49 |
--------------------------------------------------------------------------------
/extension/webpack.config.js:
--------------------------------------------------------------------------------
1 | var path = require('path');
2 |
3 | module.exports = {
4 | entry: {
5 | module: './js/module.js',
6 | timeline: './js/Timeline.js',
7 | taskchart: './js/TaskChart.js'
8 | },
9 | output: {
10 | path: path.resolve(__dirname, 'sparkmonitor/static'),
11 | filename: '[name].js',
12 | // library:'sparkmonitor',
13 | libraryTarget: 'umd'
14 | },
15 | externals: ['jquery', 'require', 'base/js/namespace', 'base/js/events', 'notebook/js/codecell', 'moment'],
16 | devtool: 'source-map',
17 | module: {
18 | rules: [
19 | {
20 | test: /\.js$/,
21 | exclude: /(node_modules|bower_components)/,
22 | use: {
23 | loader: 'babel-loader',
24 | options: {
25 | presets: ['env'],
26 |
27 | plugins: [
28 | "add-module-exports"
29 | ]
30 | }
31 |
32 | }
33 | },
34 | {
35 | test: /\.css$/,
36 | use: [
37 | 'style-loader',
38 | 'css-loader'
39 | ]
40 | },
41 | {
42 | test: /\.(png|svg|jpg|gif)$/,
43 | use: [
44 | 'file-loader'
45 | ]
46 | },
47 | {
48 | test: /\.(html)$/,
49 | use: {
50 | loader: 'html-loader',
51 | options: {
52 | attrs: [':data-src']
53 | }
54 | }
55 | },
56 | {
57 | test: /node_modules[\\\/]vis[\\\/].*\.js$/,
58 | use: {
59 | loader: 'babel-loader',
60 | options: {
61 | cacheDirectory: true,
62 | presets: ["env"],
63 | "babelrc": false,
64 | // plugins: [
65 | // "transform-es3-property-literals",
66 | // "transform-es3-member-expression-literals",
67 | // "transform-runtime"
68 | // ]
69 |
70 | }
71 | }
72 | },
73 | // {
74 | // test: /node_modules/,
75 | // use: {
76 | // loader: 'ify-loader',
77 |
78 | // },
79 | // enforce: 'post'
80 | // }
81 |
82 | ],
83 | }
84 | };
--------------------------------------------------------------------------------
/docs/jsdoc/styles/prettify-tomorrow.css:
--------------------------------------------------------------------------------
1 | /* Tomorrow Theme */
2 | /* Original theme - https://github.com/chriskempson/tomorrow-theme */
3 | /* Pretty printing styles. Used with prettify.js. */
4 | /* SPAN elements with the classes below are added by prettyprint. */
5 | /* plain text */
6 | .pln {
7 | color: #4d4d4c; }
8 |
9 | @media screen {
10 | /* string content */
11 | .str {
12 | color: #718c00; }
13 |
14 | /* a keyword */
15 | .kwd {
16 | color: #8959a8; }
17 |
18 | /* a comment */
19 | .com {
20 | color: #8e908c; }
21 |
22 | /* a type name */
23 | .typ {
24 | color: #4271ae; }
25 |
26 | /* a literal value */
27 | .lit {
28 | color: #f5871f; }
29 |
30 | /* punctuation */
31 | .pun {
32 | color: #4d4d4c; }
33 |
34 | /* lisp open bracket */
35 | .opn {
36 | color: #4d4d4c; }
37 |
38 | /* lisp close bracket */
39 | .clo {
40 | color: #4d4d4c; }
41 |
42 | /* a markup tag name */
43 | .tag {
44 | color: #c82829; }
45 |
46 | /* a markup attribute name */
47 | .atn {
48 | color: #f5871f; }
49 |
50 | /* a markup attribute value */
51 | .atv {
52 | color: #3e999f; }
53 |
54 | /* a declaration */
55 | .dec {
56 | color: #f5871f; }
57 |
58 | /* a variable name */
59 | .var {
60 | color: #c82829; }
61 |
62 | /* a function name */
63 | .fun {
64 | color: #4271ae; } }
65 | /* Use higher contrast and text-weight for printable form. */
66 | @media print, projection {
67 | .str {
68 | color: #060; }
69 |
70 | .kwd {
71 | color: #006;
72 | font-weight: bold; }
73 |
74 | .com {
75 | color: #600;
76 | font-style: italic; }
77 |
78 | .typ {
79 | color: #404;
80 | font-weight: bold; }
81 |
82 | .lit {
83 | color: #044; }
84 |
85 | .pun, .opn, .clo {
86 | color: #440; }
87 |
88 | .tag {
89 | color: #006;
90 | font-weight: bold; }
91 |
92 | .atn {
93 | color: #404; }
94 |
95 | .atv {
96 | color: #060; } }
97 | /* Style */
98 | /*
99 | pre.prettyprint {
100 | background: white;
101 | font-family: Menlo, Monaco, Consolas, monospace;
102 | font-size: 12px;
103 | line-height: 1.5;
104 | border: 1px solid #ccc;
105 | padding: 10px; }
106 | */
107 |
108 | /* Specify class=linenums on a pre to get line numbering */
109 | ol.linenums {
110 | margin-top: 0;
111 | margin-bottom: 0; }
112 |
113 | /* IE indents via margin-left */
114 | li.L0,
115 | li.L1,
116 | li.L2,
117 | li.L3,
118 | li.L4,
119 | li.L5,
120 | li.L6,
121 | li.L7,
122 | li.L8,
123 | li.L9 {
124 | /* */ }
125 |
126 | /* Alternate shading for lines */
127 | li.L1,
128 | li.L3,
129 | li.L5,
130 | li.L7,
131 | li.L9 {
132 | /* */ }
133 |
--------------------------------------------------------------------------------
/.travis.yml:
--------------------------------------------------------------------------------
1 | language: scala
2 | # dist: trusty
3 | sudo: required
4 | env:
5 | global:
6 | secure: Qw9zE4MOOkcPiUYF4jzt6tFhJogvA3d0u2pA/jMAybECjeQDMaio5AN67NbtXDU5/7VF2bab4ScWb4HMVhd30j6Mo8FmTAeuxYwVSldze82wM7/Aw2E6GARmWugC/Q5RNJKd+oIpRgHgWuepNWWpdXMuDx2mtHmL8KPShmjYRFQ9rEeiyrnUPqaO+JRT6BD13KZTb1004cFa3kK4piwOlQ7hrQ5t21YJAqkfgWMX9yybgCPIgMbPoQZFLsK2xdc0tYsBJDFkblXLleQjUyn1y7PbwgbscvLr+I75g2sN8mqR58x4ly3rpb1+8SQ3aRgCJHZUwCl1Ci2dO9RLVSgse4JPyfJ9/50epEU7TD9oNz+rXImOOlSCoVFdNEW3BOGDle9hci6AiA2ON3jESVWID7FY9dv7Fe1fEiwFoSg2cVIlPLRAF/Lt81v6OGurd7xFUUscUgELLYXTgZRnltUR7P5Na/1C/Atk/YjoenMlnhOy7DgTm54OpuZ4TZLLJOeWHS5RpeMXyl9d4SQ8ZExJCjWK0+DHb0CIze/uO6lSIIWsf2MIQKIbnUARIF34sW6/Ms3gvXQdC8qJNxkYZYbD3fcUNnsPsLAZMGC9nco4TxwO3M7oeTOpTlGJshnTg8l8XB+ppMqRFQhZyo6GQEUZQ8QVbSRGDrm+gSZnsnqFN+s=
7 | services:
8 | - docker
9 | scala: "-2.11.8"
10 | cache:
11 | yarn: true
12 | directories:
13 | - "$TRAVIS_BUILD_DIR/extension/node_modules"
14 | - "$HOME/.sbt"
15 | - "$HOME/.ivy2/cache"
16 | before_install:
17 | - nvm install 6.11.1
18 | - nvm use 6.11.1
19 | install:
20 | - cd $TRAVIS_BUILD_DIR/extension/
21 | - yarn install
22 | before_script: ''
23 | script:
24 | - cd $TRAVIS_BUILD_DIR/extension/
25 | - yarn run webpack
26 | - cd $TRAVIS_BUILD_DIR/extension/scalalistener/
27 | - sbt package
28 | - cd $TRAVIS_BUILD_DIR/extension/
29 | - python setup.py sdist --formats=gztar,zip
30 | - cd $TRAVIS_BUILD_DIR/extension/dist/
31 | - cp sparkmonitor*.tar.gz sparkmonitor.tar.gz
32 | - cp sparkmonitor*.zip sparkmonitor.zip
33 | after_success:
34 | - cd $TRAVIS_BUILD_DIR/
35 | - 'docker login -u=$DOCKER_USER -p=$DOCKER_PASS && docker build -f Dockerfile -t krishnanr/sparkmonitor
36 | . && docker push krishnanr/sparkmonitor'
37 |
38 | deploy:
39 |
40 | - provider: releases
41 | skip_cleanup: true
42 | file:
43 | - $TRAVIS_BUILD_DIR/extension/dist/sparkmonitor.tar.gz
44 | - $TRAVIS_BUILD_DIR/extension/dist/sparkmonitor.zip
45 | api_key:
46 | secure: a3buqLV2wwwAY6mkCSKT8/qHf8pFTa9/UP4Op3WPlkS2rYTAKw8cI3dAWd99dr5oCXkbbJc4aIA/e9voS1xAR+9mGYW+X3EakB8fRWnwQjg1/mRdsNp4S9wyeat1ETt4+/M1etcZed+uuuIUDfCyWgGGlu+bLGubHYqHIWhAE3lrT3PKjQVNGP/A5Tkctmoz+YE9gHoCNkFwa4cQ0p/hUeE97UT86u1RriHNJ1yKbqfX5/0FaOU6BbZogsGzk5tKBJyJtdACi3fgbLKlBPS7+aIE2wydl7PtQxwnLUV8Gitcb6+rfPQTYzQfc3vX2izfKBx6sC4hFZ433MdGw/3neyfUj1/Gh/tHnHrl4tSkt5VgKD7i4TPQiVLjt2N9tdkgZyqhjfJwit5r5IxSoSbdPsUK6uNIxDLsInFiakPyjwciczDToJihP/drelAuuWqIymKPPE70AGX1VsRI8H5JakXfkzI741ZpyiFiq3Z/b3WPqC/+bXnNS7aF5+P8SkYJVhGbMq6toq8gfYP36rYY2OAo55X7qTCqGkbxv8nAIwJNtrg3U0u5ra7ciamp6/ht8LmVVBfy0XERHzdejhqbHeyNpA1LFSiCkhvpZYWxpPgJOUbW+jkf4Ujk4fJwmvmS2FLsqMNzeOYqhUYwY5mwpmoaDjTFQ50Eu2BcouByVCw=
47 | on:
48 | repo: krishnan-r/sparkmonitor
49 | tags: true
50 | - provider: script
51 | skip_cleanup: true
52 | on:
53 | tags: true
54 | script: 'docker tag krishnanr/sparkmonitor krishnanr/sparkmonitor:$TRAVIS_TAG && docker push krishnanr/sparkmonitor:$TRAVIS_TAG'
55 |
56 |
--------------------------------------------------------------------------------
/docs/usecase_sparktraining.md:
--------------------------------------------------------------------------------
1 |
2 | **[Final Report](index.md)** |
3 | **[Installation](install.md)** |
4 | **[How it Works](how.md)** |
5 | **[Use Cases](usecases.md)** |
6 | **[Code](https://github.com/krishnan-r/sparkmonitor)** |
7 | **[License](https://github.com/krishnan-r/sparkmonitor/blob/master/LICENSE.md)**
8 |
9 |
10 | # Example Use Case - Spark Tutorial Notebooks
11 |
12 | ## Introduction
13 | This use case runs a few notebooks used at CERN for training in Apache Spark.
14 | They test a wide range of Spark APIs including reading data from files.
15 |
16 | ## Notebooks
17 | - [Spark Training Notebooks](https://github.com/prasanthkothuri/sparkTraining)
18 |
19 | ## Environment
20 | - These notebook were run with a local Apache Spark installation, using 1 executor and 4 cores, running inside a [Docker container](https://hub.docker.com/r/krishnanr/sparkmonitor/) based on Scientific Linux CERN 6.
21 |
22 | ## Monitoring the Notebook
23 |
24 | - The extension shows all the jobs that have been run from a cell
25 | - The stages for each job are shown in an expanded view which can be individually collapsed.
26 |
27 | 
28 |
29 | - An aggregated view of resource usage is provided through a graph between number of active tasks and available executor cores. This gives insight into whether the job is blocking on some I/O or waiting for other results. This view gives a picture of the level of parallelization of the tasks between cores across a cluster.
30 |
31 | 
32 |
33 | 
34 |
35 | - An event timeline shows the overall picture of what is happening in the cluster, split into jobs stages and tasks.
36 |
37 | 
38 |
39 | 
40 |
41 | - The timeline shows various tasks running on each executor as a group
42 | - It shows the time spent by the task in various phases. An overall view of this gives insight into the nature of the workload - I/O bound or CPU bound. This feature can be toggled using a checkbox.
43 | - On clicking on an item on the timeline, the corresponding details of the item are shown as a pop-up. For jobs and stages, this shows the Spark Web UI page. For tasks a custom pop-up is shown with various details.
44 |
45 | 
46 | - For more advanced details, the extension provides access to the Spark Web UI through a server proxy. This can used by advanced users for an in-depth analysis.
47 |
48 | 
49 |
--------------------------------------------------------------------------------
/extension/js/timeline.css:
--------------------------------------------------------------------------------
1 | .pm .timelinewrapper {
2 | max-height: 400px;
3 | overflow-y: auto;
4 | clear: both;
5 | }
6 |
7 | .pm .vis-labelset .vis-label .vis-inner {
8 | width: 100px;
9 | }
10 |
11 | .pm .vis-item {
12 | border-radius: 0;
13 | font-size: smaller;
14 | }
15 |
16 | .pm .vis-item .vis-item-content {
17 | padding: 0;
18 | width: 100%;
19 | }
20 |
21 | .pm .vis-time-axis {
22 | font-size: smaller;
23 | }
24 |
25 | .pm .vis-tooltip {
26 | color: white;
27 | background-color: black;
28 | }
29 |
30 | .pm .vis-item.vis-background {
31 | background-color: rgba(191, 191, 191, 0.58);
32 | }
33 |
34 | .pm .vis-custom-time {
35 | pointer-events: none;
36 | background-color: #42A5F5;
37 | }
38 |
39 | .pm .vis-item.itemfinished {
40 | /* :not(.vis-selected) { */
41 | background-color: #90dc34;
42 | border-color: #6c9d34;
43 | border: 0;
44 | }
45 |
46 | .pm .vis-item.itemfailed {
47 | /* :not(.vis-selected) { */
48 | background-color: #F44336;
49 | border-color: rgb(183, 13, 0);
50 | color: white;
51 | border: 0;
52 | }
53 |
54 | .pm .vis-item.itemfinished:active {
55 | background-color: #6c9d34;
56 | }
57 |
58 | .pm .vis-selected {
59 | border-color: #ffc200;
60 | background-color: #ffc200;
61 | border: 0;
62 | }
63 |
64 | .pm .vis-item.itemrunning {
65 | /* :not(.vis-selected) { */
66 | background-color: rgb(134, 199, 251);
67 | border: 0;
68 | }
69 |
70 | .pm .hidephases .taskbarsvg rect {
71 | stroke: none;
72 | fill: none;
73 | }
74 |
75 | .pm .hidephases .taskbarsvg {
76 | display: none;
77 | }
78 |
79 | .pm .hidephases .taskbardiv:before {
80 | content: attr(data-taskid);
81 | padding: 0px 2px;
82 | text-align: center;
83 | width: 100%;
84 | }
85 |
86 | .pm .showphases .taskbarsvg rect.scheduler-delay-proportion {
87 | fill: #80B1D3;
88 | stroke: #6B94B0;
89 | }
90 |
91 | .pm .showphases .taskbarsvg rect.deserialization-time-proportion {
92 | fill: #FB8072;
93 | stroke: #D26B5F;
94 | }
95 |
96 | .pm .showphases .taskbarsvg rect.shuffle-read-time-proportion {
97 | fill: #FDB462;
98 | stroke: #D39651;
99 | }
100 |
101 | .pm .showphases .taskbarsvg rect.executor-runtime-proportion {
102 | fill: #B3DE69;
103 | stroke: #95B957;
104 | }
105 |
106 | .pm .showphases .taskbarsvg rect.shuffle-write-time-proportion {
107 | fill: #FFED6F;
108 | stroke: #D5C65C;
109 | }
110 |
111 | .pm .showphases .taskbarsvg rect.serialization-time-proportion {
112 | fill: #BC80BD;
113 | stroke: #9D6B9E;
114 | }
115 |
116 | .pm .showphases .taskbarsvg rect.getting-result-time-proportion {
117 | fill: #8DD3C7;
118 | stroke: #75B0A6;
119 | }
120 |
121 | .pm .taskbarsvg {
122 | width: 100%;
123 | height: 20px;
124 | vertical-align: top;
125 | }
126 |
127 | .pm taskbardiv {
128 | width: 100%;
129 | height: 100%;
130 | }
131 |
132 | .pm .timelinetoolbar {
133 | padding: 0px 8px;
134 | color: #444444;
135 | font-size: small;
136 | }
137 |
138 | .pm .timecheckboxspan {
139 | margin: 0px 5px;
140 | float: right;
141 | }
--------------------------------------------------------------------------------
/docs/install.md:
--------------------------------------------------------------------------------
1 |
2 | **[Final Report](index.md)** |
3 | **[Installation](install.md)** |
4 | **[How it Works](how.md)** |
5 | **[Use Cases](usecases.md)** |
6 | **[Code](https://github.com/krishnan-r/sparkmonitor)** |
7 | **[License](https://github.com/krishnan-r/sparkmonitor/blob/master/LICENSE.md)**
8 |
9 |
10 | # Installation
11 | ## Prerequisites
12 | - PySpark on [Apache Spark](https://spark.apache.org/) version 2.1.1 or higher
13 | - [Jupyter Notebook](http://jupyter.org/) version 4.4.0 or higher
14 |
15 | ## Quick Install
16 | ```bash
17 | pip install sparkmonitor
18 | jupyter nbextension install sparkmonitor --py --user --symlink
19 | jupyter nbextension enable sparkmonitor --py --user
20 | jupyter serverextension enable --py --user sparkmonitor
21 | ipython profile create && echo "c.InteractiveShellApp.extensions.append('sparkmonitor.kernelextension')" >> $(ipython profile locate default)/ipython_kernel_config.py
22 | ```
23 | ## Detailed Instructions
24 |
25 | 1. Install the python package in the latest tagged github release. The python package contains the JavaScript resources and the listener jar file.
26 |
27 | ```bash
28 | pip install sparkmonitor
29 | ```
30 |
31 | 2. The frontend extension is symlinked (```--symlink```) into the jupyter configuration directory by `jupyter nbextension` command. The second line configures the frontend extension to load on notebook startup.
32 |
33 | ```bash
34 | jupyter nbextension install --py sparkmonitor --user --symlink
35 | jupyter nbextension enable sparkmonitor --user --py
36 | ```
37 | 3. Configure the server extension to load when the notebook server starts
38 |
39 | ```bash
40 | jupyter serverextension enable --py --user sparkmonitor
41 | ```
42 |
43 | 4. Create the default profile configuration files (Skip if config file already exists)
44 | ```bash
45 | ipython profile create
46 | ```
47 | 5. Configure the kernel to load the extension on startup. This is added to the configuration files in users home directory
48 | ```bash
49 | echo "c.InteractiveShellApp.extensions.append('sparkmonitor.kernelextension')" >> $(ipython profile locate default)/ipython_kernel_config.py
50 | ```
51 |
52 | ## Configuration
53 | By default the Spark Web UI runs on `localhost:4040`. If this is not the case, setting the environment variable `SPARKMONITOR_UI_HOST` and `SPARKMONITOR_UI_PORT` overrides the default Spark UI hostname `localhost` and port 4040 used by the Spark UI proxy.
54 |
55 | ## Build from Source
56 | Building the extension involves three parts:
57 | 1. Bundle and minify the JavaScript
58 | 2. Compile the Scala listener into a JAR file.
59 | 3. Package and install the python package.
60 |
61 | ```bash
62 | git clone https://github.com/krishnan-r/sparkmonitor
63 | cd sparkmonitor/extension
64 | #Build Javascript
65 | yarn install
66 | yarn run webpack
67 | #Build SparkListener Scala jar
68 | cd scalalistener/
69 | sbt package
70 | ```
71 | ```bash
72 | #Install the python package (in editable format -e for development)
73 | cd sparkmonitor/extension/
74 | pip install -e .
75 | # The sparkmonitor python package is now installed. Configure with jupyter as above.
76 | ```
77 |
--------------------------------------------------------------------------------
/docs/jsdoc/scripts/fulltext-search-ui.js:
--------------------------------------------------------------------------------
1 | window.SearcherDisplay = (function($) {
2 | /**
3 | * This class provides support for displaying quick search text results to users.
4 | */
5 | function SearcherDisplay() { }
6 |
7 | SearcherDisplay.prototype.init = function() {
8 | this._displayQuickSearch();
9 | };
10 |
11 | /**
12 | * This method creates the quick text search entry in navigation menu and wires all required events.
13 | */
14 | SearcherDisplay.prototype._displayQuickSearch = function() {
15 | var quickSearch = $(document.createElement("iframe")),
16 | body = $("body"),
17 | self = this;
18 |
19 | quickSearch.attr("src", "quicksearch.html");
20 | quickSearch.css("width", "0px");
21 | quickSearch.css("height", "0px");
22 |
23 | body.append(quickSearch);
24 |
25 | $(window).on("message", function(msg) {
26 | var msgData = msg.originalEvent.data;
27 |
28 | if (msgData.msgid != "docstrap.quicksearch.done") {
29 | return;
30 | }
31 |
32 | var results = msgData.results || [];
33 |
34 | self._displaySearchResults(results);
35 | });
36 |
37 | function startSearch() {
38 | var searchTerms = $('#search-input').prop("value");
39 | if (searchTerms) {
40 | quickSearch[0].contentWindow.postMessage({
41 | "searchTerms": searchTerms,
42 | "msgid": "docstrap.quicksearch.start"
43 | }, "*");
44 | }
45 | }
46 |
47 | $('#search-input').on('keyup', function(evt) {
48 | if (evt.keyCode != 13) {
49 | return;
50 | }
51 | startSearch();
52 | return false;
53 | });
54 | $('#search-submit').on('click', function() {
55 | startSearch();
56 | return false;
57 | });
58 | };
59 |
60 | /**
61 | * This method displays the quick text search results in a modal dialog.
62 | */
63 | SearcherDisplay.prototype._displaySearchResults = function(results) {
64 | var resultsHolder = $($("#searchResults").find(".modal-body")),
65 | fragment = document.createDocumentFragment(),
66 | resultsList = document.createElement("ul");
67 |
68 | resultsHolder.empty();
69 |
70 | for (var idx = 0; idx < results.length; idx++) {
71 | var result = results[idx],
72 | item = document.createElement("li"),
73 | link = document.createElement("a");
74 |
75 | link.href = result.id;
76 | link.innerHTML = result.title;
77 |
78 | item.appendChild(link)
79 | resultsList.appendChild(item);
80 | }
81 |
82 | fragment.appendChild(resultsList);
83 | resultsHolder.append(fragment);
84 |
85 | $("#searchResults").modal({"show": true});
86 | };
87 |
88 | return new SearcherDisplay();
89 | })($);
90 |
--------------------------------------------------------------------------------
/extension/js/currentcell.js:
--------------------------------------------------------------------------------
1 | /**
2 | * Module to detect the currently running cell.
3 | *
4 | * The notebook sends execution requests, and they queue up on the message channel.
5 | * There is no straight forward way to detect the currently running cell.
6 | * Here we use a queue to store execution requests and dequeue elements as the kernel becomes idle after the requests
7 | * @module currentcell
8 | */
9 |
10 | import Jupyter from 'base/js/namespace';
11 | import events from 'base/js/events';
12 | import codecell from 'notebook/js/codecell';
13 | import $ from 'jquery'
14 |
15 | var CodeCell = codecell.CodeCell;
16 | var current_cell;
17 | var last_cell;
18 | /**The list of cells queued for execution. */
19 | var cell_queue = [];
20 | var registered = false;
21 |
22 | /** Called when an execute.CodeCell event occurs. This means an execute request was sent for the current cell. */
23 | function cell_execute_called(event, data) {
24 |
25 | var cell = data.cell
26 | if (cell instanceof CodeCell) {
27 | if (cell_queue.length <= 0) {
28 | events.trigger('started.currentcell', cell)
29 | events.trigger('started' + cell.cell_id + 'currentcell', cell)
30 | }
31 | cell_queue.push(cell);
32 | current_cell = cell_queue[0];
33 | }
34 | }
35 |
36 | /** Called when the kernel becomes idle. This means that a cell finished executing. */
37 | function cell_execute_finished() {
38 | if (current_cell != null) {
39 | events.trigger('finished.currentcell', current_cell);
40 | events.trigger('finished' + current_cell.cell_id + 'currentcell', current_cell);
41 | }
42 | cell_queue.shift();
43 | current_cell = cell_queue[0]
44 | if (current_cell != null) {
45 | events.trigger('started.currentcell', current_cell)
46 | events.trigger('started' + current_cell.cell_id + 'currentcell', current_cell);
47 | }
48 | }
49 | /** @return {CodeCell} - The running cell, or null. */
50 | function getRunningCell() {
51 | return current_cell
52 | }
53 |
54 | /** @return {CodeCell} - The last run cell, or null. */
55 | function getLastCell() {
56 | return last_cell
57 | }
58 |
59 | /**
60 | * Called when a cell is deleted
61 | *
62 | * @param {event} event - The event object,
63 | * @param {data} data - data of the event, contains the cell
64 | */
65 | function cell_deleted(event, data) {
66 | var cell = data.cell;
67 | var i = cell_queue.indexOf(cell);
68 | if (i >= -1) { cell_queue.splice(i, 1); }
69 | }
70 |
71 | /** Register event listeners for detecting running cells. */
72 | function register() {
73 | if (registered) return;
74 | events.on('execute.CodeCell', cell_execute_called);
75 | events.on('kernel_idle.Kernel', cell_execute_finished);
76 | events.on('delete.Cell', cell_deleted)
77 | //TODO clear queue on execute error
78 | //For Debugging purposes. Highlights the currently running cell in grey colour.
79 | //events.on('started.currentcell', function (event, cell) { cell.element.css('background-color', '#EEEEEE') });
80 | //events.on('finished.currentcell', function (event, cell) { cell.element.css('background-color', 'white') });
81 | }
82 |
83 | export default {
84 | 'register': register,
85 | 'getRunningCell': getRunningCell,
86 | 'getLastCell': getLastCell,
87 | }
--------------------------------------------------------------------------------
/extension/js/taskdetails.css:
--------------------------------------------------------------------------------
1 | .taskdetails {
2 | font-family: sans-serif;
3 | margin: 10px;
4 | }
5 |
6 | .taskdetails .success {
7 | display: none;
8 | }
9 |
10 | .taskdetails .error {
11 | display: none;
12 | }
13 |
14 | .taskdetails .finish {
15 | display: none;
16 | }
17 |
18 | .taskdetails .metricdata {
19 | display: none;
20 | }
21 |
22 | .taskdetails rect.scheduler-delay-proportion {
23 | fill: #80B1D3;
24 | stroke: #6B94B0;
25 | }
26 |
27 | .taskdetails rect.deserialization-time-proportion {
28 | fill: #FB8072;
29 | stroke: #D26B5F;
30 | }
31 |
32 | .taskdetails rect.shuffle-read-time-proportion {
33 | fill: #FDB462;
34 | stroke: #D39651;
35 | }
36 |
37 | .taskdetails rect.executor-runtime-proportion {
38 | fill: #B3DE69;
39 | stroke: #95B957;
40 | }
41 |
42 | .taskdetails rect.shuffle-write-time-proportion {
43 | fill: #FFED6F;
44 | stroke: #D5C65C;
45 | }
46 |
47 | .taskdetails rect.serialization-time-proportion {
48 | fill: #BC80BD;
49 | stroke: #9D6B9E;
50 | }
51 |
52 | .taskdetails rect.getting-result-time-proportion {
53 | fill: #8DD3C7;
54 | stroke: #75B0A6;
55 | }
56 |
57 | .taskdetails .taskbarsvg {
58 | height: 40px;
59 | width: 100%;
60 | }
61 |
62 | .taskdetails .taskbarsvg {
63 | box-shadow: 0 0 11px 0px rgba(119, 119, 119, 0.36);
64 | }
65 |
66 | .legend-area {
67 | font-size: small;
68 | padding: 10px;
69 | margin-top: 5px;
70 | }
71 |
72 | .task-dialog {
73 | padding: 0;
74 | box-shadow: 0px 0px 6px 0px rgba(128, 128, 128, 0.83);
75 | }
76 |
77 | .task-dialog .ui-corner-all {
78 | border-radius: 0px;
79 | }
80 |
81 | .task-dialog .ui-dialog-content.ui-widget-content {
82 | padding: 0;
83 | }
84 |
85 | .task-dialog .ui-widget-header {
86 | border: 1px solid rgb(243, 118, 0);
87 | background: #f37600;
88 | color: #000;
89 | font-weight: bold;
90 | text-align: center;
91 | }
92 |
93 | .taskdetails td {
94 | text-align: center;
95 | border: 1px solid #e4e4e4;
96 | padding: 5px 20px;
97 | }
98 |
99 | .taskdetails th {
100 | text-align: center;
101 | border: 1px solid #e4e4e4;
102 | padding: 5px 20px;
103 | }
104 |
105 | .taskdetails .tasktitle {
106 | font-size: medium;
107 | text-align: center;
108 | }
109 |
110 | .taskdetails .tasktitlestage {
111 | padding: 10px;
112 | font-size: small;
113 | }
114 |
115 | .taskdetails table {
116 | width: 100%;
117 | }
118 |
119 | .taskdetails .RUNNING {
120 | background-color: #42A5F5;
121 | }
122 |
123 | .taskdetails .FAILED {
124 | background-color: #DB3636;
125 | }
126 |
127 | .taskdetails .KILLED {
128 | background-color: #DB3636;
129 | }
130 |
131 | .taskdetails .COMPLETED {
132 | background-color: #20B520;
133 | }
134 |
135 | .taskdetails .SUCCESS {
136 | background-color: #20B520;
137 | }
138 |
139 | .taskdetails .UNKNOWN {
140 | background-color: #9c27b0;
141 | }
142 |
143 | .taskdetails .COMPLETED, .taskdetails .FAILED, .taskdetails .KILLED, .taskdetails .RUNNING, .taskdetails .UNKNOWN, .taskdetails .SUCCESS {
144 | font-size: 75%;
145 | padding: 4px 8px;
146 | color: white;
147 | border-radius: 2px;
148 | }
149 |
150 | .taskdetails .legend-area table td:nth-of-type(1) {
151 | width: 20px;
152 | }
153 |
154 | .taskdetails .legend-area svg {
155 | height: 15px;
156 | }
--------------------------------------------------------------------------------
/docs/usecase_distroot.md:
--------------------------------------------------------------------------------
1 |
2 | **[Final Report](index.md)** |
3 | **[Installation](install.md)** |
4 | **[How it Works](how.md)** |
5 | **[Use Cases](usecases.md)** |
6 | **[Code](https://github.com/krishnan-r/sparkmonitor)** |
7 | **[License](https://github.com/krishnan-r/sparkmonitor/blob/master/LICENSE.md)**
8 |
9 |
10 | # A DistROOT Example
11 |
12 | ## Introduction
13 | One of the main goals of this project was to make it easier for the scientific community in leveraging the power of distributed computing for scientific analysis. In particular by combining Apache Spark and Jupyter Notebooks. [ROOT](https://root.cern.ch/) is a popular library based on C++ used for various scientific analysis tasks.
14 | This example for the SparkMonitor extension, uses the [DistROOT](https://github.com/etejedor/root-spark) module to process ROOT TTree objects in a distributed cluster using Apache Spark. The Spark job is divided into a map phase, that extracts data from the TTree and uses it to fill histograms, and a reduce phase, that merges all the histograms into a final list.
15 |
16 | ## Environment
17 | - This use case was tested on a 4 node spark cluster running on the CERN IT Infrastructure.
18 | - A test instance of [SWAN](http://swan.web.cern.ch/) - a Service for Web based ANalysis based on the Jupyter interface was used with the extension installed.
19 | - The data was uploaded to a central storage service and accessed from the cluster.
20 |
21 | ## Notebook
22 | - The DistROOT example notebook can be found [here](https://github.com/krishnan-r/sparkmonitor/blob/master/notebooks/DistROOT.ipynb)
23 |
24 | ## Monitoring
25 |
26 | - The main job in this notebook ran for 6 minutes and 6 seconds.
27 |
28 | 
29 |
30 | - On looking at the graph between tasks and executors, It is visible that, towards the end there is an under utilization of resources. The yellow on the graph shows that two executor cores were idle for around two minutes of the total six minutes the job took. This means that the workload was not efficiently balanced to make the most of the resources available. Now for an enterprise level cluster, running routine jobs, the monitoring indicates that there is potential scope for optimization of the workload.
31 |
32 | 
33 |
34 | - The event timeline provides a complementary picture that completes the story about the running workload. Here it is observed that task 9 and 11 take up more time than the others. This keeps the job waiting and the next stage, no: 2 is started only after they finish. It is possible that the tasks were waiting for a shuffle read of data between the nodes as input, which required the output of task 9 and 11. Some tasks in the mapper phase are taking longer time and the reduce phase is kept waiting, leaving some resources underutilized.
35 |
36 | 
37 |
38 | - The monitoring also provides details of a particular task when clicking on the timeline. It also shows the time spent by the task in different phases. Task 12 in this case took 5 seconds to send the computed result back to the driver, which is something dependent on the result size and network latency.
39 |
40 | 
41 |
42 |
43 |
44 | - The output of the computation, a histogram generated through the distributed Spark Job, bringing together two different paradigms of interactive analysis and distributed computing.
45 |
46 | 
47 |
48 |
49 |
--------------------------------------------------------------------------------
/extension/js/jobtable.css:
--------------------------------------------------------------------------------
1 | .pm .tdstageicon {
2 | display: block;
3 | background-image: url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABgAAAAYCAQAAABKfvVzAAAAXUlEQVR4AWMAgVGwjkGKNA3/GT4wZDAwkqABDA8zaBKtAQp/MjQwsBGnAQGvMVgTpwEB/zFMZ+AjoAEDPmUIpKGGfwzTGPho5OmfDPUMbKREnAYpSSOdgZGSxDcKADdXTK1stp++AAAAAElFTkSuQmCC);
4 | background-repeat: no-repeat;
5 | background-position: center;
6 | background-size: 100%;
7 | width: 15px;
8 | /* display: inline-block; */
9 | top: -2px;
10 | height: 24px;
11 | vertical-align: middle;
12 | transition: transform 0.4s;
13 | transform: rotate(0deg);
14 | }
15 |
16 | .pm .tdstageiconcollapsed {
17 | transform: rotate(90deg);
18 | }
19 |
20 | .pm td.stagetableoffset {
21 | background-color: #e7e7e7;
22 | }
23 |
24 | .pm th {
25 | font-size: small;
26 | background-color: #EEEEEE;
27 | border: 0px;
28 | }
29 |
30 | .pm td {
31 | background-color: white;
32 | border: 0;
33 | font-size: small;
34 | border-top: 1px solid rgba(84, 84, 84, 0.08);
35 | }
36 |
37 | .pm table {
38 | border-radius: 0px;
39 | width: 100%;
40 | border: 1px solid #CFCFCF;
41 | /* height: 10px; */
42 | }
43 |
44 | .pm tbody {
45 | height: 100px;
46 | overflow: auto;
47 | }
48 |
49 | .pm tr {
50 | border: 0px;
51 | }
52 |
53 | .pm td, .pm th {
54 | text-align: center;
55 | vertical-align: middle;
56 | height: 25px;
57 | line-height: 25px;
58 | }
59 |
60 | .pm tr .tdstagebutton:hover ~ td, tr .tdstagebutton:hover {
61 | background-color: rgba(184, 223, 255, 0.37);
62 | }
63 |
64 | .pm th.thbutton {
65 | width: 4%;
66 | }
67 |
68 | .pm th.thjobid {
69 | width: 6%;
70 | }
71 |
72 | .pm th.thjobname {
73 | width: 10%;
74 | }
75 |
76 | .pm th.thjobstatus {
77 | width: 12%;
78 | }
79 |
80 | .pm th.thjobtages {
81 | width: 10%;
82 | }
83 |
84 | .pm th.thjobtasks {
85 | width: 28%;
86 | }
87 |
88 | .pm th.thjobstart {
89 | width: 20%;
90 | }
91 |
92 | .pm th.thjobtime {
93 | width: 10%;
94 | }
95 |
96 | .pm th.thstageid {
97 | width: 8%;
98 | }
99 |
100 | .pm th.thstagename {
101 | width: 10%;
102 | }
103 |
104 | .pm th.thstagestatus {
105 | width: 17%;
106 | }
107 |
108 | .pm th.thstagetasks {
109 | width: 33%;
110 | }
111 |
112 | .pm th.thstagestart {
113 | width: 20%;
114 | }
115 |
116 | .pm th.thstageduration {
117 | width: 12%
118 | }
119 |
120 | progress {
121 | padding: 2px;
122 | }
123 |
124 | .pm .tdstatus {
125 | padding: 2px;
126 | }
127 |
128 | .pm .RUNNING {
129 | background-color: #42A5F5;
130 | }
131 |
132 | .pm .FAILED {
133 | background-color: #DB3636;
134 | }
135 |
136 | .pm .COMPLETED {
137 | background-color: #20B520;
138 | }
139 |
140 | .pm .PENDING {
141 | background-color: #9c27b0;
142 | }
143 |
144 | .pm .SKIPPED {
145 | background-color: #616161;
146 | }
147 |
148 | .pm .COMPLETED, .pm .FAILED, .pm .RUNNING, .pm .PENDING, .pm .SKIPPED {
149 | font-size: 75%;
150 | padding: 4px 8px;
151 | color: white;
152 | border-radius: 2px;
153 | }
154 |
155 | .pm .stagetable tr th {
156 | background: rgb(235, 235, 235);
157 | }
158 |
159 | .pm .cssprogress {
160 | overflow: hidden;
161 | display: block;
162 | background: #e7e7e7;
163 | width: 100%;
164 | height: 20px;
165 | padding: 0;
166 | overflow: hidden;
167 | text-align: left;
168 | position: relative;
169 | font-size: 75%;
170 | border-radius: 2px;
171 | color: white;
172 | }
173 |
174 | .pm .cssprogress .val1 {
175 | width: 0%;
176 | background: #20B520;
177 | }
178 |
179 | .pm .cssprogress .data {
180 | text-align: center;
181 | width: 100%;
182 | position: absolute;
183 | z-index: 4;
184 | line-height: 20px;
185 | }
186 |
187 | .pm .cssprogress .val2 {
188 | background: #42A5F5;
189 | width: 0%;
190 | }
191 |
192 | .pm .cssprogress span {
193 | position: relative;
194 | height: 100%;
195 | display: inline-block;
196 | position: relative;
197 | overflow: hidden;
198 | margin: 0;
199 | padding: 0;
200 | transition: width 1s;
201 | }
--------------------------------------------------------------------------------
/docs/usecase_testing.md:
--------------------------------------------------------------------------------
1 |
2 | **[Final Report](index.md)** |
3 | **[Installation](install.md)** |
4 | **[How it Works](how.md)** |
5 | **[Use Cases](usecases.md)** |
6 | **[Code](https://github.com/krishnan-r/sparkmonitor)** |
7 | **[License](https://github.com/krishnan-r/sparkmonitor/blob/master/LICENSE.md)**
8 |
9 |
10 | # A simple example notebook
11 |
12 | ## Introduction
13 | This notebook tests a majority of Spark API through pySpark.
14 | It mainly covers most [RDD](https://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-distributed-datasets-rdds) APIs and runs a random job.
15 | It also simulates some errors in Spark Jobs to test the extension
16 |
17 | ## Notebook
18 | - [Testing Extension Notebook](https://github.com/krishnan-r/sparkmonitor/blob/master/notebooks/Testing%20Extension.ipynb)
19 |
20 | ## Environment
21 | - This notebook was run with a local Apache Spark installation, using 1 executor and 4 cores.
22 |
23 | ## Monitoring the Notebook
24 |
25 | ### Automatic Configuration
26 | - The extension automatically provides a SparkConf object to enable monitoring. This object might optionally be completed by the user with additional configuration to start the Spark Application.
27 |
28 | 
29 | ### Features
30 | - A table of jobs and collapsible stages shows the jobs started by the current cell.
31 |
32 | 
33 | - An aggregated view of resource allocation - a graph between number of active tasks and executor cores. The green vertical lines show jobs start and end points. Looking at this graph, it is possible to determine at any instant the amount of executor resources utilized, and the amount that remained idle. A job that is stuck waiting for a previous result, would delay the result of the entire computation. The yellow areas in the graph are the executor cores that remained idle at that instant. A workload with more yellow implies that it is under utilizing cluster resources and not efficiently running in parallel.
34 |
35 | 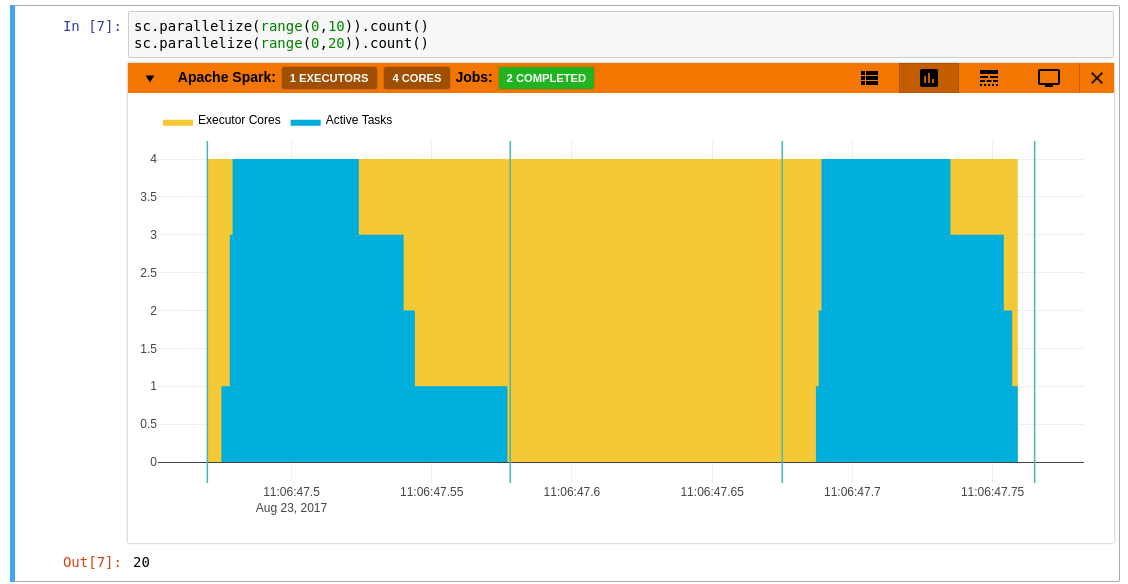
36 | - An event timeline. The timeline shows jobs stages and tasks in each executor running on the cluster. It shows the overall split up of the job's tasks across executors. Clicking on an item gives more details about it. The timeline gives a picture of what is running in the cluster. It also helps locate bottlenecks and detect any kind of delays due to particular tasks delaying the result.
37 |
38 | 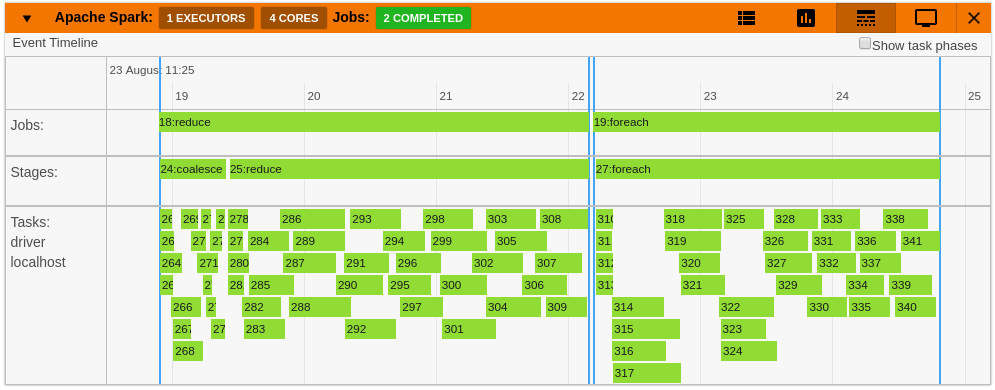
39 | ## Detecting Failures
40 | - Failed jobs show up with a red status on the title.
41 |
42 | 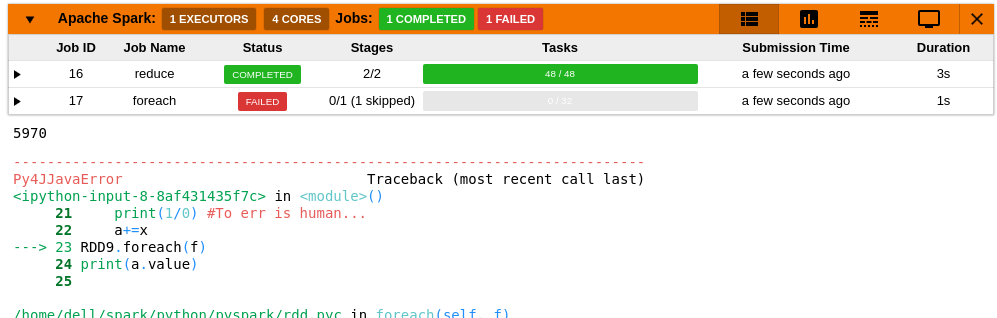
43 | - In the timeline failed jobs are highlighted in red.
44 |
45 | 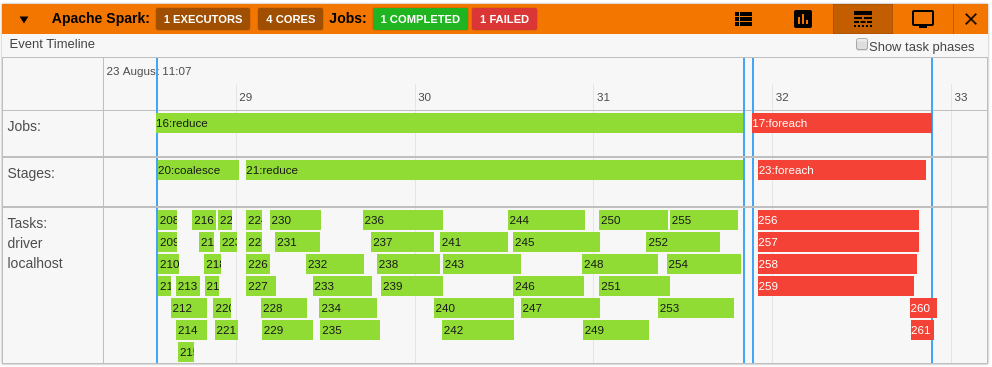
46 | - Clicking on a failed task shows the failure reason with the stack trace.
47 |
48 | 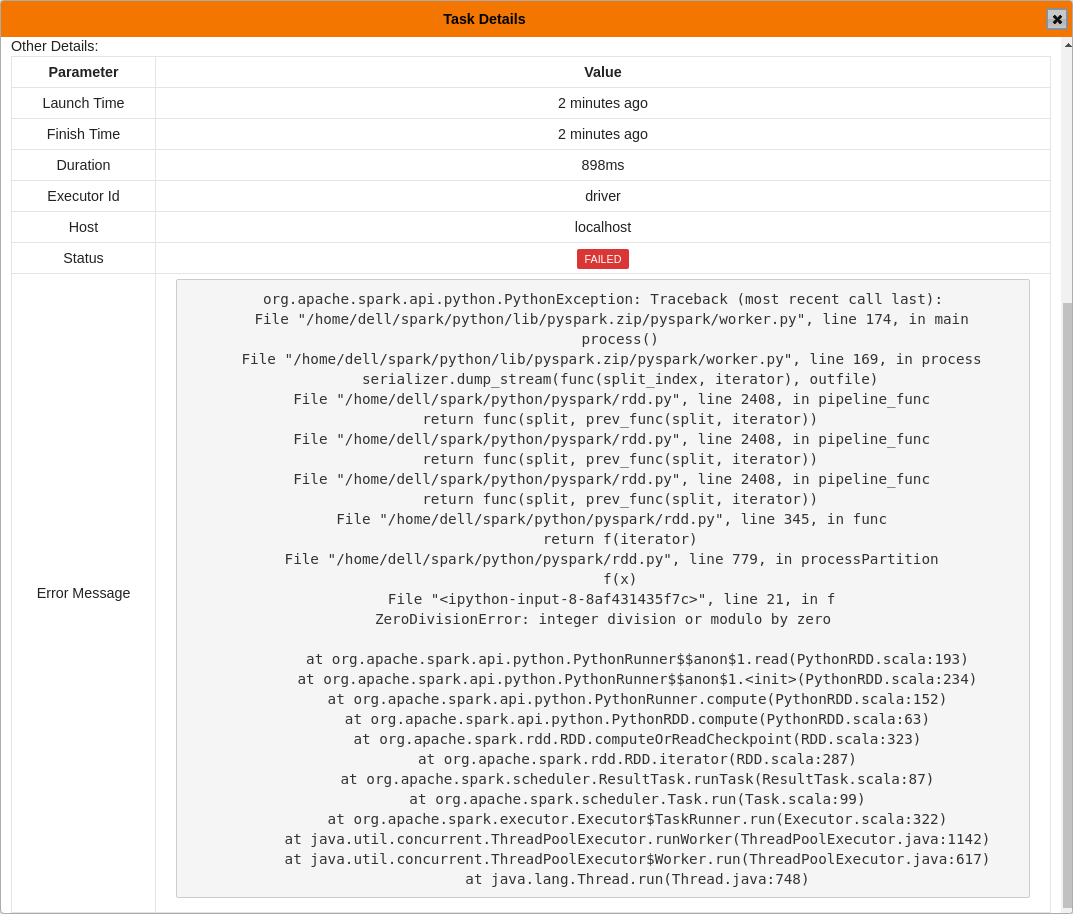
49 |
50 | ### Too many cells with Spark
51 | - In some cases there are too many cells with trivial Spark Jobs, in these cases monitoring is not really necessary. So the extension provides features to collapse/hide the display.
52 |
53 | 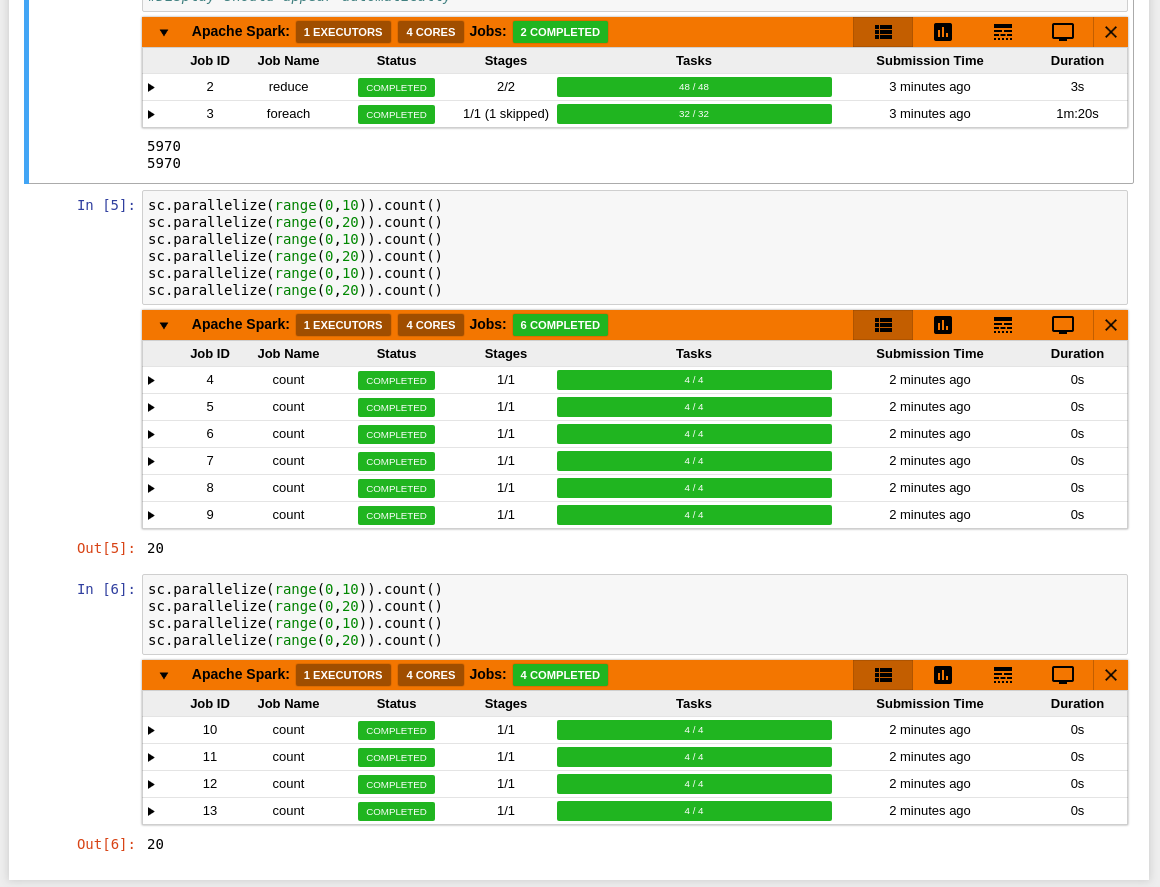
54 |
55 | - All monitoring displays can be easily be hidden and shown using the button on the toolbar.
56 |
57 | 
58 |
59 | 
60 |
61 | - An individual display can be minimized by clicking on the arrow on the top left corner.
62 |
63 | 
64 |
65 | - Clicking on the close button on the top right corner hides the display all together.
66 |
67 |
68 |
69 |
--------------------------------------------------------------------------------
/notebooks/Testing Extension.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Testing SparkMonitor Extension"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "The configuration object `SparkConf` is provided by the extension, added to the namespace as '`conf`'. \n",
15 | "The user passes this to the SparkContext \n"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": null,
21 | "metadata": {
22 | "collapsed": true
23 | },
24 | "outputs": [],
25 | "source": [
26 | "print(conf.toDebugString()) #Instance of SparkConf with options set by the extension"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "metadata": {},
32 | "source": [
33 | "User adds other options and starts the spark context"
34 | ]
35 | },
36 | {
37 | "cell_type": "code",
38 | "execution_count": null,
39 | "metadata": {},
40 | "outputs": [],
41 | "source": [
42 | "conf.setAppName('ExtensionTestingApp')\n",
43 | "#conf.setMaster('spark://dell-inspiron:7077') # if master is started using command line\n",
44 | "conf.setMaster('local[*]')\n",
45 | "from pyspark import SparkContext\n",
46 | "sc=SparkContext.getOrCreate(conf=conf) #Start the spark context"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "### Example spark job"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": null,
59 | "metadata": {
60 | "collapsed": true
61 | },
62 | "outputs": [],
63 | "source": [
64 | "import time\n",
65 | "b=sc.broadcast([3,5]) #Creating a broadcast variable available on all executors\n",
66 | "a=sc.accumulator(0) #Creating an accumulator for adding values across executors\n",
67 | "RDD0=sc.parallelize([y for y in range(0,5)]) #RDD from input python collection\n",
68 | "RDD2=sc.parallelize([z for z in range(10,15)])\n",
69 | "RDD1=RDD0.cartesian(RDD2) \n",
70 | "cached=RDD2.cache() #Testing cached RDD\n",
71 | "RDD22=RDD1.map(lambda x:x[0]+x[1]+b.value[0])\n",
72 | "RDD3=RDD22.repartition(5) # To trigger a new stage.\n",
73 | "RDD4=RDD2.map(lambda x: 3*x-b.value[0])\n",
74 | "RDD5=RDD3.filter(lambda x:x%2==0)\n",
75 | "RDD6=RDD4.filter(lambda x:x%2!=0)\n",
76 | "RDD7=RDD5.cartesian(RDD6)\n",
77 | "RDD8=RDD7.flatMap(lambda x: [x[i] for i in range(0,2)])\n",
78 | "RDD9=RDD8.union(cached)\n",
79 | "ans=RDD9.reduce(lambda x,y: x+y) # Doing a simple sum on the random data.\n",
80 | "print(ans)\n",
81 | "def f(x):\n",
82 | " global a\n",
83 | " time.sleep(0.5) #Making the job run a little longer\n",
84 | " a+=x\n",
85 | "RDD9.foreach(f)\n",
86 | "print(a.value)\n",
87 | "#Display should appear automatically"
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": null,
93 | "metadata": {},
94 | "outputs": [],
95 | "source": [
96 | "sc.parallelize(range(0,100)).count()\n",
97 | "sc.parallelize(range(0,100)).count()\n",
98 | "sc.parallelize(range(0,100)).count()\n",
99 | "sc.parallelize(range(0,100)).count()\n",
100 | "sc.parallelize(range(0,100)).count()"
101 | ]
102 | },
103 | {
104 | "cell_type": "code",
105 | "execution_count": null,
106 | "metadata": {},
107 | "outputs": [],
108 | "source": [
109 | "sc.parallelize(range(0,100)).map(lambda x:x*x).filter(lambda x:x%2==0).count()\n",
110 | "sc.parallelize(range(0,100)).map(lambda x:x*x).filter(lambda x:x%2==0).count()\n",
111 | "sc.parallelize(range(0,100)).map(lambda x:x*x).filter(lambda x:x%2==0).count()\n",
112 | "sc.parallelize(range(0,100)).map(lambda x:x*x).filter(lambda x:x%2==0).count()"
113 | ]
114 | },
115 | {
116 | "cell_type": "code",
117 | "execution_count": null,
118 | "metadata": {},
119 | "outputs": [],
120 | "source": [
121 | "sc.stop()"
122 | ]
123 | }
124 | ],
125 | "metadata": {
126 | "anaconda-cloud": {},
127 | "celltoolbar": "Edit Metadata",
128 | "kernelspec": {
129 | "display_name": "Python [conda root]",
130 | "language": "python",
131 | "name": "conda-root-py"
132 | },
133 | "language_info": {
134 | "codemirror_mode": {
135 | "name": "ipython",
136 | "version": 2
137 | },
138 | "file_extension": ".py",
139 | "mimetype": "text/x-python",
140 | "name": "python",
141 | "nbconvert_exporter": "python",
142 | "pygments_lexer": "ipython2",
143 | "version": "2.7.13"
144 | }
145 | },
146 | "nbformat": 4,
147 | "nbformat_minor": 2
148 | }
149 |
--------------------------------------------------------------------------------
/docs/how.md:
--------------------------------------------------------------------------------
1 |
2 | **[Final Report](index.md)** |
3 | **[Installation](install.md)** |
4 | **[How it Works](how.md)** |
5 | **[Use Cases](usecases.md)** |
6 | **[Code](https://github.com/krishnan-r/sparkmonitor)** |
7 | **[License](https://github.com/krishnan-r/sparkmonitor/blob/master/LICENSE.md)**
8 |
9 |
10 | # SparkMonitor - How the extension works
11 |
12 | 
13 |
14 | [Jupyter Notebook](http://jupyter.org/) is a web based application that follows a client-server architecture. It consists of a JavaScript browser client that renders the notebook interface and a web server process on the back end. The computation of the cells are outsourced to a separate kernel process running on the server. To extend the notebook, it is required to implement a separate extension component for each part.
15 |
16 | The SparkMonitor extension for Jupyter Notebook has 4 components.
17 |
18 | 1. Notebook Frontend extension written in JavaScript.
19 | 2. [IPython](https://ipython.org/) Kernel extension written in Python.
20 | 3. Notebook web server extension written in Python.
21 | 4. An implementation of [SparkListener](https://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.scheduler.SparkListener) interface written in Scala.
22 |
23 | ---
24 | ## The Frontend Extension
25 | 
26 | - Written in JavaScript.
27 | - Receives data from the IPython kernel through Jupyter's comm API mechanism for widgets.
28 | - Jupyter frontend extensions are requirejs modules that are loaded when the browser page loads.
29 | - Contains the logic for displaying the progress bars, graphs and timeline.
30 | - Keeps track of cells running using a queue by tracking execution requests and kernel busy/idle events.
31 | - Creates and renders the display if a job start event is received while a cell is running.
32 |
33 | ---
34 | ## [IPython](https://ipython.org/) Kernel Extension
35 | 
36 | - The kernel extension is an importable Python module called `sparkmonitor.kernelextension`
37 | - It is configured to load when the IPython kernel process starts.
38 | - The extension acts as a bridge between the frontend and the SparkListener callback interface.
39 | - To communicate with the SparkListener the extension opens a socket and waits for connections.
40 | - The port of the socket is exported as an environment variable. When a Spark application starts, the custom SparkListener connects to this port and forwards data.
41 | - To communicate with the frontend the extension uses the IPython Comm API provided by Jupyter.
42 | - The extension also adds to the users namespace a [SparkConf](http://spark.apache.org/docs/2.1.0/api/python/pyspark.html#pyspark.SparkConf) instance named as `conf`. This object is configured with the Spark properties that makes Spark load the custom SparkListener as well as adds the necessary JAR file paths to the Java class path.
43 |
44 |
45 | ---
46 | ## Scala [SparkListener](https://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.scheduler.SparkListener)
47 | 
48 | - Written in Scala.
49 | - The listener receives notifications of [Apache Spark](https://spark.apache.org/) application lifecycle events as callbacks.
50 | - The custom implementation used in this extension connects to a socket opened by the IPython kernel extension.
51 | - All the data is forwarded to the kernel through this socket which forwards it to the frontend JavaScript.
52 |
53 | ---
54 | ## The Notebook Webserver Extension - A Spark Web UI proxy
55 | 
56 | - Written in Python.
57 | - This module proxies the Spark UI running typically on 127.0.0.1:4040 to the user through Jupyter's web server.
58 | - Jupyter notebook is based on the [Tornado](http://www.tornadoweb.org/en/stable/) web server back end. Tornado is a Python webserver.
59 | - Jupyter webserver extensions are custom request handlers sub-classing the `IPythonHandler` class. They provide custom endpoints with additional content.
60 | - This module provides the Spark UI as an endpoint at `notebook_base_url/sparkmonitor`.
61 | - In the front end extension, the Spark UI can also be accessed as an IFrame dialog through the monitoring display.
62 | - For the Spark UI web application to work as expected, the server extension replaces all relative URLs in the requested page, adding the endpoints base URL to each.
63 |
--------------------------------------------------------------------------------
/extension/js/taskdetails.html:
--------------------------------------------------------------------------------
1 |
2 |
Task 5from Stage 6
3 |
4 |
5 |
14 |
15 |
16 | Metrics:
17 |
18 |
19 |
20 |
21 |
Phase
22 |
Time Taken
23 |
24 |
25 |
26 |
27 |
28 |
31 |
32 |
Scheduler Delay
33 |
0
34 |
35 |
36 |
37 |
40 |
41 |
Task Deserialization Time
42 |
0
43 |
44 |
45 |
46 |
49 |
50 |
Shuffle Read Time
51 |
0
52 |
53 |
54 |
55 |
58 |
59 |
Executor Computing Time
60 |
0
61 |
62 |
63 |
64 |
67 |
68 |
Shuffle Write Time
69 |
0
70 |
71 |
72 |
73 |
76 |
77 |
Result Serialization Time
78 |
0
79 |
80 |
81 |
82 |
85 |
86 |
Getting Result Time
87 |
0
88 |
89 |
90 |
91 |
92 | Other Details:
93 |
94 |
95 |
96 |
Parameter
97 |
Value
98 |
99 |
100 |
101 |
102 |
Launch Time
103 |
0
104 |
105 |
106 |
Finish Time
107 |
0
108 |
109 |
110 |
Duration
111 |
0
112 |
113 |
114 |
Executor Id
115 |
0
116 |
117 |
118 |
Host
119 |
0
120 |
121 |
122 |
Status
123 |
nil
124 |
125 |
126 |
Error Message
127 |
128 |
129 |
130 |
131 |
132 |
133 |
--------------------------------------------------------------------------------
/extension/js/taskdetails.js:
--------------------------------------------------------------------------------
1 | /**
2 | * Module to display a popup with details of a task.
3 | * @module taskdetails
4 | */
5 |
6 | import './taskdetails.css' // CSS styles
7 | import taskHTML from './taskdetails.html' // Template HTML
8 | import $ from 'jquery'; // jQuery to manipulate the DOM
9 | import moment from 'moment' // moment to format date objects
10 |
11 | /**
12 | * Shows a popup dialog with details of a task.
13 | * @param {Object} item - data about the task.
14 | */
15 | function showTaskDetails(item) {
16 | var div = $('').html(taskHTML);
17 | fillData(div, item);
18 | var options = {
19 | dialogClass: 'noTitleStuff',
20 | title: "Task Details",
21 | width: 800,
22 | height: 500,
23 | autoResize: false,
24 | dialogClass: "task-dialog",
25 | position: { my: "right", at: "right", of: window },
26 | }
27 | div.dialog(options);
28 | }
29 |
30 | /**
31 | * Fills data in the template HTML element.
32 | * @param {Object} element - the HTML element
33 | * @param {Object} item - data about the task.
34 | */
35 | function fillData(element, item) {
36 | var data = item.data;
37 | element.find('.data-taskid').text(data.taskId);
38 | element.find('.data-stageid').text(data.stageId);
39 | element.find('.data-host').text(data.host);
40 | element.find('.data-executorid').text(data.executorId);
41 | var status = $('').addClass(data.status).text(data.status)
42 | element.find('.data-status').html(status);
43 | var start = $('').addClass('timeago').attr('data-livestamp', new Date(data.launchTime)).attr('title', new Date(data.launchTime).toString()).livestamp(new Date(data.launchTime));
44 | element.find('.data-launchtime').html(start);
45 | if (data.finishTime) {
46 | var end = $('').addClass('timeago').attr('data-livestamp', new Date(data.finishTime)).attr('title', new Date(data.finishTime).toString()).livestamp(new Date(data.finishTime));
47 | element.find('.finish').show();
48 | element.find('.data-finishtime').html(end);
49 | var duration = moment.duration(new Date(data.finishTime).getTime() - new Date(data.launchTime).getTime());
50 | element.find('.data-duration').text(duration.format("d[d] h[h]:mm[m]:ss[s]:SS[ms]"));
51 | }
52 | if (data.status == "FAILED" || data.status == "KILLED") {
53 | element.find('.error').show();
54 | element.find('.data-error').text(data.errorMessage);
55 | }
56 | if (data.status == "SUCCESS" || data.status == "FAILED" || data.status == "KILLED") {
57 | var metrics = data.metrics;
58 | element.find('.metricdata').show();
59 | var e = element.find('.legend-area');
60 | var svg = element.find('.taskbarsvg');
61 | var format = "d[d] h[h]:mm[m]:ss[s]:SS[ms]";
62 | svg.find('.scheduler-delay-proportion')
63 | .attr('x', '' + metrics.schedulerDelayProportionPos + '%')
64 | .attr('width', '' + metrics.schedulerDelayProportion + '%');
65 | e.find('.scheduler-delay').text(moment.duration(metrics.schedulerDelay).format(format));
66 |
67 | svg.find('.deserialization-time-proportion')
68 | .attr('x', '' + metrics.deserializationTimeProportionPos + '%')
69 | .attr('width', '' + metrics.deserializationTimeProportion + '%');
70 | e.find('.deserialization-time').text(moment.duration(metrics.deserializationTime).format(format));
71 |
72 | svg.find('.shuffle-read-time-proportion')
73 | .attr('x', '' + metrics.shuffleReadTimeProportionPos + '%')
74 | .attr('width', '' + metrics.shuffleReadTimeProportion + '%');
75 | e.find('.shuffle-read-time').text(moment.duration(metrics.shuffleReadTime).format(format));
76 |
77 | svg.find('.executor-runtime-proportion')
78 | .attr('x', '' + metrics.executorComputingTimeProportionPos + '%')
79 | .attr('width', '' + metrics.executorComputingTimeProportion + '%');
80 | e.find('.executor-runtime').text(moment.duration(metrics.executorComputingTime).format(format));
81 |
82 | svg.find('.shuffle-write-time-proportion')
83 | .attr('x', '' + metrics.shuffleWriteTimeProportionPos + '%')
84 | .attr('width', '' + metrics.shuffleWriteTimeProportion + '%');
85 | e.find('.shuffle-write-time').text(moment.duration(metrics.shuffleWriteTime).format(format));
86 |
87 | svg.find('.serialization-time-proportion')
88 | .attr('x', '' + metrics.serializationTimeProportionPos + '%')
89 | .attr('width', '' + metrics.serializationTimeProportion + '%');
90 | e.find('.serialization-time').text(moment.duration(metrics.serializationTime).format(format));
91 |
92 | svg.find('.getting-result-time-proportion')
93 | .attr('x', '' + metrics.gettingResultTimeProportionPos + '%')
94 | .attr('width', '' + metrics.gettingResultTimeProportion + '%');
95 | e.find('.getting-result-time').text(moment.duration(metrics.gettingResultTime).format(format));
96 | }
97 | }
98 |
99 | export default {
100 | 'show': showTaskDetails,
101 | }
--------------------------------------------------------------------------------
/extension/sparkmonitor/serverextension.py:
--------------------------------------------------------------------------------
1 | """SparkMonitor Jupyter Web Server Extension
2 |
3 | This module adds a custom request handler to Jupyter web server.
4 | It proxies the Spark Web UI by default running at 127.0.0.1:4040
5 | to the endpoint notebook_base_url/sparkmonitor
6 |
7 | TODO Create unique endpoints for different kernels or spark applications.
8 | """
9 |
10 | from notebook.base.handlers import IPythonHandler
11 | import tornado.web
12 | from tornado import httpclient
13 | import json
14 | import re
15 | import os
16 | from bs4 import BeautifulSoup
17 | import asyncio
18 |
19 | proxy_root = "/sparkmonitor"
20 |
21 |
22 | class SparkMonitorHandler(IPythonHandler):
23 | """A custom tornado request handler to proxy Spark Web UI requests."""
24 |
25 |
26 | async def get(self):
27 | """Handles get requests to the Spark UI
28 |
29 | Fetches the Spark Web UI from the configured ports
30 | """
31 | # print("SPARKMONITOR_SERVER: Handler GET")
32 | baseurl = os.environ.get("SPARKMONITOR_UI_HOST", "127.0.0.1")
33 | port = os.environ.get("SPARKMONITOR_UI_PORT", "4040")
34 | url = "http://" + baseurl + ":" + port
35 | # print("SPARKMONITOR_SERVER: Request URI" + self.request.uri)
36 | # print("SPARKMONITOR_SERVER: Getting from " + url)
37 | request_path = self.request.uri[(
38 | self.request.uri.index(proxy_root) + len(proxy_root) + 1):]
39 | self.replace_path = self.request.uri[:self.request.uri.index(
40 | proxy_root) + len(proxy_root)]
41 | # print("SPARKMONITOR_SERVER: Request_path " + request_path + " \n Replace_path:" + self.replace_path)
42 | backendurl = url_path_join(url, request_path)
43 | self.debug_url = url
44 | self.backendurl = backendurl
45 | http = httpclient.AsyncHTTPClient()
46 | try:
47 | response = await http.fetch(backendurl)
48 | except Exception as e:
49 | print("SPARKMONITOR_SERVER: Spark UI Error ",e)
50 | else:
51 | self.handle_response(response)
52 |
53 | def handle_response(self, response):
54 | """Sends the fetched page as response to the GET request"""
55 | if response.error:
56 | content_type = "application/json"
57 | content = json.dumps({"error": "SPARK_UI_NOT_RUNNING",
58 | "url": self.debug_url, "backendurl": self.backendurl, "replace_path": self.replace_path})
59 | print("SPARKMONITOR_SERVER: Spark UI not running")
60 | else:
61 | content_type = response.headers["Content-Type"]
62 | # print("SPARKSERVER: CONTENT TYPE: "+ content_type + "\n")
63 | if "text/html" in content_type:
64 | content = replace(response.body, self.replace_path)
65 | elif "javascript" in content_type:
66 | body="location.origin +'" + self.replace_path + "' "
67 | content = response.body.replace(b"location.origin",body.encode())
68 | else:
69 | # Probably binary response, send it directly.
70 | content = response.body
71 | self.set_header("Content-Type", content_type)
72 | self.write(content)
73 | self.finish()
74 |
75 |
76 | def load_jupyter_server_extension(nb_server_app):
77 | """
78 | Called when the Jupyter server extension is loaded.
79 |
80 | Args:
81 | nb_server_app (NotebookWebApplication): handle to the Notebook webserver instance.
82 | """
83 | print("SPARKMONITOR_SERVER: Loading Server Extension")
84 | web_app = nb_server_app.web_app
85 | host_pattern = ".*$"
86 | route_pattern = url_path_join(web_app.settings["base_url"], proxy_root + ".*")
87 | web_app.add_handlers(host_pattern, [(route_pattern, SparkMonitorHandler)])
88 |
89 |
90 | try:
91 | import lxml
92 | except ImportError:
93 | BEAUTIFULSOUP_BUILDER = "html.parser"
94 | else:
95 | BEAUTIFULSOUP_BUILDER = "lxml"
96 | # a regular expression to match paths against the Spark on EMR proxy paths
97 | PROXY_PATH_RE = re.compile(r"\/proxy\/application_\d+_\d+\/(.*)")
98 | # a tuple of tuples with tag names and their attribute to automatically fix
99 | PROXY_ATTRIBUTES = (
100 | (("a", "link"), "href"),
101 | (("img", "script"), "src"),
102 | )
103 |
104 |
105 | def replace(content, root_url):
106 | """Replace all the links with our prefixed handler links,
107 |
108 | e.g.:
109 | /proxy/application_1467283586194_0015/static/styles.css" or
110 | /static/styles.css
111 | with
112 | /spark/static/styles.css
113 | """
114 | soup = BeautifulSoup(content, BEAUTIFULSOUP_BUILDER)
115 | for tags, attribute in PROXY_ATTRIBUTES:
116 | for tag in soup.find_all(tags, **{attribute: True}):
117 | value = tag[attribute]
118 | match = PROXY_PATH_RE.match(value)
119 | if match is not None:
120 | value = match.groups()[0]
121 | tag[attribute] = url_path_join(root_url, value)
122 | return str(soup)
123 |
124 |
125 | def url_path_join(*pieces):
126 | """Join components of url into a relative url
127 |
128 | Use to prevent double slash when joining subpath. This will leave the
129 | initial and final / in place
130 | """
131 | initial = pieces[0].startswith("/")
132 | final = pieces[-1].endswith("/")
133 | stripped = [s.strip("/") for s in pieces]
134 | result = "/".join(s for s in stripped if s)
135 | if initial:
136 | result = "/" + result
137 | if final:
138 | result = result + "/"
139 | if result == "//":
140 | result = "/"
141 | return result
142 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [](https://travis-ci.org/krishnan-r/sparkmonitor)
2 | # Spark Monitor - An extension for Jupyter Notebook
3 |
4 | ### Note: This project is now maintained at https://github.com/swan-cern/sparkmonitor
5 |
6 | ## [Google Summer of Code - Final Report](https://krishnan-r.github.io/sparkmonitor/)
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 | For the google summer of code final report of this project [click here](https://krishnan-r.github.io/sparkmonitor/)
20 |
21 | ## About
22 |
23 |
24 |
25 |
+
26 |
27 |
=
28 |
29 |
30 |
31 | SparkMonitor is an extension for Jupyter Notebook that enables the live monitoring of Apache Spark Jobs spawned from a notebook. The extension provides several features to monitor and debug a Spark job from within the notebook interface itself.
32 |
33 | ***
34 |
35 | 
36 |
37 | ## Features
38 | * Automatically displays a live monitoring tool below cells that run Spark jobs in a Jupyter notebook
39 | * A table of jobs and stages with progressbars
40 | * A timeline which shows jobs, stages, and tasks
41 | * A graph showing number of active tasks & executor cores vs time
42 | * A notebook server extension that proxies the Spark UI and displays it in an iframe popup for more details
43 | * For a detailed list of features see the use case [notebooks](https://krishnan-r.github.io/sparkmonitor/#common-use-cases-and-tests)
44 | * [How it Works](https://krishnan-r.github.io/sparkmonitor/how.html)
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 | ## Quick Installation
61 | ```bash
62 | pip install sparkmonitor
63 | jupyter nbextension install sparkmonitor --py --user --symlink
64 | jupyter nbextension enable sparkmonitor --py --user
65 | jupyter serverextension enable --py --user sparkmonitor
66 | ipython profile create && echo "c.InteractiveShellApp.extensions.append('sparkmonitor.kernelextension')" >> $(ipython profile locate default)/ipython_kernel_config.py
67 | ```
68 | #### For more detailed instructions [click here](https://krishnan-r.github.io/sparkmonitor/install.html)
69 | #### To do a quick test of the extension:
70 | ```bash
71 | docker run -it -p 8888:8888 krishnanr/sparkmonitor
72 | ```
73 |
74 | ## Integration with ROOT and SWAN
75 | At CERN, the SparkMonitor extension would find two main use cases:
76 | * Distributed analysis with [ROOT](https://root.cern.ch/) and Apache Spark using the DistROOT module. [Here](https://krishnan-r.github.io/sparkmonitor/usecase_distroot.html) is an example demonstrating this use case.
77 | * Integration with [SWAN](https://swan.web.cern.ch/), A service for web based analysis, via a modified [container image](https://github.com/krishnan-r/sparkmonitorhub) for SWAN user sessions.
78 |
79 |
--------------------------------------------------------------------------------
/docs/jsdoc/scripts/toc.js:
--------------------------------------------------------------------------------
1 | (function($) {
2 | var navbarHeight;
3 | var initialised = false;
4 | var navbarOffset;
5 |
6 | function elOffset($el) {
7 | return $el.offset().top - (navbarHeight + navbarOffset);
8 | }
9 |
10 | function scrollToHash(duringPageLoad) {
11 | var elScrollToId = location.hash.replace(/^#/, '');
12 | var $el;
13 |
14 | function doScroll() {
15 | var offsetTop = elOffset($el);
16 | window.scrollTo(window.pageXOffset || window.scrollX, offsetTop);
17 | }
18 |
19 | if (elScrollToId) {
20 | $el = $(document.getElementById(elScrollToId));
21 |
22 | if (!$el.length) {
23 | $el = $(document.getElementsByName(elScrollToId));
24 | }
25 |
26 | if ($el.length) {
27 | if (duringPageLoad) {
28 | $(window).one('scroll', function() {
29 | setTimeout(doScroll, 100);
30 | });
31 | } else {
32 | setTimeout(doScroll, 0);
33 | }
34 | }
35 | }
36 | }
37 |
38 | function init(opts) {
39 | if (initialised) {
40 | return;
41 | }
42 | initialised = true;
43 | navbarHeight = $('.navbar').height();
44 | navbarOffset = opts.navbarOffset;
45 |
46 | // some browsers move the offset after changing location.
47 | // also catch external links coming in
48 | $(window).on("hashchange", scrollToHash.bind(null, false));
49 | $(scrollToHash.bind(null, true));
50 | }
51 |
52 | $.catchAnchorLinks = function(options) {
53 | var opts = $.extend({}, jQuery.fn.toc.defaults, options);
54 | init(opts);
55 | };
56 |
57 | $.fn.toc = function(options) {
58 | var self = this;
59 | var opts = $.extend({}, jQuery.fn.toc.defaults, options);
60 |
61 | var container = $(opts.container);
62 | var tocs = [];
63 | var headings = $(opts.selectors, container);
64 | var headingOffsets = [];
65 | var activeClassName = 'active';
66 | var ANCHOR_PREFIX = "__anchor";
67 | var maxScrollTo;
68 | var visibleHeight;
69 | var headerHeight = 10; // so if the header is readable, its counted as shown
70 | init();
71 |
72 | var scrollTo = function(e) {
73 | e.preventDefault();
74 | var target = $(e.target);
75 | if (target.prop('tagName').toLowerCase() !== "a") {
76 | target = target.parent();
77 | }
78 | var elScrollToId = target.attr('href').replace(/^#/, '') + ANCHOR_PREFIX;
79 | var $el = $(document.getElementById(elScrollToId));
80 |
81 | var offsetTop = Math.min(maxScrollTo, elOffset($el));
82 |
83 | $('body,html').animate({ scrollTop: offsetTop }, 400, 'swing', function() {
84 | location.hash = '#' + elScrollToId;
85 | });
86 |
87 | $('a', self).removeClass(activeClassName);
88 | target.addClass(activeClassName);
89 | };
90 |
91 | var calcHadingOffsets = function() {
92 | maxScrollTo = $("body").height() - $(window).height();
93 | visibleHeight = $(window).height() - navbarHeight;
94 | headingOffsets = [];
95 | headings.each(function(i, heading) {
96 | var anchorSpan = $(heading).prev("span");
97 | var top = 0;
98 | if (anchorSpan.length) {
99 | top = elOffset(anchorSpan);
100 | }
101 | headingOffsets.push(top > 0 ? top : 0);
102 | });
103 | }
104 |
105 | //highlight on scroll
106 | var timeout;
107 | var highlightOnScroll = function(e) {
108 | if (!tocs.length) {
109 | return;
110 | }
111 | if (timeout) {
112 | clearTimeout(timeout);
113 | }
114 | timeout = setTimeout(function() {
115 | var top = $(window).scrollTop(),
116 | highlighted;
117 | for (var i = headingOffsets.length - 1; i >= 0; i--) {
118 | var isActive = tocs[i].hasClass(activeClassName);
119 | // at the end of the page, allow any shown header
120 | if (isActive && headingOffsets[i] >= maxScrollTo && top >= maxScrollTo) {
121 | return;
122 | }
123 | // if we have got to the first heading or the heading is the first one visible
124 | if (i === 0 || (headingOffsets[i] + headerHeight >= top && (headingOffsets[i - 1] + headerHeight <= top))) {
125 | // in the case that a heading takes up more than the visible height e.g. we are showing
126 | // only the one above, highlight the one above
127 | if (i > 0 && headingOffsets[i] - visibleHeight >= top) {
128 | i--;
129 | }
130 | $('a', self).removeClass(activeClassName);
131 | if (i >= 0) {
132 | highlighted = tocs[i].addClass(activeClassName);
133 | opts.onHighlight(highlighted);
134 | }
135 | break;
136 | }
137 | }
138 | }, 50);
139 | };
140 | if (opts.highlightOnScroll) {
141 | $(window).bind('scroll', highlightOnScroll);
142 | $(window).bind('load resize', function() {
143 | calcHadingOffsets();
144 | highlightOnScroll();
145 | });
146 | }
147 |
148 | return this.each(function() {
149 | //build TOC
150 | var el = $(this);
151 | var ul = $('
130 |
131 |
132 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
226 |
227 |
228 |
229 |
--------------------------------------------------------------------------------
/docs/index.md:
--------------------------------------------------------------------------------
1 |
2 | **[Final Report](index.md)** |
3 | **[Installation](install.md)** |
4 | **[How it Works](how.md)** |
5 | **[Use Cases](usecases.md)** |
6 | **[Code](https://github.com/krishnan-r/sparkmonitor)** |
7 | **[License](https://github.com/krishnan-r/sparkmonitor/blob/master/LICENSE.md)**
8 |
9 |
10 | # Google Summer of Code 2017 Final Report
11 | # Big Data Tools for Physics Analysis
12 |
13 | ## Introduction
14 | Jupyter Notebook is an interactive computing environment that is used to create notebooks which contain code, output, plots, widgets and theory. Jupyter notebook offers a convenient platform for interactive data analysis, scientific computing and rapid prototyping of code. A powerful tool used to perform complex computation intensive tasks is Apache Spark. Spark is a framework for large scale cluster computing in Big Data contexts. This project leverages these existing big data tools for use in an interactive scientific analysis environment. Spark jobs can be called from an IPython kernel in Jupyter Notebook using the pySpark module. The results of the computation can be visualized and plotted within the notebook interface. However to know what is happening to a running job, it is required to connect separately to the Spark web UI server. This project implements an extension called SparkMonitor to Jupyter Notebook that enables the monitoring of jobs sent from a notebook application, from within the notebook itself. The extension seamlessly integrates with the cell structure of the notebook and provides real time monitoring capabilities.
15 |
16 | ## Features
17 | - The extension integrates with the cell structure of the notebook and automatically detects jobs submitted from a notebook cell.
18 |
19 | 
20 |
21 | - It displays the jobs and stages spawned from a cell, with real time progress bars, status and resource utilization.
22 |
23 | 
24 |
25 | - The extension provides an aggregated view of the number of active tasks and available executor cores in the cluster.
26 |
27 | 
28 |
29 | - An event timeline displays the overall workload split into jobs, stages and tasks across executors in the cluster.
30 |
31 | 
32 |
33 | - The extension also integrates the Spark Web UI within the notebook page by displaying it in an IFrame pop-up.
34 |
35 | 
36 |
37 | ## Example Use Cases
38 | The extension has been tested with a range of Spark applications. [Here](usecases.md) is a list of use cases the extension has been run with.
39 |
40 |
41 | ## Integration in SWAN and CERN IT Infrastructure
42 | - The extension has been successfully integrated with a test instance of [SWAN](http://swan.web.cern.ch/), a Service for Web based ANalysis at [CERN](https://home.cern/).
43 | - SWAN allows the submission of Spark Jobs from a notebook interface to Spark clusters deployed at CERN.
44 | - SWAN encapsulates user sessions in Docker containers. The extension is installed by modifying the docker container image.
45 | - The extension is loaded to Jupyter whenever the user attaches a Spark Cluster to the notebook environment.
46 | - The customized docker image for the user environment can be found [here](https://github.com/krishnan-r/sparkmonitorhub).
47 | - Using this integration, it is now possible to monitor and debug Spark Jobs running on CERN Clusters using the notebook interface.
48 |
49 | ## Documentation
50 | ### How it Works
51 | - A detailed explanation of how different components in the extension work together can be found [here](how.md).
52 |
53 | ### Code Documentation
54 | - Documentation for the JavaScript code is available [here](jsdoc).
55 | - All the documentation for the code in Python and Scala is available within the [source files](https://github.com/krishnan-r/sparkmonitor) itself.
56 |
57 | ### Installation
58 | - The extension is available as a pip python package through [Github Releases](https://github.com/krishnan-r/sparkmonitor/releases).
59 | - To install and configure the extension or to build from source, follow the instructions [here](install.md).
60 |
61 | ## Gallery
62 |
471 |
472 |
473 |
484 |
485 |
486 |
487 |
488 |
489 |
490 |
491 |
552 |
553 |
554 |
555 |
556 |
557 |
558 |
559 |
560 |
561 |
562 |
567 |
568 |
569 |
570 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------











