├── .gitignore
├── C++
├── README.md
├── 样例
│ ├── README.md
│ ├── codes
│ │ └── nothing.cpp
│ ├── docs
│ │ └── nothing.md
│ └── imgs
│ │ └── img_1.jpg
├── 第一讲
│ ├── C++_Google_Style简介
│ │ ├── README.md
│ │ ├── codes
│ │ │ ├── base.cpp
│ │ │ ├── base.h
│ │ │ └── main.cpp
│ │ ├── docs
│ │ │ └── Google Coding Style.md
│ │ └── imgs
│ │ │ └── 01.png
│ └── C++_多文件组织简介
│ │ ├── README.md
│ │ ├── codes
│ │ ├── main.cpp
│ │ ├── occupation.cpp
│ │ ├── occupation.h
│ │ ├── salary.cpp
│ │ └── salary.h
│ │ ├── docs
│ │ └── 多文件组织.md
│ │ └── imgs
│ │ ├── img01.png
│ │ └── img02.png
├── 第七讲
│ ├── 继承与多态总结
│ │ ├── codes
│ │ │ ├── pointer_reference_to_base.cpp
│ │ │ ├── virtual_destructor.cpp
│ │ │ ├── virtual_func_abcd.cpp
│ │ │ └── virtual_func_animal.cpp
│ │ ├── docs
│ │ │ └── 继承与多态总结.md
│ │ └── readme.md
│ └── 虚函数
│ │ ├── README.md
│ │ ├── codes
│ │ ├── dynamic_cast.cpp
│ │ └── 虚函数.cpp
│ │ └── docs
│ │ └── 虚函数.md
├── 第三讲
│ ├── 左值与右值简介
│ │ ├── README.md
│ │ ├── docs
│ │ │ └── 左值与右值.md
│ │ └── imgs
│ │ │ └── 01.png
│ └── 移动语义简介
│ │ ├── README.md
│ │ ├── codes
│ │ └── 复制构造函数.cpp
│ │ └── docs
│ │ └── 移动语义.md
├── 第九讲
│ ├── 桥接模式简介
│ │ ├── codes
│ │ │ ├── bridge_pattern.h
│ │ │ └── main.cpp
│ │ ├── docs
│ │ │ └── 桥接模式简介.md
│ │ └── readme.md
│ └── 迭代器模式简介
│ │ ├── README.md
│ │ ├── codes
│ │ └── iterator.cpp
│ │ ├── docs
│ │ └── 迭代器模式简介.md
│ │ └── imgs
│ │ └── img01.png
├── 第二讲
│ ├── C++ 指针用法总结
│ │ ├── README.md
│ │ ├── codes
│ │ │ ├── Examples_1.cpp
│ │ │ └── Examples_2.cpp
│ │ └── docs
│ │ │ └── C++指针用法.md
│ └── C++ 智能指针简介
│ │ ├── README.md
│ │ ├── codes
│ │ ├── Examples_1.cpp
│ │ ├── Examples_2.cpp
│ │ └── Examples_3.cpp
│ │ └── docs
│ │ └── 三类智能指针.md
├── 第五讲
│ ├── C++11语法糖杂讲
│ │ ├── README.md
│ │ ├── codes
│ │ │ └── type_name.cpp
│ │ └── docs
│ │ │ └── C++11语法糖.md
│ └── C++_const
│ │ ├── README.md
│ │ ├── codes
│ │ ├── constants.h
│ │ └── draft.cpp
│ │ └── docs
│ │ └── Sast tutor 2022-const.md
├── 第八讲
│ ├── 工厂模式
│ │ ├── README.md
│ │ ├── codes
│ │ │ ├── 工厂方法模式.cpp
│ │ │ └── 简单工厂模式.cpp
│ │ └── docs
│ │ │ └── 工厂模式.md
│ └── 设计模式原则简介
│ │ ├── README.md
│ │ ├── codes
│ │ ├── OCP_1.cpp
│ │ ├── OCP_2.cpp
│ │ ├── OCP_3.cpp
│ │ └── SRP.cpp
│ │ └── docs
│ │ └── design pattern.md
├── 第六讲
│ └── 函数对象、lambda与参数绑定
│ │ ├── README.md
│ │ ├── codes
│ │ ├── 1FunctionObject.cpp
│ │ ├── 2lambda.cpp
│ │ └── 3bind.cpp
│ │ ├── docs
│ │ └── 第六讲:函数对象、lambda表达式与参数绑定.md
│ │ └── imgs
│ │ └── image1.png
├── 第十讲
│ └── README.md
└── 第四讲
│ ├── static修饰符用法总结
│ ├── README.md
│ ├── codes
│ │ ├── linkage
│ │ │ ├── 1.cpp
│ │ │ └── 2.cpp
│ │ ├── mem_fun.cpp
│ │ └── zoo.cpp
│ └── docs
│ │ └── Static.md
│ └── 命名空间简介
│ ├── README.md
│ ├── codes
│ ├── aliases.cpp
│ ├── namespace1.cpp
│ ├── namespace2.cpp
│ └── 多文件namespace
│ │ ├── add.h
│ │ ├── main.cpp
│ │ ├── math.cpp
│ │ └── subtract.h
│ └── docs
│ └── Namespace.md
├── MATLAB
├── 2022MatPyFly
│ ├── 第一讲
│ │ ├── README.md
│ │ ├── codes
│ │ │ ├── MATLAB_hw_week1.mlx
│ │ │ ├── MATLAB_optional_week1.mlx
│ │ │ └── MATLAB_tutor_week1.mlx
│ │ └── docs
│ │ │ └── MATLAB_安装指南.pdf
│ ├── 第三讲
│ │ ├── MATLAB_hw_week3.mlx
│ │ ├── MATLAB_tutor_week3.mlx
│ │ └── README.md
│ └── 第二讲
│ │ ├── README.md
│ │ └── codes
│ │ ├── MATLAB_hw_week2.mlx
│ │ ├── MATLAB_tutor_week2.mlx
│ │ ├── circle.m
│ │ ├── data
│ │ ├── data1.mat
│ │ ├── data2.txt
│ │ ├── data3.xlsx
│ │ ├── data4.csv
│ │ ├── image1.bmp
│ │ └── image2.mat
│ │ ├── data_hw
│ │ ├── data1.mat
│ │ ├── data2.xlsx
│ │ ├── data3.mat
│ │ ├── image1.png
│ │ └── image_22
│ │ │ ├── image1.png
│ │ │ ├── image10.png
│ │ │ ├── image11.png
│ │ │ ├── image12.png
│ │ │ ├── image2.png
│ │ │ ├── image3.png
│ │ │ ├── image4.png
│ │ │ ├── image5.png
│ │ │ ├── image6.png
│ │ │ ├── image7.png
│ │ │ ├── image8.png
│ │ │ └── image9.png
│ │ ├── fmax.m
│ │ └── fun1.m
├── README.md
└── 快速入门
│ ├── MATLAB_QuickStart_Array.mlx
│ ├── MATLAB_QuickStart_Char_and_String.mlx
│ └── test_image
│ ├── img1.jpg
│ ├── img2.jpg
│ ├── img3.jpg
│ └── img4.jpg
├── Python
├── 2022MatPyFly
│ ├── 第一讲
│ │ ├── README.md
│ │ ├── codes
│ │ │ ├── bin.txt
│ │ │ ├── dec.txt
│ │ │ ├── python_assignment_01.ipynb
│ │ │ └── python_tutorial_01.ipynb
│ │ └── docs
│ │ │ ├── Python安装指南(Windows版).pdf
│ │ │ └── Python安装指南(mac版本) .pdf
│ ├── 第三讲
│ │ ├── Dataset.rar
│ │ ├── README.md
│ │ ├── codes
│ │ │ ├── Common
│ │ │ │ ├── DataLoader.py
│ │ │ │ └── __pycache__
│ │ │ │ │ └── DataLoader.cpython-38.pyc
│ │ │ ├── LogisticRegression.py
│ │ │ ├── python_assignment_03.ipynb
│ │ │ └── python_tutorial_03.ipynb
│ │ └── docs
│ │ │ ├── 2021年夏季学期Python程序设计大作业指引.pdf
│ │ │ ├── Python安装指南(Windows版).pdf
│ │ │ └── python安装指南(mac版本).pdf
│ └── 第二讲
│ │ ├── README.md
│ │ └── codes
│ │ ├── files
│ │ ├── bin.txt
│ │ ├── dec.txt
│ │ └── example.txt
│ │ ├── python_assignment_02.ipynb
│ │ └── python_tutorial_02.ipynb
├── README.md
└── 其它
│ ├── 文档查阅
│ ├── myfile.py
│ └── 文档查阅.ipynb
│ └── 迭代_推导_生成基础
│ ├── data.txt
│ ├── 推导.ipynb
│ └── 迭代.ipynb
└── README.md
/.gitignore:
--------------------------------------------------------------------------------
1 | /.vscode
2 |
--------------------------------------------------------------------------------
/C++/README.md:
--------------------------------------------------------------------------------
1 | # 文件清单
2 |
3 | ---
4 |
5 | - 样例/:仅仅为了说明该如何出C++的教程
6 | - 第一讲/:C++多文件组织简介,C++ Google Style简介
7 | - 第二讲/:C++指针用法总结,C++智能指针简介
8 | - 第三讲/:左值与右值简介,移动语义简介
9 | - 第四讲/:static修饰符用法总结,命名空间简介
10 | - 第五讲/:const用法总结,C++11语法糖杂讲
11 | - 第六讲/:函数对象与Lambda表达式简介,参数绑定简介
12 | - 第七讲/:继承与多态总结,虚函数深入理解
13 | - 第八讲/:设计模式原则简介,工厂模式简介
14 | - 第九讲/:桥接模式简介,迭代器模式简介
15 | - 第十讲/:泛型编程与STL简介
16 |
--------------------------------------------------------------------------------
/C++/样例/README.md:
--------------------------------------------------------------------------------
1 | # 样例
2 |
3 | ## 简介
4 | 这里写本教程的内容,之后出推送的时候可以直接把它复制到推送里。
5 |
6 | ## 文件清单
7 | 一般来说,一个C++教程单元中有以下三个子文件夹:
8 | - docs/:用来存放.md教程文件
9 | - imgs/:用来存放docs/中教程所需图片(注意路径)
10 | - codes/:用来存放能运行的代码示例
11 |
12 |
13 | 各位在写这一块的时候,只要说明下各文件夹下有什么文件、有什么作用就行。
14 |
15 | ## 参考资料
16 | 咱们C++教程的主要参考来源于以下讲义、书籍与网站:
17 | - 清华大学计算机系姚海龙老师程序设计基础课件
18 | - 《C++ Primer》(第五版)
19 | - [cplusplus reference](https://www.cplusplus.com/reference/)
20 | - [learn Cpp](https://www.learncpp.com/)
21 | - [Microsoft C++ docs](https://docs.microsoft.com/en-us/cpp/cpp/?view=msvc-170)
22 | - [GeeksforGeeks C++ tutorials](https://www.geeksforgeeks.org/c-plus-plus/)
23 |
24 | 各位在写这部分的时候把自己参考的资料列出来就行。
25 |
26 | ---
27 |
28 | 下面是一些你们写README.md的时候不必出现的东西:
29 |
30 | ## 有关类图的绘制
31 |
32 | 第六至十讲可能要手画一些简单的UML类图,有关C++类间关系及类图的参考资料如下:
33 | - [UML Class Diagram Explained With C++ samples](https://cppcodetips.wordpress.com/2013/12/23/uml-class-diagram-explained-with-c-samples/)
34 | - [learn Cpp](https://www.learncpp.com/)第16章
35 | - [ C++ OOD and OOP - Class Diagram in UML](https://www.youtube.com/watch?v=thbxWbneJ6o)
36 |
37 | 关于如何绘制类图,这里有两个方案:
38 |
39 | ### 方案一、PlantUML
40 | 这里推荐[PlantUML](http://www.plantuml.com/plantuml/uml/SyfFKj2rKt3CoKnELR1Io4ZDoSa70000)。有关如何使用PlantUML画UML类图的参考资料如下:
41 | - [PlantUML类图介绍](https://plantuml.com/zh/class-diagram)
42 |
43 | 生成UML类图后,只需在.md文件中附上图片链接,并在链接前加上//https:,即可显示。简单示例如下:
44 |
45 |
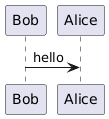
46 |
51 |
52 |
Typora中有支持,可以直接渲染。但是很遗憾,GitHub中不支持。因此,一种比较快的解决方法是直接截图(统一采用默认主题),截图后把图片存在imgs/文件夹下。
60 |
61 | mermaid绘制类图教程如下:
62 | - [csdn中的Mermaid类图入门教程](https://blog.csdn.net/u012787240/article/details/112847071)
63 | - [mermaid类图官方教程](https://mermaid-js.github.io/mermaid/#/classDiagram)
64 |
65 | 取得的效果如下图:
66 |
67 |

68 |
Typora中显示,应当能够渲染出来,但在GitHub上还是代码块):
71 | ```mermaid
72 | classDiagram
73 | classA <|-- classB : implements
74 | classC *-- classD : composition
75 | classE o-- classF : association
76 | ```
77 |
78 | - 优点:所见即所得,能在本地快速编辑
79 | - 缺点:比较朴素,并且修改的话,得重新截图
80 |
81 | ## 有关.md文件中图片显示的问题
82 |
83 | 为了使得图片能够在非本地(如GitHub)能正常显示,你可能需要手动写下图片路径:
84 |
85 | 例如现在我处于C++/样例/README.md,想要去显示位于MATLAB/快速入门/test_image/中的img1.jpg,一个恰当的做法如下:
86 |
87 |

88 |
93 |
94 |
6 |

7 |
59 |

60 |
11 |

13 |
92 |
93 |
docs/:
16 | - C++ 指针用法.md **—** 教程主要内容
17 |
18 | - codes/:
19 | - Examples_1.cpp **—** 基本操作相关代码
20 | - Examples_2.cpp **—** 函数指针相关代码
21 |
22 | ## 参考资料
23 | - 《C++ Primer》(第五版)
24 | - [关于C++中的函数指针](https://www.geeksforgeeks.org/function-pointer-in-c/)
25 | - [C++类成员指针](https://blog.csdn.net/K346K346/article/details/49471287)
26 |
--------------------------------------------------------------------------------
/C++/第二讲/C++ 指针用法总结/codes/Examples_1.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | int main(){
3 | int x{ 7 };
4 | int y{ 3 };
5 | int* ptr{ &x };
6 |
7 | std::cout << &x << std::endl;
8 | std::cout << x << std::endl;
9 | std::cout << ptr << std::endl;
10 | std::cout << *ptr << std::endl;
11 |
12 | *ptr = 9;
13 |
14 | std::cout << &x << std::endl;
15 | std::cout << x << std::endl;
16 | std::cout << ptr << std::endl;
17 | std::cout << *ptr << std::endl;
18 |
19 | ptr = &y;
20 |
21 | std::cout << &y << std::endl;
22 | std::cout << y << std::endl;
23 | std::cout << ptr << std::endl;
24 | std::cout << *ptr << std::endl;
25 |
26 | std::cout << sizeof(ptr) << std::endl;
27 | std::cout << sizeof(*ptr) << std::endl;
28 |
29 | return 0;
30 | }
--------------------------------------------------------------------------------
/C++/第二讲/C++ 指针用法总结/codes/Examples_2.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | void add(int a, int b)
3 | {
4 | std::cout << "加和为 " << a + b;
5 | }
6 | void sub(int a, int b)
7 | {
8 | std::cout << "相差为 " << a - b;
9 | }
10 | void mul(int a, int b)
11 | {
12 | std::cout << "相乘为" << a * b;
13 | }
14 | void fun1() {
15 | std::cout << "Fun1";
16 | }
17 | void fun2() {
18 | std::cout << "Fun2";
19 | }
20 | void funx(void (*fun)()){
21 | fun();
22 | }
23 |
24 | int main()
25 | {
26 |
27 | //关于函数指针数组的主程序部分
28 |
29 | /*
30 | void (*fun_ptr_arr[])(int, int) = { add, sub, mul };
31 | int x, a = 1, b = 2;
32 |
33 | std::cout << "请选择: 输入0让两数相加, 输入1让两数相减,输入2让两数相乘\n";
34 | std::cin >> x;
35 |
36 | if (x > 2)
37 | return 0;
38 | (*fun_ptr_arr[x])(a, b);
39 | return 0;
40 | */
41 |
42 | //关于函数指针作为参数传递的主程序部分
43 |
44 | /*
45 | funx(fun1);
46 | funx(fun2);
47 | return 0;
48 | */
49 | }
--------------------------------------------------------------------------------
/C++/第二讲/C++ 指针用法总结/docs/C++指针用法.md:
--------------------------------------------------------------------------------
1 | # C++指针用法
2 |
3 | ### 目录
4 |
5 | 1. 指针的基本操作
6 |
7 | 2. 部分区别与注意事项
8 |
9 | 3. 关于几类特殊指针
10 |
11 | - 空指针
12 |
13 | - 函数指针
14 |
15 | - 类成员指针
16 |
17 | ### 指针的基本操作
18 |
19 | 在准备开始了解指针之前,让我们先来讨论一些更基本的东西。
20 |
21 | 我们定义一个变量(如`char a`),当执行对应的代码时,一块内存空间将会被分配给该对象,我们为对象所赋的值将会被储存在这块内存空间中。在我们使用`a`这个变量时,程序需要去访问内存空间中储存的值,而为了区分不同对象的内存空间,每块内存空间都会有一个标识符,也称作该对象的地址。这个地址将会通过**地址运算符(&)**来进行访问,例如:
22 |
23 | ```c++
24 | #include
25 | int main(){
26 | int x{ 5 };
27 | std::cout << x << ' ' << &x << std::endl;
28 | return 0;
29 | }
30 | ```
31 |
32 | 在笔者的电脑上打印出的结果为:
33 |
34 | ``` c++
35 | 5 0000008359EFF7A4
36 | ```
37 |
38 | 地址通常是以十六进制的形式进行打印,并且省略了前缀`0x`
39 |
40 | 与获取变量地址的运算符&相对应的是**解引用运算符(*)**,其操作数是一个地址,功能是将给定地址所储存的值返回,例如`*(&x)`便是获取变量x的值。
41 |
42 | 现在,我们可以开始来聊一聊指针的相关内容了。
43 |
44 | 首先需要知道的一点是,指针是一个对象,该对象的值是另一个常规对象的地址,其定义方式也与常规对象有所区别:
45 |
46 | ```c++
47 | int a{ 5 };//声明一个整型变量a,其值为5
48 | int* ptr{ &a };//声明一个整数指针(指向整数变量地址的指针),其值为整数变量a的地址
49 | ```
50 |
51 | 也就是说,通过在类型名旁添加一个*符号,我们就能够声明一个指针变量,当然,这时候\*并不是作为解引用运算符被使用。
52 |
53 | **注意!**当在同一行中声明多个指针变量时,需要在每个指针变量前都添加一个*符号:
54 |
55 | ```c++
56 | int* a, b, c;//声明了一个整数指针a,和两个整型变量b、c
57 | int* x, * y, * z; //声明了三个整数指针x、y和z
58 | ```
59 |
60 | 在定义了一个指针变量后,该指针在默认情况下不会被初始化,**未初始化的指针被称作野指针**,直接使用野指针的情况通常是不被允许的:
61 |
62 | ```c++
63 | int* x;
64 | std::cout << x;//非法语句
65 | std::cout << *x;//非法语句
66 | std::cout << &x;//有效语句,x是一个指针对象,其本身也有自己的地址,地址用来存放指向对象的地址
67 | ```
68 |
69 | 一个指针变量的初始化与使用可以为:
70 |
71 | ```c++
72 | #include
73 | int main(){
74 | int x{ 5 };
75 | std::cout << x << ' ';
76 | int* ptr{ &x };
77 | std::cout << *ptr;
78 | }
79 | ```
80 |
81 | 在该例子中,指针变量`ptr`被初始化为指向变量`x`的地址,也即`ptr = &x`,所以使用解引用运算符`*`也就是获取变量`x`的值。
82 |
83 | 一个简单的事实是,指针变量的类型必须与其所指向对象的类型相匹配:
84 |
85 | ```c++
86 | int x{ 1 };
87 | double y{ 0.2 };
88 | int* xptr1{ &x };//合法
89 | int* xPtr2{ &y };//非法
90 | double* yptr1{ &x };//非法
91 | double* yptr2{ &y };//合法
92 | ```
93 |
94 | 指针对象在初始化后,可以通过赋值语句来改变其所指向的对象,从而获取不同对象所储存的值:
95 |
96 | ```c++
97 | int x{ 3 };
98 | int y{ 5 };
99 | int* ptr{ &x };
100 | std::cout << *ptr;//此时打印变量x的值
101 | ptr = &y;
102 | std::cout << *ptr;//此时打印变量y的值
103 | ```
104 |
105 | ### 部分区别与注意事项
106 |
107 | 在了解了关于指针的声明、初始化和赋值这些基本操作后,我们有必要对一些细节做出处理。
108 |
109 | #### 指针与引用
110 |
111 | 来看一个例子:
112 |
113 | ```c++
114 | #include
115 | int main(){
116 | int x{ 5 };
117 | int& y{ x };
118 | int* ptr{ &x };
119 |
120 | std::cout << x;
121 | std::cout << y;
122 | std::cout << *ptr;
123 |
124 | y = 2;
125 | std::cout << x;
126 | std::cout << y;
127 | std::cout << *ptr;
128 |
129 | *ptr = 3;
130 | std::cout << x;
131 | std::cout << y;
132 | std::cout << *ptr;
133 | return 0;
134 | }
135 | ```
136 |
137 | 上述程序的打印结果为:
138 |
139 | ```c++
140 | 111222333
141 | ```
142 |
143 | 在例子中我们可以发现,指针和对象的引用都能够改变对象本身的值,并且两者之间能够互通,从这个角度来看,似乎指针是通过地址运算符`&`显式获取了指向对象的地址,又通过解引用运算符`*`显式获取了所指向地址的值,而引用则只是将操作转化为隐式,两者之间没有什么差别,但其实不然,两者之间实际上有不少值得指出的区别:
144 |
145 | - 引用在定义时必须进行初始化,而指针不用(当然,我们应该要初始化,但至少不会直接报错)
146 | - 引用并没有重新创建一个对象,而指针则创建了一个对象
147 | - 引用是对于一个改定对象的别名,并且指向的对象不能改变,但是指针可以
148 | - 引用必须总是指向一个对象,而指针不用
149 | - 通常情况下,引用是安全的,但是指针是**危险的**
150 |
151 | 关于最后两点,我们将在对于空指针的讨论中看到。
152 |
153 | #### 地址操作符
154 |
155 | 通过`&`获取一个对象的地址(如`&a`)时,`&a`并不是将`a`的地址作为一个字符串返回,它返回的是一个包含操作数地址的指针,并且该指针的类型来自于其操作数本身,这能够解释我们在程序中不能通过一串地址来直接对一个指针进行赋值:
156 |
157 | ```c++
158 | int a{ 5 };//定义变量a,并且&a = 0x0012FF7C
159 | int* ptr1{ a };//合法,指针ptr1指向变量a的地址
160 | int* ptr2{ 0x0012FF7C };//非法,尽管0x0012FF7C是一个地址,但是编译器将0x0012FF7C视作一个十六进制下的整数表示
161 | ```
162 |
163 | #### 指针的大小
164 |
165 | 指针的大小与指针类型无关,只与编译可执行文件的体系结构(32位:4字节;64位:8字节)有关系:
166 |
167 | ```c++
168 | #include
169 | int main(){//假设为64位操作系统
170 | char* a;
171 | int* b;
172 | long long* c;
173 | std::cout << sizeof(a);
174 | std::cout << sizeof(b);
175 | std::cout << sizeof(c);
176 | return 0;
177 | }
178 | ```
179 |
180 | 打印语句的结果均为`8`。
181 |
182 | ### 关于几类特殊指针
183 |
184 | #### 空指针
185 |
186 | 在之前的讨论中,我们知道指针在语法上可以不用指向任何对象,但是在使用时需要事先将其初始化,那么,在我们定义一个指针的时候,如果没有一个已知的有效对象用来作用指向目标,这种情况下,我们该如何处理呢?
187 |
188 | 事实上,我们的确不需要让指针指向一个具体的对象:
189 |
190 | ```c++
191 | int* ptr{};
192 | ```
193 |
194 | 这个语句是合法的,此时指针`ptr`没有指向一个具体对象,而是储存了一个`null`值,在此之后,我们可以重新通过赋值语句来让`ptr`指向一个具体对象并进行使用,或者,我们还可以通过赋值语句来让一个已经指向具体对象的指针变成`null`指针,这需要用到关键字`nullptr`:
195 |
196 | ```c++
197 | int main(){
198 | int a{ 5 };
199 | int* ptr1{ &a };//初始化指针ptr1,并让其指向对象a
200 | int* ptr2{ nullptr };//初始化指针ptr2,并让其指向null
201 | ptr2 = nullptr;//让指针ptr2重新成为null指针
202 | }
203 | ```
204 |
205 | **注意!**与野指针类似的是,我们应当尽量避免直接对`null`指针使用解引用运算符`*`,尽管有时编译器会为`null`指针赋予一个全为`0`的空地址,但有时直接使用也会让应用程序无法运行。
206 |
207 | 为了避免以上情况的发生,我们可以通过像布尔值`true`和`false`那样来对空指针和非空指针进行检测:
208 |
209 | ```c++
210 | #include
211 | int main(){
212 | int x { 5 };
213 | int* ptr { &x };
214 | if (ptr)
215 | std::cout << "ptr is non-null\n";
216 | else
217 | std::cout << "ptr is null\n";
218 | return 0;
219 | }
220 | ```
221 |
222 | 在以上例子中,我们可以发现,指针可以隐式地转化为布尔值`true`和`false`,其中空指针被转化为`false`,而非空指针则被转化为`true`。
223 |
224 | 通过对于空指针的简单讨论,我们应该认识到,尽管指针比较灵活,但是使用指针来访问对象会给我们带来一些附加的危险,所以,在没有足够的把握时,我们**尽可能优先使用引用而不是指针**。
225 |
226 | #### 函数指针
227 |
228 | 就像指向普通对象的指针那样,在**C++**中,我们还可以声明指向函数的指针:
229 |
230 | ```c++
231 | #include
232 | void fun(int a){
233 | std::cout << "Value of a is " << a;
234 | }
235 | int main(){
236 | void (*fun_ptr)(int) = &fun;
237 | (*fun_ptr)(10);
238 | return 0;
239 | }
240 | ```
241 |
242 | 程序的运行结果为:
243 |
244 | ```c++
245 | Value of a is 10
246 | ```
247 |
248 | 但是,可以发现一个有趣的事实是,`fun`的函数指针`fun_ptr`在声明的时候添加了一个额外的括号,如果我们去掉括号(也就是`void *fun_ptr(int)`),这会发生什么呢:
249 |
250 | ```c++
251 | #include
252 | void fun(int a){
253 | std::cout << "Value of a is " << a;
254 | }
255 | int main(){
256 | void *fun_ptr(int) = &fun;
257 | (*fun_ptr)(10);
258 | return 0;
259 | }xxxxxxxxxx #include void fun(int a){ std::cout << "Value of a is " << a;}int main(){ void (*fun_ptr)(int) = &fun; (*fun_ptr)(10); return 0;}void *fun_ptr(int) = &fun;
260 | ```
261 |
262 | 在我们将上述程序中的对应语句更换后,我们会沮丧地发现这个程序将无法正常执行,原因就在于**C++**中运算符的优先级在这个语句中依旧生效:
263 |
264 | ```c++
265 | void *fun_ptr(int);
266 | ```
267 |
268 | 在上述语句中,运算符()将优先于运算符*,所以这个语句实际意味着我们声明了一个具有一个int类型参数和void\*返回值的函数`fun_ptr`。为避免这个烦恼,我们需要将运算符`*`与`fun_ptr`绑定,因此在原本正确的程序中,我们才会看到那个括号的出现。
269 |
270 | > 在这里,我们看到了`void*`,这是一个`void`类型的指针,这种指针可以被任意数据类型的指针赋值,但是不能获取对象的值,我们可以通过以下的例子简单地理解:
271 | >
272 | > ```c++
273 | >#include
274 | > int main(){
275 | > int a{ 5 };
276 | > double b{ 0.6 };
277 | >
278 | > int* ptr1{ &a };
279 | > double* ptr2{ &b };
280 | > void* ptr3;
281 | >
282 | > ptr3 = ptr1;//合法
283 | > std::cout << *ptr3 << std::endl;//非法
284 | > ptr3 = ptr2;//合法
285 | > std::cout << *ptr2 << std::endl;//非法
286 | >
287 | > return 0;
288 | > }
289 | > ```
290 | > 另外,当一个函数的参数或者返回值中有`void*`类型的数据时,如果数据的类型无法确定,那么我们就可以使用`void`类型来代替。
291 |
292 | 除了上述基本应用外,函数指针还有一些其他的使用方法。比如,我们可以通过函数名来直接获取函数的地址,以最开始的程序为例:
293 |
294 | ```c++
295 | #include
296 | void fun(int a){
297 | std::cout << "Value of a is " << a;
298 | }
299 | int main(){
300 | void (*fun_ptr)(int) = fun;
301 | fun_ptr(10);
302 | return 0;
303 | }
304 | ```
305 |
306 | 注意到,上述程序与最开始那个程序的区别有两点:1.我们删除了`void (*fun_ptr)(int) = &fun;`语句中`fun`前面的地址运算符`&`;2.`(*fun_ptr)(10);`语句中我们同样删去了解引用运算符`*`更改了函数调用,这样程序依然有效。
307 |
308 | 此外,我们还可以创建函数指针数组,并让用户来作出决策决定指针执行的具体函数,或者将函数指针作为一个具体函数的参数进行传递,这些应用的举例我们都会在附加的`cpp`文件中给出。
309 |
310 | #### 类成员指针
311 |
312 | 类成员指针主要分为**数据成员指针**和**成员函数指针**两种,使用方法与普通指针类似,但需要使用类限定符,但需要注意的两点是:1.为成员函数指针赋值时,需要显示使用&运算符,不能直接将“类名::成员函数名”赋给成员函数指针(即通过函数名直接获取函数地址);2.使用数据成员指针时,被访问的成员往往是类的公有成员,如果是类的私有成员,容易出错。
313 |
--------------------------------------------------------------------------------
/C++/第二讲/C++ 智能指针简介/README.md:
--------------------------------------------------------------------------------
1 | # 第三讲
2 |
3 | ## 简介
4 | - 内容主题:**C++ 智能指针简介**
5 | - 你将学到什么:
6 | - 为什么要引入智能指针(动态分配new & delete简介)
7 | - 三类智能指针的简单介绍
8 | - `std::unique_ptr`
9 | - `std::shared_ptr`
10 | - `std::weak_ptr`
11 |
12 | ## 文件清单
13 | - docs/:
14 | - 三类智能指针.md
15 | - codes/:
16 | - Examples_1.cpp**—**智能指针类的简单思想
17 | - Examples_2.cpp**—**`std::make_unique()`的例子
18 | - Examples_3.cpp**—**`std::make_shared()`的例子
19 |
20 |
21 |
22 | ## 参考资料
23 | - 《C++ Primer》(第五版)
24 | - [learn Cpp](https://www.learncpp.com/)
25 | - [GeeksforGeeks C++ tutorials](https://www.geeksforgeeks.org/c-plus-plus/)
26 | - [C++11 创建和使用`std::unique_ptr`](https://www.cnblogs.com/DswCnblog/p/5628195.html)
27 | - [C++11 创建和使用`std::weak_ptr`](https://blog.csdn.net/Xiejingfa/article/details/50772571)
28 |
29 |
--------------------------------------------------------------------------------
/C++/第二讲/C++ 智能指针简介/codes/Examples_1.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | template
3 | class SmartPtr {
4 | T* ptr;
5 | public:
6 | explicit SmartPtr(T* p = NULL) { ptr = p; }
7 | ~SmartPtr() { delete (ptr); }
8 | T& operator*() { return *ptr; }
9 | T* operator->() { return ptr; }
10 | };
11 |
12 | int main(){
13 | SmartPtr ptr(new int());
14 | *ptr = 1;
15 | std::cout << *ptr;
16 | return 0;
17 | }
18 |
--------------------------------------------------------------------------------
/C++/第二讲/C++ 智能指针简介/codes/Examples_2.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | class Fraction{
4 | int m_num{ 0 };
5 | int m_den{ 1 };
6 | public:
7 | Fraction(int num = 0, int den = 1):m_num{ num }, m_den{ den }{
8 | }
9 |
10 | friend std::ostream& operator<<(std::ostream& out, const Fraction& f1){
11 | out << f1.m_num << '/' << f1.m_den;
12 | return out;
13 | }
14 | };
15 |
16 | int main(){
17 | auto f1{ std::make_unique(3, 5) };
18 | std::cout << *f1 << std::endl;
19 | auto f2{ std::make_unique(4) };
20 | std::cout << f2[0] << std::endl;
21 | return 0;
22 | }
--------------------------------------------------------------------------------
/C++/第二讲/C++ 智能指针简介/codes/Examples_3.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | class Resource{
4 | public:
5 | Resource() { std::cout << "对象生成" << std::endl; }
6 | ~Resource() { std::cout << "对象摧毁" << std::endl; }
7 | };
8 |
9 | int main(){
10 | auto ptr1{ std::make_shared() };
11 | {
12 | auto ptr2{ ptr1 };
13 | std::cout << "销毁一个指针" << std::endl;
14 | }
15 | std::cout << "销毁另一个指针" << std::endl;
16 | return 0;
17 | }
--------------------------------------------------------------------------------
/C++/第二讲/C++ 智能指针简介/docs/三类智能指针.md:
--------------------------------------------------------------------------------
1 | # 三类智能指针
2 |
3 | ### 目录
4 |
5 | 1. 为什么要引入智能指针?
6 | 2. 三类智能指针简介
7 | - `std::unique_ptr`
8 | - `std::shared_ptr`
9 | - `std::weak_ptr`
10 |
11 | ### 为什么要引入智能指针?
12 |
13 | 在上一讲中,我们简单介绍了`C++`中指针的各种用法,那里所提到的指针又被叫做**原始指针**,这是因为自`C++11`以后,引入了一类新的指针——**智能指针**,它们原本有四位成员:
14 |
15 | ```c++
16 | std::auto_ptr std::unique_ptr std::shared_ptr std::weak_ptr
17 | ```
18 |
19 | 但是第一位成员因为一些缺陷,从`C++17`开始就不再被允许,所以被留下来且被广泛应用的主要是后三位,它们也正是我们本讲的重要成员。不过呢,与上一讲类似的,我们也不着急直接与这三位见面,在此之前,我们先抛出一个问题,那就是:我现在`C++`目前已有的指针整得好好的,为什么要费心费力地去使用这几个用法相对繁琐,还有一套自己独特成员函数体系的三种指针呢?
20 |
21 | 嗯……好吧,这的确是一个需要去回答的问题,在回答这一个问题的同时,我们顺带讲一讲上一讲中没有提到的`C++`原始指针的一种重要用途:**内存的动态分配与释放**。
22 |
23 | 当我们创建数组时,需要给定数组的长度:
24 |
25 | ```c++
26 | #include
27 | class Animal{
28 | ...
29 | };
30 |
31 | int main(){
32 | int a[100];
33 | char str[50];
34 | Animal cat[1000];
35 | ...
36 | return 0;
37 | }
38 | ```
39 |
40 | 为了保证我们声明的内存足够后续的使用,我们能做的最好的就是将各种数组的长度分配为我们可能使用的最大数量,并且希望不会发生意外。
41 |
42 | 但是显然,这并非是一个好方法,原因至少有三点:
43 |
44 | - 在实际应用过程中,大多数情况下并不会使用被分配内存的大部分空间,这容易导致较大的内存浪费。
45 | - 我们平时所声明的普通变量(包含基本类型变量、类对象变量等),其内存是在**栈(Stack)**上进行分配,程序的栈空间通常不会很大,比如如果申请一个`int a[1000000]`可能就会导致栈溢出的问题。
46 | - 尽管我们期望意外不会发生,但是数组溢出的情况难免还是会存在,这会给用户的使用带来不小的限制。
47 |
48 | 为了避免固定内存分配所带来的各种麻烦,`C++`提出了一个解决方案:**动态内存分配**,其与指针的使用密切相关:
49 |
50 | ```c++
51 | int* a;
52 | int n;
53 | ```
54 |
55 | 我们申明一个整数指针`a`和整型变量`n`,现在我们想要创建一个整形数组,其大小经由用户决定,那么我们该怎么做呢?
56 |
57 | 首先,当然是由用户先输入想要创建的数组的长度,这个长度由`n`来决定:
58 |
59 | ```c++
60 | std::cin >> n;
61 | ```
62 |
63 | 接下来,我们需要用到一个新的关键字:`new`:
64 |
65 | ```c++
66 | a = new int[n];
67 | ```
68 |
69 | 上面几个语句是什么意思呢,大概可以等效为:
70 |
71 | ```c++
72 | int a[n];
73 | ```
74 |
75 | 当然,这个语句是非法的,因为在`C++`的语法中数组的固定分配内存不允许为一个变量。
76 |
77 | 现在,我们通过用户决定的长度创建了一个整形数组`a[n]`,其他类型包括类对象数组(`classA* a = new classA[n]`)也是被允许的,接下来我们**几乎**把它们当成一个普通数组来进行使用就可以了。
78 |
79 | 另外,如果想要在动态分配的时候进行初始化,当然也是可以的。
80 |
81 | ```c++
82 | a = new int[5]{1, 2, 3, 4, 5};
83 | ```
84 |
85 | 而且可以指出的是,动态分配的内存是在堆(Heap)上进行的,空间很大,所以基本上不会出现开不出`int a[1000000]`这样的数组的情况。
86 |
87 | 但是,还有一点小问题,我们之前提到了“几乎”,也就是说事实上动态内存分配和普通数组还是有不同的,这体现在哪里呢?
88 |
89 | 在我们使用普通数组时,当对象生命周期结束的时候,程序会自动帮我们执行销毁工作,但是动态分配不同,我们需要明确地告诉`C++`释放内存以供重新使用,这个工作将由关键字`delete`来完成:
90 |
91 | ```c++
92 | int* a{ new int };
93 | delete a;
94 | a = nullptr;
95 | ```
96 |
97 | 通过关键字`delete`,我们将指针被分配的内存返还给了操作系统,操作系统能够另将这份内存用作他用,但是指针本身依旧存在,它可以再次被分配给一个新的内存。
98 |
99 | 到此,我们已经学会了如何简单地使用`new`和`delete`来动态分配和释放内存,对指针的应用又多了一种领会,可喜可贺,可喜可贺。
100 |
101 | 但,这与一开始我们所提出的问题有什么关系呢?让我们来看看下面这个例子:
102 |
103 | ```c++
104 | #include
105 | class A{
106 | int a1;
107 | int a2;
108 | };
109 | void Func(){
110 | A* ptr = new A();
111 | }
112 | int main(){
113 | while(1){
114 | Func();
115 | }
116 | return 0;
117 | }
118 | ```
119 |
120 | 非常简单明了,程序只是在不断地创造和销毁A类对象`ptr`,仅此而已。
121 |
122 | 但是,真的只是如此吗?我们来仔细分析一下,函数`Func`创建一个A类指针,并通过动态分配对指针分配了一个A类对象的空间,当函数结束时,对象`ptr`是一个局部变量,所以它会被销毁,但是由于我们的疏忽,没能够对对象使用`delete`,所以对象本身虽然被销毁,但内存却没有被释放,这份内存不能被其他资源使用,而在主函数体内,无效内存在不断被分配,这也就是所说的**内存泄漏**现象。由于这个原因,整个堆上的内存可能会变得无法使用,而且即使是使用了`delete`,也会有无数种方法使得内存无法被释放,例如提前退出:
123 |
124 | ```c++
125 | #include
126 | void Func(){
127 | ClassA* ptr = new ClassA();
128 | int a;
129 |
130 | std::cin >> a;
131 | if(a == 0)
132 | return;
133 | delete ptr;
134 | }
135 | ```
136 |
137 | 或者异常处理:
138 |
139 | ```c++
140 | #include
141 | void Func(){
142 | ClassA* ptr = new ClassA();
143 | int a;
144 |
145 | std::cin >> a;
146 | if(a == 0)
147 | throw 0;
148 | delete ptr;
149 | }
150 | ```
151 |
152 | 还有种种原因都可能导致这种后果,从本质上来讲,这些问题的发生是因为原始指针缺少内在机制(就像类的析构函数那样)来自行处理。
153 |
154 | 于是,为了解决这样的问题,`C++`提出了它的方案——**智能指针**。
155 |
156 | ### 三类智能指针简介
157 |
158 | 如上所说,智能指针利用了类的思想(事实上它就是一个管理动态分配对象的类),它管理动态分配的资源,并确保在适当的时间(通常在智能指针超出范围时)正确清理动态分配的对象。一种简单的智能指针类被放在了样例程序中,具体的实现方式这里不做讨论,当我们自己使用智能指针时,需要引入一个头文件:`#include`,现在我们对常用的三种智能指针进行介绍。
159 |
160 | #### `std::unique_ptr`
161 |
162 | `std::unique_ptr`在三种智能指针中被应用得最广泛,以下是一个简单的实例:
163 |
164 | ```c++
165 | #include
166 | #include
167 | int main(){
168 | std::unique_ptr ptr1(new int(5));
169 | std::cout << *ptr1;
170 | return 0;
171 | }
172 | ```
173 |
174 | 正如指针名字所指出的那样,`std::unique_ptr`被用于管理不被其他对象共享的动态分配的对象,换句话说,一个`std::unique_ptr`指针完全享有它所指向的对象的管理权限,所以复制构造和赋值操作都是不被允许的:
175 |
176 | ```c++
177 | #include
178 | #include
179 | int main(){
180 | std::unique_ptr ptr1(new int(5));
181 | std::unique_ptr ptr2(ptr1); //Error!
182 | std::unique_ptr ptr3 = ptr1; //Error!
183 | return 0;
184 | }
185 | ```
186 |
187 | 但也有一个例外,那就是从函数中返回指针:
188 |
189 | ```c++
190 | #include
191 | #include
192 | std::unique_ptr Func(int ptr)
193 | {
194 | std::unique_ptr ptr1(new int(ptr));
195 | return ptr1; // 返回unique_ptr
196 | }
197 |
198 | int main() {
199 | int p = 1;
200 | std::unique_ptr ptr = Func(p);
201 | std::cout << *ptr;
202 | }
203 | ```
204 |
205 | 另外,管理权的转移是被允许的,这将通过`std::move()`来实现:
206 |
207 | ```c++
208 | #include
209 | #include
210 | int main(){
211 | std::unique_ptr ptr1(new int(5));
212 | std::unique_ptr ptr2(std::move(ptr1));
213 |
214 | std::cout << *ptr1; //Error! ptr1 has been removed!
215 | std::cout << *ptr2;
216 | return 0;
217 | }
218 | ```
219 |
220 | 如果要判断一个`std::unique_ptr`指针是否正管理一个对象,可以将指针直接作为布尔值进行判断:
221 |
222 | ```c++
223 | #include
224 | #include
225 | int main(){
226 | std::unique_ptr ptr(new int(5));
227 | if(ptr)
228 | std::cout << *ptr;
229 | return 0;
230 | }
231 | ```
232 |
233 | 另外,从`C++14`开始,我们可以通过`std::make_unique()`来创建`std::unique_ptr`对象,关于这一点的例子我们将在样例中给出。
234 |
235 | 在固定数组、动态数组和字符串的处理上,`std::array`、`std::vector`和`std::string`一般是更好的选择,`std::unique_ptr`指针可以用于以下几种情况:
236 |
237 | - 提供异常处理安全保证
238 |
239 | 先附上本讲中出现过的一段代码:
240 |
241 | ```c++
242 | #include
243 | void Func(){
244 | ClassA* ptr = new ClassA();
245 | int a;
246 |
247 | std::cin >> a;
248 | if(a == 0)
249 | throw 0;
250 | delete ptr;
251 | }
252 | ```
253 |
254 | 通过智能指针,这段代码可以更改为:
255 |
256 | ```c++
257 | #include
258 | #include
259 | void Func(){
260 | std::unique_ptr ptr(new ClassA());
261 | int a;
262 |
263 | std::cin >> a;
264 | if(a == 0)
265 | throw 0;
266 | }
267 | ```
268 |
269 | 这样就可以保证动态资源能够被释放。
270 |
271 | - 返回函数内动态资源的所有权(从函数中返回智能指针)
272 | - 在容器中储存指针
273 | ```c++
274 | #include
275 | #include
276 | #include
277 | int main()
278 | {
279 | std::vector> vec;
280 | std::unique_ptr ptr(new int(1));
281 | vec.push_back(std::move(ptr));
282 | return 0;
283 | }
284 | ```
285 |
286 | #### `std::shared_ptr`
287 |
288 | 与`std::unique_ptr`正相反,`std::shared_ptr`指针主要用于需要多个智能指针共同享有一个资源的情况,并且可以通过成员函数`use_count()`来跟踪有多少个智能指针指向同一个对象,只要至少有一个`std::shared_ptr`指向某一个资源,即使部分指向该资源的`std::shared_ptr`被销毁,该资源也不会被立即释放:
289 |
290 | ```c++
291 | #include
292 | #include
293 |
294 | int main(){
295 | std::shared_ptr ptr1(new int(1));
296 | std::shared_ptr ptr2(ptr1);
297 | std::cout << *ptr2 << std::endl;
298 | std::cout << ptr2.use_count();
299 | return 0;
300 | }
301 | ```
302 |
303 | 然后我们来看看下面的例子:
304 |
305 | ```c++
306 | #include
307 | #include
308 | int main(){
309 | int *a = new int;
310 | std::shared_ptr ptr1 { a };
311 | {
312 | std::shared_ptr ptr2 { a };
313 | std::cout << "销毁一个智能指针 ";
314 | }
315 |
316 | std::cout << "销毁另一个智能指针";
317 | return 0;
318 | }
319 | ```
320 |
321 | 语句被打印出来——然后程序崩溃。
322 |
323 | 原因在于两个智能指针之前没有通过复制操作正确建立联系,也就是说它们各自都认为自己独立享有同一个资源,当`ptr2`超出生命周期后,它会尝试销毁资源,然后`ptr1`超出生命周期时它也会这样做,于是寄。
324 |
325 | 为了避免这样的情况,请通过复制操作使得指针之间建立联系:
326 |
327 | ```c++
328 | #include
329 | #include
330 | int main(){
331 | int *a = new int;
332 | std::shared_ptr ptr1 { a };
333 | {
334 | std::shared_ptr ptr2 { ptr1 };
335 | std::cout << "销毁一个智能指针 ";
336 | }
337 |
338 | std::cout << "销毁另一个智能指针";
339 | return 0;
340 | }
341 | ```
342 |
343 | 类似地,我们也有`std::make_shared()`用来创建`std::shared_ptr`对象,实例被放在样例之中。
344 |
345 | #### `std::weak_ptr`
346 |
347 | 前两个指针中,`std::unique_ptr`用来解决单一所有权问题,而`std::shared_ptr`用于共享所有权问题,似乎不再需要其他指针,那么`std::weak_ptr`存在的意义是什么呢?让我们来看看下面的例子:
348 |
349 | ```c++
350 | #include
351 | #include
352 | #include
353 | class Person {
354 | std::string m_name;
355 | std::shared_ptr m_partner;
356 |
357 | public:
358 | Person(const std::string& name) : m_name(name) {
359 | std::cout << m_name << " 生成" << std::endl;
360 | }
361 | ~Person() {
362 | std::cout << m_name << " 摧毁" << std::endl;
363 | }
364 | friend bool partnerUp(std::shared_ptr& p1, std::shared_ptr& p2) {
365 | if (!p1 || !p2)
366 | return false;
367 | p1->m_partner = p2;
368 | p2->m_partner = p1;
369 | std::cout << p1->m_name << " 现在与 " << p2->m_name << "成为搭档" << std::endl;
370 | return true;
371 | }
372 | };
373 |
374 | int main() {
375 | auto Zhangsan{ std::make_shared("Zhang San") };
376 | auto Lisi{ std::make_shared("Li Si") };
377 | partnerUp(Zhangsan, Lisi);
378 | return 0;
379 | }
380 | ```
381 |
382 | 程序的执行结果如下:
383 |
384 | ```c++
385 | Zhang San 生成
386 | Li Si 生成
387 | Zhang San 现在与 Li Si成为搭档
388 | ```
389 |
390 | 在上面的示例中,在调用`partnerUp()`后,有两个共享指针指向`Zhang San`(`Zhang San`和`Li Si`的`m_partner`)和两个共享指针指向`Li Si`(`Li Si`和`Zhang San`的`m_partner`)。
391 |
392 | 在`main()`结束时,`Zhang San`共享指针首先超出范围。发生这种情况时,`Zhang San`检查是否有任何其他共享指针共同拥有`Zhang San`这个人。有(`Li Si`的`m_partner`)。正因为如此,它不会释放`Zhang San`(如果它释放了,那么`Li Si`的`m_partner`将最终成为一个悬空指针)。我们现在有一个指向`Zhang San`的共享指针(`Li Si`的 m_partner)和两个指向`Li Si`的共享指针(`Li Si`和`Zhang San`的`m_partner`)。
393 |
394 | 接下来`Li Si`共享指针超出范围,同样的事情发生了。共享指针`Li Si`检查是否有任何其他共享指针共同拥有`Li Si`这个人。有(`Zhang San`的`m_partner`),所以`Li Si`没有被释放。此时,有一个指向`Li Si`的共享指针(`Zhang San`的`m_partner`)和一个指向`Zhang San`的共享指针(`Li Si`的`m_partner`)。
395 |
396 | 然后程序结束,`Li Si`或`Zhang San`这两个对象都没有被释放——`Li Si`最终阻止了`Zhang San`被摧毁,而`Zhang San`最终阻止了`Li Si`被摧毁。
397 |
398 | 实际上,当`std::shared_ptr`形成循环引用的时候就有可能产生这种情况。而`std::weak_ptr`便是为了解决这种状况而出现。
399 |
400 | `std::weak_ptr`指向一个由`std::shared_ptr`管理的对象而不影响所指对象的生命周期,也就是将一个`std::weak_ptr`绑定到一个`std::shared_ptr`不会改变`std::shared_ptr`的引用计数。不论是否有`std::weak_ptr`指向,一旦最后一个指向对象的`std::shared_ptr`被销毁,对象就会被释放。从这个角度看,`std::weak_ptr`更像是`std::shared_ptr`的一个助手而不是智能指针。因此,我们在使用`std::weak_ptr`的时候需要依靠`std::shared_ptr`:
401 |
402 | ```c++
403 | int main() {
404 | std::shared_ptr ptr1(new int(1));
405 | cout << "创建前ptr1的引用计数:" << ptr1.use_count(); // use_count = 1
406 |
407 | std::weak_ptr ptr2(ptr1);
408 | cout << "创建后ptr1的引用计数:" << ptr1.use_count(); // use_count = 1
409 | }
410 | ```
411 |
412 | 我们利用`std::weak_ptr`来解决之前所遇到的问题:
413 |
414 | ```c++
415 | #include
416 | #include
417 | #include
418 | class Person{
419 | std::string m_name;
420 | std::weak_ptr m_partner;
421 |
422 | public:
423 |
424 | Person(const std::string &name): m_name(name){
425 | std::cout << m_name << " 生成" << std::endl;
426 | }
427 | ~Person(){
428 | std::cout << m_name << " 摧毁" << std::endl;
429 | }
430 |
431 | friend bool partnerUp(std::shared_ptr &p1, std::shared_ptr &p2){
432 | if (!p1 || !p2)
433 | return false;
434 | p1->m_partner = p2;
435 | p2->m_partner = p1;
436 | std::cout << p1->m_name << " 现在与 " << p2->m_name << "成为搭档" << std::endl;
437 | return true;
438 | }
439 | };
440 |
441 | int main(){
442 | auto Zhangsan{ std::make_shared("Zhang San") };
443 | auto Lisi{ std::make_shared("Li Si") };
444 | partnerUp(Zhangsan, Lisi);
445 | return 0;
446 | }
447 | ```
448 |
449 | 于是循环引用的问题便被我们解决了。
450 |
--------------------------------------------------------------------------------
/C++/第五讲/C++11语法糖杂讲/README.md:
--------------------------------------------------------------------------------
1 | # 第五讲
2 |
3 | ## 简介
4 |
5 | - 内容主题:**C++ 11 语法糖杂讲**
6 | - 你将学到什么:
7 | - `constexpr`变量
8 | - `auto`类型指示符
9 | - 范围`for`语句
10 | - 列表初始化
11 |
12 | ## 文件清单
13 |
14 | - `docs\`
15 | - C++ 11 语法糖.md:教程的主要内容
16 |
17 | - `codes\`
18 | - type_name.cpp:相关代码
19 |
20 |
21 | ## 参考资料
22 |
23 | - 《C++ Primer》第五版
24 |
25 | - [StackOverflow上关于C++打印数据类型的讨论](https://stackoverflow.com/questions/81870/is-it-possible-to-print-a-variables-type-in-standard-c)
26 |
27 |
--------------------------------------------------------------------------------
/C++/第五讲/C++11语法糖杂讲/codes/type_name.cpp:
--------------------------------------------------------------------------------
1 | /**
2 | * @file type_name.cpp
3 | * @author Zsbyqx2020
4 | * @brief Some related code in the tutorial.
5 | * @version 0.1
6 | * @date 2022-02-15
7 | *
8 | * @copyright Copyright (c) 2022
9 | *
10 | */
11 | #define _GLIBCXX_USE_CXX11_ABI 0
12 | #include
13 | #include
14 | #ifndef _MSC_VER
15 | #include
16 | #endif
17 | #include
18 |
19 | #include
20 | #include
21 | #include
22 | #include
23 | template
24 | void type_name(std::string name) {
25 | typedef typename std::remove_reference::type TR;
26 | std::unique_ptr own(
27 | #ifndef _MSC_VER
28 | abi::__cxa_demangle(typeid(TR).name(), nullptr, nullptr, nullptr),
29 | #else
30 | nullptr,
31 | #endif
32 | std::free);
33 | std::string r = own != nullptr ? own.get() : typeid(TR).name();
34 | if (std::is_const::value) r += " const";
35 | if (std::is_volatile
::value) r += " volatile";
36 | if (std::is_lvalue_reference::value)
37 | r += "&";
38 | else if (std::is_rvalue_reference::value)
39 | r += "&&";
40 | std::cout << "delctype of " << name << " is: " << r << std::endl;
41 | }
42 | int main() {
43 | // About 'constexpr'
44 | // 指向整型常量的指针
45 | const int *p1 = nullptr;
46 | type_name("p1");
47 |
48 | // 指向整数的常量指针
49 | int *const p2 = nullptr;
50 | constexpr int *q1 = nullptr;
51 | type_name("p2");
52 | type_name("q1");
53 |
54 | // 指向整形常量的常量指针
55 | const int *const p3 = nullptr;
56 | constexpr const int *q2 = nullptr;
57 | type_name("p3");
58 | type_name("q2");
59 |
60 | // About 'auto'
61 | // 关于引用
62 | int i = 0, &r = i;
63 | auto a = r;
64 | type_name("a");
65 |
66 | // 忽略顶层const
67 | const int ci = 0, &cr = ci;
68 | auto b = ci;
69 | auto c = cr;
70 | type_name("b");
71 | type_name("c");
72 |
73 | // 保留底层const
74 | auto d = &i;
75 | auto e = &ci;
76 | const auto f = ci;
77 | type_name("d");
78 | type_name("e");
79 | type_name("f");
80 |
81 | // const引用绑定
82 | auto &g = ci;
83 | const auto &j = 42;
84 | type_name("g");
85 | type_name("j");
86 |
87 | // 范围for语句
88 | std::vector v = {1, 2, 3, 4, 5, 6};
89 | for (auto &r : v) r *= 2;
90 | for (auto i : v) std::cout << i << " ";
91 | }
--------------------------------------------------------------------------------
/C++/第五讲/C++11语法糖杂讲/docs/C++11语法糖.md:
--------------------------------------------------------------------------------
1 | # 第五讲:C++ 11 语法糖杂讲
2 |
3 | ## 5.1 `constexpr` & 常量表达式
4 |
5 | > 我们在之前的编程学习以及在 **const的基本用法** 的介绍中,已经对 C++ 中的**常量表达式**有了初步的认识。在本节的学习中,我们会针对**常量表达式**这一重要概念继续深入,并介绍 C++ 11 新引入的 `constexpr` 机制。
6 |
7 | 那么首先,什么是常量表达式呢?
8 |
9 | > **常量表达式** 是指 **值不会改变** 并且 **在编译过程就能得到计算结果** 的表达式。
10 |
11 |
12 |
13 | 根据上述的定义,显然我们可以知道:
14 |
15 | - 字面值属于常量表达式;
16 | - 用常量表达式初始化的 `const` 对象也是常量表达式;
17 |
18 | - 一个对象是不是常量表达式,由它的**数据类型**和**初始值**共同决定。
19 |
20 |
21 |
22 | 接下来我们为大家准备了一些实例,供大家学习参考。
23 |
24 | ```c++
25 | const int max_files = 20; // max_files是常量表达式
26 | const int limit = max_files + 1; // limit是常量表达式
27 | int staff_size = 27; // staff_size不是常量表达式
28 | const int sz = get_size(); // sz不是常量表达式
29 | ```
30 |
31 | - 尽管`staff_size`的初始值是字面常量,但由于其**数据类型**只是普通的`int`而不是`const int`,所以它并不是常量表达式;
32 | - 尽管`sz`本身是一个常量,但是它的**具体值**需要在**运行时**才能获取到,所以它也不是常量表达式。
33 |
34 |
35 |
36 | 在对常量表达式这一概念有了更为深入的认知之后,我们继续介绍关于 `constexpr` 变量的相关知识。
37 |
38 | > 在一个复杂系统中,很难(几乎肯定不能)分辨一个初始值到底是不是常量表达式。
39 |
40 | 基于上述情形,C++ 11 新标准规定,允许将变量声明为 **constexpr** 类型,以便于编译器验证变量的值是否属于常量表达式。声明为 `constexpr` 的变量一定是一个常量,且必须用常量表达式初始化。
41 |
42 | ```c++
43 | constexpr int mf = 20; // 20是常量表达式
44 | constexpr int limit = mf + 1; // mf + 1是常量表达式
45 | constexpr int sz = size(); // 只有当size()是一个constexpr函数时才是正确语句
46 | ```
47 |
48 |
49 |
50 | 我们已经知道,常量表达式的值需要在**编译**时就进行计算,因此我们必须对声明 `constexpr` 时用到的类型进行限制(因为并不是每一种类型都能在编译时得到结果)。能够被声明的类型一般比较简单,值也显而易见、容易得到,它们被称为“**字面值类型**”。
51 |
52 | > 到目前为止接触过的数据类型中,算术类型、引用和指针都属于字面值类型。
53 | >
54 | > 自定义类、IO 库、string 类型则不属于字面值类型。
55 |
56 |
57 |
58 | 值得一提的是,尽管指针和引用属于字面值类型,它们的初始值却受到**严格限制**。一个 **constexpr** 指针的初始值必须是 **nullptr** 或 **0**,或者是**存储于某个固定地址的对象**。
59 |
60 | > **函数体内**定义的变量一般来说并非存储于固定地址,因此不能声明为 constexpr 指针所指的变量;
61 | >
62 | > 相反地,定义于**所有函数体外**的对象地址固定不变,可以用于初始化 constexpr 指针。
63 |
64 |
65 |
66 | 此外,在 constexpr 声明中如果定义了一个指针,限定符 constexpr **仅对指针有效**,而和指针所指的对象无关。
67 |
68 | ```c++
69 | const int *p = nullptr; // p是一个指向整型常量的指针
70 | constexpr int *q = nullptr; // q是一个指向整数的常量指针
71 | ```
72 |
73 |
74 |
75 | 同样与其他常量指针类似的是,constexpr 指针不一定指向常量。
76 |
77 | ```c++
78 | constexpr int *np = nullptr; // np是一个指向整数的常量指针,值为空
79 | int j = 0;
80 | constexpr i = 42; // i的类型是整形常量
81 | // i和j都必须定义于函数体之外
82 | constexpr const int *p = &i; // p是常量指针,指向整型常量i
83 | constexpr int *p1 = &j; // p1是常量指针,指向整数j
84 | ```
85 |
86 |
87 |
88 | ## 5.2 `auto` 类型指示符
89 |
90 | 编程时,我们需要把表达式的值赋给变量,这就要求在声明变量的时候知道表达式的类型。然而在某些情况下,我们可能很难知道甚至不可能知道某些表达式的类型。C++ 11 引入的 `auto` 类型说明符就可以让**编译器代替我们**分析表达式所属的类型。
91 |
92 | > 和原先那些只对应一种特定类型的说明符(double、float)不同,auto 会让编译器通过**初始值**来判断变量的类型。
93 |
94 | - auto 定义的变量必须有初始值
95 | - 使用 auto 也能在一条语句中声明多个变量
96 | - 因为一条声明语句只能有一个基本数据类型,所以该语句中所有变量的基本数据类型应该相同
97 |
98 |
99 |
100 | > 在实际运用中,编译器推断得到的数据类型可能与初始值**不相同**,编译器会适当**改变结果类型**使之更符合**初始化规则**。
101 |
102 | - 例 1 :
103 |
104 | ```c++
105 | int i = 0, &r = i;
106 | auto a = r;
107 | // a是一个整数(r是i的别名,而i是一个整数)
108 | // 在本例中,编译器遵循“使用引用本质上是使用引用的对象”原则
109 | // 使用引用对变量进行初始化时,初始值应该是被引用的对象的值
110 | // 因而a的类型被推断为整型而不是一个引用
111 | ```
112 |
113 | - 例 2 :
114 |
115 | ```c++
116 | const int ci = i, &cr = ci;
117 | auto b = ci;
118 | // b是一个整数(ci的顶层const特性被忽略)
119 | auto c = cr;
120 | // c是一个整数(cr是ci的别名,ci的顶层const特性被忽略)
121 | auto d = &i;
122 | // d是一个整型指针(整数的地址就是指向整数的指针)
123 | auto e = &ci;
124 | // e是一个指向整型常量的指针(对常量对象取地址是底层const)
125 | const auto f = ci;
126 | // ci的推演类型是int,这种声明方式下f就可以保留const
127 |
128 | // 本例体现的是auto忽略顶层const而保留底层const的特性
129 | ```
130 |
131 | - 例 3 :
132 |
133 | ```c++
134 | auto &g = ci;
135 | // g是一个整型常量引用,绑定到ci
136 | // auto &h = 42;
137 | // 这种写法错误,不能为非常量引用绑定字面值
138 | const auto &j = 42;
139 | // 正确,可以为常量引用绑定字面值
140 |
141 | // 当引用的类型被设置为auto时,原先的初始化规则仍然适用
142 | // 设置一个类型为auto的引用时,初始值中的顶层const属性仍然保留
143 | ```
144 |
145 |
146 |
147 | ## 5.3 范围 `for` 语句
148 |
149 | `for`循环语句作为 C++ 中十分多见的语法运用,想必大家都对此比较熟悉。在 C++ 11 的新标准中,引入了一种更为简单的`for`语句,这种语句可以遍历**容器或其他序列**的所有元素。
150 |
151 | 范围`for`语句的语法形式如下:
152 |
153 | ```c++
154 | for (declaration : expression)
155 | statement
156 | ```
157 |
158 | - expression 表示的必须是一个**序列**;
159 | - declaration 定义一个**变量**,序列中的每一个元素都应该**能被转换成**该变量的类型;
160 | - 确保类型相容最简单的办法是使用`auto`类型说明符
161 | - 每次迭代都会重新定义循环控制变量,并将其**初始化**为序列中的下一个值,之后执行 statement;
162 | - statement 可以是一条单独的语句,也可以是一个块。
163 |
164 |
165 |
166 | 接下来我们会以 C++ 的`vector`为例来展示范围`for`语句的使用方法。
167 |
168 | ```c++
169 | vector v = {0,1,2,3,4,5,6,7,8,9};
170 | // 需要对元素执行写操作时,范围变量需要设置为引用类型
171 | for (auto &r : v)
172 | r *= 2;
173 | ```
174 |
175 |
176 |
177 | ## 5.4 列表初始化
178 |
179 | C++ 语言定义了初始化的很多种形式。例如要想定义一个名为`units_sold`的`int`变量并将其初始化为 0,以下的 4 条语句都可以做到这一点:
180 |
181 | ```c++
182 | int units_sold = 0;
183 | int units_sold = {0};
184 | int units_sold{0};
185 | int units_sold(0);
186 | ```
187 |
188 | > 作为 C++ 11 新标准的一部分,用`{}`来初始化变量得到了全面应用。
189 | >
190 | > 这种初始化的方式被称为列表初始化。
191 |
192 | 当用于内置类型的变量时,这种初始化形式有一个重要特点:如果我们使用列表初始化且初始值存在**丢失信息**的风险,则编译器将报错。
193 |
194 | ```c++
195 | long double ld = 3.1415926536;
196 | int a{ld}, b = {ld};
197 | // 报错:转换未执行,因为存在丢失信息的风险
198 | int c(ld), d = ld;
199 | // 正确转换:自动丢失部分值
200 | ```
201 |
202 | 此外,列表初始化也可用于初始化`vector`对象。此时,用`{}`括起来的 0 个或多个元素将会被赋值给 vector 对象。
203 |
204 | ```c++
205 | vector articles = {"a", "an", "the"};
206 | // 上述vector对象中包含列表内的3个元素
207 | ```
208 |
209 |
210 |
211 | ## 备注
212 |
213 | 本部分教程主要为大家介绍了一部分我们日常编程过程中经常能够用到的 C++ 11 的新标准和新用法,希望能为大家日后的编程学习提供一定的帮助和参考。
214 |
--------------------------------------------------------------------------------
/C++/第五讲/C++_const/README.md:
--------------------------------------------------------------------------------
1 | # 第五讲 const
2 |
3 | ## 简介
4 |
5 | - 内容主题:`C++ const简介`
6 | - 你将学到什么:
7 | - 为什么要使用const?(为什么不用别的?)
8 | - const的基本用法
9 | - const在多文件中的使用
10 |
11 | ---
12 |
13 | ## 文件清单
14 |
15 | - `docs/`
16 | - Sast tutor 2022-const.md【教程】
17 | - `codes/`
18 | - main.cpp 【示例程序】
19 | - constants.h 【示例程序】
20 |
21 | ---
22 |
23 | ## 参考资料
24 |
25 | - 清华大学计算机系姚海龙老师程序设计基础课件
26 | - learncpp [4.15](https://www.learncpp.com/cpp-tutorial/const-constexpr-and-symbolic-constants/), [6.9](https://www.learncpp.com/cpp-tutorial/sharing-global-constants-across-multiple-files-using-inline-variables/), [12.12](https://www.learncpp.com/cpp-tutorial/const-class-objects-and-member-functions/)
27 | - [const (C++) | Microsoft Docs](https://docs.microsoft.com/en-us/cpp/cpp/const-cpp?view=msvc-170)
28 | - [Runtime and Compile-time constants in C++ - GeeksforGeeks](https://www.geeksforgeeks.org/runtime-and-compile-time-constants-in-c/)
--------------------------------------------------------------------------------
/C++/第五讲/C++_const/codes/constants.h:
--------------------------------------------------------------------------------
1 | #ifndef CONSTANTS_H
2 | #define CONSTANTS_H
3 |
4 | namespace constants {
5 | const double pi = 3.1416927;
6 | const double avogadro = 6.022e23;
7 | }
8 |
9 | #endif // !CONSTANTS_H
10 |
--------------------------------------------------------------------------------
/C++/第五讲/C++_const/codes/draft.cpp:
--------------------------------------------------------------------------------
1 | #include"constants.h"
2 |
3 | #include
4 | using namespace std;
5 |
6 | class rectangle { //定义一个矩形类
7 | public:
8 | rectangle(double l, double w) : length(l), width(w) {} //构造函数
9 | double length; //长
10 | double width; //宽
11 | double get_area() /*注意此处的const*/ const { return length * width; } //求矩形的面积
12 | bool operator < (const rectangle& r) { //比较两个矩形面积的大小
13 | return get_area() < r.get_area();
14 | }
15 | };
16 | int main() {
17 | //const变量
18 | const int a = 10; //静态绑定
19 | int b;
20 | cin >> b;
21 | const int c = b; //动态绑定
22 | //a++; //常量不能修改
23 | //c++;
24 | char txt0[10];
25 | char txt1[a];
26 | //char txt2[b];
27 | //char txt3[c]; //运行时绑定的常量不能作为数组大小
28 |
29 |
30 | //const作为函数参数
31 | void func(const int* p);
32 |
33 | //类中的const
34 | const rectangle re(6, 7); //构造一个常对象
35 | re.get_area(); //可以调用常成员函数
36 | //re.length = 2; //不能修改常对象的数据
37 |
38 | rectangle a(2, 5), b(3, 4); //构造两个矩形
39 | if (a < b) cout << "矩形a的面积小于b" << endl;
40 |
41 |
42 | //多文件下的const
43 | cout << "please enter the radius:";
44 | double r;
45 | cin >> r;
46 | cout << "the area of the circle is: " << constants::pi * r * r << endl;
47 |
48 | return 0;
49 | }
50 | void func(const int* p) {
51 | int a = *p;
52 | //*p = a++; //不能修改
53 | }
--------------------------------------------------------------------------------
/C++/第五讲/C++_const/docs/Sast tutor 2022-const.md:
--------------------------------------------------------------------------------
1 | # const
2 |
3 | ### 目录
4 |
5 | 1.为什么要使用const?(为什么不用别的?)
6 |
7 | 2.const的基本用法
8 |
9 | 3.const在多文件中的使用
10 |
11 | ### 1.为什么要使用const?(为什么不用别的?)
12 |
13 | 写代码时,我们需要将**数据(*data*)**存放在**变量(*variables*)**中,通过对变量进行各种运算和操作,实现功能或解决问题。然而,随着变量的不断增多和发量的不断减少,我们有时会发现:所有数据都可以存放在变量中,但单从字面上看,有些数据比其他数据更像**变**量。
14 |
15 | 为什么这么说呢?进行某些数学计算时,我们需要用到圆周率Pi;下五子棋时,我们需要知道棋盘的大小N*N。在一段程序运行的过程中,圆周率Pi或棋盘边长N往往不会发生改变(否则,我们需要操心的恐怕是一些超出这段程序的东西,比如数学大厦是不是摇摇欲坠或者某选手是不是在作弊)。但是,如果我们在声明这些变量时仅仅使用普通的double或int类型,我们便(1)很难保证我们的代码不会在某个地方稀里糊涂地修改了这些变量,尤其是当我们同时使用n,m,i,j,k,l,p,q……以及它们的大写作为变量名的时候。同时,(2)把一堆压根不会改变的数字专门用一堆变量来存放,对总体的程序而言也是不必要的开销。为了解决这些问题,我们需要使用一些新的手段。
16 |
17 | “简单简单!这有什么难的?”小鱼儿看也不看,在程序的开头加了几行代码,它看起来好像是:
18 |
19 | ```c++
20 | #define Pi 3.1415927
21 | #define N 15
22 | #define 秋季学期假期天数 0
23 | //...
24 | ```
25 |
26 | 你也是这么想的吗?的确,我们之前学习过**宏(*macro*)**的概念和用法,也曾经在试卷上见过它,知道它会让预处理器在预处理阶段(也就是编译之前的阶段)将程序中的一些字段替换为另一些字段。但是,且不提宏命令在程序中多么容易导致错误——这个理由或许已经很充分了——还有更多原因让我们在面对那些**较为复杂的问题**时不去使用它。
27 |
28 | 1.因为它发挥作用的途径是替换文本,宏命令中的“变量”不是真正的变量,在debug时很难确定它的值。
29 |
30 | 2.宏可能在代码的其他部分引起冲突,尤其当引入的头文件个数多且宏命名不规范时。
31 |
32 | “够了够了!我直接敲数字,总不会出错了吧?”小鱼儿不服气。
33 |
34 | 对于**简单**的程序,敲数字当然没有问题。但是当程序规模变大,尤其是这些数字需要调整时,这样做就会带来很多困难。设想新人程序员小E在上班第一天就被叫去修改这样的代码:
35 |
36 | ```c++
37 | total_num = 5 * 2; //5是行数,2是列数
38 | set_rows(5);
39 | set_cols(2);
40 | get_content(total_num);
41 | show(screen);
42 | funcxxx(2);
43 | ```
44 |
45 | 小E耐着性子一个个更换这些数字时,突然犯了难:这个奇怪函数funcxxx(2)里的数字要不要改?这个2是啥???此刻,小E只想打电话给那个被优化了的前辈,请他在送外卖之余为自己好好解释一下代码里的这些数各自究竟都是些什么意思。然后,小E要给这些数字**起好名字,写好注释**~~,让自己的后辈以后能更好地接手自己的工作~~。
46 |
47 | “行吧行吧!其实我还可以用枚举类型enum……”小鱼儿好像还有话要说。
48 |
49 | 确实,还有其他方式来表示我们所说的“常量”,但现在是时候展示一个更加常见和广泛的用法了:**const**。
50 |
51 | ### 2.const的基本用法
52 |
53 | #### (1)常变量
54 |
55 | const在代码中的作用类似于形容词或副词在句子中的作用,比方说,int a是整型变量,const int a则是**常**整型变量(它也可以写作int const a,但我们不会这样写),const变量在声明之后不允许被改变,因此,我们必须在**声明的同时定义**它(给它赋值)。如果直接使用数字或表达式定义,在编译阶段就可以确定它的值,称为**静态绑定/编译时绑定**,如果只有运行过程中才能确定,则称为**动态绑定/运行时绑定**,静态绑定和动态绑定相比消耗的资源更少,但没那么灵活。
56 |
57 | ```c++
58 | const int a = 2022;
59 | const int b {2022}; //另一种写法
60 | int c;
61 | cin >> c; //键盘中输入2022,回车
62 | const int d {c}; //不直接用数字定义const变量的方法,称为运行时绑定/动态绑定
63 | ```
64 |
65 | 在C++中,静态绑定的常变量还可以用来确定数组大小:
66 |
67 | ```c++
68 | const int n = 100;
69 | char text[n]; //不会报错!
70 | ```
71 |
72 | #### (2)常·函数参数
73 |
74 | 当函数参数为指针或引用时,我们可以通过用const修饰参数来保护参数(为什么不考虑直接传递参数值的情况?请你思考),这样做可以使得指针或引用所指向的内存在函数体内无法修改,就像这样:
75 |
76 | ```c++
77 | int max(const int* a,const int* b) {
78 | //...
79 | *a = 111; //报错!不允许修改*a的值
80 | }
81 | ```
82 |
83 | 为指针添加const修饰时,const的位置决定了它的含义,理解它的关键在于看const后面紧跟的是什么,如下:
84 |
85 | ```c++
86 | const int* a; //const修饰的是int,所以a指向的内存空间中的数据不允许修改。
87 | int* const b; //const修饰的是a,所以a指向的地址不允许修改。
88 | *a = *b; //报错!
89 | b = a; //报错!
90 | ```
91 |
92 | #### (3)常 in class
93 |
94 | 学习了类的知识后,我们知道const也可以用来修饰对象,得到**常对象**。与前面类似,常对象自身的内容不能改变。请你阅读以下代码:
95 |
96 | ```c++
97 | #include
98 | using namespace std;
99 | class rectangle { //定义一个矩形类
100 | public:
101 | rectangle(double l, double w) : length(l), width(w) {} //构造函数
102 | double length; //长
103 | double width; //宽
104 |
105 | double get_area() { return length * width; } //求矩形的面积
106 | bool operator < (const rectangle& r) { //比较两个矩形面积的大小
107 | return get_area() < r.get_area();
108 | }
109 | };
110 | int main() {
111 | rectangle a(2, 5), b(3, 4); //构造两个矩形
112 | if (a < b) cout << "矩形a的面积小于b" << endl;
113 | return 0;
114 | }
115 | ```
116 |
117 | 在这段代码中,我们构造了rectangle类,并重载了它的小于号运算符<。其中虽然没有出现常对象,但出现了**对象的常引用**,在向函数传递参数时使用常引用,在函数体内这个引用就被理解为常对象,其内部数据就不会被更改。但是,如果我们把这段代码复制进编译器中,编译器会报错。**仔细看看,你能发现问题在哪吗?**
118 |
119 | 问题在于:在重载小于号时,我们调用了常引用r的get_area()函数。由于成员函数有可能修改对象内的数据,C++不允许常对象调用普通的成员函数,为此,我们需要使用的是**常成员函数**。因为get_area()函数确实没有修改成员,在本例中我们只需作如下修改就可消除bug:
120 |
121 | ```c++
122 | double get_area() { return length * width; } //普通成员函数,需要被替换
123 | double get_area() const { return length * width; } //常成员函数,可以被常对象调用,注意const的位置
124 | ```
125 |
126 | 常成员函数不能修改对象内的任何数据,不仅可以被常对象调用,也可以被普通对象调用,是不是很方便呢?有人说,代码出bug时不妨往里面加几个const,这话的确有几分道理呢。
127 |
128 | ### 3.const在多文件中的使用
129 |
130 | 当我们面临较大项目的编程时,可能会遇到这样的情况:有些常数在各个地方都要用,但是如果在每个文件里都定义一遍就太浪费了,要是它们定义时的精度不一样,还可能造成更大的问题。对此,**方法一**是利用我们在**上一讲**学过的有关**命名空间(*namespace*)**的知识,把所有常数放在同一个头文件**constants.h**里,如下(constexpr的用法我们会在稍后接触,现在只需把它理解为const):
131 |
132 | ```c++
133 | #ifndef CONSTANTS_H
134 | #define CONSTANTS_H
135 | namespace constants
136 | {
137 | constexpr double pi { 3.1415927 };
138 | constexpr double avogadro { 6.0221413e23 };
139 | // ... 其他常数
140 | }
141 | #endif
142 | ```
143 |
144 | 之后,在其他文件中,可以通过“命名空间”+“::”使用这些常数,比如在main.cpp中:
145 |
146 | ```c++
147 | #include "constants.h" // 把含常数的头文件加入这个文件
148 | #include
149 | int main()
150 | {
151 | std::cout << "Enter a radius: ";
152 | int radius{};
153 | std::cin >> radius;
154 | std::cout << "The circumference is: " << 2.0 * radius * constants::pi << '\n';
155 | return 0;
156 | }
157 | ```
158 |
159 | 如果这样做,一个好处是编译器在编译时往往会直接对这些常量进行优化(用数字直接代替它)。但是,因为使用#include会导致每个文件中都有一个constants.h(使用#ifndef等命令只能保证它在每个文件**内部**只出现一次),这种方法仍然有其不足:
160 |
161 | 1.修改一个常量值(比如调整某个参数)会要求重新编译每个包含constants.h的文件,如果项目很大,这将需要很长的时间。
162 |
163 | 2.如果常量的个数太多使得编译器无法把它们优化掉,这些“变量”会消耗许多内存。
164 |
165 | 为了避免这些问题,我们可以采取**方法二**,同样利用**上一讲**中的知识,把这些常量变成**外部变量(*external variables*)**。在方法二中,我们在**constants.cpp**而不是constants.h中实例化(赋值):
166 |
167 | ```c++
168 | #include "constants.h"
169 | namespace constants
170 | {
171 | extern const double pi { 3.1415927 };
172 | extern const double avogadro { 6.0221413e23 };
173 | // ... 其他常数
174 | }
175 | ```
176 |
177 | 而在**constants.h**中,我们只是简单地声明了这些常量(这种声明被称为**前向声明(*forward declaraion*)**):
178 |
179 | ```c++
180 | #ifndef CONSTANTS_H
181 | #define CONSTANTS_H
182 | namespace constants
183 | {
184 | extern const double pi;
185 | extern const double avogadro;
186 | // ... 其他常数(只有声明)
187 | }
188 | #endif
189 | ```
190 |
191 | (注意,这里使用的是const而不是constexpr,在学习相关知识后,你能说出为什么这里不能使用constexpr吗?)
192 |
193 | 而其他文件中的代码保持不变:
194 |
195 | ```c++
196 | #include "constants.h" // 把含常数的头文件加入这个文件
197 | #include
198 | int main()
199 | {
200 | std::cout << "Enter a radius: ";
201 | int radius{};
202 | std::cin >> radius;
203 | std::cout << "The circumference is: " << 2.0 * radius * constants::pi << '\n';
204 | return 0;
205 | }
206 | ```
207 |
208 | 在这种方法下,每个包含constants.h的文件内实际上并不包含常量们实际的取值。因此,修改常量值时只需要重新编译constants.cpp一个文件。但是,这种做法同样有缺陷:因为除了constants.cpp之外的文件在编译时只能看到constants.h中的前向声明,所以这些常量都被视为**动态绑定/运行时绑定**,无法实现静态绑定的常量的功能,编译和运行时也可能会消耗更多资源。两个方法各有长短,总而言之,这是一个权衡利弊的问题。
209 |
210 |
--------------------------------------------------------------------------------
/C++/第八讲/工厂模式/README.md:
--------------------------------------------------------------------------------
1 | ## 简介:工厂模式(factory pattern)
2 |
3 | 1、简单工厂模式(simple factory pattern)
4 |
5 | 2、工厂方法模式(factory method pattern)
6 |
7 | 3、抽象工厂模式(abstract factory pattern)
8 |
9 | ----
10 |
11 | ## 参考资料:
12 |
13 | [DesignPattern/01.SimpleFactory.md at master · FengJungle/DesignPattern · GitHub](https://github.com/FengJungle/DesignPattern/blob/master/01.SimpleFactory/01.SimpleFactory.md)
14 |
15 | [Factory Patterns - Simple Factory Pattern - CodeProject](https://www.codeproject.com/Articles/1131770/Factory-Patterns-Simple-Factory-Pattern)
16 |
17 |
--------------------------------------------------------------------------------
/C++/第八讲/工厂模式/codes/工厂方法模式.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | using namespace std;
3 |
4 | class AbstractEmployee
5 | {
6 | public:
7 | AbstractEmployee() {
8 |
9 | }
10 | virtual ~AbstractEmployee() {};
11 | virtual void nice_work() = 0;
12 | virtual void bad_work() = 0;
13 | };
14 |
15 | class Teacher :public AbstractEmployee
16 | {
17 | public:
18 | Teacher() {
19 |
20 | }
21 | ~Teacher() {};
22 | void nice_work()
23 | {
24 | cout << "The teacher works well." << endl;
25 | }
26 | void bad_work()
27 | {
28 | cout << "The teacher works badly." << endl;
29 | }
30 | };
31 |
32 | class Professor :public AbstractEmployee
33 | {
34 | public:
35 | Professor() {
36 |
37 | }
38 | ~Professor() {};
39 | void nice_work()
40 | {
41 | cout << "The professor works well." << endl;
42 | }
43 | void bad_work()
44 | {
45 | cout << "The professor works badly." << endl;
46 | }
47 | };
48 |
49 | class AbstractFactory
50 | {
51 | public:
52 | virtual shared_ptr getEmployeeEvaluation(string evaluation) = 0;
53 | virtual ~AbstractFactory() {}
54 | };
55 |
56 | class TeacherEnvaluationFactory: public AbstractFactory
57 | {
58 | public:
59 | shared_ptr getEmployeeEvaluation(string evaluation)
60 | {
61 | shared_ptr emp;
62 | emp = shared_ptr(new Teacher());
63 | if (evaluation == "Good")
64 | emp->nice_work();
65 | else if (evaluation == "Bad")
66 | emp->bad_work();
67 | return emp;
68 | }
69 | };
70 |
71 | class ProfessorEnvaluationFactory : public AbstractFactory
72 | {
73 | public:
74 | shared_ptr getEmployeeEvaluation(string evaluation)
75 | {
76 | shared_ptr emp;
77 | emp = shared_ptr(new Professor());
78 | if (evaluation == "Good")
79 | emp->nice_work();
80 | else if (evaluation == "Bad")
81 | emp->bad_work();
82 | return emp;
83 | }
84 | };
85 |
86 | int main()
87 | {
88 | shared_ptr efac = make_shared();
89 | shared_ptr emp = efac->getEmployeeEvaluation("Good");
90 | efac = make_shared();
91 | emp = efac->getEmployeeEvaluation("Good");
92 | }
93 |
--------------------------------------------------------------------------------
/C++/第八讲/工厂模式/codes/简单工厂模式.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | using namespace std;
3 |
4 | class AbstractEmployee
5 | {
6 | public:
7 | AbstractEmployee() {
8 |
9 | }
10 | virtual ~AbstractEmployee() {};
11 | virtual void nice_work() = 0;
12 | virtual void bad_work() = 0;
13 | };
14 |
15 | class Teacher :public AbstractEmployee
16 | {
17 | public:
18 | Teacher() {
19 |
20 | }
21 | ~Teacher() {};
22 | void nice_work()
23 | {
24 | cout << "The teacher works well." << endl;
25 | }
26 | void bad_work()
27 | {
28 | cout << "The teacher works badly." << endl;
29 | }
30 | };
31 |
32 | class Professor :public AbstractEmployee
33 | {
34 | public:
35 | Professor() {
36 |
37 | }
38 | ~Professor() {};
39 | void nice_work()
40 | {
41 | cout << "The professor works well." << endl;
42 | }
43 | void bad_work()
44 | {
45 | cout << "The professor works badly." << endl;
46 | }
47 | };
48 |
49 | class EnvaluationFactory
50 | {
51 | public:
52 | std::shared_ptr getEmployeeEvaluation(string employeename,string evaluation)
53 | {
54 | std::shared_ptr emp;
55 | if (employeename == "Teacher") {
56 | emp = std::shared_ptr(new Teacher());
57 | }
58 | else if (employeename == "Professor") {
59 | emp = std::shared_ptr(new Professor());
60 | }
61 | if (evaluation == "Good")
62 | emp->nice_work();
63 | else if (evaluation == "Bad")
64 | emp->bad_work();
65 | return emp;
66 | }
67 | };
68 |
69 | int main()
70 | {
71 | shared_ptr efac = std::make_shared();
72 | shared_ptr emp = efac->getEmployeeEvaluation("Teacher","Good");
73 | emp = efac->getEmployeeEvaluation("Professor", "Bad");
74 | }
75 |
--------------------------------------------------------------------------------
/C++/第八讲/工厂模式/docs/工厂模式.md:
--------------------------------------------------------------------------------
1 | ## 二、工厂模式(factory pattern)
2 |
3 | 1、简单工厂模式(simple factory pattern)
4 |
5 | 2、工厂方法模式(factory method pattern)
6 |
7 | 3、抽象工厂模式(abstract factory pattern)
8 |
9 |
10 |
11 | ----
12 |
13 | ### 1、简单工厂模式
14 |
15 | 简单工厂模式是最基础的设计模式之一,应用也十分频繁。
16 |
17 | 该模式具体框架如下:定义一个简单工厂类,它可以根据参数的不同返回不同类的实例对象,被创建的实例通常都具有共同的父类。
18 |
19 | 在简单工厂模式中,大体上有3个角色:**工厂类、抽象产品类、具体产品类**。即,工厂类可以看作一个总处理器,负责接受用户的参数,然后“制造不同的产品”,即创建各具体产品类的对象、调用函数等。各个具体产品类则是由一个抽象产品类派生出来的,这体现了OOP的“针对接口编程”等原则。
20 |
21 | 下面,我们可以通过一个例子来了解一下:就以“公司职员评价系统”为例。用户希望设计一款对不同职员的评价系统,为简单起见,设有Teacher、Professor两种职员,对职员的评价有好评与差评两种。那么,若以简单工厂模式设计代码,框架大致如下:
22 |
23 | 首先设计一个抽象职员类AbstractEmployee、由此派生出Teacher、Professor两个职员类,这两个类中有评价相关函数;
24 |
25 | 随后设计一个工厂类EnvaluationFactory,负责接收用户输入的数据,进而生成Teacher或Professor类对象以进行评价。
26 |
27 | ```c++
28 | #include
29 | using namespace std;
30 |
31 | class AbstractEmployee
32 | {
33 | public:
34 | AbstractEmployee() {
35 |
36 | }
37 | virtual ~AbstractEmployee() {};
38 | virtual void nice_work() = 0;
39 | virtual void bad_work() = 0;
40 | };
41 |
42 | class Teacher :public AbstractEmployee
43 | {
44 | public:
45 | Teacher() {
46 |
47 | }
48 | ~Teacher() {};
49 | void nice_work()
50 | {
51 | cout << "The teacher works well." << endl;
52 | }
53 | void bad_work()
54 | {
55 | cout << "The teacher works badly." << endl;
56 | }
57 | };
58 |
59 | class Professor :public AbstractEmployee
60 | {
61 | public:
62 | Professor() {
63 |
64 | }
65 | ~Professor() {};
66 | void nice_work()
67 | {
68 | cout << "The professor works well." << endl;
69 | }
70 | void bad_work()
71 | {
72 | cout << "The professor works badly." << endl;
73 | }
74 | };
75 |
76 | class EnvaluationFactory
77 | {
78 | public:
79 | std::shared_ptr getEmployeeEvaluation(string employeename,string evaluation)
80 | {//shared_ptr为智能指针
81 | std::shared_ptr emp;
82 | if (employeename == "Teacher") {
83 | emp = std::shared_ptr(new Teacher());
84 | }
85 | else if (employeename == "Professor") {
86 | emp = std::shared_ptr(new Professor());
87 | }
88 | if (evaluation == "Good")
89 | emp->nice_work();
90 | else if (evaluation == "Bad")
91 | emp->bad_work();
92 | return emp;
93 | }
94 | };
95 |
96 | int main()
97 | {
98 | shared_ptr efac = std::make_shared();
99 | shared_ptr emp = efac->getEmployeeEvaluation("Teacher","Good");
100 | emp = efac->getEmployeeEvaluation("Professor", "Bad");
101 | }
102 |
103 | /*运行结果如下:
104 | The teacher works well.
105 | The professor works badly.
106 | */
107 |
108 |
109 | ```
110 |
111 | 简单工厂模式的优点如下:
112 |
113 | 工厂类提供创建具体产品的方法,并包含一定判断逻辑,客户不必参与产品的创建过程,只需要知道对应产品的简单参数即可。
114 |
115 | 但简单工厂模式也存在明显的不足:
116 |
117 | 如前文例子,若还想再添加一类职员,我们必须再从抽象产品类派生出一个职员类,同时在工厂类的方法中增加条件分支。但是,在工厂类中的改动将违背OOP三大原则中的开闭原则(对扩展开放,对修改关闭),即在扩展功能时修改了既有的代码。另一方面,简单工厂模式所有的判断逻辑都在工厂类中实现,一旦工厂类设计故障,则整个系统都受之影响。
118 |
119 | 为此,简单工厂模式被进行了改进,形成了“工厂方法模式”。
120 |
121 | ----
122 |
123 | ### 2、工厂方法模式
124 |
125 | 简单工厂模式中,每新增一个具体产品,就需要修改工厂类内部的判断逻辑。为了不修改工厂类,遵循开闭原则,工厂方法模式中不再使用**一个**工厂类统一创建所有的具体产品,而是针对不同的产品设计了**不同**的工厂,每一个工厂只生产特定的产品。
126 |
127 | 在工厂方法模式中,大体上有4个角色:**抽象工厂类、具体工厂类、抽象产品类、具体产品类**。即,在简单工厂模式的基础上,把一个工厂变成了从一个抽象类派生出的多个工厂,各司其职,负责相应的产品“生产”。
128 |
129 | 回到上文中的职员评价系统例子,我们可以在前文的代码基础上稍加改动,部分代码如下:
130 |
131 | (只显示了改动后的部分,完整代码可以在附件中查阅)
132 |
133 | ```c++
134 | class AbstractFactory
135 | {
136 | public:
137 | virtual shared_ptr getEmployeeEvaluation(string evaluation) = 0;
138 | virtual ~AbstractFactory() {}
139 | };
140 |
141 | class TeacherEnvaluationFactory: public AbstractFactory
142 | {
143 | public:
144 | shared_ptr getEmployeeEvaluation(string evaluation)
145 | {
146 | shared_ptr emp;
147 | emp = shared_ptr(new Teacher());
148 | if (evaluation == "Good")
149 | emp->nice_work();
150 | else if (evaluation == "Bad")
151 | emp->bad_work();
152 | return emp;
153 | }
154 | };
155 |
156 | class ProfessorEnvaluationFactory : public AbstractFactory
157 | {
158 | public:
159 | shared_ptr getEmployeeEvaluation(string evaluation)
160 | {
161 | shared_ptr emp;
162 | emp = shared_ptr(new Professor());
163 | if (evaluation == "Good")
164 | emp->nice_work();
165 | else if (evaluation == "Bad")
166 | emp->bad_work();
167 | return emp;
168 | }
169 | };
170 |
171 | int main()
172 | {
173 | shared_ptr efac = make_shared();
174 | shared_ptr emp = efac->getEmployeeEvaluation("Good");
175 | efac = make_shared();
176 | emp = efac->getEmployeeEvaluation("Good");
177 | }
178 |
179 | /*运行结果如下:
180 | The teacher works well.
181 | The professor works well.
182 | */
183 |
184 | ```
185 |
186 | 如果用户希望增加一类职员,只需要增加一个相应的工厂类而不用改动原有代码。由此可以看到,相较简单工厂模式,工厂方法模式更加符合开闭原则。工厂方法模式是使用频率最高的设计模式之一,也是很多开源框架和API类库的核心模式。
187 |
188 | 但这种模式也有着相应的不足:添加新产品时需要同时添加新的产品工厂,系统中类的数量成对增加,增加了系统的复杂度,更多的类需要编译和运行,增加了系统的额外开销;工厂和产品都引入了抽象层,增加了系统的抽象层次和理解难度。
189 |
190 | ----
191 |
192 | ### 3、抽象工厂模式
193 |
194 | 抽象工厂模式可以看作对工厂方法模式进一步的拓展,即**一个工厂不只是生产一种产品,而是生产一类产品**。其原理与前文基本相同,只是增加了抽象产品类的个数(即增加了产品种类数)等,感兴趣的同学们可以尝试探究。
195 |
196 | ----
197 |
198 | ## 参考资料:
199 |
200 | [DesignPattern/01.SimpleFactory.md at master · FengJungle/DesignPattern · GitHub](https://github.com/FengJungle/DesignPattern/blob/master/01.SimpleFactory/01.SimpleFactory.md)
201 |
202 | [Factory Patterns - Simple Factory Pattern - CodeProject](https://www.codeproject.com/Articles/1131770/Factory-Patterns-Simple-Factory-Pattern)
203 |
204 |
--------------------------------------------------------------------------------
/C++/第八讲/设计模式原则简介/README.md:
--------------------------------------------------------------------------------
1 | # 第二讲 设计模式简介
2 |
3 | ## 内容介绍
4 |
5 | 1. **设计模式为什么是必要的?**
6 |
7 | 2. **OOP编程中的三大基本原则**
8 |
9 | 1. 针对接口编程,而非针对实现编程
10 |
11 | 2. 开闭原则
12 |
13 | 3. 单一职责原则
14 |
15 | 3. **扩展知识:里氏替换原则 & 迪米特法则**
16 |
17 |
18 |
19 | ## 文件清单
20 |
21 | docs:内含第二讲教程的核心文字内容和重点代码块;
22 |
23 | codes:内含关于开闭原则和单一职责原则的示例程序源代码;
24 |
25 |
26 |
27 | ## 参考文献
28 |
29 | 1. 清华大学计算机科学与技术系姚海龙老师《面向对象的程序设计》课程文件Lec10&11;
30 | 2. CSDN博文:开闭原则 https://blog.csdn.net/niu2212035673/article/details/77803672?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164475222816780366530694%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164475222816780366530694&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-5-77803672.first_rank_v2_pc_rank_v29&utm_term=开闭原则+代码+C%2B%2B&spm=1018.2226.3001.4187
31 | 3. CSDN博文:单一职责原则(C++) https://blog.csdn.net/niu2212035673/article/details/77752316?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164475951016780255268472%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164475951016780255268472&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-77752316.first_rank_v2_pc_rank_v29&utm_term=单一职责原则+C%2B%2B&spm=1018.2226.3001.4187110521613.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187
32 | 4. 知乎专栏文章:里氏替换原则 https://zhuanlan.zhihu.com/p/280765580
33 | 5. CSDN博文:C++设计原则——迪米特法则 https://blog.csdn.net/qq_42956179/article/details/115372247
--------------------------------------------------------------------------------
/C++/第八讲/设计模式原则简介/codes/OCP_1.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 |
4 | //计算器类
5 | class Calculator
6 | {
7 | public:
8 | Calculator()
9 | {
10 |
11 | }
12 | ~Calculator() {};
13 |
14 | double getompute(char c)
15 | {
16 | switch (c)
17 | {
18 | case '+':
19 | return mA + mB;
20 | break;
21 | case '-':
22 | return mA - mB;
23 | break;
24 | default:
25 | break;
26 | }
27 | }
28 | public:
29 | double mA;
30 | double mB;
31 | };
32 |
33 | //客户端
34 | int main(void)
35 | {
36 | Calculator calculator;
37 |
38 | while (true)
39 | {
40 | std::cout << "请输入数字:";
41 | std::cin >> calculator.mA;
42 | std::cout << "请输入数字:";
43 | std::cin >> calculator.mB;
44 | std::cout << "进行计算:";
45 | char c = '0';
46 | std::cin >> c;
47 |
48 | std::cout << "计算结果:" << calculator.getompute(c) << std::endl;
49 | }
50 |
51 | return 0;
52 | }
--------------------------------------------------------------------------------
/C++/第八讲/设计模式原则简介/codes/OCP_2.cpp:
--------------------------------------------------------------------------------
1 | //计算器类
2 | class Calculator
3 | {
4 | public:
5 | Calculator()
6 | {
7 |
8 | }
9 | ~Calculator() {};
10 |
11 | double getompute(char c)
12 | {
13 | switch (c)
14 | {
15 | case '+':
16 | return mA + mB;
17 | break;
18 | case '-':
19 | return mA - mB;
20 | break;
21 | case '*':
22 | return mA * mB;
23 | break;
24 | case '/':
25 | return mA / mB;
26 | break;
27 | default:
28 | break;
29 | }
30 | }
31 | public:
32 | double mA;
33 | double mB;
34 | };
--------------------------------------------------------------------------------
/C++/第八讲/设计模式原则简介/codes/OCP_3.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 |
4 | //计算器类
5 | class Calculator
6 | {
7 | public:
8 | Calculator()
9 | {
10 |
11 | }
12 | ~Calculator() {};
13 |
14 | //抽象接口类,子类实现
15 | virtual double getompute()
16 | {
17 | return 0;
18 | }
19 | public:
20 | double mA;
21 | double mB;
22 | };
23 |
24 | //除
25 | class Division : public Calculator
26 | {
27 | public:
28 | virtual double getompute()
29 | {
30 | return mA / mB;
31 | }
32 | };
33 | //乘
34 | class Multiplication : public Calculator
35 | {
36 | public:
37 | virtual double getompute()
38 | {
39 | return mA * mB;
40 | }
41 | };
42 | //减
43 | class Subtraction : public Calculator
44 | {
45 | public:
46 | virtual double getompute()
47 | {
48 | return mA - mB;
49 | }
50 | };
51 | //加
52 | class Addition : public Calculator
53 | {
54 | public:
55 | virtual double getompute()
56 | {
57 | return mA + mB;
58 | }
59 | };
60 |
61 | //工厂,根据不同的计算方式生产类
62 | Calculator* CreateCalculator(char c)
63 | {
64 | switch (c)
65 | {
66 | case '+':
67 | return new Addition;
68 | break;
69 | case '-':
70 | return new Subtraction;
71 | break;
72 | case '*':
73 | return new Multiplication;
74 | break;
75 | case '/':
76 | return new Division;
77 | break;
78 |
79 | default:
80 | return NULL;
81 | break;
82 | }
83 | }
84 |
85 | //客户端
86 | int main(void)
87 | {
88 | Calculator *calculator = NULL;
89 |
90 | calculator = CreateCalculator('-');
91 |
92 | calculator->mA = 10;
93 | calculator->mB = 5;
94 | std::cout << "计算结果:" << calculator->getompute() << std::endl;
95 |
96 | while (true) {};
97 | return 0;
98 | }
99 |
100 |
--------------------------------------------------------------------------------
/C++/第八讲/设计模式原则简介/codes/SRP.cpp:
--------------------------------------------------------------------------------
1 | //方块形状类
2 | class Shape
3 | {
4 | public:
5 | Shape();
6 | ~Shape();
7 |
8 | virtual void setShape();
9 | private:
10 | };
11 |
12 | //"一"形
13 | class Shape1 : public Shape
14 | {
15 | public:
16 | Shape1();
17 | ~Shape1();
18 |
19 | virtual void setShape();
20 | private:
21 | };
22 |
23 | //"十"形
24 | class Shape2 : public Shape
25 | {
26 | public:
27 | Shape2();
28 | ~Shape2();
29 |
30 | virtual void setShape();
31 | private:
32 | };
33 |
34 | //"L"形
35 | class Shape3 : public Shape
36 | {
37 | public:
38 | Shape3();
39 | ~Shape3();
40 |
41 | virtual void setShape();
42 | private:
43 | };
44 |
45 | //"其他"形
46 | class Shape4: public Shape
47 | {
48 | public:
49 | Shape4();
50 | ~Shape4();
51 |
52 | virtual void setShape();
53 | private:
54 | };
55 |
56 | //方块位置类
57 | class Place
58 | {
59 | public:
60 | Place();
61 | ~Place();
62 |
63 | void setPlace();
64 | private:
65 | };
66 |
67 | //游戏界面类
68 | class GameUI
69 | {
70 | public:
71 | GameUI();
72 | ~GameUI();
73 |
74 | void showViewCcon(); //游戏方块显示
75 | private:
76 | Shape *mShape; //形状
77 | Place *mPlace; //位置
78 | int mStartButton; //开始按钮
79 | int mEndButton; //结束按钮
80 | };
81 |
82 |
--------------------------------------------------------------------------------
/C++/第八讲/设计模式原则简介/docs/design pattern.md:
--------------------------------------------------------------------------------
1 | # 第二讲:设计模式简介
2 |
3 | ## 设计模式为什么是必要的?
4 |
5 | 在面向对象的程序设计中,一段好的程序必须具有以下三个特点:可读性、高效性和可扩展性。其中,我们在前面所介绍关于代码风格的教程中,解决的就是有关可读性的相关问题;而在这一讲中,我们所介绍的设计模式则可以帮助提高程序的可扩展性。这在编写大型程序或多人协作编程中是至关重要的,有助于提高代码编写的效率。
6 |
7 |
8 |
9 | ## OOP编程中的三大基本原则
10 |
11 | ### 原则一:针对接口编程,而非针对实现编程
12 |
13 | 要想弄明白这一原则的内容,我们首先要明白什么是接口类和实现类。
14 |
15 | 接口这一概念是由Java继承而来,可以与C++中的抽象类类比。而接口类则是指一个抽象类仅通过纯虚函数向外提供接口的类,通过重载这些虚函数,我们就可以得到实现具体功能的实现类。这一原则中,强调的就是在OOP编程中,我们应当尽量使用接口类而非实现类,这样可以保证未来程序的可扩展性。
16 |
17 | 两种编程方式的区别可以用以下的示例程序清楚地展现:
18 |
19 | ```C++
20 | // 针对实现编程
21 | Dog d = new Dog();
22 | d.bark();
23 |
24 | //针对接口编程
25 | Animal animal = new Dog();
26 | animal.makesound();
27 | ```
28 |
29 | 我们想实现创建狗的对象并实现狗吠的功能。当采用针对实现的编程原则时,我们必须新建一个具体的Dog类,然后调用bark方法;然而,如果采用针对接口的编程原则,我们就可以利用Dog类的构造函数生成一个Animal对象。由于多态性的保证,当Animal对象调用makesound方法时会自动调用Dog类的方法,从而实现了对bark()函数的调用。
30 |
31 | 两种方法殊途同归,然而其效用却并不相同。采用前者,虽然代码含义清晰明确,但对于每类动物,即使他们相互之间有很多共同的元素,也必须在他们相应的类中分别加以实现,完全不能代码复用,更重要的是不能反应出这些Animal的共同特征。而采用后者,我们就可以更好地实现代码的重用,并且有助于隔离变化,程序的扩展性和灵活性都要略胜一筹;
32 |
33 |
34 |
35 | ### 原则二:开闭原则
36 |
37 | 这一原则理解起来就较为简单了。所谓开闭原则,指的是代码编写过程中,应当对扩展开放,对修改封闭。这样一来,当需求改变时,我们可以进行代码复用,而不用对原始代码进行改动。
38 |
39 | 使用这一编程原则可以至少在两个层面上提升代码质量。首先,通过扩展已有代码,可以提供新的行为和功能,以满足对软件的新需求,使得变化中的程序有一定的适应性和灵活性。此外,开闭原则保证了已有的软件模块,特别是最重要的抽象模块不再修改;这就使变化中的软件系统有一定的稳定性和延续性。
40 |
41 | 为了更好地理解这一原则,我们可以用下面的程序作为例子(可参见OCP.cpp源代码)。假设我们想在Calculator类中完成加减法的运算,我们可能会这么写:
42 |
43 | ```c++
44 | class Calculator
45 | {
46 | public:
47 | Calculator()
48 | {
49 |
50 | }
51 | ~Calculator() {};
52 |
53 | double getompute(char c)
54 | {
55 | switch (c)
56 | {
57 | case '+':
58 | return mA + mB;
59 | break;
60 | case '-':
61 | return mA - mB;
62 | break;
63 | default:
64 | break;
65 | }
66 | }
67 | public:
68 | double mA;
69 | double mB;
70 | };
71 | ```
72 |
73 | 然而,现在客户提出了新的需求,计算器需要完成乘除法等新的运算,那么一个尚未经过专业OOP培训的程序员可能会对getompute() 函数进行如下的改动:
74 |
75 | ```cpp
76 | double getompute(char c)
77 | {
78 | switch (c)
79 | {
80 | case '+':
81 | return mA + mB;
82 | break;
83 | case '-':
84 | return mA - mB;
85 | break;
86 | case '*':
87 | return mA * mB;
88 | break;
89 | case '/':
90 | return mA / mB;
91 | break;
92 | default:
93 | break;
94 | }
95 | }
96 | ```
97 |
98 | 这样一来,虽然功能得到了满足,但是由于修改了类的核心代码,违背了开放封闭原则:代码没有对修改封闭。这样一来,当后期要求的功能越来越多时,程序员都需要对类的getompute() 函数进行直接修改,这极大地增加了代码出错的概率。一个符合开放封闭原则的写法则是在Calculator类中定义抽象接口类,并通过子类继承的方式增加新的功能。
99 |
100 | ```C p
101 | class Calculator
102 | {
103 | public:
104 | Calculator()
105 | {
106 |
107 | }
108 | ~Calculator() {};
109 |
110 | //抽象接口类,子类实现
111 | virtual double getompute()
112 | {
113 | return 0;
114 | }
115 | public:
116 | double mA;
117 | double mB;
118 | };
119 |
120 | //除
121 | class Division : public Calculator
122 | {
123 | public:
124 | virtual double getompute()
125 | {
126 | return mA / mB;
127 | }
128 | };
129 | //乘
130 | class Multiplication : public Calculator
131 | {
132 | public:
133 | virtual double getompute()
134 | {
135 | return mA * mB;
136 | }
137 | };
138 | ```
139 |
140 | 在这种编程规范下,功能的修改既不需要修改Calculator类的任何代码,实现新功能时又仅需要进行新的类的独立编写并继承在Calculator类下,这将极大方便了程序应对需求变化的情形,也将为多人合作下的代码编写提供了更多的方便。
141 |
142 |
143 |
144 | ### 原则三:单一职责原则
145 |
146 | 为了更好地理解什么是单一职责原则,我们首先来考虑下面这个例子:假设在工厂中,一款产品从无到有需要经过10台机器。作为工厂的管理者,我们是雇佣10名员工,让每个人拿着原材料从第一台操作到第十台比较快;还是让每个机器有一个单独的人专门负责会比较快?我想,答案是显而易见的。
147 |
148 | 工厂通过流水线式的分工,让每个人仅负责一道工序,效率有了大幅度的提高。当我们类比面向对象设计时,这种原则则被叫做单一职责原则。顾名思义,所谓单一职责原则就是一个类应该只有一个引起其变化的原因。这是一个最简单,最容易理解,但是却最不容易做到的一个设计原则。说的简单一点,就是怎样设计类以及类的方法界定的问题。
149 |
150 | 例如,我们考虑一个公司的人事管理系统。如果我们将工程师、销售人员、销售经理等等都放在职员类里考虑,其结果将会非常混乱。在这个假设下,职员类里的每个方法(例如:发工资、招投标等)都需要用if else 判断是哪种职员类型,不论从类结构或是代码实现层面上来说都会十分臃肿。更严重的是,任何职员类型,不论哪一种发生需求变化,都会改变职员类,这是我们不愿意看到的。
151 |
152 | 此外,我们还可以通过一个具体的代码示例来理解。假设我们要完成俄罗斯方块游戏的编写,里面会涉及到各种各样方块的位置和形状。如果我们不采用单一职责原则而将所有的功能都集成在一个类中,那么这个类就会因为耦合度太高而造成可维护性降低。相反,如果我们对不同类型的方块分开编写,降低了类与类之间的耦合性,那么在编程层面就可以提升效率,具体情形可以参考如下代码:
153 |
154 | ```cpp
155 | //方块形状类
156 | class Shape
157 | {
158 | public:
159 | Shape();
160 | ~Shape();
161 |
162 | virtual void setShape();
163 | private:
164 | };
165 |
166 | //"一"形
167 | class Shape1 : public Shape
168 | {
169 | public:
170 | Shape1();
171 | ~Shape1();
172 |
173 | virtual void setShape();
174 | private:
175 | };
176 |
177 | //"十"形
178 | class Shape2 : public Shape
179 | {
180 | public:
181 | Shape2();
182 | ~Shape2();
183 |
184 | virtual void setShape();
185 | private:
186 | };
187 |
188 | //"L"形
189 | class Shape3 : public Shape
190 | {
191 | public:
192 | Shape3();
193 | ~Shape3();
194 |
195 | virtual void setShape();
196 | private:
197 | };
198 |
199 | //"其他"形
200 | class Shape4: public Shape
201 | {
202 | public:
203 | Shape4();
204 | ~Shape4();
205 |
206 | virtual void setShape();
207 | private:
208 | };
209 |
210 | //方块位置类
211 | class Place
212 | {
213 | public:
214 | Place();
215 | ~Place();
216 |
217 | void setPlace();
218 | private:
219 | };
220 |
221 | //游戏界面类
222 | class GameUI
223 | {
224 | public:
225 | GameUI();
226 | ~GameUI();
227 |
228 | void showViewCcon(); //游戏方块显示
229 | private:
230 | Shape *mShape; //形状
231 | Place *mPlace; //位置
232 | int mStartButton; //开始按钮
233 | int mEndButton; //结束按钮
234 | };
235 |
236 |
237 | ```
238 |
239 | 因此,我们可以总结出,所谓的“单一职责原则”有两层含义:单一职责有两个含义:**一个是避免相同的职责分散到不同的类中,另一个是避免一个类承担太多的职责。**遵循这样的规则进行类和类的方法界定,将会使得类的结构更为清晰,便于在需求改变时对类进行合理的修改和扩展。可以说,单一职责原则既减少了类与类之间的耦合,又提高了类的可复用性,极大的提升了面向对象编程的效率。
240 |
241 |
242 |
243 | ## 扩展知识
244 |
245 | ### 里氏替换原则
246 |
247 | 里氏替换原则也是OOP的基本原则之一,所强调的是在任何基类可以出现的地方,派生类一定可以出现。因此我们可以说,它是继承复用的基石,只有当派生类可以替换掉基类,软件的功能不受到影响时,基类才能真正被复用,而派生类也能够在基类的基础上增加新的行为。在这一意义上,我们可以说里氏替换原则是对“开闭”原则的补充。而要想规范地遵从里氏替换原则,我们需要做到以下五点:
248 |
249 | 1. 子类必须完全实现父类的抽象方法,但不能覆盖父类的非抽象方法
250 |
251 | 2. 子类可以实现自己特有的方法
252 |
253 | 3. 当子类覆盖或实现父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松。
254 |
255 | 4. 当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
256 |
257 | 5. 子类的实例可以替代任何父类的实例,但反之不成立
258 |
259 | 我们可以用下面的代码示例进行说明:
260 |
261 | ```cpp
262 | #include
263 | //鸟
264 | class Bird{
265 | public:
266 | Bird(){}
267 | virtual ~Bird(){}
268 | virtual void Fly() {
269 | std::cout << "I am a bird and I am flying" << std::endl;
270 | }
271 | };
272 | //燕子
273 | class Swallow : public Bird{
274 | public:
275 | Swallow(){}
276 | ~Swallow(){}
277 | void Fly() override {
278 | std::cout << "I am a Swallow and I am flying" << std::endl;
279 | }
280 | };
281 | //大雁
282 | class WildGoose : public Bird{
283 | public:
284 | WildGoose(){}
285 | ~WildGoose(){}
286 | void Fly() override {
287 | std::cout << "I am a Wild Goose and I am flying" << std::endl;
288 | }
289 | };
290 | //模拟鸟的飞行
291 | void Fly(Bird& b){
292 | b.Fly();
293 | }
294 |
295 | int main(int argc,char * argv[]){
296 | WildGoose goose;
297 | Swallow s;
298 | Fly(s);
299 | Fly(goose);
300 | }
301 | ```
302 |
303 | 在这一段示例代码中,我们看到:定义的全局函数的参数为Bird类的对象,这使得不论我们传入的是燕子还是大雁,程序都能顺利进行。然而,如果将Fly函数改为下面的定义:
304 |
305 | ```cpp
306 | void Fly(WildGoose& wg){
307 | wg.Fly();
308 | }
309 | ```
310 |
311 | 那么我们就无法用Fly函数模拟燕子的飞行。根据里氏替换原则,在基类出现的地方都可以用派生类代替,而反之则不行。
312 |
313 |
314 |
315 | ### 迪米特法则
316 |
317 | 与之前介绍的各种原则不同,迪米特法则关注的是的是类之间的耦合性大小。事实上,这一法则并非是程序设计领域中的专属,美国人就在航天系统的设计中同样采用了这一法则。
318 |
319 | 迪米特法则又叫作最少知识原则,一个类对于其他类知道的越少越好,就是说一个对象应当对其他对象有尽可能少的了解:只和朋友通信,不和陌生人说话。在编程层面,其具有以下几个特点:
320 |
321 | 1. **如果两个类不直接通信,那么这两个类就不应该发生直接的相互作用**。
322 |
323 | 2. 在类的结构设计上,每一个类都应该尽量降低成员的访问权限
324 |
325 | 3. 该法则在适配器模式、解释模式等中有强烈的体现
326 |
327 | 4. 强调类之间的松耦合,类之间的耦合越弱,越有利于复用
328 |
329 |
330 |
--------------------------------------------------------------------------------
/C++/第六讲/函数对象、lambda与参数绑定/README.md:
--------------------------------------------------------------------------------
1 | # 第六讲
2 |
3 | ## 简介
4 |
5 | - 主题:函数对象、lambda表达式与参数绑定
6 | - 你将学到什么:
7 | - 函数对象的定义、优点、使用方法
8 | - lambda表达式的相关知识
9 | - 参数绑定、bind函数的知识
10 |
11 | ------
12 |
13 | ## 文件清单
14 |
15 | - `docs/`
16 | - 第六讲:函数对象、lambda表达式与参数绑定.md【本讲教程】
17 | - `imgs/`
18 | - image1.png
19 | - `codes/`
20 | - 1FunctionObject.cpp
21 | - 2lambda.cpp
22 | - 3bind.cpp
23 |
24 | ------
25 |
26 | ## 参考资料
27 |
28 | - 清华大学计算机系姚海龙老师程序设计基础课件
29 | - 《C++ Primer》(第五版)
30 | - [learn Cpp](https://www.learncpp.com/)
31 | - [Microsoft C++ docs](https://docs.microsoft.com/en-us/cpp/cpp/?view=msvc-170)
32 | - [GeeksforGeeks C++ tutorials](https://www.geeksforgeeks.org/c-plus-plus/)
--------------------------------------------------------------------------------
/C++/第六讲/函数对象、lambda与参数绑定/codes/1FunctionObject.cpp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ksc999/THUEEXP-SAST-Tutor/d01ad77a614a8ff9eefa3c4a64fc7e8bf7b47f08/C++/第六讲/函数对象、lambda与参数绑定/codes/1FunctionObject.cpp
--------------------------------------------------------------------------------
/C++/第六讲/函数对象、lambda与参数绑定/codes/2lambda.cpp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ksc999/THUEEXP-SAST-Tutor/d01ad77a614a8ff9eefa3c4a64fc7e8bf7b47f08/C++/第六讲/函数对象、lambda与参数绑定/codes/2lambda.cpp
--------------------------------------------------------------------------------
/C++/第六讲/函数对象、lambda与参数绑定/codes/3bind.cpp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ksc999/THUEEXP-SAST-Tutor/d01ad77a614a8ff9eefa3c4a64fc7e8bf7b47f08/C++/第六讲/函数对象、lambda与参数绑定/codes/3bind.cpp
--------------------------------------------------------------------------------
/C++/第六讲/函数对象、lambda与参数绑定/docs/第六讲:函数对象、lambda表达式与参数绑定.md:
--------------------------------------------------------------------------------
1 | ## 第六讲:函数对象、lambda表达式与参数绑定
2 |
3 | ### 一、函数对象
4 |
5 | #### 1、函数对象的定义与特点
6 |
7 | **函数对象**是可以实现操作符`()`的任何类型,简单来说,就是指一个重载了括号操作符`()`的类的对象。
8 |
9 | 这种对象使用起来如同使用一个函数。需要注意的是,重载`()`的函数,必须为该类的成员函数。
10 |
11 | 与直接函数调用相比,函数对象具有两个主要优点:
12 |
13 | - 函数对象可以包含状态;
14 | - 函数对象是一种类型,因此可以用作模板参数。
15 |
16 | #### 2、函数对象简单使用示例
17 |
18 | ###### 例1.1:生成并使用一个简单的函数对象
19 |
20 | ~~~c++
21 | #include
22 | using namespace std;
23 |
24 | class Functor {
25 | public:
26 | int operator() (int a, int b) { //重载()操作符,是成员函数
27 | return a < b;
28 | }
29 | };
30 |
31 | int main() {
32 | Functor f; //声明一个函数对象
33 | int a = 5;
34 | int b = 7;
35 | int ans = f(a,b); //此处f类似一个函数,但实际是在调用重载的()操作符
36 | cout << ans; //ans=1
37 | }
38 | ~~~
39 |
40 | ###### 例1.2:函数对象可以包含状态,即存储和传递数据(优点一)
41 |
42 | ~~~c++
43 | #include
44 | using namespace std;
45 |
46 | class F {
47 | public:
48 | F(int val) : data{val} {}
49 | bool operator() (int x) { return (x > data); }
50 | private:
51 | int data;
52 | };
53 |
54 | void Disp(int a[], int len, F op) {
55 | for (int i=0; i,
94 | class Allocator=allocator>
95 | class set
96 | ~~~
97 |
98 | 第二个模板参数是函数对象 。比如`less`中的重载函数会比较两个`int`类型的参数,如果第一个参数小于第二个,则此函数对象返回true。通过这样一个函数对象便可以实现对容器内的元素排序。
99 |
100 | ###### 函数对象用于算法中
101 |
102 | std::sort 算法默认使用元素类型的 `<` 运算符,但可能我们希望的顺序与<所定义的顺序不同,或者我们要排序的是自己定义的元素类型,此时我们需要向sort函数中传递第三个参数,此参数称为**谓词**。
103 |
104 | 注:谓词是一个可调用表达式,其返回结果是一个能用作条件的值。其分为**一元谓词**(接受单一参数)、**二元谓词**(两个参数)。接受谓词参数的算法对输入序列的元素调用谓词。
105 |
106 | 例1.3:在下面的程序中,我们给sort算法传入不同的(二元)谓词,实现特定的排序
107 |
108 | ~~~c++
109 | #include
110 | #include
111 | #include
112 | using namespace std;
113 |
114 | bool myfunction (int i,int j) { return (i>j); } //自定义比较函数
115 |
116 | class myclass { //重载()的类
117 | public:
118 | bool operator() (int i,int j) { return (i>j);}
119 | } myobject; //自定义一个函数对象myobject
120 |
121 | int main () {
122 | int myints[] = {32,71,12,45,26,80,53,33};
123 | // 将该数组的8个元素装入容器
124 | vector myvector (myints, myints+8);
125 | vector::iterator it; //迭代器,用来访问元素
126 | // 使用默认的比较函数(operator <)排列前四个元素:
127 | //(12 32 45 71) 26 80 53 33
128 | sort (myvector.begin(), myvector.begin()+4);
129 |
130 | // 使用自定义的比较函数排列后四个元素
131 | // 12 32 45 71 (80 53 33 26)
132 | sort (myvector.begin()+4, myvector.end(), myfunction);
133 |
134 | // 使用三种函数对象排序(效果一样,同operator >)
135 | //(80 71 53 45 33 32 26 12)
136 | sort (myvector.begin(), myvector.end(), myobject);
137 | sort (myvector.begin(), myvector.end(), myclass()); //myclass是类名,后面要加()
138 | sort (myvector.begin(), myvector.end(), greater()); //greater是标准库里的类型
139 |
140 | cout << "myvector contains:";
141 | //使用迭代器遍历容器内元素输出
142 | for (it=myvector.begin(); it!=myvector.end(); ++it)
143 | cout << " " << *it;
144 |
145 | return 0;
146 | }
147 | //结果:myvector contains: 80 71 53 45 33 32 26 12
148 | ~~~
149 |
150 | ### 二、lambda表达式
151 |
152 | #### 1、lambda表达式的定义
153 |
154 | - **lambda表达式**是一个能够**捕获**作用域中**变量**的未命名**函数对象**。
155 |
156 | - 一个lambda表达式表示一个可调用的代码单元,我们也可以理解为一个未命名的内联函数。
157 |
158 | 注:对于一个对象或者表达式,如果它可以使用`()`运算符,我们称之为是可调用的。即如果e是一个可调用的表达式,我们可以编写代码 `e(args);`其中`args`是一个逗号分隔的一个或多个参数列表)
159 |
160 | 函数、函数指针、重载了`()`运算符的类、lambda表达式,这四类都是可调用对象。
161 |
162 | - lambda表达式具有一个`捕获列表`、一个`参数列表`、一个`返回类型`和一个`函数体`,可以被定义在一个函数的内部。
163 |
164 | 一个lambda表达式有如下形式:
165 |
166 | ~~~c++
167 | [capture list] (paramter list) -> return type { funciton body }
168 | ~~~
169 |
170 | 其中,参数列表与返回类型可以忽略,捕获列表与函数体必须有(捕获内容可为空)。
171 |
172 | 例如下面这个lambda表达式(赋给f):
173 |
174 | ~~~c++
175 | auto f=[] { return 26; };
176 | cout << f() ; //打印26
177 | ~~~
178 |
179 | #### 2、传递参数
180 |
181 | 与一个普通函数类似,调用一个lambda时给定的实参被用来初始化lambda的形参。但是与普通函数不同的是,lambda表达式**不能有默认参数**,调用的实参数目必须与形参数目相同。
182 |
183 | 例如,我们可以这样编写一个lambda表达式用于两个字符串的比较:
184 |
185 | ~~~c++
186 | auto f=[] (const string &a, const string &b)
187 | { return a.size() < b.size();};
188 | ~~~
189 |
190 | lambda表达式是一个函数对象,上面的`f` 类似于下面这个类的对象:
191 |
192 | ~~~c++
193 | class ShorterString{
194 | public:
195 | bool operator() (const string& a,const string& b) const{
196 | return a.size() < b.size();
197 | }
198 | };
199 | ~~~
200 |
201 | 我们可将其运用在排序算法中(设words是一个string容器)(例2.1)
202 |
203 | ~~~c++
204 | sort(words.begin(),words.end(),
205 | [](const string &a, const string &b)
206 | { return a.size() < b.size();});
207 | //这相当于
208 | sort(words.begin(),words.end(),f);
209 | //也相当于
210 | sort(words.begin(),words.end(),ShorterString());
211 | ~~~
212 |
213 | #### 3、使用捕获列表
214 |
215 | - 捕获内容:**局部非static变量**
216 |
217 | - 捕获意义:一个lambda只有在其捕获列表中捕获一个它所在函数中的局部变量,才能在函数体中使用该变量。
218 |
219 | 注:局部static变量与lambda表达式所在函数之外声明的变量可以直接使用,无需捕获。
220 |
221 | ~~~c++
222 | [sz](const string &a) {return a.size()>=sz;}; //ok!(设sz是函数内局部变量)
223 | [](const string &a) {return a.size()>=sz;}; //error! (没有捕获sz)
224 | ~~~
225 |
226 | #### 4、捕获与返回
227 |
228 | 当我们定义一个lambda表达式时,编译器自动生成一个与lambda表达式对应的新的(未命名)类类型。当向一个函数传递一个lambda时,就同时定义了一个新类型与该类型的一个对象。类似的,当用auto定义一个用lambda初始化的变量时(见上上个例子),定义了一个从lambda生成的类型对象。
229 |
230 | 从lambda生成的类包含了lambda所捕获的变量作为其数据成员,该数据成员在lambda对象创建时被初始化。
231 |
232 | 类似传递参数,lambda的捕获分为值捕获和引用捕获两种方式,编写时还可以使用简单的隐式捕获方式。
233 |
234 | ##### 值捕获
235 |
236 | 类似函数中的值传递,但要注意被捕获的变量的值是在lambda创建时拷贝,而不是调用时拷贝。(例2.2)
237 |
238 | ~~~c++
239 | void func1()
240 | {
241 | int t=42; //函数内的局部变量
242 | //将t拷贝到名为f的可调用对象 值捕获
243 | //此时传入了值是42,不会随着之后t的改变而改变
244 | auto f=[t] { return t;};
245 | t=0;
246 | auto j=f(); //j=42
247 | }
248 | ~~~
249 |
250 | ##### 引用捕获
251 |
252 | 引用捕获某变量时,实际使用的是引用所绑定的对象。
253 |
254 | ~~~c++
255 | void func2()
256 | {
257 | int t=42; //局部变量
258 | //将t拷贝到名为f的可调用对象
259 | //引用捕获,结果会随着之后t的改变而改变
260 | auto f=[&t] { return t;};
261 | t=0;
262 | auto j=f(); //j=0
263 | }
264 | ~~~
265 |
266 | 注意: 引用捕获时,必须保证在lambda执行时变量是存在的。并且我们应该尽量减少捕获的数据量。
267 |
268 | ##### 隐式捕获
269 |
270 | 由编译器自动判断捕获哪些变量
271 |
272 | [=] 表示采用值捕获
273 |
274 | [&] 表示采用引用捕获
275 |
276 | 更多的捕获方式可参见下表:
277 |
278 | 
279 |
280 | ##### 可变lambda
281 |
282 | 默认情况下,lambda不会改变一个值被拷贝的变量。如果我们希望改变它,需要在参数列表后使用关键字mutable
283 |
284 | 例2.3:
285 |
286 | ~~~c++
287 | #include
288 | int main() {
289 | int ammo{ 10 };
290 | //用lambda定义一个可调用对象shoot
291 | auto shoot{
292 | [ammo]() mutable { //捕获ammo
293 | --ammo; //使用mutable后可以更改lambda中ammo的值
294 | std::cout << "Pew! " << ammo << " shot(s) left.\n";
295 | }
296 | };
297 | //调用两次
298 | shoot();
299 | shoot();
300 | //打印主函数中的ammo
301 | std::cout << ammo << " shot(s) left";
302 |
303 | return 0;
304 | }
305 | //输出:
306 | //Pew! 9 shot(s) left.
307 | //Pew! 8 shot(s) left.
308 | //10 shot(s) left
309 | ~~~
310 |
311 | 由于是值传递,所以主函数的ammo并没有发生改变。如果改为引用传递,则无需使用mutable,可以直接改变ammo,最后会输出8。
312 |
313 | #### 5、返回类型
314 |
315 | 返回类型可以被忽略,此时,如果函数体只有一个return语句,则系统自动从返回表达式类型来判断返回类型;否则,返回类型为void。
316 |
317 | 因此,当函数体包含return语句之外的其他语句时,应该指定返回类型。
318 |
319 | 例如下面的这个lambda表达式:
320 |
321 | ~~~c++
322 | [](int i) ->int //指定返回int类型
323 | { if(i<0) return -i; else return i;};
324 |
325 | //示例:lambda用于标准库里的transform算法
326 | transform(v.begin(), v.end(), v.begin(),
327 | [](int i)->int {if(i<0) return -i; else return i;});
328 | ~~~
329 |
330 | #### 6、使用小结
331 |
332 | lambda表达式允许我们在另一个函数中定义一个匿名函数。嵌套很重要,因为它允许我们避免命名空间命名污染,并定义尽可能靠近使用它的位置的函数。
333 |
334 | 对于那种只在一两个地方使用的简单操作,lambda表示式是最有用的。
335 |
336 | 如果捕获列表为空,通常可用函数代替它。
337 |
338 | lambda表达式常用在算法的谓词上,这里也体现了lambda捕获列表的优势:根据算法接受一元谓词还是二元谓词,我们传递给算法的谓词必须严格接受一个或两个参数,但有时我们又希望获得更多的参数,便可以通过捕获列表实现。
339 |
340 | 例2.4:`find_if`算法(只接受一元谓词):
341 |
342 | ~~~c++
343 | #include
344 | #include
345 | #include
346 | using namespace std;
347 | bool comp(int a, int sz){ //比较函数,接受两个参数
348 | return a > sz;
349 | }
350 | int main() {
351 | int myints[] = { 32,71,12,45,26,80,53,33 };
352 | vector myvector(myints, myints + 8);
353 | vector::iterator it;
354 |
355 | // 使用默认的比较函数(operator <)排列所有元素:
356 | //12 26 32 33 45 53 71 80
357 | sort(myvector.begin(), myvector.end());
358 | //定义比较标准sz
359 | int sz = 50;
360 |
361 | //获取一个迭代器wc,指向第一个>sz的元素
362 | //lambda表达式只接受一个参数,正确
363 | auto wc = find_if(myvector.begin(), myvector.end(),
364 | [sz](int a) {return a > sz; });
365 |
366 | //comp函数接受两个参数,不符合find_if的要求,错误
367 | //auto wc2= find_if(myvector.begin(), myvector.end(),comp);
368 |
369 | //使用迭代器输出大于50的元素
370 | for (it = wc; it != myvector.end(); ++it)
371 | cout << *it << " ";
372 |
373 | return 0;
374 | }
375 | //输出:53 71 80
376 | ~~~
377 |
378 | ### 三、参数绑定
379 |
380 | #### 1、std::bind函数
381 |
382 | 在上面的例子中,传递给`find_if`的可调用对象必须接受单一参数,自定义的comp函数就不适用了,但我们可以使用**bind**函数(定义在头文件`functional`中),来用comp函数取代lambda表达式。
383 |
384 | 调用`bind`的一般形式如下:
385 |
386 | ~~~c++
387 | auto newCallable = bind(Callable, arg_list);
388 | ~~~
389 |
390 | 可以将 bind 函数看作一个通用的函数适配器,它接受一个可调用对象`Callable`,生成一个新的可调用对象`newCallable`来 "适应" 原对象的参数列表。
391 |
392 | `arg_list `是一个逗号分隔的参数列表,当我们调用`newCallable `时,`newCallable` 会调用 `Callable`,并传递给它 `arg_list` 中的参数。
393 |
394 | `arg_list` 中的参数可能包含形如 `_n` 的名字,其中 `n` 是一个整数。这些参数是 "占位符",表示 `newCallable` 的参数,它们占据了传递给 `newCallable `的参数的 "位置"。数值 `n` 表示 生成的可调用对象中参数的位置:`_1` 为 `newCallable` 的第一个参数,`_2` 为第二个参数,依此类推。
395 |
396 | `_n` 都定义在命名空间 `placeholders` 中,且此命名空间又定义在命名空间 `std` 中。因此使用`bind`与`_n`之前应该声明:
397 |
398 | ~~~c++
399 | #include
400 | using namespace std;
401 | using namespace std::placeholders;
402 | ~~~
403 |
404 | #### 2、bind的使用
405 |
406 | 作为一个简单的例子,我们将使用`bind`生成一个调用上一个例子中的`comp`函数的对象,如下所示
407 |
408 | ~~~c++
409 | auto comp1 = bind(comp, _1, 50);
410 | //comp1是一个可调用对象,接受一个int参数(_1处)
411 | //并用此参数与50调用comp函数
412 | ~~~
413 |
414 | 之前用lambda表达式写的wc可以更换为:(例3.1)
415 |
416 | ~~~c++
417 | auto wc = find_if(myvector.begin(), myvector.end(),
418 | bind(comp, _1, sz));
419 | ~~~
420 |
421 | 这便将`comp`的第二个参数绑定到了`sz`的值(50),只接受一个参数,满足了`find_if`的要求。
422 |
423 | ##### 调整参数顺序
424 |
425 | 如前文所示,我们可以用`bind`修正参数的值,也可以重新安排参数的顺序,获得更多新的函数。
426 |
427 | 例如,`f`是一个有5个参数的可调用对象,我们生成一个新可调用对象`g`,只有两个参数,用两个占位符表示
428 |
429 | ~~~c++
430 | auto g=bind(f, a, b, _2, c, _1);
431 | ~~~
432 |
433 | 如此,a、b、c分别与`f`的第1、2、4个参数绑定起来,`g`的第1、2个参数分别与`f`的第5、3个参数绑定。
434 |
435 | 即,调用g(x, y),就是调用f(a, b, y, c, x)
436 |
437 | ##### 绑定成员函数
438 |
439 | 除了绑定普通函数,`bind`还可以绑定成员函数,这时,第一个参数表示对象的成员函数的指针,第二个参数表示对象的地址,后面是参数列表。
440 |
441 | 例3.2:
442 |
443 | ~~~c++
444 | struct Foo {
445 | void func(int x, int y)
446 | {
447 | std::cout << x-y << '\n';
448 | }
449 | int data = 10;
450 | };
451 | int main() {
452 | Foo foo;
453 | auto f = std::bind(&Foo::func, &foo, 25, std::placeholders::_1);
454 | f(5); // 20
455 | }
456 | ~~~
457 |
458 | ##### 绑定引用参数
459 |
460 | 默认情况下, `bind` 的那些不是占位符的参数被拷贝到 `bind` 返回的可调用对象中。但是, 与 lambda 类似,有时对有些绑定的参数我们希望以**引用方式传递**, 或是要绑定参数的类型无法拷贝。这时,我们必须使用标准库**`ref`函数**(头文件`functional`中)。
461 |
462 | 例3.3:输出流对象`os`无法拷贝时,用`ref`返回引用
463 |
464 | ~~~c++
465 | #include
466 | #include
467 | #include
468 | #include
469 | using namespace std;
470 | using namespace std::placeholders;
471 |
472 | ostream& disp(ostream& os, const int a, char c) {
473 | return os << a << c;
474 | }
475 |
476 | int main() {
477 | int myints[] = { 32,71,12,45,26,80,53,33 };
478 | vector myvector(myints, myints + 8);
479 | vector::iterator it;
480 | sort(myvector.begin(), myvector.end());
481 |
482 | char cc = '*';
483 | ostream &os = cout;
484 | for_each(myvector.begin(), myvector.end(),
485 | bind(disp, ref(os), _1, cc)); //使用ref返回引用
486 | return 0;
487 | }
488 | //输出:12*26*32*33*45*53*71*80*
489 | ~~~
490 |
491 |
492 |
493 |
--------------------------------------------------------------------------------
/C++/第六讲/函数对象、lambda与参数绑定/imgs/image1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ksc999/THUEEXP-SAST-Tutor/d01ad77a614a8ff9eefa3c4a64fc7e8bf7b47f08/C++/第六讲/函数对象、lambda与参数绑定/imgs/image1.png
--------------------------------------------------------------------------------
/C++/第十讲/README.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ksc999/THUEEXP-SAST-Tutor/d01ad77a614a8ff9eefa3c4a64fc7e8bf7b47f08/C++/第十讲/README.md
--------------------------------------------------------------------------------
/C++/第四讲/static修饰符用法总结/README.md:
--------------------------------------------------------------------------------
1 | # 第4讲第1节 Static修饰符用法总结
2 |
3 | ## 简介
4 |
5 | - 内容主题:Static
6 | - 你将学到什么:
7 | - static修饰符的功能
8 |
9 | ---
10 |
11 | ## 文件清单
12 |
13 | - `docs/`
14 |
15 | - Static.md【本讲教程】
16 | - `imgs/`
17 |
18 | - 无图片(只是为了统一格式)
19 | - `codes/`
20 |
21 | static部分
22 |
23 | - zoo.cpp
24 | - 1.cpp**与**2.cpp(linkage文件夹中)
25 | - mem_fun.cpp
26 |
27 |
28 | ---
29 |
30 | ## 参考资料
31 |
32 | - 清华大学计算机系姚海龙老师程序设计基础课件
33 | - 《C++ Primer》(第五版)
34 | - [learn Cpp](https://www.learncpp.com/)
35 | - [Microsoft C++ docs](https://docs.microsoft.com/en-us/cpp/cpp/?view=msvc-170)
36 | - [GeeksforGeeks C++ tutorials](https://www.geeksforgeeks.org/c-plus-plus/)
37 | - 由于上述三个网站均为英文网站,将表述转换为中文时,参考了部分CSDN上的文章,由于篇幅过多,不在此一一列出
38 |
39 |
--------------------------------------------------------------------------------
/C++/第四讲/static修饰符用法总结/codes/linkage/1.cpp:
--------------------------------------------------------------------------------
1 | #include