├── code_monitor
└── memory_monitor.py
├── conjugate_gradient
└── conjugate_gradient.py
├── forecast_auto_adjustment
├── README.md
├── README.pdf
├── data
│ ├── alibaba_stock.csv
│ ├── amazon_stock.csv
│ ├── google_stock.csv
│ └── jd_stock.csv
├── images
│ ├── alibaba_stock_adjust_forecast.png
│ ├── alibaba_stock_adjust_trendy_forecast.png
│ ├── alibaba_stock_normal_forecast.png
│ ├── amazon_stock_adjust_forecast.png
│ ├── amazon_stock_adjust_trendy_forecast.png
│ ├── amazon_stock_normal_forecast.png
│ ├── error_adjust_s1.png
│ ├── error_adjust_s2.png
│ ├── google_stock_adjust_forecast.png
│ ├── google_stock_adjust_trendy_forecast.png
│ ├── google_stock_normal_forecast.png
│ ├── jd_stock_adjust_forecast.png
│ ├── jd_stock_adjust_trendy_forecast.png
│ └── jd_stock_normal_forecast.png
├── ts_features.py
├── util.py
└── validation.py
├── forecast_reconcilation
├── README.md
├── data
│ └── reconcilation_test.csv
├── data_structure.py
└── reconcilation.py
├── forecastability
├── README.md
├── build
│ └── lib
│ │ └── forecastability
│ │ ├── __init__.py
│ │ ├── forecastability.py
│ │ ├── period_detect.py
│ │ └── util.py
├── dist
│ ├── forecastability-0.0.2-py3-none-any.whl
│ ├── forecastability-0.0.2-py3.6.egg
│ └── forecastability-0.0.2.tar.gz
├── forecastability.egg-info
│ ├── PKG-INFO
│ ├── SOURCES.txt
│ ├── dependency_links.txt
│ ├── requires.txt
│ └── top_level.txt
├── forecastability
│ ├── __init__.py
│ ├── forecastability.py
│ ├── period_detect.py
│ └── util.py
├── requirements.txt
└── setup.py
├── km
├── README.md
├── dfs vs bfs.png
└── km.py
├── nmf
├── README.md
└── nmf.py
├── period_detection
├── README.md
├── confidence.gif
├── p1.png
├── p2.png
└── period_detect.py
└── psoco
├── LICENSE
├── README.md
├── build
└── lib
│ └── psoco
│ ├── __init__.py
│ └── psoco.py
├── dist
├── psoco-0.0.0.tar.gz
├── psoco-0.0.7.tar.gz
└── psoco-0.0.8.tar.gz
├── psoco.egg-info
├── PKG-INFO
├── SOURCES.txt
├── dependency_links.txt
└── top_level.txt
├── psoco
├── __init__.py
└── psoco.py
├── setup.py
└── tests
└── tests.py
/code_monitor/memory_monitor.py:
--------------------------------------------------------------------------------
1 | # /usr/bin/python 3.6
2 | # -*-coding:utf-8-*-
3 |
4 | import subprocess
5 | import psutil
6 | import matplotlib.pyplot as plt
7 | import time
8 |
9 | cmd = "python ./slot_allocation/slot_allocation_app.py --params {\"horizon\":30,\"warehouse_id\":\"65c0eb0a5c113609bbba19e5246c5ed2\",\"customer_id\":\"5df83c373bde3c002cc4b4c3\",\"pick_zones\":[\"A\"],\"storage_zones\":[\"A\"],\"end_time\":\"20200518\",\"initialize_dist_matrix\":false,\"input_path\":\"./data/input\",\"output_path\":\"./data/output\",\"strategy_type\":1,\"dist_matrix_path\":\"./data/output\"}"
10 | process = subprocess.Popen(cmd.split(" "))
11 |
12 | pid = process.pid
13 | print("process id: ", pid)
14 |
15 | def get_memory_list():
16 | process = psutil.Process(pid)
17 | memory_list = []
18 | while process_running(process):
19 | try:
20 | memo = process.memory_info().rss / 1024 / 1024 #MB
21 | except:
22 | break
23 | memory_list.append(memo)
24 | time.sleep(2)
25 | return memory_list
26 |
27 | def process_running(process):
28 | try:
29 | memo = process.memory_info().rss / 1024 / 1024
30 | return True
31 | except:
32 | return False
33 |
34 | def plot():
35 | start = time.time()
36 | memory_list = get_memory_list()
37 | end = time.time()
38 | print("Time spent to run {}s".format(round(end-start, 2)))
39 | plt.plot([x for x in range(len(memory_list))], memory_list)
40 | plt.xlabel("record point")
41 | plt.ylabel("memory (MB)")
42 | plt.show()
43 |
44 | if __name__ == "__main__":
45 | plot()
46 |
--------------------------------------------------------------------------------
/conjugate_gradient/conjugate_gradient.py:
--------------------------------------------------------------------------------
1 | # /usr/bin/env python 3.6
2 | # -*-coding:utf-8-*-
3 |
4 | '''
5 | Conjugate Gradient Method
6 |
7 | Reference link:
8 | https://en.wikipedia.org/wiki/Conjugate_gradient_method
9 |
10 | Author: Jing Wang
11 | '''
12 |
13 | import numpy as np
14 | from copy import deepcopy
15 | import random
16 |
17 | random.seed(123)
18 |
19 | def solve(A, b, max_iter):
20 | '''
21 | Args:
22 |
23 | A (array): should be positive definite
24 | b (array):
25 | '''
26 |
27 | if A.shape[0] != b.shape[0]:
28 | raise Exception("Please check the shape of array!")
29 |
30 | threshold = 1e-10
31 | r = deepcopy(b)
32 | p = deepcopy(b)
33 | k = 0
34 | x = np.zeros_like(b)
35 | while k < max_iter:
36 |
37 | rdot = r.T.dot(r)
38 | Ap = A.dot(p)
39 |
40 | alpha = rdot / (p.T.dot(Ap))
41 | x = x + alpha * p
42 | r = r - alpha * Ap
43 |
44 | newrdot = r.T.dot(r)
45 | if np.sqrt(newrdot) < threshold:
46 | break
47 |
48 | beta = newrdot / rdot
49 |
50 | p = r + beta * p
51 |
52 | k += 1
53 | return x
54 |
55 | if __name__ == '__main__':
56 |
57 | A = np.array([[4, 1], [1, 3]])
58 | b = np.array([[1], [2]])
59 |
60 | print("A: ", A)
61 | print("b: ", b)
62 |
63 | x = np.linalg.inv(A).dot(b)
64 | x2 = solve(A, b, 10)
65 |
66 | print("x: ", x)
67 | print("x2: ", x2)
--------------------------------------------------------------------------------
/forecast_auto_adjustment/README.md:
--------------------------------------------------------------------------------
1 | # Forecast Auto-Adjustment
2 |
3 | This is a research and implement of auto-adjustment for demand forecast in rolling predict.
4 |
5 | 在滚动预测中,根据前面滚动的情况或者在调度过程中根据新加入的真实值,去调整我们模型的预测值,以实现更高的精确度。可用在高峰预测等场景。主要是根据最近的误差表现来修正模型的预测值输出,作为新的输出。
6 |
7 | 该方法适用于逐渐上涨的高峰,可能适用于LightGBM之类的树模型,根据类似点采样且不会超过历史最大值。
8 |
9 | ## Error as Feature
10 |
11 | Original Model: $f: \hat{y}_t = f(X_t)$
12 |
13 | New Model: $f: \hat{y}_t = f(X_t, e_{t-h}), e_{t-h} = y_{t-h} - \hat{y}_{t-h}$
14 |
15 | The simplest method is to add error in previous rolling as feature in current rolling. The inital error could be set 1.
16 |
17 | 最直接的方式是把上一轮滚动的预测误差$e_{t-h}$作为下一轮的特征值加入。
18 |
19 | ## Error Postprocess
20 |
21 | Assume the fitted model is going to perform as previous. For example, if the model underestimates in $t-l$ predicting $t$, then it will do the same thing in $t$ predicting $t+l$。
22 |
23 | 误差后处理方式。基于的假设是模型在该轮滚动的表现会延续上一轮的表现。比如上一轮滚动低估,该轮还是会低估。上一轮滚动高估,该轮还是会高估。
24 |
25 | Let $U$ be the event of model underestimation , $O$ be the event of model overestimation.
26 |
27 | 让$U$是模型低估事件,$O$为模型高估事件。
28 |
29 | 该方法假设:$P(U_t | U_{t-l}) = 1$和$P(O_t|O_{t-l}) = 1$
30 |
31 | Proof:
32 |
33 | 我们来证明这一假设是有一定合理性的。假如我们选用线性模型开始$\hat{y} = X\theta$。
34 |
35 |
36 | $$
37 | \hat{y}_{t-l} = X_{t-l} \theta_{t-l} \\
38 | \theta_{t-l} + \Delta \theta = \theta_t \\
39 | \Delta \theta = -\alpha \frac{d loss_{t-l}}{d X_{t-l}} \\
40 | \hat{y}_t = X_t \theta_t = X_t (\theta_{t-l} + \Delta \theta)
41 | $$
42 |
43 | 假设有个完美的模型$y = X\theta_p$,$loss = |y - \hat{y}|$。如果$\hat{y}_{t-l} \leq y_{t-l}$, 那么$\theta_{t-l} \leq \theta_p$ (如果$X_{t-l} > 0$,表示$X_{t-l}$是正定矩阵),前面低估,我们要证明后面也很可能低估。
44 |
45 | $$
46 | \begin{align}
47 | \Delta \theta &= - \alpha \frac{d(y_{t-l} - X_{t-l}\theta_{t-l})}{dX_{t-l}} = \alpha \theta_{t-l} \\
48 | \hat{y}_t &= X_t (1 + \alpha )\theta_{t-l} \leq X_t(1+\alpha) \theta_{p} = (1+\alpha) y_t
49 | \ \ \text{如果$X_t>0$}
50 | \end{align}
51 | $$
52 |
53 |
54 | 如果$\hat{y_{t-l}} > y_{t-l}$,即$\theta_{t-l} > \theta_p$。
55 |
56 |
57 | $$
58 | \begin{align}
59 | \Delta \theta &= - \alpha \theta_{t-l} \\
60 | \hat{y}_t &= X_t(1 - \alpha)\theta_{t-l} > X_t(1 - \alpha)\theta_p = (1 - \alpha)y_t
61 | \end{align}
62 | $$
63 |
64 | 由于$\alpha$比较小,我们可以近似不等式成立。$P(\hat{y_t} \leq y_t | \hat{y}_{t-l} \leq y_{t-l}) \approx 1$ , $P(\hat{y_t} > y_t | \hat{y}_{t-l} > y_{t-l}) \approx 1$。$\alpha$越小,也就是梯度更新越慢,假设越有可能成立。上述基于线性模型的情况下成立,或者当$l$相对较小的时候,我们可以认为$y_{t-l}$和$y_t$之间的接近线性的。但该假设还不能推广到更通用的情况。
65 |
66 | **当特征矩阵$X_t$是正定矩阵,且$l$较小的时候,假设大概率成立。**
67 |
68 | 该方法应用:$e_{t-l} = y_{t-l} - \hat{y}_{t-l}$, $\tilde{y}_t = \hat{y}_t + e_{t-l} $,$\tilde{y}_t$为修正后的预测结果。在实际预测中会出现两种情况,造成看起来预测偏移延迟的情况。
69 |
70 |
71 | 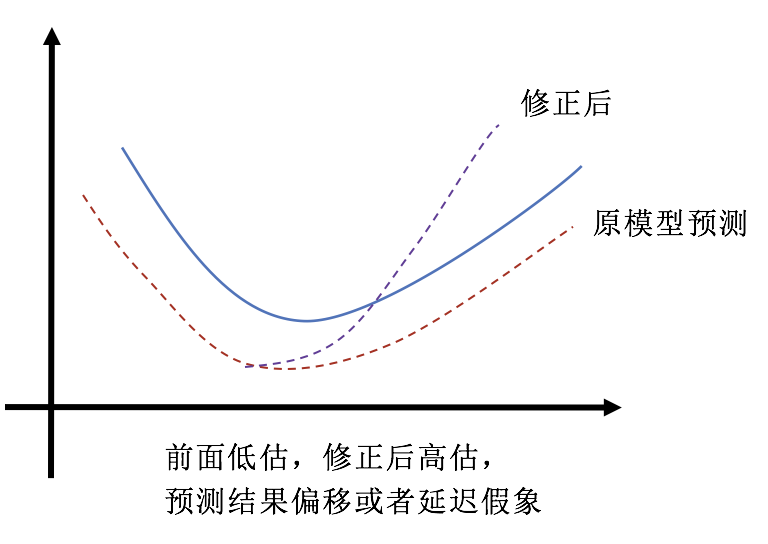 72 |
72 | 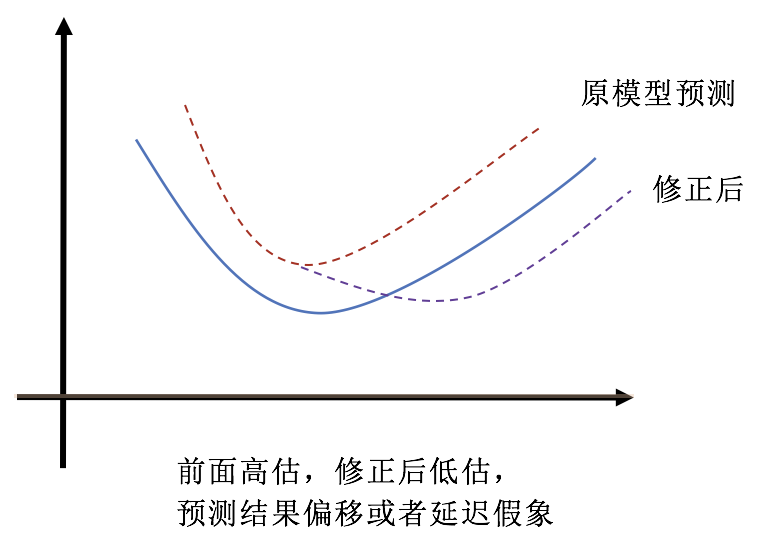 73 |
73 |
74 |
75 | 总体准确率会比后面不低估也不高估更高,因为出现误差抵消。
76 |
77 | 为了可能减少这种情况,但不一定能够提升预测指标。我们引入趋势项进行规则调整。
78 |
79 | * 如果训练集末尾趋势是增长的
80 | * 前面高估的部分沿用模型输出的原始结果,低估的部分进行误差修正
81 | * 如果训练集末尾趋势是降低的
82 | * 前面低估的部分沿用模型输出的原始结果,高估的部分进行误差修正
83 |
84 | ## Practice
85 |
86 | 我们选用Amazon,Google,Alibaba和JD四家公司两年的股票收盘价作为测试数据验证,原始预测,误差修正和误差趋势修正的对比结果。对比指标使用$MAPE$和$CV$。模型采用线性模型,特征采用一系列事件序列特征。结果如下图
87 |
88 | | 公司 | 原始预测平均MAPE | 原始预测CV | 误差修正平均MAPE | 误差修正CV | 误差趋势平均MAPE | 误差趋势CV |
89 | | ------- | ---------------- | ---------- | ---------------- | ---------- | ---------------- | ---------- |
90 | | Amazon | 0.103 | **0.608** | **0.065** | 0.638 | 0.075 | 0.776 |
91 | | Google | 0.076 | **0.650** | **0.057** | 0.766 | 0.066 | 0.768 |
92 | | Alibaba | 0.082 | 0.450 | **0.048** | **0.407** | 0.069 | 0.436 |
93 | | JD | 0.062 | 0.597 | **0.045** | **0.437** | 0.053 | 0.474 |
94 |
95 | 误差趋势的方式从效果表现来看没有误差修正好,但比原始预测要好一些。主要原因是如前所述,在计算平均MAPE和CV的时候,误差修正产生了更多的误差抵消。
96 |
97 | 示意图:
98 |
99 |
100 | 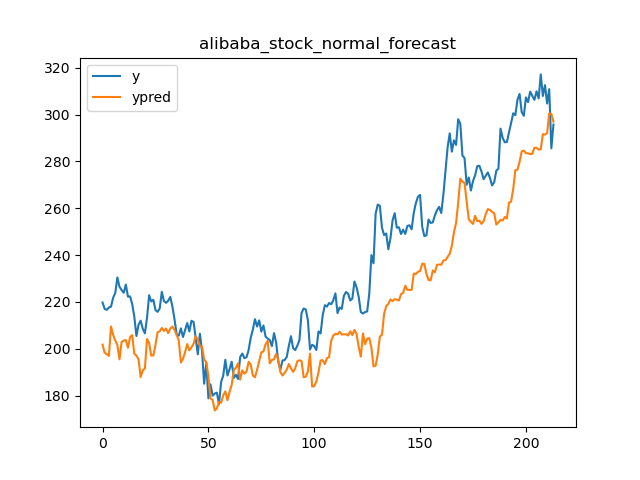 101 |
101 | 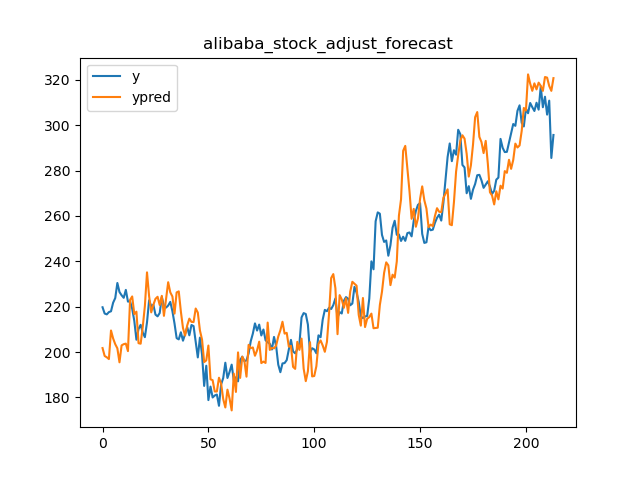 102 |
102 | 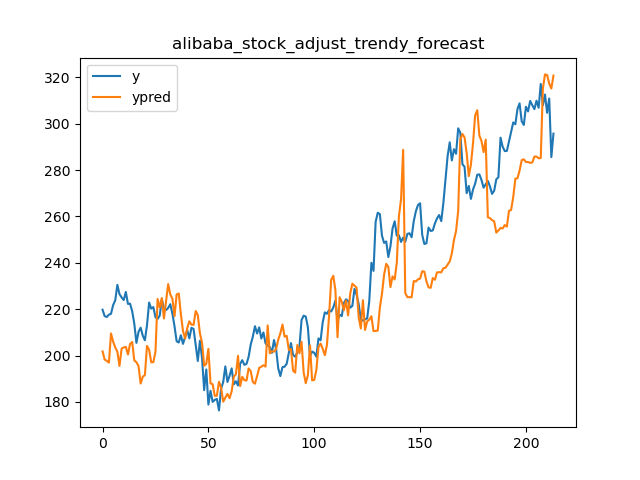 103 |
103 |
104 |
105 |
106 | 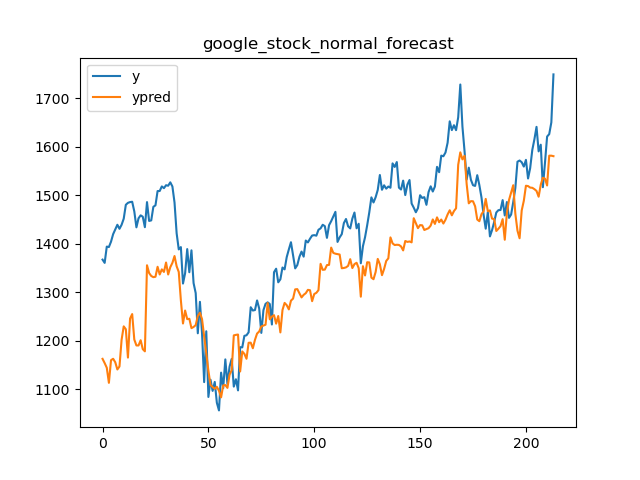 107 |
107 | 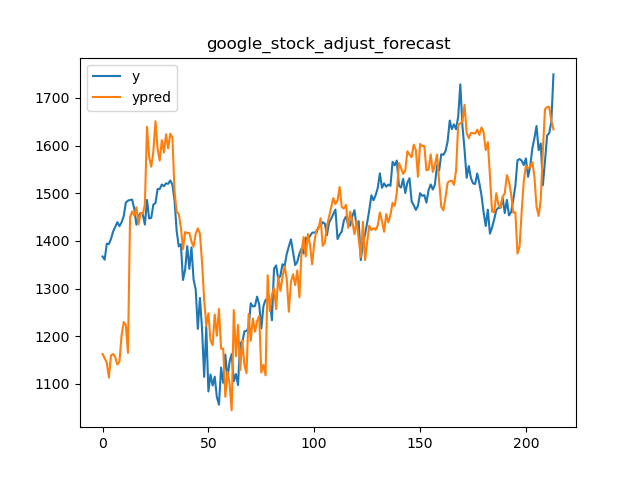 108 |
108 | 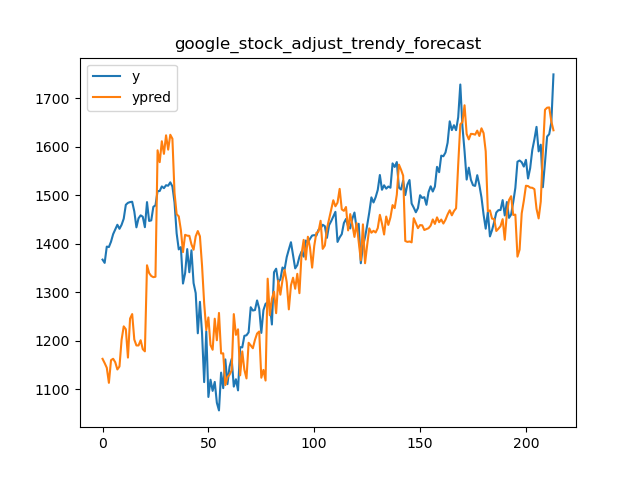 109 |
109 |
110 |
111 |
112 | 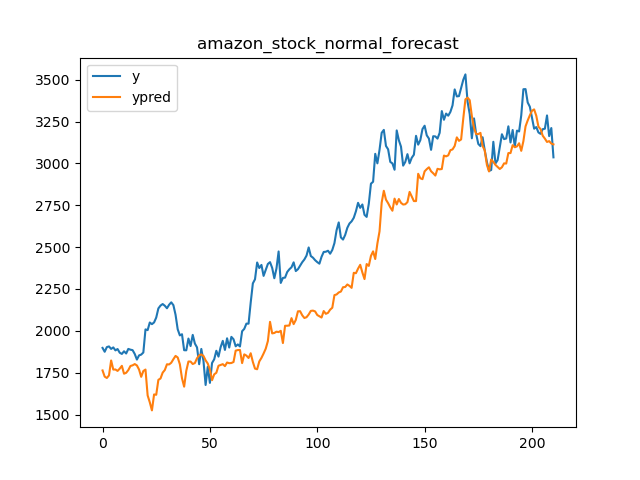 113 |
113 | 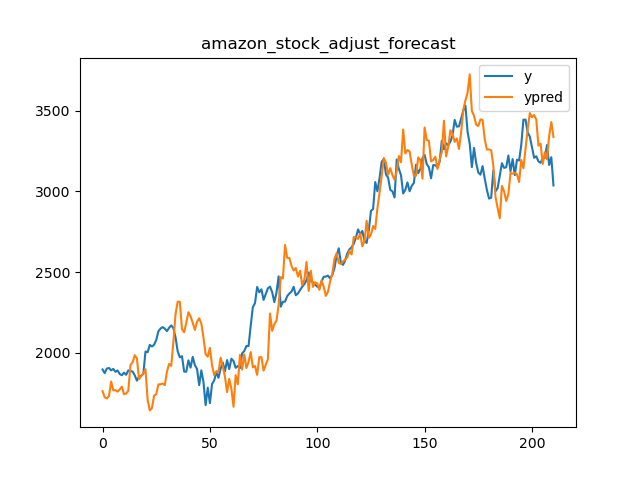 114 |
114 | 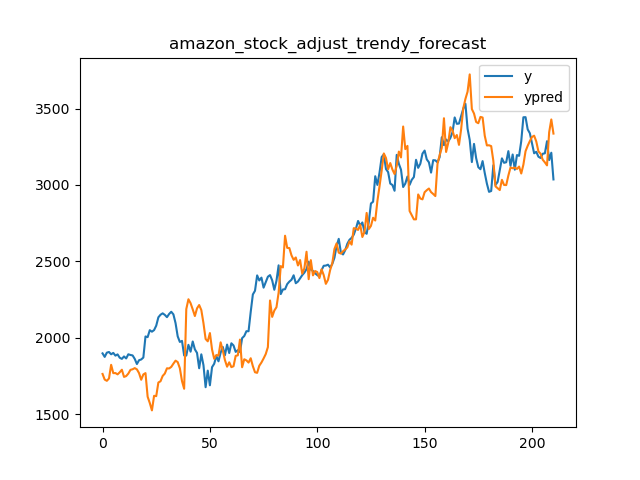 115 |
115 |
116 |
117 |
118 | 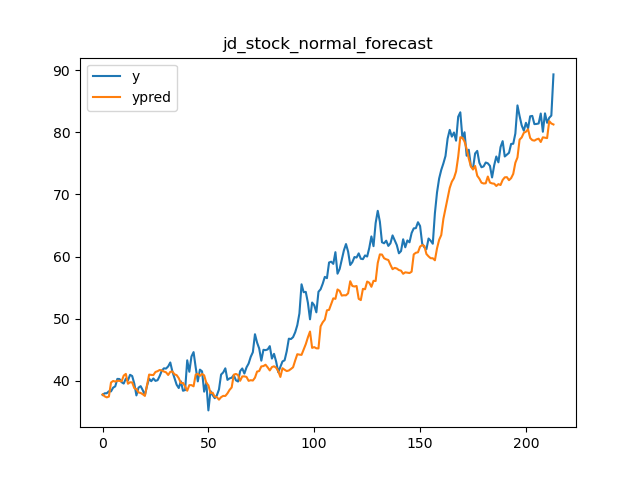 119 |
119 | 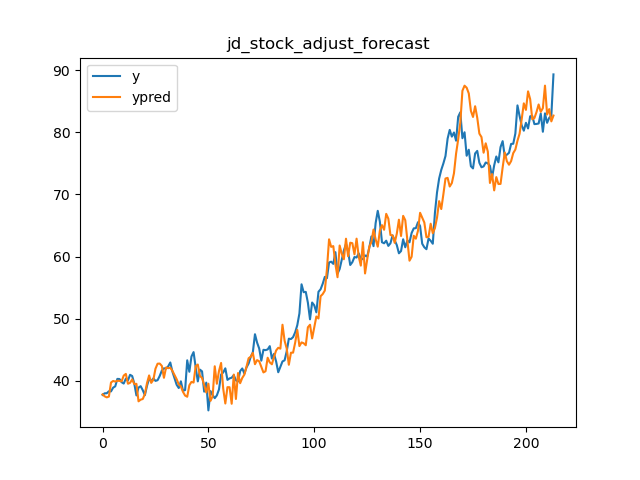 120 |
120 | 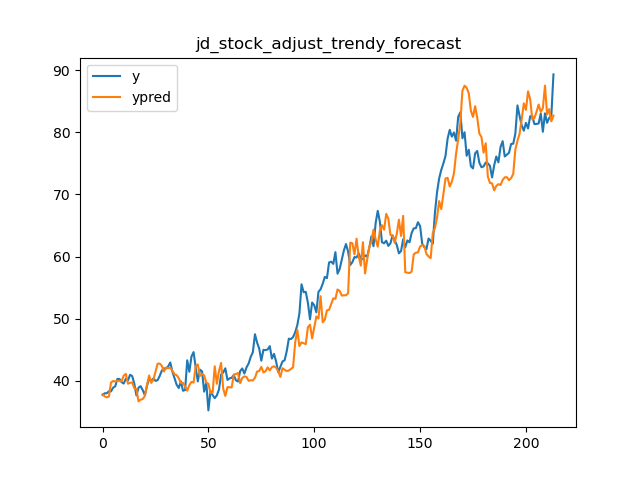 121 |
121 |
122 |
--------------------------------------------------------------------------------
/forecast_auto_adjustment/README.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/README.pdf
--------------------------------------------------------------------------------
/forecast_auto_adjustment/data/amazon_stock.csv:
--------------------------------------------------------------------------------
1 | Date,Open,High,Low,Close,Adj Close,Volume
2 | 2018-11-02,1678.589966,1697.439941,1651.829956,1665.530029,1665.530029,6955500
3 | 2018-11-05,1657.569946,1658.089966,1596.359985,1627.800049,1627.800049,5624700
4 | 2018-11-06,1618.349976,1665.000000,1614.550049,1642.810059,1642.810059,4257400
5 | 2018-11-07,1673.000000,1759.229980,1664.079956,1755.489990,1755.489990,8192200
6 | 2018-11-08,1755.000000,1784.000000,1725.109985,1754.910034,1754.910034,6534900
7 | 2018-11-09,1732.500000,1743.920044,1701.869995,1712.430054,1712.430054,5902200
8 | 2018-11-12,1698.239990,1708.550049,1630.010010,1636.849976,1636.849976,6806200
9 | 2018-11-13,1649.290039,1677.060059,1613.750000,1631.170044,1631.170044,5933300
10 | 2018-11-14,1656.319946,1673.000000,1597.069946,1599.010010,1599.010010,6486900
11 | 2018-11-15,1581.010010,1624.819946,1546.510010,1619.439941,1619.439941,8427300
12 | 2018-11-16,1587.500000,1614.479980,1573.119995,1593.410034,1593.410034,6066100
13 | 2018-11-19,1577.010010,1581.189941,1503.359985,1512.290039,1512.290039,7790000
14 | 2018-11-20,1437.500000,1534.750000,1420.000000,1495.459961,1495.459961,10878800
15 | 2018-11-21,1542.989990,1550.000000,1515.000000,1516.729980,1516.729980,5716800
16 | 2018-11-23,1517.000000,1536.199951,1501.810059,1502.060059,1502.060059,2707600
17 | 2018-11-26,1539.000000,1584.810059,1524.219971,1581.329956,1581.329956,6257700
18 | 2018-11-27,1575.989990,1597.650024,1558.010010,1581.420044,1581.420044,5783200
19 | 2018-11-28,1613.920044,1681.449951,1601.219971,1677.750000,1677.750000,8458700
20 | 2018-11-29,1674.989990,1689.989990,1652.329956,1673.569946,1673.569946,6613200
21 | 2018-11-30,1679.500000,1696.000000,1666.500000,1690.170044,1690.170044,5761800
22 | 2018-12-03,1769.459961,1778.339966,1730.000000,1772.359985,1772.359985,6862300
23 | 2018-12-04,1756.000000,1770.339966,1665.000000,1668.400024,1668.400024,8694500
24 | 2018-12-06,1614.869995,1701.050049,1609.849976,1699.189941,1699.189941,8789400
25 | 2018-12-07,1705.069946,1718.930054,1625.459961,1629.130005,1629.130005,7576100
26 | 2018-12-10,1623.839966,1657.989990,1590.869995,1641.030029,1641.030029,7494800
27 | 2018-12-11,1678.000000,1679.469971,1619.599976,1643.239990,1643.239990,6244700
28 | 2018-12-12,1669.000000,1704.989990,1660.270020,1663.540039,1663.540039,6598000
29 | 2018-12-13,1680.000000,1692.119995,1641.500000,1658.380005,1658.380005,5271300
30 | 2018-12-14,1638.000000,1642.569946,1585.000000,1591.910034,1591.910034,6367200
31 | 2018-12-17,1566.000000,1576.130005,1505.010010,1520.910034,1520.910034,8829800
32 | 2018-12-18,1540.000000,1567.550049,1523.010010,1551.479980,1551.479980,6523000
33 | 2018-12-19,1543.050049,1584.530029,1483.180054,1495.079956,1495.079956,8792200
34 | 2018-12-20,1484.000000,1509.500000,1432.689941,1460.829956,1460.829956,9991800
35 | 2018-12-21,1464.989990,1480.000000,1363.959961,1377.449951,1377.449951,13640300
36 | 2018-12-24,1346.000000,1396.030029,1307.000000,1343.959961,1343.959961,7220000
37 | 2018-12-26,1368.890015,1473.160034,1363.010010,1470.900024,1470.900024,10411800
38 | 2018-12-27,1454.199951,1469.000000,1390.310059,1461.640015,1461.640015,9722000
39 | 2018-12-28,1473.349976,1513.469971,1449.000000,1478.020020,1478.020020,8829000
40 | 2018-12-31,1510.800049,1520.760010,1487.000000,1501.969971,1501.969971,6954500
41 | 2019-01-02,1465.199951,1553.359985,1460.930054,1539.130005,1539.130005,7983100
42 | 2019-01-03,1520.010010,1538.000000,1497.109985,1500.280029,1500.280029,6975600
43 | 2019-01-04,1530.000000,1594.000000,1518.310059,1575.390015,1575.390015,9182600
44 | 2019-01-07,1602.310059,1634.560059,1589.189941,1629.510010,1629.510010,7993200
45 | 2019-01-08,1664.689941,1676.609985,1616.609985,1656.579956,1656.579956,8881400
46 | 2019-01-09,1652.979980,1667.800049,1641.400024,1659.420044,1659.420044,6348800
47 | 2019-01-10,1641.010010,1663.250000,1621.619995,1656.219971,1656.219971,6507700
48 | 2019-01-11,1640.550049,1660.290039,1636.219971,1640.560059,1640.560059,4686200
49 | 2019-01-14,1615.000000,1648.199951,1595.150024,1617.209961,1617.209961,6005900
50 | 2019-01-15,1632.000000,1675.160034,1626.010010,1674.560059,1674.560059,5998500
51 | 2019-01-16,1684.219971,1705.000000,1675.880005,1683.780029,1683.780029,6366900
52 | 2019-01-17,1680.000000,1700.170044,1677.500000,1693.219971,1693.219971,4208900
53 | 2019-01-18,1712.000000,1716.199951,1691.540039,1696.199951,1696.199951,6020500
54 | 2019-01-22,1681.000000,1681.869995,1610.199951,1632.170044,1632.170044,6416800
55 | 2019-01-23,1656.000000,1657.430054,1612.000000,1640.020020,1640.020020,5225200
56 | 2019-01-24,1641.069946,1657.260010,1631.780029,1654.930054,1654.930054,4089900
57 | 2019-01-25,1670.500000,1683.479980,1661.609985,1670.569946,1670.569946,4945900
58 | 2019-01-28,1643.589966,1645.000000,1614.089966,1637.890015,1637.890015,4837700
59 | 2019-01-29,1631.270020,1632.380005,1590.719971,1593.880005,1593.880005,4632800
60 | 2019-01-30,1623.000000,1676.949951,1619.680054,1670.430054,1670.430054,5783800
61 | 2019-01-31,1692.849976,1736.410034,1679.079956,1718.729980,1718.729980,10910300
62 | 2019-02-01,1638.880005,1673.060059,1622.010010,1626.229980,1626.229980,11506200
63 | 2019-02-04,1623.000000,1649.630005,1613.500000,1633.310059,1633.310059,4929100
64 | 2019-02-05,1643.339966,1665.260010,1642.500000,1658.810059,1658.810059,4453100
65 | 2019-02-06,1670.750000,1672.260010,1633.339966,1640.260010,1640.260010,3939900
66 | 2019-02-07,1625.000000,1625.540039,1592.910034,1614.369995,1614.369995,4626600
67 | 2019-02-08,1586.000000,1588.589966,1566.760010,1588.219971,1588.219971,5657500
68 | 2019-02-11,1600.979980,1609.290039,1586.000000,1591.000000,1591.000000,3317300
69 | 2019-02-12,1604.000000,1639.400024,1598.880005,1638.010010,1638.010010,4858600
70 | 2019-02-13,1647.000000,1656.380005,1637.109985,1640.000000,1640.000000,3560300
71 | 2019-02-14,1624.500000,1637.900024,1606.060059,1622.650024,1622.650024,4120500
72 | 2019-02-15,1627.859985,1628.910034,1604.500000,1607.949951,1607.949951,4343900
73 | 2019-02-19,1601.000000,1634.000000,1600.560059,1627.579956,1627.579956,3681700
74 | 2019-02-20,1630.000000,1634.930054,1610.119995,1622.099976,1622.099976,3337600
75 | 2019-02-21,1619.849976,1623.560059,1600.910034,1619.439941,1619.439941,3483400
76 | 2019-02-22,1623.500000,1634.939941,1621.170044,1631.560059,1631.560059,3096200
77 | 2019-02-25,1641.449951,1654.599976,1630.390015,1633.000000,1633.000000,3184500
78 | 2019-02-26,1625.979980,1639.989990,1616.130005,1636.400024,1636.400024,2665800
79 | 2019-02-27,1628.180054,1641.810059,1615.099976,1641.089966,1641.089966,3148800
80 | 2019-02-28,1635.250000,1651.770020,1633.829956,1639.829956,1639.829956,3025900
81 | 2019-03-01,1655.130005,1674.260010,1651.000000,1671.729980,1671.729980,4974900
82 | 2019-03-04,1685.000000,1709.430054,1674.359985,1696.170044,1696.170044,6167400
83 | 2019-03-05,1702.949951,1707.800049,1689.010010,1692.430054,1692.430054,3681500
84 | 2019-03-06,1695.969971,1697.750000,1668.280029,1668.949951,1668.949951,3996000
85 | 2019-03-07,1667.369995,1669.750000,1620.510010,1625.949951,1625.949951,4957000
86 | 2019-03-08,1604.010010,1622.719971,1586.569946,1620.800049,1620.800049,4667000
87 | 2019-03-11,1626.119995,1672.290039,1626.010010,1670.619995,1670.619995,3876400
88 | 2019-03-12,1669.000000,1684.270020,1660.979980,1673.099976,1673.099976,3614500
89 | 2019-03-13,1683.000000,1700.000000,1679.349976,1690.810059,1690.810059,3552000
90 | 2019-03-14,1691.199951,1702.000000,1684.339966,1686.219971,1686.219971,2946600
91 | 2019-03-15,1703.000000,1718.800049,1693.130005,1712.359985,1712.359985,7550900
92 | 2019-03-18,1712.699951,1750.000000,1712.630005,1742.150024,1742.150024,5429100
93 | 2019-03-19,1753.510010,1784.160034,1753.510010,1761.849976,1761.849976,6364200
94 | 2019-03-20,1769.939941,1799.500000,1767.030029,1797.270020,1797.270020,6265600
95 | 2019-03-21,1796.260010,1823.750000,1787.280029,1819.260010,1819.260010,5767800
96 | 2019-03-22,1810.170044,1818.979980,1763.109985,1764.770020,1764.770020,6363000
97 | 2019-03-25,1757.790039,1782.680054,1747.500000,1774.260010,1774.260010,5103800
98 | 2019-03-26,1793.000000,1805.770020,1773.359985,1783.760010,1783.760010,4865900
99 | 2019-03-27,1784.130005,1787.500000,1745.680054,1765.699951,1765.699951,4324800
100 | 2019-03-28,1770.000000,1777.930054,1753.469971,1773.420044,1773.420044,3043000
101 | 2019-03-29,1786.579956,1792.859985,1776.630005,1780.750000,1780.750000,3320800
102 | 2019-04-01,1800.109985,1815.670044,1798.729980,1814.189941,1814.189941,4238800
103 | 2019-04-02,1811.020020,1820.000000,1805.119995,1813.979980,1813.979980,3448100
104 | 2019-04-03,1826.719971,1830.000000,1809.619995,1820.699951,1820.699951,3980600
105 | 2019-04-04,1820.650024,1828.750000,1804.199951,1818.859985,1818.859985,3623900
106 | 2019-04-05,1829.000000,1838.579956,1825.189941,1837.280029,1837.280029,3640500
107 | 2019-04-08,1833.229980,1850.199951,1825.109985,1849.859985,1849.859985,3752800
108 | 2019-04-09,1845.489990,1853.089966,1831.780029,1835.839966,1835.839966,3714400
109 | 2019-04-10,1841.000000,1848.000000,1828.810059,1847.329956,1847.329956,2964000
110 | 2019-04-11,1848.699951,1849.949951,1840.310059,1844.069946,1844.069946,2654800
111 | 2019-04-12,1848.400024,1851.500000,1841.300049,1843.060059,1843.060059,3114400
112 | 2019-04-15,1842.000000,1846.849976,1818.900024,1844.869995,1844.869995,3724400
113 | 2019-04-16,1851.349976,1869.770020,1848.000000,1863.040039,1863.040039,3044600
114 | 2019-04-17,1872.989990,1876.469971,1860.439941,1864.819946,1864.819946,2893500
115 | 2019-04-18,1868.790039,1870.819946,1859.479980,1861.689941,1861.689941,2749900
116 | 2019-04-22,1855.400024,1888.420044,1845.640015,1887.310059,1887.310059,3373800
117 | 2019-04-23,1891.199951,1929.260010,1889.579956,1923.770020,1923.770020,4640400
118 | 2019-04-24,1925.000000,1929.689941,1898.160034,1901.750000,1901.750000,3675800
119 | 2019-04-25,1917.000000,1922.449951,1900.310059,1902.250000,1902.250000,6099100
120 | 2019-04-26,1929.000000,1951.000000,1898.000000,1950.630005,1950.630005,8432600
121 | 2019-04-29,1949.000000,1956.339966,1934.089966,1938.430054,1938.430054,4021300
122 | 2019-04-30,1930.099976,1935.709961,1906.949951,1926.520020,1926.520020,3506000
123 | 2019-05-01,1933.089966,1943.640015,1910.550049,1911.520020,1911.520020,3117000
124 | 2019-05-02,1913.329956,1921.550049,1881.869995,1900.819946,1900.819946,3962900
125 | 2019-05-03,1949.000000,1964.400024,1936.000000,1962.459961,1962.459961,6381600
126 | 2019-05-06,1917.979980,1959.000000,1910.500000,1950.550049,1950.550049,5417800
127 | 2019-05-07,1939.989990,1949.099976,1903.380005,1921.000000,1921.000000,5902100
128 | 2019-05-08,1918.869995,1935.369995,1910.000000,1917.770020,1917.770020,4078600
129 | 2019-05-09,1900.000000,1909.400024,1876.000000,1899.869995,1899.869995,5308300
130 | 2019-05-10,1898.000000,1903.790039,1856.000000,1889.979980,1889.979980,5718000
131 | 2019-05-13,1836.560059,1846.540039,1818.000000,1822.680054,1822.680054,5783400
132 | 2019-05-14,1839.500000,1852.439941,1815.750000,1840.119995,1840.119995,4629100
133 | 2019-05-15,1827.949951,1874.430054,1823.000000,1871.150024,1871.150024,4692600
134 | 2019-05-16,1885.939941,1917.510010,1882.290039,1907.569946,1907.569946,4707800
135 | 2019-05-17,1893.050049,1910.530029,1867.329956,1869.000000,1869.000000,4736600
136 | 2019-05-20,1852.689941,1867.780029,1835.540039,1858.969971,1858.969971,3798200
137 | 2019-05-21,1874.790039,1879.000000,1846.000000,1857.520020,1857.520020,4005100
138 | 2019-05-22,1851.780029,1871.489990,1851.000000,1859.680054,1859.680054,2936600
139 | 2019-05-23,1836.589966,1844.000000,1804.199951,1815.479980,1815.479980,4424300
140 | 2019-05-24,1835.890015,1841.760010,1817.849976,1823.280029,1823.280029,3369700
141 | 2019-05-28,1832.750000,1849.270020,1827.349976,1836.430054,1836.430054,3200000
142 | 2019-05-29,1823.119995,1830.000000,1807.530029,1819.189941,1819.189941,4279000
143 | 2019-05-30,1825.489990,1829.469971,1807.829956,1816.319946,1816.319946,3146900
144 | 2019-05-31,1790.010010,1795.589966,1772.699951,1775.069946,1775.069946,4618800
145 | 2019-06-03,1760.010010,1766.290039,1672.000000,1692.689941,1692.689941,9098700
146 | 2019-06-04,1699.239990,1730.819946,1680.890015,1729.560059,1729.560059,5679100
147 | 2019-06-05,1749.599976,1752.000000,1715.250000,1738.500000,1738.500000,4239800
148 | 2019-06-06,1737.709961,1760.000000,1726.130005,1754.359985,1754.359985,3689300
149 | 2019-06-07,1763.699951,1806.250000,1759.489990,1804.030029,1804.030029,4808200
150 | 2019-06-10,1822.000000,1884.869995,1818.000000,1860.630005,1860.630005,5371000
151 | 2019-06-11,1883.250000,1893.699951,1858.000000,1863.699951,1863.699951,4042700
152 | 2019-06-12,1853.979980,1865.000000,1844.380005,1855.319946,1855.319946,2674500
153 | 2019-06-13,1866.719971,1883.089966,1862.219971,1870.300049,1870.300049,2795800
154 | 2019-06-14,1864.000000,1876.000000,1859.000000,1869.670044,1869.670044,2851200
155 | 2019-06-17,1876.500000,1895.689941,1875.449951,1886.030029,1886.030029,2634300
156 | 2019-06-18,1901.349976,1921.670044,1899.790039,1901.369995,1901.369995,3895700
157 | 2019-06-19,1907.839966,1919.579956,1892.469971,1908.790039,1908.790039,2895300
158 | 2019-06-20,1933.329956,1935.199951,1905.800049,1918.189941,1918.189941,3217200
159 | 2019-06-21,1916.099976,1925.949951,1907.579956,1911.300049,1911.300049,3933600
160 | 2019-06-24,1912.660034,1916.859985,1901.300049,1913.900024,1913.900024,2283000
161 | 2019-06-25,1911.839966,1916.390015,1872.420044,1878.270020,1878.270020,3012300
162 | 2019-06-26,1892.479980,1903.800049,1887.319946,1897.829956,1897.829956,2441900
163 | 2019-06-27,1902.000000,1911.239990,1898.040039,1904.280029,1904.280029,2141700
164 | 2019-06-28,1909.099976,1912.939941,1884.000000,1893.630005,1893.630005,3037400
165 | 2019-07-01,1922.979980,1929.819946,1914.660034,1922.189941,1922.189941,3203300
166 | 2019-07-02,1919.380005,1934.790039,1906.630005,1934.310059,1934.310059,2645900
167 | 2019-07-03,1935.890015,1941.589966,1930.500000,1939.000000,1939.000000,1690300
168 | 2019-07-05,1928.599976,1945.900024,1925.300049,1942.910034,1942.910034,2628400
169 | 2019-07-08,1934.119995,1956.000000,1928.250000,1952.319946,1952.319946,2883400
170 | 2019-07-09,1947.800049,1990.010010,1943.479980,1988.300049,1988.300049,4345700
171 | 2019-07-10,1996.510010,2024.939941,1995.400024,2017.410034,2017.410034,4931900
172 | 2019-07-11,2025.619995,2035.800049,1995.300049,2001.069946,2001.069946,4317800
173 | 2019-07-12,2008.270020,2017.000000,2003.869995,2011.000000,2011.000000,2509300
174 | 2019-07-15,2021.400024,2022.900024,2001.550049,2020.989990,2020.989990,2981300
175 | 2019-07-16,2010.579956,2026.319946,2001.219971,2009.900024,2009.900024,2618200
176 | 2019-07-17,2007.050049,2012.000000,1992.030029,1992.030029,1992.030029,2558800
177 | 2019-07-18,1980.010010,1987.500000,1951.550049,1977.900024,1977.900024,3504300
178 | 2019-07-19,1991.209961,1996.000000,1962.229980,1964.520020,1964.520020,3185600
179 | 2019-07-22,1971.140015,1989.000000,1958.260010,1985.630005,1985.630005,2900000
180 | 2019-07-23,1995.989990,1997.790039,1973.130005,1994.489990,1994.489990,2703500
181 | 2019-07-24,1969.300049,2001.300049,1965.869995,2000.810059,2000.810059,2631300
182 | 2019-07-25,2001.000000,2001.199951,1972.719971,1973.819946,1973.819946,4136500
183 | 2019-07-26,1942.000000,1950.900024,1924.510010,1943.050049,1943.050049,4927100
184 | 2019-07-29,1930.000000,1932.229980,1890.540039,1912.449951,1912.449951,4493200
185 | 2019-07-30,1891.119995,1909.890015,1883.479980,1898.530029,1898.530029,2910900
186 | 2019-07-31,1898.109985,1899.550049,1849.439941,1866.780029,1866.780029,4470700
187 | 2019-08-01,1871.719971,1897.920044,1844.010010,1855.319946,1855.319946,4713300
188 | 2019-08-02,1845.069946,1846.359985,1808.020020,1823.239990,1823.239990,4956200
189 | 2019-08-05,1770.219971,1788.670044,1748.780029,1765.130005,1765.130005,6058200
190 | 2019-08-06,1792.229980,1793.770020,1753.400024,1787.829956,1787.829956,5070300
191 | 2019-08-07,1773.989990,1798.930054,1757.000000,1793.400024,1793.400024,4526900
192 | 2019-08-08,1806.000000,1834.260010,1798.109985,1832.890015,1832.890015,3701200
193 | 2019-08-09,1828.949951,1831.089966,1802.219971,1807.579956,1807.579956,2879800
194 | 2019-08-12,1795.989990,1800.979980,1777.000000,1784.920044,1784.920044,2905500
195 | 2019-08-13,1783.000000,1831.739990,1780.000000,1824.339966,1824.339966,3994000
196 | 2019-08-14,1793.010010,1795.650024,1757.219971,1762.959961,1762.959961,4893600
197 | 2019-08-15,1781.989990,1788.000000,1761.959961,1776.119995,1776.119995,3759100
198 | 2019-08-16,1792.890015,1802.910034,1784.550049,1792.569946,1792.569946,3018000
199 | 2019-08-19,1818.079956,1826.000000,1812.609985,1816.119995,1816.119995,2816300
200 | 2019-08-20,1814.500000,1816.819946,1799.880005,1801.380005,1801.380005,1929500
201 | 2019-08-21,1819.390015,1829.579956,1815.000000,1823.540039,1823.540039,2031800
202 | 2019-08-22,1828.000000,1829.410034,1800.099976,1804.660034,1804.660034,2653500
203 | 2019-08-23,1793.030029,1804.900024,1745.229980,1749.619995,1749.619995,5270800
204 | 2019-08-26,1766.910034,1770.000000,1743.510010,1768.869995,1768.869995,3080000
205 | 2019-08-27,1775.729980,1779.400024,1746.680054,1761.829956,1761.829956,3019700
206 | 2019-08-28,1755.000000,1767.859985,1744.050049,1764.250000,1764.250000,2419700
207 | 2019-08-29,1783.000000,1798.550049,1777.250000,1786.400024,1786.400024,3015100
208 | 2019-08-30,1797.489990,1799.739990,1764.569946,1776.290039,1776.290039,3058700
209 | 2019-09-03,1770.000000,1800.800049,1768.000000,1789.839966,1789.839966,3543000
210 | 2019-09-04,1805.000000,1807.630005,1796.229980,1800.619995,1800.619995,2324100
211 | 2019-09-05,1821.949951,1842.000000,1815.579956,1840.719971,1840.719971,3310800
212 | 2019-09-06,1838.219971,1840.650024,1826.400024,1833.510010,1833.510010,2496900
213 | 2019-09-09,1841.000000,1850.000000,1824.609985,1831.349976,1831.349976,2999500
214 | 2019-09-10,1822.750000,1825.810059,1805.339966,1820.550049,1820.550049,2613900
215 | 2019-09-11,1812.140015,1833.420044,1809.079956,1822.989990,1822.989990,2432800
216 | 2019-09-12,1837.630005,1853.660034,1834.280029,1843.550049,1843.550049,2823500
217 | 2019-09-13,1842.010010,1846.119995,1835.170044,1839.339966,1839.339966,1971300
218 | 2019-09-16,1824.020020,1825.689941,1800.199951,1807.839966,1807.839966,3675500
219 | 2019-09-17,1807.079956,1823.989990,1804.099976,1822.550049,1822.550049,1982400
220 | 2019-09-18,1817.040039,1822.060059,1795.500000,1817.459961,1817.459961,2505600
221 | 2019-09-19,1821.020020,1832.569946,1817.900024,1821.500000,1821.500000,2031500
222 | 2019-09-20,1821.709961,1830.630005,1780.920044,1794.160034,1794.160034,5341900
223 | 2019-09-23,1777.000000,1792.699951,1767.319946,1785.300049,1785.300049,2922300
224 | 2019-09-24,1790.609985,1795.709961,1735.550049,1741.609985,1741.609985,4616000
225 | 2019-09-25,1747.359985,1773.000000,1723.000000,1768.329956,1768.329956,3493200
226 | 2019-09-26,1762.790039,1763.369995,1731.500000,1739.839966,1739.839966,3536800
227 | 2019-09-27,1748.000000,1749.119995,1713.819946,1725.449951,1725.449951,3907200
228 | 2019-09-30,1726.989990,1737.459961,1709.219971,1735.910034,1735.910034,2644700
229 | 2019-10-01,1746.000000,1755.599976,1728.410034,1735.650024,1735.650024,3084500
230 | 2019-10-02,1727.739990,1728.890015,1705.000000,1713.229980,1713.229980,3301100
231 | 2019-10-03,1713.000000,1725.000000,1685.060059,1724.420044,1724.420044,3468200
232 | 2019-10-04,1726.020020,1740.579956,1719.229980,1739.650024,1739.650024,2471900
233 | 2019-10-07,1731.630005,1747.829956,1723.699951,1732.660034,1732.660034,2154700
234 | 2019-10-08,1722.489990,1727.000000,1705.000000,1705.510010,1705.510010,2542000
235 | 2019-10-09,1719.609985,1729.949951,1714.359985,1721.989990,1721.989990,2043500
236 | 2019-10-10,1725.239990,1738.290039,1713.750000,1720.260010,1720.260010,2575200
237 | 2019-10-11,1742.920044,1745.449951,1729.859985,1731.920044,1731.920044,3255000
238 | 2019-10-14,1728.910034,1741.890015,1722.000000,1736.430054,1736.430054,1910200
239 | 2019-10-15,1742.140015,1776.449951,1740.619995,1767.380005,1767.380005,3111700
240 | 2019-10-16,1773.329956,1786.239990,1770.520020,1777.430054,1777.430054,2763400
241 | 2019-10-17,1796.489990,1798.849976,1782.020020,1787.479980,1787.479980,2647400
242 | 2019-10-18,1787.800049,1793.979980,1749.199951,1757.510010,1757.510010,3362500
243 | 2019-10-21,1769.660034,1785.880005,1765.000000,1785.660034,1785.660034,2130400
244 | 2019-10-22,1788.150024,1789.780029,1762.000000,1765.729980,1765.729980,2111700
245 | 2019-10-23,1761.300049,1770.050049,1742.000000,1762.170044,1762.170044,2138200
246 | 2019-10-24,1771.089966,1788.339966,1760.270020,1780.780029,1780.780029,4446100
247 | 2019-10-25,1697.550049,1764.209961,1695.000000,1761.329956,1761.329956,9626400
248 | 2019-10-28,1748.060059,1778.699951,1742.500000,1777.079956,1777.079956,3708900
249 | 2019-10-29,1774.810059,1777.000000,1755.810059,1762.709961,1762.709961,2276900
250 | 2019-10-30,1760.239990,1782.380005,1759.119995,1779.989990,1779.989990,2449400
251 | 2019-10-31,1775.989990,1792.000000,1771.479980,1776.660034,1776.660034,2781200
252 | 2019-11-01,1788.010010,1797.449951,1785.209961,1791.439941,1791.439941,2790400
253 | 2019-11-04,1801.010010,1815.060059,1801.010010,1804.660034,1804.660034,2771900
254 | 2019-11-05,1809.160034,1810.250000,1794.000000,1801.709961,1801.709961,1885500
255 | 2019-11-06,1801.000000,1802.500000,1788.579956,1795.770020,1795.770020,2029800
256 | 2019-11-07,1803.760010,1805.900024,1783.479980,1788.199951,1788.199951,2651100
257 | 2019-11-08,1787.890015,1789.880005,1774.040039,1785.880005,1785.880005,2123300
258 | 2019-11-11,1778.000000,1780.000000,1767.130005,1771.650024,1771.650024,1946000
259 | 2019-11-12,1774.660034,1786.219971,1771.910034,1778.000000,1778.000000,2037600
260 | 2019-11-13,1773.390015,1775.000000,1747.319946,1753.109985,1753.109985,2989500
261 | 2019-11-14,1751.430054,1766.589966,1749.560059,1754.599976,1754.599976,2264800
262 | 2019-11-15,1760.050049,1761.680054,1732.859985,1739.489990,1739.489990,3927600
263 | 2019-11-18,1738.300049,1753.699951,1722.709961,1752.530029,1752.530029,2839500
264 | 2019-11-19,1756.989990,1760.680054,1743.030029,1752.790039,1752.790039,2270800
265 | 2019-11-20,1749.140015,1762.520020,1734.119995,1745.530029,1745.530029,2790000
266 | 2019-11-21,1743.000000,1746.869995,1730.359985,1734.709961,1734.709961,2662900
267 | 2019-11-22,1739.020020,1746.430054,1731.000000,1745.719971,1745.719971,2479100
268 | 2019-11-25,1753.250000,1777.420044,1753.239990,1773.839966,1773.839966,3486200
269 | 2019-11-26,1779.920044,1797.030029,1778.349976,1796.939941,1796.939941,3181200
270 | 2019-11-27,1801.000000,1824.500000,1797.310059,1818.510010,1818.510010,3025600
271 | 2019-11-29,1817.780029,1824.689941,1800.790039,1800.800049,1800.800049,1923400
272 | 2019-12-02,1804.400024,1805.550049,1762.680054,1781.599976,1781.599976,3925600
273 | 2019-12-03,1760.000000,1772.869995,1747.229980,1769.959961,1769.959961,3380900
274 | 2019-12-04,1774.010010,1789.089966,1760.219971,1760.689941,1760.689941,2670100
275 | 2019-12-05,1763.500000,1763.500000,1740.000000,1740.479980,1740.479980,2823800
276 | 2019-12-06,1751.199951,1754.400024,1740.130005,1751.599976,1751.599976,3117400
277 | 2019-12-09,1750.660034,1766.890015,1745.609985,1749.510010,1749.510010,2442800
278 | 2019-12-10,1747.400024,1750.670044,1735.000000,1739.209961,1739.209961,2514300
279 | 2019-12-11,1741.670044,1750.000000,1735.709961,1748.719971,1748.719971,2097600
280 | 2019-12-12,1750.000000,1764.000000,1745.439941,1760.329956,1760.329956,3095900
281 | 2019-12-13,1765.000000,1768.989990,1755.000000,1760.939941,1760.939941,2745700
282 | 2019-12-16,1767.000000,1769.500000,1757.050049,1769.209961,1769.209961,3145200
283 | 2019-12-17,1778.010010,1792.000000,1777.390015,1790.660034,1790.660034,3644400
284 | 2019-12-18,1795.020020,1798.199951,1782.359985,1784.030029,1784.030029,3351400
285 | 2019-12-19,1780.500000,1792.989990,1774.060059,1792.280029,1792.280029,2652800
286 | 2019-12-20,1799.619995,1802.969971,1782.449951,1786.500000,1786.500000,5150800
287 | 2019-12-23,1788.260010,1793.000000,1784.510010,1793.000000,1793.000000,2136400
288 | 2019-12-24,1793.810059,1795.569946,1787.579956,1789.209961,1789.209961,881300
289 | 2019-12-26,1801.010010,1870.459961,1799.500000,1868.770020,1868.770020,6005400
290 | 2019-12-27,1882.920044,1901.400024,1866.010010,1869.800049,1869.800049,6186600
291 | 2019-12-30,1874.000000,1884.000000,1840.619995,1846.890015,1846.890015,3674700
292 | 2019-12-31,1842.000000,1853.260010,1832.229980,1847.839966,1847.839966,2506500
293 | 2020-01-02,1875.000000,1898.010010,1864.150024,1898.010010,1898.010010,4029000
294 | 2020-01-03,1864.500000,1886.199951,1864.500000,1874.969971,1874.969971,3764400
295 | 2020-01-06,1860.000000,1903.689941,1860.000000,1902.880005,1902.880005,4061800
296 | 2020-01-07,1904.500000,1913.890015,1892.040039,1906.859985,1906.859985,4044900
297 | 2020-01-08,1898.040039,1911.000000,1886.439941,1891.969971,1891.969971,3508000
298 | 2020-01-09,1909.890015,1917.819946,1895.800049,1901.050049,1901.050049,3167300
299 | 2020-01-10,1905.369995,1906.939941,1880.000000,1883.160034,1883.160034,2853700
300 | 2020-01-13,1891.310059,1898.000000,1880.800049,1891.300049,1891.300049,2780800
301 | 2020-01-14,1885.880005,1887.109985,1858.550049,1869.439941,1869.439941,3440900
302 | 2020-01-15,1872.250000,1878.859985,1855.089966,1862.020020,1862.020020,2896600
303 | 2020-01-16,1882.989990,1885.589966,1866.020020,1877.939941,1877.939941,2659500
304 | 2020-01-17,1885.890015,1886.640015,1857.250000,1864.719971,1864.719971,3997300
305 | 2020-01-21,1865.000000,1894.270020,1860.000000,1892.000000,1892.000000,3707800
306 | 2020-01-22,1896.089966,1902.500000,1883.339966,1887.459961,1887.459961,3216300
307 | 2020-01-23,1885.109985,1889.979980,1872.760010,1884.579956,1884.579956,2484600
308 | 2020-01-24,1891.369995,1894.989990,1847.439941,1861.640015,1861.640015,3766200
309 | 2020-01-27,1820.000000,1841.000000,1815.339966,1828.339966,1828.339966,3528500
310 | 2020-01-28,1840.500000,1858.109985,1830.020020,1853.250000,1853.250000,2808000
311 | 2020-01-29,1864.000000,1874.750000,1855.020020,1858.000000,1858.000000,2088000
312 | 2020-01-30,1858.000000,1872.869995,1850.609985,1870.680054,1870.680054,6327400
313 | 2020-01-31,2051.469971,2055.719971,2002.270020,2008.719971,2008.719971,15567300
314 | 2020-02-03,2010.599976,2048.500000,2000.250000,2004.199951,2004.199951,5899100
315 | 2020-02-04,2029.880005,2059.800049,2015.369995,2049.669922,2049.669922,5289300
316 | 2020-02-05,2071.020020,2071.020020,2032.000000,2039.869995,2039.869995,4376200
317 | 2020-02-06,2041.020020,2056.300049,2024.800049,2050.229980,2050.229980,3183000
318 | 2020-02-07,2041.989990,2098.530029,2038.099976,2079.280029,2079.280029,5095300
319 | 2020-02-10,2085.010010,2135.600098,2084.959961,2133.909912,2133.909912,5056200
320 | 2020-02-11,2150.899902,2185.949951,2136.000000,2150.800049,2150.800049,5746000
321 | 2020-02-12,2163.199951,2180.250000,2155.290039,2160.000000,2160.000000,3334300
322 | 2020-02-13,2144.989990,2170.280029,2142.000000,2149.870117,2149.870117,3031800
323 | 2020-02-14,2155.679932,2159.040039,2125.889893,2134.870117,2134.870117,2606200
324 | 2020-02-18,2125.020020,2166.070068,2124.110107,2155.669922,2155.669922,2945600
325 | 2020-02-19,2167.800049,2185.100098,2161.120117,2170.219971,2170.219971,2561200
326 | 2020-02-20,2173.070068,2176.790039,2127.449951,2153.100098,2153.100098,3131300
327 | 2020-02-21,2142.149902,2144.550049,2088.000000,2095.969971,2095.969971,4646300
328 | 2020-02-24,2003.180054,2039.300049,1987.969971,2009.290039,2009.290039,6547000
329 | 2020-02-25,2026.420044,2034.599976,1958.420044,1972.739990,1972.739990,6219100
330 | 2020-02-26,1970.280029,2014.670044,1960.449951,1979.589966,1979.589966,5224600
331 | 2020-02-27,1934.380005,1975.000000,1882.760010,1884.300049,1884.300049,8144000
332 | 2020-02-28,1814.630005,1889.760010,1811.130005,1883.750000,1883.750000,9493800
333 | 2020-03-02,1906.489990,1954.510010,1870.000000,1953.949951,1953.949951,6761700
334 | 2020-03-03,1975.369995,1996.329956,1888.089966,1908.989990,1908.989990,7534500
335 | 2020-03-04,1946.569946,1978.000000,1922.000000,1975.829956,1975.829956,4772900
336 | 2020-03-05,1933.000000,1960.719971,1910.000000,1924.030029,1924.030029,4748200
337 | 2020-03-06,1875.000000,1910.869995,1869.500000,1901.089966,1901.089966,5273600
338 | 2020-03-09,1773.859985,1862.770020,1761.290039,1800.609985,1800.609985,7813200
339 | 2020-03-10,1870.880005,1894.270020,1818.170044,1891.819946,1891.819946,7133300
340 | 2020-03-11,1857.849976,1871.319946,1801.500000,1820.859985,1820.859985,5624800
341 | 2020-03-12,1721.979980,1765.000000,1675.000000,1676.609985,1676.609985,11346200
342 | 2020-03-13,1755.000000,1786.310059,1680.619995,1785.000000,1785.000000,8809700
343 | 2020-03-16,1641.510010,1759.449951,1626.030029,1689.150024,1689.150024,8917300
344 | 2020-03-17,1775.469971,1857.780029,1689.239990,1807.839966,1807.839966,10917100
345 | 2020-03-18,1750.000000,1841.660034,1745.000000,1830.000000,1830.000000,9645200
346 | 2020-03-19,1860.000000,1945.000000,1832.650024,1880.930054,1880.930054,10399900
347 | 2020-03-20,1926.310059,1957.000000,1820.729980,1846.089966,1846.089966,9817900
348 | 2020-03-23,1827.750000,1919.400024,1812.000000,1902.829956,1902.829956,7808500
349 | 2020-03-24,1951.500000,1955.000000,1900.339966,1940.099976,1940.099976,7147100
350 | 2020-03-25,1920.689941,1950.260010,1885.780029,1885.839966,1885.839966,6479100
351 | 2020-03-26,1902.000000,1956.489990,1889.290039,1955.489990,1955.489990,6221300
352 | 2020-03-27,1930.859985,1939.790039,1899.920044,1900.099976,1900.099976,5387900
353 | 2020-03-30,1922.829956,1973.630005,1912.339966,1963.949951,1963.949951,6126100
354 | 2020-03-31,1964.349976,1993.020020,1944.010010,1949.719971,1949.719971,5123600
355 | 2020-04-01,1932.969971,1944.959961,1893.000000,1907.699951,1907.699951,4121900
356 | 2020-04-02,1901.640015,1927.530029,1890.000000,1918.829956,1918.829956,4336000
357 | 2020-04-03,1911.150024,1926.329956,1889.150024,1906.589966,1906.589966,3609900
358 | 2020-04-06,1936.000000,1998.520020,1930.020020,1997.589966,1997.589966,5773200
359 | 2020-04-07,2017.109985,2035.719971,1997.619995,2011.599976,2011.599976,5114000
360 | 2020-04-08,2021.000000,2044.000000,2011.150024,2043.000000,2043.000000,3977300
361 | 2020-04-09,2044.300049,2053.000000,2017.660034,2042.760010,2042.760010,4655600
362 | 2020-04-13,2040.000000,2180.000000,2038.000000,2168.870117,2168.870117,6716700
363 | 2020-04-14,2200.469971,2292.000000,2186.209961,2283.320068,2283.320068,8087200
364 | 2020-04-15,2257.679932,2333.370117,2245.000000,2307.679932,2307.679932,6866600
365 | 2020-04-16,2346.000000,2461.000000,2335.000000,2408.189941,2408.189941,12038200
366 | 2020-04-17,2372.330078,2400.000000,2316.020020,2375.000000,2375.000000,7930000
367 | 2020-04-20,2389.949951,2444.979980,2386.050049,2393.610107,2393.610107,5770700
368 | 2020-04-21,2416.610107,2428.310059,2279.659912,2328.120117,2328.120117,7476700
369 | 2020-04-22,2369.000000,2394.000000,2351.000000,2363.489990,2363.489990,4218300
370 | 2020-04-23,2399.979980,2424.219971,2382.080078,2399.449951,2399.449951,5066600
371 | 2020-04-24,2417.000000,2420.429932,2382.000000,2410.219971,2410.219971,3831800
372 | 2020-04-27,2443.199951,2444.879883,2363.000000,2376.000000,2376.000000,5645600
373 | 2020-04-28,2372.100098,2373.500000,2306.000000,2314.080078,2314.080078,5269400
374 | 2020-04-29,2330.010010,2391.889893,2310.000000,2372.709961,2372.709961,4591600
375 | 2020-04-30,2419.840088,2475.000000,2396.010010,2474.000000,2474.000000,9534600
376 | 2020-05-01,2336.800049,2362.439941,2258.189941,2286.040039,2286.040039,9754900
377 | 2020-05-04,2256.379883,2326.979980,2256.379883,2315.989990,2315.989990,4865900
378 | 2020-05-05,2340.000000,2351.000000,2307.129883,2317.800049,2317.800049,3242500
379 | 2020-05-06,2329.439941,2357.449951,2320.000000,2351.260010,2351.260010,3117800
380 | 2020-05-07,2374.780029,2376.000000,2343.110107,2367.610107,2367.610107,3396400
381 | 2020-05-08,2372.139893,2387.239990,2357.000000,2379.610107,2379.610107,3211200
382 | 2020-05-11,2374.699951,2419.669922,2372.110107,2409.000000,2409.000000,3259200
383 | 2020-05-12,2411.850098,2419.000000,2355.000000,2356.949951,2356.949951,3074900
384 | 2020-05-13,2366.800049,2407.699951,2337.800049,2367.919922,2367.919922,4782900
385 | 2020-05-14,2361.010010,2391.370117,2353.209961,2388.850098,2388.850098,3648100
386 | 2020-05-15,2368.520020,2411.000000,2356.370117,2409.780029,2409.780029,4235000
387 | 2020-05-18,2404.350098,2433.000000,2384.010010,2426.260010,2426.260010,4366600
388 | 2020-05-19,2429.830078,2485.000000,2428.969971,2449.330078,2449.330078,4320500
389 | 2020-05-20,2477.870117,2500.010010,2467.270020,2497.939941,2497.939941,3998100
390 | 2020-05-21,2500.000000,2525.449951,2442.540039,2446.739990,2446.739990,5114400
391 | 2020-05-22,2455.010010,2469.850098,2430.129883,2436.879883,2436.879883,2867100
392 | 2020-05-26,2458.000000,2462.000000,2414.060059,2421.860107,2421.860107,3568200
393 | 2020-05-27,2404.989990,2413.580078,2330.000000,2410.389893,2410.389893,5056900
394 | 2020-05-28,2384.330078,2436.969971,2378.229980,2401.100098,2401.100098,3190200
395 | 2020-05-29,2415.939941,2442.370117,2398.199951,2442.370117,2442.370117,3529300
396 | 2020-06-01,2448.000000,2476.929932,2444.169922,2471.040039,2471.040039,2928900
397 | 2020-06-02,2467.000000,2473.530029,2445.310059,2472.409912,2472.409912,2529900
398 | 2020-06-03,2468.010010,2488.000000,2461.169922,2478.399902,2478.399902,2671000
399 | 2020-06-04,2477.429932,2507.540039,2450.010010,2460.600098,2460.600098,2948700
400 | 2020-06-05,2444.510010,2488.649902,2437.129883,2483.000000,2483.000000,3306400
401 | 2020-06-08,2500.199951,2530.000000,2487.340088,2524.060059,2524.060059,3970700
402 | 2020-06-09,2529.439941,2626.429932,2525.000000,2600.860107,2600.860107,5176000
403 | 2020-06-10,2645.000000,2722.350098,2626.260010,2647.449951,2647.449951,4946000
404 | 2020-06-11,2603.500000,2671.379883,2536.229980,2557.959961,2557.959961,5800100
405 | 2020-06-12,2601.209961,2621.479980,2503.350098,2545.020020,2545.020020,5429600
406 | 2020-06-15,2526.600098,2584.000000,2508.000000,2572.679932,2572.679932,3865100
407 | 2020-06-16,2620.000000,2620.000000,2576.000000,2615.270020,2615.270020,3585600
408 | 2020-06-17,2647.500000,2655.000000,2631.820068,2640.979980,2640.979980,2951100
409 | 2020-06-18,2647.010010,2659.639893,2636.110107,2653.979980,2653.979980,2487800
410 | 2020-06-19,2678.080078,2697.429932,2659.000000,2675.010010,2675.010010,5777000
411 | 2020-06-22,2684.500000,2715.000000,2669.000000,2713.820068,2713.820068,3208800
412 | 2020-06-23,2726.020020,2783.110107,2718.040039,2764.409912,2764.409912,4231700
413 | 2020-06-24,2780.000000,2796.000000,2721.000000,2734.399902,2734.399902,4526600
414 | 2020-06-25,2739.550049,2756.229980,2712.139893,2754.580078,2754.580078,2968700
415 | 2020-06-26,2775.060059,2782.570068,2688.000000,2692.870117,2692.870117,6500800
416 | 2020-06-29,2690.010010,2696.800049,2630.080078,2680.379883,2680.379883,4223400
417 | 2020-06-30,2685.070068,2769.629883,2675.030029,2758.820068,2758.820068,3769700
418 | 2020-07-01,2757.989990,2895.000000,2754.000000,2878.699951,2878.699951,6363400
419 | 2020-07-02,2912.010010,2955.560059,2871.100098,2890.300049,2890.300049,6593400
420 | 2020-07-06,2934.969971,3059.879883,2930.000000,3057.040039,3057.040039,6880600
421 | 2020-07-07,3058.550049,3069.550049,2990.000000,3000.120117,3000.120117,5257500
422 | 2020-07-08,3022.610107,3083.969971,3012.429932,3081.110107,3081.110107,5037600
423 | 2020-07-09,3115.989990,3193.879883,3074.000000,3182.629883,3182.629883,6388700
424 | 2020-07-10,3191.760010,3215.000000,3135.699951,3200.000000,3200.000000,5486000
425 | 2020-07-13,3251.060059,3344.290039,3068.389893,3104.000000,3104.000000,7720400
426 | 2020-07-14,3089.000000,3127.379883,2950.000000,3084.000000,3084.000000,7231900
427 | 2020-07-15,3080.229980,3098.350098,2973.179932,3008.870117,3008.870117,5788900
428 | 2020-07-16,2971.060059,3032.000000,2918.229980,2999.899902,2999.899902,6394200
429 | 2020-07-17,3009.000000,3024.000000,2948.449951,2961.969971,2961.969971,4761300
430 | 2020-07-20,3000.199951,3201.360107,2994.020020,3196.840088,3196.840088,7598200
431 | 2020-07-21,3232.489990,3240.580078,3105.719971,3138.290039,3138.290039,6135000
432 | 2020-07-22,3125.000000,3150.000000,3065.260010,3099.909912,3099.909912,4104200
433 | 2020-07-23,3098.270020,3098.270020,2970.000000,2986.550049,2986.550049,5656900
434 | 2020-07-24,2930.000000,3031.580078,2888.000000,3008.909912,3008.909912,5632400
435 | 2020-07-27,3062.000000,3098.000000,3015.770020,3055.209961,3055.209961,4170500
436 | 2020-07-28,3054.270020,3077.090088,2995.760010,3000.330078,3000.330078,3126700
437 | 2020-07-29,3030.989990,3039.159912,2996.770020,3033.530029,3033.530029,2974100
438 | 2020-07-30,3014.000000,3092.000000,3005.000000,3051.879883,3051.879883,6128300
439 | 2020-07-31,3244.000000,3246.820068,3151.000000,3164.679932,3164.679932,8085500
440 | 2020-08-03,3180.510010,3184.000000,3104.000000,3111.889893,3111.889893,5074700
441 | 2020-08-04,3101.209961,3167.239990,3101.209961,3138.830078,3138.830078,4694300
442 | 2020-08-05,3143.770020,3213.590088,3127.300049,3205.030029,3205.030029,3930000
443 | 2020-08-06,3194.360107,3247.469971,3165.429932,3225.000000,3225.000000,3940600
444 | 2020-08-07,3224.010010,3240.810059,3140.669922,3167.459961,3167.459961,3929600
445 | 2020-08-10,3170.310059,3172.510010,3101.520020,3148.159912,3148.159912,3167300
446 | 2020-08-11,3113.199951,3159.219971,3073.000000,3080.669922,3080.669922,3718100
447 | 2020-08-12,3108.000000,3174.389893,3101.419922,3162.239990,3162.239990,3527200
448 | 2020-08-13,3182.989990,3217.520020,3155.000000,3161.020020,3161.020020,3149000
449 | 2020-08-14,3178.179932,3178.239990,3120.000000,3148.020020,3148.020020,2751700
450 | 2020-08-17,3173.120117,3194.969971,3154.179932,3182.409912,3182.409912,2691200
451 | 2020-08-18,3212.000000,3320.000000,3205.820068,3312.489990,3312.489990,5346000
452 | 2020-08-19,3303.010010,3315.899902,3256.000000,3260.479980,3260.479980,4185100
453 | 2020-08-20,3252.000000,3312.620117,3238.000000,3297.370117,3297.370117,3332500
454 | 2020-08-21,3295.000000,3314.399902,3275.389893,3284.719971,3284.719971,3575900
455 | 2020-08-24,3310.149902,3380.320068,3257.560059,3307.459961,3307.459961,4666300
456 | 2020-08-25,3294.989990,3357.399902,3267.000000,3346.489990,3346.489990,3992800
457 | 2020-08-26,3351.110107,3451.739990,3344.570068,3441.850098,3441.850098,6508700
458 | 2020-08-27,3450.050049,3453.000000,3378.000000,3400.000000,3400.000000,4264800
459 | 2020-08-28,3423.000000,3433.370117,3386.500000,3401.800049,3401.800049,2897000
460 | 2020-08-31,3408.989990,3495.000000,3405.000000,3450.959961,3450.959961,4185900
461 | 2020-09-01,3489.580078,3513.870117,3467.000000,3499.120117,3499.120117,3476400
462 | 2020-09-02,3547.000000,3552.250000,3486.689941,3531.449951,3531.449951,3931500
463 | 2020-09-03,3485.000000,3488.409912,3303.000000,3368.000000,3368.000000,8161100
464 | 2020-09-04,3318.000000,3381.500000,3111.129883,3294.620117,3294.620117,8781800
465 | 2020-09-08,3144.000000,3250.850098,3130.000000,3149.840088,3149.840088,6094200
466 | 2020-09-09,3202.989990,3303.179932,3185.000000,3268.610107,3268.610107,5188700
467 | 2020-09-10,3307.219971,3349.889893,3170.550049,3175.110107,3175.110107,5330700
468 | 2020-09-11,3208.689941,3217.340088,3083.979980,3116.219971,3116.219971,5094000
469 | 2020-09-14,3172.939941,3187.389893,3096.000000,3102.969971,3102.969971,4529600
470 | 2020-09-15,3136.159912,3175.020020,3108.919922,3156.129883,3156.129883,4021500
471 | 2020-09-16,3179.989990,3187.239990,3074.149902,3078.100098,3078.100098,4512200
472 | 2020-09-17,3009.250000,3029.429932,2972.550049,3008.729980,3008.729980,6449100
473 | 2020-09-18,3031.739990,3037.800049,2905.540039,2954.909912,2954.909912,8892600
474 | 2020-09-21,2906.500000,2962.000000,2871.000000,2960.469971,2960.469971,6117900
475 | 2020-09-22,3033.840088,3133.989990,3000.199951,3128.989990,3128.989990,6948800
476 | 2020-09-23,3120.429932,3127.000000,2992.379883,2999.860107,2999.860107,5652700
477 | 2020-09-24,2977.790039,3069.300049,2965.000000,3019.790039,3019.790039,5529400
478 | 2020-09-25,3054.860107,3101.540039,2999.000000,3095.129883,3095.129883,4615200
479 | 2020-09-28,3148.850098,3175.040039,3117.169922,3174.050049,3174.050049,4224200
480 | 2020-09-29,3175.389893,3188.260010,3132.540039,3144.879883,3144.879883,3495800
481 | 2020-09-30,3141.139893,3212.879883,3133.989990,3148.729980,3148.729980,4883400
482 | 2020-10-01,3208.000000,3224.000000,3172.000000,3221.260010,3221.260010,4971900
483 | 2020-10-02,3153.629883,3195.800049,3123.000000,3125.000000,3125.000000,5613100
484 | 2020-10-05,3145.840088,3202.530029,3140.850098,3199.199951,3199.199951,3775300
485 | 2020-10-06,3165.000000,3182.000000,3090.000000,3099.959961,3099.959961,5086900
486 | 2020-10-07,3135.000000,3200.000000,3132.389893,3195.689941,3195.689941,4309400
487 | 2020-10-08,3224.989990,3233.290039,3174.989990,3190.550049,3190.550049,3174100
488 | 2020-10-09,3210.000000,3288.989990,3197.830078,3286.649902,3286.649902,4907900
489 | 2020-10-12,3349.939941,3496.239990,3339.550049,3442.929932,3442.929932,8364200
490 | 2020-10-13,3467.989990,3492.379883,3424.219971,3443.629883,3443.629883,5744700
491 | 2020-10-14,3447.000000,3464.879883,3340.000000,3363.709961,3363.709961,5828900
492 | 2020-10-15,3292.010010,3355.879883,3280.000000,3338.649902,3338.649902,5223400
493 | 2020-10-16,3363.229980,3399.659912,3160.000000,3272.709961,3272.709961,6474400
494 | 2020-10-19,3299.610107,3329.000000,3192.739990,3207.209961,3207.209961,5223600
495 | 2020-10-20,3222.280029,3266.000000,3192.010010,3217.010010,3217.010010,4509700
496 | 2020-10-21,3212.500000,3233.879883,3160.000000,3184.939941,3184.939941,4592700
497 | 2020-10-22,3189.870117,3198.750000,3121.939941,3176.399902,3176.399902,4212000
498 | 2020-10-23,3191.000000,3205.330078,3140.000000,3204.399902,3204.399902,3466700
499 | 2020-10-26,3198.739990,3282.979980,3153.300049,3207.040039,3207.040039,5901200
500 | 2020-10-27,3224.939941,3291.659912,3211.300049,3286.330078,3286.330078,4291000
501 | 2020-10-28,3249.300049,3264.020020,3162.469971,3162.780029,3162.780029,5588300
502 | 2020-10-29,3201.270020,3257.250000,3164.000000,3211.010010,3211.010010,6596500
503 | 2020-10-30,3157.750000,3167.000000,3019.000000,3036.149902,3036.149902,8386400
504 |
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/alibaba_stock_adjust_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/alibaba_stock_adjust_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/alibaba_stock_adjust_trendy_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/alibaba_stock_adjust_trendy_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/alibaba_stock_normal_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/alibaba_stock_normal_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/amazon_stock_adjust_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/amazon_stock_adjust_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/amazon_stock_adjust_trendy_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/amazon_stock_adjust_trendy_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/amazon_stock_normal_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/amazon_stock_normal_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/error_adjust_s1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/error_adjust_s1.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/error_adjust_s2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/error_adjust_s2.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/google_stock_adjust_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/google_stock_adjust_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/google_stock_adjust_trendy_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/google_stock_adjust_trendy_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/google_stock_normal_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/google_stock_normal_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/jd_stock_adjust_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/jd_stock_adjust_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/jd_stock_adjust_trendy_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/jd_stock_adjust_trendy_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/images/jd_stock_normal_forecast.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecast_auto_adjustment/images/jd_stock_normal_forecast.png
--------------------------------------------------------------------------------
/forecast_auto_adjustment/ts_features.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 | #@author: Jing Wang
3 | #@date: 09/17/2020
4 |
5 | '''
6 | 特征工程模块:时间序列生成,包括基本时间序列,lag特征和滚动特征
7 | '''
8 |
9 | import json
10 | import argparse
11 | import datetime
12 | import pandas as pd
13 | from joblib import Parallel, delayed
14 |
15 | import os
16 | import sys
17 | import util
18 |
19 | import chinese_calendar
20 |
21 | CHINESE_HOLIDAYS = chinese_calendar.constants.holidays
22 | CHINESE_WORKDAYS = chinese_calendar.constants.workdays
23 | CHINESE_LIEUDAYS = chinese_calendar.constants.in_lieu_days
24 |
25 | def get_holiday_stats(min_year, max_year):
26 | '''
27 | 计算节假日的第几天,节假日第1天,节假日最后一天
28 |
29 | Arg:
30 | min_year (int): 开始扫描的年份
31 | max_year (int): 结束扫描的年份
32 | [min_year, max_year]
33 | '''
34 | holiday_days = list(CHINESE_HOLIDAYS.keys())
35 | holiday_days.sort()
36 | holiday_index = {}
37 | holiday_first = set([])
38 | holiday_final = set([])
39 | count = 1
40 | is_prev_final = False
41 | for idx, day in enumerate(holiday_days):
42 | if day.year < min_year or day.year > max_year:
43 | continue
44 | next_day = day + datetime.timedelta(days=1)
45 | prev_day = day - datetime.timedelta(days=1)
46 | if next_day in holiday_days:
47 | if is_prev_final:
48 | holiday_first.add(day)
49 | holiday_index[day] = count
50 | is_prev_final = False
51 | count += 1
52 | else:
53 | if not prev_day in holiday_days:
54 | holiday_first.add(day)
55 | holiday_final.add(day)
56 | is_prev_final = True
57 | holiday_index[day] = count
58 | count = 1
59 | return holiday_index, holiday_first, holiday_final
60 |
61 | def get_before_after_holiday(data, before_count=5, after_count=5):
62 | '''
63 | 节假日前后统计
64 | Args:
65 | data (pd.DataFrame)
66 | before_count (int)
67 | after_count (int)
68 | '''
69 | before = {}
70 | after = {}
71 | first_day = set(data.loc[data["is_holiday_first_fea"] == 1, "ds"].tolist())
72 | final_day = set(data.loc[data["is_holiday_final_fea"] == 1, "ds"].tolist())
73 | for first in first_day:
74 | for c in range(1, before_count+1):
75 | day = first - datetime.timedelta(days=c)
76 | before[day] = c
77 | for final in final_day:
78 | for c in range(1, after_count+1):
79 | day = final + datetime.timedelta(days=c)
80 | after[day] = c
81 | data["before_holiday_day_fea"] = data["ds"].apply(lambda x: before[x] if x in before else 0)
82 | data["after_holiday_day_fea"] = data["ds"].apply(lambda x: after[x] if x in after else 0)
83 | return data
84 |
85 | def basic_ts(data):
86 | '''
87 | 根据ds生成基本的时间序列特征
88 |
89 | Args:
90 | data (DataFrame): 数据表
91 | Return:
92 | data (DataFrame): 数据表带有基本时间序列特征
93 | '''
94 | data["ds"] = data["ds"].apply(util.date_converter)
95 |
96 | # 生成时间特征 x_of_y
97 | data["day_of_week_fea"] = data["ds"].apply(lambda x: x.isoweekday() # monday表示1
98 | if isinstance(x, datetime.datetime) else None)
99 | data["day_of_month_fea"] = data["ds"].apply(lambda x: x.day
100 | if isinstance(x, datetime.datetime) else None)
101 | data["day_of_year_fea"] = data["ds"].apply(lambda x: x.timetuple().tm_yday
102 | if isinstance(x, datetime.datetime) else None)
103 | data["week_of_year_fea"] = data["ds"].apply(lambda x: x.isocalendar()[1]
104 | if isinstance(x, datetime.datetime) else None)
105 | data["month_of_year_fea"] = data["ds"].apply(lambda x: x.month
106 | if isinstance(x, datetime.datetime) else None)
107 | data["is_weekend_fea"] = data["day_of_week_fea"].apply(lambda x: 1 if x >= 6 else 0)
108 |
109 | # 是否节假日,是否工作日,是否休息日/调休
110 | data["is_holiday_fea"] = data["ds"].apply(lambda x: 1 if x.date() in CHINESE_HOLIDAYS else 0)
111 | data["is_workday_fea"] = data["ds"].apply(lambda x: 1 if x.date() in CHINESE_WORKDAYS else 0)
112 | data["is_lieuday_fea"] = data["ds"].apply(lambda x: 1 if x.date() in CHINESE_LIEUDAYS else 0)
113 |
114 | # 节假日第几天
115 | min_year = data["ds"].min().year - 1
116 | max_year = data["ds"].max().year + 1
117 | holiday_index, holiday_first, holiday_final = get_holiday_stats(min_year, max_year)
118 | data["is_holiday_first_fea"] = data["ds"].apply(lambda x: 1 if x.date() in holiday_first else 0)
119 | data["is_holiday_final_fea"] = data["ds"].apply(lambda x: 1 if x.date() in holiday_final else 0)
120 | data["holiday_day_fea"] = data["ds"].apply(lambda x: holiday_index[x.date()] if x.date() in holiday_index else 0)
121 |
122 | # 节前第几天,节后第几天
123 | data = get_before_after_holiday(data, before_count=5, after_count=5)
124 | data["ds"] = data["ds"].apply(util.date_parser)
125 | return data
126 |
127 | def lag_ts(data, lag_windows=[1, 7]):
128 | '''
129 | 根据lag_windows生成lag特征,windows的单位:天
130 |
131 | Args:
132 | data (DataFrame): 输入数据表
133 | lag_windows (list): lag时间窗口大小,单位为天
134 | '''
135 | for lag in lag_windows:
136 | data[f'{lag}_day_before_fea'] = data["y"].shift(lag)
137 | return data
138 |
139 | def roll_ts(data, roll_windows=[1, 7]):
140 | '''
141 | 滚动特征
142 |
143 | Args:
144 | data (DataFrame): 输入数据表
145 | roll_windows (list): 滚动时间窗口大小,单位为天
146 | '''
147 |
148 | for window in roll_windows:
149 | roll = data["y"].shift(1).rolling(window=window)
150 | tmp = pd.concat([roll.max(), roll.min(), roll.mean(), roll.sum(), roll.median()], axis=1)
151 | tmp.columns = [f'max_over_{window}_days_fea', f'min_over_{window}_days_fea',
152 | f'mean_over_{window}_days_fea', f'sum_over_{window}_days_fea', f'median_over_{window}_days_fea']
153 | data = pd.concat([data, tmp], axis=1)
154 | return data
155 |
156 | def ewm_ts(data, advance):
157 | '''
158 | 指数加权平均
159 |
160 | Args:
161 | data (DataFrame):输入数据表
162 | '''
163 | shifted = data["y"].shift(advance)
164 | data["ewm_fea"] = shifted.ewm(alpha=0.5, adjust=True, ignore_na=False).mean()
165 | return data
166 |
167 | def ts_single(data, lag, roll, ewm, lag_windows, roll_windows, ewm_advance):
168 | '''
169 | 基于某个ID的序列,生成关于这个ID的时间序列
170 | '''
171 | data.sort_values("ds", inplace=True)
172 |
173 | # 保证日期的连续性
174 | df = util.fill_ts(data)
175 |
176 | if lag:
177 | df = lag_ts(df, lag_windows)
178 | if roll:
179 | df = roll_ts(df, roll_windows)
180 | if ewm:
181 | df = ewm_ts(df, ewm_advance)
182 |
183 | df.drop(columns=["y"], axis=1, inplace=True)
184 | data = pd.merge(data, df, on="ds", how="left")
185 | return data
186 |
187 | def generate_ts(data, params, n_jobs=-1):
188 | if "ds" in data:
189 | data["ds"] = data["ds"].apply(lambda x: util.date_parser(util.date_converter(x)))
190 | lag = params["lag"]["flag"]
191 | roll = params["rolling"]["flag"]
192 | ewm = params["ewm"]["flag"]
193 |
194 | lag_windows = params["lag"].get("window", None)
195 | roll_windows = params["rolling"].get("window", None)
196 | ewm_advance = params["ewm"].get("advance", None)
197 | skus = data["id"].unique().tolist()
198 | results = Parallel(n_jobs=n_jobs, verbose=0)(delayed(ts_single)(data.loc[data["id"] == sku], \
199 | lag, roll, ewm, lag_windows, roll_windows, ewm_advance) for sku in skus)
200 | output = pd.concat(results, axis=0)
201 | output = basic_ts(output)
202 |
203 | # 填充0
204 | output.fillna(0, inplace=True)
205 | return output
206 |
--------------------------------------------------------------------------------
/forecast_auto_adjustment/util.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 | # Author: Xingyu Liu 01368856
3 | # Date: Feb 06, 2020
4 |
5 | #@modified: Jing Wang
6 | #@date: 09/18/2020
7 |
8 | import os
9 | import json
10 | import random
11 | import calendar
12 | import numpy as np
13 | import pandas as pd
14 |
15 | import matplotlib.pyplot as plt
16 | import seaborn as sns
17 | from datetime import timedelta, datetime
18 | from monthdelta import monthdelta
19 | import lightgbm as lgb
20 | from sklearn.model_selection import KFold
21 | from bayes_opt import BayesianOptimization
22 | from sklearn import model_selection
23 | from itertools import product
24 | from copy import deepcopy
25 | import xgboost as xgb
26 |
27 | def get_data_path():
28 | folder = os.path.split(os.path.realpath(__file__))[0] # os.path.dirname(os.path.dirname(__file__))
29 | return os.path.join(folder, "")
30 |
31 | def is_json(myjson):
32 | try:
33 | json.loads(myjson)
34 | except:
35 | return False
36 | return True
37 |
38 | def output_json(data, filename):
39 | '''
40 | output data to json
41 | :param data:
42 | :param filename:
43 | :return:
44 | '''
45 | with open(filename, 'w', encoding='utf-8') as f:
46 | json.dump(data, f, ensure_ascii=False)
47 |
48 | def draw_feature_importance(report_path, feature_importance):
49 | # draw feature importance
50 | photoLength = len(feature_importance) / 2 if len(feature_importance) > 10 else 5
51 | plt.figure(figsize=(20, photoLength))
52 | sns.barplot(x='Value', y='Feature', data=feature_importance.sort_values(by='Value', ascending=False))
53 | plt.title("LightGBM Feature Importance")
54 | plt.tight_layout()
55 | plt.savefig(report_path + "feature_importance.png")
56 |
57 | def get_dates(year, month):
58 | year = int(year)
59 | month = int(month)
60 | _, ndays = calendar.monthrange(year, month)
61 | if month < 10:
62 | mon = str(0) + str(month)
63 | else:
64 | mon = str(month)
65 | base = str(year) + mon
66 | dates = []
67 | for d in range(1, ndays):
68 | if d < 10:
69 | d = str(0) + str(d)
70 | else:
71 | d = str(d)
72 | dates.append(int(base + d))
73 | return dates
74 |
75 | def get_period_value_and_unit(period):
76 | '''
77 | 把周期字符串拆解为数值和单位
78 | :param period: 输入的周期,字符串,如"7d"
79 | :return: 周期对应的数值及单位,如返回7和"d"
80 | '''
81 | # default value
82 | period_value = 7
83 | period_unit = 'd'
84 |
85 | if period.endswith('m'):
86 | period_unit = 'm'
87 | period_value = int(period.replace('m', ''))
88 | elif period.endswith('d'):
89 | period_unit = 'd'
90 | period_value = int(period.replace('d', ''))
91 |
92 | return period_value, period_unit
93 |
94 | def add_some_time(cur_time_str, value, unit):
95 | '''
96 | 从某个时刻增加一段时间
97 | :param cur_time_str: 当前时间,字符串类型
98 | :param value: 需要增加的时间长度
99 | :param unit: 时间长度的单位
100 | :return: 结果字符串
101 | '''
102 |
103 | val_start_date = datetime.strptime(cur_time_str, '%Y-%m-%d')
104 | if unit == 'm':
105 | val_week_date = val_start_date + monthdelta(months=value)
106 | elif unit == 'd':
107 | val_week_date = val_start_date + timedelta(days=value)
108 | else:
109 | raise ValueError('Incorrect value with roll_period {}. '.format(str(value)+str(unit)))
110 |
111 | return val_week_date.strftime("%Y-%m-%d")
112 |
113 |
114 | def train_test_split(X, y, train_ratio=0.7):
115 | num_periods, num_features = X.shape
116 | train_periods = int(num_periods * train_ratio)
117 | random.seed(2)
118 | Xtr = X[:train_periods]
119 | ytr = y[:train_periods]
120 | Xte = X[train_periods:]
121 | yte = y[train_periods:]
122 | return Xtr, ytr, Xte, yte
123 |
124 |
125 | ###############################################################
126 | # metric
127 | ###############################################################
128 |
129 | # define MAPE function
130 | def mean_absolute_percentage_error(y_true, y_pred):
131 | '''
132 | :param y_true: 实际Y值
133 | :param y_pred: 预测Y值
134 | :return: MAPE
135 | '''
136 | y_true, y_pred = np.array(y_true), np.array(y_pred)
137 | mape = np.mean(np.abs((y_true - y_pred) / (y_true))) * 100
138 | return mape
139 |
140 | def MAPE_handle_zero(y_true, y_pred):
141 | '''
142 | * 此处,为了防止一些实际值为0的情况,此处分母处加了1e-2,可能会导致MAPE的值高启,需要注意。
143 | :param y_true: 实际Y值
144 | :param y_pred: 预测Y值
145 | :return: MAPE
146 | '''
147 | y_true, y_pred = np.array(y_true), np.array(y_pred)
148 | mape = np.mean(np.abs((y_true - y_pred) / (y_true + 1e-2))) * 100
149 | return mape
150 |
151 | # define WMAPE function
152 | def weighted_mean_absolute_percentage_error(y_true, y_pred):
153 | '''
154 | :param y_true: 实际Y值
155 | :param y_pred: 预测Y值
156 | :return: WMAPE
157 | '''
158 | y_true, y_pred = np.array(y_true), np.array(y_pred)
159 | wmape = 100 * np.sum(np.abs(y_true - y_pred)) / np.sum(y_true)
160 | return wmape
161 |
162 | def WMAPE_handle_zero(y_true, y_pred):
163 | '''
164 | :param y_true: 实际Y值
165 | :param y_pred: 预测Y值
166 | :return: WMAPE
167 | '''
168 | y_true, y_pred = np.array(y_true), np.array(y_pred)
169 | wmape = 100 * np.sum(np.abs(y_true - y_pred)) / (np.sum(y_true) + 1e-2)
170 | return wmape
171 |
172 |
173 | # define SMAPE function
174 | def symmetric_mean_absolute_percentage_error(y_true, y_pred):
175 | '''
176 | :param y_true: 实际Y值
177 | :param y_pred: 预测Y值
178 | :return: SMAPE
179 | '''
180 | y_true, y_pred = np.array(y_true), np.array(y_pred)
181 | smape = 2.0 * np.mean(np.abs(y_pred - y_true) / (np.abs(y_pred) + np.abs(y_true))) * 100
182 | return smape
183 |
184 | def SMAPE_handle_zero(y_true, y_pred):
185 | '''
186 | * 此处,为了防止一些实际值为0的情况,此处分母处加了0.01,可能会导致MAPE的值高启,需要注意。
187 | :param y_true: 实际Y值
188 | :param y_pred: 预测Y值
189 | :return: SMAPE
190 | '''
191 | y_true, y_pred = np.array(y_true), np.array(y_pred)
192 | smape = 2.0 * np.mean(np.abs(y_pred - y_true) / (np.abs(y_pred) + np.abs(y_true) + 1e-2)) * 100
193 | return smape
194 |
195 | def add_lag_and_window_feature_name(train_features, lag_list, window_list):
196 | '''
197 | 添加需要滚动的特征名称
198 | :param train_features:
199 | :param lag_list:
200 | :param window_list:
201 | :return:
202 | '''
203 | for lag in lag_list:
204 | train_features.append(f'{lag}_day_before')
205 | for w in window_list:
206 | train_features.extend([f'max_over_{w}_days', f'min_over_{w}_days', f'mean_over_{w}_days', f'sum_over_{w}_days'])
207 |
208 |
209 | def construct_features(data, lag_list, window_list):
210 | basic = pd.DataFrame(data.y)
211 | for lag in lag_list:
212 | tmp = basic.shift(lag)
213 | tmp.rename(columns={'y': f'{lag}_day_before'}, inplace=True)
214 | data = pd.concat([data, tmp], axis=1)
215 |
216 | for w in window_list:
217 | shifted = basic.shift(1)
218 | window = shifted.rolling(window=w)
219 | tmp = pd.concat([window.max(), window.min(), window.mean(), window.sum()], axis=1)
220 | tmp.columns = [f'max_over_{w}_days', f'min_over_{w}_days', f'mean_over_{w}_days', f'sum_over_{w}_days']
221 | data = pd.concat([data, tmp], axis=1)
222 |
223 | return data
224 |
225 | def date_converter(x):
226 | '''
227 | 转换为日期格式
228 | '''
229 | if x is None:
230 | return x
231 | try:
232 | x = str(x)
233 | except Exception:
234 | return x
235 |
236 | try:
237 | return datetime.strptime(x, "%Y-%m-%d")
238 | except Exception:
239 | try:
240 | return datetime.strptime(x, "%Y/%m/%d")
241 | except Exception:
242 | try:
243 | return datetime.strptime(x, "%Y%m%d")
244 | except Exception:
245 | return x
246 |
247 | def date_parser(x):
248 | '''
249 | 日期格式转换为string
250 | '''
251 | if not isinstance(x, datetime):
252 | return None
253 |
254 | try:
255 | return x.strftime("%Y-%m-%d")
256 | except Exception:
257 | try:
258 | return x.strptime("%Y/%m/%d")
259 | except Exception:
260 | try:
261 | return x.strptime("%Y%m%d")
262 | except Exception:
263 | return None
264 |
265 | def fill_ts(data):
266 | '''
267 | 填充时间序列,只保留两列,[ts, y]
268 | '''
269 |
270 | min_dt = date_converter(data["ds"].min())
271 | max_dt = date_converter(data["ds"].max())
272 | date_list = [date_parser(x) for x in pd.date_range(start=min_dt, end=max_dt)]
273 | date_df = pd.DataFrame(date_list, columns=["ds"])
274 | df = pd.merge(date_df, data[["ds", "y"]], on="ds", how="left")
275 | df["y"].fillna(0, inplace=True)
276 | return df
277 |
278 | def dt64_to_datetime(dt64):
279 | '''
280 | :param dt64:
281 | :return:
282 | '''
283 | if np.isnat(dt64):
284 | return None
285 | else:
286 | unix_epoch = np.datetime64(0, 's')
287 | one_second = np.timedelta64(1, 's')
288 | seconds_since_epoch = (dt64 - unix_epoch) / one_second
289 | return datetime.utcfromtimestamp(seconds_since_epoch)
290 |
291 | def get_date_diff(start_date_str, end_date_str):
292 | '''
293 | 获取日期差
294 | :param start_date_str:str
295 | :param end_date_str:str
296 | :return:
297 | '''
298 | start_date = datetime.strptime(start_date_str, "%Y-%m-%d")
299 | end_date = datetime.strptime(end_date_str, "%Y-%m-%d")
300 | ret_val = (end_date-start_date).days
301 | return ret_val
302 |
303 | def get_dates_list(start_date, end_date):
304 | '''
305 | 获取日期区间
306 | :param start_date:str
307 | :param end_date:str
308 | :return:
309 | '''
310 | date_list = []
311 | start_date = datetime.datetime.strptime(start_date, "%Y-%m-%d")
312 | end_date = datetime.datetime.strptime(end_date, "%Y-%m-%d")
313 | while start_date <= end_date:
314 | date_str = start_date.strftime("%Y-%m-%d")
315 | date_list.append(date_str)
316 | start_date += datetime.timedelta(days=1)
317 | return date_list
318 |
319 | def get_model_info(model_name, data, results, mode):
320 | 'Get model information output'
321 | train_size = len(data[data["set_flag"] == mode["train"]])
322 | val_size = len(data[data["set_flag"] == mode["validation"]])
323 | test_size = len(data[data["set_flag"] == mode["test"]])
324 | val_data = results[results["set_flag"] == mode["validation"]]
325 | y = val_data["y"]
326 | ypred = val_data["y_pred"]
327 | info = {}
328 | info["model"] = model_name
329 | info["train_set_size"] = train_size
330 | info["validation_set_size"] = val_size
331 | info["test_set_size"] = test_size
332 | info["WMAPE"] = WMAPE_handle_zero(y, ypred)
333 | return info
334 |
335 | class GridSearchCV(object):
336 |
337 | def __init__(self, params_grid, model="lightgbm", cv=5, random_state=0):
338 | self.cv = cv
339 | self.random_state = random_state
340 |
341 | basic_params = {}
342 | search_params = {}
343 | for param, values in params_grid.items():
344 | if len(values) == 1:
345 | basic_params[param] = values
346 | else:
347 | search_params[param] = values
348 | self.basic_params = basic_params
349 | self.param_grid = search_params
350 |
351 | self.model = model
352 | self.num_boost_round = 1000
353 | self.early_stopping_rounds = 250
354 |
355 | def generate_params(self):
356 | # Always sort the keys of a dictionary, for reproducibility
357 | items = sorted(self.param_grid.items())
358 | if not items:
359 | yield {}
360 | else:
361 | keys, values = zip(*items)
362 | for v in product(*values):
363 | params = dict(zip(keys, v))
364 | yield params
365 |
366 | def fit(self, X, y, features, cat_features=None, init_points=5, n_iter=5,
367 | bayes_automated_tune=False,
368 | grid_tune=True):
369 | '''
370 | Grid Search Fit
371 | Args:
372 | X (data frame)
373 | y (np array)
374 | features (list): a list of feature columns to use
375 | init_points (int): how many steps of random exploration
376 | n_iter (int): how many iterations of bayesian optimization
377 | bayes_automated_tuning (bool): automated fine tuning
378 | grid_tune (bool): grid search
379 |
380 | Note:
381 | You could just set either init_points or n_iter as 0
382 | '''
383 | self.Xtrain = X
384 | self.ytrain = y
385 | self.features = features
386 | self.cat_features = cat_features
387 |
388 | if bayes_automated_tune and len(self.param_grid) > 0:
389 | optimizer = BayesianOptimization(
390 | f=self.fold_train,
391 | pbounds=self.param_grid
392 | )
393 | optimizer.maximize(
394 | init_points=init_points,
395 | n_iter=n_iter,
396 | )
397 |
398 | # get best parameters
399 | best_param = optimizer.max["params"]
400 | for p, val in best_param.items():
401 | if p in ["min_child_samples", "num_leaves",
402 | "max_depth", "n_estimators", "random_state"]:
403 | val = int(val)
404 | self.basic_params[p] = val
405 |
406 | if grid_tune and len(self.param_grid) > 0:
407 | best_score = float("-inf")
408 | best_param = None
409 | for param in self.generate_params():
410 | score = self.fold_train(**param)
411 | if score > best_score:
412 | best_score = score
413 | best_param = deepcopy(self.basic_params)
414 | self.basic_params = best_param
415 |
416 | if "weight" not in X.columns:
417 | X["weight"] = 1
418 |
419 | Xtr, Xval, ytr, yval = model_selection.train_test_split(X, y,
420 | test_size=0.1, random_state=self.random_state)
421 |
422 | if self.cat_features is None:
423 | cat_feat = "auto"
424 | else:
425 | cat_feat = self.cat_features
426 |
427 | if self.model == "lightgbm":
428 | trn_data = lgb.Dataset(
429 | Xtr[features],
430 | label=ytr,
431 | weight=Xtr.weight,
432 | categorical_feature=cat_feat
433 | )
434 |
435 | val_data = lgb.Dataset(
436 | Xval[features],
437 | label=yval,
438 | weight=Xval.weight,
439 | categorical_feature=cat_feat
440 | )
441 |
442 | self.best_estimator_ = lgb.train(
443 | self.basic_params,
444 | trn_data,
445 | num_boost_round=self.num_boost_round,
446 | valid_sets=[trn_data, val_data],
447 | early_stopping_rounds=self.early_stopping_rounds,
448 | verbose_eval=False,
449 | )
450 | elif self.model == "xgboost":
451 | trn_data = xgb.DMatrix(Xtr[features], label=ytr)
452 | val_data = xgb.DMatrix(Xval[features], label=yval)
453 | params = {k: v[0] for k, v in self.basic_params.items()}
454 | self.best_estimator_ = xgb.train(params, trn_data,
455 | evals=[(val_data, "validation")],
456 | verbose_eval=False,
457 | num_boost_round=self.num_boost_round,
458 | early_stopping_rounds=self.early_stopping_rounds)
459 |
460 | self.best_params_ = self.basic_params
461 |
462 | def fold_train(self, **kwargs):
463 | for p, val in kwargs.items():
464 | if p in ["min_child_samples", "num_leaves", "max_depth",
465 | "n_estimators", "random_state"]:
466 | val = int(val)
467 | self.basic_params[p] = [val]
468 |
469 | scores = []
470 | Xtrain = self.Xtrain
471 | ytrain = self.ytrain
472 | features = self.features
473 |
474 | if self.cat_features is None:
475 | cat_feat = "auto"
476 | else:
477 | cat_feat = self.cat_features
478 |
479 | if "weight" not in Xtrain.columns:
480 | Xtrain["weight"] = 1
481 |
482 | folds = KFold(n_splits=self.cv, shuffle=True, random_state=self.random_state)
483 | for fold_idx, (trn_idx, val_idx) in enumerate(folds.split(Xtrain.values, ytrain)):
484 | t_x = Xtrain.iloc[trn_idx]
485 | v_x = Xtrain.iloc[val_idx]
486 | label_train = ytrain[trn_idx].ravel()
487 | label_val = ytrain[val_idx].ravel()
488 |
489 | if self.model == "lightgbm":
490 | trn_data = lgb.Dataset(
491 | t_x[features],
492 | label=label_train,
493 | weight=t_x.weight,
494 | categorical_feature=cat_feat
495 | )
496 | val_data = lgb.Dataset(
497 | v_x[features],
498 | label=label_val,
499 | weight=v_x.weight,
500 | categorical_feature=cat_feat
501 | )
502 | # start = datetime.now()
503 | regressor = lgb.train(
504 | self.basic_params,
505 | trn_data,
506 | num_boost_round=self.num_boost_round,
507 | valid_sets=[trn_data, val_data],
508 | early_stopping_rounds=self.early_stopping_rounds,
509 | verbose_eval=False,
510 | )
511 |
512 | val_feat = v_x[features]
513 | elif self.model == "xgboost":
514 | trn_data = xgb.DMatrix(t_x[features], label=label_train)
515 | val_data = xgb.DMatrix(v_x[features], label=label_val)
516 | params = {k: v[0] for k, v in self.basic_params.items()}
517 | regressor = xgb.train(params, trn_data,
518 | evals=[(val_data, "validation")],
519 | verbose_eval=False,
520 | num_boost_round=self.num_boost_round,
521 | early_stopping_rounds=self.early_stopping_rounds)
522 | val_feat = xgb.DMatrix(v_x[features])
523 |
524 | ypred = regressor.predict(val_feat).ravel()
525 | mae = np.mean(np.abs(ypred - label_val))
526 | scores.append(mae)
527 | # end = datetime.now()
528 | # print("Time spent: {}s".format((end-start).total_seconds()))
529 | # raise
530 | return -np.mean(scores)
531 |
--------------------------------------------------------------------------------
/forecast_auto_adjustment/validation.py:
--------------------------------------------------------------------------------
1 | #-*-coding:utf-8
2 | #@Author: Jing Wang
3 | #@Date: 2020-11-06 14:47:16
4 | #@Last Modified by: Jing Wang
5 | #@Last Modified time: 2020-11-06 14:47:16
6 | #@reference:
7 |
8 | import pandas as pd
9 | import numpy as np
10 | import matplotlib.pyplot as plt
11 | import matplotlib.ticker as ticker
12 | import ts_features
13 | import util
14 | from sklearn.linear_model import LinearRegression
15 |
16 | def mape(y: np.array, ypred: np.array):
17 | return np.mean(np.abs(y - ypred) / y)
18 |
19 | def generate_ts(data: pd.DataFrame):
20 | data = data[["Date", "Close"]]
21 | data.columns = ["ds", "y"]
22 | data["id"] = "amazon"
23 | params = {
24 | "lag": {
25 | "flag": True,
26 | "window": [7, 14],
27 | },
28 | "rolling": {
29 | "flag": True,
30 | "window": [7, 14],
31 | },
32 | "ewm": {
33 | "flag": True,
34 | "advance": 7
35 | }
36 | }
37 | data = ts_features.generate_ts(data, params)
38 | return data
39 |
40 | def train(data: pd.DataFrame,
41 | train_end_date: str = "2019-12-31",
42 | test_end_date: str = "2020-10-29",
43 | test_start_date: str = "2020-01-01",
44 | roll_days: int = 14,
45 | adjust: bool = False,
46 | trendy: bool = False):
47 |
48 | results = []
49 | prev_error = None
50 | losses = []
51 | lr = LinearRegression()
52 | prev_idx = data[data["ds"] <= train_end_date].index[-1]
53 | count = 0
54 | while True:
55 | train = data.iloc[:prev_idx+1]
56 | test = data.iloc[prev_idx+1: prev_idx+roll_days]
57 | roll_end_date = train["ds"].tolist()[-1]
58 | if len(test) == 0:
59 | break
60 | prev_idx = test.index.tolist()[-1]
61 | feat_cols = [c for c in data.columns.tolist() if c not in ["ds", "y", "id"]]
62 | Xtrain, Xtest = train[feat_cols], test[feat_cols]
63 | ytrain, ytest = train["y"], test["y"]
64 |
65 | regressor = lr.fit(Xtrain, ytrain)
66 | ypred = regressor.predict(Xtest)
67 |
68 | # use other error
69 | # moving_average = np.mean(ytrain[:-roll_days])
70 | # error = (ytest.ravel() - ypred.ravel()) * (ypred.ravel() > moving_average).astype(int) + \
71 | # (ytest.ravel() - moving_average) * (ypred.ravel() <= moving_average).astype(int)
72 |
73 | error = ytest.ravel() - ypred.ravel()
74 | recent = np.array(ytrain[:-roll_days])
75 | if len(recent) >= 2:
76 | trend = np.sign(recent[-1] - recent[-2])
77 | else:
78 | trend = 1
79 | if count > 0 and adjust:
80 | postprocess = prev_error[:len(ypred)]
81 | if trendy:
82 | if trend == -1:
83 | ypred[postprocess < 0] += postprocess[postprocess < 0]
84 | if trend == 1:
85 | ypred[postprocess > 0] += postprocess[postprocess > 0]
86 | else:
87 | ypred += postprocess
88 | loss = mape(ypred.ravel(), np.array(ytest).ravel())
89 | prev_error = error
90 | count += 1
91 | test["ypred"] = ypred
92 | results.append(test)
93 | losses.append(loss)
94 | if roll_end_date >= test_end_date:
95 | break
96 |
97 | return results, losses
98 |
99 | def result_plot(results, title="result_plot"):
100 | plt.figure()
101 | results = pd.concat(results, axis=0)
102 | plt.plot(range(len(results)), results["y"])
103 | plt.plot(range(len(results)), results["ypred"])
104 | plt.legend(["y", "ypred"])
105 | plt.title(title)
106 | plt.savefig(title + ".png")
107 |
108 | def evaluation(losses):
109 | mu = np.mean(losses)
110 | std = np.std(losses)
111 | cv = round(std / mu, 3)
112 | mu = round(mu, 3)
113 | return mu, cv
114 |
115 | def single_main(company, filename, test_start, test_end):
116 | data = pd.read_csv(filename)
117 | data = generate_ts(data)
118 | normal_results, normal_losses = train(data)
119 | adjust_results, adjust_losses = train(data, adjust=True)
120 | adjust_trend_results, adjust_trend_losses = train(data, test_start_date=test_start,
121 | test_end_date=test_end, adjust=True, trendy=True)
122 |
123 | result_plot(normal_results, company + "_stock_normal_forecast")
124 | result_plot(adjust_results, company + "_stock_adjust_forecast")
125 | result_plot(adjust_trend_results, company + "_stock_adjust_trendy_forecast")
126 |
127 | normal_mu, normal_cv = evaluation(normal_losses)
128 | adjust_mu, adjust_cv = evaluation(adjust_losses)
129 | adjust_trend_mu, adjust_trend_cv = evaluation(adjust_trend_losses)
130 |
131 | row = [normal_mu, normal_cv, adjust_mu, adjust_cv, adjust_trend_mu, adjust_trend_cv]
132 | return row
133 |
134 | def main():
135 | filenames = ["amazon_stock.csv", "google_stock.csv", "alibaba_stock.csv", "jd_stock.csv"]
136 | companies = ["amazon", "google", "alibaba", "jd"]
137 | test_start = "2020-01-01"
138 | test_end = "2020-10-29"
139 | results = []
140 | for f, company in zip(filenames, companies):
141 | row = single_main(company, f, test_start, test_end)
142 | results.append([company] + row)
143 | cols = ["Company", "Original Avg MAPE", "Original CV", "Adjust Avg MAPE", "Adjust CV",
144 | "Adjust Trendy MAPE", "Adjust Trendy CV"]
145 | results = pd.DataFrame(results, columns=cols)
146 | return results
147 |
148 | if __name__ == "__main__":
149 | results = main()
150 | print(results)
151 |
--------------------------------------------------------------------------------
/forecast_reconcilation/README.md:
--------------------------------------------------------------------------------
1 | # Hierarchical Forecast Reconcilation Method
2 |
3 | ## Usage
4 | * Step 1: Input DataFrame and construct hierarchy tree
5 | ```python
6 | # 数据格式参考reconcilation_test
7 | data = pd.read_csv("reconcilation_test.csv")
8 |
9 | # get all series,获取所有品牌系列信息。all代表所有的品牌之和
10 | series = data.loc[~data["series"].isna() & data["sku"].isna(),
11 | ["series"]].drop_duplicates()
12 | series = series["series"].tolist()
13 | series = [s for s in series if s != "all"]
14 | skus = data.loc[~data["sku"].isna(), ["series", "sku"]].drop_duplicates()
15 | skus = (skus["series"] + "_" + skus["sku"]).tolist()
16 |
17 | # top level is root, series, skus, 因为stores就1个,就作为root
18 | total = {"root": series} # root对应层,是第一层
19 | skus_h = {k: [v for v in skus if v.startswith(k)] for k in series}
20 | hierarchy = {**total, **skus_h}
21 |
22 | tree = HierarchyTree.from_nodes(hierarchy)
23 | ```
24 | * Step 2: Split train and validation data
25 | ```python
26 | def clear_ids(ids):
27 | cols = []
28 | for c in ids:
29 | if isinstance(c, tuple) or isinstance(c, list):
30 | cols.append(c[1])
31 | else:
32 | cols.append(c)
33 | new_cols = []
34 | for c in cols:
35 | if c.endswith("_"):
36 | if c == "all_":
37 | new_cols.append("root")
38 | else:
39 | new_cols.append(c[:-1])
40 | continue
41 | new_cols.append(c)
42 | return new_cols
43 |
44 | def mape(y, ypred):
45 | y = np.array(y).ravel()
46 | ypred = np.array(ypred).ravel()
47 | return np.abs(y-ypred) / y
48 |
49 | def preprocess(df):
50 | df.fillna("", inplace=True)
51 | df.loc[:, "id"] = df.loc[:, "series"] + "_" + df.loc[:, "sku"]
52 | df["residual"] = mape(df["y"], df["ypred"])
53 | return df
54 |
55 | train_data = data[data["flag"] == "val"] # to be changed
56 | val_data = data[data["flag"] == "val"]
57 | val_data = preprocess(val_data)
58 | train_data = preprocess(train_data)
59 |
60 | # 预测集合, forecast data
61 | forecasts = pd.pivot_table(val_data, values=["ypred"], index=["date"], columns=["id"])
62 | # mape结果, MAPE result
63 | residuals = pd.pivot_table(val_data, values=["residual"], index=["date"], columns=["id"])
64 | # historical data to calculate ratio if using top down method
65 | history = pd.pivot_table(train_data, values=["y"], index=["date"], columns=["id"])
66 | forecasts.columns = clear_ids(forecasts.columns)
67 | residuals.columns = clear_ids(residuals.columns)
68 | history.columns = clear_ids(history.columns)
69 | val_data["id"] = clear_ids(val_data["id"])
70 | ```
71 | * Step 3: run recilation method
72 | ```python
73 | res = optimal_reconcilation(forecasts, tree, method="mint", residuals=residuals)
74 | # postprocess
75 | res = pd.merge(res, val_data[["id", "y", "ypred", "date"]], how="left", on=["id", "date"])
76 | res.loc[res["id"] == "root", "id"] = "all"
77 | res["mape"] = mape(res["y"], res["ypred"])
78 | res["mape_new"] = mape(res["y"], res["ypred_new"])
79 | res[["series", "sku"]] = res["id"].str.split("_", expand=True)
80 | res.drop(columns=["id"], inplace=True)
81 | ```
82 |
83 | ## Examples
84 | To run examples,
85 | ```shell
86 | python reconcilation.py
87 | ```
88 | ## Reference:
89 | * [Hyndman, R. J., & Athanasopoulos, G. (2018). Forecasting: principles and practice. OTexts](https://otexts.com/fpp2/).
90 | * [Optimal Forecast Reconciliation for Hierarchical and Grouped Time
91 | Series Through Trace Minimization](https://robjhyndman.com/papers/MinT.pdf)
92 | * [scikit-hts](https://github.com/jingw2/scikit-hts/blob/master/hts/functions.py)
93 |
--------------------------------------------------------------------------------
/forecast_reconcilation/data/reconcilation_test.csv:
--------------------------------------------------------------------------------
1 | date,series,sku,y,ypred,flag
2 | 20200920,红胖子,粉底1,1500,1900,val
3 | 20200921,红胖子,粉底1,3000,2500,val
4 | 20200922,红胖子,粉底1,,1200,test
5 | 20200923,红胖子,粉底1,,1000,test
6 | 20200920,红胖子,粉底2,2500,2000,val
7 | 20200921,红胖子,粉底2,2000,3000,val
8 | 20200922,红胖子,粉底2,,1500,test
9 | 20200923,红胖子,粉底2,,2000,test
10 | 20200920,红胖子,,4000,3500,val
11 | 20200921,红胖子,,5000,6000,val
12 | 20200922,红胖子,,,3000,test
13 | 20200923,红胖子,,,4000,test
14 | 20200920,黑管,唇膏1,2000,1900,val
15 | 20200921,黑管,唇膏1,2000,2500,val
16 | 20200922,黑管,唇膏1,,3000,test
17 | 20200923,黑管,唇膏1,,1000,test
18 | 20200920,黑管,唇膏2,2500,2000,val
19 | 20200921,黑管,唇膏2,2000,3000,val
20 | 20200922,黑管,唇膏2,,1500,test
21 | 20200923,黑管,唇膏2,,4000,test
22 | 20200920,黑管,,4500,3500,val
23 | 20200921,黑管,,4000,6000,val
24 | 20200922,黑管,,,6000,test
25 | 20200923,黑管,,,4000,test
26 | 20200920,all,,8500,8000,val
27 | 20200921,all,,9000,11000,val
28 | 20200922,all,,,9000,test
29 | 20200923,all,,,7000,test
30 |
--------------------------------------------------------------------------------
/forecast_reconcilation/data_structure.py:
--------------------------------------------------------------------------------
1 |
2 | from collections import OrderedDict
3 |
4 | class HierarchyTree(object):
5 |
6 | def __init__(self):
7 | self._nodes = OrderedDict()
8 | self._bottom = []
9 |
10 | def add(self, node):
11 | self._nodes[node.name] = node
12 |
13 | def remove(self, node):
14 | del self._nodes[node.name]
15 | for parent in node.parent:
16 | parent.extend(node.children)
17 | self._nodes[parent.name] = parent
18 | for child in node.children:
19 | child.parent.remove(node)
20 | child.parent.extend(node.parent)
21 | self._nodes[child.name] = child
22 |
23 | def isin(self, node):
24 | return node.name in self._nodes
25 |
26 | @property
27 | def nodes(self):
28 | return self._nodes
29 |
30 | @property
31 | def num_nodes(self):
32 | return len(self._nodes)
33 |
34 | @property
35 | def root(self):
36 | return self._nodes["root"]
37 |
38 | def get_node(self, nodename):
39 | return self._nodes[nodename]
40 |
41 | @property
42 | def num_bottom_level(self):
43 | return len(self._bottom)
44 |
45 | def add_bottom(self, node):
46 | self._bottom.append(node)
47 |
48 | @property
49 | def bottom(self):
50 | return self._bottom
51 |
52 | @staticmethod
53 | def from_nodes(hierarchy: dict):
54 | tree = HierarchyTree()
55 | queue = ["root"]
56 | node = TreeNode("root")
57 | tree.add(node)
58 | while queue:
59 | nodename = queue.pop(0)
60 | node = TreeNode(nodename)
61 | if tree.isin(node):
62 | node = tree.get_node(nodename)
63 | if nodename not in hierarchy:
64 | tree.add(node)
65 | tree.add_bottom(node)
66 | continue
67 | for child in hierarchy[nodename]:
68 | child = TreeNode(child)
69 | if not tree.isin(child):
70 | child.parent.append(node)
71 | node.children.append(child)
72 | tree.add(child)
73 | else:
74 | child = tree.get_node(child.name)
75 | child.parent.append(node)
76 | node.children.append(child)
77 | queue.append(child.name)
78 | return tree
79 |
80 | def __repr__(self):
81 | print([nodename for nodename in self._nodes])
82 |
83 | class TreeNode(object):
84 |
85 | def __init__(self, name=None):
86 | self.name = name
87 | self.children = []
88 | self.parent = []
89 |
90 | def append(self, child):
91 | self._children.append(child)
92 |
93 | def __repr__(self):
94 | print(self.name)
95 |
--------------------------------------------------------------------------------
/forecast_reconcilation/reconcilation.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 | #@author: Jing Wang
3 | #@date: 09/24/2020
4 |
5 | '''
6 | Hierarchical Forecast Reconcilation
7 | 层级预测后的调和
8 | * 实现Forecasting Principles and Practice中的最优调和方法, 章节10.7
9 | * 参考代码:https://github.com/carlomazzaferro/scikit-hts/blob/master/hts/functions.py
10 | '''
11 | from data_structure import HierarchyTree
12 | import pandas as pd
13 | import numpy as np
14 |
15 | def get_summing_matrix(tree: HierarchyTree):
16 | '''
17 | 递归生成Summing Matrix
18 | '''
19 | nodename = list(tree.nodes.keys())
20 | bottoms = tree.bottom
21 | num_bottoms = tree.num_bottom_level
22 | num_nodes = tree.num_nodes
23 | mat = np.zeros((num_nodes, num_bottoms))
24 |
25 | def dfs(mat, node):
26 | idx = nodename.index(node.name)
27 | if node.name != "root" and not node.children:
28 | mat[idx, bottoms.index(node)] = 1
29 | for child in node.children:
30 | dfs(mat, child)
31 | child_idx = nodename.index(child.name)
32 | mat[idx] += mat[child_idx]
33 |
34 | dfs(mat, tree.root)
35 | return mat
36 |
37 | def get_forecast_prop(forecasts_dict: dict, tree: HierarchyTree):
38 | queue = [tree.root]
39 | props = {"root": 1}
40 | while queue:
41 | node = queue.pop(0)
42 | if len(node.children) == 0:
43 | continue
44 | s = sum([forecasts_dict[child.name][0] for child in node.children])
45 | for child in node.children:
46 | ratio = forecasts_dict[child.name][0] / s
47 | props[child.name] = props[node.name] * ratio
48 | queue.append(child)
49 | p = [props[node.name] for node in tree.bottom]
50 | p = np.asarray(p).reshape((-1, 1))
51 | return p
52 |
53 | def top_down(forecasts: pd.DataFrame,
54 | history: pd.DataFrame,
55 | tree: HierarchyTree,
56 | horizon: int = 7,
57 | method="avg_hist_prop"):
58 | '''
59 | Top down method
60 | 从上至下拆分
61 | 1. 按照历史比例: Average Historical Proportions, avg_hist_prop
62 | p_j = 1 / T * \sum_{t=1}^T y_{j, t} / y_t
63 | 2. 按照历史平均比例: Proportions of Historical Average, prop_hist_avg
64 | 3. 按预测比例: Forecast Proportions, forecast_prop
65 |
66 | forecasts and history format like this:
67 | | date | root | series1 | series_2 | series1_sku1 | series2_sku1 |
68 | | 20200922 | 1000 | 200 | 300 | 100 | 250 |
69 | date is index, pivot table
70 | '''
71 | nodenames = list(tree.nodes.keys())
72 | S = get_summing_matrix(tree)
73 | history.sort_index(inplace=True) # sort dates ascending
74 | history = history[-horizon:]
75 | history = df_to_array(history, nodenames)
76 | dates = forecasts.index.tolist()
77 |
78 | forecasts_dict = forecasts.to_dict(orient="list")
79 | forecasts = df_to_array(forecasts, nodenames)
80 | bottom_ids = [nodenames.index(bot.name) for bot in tree.bottom]
81 | root_id = nodenames.index("root")
82 |
83 | y_root = forecasts[root_id].reshape((1, -1))
84 | if method == "avg_hist_prop":
85 | p = np.mean(history[bottom_ids] / history[root_id], axis=1)
86 | p /= p.sum() # re-standardize
87 | p = p.reshape((-1, 1))
88 | if method == "prop_hist_avg":
89 | p = np.mean(history[bottom_ids], axis=1) / np.mean(history[root_id])
90 | p /= p.sum() # re-standardize
91 | p = p.reshape((-1, 1))
92 | if method == "forecast_prop":
93 | p = get_forecast_prop(forecasts_dict, tree)
94 |
95 | y = S @ p @ y_root
96 | results = pd.DataFrame(y, columns=dates)
97 | results["id"] = nodenames
98 | cols = [c for c in results.columns.tolist() if c != "id"]
99 | results = pd.melt(results, id_vars=["id"], value_vars=cols)
100 | results.columns = ["id", "date", "ypred_new"]
101 | return results
102 |
103 |
104 | def bottom_up(forecasts: pd.DataFrame, tree: HierarchyTree):
105 | '''
106 | 自下而上汇总
107 | y_tilde = S y_hat_bottom
108 | '''
109 | nodenames = list(tree.nodes.keys())
110 | S = get_summing_matrix(tree)
111 | ypred = df_to_array(forecasts, nodenames)
112 | num_bottom_level = tree.num_bottom_level
113 | bottom_pred = ypred[-num_bottom_level:, :]
114 | y = S @ bottom_pred
115 |
116 | dates = forecasts.index.tolist()
117 | results = pd.DataFrame(y, columns=dates)
118 | results["id"] = nodenames
119 | cols = [c for c in results.columns.tolist() if c != "id"]
120 | results = pd.melt(results, id_vars=["id"], value_vars=cols)
121 | results.columns = ["id", "date", "ypred_new"]
122 | return results
123 |
124 | def optimal_reconcilation(forecasts: pd.DataFrame, tree: HierarchyTree, method="ols",
125 | residuals: pd.DataFrame = None):
126 | '''
127 | Optimal Reconcilation Algorithm:
128 | 最优调和算法
129 | y_tilde = S P y_hat_bottom
130 | y_tilde = S (S^T W_h^{-1} S)^{-1} S^T W_h^{-1} y_hat_bottom
131 |
132 | S: summing matrix,反映层级汇总关系
133 | P: constraint matrix
134 | W_h: W_h = Var[y_{T+h} - y_tilde] = SP W_h P^T S^T, y_{T+h} is true value
135 |
136 | Task is to estimate W_h
137 | 1. ols: oridinary least square method,最小二乘法 W_h = k_h I
138 | 2. wls: weighted least square method,加权最小二乘法, W_h = k_h diag(W_hat1)
139 | W_hat1 = 1 / T * \sum_{t=1}^T e_t e_t^T,
140 | e_t is n dimension vector of residuals,e_t是残差/误差向量
141 | 3. nseries: W_h = k_h Omega, Omega = diag(S 1), 1 is unit vector of dimension。
142 | S列求和后取最小线
143 | 4. mint: W_h = k_h W_1, W_1 sample/residual covariance, 样本协方差矩阵,也可以用残差协方差矩阵
144 | the number of bottom-level series is much larger than T, so shrinkage covariance to
145 | diagnoal
146 |
147 | forecasts format like this:
148 | | date | all | series1 | series_2 | series1_sku1 | series2_sku1 |
149 | | 20200922 | 1000| 200 | 300 | 100 | 250 |
150 | date is index, pivot table
151 | '''
152 | nodenames = list(tree.nodes.keys())
153 | num_nodes = tree.num_nodes
154 | for name in nodenames:
155 | assert name in forecasts.columns
156 | dates = forecasts.index.tolist()
157 |
158 | S = get_summing_matrix(tree)
159 | ypred = df_to_array(forecasts, nodenames)
160 | kh = 1
161 | if method == "ols":
162 | Wh = np.eye(num_nodes) * kh
163 | if method == "wls":
164 | residuals = df_to_array(residuals, nodenames)
165 | What1 = residuals @ residuals.T
166 | diag = np.eye(num_nodes) * np.diag(What1)
167 | Wh = kh * diag
168 | if method == "nseries":
169 | diag = np.eye(num_nodes) * np.diag(np.sum(S, axis=1))
170 | Wh = kh * diag
171 | if method == "mint":
172 | residuals = df_to_array(residuals, nodenames)
173 | cov = np.cov(residuals)
174 | diag = np.eye(num_nodes) * np.diag(cov)
175 | Wh = kh * diag
176 | inv_Wh = np.linalg.inv(Wh)
177 | coef = S @ (np.linalg.inv(S.T @ inv_Wh @ S)) @ S.T @ inv_Wh
178 | y = coef @ ypred
179 |
180 | results = pd.DataFrame(y, columns=dates)
181 | results["id"] = nodenames
182 | cols = [c for c in results.columns.tolist() if c != "id"]
183 | results = pd.melt(results, id_vars=["id"], value_vars=cols)
184 | results.columns = ["id", "date", "ypred_new"]
185 | return results
186 |
187 | def df_to_array(forecasts, nodenames):
188 | '''
189 | DataFrame to array based on node names input
190 |
191 | Usage:
192 |
193 | DataFrame like this:
194 |
195 | | all | series1 | series_2 | series1_sku1 | series2_sku1 |
196 | | 1000| 200 | 300 | 100 | 250 |
197 |
198 | to Array:
199 | array([1000, 200, 300, 100, 250]).T
200 | '''
201 | forecasts = forecasts[nodenames]
202 | arr = np.asarray(forecasts).T
203 | return arr
204 |
205 | def example():
206 | data = pd.read_csv("reconcilation_test.csv")
207 | series = data.loc[~data["series"].isna() & data["sku"].isna(),
208 | ["series"]].drop_duplicates()
209 | series = series["series"].tolist()
210 | series = [s for s in series if s != "all"]
211 | skus = data.loc[~data["sku"].isna(), ["series", "sku"]].drop_duplicates()
212 | skus = (skus["series"] + "_" + skus["sku"]).tolist()
213 | # 因为stores就1个,就作为root
214 | total = {"root": series} # root对应层,是第一层
215 | skus_h = {k: [v for v in skus if v.startswith(k)] for k in series}
216 | hierarchy = {**total, **skus_h}
217 |
218 | tree = HierarchyTree.from_nodes(hierarchy)
219 |
220 | def clear_ids(ids):
221 | cols = []
222 | for c in ids:
223 | if isinstance(c, tuple) or isinstance(c, list):
224 | cols.append(c[1])
225 | else:
226 | cols.append(c)
227 | new_cols = []
228 | for c in cols:
229 | if c.endswith("_"):
230 | if c == "all_":
231 | new_cols.append("root")
232 | else:
233 | new_cols.append(c[:-1])
234 | continue
235 | new_cols.append(c)
236 | return new_cols
237 |
238 | def mape(y, ypred):
239 | y = np.array(y).ravel()
240 | ypred = np.array(ypred).ravel()
241 | return np.abs(y-ypred) / y
242 |
243 | def preprocess(df):
244 | df.fillna("", inplace=True)
245 | df.loc[:, "id"] = df.loc[:, "series"] + "_" + df.loc[:, "sku"]
246 | df["residual"] = mape(df["y"], df["ypred"])
247 | return df
248 |
249 | train_data = data[data["flag"] == "val"] # to be changed
250 | val_data = data[data["flag"] == "val"]
251 | val_data = preprocess(val_data)
252 | train_data = preprocess(train_data)
253 |
254 | forecasts = pd.pivot_table(val_data, values=["ypred"], index=["date"], columns=["id"])
255 | residuals = pd.pivot_table(val_data, values=["residual"], index=["date"], columns=["id"])
256 | history = pd.pivot_table(train_data, values=["y"], index=["date"], columns=["id"])
257 | forecasts.columns = clear_ids(forecasts.columns)
258 | residuals.columns = clear_ids(residuals.columns)
259 | history.columns = clear_ids(history.columns)
260 | val_data["id"] = clear_ids(val_data["id"])
261 |
262 | # res = optimal_reconcilation(forecasts, tree, method="mint", residuals=residuals)
263 | res = top_down(forecasts, history, tree, method="prop_hist_avg")
264 | res = pd.merge(res, val_data[["id", "y", "ypred", "date"]], how="left", on=["id", "date"])
265 | res.loc[res["id"] == "root", "id"] = "all"
266 | res["mape"] = mape(res["y"], res["ypred"])
267 | res["mape_new"] = mape(res["y"], res["ypred_new"])
268 | res[["series", "sku"]] = res["id"].str.split("_", expand=True)
269 | res.drop(columns=["id"], inplace=True)
270 | return res
271 |
272 | if __name__ == "__main__":
273 | res = example()
274 | print("result: ", res)
275 |
--------------------------------------------------------------------------------
/forecastability/README.md:
--------------------------------------------------------------------------------
1 | # Forecastability Analysis
2 |
3 | This is a tool to implement forecastability analysis, including calculating:
4 | * Frequency
5 | * Stability
6 | * Periodicity
7 | * Percent of Products that single customer occupies over 50% demands
8 |
9 | ## Input Data
10 | | columname | type | note |
11 | |---|---|---|
12 | | date | string | yyyy-mm-dd or yyyy/mm/dd |
13 | | sku_code | string | code of SKU |
14 | | customer_code | string | code of customer |
15 | | qty | float | demand quantity |
16 |
17 |
18 | ## Usage:
19 | ```python
20 | import forecastability
21 | fa = forecastability.Forecastability(data, tm="date")
22 | # calculate frequency
23 | fa.frequency()
24 | # calculate stability
25 | fa.stability()
26 | # calculate periodicity
27 | fa.periodicity()
28 | # calculate single customer percent
29 | fa.single_customer_percent()
30 | # render forecastability report
31 | fa.render("forecastability_report.html")
32 | ```
33 |
34 | ## Reference:
35 | [1] [时间周期序列周期性挖掘](https://wenku.baidu.com/view/8ad300afb8f67c1cfad6b87a.html)
36 |
37 | [2] [供应链三道防线:需求预测,库存计划,供应链执行](https://book.douban.com/subject/30223850/)
38 |
39 | [3] [Hyndman, R. J., & Athanasopoulos, G. (2018). Forecasting: principles and practice. OTexts.](https://otexts.com/fpp2/)
40 |
--------------------------------------------------------------------------------
/forecastability/build/lib/forecastability/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jingw2/solver/19e8ec16fa28ee6a02ea619e2fd94a3e526aa035/forecastability/build/lib/forecastability/__init__.py
--------------------------------------------------------------------------------
/forecastability/build/lib/forecastability/forecastability.py:
--------------------------------------------------------------------------------
1 | #-*-coding:utf-8-*-
2 | #@Author: Jing Wang
3 | #@Date: 2020-10-29 16:51:06
4 | #@Last Modified by: Jing Wang
5 | #@Last Modified time: 2020-10-29 16:51:06
6 | #@reference:
7 |
8 | '''
9 | Calculate forecastability and output report
10 | '''
11 | import util
12 | import period_detect
13 | from joblib import Parallel, delayed, parallel_backend
14 | import pandas as pd
15 |
16 | class Forecastability:
17 |
18 | def __init__(self, data, tm="date"):
19 | '''
20 | Args:
21 | data (data frame): with columns \
22 | ["date", "sku_code", "customer_code", "qty"]
23 | tm (str): time dimension, ["date", "week", "month", "year"]
24 | '''
25 | self.data = data
26 | if tm not in ["date", "week", "month", "year"]:
27 | raise Exception("Time dimension is invalid!")
28 | self.tm = tm
29 |
30 | def preprocess(self):
31 | '''
32 | Create necessary time dimension
33 | '''
34 | self.data["date"] = self.data["date"].apply(util.date_converter)
35 | self.data["year"] = self.data["date"].apply(lambda x: str(x.year))
36 | if self.tm == "week":
37 | self.data["week"] = self.data["date"].apply(lambda x: str(x.isocalendar()[1])
38 | if x.isocalendar()[1] > 9 else "0" + str(x.isocalendar()[1]))
39 | self.data["week"] = int(self.data["year"] + self.data["week"])
40 | if self.tm == "month":
41 | self.data["month"] = self.data["month"].apply(lambda x: str(x.month)
42 | if x.month > 9 else "0" + str(x.month))
43 | self.data["month"] = int(self.data["year"] + self.data["month"])
44 |
45 |
46 | def frequency(self, high=0.75, low=0.3):
47 | '''
48 | Calculate frequency of products
49 | Args:
50 | high (float): high bar for high frequency
51 | low (float): low bar for extremely low frequency
52 | '''
53 |
54 | # calculate frequency
55 | sku_date_count = self.data.groupby(["sku_code"])[self.tm].apply(lambda x: len(set(x))).reset_index()
56 | sku_date_count.columns = ["sku_code", "tm_stats"]
57 | tot_tm = len(self.data[self.tm].unique())
58 | sku_date_count["freq_stats"] = sku_date_count["tm_stats"] / tot_tm
59 |
60 | # split to high, low and extreme low
61 | def freq_split(x):
62 | if x >= high:
63 | return "高频"
64 | elif x >= low:
65 | return "低频"
66 | return "极端低频"
67 |
68 | sku_date_count["frequency"] = sku_date_count["freq_stats"].apply(freq_split)
69 | self.freq = sku_date_count[["sku_code", "frequency"]]
70 | return self.freq
71 |
72 | def stability(self, high=5, low=0.7):
73 | '''
74 | Calculate stability of products
75 | Args:
76 | high (float): high bar for extremely unstable
77 | low (float): low bar for stable
78 | '''
79 | # calculate stability
80 | groupby_demand = self.data.groupby(["sku_code", self.tm])["qty"].sum().reset_index()
81 | groupby_demand = groupby_demand.groupby(["sku_code"]).agg(["mean", "std"]).reset_index()
82 | groupby_demand.columns = ["sku_code", "mean", "std"]
83 | groupby_demand["cv"] = groupby_demand["std"] / groupby_demand["mean"]
84 |
85 | # split stability
86 | def stable_split(x):
87 | if x < low:
88 | return "稳定"
89 | elif x < high:
90 | return "不稳定"
91 | return "极端不稳定"
92 |
93 | groupby_demand["stability"] = groupby_demand["cv"].apply(stable_split)
94 | self.stable = groupby_demand[["sku_code", "stability"]]
95 | return self.stable
96 |
97 | def periodicity(self, threshold=0.8):
98 | '''
99 | Calculate periodicity based on threshold of confidence
100 | '''
101 | groupby_demand = self.data.groupby(["sku_code", self.tm])["qty"].sum().reset_index()
102 | groupby_demand = util.fill_ts(groupby_demand, self.tm)
103 | groupby_demand.sort_values(self.tm, inplace=True)
104 |
105 | skus = groupby_demand["sku_code"].unique().tolist()
106 | print("number of skus: ", len(skus))
107 | with parallel_backend("multiprocessing", n_jobs=-1):
108 | results = Parallel()(delayed(self.single_period_detection)(groupby_demand,
109 | sku, threshold, i) for i, sku in enumerate(skus))
110 | result = pd.concat(results, axis=0)
111 | result = result[result["periodicity"].apply(lambda x: len(x) > 0)]
112 | self.period = result
113 | return self.period
114 |
115 | def single_period_detection(self, groupby_demand, sku, threshold, counter):
116 | sku_demand = groupby_demand[groupby_demand["sku_code"] == sku]["qty"].tolist()
117 | period_res = period_detect.solve(sku_demand, threshold, method="dp")
118 | if period_res is None or len(period_res) == 0:
119 | return pd.DataFrame()
120 | period_res = {key: score for key, score in period_res.items() if len(set(key)) > 1}
121 | res = pd.DataFrame([[sku, period_res]], columns=["sku_code", "periodicity"])
122 | return res
123 |
124 | def single_customer_percent(self, percent=0.5):
125 | '''
126 | Calculate percent of single customer for different products
127 | Args:
128 | percent (float): percent threshold of single customer
129 | '''
130 | # week frequency 周频率计算
131 | if self.tm != "week":
132 | self.data["week"] = self.data["date"].apply(lambda x: str(x.isocalendar()[1])
133 | if x.isocalendar()[1] > 9 else "0" + str(x.isocalendar()[1]))
134 | self.data["week"] = self.data["year"] + self.data["week"]
135 | groupby_sku = self.data.groupby(["sku_code"])["week"].apply(lambda x: len(set(x))).reset_index()
136 | groupby_sku.columns = ["sku_code", "n_weeks"]
137 |
138 | # customer percent
139 | groupby_cust = self.data.groupby(["sku_code", "customer_code"])["qty"].sum().reset_index()
140 | groupby_cust.columns = ["sku_code", "customer_code", "customer_qty"]
141 | groupby_sku_sum = self.data.groupby(["sku_code"])["qty"].sum().reset_index()
142 | groupby_sku_sum.columns = ["sku_code", "qty_sum"]
143 | groupby_cust = pd.merge(groupby_cust, groupby_sku_sum, on="sku_code", how="left")
144 | groupby_cust["customer_percent"] = groupby_cust["customer_qty"] / groupby_cust["qty_sum"]
145 |
146 | # single customer percent 单一客户占比超过percent的产品比例
147 | merge_df = pd.merge(groupby_sku, groupby_cust[["sku_code",
148 | "customer_percent"]], on="sku_code", how="inner")
149 | filter_merge_df = merge_df[merge_df["customer_percent"] > percent]
150 |
151 | merge_df = merge_df.groupby(["n_weeks"])["sku_code"].apply(lambda x: len(set(x))).reset_index()
152 | merge_df.columns = ["n_weeks", "n_skus"]
153 | filter_merge_df = filter_merge_df.groupby(["n_weeks"])["sku_code"].apply(lambda x: len(set(x))).reset_index()
154 | filter_merge_df.columns = ["n_weeks", "sat_n_skus"]
155 |
156 | result = pd.merge(merge_df, filter_merge_df, on="n_weeks", how="inner")
157 | result["sku_percent"] = result["sat_n_skus"] / result["n_skus"]
158 | self.single_customer = result[["n_weeks", "sku_percent"]]
159 | return self.single_customer
160 |
161 | def render(self, filename="forecastability_report"):
162 |
163 | file = open("{}.html".format(filename), "w")
164 |
165 | # 频率和稳定性表
166 | if self.freq is not None and self.stable is not None:
167 | merge_df = pd.merge(self.freq, self.stable, on="sku_code", how="inner")
168 | high_freq = merge_df[merge_df["frequency"] == "高频"]
169 | high_stable = len(high_freq[high_freq["stability"] == "稳定"])
170 | high_unstable = len(high_freq[high_freq["stability"] == "不稳定"])
171 | high_xunstable = len(high_freq[high_freq["stability"] == "极端不稳定"])
172 |
173 | low_freq = merge_df[merge_df["frequency"] == "低频"]
174 | low_stable = len(low_freq[low_freq["stability"] == "稳定"])
175 | low_unstable = len(low_freq[low_freq["stability"] == "不稳定"])
176 | low_xunstable = len(low_freq[low_freq["stability"] == "极端不稳定"])
177 |
178 | xlow_freq = merge_df[merge_df["frequency"] == "极端低频"]
179 | xlow_stable = len(xlow_freq[xlow_freq["stability"] == "稳定"])
180 | xlow_unstable = len(xlow_freq[xlow_freq["stability"] == "不稳定"])
181 | xlow_xunstable = len(xlow_freq[xlow_freq["stability"] == "极端不稳定"])
182 |
183 | n_stable = len(merge_df[merge_df["stability"] == "稳定"])
184 | n_unstable = len(merge_df[merge_df["stability"] == "不稳定"])
185 | n_xunstable = len(merge_df[merge_df["stability"] == "极端不稳定"])
186 |
187 | start = '''
188 |
189 |
190 |
191 | Forecastability Report
192 |
193 |
194 |
195 | '''
196 | headers = ["频率/稳定性", "稳定", "不稳定", "极端不稳定", "总计"]
197 | rows = [
198 | ["高频", high_stable, high_unstable, high_xunstable, len(high_freq)],
199 | ["低频", low_stable, low_unstable, low_xunstable, len(low_freq)],
200 | ["极端低频", xlow_stable, xlow_unstable, xlow_xunstable, len(xlow_freq)],
201 | ["总计", n_stable, n_unstable, n_xunstable, len(merge_df)]
202 | ]
203 | freq_stable_table = util.get_table(headers, rows, "频率和稳定性统计表")
204 | else:
205 | freq_stable_table = ""
206 |
207 | # 周期性表
208 | if self.period is not None:
209 | headers = ["SKU编码", "周期性结果"]
210 | rows = self.period.values.tolist()
211 | period_table = util.get_table(headers, rows, "周期性识别结果表")
212 | else:
213 | period_table = ""
214 |
215 | end = ''
216 |
217 | # 单一客户占比图
218 | if self.single_customer is not None:
219 | x = self.single_customer["n_weeks"].tolist()
220 | y = [round(s * 100, 2) for s in self.single_customer["sku_percent"].tolist()]
221 | line_charts = util.get_line_charts(x, y, title="单一客户占比超过50%SKU比例和SKU频率图",
222 | xname="有需求的周数", yname="单一客户占比超过50%的SKU比例")
223 | else:
224 | line_charts = ""
225 |
226 | file.write(start + freq_stable_table + period_table + line_charts + end)
227 | file.close()
228 |
229 |
230 | if __name__ == "__main__":
231 | filename = "forecastability_test.csv"
232 | data = pd.read_csv(filename)
233 | data = data[:40000]
234 | fa = Forecastability(data)
235 | fa.preprocess()
236 | fa.frequency()
237 | fa.stability()
238 | fa.periodicity()
239 | fa.single_customer_percent()
240 | # result = fa.single_customer_percent()
241 | fa.render()
242 | # import matplotlib.pyplot as plt
243 | # plt.plot(result["n_weeks"], result["sku_percent"])
244 | # plt.show()
245 |
--------------------------------------------------------------------------------
/forecastability/build/lib/forecastability/period_detect.py:
--------------------------------------------------------------------------------
1 | # /usr/bin/env python 3.6
2 | # -*-coding:utf-8-*-
3 |
4 | '''
5 | Period Detection Solver
6 |
7 | Reference link:
8 | https://wenku.baidu.com/view/8ad300afb8f67c1cfad6b87a.html
9 |
10 | Author: Jing Wang (jingw2@foxmail.com)
11 | '''
12 | import numpy as np
13 |
14 | ## algorithm
15 | def recurse(n, m):
16 | '''
17 | recursion method
18 | find minimum ERP distance from (n - p - 1, n - 1) to (0, p)
19 |
20 | Args:
21 | n (int): starting row index
22 | m (int): starting column index
23 |
24 | Return:
25 | d (int): minimum ERP distance
26 | '''
27 | cache = {}
28 | d = 0
29 | if (n, m) in cache:
30 | return cache[(n, m)]
31 | if n == 0 and m == p:
32 | d += matrix[n][m]
33 | elif n == 0 and m > p:
34 | d += recurse(n, m - 1) + matrix[n, m]
35 | else:
36 | d += min([recurse(n-1, m-1), recurse(n-1, m)]) + matrix[n][m]
37 | cache[(n, m)] = d
38 | return d
39 |
40 | def dp(n, m):
41 | '''
42 | dynamic programming
43 | find minimum ERP distance from (n - p - 1, n - 1) to (0, p)
44 |
45 | Args:
46 | n (int): starting row index
47 | m (int): starting column index
48 |
49 | Return:
50 | minimum ERP distance
51 | '''
52 | nr, nc = matrix.shape
53 | d = np.zeros((nr, nc))
54 | for i in range(n, -1, -1):
55 | for j in range(m, p - 1, -1):
56 | if i < nr - 1 and j < nc - 1:
57 | valid = []
58 | if (j - i - 1) >= (m - n):
59 | valid.append(d[i + 1, j])
60 | if (j + 1 - i) >= (m - n):
61 | valid.append(d[i, j + 1])
62 | if (j - i) >= (m - n):
63 | valid.append(d[i + 1, j + 1])
64 | if len(valid) > 0:
65 | d[i, j] = min(valid) + matrix[i][j]
66 | else:
67 | d[i, j] = matrix[i][j]
68 | elif i < nr - 1 and j == nc - 1:
69 | if (j - i - 1) >= (m - n):
70 | d[i, j] = d[i + 1, j]+ matrix[i][j]
71 | else:
72 | d[i, j] = matrix[i, j]
73 | elif i == nr - 1 and j < nc - 1:
74 | if (j + 1 - i) >= (m - n):
75 | d[i, j] = d[i, j + 1] + matrix[i][j]
76 | else:
77 | d[i, j] = matrix[i, j]
78 |
79 |
80 | return d[0, p]
81 |
82 | def solve(s, threshold, method = "dp"):
83 | '''
84 | solve function
85 | '''
86 |
87 | # check
88 | if len(s) == 0 or len(s) == 1:
89 | return None
90 |
91 | try:
92 | s[0]
93 | s[0:]
94 | except:
95 | raise Exception("Please make sure input can be sliced!")
96 |
97 | # generate distance matrix
98 | global matrix, p
99 | n = len(s)
100 | matrix = np.zeros((n, n))
101 | for i in range(n):
102 | for j in range(n):
103 | if i == j:
104 | matrix[i, j] = float("inf") # leave the main diagonal
105 | continue
106 | if s[i] == s[j]:
107 | matrix[i, j] = 0
108 | else:
109 | matrix[i, j] = 1
110 |
111 | result = {}
112 | for p in range(1, n // 2 + 1):
113 | if method == "dp":
114 | d = dp(n - p - 1, n - 1)
115 | else:
116 | d = recurse(len(s) - p - 1, n - 1)
117 | confidence = (n - p - d) / (n - p)
118 |
119 | if confidence > threshold:
120 | result[tuple(s[:p])] = round(confidence, 3)
121 |
122 | return result
123 |
124 |
125 | s = "ababac"
126 | if __name__ == '__main__':
127 | print(solve(s, 0.7))
128 |
--------------------------------------------------------------------------------
/forecastability/build/lib/forecastability/util.py:
--------------------------------------------------------------------------------
1 | #-*-coding:utf-8-*-
2 | from datetime import datetime
3 | import pandas as pd
4 |
5 |
6 | def date_converter(x):
7 | '''
8 | 转换为日期格式
9 | '''
10 | if x is None:
11 | return x
12 | try:
13 | x = str(x)
14 | except Exception:
15 | return x
16 |
17 | try:
18 | return datetime.strptime(x, "%Y-%m-%d")
19 | except Exception:
20 | try:
21 | return datetime.strptime(x, "%Y/%m/%d")
22 | except Exception:
23 | try:
24 | return datetime.strptime(x, "%Y%m%d")
25 | except Exception:
26 | return x
27 |
28 |
29 | def date_parser(x):
30 | '''
31 | 日期格式转换为string
32 | '''
33 | if not isinstance(x, datetime):
34 | return None
35 |
36 | try:
37 | return x.strftime("%Y-%m-%d")
38 | except Exception:
39 | try:
40 | return x.strptime("%Y/%m/%d")
41 | except Exception:
42 | try:
43 | return x.strptime("%Y%m%d")
44 | except Exception:
45 | return None
46 |
47 |
48 | def fill_ts(data, tm):
49 | '''
50 | 填充时间序列,只保留两列,[ts, y]
51 | '''
52 | data[tm] = data[tm].apply(date_parser)
53 | if tm == "date":
54 | min_dt = date_converter(data[tm].min())
55 | max_dt = date_converter(data[tm].max())
56 | tm_list = [date_parser(x) for x in pd.date_range(start=min_dt, end=max_dt)]
57 | else:
58 | min_dt = data[tm].min()
59 | max_dt = data[tm].max()
60 | tm_list = list(range(min_dt, max_dt+1))
61 | tm_df = pd.DataFrame(tm_list, columns=[tm])
62 | df = pd.merge(tm_df, data[[tm, "sku_code", "qty"]], on=tm, how="left")
63 | df["qty"].fillna(0, inplace=True)
64 | return df
65 |
66 |
67 | def get_table(headers, rows, tablename):
68 | table_style = '''
69 |
127 |
128 | '''
129 | title = '{}
'.format(tablename)
130 | table = ''
131 | for h in headers:
132 | table += "| {} | ".format(h)
133 | table += '
'
134 |
135 | for r in rows:
136 | table += ''
137 | for ele in r:
138 | table += '| {} | '.format(ele)
139 | table += '
'
140 | end = '
{}
'.format(tablename)
130 | table = ''
131 | for h in headers:
132 | table += "| {} | ".format(h)
133 | table += '
'
134 |
135 | for r in rows:
136 | table += ''
137 | for ele in r:
138 | table += '| {} | '.format(ele)
139 | table += '
'
140 | end = '