├── .DS_Store
├── .idea
├── .gitignore
├── front-end-interview.iml
├── modules.xml
├── prettier.xml
└── vcs.xml
├── 1 前端面试准备.md
├── 10 offer收割机之手写代码篇.md
├── 11 offer收割机之代码输出篇.md
├── 12LeetCode面试常考题目.md
├── 13 offer收割机之Vue篇.md
├── 14 vue项目的性能优化.md
├── 2 程序员面试软技能.md
├── 3 offer收割机之HTML篇.md
├── 4 offer收割机之CSS篇.md
├── 5 offer收割机之JavaScript篇.md
├── 6 offer收割机之性能优化篇.md
├── 7 offer收割机之前端工程化篇.md
├── 8 offer收割机之计算机网络篇.md
├── 9 offer收割机之浏览器原理篇.md
├── README.md
└── erweima
├── .DS_Store
├── gong.jpg
└── we.jpg
/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kjd1000000/front-end-interview/a166c7d0119588ff4f3dd89ea5877adedc683f7e/.DS_Store
--------------------------------------------------------------------------------
/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # 默认忽略的文件
2 | /shelf/
3 | /workspace.xml
4 | # 基于编辑器的 HTTP 客户端请求
5 | /httpRequests/
6 |
--------------------------------------------------------------------------------
/.idea/front-end-interview.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/prettier.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/1 前端面试准备.md:
--------------------------------------------------------------------------------
1 |
2 | ## 一、面试准备
3 |
4 | ### 1. 利用脑图来梳理知识点
5 |
6 | 对于统一校招类的面试,要重点梳理前端的所有知识点,校招面试一般是为了做人才储备,所以看的是候选人的可塑性和学习能力;对于社招类面试,则看重的是业务能力和 JD 匹配程度,所以要针对性地整理前端知识点,针对性的内容包括:项目用到的技术细节、个人技能部分需要加强或提升的常考知识点。
7 |
8 |
9 |
10 | 所以,不仅仅简历要针对性地来写,知识点也要根据自己的经历、准备的简历、公司和职位描述来针对性地梳理。
11 |
12 |
13 |
14 | 基础知识来自于自己平时的储备,一般对着一本系统的书籍或者自己平时的笔记过一遍即可,但是提到自己做到的项目是没有固定的复习套路的,而且围绕项目可以衍生出来各种问题,都需要了解,项目讲清楚对于候选人也特别重要。基础是固定的,任何人经过一段时间都可以学完的,但是项目经历是实打实的经验。
15 |
16 |
17 |
18 | 对于项目的复习和准备,建议**列思维导图(脑图)**,针对自己重点需要讲的项目,列出用到的技术点(知识点),介绍背景、项目上线后的收益以及后续优化点。这是第一层,第二层就是针对技术点(知识点)做各种发散的问题。
19 |
20 |
21 |
22 | 注:JD(job description),是指职位描述,是其缩写。一般在招聘中,最常用到的意思就是岗位介绍和工作职责描述的意思。
23 |
24 | ### 2. 程序员应该具备哪些软技能?
25 |
26 | 程序员除了业务技能外,应该具有下面的软技能:
27 |
28 | - 韧性:抗压能力,在一定项目压力下能够迎难而上,比如勇于主动承担和解决技术难题
29 | - 责任心:对于自己做过的项目,能够出现 bug 之类主动解决
30 | - 持续学习能力:IT 行业是个需要不断充电的行业,尤其 Web 前端这些年一直在巨变,所以持续学习能力很重要
31 | - 团队合作能力:做项目不能个人英雄主义,应该融入团队,跟团队一起打仗
32 | - 交流沟通能力:经常会遇见沟通需求和交互设计的工作,应该乐于沟通分享
33 |
34 | ### 3. 准备合适的技术型简历
35 |
36 | **(1)技术型简历的重要组成部分**
37 |
38 | 一份合适的技术型简历最重要的三部分是:
39 |
40 | - 个人掌握的技能,是否有岗位需要用到的技能,及其技能掌握的熟练程度:熟悉、了解还是精通
41 | - 项目经历,项目经历是否对现在岗位有用或者有重叠,是否能够驾驭大型项目
42 | - 实习经历,对于没有经验的应届生来说,实习经历是很重要的部分,是否有大公司或者具体项目的实习经历是筛选简历的重要参考
43 |
44 |
45 |
46 | 技术型简历一般不要太花俏,关键要语言表达通顺清楚,让语言准确和容易理解,在 HR 筛选简历的时候,可以瞬间抓住他的眼球。另外如果有一些特殊奖项,也可以在简历中突出出来,比如:季度之星、最佳个人之类的奖项,应届生会有优秀毕业生、全额奖学金等。
47 |
48 |
49 |
50 | **(2)推荐使用 PDF 版本的简历**
51 |
52 | 一般来说简历会有 Word、Markdown、PDF 等版本,这里推荐使用 PDF 版本的简历,主要原因如下:
53 |
54 | - 内容丰富,布局调整方便
55 | - 字体等格式有保障,你不知道收到你简历的人用的是什么环境,PDF 版本不会因为不同操作系统等原因而受限
56 | - 便于携带和传播,始终存一份简历在手机或者邮箱内,随时发送
57 | - 不容易被涂改
58 |
59 |
60 |
61 | 一般 Windows 系统的 Word、Mac 系统的 Pages 都支持导出 PDF 格式的文件,原稿可以保存到云端或者 iCloud,方便以后修改。
62 |
63 |
64 |
65 | 虽然我们是 Web 前端工程师,但是不推荐使用 HTML 格式的简历,HTML 版本的简历容易受浏览器等环境因素影响,而且接收方不一定是技术人员,炫酷的效果对方不一定能被看到。
66 |
67 |
68 |
69 | **(3)简历最好要有针对性地来写**
70 |
71 | 简历是「**敲门砖**」,建议根据想要找的公司、岗位和职位描述来有针对性地写简历。尤其是个人技能和项目(实习)经验部分,要根据岗位要求来写,这样才能增加受邀面试的机会。
72 |
73 | > 举个例子:好友给你推荐了百度地图部门的一个 Web 前端工程师工作,并且把职位描述(JD)发给你了,里面有要求哪些技能,用到哪些技术,还有加分项。那么你写简历就应该思考自己有没有这些技能。如果没有 JD,那么至少你应该知道:地图部门肯定做一些跟地图相关的工作,如果恰巧你之前研究过地图定位,了解 HTML5 Geolocation 定位接口,那么你可以在简历里提一下。
74 |
75 | 很多时候我们并不知道简历会被谁看到,也不知道简历会被朋友/猎头投递到什么公司或者职位,那么这样的简历应该是一种「通用简历」。所谓通用简历,应该是与我们找的职位和期望的级别相匹配的简历,比如想找大概 T4 水平的 Web 前端工作,那么就应该在简历体现出来自己的技能能够达到 T4 的水平。不要拿着一两年前的简历去找工作,前端这两年发展速度很快,只靠一两年前简历上面「精通、熟悉」的库和框架,可能已经找不到工作了。
76 |
77 |
78 |
79 | 所以,写简历也是个技术活,而且是一个辛苦活!不要用千篇一律的模板!
80 |
81 |
82 |
83 | **(4)简历是面试时「点菜」用的菜单**
84 |
85 | 简历除了是「敲门砖」之外,还是供面试官提问用的「菜单」。面试官会从简历上面写的技能、项目进行提问。所以简历是候选人「反客为主」的重要工具,这也是我们一直提到的:**不要造假或者描述太出格**,而应该实事求是地写简历。简历中的技能和项目都要做好知识点梳理,尽量多地梳理出面试官可能问到的问题,并且想出怎么回答应对,**千万不要在简历上自己给自己挖坑**。
86 |
87 |
88 |
89 | 另外简历中不要出现错误的单词拼写,注意单词的大小写,比如`jQuery`之类。并且,作为一个前端工程师,简历的布局一定要合理,美观。
90 |
91 | ### 4. 收到面试邀请之后的准备
92 |
93 | 当有公司邀请我们去面试的时候,应该针对性地做一些功课。
94 |
95 | **(1)了解部门和团队**
96 |
97 | 了解部门做的事情,团队用的技术栈,前文提到这部分信息一般从 JD 当中就可以看到,如果 JD 并没有这些信息,那么可以根据面试的部门搜索下,总会找到一些零星的信息,如果实在没有任何信息,就准备岗位需要的通用技术。
98 |
99 | **(2)了解面试官**
100 |
101 | 通过邀请电话或者面试邀请邮件,可以找到面试官信息。通过这些信息查找面试官技术博客、GitHub 等,了解面试官最近关注的技术和擅长的技术,因为面试官往往会在面试的过程中问自己擅长的技术。
102 |
103 | ## 二、面试过程:
104 |
105 | ### 1. 面试过程中要注意社交礼仪
106 |
107 | - **注意社交礼仪:**虽然说 IT 行业不怎么注重工作环境,上下级也没有繁文缛节,但是在面试中还是应该注意一些社交礼仪的。像进门敲门、出门关门、站着迎人这类基本礼仪还是要做的。
108 | - **舒适但不随意的着装:**首先着装方面,不要太随意,也不要太正式,太正式的衣服可能会使人紧张,所以建议穿自己平时喜欢的衣服,关键是干净整洁。
109 | - **约个双方都舒服的面试时间:**如果 HR 打电话预约面试时间,记得一定要约个双方都舒服的时间,宁愿请假也要安排好面试时间。面试时间很重要,**提前十分钟到面试地点**,熟悉下环境,做个登记之类的,留下个守时的好印象。如果因为堵车之类的原因不能按时到达,则要在约定时间之前电话通知对方。
110 |
111 | ### 2 面试中出现的常规问题
112 |
113 | 对于面试中出现的常规问题要做好准备,比如:介绍下自己,为什么跳槽,面试最后一般会问有什么要问的。
114 |
115 | **(1)介绍自己**
116 |
117 | 介绍自己时,切忌从自己大学实习一直到最新公司全部毫无侧重地介绍,这些在简历当中都有,最好的方式是在介绍中铺垫自己的技术特长、做的项目,引导面试官问自己准备好的问题。
118 |
119 | **(2) 为什么跳槽**
120 |
121 | 这个问题一定要慎重和认真思考,诚实回答。一般这个问题是想评估你入职能够待多长时间,是否能够融入团队。每个人跳槽前肯定想了很多原因,最终才走出这一步,不管现在工作怎样,**切忌抱怨,不要吐槽,更不要说和现在领导不和睦之类的话**。 多从自身发展找原因,可以表达寻找自己心目中的好的技术团队氛围和平台机会,比如:个人遇见了天花板,希望找个更好的发展机会。
122 |
123 | ### 3. 如何介绍自己的项目经历
124 |
125 | **(1)介绍项目背景**
126 |
127 | 这个项目为什么做,当初大的环境背景是什么?还是为了解决一个什么问题而设立的项目?背景是很重要的,如果不了解背景,一上来就听一个结论性的项目,面试官可能对于项目的技术选型、技术难度会有理解偏差,甚至怀疑是否真的有过这样的项目。
128 |
129 | > 比如一上来就说:我们的项目采用了「backbone」来做框架,然后。。。而「backbone」已经是三四年前比较新鲜的技术,现在会有更好的选择方案,如果不介绍项目的时间背景,面试官肯定一脸懵逼。
130 |
131 | **(2) 承担角色**
132 |
133 | 项目涉及的人员角色有哪些,自己在其中扮演的角色是什么?
134 |
135 |
136 |
137 | 这里候选往往人会自己给自己挖坑,比如把自己在项目中起到的作用夸大等。一般来说,面试官细节追问的时候,如果候选人能够把细节或者技术方案等讲明白、讲清楚,不管他是真的做过还是跟别人做过,或者自己认真思考过,都能体现候选人的技术水平和技术视野。前提还是在你能够兜得住的可控范围之内做适当的「美化」。
138 |
139 | **(3)最终的结果和收益**
140 |
141 | 项目介绍过程中,应该介绍项目最终的结果和收益,比如项目最后经过多久的开发上线了,上线后的数据是怎样的,是否达到预期,还是带来了新的问题,遇见了问题自己后续又是怎样补救的。
142 |
143 | **(4)有始有终:项目总结和反思**
144 |
145 | 有总结和反思,才会有进步。 项目做完了往往会有一些心得和体会,这时候应该跟面试官说出来。在梳理项目的总结和反思时,可以按照下面的列表来梳理:
146 |
147 | - 收获有哪些?
148 | - 是否有做得不足的地方,怎么改进?
149 | - 是否具有可迁移性?
150 |
151 |
152 |
153 | 比如,之前详细介绍了某个项目,这个项目当时看来没有什么问题,但是现在有更好的解决方案了,候选人就应该在这里提出来:现在看来,这个项目还有 xx 的问题,我可以通过 xx 的方式来解决。再比如:做这个项目的时候,你做得比较出彩的地方,可以迁移到其他项目中直接使用,小到代码片段,大到解决方案,总会有你值得总结和梳理的地方。
154 |
155 |
156 |
157 | 介绍完项目总结这部分,也可以引导面试官往自己擅长的领域思考。比如上面提到项目中的问题,可以往你擅长的方面引导,即使面试官没有问到,你也介绍到了。
158 |
159 |
160 |
161 | 按照上面的四段体介绍项目,会让面试官感觉候选人有清晰的思路,对整个项目也有理解和想法,还能够总结反思项目的收益和问题,可谓「一箭三雕」。
162 |
163 | ### 4. 项目细节和技术点的追问
164 |
165 | 介绍项目的过程中,面试官可能会追问技术细节,所以在准备面试的时候,应该尽量把技术细节梳理清楚,技术细节包括:
166 |
167 | - 技术选型方案:当时做技术选型所面临的状况
168 | - 技术解决方案:最终确定某种技术方案的原因,比如:选择用 Vue 而没有用 React 是为什么?
169 | - 项目数据和收益
170 | - 项目中最难的地方
171 | - 遇见的坑:如使用某种框架遇见哪些坑
172 |
173 |
174 |
175 | 一般来说,做技术选型的时候需要考虑下面几个因素:
176 |
177 | - 时代:现在比较火的技术是什么,为什么火起来,解决了什么问题,能否用到我的项目中?
178 | - 团队:个人或者团队对某种技术的熟悉程度是怎样的,学习成本又是怎样的?
179 | - 业务需求:需求是怎样的,能否套用现在的成熟解决方案/库来快速解决?
180 | - 维护成本:一个解决方案的是否再能够 cover 住的范围之内?
181 |
182 |
183 |
184 | 在项目中遇见的数据和收益应该做好跟踪,保证数据的真实性和可信性。另外,遇见的坑可能是面试官问得比较多的,尤其现在比较火的一些技术(Vue、React、webpack),一般团队都在使用,所以一定要提前准备
185 |
186 | 下。
187 |
188 | ### 5. 没有做过大型项目怎么办
189 |
190 | 对于刚刚找工作的应届生,或者面试官让你进行一个大型项目的设计,候选人可能没有类似的经验。这时候不要用「我不会、没做过」一句话就带过。如果是实在没有项目可以说,那么可以提自己日常做的练手项目,或者看到一个解决方案的文章/书,提到的某个项目,抒发下自己的想法。
191 |
192 |
193 |
194 | 如果是对于面试官提出来需要你设计的项目/系统,可以按照下面几步思考:
195 |
196 | 1. 有没有遇见过类似的项目
197 | 2. 有没有读过类似解决方案的文章
198 | 3. 项目能不能拆解,拆解过程中能不能发现自己做过的项目可以用
199 | 4. 项目解决的问题是什么,这类问题有没有更好的解决方案
200 |
201 |
202 |
203 | 总之,切记不要一句「不知道、没做过」就放弃,每一次提问都是自己表现的机会。
204 |
205 | ### 6. 当被分配一个几乎不可能完成的任务时,会怎么做
206 |
207 | 这种情况下,一般通过下面方式来解决:
208 |
209 | 1. 自己先查找资料,寻找解决方案,评估自己需要怎样的资源来完成,需要多长时间
210 | 2. 能不能借助周围同事来解决问题
211 | 3. 拿着分析结果跟上级反馈,寻求帮助或者资源
212 |
213 | 突出的软技能:分析和解决问题,沟通寻求帮助。
214 |
215 | ### 7. 提问环节
216 |
217 | 面试是一个双向选择的事情,所以面试后一般会有提问环节。在提问环节,候选人最好不要什么都不问,更不要只问薪水待遇、是否加班之类的问题。
218 |
219 |
220 |
221 | 其实这个时候可以反问面试官了解团队情况、团队做的业务、本职位具体做的工作、工作的规划,甚至一些数据(可能有些问题不会直面回答)。
222 |
223 |
224 |
225 | 还可以问一些关于公司培训机会和晋升机会之类的问题。如果是一些高端职位,则可以问一下:自己的 leader 想把这个职位安排给什么样的人,希望多久的时间内可以达到怎样的水平。
226 |
227 | ## 三、HR面试:
228 |
229 | ### 1. 谈薪资——准确定位和自我估值
230 |
231 | 在准备跳槽时,每个人肯定会对自己有一个预估,做好足够的心理准备。下面谈下怎么对自己的薪酬做个评估。一般来说跳槽的薪水是根据现在薪酬的基础上浮 15~30%,具体看个人面试的情况。对于应届毕业生,大公司基本都有标准薪水,同期的应届生差别不会特别大。
232 |
233 |
234 |
235 | 除了上面的方法,还应该按照公司的技术职级进行估值。每个公司都有对应的技术职级,不同的技术职级薪酬范围是固定的,如果是小公司,则可以参考大公司的职级范围来确定薪资范围。根据职级薪资范围和自己现在薪酬基础上浮后的薪酬,做个比较,取其较高的结果。
236 |
237 |
238 |
239 | 除此之外,我们可以在**微信小程序****offershow****、牛客网**等平台看看网友分享的各个公司的薪酬体系。
240 |
241 |
242 |
243 | 当然如果面试结果很好,可以适当地提高下薪酬预期。除了这种情况,应该针对不同的性质来对 offer先做好不同的估值。这里的预期估值只是心理预期,也就是自己的「底牌」。
244 |
245 | 所谓不同性质的 offer 指的是:
246 |
247 | - 是否是自己真心喜欢的工作岗位: 如果是自己真心喜欢的工作岗位,比如对于个人成长有利,或者希望进入某个公司部门,从事某个专业方向的工作,而你自己对于薪酬又不是特别在意,这时候可以适当调低薪酬预期,以拿到这个工作机会为主。
248 | - 是否只是做 backup 的岗位:面试可能不止面试一家,对于不是特别喜欢的公司部门,那么可以把这个 offer 做为 backup,后面遇见喜欢的公司可以以此基础来谈薪水。
249 |
250 |
251 |
252 | 这时候分两种情况:如果面试结果不是很好,这种情况应该优先拿到 offer,所以可以适当降低期望薪酬;如果面试结果很好,这种情况应该多要一些薪酬,增加的薪酬可以让你加入这家公司也心里很舒服。
253 |
254 | 对于自己真正的目标职位,面试之前应该先找 backup 岗位练练手,一是为了找出面试的感觉,二是为了拿到几个 offer 做好 backup。
255 |
256 | ### 2. 跟 HR 沟通的技巧
257 |
258 | 跟 HR 沟通的时候,不要夸大现在的薪酬,HR 知道的信息往往会超出你的认知,尤其大公司还会有背景调查,所以不要撒谎,实事求是。跟 HR 沟通的技巧有以下几点:
259 |
260 | - **不要急于出价**
261 |
262 | 不要急于亮出自己的底牌,一旦你说出一个薪酬范围,自己就不能增加薪酬了,还给了对方砍价的空间。而且一个不合理的价格反而会让对方直接放弃。所以不要着急出价,先让对方出价。
263 |
264 | 同时,对于公司级别也是,不要一开始就奔着某个目标去面试,这样会加大面试的难度,比如:
265 |
266 | > 目标是拿到阿里 P7 的职位,不要说不给 P7 我就不去面试之类的,这样的要求会让对方一开始就拿 P7 的标准来面试,可能会找 P8+ 的面试官来面试你,这样会大大提升面试难度。
267 |
268 | - **要有底气足够自信**
269 |
270 | 要有底气,自信,自己按照上面的估值盘算好了想要的薪酬,那么应该有底气地说出来,并且给出具体的原因,比如:
271 |
272 | > 1. 我已经对贵公司的薪酬范围和级别有了大概的了解,我现在的水平大概范围是多少
273 | > 2. 现在公司很快就有调薪机会,自己已经很久没有调薪,年前跳槽会损失年终奖等情况
274 | > 3. 现在我已经有某个公司多少 K 的 offer
275 |
276 | 如果 HR 表示你想要的薪酬不能满足,这时候你应该给出自己评估的依据,是根据行业职级标准还是自己现有薪酬范围,这样做到有理有据。
277 |
278 | - **谈好 offer 就要尽快落实**
279 |
280 | 对于已经谈拢的薪酬待遇,一定要 HR 以发邮件 offer 的形式来确认。
281 |
282 | ## 四、其他
283 |
284 | ### 1. 总结和思考
285 |
286 | - 面试完了多总结自己哪里做得不好,哪里做得好,都记录下来,后续扬长避短
287 | - 通过面试肯定亲身体会到了公司团队文化、面试官体现出来的技术能力、专业性以及职位将来所做的事情,跟自己预期是否有差距,多个 offer 的话多做对比
288 |
289 |
290 |
291 | 每次面试应该都有所收获,毕竟花费了时间和精力。即使面不上也可以知道自己哪方面做得不好,继续加强。
292 |
293 | ### 2. 面试注意点
294 |
295 | 在面试过程中,我们经常会被问及各种问题,在回答的过程中,这里简单列举了一些“坑”。
296 |
297 | - “对不起,我真的很紧张”,即使紧张也不要说出来;
298 | - “我想知道这个职位的具体收入有多少”一开始就谈钱,你的理想、价值观、使命、目标呢?
299 | - “我的缺点是斤斤计较,不能加班,承受不了工作压力太大”不要主动告诉别人你的缺点,你来是展示你的优势的;
300 | - “我真的很想要这份工作”不要太过于表现你的欲望或绝望,这是你软弱的表现;
301 | - “我现在(之前)的老板太不好了……”向 HR 说你老板的话会变成对方对你的看法;
302 | - “我需要……能实现工作目标”招聘是为了满足公司需求,不是为你搭建舞台;
303 | - “请问面试什么时候结束”不要表现赶时间,你不尊重公司,自然不会录用你;
304 | - “我喜欢贵公司的福利待遇”你是来工作的,不是因为福利待遇才来的;“无可奉告”不违法不涉及隐私,如实告知,有准备的话不会“无可奉告”;
305 | - “工作第一年的福利待遇及带薪年假和病假等情况是什么样的”这是入职时才可以问的规定,先问只会被误会;
306 | - “我在离婚或者怀孕期间经历了非常艰难的时期”不要主动告诉对方隐私情况,你个人的事情处理不好会容易联想到工作表现;
307 | - “我没有什么问题要问”最后被问到时这样回答等同于“再也不见”。
--------------------------------------------------------------------------------
/11 offer收割机之代码输出篇.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ### 前言:
4 |
5 | **代码输出结果**也是面试中常考的题目,一段代码中可能涉及到很多的知识点,这就考察到了应聘者的基础能力。在前端面试中,常考的代码输出问题主要涉及到以下知识点:**异步编程、事件循环、this指向、作用域、变量提升、闭包、原型、继承**等,这些知识点往往不是单独出现的,而是在同一段代码中包含多个知识点。所以,笔者将这些问题大致分为四类进行讨论。这里不会系统的阐述基础知识,而是通过面试例题的形式,来讲述每个题目的知识点以及代码的执行过程。如果会了这些例题,在前端面试中多数代码输出问题就可以轻而易举的解决了。
6 |
7 |
8 |
9 | **注:**本文中所有例题收集自牛客网面经、网络博文等,如果侵权,请联系删除!
10 |
11 | ## 一、异步&事件循环
12 |
13 | ### 1. 代码输出结果
14 |
15 | ```
16 | const promise = new Promise((resolve, reject) => {
17 | console.log(1);
18 | console.log(2);
19 | });
20 | promise.then(() => {
21 | console.log(3);
22 | });
23 | console.log(4);
24 | ```
25 |
26 | 输出结果如下:
27 |
28 | ```
29 | 1
30 | 2
31 | 4
32 | ```
33 |
34 | promise.then 是微任务,它会在所有的宏任务执行完之后才会执行,同时需要promise内部的状态发生变化,因为这里内部没有发生变化,一直处于pending状态,所以不输出3。
35 |
36 | ### 2. 代码输出结果
37 |
38 | ```
39 | const promise1 = new Promise((resolve, reject) => {
40 | console.log('promise1')
41 | resolve('resolve1')
42 | })
43 | const promise2 = promise1.then(res => {
44 | console.log(res)
45 | })
46 | console.log('1', promise1);
47 | console.log('2', promise2);
48 | ```
49 |
50 | 输出结果如下:
51 |
52 | ```
53 | promise1
54 | 1 Promise{: resolve1}
55 | 2 Promise{}
56 | resolve1
57 | ```
58 |
59 | 需要注意的是,直接打印promise1,会打印出它的状态值和参数。
60 |
61 |
62 |
63 | 代码执行过程如下:
64 |
65 | 1. script是一个宏任务,按照顺序执行这些代码;
66 | 2. 首先进入Promise,执行该构造函数中的代码,打印`promise1`;
67 | 3. 碰到`resolve`函数, 将`promise1`的状态改变为`resolved`, 并将结果保存下来;
68 | 4. 碰到`promise1.then`这个微任务,将它放入微任务队列;
69 | 5. `promise2`是一个新的状态为`pending`的`Promise`;
70 | 6. 执行同步代码1, 同时打印出`promise1`的状态是`resolved`;
71 | 7. 执行同步代码2,同时打印出`promise2`的状态是`pending`;
72 | 8. 宏任务执行完毕,查找微任务队列,发现`promise1.then`这个微任务且状态为`resolved`,执行它。
73 |
74 | ### 3. 代码输出结果
75 |
76 | ```
77 | const promise = new Promise((resolve, reject) => {
78 | console.log(1);
79 | setTimeout(() => {
80 | console.log("timerStart");
81 | resolve("success");
82 | console.log("timerEnd");
83 | }, 0);
84 | console.log(2);
85 | });
86 | promise.then((res) => {
87 | console.log(res);
88 | });
89 | console.log(4);
90 | ```
91 |
92 | 输出结果如下:
93 |
94 | ```
95 | 1
96 | 2
97 | 4
98 | timerStart
99 | timerEnd
100 | success
101 | ```
102 |
103 | 代码执行过程如下:
104 |
105 | - 首先遇到Promise构造函数,会先执行里面的内容,打印`1`;
106 | - 遇到定时器`steTimeout`,它是一个宏任务,放入宏任务队列;
107 | - 继续向下执行,打印出2;
108 | - 由于`Promise`的状态此时还是`pending`,所以`promise.then`先不执行;
109 | - 继续执行下面的同步任务,打印出4;
110 | - 此时微任务队列没有任务,继续执行下一轮宏任务,执行`steTimeout`;
111 | - 首先执行`timerStart`,然后遇到了`resolve`,将`promise`的状态改为`resolved`且保存结果并将之前的`promise.then`推入微任务队列,再执行`timerEnd`;
112 | - 执行完这个宏任务,就去执行微任务`promise.then`,打印出`resolve`的结果。
113 |
114 | ### 4. 代码输出结果
115 |
116 | ```
117 | Promise.resolve().then(() => {
118 | console.log('promise1');
119 | const timer2 = setTimeout(() => {
120 | console.log('timer2')
121 | }, 0)
122 | });
123 | const timer1 = setTimeout(() => {
124 | console.log('timer1')
125 | Promise.resolve().then(() => {
126 | console.log('promise2')
127 | })
128 | }, 0)
129 | console.log('start');
130 | ```
131 |
132 | 输出结果如下:
133 |
134 | ```
135 | start
136 | promise1
137 | timer1
138 | promise2
139 | timer2
140 | ```
141 |
142 | 代码执行过程如下:
143 |
144 | 1. 首先,`Promise.resolve().then`是一个微任务,加入微任务队列
145 | 2. 执行timer1,它是一个宏任务,加入宏任务队列
146 | 3. 继续执行下面的同步代码,打印出`start`
147 | 4. 这样第一轮宏任务就执行完了,开始执行微任务`Promise.resolve().then`,打印出`promise1`
148 | 5. 遇到`timer2`,它是一个宏任务,将其加入宏任务队列,此时宏任务队列有两个任务,分别是`timer1`、`timer2`;
149 | 6. 这样第一轮微任务就执行完了,开始执行第二轮宏任务,首先执行定时器`timer1`,打印`timer1`;
150 | 7. 遇到`Promise.resolve().then`,它是一个微任务,加入微任务队列
151 | 8. 开始执行微任务队列中的任务,打印`promise2`;
152 | 9. 最后执行宏任务`timer2`定时器,打印出`timer2`;
153 |
154 | ### 5. 代码输出结果
155 |
156 | ```
157 | const promise = new Promise((resolve, reject) => {
158 | resolve('success1');
159 | reject('error');
160 | resolve('success2');
161 | });
162 | promise.then((res) => {
163 | console.log('then:', res);
164 | }).catch((err) => {
165 | console.log('catch:', err);
166 | })
167 | ```
168 |
169 | 输出结果如下:
170 |
171 | ```
172 | then:success1
173 | ```
174 |
175 | 这个题目考察的就是**Promise的状态在发生变化之后,就不会再发生变化**。开始状态由`pending`变为`resolve`,说明已经变为已完成状态,下面的两个状态的就不会再执行,同时下面的catch也不会捕获到错误。
176 |
177 | ### 6. 代码输出结果
178 |
179 | ```
180 | Promise.resolve(1)
181 | .then(2)
182 | .then(Promise.resolve(3))
183 | .then(console.log)
184 | ```
185 |
186 | 输出结果如下:
187 |
188 | ```
189 | 1
190 | Promise {: undefined}
191 | ```
192 |
193 | Promise.resolve方法的参数如果是一个原始值,或者是一个不具有then方法的对象,则Promise.resolve方法返回一个新的Promise对象,状态为resolved,Promise.resolve方法的参数,会同时传给回调函数。
194 |
195 |
196 |
197 | then方法接受的参数是函数,而如果传递的并非是一个函数,它实际上会将其解释为then(null),这就会导致前一个Promise的结果会传递下面。
198 |
199 | ### 7. 代码输出结果
200 |
201 | ```
202 | const promise1 = new Promise((resolve, reject) => {
203 | setTimeout(() => {
204 | resolve('success')
205 | }, 1000)
206 | })
207 | const promise2 = promise1.then(() => {
208 | throw new Error('error!!!')
209 | })
210 | console.log('promise1', promise1)
211 | console.log('promise2', promise2)
212 | setTimeout(() => {
213 | console.log('promise1', promise1)
214 | console.log('promise2', promise2)
215 | }, 2000)
216 | ```
217 |
218 | 输出结果如下:
219 |
220 | ```
221 | promise1 Promise {}
222 | promise2 Promise {}
223 |
224 | Uncaught (in promise) Error: error!!!
225 | promise1 Promise {: "success"}
226 | promise2 Promise {: Error: error!!}
227 | ```
228 |
229 | ### 8. 代码输出结果
230 |
231 | ```
232 | Promise.resolve(1)
233 | .then(res => {
234 | console.log(res);
235 | return 2;
236 | })
237 | .catch(err => {
238 | return 3;
239 | })
240 | .then(res => {
241 | console.log(res);
242 | });
243 | ```
244 |
245 | 输出结果如下:
246 |
247 | ```
248 | 1
249 | 2
250 | ```
251 |
252 | Promise是可以链式调用的,由于每次调用 `.then` 或者 `.catch` 都会返回一个新的 promise,从而实现了链式调用, 它并不像一般任务的链式调用一样return this。
253 |
254 |
255 |
256 | 上面的输出结果之所以依次打印出1和2,是因为`resolve(1)`之后走的是第一个then方法,并没有进catch里,所以第二个then中的res得到的实际上是第一个then的返回值。并且return 2会被包装成`resolve(2)`,被最后的then打印输出2。
257 |
258 | ### 9. 代码输出结果
259 |
260 | ```
261 | Promise.resolve().then(() => {
262 | return new Error('error!!!')
263 | }).then(res => {
264 | console.log("then: ", res)
265 | }).catch(err => {
266 | console.log("catch: ", err)
267 | })
268 | ```
269 |
270 | 输出结果如下:
271 |
272 | ```
273 | "then: " "Error: error!!!"
274 | ```
275 |
276 | 返回任意一个非 promise 的值都会被包裹成 promise 对象,因此这里的`return new Error('error!!!')`也被包裹成了`return Promise.resolve(new Error('error!!!'))`,因此它会被then捕获而不是catch。
277 |
278 | ### 10. 代码输出结果
279 |
280 | ```
281 | const promise = Promise.resolve().then(() => {
282 | return promise;
283 | })
284 | promise.catch(console.err)
285 | ```
286 |
287 | 输出结果如下:
288 |
289 | ```
290 | Uncaught (in promise) TypeError: Chaining cycle detected for promise #
291 | ```
292 |
293 | 这里其实是一个坑,`.then` 或 `.catch` 返回的值不能是 promise 本身,否则会造成死循环。
294 |
295 | ### 11. 代码输出结果
296 |
297 | ```
298 | Promise.resolve(1)
299 | .then(2)
300 | .then(Promise.resolve(3))
301 | .then(console.log)
302 | ```
303 |
304 | 输出结果如下:
305 |
306 | ```
307 | 1
308 | ```
309 |
310 | 看到这个题目,好多的then,实际上只需要记住一个原则:`.then` 或`.catch` 的参数期望是函数,传入非函数则会发生**值透传**。
311 |
312 |
313 |
314 | 第一个then和第二个then中传入的都不是函数,一个是数字,一个是对象,因此发生了透传,将`resolve(1)` 的值直接传到最后一个then里,直接打印出1。
315 |
316 | ### 12. 代码输出结果
317 |
318 | ```
319 | Promise.reject('err!!!')
320 | .then((res) => {
321 | console.log('success', res)
322 | }, (err) => {
323 | console.log('error', err)
324 | }).catch(err => {
325 | console.log('catch', err)
326 | })
327 | ```
328 |
329 | 输出结果如下:
330 |
331 | ```
332 | error err!!!
333 | ```
334 |
335 | 我们知道,`.then`函数中的两个参数:
336 |
337 | - 第一个参数是用来处理Promise成功的函数
338 | - 第二个则是处理失败的函数
339 |
340 | 也就是说`Promise.resolve('1')`的值会进入成功的函数,`Promise.reject('2')`的值会进入失败的函数。
341 |
342 |
343 |
344 | 在这道题中,错误直接被`then`的第二个参数捕获了,所以就不会被`catch`捕获了,输出结果为:`error err!!!'`
345 |
346 |
347 |
348 | 但是,如果是像下面这样:
349 |
350 | ```
351 | Promise.resolve()
352 | .then(function success (res) {
353 | throw new Error('error!!!')
354 | }, function fail1 (err) {
355 | console.log('fail1', err)
356 | }).catch(function fail2 (err) {
357 | console.log('fail2', err)
358 | })
359 | ```
360 |
361 | 在`then`的第一参数中抛出了错误,那么他就不会被第二个参数不活了,而是被后面的`catch`捕获到。
362 |
363 | ### 13. 代码输出结果
364 |
365 | ```
366 | Promise.resolve('1')
367 | .then(res => {
368 | console.log(res)
369 | })
370 | .finally(() => {
371 | console.log('finally')
372 | })
373 | Promise.resolve('2')
374 | .finally(() => {
375 | console.log('finally2')
376 | return '我是finally2返回的值'
377 | })
378 | .then(res => {
379 | console.log('finally2后面的then函数', res)
380 | })
381 | ```
382 |
383 | 输出结果如下:
384 |
385 | ```
386 | 1
387 | finally2
388 | finally
389 | finally2后面的then函数 2
390 | ```
391 |
392 | `.finally()`一般用的很少,只要记住以下几点就可以了:
393 |
394 | - `.finally()`方法不管Promise对象最后的状态如何都会执行
395 | - `.finally()`方法的回调函数不接受任何的参数,也就是说你在`.finally()`函数中是无法知道Promise最终的状态是`resolved`还是`rejected`的
396 | - 它最终返回的默认会是一个上一次的Promise对象值,不过如果抛出的是一个异常则返回异常的Promise对象。
397 | - finally本质上是then方法的特例
398 |
399 |
400 |
401 | `.finally()`的错误捕获:
402 |
403 | ```
404 | Promise.resolve('1')
405 | .finally(() => {
406 | console.log('finally1')
407 | throw new Error('我是finally中抛出的异常')
408 | })
409 | .then(res => {
410 | console.log('finally后面的then函数', res)
411 | })
412 | .catch(err => {
413 | console.log('捕获错误', err)
414 | })
415 | ```
416 |
417 | 输出结果为:
418 |
419 | ```
420 | 'finally1'
421 | '捕获错误' Error: 我是finally中抛出的异常
422 | ```
423 |
424 | ### 14. 代码输出结果
425 |
426 | ```
427 | function runAsync (x) {
428 | const p = new Promise(r => setTimeout(() => r(x, console.log(x)), 1000))
429 | return p
430 | }
431 |
432 | Promise.all([runAsync(1), runAsync(2), runAsync(3)]).then(res => console.log(res))
433 | ```
434 |
435 | 输出结果如下:
436 |
437 | ```
438 | 1
439 | 2
440 | 3
441 | [1, 2, 3]
442 | ```
443 |
444 | 首先,定义了一个Promise,来异步执行函数runAsync,该函数传入一个值x,然后间隔一秒后打印出这个x。
445 |
446 |
447 |
448 | 之后再使用`Promise.all`来执行这个函数,执行的时候,看到一秒之后输出了1,2,3,同时输出了数组[1, 2, 3],三个函数是同步执行的,并且在一个回调函数中返回了所有的结果。并且结果和函数的执行顺序是一致的。
449 |
450 | ### 15. 代码输出结果
451 |
452 | ```
453 | function runAsync (x) {
454 | const p = new Promise(r => setTimeout(() => r(x, console.log(x)), 1000))
455 | return p
456 | }
457 | function runReject (x) {
458 | const p = new Promise((res, rej) => setTimeout(() => rej(`Error: ${x}`, console.log(x)), 1000 * x))
459 | return p
460 | }
461 | Promise.all([runAsync(1), runReject(4), runAsync(3), runReject(2)])
462 | .then(res => console.log(res))
463 | .catch(err => console.log(err))
464 | ```
465 |
466 | 输出结果如下:
467 |
468 | ```
469 | // 1s后输出
470 | 1
471 | 3
472 | // 2s后输出
473 | 2
474 | Error: 2
475 | // 4s后输出
476 | 4
477 | ```
478 |
479 | 可以看到。catch捕获到了第一个错误,在这道题目中最先的错误就是`runReject(2)`的结果。如果一组异步操作中有一个异常都不会进入`.then()`的第一个回调函数参数中。会被`.then()`的第二个回调函数捕获。
480 |
481 | ### 16. 代码输出结果
482 |
483 | ```
484 | function runAsync (x) {
485 | const p = new Promise(r => setTimeout(() => r(x, console.log(x)), 1000))
486 | return p
487 | }
488 | Promise.race([runAsync(1), runAsync(2), runAsync(3)])
489 | .then(res => console.log('result: ', res))
490 | .catch(err => console.log(err))
491 | ```
492 |
493 | 输出结果如下:
494 |
495 | ```
496 | 1
497 | 'result: ' 1
498 | 2
499 | 3
500 | ```
501 |
502 | then只会捕获第一个成功的方法,其他的函数虽然还会继续执行,但是不是被then捕获了。
503 |
504 | ### 17. 代码输出结果
505 |
506 | ```
507 | function runAsync(x) {
508 | const p = new Promise(r =>
509 | setTimeout(() => r(x, console.log(x)), 1000)
510 | );
511 | return p;
512 | }
513 | function runReject(x) {
514 | const p = new Promise((res, rej) =>
515 | setTimeout(() => rej(`Error: ${x}`, console.log(x)), 1000 * x)
516 | );
517 | return p;
518 | }
519 | Promise.race([runReject(0), runAsync(1), runAsync(2), runAsync(3)])
520 | .then(res => console.log("result: ", res))
521 | .catch(err => console.log(err));
522 | ```
523 |
524 | 输出结果如下:
525 |
526 | ```
527 | 0
528 | Error: 0
529 | 1
530 | 2
531 | 3
532 | ```
533 |
534 | 可以看到在catch捕获到第一个错误之后,后面的代码还不执行,不过不会再被捕获了。
535 |
536 |
537 |
538 | 注意:`all`和`race`传入的数组中如果有会抛出异常的异步任务,那么只有最先抛出的错误会被捕获,并且是被then的第二个参数或者后面的catch捕获;但并不会影响数组中其它的异步任务的执行。
539 |
540 | ### 18. 代码输出结果
541 |
542 | ```
543 | async function async1() {
544 | console.log("async1 start");
545 | await async2();
546 | console.log("async1 end");
547 | }
548 | async function async2() {
549 | console.log("async2");
550 | }
551 | async1();
552 | console.log('start')
553 | ```
554 |
555 | 输出结果如下:
556 |
557 | ```
558 | async1 start
559 | async2
560 | start
561 | async1 end
562 | ```
563 |
564 | 代码的执行过程如下:
565 |
566 | 1. 首先执行函数中的同步代码`async1 start`,之后遇到了`await`,它会阻塞`async1`后面代码的执行,因此会先去执行`async2`中的同步代码`async2`,然后跳出`async1`;
567 | 2. 跳出`async1`函数后,执行同步代码`start`;
568 | 3. 在一轮宏任务全部执行完之后,再来执行`await`后面的内容`async1 end`。
569 |
570 |
571 |
572 | 这里可以理解为await后面的语句相当于放到了new Promise中,下一行及之后的语句相当于放在Promise.then中。
573 |
574 | ### 19. 代码输出结果
575 |
576 | ```
577 | async function async1() {
578 | console.log("async1 start");
579 | await async2();
580 | console.log("async1 end");
581 | setTimeout(() => {
582 | console.log('timer1')
583 | }, 0)
584 | }
585 | async function async2() {
586 | setTimeout(() => {
587 | console.log('timer2')
588 | }, 0)
589 | console.log("async2");
590 | }
591 | async1();
592 | setTimeout(() => {
593 | console.log('timer3')
594 | }, 0)
595 | console.log("start")
596 | ```
597 |
598 | 输出结果如下:
599 |
600 | ```
601 | async1 start
602 | async2
603 | start
604 | async1 end
605 | timer2
606 | timer3
607 | timer1
608 | ```
609 |
610 | 代码的执行过程如下:
611 |
612 | 1. 首先进入`async1`,打印出`async1 start`;
613 | 2. 之后遇到`async2`,进入`async2`,遇到定时器`timer2`,加入宏任务队列,之后打印`async2`;
614 | 3. 由于`async2`阻塞了后面代码的执行,所以执行后面的定时器`timer3`,将其加入宏任务队列,之后打印`start`;
615 | 4. 然后执行async2后面的代码,打印出`async1 end`,遇到定时器timer1,将其加入宏任务队列;
616 | 5. 最后,宏任务队列有三个任务,先后顺序为`timer2`,`timer3`,`timer1`,没有微任务,所以直接所有的宏任务按照先进先出的原则执行。
617 |
618 | ### 20. 代码输出结果
619 |
620 | ```
621 | async function async1 () {
622 | console.log('async1 start');
623 | await new Promise(resolve => {
624 | console.log('promise1')
625 | })
626 | console.log('async1 success');
627 | return 'async1 end'
628 | }
629 | console.log('srcipt start')
630 | async1().then(res => console.log(res))
631 | console.log('srcipt end')
632 | ```
633 |
634 | 输出结果如下:
635 |
636 | ```
637 | script start
638 | async1 start
639 | promise1
640 | script end
641 | ```
642 |
643 | 这里需要注意的是在`async1`中`await`后面的Promise是没有返回值的,也就是它的状态始终是`pending`状态,所以在`await`之后的内容是不会执行的,包括`async1`后面的 `.then`。
644 |
645 | ### 21. 代码输出结果
646 |
647 | ```
648 | async function async1 () {
649 | console.log('async1 start');
650 | await new Promise(resolve => {
651 | console.log('promise1')
652 | resolve('promise1 resolve')
653 | }).then(res => console.log(res))
654 | console.log('async1 success');
655 | return 'async1 end'
656 | }
657 | console.log('srcipt start')
658 | async1().then(res => console.log(res))
659 | console.log('srcipt end')
660 | ```
661 |
662 | 这里是对上面一题进行了改造,加上了resolve。
663 |
664 |
665 |
666 | 输出结果如下:
667 |
668 | ```
669 | script start
670 | async1 start
671 | promise1
672 | script end
673 | promise1 resolve
674 | async1 success
675 | async1 end
676 | ```
677 |
678 | ### 22. 代码输出结果
679 |
680 | ```
681 | async function async1() {
682 | console.log("async1 start");
683 | await async2();
684 | console.log("async1 end");
685 | }
686 |
687 | async function async2() {
688 | console.log("async2");
689 | }
690 |
691 | console.log("script start");
692 |
693 | setTimeout(function() {
694 | console.log("setTimeout");
695 | }, 0);
696 |
697 | async1();
698 |
699 | new Promise(resolve => {
700 | console.log("promise1");
701 | resolve();
702 | }).then(function() {
703 | console.log("promise2");
704 | });
705 | console.log('script end')
706 | ```
707 |
708 | 输出结果如下:
709 |
710 | ```
711 | script start
712 | async1 start
713 | async2
714 | promise1
715 | script end
716 | async1 end
717 | promise2
718 | setTimeout
719 | ```
720 |
721 | 代码执行过程如下:
722 |
723 | 1. 开头定义了async1和async2两个函数,但是并未执行,执行script中的代码,所以打印出script start;
724 | 2. 遇到定时器Settimeout,它是一个宏任务,将其加入到宏任务队列;
725 | 3. 之后执行函数async1,首先打印出async1 start;
726 | 4. 遇到await,执行async2,打印出async2,并阻断后面代码的执行,将后面的代码加入到微任务队列;
727 | 5. 然后跳出async1和async2,遇到Promise,打印出promise1;
728 | 6. 遇到resolve,将其加入到微任务队列,然后执行后面的script代码,打印出script end;
729 | 7. 之后就该执行微任务队列了,首先打印出async1 end,然后打印出promise2;
730 | 8. 执行完微任务队列,就开始执行宏任务队列中的定时器,打印出setTimeout。
731 |
732 | ### 23. 代码输出结果
733 |
734 | ```
735 | async function async1 () {
736 | await async2();
737 | console.log('async1');
738 | return 'async1 success'
739 | }
740 | async function async2 () {
741 | return new Promise((resolve, reject) => {
742 | console.log('async2')
743 | reject('error')
744 | })
745 | }
746 | async1().then(res => console.log(res))
747 | ```
748 |
749 | 输出结果如下:
750 |
751 | ```
752 | async2
753 | Uncaught (in promise) error
754 | ```
755 |
756 | 可以看到,如果async函数中抛出了错误,就会终止错误结果,不会继续向下执行。
757 |
758 |
759 |
760 | 如果想要让错误不足之处后面的代码执行,可以使用catch来捕获:
761 |
762 | ```
763 | async function async1 () {
764 | await Promise.reject('error!!!').catch(e => console.log(e))
765 | console.log('async1');
766 | return Promise.resolve('async1 success')
767 | }
768 | async1().then(res => console.log(res))
769 | console.log('script start')
770 | ```
771 |
772 | 这样的输出结果就是:
773 |
774 | ```
775 | script start
776 | error!!!
777 | async1
778 | async1 success
779 | ```
780 |
781 | ### 24. 代码输出结果
782 |
783 | ```
784 | const first = () => (new Promise((resolve, reject) => {
785 | console.log(3);
786 | let p = new Promise((resolve, reject) => {
787 | console.log(7);
788 | setTimeout(() => {
789 | console.log(5);
790 | resolve(6);
791 | console.log(p)
792 | }, 0)
793 | resolve(1);
794 | });
795 | resolve(2);
796 | p.then((arg) => {
797 | console.log(arg);
798 | });
799 | }));
800 | first().then((arg) => {
801 | console.log(arg);
802 | });
803 | console.log(4);
804 | ```
805 |
806 | 输出结果如下:
807 |
808 | ```
809 | 3
810 | 7
811 | 4
812 | 1
813 | 2
814 | 5
815 | Promise{: 1}
816 | ```
817 |
818 | 代码的执行过程如下:
819 |
820 | 1. 首先会进入Promise,打印出3,之后进入下面的Promise,打印出7;
821 | 2. 遇到了定时器,将其加入宏任务队列;
822 | 3. 执行Promise p中的resolve,状态变为resolved,返回值为1;
823 | 4. 执行Promise first中的resolve,状态变为resolved,返回值为2;
824 | 5. 遇到p.then,将其加入微任务队列,遇到first().then,将其加入任务队列;
825 | 6. 执行外面的代码,打印出4;
826 | 7. 这样第一轮宏任务就执行完了,开始执行微任务队列中的任务,先后打印出1和2;
827 | 8. 这样微任务就执行完了,开始执行下一轮宏任务,宏任务队列中有一个定时器,执行它,打印出5,由于执行已经变为resolved状态,所以`resolve(6)`不会再执行;
828 | 9. 最后`console.log(p)`打印出`Promise{: 1}`;
829 |
830 | ### 25. 代码输出结果
831 |
832 | ```
833 | const async1 = async () => {
834 | console.log('async1');
835 | setTimeout(() => {
836 | console.log('timer1')
837 | }, 2000)
838 | await new Promise(resolve => {
839 | console.log('promise1')
840 | })
841 | console.log('async1 end')
842 | return 'async1 success'
843 | }
844 | console.log('script start');
845 | async1().then(res => console.log(res));
846 | console.log('script end');
847 | Promise.resolve(1)
848 | .then(2)
849 | .then(Promise.resolve(3))
850 | .catch(4)
851 | .then(res => console.log(res))
852 | setTimeout(() => {
853 | console.log('timer2')
854 | }, 1000)
855 | ```
856 |
857 | 输出结果如下:
858 |
859 | ```
860 | script start
861 | async1
862 | promise1
863 | script end
864 | 1
865 | timer2
866 | timer1
867 | ```
868 |
869 | 代码的执行过程如下:
870 |
871 | 1. 首先执行同步带吗,打印出script start;
872 | 2. 遇到定时器timer1将其加入宏任务队列;
873 | 3. 之后是执行Promise,打印出promise1,由于Promise没有返回值,所以后面的代码不会执行;
874 | 4. 然后执行同步代码,打印出script end;
875 | 5. 继续执行下面的Promise,.then和.catch期望参数是一个函数,这里传入的是一个数字,因此就会发生值渗透,将resolve(1)的值传到最后一个then,直接打印出1;
876 | 6. 遇到第二个定时器,将其加入到微任务队列,执行微任务队列,按顺序依次执行两个定时器,但是由于定时器时间的原因,会在两秒后先打印出timer2,在四秒后打印出timer1。
877 |
878 | ### 26. 代码输出结果
879 |
880 | ```
881 | const p1 = new Promise((resolve) => {
882 | setTimeout(() => {
883 | resolve('resolve3');
884 | console.log('timer1')
885 | }, 0)
886 | resolve('resovle1');
887 | resolve('resolve2');
888 | }).then(res => {
889 | console.log(res) // resolve1
890 | setTimeout(() => {
891 | console.log(p1)
892 | }, 1000)
893 | }).finally(res => {
894 | console.log('finally', res)
895 | })
896 | ```
897 |
898 | 执行结果为如下:
899 |
900 | ```
901 | resolve1
902 | finally undefined
903 | timer1
904 | Promise{: undefined}
905 | ```
906 |
907 | ### 27. 代码输出结果
908 |
909 | ```
910 | console.log('1');
911 |
912 | setTimeout(function() {
913 | console.log('2');
914 | process.nextTick(function() {
915 | console.log('3');
916 | })
917 | new Promise(function(resolve) {
918 | console.log('4');
919 | resolve();
920 | }).then(function() {
921 | console.log('5')
922 | })
923 | })
924 | process.nextTick(function() {
925 | console.log('6');
926 | })
927 | new Promise(function(resolve) {
928 | console.log('7');
929 | resolve();
930 | }).then(function() {
931 | console.log('8')
932 | })
933 |
934 | setTimeout(function() {
935 | console.log('9');
936 | process.nextTick(function() {
937 | console.log('10');
938 | })
939 | new Promise(function(resolve) {
940 | console.log('11');
941 | resolve();
942 | }).then(function() {
943 | console.log('12')
944 | })
945 | })
946 | ```
947 |
948 | 输出结果如下:
949 |
950 | ```
951 | 1
952 | 7
953 | 6
954 | 8
955 | 2
956 | 4
957 | 3
958 | 5
959 | 9
960 | 11
961 | 10
962 | 12
963 | ```
964 |
965 | **(1)第一轮事件循环流程分析如下:**
966 |
967 | - 整体script作为第一个宏任务进入主线程,遇到`console.log`,输出1。
968 | - 遇到`setTimeout`,其回调函数被分发到宏任务Event Queue中。暂且记为`setTimeout1`。
969 | - 遇到`process.nextTick()`,其回调函数被分发到微任务Event Queue中。记为`process1`。
970 | - 遇到`Promise`,`new Promise`直接执行,输出7。`then`被分发到微任务Event Queue中。记为`then1`。
971 | - 又遇到了`setTimeout`,其回调函数被分发到宏任务Event Queue中,记为`setTimeout2`。
972 |
973 | | 宏任务Event Queue | 微任务Event Queue |
974 | | ----------------- | ----------------- |
975 | | setTimeout1 | process1 |
976 | | setTimeout2 | then1 |
977 |
978 | 上表是第一轮事件循环宏任务结束时各Event Queue的情况,此时已经输出了1和7。发现了`process1`和`then1`两个微任务:
979 |
980 | - 执行`process1`,输出6。
981 | - 执行`then1`,输出8。
982 |
983 | 第一轮事件循环正式结束,这一轮的结果是输出1,7,6,8。
984 |
985 |
986 |
987 | **(2)第二轮时间循环从**`**setTimeout1**`**宏任务开始:**
988 |
989 | - 首先输出2。接下来遇到了`process.nextTick()`,同样将其分发到微任务Event Queue中,记为`process2`。
990 | - `new Promise`立即执行输出4,`then`也分发到微任务Event Queue中,记为`then2`。
991 |
992 | | 宏任务Event Queue | 微任务Event Queue |
993 | | ----------------- | ----------------- |
994 | | setTimeout2 | process2 |
995 | | | then2 |
996 |
997 | 第二轮事件循环宏任务结束,发现有`process2`和`then2`两个微任务可以执行:
998 |
999 | - 输出3。
1000 | - 输出5。
1001 |
1002 | 第二轮事件循环结束,第二轮输出2,4,3,5。
1003 |
1004 |
1005 |
1006 | **(3)第三轮事件循环开始,此时只剩setTimeout2了,执行。**
1007 |
1008 | - 直接输出9。
1009 | - 将`process.nextTick()`分发到微任务Event Queue中。记为`process3`。
1010 | - 直接执行`new Promise`,输出11。
1011 | - 将`then`分发到微任务Event Queue中,记为`then3`。
1012 |
1013 | | 宏任务Event Queue | 微任务Event Queue |
1014 | | ----------------- | ----------------- |
1015 | | | process3 |
1016 | | | then3 |
1017 |
1018 | 第三轮事件循环宏任务执行结束,执行两个微任务`process3`和`then3`:
1019 |
1020 | - 输出10。
1021 | - 输出12。
1022 |
1023 | 第三轮事件循环结束,第三轮输出9,11,10,12。
1024 |
1025 |
1026 |
1027 | 整段代码,共进行了三次事件循环,完整的输出为1,7,6,8,2,4,3,5,9,11,10,12。
1028 |
1029 | ### 28. 代码输出结果
1030 |
1031 | ```
1032 | console.log(1)
1033 |
1034 | setTimeout(() => {
1035 | console.log(2)
1036 | })
1037 |
1038 | new Promise(resolve => {
1039 | console.log(3)
1040 | resolve(4)
1041 | }).then(d => console.log(d))
1042 |
1043 | setTimeout(() => {
1044 | console.log(5)
1045 | new Promise(resolve => {
1046 | resolve(6)
1047 | }).then(d => console.log(d))
1048 | })
1049 |
1050 | setTimeout(() => {
1051 | console.log(7)
1052 | })
1053 |
1054 | console.log(8)
1055 | ```
1056 |
1057 | 输出结果如下:
1058 |
1059 | ```
1060 | 1
1061 | 3
1062 | 8
1063 | 4
1064 | 2
1065 | 5
1066 | 6
1067 | 7
1068 | ```
1069 |
1070 | 代码执行过程如下:
1071 |
1072 | 1. 首先执行script代码,打印出1;
1073 | 2. 遇到第一个定时器,加入到宏任务队列;
1074 | 3. 遇到Promise,执行代码,打印出3,遇到resolve,将其加入到微任务队列;
1075 | 4. 遇到第二个定时器,加入到宏任务队列;
1076 | 5. 遇到第三个定时器,加入到宏任务队列;
1077 | 6. 继续执行script代码,打印出8,第一轮执行结束;
1078 | 7. 执行微任务队列,打印出第一个Promise的resolve结果:4;
1079 | 8. 开始执行宏任务队列,执行第一个定时器,打印出2;
1080 | 9. 此时没有微任务,继续执行宏任务中的第二个定时器,首先打印出5,遇到Promise,首选打印出6,遇到resolve,将其加入到微任务队列;
1081 | 10. 执行微任务队列,打印出6;
1082 | 11. 执行宏任务队列中的最后一个定时器,打印出7。
1083 |
1084 | ### 29. 代码输出结果
1085 |
1086 | ```
1087 | console.log(1);
1088 |
1089 | setTimeout(() => {
1090 | console.log(2);
1091 | Promise.resolve().then(() => {
1092 | console.log(3)
1093 | });
1094 | });
1095 |
1096 | new Promise((resolve, reject) => {
1097 | console.log(4)
1098 | resolve(5)
1099 | }).then((data) => {
1100 | console.log(data);
1101 | })
1102 |
1103 | setTimeout(() => {
1104 | console.log(6);
1105 | })
1106 |
1107 | console.log(7);
1108 | ```
1109 |
1110 | 代码输出结果如下:
1111 |
1112 | ```
1113 | 1
1114 | 4
1115 | 7
1116 | 5
1117 | 2
1118 | 3
1119 | 6
1120 | ```
1121 |
1122 | 代码执行过程如下:
1123 |
1124 | 1. 首先执行scrip代码,打印出1;
1125 | 2. 遇到第一个定时器setTimeout,将其加入到宏任务队列;
1126 | 3. 遇到Promise,执行里面的同步代码,打印出4,遇到resolve,将其加入到微任务队列;
1127 | 4. 遇到第二个定时器setTimeout,将其加入到红任务队列;
1128 | 5. 执行script代码,打印出7,至此第一轮执行完成;
1129 | 6. 指定微任务队列中的代码,打印出resolve的结果:5;
1130 | 7. 执行宏任务中的第一个定时器setTimeout,首先打印出2,然后遇到 Promise.resolve().then(),将其加入到微任务队列;
1131 | 8. 执行完这个宏任务,就开始执行微任务队列,打印出3;
1132 | 9. 继续执行宏任务队列中的第二个定时器,打印出6。
1133 |
1134 | ### 30. 代码输出结果
1135 |
1136 | ```
1137 | Promise.resolve().then(() => {
1138 | console.log('1');
1139 | throw 'Error';
1140 | }).then(() => {
1141 | console.log('2');
1142 | }).catch(() => {
1143 | console.log('3');
1144 | throw 'Error';
1145 | }).then(() => {
1146 | console.log('4');
1147 | }).catch(() => {
1148 | console.log('5');
1149 | }).then(() => {
1150 | console.log('6');
1151 | });
1152 | ```
1153 |
1154 | 执行结果如下:
1155 |
1156 | ```
1157 | 1
1158 | 3
1159 | 5
1160 | 6
1161 | ```
1162 |
1163 | 在这道题目中,我们需要知道,无论是thne还是catch中,只要throw 抛出了错误,就会被catch捕获,如果没有throw出错误,就被继续执行后面的then。
1164 |
1165 | ### 31. 代码输出结果
1166 |
1167 | ```
1168 | setTimeout(function () {
1169 | console.log(1);
1170 | }, 100);
1171 |
1172 | new Promise(function (resolve) {
1173 | console.log(2);
1174 | resolve();
1175 | console.log(3);
1176 | }).then(function () {
1177 | console.log(4);
1178 | new Promise((resove, reject) => {
1179 | console.log(5);
1180 | setTimeout(() => {
1181 | console.log(6);
1182 | }, 10);
1183 | })
1184 | });
1185 | console.log(7);
1186 | console.log(8);
1187 | ```
1188 |
1189 | 输出结果为:
1190 |
1191 | ```
1192 | 2
1193 | 3
1194 | 7
1195 | 8
1196 | 4
1197 | 5
1198 | 6
1199 | 1
1200 | ```
1201 |
1202 | 代码执行过程如下:
1203 |
1204 | 1. 首先遇到定时器,将其加入到宏任务队列;
1205 | 2. 遇到Promise,首先执行里面的同步代码,打印出2,遇到resolve,将其加入到微任务队列,执行后面同步代码,打印出3;
1206 | 3. 继续执行script中的代码,打印出7和8,至此第一轮代码执行完成;
1207 | 4. 执行微任务队列中的代码,首先打印出4,如遇到Promise,执行其中的同步代码,打印出5,遇到定时器,将其加入到宏任务队列中,此时宏任务队列中有两个定时器;
1208 | 5. 执行宏任务队列中的代码,这里我们需要注意是的第一个定时器的时间为100ms,第二个定时器的时间为10ms,所以先执行第二个定时器,打印出6;
1209 | 6. 此时微任务队列为空,继续执行宏任务队列,打印出1。
1210 |
1211 |
1212 |
1213 | 做完这道题目,我们就需要格外注意,每个定时器的时间,并不是所有定时器的时间都为0哦。
1214 |
1215 | ## 二、this
1216 |
1217 | ### 1. 代码输出结果
1218 |
1219 | ```
1220 | function foo() {
1221 | console.log( this.a );
1222 | }
1223 |
1224 | function doFoo() {
1225 | foo();
1226 | }
1227 |
1228 | var obj = {
1229 | a: 1,
1230 | doFoo: doFoo
1231 | };
1232 |
1233 | var a = 2;
1234 | obj.doFoo()
1235 | ```
1236 |
1237 | 输出结果:2
1238 |
1239 |
1240 |
1241 | 在Javascript中,this指向函数执行时的当前对象。在执行foo的时候,执行环境就是doFoo函数,执行环境为全局。所以,foo中的this是指向window的,所以会打印出2。
1242 |
1243 | ### 2. 代码输出结果
1244 |
1245 | ```
1246 | var a = 10
1247 | var obj = {
1248 | a: 20,
1249 | say: () => {
1250 | console.log(this.a)
1251 | }
1252 | }
1253 | obj.say()
1254 |
1255 | var anotherObj = { a: 30 }
1256 | obj.say.apply(anotherObj)
1257 | ```
1258 |
1259 | 输出结果:10 10
1260 |
1261 |
1262 |
1263 | 我么知道,箭头函数时不绑定this的,它的this来自原其父级所处的上下文,所以首先会打印全局中的 a 的值10。后面虽然让say方法指向了另外一个对象,但是仍不能改变箭头函数的特性,它的this仍然是指向全局的,所以依旧会输出10。
1264 |
1265 |
1266 |
1267 | 但是,如果是普通函数,那么就会有完全不一样的结果:
1268 |
1269 | ```
1270 | var a = 10
1271 | var obj = {
1272 | a: 20,
1273 | say(){
1274 | console.log(this.a)
1275 | }
1276 | }
1277 | obj.say()
1278 | var anotherObj={a:30}
1279 | obj.say.apply(anotherObj)
1280 | ```
1281 |
1282 | 输出结果:20 30
1283 |
1284 |
1285 |
1286 | 这时,say方法中的this就会指向他所在的对象,输出其中的a的值。
1287 |
1288 | ### 3. 代码输出结果
1289 |
1290 | ```
1291 | function a() {
1292 | console.log(this);
1293 | }
1294 | a.call(null);
1295 | ```
1296 |
1297 | 打印结果:window对象
1298 |
1299 |
1300 |
1301 | 根据ECMAScript262规范规定:如果第一个参数传入的对象调用者是null或者undefined,call方法将把全局对象(浏览器上是window对象)作为this的值。所以,不管传入null 还是 undefined,其this都是全局对象window。所以,在浏览器上答案是输出 window 对象。
1302 |
1303 |
1304 |
1305 | 要注意的是,在严格模式中,null 就是 null,undefined 就是 undefined:
1306 |
1307 | ```
1308 | 'use strict';
1309 |
1310 | function a() {
1311 | console.log(this);
1312 | }
1313 | a.call(null); // null
1314 | a.call(undefined); // undefined
1315 | ```
1316 |
1317 | ### 4. 代码输出结果
1318 |
1319 | ```
1320 | var obj = {
1321 | name: 'cuggz',
1322 | fun: function(){
1323 | console.log(this.name);
1324 | }
1325 | }
1326 | obj.fun() // cuggz
1327 | new obj.fun() // undefined
1328 | ```
1329 |
1330 | ### 6. 代码输出结果
1331 |
1332 | ```
1333 | var obj = {
1334 | say: function() {
1335 | var f1 = () => {
1336 | console.log("1111", this);
1337 | }
1338 | f1();
1339 | },
1340 | pro: {
1341 | getPro:() => {
1342 | console.log(this);
1343 | }
1344 | }
1345 | }
1346 | var o = obj.say;
1347 | o();
1348 | obj.say();
1349 | obj.pro.getPro();
1350 | ```
1351 |
1352 | ```
1353 | var obj = {
1354 | say: function() {
1355 | var f1 = () => {
1356 | console.log("1111", this);
1357 | }
1358 | f1();
1359 | },
1360 | pro: {
1361 | getPro:() => {
1362 | console.log(this);
1363 | }
1364 | }
1365 | }
1366 | var o = obj.say;
1367 | o();
1368 | obj.say();
1369 | obj.pro.getPro();
1370 | ```
1371 |
1372 | 输出结果:
1373 |
1374 | ```
1375 | 1111 window对象
1376 | 1111 obj对象
1377 | window对象
1378 | ```
1379 |
1380 | **解析:**
1381 |
1382 | 1. o(),o是在全局执行的,而f1是箭头函数,它是没有绑定this的,它的this指向其父级的this,其父级say方法的this指向的是全局作用域,所以会打印出window;
1383 | 2. obj.say(),谁调用say,say 的this就指向谁,所以此时this指向的是obj对象;
1384 | 3. obj.pro.getPro(),我们知道,箭头函数时不绑定this的,getPro处于pro中,而对象不构成单独的作用域,所以箭头的函数的this就指向了全局作用域window。
1385 |
1386 | ### 7. 代码输出结果
1387 |
1388 | ```
1389 | var myObject = {
1390 | foo: "bar",
1391 | func: function() {
1392 | var self = this;
1393 | console.log(this.foo);
1394 | console.log(self.foo);
1395 | (function() {
1396 | console.log(this.foo);
1397 | console.log(self.foo);
1398 | }());
1399 | }
1400 | };
1401 | myObject.func();
1402 | ```
1403 |
1404 | 输出结果:bar bar undefined bar
1405 |
1406 |
1407 |
1408 | **解析:**
1409 |
1410 | 1. 首先func是由myObject调用的,this指向myObject。又因为var self = this;所以self指向myObject。
1411 | 2. 这个立即执行匿名函数表达式是由window调用的,this指向window 。立即执行匿名函数的作用域处于myObject.func的作用域中,在这个作用域找不到self变量,沿着作用域链向上查找self变量,找到了指向 myObject对象的self。
1412 |
1413 | ### 8. 代码输出问题
1414 |
1415 | ```
1416 | window.number = 2;
1417 | var obj = {
1418 | number: 3,
1419 | db1: (function(){
1420 | console.log(this);
1421 | this.number *= 4;
1422 | return function(){
1423 | console.log(this);
1424 | this.number *= 5;
1425 | }
1426 | })()
1427 | }
1428 | var db1 = obj.db1;
1429 | db1();
1430 | obj.db1();
1431 | console.log(obj.number); // 15
1432 | console.log(window.number); // 40
1433 | ```
1434 |
1435 | 这道题目看清起来有点乱,但是实际上是考察this指向的:
1436 |
1437 | 1. 执行db1()时,this指向全局作用域,所以window.number * 4 = 8,然后执行匿名函数, 所以window.number * 5 = 40;
1438 | 2. 执行obj.db1();时,this指向obj对象,执行匿名函数,所以obj.numer * 5 = 15。
1439 |
1440 | ### 9. 代码输出结果
1441 |
1442 | ```
1443 | var length = 10;
1444 | function fn() {
1445 | console.log(this.length);
1446 | }
1447 |
1448 | var obj = {
1449 | length: 5,
1450 | method: function(fn) {
1451 | fn();
1452 | arguments[0]();
1453 | }
1454 | };
1455 |
1456 | obj.method(fn, 1);
1457 | ```
1458 |
1459 | 输出结果: 10 2
1460 |
1461 |
1462 |
1463 | **解析:**
1464 |
1465 | 1. 第一次执行fn(),this指向window对象,输出10。
1466 | 2. 第二次执行arguments[0](),相当于arguments调用方法,this指向arguments,而这里传了两个参数,故输出arguments长度为2。
1467 |
1468 | ### 10. 代码输出结果
1469 |
1470 | ```
1471 | var a = 1;
1472 | function printA(){
1473 | console.log(this.a);
1474 | }
1475 | var obj={
1476 | a:2,
1477 | foo:printA,
1478 | bar:function(){
1479 | printA();
1480 | }
1481 | }
1482 |
1483 | obj.foo(); // 2
1484 | obj.bar(); // 1
1485 | var foo = obj.foo;
1486 | foo(); // 1
1487 | ```
1488 |
1489 | 输出结果: 2 1 1
1490 |
1491 |
1492 |
1493 | **解析:**
1494 |
1495 | 1. obj.foo(),foo 的this指向obj对象,所以a会输出2;
1496 | 2. obj.bar(),printA在bar方法中执行,所以此时printA的this指向的是window,所以会输出1;
1497 | 3. foo(),foo是在全局对象中执行的,所以其this指向的是window,所以会输出1;
1498 |
1499 | ### 11. 代码输出结果
1500 |
1501 | ```
1502 | var x = 3;
1503 | var y = 4;
1504 | var obj = {
1505 | x: 1,
1506 | y: 6,
1507 | getX: function() {
1508 | var x = 5;
1509 | return function() {
1510 | return this.x;
1511 | }();
1512 | },
1513 | getY: function() {
1514 | var y = 7;
1515 | return this.y;
1516 | }
1517 | }
1518 | console.log(obj.getX()) // 3
1519 | console.log(obj.getY()) // 6
1520 | ```
1521 |
1522 | 输出结果:3 6
1523 |
1524 |
1525 |
1526 | **解析:**
1527 |
1528 | 1. 我们知道,匿名函数的this是指向全局对象的,所以this指向window,会打印出3;
1529 | 2. getY是由obj调用的,所以其this指向的是obj对象,会打印出6。
1530 |
1531 | ### 12. 代码输出结果
1532 |
1533 | ```
1534 | var a = 10;
1535 | var obt = {
1536 | a: 20,
1537 | fn: function(){
1538 | var a = 30;
1539 | console.log(this.a)
1540 | }
1541 | }
1542 | obt.fn(); // 20
1543 | obt.fn.call(); // 10
1544 | (obt.fn)(); // 20
1545 | ```
1546 |
1547 | 输出结果: 20 10 20
1548 |
1549 |
1550 |
1551 | **解析:**
1552 |
1553 | 1. obt.fn(),fn是由obt调用的,所以其this指向obt对象,会打印出20;
1554 | 2. obt.fn.call(),这里call的参数啥都没写,就表示null,我们知道如果call的参数为undefined或null,那么this就会指向全局对象this,所以会打印出 10;
1555 | 3. (obt.fn)(), 这里给表达式加了括号,而括号的作用是改变表达式的运算顺序,而在这里加与不加括号并无影响;相当于 obt.fn(),所以会打印出 20;
1556 |
1557 | ### 13. 代码输出结果
1558 |
1559 | ```
1560 | function a(xx){
1561 | this.x = xx;
1562 | return this
1563 | };
1564 | var x = a(5);
1565 | var y = a(6);
1566 |
1567 | console.log(x.x) // undefined
1568 | console.log(y.x) // 6
1569 | ```
1570 |
1571 | 输出结果: undefined 6
1572 |
1573 |
1574 |
1575 | **解析:**
1576 |
1577 | 1. 最关键的就是var x = a(5),函数a是在全局作用域调用,所以函数内部的this指向window对象。**所以 this.x = 5 就相当于:window.x = 5。**之后 return this,也就是说 var x = a(5) 中的x变量的值是window,这里的x将函数内部的x的值覆盖了。然后执行console.log(x.x), 也就是console.log(window.x),而window对象中没有x属性,所以会输出undefined。
1578 | 2. 当指向y.x时,会给全局变量中的x赋值为6,所以会打印出6。
1579 |
1580 | ### 14. 代码输出结果
1581 |
1582 | ```
1583 | function foo(something){
1584 | this.a = something
1585 | }
1586 |
1587 | var obj1 = {
1588 | foo: foo
1589 | }
1590 |
1591 | var obj2 = {}
1592 |
1593 | obj1.foo(2);
1594 | console.log(obj1.a); // 2
1595 |
1596 | obj1.foo.call(obj2, 3);
1597 | console.log(obj2.a); // 3
1598 |
1599 | var bar = new obj1.foo(4)
1600 | console.log(obj1.a); // 2
1601 | console.log(bar.a); // 4
1602 | ```
1603 |
1604 | 输出结果: 2 3 2 4
1605 |
1606 |
1607 |
1608 | **解析:**
1609 |
1610 | 1. 首先执行obj1.foo(2); 会在obj中添加a属性,其值为2。之后执行obj1.a,a是右obj1调用的,所以this指向obj,打印出2;
1611 | 2. 执行 obj1.foo.call(obj2, 3) 时,会将foo的this指向obj2,后面就和上面一样了,所以会打印出3;
1612 | 3. obj1.a会打印出2;
1613 | 4. 最后就是考察this绑定的优先级了,new 绑定是比隐式绑定优先级高,所以会输出4。
1614 |
1615 | ### 15. 代码输出结果
1616 |
1617 | ```
1618 | function foo(something){
1619 | this.a = something
1620 | }
1621 |
1622 | var obj1 = {}
1623 |
1624 | var bar = foo.bind(obj1);
1625 | bar(2);
1626 | console.log(obj1.a); // 2
1627 |
1628 | var baz = new bar(3);
1629 | console.log(obj1.a); // 2
1630 | console.log(baz.a); // 3
1631 | ```
1632 |
1633 | 输出结果: 2 2 3
1634 |
1635 |
1636 |
1637 | 这道题目和上面题目差不多,主要都是考察this绑定的优先级。记住以下结论即可:**this绑定的优先级:****new绑定 > 显式绑定 > 隐式绑定 > 默认绑定。**
1638 |
1639 | ## 三、作用域&变量提升&闭包
1640 |
1641 | ### 1. 代码输出结果
1642 |
1643 | ```
1644 | (function(){
1645 | var x = y = 1;
1646 | })();
1647 | var z;
1648 |
1649 | console.log(y); // 1
1650 | console.log(z); // undefined
1651 | console.log(x); // Uncaught ReferenceError: x is not defined
1652 | ```
1653 |
1654 | 这段代码的关键在于:var x = y = 1; 实际上这里是从右往左执行的,首先执行y = 1, 因为y没有使用var声明,所以它是一个全局变量,然后第二步是将y赋值给x,讲一个全局变量赋值给了一个局部变量,最终,x是一个局部变量,y是一个全局变量,所以打印x是报错。
1655 |
1656 | ### 2. 代码输出结果
1657 |
1658 | ```
1659 | var a, b
1660 | (function () {
1661 | console.log(a);
1662 | console.log(b);
1663 | var a = (b = 3);
1664 | console.log(a);
1665 | console.log(b);
1666 | })()
1667 | console.log(a);
1668 | console.log(b);
1669 | ```
1670 |
1671 | 输出结果:
1672 |
1673 | ```
1674 | undefined
1675 | undefined
1676 | 3
1677 | 3
1678 | undefined
1679 | 3
1680 | ```
1681 |
1682 | ```
1683 | undefined
1684 | undefined
1685 | 3
1686 | 3
1687 | undefined
1688 | 3
1689 | ```
1690 |
1691 | 这个题目和上面题目考察的知识点类似,b赋值为3,b此时是一个全局变量,而将3赋值给a,a是一个局部变量,所以最后打印的时候,a仍旧是undefined。
1692 |
1693 | ### 3. 代码输出结果
1694 |
1695 | ```
1696 | var friendName = 'World';
1697 | (function() {
1698 | if (typeof friendName === 'undefined') {
1699 | var friendName = 'Jack';
1700 | console.log('Goodbye ' + friendName);
1701 | } else {
1702 | console.log('Hello ' + friendName);
1703 | }
1704 | })();
1705 | ```
1706 |
1707 | 输出结果:Goodbye Jack
1708 |
1709 |
1710 |
1711 | 我们知道,在 JavaScript中, Function 和 var 都会被提升(变量提升),所以上面的代码就相当于:
1712 |
1713 | ```
1714 | var name = 'World!';
1715 | (function () {
1716 | var name;
1717 | if (typeof name === 'undefined') {
1718 | name = 'Jack';
1719 | console.log('Goodbye ' + name);
1720 | } else {
1721 | console.log('Hello ' + name);
1722 | }
1723 | })();
1724 | ```
1725 |
1726 | 这样,答案就一目了然了。
1727 |
1728 | ### 4. 代码输出结果
1729 |
1730 | ```
1731 | function fn1(){
1732 | console.log('fn1')
1733 | }
1734 | var fn2
1735 |
1736 | fn1()
1737 | fn2()
1738 |
1739 | fn2 = function() {
1740 | console.log('fn2')
1741 | }
1742 |
1743 | fn2()
1744 | ```
1745 |
1746 | 输出结果:
1747 |
1748 | ```
1749 | fn1
1750 | Uncaught TypeError: fn2 is not a function
1751 | fn2
1752 | ```
1753 |
1754 | 这里也是在考察变量提升,关键在于第一个fn2(),这时fn2仍是一个undefined的变量,所以会报错fn2不是一个函数。
1755 |
1756 | ### 5. 代码输出结果
1757 |
1758 | ```
1759 | function a() {
1760 | var temp = 10;
1761 | function b() {
1762 | console.log(temp); // 10
1763 | }
1764 | b();
1765 | }
1766 | a();
1767 |
1768 | function a() {
1769 | var temp = 10;
1770 | b();
1771 | }
1772 | function b() {
1773 | console.log(temp); // 报错 Uncaught ReferenceError: temp is not defined
1774 | }
1775 | a();
1776 | ```
1777 |
1778 | 在上面的两段代码中,第一段是可以正常输出,这个应该没啥问题,关键在于第二段代码,它会报错Uncaught ReferenceError: temp is not defined。这时因为在b方法执行时,temp 的值为undefined。
1779 |
1780 | ### 6. 代码输出结果
1781 |
1782 | ```
1783 | var a=3;
1784 | function c(){
1785 | alert(a);
1786 | }
1787 | (function(){
1788 | var a=4;
1789 | c();
1790 | })();
1791 | ```
1792 |
1793 | js中变量的作用域链与定义时的环境有关,与执行时无关。执行环境只会改变this、传递的参数、全局变量等
1794 |
1795 | ### 7. 代码输出问题
1796 |
1797 | ```
1798 | function fun(n, o) {
1799 | console.log(o)
1800 | return {
1801 | fun: function(m){
1802 | return fun(m, n);
1803 | }
1804 | };
1805 | }
1806 | var a = fun(0); a.fun(1); a.fun(2); a.fun(3);
1807 | var b = fun(0).fun(1).fun(2).fun(3);
1808 | var c = fun(0).fun(1); c.fun(2); c.fun(3);
1809 | ```
1810 |
1811 | 输出结果:
1812 |
1813 | ```
1814 | undefined 0 0 0
1815 | undefined 0 1 2
1816 | undefined 0 1 1
1817 | ```
1818 |
1819 | 这是一道关于闭包的题目,对于fun方法,调用之后返回的是一个对象。我们知道,当调用函数的时候传入的实参比函数声明时指定的形参个数要少,剩下的形参都将设置为undefined值。所以 `console.log(o);` 会输出undefined。而a就是是fun(0)返回的那个对象。也就是说,函数fun中参数 n 的值是0,而返回的那个对象中,需要一个参数n,而这个对象的作用域中没有n,它就继续沿着作用域向上一级的作用域中寻找n,最后在函数fun中找到了n,n的值是0。了解了这一点,其他运算就很简单了,以此类推。
1820 |
1821 | ### 8. 代码输出结果
1822 |
1823 | ```
1824 | f = function() {return true;};
1825 | g = function() {return false;};
1826 | (function() {
1827 | if (g() && [] == ![]) {
1828 | f = function f() {return false;};
1829 | function g() {return true;}
1830 | }
1831 | })();
1832 | console.log(f());
1833 | ```
1834 |
1835 | 输出结果: false
1836 |
1837 |
1838 |
1839 | 这里首先定义了两个变量f和g,我们知道变量是可以重新赋值的。后面是一个匿名自执行函数,在 if 条件中调用了函数 g(),由于在匿名函数中,又重新定义了函数g,就覆盖了外部定义的变量g,所以,这里调用的是内部函数 g 方法,返回为 true。第一个条件通过,进入第二个条件。
1840 |
1841 |
1842 |
1843 | 第二个条件是[] == ![],先看 ![] ,在 JavaScript 中,当用于布尔运算时,比如在这里,对象的非空引用被视为 true,空引用 null 则被视为 false。由于这里不是一个 null, 而是一个没有元素的数组,所以 [] 被视为 true, 而 ![] 的结果就是 false 了。当一个布尔值参与到条件运算的时候,true 会被看作 1, 而 false 会被看作 0。现在条件变成了 [] == 0 的问题了,当一个对象参与条件比较的时候,它会被求值,求值的结果是数组成为一个字符串,[] 的结果就是 '' ,而 '' 会被当作 0 ,所以,条件成立。
1844 |
1845 |
1846 |
1847 | 两个条件都成立,所以会执行条件中的代码, f 在定义是没有使用var,所以他是一个全局变量。因此,这里会通过闭包访问到外部的变量 f, 重新赋值,现在执行 f 函数返回值已经成为 false 了。而 g 则不会有这个问题,这里是一个函数内定义的 g,不会影响到外部的 g 函数。所以最后的结果就是 false。
1848 |
1849 | ## 四、原型&继承
1850 |
1851 | ### 1. 代码输出结果
1852 |
1853 | ```
1854 | function Person(name) {
1855 | this.name = name
1856 | }
1857 | var p2 = new Person('king');
1858 | console.log(p2.__proto__) //Person.prototype
1859 | console.log(p2.__proto__.__proto__) //Object.prototype
1860 | console.log(p2.__proto__.__proto__.__proto__) // null
1861 | console.log(p2.__proto__.__proto__.__proto__.__proto__)//null后面没有了,报错
1862 | console.log(p2.__proto__.__proto__.__proto__.__proto__.__proto__)//null后面没有了,报错
1863 | console.log(p2.constructor)//Person
1864 | console.log(p2.prototype)//undefined p2是实例,没有prototype属性
1865 | console.log(Person.constructor)//Function 一个空函数
1866 | console.log(Person.prototype)//打印出Person.prototype这个对象里所有的方法和属性
1867 | console.log(Person.prototype.constructor)//Person
1868 | console.log(Person.prototype.__proto__)// Object.prototype
1869 | console.log(Person.__proto__) //Function.prototype
1870 | console.log(Function.prototype.__proto__)//Object.prototype
1871 | console.log(Function.__proto__)//Function.prototype
1872 | console.log(Object.__proto__)//Function.prototype
1873 | console.log(Object.prototype.__proto__)//null
1874 | ```
1875 |
1876 | 这道义题目考察原型、原型链的基础,记住就可以了。
1877 |
1878 | ### 2. 代码输出结果
1879 |
1880 | ```
1881 | // a
1882 | function Foo () {
1883 | getName = function () {
1884 | console.log(1);
1885 | }
1886 | return this;
1887 | }
1888 | // b
1889 | Foo.getName = function () {
1890 | console.log(2);
1891 | }
1892 | // c
1893 | Foo.prototype.getName = function () {
1894 | console.log(3);
1895 | }
1896 | // d
1897 | var getName = function () {
1898 | console.log(4);
1899 | }
1900 | // e
1901 | function getName () {
1902 | console.log(5);
1903 | }
1904 |
1905 | Foo.getName(); // 2
1906 | getName(); // 4
1907 | Foo().getName(); // 1
1908 | getName(); // 1
1909 | new Foo.getName(); // 2
1910 | new Foo().getName(); // 3
1911 | new new Foo().getName(); // 3
1912 | ```
1913 |
1914 | 输出结果:2 4 1 1 2 3 3
1915 |
1916 |
1917 |
1918 | **解析:**
1919 |
1920 | 1. **Foo.getName(),**Foo为一个函数对象,对象都可以有属性,b 处定义Foo的getName属性为函数,输出2;
1921 | 2. **getName(),**这里看d、e处,d为函数表达式,e为函数声明,两者区别在于变量提升,函数声明的 5 会被后边函数表达式的 4 覆盖;
1922 | 3. **Foo().getName(),**这里要看a处,在Foo内部将全局的getName重新赋值为 console.log(1) 的函数,执行Foo()返回 this,这个this指向window,Foo().getName() 即为window.getName(),输出 1;
1923 | 4. **getName(),**上面3中,全局的getName已经被重新赋值,所以这里依然输出 1;
1924 | 5. **new Foo.getName(),**这里等价于 new (Foo.getName()),先执行 Foo.getName(),输出 2,然后new一个实例;
1925 | 6. **new Foo().getName(),**这里等价于 (new Foo()).getName(), 先new一个Foo的实例,再执行这个实例的getName方法,但是这个实例本身没有这个方法,所以去原型链__protot__上边找,实例.__protot__ === Foo.prototype,所以输出 3;
1926 | 7. **new new Foo().getName(),**这里等价于new (new Foo().getName()),如上述6,先输出 3,然后new 一个 new Foo().getName() 的实例。
1927 |
1928 | ### 3. 代码输出结果
1929 |
1930 | ```
1931 | var F = function() {};
1932 | Object.prototype.a = function() {
1933 | console.log('a');
1934 | };
1935 | Function.prototype.b = function() {
1936 | console.log('b');
1937 | }
1938 | var f = new F();
1939 | f.a();
1940 | f.b();
1941 | F.a();
1942 | F.b()
1943 | ```
1944 |
1945 | 输出结果:
1946 |
1947 | ```
1948 | a
1949 | Uncaught TypeError: f.b is not a function
1950 | a
1951 | b
1952 | ```
1953 |
1954 | **解析:**
1955 |
1956 | 1. f 并不是 Function 的实例,因为它本来就不是构造函数,调用的是 Function 原型链上的相关属性和方法,只能访问到 Object 原型链。所以 f.a() 输出 a ,而 f.b() 就报错了。
1957 | 2. F 是个构造函数,而 F 是构造函数 Function 的一个实例。因为 F instanceof Object === true,F instanceof Function === true,由此可以得出结论:F 是 Object 和 Function 两个的实例,即 F 能访问到 a, 也能访问到 b。所以 F.a() 输出 a ,F.b() 输出 b。
1958 |
1959 | ### 4. 代码输出结果
1960 |
1961 | ```
1962 | function Foo(){
1963 | Foo.a = function(){
1964 | console.log(1);
1965 | }
1966 | this.a = function(){
1967 | console.log(2)
1968 | }
1969 | }
1970 |
1971 | Foo.prototype.a = function(){
1972 | console.log(3);
1973 | }
1974 |
1975 | Foo.a = function(){
1976 | console.log(4);
1977 | }
1978 |
1979 | Foo.a();
1980 | let obj = new Foo();
1981 | obj.a();
1982 | Foo.a();
1983 | ```
1984 |
1985 | 输出结果:4 2 1
1986 |
1987 |
1988 |
1989 | **解析:**
1990 |
1991 | 1. Foo.a() 这个是调用 Foo 函数的静态方法 a,虽然 Foo 中有优先级更高的属性方法 a,但 Foo 此时没有被调用,所以此时输出 Foo 的静态方法 a 的结果:4
1992 | 2. let obj = new Foo(); 使用了 new 方法调用了函数,返回了函数实例对象,此时 Foo 函数内部的属性方法初始化,原型链建立。
1993 | 3. obj.a() ; 调用 obj 实例上的方法 a,该实例上目前有两个 a 方法:一个是内部属性方法,另一个是原型上的方法。当这两者都存在时,首先查找 ownProperty ,如果没有才去原型链上找,所以调用实例上的 a 输出:2
1994 | 4. Foo.a() ; 根据第2步可知 Foo 函数内部的属性方法已初始化,覆盖了同名的静态方法,所以输出:1
1995 |
1996 | ### 5. 代码输出结果
1997 |
1998 | ```
1999 | function Dog() {
2000 | this.name = 'puppy'
2001 | }
2002 | Dog.prototype.bark = () => {
2003 | console.log('woof!woof!')
2004 | }
2005 | const dog = new Dog()
2006 | console.log(Dog.prototype.constructor === Dog && dog.constructor === Dog && dog instanceof Dog)
2007 | ```
2008 |
2009 | 输出结果:true
2010 |
2011 |
2012 |
2013 | **解析:**
2014 |
2015 | 因为constructor是prototype上的属性,所以dog.constructor实际上就是指向Dog.prototype.constructor;constructor属性指向构造函数。instanceof而实际检测的是类型是否在实例的原型链上。
2016 |
2017 |
2018 |
2019 | constructor是prototype上的属性,这一点很容易被忽略掉。constructor和instanceof 的作用是不同的,感性地来说,constructor的限制比较严格,它只能严格对比对象的构造函数是不是指定的值;而instanceof比较松散,只要检测的类型在原型链上,就会返回true。
2020 |
2021 | ### 6. 代码输出结果
2022 |
2023 | ```
2024 | var A = {n: 4399};
2025 | var B = function(){this.n = 9999};
2026 | var C = function(){var n = 8888};
2027 | B.prototype = A;
2028 | C.prototype = A;
2029 | var b = new B();
2030 | var c = new C();
2031 | A.n++
2032 | console.log(b.n);
2033 | console.log(c.n);
2034 | ```
2035 |
2036 | 输出结果:9999 4400
2037 |
2038 |
2039 |
2040 | **解析:**
2041 |
2042 | 1. console.log(b.n),在查找b.n是首先查找 b 对象自身有没有 n 属性,如果没有会去原型(prototype)上查找,当执行var b = new B()时,函数内部this.n=9999(此时this指向 b) 返回b对象,b对象有自身的n属性,所以返回 9999。
2043 | 2. console.log(c.n),同理,当执行var c = new C()时,c对象没有自身的n属性,向上查找,找到原型 (prototype)上的 n 属性,因为 A.n++(此时对象A中的n为4400), 所以返回4400。
2044 |
2045 | ### 7. 代码输出问题
2046 |
2047 | ```
2048 | function A(){
2049 | }
2050 | function B(a){
2051 | this.a = a;
2052 | }
2053 | function C(a){
2054 | if(a){
2055 | this.a = a;
2056 | }
2057 | }
2058 | A.prototype.a = 1;
2059 | B.prototype.a = 1;
2060 | C.prototype.a = 1;
2061 |
2062 | console.log(new A().a);
2063 | console.log(new B().a);
2064 | console.log(new C(2).a);
2065 | ```
2066 |
2067 | 输出结果:1 undefined 2
2068 |
2069 |
2070 |
2071 | **解析:**
2072 |
2073 | 1. console.log(new A().a),new A()为构造函数创建的对象,本身没有a属性,所以向它的原型去找,发现原型的a属性的属性值为1,故该输出值为1;
2074 | 2. console.log(new B().a),ew B()为构造函数创建的对象,该构造函数有参数a,但该对象没有传参,故该输出值为undefined;
2075 | 3. console.log(new C(2).a),new C()为构造函数创建的对象,该构造函数有参数a,且传的实参为2,执行函数内部,发现if为真,执行this.a = 2,故属性a的值为2。
2076 |
2077 | ### 8 代码输出问题
2078 |
2079 | ```
2080 | function Parent() {
2081 | this.a = 1;
2082 | this.b = [1, 2, this.a];
2083 | this.c = { demo: 5 };
2084 | this.show = function () {
2085 | console.log(this.a , this.b , this.c.demo );
2086 | }
2087 | }
2088 |
2089 | function Child() {
2090 | this.a = 2;
2091 | this.change = function () {
2092 | this.b.push(this.a);
2093 | this.a = this.b.length;
2094 | this.c.demo = this.a++;
2095 | }
2096 | }
2097 |
2098 | Child.prototype = new Parent();
2099 | var parent = new Parent();
2100 | var child1 = new Child();
2101 | var child2 = new Child();
2102 | child1.a = 11;
2103 | child2.a = 12;
2104 | parent.show();
2105 | child1.show();
2106 | child2.show();
2107 | child1.change();
2108 | child2.change();
2109 | parent.show();
2110 | child1.show();
2111 | child2.show();
2112 | ```
2113 |
2114 | 输出结果:
2115 |
2116 | ```
2117 | parent.show(); // 1 [1,2,1] 5
2118 |
2119 | child1.show(); // 11 [1,2,1] 5
2120 | child2.show(); // 12 [1,2,1] 5
2121 |
2122 | parent.show(); // 1 [1,2,1] 5
2123 |
2124 | child1.show(); // 5 [1,2,1,11,12] 5
2125 |
2126 | child2.show(); // 6 [1,2,1,11,12] 5
2127 | ```
2128 |
2129 | 这道题目值得神帝,他涉及到的知识点很多,例如**this的指向、原型、原型链、类的继承、数据类型**等。
2130 |
2131 |
2132 |
2133 | **解析****:**
2134 |
2135 | 1. parent.show(),可以直接获得所需的值,没啥好说的;
2136 | 2. child1.show(),`Child`的构造函数原本是指向`Child`的,题目显式将`Child`类的原型对象指向了`Parent`类的一个实例,需要注意`Child.prototype`指向的是`Parent`的实例`parent`,而不是指向`Parent`这个类。
2137 | 3. child2.show(),这个也没啥好说的;
2138 | 4. parent.show(),`parent`是一个`Parent`类的实例,`Child.prorotype`指向的是`Parent`类的另一个实例,两者在堆内存中互不影响,所以上述操作不影响`parent`实例,所以输出结果不变;
2139 | 5. child1.show(),`child1`执行了`change()`方法后,发生了怎样的变化呢?
2140 |
2141 | - **this.b.push(this.a),**由于this的动态指向特性,this.b会指向`Child.prototype`上的**b**数组,this.a会指向`child1`的**a**属性,所以`Child.prototype.b`变成了**[1,2,1,11]**;
2142 | - **this.a = this.b.length,**这条语句中`this.a`和`this.b`的指向与上一句一致,故结果为`child1.a`变为**4**;
2143 | - **this.c.demo = this.a++,**由于`child1`自身属性并没有**c**这个属性,所以此处的`this.c`会指向`Child.prototype.c`,`this.a`值为**4**,为原始类型,故赋值操作时会直接赋值,`Child.prototype.c.demo`的结果为**4**,而`this.a`随后自增为**5(4 + 1 = 5)。**
2144 |
2145 | 1. `child2`执行了`change()`方法, 而`child2`和`child1`均是`Child`类的实例,所以他们的原型链指向同一个原型对象`Child.prototype`,也就是同一个`parent`实例,所以`child2.change()`中所有影响到原型对象的语句都会影响`child1`的最终输出结果。
2146 |
2147 | - **this.b.push(this.a),**由于this的动态指向特性,this.b会指向`Child.prototype`上的**b**数组,this.a会指向`child2`的**a**属性,所以`Child.prototype.b`变成了**[1,2,1,11,12]**;
2148 | - **this.a = this.b.length,**这条语句中`this.a`和`this.b`的指向与上一句一致,故结果为`child2.a`变为**5**;
2149 | - **this.c.demo = this.a++,**由于`child2`自身属性并没有**c**这个属性,所以此处的`this.c`会指向`Child.prototype.c`,故执行结果为`Child.prototype.c.demo`的值变为`child2.a`的值**5**,而`child2.a`最终自增为**6(5 + 1 = 6)。**
2150 |
2151 | ### 9. 代码输出结果
2152 |
2153 | ```
2154 | function SuperType(){
2155 | this.property = true;
2156 | }
2157 |
2158 | SuperType.prototype.getSuperValue = function(){
2159 | return this.property;
2160 | };
2161 |
2162 | function SubType(){
2163 | this.subproperty = false;
2164 | }
2165 |
2166 | SubType.prototype = new SuperType();
2167 | SubType.prototype.getSubValue = function (){
2168 | return this.subproperty;
2169 | };
2170 |
2171 | var instance = new SubType();
2172 | console.log(instance.getSuperValue());
2173 | ```
2174 |
2175 | 输出结果:true
2176 |
2177 |
2178 |
2179 | 实际上,这段代码就是在实现原型链继承,SubType继承了SuperType,本质是重写了SubType的原型对象,代之以一个新类型的实例。SubType的原型被重写了,所以instance.constructor指向的是SuperType。具体如下:
2180 |
2181 | 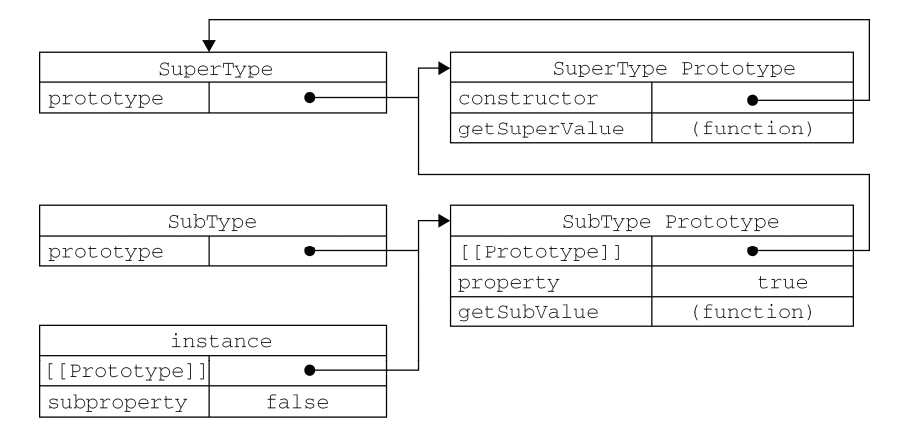
--------------------------------------------------------------------------------
/14 vue项目的性能优化.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 | Vue 框架通过数据双向绑定和虚拟 DOM 技术,帮我们处理了前端开发中最脏最累的 DOM 操作部分, 我们不再需要去考虑如何操作 DOM 以及如何最高效地操作 DOM;但 Vue 项目中仍然存在项目首屏优化、Webpack 编译配置优化等问题,所以我们仍然需要去关注 Vue 项目性能方面的优化,使项目具有更高效的性能、更好的用户体验。本文是作者通过实际项目的优化实践进行总结而来,希望读者读完本文,有一定的启发思考,从而对自己的项目进行优化起到帮助。本文内容分为以下三部分组成:
3 |
4 | Vue 代码层面的优化;
5 |
6 | webpack 配置层面的优化;
7 |
8 | 基础的 Web 技术层面的优化。
9 |
10 |
11 |
12 | ## 一、代码层面的优化
13 | **1.1、v-if 和 v-show 区分使用场景**
14 |
15 | v-if 是 真正 的条件渲染,因为它会确保在切换过程中条件块内的事件监听器和子组件适当地被销毁和重建;也是惰性的:如果在初始渲染时条件为假,则什么也不做——直到条件第一次变为真时,才会开始渲染条件块。
16 |
17 | v-show 就简单得多, 不管初始条件是什么,元素总是会被渲染,并且只是简单地基于 CSS 的 display 属性进行切换。
18 |
19 | 所以,v-if 适用于在运行时很少改变条件,不需要频繁切换条件的场景;v-show 则适用于需要非常频繁切换条件的场景。
20 |
21 | **1.2、computed 和 watch 区分使用场景**
22 |
23 | computed: 是计算属性,依赖其它属性值,并且 computed 的值有缓存,只有它依赖的属性值发生改变,下一次获取 computed 的值时才会重新计算 computed 的值;
24 |
25 | watch: 更多的是「观察」的作用,类似于某些数据的监听回调 ,每当监听的数据变化时都会执行回调进行后续操作;
26 |
27 | 运用场景:
28 |
29 | 当我们需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时,都要重新计算;
30 |
31 | 当我们需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许我们执行异步操作 ( 访问一个 API ),限制我们执行该操作的频率,并在我们得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
32 |
33 | **1.3、v-for 遍历必须为 item 添加 key,且避免同时使用 v-if**
34 |
35 | (1)v-for 遍历必须为 item 添加 key
36 |
37 | 在列表数据进行遍历渲染时,需要为每一项 item 设置唯一 key 值,方便 Vue.js 内部机制精准找到该条列表数据。当 state 更新时,新的状态值和旧的状态值对比,较快地定位到 diff 。
38 |
39 | (2)v-for 遍历避免同时使用 v-if
40 |
41 | v-for 比 v-if 优先级高,如果每一次都需要遍历整个数组,将会影响速度,尤其是当之需要渲染很小一部分的时候,必要情况下应该替换成 computed 属性。
42 |
43 | 推荐:
44 | ```
45 |
46 | -
49 | {{ user.name }}
50 |
51 |
52 | computed: {
53 | activeUsers: function () {
54 | return this.users.filter(function (user) {
55 | return user.isActive
56 | })
57 | }
58 | }
59 | ```
60 | 不推荐:
61 | ```
62 |
63 | -
67 | {{ user.name }}
68 |
69 |
70 | ```
71 | **1.4、长列表性能优化**
72 |
73 | Vue 会通过 Object.defineProperty 对数据进行劫持,来实现视图响应数据的变化,然而有些时候我们的组件就是纯粹的数据展示,不会有任何改变,我们就不需要 Vue 来劫持我们的数据,在大量数据展示的情况下,这能够很明显的减少组件初始化的时间,那如何禁止 Vue 劫持我们的数据呢?可以通过 Object.freeze 方法来冻结一个对象,一旦被冻结的对象就再也不能被修改了。
74 | ```
75 | export default {
76 | data: () => ({
77 | users: {}
78 | }),
79 | async created() {
80 | const users = await axios.get("/api/users");
81 | this.users = Object.freeze(users);
82 | }
83 | };
84 | ```
85 | **1.5、事件的销毁**
86 |
87 | Vue 组件销毁时,会自动清理它与其它实例的连接,解绑它的全部指令及事件监听器,但是仅限于组件本身的事件。如果在 js 内
88 | ```
89 | created() {
90 | addEventListener('click', this.click, false)
91 | },
92 | beforeDestroy() {
93 | removeEventListener('click', this.click, false)
94 | }
95 | ```
96 | **1.6、图片资源懒加载**
97 |
98 | 对于图片过多的页面,为了加速页面加载速度,所以很多时候我们需要将页面内未出现在可视区域内的图片先不做加载, 等到滚动到可视区域后再去加载。这样对于页面加载性能上会有很大的提升,也提高了用户体验。我们在项目中使用 Vue 的 vue-lazyload 插件:
99 |
100 | (1)安装插件
101 |
102 | ```
103 | npm install vue-lazyload --save-dev
104 | ```
105 | (2)在入口文件 man.js 中引入并使用
106 |
107 | ```
108 | import VueLazyload from 'vue-lazyload'
109 | ```
110 | 然后再 vue 中直接使用
111 |
112 |
113 | ```
114 | Vue.use(VueLazyload)
115 | ```
116 | 或者添加自定义选项
117 | ```
118 | Vue.use(VueLazyload, {
119 | preLoad: 1.3,
120 | error: 'dist/error.png',
121 | loading: 'dist/loading.gif',
122 | attempt: 1
123 | })
124 | ```
125 | (3)在 vue 文件中将 img 标签的 src 属性直接改为 v-lazy ,从而将图片显示方式更改为懒加载显示:
126 |
127 |
128 |
129 | ![]() 130 | 以上为 vue-lazyload 插件的简单使用,如果要看插件的更多参数选项,可以查看 vue-lazyload 的 github 地址。
131 |
132 | **1.7、路由懒加载**
133 | Vue 是单页面应用,可能会有很多的路由引入 ,这样使用 webpcak 打包后的文件很大,当进入首页时,加载的资源过多,页面会出现白屏的情况,不利于用户体验。如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应的组件,这样就更加高效了。这样会大大提高首屏显示的速度,但是可能其他的页面的速度就会降下来。
134 |
135 | 路由懒加载:
136 | ```
137 | const Foo = () => import('./Foo.vue')
138 | const router = new VueRouter({
139 | routes: [
140 | { path: '/foo', component: Foo }
141 | ]
142 | })
143 | ```
144 | **1.8、第三方插件的按需引入**
145 |
146 | 我们在项目中经常会需要引入第三方插件,如果我们直接引入整个插件,会导致项目的体积太大,我们可以借助 babel-plugin-component ,然后可以只引入需要的组件,以达到减小项目体积的目的。以下为项目中引入 element-ui 组件库为例:
147 |
148 | (1)首先,安装 babel-plugin-component :
149 |
150 |
151 | ```
152 | npm install babel-plugin-component -D
153 | ```
154 | (2)然后,将 .babelrc 修改为:
155 | ```
156 | {
157 | "presets": [["es2015", { "modules": false }]],
158 | "plugins": [
159 | [
160 | "component",
161 | {
162 | "libraryName": "element-ui",
163 | "styleLibraryName": "theme-chalk"
164 | }
165 | ]
166 | ]
167 | }
168 | ```
169 | (3)在 main.js 中引入部分组件:
170 | ```
171 | import Vue from 'vue';
172 | import { Button, Select } from 'element-ui';
173 |
174 | Vue.use(Button)
175 | Vue.use(Select)
176 | ```
177 | **1.9、优化无限列表性能**
178 |
179 | 如果你的应用存在非常长或者无限滚动的列表,那么需要采用 窗口化 的技术来优化性能,只需要渲染少部分区域的内容,减少重新渲染组件和创建 dom 节点的时间。你可以参考以下开源项目 vue-virtual-scroll-list 和 vue-virtual-scroller 来优化这种无限列表的场景的。
180 |
181 | **1.10、服务端渲染 SSR or 预渲染**
182 |
183 | 服务端渲染是指 Vue 在客户端将标签渲染成的整个 html 片段的工作在服务端完成,服务端形成的 html 片段直接返回给客户端这个过程就叫做服务端渲染。
184 |
185 | (1)服务端渲染的优点:
186 |
187 | 更好的 SEO:因为 SPA 页面的内容是通过 Ajax 获取,而搜索引擎爬取工具并不会等待 Ajax 异步完成后再抓取页面内容,所以在 SPA 中是抓取不到页面通过 Ajax 获取到的内容;而 SSR 是直接由服务端返回已经渲染好的页面(数据已经包含在页面中),所以搜索引擎爬取工具可以抓取渲染好的页面;
188 |
189 | 更快的内容到达时间(首屏加载更快):SPA 会等待所有 Vue 编译后的 js 文件都下载完成后,才开始进行页面的渲染,文件下载等需要一定的时间等,所以首屏渲染需要一定的时间;SSR 直接由服务端渲染好页面直接返回显示,无需等待下载 js 文件及再去渲染等,所以 SSR 有更快的内容到达时间;
190 |
191 | (2)服务端渲染的缺点:
192 |
193 | 更多的开发条件限制:例如服务端渲染只支持 beforCreate 和 created 两个钩子函数,这会导致一些外部扩展库需要特殊处理,才能在服务端渲染应用程序中运行;并且与可以部署在任何静态文件服务器上的完全静态单页面应用程序 SPA 不同,服务端渲染应用程序,需要处于 Node.js server 运行环境;
194 |
195 | 更多的服务器负载:在 Node.js 中渲染完整的应用程序,显然会比仅仅提供静态文件的 server 更加大量占用CPU 资源,因此如果你预料在高流量环境下使用,请准备相应的服务器负载,并明智地采用缓存策略。
196 |
197 | 如果你的项目的 SEO 和 首屏渲染是评价项目的关键指标,那么你的项目就需要服务端渲染来帮助你实现最佳的初始加载性能和 SEO,具体的 Vue SSR 如何实现,可以参考作者的另一篇文章《Vue SSR 踩坑之旅》。如果你的 Vue 项目只需改善少数营销页面(例如 /, /about, /contact 等)的 SEO,那么你可能需要预渲染,在构建时 (build time) 简单地生成针对特定路由的静态 HTML 文件。优点是设置预渲染更简单,并可以将你的前端作为一个完全静态的站点,具体你可以使用 prerender-spa-plugin 就可以轻松地添加预渲染 。
198 |
199 |
200 |
201 | ## 二、Webpack 层面的优化
202 |
203 | **2.1、Webpack 对图片进行压缩**
204 |
205 | 在 vue 项目中除了可以在 webpack.base.conf.js 中 url-loader 中设置 limit 大小来对图片处理,对小于 limit 的图片转化为 base64 格式,其余的不做操作。所以对有些较大的图片资源,在请求资源的时候,加载会很慢,我们可以用 image-webpack-loader来压缩图片:
206 |
207 | (1)首先,安装 image-webpack-loader :
208 | ```
209 | npm install image-webpack-loader --save-dev
210 | ```
211 | (2)然后,在 webpack.base.conf.js 中进行配置:
212 | ```
213 | {
214 | test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
215 | use:[
216 | {
217 | loader: 'url-loader',
218 | options: {
219 | limit: 10000,
220 | name: utils.assetsPath('img/[name].[hash:7].[ext]')
221 | }
222 | },
223 | {
224 | loader: 'image-webpack-loader',
225 | options: {
226 | bypassOnDebug: true,
227 | }
228 | }
229 | ]
230 | }
231 | ```
232 | 2.2、减少 ES6 转为 ES5 的冗余代码
233 | Babel 插件会在将 ES6 代码转换成 ES5 代码时会注入一些辅助函数,例如下面的 ES6 代码:
234 | ```
235 | class HelloWebpack extends Component{...}
236 | ```
237 | 这段代码再被转换成能正常运行的 ES5 代码时需要以下两个辅助函数:
238 |
239 |
240 | ```
241 | babel-runtime/helpers/createClass // 用于实现 class 语法
242 | babel-runtime/helpers/inherits // 用于实现 extends 语法
243 | ```
244 | 在默认情况下, Babel 会在每个输出文件中内嵌这些依赖的辅助函数代码,如果多个源代码文件都依赖这些辅助函数,那么这些辅助函数的代码将会出现很多次,造成代码冗余。为了不让这些辅助函数的代码重复出现,可以在依赖它们时通过 require('babel-runtime/helpers/createClass') 的方式导入,这样就能做到只让它们出现一次。babel-plugin-transform-runtime 插件就是用来实现这个作用的,将相关辅助函数进行替换成导入语句,从而减小 babel 编译出来的代码的文件大小。
245 |
246 | (1)首先,安装 babel-plugin-transform-runtime :
247 |
248 |
249 | ```
250 | npm install babel-plugin-transform-runtime --save-dev
251 | ```
252 | (2)然后,修改 .babelrc 配置文件为:
253 | ```
254 | "plugins": [
255 | "transform-runtime"
256 | ]
257 | ```
258 | 如果要看插件的更多详细内容,可以查看babel-plugin-transform-runtime 的 详细介绍。
259 |
260 | **2.3、提取公共代码**
261 |
262 | 如果项目中没有去将每个页面的第三方库和公共模块提取出来,则项目会存在以下问题:
263 |
264 | 相同的资源被重复加载,浪费用户的流量和服务器的成本。
265 |
266 | 每个页面需要加载的资源太大,导致网页首屏加载缓慢,影响用户体验。
267 |
268 | 所以我们需要将多个页面的公共代码抽离成单独的文件,来优化以上问题 。Webpack 内置了专门用于提取多个Chunk 中的公共部分的插件 CommonsChunkPlugin,我们在项目中 CommonsChunkPlugin 的配置如下:
269 |
270 | // 所有在 package.json 里面依赖的包,都会被打包进 vendor.js 这个文件中。
271 | ```
272 | new webpack.optimize.CommonsChunkPlugin({
273 | name: 'vendor',
274 | minChunks: function(module, count) {
275 | return (
276 | module.resource &&
277 | /\.js$/.test(module.resource) &&
278 | module.resource.indexOf(
279 | path.join(__dirname, '../node_modules')
280 | ) === 0
281 | );
282 | }
283 | }),
284 | // 抽取出代码模块的映射关系
285 | new webpack.optimize.CommonsChunkPlugin({
286 | name: 'manifest',
287 | chunks: ['vendor']
288 | })
289 | ```
290 | 如果要看插件的更多详细内容,可以查看 CommonsChunkPlugin 的 详细介绍。
291 |
292 | **2.4、模板预编译**
293 |
294 | 当使用 DOM 内模板或 JavaScript 内的字符串模板时,模板会在运行时被编译为渲染函数。通常情况下这个过程已经足够快了,但对性能敏感的应用还是最好避免这种用法。
295 |
296 | 预编译模板最简单的方式就是使用单文件组件——相关的构建设置会自动把预编译处理好,所以构建好的代码已经包含了编译出来的渲染函数而不是原始的模板字符串。
297 |
298 | 如果你使用 webpack,并且喜欢分离 JavaScript 和模板文件,你可以使用 vue-template-loader,它也可以在构建过程中把模板文件转换成为 JavaScript 渲染函数。
299 |
300 | **2.5、提取组件的 CSS**
301 |
302 | 当使用单文件组件时,组件内的 CSS 会以 style 标签的方式通过 JavaScript 动态注入。这有一些小小的运行时开销,如果你使用服务端渲染,这会导致一段 “无样式内容闪烁 (fouc) ” 。将所有组件的 CSS 提取到同一个文件可以避免这个问题,也会让 CSS 更好地进行压缩和缓存。
303 |
304 | 查阅这个构建工具各自的文档来了解更多:
305 |
306 | webpack + vue-loader ( vue-cli 的 webpack 模板已经预先配置好)
307 |
308 | Browserify + vueify
309 |
310 | Rollup + rollup-plugin-vue
311 |
312 | **2.6、优化 SourceMap**
313 |
314 | 我们在项目进行打包后,会将开发中的多个文件代码打包到一个文件中,并且经过压缩、去掉多余的空格、babel编译化后,最终将编译得到的代码会用于线上环境,那么这样处理后的代码和源代码会有很大的差别,当有 bug的时候,我们只能定位到压缩处理后的代码位置,无法定位到开发环境中的代码,对于开发来说不好调式定位问题,因此 sourceMap 出现了,它就是为了解决不好调式代码问题的。
315 |
316 | SourceMap 的可选值如下(+ 号越多,代表速度越快,- 号越多,代表速度越慢, o 代表中等速度 )
317 |
318 |
319 |
320 | 开发环境推荐:cheap-module-eval-source-map
321 |
322 | 生产环境推荐:cheap-module-source-map
323 |
324 | 原因如下:
325 |
326 | cheap:源代码中的列信息是没有任何作用,因此我们打包后的文件不希望包含列相关信息,只有行信息能建立打包前后的依赖关系。因此不管是开发环境或生产环境,我们都希望添加 cheap 的基本类型来忽略打包前后的列信息;
327 |
328 | module :不管是开发环境还是正式环境,我们都希望能定位到bug的源代码具体的位置,比如说某个 Vue 文件报错了,我们希望能定位到具体的 Vue 文件,因此我们也需要 module 配置;
329 |
330 | soure-map :source-map 会为每一个打包后的模块生成独立的 soucemap 文件 ,因此我们需要增加source-map 属性;
331 |
332 | eval-source-map:eval 打包代码的速度非常快,因为它不生成 map 文件,但是可以对 eval 组合使用 eval-source-map 使用会将 map 文件以 DataURL 的形式存在打包后的 js 文件中。在正式环境中不要使用 eval-source-map, 因为它会增加文件的大小,但是在开发环境中,可以试用下,因为他们打包的速度很快。
333 |
334 | **2.7、构建结果输出分析**
335 |
336 | Webpack 输出的代码可读性非常差而且文件非常大,让我们非常头疼。为了更简单、直观地分析输出结果,社区中出现了许多可视化分析工具。这些工具以图形的方式将结果更直观地展示出来,让我们快速了解问题所在。接下来讲解我们在 Vue 项目中用到的分析工具:webpack-bundle-analyzer 。
337 |
338 | 我们在项目中 webpack.prod.conf.js 进行配置:
339 | ```
340 | if (config.build.bundleAnalyzerReport) {
341 | var BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
342 | webpackConfig.plugins.push(new BundleAnalyzerPlugin());
343 | }
344 | ```
345 | 执行 $ npm run build --report 后生成分析报告如下:
346 |
347 |
348 |
349 | **2.8、Vue 项目的编译优化**
350 |
351 | 如果你的 Vue 项目使用 Webpack 编译,需要你喝一杯咖啡的时间,那么也许你需要对项目的 Webpack 配置进行优化,提高 Webpack 的构建效率。具体如何进行 Vue 项目的 Webpack 构建优化,可以参考作者的另一篇文章《 Vue 项目 Webpack 优化实践》
352 |
353 |
354 |
355 | ## 三、基础的 Web 技术优化
356 | **3.1、开启 gzip 压缩**
357 |
358 | gzip 是 GNUzip 的缩写,最早用于 UNIX 系统的文件压缩。HTTP 协议上的 gzip 编码是一种用来改进 web 应用程序性能的技术,web 服务器和客户端(浏览器)必须共同支持 gzip。目前主流的浏览器,Chrome,firefox,IE等都支持该协议。常见的服务器如 Apache,Nginx,IIS 同样支持,gzip 压缩效率非常高,通常可以达到 70% 的压缩率,也就是说,如果你的网页有 30K,压缩之后就变成了 9K 左右
359 |
360 | 以下我们以服务端使用我们熟悉的 express 为例,开启 gzip 非常简单,相关步骤如下:
361 |
362 | 安装:
363 |
364 | npm install compression --save
365 | 添加代码逻辑:
366 | ```
367 | var compression = require('compression');
368 | var app = express();
369 | app.use(compression())
370 | ```
371 | 重启服务,观察网络面板里面的 response header,如果看到如下红圈里的字段则表明 gzip 开启成功 :
372 |
373 |
374 | **3.2、浏览器缓存**
375 |
376 | 为了提高用户加载页面的速度,对静态资源进行缓存是非常必要的,根据是否需要重新向服务器发起请求来分类,将 HTTP 缓存规则分为两大类(强制缓存,对比缓存),如果对缓存机制还不是了解很清楚的,可以参考作者写的关于 HTTP 缓存的文章《深入理解HTTP缓存机制及原理》,这里不再赘述。
377 |
378 | **3.3、CDN 的使用**
379 |
380 | 浏览器从服务器上下载 CSS、js 和图片等文件时都要和服务器连接,而大部分服务器的带宽有限,如果超过限制,网页就半天反应不过来。而 CDN 可以通过不同的域名来加载文件,从而使下载文件的并发连接数大大增加,且CDN 具有更好的可用性,更低的网络延迟和丢包率 。
381 |
382 | **3.4、使用 Chrome Performance 查找性能瓶颈**
383 |
384 | Chrome 的 Performance 面板可以录制一段时间内的 js 执行细节及时间。使用 Chrome 开发者工具分析页面性能的步骤如下。
385 |
386 | 打开 Chrome 开发者工具,切换到 Performance 面板
387 |
388 | 点击 Record 开始录制
389 |
390 | 刷新页面或展开某个节点
391 |
392 | 点击 Stop 停止录制
393 |
394 | ## 原文地址:https://blog.csdn.net/qq_37939251/article/details/100031285
--------------------------------------------------------------------------------
/2 程序员面试软技能.md:
--------------------------------------------------------------------------------
1 | ## 一、如何通过HR⾯
2 |
3 | HR通常是程序员⾯试的最后⼀⾯,讲道理刷⼈的⼏率不⼤,但是依然有⼈倒在了这最后⼀关上,我们会从HR的⻆度出发来分析如何应对HR⾯.
4 |
5 | ### 1. HR⾯的⽬的
6 |
7 | HR⾯往往是把控⼈才质量的最后⼀关,与前⾯的技术⾯不同,HR⾯往往侧重员⼯⻛险的评估与基本的员⼯素质。
8 |
9 | - **录⽤⻛险评估****,**这部分是评估候选⼈是否具备稳定性,是否会带来额外的管理⻛险,是否能⻢上胜任⼯作,⽐如频繁的跳槽会带了稳定性的⻛险,HR会慎重考虑这⼀点,⽐如在⾯试中候选⼈体现出了「杠精」潜质,HR会担⼼候选⼈在⼯作中会难以与他⼈协作或者不服从管理,带来管理⻛险,再⽐如,虽然国家明确规定在招聘中不得有性别、年龄等歧视,但是⼀个⼤龄已婚妇⼥会有近期产⼦的可能性,可能会有⻓期的产假,HR也会做出评估。
10 | - **员⼯素质评估****,**这部分评估候选⼈是否具备职场的基本素质,是否有基本的沟通能⼒,是否有团队精神和合作意识等等,⽐如⼀个表现极为内向的候选⼈,HR可能会对其沟通能⼒产⽣怀疑.
11 |
12 |
13 |
14 | 所以在与HR交流中要尽量保持踏实稳重、积极乐观的态度,切忌暴露出夸夸其谈、负能量、浮躁等性格缺陷。
15 |
16 | ### 2. HR⾯的常⻅问题
17 |
18 | #### (1)你对未来3-5年的职业规划
19 |
20 | **⽬的**: 这个问题就是考察候选⼈对未来的规划能⼒,主要想通过候选⼈的规划来嗅出候选⼈对⼯作的态度、稳定性和对技术的追求.
21 |
22 | **分析**: ⼀定要在你的回到中体现对技术的追求、对团队的贡献、对⼯作的态度,不要谈⼀些假⼤空的东⻄,或者薪资、职位这些太过于功利的东⻄,⽽且最好体现出你的稳定性,如果是校招⽣或者⼯作没⼏年的新⼈最好不要涉及创业这种话题,⼀⽅⾯职场新⼈计划没⼏年就创业,这种很不切实际,说明候选⼈没法按实际出发,另⼀⽅⾯说明候选⼈的稳定性不够.
23 |
24 |
25 |
26 | 建议分三部分谈:
27 |
28 | 1. ⾸先表示考虑过这个问题(有规划),如何谈⼀谈⾃⼰的现状(结合实际).
29 | 2. 接着从⼯作本身出发,谈谈⾃⼰会如何出⾊完成本职⼯作,如何对团队贡献、如何帮助带领团队其他成员创造更多的价值、如何帮助团队扩⼤影响⼒.
30 | 3. 最后从学习出发,谈谈⾃⼰会如何精进领域知识、如何通过提升⾃⼰专业能⼒,如何反哺团队.
31 |
32 |
33 |
34 | ⾄于想成为技术leader还是技术专家,就看⾃⼰的喜好了.
35 |
36 | #### (2)如何看待加班(996)?
37 |
38 | **⽬的**: 考察候选⼈的抗压能⼒和责任⼼
39 |
40 | **分析**: 这个问题⼏乎是必问的,虽然996ICU事件闹得沸沸扬扬,但是官⽅的态度很暧昧,只⼝头批评从没有实际⾏动,基本上是默许企业违反劳动法的,除了个别外企在国内基本没可能找到不加班的公司,所以在这个⾯试题中尽量体现出⾃⼰愿意牺牲⾃我时间来帮助团队和企业的意愿就⾏了,⽽且要强调⾃⼰的责任⼼,如果真的是碰到⽆意义加班,好好学习怎么⽤vscode刷LeetCode划⽔是正道.
41 |
42 | **建议**:
43 |
44 | 1. 把加班分为紧急加班和⻓期加班
45 | 2. 对于紧急加班,表示这是每个公司都会遇到的情况,⾃⼰愿意牺牲时间帮助公司和团队
46 | 3. 对于⻓期加班,如果是⾃⼰⻓期加班那么会磨练⾃⼰的技能,提⾼⾃⼰的效率,如果是团队⻓期加班,⾃⼰会帮助团队找到问题,利⽤⾃动化⼯具或者更⾼效的协作流程来提⾼整个团队的效率,帮助⼤家摆脱加班
47 |
48 |
49 |
50 | 当然了,就算你提⾼了团队效率,还是会被安排更多的任务,加班很多时候仅仅是⽬的,,但是你不能说出来啊,尤其是⼀些候选⼈很强硬得表示⻓期加班不接受,其实可以回答的更委婉,除⾮你是真的对这个公司没兴趣,如果以进⼊这个公司为第⼀⽬的,还是做个⾼姿态⽐较好。
51 |
52 | #### (3)⾯对⼤量超过⾃⼰承受能⼒且时间有限的⼯作时你会怎么办?
53 |
54 | **⽬的**: 考察候选⼈时间管理和处理⼤量任务的能⼒,当然也会涉及⼀定的沟通能⼒
55 |
56 | **分析**: 程序员的⼯作内容可能⼤部分时间并不在写代码上,⽽是要处理各种会议、需求和沟通,通常都属于⼯作超负荷的状态,⾯对上⾯这种问题不建议以加班的⽅式来解决,因为主要考察的是你的时间管理能⼒和沟通能⼒,这些要素要在回答中体现出来
57 |
58 | 建议:
59 |
60 | 1. 将⼤量任务分解为紧急且重要、重要但不紧急、紧急但不重要、不重要且不紧急,依次完成上述任务,在这⾥体现出时间管理的能⼒
61 | 2. 与⾃⼰的领导沟通将不重要的任务放缓执⾏或者砍掉,或者派给组内的新⼈处理,在这⾥体现出沟通能⼒
62 |
63 | #### (4)你之前在上海为什么现在来北京发展?
64 |
65 | **⽬的**: 考察候选⼈的稳定性和职业选择
66 |
67 | 分析: 这个问题⼀般是上份⼯作在异地的情况下⼤概率出现,HR主要担⼼候选⼈异地换⼯作可能会不稳定,有短期内离职⻛险,这个时候不建议说"北京互联⽹公司多,机会多"这种话(合着觉得北京好跳槽?),回答最好要体现出⾃⼰的稳定性,⽐如"⼥朋友在北京,⻓期异地,准备来北京⼀起发展" "家在北京,回北京发展" 等等,潜台词就是以后会在北京发展,不会在多地之间来回摇摆.
68 |
69 | #### (5)为什么从上⼀家公司离职?
70 |
71 | ⽬的: 考察离职原因,候选⼈离职⻛险评估
72 |
73 |
74 | **分析**: 这个问题经常会在跳槽的时候问到,这个时候切忌吐槽上⼀家公司或者⾃⼰的上⼀任⽼板,尽量从职业发展的⻆度来回答,凸显⾃⼰的稳定性和渴望学习上升的决⼼,⾄于⼀些敏感话题,⽐如加班太多、薪资太低这种问题也是可以谈的,毕竟你跳槽的诉求就是解决上家公司碰到的问题,但是不能触碰刚才提到的底线问题,切忌吐槽向.
75 |
76 | **建议**:
77 |
78 | 1. 因为⼯资低、离家远、加班多、技术含量低等等原因离职
79 | 2. 因为离家远花费在路途上的时间过多,不如⽤来充电,因为加班多导致没有时间充电,⽆法提⾼等等
80 |
81 |
82 |
83 | 除了不要有负能量和吐槽向,这个部分可以坦诚得说出来
84 |
85 | #### (6)你还有其他公司的Offer吗?
86 |
87 | ⽬的: 评估候选⼈是否有短时间内⼊职其他公司的可能性
88 |
89 | 分析: 很多时候并不是候选⼈完美符合⼀个岗位的要求,HR当然想要⼀个技术更好、要钱更少、技术更匹配的候选⼈,但是候选⼈⼀般都会有这样或者那样的⼩问题。
90 |
91 |
92 |
93 | ⽐如,你的表现是可以胜任⽬前的岗位的,但是这个岗位不是很紧急,HR可能把你当做备胎,来找⼀个性价⽐更⾼的候选⼈。⽐如,你的表现很好,履历优秀,HR不知道能不能100%拿下你。所以如果你很希望加⼊这个公司,最好要做到「欲擒故纵」,既要体现⾃身的市场竞争⼒,⼜要给到HR⼀定的压⼒。所以,即使你已经拿了全北京城互联⽹公司的offer了,也不要说⾃⼰offer多如⽜⽑,⼀副满不在乎的样⼦,这样会给HR造成他⼊职可能性不⼤的错觉,因为他的选择太多了。当然,也不要跪在地上舔:"加⼊公司是我的梦想,我只等这⼀个offer",放⼼吧,⼀定被hr放到备胎⼈才库中.
94 |
95 |
96 |
97 | 建议:
98 |
99 | 1. 表明⾃⼰有三四个已经确认过的offer了(没有offer也要吹,但是不要透露具体公司)
100 | 2. 但是第⼀意向还是本公司,如果薪资差距不⼤,会优先考虑本公司
101 | 3. 再透露出,有⼀两个offer催得⽐较急,希望这边快点出结果
102 |
103 | #### (7)如何与HR谈薪资?
104 |
105 | HR与你谈论薪资经常有如下套路:
106 |
107 | - HR: 您期望的薪资是多少?
108 | - 你: 25K。
109 |
110 |
111 |
112 | OK,你已经被HR成功套路。这个时候你的最⾼价就是25K了,然后HR会顺着这个价往下砍,所以你最终的薪资⼀般都会低于25K。等你接到offer,你的⼼⾥肯定充满了各种“悔恨”:其实当时报价26、27甚⾄28、29也是可以的。
113 |
114 |
115 |
116 | 正确的回答可以这样,并且还能够反套路⼀下HR:
117 |
118 | - HR: 您期望的薪资是多少?
119 | - 你: 就我的⾯试表现,贵公司最⾼可以给多少薪⽔?
120 |
121 |
122 |
123 | 如果经验不够⽼道的HR可能就真会说出⼀个报价(如25K)来,然后,你就可以很开⼼地顺着这个价慢慢地往上谈了。所以这种情况下,你最终的薪资肯定是⼤于25K的。当然,经验⽼道的HR会给你⼀句很官⽅的套话:
124 |
125 | - HR: 您期望的薪资是多少?
126 | - 你: 就我的⾯试表现,贵公司最⾼可以给多少薪⽔?
127 | - HR: 这个暂且没法确定,要结合您⼏轮⾯试结果和⽤⼈部⻔的意⻅来综合评定。
128 |
129 |
130 |
131 | 虽然薪资很重要,但是我个⼈觉得这不是最重要的。我有以下建议:
132 |
133 | - 如果你觉得你技术⾯试效果很好,可以报⼀个⾼⼀点的薪资,这样如果HR想要你,会找你商量的。
134 | - 如果你觉得技术⾯试效果⼀般,但是你⽐较想进这家公司,可以报⼀个折中的薪资。
135 | - 如果你觉得⾯试效果很好,但是你不想进这家公司,你可以适当“漫天要价”⼀下。
136 | - 如果你觉得⾯试效果不好,但是你想进这家公司,你可以开⼀个稍微低⼀点的⼯资。
137 |
138 |
139 |
140 | 需要注意的是,⾯试求职是⼀个双向选择的过程。⾯试应该做到不卑不亢,千万不要因为⾯试结果不好,就低声下⽓地乞求⼯作,每个⼈的⼯作经历和经验都是不⼀样的,技术⾯试不好,知道⾃⼰的短板针对性地补缺补差就⾏,⽽不是在⼈事关系上动歪脑筋。
141 |
142 | ## 二、回答问题的技巧
143 |
144 | 技术⾯试通常⾄少三轮:
145 |
146 | 1. 基础⾯试: 主要考察对岗位和简历中涉及到基础知识部分的提问,包括⼀部分算法和场景设计的⾯试题,这⼀⾯可能会涉及现场coding.
147 | 2. 项⽬⾯试: 主要考察简历中涉及的项⽬,会涉及你项⽬的相关业务知识、扮演⻆⾊、技术取舍、技术攻坚等等.
148 | 3. HR⾯试: 这⼀⾯通常是HR把关,主要涉及⾏为⾯试,考察候选⼈是否价值观符合公司要求、⼯作稳定性如何、沟通协作能⼒如何等等.
149 |
150 |
151 |
152 | 当然,对于初级岗或者校招⽣会涉及⼀轮笔试,相当多的公司会在现场⾯之前进⾏⼀轮电话⾯试,⽬的是最快速有效地把不符合要求的候选⼈筛除,对于个别需要跨部⻔协作的岗位会涉及交叉⾯试,⽐如前端候选⼈会被后端的⾯试官⾯试,⼀些有管理需求的岗位或者重要岗位可能会涉及总监⾯试或者vp⾯。
153 |
154 |
155 |
156 | ⽽⼀个正常的技术⾯试流程(以项⽬⾯为例)分为⼤致三个部分:
157 |
158 | 1. ⾃我介绍
159 | 2. 项⽬(技术)考察
160 | 3. 向⾯试官提问
161 |
162 |
163 |
164 | 那么该如何准备技术⾯试,如何在⾯试中掌握主动权呢?
165 |
166 | ### 1. ⾃我介绍
167 |
168 | ⼏乎所有的⾯试都是从⾃我介绍这个环节开始的,所以我们得搞清楚为什么⾃我介绍通常作为⼀个⾯试的开头。
169 |
170 | #### (1)为什么需要⾃我介绍
171 |
172 | ⾸先,有⼀个很普遍的问题就是⾯试官很可能才刚拿到你的简历,他需要在你⾃我介绍的时候快速浏览你的简历,因为技术⾯试的⾯试官很多是⼀线的员⼯,⾯试候选⼈只是其⼯作中的⼀⼩部分,很多情况下是没有提前看过你的简历的。
173 |
174 |
175 |
176 | 其次,⾃我介绍其实是⼀个热身,⾯试官和候选⼈其实是陌⽣⼈,⾃我介绍不管是⾯试还是其他情况下,都是两个陌⽣⼈彼此交流的起点,也是缓解候选⼈与⾯试官之间尴尬的⼀种热身⽅式.
177 |
178 |
179 |
180 | 最后,⾃我介绍是展示⾃我、引出接下来技术⾯试的引⼦,是你⾃⼰指定技术⾯试⽅向的⼀次机会。
181 |
182 |
183 |
184 | 知道了以上原因,我们才能进⾏准备更好的⾃我介绍。
185 |
186 | #### (2)⾃我介绍的⼏个必备要素
187 |
188 | ⾃我介绍归根到底是⼀个热身运动,因此切忌占⽤⼤量的篇幅,上来就把⾃⼰从出⽣的经历到⼤学像流⽔账⼀样吐出来的,往往会被没耐⼼的⾯试官打断,⽽这也暴露了候选⼈讲话缺乏重点、沟通能⼒⼀般的缺点。
189 |
190 |
191 |
192 | 但是,⼀些关键信息是必须体现的,就我个⼈⽽⾔,以下信息是必备的:
193 |
194 | - 个⼈信息: ⾄少要体现出⾃⼰的姓名、岗位和⼯作年限,应届⽣则必须要介绍⾃⼰的教育背景,如果⾃⼰的前东家是个⼤⼚(⽐如BAT)最好提及,⾃⼰的学历是亮点(985或者硕博或者类似于北邮这种CS强校)最好提及,其他的什么有没有⼥朋友、是不是独⽣⼦没⼈在意,不要占⽤篇幅。这个部分重点在于「你是谁?」。
195 | - 技术能⼒: 简要地介绍⾃⼰的技术栈,切忌把⾃⼰只是简单使⽤过,写过⼏个Demo或者看了看⽂档的所谓「技术栈」也说出来,⼀旦后⾯问到算是⾃找尴尬。这个部分的重点在于「你会什么?」。
196 | - 技能擅⻓: 重点介绍⾃⼰擅⻓的技术,⽐如性能优化、⾼并发、系统架构设计或者是沟通协调能⼒等等,切忌夸⼤其词,要实事求是,这是之后考察的重点。这个部分重点⾃在于「你擅⻓什么?」。
197 |
198 | #### (3)⾃我介绍要重点匹配当前岗位的技术栈
199 |
200 | 你的⾯试简历可能包含了各种各样的技术栈,但是在⾃我介绍过程中需要匹配当前岗位的技术要求。就⽐如你⽬前⾯试的是移动端H5前端的开发岗位,就重点在⾃我介绍中突出⾃⼰在移动前端的经验,⽽此时⼤篇幅得讲述 ⾃⼰如何⽤Node⽀撑公司的web项⽬就显得很不明智.
201 |
202 | #### (4)要在⾃我介绍中做刻意引导
203 |
204 | 如果你的⾃我介绍跟流⽔账⼀样,没有任何重点,其实⾯试官也很难办,因为他都没法往下接话...
205 |
206 |
207 |
208 | ⽽只要你稍作引导,绝⼤部分⾯试官就会接你的话茬,⽐如「你在⾃我介绍中重点提及了⼀个项⽬,碰到了⼀些难点,然后被你攻克了,效果如何如何好等等」,如果我是⾯试官⼀定会问「你的xx项⽬的xx难点后来是怎么解决的?」。
209 |
210 |
211 |
212 | ⾯试官的⽬的是考察候选⼈的能⼒,对候选⼈做出评估,因此需要知道候选⼈擅⻓什么,是否匹配岗位,⾯试官绝⼤多数情况下很乐意你这种有意⽆意的引导,这样双⽅的沟通和评估会很顺利,⽽不是故意刁难候选⼈。
213 |
214 | #### (5)如何准备⾃我介绍
215 |
216 | 其实最好的⽅法也是最笨的⽅法就是把⾃我介绍写下来,这个⾃我介绍⼀定要体现上⾯提到的⼏⼤必备要素,在⾯试前简单过⼏遍,能把⾃我介绍的内容顺利得表达出来即可,切忌跟背课⽂⼀样。
217 |
218 |
219 |
220 | ⾃我介绍的时间最好控制在1-3分钟之间,这些时间⾜够⾯试官把你的简历过⼀遍了,⾯试官看完简历后正好接着你的⾃我介绍进⾏提问是最舒服的节奏,别上来开始10分钟的演讲,⾯试官等待的时候会很尴尬,这么⻓的篇幅说明你的⾃我介绍⼀定是流⽔账式的。
221 |
222 | ### 2. 技术考察
223 |
224 | ⼀个好的技术考察的开始,必须得有⾃我介绍部分好的铺垫和引导,有⼀种情况我们经常遇⻅:
225 |
226 | > 候选⼈说了⼀⼤堆⾮重点的⾃我介绍,⾯试官⼀时语塞,完全get不到候选⼈的重点,也不知道候选⼈擅⻓什么、有什么亮点项⽬,然后就在他简历的技术栈中选了本公司也在⽤的技术,候选⼈这个时候也开始冒汗,因为这个技术栈并不是他的擅⻓,回答的也磕磕绊绊,⾯试官的引导和深⼊追问也没有达到很好的效果,⾯试就在这种尴尬的⽓氛中展开了,⾯试结束后⾯试官对候选⼈的评价是技术不熟练、没有深⼊理解原理,候选⼈的感受是,⾯试官专挑⾃⼰不会的问。
227 |
228 | 所以在前⾯的部分,⼀定要做好引导,把⾯试官的问题引到我们擅⻓的领域,但是这样还不够,正所谓不打⽆准备之仗,我们依然需要针对可能出现的问题进⾏准备.
229 |
230 |
231 |
232 | 那么如何准备可能的⾯试题?
233 |
234 |
235 |
236 | ⽐如你擅⻓前端的性能优化,在⾃我介绍的部分已经做好了引导,接下来⾯试官⼀定会重点考察你性能优化的能⼒,很可能会涉及很有深度的问题,即使你擅⻓这⽅⾯的技术,但是如果没有准备也可能临场乱了阵脚.
237 |
238 | #### (1)多重提问
239 |
240 | ⾃我多重提问的意思是,当⼀个技术问题抛出的时候,你可能⾯对更深层次的追问。
241 |
242 |
243 |
244 | 依旧以前端性能优化为例,⾯试官可能的提问:
245 |
246 | 1. 你把这个⼿机端的⽩屏时间减少了150%以上,是从哪些⽅⾯⼊⼿优化的?这个问题即使你没做过前端性能优化也能回答个七七⼋⼋,⽆⾮是组件分割、缓存、tree shaking等等,这是第⼀重⽐较浅的问题。
247 | 2. 我看你⽤webpack中SplitChunksPlugin这个插件进⾏分chunk的,你分chunk的取舍是什么?哪些库分在同⼀个chunk,哪些应该分开你是如何考虑的?如果你提到了SplitChunksPlugin插件可能会有类似的追问,如果没有实际操作过的候选⼈这个时候就难以招架了,这个过程⼀定是需要⼀定的试错和取舍的.
248 | 3. 在分chunk的过程中有没有遇到什么坑?怎么解决的?其实SplitChunksPlugin这个插件有⼀个暗坑,那就是chunid⾃增性导致id不固定唯⼀,很可能⼀个新依赖就导致id全部打乱,使得http缓存失效.
249 |
250 |
251 |
252 | 以上只是针对SplitChunksPlugin插件相关的优化提问,当然也可能从你的性能测试⻆度、代码层⾯进⾏考察,但是思路是类似的。因此不能把⾃⼰准备的问题答案停留在⼀个很浅显的层⾯,⼀⽅⾯⽆法展示⾃⼰的技术深度,另⼀⽅⾯在⾯试官的深度体情况下容易丢分,因此在⾃⼰的答案后⾯多进⾏⾃我的追问,看⼀看能不能把问题做的更深⼊。
253 |
254 | #### (2)答题法则
255 |
256 | 很多⾯试相关的宝典都推荐使⽤STAR法则进⾏问题的应答,我们不想引⼊这个额外的概念,基础技术⾯试的部分⽼⽼实实回答⾯试官的问题即可,通常需要问题运⽤到这个法则的是项⽬⾯,⽐如让你介绍⼀下你最得意的项⽬,回答问题的法则有这⼏个要点:
257 |
258 | - 项⽬背景: 简要说⼀下项⽬的背景,让⾯试官知道这个项⽬是做什么的
259 | - 个⼈⻆⾊: 让⾯试官知道你在这个项⽬中扮演的⻆⾊
260 | - 难点: 让⾯试官知道你在项⽬开发过程中碰到的难点
261 | - 解决⽅案: 针对上⾯的难点你有哪⼀些解决⽅案,是如何结合业务进⾏取舍的
262 | - 总结沉淀: 在攻克上述的难点后有没有沉淀出⼀套通⽤的解决⽅案,有没有将⾃⼰的⽅案在⼤部⻔进⾏推⼴等等
263 |
264 |
265 |
266 | 重点就在于后⾯三条,也是最体现你个⼈综合素质的⼀部分,我是⾯试官的话会⾮常欣赏那种可以发现问题、找到多种⽅ 案、能对多种⽅案进⾏⽐对取舍还可以总结沉淀出通⽤解决⽅案回馈团队的⼈。从上述⼏点可以体现出⼀个⼈的技术热情、解决问题的能⼒和总结提⾼的能⼒。
267 |
268 | #### (3)刻意引导
269 |
270 | 是的,在回答⾯试官提问的时候也可以做到刻意引导。
271 |
272 |
273 |
274 | 举⼏个简单的例⼦:
275 |
276 | - 除了Vue还⽤过Angular吗? 这个时候很多候选⼈就很实诚回答「没有」,其实我们可以回答的更好,把你知道的说出来展示⾃⼰的能⼒才是最重要的,你可以说「我虽然没⽤过,但是在学习双向绑定原理的时候了解了⼀下 Angular脏检查的原理,在学习Nestjs的时候了解了依赖注⼊的原理,跟Angular也是类似的」,⾯试官⼀定会接着问你脏检查和依赖注⼊的问题,虽然你没有⽤过Angular,但是Angular的基本原理你都懂,这是很好的加分项,说明候选⼈有深⼊理解原理的意愿和触类旁通的能⼒
277 | - Vue如何实现双向绑定的? 很多候选⼈⽼⽼实实答了 object.defineproperty 如何如何操作,然后就没有了,其实你可以在回答完之后加上⼀嘴「Vue 3.0则选择了更好⽤的Proxy来替代object.defineproperty」或者「除了object.defineproperty这种数据劫持的⽅式,观察者模式和脏检查都可以实现双向绑定」,⾯试官⼤概率会问「Proxy好在哪?」或者「聊聊脏检查」等等,这样下⼀个问题就会依然在你的可控范围内
278 |
279 |
280 |
281 | 我们第⼀个例⼦把本来回答不上来的问题,转化为了成功展示⾃⼰能⼒的加分项,第⼆个例⼦让⾃⼰更多的展示了⾃⼰的能⼒,⽽且始终使⾯试官的问题在⾃⼰的可控范围内。
282 |
283 | ### 3. 向⾯试官提问
284 |
285 | 这个部分基本到了⾯试尾声了,属于做好了不影响⼤局,但是可能加分,如果做不好很容易踩雷的区域.
286 |
287 |
288 |
289 | ⾸先我们声明⼏个雷区:
290 |
291 | - 切忌问结果: 问了也⽩问,绝⼤部分公司规定不会透露结果的,你这样让⼤家很尴尬
292 | - 切忌问⼯资: 除了HR跟你谈⼯资的时候,千万别跟技术⾯试官谈⼯资,⼯资是所有公司的⾼压线,没法谈论
293 | - 切忌问技术问题: 别拿⾃⼰不会的技术难题反问⾯试官,完全没意义,⾯试官答也不是不答也不是
294 |
295 |
296 |
297 | 有⼏个⽐较好的提问可供参考:
298 |
299 | - 如果我⼊职这个岗位的话,前三个⽉你希望我能做到些什么?
300 | - 我的这个岗位的前任是为什么离职的,我什么地⽅能做的更好?
301 | - 你对这个职位理想⼈选的要求是什么?
302 |
303 |
304 |
305 | 尽量围绕你的岗位进⾏提问,这可以使得你更快得熟悉你的⼯作内容,也让⾯试官看到你对此岗位的兴趣和热情,重要的是 这些问题对于⾯试官⽽⾔既可以简略回答,也可以详细的给你讲解,如果他很热情得跟你介绍此岗位相关的情况,说明你可能表现得不错,否则的话,你可能不在他的备选名单⾥,这个时候就需要你早做打算了。
306 |
307 | ## 三、⾯试官到底想看什么样的简历?
308 |
309 | ⾯试⼀直是程序员跳槽时期⾮常热⻔的话题,虽然现在已经过了跳槽的旺季,下⼀轮跳槽季需要到年底才会出现,但是当跳槽季的时候你再看这篇⽂章可能已经晚了,过冬的粮⻝永远不是冬天准备的,⽽是秋收的时候。
310 |
311 |
312 |
313 | 简历是你进⼊⾯试的敲⻔砖,也是留给意向公司的第⼀印象,所以这个很重要,必须在这上⾯做⾜了⽂章,⼀份优秀的⾯试简历是整个⾯试成败的重中之重,我们会详细分析如何准备简历才能保证简历不被刷掉。
314 |
315 |
316 |
317 | 简历通常有这⼏部分构成:
318 |
319 | 1. 基本资料
320 | 2. 专业技能
321 | 3. ⼯作经历
322 | 4. 项⽬经历
323 | 5. 教育背景
324 |
325 |
326 |
327 | 我们会逐⼀进⾏分析。
328 |
329 | ### 1. 准备简历模板
330 |
331 | 万事开头难,简历的编写如果从头开始需要浪费很多时间,其实最快速也最聪明的办法就是先找⼀份还不错的简历模板,之后我们只需要填写信息即可。
332 |
333 |
334 |
335 | 简历模板的选择很讲究,有些简历基本不看内容就会被刷掉,这些简历⼀般会对⾯试官进⾏视觉攻击,让简历给⾯试官的第⼀印象就是反感。
336 |
337 |
338 |
339 | 有两种坑爹的简历模板:
340 |
341 | - ⼀种是经典简历模板,真是堪称『经典』,这种简历模板在我上⼩学的时候就有了,以现在的眼光看有点不够看了,配 ⾊也⽐较『魔幻』,加上表格类的简历属于low到底端的简历类型,基本上扫⼀眼就扔了,这种简历只需要3秒钟就能被⾯试官扔到垃圾堆
342 | - 另⼀种是设计感⼗⾜的简历模板,这种简历设计感⼗⾜,这五颜六⾊的配⾊⼀定能亮瞎⾯试官的双眼,这种花⾥胡哨的简历同样也是3秒钟沉到垃圾堆底部的简历。
343 |
344 |
345 |
346 | 以上两类简历模板堪称⾯试官杀⼿,我相信只要你⽤了上述两类模板,绝对连让⾯试官看第⼆眼的兴趣都没有。⾯试官筛简历要的是⾼效、清晰、内容突出,不管是HR还是技术⾯试官都想在最快速的情况下看到有效信息,你眼中所谓的『视觉效果』在别⼈眼⾥就是『视觉噪⾳』或者『视觉垃圾』,严重影响看简历的⼼情和寻找有效信息的速度。
347 |
348 | ### 2. 准备个⼈信息
349 |
350 | 个⼈信息部分主要包括姓名、电话、点⼦邮箱、求职意向,当然这四个是必填的,其它的都是选填,填好了是加分项,否则很可能减分。
351 |
352 |
353 |
354 | 接下来才是重点:
355 |
356 | 1. github:如果准备⼀个基本没有更新的博客或者没有任何贡献的github,那么给⾯试官⼀种为了放上去⽽放上去的感觉,这基本上就是在跟⾯试官说『这个候选⼈平时根本没有总结提炼的习惯』,所以如果有⻓期维护的github或者博客⼀定要放上去,质量好的话会⾮常有⽤,如果没有千万别放。
357 | 2. 学历:如果你的学历是专科、⾼中毕业之类的,还写在简历头部强调⼀遍,这就造成了你是『学渣』的印象,没有公司喜欢学渣的,这⼜增加了简历被刷的⼏率,如果是研究⽣以上学历可以写,突出⼀下学历优势,本科学历在技术⾯试领域基本上敲⻔砖级别的,没必要写。
358 | 3. 年龄:如果你是⼤龄程序员,尤其是你还在求⼀份低端岗位的时候千万别写,⼀个⼤龄程序员在求职⼀个中低端岗位,说明这些年基本原地踏步,还不能加班,到这⾥基本上此简历就凉了⼀半了。
359 | 4. 照⽚:形象优秀的可以贴,尤其是形象优秀的⼥程序媛,其它的最好不要贴,如果要贴的话,最好是贴那种PS过的⾮常职业的证件照,那种平时搞怪的、光着膀⼦的⽣活照,基本就是⾃杀⾏为。
360 |
361 | ### 3. 准备专业技能
362 |
363 | 对于程序员的专业技能其实就是技术栈,对于⾃⼰的技术栈如何描述是个很难的问题,⽐如什么算是精通?什么算是了解?什么是熟悉?
364 |
365 |
366 |
367 | 关于对技术技能的描述有很多种,有五种的也有三种的,⽽且每个⼈对词汇的理解都不⼀样,我结合相关专家的理解和⾃⼰的理解来简单阐述下描述词汇的区别,我们这⾥只讲三种的了解、熟悉、精通。
368 |
369 | - 了解:使⽤过某⼀项技术,能在别⼈指导下完成⼯作,但不能胜任复杂⼯作,也不能独⽴解决问题。
370 | - 熟悉:⼤量运⽤过的某⼀项技术,能独⽴完成⼯作,且能独⽴完成有⼀定复杂度的⼯作,在技术的应⽤层⾯不会有太⼤问题,甚⾄理解⼀点原理。
371 | - 精通:不仅可以运⽤某⼀⻔技术完成复杂项⽬,⽽且理解这项技术背后的原理,可以对此技术进⾏⼆次开发,甚⾄本身就是技术源码的贡献者。
372 |
373 |
374 |
375 | 我们就以Vue这个框架为例,如果你可以⽤vue写⼀些简单的⻚⾯,单独完成某⼏个⻚⾯的开发,但是⽆法脱离公司脚⼿架⼯作,也⽆法独⽴从0完成⼀个有⼀定复杂度的项⽬,只能称之为了解。
376 |
377 |
378 |
379 | 如果你有⼤量运⽤vue的经验,有从0独⽴完成⼀定复杂度项⽬的能⼒,可以完全脱离脚⼿架进⾏开发,且对vue的原理有⼀定的了解,可以称之为熟悉。
380 |
381 |
382 |
383 | 如果你⽤vue完成过复杂度很⾼的项⽬,⽽且⾮常熟悉vue的原理,是vue源码的主要贡献者,亦或者根据vue源码进⾏过魔改(⽐如mpvue),你可以称得上精通。
384 |
385 |
386 |
387 | 那么有两个坑是候选⼈经常犯的,『杂』和『精』,这种两个坑⼤量集中在应届⽣和刚毕业每两年的新⼿身上,其主要特点是『急于表现⾃我』、『对技术深度与⼴度出现⽆知⽽导致的过度⾃信』。
388 |
389 |
390 |
391 | ⾸先说说杂,⽐如你要应聘⼀个Java后端,⽼⽼实实把⾃⼰的java技术栈写好就⾏了,强调⼀下⾃⼰擅⻓什么即可,最好专精某领域⽐如『⾼并发』、『⾼可⽤』等等,这个时候⼀些简历⾮要给⾃⼰加戏,⾃⼰会的不会的⼀股脑往上堆,什么逆向、密码学、图形、驱动、AI都要体现出来,越杂越好,这种简历给⼈的印象就是个什么都不懂的半吊⼦。
392 |
393 |
394 |
395 | 再说说精,⼀个刚毕业的应届⽣,出来简历就各种精通,精通Java、精通Java虚拟机、精通spring全家桶、精通kafka等等,请放⼼,这种简历是不会没头没脑投过来了,这种在⼤学⾥就精通各种的天才早被他的各种学⻓介绍进了⼤⼚或者外企做某某Star重点培养了,往往看到的这种也是半吊⼦。
396 |
397 | ### 4. 准备⼯作经历
398 |
399 | ⼯作经历本身不⽤花太多笔墨去写,⾯试官主要想看的就是每段⼯作经历的持续时间、在不同公司担任的职责如何、是否有⼤⼚的⼯作经验等等。
400 |
401 |
402 |
403 | 那么什么简历在这⾥给⾯试官减分呢?
404 |
405 | - 频繁跳槽:⽐如三年换了四家公司,每个公司呆的时⻓不要超过⼀年
406 | - 常年初级岗:⽐如⼯作五六年之后依然在完成⼀些简单的项⽬开发
407 | - 末流公司经历:在技术招聘届,⼤⼚的优先级最⾼⽐如BAT、TMD甚⾄微软、⾕歌等外企,知名度独⻆兽其次,⽐如商汤、旷视等等,⼀般的互联⽹公司排在第三,就是⼯作中⼩型的互联⽹公司⼀般⼤家叫不上名字,排在最后的就是外包和传统企业的经历
408 |
409 |
410 |
411 | 所以,如果你有频繁跳槽的经历怎么办?在本公司⽼⽼实实等到满⼀年再跳槽。
412 |
413 | 如果常年初级岗怎么办?想办法晋升或者参与⼀些业界知名项⽬,再或者写⼀个有⼀定复杂度的私⼈项⽬。
414 |
415 | 如果有末流公司经历怎么办?如果是很久以前的末流公司经验可以直接不写,也没⼈在乎你很早之前的⼯作经历,如果你现在就在末流公司,赶紧想办法跳槽,去不了⼤⼚,去⾮知名的互联⽹公司也算是胜利⼤逃亡了。
416 |
417 | ### 5. 准备项⽬经历
418 |
419 | 项⽬经历不管对于社招还是校招都是重中之重,很多时候成败就在于项⽬经历这块,⼀个普通本科可以通过优秀的项⽬经历逆袭985,⼀个⼩⼚的员⼯也可以获得⼤⼚的⾯试机会。
420 |
421 |
422 |
423 | 但是必须要说⼀下项⽬经历的编写很讲究,这是为后⾯⾯试部分铺路的绝佳机会,也是直接让你的简历扑街的重点沦陷区域。
424 |
425 |
426 |
427 | 先说容易让简历扑街的⼏个坑位。
428 |
429 | #### (1)切忌流⽔账写法
430 |
431 | 项⽬经历流⽔账写法是绝⼤多数简历的通病,通篇下来就讲了⼀件事『我⼲了啥』。
432 |
433 |
434 |
435 | ⼤部分简历却是这样的:
436 |
437 | > ⽤Vue、Vuex、Vue-router、axios等技术开发电商⽹站的前端部分,主要负责⾸⻚、店铺详情、商品详情、商品列表、订单详情、订单中⼼等相关⻚⾯的开发⼯作,与设计师与后端配合,可要⾼度还原设计稿。
438 |
439 | 这个描述有什么问题? 其实看似也没啥问题,但是这种流⽔账写法太多了,完全⽆法突出⾃⼰的优势展现⾃⼰的能⼒。项⽬经历是考察重点,⾯试官想知道候选⼈在⼀次项⽬经历中扮演的⻆⾊、负责的模块、碰到的问题、解决的思路、达成的效果以及最后的总结与沉淀。
440 |
441 |
442 |
443 | ⽽上⾯的描述只显示了『我⼲了啥』,所以这种项⽬描述⼏乎是没意义的,因为对于⾯试官⽽⾔他看不到有效信息,没有有效信息的项⽬描述基本就没价值了,如果这个时候你还没有⼤⼚经历或者名校背书,基本上也就凉了。
444 |
445 | #### (2)切忌堆积项⽬
446 |
447 | 堆积项⽬这种现象往往出现在没有什么优秀项⽬经历的简历身上,候选⼈企图以数量优势掩盖质量的劣势,其实往往适得其反,项⽬经历的⼀栏最好放2-3个项⽬,⾮常优秀的项⽬可能放⼀个就⾜够了,举个极端例⼦如果有⼀天尤⾬溪写简历,其实只需要在项⽬经历那些⼀⾏『Vue.js作者』就⾏了,当然,他并不需要投简历。
448 |
449 |
450 |
451 | 有⼀些项⽬切忌放上去:
452 |
453 | - demo级项⽬:很多简历居然还在放⼀些仿xx官⽹的demo,这是⼗⾜的减分项,有⼀些则是东拼⻄凑抄了⼀些框架 的源码搞了个玩具项⽬,也没有任何价值。
454 | - 烂⼤街的项⽬:这种以vue技术栈的为最,由于视频⽹站的某⻔课程流⾏,导致⼤量的仿饿了么、仿qq⾳乐、仿美 团、仿去哪⼉,同样Java的同学也是仿电商⽹站、仿⼤众点评等等,⼗份简历5份⼀模⼀样的项⽬,你是⾯试官会怎么想。
455 | - 低质量的开源项⽬:⼀个⼤原则就是低star的尽量别放(除⾮是⾼质量代码的冷⻔项⽬),⻓期弃坑的也不要放,不要为了凑数量把低质量的项⽬暴露出来,好好藏着。
456 |
457 |
458 |
459 | 如果只放两个项⽬,最好的搭配是⼀个公司内部挑⼤梁的项⽬和⼀个社区内的开源项⽬,后者之所以可以占据⼀席之地,是因为通过你的开源项⽬,⾯试官可以通过commit完整看到你的创造过程,⽐如⼯程化建设、commit规范、代码规范、协作⽅式、代码能⼒、沟通能⼒等等,这甚⾄⽐⾯试都有⽤,没有⽐开源项⽬更能展示你综合素质的东⻄了。
460 |
461 | #### (3)切忌放虚假项⽬
462 |
463 | ⼀个项⽬做没做过只要是有经验的⾯试官⼀问便知,如果你真的靠假项⽬忽悠过了⾯试,那这个公司⼋成也有问题,⼈才把关不过硬,你可以想象你的队友都是什么⽔平,在这种公司⼤成⻓价值也不⼤。好,如果你说实在没项⽬可写了,我只能造假了,那么你应该想⼀下这多层追问。
464 |
465 |
466 |
467 | ⽐如你说你优化了⼀个前端项⽬的⾸屏性能,降低了⽩屏时间,那么⾯试官对这个性能优化问题会进⾏深挖,来考察候选⼈的实际⽔平:
468 |
469 | 1. 你的性能优化指标是怎么确定的?平均下来时间减短了多少?
470 | 2. 你的性能是如何测试的?有两种主流的性能测试⽅法你是怎么选的?
471 | 3. 你是根据哪些指标进⾏针对性优化的?
472 | 4. 除了你说的这些优化⽅法还有没有想过通过xx来解决?
473 | 5. 你的这个优化⽅法在实际操作中碰到过什么问题吗?有没有进⼀步做过测试?
474 | 6. 我们假设这么⼀种情况,⽐如xxxx,你会这么进⾏优化?
475 |
476 |
477 |
478 | ⾯试官多层追问的逻辑是这样的:**了解背景** **->** **了解⽅案** **->** **深挖⽅案** **->** **模拟场景**
479 |
480 |
481 |
482 | ⾸先得了解你性能优化的指标如何,接着需要了解你是这么测试的指标、再怎么进⾏针对性优化的,再接着提出⼀些其它解决⽅案考察你对优化场景的知识储备和⽅案决策能⼒,最后再模拟⼀个其它的业务场景,来考察你的技能迁移能⼒,看看是否是对某块领域有⼀定的了解,⽽不是只针对某个项⽬。
483 |
484 |
485 |
486 | 如果要真的在⾯试现场对答如流,那么⼀定是在某⼀块领域有⼀定知识储备的⼈,不是随随便便搞个项⽬就能蒙混过关的。
487 |
488 | #### (4)合格的项⽬经历如何写
489 |
490 | 合格的项⽬经历必须要有以下⼏点:
491 |
492 | - 项⽬概述
493 | - 个⼈职责
494 | - 项⽬难点
495 | - ⼯作成果
496 |
497 |
498 |
499 | 如果你不怕字太多,还可以选择性加⼊解决⽅案、选型思路等等,但是由于篇幅限制和为⾯试铺垫就不太建议写得太多。
500 |
501 |
502 |
503 | **项⽬概述**的⽬的是让⾯试官理解项⽬,不是每个⼈⾯试官都做过你的那种项⽬,所以需⼀个简述⽅便⾯试官理解。
504 |
505 |
506 |
507 | **个⼈职责**就是告诉⾯试官你在本项⽬中扮演的⻆⾊,是领导者?主导者?还是跟随者,你负责了哪些模块,承担了多⼤的⼯作量,以此来评估你在团队中的作⽤。
508 |
509 |
510 |
511 | **项⽬难点**的⽬的在于让⾯试官看到你碰到的技术难题,⽅便后续⾯试对项⽬进⾏⼀系列讨论。
512 |
513 | ⼯作成果就很明显了,⾯试官需要看到你在做了上述⼯作到底达成了什么成绩,这个时候最好以数据说话,⽐如访问量、⽩屏时间等等。
514 |
515 |
516 |
517 | 这个时候也切忌展开⻓篇⼤论,把技术细节⼀个个写上去,甚⾄还写了⼼路历程的都是⼤忌,⼀⽅⾯篇幅太⼤会造成视觉混乱,另⼀⽅⾯⾯试官想看到的是『简』历,不是技术总结,⾯试官要⾯对上百份简历没那么时间来看你⻓篇⼤论,⻓篇⼤论⼤可以在⾯试中展开。
518 |
519 |
520 |
521 | 最好的⽅法就是⼀⾏⽂字简单得说清楚即可,反正项⽬⾯的时候⼀定会问到,到时候好好把你准备的内容讲给⾯试官,掌握⾯试的主动权就是从项⽬经历这⼀栏中开始
522 |
523 | ### 6. 其他
524 |
525 | #### (1)教育背景
526 |
527 | 应届⽣可以写得更详细⼀点,⽐如绩点排名怎么样,有没有突出的科⽬,社招就不要写太多了,简单的⼊学时间、学校、专业即可,⽽且写你的最⾼学历即可,没必要从初中就开始写学历流⽔账,没有⼈看的。
528 |
529 | #### (2)注意事项
530 |
531 | - **⾃我评价不建议写**:技术⾯试⼏乎没⼈看你的⾃我评价,连⾯试技术问题都嫌『talk is cheap show me the code』,你的⾃我评价除了占篇幅没啥⽤处,充其量算是⾯试官的⼲扰信息。
532 | - **简历封⾯千万别搞**:这都是⼀些简历制作⽹站骗⽤户付费的伎俩,不仅是互联⽹⾏业,其它⾏业我也没⻅过要简历封⾯这种⽆⽤操作的。
533 | - **证书不建议写**:应届⽣可以酌情考虑弄个六级证书什么的,对于社招⽽⾔,列⼀堆证书甚⾄是减分项,国内的各种证你也懂的,是有多不⾃信才沦落到靠⼀堆证书来证明⾃⼰的价值。
534 | - **千万别⽤技能图表**:⾸先⽤90分、80分来评价⾃⼰的技术本身就没有什么说服⼒,也不可能这么精准,⽽且什么是90分、什么是80根本就没有⼀个公论,所以⽤⼀般的⽐较通⽤的熟悉、精通描述即可,千万别加戏,⾯试官或者HR没那么多闲⼯夫去理解你的图表,⽼⽼实实按最通⽤⾼效的⽅式描述⾃⼰的技术栈。
535 | - **简历最好⼀⻚**:程序员⼜不是设计师有时候需要作品呈现,如果你的简历超过⼀⻚那么⼀定是出问题了,要么项⽬、技术栈描述太多太杂占据⼤量篇幅,要么加了⼀堆图表或者图画来加戏,当然往往是犯前⼀个错误的更多。
--------------------------------------------------------------------------------
/3 offer收割机之HTML篇.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | ### 1. src 和 href 的区别
4 |
5 | src 和 href 都是**用来引用外部的资源**,它们的区别如下:
6 |
7 | - **src:** 表示对资源的引用,它指向的内容会嵌入到当前标签所在的位置。src 会将其指向的资源下载并应⽤到⽂档内,如请求 js 脚本。当浏览器解析到该元素时,会暂停其他资源的下载和处理,直到将该资源加载、编译、执⾏完毕,所以⼀般 js 脚本会放在页面底部。
8 | - **href:** 表示超文本引用,它指向一些网络资源,建立和当前元素或本文档的链接关系。当浏览器识别到它他指向的⽂件时,就会并行下载资源,不会停⽌对当前⽂档的处理。 常用在 a、link 等标签上。
9 |
10 | ### 2. 对 HTML 语义化的理解
11 |
12 | **语义化是指** 根据内容的结构化(内容语义化),选择合适的标签(代码语义化)。通俗来讲就是用正确的标签做正确的事情。
13 |
14 | 语义化的优点如下:
15 |
16 | - 对机器友好,带有语义的文字表现力丰富,更适合搜索引擎的爬虫爬取有效信息,有利于 SEO。除此之外,语义类还支持读屏软件,根据文章可以自动生成目录;
17 | - 对开发者友好,使用语义类标签增强了可读性,结构更加清晰,开发者能清晰的看出网页的结构,便于团队的开发与维护。
18 |
19 | 常见的语义化标签:
20 |
21 | ```html
22 | 头部
23 |
24 | 导航栏
25 |
26 | 区块(有语义化的div)
27 |
28 | 主要区域
29 |
30 | 主要内容
31 |
32 | 侧边栏
33 |
34 | 底部
35 | ```
36 |
37 | ### 3. DOCTYPE(文档类型) 的作⽤
38 |
39 | DOCTYPE 是 HTML5 中一种标准通用标记语言的文档类型声明,它的目的是**告诉浏览器(解析器)应该以什么样(html 或 xhtml)的文档类型定义**来解析文档,不同的渲染模式会影响浏览器对 CSS 代码甚⾄ JavaScript 脚本的解析。它必须声明在 HTML ⽂档的第⼀⾏。
40 |
41 | 浏览器渲染页面的两种模式(可通过 `document.compatMode` 获取,比如,语雀官网的文档类型是**CSS1Compat**):
42 |
43 | - **CSS1Compat:标准模式(Strick mode)**,默认模式,浏览器使用 W3C 的标准解析渲染页面。在标准模式中,浏览器以其支持的最高标准呈现页面。
44 | - **BackCompat:怪异模式(混杂模式)(Quick mode)**,浏览器使用自己的怪异模式解析渲染页面。在怪异模式中,页面以一种比较宽松的向后兼容的方式显示。
45 |
46 | ### 4. script 标签中 defer 和 async 的区别
47 |
48 | 如果没有 defer 或 async 属性,浏览器会立即加载并执行相应的脚本。它不会等待后续加载的文档元素,读取到就会开始加载和执行,这样就阻塞了后续文档的加载。
49 |
50 | 下图可以直观的看出三者之间的区别:
51 |
52 | 
53 |
54 | 其中蓝色代表 js 脚本网络加载时间,红色代表 js 脚本执行时间,绿色代表 html 解析。
55 |
56 | **defer 和 async 属性都是去异步加载外部的 JS 脚本文件,它们都不会阻塞页面的解析**,其区别如下:
57 |
58 | - **执行顺序:**多个带 async 属性的标签,不能保证加载的顺序;多个带 defer 属性的标签,按照加载顺序执行;
59 | - **脚本是否并行执行:**async 属性,表示**后续文档的加载和执行与 js 脚本的加载和执行是并行进行的**,即异步执行;defer 属性,**加载后续文档的过程和 js 脚本的加载**(此时仅加载不执行)**是并行进行的**(异步),js 脚本需要等到文档所有元素解析完成之后才执行,DOMContentLoaded 事件触发执行之前。
60 |
61 | ### 5. 常用的 meta 标签有哪些
62 |
63 | `meta` 标签由 `name` 和 `content` 属性定义,**用来描述网页文档的属性**,比如网页的作者,网页描述,关键词等,除了 HTTP 标准固定了一些`name`作为大家使用的共识,开发者还可以自定义 name。
64 |
65 | 常用的 meta 标签:
66 |
67 | (1)`charset`,用来描述 HTML 文档的编码类型:
68 |
69 | ```html
70 |
71 | ```
72 |
73 | (2) `keywords`,页面关键词:
74 |
75 | ```html
76 |
77 | ```
78 |
79 | (3)`description`,页面描述:
80 |
81 | ```html
82 |
83 | ```
84 |
85 | (4)`refresh`,页面重定向和刷新:
86 |
87 | ```html
88 |
89 | ```
90 |
91 | (5)`viewport`,适配移动端,可以控制视口的大小和比例:
92 |
93 | ```html
94 |
95 | ```
96 |
97 | 其中,`content` 参数有以下几种:
98 |
99 | - `width viewport` :宽度(数值/device-width)
100 | - `height viewport` :高度(数值/device-height)
101 | - `initial-scale` :初始缩放比例
102 | - `maximum-scale` :最大缩放比例
103 | - `minimum-scale` :最小缩放比例
104 | - `user-scalable` :是否允许用户缩放(yes/no)
105 |
106 | (6)搜索引擎索引方式:
107 |
108 | ```html
109 |
110 | ```
111 |
112 | 其中,`content` 参数有以下几种:
113 |
114 | - `all`:文件将被检索,且页面上的链接可以被查询;
115 | - `none`:文件将不被检索,且页面上的链接不可以被查询;
116 | - `index`:文件将被检索;
117 | - `follow`:页面上的链接可以被查询;
118 | - `noindex`:文件将不被检索;
119 | - `nofollow`:页面上的链接不可以被查询。
120 |
121 | ### 6. HTML5 有哪些更新
122 |
123 | #### 1. 语义化标签
124 |
125 | - header:定义文档的页眉(头部);
126 | - nav:定义导航链接的部分;
127 | - footer:定义文档或节的页脚(底部);
128 | - article:定义文章内容;
129 | - section:定义文档中的节(section、区段);
130 | - aside:定义其所处内容之外的内容(侧边);
131 |
132 | #### 2. 媒体标签
133 |
134 | (1) audio:音频
135 |
136 | ```html
137 |
138 | ```
139 |
140 | 属性:
141 |
142 | - controls 控制面板
143 | - autoplay 自动播放
144 | - loop=‘true’ 循环播放
145 |
146 | (2)video 视频
147 |
148 | ```html
149 |
150 | ```
151 |
152 | 属性:
153 |
154 | - poster:指定视频还没有完全下载完毕,或者用户还没有点击播放前显示的封面。默认显示当前视频文件的第一针画面,当然通过 poster 也可以自己指定。
155 | - controls 控制面板
156 | - width
157 | - height
158 |
159 | (3)source 标签
160 |
161 | 因为浏览器对视频格式支持程度不一样,为了能够兼容不同的浏览器,可以通过 source 来指定视频源。
162 |
163 | ```html
164 |
168 | ```
169 |
170 | #### 3. 表单
171 |
172 | **表单类型:**
173 |
174 | - email :能够验证当前输入的邮箱地址是否合法
175 | - url : 验证 URL
176 | - number : 只能输入数字,其他输入不了,而且自带上下增大减小箭头,max 属性可以设置为最大值,min 可以设置为最小值,value 为默认值。
177 | - search : 输入框后面会给提供一个小叉,可以删除输入的内容,更加人性化。
178 | - range : 可以提供给一个范围,其中可以设置 max 和 min 以及 value,其中 value 属性可以设置为默认值
179 | - color : 提供了一个颜色拾取器
180 | - time : 时分秒
181 | - data : 日期选择年月日
182 | - datatime : 时间和日期(目前只有 Safari 支持)
183 | - datatime-local :日期时间控件
184 | - week :周控件
185 | - month:月控件
186 |
187 | **表单属性:**
188 |
189 | - placeholder :提示信息
190 | - autofocus :自动获取焦点
191 | - autocomplete=“on” 或者 autocomplete=“off” 使用这个属性需要有两个前提:
192 |
193 | - - 表单必须提交过
194 | - 必须有 name 属性。
195 |
196 | - required:要求输入框不能为空,必须有值才能够提交。
197 | - pattern=" " 里面写入想要的正则模式,例如手机号 patte="^(+86)?\d{10}$"
198 | - multiple:可以选择多个文件或者多个邮箱
199 | - form=" form 表单的 ID"
200 |
201 | **表单事件:**
202 |
203 | - oninput 每当 input 里的输入框内容发生变化都会触发此事件。
204 | - oninvalid 当验证不通过时触发此事件。
205 |
206 | #### 4. 进度条、度量器
207 |
208 | - progress 标签:用来表示任务的进度(IE、Safari 不支持),max 用来表示任务的进度,value 表示已完成多少
209 | - meter 属性:用来显示剩余容量或剩余库存(IE、Safari 不支持)
210 |
211 | - - high/low:规定被视作高/低的范围
212 | - max/min:规定最大/小值
213 | - value:规定当前度量值
214 |
215 | 设置规则:min < low < high < max
216 |
217 | #### 5.DOM 查询操作
218 |
219 | - `document.querySelector()`
220 | - `document.querySelectorAll()`
221 |
222 | 它们选择的对象可以是标签,可以是类(需要加点),可以是 ID(需要加#)
223 |
224 | #### 6. Web 存储
225 |
226 | HTML5 提供了两种在客户端存储数据的新方法:
227 |
228 | - localStorage - 没有时间限制的数据存储
229 | - sessionStorage - 针对一个 session 的数据存储
230 |
231 | #### 7. 其他
232 |
233 | - 拖放:拖放是一种常见的特性,即抓取对象以后拖到另一个位置。设置元素可拖放:
234 |
235 | ```html
236 |
130 | 以上为 vue-lazyload 插件的简单使用,如果要看插件的更多参数选项,可以查看 vue-lazyload 的 github 地址。
131 |
132 | **1.7、路由懒加载**
133 | Vue 是单页面应用,可能会有很多的路由引入 ,这样使用 webpcak 打包后的文件很大,当进入首页时,加载的资源过多,页面会出现白屏的情况,不利于用户体验。如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应的组件,这样就更加高效了。这样会大大提高首屏显示的速度,但是可能其他的页面的速度就会降下来。
134 |
135 | 路由懒加载:
136 | ```
137 | const Foo = () => import('./Foo.vue')
138 | const router = new VueRouter({
139 | routes: [
140 | { path: '/foo', component: Foo }
141 | ]
142 | })
143 | ```
144 | **1.8、第三方插件的按需引入**
145 |
146 | 我们在项目中经常会需要引入第三方插件,如果我们直接引入整个插件,会导致项目的体积太大,我们可以借助 babel-plugin-component ,然后可以只引入需要的组件,以达到减小项目体积的目的。以下为项目中引入 element-ui 组件库为例:
147 |
148 | (1)首先,安装 babel-plugin-component :
149 |
150 |
151 | ```
152 | npm install babel-plugin-component -D
153 | ```
154 | (2)然后,将 .babelrc 修改为:
155 | ```
156 | {
157 | "presets": [["es2015", { "modules": false }]],
158 | "plugins": [
159 | [
160 | "component",
161 | {
162 | "libraryName": "element-ui",
163 | "styleLibraryName": "theme-chalk"
164 | }
165 | ]
166 | ]
167 | }
168 | ```
169 | (3)在 main.js 中引入部分组件:
170 | ```
171 | import Vue from 'vue';
172 | import { Button, Select } from 'element-ui';
173 |
174 | Vue.use(Button)
175 | Vue.use(Select)
176 | ```
177 | **1.9、优化无限列表性能**
178 |
179 | 如果你的应用存在非常长或者无限滚动的列表,那么需要采用 窗口化 的技术来优化性能,只需要渲染少部分区域的内容,减少重新渲染组件和创建 dom 节点的时间。你可以参考以下开源项目 vue-virtual-scroll-list 和 vue-virtual-scroller 来优化这种无限列表的场景的。
180 |
181 | **1.10、服务端渲染 SSR or 预渲染**
182 |
183 | 服务端渲染是指 Vue 在客户端将标签渲染成的整个 html 片段的工作在服务端完成,服务端形成的 html 片段直接返回给客户端这个过程就叫做服务端渲染。
184 |
185 | (1)服务端渲染的优点:
186 |
187 | 更好的 SEO:因为 SPA 页面的内容是通过 Ajax 获取,而搜索引擎爬取工具并不会等待 Ajax 异步完成后再抓取页面内容,所以在 SPA 中是抓取不到页面通过 Ajax 获取到的内容;而 SSR 是直接由服务端返回已经渲染好的页面(数据已经包含在页面中),所以搜索引擎爬取工具可以抓取渲染好的页面;
188 |
189 | 更快的内容到达时间(首屏加载更快):SPA 会等待所有 Vue 编译后的 js 文件都下载完成后,才开始进行页面的渲染,文件下载等需要一定的时间等,所以首屏渲染需要一定的时间;SSR 直接由服务端渲染好页面直接返回显示,无需等待下载 js 文件及再去渲染等,所以 SSR 有更快的内容到达时间;
190 |
191 | (2)服务端渲染的缺点:
192 |
193 | 更多的开发条件限制:例如服务端渲染只支持 beforCreate 和 created 两个钩子函数,这会导致一些外部扩展库需要特殊处理,才能在服务端渲染应用程序中运行;并且与可以部署在任何静态文件服务器上的完全静态单页面应用程序 SPA 不同,服务端渲染应用程序,需要处于 Node.js server 运行环境;
194 |
195 | 更多的服务器负载:在 Node.js 中渲染完整的应用程序,显然会比仅仅提供静态文件的 server 更加大量占用CPU 资源,因此如果你预料在高流量环境下使用,请准备相应的服务器负载,并明智地采用缓存策略。
196 |
197 | 如果你的项目的 SEO 和 首屏渲染是评价项目的关键指标,那么你的项目就需要服务端渲染来帮助你实现最佳的初始加载性能和 SEO,具体的 Vue SSR 如何实现,可以参考作者的另一篇文章《Vue SSR 踩坑之旅》。如果你的 Vue 项目只需改善少数营销页面(例如 /, /about, /contact 等)的 SEO,那么你可能需要预渲染,在构建时 (build time) 简单地生成针对特定路由的静态 HTML 文件。优点是设置预渲染更简单,并可以将你的前端作为一个完全静态的站点,具体你可以使用 prerender-spa-plugin 就可以轻松地添加预渲染 。
198 |
199 |
200 |
201 | ## 二、Webpack 层面的优化
202 |
203 | **2.1、Webpack 对图片进行压缩**
204 |
205 | 在 vue 项目中除了可以在 webpack.base.conf.js 中 url-loader 中设置 limit 大小来对图片处理,对小于 limit 的图片转化为 base64 格式,其余的不做操作。所以对有些较大的图片资源,在请求资源的时候,加载会很慢,我们可以用 image-webpack-loader来压缩图片:
206 |
207 | (1)首先,安装 image-webpack-loader :
208 | ```
209 | npm install image-webpack-loader --save-dev
210 | ```
211 | (2)然后,在 webpack.base.conf.js 中进行配置:
212 | ```
213 | {
214 | test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
215 | use:[
216 | {
217 | loader: 'url-loader',
218 | options: {
219 | limit: 10000,
220 | name: utils.assetsPath('img/[name].[hash:7].[ext]')
221 | }
222 | },
223 | {
224 | loader: 'image-webpack-loader',
225 | options: {
226 | bypassOnDebug: true,
227 | }
228 | }
229 | ]
230 | }
231 | ```
232 | 2.2、减少 ES6 转为 ES5 的冗余代码
233 | Babel 插件会在将 ES6 代码转换成 ES5 代码时会注入一些辅助函数,例如下面的 ES6 代码:
234 | ```
235 | class HelloWebpack extends Component{...}
236 | ```
237 | 这段代码再被转换成能正常运行的 ES5 代码时需要以下两个辅助函数:
238 |
239 |
240 | ```
241 | babel-runtime/helpers/createClass // 用于实现 class 语法
242 | babel-runtime/helpers/inherits // 用于实现 extends 语法
243 | ```
244 | 在默认情况下, Babel 会在每个输出文件中内嵌这些依赖的辅助函数代码,如果多个源代码文件都依赖这些辅助函数,那么这些辅助函数的代码将会出现很多次,造成代码冗余。为了不让这些辅助函数的代码重复出现,可以在依赖它们时通过 require('babel-runtime/helpers/createClass') 的方式导入,这样就能做到只让它们出现一次。babel-plugin-transform-runtime 插件就是用来实现这个作用的,将相关辅助函数进行替换成导入语句,从而减小 babel 编译出来的代码的文件大小。
245 |
246 | (1)首先,安装 babel-plugin-transform-runtime :
247 |
248 |
249 | ```
250 | npm install babel-plugin-transform-runtime --save-dev
251 | ```
252 | (2)然后,修改 .babelrc 配置文件为:
253 | ```
254 | "plugins": [
255 | "transform-runtime"
256 | ]
257 | ```
258 | 如果要看插件的更多详细内容,可以查看babel-plugin-transform-runtime 的 详细介绍。
259 |
260 | **2.3、提取公共代码**
261 |
262 | 如果项目中没有去将每个页面的第三方库和公共模块提取出来,则项目会存在以下问题:
263 |
264 | 相同的资源被重复加载,浪费用户的流量和服务器的成本。
265 |
266 | 每个页面需要加载的资源太大,导致网页首屏加载缓慢,影响用户体验。
267 |
268 | 所以我们需要将多个页面的公共代码抽离成单独的文件,来优化以上问题 。Webpack 内置了专门用于提取多个Chunk 中的公共部分的插件 CommonsChunkPlugin,我们在项目中 CommonsChunkPlugin 的配置如下:
269 |
270 | // 所有在 package.json 里面依赖的包,都会被打包进 vendor.js 这个文件中。
271 | ```
272 | new webpack.optimize.CommonsChunkPlugin({
273 | name: 'vendor',
274 | minChunks: function(module, count) {
275 | return (
276 | module.resource &&
277 | /\.js$/.test(module.resource) &&
278 | module.resource.indexOf(
279 | path.join(__dirname, '../node_modules')
280 | ) === 0
281 | );
282 | }
283 | }),
284 | // 抽取出代码模块的映射关系
285 | new webpack.optimize.CommonsChunkPlugin({
286 | name: 'manifest',
287 | chunks: ['vendor']
288 | })
289 | ```
290 | 如果要看插件的更多详细内容,可以查看 CommonsChunkPlugin 的 详细介绍。
291 |
292 | **2.4、模板预编译**
293 |
294 | 当使用 DOM 内模板或 JavaScript 内的字符串模板时,模板会在运行时被编译为渲染函数。通常情况下这个过程已经足够快了,但对性能敏感的应用还是最好避免这种用法。
295 |
296 | 预编译模板最简单的方式就是使用单文件组件——相关的构建设置会自动把预编译处理好,所以构建好的代码已经包含了编译出来的渲染函数而不是原始的模板字符串。
297 |
298 | 如果你使用 webpack,并且喜欢分离 JavaScript 和模板文件,你可以使用 vue-template-loader,它也可以在构建过程中把模板文件转换成为 JavaScript 渲染函数。
299 |
300 | **2.5、提取组件的 CSS**
301 |
302 | 当使用单文件组件时,组件内的 CSS 会以 style 标签的方式通过 JavaScript 动态注入。这有一些小小的运行时开销,如果你使用服务端渲染,这会导致一段 “无样式内容闪烁 (fouc) ” 。将所有组件的 CSS 提取到同一个文件可以避免这个问题,也会让 CSS 更好地进行压缩和缓存。
303 |
304 | 查阅这个构建工具各自的文档来了解更多:
305 |
306 | webpack + vue-loader ( vue-cli 的 webpack 模板已经预先配置好)
307 |
308 | Browserify + vueify
309 |
310 | Rollup + rollup-plugin-vue
311 |
312 | **2.6、优化 SourceMap**
313 |
314 | 我们在项目进行打包后,会将开发中的多个文件代码打包到一个文件中,并且经过压缩、去掉多余的空格、babel编译化后,最终将编译得到的代码会用于线上环境,那么这样处理后的代码和源代码会有很大的差别,当有 bug的时候,我们只能定位到压缩处理后的代码位置,无法定位到开发环境中的代码,对于开发来说不好调式定位问题,因此 sourceMap 出现了,它就是为了解决不好调式代码问题的。
315 |
316 | SourceMap 的可选值如下(+ 号越多,代表速度越快,- 号越多,代表速度越慢, o 代表中等速度 )
317 |
318 |
319 |
320 | 开发环境推荐:cheap-module-eval-source-map
321 |
322 | 生产环境推荐:cheap-module-source-map
323 |
324 | 原因如下:
325 |
326 | cheap:源代码中的列信息是没有任何作用,因此我们打包后的文件不希望包含列相关信息,只有行信息能建立打包前后的依赖关系。因此不管是开发环境或生产环境,我们都希望添加 cheap 的基本类型来忽略打包前后的列信息;
327 |
328 | module :不管是开发环境还是正式环境,我们都希望能定位到bug的源代码具体的位置,比如说某个 Vue 文件报错了,我们希望能定位到具体的 Vue 文件,因此我们也需要 module 配置;
329 |
330 | soure-map :source-map 会为每一个打包后的模块生成独立的 soucemap 文件 ,因此我们需要增加source-map 属性;
331 |
332 | eval-source-map:eval 打包代码的速度非常快,因为它不生成 map 文件,但是可以对 eval 组合使用 eval-source-map 使用会将 map 文件以 DataURL 的形式存在打包后的 js 文件中。在正式环境中不要使用 eval-source-map, 因为它会增加文件的大小,但是在开发环境中,可以试用下,因为他们打包的速度很快。
333 |
334 | **2.7、构建结果输出分析**
335 |
336 | Webpack 输出的代码可读性非常差而且文件非常大,让我们非常头疼。为了更简单、直观地分析输出结果,社区中出现了许多可视化分析工具。这些工具以图形的方式将结果更直观地展示出来,让我们快速了解问题所在。接下来讲解我们在 Vue 项目中用到的分析工具:webpack-bundle-analyzer 。
337 |
338 | 我们在项目中 webpack.prod.conf.js 进行配置:
339 | ```
340 | if (config.build.bundleAnalyzerReport) {
341 | var BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
342 | webpackConfig.plugins.push(new BundleAnalyzerPlugin());
343 | }
344 | ```
345 | 执行 $ npm run build --report 后生成分析报告如下:
346 |
347 |
348 |
349 | **2.8、Vue 项目的编译优化**
350 |
351 | 如果你的 Vue 项目使用 Webpack 编译,需要你喝一杯咖啡的时间,那么也许你需要对项目的 Webpack 配置进行优化,提高 Webpack 的构建效率。具体如何进行 Vue 项目的 Webpack 构建优化,可以参考作者的另一篇文章《 Vue 项目 Webpack 优化实践》
352 |
353 |
354 |
355 | ## 三、基础的 Web 技术优化
356 | **3.1、开启 gzip 压缩**
357 |
358 | gzip 是 GNUzip 的缩写,最早用于 UNIX 系统的文件压缩。HTTP 协议上的 gzip 编码是一种用来改进 web 应用程序性能的技术,web 服务器和客户端(浏览器)必须共同支持 gzip。目前主流的浏览器,Chrome,firefox,IE等都支持该协议。常见的服务器如 Apache,Nginx,IIS 同样支持,gzip 压缩效率非常高,通常可以达到 70% 的压缩率,也就是说,如果你的网页有 30K,压缩之后就变成了 9K 左右
359 |
360 | 以下我们以服务端使用我们熟悉的 express 为例,开启 gzip 非常简单,相关步骤如下:
361 |
362 | 安装:
363 |
364 | npm install compression --save
365 | 添加代码逻辑:
366 | ```
367 | var compression = require('compression');
368 | var app = express();
369 | app.use(compression())
370 | ```
371 | 重启服务,观察网络面板里面的 response header,如果看到如下红圈里的字段则表明 gzip 开启成功 :
372 |
373 |
374 | **3.2、浏览器缓存**
375 |
376 | 为了提高用户加载页面的速度,对静态资源进行缓存是非常必要的,根据是否需要重新向服务器发起请求来分类,将 HTTP 缓存规则分为两大类(强制缓存,对比缓存),如果对缓存机制还不是了解很清楚的,可以参考作者写的关于 HTTP 缓存的文章《深入理解HTTP缓存机制及原理》,这里不再赘述。
377 |
378 | **3.3、CDN 的使用**
379 |
380 | 浏览器从服务器上下载 CSS、js 和图片等文件时都要和服务器连接,而大部分服务器的带宽有限,如果超过限制,网页就半天反应不过来。而 CDN 可以通过不同的域名来加载文件,从而使下载文件的并发连接数大大增加,且CDN 具有更好的可用性,更低的网络延迟和丢包率 。
381 |
382 | **3.4、使用 Chrome Performance 查找性能瓶颈**
383 |
384 | Chrome 的 Performance 面板可以录制一段时间内的 js 执行细节及时间。使用 Chrome 开发者工具分析页面性能的步骤如下。
385 |
386 | 打开 Chrome 开发者工具,切换到 Performance 面板
387 |
388 | 点击 Record 开始录制
389 |
390 | 刷新页面或展开某个节点
391 |
392 | 点击 Stop 停止录制
393 |
394 | ## 原文地址:https://blog.csdn.net/qq_37939251/article/details/100031285
--------------------------------------------------------------------------------
/2 程序员面试软技能.md:
--------------------------------------------------------------------------------
1 | ## 一、如何通过HR⾯
2 |
3 | HR通常是程序员⾯试的最后⼀⾯,讲道理刷⼈的⼏率不⼤,但是依然有⼈倒在了这最后⼀关上,我们会从HR的⻆度出发来分析如何应对HR⾯.
4 |
5 | ### 1. HR⾯的⽬的
6 |
7 | HR⾯往往是把控⼈才质量的最后⼀关,与前⾯的技术⾯不同,HR⾯往往侧重员⼯⻛险的评估与基本的员⼯素质。
8 |
9 | - **录⽤⻛险评估****,**这部分是评估候选⼈是否具备稳定性,是否会带来额外的管理⻛险,是否能⻢上胜任⼯作,⽐如频繁的跳槽会带了稳定性的⻛险,HR会慎重考虑这⼀点,⽐如在⾯试中候选⼈体现出了「杠精」潜质,HR会担⼼候选⼈在⼯作中会难以与他⼈协作或者不服从管理,带来管理⻛险,再⽐如,虽然国家明确规定在招聘中不得有性别、年龄等歧视,但是⼀个⼤龄已婚妇⼥会有近期产⼦的可能性,可能会有⻓期的产假,HR也会做出评估。
10 | - **员⼯素质评估****,**这部分评估候选⼈是否具备职场的基本素质,是否有基本的沟通能⼒,是否有团队精神和合作意识等等,⽐如⼀个表现极为内向的候选⼈,HR可能会对其沟通能⼒产⽣怀疑.
11 |
12 |
13 |
14 | 所以在与HR交流中要尽量保持踏实稳重、积极乐观的态度,切忌暴露出夸夸其谈、负能量、浮躁等性格缺陷。
15 |
16 | ### 2. HR⾯的常⻅问题
17 |
18 | #### (1)你对未来3-5年的职业规划
19 |
20 | **⽬的**: 这个问题就是考察候选⼈对未来的规划能⼒,主要想通过候选⼈的规划来嗅出候选⼈对⼯作的态度、稳定性和对技术的追求.
21 |
22 | **分析**: ⼀定要在你的回到中体现对技术的追求、对团队的贡献、对⼯作的态度,不要谈⼀些假⼤空的东⻄,或者薪资、职位这些太过于功利的东⻄,⽽且最好体现出你的稳定性,如果是校招⽣或者⼯作没⼏年的新⼈最好不要涉及创业这种话题,⼀⽅⾯职场新⼈计划没⼏年就创业,这种很不切实际,说明候选⼈没法按实际出发,另⼀⽅⾯说明候选⼈的稳定性不够.
23 |
24 |
25 |
26 | 建议分三部分谈:
27 |
28 | 1. ⾸先表示考虑过这个问题(有规划),如何谈⼀谈⾃⼰的现状(结合实际).
29 | 2. 接着从⼯作本身出发,谈谈⾃⼰会如何出⾊完成本职⼯作,如何对团队贡献、如何帮助带领团队其他成员创造更多的价值、如何帮助团队扩⼤影响⼒.
30 | 3. 最后从学习出发,谈谈⾃⼰会如何精进领域知识、如何通过提升⾃⼰专业能⼒,如何反哺团队.
31 |
32 |
33 |
34 | ⾄于想成为技术leader还是技术专家,就看⾃⼰的喜好了.
35 |
36 | #### (2)如何看待加班(996)?
37 |
38 | **⽬的**: 考察候选⼈的抗压能⼒和责任⼼
39 |
40 | **分析**: 这个问题⼏乎是必问的,虽然996ICU事件闹得沸沸扬扬,但是官⽅的态度很暧昧,只⼝头批评从没有实际⾏动,基本上是默许企业违反劳动法的,除了个别外企在国内基本没可能找到不加班的公司,所以在这个⾯试题中尽量体现出⾃⼰愿意牺牲⾃我时间来帮助团队和企业的意愿就⾏了,⽽且要强调⾃⼰的责任⼼,如果真的是碰到⽆意义加班,好好学习怎么⽤vscode刷LeetCode划⽔是正道.
41 |
42 | **建议**:
43 |
44 | 1. 把加班分为紧急加班和⻓期加班
45 | 2. 对于紧急加班,表示这是每个公司都会遇到的情况,⾃⼰愿意牺牲时间帮助公司和团队
46 | 3. 对于⻓期加班,如果是⾃⼰⻓期加班那么会磨练⾃⼰的技能,提⾼⾃⼰的效率,如果是团队⻓期加班,⾃⼰会帮助团队找到问题,利⽤⾃动化⼯具或者更⾼效的协作流程来提⾼整个团队的效率,帮助⼤家摆脱加班
47 |
48 |
49 |
50 | 当然了,就算你提⾼了团队效率,还是会被安排更多的任务,加班很多时候仅仅是⽬的,,但是你不能说出来啊,尤其是⼀些候选⼈很强硬得表示⻓期加班不接受,其实可以回答的更委婉,除⾮你是真的对这个公司没兴趣,如果以进⼊这个公司为第⼀⽬的,还是做个⾼姿态⽐较好。
51 |
52 | #### (3)⾯对⼤量超过⾃⼰承受能⼒且时间有限的⼯作时你会怎么办?
53 |
54 | **⽬的**: 考察候选⼈时间管理和处理⼤量任务的能⼒,当然也会涉及⼀定的沟通能⼒
55 |
56 | **分析**: 程序员的⼯作内容可能⼤部分时间并不在写代码上,⽽是要处理各种会议、需求和沟通,通常都属于⼯作超负荷的状态,⾯对上⾯这种问题不建议以加班的⽅式来解决,因为主要考察的是你的时间管理能⼒和沟通能⼒,这些要素要在回答中体现出来
57 |
58 | 建议:
59 |
60 | 1. 将⼤量任务分解为紧急且重要、重要但不紧急、紧急但不重要、不重要且不紧急,依次完成上述任务,在这⾥体现出时间管理的能⼒
61 | 2. 与⾃⼰的领导沟通将不重要的任务放缓执⾏或者砍掉,或者派给组内的新⼈处理,在这⾥体现出沟通能⼒
62 |
63 | #### (4)你之前在上海为什么现在来北京发展?
64 |
65 | **⽬的**: 考察候选⼈的稳定性和职业选择
66 |
67 | 分析: 这个问题⼀般是上份⼯作在异地的情况下⼤概率出现,HR主要担⼼候选⼈异地换⼯作可能会不稳定,有短期内离职⻛险,这个时候不建议说"北京互联⽹公司多,机会多"这种话(合着觉得北京好跳槽?),回答最好要体现出⾃⼰的稳定性,⽐如"⼥朋友在北京,⻓期异地,准备来北京⼀起发展" "家在北京,回北京发展" 等等,潜台词就是以后会在北京发展,不会在多地之间来回摇摆.
68 |
69 | #### (5)为什么从上⼀家公司离职?
70 |
71 | ⽬的: 考察离职原因,候选⼈离职⻛险评估
72 |
73 |
74 | **分析**: 这个问题经常会在跳槽的时候问到,这个时候切忌吐槽上⼀家公司或者⾃⼰的上⼀任⽼板,尽量从职业发展的⻆度来回答,凸显⾃⼰的稳定性和渴望学习上升的决⼼,⾄于⼀些敏感话题,⽐如加班太多、薪资太低这种问题也是可以谈的,毕竟你跳槽的诉求就是解决上家公司碰到的问题,但是不能触碰刚才提到的底线问题,切忌吐槽向.
75 |
76 | **建议**:
77 |
78 | 1. 因为⼯资低、离家远、加班多、技术含量低等等原因离职
79 | 2. 因为离家远花费在路途上的时间过多,不如⽤来充电,因为加班多导致没有时间充电,⽆法提⾼等等
80 |
81 |
82 |
83 | 除了不要有负能量和吐槽向,这个部分可以坦诚得说出来
84 |
85 | #### (6)你还有其他公司的Offer吗?
86 |
87 | ⽬的: 评估候选⼈是否有短时间内⼊职其他公司的可能性
88 |
89 | 分析: 很多时候并不是候选⼈完美符合⼀个岗位的要求,HR当然想要⼀个技术更好、要钱更少、技术更匹配的候选⼈,但是候选⼈⼀般都会有这样或者那样的⼩问题。
90 |
91 |
92 |
93 | ⽐如,你的表现是可以胜任⽬前的岗位的,但是这个岗位不是很紧急,HR可能把你当做备胎,来找⼀个性价⽐更⾼的候选⼈。⽐如,你的表现很好,履历优秀,HR不知道能不能100%拿下你。所以如果你很希望加⼊这个公司,最好要做到「欲擒故纵」,既要体现⾃身的市场竞争⼒,⼜要给到HR⼀定的压⼒。所以,即使你已经拿了全北京城互联⽹公司的offer了,也不要说⾃⼰offer多如⽜⽑,⼀副满不在乎的样⼦,这样会给HR造成他⼊职可能性不⼤的错觉,因为他的选择太多了。当然,也不要跪在地上舔:"加⼊公司是我的梦想,我只等这⼀个offer",放⼼吧,⼀定被hr放到备胎⼈才库中.
94 |
95 |
96 |
97 | 建议:
98 |
99 | 1. 表明⾃⼰有三四个已经确认过的offer了(没有offer也要吹,但是不要透露具体公司)
100 | 2. 但是第⼀意向还是本公司,如果薪资差距不⼤,会优先考虑本公司
101 | 3. 再透露出,有⼀两个offer催得⽐较急,希望这边快点出结果
102 |
103 | #### (7)如何与HR谈薪资?
104 |
105 | HR与你谈论薪资经常有如下套路:
106 |
107 | - HR: 您期望的薪资是多少?
108 | - 你: 25K。
109 |
110 |
111 |
112 | OK,你已经被HR成功套路。这个时候你的最⾼价就是25K了,然后HR会顺着这个价往下砍,所以你最终的薪资⼀般都会低于25K。等你接到offer,你的⼼⾥肯定充满了各种“悔恨”:其实当时报价26、27甚⾄28、29也是可以的。
113 |
114 |
115 |
116 | 正确的回答可以这样,并且还能够反套路⼀下HR:
117 |
118 | - HR: 您期望的薪资是多少?
119 | - 你: 就我的⾯试表现,贵公司最⾼可以给多少薪⽔?
120 |
121 |
122 |
123 | 如果经验不够⽼道的HR可能就真会说出⼀个报价(如25K)来,然后,你就可以很开⼼地顺着这个价慢慢地往上谈了。所以这种情况下,你最终的薪资肯定是⼤于25K的。当然,经验⽼道的HR会给你⼀句很官⽅的套话:
124 |
125 | - HR: 您期望的薪资是多少?
126 | - 你: 就我的⾯试表现,贵公司最⾼可以给多少薪⽔?
127 | - HR: 这个暂且没法确定,要结合您⼏轮⾯试结果和⽤⼈部⻔的意⻅来综合评定。
128 |
129 |
130 |
131 | 虽然薪资很重要,但是我个⼈觉得这不是最重要的。我有以下建议:
132 |
133 | - 如果你觉得你技术⾯试效果很好,可以报⼀个⾼⼀点的薪资,这样如果HR想要你,会找你商量的。
134 | - 如果你觉得技术⾯试效果⼀般,但是你⽐较想进这家公司,可以报⼀个折中的薪资。
135 | - 如果你觉得⾯试效果很好,但是你不想进这家公司,你可以适当“漫天要价”⼀下。
136 | - 如果你觉得⾯试效果不好,但是你想进这家公司,你可以开⼀个稍微低⼀点的⼯资。
137 |
138 |
139 |
140 | 需要注意的是,⾯试求职是⼀个双向选择的过程。⾯试应该做到不卑不亢,千万不要因为⾯试结果不好,就低声下⽓地乞求⼯作,每个⼈的⼯作经历和经验都是不⼀样的,技术⾯试不好,知道⾃⼰的短板针对性地补缺补差就⾏,⽽不是在⼈事关系上动歪脑筋。
141 |
142 | ## 二、回答问题的技巧
143 |
144 | 技术⾯试通常⾄少三轮:
145 |
146 | 1. 基础⾯试: 主要考察对岗位和简历中涉及到基础知识部分的提问,包括⼀部分算法和场景设计的⾯试题,这⼀⾯可能会涉及现场coding.
147 | 2. 项⽬⾯试: 主要考察简历中涉及的项⽬,会涉及你项⽬的相关业务知识、扮演⻆⾊、技术取舍、技术攻坚等等.
148 | 3. HR⾯试: 这⼀⾯通常是HR把关,主要涉及⾏为⾯试,考察候选⼈是否价值观符合公司要求、⼯作稳定性如何、沟通协作能⼒如何等等.
149 |
150 |
151 |
152 | 当然,对于初级岗或者校招⽣会涉及⼀轮笔试,相当多的公司会在现场⾯之前进⾏⼀轮电话⾯试,⽬的是最快速有效地把不符合要求的候选⼈筛除,对于个别需要跨部⻔协作的岗位会涉及交叉⾯试,⽐如前端候选⼈会被后端的⾯试官⾯试,⼀些有管理需求的岗位或者重要岗位可能会涉及总监⾯试或者vp⾯。
153 |
154 |
155 |
156 | ⽽⼀个正常的技术⾯试流程(以项⽬⾯为例)分为⼤致三个部分:
157 |
158 | 1. ⾃我介绍
159 | 2. 项⽬(技术)考察
160 | 3. 向⾯试官提问
161 |
162 |
163 |
164 | 那么该如何准备技术⾯试,如何在⾯试中掌握主动权呢?
165 |
166 | ### 1. ⾃我介绍
167 |
168 | ⼏乎所有的⾯试都是从⾃我介绍这个环节开始的,所以我们得搞清楚为什么⾃我介绍通常作为⼀个⾯试的开头。
169 |
170 | #### (1)为什么需要⾃我介绍
171 |
172 | ⾸先,有⼀个很普遍的问题就是⾯试官很可能才刚拿到你的简历,他需要在你⾃我介绍的时候快速浏览你的简历,因为技术⾯试的⾯试官很多是⼀线的员⼯,⾯试候选⼈只是其⼯作中的⼀⼩部分,很多情况下是没有提前看过你的简历的。
173 |
174 |
175 |
176 | 其次,⾃我介绍其实是⼀个热身,⾯试官和候选⼈其实是陌⽣⼈,⾃我介绍不管是⾯试还是其他情况下,都是两个陌⽣⼈彼此交流的起点,也是缓解候选⼈与⾯试官之间尴尬的⼀种热身⽅式.
177 |
178 |
179 |
180 | 最后,⾃我介绍是展示⾃我、引出接下来技术⾯试的引⼦,是你⾃⼰指定技术⾯试⽅向的⼀次机会。
181 |
182 |
183 |
184 | 知道了以上原因,我们才能进⾏准备更好的⾃我介绍。
185 |
186 | #### (2)⾃我介绍的⼏个必备要素
187 |
188 | ⾃我介绍归根到底是⼀个热身运动,因此切忌占⽤⼤量的篇幅,上来就把⾃⼰从出⽣的经历到⼤学像流⽔账⼀样吐出来的,往往会被没耐⼼的⾯试官打断,⽽这也暴露了候选⼈讲话缺乏重点、沟通能⼒⼀般的缺点。
189 |
190 |
191 |
192 | 但是,⼀些关键信息是必须体现的,就我个⼈⽽⾔,以下信息是必备的:
193 |
194 | - 个⼈信息: ⾄少要体现出⾃⼰的姓名、岗位和⼯作年限,应届⽣则必须要介绍⾃⼰的教育背景,如果⾃⼰的前东家是个⼤⼚(⽐如BAT)最好提及,⾃⼰的学历是亮点(985或者硕博或者类似于北邮这种CS强校)最好提及,其他的什么有没有⼥朋友、是不是独⽣⼦没⼈在意,不要占⽤篇幅。这个部分重点在于「你是谁?」。
195 | - 技术能⼒: 简要地介绍⾃⼰的技术栈,切忌把⾃⼰只是简单使⽤过,写过⼏个Demo或者看了看⽂档的所谓「技术栈」也说出来,⼀旦后⾯问到算是⾃找尴尬。这个部分的重点在于「你会什么?」。
196 | - 技能擅⻓: 重点介绍⾃⼰擅⻓的技术,⽐如性能优化、⾼并发、系统架构设计或者是沟通协调能⼒等等,切忌夸⼤其词,要实事求是,这是之后考察的重点。这个部分重点⾃在于「你擅⻓什么?」。
197 |
198 | #### (3)⾃我介绍要重点匹配当前岗位的技术栈
199 |
200 | 你的⾯试简历可能包含了各种各样的技术栈,但是在⾃我介绍过程中需要匹配当前岗位的技术要求。就⽐如你⽬前⾯试的是移动端H5前端的开发岗位,就重点在⾃我介绍中突出⾃⼰在移动前端的经验,⽽此时⼤篇幅得讲述 ⾃⼰如何⽤Node⽀撑公司的web项⽬就显得很不明智.
201 |
202 | #### (4)要在⾃我介绍中做刻意引导
203 |
204 | 如果你的⾃我介绍跟流⽔账⼀样,没有任何重点,其实⾯试官也很难办,因为他都没法往下接话...
205 |
206 |
207 |
208 | ⽽只要你稍作引导,绝⼤部分⾯试官就会接你的话茬,⽐如「你在⾃我介绍中重点提及了⼀个项⽬,碰到了⼀些难点,然后被你攻克了,效果如何如何好等等」,如果我是⾯试官⼀定会问「你的xx项⽬的xx难点后来是怎么解决的?」。
209 |
210 |
211 |
212 | ⾯试官的⽬的是考察候选⼈的能⼒,对候选⼈做出评估,因此需要知道候选⼈擅⻓什么,是否匹配岗位,⾯试官绝⼤多数情况下很乐意你这种有意⽆意的引导,这样双⽅的沟通和评估会很顺利,⽽不是故意刁难候选⼈。
213 |
214 | #### (5)如何准备⾃我介绍
215 |
216 | 其实最好的⽅法也是最笨的⽅法就是把⾃我介绍写下来,这个⾃我介绍⼀定要体现上⾯提到的⼏⼤必备要素,在⾯试前简单过⼏遍,能把⾃我介绍的内容顺利得表达出来即可,切忌跟背课⽂⼀样。
217 |
218 |
219 |
220 | ⾃我介绍的时间最好控制在1-3分钟之间,这些时间⾜够⾯试官把你的简历过⼀遍了,⾯试官看完简历后正好接着你的⾃我介绍进⾏提问是最舒服的节奏,别上来开始10分钟的演讲,⾯试官等待的时候会很尴尬,这么⻓的篇幅说明你的⾃我介绍⼀定是流⽔账式的。
221 |
222 | ### 2. 技术考察
223 |
224 | ⼀个好的技术考察的开始,必须得有⾃我介绍部分好的铺垫和引导,有⼀种情况我们经常遇⻅:
225 |
226 | > 候选⼈说了⼀⼤堆⾮重点的⾃我介绍,⾯试官⼀时语塞,完全get不到候选⼈的重点,也不知道候选⼈擅⻓什么、有什么亮点项⽬,然后就在他简历的技术栈中选了本公司也在⽤的技术,候选⼈这个时候也开始冒汗,因为这个技术栈并不是他的擅⻓,回答的也磕磕绊绊,⾯试官的引导和深⼊追问也没有达到很好的效果,⾯试就在这种尴尬的⽓氛中展开了,⾯试结束后⾯试官对候选⼈的评价是技术不熟练、没有深⼊理解原理,候选⼈的感受是,⾯试官专挑⾃⼰不会的问。
227 |
228 | 所以在前⾯的部分,⼀定要做好引导,把⾯试官的问题引到我们擅⻓的领域,但是这样还不够,正所谓不打⽆准备之仗,我们依然需要针对可能出现的问题进⾏准备.
229 |
230 |
231 |
232 | 那么如何准备可能的⾯试题?
233 |
234 |
235 |
236 | ⽐如你擅⻓前端的性能优化,在⾃我介绍的部分已经做好了引导,接下来⾯试官⼀定会重点考察你性能优化的能⼒,很可能会涉及很有深度的问题,即使你擅⻓这⽅⾯的技术,但是如果没有准备也可能临场乱了阵脚.
237 |
238 | #### (1)多重提问
239 |
240 | ⾃我多重提问的意思是,当⼀个技术问题抛出的时候,你可能⾯对更深层次的追问。
241 |
242 |
243 |
244 | 依旧以前端性能优化为例,⾯试官可能的提问:
245 |
246 | 1. 你把这个⼿机端的⽩屏时间减少了150%以上,是从哪些⽅⾯⼊⼿优化的?这个问题即使你没做过前端性能优化也能回答个七七⼋⼋,⽆⾮是组件分割、缓存、tree shaking等等,这是第⼀重⽐较浅的问题。
247 | 2. 我看你⽤webpack中SplitChunksPlugin这个插件进⾏分chunk的,你分chunk的取舍是什么?哪些库分在同⼀个chunk,哪些应该分开你是如何考虑的?如果你提到了SplitChunksPlugin插件可能会有类似的追问,如果没有实际操作过的候选⼈这个时候就难以招架了,这个过程⼀定是需要⼀定的试错和取舍的.
248 | 3. 在分chunk的过程中有没有遇到什么坑?怎么解决的?其实SplitChunksPlugin这个插件有⼀个暗坑,那就是chunid⾃增性导致id不固定唯⼀,很可能⼀个新依赖就导致id全部打乱,使得http缓存失效.
249 |
250 |
251 |
252 | 以上只是针对SplitChunksPlugin插件相关的优化提问,当然也可能从你的性能测试⻆度、代码层⾯进⾏考察,但是思路是类似的。因此不能把⾃⼰准备的问题答案停留在⼀个很浅显的层⾯,⼀⽅⾯⽆法展示⾃⼰的技术深度,另⼀⽅⾯在⾯试官的深度体情况下容易丢分,因此在⾃⼰的答案后⾯多进⾏⾃我的追问,看⼀看能不能把问题做的更深⼊。
253 |
254 | #### (2)答题法则
255 |
256 | 很多⾯试相关的宝典都推荐使⽤STAR法则进⾏问题的应答,我们不想引⼊这个额外的概念,基础技术⾯试的部分⽼⽼实实回答⾯试官的问题即可,通常需要问题运⽤到这个法则的是项⽬⾯,⽐如让你介绍⼀下你最得意的项⽬,回答问题的法则有这⼏个要点:
257 |
258 | - 项⽬背景: 简要说⼀下项⽬的背景,让⾯试官知道这个项⽬是做什么的
259 | - 个⼈⻆⾊: 让⾯试官知道你在这个项⽬中扮演的⻆⾊
260 | - 难点: 让⾯试官知道你在项⽬开发过程中碰到的难点
261 | - 解决⽅案: 针对上⾯的难点你有哪⼀些解决⽅案,是如何结合业务进⾏取舍的
262 | - 总结沉淀: 在攻克上述的难点后有没有沉淀出⼀套通⽤的解决⽅案,有没有将⾃⼰的⽅案在⼤部⻔进⾏推⼴等等
263 |
264 |
265 |
266 | 重点就在于后⾯三条,也是最体现你个⼈综合素质的⼀部分,我是⾯试官的话会⾮常欣赏那种可以发现问题、找到多种⽅ 案、能对多种⽅案进⾏⽐对取舍还可以总结沉淀出通⽤解决⽅案回馈团队的⼈。从上述⼏点可以体现出⼀个⼈的技术热情、解决问题的能⼒和总结提⾼的能⼒。
267 |
268 | #### (3)刻意引导
269 |
270 | 是的,在回答⾯试官提问的时候也可以做到刻意引导。
271 |
272 |
273 |
274 | 举⼏个简单的例⼦:
275 |
276 | - 除了Vue还⽤过Angular吗? 这个时候很多候选⼈就很实诚回答「没有」,其实我们可以回答的更好,把你知道的说出来展示⾃⼰的能⼒才是最重要的,你可以说「我虽然没⽤过,但是在学习双向绑定原理的时候了解了⼀下 Angular脏检查的原理,在学习Nestjs的时候了解了依赖注⼊的原理,跟Angular也是类似的」,⾯试官⼀定会接着问你脏检查和依赖注⼊的问题,虽然你没有⽤过Angular,但是Angular的基本原理你都懂,这是很好的加分项,说明候选⼈有深⼊理解原理的意愿和触类旁通的能⼒
277 | - Vue如何实现双向绑定的? 很多候选⼈⽼⽼实实答了 object.defineproperty 如何如何操作,然后就没有了,其实你可以在回答完之后加上⼀嘴「Vue 3.0则选择了更好⽤的Proxy来替代object.defineproperty」或者「除了object.defineproperty这种数据劫持的⽅式,观察者模式和脏检查都可以实现双向绑定」,⾯试官⼤概率会问「Proxy好在哪?」或者「聊聊脏检查」等等,这样下⼀个问题就会依然在你的可控范围内
278 |
279 |
280 |
281 | 我们第⼀个例⼦把本来回答不上来的问题,转化为了成功展示⾃⼰能⼒的加分项,第⼆个例⼦让⾃⼰更多的展示了⾃⼰的能⼒,⽽且始终使⾯试官的问题在⾃⼰的可控范围内。
282 |
283 | ### 3. 向⾯试官提问
284 |
285 | 这个部分基本到了⾯试尾声了,属于做好了不影响⼤局,但是可能加分,如果做不好很容易踩雷的区域.
286 |
287 |
288 |
289 | ⾸先我们声明⼏个雷区:
290 |
291 | - 切忌问结果: 问了也⽩问,绝⼤部分公司规定不会透露结果的,你这样让⼤家很尴尬
292 | - 切忌问⼯资: 除了HR跟你谈⼯资的时候,千万别跟技术⾯试官谈⼯资,⼯资是所有公司的⾼压线,没法谈论
293 | - 切忌问技术问题: 别拿⾃⼰不会的技术难题反问⾯试官,完全没意义,⾯试官答也不是不答也不是
294 |
295 |
296 |
297 | 有⼏个⽐较好的提问可供参考:
298 |
299 | - 如果我⼊职这个岗位的话,前三个⽉你希望我能做到些什么?
300 | - 我的这个岗位的前任是为什么离职的,我什么地⽅能做的更好?
301 | - 你对这个职位理想⼈选的要求是什么?
302 |
303 |
304 |
305 | 尽量围绕你的岗位进⾏提问,这可以使得你更快得熟悉你的⼯作内容,也让⾯试官看到你对此岗位的兴趣和热情,重要的是 这些问题对于⾯试官⽽⾔既可以简略回答,也可以详细的给你讲解,如果他很热情得跟你介绍此岗位相关的情况,说明你可能表现得不错,否则的话,你可能不在他的备选名单⾥,这个时候就需要你早做打算了。
306 |
307 | ## 三、⾯试官到底想看什么样的简历?
308 |
309 | ⾯试⼀直是程序员跳槽时期⾮常热⻔的话题,虽然现在已经过了跳槽的旺季,下⼀轮跳槽季需要到年底才会出现,但是当跳槽季的时候你再看这篇⽂章可能已经晚了,过冬的粮⻝永远不是冬天准备的,⽽是秋收的时候。
310 |
311 |
312 |
313 | 简历是你进⼊⾯试的敲⻔砖,也是留给意向公司的第⼀印象,所以这个很重要,必须在这上⾯做⾜了⽂章,⼀份优秀的⾯试简历是整个⾯试成败的重中之重,我们会详细分析如何准备简历才能保证简历不被刷掉。
314 |
315 |
316 |
317 | 简历通常有这⼏部分构成:
318 |
319 | 1. 基本资料
320 | 2. 专业技能
321 | 3. ⼯作经历
322 | 4. 项⽬经历
323 | 5. 教育背景
324 |
325 |
326 |
327 | 我们会逐⼀进⾏分析。
328 |
329 | ### 1. 准备简历模板
330 |
331 | 万事开头难,简历的编写如果从头开始需要浪费很多时间,其实最快速也最聪明的办法就是先找⼀份还不错的简历模板,之后我们只需要填写信息即可。
332 |
333 |
334 |
335 | 简历模板的选择很讲究,有些简历基本不看内容就会被刷掉,这些简历⼀般会对⾯试官进⾏视觉攻击,让简历给⾯试官的第⼀印象就是反感。
336 |
337 |
338 |
339 | 有两种坑爹的简历模板:
340 |
341 | - ⼀种是经典简历模板,真是堪称『经典』,这种简历模板在我上⼩学的时候就有了,以现在的眼光看有点不够看了,配 ⾊也⽐较『魔幻』,加上表格类的简历属于low到底端的简历类型,基本上扫⼀眼就扔了,这种简历只需要3秒钟就能被⾯试官扔到垃圾堆
342 | - 另⼀种是设计感⼗⾜的简历模板,这种简历设计感⼗⾜,这五颜六⾊的配⾊⼀定能亮瞎⾯试官的双眼,这种花⾥胡哨的简历同样也是3秒钟沉到垃圾堆底部的简历。
343 |
344 |
345 |
346 | 以上两类简历模板堪称⾯试官杀⼿,我相信只要你⽤了上述两类模板,绝对连让⾯试官看第⼆眼的兴趣都没有。⾯试官筛简历要的是⾼效、清晰、内容突出,不管是HR还是技术⾯试官都想在最快速的情况下看到有效信息,你眼中所谓的『视觉效果』在别⼈眼⾥就是『视觉噪⾳』或者『视觉垃圾』,严重影响看简历的⼼情和寻找有效信息的速度。
347 |
348 | ### 2. 准备个⼈信息
349 |
350 | 个⼈信息部分主要包括姓名、电话、点⼦邮箱、求职意向,当然这四个是必填的,其它的都是选填,填好了是加分项,否则很可能减分。
351 |
352 |
353 |
354 | 接下来才是重点:
355 |
356 | 1. github:如果准备⼀个基本没有更新的博客或者没有任何贡献的github,那么给⾯试官⼀种为了放上去⽽放上去的感觉,这基本上就是在跟⾯试官说『这个候选⼈平时根本没有总结提炼的习惯』,所以如果有⻓期维护的github或者博客⼀定要放上去,质量好的话会⾮常有⽤,如果没有千万别放。
357 | 2. 学历:如果你的学历是专科、⾼中毕业之类的,还写在简历头部强调⼀遍,这就造成了你是『学渣』的印象,没有公司喜欢学渣的,这⼜增加了简历被刷的⼏率,如果是研究⽣以上学历可以写,突出⼀下学历优势,本科学历在技术⾯试领域基本上敲⻔砖级别的,没必要写。
358 | 3. 年龄:如果你是⼤龄程序员,尤其是你还在求⼀份低端岗位的时候千万别写,⼀个⼤龄程序员在求职⼀个中低端岗位,说明这些年基本原地踏步,还不能加班,到这⾥基本上此简历就凉了⼀半了。
359 | 4. 照⽚:形象优秀的可以贴,尤其是形象优秀的⼥程序媛,其它的最好不要贴,如果要贴的话,最好是贴那种PS过的⾮常职业的证件照,那种平时搞怪的、光着膀⼦的⽣活照,基本就是⾃杀⾏为。
360 |
361 | ### 3. 准备专业技能
362 |
363 | 对于程序员的专业技能其实就是技术栈,对于⾃⼰的技术栈如何描述是个很难的问题,⽐如什么算是精通?什么算是了解?什么是熟悉?
364 |
365 |
366 |
367 | 关于对技术技能的描述有很多种,有五种的也有三种的,⽽且每个⼈对词汇的理解都不⼀样,我结合相关专家的理解和⾃⼰的理解来简单阐述下描述词汇的区别,我们这⾥只讲三种的了解、熟悉、精通。
368 |
369 | - 了解:使⽤过某⼀项技术,能在别⼈指导下完成⼯作,但不能胜任复杂⼯作,也不能独⽴解决问题。
370 | - 熟悉:⼤量运⽤过的某⼀项技术,能独⽴完成⼯作,且能独⽴完成有⼀定复杂度的⼯作,在技术的应⽤层⾯不会有太⼤问题,甚⾄理解⼀点原理。
371 | - 精通:不仅可以运⽤某⼀⻔技术完成复杂项⽬,⽽且理解这项技术背后的原理,可以对此技术进⾏⼆次开发,甚⾄本身就是技术源码的贡献者。
372 |
373 |
374 |
375 | 我们就以Vue这个框架为例,如果你可以⽤vue写⼀些简单的⻚⾯,单独完成某⼏个⻚⾯的开发,但是⽆法脱离公司脚⼿架⼯作,也⽆法独⽴从0完成⼀个有⼀定复杂度的项⽬,只能称之为了解。
376 |
377 |
378 |
379 | 如果你有⼤量运⽤vue的经验,有从0独⽴完成⼀定复杂度项⽬的能⼒,可以完全脱离脚⼿架进⾏开发,且对vue的原理有⼀定的了解,可以称之为熟悉。
380 |
381 |
382 |
383 | 如果你⽤vue完成过复杂度很⾼的项⽬,⽽且⾮常熟悉vue的原理,是vue源码的主要贡献者,亦或者根据vue源码进⾏过魔改(⽐如mpvue),你可以称得上精通。
384 |
385 |
386 |
387 | 那么有两个坑是候选⼈经常犯的,『杂』和『精』,这种两个坑⼤量集中在应届⽣和刚毕业每两年的新⼿身上,其主要特点是『急于表现⾃我』、『对技术深度与⼴度出现⽆知⽽导致的过度⾃信』。
388 |
389 |
390 |
391 | ⾸先说说杂,⽐如你要应聘⼀个Java后端,⽼⽼实实把⾃⼰的java技术栈写好就⾏了,强调⼀下⾃⼰擅⻓什么即可,最好专精某领域⽐如『⾼并发』、『⾼可⽤』等等,这个时候⼀些简历⾮要给⾃⼰加戏,⾃⼰会的不会的⼀股脑往上堆,什么逆向、密码学、图形、驱动、AI都要体现出来,越杂越好,这种简历给⼈的印象就是个什么都不懂的半吊⼦。
392 |
393 |
394 |
395 | 再说说精,⼀个刚毕业的应届⽣,出来简历就各种精通,精通Java、精通Java虚拟机、精通spring全家桶、精通kafka等等,请放⼼,这种简历是不会没头没脑投过来了,这种在⼤学⾥就精通各种的天才早被他的各种学⻓介绍进了⼤⼚或者外企做某某Star重点培养了,往往看到的这种也是半吊⼦。
396 |
397 | ### 4. 准备⼯作经历
398 |
399 | ⼯作经历本身不⽤花太多笔墨去写,⾯试官主要想看的就是每段⼯作经历的持续时间、在不同公司担任的职责如何、是否有⼤⼚的⼯作经验等等。
400 |
401 |
402 |
403 | 那么什么简历在这⾥给⾯试官减分呢?
404 |
405 | - 频繁跳槽:⽐如三年换了四家公司,每个公司呆的时⻓不要超过⼀年
406 | - 常年初级岗:⽐如⼯作五六年之后依然在完成⼀些简单的项⽬开发
407 | - 末流公司经历:在技术招聘届,⼤⼚的优先级最⾼⽐如BAT、TMD甚⾄微软、⾕歌等外企,知名度独⻆兽其次,⽐如商汤、旷视等等,⼀般的互联⽹公司排在第三,就是⼯作中⼩型的互联⽹公司⼀般⼤家叫不上名字,排在最后的就是外包和传统企业的经历
408 |
409 |
410 |
411 | 所以,如果你有频繁跳槽的经历怎么办?在本公司⽼⽼实实等到满⼀年再跳槽。
412 |
413 | 如果常年初级岗怎么办?想办法晋升或者参与⼀些业界知名项⽬,再或者写⼀个有⼀定复杂度的私⼈项⽬。
414 |
415 | 如果有末流公司经历怎么办?如果是很久以前的末流公司经验可以直接不写,也没⼈在乎你很早之前的⼯作经历,如果你现在就在末流公司,赶紧想办法跳槽,去不了⼤⼚,去⾮知名的互联⽹公司也算是胜利⼤逃亡了。
416 |
417 | ### 5. 准备项⽬经历
418 |
419 | 项⽬经历不管对于社招还是校招都是重中之重,很多时候成败就在于项⽬经历这块,⼀个普通本科可以通过优秀的项⽬经历逆袭985,⼀个⼩⼚的员⼯也可以获得⼤⼚的⾯试机会。
420 |
421 |
422 |
423 | 但是必须要说⼀下项⽬经历的编写很讲究,这是为后⾯⾯试部分铺路的绝佳机会,也是直接让你的简历扑街的重点沦陷区域。
424 |
425 |
426 |
427 | 先说容易让简历扑街的⼏个坑位。
428 |
429 | #### (1)切忌流⽔账写法
430 |
431 | 项⽬经历流⽔账写法是绝⼤多数简历的通病,通篇下来就讲了⼀件事『我⼲了啥』。
432 |
433 |
434 |
435 | ⼤部分简历却是这样的:
436 |
437 | > ⽤Vue、Vuex、Vue-router、axios等技术开发电商⽹站的前端部分,主要负责⾸⻚、店铺详情、商品详情、商品列表、订单详情、订单中⼼等相关⻚⾯的开发⼯作,与设计师与后端配合,可要⾼度还原设计稿。
438 |
439 | 这个描述有什么问题? 其实看似也没啥问题,但是这种流⽔账写法太多了,完全⽆法突出⾃⼰的优势展现⾃⼰的能⼒。项⽬经历是考察重点,⾯试官想知道候选⼈在⼀次项⽬经历中扮演的⻆⾊、负责的模块、碰到的问题、解决的思路、达成的效果以及最后的总结与沉淀。
440 |
441 |
442 |
443 | ⽽上⾯的描述只显示了『我⼲了啥』,所以这种项⽬描述⼏乎是没意义的,因为对于⾯试官⽽⾔他看不到有效信息,没有有效信息的项⽬描述基本就没价值了,如果这个时候你还没有⼤⼚经历或者名校背书,基本上也就凉了。
444 |
445 | #### (2)切忌堆积项⽬
446 |
447 | 堆积项⽬这种现象往往出现在没有什么优秀项⽬经历的简历身上,候选⼈企图以数量优势掩盖质量的劣势,其实往往适得其反,项⽬经历的⼀栏最好放2-3个项⽬,⾮常优秀的项⽬可能放⼀个就⾜够了,举个极端例⼦如果有⼀天尤⾬溪写简历,其实只需要在项⽬经历那些⼀⾏『Vue.js作者』就⾏了,当然,他并不需要投简历。
448 |
449 |
450 |
451 | 有⼀些项⽬切忌放上去:
452 |
453 | - demo级项⽬:很多简历居然还在放⼀些仿xx官⽹的demo,这是⼗⾜的减分项,有⼀些则是东拼⻄凑抄了⼀些框架 的源码搞了个玩具项⽬,也没有任何价值。
454 | - 烂⼤街的项⽬:这种以vue技术栈的为最,由于视频⽹站的某⻔课程流⾏,导致⼤量的仿饿了么、仿qq⾳乐、仿美 团、仿去哪⼉,同样Java的同学也是仿电商⽹站、仿⼤众点评等等,⼗份简历5份⼀模⼀样的项⽬,你是⾯试官会怎么想。
455 | - 低质量的开源项⽬:⼀个⼤原则就是低star的尽量别放(除⾮是⾼质量代码的冷⻔项⽬),⻓期弃坑的也不要放,不要为了凑数量把低质量的项⽬暴露出来,好好藏着。
456 |
457 |
458 |
459 | 如果只放两个项⽬,最好的搭配是⼀个公司内部挑⼤梁的项⽬和⼀个社区内的开源项⽬,后者之所以可以占据⼀席之地,是因为通过你的开源项⽬,⾯试官可以通过commit完整看到你的创造过程,⽐如⼯程化建设、commit规范、代码规范、协作⽅式、代码能⼒、沟通能⼒等等,这甚⾄⽐⾯试都有⽤,没有⽐开源项⽬更能展示你综合素质的东⻄了。
460 |
461 | #### (3)切忌放虚假项⽬
462 |
463 | ⼀个项⽬做没做过只要是有经验的⾯试官⼀问便知,如果你真的靠假项⽬忽悠过了⾯试,那这个公司⼋成也有问题,⼈才把关不过硬,你可以想象你的队友都是什么⽔平,在这种公司⼤成⻓价值也不⼤。好,如果你说实在没项⽬可写了,我只能造假了,那么你应该想⼀下这多层追问。
464 |
465 |
466 |
467 | ⽐如你说你优化了⼀个前端项⽬的⾸屏性能,降低了⽩屏时间,那么⾯试官对这个性能优化问题会进⾏深挖,来考察候选⼈的实际⽔平:
468 |
469 | 1. 你的性能优化指标是怎么确定的?平均下来时间减短了多少?
470 | 2. 你的性能是如何测试的?有两种主流的性能测试⽅法你是怎么选的?
471 | 3. 你是根据哪些指标进⾏针对性优化的?
472 | 4. 除了你说的这些优化⽅法还有没有想过通过xx来解决?
473 | 5. 你的这个优化⽅法在实际操作中碰到过什么问题吗?有没有进⼀步做过测试?
474 | 6. 我们假设这么⼀种情况,⽐如xxxx,你会这么进⾏优化?
475 |
476 |
477 |
478 | ⾯试官多层追问的逻辑是这样的:**了解背景** **->** **了解⽅案** **->** **深挖⽅案** **->** **模拟场景**
479 |
480 |
481 |
482 | ⾸先得了解你性能优化的指标如何,接着需要了解你是这么测试的指标、再怎么进⾏针对性优化的,再接着提出⼀些其它解决⽅案考察你对优化场景的知识储备和⽅案决策能⼒,最后再模拟⼀个其它的业务场景,来考察你的技能迁移能⼒,看看是否是对某块领域有⼀定的了解,⽽不是只针对某个项⽬。
483 |
484 |
485 |
486 | 如果要真的在⾯试现场对答如流,那么⼀定是在某⼀块领域有⼀定知识储备的⼈,不是随随便便搞个项⽬就能蒙混过关的。
487 |
488 | #### (4)合格的项⽬经历如何写
489 |
490 | 合格的项⽬经历必须要有以下⼏点:
491 |
492 | - 项⽬概述
493 | - 个⼈职责
494 | - 项⽬难点
495 | - ⼯作成果
496 |
497 |
498 |
499 | 如果你不怕字太多,还可以选择性加⼊解决⽅案、选型思路等等,但是由于篇幅限制和为⾯试铺垫就不太建议写得太多。
500 |
501 |
502 |
503 | **项⽬概述**的⽬的是让⾯试官理解项⽬,不是每个⼈⾯试官都做过你的那种项⽬,所以需⼀个简述⽅便⾯试官理解。
504 |
505 |
506 |
507 | **个⼈职责**就是告诉⾯试官你在本项⽬中扮演的⻆⾊,是领导者?主导者?还是跟随者,你负责了哪些模块,承担了多⼤的⼯作量,以此来评估你在团队中的作⽤。
508 |
509 |
510 |
511 | **项⽬难点**的⽬的在于让⾯试官看到你碰到的技术难题,⽅便后续⾯试对项⽬进⾏⼀系列讨论。
512 |
513 | ⼯作成果就很明显了,⾯试官需要看到你在做了上述⼯作到底达成了什么成绩,这个时候最好以数据说话,⽐如访问量、⽩屏时间等等。
514 |
515 |
516 |
517 | 这个时候也切忌展开⻓篇⼤论,把技术细节⼀个个写上去,甚⾄还写了⼼路历程的都是⼤忌,⼀⽅⾯篇幅太⼤会造成视觉混乱,另⼀⽅⾯⾯试官想看到的是『简』历,不是技术总结,⾯试官要⾯对上百份简历没那么时间来看你⻓篇⼤论,⻓篇⼤论⼤可以在⾯试中展开。
518 |
519 |
520 |
521 | 最好的⽅法就是⼀⾏⽂字简单得说清楚即可,反正项⽬⾯的时候⼀定会问到,到时候好好把你准备的内容讲给⾯试官,掌握⾯试的主动权就是从项⽬经历这⼀栏中开始
522 |
523 | ### 6. 其他
524 |
525 | #### (1)教育背景
526 |
527 | 应届⽣可以写得更详细⼀点,⽐如绩点排名怎么样,有没有突出的科⽬,社招就不要写太多了,简单的⼊学时间、学校、专业即可,⽽且写你的最⾼学历即可,没必要从初中就开始写学历流⽔账,没有⼈看的。
528 |
529 | #### (2)注意事项
530 |
531 | - **⾃我评价不建议写**:技术⾯试⼏乎没⼈看你的⾃我评价,连⾯试技术问题都嫌『talk is cheap show me the code』,你的⾃我评价除了占篇幅没啥⽤处,充其量算是⾯试官的⼲扰信息。
532 | - **简历封⾯千万别搞**:这都是⼀些简历制作⽹站骗⽤户付费的伎俩,不仅是互联⽹⾏业,其它⾏业我也没⻅过要简历封⾯这种⽆⽤操作的。
533 | - **证书不建议写**:应届⽣可以酌情考虑弄个六级证书什么的,对于社招⽽⾔,列⼀堆证书甚⾄是减分项,国内的各种证你也懂的,是有多不⾃信才沦落到靠⼀堆证书来证明⾃⼰的价值。
534 | - **千万别⽤技能图表**:⾸先⽤90分、80分来评价⾃⼰的技术本身就没有什么说服⼒,也不可能这么精准,⽽且什么是90分、什么是80根本就没有⼀个公论,所以⽤⼀般的⽐较通⽤的熟悉、精通描述即可,千万别加戏,⾯试官或者HR没那么多闲⼯夫去理解你的图表,⽼⽼实实按最通⽤⾼效的⽅式描述⾃⼰的技术栈。
535 | - **简历最好⼀⻚**:程序员⼜不是设计师有时候需要作品呈现,如果你的简历超过⼀⻚那么⼀定是出问题了,要么项⽬、技术栈描述太多太杂占据⼤量篇幅,要么加了⼀堆图表或者图画来加戏,当然往往是犯前⼀个错误的更多。
--------------------------------------------------------------------------------
/3 offer收割机之HTML篇.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | ### 1. src 和 href 的区别
4 |
5 | src 和 href 都是**用来引用外部的资源**,它们的区别如下:
6 |
7 | - **src:** 表示对资源的引用,它指向的内容会嵌入到当前标签所在的位置。src 会将其指向的资源下载并应⽤到⽂档内,如请求 js 脚本。当浏览器解析到该元素时,会暂停其他资源的下载和处理,直到将该资源加载、编译、执⾏完毕,所以⼀般 js 脚本会放在页面底部。
8 | - **href:** 表示超文本引用,它指向一些网络资源,建立和当前元素或本文档的链接关系。当浏览器识别到它他指向的⽂件时,就会并行下载资源,不会停⽌对当前⽂档的处理。 常用在 a、link 等标签上。
9 |
10 | ### 2. 对 HTML 语义化的理解
11 |
12 | **语义化是指** 根据内容的结构化(内容语义化),选择合适的标签(代码语义化)。通俗来讲就是用正确的标签做正确的事情。
13 |
14 | 语义化的优点如下:
15 |
16 | - 对机器友好,带有语义的文字表现力丰富,更适合搜索引擎的爬虫爬取有效信息,有利于 SEO。除此之外,语义类还支持读屏软件,根据文章可以自动生成目录;
17 | - 对开发者友好,使用语义类标签增强了可读性,结构更加清晰,开发者能清晰的看出网页的结构,便于团队的开发与维护。
18 |
19 | 常见的语义化标签:
20 |
21 | ```html
22 | 头部
23 |
24 | 导航栏
25 |
26 | 区块(有语义化的div)
27 |
28 | 主要区域
29 |
30 | 主要内容
31 |
32 | 侧边栏
33 |
34 | 底部
35 | ```
36 |
37 | ### 3. DOCTYPE(文档类型) 的作⽤
38 |
39 | DOCTYPE 是 HTML5 中一种标准通用标记语言的文档类型声明,它的目的是**告诉浏览器(解析器)应该以什么样(html 或 xhtml)的文档类型定义**来解析文档,不同的渲染模式会影响浏览器对 CSS 代码甚⾄ JavaScript 脚本的解析。它必须声明在 HTML ⽂档的第⼀⾏。
40 |
41 | 浏览器渲染页面的两种模式(可通过 `document.compatMode` 获取,比如,语雀官网的文档类型是**CSS1Compat**):
42 |
43 | - **CSS1Compat:标准模式(Strick mode)**,默认模式,浏览器使用 W3C 的标准解析渲染页面。在标准模式中,浏览器以其支持的最高标准呈现页面。
44 | - **BackCompat:怪异模式(混杂模式)(Quick mode)**,浏览器使用自己的怪异模式解析渲染页面。在怪异模式中,页面以一种比较宽松的向后兼容的方式显示。
45 |
46 | ### 4. script 标签中 defer 和 async 的区别
47 |
48 | 如果没有 defer 或 async 属性,浏览器会立即加载并执行相应的脚本。它不会等待后续加载的文档元素,读取到就会开始加载和执行,这样就阻塞了后续文档的加载。
49 |
50 | 下图可以直观的看出三者之间的区别:
51 |
52 | 
53 |
54 | 其中蓝色代表 js 脚本网络加载时间,红色代表 js 脚本执行时间,绿色代表 html 解析。
55 |
56 | **defer 和 async 属性都是去异步加载外部的 JS 脚本文件,它们都不会阻塞页面的解析**,其区别如下:
57 |
58 | - **执行顺序:**多个带 async 属性的标签,不能保证加载的顺序;多个带 defer 属性的标签,按照加载顺序执行;
59 | - **脚本是否并行执行:**async 属性,表示**后续文档的加载和执行与 js 脚本的加载和执行是并行进行的**,即异步执行;defer 属性,**加载后续文档的过程和 js 脚本的加载**(此时仅加载不执行)**是并行进行的**(异步),js 脚本需要等到文档所有元素解析完成之后才执行,DOMContentLoaded 事件触发执行之前。
60 |
61 | ### 5. 常用的 meta 标签有哪些
62 |
63 | `meta` 标签由 `name` 和 `content` 属性定义,**用来描述网页文档的属性**,比如网页的作者,网页描述,关键词等,除了 HTTP 标准固定了一些`name`作为大家使用的共识,开发者还可以自定义 name。
64 |
65 | 常用的 meta 标签:
66 |
67 | (1)`charset`,用来描述 HTML 文档的编码类型:
68 |
69 | ```html
70 |
71 | ```
72 |
73 | (2) `keywords`,页面关键词:
74 |
75 | ```html
76 |
77 | ```
78 |
79 | (3)`description`,页面描述:
80 |
81 | ```html
82 |
83 | ```
84 |
85 | (4)`refresh`,页面重定向和刷新:
86 |
87 | ```html
88 |
89 | ```
90 |
91 | (5)`viewport`,适配移动端,可以控制视口的大小和比例:
92 |
93 | ```html
94 |
95 | ```
96 |
97 | 其中,`content` 参数有以下几种:
98 |
99 | - `width viewport` :宽度(数值/device-width)
100 | - `height viewport` :高度(数值/device-height)
101 | - `initial-scale` :初始缩放比例
102 | - `maximum-scale` :最大缩放比例
103 | - `minimum-scale` :最小缩放比例
104 | - `user-scalable` :是否允许用户缩放(yes/no)
105 |
106 | (6)搜索引擎索引方式:
107 |
108 | ```html
109 |
110 | ```
111 |
112 | 其中,`content` 参数有以下几种:
113 |
114 | - `all`:文件将被检索,且页面上的链接可以被查询;
115 | - `none`:文件将不被检索,且页面上的链接不可以被查询;
116 | - `index`:文件将被检索;
117 | - `follow`:页面上的链接可以被查询;
118 | - `noindex`:文件将不被检索;
119 | - `nofollow`:页面上的链接不可以被查询。
120 |
121 | ### 6. HTML5 有哪些更新
122 |
123 | #### 1. 语义化标签
124 |
125 | - header:定义文档的页眉(头部);
126 | - nav:定义导航链接的部分;
127 | - footer:定义文档或节的页脚(底部);
128 | - article:定义文章内容;
129 | - section:定义文档中的节(section、区段);
130 | - aside:定义其所处内容之外的内容(侧边);
131 |
132 | #### 2. 媒体标签
133 |
134 | (1) audio:音频
135 |
136 | ```html
137 |
138 | ```
139 |
140 | 属性:
141 |
142 | - controls 控制面板
143 | - autoplay 自动播放
144 | - loop=‘true’ 循环播放
145 |
146 | (2)video 视频
147 |
148 | ```html
149 |
150 | ```
151 |
152 | 属性:
153 |
154 | - poster:指定视频还没有完全下载完毕,或者用户还没有点击播放前显示的封面。默认显示当前视频文件的第一针画面,当然通过 poster 也可以自己指定。
155 | - controls 控制面板
156 | - width
157 | - height
158 |
159 | (3)source 标签
160 |
161 | 因为浏览器对视频格式支持程度不一样,为了能够兼容不同的浏览器,可以通过 source 来指定视频源。
162 |
163 | ```html
164 |
168 | ```
169 |
170 | #### 3. 表单
171 |
172 | **表单类型:**
173 |
174 | - email :能够验证当前输入的邮箱地址是否合法
175 | - url : 验证 URL
176 | - number : 只能输入数字,其他输入不了,而且自带上下增大减小箭头,max 属性可以设置为最大值,min 可以设置为最小值,value 为默认值。
177 | - search : 输入框后面会给提供一个小叉,可以删除输入的内容,更加人性化。
178 | - range : 可以提供给一个范围,其中可以设置 max 和 min 以及 value,其中 value 属性可以设置为默认值
179 | - color : 提供了一个颜色拾取器
180 | - time : 时分秒
181 | - data : 日期选择年月日
182 | - datatime : 时间和日期(目前只有 Safari 支持)
183 | - datatime-local :日期时间控件
184 | - week :周控件
185 | - month:月控件
186 |
187 | **表单属性:**
188 |
189 | - placeholder :提示信息
190 | - autofocus :自动获取焦点
191 | - autocomplete=“on” 或者 autocomplete=“off” 使用这个属性需要有两个前提:
192 |
193 | - - 表单必须提交过
194 | - 必须有 name 属性。
195 |
196 | - required:要求输入框不能为空,必须有值才能够提交。
197 | - pattern=" " 里面写入想要的正则模式,例如手机号 patte="^(+86)?\d{10}$"
198 | - multiple:可以选择多个文件或者多个邮箱
199 | - form=" form 表单的 ID"
200 |
201 | **表单事件:**
202 |
203 | - oninput 每当 input 里的输入框内容发生变化都会触发此事件。
204 | - oninvalid 当验证不通过时触发此事件。
205 |
206 | #### 4. 进度条、度量器
207 |
208 | - progress 标签:用来表示任务的进度(IE、Safari 不支持),max 用来表示任务的进度,value 表示已完成多少
209 | - meter 属性:用来显示剩余容量或剩余库存(IE、Safari 不支持)
210 |
211 | - - high/low:规定被视作高/低的范围
212 | - max/min:规定最大/小值
213 | - value:规定当前度量值
214 |
215 | 设置规则:min < low < high < max
216 |
217 | #### 5.DOM 查询操作
218 |
219 | - `document.querySelector()`
220 | - `document.querySelectorAll()`
221 |
222 | 它们选择的对象可以是标签,可以是类(需要加点),可以是 ID(需要加#)
223 |
224 | #### 6. Web 存储
225 |
226 | HTML5 提供了两种在客户端存储数据的新方法:
227 |
228 | - localStorage - 没有时间限制的数据存储
229 | - sessionStorage - 针对一个 session 的数据存储
230 |
231 | #### 7. 其他
232 |
233 | - 拖放:拖放是一种常见的特性,即抓取对象以后拖到另一个位置。设置元素可拖放:
234 |
235 | ```html
236 | ![]() 237 | ```
238 |
239 | - 画布(canvas ): canvas 元素使用 JavaScript 在网页上绘制图像。画布是一个矩形区域,可以控制其每一像素。canvas 拥有多种绘制路径、矩形、圆形、字符以及添加图像的方法。
240 |
241 | ```html
242 |
243 | ```
244 |
245 | - SVG:SVG 指可伸缩矢量图形,用于定义用于网络的基于矢量的图形,使用 XML 格式定义图形,图像在放大或改变尺寸的情况下其图形质量不会有损失,它是万维网联盟的标准
246 | - 地理定位:Geolocation(地理定位)用于定位用户的位置。‘
247 |
248 | **总结:**
249 |
250 | (1)新增语义化标签:nav、header、footer、aside、section、article
251 |
252 | (2)音频、视频标签:audio、video
253 |
254 | (3)数据存储:localStorage、sessionStorage
255 |
256 | (4)canvas(画布)、Geolocation(地理定位)、websocket(通信协议)
257 |
258 | (5)input 标签新增属性:placeholder、autocomplete、autofocus、required
259 |
260 | (6)history API:go、forward、back、pushstate
261 |
262 | **移除的元素有:**
263 |
264 | - 纯表现的元素:basefont,big,center,font, s,strike,tt,u;
265 | - 对可用性产生负面影响的元素:frame,frameset,noframes;
266 |
267 | ### 7. img 的 srcset 属性的作⽤?
268 |
269 | 响应式页面中经常用到根据屏幕密度设置不同的图片。这时就用到了 img 标签的 srcset 属性。srcset 属性用于设置不同屏幕密度下,img 会自动加载不同的图片。用法如下:
270 |
271 | ```html
272 |
237 | ```
238 |
239 | - 画布(canvas ): canvas 元素使用 JavaScript 在网页上绘制图像。画布是一个矩形区域,可以控制其每一像素。canvas 拥有多种绘制路径、矩形、圆形、字符以及添加图像的方法。
240 |
241 | ```html
242 |
243 | ```
244 |
245 | - SVG:SVG 指可伸缩矢量图形,用于定义用于网络的基于矢量的图形,使用 XML 格式定义图形,图像在放大或改变尺寸的情况下其图形质量不会有损失,它是万维网联盟的标准
246 | - 地理定位:Geolocation(地理定位)用于定位用户的位置。‘
247 |
248 | **总结:**
249 |
250 | (1)新增语义化标签:nav、header、footer、aside、section、article
251 |
252 | (2)音频、视频标签:audio、video
253 |
254 | (3)数据存储:localStorage、sessionStorage
255 |
256 | (4)canvas(画布)、Geolocation(地理定位)、websocket(通信协议)
257 |
258 | (5)input 标签新增属性:placeholder、autocomplete、autofocus、required
259 |
260 | (6)history API:go、forward、back、pushstate
261 |
262 | **移除的元素有:**
263 |
264 | - 纯表现的元素:basefont,big,center,font, s,strike,tt,u;
265 | - 对可用性产生负面影响的元素:frame,frameset,noframes;
266 |
267 | ### 7. img 的 srcset 属性的作⽤?
268 |
269 | 响应式页面中经常用到根据屏幕密度设置不同的图片。这时就用到了 img 标签的 srcset 属性。srcset 属性用于设置不同屏幕密度下,img 会自动加载不同的图片。用法如下:
270 |
271 | ```html
272 |  273 | ```
274 |
275 | 使用上面的代码,就能实现在屏幕密度为 1x 的情况下加载 image-128.png, 屏幕密度为 2x 时加载 image-256.png。
276 |
277 | 按照上面的实现,不同的屏幕密度都要设置图片地址,目前的屏幕密度有 1x,2x,3x,4x 四种,如果每一个图片都设置 4 张图片,加载就会很慢。所以就有了新的 srcset 标准。代码如下:
278 |
279 | ```html
280 |
283 | ```
284 |
285 | 其中 srcset 指定图片的地址和对应的图片质量。sizes 用来设置图片的尺寸零界点。对于 srcset 中的 w 单位,可以理解成图片质量。如果可视区域小于这个质量的值,就可以使用。浏览器会自动选择一个最小的可用图片。
286 |
287 | sizes 语法如下:
288 |
289 | ```
290 | sizes="[media query] [length], [media query] [length] ... "
291 | ```
292 |
293 | sizes 就是指默认显示 128px, 如果视区宽度大于 360px, 则显示 340px。
294 |
295 | ### 8. 行内元素有哪些?块级元素有哪些? 空(void)元素有那些?
296 |
297 | - 行内元素有:`a b span img input select strong`;
298 | - 块级元素有:`div ul ol li dl dt dd h1 h2 h3 h4 h5 h6 p`;
299 |
300 | 空元素,即没有内容的 HTML 元素。空元素是在开始标签中关闭的,也就是空元素没有闭合标签:
301 |
302 | - 常见的有:`
273 | ```
274 |
275 | 使用上面的代码,就能实现在屏幕密度为 1x 的情况下加载 image-128.png, 屏幕密度为 2x 时加载 image-256.png。
276 |
277 | 按照上面的实现,不同的屏幕密度都要设置图片地址,目前的屏幕密度有 1x,2x,3x,4x 四种,如果每一个图片都设置 4 张图片,加载就会很慢。所以就有了新的 srcset 标准。代码如下:
278 |
279 | ```html
280 |
283 | ```
284 |
285 | 其中 srcset 指定图片的地址和对应的图片质量。sizes 用来设置图片的尺寸零界点。对于 srcset 中的 w 单位,可以理解成图片质量。如果可视区域小于这个质量的值,就可以使用。浏览器会自动选择一个最小的可用图片。
286 |
287 | sizes 语法如下:
288 |
289 | ```
290 | sizes="[media query] [length], [media query] [length] ... "
291 | ```
292 |
293 | sizes 就是指默认显示 128px, 如果视区宽度大于 360px, 则显示 340px。
294 |
295 | ### 8. 行内元素有哪些?块级元素有哪些? 空(void)元素有那些?
296 |
297 | - 行内元素有:`a b span img input select strong`;
298 | - 块级元素有:`div ul ol li dl dt dd h1 h2 h3 h4 h5 h6 p`;
299 |
300 | 空元素,即没有内容的 HTML 元素。空元素是在开始标签中关闭的,也就是空元素没有闭合标签:
301 |
302 | - 常见的有:`
`、`
`、`![]() `、``、``、``;
303 | - 鲜见的有:``、``、``、``、``、`
`、``、``、``;
303 | - 鲜见的有:``、``、``、``、``、`