├── .gitignore
├── README.md
├── articles
├── KarmadaSchedulerPolicy.md
├── KubernetesDescheduler.md
├── KubernetesDeveloperHandbook.md
├── kube-scheduler-intro.md
└── lazy-pulling.md
└── snapshots
├── karmada-arch.png
├── karmada-roadmap.jpeg
└── karmada-schedule-process.jpeg
/.gitignore:
--------------------------------------------------------------------------------
1 | .vscode
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 云原生知识学习参考
2 | 围绕`云原生`知识体系,收集一些看过的有价值的文章。仅供学习参考,不得用于商业用途。
3 |
4 | 🌱 持续更新,`欢迎投稿!`
5 |
6 | ⭐️⭐️⭐️⭐️️️️ ️️️ 解读技术真谛,洞见技术趋势。必读。
7 | ⭐️⭐️⭐️ 技术解读深入浅出,生产环境最佳实践。强烈推荐。
8 | ⭐️⭐️️️️ 技术原理解析,讲解透彻。好文推荐。
9 | ⭐️️️️ 技术入门及使用场景介绍。拓展视野。
10 |
11 | 🌛 ️ 工具集、经验分享及技术趋势。
12 |
13 | 🎉 通告:[CNCF 项目远程带薪实习机会来啦,简历加分报酬多多!](https://mp.weixin.qq.com/s/wQyMTtw7VPpm04XhiPLltg) ([官方链接](https://github.com/cncf/mentoring/blob/main/lfx-mentorship/2021/03-Fall/README.md#timeline))
14 |
15 | --------------------------------------------------------
16 |
17 | ## Kubernetes
18 | * [万字长文:K8s 创建 pod 时,背后到底发生了什么?](https://mp.weixin.qq.com/s/HjoU_RKBQKPCQPEQZ_fBNA) ⭐️⭐️
19 | * [后 Kubernetes 时代的虚拟机管理技术之 Virtual-Kubelet 篇](https://mp.weixin.qq.com/s/Gn4O-NxVbVuagrc4uOO1RA) ⭐️
20 | * [深入理解 Kubelet 中的 PLEG is not healthy](https://fuckcloudnative.io/posts/understanding-the-pleg-is-not-healthy/) ⭐️
21 | * [Kubernetes 故障检测和自愈工具 NPD](https://mp.weixin.qq.com/s/n-t_hoo7CNTLLsjyiVD_jQ) ⭐️
22 | * [kubelet 配置资源预留的姿势](https://mp.weixin.qq.com/s/Wg9o59wvHkQV_euihCkOjw) ⭐️
23 | * [使用 kube-vip 搭建高可用 Containerd Kubernetes 集群](https://mp.weixin.qq.com/s/ypIObV4ARzo-DOY81EDc_Q) ️⭐️
24 | * [Kubernetes API 访问控制机制简介](https://mp.weixin.qq.com/s/WTABqEpp5ZWEAl4dbVySHQ) ⭐️
25 | * [调试 Kubernetes 工作负载的最简单方法](https://mp.weixin.qq.com/s/Wi7eo2hJ7TNqu_UnHvx5pg) ⭐️
26 | * [Kubernetes CRD多版本与升级机制](https://developer.aliyun.com/article/798704) ⭐️
27 | * [如何定制Kubernetes调度算法?](https://mp.weixin.qq.com/s/hSCqzT4zxTZ2Vj4T1QHWeg) ⭐️
28 |
29 | ## Etcd
30 | * [万级K8s集群背后etcd稳定性及性能优化实践](https://mp.weixin.qq.com/s/78feo0dYKcvMAv84Q24zuw) ⭐️⭐️⭐️
31 |
32 | ## Client-go
33 | * [client-go 之 Indexer 的理解](https://mp.weixin.qq.com/s/xCa6yZTk0X76IZhOx6IbHQ)️ ⭐️⭐️
34 |
35 | ## Multi-Clusters
36 | * [从karmada API角度分析多云环境下的应用资源编排:设计与实现](https://zhuanlan.zhihu.com/p/407990257?utm_source=wechat_session&utm_medium=social&utm_oi=46685577281536&utm_content=group2_article&utm_campaign=shareopn&wechatShare=1&s_r=0) ⭐️⭐️
37 |
38 | ## Container
39 | * [一文搞定 Containerd 的使用](https://mp.weixin.qq.com/s/--t74RuFGMmTGl2IT-TFrg) ⭐️⭐️⭐️
40 | * [Containerd深度剖析-runtime篇](https://mp.weixin.qq.com/s/F9-ZtsKBsrPLmtexCnaCmg) ⭐️
41 | * [Kubernetes CRI 分析 - kubelet 创建 Pod 分析](https://mp.weixin.qq.com/s/AG6H_mPuTu6-_ISQWu3YHw?forceh5=1) ⭐️
42 | * [彻底搞懂容器技术的基石: cgroup](https://mp.weixin.qq.com/s/6Ts6-aZDr8qOdnaNUqwTFQ) ⭐️
43 |
44 | ## WebAssembly
45 | * [初识 WebAssembly:灵活、可移植、高性能](https://mp.weixin.qq.com/s/sfuXGhDSCNxfElx55aboew) ⭐️
46 |
47 | ## Network
48 | * [网易轻舟对 Cilium 容器网络的探索和实践](https://mp.weixin.qq.com/s/I8eTBjwp9Nh5TmYmC94VoA) ⭐️⭐️
49 | * [eBPF 如何简化服务网格](https://mp.weixin.qq.com/s/C_budclaSOBufqQYhdh3DA) ⭐️⭐️
50 | * [读完这篇文章,就再也不怕遇到网络问题啦!](https://mp.weixin.qq.com/s/Tnerf7M_a6HUC4ucaOWzeg) ⭐️⭐️
51 | * [深入理解CNI(容器网络接口)](https://mp.weixin.qq.com/s/TpE7ZFh-b1HXvq9HyMZ17g) ⭐️⭐️
52 | * [图解 K8S 控制器 Node 生命周期管理](https://cloud.tencent.com/developer/article/1645033) ⭐️⭐️
53 | * [追踪 Kubernetes 中的网络流量](https://mp.weixin.qq.com/s/GRq7GrQD0nfYvPNpUrzHng) ⭐️⭐️
54 | * [译文:服务网格将使用 eBPF ?是的,但 Envoy 代理将继续存在](https://mp.weixin.qq.com/s/daltoMGxL6aN4BcyNX7sig) ⭐️
55 | * [Packet Traveling](https://www.practicalnetworking.net/series/packet-traveling/packet-traveling/) ⭐️
56 | * [保姆级教程,从概念到实践帮你快速上手 Apache APISIX Ingress](https://mp.weixin.qq.com/s/PixbW7-sddyU8MIvL1FBYA) ⭐️
57 | * [5 种最常见的 DNS 故障诊断及问题处理方法](https://mp.weixin.qq.com/s/-hsgZnhtPcE66Kscc_e8WA) ⭐️
58 | * [Cilium 容器网络的落地实践](https://mp.weixin.qq.com/s/p_yBxW31tGPacALVai5kZg?forceh5=1) ⭐️
59 | * [实践案例 | Kube-OVN在字节跳动的应用场景和技术探索](https://mp.weixin.qq.com/s/qMsyCEKXufa6UOz8i6zZeg) ⭐️
60 | * [eBPF 科普第一弹| 初识 eBPF,你应该知道的知识](https://mp.weixin.qq.com/s/jEgvSYwKEFDr3tuiuNFqxg) ⭐️
61 | * [云原生网络利器--Cilium 总览](https://mp.weixin.qq.com/s/_k8oXtrxkFe3EyeB3KwnrA) ⭐️
62 | * [云原生网络利器--Cilium 之 eBPF 篇](https://mp.weixin.qq.com/s/Q0iSZ1AsJmefCM0lPty6jA) ⭐️
63 |
64 | ## Storage
65 | * [如何接入 K8s 持久化存储?K8s CSI 实现机制浅析](https://mp.weixin.qq.com/s/HZhe8a7MHehs6sBOE0ck6Q) ⭐️
66 | * [机器学习平台统一化分布式存储Ceph的进阶优化](https://mp.weixin.qq.com/s/TiBbmjW-YW0tx2nStI4XBA) ⭐️
67 |
68 | ## Security
69 | * [云原生安全开源项目汇总](https://mp.weixin.qq.com/s/y7Et96lahN9raRlIzB3dCg) ⭐️
70 | * [震惊!!K8s 全面升级 Pod 安全特性:PodSecurity (v1.22)](https://mp.weixin.qq.com/s/7qcVmYVOdi8OjbKnnURmLg) ⭐️
71 | * [Kyverno 和 OPA/Gatekeeper 的一点对比](https://mp.weixin.qq.com/s/hqDTM1nnpZn7GzBviGdEcg) ⭐️
72 | * [Open Policy Agent(OPA) 入门实践](https://mp.weixin.qq.com/s?__biz=MzI5ODk5ODI4Nw==&mid=2247515795&idx=5&sn=6c29105975450ed17b14760d63c9ea32&chksm=ec9fb1f3dbe838e56e395704bd077af1cf75f7a7b0be441f6f9d9e346f2fd33b2ecdba22d025&mpshare=1&scene=1&srcid=120704l3t0KjhzULFquOeekq&sharer_sharetime=1638855116202&sharer_shareid=bcf38af5e57bf2958c0f52953575a7e6&version=3.1.20.90367&platform=mac#rd) ⭐️
73 | * [从Kubernetes事件中提取价值](https://mp.weixin.qq.com/s/Y2Fu3d1ikhkTW-AMTOje-Q) ⭐️
74 |
75 | ## MachineLearning
76 | * [网易有数机器学习平台批调度与k8s调度系统的深度解析](https://mp.weixin.qq.com/s/s-PecEMoLX-Gt5nfnibpwg)️ ⭐️⭐️
77 | * [火山引擎,云原生机器学习平台架构设计](https://mp.weixin.qq.com/s/1rw4o1LkQVuGAOIseGhTSg) ⭐️
78 | * [毫末智行 Fluid 实践:云原生 AI 让汽车变得“更聪明”](https://mp.weixin.qq.com/s/rvRUhNqM9Xq0PLDbtq62uw) ⭐️
79 |
80 | ## Observability
81 | * [云原生观测性 - OpenTelemetry](https://mp.weixin.qq.com/s/8VrOeeiOfE1fBOGh8y0ULQ) ⭐️
82 |
83 | ## Edge
84 | * [多种边缘集群管理方案对比选型](https://mp.weixin.qq.com/s/DnOvI-77jivQTmEiYkg6WQ) ⭐️
85 |
86 | ## OpenSource
87 | * [Kubernetes 开源入门手册](https://mp.weixin.qq.com/s?__biz=MzU3NDk5Nzc2OQ==&mid=2247484024&idx=1&sn=8e3d8ba79589d1078f2e0908f7b30014&scene=19#wechat_redirect) 🌛
88 | * [我们怎么做开源](https://mp.weixin.qq.com/s/9eujTFc-MOmB8xbY07-V2A) 🌛
89 | * [CNCF基金会旗下技术监督委员会(TOC)是如何运转的?](https://mp.weixin.qq.com/s?__biz=Mzg5MzE1MDgxMQ==&mid=2247483849&idx=1&sn=09999ddfde373bb6d0eb486d9d78a1f9&chksm=c03272fdf745fbeb5303f66441741a03202439d27b6ac0825d0872dcfe52b29a4ca6578a6a8c&mpshare=1&scene=1&srcid=0128p7BbbMTrKFQJpp5MmqfX&sharer_sharetime=1643375120475&sharer_shareid=a0beb11b371fd296aa09b486eb6d5824&version=3.1.20.90367&platform=mac#rd) 🌛
90 |
91 | ## Others
92 | * [100页ppt讲清楚云原生](https://mp.weixin.qq.com/s?__biz=MzIxMzEzMjM5NQ==&mid=2651053870&idx=1&sn=e88f8a63230f0abfb04cc88cdd8b566a&chksm=8c4c0a2abb3b833cd80374bfb8d9856e3a3f39deaa0265fa3d7a98327100fa74d0f8879bdc84&mpshare=1&scene=24&srcid=0830dIMYzFrpnjepmqz0Ts1K&sharer_sharetime=1630336996565&sharer_shareid=0bb4683a13715ef82bbb3b451a6e46ef&key=ad5be9c1f718c28a9a0be16cbedfa1efba1bf32c48b6e5a51901b05623873f5e9bc61cd76a4e895cb1518de5398e709ee532284f2d154089ad83a34e05a4e3195754612048f21ac9bf02f1af7b08b7a9a423d9ec3ba1fb97858f8864373e1535aa6df21b87df12c4ef8552cb04f00f53af690c70747da363dd6250ae59cba272&ascene=1&uin=MTQ4NTIyNTc1&devicetype=Windows+10+x64&version=3.1.8.90238&lang=zh_CN&exportkey=ARsgG0iR6n%2BE8A0O3vRba2o%3D&pass_ticket=asNQx57i3kOEp7K3jPghFo1jgpAQQkH1hAZyH3y5H2x%2BBPY7VTIrLiICEQXFE4II&wx_header=0&fontgear=2&st=3A5D02BE82E6A329D94465DA6AA1D7EF2C97CA6EB1167E75B0693501849F114700BA18735878492F04A5A1C9A99AC8F939E6C44D2E95C35A2D18E343B27A3075870B45E2790945F2CB19E4BA1BBE50C488447A8CF2EC7E49C201237B7906C34102784F000A930D30609F592F0F8E6B267A15C411733F0ABF8F735EDD13C68584C89F097FD4AFD6E380BEB76E9801E7A40A8F5F5EC827D8906218F144278D72A1167BA2B1A205FD66ED7E1490418AA2A80DF2923444FFCE877B065463C973B9FA&vid=1688850321012740&cst=4BDAD13415AA3D878C349F750D34999F1D9561AA6D66EE0EFC49E66D66A098D42F246FA7C555F44AFB32215FAE6EF06A&deviceid=4154b5fc-6a27-4ed7-9d18-df36a1acc76b&platform=mac) 🌛
93 | *[Wireshark的抓包和分析,看这篇就够了!](https://mp.weixin.qq.com/s/KP6ojbX12sTL-ZM-W9IOTw) 🌛
94 |
--------------------------------------------------------------------------------
/articles/KarmadaSchedulerPolicy.md:
--------------------------------------------------------------------------------
1 | ## 项目介绍
2 | [Karmada](https://github.com/karmada-io/karmada)是一个多云多集群 Kubernetes 编排系统,填补了 Kubernetes 在多集群管理方面的空白,更多详细内容可以参考 Github 主页,本文主要围绕应用层面对 Karmada 调度策略做一些简单介绍,不涉及源码。
3 |
4 | 版本号: karmada-io/karmada@be2f596ecf
5 |
6 | ## 整体架构
7 | 
8 |
9 | 这是 karmada 整体架构图,他将整个环境分成了两类集群:
10 | * Host集群
11 |
12 | karmada 控制面集群,主要有两个控制面,一个用于部署 karmada 集群,而另一个则是真正的 karmada 控制面集群。
13 |
14 | 控制面集群组件:
15 | * API-Server: 功能类似 kubernetes apiserver,可以直接使用 kubernetes 原生的 API 资源
16 | * Karmada Scheduler: 区别于 `kube-system` 中的 scheduler,kube-system 中的 scheduler只是用于负责部署 karmada 组件,这里的 scheduler 指的是 `karmada-system` 中的scheduler,工作在集群层面,将应用调度到各个 member 集群中
17 | * ETCD:存储所有的资源对象
18 | * Karmada Controllers: 主要包含了4个 controller,配置 scheduler 进行多云多集群的资源编排和调度
19 |
20 | * ClusterController: 负责 member 集群的生命周期管理
21 | * PolicyController: 负责监听 `PropagationPolicy` 资源对象和 kubernetes 原生资源对象(也包括 CRD 资源对象),实现两者的绑定并创建对应的 `ResourceBinding` 资源
22 | * BindingController: 将 `ResourceBinding` 转换为 `work` 对象,如果有对应的 `override policy` 则会运用该 `policy`
23 | * ExecutionController: 将 `work` 中包含的 kubernetes 资源对象同步到 member 集群中
24 | * Member集群
25 |
26 | 由 N 个 kubernetes 集群组成,运行实际的 workloads。
27 |
28 | ## 调度逻辑
29 | 整体调度逻辑如下图所示,图片逻辑已经比较清楚了,这里就不展开。
30 |
31 | 
32 |
33 |
34 | ## 调度策略
35 | 我们先简单部署一个 karmada 集群,直接在该项目根目录运行 `"./hack/local-up-karmada.sh"` 就可以通过 `kind` 部署一个4节点集群,一个 `master` 节点和 3个 `member` 节点。
36 |
37 | 假设我们在控制集群创建了一个副本数为5的 `nginx deployment`,现在通过`PropagationPolicy` 进行调度策略的控制。
38 |
39 | ### 副本机制
40 | 1. Duplicated 策略
41 | ```yaml
42 | kind: PropagationPolicy
43 | metadata:
44 | name: nginx-propagation
45 | spec:
46 | resourceSelectors:
47 | - apiVersion: apps/v1
48 | kind: Deployment
49 | name: nginx
50 | placement:
51 | clusterAffinity:
52 | clusterNames:
53 | - member1
54 | - member2
55 | replicaScheduling:
56 | replicaSchedulingType: Duplicated
57 | ```
58 |
59 | 简单的说就是复制,所有集群副本数都相同,此时 `member1` 和 `member2` 集群都拥有5个 `nginx` 副本,一共有10个副本。此类型适合配置同构的集群。
60 |
61 | 2. Divided 策略
62 | ```yaml
63 | kind: PropagationPolicy
64 | metadata:
65 | name: nginx-propagation
66 | spec:
67 | resourceSelectors:
68 | - apiVersion: apps/v1
69 | kind: Deployment
70 | name: nginx
71 | placement:
72 | replicaScheduling:
73 | replicaDivisionPreference: Weighted
74 | replicaSchedulingType: Divided
75 | weightPreference:
76 | staticWeightList:
77 | - targetCluster:
78 | clusterNames:
79 | - member1
80 | weight: 2
81 | - targetCluster:
82 | clusterNames:
83 | - member2
84 | weight: 3
85 | ```
86 |
87 | `Divided` 策略下`replicaDivisionPreference` 选择 `Weighted` 表示按照权重来分配副本数量, 此时,`member1` 拥有2个副本,`member2` 拥有3个副本。
88 |
89 | `replicaDivisionPreference` 值还可以是 `Aggregated`,表示根据资源空闲情况调度到尽可能少的集群。此时可能的情况是所有的5个副本都调度到了 `member1`。
90 |
91 | ### 集群调度机制
92 | 1. clusterAffinity
93 | ```yaml
94 | kind: PropagationPolicy
95 | metadata:
96 | name: nginx-propagation
97 | spec:
98 | resourceSelectors:
99 | - apiVersion: apps/v1
100 | kind: Deployment
101 | name: nginx
102 | placement:
103 | clusterAffinity:
104 | clusterNames:
105 | - member1
106 | - member2
107 | ```
108 | `clusterAffinity` 功能类似于 `nodeAffinity` 和 `podAffinity`,属于亲和性调度。
109 |
110 | 2. clusterTolerations
111 | ```yaml
112 | apiVersion: policy.karmada.io/v1alpha1
113 | kind: PropagationPolicy
114 | metadata:
115 | name: nginx-propagation
116 | spec:
117 | resourceSelectors:
118 | - apiVersion: apps/v1
119 | kind: Deployment
120 | name: nginx
121 | placement:
122 | clusterAffinity:
123 | clusterNames:
124 | - member1
125 | - member2
126 | clusterTolerations:
127 | - effect: "NoSchedule"
128 | ```
129 | 污点容忍性调度策略,用法同 `pod tolerations`。
130 |
131 |
132 | 3. spreadConstraints
133 | ```yaml
134 | apiVersion: policy.karmada.io/v1alpha1
135 | kind: PropagationPolicy
136 | metadata:
137 | name: example-policy
138 | namespace: default
139 | spec:
140 | resourceSelectors:
141 | - apiVersion: apps/v1
142 | kind: Deployment
143 | name: nginx
144 | association: false
145 | placement:
146 | spreadConstraints:
147 | - spreadByLabel: failuredomain.kubernetes.io/zone
148 | maxGroups: 3
149 | minGroups: 3
150 | ```
151 | 分布约束,`maxGroups` 表示支持最多的集群数,`minGroups` 则表示最少支持的集群数,默认是1。除了 `spreadByLabel`,还支持 `spreadByField`, `field` 目前有4类: `cluster`, `region`,`zone`, `provider`。`spreadByLabel` 和 `spreadByField` 不能共存。
152 |
153 | ### Cluster Accurate Scheduler Estimator
154 | 这是最近加入到 `karmada` 的组件,主要是用于检测调度时集群是否有足够的资源,如果没有可用资源,就放弃调度到该集群。目前作为 `scheduler` 的组件默认启动。只能工作在 `replicaSchedulingType=Divided`,`replicaDivisionPreference=Aggregated` 的模式下。
155 |
156 | ### Descheduler
157 | `descheduler` 目前还处于开发阶段,工作原理同 [`kubernetes-sigs/descheduler`](https://github.com/kubernetes-sigs/descheduler) 相同,主要解决资源调度成功后,后续集群资源调整,进行动态重调度,可参考 `kubernetes descheduler`。
158 |
159 | ### 总结
160 | `karmada` 目前已经作为 `sandbox` 项目由华为捐赠给了 `CNCF`,但是整个 `Roadmap` 还是有很多功能没有完成,我自己最近也在为该项目贡献代码,希望后续可以持续发力。
161 |
162 | 
--------------------------------------------------------------------------------
/articles/KubernetesDescheduler.md:
--------------------------------------------------------------------------------
1 | ## 一、介绍
2 | Kubernetes 调度器 kube-scheduler 通过预选和优选两个阶段来决策当前 pod 调度到哪个节点,整个决策过程是基于当前集群的快照,通过具体配置的调度策略最终决定,但是整个集群是动态的,不管是 node 还是 pod 可能会不断迁移和重建,比如节点下线,新增节点,节点标签和污点发生变化等等,此时,不管是出于集群资源优化的需求还是纠正一些不符合预期的调度结果,需要对整个集群进行重新调度,`descheduler` 应运而生。
3 |
4 |
5 | ## 二、整体配置
6 |
7 | apiVersion: "descheduler/v1alpha1"
8 | kind: "DeschedulerPolicy"
9 | nodeSelector: prod=dev
10 | evictLocalStoragePods: true
11 | evictSystemCriticalPods: true
12 | maxNoOfPodsToEvictPerNode: 40
13 | ignorePvcPods: false
14 | strategies:
15 | ...
16 |
17 |
18 | ## 三、驱逐策略
19 | ### 1. RemoveDuplicates
20 |
21 | 场景:应用高可用部署会尽可能分散部署服务副本,但是可能遇到某些节点异常下线,导致一个节点存在多副本情况,当下线的节点重新上线后,该策略可以对这些副本进行重调度,重新打散。
22 |
23 | 例子:
24 |
25 | apiVersion: "descheduler/v1alpha1"
26 | kind: "DeschedulerPolicy"
27 | strategies:
28 | "RemoveDuplicates":
29 | enabled: true
30 | params:
31 | removeDuplicates:
32 | excludeOwnerKinds:
33 | - "ReplicaSet"
34 |
35 |
36 | ### 2. LowNodeUtilization
37 |
38 | 场景:集群节点资源占用不均衡,某些节点资源使用过载,某些节点资源未充分利用,此时需要对集群资源进行再分配。
39 |
40 | 例子,targetThresholds 表示上水位,超过该水位表示该节点资源使用过载。thresholds 表示下水位。低于该水位则表示资源未充分利用。该例子表示过载节点(cpu 超过50%, mem 超过50%, pods 数超过50)将驱逐部分pod到未充分利用的节点(cpu低于50%,memory低于50%,pod数低于50)。
41 |
42 | apiVersion: "descheduler/v1alpha1"
43 | kind: "DeschedulerPolicy"
44 | strategies:
45 | "LowNodeUtilization":
46 | enabled: true
47 | params:
48 | nodeResourceUtilizationThresholds:
49 | thresholds:
50 | "cpu" : 20
51 | "memory": 20
52 | "pods": 20
53 | targetThresholds:
54 | "cpu" : 50
55 | "memory": 50
56 | "pods": 50
57 |
58 | ### 3. HighNodeUtilization
59 |
60 | 场景:集群运行尽可能少的节点,配合CA可以降低集群成本,需要和 `MostRequestedPriority` 配合使用,
61 |
62 | 例子,表示资源未充分利用节点(cpu低于20%,memory低于20%,pod数低于20)将会驱逐自身的 pod。
63 |
64 | apiVersion: "descheduler/v1alpha1"
65 | kind: "DeschedulerPolicy"
66 | strategies:
67 | "HighNodeUtilization":
68 | enabled: true
69 | params:
70 | nodeResourceUtilizationThresholds:
71 | thresholds:
72 | "cpu" : 20
73 | "memory": 20
74 | "pods": 20
75 |
76 | ### 4. RemovePodsViolatingInterPodAntiAffinity
77 |
78 | 场景:集群节点状态在不断变化,可能pod刚开始调度的时候符合 `nodeAffinity` ,后面已经不再满足,但是现在没有类似 `requiredDuringSchedulingRequiredDuringExecution` 这种强制驱逐的功能。
79 |
80 | 例子:
81 |
82 | apiVersion: "descheduler/v1alpha1"
83 | kind: "DeschedulerPolicy"
84 | strategies:
85 | "RemovePodsViolatingNodeAffinity":
86 | enabled: true
87 | params:
88 | nodeAffinityType:
89 | - "requiredDuringSchedulingIgnoredDuringExecution"
90 |
91 | ### 5. RemovePodsViolatingNodeTaints
92 |
93 | 场景:类似 `RemovePodsViolatingInterPodAntiAffinity`,驱逐不符合污点的 pod
94 |
95 | 例子:
96 |
97 | apiVersion: "descheduler/v1alpha1"
98 | kind: "DeschedulerPolicy"
99 | strategies:
100 | "RemovePodsViolatingNodeTaints":
101 | enabled: true
102 |
103 | ### 6. RemovePodsViolatingTopologySpreadConstraint
104 |
105 | 场景:驱逐不符合拓扑分布约束的 pod
106 |
107 | 例子:
108 |
109 | apiVersion: "descheduler/v1alpha1"
110 | kind: "DeschedulerPolicy"
111 | strategies:
112 | "RemovePodsViolatingTopologySpreadConstraint":
113 | enabled: true
114 | params:
115 | includeSoftConstraints: false
116 |
117 | ### 7. RemovePodsHavingTooManyRestarts
118 |
119 | 场景:pod 调度到某个节点后无法成功挂载,一直在重启,此时需要调度到其他节点。
120 |
121 | 例子,includingInitContainers 表示是否包含init容器
122 |
123 | apiVersion: "descheduler/v1alpha1"
124 | kind: "DeschedulerPolicy"
125 | strategies:
126 | "RemovePodsHavingTooManyRestarts":
127 | enabled: true
128 | params:
129 | podsHavingTooManyRestarts:
130 | podRestartThreshold: 100
131 | includingInitContainers: true
132 |
133 | ### 8. PodLifeTime
134 |
135 | 场景:驱逐处于长时间 Running 或 Pending 状态的 pod
136 |
137 | 例子,podStatusPhases 目前支持 Running 和 Pending 两种 Phase
138 |
139 | apiVersion: "descheduler/v1alpha1"
140 | kind: "DeschedulerPolicy"
141 | strategies:
142 | "PodLifeTime":
143 | enabled: true
144 | params:
145 | podLifeTime:
146 | maxPodLifeTimeSeconds: 86400
147 | podStatusPhases:
148 | - "Pending"
149 |
150 | ### 9. RemoveFailedPods
151 |
152 | 场景:驱逐失败的pod
153 |
154 | 例子:
155 |
156 | apiVersion: "descheduler/v1alpha1"
157 | kind: "DeschedulerPolicy"
158 | strategies:
159 | "RemoveFailedPods":
160 | enabled: true
161 | params:
162 | failedPods:
163 | reasons:
164 | - "NodeAffinity"
165 | includingInitContainers: true
166 | excludeOwnerKinds:
167 | - "Job"
168 | minPodLifetimeSeconds: 3600
169 |
170 |
171 | ## 四、过滤策略
172 | ### 1. Namespace
173 |
174 | 使用 `include` 和 `exclude` 进行策略配置:
175 |
176 | 例子:
177 |
178 | apiVersion: "descheduler/v1alpha1"
179 | kind: "DeschedulerPolicy"
180 | strategies:
181 | "PodLifeTime":
182 | enabled: true
183 | params:
184 | podLifeTime:
185 | maxPodLifeTimeSeconds: 86400
186 | namespaces:
187 | include:
188 | - "namespace1"
189 | - "namespace2"
190 |
191 | ### 2. Priority
192 |
193 | 低于指定 Priority 值的 pod 才能被驱逐,可以直接配置 Priority 或者指定 PriorityClass, 默认取值为 `system-cluster-critical`
194 |
195 | 例子:
196 |
197 | apiVersion: "descheduler/v1alpha1"
198 | kind: "DeschedulerPolicy"
199 | strategies:
200 | "PodLifeTime":
201 | enabled: true
202 | params:
203 | podLifeTime:
204 | maxPodLifeTimeSeconds: 86400
205 | thresholdPriority: 10000
206 | ---
207 | apiVersion: "descheduler/v1alpha1"
208 | kind: "DeschedulerPolicy"
209 | strategies:
210 | "PodLifeTime":
211 | enabled: true
212 | params:
213 | podLifeTime:
214 | maxPodLifeTimeSeconds: 86400
215 | thresholdPriorityClassName: "priorityclass1"
216 |
217 | ### 3. Label
218 | 例子:
219 |
220 | apiVersion: "descheduler/v1alpha1"
221 | kind: "DeschedulerPolicy"
222 | strategies:
223 | "PodLifeTime":
224 | enabled: true
225 | params:
226 | podLifeTime:
227 | maxPodLifeTimeSeconds: 86400
228 | labelSelector:
229 | matchLabels:
230 | component: redis
231 | matchExpressions:
232 | - {key: tier, operator: In, values: [cache]}
233 | - {key: environment, operator: NotIn, values: [dev]}
234 |
235 | ### 4. Node Fit
236 | 当 nodeFit 设置为 true,表示驱逐前需要确认驱逐后 pod 是否可以被重新调度到其他节点,如果不行,则拒接驱逐操作
237 |
238 | 例子:
239 |
240 | apiVersion: "descheduler/v1alpha1"
241 | kind: "DeschedulerPolicy"
242 | strategies:
243 | "LowNodeUtilization":
244 | enabled: true
245 | params:
246 | nodeResourceUtilizationThresholds:
247 | thresholds:
248 | "cpu" : 20
249 | "memory": 20
250 | "pods": 20
251 | targetThresholds:
252 | "cpu" : 50
253 | "memory": 50
254 | "pods": 50
255 | nodeFit: true
256 |
257 |
258 | ## 五、驱逐约束
259 | 1. 关键pod(priorityClassName 是 system-cluster-critical/system-node-critical)不会被驱逐,除非设置`evictSystemCriticalPods: true`
260 | 2. 孤立的 pod 不会被驱逐,因为他们删除后不会被重建,比如 static pod。
261 | 3. DaemonSet不会被驱逐
262 | 4. 使用本地存储的 pod 不会被驱逐,除非设置 `evictLocalStoragePods: true`
263 | 5. 使用 `LowNodeUtilization` 和 `RemovePodsViolatingInterPodAntiAffinity` 时,pod 会按照优先级从小到大的顺序被驱逐,如果优先级相同,则根据 qos 顺序驱逐
264 | 6. 正在被删除的 pod 默认不驱逐
265 | 7. pod 可以通过添加注释 `descheduler.alpha.kubernetes.io/evict` 来表示自己可以被驱逐,所有类型的 pod 都生效,比如之前无法驱逐的 static pod。
266 |
267 |
268 | ## 六、运行
269 | descheduler 支持以 [job](https://github.com/kubernetes-sigs/descheduler/blob/master/kubernetes/job/job.yaml)、[cronjob](https://github.com/kubernetes-sigs/descheduler/blob/master/kubernetes/cronjob/cronjob.yaml)、[deployment](https://github.com/kubernetes-sigs/descheduler/blob/master/kubernetes/deployment/deployment.yaml) 3种方式运行,deployment 通过设置启动参数 `--descheduling-interval` 配置执行间隔。
270 |
271 |
272 | ## 七、其他
273 | 1. `Descheduler` 尊重 `PDB`,所以可以和 PDB 结合使用保证重调度过程中服务的稳定性
274 | 2. 配合 `NPD` 和 `CA` 更好的进行集群自动化运维
275 |
276 |
277 | ## 八、 Roadmap
278 | 1. 支持 `pod affinity` 策略
279 | 2. 支持 `pending pods` 数量相关策略
280 | 3. 继续完善和 CA 的功能集成
281 | 4. 完善和 metrics 的集成
282 | 5. 考虑引入 kube-scheduler 预选流程
283 |
284 |
285 | ## 九、参考
286 | 1. https://github.com/kubernetes-sigs/descheduler
--------------------------------------------------------------------------------
/articles/KubernetesDeveloperHandbook.md:
--------------------------------------------------------------------------------
1 | ## 一. 序言
2 |
3 | 本手册旨在帮助对开源贡献感兴趣的同学快速入门,并为之后的进阶之路提供一些参考和指导意义。如果你已经是 `kubernetes approver` 及以上角色,本手册已超出该知识范畴,你可以推荐给其他感兴趣的同学阅读。
4 |
5 | 由于 Kubernetes 本身的复杂性及手册的篇幅和重点受限,本手册受众需满足以下要求:
6 | 1. 熟悉 Golang 语言
7 | 2. 了解 Kubernetes 基本组件及运行原理
8 | 3. 读过 kubernetes 源码是加分项
9 |
10 | 如果你未达到该要求,不建议直接进行 Kubernetes 开发,深入代码细节会让你迷失方向,就好比不携带地图就深入亚马逊丛林,很容易迷路。
11 |
12 | 如果你希望尽快掌握 Kubernetes 相关知识,可参考[官方文档](https://kubernetes.io/docs/concepts/)。
13 |
14 | ### Note: 本手册持续维护中!
15 |
16 |
17 | ## 二. 了解 Kubernetes 开源社区
18 | 这一章节,你需要了解整个[ Kubernetes 社区](https://github.com/kubernetes/community)是如何治理的。
19 |
20 | 1. [分布式协作]()
21 |
22 | 与公司内部集中式的项目开发模式不同,几乎所有的开源社区都是一个分布式的、松散的的组织,为此 Kubernetes 建立了一套完备的社区治理制度。
23 |
24 | 协作上,社区大多数的讨论和交流主要围绕 `issue` 和 `PR` 展开。由于 `Kubernetes` 生态十分繁荣,因此所有对 Kubernetes 的修改都十分谨慎,每个提交的 `PR` 都需要通过两个以上成员的 `Review` 以及经过几千个单元测试、集成测试、端到端测试以及扩展性测试,所有这些举措共同保证了项目的稳定。
25 |
26 | 2. [Committees(委员会)]()
27 |
28 | 委员会由多人组成,主要负责制定组织的行为规范和章程,处理一些敏感的话题。常见的委员会包括行为准则委员会,安全委员会,指导委员会。
29 |
30 | 3. [SIG](https://github.com/kubernetes-sigs)
31 |
32 | SIG 的全称是 `Special Interest Group`,即特别兴趣小组,它们是 Kubernetes 社区中关注特定模块的永久组织,Kubernetes 作为一个拥有几十万行源代码的项目,单一的小组是无法了解其实现的全貌的.
33 |
34 | Kubernetes 目前包含 20 多个 SIG,它们分别负责了 Kubernetes 项目中的不同模块,这是我们参与 Kubernetes 社区时关注最多的小组;作为刚刚参与社区的开发者,我们可以从 sig/apps、sig/node 和 sig/scheduling 这几个 SIG 开始,它们的职责相对比较明确,从这几个 SIG 的工作入手可以较快的了解社区的工作流程。
35 | 4. [KEP](https://github.com/kubernetes/enhancements/tree/master/keps/)
36 |
37 | KEP 的全称是 `Kubernetes Enhancement Proposa`,因为 Kubernetes 目前已经是比较成熟的项目了,所有的变更都会影响下游的使用者,对于`功能`和 `API` 的`修改`都需要先在 kubernetes/enhancements 仓库对应 SIG 的目录下提交提案才能实施,所有的提案都必须经过讨论、通过社区 SIG Leader 的批准。
38 |
39 | 5. [WorkingGroup](https://docs.google.com/document/d/13mwye7nvrmV11q9_Eg77z-1w3X7Q1GTbslpml4J7F3A/edit)
40 |
41 | 这是由社区贡献者自由组织的兴趣小组,对现阶段的一些方案和社区未来发展方向进行讨论,并且会周期性的举行会议。会议大家都可以参加,只是时间不是很友好,大多是在午夜时分。以`scheduling`为例,你可以查看谷歌文档[ Kubernetes Scheduling Interest Group ](https://docs.google.com/document/d/13mwye7nvrmV11q9_Eg77z-1w3X7Q1GTbslpml4J7F3A/edit#heading=h.ukbaidczvy3r)了解例次会议纪要。会议使用 `Zoom` 进行录制并且会上传到 `Youtube`, 过程中会有主持人主持,如果你是`新人`,可能会让你自我介绍😀.
42 |
43 | 6. [MemberShip](https://github.com/kubernetes/community/blob/master/community-membership.md)
44 |
45 | Kubernetes社区成员有如下四种角色:
46 |
47 | Member
48 | Reviewer
49 | Approver
50 | Subproject owner
51 |
52 | 每种角色承担不同的职责,同时也拥有不同的权限。角色晋升主要参考你对社区的贡献,具体内容可点击段首`MemberShip`超链。
53 |
54 | 7. [Issue 分类](https://hackmd.io/O_gw_sXGRLC_F0cNr3Ev1Q)
55 |
56 | `Kubernetes Issues` 有很多 `label`。如 `bug`, `feature`, `sig` 等,有时候你需要对这些 `issue` 进行手动分类,关于如何分类可以[参考此文](https://hackmd.io/O_gw_sXGRLC_F0cNr3Ev1Q)
57 |
58 |
59 | 5. [其他关注项]()
60 |
61 | [Slack](https://slack.k8s.io/)
62 |
63 | [StackOverFlow](https://stackoverflow.com/questions/tagged/kubernetes)
64 |
65 | [Discussion](https://groups.google.com/g/kubernetes-dev)
66 |
67 |
68 |
69 | ## 三. 开始你的first-good-issue
70 |
71 | * 建议阅读[官方文档](https://www.kubernetes.dev/docs/guide/contributing/)。文档详细描述了该如何提交PR,以及应该遵循什么样的原则,并给到了一些最佳实践。
72 |
73 | * 开始我们的PR之旅
74 | 1. 申请 `CLA`
75 |
76 | 当你提交 `PR` 时,Kubernetes 代码仓库CI流程会检查是否有CLA证书。
77 |
78 | 如何申请证书可以参考[官方文档](https://github.com/kubernetes/community/blob/master/CLA.md)。
79 |
80 | 2. 搜索 `first-good-issue`(你可以选择你感兴趣的或者你比较熟悉的 `SIG` )
81 |
82 | first-good-issue 是 Kubernetes 社区为培养新参与社区贡献的开发人员而准备的 issue,比较容易上手。
83 |
84 | 以 `sig/scheduling` 为例,在 `Issues` 中输入:
85 |
86 | is:issue is:open label:sig/scheduling label:"good first issue" no:assignee
87 |
88 | 该 `Filters` 表示筛选出没有被关闭的,属于 `sig/scheduling`,没有 `assign` 给别人的 `good first issue`。
89 |
90 | 如果没有相关的 `good-first-issue`,你也可以选择 `kind/documentation` 或者 `kind/cleanup` 类型 issue。
91 |
92 | 3. 了解 `issue` 上下文,确定自己能够完成就通过 `/assign` 命令标记给自己。
93 |
94 | 这里涉及到一些常见命令,如下。更多命令,见[Command-Help](https://prow.k8s.io/command-help?repo=kubernetes%2Fkubernetes)。
95 |
96 | /retitle 重命名标题
97 | /close 关闭issue
98 | /assign 将issue assign给自己
99 | /sig scheduling 分类sig/scheduling
100 | /remove-sig scheduling 取消分类
101 | /help 需要帮助,会打上标签help wanted
102 | /good-first-issue 打标签good first issue
103 | /retest 重测出错的测试用例
104 |
105 | 4. 编码
106 | 1. Fork代码仓库。 将 [kubernetes/Kubernetes](https://github.com/kubernetes/kubernetes) `fork` 到自己的 `GitHub` 账号名下。
107 |
108 | 2. Clone 自己的代码仓库
109 |
110 | git clone git@github.com:/kubernetes.git
111 |
112 | 3. 追踪源代码仓库代码变动
113 | 1. 添加upstream
114 |
115 | git remote add upstream https://github.com/kubernetes/kubernetes.git
116 | 2. `git remote -v` 检查是否添加成功,成功则显示:
117 |
118 | origin git@github.com:/kubernetes.git (fetch)
119 | origin git@github.com:/kubernetes.git (push)
120 | upstream https://github.com/kubernetes/kubernetes.git (fetch)
121 | upstream https://github.com/kubernetes/kubernetes.git (push)
122 | 3. 同步 `upstream kubernetes` 最新代码
123 |
124 | git checkout master
125 | git pull upstream master
126 | git push
127 |
128 |
129 | 4. 切分支,编码
130 |
131 | git checkout -b
132 |
133 | 5. Commit,并提交PR
134 | * 命令行
135 |
136 | git commit -s -m ''
137 | * 注意:
138 | 1. `commit push` 前先执行 `make update`
139 | 2. 如果本次修改还没有完成,可以使用 `GitHub Draft` 模式,并添加 `[WIP]` 在标题中
140 | 3. `Commit` 信息过多,且没有特别大的价值,建议合成一条 `commit` 信息
141 |
142 | git rebase -i HEAD~2
143 |
144 | 6. 提交PR
145 | 1. 在 `GitHub` 页面按照模版提交 `PR`
146 |
147 | 5. CI
148 | 1. PR提交后需要执行 `Kubernetes CI` 流程,此时需要 `Kubernetes Member` 打 `/ok-to-test` 标签,然后会自动执行 `CI`,包括验证和各种测试。可以 `@` 社区大佬或者团队成员打标签。
149 | 2. 一旦测试失败,修复后可以执行 `/retest` 重新执行失败的测试,此时,你已经可以自己打 `tag`
150 |
151 | 6. Code Review
152 | 1. 每次提交需要有2个 `Reviewer` 进行 `Code Review`, 如果通过,他们会打上 `/lgtm` 标签,表示 `looks good to me`, 代码审核完成。
153 | 2. 另外需要一个 `Approver` 打上 `/approve` 标签,表示代码可以合入主干分支,`GitHub` 机器人会自动执行 `merge` 操作。
154 | 3. `PR` 跟进没有想像中那么快,尤其是国外休假时间都比较长,`1-2周`也正常
155 |
156 | 7. 恭喜,你完成了第一个 `PR` 的提交
157 |
158 | ## 四. 如何成为Kubernetes Member
159 |
160 | 1. 官方文档要求对项目有多个贡献,并得到两个 `reviewer` 的同意。
161 |
162 | Sponsored by 2 reviewers and multiple contributions to the project
163 |
164 | 2. 贡献包括:
165 |
166 | 1. PR
167 | 2. Issue
168 | 3. Kep
169 | 4. Comment
170 | 5. Review
171 |
172 | 3. 建议:
173 | 1. 多参与社区的讨论,表达自己的观点
174 | 2. 多参与 `issue` 的解答,帮助提问者解决问题,社区的意义也在于此
175 | 3. 对源码了解不多,可以从一些简单的工作入手。如在看源代码的时候多留意一些语法、命名和重复代码问题,做一些重构相关的工作
176 | 4. 从测试入手也是一个好办法,如补全测试,或者修复测试
177 | 5. 参与一些代码的 `review`,同时可以学到一些知识。
178 | 6. 最有价值的肯定是 `feature` 的实现,或者提出一些 `kep`
179 |
180 | 4. 关于如何获得 `reviewer` 同意,可以事先通过邮件打好招呼,把自己做的一些事情同步给他们,以及自己未来在开源社区的规划。
181 |
182 | 5. 成为 `Kubernetes Member` 不是目的,而是水到渠成的结果。`期待你的加入!`
183 |
184 |
185 | ## 五. 常用命令
186 | `参考 Makefile 文件`
187 |
188 | * 单元测试(单方法)
189 |
190 | go test -v --timeout 30s k8s.io/kubectl/pkg/cmd/get -run ^TestGetSortedObjects$
191 |
192 | * 集成测试(单方法)
193 |
194 | make test-integration WHAT=./vendor/k8s.io/kubectl/pkg/cmd/get GOFLAGS="-v" KUBE_TEST_ARGS="-run ^TestRuntimeSortLess$"
195 |
196 | * E2E测试
197 |
198 | 可以使用 `GitHub` 集成的 `E2E` 测试:
199 |
200 | /test pull-kubernetes-node-kubelet-serial
201 |
--------------------------------------------------------------------------------
/articles/kube-scheduler-intro.md:
--------------------------------------------------------------------------------
1 | ## Kube-Scheduler
2 | kube-scheduler 是 kubernetes 的核心模块,属于控制面进程,负责将 pods 指派到节点上。
3 |
4 | ### SIG 介绍
5 | 1. 核心成员:[sig-scheduling](https://github.com/kubernetes/community/tree/master/sig-scheduling) 小组负责维护整个项目,目前该 sig co-chair 是 [@Huang-Wei](https://github.com/Huang-Wei) 和 [@ahg-g](https://github.com/ahg-g),除此之外,几个核心的成员包括 [@alculquicondor](https://github.com/alculquicondor),[@damemi](https://github.com/damemi)
6 |
7 | 2. 子项目:sig-scheduling 负责的项目除了k/k scheduler模块,还包括 [cluster-capacity](https://github.com/kubernetes-sigs/cluster-capacity), [descheduler](https://github.com/kubernetes-sigs/descheduler), [kube-batch](https://github.com/kubernetes-sigs/kube-batch), [kube-scheduler-simulator](https://github.com/kubernetes-sigs/kube-scheduler-simulator), [poseidon](https://github.com/kubernetes-sigs/poseidon), [scheduler-plugins](https://github.com/kubernetes-sigs/scheduler-plugins)
8 |
9 | 3. 例会:[Agenda](https://docs.google.com/document/d/13mwye7nvrmV11q9_Eg77z-1w3X7Q1GTbslpml4J7F3A/edit),往期录制可点击[往期](https://www.youtube.com/watch?v=PweKj6SU7UA&list=PL69nYSiGNLP2vwzcCOhxrL3JVBc-eaJWI)
10 |
11 | ### 社区介绍
12 | Slack:[#sig-scheduling](https://app.slack.com/client/T09NY5SBT/C09TP78DV)
13 |
14 | Group: [kubernetes-sig-scheduling](https://groups.google.com/g/kubernetes-sig-scheduling)
15 |
16 | KEP: [sig-scheduling](https://github.com/kubernetes/enhancements/tree/master/keps/sig-scheduling)
17 |
18 | Website: [kube-scheduler](https://kubernetes.io/docs/reference/command-line-tools-reference/kube-scheduler/)
19 |
--------------------------------------------------------------------------------
/articles/lazy-pulling.md:
--------------------------------------------------------------------------------
1 | ### What is eStargz?
2 |
3 | Standard-Compatible Extension to Container Image Layers for Lazy Pulling. It is a *backward-compatible extension* which means that images can be pushed to the extension-agnostic registry and can run on extension-agnostic runtimes.This extension is based on stargz (stands for *seekable tar.gz*) proposed by [Google CRFS](https://github.com/google/crfs) project (initially [discussed in Go community](https://github.com/golang/go/issues/30829)). eStargz extends stargz for chunk-level verification and runtime performance optimization.
4 |
5 | 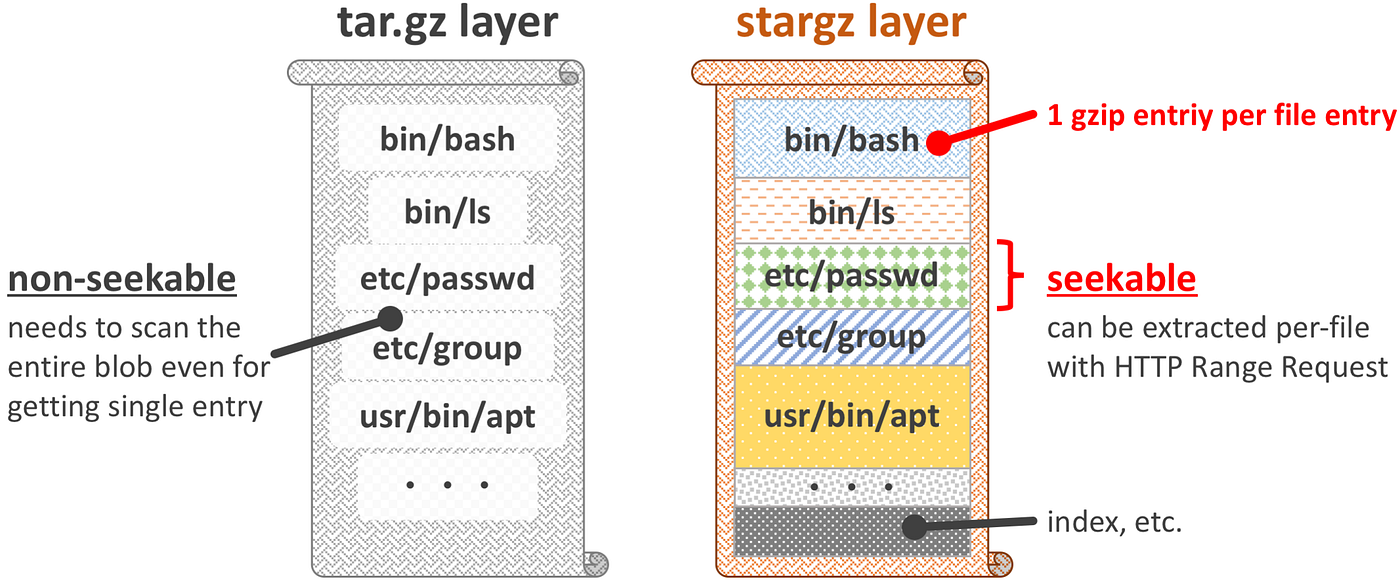
6 |
7 | 
8 |
9 | ### What is Lazy Pulling?
10 |
11 | Lazy pulling is a technique of pulling container images aiming at the faster cold start. This allows a container to startup without waiting for the entire image layer contents to be locally available. Instead, necessary files (or chunks for large files) in the layer are fetched *on-demand* during running the container.
12 |
13 | ### Why Lazy Pulling?
14 |
15 | - FAST ON START
16 |
17 | 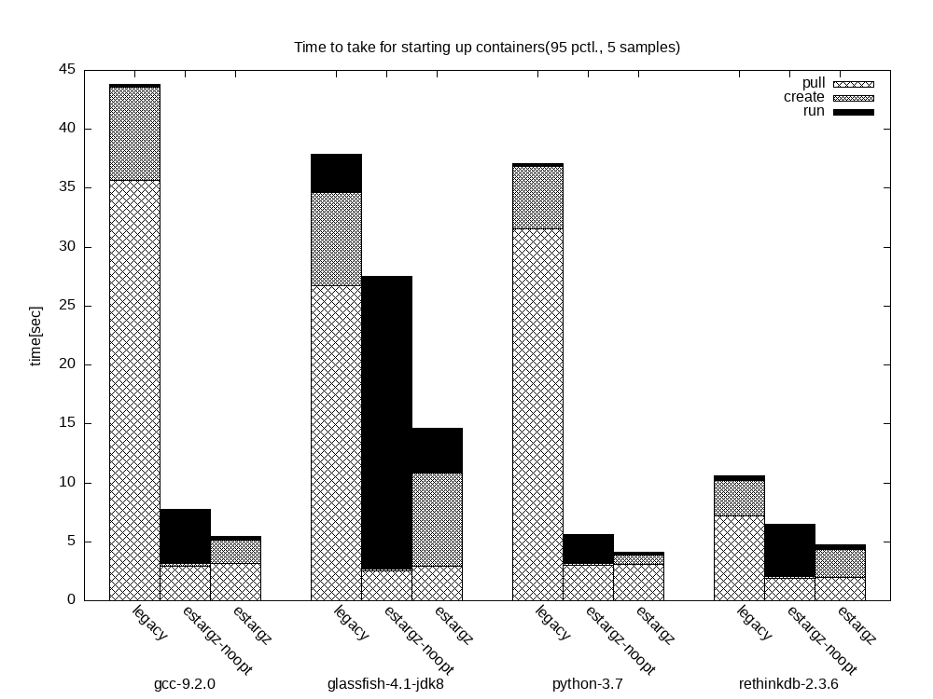
18 |
19 | - FAST ON BUILD
20 |
21 | 
22 |
23 | ### How to use Lazy Pulling
24 |
25 | 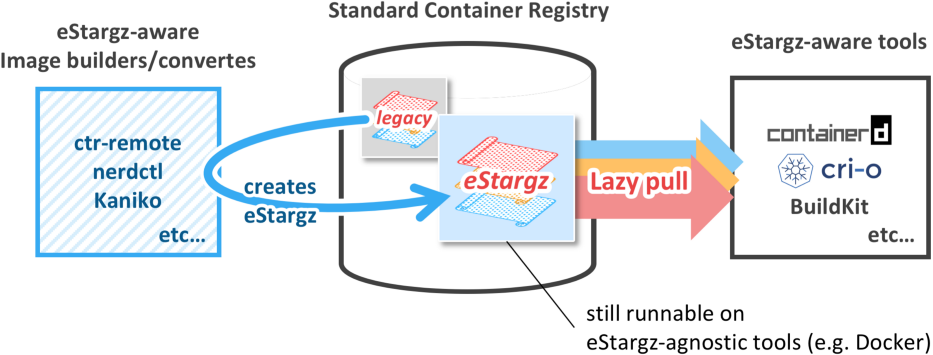
26 |
27 | ### Demo
28 |
29 | ```bash
30 | $ kind create cluster --name stargz-demo --image ghcr.io/stargz-containers/estargz-kind-node:0.7.0
31 | $ docker exec -it xxx bash
32 | ```
33 |
34 | 1. 镜像格式优化 optimize
35 |
36 | ```bash
37 | $ ctr-remote --debug i optimize --oci docker.io/jonyhy/esgz:ov1 docker.io/jonyhy/esgz:v1
38 | ```
39 |
40 | 2. 拉取效果
41 |
42 | ```bash
43 | $ ctr-remote i rpull docker.io/jonyhy/esgz:v1
44 | $ journalctl -u stargz-snapshotter --no-pager --follow
45 | ```
46 |
47 | 3. 启动效果
48 |
49 | ```bash
50 | $ ctr-remote run --rm -t --snapshotter=stargz docker.io/jonyhy/esgz:v1 test /bin/bash
51 | $ ls /.stargz-snapshotter/*
52 | $ cat /.stargz-snapshotter/*
53 | ```
54 |
55 | ### 产品结合需要满足
56 |
57 | 版本要求: https://github.com/containerd/stargz-snapshotter/issues/258
58 |
59 | 1. CRI containerd, podman or cri-o
60 | 2. fuse
61 | 3. run stargz-snapshotter or stargz-store
62 |
63 | ### Reference
64 |
65 | 1. https://medium.com/nttlabs/buildkit-lazypull-66c37690963f
66 | 2. https://github.com/containerd/stargz-snapshotter/blob/main/docs/estargz.md
67 | 3. https://medium.com/nttlabs/startup-containers-in-lightning-speed-with-lazy-image-distribution-on-containerd-243d94522361
68 | 4. https://devopstales.github.io/kubernetes/lazyimage/
69 | 5. https://github.com/containerd/stargz-snapshotter/blob/main/Dockerfile
70 | 6. https://medium.com/nttlabs/buildkit-lazypull-66c37690963f
--------------------------------------------------------------------------------
/snapshots/karmada-arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kerthcet/Blogs-CloudNative/da0e6fe6f68c700067f4ecb3c703fa369a6f0406/snapshots/karmada-arch.png
--------------------------------------------------------------------------------
/snapshots/karmada-roadmap.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kerthcet/Blogs-CloudNative/da0e6fe6f68c700067f4ecb3c703fa369a6f0406/snapshots/karmada-roadmap.jpeg
--------------------------------------------------------------------------------
/snapshots/karmada-schedule-process.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kerthcet/Blogs-CloudNative/da0e6fe6f68c700067f4ecb3c703fa369a6f0406/snapshots/karmada-schedule-process.jpeg
--------------------------------------------------------------------------------