├── .gitignore
├── .vscode
└── settings.json
├── Interpolations
└── linear_interpolation_dims=128.png
├── LICENSE.md
├── README.md
├── Reconstructions
├── recons_epoch_10.png
├── recons_epoch_20_128dims.png
└── recons_epoch_20_256dims.png
├── Samples
├── generated_samples_epoch_10.png
├── generated_samples_epoch_20_128dims.png
└── generated_samples_epoch_20_256dims.png
├── base
├── __init__.py
├── base_data_loader.py
├── base_model.py
└── base_trainer.py
├── config.json
├── data_loader
└── data_loaders.py
├── logger
├── __init__.py
├── logger.py
├── logger_config.json
└── visualization.py
├── model
├── loss.py
├── metric.py
├── model.py
└── types_.py
├── parse_config.py
├── requirements.txt
├── test.py
├── train.py
├── trainer
├── __init__.py
└── trainer.py
├── traversal_test.ipynb
└── utils
├── __init__.py
└── util.py
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | env/
12 | build/
13 | develop-eggs/
14 | dist/
15 | downloads/
16 | eggs/
17 | .eggs/
18 | lib/
19 | lib64/
20 | parts/
21 | sdist/
22 | var/
23 | wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 |
28 | # PyInstaller
29 | # Usually these files are written by a python script from a template
30 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
31 | *.manifest
32 | *.spec
33 |
34 | # Installer logs
35 | pip-log.txt
36 | pip-delete-this-directory.txt
37 |
38 | # Unit test / coverage reports
39 | htmlcov/
40 | .tox/
41 | .coverage
42 | .coverage.*
43 | .cache
44 | nosetests.xml
45 | coverage.xml
46 | *.cover
47 | .hypothesis/
48 |
49 | # Translations
50 | *.mo
51 | *.pot
52 |
53 | # Django stuff:
54 | *.log
55 | local_settings.py
56 |
57 | # Flask stuff:
58 | instance/
59 | .webassets-cache
60 |
61 | # Scrapy stuff:
62 | .scrapy
63 |
64 | # Sphinx documentation
65 | docs/_build/
66 |
67 | # PyBuilder
68 | target/
69 |
70 | # Jupyter Notebook
71 | .ipynb_checkpoints
72 |
73 | # pyenv
74 | .python-version
75 |
76 | # celery beat schedule file
77 | celerybeat-schedule
78 |
79 | # SageMath parsed files
80 | *.sage.py
81 |
82 | # dotenv
83 | .env
84 |
85 | # virtualenv
86 | .venv
87 | venv/
88 | ENV/
89 |
90 | # Spyder project settings
91 | .spyderproject
92 | .spyproject
93 |
94 | # Rope project settings
95 | .ropeproject
96 |
97 | # mkdocs documentation
98 | /site
99 |
100 | # mypy
101 | .mypy_cache/
102 |
103 | # input data, saved log, checkpoints
104 | data/
105 | input/
106 | saved/
107 | datasets/
108 |
109 | # editor, os cache directory
110 | .vscode/
111 | .idea/
112 | __MACOSX/
113 |
--------------------------------------------------------------------------------
/.vscode/settings.json:
--------------------------------------------------------------------------------
1 | {}
--------------------------------------------------------------------------------
/Interpolations/linear_interpolation_dims=128.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/julian-8897/Conv-VAE-PyTorch/d86013578435b9208468a482cb14e7a3c79d7510/Interpolations/linear_interpolation_dims=128.png
--------------------------------------------------------------------------------
/LICENSE.md:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2022 Julian Chan
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | Image Generation and Reconstruction with Convolutional Variational Autoencoder (VAE) in PyTorch
3 |
4 |
5 |
6 |
7 |  8 |
9 |
8 |
9 |  10 |
11 |
10 |
11 |  12 |
13 |
12 |
13 |
14 |
15 | ## Implementation Details
16 |
17 | A PyTorch implementation of the standard Variational Autoencoder (VAE). The amortized inference model (encoder) is parameterized by a convolutional network, while the generative model (decoder) is parameterized by a transposed convolutional network. The choice of the approximate posterior is a fully-factorized gaussian distribution with diagonal covariance.
18 |
19 | This implementation supports model training on the [CelebA dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). This project serves as a proof of concept, hence the original images (178 x 218) are scaled and cropped to (64 x 64) images in order to speed up the training process. For ease of access, the zip file which contains the dataset can be downloaded from: https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/celeba.zip.
20 |
21 | The VAE model was evaluated on several downstream tasks, such as image reconstruction and image generation. Some sample results can be found in the [Results](https://github.com/julian-8897/Vanilla-VAE-PyTorch/blob/master/README.md#--Results) section.
22 |
23 |
24 | [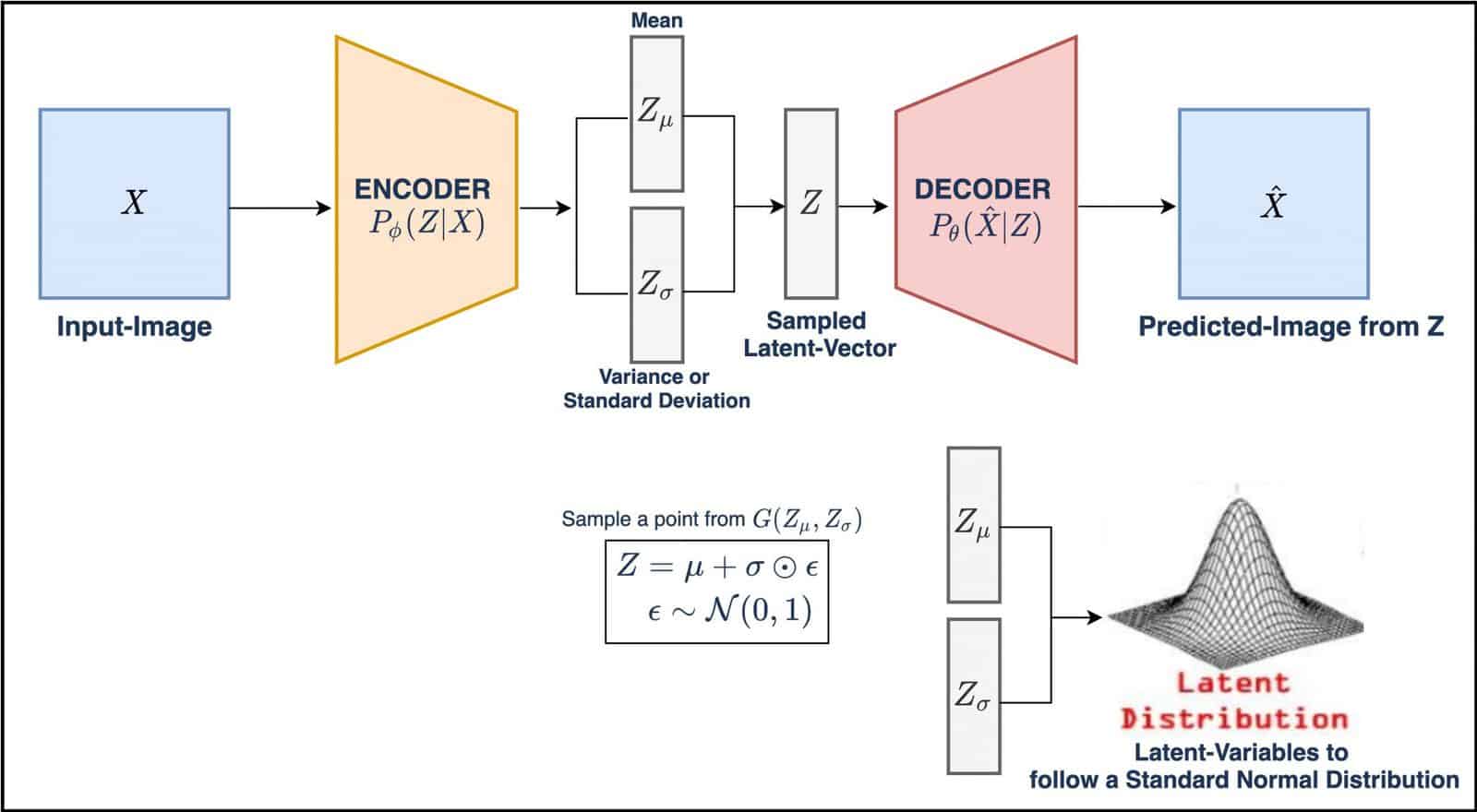](https://learnopencv.com/wp-content/uploads/2020/11/vae-diagram-1-2048x1126.jpg)
25 | *Figure 1: Visual Representation of VAE. Image source: [LearnOpenCV](https://learnopencv.com/wp-content/uploads/2020/11/vae-diagram-1-2048x1126.jpg)*
26 |
27 |
28 | ## Requirements
29 |
30 | - Python >= 3.9
31 | - PyTorch >= 1.9
32 |
33 | ## Installation Guide
34 |
35 | ```
36 | $ git clone https://github.com/julian-8897/Conv-VAE-PyTorch.git
37 | $ cd Vanilla-VAE-PyTorch
38 | $ pip install -r requirements.txt
39 | ```
40 |
41 | ## Usage
42 |
43 | ### Training
44 |
45 | To train the model, please modify the `config.json` configuration file, and run:
46 |
47 | ```
48 | python train.py --config config.json
49 | ```
50 |
51 | ### Resuming Training
52 |
53 | To resume training of the model from a checkpoint, you can run the following command:
54 |
55 | ```
56 | python train.py --resume path/to/checkpoint
57 | ```
58 |
59 | ### Testing
60 |
61 | To test the model, you can run the following command:
62 |
63 | ```
64 | python test.py --resume path/to/checkpoint
65 | ```
66 |
67 | Generated plots are stored in the 'Reconstructions' and 'Samples' folders.
68 |
69 | ---
70 |
71 |
72 | Results
73 |
74 |
75 | ## 128 Latent Dimensions
76 |
77 | | Reconstructed Samples | Generated Samples |
78 | | --------------------- | ----------------- |
79 | | ![][1] | ![][2] |
80 |
81 | ## 256 Latent Dimensions
82 |
83 | | Reconstructed Samples | Generated Samples |
84 | | --------------------- | ----------------- |
85 | | ![][3] | ![][4] |
86 |
87 | [1]: https://github.com/julian-8897/Vanilla-VAE-PyTorch/blob/master/Reconstructions/recons_epoch_20_128dims.png
88 | [2]: https://github.com/julian-8897/Vanilla-VAE-PyTorch/blob/master/Samples/generated_samples_epoch_20_128dims.png
89 | [3]: https://github.com/julian-8897/Vanilla-VAE-PyTorch/blob/master/Reconstructions/recons_epoch_20_256dims.png
90 | [4]: https://github.com/julian-8897/Vanilla-VAE-PyTorch/blob/master/Samples/generated_samples_epoch_20_256dims.png
91 |
92 | ## References
93 |
94 | 1. Original VAE paper "Auto-Encoding Variational Bayes" by Kingma & Welling:
95 | https://arxiv.org/abs/1312.6114
96 |
97 | 2. Various implementations of VAEs in PyTorch:
98 | https://github.com/AntixK/PyTorch-VAE
99 |
100 | 3. PyTorch template used in this project:
101 | https://github.com/victoresque/pytorch-template
102 |
103 | 4. A comprehensive introduction to VAEs:
104 | https://arxiv.org/pdf/1906.02691.pdf
105 |
--------------------------------------------------------------------------------
/Reconstructions/recons_epoch_10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/julian-8897/Conv-VAE-PyTorch/d86013578435b9208468a482cb14e7a3c79d7510/Reconstructions/recons_epoch_10.png
--------------------------------------------------------------------------------
/Reconstructions/recons_epoch_20_128dims.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/julian-8897/Conv-VAE-PyTorch/d86013578435b9208468a482cb14e7a3c79d7510/Reconstructions/recons_epoch_20_128dims.png
--------------------------------------------------------------------------------
/Reconstructions/recons_epoch_20_256dims.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/julian-8897/Conv-VAE-PyTorch/d86013578435b9208468a482cb14e7a3c79d7510/Reconstructions/recons_epoch_20_256dims.png
--------------------------------------------------------------------------------
/Samples/generated_samples_epoch_10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/julian-8897/Conv-VAE-PyTorch/d86013578435b9208468a482cb14e7a3c79d7510/Samples/generated_samples_epoch_10.png
--------------------------------------------------------------------------------
/Samples/generated_samples_epoch_20_128dims.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/julian-8897/Conv-VAE-PyTorch/d86013578435b9208468a482cb14e7a3c79d7510/Samples/generated_samples_epoch_20_128dims.png
--------------------------------------------------------------------------------
/Samples/generated_samples_epoch_20_256dims.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/julian-8897/Conv-VAE-PyTorch/d86013578435b9208468a482cb14e7a3c79d7510/Samples/generated_samples_epoch_20_256dims.png
--------------------------------------------------------------------------------
/base/__init__.py:
--------------------------------------------------------------------------------
1 | from .base_data_loader import *
2 | from .base_model import *
3 | from .base_trainer import *
4 |
--------------------------------------------------------------------------------
/base/base_data_loader.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from torch.utils.data import DataLoader
3 | from torch.utils.data.dataloader import default_collate
4 | from torch.utils.data.sampler import SubsetRandomSampler
5 |
6 |
7 | class BaseDataLoader(DataLoader):
8 | """
9 | Base class for all data loaders
10 | """
11 | def __init__(self, dataset, batch_size, shuffle, validation_split, num_workers, collate_fn=default_collate):
12 | self.validation_split = validation_split
13 | self.shuffle = shuffle
14 |
15 | self.batch_idx = 0
16 | self.n_samples = len(dataset)
17 |
18 | self.sampler, self.valid_sampler = self._split_sampler(self.validation_split)
19 |
20 | self.init_kwargs = {
21 | 'dataset': dataset,
22 | 'batch_size': batch_size,
23 | 'shuffle': self.shuffle,
24 | 'collate_fn': collate_fn,
25 | 'num_workers': num_workers
26 | }
27 | super().__init__(sampler=self.sampler, **self.init_kwargs)
28 |
29 | def _split_sampler(self, split):
30 | if split == 0.0:
31 | return None, None
32 |
33 | idx_full = np.arange(self.n_samples)
34 |
35 | np.random.seed(0)
36 | np.random.shuffle(idx_full)
37 |
38 | if isinstance(split, int):
39 | assert split > 0
40 | assert split < self.n_samples, "validation set size is configured to be larger than entire dataset."
41 | len_valid = split
42 | else:
43 | len_valid = int(self.n_samples * split)
44 |
45 | valid_idx = idx_full[0:len_valid]
46 | train_idx = np.delete(idx_full, np.arange(0, len_valid))
47 |
48 | train_sampler = SubsetRandomSampler(train_idx)
49 | valid_sampler = SubsetRandomSampler(valid_idx)
50 |
51 | # turn off shuffle option which is mutually exclusive with sampler
52 | self.shuffle = False
53 | self.n_samples = len(train_idx)
54 |
55 | return train_sampler, valid_sampler
56 |
57 | def split_validation(self):
58 | if self.valid_sampler is None:
59 | return None
60 | else:
61 | return DataLoader(sampler=self.valid_sampler, **self.init_kwargs)
62 |
--------------------------------------------------------------------------------
/base/base_model.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import numpy as np
3 | from abc import abstractmethod
4 |
5 |
6 | class BaseModel(nn.Module):
7 | """
8 | Base class for all models
9 | """
10 | @abstractmethod
11 | def forward(self, *inputs):
12 | """
13 | Forward pass logic
14 |
15 | :return: Model output
16 | """
17 | raise NotImplementedError
18 |
19 | def __str__(self):
20 | """
21 | Model prints with number of trainable parameters
22 | """
23 | model_parameters = filter(lambda p: p.requires_grad, self.parameters())
24 | params = sum([np.prod(p.size()) for p in model_parameters])
25 | return super().__str__() + '\nTrainable parameters: {}'.format(params)
26 |
--------------------------------------------------------------------------------
/base/base_trainer.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from abc import abstractmethod
3 | from numpy import inf
4 | from logger import TensorboardWriter
5 |
6 |
7 | class BaseTrainer:
8 | """
9 | Base class for all trainers
10 | """
11 |
12 | def __init__(self, model, criterion, optimizer, config):
13 | self.config = config
14 | self.logger = config.get_logger(
15 | 'trainer', config['trainer']['verbosity'])
16 |
17 | self.model = model
18 | self.criterion = criterion
19 | # self.metric_ftns = metric_ftns
20 | self.optimizer = optimizer
21 |
22 | cfg_trainer = config['trainer']
23 | self.epochs = cfg_trainer['epochs']
24 | self.save_period = cfg_trainer['save_period']
25 | self.monitor = cfg_trainer.get('monitor', 'off')
26 |
27 | # configuration to monitor model performance and save best
28 | if self.monitor == 'off':
29 | self.mnt_mode = 'off'
30 | self.mnt_best = 0
31 | else:
32 | self.mnt_mode, self.mnt_metric = self.monitor.split()
33 | assert self.mnt_mode in ['min', 'max']
34 |
35 | self.mnt_best = inf if self.mnt_mode == 'min' else -inf
36 | self.early_stop = cfg_trainer.get('early_stop', inf)
37 | if self.early_stop <= 0:
38 | self.early_stop = inf
39 |
40 | self.start_epoch = 1
41 |
42 | self.checkpoint_dir = config.save_dir
43 |
44 | # setup visualization writer instance
45 | self.writer = TensorboardWriter(
46 | config.log_dir, self.logger, cfg_trainer['tensorboard'])
47 |
48 | if config.resume is not None:
49 | self._resume_checkpoint(config.resume)
50 |
51 | @abstractmethod
52 | def _train_epoch(self, epoch):
53 | """
54 | Training logic for an epoch
55 |
56 | :param epoch: Current epoch number
57 | """
58 | raise NotImplementedError
59 |
60 | def train(self):
61 | """
62 | Full training logic
63 | """
64 | not_improved_count = 0
65 | for epoch in range(self.start_epoch, self.epochs + 1):
66 | result = self._train_epoch(epoch)
67 |
68 | # save logged informations into log dict
69 | log = {'epoch': epoch}
70 | log.update(result)
71 |
72 | # print logged informations to the screen
73 | for key, value in log.items():
74 | self.logger.info(' {:15s}: {}'.format(str(key), value))
75 |
76 | # evaluate model performance according to configured metric, save best checkpoint as model_best
77 | best = False
78 | if self.mnt_mode != 'off':
79 | try:
80 | # check whether model performance improved or not, according to specified metric(mnt_metric)
81 | improved = (self.mnt_mode == 'min' and log[self.mnt_metric] <= self.mnt_best) or \
82 | (self.mnt_mode ==
83 | 'max' and log[self.mnt_metric] >= self.mnt_best)
84 | except KeyError:
85 | self.logger.warning("Warning: Metric '{}' is not found. "
86 | "Model performance monitoring is disabled.".format(self.mnt_metric))
87 | self.mnt_mode = 'off'
88 | improved = False
89 |
90 | if improved:
91 | self.mnt_best = log[self.mnt_metric]
92 | not_improved_count = 0
93 | best = True
94 | else:
95 | not_improved_count += 1
96 |
97 | if not_improved_count > self.early_stop:
98 | self.logger.info("Validation performance didn\'t improve for {} epochs. "
99 | "Training stops.".format(self.early_stop))
100 | break
101 |
102 | if epoch % self.save_period == 0:
103 | self._save_checkpoint(epoch, save_best=best)
104 |
105 | def _save_checkpoint(self, epoch, save_best=False):
106 | """
107 | Saving checkpoints
108 |
109 | :param epoch: current epoch number
110 | :param log: logging information of the epoch
111 | :param save_best: if True, rename the saved checkpoint to 'model_best.pth'
112 | """
113 | arch = type(self.model).__name__
114 | state = {
115 | 'arch': arch,
116 | 'epoch': epoch,
117 | 'state_dict': self.model.state_dict(),
118 | 'optimizer': self.optimizer.state_dict(),
119 | 'monitor_best': self.mnt_best,
120 | 'config': self.config
121 | }
122 | filename = str(self.checkpoint_dir /
123 | 'checkpoint-epoch{}.pth'.format(epoch))
124 | torch.save(state, filename)
125 | self.logger.info("Saving checkpoint: {} ...".format(filename))
126 | if save_best:
127 | best_path = str(self.checkpoint_dir / 'model_best.pth')
128 | torch.save(state, best_path)
129 | self.logger.info("Saving current best: model_best.pth ...")
130 |
131 | def _resume_checkpoint(self, resume_path):
132 | """
133 | Resume from saved checkpoints
134 |
135 | :param resume_path: Checkpoint path to be resumed
136 | """
137 | resume_path = str(resume_path)
138 | self.logger.info("Loading checkpoint: {} ...".format(resume_path))
139 | checkpoint = torch.load(resume_path)
140 | self.start_epoch = checkpoint['epoch'] + 1
141 | self.mnt_best = checkpoint['monitor_best']
142 |
143 | # load architecture params from checkpoint.
144 | if checkpoint['config']['arch'] != self.config['arch']:
145 | self.logger.warning("Warning: Architecture configuration given in config file is different from that of "
146 | "checkpoint. This may yield an exception while state_dict is being loaded.")
147 | self.model.load_state_dict(checkpoint['state_dict'])
148 |
149 | # load optimizer state from checkpoint only when optimizer type is not changed.
150 | if checkpoint['config']['optimizer']['type'] != self.config['optimizer']['type']:
151 | self.logger.warning("Warning: Optimizer type given in config file is different from that of checkpoint. "
152 | "Optimizer parameters not being resumed.")
153 | else:
154 | self.optimizer.load_state_dict(checkpoint['optimizer'])
155 |
156 | self.logger.info(
157 | "Checkpoint loaded. Resume training from epoch {}".format(self.start_epoch))
158 |
--------------------------------------------------------------------------------
/config.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "VAE_CelebA",
3 | "n_gpu": 1,
4 | "arch": {
5 | "type": "VanillaVAE",
6 | "args": {
7 | "in_channels": 3,
8 | "latent_dims": 128,
9 | "flow": false
10 | }
11 | },
12 | "data_loader": {
13 | "type": "CelebDataLoader",
14 | "args": {
15 | "data_dir": "data/",
16 | "batch_size": 64,
17 | "shuffle": true,
18 | "validation_split": 0.2,
19 | "num_workers": 2
20 | }
21 | },
22 | "optimizer": {
23 | "type": "Adam",
24 | "args": {
25 | "lr": 0.005,
26 | "weight_decay": 0.0,
27 | "amsgrad": true
28 | }
29 | },
30 | "loss": "elbo_loss",
31 | "metrics": [],
32 | "lr_scheduler": {
33 | "type": "StepLR",
34 | "args": {
35 | "step_size": 50,
36 | "gamma": 0.1
37 | }
38 | },
39 | "trainer": {
40 | "epochs": 20,
41 | "save_dir": "saved/",
42 | "save_period": 1,
43 | "verbosity": 2,
44 | "monitor": "min val_loss",
45 | "early_stop": 10,
46 | "tensorboard": true
47 | }
48 | }
--------------------------------------------------------------------------------
/data_loader/data_loaders.py:
--------------------------------------------------------------------------------
1 | from torchvision import datasets, transforms
2 | from base import BaseDataLoader
3 |
4 |
5 | class MnistDataLoader(BaseDataLoader):
6 | """
7 | MNIST data loading demo using BaseDataLoader
8 | """
9 |
10 | def __init__(self, data_dir, batch_size, shuffle=True, validation_split=0.0, num_workers=1, training=True):
11 | trsfm = transforms.Compose([
12 | transforms.ToTensor(),
13 | transforms.Normalize((0.1307,), (0.3081,))
14 | ])
15 | self.data_dir = data_dir
16 | self.dataset = datasets.MNIST(
17 | self.data_dir, train=training, download=True, transform=trsfm)
18 | super().__init__(self.dataset, batch_size, shuffle, validation_split, num_workers)
19 |
20 |
21 | class CelebDataLoader(BaseDataLoader):
22 | """
23 | CelebA data loading
24 | Download and extract:
25 | https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/celeba.zip
26 | """
27 |
28 | def __init__(self, data_dir, batch_size, shuffle=True, validation_split=0.0, num_workers=1, image_size=64):
29 | transform = transforms.Compose([
30 | transforms.Resize(image_size),
31 | transforms.CenterCrop(image_size),
32 | transforms.ToTensor(),
33 | ])
34 | self.data_dir = data_dir
35 | self.dataset = datasets.ImageFolder(
36 | self.data_dir, transform=transform)
37 | super().__init__(self.dataset, batch_size, shuffle, validation_split, num_workers)
38 |
--------------------------------------------------------------------------------
/logger/__init__.py:
--------------------------------------------------------------------------------
1 | from .logger import *
2 | from .visualization import *
--------------------------------------------------------------------------------
/logger/logger.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import logging.config
3 | from pathlib import Path
4 | from utils import read_json
5 |
6 |
7 | def setup_logging(save_dir, log_config='logger/logger_config.json', default_level=logging.INFO):
8 | """
9 | Setup logging configuration
10 | """
11 | log_config = Path(log_config)
12 | if log_config.is_file():
13 | config = read_json(log_config)
14 | # modify logging paths based on run config
15 | for _, handler in config['handlers'].items():
16 | if 'filename' in handler:
17 | handler['filename'] = str(save_dir / handler['filename'])
18 |
19 | logging.config.dictConfig(config)
20 | else:
21 | print("Warning: logging configuration file is not found in {}.".format(log_config))
22 | logging.basicConfig(level=default_level)
23 |
--------------------------------------------------------------------------------
/logger/logger_config.json:
--------------------------------------------------------------------------------
1 |
2 | {
3 | "version": 1,
4 | "disable_existing_loggers": false,
5 | "formatters": {
6 | "simple": {"format": "%(message)s"},
7 | "datetime": {"format": "%(asctime)s - %(name)s - %(levelname)s - %(message)s"}
8 | },
9 | "handlers": {
10 | "console": {
11 | "class": "logging.StreamHandler",
12 | "level": "DEBUG",
13 | "formatter": "simple",
14 | "stream": "ext://sys.stdout"
15 | },
16 | "info_file_handler": {
17 | "class": "logging.handlers.RotatingFileHandler",
18 | "level": "INFO",
19 | "formatter": "datetime",
20 | "filename": "info.log",
21 | "maxBytes": 10485760,
22 | "backupCount": 20, "encoding": "utf8"
23 | }
24 | },
25 | "root": {
26 | "level": "INFO",
27 | "handlers": [
28 | "console",
29 | "info_file_handler"
30 | ]
31 | }
32 | }
--------------------------------------------------------------------------------
/logger/visualization.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | from datetime import datetime
3 |
4 |
5 | class TensorboardWriter():
6 | def __init__(self, log_dir, logger, enabled):
7 | self.writer = None
8 | self.selected_module = ""
9 |
10 | if enabled:
11 | log_dir = str(log_dir)
12 |
13 | # Retrieve vizualization writer.
14 | succeeded = False
15 | for module in ["torch.utils.tensorboard", "tensorboardX"]:
16 | try:
17 | self.writer = importlib.import_module(module).SummaryWriter(log_dir)
18 | succeeded = True
19 | break
20 | except ImportError:
21 | succeeded = False
22 | self.selected_module = module
23 |
24 | if not succeeded:
25 | message = "Warning: visualization (Tensorboard) is configured to use, but currently not installed on " \
26 | "this machine. Please install TensorboardX with 'pip install tensorboardx', upgrade PyTorch to " \
27 | "version >= 1.1 to use 'torch.utils.tensorboard' or turn off the option in the 'config.json' file."
28 | logger.warning(message)
29 |
30 | self.step = 0
31 | self.mode = ''
32 |
33 | self.tb_writer_ftns = {
34 | 'add_scalar', 'add_scalars', 'add_image', 'add_images', 'add_audio',
35 | 'add_text', 'add_histogram', 'add_pr_curve', 'add_embedding'
36 | }
37 | self.tag_mode_exceptions = {'add_histogram', 'add_embedding'}
38 | self.timer = datetime.now()
39 |
40 | def set_step(self, step, mode='train'):
41 | self.mode = mode
42 | self.step = step
43 | if step == 0:
44 | self.timer = datetime.now()
45 | else:
46 | duration = datetime.now() - self.timer
47 | self.add_scalar('steps_per_sec', 1 / duration.total_seconds())
48 | self.timer = datetime.now()
49 |
50 | def __getattr__(self, name):
51 | """
52 | If visualization is configured to use:
53 | return add_data() methods of tensorboard with additional information (step, tag) added.
54 | Otherwise:
55 | return a blank function handle that does nothing
56 | """
57 | if name in self.tb_writer_ftns:
58 | add_data = getattr(self.writer, name, None)
59 |
60 | def wrapper(tag, data, *args, **kwargs):
61 | if add_data is not None:
62 | # add mode(train/valid) tag
63 | if name not in self.tag_mode_exceptions:
64 | tag = '{}/{}'.format(tag, self.mode)
65 | add_data(tag, data, self.step, *args, **kwargs)
66 | return wrapper
67 | else:
68 | # default action for returning methods defined in this class, set_step() for instance.
69 | try:
70 | attr = object.__getattr__(name)
71 | except AttributeError:
72 | raise AttributeError("type object '{}' has no attribute '{}'".format(self.selected_module, name))
73 | return attr
74 |
--------------------------------------------------------------------------------
/model/loss.py:
--------------------------------------------------------------------------------
1 | import torch.nn.functional as F
2 | from torch import nn
3 | import torch
4 |
5 |
6 | def elbo_loss(recon_x, x, mu, logvar, beta=1):
7 | """
8 | ELBO Optimization objective for gaussian posterior
9 | (reconstruction term + regularization term)
10 | """
11 | reconstruction_function = nn.MSELoss(reduction='sum')
12 | MSE = reconstruction_function(recon_x, x)
13 |
14 | # https://arxiv.org/abs/1312.6114 (Appendix B)
15 | # 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
16 |
17 | KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
18 | KLD = torch.sum(KLD_element).mul_(-0.5)
19 |
20 | return MSE + beta*KLD
21 |
22 |
23 | def elbo_loss_flow(recon_x, x, mu, logvar, log_det):
24 | """
25 | ELBO Optimization objective for gaussian posterior
26 | (reconstruction term + regularization term)
27 | """
28 | reconstruction_function = nn.MSELoss(reduction='sum')
29 | MSE = reconstruction_function(recon_x, x)
30 |
31 | # https://arxiv.org/abs/1312.6114 (Appendix B)
32 | # 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
33 |
34 | KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
35 | KLD = torch.sum(KLD_element).mul_(-0.5)
36 |
37 | return (MSE + KLD - log_det).mean()
38 |
--------------------------------------------------------------------------------
/model/metric.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | def metric():
5 | """
6 | Implement evaluation metric here if needed
7 | """
8 | pass
9 |
--------------------------------------------------------------------------------
/model/model.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from base import BaseModel
3 | from torch import nn
4 | from torch.nn import functional as F
5 | from .types_ import *
6 |
7 |
8 | class PlanarFlow(nn.Module):
9 | def __init__(self, dim):
10 | """Instantiates one step of planar flow.
11 | Args:
12 | dim: input dimensionality.
13 | """
14 | super(PlanarFlow, self).__init__()
15 |
16 | self.u = nn.Parameter(torch.randn(1, dim))
17 | self.w = nn.Parameter(torch.randn(1, dim))
18 | self.b = nn.Parameter(torch.randn(1))
19 |
20 | def forward(self, x):
21 | """Forward pass.
22 | Args:
23 | x: input tensor (B x D).
24 | Returns:
25 | transformed x and log-determinant of Jacobian.
26 | """
27 | def m(x):
28 | return F.softplus(x) - 1.
29 |
30 | def h(x):
31 | return torch.tanh(x)
32 |
33 | def h_prime(x):
34 | return 1. - h(x)**2
35 |
36 | inner = (self.w * self.u).sum()
37 | u = self.u + (m(inner) - inner) * self.w / self.w.norm()**2
38 | activation = (self.w * x).sum(dim=1, keepdim=True) + self.b
39 | x = x + u * h(activation)
40 | psi = h_prime(activation) * self.w
41 | log_det = torch.log(torch.abs(1. + (u * psi).sum(dim=1, keepdim=True)))
42 |
43 | return x, log_det
44 |
45 |
46 | class Flow(nn.Module):
47 | def __init__(self, dim, type, length):
48 | """Instantiates a chain of flows.
49 | Args:
50 | dim: input dimensionality.
51 | type: type of flow.
52 | length: length of flow.
53 | """
54 | super(Flow, self).__init__()
55 |
56 | if type == 'planar':
57 | self.flow = nn.ModuleList([PlanarFlow(dim) for _ in range(length)])
58 | # elif type == 'radial':
59 | # self.flow = nn.ModuleList([RadialFlow(dim) for _ in range(length)])
60 | # elif type == 'householder':
61 | # self.flow = nn.ModuleList([HouseholderFlow(dim) for _ in range(length)])
62 | # elif type == 'nice':
63 | # self.flow = nn.ModuleList([NiceFlow(dim, i//2, i==(length-1)) for i in range(length)])
64 | else:
65 | self.flow = nn.ModuleList([])
66 |
67 | def forward(self, x):
68 | """Forward pass.
69 | Args:
70 | x: input tensor (B x D).
71 | Returns:
72 | transformed x and log-determinant of Jacobian.
73 | """
74 | [B, _] = list(x.size())
75 | # log_det = torch.zeros(B, 1).cuda()
76 | log_det = torch.zeros(B, 1)
77 | for i in range(len(self.flow)):
78 | x, inc = self.flow[i](x)
79 | log_det = log_det + inc
80 |
81 | return x, log_det
82 |
83 |
84 | class VanillaVAE(BaseModel):
85 |
86 | def __init__(self,
87 | in_channels: int,
88 | latent_dims: int,
89 | hidden_dims: List[int] = None,
90 | flow_check=False,
91 | **kwargs) -> None:
92 | """Instantiates the VAE model
93 |
94 | Params:
95 | in_channels (int): Number of input channels
96 | latent_dims (int): Size of latent dimensions
97 | hidden_dims (List[int]): List of hidden dimensions
98 | """
99 | super(VanillaVAE, self).__init__()
100 | self.latent_dim = latent_dims
101 | self.flow_check = flow_check
102 |
103 | if self.flow_check:
104 | self.flow = Flow(self.latent_dim, 'planar', 16)
105 |
106 | modules = []
107 | if hidden_dims is None:
108 | hidden_dims = [32, 64, 128, 256, 512]
109 |
110 | # Build Encoder
111 | for h_dim in hidden_dims:
112 | modules.append(
113 | nn.Sequential(
114 | nn.Conv2d(in_channels, out_channels=h_dim,
115 | kernel_size=3, stride=2, padding=1),
116 | nn.BatchNorm2d(h_dim),
117 | nn.LeakyReLU())
118 | )
119 | in_channels = h_dim
120 |
121 | self.encoder = nn.Sequential(*modules)
122 | self.fc_mu = nn.Linear(hidden_dims[-1]*4, latent_dims)
123 | self.fc_var = nn.Linear(hidden_dims[-1]*4, latent_dims)
124 |
125 | # Build Decoder
126 | modules = []
127 | self.decoder_input = nn.Linear(latent_dims, hidden_dims[-1] * 4)
128 |
129 | hidden_dims.reverse()
130 |
131 | for i in range(len(hidden_dims) - 1):
132 | modules.append(
133 | nn.Sequential(
134 | nn.ConvTranspose2d(hidden_dims[i],
135 | hidden_dims[i + 1],
136 | kernel_size=3,
137 | stride=2,
138 | padding=1,
139 | output_padding=1),
140 | nn.BatchNorm2d(hidden_dims[i + 1]),
141 | nn.LeakyReLU())
142 | )
143 |
144 | self.decoder = nn.Sequential(*modules)
145 |
146 | self.final_layer = nn.Sequential(
147 | nn.ConvTranspose2d(hidden_dims[-1],
148 | hidden_dims[-1],
149 | kernel_size=3,
150 | stride=2,
151 | padding=1,
152 | output_padding=1),
153 | nn.BatchNorm2d(hidden_dims[-1]),
154 | nn.LeakyReLU(),
155 | nn.Conv2d(hidden_dims[-1], out_channels=3,
156 | kernel_size=3, padding=1),
157 | nn.Tanh())
158 |
159 | def encode(self, input: Tensor) -> List[Tensor]:
160 | """
161 | Encodes the input by passing through the convolutional network
162 | and outputs the latent variables.
163 |
164 | Params:
165 | input (Tensor): Input tensor [N x C x H x W]
166 |
167 | Returns:
168 | mu (Tensor) and log_var (Tensor) of latent variables
169 | """
170 |
171 | result = self.encoder(input)
172 | result = torch.flatten(result, start_dim=1)
173 |
174 | # Split the result into mu and var components
175 | # of the latent Gaussian distribution
176 | mu = self.fc_mu(result)
177 | log_var = self.fc_var(result)
178 |
179 | if self.flow_check:
180 | z, log_det = self.reparameterize(mu, log_var)
181 | return mu, log_var, z, log_det
182 |
183 | else:
184 | z = self.reparameterize(mu, log_var)
185 | return mu, log_var, z
186 |
187 | def decode(self, z: Tensor) -> Tensor:
188 | """
189 | Maps the given latent variables
190 | onto the image space.
191 |
192 | Params:
193 | z (Tensor): Latent variable [B x D]
194 |
195 | Returns:
196 | result (Tensor) [B x C x H x W]
197 | """
198 |
199 | result = self.decoder_input(z)
200 | result = result.view(-1, 512, 2, 2)
201 | result = self.decoder(result)
202 | result = self.final_layer(result)
203 |
204 | return result
205 |
206 | def reparameterize(self, mu: Tensor, logvar: Tensor) -> Tensor:
207 | """
208 | Reparameterization trick to sample from N(mu, var) from
209 | N(0,1)
210 |
211 | Params:
212 | mu (Tensor): Mean of Gaussian latent variables [B x D]
213 | logvar (Tensor): log-Variance of Gaussian latent variables [B x D]
214 |
215 | Returns:
216 | z (Tensor) [B x D]
217 | """
218 |
219 | std = torch.exp(0.5 * logvar)
220 | eps = torch.randn_like(std)
221 | z = eps.mul(std).add_(mu)
222 |
223 | if self.flow_check:
224 | return self.flow(z)
225 |
226 | else:
227 | return z
228 |
229 | def forward(self, input: Tensor, **kwargs) -> List[Tensor]:
230 |
231 | if self.flow_check:
232 | mu, log_var, z, log_det = self.encode(input)
233 |
234 | return self.decode(z), mu, log_var, log_det
235 |
236 | else:
237 | mu, log_var, z = self.encode(input)
238 |
239 | return self.decode(z), mu, log_var
240 |
241 | def sample(self,
242 | num_samples: int,
243 | current_device: int, **kwargs) -> Tensor:
244 | """
245 | Samples from the latent space and return the corresponding
246 | image space map.
247 |
248 | Params:
249 | num_samples (Int): Number of samples
250 | current_device (Int): Device to run the model
251 |
252 | Returns:
253 | samples (Tensor)
254 | """
255 |
256 | z = torch.randn(num_samples,
257 | self.latent_dim)
258 | z = z.to(current_device)
259 | samples = self.decode(z)
260 |
261 | return samples
262 |
263 | def generate(self, x: Tensor, **kwargs) -> Tensor:
264 | """
265 | Given an input image x, returns the reconstructed image
266 |
267 | Params:
268 | x (Tensor): input image Tensor [B x C x H x W]
269 |
270 | Returns:
271 | (Tensor) [B x C x H x W]
272 | """
273 |
274 | return self.forward(x)[0]
275 |
--------------------------------------------------------------------------------
/model/types_.py:
--------------------------------------------------------------------------------
1 | from typing import List, Callable, Union, Any, TypeVar, Tuple
2 | # from torch import tensor as Tensor
3 |
4 | Tensor = TypeVar('torch.tensor')
5 |
--------------------------------------------------------------------------------
/parse_config.py:
--------------------------------------------------------------------------------
1 | import os
2 | import logging
3 | from pathlib import Path
4 | from functools import reduce, partial
5 | from operator import getitem
6 | from datetime import datetime
7 | from logger import setup_logging
8 | from utils import read_json, write_json
9 |
10 |
11 | class ConfigParser:
12 | def __init__(self, config, resume=None, modification=None, run_id=None):
13 | """
14 | class to parse configuration json file. Handles hyperparameters for training, initializations of modules, checkpoint saving
15 | and logging module.
16 | :param config: Dict containing configurations, hyperparameters for training. contents of `config.json` file for example.
17 | :param resume: String, path to the checkpoint being loaded.
18 | :param modification: Dict keychain:value, specifying position values to be replaced from config dict.
19 | :param run_id: Unique Identifier for training processes. Used to save checkpoints and training log. Timestamp is being used as default
20 | """
21 | # load config file and apply modification
22 | self._config = _update_config(config, modification)
23 | self.resume = resume
24 |
25 | # set save_dir where trained model and log will be saved.
26 | save_dir = Path(self.config['trainer']['save_dir'])
27 |
28 | exper_name = self.config['name']
29 | if run_id is None: # use timestamp as default run-id
30 | run_id = datetime.now().strftime(r'%m%d_%H%M%S')
31 | self._save_dir = save_dir / 'models' / exper_name / run_id
32 | self._log_dir = save_dir / 'log' / exper_name / run_id
33 |
34 | # make directory for saving checkpoints and log.
35 | exist_ok = run_id == ''
36 | self.save_dir.mkdir(parents=True, exist_ok=exist_ok)
37 | self.log_dir.mkdir(parents=True, exist_ok=exist_ok)
38 |
39 | # save updated config file to the checkpoint dir
40 | write_json(self.config, self.save_dir / 'config.json')
41 |
42 | # configure logging module
43 | setup_logging(self.log_dir)
44 | self.log_levels = {
45 | 0: logging.WARNING,
46 | 1: logging.INFO,
47 | 2: logging.DEBUG
48 | }
49 |
50 | @classmethod
51 | def from_args(cls, args, options=''):
52 | """
53 | Initialize this class from some cli arguments. Used in train, test.
54 | """
55 | for opt in options:
56 | args.add_argument(*opt.flags, default=None, type=opt.type)
57 | if not isinstance(args, tuple):
58 | args = args.parse_args()
59 |
60 | if args.device is not None:
61 | os.environ["CUDA_VISIBLE_DEVICES"] = args.device
62 | if args.resume is not None:
63 | resume = Path(args.resume)
64 | cfg_fname = resume.parent / 'config.json'
65 | else:
66 | msg_no_cfg = "Configuration file need to be specified. Add '-c config.json', for example."
67 | assert args.config is not None, msg_no_cfg
68 | resume = None
69 | cfg_fname = Path(args.config)
70 |
71 | config = read_json(cfg_fname)
72 | if args.config and resume:
73 | # update new config for fine-tuning
74 | config.update(read_json(args.config))
75 |
76 | # parse custom cli options into dictionary
77 | modification = {opt.target : getattr(args, _get_opt_name(opt.flags)) for opt in options}
78 | return cls(config, resume, modification)
79 |
80 | def init_obj(self, name, module, *args, **kwargs):
81 | """
82 | Finds a function handle with the name given as 'type' in config, and returns the
83 | instance initialized with corresponding arguments given.
84 |
85 | `object = config.init_obj('name', module, a, b=1)`
86 | is equivalent to
87 | `object = module.name(a, b=1)`
88 | """
89 | module_name = self[name]['type']
90 | module_args = dict(self[name]['args'])
91 | assert all([k not in module_args for k in kwargs]), 'Overwriting kwargs given in config file is not allowed'
92 | module_args.update(kwargs)
93 | return getattr(module, module_name)(*args, **module_args)
94 |
95 | def init_ftn(self, name, module, *args, **kwargs):
96 | """
97 | Finds a function handle with the name given as 'type' in config, and returns the
98 | function with given arguments fixed with functools.partial.
99 |
100 | `function = config.init_ftn('name', module, a, b=1)`
101 | is equivalent to
102 | `function = lambda *args, **kwargs: module.name(a, *args, b=1, **kwargs)`.
103 | """
104 | module_name = self[name]['type']
105 | module_args = dict(self[name]['args'])
106 | assert all([k not in module_args for k in kwargs]), 'Overwriting kwargs given in config file is not allowed'
107 | module_args.update(kwargs)
108 | return partial(getattr(module, module_name), *args, **module_args)
109 |
110 | def __getitem__(self, name):
111 | """Access items like ordinary dict."""
112 | return self.config[name]
113 |
114 | def get_logger(self, name, verbosity=2):
115 | msg_verbosity = 'verbosity option {} is invalid. Valid options are {}.'.format(verbosity, self.log_levels.keys())
116 | assert verbosity in self.log_levels, msg_verbosity
117 | logger = logging.getLogger(name)
118 | logger.setLevel(self.log_levels[verbosity])
119 | return logger
120 |
121 | # setting read-only attributes
122 | @property
123 | def config(self):
124 | return self._config
125 |
126 | @property
127 | def save_dir(self):
128 | return self._save_dir
129 |
130 | @property
131 | def log_dir(self):
132 | return self._log_dir
133 |
134 | # helper functions to update config dict with custom cli options
135 | def _update_config(config, modification):
136 | if modification is None:
137 | return config
138 |
139 | for k, v in modification.items():
140 | if v is not None:
141 | _set_by_path(config, k, v)
142 | return config
143 |
144 | def _get_opt_name(flags):
145 | for flg in flags:
146 | if flg.startswith('--'):
147 | return flg.replace('--', '')
148 | return flags[0].replace('--', '')
149 |
150 | def _set_by_path(tree, keys, value):
151 | """Set a value in a nested object in tree by sequence of keys."""
152 | keys = keys.split(';')
153 | _get_by_path(tree, keys[:-1])[keys[-1]] = value
154 |
155 | def _get_by_path(tree, keys):
156 | """Access a nested object in tree by sequence of keys."""
157 | return reduce(getitem, keys, tree)
158 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=1.9
2 | torchvision>=0.10
3 | numpy
4 | tqdm
5 | tensorboard>=2.8
6 |
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 | import torch
4 | from tqdm import tqdm
5 | import data_loader.data_loaders as module_data
6 | import model.loss as module_loss
7 | import model.metric as module_metric
8 | import model.model as module_arch
9 | from parse_config import ConfigParser
10 | from torch.nn import functional as F
11 | import torchvision.utils as vutils
12 | from torchvision import transforms
13 | from torch.autograd import Variable
14 | import os
15 | import matplotlib.pyplot as plt
16 | from mpl_toolkits.axes_grid1 import ImageGrid
17 |
18 | #Fixes PosixPath Error
19 | import pathlib
20 |
21 | temp = pathlib.PosixPath
22 | pathlib.PosixPath = pathlib.WindowsPath
23 |
24 | def latent_traversal(model, samples, n_changes=5, val_range=(-1, 1)):
25 | """ This function perform latent traversal on a VAE latent space
26 | model_path: str
27 | The absolute path of the model to load
28 | fname: str
29 | The filename to use for saving the latent traversal
30 | samples:
31 | The list of data examples to provide as input of the model
32 | n_changes: int
33 | The number of changes to perform on one latent dimension
34 | val_range: tuple
35 | The range of values that can be set for one latent dimension
36 | """
37 | # TODO: change the next two lines to retrieve the output of your encoder with pytorch
38 | # m = tf.keras.models.load_model(model_path)
39 | z_base = model.encode(samples)[-1]
40 | z_base = z_base.cpu()
41 | # END TODO
42 | r, c = n_changes, z_base.shape[1]
43 | vals = np.linspace(*val_range, r)
44 | shape = samples[0].shape
45 | for j, z in enumerate(z_base):
46 | imgs = np.empty([r * c, *shape])
47 | for i in range(c):
48 | z_iter = np.tile(z, [r, 1])
49 | z_iter[:, i] = vals
50 | z_iter = torch.from_numpy(z_iter)
51 | z_iter = z_iter.to(device)
52 | imgs[r * i:(r * i) + r] = F.sigmoid(model.decode(z_iter)[-1])
53 | plot_traversal(imgs, r, c, shape[-1] == 1, show=True)
54 | # save_figure(fname, tight=False)
55 |
56 |
57 | def plot_traversal(imgs, r, c, greyscale, show=False):
58 | fig = plt.figure(figsize=(20., 20.))
59 | grid = ImageGrid(fig, 111, nrows_ncols=(r, c), axes_pad=0, direction="column")
60 |
61 | for i, (ax, im) in enumerate(zip(grid, imgs)):
62 | ax.set_axis_off()
63 | if i % r == 0:
64 | ax.set_title("z{}".format(i // r), fontdict={'fontsize': 25})
65 | if greyscale is True:
66 | ax.imshow(im, cmap="gray")
67 | else:
68 | ax.imshow(im)
69 |
70 | fig.subplots_adjust(wspace=0, hspace=0)
71 | if show is True:
72 | plt.show()
73 |
74 | plt.savefig('traversal.png')
75 |
76 | def interpolate(autoencoder, x_1, x_2, n=12):
77 | z_1 = autoencoder.encode(x_1)[2]
78 | z_2 = autoencoder.encode(x_2)[2]
79 | z = torch.stack([z_1 + (z_2 - z_1)*t for t in np.linspace(0, 1, n)])
80 | interpolate_list = autoencoder.decode(z)
81 | interpolate_list = interpolate_list.to('cpu').detach()
82 | print(len(interpolate_list))
83 |
84 | plt.figure(figsize=(64, 64))
85 | for i in range(len(interpolate_list)):
86 | ax = plt.subplot(1, len(interpolate_list), i+1)
87 | plt.imshow(interpolate_list[i].permute(1, 2, 0).numpy())
88 | ax.get_xaxis().set_visible(False)
89 | ax.get_yaxis().set_visible(False)
90 | plt.savefig('linear_interpolation.png')
91 |
92 |
93 | def main(config):
94 | logger = config.get_logger('test')
95 |
96 | # setup data_loader instances
97 | data_loader = getattr(module_data, config['data_loader']['type'])(
98 | config['data_loader']['args']['data_dir'],
99 | batch_size=36,
100 | shuffle=False,
101 | validation_split=0.0,
102 | # training=False,
103 | num_workers=2
104 | )
105 |
106 | # build model architecture
107 | model = config.init_obj('arch', module_arch)
108 | logger.info(model)
109 |
110 | # get function handles of loss and metrics
111 | loss_fn = getattr(module_loss, config['loss'])
112 | # metric_fns = [getattr(module_metric, met) for met in config['metrics']]
113 |
114 | logger.info('Loading checkpoint: {} ...'.format(config.resume))
115 | # checkpoint = torch.load(config.resume)
116 |
117 | # loading on CPU-only machine
118 | checkpoint = torch.load(config.resume, map_location=torch.device('cpu'))
119 | state_dict = checkpoint['state_dict']
120 | if config['n_gpu'] > 1:
121 | model = torch.nn.DataParallel(model)
122 | model.load_state_dict(state_dict)
123 |
124 | # prepare model for testing
125 | device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
126 | model = model.to(device)
127 | model.eval()
128 |
129 | total_loss = 0.0
130 | # total_metrics = torch.zeros(len(metric_fns))
131 |
132 | with torch.no_grad():
133 | for i, (data, target) in enumerate(tqdm(data_loader)):
134 | data, target = data.to(device), target.to(device)
135 | output, mu, logvar = model(data)
136 |
137 | # computing loss, metrics on test set
138 | loss = loss_fn(output, data, mu, logvar)
139 | batch_size = data.shape[0]
140 | total_loss += loss.item() * batch_size
141 | # for i, metric in enumerate(metric_fns):
142 | # total_metrics[i] += metric(output, target) * batch_size
143 |
144 | # Reconstructing and generating images for a mini-batch
145 | test_input, test_label = next(iter(data_loader))
146 | test_input = test_input.to(device)
147 | test_label = test_label.to(device)
148 |
149 | recons = model.generate(test_input, labels=test_label)
150 | vutils.save_image(recons.data,
151 | os.path.join(
152 | "Reconstructions",
153 | f"recons_{logger.name}_epoch_{config['trainer']['epochs']}.png"),
154 | normalize=True,
155 | nrow=6)
156 |
157 | try:
158 | samples = model.sample(36,
159 | device,
160 | labels=test_label)
161 | vutils.save_image(samples.cpu().data,
162 | os.path.join(
163 | "Samples",
164 | f"{logger.name}.png"),
165 | normalize=True,
166 | nrow=6)
167 | except Warning:
168 | pass
169 |
170 | # linear interpolation two chosen images
171 | x_1 = test_input[1].to(device)
172 | x_1 = torch.unsqueeze(x_1, dim=0)
173 | x_2 = test_input[2].to(device)
174 | x_2 = torch.unsqueeze(x_2, dim=0)
175 | interpolate(model, x_1, x_2, n=5)
176 |
177 | n_samples = len(data_loader.sampler)
178 | log = {'loss': total_loss / n_samples}
179 | # log.update({
180 | # met.__name__: total_metrics[i].item() / n_samples for i, met in enumerate(metric_fns)
181 | # })
182 | logger.info(log)
183 |
184 |
185 | if __name__ == '__main__':
186 | args = argparse.ArgumentParser(description='PyTorch Template')
187 | args.add_argument('-c', '--config', default=None, type=str,
188 | help='config file path (default: None)')
189 | args.add_argument('-r', '--resume', default=None, type=str,
190 | help='path to latest checkpoint (default: None)')
191 | args.add_argument('-d', '--device', default=None, type=str,
192 | help='indices of GPUs to enable (default: all)')
193 |
194 | config = ConfigParser.from_args(args)
195 | main(config)
196 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import collections
3 | import torch
4 | import numpy as np
5 | import data_loader.data_loaders as module_data
6 | import model.loss as module_loss
7 | import model.metric as module_metric
8 | import model.model as module_arch
9 | from parse_config import ConfigParser
10 | from trainer import Trainer
11 | from utils import prepare_device
12 |
13 |
14 | # fix random seeds for reproducibility
15 | SEED = 123
16 | torch.manual_seed(SEED)
17 | torch.backends.cudnn.deterministic = True
18 | torch.backends.cudnn.benchmark = False
19 | np.random.seed(SEED)
20 |
21 |
22 | def main(config):
23 | logger = config.get_logger('train')
24 |
25 | # setup data_loader instances
26 | data_loader = config.init_obj('data_loader', module_data)
27 | valid_data_loader = data_loader.split_validation()
28 |
29 | # build model architecture, then print to console
30 | model = config.init_obj('arch', module_arch)
31 | logger.info(model)
32 |
33 | # prepare for (multi-device) GPU training
34 | device, device_ids = prepare_device(config['n_gpu'])
35 | model = model.to(device)
36 | if len(device_ids) > 1:
37 | model = torch.nn.DataParallel(model, device_ids=device_ids)
38 |
39 | # get function handles of loss and metrics
40 | criterion = getattr(module_loss, config['loss'])
41 | # metrics = [getattr(module_metric, met) for met in config['metrics']]
42 |
43 | # build optimizer, learning rate scheduler. delete every lines containing lr_scheduler for disabling scheduler
44 | trainable_params = filter(lambda p: p.requires_grad, model.parameters())
45 | optimizer = config.init_obj('optimizer', torch.optim, trainable_params)
46 | lr_scheduler = config.init_obj(
47 | 'lr_scheduler', torch.optim.lr_scheduler, optimizer)
48 |
49 | trainer = Trainer(model, criterion, optimizer,
50 | config=config,
51 | device=device,
52 | data_loader=data_loader,
53 | valid_data_loader=None,
54 | lr_scheduler=lr_scheduler)
55 |
56 | trainer.train()
57 |
58 |
59 | if __name__ == '__main__':
60 | args = argparse.ArgumentParser(description='PyTorch Template')
61 | args.add_argument('-c', '--config', default=None, type=str,
62 | help='config file path (default: None)')
63 | args.add_argument('-r', '--resume', default=None, type=str,
64 | help='path to latest checkpoint (default: None)')
65 | args.add_argument('-d', '--device', default=None, type=str,
66 | help='indices of GPUs to enable (default: all)')
67 |
68 | # custom cli options to modify configuration from default values given in json file.
69 | CustomArgs = collections.namedtuple('CustomArgs', 'flags type target')
70 | options = [
71 | CustomArgs(['--lr', '--learning_rate'],
72 | type=float, target='optimizer;args;lr'),
73 | CustomArgs(['--bs', '--batch_size'], type=int,
74 | target='data_loader;args;batch_size')
75 | ]
76 | config = ConfigParser.from_args(args, options)
77 | main(config)
78 |
--------------------------------------------------------------------------------
/trainer/__init__.py:
--------------------------------------------------------------------------------
1 | from .trainer import *
2 |
--------------------------------------------------------------------------------
/trainer/trainer.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | from torchvision.utils import make_grid
4 | from base import BaseTrainer
5 | from utils import inf_loop, MetricTracker
6 |
7 |
8 | class Trainer(BaseTrainer):
9 | """
10 | Trainer class
11 | """
12 |
13 | def __init__(self, model, criterion, optimizer, config, device,
14 | data_loader, valid_data_loader=None, lr_scheduler=None, len_epoch=None):
15 | super().__init__(model, criterion, optimizer, config)
16 | self.config = config
17 | self.device = device
18 | self.data_loader = data_loader
19 | if len_epoch is None:
20 | # epoch-based training
21 | self.len_epoch = len(self.data_loader)
22 | else:
23 | # iteration-based training
24 | self.data_loader = inf_loop(data_loader)
25 | self.len_epoch = len_epoch
26 | self.valid_data_loader = valid_data_loader
27 | self.do_validation = self.valid_data_loader is not None
28 | self.lr_scheduler = lr_scheduler
29 | self.log_step = int(np.sqrt(data_loader.batch_size))
30 |
31 | # self.train_metrics = MetricTracker(
32 | # 'loss', *[m.__name__ for m in self.metric_ftns], writer=self.writer)
33 | # self.valid_metrics = MetricTracker(
34 | # 'loss', *[m.__name__ for m in self.metric_ftns], writer=self.writer)
35 |
36 | self.train_metrics = MetricTracker(
37 | 'loss', writer=self.writer)
38 | self.valid_metrics = MetricTracker(
39 | 'loss', writer=self.writer)
40 |
41 | def _train_epoch(self, epoch):
42 | """
43 | Training logic for an epoch
44 |
45 | :param epoch: Integer, current training epoch.
46 | :return: A log that contains average loss and metric in this epoch.
47 | """
48 | self.model.train()
49 | self.train_metrics.reset()
50 | for batch_idx, (data, target) in enumerate(self.data_loader):
51 | data, target = data.to(self.device), target.to(self.device)
52 |
53 | self.optimizer.zero_grad()
54 | output, mu, logvar = self.model(data)
55 | loss = self.criterion(output, data, mu, logvar)
56 | loss.backward()
57 |
58 | # optional gradient clipping
59 | # torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=2.0, norm_type=2)
60 |
61 | self.optimizer.step()
62 | self.writer.set_step((epoch - 1) * self.len_epoch + batch_idx)
63 | self.train_metrics.update('loss', loss.item())
64 | # for met in self.metric_ftns:
65 | # self.train_metrics.update(met.__name__, met(output, target))
66 |
67 | if batch_idx % self.log_step == 0:
68 | self.logger.debug('Train Epoch: {} {} Loss: {:.6f}'.format(
69 | epoch,
70 | self._progress(batch_idx),
71 | loss.item()))
72 | self.writer.add_image('input', make_grid(
73 | data.cpu(), nrow=8, normalize=True))
74 |
75 | if batch_idx == self.len_epoch:
76 | break
77 | log = self.train_metrics.result()
78 |
79 | if self.do_validation:
80 | val_log = self._valid_epoch(epoch)
81 | log.update(**{'val_'+k: v for k, v in val_log.items()})
82 |
83 | if self.lr_scheduler is not None:
84 | self.lr_scheduler.step()
85 | return log
86 |
87 | def _valid_epoch(self, epoch):
88 | """
89 | Validate after training an epoch
90 |
91 | :param epoch: Integer, current training epoch.
92 | :return: A log that contains information about validation
93 | """
94 | self.model.eval()
95 | self.valid_metrics.reset()
96 | with torch.no_grad():
97 | for batch_idx, (data, target) in enumerate(self.valid_data_loader):
98 | data, target = data.to(self.device), target.to(self.device)
99 | output, mu, logvar = self.model(data)
100 | loss = self.criterion(output, data, mu, logvar)
101 |
102 | self.writer.set_step(
103 | (epoch - 1) * len(self.valid_data_loader) + batch_idx, 'valid')
104 | self.valid_metrics.update('loss', loss.item())
105 | # for met in self.metric_ftns:
106 | # self.valid_metrics.update(
107 | # met.__name__, met(output, target))
108 | self.writer.add_image('input', make_grid(
109 | data.cpu(), nrow=8, normalize=True))
110 |
111 | # add histogram of model parameters to the tensorboard
112 | for name, p in self.model.named_parameters():
113 | self.writer.add_histogram(name, p, bins='auto')
114 | return self.valid_metrics.result()
115 |
116 | def _progress(self, batch_idx):
117 | base = '[{}/{} ({:.0f}%)]'
118 | if hasattr(self.data_loader, 'n_samples'):
119 | current = batch_idx * self.data_loader.batch_size
120 | total = self.data_loader.n_samples
121 | else:
122 | current = batch_idx
123 | total = self.len_epoch
124 | return base.format(current, total, 100.0 * current / total)
125 |
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
1 | from .util import *
2 |
--------------------------------------------------------------------------------
/utils/util.py:
--------------------------------------------------------------------------------
1 | import json
2 | import torch
3 | import pandas as pd
4 | from pathlib import Path
5 | from itertools import repeat
6 | from collections import OrderedDict
7 |
8 |
9 | def ensure_dir(dirname):
10 | dirname = Path(dirname)
11 | if not dirname.is_dir():
12 | dirname.mkdir(parents=True, exist_ok=False)
13 |
14 | def read_json(fname):
15 | fname = Path(fname)
16 | with fname.open('rt') as handle:
17 | return json.load(handle, object_hook=OrderedDict)
18 |
19 | def write_json(content, fname):
20 | fname = Path(fname)
21 | with fname.open('wt') as handle:
22 | json.dump(content, handle, indent=4, sort_keys=False)
23 |
24 | def inf_loop(data_loader):
25 | ''' wrapper function for endless data loader. '''
26 | for loader in repeat(data_loader):
27 | yield from loader
28 |
29 | def prepare_device(n_gpu_use):
30 | """
31 | setup GPU device if available. get gpu device indices which are used for DataParallel
32 | """
33 | n_gpu = torch.cuda.device_count()
34 | if n_gpu_use > 0 and n_gpu == 0:
35 | print("Warning: There\'s no GPU available on this machine,"
36 | "training will be performed on CPU.")
37 | n_gpu_use = 0
38 | if n_gpu_use > n_gpu:
39 | print(f"Warning: The number of GPU\'s configured to use is {n_gpu_use}, but only {n_gpu} are "
40 | "available on this machine.")
41 | n_gpu_use = n_gpu
42 | device = torch.device('cuda:0' if n_gpu_use > 0 else 'cpu')
43 | list_ids = list(range(n_gpu_use))
44 | return device, list_ids
45 |
46 | class MetricTracker:
47 | def __init__(self, *keys, writer=None):
48 | self.writer = writer
49 | self._data = pd.DataFrame(index=keys, columns=['total', 'counts', 'average'])
50 | self.reset()
51 |
52 | def reset(self):
53 | for col in self._data.columns:
54 | self._data[col].values[:] = 0
55 |
56 | def update(self, key, value, n=1):
57 | if self.writer is not None:
58 | self.writer.add_scalar(key, value)
59 | self._data.total[key] += value * n
60 | self._data.counts[key] += n
61 | self._data.average[key] = self._data.total[key] / self._data.counts[key]
62 |
63 | def avg(self, key):
64 | return self._data.average[key]
65 |
66 | def result(self):
67 | return dict(self._data.average)
68 |
--------------------------------------------------------------------------------