├── .github
└── ISSUE_TEMPLATE
│ ├── bug-report.md
│ └── config.yml
├── .gitignore
├── Linetv.py
├── config_template.json
├── img
└── cookies.png
├── readme.md
└── requirements.txt
/.github/ISSUE_TEMPLATE/bug-report.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: 問題回報
3 | about: 有錯誤或者執行上有任何問題請用此
4 | title: ''
5 | labels: ''
6 | assignees: ''
7 |
8 | ---
9 |
10 | **發布此Issue前請先確定**
11 | 1. 版本為最新版
12 | 2. 是否已安裝相關套件
13 |
14 | **電腦環境**
15 | Python版本:
16 | FFmpeg版本:
17 | 是否有使用VPN:
18 |
19 | **問題敘述**
20 |
21 | **錯誤截圖**
22 |
23 | **錯誤Log檔**
24 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/config.yml:
--------------------------------------------------------------------------------
1 | blank_issues_enabled: false
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | share/python-wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 | MANIFEST
28 |
29 | # PyInstaller
30 | # Usually these files are written by a python script from a template
31 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
32 | *.manifest
33 | *.spec
34 |
35 | # Installer logs
36 | pip-log.txt
37 | pip-delete-this-directory.txt
38 |
39 | # Unit test / coverage reports
40 | htmlcov/
41 | .tox/
42 | .nox/
43 | .coverage
44 | .coverage.*
45 | .cache
46 | nosetests.xml
47 | coverage.xml
48 | *.cover
49 | *.py,cover
50 | .hypothesis/
51 | .pytest_cache/
52 | cover/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | .pybuilder/
76 | target/
77 |
78 | # Jupyter Notebook
79 | .ipynb_checkpoints
80 |
81 | # IPython
82 | profile_default/
83 | ipython_config.py
84 |
85 | # pyenv
86 | # For a library or package, you might want to ignore these files since the code is
87 | # intended to run in multiple environments; otherwise, check them in:
88 | # .python-version
89 |
90 | # pipenv
91 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
92 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
93 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
94 | # install all needed dependencies.
95 | #Pipfile.lock
96 |
97 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
98 | __pypackages__/
99 |
100 | # Celery stuff
101 | celerybeat-schedule
102 | celerybeat.pid
103 |
104 | # SageMath parsed files
105 | *.sage.py
106 |
107 | # Environments
108 | .env
109 | .venv
110 | env/
111 | venv/
112 | ENV/
113 | env.bak/
114 | venv.bak/
115 |
116 | # Spyder project settings
117 | .spyderproject
118 | .spyproject
119 |
120 | # Rope project settings
121 | .ropeproject
122 |
123 | # mkdocs documentation
124 | /site
125 |
126 | # mypy
127 | .mypy_cache/
128 | .dmypy.json
129 | dmypy.json
130 |
131 | # Pyre type checker
132 | .pyre/
133 |
134 | # pytype static type analyzer
135 | .pytype/
136 |
137 | # Cython debug symbols
138 | cython_debug/
139 |
140 | # VSCode
141 | .vscode/
--------------------------------------------------------------------------------
/Linetv.py:
--------------------------------------------------------------------------------
1 | import json
2 | import logging
3 | import os
4 | import re
5 | import subprocess
6 |
7 | import rich.progress
8 | import httpx
9 | from lxml import etree
10 |
11 | UA = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'
12 | session = httpx.Client()
13 | session.headers.update({'User-Agent': UA})
14 |
15 |
16 | class Parser():
17 | def __init__(self, dramaid: str):
18 | self.dramaid = str(dramaid)
19 | self.html = session.get(
20 | f'https://www.linetv.tw/drama/{self.dramaid}', follow_redirects=True)
21 | self.get_eps()
22 | self.get_behind()
23 |
24 | def get_eps(self):
25 | self.eps = []
26 | parser = etree.HTML(self.html.text)
27 | data = json.loads(parser.xpath('//head/script')[0].text[27:])
28 | for _ in data['entities']['dramaInfo']['byId'][self.dramaid]['eps_info']:
29 | self.eps.append(_['number'])
30 |
31 | def get_behind(self):
32 | self.behind = {}
33 | parser = etree.HTML(self.html.text)
34 | data = json.loads(parser.xpath(
35 | '//script[@type="application/ld+json"]')[2].text)
36 | for _trailer in data['trailer']:
37 | self.behind[_trailer['name']] = _trailer['contentUrl']
38 |
39 |
40 | class DL:
41 | class Drama():
42 | def __init__(self, dramaid: str, ep: str, lng: str, subtitle=False, no_download=False):
43 | self.dramaid = dramaid
44 | self.subtitle = subtitle
45 | self.ep = ep
46 | self.lng = lng
47 | self.no_download = no_download
48 | self.new_old = True
49 | self.dramaname = ''
50 | self.keyId = ''
51 | self.keyType = ''
52 | self.m3u8 = ''
53 | self.sub_url = ''
54 | self.urlfix = ''
55 | self.drama_key = ''
56 | self.video_url = []
57 | self.check_ffmpeg()
58 | self.get_part_url()
59 | self.get_m3u8()
60 | self.get_m3u8_key()
61 | self.dl_video()
62 | # shutil.rmtree('.')
63 |
64 | def check_ffmpeg(self):
65 | try:
66 | subprocess.Popen(
67 | 'ffmpeg -h', shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
68 | except FileNotFoundError:
69 | logging.info('本項目需要ffmpeg,請手動安裝ffmpeg')
70 | raise
71 |
72 | def get_part_url(self):
73 | req = session.get(
74 | f'https://www.linetv.tw/api/part/{self.dramaid}/eps/{self.ep}/part')
75 | try:
76 | parser = req.json()['epsInfo']['source'][0]['links'][0]
77 | except KeyError:
78 | logging.warning(req.json()['message'])
79 | return
80 | self.dramaname = req.json()['dramaInfo']['name']
81 | self.keyId = parser['keyId']
82 | self.keyType = parser['keyType']
83 | self.m3u8 = parser['link']
84 | if 'subtitle' in parser:
85 | self.sub_url = parser['subtitle']
86 | logging.debug('抓取Drama資料成功')
87 |
88 | def get_m3u8(self):
89 | self.urlfix = re.findall(r'(.*\/)\d+.*', self.m3u8)[0]
90 | self.dramaid, self.ep = re.findall(
91 | r'(\d*)\/(\d*)\/v\d', self.urlfix)[0]
92 | req = session.get(self.m3u8)
93 | try:
94 | url, self.res = re.findall(
95 | r'((\d*)\/\d*-eps-\d*_\d*p\.m3u8.*)', req.text)[-1]
96 | self.new_old = True
97 | except IndexError:
98 | url, self.res = re.findall(
99 | r'(\d*-eps-\d*_(\d*)p.\.m3u8.*)', req.text)[-1]
100 | self.new_old = False
101 |
102 | if self.new_old:
103 | m3u8url = f'{self.urlfix}{url}'
104 | m3u8 = session.get(m3u8url)
105 | self.drama_key = re.findall(r'URI=\"(.*)\"', m3u8.text)[0]
106 | m3u8 = re.sub(self.drama_key,
107 | f'{self.dramaid}-eps-{self.ep}_{self.res}p.key', m3u8.text)
108 | self.video_url.append(
109 | f'{self.urlfix}{self.res}/' + re.findall(r"(.*\.ts.*)", m3u8)[0])
110 | if self.no_download:
111 | m3u8 = re.sub(f'{self.dramaid}-eps-{self.ep}_{self.res}p.ts',
112 | f'{self.urlfix}{self.res}/{self.dramaid}-eps-{self.ep}_{self.res}p.ts', m3u8)
113 | else:
114 | m3u8 = re.sub(r'\?.*', '', m3u8)
115 | with open(os.path.join('.', f'{self.dramaid}-eps-{self.ep}_{self.res}p.m3u8'), 'w') as f:
116 | f.write(m3u8)
117 | else:
118 | m3u8url = f'{self.urlfix}{self.dramaid}-eps-{self.ep}_{self.res}p_.m3u8'
119 | m3u8 = session.get(m3u8url)
120 | self.drama_key = re.findall(r'URI=\"(.*)\"', m3u8.text)[0]
121 | m3u8 = re.sub(self.drama_key,
122 | f'{self.dramaid}-eps-{self.ep}_{self.res}p.key', m3u8.text)
123 | for _ in re.findall(r'(\d*-eps-\d*_\d*p_\d*\.ts)', m3u8):
124 | self.video_url.append(f'{self.urlfix}{_}')
125 | if self.no_download:
126 | m3u8 = re.sub(r'(\d*-eps-\d*_\d*p_\d*\.ts)',
127 | r'{}\1'.format(self.urlfix), m3u8)
128 | with open(os.path.join('.', f'{self.dramaid}-eps-{self.ep}_{self.res}p.m3u8'), 'w') as f:
129 | f.write(m3u8)
130 |
131 | def get_m3u8_key(self):
132 | if self.new_old:
133 | key = session.get(self.drama_key)
134 | with open(os.path.join('.', f'{self.dramaid}-eps-{self.ep}_{self.res}p.key'), 'wb') as f:
135 | f.write(key.content)
136 | else:
137 | data = {'keyType': self.keyType, 'keyId': self.keyId,
138 | 'dramaId': int(self.dramaid), 'eps': int(self.ep)}
139 | req = session.post(
140 | 'https://www.linetv.tw/api/part/dinosaurKeeper', json=data)
141 | token = req.json()['token']
142 | key = httpx.get(
143 | 'https://keydeliver.linetv.tw/jurassicPark', headers={'authentication': token})
144 | with open(os.path.join('.', f'{self.dramaid}-eps-{self.ep}_{self.res}p.key'), 'wb') as f:
145 | f.write(key.content)
146 |
147 | def dl_video(self):
148 | if self.no_download:
149 | return
150 |
151 | logging.info(f'正在下載:{self.dramaname} 第{self.ep}集 {self.res}P')
152 |
153 | if self.new_old:
154 | for _url in self.video_url:
155 | with open(os.path.basename(_url.split('?')[0]), 'ab') as download_file:
156 | with httpx.stream("GET", _url) as response:
157 | total = int(response.headers["Content-Length"])
158 |
159 | with rich.progress.Progress(
160 | "[progress.percentage]{task.percentage:>3.1f}%",
161 | rich.progress.BarColumn(bar_width=50),
162 | rich.progress.DownloadColumn(),
163 | rich.progress.TransferSpeedColumn(),
164 | ) as progress:
165 | download_task = progress.add_task(
166 | "Download", total=total)
167 | for chunk in response.iter_bytes():
168 | download_file.write(chunk)
169 | progress.update(
170 | download_task, completed=response.num_bytes_downloaded)
171 | else:
172 | with rich.progress.Progress(
173 | "[progress.percentage]{task.percentage:>3.1f}%",
174 | rich.progress.BarColumn(),
175 | "{task.completed}/{task.total}"
176 | ) as progress:
177 | download_task = progress.add_task(
178 | "Download", total=len(self.video_url))
179 | completed = 0
180 | for _url in self.video_url:
181 | with open(os.path.basename(_url.split('?')[0]), 'wb') as download_file:
182 | with httpx.stream("GET", _url) as response:
183 | for chunk in response.iter_bytes():
184 | download_file.write(chunk)
185 | completed += 1
186 | progress.update(
187 | download_task, completed=completed)
188 |
189 | output = os.path.join('.', f'{self.dramaname}-E{self.ep}.mp4')
190 | ffmpeg_cmd = ['ffmpeg', '-loglevel', 'quiet', '-stats', '-allowed_extensions', 'ALL',
191 | '-protocol_whitelist', 'http,https,tls,rtp,tcp,udp,crypto,httpproxy,file', '-y', '-i', f'{self.dramaid}-eps-{self.ep}_{self.res}p.m3u8', '-movflags', '+faststart', '-c', 'copy']
192 |
193 | if self.lng:
194 | ffmpeg_cmd.extend(['-metadata:s:a:0', f'language={self.lng}'])
195 | ffmpeg_cmd.extend([output])
196 | logging.info('正在合併檔案')
197 | subprocess.Popen(ffmpeg_cmd).communicate()
198 |
199 | if not os.path.exists(output):
200 | logging.info('下載失敗')
201 | return
202 | else:
203 | logging.info('下載完成')
204 |
205 | if self.sub_url and self.subtitle:
206 | sub = session.get(self.sub_url)
207 | if sub.status_code != 200:
208 | logging.info('正在下載字幕')
209 | sub = session.get(
210 | f'{self.urlfix}caption/{self.dramaid}-eps-{self.ep}.vtt')
211 | with open(f'{self.dramaname}-E{self.ep}.vtt', 'wb') as f:
212 | f.write(sub.content)
213 | vtt_to_srt = [
214 | 'ffmpeg', '-hide_banner', '-i', f'{self.dramaname}-E{self.ep}.vtt', f'{self.dramaname}-E{self.ep}.srt']
215 | subprocess.run(vtt_to_srt)
216 |
217 | # subprocess.Popen(
218 | # ['rclone', 'move', output, 'GD:', '-P']).communicate()
219 | for _ in self.video_url:
220 | os.remove(os.path.basename(_.split('?')[0]))
221 | os.remove(f'{self.dramaid}-eps-{self.ep}_{self.res}p.m3u8')
222 | os.remove(f'{self.dramaid}-eps-{self.ep}_{self.res}p.key')
223 |
224 | class Behind():
225 | def __init__(self, url: str, filename: str):
226 | logging.info(f'正在下載{filename}')
227 | videoname = filename + url.split('/')[-1][-4:]
228 |
229 | with open(videoname, 'ab') as download_file:
230 | with httpx.stream("GET", url) as response:
231 | total = int(response.headers["Content-Length"])
232 |
233 | with rich.progress.Progress(
234 | "[progress.percentage]{task.percentage:>3.1f}%",
235 | rich.progress.BarColumn(bar_width=50),
236 | rich.progress.DownloadColumn(),
237 | rich.progress.TransferSpeedColumn(),
238 | ) as progress:
239 | download_task = progress.add_task(
240 | "Download", total=total)
241 | for chunk in response.iter_bytes():
242 | download_file.write(chunk)
243 | progress.update(
244 | download_task, completed=response.num_bytes_downloaded)
245 |
246 | if not os.path.exists(videoname):
247 | logging.info('下載失敗')
248 | else:
249 | logging.info('下載成功')
250 |
251 |
252 | if __name__ == '__main__':
253 | import argparse
254 |
255 | parser = argparse.ArgumentParser()
256 | parser.add_argument('--dramaid', '-id', help='輸入DramaId')
257 | parser.add_argument('--ep', help='輸入集數')
258 | parser.add_argument('--epall', help='一次下載全部集數', action="store_true")
259 | parser.add_argument('--special', '-sp',
260 | help='一次下載全部幕後花絮和精華', action="store_true")
261 | parser.add_argument('--sub', help='若有字幕自動下載', action="store_true")
262 | parser.add_argument('--lng', help='輸入音軌語言')
263 | parser.add_argument('--no_download', help='僅下載m3u8和key',
264 | action="store_true")
265 | parser.add_argument('--debug', help='除錯模式', action="store_true")
266 | args = parser.parse_args()
267 |
268 | if args.debug:
269 | logging.basicConfig(format='%(message)s', level=logging.DEBUG, handlers=[
270 | logging.StreamHandler()])
271 | else:
272 | logging.basicConfig(format='%(message)s', level=logging.INFO)
273 |
274 | try:
275 | with open('config.json') as f:
276 | config = json.load(f)
277 | if config['access_token']:
278 | session.headers.update({'authorization': config['access_token']})
279 | logging.info('找到access_token,將採用登入模式下載')
280 | except:
281 | logging.info('找不到config.json,將採用未登入模式下載')
282 |
283 | if args.dramaid and args.special:
284 | sps = Parser(args.dramaid).behind
285 | for sp in sps:
286 | DL.Behind(sps[sp], sp)
287 |
288 | if args.dramaid and args.epall:
289 | for _ep in Parser(args.dramaid).eps:
290 | DL.Drama(args.dramaid, _ep, args.lng, args.sub, args.no_download)
291 |
292 | if args.dramaid and args.ep:
293 | if args.ep.find('-') != -1:
294 | ids = range(
295 | int(args.ep.split('-')[0]), int(args.ep.split('-')[1]) + 1)
296 | elif args.ep.find(',') != -1:
297 | ids = args.ep.split(',')
298 | else:
299 | ids = [args.ep]
300 | for _ep in ids:
301 | DL.Drama(args.dramaid, _ep, args.lng, args.sub, args.no_download)
302 |
--------------------------------------------------------------------------------
/config_template.json:
--------------------------------------------------------------------------------
1 | {
2 | "access_token": "",
3 | "refersh_token": "",
4 | "chocoID": ""
5 | }
6 |
--------------------------------------------------------------------------------
/img/cookies.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kirbyloco/LineTV-DL/dcde4262227354811bfccc304e279f44569d2085/img/cookies.png
--------------------------------------------------------------------------------
/readme.md:
--------------------------------------------------------------------------------
1 | LineTV-DL
2 | 簡易的LineTV下載工具
3 |
4 | # 注意
5 | 本下載工具需要ffmpeg,請事先將ffmpeg放入系統PATH或放在資料夾裡
6 |
7 | [FFmpeg下載點我](https://ffmpeg.org/download.html)
8 |
9 | 若影片是VIP會員限定的,需要登入帳號才可以下載
10 |
11 | # 特色
12 | 自動下載最高畫質
13 |
14 | CC字幕自動抓取(可開關)
15 |
16 | # 使用方法
17 | ## 登入帳號
18 | ```
19 | 請先將config.template.json重新命名為config.json
20 | 1. 在網頁版登入好帳號後
21 | 2. 從cookies提取access_token
22 | 3. 複製到config.json裡
23 | ```
24 | 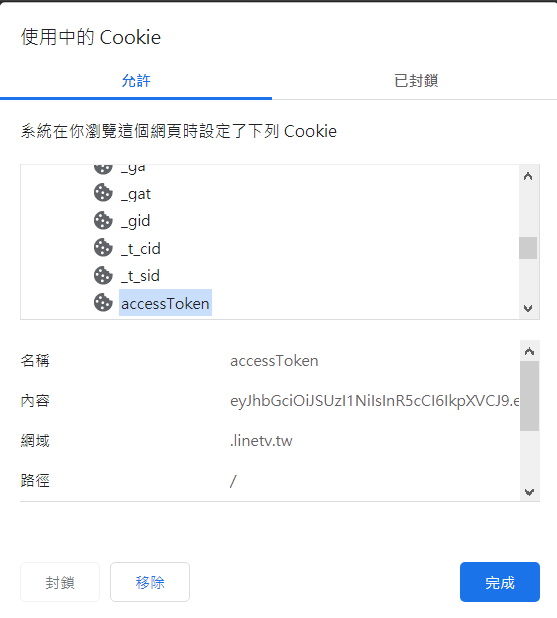
25 |
26 | ## 使用者模式
27 | 請先安裝相關套件
28 | ```
29 | pip install -r requirements.txt
30 | ```
31 | 直接輸入以下指令即可開始下載
32 | ```
33 | python Linetv.py --dramaid --ep <集數> --sub
34 | # 範例
35 | python Linetv.py --dramaid 12102 --ep 1 --sub ## 下載第一集
36 | python Linetv.py --dramaid 12102 --epall --sub ## 下載全部集數
37 | python Linetv.py --dramaid 12102 --ep 15-18 --sub ## 只下載15到18集
38 | python Linetv.py --dramaid 12102 --ep 15,18 --sub ## 只下載15和18集
39 | ```
40 | 詳細參數
41 | |指令|短指令|用途|
42 | |-|-|-|
43 | |--dramaid|-id|指定要下載的dramaid|
44 | |--ep||指定要下載的集數|
45 | |--epall||一次下載全部集數|
46 | |--special|-sp|一次下載全部幕後花絮和精華|
47 | |--sub||開啟字幕下載|
48 | |--lng||輸入音軌語言(輸入ISO 639-2標準代碼)|
49 | |--no_download||僅下載m3u8和key|
50 | |--debug||除錯模式|
51 |
52 | ## 開發者模式
53 | ```
54 | import Linetv # 匯入模組
55 |
56 | parser = Linetv.Parser('輸入在Line TV看到的ID')
57 | parser.eps ## 得到上架的集數
58 | parser.behind() ## 得到幕後花絮相關的地址
59 |
60 | Linetv.DL.Drama('輸入影集的ID', '影集的集數') # 只會下載一集
61 | Linetv.DL.Behind('輸入parser.behind回傳的網址') # 下載幕後花絮用
62 | ```
63 |
64 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | httpx
2 | lxml
3 | rich
4 |
--------------------------------------------------------------------------------