└── README.md
/README.md:
--------------------------------------------------------------------------------
1 |
2 |

3 |
31 |
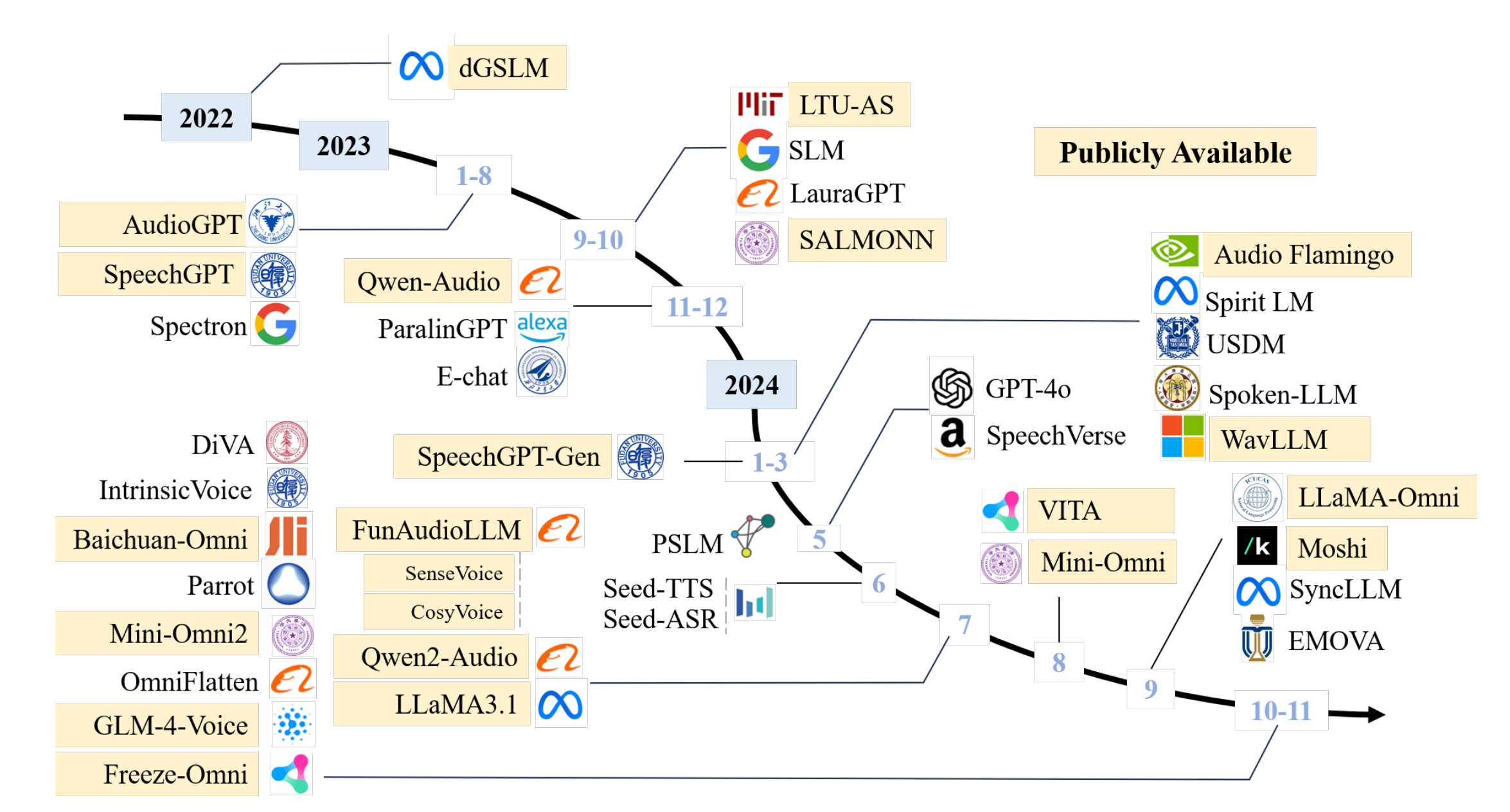
32 |
33 | Figure 1: The timeline of existing spoken dialogue models in recent years.
34 |
45 |
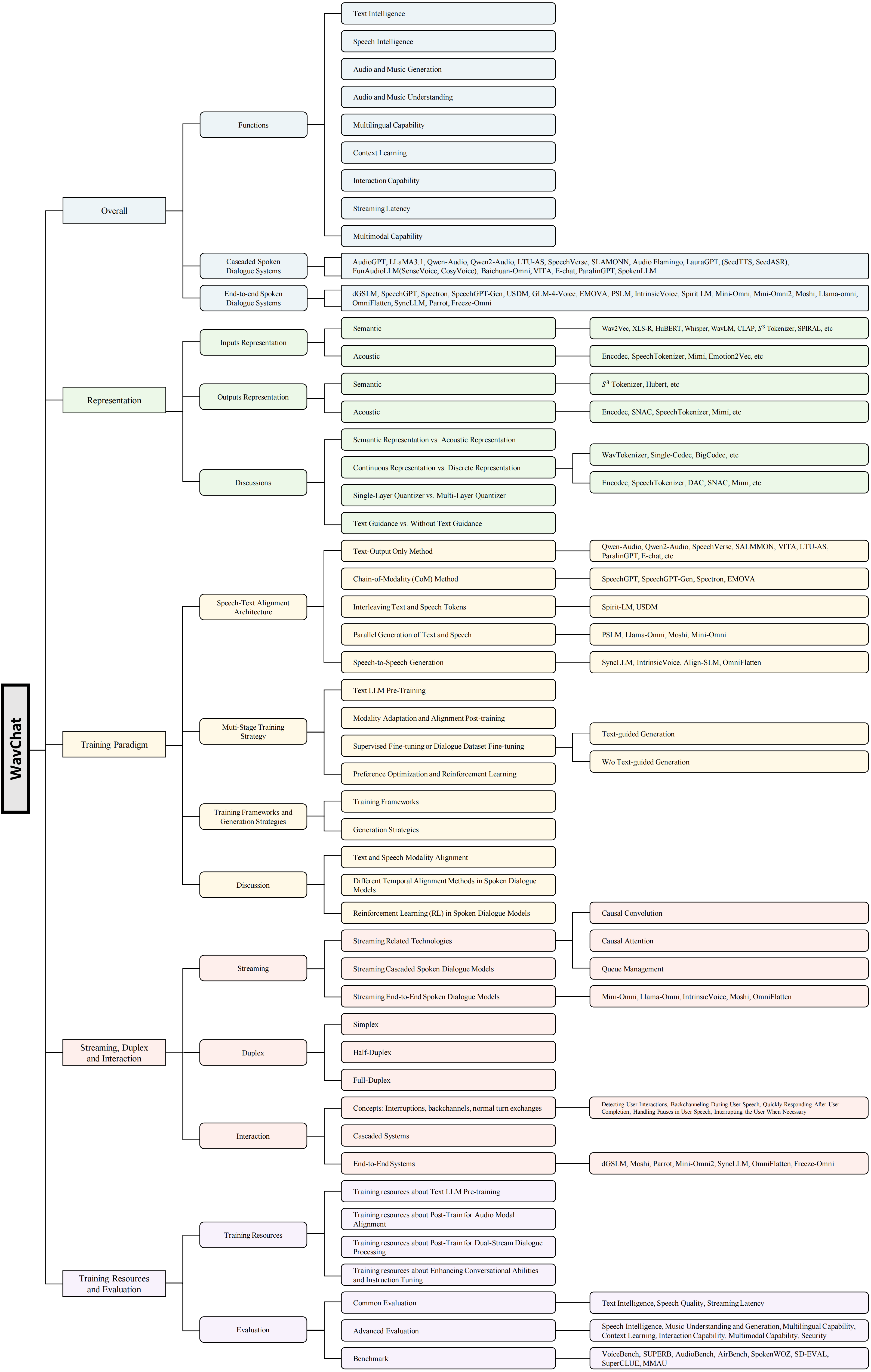
46 |
47 |
48 |
49 | Figure 2: Orgnization of this survey.
50 |
55 |
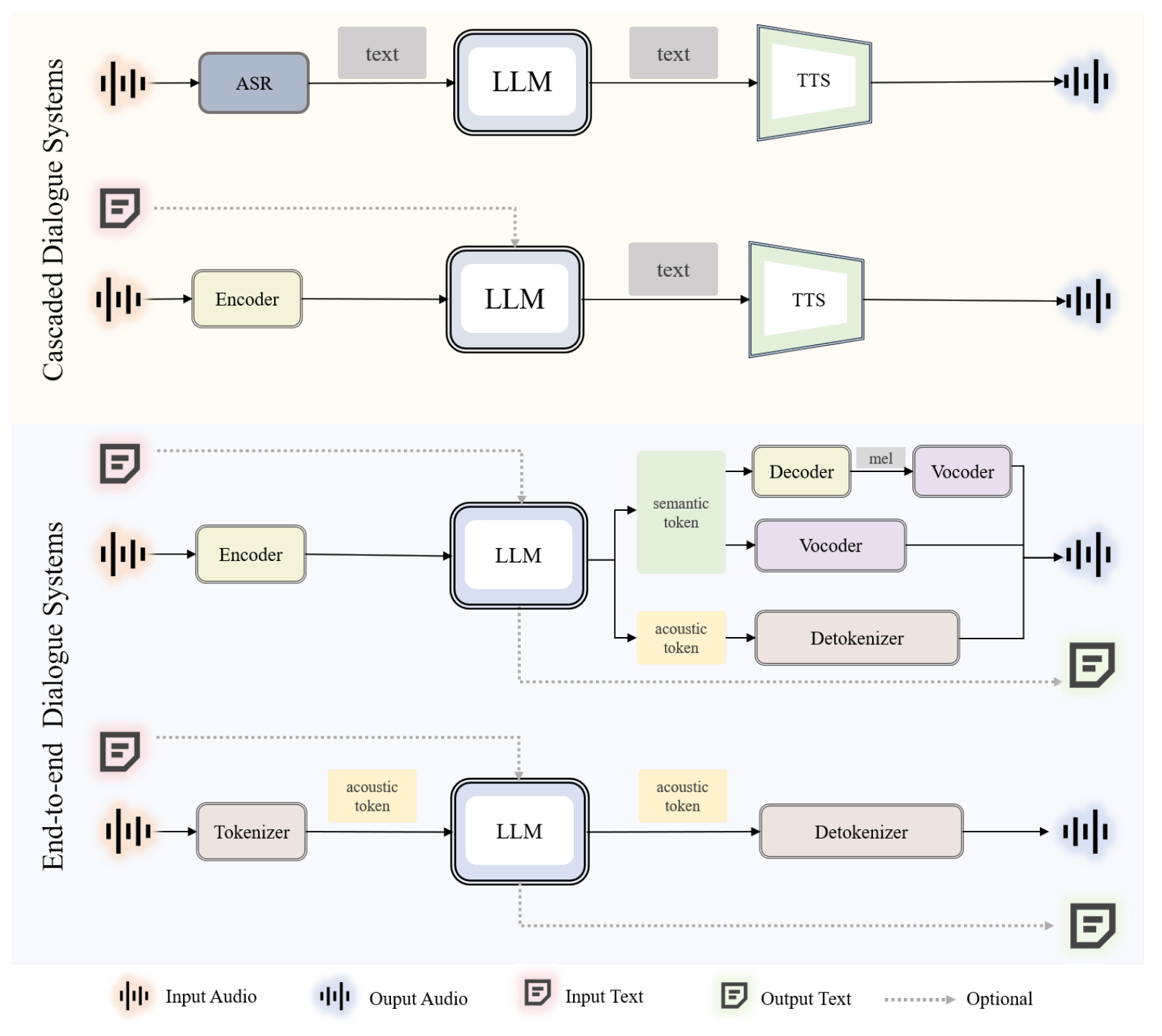
56 |
57 | Figure 3: A general overview of current spoken dialogue systems.
58 |
63 |

64 |
65 | Figure 4: An overview of the spoken dialogue systems' nine ideal capabilities.
66 |
71 |
193 |
194 | Table 1: The list of publicly available speech dialogue models and their URL
195 |
207 | Table 2: The comparison of semantic and acoustic representations
208 |
209 |
210 |
211 | And we provide a comprehensive list of publicly available codec models and their URLs.
212 |
213 |
214 |
215 |
359 |
360 |
361 | Table 3: A comprehensive list of publicly available codec models and their URLs.
362 |
363 |
364 | ## **Training Paradigm of Spoken Dialogue Model**
365 |
366 | In the Training Paradigm of Spoken Dialogue Model section, we focuse on how to adapt text-based large language models (LLMs) into dialogue systems with speech processing capabilities. The **selection and design of training paradigms** have a direct impact on the **performance, real-time performance, and multimodal alignment** of the model.
367 |
368 |
369 |
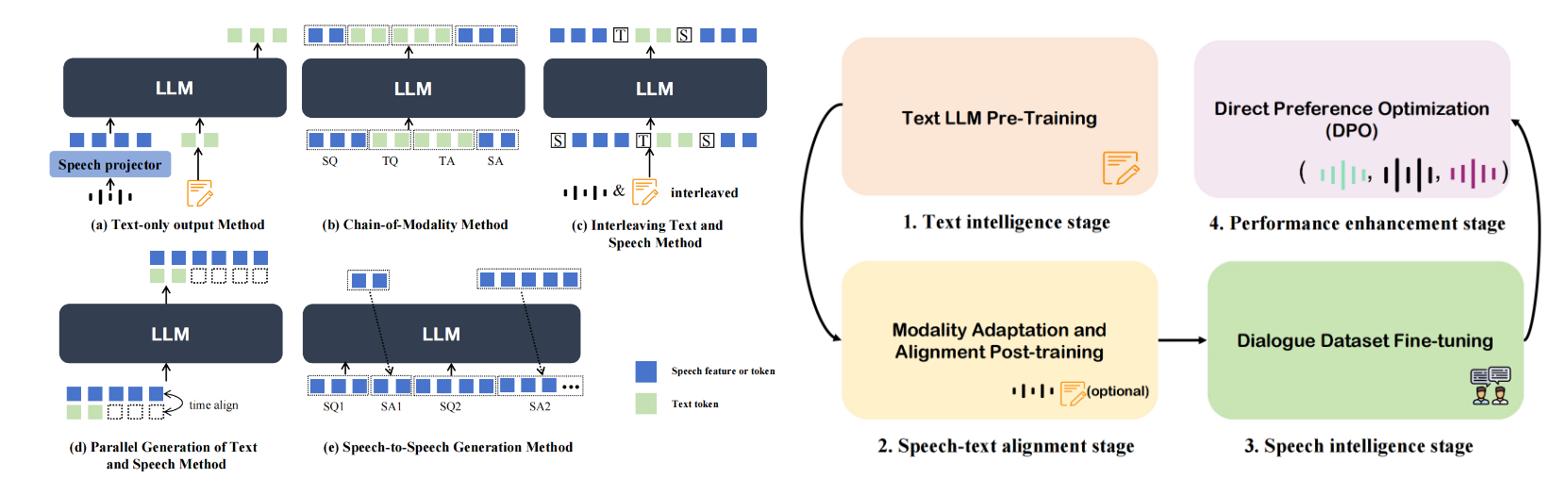
370 |
373 | Figure 5: Categorization Diagram of Spoken Dialogue Model Architectural Paradigms (left) and Diagram of Multi-stage Training Steps (right)
374 |
375 |
376 |
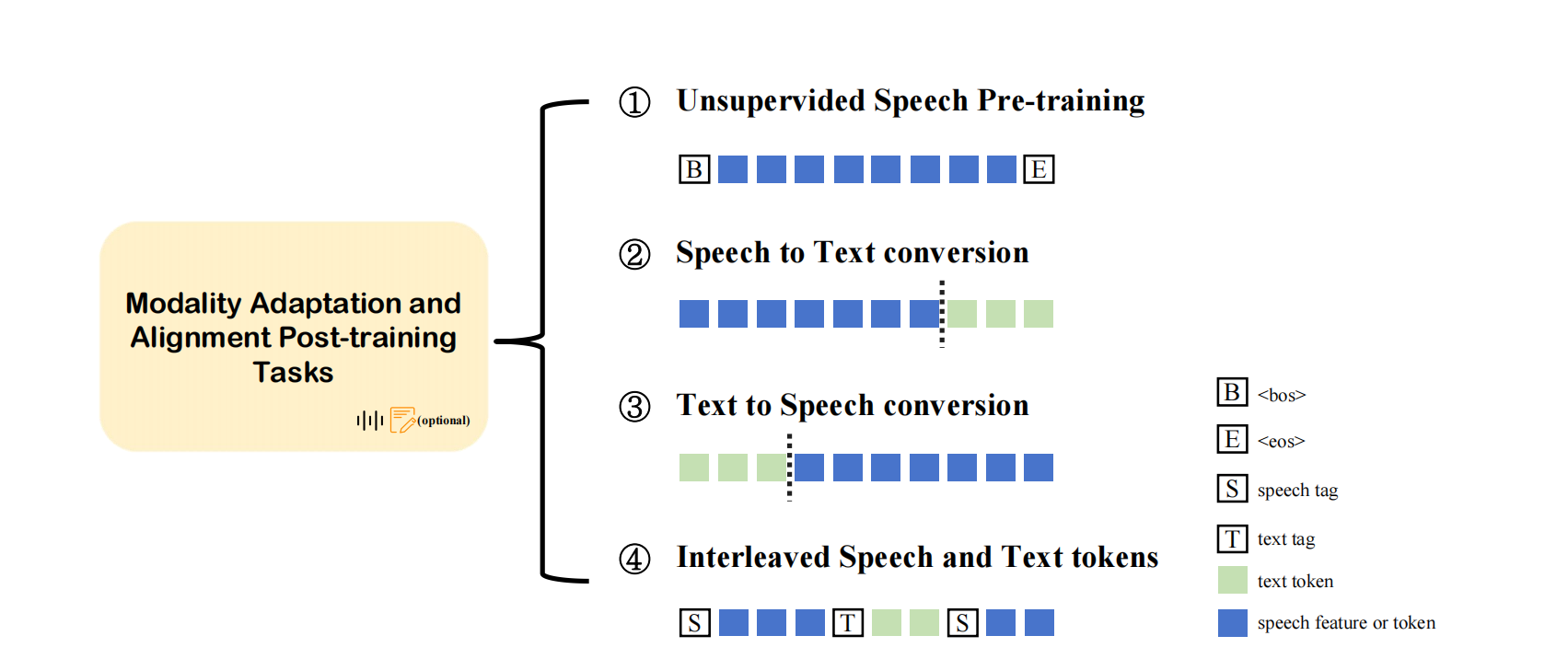
377 | And we also comprehensively summarize an overview of the Alignment Post-training Methods.
378 |
379 |
380 |
381 |
382 |
383 | Figure 6: Alignment Post-training Methods
384 |
385 | ## Streaming, Duplex, and Interaction
386 |
387 | The Streaming, Duplex, and Interaction section mainly discusses the implementation of **streaming processing, duplex communication, and interaction capabilities** inspeech dialogue models. These features are crucial for improving the response speed, naturalness, and interactivity of the model in real-time conversations.
388 |
389 |
390 |
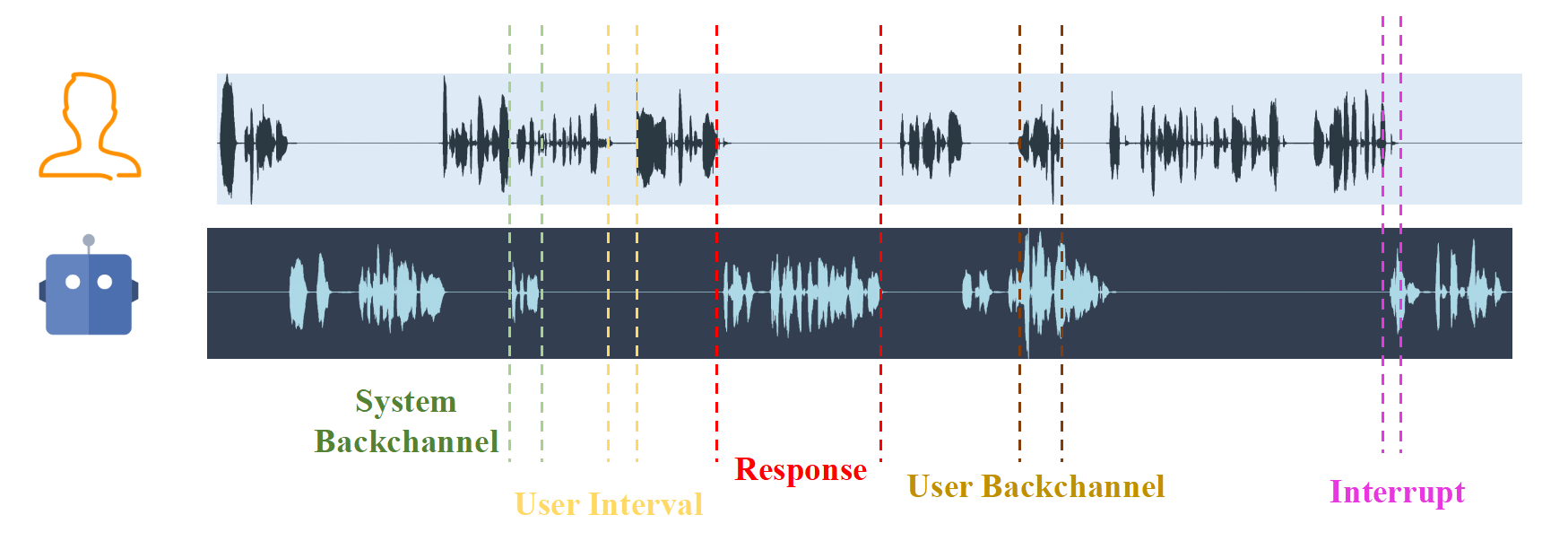
391 |
392 | Figure 7: The Example Diagram of Duplex Interaction
393 |
400 |
401 | Datasets used in the various training stages
402 |
403 |
404 | | Stage |
405 | Task |
406 | Dataset |
407 | Size |
408 | URL |
409 | Modality |
410 |
411 |
412 |
413 |
414 | | Modal Alignment |
415 | Multilingual TTS |
416 | Emilia |
417 | 101k hrs |
418 | Link |
419 | Text, Speech |
420 |
421 |
422 | | Mandarin ASR |
423 | AISHELL-1 |
424 | 170 hrs |
425 | Link |
426 | Text, Speech |
427 |
428 |
429 | | Mandarin ASR |
430 | AISHELL-2 |
431 | 1k hrs |
432 | Link |
433 | Text, Speech |
434 |
435 |
436 | | Mandarin TTS |
437 | AISHELL-3 |
438 | 85 hrs, 88,035 utt., 218 spk. |
439 | Link |
440 | Text, Speech |
441 |
442 |
443 | | TTS |
444 | LibriTTS |
445 | 585 hrs |
446 | Link |
447 | Text, Speech |
448 |
449 |
450 | | ASR |
451 | TED-LIUM |
452 | 452 hrs |
453 | Link |
454 | Text, Speech |
455 |
456 |
457 | | ASR |
458 | VoxPopuli |
459 | 1.8k hrs |
460 | Link |
461 | Text, Speech |
462 |
463 |
464 | | ASR |
465 | Librispeech |
466 | 1,000 hrs |
467 | Link |
468 | Text, Speech |
469 |
470 |
471 | | ASR |
472 | MLS |
473 | 44.5k hrs |
474 | Link |
475 | Text, Speech |
476 |
477 |
478 | | TTS |
479 | Wenetspeech |
480 | 22.4k hrs |
481 | Link |
482 | Text, Speech |
483 |
484 |
485 | | ASR |
486 | Gigaspeech |
487 | 40k hrs |
488 | Link |
489 | Text, Speech |
490 |
491 |
492 | | ASR |
493 | VCTK |
494 | 300 hrs |
495 | Link |
496 | Text, Speech |
497 |
498 |
499 | | TTS |
500 | LJSpeech |
501 | 24 hrs |
502 | Link |
503 | Text, Speech |
504 |
505 |
506 | | ASR |
507 | Common Voice |
508 | 2,500 hrs |
509 | Link |
510 | Text, Speech |
511 |
512 |
513 | | Dual-Stream Processing |
514 | Instruction |
515 | Alpaca |
516 | 52,000 items |
517 | Link |
518 | Text + TTS |
519 |
520 |
521 | | Instruction |
522 | Moss |
523 | - |
524 | Link |
525 | Text + TTS |
526 |
527 |
528 | | Instruction |
529 | BelleCN |
530 | - |
531 | Link |
532 | Text + TTS |
533 |
534 |
535 | | Dialogue |
536 | UltraChat |
537 | 1.5 million |
538 | Link |
539 | Text + TTS |
540 |
541 |
542 | | Instruction |
543 | Open-Orca |
544 | - |
545 | Link |
546 | Text + TTS |
547 |
548 |
549 | | Noise |
550 | DNS |
551 | 2425 hrs |
552 | Link |
553 | Noise data |
554 |
555 |
556 | | Noise |
557 | MUSAN |
558 | - |
559 | Link |
560 | Noise data |
561 |
562 |
563 | | Conversation Fine-Tune |
564 | Dialogue |
565 | Fisher |
566 | 964 hrs |
567 | Link |
568 | Text, Speech |
569 |
570 |
571 | | Dialogue |
572 | GPT-Talker |
573 | - |
574 | Link |
575 | Text, Speech |
576 |
577 |
578 | | Instruction |
579 | INSTRUCTS2S-200K |
580 | 200k items |
581 | Link |
582 | Text + TTS |
583 |
584 |
585 | | Instruction |
586 | Open Hermes |
587 | 900k items |
588 | Link |
589 | Text + TTS |
590 |
591 |
592 |
593 |
594 | Table 4: Datasets used in the various training stages
595 |
598 |
599 | Music and Non-Speech Sound Datasets
600 |
601 |
602 | | Dataset |
603 | Size |
604 | URL |
605 | Modality |
606 |
607 |
608 |
609 |
610 | | ESC-50 |
611 | 2,000 clips (5s each) |
612 | Link |
613 | Sound |
614 |
615 |
616 | | UrbanSound8K |
617 | 8,732 clips (<=4s each) |
618 | Link |
619 | Sound |
620 |
621 |
622 | | AudioSet |
623 | 2000k+ clips (10s each) |
624 | Link |
625 | Sound |
626 |
627 |
628 | | TUT Acoustic Scenes 2017 |
629 | 52,630 segments |
630 | Link |
631 | Sound |
632 |
633 |
634 | | Warblr |
635 | 10,000 clips |
636 | Link |
637 | Sound |
638 |
639 |
640 | | FSD50K |
641 | 51,197 clips (total 108.3 hours) |
642 | Link |
643 | Sound |
644 |
645 |
646 | | DCASE Challenge |
647 | varies annually |
648 | Link |
649 | Sound |
650 |
651 |
652 | | IRMAS |
653 | 6,705 audio files (3s each) |
654 | Link |
655 | Music |
656 |
657 |
658 | | FMA |
659 | 106,574 tracks |
660 | Link |
661 | Music |
662 |
663 |
664 | | NSynth |
665 | 305,979 notes |
666 | Link |
667 | Music |
668 |
669 |
670 | | EMOMusic |
671 | 744 songs |
672 | Link |
673 | Music |
674 |
675 |
676 | | MedleyDB |
677 | 122 multitrack recordings |
678 | Link |
679 | Music |
680 |
681 |
682 | | MagnaTagATune |
683 | 25,863 clips (30s each) |
684 | Link |
685 | Music |
686 |
687 |
688 | | MUSDB |
689 | 150 songs |
690 | Link |
691 | Music |
692 |
693 |
694 | | M4Singer |
695 | 700 songs |
696 | Link |
697 | Music |
698 |
699 |
700 | | Jamendo |
701 | 600k songs |
702 | Link |
703 | Music |
704 |
705 |
706 |
707 |
708 | Table 5: Music and Non-Speech Sound Datasets
709 |
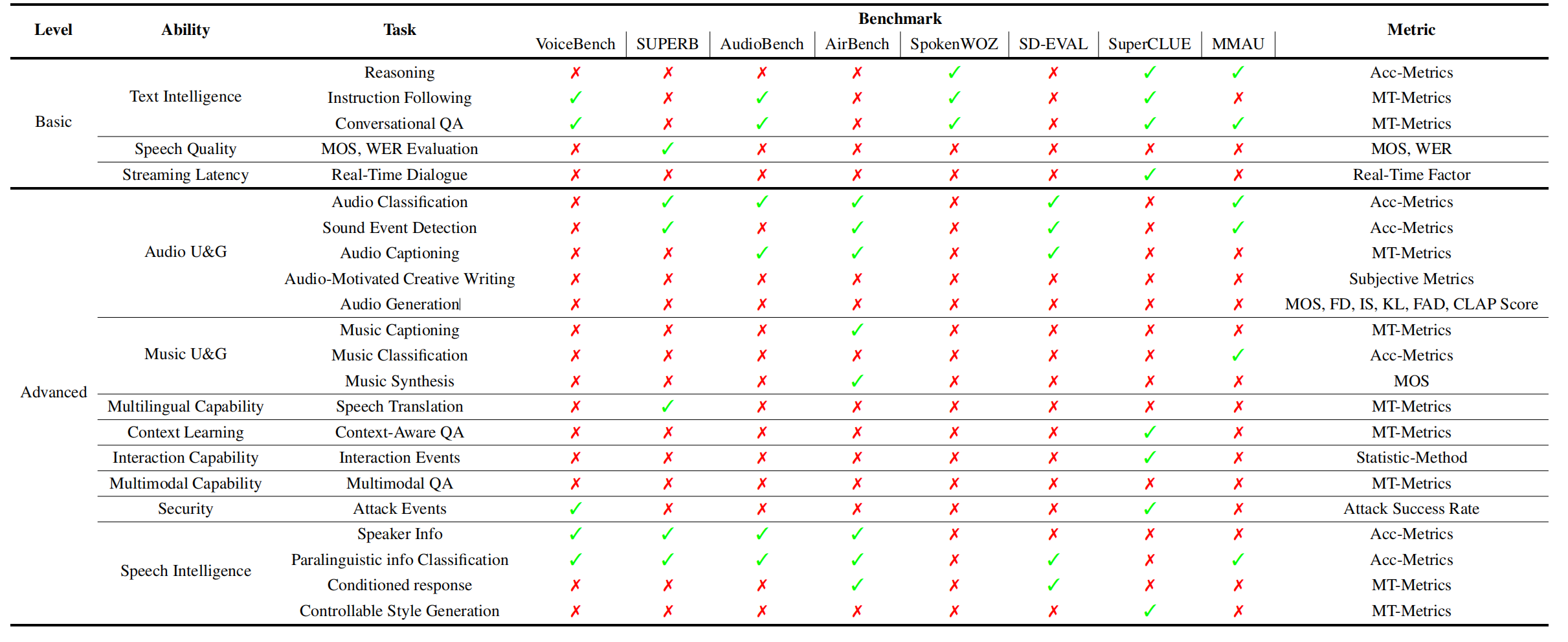
717 | Table 6: This table evaluates model performance across various abilities, common tasks, representative benchmarks, and corresponding metrics.
718 |
719 |
720 | ## Cite
721 |
722 | ```bibtex
723 | @article{ji2024wavchat,
724 | title={WavChat: A Survey of Spoken Dialogue Models},
725 | author={Ji, Shengpeng and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Lu, Jingyu and Wang, Hanting and Jiang, Ziyue and Zhou, Long and Liu, Shujie and Cheng, Xize and others},
726 | journal={arXiv preprint arXiv:2411.13577},
727 | year={2024}
728 | }
729 | ```
730 |
--------------------------------------------------------------------------------