15 |
16 | # (2) 从机器内部定位
17 | # 查看mysql服务是否开启
18 | ps -ef | grep mysqld
19 | # 查看tcp端口是否开启
20 | netstat -lnpt
21 | # 查看mysql是否指定了bind-address
22 | vim /etc/mysql/my.cnf
23 | #查看mysql的账号是否允许外部连接(需要重启mysql:/etc/init.d/mysqld restart)
24 | mysql -u root -p
25 | use mysql
26 | select user,host from user;
27 | update user set host=‘%’ where user=‘root’;
28 | 或
29 | GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'mypassword' WITH GRANT OPTION;
30 | # 查看防火墙是否开启mysql端口
31 | iptables -S
32 | /sbin/iptables -I INPUT -p tcp --dport 8011 -j ACCEPT #开启8011端口
33 | /etc/init.d/iptables restart
34 | ```
--------------------------------------------------------------------------------
/Nginx/01-Nginx简介.md:
--------------------------------------------------------------------------------
1 | - [1. 什么是nginx](#1-什么是nginx)
2 | - [2. 正向代理与反向代理](#2-正向代理与反向代理)
3 | - [2.1 概念](#21-概念)
4 | - [2.2 区别](#22-区别)
5 | - [正向代理:客户端 <一> 代理 一>服务端](#正向代理客户端-一-代理-一服务端)
6 | - [反向代理:客户端 一>代理 <一> 服务端](#反向代理客户端-一代理-一-服务端)
7 | - [3. 负载均衡](#3-负载均衡)
8 | - [4. 动静分离](#4-动静分离)
9 |
10 | # 1. 什么是nginx
11 |
12 | Nginx ("engine x") 是一个高性能的 HTTP 和反向代理服务器,特点是占有内存少,并发能力强。
13 |
14 | Nginx 可以作为静态页面的 web 服务器,同时还支持 CGI 协议的动态语言,比如 perl、php等,但是不支持 java。Java 程序只能通过与 tomcat 配合完成。Nginx 专为性能优化而开发,性能是其最重要的考量,实现上非常注重效率 ,能经受高负载的考验,有报告表明能支持高达 50,000 个并发连接数。
15 |
16 | # 2. 正向代理与反向代理
17 |
18 | ## 2.1 概念
19 |
20 | **正向代理**是一个位于客户端和目标服务器之间的代理服务器(中间服务器)。为了从原始服务器取得内容,客户端向代理服务器发送一个请求,并且指定目标服务器,之后代理向目标服务器转交并且将获得的内容返回给客户端。正向代理的情况下客户端必须要进行一些特别的设置才能使用。
21 |
22 | **反向代理**正好相反。对于客户端来说,反向代理就好像目标服务器。并且客户端不需要进行任何设置。客户端向反向代理发送请求,接着反向代理判断请求走向何处,并将请求转交给客户端,使得这些内容就好似他自己一样,一次客户端并不会感知到反向代理后面的服务,也因此不需要客户端做任何设置,只需要把反向代理服务器当成真正的服务器就好了。
23 |
24 | ## 2.2 区别
25 |
26 | 
27 |
28 | 正向代理中,proxy和client同属一个LAN,对server透明; 反向代理中,proxy和server同属一个LAN,对client透明。 实际上proxy在两种代理中做的事都是代为收发请求和响应,不过从结构上来看正好左右互换了下,所以把前者那种代理方式叫做正向代理,后者叫做反向代理。
29 |
30 | 
31 |
32 | ### 正向代理:客户端 <一> 代理 一>服务端
33 |
34 | 正向代理简单地打个租房的比方:
35 |
36 | A(客户端)想租C(服务端)的房子,但是A(客户端)并不认识C(服务端)租不到。
37 | B(代理)认识C(服务端)能租这个房子所以你找了B(代理)帮忙租到了这个房子。
38 |
39 | 这个过程中C(服务端)不认识A(客户端)只认识B(代理)
40 | C(服务端)并不知道A(客户端)租了房子,只知道房子租给了B(代理)。
41 |
42 | ### 反向代理:客户端 一>代理 <一> 服务端
43 |
44 | 反向代理也用一个租房的例子:
45 |
46 | A(客户端)想租一个房子,B(代理)就把这个房子租给了他。
47 | 这时候实际上C(服务端)才是房东。
48 | B(代理)是中介把这个房子租给了A(客户端)。
49 |
50 | 这个过程中A(客户端)并不知道这个房子到底谁才是房东
51 | 他都有可能认为这个房子就是B(代理)的
52 |
53 | **由上的例子和图,我们可以知道正向代理和反向代理的区别在于代理的对象不一样,正向代理的代理对象是客户端,反向代理的代理对象是服务端。**
54 |
55 | # 3. 负载均衡
56 |
57 | ***增加服务器的数量,然后将请求分发到各个服务器上,将原先请求集中到单个服务器上的情况改为将请求分发到多个服务器上,将负载分发到不同的服务器,也就是我们所说的负\载均衡***
58 |
59 | 
60 |
61 | # 4. 动静分离
62 |
63 | 为了加快网站的解析速度,可以把动态页面和静态页面由不同的服务器来解析,加快解析速度。降低原来单个服务器的压力。
64 |
65 | 
--------------------------------------------------------------------------------
/Nginx/04-Nginx配置实例-反向代理.md:
--------------------------------------------------------------------------------
1 | - [1. 反向代理实例一](#1-反向代理实例一)
2 | - [实现过程](#实现过程)
3 | - [1. 启动一个 tomcat,浏览器地址栏输入 127.0.0.1:8080,出现如下界面](#1-启动一个-tomcat浏览器地址栏输入-1270018080出现如下界面)
4 | - [2. 通过修改本地 host 文件,将 www.123.com 映射到 127.0.0.1](#2-通过修改本地-host-文件将-www123com-映射到-127001)
5 | - [3. **在 nginx.conf 配置文件中增加如下配置**](#3-在-nginxconf-配置文件中增加如下配置)
6 | - [2. 反向代理实例二](#2-反向代理实例二)
7 | - [实现过程](#实现过程-1)
8 | - [1.准备两个 tomcat,一个 8001 端口,一个 8002 端口,并准备好测试的页面](#1准备两个-tomcat一个-8001-端口一个-8002-端口并准备好测试的页面)
9 | - [2. 修改 nginx 的配置文件在 http 块中添加 server{}](#2-修改-nginx-的配置文件在-http-块中添加-server)
10 |
11 | # 1. 反向代理实例一
12 |
13 | 实现效果:使用 nginx 反向代理,访问 www.123.com 直接跳转到 127.0.0.1:8080
14 |
15 | ## 实现过程
16 |
17 | ### 1. 启动一个 tomcat,浏览器地址栏输入 127.0.0.1:8080,出现如下界面
18 |
19 | 
20 |
21 | ### 2. 通过修改本地 host 文件,将 www.123.com 映射到 127.0.0.1
22 |
23 | 
24 |
25 | 配置完成之后,我们便可以通过 www.123.com:8080 访问到第一步出现的 Tomcat 初始界面。那么如何只需要输入 www.123.com 便可以跳转到 Tomcat 初始界面呢?便用到 nginx 的反向代理。
26 |
27 | ### 3. **在 nginx.conf 配置文件中增加如下配置**
28 |
29 | 
30 |
31 | 如上配置,我们监听 80 端口,访问域名为 www.123.com,不加端口号时默认为 80 端口,故访问该域名时会跳转到 127.0.0.1:8080 路径上。在浏览器端输入 www.123.com 结果如下:
32 |
33 | 
34 |
35 | # 2. 反向代理实例二
36 |
37 | 实现效果:使用 nginx 反向代理,根据访问的路径跳转到不同端口的服务中 nginx 监听端口为 9001,
38 |
39 | > 访问 http://127.0.0.1:9001/edu/ 直接跳转到 127.0.0.1:8081
40 | >
41 | > 访问 http://127.0.0.1:9001/vod/ 直接跳转到 127.0.0.1:8082
42 |
43 | ## 实现过程
44 |
45 | ### 1.准备两个 tomcat,一个 8001 端口,一个 8002 端口,并准备好测试的页面
46 |
47 | ### 2. 修改 nginx 的配置文件在 http 块中添加 server{}
48 |
49 | 
50 |
51 | **location** **指令说明** 该指令用于匹配 URL。
52 |
53 | 语法如下:
54 |
55 | 
56 |
57 | 1. = :用于不含正则表达式的 uri 前,要求请求字符串与 uri 严格匹配,如果匹配成功,就停止继续向下搜索并立即处理该请求。
58 | 2. ~:用于表示 uri 包含正则表达式,并且区分大小写。
59 | 3. ~*:用于表示 uri 包含正则表达式,并且不区分大小写。
60 | 4. ^~:用于不含正则表达式的 uri 前,要求 Nginx 服务器找到标识 uri 和请求字符串匹配度最高的 location 后,立即使用此 location 处理请求,而不再使用 location 块中的正则 uri 和请求字符串做匹配。
61 |
62 | **注意:如果 uri 包含正则表达式,则必须要有 ~ 或者 ~* 标识。**
63 |
64 |
--------------------------------------------------------------------------------
/Nginx/05-Nginx配置实例-负载均衡.md:
--------------------------------------------------------------------------------
1 | - [1. **首先准备两个同时启动的** **Tomcat**](#1-首先准备两个同时启动的-tomcat)
2 | - [2. **在 nginx.conf 中进行配置**](#2-在-nginxconf-中进行配置)
3 |
4 | # 1. **首先准备两个同时启动的** **Tomcat**
5 |
6 | # 2. **在 nginx.conf 中进行配置**
7 |
8 | **在 nginx.conf 中进行配置**
9 |
10 | 
11 |
12 | 随着互联网信息的爆炸性增长,负载均衡(load balance)已经不再是一个很陌生的话题,顾名思义,负载均衡即是将负载分摊到不同的服务单元,既保证服务的可用性,又保证响应足够快,给用户很好的体验。快速增长的访问量和数据流量催生了各式各样的负载均衡产品,很多专业的负载均衡硬件提供了很好的功能,但却价格不菲,这使得负载均衡软件大受欢迎, nginx 就是其中的一个,在 linux 下有 Nginx、LVS、Haproxy 等等服务可以提供负载均衡服务,而且 Nginx 提供了几种分配方式(策略):
13 |
14 | **1、轮询(默认)**
15 |
16 | 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器 down 掉,能自动剔除。
17 |
18 | **2、weight**
19 |
20 | weight 代表权,重默认为 1,权重越高被分配的客户端越多
21 |
22 | 指定轮询几率,weight 和访问比率成正比,用于后端服务器性能不均的情况。 例如:
23 |
24 | 
25 |
26 | **3、ip_hash**
27 |
28 | 每个请求按访问 ip 的 hash 结果分配,这样每个访客固定访问一个后端服务器,可以解决 session 的问题。例如:
29 |
30 | 
31 |
32 | **4、fair(第三方)**
33 |
34 | 按后端服务器的响应时间来分配请求,响应时间短的优先分配。
35 |
36 | 
--------------------------------------------------------------------------------
/Nginx/06-Nginx配置实例-动静分离.md:
--------------------------------------------------------------------------------
1 | - [1. 什么是动静分离](#1-什么是动静分离)
2 | - [2. 准备工作](#2-准备工作)
3 | - [3. 具体配置](#3-具体配置)
4 | - [4. 最终测试](#4-最终测试)
5 |
6 | # 1. 什么是动静分离
7 |
8 | Nginx 动静分离简单来说就是把动态跟静态请求分开,不能理解成只是单纯的把动态页面和静态页面物理分离。严格意义上说应该是动态请求跟静态请求分开,可以理解成使用 Nginx 处理静态页面,Tomcat 处理动态页面。动静分离从目前实现角度来讲大致分为两种,
9 |
10 | **一种是纯粹把静态文件独立成单独的域名,放在独立的服务器上,也是目前主流推崇的方案**;
11 |
12 | **另外一种方法就是动态跟静态文件混合在一起发布,通过 nginx 来分开**。
13 |
14 | 
15 |
16 | 通过 location 指定不同的后缀名实现不同的请求转发。通过 expires 参数设置,可以使浏览器缓存过期时间,减少与服务器之前的请求和流量。具体 Expires 定义:是给一个资源设定一个过期时间,也就是说无需去服务端验证,直接通过浏览器自身确认是否过期即可,所以不会产生额外的流量。此种方法非常适合不经常变动的资源。(如果经常更新的文件,不建议使用 Expires 来缓存),我这里设置 3d,表示在这 3 天之内访问这个 URL,发送一个请求,比对服务器该文件最后更新时间没有变化,则不会从服务器抓取,返回状态码304,如果有修改,则直接从服务器重新下载,返回状态码 200。
17 |
18 | # 2. 准备工作
19 |
20 | **在 liunx 系统中准备静态资源,用于进行访问**
21 |
22 | 
23 |
24 | # 3. 具体配置
25 |
26 | **在** **nginx** **配置文件中进行配置**
27 |
28 | 
29 |
30 | # 4. 最终测试
31 |
32 | **浏览器中输入地址**
33 |
34 | http://服务器ip/image/01.jpg
35 |
36 | 
37 |
38 | **因为配置文件** **autoindex on**
39 |
40 | 
41 |
42 | **在浏览器地址栏输入地址**
43 |
44 | http://服务器ip/www/a.html
45 |
46 | 
--------------------------------------------------------------------------------
/Nginx/07-Nginx搭建高可用集群.md:
--------------------------------------------------------------------------------
1 | - [1. Keepalived+Nginx 高可用集群(主从模式)](#1-keepalivednginx-高可用集群主从模式)
2 | - [2. 配置高可用的准备工作](#2-配置高可用的准备工作)
3 | - [3. 在两台服务器上安装keepalived](#3-在两台服务器上安装keepalived)
4 | - [4. 完成高可用配置(主从配置)](#4-完成高可用配置主从配置)
5 | - [5. 最终测试](#5-最终测试)
6 |
7 | # 1. Keepalived+Nginx 高可用集群(主从模式)
8 |
9 | 
10 |
11 | # 2. 配置高可用的准备工作
12 |
13 | 1. 需要两台服务器
14 | 2. 需要keepalived
15 | 3. 需要虚拟ip
16 |
17 | # 3. 在两台服务器上安装keepalived
18 |
19 | 1. 使用yum命令安装
20 |
21 | ```shell
22 | yum install keepalived-v
23 | ```
24 |
25 | 2. 安装完成之后,在etc里面生成keepalived,有文件keepalived.conf
26 |
27 | # 4. 完成高可用配置(主从配置)
28 |
29 | 1. 修改`/etc/keepalived/keepalived.conf`配置文件
30 |
31 | ```properties
32 | global_defs {
33 |
34 | notification_email {
35 |
36 | acassen@firewall.loc
37 |
38 | failover@firewall.loc
39 |
40 | sysadmin@firewall.loc
41 |
42 | }
43 |
44 | notification_email_from Alexandre.Cassen@firewall.loc
45 |
46 | smtp_server 192.168.17.129
47 |
48 | smtp_connect_timeout 30
49 |
50 | router_id LVS_DEVEL
51 |
52 | }
53 |
54 | vrrp_script chk_http_port {
55 | script "/usr/local/src/nginx_check.sh"
56 |
57 | interval 2 #(检测脚本执行的间隔)
58 |
59 | weight 2
60 |
61 | }
62 |
63 | vrrp_instance VI_1 {
64 |
65 | state BACKUP # 备份服务器上将 MASTER 改为 BACKUP
66 |
67 | interface ens33 //网卡
68 |
69 | virtual_router_id 51 # 主、备机的 virtual_router_id 必须相同
70 |
71 | priority 100 # 主、备机取不同的优先级,主机值较大,备份机值较小
72 |
73 | advert_int 1
74 |
75 | authentication {
76 |
77 | auth_type PASS
78 |
79 |
80 | auth_pass 1111
81 |
82 | }
83 |
84 | virtual_ipaddress {
85 |
86 | 192.168.17.50 // VRRP H 虚拟地址
87 |
88 | }
89 |
90 | }
91 |
92 | ```
93 |
94 | 2. 在`/usr/local/src`添加检测脚本
95 |
96 | ```bash
97 | #!/bin/bash
98 | A=`ps -C nginx –no-header |wc -l`
99 | if [ $A -eq 0 ];
100 | then /usr/local/nginx/sbin/nginx
101 | sleep 2
102 | if [ `ps -C nginx --no-header |wc -l` -eq 0 ];
103 | then killall keepalived
104 | fi
105 | fi
106 | ```
107 |
108 | 3. 把两台服务器上nginx和keepalived启动
109 |
110 | 启动nginx
111 |
112 | ```shell
113 | systemctl start nginx
114 | ```
115 |
116 | 启动keepalived
117 |
118 | ```shell
119 | systemctl start keepalived.service
120 | ```
121 |
122 | # 5. 最终测试
123 |
124 | 1. 在浏览器地址栏输入虚拟地址ip 192.168.17.50
125 |
126 | 
127 |
128 | 
129 |
130 | 2. 把主服务器(192.168.17.129) nginx和keepalived停止,在输入192.168.17.50
131 |
132 | 
133 |
134 | 
--------------------------------------------------------------------------------
/Nginx/08-Nginx原理及优化参数配置.md:
--------------------------------------------------------------------------------
1 | - [1. master和worker](#1-master和worker)
2 | - [2. worker如何进行工作](#2-worker如何进行工作)
3 | - [3. 一个master和多个woker有好处](#3-一个master和多个woker有好处)
4 | - [4. 设置多少个worker合适](#4-设置多少个worker合适)
5 | - [5. 连接数worker_connection](#5-连接数worker_connection)
6 |
7 | # 1. master和worker
8 |
9 | 
10 |
11 | # 2. worker如何进行工作
12 |
13 | 
14 |
15 | # 3. 一个master和多个woker有好处
16 |
17 | 首先,对于每个 worker 进程来说,独立的进程,不需要加锁,所以省掉了锁带来的开销,同时在编程以及问题查找时,也会方便很多。其次,采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master 进程则很快启动新的 worker 进程。当然,worker 进程的异常退出,肯定是程序有 bug 了,异常退出,会导致当前 worker 上的所有请求失败,不过不会影响到所有请求,所以降低了风险。
18 |
19 | 1. 可以使用nginx –s reload热部署,利用nginx进行热部署操作
20 | 2. 每个woker是独立的进程,如果有其中的一个woker出现问题,其他woker独立的,继续进行争抢,实现请求过程,不会造成服务中断
21 |
22 | # 4. 设置多少个worker合适
23 |
24 | Nginx 同 redis 类似都采用了 io 多路复用机制,每个 worker 都是一个独立的进程,但每个进程里只有一个主线程,通过异步非阻塞的方式来处理请求, 即使是千上万个请求也不在话下。每个 worker 的线程可以把一个 cpu 的性能发挥到极致。所以 worker 数和服务器的 cpu 数相等是最为适宜的。设少了会浪费 cpu,设多了会造成 cpu 频繁切换上下文带来的损耗。
25 |
26 | 设置worker 数量: worker_processes 4 work 绑定 cpu(4 work 绑定 4cpu)。
27 |
28 | # 5. 连接数worker_connection
29 |
30 | 这个值是表示每个 worker 进程所能建立连接的最大值,所以,一个 nginx 能建立的最大连接数,应该是 worker_connections * worker_processes。当然,这里说的是最大连接数,对于 HTTP 请 求 本 地 资 源来 说 , 能 够 支 持 的 最大 并 发 数 量 是 worker_connections * worker_processes,如果是支持 http1.1 的浏览器每次访问要占两个连接,所以普通的静态访问最大并发数是: worker_connections * worker_processes /2,而如果是 HTTP 作 为反向代理来说,最大并发数量应该是 worker_connections *worker_processes/4。因为作为反向代理服务器,每个并发会建立与客户端的连接和与后端服务的连接,会占用两个连接。
31 |
32 | 第一个:发送请求,占用了woker 的几个连接数?
33 |
34 | 答案:2或者4个
35 |
36 | 第二个:nginx有一个master,有四个woker,每个woker支持最大的连接数1024,支持的最大并发数是多少?
37 |
38 | 普通的静态访问最大并发数是: worker_connections \* worker_processes /2,
39 |
40 | 而如果是HTTP作为反向代理来说,最大并发数量应该是worker_connections \* worker_processes/4。
--------------------------------------------------------------------------------
/Python/DIGITS/images/修改.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/krislinzhao/StudyNotes/5f03f3ad96fb24d54f0354680bc76c3011d76e01/Python/DIGITS/images/修改.jpg
--------------------------------------------------------------------------------
/Python/DIGITS/images/源码.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/krislinzhao/StudyNotes/5f03f3ad96fb24d54f0354680bc76c3011d76e01/Python/DIGITS/images/源码.jpg
--------------------------------------------------------------------------------
/Python/DIGITS/images/界面.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/krislinzhao/StudyNotes/5f03f3ad96fb24d54f0354680bc76c3011d76e01/Python/DIGITS/images/界面.jpg
--------------------------------------------------------------------------------
/Python/DIGITS/images/运行.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/krislinzhao/StudyNotes/5f03f3ad96fb24d54f0354680bc76c3011d76e01/Python/DIGITS/images/运行.jpg
--------------------------------------------------------------------------------
/Python/DIGITS/windows10下搭建的过程.md:
--------------------------------------------------------------------------------
1 | # 1.anaconda创建一个python2.7的虚拟环境py27
2 | 由于digits官方还是python2.7的版本,这是很蛋疼的一点,后面的安装各种依赖的时候非常的酸爽。由于是python2.7的环境,因此还需要下载一个[用于Python 2.7的Microsoft Visual C ++编译器](https://www.microsoft.com/en-us/download/details.aspx?id=44266)
3 | # 2.安装CUDA8和对应的cuDNN
4 | 参考博客
5 | [https://blog.csdn.net/c20081052/article/details/86683446](https://blog.csdn.net/c20081052/article/details/86683446)
6 | # 3. caffe的安装
7 | 这一步是整个过程中最难和复杂的一步,一开始我尝试的是编译caffe,但是我试了好久还是没用成功。但是我经过不懈的搜索终于在知乎上找到了一个编译好的caffe,在这里非常的感谢这位大神。
8 | [图形界面交互式机器学习:DIGITS搭建](https://zhuanlan.zhihu.com/p/54767210)
9 | ## 3.1 下载编译好的caffe
10 | 按照上面链接给出的百度云盘下载完成后解压,解压后的目录结构如下:
11 | caffe
12 | ├─bin
13 | ├─include
14 | ├─lib
15 | ├─python
16 | └─share
17 | ## 3.2 把编译好的caffe导入创建好的py27环境中
18 | 把caffe则整个文件夹复制到py27环境中(就相当于pip下载的包一样)
19 | 把它导入到D:\Anaconda3\envs\py27\Lib\site-packages(此文件夹是专门存放第三方包的)这个文件夹下面
20 | ## 3.3 添加一个CAFFE_ROOT的环境变量
21 | 在系统环境变量里面添加一个CAFFE_ROOT的环境变量并写入caffe的位置D:\Anaconda3\envs\py27\Lib\site-packages\caffe。
22 | # 4. 安装digits
23 | ## 4.1 下载digits源码
24 | ~~~bash
25 | git clone https://github.com/NVIDIA/DIGITS.git
26 | ~~~
27 | **以下都是在事先创建好的py27虚拟环境中执行的**
28 | ## 4.2 安装包
29 | ~~~bash
30 | pip install -r requirements.txt
31 | ~~~
32 | 由于是python2.7的环境因此肯定有很多包是下载不下来的,这时我就是把它后面的版本号都去掉了,把pydot改成了pydotplus,其实我不知道我这样搞对后面有没有什么影响,但是最后我是运行出来了。
33 | ## 4.3 执行 python -m pip install -e $DIGITS_ROOt
34 | 其中$DIGITS_ROO替换为你的digits根目录。执行完这一步之后会在根目录生成一个digits.egg-info目录。
35 | ## 4.4 运行digits
36 | ~~~bash
37 | python -m digits
38 | ~~~
39 | 
40 | 如果这样就表示成功了。
41 | 接下来就在浏览器中输入localhost:5000,就可以看到这样的界面了。
42 | 
43 | ## 安装digits这一步遇到的问题
44 | 如果你前面的包都下载好了,在这里你会遇到一个关于caffe的问题,这是因为跟目录结构有关。它会报一个找不到caffe和pycaffe的错误。这里我把它的源码稍微修改了一下,修改的位置是DIGITS\digits\config\caffe.py
45 | 这是我修改的地方
46 | 这是源码
47 | 我把那两个install去掉了,如果不去掉的话它会去install/bin和install/python找caffe.exe和pycaffe.exe,而我就没有install这个父目录。
48 |
49 | # 5. 训练mnist
50 | 参考下面这篇博客
51 | [使用DIGITS训练基于mnist数据集的手写数字识别模型](https://piaoling199.github.io/2018/11/14/%E4%BD%BF%E7%94%A8DIGITS%E8%AE%AD%E7%BB%83%E5%9F%BA%E4%BA%8Emnist%E6%95%B0%E6%8D%AE%E9%9B%86%E7%9A%84%E6%89%8B%E5%86%99%E6%95%B0%E5%AD%97%E8%AF%86%E5%88%AB%E6%A8%A1%E5%9E%8B/)
52 |
53 | **以下命令用到python的都是在py27虚拟环境中执行**
54 | ## 5.1 下载mnist数据集
55 | 1. 首先在digits根目录下新建一个mnist目录
56 |
57 | 2. 在digits根目录下执行
58 | ~~~bash
59 | python -m digits.download_data mnist ./mnist
60 | ~~~
61 | ## 5.2 导入刚才创建好的mnist数据集的train
62 | ## 5.3 建立一个模型训练
--------------------------------------------------------------------------------
/Python/Flask框架/flask笔记.md:
--------------------------------------------------------------------------------
1 | 在虚拟环境中将当前虚拟环境中的依赖包以及版本号生成至文件中
2 | pip freeze >requirements.txt
3 | 在新的虚拟环境中,生成项目的运行环境的完全副本
4 | pip install -r requirements.txt
5 | # 指定下载源
6 | pip install -i https://pypi.douban.com/simple/ --trusted-host pypi.douban.com -r requirements.txt
7 |
8 |
9 | flask中mysql数据库的创建
10 | 1.生成数据库
11 | python manage.py db init # 创建迁移仓库,首次使用
12 | python manage.py db migrate # 创建迁移脚本
13 | python manage.py db upgrade # 把迁移应用到数据库中
14 |
15 | 2.启动服务
16 | python manage.py runserver
17 |
18 | 过滤器
19 | 注意:自定义的过滤器名称如果和内置的过滤器重名,会覆盖内置的过滤器
20 | 字符串操作:
21 | safe:禁用转义;
22 | {{ 'hello' | safe }}
23 | capitalize:把变量值的首字母转成大写,其余字母转小写;
24 | {{ 'hello' | capitalize }}
25 | lower:把值转成小写;
26 | {{ 'HELLO' | lower }}
27 | upper:把值转成大写;
28 | {{ 'hello' | upper }}
29 | title:把值中的每个单词的首字母都转成大写;
30 | {{ 'hello' | title }}
31 | trim:把值的首尾空格去掉;
32 | {{ ' hello world ' | trim }}
33 | reverse:字符串反转;
34 | {{ 'olleh' | reverse }}
35 | format:格式化输出;
36 | {{ '%s is %d' | format('name',17) }}
37 | striptags:渲染之前把值中所有的HTML标签都删掉;
38 | {{ 'hello' | striptags }}
39 | 列表操作
40 | first:取第一个元素
41 | {{ [1,2,3,4,5,6] | first }}
42 | last:取最后一个元素
43 | {{ [1,2,3,4,5,6] | last }}
44 | length:获取列表长度
45 | {{ [1,2,3,4,5,6] | length }}
46 | sum:列表求和
47 | {{ [1,2,3,4,5,6] | sum }}
48 | sort:列表排序
49 | {{ [6,2,3,1,5,4] | sort }}
50 |
51 | flask-wtf使用
52 | https://www.jianshu.com/p/3fd2a1f155f3
53 |
--------------------------------------------------------------------------------
/Python/Flask框架/第一次flask项目结构.md:
--------------------------------------------------------------------------------
1 | flask 应用部署目录
2 | |——app 应用目录
3 | | |__ static 静态文件价(放CSS和JavaScript文件主要是用来渲染前端页面)
4 | | |__ templates 模板(放html文件,写页面的)
5 | | | |__base.html 基础模板,后面的一些模板会继承它
6 | | | |__edit_profile.html 编辑个人信息的页面
7 | | | |__index.html 根路由下的页面,欢迎界面
8 | | | |__login.html 登录页面
9 | | | |__register.html 注册页面
10 | | | |__user.html 用户页面
11 | | |__ __init__.py 初始化
12 | | |__ forms.py 表单
13 | | |__ models.py 数据库中的表
14 | | |__ routes.py 视图函数
15 | |——migrations 数据库迁移文件
16 | |——config.py 配置文件
17 | |——myblog.py 启动文件
18 | |__requirements.txt 环境文件,项目用到的包和版本
19 |
--------------------------------------------------------------------------------
/Python/Flask框架/第二次flask项目结构.md:
--------------------------------------------------------------------------------
1 | lin-cms-flask //项目
2 | |───app // app目录
3 | | │───app.py // 创建Flask app及应用扩展
4 | | │───__init__.py // 默认的包初始化文件
5 | | │
6 | | │───api // api目录
7 | | │ │———__init__.py // 默认的包初始化文件
8 | | │ │
9 | | │ ├───cms // 开发CMS API目录
10 | | │ │ │__init__.py // 创建CMS蓝图
11 | | │ │
12 | | │ ├───v1 // 开发普通API目录
13 | | │ │__init__.py // 创建v1蓝图
14 | | │
15 | | ├───config // 配置文件目录
16 | | │ │ secure.py // 有关于安全的配置
17 | | │ │ setting.py // 基础配置
18 | | | | log.py // 系统日志配置
19 | | │
20 | | ├───libs // 类库文件夹
21 | | │ │ error_code.py // 自定义异常文件
22 | | │ │ utils.py // 工具文件
23 | | │
24 | | ├───models // 模型文件夹
25 | | │ │ book.py // book模型文件
26 | | │ │ __init__.py // 默认的包初始化文件
27 | | │
28 | | ├───plugins // 插件目录
29 | | │
30 | | │
31 | | ├───validators // 校验类存放目录
32 | | │ forms.py // 校验类文件
33 | | │ __init__.py // 默认的包初始化文件
34 | |───logs //生成的日志文件
35 | |───tests //测试文件
36 | |───add_super.py //添加一个超级管理员
37 | │───code.md // 记录自定义的返回码和信息
38 | │───fake.py // 测试和做假数据的脚本
39 | |───README.MD //说明文件
40 | |───requirements.txt //依赖包文件
41 | |───starter.py // 程序的开始文件
42 |
--------------------------------------------------------------------------------
/Python/Python基础语法/platform模块.md:
--------------------------------------------------------------------------------
1 | # platform模块
2 | platform模块给我们提供了很多方法去获取操作系统的信息
3 | ~~~python
4 | import platform
5 | platform.system() #获取操作系统名称
6 | platform.platform() #获取操作系统名称及版本号
7 | platform.version() #获取操作系统版本号
8 | platform.architecture() #获取操作系统的位数,('32bit', 'ELF')
9 | platform.machine() #计算机类型,'i686'
10 | platform.node() #计算机的网络名称,'XF654'
11 | platform.processor() #计算机处理器信息,''i686'
12 | platform.uname() #包含上面所有的信息汇总
13 | ~~~
14 | 还可以获得计算机中python的一些信息
15 | ~~~python
16 | import platform
17 | platform.python_build() #python编译号(default)和日期.
18 | platform.python_compiler() #python编译器信息
19 | platform.python_branch() #python分支(子版本信息),一般为空.
20 | platform.python_implementation() #python安装履行方式,如CPython, Jython, Pypy, IronPython(.net)等
21 | platform.python_revision() #python类型修改版信息,一般为空.
22 | platform.python_version() #python版本号
23 | platform.python_version_tuple() #python版本号分割后的tuple.
24 | ~~~
25 |
--------------------------------------------------------------------------------
/Python/Python基础语法/python01.md:
--------------------------------------------------------------------------------
1 | # 1.a, b = b, a + b 等价于 (a, b) = (b, a + b)
2 |
3 | 1.在赋值之前先计算等号右边的值
4 |
5 |
6 | 2.计算时的结果不参与二次计算,而是使用原来的值进行计算
7 |
8 |
9 | 等价于下的表达:
10 |
11 |
12 | ~~~python
13 | tmp = a
14 | a = b
15 | b = tmp + b
16 | ~~~
17 |
18 | # 2.python的内置函数
19 |
20 | \- 数学相关: abs / divmod / pow / round / min / max / sum
21 |
22 | \- 序列相关: len / range / next / filter / map / sorted / slice / reversed
23 |
24 | \- 类型转换: chr / ord / str / bool / int / float / complex / bin / oct / hex
25 |
26 | \- 数据结构: dict / list / set / tuple
27 |
28 | \- 其他函数: all / any / id / input / open / print / type
29 |
30 | # 3.python常用模块
31 |
32 | \- 运行时服务相关模块: copy / pickle / sys / ...
33 |
34 | \- 数学相关模块: decimal / math / random / ...
35 |
36 | \- 字符串处理模块: codecs / re / ...
37 |
38 | \- 文件处理相关模块: shutil / gzip / ...
39 |
40 | \- 操作系统服务相关模块: datetime / os / time / logging / io / ...
41 |
42 | \- 进程和线程相关模块: multiprocessing / threading / queue
43 |
44 | \- 网络应用相关模块: ftplib / http / smtplib / urllib / ...
45 |
46 | \- Web编程相关模块: cgi / webbrowser
47 |
48 | \- 数据处理和编码模块: base64 / csv / html.parser / json / xml / ...
49 |
50 | # 4.python中的private和protected
51 |
52 | 1、_xxx 不能用于’from module import *’ 以单下划线开头的表示的是protected类型的变量。即保护类型只能允许其本身与子类进行访问。
53 |
54 | 2、__xxx 双下划线的表示的是私有类型的变量。只能是允许这个类本身进行访问了。连子类也不可以
55 |
56 | 3、__xxx___ 定义的是特列方法。像__init__之类的
57 |
58 |
--------------------------------------------------------------------------------
/Python/Python基础语法/supper()函数.md:
--------------------------------------------------------------------------------
1 | # supper()函数
2 | ## 描述
3 | 1. super() 函数是用于调用父类(超类)的一个方法。
4 | 2. super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
5 | MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表。
6 | ##语法(python3)
7 | ~~~python
8 | super().xxx
9 | ~~~
10 |
11 |
12 | ## 例子
13 |
14 |
15 | 
16 | 使用 super() 可以很好地避免构造函数被调用两次。
17 | ~~~python
18 | class A():
19 | def __init__(self):
20 | print('enter A')
21 | print('leave A')
22 |
23 |
24 | class B(A):
25 | def __init__(self):
26 | print('enter B')
27 | super().__init__()
28 | print('leave B')
29 |
30 |
31 | class C(A):
32 | def __init__(self):
33 | print('enter C')
34 | super().__init__()
35 | print('leave C')
36 |
37 |
38 | class D(B, C):
39 | def __init__(self):
40 | print('enter D')
41 | super().__init__()
42 | print('leave D')
43 |
44 |
45 | d = D()
46 | ~~~
47 | 执行结果是:
48 | ~~~python
49 | enter D
50 | enter B
51 | enter C
52 | enter A
53 | leave A
54 | leave C
55 | leave B
56 | leave D
57 | ~~~
--------------------------------------------------------------------------------
/Python/Python基础语法/作用域.md:
--------------------------------------------------------------------------------
1 | [Python中关于作用域的关键字](https://note.qidong.name/2017/07/python-legb/)
2 |
--------------------------------------------------------------------------------
/Python/Python基础语法/正则表达式.md:
--------------------------------------------------------------------------------
1 | # 正则表达式知识
2 | 符号|解释|示例|说明
3 | ----|---|----|---
4 | .|匹配除换行符以外的任意字符|b.t|可以匹配到bat / but / b#t / b1t等
5 | \w|匹配字母/数字/下划线/汉字|b\w\t|可以匹配到bat / b1t / b_t等,但是不能匹配到b#t
6 | \s|匹配任意的空白符(包括\r、\n、\t等)|love\syou|可以匹配到love you
7 | \d|匹配数字|\d\d|可以匹配到01 / 23 / 99等
8 | \b|匹配单词的开始和结束|\bThe\b|匹配到The
9 | ^|匹配字符串的开始|^The|可以匹配到The开头的字符串
10 | $|匹配字符串的结束|.exe$|可以匹配到.exe结尾的字符串
11 | \W|匹配任意不是字母/数字/下划线/汉字|b\W\t|可以匹配b#t b@t等,但不能匹配but/b1t/b_t等
12 | \S|匹配非空白字符|love\Syou|可以匹配love#you等,但不能匹配love you
13 | \D|匹配非数字|\d\D|可以匹配9a/3#/0F等
14 | \B|匹配非单词边界|\Bio\B|
15 | []|匹配来自字符集的任意单一字符| [aeiou]|可以匹配任一元音字符
16 | [^]|可以匹配不在字符集的任意单一字符|[aeiou]|可以匹配任一非元音字母字符
17 | * |匹配0次或多次| \w*
18 | +|匹配1次或多次|\w+
19 | ?|匹配0次或1次|\w?
20 | {N}|匹配N次|\w{3}
21 | {M,}|匹配至少M次|\w{3,}
22 | {M,N}|匹配M~N次|\w{3,6}
23 | \| | 分支 | foo\|bar | 可以匹配foo或者bar
24 | (?#)|注释|
25 | (exp)|匹配exp并捕获到自动命名的组中
26 | (? \ exp)|匹配exp并捕获到名为name的组中
27 | (?:exp)|匹配exp但是不捕获匹配的文本|
28 | (?=exp)|匹配exp前面的位置|\b\w+(?=ing)|可以匹配I`m dancing中的danc
29 | (?<=exp)|匹配exp后面的位置|(?<=\bdanc)\w+\b|可以匹配I love dancing and reading中的第一个ing
30 | (?!exp)|匹配后面不是exp的位置
31 | (? 100:
62 | self._score = 100
63 | else:
64 | self._score = val
65 |
66 | >>> e = Exam(60)
67 | >>> e.score
68 | 60
69 | >>> e.score = 90
70 | >>> e.score
71 | 90
72 | >>> e.score = 200
73 | >>> e.score
74 | 100
75 | ~~~
76 | 在上面,我们给方法 **score** 加上了 **@property**,于是我们可以把 score 当成一个属性来用,此时,又会创建一个新的装饰器 **score.setter**,它可以把被装饰的方法变成属性来赋值。
77 | 另外,我们也不一定要使用 score.setter 这个装饰器,这时 score 就变成一个只读属性了:
78 | ~~~python
79 | class Exam(object):
80 | def __init__(self, score):
81 | self._score = score
82 |
83 | @property
84 | def score(self):
85 | return self._score
86 |
87 | >>> e = Exam(60)
88 | >>> e.score
89 | 60
90 | >>> e.score = 200 # score 是只读属性,不能设置值
91 | ---------------------------------------------------------------------------
92 | AttributeError Traceback (most recent call last)
93 | in ()
94 | ----> 1 e.score = 200
95 |
96 | AttributeError: can't set attribute
97 | ~~~
98 | * **@property** 把方法『变成』了属性。
--------------------------------------------------------------------------------
/Python/Python基础语法/详解方法或类.md:
--------------------------------------------------------------------------------
1 | # isinstance(p_object, class_or_type_or_tuple)
2 | **这个方法的作用是判断对象是不是类的实例或者类的子类的实例**
3 | 其中第二个参数可以是元祖。
4 | # enumerate()函数
5 | ## 描述
6 | enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
7 | ## 语法
8 | ~~~python
9 | enumerate(sequence, [start=0])
10 | ~~~
11 | sequence是一个可遍历对象,start是起始索引
12 | ## 返回值
13 | 返回enumerate(枚举)对象
14 | ## for循环使用enumerate
15 | ~~~python
16 | seq = [one,two,three]
17 | for index,value in enumerate(seq):
18 | print(index,value)
19 | ~~~
--------------------------------------------------------------------------------
/Python/Python基础语法/迭代.md:
--------------------------------------------------------------------------------
1 | 默认情况下,dict迭代的是key。如果要迭代value,可以用`for value in d.values()`,如果要同时迭代key和value,可以用`for k, v in d.items()`。
2 |
3 | 我们使用`for`循环时,只要作用于一个可迭代对象,`for`循环就可以正常运行,而我们不太关心该对象究竟是list还是其他数据类型。
4 |
5 | 那么,如何判断一个对象是可迭代对象呢?方法是通过`collections`模块的`Iterable`类型判断:
6 | ~~~python
7 | >>> from collections import Iterable
8 | >>> isinstance('abc', Iterable) # str是否可迭代
9 | True
10 | >>> isinstance([1,2,3], Iterable) # list是否可迭代
11 | True
12 | >>> isinstance(123, Iterable) # 整数是否可迭代
13 | False
14 | ~~~
15 |
16 | 如果要对list实现类似Java那样的下标循环怎么办?Python内置的`enumerate`函数可以把一个list变成索引-元素对,这样就可以在`for`循环中同时迭代索引和元素本身:
17 | ~~~python
18 | >>> for i, value in enumerate(['A', 'B', 'C']):
19 | ... print(i, value)
20 | ...
21 | 0 A
22 | 1 B
23 | 2 C
24 | ~~~
25 |
26 | 上面的for循环里,同时引用了两个变量,在Python里是很常见的,比如下面的代码:
27 | ~~~python
28 | >>> for x, y in [(1, 1), (2, 4), (3, 9)]:
29 | ... print(x, y)
30 | ...
31 | 1 1
32 | 2 4
33 | 3 9
34 | ~~~
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # StudyNotes
2 |
3 | | 1 | 2 | 3 | 4 | 5 | 6 |
4 | | :--------------------------: | :-----------------------: | :--------------------: | :--: | :---------------------------: | :---------------------------: |
5 | |[Java](./Java)
 |[Spring](./Spring/README.md)
 |[Springmvc](./SpringMVC/README.md)
 |[SpringBoot](./SpringBoot)
 |[MyBatis](./MyBatis/README.md)
 | [Vue](./Vue/README.md)
 |
6 |
7 |
8 |
9 | | 1 | 2 | 3 |
10 | | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
11 | | [MySQL](./MySQL/README.md)
 | [Redis](./Redis/README.md)
 | [MongoDB](./MongoDB/README.md)
 |
12 |
13 |
14 |
15 | | 1 | 2 | 3 | 4 | 5 |
16 | | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
17 | | [Git](./Git/README.md)
 | [Docker](./Docker/README.md)
 | [Nginx](./Nginx/README.md)
 | [前端](./前端)
 | [Python](./Python)
 |
18 |
19 |
20 | **后面在个人博客上更新文章,[我的博客](https://krislinzhao.github.io/)**
21 |
--------------------------------------------------------------------------------
/Redis/09.事务.md:
--------------------------------------------------------------------------------
1 | - [1. 事务命令](#1-事务命令)
2 | - [2. 乐观锁](#2-乐观锁)
3 |
4 | # 1. 事务命令
5 |
6 | | 命令 | 说明 |
7 | | :------ | :----------- |
8 | | muitl | 开启事务命令 |
9 | | command | 普通命令 |
10 | | discard | 在提交前取消 |
11 | | exec | 提交 |
12 |
13 | 注:discard只是结束本次事务,前2条语句已经执行,造成的影响仍然还在。
14 |
15 | 语句出错有两种情况: - 语法有问题,exec时报错,所有语句取消执行,没有对数据造成影响。 - 语法本身没错,但适用对象有问题(比如 zadd 操作list对象),exec之后,会执行正确的语句,并跳过有不适当的语句,对数据会造成影响,这点由程序员负责。
16 |
17 | # 2. 乐观锁
18 |
19 | redis的事务中启用的是乐观锁,只负责监测key没有被改动,如果在事务中发现key被改动,则取消事务。使用watch命令来监控一个或多个key,使用unwatch命令来取消监控所有key。
20 |
21 | ```bash
22 | # 示例
23 | watch key
24 | muitl
25 | 操作数据...
26 | exec
27 | unwatch
28 | ```
29 |
30 | 模拟抢票,场景:用户买一张票,扣掉100元
31 |
32 | ```bash
33 | # 在zhangsan买票过程中,在提交事务前一瞬间,有人成功买到票,ticket已经改变(即使ticket还有票),导致zhangsan抢票失败。
34 | 127.0.0.1:6379> watch ticket
35 | OK
36 | 127.0.0.1:6379> multi
37 | OK
38 | 127.0.0.1:6379> decr ticket
39 | QUEUED
40 | 127.0.0.1:6379> decrby zhangsan 100
41 | QUEUED
42 | 127.0.0.1:6379> exec
43 | (nil)
44 | 127.0.0.1:6379> get zhangsan
45 | "1000"
46 | 127.0.0.1:6379> get ticket
47 | "2"
48 | 127.0.0.1:6379> unwatch
49 | OK
50 |
51 |
52 | # lisi在买票整个过程都没有人抢票,所以lisi一次抢票成功。
53 | 127.0.0.1:6379> watch ticket
54 | OK
55 | 127.0.0.1:6379> multi
56 | OK
57 | 127.0.0.1:6379> decrby lisi 100
58 | QUEUED
59 | 127.0.0.1:6379> decr ticket
60 | QUEUED
61 | 127.0.0.1:6379> exec
62 | 1) (integer) 700
63 | 2) (integer) 1
64 | 127.0.0.1:6379> unwatch
65 | ```
--------------------------------------------------------------------------------
/Redis/10.频道发布与订阅.md:
--------------------------------------------------------------------------------
1 | - [1. publish 发布频道](#1-publish-发布频道)
2 | - [2. subscribe 订阅指定频道](#2-subscribe-订阅指定频道)
3 | - [3. psubscribe 订阅已匹配频道](#3-psubscribe-订阅已匹配频道)
4 |
5 | - 发布端:publish
6 | - 订阅端:subscribe,psubscribe
7 |
8 | # 1. publish 发布频道
9 |
10 | ```bash
11 | publish 频道名称 发布内容
12 |
13 | # 示例
14 | 127.0.0.1:6379> publish music_2 "It's Not Goodbye"
15 | (integer) 1
16 | 127.0.0.1:6379> publish music "just one last dance"
17 | (integer) 2
18 | 127.0.0.1:6379> publish music "stay"
19 | (integer) 2
20 |
21 | 127.0.0.1:6379> publish music_2 "It's Not Goodbye"
22 | (integer) 1
23 | ```
24 |
25 | # 2. subscribe 订阅指定频道
26 |
27 | ```bash
28 | subscribe 频道名称
29 |
30 | # 示例
31 | 127.0.0.1:6379> subscribe music
32 | Reading messages... (press Ctrl-C to quit)
33 | 1) "subscribe"
34 | 2) "music"
35 | 3) (integer) 1
36 | 1) "message"
37 | 2) "music"
38 | 3) "just one last dance"
39 | 1) "message"
40 | 2) "music"
41 | 3) "stay" "music"
42 | 3) (integer) 1
43 | 1) "message"
44 | 2) "music"
45 | 3) "just one last dance"
46 | 1) "message"
47 | 2) "music"
48 | 3) "stay"
49 | ```
50 |
51 | # 3. psubscribe 订阅已匹配频道
52 |
53 | ```bash
54 | psubscribe 匹配频道名称
55 |
56 | # 示例
57 | 127.0.0.1:6379> psubscribe music*
58 | Reading messages... (press Ctrl-C to quit)
59 | 1) "psubscribe"
60 | 2) "music*"
61 | 3) (integer) 1
62 | 1) "pmessage"
63 | 2) "music*"
64 | 3) "music"
65 | 4) "just one last dance"
66 | 1) "pmessage"
67 | 2) "music*"
68 | 3) "music"
69 | 4) "stay"
70 |
71 | 1) "pmessage"
72 | 2) "music*"
73 | 3) "music_2"
74 | 4) "It's Not Goodbye"
75 | ```
--------------------------------------------------------------------------------
/Redis/11.redis持久化和导入导出数据库.md:
--------------------------------------------------------------------------------
1 | - [1. redis持久化](#1-redis持久化)
2 | - [1.1. rdb快照持久化](#11-rdb快照持久化)
3 | - [1.2. aof日志持久化](#12-aof日志持久化)
4 | - [2. 导入和导出数据库](#2-导入和导出数据库)
5 |
6 | # 1. redis持久化
7 |
8 | ## 1.1. rdb快照持久化
9 |
10 | rdb的工作原理:每隔N分钟或N次写操作后,从内存dump数据形成rdb文件,压缩放在备份目录,设置配置文件参数:
11 |
12 | ```bash
13 | # 打开配置文件
14 | vim /usr/local/redis/ redis.conf
15 |
16 | save 900 1 # 900秒内,有1条写入,则产生快照
17 | save 300 1000 # 如果300秒内有1000次写入,则产生快照
18 | save 60 10000 # 如果60秒内有10000次写入,则产生快照
19 | (这3个选项都屏蔽,则rdb禁用)
20 |
21 | stop-writes-on-bgsave-error yes # 后台备份进程出错时,主进程停不停止写入
22 | rdbcompression yes # 导出的rdb文件是否压缩
23 | Rdbchecksum yes # 导入rbd恢复时数据时,要不要检验rdb的完整性
24 |
25 | dbfilename dump.rdb # 导出来的rdb文件名
26 | dir /usr/local/redis/data # rdb的放置路径
27 |
28 | # 压力测试来检测是否启用了rdb快照
29 | /usr/local/redis/bin/redis-benchmark
30 | ```
31 |
32 | rdb的缺陷:在2个保存点之间断电,将会丢失1-N分钟的数据
33 |
34 | ## 1.2. aof日志持久化
35 |
36 | 工作原理:redis主进程 –> 后台日志进程 –> aof文件
37 |
38 | 设置配置文件参数:
39 |
40 | ```bash
41 | # 打开配置文件
42 | vim /usr/local/redis/ redis.conf
43 |
44 | appendonly no # 是否打开 aof日志功能
45 | appendfilename "appendonly.aof" # aof文件名,和rdb的dir公用一个路径
46 |
47 | #appendfsync always # 每1个写命令都立即同步到aof文件,安全但速度慢
48 | appendfsync everysec # 折衷方案,每秒写1次
49 | 上面方案选择一种,一般选择everysec
50 |
51 | appendfsync no # 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof文件,同步频率低,但速度快
52 |
53 | no-appendfsync-on-rewrite yes # 正在导出rdb快照的过程中,要不要停止同步aof
54 | auto-aof-rewrite-percentage 100 # aof文件大小比起上次重写时的大小,增长率100%时重写
55 | auto-aof-rewrite-min-size 64mb # aof文件至少超过64M时才重写
56 | ```
57 |
58 | 注意:如果需要持久化,一般推荐rdb和aof同时开启,同时开启后redis进程启动优先选择aof恢复数据。rdb恢复速度快。
59 |
60 | 在dump rdb过程中,aof如果停止同步,会不会丢失? 不会,所有的操作缓存在内存的队列里,dump完成后统一操作.
61 |
62 | aof重写是指什么? aof重写是指把内存中的数据,逆化成命令,写入到.aof日志里,以解决 aof日志过大的问题,手动重写aof命令:bgrewriteaof
63 |
64 | # 2. 导入和导出数据库
65 |
66 | ```bash
67 | (1) 安装redis-dump工具
68 | yum install ruby rubygems ruby-devel
69 | gem sources --remove http://ruby.taobao.org/
70 | gem sources -a https://ruby.taobao.org/
71 | gem install redis-dump -V
72 |
73 | (2) 导出redis数据
74 | redis-dump -u 127.0.0.1:6379 > test.json
75 |
76 | (3) 导入redis数据
77 | < test.json redis-load
78 | ```
79 |
80 |
--------------------------------------------------------------------------------
/Spring/06.Spring整合Junit.md:
--------------------------------------------------------------------------------
1 | # Spring学习笔记(六)Spring整合Junit
2 |
3 | # 1、Spring 整合 Junit 的配置过程
4 |
5 | 1. 导入 Spring 整合 Junit 的 jar ( 坐标 )
6 | spring-test-x.x.x.RELEASE.jar
7 | 2. 使用 Junit 提供的一个注解把原有的 main 方法替换了,替换成 Spring 提供的@Runwith
8 |
9 | 3. 告知 Spring 的运行器, Spring 和 ioc 创建是基于 xml 还是注解的,并且说明位置,用到的注解如下
10 |
11 | @ContextConfiguration
12 |
13 | Locations : 指定 xml 文件的位置,加上 classpath 关键字,表示在类路径下
14 |
15 | classes : 指定注解类所在地位置
16 |
17 | 4. 使用@Autowired 给测试类中的变量注入数据
18 |
19 | # 2、项目结构
20 | 
21 |
22 |
23 | # 3、实体类
24 | - Account.java
25 | ```java
26 | @Component
27 | public class Account {
28 | @Value("1")
29 | private Integer id;
30 | @Value("Tom")
31 | private String name;
32 | @Value("34567")
33 | private Float money;
34 |
35 | public Integer getId() {
36 | return id;
37 | }
38 |
39 | public void setId(Integer id) {
40 | this.id = id;
41 | }
42 |
43 | public String getName() {
44 | return name;
45 | }
46 |
47 | public void setName(String name) {
48 | this.name = name;
49 | }
50 |
51 | public Float getMoney() {
52 | return money;
53 | }
54 |
55 | public void setMoney(Float money) {
56 | this.money = money;
57 | }
58 |
59 | @Override
60 | public String toString() {
61 | return "Account{" +
62 | "id=" + id +
63 | ", name='" + name + '\'' +
64 | ", money=" + money +
65 | '}';
66 | }
67 | }
68 | ```
69 | # 4、测试类
70 | - AccountTest.java
71 | ```java
72 | @RunWith(SpringJUnit4ClassRunner.class)
73 | @ContextConfiguration(locations = "classpath:applicationContext.xml")
74 | public class AccountTest {
75 |
76 | @Autowired
77 | private Account account;
78 |
79 | @Test
80 | public void testAccount(){
81 | System.out.println(account);
82 | }
83 | }
84 | ```
85 |
86 | # 5、配置applicationContext.xml
87 | ```xml
88 |
89 |
93 |
94 |
95 |
96 | ```
--------------------------------------------------------------------------------
/Spring/07.AOP概述.md:
--------------------------------------------------------------------------------
1 | # Spring学习笔记(7)AOP概述
2 |
3 | # 1.什么是AOP
4 | AOP (Aspect Oriented Programing)
5 | AOP 采用了`横向抽取`机制,取代了`纵向继承`体系中重复性的代码( 性能监视、 事务管理、 安全检查、 缓存)
6 |
7 | **Spring AOP 使用纯 Java 实现, 不需要专门的编译过程和类加载器, 在运行期通过代理方式向目标类织入增强代码**
8 |
9 | **AspecJ 是一个基于 Java 语言的 AOP 框架, Spring2.0 开始,Spring AOP 引入对 Aspect 的支持, AspectJ扩展了 Java 语言, 提供了一个专门的编译器, 在编译时提供横向代码的织**
10 |
11 | # 2.SpringAOP思想
12 |
13 | 
14 |
15 | # 3.AOP 底层原理
16 | 就是代理机制
17 |
18 | * 动态代理:(JDK 中使用)
19 |
20 | * JDK 的动态代理,对实现了接口的类生成代理.
21 |
22 | # 4.Spring的AOP代理
23 |
24 | - JDK 动态代理:对实现了接口的类生成代理(缺陷就是这个类必须先实现某个接口)
25 | - CGLib 代理机制:对类生成代理(对没有实现接口的类也可以代理)
26 |
27 | # 5.AOP 的术语
28 |
29 | - `Joinpoint`(连接点):所谓连接点是指那些被拦截到的点。 在 spring 中,这些点指的是方法,因为 spring 只支持方法类型的连接点.( 即那些方法可以被拦截)
30 | - `Pointcut`(切入点):所谓切入点是指我们要对哪些 Joinpoint 进行拦截的定义.( 实际拦截的方法)
31 | - `Advice`(通知/增强):所谓通知是指拦截到Joinpoint之后所要做的事情就是通知.通知分为前置通知,后置通知,异常通知,最终通知,环绕通知(切面要完成的功能)
32 | - `Introduction`(引介):引介是一种特殊的通知在不修改类代码的前提下, Introduction 可以在运行期为类动态地添加一些方法或 Field.
33 | - `Target`(目标对象):即代理的目标对象
34 | - `Weaving`(织入):是指把增强应用到目标对象来创建新的代理对象的过程.spring 采用动态代理织入, 而 AspectJ 采用编译期织入和类装载期织入
35 | - `Proxy`(代理):一个类被 AOP 织入增强后, 就产生一个结果代理类
36 | - `Aspect`(切面):是切入点和通知(引介)的结合
37 |
38 | 
39 |
40 |
--------------------------------------------------------------------------------
/SpringBoot/01.spring boot 2.x基础及概念入门/1.2.Hello World及项目结构.md:
--------------------------------------------------------------------------------
1 | # 一、使用IntellijIDEA建立第一个spring boot 项目
2 |
3 | 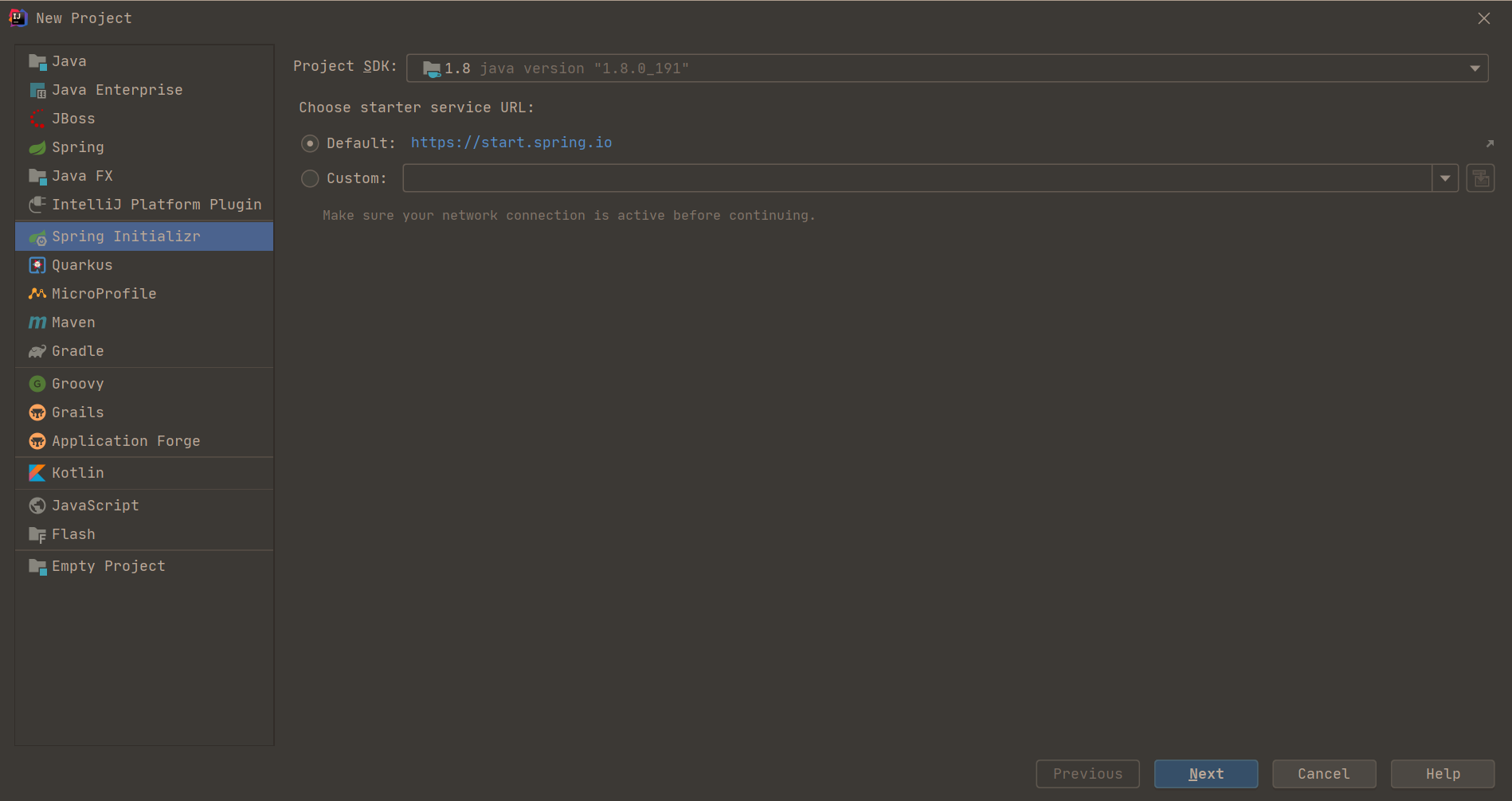
4 |
5 | 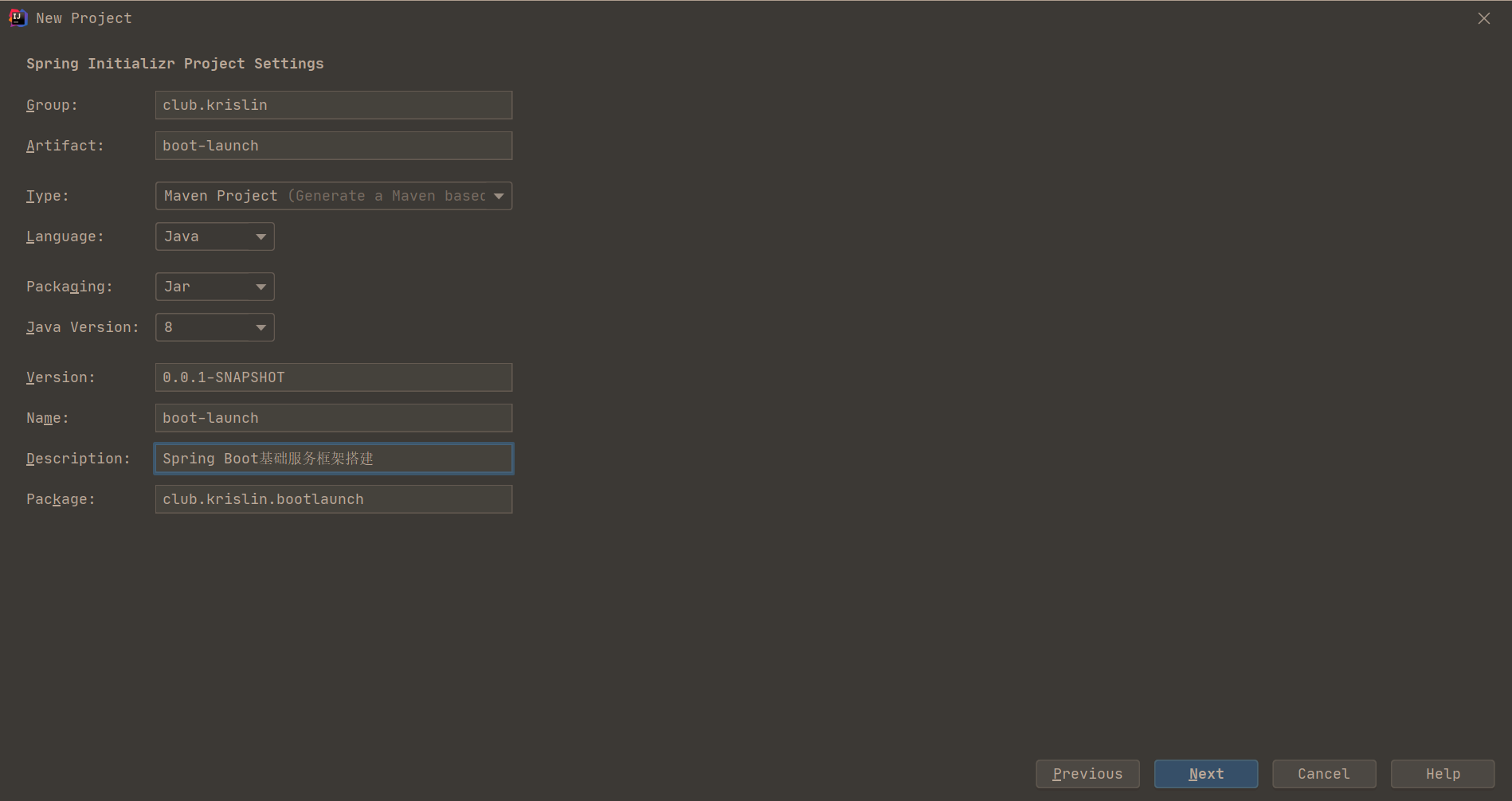
6 |
7 | 在这里可以选择我们需要依赖的第三方软件类库,包括spring-boot-web,mysql驱动,mybatis等。
8 |
9 | 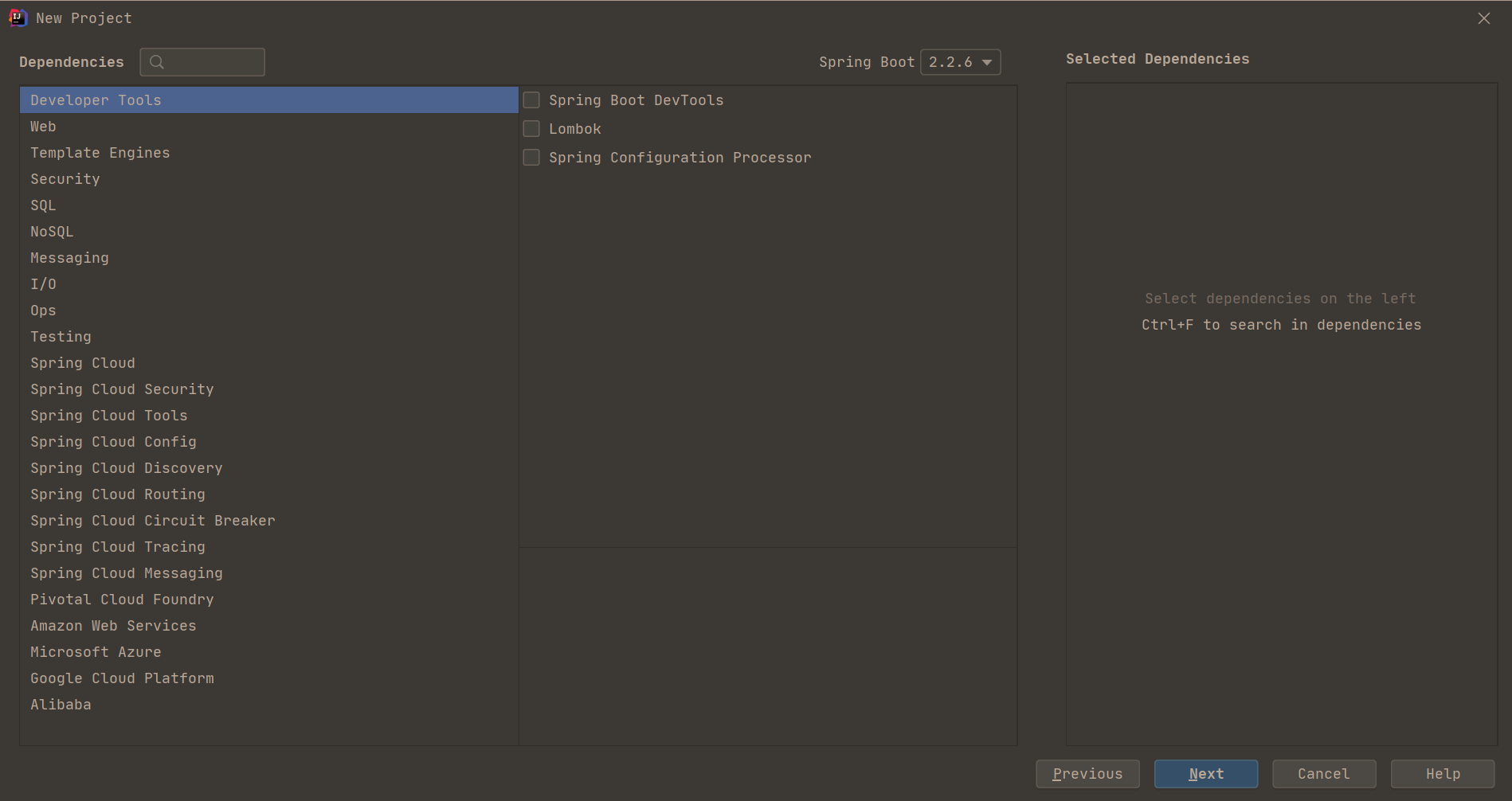
10 |
11 | 项目创建过程可能因为maven依赖项较多,下载时间比较长,耐心等待。项目构建完成之后删掉下面的这几个文件,这几个文件是maven版本控制相关的文件。我们结合IDEA管理maven,一般来说这几个文件用不到。
12 |
13 | 
14 |
15 | # 二、Hello World示例程序
16 |
17 | 将application.properties改成application.yml。yml文件和properties配置文件具有同样的功能。二者的区别在于:
18 |
19 | - yml文件的层级更加清晰直观,但是书写时需要注意格式缩进对齐。yml格式配置文件更有利于表达复杂数据结构的配置。比如:列表,对象(后面章节会详细说明)。
20 | - properties阅读上不如yml直观,好处在于书写时不用特别注意格式缩进对齐。
21 |
22 | ```yam
23 | server:
24 | port: 8888 # web应用服务端口
25 | ```
26 |
27 | 引入spring-boot-starter-web依赖
28 |
29 | ```xml
30 |
31 | org.springframework.boot
32 | spring-boot-starter-web
33 |
34 | ```
35 |
36 | 一个hello world测试Controller
37 |
38 | ```java
39 | @RestController
40 | public class HelloController {
41 | @RequestMapping("/hello")
42 | public String hello(String name) {
43 | return "hello world, " +name;
44 | }
45 | }
46 | ```
47 |
48 | 测试
49 |
50 | 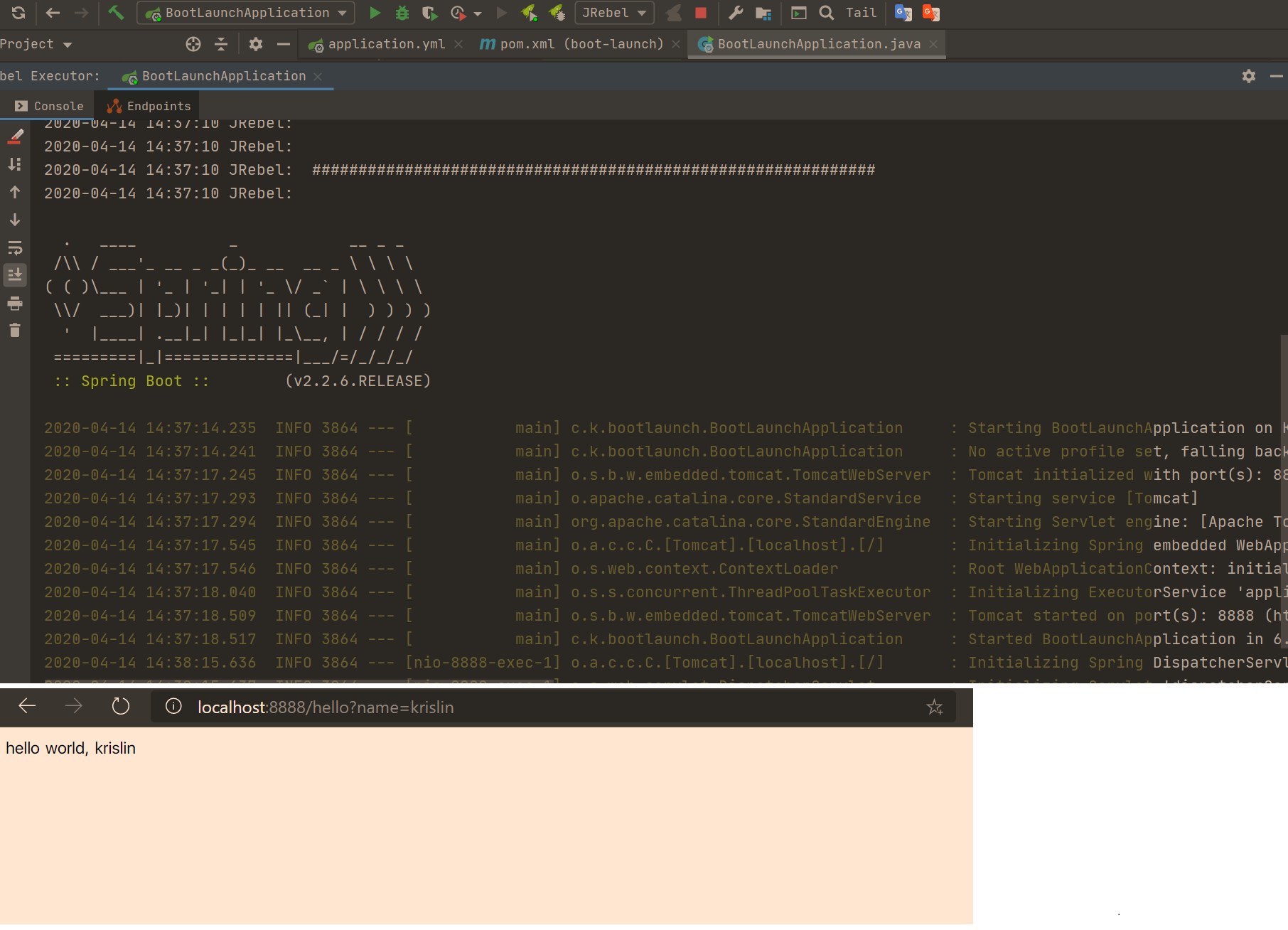
51 |
52 | # 三、项目结构目录结构简介
53 |
54 | 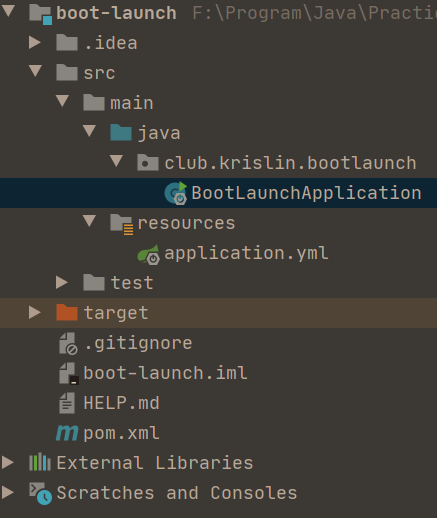
55 |
56 | 项目结构目录整体上符合maven规范要求:
57 |
58 | | 目录位置 | 功能 |
59 | | ----------------------------------------- | ------------------------------------------------------------ |
60 | | src/main/java | 项目java文件存放位置,初始化包含主程序入口 XxxApplication,可以通过直接运行该类来 启动 Spring Boot应用 |
61 | | src/main/resources | 存放静态资源,图片、CSS、JavaScript、web页面模板文件等 |
62 | | src/test | 单元测试代码目录 |
63 | | .gitignore | git版本管理排除文件 |
64 | | target文件夹 | 项目代码构建打包结果文件存放位置,不需要人为维护 |
65 | | pom.xml | maven项目配置文件 |
66 | | application.properties(application.yml) | 用于存放程序的各种依赖模块的配置信息,比如服务端口,数据库连接配置等 |
67 |
68 | - src/main/resources/static主要用来存放css、图片、js等开发用静态文件
69 | - src/main/resources/public用来存放可以直接用于访问的html文件
70 | - src/main/resources/templates用来存放web开发模板文件
--------------------------------------------------------------------------------
/SpringBoot/02.RESTful接口实现及测试/2.1.RESTful接口与http协议状态表述.md:
--------------------------------------------------------------------------------
1 | # 一、RESTful风格API的好处
2 |
3 | API(Application Programming Interface),顾名思义:是一组编程接口规范,客户端与服务端通过请求响应进行数据通信。REST(Representational State Transfer)决定了接口的形式与规则。**RESTful是基于http方法的API设计风格,而不是一种新的技术.**
4 |
5 | 1. 看Url就知道要什么资源
6 | 2. 看http method就知道针对资源干什么
7 | 3. 看http status code就知道结果如何
8 |
9 | 对接口开发提供了一种可以广泛适用的规范,为前端后端交互减少了接口交流的口舌成本,是**约定大于配置**的体现。通过下面的设计,大家来理解一下这三句话。
10 |
11 | >当然也不是所有的接口,都能用REST的形式来表述。在实际工作中,灵活运用,我们用RESTful风格的目的是为大家提供统一标准,避免不必要的沟通成本的浪费,形成一种通用的风格。就好比大家都知道:伸出大拇指表示“你很棒“的意思,绝大部分人都明白,因为你了解了这种风格习惯。但是不排除有些地区伸出大拇指表示其他意思,就不适合使用!
12 |
13 | # 二、RESTful API的设计风格
14 |
15 | ## 2.1、REST 是面向资源的(名词)
16 |
17 | REST 通过 URI 暴露资源时,会强调不要在 URI 中出现动词。比如:
18 |
19 | | 不符合REST的接口URI | 符合REST接口URI | 功能 |
20 | | :----------------------- | :-------------------- | :------------- |
21 | | GET /api/getDogs | GET /api/dogs/{id} | 获取一个小狗狗 |
22 | | GET /api/getDogs | GET /api/dogs | 获取所有小狗狗 |
23 | | GET /api/addDogs | POST /api/dogs | 添加一个小狗狗 |
24 | | GET /api/editDogs/{id} | PUT /api/dogs/{id} | 修改一个小狗狗 |
25 | | GET /api/deleteDogs/{id} | DELETE /api/dogs/{id} | 删除一个小狗狗 |
26 |
27 | ## 2.2、用HTTP方法体现对资源的操作(动词)
28 |
29 | - GET : 获取、读取资源
30 | - POST : 添加资源
31 | - PUT : 修改资源
32 | - DELETE : 删除资源
33 |
34 | 
35 |
36 | 实际上,这四个动词实际上就对应着增删改查四个操作,这就利用了HTTP动词来表示对资源的操作。
37 |
38 | ## 2.3. HTTP状态码
39 |
40 | 通过HTTP状态码体现动作的结果,不要自定义
41 |
42 | ```
43 | 200 OK
44 | 400 Bad Request
45 | 500 Internal Server Error
46 | ```
47 |
48 | 在 APP 与 API 的交互当中,其结果逃不出这三种状态:
49 |
50 | - 所有事情都按预期正确执行完毕 - 成功
51 | - APP 发生了一些错误 – 客户端错误(如:校验用户输入身份证,结果输入的是军官证,就是客户端输入错误)
52 | - API 发生了一些错误 – 服务器端错误(各种编码bug或服务内部自己导致的异常)
53 |
54 | 这三种状态与上面的状态码是一一对应的。如果你觉得这三种状态,分类处理结果太宽泛,http-status code还有很多。建议还是要遵循KISS(Keep It Stupid and Simple)原则,上面的三种状态码完全可以覆盖99%以上的场景。这三个状态码大家都记得住,而且非常常用,多了就不一定了。
55 |
56 | ## 2.4. Get方法和查询参数不应该改变数据
57 |
58 | 改变数据的事交给POST、PUT、DELETE
59 |
60 | ## 2.5. 使用复数名词
61 |
62 | /dogs 而不是 /dog
63 |
64 | ## 2.6. 复杂资源关系的表达
65 |
66 | GET /cars/711/drivers/ 返回 使用过编号711汽车的所有司机
67 | GET /cars/711/drivers/4 返回 使用过编号711汽车的4号司机
68 |
69 | ## 2.7. 高级用法:HATEOAS
70 |
71 | **HATEOAS**:Hypermedia as the Engine of Application State 超媒体作为应用状态的引擎。
72 | RESTful API最好做到HATEOAS,**即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么**。比如,当用户向api.example.com的根目录发出请求,会得到这样一个文档。
73 |
74 | ```json
75 | {"link": {
76 | "rel": "collection https://www.example.com/zoos",
77 | "href": "https://api.example.com/zoos",
78 | "title": "List of zoos",
79 | "type": "application/vnd.yourformat+json"
80 | }}
81 | ```
82 |
83 | 上面代码表示,文档中有一个link属性,用户读取这个属性就知道下一步该调用什么API或者可以调用什么API了。
84 |
85 | ## 2.8. 资源**过滤、排序、选择和分页**的表述
86 |
87 | 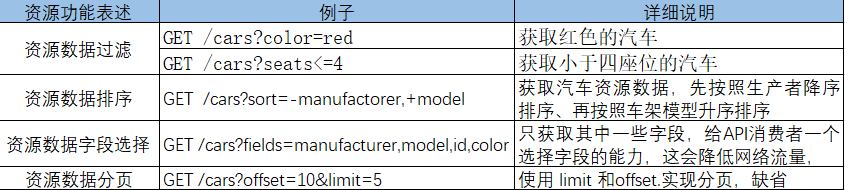
88 |
89 | ## 2.9. 版本化你的API
90 |
91 | 强制性增加API版本声明,不要发布无版本的API。如:/api/v1/blog
92 |
93 | **面向扩展开放,面向修改关闭**:也就是说一个版本的接口开发完成测试上线之后,我们一般不会对接口进行修改,如果有新的需求就开发新的接口进行功能扩展。这样做的目的是:当你的新接口上线后,不会影响使用老接口的用户。如果新接口目的是替换老接口,也不要在v1版本原接口上修改,而是开发v2版本接口,并声明v1接口废弃!
--------------------------------------------------------------------------------
/SpringBoot/02.RESTful接口实现及测试/2.6.RESTfulCRUD.md:
--------------------------------------------------------------------------------
1 | 1. 将静态资源(css,img,js)添加到项目中,放到springboot默认的静态资源文件夹下
2 | 2. 将模板文件(html)放到template文件夹下
3 |
4 |
5 |
6 | > 如果你的静态资源明明放到了静态资源文件夹下却无法访问,请检查一下是不是在自定义的配置类上加了**@EnableWebMvc注解**
--------------------------------------------------------------------------------
/SpringBoot/03.spring boot配置原理实战/3.2.详解YAML语法及占位符语法.md:
--------------------------------------------------------------------------------
1 | # 1. YAML
2 |
3 | YAML(YAML Ain't Markup Language)
4 |
5 | YAML A Markup Language:是一个标记语言
6 |
7 | YAML isn't Markup Language:不是一个标记语言;
8 |
9 | 标记语言:
10 |
11 | 以前的配置文件;大多都使用的是 **xxxx.xml**文件;
12 |
13 | YAML:**以数据为中心**,比json、xml等更适合做配置文件;
14 |
15 | # 2. YAML语法
16 |
17 | ## 2.1 基本语法
18 |
19 | k: (空格)v : 表示一堆键值对(空格必须有)
20 |
21 | 以`空格`的缩进来控制层级关系;只要是左对齐的一列数据,都是同一个层级的
22 |
23 | 次等级的前面是空格,不能使用制表符(tab)
24 |
25 | 冒号之后如果有值,那么冒号和值之间至少有一个空格,不能紧贴着
26 |
27 | ```yaml
28 | server:
29 | port: 8080
30 | path: /hello
31 | ```
32 |
33 | ## 2.2 值得写法
34 |
35 | ### 1. 字面量:普通的值(数字,字符串,布尔)
36 |
37 | ```yaml
38 | k: v
39 | ```
40 |
41 | 字符串默认不用加上单引号或者双引号;
42 |
43 | `""`:双引号;不会转义字符串里面的特殊字符;特殊字符会作为本身想表示的意思
44 |
45 | *eg:* name: "zhangsan \n lisi":输出;zhangsan 换行 lisi
46 |
47 | `''`:单引号;会转义特殊字符,特殊字符最终只是一个普通的字符串数据
48 |
49 | *eg:* name: ‘zhangsan \n lisi’:输出;zhangsan \n lisi
50 |
51 | ### 2. 对象、Map(属性和值)
52 |
53 | `k: v`在下一行来写对象的属性和值的关系;注意缩进
54 |
55 | 1. ```yaml
56 | person:
57 | name: 张三
58 | gender: 男
59 | age: 22Copy to clipboardErrorCopied
60 | ```
61 |
62 | 2. 行内写法
63 |
64 | ```yaml
65 | person: {name: 张三,gender: 男,age: 22}
66 | ```
67 |
68 | ### 3. 数组(List、Set)
69 |
70 | 1. ```yaml
71 | fruits:
72 | - 苹果
73 | - 桃子
74 | - 香蕉Copy to clipboardErrorCopied
75 | ```
76 |
77 | 2. 行内写法
78 |
79 | ```yaml
80 | fruits: [苹果,桃子,香蕉]
81 | ```
82 |
83 | # 3. 简单示例
84 |
85 | ## 一、设计一个YAML数据结构
86 |
87 | ```
88 | # 1. 一个家庭有爸爸、妈妈、孩子。
89 | # 2. 这个家庭有一个名字(family-name)叫做“happy family”
90 | # 3. 爸爸有名字(name)和年龄(age)两个属性
91 | # 4. 妈妈有两个别名
92 | # 5. 孩子除了名字(name)和年龄(age)两个属性,还有一个friends的集合
93 | # 6. 每个friend有两个属性:hobby(爱好)和性别(sex)
94 | ```
95 |
96 | 上面的数据结构用yaml该如何表示呢?
97 |
98 | ```yaml
99 | family:
100 | family-name: "happy family"
101 | father:
102 | name: zimug
103 | age: 18
104 | mother:
105 | alias:
106 | - lovely
107 | - ailice
108 | child:
109 | name: zimug
110 | age: 5
111 | friends:
112 | - hobby: football
113 | sex: male
114 | - hobby: basketball
115 | sex: female
116 | ```
117 |
118 | 或者是friends的部分写成
119 |
120 | ```yaml
121 | friends:
122 | - {hobby: football,sex: male},
123 | - {hobby: basketball,sex: female}
124 | ```
125 |
126 | ### 规则1:字符串的单引号与双引号
127 |
128 | - 双引号;不会转义字符串里面的特殊字符;特殊字符会作为本身想表示的意思,如:
129 | name: “zhangsan \n lisi”:输出;zhangsan 换行 lisi
130 | - 单引号;会转义特殊字符,特殊字符最终只是一个普通的字符串数据,如:
131 | name: ‘zhangsan \n lisi’:输出;zhangsan \n lisi
132 |
133 | ### 规则2:支持松散的语法
134 |
135 | ```
136 | family-name = familyName = family_name
137 | ```
138 |
139 | ## 二、配置文件占位符
140 |
141 | Spring Boot配置文件支持占位符,一些用法如下
142 |
143 | ### 2.1 随机数占位符
144 |
145 | ```yaml
146 | ${random.value}
147 | ${random.int}
148 | ${random.long}
149 | ${random.int(10)}
150 | ${random.int[1024,65536]}
151 | ```
152 |
153 | ### 2.2 默认值
154 |
155 | 占位符获取之前配置的值,如果没有可以是用“冒号”指定默认值
156 | 格式例如,xxxxx.yyyy是属性层级及名称,如果该属性不存在,冒号后面填写默认值
157 |
158 | ```yaml
159 | ${xxxxx.yyyy:默认值}
160 | ```
--------------------------------------------------------------------------------
/SpringBoot/03.spring boot配置原理实战/3.3.2.配置文件值注入的两种方式.md:
--------------------------------------------------------------------------------
1 | # 一、使用@Value获取配置值
2 |
3 | ```java
4 | @Data
5 | @Component
6 | public class Family {
7 |
8 | @Value("${family.family-name}")
9 | private String familyName;
10 |
11 | }
12 | ```
13 |
14 | # 二、使用@ConfigurationProperties获取配置值
15 |
16 | 下面是用于接收yml配置的实体java类,根据yml的嵌套结构,写出来对应的java类:
17 |
18 | ```java
19 | @Data
20 | @Component
21 | @ConfigurationProperties(prefix = "family")
22 | public class Family {
23 |
24 | //@Value("${family.family-name}")
25 | private String familyName;
26 | private Father father;
27 | private Mother mother;
28 | private Child child;
29 |
30 | }
31 | @Data
32 | public class Father {
33 | private String name;
34 | private Integer age;
35 | }
36 | @Data
37 | public class Mother {
38 | private String[] alias;
39 | }
40 | @Data
41 | public class Child {
42 | private String name;
43 | private Integer age;
44 | private List friends;
45 | }
46 | @Data
47 | public class Friend {
48 | private String hobby;
49 | private String sex;
50 | }
51 | ```
52 |
53 | # 三、测试用例
54 |
55 | ```java
56 | @RunWith(SpringRunner.class)
57 | @SpringBootTest
58 | public class CustomYamlTest {
59 |
60 | @Autowired
61 | Family family;
62 |
63 | @Test
64 | public void hello(){
65 | System.out.println(family.toString());
66 | }
67 | }
68 | ```
69 |
70 | 测试结果:
71 |
72 | ```bash
73 | Family(familyName=happy family, father=Father(name=zimug, age=18),
74 | mother=Mother(alias=[lovely, ailice]), child=Child(name=zimug2, age=5,
75 | friends=[Friend(hobby=football, sex=male), Friend(hobby=basketball, sex=female)]))
76 | ```
77 |
78 | # 四、比较一下二者
79 |
80 | | | @ConfigurationProperties | @Value |
81 | | :----------------------- | :----------------------- | :----------------- |
82 | | 功能 | 批量注入属性到java类 | 一个个属性指定注入 |
83 | | 松散语法绑定 | 支持 | 不支持 |
84 | | SpEL | 不支持 | 支持 |
85 | | 复杂数据类型(对象、数组) | 支持 | 不支持 |
86 | | JSR303数据校验 | 支持 | 不支持 |
--------------------------------------------------------------------------------
/SpringBoot/03.spring boot配置原理实战/3.7.profile不同环境使用不同配置.md:
--------------------------------------------------------------------------------
1 | # 一、配置文件规划
2 |
3 | 我们开发的服务通常会部署在不同的环境中,例如开发环境、测试环境,生产环境等,而不同环境需要不同的配置,例如连接不同的 `Redis`、数据库、第三方服务等等。Spring Boot 默认的配置文件是 `application.properties`(或`yml`)。那么如何实现不同的环境使用不同的配置文件呢?一个比较好的实践是为不同的环境定义不同的配置文件,如下所示:
4 | 
5 |
6 | 全局配置文件:`application.yml`
7 | 开发环境配置文件:`application-dev.yml`
8 | 测试环境配置文件:`application-test.yml`
9 | 生产环境配置文件:`application-prod.yml`
10 |
11 | # 二、yml支持多文档块方式
12 |
13 | 每个文档块使用`---`分割
14 |
15 | ```yaml
16 | server:
17 | port: 8080
18 | spring:
19 | profiles:
20 | active: prod
21 | ---
22 | server:
23 | port: 8081
24 | spring:
25 | profiles: dev
26 | ---
27 | server:
28 | port: 8082
29 | spring:
30 | profiles: prod
31 | ```
32 |
33 | 
34 |
35 | # 三、切换环境的方式
36 |
37 | ## 1. 通过配置`application.yml`
38 |
39 | `application.yml`是默认使用的配置文件,在其中通过`spring.profiles.active`设置使用哪一个配置文件,下面代码表示使用`application-prod.yml`配置,如果`application-prod.yml`和`application.yml`配置了相同的配置,比如都配置了运行端口,那`application-prod.yml`的优先级更高
40 |
41 | ```yaml
42 | #需要使用的配置文件
43 | spring:
44 | profiles:
45 | active: prod
46 | ```
47 |
48 | 
49 |
50 | ## 2. VM options、Program arguments、Active Profile
51 |
52 | VM options设置启动参数 `-Dspring.profiles.active=prod`
53 |
54 | Program arguments设置 `--spring.profiles.active=prod`
55 |
56 | Active Profile 设置 prod
57 |
58 | **这三个参数不要一起设置,会引起冲突,选一种即可**,如下图
59 |
60 | 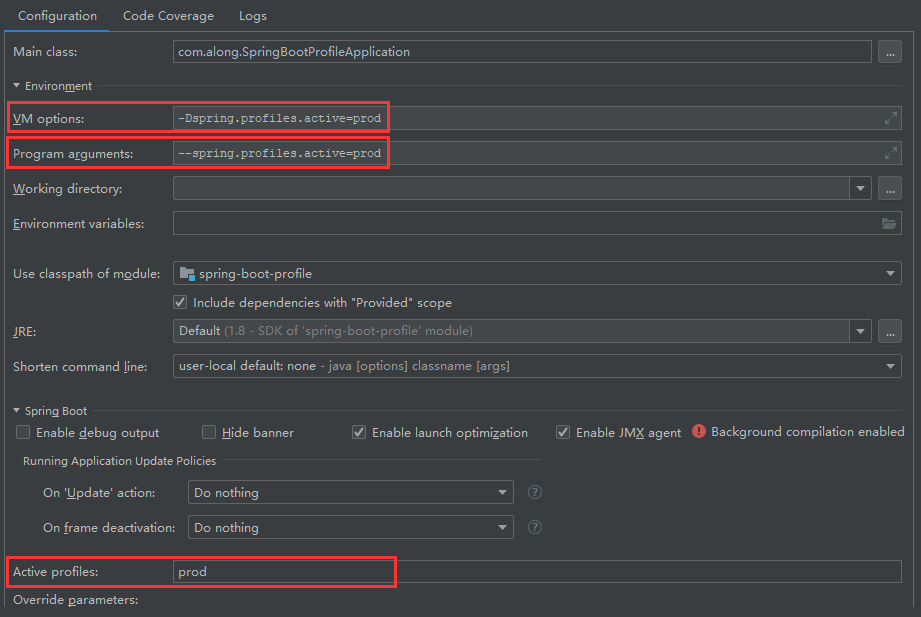
61 |
62 | ## 3.命令行方式
63 |
64 | 将项目打成jar包,在jar包的目录下打开命令行,使用如下命令启动:
65 |
66 | ```
67 | java -jar spring-boot-profile.jar --spring.profiles.active=prod
68 | ```
69 |
70 | 
71 |
72 | 关于 Spring Profiles 更多信息可以参见:[Spring Profiles](https://www.baeldung.com/spring-profiles)
--------------------------------------------------------------------------------
/SpringBoot/03.spring boot配置原理实战/3.8.配置及配置文件的加载优先级.md:
--------------------------------------------------------------------------------
1 | # 一、项目内部配置文件加载位置
2 |
3 | spring boot 启动会扫描以下位置的application.properties或者application.yml文件作为Spring boot的默认配置文件
4 |
5 | ```
6 | –file:./config/
7 | –file:./
8 | –classpath:/config/
9 | –classpath:/
10 | ```
11 |
12 | 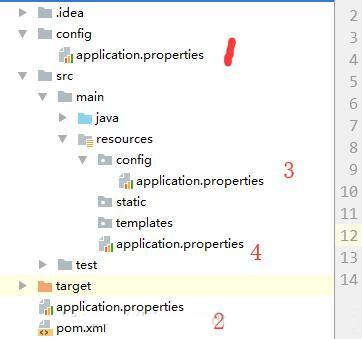
13 | 以上是按照优先级从高到低的顺序,所有位置的文件都会被加载,高优先级配置内容会覆盖低优先级配置内容。
14 |
15 | SpringBoot会从这四个位置全部加载主配置文件,如果高优先级中配置文件属性与低优先级配置文件不冲突的属性,则会共同存在—互补配置。
16 |
17 | 我们也可以通过配置spring.config.location来改变默认配置。
18 |
19 | ```
20 | java -jar Xxx-version.jar --spring.config.location=D:/application.properties
21 | ```
22 |
23 | 项目打包好以后,我们可以使用命令行参数的形式,启动项目的时候来指定配置文件的新位置。
24 |
25 | # 二、配置文件的加载顺序
26 |
27 | 配置加载顺序
28 |
29 | SpringBoot也可以从以下位置加载配置:优先级从高到低;高优先级的配置覆盖低优先级的配置,所有的配置会形成互补配置。
30 |
31 | 1. 命令行参数
32 | 2. 来自java:comp/env的JNDI属性
33 | 3. Java系统属性(System.getProperties())
34 | 4. 操作系统环境变量
35 | 5. RandomValuePropertySource配置的random.*属性值
36 | 6. jar包外部的application-{profile}.properties或application.yml(带spring.profile)配置文件
37 | 7. jar包内部的application-{profile}.properties或application.yml(带spring.profile)配置文件
38 | 8. jar包外部的application.properties或application.yml(不带spring.profile)配置文件
39 | 9. jar包内部的application.properties或application.yml(不带spring.profile)配置文件
40 | 10. @Configuration注解类上的@PropertySource
41 | 11. 通过SpringApplication.setDefaultProperties指定的默认属性
42 |
43 | 参考:[官方文档](https://docs.spring.io/spring-boot/docs/current-SNAPSHOT/reference/htmlsingle/#boot-features-external-config)
--------------------------------------------------------------------------------
/SpringBoot/03.spring boot配置原理实战/3.9.配置文件敏感字段加密.md:
--------------------------------------------------------------------------------
1 | # 一、`Jasypt`是什么
2 |
3 | 
4 | [官网](http://www.jasypt.org/)
5 |
6 | > [Jasypt](http://jasypt.org/)是一个Java库,允许开发人员以很简单的方式添加基本加密功能,而无需深入研究加密原理。利用它可以实现高安全性的,基于标准的加密技术,无论是单向和双向加密。加密密码,文本,数字,二进制文件。
7 |
8 | 1. 高安全性的,基于标准的加密技术,无论是单向和双向加密。加密密码,文本,数字,二进制文件…
9 | 2. 集成Hibernate的。
10 | 3. 可集成到Spring应用程序中,与Spring Security集成。
11 | 4. 集成的能力,用于加密的应用程序(即数据源)的配置。
12 | 5. 特定功能的高性能加密的multi-processor/multi-core系统。
13 | 6. 与任何JCE(Java Cryptography Extension)提供者使用开放的API
14 |
15 | # 二、使用bat脚本生成加密串和盐值(密钥)
16 |
17 | 为了方便,简单编写了一个bat脚本方便使用。
18 |
19 | ```bat
20 | @echo off
21 | set/p input=待加密的明文字符串:
22 | set/p password=加密密钥(盐值):
23 | echo 加密中......
24 | java -cp jasypt-1.9.2.jar org.jasypt.intf.cli.JasyptPBEStringEncryptionCLI ^
25 | input=%input% password=%password% ^
26 | algorithm=PBEWithMD5AndDES
27 | pause
28 | ```
29 |
30 | - 使用 `jasypt-1.9.2.jar`中的`org.jasypt.intf.cli.JasyptPBEStringEncryptionCLI`类进行加密
31 | - input参数是待加密的字符串,password参数是加密的密钥(盐值)
32 | - 使用PBEWithMD5AndDES算法进行加密
33 |
34 | **注意:`jasypt-1.9.2.jar` 文件需要和bat脚本放在相同目录下。
35 |
36 | 使用示例:
37 | 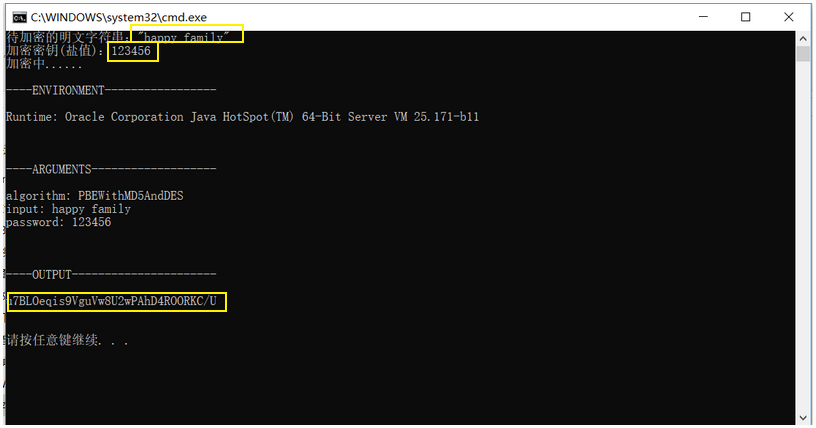
38 |
39 | **注意:相同的盐值(密钥),每次加密的结果是不同的。**
40 |
41 | # 三、`Jasypt`与spring boot整合
42 |
43 | 首先引入`Jasypt`的maven坐标
44 |
45 | ```xml
46 |
47 | com.github.ulisesbocchio
48 | jasypt-spring-boot-starter
49 | 1.18
50 |
51 | ```
52 |
53 | 在`properties`或`yml`文件中需要对明文进行加密的地方的地方,使用ENC()包裹,如原值:"happy family",加密后使用`ENC(密文)`替换。
54 |
55 | 为了方便测试,在`properties`或`yml`文件中,做如下配置
56 |
57 | ```yaml
58 | # 设置盐值(加密解密密钥),我们配置在这里只是为了测试方便
59 | # 生产环境中,切记不要这样直接进行设置,可通过环境变量、命令行等形式进行设置。下文会讲
60 | jasypt:
61 | encryptor:
62 | password: 123456
63 | ```
64 |
65 | 简单来说,就是在需要加密的值使用`ENC(`和`)`进行包裹,即:`ENC(密文)`。之后像往常一样使用`@Value("${}")`获取该配置即可,获取的是解密之后的值。
66 |
67 | # 四、如何存储盐值(密钥)更安全
68 |
69 | > 本身加解密过程都是通过`盐值`进行处理的,所以正常情况下`盐值`和`加密串`是分开存储的。**`盐值`应该放在`系统属性`、`命令行`或是`环境变量`来使用,而不是放在同一个配置文件里面。**
70 |
71 | ## 4.1 命令行存储方式示例
72 |
73 | ```
74 | java -jar xxx.jar --jasypt.encryptor.password=xxx &;
75 | ```
76 |
77 | ## 4.2 环境变量存储方式示例
78 |
79 | 设置环境变量(`linux`):
80 |
81 | ```
82 | # 打开/etc/profile文件
83 | vim /etc/profile
84 | # 文件末尾插入
85 | export JASYPT_PASSWORD = xxxx
86 | ```
87 |
88 | 启动命令:
89 |
90 | ```
91 | java -jar xxx.jar --jasypt.encryptor.password=${JASYPT_PASSWORD} &;
92 | ```
93 |
94 | # 五、这样真的安全么?
95 |
96 | **有的同学会问这样的问题:如果的`linux`主机被攻陷了怎么办,黑客不就知道了密钥?**
97 |
98 | 对于这个问题:我只能这么说,如果你的应用从内部被攻陷,在这个世界上没有一种加密方法是绝对安全的。这种加密方法只能做到:防君子不防小人。大家可能都听说过,某著名互联网公司将明文数据库密码上传到了`github`上面,导致用户信息被泄露的问题。这种加密方式,无非是将密钥与加密结果分开存放,减少个人疏忽导致的意外,增加破解难度。
99 |
100 | 如果密钥被从内部渗透暴露了,任何加密都是不安全的。就像你的组织内部有离心离德的人,无论你如何加密都不安全,你需要做的是把他找出来干掉,或者防范他加入你的组织!
--------------------------------------------------------------------------------
/SpringBoot/04.常用web开发数据库框架/4.15.一行代码实现RESTFul接口.md:
--------------------------------------------------------------------------------
1 | # 一、介绍spring data rest
2 |
3 | Spring Data REST是基于Spring Data的repository之上,可以把 repository **自动**输出为REST资源,目前支持Spring Data JPA、Spring Data MongoDB、Spring Data Neo4j、Spring Data GemFire、Spring Data Cassandra的 repository **自动**转换成REST服务。注意是**自动**。
4 |
5 | # 二、实现rest接口的最快方式
6 |
7 | ```xml
8 |
9 | org.springframework.boot
10 | spring-boot-starter-data-rest
11 |
12 | ```
13 |
14 | ```java
15 | @RepositoryRestResource(collectionResourceRel = "article",path="articles")
16 | public interface ArticleDao extends MongoRepository {
17 |
18 | }
19 | ```
20 |
21 |
22 |
23 | 参数:
24 |
25 | 1. collectionResourceRel 对应的是mongodb数据库资源文档的名称
26 | 2. path是Rest接口资源的基础路径
27 | 如:GET /articles/{id}
28 | DELETE /articles/{id}
29 |
30 | 就简单的这样一个实现,Spring Data Rest就可以基于article资源,生成一套GET、PUT、POST、DELETE的增删改查的REST接口。
--------------------------------------------------------------------------------
/SpringBoot/05.spring boot web开发/5.1.webjars与静态资源.md:
--------------------------------------------------------------------------------
1 | # 一、spring boot静态资源
2 |
3 | ## 静态资源目录
4 |
5 | SpringBoot默认配置下,提供了以下几个静态资源目录:
6 |
7 | ```
8 | /static: classpath:/static/
9 | /public: classpath:/public/
10 | /resources: classpath:/resources/
11 | /META-INF/resources:classpath:/META-INF/resources/
12 | ```
13 |
14 | 当然,可以通过spring.resources.static-locations配置指定静态文件的位置。**但是要特别注意,一旦自己指定了静态资源目录,系统默认的静态资源目录就会失效。所以系统默认的就已经足够使用了,尽量不要自定义。**
15 |
16 | ```yaml
17 | #配置静态资源
18 | spring:
19 | resources:
20 | #指定静态资源目录
21 | static-locations: classpath:/mystatic/
22 | ```
23 |
24 | ## favicon.ico图标
25 |
26 | 如果在配置的静态资源目录中有favicon.ico文件,SpringBoot会自动将其设置为应用图标。
27 |
28 | ## 欢迎页面
29 |
30 | SpringBoot支持静态和模板欢迎页,它首先在静态资源目录查看index.html文件做为首页,若未找到则查找index模板。
31 |
32 | # 二、使用WebJars管理css&js
33 |
34 | **为什么使用 WebJars?**
35 | 显而易见,因为简单。但不仅是依赖这么简单:
36 |
37 | - 清晰的管理 web 依赖
38 | - 通过 Maven, Gradle 等项目管理工具就可以下载 web 依赖
39 | - 解决 web 组件中传递依赖的问题以及版本问题
40 | - 页面依赖的版本自动检测功能
41 |
42 | WebJars是将这些通用的Web前端资源打包成Java的Jar包,然后借助Maven工具对其管理,保证这些Web资源版本唯一性,升级也比较容易。关于webjars资源,有一个专门的网站https://www.webjars.org/,我们可以到这个网站上找到自己需要的资源,在自己的工程中添加入maven依赖,即可直接使用这些资源了。
43 |
44 | ## 1.pom中引入依赖
45 |
46 | 我们可以从WebJars官方查看maven依赖,如下图
47 | 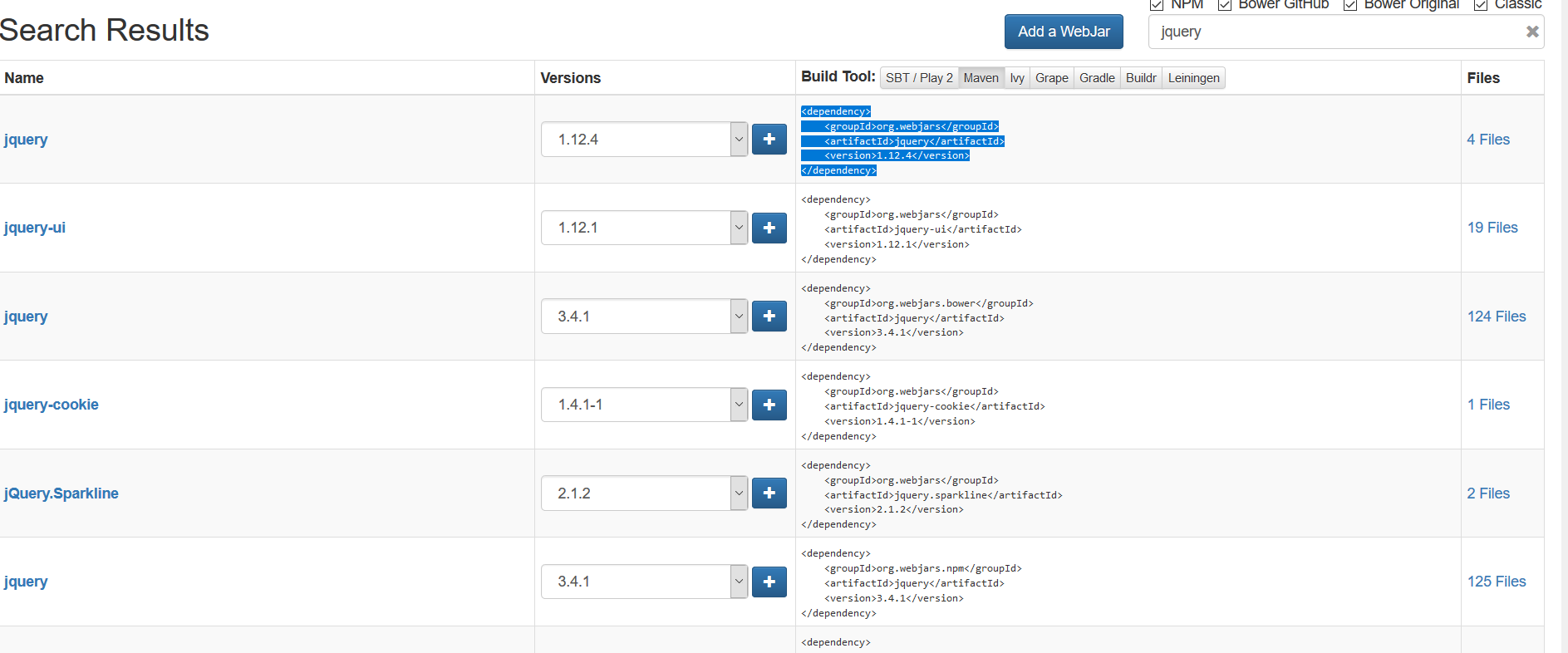
48 | 例如:将jquery引入pom文件中
49 |
50 | ```xml
51 |
52 | org.webjars
53 | jquery
54 | 3.4.1
55 |
56 | ```
57 |
58 | ## 2.访问引入的js文件
59 |
60 | SpringBoot将webjar中路径`/webjars/**`的访问重定向到项目的`classpath:/META-INF/resources/webjars/*`。例如:在html内访问静态资源可以使用目录`/webjars/jquery/3.4.1/jquery.js`.
61 |
62 | ```html
63 |
64 | ```
65 |
66 | # 三、自动检测依赖的版本
67 |
68 | 如果使用 Spring 4.2 以上的版本,并且加入 webjars-locator 组件,就不需要在 html 添加依赖的时候填写版本。
69 |
70 | ```xml
71 |
72 | org.webjars
73 | webjars-locator
74 | 0.30
75 |
76 | ```
77 |
78 | 引入 webjars-locator 值后可以省略版本号:
79 |
80 | ```html
81 |
82 | ```
83 |
84 | 注意:只能去掉版本号
--------------------------------------------------------------------------------
/SpringBoot/05.spring boot web开发/5.2.模板引擎选型与未来趋势.md:
--------------------------------------------------------------------------------
1 | # 一、java web开发经历的几个阶段
2 |
3 | 1. jsp开发阶段:现在仍然有很多企业项目使用jsp开发。可以说jsp就是页面端的servlet,jsp文件糅合了三种元素:Java代码、动态的数据、HTML代码结构。从抽象层次来看,Java代码部分不仅用来组织数据,还被用来控制HTML页面结构。这样在层次划分上属于比较含糊不清的。当然企业可以通过规范的方式去限制,不允许在jsp页面写java代码,但这只是规范层面的事,实际怎样无法控制。
4 | 2. 使用java模板引擎:在这个阶段就出现了freemarker、velocity这样的严格数据模型与业务代码分离的模板引擎。实现了严格的MVC分离,模板引擎的另外一个好处就是:宏定义或者说是组件模板,比jsp标签好用,极大的减少了重复页面组件元素的开发。另外,相对于jsp而言,模板引擎的开发效率会更高。我们都知道,JSP在第一次执行的时候需要转换成Servlet类,开发阶段进行功能调适时,需要频繁的修改JSP,每次修改都要编译和转换,那么试想一天中我们浪费在程序编译的时间有多少。但是java模板引擎,仍然是使用的服务器端的渲染技术,也就是没有办法将html页面和后台服务层面全面解耦,这就要求前端工程师和后端工程师在同一个项目结构下工作,而且前端工程师及其依赖于后端的业务数据,页面无法脱离于后端请求数据在浏览器独立运行。
5 | 3. 前端工程化:随着VUE、angularjs、reactjs的大行其道,开始实现真正的前后端分离技术。前端的工程师负责页面的美化与结构,后端工程师可以专注于业务的实现。在ajax和nodejs出现之后,可以说为前端的发展带来了革命性的变化,前端可以做自己的工程化实践。这些新的前端技术通常是“所见即所得”,写完的代码可以直接在浏览器上查看,将前端后端的串行化工作模式转变为并行工作的模式。前端专注于布局、美化,后端专注于业务。专业的人越来越专业,工作效率也更高。
6 |
7 | # 二、java模板引擎的选型。
8 |
9 | 常见的模板引擎有Freemarker、Thymeleaf、Velocity等,下面我们就分别来说一下。
10 |
11 | spring boot目前官方集成的框架只有freemarker和Thymeleaf,官方明确建议放弃velocity。很多人说thymeleaf是官方推荐的模板引擎,说实话我没找到这个说法的出处。
12 | 
13 |
14 | ## Thymeleaf
15 |
16 | Thymeleaf的最大优点也是他的最大的缺点,就是它使用静态html嵌入标签属性,浏览器可以直接打开模板文件,便于前后端联调。也就是贴近于“所见即所得”。但是也正是因为,thyme使用标签属性去放数据,也导致它的语法违反了自然人对于html的理解。另外Thymeleaf的性能一直为人所诟病。
17 | Thymeleaf代码和下面freemarker对一个对象数组遍历的代码对比一下:
18 |
19 | ```html
20 |
21 | |
22 | |
23 | |
24 | |
25 | |
26 |
27 | ```
28 |
29 | FreeMarker代码:
30 |
31 | ```html
32 | <#list users as item>
33 |
34 | | ${item.userId} |
35 | ${item.username} |
36 | ${item.password} |
37 | ${item.email} |
38 | ${item.mobile} |
39 |
40 |
41 | ```
42 |
43 | # 三、最后
44 |
45 | 综上,目前为止如果使用java模板引擎,我还是推荐freemarker。当然,我还有一个建议,去学vue、angularjs、reactjs。不要用java模板引擎。
46 | 
--------------------------------------------------------------------------------
/SpringBoot/05.spring boot web开发/5.3.web应用开发之整合jsp.md:
--------------------------------------------------------------------------------
1 | # 一、集成jsp
2 |
3 | spring-boot-starter-web 包依赖了 spring-boot-starter-tomcat 不需要再单独配置。
4 | 引入 jstl 和内嵌的 tomcat,jstl 是一个 JSP 标签集合,它封装了 JSP 应用的通用核心功能。
5 | tomcat-embed-jasper 主要用来支持 JSP 的解析和运行。
6 |
7 | ```xml
8 |
9 | org.springframework.boot
10 | spring-boot-starter-web
11 |
12 |
13 |
14 | org.apache.tomcat.embed
15 | tomcat-embed-jasper
16 |
17 |
18 |
19 | javax.servlet
20 | jstl
21 |
22 | ```
23 |
24 | spring.mvc.view.prefix 指明 jsp 文件在 webapp 下的哪个目录
25 | spring.mvc.view.suffix 指明 jsp 以什么样的后缀结尾
26 |
27 | ```yaml
28 | spring:
29 | mvc:
30 | view:
31 | suffix: .jsp
32 | prefix: /WEB-INF/jsp/
33 |
34 | debug: true
35 | ```
36 |
37 | # 二、目录结构
38 |
39 | 这个目录结构和配置文件一一对应,一定不要放错了。
40 | 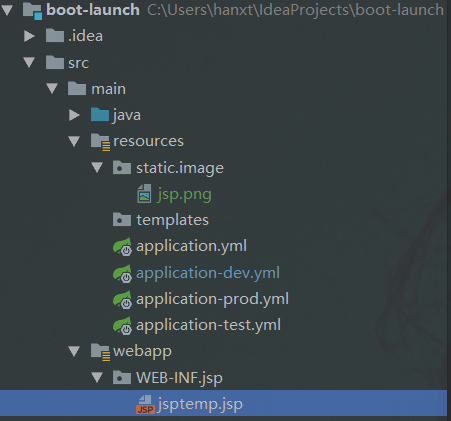
41 |
42 | - 静态资源,如:图片放在resources/static目录下面
43 | - jsp文件放在webapp.WEB-INF.jsp的下面
44 |
45 | # 三、代码测试
46 |
47 | ```java
48 | @Controller
49 | @RequestMapping("/template")
50 | public class TemplateController {
51 |
52 | @Resource(name="articleMybatisRestServiceImpl")
53 | ArticleRestService articleRestService;
54 |
55 | @GetMapping("/jsp")
56 | public String index(String name, Model model) {
57 |
58 | List articles = articleRestService.getAll();
59 |
60 | model.addAttribute("articles", articles);
61 |
62 | //模版名称,实际的目录为:src/main/webapp/WEB-INF/jsp/jsptemp.jsp
63 | return "jsptemp";
64 | }
65 | }
66 | ```
67 |
68 | jsptemp.jsp
69 |
70 | ```jsp
71 | <%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
72 | <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
73 |
74 |
75 |
76 |
77 | Title
78 |
79 |
80 |
81 |
82 | | 作者 |
83 | 教程名称 |
84 | 内容 |
85 |
86 |
87 |
88 | | ${article.author} |
89 | ${article.title} |
90 | ${article.content} |
91 |
92 |
93 |
94 |
95 |
96 |  97 |
98 |
99 | ```
100 |
101 | **注意img标签的静态资源引用路径与实际存放路径之间的关系。**]
102 |
103 | # 四、运行方法测试
104 |
105 | 因为jsp对jar运行的方式支持不好,所以要一一进行测试:
106 |
107 | 1. 使用IDEA启动类启动测试,没有问题
108 | 2. 使用`spring-boot:run -f pom.xml`测试,没有问题
109 | 3. 打成jar包通过`java -jar`方式运行,页面报错
110 | 4. 打成war包,运行于外置的tomcat,没有问题
111 |
112 | 所以,无法用jar包的形式运行jsp应用。
--------------------------------------------------------------------------------
/SpringBoot/05.spring boot web开发/5.4.web应用开发之整合freemarker.md:
--------------------------------------------------------------------------------
1 | # 一、Freemarker简介
2 |
3 | FreeMarker是一个模板引擎,一个基于模板生成文本输出的通用工具,使用纯Java编写。FreeMarker我们的第一印象是用来替代JSP的,但是与JSP 不同的是FreeMarker 模板可以在 Servlet容器之外使用。可以使用它们来生成电子邮件、 配置文件、 XML 映射等。或者直接生成HTML。
4 |
5 | 虽然FreeMarker具有一些编程的能力,但通常由Java程序准备要显示的数据,由FreeMarker生成页面,通过模板显示准备的数据(如下图)
6 |
7 | 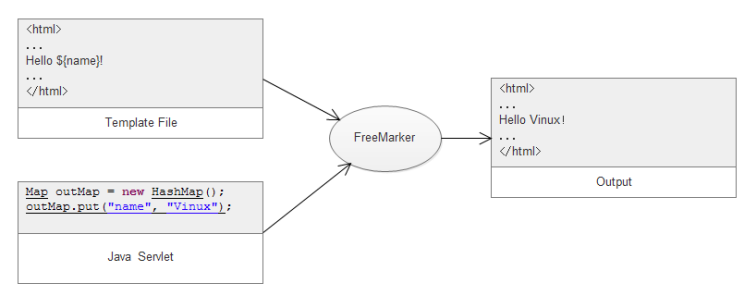
8 |
9 | # 二、整合
10 |
11 | ```xml
12 |
13 | org.springframework.boot
14 | spring-boot-starter-freemarker
15 |
16 | ```
17 |
18 | ```yaml
19 | spring:
20 | freemarker:
21 | cache: false # 缓存配置 开发阶段应该配置为false 因为经常会改
22 | suffix: .html # 模版后缀名 默认为ftl
23 | charset: UTF-8 # 文件编码
24 | template-loader-path: classpath:/templates/
25 | ```
26 |
27 |
28 |
29 | 目录结构:
30 |
31 | 
32 |
33 | # 三、代码测试
34 |
35 | ```java
36 | @Controller
37 | @RequestMapping("template")
38 | public class TemplateController {
39 | @GetMapping("/freemarker")
40 | public String index(Model model){
41 | Article article = new Article();
42 | article.setAuthor("krislin");
43 | article.setTitle("spring boot");
44 | article.setContent("spring boot学习");
45 |
46 | model.addAttribute("article",article);
47 |
48 | //模版名称,实际的目录为:resources/templates/freemarkerTemplate.html
49 | return "freemarkerTemplate";
50 | }
51 | }
52 | ```
53 |
54 | ```html
55 |
56 |
57 |
58 |
59 | freemarker简单示例
60 |
61 |
62 |
97 |
98 |
99 | ```
100 |
101 | **注意img标签的静态资源引用路径与实际存放路径之间的关系。**]
102 |
103 | # 四、运行方法测试
104 |
105 | 因为jsp对jar运行的方式支持不好,所以要一一进行测试:
106 |
107 | 1. 使用IDEA启动类启动测试,没有问题
108 | 2. 使用`spring-boot:run -f pom.xml`测试,没有问题
109 | 3. 打成jar包通过`java -jar`方式运行,页面报错
110 | 4. 打成war包,运行于外置的tomcat,没有问题
111 |
112 | 所以,无法用jar包的形式运行jsp应用。
--------------------------------------------------------------------------------
/SpringBoot/05.spring boot web开发/5.4.web应用开发之整合freemarker.md:
--------------------------------------------------------------------------------
1 | # 一、Freemarker简介
2 |
3 | FreeMarker是一个模板引擎,一个基于模板生成文本输出的通用工具,使用纯Java编写。FreeMarker我们的第一印象是用来替代JSP的,但是与JSP 不同的是FreeMarker 模板可以在 Servlet容器之外使用。可以使用它们来生成电子邮件、 配置文件、 XML 映射等。或者直接生成HTML。
4 |
5 | 虽然FreeMarker具有一些编程的能力,但通常由Java程序准备要显示的数据,由FreeMarker生成页面,通过模板显示准备的数据(如下图)
6 |
7 | 
8 |
9 | # 二、整合
10 |
11 | ```xml
12 |
13 | org.springframework.boot
14 | spring-boot-starter-freemarker
15 |
16 | ```
17 |
18 | ```yaml
19 | spring:
20 | freemarker:
21 | cache: false # 缓存配置 开发阶段应该配置为false 因为经常会改
22 | suffix: .html # 模版后缀名 默认为ftl
23 | charset: UTF-8 # 文件编码
24 | template-loader-path: classpath:/templates/
25 | ```
26 |
27 |
28 |
29 | 目录结构:
30 |
31 | 
32 |
33 | # 三、代码测试
34 |
35 | ```java
36 | @Controller
37 | @RequestMapping("template")
38 | public class TemplateController {
39 | @GetMapping("/freemarker")
40 | public String index(Model model){
41 | Article article = new Article();
42 | article.setAuthor("krislin");
43 | article.setTitle("spring boot");
44 | article.setContent("spring boot学习");
45 |
46 | model.addAttribute("article",article);
47 |
48 | //模版名称,实际的目录为:resources/templates/freemarkerTemplate.html
49 | return "freemarkerTemplate";
50 | }
51 | }
52 | ```
53 |
54 | ```html
55 |
56 |
57 |
58 |
59 | freemarker简单示例
60 |
61 |
62 | Hello Freemarker
63 |
64 |
65 |
66 | | 作者 |
67 | 教程名称 |
68 | 内容 |
69 |
70 |
71 |
72 | | ${article.author} |
73 | ${article.title} |
74 | ${article.content} |
75 |
76 |
77 |
78 |
79 |
80 |  81 |
82 |
83 | ```
84 |
85 | 访问测试地址: http://localhost:8080/template/freemarker
86 | 
87 |
88 | # 四、推荐
89 |
90 | 如果想进一步学习freemarker,请参考:
91 | http://freemarker.foofun.cn/index.html
--------------------------------------------------------------------------------
/SpringBoot/05.spring boot web开发/5.6.thymeleaf基础语法讲解.md:
--------------------------------------------------------------------------------
1 | # 一、基础语法
2 |
3 | 
4 |
5 | ## 变量表达式 `${}`
6 |
7 | 使用方法:直接使用`th:xx = "${}"` 获取对象属性 。例如:
8 |
9 | ```html
10 |
15 |
16 |
17 |
18 |
19 | ```
20 |
21 | ## 选择变量表达式 `*{}`
22 |
23 | 使用方法:首先通过`th:object` 获取对象,然后使用`th:xx = "*{}"`获取对象属性。
24 |
25 | ```html
26 |
31 | ```
32 |
33 | ## 链接表达式 `@{}`
34 |
35 | 使用方法:通过链接表达式`@{}`直接拿到应用路径,然后拼接静态资源路径。例如:
36 |
37 | ```html
38 |
39 |
40 | ```
41 |
42 | ## 其它表达式
43 |
44 | 在基础语法中,默认支持字符串连接、数学运算、布尔逻辑和三目运算等。例如:
45 |
46 | ```html
47 |
48 | ```
49 |
50 | # 二、迭代循环
51 |
52 | 想要遍历`List`集合很简单,配合`th:each` 即可快速完成迭代。例如遍历用户列表:
53 |
54 | ```html
55 |
81 |
82 |
83 | ```
84 |
85 | 访问测试地址: http://localhost:8080/template/freemarker
86 | 
87 |
88 | # 四、推荐
89 |
90 | 如果想进一步学习freemarker,请参考:
91 | http://freemarker.foofun.cn/index.html
--------------------------------------------------------------------------------
/SpringBoot/05.spring boot web开发/5.6.thymeleaf基础语法讲解.md:
--------------------------------------------------------------------------------
1 | # 一、基础语法
2 |
3 | 
4 |
5 | ## 变量表达式 `${}`
6 |
7 | 使用方法:直接使用`th:xx = "${}"` 获取对象属性 。例如:
8 |
9 | ```html
10 |
15 |
16 |
17 |
18 |
19 | ```
20 |
21 | ## 选择变量表达式 `*{}`
22 |
23 | 使用方法:首先通过`th:object` 获取对象,然后使用`th:xx = "*{}"`获取对象属性。
24 |
25 | ```html
26 |
31 | ```
32 |
33 | ## 链接表达式 `@{}`
34 |
35 | 使用方法:通过链接表达式`@{}`直接拿到应用路径,然后拼接静态资源路径。例如:
36 |
37 | ```html
38 |
39 |
40 | ```
41 |
42 | ## 其它表达式
43 |
44 | 在基础语法中,默认支持字符串连接、数学运算、布尔逻辑和三目运算等。例如:
45 |
46 | ```html
47 |
48 | ```
49 |
50 | # 二、迭代循环
51 |
52 | 想要遍历`List`集合很简单,配合`th:each` 即可快速完成迭代。例如遍历用户列表:
53 |
54 | ```html
55 |
56 | 作者:
57 | 标题:
58 | 内容:
59 |
60 | ```
61 |
62 | 在集合的迭代过程还可以获取状态变量,只需在变量后面指定状态变量名即可,状态变量可用于获取集合的下标/序号、总数、是否为单数/偶数行、是否为第一个/最后一个。例如:
63 |
64 | ```html
65 |
66 | 下标:
67 | 序号:
68 | 作者:
69 | 标题:
70 | 内容:
71 |
72 | ```
73 |
74 | **迭代下标变量用法:**
75 | 状态变量定义在一个th:每个属性和包含以下数据:
76 |
77 | 1. 当前迭代索引,从0开始。这是索引属性。index
78 | 2. 当前迭代索引,从1开始。这是统计属性。count
79 | 3. 元素的总量迭代变量。这是大小属性。 size
80 | 4. iter变量为每个迭代。这是目前的财产。 current
81 | 5. 是否当前迭代是奇数还是偶数。这些even/odd的布尔属性。
82 | 6. 是否第一个当前迭代。这是first布尔属性。
83 | 7. 是否最后一个当前迭代。这是last布尔属性。
84 |
85 | # 三、条件判断
86 |
87 | 条件判断通常用于动态页面的初始化,例如:
88 |
89 | ```html
90 |
93 | ```
94 |
95 | 如果想取反则使用unless 例如:
96 |
97 | ```html
98 |
101 | ```
--------------------------------------------------------------------------------
/SpringBoot/05.spring boot web开发/5.7.thymeleaf内置对象与工具类.md:
--------------------------------------------------------------------------------
1 | # 一、内置对象
2 |
3 | > 官方文档: [Thymeleaf 3.0 基础对象](https://www.thymeleaf.org/doc/tutorials/3.0/usingthymeleaf.html#appendix-a-expression-basic-objects)
4 |
5 | ## 七大基础对象:
6 |
7 | - `${#ctx}` 上下文对象,可用于获取其它内置对象。
8 | - `${#param}`: 上下文变量。
9 | - `${#locale}`:上下文区域设置。
10 | - `${#request}`: `HttpServletRequest`对象。
11 | - `${#response}`: `HttpServletResponse`对象。
12 | - `${#session}`: `HttpSession`对象。
13 | - `${#servletContext}`: `ServletContext`对象。
14 |
15 | ## 用法示例
16 |
17 | **locale对象操作:**
18 |
19 | ```html
20 |
21 | ```
22 |
23 | **session对象操作:**
24 |
25 | ```html
26 |
27 |
28 |
29 |
30 | ```
31 |
32 | # 二、 常用的工具类:
33 |
34 | > 官方文档: [Thymeleaf 3.0 工具类](https://www.thymeleaf.org/doc/tutorials/3.0/usingthymeleaf.html#appendix-b-expression-utility-objects)
35 |
36 | - `#strings`:字符串工具类
37 | - `#lists`:List 工具类
38 | - `#arrays`:数组工具类
39 | - `#sets`:Set 工具类
40 | - `#maps`:常用Map方法。
41 | - `#objects`:一般对象类,通常用来判断非空
42 | - `#bools`:常用的布尔方法。
43 | - `#execInfo`:获取页面模板的处理信息。
44 | - `#messages`:在变量表达式中获取外部消息的方法,与使用#{...}语法获取的方法相同。
45 | - `#uris`:转义部分URL / URI的方法。
46 | - `#conversions`:用于执行已配置的转换服务的方法。
47 | - `#dates`:时间操作和时间格式化等。
48 | - `#calendars`:用于更复杂时间的格式化。
49 | - `#numbers`:格式化数字对象的方法。
50 | - `#aggregates`:在数组或集合上创建聚合的方法。
51 | - `#ids`:处理可能重复的id属性的方法。
52 |
53 | ## 用法举例:
54 |
55 | **date工具类之日期格式化**
56 | 使用默认的日期格式(`toString`方法) 并不是我们预期的格式:`Mon Dec 03 23:16:50 CST 2018`
57 | 此时可以通过时间工具类`#dates`来对日期进行格式化:`2018-12-03 23:16:50`
58 |
59 | ```html
60 |
61 | ```
62 |
63 | **首字母大写**
64 |
65 | ```html
66 | /*
67 | * Convert the first character of every word to upper-case
68 | */
69 | ${#strings.capitalizeWords(str)} // also array*, list* and set*
70 | ```
71 |
72 | **list方法**
73 |
74 | ```html
75 | /*
76 | * Compute size
77 | */
78 | ${#lists.size(list)}
79 |
80 | /*
81 | * Check whether list is empty
82 | */
83 | ${#lists.isEmpty(list)}
84 | ```
--------------------------------------------------------------------------------
/SpringBoot/05.spring boot web开发/5.8.公共片段(标签)与内联js.md:
--------------------------------------------------------------------------------
1 | # 一、片段表达式(标签) `~{}`
2 |
3 | 使用方法:首先通过`th:fragment`定制片段 ,然后通过`th:replace` 填写片段路径和片段名。例如:
4 | 我们通常将项目里面经常重用的代码抽取为代码片段(标签)
5 |
6 | ```html
7 |
8 |
9 |
10 |
11 | ```
12 |
13 | 然后在不同的页面引用该片段,达到代码重用的目的
14 |
15 | ```html
16 |
17 |
18 | ```
19 |
20 | 在实际使用中,我们往往使用更简洁的表达,去掉表达式外壳直接填写片段名。例如:
21 |
22 | ```html
23 |
24 |
25 |
26 |
27 | ```
28 |
29 | 关于thymeleaf th:replace th:include th:insert 的区别
30 |
31 | - th:insert :保留自己的主标签,保留th:fragment的主标签。
32 | - th:replace :不要自己的主标签,保留th:fragment的主标签。
33 | - th:include :保留自己的主标签,不要th:fragment的主标签。(官方3.0后不推荐)
34 |
35 | > 值得注意的是,使用替换路径`th:replace` 开头请勿添加斜杠`/`,避免部署运行的时候出现路径报错。(因为默认拼接的路径为`spring.thymeleaf.prefix = classpath:/templates/`)
36 |
37 | 片段表达式是Thymeleaf的特色之一,细粒度可以达到标签级别,这是JSP无法做到的。
38 | 片段表达式拥有三种语法:
39 |
40 | - `~{ viewName } 表示引入完整页面`
41 | - `~{ viewName ::selector} 表示在指定页面寻找片段 其中selector可为片段名、jquery选择器等`,即可以在一个html页面内定义多个片段.
42 | - `~{ ::selector} 表示在当前页寻找`
43 |
44 | # 二、内联语法
45 |
46 | 我们之前所讲的内容都是在html标签上使用的thymeleaf的语法,那么如果我们需要在html上使用上述所讲的语法表达式,怎么做?
47 | 答:标准格式为:`[[${xx}]]` ,可以读取服务端变量,也可以调用内置对象的方法。例如获取用户变量和应用路径:
48 |
49 | ```html
50 |
55 | ```
56 |
57 | - 标签(代码片段)内引入的JS里面能使用内联表达式吗?答:不能!内联表达式仅在页面生效,因为`Thymeleaf`只负责解析一级视图,不能识别外部标签JS里面的表达式。
--------------------------------------------------------------------------------
/SpringBoot/06.生命周期内的拦截过滤与监听/6.2.spring拦截器及请求链路说明.md:
--------------------------------------------------------------------------------
1 | # 一、拦截器
2 |
3 | ## 定义
4 |
5 | 在 Servlet 规范中并没有拦截器的概念,它是面向切面编程的一种应用:在需要对方法进行增强的场景下,例如在方法调用前执行一段代码,或者在方法完成后额外执行一段操作,拦截器的一种实现方式就是动态代理。
6 | 把过滤器和拦截器放在一起比较,我觉得是没有意义的,本质上是不同概念,并没有可比性,它位于过滤器的下游,是面向 Servlet 方法的。
7 |
8 | ## 使用场景
9 |
10 | AOP 编程思想面对的是横向的切面,而非纵向的业务。举个简单的例子,每个方法处理过程中,除了业务逻辑外,我们都会有一些相同的操作:参数校验,日志打印等,虽然这些处理代码并不多,但是每个方法都要写这类东西,工作量就不小了。
11 | 能否使用程序来统一加入这类操作,而不用程序员自己手写呢?这就是切面编程思想的应用,利用 Java 的代理,在调用真正的方法之前或者之后,添加一些额外的增强功能。
12 |
13 | # 二、拦截器的实现
14 |
15 | 以上的过滤器、监听器都属于Servlet的api,我们在开发中处理利用以上的进行过滤web请求时,还可以使用Spring提供的拦截器(HandlerInterceptor)进行更加精细的控制。
16 |
17 | 编写自定义拦截器类
18 |
19 | ```java
20 | @Slf4j
21 | public class CustomHandlerInterceptor implements HandlerInterceptor{
22 |
23 | @Override
24 | public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
25 | throws Exception {
26 | log.info("preHandle:请求前调用");
27 | //返回 false 则请求中断
28 | return true;
29 | }
30 |
31 | @Override
32 | public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler,
33 | ModelAndView modelAndView) throws Exception {
34 | log.info("postHandle:请求后调用");
35 |
36 | }
37 |
38 | @Override
39 | public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex)
40 | throws Exception {
41 | log.info("afterCompletion:请求调用完成后回调方法,即在视图渲染完成后回调");
42 |
43 | }
44 |
45 | }
46 | ```
47 |
48 | 通过继承WebMvcConfigurerAdapter注册拦截器。笔者在写作完成后,发现WebMvcConfigurerAdapter类已经被废弃,请实现WebMvcConfigurer接口完成拦截器的注册。
49 |
50 | ```java
51 | @Configuration
52 | //废弃:public class MyWebMvcConfigurer extends WebMvcConfigurerAdapter{
53 | public class MyWebMvcConfigurer implements WebMvcConfigurer
54 | @Override
55 | public void addInterceptors(InterceptorRegistry registry) {
56 | //注册拦截器 拦截规则
57 | //多个拦截器时 以此添加 执行顺序按添加顺序
58 | registry.addInterceptor(getHandlerInterceptor()).addPathPatterns("/*");
59 | }
60 |
61 | @Bean
62 | public static HandlerInterceptor getHandlerInterceptor() {
63 | return new CustomHandlerInterceptor();
64 | }
65 | }
66 | ```
67 |
68 | # 三、请求链路说明
69 |
70 | 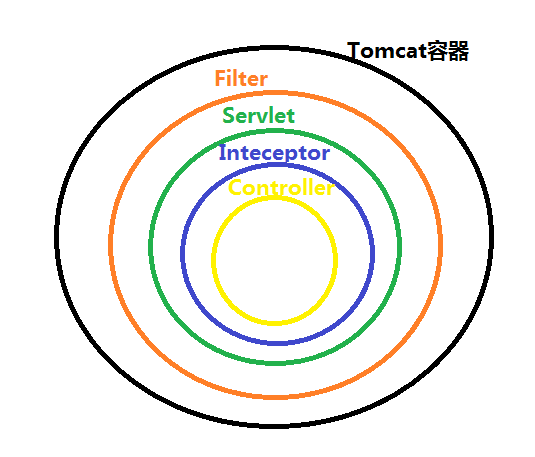
71 |
72 | 
73 |
74 | 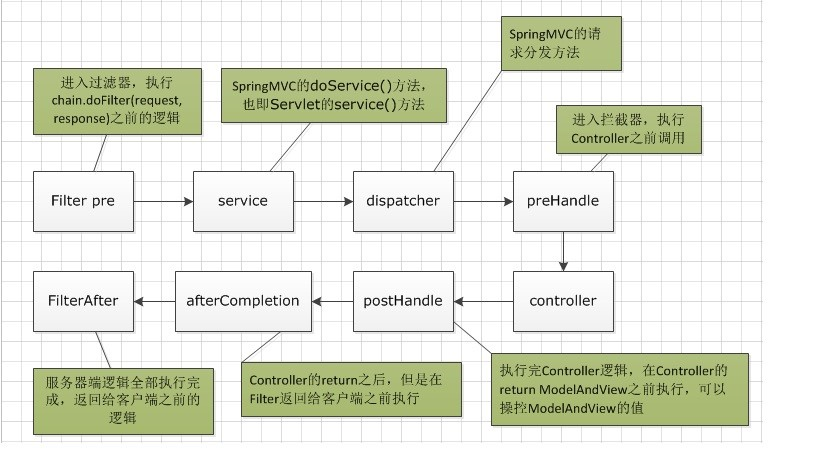
--------------------------------------------------------------------------------
/SpringBoot/06.生命周期内的拦截过滤与监听/6.4.应用启动的监听.md:
--------------------------------------------------------------------------------
1 | # 一、简介
2 |
3 | Spring Boot提供了两个接口:CommandLineRunner、ApplicationRunner,用于启动应用时做特殊处理,这些代码会在SpringApplication的run()方法运行完成之前被执行。
4 | 通常用于应用启动前的特殊代码执行、特殊数据加载、垃圾数据清理、微服务的服务发现注册、系统启动成功后的通知等。相当于Spring的ApplicationListener、Servlet的ServletContextListener。**使用二者的好处在于,可以方便的使用应用启动参数**,根据参数不同做不同的初始化操作。
5 |
6 | # 二、代码实验
7 |
8 | ## 通过@Component定义方式实现
9 |
10 | CommandLineRunner:参数是字符串数组
11 |
12 | ```java
13 | @Slf4j
14 | @Component
15 | public class CommandLineStartupRunner implements CommandLineRunner {
16 | @Override
17 | public void run(String... args) throws Exception {
18 | log.info("CommandLineRunner传入参数:{}", Arrays.toString(args));
19 | }
20 | }
21 | ```
22 |
23 | ApplicationRunner:参数被放入ApplicationArguments,通过getOptionNames()、getOptionValues()、getSourceArgs()获取参数
24 |
25 | ```java
26 | @Slf4j
27 | @Component
28 | public class AppStartupRunner implements ApplicationRunner {
29 | @Override
30 | public void run(ApplicationArguments args) throws Exception {
31 | log.info("ApplicationRunner参数: {}", args.getOptionNames());
32 | }
33 | }
34 | ```
35 |
36 | ## 通过@Bean定义方式实现
37 |
38 | ```java
39 | @Configuration
40 | public class BeanRunner {
41 | @Bean
42 | @Order(1)
43 | public CommandLineRunner runner1(){
44 | return new CommandLineRunner() {
45 | public void run(String... args){
46 | System.out.println("CommandLineRunner run1()" + Arrays.toString(args));
47 | }
48 | };
49 | }
50 |
51 | @Bean
52 | @Order(2)
53 | public CommandLineRunner runner2(){
54 | return new CommandLineRunner() {
55 | public void run(String... args){
56 | System.out.println("CommandLineRunner run2()" + Arrays.toString(args));
57 | }
58 | };
59 | }
60 |
61 | @Bean
62 | @Order(3)
63 | public CommandLineRunner runner3(){
64 | return new CommandLineRunner() {
65 | public void run(String... args){
66 | System.out.println("CommandLineRunner run3()" + Arrays.toString(args));
67 | }
68 | };
69 | }
70 | }
71 | ```
72 |
73 | 可以通过@Order设置执行顺序
74 |
75 | # 三、执行测试
76 |
77 | 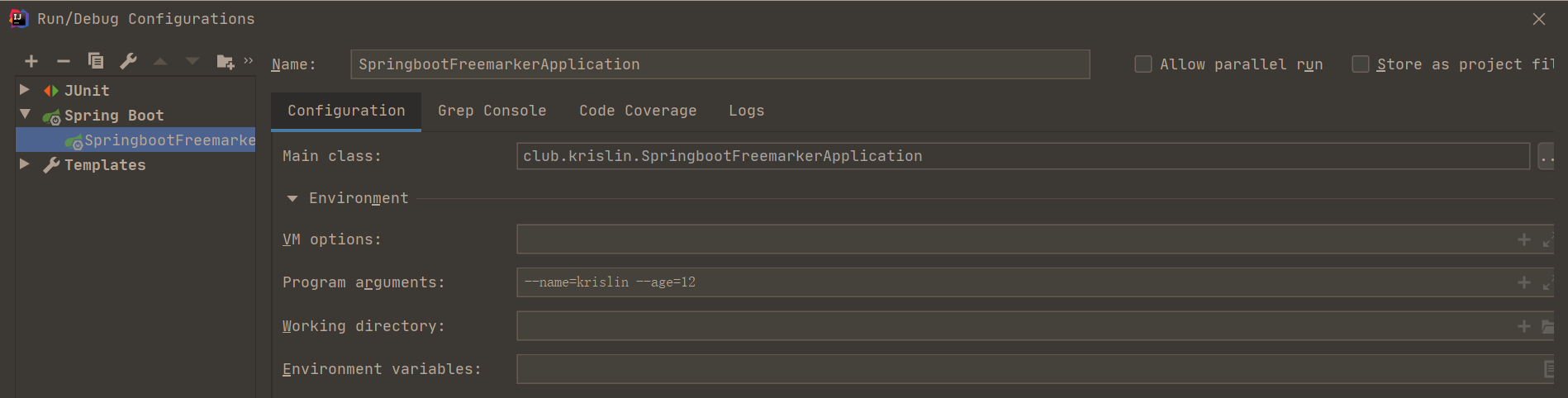
78 |
79 | 
80 |
81 | # 四、总结
82 |
83 | CommandLineRunner、ApplicationRunner的核心用法是一致的,就是用于应用启动前的特殊代码执行。ApplicationRunner的执行顺序先于CommandLineRunner;ApplicationRunner将参数封装成了对象,提供了获取参数名、参数值等方法,操作上会方便一些。
84 | 另外可以通过@Order定义执行的书序。
--------------------------------------------------------------------------------
/SpringBoot/07.嵌入式容器的配置与应用/7.1.嵌入式的容器配置与调整.md:
--------------------------------------------------------------------------------
1 | # 两种方法配置调整SpringBoot应用容器的参数
2 |
3 | - 修改配置文件
4 | - 自定义配置类
5 |
6 | ## 一、使用配置文件定制修改相关配置
7 |
8 | 在application.properties / application.yml配置所需要的属性
9 | server.xx开头的是所有servlet容器通用的配置,server.tomcat.xx开头的是tomcat特有的参数,其它类似。
10 |
11 | 关于修改配置文件application.properties。
12 | [SpringBoot项目详细的配置文件修改文档](https://docs.spring.io/spring-boot/docs/current/reference/html/common-application-properties.html#common-application-properties)
13 |
14 | 其中比较重要的有:
15 |
16 | | 参数 | 说明 |
17 | | :---------------------------------- | :--------------------------------------------------------- |
18 | | server.connection-timeout= | 连接的超时时间 |
19 | | server.tomcat.max-connections=10000 | 接受的最大请求连接数 |
20 | | server.tomcat.accept-count=100 | 当所求的线程处于工作中,被放入请求队列等待的最大的请求数量 |
21 | | server.tomcat.max-threads=200 | 最大的工作线程池数量 |
22 | | server.tomcat.min-spare-threads=10 | 最小的工作线程池数量 |
23 |
24 | ## 二、SpringBoot2.x定制和修改Servlet容器的相关配置,使用配置类
25 |
26 | 步骤:
27 | 1.建立一个配置类,加上@Configuration注解
28 | 2.添加定制器ConfigurableServletWebServerFactory
29 | 3.将定制器返回
30 |
31 | ```java
32 | @Configuration
33 | public class TomcatCustomizer {
34 |
35 | @Bean
36 | public ConfigurableServletWebServerFactory configurableServletWebServerFactory(){
37 | TomcatServletWebServerFactory factory = new TomcatServletWebServerFactory();
38 | factory.setPort(8585);
39 | return factory;
40 | }
41 | }
42 | ```
--------------------------------------------------------------------------------
/SpringBoot/07.嵌入式容器的配置与应用/7.2.切换到jetty&undertow容器.md:
--------------------------------------------------------------------------------
1 | # 一、配置
2 |
3 | ## pom配置
4 |
5 | SpringBoot默认是使用tomcat作为默认的应用容器。如果需要把tomcat替换为jetty或者undertow,需要先把tomcat相关的jar包排除出去。如下代码所示
6 |
7 | ```xml
8 |
9 | org.springframework.boot
10 | spring-boot-starter-web
11 |
12 |
13 | org.springframework.boot
14 | spring-boot-starter-tomcat
15 |
16 |
17 |
18 | ```
19 |
20 | 如果使用Jetty容器,那么添加
21 |
22 | ```xml
23 |
24 | org.springframework.boot
25 | spring-boot-starter-jetty
26 |
27 | ```
28 |
29 | 如果使用Undertow容器,那么添加
30 |
31 | ```xml
32 |
33 | org.springframework.boot
34 | spring-boot-starter-undertow
35 | war
5 | ```
6 |
7 | 将上面的代码加入到pom.xml文件刚开始的位置,如下:
8 | 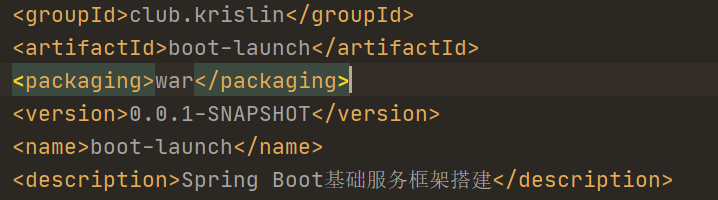
9 |
10 | # 二、 排除内置tomcat的依赖
11 |
12 | 我们使用外置的tomcat,自然要将内置的嵌入式tomcat的相关jar排除。
13 |
14 | ```xml
15 |
16 | org.springframework.boot
17 | spring-boot-starter-web
18 |
19 |
20 | org.springframework.boot
21 | spring-boot-starter-tomcat
22 |
23 |
24 |
25 | ```
26 |
27 | # 三、新增加一个类继承SpringBootServletInitializer实现configure:
28 |
29 | 为什么继承该类,SpringBootServletInitializer源码注释:
30 | Note that a WebApplicationInitializer is only needed if you are building a war file and deploying it.
31 | If you prefer to run an embedded web server then you won't need this at all.
32 | 注意,如果您正在构建WAR文件并部署它,则需要WebApplicationInitializer。如果你喜欢运行一个嵌入式Web服务器,那么你根本不需要这个。
33 |
34 | ```java
35 | public class ServletInitializer extends SpringBootServletInitializer {
36 | @Override
37 | protected SpringApplicationBuilder configure(SpringApplicationBuilder builder) {
38 | //此处的Application.class为带有@SpringBootApplication注解的启动类
39 | return builder.sources(BootLaunchApplication.class);
40 | }
41 | }
42 | ```
43 |
44 | > 注意事项:
45 | > 使用外部Tomcat部署访问的时候,application.properties(或者application.yml)中的如下配置将失效,请使用外置的tomcat的端口,tomcat的webapps下项目名进行访问。
46 |
47 | ```yaml
48 | server.port=
49 | server.servlet.context-path=
50 | ```
51 |
52 | # 四、build要有finalName标签
53 |
54 | pom.xml中的构建build代码段,要有应用最终构建打包的名称。
55 |
56 | ```xml
57 | boot-launch
58 | ```
59 |
60 | # 五、打包与运行
61 |
62 | war方式打包,打包结果将存储在项目的target目录下面。然后将war包部署到外置Tomcat上面:
63 |
64 | ```
65 | mvn clean package -Dmaven.test.skip=true
66 | ```
67 |
68 | 在外置tomcat中运行:${Tomcat_home}/bin/目录下执行startup.bat(windows)[或者startup.sh](http://xn--startup-gf7nh96s.sh/)(linux),然后通过浏览器访问应用,测试效果。
--------------------------------------------------------------------------------
/SpringBoot/08.统一全局异常处理/8.1.设计一个优秀的异常处理机制.md:
--------------------------------------------------------------------------------
1 | # 一、异常处理的乱象例举
2 |
3 | ## 乱象一:捕获异常后只输出到控制台
4 |
5 | 前端js-ajax代码
6 |
7 | ```js
8 | $.ajax({
9 | type: "GET",
10 | url: "/user/add",
11 | dataType: "json",
12 | success: function(data){
13 | alert("添加成功");
14 | }
15 | });
16 | ```
17 |
18 | 后端业务代码
19 |
20 | ```java
21 | try {
22 | // do something
23 | } catch (XyyyyException e) {
24 | e.printStackTrace();
25 | }
26 | ```
27 |
28 | 问题:
29 |
30 | 1. 后端直接将异常捕获,而且只做了日志打印。用户体验非常差,一旦后台出错,用户没有任何感知,页面无状态,。
31 | 2. 如果没有人去经常关注日志,不会有人发现系统出现异常
32 |
33 | ## 乱象二:混乱的返回方式
34 |
35 | 前端代码
36 |
37 | ```js
38 | $.ajax({
39 | type: "GET",
40 | url: "/goods/add",
41 | dataType: "json",
42 | success: function(data) {
43 | if (data.flag) {
44 | alert("添加成功");
45 | } else {
46 | alert(data.message);
47 | }
48 | },
49 | error: function(data){
50 | alert("添加失败");
51 | }
52 | });
53 | ```
54 |
55 | 后端代码
56 |
57 | ```java
58 | @RequestMapping("/goods/add")
59 | @ResponseBody
60 | public Map add(Goods goods) {
61 | Map map = new HashMap();
62 | try {
63 | // do something
64 | map.put(flag, true);
65 | } catch (Exception e) {
66 | e.printStackTrace();
67 | map.put("flag", false);
68 | map.put("message", e.getMessage());
69 | }
70 | reutrn map;
71 | }
72 | ```
73 |
74 | 问题:
75 |
76 | 1. 每个人返回的数据有每个人自己的规范,你叫flag他叫isOK,你的成功code是0,它的成功code是0000。这样导致后端书写了大量的异常返回逻辑代码,前端也随之每一个请求一套异常处理逻辑。很多重复代码。
77 | 2. 如果是前端后端一个人开发还勉强能用,如果前后端分离,就是系统灾难。
78 |
79 | 参考:
80 | https://juejin.im/post/5c3ea92a5188251e101598aa
81 |
82 | # 二、该如何设计异常处理
83 |
84 | 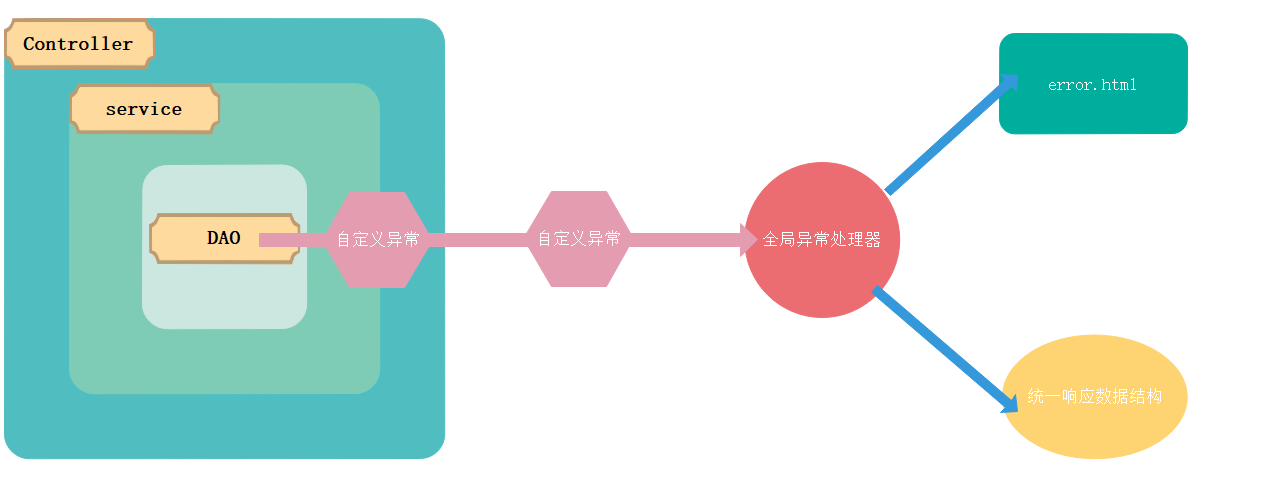
85 |
86 | ## 面向相关方友好
87 |
88 | 1. 后端开发人员职责单一,只需要将异常捕获并转换为自定义异常一直对外抛出。不需要去想页面跳转404,以及异常响应的数据结构的设计。
89 | 2. 面向前端人员友好,后端返回给前端的数据应该有统一的数据结构,统一的规范。不能一个人一个响应的数据结构。而在此过程中不需要后端开发人员做更多的工作,交给全局异常处理器去处理“异常”到“响应数据结构”的转换。
90 | 3. 面向用户友好,用户能够清楚的知道异常产生的原因。这就要求自定义异常,全局统一处理,ajax接口请求响应统一的异常数据结构,页面模板请求统一跳转到404页面。
91 | 4. 面向运维友好,将异常信息合理规范的持久化,以便查询。
92 |
93 | **为什么要将系统运行时异常捕获,转换为自定义异常抛出?**
94 | 答:因为用户不认识ConnectionTimeOutException类似这种异常是什么东西,但是转换为自定义异常就要求程序员对运行时异常进行一个翻译,比如:自定义异常里面应该有message字段,后端程序员应该明确的在message字段里面用面向用户的友好语言,说明发生了什么。
95 |
96 | # 三、开发规范
97 |
98 | 1. Controller、Service、DAO层拦截异常转换为自定义异常,不允许将异常私自截留。必须对外抛出。
99 | 2. 统一数据响应代码,使用httpstatusode,不要自定义。自定义不方便记忆。200请求成功,400用户输入错误导致的异常,500系统内部异常,999未知异常。
100 | 3. 自定义异常里面有message属性,一定用友好的语言描述异常,并赋值给message.
101 | 4. 不允许对父类Excetion统一catch,要分小类catch,这样能够清楚地将异常转换为自定义异常传递给前端。
--------------------------------------------------------------------------------
/SpringBoot/08.统一全局异常处理/8.3.全局异常处理ExceptionHandler.md:
--------------------------------------------------------------------------------
1 | # 一、全局异常处理器
2 |
3 | ControllerAdvice注解的作用就是监听所有的Controller,一旦Controller抛出CustomException,就会在@ExceptionHandler(CustomException.class)对该异常进行处理。
4 |
5 | ```java
6 | @ControllerAdvice
7 | public class WebExceptionHandler {
8 |
9 | @ExceptionHandler(CustomException.class)
10 | @ResponseBody
11 | public AjaxResponse customerException(CustomException e) {
12 | if(e.getCode() == CustomExceptionType.SYSTEM_ERROR.getCode()){
13 | //400异常不需要持久化,将异常信息以友好的方式告知用户就可以
14 | //TODO 将500异常信息持久化处理,方便运维人员处理
15 | }
16 | return AjaxResponse.error(e);
17 | }
18 |
19 | @ExceptionHandler(Exception.class)
20 | @ResponseBody
21 | public AjaxResponse exception(Exception e) {
22 | //TODO 将异常信息持久化处理,方便运维人员处理
23 |
24 | //没有被程序员发现,并转换为CustomException的异常,都是其他异常或者未知异常.
25 | return AjaxResponse.error(new CustomException(CustomExceptionType.OTHER_ERROR,"未知异常"));
26 | }
27 |
28 |
29 | }
30 | ```
31 |
32 | # 二、人为制造异常测试一下
33 |
34 | ```java
35 | @Service
36 | public class ExceptionService {
37 |
38 | //服务层,模拟系统异常
39 | public void systemBizError() throws CustomException {
40 | try {
41 | Class.forName("com.mysql.jdbc.xxxx.Driver");
42 | } catch (ClassNotFoundException e) {
43 | throw new CustomException(CustomExceptionType.SYSTEM_ERROR,"在XXX业务,myBiz()方法内,出现ClassNotFoundException");
44 | }
45 | }
46 |
47 | //服务层,模拟用户输入数据导致的校验异常
48 | public List userBizError(int input) throws CustomException {
49 | if(input < 0){ //模拟业务校验失败逻辑
50 | throw new CustomException(CustomExceptionType.USER_INPUT_ERROR,"您输入的数据不符合业务逻辑,请确认后重新输入!");
51 | }else{ //
52 | List list = new ArrayList<>();
53 | list.add("科比");
54 | list.add("詹姆斯");
55 | list.add("库里");
56 | return list;
57 | }
58 | }
59 |
60 | }
61 | ```
--------------------------------------------------------------------------------
/SpringBoot/08.统一全局异常处理/8.4.服务端数据校验与全局异常处理.md:
--------------------------------------------------------------------------------
1 | > 通常,服务端的数据校验通常不是面向用户的,提示信息还是应该以面向程序员和运维人员为主,在数据进入后台之前进行一道拦截。前端js的数据校验提示信息,是面向用户的,要更加的友好!
2 |
3 | # 一、异常校验的规范及常用注解
4 |
5 | 在web开发时,对于请求参数,一般上都需要进行参数合法性校验的,原先的写法时一个个字段一个个去判断,这种方式太不通用了,所以java的JSR 303: Bean Validation规范就是解决这个问题的。
6 | JSR 303只是个规范,并没有具体的实现,目前通常都是才有hibernate-validator进行统一参数校验。
7 |
8 | JSR303定义的校验类型
9 |
10 | | Constraint | 详细信息 |
11 | | :-------------------------- | :------------------------------------------------------- |
12 | | @Null | 被注释的元素必须为 null |
13 | | @NotNull | 被注释的元素必须不为 null |
14 | | @AssertTrue | 被注释的元素必须为 true |
15 | | @AssertFalse | 被注释的元素必须为 false |
16 | | @Min(value) | 被注释的元素必须是一个数字,其值必须大于等于指定的最小值 |
17 | | @Max(value) | 被注释的元素必须是一个数字,其值必须小于等于指定的最大值 |
18 | | @DecimalMin(value) | 被注释的元素必须是一个数字,其值必须大于等于指定的最小值 |
19 | | @DecimalMax(value) | 被注释的元素必须是一个数字,其值必须小于等于指定的最大值 |
20 | | @Size(max, min) | 被注释的元素的大小必须在指定的范围内 |
21 | | @Digits (integer, fraction) | 被注释的元素必须是一个数字,其值必须在可接受的范围内 |
22 | | @Past | 被注释的元素必须是一个过去的日期 |
23 | | @Future | 被注释的元素必须是一个将来的日期 |
24 | | @Pattern(value) | 被注释的元素必须符合指定的正则表达式 |
25 |
26 | Hibernate Validator 附加的 constraint
27 |
28 | | Constraint | 详细信息 |
29 | | :--------- | :------------------------------------- |
30 | | @Email | 被注释的元素必须是电子邮箱地址 |
31 | | @Length | 被注释的字符串的大小必须在指定的范围内 |
32 | | @NotEmpty | 被注释的字符串的必须非空 |
33 | | @Range | 被注释的元素必须在合适的范围内 |
34 |
35 | **用法:把以上注解加在ArticleVO的属性字段上,然后在参数校验的方法上加@Valid注解**
36 | 如:
37 |
38 | ```java
39 | @PutMapping("/article/{id}")
40 | public @ResponseBody AjaxResponse updateArticle(
41 | @Valid @RequestBody ArticleVO article) {
42 | //业务
43 | return AjaxResponse.success();
44 | }
45 | ```
46 |
47 | 如果感觉以上的注解仍然不够用,可以自定义注解,参考:
48 | http://blog.lqdev.cn/2018/07/20/springboot/chapter-eight/
49 |
50 | # 二、友好的数据校验异常处理(用户输入异常的全局处理)
51 |
52 | 我们已知当数据校验失败的时候,会抛出异常BindException或MethodArgumentNotValidException。所以我们对这两种异常做全局处理,防止程序员重复编码带来困扰。
53 |
54 | ```java
55 | @ExceptionHandler(MethodArgumentNotValidException.class)
56 | @ResponseBody
57 | public AjaxResponse handleBindException(MethodArgumentNotValidException ex) {
58 | FieldError fieldError = ex.getBindingResult().getFieldError();
59 | return AjaxResponse.error(new CustomException(CustomExceptionType.USER_INPUT_ERROR,fieldError.getDefaultMessage()));
60 | }
61 |
62 |
63 | @ExceptionHandler(BindException.class)
64 | @ResponseBody
65 | public AjaxResponse handleBindException(BindException ex) {
66 | FieldError fieldError = ex.getBindingResult().getFieldError();
67 | return AjaxResponse.error(new CustomException(CustomExceptionType.USER_INPUT_ERROR,fieldError.getDefaultMessage()));
68 | }
69 | ```
--------------------------------------------------------------------------------
/SpringBoot/09.日志框架与全局日志管理/9.1.日志框架的简介与选型.md:
--------------------------------------------------------------------------------
1 | # 一、日志框架简介
2 |
3 | ## 市面上的日志框架
4 |
5 | `JUL`、`JCL`、`Jboss-logging`、`logback`、`log4j`、`log4j2`、`slf4j`....
6 |
7 | | 日志门面 (日志的抽象层) | 日志实现 |
8 | | ------------------------------------------------------------ | ------------------------------------------------- |
9 | | ~~JCL(Jakarta Commons Logging)~~ **SLF4j(Simple Logging Facade for Java)** ~~jboss-loggi~~ | JUL(java.util.logging) Log4j Log4j2 **Logback** |
10 |
11 | 左边选一个门面(抽象层)、右边来选一个实现;
12 |
13 | > 例:SLF4j-->Logback
14 |
15 | Spring Boot选用 `SLF4j`和`logback`
16 |
17 | Spring Boot 默认的日志记录框架使用的是 Logback,此外我们还可以选择 Log4j 和 Log4j2。其中 Log4j 可以认为是一个过时的函数库,已经停止更新,不推荐使用,相比之下,性能和功能也是最差的。logback 虽然是 Spring Boot 默认的,但性能上还是不及 Log4j2,因此,在现阶段,日志记录首选 Log4j2。
18 |
19 | 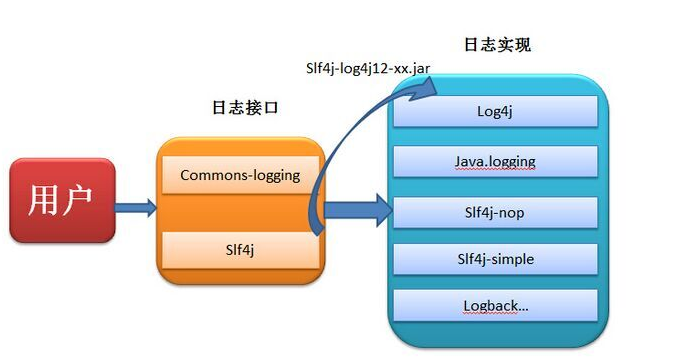
20 |
21 | 当然,在实际项目开发中,我们不会直接调用上面三款日志框架的 API 去记录日志,因为这样如果要切换日志框架的话代码需要修改的地方太多。因此,最佳实践是采用 SLF4J 来进行日志记录,SLF4J 是基于门面模式实现的一个通用日志框架,它本身并没有日志记录的功能,实际的日志记录还是需要依赖 Log4j、logback 或者 Log4j2。使用 SLF4J,可以实现简单快速地替换底层的日志框架而不会导致业务代码需要做相应的修改。SLF4J + Log4j2 是我们推荐的日志记录选型。
22 |
23 | 在使用 SLF4J 进行日志记录时,通常都需要在每个需要记录日志的类中定义 Logger 变量,如下所示:
24 |
25 | ```java
26 | import org.slf4j.Logger;
27 | import org.slf4j.LoggerFactory;
28 |
29 | @RestController
30 | public class SmsController {
31 | private static final Logger LOGGER = LoggerFactory.getLogger(SmsController.class);
32 | ...
33 | }
34 | ```
35 |
36 | 这显然属于重复性劳动,降低了开发效率,如果你在项目中引入了 Lombok,那么可以使用它提供的 @Slf4j 注解来自动生成上面那个变量,默认的变量名是 log,如果我们想采用惯用的 LOGGER 变量名,那么可以在工程的 main/java 目录中增加 lombok.config 文件,并在文件中增加 lombok.log.fieldName=LOGGER 的配置项即可。
37 |
38 | # 二、日志级别
39 |
40 | 细说各日志框架整合配置前,我们先来大致了解下,最常见的日志的几个级别:ERROR, WARN, INFO, DEBUG和TRACE。像其他的,比如ALL、OFF和FATAL之类的开发过程中应该基本上是不会涉及的。所以以下从低到高一次介绍下常见的日志级别。
41 |
42 | 1. TRACE:追踪。一般上对核心系统进行性能调试或者跟踪问题时有用,此级别很低,一般上是不开启的,开启后日志会很快就打满磁盘的。
43 | 2. DEBUG:调试。这个大家应该不陌生了。开发过程中主要是打印记录一些运行信息之类的。
44 | 3. INFO:信息。这个是最常见的了,大部分默认就是这个级别的日志。一般上记录了一些交互信息,一些请求参数等等。可方便定位问题,或者还原现场环境的时候使用。此日志相对来说是比较重要的。
45 | 4. WARN:警告。这个一般上是记录潜在的可能会引发错误的信息。比如启动时,某某配置文件不存在或者某个参数未设置之类的。
46 | 5. ERROR:错误。这个也是比较常见的,一般上是在捕获异常时输出,虽然发生了错误,但不影响系统的正常运行。但可能会导致系统出错或是宕机等。
47 |
48 | # 三、常见术语概念解析
49 |
50 | 1. appender:主要控制日志输出到哪里,比如:文件、数据库、控制台打印等
51 | 2. logger: 用来设置某一个包或者具体某一个类的日志打印级别、以及指定appender
52 | 3. root:也是一个logger,是一个特殊的logger。所有的logger最终都会将输出流交给root,除非设置logger中配置了additivity="false"。
53 | 4. rollingPolicy:所有日志都放在一个文件是不好的,所以可以指定滚动策略,按照一定周期或文件大小切割存放日志文件。
54 | 5. RolloverStrategy:日志清理策略。通常是指日志保留的时间。
55 | 6. 异步日志:单独开一个线程做日志的写操作,达到不阻塞主线程的目的
56 |
57 | # 四、性能测试结果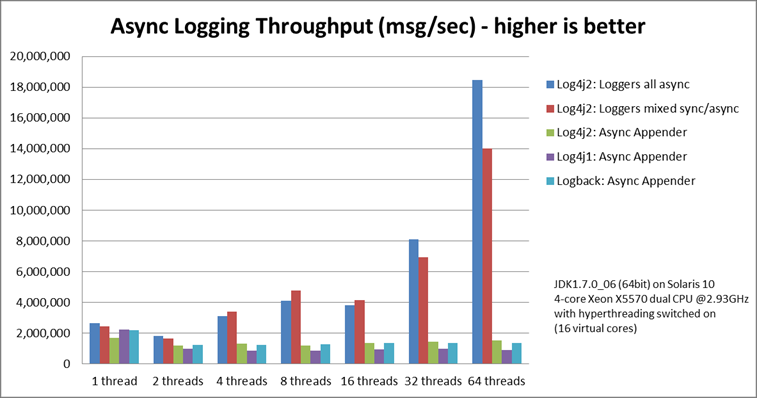
58 |
59 | 参考:[log4j2官网](http://logging.apache.org/log4j/2.x/manual/async.html)
--------------------------------------------------------------------------------
/SpringBoot/09.日志框架与全局日志管理/9.2.SEL4J使用.md:
--------------------------------------------------------------------------------
1 | # 1. 如何使用SLF4J
2 |
3 | 如何在系统中使用SLF4j :[https://www.slf4j.org](https://www.slf4j.org/)
4 |
5 | 以后开发的时候,日志记录方法的调用,不应该来直接调用日志的实现类,而是调用日志抽象层里面的方法;
6 |
7 | 给系统里面导入slf4j的jar和 logback的实现jar
8 |
9 | ```java
10 | import org.slf4j.Logger;
11 | import org.slf4j.LoggerFactory;
12 |
13 | public class HelloWorld {
14 | public static void main(String[] args) {
15 | Logger logger = LoggerFactory.getLogger(HelloWorld.class);
16 | logger.info("Hello World");
17 | }
18 | }
19 | ```
20 |
21 | 
22 |
23 | 每一个日志的实现框架都有自己的配置文件。使用slf4j以后,配置文件还是做成日志实现框架自己本身的配置文件;
24 |
25 | # 2. 遗留问题
26 |
27 | 项目中依赖的框架可能使用不同的日志:
28 |
29 | Spring(commons-logging)、Hibernate(jboss-logging)、MyBatis、xxxx
30 |
31 | 当项目是使用多种日志API时,可以统一适配到SLF4J,中间使用SLF4J或者第三方提供的日志适配器适配到SLF4J,SLF4J在底层用开发者想用的一个日志框架来进行日志系统的实现,从而达到了多种日志的统一实现。
32 |
33 | 
34 |
35 | # 3. 如何让系统中所有的日志都统一到slf4j
36 |
37 | 1. 将系统中其他日志框架先排除出去;
38 | 2. 用中间包来替换原有的日志框架(适配器的类名和包名与替换的被日志框架一致);
39 | 3. 我们导入slf4j其他的实现
--------------------------------------------------------------------------------
/SpringBoot/09.日志框架与全局日志管理/9.3.SpringBoot的日志关系.md:
--------------------------------------------------------------------------------
1 | SpringBoot使用它来做日志功能:
2 |
3 | ```xml
4 |
5 | org.springframework.boot
6 | spring-boot-starter-logging
7 |
8 | ```
9 |
10 | 底层依赖关系:
11 |
12 | 
13 |
14 | 总结:
15 |
16 | 1. SpringBoot底层也是使用slf4j+logback的方式进行日志记录
17 | 2. SpringBoot也把其他的日志都替换成了slf4j;
18 | 3. 中间替换包?
19 |
20 | ```java
21 | @SuppressWarnings("rawtypes")
22 | public abstract class LogFactory {
23 |
24 | static String UNSUPPORTED_OPERATION_IN_JCL_OVER_SLF4J = "http://www.slf4j.org/codes.html#unsupported_operation_in_jcl_over_slf4j";
25 |
26 | static LogFactory logFactory = new SLF4JLogFactory();
27 | ```
28 |
29 | 
30 |
31 | 4. 如果我们要引入其他框架,一定要把这个框架的默认日志依赖移除掉
32 |
33 | Spring框架用的是commons-logging:
34 |
35 | ```xml
36 |
37 | org.springframework
38 | spring-core
39 |
40 |
41 | commons-logging
42 | commons-logging
43 |
44 |
45 |
46 | ```
47 |
48 | **SpringBoot能自动适配所有的日志,而且底层使用slf4j+logback的方式记录日志,引入其他框架的时候,只需要把这个框架依赖的日志框架排除掉即可;**
--------------------------------------------------------------------------------
/SpringBoot/10.异步任务与定时任务/10.4.quartz简单定时任务(内存持久化).md:
--------------------------------------------------------------------------------
1 | # 一、 引入对应的 maven依赖
2 |
3 | 在 springboot2.0 后官方添加了 Quartz 框架的依赖,所以只需要在 pom 文件当中引入
4 |
5 | ```xml
6 |
7 |
8 | org.springframework.boot
9 | spring-boot-starter-quartz
10 |
11 | ```
12 |
13 | # 二、 创建一个任务类
14 |
15 | 由于 springboot2.0 自动进行了依赖所以创建的定时任务类直接继承 QuzrtzJobBean 就可以了,新建一个定时任务类:QuartzSimpleTask
16 |
17 | ```java
18 | public class QuartzSimpleTask extends QuartzJobBean {
19 | @Override
20 | protected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {
21 | System.out.println("quartz简单的定时任务执行时间:"+new Date().toLocaleString());
22 | }
23 | }
24 | ```
25 |
26 | # 三、创建 Quartz 定时配置类
27 |
28 | 将之前创建的定时任务添加到定时调度里面
29 |
30 | ```java
31 | @Configuration
32 | public class QuartzSimpleConfig {
33 | //指定具体的定时任务类
34 | @Bean
35 | public JobDetail uploadTaskDetail() {
36 | return JobBuilder.newJob(QuartzSimpleTask.class).withIdentity("QuartzSimpleTask").storeDurably().build();
37 | }
38 |
39 | @Bean
40 | public Trigger uploadTaskTrigger() {
41 | //这里设定触发执行的方式
42 | CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule("*/5 * * * * ?");
43 | // 返回任务触发器
44 | return TriggerBuilder.newTrigger().forJob(uploadTaskDetail())
45 | .withIdentity("QuartzSimpleTask")
46 | .withSchedule(scheduleBuilder)
47 | .build();
48 | }
49 | }
50 | ```
51 |
52 | 最后运行项目查看效果
--------------------------------------------------------------------------------
/SpringBoot/11.redis缓存与session共享/11.1.使用docker安装redis.md:
--------------------------------------------------------------------------------
1 | # 一、获取 redis 镜像
2 |
3 | ```
4 | docker search redis
5 | docker pull redis:5.0.5
6 | docker images
7 | ```
8 |
9 | # 二、创建容器
10 |
11 | 创建宿主机 redis 容器的数据和配置文件目录
12 |
13 | ```
14 | # 这里我们在 /home/docker 下创建
15 | mkdir /home/docker/redis/{conf,data} -p
16 | cd /home/docker/redis
17 | ```
18 |
19 | **注意:后面所有的操作命令都要在这个目录`/home/docker/redis`下进行**
20 |
21 | 获取 redis 的默认配置模版
22 |
23 | ```
24 | # 获取 redis 的默认配置模版
25 | # 这里主要是想设置下 redis 的 log / password / appendonly
26 | # redis 的 docker 运行参数提供了 --appendonly yes 但没 password
27 | wget https://raw.githubusercontent.com/antirez/redis/4.0/redis.conf -O conf/redis.conf
28 |
29 | # 直接替换编辑
30 | sed -i 's/logfile ""/logfile "access.log"/' conf/redis.conf;
31 | sed -i 's/# requirepass foobared/requirepass 123456/' conf/redis.conf;
32 | sed -i 's/appendonly no/appendonly yes/' conf/redis.conf;
33 | sed -i 's/bind 127.0.0.1/bind 0.0.0.0/' conf/redis.conf;
34 | ```
35 |
36 | > protected-mode 是在没有显式定义 bind 地址(即监听全网段),又没有设置密码 requirepass时,protected-mode 只允许本地回环 127.0.0.1 访问。改为bind 0.0.0.0
37 |
38 | 创建并运行一个名为 myredis 的容器,放到start-redis.sh脚本里面
39 |
40 | ```
41 | # 创建并运行一个名为 myredis 的容器
42 | docker run \
43 | -p 6379:6379 \
44 | -v $PWD/data:/data \
45 | -v $PWD/conf/redis.conf:/etc/redis/redis.conf \
46 | --privileged=true \
47 | --name myredis \
48 | -d redis:5.0.5 redis-server /etc/redis/redis.conf
49 |
50 | # 命令分解
51 | docker run \
52 | -p 6379:6379 \ # 端口映射 宿主机:容器
53 | -v $PWD/data:/data:rw \ # 映射数据目录 rw 为读写
54 | -v $PWD/conf/redis.conf:/etc/redis/redis.conf:ro \ # 挂载配置文件 ro 为readonly
55 | --privileged=true \ # 给与一些权限
56 | --name myredis \ # 给容器起个名字
57 | -d redis redis-server /etc/redis/redis.conf # deamon 运行容器 并使用配置文件启动容器内的 redis-server
58 | ```
59 |
60 | 查看活跃的容器
61 |
62 | ```
63 | # 查看活跃的容器
64 | docker ps
65 | # 如果没有 myredis 说明启动失败 查看错误日志
66 | docker logs myredis
67 | # 查看 myredis 的 ip 挂载 端口映射等信息
68 | docker inspect myredis
69 | # 查看 myredis 的端口映射
70 | docker port myredis
71 | ```
72 |
73 | ## 三、访问 redis 容器服务
74 |
75 | ```
76 | docker exec -it myredis bash
77 | redis-cli
78 | ```
79 |
80 | ## 四、开启防火墙端口,提供外部访问
81 |
82 | ```
83 | firewall-cmd --zone=public --add-port=6379/tcp --permanent
84 | firewall-cmd --reload
85 | firewall-cmd --query-port=6379/tcp
86 | ```
--------------------------------------------------------------------------------
/SpringBoot/11.redis缓存与session共享/11.4.使用Redis Repository操作数据.md:
--------------------------------------------------------------------------------
1 | # 一、整体操作hash对象
2 |
3 | 上一节我们操作hash对象的时候是一个属性一个属性设置的,那我们有没有办法将对象一次性hash入库呢?第一种方式我们可以使用`Jackson2HashMapper`
4 |
5 | ```java
6 | @Resource(name="redisTemplate")
7 | private HashOperations jacksonHashOperations;
8 | private HashMapper jackson2HashMapper = new Jackson2HashMapper(false);
9 | @Test
10 | public void testHashPutAll(){
11 |
12 | Person person = new Person("kobe","bryant");
13 | person.setId("1");
14 | person.setAddress(new Address("南京","中国"));
15 | //将对象以hash的形式放入数据库
16 | Map mappedHash = jackson2HashMapper.toHash(person);
17 | jacksonHashOperations.putAll("player" + person.getId(), mappedHash);
18 |
19 | //将对象从数据库取出来
20 | Map loadedHash = jacksonHashOperations.entries("player" + person.getId());
21 | Object map = jackson2HashMapper.fromHash(loadedHash);
22 | Person getback = new ObjectMapper().convertValue(map,Person.class);
23 | Assert.assertEquals(person.getFirstname(),getback.getFirstname());
24 | }
25 | ```
26 |
27 | # 二、第二种方法redis repository
28 |
29 | ```java
30 | @RedisHash("people")
31 | public class Person {
32 | @Id
33 | String id;
34 |
35 | //其他和上一节代码一样
36 |
37 | }
38 | public interface PersonRepository extends CrudRepository {
39 | // 继承CrudRepository,获取基本的CRUD操作
40 | }
41 | ```
42 |
43 | 在项目入口方法上加上注解@EnableRedisRepositories
44 |
45 | ```java
46 | @RunWith(SpringRunner.class)
47 | @SpringBootTest
48 | public class RedisRepositoryTest {
49 |
50 | @Autowired
51 | PersonRepository personRepository;
52 |
53 | @Test
54 | public void test(){
55 |
56 | Person rand = new Person("kris", "lin");
57 | rand.setAddress(new Address("杭州", "中国"));
58 | personRepository.save(rand);
59 | Optional op = personRepository.findById(rand.getId());
60 | Person p2 = op.get();
61 | personRepository.count();
62 | personRepository.delete(rand);
63 |
64 | }
65 |
66 | }
67 | ```
--------------------------------------------------------------------------------
/SpringBoot/11.redis缓存与session共享/11.5.spring cache基本用法.md:
--------------------------------------------------------------------------------
1 | # 一、为什么要做缓存
2 |
3 | - 提升性能
4 |
5 | 绝大多数情况下,select 是出现性能问题最大的地方。一方面,select 会有很多像 join、group、order、like 等这样丰富的语义,而这些语义是非常耗性能的;另一方面,大多 数应用都是读多写少,所以加剧了慢查询的问题。
6 |
7 | 分布式系统中远程调用也会耗很多性能,因为有网络开销,会导致整体的响应时间下降。为了挽救这样的性能开销,在业务允许的情况(不需要太实时的数据)下,使用缓存是非常必要的事情。
8 |
9 | - 缓解数据库压力
10 |
11 | 当用户请求增多时,数据库的压力将大大增加,通过缓存能够大大降低数据库的压力。
12 |
13 | # 二、常用缓存操作流程
14 |
15 | - **失效**:应用程序先从 cache 取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
16 | - **命中**:应用程序从 cache 中取数据,取到后返回。
17 | - **更新**:先把数据存到数据库中,成功后,再让缓存**失效或更新**。缓存操作失败,数据库事务回滚。
18 | - **删除**: 先从数据库里面删掉,再从缓存里面删掉。缓存操作失败,数据库事务回滚。
19 |
20 | # 三、spring cache
21 |
22 | 第一步:pom.xml 添加 Spring Boot 的 jar 依赖:
23 |
24 | ```xml
25 |
26 | org.springframework.boot
27 | spring-boot-starter-cache
28 |
29 | ```
30 |
31 | 第二步:添加入口启动类 `@EnableCaching`注解开启 Caching,实例如下。
32 |
33 | ```java
34 | @EnableCaching
35 | ```
36 |
37 | # 四、在`ArticleRestController`类上实现一个简单的例子
38 |
39 | 缓存对象有几个非常需要注意的点:
40 |
41 | 1. 必须实现无参的构造函数
42 | 2. 需要实现Serializable 接口和定义`serialVersionUID`(因为缓存需要使用JDK的方式序列化和反序列化),这种方法不好。因为我们要修改所有的实体类,实现Serializable接口。我们完全可以修改为使用JSON序列化与反序列化的方式,可读性更强,体积更小,速度更快。
43 |
44 | ```java
45 | @Cacheable(value="article")
46 | @GetMapping( "/article/{id}")
47 | public @ResponseBody AjaxResponse getArticle(@PathVariable Long id) {
48 | ```
49 |
50 | 第一次访问走数据库,第二次访问就走缓存了,可以下断点试一下。
51 |
52 | # 五、如何改变缓存的序列化方式
53 |
54 | ```java
55 | @Configuration
56 | public class RedisConfig {
57 | //这个函数是上一节的内容
58 | @Bean
59 | public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory) {
60 | RedisTemplate redisTemplate = new RedisTemplate();
61 | redisTemplate.setConnectionFactory(redisConnectionFactory);
62 | Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
63 |
64 | ObjectMapper objectMapper = new ObjectMapper();
65 | objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
66 | objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
67 |
68 | jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
69 |
70 | //重点在这四行代码
71 | redisTemplate.setKeySerializer(new StringRedisSerializer());
72 | redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
73 | redisTemplate.setHashKeySerializer(new StringRedisSerializer());
74 | redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
75 |
76 | redisTemplate.afterPropertiesSet();
77 | return redisTemplate;
78 | }
79 |
80 | //本节的重点配置,让缓存的序列化方式使用redisTemplate.getValueSerializer()
81 | @Bean
82 | public RedisCacheManager redisCacheManager(RedisTemplate redisTemplate) {
83 | RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(redisTemplate.getConnectionFactory());
84 | RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
85 | .serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(redisTemplate.getValueSerializer()));
86 | return new RedisCacheManager(redisCacheWriter, redisCacheConfiguration);
87 | }
88 | }
89 | ```
--------------------------------------------------------------------------------
/SpringBoot/11.redis缓存与session共享/11.6.详述缓存声明式注解的使用.md:
--------------------------------------------------------------------------------
1 | # 一、缓存注解说明:
2 |
3 | `@Cacheable` 通常应用到读取数据的方法上,如查找方法:先从缓存中读取,如果没有再调用方法获取数据,然后把数据查询结果添加到缓存中。如果缓存中查找到数据,被注解的方法将不会执行。
4 |
5 | 
6 |
7 | `@CachePut`通常应用于保存和修改方法配置,能够根据方法的请求参数对其结果进行缓存,和 @Cacheable 不同的是,它每次都会触发被注解方法的调用。
8 |
9 | 
10 |
11 | `@CachEvict` 通常应用于删除方法配置,能够根据一定的条件对缓存进行清空。可以清除一条或多条缓存。
12 |
13 | 
14 |
15 | Caching为组合注解(非常有用),请看下文。
16 |
17 | # 二、缓存注解常用策略
18 |
19 | 查询分两种:一种是查回来一个集合,一种是查一个对象。
20 | 那么,我们随便增删改一个对象,都有可能导致集合缓存与数据库数据不一致。
21 | 通常情况下,我们该怎么做才能做到一致性?**只要发生删改查,就把集合类缓存销毁**
22 | **对于查询方法:**
23 | `@Cacheable(value=“obj”)` 或 `@Cacheable(value=“objList”)`
24 | **对于修改和新增方法:**
25 |
26 | ```java
27 | @Caching(evict = {@CacheEvict(cacheNames = "objList",allEntries = true)},
28 | put={@CachePut(cacheNames = "obj",key = "#id")})
29 | ```
30 |
31 | **对于删除方法:**
32 |
33 | ```java
34 | @Caching(evict = {@CacheEvict(cacheNames = "objList",allEntries = true),
35 | @CacheEvict(cacheNames = "obj",key = "#id")})
36 | ```
37 |
38 | > 在实际的生产环境中,没有一定之规,哪种注解必须用在哪种方法上,`@CachEvict` 注解通常也用于更新方法上。数据的缓存策略,要根据资源的使用方式,做出合理的缓存策略规划。保证缓存与业务数据库的数据一致性。并做好测试,没有一定之规。
--------------------------------------------------------------------------------
/SpringBoot/11.redis缓存与session共享/11.8.集群多节点应用session共享.md:
--------------------------------------------------------------------------------
1 | # 一、spring session 共享的实现原理
2 |
3 | 1. 用户第一次请求的时候,服务端生成SESSIONID,返回浏览器端。浏览器以cookies的形式保存起来
4 | 2. 同一IP(域名),不同端口,在同一个浏览器cookies是共享的。用户访问不同IP(域名)的Cookies,在同一个浏览器一定是不一样的。对于这种情况需要在集群应用的前面加上负载均衡,如:nginx,haproxy。
5 | 3. SESSION正常是由Servlet容器来维护的,这样SESSION就无法共享。如果希望Session共享,就需要把session的存储放到一个统一的地方,如:redis。维护交给Spring session。
6 | 4. 除了Cookies可以维持Sessionid,Spring Session还提供了了另外一种方式,就是使用header传递SESSIONID。目的是为了方便类似于手机这种没有cookies的客户端进行session共享。
7 |
8 | 
9 |
10 | > 不要把跨域请求和cookies跨域名的概念搞混了。同源策略是要求IP、端口、协议全一致,不一致的请求就是跨域请求。但cookies是可以跨域共享的,但是不能跨域名(IP)共享。
11 |
12 | # 二、集成Spring session
13 |
14 | ## 1.引入spring-session-redis的maven依赖
15 |
16 | ```xml
17 |
18 | org.springframework.session
19 | spring-session-data-redis
20 |
21 |
22 | org.springframework.boot
23 | spring-boot-starter-data-redis
24 |
25 | ```
26 |
27 | ## 2.配置启用Redis的httpSession
28 |
29 | 在启动类上方加上注解
30 |
31 | ```java
32 | @EnableRedisHttpSession(maxInactiveIntervalInSeconds = 30 * 60 * 1000)
33 | ```
34 |
35 | ## 3.配置redis链接信息(application.yml)
36 |
37 | ```yaml
38 | spring:
39 |
40 | redis:
41 | database: 0
42 | host: 127.0.0.1
43 | password: 123456
44 | port: 6379
45 | ```
46 |
47 | ## 4.测试
48 |
49 | 在两个项目里面都做上面的操作,并加入如下的测试代码:
50 |
51 | ```java
52 | @RequestMapping(value="/uid",method = RequestMethod.GET)
53 | public @ResponseBody String uid(HttpSession session) {
54 | UUID uid = (UUID) session.getAttribute("uid");
55 | if (uid == null) {
56 | uid = UUID.randomUUID();
57 | }
58 | session.setAttribute("uid", uid);
59 | return session.getId();
60 | }
61 | ```
62 |
63 | ## 5. 一个项目多个端口启动
64 |
65 | 点击edit configuration
66 | 取消single instance only ,复制一份
67 |
68 | 在environment选项中的vm options 中设置不同的端口号
69 | -Dserver.port=8889 -Dspring.profiles.active=test -Ddebug
70 |
71 | 依次访问,看看效果
72 | http://localhost:8888/uid
73 | http://localhost:8889/uid
74 | http://127.0.0.1:8888/uid
75 | http://127.0.0.1:8889/uid
--------------------------------------------------------------------------------
/SpringBoot/12.整合分布式文件系统fastdfs/12.1.fastdfs简介及架构说明.md:
--------------------------------------------------------------------------------
1 | # 一、简介
2 |
3 | - FastDFS是一个轻量级的开源分布式文件系统。
4 | - FastDFS主要解决了大容量的文件存储和高并发访问的问题,文件存取时实现了负载均衡。
5 | - FastDFS实现了软件方式的RAID,可以使用廉价的IDE硬盘进行存储
6 | - 支持存储服务器在线扩容
7 | - 支持相同内容的文件只保存一份,节约磁盘空间
8 | - FastDFS特别适合大中型网站使用,用来存储资源文件(如:图片、文档、音频、视频等等)
9 |
10 | # 二、架构说明
11 |
12 | - Tracker:管理集群,tracker 也可以实现集群。每个 tracker 节点地位平等。收集 Storage 集群的状态。
13 | - Storage:实际保存文件 Storage 分为多个组,每个组之间保存的文件是不同的。每个组内部可以有多个成员,
14 |
15 | 组成员内部保存的内容是一样的,组成员的地位是一致的,没有主从的概念。
16 | 
17 |
18 | 说明 nginx + fileid(文件路径),http访问
19 | 
20 |
21 | # 三、好处:
22 |
23 | 1. 将文件的管理与具体业务应用解耦,可以多个应用共用一套fastDFS集群,分成不同的组
24 | 2. 图片访问,只需要将http-url交给浏览器。nginx提供访问服务。
25 | 3. 方便统一备份,一组的多个storage就是彼此的备份
26 | 4. 可以将图片浏览,文件下载的压力分散给nginx服务。应用自己专心做业务。
27 | 5. 缩略图,防盗链等等
--------------------------------------------------------------------------------
/SpringBoot/12.整合分布式文件系统fastdfs/12.2.使用docker安装fastdfs.md:
--------------------------------------------------------------------------------
1 | # 一、安装
2 |
3 | - 拉取镜像
4 |
5 | ```
6 | # docker pull delron/fastdfs
7 | Using default tag: latest
8 | latest: Pulling from delron/fastdfs
9 | 43db9dbdcb30: Pull complete
10 | 85a9cd1fcca2: Pull complete
11 | c23af8496102: Pull complete
12 | e88c36ca55d8: Pull complete
13 | 492fed9ec7f3: Pull complete
14 | 0c1d41dbb2bd: Pull complete
15 | 99b513124929: Pull complete
16 | bf3f5901a13d: Pull complete
17 | 88bf4f57c2c5: Pull complete
18 | Digest: sha256:f3fb622783acee7918b53f8a76c655017917631c52780bebb556d29290955b13
19 | Status: Downloaded newer image for delron/fastdfs
20 | ```
21 |
22 | - 创建本机存储目录
23 |
24 | ```
25 | rm -fR /home/docker/fastdfs/{tracker,storage}
26 | mkdir /home/docker/fastdfs/{tracker,storage} -p
27 | ```
28 |
29 | - 启动tracker
30 |
31 | ```
32 | docker run -d \
33 | --network=host \
34 | --name tracker \
35 | -v /home/docker/fastdfs/tracker:/var/fdfs \
36 | delron/fastdfs tracker
37 | ```
38 |
39 | - 启动storage
40 |
41 | ```
42 | docker run -d \
43 | --network=host \
44 | --name storage \
45 | -e TRACKER_SERVER=192.168.161.3:22122 \
46 | -v /home/docker/fastdfs/storage:/var/fdfs \
47 | -e GROUP_NAME=group1 \
48 | delron/fastdfs storage
49 | ```
50 |
51 | # 二、开启宿主机防火墙端口,morunchang/fastdfs镜像在构建的时候为nginx配置的端口为8888
52 |
53 | ```
54 | firewall-cmd --zone=public --add-port=22122/tcp --permanent
55 | firewall-cmd --zone=public --add-port=23000/tcp --permanent
56 | firewall-cmd --zone=public --add-port=8888/tcp --permanent
57 | firewall-cmd --reload
58 | # 查看是否开放
59 | firewall-cmd --query-port=22122/tcp
60 | firewall-cmd --query-port=23000/tcp
61 | firewall-cmd --query-port=8888/tcp
62 | ```
63 |
64 | # 三、测试一下安装结果
65 |
66 | FastDFS安装包中,自带了客户端程序,可以使用这个命令行客户端进行文件上传及下载测试。
67 | 在宿主机执行命令
68 | 3.1上传文件(是容器里面的文件)
69 |
70 | ```
71 | # docker exec -i storage /usr/bin/fdfs_upload_file /etc/fdfs/client.conf ./README
72 | group1/M00/00/00/wKgBW10lZHCAC8TaAAAAMT6WPfM3645854
73 | ```
74 |
75 | 3.2 查看fastdfs文件系统信息
76 |
77 | ```
78 | # docker exec -i storage fdfs_file_info /etc/fdfs/client.conf group1/M00/00/00/wKgBW10lZHCAC8TaAAAAMT6WPfM3645854
79 | source storage id: 0
80 | source ip address: 192.168.1.91
81 | file create timestamp: 2019-07-10 04:07:12
82 | file size: 49
83 | file crc32: 1050033651 (0x3E963DF3)
84 | ```
85 |
86 | 3.3 下载文件,不会下载到宿主机,去容器里面看
87 |
88 | ```
89 | # docker exec -i storage fdfs_download_file /etc/fdfs/client.conf group1/M00/00/00/wKgBW10lZHCAC8TaAAAAMT6WPfM3645854
90 | ```
91 |
92 | 3.4 查看集群状态
93 |
94 | ```
95 | # docker exec -i storage fdfs_monitor /etc/fdfs/storage.conf
96 | ```
--------------------------------------------------------------------------------
/SpringBoot/12.整合分布式文件系统fastdfs/12.4.整合fastdfs操作文件数据.md:
--------------------------------------------------------------------------------
1 | # 一、整合fastdfs
2 |
3 | ### 引入maven依赖坐标
4 |
5 | ```xml
6 |
7 | club.krislin.spring
8 | krislin-fastdfs-spring-boot-starter
9 | 1.0.0
10 |
11 | ```
12 |
13 | ### 在application.yml里面加上如下配置:
14 |
15 | ```yaml
16 | krislin:
17 | fastdfs:
18 | httpserver: http://192.168.161.3:8888/ #这个不是fastdfs属性,但是填上之后,在使用FastDFSClientUtil会得到完整的http文件访问路径
19 | connect_timeout: 5
20 | network_timeout: 30
21 | charset: UTF-8
22 | tracker_server: # tracker_server 可以配置成数组
23 | - 192.168.161.3:22122
24 | max_total: 50
25 | http_anti_steal_token: false # 如果有防盗链的话,这里true
26 | http_secret_key: # 有防盗链,这里填secret_key
27 | ```
28 |
29 | ### 使用方式
30 |
31 | ```java
32 | // 使用fastDFSClientUtil提供的方法上传、下载、删除
33 | @Resource
34 | FastDFSClientUtil fastDFSClientUtil;
35 | ```
36 |
37 | # 二、测试一下
38 |
39 | ```java
40 | @Controller
41 | @RequestMapping("fastdfs")
42 | public class FastdfsController {
43 |
44 | @Resource
45 | private FastDFSClientUtil fastDFSClientUtil;
46 |
47 | @PostMapping("/upload")
48 | @ResponseBody
49 | public AjaxResponse upload(@RequestParam("file") MultipartFile file) {
50 |
51 | String fileId;
52 | try {
53 | String originalfileName = file.getOriginalFilename();
54 | fileId = fastDFSClientUtil.uploadFile(file.getBytes(),originalfileName.substring(originalfileName.lastIndexOf(".")));
55 | return AjaxResponse.success(fastDFSClientUtil.getSourceUrl(fileId));
56 | } catch (Exception e) {
57 | throw new CustomException(CustomExceptionType.SYSTEM_ERROR,"文件上传图片服务器失败");
58 | }
59 | }
60 |
61 |
62 | @DeleteMapping("/delete")
63 | @ResponseBody
64 | public AjaxResponse upload(@RequestParam String fileid) {
65 | try {
66 | fastDFSClientUtil.delete(fileid);
67 | } catch (Exception e) {
68 | throw new CustomException(CustomExceptionType.SYSTEM_ERROR,"文件删除失败");
69 | }
70 | return AjaxResponse.success();
71 | }
72 |
73 |
74 | }
75 | ```
76 |
77 | postman文件上传配置:
78 |
79 | 
--------------------------------------------------------------------------------
/SpringBoot/13.服务器推送技术/13.1.主流服务器推送技术说明.md:
--------------------------------------------------------------------------------
1 | # 一、需求与背景
2 |
3 | 若干年前,所有的请求都是由浏览器端发起,浏览器本身并没有接受请求的能力。所以一些特殊需求都是用ajax轮询的方式来实现的。
4 |
5 | 比如对于某些需要实时更新的数据(例如Facebook/Twitter 更新、股价更新、新的博文、赛事结果等)。又例如我们通过页面启动一个定时任务,前端想知道任务后台的的实时运行状态,就需要以较小的间隔,频繁的向服务器建立http连接询问定时任务是否完成,然后更新页面状态。但这样做的后果就是浪费大量流量,对服务端造成了巨大压力。
6 |
7 | 在html5被广泛推广之后,我们可以使用服务端主动推动数据的方式来,解决上面提到的问题。
8 |
9 | # 二、服务端推送常用技术
10 |
11 | 1、全双工通信:WebSocket
12 | 全双工的,全双工就是双向通信,http协议是“对讲机”之间的通话,那我们websocket就是移动电话。本质上是一个额外的tcp连接,建立和关闭时握手使用http协议,其他数据传输不使用http协议 ,更加复杂一些,比较适用于需要进行复杂双向实时数据通讯的场景。
13 |
14 | 
15 |
16 | 2、服务端主动推送:SSE (Server Send Event)
17 | html5新标准,用来从服务端实时推送数据到浏览器端, 直接建立在当前http连接上,本质上是保持一个http长连接,轻量协议 。客户端发送一个请求到服务端 ,服务端保持这个请求直到一个新的消息准备好,将消息返回至客户端,此时不关闭连接,仍然保持它,供其它消息使用。SSE的一大特色就是重复利用一个连接来处理每一个消息(又称event)。
18 |
19 | # 三、websocket与SSE比较
20 |
21 | | | 是否基于新协议 | 是否双向通信 | 是否支持跨域 | 编码难度 |
22 | | :-------- | :------------- | :--------------- | :--------------------- | :------- |
23 | | SSE | 否(`Http`) | 否(服务器单向) | 否(Firefox 支持跨域) | 低 |
24 | | WebSocket | 是(`ws`) | 是 | 是 | 略高 |
25 |
26 | **但是IE和Edge浏览器不支持SSE。**
27 | 
--------------------------------------------------------------------------------
/SpringBoot/14.消息队列的整合与使用/14.1.消息队列与JMS规范简介.md:
--------------------------------------------------------------------------------
1 | # 一、为什么使用消息队列
2 |
3 | **看完下面这个故事,相信你能理解消息队列的作用与好处:**
4 | 转载自知乎:https://www.zhihu.com/question/34243607
5 |
6 | 小红是小明的姐姐。小红希望小明多读书,常寻找好书给小明看,之前的方式是这样:小红问小明什么时候有空,把书给小明送去,并亲眼监督小明读完书才走。久而久之,两人都觉得麻烦。后来的方式改成了:小红对小明说「我放到书架上的书你都要看」,然后小红每次发现不错的书都放到书架上,小明则看到书架上有书就拿下来看。
7 |
8 | **书架就是一个消息队列,小红是生产者,小明是消费者。**
9 |
10 | ### 这带来的好处有
11 |
12 | 1. 小红想给小明书的时候,不必问小明什么时候有空,亲手把书交给他了,小红只把书放到书架上就行了。这样小红小明的时间都更自由。这个实际上就是消息队列的好处之一:解耦,降低了应用之间的耦合度。
13 | 2. 小红相信小明的读书自觉和读书能力,不必亲眼观察小明的读书过程,小红只要做一个放书的动作,很节省时间。消息队列好处之异步操作,并行处理。小红作为数据生产者应用业务处理的的效率提高,他不用等待消费者的反馈,就可以去处理其他事情。
14 | 3. 当明天有另一个爱读书的小伙伴小强加入,小红仍旧只需要把书放到书架上,小明和小强从书架上取书即可。消息队列好处之易于扩展,一个人看不完的书多人看,一个人干不完的事多个人干。
15 | 4. 书架上的书放在那里,小明阅读速度快就早点看完,阅读速度慢就晚点看完,没关系,比起小红把书递给小明并监督小明读完的方式,小明的压力会小一些。这就好比应用压力非常大的时候,消息队列起一个缓冲与持久化的作用,降低后端数据库等操作的压力。数据库快就快做,数据库处理慢就慢点做。不要一下把压力都交给数据库,会卡死。
16 |
17 | ### 消息队列使用成本
18 |
19 | 1. 引入复杂度
20 | 毫无疑问,「书架」这东西是多出来的,需要地方放它,还需要防盗。
21 | 2. 暂时的不一致性
22 | 假如妈妈问小红「小明最近读了什么书」,在以前的方式里,小红因为亲眼监督小明读完书了,可以底气十足地告诉妈妈,但新的方式里,小红回答妈妈之后会心想「小明应该会很快看完吧……」
23 |
24 | 这中间存在着一段「妈妈认为小明看了某书,而小明其实还没看」的时期,当然,小明最终的阅读状态与妈妈的认知会是一致的,这就是所谓的「最终一致性」。
25 |
26 | # 二、JMS规范之消息传递模型
27 |
28 | JMS支持两种不同的消息传递模型:
29 |
30 | 1、Point-to-Point(P2P)
31 |
32 | 2、Publish/Subscribe(Pub/Sub)
33 |
34 | ### P2P模型
35 |
36 | 在P2P模型中,一条消息仅传递给一个接收者。队列负责保存该消息,直到接收器准备就绪。
37 |
38 | 
39 | P2P的特点:
40 |
41 | 1. 每个消息只有一个消费者(Consumer)(即一旦被消费,消息就不再在消息队列中)。
42 | 2. 生产者和消费者之间在时间上没有依赖性,也就是说当生产者发送了消息之后,不管消费者有没有正在运行,它不会影响到消息被发送到队列。
43 | 3. 每条消息仅会传送给一个消费者。可能会有多个消费者在一个队列中侦听,但是每个队列中的消息只能被队列中的一个消费者所消费。
44 | 4. 消息存在先后顺序。一个队列会按照消息服务器将消息放入队列中的顺序,把它们传送给消费者。当已被消费时,就会从队列头部将它们删除(除非使用了消息优先级)。
45 | 5. 消费者在成功接收消息之后需向队列应答成功。如果你希望发送的每个消息都应该被成功处理的话,那么你需要使用P2P模式。
46 |
47 | ### Publish/Subscribe模型
48 |
49 | 在Pub / Sub模型中,一条消息被传递给所有订阅者。这就像广播。在这里,主题被用作负责保存和传递消息的面向消息的中间件。
50 |
51 | 
52 |
53 | Publish/Subscribe的特点:
54 |
55 | 1. 每个消息可以有多个消费者;
56 | 2. 发布者和订阅者之间有时间上的依赖性。针对某个主题的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息,而且为了消费消息,订阅者必须保持运行的状态。
57 | 3. 为了缓和这样严格的时间相关性,JMS允许订阅者创建一个可持久化的订阅。这样,即使订阅者没有被激活(运行),它也能在激活后接收到发布者的消息。
58 | 4. 每条消息都会传送给称为订阅者的多个消息消费者。订阅者有许多类型,包括持久型、非持久型和动态型。
59 | 5. 发布者通常不会知道、也意识不到哪一个订阅者正在接收主题消息。
--------------------------------------------------------------------------------
/SpringBoot/14.消息队列的整合与使用/14.2.使用docker安装activeMQ.md:
--------------------------------------------------------------------------------
1 | # 一、docker安装activeMQ
2 |
3 | 查询activeMQ可用镜像版本
4 |
5 | ```
6 | docker search activemq
7 | ```
8 |
9 | 
10 |
11 | 拉取镜像
12 |
13 | ```
14 | docker pull webcenter/activemq
15 | ```
16 |
17 | 
18 |
19 | ```
20 | docker run -d --name myactivemq -p 61616:61616 -p 8161:8161 webcenter/activemq:latest
21 | ```
22 |
23 | # 二、开放防火墙
24 |
25 | ```
26 | firewall-cmd --zone=public --add-port=61616/tcp --permanent
27 | firewall-cmd --zone=public --add-port=8161/tcp --permanent
28 | firewall-cmd --reload
29 | # 查看是否开放
30 | firewall-cmd --query-port=61616/tcp
31 | firewall-cmd --query-port=8161/tcp
32 | ```
33 |
34 | 
35 |
36 | # 三、访问admin管理界面
37 |
38 | http://192.168.18.137:8161/admin/topics.jsp
39 | 默认账号密码都是admin
40 |
41 | 点击manage activemq broker就可以进入管理页面(需要输入账号密码)。
42 | 
43 | 表示安装成功了!
--------------------------------------------------------------------------------
/SpringBoot/14.消息队列的整合与使用/14.3.activeMQ实现点对点队列.md:
--------------------------------------------------------------------------------
1 | # 一、整合ActiveMQ
2 |
3 | ```xml
4 |
5 |
6 | org.springframework.boot
7 | spring-boot-starter-activemq
8 |
9 |
10 | org.apache.activemq
11 | activemq-pool
12 |
13 |
14 | ```
15 |
16 | ```yaml
17 | spring:
18 | activemq:
19 | user: admin
20 | password: admin
21 | broker-url: tcp://192.168.18.137:61616
22 | in-memory: false
23 | pool:
24 | enabled: true
25 | max-connections: 50
26 | packages:
27 | trust-all: true #是否信任所有包,信任后所有包内的对象均可序列化传输
28 | ```
29 |
30 |
31 |
32 | ```java
33 | @EnableJms //开启消息中间件的服务能力
34 | @Configuration
35 | public class CostomActiveMQConfig {
36 |
37 | //配置一个消息队列(P2P模式)
38 | @Bean
39 | public Queue messageQueue() {
40 | //这里相当于为消息队列起一个名字用于生产消费用户访问日志
41 | return new ActiveMQQueue("message.queue");
42 | }
43 | }
44 | ```
45 |
46 | # 二、实现点对点模型消息
47 |
48 | 消息对象,必须实现Serializable 接口
49 |
50 | ```java
51 | @Data
52 | @AllArgsConstructor
53 | public class QueenMessage implements Serializable {
54 |
55 | private String title;
56 |
57 | private String content;
58 |
59 | }
60 | ```
61 |
62 | 消费者示例
63 |
64 | ```java
65 | @Component
66 | @Slf4j
67 | public class P2pConsumerListener {
68 | @JmsListener(destination = "message.queue")
69 | public void insertVisitLog(QueenMessage queenMessage) {
70 | log.info("消费者接收数据 : " + queenMessage);
71 | }
72 | }
73 | ```
74 |
75 | 生产者测试示例
76 |
77 | ```java
78 | @RestController
79 | public class P2pProducerController {
80 | @Resource
81 | private JmsMessagingTemplate jmsMessagingTemplate;
82 |
83 | @Resource
84 | private Queue messageQueue;
85 |
86 | @RequestMapping("/send")
87 | public QueenMessage send(){
88 | QueenMessage queenMessage = new QueenMessage("测试","测试内容");
89 |
90 | jmsMessagingTemplate.convertAndSend(messageQueue,queenMessage);
91 | return queenMessage;
92 | }
93 | }
94 | ```
95 |
96 | 浏览器访问http://localhost:8080/send,后台打印出:
97 | 
--------------------------------------------------------------------------------
/SpringBoot/14.消息队列的整合与使用/14.4.activeMQ实现发布订阅队列.md:
--------------------------------------------------------------------------------
1 | # 一、实现发布订阅模型消息
2 |
3 | 发布订阅模型:比如抖音小视频,某网红发布新视频,多名粉丝收到消息
4 |
5 | 默认ActiveMQ只支持点对点模型,想要开启发布订阅模型,需要进行配置
6 |
7 | ```yaml
8 | jms:
9 | pub-sub-domain: true
10 | ```
11 |
12 | 在CostomActiveMQConfig管理主题对象,这回return的是ActiveMQTopic,而不是ActiveMQQueue
13 |
14 | ```java
15 | @Bean
16 | public Topic topic() {
17 | return new ActiveMQTopic("message.topic");
18 | }
19 | ```
20 |
21 | 定义多个消费者,注意发送端的参数类型要与接收端一致,都是QueenMessage queenMessage
22 |
23 | ```java
24 | @Component
25 | public class TopicConsumer {
26 | @JmsListener(destination = "message.topic")
27 | public void receiver1(QueenMessage queenMessage) {
28 | System.out.println("TopicConsumer : receiver1 : " + queenMessage);
29 | }
30 |
31 | @JmsListener(destination = "message.topic")
32 | public void receiver2(QueenMessage queenMessage) {
33 | System.out.println("TopicConsumer : receiver2 : " + queenMessage);
34 | }
35 |
36 | @JmsListener(destination = "message.topic")
37 | public void receiver3(QueenMessage queenMessage) {
38 | System.out.println("TopicConsumer : receiver3 : " + queenMessage);
39 | }
40 | }
41 | ```
42 |
43 | 定义一个生产者控制器
44 |
45 | ```java
46 | @RestController
47 | public class TopicProducerController {
48 |
49 | @Resource
50 | private JmsMessagingTemplate jmsMessagingTemplate;
51 |
52 | @Resource
53 | private Topic messageTopic;
54 |
55 | @RequestMapping("/sendtopic")
56 | public QueenMessage send(){
57 | QueenMessage queenMessage = new QueenMessage("测试","测试内容");
58 | jmsMessagingTemplate.convertAndSend(messageTopic,queenMessage);
59 | return queenMessage;
60 | }
61 | }
62 | ```
63 |
64 | 再试试,输出的结果如下:
65 |
66 | ```
67 | TopicConsumer : receiver1 : QueenMessage(title=测试, content=测试内容)
68 | TopicConsumer : receiver3 : QueenMessage(title=测试, content=测试内容)
69 | TopicConsumer : receiver2 : QueenMessage(title=测试, content=测试内容)
70 | ```
--------------------------------------------------------------------------------
/SpringBoot/14.消息队列的整合与使用/14.5.docker安装RocketMQ.md:
--------------------------------------------------------------------------------
1 | # 一、rocketMQ部署架构
2 |
3 | 
4 |
5 | 1. NameServer:消息队列的大脑,同时监控消息队列,存储关于队列的基本信息,如各个队列的分布,ip、服务地址、目前的健康状况、队列的处理进度等。多个Nmaeserver之间没有通信。
6 | 2. broker:队列服务,负责接受请求并分发请求。数据存储、消息分发的负载均衡。可以是master-slave的主从结构。
7 | 3. console-ng:消息队列的监控控制台
8 |
9 | # 二、安装nameserver和broker
10 |
11 | > 注意:安装rocketMQ,虚拟机磁盘空间要足够。最小10G空余磁盘空间为好。
12 |
13 | 下载rocketMQ镜像
14 |
15 | ```
16 | docker pull rocketmqinc/rocketmq
17 | ```
18 |
19 | 新建本机数据存储文件夹
20 |
21 | ```
22 | rm -fR /home/rocketmq/data/;
23 | mkdir -p /home/rocketmq/data/namesrv/{logs,store};
24 | mkdir -p /home/rocketmq/data/broker/{logs,store,conf};
25 | ```
26 |
27 | 启动nameserver
28 |
29 | ```
30 | docker run -d -p 9876:9876 \
31 | -v /home/rocketmq/data/namesrv/logs:/root/logs \
32 | -v /home/rocketmq/data/namesrv/store:/root/store \
33 | --name rmqnamesrv \
34 | -e "MAX_POSSIBLE_HEAP=256000000" \
35 | rocketmqinc/rocketmq sh mqnamesrv
36 | ```
37 |
38 | 将以下配置文件放入本机目录/home/rocketmq/data/broker/conf/broker.conf
39 |
40 | ```
41 | brokerClusterName = DefaultCluster
42 | brokerName = broker-a
43 | brokerId = 0
44 | deleteWhen = 04
45 | fileReservedTime = 48
46 | brokerRole = ASYNC_MASTER
47 | flushDiskType = ASYNC_FLUSH
48 | #修改这个ip为你的物理主机ip
49 | brokerIP1=192.168.18.137
50 | ```
51 |
52 | 参考第四小节内容,先把防火墙的9876端口开放,启动broker
53 |
54 | ```
55 | docker run -d -p 10911:10911 -p 10909:10909 \
56 | -v /home/rocketmq/data/broker/logs:/root/logs \
57 | -v /home/rocketmq/data/broker/store:/root/store \
58 | -v /home/rocketmq/data/broker/conf/broker.conf:/opt/rocketmq-4.4.0/conf/broker.conf \
59 | --name rmqbroker --link rmqnamesrv:namesrv \
60 | -e "NAMESRV_ADDR=namesrv:9876" \
61 | -e "MAX_POSSIBLE_HEAP=256000000" \
62 | rocketmqinc/rocketmq sh mqbroker -c /opt/rocketmq-4.4.0/conf/broker.conf
63 | ```
64 |
65 | # 三、RocketMQ控制台
66 |
67 | 1. 拉取镜像
68 |
69 | ```
70 | docker pull styletang/rocketmq-console-ng
71 | ```
72 |
73 | 1. 创建container,并启动
74 |
75 | ```
76 | docker run -d \
77 | -e "JAVA_OPTS=-Drocketmq.namesrv.addr=172.17.0.2:9876 -Dcom.rocketmq.sendMessageWithVIPChannel=false" \
78 | -p 8999:8080 -t styletang/rocketmq-console-ng
79 | ```
80 |
81 | 因为服务器的8080端口经常冲突,我们使用8999端口提供控制台容器服务
82 |
83 | > 特别注意
84 | >
85 | > 1. 必须先启动`namesrv`,再启动`broker`,否则报错
86 | > 2. 创建控制台的container时,`-Drocketmq.namesrv.addr`必须指定为`namesrv`所在container的IP
87 |
88 | 可以通过以下命令来查看每个container的IP地址
89 |
90 | ```
91 | docker inspect --format='{{.Name}} - {{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' $(docker ps -aq)
92 | ```
93 |
94 | # 四、防火墙开放端口
95 |
96 | ```
97 | firewall-cmd --zone=public --add-port=9876/tcp --permanent
98 | firewall-cmd --zone=public --add-port=10911/tcp --permanent
99 | firewall-cmd --zone=public --add-port=10909/tcp --permanent
100 | firewall-cmd --zone=public --add-port=8999/tcp --permanent
101 | firewall-cmd --reload
102 |
103 | #查看是否开放端口
104 |
105 | firewall-cmd --query-port=9876/tcp
106 | firewall-cmd --query-port=10911/tcp
107 | firewall-cmd --query-port=10909/tcp
108 | firewall-cmd --query-port=8999/tcp
109 | ```
110 |
111 | 访问http://192.168.18.137:8999
--------------------------------------------------------------------------------
/SpringBoot/14.消息队列的整合与使用/14.6.RocketMQ实现2种消费模式.md:
--------------------------------------------------------------------------------
1 | # 一、引入依赖
2 |
3 | 新建SpringBoot项目,引入如下依赖:
4 |
5 | ```xml
6 |
7 | org.apache.rocketmq
8 | rocketmq-spring-boot-starter
9 | 2.0.3
10 |
11 | ```
12 |
13 | # 二、编写配置
14 |
15 | ```yaml
16 | rocketmq:
17 | name-server: 192.168.18.137:9876 # 自己的RocketMQ服务地址
18 | producer:
19 | send-message-timeout: 300000
20 | group: launch-group
21 | ```
22 |
23 | # 三、编写接口
24 |
25 | 定义一个常量配置类
26 |
27 | ```java
28 | public class RocketContants {
29 |
30 | public static final String TEST_TOPIC = "test-topic";
31 |
32 | public static final String CONSUMER_GROUP1 = "my-consumer_test-topic";
33 | }
34 | ```
35 |
36 | 对外暴露一个接口用于发送消息
37 |
38 | ```java
39 | @RestController
40 | public class ProducerController {
41 |
42 | @Resource
43 | private RocketMQTemplate rocketMQTemplate;
44 |
45 | @GetMapping("/rmqsend")
46 | public String send(String msg) {
47 | rocketMQTemplate.convertAndSend(RocketContants.TEST_TOPIC,msg);
48 | return "success";
49 | }
50 | }
51 | ```
52 |
53 | # 四、消费监听
54 |
55 | 消费者需要实现`RocketMQListener`接口:
56 |
57 | ```java
58 | @Service
59 | @RocketMQMessageListener(consumerGroup = RocketContants.CONSUMER_GROUP1, topic = RocketContants.TEST_TOPIC)
60 | public class RocketConsumer implements RocketMQListener {
61 |
62 | @Override
63 | public void onMessage(String message) {
64 | System.err.println("接收到消息:" + message);
65 | }
66 | }
67 | ```
68 |
69 | 输出:
70 | 
71 |
72 | # 五、消费者组
73 |
74 | - 新建一个RocketConsumer2,如果和RocketConsumer 是同一个组consumerGroup ,一条消息二者选其一消费一次,而且呈现负载均衡分布。即:同一个消费者组的消费者订阅同一话题,组内只能消费一次消息。
75 | - 新建一个RocketConsumer2,如果和RocketConsumer 不是同一个组consumerGroup ,一条消息被消费两次。即:不同消费者组订阅同一话题,组内只消费一次,但多组消费多次。
76 | 
77 |
78 |
--------------------------------------------------------------------------------
/SpringBoot/14.消息队列的整合与使用/14.7.RocketMQ实现分布式事务.md:
--------------------------------------------------------------------------------
1 | # 一、参考:
2 |
3 | [RocketMQ 事务消息的使用与原理分析](http://silence.work/2018/08/22/RocketMQ-4-3事务使用与分析/)
4 |
5 |
6 |
--------------------------------------------------------------------------------
/SpringBoot/15.邮件发送的整合与使用/15.2.发送html和基于模板的邮件.md:
--------------------------------------------------------------------------------
1 | # 一、发送html邮件服务
2 |
3 | ```java
4 | /**
5 | * 发送html邮件
6 | */
7 | public void sendHtmlMail(String to, String subject, String content) throws MessagingException {
8 | //注意这里使用的是MimeMessage
9 | MimeMessage message = mailSender.createMimeMessage();
10 | MimeMessageHelper helper = new MimeMessageHelper(message, true);
11 | helper.setFrom(fromEmail);
12 | helper.setTo(to);
13 | helper.setSubject(subject);
14 | //第二个参数是否是html,true
15 | helper.setText(content, true);
16 |
17 | mailSender.send(message);
18 | }
19 | ```
20 |
21 | 测试用例
22 |
23 | ```java
24 | @Test
25 | public void sendHtmlMail() throws MessagingException {
26 | mailService.sendHtmlMail("3162507037@qq.com","一封html测试邮件","\n"
27 | + " \n"
28 | +"
\"一封html测试邮件\"
\n"
29 | +"
http://www.zimug.com"
30 | + "
\n"
32 | + "
Hello Freemarker
73 |
74 |
75 |
76 | | firstName |
77 | lastName |
78 |
79 |
80 | <#list people as person>
81 |
82 | | ${person.firstname} |
83 | ${person.lastname} |
84 |
85 |
86 |
87 |
88 |
89 |
90 | ```
91 |
92 |
93 |
94 | 
--------------------------------------------------------------------------------
/SpringBoot/15.邮件发送的整合与使用/15.3.发送带附件和内联附件邮件.md:
--------------------------------------------------------------------------------
1 | # 一、发送带附件的邮件
2 |
3 | ```java
4 | /**
5 | * 发送带附件的邮件
6 | */
7 | public void sendAttachmentsMail(String to, String subject, String content, String filePath) throws MessagingException {
8 | MimeMessage message = mailSender.createMimeMessage();
9 | //带附件第二个参数true
10 | MimeMessageHelper helper = new MimeMessageHelper(message, true);
11 | helper.setFrom(fromEmail);
12 | helper.setTo(to);
13 | helper.setSubject(subject);
14 | helper.setText(content, true);
15 |
16 | FileSystemResource file = new FileSystemResource(new File(filePath));
17 | String fileName = filePath.substring(filePath.lastIndexOf(File.separator));
18 | helper.addAttachment(fileName, file);
19 |
20 | mailSender.send(message);
21 | }
22 | ```
23 |
24 | 测试
25 |
26 | ```java
27 | @Test
28 | public void sendAttachmentsMail() throws MessagingException {
29 | String filePath = "D:\\courseview\\springboot\\template.png";
30 | mailService.sendAttachmentsMail("3162507037@qq.com", "这是一封带附件的邮件", "邮件中有附件,请注意查收!", filePath);
31 | }
32 | ```
33 |
34 | 邮件结果展示
35 | 
36 |
37 | # 二、发送内联附件的邮件
38 |
39 | ```java
40 | /**
41 | * 发送正文中有静态资源的邮件
42 | */
43 | public void sendResourceMail(String to, String subject, String content, String rscPath, String rscId) throws MessagingException {
44 | MimeMessage message = mailSender.createMimeMessage();
45 |
46 | MimeMessageHelper helper = new MimeMessageHelper(message, true);
47 | helper.setFrom(fromEmail);
48 | helper.setTo(to);
49 | helper.setSubject(subject);
50 | helper.setText(content, true);
51 |
52 | FileSystemResource res = new FileSystemResource(new File(rscPath));
53 | helper.addInline(rscId, res);
54 |
55 | mailSender.send(message);
56 | }
57 | ```
58 |
59 | 测试
60 |
61 | ```java
62 | @Test
63 | public void sendResourceMail() throws MessagingException {
64 | String rscId = "krislin";
65 | String content = "这是有图片的邮件
 ";
66 | String imgPath = "E:\\picture\\壁纸\\wallhaven-698428.jpg";
67 | mailService.sendResourceMail("3162507037@qq.com", "这邮件中含有图片", content, imgPath, rscId);
68 |
69 | }
70 | ```
71 |
72 | 邮件结果展示:
73 |
74 | 
--------------------------------------------------------------------------------
/SpringMVC/README.md:
--------------------------------------------------------------------------------
1 | # [01.框架原理和入门配置](01.框架原理和入门配置.md)
2 | - [springmvc学习笔记(1)-框架原理和入门配置](01.框架原理和入门配置.md/#springmvc学习笔记1-框架原理和入门配置)
3 | - [springmvc框架原理](01.框架原理和入门配置.md/#springmvc框架原理)
4 | - [什么是mvc?](01.框架原理和入门配置.md/#什么是mvc)
5 | - [Springmvc框架原理](01.框架原理和入门配置.md/#springmvc框架原理-1)
6 | - [Springmvc和spring什么关系?](01.框架原理和入门配置.md/#springmvc和spring什么关系)
7 | - [SpringMVC入门程序](01.框架原理和入门配置.md/#springmvc入门程序)
8 | - [1.所需的包](01.框架原理和入门配置.md/#1所需的包)
9 | - [2.配置SpringMVC的前端控制器](01.框架原理和入门配置.md/#2配置springmvc的前端控制器)
10 | - [3.springmvc配置](01.框架原理和入门配置.md/#3springmvc配置)
11 | - [4.编写Controller](01.框架原理和入门配置.md/#4编写controller)
12 | - [5.编写success.jsp](01.框架原理和入门配置.md/#5编写successjsp)
13 | - [SpringMVC入门程序的流程](01.框架原理和入门配置.md/#springmvc入门程序的流程)
14 |
15 | # [02.非注解的处理器映射器和适配器](02.非注解的处理器映射器和适配器.md)
16 | - [springmvc学习笔记(2)-非注解的处理器映射器和适配器](02.非注解的处理器映射器和适配器.md/#springmvc学习笔记2-非注解的处理器映射器和适配器)
17 | - [1.导入的依赖](02.非注解的处理器映射器和适配器.md/#1导入的依赖)
18 | - [2.配置DispatcherServlet核心分发器(web.xml)](02.非注解的处理器映射器和适配器.md/#2配置dispatcherservlet核心分发器webxml)
19 | - [3.配置HandlerMapping映射器(springmvc.xml)](02.非注解的处理器映射器和适配器.md/#3配置handlermapping映射器springmvcxml)
20 | - [4.配置HandlerAdapter适配器(springmvc.xml)](02.非注解的处理器映射器和适配器.md/#4配置handleradapter适配器springmvcxml)
21 | - [5.编写一个Controller类](02.非注解的处理器映射器和适配器.md/#5编写一个controller类)
22 | - [6.配置自定义控制器(springmvc.xml)](02.非注解的处理器映射器和适配器.md/#6配置自定义控制器springmvcxml)
23 | - [7.定义一个相应页面](02.非注解的处理器映射器和适配器.md/#7定义一个相应页面)
24 | - [8.配置视图解析器(springmvc.xml)](02.非注解的处理器映射器和适配器.md/#8配置视图解析器springmvcxml)
25 | - [9.分析程序执行流程](02.非注解的处理器映射器和适配器.md/#9分析程序执行流程)
26 | - [10.主要配置步骤](02.非注解的处理器映射器和适配器.md/#10主要配置步骤)
--------------------------------------------------------------------------------
/前端/AJAX/AJAX基本步骤.md:
--------------------------------------------------------------------------------
1 | # AJAX请求
2 | 
3 |
4 | # 创建XHR
5 | 创建XHR对象 XMLHttpRequest
6 | XHR对象是一个javascript对象,它可以在用户没有感觉的情况下,就像背后运行的一根小线程一般,悄悄的和服务器进行数据交互
7 | AJAX就是通过它做到无刷新效果的
8 | ~~~javascript
9 |
13 | ~~~
14 |
15 | # 设置并发出请求
16 | XHR对象的作用是和服务器进行交互,所以既会发消息给服务器,也能接受服务器返回的响应。
17 | 当服务器响应回来的时候,调用怎么处理呢?
18 | 通过` xmlhttp.onreadystatechange=checkResult `就可以指定用`checkResult` 函数进行处理。
19 |
20 |
21 | # 设置并发出请求
22 | 通过open函数设置背后的这个小线程,将要访问的页面url ,在本例中就是
23 | /study/checkName.jsp
24 | `xmlhttp.open("GET",url,true);`
25 | 通过send函数进行实际的访问
26 | `xmlhttp.send(null);`
27 | `null`表示没有参数,因为参数已经通过`GET` 方式,放在`url`里了。
28 | 只有在用`POST`,并且需要发送参数的时候,才会使用到`send`。
29 | 类似这样:
30 | `xmlhttp.send("user="+username+"&password="+password)`
31 |
32 | # 处理响应信息
33 | 在checkResult 函数中处理响应
34 | ~~~javascript
35 | function checkResult(){
36 | if (xmlhttp.readyState==4 && xmlhttp.status==200)
37 | document.getElementById('checkResult').innerHTML=xmlhttp.responseText;
38 | }
39 | ~~~
40 |
41 | `xmlhttp.readyState` 4 表示请求已完成
42 | `xmlhttp.status` 200 表示响应成功
43 | `xmlhttp.responseText`; 用于获取服务端传回来的文本
44 | `document.getElementById('checkResult').innerHTML` 设置span的内容为服务端传递回来的文本
45 |
46 | # 步骤
47 | 1. 创建XHR对象
48 | 2. 设置响应函数
49 | 3. 设置要访问的页面
50 | 4. 发出请求
51 | 5. 当服务端的响应返回,响应函数被调用。
52 | 6. 在响应函数中,判断响应是否成功,如果成功获取服务端返回的文本,并显示在span中。
53 |
54 | ~~~javascript
55 | 输入账号 :
56 |
57 |
58 |
59 |
77 | ~~~
--------------------------------------------------------------------------------
/前端/HTML和CSS/CSS笔记.md:
--------------------------------------------------------------------------------
1 | # 盒子模型
2 | 外边距:margin
3 | 作用:用来设置元素与元素之间的间隔
4 | 居中设置:margin:0px auto; 上下间隔是0px,水平居中
5 | 边框:boder
6 | 作用:设置内容和边框之间的距离
7 | 注意:内边距不会改变内容区域的大小 可以单独的设置上下左右的内边距
8 | 内容区域:
9 | 作用:改变内容区域的大小
10 | 设置宽和高即可以改变内容区域的大小
11 |
12 | # css的定位学习:
13 | position
14 | 相对定位:relative
15 | 作用:相对元素原有位置移动指定的距离(相对自己原有的位置)
16 | 可以使用top,left,right,bottom来进行设置
17 | 注意:
18 | 其他元素的位置不改变
19 | 绝对定位:absolute
20 | 作用:可以使元素参照界面或者相对父元素来进行移动
21 | 注意:
22 | 如果父级元素成为参照元素,必须使用相对定位属性
23 | 默认情况下是以界面为基准进行移动.
24 | 固定定位:fixed
25 | 作用:将元素固定在界面的指定位置,不会随着滚动条的移动而改变位置.
26 | 以上定位 都可以使用top,left,right,bottom来进行移动
27 | z-index:此属性是用来声明元素的显示级别的
--------------------------------------------------------------------------------
/前端/HTML和CSS/HTML笔记.md:
--------------------------------------------------------------------------------
1 | # [HTML元素网站](http://www.html5star.com/manual/html5label-meaning/)
2 |
3 | # 列表
4 | 
5 |
6 | # 表单
7 | 
8 |
9 |
10 | 
11 |
12 | 
13 |
14 | # 表格
15 | 1. \
";
66 | String imgPath = "E:\\picture\\壁纸\\wallhaven-698428.jpg";
67 | mailService.sendResourceMail("3162507037@qq.com", "这邮件中含有图片", content, imgPath, rscId);
68 |
69 | }
70 | ```
71 |
72 | 邮件结果展示:
73 |
74 | 
--------------------------------------------------------------------------------
/SpringMVC/README.md:
--------------------------------------------------------------------------------
1 | # [01.框架原理和入门配置](01.框架原理和入门配置.md)
2 | - [springmvc学习笔记(1)-框架原理和入门配置](01.框架原理和入门配置.md/#springmvc学习笔记1-框架原理和入门配置)
3 | - [springmvc框架原理](01.框架原理和入门配置.md/#springmvc框架原理)
4 | - [什么是mvc?](01.框架原理和入门配置.md/#什么是mvc)
5 | - [Springmvc框架原理](01.框架原理和入门配置.md/#springmvc框架原理-1)
6 | - [Springmvc和spring什么关系?](01.框架原理和入门配置.md/#springmvc和spring什么关系)
7 | - [SpringMVC入门程序](01.框架原理和入门配置.md/#springmvc入门程序)
8 | - [1.所需的包](01.框架原理和入门配置.md/#1所需的包)
9 | - [2.配置SpringMVC的前端控制器](01.框架原理和入门配置.md/#2配置springmvc的前端控制器)
10 | - [3.springmvc配置](01.框架原理和入门配置.md/#3springmvc配置)
11 | - [4.编写Controller](01.框架原理和入门配置.md/#4编写controller)
12 | - [5.编写success.jsp](01.框架原理和入门配置.md/#5编写successjsp)
13 | - [SpringMVC入门程序的流程](01.框架原理和入门配置.md/#springmvc入门程序的流程)
14 |
15 | # [02.非注解的处理器映射器和适配器](02.非注解的处理器映射器和适配器.md)
16 | - [springmvc学习笔记(2)-非注解的处理器映射器和适配器](02.非注解的处理器映射器和适配器.md/#springmvc学习笔记2-非注解的处理器映射器和适配器)
17 | - [1.导入的依赖](02.非注解的处理器映射器和适配器.md/#1导入的依赖)
18 | - [2.配置DispatcherServlet核心分发器(web.xml)](02.非注解的处理器映射器和适配器.md/#2配置dispatcherservlet核心分发器webxml)
19 | - [3.配置HandlerMapping映射器(springmvc.xml)](02.非注解的处理器映射器和适配器.md/#3配置handlermapping映射器springmvcxml)
20 | - [4.配置HandlerAdapter适配器(springmvc.xml)](02.非注解的处理器映射器和适配器.md/#4配置handleradapter适配器springmvcxml)
21 | - [5.编写一个Controller类](02.非注解的处理器映射器和适配器.md/#5编写一个controller类)
22 | - [6.配置自定义控制器(springmvc.xml)](02.非注解的处理器映射器和适配器.md/#6配置自定义控制器springmvcxml)
23 | - [7.定义一个相应页面](02.非注解的处理器映射器和适配器.md/#7定义一个相应页面)
24 | - [8.配置视图解析器(springmvc.xml)](02.非注解的处理器映射器和适配器.md/#8配置视图解析器springmvcxml)
25 | - [9.分析程序执行流程](02.非注解的处理器映射器和适配器.md/#9分析程序执行流程)
26 | - [10.主要配置步骤](02.非注解的处理器映射器和适配器.md/#10主要配置步骤)
--------------------------------------------------------------------------------
/前端/AJAX/AJAX基本步骤.md:
--------------------------------------------------------------------------------
1 | # AJAX请求
2 | 
3 |
4 | # 创建XHR
5 | 创建XHR对象 XMLHttpRequest
6 | XHR对象是一个javascript对象,它可以在用户没有感觉的情况下,就像背后运行的一根小线程一般,悄悄的和服务器进行数据交互
7 | AJAX就是通过它做到无刷新效果的
8 | ~~~javascript
9 |
13 | ~~~
14 |
15 | # 设置并发出请求
16 | XHR对象的作用是和服务器进行交互,所以既会发消息给服务器,也能接受服务器返回的响应。
17 | 当服务器响应回来的时候,调用怎么处理呢?
18 | 通过` xmlhttp.onreadystatechange=checkResult `就可以指定用`checkResult` 函数进行处理。
19 |
20 |
21 | # 设置并发出请求
22 | 通过open函数设置背后的这个小线程,将要访问的页面url ,在本例中就是
23 | /study/checkName.jsp
24 | `xmlhttp.open("GET",url,true);`
25 | 通过send函数进行实际的访问
26 | `xmlhttp.send(null);`
27 | `null`表示没有参数,因为参数已经通过`GET` 方式,放在`url`里了。
28 | 只有在用`POST`,并且需要发送参数的时候,才会使用到`send`。
29 | 类似这样:
30 | `xmlhttp.send("user="+username+"&password="+password)`
31 |
32 | # 处理响应信息
33 | 在checkResult 函数中处理响应
34 | ~~~javascript
35 | function checkResult(){
36 | if (xmlhttp.readyState==4 && xmlhttp.status==200)
37 | document.getElementById('checkResult').innerHTML=xmlhttp.responseText;
38 | }
39 | ~~~
40 |
41 | `xmlhttp.readyState` 4 表示请求已完成
42 | `xmlhttp.status` 200 表示响应成功
43 | `xmlhttp.responseText`; 用于获取服务端传回来的文本
44 | `document.getElementById('checkResult').innerHTML` 设置span的内容为服务端传递回来的文本
45 |
46 | # 步骤
47 | 1. 创建XHR对象
48 | 2. 设置响应函数
49 | 3. 设置要访问的页面
50 | 4. 发出请求
51 | 5. 当服务端的响应返回,响应函数被调用。
52 | 6. 在响应函数中,判断响应是否成功,如果成功获取服务端返回的文本,并显示在span中。
53 |
54 | ~~~javascript
55 | 输入账号 :
56 |
57 |
58 |
59 |
77 | ~~~
--------------------------------------------------------------------------------
/前端/HTML和CSS/CSS笔记.md:
--------------------------------------------------------------------------------
1 | # 盒子模型
2 | 外边距:margin
3 | 作用:用来设置元素与元素之间的间隔
4 | 居中设置:margin:0px auto; 上下间隔是0px,水平居中
5 | 边框:boder
6 | 作用:设置内容和边框之间的距离
7 | 注意:内边距不会改变内容区域的大小 可以单独的设置上下左右的内边距
8 | 内容区域:
9 | 作用:改变内容区域的大小
10 | 设置宽和高即可以改变内容区域的大小
11 |
12 | # css的定位学习:
13 | position
14 | 相对定位:relative
15 | 作用:相对元素原有位置移动指定的距离(相对自己原有的位置)
16 | 可以使用top,left,right,bottom来进行设置
17 | 注意:
18 | 其他元素的位置不改变
19 | 绝对定位:absolute
20 | 作用:可以使元素参照界面或者相对父元素来进行移动
21 | 注意:
22 | 如果父级元素成为参照元素,必须使用相对定位属性
23 | 默认情况下是以界面为基准进行移动.
24 | 固定定位:fixed
25 | 作用:将元素固定在界面的指定位置,不会随着滚动条的移动而改变位置.
26 | 以上定位 都可以使用top,left,right,bottom来进行移动
27 | z-index:此属性是用来声明元素的显示级别的
--------------------------------------------------------------------------------
/前端/HTML和CSS/HTML笔记.md:
--------------------------------------------------------------------------------
1 | # [HTML元素网站](http://www.html5star.com/manual/html5label-meaning/)
2 |
3 | # 列表
4 | 
5 |
6 | # 表单
7 | 
8 |
9 |
10 | 
11 |
12 | 
13 |
14 | # 表格
15 | 1. \元素创建一个表。
16 | 2. \元素添加行的表。
17 | 3. 要将数据添加到行中,可以使用\| 元素。
18 | 4. 表标题阐明了数据的含义。标题与\ | 元素一起添加。
19 | 5. 表数据可以使用**colspan**属性跨越列。
20 | 6. 表数据可以使用**rowspan**属性跨越行。
21 | 7. 表可以分为三个主要部分:头,主体和页脚。
22 | 8. 使用该\元素创建表格的头部。
23 | 9. 使用该\ |
元素创建表的主体。
24 | 10. 使用\元素创建表的页脚。
25 |
--------------------------------------------------------------------------------
/前端/JQuery/JQuery CSS.md:
--------------------------------------------------------------------------------
1 | # 增加class
2 | 通过addClass() 增加一个样式中的class
3 | ~~~javascript
4 |
13 |
14 |
15 |
16 |
17 |
22 |
23 |
24 |
25 | Hello JQuery
26 |
27 |
28 | ~~~
29 |
30 | # 删除class
31 | 通过removeClass() 删除一个样式中的class
32 | ~~~javascript
33 | script>
34 | $(function(){
35 | $("#b1").click(function(){
36 | $("#d").removeClass("pink");
37 | });
38 |
39 | });
40 |
41 |
42 |
43 |
44 |
45 |
46 |
51 |
52 |
53 |
54 | Hello JQuery
55 |
56 |
57 | ~~~
58 |
59 | # 切换class
60 | 通过toggleClass() 切换一个样式中的class
61 | 这里的切换,指得是:
62 | 如果存在就删除
63 | 如果不存在,就添加
64 | ~~~javascript
65 |
74 |
75 |
76 |
77 |
78 |
83 |
84 |
85 |
86 | Hello JQuery
87 |
88 |
89 | ~~~
90 |
91 | # css函数
92 | 通过css函数 直接设置样式
93 | `css(property,value)`
94 | 第一个参数是样式属性,第二个参数是样式值
95 | `css({p1:v1,p2:v2})`
96 |
97 | 参数是 {} 包含的属性值对。
98 | 属性值对之间用 逗号,分割
99 | 属性值之间用 冒号 :分割
100 | 属性和值都需要用引号 “
101 |
102 | ~~~javascript
103 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 | 单一样式,只设置背景色
124 |
125 |
126 |
127 |
128 |
129 | 多种样式,不仅设置背景色,还设置字体颜色
130 |
131 |
132 | ~~~
--------------------------------------------------------------------------------
/前端/JQuery/JQuery常见方法.md:
--------------------------------------------------------------------------------
1 | # 取值
2 | 通过JQuery对象的`val()`方法获取值
3 | 相当于` document.getElementById("input1").value;`
4 | ~~~javascript
5 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 | ~~~
21 |
22 | # 获取元素内容,如果有子元素,保留标签
23 | 通过html() 获取元素内容,如果有子元素,保留标签
24 | ~~~javascript
25 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 | 这是div的内容
41 | 这是div里的span
42 |
43 |
44 | ~~~
45 |
46 | # 获取元素内容,如果有子元素,不包含子元素标签
47 | 通过text() 获取元素内容,如果有子元素,不包含标签
48 | ~~~javascript
49 |
50 |
51 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 | 这是div的内容
67 | 这是div里的span
68 |
69 |
70 | ~~~
71 |
72 |
--------------------------------------------------------------------------------