├── .flake8
├── .github
├── scripts
│ ├── install_cuda.sh
│ ├── install_cudnn.sh
│ └── install_torch.sh
└── workflows
│ ├── run_tests_cpu.yml
│ ├── run_tests_cuda.yml
│ └── style_check.yml
├── .gitignore
├── CMakeLists.txt
├── LICENSE
├── MANIFEST.in
├── README.md
├── cmake
├── Modules
│ ├── FetchContent.cmake
│ ├── FetchContent
│ │ └── CMakeLists.cmake.in
│ └── README.md
├── googletest.cmake
├── pybind11.cmake
├── select_compute_arch.cmake
├── torch.cmake
└── transform.cmake
├── fast_rnnt
├── CMakeLists.txt
├── csrc
│ ├── CMakeLists.txt
│ ├── device_guard.h
│ ├── mutual_information.h
│ ├── mutual_information_cpu.cu
│ └── mutual_information_cuda.cu
└── python
│ ├── CMakeLists.txt
│ ├── csrc
│ ├── CMakeLists.txt
│ ├── fast_rnnt.cu
│ ├── fast_rnnt.h
│ ├── mutual_information.cu
│ └── mutual_information.h
│ ├── fast_rnnt
│ ├── __init__.py
│ ├── mutual_information.py
│ └── rnnt_loss.py
│ └── tests
│ ├── CMakeLists.txt
│ ├── mutual_information_test.py
│ └── rnnt_loss_test.py
├── package.sh
├── requirements.txt
└── setup.py
/.flake8:
--------------------------------------------------------------------------------
1 | [flake8]
2 | show-source=true
3 | statistics=true
4 | max-line-length=80
5 |
6 | exclude =
7 | .git,
8 | .github,
9 | setup.py,
10 | build,
11 |
--------------------------------------------------------------------------------
/.github/scripts/install_cuda.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | #
3 | # Copyright 2020 Mobvoi Inc. (authors: Fangjun Kuang)
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 |
17 | echo "cuda version: $cuda"
18 |
19 | case "$cuda" in
20 | 10.0)
21 | url=https://developer.nvidia.com/compute/cuda/10.0/Prod/local_installers/cuda_10.0.130_410.48_linux
22 | ;;
23 | 10.1)
24 | # WARNING: there are bugs in
25 | # https://developer.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.105_418.39_linux.run
26 | # with GCC 7. Please use the following version
27 | url=http://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run
28 | ;;
29 | 10.2)
30 | url=http://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run
31 | ;;
32 | 11.0)
33 | url=http://developer.download.nvidia.com/compute/cuda/11.0.2/local_installers/cuda_11.0.2_450.51.05_linux.run
34 | ;;
35 | 11.1)
36 | # url=https://developer.download.nvidia.com/compute/cuda/11.1.0/local_installers/cuda_11.1.0_455.23.05_linux.run
37 | url=https://developer.download.nvidia.com/compute/cuda/11.1.1/local_installers/cuda_11.1.1_455.32.00_linux.run
38 | ;;
39 | 11.3)
40 | # url=https://developer.download.nvidia.com/compute/cuda/11.3.0/local_installers/cuda_11.3.0_465.19.01_linux.run
41 | url=https://developer.download.nvidia.com/compute/cuda/11.3.1/local_installers/cuda_11.3.1_465.19.01_linux.run
42 | ;;
43 | 11.5)
44 | url=https://developer.download.nvidia.com/compute/cuda/11.5.2/local_installers/cuda_11.5.2_495.29.05_linux.run
45 | ;;
46 | 11.6)
47 | url=https://developer.download.nvidia.com/compute/cuda/11.6.2/local_installers/cuda_11.6.2_510.47.03_linux.run
48 | ;;
49 | 11.7)
50 | url=https://developer.download.nvidia.com/compute/cuda/11.7.1/local_installers/cuda_11.7.1_515.65.01_linux.run
51 | ;;
52 | *)
53 | echo "Unknown cuda version: $cuda"
54 | exit 1
55 | ;;
56 | esac
57 |
58 | function retry() {
59 | $* || (sleep 1 && $*) || (sleep 2 && $*) || (sleep 4 && $*) || (sleep 8 && $*)
60 | }
61 |
62 | retry curl -LSs -O $url
63 | filename=$(basename $url)
64 | echo "filename: $filename"
65 | chmod +x ./$filename
66 | sudo ./$filename --toolkit --silent
67 | rm -fv ./$filename
68 |
69 | export CUDA_HOME=/usr/local/cuda
70 | export PATH=$CUDA_HOME/bin:$PATH
71 | export LD_LIBRARY_PATH=$CUDA_HOME/lib:$LD_LIBRARY_PATH
72 | export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
73 |
--------------------------------------------------------------------------------
/.github/scripts/install_cudnn.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | #
3 | # Copyright 2020 Mobvoi Inc. (authors: Fangjun Kuang)
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 |
17 | case $cuda in
18 | 10.0)
19 | filename=cudnn-10.0-linux-x64-v7.6.5.32.tgz
20 | ;;
21 | 10.1)
22 | filename=cudnn-10.1-linux-x64-v8.0.2.39.tgz
23 | ;;
24 | 10.2)
25 | filename=cudnn-10.2-linux-x64-v8.0.2.39.tgz
26 | ;;
27 | 11.0)
28 | filename=cudnn-11.0-linux-x64-v8.0.5.39.tgz
29 | ;;
30 | 11.1)
31 | filename=cudnn-11.1-linux-x64-v8.0.4.30.tgz
32 | ;;
33 | 11.3)
34 | filename=cudnn-11.3-linux-x64-v8.2.0.53.tgz
35 | ;;
36 | 11.5)
37 | filename=cudnn-11.3-linux-x64-v8.2.0.53.tgz
38 | ;;
39 | 11.6)
40 | filename=cudnn-11.3-linux-x64-v8.2.0.53.tgz
41 | ;;
42 | 11.7)
43 | filename=cudnn-11.3-linux-x64-v8.2.0.53.tgz
44 | ;;
45 | *)
46 | echo "Unsupported cuda version: $cuda"
47 | exit 1
48 | ;;
49 | esac
50 |
51 | command -v git-lfs >/dev/null 2>&1 || { echo >&2 "\nPlease install 'git-lfs' first."; exit 2; }
52 |
53 | GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/csukuangfj/cudnn
54 | cd cudnn
55 | git lfs pull --include="$filename"
56 |
57 | sudo tar xf ./$filename --strip-components=1 -C /usr/local/cuda
58 |
59 | # save disk space
60 | git lfs prune && cd .. && rm -rf cudnn
61 |
62 | sudo sed -i '59i#define CUDNN_MAJOR 8' /usr/local/cuda/include/cudnn.h
63 |
--------------------------------------------------------------------------------
/.github/scripts/install_torch.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | #
3 | # Copyright 2020 Mobvoi Inc. (authors: Fangjun Kuang)
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 |
17 | echo "torch version: $torch"
18 | echo "cuda version: $cuda"
19 |
20 | case ${torch} in
21 | 1.5.*)
22 | case ${cuda} in
23 | 10.1)
24 | package="torch==${torch}+cu101"
25 | url=https://download.pytorch.org/whl/torch_stable.html
26 | ;;
27 | 10.2)
28 | package="torch==${torch}"
29 | # Leave url empty to use PyPI.
30 | # torch_stable provides cu92 but we want cu102
31 | url=
32 | ;;
33 | esac
34 | ;;
35 | 1.6.0)
36 | case ${cuda} in
37 | 10.1)
38 | package="torch==1.6.0+cu101"
39 | url=https://download.pytorch.org/whl/torch_stable.html
40 | ;;
41 | 10.2)
42 | package="torch==1.6.0"
43 | # Leave it empty to use PyPI.
44 | # torch_stable provides cu92 but we want cu102
45 | url=
46 | ;;
47 | esac
48 | ;;
49 | 1.7.*)
50 | case ${cuda} in
51 | 10.1)
52 | package="torch==${torch}+cu101"
53 | url=https://download.pytorch.org/whl/torch_stable.html
54 | ;;
55 | 10.2)
56 | package="torch==${torch}"
57 | # Leave it empty to use PyPI.
58 | # torch_stable provides cu92 but we want cu102
59 | url=
60 | ;;
61 | 11.0)
62 | package="torch==${torch}+cu110"
63 | url=https://download.pytorch.org/whl/torch_stable.html
64 | ;;
65 | esac
66 | ;;
67 | 1.8.*)
68 | case ${cuda} in
69 | 10.1)
70 | package="torch==${torch}+cu101"
71 | url=https://download.pytorch.org/whl/torch_stable.html
72 | ;;
73 | 10.2)
74 | package="torch==${torch}"
75 | # Leave it empty to use PyPI.
76 | url=
77 | ;;
78 | 11.1)
79 | package="torch==${torch}+cu111"
80 | url=https://download.pytorch.org/whl/torch_stable.html
81 | ;;
82 | esac
83 | ;;
84 | 1.9.*)
85 | case ${cuda} in
86 | 10.2)
87 | package="torch==${torch}"
88 | # Leave it empty to use PyPI.
89 | url=
90 | ;;
91 | 11.1)
92 | package="torch==${torch}+cu111"
93 | url=https://download.pytorch.org/whl/torch_stable.html
94 | ;;
95 | esac
96 | ;;
97 | 1.10.*)
98 | case ${cuda} in
99 | 10.2)
100 | package="torch==${torch}"
101 | # Leave it empty to use PyPI.
102 | url=
103 | ;;
104 | 11.1)
105 | package="torch==${torch}+cu111"
106 | url=https://download.pytorch.org/whl/torch_stable.html
107 | ;;
108 | 11.3)
109 | package="torch==${torch}+cu113"
110 | url=https://download.pytorch.org/whl/torch_stable.html
111 | ;;
112 | esac
113 | ;;
114 | 1.11.*)
115 | case ${cuda} in
116 | 10.2)
117 | package="torch==${torch}"
118 | # Leave it empty to use PyPI.
119 | url=
120 | ;;
121 | 11.3)
122 | package="torch==${torch}+cu113"
123 | url=https://download.pytorch.org/whl/torch_stable.html
124 | ;;
125 | 11.5)
126 | package="torch==${torch}+cu115"
127 | url=https://download.pytorch.org/whl/torch_stable.html
128 | ;;
129 | esac
130 | ;;
131 | 1.12.*)
132 | case ${cuda} in
133 | 10.2)
134 | package="torch==${torch}"
135 | # Leave it empty to use PyPI.
136 | url=
137 | ;;
138 | 11.3)
139 | package="torch==${torch}+cu113"
140 | url=https://download.pytorch.org/whl/torch_stable.html
141 | ;;
142 | 11.6)
143 | package="torch==${torch}+cu116"
144 | url=https://download.pytorch.org/whl/torch_stable.html
145 | ;;
146 | esac
147 | ;;
148 | 1.13.*)
149 | case ${cuda} in
150 | 11.6)
151 | package="torch==${torch}+cu116"
152 | url=https://download.pytorch.org/whl/torch_stable.html
153 | ;;
154 | 11.7)
155 | package="torch==${torch}"
156 | # Leave it empty to use PyPI.
157 | url=
158 | ;;
159 | esac
160 | ;;
161 | 2.0.*)
162 | case ${cuda} in
163 | 11.7)
164 | package="torch==${torch}+cu117"
165 | url=https://download.pytorch.org/whl/torch_stable.html
166 | ;;
167 | 11.8)
168 | package="torch==${torch}+cu118"
169 | url=https://download.pytorch.org/whl/torch_stable.html
170 | ;;
171 | esac
172 | ;;
173 | *)
174 | echo "Unsupported PyTorch version: ${torch}"
175 | exit 1
176 | ;;
177 | esac
178 |
179 | function retry() {
180 | $* || (sleep 1 && $*) || (sleep 2 && $*) || (sleep 4 && $*) || (sleep 8 && $*)
181 | }
182 |
183 | if [ x"${url}" == "x" ]; then
184 | retry python3 -m pip install -q $package
185 | else
186 | retry python3 -m pip install -q $package -f $url
187 | fi
188 |
189 | rm -rfv ~/.cache/pip
190 |
--------------------------------------------------------------------------------
/.github/workflows/run_tests_cpu.yml:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Xiaomi Corp. (Wei Kang)
2 |
3 | # See ../../LICENSE for clarification regarding multiple authors
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 |
17 | # refer to https://github.com/actions/starter-workflows/pull/47/files
18 |
19 | name: run-tests-cpu
20 |
21 | on:
22 | push:
23 | branches:
24 | - master
25 | paths:
26 | - '.github/workflows/run_tests_cpu.yml'
27 | - 'CMakeLists.txt'
28 | - 'cmake/**'
29 | - 'fast_rnnt/csrc/**'
30 | - 'fast_rnnt/python/**'
31 | pull_request:
32 | branches:
33 | - master
34 | paths:
35 | - '.github/workflows/run_tests_cpu.yml'
36 | - 'CMakeLists.txt'
37 | - 'cmake/**'
38 | - 'fast_rnnt/csrc/**'
39 | - 'fast_rnnt/python/**'
40 |
41 | concurrency:
42 | group: run-tests-cpu-${{ github.ref }}
43 | cancel-in-progress: true
44 |
45 | jobs:
46 | run-tests-cpu:
47 | runs-on: ${{ matrix.os }}
48 | strategy:
49 | fail-fast: false
50 | matrix:
51 | os: [ubuntu-latest, macos-latest]
52 | torch: ["1.12.1"]
53 | torchaudio: ["0.12.1"]
54 | python-version: ["3.9"]
55 | build_type: ["Release", "Debug"]
56 |
57 | steps:
58 | # refer to https://github.com/actions/checkout
59 | - uses: actions/checkout@v2
60 |
61 | - name: Display GCC version
62 | run: |
63 | gcc --version
64 |
65 | - name: Display clang version
66 | if: startsWith(matrix.os, 'macos')
67 | run: |
68 | clang --version
69 |
70 | - name: Setup Python ${{ matrix.python-version }}
71 | uses: actions/setup-python@v2
72 | with:
73 | python-version: ${{ matrix.python-version }}
74 |
75 | - name: Display Python version
76 | run: python -c "import sys; print(sys.version)"
77 |
78 | - name: Install PyTorch ${{ matrix.torch }}
79 | if: startsWith(matrix.os, 'ubuntu')
80 | shell: bash
81 | run: |
82 | python3 -m pip install -qq --upgrade pip
83 | python3 -m pip install -qq torch==${{ matrix.torch }}+cpu -f https://download.pytorch.org/whl/torch_stable.html
84 | python3 -m pip install -qq torchaudio==${{ matrix.torchaudio }} -f https://download.pytorch.org/whl/cpu/torch_stable.html
85 | python3 -c "import torch; print('torch version:', torch.__version__)"
86 |
87 | python3 -m torch.utils.collect_env
88 |
89 | - name: Install PyTorch ${{ matrix.torch }}
90 | if: startsWith(matrix.os, 'macos')
91 | shell: bash
92 | run: |
93 | python3 -m pip install -qq --upgrade pip
94 | python3 -m pip install -qq torch==${{ matrix.torch }}
95 | python3 -m pip install -qq torchaudio==${{ matrix.torchaudio }}
96 | python3 -c "import torch; print('torch version:', torch.__version__)"
97 |
98 | python3 -m torch.utils.collect_env
99 |
100 | - name: Configure CMake
101 | shell: bash
102 | env:
103 | torch: ${{ matrix.torch }}
104 | run: |
105 | mkdir build
106 | cd build
107 | cmake -DCMAKE_BUILD_TYPE=${{ matrix.build_type }} -DFT_WITH_CUDA=OFF ..
108 |
109 | - name: ${{ matrix.build_type }} Build
110 | shell: bash
111 | run: |
112 | cd build
113 | make -j2 VERBOSE=1
114 |
115 | - name: Display Build Information
116 | shell: bash
117 | run: |
118 | export PYTHONPATH=$PWD/fast_rnnt/python:$PWD/build/lib:$PYTHONPATH
119 |
120 | - name: Run Tests
121 | shell: bash
122 | run: |
123 | cd build
124 | ctest --output-on-failure
125 |
--------------------------------------------------------------------------------
/.github/workflows/run_tests_cuda.yml:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Xiaomi Corp. (Wei Kang)
2 |
3 | # See ../../LICENSE for clarification regarding multiple authors
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 |
17 | name: run-tests-cuda
18 |
19 | on:
20 | push:
21 | branches:
22 | - master
23 | paths:
24 | - '.github/workflows/run_tests_cuda.yml'
25 | - 'CMakeLists.txt'
26 | - 'cmake/**'
27 | - 'fast_rnnt/csrc/**'
28 | - 'fast_rnnt/python/**'
29 | pull_request:
30 | branches:
31 | - master
32 | paths:
33 | - '.github/workflows/run_tests_cuda.yml'
34 | - 'CMakeLists.txt'
35 | - 'cmake/**'
36 | - 'fast_rnnt/csrc/**'
37 | - 'fast_rnnt/python/**'
38 |
39 | concurrency:
40 | group: run-tests-${{ github.ref }}
41 | cancel-in-progress: true
42 |
43 | jobs:
44 | run-tests:
45 | runs-on: ${{ matrix.os }}
46 | strategy:
47 | fail-fast: false
48 | matrix:
49 | os: [ubuntu-latest]
50 | cuda: ["11.6"]
51 | torch: ["1.12.1"]
52 | python-version: ["3.9"]
53 | build_type: ["Release", "Debug"]
54 |
55 | steps:
56 | # refer to https://github.com/actions/checkout
57 | - uses: actions/checkout@v2
58 |
59 | - name: Install CUDA Toolkit ${{ matrix.cuda }}
60 | env:
61 | cuda: ${{ matrix.cuda }}
62 | run: |
63 | source ./.github/scripts/install_cuda.sh
64 | echo "CUDA_HOME=${CUDA_HOME}" >> $GITHUB_ENV
65 | echo "${CUDA_HOME}/bin" >> $GITHUB_PATH
66 | echo "LD_LIBRARY_PATH=${CUDA_HOME}/lib:${CUDA_HOME}/lib64:${LD_LIBRARY_PATH}" >> $GITHUB_ENV
67 | shell: bash
68 |
69 | - name: Display NVCC version
70 | run: |
71 | which nvcc
72 | nvcc --version
73 |
74 | - name: Display GCC version
75 | run: |
76 | gcc --version
77 |
78 | - name: Setup Python ${{ matrix.python-version }}
79 | uses: actions/setup-python@v2
80 | with:
81 | python-version: ${{ matrix.python-version }}
82 |
83 | - name: Display Python version
84 | run: python -c "import sys; print(sys.version)"
85 |
86 | - name: Install PyTorch ${{ matrix.torch }}
87 | env:
88 | cuda: ${{ matrix.cuda }}
89 | torch: ${{ matrix.torch }}
90 | shell: bash
91 | run: |
92 | python3 -m pip install -qq --upgrade pip
93 |
94 | ./.github/scripts/install_torch.sh
95 | python3 -c "import torch; print('torch version:', torch.__version__)"
96 |
97 | - name: Install git lfs
98 | run: |
99 | sudo apt-get install -y git-lfs
100 |
101 | - name: Download cudnn 8.0
102 | env:
103 | cuda: ${{ matrix.cuda }}
104 | run: |
105 | ./.github/scripts/install_cudnn.sh
106 |
107 | - name: Configure CMake
108 | shell: bash
109 | env:
110 | torch: ${{ matrix.torch }}
111 | run: |
112 | mkdir build
113 | cd build
114 | cmake -DCMAKE_BUILD_TYPE=${{ matrix.build_type }} ..
115 |
116 | - name: ${{ matrix.build_type }} Build
117 | shell: bash
118 | run: |
119 | echo "number of cores: $(nproc)"
120 | cd build
121 | # we cannot use -j here because of limited RAM
122 | # of the VM provided by GitHub actions
123 | make VERBOSE=1 -j2
124 |
125 | - name: Display Build Information
126 | shell: bash
127 | run: |
128 | export PYTHONPATH=$PWD/fast_rnnt/python:$PWD/build/lib:$PYTHONPATH
129 |
130 | - name: Run Tests
131 | shell: bash
132 | run: |
133 | cd build
134 | ctest --output-on-failure
135 |
--------------------------------------------------------------------------------
/.github/workflows/style_check.yml:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Xiaomi Corp. (Fangjun Kuang
2 | # Wei Kang)
3 | # See ../../LICENSE for clarification regarding multiple authors
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 |
17 | name: style_check
18 |
19 | on:
20 | push:
21 | branches:
22 | - master
23 | pull_request:
24 | branches:
25 | - master
26 |
27 | concurrency:
28 | group: style_check-${{ github.ref }}
29 | cancel-in-progress: true
30 |
31 | jobs:
32 | style_check:
33 | runs-on: ${{ matrix.os }}
34 | strategy:
35 | matrix:
36 | os: [ubuntu-latest]
37 | python-version: [3.8]
38 | fail-fast: false
39 |
40 | steps:
41 | - uses: actions/checkout@v2
42 | with:
43 | fetch-depth: 0
44 |
45 | - name: Setup Python ${{ matrix.python-version }}
46 | uses: actions/setup-python@v1
47 | with:
48 | python-version: ${{ matrix.python-version }}
49 |
50 | - name: Install Python dependencies
51 | run: |
52 | python3 -m pip install --upgrade pip black==22.3.0 flake8==5.0.4 click==8.1.0
53 | # Click issue fixed in https://github.com/psf/black/pull/2966
54 |
55 | - name: Run flake8
56 | shell: bash
57 | working-directory: ${{github.workspace}}
58 | run: |
59 | # stop the build if there are Python syntax errors or undefined names
60 | flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
61 | # exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
62 | flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 \
63 | --statistics --extend-ignore=E203,E266,E501,F401,E402,F403,F841,W503
64 |
65 | - name: Run black
66 | shell: bash
67 | working-directory: ${{github.workspace}}
68 | run: |
69 | black -l 80 --check --diff .
70 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .DS_Store
2 | .idea
3 | venv*
4 | deploy*
5 | **/__pycache__
6 | **/build*
7 | Testing*
8 | dist/*
9 | *egg-info*/*
10 |
11 |
--------------------------------------------------------------------------------
/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | if("x${CMAKE_SOURCE_DIR}" STREQUAL "x${CMAKE_BINARY_DIR}")
2 | message(FATAL_ERROR "\
3 | In-source build is not a good practice.
4 | Please use:
5 | mkdir build
6 | cd build
7 | cmake ..
8 | to build this project"
9 | )
10 | endif()
11 |
12 | cmake_minimum_required(VERSION 3.8 FATAL_ERROR)
13 |
14 | set(CMAKE_DISABLE_FIND_PACKAGE_MKL TRUE)
15 | set(languages CXX)
16 | set(_FT_WITH_CUDA ON)
17 |
18 | # the following settings are modified from cub/CMakeLists.txt
19 | set(CMAKE_CXX_STANDARD 14 CACHE STRING "The C++ version to be used.")
20 | set(CMAKE_CXX_STANDARD_REQUIRED ON)
21 | set(CMAKE_CXX_EXTENSIONS OFF)
22 |
23 | message(STATUS "C++ Standard version: ${CMAKE_CXX_STANDARD}")
24 |
25 |
26 | find_program(FT_HAS_NVCC nvcc)
27 | if(NOT FT_HAS_NVCC AND "$ENV{CUDACXX}" STREQUAL "")
28 | message(STATUS "No NVCC detected. Disable CUDA support")
29 | set(_FT_WITH_CUDA OFF)
30 | endif()
31 |
32 | if(APPLE OR (DEFINED FT_WITH_CUDA AND NOT FT_WITH_CUDA))
33 | if(_FT_WITH_CUDA)
34 | message(STATUS "Disable CUDA support")
35 | set(_FT_WITH_CUDA OFF)
36 | endif()
37 | endif()
38 |
39 | if(_FT_WITH_CUDA)
40 | set(languages ${languages} CUDA)
41 | if(NOT DEFINED FT_WITH_CUDA)
42 | set(FT_WITH_CUDA ON)
43 | endif()
44 | endif()
45 |
46 | message(STATUS "Enabled languages: ${languages}")
47 |
48 | project(fast_rnnt ${languages})
49 |
50 | set(FT_VERSION "1.2")
51 |
52 | set(ALLOWABLE_BUILD_TYPES Debug Release RelWithDebInfo MinSizeRel)
53 | set(DEFAULT_BUILD_TYPE "Release")
54 | set_property(CACHE CMAKE_BUILD_TYPE PROPERTY STRINGS "${ALLOWABLE_BUILD_TYPES}")
55 | if(NOT CMAKE_BUILD_TYPE AND NOT CMAKE_CONFIGURATION_TYPES)
56 | # CMAKE_CONFIGURATION_TYPES: with config type values from other generators (IDE).
57 | message(STATUS "No CMAKE_BUILD_TYPE given, default to ${DEFAULT_BUILD_TYPE}")
58 | set(CMAKE_BUILD_TYPE "${DEFAULT_BUILD_TYPE}")
59 | elseif(NOT CMAKE_BUILD_TYPE IN_LIST ALLOWABLE_BUILD_TYPES)
60 | message(FATAL_ERROR "Invalid build type: ${CMAKE_BUILD_TYPE}, \
61 | choose one from ${ALLOWABLE_BUILD_TYPES}")
62 | endif()
63 |
64 | option(FT_BUILD_TESTS "Whether to build tests or not" ON)
65 | option(BUILD_SHARED_LIBS "Whether to build shared libs" ON)
66 |
67 | set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY "${CMAKE_BINARY_DIR}/lib")
68 | set(CMAKE_LIBRARY_OUTPUT_DIRECTORY "${CMAKE_BINARY_DIR}/lib")
69 | set(CMAKE_RUNTIME_OUTPUT_DIRECTORY "${CMAKE_BINARY_DIR}/bin")
70 |
71 | set(CMAKE_SKIP_BUILD_RPATH FALSE)
72 | set(BUILD_RPATH_USE_ORIGIN TRUE)
73 | set(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
74 | set(CMAKE_INSTALL_RPATH "$ORIGIN")
75 | set(CMAKE_BUILD_RPATH "$ORIGIN")
76 |
77 | if(FT_WITH_CUDA)
78 | add_definitions(-DFT_WITH_CUDA)
79 | # Force CUDA C++ standard to be the same as the C++ standard used.
80 | #
81 | # Now, CMake is unaligned with reality on standard versions: https://gitlab.kitware.com/cmake/cmake/issues/18597
82 | # which means that using standard CMake methods, it's impossible to actually sync the CXX and CUDA versions for pre-11
83 | # versions of C++; CUDA accepts 98 but translates that to 03, while CXX doesn't accept 03 (and doesn't translate that to 03).
84 | # In case this gives You, dear user, any trouble, please escalate the above CMake bug, so we can support reality properly.
85 | if(DEFINED CMAKE_CUDA_STANDARD)
86 | message(WARNING "You've set CMAKE_CUDA_STANDARD; please note that this variable is ignored, and CMAKE_CXX_STANDARD"
87 | " is used as the C++ standard version for both C++ and CUDA.")
88 | endif()
89 |
90 |
91 | unset(CMAKE_CUDA_STANDARD CACHE)
92 | set(CMAKE_CUDA_STANDARD ${CMAKE_CXX_STANDARD})
93 |
94 | include(cmake/select_compute_arch.cmake)
95 | cuda_select_nvcc_arch_flags(FT_COMPUTE_ARCH_FLAGS)
96 | message(STATUS "FT_COMPUTE_ARCH_FLAGS: ${FT_COMPUTE_ARCH_FLAGS}")
97 |
98 | # set(OT_COMPUTE_ARCHS 30 32 35 50 52 53 60 61 62 70 72)
99 | # message(WARNING "arch 62/72 are not supported for now")
100 |
101 | # see https://arnon.dk/matching-sm-architectures-arch-and-gencode-for-various-nvidia-cards/
102 | # https://www.myzhar.com/blog/tutorials/tutorial-nvidia-gpu-cuda-compute-capability/
103 | set(FT_COMPUTE_ARCH_CANDIDATES 35 50 60 61 70 75)
104 | if(CUDA_VERSION VERSION_GREATER "11.0")
105 | list(APPEND FT_COMPUTE_ARCH_CANDIDATES 80 86)
106 | endif()
107 | message(STATUS "FT_COMPUTE_ARCH_CANDIDATES ${FT_COMPUTE_ARCH_CANDIDATES}")
108 |
109 | set(FT_COMPUTE_ARCHS)
110 |
111 | foreach(COMPUTE_ARCH IN LISTS FT_COMPUTE_ARCH_CANDIDATES)
112 | if("${FT_COMPUTE_ARCH_FLAGS}" MATCHES ${COMPUTE_ARCH})
113 | message(STATUS "Adding arch ${COMPUTE_ARCH}")
114 | list(APPEND FT_COMPUTE_ARCHS ${COMPUTE_ARCH})
115 | else()
116 | message(STATUS "Skipping arch ${COMPUTE_ARCH}")
117 | endif()
118 | endforeach()
119 |
120 | if(NOT FT_COMPUTE_ARCHS)
121 | set(FT_COMPUTE_ARCHS ${FT_COMPUTE_ARCH_CANDIDATES})
122 | endif()
123 |
124 | message(STATUS "FT_COMPUTE_ARCHS: ${FT_COMPUTE_ARCHS}")
125 |
126 | foreach(COMPUTE_ARCH IN LISTS FT_COMPUTE_ARCHS)
127 | set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} --expt-extended-lambda -gencode arch=compute_${COMPUTE_ARCH},code=sm_${COMPUTE_ARCH}")
128 | set(CMAKE_CUDA_ARCHITECTURES "${COMPUTE_ARCH}-real;${COMPUTE_ARCH}-virtual;${CMAKE_CUDA_ARCHITECTURES}")
129 | endforeach()
130 | endif()
131 |
132 | list(APPEND CMAKE_MODULE_PATH ${CMAKE_SOURCE_DIR}/cmake/Modules)
133 | list(APPEND CMAKE_MODULE_PATH ${CMAKE_SOURCE_DIR}/cmake)
134 |
135 | include(pybind11)
136 | include(torch)
137 |
138 | if(FT_BUILD_TESTS)
139 | enable_testing()
140 | include(googletest)
141 | endif()
142 |
143 | add_subdirectory(fast_rnnt)
144 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 |
2 | Legal Notices
3 |
4 | NOTE (this is not from the Apache License): The copyright model is that
5 | authors (or their employers, if noted in individual files) own their
6 | individual contributions. The authors' contributions can be discerned
7 | from the git history.
8 |
9 | -------------------------------------------------------------------------
10 |
11 | Apache License
12 | Version 2.0, January 2004
13 | http://www.apache.org/licenses/
14 |
15 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
16 |
17 | 1. Definitions.
18 |
19 | "License" shall mean the terms and conditions for use, reproduction,
20 | and distribution as defined by Sections 1 through 9 of this document.
21 |
22 | "Licensor" shall mean the copyright owner or entity authorized by
23 | the copyright owner that is granting the License.
24 |
25 | "Legal Entity" shall mean the union of the acting entity and all
26 | other entities that control, are controlled by, or are under common
27 | control with that entity. For the purposes of this definition,
28 | "control" means (i) the power, direct or indirect, to cause the
29 | direction or management of such entity, whether by contract or
30 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
31 | outstanding shares, or (iii) beneficial ownership of such entity.
32 |
33 | "You" (or "Your") shall mean an individual or Legal Entity
34 | exercising permissions granted by this License.
35 |
36 | "Source" form shall mean the preferred form for making modifications,
37 | including but not limited to software source code, documentation
38 | source, and configuration files.
39 |
40 | "Object" form shall mean any form resulting from mechanical
41 | transformation or translation of a Source form, including but
42 | not limited to compiled object code, generated documentation,
43 | and conversions to other media types.
44 |
45 | "Work" shall mean the work of authorship, whether in Source or
46 | Object form, made available under the License, as indicated by a
47 | copyright notice that is included in or attached to the work
48 | (an example is provided in the Appendix below).
49 |
50 | "Derivative Works" shall mean any work, whether in Source or Object
51 | form, that is based on (or derived from) the Work and for which the
52 | editorial revisions, annotations, elaborations, or other modifications
53 | represent, as a whole, an original work of authorship. For the purposes
54 | of this License, Derivative Works shall not include works that remain
55 | separable from, or merely link (or bind by name) to the interfaces of,
56 | the Work and Derivative Works thereof.
57 |
58 | "Contribution" shall mean any work of authorship, including
59 | the original version of the Work and any modifications or additions
60 | to that Work or Derivative Works thereof, that is intentionally
61 | submitted to Licensor for inclusion in the Work by the copyright owner
62 | or by an individual or Legal Entity authorized to submit on behalf of
63 | the copyright owner. For the purposes of this definition, "submitted"
64 | means any form of electronic, verbal, or written communication sent
65 | to the Licensor or its representatives, including but not limited to
66 | communication on electronic mailing lists, source code control systems,
67 | and issue tracking systems that are managed by, or on behalf of, the
68 | Licensor for the purpose of discussing and improving the Work, but
69 | excluding communication that is conspicuously marked or otherwise
70 | designated in writing by the copyright owner as "Not a Contribution."
71 |
72 | "Contributor" shall mean Licensor and any individual or Legal Entity
73 | on behalf of whom a Contribution has been received by Licensor and
74 | subsequently incorporated within the Work.
75 |
76 | 2. Grant of Copyright License. Subject to the terms and conditions of
77 | this License, each Contributor hereby grants to You a perpetual,
78 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
79 | copyright license to reproduce, prepare Derivative Works of,
80 | publicly display, publicly perform, sublicense, and distribute the
81 | Work and such Derivative Works in Source or Object form.
82 |
83 | 3. Grant of Patent License. Subject to the terms and conditions of
84 | this License, each Contributor hereby grants to You a perpetual,
85 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
86 | (except as stated in this section) patent license to make, have made,
87 | use, offer to sell, sell, import, and otherwise transfer the Work,
88 | where such license applies only to those patent claims licensable
89 | by such Contributor that are necessarily infringed by their
90 | Contribution(s) alone or by combination of their Contribution(s)
91 | with the Work to which such Contribution(s) was submitted. If You
92 | institute patent litigation against any entity (including a
93 | cross-claim or counterclaim in a lawsuit) alleging that the Work
94 | or a Contribution incorporated within the Work constitutes direct
95 | or contributory patent infringement, then any patent licenses
96 | granted to You under this License for that Work shall terminate
97 | as of the date such litigation is filed.
98 |
99 | 4. Redistribution. You may reproduce and distribute copies of the
100 | Work or Derivative Works thereof in any medium, with or without
101 | modifications, and in Source or Object form, provided that You
102 | meet the following conditions:
103 |
104 | (a) You must give any other recipients of the Work or
105 | Derivative Works a copy of this License; and
106 |
107 | (b) You must cause any modified files to carry prominent notices
108 | stating that You changed the files; and
109 |
110 | (c) You must retain, in the Source form of any Derivative Works
111 | that You distribute, all copyright, patent, trademark, and
112 | attribution notices from the Source form of the Work,
113 | excluding those notices that do not pertain to any part of
114 | the Derivative Works; and
115 |
116 | (d) If the Work includes a "NOTICE" text file as part of its
117 | distribution, then any Derivative Works that You distribute must
118 | include a readable copy of the attribution notices contained
119 | within such NOTICE file, excluding those notices that do not
120 | pertain to any part of the Derivative Works, in at least one
121 | of the following places: within a NOTICE text file distributed
122 | as part of the Derivative Works; within the Source form or
123 | documentation, if provided along with the Derivative Works; or,
124 | within a display generated by the Derivative Works, if and
125 | wherever such third-party notices normally appear. The contents
126 | of the NOTICE file are for informational purposes only and
127 | do not modify the License. You may add Your own attribution
128 | notices within Derivative Works that You distribute, alongside
129 | or as an addendum to the NOTICE text from the Work, provided
130 | that such additional attribution notices cannot be construed
131 | as modifying the License.
132 |
133 | You may add Your own copyright statement to Your modifications and
134 | may provide additional or different license terms and conditions
135 | for use, reproduction, or distribution of Your modifications, or
136 | for any such Derivative Works as a whole, provided Your use,
137 | reproduction, and distribution of the Work otherwise complies with
138 | the conditions stated in this License.
139 |
140 | 5. Submission of Contributions. Unless You explicitly state otherwise,
141 | any Contribution intentionally submitted for inclusion in the Work
142 | by You to the Licensor shall be under the terms and conditions of
143 | this License, without any additional terms or conditions.
144 | Notwithstanding the above, nothing herein shall supersede or modify
145 | the terms of any separate license agreement you may have executed
146 | with Licensor regarding such Contributions.
147 |
148 | 6. Trademarks. This License does not grant permission to use the trade
149 | names, trademarks, service marks, or product names of the Licensor,
150 | except as required for reasonable and customary use in describing the
151 | origin of the Work and reproducing the content of the NOTICE file.
152 |
153 | 7. Disclaimer of Warranty. Unless required by applicable law or
154 | agreed to in writing, Licensor provides the Work (and each
155 | Contributor provides its Contributions) on an "AS IS" BASIS,
156 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
157 | implied, including, without limitation, any warranties or conditions
158 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
159 | PARTICULAR PURPOSE. You are solely responsible for determining the
160 | appropriateness of using or redistributing the Work and assume any
161 | risks associated with Your exercise of permissions under this License.
162 |
163 | 8. Limitation of Liability. In no event and under no legal theory,
164 | whether in tort (including negligence), contract, or otherwise,
165 | unless required by applicable law (such as deliberate and grossly
166 | negligent acts) or agreed to in writing, shall any Contributor be
167 | liable to You for damages, including any direct, indirect, special,
168 | incidental, or consequential damages of any character arising as a
169 | result of this License or out of the use or inability to use the
170 | Work (including but not limited to damages for loss of goodwill,
171 | work stoppage, computer failure or malfunction, or any and all
172 | other commercial damages or losses), even if such Contributor
173 | has been advised of the possibility of such damages.
174 |
175 | 9. Accepting Warranty or Additional Liability. While redistributing
176 | the Work or Derivative Works thereof, You may choose to offer,
177 | and charge a fee for, acceptance of support, warranty, indemnity,
178 | or other liability obligations and/or rights consistent with this
179 | License. However, in accepting such obligations, You may act only
180 | on Your own behalf and on Your sole responsibility, not on behalf
181 | of any other Contributor, and only if You agree to indemnify,
182 | defend, and hold each Contributor harmless for any liability
183 | incurred by, or claims asserted against, such Contributor by reason
184 | of your accepting any such warranty or additional liability.
185 |
186 | END OF TERMS AND CONDITIONS
187 |
188 | APPENDIX: How to apply the Apache License to your work.
189 |
190 | To apply the Apache License to your work, attach the following
191 | boilerplate notice, with the fields enclosed by brackets "[]"
192 | replaced with your own identifying information. (Don't include
193 | the brackets!) The text should be enclosed in the appropriate
194 | comment syntax for the file format. We also recommend that a
195 | file or class name and description of purpose be included on the
196 | same "printed page" as the copyright notice for easier
197 | identification within third-party archives.
198 |
199 | Copyright [yyyy] [name of copyright owner]
200 |
201 | Licensed under the Apache License, Version 2.0 (the "License");
202 | you may not use this file except in compliance with the License.
203 | You may obtain a copy of the License at
204 |
205 | http://www.apache.org/licenses/LICENSE-2.0
206 |
207 | Unless required by applicable law or agreed to in writing, software
208 | distributed under the License is distributed on an "AS IS" BASIS,
209 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
210 | See the License for the specific language governing permissions and
211 | limitations under the License.
212 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include requirements.txt
2 | include README.md
3 | include LICENSE*
4 | include CMakeLists.txt
5 | recursive-include fast_rnnt *.*
6 | recursive-include cmake *.*
7 | global-exclude *.pyc
8 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | This project implements a method for faster and more memory-efficient RNN-T loss computation, called `pruned rnnt`.
3 |
4 | Note: There is also a fast RNN-T loss implementation in [k2](https://github.com/k2-fsa/k2) project, which shares the same code here. We make `fast_rnnt` a stand-alone project in case someone wants only this rnnt loss.
5 |
6 | ## How does the pruned-rnnt work ?
7 |
8 | We first obtain pruning bounds for the RNN-T recursion using a simple joiner network that is just an addition of the encoder and decoder, then we use those pruning bounds to evaluate the full, non-linear joiner network.
9 |
10 | The picture below display the gradients (obtained by `rnnt_loss_simple` with `return_grad=true`) of lattice nodes, at each time frame, only a small set of nodes have a non-zero gradient, which justifies the pruned RNN-T loss, i.e., putting a limit on the number of symbols per frame.
11 |
12 | 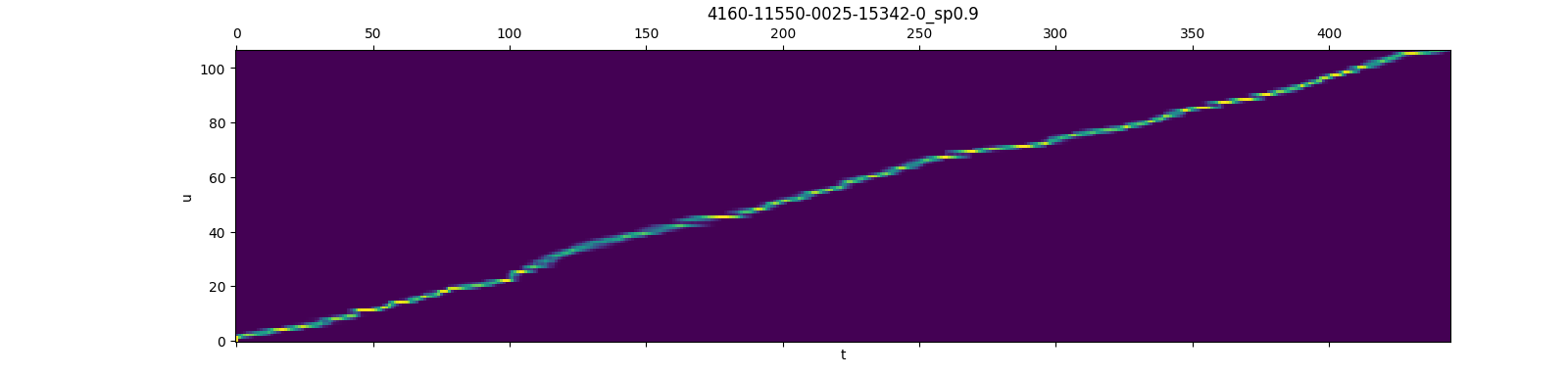 13 |
14 | > This picture is taken from [here](https://github.com/k2-fsa/icefall/pull/251)
15 |
16 | ## Installation
17 |
18 | You can install it via `pip`:
19 |
20 | ```
21 | pip install fast_rnnt
22 | ```
23 |
24 | You can also install from source:
25 |
26 | ```
27 | git clone https://github.com/danpovey/fast_rnnt.git
28 | cd fast_rnnt
29 | python setup.py install
30 | ```
31 |
32 | To check that `fast_rnnt` was installed successfully, please run
33 |
34 | ```
35 | python3 -c "import fast_rnnt; print(fast_rnnt.__version__)"
36 | ```
37 |
38 | which should print the version of the installed `fast_rnnt`, e.g., `1.0`.
39 |
40 |
41 | ### How to display installation log ?
42 |
43 | Use
44 |
45 | ```
46 | pip install --verbose fast_rnnt
47 | ```
48 |
49 | ### How to reduce installation time ?
50 |
51 | Use
52 |
53 | ```
54 | export FT_MAKE_ARGS="-j"
55 | pip install --verbose fast_rnnt
56 | ```
57 |
58 | It will pass `-j` to `make`.
59 |
60 | ### Which version of PyTorch is supported ?
61 |
62 | It has been tested on PyTorch >= 1.5.0.
63 |
64 | Note: The cuda version of the Pytorch should be the same as the cuda version in your environment,
65 | or it will cause a compilation error.
66 |
67 |
68 | ### How to install a CPU version of `fast_rnnt` ?
69 |
70 | Use
71 |
72 | ```
73 | export FT_CMAKE_ARGS="-DCMAKE_BUILD_TYPE=Release -DFT_WITH_CUDA=OFF"
74 | export FT_MAKE_ARGS="-j"
75 | pip install --verbose fast_rnnt
76 | ```
77 |
78 | It will pass `-DCMAKE_BUILD_TYPE=Release -DFT_WITH_CUDA=OFF` to `cmake`.
79 |
80 | ### Where to get help if I have problems with the installation ?
81 |
82 | Please file an issue at
83 | and describe your problem there.
84 |
85 |
86 | ## Usage
87 |
88 | ### For rnnt_loss_simple
89 |
90 | This is a simple case of the RNN-T loss, where the joiner network is just
91 | addition.
92 |
93 | Note: termination_symbol plays the role of blank in other RNN-T loss implementations, we call it termination_symbol as it terminates symbols of current frame.
94 |
95 | ```python
96 | am = torch.randn((B, T, C), dtype=torch.float32)
97 | lm = torch.randn((B, S + 1, C), dtype=torch.float32)
98 | symbols = torch.randint(0, C, (B, S))
99 | termination_symbol = 0
100 |
101 | boundary = torch.zeros((B, 4), dtype=torch.int64)
102 | boundary[:, 2] = target_lengths
103 | boundary[:, 3] = num_frames
104 |
105 | loss = fast_rnnt.rnnt_loss_simple(
106 | lm=lm,
107 | am=am,
108 | symbols=symbols,
109 | termination_symbol=termination_symbol,
110 | boundary=boundary,
111 | reduction="sum",
112 | )
113 | ```
114 |
115 | ### For rnnt_loss_smoothed
116 |
117 | The same as `rnnt_loss_simple`, except that it supports `am_only` & `lm_only` smoothing
118 | that allows you to make the loss-function one of the form:
119 |
120 | lm_only_scale * lm_probs +
121 | am_only_scale * am_probs +
122 | (1-lm_only_scale-am_only_scale) * combined_probs
123 |
124 | where `lm_probs` and `am_probs` are the probabilities given the lm and acoustic model independently.
125 |
126 | ```python
127 | am = torch.randn((B, T, C), dtype=torch.float32)
128 | lm = torch.randn((B, S + 1, C), dtype=torch.float32)
129 | symbols = torch.randint(0, C, (B, S))
130 | termination_symbol = 0
131 |
132 | boundary = torch.zeros((B, 4), dtype=torch.int64)
133 | boundary[:, 2] = target_lengths
134 | boundary[:, 3] = num_frames
135 |
136 | loss = fast_rnnt.rnnt_loss_smoothed(
137 | lm=lm,
138 | am=am,
139 | symbols=symbols,
140 | termination_symbol=termination_symbol,
141 | lm_only_scale=0.25,
142 | am_only_scale=0.0
143 | boundary=boundary,
144 | reduction="sum",
145 | )
146 | ```
147 |
148 | ### For rnnt_loss_pruned
149 |
150 | `rnnt_loss_pruned` can not be used alone, it needs the gradients returned by `rnnt_loss_simple/rnnt_loss_smoothed` to get pruning bounds.
151 |
152 | ```python
153 | am = torch.randn((B, T, C), dtype=torch.float32)
154 | lm = torch.randn((B, S + 1, C), dtype=torch.float32)
155 | symbols = torch.randint(0, C, (B, S))
156 | termination_symbol = 0
157 |
158 | boundary = torch.zeros((B, 4), dtype=torch.int64)
159 | boundary[:, 2] = target_lengths
160 | boundary[:, 3] = num_frames
161 |
162 | # rnnt_loss_simple can be also rnnt_loss_smoothed
163 | simple_loss, (px_grad, py_grad) = fast_rnnt.rnnt_loss_simple(
164 | lm=lm,
165 | am=am,
166 | symbols=symbols,
167 | termination_symbol=termination_symbol,
168 | boundary=boundary,
169 | reduction="sum",
170 | return_grad=True,
171 | )
172 | s_range = 5 # can be other values
173 | ranges = fast_rnnt.get_rnnt_prune_ranges(
174 | px_grad=px_grad,
175 | py_grad=py_grad,
176 | boundary=boundary,
177 | s_range=s_range,
178 | )
179 |
180 | am_pruned, lm_pruned = fast_rnnt.do_rnnt_pruning(am=am, lm=lm, ranges=ranges)
181 |
182 | logits = model.joiner(am_pruned, lm_pruned)
183 | pruned_loss = fast_rnnt.rnnt_loss_pruned(
184 | logits=logits,
185 | symbols=symbols,
186 | ranges=ranges,
187 | termination_symbol=termination_symbol,
188 | boundary=boundary,
189 | reduction="sum",
190 | )
191 | ```
192 |
193 | You can also find recipes [here](https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/pruned_transducer_stateless) that uses `rnnt_loss_pruned` to train a model.
194 |
195 |
196 | ### For rnnt_loss
197 |
198 | The `unprund rnnt_loss` is the same as `torchaudio rnnt_loss`, it produces same output as torchaudio for the same input.
199 |
200 | ```python
201 | logits = torch.randn((B, S, T, C), dtype=torch.float32)
202 | symbols = torch.randint(0, C, (B, S))
203 | termination_symbol = 0
204 |
205 | boundary = torch.zeros((B, 4), dtype=torch.int64)
206 | boundary[:, 2] = target_lengths
207 | boundary[:, 3] = num_frames
208 |
209 | loss = fast_rnnt.rnnt_loss(
210 | logits=logits,
211 | symbols=symbols,
212 | termination_symbol=termination_symbol,
213 | boundary=boundary,
214 | reduction="sum",
215 | )
216 | ```
217 |
218 |
219 | ## Benchmarking
220 |
221 | The [repo](https://github.com/csukuangfj/transducer-loss-benchmarking) compares the speed and memory usage of several transducer losses, the summary in the following table is taken from there, you can check the repository for more details.
222 |
223 | Note: As we declared above, `fast_rnnt` is also implemented in [k2](https://github.com/k2-fsa/k2) project, so `k2` and `fast_rnnt` are equivalent in the benchmarking.
224 |
225 | |Name |Average step time (us) | Peak memory usage (MB)|
226 | |--------------------|-----------------------|-----------------------|
227 | |torchaudio |601447 |12959.2 |
228 | |fast_rnnt(unpruned) |274407 |15106.5 |
229 | |fast_rnnt(pruned) |38112 |2647.8 |
230 | |optimized_transducer|567684 |10903.1 |
231 | |warprnnt_numba |229340 |13061.8 |
232 | |warp-transducer |210772 |13061.8 |
233 |
--------------------------------------------------------------------------------
/cmake/Modules/FetchContent/CMakeLists.cmake.in:
--------------------------------------------------------------------------------
1 | # Distributed under the OSI-approved BSD 3-Clause License. See accompanying
2 | # file Copyright.txt or https://cmake.org/licensing for details.
3 |
4 | cmake_minimum_required(VERSION ${CMAKE_VERSION})
5 |
6 | # We name the project and the target for the ExternalProject_Add() call
7 | # to something that will highlight to the user what we are working on if
8 | # something goes wrong and an error message is produced.
9 |
10 | project(${contentName}-populate NONE)
11 |
12 | include(ExternalProject)
13 | ExternalProject_Add(${contentName}-populate
14 | ${ARG_EXTRA}
15 | SOURCE_DIR "${ARG_SOURCE_DIR}"
16 | BINARY_DIR "${ARG_BINARY_DIR}"
17 | CONFIGURE_COMMAND ""
18 | BUILD_COMMAND ""
19 | INSTALL_COMMAND ""
20 | TEST_COMMAND ""
21 | )
22 |
--------------------------------------------------------------------------------
/cmake/Modules/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## FetchContent
3 |
4 | `FetchContent.cmake` and `FetchContent/CMakeLists.cmake.in`
5 | are copied from `cmake/3.11.0/share/cmake-3.11/Modules`.
6 |
--------------------------------------------------------------------------------
/cmake/googletest.cmake:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2021 Xiaomi Corporation (authors: Fangjun Kuang)
2 | # See ../LICENSE for clarification regarding multiple authors
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | function(download_googltest)
17 | if(CMAKE_VERSION VERSION_LESS 3.11)
18 | # FetchContent is available since 3.11,
19 | # we've copied it to ${CMAKE_SOURCE_DIR}/cmake/Modules
20 | # so that it can be used in lower CMake versions.
21 | list(APPEND CMAKE_MODULE_PATH ${CMAKE_SOURCE_DIR}/cmake/Modules)
22 | endif()
23 |
24 | include(FetchContent)
25 |
26 | set(googletest_URL "https://github.com/google/googletest/archive/release-1.10.0.tar.gz")
27 | set(googletest_HASH "SHA256=9dc9157a9a1551ec7a7e43daea9a694a0bb5fb8bec81235d8a1e6ef64c716dcb")
28 |
29 | set(BUILD_GMOCK ON CACHE BOOL "" FORCE)
30 | set(INSTALL_GTEST OFF CACHE BOOL "" FORCE)
31 | set(gtest_disable_pthreads ON CACHE BOOL "" FORCE)
32 | set(gtest_force_shared_crt ON CACHE BOOL "" FORCE)
33 |
34 | FetchContent_Declare(googletest
35 | URL ${googletest_URL}
36 | URL_HASH ${googletest_HASH}
37 | )
38 |
39 | FetchContent_GetProperties(googletest)
40 | if(NOT googletest_POPULATED)
41 | message(STATUS "Downloading googletest")
42 | FetchContent_Populate(googletest)
43 | endif()
44 | message(STATUS "googletest is downloaded to ${googletest_SOURCE_DIR}")
45 | message(STATUS "googletest's binary dir is ${googletest_BINARY_DIR}")
46 |
47 | if(APPLE)
48 | set(CMAKE_MACOSX_RPATH ON) # to solve the following warning on macOS
49 | endif()
50 | #[==[
51 | -- Generating done
52 | Policy CMP0042 is not set: MACOSX_RPATH is enabled by default. Run "cmake
53 | --help-policy CMP0042" for policy details. Use the cmake_policy command to
54 | set the policy and suppress this warning.
55 |
56 | MACOSX_RPATH is not specified for the following targets:
57 |
58 | gmock
59 | gmock_main
60 | gtest
61 | gtest_main
62 |
63 | This warning is for project developers. Use -Wno-dev to suppress it.
64 | ]==]
65 |
66 | add_subdirectory(${googletest_SOURCE_DIR} ${googletest_BINARY_DIR} EXCLUDE_FROM_ALL)
67 |
68 | target_include_directories(gtest
69 | INTERFACE
70 | ${googletest_SOURCE_DIR}/googletest/include
71 | ${googletest_SOURCE_DIR}/googlemock/include
72 | )
73 | endfunction()
74 |
75 | download_googltest()
76 |
--------------------------------------------------------------------------------
/cmake/pybind11.cmake:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2021 Xiaomi Corporation (authors: Fangjun Kuang)
2 | # See ../LICENSE for clarification regarding multiple authors
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | function(download_pybind11)
17 | if(CMAKE_VERSION VERSION_LESS 3.11)
18 | list(APPEND CMAKE_MODULE_PATH ${CMAKE_SOURCE_DIR}/cmake/Modules)
19 | endif()
20 |
21 | include(FetchContent)
22 |
23 | set(pybind11_URL "https://github.com/pybind/pybind11/archive/v2.6.0.tar.gz")
24 | set(pybind11_HASH "SHA256=90b705137b69ee3b5fc655eaca66d0dc9862ea1759226f7ccd3098425ae69571")
25 |
26 | set(double_quotes "\"")
27 | set(dollar "\$")
28 | set(semicolon "\;")
29 | if(NOT WIN32)
30 | FetchContent_Declare(pybind11
31 | URL ${pybind11_URL}
32 | URL_HASH ${pybind11_HASH}
33 | )
34 | else()
35 | FetchContent_Declare(pybind11
36 | URL ${pybind11_URL}
37 | URL_HASH ${pybind11_HASH}
38 | )
39 | endif()
40 |
41 | FetchContent_GetProperties(pybind11)
42 | if(NOT pybind11_POPULATED)
43 | message(STATUS "Downloading pybind11")
44 | FetchContent_Populate(pybind11)
45 | endif()
46 | message(STATUS "pybind11 is downloaded to ${pybind11_SOURCE_DIR}")
47 | add_subdirectory(${pybind11_SOURCE_DIR} ${pybind11_BINARY_DIR} EXCLUDE_FROM_ALL)
48 | endfunction()
49 |
50 | download_pybind11()
51 |
--------------------------------------------------------------------------------
/cmake/select_compute_arch.cmake:
--------------------------------------------------------------------------------
1 | #
2 | # This file is copied from
3 | # https://github.com/pytorch/pytorch/blob/master/cmake/Modules_CUDA_fix/upstream/FindCUDA/select_compute_arch.cmake
4 | #
5 | #
6 | # Synopsis:
7 | # CUDA_SELECT_NVCC_ARCH_FLAGS(out_variable [target_CUDA_architectures])
8 | # -- Selects GPU arch flags for nvcc based on target_CUDA_architectures
9 | # target_CUDA_architectures : Auto | Common | All | LIST(ARCH_AND_PTX ...)
10 | # - "Auto" detects local machine GPU compute arch at runtime.
11 | # - "Common" and "All" cover common and entire subsets of architectures
12 | # ARCH_AND_PTX : NAME | NUM.NUM | NUM.NUM(NUM.NUM) | NUM.NUM+PTX
13 | # NAME: Kepler Maxwell Kepler+Tegra Kepler+Tesla Maxwell+Tegra Pascal Volta Turing Ampere
14 | # NUM: Any number. Only those pairs are currently accepted by NVCC though:
15 | # 3.5 3.7 5.0 5.2 5.3 6.0 6.2 7.0 7.2 7.5 8.0
16 | # Returns LIST of flags to be added to CUDA_NVCC_FLAGS in ${out_variable}
17 | # Additionally, sets ${out_variable}_readable to the resulting numeric list
18 | # Example:
19 | # CUDA_SELECT_NVCC_ARCH_FLAGS(ARCH_FLAGS 3.0 3.5+PTX 5.2(5.0) Maxwell)
20 | # LIST(APPEND CUDA_NVCC_FLAGS ${ARCH_FLAGS})
21 | #
22 | # More info on CUDA architectures: https://en.wikipedia.org/wiki/CUDA
23 | #
24 |
25 | if(CMAKE_CUDA_COMPILER_LOADED OR DEFINED CMAKE_CUDA_COMPILER_ID) # CUDA as a language
26 | if(CMAKE_CUDA_COMPILER_ID STREQUAL "NVIDIA"
27 | AND CMAKE_CUDA_COMPILER_VERSION MATCHES "^([0-9]+\\.[0-9]+)")
28 | set(CUDA_VERSION "${CMAKE_MATCH_1}")
29 | endif()
30 | endif()
31 |
32 | # See: https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html#gpu-feature-list
33 |
34 | # This list will be used for CUDA_ARCH_NAME = All option
35 | set(CUDA_KNOWN_GPU_ARCHITECTURES "Kepler" "Maxwell")
36 |
37 | # This list will be used for CUDA_ARCH_NAME = Common option (enabled by default)
38 | set(CUDA_COMMON_GPU_ARCHITECTURES "3.5" "5.0")
39 |
40 | if(CUDA_VERSION VERSION_LESS "7.0")
41 | set(CUDA_LIMIT_GPU_ARCHITECTURE "5.2")
42 | endif()
43 |
44 | # This list is used to filter CUDA archs when autodetecting
45 | set(CUDA_ALL_GPU_ARCHITECTURES "3.5" "5.0")
46 |
47 | if(CUDA_VERSION VERSION_GREATER "6.5")
48 | list(APPEND CUDA_KNOWN_GPU_ARCHITECTURES "Kepler+Tegra" "Kepler+Tesla" "Maxwell+Tegra")
49 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "5.2")
50 |
51 | if(CUDA_VERSION VERSION_LESS "8.0")
52 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "5.2+PTX")
53 | set(CUDA_LIMIT_GPU_ARCHITECTURE "6.0")
54 | endif()
55 | endif()
56 |
57 | if(CUDA_VERSION VERSION_GREATER "7.5")
58 | list(APPEND CUDA_KNOWN_GPU_ARCHITECTURES "Pascal")
59 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "6.0" "6.1")
60 | list(APPEND CUDA_ALL_GPU_ARCHITECTURES "6.0" "6.1" "6.2")
61 |
62 | if(CUDA_VERSION VERSION_LESS "9.0")
63 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "6.2+PTX")
64 | set(CUDA_LIMIT_GPU_ARCHITECTURE "7.0")
65 | endif()
66 | endif ()
67 |
68 | if(CUDA_VERSION VERSION_GREATER "8.5")
69 | list(APPEND CUDA_KNOWN_GPU_ARCHITECTURES "Volta")
70 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "7.0")
71 | list(APPEND CUDA_ALL_GPU_ARCHITECTURES "7.0" "7.2")
72 |
73 | if(CUDA_VERSION VERSION_LESS "10.0")
74 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "7.2+PTX")
75 | set(CUDA_LIMIT_GPU_ARCHITECTURE "8.0")
76 | endif()
77 | endif()
78 |
79 | if(CUDA_VERSION VERSION_GREATER "9.5")
80 | list(APPEND CUDA_KNOWN_GPU_ARCHITECTURES "Turing")
81 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "7.5")
82 | list(APPEND CUDA_ALL_GPU_ARCHITECTURES "7.5")
83 |
84 | if(CUDA_VERSION VERSION_LESS "11.0")
85 | set(CUDA_LIMIT_GPU_ARCHITECTURE "8.0")
86 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "7.5+PTX")
87 | endif()
88 | endif()
89 |
90 | if(CUDA_VERSION VERSION_GREATER "10.5")
91 | list(APPEND CUDA_KNOWN_GPU_ARCHITECTURES "Ampere")
92 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "8.0")
93 | list(APPEND CUDA_ALL_GPU_ARCHITECTURES "8.0")
94 |
95 | if(CUDA_VERSION VERSION_LESS "11.1")
96 | set(CUDA_LIMIT_GPU_ARCHITECTURE "8.6")
97 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "8.0+PTX")
98 | endif()
99 | endif()
100 |
101 | if(CUDA_VERSION VERSION_GREATER "11.0")
102 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "8.6" "8.6+PTX")
103 | list(APPEND CUDA_ALL_GPU_ARCHITECTURES "8.6")
104 |
105 | if(CUDA_VERSION VERSION_LESS "12.0")
106 | set(CUDA_LIMIT_GPU_ARCHITECTURE "9.0")
107 | endif()
108 | endif()
109 |
110 | ################################################################################################
111 | # A function for automatic detection of GPUs installed (if autodetection is enabled)
112 | # Usage:
113 | # CUDA_DETECT_INSTALLED_GPUS(OUT_VARIABLE)
114 | #
115 | function(CUDA_DETECT_INSTALLED_GPUS OUT_VARIABLE)
116 | if(NOT CUDA_GPU_DETECT_OUTPUT)
117 | if(CMAKE_CUDA_COMPILER_LOADED OR DEFINED CMAKE_CUDA_COMPILER_ID) # CUDA as a language
118 | set(file "${PROJECT_BINARY_DIR}/detect_cuda_compute_capabilities.cu")
119 | else()
120 | set(file "${PROJECT_BINARY_DIR}/detect_cuda_compute_capabilities.cpp")
121 | endif()
122 |
123 | file(WRITE ${file} ""
124 | "#include \n"
125 | "#include \n"
126 | "int main()\n"
127 | "{\n"
128 | " int count = 0;\n"
129 | " if (cudaSuccess != cudaGetDeviceCount(&count)) return -1;\n"
130 | " if (count == 0) return -1;\n"
131 | " for (int device = 0; device < count; ++device)\n"
132 | " {\n"
133 | " cudaDeviceProp prop;\n"
134 | " if (cudaSuccess == cudaGetDeviceProperties(&prop, device))\n"
135 | " std::printf(\"%d.%d \", prop.major, prop.minor);\n"
136 | " }\n"
137 | " return 0;\n"
138 | "}\n")
139 |
140 | if(CMAKE_CUDA_COMPILER_LOADED OR DEFINED CMAKE_CUDA_COMPILER_ID) # CUDA as a language
141 | try_run(run_result compile_result ${PROJECT_BINARY_DIR} ${file}
142 | RUN_OUTPUT_VARIABLE compute_capabilities)
143 | else()
144 | try_run(run_result compile_result ${PROJECT_BINARY_DIR} ${file}
145 | CMAKE_FLAGS "-DINCLUDE_DIRECTORIES=${CUDA_INCLUDE_DIRS}"
146 | LINK_LIBRARIES ${CUDA_LIBRARIES}
147 | RUN_OUTPUT_VARIABLE compute_capabilities)
148 | endif()
149 |
150 | # Filter unrelated content out of the output.
151 | string(REGEX MATCHALL "[0-9]+\\.[0-9]+" compute_capabilities "${compute_capabilities}")
152 |
153 | if(run_result EQUAL 0)
154 | string(REPLACE "2.1" "2.1(2.0)" compute_capabilities "${compute_capabilities}")
155 | set(CUDA_GPU_DETECT_OUTPUT ${compute_capabilities}
156 | CACHE INTERNAL "Returned GPU architectures from detect_gpus tool" FORCE)
157 | endif()
158 | endif()
159 |
160 | if(NOT CUDA_GPU_DETECT_OUTPUT)
161 | message(STATUS "Automatic GPU detection failed. Building for common architectures.")
162 | set(${OUT_VARIABLE} ${CUDA_COMMON_GPU_ARCHITECTURES} PARENT_SCOPE)
163 | else()
164 | # Filter based on CUDA version supported archs
165 | set(CUDA_GPU_DETECT_OUTPUT_FILTERED "")
166 | separate_arguments(CUDA_GPU_DETECT_OUTPUT)
167 | foreach(ITEM IN ITEMS ${CUDA_GPU_DETECT_OUTPUT})
168 | if(CUDA_LIMIT_GPU_ARCHITECTURE AND (ITEM VERSION_GREATER CUDA_LIMIT_GPU_ARCHITECTURE OR
169 | ITEM VERSION_EQUAL CUDA_LIMIT_GPU_ARCHITECTURE))
170 | list(GET CUDA_COMMON_GPU_ARCHITECTURES -1 NEWITEM)
171 | string(APPEND CUDA_GPU_DETECT_OUTPUT_FILTERED " ${NEWITEM}")
172 | else()
173 | string(APPEND CUDA_GPU_DETECT_OUTPUT_FILTERED " ${ITEM}")
174 | endif()
175 | endforeach()
176 |
177 | set(${OUT_VARIABLE} ${CUDA_GPU_DETECT_OUTPUT_FILTERED} PARENT_SCOPE)
178 | endif()
179 | endfunction()
180 |
181 |
182 | ################################################################################################
183 | # Function for selecting GPU arch flags for nvcc based on CUDA architectures from parameter list
184 | # Usage:
185 | # SELECT_NVCC_ARCH_FLAGS(out_variable [list of CUDA compute archs])
186 | function(CUDA_SELECT_NVCC_ARCH_FLAGS out_variable)
187 | set(CUDA_ARCH_LIST "${ARGN}")
188 |
189 | if("X${CUDA_ARCH_LIST}" STREQUAL "X" )
190 | set(CUDA_ARCH_LIST "Auto")
191 | endif()
192 |
193 | set(cuda_arch_bin)
194 | set(cuda_arch_ptx)
195 |
196 | if("${CUDA_ARCH_LIST}" STREQUAL "All")
197 | set(CUDA_ARCH_LIST ${CUDA_KNOWN_GPU_ARCHITECTURES})
198 | elseif("${CUDA_ARCH_LIST}" STREQUAL "Common")
199 | set(CUDA_ARCH_LIST ${CUDA_COMMON_GPU_ARCHITECTURES})
200 | elseif("${CUDA_ARCH_LIST}" STREQUAL "Auto")
201 | CUDA_DETECT_INSTALLED_GPUS(CUDA_ARCH_LIST)
202 | message(STATUS "Autodetected CUDA architecture(s): ${CUDA_ARCH_LIST}")
203 | endif()
204 |
205 | # Now process the list and look for names
206 | string(REGEX REPLACE "[ \t]+" ";" CUDA_ARCH_LIST "${CUDA_ARCH_LIST}")
207 | list(REMOVE_DUPLICATES CUDA_ARCH_LIST)
208 | foreach(arch_name ${CUDA_ARCH_LIST})
209 | set(arch_bin)
210 | set(arch_ptx)
211 | set(add_ptx FALSE)
212 | # Check to see if we are compiling PTX
213 | if(arch_name MATCHES "(.*)\\+PTX$")
214 | set(add_ptx TRUE)
215 | set(arch_name ${CMAKE_MATCH_1})
216 | endif()
217 | if(arch_name MATCHES "^([0-9]\\.[0-9](\\([0-9]\\.[0-9]\\))?)$")
218 | set(arch_bin ${CMAKE_MATCH_1})
219 | set(arch_ptx ${arch_bin})
220 | else()
221 | # Look for it in our list of known architectures
222 | if(${arch_name} STREQUAL "Kepler+Tesla")
223 | set(arch_bin 3.7)
224 | elseif(${arch_name} STREQUAL "Kepler")
225 | set(arch_bin 3.5)
226 | set(arch_ptx 3.5)
227 | elseif(${arch_name} STREQUAL "Maxwell+Tegra")
228 | set(arch_bin 5.3)
229 | elseif(${arch_name} STREQUAL "Maxwell")
230 | set(arch_bin 5.0 5.2)
231 | set(arch_ptx 5.2)
232 | elseif(${arch_name} STREQUAL "Pascal")
233 | set(arch_bin 6.0 6.1)
234 | set(arch_ptx 6.1)
235 | elseif(${arch_name} STREQUAL "Volta")
236 | set(arch_bin 7.0 7.0)
237 | set(arch_ptx 7.0)
238 | elseif(${arch_name} STREQUAL "Turing")
239 | set(arch_bin 7.5)
240 | set(arch_ptx 7.5)
241 | elseif(${arch_name} STREQUAL "Ampere")
242 | set(arch_bin 8.0)
243 | set(arch_ptx 8.0)
244 | else()
245 | message(SEND_ERROR "Unknown CUDA Architecture Name ${arch_name} in CUDA_SELECT_NVCC_ARCH_FLAGS")
246 | endif()
247 | endif()
248 | if(NOT arch_bin)
249 | message(SEND_ERROR "arch_bin wasn't set for some reason")
250 | endif()
251 | list(APPEND cuda_arch_bin ${arch_bin})
252 | if(add_ptx)
253 | if (NOT arch_ptx)
254 | set(arch_ptx ${arch_bin})
255 | endif()
256 | list(APPEND cuda_arch_ptx ${arch_ptx})
257 | endif()
258 | endforeach()
259 |
260 | # remove dots and convert to lists
261 | string(REGEX REPLACE "\\." "" cuda_arch_bin "${cuda_arch_bin}")
262 | string(REGEX REPLACE "\\." "" cuda_arch_ptx "${cuda_arch_ptx}")
263 | string(REGEX MATCHALL "[0-9()]+" cuda_arch_bin "${cuda_arch_bin}")
264 | string(REGEX MATCHALL "[0-9]+" cuda_arch_ptx "${cuda_arch_ptx}")
265 |
266 | if(cuda_arch_bin)
267 | list(REMOVE_DUPLICATES cuda_arch_bin)
268 | endif()
269 | if(cuda_arch_ptx)
270 | list(REMOVE_DUPLICATES cuda_arch_ptx)
271 | endif()
272 |
273 | set(nvcc_flags "")
274 | set(nvcc_archs_readable "")
275 |
276 | # Tell NVCC to add binaries for the specified GPUs
277 | foreach(arch ${cuda_arch_bin})
278 | if(arch MATCHES "([0-9]+)\\(([0-9]+)\\)")
279 | # User explicitly specified ARCH for the concrete CODE
280 | list(APPEND nvcc_flags -gencode arch=compute_${CMAKE_MATCH_2},code=sm_${CMAKE_MATCH_1})
281 | list(APPEND nvcc_archs_readable sm_${CMAKE_MATCH_1})
282 | else()
283 | # User didn't explicitly specify ARCH for the concrete CODE, we assume ARCH=CODE
284 | list(APPEND nvcc_flags -gencode arch=compute_${arch},code=sm_${arch})
285 | list(APPEND nvcc_archs_readable sm_${arch})
286 | endif()
287 | endforeach()
288 |
289 | # Tell NVCC to add PTX intermediate code for the specified architectures
290 | foreach(arch ${cuda_arch_ptx})
291 | list(APPEND nvcc_flags -gencode arch=compute_${arch},code=compute_${arch})
292 | list(APPEND nvcc_archs_readable compute_${arch})
293 | endforeach()
294 |
295 | string(REPLACE ";" " " nvcc_archs_readable "${nvcc_archs_readable}")
296 | set(${out_variable} ${nvcc_flags} PARENT_SCOPE)
297 | set(${out_variable}_readable ${nvcc_archs_readable} PARENT_SCOPE)
298 | endfunction()
299 |
--------------------------------------------------------------------------------
/cmake/torch.cmake:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2021 Xiaomi Corporation (authors: Fangjun Kuang)
2 | # PYTHON_EXECUTABLE is set by pybind11.cmake
3 | message(STATUS "Python executable: ${PYTHON_EXECUTABLE}")
4 | execute_process(
5 | COMMAND "${PYTHON_EXECUTABLE}" -c "import os; import torch; print(os.path.dirname(torch.__file__))"
6 | OUTPUT_STRIP_TRAILING_WHITESPACE
7 | OUTPUT_VARIABLE TORCH_DIR
8 | )
9 |
10 | list(APPEND CMAKE_PREFIX_PATH "${TORCH_DIR}")
11 | find_package(Torch REQUIRED)
12 |
13 | # set the global CMAKE_CXX_FLAGS so that
14 | # optimized_transducer uses the same abi flag as PyTorch
15 | set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
16 | if(OT_WITH_CUDA)
17 | set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} ${TORCH_CXX_FLAGS}")
18 | endif()
19 |
20 |
21 | execute_process(
22 | COMMAND "${PYTHON_EXECUTABLE}" -c "import torch; print(torch.__version__.split('.')[0])"
23 | OUTPUT_STRIP_TRAILING_WHITESPACE
24 | OUTPUT_VARIABLE OT_TORCH_VERSION_MAJOR
25 | )
26 |
27 | execute_process(
28 | COMMAND "${PYTHON_EXECUTABLE}" -c "import torch; print(torch.__version__.split('.')[1])"
29 | OUTPUT_STRIP_TRAILING_WHITESPACE
30 | OUTPUT_VARIABLE OT_TORCH_VERSION_MINOR
31 | )
32 |
33 | execute_process(
34 | COMMAND "${PYTHON_EXECUTABLE}" -c "import torch; print(torch.__version__)"
35 | OUTPUT_STRIP_TRAILING_WHITESPACE
36 | OUTPUT_VARIABLE TORCH_VERSION
37 | )
38 |
39 | message(STATUS "PyTorch version: ${TORCH_VERSION}")
40 |
41 | if(OT_WITH_CUDA)
42 | execute_process(
43 | COMMAND "${PYTHON_EXECUTABLE}" -c "import torch; print(torch.version.cuda)"
44 | OUTPUT_STRIP_TRAILING_WHITESPACE
45 | OUTPUT_VARIABLE TORCH_CUDA_VERSION
46 | )
47 |
48 | message(STATUS "PyTorch cuda version: ${TORCH_CUDA_VERSION}")
49 |
50 | if(NOT CUDA_VERSION VERSION_EQUAL TORCH_CUDA_VERSION)
51 | message(FATAL_ERROR
52 | "PyTorch ${TORCH_VERSION} is compiled with CUDA ${TORCH_CUDA_VERSION}.\n"
53 | "But you are using CUDA ${CUDA_VERSION} to compile optimized_transducer.\n"
54 | "Please try to use the same CUDA version for PyTorch and optimized_transducer.\n"
55 | "**You can remove this check if you are sure this will not cause "
56 | "problems**\n"
57 | )
58 | endif()
59 |
60 | # Solve the following error for NVCC:
61 | # unknown option `-Wall`
62 | #
63 | # It contains only some -Wno-* flags, so it is OK
64 | # to set them to empty
65 | set_property(TARGET torch_cuda
66 | PROPERTY
67 | INTERFACE_COMPILE_OPTIONS ""
68 | )
69 | set_property(TARGET torch_cpu
70 | PROPERTY
71 | INTERFACE_COMPILE_OPTIONS ""
72 | )
73 | endif()
74 |
--------------------------------------------------------------------------------
/cmake/transform.cmake:
--------------------------------------------------------------------------------
1 | # Copyright 2021 Fangjun Kuang (csukuangfj@gmail.com)
2 | # See ../LICENSE for clarification regarding multiple authors
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | # This function is used to copy foo.cu to foo.cc
17 | # Usage:
18 | #
19 | # transform(OUTPUT_VARIABLE output_variable_name SRCS foo.cu bar.cu)
20 | #
21 | function(transform)
22 | set(optional_args "") # there are no optional arguments
23 | set(one_value_arg OUTPUT_VARIABLE)
24 | set(multi_value_args SRCS)
25 |
26 | cmake_parse_arguments(MY "${optional_args}" "${one_value_arg}" "${multi_value_args}" ${ARGN})
27 | foreach(src IN LISTS MY_SRCS)
28 | get_filename_component(src_name ${src} NAME_WE)
29 | get_filename_component(src_dir ${src} DIRECTORY)
30 | set(dst ${CMAKE_CURRENT_BINARY_DIR}/${src_dir}/${src_name}.cc)
31 |
32 | list(APPEND ans ${dst})
33 | message(STATUS "Renaming ${CMAKE_CURRENT_SOURCE_DIR}/${src} to ${dst}")
34 | configure_file(${src} ${dst})
35 | endforeach()
36 | set(${MY_OUTPUT_VARIABLE} ${ans} PARENT_SCOPE)
37 | endfunction()
38 |
--------------------------------------------------------------------------------
/fast_rnnt/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | add_subdirectory(csrc)
2 | add_subdirectory(python)
3 |
--------------------------------------------------------------------------------
/fast_rnnt/csrc/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | include_directories(${CMAKE_SOURCE_DIR})
2 |
3 | # it is located in fast_rnnt/cmake/transform.cmake
4 | include(transform)
5 |
6 | set(srcs
7 | mutual_information_cpu.cu
8 | )
9 |
10 | if(NOT FT_WITH_CUDA)
11 | transform(OUTPUT_VARIABLE srcs SRCS ${srcs})
12 | else()
13 | list(APPEND srcs mutual_information_cuda.cu)
14 | endif()
15 |
16 | add_library(mutual_information_core ${srcs})
17 | target_link_libraries(mutual_information_core PUBLIC ${TORCH_LIBRARIES})
18 | # for
19 | target_include_directories(mutual_information_core PUBLIC ${PYTHON_INCLUDE_DIRS})
20 |
--------------------------------------------------------------------------------
/fast_rnnt/csrc/device_guard.h:
--------------------------------------------------------------------------------
1 | /**
2 | * Copyright 2022 Xiaomi Corporation (authors: Fangjun Kuang, Wei Kang)
3 | *
4 | * See LICENSE for clarification regarding multiple authors
5 | *
6 | * Licensed under the Apache License, Version 2.0 (the "License");
7 | * you may not use this file except in compliance with the License.
8 | * You may obtain a copy of the License at
9 | *
10 | * http://www.apache.org/licenses/LICENSE-2.0
11 | *
12 | * Unless required by applicable law or agreed to in writing, software
13 | * distributed under the License is distributed on an "AS IS" BASIS,
14 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | * See the License for the specific language governing permissions and
16 | * limitations under the License.
17 | */
18 |
19 | #ifndef FAST_RNNT_CSRC_DEVICE_GUARD_H_
20 | #define FAST_RNNT_CSRC_DEVICE_GUARD_H_
21 |
22 | #include "torch/script.h"
23 |
24 | // This file is modified from
25 | // https://github.com/k2-fsa/k2/blob/master/k2/csrc/device_guard.h
26 | namespace fast_rnnt {
27 |
28 | // DeviceGuard is an RAII class. Its sole purpose is to restore
29 | // the previous default cuda device if a CUDA context changes the
30 | // current default cuda device.
31 | class DeviceGuard {
32 | public:
33 | explicit DeviceGuard(torch::Device device) {
34 | if (device.type() == torch::kCUDA) {
35 | old_device_ = GetDevice();
36 | new_device_ = device.index();
37 | if (old_device_ != new_device_)
38 | SetDevice(new_device_);
39 | }
40 | // else do nothing
41 | }
42 |
43 | explicit DeviceGuard(int32_t new_device) : new_device_(new_device) {
44 | if (new_device != -1) {
45 | old_device_ = GetDevice();
46 | if (old_device_ != new_device)
47 | SetDevice(new_device);
48 | }
49 | }
50 |
51 | ~DeviceGuard() {
52 | if (old_device_ != -1 && old_device_ != new_device_) {
53 | // restore the previous device
54 | SetDevice(old_device_);
55 | }
56 | // else it was either a CPU context or the device IDs
57 | // were the same
58 | }
59 |
60 | DeviceGuard(const DeviceGuard &) = delete;
61 | DeviceGuard &operator=(const DeviceGuard &) = delete;
62 |
63 | DeviceGuard(DeviceGuard &&) = delete;
64 | DeviceGuard &operator=(DeviceGuard &&) = delete;
65 |
66 | private:
67 | static int32_t GetDevice() {
68 | #ifdef FT_WITH_CUDA
69 | int32_t device;
70 | auto s = cudaGetDevice(&device);
71 | TORCH_CHECK(s == cudaSuccess, cudaGetErrorString(s));
72 | return device;
73 | #else
74 | return -1;
75 | #endif
76 | }
77 |
78 | static void SetDevice(int32_t device) {
79 | #ifdef FT_WITH_CUDA
80 | auto s = cudaSetDevice(device);
81 | TORCH_CHECK(s == cudaSuccess, cudaGetErrorString(s));
82 | #else
83 | return;
84 | #endif
85 | }
86 |
87 | private:
88 | int32_t old_device_ = -1;
89 | int32_t new_device_ = -1;
90 | };
91 |
92 | } // namespace fast_rnnt
93 |
94 | #endif // FAST_RNNT_CSRC_DEVICE_GUARD_H_
95 |
--------------------------------------------------------------------------------
/fast_rnnt/csrc/mutual_information.h:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2021 Xiaomi Corporation (authors: Daniel Povey)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #ifndef FAST_RNNT_CSRC_MUTUAL_INFORMATION_H_
22 | #define FAST_RNNT_CSRC_MUTUAL_INFORMATION_H_
23 |
24 | #include
25 | #include
26 | #include "torch/extension.h"
27 |
28 | #ifdef __CUDA_ARCH__
29 | #define FT_CUDA_HOSTDEV __host__ __device__
30 | #else
31 | #define FT_CUDA_HOSTDEV
32 | #endif
33 |
34 | namespace fast_rnnt {
35 |
36 | FT_CUDA_HOSTDEV inline double LogAdd(double x, double y) {
37 | double diff;
38 | if (x < y) {
39 | diff = x - y;
40 | x = y;
41 | } else {
42 | diff = y - x;
43 | }
44 | // diff is negative. x is now the larger one.
45 | if (diff - diff != 0)
46 | return x; // x and y are probably -inf. Return the larger one.
47 | else
48 | return x + log1p(exp(diff));
49 | }
50 |
51 | // returns log(exp(x) + exp(y)).
52 | FT_CUDA_HOSTDEV inline float LogAdd(float x, float y) {
53 | float diff;
54 | if (x < y) {
55 | diff = x - y;
56 | x = y;
57 | } else {
58 | diff = y - x;
59 | }
60 | // diff is negative. x is now the larger one.
61 | if (diff - diff != 0)
62 | return x; // x and y are probably -inf. Return the larger one.
63 | else
64 | return x + log1p(exp(diff));
65 | }
66 |
67 | /*
68 | Forward of mutual_information. See also comment of `mutual_information`
69 | in ../pyhton/fast_rnnt/mutual_information.py. This is the core recursion
70 | in the sequence-to-sequence mutual information computation.
71 |
72 | @param px Tensor of shape [B][S][T + 1] if not modified, [B][S][T] if
73 | modified. `modified` can be worked out from this. In not-modified case,
74 | it can be thought of as the log-odds ratio of generating the next x in
75 | the sequence, i.e.
76 | px[b][s][t] is the log of
77 | p(x_s | x_0..x_{s-1}, y_0..y_{s-1}) / p(x_s),
78 | i.e. the log-prob of generating x_s given subsequences of
79 | lengths (s, t), divided by the prior probability of generating x_s.
80 | (See mutual_information.py for more info).
81 | @param py The log-odds ratio of generating the next y in the sequence.
82 | Shape [B][S + 1][T]
83 | @param p This function writes to p[b][s][t] the mutual information between
84 | sub-sequences of x and y of length s and t respectively, from the
85 | b'th sequences in the batch. Its shape is [B][S + 1][T + 1].
86 | Concretely, this function implements the following recursion,
87 | in the case where s_begin == t_begin == 0:
88 |
89 | p[b,0,0] = 0.0
90 | if not modified:
91 | p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
92 | p[b,s,t-1] + py[b,s,t-1])
93 | if modified:
94 | p[b,s,t] = log_add(p[b,s-1,t-1] + px[b,s-1,t-1],
95 | p[b,s,t-1] + py[b,s,t-1])
96 | ... treating values with any -1 index as -infinity.
97 | .. if `boundary` is set, we start from p[b,s_begin,t_begin]=0.0.
98 | @param boundary If set, a tensor of shape [B][4] of type int64_t, which
99 | contains, where for each batch element b, boundary[b]
100 | equals [s_begin, t_begin, s_end, t_end]
101 | which are the beginning and end (i.e. one-past-the-last)
102 | of the x and y sequences that we should process.
103 | Alternatively, may be a tensor of shape [0][0] and type
104 | int64_t; the elements will default to (0, 0, S, T).
105 | @return A tensor `ans` of shape [B], where this function will set
106 | ans[b] = p[b][s_end][t_end],
107 | with s_end and t_end being (S, T) if `boundary` was specified,
108 | and (boundary[b][2], boundary[b][3]) otherwise.
109 | `ans` represents the mutual information between each pair of
110 | sequences (i.e. x[b] and y[b], although the sequences are not
111 | supplied directly to this function).
112 |
113 | The block-dim and grid-dim must both be 1-dimensional, and the block-dim must
114 | be at least 128.
115 | */
116 | torch::Tensor MutualInformationCpu(
117 | torch::Tensor px, // [B][S][T+1]
118 | torch::Tensor py, // [B][S+1][T]
119 | torch::optional boundary, // [B][4], int64_t.
120 | torch::Tensor p); // [B][S+1][T+1]; an output
121 |
122 | torch::Tensor MutualInformationCuda(
123 | torch::Tensor px, // [B][S][T+1] if !modified, [B][S][T] if modified.
124 | torch::Tensor py, // [B][S+1][T]
125 | torch::optional boundary, // [B][4], int64_t.
126 | torch::Tensor p); // [B][S+1][T+1]; an output
127 |
128 | /*
129 | backward of mutual_information; returns (grad_px, grad_py)
130 |
131 | if overwrite_ans_grad == true, this function will overwrite ans_grad with a
132 | value that, if the computation worked correctly, should be identical to or
133 | very close to the value of ans_grad at entry. This can be used
134 | to validate the correctness of this code.
135 | */
136 | std::vector
137 | MutualInformationBackwardCpu(torch::Tensor px, torch::Tensor py,
138 | torch::optional boundary,
139 | torch::Tensor p, torch::Tensor ans_grad);
140 |
141 | std::vector MutualInformationBackwardCuda(
142 | torch::Tensor px, torch::Tensor py, torch::optional boundary,
143 | torch::Tensor p, torch::Tensor ans_grad, bool overwrite_ans_grad);
144 |
145 | } // namespace fast_rnnt
146 |
147 | #endif // FAST_RNNT_CSRC_MUTUAL_INFORMATION_H_
148 |
--------------------------------------------------------------------------------
/fast_rnnt/csrc/mutual_information_cpu.cu:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2021 Xiaomi Corporation (authors: Daniel Povey)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #include
22 | #include "fast_rnnt/csrc/mutual_information.h"
23 |
24 | namespace fast_rnnt {
25 |
26 | // forward of mutual_information. See """... """ comment of
27 | // `mutual_information_recursion` in
28 | // in python/fast_rnnt/mutual_information.py for documentation of the
29 | // behavior of this function.
30 |
31 | // px: of shape [B, S, T+1] if !modified, else [B, S, T] <-- work out
32 | // `modified` from this.
33 | // py: of shape [B, S+1, T]
34 | // boundary: of shape [B, 4], containing (s_begin, t_begin, s_end, t_end)
35 | // defaulting to (0, 0, S, T).
36 | // p: of shape (S+1, T+1)
37 | // Computes the recursion:
38 | // if !modified:
39 | // p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
40 | // p[b,s,t-1] + py[b,s,t-1])
41 | // if modified:
42 | // p[b,s,t] = log_add(p[b,s-1,t-1] + px[b,s-1,t-1],
43 | // p[b,s,t-1] + py[b,s,t-1])
44 |
45 | // .. treating out-of-range elements as -infinity and with special cases:
46 | // p[b, s_begin, t_begin] = 0.0
47 | //
48 | // and this function returns a tensor of shape (B,) consisting of elements
49 | // p[b, s_end, t_end]
50 | torch::Tensor MutualInformationCpu(torch::Tensor px, torch::Tensor py,
51 | torch::optional opt_boundary,
52 | torch::Tensor p) {
53 | TORCH_CHECK(px.dim() == 3, "px must be 3-dimensional");
54 | TORCH_CHECK(py.dim() == 3, "py must be 3-dimensional.");
55 | TORCH_CHECK(p.dim() == 3, "p must be 3-dimensional.");
56 | TORCH_CHECK(px.device().is_cpu() && py.device().is_cpu() &&
57 | p.device().is_cpu(),
58 | "inputs must be CPU tensors");
59 |
60 | bool modified = (px.size(2) == py.size(2));
61 |
62 | auto scalar_t = px.scalar_type();
63 | auto opts = torch::TensorOptions().dtype(scalar_t).device(px.device());
64 |
65 | const int B = px.size(0), S = px.size(1), T = py.size(2);
66 | TORCH_CHECK(px.size(2) == (modified ? T : T + 1));
67 | TORCH_CHECK(py.size(0) == B && py.size(1) == S + 1 && py.size(2) == T);
68 | TORCH_CHECK(p.size(0) == B && p.size(1) == S + 1 && p.size(2) == T + 1);
69 |
70 | auto boundary = opt_boundary.value_or(
71 | torch::tensor({0, 0, S, T},
72 | torch::dtype(torch::kInt64).device(torch::kCPU))
73 | .reshape({1, 4})
74 | .expand({B, 4}));
75 | TORCH_CHECK(boundary.dim() == 2, "boundary must be 2-dimensional.");
76 | TORCH_CHECK(boundary.size(0) == B && boundary.size(1) == 4);
77 | TORCH_CHECK(boundary.device().is_cpu() && boundary.dtype() == torch::kInt64);
78 |
79 | torch::Tensor ans = torch::empty({B}, opts);
80 |
81 | AT_DISPATCH_FLOATING_TYPES(
82 | px.scalar_type(), "mutual_information_cpu_loop", ([&] {
83 | auto px_a = px.accessor(),
84 | py_a = py.accessor(), p_a = p.accessor();
85 | auto boundary_a = boundary.accessor();
86 | auto ans_a = ans.accessor();
87 |
88 | int t_offset = (modified ? -1 : 0);
89 | for (int b = 0; b < B; b++) {
90 | int s_begin = boundary_a[b][0];
91 | int t_begin = boundary_a[b][1];
92 | int s_end = boundary_a[b][2];
93 | int t_end = boundary_a[b][3];
94 | p_a[b][s_begin][t_begin] = 0.0;
95 | if (modified) {
96 | for (int s = s_begin + 1; s <= s_end; ++s)
97 | p_a[b][s][t_begin] = -std::numeric_limits::infinity();
98 | } else {
99 | // note: t_offset = 0 so don't need t_begin + t_offset below.
100 | for (int s = s_begin + 1; s <= s_end; ++s)
101 | p_a[b][s][t_begin] =
102 | p_a[b][s - 1][t_begin] + px_a[b][s - 1][t_begin];
103 | }
104 | for (int t = t_begin + 1; t <= t_end; ++t)
105 | p_a[b][s_begin][t] =
106 | p_a[b][s_begin][t - 1] + py_a[b][s_begin][t - 1];
107 | for (int s = s_begin + 1; s <= s_end; ++s) {
108 | scalar_t p_s_t1 = p_a[b][s][t_begin];
109 | for (int t = t_begin + 1; t <= t_end; ++t) {
110 | // The following statement is a small optimization of:
111 | // p_a[b][s][t] = LogAdd(
112 | // p_a[b][s - 1][t + t_offset] + px_a[b][s -1][t + t_offset],
113 | // p_a[b][s][t - 1] + py_a[b][s][t - 1]);
114 | // .. which obtains p_a[b][s][t - 1] from a register.
115 | p_a[b][s][t] = p_s_t1 = LogAdd(p_a[b][s - 1][t + t_offset] +
116 | px_a[b][s - 1][t + t_offset],
117 | p_s_t1 + py_a[b][s][t - 1]);
118 | }
119 | }
120 | ans_a[b] = p_a[b][s_end][t_end];
121 | }
122 | }));
123 | return ans;
124 | }
125 |
126 | // backward of mutual_information. Returns (px_grad, py_grad).
127 | // p corresponds to what we computed in the forward pass.
128 | std::vector
129 | MutualInformationBackwardCpu(torch::Tensor px, torch::Tensor py,
130 | torch::optional opt_boundary,
131 | torch::Tensor p, torch::Tensor ans_grad) {
132 | TORCH_CHECK(px.dim() == 3, "px must be 3-dimensional");
133 | TORCH_CHECK(py.dim() == 3, "py must be 3-dimensional.");
134 | TORCH_CHECK(p.dim() == 3, "p must be 3-dimensional.");
135 | TORCH_CHECK(ans_grad.dim() == 1, "ans_grad must be 1-dimensional.");
136 |
137 | bool modified = (px.size(2) == py.size(2));
138 |
139 | TORCH_CHECK(px.device().is_cpu() && py.device().is_cpu() &&
140 | p.device().is_cpu() && ans_grad.device().is_cpu(),
141 | "inputs must be CPU tensors");
142 |
143 | auto scalar_t = px.scalar_type();
144 | auto opts = torch::TensorOptions().dtype(scalar_t).device(px.device());
145 |
146 | const int B = px.size(0), S = px.size(1), T = py.size(2);
147 | TORCH_CHECK(px.size(2) == (modified ? T : T + 1));
148 | TORCH_CHECK(py.size(0) == B && py.size(1) == S + 1);
149 | TORCH_CHECK(p.size(0) == B && p.size(1) == S + 1 && p.size(2) == T + 1);
150 |
151 | auto boundary = opt_boundary.value_or(
152 | torch::tensor({0, 0, S, T},
153 | torch::dtype(torch::kInt64).device(torch::kCPU))
154 | .reshape({1, 4})
155 | .expand({B, 4}));
156 | TORCH_CHECK(boundary.dim() == 2, "boundary must be 2-dimensional.");
157 | TORCH_CHECK(boundary.size(0) == B && boundary.size(1) == 4);
158 | TORCH_CHECK(boundary.device().is_cpu() && boundary.dtype() == torch::kInt64);
159 |
160 | bool has_boundary = opt_boundary.has_value();
161 | int T1 = T + (modified ? 0 : 1);
162 | torch::Tensor p_grad = torch::zeros({B, S + 1, T + 1}, opts),
163 | px_grad = (has_boundary ? torch::zeros({B, S, T1}, opts)
164 | : torch::empty({B, S, T1}, opts)),
165 | py_grad = (has_boundary ? torch::zeros({B, S + 1, T}, opts)
166 | : torch::empty({B, S + 1, T}, opts));
167 |
168 | AT_DISPATCH_FLOATING_TYPES(
169 | px.scalar_type(), "mutual_information_cpu_backward_loop", ([&] {
170 | auto px_a = px.accessor(), p_a = p.accessor(),
171 | p_grad_a = p_grad.accessor(),
172 | px_grad_a = px_grad.accessor(),
173 | py_grad_a = py_grad.accessor();
174 |
175 | auto ans_grad_a = ans_grad.accessor();
176 | auto boundary_a = boundary.accessor();
177 | int t_offset = (modified ? -1 : 0);
178 |
179 | for (int b = 0; b < B; b++) {
180 | int s_begin = boundary_a[b][0];
181 | int t_begin = boundary_a[b][1];
182 | int s_end = boundary_a[b][2];
183 | int t_end = boundary_a[b][3];
184 | // Backprop for: ans_a[b] = p_a[b][s_end][t_end];
185 | p_grad_a[b][s_end][t_end] = ans_grad_a[b];
186 |
187 | for (int s = s_end; s > s_begin; --s) {
188 | for (int t = t_end; t > t_begin; --t) {
189 | // The s,t indexes correspond to
190 | // The statement we are backpropagating here is:
191 | // p_a[b][s][t] = LogAdd(
192 | // p_a[b][s - 1][t + t_offset] + px_a[b][s - 1][t + t_offset],
193 | // p_a[b][s][t - 1] + py_a[b][s][t - 1]);
194 | // .. which obtains p_a[b][s][t - 1] from a register.
195 | scalar_t term1 = p_a[b][s - 1][t + t_offset] +
196 | px_a[b][s - 1][t + t_offset],
197 | // term2 = p_a[b][s][t - 1] + py_a[b][s][t - 1], <-- not
198 | // actually needed..
199 | total = p_a[b][s][t];
200 | if (total - total != 0)
201 | total = 0;
202 | scalar_t term1_deriv = exp(term1 - total),
203 | term2_deriv = 1.0 - term1_deriv,
204 | grad = p_grad_a[b][s][t];
205 | scalar_t term1_grad, term2_grad;
206 | if (term1_deriv - term1_deriv == 0.0) {
207 | term1_grad = term1_deriv * grad;
208 | term2_grad = term2_deriv * grad;
209 | } else {
210 | // could happen if total == -inf
211 | term1_grad = term2_grad = 0.0;
212 | }
213 | px_grad_a[b][s - 1][t + t_offset] = term1_grad;
214 | p_grad_a[b][s - 1][t + t_offset] = term1_grad;
215 | py_grad_a[b][s][t - 1] = term2_grad;
216 | p_grad_a[b][s][t - 1] += term2_grad;
217 | }
218 | }
219 | for (int t = t_end; t > t_begin; --t) {
220 | // Backprop for:
221 | // p_a[b][s_begin][t] =
222 | // p_a[b][s_begin][t - 1] + py_a[b][s_begin][t - 1];
223 | scalar_t this_p_grad = p_grad_a[b][s_begin][t];
224 | p_grad_a[b][s_begin][t - 1] += this_p_grad;
225 | py_grad_a[b][s_begin][t - 1] = this_p_grad;
226 | }
227 | if (!modified) {
228 | for (int s = s_end; s > s_begin; --s) {
229 | // Backprop for:
230 | // p_a[b][s][t_begin] =
231 | // p_a[b][s - 1][t_begin] + px_a[b][s - 1][t_begin];
232 | scalar_t this_p_grad = p_grad_a[b][s][t_begin];
233 | p_grad_a[b][s - 1][t_begin] += this_p_grad;
234 | px_grad_a[b][s - 1][t_begin] = this_p_grad;
235 | }
236 | } // else these were all -infinity's and there is nothing to
237 | // backprop.
238 | // There is no backprop for:
239 | // p_a[b][s_begin][t_begin] = 0.0;
240 | // .. but we can use this for a check, that the grad at the beginning
241 | // of the sequence is equal to the grad at the end of the sequence.
242 | if (ans_grad_a[b] != 0.0) {
243 | float grad_ratio = p_grad_a[b][s_begin][t_begin] / ans_grad_a[b];
244 | if (fabs(grad_ratio - 1.0) > 0.01) {
245 | std::cout
246 | << "Warning: mutual_information backprop: expected these "
247 | << "numbers to be the same:"
248 | << static_cast(p_grad_a[b][s_begin][t_begin]) << " vs "
249 | << static_cast(ans_grad_a[b]);
250 | }
251 | }
252 | }
253 | }));
254 |
255 | return std::vector({px_grad, py_grad});
256 | }
257 | } // namespace fast_rnnt
258 |
--------------------------------------------------------------------------------
/fast_rnnt/csrc/mutual_information_cuda.cu:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2021 Xiaomi Corporation (authors: Daniel Povey)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #include // for getCurrentCUDAStream()
22 | #include
23 |
24 | #include "fast_rnnt/csrc/mutual_information.h"
25 |
26 | namespace fast_rnnt {
27 | /*
28 | Forward of mutual_information. Each thread block computes blocks of the 'p'
29 | array of (s, t) shape equal to (BLOCK_SIZE, BLOCK_SIZE), e.g. (32, 32).
30 | Thread-blocks loop over such blocks, but they might loop only once if there is
31 | not that much data to process. We sequentially launch thread groups in
32 | such a way that thread-blocks within a group do not depend on each other
33 | (see the "iter" parameter). The blocks of the 'image' (i.e. of the p matrix)
34 | that each group handles are arranged in a diagonal.
35 |
36 | Template args:
37 | scalar_t: the floating-point type, e.g. float, double; maybe eventually
38 | half, although I think we don't support LogAdd for half yet.
39 | BLOCK_SIZE: an integer power of two no greater than 32 (this limitation
40 | is because we assume BLOCK_SIZE + 1 <= 64 in some data-loading
41 | code).
42 | Args:
43 | px: Tensor of shape [B][S][T + 1], if !modified; [B][S][T] if modified;
44 | may be interpreted as the log-odds ratio of
45 | generating the next x in the sequence, i.e.
46 | px[b][s][t] is the log of
47 | p(x_s | x_0..x_{s-1}, y_0..y_{s-1}) / p(x_s),
48 | i.e. the log-prob of generating x_s given subsequences of lengths
49 | (s, t), divided by the prior probability of generating x_s. (See
50 | mutual_information.py for more info).
51 | py: The log-odds ratio of generating the next y in the sequence.
52 | Shape [B][S + 1][T]
53 | p: This function writes to p[b][s][t] the mutual information between
54 | sub-sequences of x and y of length s and t respectively, from the
55 | b'th sequences in the batch. Its shape is [B][S + 1][T + 1].
56 | Concretely, this function implements the following recursion,
57 | in the case where s_begin == t_begin == 0:
58 |
59 | p[b,0,0] = 0.0
60 | if not `modified`:
61 | p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
62 | p[b,s,t-1] + py[b,s,t-1]) (eq. 0)
63 | if `modified`:
64 | p[b,s,t] = log_add(p[b,s-1,t-t] + px[b,s-1,t-1],
65 | p[b,s,t-1] + py[b,s,t-1]) (eq. 0)
66 |
67 | treating values with any -1 index as -infinity.
68 | .. if `boundary` is set, we start from p[b,s_begin,t_begin]=0.0.
69 | boundary: If set, a tensor of shape [B][4] of type int64_t, which
70 | contains, where for each batch element b, boundary[b] equals
71 | [s_begin, t_begin, s_end, t_end]
72 | which are the beginning and end (i.e. one-past-the-last) of the
73 | x and y sequences that we should process. Otherwise, must be
74 | a tensor of shape [0][0] of type int64_t; the values will
75 | default to (0, 0, S, T).
76 | ans: a tensor `ans` of shape [B], where this function will set
77 | ans[b] = p[b][s_end][t_end],
78 | with s_end and t_end being (S, T) if `boundary` was specified,
79 | and (boundary[b][2], boundary[b][3]) otherwise.
80 | `ans` represents the mutual information between each pair of
81 | sequences (i.e. x[b] and y[b], although the sequences are not
82 | supplied directly to this function).
83 |
84 | The block-dim and grid-dim must both be 1-dimensional, and the block-dim must
85 | be at least 128.
86 | */
87 | template // e.g. BLOCK_SIZE == 16 or 32.
89 | __global__ void mutual_information_kernel(
90 | // B, S, T + 1, i.e. batch, x_seq_length, y_seq_length + 1
91 | torch::PackedTensorAccessor32 px,
92 | torch::PackedTensorAccessor32 py, // B, S + 1, T.
93 | // B, S + 1, T + 1. This is an output.
94 | torch::PackedTensorAccessor32 p,
95 | // B, 4; or 0, 0 if boundaries are the defaults (0, 0, S, T)
96 | torch::PackedTensorAccessor32 boundary,
97 | torch::PackedTensorAccessor32 ans, // [B]
98 | int iter) { // This kernel is sequentially called with 'iter' = 0, 1, 2 and
99 | // so on, up to num_iters - 1 where num_iters = num_s_blocks +
100 | // num_t_blocks - 1 num_s_blocks = S / BLOCK_SIZE + 1
101 | // num_t_blocks = T / BLOCK_SIZE + 1
102 | // so that each group depends on the previous group...
103 | const int B = px.size(0), S = px.size(1), T = py.size(2);
104 | const bool modified = (px.size(2) == T);
105 | const int t_offset = (modified ? -1 : 0); // see CPU code to understand.
106 |
107 | // num_s_blocks and num_t_blocks are the number of blocks we need to cover the
108 | // array of size (S, T) with blocks of this size, in the s and t directions
109 | // respectively.
110 | // You can read the following expressions as simplifications of, for example,
111 | // num_s_blocks = ((S + 1) + BLOCK_SIZE - 1) / BLOCK_SIZE,
112 | // i.e. rounding-up division of (S + 1) by BLOCK_SIZE, and the same for (T +
113 | // 1).
114 | const int num_s_blocks = S / BLOCK_SIZE + 1;
115 | //, num_t_blocks = T / BLOCK_SIZE + 1;
116 |
117 | // num_blocks_this_iter is an upper bound on the number of blocks of size
118 | // (BLOCK_SIZE by BLOCK_SIZE) that might be active on this iteration (`iter`).
119 | // These iterations start from the bottom left of the image so that on iter ==
120 | // 0 we process only one block with block-index (0, 0) then on iter == 1 we
121 | // process block-indexes (1, 0) and (0, 1); and then on iter==2 we process (2,
122 | // 0), (1, 1) and (0, 2); and so on. We also will never have more than
123 | // `num_s_blocks` blocks (We'll never have more than num_t_blocks either, but
124 | // the numbering we use corresponds to s and not t, so when we hit the
125 | // num_t_blocks limit, the blocks with the lowest s indexes would just not be
126 | // active and we'll 'continue' in the loop below).
127 | int num_blocks_this_iter = min(iter + 1, num_s_blocks);
128 |
129 | // For the block with s_block_begin == 0 and t_block_begin == 0 (for
130 | // easy illustration), px_buf[s][t] will contain px[s - 1][t + t_offset]; or
131 | // -infinity. for out-of-range indexes into px. Likewise, py_buf[s][t] will
132 | // contain (py[s][t - 1]).
133 | __shared__ scalar_t px_buf[BLOCK_SIZE][BLOCK_SIZE],
134 | py_buf[BLOCK_SIZE][BLOCK_SIZE];
135 |
136 | // p_buf[s][t] == p[s+s_block_begin-1][t+t_block_begin-1]
137 | // 1st row/col of p_buf correspond to the previously computed blocks (lower
138 | // `iter`), or to negative indexes into p. So, for the origin block,
139 | // p_buf[s][t] corresponds to p[s - 1][t - 1]; or -inf for
140 | // out-of-range values.
141 | __shared__ scalar_t p_buf[BLOCK_SIZE + 1][BLOCK_SIZE + 1];
142 |
143 | // boundary_buf will be used to store the b'th row of `boundary` if we have
144 | // boundary information supplied; or (0, 0, S, T) otherwise.
145 | __shared__ int64_t boundary_buf[4];
146 |
147 | if (threadIdx.x == 0) {
148 | boundary_buf[0] = 0;
149 | boundary_buf[1] = 0;
150 | boundary_buf[2] = S;
151 | boundary_buf[3] = T;
152 | }
153 |
154 | // batch_block_iter iterates over batch elements (index b) and block
155 | // indexes in the range [0..num_blocks_this_iter-1], combining both
156 | // batch and block indexes.
157 | for (int batch_block_iter = blockIdx.x;
158 | batch_block_iter < B * num_blocks_this_iter;
159 | batch_block_iter += gridDim.x) {
160 | int block = batch_block_iter / B,
161 | b = batch_block_iter % B; // b is the index into the batch
162 |
163 | // Note: `block` can be no greater than `iter` because num_blocks_this_iter
164 | // <= iter + 1, i.e. iter >= num_blocks_this_iter - 1; and
165 | // block < num_blocks_this_iter, so iter - block >= 0.
166 | int s_block_begin = block * BLOCK_SIZE,
167 | t_block_begin = (iter - block) * BLOCK_SIZE;
168 | bool is_origin_block = (s_block_begin + t_block_begin == 0);
169 |
170 | __syncthreads();
171 |
172 | if (threadIdx.x < 4)
173 | boundary_buf[threadIdx.x] = boundary[b][threadIdx.x];
174 |
175 | __syncthreads();
176 |
177 | int s_begin = boundary_buf[0], t_begin = boundary_buf[1],
178 | s_end = boundary_buf[2], t_end = boundary_buf[3];
179 |
180 | s_block_begin += s_begin;
181 | t_block_begin += t_begin;
182 |
183 | // block_S and block_T are the actual sizes of this block (the block of `p`
184 | // that we will write), no greater than (BLOCK_SIZE, BLOCK_SIZE) but
185 | // possibly less than that if we are towards the end of the sequence. The
186 | // last element in the output matrix p that we need to write is (s_end,
187 | // t_end), i.e. the one-past-the-end index is (s_end + 1, t_end + 1).
188 | int block_S = min(BLOCK_SIZE, s_end + 1 - s_block_begin),
189 | block_T = min(BLOCK_SIZE, t_end + 1 - t_block_begin);
190 |
191 | if (block_S <= 0 || block_T <= 0)
192 | continue;
193 |
194 | // Load px_buf and py_buf.
195 | for (int i = threadIdx.x; i < BLOCK_SIZE * BLOCK_SIZE; i += blockDim.x) {
196 | int s_in_block = i / BLOCK_SIZE, t_in_block = i % BLOCK_SIZE,
197 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin,
198 | t_off = t + t_offset;
199 | // comparing as unsigned int makes sure the index is nonnegative.
200 | // Caution: if s_begin > 0 or t_begin > 0 we may end up loading some px
201 | // and py values that are outside the proper boundaries that we need, but
202 | // the corresponding p_buf values will end up being 0 so this won't
203 | // matter.
204 | scalar_t this_px = -INFINITY;
205 | // Below, "&& t <= t_end" can be interpreted as:
206 | // "&& (modified ? t_off < t_end : t_off <= t_end)
207 | // [since px's last valid index is t_end - 1 if modified, else t_end.
208 | if (s > s_begin && s <= s_end && t_off >= t_begin && t <= t_end)
209 | this_px = px[b][s - 1][t_off];
210 |
211 | px_buf[s_in_block][t_in_block] = this_px;
212 |
213 | scalar_t this_py = -INFINITY;
214 | if (t > t_begin && t <= t_end && s <= s_end)
215 | this_py = py[b][s][t - 1];
216 | py_buf[s_in_block][t_in_block] = this_py;
217 | }
218 |
219 | // Load the 1st row and 1st column of p_buf.
220 | // This is the context from previously computed blocks of the
221 | // image. Remember: p_buf[s][t] will correspond to p[s + s_block_begin -
222 | // 1][t + t_block_begin - 1]
223 | if (threadIdx.x <= BLOCK_SIZE) {
224 | // s_in_p_buf and t_in_pbuf are simply the indexes into p_buf
225 | int s_in_p_buf = threadIdx.x, t_in_p_buf = 0,
226 | s = s_in_p_buf + s_block_begin - 1,
227 | t = t_in_p_buf + t_block_begin - 1;
228 |
229 | scalar_t this_p = -INFINITY;
230 | if (s >= s_begin && s <= s_end && t >= t_begin && t <= t_end)
231 | this_p = p[b][s][t];
232 | p_buf[s_in_p_buf][t_in_p_buf] = this_p;
233 | } else if (static_cast(static_cast(threadIdx.x) - 64) <=
234 | static_cast(BLOCK_SIZE)) {
235 | // Another warp handles the other leg. Checking as unsigned
236 | // tests that threadIdx.x - 64 is both >= 0 and <= BLOCK_SIZE
237 | int s_in_p_buf = 0, t_in_p_buf = static_cast(threadIdx.x) - 64,
238 | s = s_in_p_buf + s_block_begin - 1,
239 | t = t_in_p_buf + t_block_begin - 1;
240 |
241 | scalar_t this_p = -INFINITY;
242 | if (s >= s_begin && s <= s_end && t >= t_begin && t <= t_end)
243 | this_p = p[b][s][t];
244 | p_buf[s_in_p_buf][t_in_p_buf] = this_p;
245 | }
246 |
247 | __syncthreads();
248 |
249 | // from here to the next __syncthreads(), only the 1st warp should be active
250 | // so we shouldn't need to synchronize. (implicit within-warp
251 | // synchronization).
252 |
253 | if (threadIdx.x == 0) {
254 | // This if-statement is an optimization and modification of the loop below
255 | // for the value i == 0, i.e. inner-iteration == 0. The modification is
256 | // to set p_buf to 1.0 = exp(0.0) if this is the "origin block",
257 | // i.e. s == s_begin, t == t_begin. This corresponds to the
258 | // probability of the pair of sequences of length (0, 0).
259 | p_buf[1][1] =
260 | (is_origin_block ? 0.0
261 | : LogAdd(
262 | // px_buf has t_offset applied.
263 | p_buf[0][1 + t_offset] + px_buf[0][0],
264 | p_buf[1][0] + py_buf[0][0]));
265 | }
266 |
267 | int s = threadIdx.x;
268 | for (int i = 1; i < block_S + block_T - 1; ++i) {
269 | __syncwarp();
270 | // i is the inner iteration, which corresponds to the (s + t) indexes of
271 | // the elements within the block that we write. So i == 0 writes
272 | // positions (s, t) == (0, 0) (but we treated i == 0 as a special case
273 | // above); i == 1 writes (0, 1) and (1, 0); i == 2 writes (0, 2), (1, 1)
274 | // and (2, 1); and so on. Note: not many threads participate in this
275 | // part, only up to BLOCK_SIZE at most. Unfortunately we couldn't figure
276 | // out a very meaningful way for more threads to do work, that looked like
277 | // it would really speed things up.
278 | // So this kernel does (2 * BLOCK_SIZE) iterations, which may seem a lot,
279 | // but we do at least do the I/O in an efficient way and keep the
280 | // inner loop simple and fast (e.g. no exp() or log()).
281 | int t = i - s;
282 | if (s < block_S &&
283 | static_cast(t) < static_cast(block_T)) {
284 | // p_buf is indexed by s + 1 and t + 1 because it has an extra initial
285 | // row and column for context from previous blocks. Taking into account
286 | // the way these buffers relate to the tensors p, px and py,
287 | // can be interpreted as follows,
288 | // writing sbb for s_block_begin and tbb for t_block_begin:
289 | //
290 | // p[b][s+sbb][t+tbb] = LogAdd(p[b][s+sbb-1][t+tbb] +
291 | // px[s+sbb-1][t+tbb],
292 | // p[b][s+sbb][t+tbb-1] +
293 | // py[s+sbb][t+tbb-1]
294 | //
295 | // where you can see that apart from the offsets of tbb and sbb, this is
296 | // the same as the recursion defined for p in
297 | // mutual_information.py:mutual_information_recursion(); and (eq. 0)
298 | // above.
299 |
300 | // note: px_buf has t_offset applied..
301 | p_buf[s + 1][t + 1] = LogAdd(p_buf[s][t + 1 + t_offset] + px_buf[s][t],
302 | p_buf[s + 1][t] + py_buf[s][t]);
303 | // We don't need to do __syncthreads() in this loop because all the
304 | // threads that are active are in the same warp. (However, in future,
305 | // if NVidia changes some things, we might need to sync here).
306 | }
307 | }
308 | __syncthreads();
309 |
310 | // Write out the data to p;
311 | for (int i = threadIdx.x; i < BLOCK_SIZE * BLOCK_SIZE; i += blockDim.x) {
312 | int s_in_block = i / BLOCK_SIZE, t_in_block = i % BLOCK_SIZE,
313 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
314 | if (s_in_block < block_S && t_in_block < block_T) {
315 | scalar_t this_p = p_buf[s_in_block + 1][t_in_block + 1];
316 | p[b][s][t] = this_p;
317 | }
318 | }
319 |
320 | __syncthreads();
321 |
322 | if (threadIdx.x == 0) {
323 | // Write `ans`, if this is the final (top-right) block in its sequence
324 | // Logically, the following equation corresponds to:
325 | // ans[b] = p[b][s_end][t_end]
326 | if (s_block_begin + block_S - 1 == s_end &&
327 | t_block_begin + block_T - 1 == t_end) {
328 | // you could read block_S below as block_S - 1 + 1, meaning,
329 | // it's the last index in a block of size block_S, but the indexes into
330 | // p_buf have a "+ 1". Likewise for block_T.
331 | ans[b] = p_buf[block_S][block_T];
332 | }
333 | }
334 | }
335 | }
336 |
337 | // like exp(), but returns 0 if arg is inf/nan, or if result would be
338 | // infinity or nan (note: this can happen for out-of-range elements
339 | // when setting px_buf and py_buf is block_S != BLOCK_SIZE or
340 | // block_T != BLOCK_SIZE, and it's a problem because even though
341 | // out-of-range gradients are zero, if we multiply them by infinity
342 | // we get NaN.
343 | template __forceinline__ __device__ Real safe_exp(Real x) {
344 | if (x - x != 0)
345 | return 0;
346 | else {
347 | Real ans = exp(x);
348 | if (ans - ans != 0.0)
349 | return 0;
350 | return ans;
351 | }
352 | }
353 |
354 | /*
355 | Backward of mutual_information.
356 |
357 | The forward pass is:
358 |
359 | p[b,s,t] = log_add(p[b,s-1,t+t_offset] + px[b,s-1,t+t_offset],
360 | p[b,s,t-1] + py[b,s,t-1]) (eq. 0)
361 |
362 | where t_offset = (modified ? -1 : 0)
363 |
364 | The backprop for the above, implemented in the obvious way, would be as
365 | follows (note, we define term1 and term2 with offsets in the indexes, which
366 | will be convenient later..):
367 |
368 | term1(b,s-1,t+t_offset) =
369 | exp(p[b,s-1,t+t_offset] + px[b,s-1,t+t_offset] - p[b,s,t]) (0a)
370 | term2(b,s,t-1) = exp(p[b,s,t-1] + py[b,s,t-1] - p[b,s,t]) (0b)
371 |
372 | p_grad[b,s-1,t+t_offset] += p_grad[b,s,t] * term1(b,s-1,t+t_offset) (1a)
373 | px_grad[b,s-1,t+t_offset] += p_grad[b,s,t] * term1(b,s-1,t+t_offset) (1b)
374 | p_grad[b,s,t-1] += p_grad[b,s,t] * term2(b,s,t-1) (1c)
375 | py_grad[b,s,t-1] += p_grad[b,s,t] * term2(b,s,t-1) (1d)
376 |
377 | Adding 1 and -t_offset to the s and t indexes of (1a) an (1b), and
378 | 1 to the t index of (1c) and (1d), the equations become:
379 |
380 | p_grad[b,s,t] += p_grad[b,s+1,t-t_offset] * term1(b,s,t) (2a)
381 | px_grad[b,s,t] += p_grad[b,s+1,t-t_offset] * term1(b,s,t) (2b)
382 | p_grad[b,s,t] += p_grad[b,s,t+1] * term2(b,s,t) (2c)
383 | py_grad[b,s,t] += p_grad[b,s,t+1] * term2(b,s,t) (2d)
384 |
385 | .. and replacing "+=" with "=", we can write:
386 |
387 | p_grad[b,s,t] = p_grad[b,s+1,t-t_offset] * term1(b,s,t) + (3a)
388 | p_grad[b,s,t+1] * term2(b,s,t)
389 | px_grad[b,s,t] = p_grad[b,s+1,t-t_offset] * term1(b,s,t) (3b)
390 | py_grad[b,s,t] = p_grad[b,s,t+1] * term2(b,s,t) (3c)
391 |
392 | Writing the definitions of term1 and term2 in a more convenient way:
393 | term1(b,s,t) = exp(p[b,s,t] + px[b,s,t] - p[b,s+1,t-t_offset]) (4a)
394 | term2(b,s,t) = exp(p[b,s,t] + py[b,s,t] - p[b,s,t+1]) (4b)
395 |
396 | The backward pass will be slightly different from the forward pass in terms of
397 | how we store and index p (and p_grad), because for writing a particular block
398 | of p_grad, we need context on the top and right instead of the bottom and
399 | left. So there are offsets of 1.
400 | */
401 | template
402 | __global__ void mutual_information_backward_kernel(
403 | torch::PackedTensorAccessor32
404 | px, // B, S, T + 1 if !modified; B, S, T if modified.
405 | torch::PackedTensorAccessor32 py, // B, S + 1, T.
406 | // B, S + 1, T + 1. Produced in forward pass.
407 | torch::PackedTensorAccessor32 p,
408 | // [B]. This is an input.
409 | torch::PackedTensorAccessor32 ans_grad,
410 | torch::PackedTensorAccessor32
411 | p_grad, // B, S + 1, T + 1 if !modified; B, S, T if modified.
412 | torch::PackedTensorAccessor32 px_grad, // B, S, T + 1.
413 | torch::PackedTensorAccessor32 py_grad, // B, S + 1, T.
414 | // B, 4; or 0, 0 if boundaries are the defaults (0, 0, S, T)
415 | torch::PackedTensorAccessor32 boundary,
416 | int iter, // This kernel is sequentially called with 'iter' = num_iters
417 | // - 1, num_iters - 2, .. 0, where num_iters can be taken to
418 | // be any sufficiently large number but will actually be:
419 | // num_s_blocks + num_t_blocks - 1 where num_s_blocks = S /
420 | // BLOCK_SIZE + 1 and num_t_blocks = T / BLOCK_SIZE + 1
421 | bool overwrite_ans_grad) { // If overwrite_ans_grad == true, this function
422 | // will overwrite ans_grad with a value which,
423 | // if everything is working correctly, should be
424 | // identical or very close to the value of
425 | // ans_grad that was passed in.
426 | const int B = px.size(0), S = px.size(1), T = py.size(2);
427 | const bool modified = (px.size(2) == T);
428 | const int neg_t_offset = (modified ? 1 : 0);
429 |
430 | // For statements that are the same as the forward pass, we are omitting some
431 | // comments. We'll focus, in the comments, on differences from the forward
432 | // pass.
433 | const int num_s_blocks = S / BLOCK_SIZE + 1,
434 | // num_t_blocks = T / BLOCK_SIZE + 1,
435 | num_blocks_this_iter = min(iter + 1, num_s_blocks);
436 |
437 | // px_buf and py_buf are used temporarily to store the px and py values,
438 | // but then modified to store the "xderiv" and "yderiv" values defined
439 | // in (eq. 5) and (eq. 6) above. For out-of-range values, we'll write 0.0
440 | // here.
441 | // Initially (before xderiv/yderiv are written):
442 | // px_buf[s][t] contains px[s+s_block_begin][t+t_block_begin];
443 | // py_buf[s][t] contains py[s+s_block_begin][t+t_block_begin].
444 | // Later (see eq. 4 and eq. 5):
445 | // px_buf[s][t] contains term1(b,ss,tt) ==
446 | // exp(p[b][ss][tt] + px[b][ss][tt] - p[b][ss + 1][tt-t_offset]),
447 | // py_buf[s][t] contains term2(b,ss,tt) ==
448 |
449 | // where ss == s + s_block_begin, tt = t + t_block_begin.
450 | // Unlike in the forward code, there is no offset of 1 in the indexes.
451 | __shared__ scalar_t px_buf[BLOCK_SIZE][BLOCK_SIZE],
452 | py_buf[BLOCK_SIZE][BLOCK_SIZE];
453 |
454 | // p_buf is initially used to store p, and then (after we are done putting
455 | // term1 and term2 into px_buf and py_buf) it is repurposed to store
456 | // p_grad.
457 | //
458 | // Unlike in the forward pass, p_buf has the same numbering as px_buf and
459 | // py_buf, it's not offset by 1: e.g., for the origin block, p_buf[0][0]
460 | // refers to p[0][0] and not p[-1][-1]. The p_buf block is larger by 1 than
461 | // the block for px_buf and py_buf; unlike in the forward pass, we store
462 | // context on the top and right, not the bottom and left, i.e. the elements at
463 | // (one past the largest indexes in the block).
464 | //
465 | // For out-of-range elements of p_buf, we'll put zero.
466 | __shared__ scalar_t p_buf[BLOCK_SIZE + 1][BLOCK_SIZE + 1];
467 |
468 | // boundary_buf will be used to store the b'th row of `boundary` if we have
469 | // boundary information supplied; or (0, 0, S, T) if not.
470 | __shared__ int64_t boundary_buf[4];
471 |
472 | if (threadIdx.x == 0) {
473 | boundary_buf[0] = 0;
474 | boundary_buf[1] = 0;
475 | boundary_buf[2] = S;
476 | boundary_buf[3] = T;
477 | }
478 |
479 | // batch_block_iter iterates over both batch elements (index b), and block
480 | // indexes in the range [0..num_blocks_this_iter-1]. The order here
481 | // doesn't matter, since there are no interdependencies between these
482 | // blocks (they are on a diagonal).
483 | for (int batch_block_iter = blockIdx.x;
484 | batch_block_iter < B * num_blocks_this_iter;
485 | batch_block_iter += gridDim.x) {
486 | int block = batch_block_iter / B, b = batch_block_iter % B;
487 | int s_block_begin = block * BLOCK_SIZE,
488 | t_block_begin = (iter - block) * BLOCK_SIZE;
489 |
490 | if (threadIdx.x < 4)
491 | boundary_buf[threadIdx.x] = boundary[b][threadIdx.x];
492 | __syncthreads();
493 |
494 | int s_begin = boundary_buf[0], t_begin = boundary_buf[1],
495 | s_end = boundary_buf[2], t_end = boundary_buf[3];
496 | s_block_begin += s_begin;
497 | t_block_begin += t_begin;
498 |
499 | // block_S and block_T are the actual sizes of this block, no greater than
500 | // (BLOCK_SIZE, BLOCK_SIZE) but possibly less than that if we are towards
501 | // the end of the sequence.
502 | // The last element of the output matrix p_grad we write is (s_end, t_end),
503 | // i.e. the one-past-the-end index of p_grad is (s_end + 1, t_end + 1).
504 | int block_S = min(BLOCK_SIZE, s_end + 1 - s_block_begin),
505 | block_T = min(BLOCK_SIZE, t_end + 1 - t_block_begin);
506 |
507 | if (block_S <= 0 || block_T <= 0)
508 | continue;
509 |
510 | // Load px_buf and py_buf. At this point we just set them to the px and py
511 | // for this block.
512 | for (int i = threadIdx.x; i < BLOCK_SIZE * BLOCK_SIZE; i += blockDim.x) {
513 | int s_in_block = i / BLOCK_SIZE, t_in_block = i % BLOCK_SIZE,
514 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
515 | // We let px and py default to -infinity if they are out of range, which
516 | // will cause xderiv and yderiv for out-of-range values to be zero, and
517 | // cause correct behavior in edge cases (for the top and right blocks).
518 | // The issue is that p and p_grad are of larger size than px and py.
519 | scalar_t this_px = -INFINITY;
520 | if (s < s_end && t <= t_end)
521 | this_px = px[b][s][t];
522 | px_buf[s_in_block][t_in_block] = this_px;
523 | scalar_t this_py = -INFINITY;
524 | if (s <= s_end && t < t_end)
525 | this_py = py[b][s][t];
526 | py_buf[s_in_block][t_in_block] = this_py;
527 | }
528 | __syncthreads();
529 |
530 | // load p.
531 | for (int i = threadIdx.x; i < (BLOCK_SIZE + 1) * (BLOCK_SIZE + 1);
532 | i += blockDim.x) {
533 | int s_in_block = i / (BLOCK_SIZE + 1), t_in_block = i % (BLOCK_SIZE + 1),
534 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
535 | // Setting 0.0 for out-of-bounds elements of p, together with setting
536 | // -INFINITY for out-of-bounds elements of px_buf and py_buf, will
537 | // ensure that we do the right thing in top and right edge cases,
538 | // i.e. that no derivatives will be propagated from out-of-bounds points
539 | // because the corresponding xderiv and yderiv values will be zero.
540 | scalar_t this_p = 0.0;
541 | if (s <= s_end && t <= t_end)
542 | this_p = p[b][s][t];
543 | // if this_p is -inf, replace with large finite negative value, to avoid
544 | // NaN's below.
545 | // TODO: use a value that would work correctly in half precision
546 | if (this_p < -1.0e+30)
547 | this_p = -1.0e+30;
548 | p_buf[s_in_block][t_in_block] = this_p;
549 | }
550 | __syncthreads();
551 |
552 | // Set term1 and term2; see equations (4a) and (4b) above.
553 | for (int i = threadIdx.x; i < BLOCK_SIZE * BLOCK_SIZE; i += blockDim.x) {
554 | // We can apply this formula to the entire block even if we are processing
555 | // a partial block; we have ensured that x_buf and y_buf contain
556 | // -infinity, and p contains 0, for out-of-range elements, so we'll get
557 | // x_buf and y_buf containing 0 after applying the following formulas.
558 | int s = i / BLOCK_SIZE, t = i % BLOCK_SIZE;
559 | // Mathematically the following is doing:
560 | // term1(b,s,t) = exp(p[b,s,t] + px[b,s,t] - p[b,s+1,t-t_offset]) (4a)
561 | // (with an offset on the s and t indexes)
562 | // Use safe_exp() not exp(), as we could have (-inf) - (-inf) = nan, want
563 | // any finite number in this case as derivs would be zero.
564 | // Also want -inf->zero.
565 | px_buf[s][t] =
566 | safe_exp(p_buf[s][t] + px_buf[s][t] - p_buf[s + 1][t + neg_t_offset]);
567 | // Mathematically the following is doing:
568 | // term2(b,s,t) = exp(p[b,s,t] + py[b,s,t] - p[b,s,t+1]) (4b)
569 | // (with an offset on the s and t indexes)
570 | py_buf[s][t] = safe_exp(p_buf[s][t] + py_buf[s][t] - p_buf[s][t + 1]);
571 | }
572 |
573 | __syncthreads();
574 |
575 | // Load p_grad for the top and right elements in p_buf: i.e. for elements
576 | // p_buf[s][t] where s == block_S (exclusive-or) t == block_T.
577 | // These are the p_grad values computed by previous instances of this kernel
578 | // If this is one of the top or right blocks, some or all of the p_grad
579 | // values we'd be reading here will be out of range, and we use zeros
580 | // to ensure no gradient gets propagated from those positions.
581 | if (threadIdx.x <= block_S) {
582 | int s_in_block = threadIdx.x, t_in_block = block_T,
583 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
584 | p_buf[s_in_block][t_in_block] =
585 | (s <= s_end && t <= t_end ? p_grad[b][s][t] : 0.0);
586 | } else if (static_cast(static_cast(threadIdx.x) - 64) <
587 | static_cast(block_T)) {
588 | // casting to unsigned before the comparison tests for both negative and
589 | // out-of-range values of (int)threadIdx.x - 64.
590 | int s_in_block = block_S, t_in_block = static_cast(threadIdx.x) - 64,
591 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
592 | p_buf[s_in_block][t_in_block] =
593 | (s <= s_end && t <= t_end ? p_grad[b][s][t] : 0.0);
594 | }
595 |
596 | __syncthreads();
597 |
598 | // The highest-numbered value in p_buf that we need (corresponding,
599 | // of course, to p_grad), is:
600 | // p_buf[block_S - 1][block_T - 1],
601 | // and the inner iteration number (i) on which we set this is the sum of
602 | // these indexes, i.e. (block_S - 1) + (block_T - 1).
603 | bool is_final_block = (s_block_begin + block_S == s_end + 1 &&
604 | t_block_begin + block_T == t_end + 1);
605 |
606 | int first_iter = block_S + block_T - 2;
607 | if (is_final_block) {
608 | // The following statement corresponds to:
609 | // p_grad[b][s_end][t_end] = ans_grad[b]
610 | // Normally this element of p_buf would be set by the first iteration of
611 | // the loop below, so if it's set this way we have to decrement first_iter
612 | // to prevent it from being overwritten.
613 | p_buf[block_S - 1][block_T - 1] = ans_grad[b];
614 | --first_iter;
615 | }
616 |
617 | {
618 | int s = threadIdx.x;
619 | for (int i = first_iter; i >= 0; --i) {
620 | __syncwarp();
621 | int t = i - s;
622 | if (s < block_S &&
623 | static_cast(t) < static_cast(block_T)) {
624 | // The following statement is really operating on the gradients;
625 | // it corresponds, with offsets of s_block_begin and t_block_begin
626 | // on the indexes, to equation (3a) above, i.e.:
627 | // p_grad[b,s,t] =
628 | // p_grad[b,s+1,t-t_offset] * term1(b,s,t) + (3a)
629 | // p_grad[b,s,t+1] * term2(b,s,t)
630 | p_buf[s][t] = (p_buf[s + 1][t + neg_t_offset] * px_buf[s][t] +
631 | p_buf[s][t + 1] * py_buf[s][t]);
632 | }
633 | }
634 | }
635 |
636 | __syncthreads();
637 |
638 | // Write out p_grad, px_grad and py_grad.
639 | for (int i = threadIdx.x; i < BLOCK_SIZE * BLOCK_SIZE; i += blockDim.x) {
640 | int s_in_block = i / BLOCK_SIZE, t_in_block = i % BLOCK_SIZE,
641 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
642 | // s_end and t_end are the one-past-the-end of the (x,y) sequences, but
643 | // the one-past-the-end element of p_grad would be (s_end + 1, t_end + 1).
644 | if (t <= t_end && s <= s_end) {
645 | p_grad[b][s][t] = p_buf[s_in_block][t_in_block];
646 |
647 | if (s < s_end && t <= t_end - neg_t_offset) {
648 | // write px_grad, which is of shape [B][S][T + 1] if !modified,
649 | // [B][S][T] if modified. the condition "t <= t_end - neg_t_offset"
650 | // becomes "t <= t_end" if !modified, and "t <= t_end - 1" if
651 | // modified, keeping us within the bounds of px_grad.
652 |
653 | // From (eq. 3b):
654 | // px_grad[b,s,t] = p_grad[b,s+1,t-t_offset] * term1(b,s,t)
655 | px_grad[b][s][t] = (p_buf[s_in_block + 1][t_in_block + neg_t_offset] *
656 | px_buf[s_in_block][t_in_block]);
657 | }
658 | if (t < t_end) { // write py_grad, which is of shape [B][S + 1][T]
659 | // from (eq. 3c):
660 | // py_grad[b,s,t] = p_grad[b,s,t+1] * term2(b,s,t)
661 | py_grad[b][s][t] = (p_buf[s_in_block][t_in_block + 1] *
662 | py_buf[s_in_block][t_in_block]);
663 | }
664 | }
665 | }
666 |
667 | if (threadIdx.x == 0 && s_block_begin == s_begin &&
668 | t_block_begin == t_begin && overwrite_ans_grad)
669 | ans_grad[b] = p_buf[0][0];
670 | }
671 | }
672 |
673 | // forward of mutual_information. See """... """ comment of
674 | // `mutual_information` in mutual_information.py for documentation of the
675 | // behavior of this function.
676 | torch::Tensor MutualInformationCuda(torch::Tensor px, torch::Tensor py,
677 | torch::optional opt_boundary,
678 | torch::Tensor p) {
679 | TORCH_CHECK(px.dim() == 3, "px must be 3-dimensional");
680 | TORCH_CHECK(py.dim() == 3, "py must be 3-dimensional.");
681 | TORCH_CHECK(p.dim() == 3, "p must be 3-dimensional.");
682 | TORCH_CHECK(px.device().is_cuda() && py.device().is_cuda() &&
683 | p.device().is_cuda(),
684 | "inputs must be CUDA tensors");
685 |
686 | auto scalar_t = px.scalar_type();
687 | auto opts = torch::TensorOptions().dtype(scalar_t).device(px.device());
688 |
689 | const int B = px.size(0), S = px.size(1), T = py.size(2);
690 | TORCH_CHECK(px.size(2) == T || px.size(2) == T + 1);
691 | TORCH_CHECK(py.size(0) == B && py.size(1) == S + 1 && py.size(2) == T);
692 | TORCH_CHECK(p.size(0) == B && p.size(1) == S + 1 && p.size(2) == T + 1);
693 |
694 | auto boundary = opt_boundary.value_or(
695 | torch::tensor({0, 0, S, T},
696 | torch::dtype(torch::kInt64).device(px.device()))
697 | .reshape({1, 4})
698 | .expand({B, 4}));
699 | TORCH_CHECK(boundary.size(0) == B && boundary.size(1) == 4);
700 | TORCH_CHECK(boundary.device().is_cuda() && boundary.dtype() == torch::kInt64);
701 |
702 | torch::Tensor ans = torch::empty({B}, opts);
703 |
704 | // num_threads and num_blocks and BLOCK_SIZE can be tuned.
705 | // (however, num_threads may not be less than 128).
706 | const int num_threads = 128, num_blocks = 256, BLOCK_SIZE = 32;
707 |
708 | // The blocks cover the 'p' matrix, which is of size (B, S+1, T+1),
709 | // so dividing by BLOCK_SIZE rounding up we get e.g.
710 | // (S+1 + BLOCK_SIZE-1) / BLOCK_SIZE == S / BLOCK_SIZE + 1
711 | const int num_s_blocks = S / BLOCK_SIZE + 1,
712 | num_t_blocks = T / BLOCK_SIZE + 1,
713 | num_iters = num_s_blocks + num_t_blocks - 1;
714 |
715 | AT_DISPATCH_FLOATING_TYPES(
716 | px.scalar_type(), "mutual_information_cuda_stub", ([&] {
717 | for (int iter = 0; iter < num_iters; ++iter) {
718 | mutual_information_kernel
719 | <<>>(
720 | px.packed_accessor32(),
721 | py.packed_accessor32(),
722 | p.packed_accessor32(),
723 | boundary.packed_accessor32(),
724 | ans.packed_accessor32(), iter);
725 | }
726 | }));
727 | return ans;
728 | }
729 |
730 | // backward of mutual_information; returns (grad_px, grad_py)
731 | // If overwrite_ans_grad == true, will overwrite ans_grad with a value which
732 | // should be identical to the original ans_grad if the computation worked
733 | // as it should.
734 | std::vector
735 | MutualInformationBackwardCuda(torch::Tensor px, torch::Tensor py,
736 | torch::optional opt_boundary,
737 | torch::Tensor p, torch::Tensor ans_grad,
738 | bool overwrite_ans_grad) {
739 | TORCH_CHECK(px.dim() == 3, "px must be 3-dimensional");
740 | TORCH_CHECK(py.dim() == 3, "py must be 3-dimensional.");
741 | TORCH_CHECK(p.dim() == 3, "p must be 3-dimensional.");
742 | TORCH_CHECK(ans_grad.dim() == 1, "ans_grad must be 1-dimensional.");
743 |
744 | TORCH_CHECK(px.device().is_cuda() && py.device().is_cuda() &&
745 | p.device().is_cuda() && ans_grad.device().is_cuda() &&
746 | "inputs must be CUDA tensors");
747 |
748 | auto scalar_t = px.scalar_type();
749 | auto opts = torch::TensorOptions().dtype(scalar_t).device(px.device());
750 |
751 | const int B = px.size(0), S = px.size(1), T = py.size(2);
752 |
753 | TORCH_CHECK(px.size(2) == T ||
754 | px.size(2) == T + 1); // modified case || not-modified case
755 | const bool modified = (px.size(2) == T);
756 | TORCH_CHECK(py.size(0) == B && py.size(1) == S + 1);
757 | TORCH_CHECK(p.size(0) == B && p.size(1) == S + 1 && p.size(2) == T + 1);
758 |
759 | auto boundary = opt_boundary.value_or(
760 | torch::tensor({0, 0, S, T},
761 | torch::dtype(torch::kInt64).device(px.device()))
762 | .reshape({1, 4})
763 | .expand({B, 4}));
764 | TORCH_CHECK(boundary.size(0) == B && boundary.size(1) == 4);
765 | TORCH_CHECK(boundary.device().is_cuda() && boundary.dtype() == torch::kInt64);
766 | TORCH_CHECK(ans_grad.size(0) == B);
767 |
768 | bool has_boundary = opt_boundary.has_value();
769 |
770 | int T1 = T + (modified ? 0 : 1);
771 | torch::Tensor p_grad = torch::empty({B, S + 1, T + 1}, opts),
772 | px_grad = (has_boundary ? torch::zeros({B, S, T1}, opts)
773 | : torch::empty({B, S, T1}, opts)),
774 | py_grad = (has_boundary ? torch::zeros({B, S + 1, T}, opts)
775 | : torch::empty({B, S + 1, T}, opts));
776 |
777 | // num_threads and num_blocks and BLOCK_SIZE can be tuned.
778 | // (however, num_threads may not be less than 128).
779 | const int num_threads = 128, num_blocks = 256, BLOCK_SIZE = 32;
780 |
781 | // The blocks cover the 'p' matrix, which is of size (B, S+1, T+1),
782 | // so dividing by BLOCK_SIZE rounding up we get e.g.
783 | // (S+1 + BLOCK_SIZE-1) / BLOCK_SIZE == S / BLOCK_SIZE + 1
784 | const int num_s_blocks = S / BLOCK_SIZE + 1,
785 | num_t_blocks = T / BLOCK_SIZE + 1,
786 | num_iters = num_s_blocks + num_t_blocks - 1;
787 |
788 | AT_DISPATCH_FLOATING_TYPES(
789 | px.scalar_type(), "mutual_information_backward_stub", ([&] {
790 | for (int iter = num_iters - 1; iter >= 0; --iter) {
791 | mutual_information_backward_kernel
792 | <<>>(
793 | px.packed_accessor32(),
794 | py.packed_accessor32(),
795 | p.packed_accessor32(),
796 | ans_grad.packed_accessor32(),
797 | p_grad.packed_accessor32(),
798 | px_grad.packed_accessor32(),
799 | py_grad.packed_accessor32(),
800 | boundary.packed_accessor32(), iter,
801 | overwrite_ans_grad);
802 | }
803 | }));
804 | return std::vector({px_grad, py_grad});
805 | }
806 | } // namespace fast_rnnt
807 |
--------------------------------------------------------------------------------
/fast_rnnt/python/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | add_subdirectory(csrc)
2 | add_subdirectory(tests)
3 |
--------------------------------------------------------------------------------
/fast_rnnt/python/csrc/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | include_directories(${CMAKE_SOURCE_DIR})
2 |
3 | include(transform)
4 |
5 | # please keep the list sorted
6 | set(fast_rnnt_srcs
7 | fast_rnnt.cu
8 | mutual_information.cu
9 | )
10 |
11 | if(NOT FT_WITH_CUDA)
12 | transform(OUTPUT_VARIABLE fast_rnnt_srcs SRCS ${fast_rnnt_srcs})
13 | endif()
14 |
15 |
16 | pybind11_add_module(_fast_rnnt ${fast_rnnt_srcs})
17 | target_link_libraries(_fast_rnnt PRIVATE mutual_information_core)
18 |
19 | if(APPLE)
20 | target_link_libraries(_fast_rnnt
21 | PRIVATE
22 | ${TORCH_DIR}/lib/libtorch_python.dylib
23 | )
24 | elseif(UNIX)
25 | target_link_libraries(_fast_rnnt
26 | PRIVATE
27 | ${PYTHON_LIBRARY}
28 | ${TORCH_DIR}/lib/libtorch_python.so
29 | )
30 | endif()
31 |
--------------------------------------------------------------------------------
/fast_rnnt/python/csrc/fast_rnnt.cu:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2022 Xiaomi Corporation (authors: Wei Kang)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #include "fast_rnnt/python/csrc/fast_rnnt.h"
22 | #include "fast_rnnt/python/csrc/mutual_information.h"
23 |
24 | PYBIND11_MODULE(_fast_rnnt, m) {
25 | m.doc() = "Python wrapper for Fast Rnnt.";
26 |
27 | fast_rnnt::PybindMutualInformation(m);
28 | }
29 |
--------------------------------------------------------------------------------
/fast_rnnt/python/csrc/fast_rnnt.h:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2022 Xiaomi Corporation (authors: Wei Kang)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #ifndef FAST_RNNT_PYTHON_CSRC_FAST_RNNT_H_
22 | #define FAST_RNNT_PYTHON_CSRC_FAST_RNNT_H_
23 |
24 | #include "pybind11/pybind11.h"
25 |
26 | namespace py = pybind11;
27 |
28 | #endif // FAST_RNNT_PYTHON_CSRC_FAST_RNNT_H_
29 |
--------------------------------------------------------------------------------
/fast_rnnt/python/csrc/mutual_information.cu:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2022 Xiaomi Corporation (authors: Wei Kang)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #include "fast_rnnt/csrc/device_guard.h"
22 | #include "fast_rnnt/csrc/mutual_information.h"
23 | #include "fast_rnnt/python/csrc/mutual_information.h"
24 |
25 | namespace fast_rnnt {
26 | void PybindMutualInformation(py::module &m) {
27 | m.def(
28 | "mutual_information_forward",
29 | [](torch::Tensor px, torch::Tensor py,
30 | torch::optional boundary,
31 | torch::Tensor p) -> torch::Tensor {
32 | fast_rnnt::DeviceGuard guard(px.device());
33 | if (px.device().is_cpu()) {
34 | return MutualInformationCpu(px, py, boundary, p);
35 | } else {
36 | #ifdef FT_WITH_CUDA
37 | return MutualInformationCuda(px, py, boundary, p);
38 | #else
39 | TORCH_CHECK(false, "Failed to find native CUDA module, make sure "
40 | "that you compiled the code with K2_WITH_CUDA.");
41 | return torch::Tensor();
42 | #endif
43 | }
44 | },
45 | py::arg("px"), py::arg("py"), py::arg("boundary"), py::arg("p"));
46 |
47 | m.def(
48 | "mutual_information_backward",
49 | [](torch::Tensor px, torch::Tensor py,
50 | torch::optional boundary, torch::Tensor p,
51 | torch::Tensor ans_grad) -> std::vector {
52 | fast_rnnt::DeviceGuard guard(px.device());
53 | if (px.device().is_cpu()) {
54 | return MutualInformationBackwardCpu(px, py, boundary, p, ans_grad);
55 | } else {
56 | #ifdef FT_WITH_CUDA
57 | return MutualInformationBackwardCuda(px, py, boundary, p, ans_grad,
58 | true);
59 | #else
60 | TORCH_CHECK(false, "Failed to find native CUDA module, make sure "
61 | "that you compiled the code with K2_WITH_CUDA.");
62 | return std::vector();
63 | #endif
64 | }
65 | },
66 | py::arg("px"), py::arg("py"), py::arg("boundary"), py::arg("p"),
67 | py::arg("ans_grad"));
68 |
69 | m.def("with_cuda", []() -> bool {
70 | #ifdef FT_WITH_CUDA
71 | return true;
72 | #else
73 | return false;
74 | #endif
75 | });
76 | }
77 | } // namespace fast_rnnt
78 |
--------------------------------------------------------------------------------
/fast_rnnt/python/csrc/mutual_information.h:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2022 Xiaomi Corporation (authors: Wei Kang)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #ifndef FAST_RNNT_PYTHON_CSRC_MUTUAL_INFORMATION_H_
22 | #define FAST_RNNT_PYTHON_CSRC_MUTUAL_INFORMATION_H_
23 |
24 | #include "fast_rnnt/python/csrc/fast_rnnt.h"
25 |
26 | namespace fast_rnnt {
27 |
28 | void PybindMutualInformation(py::module &m);
29 |
30 | } // namespace fast_rnnt
31 |
32 | #endif // FAST_RNNT_PYTHON_CSRC_MUTUAL_INFORMATION_H_
33 |
--------------------------------------------------------------------------------
/fast_rnnt/python/fast_rnnt/__init__.py:
--------------------------------------------------------------------------------
1 | from _fast_rnnt import with_cuda
2 |
3 | from .mutual_information import mutual_information_recursion
4 | from .mutual_information import joint_mutual_information_recursion
5 |
6 | from .rnnt_loss import do_rnnt_pruning
7 | from .rnnt_loss import get_rnnt_logprobs
8 | from .rnnt_loss import get_rnnt_logprobs_joint
9 | from .rnnt_loss import get_rnnt_logprobs_pruned
10 | from .rnnt_loss import get_rnnt_logprobs_smoothed
11 | from .rnnt_loss import get_rnnt_prune_ranges
12 | from .rnnt_loss import rnnt_loss
13 | from .rnnt_loss import rnnt_loss_pruned
14 | from .rnnt_loss import rnnt_loss_simple
15 | from .rnnt_loss import rnnt_loss_smoothed
16 |
--------------------------------------------------------------------------------
/fast_rnnt/python/fast_rnnt/mutual_information.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2021 Xiaomi Corporation (authors: Daniel Povey, Wei Kang)
2 | #
3 | # See ../../../LICENSE for clarification regarding multiple authors
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 |
17 | import os
18 | import torch
19 | import _fast_rnnt
20 | from torch import Tensor
21 | from typing import Tuple, Optional, Sequence, Union, List
22 |
23 |
24 | class MutualInformationRecursionFunction(torch.autograd.Function):
25 | """A recursion that is useful in computing mutual information between two
26 | sequences of real vectors, but may be useful more generally in
27 | sequence-to-sequence tasks where monotonic alignment between pairs of
28 | sequences is desired.
29 | """
30 |
31 | @staticmethod
32 | def forward(
33 | ctx,
34 | px: torch.Tensor,
35 | py: torch.Tensor,
36 | pxy_grads: List[Optional[torch.Tensor]],
37 | boundary: Optional[torch.Tensor] = None,
38 | return_grad: bool = False,
39 | ) -> torch.Tensor:
40 | """
41 | Computing mutual information between two sequences of real vectors.
42 | Args:
43 | px:
44 | A torch.Tensor of some floating point type, with shape
45 | ``[B][S][T+1]`` where ``B`` is the batch size, ``S`` is the
46 | length of the ``x`` sequence (including representations of
47 | ``EOS`` symbols but not ``BOS`` symbols), and ``T`` is the
48 | length of the ``y`` sequence (including representations of
49 | ``EOS`` symbols but not ``BOS`` symbols). In the mutual
50 | information application, ``px[b][s][t]`` would represent the
51 | following log odds ratio; ignoring the b index on the right
52 | to make the notation more
53 | compact::
54 |
55 | px[b][s][t] = log [ p(x_s | x_{0..s-1}, y_{0..t-1}) / p(x_s) ]
56 |
57 | This expression also implicitly includes the log-probability of
58 | choosing to generate an ``x`` value as opposed to a ``y`` value. In
59 | practice it might be computed as ``a + b``, where ``a`` is the log
60 | probability of choosing to extend the sequence of length ``(s,t)``
61 | with an ``x`` as opposed to a ``y`` value; and ``b`` might in
62 | practice be of the form::
63 |
64 | log(N exp f(x_s, y_{t-1}) / sum_t' exp f(x_s, y_t'))
65 |
66 | where ``N`` is the number of terms that the sum over ``t'``
67 | included, which might include some or all of the other sequences as
68 | well as this one.
69 |
70 | Note:
71 | we don't require ``px`` and py to be contiguous, but the
72 | code assumes for optimization purposes that the ``T`` axis has
73 | stride 1.
74 |
75 | py:
76 | A torch.Tensor of the same dtype as ``px``, with shape
77 | ``[B][S+1][T]``, representing::
78 |
79 | py[b][s][t] = log [ p(y_t | x_{0..s-1}, y_{0..t-1}) / p(y_t) ]
80 |
81 | This function does not treat ``x`` and ``y`` differently; the only
82 | difference is that for optimization purposes we assume the last axis
83 | (the ``t`` axis) has stride of 1; this is true if ``px`` and ``py``
84 | are contiguous.
85 |
86 | pxy_grads:
87 | A List to store the return grads of ``px`` and ``py``
88 | if return_grad == True.
89 | Remain unchanged if return_grad == False.
90 |
91 | See `this PR ` for more
92 | information about why we add this parameter.
93 |
94 | Note:
95 | the length of the list must be 2, where the first element
96 | represents the grads of ``px`` and the second one represents
97 | the grads of ``py``.
98 |
99 | boundary:
100 | If supplied, a torch.LongTensor of shape ``[B][4]``, where each
101 | row contains ``[s_begin, t_begin, s_end, t_end]``,
102 | with ``0 <= s_begin <= s_end < S`` and ``0 <= t_begin <= t_end < T``
103 | (this implies that empty sequences are allowed).
104 | If not supplied, the values ``[0, 0, S, T]`` will be assumed.
105 | These are the beginning and one-past-the-last positions in the
106 | ``x`` and ``y`` sequences respectively, and can be used if not
107 | all sequences are
108 | of the same length.
109 |
110 | return_grad:
111 | Whether to return grads of ``px`` and ``py``, this grad standing
112 | for the occupation probability is the output of the backward with a
113 | ``fake gradient`` the ``fake gradient`` is the same as the gradient
114 | you'd get if you did
115 | ``torch.autograd.grad((scores.sum()), [px, py])``.
116 | This is useful to implement the pruned version of rnnt loss.
117 |
118 | Returns:
119 | Returns a torch.Tensor of shape ``[B]``, containing the log of
120 | the mutual information between the b'th pair of sequences. This is
121 | defined by the following recursion on ``p[b,s,t]`` (where ``p``
122 | is of shape ``[B,S+1,T+1]``), representing a mutual information
123 | between sub-sequences of lengths ``s`` and ``t``::
124 |
125 | p[b,0,0] = 0.0
126 | p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
127 | p[b,s,t-1] + py[b,s,t-1])
128 | (if s > 0 or t > 0)
129 |
130 | where we handle edge cases by treating quantities with negative
131 | indexes as **-infinity**. The extension to cases where the
132 | boundaries are specified should be obvious; it just works on
133 | shorter sequences with offsets into ``px`` and ``py``.
134 | """
135 | (B, S, T1) = px.shape
136 | T = py.shape[-1]
137 | assert T1 in [T, T + 1]
138 | assert py.shape == (B, S + 1, T)
139 | if boundary is not None:
140 | assert boundary.shape == (B, 4)
141 |
142 | # p is a tensor of shape (B, S + 1, T + 1) were p[s][t] is the
143 | # the mutual information of the pair of subsequences of x and y that
144 | # are of length s and t respectively. p[0][0] will be 0.0 and p[S][T]
145 | # is the mutual information of the entire pair of sequences,
146 | # i.e. of lengths S and T respectively.
147 | # It is computed as follows (in C++ and CUDA):
148 | # p[b,0,0] = 0.0
149 | # p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
150 | # p[b,s,t-1] + py[b,s,t-1])
151 | # if s > 0 or t > 0,
152 | # treating values with any -1 index as -infinity.
153 | # .. if `boundary` is set, we start fom p[b,s_begin,t_begin]=0.0.
154 |
155 | p = torch.empty(B, S + 1, T + 1, device=px.device, dtype=px.dtype)
156 |
157 | ans = _fast_rnnt.mutual_information_forward(px, py, boundary, p)
158 |
159 | px_grad, py_grad = None, None
160 | if return_grad or px.requires_grad or py.requires_grad:
161 | ans_grad = torch.ones(B, device=px.device, dtype=px.dtype)
162 | (px_grad, py_grad) = _fast_rnnt.mutual_information_backward(
163 | px, py, boundary, p, ans_grad
164 | )
165 | ctx.save_for_backward(px_grad, py_grad)
166 | assert len(pxy_grads) == 2
167 | pxy_grads[0] = px_grad
168 | pxy_grads[1] = py_grad
169 |
170 | return ans
171 |
172 | @staticmethod
173 | def backward(
174 | ctx, ans_grad: Tensor
175 | ) -> Tuple[torch.Tensor, torch.Tensor, None, None, None]:
176 | (px_grad, py_grad) = ctx.saved_tensors
177 | (B,) = ans_grad.shape
178 | ans_grad = ans_grad.reshape(B, 1, 1) # (B, 1, 1)
179 | px_grad *= ans_grad
180 | py_grad *= ans_grad
181 | return (px_grad, py_grad, None, None, None)
182 |
183 |
184 | def mutual_information_recursion(
185 | px: Tensor,
186 | py: Tensor,
187 | boundary: Optional[Tensor] = None,
188 | return_grad: bool = False,
189 | ) -> Union[Tuple[Tensor, Tuple[Tensor, Tensor]], Tensor]:
190 | """A recursion that is useful in computing mutual information between two
191 | sequences of real vectors, but may be useful more generally in
192 | sequence-to-sequence tasks where monotonic alignment between pairs of
193 | sequences is desired. The definitions of the arguments are definitions that
194 | would be used when computing this type of mutual information, but you can
195 | also view them as arbitrary quantities and just make use of the formula
196 | computed by this function.
197 |
198 | Args:
199 | px:
200 | A torch.Tensor of some floating point type, with shape ``[B][S][T+1]``,
201 | where ``B`` is the batch size, ``S`` is the length of the ``x`` sequence
202 | (including representations of ``EOS`` symbols but not ``BOS`` symbols),
203 | and ``T`` is the length of the ``y`` sequence (including representations
204 | of ``EOS`` symbols but not ``BOS`` symbols). In the mutual information
205 | application, ``px[b][s][t]`` would represent the following log odds
206 | ratio; ignoring the b index on the right to make the notation more
207 | compact::
208 |
209 | px[b][s][t] = log [ p(x_s | x_{0..s-1}, y_{0..t-1}) / p(x_s) ]
210 |
211 | This expression also implicitly includes the log-probability of
212 | choosing to generate an ``x`` value as opposed to a ``y`` value. In
213 | practice it might be computed as ``a + b``, where ``a`` is the log
214 | probability of choosing to extend the sequence of length ``(s,t)``
215 | with an ``x`` as opposed to a ``y`` value; and ``b`` might in practice
216 | be of the form::
217 |
218 | log(N exp f(x_s, y_{t-1}) / sum_t' exp f(x_s, y_t'))
219 |
220 | where ``N`` is the number of terms that the sum over ``t'`` included,
221 | which might include some or all of the other sequences as well as this
222 | one.
223 |
224 | Note:
225 | we don't require ``px`` and py to be contiguous, but the
226 | code assumes for optimization purposes that the ``T`` axis has
227 | stride 1.
228 |
229 | py:
230 | A torch.Tensor of the same dtype as ``px``, with shape ``[B][S+1][T]``,
231 | representing::
232 |
233 | py[b][s][t] = log [ p(y_t | x_{0..s-1}, y_{0..t-1}) / p(y_t) ]
234 |
235 | This function does not treat ``x`` and ``y`` differently; the only
236 | difference is that for optimization purposes we assume the last axis
237 | (the ``t`` axis) has stride of 1; this is true if ``px`` and ``py`` are
238 | contiguous.
239 |
240 | boundary:
241 | If supplied, a torch.LongTensor of shape ``[B][4]``, where each
242 | row contains ``[s_begin, t_begin, s_end, t_end]``,
243 | with ``0 <= s_begin <= s_end < S`` and ``0 <= t_begin <= t_end < T``
244 | (this implies that empty sequences are allowed).
245 | If not supplied, the values ``[0, 0, S, T]`` will be assumed.
246 | These are the beginning and one-past-the-last positions in the ``x`` and
247 | ``y`` sequences respectively, and can be used if not all sequences are
248 | of the same length.
249 |
250 | return_grad:
251 | Whether to return grads of ``px`` and ``py``, this grad standing for the
252 | occupation probability is the output of the backward with a
253 | ``fake gradient`` the ``fake gradient`` is the same as the gradient
254 | you'd get if you did ``torch.autograd.grad((scores.sum()), [px, py])``.
255 | This is useful to implement the pruned version of rnnt loss.
256 |
257 | Returns:
258 | Returns a torch.Tensor of shape ``[B]``, containing the log of the mutual
259 | information between the b'th pair of sequences. This is defined by
260 | the following recursion on ``p[b,s,t]`` (where ``p`` is of shape
261 | ``[B,S+1,T+1]``), representing a mutual information between sub-sequences
262 | of lengths ``s`` and ``t``::
263 |
264 | p[b,0,0] = 0.0
265 | if !modified:
266 | p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
267 | p[b,s,t-1] + py[b,s,t-1])
268 | if modified:
269 | p[b,s,t] = log_add(p[b,s-1,t-1] + px[b,s-1,t-1],
270 | p[b,s,t-1] + py[b,s,t-1])
271 |
272 | where we handle edge cases by treating quantities with negative indexes
273 | as **-infinity**. The extension to cases where the boundaries are
274 | specified should be obvious; it just works on shorter sequences with
275 | offsets into ``px`` and ``py``.
276 | """
277 | assert px.ndim == 3
278 | B, S, T1 = px.shape
279 | T = py.shape[-1]
280 | assert px.shape[-1] in [T, T + 1] # if T, then "modified".
281 | assert py.shape == (B, S + 1, T)
282 | assert px.dtype == py.dtype
283 | if boundary is not None:
284 | assert boundary.dtype == torch.int64
285 | assert boundary.shape == (B, 4)
286 | for s_begin, t_begin, s_end, t_end in boundary.tolist():
287 | assert 0 <= s_begin <= s_end <= S
288 | assert 0 <= t_begin <= t_end <= T
289 |
290 | # The following statements are for efficiency
291 | px, py = px.contiguous(), py.contiguous()
292 |
293 | pxy_grads = [None, None]
294 | scores = MutualInformationRecursionFunction.apply(
295 | px, py, pxy_grads, boundary, return_grad
296 | )
297 | px_grad, py_grad = pxy_grads
298 | return (scores, (px_grad, py_grad)) if return_grad else scores
299 |
300 |
301 | def _inner_product(a: Tensor, b: Tensor) -> Tensor:
302 | """
303 | Does inner product on the last dimension, with expected broadcasting,
304 | i.e. equivalent to (a * b).sum(dim=-1)
305 | without creating a large temporary.
306 | """
307 | assert a.shape[-1] == b.shape[-1] # The last dim must be equal
308 | a = a.unsqueeze(-2) # (..., 1, K)
309 | b = b.unsqueeze(-1) # (..., K, 1)
310 | c = torch.matmul(a, b) # (..., 1, 1)
311 | return c.squeeze(-1).squeeze(-1)
312 |
313 |
314 | def joint_mutual_information_recursion(
315 | px: Sequence[Tensor],
316 | py: Sequence[Tensor],
317 | boundary: Optional[Tensor] = None,
318 | ) -> Sequence[Tensor]:
319 | """A recursion that is useful for modifications of RNN-T and similar loss
320 | functions, where the recursion probabilities have a number of terms and you
321 | want them reported separately. See mutual_information_recursion() for more
322 | documentation of the basic aspects of this.
323 |
324 | Args:
325 | px:
326 | a sequence of Tensors, each of the same shape [B][S][T+1]
327 | py:
328 | a sequence of Tensor, each of the same shape [B][S+1][T],
329 | the sequence must be the same length as px.
330 | boundary:
331 | optionally, a LongTensor of shape [B][4] containing rows
332 | [s_begin, t_begin, s_end, t_end], with 0 <= s_begin <= s_end < S
333 | and 0 <= t_begin <= t_end < T, defaulting to [0, 0, S, T].
334 | These are the beginning and one-past-the-last positions in the x
335 | and y sequences respectively, and can be used if not all
336 | sequences are of the same length.
337 | Returns:
338 | a Tensor of shape (len(px), B),
339 | whose sum over dim 0 is the total log-prob of the recursion mentioned
340 | below, per sequence. The first element of the sequence of length len(px)
341 | is "special", in that it has an offset term reflecting the difference
342 | between sum-of-log and log-of-sum; for more interpretable loss values,
343 | the "main" part of your loss function should be first.
344 |
345 | The recursion below applies if boundary == None, when it defaults
346 | to (0, 0, S, T); where px_sum, py_sum are the sums of the elements of px
347 | and py::
348 |
349 | p = tensor of shape (B, S+1, T+1), containing -infinity
350 | p[b,0,0] = 0.0
351 | # do the following in loop over s and t:
352 | p[b,s,t] = log_add(p[b,s-1,t] + px_sum[b,s-1,t],
353 | p[b,s,t-1] + py_sum[b,s,t-1])
354 | (if s > 0 or t > 0)
355 | return b[:][S][T]
356 |
357 | This function lets you implement the above recursion efficiently, except
358 | that it gives you a breakdown of the contribution from all the elements of
359 | px and py separately. As noted above, the first element of the
360 | sequence is "special".
361 | """
362 | N = len(px)
363 | assert len(py) == N and N > 0
364 | B, S, T1 = px[0].shape
365 | T = py[0].shape[2]
366 | assert T1 in [T, T + 1] # T if modified...
367 | assert py[0].shape == (B, S + 1, T)
368 | assert px[0].dtype == py[0].dtype
369 |
370 | px_cat = torch.stack(
371 | px, dim=0
372 | ) # (N, B, S, T+1) if !modified,(N, B, S, T) if modified.
373 | py_cat = torch.stack(py, dim=0) # (N, B, S+1, T)
374 | px_tot = px_cat.sum(dim=0) # (B, S, T+1)
375 | py_tot = py_cat.sum(dim=0) # (B, S+1, T)
376 |
377 | if boundary is not None:
378 | assert boundary.dtype == torch.int64
379 | assert boundary.shape == (B, 4)
380 | for s_begin, t_begin, s_end, t_end in boundary.tolist():
381 | assert 0 <= s_begin <= s_end <= S
382 | assert 0 <= t_begin <= t_end <= T
383 |
384 | # The following statements are for efficiency
385 | px_tot, py_tot = px_tot.contiguous(), py_tot.contiguous()
386 |
387 | assert px_tot.ndim == 3
388 | assert py_tot.ndim == 3
389 |
390 | p = torch.empty(B, S + 1, T + 1, device=px_tot.device, dtype=px_tot.dtype)
391 |
392 | # note, tot_probs is without grad.
393 | tot_probs = _fast_rnnt.mutual_information_forward(
394 | px_tot, py_tot, boundary, p
395 | )
396 |
397 | # this is a kind of "fake gradient" that we use, in effect to compute
398 | # occupation probabilities. The backprop will work regardless of the
399 | # actual derivative w.r.t. the total probs.
400 | ans_grad = torch.ones(B, device=px_tot.device, dtype=px_tot.dtype)
401 |
402 | (px_grad, py_grad) = _fast_rnnt.mutual_information_backward(
403 | px_tot, py_tot, boundary, p, ans_grad
404 | )
405 |
406 | px_grad = px_grad.reshape(1, B, -1)
407 | py_grad = py_grad.reshape(1, B, -1)
408 | px_cat = px_cat.reshape(N, B, -1)
409 | py_cat = py_cat.reshape(N, B, -1)
410 | # get rid of -inf, would generate nan on product with 0
411 | px_cat = px_cat.clamp(min=torch.finfo(px_cat.dtype).min)
412 | py_cat = py_cat.clamp(min=torch.finfo(py_cat.dtype).min)
413 |
414 | x_prods = _inner_product(px_grad, px_cat) # (N, B)
415 | y_prods = _inner_product(py_grad, py_cat) # (N, B)
416 |
417 | # If all the occupation counts were exactly 1.0 (i.e. no partial counts),
418 | # "prods" should be equal to "tot_probs"; however, in general, "tot_probs"
419 | # will be more positive due to the difference between log-of-sum and
420 | # sum-of-log
421 | prods = x_prods + y_prods # (N, B)
422 | with torch.no_grad():
423 | offset = tot_probs - prods.sum(dim=0) # (B,)
424 | prods[0] += offset
425 | return prods # (N, B)
426 |
--------------------------------------------------------------------------------
/fast_rnnt/python/tests/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | function(fast_rnnt_add_py_test source)
2 | get_filename_component(name ${source} NAME_WE)
3 | set(name "${name}_py")
4 |
5 | add_test(NAME ${name}
6 | COMMAND
7 | "${PYTHON_EXECUTABLE}"
8 | "${CMAKE_CURRENT_SOURCE_DIR}/${source}"
9 | )
10 |
11 | get_filename_component(fast_rnnt_path ${CMAKE_CURRENT_LIST_DIR} DIRECTORY)
12 |
13 | set_property(TEST ${name}
14 | PROPERTY ENVIRONMENT "PYTHONPATH=${fast_rnnt_path}:$:$ENV{PYTHONPATH}"
15 | )
16 | endfunction()
17 |
18 | # please sort the files in alphabetic order
19 | set(py_test_files
20 | mutual_information_test.py
21 | rnnt_loss_test.py
22 | )
23 |
24 | foreach(source IN LISTS py_test_files)
25 | fast_rnnt_add_py_test(${source})
26 | endforeach()
27 |
--------------------------------------------------------------------------------
/fast_rnnt/python/tests/mutual_information_test.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | #
3 | # Copyright 2021 Xiaomi Corporation (authors: Daniel Povey,
4 | # Wei Kang)
5 | #
6 | # See ../../../LICENSE for clarification regarding multiple authors
7 | #
8 | # Licensed under the Apache License, Version 2.0 (the "License");
9 | # you may not use this file except in compliance with the License.
10 | # You may obtain a copy of the License at
11 | #
12 | # http://www.apache.org/licenses/LICENSE-2.0
13 | #
14 | # Unless required by applicable law or agreed to in writing, software
15 | # distributed under the License is distributed on an "AS IS" BASIS,
16 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | # See the License for the specific language governing permissions and
18 | # limitations under the License.
19 |
20 | # To run this single test, use
21 | #
22 | # ctest --verbose -R mutual_information_test_py
23 |
24 | import random
25 | import unittest
26 |
27 | import fast_rnnt
28 | import torch
29 |
30 |
31 | # Caution: this will fail occasionally due to cutoffs not being quite large
32 | # enough. As long as it passes most of the time, it's OK.
33 | class TestMutualInformation(unittest.TestCase):
34 | @classmethod
35 | def setUpClass(cls):
36 | cls.devices = [torch.device("cpu")]
37 | if torch.cuda.is_available() and fast_rnnt.with_cuda():
38 | cls.devices.append(torch.device("cuda", 0))
39 | if torch.cuda.device_count() > 1:
40 | torch.cuda.set_device(1)
41 | cls.devices.append(torch.device("cuda", 1))
42 | cls.dtypes = [torch.float32, torch.float64]
43 |
44 | def test_mutual_information_basic(self):
45 | for _iter in range(10):
46 | (B, S, T) = (
47 | random.randint(1, 10),
48 | random.randint(1, 16),
49 | random.randint(1, 500),
50 | )
51 | random_px = random.random() < 0.2
52 | random_py = random.random() < 0.2
53 | random_boundary = random.random() < 0.7
54 | big_px = random.random() < 0.2
55 | big_py = random.random() < 0.2
56 |
57 | modified = random.random() < 0.5
58 |
59 | if modified and T < S:
60 | T = S + random.randint(0, 30)
61 |
62 | for dtype in self.dtypes:
63 | for device in self.devices:
64 | if random_boundary:
65 |
66 | def get_boundary_row():
67 | this_S = random.randint(
68 | 0, S
69 | ) # allow empty sequence
70 | this_T = random.randint(
71 | this_S if modified else 1, T
72 | )
73 | s_begin = random.randint(0, S - this_S)
74 | t_begin = random.randint(0, T - this_T)
75 | s_end = s_begin + this_S
76 | t_end = t_begin + this_T
77 | return [s_begin, t_begin, s_end, t_end]
78 |
79 | if device == torch.device("cpu"):
80 | boundary = torch.tensor(
81 | [get_boundary_row() for _ in range(B)],
82 | dtype=torch.int64,
83 | device=device,
84 | )
85 | else:
86 | boundary = boundary.to(device)
87 | else:
88 | # Use default boundary, but either specified directly
89 | # or not.
90 | if random.random() < 0.5:
91 | boundary = (
92 | torch.tensor([0, 0, S, T], dtype=torch.int64)
93 | .unsqueeze(0)
94 | .expand(B, 4)
95 | .to(device)
96 | )
97 | else:
98 | boundary = None
99 |
100 | if device == torch.device("cpu"):
101 | if random_px:
102 | # log of an odds ratio
103 | px = torch.randn(
104 | B, S, T + (0 if modified else 1), dtype=dtype
105 | ).to(device)
106 | if S > 1 and not random_boundary and not modified:
107 | px[:, :, -1:] = float("-inf")
108 | else:
109 | # log of an odds ratio
110 | px = torch.zeros(
111 | B, S, T + (0 if modified else 1), dtype=dtype
112 | ).to(device)
113 | # px and py get exponentiated, and then multiplied
114 | # together up to 32 times (BLOCK_SIZE in the CUDA code),
115 | # so 15 is actually a big number that could lead to
116 | # overflow.
117 | if big_px:
118 | px += 15.0
119 | if random_py:
120 | # log of an odds ratio
121 | py = torch.randn(B, S + 1, T, dtype=dtype).to(
122 | device
123 | )
124 | else:
125 | # log of an odds ratio
126 | py = torch.zeros(B, S + 1, T, dtype=dtype).to(
127 | device
128 | )
129 | if big_py:
130 | py += 15.0
131 |
132 | else:
133 | px = px.to(device).detach()
134 | py = py.to(device).detach()
135 | px.requires_grad = True
136 | py.requires_grad = True
137 |
138 | m = fast_rnnt.mutual_information_recursion(px, py, boundary)
139 |
140 | m2 = fast_rnnt.joint_mutual_information_recursion(
141 | (px,), (py,), boundary
142 | )
143 |
144 | m3 = fast_rnnt.joint_mutual_information_recursion(
145 | (px * 0.5, px * 0.5), (py * 0.5, py * 0.5), boundary
146 | )
147 |
148 | # it is supposed to be identical only after
149 | # summing over dim 0, corresponding to the
150 | # sequence dim
151 | m3 = m3.sum(dim=0)
152 |
153 | assert torch.allclose(m, m2)
154 | assert torch.allclose(m, m3)
155 |
156 | # the loop this is in checks that the CPU and CUDA versions
157 | # give the same derivative;
158 | # by randomizing which of m, m2 or m3 we backprop, we also
159 | # ensure that the joint version of the code gives the same
160 | # derivative as the regular version
161 | scale = 3
162 | if random.random() < 0.5:
163 | (m.sum() * scale).backward()
164 | elif random.random() < 0.5:
165 | (m2.sum() * scale).backward()
166 | else:
167 | (m3.sum() * scale).backward()
168 |
169 | if device == torch.device("cpu"):
170 | expected_px_grad = px.grad
171 | expected_py_grad = py.grad
172 | expected_m = m
173 | assert torch.allclose(
174 | px.grad,
175 | expected_px_grad.to(device),
176 | atol=1.0e-02,
177 | rtol=1.0e-02,
178 | )
179 | assert torch.allclose(
180 | py.grad,
181 | expected_py_grad.to(device),
182 | atol=1.0e-02,
183 | rtol=1.0e-02,
184 | )
185 | assert torch.allclose(
186 | m, expected_m.to(device), atol=1.0e-02, rtol=1.0e-02
187 | )
188 |
189 | def test_mutual_information_deriv(self):
190 | for _iter in range(10):
191 | (B, S, T) = (
192 | random.randint(1, 100),
193 | random.randint(1, 200),
194 | random.randint(1, 200),
195 | )
196 | random_px = random.random() < 0.2
197 | random_py = random.random() < 0.2
198 | random_boundary = random.random() < 0.7
199 | big_px = random.random() < 0.2
200 | big_py = random.random() < 0.2
201 |
202 | modified = random.random() < 0.5
203 |
204 | if modified and T < S:
205 | T = S + random.randint(0, 30)
206 |
207 | for dtype in self.dtypes:
208 | for device in self.devices:
209 | if random_boundary:
210 |
211 | def get_boundary_row():
212 | this_S = random.randint(1, S)
213 | this_T = random.randint(
214 | this_S if modified else 1, T
215 | )
216 | s_begin = random.randint(0, S - this_S)
217 | t_begin = random.randint(0, T - this_T)
218 | s_end = s_begin + this_S
219 | t_end = t_begin + this_T
220 | return [s_begin, t_begin, s_end, t_end]
221 |
222 | if device == torch.device("cpu"):
223 | boundary = torch.tensor(
224 | [get_boundary_row() for _ in range(B)],
225 | dtype=torch.int64,
226 | device=device,
227 | )
228 | else:
229 | boundary = boundary.to(device)
230 | else:
231 | # Use default boundary, but either specified directly
232 | # or not.
233 | if random.random() < 0.5:
234 | boundary = (
235 | torch.tensor([0, 0, S, T], dtype=torch.int64)
236 | .unsqueeze(0)
237 | .expand(B, 4)
238 | .to(device)
239 | )
240 | else:
241 | boundary = None
242 |
243 | T1 = T + (0 if modified else 1)
244 | if device == torch.device("cpu"):
245 | if random_px:
246 | # log of an odds ratio
247 | px = torch.randn(B, S, T1, dtype=dtype).to(device)
248 | else:
249 | # log of an odds ratio
250 | px = torch.zeros(B, S, T1, dtype=dtype).to(device)
251 | # px and py get exponentiated, and then multiplied
252 | # together up to 32 times (BLOCK_SIZE in the CUDA code),
253 | # so 15 is actually a big number that could lead to
254 | # overflow.
255 | if big_px:
256 | px += 15.0
257 | if random_py:
258 | # log of an odds ratio
259 | py = torch.randn(B, S + 1, T, dtype=dtype).to(
260 | device
261 | )
262 | else:
263 | # log of an odds ratio
264 | py = torch.zeros(B, S + 1, T, dtype=dtype).to(
265 | device
266 | )
267 | if big_py:
268 | py += 15.0
269 | else:
270 | px = px.to(device).detach()
271 | py = py.to(device).detach()
272 | px.requires_grad = True
273 | py.requires_grad = True
274 |
275 | m = fast_rnnt.mutual_information_recursion(px, py, boundary)
276 |
277 | m_grad = torch.randn(B, dtype=dtype, device=device)
278 | m.backward(gradient=m_grad)
279 | delta = 1.0e-04
280 | delta_px = delta * torch.randn_like(px)
281 | m2 = fast_rnnt.mutual_information_recursion(
282 | px + delta_px, py, boundary
283 | )
284 | delta_m = m2 - m
285 | observed_delta = (delta_m * m_grad).sum().to("cpu")
286 | predicted_delta = (delta_px * px.grad).sum().to("cpu")
287 |
288 | atol = 1.0e-02 if dtype == torch.float32 else 1.0e-04
289 | rtol = 1.0e-02 if dtype == torch.float32 else 1.0e-04
290 |
291 | assert torch.allclose(
292 | observed_delta, predicted_delta, atol=atol, rtol=rtol
293 | )
294 |
295 | delta_py = delta * torch.randn_like(py)
296 | m2 = fast_rnnt.mutual_information_recursion(
297 | px, py + delta_py, boundary
298 | )
299 | delta_m = m2 - m
300 | observed_delta = (delta_m * m_grad).sum().to("cpu")
301 | predicted_delta = (delta_py * py.grad).sum().to("cpu")
302 |
303 | assert torch.allclose(
304 | observed_delta, predicted_delta, atol=atol, rtol=rtol
305 | )
306 |
307 |
308 | if __name__ == "__main__":
309 | unittest.main()
310 |
--------------------------------------------------------------------------------
/fast_rnnt/python/tests/rnnt_loss_test.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | #
3 | # Copyright 2021 Xiaomi Corporation (authors: Daniel Povey,
4 | # Wei Kang)
5 | #
6 | # See ../../../LICENSE for clarification regarding multiple authors
7 | #
8 | # Licensed under the Apache License, Version 2.0 (the "License");
9 | # you may not use this file except in compliance with the License.
10 | # You may obtain a copy of the License at
11 | #
12 | # http://www.apache.org/licenses/LICENSE-2.0
13 | #
14 | # Unless required by applicable law or agreed to in writing, software
15 | # distributed under the License is distributed on an "AS IS" BASIS,
16 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | # See the License for the specific language governing permissions and
18 | # limitations under the License.
19 |
20 | # To run this single test, use
21 | #
22 | # ctest --verbose -R rnnt_loss_test_py
23 |
24 | import unittest
25 |
26 | import fast_rnnt
27 | import random
28 | import torch
29 |
30 |
31 | class TestRnntLoss(unittest.TestCase):
32 | @classmethod
33 | def setUpClass(cls):
34 | cls.devices = [torch.device("cpu")]
35 | if torch.cuda.is_available() and fast_rnnt.with_cuda():
36 | cls.devices.append(torch.device("cuda", 0))
37 | if torch.cuda.device_count() > 1:
38 | torch.cuda.set_device(1)
39 | cls.devices.append(torch.device("cuda", 1))
40 | try:
41 | import torchaudio
42 | import torchaudio.functional
43 |
44 | if hasattr(torchaudio.functional, "rnnt_loss"):
45 | cls.has_torch_rnnt_loss = True
46 | else:
47 | cls.has_torch_rnnt_loss = False
48 | print(
49 | f"Current torchaudio version: {torchaudio.__version__}\n"
50 | "Skipping the tests of comparing rnnt loss with torch "
51 | "one, to enable these tests please install a "
52 | "version >= 0.10.0"
53 | )
54 | except ImportError as e:
55 | cls.has_torch_rnnt_loss = False
56 | print(
57 | f"Import torchaudio error, error message: {e}\n"
58 | "Skipping the tests of comparing rnnt loss with torch "
59 | "one, to enable these tests, please install torchaudio "
60 | "with version >= 0.10.0"
61 | )
62 |
63 | def test_rnnt_loss_basic(self):
64 | B = 1
65 | S = 3
66 | T = 4
67 | # C = 3
68 | for device in self.devices:
69 | # lm: [B][S+1][C]
70 | lm = torch.tensor(
71 | [[[0, 0, 1], [0, 1, 1], [1, 0, 1], [2, 2, 0]]],
72 | dtype=torch.float,
73 | device=device,
74 | )
75 | # am: [B][T][C]
76 | am = torch.tensor(
77 | [[[0, 1, 2], [0, 0, 0], [0, 2, 4], [0, 3, 3]]],
78 | dtype=torch.float,
79 | device=device,
80 | )
81 | termination_symbol = 2
82 | symbols = torch.tensor([[0, 1, 0]], dtype=torch.long, device=device)
83 |
84 | px, py = fast_rnnt.get_rnnt_logprobs(
85 | lm=lm,
86 | am=am,
87 | symbols=symbols,
88 | termination_symbol=termination_symbol,
89 | )
90 | assert px.shape == (B, S, T + 1)
91 | assert py.shape == (B, S + 1, T)
92 | assert symbols.shape == (B, S)
93 | m = fast_rnnt.mutual_information_recursion(
94 | px=px, py=py, boundary=None
95 | )
96 |
97 | if device == torch.device("cpu"):
98 | expected = -m
99 | assert torch.allclose(-m, expected.to(device))
100 |
101 | # test rnnt_loss_simple
102 | m = fast_rnnt.rnnt_loss_simple(
103 | lm=lm,
104 | am=am,
105 | symbols=symbols,
106 | termination_symbol=termination_symbol,
107 | boundary=None,
108 | reduction="none",
109 | )
110 | assert torch.allclose(m, expected.to(device))
111 |
112 | # test rnnt_loss_smoothed
113 | m = fast_rnnt.rnnt_loss_smoothed(
114 | lm=lm,
115 | am=am,
116 | symbols=symbols,
117 | termination_symbol=termination_symbol,
118 | lm_only_scale=0.0,
119 | am_only_scale=0.0,
120 | boundary=None,
121 | reduction="none",
122 | )
123 | assert torch.allclose(m, expected.to(device))
124 |
125 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
126 |
127 | # test rnnt_loss
128 | m = fast_rnnt.rnnt_loss(
129 | logits=logits,
130 | symbols=symbols,
131 | termination_symbol=termination_symbol,
132 | boundary=None,
133 | reduction="none",
134 | )
135 | assert torch.allclose(m, expected.to(device))
136 |
137 | # compare with torchaudio rnnt_loss
138 | if self.has_torch_rnnt_loss:
139 | import torchaudio.functional
140 |
141 | m = torchaudio.functional.rnnt_loss(
142 | logits=logits,
143 | targets=symbols.int(),
144 | logit_lengths=torch.tensor(
145 | [T] * B, dtype=torch.int32, device=device
146 | ),
147 | target_lengths=torch.tensor(
148 | [S] * B, dtype=torch.int32, device=device
149 | ),
150 | blank=termination_symbol,
151 | reduction="none",
152 | )
153 | assert torch.allclose(m, expected.to(device))
154 |
155 | # should be invariant to adding a constant for any frame.
156 | lm += torch.randn(B, S + 1, 1, device=device)
157 | am += torch.randn(B, T, 1, device=device)
158 |
159 | m = fast_rnnt.rnnt_loss_simple(
160 | lm=lm,
161 | am=am,
162 | symbols=symbols,
163 | termination_symbol=termination_symbol,
164 | boundary=None,
165 | reduction="none",
166 | )
167 | assert torch.allclose(m, expected.to(device))
168 |
169 | m = fast_rnnt.rnnt_loss_smoothed(
170 | lm=lm,
171 | am=am,
172 | symbols=symbols,
173 | termination_symbol=termination_symbol,
174 | lm_only_scale=0.0,
175 | am_only_scale=0.0,
176 | boundary=None,
177 | reduction="none",
178 | )
179 | assert torch.allclose(m, expected.to(device))
180 |
181 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
182 | m = fast_rnnt.rnnt_loss(
183 | logits=logits,
184 | symbols=symbols,
185 | termination_symbol=termination_symbol,
186 | boundary=None,
187 | reduction="none",
188 | )
189 | assert torch.allclose(m, expected.to(device))
190 |
191 | def test_rnnt_loss_random(self):
192 | B = 5
193 | S = 20
194 | T = 300
195 | C = 100
196 | frames = torch.randint(S, T, (B,))
197 | seq_length = torch.randint(3, S - 1, (B,))
198 | T = torch.max(frames)
199 | S = torch.max(seq_length)
200 |
201 | am_ = torch.randn((B, T, C), dtype=torch.float32)
202 | lm_ = torch.randn((B, S + 1, C), dtype=torch.float32)
203 | symbols_ = torch.randint(0, C - 1, (B, S))
204 | termination_symbol = C - 1
205 |
206 | boundary_ = torch.zeros((B, 4), dtype=torch.int64)
207 | boundary_[:, 2] = seq_length
208 | boundary_[:, 3] = frames
209 |
210 | for rnnt_type in ["regular", "modified", "constrained"]:
211 | for device in self.devices:
212 | # lm: [B][S+1][C]
213 | lm = lm_.to(device)
214 | # am: [B][T][C]
215 | am = am_.to(device)
216 | symbols = symbols_.to(device)
217 | boundary = boundary_.to(device)
218 |
219 | px, py = fast_rnnt.get_rnnt_logprobs(
220 | lm=lm,
221 | am=am,
222 | symbols=symbols,
223 | termination_symbol=termination_symbol,
224 | boundary=boundary,
225 | rnnt_type=rnnt_type,
226 | )
227 | assert (
228 | px.shape == (B, S, T)
229 | if rnnt_type != "regular"
230 | else (B, S, T + 1)
231 | )
232 | assert py.shape == (B, S + 1, T)
233 | assert symbols.shape == (B, S)
234 | m = fast_rnnt.mutual_information_recursion(
235 | px=px, py=py, boundary=boundary
236 | )
237 |
238 | if device == torch.device("cpu"):
239 | expected = -torch.mean(m)
240 | assert torch.allclose(-torch.mean(m), expected.to(device))
241 |
242 | m = fast_rnnt.rnnt_loss_simple(
243 | lm=lm,
244 | am=am,
245 | symbols=symbols,
246 | termination_symbol=termination_symbol,
247 | boundary=boundary,
248 | rnnt_type=rnnt_type,
249 | )
250 | assert torch.allclose(m, expected.to(device))
251 |
252 | m = fast_rnnt.rnnt_loss_smoothed(
253 | lm=lm,
254 | am=am,
255 | symbols=symbols,
256 | termination_symbol=termination_symbol,
257 | lm_only_scale=0.0,
258 | am_only_scale=0.0,
259 | boundary=boundary,
260 | rnnt_type=rnnt_type,
261 | )
262 | assert torch.allclose(m, expected.to(device))
263 |
264 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
265 | m = fast_rnnt.rnnt_loss(
266 | logits=logits,
267 | symbols=symbols,
268 | termination_symbol=termination_symbol,
269 | boundary=boundary,
270 | rnnt_type=rnnt_type,
271 | )
272 | assert torch.allclose(m, expected.to(device))
273 |
274 | # compare with torchaudio rnnt_loss
275 | if self.has_torch_rnnt_loss and rnnt_type == "regular":
276 | import torchaudio.functional
277 |
278 | m = torchaudio.functional.rnnt_loss(
279 | logits=logits,
280 | targets=symbols.int(),
281 | logit_lengths=boundary[:, 3].int(),
282 | target_lengths=boundary[:, 2].int(),
283 | blank=termination_symbol,
284 | )
285 | assert torch.allclose(m, expected.to(device))
286 |
287 | # should be invariant to adding a constant for any frame.
288 | lm += torch.randn(B, S + 1, 1, device=device)
289 | am += torch.randn(B, T, 1, device=device)
290 |
291 | m = fast_rnnt.rnnt_loss_simple(
292 | lm=lm,
293 | am=am,
294 | symbols=symbols,
295 | termination_symbol=termination_symbol,
296 | boundary=boundary,
297 | rnnt_type=rnnt_type,
298 | )
299 | assert torch.allclose(m, expected.to(device))
300 |
301 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
302 | m = fast_rnnt.rnnt_loss(
303 | logits=logits,
304 | symbols=symbols,
305 | termination_symbol=termination_symbol,
306 | boundary=boundary,
307 | rnnt_type=rnnt_type,
308 | )
309 | assert torch.allclose(m, expected.to(device))
310 |
311 | m = fast_rnnt.rnnt_loss_smoothed(
312 | lm=lm,
313 | am=am,
314 | symbols=symbols,
315 | termination_symbol=termination_symbol,
316 | lm_only_scale=0.0,
317 | am_only_scale=0.0,
318 | boundary=boundary,
319 | rnnt_type=rnnt_type,
320 | )
321 | assert torch.allclose(m, expected.to(device))
322 |
323 | def test_rnnt_loss_gradient(self):
324 | if self.has_torch_rnnt_loss:
325 | import torchaudio.functional
326 |
327 | B = 5
328 | S = 20
329 | T = 300
330 | C = 100
331 | frames = torch.randint(S, T, (B,))
332 | seq_length = torch.randint(3, S - 1, (B,))
333 | T = torch.max(frames)
334 | S = torch.max(seq_length)
335 |
336 | am_ = torch.randn((B, T, C), dtype=torch.float32)
337 | lm_ = torch.randn((B, S + 1, C), dtype=torch.float32)
338 | symbols_ = torch.randint(0, C - 1, (B, S))
339 | termination_symbol = C - 1
340 |
341 | boundary_ = torch.zeros((B, 4), dtype=torch.int64)
342 | boundary_[:, 2] = seq_length
343 | boundary_[:, 3] = frames
344 |
345 | for device in self.devices:
346 | # lm: [B][S+1][C]
347 | lm = lm_.to(device)
348 | # am: [B][T][C]
349 | am = am_.to(device)
350 | symbols = symbols_.to(device)
351 | boundary = boundary_.to(device)
352 |
353 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
354 | logits.requires_grad_()
355 | fast_loss = fast_rnnt.rnnt_loss(
356 | logits=logits,
357 | symbols=symbols,
358 | termination_symbol=termination_symbol,
359 | boundary=boundary,
360 | )
361 | fast_grad = torch.autograd.grad(fast_loss, logits)
362 | fast_grad = fast_grad[0]
363 |
364 | logits2 = logits.detach().clone().float()
365 | logits2.requires_grad_()
366 | torch_loss = torchaudio.functional.rnnt_loss(
367 | logits=logits2,
368 | targets=symbols.int(),
369 | logit_lengths=boundary[:, 3].int(),
370 | target_lengths=boundary[:, 2].int(),
371 | blank=termination_symbol,
372 | )
373 | torch_grad = torch.autograd.grad(torch_loss, logits2)
374 | torch_grad = torch_grad[0]
375 |
376 | assert torch.allclose(
377 | fast_loss, torch_loss, atol=1e-2, rtol=1e-2
378 | )
379 |
380 | assert torch.allclose(
381 | fast_grad, torch_grad, atol=1e-2, rtol=1e-2
382 | )
383 |
384 | def test_rnnt_loss_smoothed(self):
385 | B = 1
386 | S = 3
387 | T = 4
388 | # C = 3
389 | for device in self.devices:
390 | # lm: [B][S+1][C]
391 | lm = torch.tensor(
392 | [[[0, 0, 1], [0, 1, 1], [1, 0, 1], [2, 2, 0]]],
393 | dtype=torch.float,
394 | device=device,
395 | )
396 | # am: [B][T][C]
397 | am = torch.tensor(
398 | [[[0, 1, 2], [0, 0, 0], [0, 2, 4], [0, 3, 3]]],
399 | dtype=torch.float,
400 | device=device,
401 | )
402 |
403 | termination_symbol = 2
404 | symbols = torch.tensor([[0, 1, 0]], dtype=torch.long, device=device)
405 |
406 | m = fast_rnnt.rnnt_loss_smoothed(
407 | lm=lm,
408 | am=am,
409 | symbols=symbols,
410 | termination_symbol=termination_symbol,
411 | lm_only_scale=0.0,
412 | am_only_scale=0.333,
413 | boundary=None,
414 | )
415 |
416 | if device == torch.device("cpu"):
417 | expected = m
418 | assert torch.allclose(m, expected.to(device))
419 |
420 | # should be invariant to adding a constant for any frame.
421 | lm += torch.randn(B, S + 1, 1, device=device)
422 | am += torch.randn(B, T, 1, device=device)
423 |
424 | m = fast_rnnt.rnnt_loss_smoothed(
425 | lm=lm,
426 | am=am,
427 | symbols=symbols,
428 | termination_symbol=termination_symbol,
429 | lm_only_scale=0.0,
430 | am_only_scale=0.333,
431 | boundary=None,
432 | )
433 | assert torch.allclose(m, expected.to(device))
434 |
435 | def test_rnnt_loss_pruned(self):
436 | B = 4
437 | T = 300
438 | S = 50
439 | C = 10
440 |
441 | frames = torch.randint(S, T, (B,))
442 | seq_length = torch.randint(3, S - 1, (B,))
443 | T = torch.max(frames)
444 | S = torch.max(seq_length)
445 |
446 | am_ = torch.randn((B, T, C), dtype=torch.float64)
447 | lm_ = torch.randn((B, S + 1, C), dtype=torch.float64)
448 | symbols_ = torch.randint(0, C - 1, (B, S))
449 | terminal_symbol = C - 1
450 |
451 | boundary_ = torch.zeros((B, 4), dtype=torch.int64)
452 | boundary_[:, 2] = seq_length
453 | boundary_[:, 3] = frames
454 |
455 | for rnnt_type in ["regular", "modified", "constrained"]:
456 | for device in self.devices:
457 | # normal rnnt
458 | am = am_.to(device)
459 | lm = lm_.to(device)
460 | symbols = symbols_.to(device)
461 | boundary = boundary_.to(device)
462 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
463 | logits = logits.float()
464 |
465 | # nonlinear transform
466 | logits = torch.sigmoid(logits)
467 | fast_loss = fast_rnnt.rnnt_loss(
468 | logits=logits,
469 | symbols=symbols,
470 | termination_symbol=terminal_symbol,
471 | boundary=boundary,
472 | rnnt_type=rnnt_type,
473 | )
474 |
475 | print(f"Unpruned rnnt loss with {rnnt_type} rnnt : {fast_loss}")
476 |
477 | # pruning
478 | simple_loss, (px_grad, py_grad) = fast_rnnt.rnnt_loss_simple(
479 | lm=lm,
480 | am=am,
481 | symbols=symbols,
482 | termination_symbol=terminal_symbol,
483 | boundary=boundary,
484 | rnnt_type=rnnt_type,
485 | return_grad=True,
486 | reduction="none",
487 | )
488 |
489 | for r in range(2, 50, 5):
490 | ranges = fast_rnnt.get_rnnt_prune_ranges(
491 | px_grad=px_grad,
492 | py_grad=py_grad,
493 | boundary=boundary,
494 | s_range=r,
495 | )
496 | # (B, T, r, C)
497 | pruned_am, pruned_lm = fast_rnnt.do_rnnt_pruning(
498 | am=am, lm=lm, ranges=ranges
499 | )
500 |
501 | logits = pruned_am + pruned_lm
502 |
503 | # nonlinear transform
504 | logits = torch.sigmoid(logits)
505 |
506 | pruned_loss = fast_rnnt.rnnt_loss_pruned(
507 | logits=logits,
508 | symbols=symbols,
509 | ranges=ranges,
510 | termination_symbol=terminal_symbol,
511 | boundary=boundary,
512 | rnnt_type=rnnt_type,
513 | reduction="none",
514 | )
515 | print(f"Pruning loss with range {r} : {pruned_loss}")
516 |
517 | # Test the sequences that only have small number of symbols,
518 | # at this circumstance, the s_range would be greater than S, which will
519 | # raise errors (like, nan or inf loss) in our previous versions.
520 | def test_rnnt_loss_pruned_small_symbols_number(self):
521 | B = 2
522 | T = 20
523 | S = 3
524 | C = 10
525 |
526 | frames = torch.randint(S + 1, T, (B,))
527 | seq_lengths = torch.randint(1, S, (B,))
528 | T = torch.max(frames)
529 | S = torch.max(seq_lengths)
530 |
531 | am_ = torch.randn((B, T, C), dtype=torch.float64)
532 | lm_ = torch.randn((B, S + 1, C), dtype=torch.float64)
533 | symbols_ = torch.randint(0, C, (B, S))
534 | terminal_symbol = C - 1
535 |
536 | boundary_ = torch.zeros((B, 4), dtype=torch.int64)
537 | boundary_[:, 2] = seq_lengths
538 | boundary_[:, 3] = frames
539 |
540 | print(f"B = {B}, T = {T}, S = {S}, C = {C}")
541 |
542 | for rnnt_type in ["regular", "modified", "constrained"]:
543 | for device in self.devices:
544 | # normal rnnt
545 | am = am_.to(device)
546 | lm = lm_.to(device)
547 | symbols = symbols_.to(device)
548 | boundary = boundary_.to(device)
549 |
550 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
551 | logits = logits.float()
552 |
553 | # nonlinear transform
554 | logits = torch.sigmoid(logits)
555 |
556 | loss = fast_rnnt.rnnt_loss(
557 | logits=logits,
558 | symbols=symbols,
559 | termination_symbol=terminal_symbol,
560 | boundary=boundary,
561 | rnnt_type=rnnt_type,
562 | reduction="none",
563 | )
564 |
565 | print(f"Unpruned rnnt loss with {rnnt_type} rnnt : {loss}")
566 |
567 | # pruning
568 | simple_loss, (px_grad, py_grad) = fast_rnnt.rnnt_loss_simple(
569 | lm=lm,
570 | am=am,
571 | symbols=symbols,
572 | termination_symbol=terminal_symbol,
573 | boundary=boundary,
574 | rnnt_type=rnnt_type,
575 | return_grad=True,
576 | reduction="none",
577 | )
578 |
579 | S0 = 2
580 | if rnnt_type != "regular":
581 | S0 = 1
582 |
583 | for r in range(S0, S + 2):
584 | ranges = fast_rnnt.get_rnnt_prune_ranges(
585 | px_grad=px_grad,
586 | py_grad=py_grad,
587 | boundary=boundary,
588 | s_range=r,
589 | )
590 | # (B, T, r, C)
591 | pruned_am, pruned_lm = fast_rnnt.do_rnnt_pruning(
592 | am=am, lm=lm, ranges=ranges
593 | )
594 |
595 | logits = pruned_am + pruned_lm
596 |
597 | # nonlinear transform
598 | logits = torch.sigmoid(logits)
599 |
600 | pruned_loss = fast_rnnt.rnnt_loss_pruned(
601 | logits=logits,
602 | symbols=symbols,
603 | ranges=ranges,
604 | termination_symbol=terminal_symbol,
605 | boundary=boundary,
606 | rnnt_type=rnnt_type,
607 | reduction="none",
608 | )
609 | print(f"Pruned loss with range {r} : {pruned_loss}")
610 |
611 | # Test low s_range values with large S and small T,
612 | # at this circumstance, the s_range would not be enough
613 | # to cover the whole sequence length (in regular rnnt mode)
614 | # and would result in inf loss
615 | def test_rnnt_loss_pruned_small_s_range(self):
616 | B = 2
617 | T = 2
618 | S = 10
619 | C = 10
620 |
621 | frames = torch.randint(1, T, (B,))
622 | seq_lengths = torch.randint(1, S, (B,))
623 | T = torch.max(frames)
624 | S = torch.max(seq_lengths)
625 |
626 | am_ = torch.randn((B, T, C), dtype=torch.float64)
627 | lm_ = torch.randn((B, S + 1, C), dtype=torch.float64)
628 | symbols_ = torch.randint(0, C, (B, S))
629 | terminal_symbol = C - 1
630 |
631 | boundary_ = torch.zeros((B, 4), dtype=torch.int64)
632 | boundary_[:, 2] = seq_lengths
633 | boundary_[:, 3] = frames
634 |
635 | print(f"B = {B}, T = {T}, S = {S}, C = {C}")
636 |
637 | for rnnt_type in ["regular"]:
638 | for device in self.devices:
639 | # normal rnnt
640 | am = am_.to(device)
641 | lm = lm_.to(device)
642 | symbols = symbols_.to(device)
643 | boundary = boundary_.to(device)
644 |
645 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
646 | logits = logits.float()
647 |
648 | # nonlinear transform
649 | logits = torch.sigmoid(logits)
650 |
651 | loss = fast_rnnt.rnnt_loss(
652 | logits=logits,
653 | symbols=symbols,
654 | termination_symbol=terminal_symbol,
655 | boundary=boundary,
656 | rnnt_type=rnnt_type,
657 | reduction="none",
658 | )
659 |
660 | print(f"Unpruned rnnt loss with {rnnt_type} rnnt : {loss}")
661 |
662 | # pruning
663 | simple_loss, (px_grad, py_grad) = fast_rnnt.rnnt_loss_simple(
664 | lm=lm,
665 | am=am,
666 | symbols=symbols,
667 | termination_symbol=terminal_symbol,
668 | boundary=boundary,
669 | rnnt_type=rnnt_type,
670 | return_grad=True,
671 | reduction="none",
672 | )
673 |
674 | S0 = 2
675 |
676 | for r in range(S0, S + 2):
677 | ranges = fast_rnnt.get_rnnt_prune_ranges(
678 | px_grad=px_grad,
679 | py_grad=py_grad,
680 | boundary=boundary,
681 | s_range=r,
682 | )
683 | # (B, T, r, C)
684 | pruned_am, pruned_lm = fast_rnnt.do_rnnt_pruning(
685 | am=am, lm=lm, ranges=ranges
686 | )
687 |
688 | logits = pruned_am + pruned_lm
689 |
690 | # nonlinear transform
691 | logits = torch.sigmoid(logits)
692 |
693 | pruned_loss = fast_rnnt.rnnt_loss_pruned(
694 | logits=logits,
695 | symbols=symbols,
696 | ranges=ranges,
697 | termination_symbol=terminal_symbol,
698 | boundary=boundary,
699 | rnnt_type=rnnt_type,
700 | reduction="none",
701 | )
702 | assert (
703 | not pruned_loss.isinf().any()
704 | ), f"Pruned loss is inf for r={r}, S={S}, T={T}: {pruned_loss}"
705 | print(f"Pruned loss with range {r} : {pruned_loss}")
706 |
707 |
708 | if __name__ == "__main__":
709 | unittest.main()
710 |
--------------------------------------------------------------------------------
/package.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 |
3 | ROOT=$(realpath $(dirname $0))
4 | cd ${ROOT}
5 |
6 | python3 -m pip install --upgrade setuptools wheel twine
7 | python3 setup.py sdist
8 | echo "Inspect dist and upload with \"python3 -m twine upload dist/*\""
9 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=1.5
2 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | #
3 | # Copyright (c) 2022 Xiaomi Corporation (author: Wei Kang)
4 |
5 | import glob
6 | import os
7 | import re
8 | import shutil
9 | import sys
10 |
11 | import setuptools
12 | from setuptools.command.build_ext import build_ext
13 |
14 | cur_dir = os.path.dirname(os.path.abspath(__file__))
15 |
16 |
17 | def cmake_extension(name, *args, **kwargs) -> setuptools.Extension:
18 | kwargs["language"] = "c++"
19 | sources = []
20 | return setuptools.Extension(name, sources, *args, **kwargs)
21 |
22 |
23 | class BuildExtension(build_ext):
24 | def build_extension(self, ext: setuptools.extension.Extension):
25 | # build/temp.linux-x86_64-3.8
26 | build_dir = self.build_temp
27 | os.makedirs(build_dir, exist_ok=True)
28 |
29 | # build/lib.linux-x86_64-3.8
30 | os.makedirs(self.build_lib, exist_ok=True)
31 |
32 | ft_dir = os.path.dirname(os.path.abspath(__file__))
33 |
34 | cmake_args = os.environ.get("FT_CMAKE_ARGS", "")
35 | make_args = os.environ.get("FT_MAKE_ARGS", "")
36 | system_make_args = os.environ.get("MAKEFLAGS", "")
37 |
38 | if cmake_args == "":
39 | cmake_args = "-DCMAKE_BUILD_TYPE=Release -DFT_BUILD_TESTS=OFF"
40 |
41 | if make_args == "" and system_make_args == "":
42 | make_args = " -j "
43 |
44 | if "PYTHON_EXECUTABLE" not in cmake_args:
45 | print(f"Setting PYTHON_EXECUTABLE to {sys.executable}")
46 | cmake_args += f" -DPYTHON_EXECUTABLE={sys.executable}"
47 |
48 | build_cmd = f"""
49 | cd {self.build_temp}
50 |
51 | cmake {cmake_args} {ft_dir}
52 |
53 | make {make_args} _fast_rnnt
54 | """
55 | print(f"build command is:\n{build_cmd}")
56 |
57 | ret = os.system(build_cmd)
58 | if ret != 0:
59 | raise Exception(
60 | "\nBuild fast_rnnt failed. Please check the error "
61 | "message.\n"
62 | "You can ask for help by creating an issue on GitHub.\n"
63 | "\nClick:\n"
64 | "\thttps://github.com/danpovey/fast_rnnt/issues/new\n" # noqa
65 | )
66 | lib_so = glob.glob(f"{build_dir}/lib/*.so*")
67 | for so in lib_so:
68 | print(f"Copying {so} to {self.build_lib}/")
69 | shutil.copy(f"{so}", f"{self.build_lib}/")
70 |
71 | # macos
72 | lib_so = glob.glob(f"{build_dir}/lib/*.dylib*")
73 | for so in lib_so:
74 | print(f"Copying {so} to {self.build_lib}/")
75 | shutil.copy(f"{so}", f"{self.build_lib}/")
76 |
77 |
78 | def read_long_description():
79 | with open("README.md", encoding="utf8") as f:
80 | readme = f.read()
81 | return readme
82 |
83 |
84 | def get_package_version():
85 | with open("CMakeLists.txt") as f:
86 | content = f.read()
87 |
88 | latest_version = re.search(r"set\(FT_VERSION (.*)\)", content).group(1)
89 | latest_version = latest_version.strip('"')
90 | return latest_version
91 |
92 |
93 | def get_requirements():
94 | with open("requirements.txt", encoding="utf8") as f:
95 | requirements = f.read().splitlines()
96 |
97 | return requirements
98 |
99 |
100 | package_name = "fast_rnnt"
101 |
102 | with open("fast_rnnt/python/fast_rnnt/__init__.py", "a") as f:
103 | f.write(f"__version__ = '{get_package_version()}'\n")
104 |
105 | setuptools.setup(
106 | name=package_name,
107 | version=get_package_version(),
108 | author="Dan Povey",
109 | author_email="dpovey@gmail.com",
110 | package_dir={
111 | package_name: "fast_rnnt/python/fast_rnnt",
112 | },
113 | packages=[package_name],
114 | url="https://github.com/danpovey/fast_rnnt",
115 | description="Fast and memory-efficient RNN-T loss.",
116 | long_description=read_long_description(),
117 | long_description_content_type="text/markdown",
118 | install_requires=get_requirements(),
119 | ext_modules=[cmake_extension("_fast_rnnt")],
120 | cmdclass={"build_ext": BuildExtension},
121 | zip_safe=False,
122 | classifiers=[
123 | "Programming Language :: C++",
124 | "Programming Language :: Python",
125 | "Topic :: Scientific/Engineering :: Artificial Intelligence",
126 | ],
127 | license="Apache licensed, as found in the LICENSE file",
128 | )
129 |
--------------------------------------------------------------------------------
13 |
14 | > This picture is taken from [here](https://github.com/k2-fsa/icefall/pull/251)
15 |
16 | ## Installation
17 |
18 | You can install it via `pip`:
19 |
20 | ```
21 | pip install fast_rnnt
22 | ```
23 |
24 | You can also install from source:
25 |
26 | ```
27 | git clone https://github.com/danpovey/fast_rnnt.git
28 | cd fast_rnnt
29 | python setup.py install
30 | ```
31 |
32 | To check that `fast_rnnt` was installed successfully, please run
33 |
34 | ```
35 | python3 -c "import fast_rnnt; print(fast_rnnt.__version__)"
36 | ```
37 |
38 | which should print the version of the installed `fast_rnnt`, e.g., `1.0`.
39 |
40 |
41 | ### How to display installation log ?
42 |
43 | Use
44 |
45 | ```
46 | pip install --verbose fast_rnnt
47 | ```
48 |
49 | ### How to reduce installation time ?
50 |
51 | Use
52 |
53 | ```
54 | export FT_MAKE_ARGS="-j"
55 | pip install --verbose fast_rnnt
56 | ```
57 |
58 | It will pass `-j` to `make`.
59 |
60 | ### Which version of PyTorch is supported ?
61 |
62 | It has been tested on PyTorch >= 1.5.0.
63 |
64 | Note: The cuda version of the Pytorch should be the same as the cuda version in your environment,
65 | or it will cause a compilation error.
66 |
67 |
68 | ### How to install a CPU version of `fast_rnnt` ?
69 |
70 | Use
71 |
72 | ```
73 | export FT_CMAKE_ARGS="-DCMAKE_BUILD_TYPE=Release -DFT_WITH_CUDA=OFF"
74 | export FT_MAKE_ARGS="-j"
75 | pip install --verbose fast_rnnt
76 | ```
77 |
78 | It will pass `-DCMAKE_BUILD_TYPE=Release -DFT_WITH_CUDA=OFF` to `cmake`.
79 |
80 | ### Where to get help if I have problems with the installation ?
81 |
82 | Please file an issue at
83 | and describe your problem there.
84 |
85 |
86 | ## Usage
87 |
88 | ### For rnnt_loss_simple
89 |
90 | This is a simple case of the RNN-T loss, where the joiner network is just
91 | addition.
92 |
93 | Note: termination_symbol plays the role of blank in other RNN-T loss implementations, we call it termination_symbol as it terminates symbols of current frame.
94 |
95 | ```python
96 | am = torch.randn((B, T, C), dtype=torch.float32)
97 | lm = torch.randn((B, S + 1, C), dtype=torch.float32)
98 | symbols = torch.randint(0, C, (B, S))
99 | termination_symbol = 0
100 |
101 | boundary = torch.zeros((B, 4), dtype=torch.int64)
102 | boundary[:, 2] = target_lengths
103 | boundary[:, 3] = num_frames
104 |
105 | loss = fast_rnnt.rnnt_loss_simple(
106 | lm=lm,
107 | am=am,
108 | symbols=symbols,
109 | termination_symbol=termination_symbol,
110 | boundary=boundary,
111 | reduction="sum",
112 | )
113 | ```
114 |
115 | ### For rnnt_loss_smoothed
116 |
117 | The same as `rnnt_loss_simple`, except that it supports `am_only` & `lm_only` smoothing
118 | that allows you to make the loss-function one of the form:
119 |
120 | lm_only_scale * lm_probs +
121 | am_only_scale * am_probs +
122 | (1-lm_only_scale-am_only_scale) * combined_probs
123 |
124 | where `lm_probs` and `am_probs` are the probabilities given the lm and acoustic model independently.
125 |
126 | ```python
127 | am = torch.randn((B, T, C), dtype=torch.float32)
128 | lm = torch.randn((B, S + 1, C), dtype=torch.float32)
129 | symbols = torch.randint(0, C, (B, S))
130 | termination_symbol = 0
131 |
132 | boundary = torch.zeros((B, 4), dtype=torch.int64)
133 | boundary[:, 2] = target_lengths
134 | boundary[:, 3] = num_frames
135 |
136 | loss = fast_rnnt.rnnt_loss_smoothed(
137 | lm=lm,
138 | am=am,
139 | symbols=symbols,
140 | termination_symbol=termination_symbol,
141 | lm_only_scale=0.25,
142 | am_only_scale=0.0
143 | boundary=boundary,
144 | reduction="sum",
145 | )
146 | ```
147 |
148 | ### For rnnt_loss_pruned
149 |
150 | `rnnt_loss_pruned` can not be used alone, it needs the gradients returned by `rnnt_loss_simple/rnnt_loss_smoothed` to get pruning bounds.
151 |
152 | ```python
153 | am = torch.randn((B, T, C), dtype=torch.float32)
154 | lm = torch.randn((B, S + 1, C), dtype=torch.float32)
155 | symbols = torch.randint(0, C, (B, S))
156 | termination_symbol = 0
157 |
158 | boundary = torch.zeros((B, 4), dtype=torch.int64)
159 | boundary[:, 2] = target_lengths
160 | boundary[:, 3] = num_frames
161 |
162 | # rnnt_loss_simple can be also rnnt_loss_smoothed
163 | simple_loss, (px_grad, py_grad) = fast_rnnt.rnnt_loss_simple(
164 | lm=lm,
165 | am=am,
166 | symbols=symbols,
167 | termination_symbol=termination_symbol,
168 | boundary=boundary,
169 | reduction="sum",
170 | return_grad=True,
171 | )
172 | s_range = 5 # can be other values
173 | ranges = fast_rnnt.get_rnnt_prune_ranges(
174 | px_grad=px_grad,
175 | py_grad=py_grad,
176 | boundary=boundary,
177 | s_range=s_range,
178 | )
179 |
180 | am_pruned, lm_pruned = fast_rnnt.do_rnnt_pruning(am=am, lm=lm, ranges=ranges)
181 |
182 | logits = model.joiner(am_pruned, lm_pruned)
183 | pruned_loss = fast_rnnt.rnnt_loss_pruned(
184 | logits=logits,
185 | symbols=symbols,
186 | ranges=ranges,
187 | termination_symbol=termination_symbol,
188 | boundary=boundary,
189 | reduction="sum",
190 | )
191 | ```
192 |
193 | You can also find recipes [here](https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/pruned_transducer_stateless) that uses `rnnt_loss_pruned` to train a model.
194 |
195 |
196 | ### For rnnt_loss
197 |
198 | The `unprund rnnt_loss` is the same as `torchaudio rnnt_loss`, it produces same output as torchaudio for the same input.
199 |
200 | ```python
201 | logits = torch.randn((B, S, T, C), dtype=torch.float32)
202 | symbols = torch.randint(0, C, (B, S))
203 | termination_symbol = 0
204 |
205 | boundary = torch.zeros((B, 4), dtype=torch.int64)
206 | boundary[:, 2] = target_lengths
207 | boundary[:, 3] = num_frames
208 |
209 | loss = fast_rnnt.rnnt_loss(
210 | logits=logits,
211 | symbols=symbols,
212 | termination_symbol=termination_symbol,
213 | boundary=boundary,
214 | reduction="sum",
215 | )
216 | ```
217 |
218 |
219 | ## Benchmarking
220 |
221 | The [repo](https://github.com/csukuangfj/transducer-loss-benchmarking) compares the speed and memory usage of several transducer losses, the summary in the following table is taken from there, you can check the repository for more details.
222 |
223 | Note: As we declared above, `fast_rnnt` is also implemented in [k2](https://github.com/k2-fsa/k2) project, so `k2` and `fast_rnnt` are equivalent in the benchmarking.
224 |
225 | |Name |Average step time (us) | Peak memory usage (MB)|
226 | |--------------------|-----------------------|-----------------------|
227 | |torchaudio |601447 |12959.2 |
228 | |fast_rnnt(unpruned) |274407 |15106.5 |
229 | |fast_rnnt(pruned) |38112 |2647.8 |
230 | |optimized_transducer|567684 |10903.1 |
231 | |warprnnt_numba |229340 |13061.8 |
232 | |warp-transducer |210772 |13061.8 |
233 |
--------------------------------------------------------------------------------
/cmake/Modules/FetchContent/CMakeLists.cmake.in:
--------------------------------------------------------------------------------
1 | # Distributed under the OSI-approved BSD 3-Clause License. See accompanying
2 | # file Copyright.txt or https://cmake.org/licensing for details.
3 |
4 | cmake_minimum_required(VERSION ${CMAKE_VERSION})
5 |
6 | # We name the project and the target for the ExternalProject_Add() call
7 | # to something that will highlight to the user what we are working on if
8 | # something goes wrong and an error message is produced.
9 |
10 | project(${contentName}-populate NONE)
11 |
12 | include(ExternalProject)
13 | ExternalProject_Add(${contentName}-populate
14 | ${ARG_EXTRA}
15 | SOURCE_DIR "${ARG_SOURCE_DIR}"
16 | BINARY_DIR "${ARG_BINARY_DIR}"
17 | CONFIGURE_COMMAND ""
18 | BUILD_COMMAND ""
19 | INSTALL_COMMAND ""
20 | TEST_COMMAND ""
21 | )
22 |
--------------------------------------------------------------------------------
/cmake/Modules/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## FetchContent
3 |
4 | `FetchContent.cmake` and `FetchContent/CMakeLists.cmake.in`
5 | are copied from `cmake/3.11.0/share/cmake-3.11/Modules`.
6 |
--------------------------------------------------------------------------------
/cmake/googletest.cmake:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2021 Xiaomi Corporation (authors: Fangjun Kuang)
2 | # See ../LICENSE for clarification regarding multiple authors
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | function(download_googltest)
17 | if(CMAKE_VERSION VERSION_LESS 3.11)
18 | # FetchContent is available since 3.11,
19 | # we've copied it to ${CMAKE_SOURCE_DIR}/cmake/Modules
20 | # so that it can be used in lower CMake versions.
21 | list(APPEND CMAKE_MODULE_PATH ${CMAKE_SOURCE_DIR}/cmake/Modules)
22 | endif()
23 |
24 | include(FetchContent)
25 |
26 | set(googletest_URL "https://github.com/google/googletest/archive/release-1.10.0.tar.gz")
27 | set(googletest_HASH "SHA256=9dc9157a9a1551ec7a7e43daea9a694a0bb5fb8bec81235d8a1e6ef64c716dcb")
28 |
29 | set(BUILD_GMOCK ON CACHE BOOL "" FORCE)
30 | set(INSTALL_GTEST OFF CACHE BOOL "" FORCE)
31 | set(gtest_disable_pthreads ON CACHE BOOL "" FORCE)
32 | set(gtest_force_shared_crt ON CACHE BOOL "" FORCE)
33 |
34 | FetchContent_Declare(googletest
35 | URL ${googletest_URL}
36 | URL_HASH ${googletest_HASH}
37 | )
38 |
39 | FetchContent_GetProperties(googletest)
40 | if(NOT googletest_POPULATED)
41 | message(STATUS "Downloading googletest")
42 | FetchContent_Populate(googletest)
43 | endif()
44 | message(STATUS "googletest is downloaded to ${googletest_SOURCE_DIR}")
45 | message(STATUS "googletest's binary dir is ${googletest_BINARY_DIR}")
46 |
47 | if(APPLE)
48 | set(CMAKE_MACOSX_RPATH ON) # to solve the following warning on macOS
49 | endif()
50 | #[==[
51 | -- Generating done
52 | Policy CMP0042 is not set: MACOSX_RPATH is enabled by default. Run "cmake
53 | --help-policy CMP0042" for policy details. Use the cmake_policy command to
54 | set the policy and suppress this warning.
55 |
56 | MACOSX_RPATH is not specified for the following targets:
57 |
58 | gmock
59 | gmock_main
60 | gtest
61 | gtest_main
62 |
63 | This warning is for project developers. Use -Wno-dev to suppress it.
64 | ]==]
65 |
66 | add_subdirectory(${googletest_SOURCE_DIR} ${googletest_BINARY_DIR} EXCLUDE_FROM_ALL)
67 |
68 | target_include_directories(gtest
69 | INTERFACE
70 | ${googletest_SOURCE_DIR}/googletest/include
71 | ${googletest_SOURCE_DIR}/googlemock/include
72 | )
73 | endfunction()
74 |
75 | download_googltest()
76 |
--------------------------------------------------------------------------------
/cmake/pybind11.cmake:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2021 Xiaomi Corporation (authors: Fangjun Kuang)
2 | # See ../LICENSE for clarification regarding multiple authors
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | function(download_pybind11)
17 | if(CMAKE_VERSION VERSION_LESS 3.11)
18 | list(APPEND CMAKE_MODULE_PATH ${CMAKE_SOURCE_DIR}/cmake/Modules)
19 | endif()
20 |
21 | include(FetchContent)
22 |
23 | set(pybind11_URL "https://github.com/pybind/pybind11/archive/v2.6.0.tar.gz")
24 | set(pybind11_HASH "SHA256=90b705137b69ee3b5fc655eaca66d0dc9862ea1759226f7ccd3098425ae69571")
25 |
26 | set(double_quotes "\"")
27 | set(dollar "\$")
28 | set(semicolon "\;")
29 | if(NOT WIN32)
30 | FetchContent_Declare(pybind11
31 | URL ${pybind11_URL}
32 | URL_HASH ${pybind11_HASH}
33 | )
34 | else()
35 | FetchContent_Declare(pybind11
36 | URL ${pybind11_URL}
37 | URL_HASH ${pybind11_HASH}
38 | )
39 | endif()
40 |
41 | FetchContent_GetProperties(pybind11)
42 | if(NOT pybind11_POPULATED)
43 | message(STATUS "Downloading pybind11")
44 | FetchContent_Populate(pybind11)
45 | endif()
46 | message(STATUS "pybind11 is downloaded to ${pybind11_SOURCE_DIR}")
47 | add_subdirectory(${pybind11_SOURCE_DIR} ${pybind11_BINARY_DIR} EXCLUDE_FROM_ALL)
48 | endfunction()
49 |
50 | download_pybind11()
51 |
--------------------------------------------------------------------------------
/cmake/select_compute_arch.cmake:
--------------------------------------------------------------------------------
1 | #
2 | # This file is copied from
3 | # https://github.com/pytorch/pytorch/blob/master/cmake/Modules_CUDA_fix/upstream/FindCUDA/select_compute_arch.cmake
4 | #
5 | #
6 | # Synopsis:
7 | # CUDA_SELECT_NVCC_ARCH_FLAGS(out_variable [target_CUDA_architectures])
8 | # -- Selects GPU arch flags for nvcc based on target_CUDA_architectures
9 | # target_CUDA_architectures : Auto | Common | All | LIST(ARCH_AND_PTX ...)
10 | # - "Auto" detects local machine GPU compute arch at runtime.
11 | # - "Common" and "All" cover common and entire subsets of architectures
12 | # ARCH_AND_PTX : NAME | NUM.NUM | NUM.NUM(NUM.NUM) | NUM.NUM+PTX
13 | # NAME: Kepler Maxwell Kepler+Tegra Kepler+Tesla Maxwell+Tegra Pascal Volta Turing Ampere
14 | # NUM: Any number. Only those pairs are currently accepted by NVCC though:
15 | # 3.5 3.7 5.0 5.2 5.3 6.0 6.2 7.0 7.2 7.5 8.0
16 | # Returns LIST of flags to be added to CUDA_NVCC_FLAGS in ${out_variable}
17 | # Additionally, sets ${out_variable}_readable to the resulting numeric list
18 | # Example:
19 | # CUDA_SELECT_NVCC_ARCH_FLAGS(ARCH_FLAGS 3.0 3.5+PTX 5.2(5.0) Maxwell)
20 | # LIST(APPEND CUDA_NVCC_FLAGS ${ARCH_FLAGS})
21 | #
22 | # More info on CUDA architectures: https://en.wikipedia.org/wiki/CUDA
23 | #
24 |
25 | if(CMAKE_CUDA_COMPILER_LOADED OR DEFINED CMAKE_CUDA_COMPILER_ID) # CUDA as a language
26 | if(CMAKE_CUDA_COMPILER_ID STREQUAL "NVIDIA"
27 | AND CMAKE_CUDA_COMPILER_VERSION MATCHES "^([0-9]+\\.[0-9]+)")
28 | set(CUDA_VERSION "${CMAKE_MATCH_1}")
29 | endif()
30 | endif()
31 |
32 | # See: https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html#gpu-feature-list
33 |
34 | # This list will be used for CUDA_ARCH_NAME = All option
35 | set(CUDA_KNOWN_GPU_ARCHITECTURES "Kepler" "Maxwell")
36 |
37 | # This list will be used for CUDA_ARCH_NAME = Common option (enabled by default)
38 | set(CUDA_COMMON_GPU_ARCHITECTURES "3.5" "5.0")
39 |
40 | if(CUDA_VERSION VERSION_LESS "7.0")
41 | set(CUDA_LIMIT_GPU_ARCHITECTURE "5.2")
42 | endif()
43 |
44 | # This list is used to filter CUDA archs when autodetecting
45 | set(CUDA_ALL_GPU_ARCHITECTURES "3.5" "5.0")
46 |
47 | if(CUDA_VERSION VERSION_GREATER "6.5")
48 | list(APPEND CUDA_KNOWN_GPU_ARCHITECTURES "Kepler+Tegra" "Kepler+Tesla" "Maxwell+Tegra")
49 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "5.2")
50 |
51 | if(CUDA_VERSION VERSION_LESS "8.0")
52 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "5.2+PTX")
53 | set(CUDA_LIMIT_GPU_ARCHITECTURE "6.0")
54 | endif()
55 | endif()
56 |
57 | if(CUDA_VERSION VERSION_GREATER "7.5")
58 | list(APPEND CUDA_KNOWN_GPU_ARCHITECTURES "Pascal")
59 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "6.0" "6.1")
60 | list(APPEND CUDA_ALL_GPU_ARCHITECTURES "6.0" "6.1" "6.2")
61 |
62 | if(CUDA_VERSION VERSION_LESS "9.0")
63 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "6.2+PTX")
64 | set(CUDA_LIMIT_GPU_ARCHITECTURE "7.0")
65 | endif()
66 | endif ()
67 |
68 | if(CUDA_VERSION VERSION_GREATER "8.5")
69 | list(APPEND CUDA_KNOWN_GPU_ARCHITECTURES "Volta")
70 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "7.0")
71 | list(APPEND CUDA_ALL_GPU_ARCHITECTURES "7.0" "7.2")
72 |
73 | if(CUDA_VERSION VERSION_LESS "10.0")
74 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "7.2+PTX")
75 | set(CUDA_LIMIT_GPU_ARCHITECTURE "8.0")
76 | endif()
77 | endif()
78 |
79 | if(CUDA_VERSION VERSION_GREATER "9.5")
80 | list(APPEND CUDA_KNOWN_GPU_ARCHITECTURES "Turing")
81 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "7.5")
82 | list(APPEND CUDA_ALL_GPU_ARCHITECTURES "7.5")
83 |
84 | if(CUDA_VERSION VERSION_LESS "11.0")
85 | set(CUDA_LIMIT_GPU_ARCHITECTURE "8.0")
86 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "7.5+PTX")
87 | endif()
88 | endif()
89 |
90 | if(CUDA_VERSION VERSION_GREATER "10.5")
91 | list(APPEND CUDA_KNOWN_GPU_ARCHITECTURES "Ampere")
92 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "8.0")
93 | list(APPEND CUDA_ALL_GPU_ARCHITECTURES "8.0")
94 |
95 | if(CUDA_VERSION VERSION_LESS "11.1")
96 | set(CUDA_LIMIT_GPU_ARCHITECTURE "8.6")
97 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "8.0+PTX")
98 | endif()
99 | endif()
100 |
101 | if(CUDA_VERSION VERSION_GREATER "11.0")
102 | list(APPEND CUDA_COMMON_GPU_ARCHITECTURES "8.6" "8.6+PTX")
103 | list(APPEND CUDA_ALL_GPU_ARCHITECTURES "8.6")
104 |
105 | if(CUDA_VERSION VERSION_LESS "12.0")
106 | set(CUDA_LIMIT_GPU_ARCHITECTURE "9.0")
107 | endif()
108 | endif()
109 |
110 | ################################################################################################
111 | # A function for automatic detection of GPUs installed (if autodetection is enabled)
112 | # Usage:
113 | # CUDA_DETECT_INSTALLED_GPUS(OUT_VARIABLE)
114 | #
115 | function(CUDA_DETECT_INSTALLED_GPUS OUT_VARIABLE)
116 | if(NOT CUDA_GPU_DETECT_OUTPUT)
117 | if(CMAKE_CUDA_COMPILER_LOADED OR DEFINED CMAKE_CUDA_COMPILER_ID) # CUDA as a language
118 | set(file "${PROJECT_BINARY_DIR}/detect_cuda_compute_capabilities.cu")
119 | else()
120 | set(file "${PROJECT_BINARY_DIR}/detect_cuda_compute_capabilities.cpp")
121 | endif()
122 |
123 | file(WRITE ${file} ""
124 | "#include \n"
125 | "#include \n"
126 | "int main()\n"
127 | "{\n"
128 | " int count = 0;\n"
129 | " if (cudaSuccess != cudaGetDeviceCount(&count)) return -1;\n"
130 | " if (count == 0) return -1;\n"
131 | " for (int device = 0; device < count; ++device)\n"
132 | " {\n"
133 | " cudaDeviceProp prop;\n"
134 | " if (cudaSuccess == cudaGetDeviceProperties(&prop, device))\n"
135 | " std::printf(\"%d.%d \", prop.major, prop.minor);\n"
136 | " }\n"
137 | " return 0;\n"
138 | "}\n")
139 |
140 | if(CMAKE_CUDA_COMPILER_LOADED OR DEFINED CMAKE_CUDA_COMPILER_ID) # CUDA as a language
141 | try_run(run_result compile_result ${PROJECT_BINARY_DIR} ${file}
142 | RUN_OUTPUT_VARIABLE compute_capabilities)
143 | else()
144 | try_run(run_result compile_result ${PROJECT_BINARY_DIR} ${file}
145 | CMAKE_FLAGS "-DINCLUDE_DIRECTORIES=${CUDA_INCLUDE_DIRS}"
146 | LINK_LIBRARIES ${CUDA_LIBRARIES}
147 | RUN_OUTPUT_VARIABLE compute_capabilities)
148 | endif()
149 |
150 | # Filter unrelated content out of the output.
151 | string(REGEX MATCHALL "[0-9]+\\.[0-9]+" compute_capabilities "${compute_capabilities}")
152 |
153 | if(run_result EQUAL 0)
154 | string(REPLACE "2.1" "2.1(2.0)" compute_capabilities "${compute_capabilities}")
155 | set(CUDA_GPU_DETECT_OUTPUT ${compute_capabilities}
156 | CACHE INTERNAL "Returned GPU architectures from detect_gpus tool" FORCE)
157 | endif()
158 | endif()
159 |
160 | if(NOT CUDA_GPU_DETECT_OUTPUT)
161 | message(STATUS "Automatic GPU detection failed. Building for common architectures.")
162 | set(${OUT_VARIABLE} ${CUDA_COMMON_GPU_ARCHITECTURES} PARENT_SCOPE)
163 | else()
164 | # Filter based on CUDA version supported archs
165 | set(CUDA_GPU_DETECT_OUTPUT_FILTERED "")
166 | separate_arguments(CUDA_GPU_DETECT_OUTPUT)
167 | foreach(ITEM IN ITEMS ${CUDA_GPU_DETECT_OUTPUT})
168 | if(CUDA_LIMIT_GPU_ARCHITECTURE AND (ITEM VERSION_GREATER CUDA_LIMIT_GPU_ARCHITECTURE OR
169 | ITEM VERSION_EQUAL CUDA_LIMIT_GPU_ARCHITECTURE))
170 | list(GET CUDA_COMMON_GPU_ARCHITECTURES -1 NEWITEM)
171 | string(APPEND CUDA_GPU_DETECT_OUTPUT_FILTERED " ${NEWITEM}")
172 | else()
173 | string(APPEND CUDA_GPU_DETECT_OUTPUT_FILTERED " ${ITEM}")
174 | endif()
175 | endforeach()
176 |
177 | set(${OUT_VARIABLE} ${CUDA_GPU_DETECT_OUTPUT_FILTERED} PARENT_SCOPE)
178 | endif()
179 | endfunction()
180 |
181 |
182 | ################################################################################################
183 | # Function for selecting GPU arch flags for nvcc based on CUDA architectures from parameter list
184 | # Usage:
185 | # SELECT_NVCC_ARCH_FLAGS(out_variable [list of CUDA compute archs])
186 | function(CUDA_SELECT_NVCC_ARCH_FLAGS out_variable)
187 | set(CUDA_ARCH_LIST "${ARGN}")
188 |
189 | if("X${CUDA_ARCH_LIST}" STREQUAL "X" )
190 | set(CUDA_ARCH_LIST "Auto")
191 | endif()
192 |
193 | set(cuda_arch_bin)
194 | set(cuda_arch_ptx)
195 |
196 | if("${CUDA_ARCH_LIST}" STREQUAL "All")
197 | set(CUDA_ARCH_LIST ${CUDA_KNOWN_GPU_ARCHITECTURES})
198 | elseif("${CUDA_ARCH_LIST}" STREQUAL "Common")
199 | set(CUDA_ARCH_LIST ${CUDA_COMMON_GPU_ARCHITECTURES})
200 | elseif("${CUDA_ARCH_LIST}" STREQUAL "Auto")
201 | CUDA_DETECT_INSTALLED_GPUS(CUDA_ARCH_LIST)
202 | message(STATUS "Autodetected CUDA architecture(s): ${CUDA_ARCH_LIST}")
203 | endif()
204 |
205 | # Now process the list and look for names
206 | string(REGEX REPLACE "[ \t]+" ";" CUDA_ARCH_LIST "${CUDA_ARCH_LIST}")
207 | list(REMOVE_DUPLICATES CUDA_ARCH_LIST)
208 | foreach(arch_name ${CUDA_ARCH_LIST})
209 | set(arch_bin)
210 | set(arch_ptx)
211 | set(add_ptx FALSE)
212 | # Check to see if we are compiling PTX
213 | if(arch_name MATCHES "(.*)\\+PTX$")
214 | set(add_ptx TRUE)
215 | set(arch_name ${CMAKE_MATCH_1})
216 | endif()
217 | if(arch_name MATCHES "^([0-9]\\.[0-9](\\([0-9]\\.[0-9]\\))?)$")
218 | set(arch_bin ${CMAKE_MATCH_1})
219 | set(arch_ptx ${arch_bin})
220 | else()
221 | # Look for it in our list of known architectures
222 | if(${arch_name} STREQUAL "Kepler+Tesla")
223 | set(arch_bin 3.7)
224 | elseif(${arch_name} STREQUAL "Kepler")
225 | set(arch_bin 3.5)
226 | set(arch_ptx 3.5)
227 | elseif(${arch_name} STREQUAL "Maxwell+Tegra")
228 | set(arch_bin 5.3)
229 | elseif(${arch_name} STREQUAL "Maxwell")
230 | set(arch_bin 5.0 5.2)
231 | set(arch_ptx 5.2)
232 | elseif(${arch_name} STREQUAL "Pascal")
233 | set(arch_bin 6.0 6.1)
234 | set(arch_ptx 6.1)
235 | elseif(${arch_name} STREQUAL "Volta")
236 | set(arch_bin 7.0 7.0)
237 | set(arch_ptx 7.0)
238 | elseif(${arch_name} STREQUAL "Turing")
239 | set(arch_bin 7.5)
240 | set(arch_ptx 7.5)
241 | elseif(${arch_name} STREQUAL "Ampere")
242 | set(arch_bin 8.0)
243 | set(arch_ptx 8.0)
244 | else()
245 | message(SEND_ERROR "Unknown CUDA Architecture Name ${arch_name} in CUDA_SELECT_NVCC_ARCH_FLAGS")
246 | endif()
247 | endif()
248 | if(NOT arch_bin)
249 | message(SEND_ERROR "arch_bin wasn't set for some reason")
250 | endif()
251 | list(APPEND cuda_arch_bin ${arch_bin})
252 | if(add_ptx)
253 | if (NOT arch_ptx)
254 | set(arch_ptx ${arch_bin})
255 | endif()
256 | list(APPEND cuda_arch_ptx ${arch_ptx})
257 | endif()
258 | endforeach()
259 |
260 | # remove dots and convert to lists
261 | string(REGEX REPLACE "\\." "" cuda_arch_bin "${cuda_arch_bin}")
262 | string(REGEX REPLACE "\\." "" cuda_arch_ptx "${cuda_arch_ptx}")
263 | string(REGEX MATCHALL "[0-9()]+" cuda_arch_bin "${cuda_arch_bin}")
264 | string(REGEX MATCHALL "[0-9]+" cuda_arch_ptx "${cuda_arch_ptx}")
265 |
266 | if(cuda_arch_bin)
267 | list(REMOVE_DUPLICATES cuda_arch_bin)
268 | endif()
269 | if(cuda_arch_ptx)
270 | list(REMOVE_DUPLICATES cuda_arch_ptx)
271 | endif()
272 |
273 | set(nvcc_flags "")
274 | set(nvcc_archs_readable "")
275 |
276 | # Tell NVCC to add binaries for the specified GPUs
277 | foreach(arch ${cuda_arch_bin})
278 | if(arch MATCHES "([0-9]+)\\(([0-9]+)\\)")
279 | # User explicitly specified ARCH for the concrete CODE
280 | list(APPEND nvcc_flags -gencode arch=compute_${CMAKE_MATCH_2},code=sm_${CMAKE_MATCH_1})
281 | list(APPEND nvcc_archs_readable sm_${CMAKE_MATCH_1})
282 | else()
283 | # User didn't explicitly specify ARCH for the concrete CODE, we assume ARCH=CODE
284 | list(APPEND nvcc_flags -gencode arch=compute_${arch},code=sm_${arch})
285 | list(APPEND nvcc_archs_readable sm_${arch})
286 | endif()
287 | endforeach()
288 |
289 | # Tell NVCC to add PTX intermediate code for the specified architectures
290 | foreach(arch ${cuda_arch_ptx})
291 | list(APPEND nvcc_flags -gencode arch=compute_${arch},code=compute_${arch})
292 | list(APPEND nvcc_archs_readable compute_${arch})
293 | endforeach()
294 |
295 | string(REPLACE ";" " " nvcc_archs_readable "${nvcc_archs_readable}")
296 | set(${out_variable} ${nvcc_flags} PARENT_SCOPE)
297 | set(${out_variable}_readable ${nvcc_archs_readable} PARENT_SCOPE)
298 | endfunction()
299 |
--------------------------------------------------------------------------------
/cmake/torch.cmake:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2021 Xiaomi Corporation (authors: Fangjun Kuang)
2 | # PYTHON_EXECUTABLE is set by pybind11.cmake
3 | message(STATUS "Python executable: ${PYTHON_EXECUTABLE}")
4 | execute_process(
5 | COMMAND "${PYTHON_EXECUTABLE}" -c "import os; import torch; print(os.path.dirname(torch.__file__))"
6 | OUTPUT_STRIP_TRAILING_WHITESPACE
7 | OUTPUT_VARIABLE TORCH_DIR
8 | )
9 |
10 | list(APPEND CMAKE_PREFIX_PATH "${TORCH_DIR}")
11 | find_package(Torch REQUIRED)
12 |
13 | # set the global CMAKE_CXX_FLAGS so that
14 | # optimized_transducer uses the same abi flag as PyTorch
15 | set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
16 | if(OT_WITH_CUDA)
17 | set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} ${TORCH_CXX_FLAGS}")
18 | endif()
19 |
20 |
21 | execute_process(
22 | COMMAND "${PYTHON_EXECUTABLE}" -c "import torch; print(torch.__version__.split('.')[0])"
23 | OUTPUT_STRIP_TRAILING_WHITESPACE
24 | OUTPUT_VARIABLE OT_TORCH_VERSION_MAJOR
25 | )
26 |
27 | execute_process(
28 | COMMAND "${PYTHON_EXECUTABLE}" -c "import torch; print(torch.__version__.split('.')[1])"
29 | OUTPUT_STRIP_TRAILING_WHITESPACE
30 | OUTPUT_VARIABLE OT_TORCH_VERSION_MINOR
31 | )
32 |
33 | execute_process(
34 | COMMAND "${PYTHON_EXECUTABLE}" -c "import torch; print(torch.__version__)"
35 | OUTPUT_STRIP_TRAILING_WHITESPACE
36 | OUTPUT_VARIABLE TORCH_VERSION
37 | )
38 |
39 | message(STATUS "PyTorch version: ${TORCH_VERSION}")
40 |
41 | if(OT_WITH_CUDA)
42 | execute_process(
43 | COMMAND "${PYTHON_EXECUTABLE}" -c "import torch; print(torch.version.cuda)"
44 | OUTPUT_STRIP_TRAILING_WHITESPACE
45 | OUTPUT_VARIABLE TORCH_CUDA_VERSION
46 | )
47 |
48 | message(STATUS "PyTorch cuda version: ${TORCH_CUDA_VERSION}")
49 |
50 | if(NOT CUDA_VERSION VERSION_EQUAL TORCH_CUDA_VERSION)
51 | message(FATAL_ERROR
52 | "PyTorch ${TORCH_VERSION} is compiled with CUDA ${TORCH_CUDA_VERSION}.\n"
53 | "But you are using CUDA ${CUDA_VERSION} to compile optimized_transducer.\n"
54 | "Please try to use the same CUDA version for PyTorch and optimized_transducer.\n"
55 | "**You can remove this check if you are sure this will not cause "
56 | "problems**\n"
57 | )
58 | endif()
59 |
60 | # Solve the following error for NVCC:
61 | # unknown option `-Wall`
62 | #
63 | # It contains only some -Wno-* flags, so it is OK
64 | # to set them to empty
65 | set_property(TARGET torch_cuda
66 | PROPERTY
67 | INTERFACE_COMPILE_OPTIONS ""
68 | )
69 | set_property(TARGET torch_cpu
70 | PROPERTY
71 | INTERFACE_COMPILE_OPTIONS ""
72 | )
73 | endif()
74 |
--------------------------------------------------------------------------------
/cmake/transform.cmake:
--------------------------------------------------------------------------------
1 | # Copyright 2021 Fangjun Kuang (csukuangfj@gmail.com)
2 | # See ../LICENSE for clarification regarding multiple authors
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | # This function is used to copy foo.cu to foo.cc
17 | # Usage:
18 | #
19 | # transform(OUTPUT_VARIABLE output_variable_name SRCS foo.cu bar.cu)
20 | #
21 | function(transform)
22 | set(optional_args "") # there are no optional arguments
23 | set(one_value_arg OUTPUT_VARIABLE)
24 | set(multi_value_args SRCS)
25 |
26 | cmake_parse_arguments(MY "${optional_args}" "${one_value_arg}" "${multi_value_args}" ${ARGN})
27 | foreach(src IN LISTS MY_SRCS)
28 | get_filename_component(src_name ${src} NAME_WE)
29 | get_filename_component(src_dir ${src} DIRECTORY)
30 | set(dst ${CMAKE_CURRENT_BINARY_DIR}/${src_dir}/${src_name}.cc)
31 |
32 | list(APPEND ans ${dst})
33 | message(STATUS "Renaming ${CMAKE_CURRENT_SOURCE_DIR}/${src} to ${dst}")
34 | configure_file(${src} ${dst})
35 | endforeach()
36 | set(${MY_OUTPUT_VARIABLE} ${ans} PARENT_SCOPE)
37 | endfunction()
38 |
--------------------------------------------------------------------------------
/fast_rnnt/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | add_subdirectory(csrc)
2 | add_subdirectory(python)
3 |
--------------------------------------------------------------------------------
/fast_rnnt/csrc/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | include_directories(${CMAKE_SOURCE_DIR})
2 |
3 | # it is located in fast_rnnt/cmake/transform.cmake
4 | include(transform)
5 |
6 | set(srcs
7 | mutual_information_cpu.cu
8 | )
9 |
10 | if(NOT FT_WITH_CUDA)
11 | transform(OUTPUT_VARIABLE srcs SRCS ${srcs})
12 | else()
13 | list(APPEND srcs mutual_information_cuda.cu)
14 | endif()
15 |
16 | add_library(mutual_information_core ${srcs})
17 | target_link_libraries(mutual_information_core PUBLIC ${TORCH_LIBRARIES})
18 | # for
19 | target_include_directories(mutual_information_core PUBLIC ${PYTHON_INCLUDE_DIRS})
20 |
--------------------------------------------------------------------------------
/fast_rnnt/csrc/device_guard.h:
--------------------------------------------------------------------------------
1 | /**
2 | * Copyright 2022 Xiaomi Corporation (authors: Fangjun Kuang, Wei Kang)
3 | *
4 | * See LICENSE for clarification regarding multiple authors
5 | *
6 | * Licensed under the Apache License, Version 2.0 (the "License");
7 | * you may not use this file except in compliance with the License.
8 | * You may obtain a copy of the License at
9 | *
10 | * http://www.apache.org/licenses/LICENSE-2.0
11 | *
12 | * Unless required by applicable law or agreed to in writing, software
13 | * distributed under the License is distributed on an "AS IS" BASIS,
14 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | * See the License for the specific language governing permissions and
16 | * limitations under the License.
17 | */
18 |
19 | #ifndef FAST_RNNT_CSRC_DEVICE_GUARD_H_
20 | #define FAST_RNNT_CSRC_DEVICE_GUARD_H_
21 |
22 | #include "torch/script.h"
23 |
24 | // This file is modified from
25 | // https://github.com/k2-fsa/k2/blob/master/k2/csrc/device_guard.h
26 | namespace fast_rnnt {
27 |
28 | // DeviceGuard is an RAII class. Its sole purpose is to restore
29 | // the previous default cuda device if a CUDA context changes the
30 | // current default cuda device.
31 | class DeviceGuard {
32 | public:
33 | explicit DeviceGuard(torch::Device device) {
34 | if (device.type() == torch::kCUDA) {
35 | old_device_ = GetDevice();
36 | new_device_ = device.index();
37 | if (old_device_ != new_device_)
38 | SetDevice(new_device_);
39 | }
40 | // else do nothing
41 | }
42 |
43 | explicit DeviceGuard(int32_t new_device) : new_device_(new_device) {
44 | if (new_device != -1) {
45 | old_device_ = GetDevice();
46 | if (old_device_ != new_device)
47 | SetDevice(new_device);
48 | }
49 | }
50 |
51 | ~DeviceGuard() {
52 | if (old_device_ != -1 && old_device_ != new_device_) {
53 | // restore the previous device
54 | SetDevice(old_device_);
55 | }
56 | // else it was either a CPU context or the device IDs
57 | // were the same
58 | }
59 |
60 | DeviceGuard(const DeviceGuard &) = delete;
61 | DeviceGuard &operator=(const DeviceGuard &) = delete;
62 |
63 | DeviceGuard(DeviceGuard &&) = delete;
64 | DeviceGuard &operator=(DeviceGuard &&) = delete;
65 |
66 | private:
67 | static int32_t GetDevice() {
68 | #ifdef FT_WITH_CUDA
69 | int32_t device;
70 | auto s = cudaGetDevice(&device);
71 | TORCH_CHECK(s == cudaSuccess, cudaGetErrorString(s));
72 | return device;
73 | #else
74 | return -1;
75 | #endif
76 | }
77 |
78 | static void SetDevice(int32_t device) {
79 | #ifdef FT_WITH_CUDA
80 | auto s = cudaSetDevice(device);
81 | TORCH_CHECK(s == cudaSuccess, cudaGetErrorString(s));
82 | #else
83 | return;
84 | #endif
85 | }
86 |
87 | private:
88 | int32_t old_device_ = -1;
89 | int32_t new_device_ = -1;
90 | };
91 |
92 | } // namespace fast_rnnt
93 |
94 | #endif // FAST_RNNT_CSRC_DEVICE_GUARD_H_
95 |
--------------------------------------------------------------------------------
/fast_rnnt/csrc/mutual_information.h:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2021 Xiaomi Corporation (authors: Daniel Povey)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #ifndef FAST_RNNT_CSRC_MUTUAL_INFORMATION_H_
22 | #define FAST_RNNT_CSRC_MUTUAL_INFORMATION_H_
23 |
24 | #include
25 | #include
26 | #include "torch/extension.h"
27 |
28 | #ifdef __CUDA_ARCH__
29 | #define FT_CUDA_HOSTDEV __host__ __device__
30 | #else
31 | #define FT_CUDA_HOSTDEV
32 | #endif
33 |
34 | namespace fast_rnnt {
35 |
36 | FT_CUDA_HOSTDEV inline double LogAdd(double x, double y) {
37 | double diff;
38 | if (x < y) {
39 | diff = x - y;
40 | x = y;
41 | } else {
42 | diff = y - x;
43 | }
44 | // diff is negative. x is now the larger one.
45 | if (diff - diff != 0)
46 | return x; // x and y are probably -inf. Return the larger one.
47 | else
48 | return x + log1p(exp(diff));
49 | }
50 |
51 | // returns log(exp(x) + exp(y)).
52 | FT_CUDA_HOSTDEV inline float LogAdd(float x, float y) {
53 | float diff;
54 | if (x < y) {
55 | diff = x - y;
56 | x = y;
57 | } else {
58 | diff = y - x;
59 | }
60 | // diff is negative. x is now the larger one.
61 | if (diff - diff != 0)
62 | return x; // x and y are probably -inf. Return the larger one.
63 | else
64 | return x + log1p(exp(diff));
65 | }
66 |
67 | /*
68 | Forward of mutual_information. See also comment of `mutual_information`
69 | in ../pyhton/fast_rnnt/mutual_information.py. This is the core recursion
70 | in the sequence-to-sequence mutual information computation.
71 |
72 | @param px Tensor of shape [B][S][T + 1] if not modified, [B][S][T] if
73 | modified. `modified` can be worked out from this. In not-modified case,
74 | it can be thought of as the log-odds ratio of generating the next x in
75 | the sequence, i.e.
76 | px[b][s][t] is the log of
77 | p(x_s | x_0..x_{s-1}, y_0..y_{s-1}) / p(x_s),
78 | i.e. the log-prob of generating x_s given subsequences of
79 | lengths (s, t), divided by the prior probability of generating x_s.
80 | (See mutual_information.py for more info).
81 | @param py The log-odds ratio of generating the next y in the sequence.
82 | Shape [B][S + 1][T]
83 | @param p This function writes to p[b][s][t] the mutual information between
84 | sub-sequences of x and y of length s and t respectively, from the
85 | b'th sequences in the batch. Its shape is [B][S + 1][T + 1].
86 | Concretely, this function implements the following recursion,
87 | in the case where s_begin == t_begin == 0:
88 |
89 | p[b,0,0] = 0.0
90 | if not modified:
91 | p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
92 | p[b,s,t-1] + py[b,s,t-1])
93 | if modified:
94 | p[b,s,t] = log_add(p[b,s-1,t-1] + px[b,s-1,t-1],
95 | p[b,s,t-1] + py[b,s,t-1])
96 | ... treating values with any -1 index as -infinity.
97 | .. if `boundary` is set, we start from p[b,s_begin,t_begin]=0.0.
98 | @param boundary If set, a tensor of shape [B][4] of type int64_t, which
99 | contains, where for each batch element b, boundary[b]
100 | equals [s_begin, t_begin, s_end, t_end]
101 | which are the beginning and end (i.e. one-past-the-last)
102 | of the x and y sequences that we should process.
103 | Alternatively, may be a tensor of shape [0][0] and type
104 | int64_t; the elements will default to (0, 0, S, T).
105 | @return A tensor `ans` of shape [B], where this function will set
106 | ans[b] = p[b][s_end][t_end],
107 | with s_end and t_end being (S, T) if `boundary` was specified,
108 | and (boundary[b][2], boundary[b][3]) otherwise.
109 | `ans` represents the mutual information between each pair of
110 | sequences (i.e. x[b] and y[b], although the sequences are not
111 | supplied directly to this function).
112 |
113 | The block-dim and grid-dim must both be 1-dimensional, and the block-dim must
114 | be at least 128.
115 | */
116 | torch::Tensor MutualInformationCpu(
117 | torch::Tensor px, // [B][S][T+1]
118 | torch::Tensor py, // [B][S+1][T]
119 | torch::optional boundary, // [B][4], int64_t.
120 | torch::Tensor p); // [B][S+1][T+1]; an output
121 |
122 | torch::Tensor MutualInformationCuda(
123 | torch::Tensor px, // [B][S][T+1] if !modified, [B][S][T] if modified.
124 | torch::Tensor py, // [B][S+1][T]
125 | torch::optional boundary, // [B][4], int64_t.
126 | torch::Tensor p); // [B][S+1][T+1]; an output
127 |
128 | /*
129 | backward of mutual_information; returns (grad_px, grad_py)
130 |
131 | if overwrite_ans_grad == true, this function will overwrite ans_grad with a
132 | value that, if the computation worked correctly, should be identical to or
133 | very close to the value of ans_grad at entry. This can be used
134 | to validate the correctness of this code.
135 | */
136 | std::vector
137 | MutualInformationBackwardCpu(torch::Tensor px, torch::Tensor py,
138 | torch::optional boundary,
139 | torch::Tensor p, torch::Tensor ans_grad);
140 |
141 | std::vector MutualInformationBackwardCuda(
142 | torch::Tensor px, torch::Tensor py, torch::optional boundary,
143 | torch::Tensor p, torch::Tensor ans_grad, bool overwrite_ans_grad);
144 |
145 | } // namespace fast_rnnt
146 |
147 | #endif // FAST_RNNT_CSRC_MUTUAL_INFORMATION_H_
148 |
--------------------------------------------------------------------------------
/fast_rnnt/csrc/mutual_information_cpu.cu:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2021 Xiaomi Corporation (authors: Daniel Povey)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #include
22 | #include "fast_rnnt/csrc/mutual_information.h"
23 |
24 | namespace fast_rnnt {
25 |
26 | // forward of mutual_information. See """... """ comment of
27 | // `mutual_information_recursion` in
28 | // in python/fast_rnnt/mutual_information.py for documentation of the
29 | // behavior of this function.
30 |
31 | // px: of shape [B, S, T+1] if !modified, else [B, S, T] <-- work out
32 | // `modified` from this.
33 | // py: of shape [B, S+1, T]
34 | // boundary: of shape [B, 4], containing (s_begin, t_begin, s_end, t_end)
35 | // defaulting to (0, 0, S, T).
36 | // p: of shape (S+1, T+1)
37 | // Computes the recursion:
38 | // if !modified:
39 | // p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
40 | // p[b,s,t-1] + py[b,s,t-1])
41 | // if modified:
42 | // p[b,s,t] = log_add(p[b,s-1,t-1] + px[b,s-1,t-1],
43 | // p[b,s,t-1] + py[b,s,t-1])
44 |
45 | // .. treating out-of-range elements as -infinity and with special cases:
46 | // p[b, s_begin, t_begin] = 0.0
47 | //
48 | // and this function returns a tensor of shape (B,) consisting of elements
49 | // p[b, s_end, t_end]
50 | torch::Tensor MutualInformationCpu(torch::Tensor px, torch::Tensor py,
51 | torch::optional opt_boundary,
52 | torch::Tensor p) {
53 | TORCH_CHECK(px.dim() == 3, "px must be 3-dimensional");
54 | TORCH_CHECK(py.dim() == 3, "py must be 3-dimensional.");
55 | TORCH_CHECK(p.dim() == 3, "p must be 3-dimensional.");
56 | TORCH_CHECK(px.device().is_cpu() && py.device().is_cpu() &&
57 | p.device().is_cpu(),
58 | "inputs must be CPU tensors");
59 |
60 | bool modified = (px.size(2) == py.size(2));
61 |
62 | auto scalar_t = px.scalar_type();
63 | auto opts = torch::TensorOptions().dtype(scalar_t).device(px.device());
64 |
65 | const int B = px.size(0), S = px.size(1), T = py.size(2);
66 | TORCH_CHECK(px.size(2) == (modified ? T : T + 1));
67 | TORCH_CHECK(py.size(0) == B && py.size(1) == S + 1 && py.size(2) == T);
68 | TORCH_CHECK(p.size(0) == B && p.size(1) == S + 1 && p.size(2) == T + 1);
69 |
70 | auto boundary = opt_boundary.value_or(
71 | torch::tensor({0, 0, S, T},
72 | torch::dtype(torch::kInt64).device(torch::kCPU))
73 | .reshape({1, 4})
74 | .expand({B, 4}));
75 | TORCH_CHECK(boundary.dim() == 2, "boundary must be 2-dimensional.");
76 | TORCH_CHECK(boundary.size(0) == B && boundary.size(1) == 4);
77 | TORCH_CHECK(boundary.device().is_cpu() && boundary.dtype() == torch::kInt64);
78 |
79 | torch::Tensor ans = torch::empty({B}, opts);
80 |
81 | AT_DISPATCH_FLOATING_TYPES(
82 | px.scalar_type(), "mutual_information_cpu_loop", ([&] {
83 | auto px_a = px.accessor(),
84 | py_a = py.accessor(), p_a = p.accessor();
85 | auto boundary_a = boundary.accessor();
86 | auto ans_a = ans.accessor();
87 |
88 | int t_offset = (modified ? -1 : 0);
89 | for (int b = 0; b < B; b++) {
90 | int s_begin = boundary_a[b][0];
91 | int t_begin = boundary_a[b][1];
92 | int s_end = boundary_a[b][2];
93 | int t_end = boundary_a[b][3];
94 | p_a[b][s_begin][t_begin] = 0.0;
95 | if (modified) {
96 | for (int s = s_begin + 1; s <= s_end; ++s)
97 | p_a[b][s][t_begin] = -std::numeric_limits::infinity();
98 | } else {
99 | // note: t_offset = 0 so don't need t_begin + t_offset below.
100 | for (int s = s_begin + 1; s <= s_end; ++s)
101 | p_a[b][s][t_begin] =
102 | p_a[b][s - 1][t_begin] + px_a[b][s - 1][t_begin];
103 | }
104 | for (int t = t_begin + 1; t <= t_end; ++t)
105 | p_a[b][s_begin][t] =
106 | p_a[b][s_begin][t - 1] + py_a[b][s_begin][t - 1];
107 | for (int s = s_begin + 1; s <= s_end; ++s) {
108 | scalar_t p_s_t1 = p_a[b][s][t_begin];
109 | for (int t = t_begin + 1; t <= t_end; ++t) {
110 | // The following statement is a small optimization of:
111 | // p_a[b][s][t] = LogAdd(
112 | // p_a[b][s - 1][t + t_offset] + px_a[b][s -1][t + t_offset],
113 | // p_a[b][s][t - 1] + py_a[b][s][t - 1]);
114 | // .. which obtains p_a[b][s][t - 1] from a register.
115 | p_a[b][s][t] = p_s_t1 = LogAdd(p_a[b][s - 1][t + t_offset] +
116 | px_a[b][s - 1][t + t_offset],
117 | p_s_t1 + py_a[b][s][t - 1]);
118 | }
119 | }
120 | ans_a[b] = p_a[b][s_end][t_end];
121 | }
122 | }));
123 | return ans;
124 | }
125 |
126 | // backward of mutual_information. Returns (px_grad, py_grad).
127 | // p corresponds to what we computed in the forward pass.
128 | std::vector
129 | MutualInformationBackwardCpu(torch::Tensor px, torch::Tensor py,
130 | torch::optional opt_boundary,
131 | torch::Tensor p, torch::Tensor ans_grad) {
132 | TORCH_CHECK(px.dim() == 3, "px must be 3-dimensional");
133 | TORCH_CHECK(py.dim() == 3, "py must be 3-dimensional.");
134 | TORCH_CHECK(p.dim() == 3, "p must be 3-dimensional.");
135 | TORCH_CHECK(ans_grad.dim() == 1, "ans_grad must be 1-dimensional.");
136 |
137 | bool modified = (px.size(2) == py.size(2));
138 |
139 | TORCH_CHECK(px.device().is_cpu() && py.device().is_cpu() &&
140 | p.device().is_cpu() && ans_grad.device().is_cpu(),
141 | "inputs must be CPU tensors");
142 |
143 | auto scalar_t = px.scalar_type();
144 | auto opts = torch::TensorOptions().dtype(scalar_t).device(px.device());
145 |
146 | const int B = px.size(0), S = px.size(1), T = py.size(2);
147 | TORCH_CHECK(px.size(2) == (modified ? T : T + 1));
148 | TORCH_CHECK(py.size(0) == B && py.size(1) == S + 1);
149 | TORCH_CHECK(p.size(0) == B && p.size(1) == S + 1 && p.size(2) == T + 1);
150 |
151 | auto boundary = opt_boundary.value_or(
152 | torch::tensor({0, 0, S, T},
153 | torch::dtype(torch::kInt64).device(torch::kCPU))
154 | .reshape({1, 4})
155 | .expand({B, 4}));
156 | TORCH_CHECK(boundary.dim() == 2, "boundary must be 2-dimensional.");
157 | TORCH_CHECK(boundary.size(0) == B && boundary.size(1) == 4);
158 | TORCH_CHECK(boundary.device().is_cpu() && boundary.dtype() == torch::kInt64);
159 |
160 | bool has_boundary = opt_boundary.has_value();
161 | int T1 = T + (modified ? 0 : 1);
162 | torch::Tensor p_grad = torch::zeros({B, S + 1, T + 1}, opts),
163 | px_grad = (has_boundary ? torch::zeros({B, S, T1}, opts)
164 | : torch::empty({B, S, T1}, opts)),
165 | py_grad = (has_boundary ? torch::zeros({B, S + 1, T}, opts)
166 | : torch::empty({B, S + 1, T}, opts));
167 |
168 | AT_DISPATCH_FLOATING_TYPES(
169 | px.scalar_type(), "mutual_information_cpu_backward_loop", ([&] {
170 | auto px_a = px.accessor(), p_a = p.accessor(),
171 | p_grad_a = p_grad.accessor(),
172 | px_grad_a = px_grad.accessor(),
173 | py_grad_a = py_grad.accessor();
174 |
175 | auto ans_grad_a = ans_grad.accessor();
176 | auto boundary_a = boundary.accessor();
177 | int t_offset = (modified ? -1 : 0);
178 |
179 | for (int b = 0; b < B; b++) {
180 | int s_begin = boundary_a[b][0];
181 | int t_begin = boundary_a[b][1];
182 | int s_end = boundary_a[b][2];
183 | int t_end = boundary_a[b][3];
184 | // Backprop for: ans_a[b] = p_a[b][s_end][t_end];
185 | p_grad_a[b][s_end][t_end] = ans_grad_a[b];
186 |
187 | for (int s = s_end; s > s_begin; --s) {
188 | for (int t = t_end; t > t_begin; --t) {
189 | // The s,t indexes correspond to
190 | // The statement we are backpropagating here is:
191 | // p_a[b][s][t] = LogAdd(
192 | // p_a[b][s - 1][t + t_offset] + px_a[b][s - 1][t + t_offset],
193 | // p_a[b][s][t - 1] + py_a[b][s][t - 1]);
194 | // .. which obtains p_a[b][s][t - 1] from a register.
195 | scalar_t term1 = p_a[b][s - 1][t + t_offset] +
196 | px_a[b][s - 1][t + t_offset],
197 | // term2 = p_a[b][s][t - 1] + py_a[b][s][t - 1], <-- not
198 | // actually needed..
199 | total = p_a[b][s][t];
200 | if (total - total != 0)
201 | total = 0;
202 | scalar_t term1_deriv = exp(term1 - total),
203 | term2_deriv = 1.0 - term1_deriv,
204 | grad = p_grad_a[b][s][t];
205 | scalar_t term1_grad, term2_grad;
206 | if (term1_deriv - term1_deriv == 0.0) {
207 | term1_grad = term1_deriv * grad;
208 | term2_grad = term2_deriv * grad;
209 | } else {
210 | // could happen if total == -inf
211 | term1_grad = term2_grad = 0.0;
212 | }
213 | px_grad_a[b][s - 1][t + t_offset] = term1_grad;
214 | p_grad_a[b][s - 1][t + t_offset] = term1_grad;
215 | py_grad_a[b][s][t - 1] = term2_grad;
216 | p_grad_a[b][s][t - 1] += term2_grad;
217 | }
218 | }
219 | for (int t = t_end; t > t_begin; --t) {
220 | // Backprop for:
221 | // p_a[b][s_begin][t] =
222 | // p_a[b][s_begin][t - 1] + py_a[b][s_begin][t - 1];
223 | scalar_t this_p_grad = p_grad_a[b][s_begin][t];
224 | p_grad_a[b][s_begin][t - 1] += this_p_grad;
225 | py_grad_a[b][s_begin][t - 1] = this_p_grad;
226 | }
227 | if (!modified) {
228 | for (int s = s_end; s > s_begin; --s) {
229 | // Backprop for:
230 | // p_a[b][s][t_begin] =
231 | // p_a[b][s - 1][t_begin] + px_a[b][s - 1][t_begin];
232 | scalar_t this_p_grad = p_grad_a[b][s][t_begin];
233 | p_grad_a[b][s - 1][t_begin] += this_p_grad;
234 | px_grad_a[b][s - 1][t_begin] = this_p_grad;
235 | }
236 | } // else these were all -infinity's and there is nothing to
237 | // backprop.
238 | // There is no backprop for:
239 | // p_a[b][s_begin][t_begin] = 0.0;
240 | // .. but we can use this for a check, that the grad at the beginning
241 | // of the sequence is equal to the grad at the end of the sequence.
242 | if (ans_grad_a[b] != 0.0) {
243 | float grad_ratio = p_grad_a[b][s_begin][t_begin] / ans_grad_a[b];
244 | if (fabs(grad_ratio - 1.0) > 0.01) {
245 | std::cout
246 | << "Warning: mutual_information backprop: expected these "
247 | << "numbers to be the same:"
248 | << static_cast(p_grad_a[b][s_begin][t_begin]) << " vs "
249 | << static_cast(ans_grad_a[b]);
250 | }
251 | }
252 | }
253 | }));
254 |
255 | return std::vector({px_grad, py_grad});
256 | }
257 | } // namespace fast_rnnt
258 |
--------------------------------------------------------------------------------
/fast_rnnt/csrc/mutual_information_cuda.cu:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2021 Xiaomi Corporation (authors: Daniel Povey)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #include // for getCurrentCUDAStream()
22 | #include
23 |
24 | #include "fast_rnnt/csrc/mutual_information.h"
25 |
26 | namespace fast_rnnt {
27 | /*
28 | Forward of mutual_information. Each thread block computes blocks of the 'p'
29 | array of (s, t) shape equal to (BLOCK_SIZE, BLOCK_SIZE), e.g. (32, 32).
30 | Thread-blocks loop over such blocks, but they might loop only once if there is
31 | not that much data to process. We sequentially launch thread groups in
32 | such a way that thread-blocks within a group do not depend on each other
33 | (see the "iter" parameter). The blocks of the 'image' (i.e. of the p matrix)
34 | that each group handles are arranged in a diagonal.
35 |
36 | Template args:
37 | scalar_t: the floating-point type, e.g. float, double; maybe eventually
38 | half, although I think we don't support LogAdd for half yet.
39 | BLOCK_SIZE: an integer power of two no greater than 32 (this limitation
40 | is because we assume BLOCK_SIZE + 1 <= 64 in some data-loading
41 | code).
42 | Args:
43 | px: Tensor of shape [B][S][T + 1], if !modified; [B][S][T] if modified;
44 | may be interpreted as the log-odds ratio of
45 | generating the next x in the sequence, i.e.
46 | px[b][s][t] is the log of
47 | p(x_s | x_0..x_{s-1}, y_0..y_{s-1}) / p(x_s),
48 | i.e. the log-prob of generating x_s given subsequences of lengths
49 | (s, t), divided by the prior probability of generating x_s. (See
50 | mutual_information.py for more info).
51 | py: The log-odds ratio of generating the next y in the sequence.
52 | Shape [B][S + 1][T]
53 | p: This function writes to p[b][s][t] the mutual information between
54 | sub-sequences of x and y of length s and t respectively, from the
55 | b'th sequences in the batch. Its shape is [B][S + 1][T + 1].
56 | Concretely, this function implements the following recursion,
57 | in the case where s_begin == t_begin == 0:
58 |
59 | p[b,0,0] = 0.0
60 | if not `modified`:
61 | p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
62 | p[b,s,t-1] + py[b,s,t-1]) (eq. 0)
63 | if `modified`:
64 | p[b,s,t] = log_add(p[b,s-1,t-t] + px[b,s-1,t-1],
65 | p[b,s,t-1] + py[b,s,t-1]) (eq. 0)
66 |
67 | treating values with any -1 index as -infinity.
68 | .. if `boundary` is set, we start from p[b,s_begin,t_begin]=0.0.
69 | boundary: If set, a tensor of shape [B][4] of type int64_t, which
70 | contains, where for each batch element b, boundary[b] equals
71 | [s_begin, t_begin, s_end, t_end]
72 | which are the beginning and end (i.e. one-past-the-last) of the
73 | x and y sequences that we should process. Otherwise, must be
74 | a tensor of shape [0][0] of type int64_t; the values will
75 | default to (0, 0, S, T).
76 | ans: a tensor `ans` of shape [B], where this function will set
77 | ans[b] = p[b][s_end][t_end],
78 | with s_end and t_end being (S, T) if `boundary` was specified,
79 | and (boundary[b][2], boundary[b][3]) otherwise.
80 | `ans` represents the mutual information between each pair of
81 | sequences (i.e. x[b] and y[b], although the sequences are not
82 | supplied directly to this function).
83 |
84 | The block-dim and grid-dim must both be 1-dimensional, and the block-dim must
85 | be at least 128.
86 | */
87 | template // e.g. BLOCK_SIZE == 16 or 32.
89 | __global__ void mutual_information_kernel(
90 | // B, S, T + 1, i.e. batch, x_seq_length, y_seq_length + 1
91 | torch::PackedTensorAccessor32 px,
92 | torch::PackedTensorAccessor32 py, // B, S + 1, T.
93 | // B, S + 1, T + 1. This is an output.
94 | torch::PackedTensorAccessor32 p,
95 | // B, 4; or 0, 0 if boundaries are the defaults (0, 0, S, T)
96 | torch::PackedTensorAccessor32 boundary,
97 | torch::PackedTensorAccessor32 ans, // [B]
98 | int iter) { // This kernel is sequentially called with 'iter' = 0, 1, 2 and
99 | // so on, up to num_iters - 1 where num_iters = num_s_blocks +
100 | // num_t_blocks - 1 num_s_blocks = S / BLOCK_SIZE + 1
101 | // num_t_blocks = T / BLOCK_SIZE + 1
102 | // so that each group depends on the previous group...
103 | const int B = px.size(0), S = px.size(1), T = py.size(2);
104 | const bool modified = (px.size(2) == T);
105 | const int t_offset = (modified ? -1 : 0); // see CPU code to understand.
106 |
107 | // num_s_blocks and num_t_blocks are the number of blocks we need to cover the
108 | // array of size (S, T) with blocks of this size, in the s and t directions
109 | // respectively.
110 | // You can read the following expressions as simplifications of, for example,
111 | // num_s_blocks = ((S + 1) + BLOCK_SIZE - 1) / BLOCK_SIZE,
112 | // i.e. rounding-up division of (S + 1) by BLOCK_SIZE, and the same for (T +
113 | // 1).
114 | const int num_s_blocks = S / BLOCK_SIZE + 1;
115 | //, num_t_blocks = T / BLOCK_SIZE + 1;
116 |
117 | // num_blocks_this_iter is an upper bound on the number of blocks of size
118 | // (BLOCK_SIZE by BLOCK_SIZE) that might be active on this iteration (`iter`).
119 | // These iterations start from the bottom left of the image so that on iter ==
120 | // 0 we process only one block with block-index (0, 0) then on iter == 1 we
121 | // process block-indexes (1, 0) and (0, 1); and then on iter==2 we process (2,
122 | // 0), (1, 1) and (0, 2); and so on. We also will never have more than
123 | // `num_s_blocks` blocks (We'll never have more than num_t_blocks either, but
124 | // the numbering we use corresponds to s and not t, so when we hit the
125 | // num_t_blocks limit, the blocks with the lowest s indexes would just not be
126 | // active and we'll 'continue' in the loop below).
127 | int num_blocks_this_iter = min(iter + 1, num_s_blocks);
128 |
129 | // For the block with s_block_begin == 0 and t_block_begin == 0 (for
130 | // easy illustration), px_buf[s][t] will contain px[s - 1][t + t_offset]; or
131 | // -infinity. for out-of-range indexes into px. Likewise, py_buf[s][t] will
132 | // contain (py[s][t - 1]).
133 | __shared__ scalar_t px_buf[BLOCK_SIZE][BLOCK_SIZE],
134 | py_buf[BLOCK_SIZE][BLOCK_SIZE];
135 |
136 | // p_buf[s][t] == p[s+s_block_begin-1][t+t_block_begin-1]
137 | // 1st row/col of p_buf correspond to the previously computed blocks (lower
138 | // `iter`), or to negative indexes into p. So, for the origin block,
139 | // p_buf[s][t] corresponds to p[s - 1][t - 1]; or -inf for
140 | // out-of-range values.
141 | __shared__ scalar_t p_buf[BLOCK_SIZE + 1][BLOCK_SIZE + 1];
142 |
143 | // boundary_buf will be used to store the b'th row of `boundary` if we have
144 | // boundary information supplied; or (0, 0, S, T) otherwise.
145 | __shared__ int64_t boundary_buf[4];
146 |
147 | if (threadIdx.x == 0) {
148 | boundary_buf[0] = 0;
149 | boundary_buf[1] = 0;
150 | boundary_buf[2] = S;
151 | boundary_buf[3] = T;
152 | }
153 |
154 | // batch_block_iter iterates over batch elements (index b) and block
155 | // indexes in the range [0..num_blocks_this_iter-1], combining both
156 | // batch and block indexes.
157 | for (int batch_block_iter = blockIdx.x;
158 | batch_block_iter < B * num_blocks_this_iter;
159 | batch_block_iter += gridDim.x) {
160 | int block = batch_block_iter / B,
161 | b = batch_block_iter % B; // b is the index into the batch
162 |
163 | // Note: `block` can be no greater than `iter` because num_blocks_this_iter
164 | // <= iter + 1, i.e. iter >= num_blocks_this_iter - 1; and
165 | // block < num_blocks_this_iter, so iter - block >= 0.
166 | int s_block_begin = block * BLOCK_SIZE,
167 | t_block_begin = (iter - block) * BLOCK_SIZE;
168 | bool is_origin_block = (s_block_begin + t_block_begin == 0);
169 |
170 | __syncthreads();
171 |
172 | if (threadIdx.x < 4)
173 | boundary_buf[threadIdx.x] = boundary[b][threadIdx.x];
174 |
175 | __syncthreads();
176 |
177 | int s_begin = boundary_buf[0], t_begin = boundary_buf[1],
178 | s_end = boundary_buf[2], t_end = boundary_buf[3];
179 |
180 | s_block_begin += s_begin;
181 | t_block_begin += t_begin;
182 |
183 | // block_S and block_T are the actual sizes of this block (the block of `p`
184 | // that we will write), no greater than (BLOCK_SIZE, BLOCK_SIZE) but
185 | // possibly less than that if we are towards the end of the sequence. The
186 | // last element in the output matrix p that we need to write is (s_end,
187 | // t_end), i.e. the one-past-the-end index is (s_end + 1, t_end + 1).
188 | int block_S = min(BLOCK_SIZE, s_end + 1 - s_block_begin),
189 | block_T = min(BLOCK_SIZE, t_end + 1 - t_block_begin);
190 |
191 | if (block_S <= 0 || block_T <= 0)
192 | continue;
193 |
194 | // Load px_buf and py_buf.
195 | for (int i = threadIdx.x; i < BLOCK_SIZE * BLOCK_SIZE; i += blockDim.x) {
196 | int s_in_block = i / BLOCK_SIZE, t_in_block = i % BLOCK_SIZE,
197 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin,
198 | t_off = t + t_offset;
199 | // comparing as unsigned int makes sure the index is nonnegative.
200 | // Caution: if s_begin > 0 or t_begin > 0 we may end up loading some px
201 | // and py values that are outside the proper boundaries that we need, but
202 | // the corresponding p_buf values will end up being 0 so this won't
203 | // matter.
204 | scalar_t this_px = -INFINITY;
205 | // Below, "&& t <= t_end" can be interpreted as:
206 | // "&& (modified ? t_off < t_end : t_off <= t_end)
207 | // [since px's last valid index is t_end - 1 if modified, else t_end.
208 | if (s > s_begin && s <= s_end && t_off >= t_begin && t <= t_end)
209 | this_px = px[b][s - 1][t_off];
210 |
211 | px_buf[s_in_block][t_in_block] = this_px;
212 |
213 | scalar_t this_py = -INFINITY;
214 | if (t > t_begin && t <= t_end && s <= s_end)
215 | this_py = py[b][s][t - 1];
216 | py_buf[s_in_block][t_in_block] = this_py;
217 | }
218 |
219 | // Load the 1st row and 1st column of p_buf.
220 | // This is the context from previously computed blocks of the
221 | // image. Remember: p_buf[s][t] will correspond to p[s + s_block_begin -
222 | // 1][t + t_block_begin - 1]
223 | if (threadIdx.x <= BLOCK_SIZE) {
224 | // s_in_p_buf and t_in_pbuf are simply the indexes into p_buf
225 | int s_in_p_buf = threadIdx.x, t_in_p_buf = 0,
226 | s = s_in_p_buf + s_block_begin - 1,
227 | t = t_in_p_buf + t_block_begin - 1;
228 |
229 | scalar_t this_p = -INFINITY;
230 | if (s >= s_begin && s <= s_end && t >= t_begin && t <= t_end)
231 | this_p = p[b][s][t];
232 | p_buf[s_in_p_buf][t_in_p_buf] = this_p;
233 | } else if (static_cast(static_cast(threadIdx.x) - 64) <=
234 | static_cast(BLOCK_SIZE)) {
235 | // Another warp handles the other leg. Checking as unsigned
236 | // tests that threadIdx.x - 64 is both >= 0 and <= BLOCK_SIZE
237 | int s_in_p_buf = 0, t_in_p_buf = static_cast(threadIdx.x) - 64,
238 | s = s_in_p_buf + s_block_begin - 1,
239 | t = t_in_p_buf + t_block_begin - 1;
240 |
241 | scalar_t this_p = -INFINITY;
242 | if (s >= s_begin && s <= s_end && t >= t_begin && t <= t_end)
243 | this_p = p[b][s][t];
244 | p_buf[s_in_p_buf][t_in_p_buf] = this_p;
245 | }
246 |
247 | __syncthreads();
248 |
249 | // from here to the next __syncthreads(), only the 1st warp should be active
250 | // so we shouldn't need to synchronize. (implicit within-warp
251 | // synchronization).
252 |
253 | if (threadIdx.x == 0) {
254 | // This if-statement is an optimization and modification of the loop below
255 | // for the value i == 0, i.e. inner-iteration == 0. The modification is
256 | // to set p_buf to 1.0 = exp(0.0) if this is the "origin block",
257 | // i.e. s == s_begin, t == t_begin. This corresponds to the
258 | // probability of the pair of sequences of length (0, 0).
259 | p_buf[1][1] =
260 | (is_origin_block ? 0.0
261 | : LogAdd(
262 | // px_buf has t_offset applied.
263 | p_buf[0][1 + t_offset] + px_buf[0][0],
264 | p_buf[1][0] + py_buf[0][0]));
265 | }
266 |
267 | int s = threadIdx.x;
268 | for (int i = 1; i < block_S + block_T - 1; ++i) {
269 | __syncwarp();
270 | // i is the inner iteration, which corresponds to the (s + t) indexes of
271 | // the elements within the block that we write. So i == 0 writes
272 | // positions (s, t) == (0, 0) (but we treated i == 0 as a special case
273 | // above); i == 1 writes (0, 1) and (1, 0); i == 2 writes (0, 2), (1, 1)
274 | // and (2, 1); and so on. Note: not many threads participate in this
275 | // part, only up to BLOCK_SIZE at most. Unfortunately we couldn't figure
276 | // out a very meaningful way for more threads to do work, that looked like
277 | // it would really speed things up.
278 | // So this kernel does (2 * BLOCK_SIZE) iterations, which may seem a lot,
279 | // but we do at least do the I/O in an efficient way and keep the
280 | // inner loop simple and fast (e.g. no exp() or log()).
281 | int t = i - s;
282 | if (s < block_S &&
283 | static_cast(t) < static_cast(block_T)) {
284 | // p_buf is indexed by s + 1 and t + 1 because it has an extra initial
285 | // row and column for context from previous blocks. Taking into account
286 | // the way these buffers relate to the tensors p, px and py,
287 | // can be interpreted as follows,
288 | // writing sbb for s_block_begin and tbb for t_block_begin:
289 | //
290 | // p[b][s+sbb][t+tbb] = LogAdd(p[b][s+sbb-1][t+tbb] +
291 | // px[s+sbb-1][t+tbb],
292 | // p[b][s+sbb][t+tbb-1] +
293 | // py[s+sbb][t+tbb-1]
294 | //
295 | // where you can see that apart from the offsets of tbb and sbb, this is
296 | // the same as the recursion defined for p in
297 | // mutual_information.py:mutual_information_recursion(); and (eq. 0)
298 | // above.
299 |
300 | // note: px_buf has t_offset applied..
301 | p_buf[s + 1][t + 1] = LogAdd(p_buf[s][t + 1 + t_offset] + px_buf[s][t],
302 | p_buf[s + 1][t] + py_buf[s][t]);
303 | // We don't need to do __syncthreads() in this loop because all the
304 | // threads that are active are in the same warp. (However, in future,
305 | // if NVidia changes some things, we might need to sync here).
306 | }
307 | }
308 | __syncthreads();
309 |
310 | // Write out the data to p;
311 | for (int i = threadIdx.x; i < BLOCK_SIZE * BLOCK_SIZE; i += blockDim.x) {
312 | int s_in_block = i / BLOCK_SIZE, t_in_block = i % BLOCK_SIZE,
313 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
314 | if (s_in_block < block_S && t_in_block < block_T) {
315 | scalar_t this_p = p_buf[s_in_block + 1][t_in_block + 1];
316 | p[b][s][t] = this_p;
317 | }
318 | }
319 |
320 | __syncthreads();
321 |
322 | if (threadIdx.x == 0) {
323 | // Write `ans`, if this is the final (top-right) block in its sequence
324 | // Logically, the following equation corresponds to:
325 | // ans[b] = p[b][s_end][t_end]
326 | if (s_block_begin + block_S - 1 == s_end &&
327 | t_block_begin + block_T - 1 == t_end) {
328 | // you could read block_S below as block_S - 1 + 1, meaning,
329 | // it's the last index in a block of size block_S, but the indexes into
330 | // p_buf have a "+ 1". Likewise for block_T.
331 | ans[b] = p_buf[block_S][block_T];
332 | }
333 | }
334 | }
335 | }
336 |
337 | // like exp(), but returns 0 if arg is inf/nan, or if result would be
338 | // infinity or nan (note: this can happen for out-of-range elements
339 | // when setting px_buf and py_buf is block_S != BLOCK_SIZE or
340 | // block_T != BLOCK_SIZE, and it's a problem because even though
341 | // out-of-range gradients are zero, if we multiply them by infinity
342 | // we get NaN.
343 | template __forceinline__ __device__ Real safe_exp(Real x) {
344 | if (x - x != 0)
345 | return 0;
346 | else {
347 | Real ans = exp(x);
348 | if (ans - ans != 0.0)
349 | return 0;
350 | return ans;
351 | }
352 | }
353 |
354 | /*
355 | Backward of mutual_information.
356 |
357 | The forward pass is:
358 |
359 | p[b,s,t] = log_add(p[b,s-1,t+t_offset] + px[b,s-1,t+t_offset],
360 | p[b,s,t-1] + py[b,s,t-1]) (eq. 0)
361 |
362 | where t_offset = (modified ? -1 : 0)
363 |
364 | The backprop for the above, implemented in the obvious way, would be as
365 | follows (note, we define term1 and term2 with offsets in the indexes, which
366 | will be convenient later..):
367 |
368 | term1(b,s-1,t+t_offset) =
369 | exp(p[b,s-1,t+t_offset] + px[b,s-1,t+t_offset] - p[b,s,t]) (0a)
370 | term2(b,s,t-1) = exp(p[b,s,t-1] + py[b,s,t-1] - p[b,s,t]) (0b)
371 |
372 | p_grad[b,s-1,t+t_offset] += p_grad[b,s,t] * term1(b,s-1,t+t_offset) (1a)
373 | px_grad[b,s-1,t+t_offset] += p_grad[b,s,t] * term1(b,s-1,t+t_offset) (1b)
374 | p_grad[b,s,t-1] += p_grad[b,s,t] * term2(b,s,t-1) (1c)
375 | py_grad[b,s,t-1] += p_grad[b,s,t] * term2(b,s,t-1) (1d)
376 |
377 | Adding 1 and -t_offset to the s and t indexes of (1a) an (1b), and
378 | 1 to the t index of (1c) and (1d), the equations become:
379 |
380 | p_grad[b,s,t] += p_grad[b,s+1,t-t_offset] * term1(b,s,t) (2a)
381 | px_grad[b,s,t] += p_grad[b,s+1,t-t_offset] * term1(b,s,t) (2b)
382 | p_grad[b,s,t] += p_grad[b,s,t+1] * term2(b,s,t) (2c)
383 | py_grad[b,s,t] += p_grad[b,s,t+1] * term2(b,s,t) (2d)
384 |
385 | .. and replacing "+=" with "=", we can write:
386 |
387 | p_grad[b,s,t] = p_grad[b,s+1,t-t_offset] * term1(b,s,t) + (3a)
388 | p_grad[b,s,t+1] * term2(b,s,t)
389 | px_grad[b,s,t] = p_grad[b,s+1,t-t_offset] * term1(b,s,t) (3b)
390 | py_grad[b,s,t] = p_grad[b,s,t+1] * term2(b,s,t) (3c)
391 |
392 | Writing the definitions of term1 and term2 in a more convenient way:
393 | term1(b,s,t) = exp(p[b,s,t] + px[b,s,t] - p[b,s+1,t-t_offset]) (4a)
394 | term2(b,s,t) = exp(p[b,s,t] + py[b,s,t] - p[b,s,t+1]) (4b)
395 |
396 | The backward pass will be slightly different from the forward pass in terms of
397 | how we store and index p (and p_grad), because for writing a particular block
398 | of p_grad, we need context on the top and right instead of the bottom and
399 | left. So there are offsets of 1.
400 | */
401 | template
402 | __global__ void mutual_information_backward_kernel(
403 | torch::PackedTensorAccessor32
404 | px, // B, S, T + 1 if !modified; B, S, T if modified.
405 | torch::PackedTensorAccessor32 py, // B, S + 1, T.
406 | // B, S + 1, T + 1. Produced in forward pass.
407 | torch::PackedTensorAccessor32 p,
408 | // [B]. This is an input.
409 | torch::PackedTensorAccessor32 ans_grad,
410 | torch::PackedTensorAccessor32
411 | p_grad, // B, S + 1, T + 1 if !modified; B, S, T if modified.
412 | torch::PackedTensorAccessor32 px_grad, // B, S, T + 1.
413 | torch::PackedTensorAccessor32 py_grad, // B, S + 1, T.
414 | // B, 4; or 0, 0 if boundaries are the defaults (0, 0, S, T)
415 | torch::PackedTensorAccessor32 boundary,
416 | int iter, // This kernel is sequentially called with 'iter' = num_iters
417 | // - 1, num_iters - 2, .. 0, where num_iters can be taken to
418 | // be any sufficiently large number but will actually be:
419 | // num_s_blocks + num_t_blocks - 1 where num_s_blocks = S /
420 | // BLOCK_SIZE + 1 and num_t_blocks = T / BLOCK_SIZE + 1
421 | bool overwrite_ans_grad) { // If overwrite_ans_grad == true, this function
422 | // will overwrite ans_grad with a value which,
423 | // if everything is working correctly, should be
424 | // identical or very close to the value of
425 | // ans_grad that was passed in.
426 | const int B = px.size(0), S = px.size(1), T = py.size(2);
427 | const bool modified = (px.size(2) == T);
428 | const int neg_t_offset = (modified ? 1 : 0);
429 |
430 | // For statements that are the same as the forward pass, we are omitting some
431 | // comments. We'll focus, in the comments, on differences from the forward
432 | // pass.
433 | const int num_s_blocks = S / BLOCK_SIZE + 1,
434 | // num_t_blocks = T / BLOCK_SIZE + 1,
435 | num_blocks_this_iter = min(iter + 1, num_s_blocks);
436 |
437 | // px_buf and py_buf are used temporarily to store the px and py values,
438 | // but then modified to store the "xderiv" and "yderiv" values defined
439 | // in (eq. 5) and (eq. 6) above. For out-of-range values, we'll write 0.0
440 | // here.
441 | // Initially (before xderiv/yderiv are written):
442 | // px_buf[s][t] contains px[s+s_block_begin][t+t_block_begin];
443 | // py_buf[s][t] contains py[s+s_block_begin][t+t_block_begin].
444 | // Later (see eq. 4 and eq. 5):
445 | // px_buf[s][t] contains term1(b,ss,tt) ==
446 | // exp(p[b][ss][tt] + px[b][ss][tt] - p[b][ss + 1][tt-t_offset]),
447 | // py_buf[s][t] contains term2(b,ss,tt) ==
448 |
449 | // where ss == s + s_block_begin, tt = t + t_block_begin.
450 | // Unlike in the forward code, there is no offset of 1 in the indexes.
451 | __shared__ scalar_t px_buf[BLOCK_SIZE][BLOCK_SIZE],
452 | py_buf[BLOCK_SIZE][BLOCK_SIZE];
453 |
454 | // p_buf is initially used to store p, and then (after we are done putting
455 | // term1 and term2 into px_buf and py_buf) it is repurposed to store
456 | // p_grad.
457 | //
458 | // Unlike in the forward pass, p_buf has the same numbering as px_buf and
459 | // py_buf, it's not offset by 1: e.g., for the origin block, p_buf[0][0]
460 | // refers to p[0][0] and not p[-1][-1]. The p_buf block is larger by 1 than
461 | // the block for px_buf and py_buf; unlike in the forward pass, we store
462 | // context on the top and right, not the bottom and left, i.e. the elements at
463 | // (one past the largest indexes in the block).
464 | //
465 | // For out-of-range elements of p_buf, we'll put zero.
466 | __shared__ scalar_t p_buf[BLOCK_SIZE + 1][BLOCK_SIZE + 1];
467 |
468 | // boundary_buf will be used to store the b'th row of `boundary` if we have
469 | // boundary information supplied; or (0, 0, S, T) if not.
470 | __shared__ int64_t boundary_buf[4];
471 |
472 | if (threadIdx.x == 0) {
473 | boundary_buf[0] = 0;
474 | boundary_buf[1] = 0;
475 | boundary_buf[2] = S;
476 | boundary_buf[3] = T;
477 | }
478 |
479 | // batch_block_iter iterates over both batch elements (index b), and block
480 | // indexes in the range [0..num_blocks_this_iter-1]. The order here
481 | // doesn't matter, since there are no interdependencies between these
482 | // blocks (they are on a diagonal).
483 | for (int batch_block_iter = blockIdx.x;
484 | batch_block_iter < B * num_blocks_this_iter;
485 | batch_block_iter += gridDim.x) {
486 | int block = batch_block_iter / B, b = batch_block_iter % B;
487 | int s_block_begin = block * BLOCK_SIZE,
488 | t_block_begin = (iter - block) * BLOCK_SIZE;
489 |
490 | if (threadIdx.x < 4)
491 | boundary_buf[threadIdx.x] = boundary[b][threadIdx.x];
492 | __syncthreads();
493 |
494 | int s_begin = boundary_buf[0], t_begin = boundary_buf[1],
495 | s_end = boundary_buf[2], t_end = boundary_buf[3];
496 | s_block_begin += s_begin;
497 | t_block_begin += t_begin;
498 |
499 | // block_S and block_T are the actual sizes of this block, no greater than
500 | // (BLOCK_SIZE, BLOCK_SIZE) but possibly less than that if we are towards
501 | // the end of the sequence.
502 | // The last element of the output matrix p_grad we write is (s_end, t_end),
503 | // i.e. the one-past-the-end index of p_grad is (s_end + 1, t_end + 1).
504 | int block_S = min(BLOCK_SIZE, s_end + 1 - s_block_begin),
505 | block_T = min(BLOCK_SIZE, t_end + 1 - t_block_begin);
506 |
507 | if (block_S <= 0 || block_T <= 0)
508 | continue;
509 |
510 | // Load px_buf and py_buf. At this point we just set them to the px and py
511 | // for this block.
512 | for (int i = threadIdx.x; i < BLOCK_SIZE * BLOCK_SIZE; i += blockDim.x) {
513 | int s_in_block = i / BLOCK_SIZE, t_in_block = i % BLOCK_SIZE,
514 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
515 | // We let px and py default to -infinity if they are out of range, which
516 | // will cause xderiv and yderiv for out-of-range values to be zero, and
517 | // cause correct behavior in edge cases (for the top and right blocks).
518 | // The issue is that p and p_grad are of larger size than px and py.
519 | scalar_t this_px = -INFINITY;
520 | if (s < s_end && t <= t_end)
521 | this_px = px[b][s][t];
522 | px_buf[s_in_block][t_in_block] = this_px;
523 | scalar_t this_py = -INFINITY;
524 | if (s <= s_end && t < t_end)
525 | this_py = py[b][s][t];
526 | py_buf[s_in_block][t_in_block] = this_py;
527 | }
528 | __syncthreads();
529 |
530 | // load p.
531 | for (int i = threadIdx.x; i < (BLOCK_SIZE + 1) * (BLOCK_SIZE + 1);
532 | i += blockDim.x) {
533 | int s_in_block = i / (BLOCK_SIZE + 1), t_in_block = i % (BLOCK_SIZE + 1),
534 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
535 | // Setting 0.0 for out-of-bounds elements of p, together with setting
536 | // -INFINITY for out-of-bounds elements of px_buf and py_buf, will
537 | // ensure that we do the right thing in top and right edge cases,
538 | // i.e. that no derivatives will be propagated from out-of-bounds points
539 | // because the corresponding xderiv and yderiv values will be zero.
540 | scalar_t this_p = 0.0;
541 | if (s <= s_end && t <= t_end)
542 | this_p = p[b][s][t];
543 | // if this_p is -inf, replace with large finite negative value, to avoid
544 | // NaN's below.
545 | // TODO: use a value that would work correctly in half precision
546 | if (this_p < -1.0e+30)
547 | this_p = -1.0e+30;
548 | p_buf[s_in_block][t_in_block] = this_p;
549 | }
550 | __syncthreads();
551 |
552 | // Set term1 and term2; see equations (4a) and (4b) above.
553 | for (int i = threadIdx.x; i < BLOCK_SIZE * BLOCK_SIZE; i += blockDim.x) {
554 | // We can apply this formula to the entire block even if we are processing
555 | // a partial block; we have ensured that x_buf and y_buf contain
556 | // -infinity, and p contains 0, for out-of-range elements, so we'll get
557 | // x_buf and y_buf containing 0 after applying the following formulas.
558 | int s = i / BLOCK_SIZE, t = i % BLOCK_SIZE;
559 | // Mathematically the following is doing:
560 | // term1(b,s,t) = exp(p[b,s,t] + px[b,s,t] - p[b,s+1,t-t_offset]) (4a)
561 | // (with an offset on the s and t indexes)
562 | // Use safe_exp() not exp(), as we could have (-inf) - (-inf) = nan, want
563 | // any finite number in this case as derivs would be zero.
564 | // Also want -inf->zero.
565 | px_buf[s][t] =
566 | safe_exp(p_buf[s][t] + px_buf[s][t] - p_buf[s + 1][t + neg_t_offset]);
567 | // Mathematically the following is doing:
568 | // term2(b,s,t) = exp(p[b,s,t] + py[b,s,t] - p[b,s,t+1]) (4b)
569 | // (with an offset on the s and t indexes)
570 | py_buf[s][t] = safe_exp(p_buf[s][t] + py_buf[s][t] - p_buf[s][t + 1]);
571 | }
572 |
573 | __syncthreads();
574 |
575 | // Load p_grad for the top and right elements in p_buf: i.e. for elements
576 | // p_buf[s][t] where s == block_S (exclusive-or) t == block_T.
577 | // These are the p_grad values computed by previous instances of this kernel
578 | // If this is one of the top or right blocks, some or all of the p_grad
579 | // values we'd be reading here will be out of range, and we use zeros
580 | // to ensure no gradient gets propagated from those positions.
581 | if (threadIdx.x <= block_S) {
582 | int s_in_block = threadIdx.x, t_in_block = block_T,
583 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
584 | p_buf[s_in_block][t_in_block] =
585 | (s <= s_end && t <= t_end ? p_grad[b][s][t] : 0.0);
586 | } else if (static_cast(static_cast(threadIdx.x) - 64) <
587 | static_cast(block_T)) {
588 | // casting to unsigned before the comparison tests for both negative and
589 | // out-of-range values of (int)threadIdx.x - 64.
590 | int s_in_block = block_S, t_in_block = static_cast(threadIdx.x) - 64,
591 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
592 | p_buf[s_in_block][t_in_block] =
593 | (s <= s_end && t <= t_end ? p_grad[b][s][t] : 0.0);
594 | }
595 |
596 | __syncthreads();
597 |
598 | // The highest-numbered value in p_buf that we need (corresponding,
599 | // of course, to p_grad), is:
600 | // p_buf[block_S - 1][block_T - 1],
601 | // and the inner iteration number (i) on which we set this is the sum of
602 | // these indexes, i.e. (block_S - 1) + (block_T - 1).
603 | bool is_final_block = (s_block_begin + block_S == s_end + 1 &&
604 | t_block_begin + block_T == t_end + 1);
605 |
606 | int first_iter = block_S + block_T - 2;
607 | if (is_final_block) {
608 | // The following statement corresponds to:
609 | // p_grad[b][s_end][t_end] = ans_grad[b]
610 | // Normally this element of p_buf would be set by the first iteration of
611 | // the loop below, so if it's set this way we have to decrement first_iter
612 | // to prevent it from being overwritten.
613 | p_buf[block_S - 1][block_T - 1] = ans_grad[b];
614 | --first_iter;
615 | }
616 |
617 | {
618 | int s = threadIdx.x;
619 | for (int i = first_iter; i >= 0; --i) {
620 | __syncwarp();
621 | int t = i - s;
622 | if (s < block_S &&
623 | static_cast(t) < static_cast(block_T)) {
624 | // The following statement is really operating on the gradients;
625 | // it corresponds, with offsets of s_block_begin and t_block_begin
626 | // on the indexes, to equation (3a) above, i.e.:
627 | // p_grad[b,s,t] =
628 | // p_grad[b,s+1,t-t_offset] * term1(b,s,t) + (3a)
629 | // p_grad[b,s,t+1] * term2(b,s,t)
630 | p_buf[s][t] = (p_buf[s + 1][t + neg_t_offset] * px_buf[s][t] +
631 | p_buf[s][t + 1] * py_buf[s][t]);
632 | }
633 | }
634 | }
635 |
636 | __syncthreads();
637 |
638 | // Write out p_grad, px_grad and py_grad.
639 | for (int i = threadIdx.x; i < BLOCK_SIZE * BLOCK_SIZE; i += blockDim.x) {
640 | int s_in_block = i / BLOCK_SIZE, t_in_block = i % BLOCK_SIZE,
641 | s = s_in_block + s_block_begin, t = t_in_block + t_block_begin;
642 | // s_end and t_end are the one-past-the-end of the (x,y) sequences, but
643 | // the one-past-the-end element of p_grad would be (s_end + 1, t_end + 1).
644 | if (t <= t_end && s <= s_end) {
645 | p_grad[b][s][t] = p_buf[s_in_block][t_in_block];
646 |
647 | if (s < s_end && t <= t_end - neg_t_offset) {
648 | // write px_grad, which is of shape [B][S][T + 1] if !modified,
649 | // [B][S][T] if modified. the condition "t <= t_end - neg_t_offset"
650 | // becomes "t <= t_end" if !modified, and "t <= t_end - 1" if
651 | // modified, keeping us within the bounds of px_grad.
652 |
653 | // From (eq. 3b):
654 | // px_grad[b,s,t] = p_grad[b,s+1,t-t_offset] * term1(b,s,t)
655 | px_grad[b][s][t] = (p_buf[s_in_block + 1][t_in_block + neg_t_offset] *
656 | px_buf[s_in_block][t_in_block]);
657 | }
658 | if (t < t_end) { // write py_grad, which is of shape [B][S + 1][T]
659 | // from (eq. 3c):
660 | // py_grad[b,s,t] = p_grad[b,s,t+1] * term2(b,s,t)
661 | py_grad[b][s][t] = (p_buf[s_in_block][t_in_block + 1] *
662 | py_buf[s_in_block][t_in_block]);
663 | }
664 | }
665 | }
666 |
667 | if (threadIdx.x == 0 && s_block_begin == s_begin &&
668 | t_block_begin == t_begin && overwrite_ans_grad)
669 | ans_grad[b] = p_buf[0][0];
670 | }
671 | }
672 |
673 | // forward of mutual_information. See """... """ comment of
674 | // `mutual_information` in mutual_information.py for documentation of the
675 | // behavior of this function.
676 | torch::Tensor MutualInformationCuda(torch::Tensor px, torch::Tensor py,
677 | torch::optional opt_boundary,
678 | torch::Tensor p) {
679 | TORCH_CHECK(px.dim() == 3, "px must be 3-dimensional");
680 | TORCH_CHECK(py.dim() == 3, "py must be 3-dimensional.");
681 | TORCH_CHECK(p.dim() == 3, "p must be 3-dimensional.");
682 | TORCH_CHECK(px.device().is_cuda() && py.device().is_cuda() &&
683 | p.device().is_cuda(),
684 | "inputs must be CUDA tensors");
685 |
686 | auto scalar_t = px.scalar_type();
687 | auto opts = torch::TensorOptions().dtype(scalar_t).device(px.device());
688 |
689 | const int B = px.size(0), S = px.size(1), T = py.size(2);
690 | TORCH_CHECK(px.size(2) == T || px.size(2) == T + 1);
691 | TORCH_CHECK(py.size(0) == B && py.size(1) == S + 1 && py.size(2) == T);
692 | TORCH_CHECK(p.size(0) == B && p.size(1) == S + 1 && p.size(2) == T + 1);
693 |
694 | auto boundary = opt_boundary.value_or(
695 | torch::tensor({0, 0, S, T},
696 | torch::dtype(torch::kInt64).device(px.device()))
697 | .reshape({1, 4})
698 | .expand({B, 4}));
699 | TORCH_CHECK(boundary.size(0) == B && boundary.size(1) == 4);
700 | TORCH_CHECK(boundary.device().is_cuda() && boundary.dtype() == torch::kInt64);
701 |
702 | torch::Tensor ans = torch::empty({B}, opts);
703 |
704 | // num_threads and num_blocks and BLOCK_SIZE can be tuned.
705 | // (however, num_threads may not be less than 128).
706 | const int num_threads = 128, num_blocks = 256, BLOCK_SIZE = 32;
707 |
708 | // The blocks cover the 'p' matrix, which is of size (B, S+1, T+1),
709 | // so dividing by BLOCK_SIZE rounding up we get e.g.
710 | // (S+1 + BLOCK_SIZE-1) / BLOCK_SIZE == S / BLOCK_SIZE + 1
711 | const int num_s_blocks = S / BLOCK_SIZE + 1,
712 | num_t_blocks = T / BLOCK_SIZE + 1,
713 | num_iters = num_s_blocks + num_t_blocks - 1;
714 |
715 | AT_DISPATCH_FLOATING_TYPES(
716 | px.scalar_type(), "mutual_information_cuda_stub", ([&] {
717 | for (int iter = 0; iter < num_iters; ++iter) {
718 | mutual_information_kernel
719 | <<>>(
720 | px.packed_accessor32(),
721 | py.packed_accessor32(),
722 | p.packed_accessor32(),
723 | boundary.packed_accessor32(),
724 | ans.packed_accessor32(), iter);
725 | }
726 | }));
727 | return ans;
728 | }
729 |
730 | // backward of mutual_information; returns (grad_px, grad_py)
731 | // If overwrite_ans_grad == true, will overwrite ans_grad with a value which
732 | // should be identical to the original ans_grad if the computation worked
733 | // as it should.
734 | std::vector
735 | MutualInformationBackwardCuda(torch::Tensor px, torch::Tensor py,
736 | torch::optional opt_boundary,
737 | torch::Tensor p, torch::Tensor ans_grad,
738 | bool overwrite_ans_grad) {
739 | TORCH_CHECK(px.dim() == 3, "px must be 3-dimensional");
740 | TORCH_CHECK(py.dim() == 3, "py must be 3-dimensional.");
741 | TORCH_CHECK(p.dim() == 3, "p must be 3-dimensional.");
742 | TORCH_CHECK(ans_grad.dim() == 1, "ans_grad must be 1-dimensional.");
743 |
744 | TORCH_CHECK(px.device().is_cuda() && py.device().is_cuda() &&
745 | p.device().is_cuda() && ans_grad.device().is_cuda() &&
746 | "inputs must be CUDA tensors");
747 |
748 | auto scalar_t = px.scalar_type();
749 | auto opts = torch::TensorOptions().dtype(scalar_t).device(px.device());
750 |
751 | const int B = px.size(0), S = px.size(1), T = py.size(2);
752 |
753 | TORCH_CHECK(px.size(2) == T ||
754 | px.size(2) == T + 1); // modified case || not-modified case
755 | const bool modified = (px.size(2) == T);
756 | TORCH_CHECK(py.size(0) == B && py.size(1) == S + 1);
757 | TORCH_CHECK(p.size(0) == B && p.size(1) == S + 1 && p.size(2) == T + 1);
758 |
759 | auto boundary = opt_boundary.value_or(
760 | torch::tensor({0, 0, S, T},
761 | torch::dtype(torch::kInt64).device(px.device()))
762 | .reshape({1, 4})
763 | .expand({B, 4}));
764 | TORCH_CHECK(boundary.size(0) == B && boundary.size(1) == 4);
765 | TORCH_CHECK(boundary.device().is_cuda() && boundary.dtype() == torch::kInt64);
766 | TORCH_CHECK(ans_grad.size(0) == B);
767 |
768 | bool has_boundary = opt_boundary.has_value();
769 |
770 | int T1 = T + (modified ? 0 : 1);
771 | torch::Tensor p_grad = torch::empty({B, S + 1, T + 1}, opts),
772 | px_grad = (has_boundary ? torch::zeros({B, S, T1}, opts)
773 | : torch::empty({B, S, T1}, opts)),
774 | py_grad = (has_boundary ? torch::zeros({B, S + 1, T}, opts)
775 | : torch::empty({B, S + 1, T}, opts));
776 |
777 | // num_threads and num_blocks and BLOCK_SIZE can be tuned.
778 | // (however, num_threads may not be less than 128).
779 | const int num_threads = 128, num_blocks = 256, BLOCK_SIZE = 32;
780 |
781 | // The blocks cover the 'p' matrix, which is of size (B, S+1, T+1),
782 | // so dividing by BLOCK_SIZE rounding up we get e.g.
783 | // (S+1 + BLOCK_SIZE-1) / BLOCK_SIZE == S / BLOCK_SIZE + 1
784 | const int num_s_blocks = S / BLOCK_SIZE + 1,
785 | num_t_blocks = T / BLOCK_SIZE + 1,
786 | num_iters = num_s_blocks + num_t_blocks - 1;
787 |
788 | AT_DISPATCH_FLOATING_TYPES(
789 | px.scalar_type(), "mutual_information_backward_stub", ([&] {
790 | for (int iter = num_iters - 1; iter >= 0; --iter) {
791 | mutual_information_backward_kernel
792 | <<>>(
793 | px.packed_accessor32(),
794 | py.packed_accessor32(),
795 | p.packed_accessor32(),
796 | ans_grad.packed_accessor32(),
797 | p_grad.packed_accessor32(),
798 | px_grad.packed_accessor32(),
799 | py_grad.packed_accessor32(),
800 | boundary.packed_accessor32(), iter,
801 | overwrite_ans_grad);
802 | }
803 | }));
804 | return std::vector({px_grad, py_grad});
805 | }
806 | } // namespace fast_rnnt
807 |
--------------------------------------------------------------------------------
/fast_rnnt/python/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | add_subdirectory(csrc)
2 | add_subdirectory(tests)
3 |
--------------------------------------------------------------------------------
/fast_rnnt/python/csrc/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | include_directories(${CMAKE_SOURCE_DIR})
2 |
3 | include(transform)
4 |
5 | # please keep the list sorted
6 | set(fast_rnnt_srcs
7 | fast_rnnt.cu
8 | mutual_information.cu
9 | )
10 |
11 | if(NOT FT_WITH_CUDA)
12 | transform(OUTPUT_VARIABLE fast_rnnt_srcs SRCS ${fast_rnnt_srcs})
13 | endif()
14 |
15 |
16 | pybind11_add_module(_fast_rnnt ${fast_rnnt_srcs})
17 | target_link_libraries(_fast_rnnt PRIVATE mutual_information_core)
18 |
19 | if(APPLE)
20 | target_link_libraries(_fast_rnnt
21 | PRIVATE
22 | ${TORCH_DIR}/lib/libtorch_python.dylib
23 | )
24 | elseif(UNIX)
25 | target_link_libraries(_fast_rnnt
26 | PRIVATE
27 | ${PYTHON_LIBRARY}
28 | ${TORCH_DIR}/lib/libtorch_python.so
29 | )
30 | endif()
31 |
--------------------------------------------------------------------------------
/fast_rnnt/python/csrc/fast_rnnt.cu:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2022 Xiaomi Corporation (authors: Wei Kang)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #include "fast_rnnt/python/csrc/fast_rnnt.h"
22 | #include "fast_rnnt/python/csrc/mutual_information.h"
23 |
24 | PYBIND11_MODULE(_fast_rnnt, m) {
25 | m.doc() = "Python wrapper for Fast Rnnt.";
26 |
27 | fast_rnnt::PybindMutualInformation(m);
28 | }
29 |
--------------------------------------------------------------------------------
/fast_rnnt/python/csrc/fast_rnnt.h:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2022 Xiaomi Corporation (authors: Wei Kang)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #ifndef FAST_RNNT_PYTHON_CSRC_FAST_RNNT_H_
22 | #define FAST_RNNT_PYTHON_CSRC_FAST_RNNT_H_
23 |
24 | #include "pybind11/pybind11.h"
25 |
26 | namespace py = pybind11;
27 |
28 | #endif // FAST_RNNT_PYTHON_CSRC_FAST_RNNT_H_
29 |
--------------------------------------------------------------------------------
/fast_rnnt/python/csrc/mutual_information.cu:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2022 Xiaomi Corporation (authors: Wei Kang)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #include "fast_rnnt/csrc/device_guard.h"
22 | #include "fast_rnnt/csrc/mutual_information.h"
23 | #include "fast_rnnt/python/csrc/mutual_information.h"
24 |
25 | namespace fast_rnnt {
26 | void PybindMutualInformation(py::module &m) {
27 | m.def(
28 | "mutual_information_forward",
29 | [](torch::Tensor px, torch::Tensor py,
30 | torch::optional boundary,
31 | torch::Tensor p) -> torch::Tensor {
32 | fast_rnnt::DeviceGuard guard(px.device());
33 | if (px.device().is_cpu()) {
34 | return MutualInformationCpu(px, py, boundary, p);
35 | } else {
36 | #ifdef FT_WITH_CUDA
37 | return MutualInformationCuda(px, py, boundary, p);
38 | #else
39 | TORCH_CHECK(false, "Failed to find native CUDA module, make sure "
40 | "that you compiled the code with K2_WITH_CUDA.");
41 | return torch::Tensor();
42 | #endif
43 | }
44 | },
45 | py::arg("px"), py::arg("py"), py::arg("boundary"), py::arg("p"));
46 |
47 | m.def(
48 | "mutual_information_backward",
49 | [](torch::Tensor px, torch::Tensor py,
50 | torch::optional boundary, torch::Tensor p,
51 | torch::Tensor ans_grad) -> std::vector {
52 | fast_rnnt::DeviceGuard guard(px.device());
53 | if (px.device().is_cpu()) {
54 | return MutualInformationBackwardCpu(px, py, boundary, p, ans_grad);
55 | } else {
56 | #ifdef FT_WITH_CUDA
57 | return MutualInformationBackwardCuda(px, py, boundary, p, ans_grad,
58 | true);
59 | #else
60 | TORCH_CHECK(false, "Failed to find native CUDA module, make sure "
61 | "that you compiled the code with K2_WITH_CUDA.");
62 | return std::vector();
63 | #endif
64 | }
65 | },
66 | py::arg("px"), py::arg("py"), py::arg("boundary"), py::arg("p"),
67 | py::arg("ans_grad"));
68 |
69 | m.def("with_cuda", []() -> bool {
70 | #ifdef FT_WITH_CUDA
71 | return true;
72 | #else
73 | return false;
74 | #endif
75 | });
76 | }
77 | } // namespace fast_rnnt
78 |
--------------------------------------------------------------------------------
/fast_rnnt/python/csrc/mutual_information.h:
--------------------------------------------------------------------------------
1 | /**
2 | * @copyright
3 | * Copyright 2022 Xiaomi Corporation (authors: Wei Kang)
4 | *
5 | * @copyright
6 | * See LICENSE for clarification regarding multiple authors
7 | *
8 | * Licensed under the Apache License, Version 2.0 (the "License");
9 | * you may not use this file except in compliance with the License.
10 | * You may obtain a copy of the License at
11 | *
12 | * http://www.apache.org/licenses/LICENSE-2.0
13 | *
14 | * Unless required by applicable law or agreed to in writing, software
15 | * distributed under the License is distributed on an "AS IS" BASIS,
16 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | * See the License for the specific language governing permissions and
18 | * limitations under the License.
19 | */
20 |
21 | #ifndef FAST_RNNT_PYTHON_CSRC_MUTUAL_INFORMATION_H_
22 | #define FAST_RNNT_PYTHON_CSRC_MUTUAL_INFORMATION_H_
23 |
24 | #include "fast_rnnt/python/csrc/fast_rnnt.h"
25 |
26 | namespace fast_rnnt {
27 |
28 | void PybindMutualInformation(py::module &m);
29 |
30 | } // namespace fast_rnnt
31 |
32 | #endif // FAST_RNNT_PYTHON_CSRC_MUTUAL_INFORMATION_H_
33 |
--------------------------------------------------------------------------------
/fast_rnnt/python/fast_rnnt/__init__.py:
--------------------------------------------------------------------------------
1 | from _fast_rnnt import with_cuda
2 |
3 | from .mutual_information import mutual_information_recursion
4 | from .mutual_information import joint_mutual_information_recursion
5 |
6 | from .rnnt_loss import do_rnnt_pruning
7 | from .rnnt_loss import get_rnnt_logprobs
8 | from .rnnt_loss import get_rnnt_logprobs_joint
9 | from .rnnt_loss import get_rnnt_logprobs_pruned
10 | from .rnnt_loss import get_rnnt_logprobs_smoothed
11 | from .rnnt_loss import get_rnnt_prune_ranges
12 | from .rnnt_loss import rnnt_loss
13 | from .rnnt_loss import rnnt_loss_pruned
14 | from .rnnt_loss import rnnt_loss_simple
15 | from .rnnt_loss import rnnt_loss_smoothed
16 |
--------------------------------------------------------------------------------
/fast_rnnt/python/fast_rnnt/mutual_information.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2021 Xiaomi Corporation (authors: Daniel Povey, Wei Kang)
2 | #
3 | # See ../../../LICENSE for clarification regarding multiple authors
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 |
17 | import os
18 | import torch
19 | import _fast_rnnt
20 | from torch import Tensor
21 | from typing import Tuple, Optional, Sequence, Union, List
22 |
23 |
24 | class MutualInformationRecursionFunction(torch.autograd.Function):
25 | """A recursion that is useful in computing mutual information between two
26 | sequences of real vectors, but may be useful more generally in
27 | sequence-to-sequence tasks where monotonic alignment between pairs of
28 | sequences is desired.
29 | """
30 |
31 | @staticmethod
32 | def forward(
33 | ctx,
34 | px: torch.Tensor,
35 | py: torch.Tensor,
36 | pxy_grads: List[Optional[torch.Tensor]],
37 | boundary: Optional[torch.Tensor] = None,
38 | return_grad: bool = False,
39 | ) -> torch.Tensor:
40 | """
41 | Computing mutual information between two sequences of real vectors.
42 | Args:
43 | px:
44 | A torch.Tensor of some floating point type, with shape
45 | ``[B][S][T+1]`` where ``B`` is the batch size, ``S`` is the
46 | length of the ``x`` sequence (including representations of
47 | ``EOS`` symbols but not ``BOS`` symbols), and ``T`` is the
48 | length of the ``y`` sequence (including representations of
49 | ``EOS`` symbols but not ``BOS`` symbols). In the mutual
50 | information application, ``px[b][s][t]`` would represent the
51 | following log odds ratio; ignoring the b index on the right
52 | to make the notation more
53 | compact::
54 |
55 | px[b][s][t] = log [ p(x_s | x_{0..s-1}, y_{0..t-1}) / p(x_s) ]
56 |
57 | This expression also implicitly includes the log-probability of
58 | choosing to generate an ``x`` value as opposed to a ``y`` value. In
59 | practice it might be computed as ``a + b``, where ``a`` is the log
60 | probability of choosing to extend the sequence of length ``(s,t)``
61 | with an ``x`` as opposed to a ``y`` value; and ``b`` might in
62 | practice be of the form::
63 |
64 | log(N exp f(x_s, y_{t-1}) / sum_t' exp f(x_s, y_t'))
65 |
66 | where ``N`` is the number of terms that the sum over ``t'``
67 | included, which might include some or all of the other sequences as
68 | well as this one.
69 |
70 | Note:
71 | we don't require ``px`` and py to be contiguous, but the
72 | code assumes for optimization purposes that the ``T`` axis has
73 | stride 1.
74 |
75 | py:
76 | A torch.Tensor of the same dtype as ``px``, with shape
77 | ``[B][S+1][T]``, representing::
78 |
79 | py[b][s][t] = log [ p(y_t | x_{0..s-1}, y_{0..t-1}) / p(y_t) ]
80 |
81 | This function does not treat ``x`` and ``y`` differently; the only
82 | difference is that for optimization purposes we assume the last axis
83 | (the ``t`` axis) has stride of 1; this is true if ``px`` and ``py``
84 | are contiguous.
85 |
86 | pxy_grads:
87 | A List to store the return grads of ``px`` and ``py``
88 | if return_grad == True.
89 | Remain unchanged if return_grad == False.
90 |
91 | See `this PR ` for more
92 | information about why we add this parameter.
93 |
94 | Note:
95 | the length of the list must be 2, where the first element
96 | represents the grads of ``px`` and the second one represents
97 | the grads of ``py``.
98 |
99 | boundary:
100 | If supplied, a torch.LongTensor of shape ``[B][4]``, where each
101 | row contains ``[s_begin, t_begin, s_end, t_end]``,
102 | with ``0 <= s_begin <= s_end < S`` and ``0 <= t_begin <= t_end < T``
103 | (this implies that empty sequences are allowed).
104 | If not supplied, the values ``[0, 0, S, T]`` will be assumed.
105 | These are the beginning and one-past-the-last positions in the
106 | ``x`` and ``y`` sequences respectively, and can be used if not
107 | all sequences are
108 | of the same length.
109 |
110 | return_grad:
111 | Whether to return grads of ``px`` and ``py``, this grad standing
112 | for the occupation probability is the output of the backward with a
113 | ``fake gradient`` the ``fake gradient`` is the same as the gradient
114 | you'd get if you did
115 | ``torch.autograd.grad((scores.sum()), [px, py])``.
116 | This is useful to implement the pruned version of rnnt loss.
117 |
118 | Returns:
119 | Returns a torch.Tensor of shape ``[B]``, containing the log of
120 | the mutual information between the b'th pair of sequences. This is
121 | defined by the following recursion on ``p[b,s,t]`` (where ``p``
122 | is of shape ``[B,S+1,T+1]``), representing a mutual information
123 | between sub-sequences of lengths ``s`` and ``t``::
124 |
125 | p[b,0,0] = 0.0
126 | p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
127 | p[b,s,t-1] + py[b,s,t-1])
128 | (if s > 0 or t > 0)
129 |
130 | where we handle edge cases by treating quantities with negative
131 | indexes as **-infinity**. The extension to cases where the
132 | boundaries are specified should be obvious; it just works on
133 | shorter sequences with offsets into ``px`` and ``py``.
134 | """
135 | (B, S, T1) = px.shape
136 | T = py.shape[-1]
137 | assert T1 in [T, T + 1]
138 | assert py.shape == (B, S + 1, T)
139 | if boundary is not None:
140 | assert boundary.shape == (B, 4)
141 |
142 | # p is a tensor of shape (B, S + 1, T + 1) were p[s][t] is the
143 | # the mutual information of the pair of subsequences of x and y that
144 | # are of length s and t respectively. p[0][0] will be 0.0 and p[S][T]
145 | # is the mutual information of the entire pair of sequences,
146 | # i.e. of lengths S and T respectively.
147 | # It is computed as follows (in C++ and CUDA):
148 | # p[b,0,0] = 0.0
149 | # p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
150 | # p[b,s,t-1] + py[b,s,t-1])
151 | # if s > 0 or t > 0,
152 | # treating values with any -1 index as -infinity.
153 | # .. if `boundary` is set, we start fom p[b,s_begin,t_begin]=0.0.
154 |
155 | p = torch.empty(B, S + 1, T + 1, device=px.device, dtype=px.dtype)
156 |
157 | ans = _fast_rnnt.mutual_information_forward(px, py, boundary, p)
158 |
159 | px_grad, py_grad = None, None
160 | if return_grad or px.requires_grad or py.requires_grad:
161 | ans_grad = torch.ones(B, device=px.device, dtype=px.dtype)
162 | (px_grad, py_grad) = _fast_rnnt.mutual_information_backward(
163 | px, py, boundary, p, ans_grad
164 | )
165 | ctx.save_for_backward(px_grad, py_grad)
166 | assert len(pxy_grads) == 2
167 | pxy_grads[0] = px_grad
168 | pxy_grads[1] = py_grad
169 |
170 | return ans
171 |
172 | @staticmethod
173 | def backward(
174 | ctx, ans_grad: Tensor
175 | ) -> Tuple[torch.Tensor, torch.Tensor, None, None, None]:
176 | (px_grad, py_grad) = ctx.saved_tensors
177 | (B,) = ans_grad.shape
178 | ans_grad = ans_grad.reshape(B, 1, 1) # (B, 1, 1)
179 | px_grad *= ans_grad
180 | py_grad *= ans_grad
181 | return (px_grad, py_grad, None, None, None)
182 |
183 |
184 | def mutual_information_recursion(
185 | px: Tensor,
186 | py: Tensor,
187 | boundary: Optional[Tensor] = None,
188 | return_grad: bool = False,
189 | ) -> Union[Tuple[Tensor, Tuple[Tensor, Tensor]], Tensor]:
190 | """A recursion that is useful in computing mutual information between two
191 | sequences of real vectors, but may be useful more generally in
192 | sequence-to-sequence tasks where monotonic alignment between pairs of
193 | sequences is desired. The definitions of the arguments are definitions that
194 | would be used when computing this type of mutual information, but you can
195 | also view them as arbitrary quantities and just make use of the formula
196 | computed by this function.
197 |
198 | Args:
199 | px:
200 | A torch.Tensor of some floating point type, with shape ``[B][S][T+1]``,
201 | where ``B`` is the batch size, ``S`` is the length of the ``x`` sequence
202 | (including representations of ``EOS`` symbols but not ``BOS`` symbols),
203 | and ``T`` is the length of the ``y`` sequence (including representations
204 | of ``EOS`` symbols but not ``BOS`` symbols). In the mutual information
205 | application, ``px[b][s][t]`` would represent the following log odds
206 | ratio; ignoring the b index on the right to make the notation more
207 | compact::
208 |
209 | px[b][s][t] = log [ p(x_s | x_{0..s-1}, y_{0..t-1}) / p(x_s) ]
210 |
211 | This expression also implicitly includes the log-probability of
212 | choosing to generate an ``x`` value as opposed to a ``y`` value. In
213 | practice it might be computed as ``a + b``, where ``a`` is the log
214 | probability of choosing to extend the sequence of length ``(s,t)``
215 | with an ``x`` as opposed to a ``y`` value; and ``b`` might in practice
216 | be of the form::
217 |
218 | log(N exp f(x_s, y_{t-1}) / sum_t' exp f(x_s, y_t'))
219 |
220 | where ``N`` is the number of terms that the sum over ``t'`` included,
221 | which might include some or all of the other sequences as well as this
222 | one.
223 |
224 | Note:
225 | we don't require ``px`` and py to be contiguous, but the
226 | code assumes for optimization purposes that the ``T`` axis has
227 | stride 1.
228 |
229 | py:
230 | A torch.Tensor of the same dtype as ``px``, with shape ``[B][S+1][T]``,
231 | representing::
232 |
233 | py[b][s][t] = log [ p(y_t | x_{0..s-1}, y_{0..t-1}) / p(y_t) ]
234 |
235 | This function does not treat ``x`` and ``y`` differently; the only
236 | difference is that for optimization purposes we assume the last axis
237 | (the ``t`` axis) has stride of 1; this is true if ``px`` and ``py`` are
238 | contiguous.
239 |
240 | boundary:
241 | If supplied, a torch.LongTensor of shape ``[B][4]``, where each
242 | row contains ``[s_begin, t_begin, s_end, t_end]``,
243 | with ``0 <= s_begin <= s_end < S`` and ``0 <= t_begin <= t_end < T``
244 | (this implies that empty sequences are allowed).
245 | If not supplied, the values ``[0, 0, S, T]`` will be assumed.
246 | These are the beginning and one-past-the-last positions in the ``x`` and
247 | ``y`` sequences respectively, and can be used if not all sequences are
248 | of the same length.
249 |
250 | return_grad:
251 | Whether to return grads of ``px`` and ``py``, this grad standing for the
252 | occupation probability is the output of the backward with a
253 | ``fake gradient`` the ``fake gradient`` is the same as the gradient
254 | you'd get if you did ``torch.autograd.grad((scores.sum()), [px, py])``.
255 | This is useful to implement the pruned version of rnnt loss.
256 |
257 | Returns:
258 | Returns a torch.Tensor of shape ``[B]``, containing the log of the mutual
259 | information between the b'th pair of sequences. This is defined by
260 | the following recursion on ``p[b,s,t]`` (where ``p`` is of shape
261 | ``[B,S+1,T+1]``), representing a mutual information between sub-sequences
262 | of lengths ``s`` and ``t``::
263 |
264 | p[b,0,0] = 0.0
265 | if !modified:
266 | p[b,s,t] = log_add(p[b,s-1,t] + px[b,s-1,t],
267 | p[b,s,t-1] + py[b,s,t-1])
268 | if modified:
269 | p[b,s,t] = log_add(p[b,s-1,t-1] + px[b,s-1,t-1],
270 | p[b,s,t-1] + py[b,s,t-1])
271 |
272 | where we handle edge cases by treating quantities with negative indexes
273 | as **-infinity**. The extension to cases where the boundaries are
274 | specified should be obvious; it just works on shorter sequences with
275 | offsets into ``px`` and ``py``.
276 | """
277 | assert px.ndim == 3
278 | B, S, T1 = px.shape
279 | T = py.shape[-1]
280 | assert px.shape[-1] in [T, T + 1] # if T, then "modified".
281 | assert py.shape == (B, S + 1, T)
282 | assert px.dtype == py.dtype
283 | if boundary is not None:
284 | assert boundary.dtype == torch.int64
285 | assert boundary.shape == (B, 4)
286 | for s_begin, t_begin, s_end, t_end in boundary.tolist():
287 | assert 0 <= s_begin <= s_end <= S
288 | assert 0 <= t_begin <= t_end <= T
289 |
290 | # The following statements are for efficiency
291 | px, py = px.contiguous(), py.contiguous()
292 |
293 | pxy_grads = [None, None]
294 | scores = MutualInformationRecursionFunction.apply(
295 | px, py, pxy_grads, boundary, return_grad
296 | )
297 | px_grad, py_grad = pxy_grads
298 | return (scores, (px_grad, py_grad)) if return_grad else scores
299 |
300 |
301 | def _inner_product(a: Tensor, b: Tensor) -> Tensor:
302 | """
303 | Does inner product on the last dimension, with expected broadcasting,
304 | i.e. equivalent to (a * b).sum(dim=-1)
305 | without creating a large temporary.
306 | """
307 | assert a.shape[-1] == b.shape[-1] # The last dim must be equal
308 | a = a.unsqueeze(-2) # (..., 1, K)
309 | b = b.unsqueeze(-1) # (..., K, 1)
310 | c = torch.matmul(a, b) # (..., 1, 1)
311 | return c.squeeze(-1).squeeze(-1)
312 |
313 |
314 | def joint_mutual_information_recursion(
315 | px: Sequence[Tensor],
316 | py: Sequence[Tensor],
317 | boundary: Optional[Tensor] = None,
318 | ) -> Sequence[Tensor]:
319 | """A recursion that is useful for modifications of RNN-T and similar loss
320 | functions, where the recursion probabilities have a number of terms and you
321 | want them reported separately. See mutual_information_recursion() for more
322 | documentation of the basic aspects of this.
323 |
324 | Args:
325 | px:
326 | a sequence of Tensors, each of the same shape [B][S][T+1]
327 | py:
328 | a sequence of Tensor, each of the same shape [B][S+1][T],
329 | the sequence must be the same length as px.
330 | boundary:
331 | optionally, a LongTensor of shape [B][4] containing rows
332 | [s_begin, t_begin, s_end, t_end], with 0 <= s_begin <= s_end < S
333 | and 0 <= t_begin <= t_end < T, defaulting to [0, 0, S, T].
334 | These are the beginning and one-past-the-last positions in the x
335 | and y sequences respectively, and can be used if not all
336 | sequences are of the same length.
337 | Returns:
338 | a Tensor of shape (len(px), B),
339 | whose sum over dim 0 is the total log-prob of the recursion mentioned
340 | below, per sequence. The first element of the sequence of length len(px)
341 | is "special", in that it has an offset term reflecting the difference
342 | between sum-of-log and log-of-sum; for more interpretable loss values,
343 | the "main" part of your loss function should be first.
344 |
345 | The recursion below applies if boundary == None, when it defaults
346 | to (0, 0, S, T); where px_sum, py_sum are the sums of the elements of px
347 | and py::
348 |
349 | p = tensor of shape (B, S+1, T+1), containing -infinity
350 | p[b,0,0] = 0.0
351 | # do the following in loop over s and t:
352 | p[b,s,t] = log_add(p[b,s-1,t] + px_sum[b,s-1,t],
353 | p[b,s,t-1] + py_sum[b,s,t-1])
354 | (if s > 0 or t > 0)
355 | return b[:][S][T]
356 |
357 | This function lets you implement the above recursion efficiently, except
358 | that it gives you a breakdown of the contribution from all the elements of
359 | px and py separately. As noted above, the first element of the
360 | sequence is "special".
361 | """
362 | N = len(px)
363 | assert len(py) == N and N > 0
364 | B, S, T1 = px[0].shape
365 | T = py[0].shape[2]
366 | assert T1 in [T, T + 1] # T if modified...
367 | assert py[0].shape == (B, S + 1, T)
368 | assert px[0].dtype == py[0].dtype
369 |
370 | px_cat = torch.stack(
371 | px, dim=0
372 | ) # (N, B, S, T+1) if !modified,(N, B, S, T) if modified.
373 | py_cat = torch.stack(py, dim=0) # (N, B, S+1, T)
374 | px_tot = px_cat.sum(dim=0) # (B, S, T+1)
375 | py_tot = py_cat.sum(dim=0) # (B, S+1, T)
376 |
377 | if boundary is not None:
378 | assert boundary.dtype == torch.int64
379 | assert boundary.shape == (B, 4)
380 | for s_begin, t_begin, s_end, t_end in boundary.tolist():
381 | assert 0 <= s_begin <= s_end <= S
382 | assert 0 <= t_begin <= t_end <= T
383 |
384 | # The following statements are for efficiency
385 | px_tot, py_tot = px_tot.contiguous(), py_tot.contiguous()
386 |
387 | assert px_tot.ndim == 3
388 | assert py_tot.ndim == 3
389 |
390 | p = torch.empty(B, S + 1, T + 1, device=px_tot.device, dtype=px_tot.dtype)
391 |
392 | # note, tot_probs is without grad.
393 | tot_probs = _fast_rnnt.mutual_information_forward(
394 | px_tot, py_tot, boundary, p
395 | )
396 |
397 | # this is a kind of "fake gradient" that we use, in effect to compute
398 | # occupation probabilities. The backprop will work regardless of the
399 | # actual derivative w.r.t. the total probs.
400 | ans_grad = torch.ones(B, device=px_tot.device, dtype=px_tot.dtype)
401 |
402 | (px_grad, py_grad) = _fast_rnnt.mutual_information_backward(
403 | px_tot, py_tot, boundary, p, ans_grad
404 | )
405 |
406 | px_grad = px_grad.reshape(1, B, -1)
407 | py_grad = py_grad.reshape(1, B, -1)
408 | px_cat = px_cat.reshape(N, B, -1)
409 | py_cat = py_cat.reshape(N, B, -1)
410 | # get rid of -inf, would generate nan on product with 0
411 | px_cat = px_cat.clamp(min=torch.finfo(px_cat.dtype).min)
412 | py_cat = py_cat.clamp(min=torch.finfo(py_cat.dtype).min)
413 |
414 | x_prods = _inner_product(px_grad, px_cat) # (N, B)
415 | y_prods = _inner_product(py_grad, py_cat) # (N, B)
416 |
417 | # If all the occupation counts were exactly 1.0 (i.e. no partial counts),
418 | # "prods" should be equal to "tot_probs"; however, in general, "tot_probs"
419 | # will be more positive due to the difference between log-of-sum and
420 | # sum-of-log
421 | prods = x_prods + y_prods # (N, B)
422 | with torch.no_grad():
423 | offset = tot_probs - prods.sum(dim=0) # (B,)
424 | prods[0] += offset
425 | return prods # (N, B)
426 |
--------------------------------------------------------------------------------
/fast_rnnt/python/tests/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | function(fast_rnnt_add_py_test source)
2 | get_filename_component(name ${source} NAME_WE)
3 | set(name "${name}_py")
4 |
5 | add_test(NAME ${name}
6 | COMMAND
7 | "${PYTHON_EXECUTABLE}"
8 | "${CMAKE_CURRENT_SOURCE_DIR}/${source}"
9 | )
10 |
11 | get_filename_component(fast_rnnt_path ${CMAKE_CURRENT_LIST_DIR} DIRECTORY)
12 |
13 | set_property(TEST ${name}
14 | PROPERTY ENVIRONMENT "PYTHONPATH=${fast_rnnt_path}:$:$ENV{PYTHONPATH}"
15 | )
16 | endfunction()
17 |
18 | # please sort the files in alphabetic order
19 | set(py_test_files
20 | mutual_information_test.py
21 | rnnt_loss_test.py
22 | )
23 |
24 | foreach(source IN LISTS py_test_files)
25 | fast_rnnt_add_py_test(${source})
26 | endforeach()
27 |
--------------------------------------------------------------------------------
/fast_rnnt/python/tests/mutual_information_test.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | #
3 | # Copyright 2021 Xiaomi Corporation (authors: Daniel Povey,
4 | # Wei Kang)
5 | #
6 | # See ../../../LICENSE for clarification regarding multiple authors
7 | #
8 | # Licensed under the Apache License, Version 2.0 (the "License");
9 | # you may not use this file except in compliance with the License.
10 | # You may obtain a copy of the License at
11 | #
12 | # http://www.apache.org/licenses/LICENSE-2.0
13 | #
14 | # Unless required by applicable law or agreed to in writing, software
15 | # distributed under the License is distributed on an "AS IS" BASIS,
16 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | # See the License for the specific language governing permissions and
18 | # limitations under the License.
19 |
20 | # To run this single test, use
21 | #
22 | # ctest --verbose -R mutual_information_test_py
23 |
24 | import random
25 | import unittest
26 |
27 | import fast_rnnt
28 | import torch
29 |
30 |
31 | # Caution: this will fail occasionally due to cutoffs not being quite large
32 | # enough. As long as it passes most of the time, it's OK.
33 | class TestMutualInformation(unittest.TestCase):
34 | @classmethod
35 | def setUpClass(cls):
36 | cls.devices = [torch.device("cpu")]
37 | if torch.cuda.is_available() and fast_rnnt.with_cuda():
38 | cls.devices.append(torch.device("cuda", 0))
39 | if torch.cuda.device_count() > 1:
40 | torch.cuda.set_device(1)
41 | cls.devices.append(torch.device("cuda", 1))
42 | cls.dtypes = [torch.float32, torch.float64]
43 |
44 | def test_mutual_information_basic(self):
45 | for _iter in range(10):
46 | (B, S, T) = (
47 | random.randint(1, 10),
48 | random.randint(1, 16),
49 | random.randint(1, 500),
50 | )
51 | random_px = random.random() < 0.2
52 | random_py = random.random() < 0.2
53 | random_boundary = random.random() < 0.7
54 | big_px = random.random() < 0.2
55 | big_py = random.random() < 0.2
56 |
57 | modified = random.random() < 0.5
58 |
59 | if modified and T < S:
60 | T = S + random.randint(0, 30)
61 |
62 | for dtype in self.dtypes:
63 | for device in self.devices:
64 | if random_boundary:
65 |
66 | def get_boundary_row():
67 | this_S = random.randint(
68 | 0, S
69 | ) # allow empty sequence
70 | this_T = random.randint(
71 | this_S if modified else 1, T
72 | )
73 | s_begin = random.randint(0, S - this_S)
74 | t_begin = random.randint(0, T - this_T)
75 | s_end = s_begin + this_S
76 | t_end = t_begin + this_T
77 | return [s_begin, t_begin, s_end, t_end]
78 |
79 | if device == torch.device("cpu"):
80 | boundary = torch.tensor(
81 | [get_boundary_row() for _ in range(B)],
82 | dtype=torch.int64,
83 | device=device,
84 | )
85 | else:
86 | boundary = boundary.to(device)
87 | else:
88 | # Use default boundary, but either specified directly
89 | # or not.
90 | if random.random() < 0.5:
91 | boundary = (
92 | torch.tensor([0, 0, S, T], dtype=torch.int64)
93 | .unsqueeze(0)
94 | .expand(B, 4)
95 | .to(device)
96 | )
97 | else:
98 | boundary = None
99 |
100 | if device == torch.device("cpu"):
101 | if random_px:
102 | # log of an odds ratio
103 | px = torch.randn(
104 | B, S, T + (0 if modified else 1), dtype=dtype
105 | ).to(device)
106 | if S > 1 and not random_boundary and not modified:
107 | px[:, :, -1:] = float("-inf")
108 | else:
109 | # log of an odds ratio
110 | px = torch.zeros(
111 | B, S, T + (0 if modified else 1), dtype=dtype
112 | ).to(device)
113 | # px and py get exponentiated, and then multiplied
114 | # together up to 32 times (BLOCK_SIZE in the CUDA code),
115 | # so 15 is actually a big number that could lead to
116 | # overflow.
117 | if big_px:
118 | px += 15.0
119 | if random_py:
120 | # log of an odds ratio
121 | py = torch.randn(B, S + 1, T, dtype=dtype).to(
122 | device
123 | )
124 | else:
125 | # log of an odds ratio
126 | py = torch.zeros(B, S + 1, T, dtype=dtype).to(
127 | device
128 | )
129 | if big_py:
130 | py += 15.0
131 |
132 | else:
133 | px = px.to(device).detach()
134 | py = py.to(device).detach()
135 | px.requires_grad = True
136 | py.requires_grad = True
137 |
138 | m = fast_rnnt.mutual_information_recursion(px, py, boundary)
139 |
140 | m2 = fast_rnnt.joint_mutual_information_recursion(
141 | (px,), (py,), boundary
142 | )
143 |
144 | m3 = fast_rnnt.joint_mutual_information_recursion(
145 | (px * 0.5, px * 0.5), (py * 0.5, py * 0.5), boundary
146 | )
147 |
148 | # it is supposed to be identical only after
149 | # summing over dim 0, corresponding to the
150 | # sequence dim
151 | m3 = m3.sum(dim=0)
152 |
153 | assert torch.allclose(m, m2)
154 | assert torch.allclose(m, m3)
155 |
156 | # the loop this is in checks that the CPU and CUDA versions
157 | # give the same derivative;
158 | # by randomizing which of m, m2 or m3 we backprop, we also
159 | # ensure that the joint version of the code gives the same
160 | # derivative as the regular version
161 | scale = 3
162 | if random.random() < 0.5:
163 | (m.sum() * scale).backward()
164 | elif random.random() < 0.5:
165 | (m2.sum() * scale).backward()
166 | else:
167 | (m3.sum() * scale).backward()
168 |
169 | if device == torch.device("cpu"):
170 | expected_px_grad = px.grad
171 | expected_py_grad = py.grad
172 | expected_m = m
173 | assert torch.allclose(
174 | px.grad,
175 | expected_px_grad.to(device),
176 | atol=1.0e-02,
177 | rtol=1.0e-02,
178 | )
179 | assert torch.allclose(
180 | py.grad,
181 | expected_py_grad.to(device),
182 | atol=1.0e-02,
183 | rtol=1.0e-02,
184 | )
185 | assert torch.allclose(
186 | m, expected_m.to(device), atol=1.0e-02, rtol=1.0e-02
187 | )
188 |
189 | def test_mutual_information_deriv(self):
190 | for _iter in range(10):
191 | (B, S, T) = (
192 | random.randint(1, 100),
193 | random.randint(1, 200),
194 | random.randint(1, 200),
195 | )
196 | random_px = random.random() < 0.2
197 | random_py = random.random() < 0.2
198 | random_boundary = random.random() < 0.7
199 | big_px = random.random() < 0.2
200 | big_py = random.random() < 0.2
201 |
202 | modified = random.random() < 0.5
203 |
204 | if modified and T < S:
205 | T = S + random.randint(0, 30)
206 |
207 | for dtype in self.dtypes:
208 | for device in self.devices:
209 | if random_boundary:
210 |
211 | def get_boundary_row():
212 | this_S = random.randint(1, S)
213 | this_T = random.randint(
214 | this_S if modified else 1, T
215 | )
216 | s_begin = random.randint(0, S - this_S)
217 | t_begin = random.randint(0, T - this_T)
218 | s_end = s_begin + this_S
219 | t_end = t_begin + this_T
220 | return [s_begin, t_begin, s_end, t_end]
221 |
222 | if device == torch.device("cpu"):
223 | boundary = torch.tensor(
224 | [get_boundary_row() for _ in range(B)],
225 | dtype=torch.int64,
226 | device=device,
227 | )
228 | else:
229 | boundary = boundary.to(device)
230 | else:
231 | # Use default boundary, but either specified directly
232 | # or not.
233 | if random.random() < 0.5:
234 | boundary = (
235 | torch.tensor([0, 0, S, T], dtype=torch.int64)
236 | .unsqueeze(0)
237 | .expand(B, 4)
238 | .to(device)
239 | )
240 | else:
241 | boundary = None
242 |
243 | T1 = T + (0 if modified else 1)
244 | if device == torch.device("cpu"):
245 | if random_px:
246 | # log of an odds ratio
247 | px = torch.randn(B, S, T1, dtype=dtype).to(device)
248 | else:
249 | # log of an odds ratio
250 | px = torch.zeros(B, S, T1, dtype=dtype).to(device)
251 | # px and py get exponentiated, and then multiplied
252 | # together up to 32 times (BLOCK_SIZE in the CUDA code),
253 | # so 15 is actually a big number that could lead to
254 | # overflow.
255 | if big_px:
256 | px += 15.0
257 | if random_py:
258 | # log of an odds ratio
259 | py = torch.randn(B, S + 1, T, dtype=dtype).to(
260 | device
261 | )
262 | else:
263 | # log of an odds ratio
264 | py = torch.zeros(B, S + 1, T, dtype=dtype).to(
265 | device
266 | )
267 | if big_py:
268 | py += 15.0
269 | else:
270 | px = px.to(device).detach()
271 | py = py.to(device).detach()
272 | px.requires_grad = True
273 | py.requires_grad = True
274 |
275 | m = fast_rnnt.mutual_information_recursion(px, py, boundary)
276 |
277 | m_grad = torch.randn(B, dtype=dtype, device=device)
278 | m.backward(gradient=m_grad)
279 | delta = 1.0e-04
280 | delta_px = delta * torch.randn_like(px)
281 | m2 = fast_rnnt.mutual_information_recursion(
282 | px + delta_px, py, boundary
283 | )
284 | delta_m = m2 - m
285 | observed_delta = (delta_m * m_grad).sum().to("cpu")
286 | predicted_delta = (delta_px * px.grad).sum().to("cpu")
287 |
288 | atol = 1.0e-02 if dtype == torch.float32 else 1.0e-04
289 | rtol = 1.0e-02 if dtype == torch.float32 else 1.0e-04
290 |
291 | assert torch.allclose(
292 | observed_delta, predicted_delta, atol=atol, rtol=rtol
293 | )
294 |
295 | delta_py = delta * torch.randn_like(py)
296 | m2 = fast_rnnt.mutual_information_recursion(
297 | px, py + delta_py, boundary
298 | )
299 | delta_m = m2 - m
300 | observed_delta = (delta_m * m_grad).sum().to("cpu")
301 | predicted_delta = (delta_py * py.grad).sum().to("cpu")
302 |
303 | assert torch.allclose(
304 | observed_delta, predicted_delta, atol=atol, rtol=rtol
305 | )
306 |
307 |
308 | if __name__ == "__main__":
309 | unittest.main()
310 |
--------------------------------------------------------------------------------
/fast_rnnt/python/tests/rnnt_loss_test.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | #
3 | # Copyright 2021 Xiaomi Corporation (authors: Daniel Povey,
4 | # Wei Kang)
5 | #
6 | # See ../../../LICENSE for clarification regarding multiple authors
7 | #
8 | # Licensed under the Apache License, Version 2.0 (the "License");
9 | # you may not use this file except in compliance with the License.
10 | # You may obtain a copy of the License at
11 | #
12 | # http://www.apache.org/licenses/LICENSE-2.0
13 | #
14 | # Unless required by applicable law or agreed to in writing, software
15 | # distributed under the License is distributed on an "AS IS" BASIS,
16 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | # See the License for the specific language governing permissions and
18 | # limitations under the License.
19 |
20 | # To run this single test, use
21 | #
22 | # ctest --verbose -R rnnt_loss_test_py
23 |
24 | import unittest
25 |
26 | import fast_rnnt
27 | import random
28 | import torch
29 |
30 |
31 | class TestRnntLoss(unittest.TestCase):
32 | @classmethod
33 | def setUpClass(cls):
34 | cls.devices = [torch.device("cpu")]
35 | if torch.cuda.is_available() and fast_rnnt.with_cuda():
36 | cls.devices.append(torch.device("cuda", 0))
37 | if torch.cuda.device_count() > 1:
38 | torch.cuda.set_device(1)
39 | cls.devices.append(torch.device("cuda", 1))
40 | try:
41 | import torchaudio
42 | import torchaudio.functional
43 |
44 | if hasattr(torchaudio.functional, "rnnt_loss"):
45 | cls.has_torch_rnnt_loss = True
46 | else:
47 | cls.has_torch_rnnt_loss = False
48 | print(
49 | f"Current torchaudio version: {torchaudio.__version__}\n"
50 | "Skipping the tests of comparing rnnt loss with torch "
51 | "one, to enable these tests please install a "
52 | "version >= 0.10.0"
53 | )
54 | except ImportError as e:
55 | cls.has_torch_rnnt_loss = False
56 | print(
57 | f"Import torchaudio error, error message: {e}\n"
58 | "Skipping the tests of comparing rnnt loss with torch "
59 | "one, to enable these tests, please install torchaudio "
60 | "with version >= 0.10.0"
61 | )
62 |
63 | def test_rnnt_loss_basic(self):
64 | B = 1
65 | S = 3
66 | T = 4
67 | # C = 3
68 | for device in self.devices:
69 | # lm: [B][S+1][C]
70 | lm = torch.tensor(
71 | [[[0, 0, 1], [0, 1, 1], [1, 0, 1], [2, 2, 0]]],
72 | dtype=torch.float,
73 | device=device,
74 | )
75 | # am: [B][T][C]
76 | am = torch.tensor(
77 | [[[0, 1, 2], [0, 0, 0], [0, 2, 4], [0, 3, 3]]],
78 | dtype=torch.float,
79 | device=device,
80 | )
81 | termination_symbol = 2
82 | symbols = torch.tensor([[0, 1, 0]], dtype=torch.long, device=device)
83 |
84 | px, py = fast_rnnt.get_rnnt_logprobs(
85 | lm=lm,
86 | am=am,
87 | symbols=symbols,
88 | termination_symbol=termination_symbol,
89 | )
90 | assert px.shape == (B, S, T + 1)
91 | assert py.shape == (B, S + 1, T)
92 | assert symbols.shape == (B, S)
93 | m = fast_rnnt.mutual_information_recursion(
94 | px=px, py=py, boundary=None
95 | )
96 |
97 | if device == torch.device("cpu"):
98 | expected = -m
99 | assert torch.allclose(-m, expected.to(device))
100 |
101 | # test rnnt_loss_simple
102 | m = fast_rnnt.rnnt_loss_simple(
103 | lm=lm,
104 | am=am,
105 | symbols=symbols,
106 | termination_symbol=termination_symbol,
107 | boundary=None,
108 | reduction="none",
109 | )
110 | assert torch.allclose(m, expected.to(device))
111 |
112 | # test rnnt_loss_smoothed
113 | m = fast_rnnt.rnnt_loss_smoothed(
114 | lm=lm,
115 | am=am,
116 | symbols=symbols,
117 | termination_symbol=termination_symbol,
118 | lm_only_scale=0.0,
119 | am_only_scale=0.0,
120 | boundary=None,
121 | reduction="none",
122 | )
123 | assert torch.allclose(m, expected.to(device))
124 |
125 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
126 |
127 | # test rnnt_loss
128 | m = fast_rnnt.rnnt_loss(
129 | logits=logits,
130 | symbols=symbols,
131 | termination_symbol=termination_symbol,
132 | boundary=None,
133 | reduction="none",
134 | )
135 | assert torch.allclose(m, expected.to(device))
136 |
137 | # compare with torchaudio rnnt_loss
138 | if self.has_torch_rnnt_loss:
139 | import torchaudio.functional
140 |
141 | m = torchaudio.functional.rnnt_loss(
142 | logits=logits,
143 | targets=symbols.int(),
144 | logit_lengths=torch.tensor(
145 | [T] * B, dtype=torch.int32, device=device
146 | ),
147 | target_lengths=torch.tensor(
148 | [S] * B, dtype=torch.int32, device=device
149 | ),
150 | blank=termination_symbol,
151 | reduction="none",
152 | )
153 | assert torch.allclose(m, expected.to(device))
154 |
155 | # should be invariant to adding a constant for any frame.
156 | lm += torch.randn(B, S + 1, 1, device=device)
157 | am += torch.randn(B, T, 1, device=device)
158 |
159 | m = fast_rnnt.rnnt_loss_simple(
160 | lm=lm,
161 | am=am,
162 | symbols=symbols,
163 | termination_symbol=termination_symbol,
164 | boundary=None,
165 | reduction="none",
166 | )
167 | assert torch.allclose(m, expected.to(device))
168 |
169 | m = fast_rnnt.rnnt_loss_smoothed(
170 | lm=lm,
171 | am=am,
172 | symbols=symbols,
173 | termination_symbol=termination_symbol,
174 | lm_only_scale=0.0,
175 | am_only_scale=0.0,
176 | boundary=None,
177 | reduction="none",
178 | )
179 | assert torch.allclose(m, expected.to(device))
180 |
181 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
182 | m = fast_rnnt.rnnt_loss(
183 | logits=logits,
184 | symbols=symbols,
185 | termination_symbol=termination_symbol,
186 | boundary=None,
187 | reduction="none",
188 | )
189 | assert torch.allclose(m, expected.to(device))
190 |
191 | def test_rnnt_loss_random(self):
192 | B = 5
193 | S = 20
194 | T = 300
195 | C = 100
196 | frames = torch.randint(S, T, (B,))
197 | seq_length = torch.randint(3, S - 1, (B,))
198 | T = torch.max(frames)
199 | S = torch.max(seq_length)
200 |
201 | am_ = torch.randn((B, T, C), dtype=torch.float32)
202 | lm_ = torch.randn((B, S + 1, C), dtype=torch.float32)
203 | symbols_ = torch.randint(0, C - 1, (B, S))
204 | termination_symbol = C - 1
205 |
206 | boundary_ = torch.zeros((B, 4), dtype=torch.int64)
207 | boundary_[:, 2] = seq_length
208 | boundary_[:, 3] = frames
209 |
210 | for rnnt_type in ["regular", "modified", "constrained"]:
211 | for device in self.devices:
212 | # lm: [B][S+1][C]
213 | lm = lm_.to(device)
214 | # am: [B][T][C]
215 | am = am_.to(device)
216 | symbols = symbols_.to(device)
217 | boundary = boundary_.to(device)
218 |
219 | px, py = fast_rnnt.get_rnnt_logprobs(
220 | lm=lm,
221 | am=am,
222 | symbols=symbols,
223 | termination_symbol=termination_symbol,
224 | boundary=boundary,
225 | rnnt_type=rnnt_type,
226 | )
227 | assert (
228 | px.shape == (B, S, T)
229 | if rnnt_type != "regular"
230 | else (B, S, T + 1)
231 | )
232 | assert py.shape == (B, S + 1, T)
233 | assert symbols.shape == (B, S)
234 | m = fast_rnnt.mutual_information_recursion(
235 | px=px, py=py, boundary=boundary
236 | )
237 |
238 | if device == torch.device("cpu"):
239 | expected = -torch.mean(m)
240 | assert torch.allclose(-torch.mean(m), expected.to(device))
241 |
242 | m = fast_rnnt.rnnt_loss_simple(
243 | lm=lm,
244 | am=am,
245 | symbols=symbols,
246 | termination_symbol=termination_symbol,
247 | boundary=boundary,
248 | rnnt_type=rnnt_type,
249 | )
250 | assert torch.allclose(m, expected.to(device))
251 |
252 | m = fast_rnnt.rnnt_loss_smoothed(
253 | lm=lm,
254 | am=am,
255 | symbols=symbols,
256 | termination_symbol=termination_symbol,
257 | lm_only_scale=0.0,
258 | am_only_scale=0.0,
259 | boundary=boundary,
260 | rnnt_type=rnnt_type,
261 | )
262 | assert torch.allclose(m, expected.to(device))
263 |
264 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
265 | m = fast_rnnt.rnnt_loss(
266 | logits=logits,
267 | symbols=symbols,
268 | termination_symbol=termination_symbol,
269 | boundary=boundary,
270 | rnnt_type=rnnt_type,
271 | )
272 | assert torch.allclose(m, expected.to(device))
273 |
274 | # compare with torchaudio rnnt_loss
275 | if self.has_torch_rnnt_loss and rnnt_type == "regular":
276 | import torchaudio.functional
277 |
278 | m = torchaudio.functional.rnnt_loss(
279 | logits=logits,
280 | targets=symbols.int(),
281 | logit_lengths=boundary[:, 3].int(),
282 | target_lengths=boundary[:, 2].int(),
283 | blank=termination_symbol,
284 | )
285 | assert torch.allclose(m, expected.to(device))
286 |
287 | # should be invariant to adding a constant for any frame.
288 | lm += torch.randn(B, S + 1, 1, device=device)
289 | am += torch.randn(B, T, 1, device=device)
290 |
291 | m = fast_rnnt.rnnt_loss_simple(
292 | lm=lm,
293 | am=am,
294 | symbols=symbols,
295 | termination_symbol=termination_symbol,
296 | boundary=boundary,
297 | rnnt_type=rnnt_type,
298 | )
299 | assert torch.allclose(m, expected.to(device))
300 |
301 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
302 | m = fast_rnnt.rnnt_loss(
303 | logits=logits,
304 | symbols=symbols,
305 | termination_symbol=termination_symbol,
306 | boundary=boundary,
307 | rnnt_type=rnnt_type,
308 | )
309 | assert torch.allclose(m, expected.to(device))
310 |
311 | m = fast_rnnt.rnnt_loss_smoothed(
312 | lm=lm,
313 | am=am,
314 | symbols=symbols,
315 | termination_symbol=termination_symbol,
316 | lm_only_scale=0.0,
317 | am_only_scale=0.0,
318 | boundary=boundary,
319 | rnnt_type=rnnt_type,
320 | )
321 | assert torch.allclose(m, expected.to(device))
322 |
323 | def test_rnnt_loss_gradient(self):
324 | if self.has_torch_rnnt_loss:
325 | import torchaudio.functional
326 |
327 | B = 5
328 | S = 20
329 | T = 300
330 | C = 100
331 | frames = torch.randint(S, T, (B,))
332 | seq_length = torch.randint(3, S - 1, (B,))
333 | T = torch.max(frames)
334 | S = torch.max(seq_length)
335 |
336 | am_ = torch.randn((B, T, C), dtype=torch.float32)
337 | lm_ = torch.randn((B, S + 1, C), dtype=torch.float32)
338 | symbols_ = torch.randint(0, C - 1, (B, S))
339 | termination_symbol = C - 1
340 |
341 | boundary_ = torch.zeros((B, 4), dtype=torch.int64)
342 | boundary_[:, 2] = seq_length
343 | boundary_[:, 3] = frames
344 |
345 | for device in self.devices:
346 | # lm: [B][S+1][C]
347 | lm = lm_.to(device)
348 | # am: [B][T][C]
349 | am = am_.to(device)
350 | symbols = symbols_.to(device)
351 | boundary = boundary_.to(device)
352 |
353 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
354 | logits.requires_grad_()
355 | fast_loss = fast_rnnt.rnnt_loss(
356 | logits=logits,
357 | symbols=symbols,
358 | termination_symbol=termination_symbol,
359 | boundary=boundary,
360 | )
361 | fast_grad = torch.autograd.grad(fast_loss, logits)
362 | fast_grad = fast_grad[0]
363 |
364 | logits2 = logits.detach().clone().float()
365 | logits2.requires_grad_()
366 | torch_loss = torchaudio.functional.rnnt_loss(
367 | logits=logits2,
368 | targets=symbols.int(),
369 | logit_lengths=boundary[:, 3].int(),
370 | target_lengths=boundary[:, 2].int(),
371 | blank=termination_symbol,
372 | )
373 | torch_grad = torch.autograd.grad(torch_loss, logits2)
374 | torch_grad = torch_grad[0]
375 |
376 | assert torch.allclose(
377 | fast_loss, torch_loss, atol=1e-2, rtol=1e-2
378 | )
379 |
380 | assert torch.allclose(
381 | fast_grad, torch_grad, atol=1e-2, rtol=1e-2
382 | )
383 |
384 | def test_rnnt_loss_smoothed(self):
385 | B = 1
386 | S = 3
387 | T = 4
388 | # C = 3
389 | for device in self.devices:
390 | # lm: [B][S+1][C]
391 | lm = torch.tensor(
392 | [[[0, 0, 1], [0, 1, 1], [1, 0, 1], [2, 2, 0]]],
393 | dtype=torch.float,
394 | device=device,
395 | )
396 | # am: [B][T][C]
397 | am = torch.tensor(
398 | [[[0, 1, 2], [0, 0, 0], [0, 2, 4], [0, 3, 3]]],
399 | dtype=torch.float,
400 | device=device,
401 | )
402 |
403 | termination_symbol = 2
404 | symbols = torch.tensor([[0, 1, 0]], dtype=torch.long, device=device)
405 |
406 | m = fast_rnnt.rnnt_loss_smoothed(
407 | lm=lm,
408 | am=am,
409 | symbols=symbols,
410 | termination_symbol=termination_symbol,
411 | lm_only_scale=0.0,
412 | am_only_scale=0.333,
413 | boundary=None,
414 | )
415 |
416 | if device == torch.device("cpu"):
417 | expected = m
418 | assert torch.allclose(m, expected.to(device))
419 |
420 | # should be invariant to adding a constant for any frame.
421 | lm += torch.randn(B, S + 1, 1, device=device)
422 | am += torch.randn(B, T, 1, device=device)
423 |
424 | m = fast_rnnt.rnnt_loss_smoothed(
425 | lm=lm,
426 | am=am,
427 | symbols=symbols,
428 | termination_symbol=termination_symbol,
429 | lm_only_scale=0.0,
430 | am_only_scale=0.333,
431 | boundary=None,
432 | )
433 | assert torch.allclose(m, expected.to(device))
434 |
435 | def test_rnnt_loss_pruned(self):
436 | B = 4
437 | T = 300
438 | S = 50
439 | C = 10
440 |
441 | frames = torch.randint(S, T, (B,))
442 | seq_length = torch.randint(3, S - 1, (B,))
443 | T = torch.max(frames)
444 | S = torch.max(seq_length)
445 |
446 | am_ = torch.randn((B, T, C), dtype=torch.float64)
447 | lm_ = torch.randn((B, S + 1, C), dtype=torch.float64)
448 | symbols_ = torch.randint(0, C - 1, (B, S))
449 | terminal_symbol = C - 1
450 |
451 | boundary_ = torch.zeros((B, 4), dtype=torch.int64)
452 | boundary_[:, 2] = seq_length
453 | boundary_[:, 3] = frames
454 |
455 | for rnnt_type in ["regular", "modified", "constrained"]:
456 | for device in self.devices:
457 | # normal rnnt
458 | am = am_.to(device)
459 | lm = lm_.to(device)
460 | symbols = symbols_.to(device)
461 | boundary = boundary_.to(device)
462 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
463 | logits = logits.float()
464 |
465 | # nonlinear transform
466 | logits = torch.sigmoid(logits)
467 | fast_loss = fast_rnnt.rnnt_loss(
468 | logits=logits,
469 | symbols=symbols,
470 | termination_symbol=terminal_symbol,
471 | boundary=boundary,
472 | rnnt_type=rnnt_type,
473 | )
474 |
475 | print(f"Unpruned rnnt loss with {rnnt_type} rnnt : {fast_loss}")
476 |
477 | # pruning
478 | simple_loss, (px_grad, py_grad) = fast_rnnt.rnnt_loss_simple(
479 | lm=lm,
480 | am=am,
481 | symbols=symbols,
482 | termination_symbol=terminal_symbol,
483 | boundary=boundary,
484 | rnnt_type=rnnt_type,
485 | return_grad=True,
486 | reduction="none",
487 | )
488 |
489 | for r in range(2, 50, 5):
490 | ranges = fast_rnnt.get_rnnt_prune_ranges(
491 | px_grad=px_grad,
492 | py_grad=py_grad,
493 | boundary=boundary,
494 | s_range=r,
495 | )
496 | # (B, T, r, C)
497 | pruned_am, pruned_lm = fast_rnnt.do_rnnt_pruning(
498 | am=am, lm=lm, ranges=ranges
499 | )
500 |
501 | logits = pruned_am + pruned_lm
502 |
503 | # nonlinear transform
504 | logits = torch.sigmoid(logits)
505 |
506 | pruned_loss = fast_rnnt.rnnt_loss_pruned(
507 | logits=logits,
508 | symbols=symbols,
509 | ranges=ranges,
510 | termination_symbol=terminal_symbol,
511 | boundary=boundary,
512 | rnnt_type=rnnt_type,
513 | reduction="none",
514 | )
515 | print(f"Pruning loss with range {r} : {pruned_loss}")
516 |
517 | # Test the sequences that only have small number of symbols,
518 | # at this circumstance, the s_range would be greater than S, which will
519 | # raise errors (like, nan or inf loss) in our previous versions.
520 | def test_rnnt_loss_pruned_small_symbols_number(self):
521 | B = 2
522 | T = 20
523 | S = 3
524 | C = 10
525 |
526 | frames = torch.randint(S + 1, T, (B,))
527 | seq_lengths = torch.randint(1, S, (B,))
528 | T = torch.max(frames)
529 | S = torch.max(seq_lengths)
530 |
531 | am_ = torch.randn((B, T, C), dtype=torch.float64)
532 | lm_ = torch.randn((B, S + 1, C), dtype=torch.float64)
533 | symbols_ = torch.randint(0, C, (B, S))
534 | terminal_symbol = C - 1
535 |
536 | boundary_ = torch.zeros((B, 4), dtype=torch.int64)
537 | boundary_[:, 2] = seq_lengths
538 | boundary_[:, 3] = frames
539 |
540 | print(f"B = {B}, T = {T}, S = {S}, C = {C}")
541 |
542 | for rnnt_type in ["regular", "modified", "constrained"]:
543 | for device in self.devices:
544 | # normal rnnt
545 | am = am_.to(device)
546 | lm = lm_.to(device)
547 | symbols = symbols_.to(device)
548 | boundary = boundary_.to(device)
549 |
550 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
551 | logits = logits.float()
552 |
553 | # nonlinear transform
554 | logits = torch.sigmoid(logits)
555 |
556 | loss = fast_rnnt.rnnt_loss(
557 | logits=logits,
558 | symbols=symbols,
559 | termination_symbol=terminal_symbol,
560 | boundary=boundary,
561 | rnnt_type=rnnt_type,
562 | reduction="none",
563 | )
564 |
565 | print(f"Unpruned rnnt loss with {rnnt_type} rnnt : {loss}")
566 |
567 | # pruning
568 | simple_loss, (px_grad, py_grad) = fast_rnnt.rnnt_loss_simple(
569 | lm=lm,
570 | am=am,
571 | symbols=symbols,
572 | termination_symbol=terminal_symbol,
573 | boundary=boundary,
574 | rnnt_type=rnnt_type,
575 | return_grad=True,
576 | reduction="none",
577 | )
578 |
579 | S0 = 2
580 | if rnnt_type != "regular":
581 | S0 = 1
582 |
583 | for r in range(S0, S + 2):
584 | ranges = fast_rnnt.get_rnnt_prune_ranges(
585 | px_grad=px_grad,
586 | py_grad=py_grad,
587 | boundary=boundary,
588 | s_range=r,
589 | )
590 | # (B, T, r, C)
591 | pruned_am, pruned_lm = fast_rnnt.do_rnnt_pruning(
592 | am=am, lm=lm, ranges=ranges
593 | )
594 |
595 | logits = pruned_am + pruned_lm
596 |
597 | # nonlinear transform
598 | logits = torch.sigmoid(logits)
599 |
600 | pruned_loss = fast_rnnt.rnnt_loss_pruned(
601 | logits=logits,
602 | symbols=symbols,
603 | ranges=ranges,
604 | termination_symbol=terminal_symbol,
605 | boundary=boundary,
606 | rnnt_type=rnnt_type,
607 | reduction="none",
608 | )
609 | print(f"Pruned loss with range {r} : {pruned_loss}")
610 |
611 | # Test low s_range values with large S and small T,
612 | # at this circumstance, the s_range would not be enough
613 | # to cover the whole sequence length (in regular rnnt mode)
614 | # and would result in inf loss
615 | def test_rnnt_loss_pruned_small_s_range(self):
616 | B = 2
617 | T = 2
618 | S = 10
619 | C = 10
620 |
621 | frames = torch.randint(1, T, (B,))
622 | seq_lengths = torch.randint(1, S, (B,))
623 | T = torch.max(frames)
624 | S = torch.max(seq_lengths)
625 |
626 | am_ = torch.randn((B, T, C), dtype=torch.float64)
627 | lm_ = torch.randn((B, S + 1, C), dtype=torch.float64)
628 | symbols_ = torch.randint(0, C, (B, S))
629 | terminal_symbol = C - 1
630 |
631 | boundary_ = torch.zeros((B, 4), dtype=torch.int64)
632 | boundary_[:, 2] = seq_lengths
633 | boundary_[:, 3] = frames
634 |
635 | print(f"B = {B}, T = {T}, S = {S}, C = {C}")
636 |
637 | for rnnt_type in ["regular"]:
638 | for device in self.devices:
639 | # normal rnnt
640 | am = am_.to(device)
641 | lm = lm_.to(device)
642 | symbols = symbols_.to(device)
643 | boundary = boundary_.to(device)
644 |
645 | logits = am.unsqueeze(2) + lm.unsqueeze(1)
646 | logits = logits.float()
647 |
648 | # nonlinear transform
649 | logits = torch.sigmoid(logits)
650 |
651 | loss = fast_rnnt.rnnt_loss(
652 | logits=logits,
653 | symbols=symbols,
654 | termination_symbol=terminal_symbol,
655 | boundary=boundary,
656 | rnnt_type=rnnt_type,
657 | reduction="none",
658 | )
659 |
660 | print(f"Unpruned rnnt loss with {rnnt_type} rnnt : {loss}")
661 |
662 | # pruning
663 | simple_loss, (px_grad, py_grad) = fast_rnnt.rnnt_loss_simple(
664 | lm=lm,
665 | am=am,
666 | symbols=symbols,
667 | termination_symbol=terminal_symbol,
668 | boundary=boundary,
669 | rnnt_type=rnnt_type,
670 | return_grad=True,
671 | reduction="none",
672 | )
673 |
674 | S0 = 2
675 |
676 | for r in range(S0, S + 2):
677 | ranges = fast_rnnt.get_rnnt_prune_ranges(
678 | px_grad=px_grad,
679 | py_grad=py_grad,
680 | boundary=boundary,
681 | s_range=r,
682 | )
683 | # (B, T, r, C)
684 | pruned_am, pruned_lm = fast_rnnt.do_rnnt_pruning(
685 | am=am, lm=lm, ranges=ranges
686 | )
687 |
688 | logits = pruned_am + pruned_lm
689 |
690 | # nonlinear transform
691 | logits = torch.sigmoid(logits)
692 |
693 | pruned_loss = fast_rnnt.rnnt_loss_pruned(
694 | logits=logits,
695 | symbols=symbols,
696 | ranges=ranges,
697 | termination_symbol=terminal_symbol,
698 | boundary=boundary,
699 | rnnt_type=rnnt_type,
700 | reduction="none",
701 | )
702 | assert (
703 | not pruned_loss.isinf().any()
704 | ), f"Pruned loss is inf for r={r}, S={S}, T={T}: {pruned_loss}"
705 | print(f"Pruned loss with range {r} : {pruned_loss}")
706 |
707 |
708 | if __name__ == "__main__":
709 | unittest.main()
710 |
--------------------------------------------------------------------------------
/package.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 |
3 | ROOT=$(realpath $(dirname $0))
4 | cd ${ROOT}
5 |
6 | python3 -m pip install --upgrade setuptools wheel twine
7 | python3 setup.py sdist
8 | echo "Inspect dist and upload with \"python3 -m twine upload dist/*\""
9 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=1.5
2 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | #
3 | # Copyright (c) 2022 Xiaomi Corporation (author: Wei Kang)
4 |
5 | import glob
6 | import os
7 | import re
8 | import shutil
9 | import sys
10 |
11 | import setuptools
12 | from setuptools.command.build_ext import build_ext
13 |
14 | cur_dir = os.path.dirname(os.path.abspath(__file__))
15 |
16 |
17 | def cmake_extension(name, *args, **kwargs) -> setuptools.Extension:
18 | kwargs["language"] = "c++"
19 | sources = []
20 | return setuptools.Extension(name, sources, *args, **kwargs)
21 |
22 |
23 | class BuildExtension(build_ext):
24 | def build_extension(self, ext: setuptools.extension.Extension):
25 | # build/temp.linux-x86_64-3.8
26 | build_dir = self.build_temp
27 | os.makedirs(build_dir, exist_ok=True)
28 |
29 | # build/lib.linux-x86_64-3.8
30 | os.makedirs(self.build_lib, exist_ok=True)
31 |
32 | ft_dir = os.path.dirname(os.path.abspath(__file__))
33 |
34 | cmake_args = os.environ.get("FT_CMAKE_ARGS", "")
35 | make_args = os.environ.get("FT_MAKE_ARGS", "")
36 | system_make_args = os.environ.get("MAKEFLAGS", "")
37 |
38 | if cmake_args == "":
39 | cmake_args = "-DCMAKE_BUILD_TYPE=Release -DFT_BUILD_TESTS=OFF"
40 |
41 | if make_args == "" and system_make_args == "":
42 | make_args = " -j "
43 |
44 | if "PYTHON_EXECUTABLE" not in cmake_args:
45 | print(f"Setting PYTHON_EXECUTABLE to {sys.executable}")
46 | cmake_args += f" -DPYTHON_EXECUTABLE={sys.executable}"
47 |
48 | build_cmd = f"""
49 | cd {self.build_temp}
50 |
51 | cmake {cmake_args} {ft_dir}
52 |
53 | make {make_args} _fast_rnnt
54 | """
55 | print(f"build command is:\n{build_cmd}")
56 |
57 | ret = os.system(build_cmd)
58 | if ret != 0:
59 | raise Exception(
60 | "\nBuild fast_rnnt failed. Please check the error "
61 | "message.\n"
62 | "You can ask for help by creating an issue on GitHub.\n"
63 | "\nClick:\n"
64 | "\thttps://github.com/danpovey/fast_rnnt/issues/new\n" # noqa
65 | )
66 | lib_so = glob.glob(f"{build_dir}/lib/*.so*")
67 | for so in lib_so:
68 | print(f"Copying {so} to {self.build_lib}/")
69 | shutil.copy(f"{so}", f"{self.build_lib}/")
70 |
71 | # macos
72 | lib_so = glob.glob(f"{build_dir}/lib/*.dylib*")
73 | for so in lib_so:
74 | print(f"Copying {so} to {self.build_lib}/")
75 | shutil.copy(f"{so}", f"{self.build_lib}/")
76 |
77 |
78 | def read_long_description():
79 | with open("README.md", encoding="utf8") as f:
80 | readme = f.read()
81 | return readme
82 |
83 |
84 | def get_package_version():
85 | with open("CMakeLists.txt") as f:
86 | content = f.read()
87 |
88 | latest_version = re.search(r"set\(FT_VERSION (.*)\)", content).group(1)
89 | latest_version = latest_version.strip('"')
90 | return latest_version
91 |
92 |
93 | def get_requirements():
94 | with open("requirements.txt", encoding="utf8") as f:
95 | requirements = f.read().splitlines()
96 |
97 | return requirements
98 |
99 |
100 | package_name = "fast_rnnt"
101 |
102 | with open("fast_rnnt/python/fast_rnnt/__init__.py", "a") as f:
103 | f.write(f"__version__ = '{get_package_version()}'\n")
104 |
105 | setuptools.setup(
106 | name=package_name,
107 | version=get_package_version(),
108 | author="Dan Povey",
109 | author_email="dpovey@gmail.com",
110 | package_dir={
111 | package_name: "fast_rnnt/python/fast_rnnt",
112 | },
113 | packages=[package_name],
114 | url="https://github.com/danpovey/fast_rnnt",
115 | description="Fast and memory-efficient RNN-T loss.",
116 | long_description=read_long_description(),
117 | long_description_content_type="text/markdown",
118 | install_requires=get_requirements(),
119 | ext_modules=[cmake_extension("_fast_rnnt")],
120 | cmdclass={"build_ext": BuildExtension},
121 | zip_safe=False,
122 | classifiers=[
123 | "Programming Language :: C++",
124 | "Programming Language :: Python",
125 | "Topic :: Scientific/Engineering :: Artificial Intelligence",
126 | ],
127 | license="Apache licensed, as found in the LICENSE file",
128 | )
129 |
--------------------------------------------------------------------------------