├── .gitignore
├── .travis.yml
├── Dockerfile
├── LICENSE
├── MANIFEST.in
├── README.md
├── appveyor.yml
├── examples
└── intro.ipynb
├── setup.py
├── tests
├── __init__.py
├── test_notebook.py
└── testnb.ipynb
└── tlaplus_jupyter
├── __init__.py
├── __main__.py
├── assets
└── kernel.js
├── install.py
└── kernel.py
/.gitignore:
--------------------------------------------------------------------------------
1 | __pycache__/
2 | *.pyc
3 | *.egg-info
4 | /dist/
5 | /build/
6 | /MANIFEST
7 | tla2tools.jar
8 |
--------------------------------------------------------------------------------
/.travis.yml:
--------------------------------------------------------------------------------
1 | ---
2 | language: python
3 | python:
4 | - 3.8
5 | - 3.7
6 | - 3.6
7 | - 3.5
8 | - 2.7
9 | install:
10 | - pip install .
11 | - python -m tlaplus_jupyter.install
12 | script:
13 | - python setup.py test
14 | os:
15 | - linux
16 |
--------------------------------------------------------------------------------
/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM openjdk:13-alpine3.10
2 |
3 | RUN apk add --update gcc libc-dev zeromq-dev python3-dev linux-headers libffi-dev
4 |
5 | ARG NB_USER=leslie
6 | ARG NB_UID=1000
7 | ENV NB_USER ${NB_USER}
8 | ENV NB_UID ${NB_UID}
9 | RUN addgroup ${NB_USER} && adduser -D -G ${NB_USER} -u ${NB_UID} ${NB_USER}
10 | COPY ./examples /home/${NB_USER}
11 | RUN chown -R ${NB_USER} /home/${NB_USER}
12 |
13 | RUN pip3 install tlaplus_jupyter
14 | RUN python3 -m tlaplus_jupyter.install
15 |
16 | USER ${NB_USER}
17 | WORKDIR /home/${NB_USER}
18 | CMD ["jupyter", "notebook", "--ip", "0.0.0.0"]
19 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | BSD 3-Clause License
2 |
3 | Copyright (c) 2019, Stas Kelvich
4 | Copyright (c) 2017, Project Jupyter Contributors
5 | All rights reserved.
6 |
7 | Redistribution and use in source and binary forms, with or without
8 | modification, are permitted provided that the following conditions are met:
9 |
10 | * Redistributions of source code must retain the above copyright notice, this
11 | list of conditions and the following disclaimer.
12 |
13 | * Redistributions in binary form must reproduce the above copyright notice,
14 | this list of conditions and the following disclaimer in the documentation
15 | and/or other materials provided with the distribution.
16 |
17 | * Neither the name of the copyright holder nor the names of its
18 | contributors may be used to endorse or promote products derived from
19 | this software without specific prior written permission.
20 |
21 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
31 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include README.md
2 | include tlaplus_jupyter/assets/kernel.js
3 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [](https://ci.appveyor.com/project/kelvich/tlaplus-jupyter/branch/master)
2 | [](https://travis-ci.org/kelvich/tlaplus_jupyter)
3 | [](https://mybinder.org/v2/gh/kelvich/tlaplus_jupyter/master?filepath=intro.ipynb)
4 |
5 | # tlaplus_jupyter
6 |
7 | Jupyter kernel for TLA⁺ and Pluscal specification languages.
8 | * Syntax highlight based on official lexer.
9 | * REPL functionality for expressions.
10 | * Can be executed online with Binder. [Try it now!](https://mybinder.org/v2/gh/kelvich/tlaplus_jupyter/master?filepath=intro.ipynb)
11 | * No need to install TLA Toolbox: Java and Python will be enough.
12 |
13 |
14 | 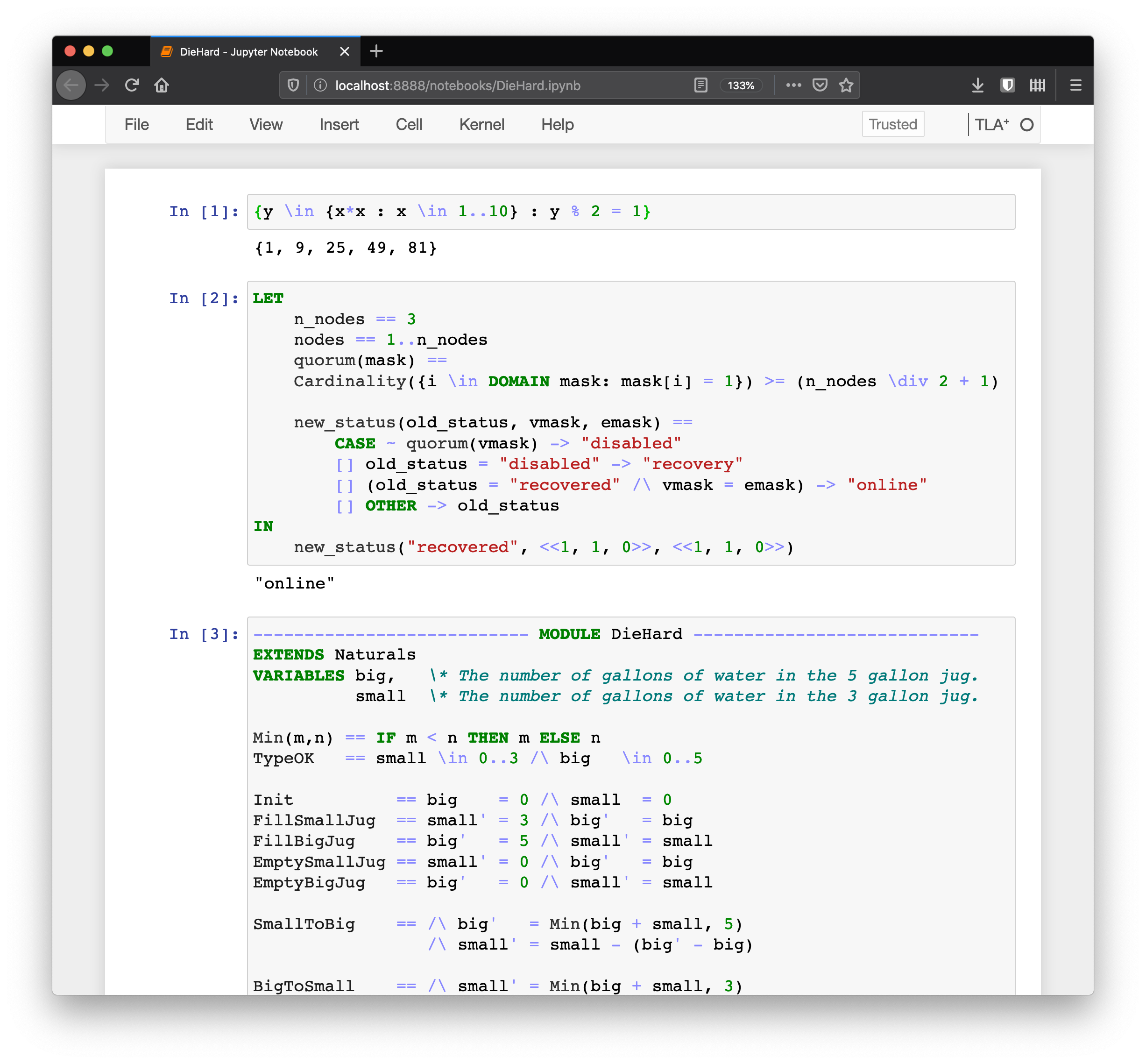 15 |
15 |
16 |
17 | ## Installation
18 |
19 | `tlaplus_jupyter` is a python package installable with `pip`. Python 2 and 3 are supported. To install run:
20 |
21 | ```
22 | pip install tlaplus_jupyter
23 | python -m tlaplus_jupyter.install
24 | ```
25 |
26 | The last step will register `tlaplus_jupyter` as a Jupyter kernel in your system and will download `tla2tools.jar`. After that Jupyter can be started as usual:
27 |
28 | ```
29 | jupyter notebook
30 | ```
31 |
32 | To create a new TLA⁺ notebook click on the `New` button and select TLA⁺ in a dropdown menu. It is also handy to enable line numbering inside cells (View > Toggle Line Numbers) since syntax checker refers to problems by their line numbers.
33 |
34 | Note that by default `python -m tlaplus_jupyter.install` enables TLC execution [statistics collection](https://github.com/tlaplus/tlaplus/blob/master/tlatools/src/util/ExecutionStatisticsCollector.md). Pass `--help` to see how to opt out.
35 |
36 | ## Usage
37 |
38 | Basic usage is explained in an [intro notebook](https://mybinder.org/v2/gh/kelvich/tlaplus_jupyter/master?filepath=intro.ipynb).
39 |
40 | `tlaplus_jupyter` supports several types of cells with different behavior on execution:
41 |
42 | 1. Cells with `full module definition`. Upon execution kernel will perform syntax check (with tla2sany.SANY) and report errors if any. If the module contains Pluscal program kernel will also translate it to TLA.
43 |
44 | 2. Cell starting with `%tlc:ModuleName` where `ModuleName` is the name of one of the modules previously executed. In this case, the cell is treated as a config file for the TLC model checker. For example to check spec `Spec` and invariant `TypeOk` of model `DieHardTLA` execute following:
45 | ```
46 | %tlc:DieHardTLA
47 | SPECIFICATION Spec
48 | INVARIANT TypeOK
49 | ```
50 |
51 | Init and next state formula can be set after keywords `INIT` and `NEXT` correspondingly. Constant definitions should follow `CONSTANTS` keyword separated by newline or commas. Description of possible config statements and syntax is given in chapter 14 of [Specifying systems](https://www.microsoft.com/en-us/research/publication/specifying-systems-the-tla-language-and-tools-for-hardware-and-software-engineers/) book.
52 |
53 | Custom TLC flags may be specified after the module name:
54 | ```
55 | %tlc:DieHardTLA -deadlock
56 | SPECIFICATION Spec
57 | ```
58 |
59 | TLC evaluation happens in the context of all defined modules. So if model refers to another model that other model should be at some cell too.
60 |
61 | 3. Cells containing neither `%`-magic nor module definition are treated as a constant expression and will print its results on execution. As with `!tlc` evaluation happens in the context of all defined modules, so the expression can refer to anything defined in evaluated modules.
62 |
63 | 4. Command `%log` / `%log on` / `%log off` correspondingly shows kernel log / enables logging / disables logging for currently open notebook.
64 |
65 | ## Sharing executable models with Binder
66 |
67 | TLA⁺ models shared on Github can be easily made runnable by coping [Dockerfile](Dockerfile) to the repository root. After that, URL to such repo can be used at [Binder](https://mybinder.org) to start a dynamic TLA⁺ environment.
68 |
69 | ## Related Projects
70 |
71 | [vscode-tlaplus](https://github.com/alygin/vscode-tlaplus) Cool plugin for VSCode editor with syntax highlight and custom widgets for displaying traces.
72 |
73 | ## License
74 |
75 | [BSD](LICENSE)
76 |
--------------------------------------------------------------------------------
/appveyor.yml:
--------------------------------------------------------------------------------
1 | ---
2 | environment:
3 | matrix:
4 | - TOXENV: py27
5 | - TOXENV: py37
6 | - TOXENV: py38
7 | build: off
8 | install:
9 | - pip install .
10 | - python -m tlaplus_jupyter.install
11 | test_script:
12 | - python setup.py test
13 |
--------------------------------------------------------------------------------
/examples/intro.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Constant expressions\n",
8 | "\n",
9 | "Bare statement in a cell is treated as a constant expression and will be immediately evaluated upon cell execution. For example, to a get set of all odd squares of the first ten numbers we may execute:"
10 | ]
11 | },
12 | {
13 | "cell_type": "code",
14 | "execution_count": null,
15 | "metadata": {},
16 | "outputs": [],
17 | "source": [
18 | "{sq \\in {x*x: x \\in 1..10}: sq%2=1}"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "For more complex expression it is handy to use `LET ... IN ...` construct:"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": null,
31 | "metadata": {},
32 | "outputs": [],
33 | "source": [
34 | "LET\n",
35 | " n_nodes == 3\n",
36 | " nodes == 1..n_nodes\n",
37 | " quorum(mask) == Cardinality({i \\in DOMAIN mask: mask[i] = 1}) >= (n_nodes \\div 2 + 1)\n",
38 | " new_status(old_status, vmask, emask) ==\n",
39 | " CASE ~ quorum(vmask) -> \"disabled\"\n",
40 | " [] old_status = \"disabled\" -> \"recovery\"\n",
41 | " [] (old_status = \"recovered\" /\\ vmask = emask) -> \"online\"\n",
42 | " [] OTHER -> old_status\n",
43 | "IN\n",
44 | " new_status(\"recovered\", <<1, 1, 0>>, <<1, 1, 0>>)"
45 | ]
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "metadata": {},
50 | "source": [
51 | "## Modules\n",
52 | "\n",
53 | "Cells starting with four dashes are treated as a module definition. Upon evaluation kernel will perform basic syntax checks with `tla2sany` and report errors if there will be any. Let's evaluate `DieHard` spec from [The TLA+ Video Course](https://lamport.azurewebsites.net/video/videos.html):"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": null,
59 | "metadata": {},
60 | "outputs": [],
61 | "source": [
62 | "--------------------------- MODULE DieHard ----------------------------\n",
63 | "EXTENDS Naturals\n",
64 | "VARIABLES big, \\* The number of gallons of water in the 5 gallon jug.\n",
65 | " small \\* The number of gallons of water in the 3 gallon jug.\n",
66 | "\n",
67 | "Min(m,n) == IF m < n THEN m ELSE n\n",
68 | "TypeOK == small \\in 0..3 /\\ big \\in 0..5\n",
69 | "\n",
70 | "Init == big = 0 /\\ small = 0\n",
71 | "FillSmallJug == small' = 3 /\\ big' = big\n",
72 | "FillBigJug == big' = 5 /\\ small' = small\n",
73 | "EmptySmallJug == small' = 0 /\\ big' = big\n",
74 | "EmptyBigJug == big' = 0 /\\ small' = small\n",
75 | "\n",
76 | "SmallToBig == /\\ big' = Min(big + small, 5)\n",
77 | " /\\ small' = small - (big' - big)\n",
78 | "\n",
79 | "BigToSmall == /\\ small' = Min(big + small, 3) \n",
80 | " /\\ big' = big - (small' - small)\n",
81 | "\n",
82 | "Next == \\/ FillSmallJug \n",
83 | " \\/ FillBigJug \n",
84 | " \\/ EmptySmallJug \n",
85 | " \\/ EmptyBigJug \n",
86 | " \\/ SmallToBig \n",
87 | " \\/ BigToSmall \n",
88 | "\n",
89 | "Spec == Init /\\ [][Next]_<>\n",
90 | "NotSolved == big # 4\n",
91 | "\n",
92 | "============================================================================="
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "## TLC\n",
100 | "\n",
101 | "To check a model `TLC` will need a configuration file. In that file among a lot of things we may:\n",
102 | "* Set model constants to specific values\n",
103 | "* Provide the name of specification formula or Init/Next formulas\n",
104 | "* Mention symmetries\n",
105 | "\n",
106 | "To indicate kernel that given cell is a `TLC` config cell needs to be started with line `%tlc:ModelName` where ModelName is the name of a module to be checked. The module should be already evaluated in some other cell before running `TLC`. \n",
107 | "\n",
108 | "Upon evaluation of such a cell kernel will run `TLC` with the number of workers equal to number of cores on the jupyter server. Any `TLC` output will be dynamically sent to the notebook. By default `TLC` prints it's progress once in a minute.\n",
109 | "\n",
110 | "For example, to check `DieHard` model we may run:"
111 | ]
112 | },
113 | {
114 | "cell_type": "code",
115 | "execution_count": null,
116 | "metadata": {},
117 | "outputs": [],
118 | "source": [
119 | "%tlc:DieHard\n",
120 | "SPECIFICATION Spec\n",
121 | "INVARIANTS TypeOK NotSolved"
122 | ]
123 | },
124 | {
125 | "cell_type": "markdown",
126 | "metadata": {},
127 | "source": [
128 | "If we need to pass some custom command-line option to `TLC` we may put them after the `%tlc:ModelName` prefix. Like that:"
129 | ]
130 | },
131 | {
132 | "cell_type": "code",
133 | "execution_count": null,
134 | "metadata": {},
135 | "outputs": [],
136 | "source": [
137 | "%tlc:DieHard -deadlock -workers 1\n",
138 | "SPECIFICATION Spec\n",
139 | "INVARIANTS TypeOK"
140 | ]
141 | }
142 | ],
143 | "metadata": {
144 | "kernelspec": {
145 | "display_name": "TLA⁺",
146 | "language": "tla",
147 | "name": "tlaplus_jupyter"
148 | },
149 | "language_info": {
150 | "codemirror_mode": "tlaplus",
151 | "file_extension": ".tla",
152 | "mimetype": "text/x-tlaplus",
153 | "name": "tlaplus"
154 | }
155 | },
156 | "nbformat": 4,
157 | "nbformat_minor": 2
158 | }
159 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | # coding: utf-8
2 |
3 | from setuptools import setup
4 |
5 | with open('README.md') as f:
6 | readme = f.read()
7 |
8 | setup(
9 | name='tlaplus_jupyter',
10 | version='0.1.1',
11 | packages=['tlaplus_jupyter'],
12 | description='Jupyter kernel for TLA⁺',
13 | author='Stas Kelvich',
14 | author_email='stas.kelvich@gmail.com',
15 | url='https://github.com/kelvich/tlaplus_jupyter',
16 | keywords=['jupyter', 'tla', 'tlaplus', 'pluscal'],
17 | long_description=readme,
18 | long_description_content_type="text/markdown",
19 | include_package_data=True,
20 | python_requires=">=2.6, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*",
21 | test_suite='tests',
22 | install_requires=[
23 | # Whole 'notebook' package is not actually needed -- only 'jupyter-client' is
24 | # mandatory. But dependency on 'notebook' simplifies installation.
25 | 'notebook>=5',
26 | 'ipykernel>=4.10',
27 | 'future>=0.16',
28 | 'psutil>=4'
29 | ],
30 | zip_safe=False,
31 | license='BSD',
32 | platforms='Platform Independent',
33 | classifiers=[
34 | 'Topic :: Software Development :: Interpreters',
35 | 'Topic :: Software Development :: Quality Assurance',
36 | 'Topic :: Scientific/Engineering :: Mathematics'
37 | ]
38 | )
39 |
--------------------------------------------------------------------------------
/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kelvich/tlaplus_jupyter/87db8499a6bf25b77ba299a60bd36d5d881665f2/tests/__init__.py
--------------------------------------------------------------------------------
/tests/test_notebook.py:
--------------------------------------------------------------------------------
1 | import os
2 | import nbformat
3 |
4 | from nbconvert.preprocessors import ExecutePreprocessor
5 | from unittest import TestCase
6 |
7 |
8 | class TestNotebook(TestCase):
9 |
10 | @classmethod
11 | def setUpClass(cls):
12 | notebook_path = os.path.join(os.path.dirname(__file__), 'testnb.ipynb')
13 | with open(notebook_path) as f:
14 | nb = nbformat.read(f, as_version=4)
15 |
16 | proc = ExecutePreprocessor(timeout=600)
17 | proc.allow_errors = True
18 | proc.preprocess(nb, {'metadata': {'path': '/'}})
19 |
20 | cls.cells = nb.cells
21 |
22 | def test_expr(self):
23 | cell = self.cells[0]
24 | self.assertEqual(cell.execution_count, 1)
25 | res = '{<<1, 1>>, <<1, 2>>, <<1, 3>>, <<2, 2>>, <<2, 3>>, <<3, 3>>}'
26 | self.assertEqual(cell.outputs[0]['text'], res)
27 |
28 | def test_module(self):
29 | cell = self.cells[1]
30 | self.assertEqual(cell.execution_count, 2)
31 | self.assertEqual(cell.outputs, [])
32 |
33 | def test_tlc_run(self):
34 | cell = self.cells[2]
35 | self.assertEqual(cell.execution_count, 3)
36 | text = "".join([o.text for o in cell.outputs])
37 | self.assertTrue('97 states generated' in text)
38 |
39 | def test_expr_error(self):
40 | cell = self.cells[3]
41 | self.assertEqual(cell.execution_count, 4)
42 | text = cell.outputs[0].text
43 | self.assertTrue('Could not parse ' in text)
44 |
--------------------------------------------------------------------------------
/tests/testnb.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "{e \\in ( (1..3)\\X(1..3) ): e[1] <= e[2]}"
10 | ]
11 | },
12 | {
13 | "cell_type": "code",
14 | "execution_count": null,
15 | "metadata": {},
16 | "outputs": [],
17 | "source": [
18 | "------------------------------ MODULE DieHardTLA ------------------------------\n",
19 | "EXTENDS Integers\n",
20 | "\n",
21 | "VARIABLES small, big \n",
22 | " \n",
23 | "TypeOK == /\\ small \\in 0..3 \n",
24 | " /\\ big \\in 0..5\n",
25 | "\n",
26 | "Init == /\\ big = 0 \n",
27 | " /\\ small = 0\n",
28 | "\n",
29 | "FillSmall == /\\ small' = 3 \n",
30 | " /\\ big' = big\n",
31 | "\n",
32 | "FillBig == /\\ big' = 5 \n",
33 | " /\\ small' = small\n",
34 | "\n",
35 | "EmptySmall == /\\ small' = 0 \n",
36 | " /\\ big' = big\n",
37 | "\n",
38 | "EmptyBig == /\\ big' = 0 \n",
39 | " /\\ small' = small\n",
40 | "\n",
41 | "SmallToBig == IF big + small =< 5\n",
42 | " THEN /\\ big' = big + small\n",
43 | " /\\ small' = 0\n",
44 | " ELSE /\\ big' = 5\n",
45 | " /\\ small' = small - (5 - big)\n",
46 | " \n",
47 | "BigToSmall == IF big + small =< 3\n",
48 | " THEN /\\ big' = 0 \n",
49 | " /\\ small' = big + small\n",
50 | " ELSE /\\ big' = small - (3 - big)\n",
51 | " /\\ small' = 3\n",
52 | "\n",
53 | "Next == \\/ FillSmall \n",
54 | " \\/ FillBig \n",
55 | " \\/ EmptySmall \n",
56 | " \\/ EmptyBig \n",
57 | " \\/ SmallToBig \n",
58 | " \\/ BigToSmall \n",
59 | " \n",
60 | "Spec == Init /\\ [][Next]_<> \n",
61 | "============================================================================="
62 | ]
63 | },
64 | {
65 | "cell_type": "code",
66 | "execution_count": null,
67 | "metadata": {},
68 | "outputs": [],
69 | "source": [
70 | "%tlc:DieHardTLA\n",
71 | "SPECIFICATION\n",
72 | "Spec\n",
73 | "INVARIANT\n",
74 | "TypeOK"
75 | ]
76 | },
77 | {
78 | "cell_type": "code",
79 | "execution_count": null,
80 | "metadata": {},
81 | "outputs": [],
82 | "source": [
83 | "!!!"
84 | ]
85 | }
86 | ],
87 | "metadata": {
88 | "kernelspec": {
89 | "display_name": "TLA⁺",
90 | "language": "tla",
91 | "name": "tlaplus_jupyter"
92 | },
93 | "language_info": {
94 | "codemirror_mode": "tlaplus",
95 | "file_extension": ".tla",
96 | "mimetype": "text/x-tlaplus",
97 | "name": "tlaplus"
98 | }
99 | },
100 | "nbformat": 4,
101 | "nbformat_minor": 2
102 | }
103 |
--------------------------------------------------------------------------------
/tlaplus_jupyter/__init__.py:
--------------------------------------------------------------------------------
1 | __version__ = '0.1'
2 |
3 | from .kernel import TLAPlusKernel
4 |
--------------------------------------------------------------------------------
/tlaplus_jupyter/__main__.py:
--------------------------------------------------------------------------------
1 | from ipykernel.kernelapp import IPKernelApp
2 | from . import TLAPlusKernel
3 |
4 | IPKernelApp.launch_instance(kernel_class=TLAPlusKernel)
5 |
--------------------------------------------------------------------------------
/tlaplus_jupyter/assets/kernel.js:
--------------------------------------------------------------------------------
1 | define(['codemirror/addon/mode/simple', "base/js/namespace", 'codemirror/lib/codemirror'], function (cmsm, IPython, CodeMirror) {
2 |
3 | load_mode = function () {
4 |
5 | console.log("tlaplus kernel.js loaded");
6 |
7 | var re_join = function (arr) {
8 | return new RegExp('^' + arr.map(function (w) { return w.source }).join('|') + '$')
9 | };
10 |
11 | var reserwed_words_re = re_join([
12 | /ACTION/, /ASSUME/, /ASSUMPTION/, /AXIOM/, /BY/, /CASE/, /CHOOSE/, /CONSTANTS/,
13 | /CONSTANT/, /COROLLARY/, /DEF/, /DEFINE/, /DEFS/, /DOMAIN/, /ELSE/, /ENABLED/,
14 | /EXCEPT/, /EXTENDS/, /HAVE/, /HIDE/, /IF/, /INSTANCE/, /IN/, /LET/, /LAMBDA/,
15 | /LEMMA/, /LOCAL/, /MODULE/, /NEW/, /OBVIOUS/, /OMITTED/, /ONLY/, /OTHER/, /PICK/,
16 | /PROOF/, /PROPOSITION/, /PROVE/, /QED/, /RECURSIVE/, /SF_/, /STATE/, /SUFFICES/,
17 | /SUBSET/, /TAKE/, /TEMPORAL/, /THEN/, /THEOREM/, /UNCHANGED/, /UNION/, /USE/,
18 | /VARIABLES/, /VARIABLE/, /WF_/, /WITH/, /WITNESS/
19 | ]);
20 |
21 | // < IDENTIFIER : | | | | | | "@" >
22 | // < #CASE0 : "_" ( | "_" | )* ( | "_" | )* >
23 | // | < #CASE1 : ( | "_" | )* ( | "_" | )* >
24 | // | < #CASE2 : ("W" | "S") ( ( ["a"-"z","A"-"E", "G"-"Z", "_"] | ) ( | "_" | )* )? >
25 | // | < #CASE3 : ("WF" | "SF") ( ( | ) ( | "_" | )* )? >
26 | // | < #CASE6 : ( ["a"-"z","A"-"R", "T"-"V", "X"-"Z"]) ( | "_" | )* >
27 | // | < #CASEN : ()+ ( | | "_" )* >
28 | var identifier_re = /(?!WF_|SF_)\w*[A-Za-z]\w*/;
29 | var function_re = /(?!WF_|SF_)\w*[A-Za-z]\w*\s*(?=\()/;
30 | var definition_re = /(?!WF_|SF_)\w*[A-Za-z]\w*\s*(?===)/;
31 |
32 | // ()+
33 | // | "0"
34 | // | ("\\" ["o","O"] (["0"-"7"])+)
35 | // | ("\\" ["b","B"] (["0","1"])+)
36 | // | ("\\" ["h","H"] (["0"-"9","a"-"f","A"-"F"])+ )
37 | var number_re = /\d+|\\[oO][0-7]+|\\[bB][0-1]+|\\[bB][\da-fA-F]+/;
38 |
39 | // "\""
40 | // ( (~["\"", "`", "\n", "\r", "\\" ])
41 | // | ( "`" ( ~["'" ] )* "'")
42 | // | ( "\\" ["n","t","r","f","\\", "\""] )
43 | // )*
44 | // "\""
45 | var string_re = /"(?:[^\\"]|\\.)*"?/;
46 |
47 | var extra_ops_re = re_join([
48 | /\\E/, /\\exists/, /\\A/, /\\forall/, /\\EE/, /\\AA/,/::/, /<>_/, />>/, /\|->/,
49 | /->/, /<-/
50 | ]);
51 | var prefix_re = re_join([
52 | /\\lnot/, /\\neg/, /~/, /\[\]/, /<>/
53 | ]);
54 | var infix_re = re_join([
55 | /\\approx/, /\\asymp/, /\\bigcirc/, /\\bullet/, /\\cap/, /\\cdot/,
56 | /\\circ/, /\\cong/, /\\cup/, /\\div/, /\\doteq/, /\\equiv/, /\\geq/, /\\gg/, /\\in/,
57 | /\\intersect/, /\\union/, /\\land/, /\\leq/, /\\ll/, /\\lor/, /\\o/, /\\odot/,
58 | /\\ominus/, /\\oplus/, /\\oslash/, /\\otimes/, /\\preceq/, /\\prec/, /\\propto/,
59 | /\\simeq/, /\\sim/, /\\sqcap/, /\\sqcup/, /\\sqsubseteq/, /\\sqsupseteq/, /\\sqsubset/,
60 | /\\sqsupset/, /\\star/, /\\subseteq/, /\\subset/, /\\succeq/, /\\succ/, /\\supseteq/,
61 | /\\supset/, /\\uplus/, /\\wr/, /\\/, /~>/, /=>/, /=/, /\*\*/, /<=>/, /<:/, /<=/, /=/, />/, /\.\.\./, /\.\./, /\|\|/,
64 | /\|/, /\|-/, /\|=/, /\$\$/, /\$/, /\?\?/, /%%/, /%/, /@@/, /!!/, /:>/, /:=/, /::=/,
65 | /\(\+\)/, /\(-\)/, /\(\.\)/, /\(\/\)/, /\(\\X\)/, /\\notin/, /\\times/, /\\X/
66 | ]);
67 | var postfix_re = re_join([/'/, /\^\+/, /\^\*/, /\^#/, /-\./]);
68 |
69 | var pluscal_reserved_words_re = re_join([
70 | /fair/, /algorithm/, /assert/, /await/, /begin/, /end/, /call/, /define/, /do/,
71 | /either/, /or/, /goto/, /if/, /then/, /else/, /elsif/, /macro/, /print/, /procedure/,
72 | /process/, /return/, /skip/, /variables/, /variable/, /while/, /with/, /when/
73 | ]);
74 | var pluscal_label_re = /\s*(?!WF_|SF_)\w*[A-Za-z]\w*:/;
75 |
76 | var cfg_reserwed_words_re = re_join([
77 | /CONSTANTS/, /CONSTANT/, /CONSTRAINTS/, /CONSTRAINT/, /ACTION_CONSTRAINTS/,
78 | /ACTION_CONSTRAINT/, /INVARIANTS/, /INVARIANT/, /INIT/, /NEXT/, /VIEW/, /SYMMETRY/,
79 | /SPECIFICATION/, /PROPERTY/, /PROPERTIES/, /TYPE_CONSTRAINT/, /TYPE/
80 | ]);
81 |
82 | CodeMirror.defineSimpleMode("tlaplus", {
83 |
84 | start: [
85 | { regex: cfg_reserwed_words_re, token: "keyword" },
86 | { regex: reserwed_words_re, token: "keyword" },
87 | { regex: definition_re, token: "variable-2" },
88 | { regex: function_re, token: "variable-3" },
89 | { regex: identifier_re, token: "variable" },
90 |
91 | { regex: number_re, token: "number" },
92 | { regex: string_re, token: "string" },
93 |
94 | { regex: /\\\*.*/, token: "comment" },
95 | { regex: /\(\*/, token: "comment", push: "block_comment" },
96 |
97 | { regex: prefix_re, token: "atom" },
98 | { regex: infix_re, token: "atom" },
99 | { regex: postfix_re, token: "atom" },
100 | { regex: extra_ops_re, token: "atom"}
101 | ],
102 |
103 | pluscal: [
104 | { regex: pluscal_reserved_words_re, token: "keyword" },
105 | { regex: reserwed_words_re, token: "keyword" },
106 | { regex: pluscal_label_re, token: "atom", sol: true },
107 | { regex: identifier_re, token: "variable" },
108 |
109 | { regex: number_re, token: "number" },
110 | { regex: string_re, token: "string" },
111 |
112 | { regex: /\\\*.*/, token: "comment" },
113 | { regex: /\(\*/, token: "comment", push: "block_comment" },
114 | { regex: /.*?\*\)/, token: "keyword", next: "start"},
115 |
116 | { regex: prefix_re, token: "atom" },
117 | { regex: infix_re, token: "atom" },
118 | { regex: postfix_re, token: "atom" },
119 | { regex: extra_ops_re, token: "atom"}
120 | ],
121 |
122 | block_comment: [
123 | { regex: /.*?--(?:algorithm|fair)/, token: "keyword", next: "pluscal" },
124 | { regex: /.*?\(\*/, token: "comment", push: "block_comment" },
125 | { regex: /.*?\*\)/, token: "comment", pop: true},
126 | { regex: /.*/, token: "comment" }
127 | ],
128 |
129 | meta: {
130 | dontIndentStates: ["block_comment"],
131 | lineComment: '\\*'
132 | }
133 | });
134 |
135 | CodeMirror.defineMIME("text/x-tlaplus", "tlaplus");
136 |
137 | // Assorted kludges to deal with the fact that all this stuff can be loaded
138 | // after the notebook was fully rendered.
139 |
140 | // Set default mode for a new cells
141 | IPython.CodeCell.options_default["cm_config"]["mode"] = "tlaplus";
142 |
143 | // Highlight existing code cells
144 | [...document.querySelectorAll('.code_cell .CodeMirror')].forEach(c => {
145 | c.CodeMirror.setOption('mode', 'tlaplus');
146 | });
147 |
148 | Jupyter.notebook.get_cells().forEach(function(c) {
149 | // Fix mode on existing code cells
150 | if (c.cell_type == "code") {
151 | c._options.cm_config['mode'] = 'tlaplus';
152 | }
153 | // Re-render markdown in case it has code block with our mode
154 | else if (c.cell_type == "markdown") {
155 | c.unrender();
156 | c.render();
157 | }
158 | });
159 | }
160 |
161 | return {
162 | onload: function () {
163 | load_mode();
164 | // Enforce late loading:
165 | // setTimeout(load_mode, 3000);
166 | }
167 | }
168 | });
169 |
--------------------------------------------------------------------------------
/tlaplus_jupyter/install.py:
--------------------------------------------------------------------------------
1 | # coding: utf-8
2 |
3 | import argparse
4 | import json
5 | import os
6 | import sys
7 | import shutil
8 | import binascii
9 |
10 | from future.standard_library import install_aliases
11 | install_aliases()
12 | from urllib.request import urlretrieve
13 |
14 | from jupyter_client.kernelspec import KernelSpecManager
15 | from IPython.utils.tempdir import TemporaryDirectory
16 |
17 | TOOLS_URI = "https://github.com/tlaplus/tlaplus/releases/download/v1.7.2/tla2tools.jar"
18 |
19 | kernel_json = {
20 | "argv": [sys.executable, "-m", "tlaplus_jupyter", "-f", "{connection_file}"],
21 | "display_name": "TLA⁺",
22 | "language": "tla",
23 | "codemirror_mode": "tlaplus"
24 | }
25 |
26 | def install_my_kernel_spec(user=True, prefix=None):
27 | with TemporaryDirectory() as td:
28 | os.chmod(td, 0o755) # Starts off as 700, not user readable
29 | with open(os.path.join(td, 'kernel.json'), 'w') as f:
30 | json.dump(kernel_json, f, sort_keys=True)
31 |
32 | # copy kernel.js
33 | js_path = os.path.join(os.path.dirname(__file__), 'assets', 'kernel.js')
34 | shutil.copy(js_path, td)
35 |
36 | print('Installing Jupyter kernel spec')
37 | KernelSpecManager().install_kernel_spec(td, 'tlaplus_jupyter', user=user, prefix=prefix)
38 |
39 | def _is_root():
40 | try:
41 | return os.geteuid() == 0
42 | except AttributeError:
43 | return False # assume not an admin on non-Unix platforms
44 |
45 | def main(argv=None):
46 | ap = argparse.ArgumentParser(formatter_class=argparse.RawTextHelpFormatter)
47 | ap.add_argument('--user', action='store_true',
48 | help="Install to the per-user kernels registry. Default if not root.")
49 | ap.add_argument('--sys-prefix', action='store_true',
50 | help="Install to sys.prefix (e.g. a virtualenv or conda env)")
51 | ap.add_argument('--prefix',
52 | help="Install to the given prefix. "
53 | "Kernelspec will be installed in\n"
54 | "{PREFIX}/share/jupyter/kernels/")
55 | ap.add_argument('--tlc-exec-stats', choices=['share', 'no-id', 'disable'],
56 | default="share",
57 | help="Share execution statistics to guide TLC development.\n"
58 | " share -- always share execution statistics\n"
59 | " no-id -- share without installation identifier\n"
60 | " disable -- never share\n"
61 | "Default is to share. Re-installation with a new value will override\n"
62 | "previous decision. Details of data collected can be found at\n"
63 | "https://github.com/tlaplus/tlaplus/blob/master/tlatools/src/util/ExecutionStatisticsCollector.md"
64 | )
65 | args = ap.parse_args(argv)
66 |
67 | if args.sys_prefix:
68 | args.prefix = sys.prefix
69 | if not args.prefix and not _is_root():
70 | args.user = True
71 |
72 | install_my_kernel_spec(user=args.user, prefix=args.prefix)
73 |
74 | # install tla2tools.jar
75 | vendor_dir = os.path.join(os.path.dirname(__file__), 'vendor')
76 | if not os.path.isdir(vendor_dir):
77 | os.mkdir(vendor_dir)
78 | jar_path = os.path.join(vendor_dir, 'tla2tools.jar')
79 | print("Downloading tla2tools.jar to " + jar_path)
80 | urlretrieve(TOOLS_URI, jar_path)
81 |
82 | # install stats collector id
83 | tla_dir = os.path.join(os.path.expanduser("~"), ".tlaplus")
84 | if not os.path.isdir(tla_dir):
85 | os.mkdir(tla_dir)
86 | statfile_path = os.path.join(tla_dir, "esc.txt")
87 |
88 | old_content = None
89 | if os.path.isfile(statfile_path):
90 | with open(statfile_path, "r") as f:
91 | old_content = f.read().strip()
92 |
93 | with open(statfile_path, "w") as f:
94 | if args.tlc_exec_stats == "share":
95 | # do not rewrite id if it is already present
96 | if old_content == None or len(old_content) != 32:
97 | token = binascii.b2a_hex(os.urandom(16)).decode()
98 | f.write(token)
99 | else:
100 | f.write(old_content)
101 | elif args.tlc_exec_stats == "no-id":
102 | f.write("RANDOM_IDENTIFIER")
103 | else:
104 | f.write("NO_STATISTICS")
105 | f.write("\n")
106 |
107 | if __name__ == '__main__':
108 | main()
109 |
--------------------------------------------------------------------------------
/tlaplus_jupyter/kernel.py:
--------------------------------------------------------------------------------
1 | # coding: utf-8
2 |
3 | import os
4 | import tempfile
5 | import re
6 | import logging
7 | import shutil
8 | import psutil
9 | import subprocess
10 | import traceback
11 |
12 | from ipykernel.kernelbase import Kernel
13 |
14 |
15 | class TLAPlusKernel(Kernel):
16 | implementation = 'tlaplus_jupyter'
17 | implementation_version = '0.1'
18 | language = 'TLA⁺'
19 | language_version = '2.13'
20 | language_info = {
21 | 'name': 'tlaplus',
22 | 'mimetype': 'text/x-tlaplus',
23 | 'file_extension': '.tla',
24 | 'codemirror_mode': 'tlaplus'
25 | }
26 | banner = "TLA⁺"
27 |
28 | def __init__(self, *args, **kwargs):
29 | super(TLAPlusKernel, self).__init__(*args, **kwargs)
30 | self.modules = {}
31 | self.vendor_path = os.path.join(os.path.dirname(__file__), 'vendor')
32 | self.logfile = None
33 |
34 | def get_workspace(self):
35 | workspace = tempfile.mkdtemp()
36 | # dump defined modules
37 | for module in self.modules:
38 | f = open(os.path.join(workspace, module + '.tla'), 'w')
39 | f.write(self.modules[module])
40 | f.close()
41 | return workspace
42 |
43 | def java_command(self):
44 | return [
45 | 'java',
46 | '-XX:+UseParallelGC',
47 | '-Dtlc2.TLC.ide=tlaplus_jupyter',
48 | '-cp', os.path.join(self.vendor_path, 'tla2tools.jar')
49 | ]
50 |
51 | def run_proc(self, cmd, workspace):
52 | logging.info("run_proc started '%s'", cmd)
53 |
54 | proc = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, cwd=workspace)
55 | out, _ = proc.communicate()
56 | out = out.decode()
57 |
58 | logging.info(out)
59 | logging.info("run_proc finished (rc=%d)", proc.returncode)
60 |
61 | return (out, proc.returncode)
62 |
63 | def respond(self, res):
64 | self.send_response(self.iopub_socket, 'stream', {
65 | 'name': 'stdout',
66 | 'text': res
67 | })
68 |
69 | return {
70 | 'status': 'ok',
71 | 'execution_count': self.execution_count,
72 | 'user_expressions': {},
73 | }
74 |
75 | def respond_with_error(self, err):
76 | self.send_response(self.iopub_socket, 'stream', {
77 | 'name': 'stderr',
78 | 'text': err
79 | })
80 | return {
81 | 'status': 'error',
82 | 'execution_count': self.execution_count,
83 | 'user_expressions': {},
84 | }
85 |
86 | def do_execute(self, payload, silent, store_history=True, user_expressions=None,
87 | allow_stdin=False):
88 | """Route execute request depending on type."""
89 |
90 | try:
91 | # module
92 | if re.match(r'^\s*-----*\s*MODULE\s', payload):
93 | return self.eval_module(payload)
94 |
95 | # run config
96 | elif re.match(r'^\s*%tlc:', payload):
97 | return self.eval_tlc_config(payload)
98 |
99 | # tollge log collection
100 | elif re.match(r'^\s*%log', payload):
101 | return self.toggle_log(payload)
102 |
103 | # otherwise treat payload as a constant expression
104 | else:
105 | return self.eval_expr(payload)
106 |
107 | except Exception:
108 | return self.respond_with_error(traceback.format_exc())
109 |
110 | def eval_module(self, module_src):
111 |
112 | logging.info("eval_module '%s'", module_src)
113 |
114 | match = re.match(r'^\s*-----*\s*MODULE\s+(\w+)\s', module_src)
115 | if not match:
116 | return self.respond_with_error("Can't parse module name, please check module header.")
117 |
118 | module_name = match.group(1)
119 | self.modules[module_name] = module_src
120 |
121 | workspace = self.get_workspace()
122 | new_src = None
123 |
124 | cmd = self.java_command()
125 | cmd += ['tla2sany.SANY']
126 | cmd += [module_name + '.tla']
127 |
128 | out, rc = self.run_proc(cmd, workspace)
129 |
130 | if rc != 0:
131 | shutil.rmtree(workspace)
132 | return self.respond_with_error(out)
133 |
134 | # run pcal.trans if needed
135 | if '--algorithm' in module_src or '--fair' in module_src:
136 | cmd = self.java_command()
137 | cmd += ['pcal.trans']
138 | cmd += [module_name + '.tla']
139 |
140 | out, rc = self.run_proc(cmd, workspace)
141 | if rc != 0:
142 | shutil.rmtree(workspace)
143 | return self.respond_with_error(out)
144 |
145 | # read rewritten tla file with translation
146 | with open(os.path.join(workspace, module_name + '.tla')) as f:
147 | new_src = f.read()
148 |
149 | self.modules[module_name] = new_src
150 | logging.info("eval_module update module src '%s'", new_src)
151 |
152 | shutil.rmtree(workspace)
153 | return {
154 | 'status': 'ok',
155 | 'execution_count': self.execution_count,
156 | 'payload': [
157 | {
158 | "source": "set_next_input",
159 | "text": new_src,
160 | "replace": True,
161 | } if new_src else {}
162 | ],
163 | 'user_expressions': {},
164 | }
165 |
166 | def eval_tlc_config(self, cfg):
167 | logging.info("eval_tlc_config '%s'", cfg)
168 |
169 | tlc_re = r'^\s*%tlc:([^\s]*)(.*)'
170 | match = re.match(tlc_re, cfg)
171 | module_name = match.group(1)
172 | extra_params = match.group(2).strip()
173 | extra_params = [] if extra_params == '' else extra_params.split()
174 |
175 | # bail out if module is not found
176 | if module_name not in self.modules:
177 | err = "Module '{}' not found.\n".format(module_name)
178 | err += "Module should be defined and evaluated in some cell before TLC run."
179 | return self.respond_with_error(err)
180 |
181 | # XXX: move to with and fill
182 | workspace = self.get_workspace()
183 |
184 | # dump config
185 | # XXX: with
186 | cfg = re.sub(tlc_re, '', cfg)
187 | f = open(os.path.join(workspace, 'run.cfg'), 'w')
188 | f.write(cfg)
189 | f.close()
190 |
191 | cmd = self.java_command()
192 | cmd += ['tlc2.TLC']
193 | cmd += ['-workers', str(psutil.cpu_count())]
194 | cmd += ['-config', 'run.cfg']
195 | cmd += extra_params
196 | cmd += [module_name + '.tla']
197 |
198 | # run TLC and redirect stderr to stdout
199 | logging.info("running '%s'", cmd)
200 | proc = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, cwd=workspace)
201 | with proc.stdout:
202 | for line in iter(proc.stdout.readline, b''):
203 | self.send_response(self.iopub_socket, 'stream', {
204 | 'name': 'stdout',
205 | 'text': line.decode()
206 | })
207 | logging.info("> ", line.decode())
208 |
209 | # wait for proc to exit and set returncode
210 | proc.wait()
211 | logging.info("tlc finished with rc=%d", proc.returncode)
212 |
213 | shutil.rmtree(workspace)
214 |
215 | # make sence to show all command if some TLC keywords were set
216 | if extra_params and proc.returncode != 0:
217 | self.send_response(self.iopub_socket, 'stream', {
218 | 'name': 'stderr',
219 | 'text': "Failed command was: '%s'" % ' '.join(cmd)
220 | })
221 |
222 | return {
223 | 'status': 'ok' if proc.returncode == 0 else 'error',
224 | 'execution_count': self.execution_count,
225 | 'user_expressions': {},
226 | }
227 |
228 |
229 | def eval_expr(self, expr):
230 |
231 | logging.info("got expression '%s'", expr)
232 |
233 | # Wrap output in EXPR_BEGIN/EXPR_END to catch it later.
234 | # That method is due to github.com/will62794 and looks much nicer then
235 | # a regex-based set matching used in tla toolbox itself.
236 | model_src = """---- MODULE expr ----
237 | EXTENDS Naturals, Reals, Sequences, Bags, FiniteSets, TLC
238 | ASSUME PrintT("EXPR_BEGIN") /\ PrintT(
239 | %s
240 | ) /\ PrintT("EXPR_END")
241 | ====\n""" % (expr)
242 | self.modules['expr'] = model_src
243 |
244 | logging.info("eval_expr final source '%s'", model_src)
245 |
246 | workspace = self.get_workspace()
247 |
248 | # dump config
249 | f = open(os.path.join(workspace, 'run.cfg'), 'w')
250 | f.write('')
251 | f.close()
252 |
253 | cmd = self.java_command()
254 | cmd += ['tlc2.TLC']
255 | cmd += ['-config', 'run.cfg']
256 | cmd += ['expr.tla']
257 |
258 | out, rc = self.run_proc(cmd, workspace)
259 |
260 | shutil.rmtree(workspace)
261 |
262 | raw_lines = out.splitlines()
263 |
264 | if rc != 0 or not ('"EXPR_BEGIN"' in raw_lines and '"EXPR_END"' in raw_lines):
265 | return self.respond_with_error(model_src + "\n" + out)
266 |
267 | start = raw_lines.index('"EXPR_BEGIN"')
268 | stop = raw_lines.index('"EXPR_END"')
269 | res = "\n".join(raw_lines[start+1:stop])
270 |
271 | return self.respond(res)
272 |
273 |
274 | def toggle_log(self, payload):
275 | """Runtime accessible logger"""
276 |
277 | cmd = re.match(r'^\s*%log\s*([^\s]*)', payload).group(1)
278 |
279 | if cmd == "on":
280 | if not self.logfile:
281 | self.logfile = tempfile.NamedTemporaryFile(delete=False)
282 |
283 | handler = logging.FileHandler(self.logfile.name, 'a')
284 | logger = logging.getLogger()
285 | logger.setLevel(logging.DEBUG)
286 | logger.addHandler(handler)
287 |
288 | return self.respond("Logging enabled")
289 | else:
290 | return self.respond("Logging already enabled")
291 |
292 | elif cmd == "off":
293 | logger = logging.getLogger()
294 | logger.setLevel(logging.ERROR)
295 | for handle in logger.handlers:
296 | logger.removeHandler(handle)
297 | if self.logfile:
298 | self.logfile.close()
299 | os.unlink(self.logfile.name)
300 | self.logfile = None
301 |
302 | return self.respond("Logging disabled")
303 |
304 | elif cmd == "":
305 | if self.logfile:
306 | with open(self.logfile.name, 'r') as file:
307 | data = file.read()
308 | return self.respond(data)
309 | else:
310 | return self.respond_with_error("You need to enable logging first by evaluating '%log on'")
311 |
312 | else:
313 | return self.respond_with_error("Unknown log command. Valid command are '%log'/'%log on'/'%log off'")
314 |
--------------------------------------------------------------------------------