26 |
27 | ### 2. LinkedList
28 | 
29 | - 일렬로 연결된 데이터를 저장할 때 사용하는 자료구조
30 | - 이중 연결 리스트의 형태를 가지고 있다.
31 | - 초기화시 설정된 리스트의 크기를 이후에 변경할 수 있다.
32 | - 포인터를 통해 다음 데이터의 위치를 가리키고 있다.
33 | - 불연속적인 메모리 공간에 데이터를 저장하기 때문에, 검색 성능이 좋지 않다.
34 | - 검색 시, 시작이나 끝에서부터 원하는 인덱스에 도달할 때까지 **순차적으로** 저장된 다음 주소를 탐색하므로 성능이 좋지 않다. (**O(N)**)
35 | - 삽입/삭제 시,
36 | - 시작이나 끝 요소에 접근할 때, **O(1)**
37 | - LinkedList는 head(시작)와 tail(끝)을 갖는 이중 연결 리스트의 구조이다.
38 | - 그 외 요소에 접근할 때, **O(N)**
39 | - 원하는 인덱스에 도달할 때까지 순차적인 접근을 한다. - O(N)
40 | - `index-1`의 노드의 next와 `index+1`의 prev를 삽입/삭제할 노드 정보로 변경하는 시간은 상수시간이다. - O(1)
41 | - 새로운 요소가 추가될 때, 런타임에 메모리를 할당한다. (동적 메모리 할당)
42 | - Heap 영역에 메모리 할당이 이루어진다.
43 |
44 |
45 |
46 | ### 3. ArrayList
47 | - Array를 사용해 만든 List형 자료구조
48 | - 내부적으로 데이터를 배열의 형태로 관리한다.
49 | - 초기화시 설정된 배열의 크기를 이후에 변경할 수 있다.
50 | - 검색 시, 인덱스 기반 탐색을 하므로 성능이 좋다. (**O(1)**)
51 | - 삽입/삭제 시, 임시 배열을 생성해 데이터를 복사하는 방법을 사용한다. 이는 새로운 메모리를 할당하는 방법으로, 성능이 좋지 않다. (**O(N)**)
52 | - 삽입: 기존에 있던 배열에서, 추가하고 싶은 index부터 마지막 index까지 한 칸씩 뒤로 미루는 연산을 한다.
53 | - 삭제: 삭제된 index + 1부터 마지막 index까지 한 칸씩 앞으로 당기는 연산을 한다.
54 |
55 |
56 |
57 | ### 4. 정리
58 | ||Array|ArrayList|LinkedList
59 | |:---:|:---:|:---:|:---:|
60 | |get/set|O(1)|O(1)|O(N)|
61 | |add(시작)|O(N)|O(N)|O(1)|
62 | |add(끝)|O(N)|O(1)|O(1)|
63 | |add(일반)|O(N)|O(N)|O(N)|
64 | |remove(시작)|O(N)|O(N)|O(1)|
65 | |remove(끝)|O(N)|O(1)|O(1)|
66 | |remove(일반)|O(N)|O(N)|O(N)|
67 |
68 |
69 |
70 | - 일반적으로 검색, 수정을 자주 사용한다면, `Array , ArrayList`
71 | - 데이터의 크기가 고정적일 때, `Array`
72 | - 데이터의 크기가 가변적일 때, `ArrayList`
73 | - 잦은 삽입, 삭제가 발생한다면, `LinkedList`
74 | - 공간 복잡도의 경우, 종종 ArrayList가 LinkedList보다 빠른 경우가 발생한다.
75 | - ArrayList는 연속된 메모리 공간 안에 데이터가 저장되기 때문이다.
76 | - LinkedList는 요소마다 두 개의 참조 노드가 필요하고, 메모리 공간에 비연속적으로 노드가 흩어져 있을 수 있다.
--------------------------------------------------------------------------------
/algorithm/jsy/mst.md:
--------------------------------------------------------------------------------
1 | # :question: MST(Minimal Spanning Tree)
2 |
3 | #### reference
4 | https://gmlwjd9405.github.io/2018/08/28/algorithm-mst.html
5 | https://onepwnman.github.io/MST/
6 | https://devraphy.tistory.com/83
7 | https://it-earth.tistory.com/98
8 |
9 |
10 | ## Question
11 | 1. 최소비용 신장트리(MST)가 무엇인지 설명하고, 대표 알고리즘 2개(크루스칼, 프림)를 비교해주세요.
12 | - 최소비용 신장트리는 간선들의 가중치를 고려하여 최소 비용을 갖도록 하는 신장트리입니다. 신장트리는 가장 적은 개수의 간선으로 모든 정점을 연결하는 트리를 뜻합니다.
13 | - 크루스칼은 시작 정점을 정하지 않고 최소 비용의 간선을 순서대로 대입하면서 트리를 구성해나가기 때문에, 사이클 여부를 항상 확인해야합니다. 반면, 프림은 시작 정점을 정하고 해당 정점에서 최소 비용(거리)을 갖는 정점을 선택하면서 트리를 확장시키기 때문에 사이클을 이루지 않으므로, 사이클 여부를 확인하는 과정이 필요하지 않습니다.
14 | - 이러한 점에서 크루스칼은 간선 중심의 알고리즘, 프림은 정점 중심의 알고리즘이라는 차이점을 가지고 있다고 할 수 있습니다.
15 |
16 |
17 | ## :nerd_face: What I study
18 | ### 1. Spanning Tree (신장 트리)
19 | 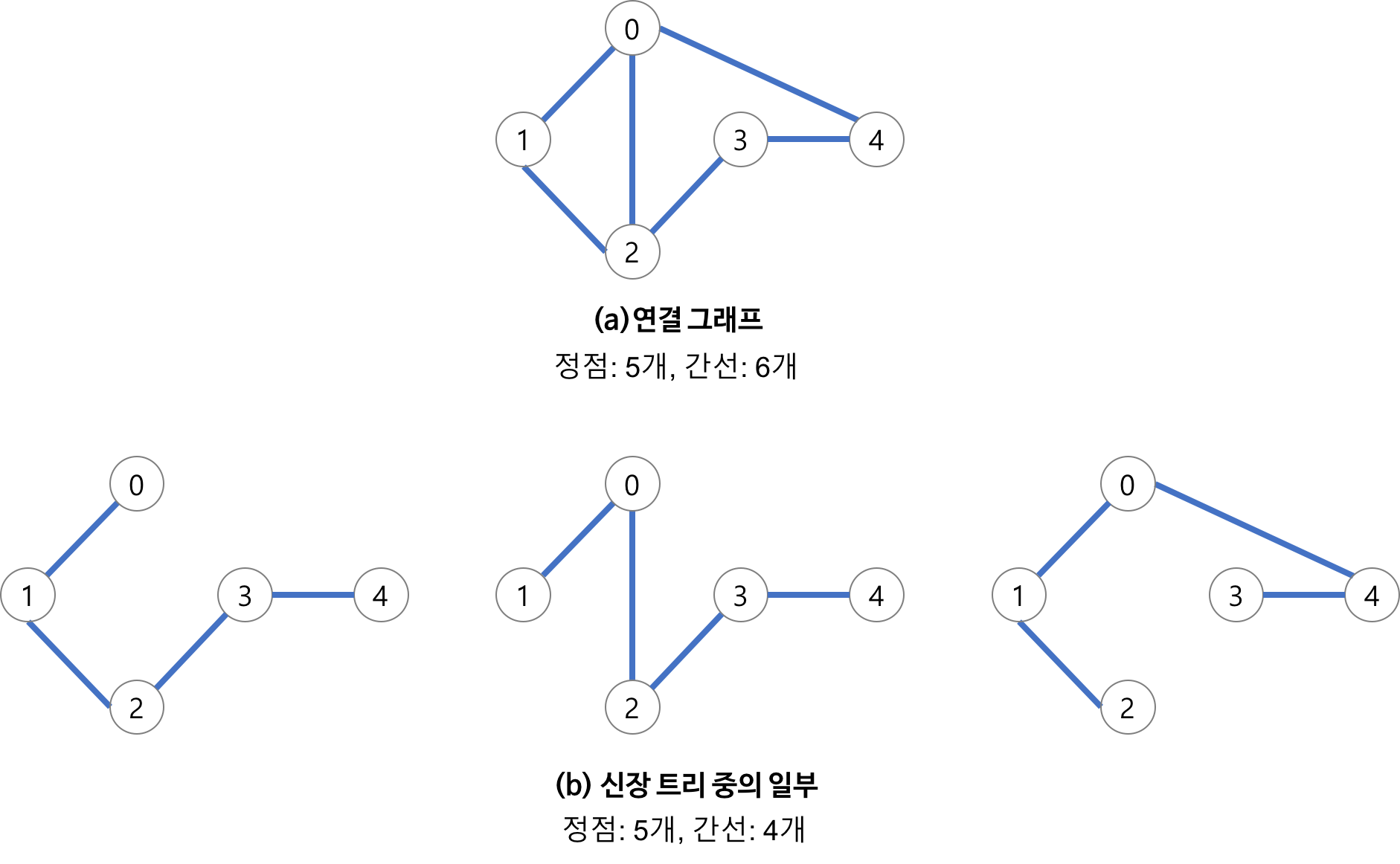
20 | - 그래프 내의 모든 정점을 포함하는 트리
21 | - 그래프의 최소 연결 부분 그래프
22 | - 가장 적은 개수의 간선으로 모든 정점을 연결할 수 있다.
23 |
24 | #### 1-1. 특징
25 | - **모든 정점들이 연결**되어 있어야 한다.
26 | - **사이클이 포함되서는 안된다.**
27 | - 그래프가 `n`개의 정점을 가지고 있다면, 정확히 `n-1` 개의 간선으로 연결한다.
28 | - n개의 정점을 가지는 그래프의 최소 간선의 수 : `n-1`개
29 | - ex) 통신 네트워크 구축 - 최소의 케이블(링크)을 사용하여 연결하고자 하는 경우
30 |
31 |
32 |
33 | ### 2. MST (Minimal Spanning Tree, 최소 신장 트리)
34 | - Spanning Tree 중 사용된 간선들의 가중치를 고려하여 최소 비용을 갖는 트리
35 | - 가장 적은 개수의 간선과 비용으로, 모든 정점을 연결할 수 있다.
36 | - cf) 절대적이진 않지만, 간선이 적으면 kruskal, 간선이 많으면 prim 이 유리하다.
37 |
38 | #### 2-1. 특징
39 | - **모든 정점들이 연결**되어 있어야 한다.
40 | - **사이클이 포함되서는 안된다.**
41 | - 그래프가 `n`개의 정점을 가지고 있다면, 정확히 `n-1` 개의 간선으로 연결한다.
42 | - ***간선의 가중치의 합이 최소여야 한다.***
43 | - ex) 통신망, 도로망, 유통망에서 '길이, 구축 비용, 전송 시간'(이게 가중치를 의미함) 등을 최소로 하여 구축하고자 하는 경우
44 |
45 |
46 |
47 | ### 3. Kruskal MST Algorithm
48 | 
49 | - **Greedy하게** 네트워크의 모든 정점을 최소 비용으로 연결하는 최적 해답을 구하는 알고리즘
50 | - **간선 중심**으로 간선 선택을 기반으로 하는 알고리즘
51 | - 이전 단계에서 만들어진 신장 트리와는 상관없이 **무조건 최소 간선만을 선택**한다.
52 | - kruskal 알고리즘은 최적의 해답을 주는 것으로 검증되어 있으므로, 따로 증명하지 않아도 된다.
53 | - cf) greedy ? 그 순간에는 최적이지만, 전체적인 관점에서 최적이라는 보장이 없기 때문에 반드시 검증해야 한다.
54 |
55 | #### 3-1. 동작
56 | 1. 그래프의 모든 간선들을 리스트로 담아, 가중치의 오름차순으로 정렬한다.
57 | 2. 정렬된 간선 리스트에서, 가중치가 가장 작은 간선을 선택한다.
58 | 3. 사이클을 형성하지 않는다면, 해당 간선을 현재의 MST의 집합에 추가한다.
59 | 4. 위의 과정을 반복한다.
60 |
61 | #### 3-2. 구현
62 | - 가중치를 저장하여, Edge 관리를 해야한다.
63 | - union-find 를 사용하여 구현한다.
64 | - 왜? 현재 선택된 간선이 MST 집합에서 사이클을 이루는 간선인지 확인(**find**) -> 사이클을 형성하지 않는다고 확인되면, MST 집합에 합침(**union**)
65 |
66 | #### 3-3. 시간복잡도
67 | 
68 | - 간선이 e개일 때, `O(elog(e))` 의 시간복잡도를 갖는다.
69 | - 간선들을 정렬하는 시간에 영향을 많이 받는다.
70 | - 정점의 개수에 비해 간선의 개수가 적은 경우 유리하다.
71 |
72 | 1. 모든 정점(n개)을 독립적인 집합으로 만든다. `O(n)`
73 | - 노드의 개수만큼 parent, rank(depth) 집합을 초기화한다.
74 | - 전체 시간복잡도에 큰 영향을 미치지 않으므로 삭제
75 | 2. 그래프의 모든 간선을 가중치 기준으로 오름차순 정렬한다 `O(elog(e))`
76 | 3. 2개 부분집합 각각의 루트노드를 확인(find)하고, 루트노드가 서로 다른 경우 union한다 `O(1)`
77 | - union-by-rank 기법과 path compression 기법을 사용하면 상수에 가까운 시간복잡도를 갖는다.
78 |
79 |
80 |
81 | ### 4. Prim MST Algorithm
82 | 
83 | - 시작 정점에서부터 출발하여 신장트리 집합(MST)을 단계적으로 확장해나가는 알고리즘
84 | - **정점 중심**으로 정점 선택을 기반으로 하는 알고리즘
85 | - 이전 단계에서 만들어진 **신장 트리를 확장**해나간다.
86 |
87 | #### 4-1. 동작
88 | 1. 시작 단계에서는 **시작 정점만이** MST 집합에 포함된다.
89 | 2. 앞 단계에서 만들어진 **MST 집합에 인접한 정점들** 중에서 **1)방문한 적이 없으며, 2)가장 낮은 가중치를 갖는 정점을 선택**하여, 트리를 확장한다.
90 | 3. 위의 과정을 트리가 `n-1`개의 간선을 가질 때까지 반복한다.
91 |
92 | #### 4-2. 구현
93 | - 가중치를 저장하여, Edge 관리를 해야한다.
94 | - priority queue, queue 를 사용하여 구현한다.
95 | - 왜? priority queue는 MST의 정점과 인접한 간선 중 최소 가중치 간선(**우선순위**)을 먼저 뽑아내기 위해 사용하고, queue는 정점 방문 스케줄링 관리를 위해 사용한다.
96 |
97 | #### 4-3. 시간복잡도
98 | #### 4-3-1) 우선순위 큐를 사용하지 않을 때
99 | - 정점이 n개일 때, `O(n^2)` 의 시간복잡도를 갖는다.
100 | - 최소 비용의 정점을 찾는 시간에 영향을 많이 받는다.
101 |
102 | 1. 모든 정점을 초기화한다. `O(n)`
103 | - 전체 시간복잡도에 큰 영향을 미치지 않으므로 삭제
104 | 2. 최악의 경우 시작 정점 집합과 그렇지 않은 집합의 모든 노드를 탐색하게 된다. `O(n^2)`
105 | - 주 반복문이 정점의 수 n만큼 반복, 내부 반복문이 모든 노드를 또 n만큼 반복하면서 탐색
106 |
107 | #### 4-3-2) 우선순위 큐를 사용할 때
108 | - 정점이 n개일 때, `O(elog(n))` 의 시간복잡도를 갖는다.
109 | - 간선의 개수에 비해 정점의 개수가 적은 경우 유리하다.
110 |
111 | 1. 모든 정점을 초기화한다. `O(n)`
112 | - 전체 시간복잡도에 큰 영향을 미치지 않으므로 삭제
113 | 2. 우선순위 큐의 push/pop 연산 `O(log(n))`
114 | 3. 모든 간선(e개)을 확인하기 위해, 우선순위 큐에 간선을 push/pop하는 연산 최대 e번 수행 `O(e)`
115 |
--------------------------------------------------------------------------------
/algorithm/yij/Cryptography.md:
--------------------------------------------------------------------------------
1 | # Cryptography - 암호화 알고리즘
2 |
3 | 암호화 알고리즘은 암호화/복호화에 사용되는 키, 그리고 양방향 가능 유무를 기준으로 분류할 수 있다.
4 |
5 |
6 |
7 | ## Symmetric-Key Algorithm
8 |
9 | 대칭 키 암호는 암호화 알고리즘의 한 종류로, 암호화와 복호화에 같은 암호 키를 사용하는 알고리즘을 의미한다.
10 |
11 | 암호화를 하는 송신자가 평문을 암호화 하고, 해당 암호 키를 공유해서 복호화를 하는 수신자는 암호문을 복원한다. 공유되는 암호 키를 **대칭 키**라고 한다.
12 |
13 | 공개 키 암호화 방식과 비교해서 계산 속도가 빠르다는 장점이 있지만, 같은 키를 공유해야 하기 때문에 언젠가 한 번은 키를 전달해야 하는데, 전송 과정에서 탈취당할 수 있다는 위험성이 있다.
14 |
15 |
16 |
17 | ## Public-Key Algorithm
18 |
19 | 
20 |
21 | 암호화와 복호화에 이용하는 키가 다른 방식을 말한다. 이 알고리즘은 공개 키 암호 또는 비대칭 암호라고 부른다.
22 |
23 | 두 개의 키를 사용하는데 전체에서 공유하는 암호 키를 **공개 키**, 특정 사용자만이 가지고 있는 암호 키를 **개인 키**라고 한다. 어느 하나의 키로 암호화한 암호문은 다른 쪽의 키로 복호화할 수 있다. 대칭 키 암호보다 복잡한 계산을 사용하기 때문에, 실제에서는 대칭 키 방식과 혼합해서 사용한다.
24 |
25 | 이 때 사용되는 방식은 두 가지가 있다.
26 |
27 | ### 공개 키 암호
28 |
29 | 공개 키를 이용해서 암호화하고, 특정 개인 키를 가진 사용자만이 해당 암호문을 복호화할 수 있다. 대칭 키를 이용했을 때의 단점인 키의 공유가 발생하지 않기 때문에 두 단말 간에 정보를 안전하게 공유할 수 있다.
30 |
31 | > 1. A는 공개 키를 공개한다.
32 | > 2. B는 공개 키로 전달하려는 평문을 암호화 한다.
33 | > 3. B가 A에게 암호문을 전달한다.
34 | > 4. A는 개인 키를 이용해서 암호문을 복호화한다.
35 |
36 | ### 공개 키 서명
37 |
38 | 개인 키를 이용해서 암호화하고, 공개 키를 이용해서 해당 암호문을 복호화할 수 있다. 누구나 해당 암호문을 복호화할 수 있으므로, 개인 키를 가진 사용자로부터의 신뢰할 수 있는 정보인지 검증하는 용도로 쓰인다.
39 |
40 | > 1. A는 공개 키를 공개한다.
41 | > 2. A는 평문을 자신의 개인 키로 암호화 한다.
42 | > 3. 다른 사용자는 해당 암호문을 A의 공개 키를 이용해서 복호화한다.
43 | > 4. 해당 문서가 변조되었다면 원래의 평문을 복원할 수 없으므로, 문서의 발행 출처와 변조 여부를 확인할 수 있다.
44 |
45 |
46 |
47 | ## 대칭 키 + 비대칭 키
48 |
49 | 대칭 키 방식과 공개 키 암호 방식의 장단점이 명확하기 때문에 두 방식을 혼합해서 사용한다.
50 |
51 | 1. 송신자 측에서는 대칭 키로 사용할 암호 키를 공개 키로 암호화한다.
52 | 2. 암호화된 대칭 키를 전송한다. 이 암호문은 수신자 측만 복호화할 수 있기에 탈취당해도 안전하다.
53 | 3. 수신자는 암호문을 복호화 해서 공개 키를 얻는다.
54 | 4. 송신자와 수신자가 공유한 대칭 키를 이용해서 이후에는 해당 대칭 키를 이용한 암호화 방식을 사용해서 통신한다.
55 |
56 |
57 |
58 | ## One-Way Encryption
59 |
60 | 
61 |
62 | 위의 두 암호화 알고리즘은 암호 키를 사용해서 평문을 암호문으로 암호화, 암호문을 평문으로 복호화할 수 있었다. 하지만 **Cryptographic hash function(암호화 해시 함수)를 사용한 단방향 암호화 방식**은 평문을 암호화한 뒤로는 복호화할 수 없는 암호화 방식이다. 이 암호화 방식은 패스워드 저장과 같이, 반드시 원본 데이터를 복원해내지 않아도 되는 경우에 사용한다(ex. 서버의 데이터베이스에 저장하는 패스워드는 복호화 될 필요가 없고, 사용자가 패스워드를 입력할 때 마다 암호화 한 값을 비교하면 된다).
--------------------------------------------------------------------------------
/database/README.md:
--------------------------------------------------------------------------------
1 | # 1) Database
2 | - contributor : [김경원](https://github.com/shining8543) , [윤이진](https://github.com/483759) , [이현경](https://github.com/honggoii) , [진수연](https://github.com/jjuyeon)
3 |
4 |
5 | ### :notebook_with_decorative_cover: 무결성 (integrity)
6 | 1. 무결성에 대해 설명해주세요.
7 | 2. 무결성을 유지하려는 이유가 무엇인가요?
8 |
9 |
10 |
11 | ### :notebook_with_decorative_cover: 인덱스 (Index)
12 | 1. DB 인덱스에 대해 설명해주세요.
13 | 2. DB 인덱스를 사용하는 이유는 무엇인가요?
14 | 3. DB 인덱스에 해쉬 보다 B Tree를 쓰는 이유는 무엇인가요?
15 |
16 |
17 |
18 | ### :notebook_with_decorative_cover: 관계형 DB vs 비관계형 DB
19 | 1. 관계형 DB 와 비관계형 DB 의 차이점에 대해 설명해주세요.
20 | 2. RDBMS과 비교하였을 때 NoSQL의 장점을 설명해보세요.
21 | 3. 어떤상황에서 NoSQL을 쓰는 것이 더 적합한가?
22 |
23 |
24 |
25 | ### :notebook_with_decorative_cover: 트랜잭션 (Transaction)
26 | 1. 트랜잭션이란?
27 | 2. 트랜잭션의 성질 ACID
28 | 3. 트랜잭션을 병행으로 처리할 때 발생할 수 있는 문제점과 이를 방지하기 위한 방법
29 | 4. (3-1) Locking 제어 기법을 사용할 때 Locking 단위를 크게/작게 했을 때의 차이점
30 | 5. (3-2) Locking 제어가 일으킬 수 있는 문제점
31 | 6. 트랜잭션에 의해 발생할 수 있는 데드락에 대해 설명
32 | 7. (6-1) 데드락을 방지할 수 있는 방법은?
33 | 8. 트랜잭션 격리 수준의 각 레벨에 대해 간략하게 설명
34 | 9. COMMIT과 ROLLBACK에 대해 설명해주세요.
35 |
36 |
37 |
38 | ### :notebook_with_decorative_cover: 데이터 모델링
39 | 1. 다양한 데이터 모델에 대해서 설명해주세요.
40 | 2. 데이터 모델링의 디자인 스키마에 대해서 설명해주세요.
41 | 3. 위에서 답변한 스키마 중에서 어떤 것이 더 낫습니까?
42 |
43 |
44 |
45 | ### :notebook_with_decorative_cover: 정규화 (Normalization)
46 | 1. 정규화란 무엇인지, 필요한 이유와 함께 답변해주세요.
47 | 2. 각 정규화 단계에 대해 **만족되어야 할 조건**을 중심으로 설명해주세요.
48 | 3. 함수적 종속에 대해 설명해주세요.
49 | 4. 완전함수적 종속/부분함수적 종속/이행함수적 종속에 대해 설명해주세요.
50 | 5. 역정규화를 하는 이유는 무엇인가요?
51 |
52 |
53 |
54 | ### :notebook_with_decorative_cover: 기타
55 | 1. 데이터베이스 장애에 대해 설명해주세요.
56 | 2. 데이터베이스 회복 기법에 대해 설명해주세요.
57 | 3. SQL Injection에 대해 설명해주세요
58 | 4. HINT(힌트)는 무엇인가요?
59 |
60 |
61 |
62 | #### 참고 자료
63 | - DBMS는 어떻게 트랜잭션을 관리할까? - https://d2.naver.com/helloworld/407507
64 | - 성능 향상을 위한 SQL 작성법 - https://d2.naver.com/helloworld/1155
65 | - CUBRID Internals - 키와 인덱스의 관계 - https://d2.naver.com/helloworld/1043622
--------------------------------------------------------------------------------
/database/jsy/README.md:
--------------------------------------------------------------------------------
1 | # Suyeon Jin
2 |
3 | |Study|바로가기|
4 | |---|---|
5 | |인덱스|[:white_check_mark:](../jsy/index.md)|
6 | |관계형vs비관계형|[:white_check_mark:](../jsy/db.md)|
7 | |트랜잭션|[:white_check_mark:](../jsy/transaction.md)|
8 | |데이터 모델링|[:white_check_mark:](../jsy/modeling.md)|
9 | |정규화|[:white_check_mark:](../jsy/normalization.md)|
10 | |HINT|[:white_check_mark:](../jsy/hint.md)|
11 |
--------------------------------------------------------------------------------
/database/jsy/db.md:
--------------------------------------------------------------------------------
1 | # :question: 관계형 DB vs 비관계형 DB
2 |
3 | #### reference
4 | https://yubh1017.tistory.com/56
5 | https://siyoon210.tistory.com/130
6 | https://kosaf04pyh.tistory.com/202
7 |
8 |
9 | ## Question
10 | 1. [관계형 DB 와 비관계형 DB 의 차이점에 대해 설명해주세요.](#3-rdbms-vs-nosql)
11 | - 관계형 DB는 데이터를 **1) 정해진 스키마에 따라 2) 관계(relation)를 통해서 연결된 여러개의 테이블에 분산**하여 관리합니다.
12 | - 반면, 비관계형 DB는 **스키마, 관계를 사용하지 않고** 유연하게 데이터를 관리합니다.
13 | 2. [RDBMS과 비교하였을 때 NoSQL의 장점을 설명해보세요.](#2-nosql)
14 | - 가변적인 데이터구조로 데이터를 저장할 수 있어 유연성이 높기 때문에, **언제든지 저장된 데이터를 조정하거나 새로운 필드를 추가할 수 있습니다.**
15 | 3. [어떤상황에서 NoSQL을 쓰는 것이 더 적합한가?](#2-nosql)
16 | - 정확한 데이터 구조를 알 수 없는 경우 (변경/확장될 수 있는 경우)
17 | - 데이터의 양이 엄청나게 많은 경우
18 | - 읽기(read)처리는 자주하지만, 데이터를 자주 변경(update)하지 않는 경우
19 |
20 |
21 | ## :nerd_face: What I study
22 | ### 1. RDBMS(Relational Data Management System)
23 | 
24 | - 관계형 데이터베이스를 관리하는 프로그램
25 | #### 1) 관계형 데이터베이스의 특징
26 | - 서비스할 데이터(Entity)에 기반하여 모델링한다.
27 | - 데이터의 분류, 정렬, 탐색 속도가 빠르다.
28 | - 데이터의 무결성을 보장한다.
29 | - 무결성을 보장하기 위해, 데이터베이스에 여러 [제약조건](#cf-무결성-제약조건)이 존재한다.
30 | - 스키마는 사전에 계획되고 알려져야 한다. 즉, 개발자가 데이터 모델을 만든 뒤, 고객의 요구사항을 맞춰나가는 형식이다.
31 | - 기존에 작성된 스키마를 수정하기 어렵다.
32 | #### 2) 장점
33 | - 명확하게(엄격하게) 정의된 스키마를 사용한다. = 데이터 무결성을 보장한다.
34 | - 관계는 각 데이터를 중복없이 한번만 저장된다.
35 | #### 3) 단점
36 | - 나중에 수정하기 매우 힘들어질 수도 있다.
37 | - 관계를 통해서 데이터가 관리되기 때문에, JOIN문이 많은 복잡한 쿼리가 발생한다.
38 | - 수직적인 확장만 가능하다.
39 | #### 4) 사용하면 좋은 경우
40 | - 관계를 맺고 있는(JOIN) 데이터가 자주 변경되는 어플리케이션일 경우
41 | - 이후에 구조가 변경될 일이 없는 경우
42 | - 명확한 스키마가 사용자와 데이터에게 중요한 경우
43 |
44 |
45 | ### 2. NoSQL
46 | 
47 | - RDBMS(SQL)과 반대되는 접근 방식
48 | #### 1) 비관계형 데이터베이스의 특징
49 | - 가장 큰 특징은 ***스키마도 없고, 관계도 없다***는 것이다.
50 | - 개발할 어플리케이션의 데이터 접근 패턴에 부합하도록 모델링한다.
51 | - 다른 구조의 데이터를 같은 **컬렉션(=SQL에서의 테이블)**에 추가할 수 있다.
52 | - 일반적으로 관련 데이터는 관계형 데이터베이스처럼 여러 테이블에 나누어 담지 않고, 동일한 컬렉션에 넣는다.
53 | - 여러 테이블을 연결할 필요 없이 이미 필요한 모든 것을 갖춘 문서를 작성한다. -> JOIN이라는 개념이 존재하지 않는다.
54 | #### 2) 장점
55 | - 스키마가 없기 때문에 훨씬 유연하다. = 언제든지 저장된 데이터를 조정하고 새로운 필드를 추가할 수 있다.
56 | - 데이터는 애플리케이션이 필요로 하는 형식으로 저장한다. (데이터 read 속도 향상)
57 | - 수직, 수평 확장이 가능함으로 데이터베이스가 어플리케이션에서 발생하는 모든 read/write 요청에 대한 처리를 가능하게 한다.
58 | #### 3) 단점
59 | - 여러 컬렉션에 중복된 데이터가 변경된 경우, 여러 개의 컬렉션에서 데이터를 다 바꿔야한다. -> 하나라도 놓치면 서로 영향을 줄 위험이 있다.
60 | - 그러므로, update 연산을 해야하는 경우 모든 컬렉션에서 수행되어야 한다.
61 | #### 4) 사용하면 좋은 경우
62 | - 정확한 데이터 구조를 알 수 없는 경우 (변경/확장될 수 있는 경우)
63 | - 데이터의 양이 엄청나게 많은 경우(수평적 확장)
64 | - 읽기(read)처리는 자주하지만, 데이터를 자주 변경(update)하지 않는 경우
65 |
66 |
67 | ### 3. RDBMS vs NoSQL
68 | ||RDBMS|NoSQL|
69 | |---|---|---|
70 | ||레코드(record)|문서(document)|
71 | ||테이블(table)|컬렉션(collection)|
72 | |관리방법|스키마, 관계에 따라 데이터 관리|유연한 데이터 관리(스키마, 관계X)|
73 | |장점|데이터 무결성 보장|JOIN 연산 없음|
74 | |단점|수정이 힘듦|데이터가 여러 컬렉션에 중복되어 있음|
75 | |확장성|수직적 확장|수직/수평적 확장|
76 |
77 |
78 |
79 |
80 | ### cf) 무결성 제약조건
81 | - 개체 무결성
82 | - 기본키는 null값이 될 수 없다.
83 | - 참조 무결성
84 | - 외래키는 참조할 수 없는 값을 가질 수 없다.
85 | - 도메인 무결성
86 | - 특정 속성값은 그 속성이 정의된 도메인에 속한 값이어야 한다.
87 | - 키 무결성
88 | - 릴레이션에는 최소한 하나의 키가 존재해야 한다.
89 | - null 무결성
90 | - 특정 속성은 null값을 가질 수 없다.
91 | - 고유 무결성
92 | - 특정 속성값은 서로 달라야 한다.
93 |
--------------------------------------------------------------------------------
/database/jsy/hint.md:
--------------------------------------------------------------------------------
1 | # :question: HINT (Oracle)
2 |
3 | #### reference
4 | https://gent.tistory.com/306
5 | https://gurume.tistory.com/entry/%EC%98%A4%EB%9D%BC%ED%81%B4-%EC%9E%90%EC%A3%BC%EC%82%AC%EC%9A%A9%ED%95%98%EB%8A%94-%ED%9E%8C%ED%8A%B8%EB%AA%A9%EB%A1%9D-%EC%A0%95%EB%A6%AC%EC%B9%9C%EC%A0%88%ED%95%9C-sql-%ED%8A%9C%EB%8B%9D
6 |
7 |
8 | ## Question
9 | 1. HINT(힌트)는 무엇인가요?
10 | - 오라클에서 SQL을 튜닝하기 위한 지시구문으로 옵티마이저가 최적의 계획으로 SQL문을 처리하지 못하는 경우에 개발자가 직접 최적의 실행 계획을 제공하는 것입니다.
11 | - 개발자가 SQL문 실행을 위한 데이터 스캐닝 경로, 조인 방법 등을 작성하여 옵티마이저에게 알려줍니다.
12 |
13 |
14 |
15 | ## :nerd_face: What I study
16 | ### 1. HINT
17 |
18 | #### 1-1) 목적
19 | - 오라클 서버가 업그레이드되면서 옵티마이저의 성능도 함께 향상되어 쿼리 실행시 최적의 방법으로 실행해준다.
20 | - 하지만 옵티마이저가 항상 최적의 실행 경로를 만들어내기는 불가능하기 때문에 개발자(DBA)가 **직접 최적의 실행경로를 작성**해줘야 하는 경우가 생긴다. (튜닝)
21 | - -> 이때 사용하는 것이 **HINT** 절이다!
22 | - ex) 인덱스 힌트: DBA는 한 쿼리에서 어떤 인덱스의 선택도가 높은지 파악한 후, 옵티마이저에 의존한 실행계획보다 효율적인 실행 계획을 만들어 내어야 한다.
23 |
24 | #### 1-2) 사용법
25 | - 액세스 경로, 조인 순서, 병렬 및 직렬 처리, 옵티마이저의 목표 변경, 데이터 값 정렬에 사용된다.
26 | - HINT는 쿼리 서두에 명시한다.
27 | - 첫 줄에 힌트 주석(`/*+(힌트명)*/`)을 작성하면 된다.
28 | - 여러 개의 힌트를 명시할 수 있고, 공백으로 구분된다.
29 | - 공백이 아니면 힌트가 적용되지 않는다.
30 | - 단, 힌트 안의 괄호 사이에는 쉼표를 사용할 수 있다.
31 | - 힌트 안의 괄호가 명시되는 테이블은 `ALIAS`으로 정의되며, 스키마까지 포함해서 작성하지 않는다.
32 | - 주석에 꼭 `+`를 붙여야 힌트절이 실행되며, 없으면 일반 주석으로 간주된다.
33 |
34 | ```
35 | -- 인덱스 힌트(index_asc) : 인덱스 영역에서 순방향으로 스캔해라
36 | SELECT /*+ index_asc(e idx_myemp1_ename) */ EMPNO, ENAME, SAL FROM MYEMP1 e WHERE ENAME >= '가'
37 | ```
38 |
39 | - HINT 쿼리에 오타가 있는 경우, 무시되어 HINT가 없는 것처럼 동작한다.
40 | - 무분별한 HINT의 사용은 성능의 저하를 초래하기 때문에, 최적의 실행 경로를 알고 있을 경우 적절하게 사용되어야 한다.
41 |
42 | #### 1-3) 종류
43 | ##### 출처: https://gurume.tistory.com/entry/오라클-자주사용하는-힌트목록-정리친절한-sql-튜닝
44 |
45 |
46 | 1. 최적화 목표
47 | - `/*+ALL_LOWS */` : 전체 처리속도 최적화
48 | - `/*+FIRST_ROWS(N) */` : 최초 N건 응답속도 최적화
49 |
50 | 2. 액세스 방식
51 | - `/*+FULL */` : 인덱스 타지말고 바로 테이블 풀스캔으로 접근해라
52 | - `/*+INDEX */` : 인덱스를 타라
53 | - `/*+INDEX_DESC */` : 인덱스를 ORDER BY DESC 역순으로 타라 (시간, 결과값등 최근인 것 혹은 MAX값 구할때 좋음)
54 | - `/*+INDEX_FFS */` : INDEX FAST FULL SCAN으로 타라
55 | - `/*+INDEX_SS */` : INDEX SKIP SCAN
56 |
57 | 3. 조인순서
58 | - `/*+ORDERED */` : FROM절에 나열된 테이블 순서대로 조인해라
59 | - `/*+LEADING */`: 힌트절에 열거한 테이블 순서대로 조인해라
60 | - ex) `/*+ LEADING (A B C)*/` (A,B,C 순서대로 조인)
61 |
62 | 4. 조인방식
63 | - `/*+USE_NL */` : NL(NESTED LOOP - 중첩루프)방식 조인 유도
64 | - `/*+USE_MERGE */` : 소트머지 조인으로 유도
65 | - `/*+USE_HASH */` : 해시조인으로 유도
66 | - `/*+NL_SJ */` : NL SEMI조인으로 유도
67 | - `/*+MERGE_SJ */` : 소트머지 세미조인으로 유도
68 | - `/*+HASH_SJ */` : 해시 세미조인으로 유도
69 |
70 | 5. 서브쿼리팩토링
71 | - `/*+MATERIALIZE */` : WITH문으로 정의한 집합을 물리적으로 생성하도록 유도
72 | - ex) `WITH /*+ MATERIALIZE*/ T AS (SELECT ...)`
73 | - `/*+INLINE */` : WITH문으로 정의한 집합을 물리적으로 생성하지않고 INLINE 처리하도록 유도
74 | - ex) `WITH /*+ INLINE*/ T AS (SELECT ...)`
75 |
76 | 6. 쿼리변환
77 | - `/*+ MEERGE */` : 뷰 MERGING 유도
78 | - `/*+NO_MERGE */` : 뷰 MERGING 방지
79 | - `/*+UNNEST */` : 서브쿼리 UNNESTING 유도
80 | - `/*+NO_UNNEST */` : 서브쿼리 UNNESTING 방지
81 | - `/*+PUSH_PRED */` : 조인조건 PUSHDOWN 유도
82 | - `/*+NO_PUSH_PRED */` : 조인조건 PUSHDOWN 방지
83 | - `/*+USE_CONCAT */` : OR 또는 IN-LIST조건을 OR-EXPANSION으로 유도
84 | - `/*+NO_EXPAND */` : OR 또는 IN-LIST 조건에 대한 OR-EXPANSION방지
85 |
86 | 7. 병렬처리
87 |
88 | - `/*+PARALLEL */` : 테이블 스캔, DML 병렬방식으로 처리하도록 할때 사용, 단일 대형 테이블의 접근시 정말 많이 쓴다.
89 | - ex) `/*+ PARALLEL(T1 4)*/`
90 | - `/*+PARALLEL_INDEX */` : 인덱스 스캔을 병렬방식으로 처리하도록 유도
91 | - `/*+PQ_DISTRIBUTE */` : 병렬수행시 데이터 분배방식 결정
92 | - ex) PQ_DISTRIBUTE(T1 HASH(--BUILD INPUT) HASH(--PROBE TABLE))
93 |
94 | 8. 기타
95 |
96 | - `/*+APPEND*/` : DIRECT PATH INSERT유도로 INSERT문에 주로 많이 쓴다.
97 | - `/*+DRIVING_SITE */` : DB LINK REMOTE쿼리에 대한 최적화 및 실행 주체 지정 (LOCAL 또는 REMOTE)
98 | - `/*+PUSH_SUBQ */` : 서브쿼리를 가급적 빨리 필터링하도록 유도
99 | - `/*+NO_PUSH_SUBQ */` : 서브쿼리를 가급적 늦게 필터링하도록 유도
--------------------------------------------------------------------------------
/database/jsy/index.md:
--------------------------------------------------------------------------------
1 | # :question: 인덱스 (Index)
2 |
3 | #### reference
4 | https://helloinyong.tistory.com/296
5 | https://zorba91.tistory.com/293
6 |
7 |
8 | ## Question
9 | 1. [DB 인덱스에 대해 설명해주세요.](#1-index)
10 | - DB의 데이터를 논리적으로 정렬하여 검색과 정렬 작업의 속도를 높이기 위해 사용되는 방법입니다.
11 | - 책의 목차, 색인과 같다고 할 수 있습니다.
12 |
13 |
14 | 2. DB 인덱스를 사용하는 이유는 무엇인가요?
15 | - ***테이블을 조회하는 속도와 그에 따른 성능을 향상***시킬 수 있으며, 그에 따른 ***전반적인 시스템 부화를 줄일 수*** 있습니다.
16 |
17 |
18 | 3. [DB 인덱스에 해쉬 보다 B Tree(B- Tree)를 쓰는 이유는 무엇인가요?](#2-hash-table)
19 | - 해시 테이블은 단 하나의 데이터를 탐색하는, 등호(=) 연산에만 특화되어 있습니다.
20 | - DB는 기준 값보다 크거나 작은 요소들을 탐색하는, 부등호(<,>) 연산이 자주 발생될 수 있으므로 DB 인덱스 용도로 해시 테이블은 어울리지 않습니다.
21 |
22 |
23 |
24 | ## :nerd_face: What I study
25 | ### 1. Index
26 | - DB Index에 대한 설명
27 | - 기본키는 항상 DBMS가 내부적으로 정렬된 목록을 관리한다. -> 기본키에 대해서 특정 행을 가져올 때 빠르게 처리됨.
28 | - 기본키 외의 다른 열의 내용을 검색하거나 정렬할 때는 하나하나 대조해보기 때문에 시간이 오래걸린다. -> 이를 인덱스로 정의해두면 검색 속도가 향상됨!
29 | - 즉, 데이터와 데이터의 위치를 포함한 자료구조인 인덱스를 생성하여 빠르게 조회한다!
30 | - 장점
31 | - 테이블 조회 속도, 성능 향상
32 | - 전반적인 시스템 부화 감소
33 | - 단점
34 | - 데이터 변경 작업이 자주 일어나는 경우, Index를 재작성해야 한다. (성능에 영향을 미침)
35 | - 인덱스를 관리하기 위해 DB에 추가 저장공간이 필요하다.
36 | - 사용하면 좋은 경우
37 | - where, join문에 자주 사용되는 컬럼
38 | - DML(insert, update, delete)가 자주 발생하지 않는 컬럼
39 | - 데이터의 중복도가 낮은 컬럼
40 | - 규모가 작지 않은 테이블
41 |
42 |
43 | ### 2. Hash Table
44 | 
45 | - 해시 테이블은 해시 함수를 통해 나온 해시 값을 이용하여 저장된 메모리 공간에 한 번에 접근한다.
46 | - O(1) (왜? 단 하나의 데이터를 탐색하는 시간)
47 | - 모든 값이 정렬되어 있지 않으므로, 해시 테이블에서는 특정 기준보다 크거나 작은 값을 찾을 수 없다. (부등호 연산에 매우 비효율적)
48 | - 즉, 해시 테이블은 단 하나의 데이터를 탐색하는, 등호 연산에 매우 효율적이다.
49 |
50 |
51 | ### 3. B Tree
52 | #### 1) B- Tree
53 | 
54 | - DB 인덱스에서 사용되는 자료구조
55 | - ***데이터가 정렬된 상태로 유지되는 것***이 핵심이다.
56 | - B- tree는 루트로부터 리프까지의 거리가 일정한 **균형트리**이다.
57 | 
58 | - 데이터 갱신이 자주 발생하면 서서히 균형이 깨지고, 성능에도 나쁜 영향을 미치게 된다.
59 | - 데이터 갱신이 자주 발생하는 테이블의 인덱스는 인덱스 재구성을 통해 트리의 균형을 되찾는 작업이 필요하다.
60 | #### 2) B+ Tree
61 | 
62 | - B- tree의 확장개념
63 | - ex) InnoDB (MYSQL DB engine)
64 | - 리프 노드에만 key, data를 저장한다. -> 사용되는 메모리 양을 줄일 수 있다.
65 | - 하나의 노드에 더 많은 key들을 담을 수 있으므로, 트리의 높이가 낮아진다.
--------------------------------------------------------------------------------
/database/jsy/modeling.md:
--------------------------------------------------------------------------------
1 | # :question: 데이터 모델링
2 |
3 | #### reference
4 | https://rutgo-letsgo.tistory.com/138
5 | https://prinha.tistory.com/entry/DB-3%EB%8B%A8%EA%B3%84-%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%EC%8B%9C%EC%8A%A4%ED%85%9C-%EC%99%B8%EB%B6%80%EA%B0%9C%EB%85%90%EB%82%B4%EB%B6%80%EC%8A%A4%ED%82%A4%EB%A7%88
6 |
7 |
8 | ## Question
9 | 1. [다양한 데이터 모델에 대해서 설명해주세요.](#1-data-modeling)
10 | - 데이터 모델에는 '개념 모델, 논리 모델, 물리 모델'이 있습니다.
11 | - 개념 모델에서는 데이터 모델의 첫 단계로 엔티티와 관계 위주로 모델링이 됩니다.
12 | - 논리 모델에서는 누가, 어떻게 데이터에 접근하는 지 등 비즈니스 정보의 구조, 규칙 등이 명확하게 모델링이 됩니다.
13 | - 물리 모델에서는 논리 모델을 각 DBMS의 특성에 맞게 데이터 베이스 저장 구조(물리 데이터 모델)로 변환하는 모델링이 됩니다.
14 |
15 |
16 | 2. [데이터 모델링의 디자인 스키마에 대해서 설명해주세요.](#2-database-schema)
17 | - 스키마에는 '외부 스키마, 개념 스키마, 내부 스키마'가 있습니다.
18 | - 외부 스키마는 외부 단계에서 사용자에게 필요한 데이터베이스를 정의한 스키마입니다.
19 | - 개념 스키마는 개념 단계에서 데이터베이스 전체의 논리적 구조를 정의한 스키마입니다.
20 | - 내부 스키마는 전체 데이터베이스가 저장 장치에 실제로 저장되는 방법을 정의한 스키마입니다.
21 | - 즉, 외부>개념>내부 와 같이 추상화 레벨이 높아진다.
22 |
23 |
24 | 3. 위에서 답변한 스키마 중에서 어떤 것이 더 낫습니까?
25 |
26 |
27 |
28 | ## :nerd_face: What I study
29 | ### 1. Data Modeling
30 | - 데이터 모델: 현실 세계의 정보들을 컴퓨터에 표현하기 위해서 단순화, 추상화하여 체계적으로 표현한 개념적 모형 (다른 데이터 객체와 규칙들 간의 연결을 나타냄)
31 | - 데이터 모델링: 데이터베이스에 저장될 데이터에 대한 데이터 모델링을 하는 프로세스
32 | #### 1) 개념 모델
33 | - 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정이다.
34 | - 엔티티와 관계 위주로 모델링이 된다.
35 | - 속성들로 기술된 개체 타입과 타입들 간의 관계를 정의한다.
36 | - 개체를 인간이 이해할 수 있는 정보 구조로 표현하기 때문에 정보 모델이라고도 한다.
37 | #### 2) 논리 모델
38 | - 3개의 모델 중 가장 핵심이 되는 모델!
39 | - **특정 DBMS는 특정 논리 모델 하나만 선정하여 사용한다!**
40 | - 개념적 모델링에서 얻은 개념적 구조를 컴퓨터가 이해하고 처리할 수 있도록 변환하는 과정이다.
41 | - 필드로 기술된 데이터 타입과 이들 간의 관계를 정의한다.
42 | - 데이터 요소의 구조를 정의하고 이들간의 관계를 설정한다.
43 | - 비즈니스 정보의 구조, 규칙등을 명확하게 표현해야 한다.
44 | - 개체 명칭, 속성 명칭, 데이터 형태, 길이 등을 고려
45 | #### 3) 물리 모델
46 | - 논리 모델을 특정 데이터베이스로 설계한다.
47 | - 논리 모델을 각 DBMS의 특성에 맞게 데이터 베이스 저장 구조(물리 데이터 모델)로 변환한다.
48 | - 실제 저장 공간, 분산, 저장 방법 등을 고려
49 |
50 |
51 | ### 2. Database Schema
52 | - 스키마: 데이터베이스에 저장되는 ***데이터 구조와 제약조건을 정의***한 것
53 | - 데이터베이스를 쉽게 이해하고 사용할 수 있도록 하나의 데이터베이스를 관점에 따라 세 단계로 나눴다.
54 | - 각 단계별로 다른 추상화를 제공한다.
55 | #### 1) 외부 스키마(External schema)
56 | - **데이터베이스 하나에 외부 스키마가 여러 개 존재할 수 있다.**
57 | - 사용자에게 필요한 데이터베이스를 정의한 스키마
58 | - 각 사용자가 생각하는 데이터베이스의 논리적 구조이다.
59 | - 사용자마다 다른 구조를 가진다.
60 | #### 2) 개념 스키마(Conceptual schema)
61 | - **데이터베이스 하나에 개념 스키마가 하나만 존재한다.**
62 | - 데이터베이스 전체의 논리적 구조를 정의한 스키마
63 | - 정의 대상:
64 | - 어떤 데이터가 저장되는지
65 | - 데이터들 간에는 어떤 관계가 존재하는지
66 | - 어떤 제약조건이 존재하는지
67 | - 데이터에 대한 보안 정책
68 | - 데이터에 대한 접근 권한 등등
69 | #### 3) 내부 스키마(Internal schema)
70 | - **데이터베이스 하나에 내부 스키마가 하나만 존재한다.**
71 | - 전체 데이터베이스가 저장 장치에 실제로 저장되는 방법을 정의한 스키마
72 | - 데이터베이스가 물리적으로 저장한 형식을 나타낸다.
73 | - 레코드 구조, 필드 크기, 레코드 접근 경로 등 물리적인 저장 구조를 정의한다.
74 |
75 | 
--------------------------------------------------------------------------------
/database/jsy/normalization.md:
--------------------------------------------------------------------------------
1 | # :question: 정규화 (Normalization)
2 |
3 | #### reference
4 | https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=dydghdkdl&logNo=221165683361
5 | https://m.blog.naver.com/cjw950607/221460234203
6 | https://nirsa.tistory.com/107
7 |
8 |
9 | ## Question
10 | 1. [정규화란 무엇인지, 필요한 이유와 함께 답변해주세요.](#1-normalization)
11 | - 하나의 릴레이션에 하나의 의미만 존재할 수 있도록 릴레이션을 분해하는 과정을 뜻합니다.
12 | - 데이터의 중복을 최소화하고 일관성을 보장하기 위해 정규화 과정을 거칩니다.
13 |
14 |
15 | 2. [각 정규화 단계에 대해 **만족되어야 할 조건**을 중심으로 설명해주세요.](#2-정규화-단계)
16 | - 총 5(+1)단계로 구성되어 있습니다.
17 | - 제 1정규화는 ***각 컬럼들의 값이 원자값을 가지도록 바꾸는 정규화***를 말합니다.
18 | - 제 2정규화는 ***테이블의 모든 컬럼에서 부분적 함수 종속을 제거하는 정규화***를 말합니다.
19 | - 제 3정규화는 ***기본키를 제외한 속성들 간의 이행적 함수 종속을 제거하는 정규화***를 말합니다.
20 | - BNCF는 ***결정자이면서 후보키가 아닌 것을 제거하는 정규화***를 말합니다.
21 | - 제 4정규화는 ***결합 종속성을 제거하는 정규화***를 말합니다.
22 | - 제 5정규화는 ***합성키에 순환 종속성을 제거하는 정규화***를 말합니다.
23 |
24 |
25 | ## :nerd_face: What I study
26 | ### 1. Normalization
27 | - 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스
28 | - 목적: 데이터 구조의 안정성 최대화, 중복 배제를 통한 DML 이상 발생 방지
29 | - 정규화를 거치지 않으면 이상(Anormaly) 문제가 발생한다.
30 | - 모든 테이블을 정규화하는 것은 좋지 않다. (JOIN 연산이 많아져 성능의 저하가 발생할 수 있기 때문)
31 |
32 | #### 1) 장점
33 | - 이상(Anormaly) 현상을 방지하여 유연한 데이터 구축이 가능해진다.
34 | - 불필요한 쿼리(ex. 서브쿼리)를 제거할 수 있다.
35 | - 새로운 데이터 형의 추가로 인한 확장 시, 구조를 최소한으로 변경할 수 있다.
36 | #### 2) 단점
37 | - 릴레이션의 분해로 인해 릴레이션 간 JOIN연산이 많아진다. -> 질의 응답시간이 느려질 수 있다. (성능 저하)
38 | - 위의 해결방법으로는 '반정규화'를 적용해볼 수 있다.
39 |
40 |
41 | ### 2. 정규화 단계
42 | - 정규화는 1-5 정규화까지 있지만, 실무에서는 대체로 1-3 정규화까지의 과정을 거친다.
43 | #### 1) 1NF
44 | Before|After
45 | :-------------------------:|:-------------------------:
46 |  | 
47 |
48 | - 릴레이션에 속한 모든 속성의 도메인(속성값)이 원자 값으로만 구성되어야 한다.
49 | - 테이블의 각 컬럼의 유형은 유일해야 한다.
50 | #### 2) 2NF
51 | Before|After
52 | :-------------------------:|:-------------------------:
53 |  | 
54 | - 제 1정규화를 만족해야 한다.
55 | - 모든 속성들은 오직 개체의 고유 식별자(유일키)에만 의존해야 한다.
56 | - 기본키를 제외한 속성이 기본키에 완전 함수 종속되어야 한다.
57 | #### 3) 3NF
58 | - **면접질문 빈도수가 가장 높은 정규화**
59 |
60 | Before|After
61 | :-------------------------:|:-------------------------:
62 |  | 
63 | - 제 2정규화를 만족해야 한다.
64 | - 테이블의 키 외에 다른 속성에 의존하는 요소가 존재하면 안된다.
65 | - 위와 같은 요소가 존재할 경우, 다른 새로운 테이블로 옮긴다.
66 | - 3NF까지 완성되면 데이터베이스는 정규화된 것으로 간주한다.
67 | #### 4) BNCF
68 | - 제 3정규화를 만족해야 한다.
69 | - 모든 테이블들은 오직 하나의 기본키를 가져야 한다.
70 | - 결정자이면서 후보키가 아닌 것을 제거한다.
71 | #### 5) 4NF
72 | - BNCF를 만족해야 한다.
73 | - 테이블은 하나의 키(pk)에 여러 값을 가질 수 없다. (결합 종속성 제거)
74 | - 다치 종속을 제거한다.
75 | #### 6) 5NF
76 | - 제 4정규화를 만족해야 한다.
77 | - 후보키를 통하지 않는 조인 종속을 제거한다.
78 |
79 |
80 | ### 3. 함수적 종속
81 | - 테이블 속성들간의 관계에 대한 제약조건
82 | - 속성 A가 속성 B를 결정할 때, B는 A에 함수적으로 종속된다고 한다.
83 | #### **1) 완전함수종속**
84 | - 함수적 종속에서 X의 값이 여러 요소일 경우, 즉, {X1, X2} -> Y일 경우, X1과 X2가 Y의 값을 결정할 때를 의미한다.
85 | #### **2) 부분함수종속**
86 | - X1, X2 중 하나만 Y의 값을 정할 때를 의미한다.
87 | #### **3) 이행적함수종속**
88 | - 세 가지 종속간의 종속이 (X->Y) & (Y->Z) 일 경우 X->Z가 성립되는 종속을 의미한다.
89 |
90 |
91 | ### 4. Anomaly 현상
92 | - 정규화를 거치지 않아 데이터가 불필요하게 중복되어 생기는 예기치 않게 발생하는 문제
93 | - 좋은 관계형 데이터베이스를 설계하기 위해서는 정보의 이상 현상이 생기지 않도록 고려해야 한다.
94 | #### 1) 갱신 이상
95 | - 릴레이션에서 튜플의 속성값을 변경할 때, 일부 튜플만 변경되는 현상
96 | #### 2) 삽입 이상
97 | - 릴레이션에 데이터를 삽입할 때, 원하지 않는값이 삽입되는 현상
98 | #### 3) 삭제 이상
99 | - 릴레이션에서 튜플을 삭제할 때, 원하지 않는 다른 값들도 연쇄적으로 삭제되는 현상
100 |
--------------------------------------------------------------------------------
/database/yij/Concurrency Control Mechanisms 7905a96a94f94aa2844ac41618bbc858.md:
--------------------------------------------------------------------------------
1 | # Concurrency Control Mechanisms
2 |
3 | # Database Lock ❓
4 |
5 | 
6 |
7 | RDBMS에서 트랜잭션 시스템에 적용되는 동시성 제어 방법.
8 |
9 | 특정 트랜잭션이 레코드에 접근 중 일때 다른 트랜잭션이 해당 데이터에 접근하지 못 하게 막는 것을 의미한다. 일반적으로 Lock의 단위가 너무 작으면 독립성이 보장받지 못 하고, 너무 크면 트랜잭션이 직렬화 되어 수행 시간이 느려진다.
10 |
11 | # Optimistic Concurrency Control
12 |
13 | 
14 |
15 | 여러 트랜잭션이 **서로 간섭하지 않고 자주 완료될 수 있다**고 가정하는 동시성 제어 방식.
16 |
17 | 일반적으로 Block Contention(동일한 인덱스나 데이터 블록에 동시에 액세스하기 위해 경쟁하는 프로세스 또는 인스턴스)이 낮은 환경에서 사용한다.
18 |
19 | 원하는 규칙이 커밋 시 **위반되면 트랜잭션을 즉시 중단하고 다시 실행**하기 때문에 오버헤드가 발생한다. 너무 많은 트랜잭션이 중단되지 않는 상황일 경우 **일반적으로 좋은 전략**이다.
20 |
21 | ## 실행 과정
22 |
23 | ### Begin
24 |
25 | 트랜잭션의 시작을 표시하는 타임스탬프 기록
26 |
27 | ### Modify
28 |
29 | 데이터베이스 값을 읽고 변경 사항을 임시로 기록
30 |
31 | ### Validate
32 |
33 | - 이 트랜잭션이 사용(Read/Write)한 데이터를 다른 트랜잭션이 수정했는지 확인
34 | - 시작 시간 이후에 완료된 트랜잭션과 유효성 검사 시간에 여전히 활성 상태인 트랜잭션 포함
35 |
36 | ### Commit/Rollback
37 |
38 | - 충돌이 없으면 모든 변경 사항 적용
39 | - 충돌이 있는 경우 일반적으로 트랜잭션을 중단하여 해결
40 |
41 | ## 특징
42 |
43 | ### 장점
44 |
45 | 충돌이 드물 경우 락을 관리하는 비용 없이 트랜잭션을 완료할 수 있고, 다른 트랜잭션의 락이 해제될 때 까지 기다리지 않고도 높은 처리량을 기대할 수 있다.
46 |
47 | ### 단점
48 |
49 | 데이터 리소스에 대한 경합이 빈번한 경우, 트랜잭션을 반복적으로 다시 실행해야 하기 때문에 성능이 크게 저하된다.
50 |
51 | - Redis가 WATCH 명령어를 통해 OCC를 제공한다
52 | - MySQL이 Group Replication 구성을 위해 OCC를 구현한다
53 | - Elasticsearch의 검색 엔진은 버전 속성을 통해 OCC를 지원한다
54 |
55 | ## OCC in JPA
56 |
57 | ```java
58 | @Entity
59 | public class Student {
60 | @Id
61 | private Long id;
62 | private String name;
63 | private String lastName;
64 | @Version
65 | private Integer version;
66 | // getters and setters
67 | }
68 | ```
69 |
70 | JPA에서는 `@Version` 어노테이션을 이용해서 낙관적 락을 사용할 수 있다. 이를 통해 외부에서 값을 검색할 수는 있지만 업데이트하거나 증가하도록 허용해서는 안 된다(Persistence Provider에게만 권한을 주어서 데이터의 일관성 유지).
71 |
72 | 이 때 지켜야 할 몇 가지 규칙이 있는데,
73 |
74 | 1. 각 Entity Class에는 `@Version` 특성이 하나만 존재해야 한다
75 | 2. 여러 Table에 매핑된 경우 주 테이블에 배치돼야 한다
76 | 3. 유형은 int, long, short 혹은 Integer, Long, Short, java.sql 중 하나여야 한다.
77 |
78 | # Pessimistic Concurrency Control
79 |
80 | 
81 |
82 | 여러 트랜잭션이 자주 간섭된다고 가정하는 동시성 제어 방식.
83 |
84 | 규칙 위반을 유발하는 경우 위반 가능성이 사라질 때 까지 트랜잭션 작업을 차단한다. 일반적으로 **Shared Lock, Exclusive Lock**을 통해 이를 구현한다.
85 |
86 | OCC에 비해 높은 무결성을 가지고 있지만, 교착 상태가 발생할 가능성이 존재한다.
87 |
88 | ### Shared Lock
89 |
90 | 트랜잭션이 읽기를 할 때 사용되는 락의 종류이다. 트랜잭션이 데이터를 조회할 때 공유락을 걸게 되면, 다른 트랜잭션은 그 데이터를 읽을 수 있고 변경이나 삭제는 불가능하다.
91 |
92 | ### Exclusive Lock
93 |
94 | 배타락은 수정/삭제를 할 때 거는 락의 종류이다. 배타락을 걸게 되면 다른 트랜잭션은 그 데이터에 읽기/수정/삭제 연산을 할 수 없고, 어떠한 락도 걸 수 없다.
95 |
--------------------------------------------------------------------------------
/java/README.md:
--------------------------------------------------------------------------------
1 | # 4) JAVA
2 | - contributor : [김경원](https://github.com/shining8543) , [윤이진](https://github.com/483759) , [이현경](https://github.com/honggoii) , [진수연](https://github.com/jjuyeon)
3 |
4 |
5 | ### :notebook_with_decorative_cover: JAVA
6 | 1. 객체지향에 대해서 설명하세요.
7 | 2. 객체지향의 SOLID 원칙에 대해 설명해주세요.
8 | 3. Java의 구동원리(컴파일 과정)를 설명해주세요.
9 | 4. Java의 Garbage Collection 동작 과정을 설명해주세요.
10 | 5. 쓰레드란 무엇이고, 싱글쓰레드와 멀티쓰레드의 차이를 설명해주세요.
11 | 6. 클래스는 무엇이고, 객체는 무엇인지 설명해주세요.
12 | 7. 인터페이스와 추상클래스의 차이점은 무엇인지 설명해주세요.
13 | 8. 직렬화가 무엇인지 설명하세요.
14 | 9. Call by Value와 Call by Reference의 차이에 대해 설명해주세요.
15 | 10. Checked Exception과 Unchecked Exception의 차이를 설명해주세요.
16 | 11. JVM의 역할에 대해 설명해주세요.
17 | 12. JDBC란 무엇인가요?
18 | 13. Thread-Safe에 대해 설명해주세요
19 |
20 | ### :notebook_with_decorative_cover: JAVA 자료구조
21 | 1. Java의 HashMap과 HashTable의 차이점을 설명해주세요.
22 | 2. Java의 원시타입들은 무엇이 있으며 각각 몇 바이트를 차지하는지 설명해주세요.
23 | 3. String, StringBuffer, StringBuilder의 차이를 설명하세요.
24 | 4. String형 객체를 ""로 만들었을 때와 new 키워드를 이용해서 만들었을 때의 차이점은? (String Pool)
25 | 5. 오버라이딩과 오버로딩이 무엇이며 어떤 차이점이 있는지 설명해주세요.
26 | 6. Generic에 대해 설명해주세요.
27 | 7. 오토 박싱과 언박싱에 대해 설명해주세요.
28 | 8. 업캐스팅과 다운캐스팅의 차이에 대해 설명해주세요.
29 | 9. Wrapper Class에 대해 설명해주세요.
30 | 10. Date 대신 LocalDate를 사용하는 이유에 대해서 설명하세요.
31 |
32 | ### :notebook_with_decorative_cover: JAVA 라이브러리 & 프레임워크
33 | 1. '=='과 'equals()'의 차이에 대해 설명하세요.
34 | 2. 자바 컬렉션에 대해서 설명해주세요. (정의, 종류)
35 | 3. 컬렉션 프레임워크에 속한 List, Set, Map에 대해 설명해주세요.
36 | 4. 정규 표현식에 대해 설명해주세요.
37 |
38 | ### :notebook_with_decorative_cover: Design Pattern
39 | 1. 싱글톤 패턴이란 무엇인지 설명해주세요.
--------------------------------------------------------------------------------
/java/jsy/README.md:
--------------------------------------------------------------------------------
1 | # Suyeon Jin
2 |
3 | |Study|바로가기|
4 | |---|---|
5 | |OOP|[:white_check_mark:](../jsy/oop.md)|
6 | |JVM|[:white_check_mark:](../jsy/jvm.md)|
7 | |JAVA|[:white_check_mark:](../jsy/java.md)|
8 | |JAVA 자료구조|[:white_check_mark:](../jsy/structure.md)|
9 | |JAVA String|[:white_check_mark:](../jsy/string.md)|
10 | |JAVA 라이브러리|[:white_check_mark:](../jsy/lib.md)|
11 | |JAVA 호출방식|[:white_check_mark:](../jsy/call.md)|
12 | |JAVA 예외처리|[:white_check_mark:](../jsy/exception.md)|
13 | |JAVA 디자인패턴|[:white_check_mark:](../jsy/pattern.md)|
14 | |JDBC|[:white_check_mark:](./jdbc.md)|
--------------------------------------------------------------------------------
/java/jsy/call.md:
--------------------------------------------------------------------------------
1 | # :question: JAVA 의 호출방식
2 |
3 | #### reference
4 | https://devlog-wjdrbs96.tistory.com/44
5 | https://sleepyeyes.tistory.com/11
6 |
7 |
8 | ## Question
9 | 1. [Call by Value와 Call by Reference의 차이에 대해 설명해주세요.](#2-call-by-reference)
10 | - Call by Value는 실제 값에 의한 호출 방법이고, Call by Reference는 참조에 의한 호출 방법입니다.
11 | - 좀 더 구체적으로, Call by Value는 함수의 매개변수 값을 복사하여 전달하는 방식으로, 전달받은 값이 변경되어도 원본 값은 변경되지 않고 유지됩니다.
12 | - 반면, Call by Reference는 매개변수의 레퍼런스를 전달하는 방식으로, 전달받은 값이 변경되면 원본 값도 같이 변경됩니다.
13 |
14 |
15 | ## :nerd_face: What I study
16 | ### 1. Call by Value
17 | - 값에 의한 호출
18 | - JAVA는 항상 ```Call by Value```로 값을 넘긴다.
19 | - 함수가 호출될 때, 메모리 공간 안에는 함수를 위한 임시 공간이 생성된다.
20 | - 함수가 종료되면 임시로 생성되었던 공간은 사라진다.
21 | - 함수 호출시 **인자로 전달되는 변수의 값을 복사하여 함수의 인자로 전달한다.**
22 | - 원본의 데이터가 변경될 가능성이 없다.
23 | - 인자를 넘겨줄 때마다 메모리 공간을 할당해야해서 메모리 공간을 더 잡아먹는다.
24 | - 복사된 인자는 함수 안에서 지역적으로 사용되는 local value의 특성을 가진다.
25 | - 따라서 함수 안에서 인자의 값이 변경되어도, ***외부의 변수의 값은 변경되지 않는다.***
26 |
27 |
28 | ### 2. Call by Reference
29 | - 참조에 의한 호출
30 | - 함수가 호출될 때, 메모리 공간 안에는 함수를 위한 임시 공간이 생성된다.
31 | - 함수가 종료되면 임시로 생성되었던 공간은 사라진다.
32 | - 함수 호출시 **인자로 전달되는 변수의 레퍼런스를 전달한다.**
33 | - 메모리 공간을 더 잡아먹지는 않는다.
34 | - 원본 값이 변경될 수 있다는 위험이 존재한다.
35 | - 따라서 함수 안에서 인자의 값이 변경되면, ***인자로 전달된 변수의 값도 함께 변경된다.***
36 |
37 | ||Call by Value|Call by Reference|
38 | |:---:|:---:|:---:|
39 | |호출|값에 의한 호출|참조에 의한 호출|
40 | |처리방식|전달받은 값을 복사|전달받은 값을 직접 참조|
41 | |전달받은 값을 변경했을 때|원본은 변하지 않음|원본도 같이 변함|
42 |
43 |
44 |
45 | ### 3. JAVA 의 호출방식
46 | - JAVA에서 함수의 인자로 전달되는 데이터 타입이 **원시 타입**인 경우 value로 ***해당하는 변수의 값***을 복사해서 전달한다. ***call by value***
47 | - 따라서 함수 안에서 인자의 값이 변경되어도, **외부의 변수의 값은 변경되지 않는다.**
48 | ```java
49 | public class Main {
50 | public static void main(String[] args) {
51 | int n = 10;
52 | System.out.print(n); // 10
53 | primitive(n);
54 | System.out.println(n); // 10
55 | }
56 |
57 | public static void primitive(int n) { // 원시 타입을 함수의 인자로 전달
58 | n -= 5;
59 | System.out.println(n); // 5
60 | }
61 | }
62 | ```
63 |
64 |
65 | - JAVA에서 함수의 인자로 전달되는 데이터 타입이 **참조 타입**인 경우 value로 ***해당 객체의 주소 값***을 복사하여 넘긴다. ***call by value***
66 | - JAVA는 C/C++과 같이 변수의 주소값 자체를 가져올 방법이 없으며, 이를 넘길 수 있는 방법도 없다.
67 | - 따라서 **원본 객체의 property까지는 접근이 가능하나, 원본 객체 자체를 변경할 수는 없다.**
68 | ```java
69 | public class Main {
70 | public static void main(String[] args) {
71 | int[] arr = {1, 2, 3};
72 | for (int num : arr) { // 1 2 3
73 | System.out.print(num + " ");
74 | }
75 |
76 | reference(arr);
77 |
78 | for (int num : arr) { // 10 20 30
79 | System.out.print(num + " ");
80 | }
81 | }
82 |
83 | // 참조형의 경우, 주소값이 전달되므로 값을 변경하면 원본도 영향을 받는다.
84 | public static void reference(int[] a) {
85 | for (int i = 0; i < a.length; i++) {
86 | a[i] *= 10;
87 | }
88 | }
89 | }
90 | ```
91 |
92 | ```java
93 | public class Main2 {
94 | /* parameter는 참조변수 Person 자체의 reference가 아닌 Object가 "저장하고 있는 주소값(value)" */
95 | public static void assignNewPerson(Person p) {
96 | p = new Person("yeon");
97 | }
98 | public static void changeName(Person p) {
99 | p.setName("yeon");
100 | }
101 |
102 | public static void main(String[] args) {
103 | Person p = new Person("su");
104 |
105 | assignNewPerson(p);
106 | System.out.println(p); // name is su
107 |
108 | changeName(p);
109 | System.out.println(p); // name is yeon
110 | }
111 | }
112 | ```
--------------------------------------------------------------------------------
/java/jsy/exception.md:
--------------------------------------------------------------------------------
1 | # :question: JAVA 의 예외처리
2 |
3 | #### reference
4 | https://cheese10yun.github.io/checked-exception/
5 | https://devlog-wjdrbs96.tistory.com/351
6 |
7 |
8 | ## Question
9 | 1. [Checked Exception과 Unchecked Exception의 차이를 설명해주세요.](#1-checked-exception)
10 | - Runtime Exception을 상속하지 않는 클래스를 Checked exception이라고 하며, 상속하는 클래스는 Unchecked exception이라고 합니다.
11 | - Checked exception은 반드시 예외 처리를 해야 하지만, Unchecked exception은 명시적으로 하지 않아도 된다는 차이점이 있습니다.
12 |
13 |
14 | ## :nerd_face: What I study
15 | ### 1. Checked Exception
16 | - ***반드시 명시적으로 예외 처리를 해야한다.***
17 | - **try-catch문**을 사용하여 예외 처리를 하거나, **throw**를 통해서 호출한 메소드로 예외를 던져야 한다.
18 | - 트랜잭션 rollback이 되지 않고 commit까지 완료된다.
19 | - Exception을 상속 받는 하위 클래스 중, Runtime Exception을 제외한 모든 예외 클래스
20 |
21 |
22 | ### 2. Unchecked Exception
23 | - ***명시적으로 예외 처리를 강제하지 않는다.***
24 | - 실행 중에 발생할 수 있는 예외이다.
25 | - 트랜잭션 rollback이 진행된다.
26 | - Runtime Exception을 상속받는 모든 예외 클래스
27 |
28 |
29 | ||Checked Exception|Unchecked Exception|
30 | |:---:|:---:|:---:|
31 | |처리 여부|필수|Optional|
32 | |확인시점|컴파일 단계|실행 단계|
33 | |Rollback 여부|X|O|
34 | |ex|IO Exception, SQL Exception|NullPointer Exception, IllegalArgument Exception|
35 |
36 |
37 |
38 | ### 3. Error
39 | - 시스템 레벨에서 발생하는 심각한 수준의 오류를 의미한다.
40 | - 개발자가 예측하기 쉽지 않으며, 직접 처리할 수 있는 방법도 없다.
41 | - 그러므로 개발 시 예외 처리에 신경쓰지 않아도 된다.
42 | - ex. OutOfMemory Error, StackOverFlow Error
--------------------------------------------------------------------------------
/java/jsy/java.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/jjuyeon/Tech-Interview-Study/f5f4978becafb443db02eee145e58f6a1618dfa2/java/jsy/java.png
--------------------------------------------------------------------------------
/java/jsy/jdbc.md:
--------------------------------------------------------------------------------
1 | # :question: JDBC
2 |
3 | #### reference
4 | https://devlog-wjdrbs96.tistory.com/139
5 | https://shs2810.tistory.com/18
6 |
7 |
8 | ## Question
9 | 1. JDBC란 무엇인가요?
10 | - JDBC는 데이터베이스와 연결되어 데이터를 주고 받을 수 있도록 하는 API 입니다.
11 | - JDBC의 특징으로는 데이터베이스의 종류에 종속되지 않는다는 점과 응용프로그램과 DBMS 간의 통신을 중간에서 변역해주는 역할을 한다는 것입니다.
12 |
13 |
14 | ## :nerd_face: What I study
15 |
16 | ### JDBC
17 | - Java DataBase Connectivity
18 | - 자바 언어로 데이터베이스와 연결되어 데이터를 주고 받을 수 있도록 사용되는 라이브러리(API)
19 | - DBMS에 종속되지 않는 관련 API를 제공한다.
20 | - 데이터베이스 종류에 상관없다.
21 | - 응용프로그램과 DBMS간의 통신을 중간에서 번역해주는 역할을 한다.
22 |
23 |
24 |
25 | 
26 |
27 | - JDBC Driver: 각 DBMS에서 제공하는 라이브러리 압축파일
28 | - JDBC API : 다양한 클래스와 인터페이스로 구성된 패키지 `java.sql`로 구성되어 있다.
29 | - 데이터베이스를 연결하여 테이블 형태의 자료를 참조
30 | - SQL문 질의
31 | - SQL문 결과 처리
32 | - 구체적인 메소드 설명 [https://shs2810.tistory.com/18]
33 |
34 |
35 |
36 | ### JDBC를 이용한 데이터베이스 연동 과정
37 | 
38 |
39 | 1. JDBC 드라이버 Load
40 | - 데이터베이스와의 연결을 위해 드라이버를 로딩한다.
41 | 2. Connection 객체 생성
42 | - 데이터베이스와의 연결을 위해 URL과 계정 정보가 필요하다.
43 | 3. Statement 객체 생성
44 | - SQL 구문을 정의하고, 쿼리 전송 전에 변수를 세팅한다.
45 | 4. Query 수행
46 | - executeUpdate
47 | - SQL Query문이 INSERT, DELETE, UPDATE인 경우
48 | - 반환 타입은 int
49 | - executeQuery
50 | - SQL Query문이 SELECT인 경우
51 | - 반환 타입은 ResultSet
52 | 5. Resultset 객체로부터 데이터 추출 (SELECT인 경우)
53 | - 데이터베이스 조회 결과집합에 대한 표준
54 | - `next()`를 통해 DB의 테이블 안에 row를 조회한다.
55 | - `getString()`, `getInt()` 등을 통해 한 행의 특정 column을 조회한다.
56 | 6. Close (Resultset, Statement, Connection)
57 | - 열어줬던 객체들을 하나씩 닫아준다.
--------------------------------------------------------------------------------
/java/jsy/lib.md:
--------------------------------------------------------------------------------
1 | # :question: JAVA 의 라이브러리
2 |
3 | #### reference
4 | https://snd-snd.tistory.com/18
5 | https://milkoon1.tistory.com/44
6 |
7 |
8 | ## Question
9 | 1. [자바 컬렉션에 대해서 설명해주세요.](#1-collection-framework)
10 | - 자바에서 컬렉션이란 객체나 데이터를 효율적으로 관리할 수 있는 방법을 모아둔 라이브러리입니다. 컬렉션 프레임워크는 크게 두개로 나눌 수 있는데, 순서나 집합적인 저장 공간의 명세를 나타내는 Collection 인터페이스와 key와 value로 데이터를 핸들링하는 명세를 정의하는 Map 인터페이스로 나눌 수 있습니다.
11 |
12 |
13 | 2. [컬렉션 프레임워크에 속한 List, Set, Map에 대해 설명해주세요.](#1-3-list-vs-set-vs-map)
14 | - 3개의 인터페이스 모두 하나 이상의 element를 저장한다는 공통점이 있습니다.
15 | - List는 순서가 존재하고 중복이 허용됩니다. Set은 집합적인 개념을 가지며, 순서가 없고 Element의 중복은 허용되지 않습니다. Map은 (key,value) 쌍으로 이루어져 있으며 순서가 없으며 key값은 중복될 수 없습니다.
16 |
17 |
18 | 3. [정규 표현식에 대해 설명해주세요.]()
19 |
20 |
21 |
22 | ## :nerd_face: What I study
23 | ### 1. Collection Framework
24 | 
25 | - 객체나 데이터를 효율적으로 관리(추가, 삭제, 검색)할 수 있는 표준화된 방법을 모아둔 클래스의 집합/라이브러리
26 | - 컬렉션을 쉽고 편리하게 다룰 수 있는 다양한 인터페이스와 클래스를 제공한다.
27 | - 배열의 단점을 보완해준다.
28 | - ```java.util``` 패키지에 포함되어 있다.
29 | - Map과 Collection 인터페이스가 존재한다.
30 | - 사용목적에 따라 Map, List, Set 각각의 하위 구현체를 선택한다.
31 |
32 | 
33 | ### 1-1) Collection
34 | #### List
35 | - 순서가 있는 Collection
36 | - 데이터를 중복해서 포함할 수 있다.
37 | - 순차적으로 대량의 데이터를 접근하거나 입력할 때 사용된다.
38 |
39 |
40 | - LinkedList와 ArrayList의 차이점
41 |
42 | ||LinkedList|ArrayList|
43 | |:---:|:---:|:---:|
44 | |데이터 관리|특정 데이터 타입의 배열|노드에 데이터를 저장하고 앞 뒤 노드의 주소값을 연결|
45 | |삽입/삭제|O(1)|O(n)|
46 | |검색|O(n)|O(1)|
47 |
48 |
49 | - Vector와 ArrayList의 차이점
50 |
51 | ||Vector|ArrayList|
52 | |:---:|:---:|:---:|
53 | |동기화 처리|O|X|
54 | |스레드 접근|한 번에 하나의 스레드|한 번에 여러 개 스레드|
55 | |속도|느림|빠름 (멀티스레드 상황 제외)|
56 |
57 | #### Set
58 | - 집합적인 개념의 Collection
59 | - 순서가 없다.
60 | - 데이터를 중복할 수 없다.
61 | - 순차적인 접근을 위해 Iterator를 사용한다.
62 |
63 |
64 |
65 | ### 1-2) Map
66 | - 검색할 수 있는 인터페이스
67 | - 순서가 없다.
68 | - 많은 양의 데이터에서 원하는 특정 데이터에 접근할 때 사용한다.
69 | - 데이터를 삽입할 때, (key-value) 쌍으로 삽입된다.
70 | - 검색 시에는, key를 이용해서 value를 얻을 수 있다.
71 | - 동일한 데이터를 key로 사용할 수 없다.
72 |
73 |
74 | - HashMap과 HashTable의 차이점
75 |
76 | - key, value로 데이터를 관리하고 key를 이용하여 데이터를 검색한다.
77 |
78 | ||HashMap|HashTable|
79 | |:---:|:---:|:---:|
80 | |동기화 여부|X|O|
81 | |멀티 스레드 세이프|X|O|
82 | |속도|빠름|느림 (동기화 처리 비용 때문)|
83 |
84 |
85 | TreeMap과 TreeSet의 차이점
86 | - 큰 차이점은 Map과 Set의 차이이다.
87 | - 둘다 Red Black Tree를 기반으로 이루어져 있다.
88 | - cf) Red Black Tree: balanced binary search tree, BST에서 발생하는 불균형 문제를 색깔을 통해 자체적으로 해결한다.
89 |
90 |
91 |
92 | ### 1-3) List vs Set vs Map
93 |
94 | ||List|Set|Map|
95 | |:---:|:---:|:---:|:---:|
96 | |특징|순서 O, 중복 O|순서X, 중복X|순서X, key에 대한 중복X|
97 | |장점|가변적인 자료구조 사이즈|빠른 속도|빠른 속도|
98 | |단점|원하는 데이터가 뒤쪽에 위치하면 속도가 느림|정렬하려면 별도의 처리가 필요|key의 검색 속도가 검색 속도를 좌우함|
99 |
100 |
--------------------------------------------------------------------------------
/java/jsy/oop.md:
--------------------------------------------------------------------------------
1 | # :question: 객체지향 (OOP)
2 |
3 | #### reference
4 | https://jeong-pro.tistory.com/95
5 | https://youngjinmo.github.io/2021/04/principles-of-oop/
6 | https://victorydntmd.tistory.com/291
7 |
8 |
9 | ## Question
10 | 1. [객체지향에 대해서 설명하세요.](#객체지향-oop)
11 | - 프로그래밍에서 필요한 **데이터를 추상화**시켜 **상태와 행위를 가진 객체를 만들고**, **그 객체들 간의 유기적인 상호작용을 통해 로직을 구성**하는 프로그래밍 방법입니다.
12 |
13 |
14 | 2. [객체지향의 SOLID 원칙에 대해 설명해주세요.](#3-oop의-5가지-설계-원칙-solid)
15 | - 단일 책임 원칙 S, 개방 폐쇄 원칙 O, 리스코프 치환 원칙 L, 인터페이스 분리 원칙 I, 의존관계 역전 원칙 D를 말합니다.
16 | - 단일 책임 원칙은 **클래스는 단 하나의 목적을 가져야 한다는 원칙**이고, 개방 폐쇄 원칙은 **기존의 코드를 변경하지 않으면서, 기능을 추가할 수 있도록 해야한다는 원칙**입니다. 리스코프 치환 원칙은 **상위 타입의 객체를 하위 타입으로 바꾸더라도 프로그램이 잘 작동되어야 한다는 원칙**이고, 인터페이스 분리 원칙은 **사용하지 않는 메소드에 의존하지 않도록 인터페이스를 분리해야 한다는 원칙**입니다. 마지막으로 의존관계 역전 원칙은 **객체들이 서로 정보를 주고 받을 때, 추상화에 의존해야 하며, 구체화에 의존해서는 안된다는 원칙**입니다.
17 | - 이 원칙을 잘 사용하면, 시간이 지나도 유지보수와 확장이 쉬운 소프트웨어를 만들 수 있습니다.
18 |
19 |
20 |
21 | ## :nerd_face: What I study
22 | ### 객체지향 (OOP)
23 | - 프로그래밍에서 필요한 데이터를 추상화시켜 상태와 행위를 가진 객체를 만들고 그 객체들 간의 유기적인 상호작용을 통해 로직을 구성하는 프로그래밍 방법
24 |
25 | #### 1) 장점
26 | - 코드 재사용이 용이하다.
27 | - 남이 만든 클래스를 가져와서 이용할 수 있고, 상속을 통해 확장해서 사용할 수 있다.
28 | - 유지보수가 쉽다.
29 | - 수정해야할 부분이 클래스 내부에 멤버 변수 혹은 메서드로 있기 때문에 해당 부분만 수정하면 된다.
30 | - 대형 프로젝트에 적합하다.
31 | - 클래스 단위로 모듈화시켜서 개발할 수 있으므로 업무 분담이 쉽다.
32 |
33 | #### 2) 단점
34 | - 처리속도가 상대적으로 느리다.
35 | - 객체 간의 정보 교환이 모두 메세지 교환을 통해 일어나므로 실행 시스템에 많은 오버헤드가 발생한다.
36 | - 하드웨어의 발전으로 위의 단점은 어느정도 해결되었다.
37 | - 객체가 많으면 용량이 커질 수 있다.
38 | - 프로그램을 설계할 때 많은 시간과 노력이 필요하다.
39 |
40 | #### 3) OOP의 5가지 설계 원칙 (SOLID)
41 | - ***SRP(Single Responsibility Principle, 단일 책임 원칙)***
42 | - 클래스는 단 하나의 목적을 가져야 하며, 클래스를 변경하는 이유는 단 하나의 이유여야 한다.
43 | - 시스템에 변화가 생기더라도 클래스가 받는 영향을 최소화 할 수 있다.
44 | - ***OCP(Open-Closed Principle, 개방 폐쇄 원칙)***
45 | - 클래스는 확장에 열려 있고, 변경에는 닫혀 있어야 한다.
46 | - 새로운 변경사항이 발생했을 때 유연하게 코드를 추가 또는 수정할 수 있어야 한다.
47 | - ***LSP(Liskov Substitution Principle, 리스코프 치환 원칙)***
48 | - 상위 타입의 객체를 하위 타입으로 바꾸어도 프로그램은 일관되게 동작되어야 한다.
49 | - 프로그램의 객체는 프로그램의 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 한다.
50 | - ***ISP(Interface Segragation Principle, 인터페이스 분리 원칙)***
51 | - 클라이언트는 사용하지 않는 메소드에 의존하지 않도록 인터페이스를 분리해야 한다.
52 | - 특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다.
53 | - ***DIP(Dependency Inversion Principle, 의존관계 역전 원칙)***
54 | - 클라이언트는 추상화(인터페이스)에 의존해야 하며, 구체화(구현된 클래스)에 의존해서는 안된다.
55 | - 객체들이 서로 정보를 주고 받을 때 의존 관계가 형성되는데, 이때 객체들은 나름대로의 원칙을 가지고 정보를 주고 받아야 한다.
56 |
57 | #### 4) OOP의 특징
58 | - 캡슐화
59 | - 객체가 독립적으로 역할을 할 수 있도록 연관 있는 데이터와 기능을 하나로 묶어 관리하는 것을 의미한다.
60 | - 실제로 구현되는 부분을 외부에 드러나지 않도록 하여 정보를 은닉할 수 있다.
61 | - 데이터를 보이지 않고 외부와 상호작용을 할 때는 메소드를 이용하여 통신을 한다.
62 | - 상속
63 | - 하나의 클래스가 가진 특징을 다른 클래스가 그대로 물려받는 것을 의미한다.
64 | - 기존 코드를 재활용하여 사용함으로써 새로운 클래스를 생성하는 것이다.
65 | - 추상화
66 | - 객체들의 공통적인 특징(기능, 속성)을 도출하는 것을 의미한다.
67 | - 인터페이스로 공통적인 특성들을 묶어 표현하는 것이다.
68 | - 다형성
69 | - 다른 방법으로 동작하는 함수를 동일한 이름으로 호출하는 것을 의미한다.
70 | - ex) 오버라이딩(Overriding), 오버로딩(Overloading)
71 | 1. 오버라이딩
72 | - 부모클래스의 메서드와 같은 이름, 매개변수를 재정의하는 것
73 | 2. 오버로딩
74 | - 같은 이름의 함수를 여러개 정의하고, 매개변수의 타입과 개수를 다르게 하여 매개변수에 따라 다르게 호출할 수 있게 하는 것
75 |
76 | ### cf) 절차지향
77 | - 위에서 아래로 순차적으로 처리가 중요한 기법
78 | - 컴퓨터의 실제 처리 구조와 유사해서 속도가 빠르다.
79 | - 순서가 중요하다. 순서가 바뀌면 에러가 나거나 결과가 동일하지 않을 수 있다.
--------------------------------------------------------------------------------
/java/jsy/pattern.md:
--------------------------------------------------------------------------------
1 | # :question: JAVA 의 디자인 패턴
2 |
3 | #### reference
4 |
5 |
6 | ## Question
7 | 1. [싱글톤 패턴이란 무엇인지 설명해주세요.]()
8 |
9 |
10 | ## :nerd_face: What I study
11 | ### Singleton pattern
--------------------------------------------------------------------------------
/java/jsy/string.md:
--------------------------------------------------------------------------------
1 | # :question: JAVA 의 String
2 |
3 | #### reference
4 | https://github.com/WeareSoft/tech-interview/blob/master/contents/java.md#java%EC%97%90%EC%84%9C-%EC%99%80-equals%EC%9D%98-%EC%B0%A8%EC%9D%B4
5 |
6 |
7 | ## Question
8 | 1. ['=='과 'equals()'의 차이에 대해 설명하세요.](#1-문자열-비교)
9 | - 동등연산자 ==는 두 객체가 같은 메모리 공간을 가리키는지 확인합니다. 즉, 비교하고자 하는 대상의 주소값을 비교합니다.
10 | - 객체 비교 메소드 equals()는 두 객체의 값이 같은지 확인합니다. 즉, 비교하고자 하는 대상의 내용 자체를 비교합니다.
11 |
15 |
16 | 3. [String형 객체를 ""로 만들었을 때와 new 키워드를 이용해서 만들었을 때의 차이점은?]()
17 |
18 |
19 | ## :nerd_face: What I study
20 | ### 1. 문자열 비교
21 | #### 1-1) == 연산자
22 | - 동등 연산자
23 | - 두 객체가 같은 메모리 공간을 가리키는지 확인하는 **참조 비교**를 한다.
24 | - 비교하고자 하는 대상의 **주소값**을 비교한다.
25 | - boolean type으로 반환한다.
26 | - 모든 원시 타입에 대해 적용할 수 있다.
27 | #### 1-2) equals() 메소드
28 | - 객체 비교 메소드
29 | - 두 객체의 값이 같은지 확인하는 **내용 비교**를 한다.
30 | - 비교하고자 하는 대상의 **내용 자체**를 비교한다.
31 | - boolean type으로 반환한다.
32 | - 원시 타입에는 적용할 수 없다.
33 |
34 | ```java
35 | // Thread 객체
36 | Thread t1 = new Thread();
37 | Thread t2 = new Thread(); // 새로운 객체 생성. 즉, s1과 다른 객체.
38 | Thread t3 = t1; // 같은 대상을 가리킨다.
39 | // String 객체
40 | String s1 = new String("JAVA");
41 | String s2 = new String("JAVA");
42 | String s3 = "JAVA";
43 | String s4 = "JAVA";
44 |
45 | System.out.println(t1 == t3); // true
46 | System.out.println(t1 == t2); // false(서로 다른 객체이므로 별도의 주소를 갖는다.)
47 | System.out.println(s1 == s2); // false(서로 다른 객체)
48 | System.out.println(s2 == s3); // false(서로 다른 객체)
49 | System.out.println(s3 == s4); // true
50 |
51 | System.out.println(t1.equals(t2)); // false
52 | System.out.println(s1.equals(s2)); // true(모두 "JAVA"라는 동일한 내용을 갖는다.)
53 | System.out.println(s1.equals(s3)); // true
54 | System.out.println(s3.equals(s4)); // true
55 | ```
--------------------------------------------------------------------------------
/java/kkw/CallBy.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | ## `Call By Value`
5 | - 메소드 호출 시에 사용되는 인자의 메모리에 저장되어 있는 값(Value)를 복사하여 보내는 방법
6 | - Primitive Type 들은 Call By Value로 넘어간다.
7 |
8 | ```
9 |
10 | int a = 10
11 | plus(a);
12 | System.out.println(a);
13 |
14 | void plus(int a){
15 | a += 10;
16 | }
17 |
18 | 결과 : 10
19 | //값만 복사될 뿐 원본 인자에는 영향을 주지 못한다.
20 |
21 | ```
22 |
23 |
24 | ## `Call By Reference`
25 | - 메소드 호출 시에 사용되는 인자 값의 메모리에 저장된 주소(Address)값을 복사하여 보낸다.
26 | - Reference Type 들은 Call By Reference로 넘어간다
27 |
28 | ```
29 | int a[] = {10};
30 | a[0] = 10;
31 | plus(a);
32 | System.out.println(a);
33 |
34 | void plus(int[] a){
35 | a[0] += 10;
36 | }
37 |
38 | 결과 : 20
39 | //주소 값이 넘어갔기에 원본 인자 값이 변한다.
40 | ```
41 |
42 | ## 그렇다면 String 은 ?
43 | - JAVA의 공식 API 문서에 따르면 primitive type은 `boolean, byte, short, int, long, char, floag, double`으로 명시하고 있다.
44 | - 그렇다면 String을 매개변수로 넘길경우 Call-By-Reference 이므로 값이 변경되어야 한다.
45 |
46 | ```
47 | String a = "hello";
48 | test(a);
49 | System.out.println(a);
50 |
51 | void test(String a){
52 | a = "world";
53 | }
54 |
55 | 결과 : hello
56 | ```
57 |
58 | - 하지만 실제로 테스트 해보면 원본 값에 전혀 영향을 끼치지 못한다.
59 |
60 | ## 왜 그런걸까?
61 | - 자바는 엄밀하게 말하면 항상 `Call By Value` 이다.
62 | - 다음을 보자
63 | ```
64 | class Node{
65 | int num;
66 | Node(int num){
67 | this.num = num;
68 | }
69 |
70 | void test(Node node){
71 | node = new Node(20);
72 | }
73 |
74 | main(){
75 |
76 | Node node = new Node(10);
77 | test(node);
78 | System.out.println(node.num);
79 | //결과는?
80 | }
81 | }
82 | ```
83 | - `Call By Reference` 라면 결과값이 `20`이 나올테지만, 실제로 돌려보면 결과값은 `10`이 출력된다
84 | - 이는 Java가 Reference Type 들의 객체를 전달하는게 아니라 그 변수가 가지고 있는 주소 값을 복사하여 전달하기 때문이다.
85 | - 우리는 Stack에게 새로운 주소를 주는 Object 방식으로는 원본 값에 어떠한 변화도 줄 수 없다는 뜻이다.
86 |
87 | ## 그래도 주소값이 전달되니깐 수정할 수 있지않아요?
88 | - String의 특징 중 하나는 불변성(immutable)이다.
89 | - String 인스턴스를 생성하게 되면, JVM은 Stack에 변수의 메모리를 할당하고 Heap 영역 내부에 String Pool 을 가르키고 있게 된다.
90 |
91 | 
92 |
93 | - JAVA에서는 String 값이 수정될 경우, String Pool에 새로 할당하여 그 주소값을 반환해준다.
94 | - 그렇다는 것은 매개변수로 넘어간 String은 결국 원본 String의 Stack 영역이 가르키고 있는 주소 값을 복사했을 뿐이므로, 메소드 내 지역변수 String의 Stack 영역의 참조값을 수정하여도 원본 String에는 아무 영향이 없는 것이다.
95 |
--------------------------------------------------------------------------------
/java/kkw/OOP.md:
--------------------------------------------------------------------------------
1 | # 객체지향 프로그래밍(Object-Oriented Programming)
2 |
3 | ## 객체지향 프로그래밍
4 | - 프로그래밍에서 필요한 데이터를 추상화시켜 상태와 행위를 가진 객체를 만들고 그 객체들 간의 유기적인 상호작용을 통해 로직을 구성하는 프로그래밍 방법
5 |
6 |
7 | ## 객체지향 vs 절차지향
8 | - 객체지향
9 | - 장점
10 | - 코드 재사용성이 용이
11 | - 개발(코딩)이 간단
12 | - 유지보수가 쉬움
13 | - 대규모 프로젝트에 적합
14 | - 단점
15 | - 처리 속도가 느림
16 | - 객체에 따른 용량이 증가함
17 | - 설계 단계에 시간이 많이 소요됨
18 | - 절차지향
19 | - 장점
20 | - 처리 속도가 빠름
21 | - 초기 프로그래밍 언어로 컴퓨터의 처리구조와 비슷해 실행 속도가 빠름
22 | - 단점
23 | - 유지보수가 어려움
24 | - 대규모 프로젝트에 부적합
25 | - 프로그램 분석이 어려움
26 |
27 |
28 | ## 클래스와 인스턴스
29 | - 클래스
30 | - 객체를 만들어 내기 위한 설계도 혹은 틀
31 | - 집단에 속하는 속성(attribute)와 행위(behavior)를 변수와 메소드로 정의한 것
32 | - 객체
33 | - 소프트웨어 세계에서 구현할 대상
34 | - 클래스에 선언된 모양 그대로 생성된 실체
35 | - 클래스의 인스턴스라고도 부름
36 | - OOP의 관점에서 클래스의 타입으로 선언되었을 때 '객체'라고 부름
37 | - 객체는 모든 인스턴스를 대표하는 포괄적인 의미를 가짐
38 | - 인스턴스
39 | - 클래스에서 정의한 것을 토대로 실제 메모리상에 할당된 것
40 | - 인스턴스는 어떤 원본(추상적인 개념)으로부터 생성된 복제본을 의미
41 | - 추상적인 개념(또는 명세)과 구체적인 객체 사이의 관계 에 초점을 맞출 경우에 사용
42 |
43 | ## 추상화(Abstraction)
44 | - 객체들의 공통적인 특징(기능, 속성)을 도출하는 것
45 | - 객체지향 관점에서는 클래스를 정의하는 것을 의미
46 | - abstract 클래스와 abstract 메소드와는 다른 이야기
47 |
48 | ## 캡슐화(Encapsulation)
49 | - 객체의 속성과 메소드를 하나로 묶고, 실제 구현 내용 일부를 외부에 감추어 은닉하는 것
50 | - JAVA의 접근 지정자
51 | - Public : 접근 제한 없음
52 | - Protected : 동일 패키지와 상속 받은 클래스 내부에서만 접근 가능
53 | - default : 동일 패키지 내에서만 접근 가능
54 | - private : 동일 클래스 내에서만 가능
55 |
56 | ## 상속(Inheritance)
57 | - 부모 클래스의 속성과 기능을 이어받아 사용하는 것을 말함
58 |
59 | ## 다형성(Polymorphism)
60 | - 하나의 클래스나 메소드가 상황에 따라 다른 의미로 해석될 수 있는 것
61 | - 오버라이딩(Overriding) : 하위 클래스가 상위 클래스의 메소드를 재정의하여 사용하는 것
62 | - 오버로딩(Overloading) : 같은 이름의 메소드가 다양한 입력을 처리할 수 있도록 하는 것
63 |
--------------------------------------------------------------------------------
/java/kkw/Regular_Expression.md:
--------------------------------------------------------------------------------
1 | ## 정규 표현식(Regular Expression)
2 | - 특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 형식 언어
3 |
4 |
5 |
6 | ## 자바의 정규표현식 사용법
7 | - `java.util.regex` 의 `Pattern` 클래스와 `Matcher` 클래스를 이용하여 정규 표현식을 사용 가능
8 | - String의 matches 함수를 이용하여 사용 가능
9 | - 아래와 같은 방법으로 정규표현식과 대상 문자열이 일치하는지 확인 가능
10 |
11 | ```java
12 | Pattern p = Pattern.compile("a*b");
13 | Matcher m = p.matcher("aaaab");
14 | boolean b = m.matches();
15 | ```
16 |
17 | ```java
18 | boolean b = Pattern.matches("a*b", "aaaab")
19 | ```
20 |
21 | ```java
22 | String str = "aaaab";
23 | String regex = "a*b";
24 |
25 | boolean b = str.matches(regex);
26 | ```
27 |
28 | ### Pattern 클래스
29 | - 우선 순위
30 | 1. Literal escape : \x
31 | 2. Grouping [...]
32 | 3. Range a-z
33 | 4. Union [a-e][i-u]
34 | 5. Intersection [a-z&&[aeiou]]
35 | - compile(String regex) : 주어진 정규표현식(regex)으로 패턴을 만듬
36 | - matcher(CharSequense input) : 대상 문자열(input)이 패턴과 일치할 경우 true를 반환
37 | - pattern() : 만들어진 패턴을 String으로 반환함
38 |
39 |
40 | ### Matcher 클래스
41 | - 대상 문자열의 패턴을 해석하고, 주어진 패턴과 일치하는지 판별할 때 주로 사용
42 | - matches() : 대상 문자열과 패턴이 일치할 경우 true를 반환
43 | - find() : 대상 문자열과 패턴이 일치하는 경우 true를 반환하고, 그 위치로 이동
44 | - start() : 매칭되는 문자열 시작위치를 반환
45 | - end() : 매칭되는 문자열 끝 다음 위치를 반환
46 | - group() : 매칭된 부분을 반환
47 |
48 | ### 정규 표현식 문법
49 | - 
50 |
51 |
52 | -
53 | |횟수|0|1|2+|
54 | |:--:|:--:|:--:|:--:|
55 | |?|O|O|X|
56 | |*|O|O|O|
57 | |+|X|O|O|
58 |
59 | - Greedy : 매칭을 위해서 입력된 문자열 전체를 읽어서 확인하고 뒤에서 한자씩 빼면서 끝까지 확인합니다.
60 | - Reluctant : 입력된 문자열에서 한글자씩 확인해 나갑니다. 마지막에 확인하는 것은 전체 문자열 입니다.
61 | - Possessive : 입력된 전체 문자열을 확인합니다. Greedy와 달리 뒤에서 빼면서 확인하지 않습니다.
62 | - |Greedy|Reluctant|Possessive|Meaning|
63 | |:--:|:--:|:--:|:--:|
64 | |x?|x??|x?+|x, 1번 혹은 0번|
65 | |x*|x*?|x*+|x, 0번 이상|
66 | |x+|x+?|x++|x, 1번 이상|
67 | |x{n}|x{n}?|x{n}+|x, 정확하게 n번 반복|
68 | |x{n,}|x{n,}?|x{n,}+|x, 적어도 n번 반복|
69 | |x{n,m}|x{n,m}?|x{n,m}+|x, 적어도 n번 이상 m번 이하로 반복|
70 |
71 |
72 |
73 | ### 참고 사이트
74 | - https://docs.oracle.com/javase/8/docs/api/java/util/regex/Pattern.html#sum
75 | - https://offbyone.tistory.com/400
--------------------------------------------------------------------------------
/java/kkw/String.md:
--------------------------------------------------------------------------------
1 | ## String
2 | - 불변성(immutable)
3 | - 생성 시 String pool 이라는 공간에 생성, 생성되면 그 인스턴스의 메모리 공간은 절대 변하지 않음
4 | - `+` 연산이나 `String.concat()` 을 이용해서 문자열 값에 변화를 줘도 메모리 공간 내의 값이 변하는게 아니라 새로운 메모리를 할당받아 새로운 String 클래스 객체를 할당받는 것 -> 연산마다 오버헤드가 발생함
5 | - 위의 경우 GC에 의해 기존의 문자열이 제거되어야 함 (언제 제거될 지 모름)
6 | - 대신, 조회의 경우 타 클래스보다 빠르게 읽을 수 있음
7 |
8 |
9 | ## StringBuilder,
10 | - 가변성(mutable)
11 | - 문자열 연산이 자주 일어날 때 성능이 좋음
12 | - StringBuilder는 동기화가 불가능
13 | - 싱글스레드나 동기화가 필요없는 멀티 스레드 환경에서 유리
14 |
15 | ## StringBuffer
16 | - 가변성(mutable)
17 | - 문자열 연산이 자주 일어날 때 성능이 좋음
18 | - 동기화가 가능함 -> Thread-safe함
19 | - 멀티 스레드 환경에서 유리
20 |
21 | 
--------------------------------------------------------------------------------
/java/kkw/serialization.md:
--------------------------------------------------------------------------------
1 | # 직렬화(Serialization)
2 |
3 | ## 직렬화(Serialization)란?
4 | - 자바 시스템 내부에서 사용되는 객체 또는 데이터를 외부의 자바 시스템에서도 사용할 수 있도록 Byte 형태로 데이터 변환하는 기술
5 | - 시스템적으로 이야기하면 JVM의 메모리에 상주(힙 or 스택)되어 있는 데이터를 Byte형태로 변환하는 기술과 직렬화된 바이트 형태의 데이털르 객체로 변환해서 JVM으로 상주시키는 형태를 같이 이야기함
6 |
7 | ## 직렬화 조건
8 | - 자바 `기본(Primitive)타입`과 `java.io.Serializable` 인터페이스를 상속받은 `객체`는 직렬화 할 수 있는 기본 조건을 가짐
9 | - `java.io.ObjectOutputStream`를 이용하여 직렬화함
10 |
11 | ## 역직렬화 조건
12 | - 직렬화 대상이 도니 객체의 클래스가 클래스 패스에 존재해야 하며 import 되어 있어야함
13 | - 자바 직렬화 대상 객체는 동일한 `serialVersionUID`를 가지고 있어야함
14 | ```
15 | private static final long serialVersionUID = 1L;
16 | ```
17 | - `java.io.ObjectInputStream` 를 가지고 역직렬화함
18 |
19 | ## 직렬화 방법
20 | - 다량의 데이터 직렬화 시 CSV 구조가 많이 쓰이고, 구조적인 데이터는 이전에는 XML 형태를 많이 썻지만 최근에는 JSON 형태로 많이 쓰고 있음
21 | - 문자열 형태
22 | - CSV
23 | - 데이터를 표현하는 방법 중 가장 많이 사용되는 방법으로 콤마(,) 기준으로 데이터를 구분
24 | - JSON
25 | - 최근에 가장 많이 사용됨
26 | - 자바스크립트에서 쉽게 사용이 가능
27 | - 다른 데이터 방식에 비해 오버헤드가 적음
28 |
29 |
30 |
31 |
32 | ## 자바의 직렬화 사용하는 이유
33 | - 자바 직렬화 형태의 데이터 교환은 자바 시스템 간의 데이터 교환을 위해서 사용
34 | - 자바 직렬화는 자바 시스템에 최적화 되어 있어 성능이 우수함
35 | - 복잡한 데이터 구조의 클래스의 객체도 직렬화 기본 조건만 지키면 큰 작업 없이 바로 직렬화 및 역직렬화가 가능
36 | - 데이터 타입이 자동으로 맞춰지기에 관련 부분을 신경 안 써주어도 됨
37 |
38 | ## 직렬화 사용 시 주의해야할 점
39 | - 외부 저장소로 저장되는 데이터는 짧은 만료시간의 데이터를 제외하고 자바 직렬화 사용을 지양한다 -> 호환성 문제가 발생할 수 있음
40 | - 역직렬화시 반드시 예외가 생긴다는 것을 생각하고 개발 하여야함
41 | - 클래스 구조가 변경될 시 에러가 발생할 수 있음 -> serialVersionUID 값을 관리해주어 방지함
42 | - 멤버 변수명은 같은데 타입이 변경되는 경우(int -> long) 에러가 발생 -> 타입에 대해 엄격함
43 | - serialVersionUID의 값은 개발 시 직접 관리하도록 함
44 | - 멤버 변수 타입 변경을 지양하도록 함
45 | - 개발자가 직접 컨트롤하기 힘든 객체(프레임워크, 라이브러리에서 제공하는 객체)는 직렬화를 지양함
46 | - **역직렬 화가 되지 않을 때와 같은 예외처리는 기본적으로 해주기**
47 | - 자바 직렬화시에 기본적으로 타입에 대한 정보 등 클래스의 메타 정보도 가지고 있기 때문에 상대적으로 다른 포맷에 비해서 용량이 큼
48 |
49 | ## 결론
50 | - 장점도 많지만 단점도 많음 -> 신경을 많이 써주어야함
51 | 1. 외부 저장소로 저장되는 데이터는 짧은 만료 시간의 데이터를 제외하고 자바 직렬화를 사용을 지양
52 | 2. 역직렬화시 반드시 예외가 발생하는 것을 염두하고 개발
53 | 3. 자주 변경되는 데이터는 직렬화를 사용하지 않음
54 | 4. 긴 만료 시간을 가지는 데이터는 JSON 등 다른 포맷을 사용하여 저장
55 |
56 |
57 | ## 언제 어디서 사용하는가?
58 | - JVM 메모리에서만 상주되어 있는 객체 데이터를 그대로 영속화(Persistence)가 필요할 때 사용
59 | - 시스템이 종료 되어도 없어지지 않으며 영속화된 데이터 이기에 네트워크로 전송도 가능함
60 | - 서블릿 세션
61 | - 캐시
62 | - 자바 RMI(Remote Method Invocation)
--------------------------------------------------------------------------------
/java/kkw/singleton.md:
--------------------------------------------------------------------------------
1 | ## 싱글톤 패턴(Singleton Pattern)
2 | - 애플리케이션이 시작될 때, 어떤 클래스가 최초 한 번만 메모리를 할당하고 해당 메모리에 인스턴스를 만들어 사용하는 패턴
3 | - JAVA의 싱글톤 패턴은 private한 생성자와 static method를 사용한다는 특징이 있다.
4 |
5 | ### 사용하는 이유
6 | - 객체를 생성할 때마다 메모리 영역을 할당 받고, new를 통해 매번 새로운 객체를 생성하는 것으로 메모리 낭비를 방지할 수 있다.
7 | - 싱글톤으로 구현된 인스턴스는 static 하므로, 공유가 가능하다는 장점이 있다.
8 | - 인스턴스가 절대적으로 한 개만 존재하는 것을 보장해줄 수 있음
9 |
10 | ### 단점
11 | - 싱글톤 인스턴스가 너무 많은 작업을 하게 되면, 결합도가 높아진다는 단점이 있다
12 | -> 결합도가 높아지면 유지보수가 힘들고, 테스트 진행이 어려울 수 있음
13 | - 멀티 스레드 환경에서 동기화 처리를 해주어야함
14 |
15 |
16 | ### 구현
17 | - Eager Initialization(이른 초기화, Thread-Safe)
18 | ```Java
19 | public class Singleton{
20 | private static Singleton instance = new Singleton();
21 | private Singleton(){}
22 | public static Singleton getInstance(){
23 | return instance;
24 | }
25 | }
26 | ```
27 | - 클래스 로더에 의해 클래스가 초기화 되는 시점에서 Static binding을 통해 인스턴스를 메모리에 등록해서 사용하는 방식
28 | - 클래스 로더에 의해 클래스가 최초로 로딩될 때 객체가 생성됨
29 |
30 |
31 | - Lazy Initialization with synchronized
32 | ```Java
33 | public class Singleton {
34 | private static Singleton instance;
35 |
36 | private Singleton() {}
37 |
38 | public static synchronzied Singleton getInstance() {
39 | if(instance == null) {
40 | instance = new Singleton();
41 | }
42 | return uniqueInstance;
43 | }
44 | }
45 | ```
46 | - 인스턴스가 필요한 시점에 요청하여 Dynamic Binding을 통해 인스턴스를 생성하는 방식
47 | - 인스턴스가 생성여부와 상관 없이 동기화 블록을 거치기 때문에 성능이 떨어짐
48 |
49 | - Lazy Initialization (Double Checking Locking, DCL)
50 | ```JAVA
51 | public class Singleton {
52 | private volatile static Singleton instance;
53 |
54 | private Sigleton() {}
55 |
56 | public Singleton getInstance() {
57 | if(instance == null) {
58 | synchronized(Singleton.class) {
59 | if(instance == null) {
60 | instance = new Singleton();
61 | }
62 | }
63 | }
64 | return instance;
65 | }
66 | }
67 | ```
68 | - volatile 키워드를 사용하는 방식
69 | - volatile 사용하는 이유
70 | - 멀티 스레드 환경에서 작업을 수행하는 동안 성능 향상을 위해 Main Memory에서 읽은 변수 값을 CPU Cache에 저장하게 됨
71 | - 멀티 스레드 환경에서는 각각의 스레드가 변수 값을 읽어올 때, 각각 CPU Cache에 저장된 값이 다르기 때문에 변수값 불일치 문제가 발생할 수 있음
72 | - volatile 키워드를 사용하여 변수가 Main Memory에 있는 것이 보장되므로 위의 문제를 해결 할 수 있음
73 |
74 | Lazy Initialization (Lazy Holder)
75 | ```Java
76 | public class Singleton {
77 | private Singleton() {}
78 |
79 | private static class LazyHolder() {
80 | private static final Singleton instance = new Singleton();
81 | }
82 |
83 | public static Singleton getInstance() {
84 | return LazyHolder.instance;
85 | }
86 | }
87 | ```
88 | - static 영역에서 초기화를 해주지만, 객체가 필요한 시점까지 초기화를 미루는 방식
89 | - static 멤버 클래스라도, 내부 클래스에 변수가 없기 때문에 클래스 로더가 초기화할 때 초기화 하지 않고 메소드를 호출할 때 Dynamic binding 하게 됨
90 | - 위의 방법들보다 성능이 뛰어남
--------------------------------------------------------------------------------
/java/lhk/collectionsFramework.md:
--------------------------------------------------------------------------------
1 | ## Java의 데이터 타입
2 | ### primitive 데이터 타입
3 | - 정수타입 : byte, short, int, long
4 | - 소수타입 : float, double
5 | - bool 타입 : boolean
6 | - 문자타입 : char
7 |
8 | 각 primitive 별 참조타입이 존재한다.
9 |
10 | ### Wrapper 타입
11 | - 정수타입 : Byte, Short, Integer, Long
12 | - 소수타입 : Float, Double
13 | - bool 타입 : Boolean
14 | - 문자타입 : Character
15 |
16 | ## 오토박싱과 언박싱 개념 등장
17 | Collection 자료구조가 추가되면서 preimitive 타입을 Collection에 담을 수 없어 내부로 감싼 Wrapper 타입을 활용하게 되었다.
18 | JDK1.5 이전에는 기본형과 참조형 간의 연산이 불가능해서 기본형을 래퍼 클래스 객체로 만들어서 연산했다.
19 | 컴파일러가 자동으로 코드를 변환해주어 기본형과 참조형 간에 연산이 가능해졌다.
20 |
21 |
22 | ```Java
23 | // 컴파일 전
24 | int i = 100;
25 | Integer obj = new Integer(500);
26 |
27 | int sum = i + obj;
28 | ```
29 |
30 | ```Java
31 | // 컴파일 후
32 | int i = 100;
33 | Integer obj = new Integer(500);
34 |
35 | int sum = i + obj.intValue();
36 | ```
37 |
38 | ## 오토박싱(autoboxing)
39 | 기본형 값을 래퍼 클래스 객체로 자동 변환해주는 것
40 |
41 | ## 언박싱(unboxing)
42 | 래퍼 클래스 객체를 기본형 값으로 자동 변환해주는 것
43 |
44 | ```Java
45 | ArrayList list = new ArrayList();
46 | list.add(100); // 100 -> new Integer(100) [autoboxing]
47 |
48 | int value = list.get(0); // Integer(100) -> 100 [unboxing]
49 | ```
50 |
51 | ## 오토박싱과 언박싱의 단점
52 | 컴파일러가 자동으로 지원해주어서 편리하지만, 다른 타입간의 형변환은 성능에 영향을 끼치므로 지양하는 것이 좋다.
53 |
54 |
55 | # Collections Framework
56 | 데이터 군을 다르고 표현하기 위한 단일화된 구조 (Java API 문서)
57 |
58 | ## List
59 | ### 특징
60 | - 순서가 있다.
61 | - 중복을 허용한다.
62 |
63 | ### 구현 클래스
64 | - ArrayList
65 | - 기존의 Vector를 개선한 것으로, Vector보다 사용을 권장한다.
66 | - 원하는 데이터에 접근하는데 빠르다.
67 | - 데이터 추가/삭제 시 이후 요소들도 한 칸씩 이동해줘야해서 데이터 개수가 많을수록 시간이 오래걸린다.
68 | - 크기를 변경할 수 없다.
69 | - LinkedList
70 | - 데이터 추가/삭제가 빠르다.
71 | - 데이터에 접근하는 데 느리다.
72 | - 데이터가 많을수록 접근성이 떨어진다.
73 | - Stack
74 | - Vector를 상속받아 구현
75 | - 수식 계산, 괄호검사, 웹브라우저 뒤로가기/앞으로가기
76 | - Vector
77 |
78 |
79 | ## Set
80 | ### 특징
81 | - 순서를 유지하지 않는다.
82 | - 중복을 허용하지 않는다.
83 |
84 | ### 구현 클래스
85 | - HashSet
86 | - 가장 대표적인 클래스
87 | - 중복된 용소를 추가하려고하면 false를 반환하여 실패를 알린다.
88 | - TreeSet
89 | - 이진 검색 트리 자료구조의 형태로 데이터를 저장한다.
90 | - 이진 검색 트리의 성능을 향상시킨 레드블랙트리로 구현되어 있다.
91 |
92 |
93 | ## Map
94 | ### 특징
95 | - Key와 Value의 쌍으로 이루어진 집합
96 | - 순서를 유지하지 않는다.
97 | - Key는 중복을 허용하지 않고, Value는 중복을 허용한다.
98 |
99 | ### 구현 클래스
100 | - HashMap
101 | - Hashtable보다 새로운 버전인 HashMap 사용 권장 (속도 향상)
102 | - 많은 양의 데이터를 검색하는데 뛰어난 성능을 가진다.
103 | - TreeMap
104 | - 정렬과 검색에 적합
105 | - Hashtable
106 | - 동기화를 하기때문에 속도가 느리다.
107 | - Properties
108 | - Hashtable을 상속받아서 구현
109 |
110 |
111 | ## 람다식
112 | Java 8에서 새로 추가된 것 중 하나이다. 익명 함수라고도 하며, 메서드를 하나의 식으로 표현한 것을 말한다.
113 | 모든 메서드는 클래스에 포함되어야 하므로 클래스를 만들어 객체를 생성해야 메서드를 호출할 수 있다.
114 | 하지만 람다식은 그 자체로서 메서드 역할을 수행할 수 있어서 변수처럼 다루는 것이 가능하다.
115 |
116 | ## 람다식 작성하기
117 |
118 | 1. 메서드에서 이름과 반환타입을 제거하고 매개변수 선언부와 몸통 사이에 `->` 를 추가한다.
119 | ```Java
120 | // 기존 메서드
121 | int max(int a, int b) {
122 | return a > b ? a : b;
123 | }
124 |
125 | // 람다식 표현
126 | (int a, int b) -> { return a > b ? a : b; }
127 | ```
128 |
129 | 2. 반환값이 있거나 반환값이 없어도 괄호 안의 문장이 하나이면 괄호를 생략하고 식으로 표현할 수 있다.
130 |
131 | ```Java
132 | (int a, int b) -> a > b ? a : b
133 | ```
134 |
135 | 3. 매개변수 타입이 추론 가능하면 생략가능하다. 대부분 생략 가능하다.
136 | ```Java
137 | (a, b) -> a > b ? a : b
138 | ```
139 |
140 | ```Java
141 | // 기존 메서드
142 | int square(int x) {
143 | return x * x;
144 | }
145 |
146 | // 1. 이름과 반환 타입을 제거하고 식으로 표현한다.
147 | (int x) -> x * x
148 |
149 | // 2. 타입을 생략한다.
150 | (x) -> x * x
151 |
152 | // 3. 매개변수가 하나이면 괄호를 생략한다.
153 | x -> x * x
154 | ```
155 |
156 | ## 함수형 인터페이스
157 | 람다식으로 정의된 익명 객체를 호출하기 위해서는 참조 변수가 필요하다. 이때, 참조 변수의 타입으로 람다식과 동등한 메서드가 정의된 인터페이스를 사용할 수 있다.
158 | 즉, 람다식을 다루기 위한 인터페이스를 말한다.
159 | 람다식과 인터페이스의 메서드가 1:1로 연결되기 위해, 오직 하나의 추상 메서드만 정의되어 있어야 한다는 제약이 있다.
160 | ```Java
161 | MyFunction f = (int a, int b) -> a > b ? a : b;
162 | int bif = f.max(5, 3) // 호출
163 |
164 | @FunctionalInterface
165 | interface MyFunction {
166 | public abstract int max(int a, int b);
167 | }
168 | ```
169 |
--------------------------------------------------------------------------------
/java/lhk/generic.md:
--------------------------------------------------------------------------------
1 | # 제네릭
2 | 데이터 타입을 일반화(generalize) 하는 것으로 컴파일시 데이터 타입을 체크해준다.
3 | 런타임 에러에서 발생할 수 있는 형변환 에러를 컴파일 에러로 잡을 수 있다.
4 |
5 | 제네릭을 사용하지 않는 코드와의 호환성을 위해 컴파일시, 제네릭 타입은 변환된다.
6 |
7 | 제네릭 전에는 형변환 에러가 발생하여 컴파일 에러는 나지 않지만, 런타임 에러가 발생하여 프로그램이 종료되었다.
8 | ```Java
9 | public class GenericEx {
10 | public static void main(String[] args) {
11 | ArrayList list = new ArrayList();
12 | list.add(10);
13 | list.add("100"); // 컴파일 됨
14 |
15 | System.out.println(list): // 형변환에러 발생
16 | }
17 | }
18 | ```
19 |
20 | 제네릭이 등장한 JDK 1.5 이후부터는 제네릭 클래스의 참조변수와 생성자에 다음과 같이 선언해주는 것이 좋다.
21 | 참조변수와 생성자에 대입한 타입은 일치해야 한다. JDK 1.7 이후부터는 생성자 대입한 타입은 생략 가능하다.
22 | ```Java
23 | ArrayList list = new ArrayList(); // JDK 1.5 이전
24 | ArrayList