,l_e)$$。其中,$$S_e,T_e$$分别是源域和目标域,这个我们都知道。$$a_e$$表示一个迁移学习算法,这个算法有个下标叫$$e$$,表示它是第$$e$$种算法。与之对应,选择了这种算法,它对不迁移情况下的表现有个提升效果,这个效果就叫做$$le$$。
42 |
43 | 总结一下,什么叫迁移学习的经验?就是说,在一对迁移任务中,我选择了哪种算法后,这种算法对于我任务效果有多少提升。这个东西,就叫做迁移!这和我们人类学习也是具有相似性的:人们常说,失败是成功之母,爱迪生说,我实验了2000多种材料做灯泡都是失败的,但是我最起码知道了这2000多种材料不适合做灯泡!这就是人类的经验!我们人类就是从跌倒中爬起,从失败中总结教训,然后不断进步。学习算法也可以!
44 |
45 | 后面的过程就是,综合性地学习这个迁移过程,使得算法根据以往的经验,得到一个特征变换矩阵$$\mathbf{W}$$。学习到了这个变换矩阵以后,下一步的工作就是要把学习到的东西应用于新来的数据。如何针对新来的数据进行迁移?我们本能地要利用刚刚学习到的这个$$\mathbf{W}$$。但是不要忘了,这个变换矩阵只是对旧的那些经验学习到的,对新的数据可能效果不好,不能直接用。怎么办?我们要更新它!
46 |
47 | 这里要注意的是,针对新来的数据,我们的这个变换矩阵应该是有所改变的:这也对,数据变了,当然变换矩阵就要变。那么,如何更新?作者在这里提出的方法是,新的矩阵应该是能在新的数据上表现效果最好的那个。这时,我们的问题就完成了。
48 |
49 | 下图简要表示了该算法的学习过程。
50 |
51 | 
52 |
53 | 这有点类似增量学习的工作:模型针对新数据不断更新优化。这部分的研究才刚刚开始。
54 |
55 | ## 在线迁移学习
56 |
57 | 我们都知道迁移学习可以用来解决训练数据缺失的问题,很多迁移学习方法都获得了长足的进步。给定一个要学习的目标域数据,我们可以用已知标签的源域数据来给这个目标域数据构造一个分类器。但是这些方法都存在很大的一个问题:它们都是采用离线方式(offline)进行的。什么是离线方式?就是说,一开始,源域和目标域数据都是给出来的,我们直接做完迁移,这个过程就结束了。We are done。
58 |
59 | 但是真实的应用往往不是这样的:数据往往是一点一点源源不断送来的。也就是说,我们一开始的时候,也许只有源域数据,目标域数据要一点一点才能过来。这就是所谓的“在线迁移学习”。这个概念脱胎于“在线学习”的模式,在线学习是机器学习中一个重要的研究概念。
60 |
61 | 就目前来说,在线迁移学习方面的工作较少。第一篇在线迁移学习的工作由新加坡管理大学的Steven Hoi发表在2010年的机器学习顶级会议ICML上。作者提出了[OTL框架](https://www.sciencedirect.com/science/article/pii/S0004370214000800),可以对同构和异构数据很好地进行迁移学习。
62 |
63 | 近年来,研究者发表了一些在线迁移学习相关的文章。其中包括在多个源域和目标域上的OTL([wu2017online](https://link.springer.com/article/10.1007/s10115-016-1021-1)),在线特征选择迁移变换([wang2014online](https://ieeexplore.ieee.org/abstract/document/6522405/)},在线样本集成迁移([gao2012online](https://ieeexplore.ieee.org/abstract/document/6460281/))等。
64 |
65 | 特别地,[jaini2016online](https://openreview.net/forum?id=ByqiJIqxg¬eId=ByqiJIqxg)提出了用贝叶斯的方法学习在线的HMM迁移学习模型,并应用于行为识别、睡眠监测,以及未来流量分析。这是一篇有代表性的应用工作。
66 |
67 | 总结来看,目前在在线迁移学习方面的研究工作总体较少,发展空间巨大。在可以预见的未来,我们期待更多的研究者可以从事这一领域的研究。将深度网络、对抗学习结合入在线迁移学习,使得这一领域的发展越来越好。
68 |
69 | ## 迁移强化学习
70 |
71 | Google公司的AlphaGo系列在围棋方面的成就让强化学习这一术语变得炙手可热。用深度神经网络来进行强化学习也理所当然地成为了研究热点之一。不同于传统的机器学习需要大量的标签才可以训练学习模型,强化学习采用的是边获得样例边学习的方式。特定的反馈函数决定了算法的最优决策。
72 |
73 | 深度强化学习同时也面临着重大的挑战:没有足够的训练数据。在这个方面,迁移学习却可以利用其他数据上训练好的模型帮助训练。尽管迁移学习已经被应用于强化学习([taylor2009transfer](http://www.jmlr.org/papers/v10/taylor09a.html)),但是它的发展空间仍然还很大。强化学习在自动驾驶、机器人、路径规划等领域正发挥着越来越重要的作用。我们期待在未来有更多的研究成果可以问世。
74 |
75 | ## 迁移学习的可解释性
76 |
77 | 深度学习取得众多突破性成果的同时,其面临的可解释性不强却始终是一个挑战。现有的深度学习方法还停留在"黑盒子"阶段,无法产生足够有说服力的解释。同样的,迁移学习也有这个问题。即使世间万物都有联系,它们更深层次的关系也尚未得到探索。领域之间的相似性也正如同海森堡"测不准原理"一般无法给出有效的结论。为什么领域A和领域B更相似,而和领域C较不相似?目前也只是停留在经验阶段,缺乏有效的理论证明。
78 |
79 | 另外,迁移学习算法也存在着可解释性弱的问题。现有的算法均只是完成了一个迁移学习任务。但是在学习过程中,知识是如何进行迁移的,这一点还有待进一步的实验和理论验证。最近,澳大利亚悉尼大学的研究者们发表在国际人工智能联合会IJCAI 2017上的研究成果有助于理解特征是如何迁移的~\cite{liu2017understanding}。
80 |
81 | 用深度网络来做迁移学习,其可解释性同样有待探索。最近,Google Brain的研究者们提出了神经网络的"核磁共振"现象~\footnote{\url{https://github.com/tensorflow/lucid}},对神经网络的可解释性进行了有趣的探索。
82 |
83 |
--------------------------------------------------------------------------------
/markdown/chap12/chap12_conclusion.md:
--------------------------------------------------------------------------------
1 | # 第12章 总结
2 |
3 | 本手册是在迁移学习领域的研究经验总结。主要简明地介绍了迁移学习的基本概念、迁移学习的必要性、研究领域和基本方法。重点介绍了几大类常用的迁移学习方法:数据分布自适应方法、特征选择方法、子空间学习方法、以及目前最热门的深度迁移学习方法。除此之外,我们也结合最近的一些研究成果对未来迁移学习进行了一些展望。附录中提供了一些迁移学习领域的常用学习资源,以方便感兴趣的读者快速开始学习。
--------------------------------------------------------------------------------
/markdown/chap13/chap13_appendix.md:
--------------------------------------------------------------------------------
1 | # 附录
2 |
3 | ## 迁移学习相关的期刊和会议
4 |
5 | 迁移学习仍然是一个蓬勃发展的研究领域。最近几年,在顶级期刊和会议上,越来越多的研究者开始发表文章,不断提出迁移学习的新方法,不断开拓迁移学习的新应用领域。
6 |
7 | 在这里,我们对迁移学习相关的国际期刊和会议作一小结,以方便初学者寻找合适的论文。这些期刊会议可以在下表中找到。
8 |
9 | | 序号 | 简称 | 全称 | 领域 |
10 | |:--------:|:-----:|:--------------------------------------------------------------------------------------------------------:|:------------:|
11 | | 国际期刊 | | | |
12 | | 1 | JMLR | Journal of Machine Learning Research | 机器学习 |
13 | | 2 | MLJ | Machine Learning Journal | 机器学习 |
14 | | 3 | AIJ | Artificial Intelligence Journal | 人工智能 |
15 | | 4 | TKDE | IEEE Transactions on Knowledge and Data Engineering | 数据挖掘 |
16 | | 5 | TIST | ACM Transactions on Intelligent Science and Technology | 数据挖掘 |
17 | | 6 | PAMI | IEEE Transactions on Pattern Analysis and Machine Intelligence | 计算机视觉 |
18 | | 7 | IJCV | International Journal of Computer Vision | 计算机视觉 |
19 | | 8 | TIP | IEEE Transactions on Image Processing | 计算机视觉 |
20 | | 9 | PR | Pattern Recognition | 模式识别 |
21 | | 10 | PRL | Pattern Recognition Letters | 模式识别 |
22 | | 国际会议 | | | |
23 | | 1 | ICML | International Conference on Machine Learning | 机器学习 |
24 | | 2 | NIPS | Annual Conference on Neural Information Processing System | 机器学习 |
25 | | 3 | IJCAI | International Joint Conference on Artificial Intelligence | 人工智能 |
26 | | 4 | AAAI | AAAI conference on Artificial Intelligence | 人工智能 |
27 | | 5 | KDD | \begin{tabular}[c]{@{}c@{}}ACM SIGKDD\\ Conference on Knowledge Discovery and Data Mining\end{tabular} | 数据挖掘 |
28 | | 6 | ICDM | IEEE International Conference on Data Mining | 数据挖掘 |
29 | | 7 | CVPR | \begin{tabular}[c]{@{}c@{}}IEEE Conference on Computer Vision and\\ Pattern Recognition\end{tabular} | 计算机视觉 |
30 | | 8 | ICCV | IEEE International Conference on Computer Vision | 计算机视觉 |
31 | | 9 | ECCV | European Conference on Computer Vision | 计算机视觉 |
32 | | 10 | WWW | International World Wide Web Conferences | 文本、互联网 |
33 | | 11 | CIKM | International Conference on Information and Knowledge Management | 文本分析 |
34 | | 12 | ACMMM | ACM International Conference on Multimedia | 多媒体 |
35 |
--------------------------------------------------------------------------------
/markdown/chap13/chap13_data.md:
--------------------------------------------------------------------------------
1 | # 迁移学习常用算法及数据资源
2 |
3 | 为了研究及测试算法性能,收集了若干来自图像、文本、及时间序列的公开数据集。并且,为了与自己所研究的算法进行对比,收集了领域内若干较前沿的算法及其相关代码,以便后期进行算法的比较测试。
4 |
5 | ## 数据集
6 |
7 | 下表收集了迁移学习领域常用的数据集。这些数据集的详细介绍和下载地址,在[Github](https://github.com/jindongwang/transferlearning/blob/master/doc/dataset.md)上可以找到。我们还在[Benchmark](https://github.com/jindongwang/transferlearning/blob/master/doc/benchmark.md)上提供了一些常用算法的实验结果。
8 |
9 | | 序号 | 数据集 | 类型 | 样本数 | 特征数 | 类别数 |
10 | |:-------------:|:---------------:|:-------------:|:---------------:|:---------------:|:---------------:|
11 | | 1 | USPS | 字符识别 | 1800 | 256 | 10 |
12 | | 2 | MNIST | 字符识别 | 2000 | 256 | 10 |
13 | | 3 | PIE | 人脸识别 | 11554 | 1024 | 68 |
14 | | 4 | COIL20 | 对象识别 | 1440 | 1024 | 20 |
15 | | 5 | Office+Caltech | 对象识别 | 2533 | 800 | 10 |
16 | | 6 | ImageNet | 图像分类 | 7341 | 4096 | 5 |
17 | | 7 | VOC2007 | 图像分类 | 3376 | 4096 | 5 |
18 | | 8 | LabelMe | 图像分类 | 2656 | 4096 | 5 |
19 | | 9 | SUN09 | 图像分类 | 3282 | 4096 | 5 |
20 | | 10 | Caltech101 | 图像分类 | 1415 | 4096 | 5 |
21 | | 11 | 20newsgroup | 文本分类 | 25804 | / | 6 |
22 | | 12 | Reuters-21578 | 文本分类 | 4771 | / | 3 |
23 | | 13 | OPPORTUNITY | 行为识别 | 701366 | 27 | 4 |
24 | | 14 | DSADS | 行为识别 | 2844868 | 27 | 19 |
25 | | 15 | PAMAP2 | 行为识别 | 1140000 | 27 | 18 |
26 |
27 |
28 | ## 手写体识别图像数据集
29 |
30 | MNIST和USPS是两个通用的手写体识别数据集,它们被广泛地应用于机器学习算法评测的各个方面。USPS数据集包括7,291张训练图片和2,007张测试图片,图片大小为16$$\times$$16。MNIST数据集包括60,000张训练图片和10,000张测试图片,图片大小28$$\times$$28。USPS和MNIST数据集分别服从显著不同的概率分布,两个数据集都包含10个类别,每个类别是1-10之间的某个字符。为了构造迁移学习人物,在USPS中随机选取1,800张图片作为辅助数据、在MNIST中随机选取2,000张图片作为目标数据。交换辅助领域和目标领域可以得到另一个分类任务MNIST vs USPS。图片预处理包括:将所有图片大小线性缩放为16$$\times$$16,每幅图片用256维的特征向量表征,编码了图片的像素灰度值信息。辅助领域和目标领域共享特征空间和类别空间,但数据分布显著不同。
31 |
32 | ## 人脸识别图像数据集
33 |
34 | PIE代表“朝向、光照、表情”的英文单词首字母,该数据集是人脸识别的基准测试集,包括68个不同人物的41,368幅人脸照片,图片大小为32$$\times$$32,每个人物的照片由13个同步的相机(不同朝向)、21个不同曝光程度拍摄。简单起见,实验中采用PIE的预处理集,包括2个不同子集PIE1和PIE2,是从正面朝向的人脸照片集合(C27)中按照不同的光照和曝光条件随机选出。按如下方法构造分类任务PIEI vs PIE2:将PIE1作为辅助领域、PIE2作为目标领域;交换辅助领域和目标领域可以得到分类任务PIE2 vs PIEI。这样,辅助领域和目标领域分别由不同光照、曝光条件的人脸照片组成,从而服从显著不同的概率分布。
35 |
36 | ## 对象识别数据集
37 |
38 | COIL20包含20个对象类别共1,440张图片;每个对象类别包括72张图片,每张图片拍摄时对象水平旋转5度(共360度)。每幅图片大小为32$$\times$$32,表征为1,024维的向量。实验中将该数据集划分为两个不相交的子集COIL1和COIL2:COIL1包括位于拍摄角度为$$[0\textdegree,85\textdegree]\cup[180\textdegree,265\textdegree]$$(第一、三象限)的所有图片;COIL2包括位于拍摄角度为$$[90\textdegree,175\textdegree]\cup[270\textdegree,355\textdegree]$$(第二、四象限)的所有图片。这样,子集COIL1和COIL2的图片因为拍摄角度不同而服从不同的概率分布。将COIL1作为辅助领域、COIL2作为目标领域,可以构造跨领域分类任务COIL1 vs COIL2;交换辅助领域和目标领域,可以得到另外一个分类任务COIL2 vs COIL1。
39 |
40 | Office是视觉迁移学习的主流基准数据集,包含3个对象领域Amazon(在线电商图片)、Webcam(网络摄像头拍摄的低解析度图片)、DSLR(单反相机拍摄的高解析度图片),共有4,652张图片31个类别标签。Caltech-256是对象识别的基准数据集,包括1个对象领域Caltech,共有30,607张图片256个类别标签。对每张图片抽取SURF特征,并向量化为800维的直方图表征,所有直方图向量都进行减均值除方差的归一化处理,直方图码表由K均值聚类算法在Amazon子集上生成。具体共有4个领域C(Caltech-256), A(Amazon), W(Webcam)和D(DSLR),从中随机选取2个不同的领域作为辅助领域和目标领域,则可构造$$4 \times 3 = 12$$个跨领域视觉对象识别任务,如$$A \rightarrow D, A \rightarrow C, \cdots, C \rightarrow W$$。
41 |
42 | ## 大规模图像分类数据集
43 |
44 | 大规模图像分类数据集包含了来自5个域的图像数据:ImageNet、VOC 2007、SUN、LabelMe、以及Caltech。它们包含5个类别的图像数据:鸟,猫,椅子,狗,人。对于每个域的数据,均使用DeCaf~\cite{donahue2014decaf}进行特征提取,并取第6层的特征作为实验使用,简称DeCaf6特征。每个样本有4096个维度。
45 |
46 | ## 通用文本分类数据集
47 |
48 | 20-Newsgroups数据集包含约20,000个文档,4个大类分别为comp, rec,sci和talk,每个大类包含4个子类,详细信息如表2.2所示。在实验中构造了6组跨领域二分类任务,每组任务由4个大类中随机选取2个大类构成,一个大类记为正例,另一个大类记为负例,6个任务组具体为comp vs rec, comp vs sci, comp vs talk, rec vs sci, rec vs talk和、sci vs talk。每个跨领域分类任务(包括辅助领域和目标领域)按如下方法生成:每个任务组p VS的两个大类p和Q分别包含4个子类P1、P2、P3、P4和Q1、Q2、Q3、Q4;随机选取p的两个子类(如P1、P2)与Q的两个子类(如Q1、Q2)构成辅助领域,其余子类(P的P3和P4和Q3和Q4构成目标领域。以上构造策略既保证辅助领域和目标领域是相关的,因为它们都来自同样的大类;又保证辅助领域和目标领域是不同的,因为它们来自不同的子类。每个任务组P VS Q可以生成36个分类任务,总计6个任务组共生成6$$\times$$36 = 216个分类任务。数据集经过文本预处理后包含25,804个词项特征和15,033个文档,每个文档由tf-idf向量表征。
49 |
50 | Reuters-21578是一个较难的文本数据集,包含多个大类和子类。其中最大3个大类为orgs, people和place,可构造6个跨领域文本分类任务orgs vs people,people vs orgs, orgs vs place, place vs orgs, people vs place和place vs people。
51 |
52 | ## 行为识别公开数据集
53 |
54 | 行为识别是典型的时间序列分类任务。为了测试算法在时间序列任务上的性能,收集了3个公开的行为识别数据集:OPPORTUNITY、DASDS和PAMAP2。OPPORTUNITY数据集包含4个用户在智能家居中的多种不同层次的行为。DAADS数据集包含8个人的19种日常行为。PAMAP2数据集包含9个人的18种日常生活行为。所有数据集均包括加速度计、陀螺仪和磁力计三种运动传感器。
55 |
56 | ## 算法:
57 |
58 | 收集的数据表征、迁移学习等相关领域的基准算法在持续更新的[Github](https://github.com/jindongwang/transferlearning)上提供了各种算法的实现代码。
59 |
--------------------------------------------------------------------------------
/markdown/index.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | 这是《迁移学习简明手册》的网页版。为了方便读者阅读和维护,我们特别加入了网页版(采用markdown编写)。有任何问题、建议,均可以通过其链接的github进行提交。修改后,此网页会自动更新。
4 |
5 | 联系:jindongwang@outlook.com。
--------------------------------------------------------------------------------
/shou-ce-shuo-ming.md:
--------------------------------------------------------------------------------
1 | # 手册说明
2 |
3 | 本手册的编写目的是帮助迁移学习领域的初学者快速进行入门。我们尽可能绕开那些非常理论的概念,只讲经验方法。我们还配有多方面的代码、数据、论文资料,最大限度地方便初学者。
4 |
5 | 本手册的方法部分,关注点是近年来持续走热的领域自适应\(Domain Adaptation\)问题。迁移学习还有其他众多的研究领域。由于作者研究兴趣所在和能力所限,对其他部分的研究只是粗略介绍。非常欢迎从事其他领域研究的读者提供内容。
6 |
7 | 本手册的每一章节都是**自包含**的,因此,初学者不必从头开始阅读每一部分。直接阅读自己需要的或者自己感兴趣的部分即可。本手册每一章节的信息如下:
8 |
9 | 第1章介绍了迁移学习的概念,重点解决什么是迁移学习、为什么要进行迁移学习这两个问题。
10 |
11 | 第2章介绍了迁移学习的研究领域。
12 |
13 | 第3章介绍了迁移学习的应用领域。
14 |
15 | 第4章是迁移学习领域的一些基本知识,包括问题定义,域和任务的表示,以及迁移学习的总体思路。特别地,我们提供了较为全面的度量准则介绍。度量准则是迁移学习领域重要的工具。
16 |
17 | 第5章简要介绍了迁移学习的四种基本方法,即基于样本迁移、基于特征迁移、基于模型迁移、基于关系迁移。
18 |
19 | 第6章到第8章,介绍了领域自适应的3大类基本的方法,分别是:数据分布自适应法、特征选择法、子空间学习法。
20 |
21 | 第9章重点介绍了目前主流的深度迁移学习方法。
22 |
23 | 第10章提供了简单的上手实践教程。
24 |
25 | 第11章对迁移学习进行了展望,提出了未来几个可能的研究方向。
26 |
27 | 第12章是对全手册的总结。
28 |
29 | 第13章是附录,提供了迁移学习领域相关的学习资源,以供读者参考。
30 |
31 | 由于作者水平有限,不足和错误之处,敬请不吝批评指正。
32 |
33 | 手册的相关资源:
34 |
35 | 我们在Github上持续维护了迁移学习的资源仓库,包括论文、代码、文档、比赛等,请读者持续关注:[https://github.com/jindongwang/transferlearning,配合本手册更香哦!](https://github.com/jindongwang/transferlearning,配合本手册更香哦!)
36 |
37 | 网站\(内含勘误表\):[http://t.cn/RmasEFe](http://t.cn/RmasEFe)
38 |
39 | 开发维护地址: [http://github.com/jindongwang/transferlearning-tutorial](http://github.com/jindongwang/transferlearning-tutorial)
40 |
41 | 作者的联系方式:
42 |
43 | * 邮箱: jindongwang@outlook.com
44 | * 知乎: 王晋东不在家
45 | * 微博: 秦汉日记
46 | * 个人网站: [http://jd92.wang。](http://jd92.wang。)
47 |
48 |
--------------------------------------------------------------------------------
/src/chaps/ch00_prefix.tex:
--------------------------------------------------------------------------------
1 | \newpage
2 |
3 | \pagenumbering{Roman}
4 | \setcounter{page}{1}
5 |
6 | \section*{写在前面}
7 | \addcontentsline{toc}{section}{写在前面}
8 |
9 | 一直以来都有这样的愿望:无论学习什么知识,总是希望可以快速准确地找到对应的有价值资源进行学习。我相信我们每个人都梦寐以求。然而,越来越多的学科,尤其是我目前从事的计算机科学、人工智能领域,当下正在飞速地发展着。太多的新知识都难以事半功倍地找到快速入手的教程。庄子曰:\textit{“吾生也有涯,而知也无涯。以有涯随无涯,殆已。”}
10 |
11 | 我只是迁移学习领域一个很普通的博士生,也同样经历了由“一问三不知”到“稍稍理解”的艰难过程。我在2016年初入门迁移学习之时,迁移学习这个概念还未曾像今天一样炙手可热。当时所能找到的学习资源只有两种:别人已发表的论文和已做过的演讲。这些还是不够简单、不够直观。我需要从如此众多的材料中不断归纳,才能站在博士研究的那个圈子的边缘,以便将来可以做出一点点贡献,往圆圈外突破一点点。
12 |
13 | 相信不只是我,任何一个刚刚入门的学习者都会经历此过程。
14 |
15 | \textit{“沉舟侧畔千帆过,病树前头万木春。”}
16 |
17 | 已所不欲,勿施于人。正是因为我在初学之时也经历过如此沮丧的时期,我才在Github上对迁移学习进行了整理归纳,在知乎网上以“\textit{王晋东不在家}”为名分享自己对于迁移学习和机器学习的理解和教训、在线上线下与大家讨论相关的问题。很欣慰的是,这些免费开放的资源或多或少地,帮助到了一些初学者,使他们更快速地步入迁移学习之门。
18 |
19 | 但这些还是不太够。Github上的资源模式已经固定,目前主要是进行日常更新,不断加入新的论文和代码。目前还是缺乏一个人人都能上手的初学者教程。也只一次,有读者提问有没有相关的入门教程,能真正从0到1帮助初学者进行入门。
20 |
21 | 最近,南京大学博士(现任旷视科技南京研究院负责人)魏秀参学长写了一本《解析卷积神经网络—深度学习实践手册》,给很多深度学习的初学者提供了帮助。受他的启发,我也决定将自己在迁移学习领域的一些学习心得体会整理成一本手册,免费进行分享。希望能借此方式,帮助更多的初学者。\textit{我们不谈风月,只谈干货。}
22 |
23 | 我不是大佬,我也是迁移学习路上的一名小学生。迁移学习领域比我做的好的同龄人太多了。因此,不敢谈什么\textit{指导}。所有的目的都仅为\textit{分享}。
24 |
25 | 本手册在互联网上免费开放。随着作者理解的深入(以及其他有意者的增补),本手册肯定会不断修改、越来越好。因此,我打算效仿软件的开发、采取版本更新的方式进行管理。
26 |
27 | 希望未来可以有更多的有志之士加入,让我们的教程日渐丰富。
28 |
29 | \newpage
30 |
31 | \section*{致谢}
32 | \addcontentsline{toc}{section}{致谢}
33 |
34 | 本手册编写过程中得到了许多人的帮助。在此对他们表示感谢。
35 |
36 | 感谢我的导师、中国科学院计算技术研究所的陈益强研究员。是他一直以来保持着对我的信心,相信我能做出好的研究成果,不断鼓励我,经常与我讨论以明确问题,才有了今天的我。陈老师给我提供了优良的实验环境。我一定会更加努力地科研,做出更多更好的研究成果。
37 |
38 | 感谢香港科技大学计算机系的杨强教授。杨教授作为迁移学习领域国际泰斗,经常不厌其烦地回答我一些研究上的问题。能够得到杨教授的指导,是我的幸运。希望我能在杨教授带领下,做出更踏实的研究成果。
39 |
40 | 感谢新加坡南洋理工大学的于涵老师。作为我论文的共同作者,于老师认真的写作态度、对论文的把控能力是我一直学习的榜样。于老师还经常鼓励我,希望可以和于老师有着更多合作,发表更好的文章。
41 |
42 | 感谢清华大学龙明盛助理教授。龙老师在迁移学习领域发表了众多高质量的研究成果,是我入门时学习的榜样。龙老师还经常对我的研究给予指导。希望有机会可以真正和龙老师合作。
43 |
44 | 感谢美国伊利诺伊大学芝加哥分校的Philip S. Yu教授对我的指导和鼓励。
45 |
46 | 感谢新加坡A*STAR的郝书吉老师。我博士生涯的发表的第一篇论文是和郝老师合作完成的。正是有了第一篇论文被发表,才增强了我的自信,在接下来的研究中放平心态。
47 |
48 | 感谢我的好基友、西安电子科技大学博士生段然同学和我的同病相怜,让我们可以一起吐槽读博生活。
49 |
50 | 感谢我的室友沈建飞、以及实验室同学的支持。
51 |
52 | 感谢我的知乎粉丝和所有交流过迁移学习的学者对我的支持。
53 |
54 | 最后感谢我的女友和父母对我的支持。
55 |
56 | 本手册中出现的插图,绝大多数来源于相应论文的配图。感谢这些作者做出的优秀的研究成果。希望我能早日作出可以比肩的研究。
57 |
58 | \newpage
59 | \section*{说明}
60 | \addcontentsline{toc}{section}{手册说明}
61 | 本手册的编写目的是帮助迁移学习领域的初学者快速进行入门。我们尽可能绕开那些非常理论的概念,只讲经验方法。我们还配有多方面的代码、数据、论文资料,最大限度地方便初学者。
62 |
63 | 本手册的方法部分,关注点是近年来持续走热的领域自适应(Domain Adaptation)问题。迁移学习还有其他众多的研究领域。由于作者研究兴趣所在和能力所限,对其他部分的研究只是粗略介绍。非常欢迎从事其他领域研究的读者提供内容。
64 |
65 | 本手册的每一章节都是\textit{自包含}的,因此,初学者不必从头开始阅读每一部分。直接阅读自己需要的或者自己感兴趣的部分即可。本手册每一章节的信息如下:
66 |
67 | 第1章介绍了迁移学习的概念,重点解决什么是迁移学习、为什么要进行迁移学习这两个问题。
68 |
69 | 第2章介绍了迁移学习的研究领域。
70 |
71 | 第3章介绍了迁移学习的应用领域。
72 |
73 | 第4章是迁移学习领域的一些基本知识,包括问题定义,域和任务的表示,以及迁移学习的总体思路。特别地,我们提供了较为全面的度量准则介绍。度量准则是迁移学习领域重要的工具。
74 |
75 | 第5章简要介绍了迁移学习的四种基本方法,即基于样本迁移、基于特征迁移、基于模型迁移、基于关系迁移。
76 |
77 | 第6章到第8章,介绍了领域自适应的3大类基本的方法,分别是:数据分布自适应法、特征选择法、子空间学习法。
78 |
79 | 第9章重点介绍了目前主流的深度迁移学习方法。
80 |
81 | 第10章提供了简单的上手实践教程。
82 |
83 | 第11章对迁移学习进行了展望,提出了未来几个可能的研究方向。
84 |
85 | 第12章是对全手册的总结。
86 |
87 | 第13章是附录,提供了迁移学习领域相关的学习资源,以供读者参考。
88 |
89 | \textit{\\由于作者水平有限,不足和错误之处,敬请不吝批评指正。}
90 |
91 | \textbf{手册的相关资源:}
92 |
93 | 我们在Github上持续维护了迁移学习的资源仓库,包括论文、代码、文档、比赛等,请读者持续关注:\url{https://github.com/jindongwang/transferlearning},配合本手册更香哦!
94 |
95 | 网站(内含勘误表):\url{http://t.cn/RmasEFe}
96 |
97 | 开发维护地址: \url{http://github.com/jindongwang/transferlearning-tutorial}
98 |
99 | 作者的联系方式:
100 |
101 | \textit{邮箱}: {\ttfamily jindongwang@outlook.com},\textit{知乎}:{\ttfamily 王晋东不在家}。
102 |
103 | \textit{微博}:{\ttfamily 秦汉日记},\textit{个人网站}:\url{http://jd92.wang}。
104 |
--------------------------------------------------------------------------------
/src/chaps/ch01_introduction.tex:
--------------------------------------------------------------------------------
1 | \newpage
2 |
3 | \pagenumbering{arabic}
4 |
5 | \setcounter{page}{1}
6 |
7 | \section{迁移学习基本概念} \label{overview}%------------------------------
8 |
9 | \subsection{引子}
10 |
11 | 冬末春初,北京的天气渐渐暖了起来。这是一句再平常不过的气候描述。对于我们在北半球生活的人来说,这似乎是一个司空见惯的现象。北京如此,纽约如此,东京如此,巴黎也如此。然而此刻,假如我问你,阿根廷的首都布宜诺斯艾利斯,天气如何?稍稍有点地理常识的人就该知道,阿根廷位于南半球,天气恰恰相反:正是夏末秋初的时候,天气渐渐凉了起来。
12 |
13 | 我们何以根据北京的天气来推测出纽约、东京和巴黎的天气?我们又何以不能用相同的方式来推测阿根廷的天气?
14 |
15 | 答案显而易见:因为它们的地理位置不同。除去阿根廷在南半球之外,其他几个城市均位于北半球,故而天气变化相似。
16 |
17 | 我们可以利用这些地点\textit{地理位置的相似性和差异性},很容易地推测出其他地点的天气。这样一个简单的事实,就引出了我们要介绍的主题:\textit{迁移学习}。
18 |
19 | \subsection{迁移学习的概念}
20 |
21 | 迁移学习,顾名思义,就是要进行迁移。放到我们人工智能和机器学习的学科里讲,迁移学习是一种学习的思想和模式。
22 |
23 | 我们都对机器学习有了基本的了解。机器学习是人工智能的一大类重要方法,也是目前发展最迅速、效果最显著的方法。机器学习解决的是让机器自主地从数据中获取知识,从而应用于新的问题中。迁移学习作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。
24 |
25 | 迁移学习的核心问题是,找到新问题和原问题之间的相似性,才可以顺利地实现知识的迁移。比如在我们一开始说的天气问题中,那些北半球的天气之所以相似,是因为它们的地理位置相似;而南北半球的天气之所以有差异,也是因为地理位置有根本不同。
26 |
27 | 其实我们人类对于迁移学习这种能力,是与生俱来的。比如,我们如果已经会打乒乓球,就可以类比着学习打网球。再比如,我们如果已经会下中国象棋,就可以类比着下国际象棋。因为这些活动之间,往往有着极高的相似性。生活中常用的“\textit{举一反三}”、“\textit{照猫画虎}”就很好地体现了迁移学习的思想。
28 |
29 | 回到我们的问题中来。我们用更加学术更加机器学习的语言来对迁移学习下一个定义。迁移学习,是指利用数据、任务、或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。
30 |
31 | 迁移学习最权威的综述文章是香港科技大学杨强教授团队的A survey on transfer learning~\cite{pan2010survey}。
32 |
33 | 图~\ref{fig-transfer}简要表示了一个迁移学习过程。图~\ref{fig-example}给出了生活中常见的迁移学习的例子。
34 |
35 | \begin{figure}[htbp]
36 | \centering
37 | \includegraphics[scale=0.5]{./figures/fig-introduction-transfer.pdf}
38 | \caption{迁移学习示意图}
39 | \label{fig-transfer}
40 | \end{figure}
41 |
42 | \begin{figure}[htbp]
43 | \centering
44 | \includegraphics[scale=0.5]{./figures/fig-introduction-example.pdf}
45 | \caption{迁移学习的例子}
46 | \label{fig-example}
47 | \end{figure}
48 |
49 | 值得一提的是,新华社报道指出,迁移学习是中国领先于世界的少数几个人工智能领域之一~\cite{xinhua}。中国的人工智能赶超的机会来了!
50 |
51 |
52 | \subsection{为什么需要迁移学习?}
53 |
54 | 了解了迁移学习的概念之后,紧接着还有一个非常重要的问题:迁移学习的目的是什么? 或者说,\textit{为什么要用迁移学习}?
55 |
56 | 我们把原因概括为以下四个方面:
57 |
58 | \textbf{1. 大数据与少标注之间的矛盾。}
59 |
60 | \begin{figure}[htbp]
61 | \centering
62 | \includegraphics[scale=0.42]{./figures/fig-introduction-data.pdf}
63 | \caption{多种多样的数据来源}
64 | \label{fig-introduction-data}
65 | \end{figure}
66 |
67 | 我们正处在一个大数据时代,每天每时,社交网络、智能交通、视频监控、行业物流等,都产生着海量的图像、文本、语音等各类数据。数据的增多,使得机器学习和深度学习模型可以依赖于如此\textit{海量的数据},持续不断地训练和更新相应的模型,使得模型的性能越来越好,越来越适合特定场景的应用。然而,这些大数据带来了严重的问题:总是缺乏完善的\textit{数据标注}。
68 |
69 | 众所周知,机器学习模型的训练和更新,均依赖于数据的标注。然而,尽管我们可以获取到海量的数据,这些数据往往是很初级的原始形态,很少有数据被加以正确的人工标注。数据的标注是一个耗时且昂贵的操作,目前为止,尚未有行之有效的方式来解决这一问题。这给机器学习和深度学习的模型训练和更新带来了挑战。反过来说,特定的领域,因为没有足够的标定数据用来学习,使得这些领域一直不能很好的发展。
70 |
71 | \textbf{2. 大数据与弱计算之间的矛盾。}
72 |
73 | 大数据,就需要大设备、强计算能力的设备来进行存储和计算。然而,大数据的大计算能力,是"有钱人"才能玩得起的游戏。比如Google,Facebook,Microsoft,这些巨无霸公司有着雄厚的计算能力去利用这些数据训练模型。例如,ResNet需要很长的时间进行训练。Google TPU也都是有钱人的才可以用得起的。
74 |
75 | 绝大多数普通用户是不可能具有这些强计算能力的。这就引发了大数据和弱计算之间的矛盾。在这种情况下,普通人想要利用这些海量的大数据去训练模型完成自己的任务,基本上不太可能。那么如何让普通人也能利用这些数据和模型?
76 |
77 | \begin{figure}[htbp]
78 | \centering
79 | \includegraphics[scale=0.42]{./figures/fig-introduction-bigdata.pdf}
80 | \caption{大数据与强计算能力}
81 | \label{fig-bigdata}
82 | \end{figure}
83 |
84 | \textbf{3. 普适化模型与个性化需求之间的矛盾。}
85 |
86 | 机器学习的目标是构建一个尽可能通用的模型,使得这个模型对于不同用户、不同设备、不同环境、不同需求,都可以很好地进行满足。这是我们的美好愿景。这就是要尽可能地提高机器学习模型的\textit{泛化能力},使之适应不同的数据情形。基于这样的愿望,我们构建了多种多样的普适化模型,来服务于现实应用。然而,这只能是我们竭尽全力想要做的,目前却始终无法彻底解决的问题。人们的个性化需求五花八门,短期内根本无法用一个通用的模型去满足。比如导航模型,可以定位及导航所有的路线。但是不同的人有不同的需求。比如有的人喜欢走高速,有的人喜欢走偏僻小路,这就是个性化需求。并且,不同的用户,通常都有不同的\textit{隐私需求}。这也是构建应用需要着重考虑的。
87 |
88 | 所以目前的情况是,我们对于每一个通用的任务都构建了一个通用的模型。这个模型可以解决绝大多数的公共问题。但是具体到每个个体、每个需求,都存在其唯一性和特异性,一个普适化的通用模型根本无法满足。那么,能否将这个通用的模型加以改造和适配,使其更好地服务于人们的个性化需求?
89 |
90 | \begin{figure}[htbp]
91 | \centering
92 | \includegraphics[scale=0.45]{./figures/fig-introduction-model.pdf}
93 | \caption{普适化模型与个性化需求}
94 | \label{fig-privacy}
95 | \end{figure}
96 |
97 | \textbf{4. 特定应用的需求。}
98 |
99 | 机器学习已经被广泛应用于现实生活中。在这些应用中,也存在着一些特定的应用,它们面临着一些现实存在的问题。比如推荐系统的\textit{冷启动}问题。一个新的推荐系统,没有足够的用户数据,如何进行精准的推荐? 一个崭新的图片标注系统,没有足够的标签,如何进行精准的服务?现实世界中的应用驱动着我们去开发更加便捷更加高效的机器学习方法来加以解决。
100 |
101 | \begin{figure}[htbp]
102 | \centering
103 | \includegraphics[scale=0.45]{./figures/fig-introduction-coldstart.pdf}
104 | \caption{特定应用需求:冷启动}
105 | \label{fig-coldstart}
106 | \end{figure}
107 |
108 | 上述存在的几个重要问题,使得传统的机器学习方法疲于应对。迁移学习则可以很好地进行解决。那么,\textbf{迁移学习是如何进行解决的呢?}
109 |
110 | 1. 大数据与少标注:迁移数据标注
111 |
112 | 单纯地凭借少量的标注数据,无法准确地训练高可用度的模型。为了解决这个问题,我们直观的想法是:多增加一些标注数据不就行了?但是不依赖于人工,如何增加标注数据?
113 |
114 | 利用迁移学习的思想,我们可以寻找一些与目标数据相近的有标注的数据,从而利用这些数据来构建模型,增加我们目标数据的标注。
115 |
116 | 2. 大数据与弱计算:模型迁移
117 |
118 | 不可能所有人都有能力利用大数据快速进行模型的训练。利用迁移学习的思想,我们可以将那些大公司在大数据上训练好的模型,迁移到我们的任务中。针对于我们的任务进行微调,从而我们也可以拥有在大数据上训练好的模型。更进一步,我们可以将这些模型针对我们的任务进行自适应更新,从而取得更好的效果。
119 |
120 | 3. 普适化模型与个性化需求:自适应学习
121 |
122 | 为了解决个性化需求的挑战,我们利用迁移学习的思想,进行自适应的学习。考虑到不同用户之间的相似性和差异性,我们对普适化模型进行灵活的调整,以便完成我们的任务。
123 |
124 | 4. 特定应用的需求:相似领域知识迁移
125 |
126 | 为了满足特定领域应用的需求,我们可以利用上述介绍过的手段,从数据和模型方法上进行迁移学习。
127 |
128 | 表\ref{tb-whytransfer}概括地描述了迁移学习的必要性。
129 |
130 | \begin{table}[htbp]
131 | \centering
132 | \caption{迁移学习的必要性}
133 | \label{tb-whytransfer}
134 | \begin{tabular}{|c|c|c|}
135 | \hline
136 | \textbf{矛盾} & \textbf{传统机器学习} & \textbf{迁移学习} \\ \hline
137 | 大数据与少标注 & 增加人工标注,但是昂贵且耗时 & 数据的迁移标注 \\ \hline
138 | 大数据与弱计算 & 只能依赖强大计算能力,但是受众少 & 模型迁移 \\ \hline
139 | 普适化模型与个性化需求 & 通用模型无法满足个性化需求 & 模型自适应调整 \\ \hline
140 | 特定应用 & 冷启动问题无法解决 & 数据迁移 \\ \hline
141 | \end{tabular}
142 | \end{table}
143 |
144 | \subsection{与已有概念的区别和联系}
145 |
146 | 迁移学习并不是一个横空出世的概念,它与许多已有的概念都有些联系,但是也有着一些区别。我们在这里汇总一些与迁移学习非常接近的概念,并简述迁移学习与它们的区别和联系。
147 |
148 | \textbf{1. 迁移学习 VS 传统机器学习:}
149 |
150 | 迁移学习属于机器学习的一类,但它在如下几个方面有别于传统的机器学习(表~\ref{tb-introduction-machinelearning}):
151 |
152 | \begin{table}[htbp]
153 | \centering
154 | \caption{传统机器学习与迁移学习的区别}
155 | \label{tb-introduction-machinelearning}
156 | \begin{tabular}{|l|l|l|}
157 | \hline
158 | \multicolumn{1}{|c|}{\textbf{比较项目}} & \multicolumn{1}{c|}{\textbf{传统机器学习}} & \multicolumn{1}{c|}{\textbf{迁移学习}} \\ \hline
159 | 数据分布 & 训练和测试数据服从相同的分布 & 训练和测试数据服从不同的分布 \\ \hline
160 | 数据标注 & 需要足够的数据标注来训练模型 & 不需要足够的数据标注 \\ \hline
161 | 模型 & 每个任务分别建模 & 模型可以在不同任务之间迁移 \\ \hline
162 | \end{tabular}
163 | \end{table}
164 |
165 | \textbf{2. 迁移学习 VS 多任务学习:}
166 |
167 | 多任务学习指多个相关的任务一起协同学习;迁移学习则强调知识由一个领域迁移到另一个领域的过程。迁移是思想,多任务是其中的一个具体形式。
168 |
169 | \textbf{3. 迁移学习 VS 终身学习:}
170 |
171 | 终身学习可以认为是序列化的多任务学习,在已经学习好若干个任务之后,面对新的任务可以继续学习而不遗忘之前学习的任务。迁移学习则侧重于模型的迁移和共同学习。
172 |
173 | \textbf{4. 迁移学习 VS 领域自适应:}
174 |
175 | 领域自适应问题是迁移学习的研究内容之一,它侧重于解决特征空间一致、类别空间一致,仅特征分布不一致的问题。而迁移学习也可以解决上述内容不一致的情况。
176 |
177 | \textbf{5. 迁移学习 VS 增量学习:}
178 |
179 | 增量学习侧重解决数据不断到来,模型不断更新的问题。迁移学习显然和其有着不同之处。
180 |
181 | \textbf{6. 迁移学习 VS 自我学习:}
182 |
183 | 自我学习指的是模型不断地从自身处进行更新,而迁移学习强调知识在不同的领域间进行迁移。
184 |
185 | \textbf{7. 迁移学习 VS 协方差漂移}
186 |
187 | 协方差漂移指数据的边缘概率分布发生变化。领域自适应研究问题解决的就是协方差漂移现象。
188 |
189 | \subsection{负迁移}
190 | 我们都希望迁移学习能够比较顺利地进行,我们得到的结果也是满足我们要求的,皆大欢喜。然而,事情却并不总是那么顺利。这就引入了迁移学习中的一个负面现象,也就是所谓的\textbf{负迁移}。
191 |
192 | 用我们熟悉的成语来描述:如果说成功的迁移学习是“举一反三”、“照猫画虎”,那么负迁移则是“\textit{东施效颦}”。东施已经模仿西施捂着胸口皱着眉头,为什么她还是那么丑?
193 |
194 | 要理解负迁移,首先要理解什么是迁移学习。迁移学习指的是,利用数据和领域之间存在的相似性关系,把之前学习到的知识,应用于新的未知领域。迁移学习的核心问题是,找到两个领域的相似性。找到了这个相似性,就可以合理地利用,从而很好地完成迁移学习任务。比如,之前会骑自行车,要学习骑摩托车,这种相似性指的就是自行车和摩托车之间的相似性以及骑车体验的相似性。这种相似性在我们人类看来是可以接受的。
195 |
196 | 所以,如果这个相似性找的不合理,也就是说,\textit{两个领域之间不存在相似性,或者基本不相似},那么,就会大大损害迁移学习的效果。还是拿骑自行车来说,你要拿骑自行车的经验来学习开汽车,这显然是不太可能的。因为自行车和汽车之间基本不存在什么相似性。所以,这个任务基本上完不成。这时候,我们可以说出现了\textbf{负迁移(Negative Transfer)}。
197 |
198 | 所以,为什么东施和西施做了一样的动作,反而变得更丑了?\textit{因为东施和西施之间压根就不存在相似性。}
199 |
200 | 迁移学习领域权威学者、香港科技大学杨强教授发表的迁移学习的综述文章A survey on transfer learning~\cite{pan2010survey}给出了负迁移的一个定义:
201 |
202 | \textit{负迁移指的是,在源域上学习到的知识,对于目标域上的学习产生负面作用。}
203 |
204 | 文章也引用了一些经典的解决负迁移问题的文献。但是普遍较老,这里就不说了。
205 |
206 | 所以,产生负迁移的原因主要有:
207 |
208 | \begin{itemize}
209 | \item 数据问题:源域和目标域压根不相似,谈何迁移?
210 | \item 方法问题:源域和目标域是相似的,但是,迁移学习方法不够好,没找到可迁移的成分。
211 | \end{itemize}
212 |
213 | 负迁移给迁移学习的研究和应用带来了负面影响。在实际应用中,找到合理的相似性,并且选择或开发合理的迁移学习方法,能够避免负迁移现象。
214 |
215 | \textbf{最新的研究成果}
216 |
217 | 随着研究的深入,已经有新的研究成果在逐渐克服负迁移的影响。杨强教授团队2015在数据挖掘领域顶级会议KDD上发表了传递迁移学习文章Transitive transfer learning~\cite{tan2015transitive},提出了传递迁移学习的思想。传统迁移学习就好比是\textit{踩着一块石头过河},传递迁移学习就好比是\textit{踩着连续的两块石头}。
218 |
219 | 更进一步,杨强教授团队在2017年人工智能领域顶级会议AAAI上发表了远领域迁移学习的文章Distant domain transfer learning~\cite{tan2017distant},可以用人脸来识别飞机!这就好比是\textit{踩着一连串石头过河}。这些研究的意义在于,传统迁移学习只有两个领域足够相似才可以完成,而当两个领域不相似时,传递迁移学习却可以利用处于这两个领域之间的若干领域,将知识传递式的完成迁移。这个是很有意义的工作,可以视为解决负迁移的有效思想和方法。可以预见在未来会有更多的应用前景。
220 |
221 | 图~\ref{fig-negative}对传递迁移学习给出了简明的示意。
222 |
223 | \begin{figure}[htbp]
224 | \centering
225 | \includegraphics[scale=0.45]{./figures/fig-introduction-negativetransfer.pdf}
226 | \caption{传递式迁移学习示意图}
227 | \label{fig-negative}
228 | \end{figure}
229 |
230 |
--------------------------------------------------------------------------------
/src/chaps/ch02_research_area.tex:
--------------------------------------------------------------------------------
1 | \newpage
2 | \section{迁移学习的研究领域} %--------c----------------------
3 |
4 | 依据目前较流行的机器学习分类方法,机器学习主要可以分为有监督、半监督和无监督机器学习三大类。同理,迁移学习也可以进行这样的分类。需要注意的是,依据的分类准则不同,分类结果也不同。在这一点上,并没有一个统一的说法。我们在这里仅根据目前较流行的方法,对迁移学习的研究领域进行一个大致的划分。
5 |
6 | 图~\ref{fig-area}给出了迁移学习的常用分类方法总结。
7 |
8 | \begin{figure}[htbp]
9 | \centering
10 | \includegraphics[scale=0.6]{./figures/fig-area.pdf}
11 | \caption{迁移学习的研究领域与研究方法分类}
12 | \label{fig-area}
13 | \end{figure}
14 |
15 | 大体上讲,迁移学习的分类可以按照四个准则进行:\textit{按目标域有无标签分、按学习方法分、按特征分、按离线与在线形式分}。不同的分类方式对应着不同的专业名词。当然,即使是一个分类下的研究领域,也可能同时处于另一个分类下。下面我们对这些分类方法及相应的领域作简单描述。
16 |
17 | \subsection{按目标域标签分}
18 | 这种分类方式最为直观。类比机器学习,按照目标领域有无标签,迁移学习可以分为以下三个大类:
19 |
20 | \begin{enumerate}
21 | \item 监督迁移学习 (Supervised Transfer Learning)
22 | \item 半监督迁移学习 (Semi-Supervised Transfer Learning)
23 | \item 无监督迁移学习 (Unsupervised Transfer Learning)
24 | \end{enumerate}
25 |
26 | 显然,少标签或无标签的问题(半监督和无监督迁移学习),是研究的热点和难点。这也是本手册重点关注的领域。
27 |
28 | \subsection{按学习方法分类}
29 | 按学习方法的分类形式,最早在迁移学习领域的权威综述文章~\cite{pan2010survey}给出定义。它将迁移学习方法分为以下四个大类:
30 |
31 | \begin{enumerate}
32 | \item 基于样本的迁移学习方法 (Instance based Transfer Learning)
33 | \item 基于特征的迁移学习方法 (Feature based Transfer Learning)
34 | \item 基于模型的迁移学习方法 (Model based Transfer Learning)
35 | \item 基于关系的迁移学习方法 (Relation based Transfer Learning)
36 | \end{enumerate}
37 |
38 | 这是一个很直观的分类方式,按照数据、特征、模型的机器学习逻辑进行区分,再加上不属于这三者中的关系模式。
39 |
40 | 基于实例的迁移,简单来说就是通过权重重用,对源域和目标域的样例进行迁移。就是说直接对不同的样本赋予不同权重,比如说相似的样本,我就给它高权重,这样我就完成了迁移,非常简单非常非常直接。
41 |
42 | 基于特征的迁移,就是更进一步对特征进行变换。意思是说,假设源域和目标域的特征原来不在一个空间,或者说它们在原来那个空间上不相似,那我们就想办法把它们变换到一个空间里面,那这些特征不就相似了?这个思路也非常直接。这个方法是用得非常多的,一直在研究,目前是感觉是研究最热的。
43 |
44 | 基于模型的迁移,就是说构建参数共享的模型。这个主要就是在神经网络里面用的特别多,因为神经网络的结构可以直接进行迁移。比如说神经网络最经典的finetune就是模型参数迁移的很好的体现。
45 |
46 | 基于关系的迁移,这个方法用的比较少,这个主要就是说挖掘和利用关系进行类比迁移。比如老师上课、学生听课就可以类比为公司开会的场景。这个就是一种关系的迁移。
47 |
48 | 目前最热的就是基于特征还有模型的迁移,然后基于实例的迁移方法和他们结合起来使用。
49 |
50 | 迁移学习方法是本手册的重点。我们在后续的篇幅中介绍。
51 |
52 | \subsection{按特征分类}
53 |
54 | 按照特征的属性进行分类,也是一种常用的分类方法。这在最近的迁移学习综述~\cite{weiss2016survey}中给出。按照特征属性,迁移学习可以分为两个大类:
55 |
56 | \begin{enumerate}
57 | \item 同构迁移学习 (Homogeneous Transfer Learning)
58 | \item 异构迁移学习 (Heterogeneous Transfer Learning)
59 | \end{enumerate}
60 |
61 | 这也是一种很直观的方式:如果特征语义和维度都相同,那么就是同构;反之,如果特征完全不相同,那么就是异构。举个例子来说,不同图片的迁移,就可以认为是同构;而图片到文本的迁移,则是异构的。
62 |
63 | \subsection{按离线与在线形式分}
64 |
65 | 按照离线学习与在线学习的方式,迁移学习还可以被分为:
66 |
67 | \begin{enumerate}
68 | \item 离线迁移学习 (Offline Transfer Learning)
69 | \item 在线迁移学习 (Online Transfer Learning)
70 | \end{enumerate}
71 |
72 | 目前,绝大多数的迁移学习方法,都采用了离线方式。即,源域和目标域均是给定的,迁移一次即可。这种方式的缺点是显而易见的:算法无法对新加入的数据进行学习,模型也无法得到更新。与之相对的,是在线的方式。即随着数据的动态加入,迁移学习算法也可以不断地更新。
--------------------------------------------------------------------------------
/src/chaps/ch03_application.tex:
--------------------------------------------------------------------------------
1 | \newpage
2 |
3 | \section{迁移学习的应用}
4 |
5 | 迁移学习是机器学习领域的一个重要分支。因此,其应用并不局限于特定的领域。凡是满足迁移学习问题情景的应用,迁移学习都可以发挥作用。这些领域包括但不限于计算机视觉、文本分类、行为识别、自然语言处理、室内定位、视频监控、舆情分析、人机交互等。图~\ref{fig-app-all}展示了迁移学习可能的应用领域。
6 |
7 | 下面我们选择几个研究热点,对迁移学习在这些领域的应用场景作一简单介绍。
8 |
9 | \begin{figure}[htbp]
10 | \centering
11 | \includegraphics[scale=0.42]{./figures/fig-app-all.pdf}
12 | \caption{迁移学习的应用领域概览}
13 | \label{fig-app-all}
14 | \end{figure}
15 |
16 | \subsection{计算机视觉}
17 |
18 | 迁移学习已被广泛地应用于计算机视觉的研究中。特别地,在计算机视觉中,迁移学习方法被称为Domain Adaptation。Domain adaptation的应用场景有很多,比如图片分类、图片哈希等。
19 |
20 | 图~\ref{fig-app-cv}展示了不同的迁移学习图片分类任务示意。同一类图片,不同的拍摄角度、不同光照、不同背景,都会造成特征分布发生改变。因此,使用迁移学习构建跨领域的鲁棒分类器是十分重要的。
21 |
22 | \begin{figure}[htbp]
23 | \centering
24 | \includegraphics[scale=0.42]{./figures/fig-app-cv.pdf}
25 | \caption{迁移学习图片分类任务}
26 | \label{fig-app-cv}
27 | \end{figure}
28 |
29 | 计算机视觉三大顶会(CVPR、ICCV、ECCV)每年都会发表大量的文章对迁移学习在视觉领域的应用进行介绍。
30 |
31 | \subsection{文本分类}
32 |
33 | 由于文本数据有其领域特殊性,因此,在一个领域上训练的分类器,不能直接拿来作用到另一个领域上。这就需要用到迁移学习。例如,在电影评论文本数据集上训练好的分类器,不能直接用于图书评论的预测。这就需要进行迁移学习。图~\ref{fig-app-text}是一个由电子产品评论迁移到DVD评论的迁移学习任务。
34 |
35 | \begin{figure}[htbp]
36 | \centering
37 | \includegraphics[scale=0.4]{./figures/fig-app-text.pdf}
38 | \caption{迁移学习文本分类任务}
39 | \label{fig-app-text}
40 | \end{figure}
41 |
42 | 文本和网络领域顶级会议WWW和CIKM每年有大量的文章对迁移学习在文本领域的应用作介绍。
43 |
44 | \subsection{时间序列}
45 |
46 | \textit{行为识别}(Activity Recognition)主要通过佩戴在用户身体上的传感器,研究用户的行为。行为数据是一种时间序列数据。不同用户、不同环境、不同位置、不同设备,都会导致时间序列数据的分布发生变化。此时,也需要进行迁移学习。图~\ref{fig-app-activity}展示了同一用户不同位置的信号差异性。在这个领域,华盛顿州立大学的Diane Cook等人在2013年发表的关于迁移学习在行为识别领域的综述文章~\cite{cook2013transfer}是很好的参考资料。
47 |
48 | \begin{figure}[htbp]
49 | \centering
50 | \includegraphics[scale=0.42]{./figures/fig-app-time.pdf}
51 | \caption{不同位置的传感器信号差异示意图}
52 | \label{fig-app-activity}
53 | \end{figure}
54 |
55 | \textit{室内定位}(Indoor Location)与传统的室外用GPS定位不同,它通过WiFi、蓝牙等设备研究人在室内的位置。不同用户、不同环境、不同时刻也会使得采集的信号分布发生变化。图~\ref{fig-app-location}展示了不同时间、不同设备的WiFi信号变化。
56 |
57 | \begin{figure}[htbp]
58 | \centering
59 | \includegraphics[scale=0.42]{./figures/fig-app-location.pdf}
60 | \caption{室内定位由于时间和设备的变化导致的信号变化}
61 | \label{fig-app-location}
62 | \end{figure}
63 |
64 | \subsection{医疗健康}
65 |
66 | 医疗健康领域的研究正变得越来越重要。不同于其他领域,医疗领域研究的难点问题是,\textit{无法获取足够有效的医疗数据}。在这一领域,迁移学习同样也变得越来越重要。
67 |
68 | 最近,顶级生物期刊细胞杂志报道了由张康教授领导的广州妇女儿童医疗中心和加州大学圣迭戈分校团队的重磅研究成果:基于深度学习开发出一个能诊断眼病和肺炎两大类疾病的AI系统~\cite{kermany2018identifying},准确性匹敌顶尖医生。这不仅是中国研究团队首次在顶级生物医学杂志发表有关医学人工智能的研究成果;也是世界范围内首次使用如此庞大的标注好的高质量数据进行\textbf{迁移学习},并取得高度精确的诊断结果,达到匹敌甚至超越人类医生的准确性;还是全世界首次实现用AI精确推荐治疗手段。细胞杂志封面报道了该研究成果。
69 |
70 | 我们可以预见到的是,迁移学习对于那些不易获取标注数据的领域,将会发挥越来越重要的作用。
--------------------------------------------------------------------------------
/src/chaps/ch04_basic.tex:
--------------------------------------------------------------------------------
1 | \newpage
2 | \section{基础知识}
3 |
4 | 本部分介绍迁移学习领域的一些基本知识。我们对迁移学习的问题进行简单的形式化,给出迁移学习的总体思路,并且介绍目前常用的一些度量准则。本部分中出现的所有符号和表示形式,是以后章节的基础。已有相关知识的读者可以直接跳过。
5 |
6 | \subsection{迁移学习的问题形式化}
7 |
8 | 迁移学习的问题形式化,是进行一切研究的前提。在迁移学习中,有两个基本的概念:\textbf{领域(Domain)}和\textbf{任务(Task)}。它们是最基础的概念。定义如下:
9 |
10 | \subsubsection{领域}
11 |
12 | \textbf{领域(Domain):} 是进行学习的主体。领域主要由两部分构成:\textit{数据}和\textit{生成这些数据的概率分布}。通常我们用花体$\mathcal{D}$来表示一个domain,用大写斜体$P$来表示一个概率分布。
13 |
14 | 特别地,因为涉及到迁移,所以对应于两个基本的领域:\textbf{源领域(Source Domain)}和\textbf{目标领域(Target Domain)}。这两个概念很好理解。源领域就是有知识、有大量数据标注的领域,是我们要迁移的对象;目标领域就是我们最终要赋予知识、赋予标注的对象。知识从源领域传递到目标领域,就完成了迁移。
15 |
16 | 领域上的数据,我们通常用小写粗体$\mathbf{x}$来表示,它也是向量的表示形式。例如,$\mathbf{x}_i$就表示第$i$个样本或特征。用大写的黑体$\mathbf{X}$表示一个领域的数据,这是一种矩阵形式。我们用大写花体$\mathcal{X}$来表示数据的特征空间。
17 |
18 | 通常我们用小写下标$s$和$t$来分别指代两个领域。结合领域的表示方式,则:$\mathcal{D}_s$表示源领域,$\mathcal{D}_t$表示目标领域。
19 |
20 | 值得注意的是,概率分布$P$通常只是一个逻辑上的概念,即我们认为不同领域有不同的概率分布,却一般不给出(也难以给出)$P$的具体形式。
21 |
22 | \subsubsection{任务}
23 |
24 | \textbf{任务(Task):} 是学习的目标。任务主要由两部分组成:\textit{标签}和\textit{标签对应的函数}。通常我们用花体$\mathcal{Y}$来表示一个标签空间,用$f(\cdot)$来表示一个学习函数。
25 |
26 | 相应地,源领域和目标领域的类别空间就可以分别表示为$\mathcal{Y}_s$和$\mathcal{Y}_t$。我们用小写$y_s$和$y_t$分别表示源领域和目标领域的实际类别。
27 |
28 | \subsubsection{迁移学习}
29 |
30 | 有了上面领域和任务的定义,我们就可以对迁移学习进行形式化。
31 |
32 | \textbf{迁移学习(Transfer Learning):} 给定一个有标记的源域$\mathcal{D}_s=\{\mathbf{x}_{i},y_{i}\}^n_{i=1}$和一个无标记的目标域$\mathcal{D}_t=\{\mathbf{x}_{j}\}^{n+m}_{j=n+1}$。这两个领域的数据分布$P(\mathbf{x}_s)$和P($\mathbf{x}_t)$不同,即$P(\mathbf{x}_s) \ne P(\mathbf{x}_t)$。迁移学习的目的就是要借助$\mathcal{D}_s$的知识,来学习目标域$\mathcal{D}_t$的知识(标签)。
33 |
34 | 更进一步,结合我们前面说过的迁移学习研究领域,迁移学习的定义需要进行如下的考虑:
35 |
36 | (1) 特征空间的异同,即$\mathcal{X}_s$和$\mathcal{X}_t$是否相等。
37 |
38 | (2) 类别空间的异同:即$\mathcal{Y}_s$和$\mathcal{Y}_t$是否相等。
39 |
40 | (3) 条件概率分布的异同:即$Q_s(y_s|\mathbf{x}_s)$和$Q_t(y_t|\mathbf{x}_t)$是否相等。
41 |
42 | 结合上述形式化,我们给出\textbf{领域自适应(Domain Adaptation)}这一热门研究方向的定义:
43 |
44 | \textbf{领域自适应(Domain Adaptation):} 给定一个有标记的源域$\mathcal{D}_s=\{\mathbf{x}_{i},y_{i}\}^n_{i=1}$和一个无标记的目标域$\mathcal{D}_t=\{\mathbf{x}_{j}\}^{n+m}_{j=n+1}$,假定它们的特征空间相同,即$\mathcal{X}_s = \mathcal{X}_t$,并且它们的类别空间也相同,即$\mathcal{Y}_s = \mathcal{Y}_t$以及条件概率分布也相同,即$Q_s(y_s|\mathbf{x}_s) = Q_t(y_t|\mathbf{x}_t)$。但是这两个域的边缘分布不同,即$P_s(\mathbf{x}_s) \ne P_t(\mathbf{x}_t)$。迁移学习的目标就是,利用有标记的数据$\mathcal{D}_s$去学习一个分类器$f:\mathbf{x}_t \mapsto \mathbf{y}_t$来预测目标域$\mathcal{D}_t$的标签$\mathbf{y}_t \in \mathcal{Y}_t$.
45 |
46 | 在实际的研究和应用中,读者可以针对自己的不同任务,结合上述表述,灵活地给出相关的形式化定义。
47 |
48 | \textbf{符号小结}
49 |
50 | 我们已经基本介绍了迁移学习中常用的符号。表~\ref{tb-symbol}是一个符号表:
51 |
52 | \begin{table}[htbp]
53 | \centering
54 | \caption{迁移学习形式化表示常用符号}
55 | \label{tb-symbol}
56 | \begin{tabular}{|c|c|}
57 | \hline
58 | \textbf{符号} & \textbf{含义} \\ \hline
59 | 下标$s$ / $t$ & 指示源域 / 目标域 \\ \hline
60 | $\mathcal{D}_s$ / $\mathcal{D}_t$ & 源域数据 / 目标域数据 \\ \hline
61 | $\mathbf{x}$ / $\mathbf{X}$ / $\mathcal{X}$ & 向量 / 矩阵 / 特征空间 \\ \hline
62 | $\mathbf{y}$ / $\mathcal{Y}$ & 类别向量 / 类别空间 \\ \hline
63 | $(n,m)$ [或 $(n_1,n_2)$ 或 $(n_s,n_t)$] & (源域样本数,目标域样本数) \\ \hline
64 | $P(\mathbf{x}_s)$ / $P(\mathbf{x}_t)$ & 源域数据 / 目标域数据的边缘分布 \\ \hline
65 | $Q(\mathbf{y}_s | \mathbf{x}_s)$ / $Q(\mathbf{y}_t | \mathbf{x}_t)$ & 源域数据 / 目标域数据的条件分布 \\ \hline
66 | $f(\cdot)$ & 要学习的目标函数 \\ \hline
67 | \end{tabular}
68 | \end{table}
69 |
70 | \subsection{总体思路}
71 |
72 | 形式化之后,我们可以进行迁移学习的研究。迁移学习的总体思路可以概括为:\textit{开发算法来最大限度地利用有标注的领域的知识,来辅助目标领域的知识获取和学习}。
73 |
74 | 迁移学习的核心是,找到源领域和目标领域之间的\textbf{相似性},并加以合理利用。这种相似性非常普遍。比如,不同人的身体构造是相似的;自行车和摩托车的骑行方式是相似的;国际象棋和中国象棋是相似的;羽毛球和网球的打球方式是相似的。这种相似性也可以理解为\textbf{不变量}。以不变应万变,才能立于不败之地。
75 |
76 | 举一个杨强教授经常举的例子来说明:我们都知道在中国大陆开车时,驾驶员坐在左边,靠马路右侧行驶。这是基本的规则。然而,如果在英国、香港等地区开车,驾驶员是坐在右边,需要靠马路左侧行驶。那么,如果我们从中国大陆到了香港,应该如何快速地适应他们的开车方式呢?诀窍就是找到这里的不变量:\textit{不论在哪个地区,驾驶员都是紧靠马路中间。}这就是我们这个开车问题中的不变量。
77 |
78 | 找到相似性(不变量),是进行迁移学习的核心。
79 |
80 | 有了这种相似性后,下一步工作就是,\textit{如何度量和利用这种相似性}。度量工作的目标有两点:一是很好地度量两个领域的相似性,不仅定性地告诉我们它们是否相似,更\textit{定量}地给出相似程度。二是以度量为准则,通过我们所要采用的学习手段,增大两个领域之间的相似性,从而完成迁移学习。
81 |
82 | \textbf{一句话总结:} \textit{相似性是核心,度量准则是重要手段}。
83 |
84 | \subsection{度量准则}
85 |
86 | 度量不仅是机器学习和统计学等学科中使用的基础手段,也是迁移学习中的重要工具。它的核心就是衡量两个数据域的差异。计算两个向量(点、矩阵)的距离和相似度是许多机器学习算法的基础,有时候一个好的距离度量就能决定算法最后的结果好坏。比如KNN分类算法就对距离非常敏感。本质上就是找一个变换使得源域和目标域的距离最小(相似度最大)。所以,相似度和距离度量在机器学习中非常重要。
87 |
88 | 这里给出常用的度量手段,它们都是迁移学习研究中非常常见的度量准则。对这些准则有很好的理解,可以帮助我们设计出更加好用的算法。用一个简单的式子来表示,度量就是描述源域和目标域这两个领域的距离:
89 |
90 | \begin{equation}
91 | \label{eq-distance}
92 | DISTANCE(\mathcal{D}_s,\mathcal{D}_t) = \mathrm{DistanceMeasure}(\cdot,\cdot)
93 | \end{equation}
94 |
95 | 下面我们从距离和相似度度量准则几个方面进行简要介绍。
96 |
97 | \subsubsection{常见的几种距离}
98 |
99 | \textbf{1. 欧氏距离}
100 |
101 | 定义在两个向量(空间中的两个点)上:点$\mathbf{x}$和点$\mathbf{y}$的欧氏距离为:
102 |
103 | \begin{equation}
104 | \label{eq-dist-eculidean}
105 | d_{Euclidean}=\sqrt{(\mathbf{x}-\mathbf{y})^\top (\mathbf{x}-\mathbf{y})}
106 | \end{equation}
107 |
108 | c
109 | \textbf{2. 闵可夫斯基距离}
110 |
111 | Minkowski distance, 两个向量(点)的$p$阶距离:
112 |
113 | \begin{equation}
114 | \label{eq-dist-minkowski}
115 | d_{Minkowski}=(||\mathbf{x}-\mathbf{y}||^p)^{1/p}
116 | \end{equation}
117 |
118 | 当$p=1$时就是曼哈顿距离,当$p=2$时就是欧氏距离。
119 |
120 | \textbf{3. 马氏距离}
121 |
122 | 定义在两个向量(两个点)上,这两个数据在同一个分布里。点$\mathbf{x}$和点$\mathbf{y}$的马氏距离为:
123 |
124 | \begin{equation}
125 | \label{eq-dist-maha}
126 | d_{Mahalanobis}=\sqrt{(\mathbf{x}-\mathbf{y})^\top \Sigma^{-1} (\mathbf{x}-\mathbf{y})}
127 | \end{equation}
128 |
129 | 其中,$\Sigma$是这个分布的协方差。
130 |
131 | 当$\Sigma=\mathbf{I}$时,马氏距离退化为欧氏距离。
132 |
133 | \subsubsection{相似度}
134 |
135 | \textbf{1. 余弦相似度}
136 |
137 | 衡量两个向量的相关性(夹角的余弦)。向量$\mathbf{x},\mathbf{y}$的余弦相似度为:
138 |
139 | \begin{equation}
140 | \label{eq-dist-cosine}
141 | \cos (\mathbf{x},\mathbf{y}) = \frac{\mathbf{x} \cdot \mathbf{y}}{|\mathbf{x}|\cdot |\mathbf{y}|}
142 | \end{equation}
143 |
144 | \textbf{2. 互信息}
145 |
146 | 定义在两个概率分布$X,Y$上,$x \in X, y \in Y$。它们的互信息为:
147 |
148 | \begin{equation}
149 | \label{eq-dist-info}
150 | I(X;Y)=\sum_{x \in X} \sum_{y \in Y} p(x,y) \log \frac{p(x,y)}{p(x)p(y)}
151 | \end{equation}
152 |
153 | \textbf{3. 皮尔逊相关系数}
154 |
155 | 衡量两个随机变量的相关性。随机变量$X,Y$的Pearson相关系数为:
156 |
157 | \begin{equation}
158 | \label{eq-dist-pearson}
159 | \rho_{X,Y}=\frac{Cov(X,Y)}{\sigma_X \sigma_Y}
160 | \end{equation}
161 |
162 | 理解:协方差矩阵除以标准差之积。
163 |
164 | 范围:$[-1,1]$,绝对值越大表示(正/负)相关性越大。
165 |
166 | \textbf{4. Jaccard相关系数}
167 |
168 | 对两个集合$X,Y$,判断他们的相关性,借用集合的手段:
169 |
170 | \begin{equation}
171 | \label{eq-dist-jaccard}
172 | J=\frac{X \cap Y}{X \cup Y}
173 | \end{equation}
174 |
175 | 理解:两个集合的交集除以并集。
176 |
177 | 扩展:Jaccard距离=$1-J$。
178 |
179 | \subsubsection{KL散度与JS距离}
180 |
181 | KL散度和JS距离是迁移学习中被广泛应用的度量手段。
182 |
183 | \textbf{1. KL散度}
184 |
185 | Kullback–Leibler divergence,又叫做\textit{相对熵},衡量两个概率分布$P(x),Q(x)$的距离:
186 |
187 | \begin{equation}
188 | \label{eq-dist-kl}
189 | D_{KL}(P||Q)=\sum_{i=1} P(x) \log \frac{P(x)}{Q(x)}
190 | \end{equation}
191 |
192 | 这是一个非对称距离:$D_{KL}(P||Q) \ne D_{KL}(Q||P)$.
193 |
194 | \textbf{2. JS距离}
195 |
196 | Jensen–Shannon divergence,基于KL散度发展而来,是对称度量:
197 |
198 | \begin{equation}
199 | \label{eq-dist-js}
200 | JSD(P||Q)= \frac{1}{2} D_{KL}(P||M) + \frac{1}{2} D_{KL}(Q||M)
201 | \end{equation}
202 |
203 | 其中$M=\frac{1}{2}(P+Q)$。
204 |
205 | \subsubsection{最大均值差异MMD}
206 |
207 | 最大均值差异是迁移学习中使用频率最高的度量。Maximum mean discrepancy,它度量在再生希尔伯特空间中两个分布的距离,是一种核学习方法。两个随机变量的MMD平方距离为
208 |
209 | \begin{equation}
210 | \label{eq-dist-mmd}
211 | MMD^2(X,Y)=\left \Vert \sum_{i=1}^{n_1}\phi(\mathbf{x}_i)- \sum_{j=1}^{n_2}\phi(\mathbf{y}_j) \right \Vert^2_\mathcal{H}
212 | \end{equation}
213 |
214 | 其中$\phi(\cdot)$是映射,用于把原变量映射到\textit{再生核希尔伯特空间}(Reproducing Kernel Hilbert Space, RKHS)~\cite{borgwardt2006integrating}中。什么是RKHS?形式化定义太复杂,简单来说希尔伯特空间是对于函数的内积完备的,而再生核希尔伯特空间是具有再生性$\langle K(x,\cdot),K(y,\cdot)\rangle_\mathcal{H}=K(x,y)$的希尔伯特空间。就是比欧几里得空间更高端的。将平方展开后,RKHS空间中的内积就可以转换成核函数,所以最终MMD可以直接通过核函数进行计算。
215 |
216 | 理解:就是求两堆数据在RKHS中的\textit{均值}的距离。
217 |
218 | \textit{Multiple-kernel MMD}:多核的MMD,简称MK-MMD。现有的MMD方法是基于单一核变换的,多核的MMD假设最优的核可以由多个核线性组合得到。多核MMD的提出和计算方法在文献~\cite{gretton2012optimal}中形式化给出。MK-MMD在许多后来的方法中被大量使用,最著名的方法是DAN~\cite{long2015learning}。我们将在后续单独介绍此工作。
219 |
220 | \subsubsection{Principal Angle}
221 |
222 | 也是将两个分布映射到高维空间(格拉斯曼流形)中,在流形中两堆数据就可以看成两个点。Principal angle是求这两堆数据的对应维度的夹角之和。
223 |
224 | 对于两个矩阵$\mathbf{X},\mathbf{Y}$,计算方法:首先正交化(用PCA)两个矩阵,然后:
225 |
226 | \begin{equation}
227 | \label{eq-dist-pa}
228 | PA(\mathbf{X},\mathbf{Y})=\sum_{i=1}^{\min(m,n)} \sin \theta_i
229 | \end{equation}
230 |
231 | 其中$m,n$分别是两个矩阵的维度,$\theta_i$是两个矩阵第$i$个维度的夹角,$\Theta=\{\theta_1,\theta_2,\cdots,\theta_t\}$是两个矩阵SVD后的角度:
232 |
233 | \begin{equation}
234 | \mathbf{X}^\top\mathbf{Y}=\mathbf{U} (\cos \Theta) \mathbf{V}^\top
235 | \end{equation}
236 |
237 | \subsubsection{A-distance}
238 |
239 | $\mathcal{A}$-distance是一个很简单却很有用的度量。文献\cite{ben2007analysis}介绍了此距离,它可以用来估计不同分布之间的差异性。$\mathcal{A}$-distance被定义为建立一个线性分类器来区分两个数据领域的hinge损失(也就是进行二类分类的hinge损失)。它的计算方式是,我们首先在源域和目标域上训练一个二分类器$h$,使得这个分类器可以区分样本是来自于哪一个领域。我们用$err(h)$来表示分类器的损失,则$\mathcal{A}$-distance定义为:
240 |
241 | \begin{equation}
242 | \label{eq-dist-adist}
243 | \mathcal{A}(\mathcal{D}_s,\mathcal{D}_t) = 2(1 - 2 err(h))
244 | \end{equation}
245 |
246 | $\mathcal{A}$-distance通常被用来计算两个领域数据的相似性程度,以便与实验结果进行验证对比。
247 |
248 | \subsubsection{Hilbert-Schmidt Independence Criterion}
249 |
250 | 希尔伯特-施密特独立性系数,Hilbert-Schmidt Independence Criterion,用来检验两组数据的独立性:
251 | \begin{equation}
252 | HSIC(X,Y) = trace(HXHY)
253 | \end{equation}
254 | 其中$X,Y$是两堆数据的kernel形式。
255 |
256 | \subsubsection{Wasserstein Distance}
257 |
258 | Wasserstein Distance是一套用来衡量两个概率分部之间距离的度量方法。该距离在一个度量空间$(M,\rho)$上定义,其中$\rho(x,y)$表示集合$M$中两个实例$x$和$y$的距离函数,比如欧几里得距离。两个概率分布$\mathbb{P}$和$\mathbb{Q}$之间的$p{\text{-th}}$ Wasserstein distance可以被定义为
259 |
260 | \begin{equation}
261 | W_p(\mathbb{P}, \mathbb{Q}) = \Big(\inf_{\mu \in \Gamma(\mathbb{P}, \mathbb{Q}) } \int \rho(x,y)^p d\mu(x,y) \Big)^{1/p},
262 | \end{equation}
263 |
264 | 其中$\Gamma(\mathbb{P}, \mathbb{Q})$是在集合$M\times M$内所有的以$\mathbb{P}$和$\mathbb{Q}$为边缘分布的联合分布。著名的Kantorovich-Rubinstein定理表示当$M$是可分离的时候,第一Wasserstein distance可以等价地表示成一个积分概率度量(integral probability metric)的形式
265 |
266 | \begin{equation}
267 | W_1(\mathbb{P},\mathbb{Q})= \sup_{\left \| f \right \|_L \leq 1} \mathbb{E}_{x \sim \mathbb{P}}[f(x)] - \mathbb{E}_{x \sim \mathbb{Q}}[f(x)],
268 | \end{equation}
269 | 其中$\left \| f \right \|_L = \sup{|f(x) - f(y)|} / \rho(x,y)$并且$\left \| f \right \|_L \leq 1$称为$1-$利普希茨条件。
270 |
271 | \subsection{迁移学习的理论保证*}
272 | \textit{
273 | 本部分的标题中带有*号,有一些难度,为可看可不看的内容。此部分最常见的形式是当自己提出的算法需要理论证明时,可以借鉴。}
274 |
275 | 在第一章里我们介绍了两个重要的概念:迁移学习是什么,以及为什么需要迁移学习。但是,还有一个重要的问题没有得到解答:\textit{为什么可以进行迁移}?也就是说,迁移学习的可行性还没有探讨。
276 |
277 | 值得注意的是,就目前的研究成果来说,迁移学习领域的理论工作非常匮乏。我们在这里仅回答一个问题:为什么数据分布不同的两个领域之间,知识可以进行迁移?或者说,到底达到什么样的误差范围,我们才认为知识可以进行迁移?
278 |
279 | 加拿大滑铁卢大学的Ben-David等人从2007年开始,连续发表了三篇文章~\cite{ben2007analysis,blitzer2008learning,ben2010theory}对迁移学习的理论进行探讨。在文中,作者将此称之为“Learning from different domains”。在三篇文章也成为了迁移学习理论方面的经典文章。文章主要回答的问题就是:在怎样的误差范围内,从不同领域进行学习是可行的?
280 |
281 | \textbf{学习误差:} 给定两个领域$\mathcal{D}_s,\mathcal{D}_t$,$X$是定义在它们之上的数据,一个假设类$\mathcal{H}$。则两个领域$\mathcal{D}_s,\mathcal{D}_t$之间的$\mathcal{H}$-divergence被定义为
282 |
283 | \begin{equation}
284 | \hat{d}_{\mathcal{H}}(\mathcal{D}_s,\mathcal{D}_t) = 2 \sup_{\eta \in \mathcal{H}} \left|\underset{\mathbf{x} \in \mathcal{D}_s}{P}[\eta(\mathbf{x}) = 1] - \underset{\mathbf{x} \in \mathcal{D}_t}{P}[\eta(\mathbf{x}) = 1] \right|
285 | \end{equation}
286 |
287 | 因此,这个$\mathcal{H}$-divergence依赖于假设$\mathcal{H}$来判别数据是来自于$\mathcal{D}_s$还是$\mathcal{D}_t$。作者证明了,对于一个对称的$\mathcal{H}$,我们可以通过如下的方式进行计算
288 |
289 | \begin{equation}
290 | d_\mathcal{H} (\mathcal{D}_s,\mathcal{D}_t) = 2 \left(1 - \min_{\eta \in \mathcal{H}} \left[\frac{1}{n_1} \sum_{i=1}^{n_1} I[\eta(\mathbf{x}_i)=0] + \frac{1}{n_2} \sum_{i=1}^{n_2} I[\eta(\mathbf{x}_i)=1]\right] \right)
291 | \end{equation}
292 | 其中$I[a]$为指示函数:当$a$成立时其值为1,否则其值为0。
293 |
294 | \textbf{在目标领域的泛化界:}
295 |
296 | 假设$\mathcal{H}$为一个具有$d$个VC维的假设类,则对于任意的$\eta \in \mathcal{H}$,下面的不等式有$1 - \delta$的概率成立:
297 |
298 | \begin{equation}
299 | R_{\mathcal{D}_t}(\eta) \le R_s(\eta) + \sqrt{\frac{4}{n}(d \log \frac{2en}{d} + \log \frac{4}{\delta})} + \hat{d}_{\mathcal{H}}(\mathcal{D}_s,\mathcal{D}_t) + 4 \sqrt{\frac{4}{n}(d \log \frac{2n}{d} + \log \frac{4}{\delta})} + \beta
300 | \end{equation}
301 | 其中
302 | \begin{equation}
303 | \beta \ge \inf_{\eta^\star \in \mathcal{H}} [R_{\mathcal{D}_s}(\eta^\star) + R_{\mathcal{D}_t}(\eta^\star)]
304 | \end{equation}
305 | 并且
306 | \begin{equation}
307 | R_{s}(\eta) = \frac{1}{n} \sum_{i=1}^{m} I[\eta(\mathbf{x}_i) \ne y_i]
308 | \end{equation}
309 |
310 | 具体的理论证明细节,请参照上述提到的三篇文章。
311 |
312 | 在自己的研究中,如果需要进行相关的证明,可以参考一些已经发表的文章的写法,例如~\cite{long2014adaptation}等。
313 |
314 | 另外,英国的Gretton等人也在进行一些学习理论方面的研究,有兴趣的读者可以关注他的个人主页:\url{http://www.gatsby.ucl.ac.uk/~gretton/}。
315 |
--------------------------------------------------------------------------------
/src/chaps/ch05_method.tex:
--------------------------------------------------------------------------------
1 | \newpage
2 | \section{迁移学习的基本方法} \label{whytransfer}
3 |
4 | 按照迁移学习领域权威综述文章A survey on transfer learning~\cite{pan2010survey},迁移学习的基本方法可以分为四种。这四种基本的方法分别是:\textit{基于样本的迁移},\textit{基于模型的迁移},\textit{基于特征的迁移},及\textit{基于关系的迁移}。
5 |
6 | 本部分简要叙述各种方法的基本原理和代表性相关工作。基于特征和模型的迁移方法是我们的重点。因此,在后续的章节中,将会更加深入地讨论和分析。
7 |
8 | \subsection{基于样本迁移}
9 |
10 | 基于样本的迁移学习方法(Instance based Transfer Learning)根据一定的权重生成规则,对数据样本进行重用,来进行迁移学习。图~\ref{fig-method-instance}形象地表示了基于样本迁移方法的思想。源域中存在不同种类的动物,如狗、鸟、猫等,目标域只有狗这一种类别。在迁移时,为了最大限度地和目标域相似,我们可以人为地\textit{提高}源域中属于狗这个类别的样本权重。
11 |
12 | \begin{figure}[htbp]
13 | \centering
14 | \includegraphics[scale=0.4]{./figures/fig-method-instance.pdf}
15 | \caption{基于样本的迁移学习方法示意图}
16 | \label{fig-method-instance}
17 | \end{figure}
18 |
19 | 在迁移学习中,对于源域$\mathcal{D}_s$和目标域$\mathcal{D}_t$,通常假定产生它们的概率分布是不同且未知的($P(\mathbf{x}_s) \ne P(\mathbf{x}_t)$)。另外,由于实例的维度和数量通常都非常大,因此,直接对$P(\mathbf{x}_s)$和$P(\mathbf{x}_t)$进行估计是不可行的。因而,大量的研究工作~\cite{khan2016adapting,zadrozny2004learning,cortes2008sample,dai2007boosting,tan2015transitive,tan2017distant}着眼于对源域和目标域的分布比值进行估计($P(\mathbf{x}_t)/P(\mathbf{x}_s)$)。所估计得到的比值即为样本的权重。这些方法通常都假设$\frac{P(\mathbf{x}_t)}{P(\mathbf{x}_s)}<\infty$并且源域和目标域的条件概率分布相同($P(y|\mathbf{x}_s)=P(y|\mathbf{x}_t)$)。特别地,上海交通大学Dai等人~\cite{dai2007boosting}提出了TrAdaboost方法,将AdaBoost的思想应用于迁移学习中,提高有利于目标分类任务的实例权重、降低
20 | 不利于目标分类任务的实例权重,并基于PAC理论推导了模型的泛化误差上界。TrAdaBoost方法是此方面的经典研究之一。文献~\cite{huang2007correcting}提出核均值匹配方法(Kernel Mean Matching, KMM)对于概率分布进行估计,目标是使得加权后的源域和目标域的概率分布尽可能相近。在最新的研究成果中,香港科技大学的Tan等人扩展了实例迁移学习方法的应用场景,提出了传递迁移学习方法(Transitive Transfer Learning, TTL)~\cite{tan2015transitive}和远域迁移学习(Distant Domain Transfer Learning, DDTL)~\cite{tan2017distant},利用联合矩阵分解和深度神经网络,将迁移学习应用于多个不相似的领域之间的知识共享,取得了良好的效果。
21 |
22 | 虽然实例权重法具有较好的理论支撑、容易推导泛化误差上界,但这类方法通常只在领域间分布差异较小时有效,因此对自然语言处理、计算机视觉等任务效果并不理想。而基于特征表示的迁移学习方法效果更好,是我们研究的重点。
23 |
24 | \subsection{基于特征迁移}
25 |
26 | 基于特征的迁移方法(Feature based Transfer Learning)是指将通过特征变换的方式互相迁移~\cite{liu2011cross,zheng2008transferring,hu2011transfer},来减少源域和目标域之间的差距;或者将源域和目标域的数据特征变换到统一特征空间中~\cite{pan2011domain,long2014transfer,duan2012domain},然后利用传统的机器学习方法进行分类识别。根据特征的同构和异构性,又可以分为同构和异构迁移学习。图~\ref{fig-method-feature}很形象地表示了两种基于特征的迁移学习方法。
27 |
28 | \begin{figure}[htbp]
29 | \centering
30 | \includegraphics[scale=0.4]{./figures/fig-method-feature.pdf}
31 | \caption{基于特征的迁移学习方法示意图}
32 | \label{fig-method-feature}
33 | \end{figure}
34 |
35 | 基于特征的迁移学习方法是迁移学习领域中\textit{最热门}的研究方法,这类方法通常假设源域和目标域间有一些交叉的特征。香港科技大学的Pan等人~\cite{pan2011domain}提出的迁移成分分析方法(Transfer Component Analysis, TCA)是其中较为典型的一个方法。该方法的核心内容是以最大均值差异(Maximum Mean Discrepancy, MMD)~\cite{borgwardt2006integrating}作为度量准则,将不同数据领域中的分布差异最小化。加州大学伯克利分校的Blitzer等人~\cite{blitzer2006domain}提出了一种基于结构对应的学习方法(Structural Corresponding Learning, SCL),该算法可以通过映射将一个空间中独有的一些特征变换到其他所有空间中的轴特征上,然后在该特征上使用机器学习的算法进行分类预测。清华大学龙明盛等人~\cite{long2014transfer}提出在最小化分布距离的同时,加入实例选择的迁移联合匹配(Tranfer Joint Matching, TJM)方法,将实例和特征迁移学习方法进行了有机的结合。澳大利亚卧龙岗大学的Jing Zhang等人~\cite{zhang2017joint}提出对于源域和目标域各自训练不同的变换矩阵,从而达到迁移学习的目标。
36 |
37 | 近年来,基于特征的迁移学习方法大多与神经网络进行结合~\cite{long2015learning,long2016deep,long2017deep,sener2016learning},在神经网络的训练中进行学习特征和模型的迁移。由于本文的研究重点即是基于特征的迁移学习方法,因此,我们在本小节对这类方法不作过多介绍。在下一小节中,我们将从不同的研究层面,系统地介绍这类工作。
38 |
39 | \subsection{基于模型迁移}
40 |
41 | 基于模型的迁移方法(Parameter/Model based Transfer Learning)是指从源域和目标域中找到他们之间共享的参数信息,以实现迁移的方法。这种迁移方式要求的假设条件是:\textit{源域中的数据与目标域中的数据可以共享一些模型的参数}。其中的代表性工作主要有~\cite{zhao2010cross,zhao2011cross,pan2008transferring,pan2008transfer}。图~\ref{fig-method-model}形象地表示了基于模型的迁移学习方法的基本思想。
42 |
43 | \begin{figure}[htbp]
44 | \centering
45 | \includegraphics[scale=0.4]{./figures/fig-method-model.pdf}
46 | \caption{基于模型的迁移学习方法示意图}
47 | \label{fig-method-model}
48 | \end{figure}
49 |
50 | 其中,中科院计算所的Zhao等人~\cite{zhao2011cross}提出了TransEMDT方法。该方法首先针对已有标记的数据,利用决策树构建鲁棒性的行为识别模型,然后针对无标定数据,利用K-Means聚类方法寻找最优化的标定参数。西安邮电大学的Deng等人~\cite{deng2014cross}也用超限学习机做了类似的工作。香港科技大学的Pan等人~\cite{pan2008transfer}利用HMM,针对Wifi室内定位在不同设备、不同时间和不同空间下动态变化的特点,进行不同分布下的室内定位研究。另一部分研究人员对支持向量机SVM进行了改进研究~\cite{nater2011transferring,li2012cross}。这些方法假定SVM中的权重向量$\mathbf{w}$可以分成两个部分:$\mathbf{w}=\mathbf{w_o}+\mathbf{v}$,其中$\mathbf{w}_0$代表源域和目标域的共享部分,$\mathbf{v}$代表了对于不同领域的特定处理。在最新的研究成果中,香港科技大学的Wei等人~\cite{wei2016instilling}将社交信息加入迁移学习方法的正则项中,对方法进行了改进。清华大学龙明盛等人~\cite{long2015learning,long2016deep,long2017deep}改进了深度网络结构,通过在网络中加入概率分布适配层,进一步提高了深度迁移学习网络对于大数据的泛化能力。
51 |
52 | 通过对现有工作的调研可以发现,目前绝大多数基于模型的迁移学习方法都与深度神经网络进行结合~\cite{long2015learning,long2016deep,long2017deep,tzeng2015simultaneous,long2016deep}。这些方法对现有的一些神经网络结构进行修改,在网络中加入领域适配层,然后联合进行训练。因此,这些方法也可以看作是基于模型、特征的方法的结合。
53 |
54 | \subsection{基于关系迁移}
55 |
56 | 基于关系的迁移学习方法(Relation Based Transfer Learning)与上述三种方法具有截然不同的思路。这种方法比较关注源域和目标域的样本之间的关系。图~\ref{fig-method-relation}形象地表示了不同领域之间相似的关系。
57 |
58 | \begin{figure}[htbp]
59 | \centering
60 | \includegraphics[scale=0.4]{./figures/fig-method-relation.pdf}
61 | \caption{基于关系的迁移学习方法示意图}
62 | \label{fig-method-relation}
63 | \end{figure}
64 |
65 | 就目前来说,基于关系的迁移学习方法的相关研究工作非常少,仅有几篇连贯式的文章讨论:\cite{mihalkova2007mapping,mihalkova2008transfer,davis2009deep}。这些文章都借助于马尔科夫逻辑网络(Markov Logic Net)来挖掘不同领域之间的关系相似性。
66 |
67 | \begin{figure}[htbp]
68 | \centering
69 | \includegraphics[scale=0.3]{./figures/fig-method-relation2.pdf}
70 | \caption{基于马尔科夫逻辑网的关系迁移}
71 | \label{fig-method-relation2}
72 | \end{figure}
73 |
74 | 我们将重点讨论基于特征和基于模型的迁移学习方法,这也是目前绝大多数研究工作的热点。
--------------------------------------------------------------------------------
/src/chaps/ch07_featureselect.tex:
--------------------------------------------------------------------------------
1 | \newpage
2 |
3 | \section{第二类方法:特征选择}
4 |
5 | 特征选择法的基本假设是:源域和目标域中均含有一部分公共的特征,在这部分公共的特征上,源领域和目标领域的数据分布是一致的。因此,此类方法的目标就是,通过机器学习方法,选择出这部分共享的特征,即可依据这些特征构建模型。
6 |
7 | 图~\ref{fig-feature}形象地表示了特征选择法的主要思路。
8 |
9 | \begin{figure}[htbp]
10 | \centering
11 | \includegraphics[scale=0.5]{./figures/fig-feature.pdf}
12 | \caption{特征选择法示意图}
13 | \label{fig-feature}
14 | \end{figure}
15 |
16 | \subsection{核心方法}
17 |
18 | 这这个领域比较经典的一个方法是发表在2006年的ECML-PKDD会议上,作者提出了一个叫做SCL的方法(Structural Correspondence Learning)~\cite{blitzer2006domain}。这个方法的目标就是我们说的,找到两个领域公共的那些特征。作者将这些公共的特征叫做Pivot feature。找出来这些Pivot feature,就完成了迁移学习的任务。
19 |
20 | \begin{figure}[htbp]
21 | \centering
22 | \includegraphics[scale=0.3]{./figures/fig-feature-pivot.pdf}
23 | \caption{特征选择法中的Pivot feature示意图}
24 | \label{fig-feature-pivot}
25 | \end{figure}
26 |
27 | 图~\ref{fig-feature-pivot}形象地展示了Pivot feature的含义。Pivot feature指的是在文本分类中,在不同领域中出现频次较高的那些词。
28 |
29 |
30 | \subsection{扩展}
31 |
32 | SCL方法是特征选择方面的经典研究工作。基于SCL,也出现了一些扩展工作。
33 |
34 | \begin{itemize}
35 | \item Joint feature selection and subspace learning~\cite{gu2011joint}:特征选择+子空间学习
36 | \item TJM (Transfer Joint Matching)~\cite{long2014transfer}: 在优化目标中同时进行边缘分布自适应和源域样本选择
37 | \item FSSL (Feature Selection and Structure Preservation)~\cite{li2016joint}: 特征选择+信息不变性
38 | \end{itemize}
39 |
40 | \subsection{小结}
41 |
42 | \begin{itemize}
43 | \item 特征选择法从源域和目标域中选择提取共享的特征,建立统一模型
44 | \item 通常与分布自适应方法进行结合
45 | \item 通常采用稀疏表示$||\mathbf{A}||_{2,1}$实现特征选择
46 | \end{itemize}
47 |
--------------------------------------------------------------------------------
/src/chaps/ch08_subspacelearn.tex:
--------------------------------------------------------------------------------
1 | \newpage
2 | \section{第三类方法:子空间学习}
3 |
4 | 子空间学习法通常假设源域和目标域数据在变换后的子空间中会有着相似的分布。我们按照特征变换的形式,将子空间学习法分为两种:\textit{基于统计特征变换的统计特征对齐方法},以及\textit{基于流形变换的流形学习方法}。下面我们分别介绍这两种方法的基本思路和代表性研究成果。
5 |
6 | \subsection{统计特征对齐}
7 |
8 | 统计特征对齐方法主要将数据的统计特征进行变换对齐。对齐后的数据,可以利用传统机器学习方法构建分类器进行学习。
9 |
10 | SA方法(Subspace Alignment,子空间对齐)~\cite{fernando2013unsupervised}是其中的代表性成果。SA方法直接寻求一个线性变换$\mathbf{M}$,将不同的数据实现变换对齐。SA方法的优化目标如下:
11 |
12 | \begin{equation}
13 | F(\mathbf{M}) = ||\mathbf{X}_s \mathbf{M} - \mathbf{X}_t||^2_F
14 | \end{equation}
15 |
16 | 则变换$\mathbf{M}$的值为:
17 |
18 | \begin{equation}
19 | \mathbf{M}^\star = \arg \min_\mathbf{M} (F(\mathbf{M}))
20 | \end{equation}
21 |
22 | 可以直接获得上述优化问题的闭式解:
23 |
24 | \begin{equation}
25 | F(\mathbf{M}) = ||\mathbf{X}^\top_s \mathbf{X}_s \mathbf{M} - \mathbf{X}^\top_s \mathbf{X}_t||^2_F = ||\mathbf{M} - \mathbf{X}^\top_s \mathbf{X}_t||^2_F
26 | \end{equation}
27 |
28 | SA方法实现简单,计算过程高效,是子空间学习的代表性方法。
29 |
30 | 基于SA方法,Sun等人在2015年提出了SDA方法(Subspace Distribution Alignment)~\cite{sun2015subspace}。该方法在SA的基础上,加入了概率分布自适应。图~\ref{fig-subspace-sda}示意了该方法的简单流程。SDA方法提出,除了子空间变换矩阵$\mathbf{T}$之外,还应当增加一个概率分布自适应变换$\mathbf{A}$。SDA方法的优化目标如下:
31 |
32 | \begin{equation}
33 | \mathbf{M} = \mathbf{X}_s \mathbf{T} \mathbf{A} \mathbf{X}^\top_t
34 | \end{equation}
35 |
36 | \begin{figure}[htbp]
37 | \centering
38 | \includegraphics[scale=0.6]{./figures/fig-subspace-sda.pdf}
39 | \caption{SDA方法的示意图}
40 | \label{fig-subspace-sda}
41 | \end{figure}
42 |
43 | 有别于SA和SDA方法只进行源域和目标域的一阶特征对齐,Sun等人提出了CORAL方法(CORrelation ALignment),对两个领域进行二阶特征对齐。假设$\mathbf{C}_s$和$\mathbf{C}_t$分别是源领域和目标领域的协方差矩阵,则CORAL方法学习一个二阶特征变换$\mathbf{A}$,使得源域和目标域的特征距离最小:
44 |
45 | \begin{equation}
46 | \min_\mathbf{A} ||\mathbf{A}^\top \mathbf{C}_s \mathbf{A} - \mathbf{C}_t||^2_F
47 | \end{equation}
48 |
49 | CORAL方法的求解同样非常简单且高效。CORAL方法被应用到神经网络中,提出了DeepCORAL方法~\cite{sun2016deep}。作者将CORAL度量作为一个神经网络的损失进行计算。图展示了DeepCORAL方法的网络结构。
50 |
51 | \begin{figure}[htbp]
52 | \centering
53 | \includegraphics[scale=0.4]{./figures/fig-subspace-deepcoral.pdf}
54 | \caption{Deep-CORAL方法示意图}
55 | \label{fig-subspace-deepcoral}
56 | \end{figure}
57 |
58 | CORAL损失被定义为源域和目标域的二阶统计特征距离:
59 |
60 | \begin{equation}
61 | \ell_{CORAL} = \frac{1}{4d^2} ||\mathbf{C}_s - \mathbf{C}_t||^2_F
62 | \end{equation}
63 |
64 | \subsection{流形学习}
65 |
66 | 流形学习自从2000年在Science上被提出来以后,就成为了机器学习和数据挖掘领域的热门问题。它的基本假设是,现有的数据是从一个\textit{高维空间}中采样出来的,所以,它具有高维空间中的低维流形结构。流形就是一种几何对象(就是我们能想像能观测到的)。通俗点说,我们无法从原始的数据表达形式明显看出数据所具有的结构特征,那我把它想像成是处在一个高维空间,在这个高维空间里它是有个形状的。一个很好的例子就是星座。满天星星怎么描述?我们想像它们在一个更高维的宇宙空间里是有形状的,这就有了各自星座,比如织女座、猎户座。流形学习的经典方法有Isomap、locally linear embedding、laplacian eigenmap等。
67 |
68 | 流形空间中的距离度量:两点之间什么最短?在二维上是直线(线段),可在三维呢?地球上的两个点的最短距离可不是直线,它是把地球展开成二维平面后画的那条直线。那条线在三维的地球上就是一条曲线。这条曲线就表示了两个点之间的最短距离,我们叫它\textit{测地线}。更通俗一点,\textit{两点之间,测地线最短}。在流形学习中,我们遇到测量距离的时候,更多的时候用的就是这个测地线。在我们要介绍的GFK方法中,也是利用了这个测地线距离。比如在下面的图中,从A到C最短的距离在就是展开后的线段,但是在三维球体上看,它却是一条曲线。
69 |
70 | \begin{figure}[htbp]
71 | \centering
72 | \includegraphics[scale=0.4]{./figures/fig-subspace-earth.pdf}
73 | \caption{三维空间中两点之间的距离示意图}
74 | \label{fig-subspace-earth}
75 | \end{figure}
76 |
77 | 由于在流形空间中的特征通常都有着很好的几何性质,可以避免特征扭曲,因此我们首先将原始空间下的特征变换到流形空间中。在众多已知的流形中,Grassmann流形$\mathbb{G}(d)$可以通过将原始的$d$维子空间(特征向量)看作它基础的元素,从而可以帮助学习分类器。在Grassmann流形中,特征变换和分布适配通常都有着有效的数值形式,因此在迁移学习问题中可以被很高效地表示和求解~\cite{hamm2008grassmann}。因此,利用Grassmann流形空间中来进行迁移学习是可行的。现存有很多方法可以将原始特征变换到流形空间中~\cite{gopalan2011domain,baktashmotlagh2014domain}。
78 |
79 | 在众多的基于流形变换的迁移学习方法中,GFK(Geodesic Flow Kernel)方法~\cite{gong2012geodesic}是最为代表性的一个。GFK是在2011年发表在ICCV上的SGF方法~\cite{gopalan2011domain}发展起来的。我们首先介绍SGF方法。
80 |
81 | SGF方法从\textit{增量学习}中得到启发:人类从一个点想到达另一个点,需要从这个点一步一步走到那一个点。那么,如果我们把源域和目标域都分别看成是高维空间中的两个点,由源域变换到目标域的过程不就完成了迁移学习吗?也就是说,\textit{路是一步一步走出来的}。
82 |
83 | 于是SGF就做了这个事情。它是怎么做的呢?把源域和目标域分别看成高维空间(即Grassmann流形)中的两个点,在这两个点的测地线距离上取$d$个中间点,然后依次连接起来。这样,源域和目标域就构成了一条测地线的路径。我们只需要找到合适的每一步的变换,就能从源域变换到目标域了。图~\ref{fig-subspace-sgf}是SGF方法的示意图。
84 |
85 | \begin{figure}[htbp]
86 | \centering
87 | \includegraphics[scale=0.5]{./figures/fig-subspace-sgf.pdf}
88 | \caption{SGF流形迁移学习方法示意图}
89 | \label{fig-subspace-sgf}
90 | \end{figure}
91 |
92 | SGF方法的主要贡献在于:提出了这种变换的计算及实现了相应的算法。但是它有很明显的缺点:到底需要找几个中间点?SGF也没能给出答案,就是说这个参数$d$是没法估计的,没有一个好的方法。这个问题在GFK中被回答了。
93 |
94 | GFK方法首先解决SGF的问题:如何确定中间点的个数$d$。它通过提出一种核学习的方法,利用路径上的无穷个点的\textit{积分},把这个问题解决了。这是第一个贡献。然后,它又解决了第二个问题:当有多个源域的时候,我们如何决定使用哪个源域跟目标域进行迁移?GFK通过提出Rank of Domain度量,度量出跟目标域最近的源域,来解决这个问题。图~\ref{fig-subspace-gfk}是GFK方法的示意图。
95 |
96 | \begin{figure}[htbp]
97 | \centering
98 | \includegraphics[scale=0.5]{./figures/fig-subspace-gfk.pdf}
99 | \caption{GFK流形迁移学习方法示意图}
100 | \label{fig-subspace-gfk}
101 | \end{figure}
102 |
103 | 用$\mathcal{S}_s$和$\mathcal{S}_t$分别表示源域和目标域经过主成分分析(PCA)之后的子空间,则G可以视为所有的d维子空间的集合。每一个$d$维的原始子空间都可以被看作$\mathbb{G}$上的一个点。因此,在两点之间的测地线$\{\Phi(t):0 \leq t \leq 1\}$可以在两个子空间之间构成一条路径。如果我们令$\mathcal{S}_s=\Phi(0)$,$\mathcal{S}_t=\Phi(1)$,则寻找一条从$\Phi\left(0\right)$到$\Phi\left(1\right)$的测地线就等同于将原始的特征变换到一个无穷维度的空间中,最终减小域之间的漂移现象。这种方法可以被看作是一种从$\Phi\left(0\right)$到$\Phi\left(1\right)$的增量式“行走”方法。
104 |
105 | 特别地,流形空间中的特征可以被表示为$\mathbf{z}=\Phi\left(t\right)^\top \mathbf{x}$。变换后的特征$\mathbf{z}_i$和$\mathbf{z}_j$的内积定义了一个半正定(positive semidefinite)的测地线流式核
106 | \begin{equation}
107 | \langle\mathbf{z}_i,\mathbf{z}_j\rangle= \int_{0}^{1} (\Phi(t)^T \mathbf{x}_i)^T (\Phi(t)^T \mathbf{x}_j) \, dt = \mathbf{x}^T_i \mathbf{G} \mathbf{x}_j
108 | \end{equation}
109 |
110 | GFK方法详细的计算过程可以参考原始的文章,我们在这里不再赘述。
111 |
112 | \subsection{扩展与小结}
113 |
114 | 子空间学习方法和概率分布自适应方法可以有机地进行组合,克服各自的缺点。下面是一些相关工作。
115 |
116 | \begin{itemize}
117 | \item DIP (Domain-Invariant Projection)~\cite{baktashmotlagh2013unsupervised}: 边缘分布自适应+流形变换
118 | \item \cite{baktashmotlagh2014domain}: 统计流形法,在黎曼流形上进行距离度量。
119 | \end{itemize}
120 |
121 | 最近的一些工作~\cite{sun2016deep}显示,子空间学习法和神经网络的结合会更好。
122 |
--------------------------------------------------------------------------------
/src/chaps/ch11_future.tex:
--------------------------------------------------------------------------------
1 | \newpage
2 |
3 | \section{迁移学习前沿}
4 |
5 | 从我们上述介绍的多种迁移学习方法来看,领域自适应(Domain Adaptation)作为迁移学习的重要分类,在近年来已经取得了大量的研究成果。但是,迁移学习仍然是一个活跃的领域,仍然有大量的问题没有被很好地解决。
6 |
7 | 本节我们简要介绍一些迁移学习领域较新的研究成果。并且,管中窥豹,展望迁移学习未来可能的研究方向。
8 |
9 | \subsection{机器智能与人类经验结合迁移}
10 |
11 | 机器学习的目的是让机器从众多的数据中发掘知识,从而可以指导人的行为。这样看来,似乎“全自动”是我们的终极目标。我们理想中的机器学习系统,似乎就应该完全不依赖于人的干预,靠算法和数据就能完成所有的任务。Google Deepmind公司最新发布的AlphaZero~\cite{silver2017mastering}就实现了这样的愿景:\textit{算法完全不依赖于人提供知识,从零开始掌握围棋知识,最终打败人类围棋冠军。}随着机器学习的发展,似乎人的角色也会越来越不重要。
12 |
13 | 然而,在目前看来,机器想完全不依赖于人的经验,就必须付出巨大的时间和计算代价。普通人也许根本无法掌握这样的能力。那么,如果在机器智能中,特别是迁移学习的机器智能中,加入人的经验,可以大幅度提高算法的训练水平,这岂不是我们喜闻乐见的?
14 |
15 | 来自斯坦福大学的研究人员2017年发表在人工智能顶级会议AAAI上的研究成果就率先实践了这一想法~\cite{stewart2017label}。研究人员提出了一种无需人工标注的神经网络,对视频数据进行分析预测。在该成果中,研究人员的目标是用神经网络预测扔出的枕头的下落轨迹。不同于传统的神经网络需要大量标注,该方法完全不使用人工标注。取而代之的是,将人类的知识赋予神经网络。
16 |
17 | 我们都知道,抛出的物体往往会沿着\textit{抛物线}的轨迹进行运动。这就是研究人员所利用的核心知识。计算机对于这一点并不知情。因此,在网络中,如果加入抛物线这一基本的先验知识,则会极大地促进网络的训练。并且,最终会取得比单纯依赖算法本身更好的效果。
18 |
19 | 我们认为将机器智能与人类经验结合起来的迁移学习应该是未来的发展方向之一。期待这方面有更多的研究成果发表。
20 |
21 | \subsection{传递式迁移学习}
22 |
23 | 迁移学习的核心是找到两个领域的相似性。这是成功进行迁移的保证。但是,假如我们的领域数据本身就不存在相似性,或者相似性极小,这时候就很容易出现负迁移。负迁移是迁移学习研究中极力需要避免的。
24 |
25 | 我们由两个领域的相似性推广开来,其实世间万事万物都有一定的联系。表面上看似无关的两个领域,它们也可以由中间的领域构成联系。也就是一种传递式的相似性。例如,领域A和领域B从表面上看,完全不相似。那么,是否可以找到中间的一个领域C,领域C与A和B都有一定的相似性?这样,知识原来不能直接从领域A迁移到领域B,加入C以后,就可以先从A迁移到C,再从C迁移到B。这就是传递迁移学习。
26 |
27 | 香港科技大学杨强教授的团队率先在2015年数据挖掘顶级会议KDD上提出了这一概念:Transitive transfer learning~\cite{tan2015transitive}。随后,作者又进行了进一步的扩展,将三个领域的迁移,扩展到多个领域。这也是符合我们认知的:原先完全不相似的两个领域,如果它们中间存在若干领域都与这两个领域相似,那么就可以构成一条相似性链条,知识就可以进行链式的迁移。作者提出了远领域的迁移学习(Distant Domain Transfer Learning)~\cite{tan2017distant},用卷积神经网络解决了这一问题。
28 |
29 | 在远领域迁移学习中,作者做出了看起来并不符合常人认知的实验:由人脸图片训练好的分类器,迁移识别飞机图像。研究人员采用了人脸和飞机中间的一系列类别,例如头像、头盔、水壶、交通工具等。在实验中,算法自动地选择相似的领域进行迁移。结果表明,在初始迁移阶段,算法选择的大多是与源领域较为相似的类别;随着迁移的进行,算法会越来越倾向于选择与目标领域相似的类别。这也是符合我们的基本认知的。最终的对比实验表明,这种远领域的迁移学习比直接训练分类器的精度会有极大的提升。图~\ref{fig-future-ddtl}展示了知识迁移的过程。
30 |
31 | \begin{figure}[htbp]
32 | \centering
33 | \includegraphics[scale=0.35]{./figures/fig-future-ddtl.pdf}
34 | \caption{远领域迁移学习示意图}
35 | \label{fig-future-ddtl}
36 | \end{figure}
37 |
38 | 传递迁移学习目前的研究成果还十分稀少。我们期待这一领域会有更多好的成果出现。
39 |
40 | \subsection{终身迁移学习}
41 |
42 | 我们在进行迁移学习时,往往不知道应该选择怎么样的算法。通常都通过人为地不断尝试来确定要用的方法。这个过程无疑是浪费时间,而且充满了不确定性。已有的迁移学习方法,基本都是这样。我们在拿到一个新问题时,如何选择迁移学习算法达到最好的效果?从人的学习过程中来说,人总是可以从以前的经验中学习知识。那么,既然我们已经实验了很多次迁移学习算法,我们能不能让机器也可以从我们这些实验中选择知识?这是符合我们人类认知的:不可能每遇到一个新问题,我们就从头开始做吧?
43 |
44 | 同样是来自香港科技大学杨强教授团队就开始了这一方面的研究工作。他们提出一种学习迁移(L2T, Learning to Transfer)的框架~\cite{wei2017learning},解决\textit{何时迁移、要迁移什么、怎么迁移}的问题。方法分为两个部分:从已有的迁移学习方法和结果中学习迁移的经验,然后再把这些学习到的经验应用到新来的数据。
45 |
46 | 首先要明确学习目标。跟以前的迁移学习方法都有所不同,以往的方法都是要学习最好的迁移函数,而这个问题的目标是要使得方法尽可能地具有泛化能力。因此,它的学习目标是:\textbf{以往的经验}!对的,就是经验。这也是符合我们人类认知的。我们一般都是知道的越多,这个人越厉害(当然,《权利的游戏》里的Jon Snow除外,因为他什么也不知道)。因此,这个方法的目标就是要尽可能多地从以往的迁移知识中学习经验,使之对于后来的问题具有最好的泛化能力。
47 |
48 | 那么\textit{什么是迁移的经验}?这个在文中叫做transfer learning experience。作者这样定义:$Ee=(S_e,T_e,a_e,l_e)$。其中,$S_e,T_e$分别是源域和目标域,这个我们都知道。$a_e$表示一个迁移学习算法,这个算法有个下标叫$e$,表示它是第$e$种算法。与之对应,选择了这种算法,它对不迁移情况下的表现有个提升效果,这个效果就叫做$le$。
49 |
50 | 总结一下,什么叫迁移学习的经验?就是说,在一对迁移任务中,我选择了哪种算法后,这种算法对于我任务效果有多少提升。这个东西,就叫做迁移!这和我们人类学习也是具有相似性的:人们常说,失败是成功之母,爱迪生说,我实验了2000多种材料做灯泡都是失败的,但是我最起码知道了这2000多种材料不适合做灯泡!这就是人类的经验!我们人类就是从跌倒中爬起,从失败中总结教训,然后不断进步。学习算法也可以!
51 |
52 | 后面的过程就是,综合性地学习这个迁移过程,使得算法根据以往的经验,得到一个特征变换矩阵$\mathbf{W}$。学习到了这个变换矩阵以后,下一步的工作就是要把学习到的东西应用于新来的数据。如何针对新来的数据进行迁移?我们本能地要利用刚刚学习到的这个$\mathbf{W}$。但是不要忘了,这个变换矩阵只是对旧的那些经验学习到的,对新的数据可能效果不好,不能直接用。怎么办?我们要更新它!
53 |
54 | 这里要注意的是,针对新来的数据,我们的这个变换矩阵应该是有所改变的:这也对,数据变了,当然变换矩阵就要变。那么,如何更新?作者在这里提出的方法是,新的矩阵应该是能在新的数据上表现效果最好的那个。这时,我们的问题就完成了。
55 |
56 | 图~\ref{fig-future-l2t}简要表示了该算法的学习过程。
57 |
58 | \begin{figure}[htbp]
59 | \centering
60 | \includegraphics[scale=0.35]{./figures/fig-future-l2t.pdf}
61 | \caption{终身迁移学习示意图}
62 | \label{fig-future-l2t}
63 | \end{figure}
64 |
65 | 这有点类似增量学习的工作:模型针对新数据不断更新优化。这部分的研究才刚刚开始。
66 |
67 | \subsection{在线迁移学习}
68 |
69 | 我们都知道迁移学习可以用来解决训练数据缺失的问题,很多迁移学习方法都获得了长足的进步。给定一个要学习的目标域数据,我们可以用已知标签的源域数据来给这个目标域数据构造一个分类器。但是这些方法都存在很大的一个问题:它们都是采用离线方式(offline)进行的。什么是离线方式?就是说,一开始,源域和目标域数据都是给出来的,我们直接做完迁移,这个过程就结束了。We are done。
70 |
71 | 但是真实的应用往往不是这样的:数据往往是一点一点源源不断送来的。也就是说,我们一开始的时候,也许只有源域数据,目标域数据要一点一点才能过来。这就是所谓的“在线迁移学习”。这个概念脱胎于“在线学习”的模式,在线学习是机器学习中一个重要的研究概念。
72 |
73 | 就目前来说,在线迁移学习方面的工作较少。第一篇在线迁移学习的工作由新加坡管理大学的Steven Hoi发表在2010年的机器学习顶级会议ICML上。作者提出了OTL框架~\cite{zhao2010otl},可以对同构和异构数据很好地进行迁移学习。
74 |
75 | 近年来,研究者发表了一些在线迁移学习相关的文章。其中包括在多个源域和目标域上的OTL~\cite{wu2017online,yan2017online},在线特征选择迁移变换~\cite{wang2014online,zhang2017online},在线样本集成迁移~\cite{gao2012online,patilknowledge}等。
76 |
77 | 特别地,\cite{jaini2016online}提出了用贝叶斯的方法学习在线的HMM迁移学习模型,并应用于行为识别、睡眠监测,以及未来流量分析。这是一篇有代表性的应用工作。
78 |
79 | 总结来看,目前在在线迁移学习方面的研究工作总体较少,发展空间巨大。在可以预见的未来,我们期待更多的研究者可以从事这一领域的研究。将深度网络、对抗学习结合入在线迁移学习,使得这一领域的发展越来越好。
80 |
81 | \subsection{迁移强化学习}
82 |
83 | Google公司的AlphaGo系列在围棋方面的成就让\textit{强化学习}这一术语变得炙手可热。用深度神经网络来进行强化学习也理所当然地成为了研究热点之一。不同于传统的机器学习需要大量的标签才可以训练学习模型,强化学习采用的是\textit{边获得样例边学习}的方式。特定的反馈函数决定了算法的最优决策。
84 |
85 | 深度强化学习同时也面临着重大的挑战:没有足够的训练数据。在这个方面,迁移学习却可以利用其他数据上训练好的模型帮助训练。尽管迁移学习已经被应用于强化学习~\cite{taylor2009transfer},但是它的发展空间仍然还很大。强化学习在自动驾驶、机器人、路径规划等领域正发挥着越来越重要的作用。我们期待在未来有更多的研究成果可以问世。
86 |
87 | \subsection{迁移学习的可解释性}
88 |
89 | 深度学习取得众多突破性成果的同时,其面临的可解释性不强却始终是一个挑战。现有的深度学习方法还停留在"黑盒子"阶段,无法产生足够有说服力的解释。同样的,迁移学习也有这个问题。即使世间万物都有联系,它们更深层次的关系也尚未得到探索。领域之间的相似性也正如同海森堡"测不准原理"一般无法给出有效的结论。为什么领域A和领域B更相似,而和领域C较不相似?目前也只是停留在经验阶段,缺乏有效的理论证明。
90 |
91 | 另外,迁移学习算法也存在着可解释性弱的问题。现有的算法均只是完成了一个迁移学习任务。但是在学习过程中,知识是如何进行迁移的,这一点还有待进一步的实验和理论验证。最近,澳大利亚悉尼大学的研究者们发表在国际人工智能联合会IJCAI 2017上的研究成果有助于理解特征是如何迁移的~\cite{liu2017understanding}。
92 |
93 | 用深度网络来做迁移学习,其可解释性同样有待探索。最近,Google Brain的研究者们提出了神经网络的"核磁共振"现象~\footnote{\url{https://github.com/tensorflow/lucid}},对神经网络的可解释性进行了有趣的探索。
94 |
95 |
--------------------------------------------------------------------------------
/src/chaps/ch12_conclusion.tex:
--------------------------------------------------------------------------------
1 | \newpage
2 | \section{总结语}
3 |
4 | 本手册是在迁移学习领域的研究经验总结。主要简明地介绍了迁移学习的基本概念、迁移学习的必要性、研究领域和基本方法。重点介绍了几大类常用的迁移学习方法:数据分布自适应方法、特征选择方法、子空间学习方法、以及目前最热门的深度迁移学习方法。除此之外,我们也结合最近的一些研究成果对未来迁移学习进行了一些展望。附录中提供了一些迁移学习领域的常用学习资源,以方便感兴趣的读者快速开始学习。
--------------------------------------------------------------------------------
/src/chaps/combine.tex:
--------------------------------------------------------------------------------
1 | \section{常用方法的组合}
--------------------------------------------------------------------------------
/src/figures/fig-8_1.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-8_1.pdf
--------------------------------------------------------------------------------
/src/figures/fig-8_2.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-8_2.pdf
--------------------------------------------------------------------------------
/src/figures/fig-8_3.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-8_3.pdf
--------------------------------------------------------------------------------
/src/figures/fig-app-all.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-app-all.pdf
--------------------------------------------------------------------------------
/src/figures/fig-app-cv.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-app-cv.pdf
--------------------------------------------------------------------------------
/src/figures/fig-app-location.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-app-location.pdf
--------------------------------------------------------------------------------
/src/figures/fig-app-text.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-app-text.pdf
--------------------------------------------------------------------------------
/src/figures/fig-app-time.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-app-time.pdf
--------------------------------------------------------------------------------
/src/figures/fig-area.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-area.pdf
--------------------------------------------------------------------------------
/src/figures/fig-deep-84.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-deep-84.pdf
--------------------------------------------------------------------------------
/src/figures/fig-deep-adabn.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-deep-adabn.pdf
--------------------------------------------------------------------------------
/src/figures/fig-deep-compare.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-deep-compare.pdf
--------------------------------------------------------------------------------
/src/figures/fig-deep-dan.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-deep-dan.pdf
--------------------------------------------------------------------------------
/src/figures/fig-deep-ddc.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-deep-ddc.pdf
--------------------------------------------------------------------------------
/src/figures/fig-deep-dsn.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-deep-dsn.pdf
--------------------------------------------------------------------------------
/src/figures/fig-deep-finetune.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-deep-finetune.pdf
--------------------------------------------------------------------------------
/src/figures/fig-deep-jan.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-deep-jan.pdf
--------------------------------------------------------------------------------
/src/figures/fig-deep-partial.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-deep-partial.pdf
--------------------------------------------------------------------------------
/src/figures/fig-deep-softlabel.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-deep-softlabel.pdf
--------------------------------------------------------------------------------
/src/figures/fig-deep-tzeng2015.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-deep-tzeng2015.pdf
--------------------------------------------------------------------------------
/src/figures/fig-distribution-bdammd.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-distribution-bdammd.pdf
--------------------------------------------------------------------------------
/src/figures/fig-distribution-daan.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-distribution-daan.png
--------------------------------------------------------------------------------
/src/figures/fig-distribution-deep.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-distribution-deep.pdf
--------------------------------------------------------------------------------
/src/figures/fig-distribution-mu.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-distribution-mu.pdf
--------------------------------------------------------------------------------
/src/figures/fig-distribution-source.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-distribution-source.pdf
--------------------------------------------------------------------------------
/src/figures/fig-distribution-stl.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-distribution-stl.pdf
--------------------------------------------------------------------------------
/src/figures/fig-distribution-target1.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-distribution-target1.pdf
--------------------------------------------------------------------------------
/src/figures/fig-distribution-target2.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-distribution-target2.pdf
--------------------------------------------------------------------------------
/src/figures/fig-distribution-tca.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-distribution-tca.pdf
--------------------------------------------------------------------------------
/src/figures/fig-feature-pivot.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-feature-pivot.pdf
--------------------------------------------------------------------------------
/src/figures/fig-feature.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-feature.pdf
--------------------------------------------------------------------------------
/src/figures/fig-future-ddtl.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-future-ddtl.pdf
--------------------------------------------------------------------------------
/src/figures/fig-future-l2t.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-future-l2t.pdf
--------------------------------------------------------------------------------
/src/figures/fig-future-labelfree.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-future-labelfree.pdf
--------------------------------------------------------------------------------
/src/figures/fig-introduction-bigdata.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-introduction-bigdata.pdf
--------------------------------------------------------------------------------
/src/figures/fig-introduction-coldstart.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-introduction-coldstart.pdf
--------------------------------------------------------------------------------
/src/figures/fig-introduction-data.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-introduction-data.pdf
--------------------------------------------------------------------------------
/src/figures/fig-introduction-example.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-introduction-example.pdf
--------------------------------------------------------------------------------
/src/figures/fig-introduction-model.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-introduction-model.pdf
--------------------------------------------------------------------------------
/src/figures/fig-introduction-negativetransfer.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-introduction-negativetransfer.pdf
--------------------------------------------------------------------------------
/src/figures/fig-introduction-transfer.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-introduction-transfer.pdf
--------------------------------------------------------------------------------
/src/figures/fig-method-feature.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-method-feature.pdf
--------------------------------------------------------------------------------
/src/figures/fig-method-instance.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-method-instance.pdf
--------------------------------------------------------------------------------
/src/figures/fig-method-model.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-method-model.pdf
--------------------------------------------------------------------------------
/src/figures/fig-method-relation.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-method-relation.pdf
--------------------------------------------------------------------------------
/src/figures/fig-method-relation2.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-method-relation2.pdf
--------------------------------------------------------------------------------
/src/figures/fig-subspace-deepcoral.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-subspace-deepcoral.pdf
--------------------------------------------------------------------------------
/src/figures/fig-subspace-earth.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-subspace-earth.pdf
--------------------------------------------------------------------------------
/src/figures/fig-subspace-gfk.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-subspace-gfk.pdf
--------------------------------------------------------------------------------
/src/figures/fig-subspace-sda.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-subspace-sda.pdf
--------------------------------------------------------------------------------
/src/figures/fig-subspace-sgf.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-subspace-sgf.pdf
--------------------------------------------------------------------------------
/src/figures/fig-whydeep.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/fig-whydeep.pdf
--------------------------------------------------------------------------------
/src/figures/l1sys.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/l1sys.pdf
--------------------------------------------------------------------------------
/src/figures/png/fig-8_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-8_1.png
--------------------------------------------------------------------------------
/src/figures/png/fig-8_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-8_2.png
--------------------------------------------------------------------------------
/src/figures/png/fig-8_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-8_3.png
--------------------------------------------------------------------------------
/src/figures/png/fig-app-all.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-app-all.png
--------------------------------------------------------------------------------
/src/figures/png/fig-app-cv.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-app-cv.png
--------------------------------------------------------------------------------
/src/figures/png/fig-app-location.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-app-location.png
--------------------------------------------------------------------------------
/src/figures/png/fig-app-text.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-app-text.png
--------------------------------------------------------------------------------
/src/figures/png/fig-app-time.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-app-time.png
--------------------------------------------------------------------------------
/src/figures/png/fig-area.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-area.png
--------------------------------------------------------------------------------
/src/figures/png/fig-dda.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-dda.png
--------------------------------------------------------------------------------
/src/figures/png/fig-deep-84.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-deep-84.png
--------------------------------------------------------------------------------
/src/figures/png/fig-deep-adabn.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-deep-adabn.png
--------------------------------------------------------------------------------
/src/figures/png/fig-deep-compare.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-deep-compare.png
--------------------------------------------------------------------------------
/src/figures/png/fig-deep-dan.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-deep-dan.png
--------------------------------------------------------------------------------
/src/figures/png/fig-deep-ddc.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-deep-ddc.png
--------------------------------------------------------------------------------
/src/figures/png/fig-deep-dsn.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-deep-dsn.png
--------------------------------------------------------------------------------
/src/figures/png/fig-deep-finetune.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-deep-finetune.png
--------------------------------------------------------------------------------
/src/figures/png/fig-deep-jan.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-deep-jan.png
--------------------------------------------------------------------------------
/src/figures/png/fig-deep-partial.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-deep-partial.png
--------------------------------------------------------------------------------
/src/figures/png/fig-deep-softlabel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-deep-softlabel.png
--------------------------------------------------------------------------------
/src/figures/png/fig-deep-tzeng2015.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-deep-tzeng2015.png
--------------------------------------------------------------------------------
/src/figures/png/fig-distribution-bdammd.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-distribution-bdammd.png
--------------------------------------------------------------------------------
/src/figures/png/fig-distribution-deep.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-distribution-deep.png
--------------------------------------------------------------------------------
/src/figures/png/fig-distribution-mu.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-distribution-mu.png
--------------------------------------------------------------------------------
/src/figures/png/fig-distribution-overview.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-distribution-overview.jpg
--------------------------------------------------------------------------------
/src/figures/png/fig-distribution-source.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-distribution-source.png
--------------------------------------------------------------------------------
/src/figures/png/fig-distribution-stl.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-distribution-stl.png
--------------------------------------------------------------------------------
/src/figures/png/fig-distribution-target1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-distribution-target1.png
--------------------------------------------------------------------------------
/src/figures/png/fig-distribution-target2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-distribution-target2.png
--------------------------------------------------------------------------------
/src/figures/png/fig-distribution-tca.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-distribution-tca.png
--------------------------------------------------------------------------------
/src/figures/png/fig-feature-pivot.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-feature-pivot.png
--------------------------------------------------------------------------------
/src/figures/png/fig-feature.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-feature.png
--------------------------------------------------------------------------------
/src/figures/png/fig-future-ddtl.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-future-ddtl.png
--------------------------------------------------------------------------------
/src/figures/png/fig-future-l2t.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-future-l2t.png
--------------------------------------------------------------------------------
/src/figures/png/fig-future-labelfree.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-future-labelfree.png
--------------------------------------------------------------------------------
/src/figures/png/fig-introduction-bigdata.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-introduction-bigdata.png
--------------------------------------------------------------------------------
/src/figures/png/fig-introduction-coldstart.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-introduction-coldstart.png
--------------------------------------------------------------------------------
/src/figures/png/fig-introduction-data.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-introduction-data.png
--------------------------------------------------------------------------------
/src/figures/png/fig-introduction-example.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-introduction-example.png
--------------------------------------------------------------------------------
/src/figures/png/fig-introduction-model.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-introduction-model.png
--------------------------------------------------------------------------------
/src/figures/png/fig-introduction-negativetransfer.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-introduction-negativetransfer.png
--------------------------------------------------------------------------------
/src/figures/png/fig-introduction-transfer.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-introduction-transfer.png
--------------------------------------------------------------------------------
/src/figures/png/fig-method-feature.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-method-feature.png
--------------------------------------------------------------------------------
/src/figures/png/fig-method-instance.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-method-instance.png
--------------------------------------------------------------------------------
/src/figures/png/fig-method-model.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-method-model.png
--------------------------------------------------------------------------------
/src/figures/png/fig-method-relation.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-method-relation.png
--------------------------------------------------------------------------------
/src/figures/png/fig-method-relation2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-method-relation2.png
--------------------------------------------------------------------------------
/src/figures/png/fig-subspace-deepcoral.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-subspace-deepcoral.png
--------------------------------------------------------------------------------
/src/figures/png/fig-subspace-earth.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-subspace-earth.png
--------------------------------------------------------------------------------
/src/figures/png/fig-subspace-gfk.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-subspace-gfk.png
--------------------------------------------------------------------------------
/src/figures/png/fig-subspace-sda.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-subspace-sda.png
--------------------------------------------------------------------------------
/src/figures/png/fig-subspace-sgf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-subspace-sgf.png
--------------------------------------------------------------------------------
/src/figures/png/fig-whydeep.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/fig-whydeep.png
--------------------------------------------------------------------------------
/src/figures/png/gitbook_first.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/gitbook_first.png
--------------------------------------------------------------------------------
/src/figures/png/l1sys.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/figures/png/l1sys.png
--------------------------------------------------------------------------------
/src/main.tex:
--------------------------------------------------------------------------------
1 | \documentclass[a4paper]{article}
2 |
3 | \usepackage[top=1in, bottom=1in, left=1.25in, right=1.25in]{geometry}
4 | \usepackage{titlesec}
5 | \usepackage{ctex}
6 | \usepackage[linktoc=all,breaklinks=true,urlcolor=magenta,colorlinks=true,bookmarksnumbered=true]{hyperref}
7 | \usepackage{booktabs} % For formal tables
8 | \usepackage{epsfig}
9 | \usepackage{graphicx}
10 | \usepackage{amsmath}
11 | \usepackage{amssymb}
12 | \usepackage{bm}
13 | \usepackage{algorithm}
14 | \usepackage{algorithmic}
15 | \usepackage{url}
16 | \usepackage{subfigure}
17 | \usepackage{bbding}
18 | \usepackage{multirow}
19 | \usepackage{enumitem}
20 | \usepackage{multicol}
21 | \usepackage{listings}
22 | \usepackage{color}
23 | \usepackage{subfigure}
24 | \newcommand*{\Scale}[2][4]{\scalebox{#1}{$#2$}}%
25 |
26 | \makeatletter % `@' now normal "letter"
27 | \@addtoreset{equation}{section}
28 | \makeatother % `@' is restored as "non-letter"
29 | \renewcommand\theequation{\oldstylenums{\thesection}%
30 | .\oldstylenums{\arabic{equation}}}
31 |
32 | %-----------------------------------------BEGIN DOC----------------------------------------
33 |
34 | \begin{document}
35 |
36 | \newpagestyle{main}{
37 | \sethead{}{迁移学习简明手册}{} %设置页眉
38 | \setfoot{}{\thepage}{} %设置页脚,可以在页脚添加 \thepage 显示页数
39 | \headrule % 添加页眉的下划线c
40 | }
41 | \pagestyle{main} %使用该style
42 |
43 | \renewcommand{\refname}{参考文献}
44 | \renewcommand{\figurename}{图}
45 | \renewcommand{\tablename}{表}
46 | \renewcommand{\contentsname}{目录}
47 | \renewcommand{\today}{\number\year 年 \number\month 月 \number\day 日}
48 |
49 |
50 | \title{{\Huge 迁移学习简明手册{\large\linebreak\\}}{\Large 一点心得体会\\版本号:v1.1\linebreak\linebreak
51 | }}
52 | \author{\\
53 | 王晋东\\中国科学院计算技术研究所\\\href{http://tutorial.transferlearning.xyz}{tutorial.transferlearning.xyz}}
54 | \date{2018年4月初稿\\
55 | 2019年10月最新修改}
56 | \maketitle
57 | \thispagestyle{empty}
58 |
59 | \newpage
60 |
61 | %-----------------------------------------ABSTRACT-------------------------------------
62 | \thispagestyle{empty}
63 | \begin{center}
64 | {\Large\bf{摘\ 要\\}}
65 | \end{center}
66 |
67 | 迁移学习作为机器学习的一大分支,已经取得了长足的进步。本手册简明地介绍迁移学习的概念与基本方法,并对其中的领域自适应问题中的若干代表性方法进行讲述。最后简要探讨迁移学习未来可能的方向。
68 |
69 | 本手册编写的目的是帮助迁移学习领域的初学者快速入门并掌握基本方法,为自己的研究和应用工作打下良好基础。
70 |
71 | 本手册的编写逻辑很简单:是什么——介绍迁移学习;为什么——为什么要用迁移学习、为什么能用;怎么办——如何进行迁移(迁移学习方法)。其中,是什么和为什么解决概念问题,这是一切的前提;怎么办是我们的重点,也占据了最多的篇幅。为了最大限度地方便初学者,我们还特别编写了一章上手实践,直接分享实现代码和心得体会。
72 | \newpage
73 |
74 | \thispagestyle{empty}
75 | \section*{推荐语}
76 |
77 | \textit{看了王晋东同学的“迁移学习小册子”, 点三个赞!迁移学习被认为是机器学习的下一个爆点,但介绍迁移学习的文章却很有限。 这个册子深入浅出,既回顾了迁移学习的发展历史,又囊括了迁移学习的最新进展。 语言流畅,简明通透。 应该对机器学习的入门和提高都有很大帮助!}
78 |
79 | ——杨强 (迁移学习权威学者,香港科技大学教授,IJCAI president, AAAI/ACM fellow)
80 |
81 | \newpage
82 | %-----------------------------------------ABSTRACT-------------------------------------
83 | %-----------------------------------------CONTENT-------------------------------------
84 | \pagenumbering{Roman}
85 | \setcounter{page}{1}
86 | \begingroup
87 | \begin{multicols}{2}[
88 | \setlength{\columnseprule}{.4pt}
89 | \setlength{\columnsep}{18pt}]
90 | \tableofcontents
91 | \end{multicols}
92 | \endgroup
93 | \newpage
94 |
95 | %------------------------------------------TEXT--------------------------------------------
96 |
97 | %----------------------------------------OVERVIEW-----------------------------------------
98 | \input{chaps/ch00_prefix}
99 | \input{chaps/ch01_introduction}
100 | \input{chaps/ch02_research_area}
101 | \input{chaps/ch03_application}
102 | \input{chaps/ch04_basic}
103 | \input{chaps/ch05_method}
104 | \input{chaps/ch06_distributionadapt}
105 | \input{chaps/ch07_featureselect}
106 | \input{chaps/ch08_subspacelearn}
107 | \input{chaps/ch09_deep}
108 | \input{chaps/ch10_practice}
109 | \input{chaps/ch11_future}
110 | \input{chaps/ch12_conclusion}
111 | \input{chaps/ch13_appendix}
112 |
113 | %----------------------------------SYSTEM DESIGN------------------------------------------
114 |
115 |
116 | % -----------------------------------REFERENCE----------------------------------------
117 |
118 |
119 | \bibliographystyle{apalike}
120 | \bibliography{refs}
121 |
122 | \end{document}
123 |
124 | %%% Local Variables:
125 | %%% mode: xelatex
126 | %%% TeX-master: t
127 | %%% End:
128 |
--------------------------------------------------------------------------------
/src/main.toc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jindongwang/transferlearning-tutorial/2ae0b46c748a79c899996561263fe12d5a49efa5/src/main.toc
--------------------------------------------------------------------------------
/src/makepdf_mac.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ERROR="Too few arguments : no file name specified"
4 | [[ $# -eq 0 ]] && echo $ERROR && exit # no args? ... print error and exit
5 |
6 | if [ -f $1.tex ];then
7 | xelatex $1
8 | bibtex $1
9 | xelatex $1
10 | xelatex $1
11 | rm *.lof *.lot *.out *.log *.aux *.bbl *.blg *.bak *.sav *.dvi *.gz
12 | fi
13 |
--------------------------------------------------------------------------------
/src/pdf2img.py:
--------------------------------------------------------------------------------
1 | from pdf2image import convert_from_path
2 | import glob
3 | import os
4 |
5 | files = glob.glob('src/figures/*.pdf')
6 | for item in files:
7 |
8 | file_name = item.split('\\')[1].split('.')[0]
9 | png_name = os.path.join(item.split('\\')[0] + '/png',file_name + '.png')
10 | pages = convert_from_path(item, 500)
11 | for page in pages:
12 | page.save(png_name, 'png')
--------------------------------------------------------------------------------
/web/assets/css/main.css:
--------------------------------------------------------------------------------
1 | body {
2 | line-height: 1.5;
3 | margin: 2% 10% 2% 10%;
4 | font-family: Arial;
5 | }
6 |
7 | .header {
8 | text-align: center;
9 | font-size: 22px;
10 | }
11 |
12 | .myicon {
13 | width: 100;
14 | float:left;
15 | margin-right: 15px;
16 | }
17 |
18 | .sectiontitle {
19 | font-size: 18px;
20 | font-weight: bold;
21 | }
22 |
23 | .sectioncontent {
24 | font-size: 16px;
25 | font-weight: normal;
26 |
27 | }
28 |
29 | .date {
30 | font-size: 14px;
31 | font-style: italic;
32 | }
33 |
34 | .email {
35 | font-size: 12px;
36 | }
37 |
38 | .appicon {
39 | width: 25;
40 | }
41 |
42 | .new{
43 | height: 20px;
44 | widows: 40px;
45 | }
46 |
47 | .author{
48 | color:#080808;
49 | }
50 |
51 | .venue{
52 | color:#080808;
53 | font-style: italic;
54 | }
55 |
56 | .article{
57 | color:#000000;
58 | font-weight: bold;
59 | }
60 |
61 | .image{
62 | height: 30px;
63 | width:30px;
64 | }
65 |
66 | a:link {
67 | color:#337ab7;
68 | text-decoration:none;
69 | }
70 |
71 | a:hover {
72 | color:#337adf;
73 | text-decoration:underline;
74 | }
75 |
76 | a:visited {
77 | color:#337ab7;
78 | text-decoration:none;
79 | }
80 |
81 | .category{
82 | color:#000000;
83 | font-weight: bold;
84 | font-size: 17px;
85 | }
--------------------------------------------------------------------------------
/web/transfer_tutorial.html:
--------------------------------------------------------------------------------
1 |
2 |
3 | 迁移学习简明手册
4 |
5 |
6 |
7 |
8 |
17 |
18 |
19 |
20 |
21 | 迁移学习简明手册
22 |
23 |
24 |
25 |
26 |
27 | 摘要
28 |
29 |
30 | 迁移学习作为机器学习的一大分支,已经取得了长足的进步。本手册简明地介绍迁移学习的概念与基本方法,并对其中的领域自适应问题中的若干代表性方法进行讲述。最后简要探讨迁移学习未来可能的方向。本手册编写的目的是帮助迁移学习领域的初学者快速入门并掌握基本方法,为自己的研究和应用工作打下良好基础。
31 | 本手册的编写逻辑很简单:是什么——介绍迁移学习;为什么——为什么要用迁移学习、为什么能用;怎么办——如何进行迁移 (迁移学习方法)。其中,是什么和为什么解决概念问题,这是一切的前提;怎么办是我们的重点,也占据了最多的篇幅。为了最大限度地方便初学者,我们还特别编写了一章上手实践,直接分享实现代码和心得体会。
32 |
33 |
35 |
36 |
37 | 写在前面
38 |
39 |
40 | 一直以来都有这样的愿望:无论学习什么知识,总是希望可以快速准确地找到对应的有价值资源进行学习。我相信我们每个人都梦寐以求。然而,越来越多的学科,尤其是我目前从事的计算机科学、人工智能领域,当下正在飞速地发展着。太多的新知识都难以事半功倍地找到快速入手的教程。庄子曰: “吾生也有涯,而知也无涯。以有涯随无涯,殆已。”
41 |
42 | 我只是迁移学习领域一个很普通的博士生,也同样经历了由“一问三不知”到“稍稍理解”的艰难过程。我在 2016 年初入门迁移学习之时,迁移学习这个概念还未曾像今天一样炙手可热。当时所能找到的学习资源只有两种:别人已发表的论文和已做过的演讲。这些还是不够简单、不够直观。我需要从如此众多的材料中不断归纳,才能站在博士研究的那个圈子的边缘,以便将来可以做出一点点贡献,往圆圈外突破一点点。
43 |
44 | 相信不只是我,任何一个刚刚入门的学习者都会经历此过程。
45 |
46 | “沉舟侧畔千帆过,病树前头万木春。”
47 |
48 | 已所不欲,勿施于人。正是因为我在初学之时也经历过如此沮丧的时期,我才在 Github上对迁移学习进行了整理归纳,在知乎网上以“王晋东不在家”为名分享自己对于迁移学习和机器学习的理解和教训、在线上线下与大家讨论相关的问题。很欣慰的是,这些免费开放的资源或多或少地,帮助到了一些初学者,使他们更快速地步入迁移学习之门。
49 |
50 | 但这些还是不太够。 Github 上的资源模式已经固定,目前主要是进行日常更新,不断加入新的论文和代码。目前还是缺乏一个人人都能上手的初学者教程。也不只一次,有读者提问有没有相关的入门教程,能真正从0到1帮助初学者进行入门。
51 |
52 | 最近,南京大学博士(现任旷视科技南京研究院负责人)魏秀参学长写了一本《解析卷积神经网络—深度学习实践手册》,给很多深度学习的初学者提供了帮助。受他的启发,我也决定将自己在迁移学习领域的一些学习心得体会整理成一本手册,免费进行分享。希望能借此方式,帮助更多的初学者。 我们不谈风月,只谈干货。
53 |
54 | 我不是大佬,我也是迁移学习路上的一名小学生。迁移学习领域比我做的好的同龄人太多了。因此,不敢谈什么指导。所有的目的都仅为分享。
55 |
56 | 本手册在互联网上免费开放。随着作者理解的深入 (以及其他有意者的增补),本手册肯定会不断修改、越来越好。因此,我打算效仿软件的开发、采取版本更新的方式进行管理。
57 |
58 | 希望未来可以有更多的有志之士加入,让我们的教程日渐丰富。
59 |
60 |
62 |
63 |
72 |
73 |
74 |
75 | 勘误表
76 |
77 |
78 |
79 | -
80 | 4.1.1节最后一段最后一句话:“... 却并给出(也难以给出)P 的具体形式。” 应为: “... 却并未给出(也难以给出)P的具体形式。”
81 |
82 | -
83 | TCA的介绍中“TCA假设存在一个特征映射$\phi$,使得映射后数据的分布$P(\phi(\mathbf{x}_s)) \approx P(\phi(\mathbf{x}_s))$” 这里的公式应改为 “$P(\phi(\mathbf{x}_s)) \approx P(\phi(\mathbf{x}_t))$”
84 |
85 |
86 | -
87 | 图27名称应为”DeepCORAL方法示意图“
88 |
89 |
90 | -
91 | 公式6.18(JDA)的统一优化目标的分子项应该和6.17一样,原版本印刷错误
92 |
93 |
94 | -
95 | 人脸识别图像数据集这一小节中 “...按照不同的关照和曝光条件随机选出。“ 改为 “...光照和曝光条件...”
96 |
97 | -
98 | 9.3.3小节中“其核心在于,找到网络需要进行自适应层,并且对这些导加上自适应的损失度量” 改为 “其核心在于,找到网络需要进行自适应层,并且对这些层加上自适应的损失度量”
99 |
100 |
101 | -
102 | 公式4.19第二个指示函数中是否应该是η(xi)=1而不是η(xi)=0
103 |
104 |
105 | -
106 | 删除第14页余弦相似度引用文章。
107 |
108 |
109 | -
110 | 第11章终身迁移学习中,试验2000种灯泡材料,不是爱因斯坦说的,是爱迪生说的。
111 |
112 |
113 | -
114 | 第14页,公式4.3。闵可夫斯基距离公式应是范数||·||表示才对。
115 |
116 |
117 |
118 |
120 |
121 |
128 |
129 |
130 |
--------------------------------------------------------------------------------
/xie-zai-qian-mian.md:
--------------------------------------------------------------------------------
1 | # 写在前面
2 |
3 | 一直以来都有这样的愿望:无论学习什么知识,总是希望可以快速准确地找到对应的有价值资源进行学习。我相信我们每个人都梦寐以求。然而,越来越多的学科,尤其是我目前从事的计算机科学、人工智能领域,当下正在飞速地发展着。太多的新知识都难以事半功倍地找到快速入手的教程。
4 |
5 | > “吾生也有涯,而知也无涯。以有涯随无涯,殆已。” -- 庄子
6 |
7 | 我只是迁移学习领域一个很普通的博士生,也同样经历了由“一问三不知”到“稍稍理解”的艰难过程。我在2016年初入门迁移学习之时,迁移学习这个概念还未曾像今天一样炙手可热。当时所能找到的学习资源只有两种:别人已发表的论文和已做过的演讲。这些还是不够简单、不够直观。我需要从如此众多的材料中不断归纳,才能站在博士研究的那个圈子的边缘,以便将来可以做出一点点贡献,往圆圈外突破一点点。
8 |
9 | 相信不只是我,任何一个刚刚入门的学习者都会经历此过程。
10 |
11 | > “沉舟侧畔千帆过,病树前头万木春。”
12 |
13 | 已所不欲,勿施于人。正是因为我在初学之时也经历过如此沮丧的时期,我才在Github上对迁移学习进行了整理归纳,在知乎网上以**“王晋东不在家”**为名分享自己对于迁移学习和机器学习的理解和教训、在线上线下与大家讨论相关的问题。很欣慰的是,这些免费开放的资源或多或少地,帮助到了一些初学者,使他们更快速地步入迁移学习之门。
14 |
15 | 但这些还是不太够。Github上的资源模式已经固定,目前主要是进行日常更新,不断加入新的论文和代码。目前还是缺乏一个人人都能上手的初学者教程。也只一次,有读者提问有没有相关的入门教程,能真正从0到1帮助初学者进行入门。
16 |
17 | 最近,南京大学博士\(现任旷视科技南京研究院负责人\)魏秀参学长写了一本《解析卷积神经网络—深度学习实践手册》,给很多深度学习的初学者提供了帮助。受他的启发,我也决定将自己在迁移学习领域的一些学习心得体会整理成一本手册,免费进行分享。希望能借此方式,帮助更多的初学者。
18 |
19 | > 我们不谈风月,只谈干货。
20 |
21 | 我不是大佬,我也是迁移学习路上的一名小学生。迁移学习领域比我做的好的同龄人太多了。因此,不敢谈什么**指导**。所有的目的都仅为**分享**。
22 |
23 | 本手册在互联网上免费开放。随着作者理解的深入\(以及其他有意者的增补\),本手册肯定会不断修改、越来越好。因此,我打算效仿软件的开发、采取版本更新的方式进行管理。
24 |
25 | 希望未来可以有更多的有志之士加入,让我们的教程日渐丰富。
26 |
27 |
--------------------------------------------------------------------------------
/zhi-xie.md:
--------------------------------------------------------------------------------
1 | # 致谢
2 |
3 | 本手册编写过程中得到了许多人的帮助。在此对他们表示感谢。
4 |
5 | 感谢我的导师、中国科学院计算技术研究所的陈益强研究员。是他一直以来保持着对我的信心,相信我能做出好的研究成果,不断鼓励我,经常与我讨论以明确问题,才有了今天的我。陈老师给我提供了优良的实验环境。我一定会更加努力地科研,做出更多更好的研究成果。
6 |
7 | 感谢香港科技大学计算机系的杨强教授。杨教授作为迁移学习领域国际泰斗,经常不厌其烦地回答我一些研究上的问题。能够得到杨教授的指导,是我的幸运。希望我能在杨教授带领下,做出更踏实的研究成果。
8 |
9 | 感谢新加坡南洋理工大学的于涵老师。作为我论文的共同作者,于老师认真的写作态度、对论文的把控能力是我一直学习的榜样。于老师还经常鼓励我,希望可以和于老师有着更多合作,发表更好的文章。
10 |
11 | 感谢清华大学龙明盛助理教授。龙老师在迁移学习领域发表了众多高质量的研究成果,是我入门时学习的榜样。龙老师还经常对我的研究给予指导。希望有机会可以真正和龙老师合作。
12 |
13 | 感谢美国伊利诺伊大学芝加哥分校的Philip S. Yu教授对我的指导和鼓励。
14 |
15 | 感谢新加坡A\*STAR的郝书吉老师。我博士生涯的发表的第一篇论文是和郝老师合作完成的。正是有了第一篇论文被发表,才增强了我的自信,在接下来的研究中放平心态。
16 |
17 | 感谢我的好基友、西安电子科技大学博士生段然同学和我的同病相怜,让我们可以一起吐槽读博生活。
18 |
19 | 感谢我的室友沈建飞、以及实验室同学的支持。
20 |
21 | 感谢我的知乎粉丝和所有交流过迁移学习的学者对我的支持。
22 |
23 | 最后感谢我的女友和父母对我的支持。
24 |
25 | 本手册中出现的插图,绝大多数来源于相应论文的配图。感谢这些作者做出的优秀的研究成果。希望我能早日作出可以比肩的研究。
26 |
27 |
--------------------------------------------------------------------------------