├── .gitignore
├── LICENSE
├── README.md
├── clipboard.py
├── icon.png
├── imgurpython
├── __init__.py
├── client.py
├── helpers
│ ├── __init__.py
│ ├── error.py
│ └── format.py
└── imgur
│ ├── __init__.py
│ └── models
│ ├── __init__.py
│ ├── account.py
│ ├── account_settings.py
│ ├── album.py
│ ├── comment.py
│ ├── conversation.py
│ ├── custom_gallery.py
│ ├── gallery_album.py
│ ├── gallery_image.py
│ ├── image.py
│ ├── message.py
│ ├── notification.py
│ ├── tag.py
│ └── tag_vote.py
├── info.plist
├── oss2
├── __init__.py
├── api.py
├── auth.py
├── compat.py
├── crypto.py
├── defaults.py
├── exceptions.py
├── http.py
├── iterators.py
├── models.py
├── resumable.py
├── task_queue.py
├── utils.py
└── xml_utils.py
├── qcloud_cos
├── __init__.py
├── cos_auth.py
├── cos_client.py
├── cos_comm.py
├── cos_exception.py
├── cos_threadpool.py
├── demo.py
├── streambody.py
└── xml2dict.py
├── requirements.txt
├── util.py
├── wntc.py
└── 程序示意图.eddx
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea
2 | *.pyc
3 | *.swp
4 | .DB_store
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 万能图床
2 |
3 | 这是一个方便的剪贴板图片上传实用工具,且同时可上传至多个云(已实现同时上传至腾讯云和阿里云)
4 | 图片上传到图床之后,会自动把上传返回的链接放置到系统剪切版上,整个过程只需要两步:
5 |
6 | 1. 截图/复制本地图片/复制网络图片链接
7 | 2. 快捷键 `cmd + opt + p` 进行上传 (或者用调用alfred 输入关键字wn 或 tc 或你自定义的关键字 )
8 |
9 |
10 | 上传完成之后,返回的图片链接自动放入到系统剪切版中,可以直接使用`cmd + V` 使用。
11 | 
12 |
13 | ----
14 | ## 支持列表
15 | - [X] 阿里云oss
16 | - [x] 腾讯云cos
17 | - [x] imgur
18 | - [ ] 七牛云
19 | - [ ] 坚果云
20 |
21 |
22 | ## 运行环境
23 |
24 | - macOs 10.13.6
25 | - alfred v3.6.2 开通PowerPack
26 | - python 2.7 mac系统默认
27 | - python依赖库
28 | - PyObjC
29 | - cos-python-sdk-v5
30 | - oss2
31 | - requests
32 |
33 |
34 | ## 配置说明
35 | 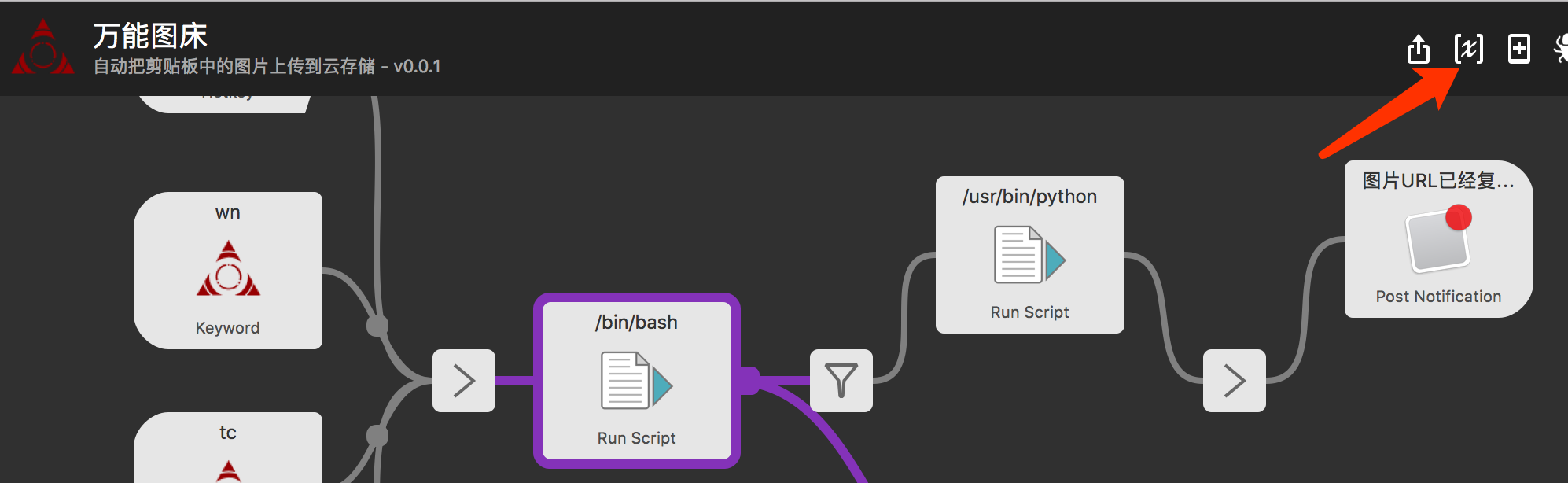
36 |
37 | |name|说明|
38 | |--|--|
39 | |debug|是否开启debug模式(会弹出多余信息)|
40 | |keyword|自定义关键字启动万能图床|
41 | |favor_yun|如果配置了多个云,配置该项会将该项的url拷贝到剪贴板里|
42 | |cos_bucket_name|腾讯云存储桶名称|
43 | |cos_is_cdn|是否使用cdn链接,前提是你开通了cdn|
44 | |cos_cdn_domain|开通了cdn的域名 如cossh.myqcloud.com|
45 | |cos_region|域名中的地域信息。枚举值参见 可用地域 文档,如:ap-beijing, ap-hongkong, eu-frankfurt 等|
46 | |cos_secret_id|开发者拥有的项目身份识别 ID,用以身份认证|
47 | |cos_secret_key|开发者拥有的项目身份密钥|
48 | |oss.AccessKeyId|开发者拥有的项目身份识别 ID,用以身份认证|
49 | |oss.AccessKeySecret|开发者拥有的项目身份密钥|
50 | |oss.bucket_name||
51 | |oss.endpoint||
52 | |imgur_use|是否使用imgur(可选)因为需要翻墙速度慢大部分人默认可关闭 true/false|
53 | |imgur_client_id||
54 | |imgur_client_secret||
55 | |imgur_access_token||
56 | |imgur_refresh_token||
57 | |imgur_album|可选|
58 | |porxyconf|如:http://127.0.0.1:58555 代理设置 imgur可能需要翻墙|
59 |
60 | #### 腾讯云
61 | 
62 | https://cloud.tencent.com/document/product/436/7751
63 | #### 阿里云
64 | 
65 | https://help.aliyun.com/document_detail/52834.html?spm=a2c4g.11186623.6.677.84qFxY
66 |
67 | ---
68 |
69 |
70 | ## 特性
71 | . 极速截图转图片链接
72 | 2. 极速本地图片转图片链接
73 | 3. 极速网络图片转自定义图片链接
74 | - 直接将图片粘贴为markdown支持的图片链接
75 | - 自动图片上传,失败通知栏通知
76 | - 方便的图片上传工具
77 |
78 | ## 使用
79 |
80 | 首先请确认依赖库安装成功;然后导入Alfred工作流;
81 |
82 | #### 通过截图上传
83 |
84 | 使用任意截图工具截图之后,,按下 `cmd + opt + p` ,再在任意编辑器里面你需要插入markdown格式图片的地方,按下cmd + V即可!
85 |
86 | #### 通过本地图片上传
87 |
88 | 如果你已经有一张图片了,希望上传到图床得到一个链接;
89 | 直接复制本地图片,然后按下 `cmd + opt + p`就能得到图床的链接!
90 |
91 | ## TODO
92 | - 选中任何文件即可上传到云上
93 | - 增加 七牛云、坚果云等
94 |
95 | ## 版本
96 | ###v1.1
97 | - 增加imgur支持
98 | - 增加cos的cdn域名自定义
99 | ###v1.0
100 | - 增加腾讯云cos
101 | ###v0.1
102 | - 可以使用阿里云oss
103 |
104 | ## 鸣谢
105 | - https://github.com/Imgur/imgurpython
--------------------------------------------------------------------------------
/clipboard.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import os
3 | import tempfile
4 | import imghdr
5 | import shutil
6 |
7 | from AppKit import NSPasteboard, NSPasteboardTypePNG, \
8 | NSPasteboardTypeTIFF, NSPasteboardTypeString, \
9 | NSFilenamesPboardType
10 |
11 | # image_file, need_format, need_compress
12 | NONE_IMG = (None, False, None)
13 |
14 |
15 | def _convert_to_png(from_path, to_path):
16 | # convert it to png file
17 | os.system('sips -s format png %s --out %s' % (from_path, to_path))
18 |
19 |
20 | def get_paste_img_file():
21 | ''' get a img file from clipboard;
22 | the return object is a `tempfile.NamedTemporaryFile`
23 | you can use the name field to access the file path.
24 | the tmp file will be delete as soon as possible(when gc happened or close explicitly)
25 | you can not just return a path, must hold the reference'''
26 |
27 | pb = NSPasteboard.generalPasteboard()
28 | data_type = pb.types()
29 |
30 | supported_image_format = (NSPasteboardTypePNG, NSPasteboardTypeTIFF)
31 | if NSFilenamesPboardType in data_type:
32 | # file in clipboard
33 | img_path = pb.propertyListForType_(NSFilenamesPboardType)[0]
34 | img_type = imghdr.what(img_path)
35 |
36 | if not img_type:
37 | # not image file
38 | return NONE_IMG
39 |
40 | if img_type not in ('png', 'jpeg', 'gif'):
41 | # now only support png & jpg & gif
42 | return NONE_IMG
43 |
44 | is_gif = img_type == 'gif'
45 | _file = tempfile.NamedTemporaryFile(suffix=img_type)
46 | tmp_clipboard_img_file = tempfile.NamedTemporaryFile()
47 | shutil.copy(img_path, tmp_clipboard_img_file.name)
48 | if not is_gif:
49 | _convert_to_png(tmp_clipboard_img_file.name, _file.name)
50 | else:
51 | shutil.copy(tmp_clipboard_img_file.name, _file.name)
52 | tmp_clipboard_img_file.close()
53 | return _file, False, 'gif' if is_gif else 'png'
54 |
55 | if NSPasteboardTypeString in data_type:
56 | # make this be first, because plain text may be TIFF format?
57 | # string todo, recognise url of png & jpg
58 | return NONE_IMG
59 |
60 | if any(filter(lambda f: f in data_type, supported_image_format)):
61 | # do not care which format it is, we convert it to png finally
62 | # system screen shotcut is png, QQ is tiff
63 | tmp_clipboard_img_file = tempfile.NamedTemporaryFile()
64 | print tmp_clipboard_img_file.name
65 | png_file = tempfile.NamedTemporaryFile(suffix='png')
66 | for fmt in supported_image_format:
67 | data = pb.dataForType_(fmt)
68 | if data: break
69 | ret = data.writeToFile_atomically_(tmp_clipboard_img_file.name, False)
70 | if not ret: return NONE_IMG
71 |
72 | _convert_to_png(tmp_clipboard_img_file.name, png_file.name)
73 | # close the file explicitly
74 | tmp_clipboard_img_file.close()
75 | return png_file, True, 'png'
76 |
77 |
78 | if __name__ == '__main__':
79 | get_paste_img_file()
--------------------------------------------------------------------------------
/icon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/juforg/wntc.alfredworkflow/9f1ddbd83727a9e972fd26fd63486065021a7ae2/icon.png
--------------------------------------------------------------------------------
/imgurpython/__init__.py:
--------------------------------------------------------------------------------
1 | from .client import ImgurClient
--------------------------------------------------------------------------------
/imgurpython/helpers/__init__.py:
--------------------------------------------------------------------------------
1 | from ..imgur.models.comment import Comment
2 | from ..imgur.models.notification import Notification
3 | from ..imgur.models.gallery_album import GalleryAlbum
4 | from ..imgur.models.gallery_image import GalleryImage
--------------------------------------------------------------------------------
/imgurpython/helpers/error.py:
--------------------------------------------------------------------------------
1 | class ImgurClientError(Exception):
2 | def __init__(self, error_message, status_code=None):
3 | self.status_code = status_code
4 | self.error_message = error_message
5 |
6 | def __str__(self):
7 | if self.status_code:
8 | return "(%s) %s" % (self.status_code, self.error_message)
9 | else:
10 | return self.error_message
11 |
12 |
13 | class ImgurClientRateLimitError(Exception):
14 | def __str__(self):
15 | return 'Rate-limit exceeded!'
16 |
--------------------------------------------------------------------------------
/imgurpython/helpers/format.py:
--------------------------------------------------------------------------------
1 | from ..helpers import Comment
2 | from ..helpers import GalleryAlbum
3 | from ..helpers import GalleryImage
4 | from ..helpers import Notification
5 |
6 |
7 | def build_comment_tree(children):
8 | children_objects = []
9 | for child in children:
10 | to_insert = Comment(child)
11 | to_insert.children = build_comment_tree(to_insert.children)
12 | children_objects.append(to_insert)
13 |
14 | return children_objects
15 |
16 |
17 | def format_comment_tree(response):
18 | if isinstance(response, list):
19 | result = []
20 | for comment in response:
21 | formatted = Comment(comment)
22 | formatted.children = build_comment_tree(comment['children'])
23 | result.append(formatted)
24 | else:
25 | result = Comment(response)
26 | result.children = build_comment_tree(response['children'])
27 |
28 | return result
29 |
30 |
31 | def build_gallery_images_and_albums(response):
32 | if isinstance(response, list):
33 | result = []
34 | for item in response:
35 | if item['is_album']:
36 | result.append(GalleryAlbum(item))
37 | else:
38 | result.append(GalleryImage(item))
39 | else:
40 | if response['is_album']:
41 | result = GalleryAlbum(response)
42 | else:
43 | result = GalleryImage(response)
44 |
45 | return result
46 |
47 |
48 | def build_notifications(response):
49 | result = {
50 | 'replies': [],
51 | 'messages': [Notification(
52 | item['id'],
53 | item['account_id'],
54 | item['viewed'],
55 | item['content']
56 | ) for item in response['messages']]
57 | }
58 |
59 | for item in response['replies']:
60 | notification = Notification(
61 | item['id'],
62 | item['account_id'],
63 | item['viewed'],
64 | item['content']
65 | )
66 | notification.content = format_comment_tree(item['content'])
67 | result['replies'].append(notification)
68 |
69 | return result
70 |
71 |
72 | def build_notification(item):
73 | notification = Notification(
74 | item['id'],
75 | item['account_id'],
76 | item['viewed'],
77 | item['content']
78 | )
79 |
80 | if 'comment' in notification.content:
81 | notification.content = format_comment_tree(item['content'])
82 |
83 | return notification
84 |
--------------------------------------------------------------------------------
/imgurpython/imgur/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/juforg/wntc.alfredworkflow/9f1ddbd83727a9e972fd26fd63486065021a7ae2/imgurpython/imgur/__init__.py
--------------------------------------------------------------------------------
/imgurpython/imgur/models/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/juforg/wntc.alfredworkflow/9f1ddbd83727a9e972fd26fd63486065021a7ae2/imgurpython/imgur/models/__init__.py
--------------------------------------------------------------------------------
/imgurpython/imgur/models/account.py:
--------------------------------------------------------------------------------
1 | class Account(object):
2 |
3 | def __init__(self, account_id, url, bio, reputation, created, pro_expiration):
4 | self.id = account_id
5 | self.url = url
6 | self.bio = bio
7 | self.reputation = reputation
8 | self.created = created
9 | self.pro_expiration = pro_expiration
10 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/account_settings.py:
--------------------------------------------------------------------------------
1 | class AccountSettings(object):
2 |
3 | def __init__(self, email, high_quality, public_images, album_privacy, pro_expiration, accepted_gallery_terms,
4 | active_emails, messaging_enabled, blocked_users):
5 | self.email = email
6 | self.high_quality = high_quality
7 | self.public_images = public_images
8 | self.album_privacy = album_privacy
9 | self.pro_expiration = pro_expiration
10 | self.accepted_gallery_terms = accepted_gallery_terms
11 | self.active_emails = active_emails
12 | self.messaging_enabled = messaging_enabled
13 | self.blocked_users = blocked_users
14 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/album.py:
--------------------------------------------------------------------------------
1 | class Album(object):
2 |
3 | # See documentation at https://api.imgur.com/ for available fields
4 | def __init__(self, *initial_data, **kwargs):
5 | for dictionary in initial_data:
6 | for key in dictionary:
7 | setattr(self, key, dictionary[key])
8 | for key in kwargs:
9 | setattr(self, key, kwargs[key])
10 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/comment.py:
--------------------------------------------------------------------------------
1 | class Comment(object):
2 |
3 | # See documentation at https://api.imgur.com/ for available fields
4 | def __init__(self, *initial_data, **kwargs):
5 | for dictionary in initial_data:
6 | for key in dictionary:
7 | setattr(self, key, dictionary[key])
8 | for key in kwargs:
9 | setattr(self, key, kwargs[key])
10 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/conversation.py:
--------------------------------------------------------------------------------
1 | from .message import Message
2 |
3 | class Conversation(object):
4 |
5 | def __init__(self, conversation_id, last_message_preview, datetime, with_account_id, with_account, message_count, messages=None,
6 | done=None, page=None):
7 | self.id = conversation_id
8 | self.last_message_preview = last_message_preview
9 | self.datetime = datetime
10 | self.with_account_id = with_account_id
11 | self.with_account = with_account
12 | self.message_count = message_count
13 | self.page = page
14 | self.done = done
15 |
16 | if messages:
17 | self.messages = [Message(
18 | message['id'],
19 | message['from'],
20 | message['account_id'],
21 | message['sender_id'],
22 | message['body'],
23 | message['conversation_id'],
24 | message['datetime'],
25 | ) for message in messages]
26 | else:
27 | self.messages = None
28 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/custom_gallery.py:
--------------------------------------------------------------------------------
1 | from .gallery_album import GalleryAlbum
2 | from .gallery_image import GalleryImage
3 |
4 |
5 | class CustomGallery(object):
6 |
7 | def __init__(self, custom_gallery_id, name, datetime, account_url, link, tags, item_count=None, items=None):
8 | self.id = custom_gallery_id
9 | self.name = name
10 | self.datetime = datetime
11 | self.account_url = account_url
12 | self.link = link
13 | self.tags = tags
14 | self.item_count = item_count
15 | self.items = [GalleryAlbum(item) if item['is_album'] else GalleryImage(item) for item in items] \
16 | if items else None
17 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/gallery_album.py:
--------------------------------------------------------------------------------
1 | class GalleryAlbum(object):
2 |
3 | # See documentation at https://api.imgur.com/ for available fields
4 | def __init__(self, *initial_data, **kwargs):
5 | for dictionary in initial_data:
6 | for key in dictionary:
7 | setattr(self, key, dictionary[key])
8 | for key in kwargs:
9 | setattr(self, key, kwargs[key])
10 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/gallery_image.py:
--------------------------------------------------------------------------------
1 | class GalleryImage(object):
2 |
3 | # See documentation at https://api.imgur.com/ for available fields
4 | def __init__(self, *initial_data, **kwargs):
5 | for dictionary in initial_data:
6 | for key in dictionary:
7 | setattr(self, key, dictionary[key])
8 | for key in kwargs:
9 | setattr(self, key, kwargs[key])
10 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/image.py:
--------------------------------------------------------------------------------
1 | class Image(object):
2 |
3 | # See documentation at https://api.imgur.com/ for available fields
4 | def __init__(self, *initial_data, **kwargs):
5 | for dictionary in initial_data:
6 | for key in dictionary:
7 | setattr(self, key, dictionary[key])
8 | for key in kwargs:
9 | setattr(self, key, kwargs[key])
10 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/message.py:
--------------------------------------------------------------------------------
1 | class Message(object):
2 |
3 | def __init__(self, message_id, from_user, account_id, sender_id, body, conversation_id, datetime):
4 | self.id = message_id
5 | self.from_user = from_user
6 | self.account_id = account_id
7 | self.sender_id = sender_id
8 | self.body = body
9 | self.conversation_id = conversation_id
10 | self.datetime = datetime
11 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/notification.py:
--------------------------------------------------------------------------------
1 | class Notification(object):
2 |
3 | def __init__(self, notification_id, account_id, viewed, content):
4 | self.id = notification_id
5 | self.account_id = account_id
6 | self.viewed = viewed
7 | self.content = content
8 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/tag.py:
--------------------------------------------------------------------------------
1 | from .gallery_album import GalleryAlbum
2 | from .gallery_image import GalleryImage
3 |
4 |
5 | class Tag(object):
6 |
7 | def __init__(self, name, followers, total_items, following, items):
8 | self.name = name
9 | self.followers = followers
10 | self.total_items = total_items
11 | self.following = following
12 | self.items = [GalleryAlbum(item) if item['is_album'] else GalleryImage(item) for item in items] \
13 | if items else None
14 |
--------------------------------------------------------------------------------
/imgurpython/imgur/models/tag_vote.py:
--------------------------------------------------------------------------------
1 | class TagVote(object):
2 |
3 | def __init__(self, ups, downs, name, author):
4 | self.ups = ups
5 | self.downs = downs
6 | self.name = name
7 | self.author = author
8 |
--------------------------------------------------------------------------------
/info.plist:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | bundleid
6 | vip.appcity.workflow.wntc
7 | category
8 | Tools
9 | connections
10 |
11 | 1B8C5911-370C-4CC5-9D1A-AC88FB9BB559
12 |
13 |
14 | destinationuid
15 | 81BB8436-F1AC-4BF0-8C55-48EDB89350E1
16 | modifiers
17 | 0
18 | modifiersubtext
19 |
20 | vitoclose
21 |
22 |
23 |
24 | 2AD8D366-9A61-4E49-B504-A38B2270A457
25 |
26 |
27 | destinationuid
28 | 998E6417-75A5-4F99-AF80-4465E34811E7
29 | modifiers
30 | 0
31 | modifiersubtext
32 |
33 | vitoclose
34 |
35 |
36 |
37 | 635B6602-02AB-4983-BD28-9246A16767DE
38 |
39 |
40 | destinationuid
41 | 1B8C5911-370C-4CC5-9D1A-AC88FB9BB559
42 | modifiers
43 | 0
44 | modifiersubtext
45 |
46 | vitoclose
47 |
48 |
49 |
50 | 81BB8436-F1AC-4BF0-8C55-48EDB89350E1
51 |
52 |
53 | destinationuid
54 | 5C371D2A-F080-4EAC-A91C-B9735DAAFC91
55 | modifiers
56 | 0
57 | modifiersubtext
58 |
59 | vitoclose
60 |
61 |
62 |
63 | 998E6417-75A5-4F99-AF80-4465E34811E7
64 |
65 |
66 | destinationuid
67 | E117BAD6-E9A8-4553-B6B7-8E87A4BB8644
68 | modifiers
69 | 0
70 | modifiersubtext
71 |
72 | vitoclose
73 |
74 |
75 |
76 | A2F9CEE3-9D3C-4E97-A5ED-DF3291610B7C
77 |
78 |
79 | destinationuid
80 | 998E6417-75A5-4F99-AF80-4465E34811E7
81 | modifiers
82 | 0
83 | modifiersubtext
84 |
85 | vitoclose
86 |
87 |
88 |
89 | DE2E602F-313F-4D10-849E-78A4B46F5EAD
90 |
91 |
92 | destinationuid
93 | 998E6417-75A5-4F99-AF80-4465E34811E7
94 | modifiers
95 | 0
96 | modifiersubtext
97 |
98 | vitoclose
99 |
100 |
101 |
102 | E117BAD6-E9A8-4553-B6B7-8E87A4BB8644
103 |
104 |
105 | destinationuid
106 | 635B6602-02AB-4983-BD28-9246A16767DE
107 | modifiers
108 | 0
109 | modifiersubtext
110 |
111 | vitoclose
112 |
113 |
114 |
115 | destinationuid
116 | 8A455598-2D3E-4F17-B286-D7A58AB04A3C
117 | modifiers
118 | 0
119 | modifiersubtext
120 |
121 | vitoclose
122 |
123 |
124 |
125 | EA346044-4CD8-4752-8DE1-73CEFFDBFAAA
126 |
127 |
128 | destinationuid
129 | 998E6417-75A5-4F99-AF80-4465E34811E7
130 | modifiers
131 | 0
132 | modifiersubtext
133 |
134 | vitoclose
135 |
136 |
137 |
138 |
139 | createdby
140 | juforg
141 | description
142 | 自动把剪贴板中的图片上传到云存储
143 | disabled
144 |
145 | name
146 | 万能图床
147 | objects
148 |
149 |
150 | config
151 |
152 | action
153 | 0
154 | argument
155 | 0
156 | focusedappvariable
157 |
158 | focusedappvariablename
159 |
160 | hotkey
161 | 35
162 | hotmod
163 | 1572864
164 | hotstring
165 | P
166 | leftcursor
167 |
168 | modsmode
169 | 0
170 | relatedAppsMode
171 | 0
172 |
173 | type
174 | alfred.workflow.trigger.hotkey
175 | uid
176 | 2AD8D366-9A61-4E49-B504-A38B2270A457
177 | version
178 | 2
179 |
180 |
181 | config
182 |
183 | lastpathcomponent
184 |
185 | onlyshowifquerypopulated
186 |
187 | removeextension
188 |
189 | text
190 | {query}
191 | title
192 | 图片URL已经复制到剪贴板
193 |
194 | type
195 | alfred.workflow.output.notification
196 | uid
197 | 5C371D2A-F080-4EAC-A91C-B9735DAAFC91
198 | version
199 | 1
200 |
201 |
202 | config
203 |
204 | concurrently
205 |
206 | escaping
207 | 68
208 | script
209 | import sys
210 | import re
211 | query = """
212 | {query}
213 | """
214 | l = re.findall('(?<=\().+?(?=\))',query,re.I)
215 | if l.__len__() >0:
216 | sys.stdout.write(l[0])
217 | scriptargtype
218 | 0
219 | scriptfile
220 |
221 | type
222 | 3
223 |
224 | type
225 | alfred.workflow.action.script
226 | uid
227 | 1B8C5911-370C-4CC5-9D1A-AC88FB9BB559
228 | version
229 | 2
230 |
231 |
232 | config
233 |
234 | argumenttype
235 | 1
236 | keyword
237 | wn
238 | subtext
239 | 自动上传剪贴板图片
240 | text
241 | 万能图床
242 | withspace
243 |
244 |
245 | type
246 | alfred.workflow.input.keyword
247 | uid
248 | DE2E602F-313F-4D10-849E-78A4B46F5EAD
249 | version
250 | 1
251 |
252 |
253 | config
254 |
255 | concurrently
256 |
257 | escaping
258 | 68
259 | script
260 | python wntc.py "{query}"
261 | scriptargtype
262 | 0
263 | scriptfile
264 |
265 | type
266 | 0
267 |
268 | type
269 | alfred.workflow.action.script
270 | uid
271 | E117BAD6-E9A8-4553-B6B7-8E87A4BB8644
272 | version
273 | 2
274 |
275 |
276 | config
277 |
278 | inputstring
279 | {query}
280 | matchcasesensitive
281 |
282 | matchmode
283 | 2
284 | matchstring
285 | !\[.*\]\((.+)\)
286 |
287 | type
288 | alfred.workflow.utility.filter
289 | uid
290 | 635B6602-02AB-4983-BD28-9246A16767DE
291 | version
292 | 1
293 |
294 |
295 | config
296 |
297 | argument
298 | {query}
299 | variables
300 |
301 |
302 | type
303 | alfred.workflow.utility.argument
304 | uid
305 | 81BB8436-F1AC-4BF0-8C55-48EDB89350E1
306 | version
307 | 1
308 |
309 |
310 | config
311 |
312 | argument
313 | {query}
314 | variables
315 |
316 | vardate
317 | {date:short}
318 | vartime
319 | {time}
320 | yuncode
321 | {query}
322 |
323 |
324 | type
325 | alfred.workflow.utility.argument
326 | uid
327 | 998E6417-75A5-4F99-AF80-4465E34811E7
328 | version
329 | 1
330 |
331 |
332 | config
333 |
334 | argumenttype
335 | 1
336 | keyword
337 | tc
338 | subtext
339 | 自动上传剪贴板图片
340 | text
341 | 万能图床
342 | withspace
343 |
344 |
345 | type
346 | alfred.workflow.input.keyword
347 | uid
348 | A2F9CEE3-9D3C-4E97-A5ED-DF3291610B7C
349 | version
350 | 1
351 |
352 |
353 | config
354 |
355 | argument
356 | '{query}', {allvars}
357 | cleardebuggertext
358 |
359 | processoutputs
360 |
361 |
362 | type
363 | alfred.workflow.utility.debug
364 | uid
365 | 8A455598-2D3E-4F17-B286-D7A58AB04A3C
366 | version
367 | 1
368 |
369 |
370 | config
371 |
372 | argumenttype
373 | 0
374 | keyword
375 | {var:keyword}
376 | subtext
377 | 本workflow configuration设置的关键字
378 | text
379 | 万能图床
380 | withspace
381 |
382 |
383 | type
384 | alfred.workflow.input.keyword
385 | uid
386 | EA346044-4CD8-4752-8DE1-73CEFFDBFAAA
387 | version
388 | 1
389 |
390 |
391 | readme
392 | 无论用哪个工具截图后,在�剪贴板中都有这个图片的二进制信息,把这个二进制信息自动上传到各大图床平台上
393 | 目前支持的云有 阿里云(oss)腾讯云(cos)
394 |
395 | |debug|是否开启debug模式(会弹出多余信息)|
396 | |keyword|自定义关键字启动万能图床|
397 | |favor_yun|如果配置了多个云,配置该项会将该项的url拷贝到剪贴板里,可选配置:oss,cos,imgur|
398 | |cos_bucket_name|腾讯云存储桶名称|
399 | |cos_is_cdn|是否使用cdn链接,前提是你开通了cdn|
400 | |cos_region|域名中的地域信息。枚举值参见 可用地域 文档,如:ap-beijing, ap-hongkong, eu-frankfurt 等|
401 | |cos_secret_id|开发者拥有的项目身份识别 ID,用以身份认证|
402 | |cos_secret_key|开发者拥有的项目身份密钥|
403 | |oss.AccessKeyId|开发者拥有的项目身份识别 ID,用以身份认证|
404 | |oss.AccessKeySecret|开发者拥有的项目身份密钥|
405 | |oss.bucket_name||
406 | |oss.endpoint||
407 | |imgur_use|是否使用imgur(可选)因为需要翻墙速度慢大部分人默认可关闭 true/false|
408 | |imgur_client_id||
409 | |imgur_client_secret||
410 | |imgur_access_token||
411 | |imgur_refresh_token||
412 | |imgur_album|可选|
413 | |porxyconf|如:http://127.0.0.1:58555 代理设置 imgur可能需要翻墙|
414 | uidata
415 |
416 | 1B8C5911-370C-4CC5-9D1A-AC88FB9BB559
417 |
418 | xpos
419 | 600
420 | ypos
421 | 220
422 |
423 | 2AD8D366-9A61-4E49-B504-A38B2270A457
424 |
425 | xpos
426 | 90
427 | ypos
428 | 80
429 |
430 | 5C371D2A-F080-4EAC-A91C-B9735DAAFC91
431 |
432 | xpos
433 | 860
434 | ypos
435 | 210
436 |
437 | 635B6602-02AB-4983-BD28-9246A16767DE
438 |
439 | xpos
440 | 520
441 | ypos
442 | 330
443 |
444 | 81BB8436-F1AC-4BF0-8C55-48EDB89350E1
445 |
446 | xpos
447 | 770
448 | ypos
449 | 330
450 |
451 | 8A455598-2D3E-4F17-B286-D7A58AB04A3C
452 |
453 | xpos
454 | 660
455 | ypos
456 | 500
457 |
458 | 998E6417-75A5-4F99-AF80-4465E34811E7
459 |
460 | xpos
461 | 280
462 | ypos
463 | 330
464 |
465 | A2F9CEE3-9D3C-4E97-A5ED-DF3291610B7C
466 |
467 | xpos
468 | 90
469 | ypos
470 | 370
471 |
472 | DE2E602F-313F-4D10-849E-78A4B46F5EAD
473 |
474 | xpos
475 | 90
476 | ypos
477 | 230
478 |
479 | E117BAD6-E9A8-4553-B6B7-8E87A4BB8644
480 |
481 | xpos
482 | 350
483 | ypos
484 | 300
485 |
486 | EA346044-4CD8-4752-8DE1-73CEFFDBFAAA
487 |
488 | note
489 | 自定义关键字
490 | 自己在右上角[X] 中配置的keyword 触发本工作流
491 | xpos
492 | 90
493 | ypos
494 | 500
495 |
496 |
497 | variables
498 |
499 | cos_bucket_name
500 | wntc-1251220317
501 | cos_cdn_domain
502 | cossh.myqcloud.com
503 | cos_is_cdn
504 | true
505 | cos_region
506 | ap-shanghai
507 | cos_secret_id
508 | AKIDurgMrBPF9vgFdpcyytdExX3S0ZBc3uNt
509 | cos_secret_key
510 | gFnEUaUCicQ6as0GtcDctz1sqfcOIBxc
511 | debug
512 | false
513 | favor_yun
514 | cos
515 | imgur_access_token
516 | 9ac4a950705753af07916e0e090a6db8af6229ae
517 | imgur_client_id
518 | 4006e10bc9bfa9d
519 | imgur_client_secret
520 | 9cc6f213b55cf5678b999e4c0fcf1f9f8788de11
521 | imgur_refresh_token
522 | 8e1a904b3c6857935522266a8143a65cb87b958a
523 | imgur_use
524 | false
525 | keyword
526 | wntc
527 | oss.AccessKeyId
528 | a0yPloym0g6sXsyC
529 | oss.AccessKeySecret
530 | cVm1WlvFNueSSEsIg9qQ3ORzQw6wwa
531 | oss.bucket_name
532 | wntc
533 | oss.endpoint
534 | oss-cn-shanghai.aliyuncs.com
535 | porxyconf
536 | http://127.0.0.1:58555
537 |
538 | variablesdontexport
539 |
540 | imgur_client_id
541 | oss.AccessKeyId
542 | cos_bucket_name
543 | imgur_client_secret
544 | imgur_refresh_token
545 | oss.AccessKeySecret
546 | cos_secret_id
547 | cos_secret_key
548 | imgur_access_token
549 |
550 | version
551 | 0.0.1
552 | webaddress
553 | http://appcity.vip
554 |
555 |
556 |
--------------------------------------------------------------------------------
/oss2/__init__.py:
--------------------------------------------------------------------------------
1 | __version__ = '2.5.0'
2 |
3 | from . import models, exceptions
4 |
5 | from .api import Service, Bucket, CryptoBucket
6 | from .auth import Auth, AuthV2, AnonymousAuth, StsAuth, AUTH_VERSION_1, AUTH_VERSION_2, make_auth
7 | from .http import Session, CaseInsensitiveDict
8 |
9 |
10 | from .iterators import (BucketIterator, ObjectIterator,
11 | MultipartUploadIterator, ObjectUploadIterator,
12 | PartIterator, LiveChannelIterator)
13 |
14 |
15 | from .resumable import resumable_upload, resumable_download, ResumableStore, ResumableDownloadStore, determine_part_size
16 | from .resumable import make_upload_store, make_download_store
17 |
18 |
19 | from .compat import to_bytes, to_string, to_unicode, urlparse, urlquote, urlunquote
20 |
21 | from .utils import SizedFileAdapter, make_progress_adapter
22 | from .utils import content_type_by_name, is_valid_bucket_name
23 | from .utils import http_date, http_to_unixtime, iso8601_to_unixtime, date_to_iso8601, iso8601_to_date
24 |
25 |
26 | from .models import BUCKET_ACL_PRIVATE, BUCKET_ACL_PUBLIC_READ, BUCKET_ACL_PUBLIC_READ_WRITE
27 | from .models import OBJECT_ACL_DEFAULT, OBJECT_ACL_PRIVATE, OBJECT_ACL_PUBLIC_READ, OBJECT_ACL_PUBLIC_READ_WRITE
28 | from .models import BUCKET_STORAGE_CLASS_STANDARD, BUCKET_STORAGE_CLASS_IA, BUCKET_STORAGE_CLASS_ARCHIVE
29 |
30 | from .crypto import LocalRsaProvider, AliKMSProvider
31 |
--------------------------------------------------------------------------------
/oss2/auth.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | import hmac
4 | import hashlib
5 | import time
6 |
7 | from . import utils
8 | from .compat import urlquote, to_bytes
9 |
10 | from .defaults import get_logger
11 | import logging
12 |
13 | AUTH_VERSION_1 = 'v1'
14 | AUTH_VERSION_2 = 'v2'
15 |
16 |
17 | def make_auth(access_key_id, access_key_secret, auth_version=AUTH_VERSION_1):
18 | if auth_version == AUTH_VERSION_2:
19 | return AuthV2(access_key_id.strip(), access_key_secret.strip())
20 | else:
21 | return Auth(access_key_id.strip(), access_key_secret.strip())
22 |
23 |
24 | class AuthBase(object):
25 | """用于保存用户AccessKeyId、AccessKeySecret,以及计算签名的对象。"""
26 | def __init__(self, access_key_id, access_key_secret):
27 | self.id = access_key_id.strip()
28 | self.secret = access_key_secret.strip()
29 |
30 | def _sign_rtmp_url(self, url, bucket_name, channel_name, playlist_name, expires, params):
31 | expiration_time = int(time.time()) + expires
32 |
33 | canonicalized_resource = "/%s/%s" % (bucket_name, channel_name)
34 | canonicalized_params = []
35 |
36 | if params:
37 | items = params.items()
38 | for k, v in items:
39 | if k != "OSSAccessKeyId" and k != "Signature" and k != "Expires" and k != "SecurityToken":
40 | canonicalized_params.append((k, v))
41 |
42 | canonicalized_params.sort(key=lambda e: e[0])
43 | canon_params_str = ''
44 | for k, v in canonicalized_params:
45 | canon_params_str += '%s:%s\n' % (k, v)
46 |
47 | p = params if params else {}
48 | string_to_sign = str(expiration_time) + "\n" + canon_params_str + canonicalized_resource
49 | get_logger().debug('string_to_sign={0}'.format(string_to_sign))
50 |
51 | h = hmac.new(to_bytes(self.secret), to_bytes(string_to_sign), hashlib.sha1)
52 | signature = utils.b64encode_as_string(h.digest())
53 |
54 | p['OSSAccessKeyId'] = self.id
55 | p['Expires'] = str(expiration_time)
56 | p['Signature'] = signature
57 |
58 | return url + '?' + '&'.join(_param_to_quoted_query(k, v) for k, v in p.items())
59 |
60 |
61 | class Auth(AuthBase):
62 | """签名版本1"""
63 | _subresource_key_set = frozenset(
64 | ['response-content-type', 'response-content-language',
65 | 'response-cache-control', 'logging', 'response-content-encoding',
66 | 'acl', 'uploadId', 'uploads', 'partNumber', 'group', 'link',
67 | 'delete', 'website', 'location', 'objectInfo', 'objectMeta',
68 | 'response-expires', 'response-content-disposition', 'cors', 'lifecycle',
69 | 'restore', 'qos', 'referer', 'stat', 'bucketInfo', 'append', 'position', 'security-token',
70 | 'live', 'comp', 'status', 'vod', 'startTime', 'endTime', 'x-oss-process',
71 | 'symlink', 'callback', 'callback-var']
72 | )
73 |
74 | def _sign_request(self, req, bucket_name, key):
75 | req.headers['date'] = utils.http_date()
76 |
77 | signature = self.__make_signature(req, bucket_name, key)
78 | req.headers['authorization'] = "OSS {0}:{1}".format(self.id, signature)
79 |
80 | def _sign_url(self, req, bucket_name, key, expires):
81 | expiration_time = int(time.time()) + expires
82 |
83 | req.headers['date'] = str(expiration_time)
84 | signature = self.__make_signature(req, bucket_name, key)
85 |
86 | req.params['OSSAccessKeyId'] = self.id
87 | req.params['Expires'] = str(expiration_time)
88 | req.params['Signature'] = signature
89 |
90 | return req.url + '?' + '&'.join(_param_to_quoted_query(k, v) for k, v in req.params.items())
91 |
92 | def __make_signature(self, req, bucket_name, key):
93 | string_to_sign = self.__get_string_to_sign(req, bucket_name, key)
94 |
95 | get_logger().debug('string_to_sign={0}'.format(string_to_sign))
96 |
97 | h = hmac.new(to_bytes(self.secret), to_bytes(string_to_sign), hashlib.sha1)
98 | return utils.b64encode_as_string(h.digest())
99 |
100 | def __get_string_to_sign(self, req, bucket_name, key):
101 | resource_string = self.__get_resource_string(req, bucket_name, key)
102 | headers_string = self.__get_headers_string(req)
103 |
104 | content_md5 = req.headers.get('content-md5', '')
105 | content_type = req.headers.get('content-type', '')
106 | date = req.headers.get('date', '')
107 | return '\n'.join([req.method,
108 | content_md5,
109 | content_type,
110 | date,
111 | headers_string + resource_string])
112 |
113 | def __get_headers_string(self, req):
114 | headers = req.headers
115 | canon_headers = []
116 | for k, v in headers.items():
117 | lower_key = k.lower()
118 | if lower_key.startswith('x-oss-'):
119 | canon_headers.append((lower_key, v))
120 |
121 | canon_headers.sort(key=lambda x: x[0])
122 |
123 | if canon_headers:
124 | return '\n'.join(k + ':' + v for k, v in canon_headers) + '\n'
125 | else:
126 | return ''
127 |
128 | def __get_resource_string(self, req, bucket_name, key):
129 | if not bucket_name:
130 | return '/'
131 | else:
132 | return '/{0}/{1}{2}'.format(bucket_name, key, self.__get_subresource_string(req.params))
133 |
134 | def __get_subresource_string(self, params):
135 | if not params:
136 | return ''
137 |
138 | subresource_params = []
139 | for key, value in params.items():
140 | if key in self._subresource_key_set:
141 | subresource_params.append((key, value))
142 |
143 | subresource_params.sort(key=lambda e: e[0])
144 |
145 | if subresource_params:
146 | return '?' + '&'.join(self.__param_to_query(k, v) for k, v in subresource_params)
147 | else:
148 | return ''
149 |
150 | def __param_to_query(self, k, v):
151 | if v:
152 | return k + '=' + v
153 | else:
154 | return k
155 |
156 |
157 | class AnonymousAuth(object):
158 | """用于匿名访问。
159 |
160 | .. note::
161 | 匿名用户只能读取public-read的Bucket,或只能读取、写入public-read-write的Bucket。
162 | 不能进行Service、Bucket相关的操作,也不能罗列文件等。
163 | """
164 | def _sign_request(self, req, bucket_name, key):
165 | pass
166 |
167 | def _sign_url(self, req, bucket_name, key, expires):
168 | return req.url + '?' + '&'.join(_param_to_quoted_query(k, v) for k, v in req.params.items())
169 |
170 | def _sign_rtmp_url(self, url, bucket_name, channel_name, playlist_name, expires, params):
171 | return url + '?' + '&'.join(_param_to_quoted_query(k, v) for k, v in params.items())
172 |
173 |
174 | class StsAuth(object):
175 | """用于STS临时凭证访问。可以通过官方STS客户端获得临时密钥(AccessKeyId、AccessKeySecret)以及临时安全令牌(SecurityToken)。
176 |
177 | 注意到临时凭证会在一段时间后过期,在此之前需要重新获取临时凭证,并更新 :class:`Bucket ` 的 `auth` 成员变量为新
178 | 的 `StsAuth` 实例。
179 |
180 | :param str access_key_id: 临时AccessKeyId
181 | :param str access_key_secret: 临时AccessKeySecret
182 | :param str security_token: 临时安全令牌(SecurityToken)
183 | :param str auth_version: 需要生成auth的版本,默认为AUTH_VERSION_1(v1)
184 | """
185 | def __init__(self, access_key_id, access_key_secret, security_token, auth_version=AUTH_VERSION_1):
186 | self.__auth = make_auth(access_key_id, access_key_secret, auth_version)
187 | self.__security_token = security_token
188 |
189 | def _sign_request(self, req, bucket_name, key):
190 | req.headers['x-oss-security-token'] = self.__security_token
191 | self.__auth._sign_request(req, bucket_name, key)
192 |
193 | def _sign_url(self, req, bucket_name, key, expires):
194 | req.params['security-token'] = self.__security_token
195 | return self.__auth._sign_url(req, bucket_name, key, expires)
196 |
197 | def _sign_rtmp_url(self, url, bucket_name, channel_name, playlist_name, expires, params):
198 | params['security-token'] = self.__security_token
199 | return self.__auth._sign_rtmp_url(url, bucket_name, channel_name, playlist_name, expires, params)
200 |
201 |
202 | def _param_to_quoted_query(k, v):
203 | if v:
204 | return urlquote(k, '') + '=' + urlquote(v, '')
205 | else:
206 | return urlquote(k, '')
207 |
208 |
209 | def v2_uri_encode(raw_text):
210 | raw_text = to_bytes(raw_text)
211 |
212 | res = ''
213 | for b in raw_text:
214 | if isinstance(b, int):
215 | c = chr(b)
216 | else:
217 | c = b
218 |
219 | if (c >= 'A' and c <= 'Z') or (c >= 'a' and c <= 'z')\
220 | or (c >= '0' and c <= '9') or c in ['_', '-', '~', '.']:
221 | res += c
222 | else:
223 | res += "%{0:02X}".format(ord(c))
224 |
225 | return res
226 |
227 |
228 | _DEFAULT_ADDITIONAL_HEADERS = set(['range',
229 | 'if-modified-since'])
230 |
231 |
232 | class AuthV2(AuthBase):
233 | """签名版本2,与版本1的区别在:
234 | 1. 使用SHA256算法,具有更高的安全性
235 | 2. 参数计算包含所有的HTTP查询参数
236 | """
237 | def _sign_request(self, req, bucket_name, key, in_additional_headers=None):
238 | """把authorization放入req的header里面
239 |
240 | :param req: authorization信息将会加入到这个请求的header里面
241 | :type req: oss2.http.Request
242 |
243 | :param bucket_name: bucket名称
244 | :param key: OSS文件名
245 | :param in_additional_headers: 加入签名计算的额外header列表
246 | """
247 | if in_additional_headers is None:
248 | in_additional_headers = _DEFAULT_ADDITIONAL_HEADERS
249 |
250 | additional_headers = self.__get_additional_headers(req, in_additional_headers)
251 |
252 | req.headers['date'] = utils.http_date()
253 |
254 | signature = self.__make_signature(req, bucket_name, key, additional_headers)
255 |
256 | if additional_headers:
257 | req.headers['authorization'] = "OSS2 AccessKeyId:{0},AdditionalHeaders:{1},Signature:{2}"\
258 | .format(self.id, ';'.join(additional_headers), signature)
259 | else:
260 | req.headers['authorization'] = "OSS2 AccessKeyId:{0},Signature:{1}".format(self.id, signature)
261 |
262 | def _sign_url(self, req, bucket_name, key, expires, in_additional_headers=None):
263 | """返回一个签过名的URL
264 |
265 | :param req: 需要签名的请求
266 | :type req: oss2.http.Request
267 |
268 | :param bucket_name: bucket名称
269 | :param key: OSS文件名
270 | :param int expires: 返回的url将在`expires`秒后过期.
271 | :param in_additional_headers: 加入签名计算的额外header列表
272 |
273 | :return: a signed URL
274 | """
275 |
276 | if in_additional_headers is None:
277 | in_additional_headers = set()
278 |
279 | additional_headers = self.__get_additional_headers(req, in_additional_headers)
280 |
281 | expiration_time = int(time.time()) + expires
282 |
283 | req.headers['date'] = str(expiration_time) # re-use __make_signature by setting the 'date' header
284 |
285 | req.params['x-oss-signature-version'] = 'OSS2'
286 | req.params['x-oss-expires'] = str(expiration_time)
287 | req.params['x-oss-access-key-id'] = self.id
288 |
289 | signature = self.__make_signature(req, bucket_name, key, additional_headers)
290 |
291 | req.params['x-oss-signature'] = signature
292 |
293 | return req.url + '?' + '&'.join(_param_to_quoted_query(k, v) for k, v in req.params.items())
294 |
295 | def __make_signature(self, req, bucket_name, key, additional_headers):
296 | string_to_sign = self.__get_string_to_sign(req, bucket_name, key, additional_headers)
297 |
298 | logging.info('string_to_sign={0}'.format(string_to_sign))
299 |
300 | h = hmac.new(to_bytes(self.secret), to_bytes(string_to_sign), hashlib.sha256)
301 | return utils.b64encode_as_string(h.digest())
302 |
303 | def __get_additional_headers(self, req, in_additional_headers):
304 | # we add a header into additional_headers only if it is already in req's headers.
305 |
306 | additional_headers = set(h.lower() for h in in_additional_headers)
307 | keys_in_header = set(k.lower() for k in req.headers.keys())
308 |
309 | return additional_headers & keys_in_header
310 |
311 | def __get_string_to_sign(self, req, bucket_name, key, additional_header_list):
312 | verb = req.method
313 | content_md5 = req.headers.get('content-md5', '')
314 | content_type = req.headers.get('content-type', '')
315 | date = req.headers.get('date', '')
316 |
317 | canonicalized_oss_headers = self.__get_canonicalized_oss_headers(req, additional_header_list)
318 | additional_headers = ';'.join(sorted(additional_header_list))
319 | canonicalized_resource = self.__get_resource_string(req, bucket_name, key)
320 |
321 | return verb + '\n' +\
322 | content_md5 + '\n' +\
323 | content_type + '\n' +\
324 | date + '\n' +\
325 | canonicalized_oss_headers +\
326 | additional_headers + '\n' +\
327 | canonicalized_resource
328 |
329 | def __get_resource_string(self, req, bucket_name, key):
330 | if bucket_name:
331 | encoded_uri = v2_uri_encode('/' + bucket_name + '/' + key)
332 | else:
333 | encoded_uri = v2_uri_encode('/')
334 |
335 | logging.info('encoded_uri={0} key={1}'.format(encoded_uri, key))
336 |
337 | return encoded_uri + self.__get_canonalized_query_string(req)
338 |
339 | def __get_canonalized_query_string(self, req):
340 | encoded_params = {}
341 | for param, value in req.params.items():
342 | encoded_params[v2_uri_encode(param)] = v2_uri_encode(value)
343 |
344 | if not encoded_params:
345 | return ''
346 |
347 | sorted_params = sorted(encoded_params.items(), key=lambda e: e[0])
348 | return '?' + '&'.join(self.__param_to_query(k, v) for k, v in sorted_params)
349 |
350 | def __param_to_query(self, k, v):
351 | if v:
352 | return k + '=' + v
353 | else:
354 | return k
355 |
356 | def __get_canonicalized_oss_headers(self, req, additional_headers):
357 | """
358 | :param additional_headers: 小写的headers列表, 并且这些headers都不以'x-oss-'为前缀.
359 | """
360 | canon_headers = []
361 |
362 | for k, v in req.headers.items():
363 | lower_key = k.lower()
364 | if lower_key.startswith('x-oss-') or lower_key in additional_headers:
365 | canon_headers.append((lower_key, v))
366 |
367 | canon_headers.sort(key=lambda x: x[0])
368 |
369 | return ''.join(v[0] + ':' + v[1] + '\n' for v in canon_headers)
370 |
--------------------------------------------------------------------------------
/oss2/compat.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | 兼容Python版本
5 | """
6 |
7 | import sys
8 |
9 | is_py2 = (sys.version_info[0] == 2)
10 | is_py3 = (sys.version_info[0] == 3)
11 | is_py33 = (sys.version_info[0] == 3 and sys.version_info[1] == 3)
12 |
13 |
14 | try:
15 | import simplejson as json
16 | except (ImportError, SyntaxError):
17 | import json
18 |
19 |
20 | if is_py2:
21 | from urllib import quote as urlquote, unquote as urlunquote
22 | from urlparse import urlparse
23 |
24 |
25 | def to_bytes(data):
26 | """若输入为unicode, 则转为utf-8编码的bytes;其他则原样返回。"""
27 | if isinstance(data, unicode):
28 | return data.encode('utf-8')
29 | else:
30 | return data
31 |
32 | def to_string(data):
33 | """把输入转换为str对象"""
34 | return to_bytes(data)
35 |
36 | def to_unicode(data):
37 | """把输入转换为unicode,要求输入是unicode或者utf-8编码的bytes。"""
38 | if isinstance(data, bytes):
39 | return data.decode('utf-8')
40 | else:
41 | return data
42 |
43 | def stringify(input):
44 | if isinstance(input, dict):
45 | return dict([(stringify(key), stringify(value)) for key,value in input.iteritems()])
46 | elif isinstance(input, list):
47 | return [stringify(element) for element in input]
48 | elif isinstance(input, unicode):
49 | return input.encode('utf-8')
50 | else:
51 | return input
52 |
53 | builtin_str = str
54 | bytes = str
55 | str = unicode
56 |
57 |
58 | elif is_py3:
59 | from urllib.parse import quote as urlquote, unquote as urlunquote
60 | from urllib.parse import urlparse
61 |
62 | def to_bytes(data):
63 | """若输入为str(即unicode),则转为utf-8编码的bytes;其他则原样返回"""
64 | if isinstance(data, str):
65 | return data.encode(encoding='utf-8')
66 | else:
67 | return data
68 |
69 | def to_string(data):
70 | """若输入为bytes,则认为是utf-8编码,并返回str"""
71 | if isinstance(data, bytes):
72 | return data.decode('utf-8')
73 | else:
74 | return data
75 |
76 | def to_unicode(data):
77 | """把输入转换为unicode,要求输入是unicode或者utf-8编码的bytes。"""
78 | return to_string(data)
79 |
80 | def stringify(input):
81 | return input
82 |
83 | builtin_str = str
84 | bytes = bytes
85 | str = str
--------------------------------------------------------------------------------
/oss2/crypto.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | oss2.encryption
5 | ~~~~~~~~~~~~~~
6 |
7 | 该模块包含了客户端加解密相关的函数和类。
8 | """
9 | import json
10 | from functools import partial
11 |
12 | from oss2.utils import b64decode_from_string, b64encode_as_string
13 | from . import utils
14 | from .compat import to_string, to_bytes, to_unicode
15 | from .exceptions import OssError, ClientError, OpenApiFormatError, OpenApiServerError
16 |
17 | from Crypto.Cipher import PKCS1_OAEP
18 | from Crypto.PublicKey import RSA
19 | from requests.structures import CaseInsensitiveDict
20 |
21 | from aliyunsdkcore import client
22 | from aliyunsdkcore.acs_exception.exceptions import ServerException, ClientException
23 | from aliyunsdkcore.http import protocol_type, format_type, method_type
24 | from aliyunsdkkms.request.v20160120 import ListKeysRequest, GenerateDataKeyRequest, DecryptRequest, EncryptRequest
25 |
26 | import os
27 |
28 |
29 | class BaseCryptoProvider(object):
30 | """CryptoProvider 基类,提供基础的数据加密解密adapter
31 |
32 | """
33 | def __init__(self, cipher):
34 | self.plain_key = None
35 | self.plain_start = None
36 | self.cipher = cipher
37 |
38 | def make_encrypt_adapter(self, stream, key, start):
39 | return utils.make_cipher_adapter(stream, partial(self.cipher.encrypt, self.cipher(key, start)))
40 |
41 | def make_decrypt_adapter(self, stream, key, start):
42 | return utils.make_cipher_adapter(stream, partial(self.cipher.decrypt, self.cipher(key, start)))
43 |
44 |
45 | _LOCAL_RSA_TMP_DIR = '.oss-local-rsa'
46 |
47 |
48 | class LocalRsaProvider(BaseCryptoProvider):
49 | """使用本地RSA加密数据密钥。
50 |
51 | :param str dir: 本地RSA公钥私钥存储路径
52 | :param str key: 本地RSA公钥私钥名称前缀
53 | :param str passphrase: 本地RSA公钥私钥密码
54 | :param class cipher: 数据加密,默认aes256,用户可自行实现对称加密算法,需符合AESCipher注释规则
55 | """
56 |
57 | PUB_KEY_FILE = '.public_key.pem'
58 | PRIV_KEY_FILE = '.private_key.pem'
59 |
60 | def __init__(self, dir=None, key='', passphrase=None, cipher=utils.AESCipher):
61 | super(LocalRsaProvider, self).__init__(cipher=cipher)
62 | self.dir = dir or os.path.join(os.path.expanduser('~'), _LOCAL_RSA_TMP_DIR)
63 |
64 | utils.makedir_p(self.dir)
65 |
66 | priv_key_full_path = os.path.join(self.dir, key + self.PRIV_KEY_FILE)
67 | pub_key_full_path = os.path.join(self.dir, key + self.PUB_KEY_FILE)
68 | try:
69 | if os.path.exists(priv_key_full_path) and os.path.exists(pub_key_full_path):
70 | with open(priv_key_full_path, 'rb') as f:
71 | self.__decrypt_obj = PKCS1_OAEP.new(RSA.importKey(f.read(), passphrase=passphrase))
72 |
73 | with open(pub_key_full_path, 'rb') as f:
74 | self.__encrypt_obj = PKCS1_OAEP.new(RSA.importKey(f.read(), passphrase=passphrase))
75 |
76 | else:
77 | private_key = RSA.generate(2048)
78 | public_key = private_key.publickey()
79 |
80 | self.__encrypt_obj = PKCS1_OAEP.new(public_key)
81 | self.__decrypt_obj = PKCS1_OAEP.new(private_key)
82 |
83 | with open(priv_key_full_path, 'wb') as f:
84 | f.write(private_key.exportKey(passphrase=passphrase))
85 |
86 | with open(pub_key_full_path, 'wb') as f:
87 | f.write(public_key.exportKey(passphrase=passphrase))
88 | except (ValueError, TypeError, IndexError) as e:
89 | raise ClientError(str(e))
90 |
91 | def build_header(self, headers=None):
92 | if not isinstance(headers, CaseInsensitiveDict):
93 | headers = CaseInsensitiveDict(headers)
94 |
95 | if 'content-md5' in headers:
96 | headers['x-oss-meta-unencrypted-content-md5'] = headers['content-md5']
97 | del headers['content-md5']
98 |
99 | if 'content-length' in headers:
100 | headers['x-oss-meta-unencrypted-content-length'] = headers['content-length']
101 | del headers['content-length']
102 |
103 | headers['x-oss-meta-oss-crypto-key'] = b64encode_as_string(self.__encrypt_obj.encrypt(self.plain_key))
104 | headers['x-oss-meta-oss-crypto-start'] = b64encode_as_string(self.__encrypt_obj.encrypt(to_bytes(str(self.plain_start))))
105 | headers['x-oss-meta-oss-cek-alg'] = self.cipher.ALGORITHM
106 | headers['x-oss-meta-oss-wrap-alg'] = 'rsa'
107 |
108 | self.plain_key = None
109 | self.plain_start = None
110 |
111 | return headers
112 |
113 | def get_key(self):
114 | self.plain_key = self.cipher.get_key()
115 | return self.plain_key
116 |
117 | def get_start(self):
118 | self.plain_start = self.cipher.get_start()
119 | return self.plain_start
120 |
121 | def decrypt_oss_meta_data(self, headers, key, conv=lambda x:x):
122 | try:
123 | return conv(self.__decrypt_obj.decrypt(utils.b64decode_from_string(headers[key])))
124 | except:
125 | return None
126 |
127 |
128 | class AliKMSProvider(BaseCryptoProvider):
129 | """使用aliyun kms服务加密数据密钥。kms的详细说明参见
130 | https://help.aliyun.com/product/28933.html?spm=a2c4g.11186623.3.1.jlYT4v
131 | 此接口在py3.3下暂时不可用,详见
132 | https://github.com/aliyun/aliyun-openapi-python-sdk/issues/61
133 |
134 | :param str access_key_id: 可以访问kms密钥服务的access_key_id
135 | :param str access_key_secret: 可以访问kms密钥服务的access_key_secret
136 | :param str region: kms密钥服务地区
137 | :param str cmkey: 用户主密钥
138 | :param str sts_token: security token,如果使用的是临时AK需提供
139 | :param str passphrase: kms密钥服务密码
140 | :param class cipher: 数据加密,默认aes256,当前仅支持默认实现
141 | """
142 | def __init__(self, access_key_id, access_key_secret, region, cmkey, sts_token = None, passphrase=None, cipher=utils.AESCipher):
143 |
144 | if not issubclass(cipher, utils.AESCipher):
145 | raise ClientError('AliKMSProvider only support AES256 cipher')
146 |
147 | super(AliKMSProvider, self).__init__(cipher=cipher)
148 | self.cmkey = cmkey
149 | self.sts_token = sts_token
150 | self.context = '{"x-passphrase":"' + passphrase + '"}' if passphrase else ''
151 | self.clt = client.AcsClient(access_key_id, access_key_secret, region)
152 |
153 | self.encrypted_key = None
154 |
155 | def build_header(self, headers=None):
156 | if not isinstance(headers, CaseInsensitiveDict):
157 | headers = CaseInsensitiveDict(headers)
158 | if 'content-md5' in headers:
159 | headers['x-oss-meta-unencrypted-content-md5'] = headers['content-md5']
160 | del headers['content-md5']
161 |
162 | if 'content-length' in headers:
163 | headers['x-oss-meta-unencrypted-content-length'] = headers['content-length']
164 | del headers['content-length']
165 |
166 | headers['x-oss-meta-oss-crypto-key'] = self.encrypted_key
167 | headers['x-oss-meta-oss-crypto-start'] = self.__encrypt_data(to_bytes(str(self.plain_start)))
168 | headers['x-oss-meta-oss-cek-alg'] = self.cipher.ALGORITHM
169 | headers['x-oss-meta-oss-wrap-alg'] = 'kms'
170 |
171 | self.encrypted_key = None
172 | self.plain_start = None
173 |
174 | return headers
175 |
176 | def get_key(self):
177 | plain_key, self.encrypted_key = self.__generate_data_key()
178 | return plain_key
179 |
180 | def get_start(self):
181 | self.plain_start = utils.random_counter()
182 | return self.plain_start
183 |
184 | def __generate_data_key(self):
185 | req = GenerateDataKeyRequest.GenerateDataKeyRequest()
186 |
187 | req.set_accept_format(format_type.JSON)
188 | req.set_method(method_type.POST)
189 |
190 | req.set_KeyId(self.cmkey)
191 | req.set_KeySpec('AES_256')
192 | req.set_NumberOfBytes(32)
193 | req.set_EncryptionContext(self.context)
194 | if self.sts_token:
195 | req.set_STSToken(self.sts_token)
196 |
197 | resp = self.__do(req)
198 |
199 | return b64decode_from_string(resp['Plaintext']), resp['CiphertextBlob']
200 |
201 | def __encrypt_data(self, data):
202 | req = EncryptRequest.EncryptRequest()
203 |
204 | req.set_accept_format(format_type.JSON)
205 | req.set_method(method_type.POST)
206 | req.set_KeyId(self.cmkey)
207 | req.set_Plaintext(data)
208 | req.set_EncryptionContext(self.context)
209 | if self.sts_token:
210 | req.set_STSToken(self.sts_token)
211 |
212 | resp = self.__do(req)
213 |
214 | return resp['CiphertextBlob']
215 |
216 | def __decrypt_data(self, data):
217 | req = DecryptRequest.DecryptRequest()
218 |
219 | req.set_accept_format(format_type.JSON)
220 | req.set_method(method_type.POST)
221 | req.set_CiphertextBlob(data)
222 | req.set_EncryptionContext(self.context)
223 | if self.sts_token:
224 | req.set_STSToken(self.sts_token)
225 |
226 | resp = self.__do(req)
227 | return resp['Plaintext']
228 |
229 | def __do(self, req):
230 |
231 | try:
232 | body = self.clt.do_action_with_exception(req)
233 |
234 | return json.loads(to_unicode(body))
235 | except ServerException as e:
236 | raise OpenApiServerError(e.http_status, e.request_id, e.message, e.error_code)
237 | except ClientException as e:
238 | raise ClientError(e.message)
239 | except (ValueError, TypeError) as e:
240 | raise OpenApiFormatError('Json Error: ' + str(e))
241 |
242 | def decrypt_oss_meta_data(self, headers, key, conv=lambda x: x):
243 | try:
244 | if key.lower() == 'x-oss-meta-oss-crypto-key'.lower():
245 | return conv(b64decode_from_string(self.__decrypt_data(headers[key])))
246 | else:
247 | return conv(self.__decrypt_data(headers[key]))
248 | except OssError as e:
249 | raise e
250 | except:
251 | return None
--------------------------------------------------------------------------------
/oss2/defaults.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | oss2.defaults
5 | ~~~~~~~~~~~~~
6 |
7 | 全局缺省变量。
8 |
9 | """
10 |
11 | import logging
12 |
13 |
14 | def get(value, default_value):
15 | if value is None:
16 | return default_value
17 | else:
18 | return value
19 |
20 |
21 | #: 连接超时时间
22 | connect_timeout = 60
23 |
24 | #: 缺省重试次数
25 | request_retries = 3
26 |
27 | #: 对于某些接口,上传数据长度大于或等于该值时,就采用分片上传。
28 | multipart_threshold = 10 * 1024 * 1024
29 |
30 | #: 分片上传缺省线程数
31 | multipart_num_threads = 1
32 |
33 | #: 缺省分片大小
34 | part_size = 10 * 1024 * 1024
35 |
36 |
37 | #: 每个Session连接池大小
38 | connection_pool_size = 10
39 |
40 |
41 | #: 对于断点下载,如果OSS文件大小大于该值就进行并行下载(multiget)
42 | multiget_threshold = 100 * 1024 * 1024
43 |
44 | #: 并行下载(multiget)缺省线程数
45 | multiget_num_threads = 4
46 |
47 | #: 并行下载(multiget)的缺省分片大小
48 | multiget_part_size = 10 * 1024 * 1024
49 |
50 | #: 缺省 Logger
51 | logger = logging.getLogger()
52 |
53 |
54 | def get_logger():
55 | return logger
56 |
--------------------------------------------------------------------------------
/oss2/exceptions.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | oss2.exceptions
5 | ~~~~~~~~~~~~~~
6 |
7 | 异常类。
8 | """
9 |
10 | import re
11 |
12 | import xml.etree.ElementTree as ElementTree
13 | from xml.parsers import expat
14 |
15 |
16 | from .compat import to_string
17 |
18 |
19 | _OSS_ERROR_TO_EXCEPTION = {} # populated at end of module
20 |
21 |
22 | OSS_CLIENT_ERROR_STATUS = -1
23 | OSS_REQUEST_ERROR_STATUS = -2
24 | OSS_INCONSISTENT_ERROR_STATUS = -3
25 | OSS_FORMAT_ERROR_STATUS = -4
26 |
27 |
28 | class OssError(Exception):
29 | def __init__(self, status, headers, body, details):
30 | #: HTTP 状态码
31 | self.status = status
32 |
33 | #: 请求ID,用于跟踪一个OSS请求。提交工单时,最好能够提供请求ID
34 | self.request_id = headers.get('x-oss-request-id', '')
35 |
36 | #: HTTP响应体(部分)
37 | self.body = body
38 |
39 | #: 详细错误信息,是一个string到string的dict
40 | self.details = details
41 |
42 | #: OSS错误码
43 | self.code = self.details.get('Code', '')
44 |
45 | #: OSS错误信息
46 | self.message = self.details.get('Message', '')
47 |
48 | def __str__(self):
49 | error = {'status': self.status,
50 | 'request-id': self.request_id,
51 | 'details': self.details}
52 | return str(error)
53 |
54 | def _str_with_body(self):
55 | error = {'status': self.status,
56 | 'request-id': self.request_id,
57 | 'details': self.body}
58 | return str(error)
59 |
60 |
61 | class ClientError(OssError):
62 | def __init__(self, message):
63 | OssError.__init__(self, OSS_CLIENT_ERROR_STATUS, {}, 'ClientError: ' + message, {})
64 |
65 | def __str__(self):
66 | return self._str_with_body()
67 |
68 |
69 | class RequestError(OssError):
70 | def __init__(self, e):
71 | OssError.__init__(self, OSS_REQUEST_ERROR_STATUS, {}, 'RequestError: ' + str(e), {})
72 | self.exception = e
73 |
74 | def __str__(self):
75 | return self._str_with_body()
76 |
77 |
78 | class InconsistentError(OssError):
79 | def __init__(self, message, request_id=''):
80 | OssError.__init__(self, OSS_INCONSISTENT_ERROR_STATUS, {'x-oss-request-id': request_id}, 'InconsistentError: ' + message, {})
81 |
82 | def __str__(self):
83 | return self._str_with_body()
84 |
85 |
86 | class OpenApiFormatError(OssError):
87 | def __init__(self, message):
88 | OssError.__init__(self, OSS_FORMAT_ERROR_STATUS, {}, message, {})
89 |
90 | def __str__(self):
91 | return self._str_with_body()
92 |
93 |
94 | class OpenApiServerError(OssError):
95 | def __init__(self, status, request_id, message, error_code):
96 | OssError.__init__(self, status, {'x-oss-request-id': request_id}, '', {'Code': error_code, 'Message': message})
97 |
98 |
99 | class ServerError(OssError):
100 | pass
101 |
102 |
103 | class NotFound(ServerError):
104 | status = 404
105 | code = ''
106 |
107 |
108 | class MalformedXml(ServerError):
109 | status = 400
110 | code = 'MalformedXML'
111 |
112 |
113 | class InvalidRequest(ServerError):
114 | status = 400
115 | code = 'InvalidRequest'
116 |
117 |
118 | class OperationNotSupported(ServerError):
119 | status = 400
120 | code = 'OperationNotSupported'
121 |
122 |
123 | class RestoreAlreadyInProgress(ServerError):
124 | status = 409
125 | code = 'RestoreAlreadyInProgress'
126 |
127 |
128 | class InvalidArgument(ServerError):
129 | status = 400
130 | code = 'InvalidArgument'
131 |
132 | def __init__(self, status, headers, body, details):
133 | super(InvalidArgument, self).__init__(status, headers, body, details)
134 | self.name = details.get('ArgumentName')
135 | self.value = details.get('ArgumentValue')
136 |
137 |
138 | class InvalidDigest(ServerError):
139 | status = 400
140 | code = 'InvalidDigest'
141 |
142 |
143 | class InvalidObjectName(ServerError):
144 | status = 400
145 | code = 'InvalidObjectName'
146 |
147 |
148 | class NoSuchBucket(NotFound):
149 | status = 404
150 | code = 'NoSuchBucket'
151 |
152 |
153 | class NoSuchKey(NotFound):
154 | status = 404
155 | code = 'NoSuchKey'
156 |
157 |
158 | class NoSuchUpload(NotFound):
159 | status = 404
160 | code = 'NoSuchUpload'
161 |
162 |
163 | class NoSuchWebsite(NotFound):
164 | status = 404
165 | code = 'NoSuchWebsiteConfiguration'
166 |
167 |
168 | class NoSuchLifecycle(NotFound):
169 | status = 404
170 | code = 'NoSuchLifecycle'
171 |
172 |
173 | class NoSuchCors(NotFound):
174 | status = 404
175 | code = 'NoSuchCORSConfiguration'
176 |
177 |
178 | class NoSuchLiveChannel(NotFound):
179 | status = 404
180 | code = 'NoSuchLiveChannel'
181 |
182 |
183 | class Conflict(ServerError):
184 | status = 409
185 | code = ''
186 |
187 |
188 | class BucketNotEmpty(Conflict):
189 | status = 409
190 | code = 'BucketNotEmpty'
191 |
192 |
193 | class PositionNotEqualToLength(Conflict):
194 | status = 409
195 | code = 'PositionNotEqualToLength'
196 |
197 | def __init__(self, status, headers, body, details):
198 | super(PositionNotEqualToLength, self).__init__(status, headers, body, details)
199 | self.next_position = int(headers['x-oss-next-append-position'])
200 |
201 |
202 | class ObjectNotAppendable(Conflict):
203 | status = 409
204 | code = 'ObjectNotAppendable'
205 |
206 |
207 | class ChannelStillLive(Conflict):
208 | status = 409
209 | code = 'ChannelStillLive'
210 |
211 |
212 | class LiveChannelDisabled(Conflict):
213 | status = 409
214 | code = 'LiveChannelDisabled'
215 |
216 |
217 | class PreconditionFailed(ServerError):
218 | status = 412
219 | code = 'PreconditionFailed'
220 |
221 |
222 | class NotModified(ServerError):
223 | status = 304
224 | code = ''
225 |
226 |
227 | class AccessDenied(ServerError):
228 | status = 403
229 | code = 'AccessDenied'
230 |
231 |
232 | def make_exception(resp):
233 | status = resp.status
234 | headers = resp.headers
235 | body = resp.read(4096)
236 | details = _parse_error_body(body)
237 | code = details.get('Code', '')
238 |
239 | try:
240 | klass = _OSS_ERROR_TO_EXCEPTION[(status, code)]
241 | return klass(status, headers, body, details)
242 | except KeyError:
243 | return ServerError(status, headers, body, details)
244 |
245 |
246 | def _walk_subclasses(klass):
247 | for sub in klass.__subclasses__():
248 | yield sub
249 | for subsub in _walk_subclasses(sub):
250 | yield subsub
251 |
252 |
253 | for klass in _walk_subclasses(ServerError):
254 | status = getattr(klass, 'status', None)
255 | code = getattr(klass, 'code', None)
256 |
257 | if status is not None and code is not None:
258 | _OSS_ERROR_TO_EXCEPTION[(status, code)] = klass
259 |
260 |
261 | # XML parsing exceptions have changed in Python2.7 and ElementTree 1.3
262 | if hasattr(ElementTree, 'ParseError'):
263 | ElementTreeParseError = (ElementTree.ParseError, expat.ExpatError)
264 | else:
265 | ElementTreeParseError = (expat.ExpatError)
266 |
267 |
268 | def _parse_error_body(body):
269 | try:
270 | root = ElementTree.fromstring(body)
271 | if root.tag != 'Error':
272 | return {}
273 |
274 | details = {}
275 | for child in root:
276 | details[child.tag] = child.text
277 | return details
278 | except ElementTreeParseError:
279 | return _guess_error_details(body)
280 |
281 |
282 | def _guess_error_details(body):
283 | details = {}
284 | body = to_string(body)
285 |
286 | if '' not in body or '' not in body:
287 | return details
288 |
289 | m = re.search('(.*)', body)
290 | if m:
291 | details['Code'] = m.group(1)
292 |
293 | m = re.search('(.*)', body)
294 | if m:
295 | details['Message'] = m.group(1)
296 |
297 | return details
298 |
--------------------------------------------------------------------------------
/oss2/http.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | oss2.http
5 | ~~~~~~~~
6 |
7 | 这个模块包含了HTTP Adapters。尽管OSS Python SDK内部使用requests库进行HTTP通信,但是对使用者是透明的。
8 | 该模块中的 `Session` 、 `Request` 、`Response` 对requests的对应的类做了简单的封装。
9 | """
10 |
11 | import platform
12 |
13 | import requests
14 | from requests.structures import CaseInsensitiveDict
15 |
16 | from . import __version__, defaults
17 | from .compat import to_bytes
18 | from .exceptions import RequestError
19 | from .utils import file_object_remaining_bytes, SizedFileAdapter
20 |
21 |
22 | _USER_AGENT = 'aliyun-sdk-python/{0}({1}/{2}/{3};{4})'.format(
23 | __version__, platform.system(), platform.release(), platform.machine(), platform.python_version())
24 |
25 |
26 | class Session(object):
27 | """属于同一个Session的请求共享一组连接池,如有可能也会重用HTTP连接。"""
28 | def __init__(self):
29 | self.session = requests.Session()
30 |
31 | psize = defaults.connection_pool_size
32 | self.session.mount('http://', requests.adapters.HTTPAdapter(pool_connections=psize, pool_maxsize=psize))
33 | self.session.mount('https://', requests.adapters.HTTPAdapter(pool_connections=psize, pool_maxsize=psize))
34 |
35 | def do_request(self, req, timeout):
36 | try:
37 | return Response(self.session.request(req.method, req.url,
38 | data=req.data,
39 | params=req.params,
40 | headers=req.headers,
41 | stream=True,
42 | timeout=timeout))
43 | except requests.RequestException as e:
44 | raise RequestError(e)
45 |
46 |
47 | class Request(object):
48 | def __init__(self, method, url,
49 | data=None,
50 | params=None,
51 | headers=None,
52 | app_name=''):
53 | self.method = method
54 | self.url = url
55 | self.data = _convert_request_body(data)
56 | self.params = params or {}
57 |
58 | if not isinstance(headers, CaseInsensitiveDict):
59 | self.headers = CaseInsensitiveDict(headers)
60 | else:
61 | self.headers = headers
62 |
63 | # tell requests not to add 'Accept-Encoding: gzip, deflate' by default
64 | if 'Accept-Encoding' not in self.headers:
65 | self.headers['Accept-Encoding'] = None
66 |
67 | if 'User-Agent' not in self.headers:
68 | if app_name:
69 | self.headers['User-Agent'] = _USER_AGENT + '/' + app_name
70 | else:
71 | self.headers['User-Agent'] = _USER_AGENT
72 |
73 |
74 | _CHUNK_SIZE = 8 * 1024
75 |
76 |
77 | class Response(object):
78 | def __init__(self, response):
79 | self.response = response
80 | self.status = response.status_code
81 | self.headers = response.headers
82 |
83 | # When a response contains no body, iter_content() cannot
84 | # be run twice (requests.exceptions.StreamConsumedError will be raised).
85 | # For details of the issue, please see issue #82
86 | #
87 | # To work around this issue, we simply return b'' when everything has been read.
88 | #
89 | # Note you cannot use self.response.raw.read() to implement self.read(), because
90 | # raw.read() does not uncompress response body when the encoding is gzip etc., and
91 | # we try to avoid depends on details of self.response.raw.
92 | self.__all_read = False
93 |
94 | def read(self, amt=None):
95 | if self.__all_read:
96 | return b''
97 |
98 | if amt is None:
99 | content_list = []
100 | for chunk in self.response.iter_content(_CHUNK_SIZE):
101 | content_list.append(chunk)
102 | content = b''.join(content_list)
103 |
104 | self.__all_read = True
105 | return content
106 | else:
107 | try:
108 | return next(self.response.iter_content(amt))
109 | except StopIteration:
110 | self.__all_read = True
111 | return b''
112 |
113 | def __iter__(self):
114 | return self.response.iter_content(_CHUNK_SIZE)
115 |
116 |
117 | # requests对于具有fileno()方法的file object,会用fileno()的返回值作为Content-Length。
118 | # 这对于已经读取了部分内容,或执行了seek()的file object是不正确的。
119 | #
120 | # _convert_request_body()对于支持seek()和tell() file object,确保是从
121 | # 当前位置读取,且只读取当前位置到文件结束的内容。
122 | def _convert_request_body(data):
123 | data = to_bytes(data)
124 |
125 | if hasattr(data, '__len__'):
126 | return data
127 |
128 | if hasattr(data, 'seek') and hasattr(data, 'tell'):
129 | return SizedFileAdapter(data, file_object_remaining_bytes(data))
130 |
131 | return data
132 |
133 |
134 |
--------------------------------------------------------------------------------
/oss2/iterators.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | oss2.iterators
5 | ~~~~~~~~~~~~~~
6 |
7 | 该模块包含了一些易于使用的迭代器,可以用来遍历Bucket、文件、分片上传等。
8 | """
9 |
10 | from .models import MultipartUploadInfo, SimplifiedObjectInfo
11 | from .exceptions import ServerError
12 |
13 | from . import defaults
14 |
15 |
16 | class _BaseIterator(object):
17 | def __init__(self, marker, max_retries):
18 | self.is_truncated = True
19 | self.next_marker = marker
20 |
21 | max_retries = defaults.get(max_retries, defaults.request_retries)
22 | self.max_retries = max_retries if max_retries > 0 else 1
23 |
24 | self.entries = []
25 |
26 | def _fetch(self):
27 | raise NotImplemented # pragma: no cover
28 |
29 | def __iter__(self):
30 | return self
31 |
32 | def __next__(self):
33 | while True:
34 | if self.entries:
35 | return self.entries.pop(0)
36 |
37 | if not self.is_truncated:
38 | raise StopIteration
39 |
40 | self.fetch_with_retry()
41 |
42 | def next(self):
43 | return self.__next__()
44 |
45 | def fetch_with_retry(self):
46 | for i in range(self.max_retries):
47 | try:
48 | self.is_truncated, self.next_marker = self._fetch()
49 | except ServerError as e:
50 | if e.status // 100 != 5:
51 | raise
52 |
53 | if i == self.max_retries - 1:
54 | raise
55 | else:
56 | return
57 |
58 |
59 | class BucketIterator(_BaseIterator):
60 | """遍历用户Bucket的迭代器。
61 |
62 | 每次迭代返回的是 :class:`SimplifiedBucketInfo ` 对象。
63 |
64 | :param service: :class:`Service ` 对象
65 | :param prefix: 只列举匹配该前缀的Bucket
66 | :param marker: 分页符。只列举Bucket名字典序在此之后的Bucket
67 | :param max_keys: 每次调用 `list_buckets` 时的max_keys参数。注意迭代器返回的数目可能会大于该值。
68 | """
69 | def __init__(self, service, prefix='', marker='', max_keys=100, max_retries=None):
70 | super(BucketIterator, self).__init__(marker, max_retries)
71 | self.service = service
72 | self.prefix = prefix
73 | self.max_keys = max_keys
74 |
75 | def _fetch(self):
76 | result = self.service.list_buckets(prefix=self.prefix,
77 | marker=self.next_marker,
78 | max_keys=self.max_keys)
79 | self.entries = result.buckets
80 |
81 | return result.is_truncated, result.next_marker
82 |
83 |
84 | class ObjectIterator(_BaseIterator):
85 | """遍历Bucket里文件的迭代器。
86 |
87 | 每次迭代返回的是 :class:`SimplifiedObjectInfo ` 对象。
88 | 当 `SimplifiedObjectInfo.is_prefix()` 返回True时,表明是公共前缀(目录)。
89 |
90 | :param bucket: :class:`Bucket ` 对象
91 | :param prefix: 只列举匹配该前缀的文件
92 | :param delimiter: 目录分隔符
93 | :param marker: 分页符
94 | :param max_keys: 每次调用 `list_objects` 时的max_keys参数。注意迭代器返回的数目可能会大于该值。
95 | """
96 | def __init__(self, bucket, prefix='', delimiter='', marker='', max_keys=100, max_retries=None):
97 | super(ObjectIterator, self).__init__(marker, max_retries)
98 |
99 | self.bucket = bucket
100 | self.prefix = prefix
101 | self.delimiter = delimiter
102 | self.max_keys = max_keys
103 |
104 | def _fetch(self):
105 | result = self.bucket.list_objects(prefix=self.prefix,
106 | delimiter=self.delimiter,
107 | marker=self.next_marker,
108 | max_keys=self.max_keys)
109 | self.entries = result.object_list + [SimplifiedObjectInfo(prefix, None, None, None, None, None)
110 | for prefix in result.prefix_list]
111 | self.entries.sort(key=lambda obj: obj.key)
112 |
113 | return result.is_truncated, result.next_marker
114 |
115 |
116 | class MultipartUploadIterator(_BaseIterator):
117 | """遍历Bucket里未完成的分片上传。
118 |
119 | 每次返回 :class:`MultipartUploadInfo ` 对象。
120 | 当 `MultipartUploadInfo.is_prefix()` 返回True时,表明是公共前缀(目录)。
121 |
122 | :param bucket: :class:`Bucket ` 对象
123 | :param prefix: 仅列举匹配该前缀的文件的分片上传
124 | :param delimiter: 目录分隔符
125 | :param key_marker: 文件名分页符
126 | :param upload_id_marker: 分片上传ID分页符
127 | :param max_uploads: 每次调用 `list_multipart_uploads` 时的max_uploads参数。注意迭代器返回的数目可能会大于该值。
128 | """
129 | def __init__(self, bucket,
130 | prefix='', delimiter='', key_marker='', upload_id_marker='',
131 | max_uploads=1000, max_retries=None):
132 | super(MultipartUploadIterator, self).__init__(key_marker, max_retries)
133 |
134 | self.bucket = bucket
135 | self.prefix = prefix
136 | self.delimiter = delimiter
137 | self.next_upload_id_marker = upload_id_marker
138 | self.max_uploads = max_uploads
139 |
140 | def _fetch(self):
141 | result = self.bucket.list_multipart_uploads(prefix=self.prefix,
142 | delimiter=self.delimiter,
143 | key_marker=self.next_marker,
144 | upload_id_marker=self.next_upload_id_marker,
145 | max_uploads=self.max_uploads)
146 | self.entries = result.upload_list + [MultipartUploadInfo(prefix, None, None) for prefix in result.prefix_list]
147 | self.entries.sort(key=lambda u: u.key)
148 |
149 | self.next_upload_id_marker = result.next_upload_id_marker
150 | return result.is_truncated, result.next_key_marker
151 |
152 |
153 | class ObjectUploadIterator(_BaseIterator):
154 | """遍历一个Object所有未完成的分片上传。
155 |
156 | 每次返回 :class:`MultipartUploadInfo ` 对象。
157 | 当 `MultipartUploadInfo.is_prefix()` 返回True时,表明是公共前缀(目录)。
158 |
159 | :param bucket: :class:`Bucket ` 对象
160 | :param key: 文件名
161 | :param max_uploads: 每次调用 `list_multipart_uploads` 时的max_uploads参数。注意迭代器返回的数目可能会大于该值。
162 | """
163 | def __init__(self, bucket, key, max_uploads=1000, max_retries=None):
164 | super(ObjectUploadIterator, self).__init__('', max_retries)
165 | self.bucket = bucket
166 | self.key = key
167 | self.next_upload_id_marker = ''
168 | self.max_uploads = max_uploads
169 |
170 | def _fetch(self):
171 | result = self.bucket.list_multipart_uploads(prefix=self.key,
172 | key_marker=self.next_marker,
173 | upload_id_marker=self.next_upload_id_marker,
174 | max_uploads=self.max_uploads)
175 |
176 | self.entries = [u for u in result.upload_list if u.key == self.key]
177 | self.next_upload_id_marker = result.next_upload_id_marker
178 |
179 | if not result.is_truncated or not self.entries:
180 | return False, result.next_key_marker
181 |
182 | if result.next_key_marker > self.key:
183 | return False, result.next_key_marker
184 |
185 | return result.is_truncated, result.next_key_marker
186 |
187 |
188 | class PartIterator(_BaseIterator):
189 | """遍历一个分片上传会话中已经上传的分片。
190 |
191 | 每次返回 :class:`PartInfo ` 对象。
192 |
193 | :param bucket: :class:`Bucket ` 对象
194 | :param key: 文件名
195 | :param upload_id: 分片上传ID
196 | :param marker: 分页符
197 | :param max_parts: 每次调用 `list_parts` 时的max_parts参数。注意迭代器返回的数目可能会大于该值。
198 | """
199 | def __init__(self, bucket, key, upload_id,
200 | marker='0', max_parts=1000, max_retries=None):
201 | super(PartIterator, self).__init__(marker, max_retries)
202 |
203 | self.bucket = bucket
204 | self.key = key
205 | self.upload_id = upload_id
206 | self.max_parts = max_parts
207 |
208 | def _fetch(self):
209 | result = self.bucket.list_parts(self.key, self.upload_id,
210 | marker=self.next_marker,
211 | max_parts=self.max_parts)
212 | self.entries = result.parts
213 |
214 | return result.is_truncated, result.next_marker
215 |
216 |
217 | class LiveChannelIterator(_BaseIterator):
218 | """遍历Bucket里文件的迭代器。
219 |
220 | 每次迭代返回的是 :class:`LiveChannelInfo ` 对象。
221 |
222 | :param bucket: :class:`Bucket ` 对象
223 | :param prefix: 只列举匹配该前缀的文件
224 | :param marker: 分页符
225 | :param max_keys: 每次调用 `list_live_channel` 时的max_keys参数。注意迭代器返回的数目可能会大于该值。
226 | """
227 | def __init__(self, bucket, prefix='', marker='', max_keys=100, max_retries=None):
228 | super(LiveChannelIterator, self).__init__(marker, max_retries)
229 |
230 | self.bucket = bucket
231 | self.prefix = prefix
232 | self.max_keys = max_keys
233 |
234 | def _fetch(self):
235 | result = self.bucket.list_live_channel(prefix=self.prefix,
236 | marker=self.next_marker,
237 | max_keys=self.max_keys)
238 | self.entries = result.channels
239 |
240 | return result.is_truncated, result.next_marker
241 |
242 |
--------------------------------------------------------------------------------
/oss2/models.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | oss2.models
5 | ~~~~~~~~~~
6 |
7 | 该模块包含Python SDK API接口所需要的输入参数以及返回值类型。
8 | """
9 |
10 | from .utils import http_to_unixtime, make_progress_adapter, make_crc_adapter
11 | from .exceptions import ClientError, InconsistentError
12 | from .compat import urlunquote
13 |
14 | class PartInfo(object):
15 | """表示分片信息的文件。
16 |
17 | 该文件既用于 :func:`list_parts ` 的输出,也用于 :func:`complete_multipart_upload
18 | ` 的输入。
19 |
20 | :param int part_number: 分片号
21 | :param str etag: 分片的ETag
22 | :param int size: 分片的大小。仅用在 `list_parts` 的结果里。
23 | :param int last_modified: 该分片最后修改的时间戳,类型为int。参考 :ref:`unix_time`
24 | """
25 | def __init__(self, part_number, etag, size=None, last_modified=None):
26 | self.part_number = part_number
27 | self.etag = etag
28 | self.size = size
29 | self.last_modified = last_modified
30 |
31 |
32 | def _hget(headers, key, converter=lambda x: x):
33 | if key in headers:
34 | return converter(headers[key])
35 | else:
36 | return None
37 |
38 |
39 | def _get_etag(headers):
40 | return _hget(headers, 'etag', lambda x: x.strip('"'))
41 |
42 |
43 | class RequestResult(object):
44 | def __init__(self, resp):
45 | #: HTTP响应
46 | self.resp = resp
47 |
48 | #: HTTP状态码
49 | self.status = resp.status
50 |
51 | #: HTTP头
52 | self.headers = resp.headers
53 |
54 | #: 请求ID,用于跟踪一个OSS请求。提交工单时,最后能够提供请求ID
55 | self.request_id = resp.headers.get('x-oss-request-id', '')
56 |
57 |
58 | class HeadObjectResult(RequestResult):
59 | def __init__(self, resp):
60 | super(HeadObjectResult, self).__init__(resp)
61 |
62 | #: 文件类型,可以是'Normal'、'Multipart'、'Appendable'等
63 | self.object_type = _hget(self.headers, 'x-oss-object-type')
64 |
65 | #: 文件最后修改时间,类型为int。参考 :ref:`unix_time` 。
66 |
67 | self.last_modified = _hget(self.headers, 'last-modified', http_to_unixtime)
68 |
69 | #: 文件的MIME类型
70 | self.content_type = _hget(self.headers, 'content-type')
71 |
72 | #: Content-Length,可能是None。
73 | self.content_length = _hget(self.headers, 'content-length', int)
74 |
75 | #: HTTP ETag
76 | self.etag = _get_etag(self.headers)
77 |
78 |
79 | class GetObjectMetaResult(RequestResult):
80 | def __init__(self, resp):
81 | super(GetObjectMetaResult, self).__init__(resp)
82 |
83 | #: 文件最后修改时间,类型为int。参考 :ref:`unix_time` 。
84 | self.last_modified = _hget(self.headers, 'last-modified', http_to_unixtime)
85 |
86 | #: Content-Length,文件大小,类型为int。
87 | self.content_length = _hget(self.headers, 'content-length', int)
88 |
89 | #: HTTP ETag
90 | self.etag = _get_etag(self.headers)
91 |
92 |
93 | class GetSymlinkResult(RequestResult):
94 | def __init__(self, resp):
95 | super(GetSymlinkResult, self).__init__(resp)
96 |
97 | #: 符号连接的目标文件
98 | self.target_key = urlunquote(_hget(self.headers, 'x-oss-symlink-target'))
99 |
100 |
101 | class GetObjectResult(HeadObjectResult):
102 | def __init__(self, resp, progress_callback=None, crc_enabled=False, crypto_provider=None):
103 | super(GetObjectResult, self).__init__(resp)
104 | self.__crc_enabled = crc_enabled
105 | self.__crypto_provider = crypto_provider
106 |
107 | if _hget(resp.headers, 'x-oss-meta-oss-crypto-key') and _hget(resp.headers, 'Content-Range'):
108 | raise ClientError('Could not get an encrypted object using byte-range parameter')
109 |
110 | if progress_callback:
111 | self.stream = make_progress_adapter(self.resp, progress_callback, self.content_length)
112 | else:
113 | self.stream = self.resp
114 |
115 | self.__crc = _hget(self.headers, 'x-oss-hash-crc64ecma', int)
116 | if self.__crc_enabled:
117 | self.stream = make_crc_adapter(self.stream)
118 |
119 | if self.__crypto_provider:
120 | key = self.__crypto_provider.decrypt_oss_meta_data(resp.headers, 'x-oss-meta-oss-crypto-key')
121 | start = self.__crypto_provider.decrypt_oss_meta_data(resp.headers, 'x-oss-meta-oss-crypto-start')
122 | cek_alg = _hget(resp.headers, 'x-oss-meta-oss-cek-alg')
123 | if key and start and cek_alg:
124 | self.stream = self.__crypto_provider.make_decrypt_adapter(self.stream, key, start)
125 | else:
126 | raise InconsistentError('all metadata keys are required for decryption (x-oss-meta-oss-crypto-key, \
127 | x-oss-meta-oss-crypto-start, x-oss-meta-oss-cek-alg)', self.request_id)
128 |
129 | def read(self, amt=None):
130 | return self.stream.read(amt)
131 |
132 | def __iter__(self):
133 | return iter(self.stream)
134 |
135 | @property
136 | def client_crc(self):
137 | if self.__crc_enabled:
138 | return self.stream.crc
139 | else:
140 | return None
141 |
142 | @property
143 | def server_crc(self):
144 | return self.__crc
145 |
146 |
147 | class PutObjectResult(RequestResult):
148 | def __init__(self, resp):
149 | super(PutObjectResult, self).__init__(resp)
150 |
151 | #: HTTP ETag
152 | self.etag = _get_etag(self.headers)
153 |
154 | #: 文件上传后,OSS上文件的CRC64值
155 | self.crc = _hget(resp.headers, 'x-oss-hash-crc64ecma', int)
156 |
157 |
158 | class AppendObjectResult(RequestResult):
159 | def __init__(self, resp):
160 | super(AppendObjectResult, self).__init__(resp)
161 |
162 | #: HTTP ETag
163 | self.etag = _get_etag(self.headers)
164 |
165 | #: 本次追加写完成后,OSS上文件的CRC64值
166 | self.crc = _hget(resp.headers, 'x-oss-hash-crc64ecma', int)
167 |
168 | #: 下次追加写的偏移
169 | self.next_position = _hget(resp.headers, 'x-oss-next-append-position', int)
170 |
171 |
172 | class BatchDeleteObjectsResult(RequestResult):
173 | def __init__(self, resp):
174 | super(BatchDeleteObjectsResult, self).__init__(resp)
175 |
176 | #: 已经删除的文件名列表
177 | self.deleted_keys = []
178 |
179 |
180 | class InitMultipartUploadResult(RequestResult):
181 | def __init__(self, resp):
182 | super(InitMultipartUploadResult, self).__init__(resp)
183 |
184 | #: 新生成的Upload ID
185 | self.upload_id = None
186 |
187 |
188 | class ListObjectsResult(RequestResult):
189 | def __init__(self, resp):
190 | super(ListObjectsResult, self).__init__(resp)
191 |
192 | #: True表示还有更多的文件可以罗列;False表示已经列举完毕。
193 | self.is_truncated = False
194 |
195 | #: 下一次罗列的分页标记符,即,可以作为 :func:`list_objects ` 的 `marker` 参数。
196 | self.next_marker = ''
197 |
198 | #: 本次罗列得到的文件列表。其中元素的类型为 :class:`SimplifiedObjectInfo` 。
199 | self.object_list = []
200 |
201 | #: 本次罗列得到的公共前缀列表,类型为str列表。
202 | self.prefix_list = []
203 |
204 |
205 | class SimplifiedObjectInfo(object):
206 | def __init__(self, key, last_modified, etag, type, size, storage_class):
207 | #: 文件名,或公共前缀名。
208 | self.key = key
209 |
210 | #: 文件的最后修改时间
211 | self.last_modified = last_modified
212 |
213 | #: HTTP ETag
214 | self.etag = etag
215 |
216 | #: 文件类型
217 | self.type = type
218 |
219 | #: 文件大小
220 | self.size = size
221 |
222 | #: 文件的存储类别,是一个字符串。
223 | self.storage_class = storage_class
224 |
225 | def is_prefix(self):
226 | """如果是公共前缀,返回True;是文件,则返回False"""
227 | return self.last_modified is None
228 |
229 |
230 | OBJECT_ACL_DEFAULT = 'default'
231 | OBJECT_ACL_PRIVATE = 'private'
232 | OBJECT_ACL_PUBLIC_READ = 'public-read'
233 | OBJECT_ACL_PUBLIC_READ_WRITE = 'public-read-write'
234 |
235 |
236 | class GetObjectAclResult(RequestResult):
237 | def __init__(self, resp):
238 | super(GetObjectAclResult, self).__init__(resp)
239 |
240 | #: 文件的ACL,其值可以是 `OBJECT_ACL_DEFAULT`、`OBJECT_ACL_PRIVATE`、`OBJECT_ACL_PUBLIC_READ`或
241 | #: `OBJECT_ACL_PUBLIC_READ_WRITE`
242 | self.acl = ''
243 |
244 |
245 | class SimplifiedBucketInfo(object):
246 | """:func:`list_buckets ` 结果中的单个元素类型。"""
247 | def __init__(self, name, location, creation_date):
248 | #: Bucket名
249 | self.name = name
250 |
251 | #: Bucket的区域
252 | self.location = location
253 |
254 | #: Bucket的创建时间,类型为int。参考 :ref:`unix_time`。
255 | self.creation_date = creation_date
256 |
257 |
258 | class ListBucketsResult(RequestResult):
259 | def __init__(self, resp):
260 | super(ListBucketsResult, self).__init__(resp)
261 |
262 | #: True表示还有更多的Bucket可以罗列;False表示已经列举完毕。
263 | self.is_truncated = False
264 |
265 | #: 下一次罗列的分页标记符,即,可以作为 :func:`list_buckets ` 的 `marker` 参数。
266 | self.next_marker = ''
267 |
268 | #: 得到的Bucket列表,类型为 :class:`SimplifiedBucketInfo` 。
269 | self.buckets = []
270 |
271 |
272 | class MultipartUploadInfo(object):
273 | def __init__(self, key, upload_id, initiation_date):
274 | #: 文件名
275 | self.key = key
276 |
277 | #: 分片上传ID
278 | self.upload_id = upload_id
279 |
280 | #: 分片上传初始化的时间,类型为int。参考 :ref:`unix_time`
281 | self.initiation_date = initiation_date
282 |
283 | def is_prefix(self):
284 | """如果是公共前缀则返回True"""
285 | return self.upload_id is None
286 |
287 |
288 | class ListMultipartUploadsResult(RequestResult):
289 | def __init__(self, resp):
290 | super(ListMultipartUploadsResult, self).__init__(resp)
291 |
292 | #: True表示还有更多的为完成分片上传可以罗列;False表示已经列举完毕。
293 | self.is_truncated = False
294 |
295 | #: 文件名分页符
296 | self.next_key_marker = ''
297 |
298 | #: 分片上传ID分页符
299 | self.next_upload_id_marker = ''
300 |
301 | #: 分片上传列表。类型为`MultipartUploadInfo`列表。
302 | self.upload_list = []
303 |
304 | #: 公共前缀列表。类型为str列表。
305 | self.prefix_list = []
306 |
307 |
308 | class ListPartsResult(RequestResult):
309 | def __init__(self, resp):
310 | super(ListPartsResult, self).__init__(resp)
311 |
312 | # True表示还有更多的Part可以罗列;False表示已经列举完毕。
313 | self.is_truncated = False
314 |
315 | # 下一个分页符
316 | self.next_marker = ''
317 |
318 | # 罗列出的Part信息,类型为 `PartInfo` 列表。
319 | self.parts = []
320 |
321 |
322 | BUCKET_ACL_PRIVATE = 'private'
323 | BUCKET_ACL_PUBLIC_READ = 'public-read'
324 | BUCKET_ACL_PUBLIC_READ_WRITE = 'public-read-write'
325 |
326 | BUCKET_STORAGE_CLASS_STANDARD = 'Standard'
327 | BUCKET_STORAGE_CLASS_IA = 'IA'
328 | BUCKET_STORAGE_CLASS_ARCHIVE = 'Archive'
329 |
330 |
331 | class GetBucketAclResult(RequestResult):
332 | def __init__(self, resp):
333 | super(GetBucketAclResult, self).__init__(resp)
334 |
335 | #: Bucket的ACL,其值可以是 `BUCKET_ACL_PRIVATE`、`BUCKET_ACL_PUBLIC_READ`或`BUCKET_ACL_PUBLIC_READ_WRITE`。
336 | self.acl = ''
337 |
338 |
339 | class GetBucketLocationResult(RequestResult):
340 | def __init__(self, resp):
341 | super(GetBucketLocationResult, self).__init__(resp)
342 |
343 | #: Bucket所在的数据中心
344 | self.location = ''
345 |
346 |
347 | class BucketLogging(object):
348 | """Bucket日志配置信息。
349 |
350 | :param str target_bucket: 存储日志到这个Bucket。
351 | :param str target_prefix: 生成的日志文件名加上该前缀。
352 | """
353 | def __init__(self, target_bucket, target_prefix):
354 | self.target_bucket = target_bucket
355 | self.target_prefix = target_prefix
356 |
357 |
358 | class GetBucketLoggingResult(RequestResult, BucketLogging):
359 | def __init__(self, resp):
360 | RequestResult.__init__(self, resp)
361 | BucketLogging.__init__(self, '', '')
362 |
363 |
364 | class BucketCreateConfig(object):
365 | def __init__(self, storage_class):
366 | self.storage_class = storage_class
367 |
368 |
369 | class BucketStat(object):
370 | def __init__(self, storage_size_in_bytes, object_count, multi_part_upload_count):
371 | self.storage_size_in_bytes = storage_size_in_bytes
372 | self.object_count = object_count
373 | self.multi_part_upload_count = multi_part_upload_count
374 |
375 |
376 | class AccessControlList(object):
377 | def __init__(self, grant):
378 | self.grant = grant
379 |
380 |
381 | class Owner(object):
382 | def __init__(self, display_name, owner_id):
383 | self.display_name = display_name
384 | self.id = owner_id
385 |
386 |
387 | class BucketInfo(object):
388 | def __init__(self, name=None, owner=None, location=None, storage_class=None, intranet_endpoint=None,
389 | extranet_endpoint=None, creation_date=None, acl=None):
390 | self.name = name
391 | self.owner = owner
392 | self.location = location
393 | self.storage_class = storage_class
394 | self.intranet_endpoint = intranet_endpoint
395 | self.extranet_endpoint = extranet_endpoint
396 | self.creation_date = creation_date
397 | self.acl = acl
398 |
399 |
400 | class GetBucketStatResult(RequestResult, BucketStat):
401 | def __init__(self, resp):
402 | RequestResult.__init__(self, resp)
403 | BucketStat.__init__(self, 0, 0, 0)
404 |
405 |
406 | class GetBucketInfoResult(RequestResult, BucketInfo):
407 | def __init__(self, resp):
408 | RequestResult.__init__(self, resp)
409 | BucketInfo.__init__(self)
410 |
411 |
412 | class BucketReferer(object):
413 | """Bucket防盗链设置。
414 |
415 | :param bool allow_empty_referer: 是否允许空的Referer。
416 | :param referers: Referer列表,每个元素是一个str。
417 | """
418 | def __init__(self, allow_empty_referer, referers):
419 | self.allow_empty_referer = allow_empty_referer
420 | self.referers = referers
421 |
422 |
423 | class GetBucketRefererResult(RequestResult, BucketReferer):
424 | def __init__(self, resp):
425 | RequestResult.__init__(self, resp)
426 | BucketReferer.__init__(self, False, [])
427 |
428 |
429 | class BucketWebsite(object):
430 | """静态网站托管配置。
431 |
432 | :param str index_file: 索引页面文件
433 | :param str error_file: 404页面文件
434 | """
435 | def __init__(self, index_file, error_file):
436 | self.index_file = index_file
437 | self.error_file = error_file
438 |
439 |
440 | class GetBucketWebsiteResult(RequestResult, BucketWebsite):
441 | def __init__(self, resp):
442 | RequestResult.__init__(self, resp)
443 | BucketWebsite.__init__(self, '', '')
444 |
445 |
446 | class LifecycleExpiration(object):
447 | """过期删除操作。
448 |
449 | :param days: 表示在文件修改后过了这么多天,就会匹配规则,从而被删除
450 | :param date: 表示在该日期之后,规则就一直生效。即每天都会对符合前缀的文件执行删除操作(如,删除),而不管文件是什么时候生成的。
451 | *不建议使用*
452 | :param created_before_date: delete files if their last modified time earlier than created_before_date
453 |
454 | :type date: `datetime.date`
455 | """
456 | def __init__(self, days=None, date=None, created_before_date=None):
457 | not_none_fields = 0
458 | if days is not None:
459 | not_none_fields += 1
460 | if date is not None:
461 | not_none_fields += 1
462 | if created_before_date is not None:
463 | not_none_fields += 1
464 |
465 | if not_none_fields > 1:
466 | raise ClientError('More than one field(days, date and created_before_date) has been specified')
467 |
468 | self.days = days
469 | self.date = date
470 | self.created_before_date = created_before_date
471 |
472 |
473 | class AbortMultipartUpload(object):
474 | """删除parts
475 |
476 | :param days: 删除相对最后修改时间days天之后的parts
477 | :param created_before_date: 删除最后修改时间早于created_before_date的parts
478 |
479 | """
480 | def __init__(self, days=None, created_before_date=None):
481 | if days is not None and created_before_date is not None:
482 | raise ClientError('days and created_before_date should not be both specified')
483 |
484 | self.days = days
485 | self.created_before_date = created_before_date
486 |
487 |
488 | class StorageTransition(object):
489 | """transit objects
490 |
491 | :param days: 将相对最后修改时间days天之后的Object转储
492 | :param created_before_date: 将最后修改时间早于created_before_date的对象转储
493 | :param storage_class: 对象转储到OSS的目标存储类型
494 | """
495 | def __init__(self, days=None, created_before_date=None, storage_class=None):
496 | if days is not None and created_before_date is not None:
497 | raise ClientError('days and created_before_date should not be both specified')
498 |
499 | self.days = days
500 | self.created_before_date = created_before_date
501 | self.storage_class = storage_class
502 |
503 |
504 | class LifecycleRule(object):
505 | """生命周期规则。
506 |
507 | :param id: 规则名
508 | :param prefix: 只有文件名匹配该前缀的文件才适用本规则
509 | :param expiration: 过期删除操作。
510 | :type expiration: :class:`LifecycleExpiration`
511 | :param status: 启用还是禁止该规则。可选值为 `LifecycleRule.ENABLED` 或 `LifecycleRule.DISABLED`
512 | """
513 |
514 | ENABLED = 'Enabled'
515 | DISABLED = 'Disabled'
516 |
517 | def __init__(self, id, prefix,
518 | status=ENABLED, expiration=None,
519 | abort_multipart_upload=None,
520 | storage_transitions=None):
521 | self.id = id
522 | self.prefix = prefix
523 | self.status = status
524 | self.expiration = expiration
525 | self.abort_multipart_upload = abort_multipart_upload
526 | self.storage_transitions = storage_transitions
527 |
528 |
529 | class BucketLifecycle(object):
530 | """Bucket的生命周期配置。
531 |
532 | :param rules: 规则列表,
533 | :type rules: list of :class:`LifecycleRule`
534 | """
535 | def __init__(self, rules=None):
536 | self.rules = rules or []
537 |
538 |
539 | class GetBucketLifecycleResult(RequestResult, BucketLifecycle):
540 | def __init__(self, resp):
541 | RequestResult.__init__(self, resp)
542 | BucketLifecycle.__init__(self)
543 |
544 |
545 | class CorsRule(object):
546 | """CORS(跨域资源共享)规则。
547 |
548 | :param allowed_origins: 允许跨域访问的域。
549 | :type allowed_origins: list of str
550 |
551 | :param allowed_methods: 允许跨域访问的HTTP方法,如'GET'等。
552 | :type allowed_methods: list of str
553 |
554 | :param allowed_headers: 允许跨域访问的HTTP头部。
555 | :type allowed_headers: list of str
556 |
557 |
558 | """
559 | def __init__(self,
560 | allowed_origins=None,
561 | allowed_methods=None,
562 | allowed_headers=None,
563 | expose_headers=None,
564 | max_age_seconds=None):
565 | self.allowed_origins = allowed_origins or []
566 | self.allowed_methods = allowed_methods or []
567 | self.allowed_headers = allowed_headers or []
568 | self.expose_headers = expose_headers or []
569 | self.max_age_seconds = max_age_seconds
570 |
571 |
572 | class BucketCors(object):
573 | def __init__(self, rules=None):
574 | self.rules = rules or []
575 |
576 |
577 | class GetBucketCorsResult(RequestResult, BucketCors):
578 | def __init__(self, resp):
579 | RequestResult.__init__(self, resp)
580 | BucketCors.__init__(self)
581 |
582 |
583 | class LiveChannelInfoTarget(object):
584 | """Live channel中的Target节点,包含目标协议的一些参数。
585 |
586 | :param type: 协议,目前仅支持HLS。
587 | :type type: str
588 |
589 | :param frag_duration: HLS协议下生成的ts文件的期望时长,单位为秒。
590 | :type frag_duration: int
591 |
592 | :param frag_count: HLS协议下m3u8文件里ts文件的数量。
593 | :type frag_count: int"""
594 |
595 | def __init__(self,
596 | type = 'HLS',
597 | frag_duration = 5,
598 | frag_count = 3,
599 | playlist_name = ''):
600 | self.type = type
601 | self.frag_duration = frag_duration
602 | self.frag_count = frag_count
603 | self.playlist_name = playlist_name
604 |
605 |
606 | class LiveChannelInfo(object):
607 | """Live channel(直播频道)配置。
608 |
609 | :param status: 直播频道的状态,合法的值为"enabled"和"disabled"。
610 | :type status: str
611 |
612 | :param description: 直播频道的描述信息,最长为128字节。
613 | :type description: str
614 |
615 | :param target: 直播频道的推流目标节点,包含目标协议相关的参数。
616 | :type class:`LiveChannelInfoTarget `
617 |
618 | :param last_modified: 直播频道的最后修改时间,这个字段仅在`ListLiveChannel`时使用。
619 | :type last_modified: int, 参考 :ref:`unix_time`。
620 |
621 | :param name: 直播频道的名称。
622 | :type name: str
623 |
624 | :param play_url: 播放地址。
625 | :type play_url: str
626 |
627 | :param publish_url: 推流地址。
628 | :type publish_url: str"""
629 |
630 | def __init__(self,
631 | status = 'enabled',
632 | description = '',
633 | target = None,
634 | last_modified = None,
635 | name = None,
636 | play_url = None,
637 | publish_url = None):
638 | self.status = status
639 | self.description = description
640 | self.target = target
641 | self.last_modified = last_modified
642 | self.name = name
643 | self.play_url = play_url
644 | self.publish_url = publish_url
645 |
646 |
647 | class LiveChannelList(object):
648 | """List直播频道的结果。
649 |
650 | :param prefix: List直播频道使用的前缀。
651 | :type prefix: str
652 |
653 | :param marker: List直播频道使用的marker。
654 | :type marker: str
655 |
656 | :param max_keys: List时返回的最多的直播频道的条数。
657 | :type max_keys: int
658 |
659 | :param is_truncated: 本次List是否列举完所有的直播频道
660 | :type is_truncated: bool
661 |
662 | :param next_marker: 下一次List直播频道使用的marker。
663 | :type marker: str
664 |
665 | :param channels: List返回的直播频道列表
666 | :type channels: list,类型为 :class:`LiveChannelInfo`"""
667 |
668 | def __init__(self,
669 | prefix = '',
670 | marker = '',
671 | max_keys = 100,
672 | is_truncated = False,
673 | next_marker = ''):
674 | self.prefix = prefix
675 | self.marker = marker
676 | self.max_keys = max_keys
677 | self.is_truncated = is_truncated
678 | self.next_marker = next_marker
679 | self.channels = []
680 |
681 |
682 | class LiveChannelVideoStat(object):
683 | """LiveStat中的Video节点。
684 |
685 | :param width: 视频的宽度。
686 | :type width: int
687 |
688 | :param height: 视频的高度。
689 | :type height: int
690 |
691 | :param frame_rate: 帧率。
692 | :type frame_rate: int
693 |
694 | :param codec: 编码方式。
695 | :type codec: str
696 |
697 | :param bandwidth: 码率。
698 | :type bandwidth: int"""
699 |
700 | def __init__(self,
701 | width = 0,
702 | height = 0,
703 | frame_rate = 0,
704 | codec = '',
705 | bandwidth = 0):
706 | self.width = width
707 | self.height = height
708 | self.frame_rate = frame_rate
709 | self.codec = codec
710 | self.bandwidth = bandwidth
711 |
712 |
713 | class LiveChannelAudioStat(object):
714 | """LiveStat中的Audio节点。
715 |
716 | :param codec: 编码方式。
717 | :type codec: str
718 |
719 | :param sample_rate: 采样率。
720 | :type sample_rate: int
721 |
722 | :param bandwidth: 码率。
723 | :type bandwidth: int"""
724 |
725 | def __init__(self,
726 | codec = '',
727 | sample_rate = 0,
728 | bandwidth = 0):
729 | self.codec = codec
730 | self.sample_rate = sample_rate
731 | self.bandwidth = bandwidth
732 |
733 |
734 | class LiveChannelStat(object):
735 | """LiveStat结果。
736 |
737 | :param status: 直播状态。
738 | :type codec: str
739 |
740 | :param remote_addr: 客户端的地址。
741 | :type remote_addr: str
742 |
743 | :param connected_time: 本次推流开始时间。
744 | :type connected_time: int, unix time
745 |
746 | :param video: 视频描述信息。
747 | :type video: class:`LiveChannelVideoStat `
748 |
749 | :param audio: 音频描述信息。
750 | :type audio: class:`LiveChannelAudioStat `"""
751 |
752 | def __init__(self,
753 | status = '',
754 | remote_addr = '',
755 | connected_time = '',
756 | video = None,
757 | audio = None):
758 | self.status = status
759 | self.remote_addr = remote_addr
760 | self.connected_time = connected_time
761 | self.video = video
762 | self.audio = audio
763 |
764 |
765 | class LiveRecord(object):
766 | """直播频道中的推流记录信息
767 |
768 | :param start_time: 本次推流开始时间。
769 | :type start_time: int,参考 :ref:`unix_time`。
770 |
771 | :param end_time: 本次推流结束时间。
772 | :type end_time: int, 参考 :ref:`unix_time`。
773 |
774 | :param remote_addr: 推流时客户端的地址。
775 | :type remote_addr: str"""
776 |
777 | def __init__(self,
778 | start_time = '',
779 | end_time = '',
780 | remote_addr = ''):
781 | self.start_time = start_time
782 | self.end_time = end_time
783 | self.remote_addr = remote_addr
784 |
785 |
786 | class LiveChannelHistory(object):
787 | """直播频道下的推流记录。"""
788 |
789 | def __init__(self):
790 | self.records = []
791 |
792 |
793 | class CreateLiveChannelResult(RequestResult, LiveChannelInfo):
794 | def __init__(self, resp):
795 | RequestResult.__init__(self, resp)
796 | LiveChannelInfo.__init__(self)
797 |
798 |
799 | class GetLiveChannelResult(RequestResult, LiveChannelInfo):
800 | def __init__(self, resp):
801 | RequestResult.__init__(self, resp)
802 | LiveChannelInfo.__init__(self)
803 |
804 |
805 | class ListLiveChannelResult(RequestResult, LiveChannelList):
806 | def __init__(self, resp):
807 | RequestResult.__init__(self, resp)
808 | LiveChannelList.__init__(self)
809 |
810 |
811 | class GetLiveChannelStatResult(RequestResult, LiveChannelStat):
812 | def __init__(self, resp):
813 | RequestResult.__init__(self, resp)
814 | LiveChannelStat.__init__(self)
815 |
816 | class GetLiveChannelHistoryResult(RequestResult, LiveChannelHistory):
817 | def __init__(self, resp):
818 | RequestResult.__init__(self, resp)
819 | LiveChannelHistory.__init__(self)
820 |
--------------------------------------------------------------------------------
/oss2/task_queue.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | import threading
4 | import sys
5 |
6 | from .defaults import get_logger
7 |
8 | try:
9 | import Queue as queue
10 | except ImportError:
11 | import queue
12 |
13 | import traceback
14 |
15 |
16 | class TaskQueue(object):
17 | def __init__(self, producer, consumers):
18 | self.__producer = producer
19 | self.__consumers = consumers
20 |
21 | self.__threads = []
22 |
23 | # must be an infinite queue, otherwise producer may be blocked after all consumers being dead.
24 | self.__queue = queue.Queue()
25 |
26 | self.__lock = threading.Lock()
27 | self.__exc_info = None
28 | self.__exc_stack = ''
29 |
30 | def run(self):
31 | self.__add_and_run(threading.Thread(target=self.__producer_func))
32 |
33 | for c in self.__consumers:
34 | self.__add_and_run(threading.Thread(target=self.__consumer_func, args=(c,)))
35 |
36 | # give KeyboardInterrupt chances to happen by joining with timeouts.
37 | while self.__any_active():
38 | for t in self.__threads:
39 | t.join(1)
40 |
41 | if self.__exc_info:
42 | get_logger().debug('An exception was thrown by producer or consumer, backtrace: {0}'.format(self.__exc_stack))
43 | raise self.__exc_info[1]
44 |
45 | def put(self, data):
46 | assert data is not None
47 | self.__queue.put(data)
48 |
49 | def get(self):
50 | return self.__queue.get()
51 |
52 | def ok(self):
53 | with self.__lock:
54 | return self.__exc_info is None
55 |
56 | def __add_and_run(self, thread):
57 | thread.daemon = True
58 | thread.start()
59 | self.__threads.append(thread)
60 |
61 | def __any_active(self):
62 | return any(t.is_alive() for t in self.__threads)
63 |
64 | def __producer_func(self):
65 | try:
66 | self.__producer(self)
67 | except:
68 | self.__on_exception(sys.exc_info())
69 | self.__put_end()
70 | else:
71 | self.__put_end()
72 |
73 | def __consumer_func(self, consumer):
74 | try:
75 | consumer(self)
76 | except:
77 | self.__on_exception(sys.exc_info())
78 |
79 | def __put_end(self):
80 | for i in range(len(self.__consumers)):
81 | self.__queue.put(None)
82 |
83 | def __on_exception(self, exc_info):
84 | with self.__lock:
85 | if self.__exc_info is None:
86 | self.__exc_info = exc_info
87 | self.__exc_stack = traceback.format_exc()
88 |
89 |
90 |
91 |
--------------------------------------------------------------------------------
/oss2/utils.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | oss2.utils
5 | ----------
6 |
7 | 工具函数模块。
8 | """
9 |
10 | from email.utils import formatdate
11 |
12 | import os.path
13 | import mimetypes
14 | import socket
15 | import hashlib
16 | import base64
17 | import threading
18 | import calendar
19 | import datetime
20 | import time
21 | import errno
22 |
23 | import binascii
24 | import crcmod
25 | import re
26 | import random
27 |
28 | from Crypto.Cipher import AES
29 | from Crypto import Random
30 | from Crypto.Util import Counter
31 |
32 | from .compat import to_string, to_bytes
33 | from .exceptions import ClientError, InconsistentError, RequestError, OpenApiFormatError
34 |
35 |
36 | _EXTRA_TYPES_MAP = {
37 | ".js": "application/javascript",
38 | ".xlsx": "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet",
39 | ".xltx": "application/vnd.openxmlformats-officedocument.spreadsheetml.template",
40 | ".potx": "application/vnd.openxmlformats-officedocument.presentationml.template",
41 | ".ppsx": "application/vnd.openxmlformats-officedocument.presentationml.slideshow",
42 | ".pptx": "application/vnd.openxmlformats-officedocument.presentationml.presentation",
43 | ".sldx": "application/vnd.openxmlformats-officedocument.presentationml.slide",
44 | ".docx": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
45 | ".dotx": "application/vnd.openxmlformats-officedocument.wordprocessingml.template",
46 | ".xlam": "application/vnd.ms-excel.addin.macroEnabled.12",
47 | ".xlsb": "application/vnd.ms-excel.sheet.binary.macroEnabled.12",
48 | ".apk": "application/vnd.android.package-archive"
49 | }
50 |
51 |
52 | def b64encode_as_string(data):
53 | return to_string(base64.b64encode(to_bytes(data)))
54 |
55 |
56 | def b64decode_from_string(data):
57 | try:
58 | return base64.b64decode(to_string(data))
59 | except (TypeError, binascii.Error) as e:
60 | raise OpenApiFormatError('Base64 Error: ' + to_string(data))
61 |
62 |
63 | def content_md5(data):
64 | """计算data的MD5值,经过Base64编码并返回str类型。
65 |
66 | 返回值可以直接作为HTTP Content-Type头部的值
67 | """
68 | m = hashlib.md5(to_bytes(data))
69 | return b64encode_as_string(m.digest())
70 |
71 |
72 | def md5_string(data):
73 | """返回 `data` 的MD5值,以十六进制可读字符串(32个小写字符)的方式。"""
74 | return hashlib.md5(to_bytes(data)).hexdigest()
75 |
76 |
77 | def content_type_by_name(name):
78 | """根据文件名,返回Content-Type。"""
79 | ext = os.path.splitext(name)[1].lower()
80 | if ext in _EXTRA_TYPES_MAP:
81 | return _EXTRA_TYPES_MAP[ext]
82 |
83 | return mimetypes.guess_type(name)[0]
84 |
85 |
86 | def set_content_type(headers, name):
87 | """根据文件名在headers里设置Content-Type。如果headers中已经存在Content-Type,则直接返回。"""
88 | headers = headers or {}
89 |
90 | if 'Content-Type' in headers:
91 | return headers
92 |
93 | content_type = content_type_by_name(name)
94 | if content_type:
95 | headers['Content-Type'] = content_type
96 |
97 | return headers
98 |
99 |
100 | def is_ip_or_localhost(netloc):
101 | """判断网络地址是否为IP或localhost。"""
102 | loc = netloc.split(':')[0]
103 | if loc == 'localhost':
104 | return True
105 |
106 | try:
107 | socket.inet_aton(loc)
108 | except socket.error:
109 | return False
110 |
111 | return True
112 |
113 |
114 | _ALPHA_NUM = 'abcdefghijklmnopqrstuvwxyz0123456789'
115 | _HYPHEN = '-'
116 | _BUCKET_NAME_CHARS = set(_ALPHA_NUM + _HYPHEN)
117 |
118 |
119 | def is_valid_bucket_name(name):
120 | """判断是否为合法的Bucket名"""
121 | if len(name) < 3 or len(name) > 63:
122 | return False
123 |
124 | if name[-1] == _HYPHEN:
125 | return False
126 |
127 | if name[0] not in _ALPHA_NUM:
128 | return False
129 |
130 | return set(name) <= _BUCKET_NAME_CHARS
131 |
132 |
133 | class SizedFileAdapter(object):
134 | """通过这个适配器(Adapter),可以把原先的 `file_object` 的长度限制到等于 `size`。"""
135 | def __init__(self, file_object, size):
136 | self.file_object = file_object
137 | self.size = size
138 | self.offset = 0
139 |
140 | def read(self, amt=None):
141 | if self.offset >= self.size:
142 | return ''
143 |
144 | if (amt is None or amt < 0) or (amt + self.offset >= self.size):
145 | data = self.file_object.read(self.size - self.offset)
146 | self.offset = self.size
147 | return data
148 |
149 | self.offset += amt
150 | return self.file_object.read(amt)
151 |
152 | @property
153 | def len(self):
154 | return self.size
155 |
156 |
157 | def how_many(m, n):
158 | return (m + n - 1) // n
159 |
160 |
161 | def file_object_remaining_bytes(fileobj):
162 | current = fileobj.tell()
163 |
164 | fileobj.seek(0, os.SEEK_END)
165 | end = fileobj.tell()
166 | fileobj.seek(current, os.SEEK_SET)
167 |
168 | return end - current
169 |
170 |
171 | def _has_data_size_attr(data):
172 | return hasattr(data, '__len__') or hasattr(data, 'len') or (hasattr(data, 'seek') and hasattr(data, 'tell'))
173 |
174 |
175 | def _get_data_size(data):
176 | if hasattr(data, '__len__'):
177 | return len(data)
178 |
179 | if hasattr(data, 'len'):
180 | return data.len
181 |
182 | if hasattr(data, 'seek') and hasattr(data, 'tell'):
183 | return file_object_remaining_bytes(data)
184 |
185 | return None
186 |
187 |
188 | _CHUNK_SIZE = 8 * 1024
189 |
190 |
191 | def make_progress_adapter(data, progress_callback, size=None):
192 | """返回一个适配器,从而在读取 `data` ,即调用read或者对其进行迭代的时候,能够
193 | 调用进度回调函数。当 `size` 没有指定,且无法确定时,上传回调函数返回的总字节数为None。
194 |
195 | :param data: 可以是bytes、file object或iterable
196 | :param progress_callback: 进度回调函数,参见 :ref:`progress_callback`
197 | :param size: 指定 `data` 的大小,可选
198 |
199 | :return: 能够调用进度回调函数的适配器
200 | """
201 | data = to_bytes(data)
202 |
203 | if size is None:
204 | size = _get_data_size(data)
205 |
206 | if size is None:
207 | if hasattr(data, 'read'):
208 | return _FileLikeAdapter(data, progress_callback)
209 | elif hasattr(data, '__iter__'):
210 | return _IterableAdapter(data, progress_callback)
211 | else:
212 | raise ClientError('{0} is not a file object, nor an iterator'.format(data.__class__.__name__))
213 | else:
214 | return _BytesAndFileAdapter(data, progress_callback, size)
215 |
216 |
217 | def make_crc_adapter(data, init_crc=0):
218 | """返回一个适配器,从而在读取 `data` ,即调用read或者对其进行迭代的时候,能够计算CRC。
219 |
220 | :param data: 可以是bytes、file object或iterable
221 | :param init_crc: 初始CRC值,可选
222 |
223 | :return: 能够调用计算CRC函数的适配器
224 | """
225 | data = to_bytes(data)
226 |
227 | # bytes or file object
228 | if _has_data_size_attr(data):
229 | return _BytesAndFileAdapter(data,
230 | size=_get_data_size(data),
231 | crc_callback=Crc64(init_crc))
232 | # file-like object
233 | elif hasattr(data, 'read'):
234 | return _FileLikeAdapter(data, crc_callback=Crc64(init_crc))
235 | # iterator
236 | elif hasattr(data, '__iter__'):
237 | return _IterableAdapter(data, crc_callback=Crc64(init_crc))
238 | else:
239 | raise ClientError('{0} is not a file object, nor an iterator'.format(data.__class__.__name__))
240 |
241 |
242 | def make_cipher_adapter(data, cipher_callback):
243 | """返回一个适配器,从而在读取 `data` ,即调用read或者对其进行迭代的时候,能够进行加解密操作。
244 |
245 | :param data: 可以是bytes、file object或iterable
246 | :param operation: 进行加密或解密操作
247 | :param key: 对称加密中的密码,长度必须为16/24/32 bytes
248 | :param start: 计数器初始值
249 |
250 | :return: 能够客户端加密函数的适配器
251 | """
252 | data = to_bytes(data)
253 |
254 | # bytes or file object
255 | if _has_data_size_attr(data):
256 | return _BytesAndFileAdapter(data,
257 | size=_get_data_size(data),
258 | cipher_callback=cipher_callback)
259 | # file-like object
260 | elif hasattr(data, 'read'):
261 | return _FileLikeAdapter(data, cipher_callback=cipher_callback)
262 | # iterator
263 | elif hasattr(data, '__iter__'):
264 | return _IterableAdapter(data, cipher_callback=cipher_callback)
265 | else:
266 | raise ClientError('{0} is not a file object, nor an iterator'.format(data.__class__.__name__))
267 |
268 |
269 | def check_crc(operation, client_crc, oss_crc, request_id):
270 | if client_crc is not None and oss_crc is not None and client_crc != oss_crc:
271 | raise InconsistentError('the crc of {0} between client and oss is not inconsistent'.format(operation),
272 | request_id)
273 |
274 | def _invoke_crc_callback(crc_callback, content):
275 | if crc_callback:
276 | crc_callback(content)
277 |
278 |
279 | def _invoke_progress_callback(progress_callback, consumed_bytes, total_bytes):
280 | if progress_callback:
281 | progress_callback(consumed_bytes, total_bytes)
282 |
283 |
284 | def _invoke_cipher_callback(cipher_callback, content):
285 | if cipher_callback:
286 | content = cipher_callback(content)
287 | return content
288 |
289 |
290 | class _IterableAdapter(object):
291 | def __init__(self, data, progress_callback=None, crc_callback=None, cipher_callback=None):
292 | self.iter = iter(data)
293 | self.progress_callback = progress_callback
294 | self.offset = 0
295 |
296 | self.crc_callback = crc_callback
297 | self.cipher_callback = cipher_callback
298 |
299 | def __iter__(self):
300 | return self
301 |
302 | def __next__(self):
303 | return self.next()
304 |
305 | def next(self):
306 | _invoke_progress_callback(self.progress_callback, self.offset, None)
307 |
308 | content = next(self.iter)
309 | self.offset += len(content)
310 |
311 | _invoke_crc_callback(self.crc_callback, content)
312 |
313 | content = _invoke_cipher_callback(self.cipher_callback, content)
314 |
315 | return content
316 |
317 | @property
318 | def crc(self):
319 | if self.crc_callback:
320 | return self.crc_callback.crc
321 | elif self.iter:
322 | return self.iter.crc
323 | else:
324 | return None
325 |
326 |
327 | class _FileLikeAdapter(object):
328 | """通过这个适配器,可以给无法确定内容长度的 `fileobj` 加上进度监控。
329 |
330 | :param fileobj: file-like object,只要支持read即可
331 | :param progress_callback: 进度回调函数
332 | """
333 | def __init__(self, fileobj, progress_callback=None, crc_callback=None, cipher_callback=None):
334 | self.fileobj = fileobj
335 | self.progress_callback = progress_callback
336 | self.offset = 0
337 |
338 | self.crc_callback = crc_callback
339 | self.cipher_callback = cipher_callback
340 |
341 | def __iter__(self):
342 | return self
343 |
344 | def __next__(self):
345 | return self.next()
346 |
347 | def next(self):
348 | content = self.read(_CHUNK_SIZE)
349 |
350 | if content:
351 | return content
352 | else:
353 | raise StopIteration
354 |
355 | def read(self, amt=None):
356 | content = self.fileobj.read(amt)
357 | if not content:
358 | _invoke_progress_callback(self.progress_callback, self.offset, None)
359 | else:
360 | _invoke_progress_callback(self.progress_callback, self.offset, None)
361 |
362 | self.offset += len(content)
363 |
364 | _invoke_crc_callback(self.crc_callback, content)
365 |
366 | content = _invoke_cipher_callback(self.cipher_callback, content)
367 |
368 | return content
369 |
370 | @property
371 | def crc(self):
372 | if self.crc_callback:
373 | return self.crc_callback.crc
374 | elif self.fileobj:
375 | return self.fileobj.crc
376 | else:
377 | return None
378 |
379 |
380 | class _BytesAndFileAdapter(object):
381 | """通过这个适配器,可以给 `data` 加上进度监控。
382 |
383 | :param data: 可以是unicode字符串(内部会转换为UTF-8编码的bytes)、bytes或file object
384 | :param progress_callback: 用户提供的进度报告回调,形如 callback(bytes_read, total_bytes)。
385 | 其中bytes_read是已经读取的字节数;total_bytes是总的字节数。
386 | :param int size: `data` 包含的字节数。
387 | """
388 | def __init__(self, data, progress_callback=None, size=None, crc_callback=None, cipher_callback=None):
389 | self.data = to_bytes(data)
390 | self.progress_callback = progress_callback
391 | self.size = size
392 | self.offset = 0
393 |
394 | self.crc_callback = crc_callback
395 | self.cipher_callback = cipher_callback
396 |
397 | @property
398 | def len(self):
399 | return self.size
400 |
401 | # for python 2.x
402 | def __bool__(self):
403 | return True
404 | # for python 3.x
405 | __nonzero__=__bool__
406 |
407 | def __iter__(self):
408 | return self
409 |
410 | def __next__(self):
411 | return self.next()
412 |
413 | def next(self):
414 | content = self.read(_CHUNK_SIZE)
415 |
416 | if content:
417 | return content
418 | else:
419 | raise StopIteration
420 |
421 | def read(self, amt=None):
422 | if self.offset >= self.size:
423 | return ''
424 |
425 | if amt is None or amt < 0:
426 | bytes_to_read = self.size - self.offset
427 | else:
428 | bytes_to_read = min(amt, self.size - self.offset)
429 |
430 | if isinstance(self.data, bytes):
431 | content = self.data[self.offset:self.offset+bytes_to_read]
432 | else:
433 | content = self.data.read(bytes_to_read)
434 |
435 | self.offset += bytes_to_read
436 |
437 | _invoke_progress_callback(self.progress_callback, min(self.offset, self.size), self.size)
438 |
439 | _invoke_crc_callback(self.crc_callback, content)
440 |
441 | content = _invoke_cipher_callback(self.cipher_callback, content)
442 |
443 | return content
444 |
445 | @property
446 | def crc(self):
447 | if self.crc_callback:
448 | return self.crc_callback.crc
449 | elif self.data:
450 | return self.data.crc
451 | else:
452 | return None
453 |
454 |
455 | class Crc64(object):
456 |
457 | _POLY = 0x142F0E1EBA9EA3693
458 | _XOROUT = 0XFFFFFFFFFFFFFFFF
459 |
460 | def __init__(self, init_crc=0):
461 | self.crc64 = crcmod.Crc(self._POLY, initCrc=init_crc, rev=True, xorOut=self._XOROUT)
462 |
463 | def __call__(self, data):
464 | self.update(data)
465 |
466 | def update(self, data):
467 | self.crc64.update(data)
468 |
469 | @property
470 | def crc(self):
471 | return self.crc64.crcValue
472 |
473 |
474 | def random_aes256_key():
475 | return Random.new().read(_AES_256_KEY_SIZE)
476 |
477 |
478 | def random_counter(begin=1, end=10):
479 | return random.randint(begin, end)
480 |
481 |
482 | # aes 256, key always is 32 bytes
483 | _AES_256_KEY_SIZE = 32
484 |
485 | _AES_CTR_COUNTER_BITS_LEN = 8 * 16
486 |
487 | _AES_GCM = 'AES/GCM/NoPadding'
488 |
489 |
490 | class AESCipher:
491 | """AES256 加密实现。
492 | :param str key: 对称加密数据密钥
493 | :param str start: 对称加密初始随机值
494 | .. note::
495 | 用户可自行实现对称加密算法,需服务如下规则:
496 | 1、提供对称加密算法名,ALGORITHM
497 | 2、提供静态方法,返回加密密钥和初始随机值(若算法不需要初始随机值,也需要提供)
498 | 3、提供加密解密方法
499 | """
500 | ALGORITHM = _AES_GCM
501 |
502 | @staticmethod
503 | def get_key():
504 | return random_aes256_key()
505 |
506 | @staticmethod
507 | def get_start():
508 | return random_counter()
509 |
510 | def __init__(self, key=None, start=None):
511 | self.key = key
512 | if not self.key:
513 | self.key = random_aes256_key()
514 | if not start:
515 | self.start = random_counter()
516 | else:
517 | self.start = int(start)
518 | ctr = Counter.new(_AES_CTR_COUNTER_BITS_LEN, initial_value=self.start)
519 | self.__cipher = AES.new(self.key, AES.MODE_CTR, counter=ctr)
520 |
521 | def encrypt(self, raw):
522 | return self.__cipher.encrypt(raw)
523 |
524 | def decrypt(self, enc):
525 | return self.__cipher.decrypt(enc)
526 |
527 |
528 | _STRPTIME_LOCK = threading.Lock()
529 |
530 | _ISO8601_FORMAT = "%Y-%m-%dT%H:%M:%S.000Z"
531 |
532 | # A regex to match HTTP Last-Modified header, whose format is 'Sat, 05 Dec 2015 11:10:29 GMT'.
533 | # Its strftime/strptime format is '%a, %d %b %Y %H:%M:%S GMT'
534 |
535 | _HTTP_GMT_RE = re.compile(
536 | r'(?:Mon|Tue|Wed|Thu|Fri|Sat|Sun), (?P0[1-9]|([1-2]\d)|(3[0-1])) (?PJan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) (?P\d+) (?P([0-1]\d)|(2[0-3])):(?P[0-5]\d):(?P[0-5]\d) GMT$'
537 | )
538 |
539 | _ISO8601_RE = re.compile(
540 | r'(?P\d+)-(?P01|02|03|04|05|06|07|08|09|10|11|12)-(?P0[1-9]|([1-2]\d)|(3[0-1]))T(?P([0-1]\d)|(2[0-3])):(?P[0-5]\d):(?P[0-5]\d)\.000Z$'
541 | )
542 |
543 | _MONTH_MAPPING = {
544 | 'Jan': 1,
545 | 'Feb': 2,
546 | 'Mar': 3,
547 | 'Apr': 4,
548 | 'May': 5,
549 | 'Jun': 6,
550 | 'Jul': 7,
551 | 'Aug': 8,
552 | 'Sep': 9,
553 | 'Oct': 10,
554 | 'Nov': 11,
555 | 'Dec': 12
556 | }
557 |
558 |
559 | def to_unixtime(time_string, format_string):
560 | with _STRPTIME_LOCK:
561 | return int(calendar.timegm(time.strptime(time_string, format_string)))
562 |
563 |
564 | def http_date(timeval=None):
565 | """返回符合HTTP标准的GMT时间字符串,用strftime的格式表示就是"%a, %d %b %Y %H:%M:%S GMT"。
566 | 但不能使用strftime,因为strftime的结果是和locale相关的。
567 | """
568 | return formatdate(timeval, usegmt=True)
569 |
570 |
571 | def http_to_unixtime(time_string):
572 | """把HTTP Date格式的字符串转换为UNIX时间(自1970年1月1日UTC零点的秒数)。
573 |
574 | HTTP Date形如 `Sat, 05 Dec 2015 11:10:29 GMT` 。
575 | """
576 | m = _HTTP_GMT_RE.match(time_string)
577 |
578 | if not m:
579 | raise ValueError(time_string + " is not in valid HTTP date format")
580 |
581 | day = int(m.group('day'))
582 | month = _MONTH_MAPPING[m.group('month')]
583 | year = int(m.group('year'))
584 | hour = int(m.group('hour'))
585 | minute = int(m.group('minute'))
586 | second = int(m.group('second'))
587 |
588 | tm = datetime.datetime(year, month, day, hour, minute, second).timetuple()
589 |
590 | return calendar.timegm(tm)
591 |
592 |
593 | def iso8601_to_unixtime(time_string):
594 | """把ISO8601时间字符串(形如,2012-02-24T06:07:48.000Z)转换为UNIX时间,精确到秒。"""
595 |
596 | m = _ISO8601_RE.match(time_string)
597 |
598 | if not m:
599 | raise ValueError(time_string + " is not in valid ISO8601 format")
600 |
601 | day = int(m.group('day'))
602 | month = int(m.group('month'))
603 | year = int(m.group('year'))
604 | hour = int(m.group('hour'))
605 | minute = int(m.group('minute'))
606 | second = int(m.group('second'))
607 |
608 | tm = datetime.datetime(year, month, day, hour, minute, second).timetuple()
609 |
610 | return calendar.timegm(tm)
611 |
612 |
613 | def date_to_iso8601(d):
614 | return d.strftime(_ISO8601_FORMAT) # It's OK to use strftime, since _ISO8601_FORMAT is not locale dependent
615 |
616 |
617 | def iso8601_to_date(time_string):
618 | timestamp = iso8601_to_unixtime(time_string)
619 | return datetime.date.fromtimestamp(timestamp)
620 |
621 |
622 | def makedir_p(dirpath):
623 | try:
624 | os.makedirs(dirpath)
625 | except os.error as e:
626 | if e.errno != errno.EEXIST:
627 | raise
628 |
629 |
630 | def silently_remove(filename):
631 | """删除文件,如果文件不存在也不报错。"""
632 | try:
633 | os.remove(filename)
634 | except OSError as e:
635 | if e.errno != errno.ENOENT:
636 | raise
637 |
638 |
639 | def force_rename(src, dst):
640 | try:
641 | os.rename(src, dst)
642 | except OSError as e:
643 | if e.errno == errno.EEXIST:
644 | silently_remove(dst)
645 | os.rename(src, dst)
646 | else:
647 | raise
648 |
649 |
650 | def copyfileobj_and_verify(fsrc, fdst, expected_len,
651 | chunk_size=16*1024,
652 | request_id=''):
653 | """copy data from file-like object fsrc to file-like object fdst, and verify length"""
654 |
655 | num_read = 0
656 |
657 | while 1:
658 | buf = fsrc.read(chunk_size)
659 | if not buf:
660 | break
661 |
662 | num_read += len(buf)
663 | fdst.write(buf)
664 |
665 | if num_read != expected_len:
666 | raise InconsistentError("IncompleteRead from source", request_id)
667 |
--------------------------------------------------------------------------------
/oss2/xml_utils.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | oss2.xml_utils
5 | ~~~~~~~~~~~~~~
6 |
7 | XML处理相关。
8 |
9 | 主要包括两类接口:
10 | - parse_开头的函数:用来解析服务器端返回的XML
11 | - to_开头的函数:用来生成发往服务器端的XML
12 |
13 | """
14 |
15 | import xml.etree.ElementTree as ElementTree
16 |
17 | from .models import (SimplifiedObjectInfo,
18 | SimplifiedBucketInfo,
19 | PartInfo,
20 | MultipartUploadInfo,
21 | LifecycleRule,
22 | LifecycleExpiration,
23 | CorsRule,
24 | LiveChannelInfoTarget,
25 | LiveChannelInfo,
26 | LiveRecord,
27 | LiveChannelVideoStat,
28 | LiveChannelAudioStat,
29 | Owner,
30 | AccessControlList,
31 | AbortMultipartUpload,
32 | StorageTransition)
33 |
34 | from .compat import urlunquote, to_unicode, to_string
35 | from .utils import iso8601_to_unixtime, date_to_iso8601, iso8601_to_date
36 |
37 |
38 | def _find_tag(parent, path):
39 | child = parent.find(path)
40 | if child is None:
41 | raise RuntimeError("parse xml: " + path + " could not be found under " + parent.tag)
42 |
43 | if child.text is None:
44 | return ''
45 |
46 | return to_string(child.text)
47 |
48 |
49 | def _find_bool(parent, path):
50 | text = _find_tag(parent, path)
51 | if text == 'true':
52 | return True
53 | elif text == 'false':
54 | return False
55 | else:
56 | raise RuntimeError("parse xml: value of " + path + " is not a boolean under " + parent.tag)
57 |
58 |
59 | def _find_int(parent, path):
60 | return int(_find_tag(parent, path))
61 |
62 |
63 | def _find_object(parent, path, url_encoded):
64 | name = _find_tag(parent, path)
65 | if url_encoded:
66 | return urlunquote(name)
67 | else:
68 | return name
69 |
70 |
71 | def _find_all_tags(parent, tag):
72 | return [to_string(node.text) or '' for node in parent.findall(tag)]
73 |
74 |
75 | def _is_url_encoding(root):
76 | node = root.find('EncodingType')
77 | if node is not None and to_string(node.text) == 'url':
78 | return True
79 | else:
80 | return False
81 |
82 |
83 | def _node_to_string(root):
84 | return ElementTree.tostring(root, encoding='utf-8')
85 |
86 |
87 | def _add_node_list(parent, tag, entries):
88 | for e in entries:
89 | _add_text_child(parent, tag, e)
90 |
91 |
92 | def _add_text_child(parent, tag, text):
93 | ElementTree.SubElement(parent, tag).text = to_unicode(text)
94 |
95 | def _add_node_child(parent, tag):
96 | return ElementTree.SubElement(parent, tag)
97 |
98 | def parse_list_objects(result, body):
99 | root = ElementTree.fromstring(body)
100 | url_encoded = _is_url_encoding(root)
101 | result.is_truncated = _find_bool(root, 'IsTruncated')
102 | if result.is_truncated:
103 | result.next_marker = _find_object(root, 'NextMarker', url_encoded)
104 |
105 | for contents_node in root.findall('Contents'):
106 | result.object_list.append(SimplifiedObjectInfo(
107 | _find_object(contents_node, 'Key', url_encoded),
108 | iso8601_to_unixtime(_find_tag(contents_node, 'LastModified')),
109 | _find_tag(contents_node, 'ETag').strip('"'),
110 | _find_tag(contents_node, 'Type'),
111 | int(_find_tag(contents_node, 'Size')),
112 | _find_tag(contents_node, 'StorageClass')
113 | ))
114 |
115 | for prefix_node in root.findall('CommonPrefixes'):
116 | result.prefix_list.append(_find_object(prefix_node, 'Prefix', url_encoded))
117 |
118 | return result
119 |
120 |
121 | def parse_list_buckets(result, body):
122 | root = ElementTree.fromstring(body)
123 |
124 | if root.find('IsTruncated') is None:
125 | result.is_truncated = False
126 | else:
127 | result.is_truncated = _find_bool(root, 'IsTruncated')
128 |
129 | if result.is_truncated:
130 | result.next_marker = _find_tag(root, 'NextMarker')
131 |
132 | for bucket_node in root.findall('Buckets/Bucket'):
133 | result.buckets.append(SimplifiedBucketInfo(
134 | _find_tag(bucket_node, 'Name'),
135 | _find_tag(bucket_node, 'Location'),
136 | iso8601_to_unixtime(_find_tag(bucket_node, 'CreationDate'))
137 | ))
138 |
139 |
140 | def parse_init_multipart_upload(result, body):
141 | root = ElementTree.fromstring(body)
142 | result.upload_id = _find_tag(root, 'UploadId')
143 |
144 | return result
145 |
146 |
147 | def parse_list_multipart_uploads(result, body):
148 | root = ElementTree.fromstring(body)
149 |
150 | url_encoded = _is_url_encoding(root)
151 |
152 | result.is_truncated = _find_bool(root, 'IsTruncated')
153 | result.next_key_marker = _find_object(root, 'NextKeyMarker', url_encoded)
154 | result.next_upload_id_marker = _find_tag(root, 'NextUploadIdMarker')
155 |
156 | for upload_node in root.findall('Upload'):
157 | result.upload_list.append(MultipartUploadInfo(
158 | _find_object(upload_node, 'Key', url_encoded),
159 | _find_tag(upload_node, 'UploadId'),
160 | iso8601_to_unixtime(_find_tag(upload_node, 'Initiated'))
161 | ))
162 |
163 | for prefix_node in root.findall('CommonPrefixes'):
164 | result.prefix_list.append(_find_object(prefix_node, 'Prefix', url_encoded))
165 |
166 | return result
167 |
168 |
169 | def parse_list_parts(result, body):
170 | root = ElementTree.fromstring(body)
171 |
172 | result.is_truncated = _find_bool(root, 'IsTruncated')
173 | result.next_marker = _find_tag(root, 'NextPartNumberMarker')
174 | for part_node in root.findall('Part'):
175 | result.parts.append(PartInfo(
176 | _find_int(part_node, 'PartNumber'),
177 | _find_tag(part_node, 'ETag').strip('"'),
178 | size=_find_int(part_node, 'Size'),
179 | last_modified=iso8601_to_unixtime(_find_tag(part_node, 'LastModified'))
180 | ))
181 |
182 | return result
183 |
184 |
185 | def parse_batch_delete_objects(result, body):
186 | if not body:
187 | return result
188 |
189 | root = ElementTree.fromstring(body)
190 | url_encoded = _is_url_encoding(root)
191 |
192 | for deleted_node in root.findall('Deleted'):
193 | result.deleted_keys.append(_find_object(deleted_node, 'Key', url_encoded))
194 |
195 | return result
196 |
197 |
198 | def parse_get_bucket_acl(result, body):
199 | root = ElementTree.fromstring(body)
200 | result.acl = _find_tag(root, 'AccessControlList/Grant')
201 |
202 | return result
203 |
204 | parse_get_object_acl = parse_get_bucket_acl
205 |
206 |
207 | def parse_get_bucket_location(result, body):
208 | result.location = to_string(ElementTree.fromstring(body).text)
209 | return result
210 |
211 |
212 | def parse_get_bucket_logging(result, body):
213 | root = ElementTree.fromstring(body)
214 |
215 | if root.find('LoggingEnabled/TargetBucket') is not None:
216 | result.target_bucket = _find_tag(root, 'LoggingEnabled/TargetBucket')
217 |
218 | if root.find('LoggingEnabled/TargetPrefix') is not None:
219 | result.target_prefix = _find_tag(root, 'LoggingEnabled/TargetPrefix')
220 |
221 | return result
222 |
223 |
224 | def parse_get_bucket_stat(result, body):
225 | root = ElementTree.fromstring(body)
226 |
227 | result.storage_size_in_bytes = _find_int(root, 'Storage')
228 | result.object_count = _find_int(root, 'ObjectCount')
229 | result.multi_part_upload_count = _find_int(root, 'MultipartUploadCount')
230 |
231 | return result
232 |
233 |
234 | def parse_get_bucket_info(result, body):
235 | root = ElementTree.fromstring(body)
236 |
237 | result.name = _find_tag(root, 'Bucket/Name')
238 | result.creation_date = _find_tag(root, 'Bucket/CreationDate')
239 | result.storage_class = _find_tag(root, 'Bucket/StorageClass')
240 | result.extranet_endpoint = _find_tag(root, 'Bucket/ExtranetEndpoint')
241 | result.intranet_endpoint = _find_tag(root, 'Bucket/IntranetEndpoint')
242 | result.location = _find_tag(root, 'Bucket/Location')
243 | result.owner = Owner(_find_tag(root, 'Bucket/Owner/DisplayName'), _find_tag(root, 'Bucket/Owner/ID'))
244 | result.acl = AccessControlList(_find_tag(root, 'Bucket/AccessControlList/Grant'))
245 |
246 | return result
247 |
248 |
249 | def parse_get_bucket_referer(result, body):
250 | root = ElementTree.fromstring(body)
251 |
252 | result.allow_empty_referer = _find_bool(root, 'AllowEmptyReferer')
253 | result.referers = _find_all_tags(root, 'RefererList/Referer')
254 |
255 | return result
256 |
257 |
258 | def parse_get_bucket_websiste(result, body):
259 | root = ElementTree.fromstring(body)
260 |
261 | result.index_file = _find_tag(root, 'IndexDocument/Suffix')
262 | result.error_file = _find_tag(root, 'ErrorDocument/Key')
263 |
264 | return result
265 |
266 |
267 | def parse_create_live_channel(result, body):
268 | root = ElementTree.fromstring(body)
269 |
270 | result.play_url = _find_tag(root, 'PlayUrls/Url')
271 | result.publish_url = _find_tag(root, 'PublishUrls/Url')
272 |
273 | return result
274 |
275 |
276 | def parse_get_live_channel(result, body):
277 | root = ElementTree.fromstring(body)
278 |
279 | result.status = _find_tag(root, 'Status')
280 | result.description = _find_tag(root, 'Description')
281 |
282 | target = LiveChannelInfoTarget()
283 | target.type = _find_tag(root, 'Target/Type')
284 | target.frag_duration = _find_tag(root, 'Target/FragDuration')
285 | target.frag_count = _find_tag(root, 'Target/FragCount')
286 | target.playlist_name = _find_tag(root, 'Target/PlaylistName')
287 |
288 | result.target = target
289 |
290 | return result
291 |
292 |
293 | def parse_list_live_channel(result, body):
294 | root = ElementTree.fromstring(body)
295 |
296 | result.prefix = _find_tag(root, 'Prefix')
297 | result.marker = _find_tag(root, 'Marker')
298 | result.max_keys = _find_int(root, 'MaxKeys')
299 | result.is_truncated = _find_bool(root, 'IsTruncated')
300 |
301 | if result.is_truncated:
302 | result.next_marker = _find_tag(root, 'NextMarker')
303 |
304 | channels = root.findall('LiveChannel')
305 | for channel in channels:
306 | tmp = LiveChannelInfo()
307 | tmp.name = _find_tag(channel, 'Name')
308 | tmp.description = _find_tag(channel, 'Description')
309 | tmp.status = _find_tag(channel, 'Status')
310 | tmp.last_modified = iso8601_to_unixtime(_find_tag(channel, 'LastModified'))
311 | tmp.play_url = _find_tag(channel, 'PlayUrls/Url')
312 | tmp.publish_url = _find_tag(channel, 'PublishUrls/Url')
313 |
314 | result.channels.append(tmp)
315 |
316 | return result
317 |
318 |
319 | def parse_stat_video(video_node, video):
320 | video.width = _find_int(video_node, 'Width')
321 | video.height = _find_int(video_node, 'Height')
322 | video.frame_rate = _find_int(video_node, 'FrameRate')
323 | video.bandwidth = _find_int(video_node, 'Bandwidth')
324 | video.codec = _find_tag(video_node, 'Codec')
325 |
326 |
327 | def parse_stat_audio(audio_node, audio):
328 | audio.bandwidth = _find_int(audio_node, 'Bandwidth')
329 | audio.sample_rate = _find_int(audio_node, 'SampleRate')
330 | audio.codec = _find_tag(audio_node, 'Codec')
331 |
332 |
333 | def parse_live_channel_stat(result, body):
334 | root = ElementTree.fromstring(body)
335 |
336 | result.status = _find_tag(root, 'Status')
337 | if root.find('RemoteAddr') is not None:
338 | result.remote_addr = _find_tag(root, 'RemoteAddr')
339 | if root.find('ConnectedTime') is not None:
340 | result.connected_time = iso8601_to_unixtime(_find_tag(root, 'ConnectedTime'))
341 |
342 | video_node = root.find('Video')
343 | audio_node = root.find('Audio')
344 |
345 | if video_node is not None:
346 | result.video = LiveChannelVideoStat()
347 | parse_stat_video(video_node, result.video)
348 | if audio_node is not None:
349 | result.audio = LiveChannelAudioStat()
350 | parse_stat_audio(audio_node, result.audio)
351 |
352 | return result
353 |
354 |
355 | def parse_live_channel_history(result, body):
356 | root = ElementTree.fromstring(body)
357 |
358 | records = root.findall('LiveRecord')
359 | for record in records:
360 | tmp = LiveRecord()
361 | tmp.start_time = iso8601_to_unixtime(_find_tag(record, 'StartTime'))
362 | tmp.end_time = iso8601_to_unixtime(_find_tag(record, 'EndTime'))
363 | tmp.remote_addr = _find_tag(record, 'RemoteAddr')
364 | result.records.append(tmp)
365 |
366 | return result
367 |
368 |
369 | def parse_lifecycle_expiration(expiration_node):
370 | if expiration_node is None:
371 | return None
372 |
373 | expiration = LifecycleExpiration()
374 |
375 | if expiration_node.find('Days') is not None:
376 | expiration.days = _find_int(expiration_node, 'Days')
377 | elif expiration_node.find('Date') is not None:
378 | expiration.date = iso8601_to_date(_find_tag(expiration_node, 'Date'))
379 |
380 | return expiration
381 |
382 |
383 | def parse_lifecycle_abort_multipart_upload(abort_multipart_upload_node):
384 | if abort_multipart_upload_node is None:
385 | return None
386 | abort_multipart_upload = AbortMultipartUpload()
387 |
388 | if abort_multipart_upload_node.find('Days') is not None:
389 | abort_multipart_upload.days = _find_int(abort_multipart_upload_node, 'Days')
390 | elif abort_multipart_upload_node.find('CreatedBeforeDate') is not None:
391 | abort_multipart_upload.created_before_date = iso8601_to_date(_find_tag(abort_multipart_upload_node,
392 | 'CreatedBeforeDate'))
393 | return abort_multipart_upload
394 |
395 |
396 | def parse_lifecycle_storage_transitions(storage_transition_nodes):
397 | storage_transitions = []
398 | for storage_transition_node in storage_transition_nodes:
399 | storage_class = _find_tag(storage_transition_node, 'StorageClass')
400 | storage_transition = StorageTransition(storage_class=storage_class)
401 | if storage_transition_node.find('Days') is not None:
402 | storage_transition.days = _find_int(storage_transition_node, 'Days')
403 | elif storage_transition_node.find('CreatedBeforeDate') is not None:
404 | storage_transition.created_before_date = iso8601_to_date(_find_tag(storage_transition_node,
405 | 'CreatedBeforeDate'))
406 |
407 | storage_transitions.append(storage_transition)
408 |
409 | return storage_transitions
410 |
411 |
412 | def parse_get_bucket_lifecycle(result, body):
413 | root = ElementTree.fromstring(body)
414 |
415 | for rule_node in root.findall('Rule'):
416 | expiration = parse_lifecycle_expiration(rule_node.find('Expiration'))
417 | abort_multipart_upload = parse_lifecycle_abort_multipart_upload(rule_node.find('AbortMultipartUpload'))
418 | storage_transitions = parse_lifecycle_storage_transitions(rule_node.findall('Transition'))
419 | rule = LifecycleRule(
420 | _find_tag(rule_node, 'ID'),
421 | _find_tag(rule_node, 'Prefix'),
422 | status=_find_tag(rule_node, 'Status'),
423 | expiration=expiration,
424 | abort_multipart_upload=abort_multipart_upload,
425 | storage_transitions=storage_transitions
426 | )
427 | result.rules.append(rule)
428 |
429 | return result
430 |
431 |
432 | def parse_get_bucket_cors(result, body):
433 | root = ElementTree.fromstring(body)
434 |
435 | for rule_node in root.findall('CORSRule'):
436 | rule = CorsRule()
437 | rule.allowed_origins = _find_all_tags(rule_node, 'AllowedOrigin')
438 | rule.allowed_methods = _find_all_tags(rule_node, 'AllowedMethod')
439 | rule.allowed_headers = _find_all_tags(rule_node, 'AllowedHeader')
440 | rule.expose_headers = _find_all_tags(rule_node, 'ExposeHeader')
441 |
442 | max_age_node = rule_node.find('MaxAgeSeconds')
443 | if max_age_node is not None:
444 | rule.max_age_seconds = int(max_age_node.text)
445 |
446 | result.rules.append(rule)
447 |
448 | return result
449 |
450 |
451 | def to_complete_upload_request(parts):
452 | root = ElementTree.Element('CompleteMultipartUpload')
453 | for p in parts:
454 | part_node = ElementTree.SubElement(root, "Part")
455 | _add_text_child(part_node, 'PartNumber', str(p.part_number))
456 | _add_text_child(part_node, 'ETag', '"{0}"'.format(p.etag))
457 |
458 | return _node_to_string(root)
459 |
460 |
461 | def to_batch_delete_objects_request(keys, quiet):
462 | root_node = ElementTree.Element('Delete')
463 |
464 | _add_text_child(root_node, 'Quiet', str(quiet).lower())
465 |
466 | for key in keys:
467 | object_node = ElementTree.SubElement(root_node, 'Object')
468 | _add_text_child(object_node, 'Key', key)
469 |
470 | return _node_to_string(root_node)
471 |
472 |
473 | def to_put_bucket_config(bucket_config):
474 | root = ElementTree.Element('CreateBucketConfiguration')
475 |
476 | _add_text_child(root, 'StorageClass', str(bucket_config.storage_class))
477 |
478 | return _node_to_string(root)
479 |
480 |
481 | def to_put_bucket_logging(bucket_logging):
482 | root = ElementTree.Element('BucketLoggingStatus')
483 |
484 | if bucket_logging.target_bucket:
485 | logging_node = ElementTree.SubElement(root, 'LoggingEnabled')
486 | _add_text_child(logging_node, 'TargetBucket', bucket_logging.target_bucket)
487 | _add_text_child(logging_node, 'TargetPrefix', bucket_logging.target_prefix)
488 |
489 | return _node_to_string(root)
490 |
491 |
492 | def to_put_bucket_referer(bucket_referer):
493 | root = ElementTree.Element('RefererConfiguration')
494 |
495 | _add_text_child(root, 'AllowEmptyReferer', str(bucket_referer.allow_empty_referer).lower())
496 | list_node = ElementTree.SubElement(root, 'RefererList')
497 |
498 | for r in bucket_referer.referers:
499 | _add_text_child(list_node, 'Referer', r)
500 |
501 | return _node_to_string(root)
502 |
503 |
504 | def to_put_bucket_website(bucket_websiste):
505 | root = ElementTree.Element('WebsiteConfiguration')
506 |
507 | index_node = ElementTree.SubElement(root, 'IndexDocument')
508 | _add_text_child(index_node, 'Suffix', bucket_websiste.index_file)
509 |
510 | error_node = ElementTree.SubElement(root, 'ErrorDocument')
511 | _add_text_child(error_node, 'Key', bucket_websiste.error_file)
512 |
513 | return _node_to_string(root)
514 |
515 |
516 | def to_put_bucket_lifecycle(bucket_lifecycle):
517 | root = ElementTree.Element('LifecycleConfiguration')
518 |
519 | for rule in bucket_lifecycle.rules:
520 | rule_node = ElementTree.SubElement(root, 'Rule')
521 | _add_text_child(rule_node, 'ID', rule.id)
522 | _add_text_child(rule_node, 'Prefix', rule.prefix)
523 | _add_text_child(rule_node, 'Status', rule.status)
524 |
525 | expiration = rule.expiration
526 | if expiration:
527 | expiration_node = ElementTree.SubElement(rule_node, 'Expiration')
528 |
529 | if expiration.days is not None:
530 | _add_text_child(expiration_node, 'Days', str(expiration.days))
531 | elif expiration.date is not None:
532 | _add_text_child(expiration_node, 'Date', date_to_iso8601(expiration.date))
533 | elif expiration.created_before_date is not None:
534 | _add_text_child(expiration_node, 'CreatedBeforeDate', date_to_iso8601(expiration.created_before_date))
535 |
536 | abort_multipart_upload = rule.abort_multipart_upload
537 | if abort_multipart_upload:
538 | abort_multipart_upload_node = ElementTree.SubElement(rule_node, 'AbortMultipartUpload')
539 | if abort_multipart_upload.days is not None:
540 | _add_text_child(abort_multipart_upload_node, 'Days', str(abort_multipart_upload.days))
541 | elif abort_multipart_upload.created_before_date is not None:
542 | _add_text_child(abort_multipart_upload_node, 'CreatedBeforeDate',
543 | date_to_iso8601(abort_multipart_upload.created_before_date))
544 |
545 | storage_transitions = rule.storage_transitions
546 | if storage_transitions:
547 | for storage_transition in storage_transitions:
548 | storage_transition_node = ElementTree.SubElement(rule_node, 'Transition')
549 | _add_text_child(storage_transition_node, 'StorageClass', str(storage_transition.storage_class))
550 | if storage_transition.days is not None:
551 | _add_text_child(storage_transition_node, 'Days', str(storage_transition.days))
552 | elif storage_transition.created_before_date is not None:
553 | _add_text_child(storage_transition_node, 'CreatedBeforeDate',
554 | date_to_iso8601(storage_transition.created_before_date))
555 |
556 | return _node_to_string(root)
557 |
558 |
559 | def to_put_bucket_cors(bucket_cors):
560 | root = ElementTree.Element('CORSConfiguration')
561 |
562 | for rule in bucket_cors.rules:
563 | rule_node = ElementTree.SubElement(root, 'CORSRule')
564 | _add_node_list(rule_node, 'AllowedOrigin', rule.allowed_origins)
565 | _add_node_list(rule_node, 'AllowedMethod', rule.allowed_methods)
566 | _add_node_list(rule_node, 'AllowedHeader', rule.allowed_headers)
567 | _add_node_list(rule_node, 'ExposeHeader', rule.expose_headers)
568 |
569 | if rule.max_age_seconds is not None:
570 | _add_text_child(rule_node, 'MaxAgeSeconds', str(rule.max_age_seconds))
571 |
572 | return _node_to_string(root)
573 |
574 | def to_create_live_channel(live_channel):
575 | root = ElementTree.Element('LiveChannelConfiguration')
576 |
577 | _add_text_child(root, 'Description', live_channel.description)
578 | _add_text_child(root, 'Status', live_channel.status)
579 | target_node = _add_node_child(root, 'Target')
580 |
581 | _add_text_child(target_node, 'Type', live_channel.target.type)
582 | _add_text_child(target_node, 'FragDuration', str(live_channel.target.frag_duration))
583 | _add_text_child(target_node, 'FragCount', str(live_channel.target.frag_count))
584 | _add_text_child(target_node, 'PlaylistName', str(live_channel.target.playlist_name))
585 |
586 | return _node_to_string(root)
587 |
--------------------------------------------------------------------------------
/qcloud_cos/__init__.py:
--------------------------------------------------------------------------------
1 | from .cos_client import CosS3Client
2 | from .cos_client import CosConfig
3 | from .cos_exception import CosServiceError
4 | from .cos_exception import CosClientError
5 | from .cos_auth import CosS3Auth
6 | from .cos_comm import get_date
7 |
--------------------------------------------------------------------------------
/qcloud_cos/cos_auth.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | from six.moves.urllib.parse import quote, unquote, urlparse, urlencode
4 | import hmac
5 | import time
6 | import hashlib
7 | import logging
8 | from requests.auth import AuthBase
9 | from .cos_comm import to_unicode, to_bytes
10 | logger = logging.getLogger(__name__)
11 |
12 |
13 | def filter_headers(data):
14 | """只设置host content-type 还有x开头的头部.
15 |
16 | :param data(dict): 所有的头部信息.
17 | :return(dict): 计算进签名的头部.
18 | """
19 | headers = {}
20 | for i in data:
21 | if i == 'Content-Type' or i == 'Host' or i[0] == 'x' or i[0] == 'X':
22 | headers[i] = data[i]
23 | return headers
24 |
25 |
26 | class CosS3Auth(AuthBase):
27 |
28 | def __init__(self, secret_id, secret_key, key=None, params={}, expire=10000):
29 | self._secret_id = secret_id
30 | self._secret_key = secret_key
31 | self._expire = expire
32 | self._params = params
33 | if key:
34 | key = to_unicode(key)
35 | if key[0] == u'/':
36 | self._path = key
37 | else:
38 | self._path = u'/' + key
39 | else:
40 | self._path = u'/'
41 |
42 | def __call__(self, r):
43 | path = self._path
44 | uri_params = self._params
45 | headers = filter_headers(r.headers)
46 | uri_params = dict([(k.lower(), v) for k, v in uri_params.items()])
47 | # reserved keywords in headers urlencode are -_.~, notice that / should be encoded and space should not be encoded to plus sign(+)
48 | headers = dict([(k.lower(), quote(to_bytes(v), '-_.~')) for k, v in headers.items()]) # headers中的key转换为小写,value进行encode
49 | uri_params = dict([(k.lower(), v) for k, v in uri_params.items()])
50 | format_str = u"{method}\n{host}\n{params}\n{headers}\n".format(
51 | method=r.method.lower(),
52 | host=path,
53 | params=urlencode(sorted(uri_params.items())).replace('+', '%20'),
54 | headers='&'.join(map(lambda tupl: "%s=%s" % (tupl[0], tupl[1]), sorted(headers.items())))
55 | )
56 | logger.debug("format str: " + format_str)
57 |
58 | start_sign_time = int(time.time())
59 | sign_time = "{bg_time};{ed_time}".format(bg_time=start_sign_time-60, ed_time=start_sign_time+self._expire)
60 | sha1 = hashlib.sha1()
61 | sha1.update(to_bytes(format_str))
62 |
63 | str_to_sign = "sha1\n{time}\n{sha1}\n".format(time=sign_time, sha1=sha1.hexdigest())
64 | logger.debug('str_to_sign: ' + str(str_to_sign))
65 | sign_key = hmac.new(to_bytes(self._secret_key), to_bytes(sign_time), hashlib.sha1).hexdigest()
66 | sign = hmac.new(to_bytes(sign_key), to_bytes(str_to_sign), hashlib.sha1).hexdigest()
67 | logger.debug('sign_key: ' + str(sign_key))
68 | logger.debug('sign: ' + str(sign))
69 | sign_tpl = "q-sign-algorithm=sha1&q-ak={ak}&q-sign-time={sign_time}&q-key-time={key_time}&q-header-list={headers}&q-url-param-list={params}&q-signature={sign}"
70 |
71 | r.headers['Authorization'] = sign_tpl.format(
72 | ak=self._secret_id,
73 | sign_time=sign_time,
74 | key_time=sign_time,
75 | params=';'.join(sorted(map(lambda k: k.lower(), uri_params.keys()))),
76 | headers=';'.join(sorted(headers.keys())),
77 | sign=sign
78 | )
79 | logger.debug("sign_key" + str(sign_key))
80 | logger.debug(r.headers['Authorization'])
81 | logger.debug("request headers: " + str(r.headers))
82 | return r
83 |
84 |
85 | if __name__ == "__main__":
86 | pass
87 |
--------------------------------------------------------------------------------
/qcloud_cos/cos_comm.py:
--------------------------------------------------------------------------------
1 | # -*- coding=utf-8
2 |
3 | from six import text_type, binary_type, string_types
4 | from six.moves.urllib.parse import quote, unquote
5 | import hashlib
6 | import base64
7 | import os
8 | import io
9 | import re
10 | import sys
11 | import xml.dom.minidom
12 | import xml.etree.ElementTree
13 | from datetime import datetime
14 | from dicttoxml import dicttoxml
15 | from .xml2dict import Xml2Dict
16 | from .cos_exception import CosClientError
17 | from .cos_exception import CosServiceError
18 |
19 | SINGLE_UPLOAD_LENGTH = 5*1024*1024*1024 # 单次上传文件最大为5G
20 | LOGGING_UIN = 'id="qcs::cam::uin/100001001014:uin/100001001014"'
21 | # kwargs中params到http headers的映射
22 | maplist = {
23 | 'ContentLength': 'Content-Length',
24 | 'ContentMD5': 'Content-MD5',
25 | 'ContentType': 'Content-Type',
26 | 'CacheControl': 'Cache-Control',
27 | 'ContentDisposition': 'Content-Disposition',
28 | 'ContentEncoding': 'Content-Encoding',
29 | 'ContentLanguage': 'Content-Language',
30 | 'Expires': 'Expires',
31 | 'ResponseContentType': 'response-content-type',
32 | 'ResponseContentLanguage': 'response-content-language',
33 | 'ResponseExpires': 'response-expires',
34 | 'ResponseCacheControl': 'response-cache-control',
35 | 'ResponseContentDisposition': 'response-content-disposition',
36 | 'ResponseContentEncoding': 'response-content-encoding',
37 | 'Metadata': 'Metadata',
38 | 'ACL': 'x-cos-acl',
39 | 'GrantFullControl': 'x-cos-grant-full-control',
40 | 'GrantWrite': 'x-cos-grant-write',
41 | 'GrantRead': 'x-cos-grant-read',
42 | 'StorageClass': 'x-cos-storage-class',
43 | 'Range': 'Range',
44 | 'IfMatch': 'If-Match',
45 | 'IfNoneMatch': 'If-None-Match',
46 | 'IfModifiedSince': 'If-Modified-Since',
47 | 'IfUnmodifiedSince': 'If-Unmodified-Since',
48 | 'CopySourceIfMatch': 'x-cos-copy-source-If-Match',
49 | 'CopySourceIfNoneMatch': 'x-cos-copy-source-If-None-Match',
50 | 'CopySourceIfModifiedSince': 'x-cos-copy-source-If-Modified-Since',
51 | 'CopySourceIfUnmodifiedSince': 'x-cos-copy-source-If-Unmodified-Since',
52 | 'VersionId': 'versionId',
53 | 'ServerSideEncryption': 'x-cos-server-side-encryption',
54 | 'SSECustomerAlgorithm': 'x-cos-server-side-encryption-customer-algorithm',
55 | 'SSECustomerKey': 'x-cos-server-side-encryption-customer-key',
56 | 'SSECustomerKeyMD5': 'x-cos-server-side-encryption-customer-key-MD5',
57 | 'SSEKMSKeyId': 'x-cos-server-side-encryption-cos-kms-key-id',
58 | 'Referer': 'Referer'
59 | }
60 |
61 |
62 | def to_unicode(s):
63 | """将字符串转为unicode"""
64 | if isinstance(s, binary_type):
65 | try:
66 | return s.decode('utf-8')
67 | except UnicodeDecodeError as e:
68 | raise CosClientError('your bytes strings can not be decoded in utf8, utf8 support only!')
69 | return s
70 |
71 |
72 | def to_bytes(s):
73 | """将字符串转为bytes"""
74 | if isinstance(s, text_type):
75 | try:
76 | return s.encode('utf-8')
77 | except UnicodeEncodeError as e:
78 | raise CosClientError('your unicode strings can not encoded in utf8, utf8 support only!')
79 | return s
80 |
81 |
82 | def get_raw_md5(data):
83 | """计算md5 md5的输入必须为bytes"""
84 | data = to_bytes(data)
85 | m2 = hashlib.md5(data)
86 | etag = '"' + str(m2.hexdigest()) + '"'
87 | return etag
88 |
89 |
90 | def get_md5(data):
91 | """计算 base64 md5 md5的输入必须为bytes"""
92 | data = to_bytes(data)
93 | m2 = hashlib.md5(data)
94 | MD5 = base64.standard_b64encode(m2.digest())
95 | return MD5
96 |
97 |
98 | def get_content_md5(body):
99 | """计算任何输入流的md5值"""
100 | body_type = type(body)
101 | if body_type == string_types:
102 | return get_md5(body)
103 | elif hasattr(body, 'tell') and hasattr(body, 'seek') and hasattr(body, 'read'):
104 | file_position = body.tell() # 记录文件当前位置
105 | md5_str = get_md5(body.read())
106 | body.seek(file_position) # 恢复初始的文件位置
107 | return md5_str
108 | return None
109 |
110 |
111 | def dict_to_xml(data):
112 | """V5使用xml格式,将输入的dict转换为xml"""
113 | doc = xml.dom.minidom.Document()
114 | root = doc.createElement('CompleteMultipartUpload')
115 | doc.appendChild(root)
116 |
117 | if 'Part' not in data:
118 | raise CosClientError("Invalid Parameter, Part Is Required!")
119 |
120 | for i in data['Part']:
121 | nodePart = doc.createElement('Part')
122 |
123 | if 'PartNumber' not in i:
124 | raise CosClientError("Invalid Parameter, PartNumber Is Required!")
125 |
126 | nodeNumber = doc.createElement('PartNumber')
127 | nodeNumber.appendChild(doc.createTextNode(str(i['PartNumber'])))
128 |
129 | if 'ETag' not in i:
130 | raise CosClientError("Invalid Parameter, ETag Is Required!")
131 |
132 | nodeETag = doc.createElement('ETag')
133 | nodeETag.appendChild(doc.createTextNode(str(i['ETag'])))
134 |
135 | nodePart.appendChild(nodeNumber)
136 | nodePart.appendChild(nodeETag)
137 | root.appendChild(nodePart)
138 | return doc.toxml('utf-8')
139 |
140 |
141 | def xml_to_dict(data, origin_str="", replace_str=""):
142 | """V5使用xml格式,将response中的xml转换为dict"""
143 | root = xml.etree.ElementTree.fromstring(data)
144 | xmldict = Xml2Dict(root)
145 | xmlstr = str(xmldict)
146 | xmlstr = xmlstr.replace("{http://www.qcloud.com/document/product/436/7751}", "")
147 | xmlstr = xmlstr.replace("{https://cloud.tencent.com/document/product/436}", "")
148 | xmlstr = xmlstr.replace("{http://doc.s3.amazonaws.com/2006-03-01}", "")
149 | xmlstr = xmlstr.replace("{http://www.w3.org/2001/XMLSchema-instance}", "")
150 | if origin_str:
151 | xmlstr = xmlstr.replace(origin_str, replace_str)
152 | xmldict = eval(xmlstr)
153 | return xmldict
154 |
155 |
156 | def get_id_from_xml(data, name):
157 | """解析xml中的特定字段"""
158 | tree = xml.dom.minidom.parseString(data)
159 | root = tree.documentElement
160 | result = root.getElementsByTagName(name)
161 | # use childNodes to get a list, if has no child get itself
162 | return result[0].childNodes[0].nodeValue
163 |
164 |
165 | def mapped(headers):
166 | """S3到COS参数的一个映射"""
167 | _headers = dict()
168 | for i in headers:
169 | if i in maplist:
170 | if i == 'Metadata':
171 | for meta in headers[i]:
172 | _headers[meta] = headers[i][meta]
173 | else:
174 | _headers[maplist[i]] = headers[i]
175 | else:
176 | raise CosClientError('No Parameter Named ' + i + ' Please Check It')
177 | return _headers
178 |
179 |
180 | def format_xml(data, root, lst=list()):
181 | """将dict转换为xml, xml_config是一个bytes"""
182 | xml_config = dicttoxml(data, item_func=lambda x: x, custom_root=root, attr_type=False)
183 | for i in lst:
184 | xml_config = xml_config.replace(to_bytes(i+i), to_bytes(i))
185 | return xml_config
186 |
187 |
188 | def format_values(data):
189 | """格式化headers和params中的values为bytes"""
190 | for i in data:
191 | data[i] = to_bytes(data[i])
192 | return data
193 |
194 |
195 | def format_region(region):
196 | """格式化地域"""
197 | if not isinstance(region, string_types):
198 | raise CosClientError("region is not string type")
199 | if not region:
200 | raise CosClientError("region is required not empty!")
201 | region = to_unicode(region)
202 | if not re.match('^[A-Za-z0-9][A-Za-z0-9.\-]*[A-Za-z0-9]$', region):
203 | raise CosClientError("region format is illegal, only digit, letter and - is allowed!")
204 | if region.find(u'cos.') != -1:
205 | return region # 传入cos.ap-beijing-1这样显示加上cos.的region
206 | if region == u'cn-north' or region == u'cn-south' or region == u'cn-east' or region == u'cn-south-2' or region == u'cn-southwest' or region == u'sg':
207 | return region # 老域名不能加cos.
208 | # 支持v4域名映射到v5
209 | if region == u'cossh':
210 | return u'cos.ap-shanghai'
211 | if region == u'cosgz':
212 | return u'cos.ap-guangzhou'
213 | if region == 'cosbj':
214 | return u'cos.ap-beijing'
215 | if region == 'costj':
216 | return u'cos.ap-beijing-1'
217 | if region == u'coscd':
218 | return u'cos.ap-chengdu'
219 | if region == u'cossgp':
220 | return u'cos.ap-singapore'
221 | if region == u'coshk':
222 | return u'cos.ap-hongkong'
223 | if region == u'cosca':
224 | return u'cos.na-toronto'
225 | if region == u'cosger':
226 | return u'cos.eu-frankfurt'
227 |
228 | return u'cos.' + region # 新域名加上cos.
229 |
230 |
231 | def format_bucket(bucket, appid):
232 | """兼容新老bucket长短命名,appid为空默认为长命名,appid不为空则认为是短命名"""
233 | if not isinstance(bucket, string_types):
234 | raise CosClientError("bucket is not string")
235 | if not bucket:
236 | raise CosClientError("bucket is required not empty")
237 | if not (re.match('^[A-Za-z0-9][A-Za-z0-9\-]*[A-Za-z0-9]$', bucket) or re.match('^[A-Za-z0-9]$', bucket)):
238 | raise CosClientError("bucket format is illegal, only digit, letter and - is allowed!")
239 | # appid为空直接返回bucket
240 | if not appid:
241 | return to_unicode(bucket)
242 | if not isinstance(appid, string_types):
243 | raise CosClientError("appid is not string")
244 | bucket = to_unicode(bucket)
245 | appid = to_unicode(appid)
246 | # appid不为空,检查是否以-appid结尾
247 | if bucket.endswith(u"-"+appid):
248 | return bucket
249 | return bucket + u"-" + appid
250 |
251 |
252 | def format_path(path):
253 | """检查path是否合法,格式化path"""
254 | if not isinstance(path, string_types):
255 | raise CosClientError("key is not string")
256 | if not path:
257 | raise CosClientError("Key is required not empty")
258 | path = to_unicode(path)
259 | if path[0] == u'/':
260 | path = path[1:]
261 | # 提前对path进行encode
262 | path = quote(to_bytes(path), b'/-_.~')
263 | return path
264 |
265 |
266 | def get_copy_source_info(CopySource):
267 | """获取拷贝源的所有信息"""
268 | appid = u""
269 | versionid = u""
270 | if 'Appid' in CopySource:
271 | appid = CopySource['Appid']
272 | if 'Bucket' in CopySource:
273 | bucket = CopySource['Bucket']
274 | bucket = format_bucket(bucket, appid)
275 | else:
276 | raise CosClientError('CopySource Need Parameter Bucket')
277 | if 'Region' in CopySource:
278 | region = CopySource['Region']
279 | region = format_region(region)
280 | else:
281 | raise CosClientError('CopySource Need Parameter Region')
282 | if 'Key' in CopySource:
283 | path = to_unicode(CopySource['Key'])
284 | else:
285 | raise CosClientError('CopySource Need Parameter Key')
286 | if 'VersionId' in CopySource:
287 | versionid = to_unicode(CopySource['VersionId'])
288 | return bucket, path, region, versionid
289 |
290 |
291 | def gen_copy_source_url(CopySource):
292 | """拼接拷贝源url"""
293 | bucket, path, region, versionid = get_copy_source_info(CopySource)
294 | path = format_path(path)
295 | if versionid != u'':
296 | path = path + u'?versionId=' + versionid
297 | url = u"{bucket}.{region}.myqcloud.com/{path}".format(
298 | bucket=bucket,
299 | region=region,
300 | path=path
301 | )
302 | return url
303 |
304 |
305 | def gen_copy_source_range(begin_range, end_range):
306 | """拼接bytes=begin-end形式的字符串"""
307 | range = u"bytes={first}-{end}".format(
308 | first=to_unicode(begin_range),
309 | end=to_unicode(end_range)
310 | )
311 | return range
312 |
313 |
314 | def check_object_content_length(data):
315 | """put_object接口和upload_part接口的文件大小不允许超过5G"""
316 | content_len = 0
317 | if type(data) is string_types:
318 | content_len = len(to_bytes(data))
319 | elif hasattr(data, 'fileno') and hasattr(data, 'tell'):
320 | fileno = data.fileno()
321 | total_length = os.fstat(fileno).st_size
322 | # current_position = data.tell()
323 | content_len = total_length # - current_position
324 | if content_len > SINGLE_UPLOAD_LENGTH:
325 | raise CosClientError('The object size you upload can not be larger than 5GB in put_object or upload_part')
326 | return None
327 |
328 |
329 | def deal_with_empty_file_stream(data):
330 | """对于文件流的剩余长度为0的情况下,返回空字节流"""
331 | if hasattr(data, 'fileno') and hasattr(data, 'tell'):
332 | try:
333 | fileno = data.fileno()
334 | total_length = os.fstat(fileno).st_size
335 | # current_position = data.tell()
336 | if total_length == 0:
337 | return b""
338 | except io.UnsupportedOperation:
339 | return b""
340 | return data
341 |
342 |
343 | def format_dict(data, key_lst):
344 | """转换返回dict中的可重复字段为list"""
345 | for key in key_lst:
346 | # 将dict转为list,保持一致
347 | if key in data and isinstance(data[key], dict):
348 | lst = []
349 | lst.append(data[key])
350 | data[key] = lst
351 | return data
352 |
353 |
354 | def decode_result(data, key_lst, multi_key_list):
355 | """decode结果中的字段"""
356 | for key in key_lst:
357 | if key in data and data[key]:
358 | data[key] = unquote(data[key])
359 | for multi_key in multi_key_list:
360 | if multi_key[0] in data:
361 | for item in data[multi_key[0]]:
362 | if multi_key[1] in item and item[multi_key[1]]:
363 | item[multi_key[1]] = unquote(item[multi_key[1]])
364 | return data
365 |
366 |
367 | def get_date(yy, mm, dd):
368 | """获取lifecycle中Date字段"""
369 | date_str = datetime(yy, mm, dd).isoformat()
370 | final_date_str = date_str+'+08:00'
371 | return final_date_str
372 |
--------------------------------------------------------------------------------
/qcloud_cos/cos_exception.py:
--------------------------------------------------------------------------------
1 | # -*- coding=utf-8
2 |
3 | import xml.dom.minidom
4 |
5 |
6 | class CosException(Exception):
7 | def __init__(self, message):
8 | Exception.__init__(self, message)
9 |
10 |
11 | def digest_xml(data):
12 | msg = dict()
13 | try:
14 | tree = xml.dom.minidom.parseString(data)
15 | root = tree.documentElement
16 |
17 | result = root.getElementsByTagName('Code')
18 | msg['code'] = result[0].childNodes[0].nodeValue
19 |
20 | result = root.getElementsByTagName('Message')
21 | msg['message'] = result[0].childNodes[0].nodeValue
22 |
23 | result = root.getElementsByTagName('Resource')
24 | msg['resource'] = result[0].childNodes[0].nodeValue
25 |
26 | result = root.getElementsByTagName('RequestId')
27 | msg['requestid'] = result[0].childNodes[0].nodeValue
28 |
29 | result = root.getElementsByTagName('TraceId')
30 | msg['traceid'] = result[0].childNodes[0].nodeValue
31 | return msg
32 | except Exception as e:
33 | return "Response Error Msg Is INVALID"
34 |
35 |
36 | class CosClientError(CosException):
37 | """Client端错误,如timeout"""
38 | def __init__(self, message):
39 | CosException.__init__(self, message)
40 |
41 |
42 | class CosServiceError(CosException):
43 | """COS Server端错误,可以获取特定的错误信息"""
44 | def __init__(self, method, message, status_code):
45 | CosException.__init__(self, message)
46 | if method == 'HEAD': # 对HEAD进行特殊处理
47 | self._origin_msg = ''
48 | self._digest_msg = message
49 | else:
50 | self._origin_msg = message
51 | self._digest_msg = digest_xml(message)
52 | self._status_code = status_code
53 |
54 | def get_origin_msg(self):
55 | """获取原始的XML格式错误信息"""
56 | return self._origin_msg
57 |
58 | def get_digest_msg(self):
59 | """获取经过处理的dict格式的错误信息"""
60 | return self._digest_msg
61 |
62 | def get_status_code(self):
63 | """获取http error code"""
64 | return self._status_code
65 |
66 | def get_error_code(self):
67 | """获取COS定义的错误码描述,服务器返回错误信息格式出错时,返回空 """
68 | if isinstance(self._digest_msg, dict):
69 | return self._digest_msg['code']
70 | return "Unknown"
71 |
72 | def get_error_msg(self):
73 | if isinstance(self._digest_msg, dict):
74 | return self._digest_msg['message']
75 | return "Unknown"
76 |
77 | def get_resource_location(self):
78 | if isinstance(self._digest_msg, dict):
79 | return self._digest_msg['resource']
80 | return "Unknown"
81 |
82 | def get_trace_id(self):
83 | if isinstance(self._digest_msg, dict):
84 | return self._digest_msg['requestid']
85 | return "Unknown"
86 |
87 | def get_request_id(self):
88 | if isinstance(self._digest_msg, dict):
89 | return self._digest_msg['traceid']
90 | return "Unknown"
91 |
--------------------------------------------------------------------------------
/qcloud_cos/cos_threadpool.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | from threading import Thread
4 | from logging import getLogger
5 | from six.moves import queue
6 | from threading import Lock
7 | import gc
8 | logger = getLogger(__name__)
9 |
10 |
11 | class WorkerThread(Thread):
12 | def __init__(self, task_queue, *args, **kwargs):
13 | super(WorkerThread, self).__init__(*args, **kwargs)
14 |
15 | self._task_queue = task_queue
16 | self._succ_task_num = 0
17 | self._fail_task_num = 0
18 | self._ret = list()
19 |
20 | def run(self):
21 | while True:
22 | func, args, kwargs = self._task_queue.get()
23 | # 判断线程是否需要退出
24 | if func is None:
25 | return
26 | try:
27 | ret = func(*args, **kwargs)
28 | self._succ_task_num += 1
29 | self._ret.append(ret)
30 |
31 | except Exception as e:
32 | logger.warn(str(e))
33 | self._fail_task_num += 1
34 | self._ret.append(e)
35 | finally:
36 | self._task_queue.task_done()
37 | if self._task_queue.empty():
38 | break
39 |
40 | def get_result(self):
41 | return self._succ_task_num, self._fail_task_num, self._ret
42 |
43 |
44 | class SimpleThreadPool:
45 |
46 | def __init__(self, num_threads=5, num_queue=0):
47 | self._num_threads = num_threads
48 | self._queue = queue.Queue(num_queue)
49 | self._lock = Lock()
50 | self._active = False
51 | self._workers = list()
52 | self._finished = False
53 |
54 | def add_task(self, func, *args, **kwargs):
55 | if not self._active:
56 | with self._lock:
57 | if not self._active:
58 | self._workers = []
59 | self._active = True
60 |
61 | for i in range(self._num_threads):
62 | w = WorkerThread(self._queue)
63 | self._workers.append(w)
64 | w.start()
65 |
66 | self._queue.put((func, args, kwargs))
67 |
68 | def wait_completion(self):
69 | self._queue.join()
70 | self._finished = True
71 | # 已经结束的任务, 需要将线程都退出, 防止卡死
72 | for i in range(self._num_threads):
73 | self._queue.put((None, None, None))
74 |
75 | self._active = False
76 |
77 | def get_result(self):
78 | assert self._finished
79 | detail = [worker.get_result() for worker in self._workers]
80 | succ_all = all([tp[1] == 0 for tp in detail])
81 | return {'success_all': succ_all, 'detail': detail}
82 |
83 |
84 | if __name__ == '__main__':
85 |
86 | pool = SimpleThreadPool(2)
87 |
88 | def task_sleep(x):
89 | from time import sleep
90 | sleep(x)
91 | return 'hello, sleep %d seconds' % x
92 |
93 | def raise_exception():
94 | raise ValueError("Pa! Exception!")
95 | for i in range(1000):
96 | pool.add_task(task_sleep, 0.001)
97 | print(i)
98 | pool.add_task(task_sleep, 0)
99 | pool.add_task(task_sleep, 0)
100 | # pool.add_task(raise_exception)
101 | # pool.add_task(raise_exception)
102 |
103 | pool.wait_completion()
104 | print(pool.get_result())
105 | # [(1, 0, ['hello, sleep 5 seconds']), (2, 1, ['hello, sleep 2 seconds', 'hello, sleep 3 seconds', ValueError('Pa! Exception!',)])]
106 |
--------------------------------------------------------------------------------
/qcloud_cos/demo.py:
--------------------------------------------------------------------------------
1 | # -*- coding=utf-8
2 | from qcloud_cos import CosConfig
3 | from qcloud_cos import CosS3Client
4 | from qcloud_cos import CosServiceError
5 | from qcloud_cos import CosClientError
6 |
7 | import sys
8 | import logging
9 |
10 | # 腾讯云COSV5Python SDK, 目前可以支持Python2.6与Python2.7以及Python3.x
11 |
12 | # pip安装指南:pip install -U cos-python-sdk-v5
13 |
14 | # cos最新可用地域,参照https://www.qcloud.com/document/product/436/6224
15 |
16 | logging.basicConfig(level=logging.INFO, stream=sys.stdout)
17 |
18 | # 设置用户属性, 包括secret_id, secret_key, region
19 | # appid已在配置中移除,请在参数Bucket中带上appid。Bucket由bucketname-appid组成
20 | secret_id = 'AKID15IsskiBQACGbAo6WhgcQbVls7HmuG00' # 替换为用户的secret_id
21 | secret_key = 'csivKvxxrMvSvQpMWHuIz12pThQQlWRW' # 替换为用户的secret_key
22 | region = 'ap-beijing-1' # 替换为用户的region
23 | token = '' # 使用临时秘钥需要传入Token,默认为空,可不填
24 | config = CosConfig(Region=region, Secret_id=secret_id, Secret_key=secret_key, Token=token) # 获取配置对象
25 | client = CosS3Client(config)
26 |
27 | # 文件流 简单上传
28 | file_name = 'test.txt'
29 | with open('test.txt', 'rb') as fp:
30 | response = client.put_object(
31 | Bucket='test04-123456789', # Bucket由bucketname-appid组成
32 | Body=fp,
33 | Key=file_name,
34 | StorageClass='STANDARD',
35 | ContentType='text/html; charset=utf-8'
36 | )
37 | print(response['ETag'])
38 |
39 | # 字节流 简单上传
40 | response = client.put_object(
41 | Bucket='test04-123456789',
42 | Body=b'abcdefg',
43 | Key=file_name
44 | )
45 | print(response['ETag'])
46 |
47 | # 本地路径 简单上传
48 | response = client.put_object_from_local_file(
49 | Bucket='test04-123456789',
50 | LocalFilePath='local.txt',
51 | Key=file_name,
52 | )
53 | print(response['ETag'])
54 |
55 | # 设置HTTP头部 简单上传
56 | response = client.put_object(
57 | Bucket='test04-123456789',
58 | Body=b'test',
59 | Key=file_name,
60 | ContentType='text/html; charset=utf-8'
61 | )
62 | print(response['ETag'])
63 |
64 | # 设置自定义头部 简单上传
65 | response = client.put_object(
66 | Bucket='test04-123456789',
67 | Body=b'test',
68 | Key=file_name,
69 | Metadata={
70 | 'x-cos-meta-key1': 'value1',
71 | 'x-cos-meta-key2': 'value2'
72 | }
73 | )
74 | print(response['ETag'])
75 |
76 | # 高级上传接口(推荐)
77 | response = client.upload_file(
78 | Bucket='test04-123456789',
79 | LocalFilePath='local.txt',
80 | Key=file_name,
81 | PartSize=10,
82 | MAXThread=10
83 | )
84 | print(response['ETag'])
85 |
86 | # 文件下载 获取文件到本地
87 | response = client.get_object(
88 | Bucket='test04-123456789',
89 | Key=file_name,
90 | )
91 | response['Body'].get_stream_to_file('output.txt')
92 |
93 | # 文件下载 获取文件流
94 | response = client.get_object(
95 | Bucket='test04-123456789',
96 | Key=file_name,
97 | )
98 | fp = response['Body'].get_raw_stream()
99 | print(fp.read(2))
100 |
101 | # 文件下载 设置Response HTTP 头部
102 | response = client.get_object(
103 | Bucket='test04-123456789',
104 | Key=file_name,
105 | ResponseContentType='text/html; charset=utf-8'
106 | )
107 | print(response['Content-Type'])
108 | fp = response['Body'].get_raw_stream()
109 | print(fp.read(2))
110 |
111 | # 文件下载 指定下载范围
112 | response = client.get_object(
113 | Bucket='test04-123456789',
114 | Key=file_name,
115 | Range='bytes=0-10'
116 | )
117 | fp = response['Body'].get_raw_stream()
118 | print(fp.read())
119 |
120 | # 文件下载 捕获异常
121 | try:
122 | response = client.get_object(
123 | Bucket='test04-123456789',
124 | Key='not_exist.txt',
125 | )
126 | fp = response['Body'].get_raw_stream()
127 | print(fp.read(2))
128 | except CosServiceError as e:
129 | print(e.get_origin_msg())
130 | print(e.get_digest_msg())
131 | print(e.get_status_code())
132 | print(e.get_error_code())
133 | print(e.get_error_msg())
134 | print(e.get_resource_location())
135 | print(e.get_trace_id())
136 | print(e.get_request_id())
137 |
--------------------------------------------------------------------------------
/qcloud_cos/streambody.py:
--------------------------------------------------------------------------------
1 | # -*- coding=utf-8
2 |
3 |
4 | class StreamBody():
5 | def __init__(self, rt):
6 | self._rt = rt
7 |
8 | def get_raw_stream(self):
9 | return self._rt.raw
10 |
11 | def get_stream(self, chunk_size=1024):
12 | return self._rt.iter_content(chunk_size=chunk_size)
13 |
14 | def get_stream_to_file(self, file_name):
15 | if 'Content-Length' in self._rt.headers:
16 | content_len = int(self._rt.headers['Content-Length'])
17 | else:
18 | raise IOError("download failed without Content-Length header")
19 |
20 | file_len = 0
21 | with open(file_name, 'wb') as fp:
22 | for chunk in self._rt.iter_content(chunk_size=1024):
23 | if chunk:
24 | file_len += len(chunk)
25 | fp.write(chunk)
26 | fp.flush()
27 | fp.close()
28 | if file_len != content_len:
29 | raise IOError("download failed with incomplete file")
30 |
--------------------------------------------------------------------------------
/qcloud_cos/xml2dict.py:
--------------------------------------------------------------------------------
1 | # -*- coding=utf-8
2 | import xml.etree.ElementTree
3 |
4 |
5 | class Xml2Dict(dict):
6 |
7 | def __init__(self, parent_node):
8 | if parent_node.items():
9 | self.updateDict(dict(parent_node.items()))
10 | for element in parent_node:
11 | if len(element):
12 | aDict = Xml2Dict(element)
13 | self.updateDict({element.tag: aDict})
14 | elif element.items():
15 | elementattrib = element.items()
16 | if element.text:
17 | elementattrib.append((element.tag, element.text))
18 | self.updateDict({element.tag: dict(elementattrib)})
19 | else:
20 | self.updateDict({element.tag: element.text})
21 |
22 | def updateDict(self, aDict):
23 | for key in aDict:
24 | if key in self:
25 | value = self.pop(key)
26 | if type(value) is not list:
27 | lst = list()
28 | lst.append(value)
29 | lst.append(aDict[key])
30 | self.update({key: lst})
31 | else:
32 | value.append(aDict[key])
33 | self.update({key: value})
34 | else:
35 | self.update({key: aDict[key]})
36 |
37 |
38 | if __name__ == "__main__":
39 | s = """
40 |
41 | 10
42 | 1test1
43 | 2test2
44 | 3test3
45 | """
46 | root = xml.etree.ElementTree.fromstring(s)
47 | xmldict = Xml2Dict(root)
48 | print(xmldict)
49 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | pip
2 | oss2
--------------------------------------------------------------------------------
/util.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8
2 | import os
3 | import pip
4 | import imp
5 | import requests
6 | from qcloud_cos import CosConfig
7 | from qcloud_cos import CosS3Client
8 |
9 | debug = os.getenv('debug')=="true" and True or False
10 |
11 | """
12 | oss 阿里云配置
13 | """
14 | AccessKeyId = os.getenv('oss.AccessKeyId')
15 | AccessKeySecret = os.getenv('oss.AccessKeySecret')
16 | bucket_name = os.getenv('oss.bucket_name')
17 | endpoint = os.getenv('oss.endpoint')
18 | endpointurl = "http://%s" % endpoint
19 | """
20 | cos 腾讯云配置
21 | """
22 | cos_bucket_name = os.getenv('cos_bucket_name')
23 | cos_is_cdn = os.getenv('cos_is_cdn')
24 | cos_cdn_domain = os.getenv('cos_cdn_domain')
25 | cos_region = os.getenv('cos_region')
26 | cos_secret_id = os.getenv('cos_secret_id')
27 | cos_secret_key = os.getenv('cos_secret_key')
28 | """
29 | imgur 配置
30 | """
31 | imgur_client_id = os.getenv('imgur_client_id')
32 | imgur_client_secret = os.getenv('imgur_client_secret')
33 | imgur_access_token = os.getenv('imgur_access_token')
34 | imgur_refresh_token = os.getenv('imgur_refresh_token')
35 | imgur_use = os.getenv('imgur_use')
36 | imgur_album = os.getenv('imgur_album')
37 | porxyconf = os.getenv('porxyconf')
38 | PROXY_LIST = {
39 | 'http': porxyconf ,
40 | 'https': porxyconf
41 | }
42 | credentials= []
43 |
44 | def notice(msg, title="【万能图床】提示", subtitle=''):
45 | ''' notoce message in notification center'''
46 | os.system('osascript -e \'display notification "%s" with title "%s"\'' % (msg, title))
47 |
48 |
49 | def install_and_load(package):
50 | pip.main(['install', package])
51 |
52 | f, fname, desc = imp.find_module(package)
53 | return imp.load_module(package, f, fname, desc)
54 |
55 |
56 | """
57 | 检查指定云是否配置正确
58 | """
59 |
60 |
61 | def checkConfig(yuncode):
62 | if 'oss' == yuncode:
63 | return checkOssConfig()
64 | elif yuncode == 'cos':
65 | return checkCosConfig()
66 | elif yuncode == 'imgur':
67 | return checkImgurConfig()
68 | else:
69 | return False
70 |
71 |
72 | """
73 | 获取所有配置正确的云code
74 | """
75 |
76 |
77 | def getAllConfiged():
78 | list = []
79 | if (checkOssConfig()):
80 | list.append('oss')
81 | if (checkCosConfig()):
82 | list.append('cos')
83 | if (checkImgurConfig()):
84 | list.append('imgur')
85 | return list
86 |
87 | """检查阿里云云配置是否配全"""
88 | def checkOssConfig():
89 | if (AccessKeyId is not None
90 | and AccessKeySecret is not None
91 | and bucket_name is not None
92 | and endpoint is not None
93 | ):
94 | return True
95 | else:
96 | return False
97 |
98 | """检查腾讯云配置是否配全"""
99 | def checkCosConfig():
100 | if (cos_bucket_name is not None
101 | and cos_is_cdn is not None
102 | and cos_region is not None
103 | and cos_secret_id is not None
104 | and cos_secret_key is not None
105 | ):
106 | return True
107 | else:
108 | return False
109 | """检查imgur配置是否配全"""
110 | def checkImgurConfig():
111 | if (((imgur_use is not None
112 | and imgur_use == 'true' )or imgur_use is None)
113 | and imgur_client_id is not None
114 | and imgur_client_secret is not None
115 | and imgur_access_token is not None
116 | and imgur_refresh_token is not None
117 | ):
118 | return True
119 | else:
120 | return False
121 |
122 |
123 | """
124 | 上传到阿里云
125 | """
126 | def uploadOssObj(objtype, name, obj):
127 | try:
128 | import oss2
129 | except:
130 | oss2 = install_and_load('oss2')
131 | auth = oss2.Auth(AccessKeyId, AccessKeySecret)
132 | bucket = oss2.Bucket(auth, endpointurl, bucket_name)
133 | if debug : notice("上传到阿里云!%s %s" % (endpointurl,bucket_name))
134 | if ('localfile' == objtype):
135 | bucket.put_object_from_file(name, obj)
136 | elif 'url' == objtype:
137 | input = requests.get(obj)
138 | bucket.put_object(name, input)
139 | else:
140 | if debug: notice("阿里云不支持【%s】上传" % objtype)
141 |
142 | def getOssMKurl(upload_name):
143 | return '' % (bucket_name,endpoint,upload_name)
144 |
145 | """
146 | 上传到腾讯云
147 | """
148 | def uploadCosObj(objtype, name, obj):
149 | token = ''
150 | config = CosConfig(Region=cos_region, Secret_id=cos_secret_id, Secret_key=cos_secret_key, Token=token)
151 | # 2. 获取客户端对象
152 | client = CosS3Client(config)
153 | if debug: notice("上传到腾讯云!%s" % ( cos_bucket_name))
154 | if ('localfile' == objtype):
155 | response = client.put_object_from_local_file(
156 | Bucket=cos_bucket_name,
157 | LocalFilePath=obj,
158 | Key=name,
159 | )
160 | if debug: notice("上传到腾讯云返回:%s" % (response))
161 | elif 'url' == objtype:
162 | if debug: notice("腾讯云不支持url上传" )
163 | else:
164 | if debug: notice("腾讯云不支持【%s】上传" % objtype)
165 |
166 | def getCosMKurl(upload_name):
167 | if 'true' == cos_is_cdn:
168 | return '' % (cos_bucket_name,cos_cdn_domain,upload_name)
169 | else:
170 | return '' % (cos_bucket_name,upload_name)
171 |
172 | """
173 | 上传到imgur
174 | """
175 | def uploadImgurObj(objtype, name, obj):
176 | from imgurpython import ImgurClient
177 | import time
178 | client = ImgurClient(imgur_client_id, imgur_client_secret,access_token=imgur_access_token,refresh_token=imgur_refresh_token,proxies=PROXY_LIST)
179 | if debug: notice("上传到imgur!%s" % (imgur_album))
180 | config = {
181 | 'album': imgur_album,
182 | 'name': name,
183 | 'title': name,
184 | 'description': '{0} 通过wntc万能图床上传 https://github.com/juforg/wntc.alfredworkflow'.format(time.strftime('%Y/%-m/%-d %H:%M:%S',time.localtime(time.time())))
185 | }
186 | if ('localfile' == objtype):
187 | image = client.upload_from_path(obj, config=config, anon=False)
188 | # print(json.dumps(image))
189 | if debug: notice("上传到imgur返回:%s" % (response))
190 | elif 'url' == objtype:
191 | if debug: notice("imgur不支持url上传" )
192 | else:
193 | if debug: notice("imgur不支持【%s】上传" % objtype)
194 |
195 | return '' % (image['link'])
196 |
197 |
198 | def get_input(string):
199 | ''' Get input from console regardless of python 2 or 3 '''
200 | try:
201 | return raw_input(string)
202 | except:
203 | return input(string)
204 |
205 | if __name__ == "__main__":
206 | try:
207 | import oss2
208 | except:
209 | print("err p")
210 |
--------------------------------------------------------------------------------
/wntc.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | from clipboard import get_paste_img_file
3 | from util import *
4 | import os
5 | import sys
6 | import time
7 |
8 | debug = os.getenv('debug')=="true" and True or False
9 | favor_yun = os.getenv('favor_yun') ##优先云代码
10 | vardate = time.strftime('%Y/%-m/%-d',time.localtime(time.time()))
11 | yuncode = '' #指定云代码
12 | upload_name='' #上传文件名
13 | yuncodelist = [] #有效云code 都会上传
14 | markdown_url = '' # 最终在剪贴板中的url
15 | url_dict = {}
16 |
17 | if len(sys.argv) > 1 and sys.argv[1]:
18 | yuncode = sys.argv[1]
19 | if yuncode:
20 | if checkConfig(yuncode) :
21 | yuncodelist.append(yuncode)
22 | else:
23 | notice("占不支持该云!%s" % yuncode)
24 | else:
25 | if debug: notice("获取所有有用配置")
26 | yuncodelist = getAllConfiged()
27 | if debug : notice("有效配置 %s 个 " % (yuncodelist.__len__()),'debug')
28 |
29 | if(yuncodelist.__len__() == 0 ):
30 | notice("未正确配置图床信息!请在Alfred workflow 配置!")
31 | else:
32 | img_file, need_format, format = get_paste_img_file()
33 | if img_file is not None:
34 | upload_name = "%s/%s.%s" % (vardate,int(time.time() * 1000), format)
35 | if debug: notice("文件名:%s" % upload_name,'debug')
36 | for i in yuncodelist:
37 | if 'oss' == i:
38 | uploadOssObj('localfile',upload_name,img_file.name)
39 | url_dict['oss'] = getOssMKurl(upload_name)
40 | elif 'cos' ==i:
41 | uploadCosObj('localfile',upload_name,img_file.name)
42 | url_dict['cos'] = getCosMKurl(upload_name)
43 | elif 'imgur' == i:
44 | url_dict['imgur'] = uploadImgurObj('localfile',upload_name,img_file.name)
45 | else:
46 | if debug: notice("该云尚未实现!%s" % i)
47 | if url_dict:
48 | if favor_yun and url_dict.has_key(favor_yun):
49 | markdown_url = url_dict[favor_yun]
50 | else:
51 | markdown_url = url_dict.values()[0]
52 |
53 | if markdown_url:
54 | os.system("echo '%s' | pbcopy" % markdown_url)
55 | sys.stdout.write(markdown_url)
56 | else:
57 | notice("剪贴板无图片!")
58 | sys.stdout.write(yuncode)
59 |
--------------------------------------------------------------------------------
/程序示意图.eddx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/juforg/wntc.alfredworkflow/9f1ddbd83727a9e972fd26fd63486065021a7ae2/程序示意图.eddx
--------------------------------------------------------------------------------