 38 |
38 |  34 |
35 | ### Tutorial videos
36 |
37 |
38 |
39 |
40 | # :computer: Installation
41 |
42 | ## Hardware
43 |
44 | * OS: Ubuntu 18.04
45 | * NVIDIA GPU with **CUDA>=10.1** (tested with 1 RTX2080Ti)
46 |
47 | ## Software
48 |
49 | * Clone this repo by `git clone --recursive https://github.com/kwea123/nerf_pl`
50 | * Python>=3.6 (installation via [anaconda](https://www.anaconda.com/distribution/) is recommended, use `conda create -n nerf_pl python=3.6` to create a conda environment and activate it by `conda activate nerf_pl`)
51 | * Python libraries
52 | * Install core requirements by `pip install -r requirements.txt`
53 | * Install `torchsearchsorted` by `cd torchsearchsorted` then `pip install .`
54 |
55 | # :key: Training
56 |
57 | Please see each subsection for training on different datasets. Available training datasets:
58 |
59 | * [Blender](#blender) (Realistic Synthetic 360)
60 | * [LLFF](#llff) (Real Forward-Facing)
61 | * [Your own data](#your-own-data) (Forward-Facing/360 inward-facing)
62 |
63 | ## Blender
64 |
34 |
35 | ### Tutorial videos
36 |
37 |
38 |
39 |
40 | # :computer: Installation
41 |
42 | ## Hardware
43 |
44 | * OS: Ubuntu 18.04
45 | * NVIDIA GPU with **CUDA>=10.1** (tested with 1 RTX2080Ti)
46 |
47 | ## Software
48 |
49 | * Clone this repo by `git clone --recursive https://github.com/kwea123/nerf_pl`
50 | * Python>=3.6 (installation via [anaconda](https://www.anaconda.com/distribution/) is recommended, use `conda create -n nerf_pl python=3.6` to create a conda environment and activate it by `conda activate nerf_pl`)
51 | * Python libraries
52 | * Install core requirements by `pip install -r requirements.txt`
53 | * Install `torchsearchsorted` by `cd torchsearchsorted` then `pip install .`
54 |
55 | # :key: Training
56 |
57 | Please see each subsection for training on different datasets. Available training datasets:
58 |
59 | * [Blender](#blender) (Realistic Synthetic 360)
60 | * [LLFF](#llff) (Real Forward-Facing)
61 | * [Your own data](#your-own-data) (Forward-Facing/360 inward-facing)
62 |
63 | ## Blender
64 |
164 |  165 |
165 |  166 |
166 |
175 |
176 |  177 |
178 |
177 |
178 |  179 |
179 |
 25 |
26 | by projecting the vertices onto this input image:
27 |
28 |
25 |
26 | by projecting the vertices onto this input image:
27 |
28 |  29 |
30 | You'll notice the face appears on the mantle. Why is that? It is because of **occlusion**.
31 |
32 | From the input image view, that spurious part of the mantle is actually occluded (blocked) by the face, so in reality we **shouldn't** assign color to it, but the above process assigns it the same color as the face because those vertices are projected onto the face (in pixel coordinate) as well!
33 |
34 | So the problem becomes: How do we correctly infer occlusion information, to know which vertices shouldn't be assigned colors? I tried two methods, where the first turns out to not work well:
35 |
36 | 1. Use depth information
37 |
38 | The first intuitive way is to leverage vertices' depths (which is obtained when projecting vertices onto image plane): if two (or more) vertices are projected onto the **same** pixel coordinates, then only the nearest vertex will be assigned color, the rest remains untouched. However, this method won't work since no any two pixels will be projected onto the exact same location! As we mentioned earlier, the pixel coordinates are floating numbers, so it is impossible for they to be exactly the same. If we round the numbers to integers (which I tried as well), then this method works, but with still a lot of misclassified (occluded/non occluded) vertices in my experiments.
39 |
40 | 2. Leverage NeRF model
41 |
42 | What I find a intelligent way to infer occlusion is by using NeRF model. Recall that nerf model can estimate the opacity (or density) along a ray path (the following figure c):
43 | 
44 | We can leverage that information to tell if a vertex is occluded or not. More concretely, we form rays originating from the camera origin, destinating (ending) at the vertices, and compute the total opacity along these rays. If a vertex is not occluded, the opacity will be small; otherwise, the value will be large, meaning that something lies between the vertex and the camera.
45 |
46 | After applying this method, this is what we get (by projecting the vertices onto the input view as above):
47 |
29 |
30 | You'll notice the face appears on the mantle. Why is that? It is because of **occlusion**.
31 |
32 | From the input image view, that spurious part of the mantle is actually occluded (blocked) by the face, so in reality we **shouldn't** assign color to it, but the above process assigns it the same color as the face because those vertices are projected onto the face (in pixel coordinate) as well!
33 |
34 | So the problem becomes: How do we correctly infer occlusion information, to know which vertices shouldn't be assigned colors? I tried two methods, where the first turns out to not work well:
35 |
36 | 1. Use depth information
37 |
38 | The first intuitive way is to leverage vertices' depths (which is obtained when projecting vertices onto image plane): if two (or more) vertices are projected onto the **same** pixel coordinates, then only the nearest vertex will be assigned color, the rest remains untouched. However, this method won't work since no any two pixels will be projected onto the exact same location! As we mentioned earlier, the pixel coordinates are floating numbers, so it is impossible for they to be exactly the same. If we round the numbers to integers (which I tried as well), then this method works, but with still a lot of misclassified (occluded/non occluded) vertices in my experiments.
39 |
40 | 2. Leverage NeRF model
41 |
42 | What I find a intelligent way to infer occlusion is by using NeRF model. Recall that nerf model can estimate the opacity (or density) along a ray path (the following figure c):
43 | 
44 | We can leverage that information to tell if a vertex is occluded or not. More concretely, we form rays originating from the camera origin, destinating (ending) at the vertices, and compute the total opacity along these rays. If a vertex is not occluded, the opacity will be small; otherwise, the value will be large, meaning that something lies between the vertex and the camera.
45 |
46 | After applying this method, this is what we get (by projecting the vertices onto the input view as above):
47 |  48 |
49 | The spurious face on the mantle disappears, and the colored pixels are almost exactly the ones we can observe from the image. By default we set the vertices to be all black, so a black vertex means it's occluded in this view, but will be assigned color when we change to other views.
50 |
51 |
52 | # Finally...
53 |
54 | This is the final result:
55 |
56 |
57 |
58 | We can then export this `.ply` file to any other format, and embed in programs like I did in Unity:
59 | (I use [this plugin](https://github.com/kwea123/Pcx) to import `.ply` file to unity, and made some modifications so that it can also read mesh triangles, not only the points)
60 |
61 | 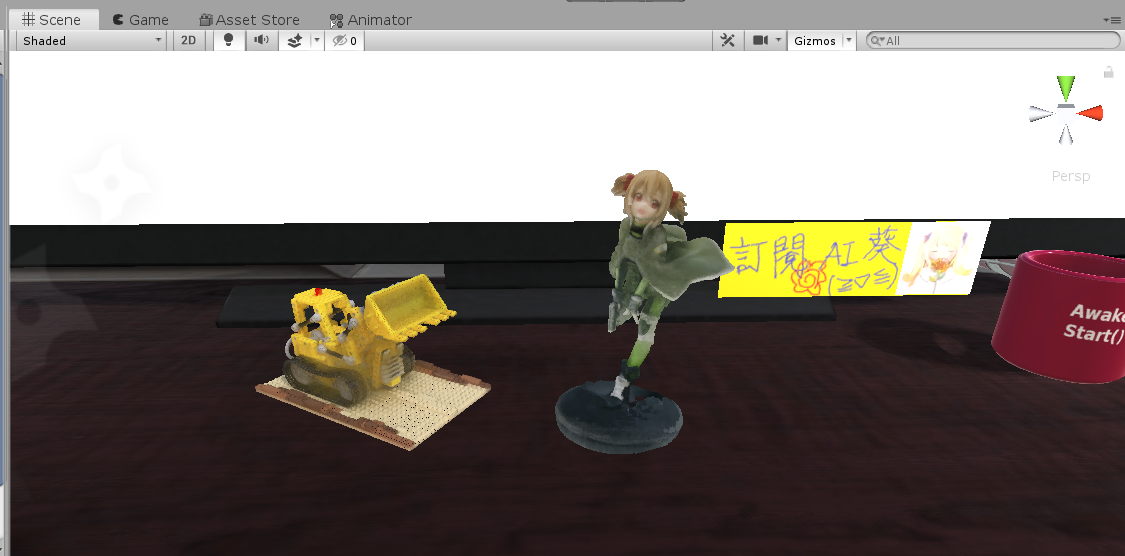
62 |
63 | The meshes can be attached a meshcollider so that they can interact with other objects. You can see [this video](https://youtu.be/I2M0xhnrBos) for a demo.
64 |
65 | ## Further reading
66 | The author suggested [another way](https://github.com/bmild/nerf/issues/44#issuecomment-622961303) to extract color, in my experiments it doesn't turn out to be good, but the idea is reasonable and interesting. You can also test this by setting `--use_vertex_normal`.
67 |
--------------------------------------------------------------------------------
/datasets/__init__.py:
--------------------------------------------------------------------------------
1 | from .blender import BlenderDataset
2 | from .llff import LLFFDataset
3 |
4 | dataset_dict = {'blender': BlenderDataset,
5 | 'llff': LLFFDataset}
--------------------------------------------------------------------------------
/datasets/blender.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch.utils.data import Dataset
3 | import json
4 | import numpy as np
5 | import os
6 | from PIL import Image
7 | from torchvision import transforms as T
8 |
9 | from .ray_utils import *
10 |
11 | class BlenderDataset(Dataset):
12 | def __init__(self, root_dir, split='train', img_wh=(800, 800)):
13 | self.root_dir = root_dir
14 | self.split = split
15 | assert img_wh[0] == img_wh[1], 'image width must equal image height!'
16 | self.img_wh = img_wh
17 | self.define_transforms()
18 |
19 | self.read_meta()
20 | self.white_back = True
21 |
22 | def read_meta(self):
23 | with open(os.path.join(self.root_dir,
24 | f"transforms_{self.split}.json"), 'r') as f:
25 | self.meta = json.load(f)
26 |
27 | w, h = self.img_wh
28 | self.focal = 0.5*800/np.tan(0.5*self.meta['camera_angle_x']) # original focal length
29 | # when W=800
30 |
31 | self.focal *= self.img_wh[0]/800 # modify focal length to match size self.img_wh
32 |
33 | # bounds, common for all scenes
34 | self.near = 2.0
35 | self.far = 6.0
36 | self.bounds = np.array([self.near, self.far])
37 |
38 | # ray directions for all pixels, same for all images (same H, W, focal)
39 | self.directions = \
40 | get_ray_directions(h, w, self.focal) # (h, w, 3)
41 |
42 | if self.split == 'train': # create buffer of all rays and rgb data
43 | self.image_paths = []
44 | self.poses = []
45 | self.all_rays = []
46 | self.all_rgbs = []
47 | for frame in self.meta['frames']:
48 | pose = np.array(frame['transform_matrix'])[:3, :4]
49 | self.poses += [pose]
50 | c2w = torch.FloatTensor(pose)
51 |
52 | image_path = os.path.join(self.root_dir, f"{frame['file_path']}.png")
53 | self.image_paths += [image_path]
54 | img = Image.open(image_path)
55 | img = img.resize(self.img_wh, Image.LANCZOS)
56 | img = self.transform(img) # (4, h, w)
57 | img = img.view(4, -1).permute(1, 0) # (h*w, 4) RGBA
58 | img = img[:, :3]*img[:, -1:] + (1-img[:, -1:]) # blend A to RGB
59 | self.all_rgbs += [img]
60 |
61 | rays_o, rays_d = get_rays(self.directions, c2w) # both (h*w, 3)
62 |
63 | self.all_rays += [torch.cat([rays_o, rays_d,
64 | self.near*torch.ones_like(rays_o[:, :1]),
65 | self.far*torch.ones_like(rays_o[:, :1])],
66 | 1)] # (h*w, 8)
67 |
68 | self.all_rays = torch.cat(self.all_rays, 0) # (len(self.meta['frames])*h*w, 3)
69 | self.all_rgbs = torch.cat(self.all_rgbs, 0) # (len(self.meta['frames])*h*w, 3)
70 |
71 | def define_transforms(self):
72 | self.transform = T.ToTensor()
73 |
74 | def __len__(self):
75 | if self.split == 'train':
76 | return len(self.all_rays)
77 | if self.split == 'val':
78 | return 8 # only validate 8 images (to support <=8 gpus)
79 | return len(self.meta['frames'])
80 |
81 | def __getitem__(self, idx):
82 | if self.split == 'train': # use data in the buffers
83 | sample = {'rays': self.all_rays[idx],
84 | 'rgbs': self.all_rgbs[idx]}
85 |
86 | else: # create data for each image separately
87 | frame = self.meta['frames'][idx]
88 | c2w = torch.FloatTensor(frame['transform_matrix'])[:3, :4]
89 |
90 | img = Image.open(os.path.join(self.root_dir, f"{frame['file_path']}.png"))
91 | img = img.resize(self.img_wh, Image.LANCZOS)
92 | img = self.transform(img) # (4, H, W)
93 | valid_mask = (img[-1]>0).flatten() # (H*W) valid color area
94 | img = img.view(4, -1).permute(1, 0) # (H*W, 4) RGBA
95 | img = img[:, :3]*img[:, -1:] + (1-img[:, -1:]) # blend A to RGB
96 |
97 | rays_o, rays_d = get_rays(self.directions, c2w)
98 |
99 | rays = torch.cat([rays_o, rays_d,
100 | self.near*torch.ones_like(rays_o[:, :1]),
101 | self.far*torch.ones_like(rays_o[:, :1])],
102 | 1) # (H*W, 8)
103 |
104 | sample = {'rays': rays,
105 | 'rgbs': img,
106 | 'c2w': c2w,
107 | 'valid_mask': valid_mask}
108 |
109 | return sample
--------------------------------------------------------------------------------
/datasets/depth_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import re
3 | import sys
4 |
5 | def read_pfm(filename):
6 | file = open(filename, 'rb')
7 | color = None
8 | width = None
9 | height = None
10 | scale = None
11 | endian = None
12 |
13 | header = file.readline().decode('utf-8').rstrip()
14 | if header == 'PF':
15 | color = True
16 | elif header == 'Pf':
17 | color = False
18 | else:
19 | raise Exception('Not a PFM file.')
20 |
21 | dim_match = re.match(r'^(\d+)\s(\d+)\s$', file.readline().decode('utf-8'))
22 | if dim_match:
23 | width, height = map(int, dim_match.groups())
24 | else:
25 | raise Exception('Malformed PFM header.')
26 |
27 | scale = float(file.readline().rstrip())
28 | if scale < 0: # little-endian
29 | endian = '<'
30 | scale = -scale
31 | else:
32 | endian = '>' # big-endian
33 |
34 | data = np.fromfile(file, endian + 'f')
35 | shape = (height, width, 3) if color else (height, width)
36 |
37 | data = np.reshape(data, shape)
38 | data = np.flipud(data)
39 | file.close()
40 | return data, scale
41 |
42 |
43 | def save_pfm(filename, image, scale=1):
44 | file = open(filename, "wb")
45 | color = None
46 |
47 | image = np.flipud(image)
48 |
49 | if image.dtype.name != 'float32':
50 | raise Exception('Image dtype must be float32.')
51 |
52 | if len(image.shape) == 3 and image.shape[2] == 3: # color image
53 | color = True
54 | elif len(image.shape) == 2 or len(image.shape) == 3 and image.shape[2] == 1: # greyscale
55 | color = False
56 | else:
57 | raise Exception('Image must have H x W x 3, H x W x 1 or H x W dimensions.')
58 |
59 | file.write('PF\n'.encode('utf-8') if color else 'Pf\n'.encode('utf-8'))
60 | file.write('{} {}\n'.format(image.shape[1], image.shape[0]).encode('utf-8'))
61 |
62 | endian = image.dtype.byteorder
63 |
64 | if endian == '<' or endian == '=' and sys.byteorder == 'little':
65 | scale = -scale
66 |
67 | file.write(('%f\n' % scale).encode('utf-8'))
68 |
69 | image.tofile(file)
70 | file.close()
--------------------------------------------------------------------------------
/datasets/llff.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch.utils.data import Dataset
3 | import glob
4 | import numpy as np
5 | import os
6 | from PIL import Image
7 | from torchvision import transforms as T
8 |
9 | from .ray_utils import *
10 |
11 |
12 | def normalize(v):
13 | """Normalize a vector."""
14 | return v/np.linalg.norm(v)
15 |
16 |
17 | def average_poses(poses):
18 | """
19 | Calculate the average pose, which is then used to center all poses
20 | using @center_poses. Its computation is as follows:
21 | 1. Compute the center: the average of pose centers.
22 | 2. Compute the z axis: the normalized average z axis.
23 | 3. Compute axis y': the average y axis.
24 | 4. Compute x' = y' cross product z, then normalize it as the x axis.
25 | 5. Compute the y axis: z cross product x.
26 |
27 | Note that at step 3, we cannot directly use y' as y axis since it's
28 | not necessarily orthogonal to z axis. We need to pass from x to y.
29 |
30 | Inputs:
31 | poses: (N_images, 3, 4)
32 |
33 | Outputs:
34 | pose_avg: (3, 4) the average pose
35 | """
36 | # 1. Compute the center
37 | center = poses[..., 3].mean(0) # (3)
38 |
39 | # 2. Compute the z axis
40 | z = normalize(poses[..., 2].mean(0)) # (3)
41 |
42 | # 3. Compute axis y' (no need to normalize as it's not the final output)
43 | y_ = poses[..., 1].mean(0) # (3)
44 |
45 | # 4. Compute the x axis
46 | x = normalize(np.cross(y_, z)) # (3)
47 |
48 | # 5. Compute the y axis (as z and x are normalized, y is already of norm 1)
49 | y = np.cross(z, x) # (3)
50 |
51 | pose_avg = np.stack([x, y, z, center], 1) # (3, 4)
52 |
53 | return pose_avg
54 |
55 |
56 | def center_poses(poses):
57 | """
58 | Center the poses so that we can use NDC.
59 | See https://github.com/bmild/nerf/issues/34
60 |
61 | Inputs:
62 | poses: (N_images, 3, 4)
63 |
64 | Outputs:
65 | poses_centered: (N_images, 3, 4) the centered poses
66 | pose_avg: (3, 4) the average pose
67 | """
68 |
69 | pose_avg = average_poses(poses) # (3, 4)
70 | pose_avg_homo = np.eye(4)
71 | pose_avg_homo[:3] = pose_avg # convert to homogeneous coordinate for faster computation
72 | # by simply adding 0, 0, 0, 1 as the last row
73 | last_row = np.tile(np.array([0, 0, 0, 1]), (len(poses), 1, 1)) # (N_images, 1, 4)
74 | poses_homo = \
75 | np.concatenate([poses, last_row], 1) # (N_images, 4, 4) homogeneous coordinate
76 |
77 | poses_centered = np.linalg.inv(pose_avg_homo) @ poses_homo # (N_images, 4, 4)
78 | poses_centered = poses_centered[:, :3] # (N_images, 3, 4)
79 |
80 | return poses_centered, np.linalg.inv(pose_avg_homo)
81 |
82 |
83 | def create_spiral_poses(radii, focus_depth, n_poses=120):
84 | """
85 | Computes poses that follow a spiral path for rendering purpose.
86 | See https://github.com/Fyusion/LLFF/issues/19
87 | In particular, the path looks like:
88 | https://tinyurl.com/ybgtfns3
89 |
90 | Inputs:
91 | radii: (3) radii of the spiral for each axis
92 | focus_depth: float, the depth that the spiral poses look at
93 | n_poses: int, number of poses to create along the path
94 |
95 | Outputs:
96 | poses_spiral: (n_poses, 3, 4) the poses in the spiral path
97 | """
98 |
99 | poses_spiral = []
100 | for t in np.linspace(0, 4*np.pi, n_poses+1)[:-1]: # rotate 4pi (2 rounds)
101 | # the parametric function of the spiral (see the interactive web)
102 | center = np.array([np.cos(t), -np.sin(t), -np.sin(0.5*t)]) * radii
103 |
104 | # the viewing z axis is the vector pointing from the @focus_depth plane
105 | # to @center
106 | z = normalize(center - np.array([0, 0, -focus_depth]))
107 |
108 | # compute other axes as in @average_poses
109 | y_ = np.array([0, 1, 0]) # (3)
110 | x = normalize(np.cross(y_, z)) # (3)
111 | y = np.cross(z, x) # (3)
112 |
113 | poses_spiral += [np.stack([x, y, z, center], 1)] # (3, 4)
114 |
115 | return np.stack(poses_spiral, 0) # (n_poses, 3, 4)
116 |
117 |
118 | def create_spheric_poses(radius, n_poses=120):
119 | """
120 | Create circular poses around z axis.
121 | Inputs:
122 | radius: the (negative) height and the radius of the circle.
123 |
124 | Outputs:
125 | spheric_poses: (n_poses, 3, 4) the poses in the circular path
126 | """
127 | def spheric_pose(theta, phi, radius):
128 | trans_t = lambda t : np.array([
129 | [1,0,0,0],
130 | [0,1,0,-0.9*t],
131 | [0,0,1,t],
132 | [0,0,0,1],
133 | ])
134 |
135 | rot_phi = lambda phi : np.array([
136 | [1,0,0,0],
137 | [0,np.cos(phi),-np.sin(phi),0],
138 | [0,np.sin(phi), np.cos(phi),0],
139 | [0,0,0,1],
140 | ])
141 |
142 | rot_theta = lambda th : np.array([
143 | [np.cos(th),0,-np.sin(th),0],
144 | [0,1,0,0],
145 | [np.sin(th),0, np.cos(th),0],
146 | [0,0,0,1],
147 | ])
148 |
149 | c2w = rot_theta(theta) @ rot_phi(phi) @ trans_t(radius)
150 | c2w = np.array([[-1,0,0,0],[0,0,1,0],[0,1,0,0],[0,0,0,1]]) @ c2w
151 | return c2w[:3]
152 |
153 | spheric_poses = []
154 | for th in np.linspace(0, 2*np.pi, n_poses+1)[:-1]:
155 | spheric_poses += [spheric_pose(th, -np.pi/5, radius)] # 36 degree view downwards
156 | return np.stack(spheric_poses, 0)
157 |
158 |
159 | class LLFFDataset(Dataset):
160 | def __init__(self, root_dir, split='train', img_wh=(504, 378), spheric_poses=False, val_num=1):
161 | """
162 | spheric_poses: whether the images are taken in a spheric inward-facing manner
163 | default: False (forward-facing)
164 | val_num: number of val images (used for multigpu training, validate same image for all gpus)
165 | """
166 | self.root_dir = root_dir
167 | self.split = split
168 | self.img_wh = img_wh
169 | self.spheric_poses = spheric_poses
170 | self.val_num = max(1, val_num) # at least 1
171 | self.define_transforms()
172 |
173 | self.read_meta()
174 | self.white_back = False
175 |
176 | def read_meta(self):
177 | poses_bounds = np.load(os.path.join(self.root_dir,
178 | 'poses_bounds.npy')) # (N_images, 17)
179 | self.image_paths = sorted(glob.glob(os.path.join(self.root_dir, 'images/*')))
180 | # load full resolution image then resize
181 | if self.split in ['train', 'val']:
182 | assert len(poses_bounds) == len(self.image_paths), \
183 | 'Mismatch between number of images and number of poses! Please rerun COLMAP!'
184 |
185 | poses = poses_bounds[:, :15].reshape(-1, 3, 5) # (N_images, 3, 5)
186 | self.bounds = poses_bounds[:, -2:] # (N_images, 2)
187 |
188 | # Step 1: rescale focal length according to training resolution
189 | H, W, self.focal = poses[0, :, -1] # original intrinsics, same for all images
190 | assert H*self.img_wh[0] == W*self.img_wh[1], \
191 | f'You must set @img_wh to have the same aspect ratio as ({W}, {H}) !'
192 |
193 | self.focal *= self.img_wh[0]/W
194 |
195 | # Step 2: correct poses
196 | # Original poses has rotation in form "down right back", change to "right up back"
197 | # See https://github.com/bmild/nerf/issues/34
198 | poses = np.concatenate([poses[..., 1:2], -poses[..., :1], poses[..., 2:4]], -1)
199 | # (N_images, 3, 4) exclude H, W, focal
200 | self.poses, self.pose_avg = center_poses(poses)
201 | distances_from_center = np.linalg.norm(self.poses[..., 3], axis=1)
202 | val_idx = np.argmin(distances_from_center) # choose val image as the closest to
203 | # center image
204 |
205 | # Step 3: correct scale so that the nearest depth is at a little more than 1.0
206 | # See https://github.com/bmild/nerf/issues/34
207 | near_original = self.bounds.min()
208 | scale_factor = near_original*0.75 # 0.75 is the default parameter
209 | # the nearest depth is at 1/0.75=1.33
210 | self.bounds /= scale_factor
211 | self.poses[..., 3] /= scale_factor
212 |
213 | # ray directions for all pixels, same for all images (same H, W, focal)
214 | self.directions = \
215 | get_ray_directions(self.img_wh[1], self.img_wh[0], self.focal) # (H, W, 3)
216 |
217 | if self.split == 'train': # create buffer of all rays and rgb data
218 | # use first N_images-1 to train, the LAST is val
219 | self.all_rays = []
220 | self.all_rgbs = []
221 | for i, image_path in enumerate(self.image_paths):
222 | if i == val_idx: # exclude the val image
223 | continue
224 | c2w = torch.FloatTensor(self.poses[i])
225 |
226 | img = Image.open(image_path).convert('RGB')
227 | assert img.size[1]*self.img_wh[0] == img.size[0]*self.img_wh[1], \
228 | f'''{image_path} has different aspect ratio than img_wh,
229 | please check your data!'''
230 | img = img.resize(self.img_wh, Image.LANCZOS)
231 | img = self.transform(img) # (3, h, w)
232 | img = img.view(3, -1).permute(1, 0) # (h*w, 3) RGB
233 | self.all_rgbs += [img]
234 |
235 | rays_o, rays_d = get_rays(self.directions, c2w) # both (h*w, 3)
236 | if not self.spheric_poses:
237 | near, far = 0, 1
238 | rays_o, rays_d = get_ndc_rays(self.img_wh[1], self.img_wh[0],
239 | self.focal, 1.0, rays_o, rays_d)
240 | # near plane is always at 1.0
241 | # near and far in NDC are always 0 and 1
242 | # See https://github.com/bmild/nerf/issues/34
243 | else:
244 | near = self.bounds.min()
245 | far = min(8 * near, self.bounds.max()) # focus on central object only
246 |
247 | self.all_rays += [torch.cat([rays_o, rays_d,
248 | near*torch.ones_like(rays_o[:, :1]),
249 | far*torch.ones_like(rays_o[:, :1])],
250 | 1)] # (h*w, 8)
251 |
252 | self.all_rays = torch.cat(self.all_rays, 0) # ((N_images-1)*h*w, 8)
253 | self.all_rgbs = torch.cat(self.all_rgbs, 0) # ((N_images-1)*h*w, 3)
254 |
255 | elif self.split == 'val':
256 | print('val image is', self.image_paths[val_idx])
257 | self.c2w_val = self.poses[val_idx]
258 | self.image_path_val = self.image_paths[val_idx]
259 |
260 | else: # for testing, create a parametric rendering path
261 | if self.split.endswith('train'): # test on training set
262 | self.poses_test = self.poses
263 | elif not self.spheric_poses:
264 | focus_depth = 3.5 # hardcoded, this is numerically close to the formula
265 | # given in the original repo. Mathematically if near=1
266 | # and far=infinity, then this number will converge to 4
267 | radii = np.percentile(np.abs(self.poses[..., 3]), 90, axis=0)
268 | self.poses_test = create_spiral_poses(radii, focus_depth)
269 | else:
270 | radius = 1.1 * self.bounds.min()
271 | self.poses_test = create_spheric_poses(radius)
272 |
273 | def define_transforms(self):
274 | self.transform = T.ToTensor()
275 |
276 | def __len__(self):
277 | if self.split == 'train':
278 | return len(self.all_rays)
279 | if self.split == 'val':
280 | return self.val_num
281 | return len(self.poses_test)
282 |
283 | def __getitem__(self, idx):
284 | if self.split == 'train': # use data in the buffers
285 | sample = {'rays': self.all_rays[idx],
286 | 'rgbs': self.all_rgbs[idx]}
287 |
288 | else:
289 | if self.split == 'val':
290 | c2w = torch.FloatTensor(self.c2w_val)
291 | else:
292 | c2w = torch.FloatTensor(self.poses_test[idx])
293 |
294 | rays_o, rays_d = get_rays(self.directions, c2w)
295 | if not self.spheric_poses:
296 | near, far = 0, 1
297 | rays_o, rays_d = get_ndc_rays(self.img_wh[1], self.img_wh[0],
298 | self.focal, 1.0, rays_o, rays_d)
299 | else:
300 | near = self.bounds.min()
301 | far = min(8 * near, self.bounds.max())
302 |
303 | rays = torch.cat([rays_o, rays_d,
304 | near*torch.ones_like(rays_o[:, :1]),
305 | far*torch.ones_like(rays_o[:, :1])],
306 | 1) # (h*w, 8)
307 |
308 | sample = {'rays': rays,
309 | 'c2w': c2w}
310 |
311 | if self.split == 'val':
312 | img = Image.open(self.image_path_val).convert('RGB')
313 | img = img.resize(self.img_wh, Image.LANCZOS)
314 | img = self.transform(img) # (3, h, w)
315 | img = img.view(3, -1).permute(1, 0) # (h*w, 3)
316 | sample['rgbs'] = img
317 |
318 | return sample
319 |
--------------------------------------------------------------------------------
/datasets/ray_utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from kornia import create_meshgrid
3 |
4 |
5 | def get_ray_directions(H, W, focal):
6 | """
7 | Get ray directions for all pixels in camera coordinate.
8 | Reference: https://www.scratchapixel.com/lessons/3d-basic-rendering/
9 | ray-tracing-generating-camera-rays/standard-coordinate-systems
10 |
11 | Inputs:
12 | H, W, focal: image height, width and focal length
13 |
14 | Outputs:
15 | directions: (H, W, 3), the direction of the rays in camera coordinate
16 | """
17 | grid = create_meshgrid(H, W, normalized_coordinates=False)[0]
18 | i, j = grid.unbind(-1)
19 | # the direction here is without +0.5 pixel centering as calibration is not so accurate
20 | # see https://github.com/bmild/nerf/issues/24
21 | directions = \
22 | torch.stack([(i-W/2)/focal, -(j-H/2)/focal, -torch.ones_like(i)], -1) # (H, W, 3)
23 |
24 | return directions
25 |
26 |
27 | def get_rays(directions, c2w):
28 | """
29 | Get ray origin and normalized directions in world coordinate for all pixels in one image.
30 | Reference: https://www.scratchapixel.com/lessons/3d-basic-rendering/
31 | ray-tracing-generating-camera-rays/standard-coordinate-systems
32 |
33 | Inputs:
34 | directions: (H, W, 3) precomputed ray directions in camera coordinate
35 | c2w: (3, 4) transformation matrix from camera coordinate to world coordinate
36 |
37 | Outputs:
38 | rays_o: (H*W, 3), the origin of the rays in world coordinate
39 | rays_d: (H*W, 3), the normalized direction of the rays in world coordinate
40 | """
41 | # Rotate ray directions from camera coordinate to the world coordinate
42 | rays_d = directions @ c2w[:, :3].T # (H, W, 3)
43 | rays_d = rays_d / torch.norm(rays_d, dim=-1, keepdim=True)
44 | # The origin of all rays is the camera origin in world coordinate
45 | rays_o = c2w[:, 3].expand(rays_d.shape) # (H, W, 3)
46 |
47 | rays_d = rays_d.view(-1, 3)
48 | rays_o = rays_o.view(-1, 3)
49 |
50 | return rays_o, rays_d
51 |
52 |
53 | def get_ndc_rays(H, W, focal, near, rays_o, rays_d):
54 | """
55 | Transform rays from world coordinate to NDC.
56 | NDC: Space such that the canvas is a cube with sides [-1, 1] in each axis.
57 | For detailed derivation, please see:
58 | http://www.songho.ca/opengl/gl_projectionmatrix.html
59 | https://github.com/bmild/nerf/files/4451808/ndc_derivation.pdf
60 |
61 | In practice, use NDC "if and only if" the scene is unbounded (has a large depth).
62 | See https://github.com/bmild/nerf/issues/18
63 |
64 | Inputs:
65 | H, W, focal: image height, width and focal length
66 | near: (N_rays) or float, the depths of the near plane
67 | rays_o: (N_rays, 3), the origin of the rays in world coordinate
68 | rays_d: (N_rays, 3), the direction of the rays in world coordinate
69 |
70 | Outputs:
71 | rays_o: (N_rays, 3), the origin of the rays in NDC
72 | rays_d: (N_rays, 3), the direction of the rays in NDC
73 | """
74 | # Shift ray origins to near plane
75 | t = -(near + rays_o[...,2]) / rays_d[...,2]
76 | rays_o = rays_o + t[...,None] * rays_d
77 |
78 | # Store some intermediate homogeneous results
79 | ox_oz = rays_o[...,0] / rays_o[...,2]
80 | oy_oz = rays_o[...,1] / rays_o[...,2]
81 |
82 | # Projection
83 | o0 = -1./(W/(2.*focal)) * ox_oz
84 | o1 = -1./(H/(2.*focal)) * oy_oz
85 | o2 = 1. + 2. * near / rays_o[...,2]
86 |
87 | d0 = -1./(W/(2.*focal)) * (rays_d[...,0]/rays_d[...,2] - ox_oz)
88 | d1 = -1./(H/(2.*focal)) * (rays_d[...,1]/rays_d[...,2] - oy_oz)
89 | d2 = 1 - o2
90 |
91 | rays_o = torch.stack([o0, o1, o2], -1) # (B, 3)
92 | rays_d = torch.stack([d0, d1, d2], -1) # (B, 3)
93 |
94 | return rays_o, rays_d
--------------------------------------------------------------------------------
/docs/.gitignore:
--------------------------------------------------------------------------------
1 | _site
2 | .sass-cache
3 | .jekyll-cache
4 | .jekyll-metadata
5 | vendor
6 |
--------------------------------------------------------------------------------
/docs/Gemfile:
--------------------------------------------------------------------------------
1 | source 'https://rubygems.org'
2 | gem 'github-pages', group: :jekyll_plugins
3 |
--------------------------------------------------------------------------------
/docs/Gemfile.lock:
--------------------------------------------------------------------------------
1 | GEM
2 | remote: https://rubygems.org/
3 | specs:
4 | activesupport (>= 6.0.3.1)
5 | concurrent-ruby (~> 1.0, >= 1.0.2)
6 | i18n (>= 0.7, < 2)
7 | minitest (~> 5.1)
8 | tzinfo (~> 1.1)
9 | zeitwerk (~> 2.2, >= 2.2.2)
10 | addressable (2.7.0)
11 | public_suffix (>= 2.0.2, < 5.0)
12 | coffee-script (2.4.1)
13 | coffee-script-source
14 | execjs
15 | coffee-script-source (1.11.1)
16 | colorator (1.1.0)
17 | commonmarker (0.17.13)
18 | ruby-enum (~> 0.5)
19 | concurrent-ruby (1.1.6)
20 | dnsruby (1.61.3)
21 | addressable (~> 2.5)
22 | em-websocket (0.5.1)
23 | eventmachine (>= 0.12.9)
24 | http_parser.rb (~> 0.6.0)
25 | ethon (0.12.0)
26 | ffi (>= 1.3.0)
27 | eventmachine (1.2.7)
28 | execjs (2.7.0)
29 | faraday (1.0.1)
30 | multipart-post (>= 1.2, < 3)
31 | ffi (1.12.2)
32 | forwardable-extended (2.6.0)
33 | gemoji (3.0.1)
34 | github-pages (204)
35 | github-pages-health-check (= 1.16.1)
36 | jekyll (= 3.8.5)
37 | jekyll-avatar (= 0.7.0)
38 | jekyll-coffeescript (= 1.1.1)
39 | jekyll-commonmark-ghpages (= 0.1.6)
40 | jekyll-default-layout (= 0.1.4)
41 | jekyll-feed (= 0.13.0)
42 | jekyll-gist (= 1.5.0)
43 | jekyll-github-metadata (= 2.13.0)
44 | jekyll-mentions (= 1.5.1)
45 | jekyll-optional-front-matter (= 0.3.2)
46 | jekyll-paginate (= 1.1.0)
47 | jekyll-readme-index (= 0.3.0)
48 | jekyll-redirect-from (= 0.15.0)
49 | jekyll-relative-links (= 0.6.1)
50 | jekyll-remote-theme (= 0.4.1)
51 | jekyll-sass-converter (= 1.5.2)
52 | jekyll-seo-tag (= 2.6.1)
53 | jekyll-sitemap (= 1.4.0)
54 | jekyll-swiss (= 1.0.0)
55 | jekyll-theme-architect (= 0.1.1)
56 | jekyll-theme-cayman (= 0.1.1)
57 | jekyll-theme-dinky (= 0.1.1)
58 | jekyll-theme-hacker (= 0.1.1)
59 | jekyll-theme-leap-day (= 0.1.1)
60 | jekyll-theme-merlot (= 0.1.1)
61 | jekyll-theme-midnight (= 0.1.1)
62 | jekyll-theme-minimal (= 0.1.1)
63 | jekyll-theme-modernist (= 0.1.1)
64 | jekyll-theme-primer (= 0.5.4)
65 | jekyll-theme-slate (= 0.1.1)
66 | jekyll-theme-tactile (= 0.1.1)
67 | jekyll-theme-time-machine (= 0.1.1)
68 | jekyll-titles-from-headings (= 0.5.3)
69 | jemoji (= 0.11.1)
70 | kramdown (>= 2.3.0)
71 | liquid (= 4.0.3)
72 | mercenary (~> 0.3)
73 | minima (= 2.5.1)
74 | nokogiri (>= 1.11.0.rc4, < 2.0)
75 | rouge (= 3.13.0)
76 | terminal-table (~> 1.4)
77 | github-pages-health-check (1.16.1)
78 | addressable (~> 2.3)
79 | dnsruby (~> 1.60)
80 | octokit (~> 4.0)
81 | public_suffix (~> 3.0)
82 | typhoeus (~> 1.3)
83 | html-pipeline (2.12.3)
84 | activesupport (>= 2)
85 | nokogiri (>= 1.4)
86 | http_parser.rb (0.6.0)
87 | i18n (0.9.5)
88 | concurrent-ruby (~> 1.0)
89 | jekyll (3.8.5)
90 | addressable (~> 2.4)
91 | colorator (~> 1.0)
92 | em-websocket (~> 0.5)
93 | i18n (~> 0.7)
94 | jekyll-sass-converter (~> 1.0)
95 | jekyll-watch (~> 2.0)
96 | kramdown (~> 1.14)
97 | liquid (~> 4.0)
98 | mercenary (~> 0.3.3)
99 | pathutil (~> 0.9)
100 | rouge (>= 1.7, < 4)
101 | safe_yaml (~> 1.0)
102 | jekyll-avatar (0.7.0)
103 | jekyll (>= 3.0, < 5.0)
104 | jekyll-coffeescript (1.1.1)
105 | coffee-script (~> 2.2)
106 | coffee-script-source (~> 1.11.1)
107 | jekyll-commonmark (1.3.1)
108 | commonmarker (~> 0.14)
109 | jekyll (>= 3.7, < 5.0)
110 | jekyll-commonmark-ghpages (0.1.6)
111 | commonmarker (~> 0.17.6)
112 | jekyll-commonmark (~> 1.2)
113 | rouge (>= 2.0, < 4.0)
114 | jekyll-default-layout (0.1.4)
115 | jekyll (~> 3.0)
116 | jekyll-feed (0.13.0)
117 | jekyll (>= 3.7, < 5.0)
118 | jekyll-gist (1.5.0)
119 | octokit (~> 4.2)
120 | jekyll-github-metadata (2.13.0)
121 | jekyll (>= 3.4, < 5.0)
122 | octokit (~> 4.0, != 4.4.0)
123 | jekyll-mentions (1.5.1)
124 | html-pipeline (~> 2.3)
125 | jekyll (>= 3.7, < 5.0)
126 | jekyll-optional-front-matter (0.3.2)
127 | jekyll (>= 3.0, < 5.0)
128 | jekyll-paginate (1.1.0)
129 | jekyll-readme-index (0.3.0)
130 | jekyll (>= 3.0, < 5.0)
131 | jekyll-redirect-from (0.15.0)
132 | jekyll (>= 3.3, < 5.0)
133 | jekyll-relative-links (0.6.1)
134 | jekyll (>= 3.3, < 5.0)
135 | jekyll-remote-theme (0.4.1)
136 | addressable (~> 2.0)
137 | jekyll (>= 3.5, < 5.0)
138 | rubyzip (>= 1.3.0)
139 | jekyll-sass-converter (1.5.2)
140 | sass (~> 3.4)
141 | jekyll-seo-tag (2.6.1)
142 | jekyll (>= 3.3, < 5.0)
143 | jekyll-sitemap (1.4.0)
144 | jekyll (>= 3.7, < 5.0)
145 | jekyll-swiss (1.0.0)
146 | jekyll-theme-architect (0.1.1)
147 | jekyll (~> 3.5)
148 | jekyll-seo-tag (~> 2.0)
149 | jekyll-theme-cayman (0.1.1)
150 | jekyll (~> 3.5)
151 | jekyll-seo-tag (~> 2.0)
152 | jekyll-theme-dinky (0.1.1)
153 | jekyll (~> 3.5)
154 | jekyll-seo-tag (~> 2.0)
155 | jekyll-theme-hacker (0.1.1)
156 | jekyll (~> 3.5)
157 | jekyll-seo-tag (~> 2.0)
158 | jekyll-theme-leap-day (0.1.1)
159 | jekyll (~> 3.5)
160 | jekyll-seo-tag (~> 2.0)
161 | jekyll-theme-merlot (0.1.1)
162 | jekyll (~> 3.5)
163 | jekyll-seo-tag (~> 2.0)
164 | jekyll-theme-midnight (0.1.1)
165 | jekyll (~> 3.5)
166 | jekyll-seo-tag (~> 2.0)
167 | jekyll-theme-minimal (0.1.1)
168 | jekyll (~> 3.5)
169 | jekyll-seo-tag (~> 2.0)
170 | jekyll-theme-modernist (0.1.1)
171 | jekyll (~> 3.5)
172 | jekyll-seo-tag (~> 2.0)
173 | jekyll-theme-primer (0.5.4)
174 | jekyll (> 3.5, < 5.0)
175 | jekyll-github-metadata (~> 2.9)
176 | jekyll-seo-tag (~> 2.0)
177 | jekyll-theme-slate (0.1.1)
178 | jekyll (~> 3.5)
179 | jekyll-seo-tag (~> 2.0)
180 | jekyll-theme-tactile (0.1.1)
181 | jekyll (~> 3.5)
182 | jekyll-seo-tag (~> 2.0)
183 | jekyll-theme-time-machine (0.1.1)
184 | jekyll (~> 3.5)
185 | jekyll-seo-tag (~> 2.0)
186 | jekyll-titles-from-headings (0.5.3)
187 | jekyll (>= 3.3, < 5.0)
188 | jekyll-watch (2.2.1)
189 | listen (~> 3.0)
190 | jemoji (0.11.1)
191 | gemoji (~> 3.0)
192 | html-pipeline (~> 2.2)
193 | jekyll (>= 3.0, < 5.0)
194 | kramdown (>= 2.3.0)
195 | liquid (4.0.3)
196 | listen (3.2.1)
197 | rb-fsevent (~> 0.10, >= 0.10.3)
198 | rb-inotify (~> 0.9, >= 0.9.10)
199 | mercenary (0.3.6)
200 | mini_portile2 (2.4.0)
201 | minima (2.5.1)
202 | jekyll (>= 3.5, < 5.0)
203 | jekyll-feed (~> 0.9)
204 | jekyll-seo-tag (~> 2.1)
205 | minitest (5.14.1)
206 | multipart-post (2.1.1)
207 | nokogiri (1.10.9)
208 | mini_portile2 (~> 2.4.0)
209 | octokit (4.18.0)
210 | faraday (>= 0.9)
211 | sawyer (~> 0.8.0, >= 0.5.3)
212 | pathutil (0.16.2)
213 | forwardable-extended (~> 2.6)
214 | public_suffix (3.1.1)
215 | rb-fsevent (0.10.4)
216 | rb-inotify (0.10.1)
217 | ffi (~> 1.0)
218 | rouge (3.13.0)
219 | ruby-enum (0.8.0)
220 | i18n
221 | rubyzip (2.3.0)
222 | safe_yaml (1.0.5)
223 | sass (3.7.4)
224 | sass-listen (~> 4.0.0)
225 | sass-listen (4.0.0)
226 | rb-fsevent (~> 0.9, >= 0.9.4)
227 | rb-inotify (~> 0.9, >= 0.9.7)
228 | sawyer (0.8.2)
229 | addressable (>= 2.3.5)
230 | faraday (> 0.8, < 2.0)
231 | terminal-table (1.8.0)
232 | unicode-display_width (~> 1.1, >= 1.1.1)
233 | thread_safe (0.3.6)
234 | typhoeus (1.4.0)
235 | ethon (>= 0.9.0)
236 | tzinfo (1.2.7)
237 | thread_safe (~> 0.1)
238 | unicode-display_width (1.7.0)
239 | zeitwerk (2.3.0)
240 |
241 | PLATFORMS
242 | ruby
243 |
244 | DEPENDENCIES
245 | github-pages
246 |
247 | BUNDLED WITH
248 | 2.1.4
249 |
--------------------------------------------------------------------------------
/docs/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-slate
2 |
--------------------------------------------------------------------------------
/docs/index.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 | # Author of this implementation
11 |
19 |
20 |
80 |
81 |
82 | # Call for contribution
83 | If you are expert in Unity and know how to make more visual appealing effects for the models shown above, feel free to contact me! I can share my code and data with you, and put your name on my github page!
84 |
--------------------------------------------------------------------------------
/docs/style.css:
--------------------------------------------------------------------------------
1 | #main_content {
2 | max-width: 960px;
3 | }
4 |
5 | .slick-slide {
6 | margin: 0 10px;
7 | }
8 |
9 | .slick-prev{
10 | left: -40px;
11 | }
12 |
13 | .slick-prev:before {
14 | font-size: 40px;
15 | color: blueviolet;
16 | }
17 | .slick-next:before {
18 | font-size: 40px;
19 | color: blueviolet;
20 | }
21 |
22 | .slick-dots li button:before{
23 | font-size: 20px;
24 | line-height: 20px;
25 | }
--------------------------------------------------------------------------------
/eval.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import os
3 | import numpy as np
4 | from collections import defaultdict
5 | from tqdm import tqdm
6 | import imageio
7 | from argparse import ArgumentParser
8 |
9 | from models.rendering import render_rays
10 | from models.nerf import *
11 |
12 | from utils import load_ckpt
13 | import metrics
14 |
15 | from datasets import dataset_dict
16 | from datasets.depth_utils import *
17 |
18 | torch.backends.cudnn.benchmark = True
19 |
20 | def get_opts():
21 | parser = ArgumentParser()
22 | parser.add_argument('--root_dir', type=str,
23 | default='/home/ubuntu/data/nerf_example_data/nerf_synthetic/lego',
24 | help='root directory of dataset')
25 | parser.add_argument('--dataset_name', type=str, default='blender',
26 | choices=['blender', 'llff'],
27 | help='which dataset to validate')
28 | parser.add_argument('--scene_name', type=str, default='test',
29 | help='scene name, used as output folder name')
30 | parser.add_argument('--split', type=str, default='test',
31 | help='test or test_train')
32 | parser.add_argument('--img_wh', nargs="+", type=int, default=[800, 800],
33 | help='resolution (img_w, img_h) of the image')
34 | parser.add_argument('--spheric_poses', default=False, action="store_true",
35 | help='whether images are taken in spheric poses (for llff)')
36 |
37 | parser.add_argument('--N_samples', type=int, default=64,
38 | help='number of coarse samples')
39 | parser.add_argument('--N_importance', type=int, default=128,
40 | help='number of additional fine samples')
41 | parser.add_argument('--use_disp', default=False, action="store_true",
42 | help='use disparity depth sampling')
43 | parser.add_argument('--chunk', type=int, default=32*1024*4,
44 | help='chunk size to split the input to avoid OOM')
45 |
46 | parser.add_argument('--ckpt_path', type=str, required=True,
47 | help='pretrained checkpoint path to load')
48 |
49 | parser.add_argument('--save_depth', default=False, action="store_true",
50 | help='whether to save depth prediction')
51 | parser.add_argument('--depth_format', type=str, default='pfm',
52 | choices=['pfm', 'bytes'],
53 | help='which format to save')
54 |
55 | return parser.parse_args()
56 |
57 |
58 | @torch.no_grad()
59 | def batched_inference(models, embeddings,
60 | rays, N_samples, N_importance, use_disp,
61 | chunk,
62 | white_back):
63 | """Do batched inference on rays using chunk."""
64 | B = rays.shape[0]
65 | chunk = 1024*32
66 | results = defaultdict(list)
67 | for i in range(0, B, chunk):
68 | rendered_ray_chunks = \
69 | render_rays(models,
70 | embeddings,
71 | rays[i:i+chunk],
72 | N_samples,
73 | use_disp,
74 | 0,
75 | 0,
76 | N_importance,
77 | chunk,
78 | dataset.white_back,
79 | test_time=True)
80 |
81 | for k, v in rendered_ray_chunks.items():
82 | results[k] += [v]
83 |
84 | for k, v in results.items():
85 | results[k] = torch.cat(v, 0)
86 | return results
87 |
88 |
89 | if __name__ == "__main__":
90 | args = get_opts()
91 | w, h = args.img_wh
92 |
93 | kwargs = {'root_dir': args.root_dir,
94 | 'split': args.split,
95 | 'img_wh': tuple(args.img_wh)}
96 | if args.dataset_name == 'llff':
97 | kwargs['spheric_poses'] = args.spheric_poses
98 | dataset = dataset_dict[args.dataset_name](**kwargs)
99 |
100 | embedding_xyz = Embedding(3, 10)
101 | embedding_dir = Embedding(3, 4)
102 | nerf_coarse = NeRF()
103 | nerf_fine = NeRF()
104 | load_ckpt(nerf_coarse, args.ckpt_path, model_name='nerf_coarse')
105 | load_ckpt(nerf_fine, args.ckpt_path, model_name='nerf_fine')
106 | nerf_coarse.cuda().eval()
107 | nerf_fine.cuda().eval()
108 |
109 | models = [nerf_coarse, nerf_fine]
110 | embeddings = [embedding_xyz, embedding_dir]
111 |
112 | imgs = []
113 | psnrs = []
114 | dir_name = f'results/{args.dataset_name}/{args.scene_name}'
115 | os.makedirs(dir_name, exist_ok=True)
116 |
117 | for i in tqdm(range(len(dataset))):
118 | sample = dataset[i]
119 | rays = sample['rays'].cuda()
120 | results = batched_inference(models, embeddings, rays,
121 | args.N_samples, args.N_importance, args.use_disp,
122 | args.chunk,
123 | dataset.white_back)
124 |
125 | img_pred = results['rgb_fine'].view(h, w, 3).cpu().numpy()
126 |
127 | if args.save_depth:
128 | depth_pred = results['depth_fine'].view(h, w).cpu().numpy()
129 | depth_pred = np.nan_to_num(depth_pred)
130 | if args.depth_format == 'pfm':
131 | save_pfm(os.path.join(dir_name, f'depth_{i:03d}.pfm'), depth_pred)
132 | else:
133 | with open(f'depth_{i:03d}', 'wb') as f:
134 | f.write(depth_pred.tobytes())
135 |
136 | img_pred_ = (img_pred*255).astype(np.uint8)
137 | imgs += [img_pred_]
138 | imageio.imwrite(os.path.join(dir_name, f'{i:03d}.png'), img_pred_)
139 |
140 | if 'rgbs' in sample:
141 | rgbs = sample['rgbs']
142 | img_gt = rgbs.view(h, w, 3)
143 | psnrs += [metrics.psnr(img_gt, img_pred).item()]
144 |
145 | imageio.mimsave(os.path.join(dir_name, f'{args.scene_name}.gif'), imgs, fps=30)
146 |
147 | if psnrs:
148 | mean_psnr = np.mean(psnrs)
149 | print(f'Mean PSNR : {mean_psnr:.2f}')
--------------------------------------------------------------------------------
/extract_color_mesh.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import os
3 | import numpy as np
4 | import cv2
5 | from PIL import Image
6 | from collections import defaultdict
7 | from tqdm import tqdm
8 | import mcubes
9 | import open3d as o3d
10 | from plyfile import PlyData, PlyElement
11 | from argparse import ArgumentParser
12 |
13 | from models.rendering import *
14 | from models.nerf import *
15 |
16 | from utils import load_ckpt
17 |
18 | from datasets import dataset_dict
19 |
20 | torch.backends.cudnn.benchmark = True
21 |
22 | def get_opts():
23 | parser = ArgumentParser()
24 | parser.add_argument('--root_dir', type=str,
25 | default='/home/ubuntu/data/nerf_example_data/nerf_synthetic/lego',
26 | help='root directory of dataset')
27 | parser.add_argument('--dataset_name', type=str, default='blender',
28 | choices=['blender', 'llff'],
29 | help='which dataset to validate')
30 | parser.add_argument('--scene_name', type=str, default='test',
31 | help='scene name, used as output ply filename')
32 | parser.add_argument('--img_wh', nargs="+", type=int, default=[800, 800],
33 | help='resolution (img_w, img_h) of the image')
34 |
35 | parser.add_argument('--N_samples', type=int, default=64,
36 | help='number of samples to infer the acculmulated opacity')
37 | parser.add_argument('--chunk', type=int, default=32*1024,
38 | help='chunk size to split the input to avoid OOM')
39 | parser.add_argument('--ckpt_path', type=str, required=True,
40 | help='pretrained checkpoint path to load')
41 |
42 | parser.add_argument('--N_grid', type=int, default=256,
43 | help='size of the grid on 1 side, larger=higher resolution')
44 | parser.add_argument('--x_range', nargs="+", type=float, default=[-1.0, 1.0],
45 | help='x range of the object')
46 | parser.add_argument('--y_range', nargs="+", type=float, default=[-1.0, 1.0],
47 | help='x range of the object')
48 | parser.add_argument('--z_range', nargs="+", type=float, default=[-1.0, 1.0],
49 | help='x range of the object')
50 | parser.add_argument('--sigma_threshold', type=float, default=20.0,
51 | help='threshold to consider a location is occupied')
52 | parser.add_argument('--occ_threshold', type=float, default=0.2,
53 | help='''threshold to consider a vertex is occluded.
54 | larger=fewer occluded pixels''')
55 |
56 | #### method using vertex normals ####
57 | parser.add_argument('--use_vertex_normal', action="store_true",
58 | help='use vertex normals to compute color')
59 | parser.add_argument('--N_importance', type=int, default=64,
60 | help='number of fine samples to infer the acculmulated opacity')
61 | parser.add_argument('--near_t', type=float, default=1.0,
62 | help='the near bound factor to start the ray')
63 |
64 | return parser.parse_args()
65 |
66 |
67 | @torch.no_grad()
68 | def f(models, embeddings, rays, N_samples, N_importance, chunk, white_back):
69 | """Do batched inference on rays using chunk."""
70 | B = rays.shape[0]
71 | results = defaultdict(list)
72 | for i in range(0, B, chunk):
73 | rendered_ray_chunks = \
74 | render_rays(models,
75 | embeddings,
76 | rays[i:i+chunk],
77 | N_samples,
78 | False,
79 | 0,
80 | 0,
81 | N_importance,
82 | chunk,
83 | white_back,
84 | test_time=True)
85 |
86 | for k, v in rendered_ray_chunks.items():
87 | results[k] += [v]
88 |
89 | for k, v in results.items():
90 | results[k] = torch.cat(v, 0)
91 | return results
92 |
93 |
94 | if __name__ == "__main__":
95 | args = get_opts()
96 |
97 | kwargs = {'root_dir': args.root_dir,
98 | 'img_wh': tuple(args.img_wh)}
99 | if args.dataset_name == 'llff':
100 | kwargs['spheric_poses'] = True
101 | kwargs['split'] = 'test'
102 | else:
103 | kwargs['split'] = 'train'
104 | dataset = dataset_dict[args.dataset_name](**kwargs)
105 |
106 | embedding_xyz = Embedding(3, 10)
107 | embedding_dir = Embedding(3, 4)
108 | embeddings = [embedding_xyz, embedding_dir]
109 | nerf_fine = NeRF()
110 | load_ckpt(nerf_fine, args.ckpt_path, model_name='nerf_fine')
111 | nerf_fine.cuda().eval()
112 |
113 | # define the dense grid for query
114 | N = args.N_grid
115 | xmin, xmax = args.x_range
116 | ymin, ymax = args.y_range
117 | zmin, zmax = args.z_range
118 | # assert xmax-xmin == ymax-ymin == zmax-zmin, 'the ranges must have the same length!'
119 | x = np.linspace(xmin, xmax, N)
120 | y = np.linspace(ymin, ymax, N)
121 | z = np.linspace(zmin, zmax, N)
122 |
123 | xyz_ = torch.FloatTensor(np.stack(np.meshgrid(x, y, z), -1).reshape(-1, 3)).cuda()
124 | dir_ = torch.zeros_like(xyz_).cuda()
125 | # sigma is independent of direction, so any value here will produce the same result
126 |
127 | # predict sigma (occupancy) for each grid location
128 | print('Predicting occupancy ...')
129 | with torch.no_grad():
130 | B = xyz_.shape[0]
131 | out_chunks = []
132 | for i in tqdm(range(0, B, args.chunk)):
133 | xyz_embedded = embedding_xyz(xyz_[i:i+args.chunk]) # (N, embed_xyz_channels)
134 | dir_embedded = embedding_dir(dir_[i:i+args.chunk]) # (N, embed_dir_channels)
135 | xyzdir_embedded = torch.cat([xyz_embedded, dir_embedded], 1)
136 | out_chunks += [nerf_fine(xyzdir_embedded)]
137 | rgbsigma = torch.cat(out_chunks, 0)
138 |
139 | sigma = rgbsigma[:, -1].cpu().numpy()
140 | sigma = np.maximum(sigma, 0).reshape(N, N, N)
141 |
142 | # perform marching cube algorithm to retrieve vertices and triangle mesh
143 | print('Extracting mesh ...')
144 | vertices, triangles = mcubes.marching_cubes(sigma, args.sigma_threshold)
145 |
146 | ##### Until mesh extraction here, it is the same as the original repo. ######
147 |
148 | vertices_ = (vertices/N).astype(np.float32)
149 | ## invert x and y coordinates (WHY? maybe because of the marching cubes algo)
150 | x_ = (ymax-ymin) * vertices_[:, 1] + ymin
151 | y_ = (xmax-xmin) * vertices_[:, 0] + xmin
152 | vertices_[:, 0] = x_
153 | vertices_[:, 1] = y_
154 | vertices_[:, 2] = (zmax-zmin) * vertices_[:, 2] + zmin
155 | vertices_.dtype = [('x', 'f4'), ('y', 'f4'), ('z', 'f4')]
156 |
157 | face = np.empty(len(triangles), dtype=[('vertex_indices', 'i4', (3,))])
158 | face['vertex_indices'] = triangles
159 |
160 | PlyData([PlyElement.describe(vertices_[:, 0], 'vertex'),
161 | PlyElement.describe(face, 'face')]).write(f'{args.scene_name}.ply')
162 |
163 | # remove noise in the mesh by keeping only the biggest cluster
164 | print('Removing noise ...')
165 | mesh = o3d.io.read_triangle_mesh(f"{args.scene_name}.ply")
166 | idxs, count, _ = mesh.cluster_connected_triangles()
167 | max_cluster_idx = np.argmax(count)
168 | triangles_to_remove = [i for i in range(len(face)) if idxs[i] != max_cluster_idx]
169 | mesh.remove_triangles_by_index(triangles_to_remove)
170 | mesh.remove_unreferenced_vertices()
171 | print(f'Mesh has {len(mesh.vertices)/1e6:.2f} M vertices and {len(mesh.triangles)/1e6:.2f} M faces.')
172 |
173 | vertices_ = np.asarray(mesh.vertices).astype(np.float32)
174 | triangles = np.asarray(mesh.triangles)
175 |
176 | # perform color prediction
177 | # Step 0. define constants (image width, height and intrinsics)
178 | W, H = args.img_wh
179 | K = np.array([[dataset.focal, 0, W/2],
180 | [0, dataset.focal, H/2],
181 | [0, 0, 1]]).astype(np.float32)
182 |
183 | # Step 1. transform vertices into world coordinate
184 | N_vertices = len(vertices_)
185 | vertices_homo = np.concatenate([vertices_, np.ones((N_vertices, 1))], 1) # (N, 4)
186 |
187 | if args.use_vertex_normal: ## use normal vector method as suggested by the author.
188 | ## see https://github.com/bmild/nerf/issues/44
189 | mesh.compute_vertex_normals()
190 | rays_d = torch.FloatTensor(np.asarray(mesh.vertex_normals))
191 | near = dataset.bounds.min() * torch.ones_like(rays_d[:, :1])
192 | far = dataset.bounds.max() * torch.ones_like(rays_d[:, :1])
193 | rays_o = torch.FloatTensor(vertices_) - rays_d * near * args.near_t
194 |
195 | nerf_coarse = NeRF()
196 | load_ckpt(nerf_coarse, args.ckpt_path, model_name='nerf_coarse')
197 | nerf_coarse.cuda().eval()
198 |
199 | results = f([nerf_coarse, nerf_fine], embeddings,
200 | torch.cat([rays_o, rays_d, near, far], 1).cuda(),
201 | args.N_samples,
202 | args.N_importance,
203 | args.chunk,
204 | dataset.white_back)
205 |
206 | else: ## use my color average method. see README_mesh.md
207 | ## buffers to store the final averaged color
208 | non_occluded_sum = np.zeros((N_vertices, 1))
209 | v_color_sum = np.zeros((N_vertices, 3))
210 |
211 | # Step 2. project the vertices onto each training image to infer the color
212 | print('Fusing colors ...')
213 | for idx in tqdm(range(len(dataset.image_paths))):
214 | ## read image of this pose
215 | image = Image.open(dataset.image_paths[idx]).convert('RGB')
216 | image = image.resize(tuple(args.img_wh), Image.LANCZOS)
217 | image = np.array(image)
218 |
219 | ## read the camera to world relative pose
220 | P_c2w = np.concatenate([dataset.poses[idx], np.array([0, 0, 0, 1]).reshape(1, 4)], 0)
221 | P_w2c = np.linalg.inv(P_c2w)[:3] # (3, 4)
222 | ## project vertices from world coordinate to camera coordinate
223 | vertices_cam = (P_w2c @ vertices_homo.T) # (3, N) in "right up back"
224 | vertices_cam[1:] *= -1 # (3, N) in "right down forward"
225 | ## project vertices from camera coordinate to pixel coordinate
226 | vertices_image = (K @ vertices_cam).T # (N, 3)
227 | depth = vertices_image[:, -1:]+1e-5 # the depth of the vertices, used as far plane
228 | vertices_image = vertices_image[:, :2]/depth
229 | vertices_image = vertices_image.astype(np.float32)
230 | vertices_image[:, 0] = np.clip(vertices_image[:, 0], 0, W-1)
231 | vertices_image[:, 1] = np.clip(vertices_image[:, 1], 0, H-1)
232 |
233 | ## compute the color on these projected pixel coordinates
234 | ## using bilinear interpolation.
235 | ## NOTE: opencv's implementation has a size limit of 32768 pixels per side,
236 | ## so we split the input into chunks.
237 | colors = []
238 | remap_chunk = int(3e4)
239 | for i in range(0, N_vertices, remap_chunk):
240 | colors += [cv2.remap(image,
241 | vertices_image[i:i+remap_chunk, 0],
242 | vertices_image[i:i+remap_chunk, 1],
243 | interpolation=cv2.INTER_LINEAR)[:, 0]]
244 | colors = np.vstack(colors) # (N_vertices, 3)
245 |
246 | ## predict occlusion of each vertex
247 | ## we leverage the concept of NeRF by constructing rays coming out from the camera
248 | ## and hitting each vertex; by computing the accumulated opacity along this path,
249 | ## we can know if the vertex is occluded or not.
250 | ## for vertices that appear to be occluded from every input view, we make the
251 | ## assumption that its color is the same as its neighbors that are facing our side.
252 | ## (think of a surface with one side facing us: we assume the other side has the same color)
253 |
254 | ## ray's origin is camera origin
255 | rays_o = torch.FloatTensor(dataset.poses[idx][:, -1]).expand(N_vertices, 3)
256 | ## ray's direction is the vector pointing from camera origin to the vertices
257 | rays_d = torch.FloatTensor(vertices_) - rays_o # (N_vertices, 3)
258 | rays_d = rays_d / torch.norm(rays_d, dim=-1, keepdim=True)
259 | near = dataset.bounds.min() * torch.ones_like(rays_o[:, :1])
260 | ## the far plane is the depth of the vertices, since what we want is the accumulated
261 | ## opacity along the path from camera origin to the vertices
262 | far = torch.FloatTensor(depth) * torch.ones_like(rays_o[:, :1])
263 | results = f([nerf_fine], embeddings,
264 | torch.cat([rays_o, rays_d, near, far], 1).cuda(),
265 | args.N_samples,
266 | 0,
267 | args.chunk,
268 | dataset.white_back)
269 | opacity = results['opacity_coarse'].cpu().numpy()[:, np.newaxis] # (N_vertices, 1)
270 | opacity = np.nan_to_num(opacity, 1)
271 |
272 | non_occluded = np.ones_like(non_occluded_sum) * 0.1/depth # weight by inverse depth
273 | # near=more confident in color
274 | non_occluded += opacity < args.occ_threshold
275 |
276 | v_color_sum += colors * non_occluded
277 | non_occluded_sum += non_occluded
278 |
279 | # Step 3. combine the output and write to file
280 | if args.use_vertex_normal:
281 | v_colors = results['rgb_fine'].cpu().numpy() * 255.0
282 | else: ## the combined color is the average color among all views
283 | v_colors = v_color_sum/non_occluded_sum
284 | v_colors = v_colors.astype(np.uint8)
285 | v_colors.dtype = [('red', 'u1'), ('green', 'u1'), ('blue', 'u1')]
286 | vertices_.dtype = [('x', 'f4'), ('y', 'f4'), ('z', 'f4')]
287 | vertex_all = np.empty(N_vertices, vertices_.dtype.descr+v_colors.dtype.descr)
288 | for prop in vertices_.dtype.names:
289 | vertex_all[prop] = vertices_[prop][:, 0]
290 | for prop in v_colors.dtype.names:
291 | vertex_all[prop] = v_colors[prop][:, 0]
292 |
293 | face = np.empty(len(triangles), dtype=[('vertex_indices', 'i4', (3,))])
294 | face['vertex_indices'] = triangles
295 |
296 | PlyData([PlyElement.describe(vertex_all, 'vertex'),
297 | PlyElement.describe(face, 'face')]).write(f'{args.scene_name}.ply')
298 |
299 | print('Done!')
300 |
--------------------------------------------------------------------------------
/extract_mesh.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "import torch\n",
10 | "from collections import defaultdict\n",
11 | "import numpy as np\n",
12 | "import mcubes\n",
13 | "import trimesh\n",
14 | "\n",
15 | "from models.rendering import *\n",
16 | "from models.nerf import *\n",
17 | "\n",
18 | "from datasets import dataset_dict\n",
19 | "\n",
20 | "from utils import load_ckpt"
21 | ]
22 | },
23 | {
24 | "cell_type": "markdown",
25 | "metadata": {},
26 | "source": [
27 | "# Load model and data"
28 | ]
29 | },
30 | {
31 | "cell_type": "code",
32 | "execution_count": null,
33 | "metadata": {},
34 | "outputs": [],
35 | "source": [
36 | "# Change here #\n",
37 | "img_wh = (800, 800) # full resolution of the input images\n",
38 | "dataset_name = 'blender' # blender or llff (own data)\n",
39 | "scene_name = 'lego' # whatever you want\n",
40 | "root_dir = '/home/ubuntu/data/nerf_example_data/nerf_synthetic/lego/' # the folder containing data\n",
41 | "ckpt_path = 'ckpts/exp2/epoch=05.ckpt' # the model path\n",
42 | "###############\n",
43 | "\n",
44 | "kwargs = {'root_dir': root_dir,\n",
45 | " 'img_wh': img_wh}\n",
46 | "if dataset_name == 'llff':\n",
47 | " kwargs['spheric_poses'] = True\n",
48 | " kwargs['split'] = 'test'\n",
49 | "else:\n",
50 | " kwargs['split'] = 'train'\n",
51 | " \n",
52 | "chunk = 1024*32\n",
53 | "dataset = dataset_dict[dataset_name](**kwargs)\n",
54 | "\n",
55 | "embedding_xyz = Embedding(3, 10)\n",
56 | "embedding_dir = Embedding(3, 4)\n",
57 | "\n",
58 | "nerf_fine = NeRF()\n",
59 | "load_ckpt(nerf_fine, ckpt_path, model_name='nerf_fine')\n",
60 | "nerf_fine.cuda().eval();"
61 | ]
62 | },
63 | {
64 | "cell_type": "markdown",
65 | "metadata": {},
66 | "source": [
67 | "# Search for tight bounds of the object (trial and error!)"
68 | ]
69 | },
70 | {
71 | "cell_type": "code",
72 | "execution_count": null,
73 | "metadata": {},
74 | "outputs": [],
75 | "source": [
76 | "### Tune these parameters until the whole object lies tightly in range with little noise ###\n",
77 | "N = 128 # controls the resolution, set this number small here because we're only finding\n",
78 | " # good ranges here, not yet for mesh reconstruction; we can set this number high\n",
79 | " # when it comes to final reconstruction.\n",
80 | "xmin, xmax = -1.2, 1.2 # left/right range\n",
81 | "ymin, ymax = -1.2, 1.2 # forward/backward range\n",
82 | "zmin, zmax = -1.2, 1.2 # up/down range\n",
83 | "## Attention! the ranges MUST have the same length!\n",
84 | "sigma_threshold = 50. # controls the noise (lower=maybe more noise; higher=some mesh might be missing)\n",
85 | "############################################################################################\n",
86 | "\n",
87 | "x = np.linspace(xmin, xmax, N)\n",
88 | "y = np.linspace(ymin, ymax, N)\n",
89 | "z = np.linspace(zmin, zmax, N)\n",
90 | "\n",
91 | "xyz_ = torch.FloatTensor(np.stack(np.meshgrid(x, y, z), -1).reshape(-1, 3)).cuda()\n",
92 | "dir_ = torch.zeros_like(xyz_).cuda()\n",
93 | "\n",
94 | "with torch.no_grad():\n",
95 | " B = xyz_.shape[0]\n",
96 | " out_chunks = []\n",
97 | " for i in range(0, B, chunk):\n",
98 | " xyz_embedded = embedding_xyz(xyz_[i:i+chunk]) # (N, embed_xyz_channels)\n",
99 | " dir_embedded = embedding_dir(dir_[i:i+chunk]) # (N, embed_dir_channels)\n",
100 | " xyzdir_embedded = torch.cat([xyz_embedded, dir_embedded], 1)\n",
101 | " out_chunks += [nerf_fine(xyzdir_embedded)]\n",
102 | " rgbsigma = torch.cat(out_chunks, 0)\n",
103 | " \n",
104 | "sigma = rgbsigma[:, -1].cpu().numpy()\n",
105 | "sigma = np.maximum(sigma, 0)\n",
106 | "sigma = sigma.reshape(N, N, N)\n",
107 | "\n",
108 | "# The below lines are for visualization, COMMENT OUT once you find the best range and increase N!\n",
109 | "vertices, triangles = mcubes.marching_cubes(sigma, sigma_threshold)\n",
110 | "mesh = trimesh.Trimesh(vertices/N, triangles)\n",
111 | "mesh.show()"
112 | ]
113 | },
114 | {
115 | "cell_type": "code",
116 | "execution_count": null,
117 | "metadata": {},
118 | "outputs": [],
119 | "source": [
120 | "# # You can already export \"colorless\" mesh if you don't need color\n",
121 | "# mcubes.export_mesh(vertices, triangles, f\"{scene_name}.dae\")"
122 | ]
123 | },
124 | {
125 | "cell_type": "markdown",
126 | "metadata": {},
127 | "source": [
128 | "# Generate .vol file for volume rendering in Unity"
129 | ]
130 | },
131 | {
132 | "cell_type": "code",
133 | "execution_count": null,
134 | "metadata": {},
135 | "outputs": [],
136 | "source": [
137 | "assert N==512, \\\n",
138 | " 'Please set N to 512 in the two above cell! Remember to comment out the visualization code (last 3 lines)!'\n",
139 | "\n",
140 | "a = 1-np.exp(-(xmax-xmin)/N*sigma)\n",
141 | "a = a.flatten()\n",
142 | "rgb = (rgbsigma[:, :3].numpy()*255).astype(np.uint32)\n",
143 | "i = np.where(a>0)[0] # valid indices (alpha>0)\n",
144 | "\n",
145 | "rgb = rgb[i]\n",
146 | "a = a[i]\n",
147 | "s = rgb.dot(np.array([1<<24, 1<<16, 1<<8])) + (a*255).astype(np.uint32)\n",
148 | "res = np.stack([i, s], -1).astype(np.uint32).flatten()\n",
149 | "with open(f'{scene_name}.vol', 'wb') as f:\n",
150 | " f.write(res.tobytes())"
151 | ]
152 | },
153 | {
154 | "cell_type": "markdown",
155 | "metadata": {},
156 | "source": [
157 | "# Extract colored mesh\n",
158 | "\n",
159 | "Once you find the best range, now **RESTART** the notebook, and copy the configs to the following cell\n",
160 | "and execute it."
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": null,
166 | "metadata": {},
167 | "outputs": [],
168 | "source": [
169 | "# Copy the variables you have above here! ####\n",
170 | "img_wh = (800, 800) # full resolution of the input images\n",
171 | "dataset_name = 'blender' # blender or llff (own data)\n",
172 | "scene_name = 'lego' # whatever you want\n",
173 | "root_dir = '/home/ubuntu/data/nerf_example_data/nerf_synthetic/lego/' # the folder containing data\n",
174 | "ckpt_path = 'ckpts/exp2/epoch=05.ckpt' # the model path\n",
175 | "\n",
176 | "N = 128 # controls the resolution, set this number small here because we're only finding\n",
177 | " # good ranges here, not yet for mesh reconstruction; we can set this number high\n",
178 | " # when it comes to final reconstruction.\n",
179 | "xmin, xmax = -1.2, 1.2 # left/right range\n",
180 | "ymin, ymax = -1.2, 1.2 # forward/backward range\n",
181 | "zmin, zmax = -1.2, 1.2 # up/down range\n",
182 | "sigma_threshold = 50. # controls the noise (lower=maybe more noise; higher=some mesh might be missing)\n",
183 | "###############################################\n",
184 | "\n",
185 | "import os\n",
186 | "os.environ['ROOT_DIR'] = root_dir\n",
187 | "os.environ['DATASET_NAME'] = dataset_name\n",
188 | "os.environ['SCENE_NAME'] = scene_name\n",
189 | "os.environ['IMG_SIZE'] = f\"{img_wh[0]} {img_wh[1]}\"\n",
190 | "os.environ['CKPT_PATH'] = ckpt_path\n",
191 | "os.environ['N_GRID'] = \"256\" # final resolution. You can set this number high to preserve more details\n",
192 | "os.environ['X_RANGE'] = f\"{xmin} {xmax}\"\n",
193 | "os.environ['Y_RANGE'] = f\"{ymin} {ymax}\"\n",
194 | "os.environ['Z_RANGE'] = f\"{zmin} {zmax}\"\n",
195 | "os.environ['SIGMA_THRESHOLD'] = str(sigma_threshold)\n",
196 | "os.environ['OCC_THRESHOLD'] = \"0.2\" # probably doesn't require tuning. If you find the color is not close\n",
197 | " # to real, try to set this number smaller (the effect of this number\n",
198 | " # is explained in my youtube video)\n",
199 | "\n",
200 | "!python extract_color_mesh.py \\\n",
201 | " --root_dir $ROOT_DIR \\\n",
202 | " --dataset_name $DATASET_NAME \\\n",
203 | " --scene_name $SCENE_NAME \\\n",
204 | " --img_wh $IMG_SIZE \\\n",
205 | " --ckpt_path $CKPT_PATH \\\n",
206 | " --N_grid $N_GRID \\\n",
207 | " --x_range $X_RANGE \\\n",
208 | " --y_range $Y_RANGE \\\n",
209 | " --z_range $Z_RANGE \\\n",
210 | " --sigma_threshold $SIGMA_THRESHOLD \\\n",
211 | " --occ_threshold $OCC_THRESHOLD"
212 | ]
213 | },
214 | {
215 | "cell_type": "code",
216 | "execution_count": null,
217 | "metadata": {},
218 | "outputs": [],
219 | "source": []
220 | }
221 | ],
222 | "metadata": {
223 | "kernelspec": {
224 | "display_name": "nerf_pl",
225 | "language": "python",
226 | "name": "nerf_pl"
227 | },
228 | "language_info": {
229 | "codemirror_mode": {
230 | "name": "ipython",
231 | "version": 3
232 | },
233 | "file_extension": ".py",
234 | "mimetype": "text/x-python",
235 | "name": "python",
236 | "nbconvert_exporter": "python",
237 | "pygments_lexer": "ipython3",
238 | "version": "3.6.10"
239 | }
240 | },
241 | "nbformat": 4,
242 | "nbformat_minor": 4
243 | }
244 |
--------------------------------------------------------------------------------
/losses.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 |
4 | class MSELoss(nn.Module):
5 | def __init__(self):
6 | super(MSELoss, self).__init__()
7 | self.loss = nn.MSELoss(reduction='mean')
8 |
9 | def forward(self, inputs, targets):
10 | loss = self.loss(inputs['rgb_coarse'], targets)
11 | if 'rgb_fine' in inputs:
12 | loss += self.loss(inputs['rgb_fine'], targets)
13 |
14 | return loss
15 |
16 |
17 | loss_dict = {'mse': MSELoss}
--------------------------------------------------------------------------------
/metrics.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from kornia.losses import ssim as dssim
3 |
4 | def mse(image_pred, image_gt, valid_mask=None, reduction='mean'):
5 | value = (image_pred-image_gt)**2
6 | if valid_mask is not None:
7 | value = value[valid_mask]
8 | if reduction == 'mean':
9 | return torch.mean(value)
10 | return value
11 |
12 | def psnr(image_pred, image_gt, valid_mask=None, reduction='mean'):
13 | return -10*torch.log10(mse(image_pred, image_gt, valid_mask, reduction))
14 |
15 | def ssim(image_pred, image_gt, reduction='mean'):
16 | """
17 | image_pred and image_gt: (1, 3, H, W)
18 | """
19 | dssim_ = dssim(image_pred, image_gt, 3, reduction) # dissimilarity in [0, 1]
20 | return 1-2*dssim_ # in [-1, 1]
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kwea123/nerf_pl/52aeb387da64a9ad9a0f914ea9b049ffc598b20c/models/__init__.py
--------------------------------------------------------------------------------
/models/nerf.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 |
4 | class Embedding(nn.Module):
5 | def __init__(self, in_channels, N_freqs, logscale=True):
6 | """
7 | Defines a function that embeds x to (x, sin(2^k x), cos(2^k x), ...)
8 | in_channels: number of input channels (3 for both xyz and direction)
9 | """
10 | super(Embedding, self).__init__()
11 | self.N_freqs = N_freqs
12 | self.in_channels = in_channels
13 | self.funcs = [torch.sin, torch.cos]
14 | self.out_channels = in_channels*(len(self.funcs)*N_freqs+1)
15 |
16 | if logscale:
17 | self.freq_bands = 2**torch.linspace(0, N_freqs-1, N_freqs)
18 | else:
19 | self.freq_bands = torch.linspace(1, 2**(N_freqs-1), N_freqs)
20 |
21 | def forward(self, x):
22 | """
23 | Embeds x to (x, sin(2^k x), cos(2^k x), ...)
24 | Different from the paper, "x" is also in the output
25 | See https://github.com/bmild/nerf/issues/12
26 |
27 | Inputs:
28 | x: (B, self.in_channels)
29 |
30 | Outputs:
31 | out: (B, self.out_channels)
32 | """
33 | out = [x]
34 | for freq in self.freq_bands:
35 | for func in self.funcs:
36 | out += [func(freq*x)]
37 |
38 | return torch.cat(out, -1)
39 |
40 |
41 | class NeRF(nn.Module):
42 | def __init__(self,
43 | D=8, W=256,
44 | in_channels_xyz=63, in_channels_dir=27,
45 | skips=[4]):
46 | """
47 | D: number of layers for density (sigma) encoder
48 | W: number of hidden units in each layer
49 | in_channels_xyz: number of input channels for xyz (3+3*10*2=63 by default)
50 | in_channels_dir: number of input channels for direction (3+3*4*2=27 by default)
51 | skips: add skip connection in the Dth layer
52 | """
53 | super(NeRF, self).__init__()
54 | self.D = D
55 | self.W = W
56 | self.in_channels_xyz = in_channels_xyz
57 | self.in_channels_dir = in_channels_dir
58 | self.skips = skips
59 |
60 | # xyz encoding layers
61 | for i in range(D):
62 | if i == 0:
63 | layer = nn.Linear(in_channels_xyz, W)
64 | elif i in skips:
65 | layer = nn.Linear(W+in_channels_xyz, W)
66 | else:
67 | layer = nn.Linear(W, W)
68 | layer = nn.Sequential(layer, nn.ReLU(True))
69 | setattr(self, f"xyz_encoding_{i+1}", layer)
70 | self.xyz_encoding_final = nn.Linear(W, W)
71 |
72 | # direction encoding layers
73 | self.dir_encoding = nn.Sequential(
74 | nn.Linear(W+in_channels_dir, W//2),
75 | nn.ReLU(True))
76 |
77 | # output layers
78 | self.sigma = nn.Linear(W, 1)
79 | self.rgb = nn.Sequential(
80 | nn.Linear(W//2, 3),
81 | nn.Sigmoid())
82 |
83 | def forward(self, x, sigma_only=False):
84 | """
85 | Encodes input (xyz+dir) to rgb+sigma (not ready to render yet).
86 | For rendering this ray, please see rendering.py
87 |
88 | Inputs:
89 | x: (B, self.in_channels_xyz(+self.in_channels_dir))
90 | the embedded vector of position and direction
91 | sigma_only: whether to infer sigma only. If True,
92 | x is of shape (B, self.in_channels_xyz)
93 |
94 | Outputs:
95 | if sigma_ony:
96 | sigma: (B, 1) sigma
97 | else:
98 | out: (B, 4), rgb and sigma
99 | """
100 | if not sigma_only:
101 | input_xyz, input_dir = \
102 | torch.split(x, [self.in_channels_xyz, self.in_channels_dir], dim=-1)
103 | else:
104 | input_xyz = x
105 |
106 | xyz_ = input_xyz
107 | for i in range(self.D):
108 | if i in self.skips:
109 | xyz_ = torch.cat([input_xyz, xyz_], -1)
110 | xyz_ = getattr(self, f"xyz_encoding_{i+1}")(xyz_)
111 |
112 | sigma = self.sigma(xyz_)
113 | if sigma_only:
114 | return sigma
115 |
116 | xyz_encoding_final = self.xyz_encoding_final(xyz_)
117 |
118 | dir_encoding_input = torch.cat([xyz_encoding_final, input_dir], -1)
119 | dir_encoding = self.dir_encoding(dir_encoding_input)
120 | rgb = self.rgb(dir_encoding)
121 |
122 | out = torch.cat([rgb, sigma], -1)
123 |
124 | return out
--------------------------------------------------------------------------------
/models/rendering.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torchsearchsorted import searchsorted
3 |
4 | __all__ = ['render_rays']
5 |
6 | """
7 | Function dependencies: (-> means function calls)
8 |
9 | @render_rays -> @inference
10 |
11 | @render_rays -> @sample_pdf if there is fine model
12 | """
13 |
14 | def sample_pdf(bins, weights, N_importance, det=False, eps=1e-5):
15 | """
16 | Sample @N_importance samples from @bins with distribution defined by @weights.
17 |
18 | Inputs:
19 | bins: (N_rays, N_samples_+1) where N_samples_ is "the number of coarse samples per ray - 2"
20 | weights: (N_rays, N_samples_)
21 | N_importance: the number of samples to draw from the distribution
22 | det: deterministic or not
23 | eps: a small number to prevent division by zero
24 |
25 | Outputs:
26 | samples: the sampled samples
27 | """
28 | N_rays, N_samples_ = weights.shape
29 | weights = weights + eps # prevent division by zero (don't do inplace op!)
30 | pdf = weights / torch.sum(weights, -1, keepdim=True) # (N_rays, N_samples_)
31 | cdf = torch.cumsum(pdf, -1) # (N_rays, N_samples), cumulative distribution function
32 | cdf = torch.cat([torch.zeros_like(cdf[: ,:1]), cdf], -1) # (N_rays, N_samples_+1)
33 | # padded to 0~1 inclusive
34 |
35 | if det:
36 | u = torch.linspace(0, 1, N_importance, device=bins.device)
37 | u = u.expand(N_rays, N_importance)
38 | else:
39 | u = torch.rand(N_rays, N_importance, device=bins.device)
40 | u = u.contiguous()
41 |
42 | inds = searchsorted(cdf, u, side='right')
43 | below = torch.clamp_min(inds-1, 0)
44 | above = torch.clamp_max(inds, N_samples_)
45 |
46 | inds_sampled = torch.stack([below, above], -1).view(N_rays, 2*N_importance)
47 | cdf_g = torch.gather(cdf, 1, inds_sampled).view(N_rays, N_importance, 2)
48 | bins_g = torch.gather(bins, 1, inds_sampled).view(N_rays, N_importance, 2)
49 |
50 | denom = cdf_g[...,1]-cdf_g[...,0]
51 | denom[denom
48 |
49 | The spurious face on the mantle disappears, and the colored pixels are almost exactly the ones we can observe from the image. By default we set the vertices to be all black, so a black vertex means it's occluded in this view, but will be assigned color when we change to other views.
50 |
51 |
52 | # Finally...
53 |
54 | This is the final result:
55 |
56 |
57 |
58 | We can then export this `.ply` file to any other format, and embed in programs like I did in Unity:
59 | (I use [this plugin](https://github.com/kwea123/Pcx) to import `.ply` file to unity, and made some modifications so that it can also read mesh triangles, not only the points)
60 |
61 | 
62 |
63 | The meshes can be attached a meshcollider so that they can interact with other objects. You can see [this video](https://youtu.be/I2M0xhnrBos) for a demo.
64 |
65 | ## Further reading
66 | The author suggested [another way](https://github.com/bmild/nerf/issues/44#issuecomment-622961303) to extract color, in my experiments it doesn't turn out to be good, but the idea is reasonable and interesting. You can also test this by setting `--use_vertex_normal`.
67 |
--------------------------------------------------------------------------------
/datasets/__init__.py:
--------------------------------------------------------------------------------
1 | from .blender import BlenderDataset
2 | from .llff import LLFFDataset
3 |
4 | dataset_dict = {'blender': BlenderDataset,
5 | 'llff': LLFFDataset}
--------------------------------------------------------------------------------
/datasets/blender.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch.utils.data import Dataset
3 | import json
4 | import numpy as np
5 | import os
6 | from PIL import Image
7 | from torchvision import transforms as T
8 |
9 | from .ray_utils import *
10 |
11 | class BlenderDataset(Dataset):
12 | def __init__(self, root_dir, split='train', img_wh=(800, 800)):
13 | self.root_dir = root_dir
14 | self.split = split
15 | assert img_wh[0] == img_wh[1], 'image width must equal image height!'
16 | self.img_wh = img_wh
17 | self.define_transforms()
18 |
19 | self.read_meta()
20 | self.white_back = True
21 |
22 | def read_meta(self):
23 | with open(os.path.join(self.root_dir,
24 | f"transforms_{self.split}.json"), 'r') as f:
25 | self.meta = json.load(f)
26 |
27 | w, h = self.img_wh
28 | self.focal = 0.5*800/np.tan(0.5*self.meta['camera_angle_x']) # original focal length
29 | # when W=800
30 |
31 | self.focal *= self.img_wh[0]/800 # modify focal length to match size self.img_wh
32 |
33 | # bounds, common for all scenes
34 | self.near = 2.0
35 | self.far = 6.0
36 | self.bounds = np.array([self.near, self.far])
37 |
38 | # ray directions for all pixels, same for all images (same H, W, focal)
39 | self.directions = \
40 | get_ray_directions(h, w, self.focal) # (h, w, 3)
41 |
42 | if self.split == 'train': # create buffer of all rays and rgb data
43 | self.image_paths = []
44 | self.poses = []
45 | self.all_rays = []
46 | self.all_rgbs = []
47 | for frame in self.meta['frames']:
48 | pose = np.array(frame['transform_matrix'])[:3, :4]
49 | self.poses += [pose]
50 | c2w = torch.FloatTensor(pose)
51 |
52 | image_path = os.path.join(self.root_dir, f"{frame['file_path']}.png")
53 | self.image_paths += [image_path]
54 | img = Image.open(image_path)
55 | img = img.resize(self.img_wh, Image.LANCZOS)
56 | img = self.transform(img) # (4, h, w)
57 | img = img.view(4, -1).permute(1, 0) # (h*w, 4) RGBA
58 | img = img[:, :3]*img[:, -1:] + (1-img[:, -1:]) # blend A to RGB
59 | self.all_rgbs += [img]
60 |
61 | rays_o, rays_d = get_rays(self.directions, c2w) # both (h*w, 3)
62 |
63 | self.all_rays += [torch.cat([rays_o, rays_d,
64 | self.near*torch.ones_like(rays_o[:, :1]),
65 | self.far*torch.ones_like(rays_o[:, :1])],
66 | 1)] # (h*w, 8)
67 |
68 | self.all_rays = torch.cat(self.all_rays, 0) # (len(self.meta['frames])*h*w, 3)
69 | self.all_rgbs = torch.cat(self.all_rgbs, 0) # (len(self.meta['frames])*h*w, 3)
70 |
71 | def define_transforms(self):
72 | self.transform = T.ToTensor()
73 |
74 | def __len__(self):
75 | if self.split == 'train':
76 | return len(self.all_rays)
77 | if self.split == 'val':
78 | return 8 # only validate 8 images (to support <=8 gpus)
79 | return len(self.meta['frames'])
80 |
81 | def __getitem__(self, idx):
82 | if self.split == 'train': # use data in the buffers
83 | sample = {'rays': self.all_rays[idx],
84 | 'rgbs': self.all_rgbs[idx]}
85 |
86 | else: # create data for each image separately
87 | frame = self.meta['frames'][idx]
88 | c2w = torch.FloatTensor(frame['transform_matrix'])[:3, :4]
89 |
90 | img = Image.open(os.path.join(self.root_dir, f"{frame['file_path']}.png"))
91 | img = img.resize(self.img_wh, Image.LANCZOS)
92 | img = self.transform(img) # (4, H, W)
93 | valid_mask = (img[-1]>0).flatten() # (H*W) valid color area
94 | img = img.view(4, -1).permute(1, 0) # (H*W, 4) RGBA
95 | img = img[:, :3]*img[:, -1:] + (1-img[:, -1:]) # blend A to RGB
96 |
97 | rays_o, rays_d = get_rays(self.directions, c2w)
98 |
99 | rays = torch.cat([rays_o, rays_d,
100 | self.near*torch.ones_like(rays_o[:, :1]),
101 | self.far*torch.ones_like(rays_o[:, :1])],
102 | 1) # (H*W, 8)
103 |
104 | sample = {'rays': rays,
105 | 'rgbs': img,
106 | 'c2w': c2w,
107 | 'valid_mask': valid_mask}
108 |
109 | return sample
--------------------------------------------------------------------------------
/datasets/depth_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import re
3 | import sys
4 |
5 | def read_pfm(filename):
6 | file = open(filename, 'rb')
7 | color = None
8 | width = None
9 | height = None
10 | scale = None
11 | endian = None
12 |
13 | header = file.readline().decode('utf-8').rstrip()
14 | if header == 'PF':
15 | color = True
16 | elif header == 'Pf':
17 | color = False
18 | else:
19 | raise Exception('Not a PFM file.')
20 |
21 | dim_match = re.match(r'^(\d+)\s(\d+)\s$', file.readline().decode('utf-8'))
22 | if dim_match:
23 | width, height = map(int, dim_match.groups())
24 | else:
25 | raise Exception('Malformed PFM header.')
26 |
27 | scale = float(file.readline().rstrip())
28 | if scale < 0: # little-endian
29 | endian = '<'
30 | scale = -scale
31 | else:
32 | endian = '>' # big-endian
33 |
34 | data = np.fromfile(file, endian + 'f')
35 | shape = (height, width, 3) if color else (height, width)
36 |
37 | data = np.reshape(data, shape)
38 | data = np.flipud(data)
39 | file.close()
40 | return data, scale
41 |
42 |
43 | def save_pfm(filename, image, scale=1):
44 | file = open(filename, "wb")
45 | color = None
46 |
47 | image = np.flipud(image)
48 |
49 | if image.dtype.name != 'float32':
50 | raise Exception('Image dtype must be float32.')
51 |
52 | if len(image.shape) == 3 and image.shape[2] == 3: # color image
53 | color = True
54 | elif len(image.shape) == 2 or len(image.shape) == 3 and image.shape[2] == 1: # greyscale
55 | color = False
56 | else:
57 | raise Exception('Image must have H x W x 3, H x W x 1 or H x W dimensions.')
58 |
59 | file.write('PF\n'.encode('utf-8') if color else 'Pf\n'.encode('utf-8'))
60 | file.write('{} {}\n'.format(image.shape[1], image.shape[0]).encode('utf-8'))
61 |
62 | endian = image.dtype.byteorder
63 |
64 | if endian == '<' or endian == '=' and sys.byteorder == 'little':
65 | scale = -scale
66 |
67 | file.write(('%f\n' % scale).encode('utf-8'))
68 |
69 | image.tofile(file)
70 | file.close()
--------------------------------------------------------------------------------
/datasets/llff.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch.utils.data import Dataset
3 | import glob
4 | import numpy as np
5 | import os
6 | from PIL import Image
7 | from torchvision import transforms as T
8 |
9 | from .ray_utils import *
10 |
11 |
12 | def normalize(v):
13 | """Normalize a vector."""
14 | return v/np.linalg.norm(v)
15 |
16 |
17 | def average_poses(poses):
18 | """
19 | Calculate the average pose, which is then used to center all poses
20 | using @center_poses. Its computation is as follows:
21 | 1. Compute the center: the average of pose centers.
22 | 2. Compute the z axis: the normalized average z axis.
23 | 3. Compute axis y': the average y axis.
24 | 4. Compute x' = y' cross product z, then normalize it as the x axis.
25 | 5. Compute the y axis: z cross product x.
26 |
27 | Note that at step 3, we cannot directly use y' as y axis since it's
28 | not necessarily orthogonal to z axis. We need to pass from x to y.
29 |
30 | Inputs:
31 | poses: (N_images, 3, 4)
32 |
33 | Outputs:
34 | pose_avg: (3, 4) the average pose
35 | """
36 | # 1. Compute the center
37 | center = poses[..., 3].mean(0) # (3)
38 |
39 | # 2. Compute the z axis
40 | z = normalize(poses[..., 2].mean(0)) # (3)
41 |
42 | # 3. Compute axis y' (no need to normalize as it's not the final output)
43 | y_ = poses[..., 1].mean(0) # (3)
44 |
45 | # 4. Compute the x axis
46 | x = normalize(np.cross(y_, z)) # (3)
47 |
48 | # 5. Compute the y axis (as z and x are normalized, y is already of norm 1)
49 | y = np.cross(z, x) # (3)
50 |
51 | pose_avg = np.stack([x, y, z, center], 1) # (3, 4)
52 |
53 | return pose_avg
54 |
55 |
56 | def center_poses(poses):
57 | """
58 | Center the poses so that we can use NDC.
59 | See https://github.com/bmild/nerf/issues/34
60 |
61 | Inputs:
62 | poses: (N_images, 3, 4)
63 |
64 | Outputs:
65 | poses_centered: (N_images, 3, 4) the centered poses
66 | pose_avg: (3, 4) the average pose
67 | """
68 |
69 | pose_avg = average_poses(poses) # (3, 4)
70 | pose_avg_homo = np.eye(4)
71 | pose_avg_homo[:3] = pose_avg # convert to homogeneous coordinate for faster computation
72 | # by simply adding 0, 0, 0, 1 as the last row
73 | last_row = np.tile(np.array([0, 0, 0, 1]), (len(poses), 1, 1)) # (N_images, 1, 4)
74 | poses_homo = \
75 | np.concatenate([poses, last_row], 1) # (N_images, 4, 4) homogeneous coordinate
76 |
77 | poses_centered = np.linalg.inv(pose_avg_homo) @ poses_homo # (N_images, 4, 4)
78 | poses_centered = poses_centered[:, :3] # (N_images, 3, 4)
79 |
80 | return poses_centered, np.linalg.inv(pose_avg_homo)
81 |
82 |
83 | def create_spiral_poses(radii, focus_depth, n_poses=120):
84 | """
85 | Computes poses that follow a spiral path for rendering purpose.
86 | See https://github.com/Fyusion/LLFF/issues/19
87 | In particular, the path looks like:
88 | https://tinyurl.com/ybgtfns3
89 |
90 | Inputs:
91 | radii: (3) radii of the spiral for each axis
92 | focus_depth: float, the depth that the spiral poses look at
93 | n_poses: int, number of poses to create along the path
94 |
95 | Outputs:
96 | poses_spiral: (n_poses, 3, 4) the poses in the spiral path
97 | """
98 |
99 | poses_spiral = []
100 | for t in np.linspace(0, 4*np.pi, n_poses+1)[:-1]: # rotate 4pi (2 rounds)
101 | # the parametric function of the spiral (see the interactive web)
102 | center = np.array([np.cos(t), -np.sin(t), -np.sin(0.5*t)]) * radii
103 |
104 | # the viewing z axis is the vector pointing from the @focus_depth plane
105 | # to @center
106 | z = normalize(center - np.array([0, 0, -focus_depth]))
107 |
108 | # compute other axes as in @average_poses
109 | y_ = np.array([0, 1, 0]) # (3)
110 | x = normalize(np.cross(y_, z)) # (3)
111 | y = np.cross(z, x) # (3)
112 |
113 | poses_spiral += [np.stack([x, y, z, center], 1)] # (3, 4)
114 |
115 | return np.stack(poses_spiral, 0) # (n_poses, 3, 4)
116 |
117 |
118 | def create_spheric_poses(radius, n_poses=120):
119 | """
120 | Create circular poses around z axis.
121 | Inputs:
122 | radius: the (negative) height and the radius of the circle.
123 |
124 | Outputs:
125 | spheric_poses: (n_poses, 3, 4) the poses in the circular path
126 | """
127 | def spheric_pose(theta, phi, radius):
128 | trans_t = lambda t : np.array([
129 | [1,0,0,0],
130 | [0,1,0,-0.9*t],
131 | [0,0,1,t],
132 | [0,0,0,1],
133 | ])
134 |
135 | rot_phi = lambda phi : np.array([
136 | [1,0,0,0],
137 | [0,np.cos(phi),-np.sin(phi),0],
138 | [0,np.sin(phi), np.cos(phi),0],
139 | [0,0,0,1],
140 | ])
141 |
142 | rot_theta = lambda th : np.array([
143 | [np.cos(th),0,-np.sin(th),0],
144 | [0,1,0,0],
145 | [np.sin(th),0, np.cos(th),0],
146 | [0,0,0,1],
147 | ])
148 |
149 | c2w = rot_theta(theta) @ rot_phi(phi) @ trans_t(radius)
150 | c2w = np.array([[-1,0,0,0],[0,0,1,0],[0,1,0,0],[0,0,0,1]]) @ c2w
151 | return c2w[:3]
152 |
153 | spheric_poses = []
154 | for th in np.linspace(0, 2*np.pi, n_poses+1)[:-1]:
155 | spheric_poses += [spheric_pose(th, -np.pi/5, radius)] # 36 degree view downwards
156 | return np.stack(spheric_poses, 0)
157 |
158 |
159 | class LLFFDataset(Dataset):
160 | def __init__(self, root_dir, split='train', img_wh=(504, 378), spheric_poses=False, val_num=1):
161 | """
162 | spheric_poses: whether the images are taken in a spheric inward-facing manner
163 | default: False (forward-facing)
164 | val_num: number of val images (used for multigpu training, validate same image for all gpus)
165 | """
166 | self.root_dir = root_dir
167 | self.split = split
168 | self.img_wh = img_wh
169 | self.spheric_poses = spheric_poses
170 | self.val_num = max(1, val_num) # at least 1
171 | self.define_transforms()
172 |
173 | self.read_meta()
174 | self.white_back = False
175 |
176 | def read_meta(self):
177 | poses_bounds = np.load(os.path.join(self.root_dir,
178 | 'poses_bounds.npy')) # (N_images, 17)
179 | self.image_paths = sorted(glob.glob(os.path.join(self.root_dir, 'images/*')))
180 | # load full resolution image then resize
181 | if self.split in ['train', 'val']:
182 | assert len(poses_bounds) == len(self.image_paths), \
183 | 'Mismatch between number of images and number of poses! Please rerun COLMAP!'
184 |
185 | poses = poses_bounds[:, :15].reshape(-1, 3, 5) # (N_images, 3, 5)
186 | self.bounds = poses_bounds[:, -2:] # (N_images, 2)
187 |
188 | # Step 1: rescale focal length according to training resolution
189 | H, W, self.focal = poses[0, :, -1] # original intrinsics, same for all images
190 | assert H*self.img_wh[0] == W*self.img_wh[1], \
191 | f'You must set @img_wh to have the same aspect ratio as ({W}, {H}) !'
192 |
193 | self.focal *= self.img_wh[0]/W
194 |
195 | # Step 2: correct poses
196 | # Original poses has rotation in form "down right back", change to "right up back"
197 | # See https://github.com/bmild/nerf/issues/34
198 | poses = np.concatenate([poses[..., 1:2], -poses[..., :1], poses[..., 2:4]], -1)
199 | # (N_images, 3, 4) exclude H, W, focal
200 | self.poses, self.pose_avg = center_poses(poses)
201 | distances_from_center = np.linalg.norm(self.poses[..., 3], axis=1)
202 | val_idx = np.argmin(distances_from_center) # choose val image as the closest to
203 | # center image
204 |
205 | # Step 3: correct scale so that the nearest depth is at a little more than 1.0
206 | # See https://github.com/bmild/nerf/issues/34
207 | near_original = self.bounds.min()
208 | scale_factor = near_original*0.75 # 0.75 is the default parameter
209 | # the nearest depth is at 1/0.75=1.33
210 | self.bounds /= scale_factor
211 | self.poses[..., 3] /= scale_factor
212 |
213 | # ray directions for all pixels, same for all images (same H, W, focal)
214 | self.directions = \
215 | get_ray_directions(self.img_wh[1], self.img_wh[0], self.focal) # (H, W, 3)
216 |
217 | if self.split == 'train': # create buffer of all rays and rgb data
218 | # use first N_images-1 to train, the LAST is val
219 | self.all_rays = []
220 | self.all_rgbs = []
221 | for i, image_path in enumerate(self.image_paths):
222 | if i == val_idx: # exclude the val image
223 | continue
224 | c2w = torch.FloatTensor(self.poses[i])
225 |
226 | img = Image.open(image_path).convert('RGB')
227 | assert img.size[1]*self.img_wh[0] == img.size[0]*self.img_wh[1], \
228 | f'''{image_path} has different aspect ratio than img_wh,
229 | please check your data!'''
230 | img = img.resize(self.img_wh, Image.LANCZOS)
231 | img = self.transform(img) # (3, h, w)
232 | img = img.view(3, -1).permute(1, 0) # (h*w, 3) RGB
233 | self.all_rgbs += [img]
234 |
235 | rays_o, rays_d = get_rays(self.directions, c2w) # both (h*w, 3)
236 | if not self.spheric_poses:
237 | near, far = 0, 1
238 | rays_o, rays_d = get_ndc_rays(self.img_wh[1], self.img_wh[0],
239 | self.focal, 1.0, rays_o, rays_d)
240 | # near plane is always at 1.0
241 | # near and far in NDC are always 0 and 1
242 | # See https://github.com/bmild/nerf/issues/34
243 | else:
244 | near = self.bounds.min()
245 | far = min(8 * near, self.bounds.max()) # focus on central object only
246 |
247 | self.all_rays += [torch.cat([rays_o, rays_d,
248 | near*torch.ones_like(rays_o[:, :1]),
249 | far*torch.ones_like(rays_o[:, :1])],
250 | 1)] # (h*w, 8)
251 |
252 | self.all_rays = torch.cat(self.all_rays, 0) # ((N_images-1)*h*w, 8)
253 | self.all_rgbs = torch.cat(self.all_rgbs, 0) # ((N_images-1)*h*w, 3)
254 |
255 | elif self.split == 'val':
256 | print('val image is', self.image_paths[val_idx])
257 | self.c2w_val = self.poses[val_idx]
258 | self.image_path_val = self.image_paths[val_idx]
259 |
260 | else: # for testing, create a parametric rendering path
261 | if self.split.endswith('train'): # test on training set
262 | self.poses_test = self.poses
263 | elif not self.spheric_poses:
264 | focus_depth = 3.5 # hardcoded, this is numerically close to the formula
265 | # given in the original repo. Mathematically if near=1
266 | # and far=infinity, then this number will converge to 4
267 | radii = np.percentile(np.abs(self.poses[..., 3]), 90, axis=0)
268 | self.poses_test = create_spiral_poses(radii, focus_depth)
269 | else:
270 | radius = 1.1 * self.bounds.min()
271 | self.poses_test = create_spheric_poses(radius)
272 |
273 | def define_transforms(self):
274 | self.transform = T.ToTensor()
275 |
276 | def __len__(self):
277 | if self.split == 'train':
278 | return len(self.all_rays)
279 | if self.split == 'val':
280 | return self.val_num
281 | return len(self.poses_test)
282 |
283 | def __getitem__(self, idx):
284 | if self.split == 'train': # use data in the buffers
285 | sample = {'rays': self.all_rays[idx],
286 | 'rgbs': self.all_rgbs[idx]}
287 |
288 | else:
289 | if self.split == 'val':
290 | c2w = torch.FloatTensor(self.c2w_val)
291 | else:
292 | c2w = torch.FloatTensor(self.poses_test[idx])
293 |
294 | rays_o, rays_d = get_rays(self.directions, c2w)
295 | if not self.spheric_poses:
296 | near, far = 0, 1
297 | rays_o, rays_d = get_ndc_rays(self.img_wh[1], self.img_wh[0],
298 | self.focal, 1.0, rays_o, rays_d)
299 | else:
300 | near = self.bounds.min()
301 | far = min(8 * near, self.bounds.max())
302 |
303 | rays = torch.cat([rays_o, rays_d,
304 | near*torch.ones_like(rays_o[:, :1]),
305 | far*torch.ones_like(rays_o[:, :1])],
306 | 1) # (h*w, 8)
307 |
308 | sample = {'rays': rays,
309 | 'c2w': c2w}
310 |
311 | if self.split == 'val':
312 | img = Image.open(self.image_path_val).convert('RGB')
313 | img = img.resize(self.img_wh, Image.LANCZOS)
314 | img = self.transform(img) # (3, h, w)
315 | img = img.view(3, -1).permute(1, 0) # (h*w, 3)
316 | sample['rgbs'] = img
317 |
318 | return sample
319 |
--------------------------------------------------------------------------------
/datasets/ray_utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from kornia import create_meshgrid
3 |
4 |
5 | def get_ray_directions(H, W, focal):
6 | """
7 | Get ray directions for all pixels in camera coordinate.
8 | Reference: https://www.scratchapixel.com/lessons/3d-basic-rendering/
9 | ray-tracing-generating-camera-rays/standard-coordinate-systems
10 |
11 | Inputs:
12 | H, W, focal: image height, width and focal length
13 |
14 | Outputs:
15 | directions: (H, W, 3), the direction of the rays in camera coordinate
16 | """
17 | grid = create_meshgrid(H, W, normalized_coordinates=False)[0]
18 | i, j = grid.unbind(-1)
19 | # the direction here is without +0.5 pixel centering as calibration is not so accurate
20 | # see https://github.com/bmild/nerf/issues/24
21 | directions = \
22 | torch.stack([(i-W/2)/focal, -(j-H/2)/focal, -torch.ones_like(i)], -1) # (H, W, 3)
23 |
24 | return directions
25 |
26 |
27 | def get_rays(directions, c2w):
28 | """
29 | Get ray origin and normalized directions in world coordinate for all pixels in one image.
30 | Reference: https://www.scratchapixel.com/lessons/3d-basic-rendering/
31 | ray-tracing-generating-camera-rays/standard-coordinate-systems
32 |
33 | Inputs:
34 | directions: (H, W, 3) precomputed ray directions in camera coordinate
35 | c2w: (3, 4) transformation matrix from camera coordinate to world coordinate
36 |
37 | Outputs:
38 | rays_o: (H*W, 3), the origin of the rays in world coordinate
39 | rays_d: (H*W, 3), the normalized direction of the rays in world coordinate
40 | """
41 | # Rotate ray directions from camera coordinate to the world coordinate
42 | rays_d = directions @ c2w[:, :3].T # (H, W, 3)
43 | rays_d = rays_d / torch.norm(rays_d, dim=-1, keepdim=True)
44 | # The origin of all rays is the camera origin in world coordinate
45 | rays_o = c2w[:, 3].expand(rays_d.shape) # (H, W, 3)
46 |
47 | rays_d = rays_d.view(-1, 3)
48 | rays_o = rays_o.view(-1, 3)
49 |
50 | return rays_o, rays_d
51 |
52 |
53 | def get_ndc_rays(H, W, focal, near, rays_o, rays_d):
54 | """
55 | Transform rays from world coordinate to NDC.
56 | NDC: Space such that the canvas is a cube with sides [-1, 1] in each axis.
57 | For detailed derivation, please see:
58 | http://www.songho.ca/opengl/gl_projectionmatrix.html
59 | https://github.com/bmild/nerf/files/4451808/ndc_derivation.pdf
60 |
61 | In practice, use NDC "if and only if" the scene is unbounded (has a large depth).
62 | See https://github.com/bmild/nerf/issues/18
63 |
64 | Inputs:
65 | H, W, focal: image height, width and focal length
66 | near: (N_rays) or float, the depths of the near plane
67 | rays_o: (N_rays, 3), the origin of the rays in world coordinate
68 | rays_d: (N_rays, 3), the direction of the rays in world coordinate
69 |
70 | Outputs:
71 | rays_o: (N_rays, 3), the origin of the rays in NDC
72 | rays_d: (N_rays, 3), the direction of the rays in NDC
73 | """
74 | # Shift ray origins to near plane
75 | t = -(near + rays_o[...,2]) / rays_d[...,2]
76 | rays_o = rays_o + t[...,None] * rays_d
77 |
78 | # Store some intermediate homogeneous results
79 | ox_oz = rays_o[...,0] / rays_o[...,2]
80 | oy_oz = rays_o[...,1] / rays_o[...,2]
81 |
82 | # Projection
83 | o0 = -1./(W/(2.*focal)) * ox_oz
84 | o1 = -1./(H/(2.*focal)) * oy_oz
85 | o2 = 1. + 2. * near / rays_o[...,2]
86 |
87 | d0 = -1./(W/(2.*focal)) * (rays_d[...,0]/rays_d[...,2] - ox_oz)
88 | d1 = -1./(H/(2.*focal)) * (rays_d[...,1]/rays_d[...,2] - oy_oz)
89 | d2 = 1 - o2
90 |
91 | rays_o = torch.stack([o0, o1, o2], -1) # (B, 3)
92 | rays_d = torch.stack([d0, d1, d2], -1) # (B, 3)
93 |
94 | return rays_o, rays_d
--------------------------------------------------------------------------------
/docs/.gitignore:
--------------------------------------------------------------------------------
1 | _site
2 | .sass-cache
3 | .jekyll-cache
4 | .jekyll-metadata
5 | vendor
6 |
--------------------------------------------------------------------------------
/docs/Gemfile:
--------------------------------------------------------------------------------
1 | source 'https://rubygems.org'
2 | gem 'github-pages', group: :jekyll_plugins
3 |
--------------------------------------------------------------------------------
/docs/Gemfile.lock:
--------------------------------------------------------------------------------
1 | GEM
2 | remote: https://rubygems.org/
3 | specs:
4 | activesupport (>= 6.0.3.1)
5 | concurrent-ruby (~> 1.0, >= 1.0.2)
6 | i18n (>= 0.7, < 2)
7 | minitest (~> 5.1)
8 | tzinfo (~> 1.1)
9 | zeitwerk (~> 2.2, >= 2.2.2)
10 | addressable (2.7.0)
11 | public_suffix (>= 2.0.2, < 5.0)
12 | coffee-script (2.4.1)
13 | coffee-script-source
14 | execjs
15 | coffee-script-source (1.11.1)
16 | colorator (1.1.0)
17 | commonmarker (0.17.13)
18 | ruby-enum (~> 0.5)
19 | concurrent-ruby (1.1.6)
20 | dnsruby (1.61.3)
21 | addressable (~> 2.5)
22 | em-websocket (0.5.1)
23 | eventmachine (>= 0.12.9)
24 | http_parser.rb (~> 0.6.0)
25 | ethon (0.12.0)
26 | ffi (>= 1.3.0)
27 | eventmachine (1.2.7)
28 | execjs (2.7.0)
29 | faraday (1.0.1)
30 | multipart-post (>= 1.2, < 3)
31 | ffi (1.12.2)
32 | forwardable-extended (2.6.0)
33 | gemoji (3.0.1)
34 | github-pages (204)
35 | github-pages-health-check (= 1.16.1)
36 | jekyll (= 3.8.5)
37 | jekyll-avatar (= 0.7.0)
38 | jekyll-coffeescript (= 1.1.1)
39 | jekyll-commonmark-ghpages (= 0.1.6)
40 | jekyll-default-layout (= 0.1.4)
41 | jekyll-feed (= 0.13.0)
42 | jekyll-gist (= 1.5.0)
43 | jekyll-github-metadata (= 2.13.0)
44 | jekyll-mentions (= 1.5.1)
45 | jekyll-optional-front-matter (= 0.3.2)
46 | jekyll-paginate (= 1.1.0)
47 | jekyll-readme-index (= 0.3.0)
48 | jekyll-redirect-from (= 0.15.0)
49 | jekyll-relative-links (= 0.6.1)
50 | jekyll-remote-theme (= 0.4.1)
51 | jekyll-sass-converter (= 1.5.2)
52 | jekyll-seo-tag (= 2.6.1)
53 | jekyll-sitemap (= 1.4.0)
54 | jekyll-swiss (= 1.0.0)
55 | jekyll-theme-architect (= 0.1.1)
56 | jekyll-theme-cayman (= 0.1.1)
57 | jekyll-theme-dinky (= 0.1.1)
58 | jekyll-theme-hacker (= 0.1.1)
59 | jekyll-theme-leap-day (= 0.1.1)
60 | jekyll-theme-merlot (= 0.1.1)
61 | jekyll-theme-midnight (= 0.1.1)
62 | jekyll-theme-minimal (= 0.1.1)
63 | jekyll-theme-modernist (= 0.1.1)
64 | jekyll-theme-primer (= 0.5.4)
65 | jekyll-theme-slate (= 0.1.1)
66 | jekyll-theme-tactile (= 0.1.1)
67 | jekyll-theme-time-machine (= 0.1.1)
68 | jekyll-titles-from-headings (= 0.5.3)
69 | jemoji (= 0.11.1)
70 | kramdown (>= 2.3.0)
71 | liquid (= 4.0.3)
72 | mercenary (~> 0.3)
73 | minima (= 2.5.1)
74 | nokogiri (>= 1.11.0.rc4, < 2.0)
75 | rouge (= 3.13.0)
76 | terminal-table (~> 1.4)
77 | github-pages-health-check (1.16.1)
78 | addressable (~> 2.3)
79 | dnsruby (~> 1.60)
80 | octokit (~> 4.0)
81 | public_suffix (~> 3.0)
82 | typhoeus (~> 1.3)
83 | html-pipeline (2.12.3)
84 | activesupport (>= 2)
85 | nokogiri (>= 1.4)
86 | http_parser.rb (0.6.0)
87 | i18n (0.9.5)
88 | concurrent-ruby (~> 1.0)
89 | jekyll (3.8.5)
90 | addressable (~> 2.4)
91 | colorator (~> 1.0)
92 | em-websocket (~> 0.5)
93 | i18n (~> 0.7)
94 | jekyll-sass-converter (~> 1.0)
95 | jekyll-watch (~> 2.0)
96 | kramdown (~> 1.14)
97 | liquid (~> 4.0)
98 | mercenary (~> 0.3.3)
99 | pathutil (~> 0.9)
100 | rouge (>= 1.7, < 4)
101 | safe_yaml (~> 1.0)
102 | jekyll-avatar (0.7.0)
103 | jekyll (>= 3.0, < 5.0)
104 | jekyll-coffeescript (1.1.1)
105 | coffee-script (~> 2.2)
106 | coffee-script-source (~> 1.11.1)
107 | jekyll-commonmark (1.3.1)
108 | commonmarker (~> 0.14)
109 | jekyll (>= 3.7, < 5.0)
110 | jekyll-commonmark-ghpages (0.1.6)
111 | commonmarker (~> 0.17.6)
112 | jekyll-commonmark (~> 1.2)
113 | rouge (>= 2.0, < 4.0)
114 | jekyll-default-layout (0.1.4)
115 | jekyll (~> 3.0)
116 | jekyll-feed (0.13.0)
117 | jekyll (>= 3.7, < 5.0)
118 | jekyll-gist (1.5.0)
119 | octokit (~> 4.2)
120 | jekyll-github-metadata (2.13.0)
121 | jekyll (>= 3.4, < 5.0)
122 | octokit (~> 4.0, != 4.4.0)
123 | jekyll-mentions (1.5.1)
124 | html-pipeline (~> 2.3)
125 | jekyll (>= 3.7, < 5.0)
126 | jekyll-optional-front-matter (0.3.2)
127 | jekyll (>= 3.0, < 5.0)
128 | jekyll-paginate (1.1.0)
129 | jekyll-readme-index (0.3.0)
130 | jekyll (>= 3.0, < 5.0)
131 | jekyll-redirect-from (0.15.0)
132 | jekyll (>= 3.3, < 5.0)
133 | jekyll-relative-links (0.6.1)
134 | jekyll (>= 3.3, < 5.0)
135 | jekyll-remote-theme (0.4.1)
136 | addressable (~> 2.0)
137 | jekyll (>= 3.5, < 5.0)
138 | rubyzip (>= 1.3.0)
139 | jekyll-sass-converter (1.5.2)
140 | sass (~> 3.4)
141 | jekyll-seo-tag (2.6.1)
142 | jekyll (>= 3.3, < 5.0)
143 | jekyll-sitemap (1.4.0)
144 | jekyll (>= 3.7, < 5.0)
145 | jekyll-swiss (1.0.0)
146 | jekyll-theme-architect (0.1.1)
147 | jekyll (~> 3.5)
148 | jekyll-seo-tag (~> 2.0)
149 | jekyll-theme-cayman (0.1.1)
150 | jekyll (~> 3.5)
151 | jekyll-seo-tag (~> 2.0)
152 | jekyll-theme-dinky (0.1.1)
153 | jekyll (~> 3.5)
154 | jekyll-seo-tag (~> 2.0)
155 | jekyll-theme-hacker (0.1.1)
156 | jekyll (~> 3.5)
157 | jekyll-seo-tag (~> 2.0)
158 | jekyll-theme-leap-day (0.1.1)
159 | jekyll (~> 3.5)
160 | jekyll-seo-tag (~> 2.0)
161 | jekyll-theme-merlot (0.1.1)
162 | jekyll (~> 3.5)
163 | jekyll-seo-tag (~> 2.0)
164 | jekyll-theme-midnight (0.1.1)
165 | jekyll (~> 3.5)
166 | jekyll-seo-tag (~> 2.0)
167 | jekyll-theme-minimal (0.1.1)
168 | jekyll (~> 3.5)
169 | jekyll-seo-tag (~> 2.0)
170 | jekyll-theme-modernist (0.1.1)
171 | jekyll (~> 3.5)
172 | jekyll-seo-tag (~> 2.0)
173 | jekyll-theme-primer (0.5.4)
174 | jekyll (> 3.5, < 5.0)
175 | jekyll-github-metadata (~> 2.9)
176 | jekyll-seo-tag (~> 2.0)
177 | jekyll-theme-slate (0.1.1)
178 | jekyll (~> 3.5)
179 | jekyll-seo-tag (~> 2.0)
180 | jekyll-theme-tactile (0.1.1)
181 | jekyll (~> 3.5)
182 | jekyll-seo-tag (~> 2.0)
183 | jekyll-theme-time-machine (0.1.1)
184 | jekyll (~> 3.5)
185 | jekyll-seo-tag (~> 2.0)
186 | jekyll-titles-from-headings (0.5.3)
187 | jekyll (>= 3.3, < 5.0)
188 | jekyll-watch (2.2.1)
189 | listen (~> 3.0)
190 | jemoji (0.11.1)
191 | gemoji (~> 3.0)
192 | html-pipeline (~> 2.2)
193 | jekyll (>= 3.0, < 5.0)
194 | kramdown (>= 2.3.0)
195 | liquid (4.0.3)
196 | listen (3.2.1)
197 | rb-fsevent (~> 0.10, >= 0.10.3)
198 | rb-inotify (~> 0.9, >= 0.9.10)
199 | mercenary (0.3.6)
200 | mini_portile2 (2.4.0)
201 | minima (2.5.1)
202 | jekyll (>= 3.5, < 5.0)
203 | jekyll-feed (~> 0.9)
204 | jekyll-seo-tag (~> 2.1)
205 | minitest (5.14.1)
206 | multipart-post (2.1.1)
207 | nokogiri (1.10.9)
208 | mini_portile2 (~> 2.4.0)
209 | octokit (4.18.0)
210 | faraday (>= 0.9)
211 | sawyer (~> 0.8.0, >= 0.5.3)
212 | pathutil (0.16.2)
213 | forwardable-extended (~> 2.6)
214 | public_suffix (3.1.1)
215 | rb-fsevent (0.10.4)
216 | rb-inotify (0.10.1)
217 | ffi (~> 1.0)
218 | rouge (3.13.0)
219 | ruby-enum (0.8.0)
220 | i18n
221 | rubyzip (2.3.0)
222 | safe_yaml (1.0.5)
223 | sass (3.7.4)
224 | sass-listen (~> 4.0.0)
225 | sass-listen (4.0.0)
226 | rb-fsevent (~> 0.9, >= 0.9.4)
227 | rb-inotify (~> 0.9, >= 0.9.7)
228 | sawyer (0.8.2)
229 | addressable (>= 2.3.5)
230 | faraday (> 0.8, < 2.0)
231 | terminal-table (1.8.0)
232 | unicode-display_width (~> 1.1, >= 1.1.1)
233 | thread_safe (0.3.6)
234 | typhoeus (1.4.0)
235 | ethon (>= 0.9.0)
236 | tzinfo (1.2.7)
237 | thread_safe (~> 0.1)
238 | unicode-display_width (1.7.0)
239 | zeitwerk (2.3.0)
240 |
241 | PLATFORMS
242 | ruby
243 |
244 | DEPENDENCIES
245 | github-pages
246 |
247 | BUNDLED WITH
248 | 2.1.4
249 |
--------------------------------------------------------------------------------
/docs/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-slate
2 |
--------------------------------------------------------------------------------
/docs/index.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 | # Author of this implementation
11 |
19 |
20 |
80 |
81 |
82 | # Call for contribution
83 | If you are expert in Unity and know how to make more visual appealing effects for the models shown above, feel free to contact me! I can share my code and data with you, and put your name on my github page!
84 |
--------------------------------------------------------------------------------
/docs/style.css:
--------------------------------------------------------------------------------
1 | #main_content {
2 | max-width: 960px;
3 | }
4 |
5 | .slick-slide {
6 | margin: 0 10px;
7 | }
8 |
9 | .slick-prev{
10 | left: -40px;
11 | }
12 |
13 | .slick-prev:before {
14 | font-size: 40px;
15 | color: blueviolet;
16 | }
17 | .slick-next:before {
18 | font-size: 40px;
19 | color: blueviolet;
20 | }
21 |
22 | .slick-dots li button:before{
23 | font-size: 20px;
24 | line-height: 20px;
25 | }
--------------------------------------------------------------------------------
/eval.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import os
3 | import numpy as np
4 | from collections import defaultdict
5 | from tqdm import tqdm
6 | import imageio
7 | from argparse import ArgumentParser
8 |
9 | from models.rendering import render_rays
10 | from models.nerf import *
11 |
12 | from utils import load_ckpt
13 | import metrics
14 |
15 | from datasets import dataset_dict
16 | from datasets.depth_utils import *
17 |
18 | torch.backends.cudnn.benchmark = True
19 |
20 | def get_opts():
21 | parser = ArgumentParser()
22 | parser.add_argument('--root_dir', type=str,
23 | default='/home/ubuntu/data/nerf_example_data/nerf_synthetic/lego',
24 | help='root directory of dataset')
25 | parser.add_argument('--dataset_name', type=str, default='blender',
26 | choices=['blender', 'llff'],
27 | help='which dataset to validate')
28 | parser.add_argument('--scene_name', type=str, default='test',
29 | help='scene name, used as output folder name')
30 | parser.add_argument('--split', type=str, default='test',
31 | help='test or test_train')
32 | parser.add_argument('--img_wh', nargs="+", type=int, default=[800, 800],
33 | help='resolution (img_w, img_h) of the image')
34 | parser.add_argument('--spheric_poses', default=False, action="store_true",
35 | help='whether images are taken in spheric poses (for llff)')
36 |
37 | parser.add_argument('--N_samples', type=int, default=64,
38 | help='number of coarse samples')
39 | parser.add_argument('--N_importance', type=int, default=128,
40 | help='number of additional fine samples')
41 | parser.add_argument('--use_disp', default=False, action="store_true",
42 | help='use disparity depth sampling')
43 | parser.add_argument('--chunk', type=int, default=32*1024*4,
44 | help='chunk size to split the input to avoid OOM')
45 |
46 | parser.add_argument('--ckpt_path', type=str, required=True,
47 | help='pretrained checkpoint path to load')
48 |
49 | parser.add_argument('--save_depth', default=False, action="store_true",
50 | help='whether to save depth prediction')
51 | parser.add_argument('--depth_format', type=str, default='pfm',
52 | choices=['pfm', 'bytes'],
53 | help='which format to save')
54 |
55 | return parser.parse_args()
56 |
57 |
58 | @torch.no_grad()
59 | def batched_inference(models, embeddings,
60 | rays, N_samples, N_importance, use_disp,
61 | chunk,
62 | white_back):
63 | """Do batched inference on rays using chunk."""
64 | B = rays.shape[0]
65 | chunk = 1024*32
66 | results = defaultdict(list)
67 | for i in range(0, B, chunk):
68 | rendered_ray_chunks = \
69 | render_rays(models,
70 | embeddings,
71 | rays[i:i+chunk],
72 | N_samples,
73 | use_disp,
74 | 0,
75 | 0,
76 | N_importance,
77 | chunk,
78 | dataset.white_back,
79 | test_time=True)
80 |
81 | for k, v in rendered_ray_chunks.items():
82 | results[k] += [v]
83 |
84 | for k, v in results.items():
85 | results[k] = torch.cat(v, 0)
86 | return results
87 |
88 |
89 | if __name__ == "__main__":
90 | args = get_opts()
91 | w, h = args.img_wh
92 |
93 | kwargs = {'root_dir': args.root_dir,
94 | 'split': args.split,
95 | 'img_wh': tuple(args.img_wh)}
96 | if args.dataset_name == 'llff':
97 | kwargs['spheric_poses'] = args.spheric_poses
98 | dataset = dataset_dict[args.dataset_name](**kwargs)
99 |
100 | embedding_xyz = Embedding(3, 10)
101 | embedding_dir = Embedding(3, 4)
102 | nerf_coarse = NeRF()
103 | nerf_fine = NeRF()
104 | load_ckpt(nerf_coarse, args.ckpt_path, model_name='nerf_coarse')
105 | load_ckpt(nerf_fine, args.ckpt_path, model_name='nerf_fine')
106 | nerf_coarse.cuda().eval()
107 | nerf_fine.cuda().eval()
108 |
109 | models = [nerf_coarse, nerf_fine]
110 | embeddings = [embedding_xyz, embedding_dir]
111 |
112 | imgs = []
113 | psnrs = []
114 | dir_name = f'results/{args.dataset_name}/{args.scene_name}'
115 | os.makedirs(dir_name, exist_ok=True)
116 |
117 | for i in tqdm(range(len(dataset))):
118 | sample = dataset[i]
119 | rays = sample['rays'].cuda()
120 | results = batched_inference(models, embeddings, rays,
121 | args.N_samples, args.N_importance, args.use_disp,
122 | args.chunk,
123 | dataset.white_back)
124 |
125 | img_pred = results['rgb_fine'].view(h, w, 3).cpu().numpy()
126 |
127 | if args.save_depth:
128 | depth_pred = results['depth_fine'].view(h, w).cpu().numpy()
129 | depth_pred = np.nan_to_num(depth_pred)
130 | if args.depth_format == 'pfm':
131 | save_pfm(os.path.join(dir_name, f'depth_{i:03d}.pfm'), depth_pred)
132 | else:
133 | with open(f'depth_{i:03d}', 'wb') as f:
134 | f.write(depth_pred.tobytes())
135 |
136 | img_pred_ = (img_pred*255).astype(np.uint8)
137 | imgs += [img_pred_]
138 | imageio.imwrite(os.path.join(dir_name, f'{i:03d}.png'), img_pred_)
139 |
140 | if 'rgbs' in sample:
141 | rgbs = sample['rgbs']
142 | img_gt = rgbs.view(h, w, 3)
143 | psnrs += [metrics.psnr(img_gt, img_pred).item()]
144 |
145 | imageio.mimsave(os.path.join(dir_name, f'{args.scene_name}.gif'), imgs, fps=30)
146 |
147 | if psnrs:
148 | mean_psnr = np.mean(psnrs)
149 | print(f'Mean PSNR : {mean_psnr:.2f}')
--------------------------------------------------------------------------------
/extract_color_mesh.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import os
3 | import numpy as np
4 | import cv2
5 | from PIL import Image
6 | from collections import defaultdict
7 | from tqdm import tqdm
8 | import mcubes
9 | import open3d as o3d
10 | from plyfile import PlyData, PlyElement
11 | from argparse import ArgumentParser
12 |
13 | from models.rendering import *
14 | from models.nerf import *
15 |
16 | from utils import load_ckpt
17 |
18 | from datasets import dataset_dict
19 |
20 | torch.backends.cudnn.benchmark = True
21 |
22 | def get_opts():
23 | parser = ArgumentParser()
24 | parser.add_argument('--root_dir', type=str,
25 | default='/home/ubuntu/data/nerf_example_data/nerf_synthetic/lego',
26 | help='root directory of dataset')
27 | parser.add_argument('--dataset_name', type=str, default='blender',
28 | choices=['blender', 'llff'],
29 | help='which dataset to validate')
30 | parser.add_argument('--scene_name', type=str, default='test',
31 | help='scene name, used as output ply filename')
32 | parser.add_argument('--img_wh', nargs="+", type=int, default=[800, 800],
33 | help='resolution (img_w, img_h) of the image')
34 |
35 | parser.add_argument('--N_samples', type=int, default=64,
36 | help='number of samples to infer the acculmulated opacity')
37 | parser.add_argument('--chunk', type=int, default=32*1024,
38 | help='chunk size to split the input to avoid OOM')
39 | parser.add_argument('--ckpt_path', type=str, required=True,
40 | help='pretrained checkpoint path to load')
41 |
42 | parser.add_argument('--N_grid', type=int, default=256,
43 | help='size of the grid on 1 side, larger=higher resolution')
44 | parser.add_argument('--x_range', nargs="+", type=float, default=[-1.0, 1.0],
45 | help='x range of the object')
46 | parser.add_argument('--y_range', nargs="+", type=float, default=[-1.0, 1.0],
47 | help='x range of the object')
48 | parser.add_argument('--z_range', nargs="+", type=float, default=[-1.0, 1.0],
49 | help='x range of the object')
50 | parser.add_argument('--sigma_threshold', type=float, default=20.0,
51 | help='threshold to consider a location is occupied')
52 | parser.add_argument('--occ_threshold', type=float, default=0.2,
53 | help='''threshold to consider a vertex is occluded.
54 | larger=fewer occluded pixels''')
55 |
56 | #### method using vertex normals ####
57 | parser.add_argument('--use_vertex_normal', action="store_true",
58 | help='use vertex normals to compute color')
59 | parser.add_argument('--N_importance', type=int, default=64,
60 | help='number of fine samples to infer the acculmulated opacity')
61 | parser.add_argument('--near_t', type=float, default=1.0,
62 | help='the near bound factor to start the ray')
63 |
64 | return parser.parse_args()
65 |
66 |
67 | @torch.no_grad()
68 | def f(models, embeddings, rays, N_samples, N_importance, chunk, white_back):
69 | """Do batched inference on rays using chunk."""
70 | B = rays.shape[0]
71 | results = defaultdict(list)
72 | for i in range(0, B, chunk):
73 | rendered_ray_chunks = \
74 | render_rays(models,
75 | embeddings,
76 | rays[i:i+chunk],
77 | N_samples,
78 | False,
79 | 0,
80 | 0,
81 | N_importance,
82 | chunk,
83 | white_back,
84 | test_time=True)
85 |
86 | for k, v in rendered_ray_chunks.items():
87 | results[k] += [v]
88 |
89 | for k, v in results.items():
90 | results[k] = torch.cat(v, 0)
91 | return results
92 |
93 |
94 | if __name__ == "__main__":
95 | args = get_opts()
96 |
97 | kwargs = {'root_dir': args.root_dir,
98 | 'img_wh': tuple(args.img_wh)}
99 | if args.dataset_name == 'llff':
100 | kwargs['spheric_poses'] = True
101 | kwargs['split'] = 'test'
102 | else:
103 | kwargs['split'] = 'train'
104 | dataset = dataset_dict[args.dataset_name](**kwargs)
105 |
106 | embedding_xyz = Embedding(3, 10)
107 | embedding_dir = Embedding(3, 4)
108 | embeddings = [embedding_xyz, embedding_dir]
109 | nerf_fine = NeRF()
110 | load_ckpt(nerf_fine, args.ckpt_path, model_name='nerf_fine')
111 | nerf_fine.cuda().eval()
112 |
113 | # define the dense grid for query
114 | N = args.N_grid
115 | xmin, xmax = args.x_range
116 | ymin, ymax = args.y_range
117 | zmin, zmax = args.z_range
118 | # assert xmax-xmin == ymax-ymin == zmax-zmin, 'the ranges must have the same length!'
119 | x = np.linspace(xmin, xmax, N)
120 | y = np.linspace(ymin, ymax, N)
121 | z = np.linspace(zmin, zmax, N)
122 |
123 | xyz_ = torch.FloatTensor(np.stack(np.meshgrid(x, y, z), -1).reshape(-1, 3)).cuda()
124 | dir_ = torch.zeros_like(xyz_).cuda()
125 | # sigma is independent of direction, so any value here will produce the same result
126 |
127 | # predict sigma (occupancy) for each grid location
128 | print('Predicting occupancy ...')
129 | with torch.no_grad():
130 | B = xyz_.shape[0]
131 | out_chunks = []
132 | for i in tqdm(range(0, B, args.chunk)):
133 | xyz_embedded = embedding_xyz(xyz_[i:i+args.chunk]) # (N, embed_xyz_channels)
134 | dir_embedded = embedding_dir(dir_[i:i+args.chunk]) # (N, embed_dir_channels)
135 | xyzdir_embedded = torch.cat([xyz_embedded, dir_embedded], 1)
136 | out_chunks += [nerf_fine(xyzdir_embedded)]
137 | rgbsigma = torch.cat(out_chunks, 0)
138 |
139 | sigma = rgbsigma[:, -1].cpu().numpy()
140 | sigma = np.maximum(sigma, 0).reshape(N, N, N)
141 |
142 | # perform marching cube algorithm to retrieve vertices and triangle mesh
143 | print('Extracting mesh ...')
144 | vertices, triangles = mcubes.marching_cubes(sigma, args.sigma_threshold)
145 |
146 | ##### Until mesh extraction here, it is the same as the original repo. ######
147 |
148 | vertices_ = (vertices/N).astype(np.float32)
149 | ## invert x and y coordinates (WHY? maybe because of the marching cubes algo)
150 | x_ = (ymax-ymin) * vertices_[:, 1] + ymin
151 | y_ = (xmax-xmin) * vertices_[:, 0] + xmin
152 | vertices_[:, 0] = x_
153 | vertices_[:, 1] = y_
154 | vertices_[:, 2] = (zmax-zmin) * vertices_[:, 2] + zmin
155 | vertices_.dtype = [('x', 'f4'), ('y', 'f4'), ('z', 'f4')]
156 |
157 | face = np.empty(len(triangles), dtype=[('vertex_indices', 'i4', (3,))])
158 | face['vertex_indices'] = triangles
159 |
160 | PlyData([PlyElement.describe(vertices_[:, 0], 'vertex'),
161 | PlyElement.describe(face, 'face')]).write(f'{args.scene_name}.ply')
162 |
163 | # remove noise in the mesh by keeping only the biggest cluster
164 | print('Removing noise ...')
165 | mesh = o3d.io.read_triangle_mesh(f"{args.scene_name}.ply")
166 | idxs, count, _ = mesh.cluster_connected_triangles()
167 | max_cluster_idx = np.argmax(count)
168 | triangles_to_remove = [i for i in range(len(face)) if idxs[i] != max_cluster_idx]
169 | mesh.remove_triangles_by_index(triangles_to_remove)
170 | mesh.remove_unreferenced_vertices()
171 | print(f'Mesh has {len(mesh.vertices)/1e6:.2f} M vertices and {len(mesh.triangles)/1e6:.2f} M faces.')
172 |
173 | vertices_ = np.asarray(mesh.vertices).astype(np.float32)
174 | triangles = np.asarray(mesh.triangles)
175 |
176 | # perform color prediction
177 | # Step 0. define constants (image width, height and intrinsics)
178 | W, H = args.img_wh
179 | K = np.array([[dataset.focal, 0, W/2],
180 | [0, dataset.focal, H/2],
181 | [0, 0, 1]]).astype(np.float32)
182 |
183 | # Step 1. transform vertices into world coordinate
184 | N_vertices = len(vertices_)
185 | vertices_homo = np.concatenate([vertices_, np.ones((N_vertices, 1))], 1) # (N, 4)
186 |
187 | if args.use_vertex_normal: ## use normal vector method as suggested by the author.
188 | ## see https://github.com/bmild/nerf/issues/44
189 | mesh.compute_vertex_normals()
190 | rays_d = torch.FloatTensor(np.asarray(mesh.vertex_normals))
191 | near = dataset.bounds.min() * torch.ones_like(rays_d[:, :1])
192 | far = dataset.bounds.max() * torch.ones_like(rays_d[:, :1])
193 | rays_o = torch.FloatTensor(vertices_) - rays_d * near * args.near_t
194 |
195 | nerf_coarse = NeRF()
196 | load_ckpt(nerf_coarse, args.ckpt_path, model_name='nerf_coarse')
197 | nerf_coarse.cuda().eval()
198 |
199 | results = f([nerf_coarse, nerf_fine], embeddings,
200 | torch.cat([rays_o, rays_d, near, far], 1).cuda(),
201 | args.N_samples,
202 | args.N_importance,
203 | args.chunk,
204 | dataset.white_back)
205 |
206 | else: ## use my color average method. see README_mesh.md
207 | ## buffers to store the final averaged color
208 | non_occluded_sum = np.zeros((N_vertices, 1))
209 | v_color_sum = np.zeros((N_vertices, 3))
210 |
211 | # Step 2. project the vertices onto each training image to infer the color
212 | print('Fusing colors ...')
213 | for idx in tqdm(range(len(dataset.image_paths))):
214 | ## read image of this pose
215 | image = Image.open(dataset.image_paths[idx]).convert('RGB')
216 | image = image.resize(tuple(args.img_wh), Image.LANCZOS)
217 | image = np.array(image)
218 |
219 | ## read the camera to world relative pose
220 | P_c2w = np.concatenate([dataset.poses[idx], np.array([0, 0, 0, 1]).reshape(1, 4)], 0)
221 | P_w2c = np.linalg.inv(P_c2w)[:3] # (3, 4)
222 | ## project vertices from world coordinate to camera coordinate
223 | vertices_cam = (P_w2c @ vertices_homo.T) # (3, N) in "right up back"
224 | vertices_cam[1:] *= -1 # (3, N) in "right down forward"
225 | ## project vertices from camera coordinate to pixel coordinate
226 | vertices_image = (K @ vertices_cam).T # (N, 3)
227 | depth = vertices_image[:, -1:]+1e-5 # the depth of the vertices, used as far plane
228 | vertices_image = vertices_image[:, :2]/depth
229 | vertices_image = vertices_image.astype(np.float32)
230 | vertices_image[:, 0] = np.clip(vertices_image[:, 0], 0, W-1)
231 | vertices_image[:, 1] = np.clip(vertices_image[:, 1], 0, H-1)
232 |
233 | ## compute the color on these projected pixel coordinates
234 | ## using bilinear interpolation.
235 | ## NOTE: opencv's implementation has a size limit of 32768 pixels per side,
236 | ## so we split the input into chunks.
237 | colors = []
238 | remap_chunk = int(3e4)
239 | for i in range(0, N_vertices, remap_chunk):
240 | colors += [cv2.remap(image,
241 | vertices_image[i:i+remap_chunk, 0],
242 | vertices_image[i:i+remap_chunk, 1],
243 | interpolation=cv2.INTER_LINEAR)[:, 0]]
244 | colors = np.vstack(colors) # (N_vertices, 3)
245 |
246 | ## predict occlusion of each vertex
247 | ## we leverage the concept of NeRF by constructing rays coming out from the camera
248 | ## and hitting each vertex; by computing the accumulated opacity along this path,
249 | ## we can know if the vertex is occluded or not.
250 | ## for vertices that appear to be occluded from every input view, we make the
251 | ## assumption that its color is the same as its neighbors that are facing our side.
252 | ## (think of a surface with one side facing us: we assume the other side has the same color)
253 |
254 | ## ray's origin is camera origin
255 | rays_o = torch.FloatTensor(dataset.poses[idx][:, -1]).expand(N_vertices, 3)
256 | ## ray's direction is the vector pointing from camera origin to the vertices
257 | rays_d = torch.FloatTensor(vertices_) - rays_o # (N_vertices, 3)
258 | rays_d = rays_d / torch.norm(rays_d, dim=-1, keepdim=True)
259 | near = dataset.bounds.min() * torch.ones_like(rays_o[:, :1])
260 | ## the far plane is the depth of the vertices, since what we want is the accumulated
261 | ## opacity along the path from camera origin to the vertices
262 | far = torch.FloatTensor(depth) * torch.ones_like(rays_o[:, :1])
263 | results = f([nerf_fine], embeddings,
264 | torch.cat([rays_o, rays_d, near, far], 1).cuda(),
265 | args.N_samples,
266 | 0,
267 | args.chunk,
268 | dataset.white_back)
269 | opacity = results['opacity_coarse'].cpu().numpy()[:, np.newaxis] # (N_vertices, 1)
270 | opacity = np.nan_to_num(opacity, 1)
271 |
272 | non_occluded = np.ones_like(non_occluded_sum) * 0.1/depth # weight by inverse depth
273 | # near=more confident in color
274 | non_occluded += opacity < args.occ_threshold
275 |
276 | v_color_sum += colors * non_occluded
277 | non_occluded_sum += non_occluded
278 |
279 | # Step 3. combine the output and write to file
280 | if args.use_vertex_normal:
281 | v_colors = results['rgb_fine'].cpu().numpy() * 255.0
282 | else: ## the combined color is the average color among all views
283 | v_colors = v_color_sum/non_occluded_sum
284 | v_colors = v_colors.astype(np.uint8)
285 | v_colors.dtype = [('red', 'u1'), ('green', 'u1'), ('blue', 'u1')]
286 | vertices_.dtype = [('x', 'f4'), ('y', 'f4'), ('z', 'f4')]
287 | vertex_all = np.empty(N_vertices, vertices_.dtype.descr+v_colors.dtype.descr)
288 | for prop in vertices_.dtype.names:
289 | vertex_all[prop] = vertices_[prop][:, 0]
290 | for prop in v_colors.dtype.names:
291 | vertex_all[prop] = v_colors[prop][:, 0]
292 |
293 | face = np.empty(len(triangles), dtype=[('vertex_indices', 'i4', (3,))])
294 | face['vertex_indices'] = triangles
295 |
296 | PlyData([PlyElement.describe(vertex_all, 'vertex'),
297 | PlyElement.describe(face, 'face')]).write(f'{args.scene_name}.ply')
298 |
299 | print('Done!')
300 |
--------------------------------------------------------------------------------
/extract_mesh.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "import torch\n",
10 | "from collections import defaultdict\n",
11 | "import numpy as np\n",
12 | "import mcubes\n",
13 | "import trimesh\n",
14 | "\n",
15 | "from models.rendering import *\n",
16 | "from models.nerf import *\n",
17 | "\n",
18 | "from datasets import dataset_dict\n",
19 | "\n",
20 | "from utils import load_ckpt"
21 | ]
22 | },
23 | {
24 | "cell_type": "markdown",
25 | "metadata": {},
26 | "source": [
27 | "# Load model and data"
28 | ]
29 | },
30 | {
31 | "cell_type": "code",
32 | "execution_count": null,
33 | "metadata": {},
34 | "outputs": [],
35 | "source": [
36 | "# Change here #\n",
37 | "img_wh = (800, 800) # full resolution of the input images\n",
38 | "dataset_name = 'blender' # blender or llff (own data)\n",
39 | "scene_name = 'lego' # whatever you want\n",
40 | "root_dir = '/home/ubuntu/data/nerf_example_data/nerf_synthetic/lego/' # the folder containing data\n",
41 | "ckpt_path = 'ckpts/exp2/epoch=05.ckpt' # the model path\n",
42 | "###############\n",
43 | "\n",
44 | "kwargs = {'root_dir': root_dir,\n",
45 | " 'img_wh': img_wh}\n",
46 | "if dataset_name == 'llff':\n",
47 | " kwargs['spheric_poses'] = True\n",
48 | " kwargs['split'] = 'test'\n",
49 | "else:\n",
50 | " kwargs['split'] = 'train'\n",
51 | " \n",
52 | "chunk = 1024*32\n",
53 | "dataset = dataset_dict[dataset_name](**kwargs)\n",
54 | "\n",
55 | "embedding_xyz = Embedding(3, 10)\n",
56 | "embedding_dir = Embedding(3, 4)\n",
57 | "\n",
58 | "nerf_fine = NeRF()\n",
59 | "load_ckpt(nerf_fine, ckpt_path, model_name='nerf_fine')\n",
60 | "nerf_fine.cuda().eval();"
61 | ]
62 | },
63 | {
64 | "cell_type": "markdown",
65 | "metadata": {},
66 | "source": [
67 | "# Search for tight bounds of the object (trial and error!)"
68 | ]
69 | },
70 | {
71 | "cell_type": "code",
72 | "execution_count": null,
73 | "metadata": {},
74 | "outputs": [],
75 | "source": [
76 | "### Tune these parameters until the whole object lies tightly in range with little noise ###\n",
77 | "N = 128 # controls the resolution, set this number small here because we're only finding\n",
78 | " # good ranges here, not yet for mesh reconstruction; we can set this number high\n",
79 | " # when it comes to final reconstruction.\n",
80 | "xmin, xmax = -1.2, 1.2 # left/right range\n",
81 | "ymin, ymax = -1.2, 1.2 # forward/backward range\n",
82 | "zmin, zmax = -1.2, 1.2 # up/down range\n",
83 | "## Attention! the ranges MUST have the same length!\n",
84 | "sigma_threshold = 50. # controls the noise (lower=maybe more noise; higher=some mesh might be missing)\n",
85 | "############################################################################################\n",
86 | "\n",
87 | "x = np.linspace(xmin, xmax, N)\n",
88 | "y = np.linspace(ymin, ymax, N)\n",
89 | "z = np.linspace(zmin, zmax, N)\n",
90 | "\n",
91 | "xyz_ = torch.FloatTensor(np.stack(np.meshgrid(x, y, z), -1).reshape(-1, 3)).cuda()\n",
92 | "dir_ = torch.zeros_like(xyz_).cuda()\n",
93 | "\n",
94 | "with torch.no_grad():\n",
95 | " B = xyz_.shape[0]\n",
96 | " out_chunks = []\n",
97 | " for i in range(0, B, chunk):\n",
98 | " xyz_embedded = embedding_xyz(xyz_[i:i+chunk]) # (N, embed_xyz_channels)\n",
99 | " dir_embedded = embedding_dir(dir_[i:i+chunk]) # (N, embed_dir_channels)\n",
100 | " xyzdir_embedded = torch.cat([xyz_embedded, dir_embedded], 1)\n",
101 | " out_chunks += [nerf_fine(xyzdir_embedded)]\n",
102 | " rgbsigma = torch.cat(out_chunks, 0)\n",
103 | " \n",
104 | "sigma = rgbsigma[:, -1].cpu().numpy()\n",
105 | "sigma = np.maximum(sigma, 0)\n",
106 | "sigma = sigma.reshape(N, N, N)\n",
107 | "\n",
108 | "# The below lines are for visualization, COMMENT OUT once you find the best range and increase N!\n",
109 | "vertices, triangles = mcubes.marching_cubes(sigma, sigma_threshold)\n",
110 | "mesh = trimesh.Trimesh(vertices/N, triangles)\n",
111 | "mesh.show()"
112 | ]
113 | },
114 | {
115 | "cell_type": "code",
116 | "execution_count": null,
117 | "metadata": {},
118 | "outputs": [],
119 | "source": [
120 | "# # You can already export \"colorless\" mesh if you don't need color\n",
121 | "# mcubes.export_mesh(vertices, triangles, f\"{scene_name}.dae\")"
122 | ]
123 | },
124 | {
125 | "cell_type": "markdown",
126 | "metadata": {},
127 | "source": [
128 | "# Generate .vol file for volume rendering in Unity"
129 | ]
130 | },
131 | {
132 | "cell_type": "code",
133 | "execution_count": null,
134 | "metadata": {},
135 | "outputs": [],
136 | "source": [
137 | "assert N==512, \\\n",
138 | " 'Please set N to 512 in the two above cell! Remember to comment out the visualization code (last 3 lines)!'\n",
139 | "\n",
140 | "a = 1-np.exp(-(xmax-xmin)/N*sigma)\n",
141 | "a = a.flatten()\n",
142 | "rgb = (rgbsigma[:, :3].numpy()*255).astype(np.uint32)\n",
143 | "i = np.where(a>0)[0] # valid indices (alpha>0)\n",
144 | "\n",
145 | "rgb = rgb[i]\n",
146 | "a = a[i]\n",
147 | "s = rgb.dot(np.array([1<<24, 1<<16, 1<<8])) + (a*255).astype(np.uint32)\n",
148 | "res = np.stack([i, s], -1).astype(np.uint32).flatten()\n",
149 | "with open(f'{scene_name}.vol', 'wb') as f:\n",
150 | " f.write(res.tobytes())"
151 | ]
152 | },
153 | {
154 | "cell_type": "markdown",
155 | "metadata": {},
156 | "source": [
157 | "# Extract colored mesh\n",
158 | "\n",
159 | "Once you find the best range, now **RESTART** the notebook, and copy the configs to the following cell\n",
160 | "and execute it."
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": null,
166 | "metadata": {},
167 | "outputs": [],
168 | "source": [
169 | "# Copy the variables you have above here! ####\n",
170 | "img_wh = (800, 800) # full resolution of the input images\n",
171 | "dataset_name = 'blender' # blender or llff (own data)\n",
172 | "scene_name = 'lego' # whatever you want\n",
173 | "root_dir = '/home/ubuntu/data/nerf_example_data/nerf_synthetic/lego/' # the folder containing data\n",
174 | "ckpt_path = 'ckpts/exp2/epoch=05.ckpt' # the model path\n",
175 | "\n",
176 | "N = 128 # controls the resolution, set this number small here because we're only finding\n",
177 | " # good ranges here, not yet for mesh reconstruction; we can set this number high\n",
178 | " # when it comes to final reconstruction.\n",
179 | "xmin, xmax = -1.2, 1.2 # left/right range\n",
180 | "ymin, ymax = -1.2, 1.2 # forward/backward range\n",
181 | "zmin, zmax = -1.2, 1.2 # up/down range\n",
182 | "sigma_threshold = 50. # controls the noise (lower=maybe more noise; higher=some mesh might be missing)\n",
183 | "###############################################\n",
184 | "\n",
185 | "import os\n",
186 | "os.environ['ROOT_DIR'] = root_dir\n",
187 | "os.environ['DATASET_NAME'] = dataset_name\n",
188 | "os.environ['SCENE_NAME'] = scene_name\n",
189 | "os.environ['IMG_SIZE'] = f\"{img_wh[0]} {img_wh[1]}\"\n",
190 | "os.environ['CKPT_PATH'] = ckpt_path\n",
191 | "os.environ['N_GRID'] = \"256\" # final resolution. You can set this number high to preserve more details\n",
192 | "os.environ['X_RANGE'] = f\"{xmin} {xmax}\"\n",
193 | "os.environ['Y_RANGE'] = f\"{ymin} {ymax}\"\n",
194 | "os.environ['Z_RANGE'] = f\"{zmin} {zmax}\"\n",
195 | "os.environ['SIGMA_THRESHOLD'] = str(sigma_threshold)\n",
196 | "os.environ['OCC_THRESHOLD'] = \"0.2\" # probably doesn't require tuning. If you find the color is not close\n",
197 | " # to real, try to set this number smaller (the effect of this number\n",
198 | " # is explained in my youtube video)\n",
199 | "\n",
200 | "!python extract_color_mesh.py \\\n",
201 | " --root_dir $ROOT_DIR \\\n",
202 | " --dataset_name $DATASET_NAME \\\n",
203 | " --scene_name $SCENE_NAME \\\n",
204 | " --img_wh $IMG_SIZE \\\n",
205 | " --ckpt_path $CKPT_PATH \\\n",
206 | " --N_grid $N_GRID \\\n",
207 | " --x_range $X_RANGE \\\n",
208 | " --y_range $Y_RANGE \\\n",
209 | " --z_range $Z_RANGE \\\n",
210 | " --sigma_threshold $SIGMA_THRESHOLD \\\n",
211 | " --occ_threshold $OCC_THRESHOLD"
212 | ]
213 | },
214 | {
215 | "cell_type": "code",
216 | "execution_count": null,
217 | "metadata": {},
218 | "outputs": [],
219 | "source": []
220 | }
221 | ],
222 | "metadata": {
223 | "kernelspec": {
224 | "display_name": "nerf_pl",
225 | "language": "python",
226 | "name": "nerf_pl"
227 | },
228 | "language_info": {
229 | "codemirror_mode": {
230 | "name": "ipython",
231 | "version": 3
232 | },
233 | "file_extension": ".py",
234 | "mimetype": "text/x-python",
235 | "name": "python",
236 | "nbconvert_exporter": "python",
237 | "pygments_lexer": "ipython3",
238 | "version": "3.6.10"
239 | }
240 | },
241 | "nbformat": 4,
242 | "nbformat_minor": 4
243 | }
244 |
--------------------------------------------------------------------------------
/losses.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 |
4 | class MSELoss(nn.Module):
5 | def __init__(self):
6 | super(MSELoss, self).__init__()
7 | self.loss = nn.MSELoss(reduction='mean')
8 |
9 | def forward(self, inputs, targets):
10 | loss = self.loss(inputs['rgb_coarse'], targets)
11 | if 'rgb_fine' in inputs:
12 | loss += self.loss(inputs['rgb_fine'], targets)
13 |
14 | return loss
15 |
16 |
17 | loss_dict = {'mse': MSELoss}
--------------------------------------------------------------------------------
/metrics.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from kornia.losses import ssim as dssim
3 |
4 | def mse(image_pred, image_gt, valid_mask=None, reduction='mean'):
5 | value = (image_pred-image_gt)**2
6 | if valid_mask is not None:
7 | value = value[valid_mask]
8 | if reduction == 'mean':
9 | return torch.mean(value)
10 | return value
11 |
12 | def psnr(image_pred, image_gt, valid_mask=None, reduction='mean'):
13 | return -10*torch.log10(mse(image_pred, image_gt, valid_mask, reduction))
14 |
15 | def ssim(image_pred, image_gt, reduction='mean'):
16 | """
17 | image_pred and image_gt: (1, 3, H, W)
18 | """
19 | dssim_ = dssim(image_pred, image_gt, 3, reduction) # dissimilarity in [0, 1]
20 | return 1-2*dssim_ # in [-1, 1]
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kwea123/nerf_pl/52aeb387da64a9ad9a0f914ea9b049ffc598b20c/models/__init__.py
--------------------------------------------------------------------------------
/models/nerf.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 |
4 | class Embedding(nn.Module):
5 | def __init__(self, in_channels, N_freqs, logscale=True):
6 | """
7 | Defines a function that embeds x to (x, sin(2^k x), cos(2^k x), ...)
8 | in_channels: number of input channels (3 for both xyz and direction)
9 | """
10 | super(Embedding, self).__init__()
11 | self.N_freqs = N_freqs
12 | self.in_channels = in_channels
13 | self.funcs = [torch.sin, torch.cos]
14 | self.out_channels = in_channels*(len(self.funcs)*N_freqs+1)
15 |
16 | if logscale:
17 | self.freq_bands = 2**torch.linspace(0, N_freqs-1, N_freqs)
18 | else:
19 | self.freq_bands = torch.linspace(1, 2**(N_freqs-1), N_freqs)
20 |
21 | def forward(self, x):
22 | """
23 | Embeds x to (x, sin(2^k x), cos(2^k x), ...)
24 | Different from the paper, "x" is also in the output
25 | See https://github.com/bmild/nerf/issues/12
26 |
27 | Inputs:
28 | x: (B, self.in_channels)
29 |
30 | Outputs:
31 | out: (B, self.out_channels)
32 | """
33 | out = [x]
34 | for freq in self.freq_bands:
35 | for func in self.funcs:
36 | out += [func(freq*x)]
37 |
38 | return torch.cat(out, -1)
39 |
40 |
41 | class NeRF(nn.Module):
42 | def __init__(self,
43 | D=8, W=256,
44 | in_channels_xyz=63, in_channels_dir=27,
45 | skips=[4]):
46 | """
47 | D: number of layers for density (sigma) encoder
48 | W: number of hidden units in each layer
49 | in_channels_xyz: number of input channels for xyz (3+3*10*2=63 by default)
50 | in_channels_dir: number of input channels for direction (3+3*4*2=27 by default)
51 | skips: add skip connection in the Dth layer
52 | """
53 | super(NeRF, self).__init__()
54 | self.D = D
55 | self.W = W
56 | self.in_channels_xyz = in_channels_xyz
57 | self.in_channels_dir = in_channels_dir
58 | self.skips = skips
59 |
60 | # xyz encoding layers
61 | for i in range(D):
62 | if i == 0:
63 | layer = nn.Linear(in_channels_xyz, W)
64 | elif i in skips:
65 | layer = nn.Linear(W+in_channels_xyz, W)
66 | else:
67 | layer = nn.Linear(W, W)
68 | layer = nn.Sequential(layer, nn.ReLU(True))
69 | setattr(self, f"xyz_encoding_{i+1}", layer)
70 | self.xyz_encoding_final = nn.Linear(W, W)
71 |
72 | # direction encoding layers
73 | self.dir_encoding = nn.Sequential(
74 | nn.Linear(W+in_channels_dir, W//2),
75 | nn.ReLU(True))
76 |
77 | # output layers
78 | self.sigma = nn.Linear(W, 1)
79 | self.rgb = nn.Sequential(
80 | nn.Linear(W//2, 3),
81 | nn.Sigmoid())
82 |
83 | def forward(self, x, sigma_only=False):
84 | """
85 | Encodes input (xyz+dir) to rgb+sigma (not ready to render yet).
86 | For rendering this ray, please see rendering.py
87 |
88 | Inputs:
89 | x: (B, self.in_channels_xyz(+self.in_channels_dir))
90 | the embedded vector of position and direction
91 | sigma_only: whether to infer sigma only. If True,
92 | x is of shape (B, self.in_channels_xyz)
93 |
94 | Outputs:
95 | if sigma_ony:
96 | sigma: (B, 1) sigma
97 | else:
98 | out: (B, 4), rgb and sigma
99 | """
100 | if not sigma_only:
101 | input_xyz, input_dir = \
102 | torch.split(x, [self.in_channels_xyz, self.in_channels_dir], dim=-1)
103 | else:
104 | input_xyz = x
105 |
106 | xyz_ = input_xyz
107 | for i in range(self.D):
108 | if i in self.skips:
109 | xyz_ = torch.cat([input_xyz, xyz_], -1)
110 | xyz_ = getattr(self, f"xyz_encoding_{i+1}")(xyz_)
111 |
112 | sigma = self.sigma(xyz_)
113 | if sigma_only:
114 | return sigma
115 |
116 | xyz_encoding_final = self.xyz_encoding_final(xyz_)
117 |
118 | dir_encoding_input = torch.cat([xyz_encoding_final, input_dir], -1)
119 | dir_encoding = self.dir_encoding(dir_encoding_input)
120 | rgb = self.rgb(dir_encoding)
121 |
122 | out = torch.cat([rgb, sigma], -1)
123 |
124 | return out
--------------------------------------------------------------------------------
/models/rendering.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torchsearchsorted import searchsorted
3 |
4 | __all__ = ['render_rays']
5 |
6 | """
7 | Function dependencies: (-> means function calls)
8 |
9 | @render_rays -> @inference
10 |
11 | @render_rays -> @sample_pdf if there is fine model
12 | """
13 |
14 | def sample_pdf(bins, weights, N_importance, det=False, eps=1e-5):
15 | """
16 | Sample @N_importance samples from @bins with distribution defined by @weights.
17 |
18 | Inputs:
19 | bins: (N_rays, N_samples_+1) where N_samples_ is "the number of coarse samples per ray - 2"
20 | weights: (N_rays, N_samples_)
21 | N_importance: the number of samples to draw from the distribution
22 | det: deterministic or not
23 | eps: a small number to prevent division by zero
24 |
25 | Outputs:
26 | samples: the sampled samples
27 | """
28 | N_rays, N_samples_ = weights.shape
29 | weights = weights + eps # prevent division by zero (don't do inplace op!)
30 | pdf = weights / torch.sum(weights, -1, keepdim=True) # (N_rays, N_samples_)
31 | cdf = torch.cumsum(pdf, -1) # (N_rays, N_samples), cumulative distribution function
32 | cdf = torch.cat([torch.zeros_like(cdf[: ,:1]), cdf], -1) # (N_rays, N_samples_+1)
33 | # padded to 0~1 inclusive
34 |
35 | if det:
36 | u = torch.linspace(0, 1, N_importance, device=bins.device)
37 | u = u.expand(N_rays, N_importance)
38 | else:
39 | u = torch.rand(N_rays, N_importance, device=bins.device)
40 | u = u.contiguous()
41 |
42 | inds = searchsorted(cdf, u, side='right')
43 | below = torch.clamp_min(inds-1, 0)
44 | above = torch.clamp_max(inds, N_samples_)
45 |
46 | inds_sampled = torch.stack([below, above], -1).view(N_rays, 2*N_importance)
47 | cdf_g = torch.gather(cdf, 1, inds_sampled).view(N_rays, N_importance, 2)
48 | bins_g = torch.gather(bins, 1, inds_sampled).view(N_rays, N_importance, 2)
49 |
50 | denom = cdf_g[...,1]-cdf_g[...,0]
51 | denom[denom