├── .editorconfig
├── .github
├── ISSUE_TEMPLATE
│ ├── bug_report.md
│ └── feature_request.md
├── PULL_REQUEST_TEMPLATE.md
└── workflows
│ ├── docs.yml
│ └── test.yml
├── .gitignore
├── CHANGELOG.md
├── CONTRIBUTING.md
├── LICENSE
├── MANIFEST.in
├── README.md
├── docs
├── mkdocs.yml
└── src
│ ├── CONTRIBUTING.md
│ ├── addendum.md
│ ├── comparison_with_ipystata.md
│ ├── getting_started.md
│ ├── helpers
│ └── helpers.js
│ ├── img
│ ├── atom.png
│ ├── atom_help_magic.png
│ ├── browse_atom.png
│ ├── browse_notebook.png
│ ├── esttab-html-file.png
│ ├── esttab-html-jupyterlab.png
│ ├── esttab-latex-jupyterlab.png
│ ├── esttab-latex-pdf.png
│ ├── hydrogen-watch-browse.gif
│ ├── hydrogen-watch-graph.gif
│ ├── jupyter_console.png
│ ├── jupyter_notebook.png
│ ├── jupyter_notebook_example.gif
│ ├── jupyterlab_autocompletion.png
│ ├── mobaxterm-local-port-forwarding.png
│ ├── notebook_help_magic.png
│ ├── nteract.pdf
│ ├── nteract.png
│ ├── starting_jupyter_notebook.gif
│ ├── stata_kernel_example.gif
│ └── subscribe-to-releases.png
│ ├── index.md
│ ├── license.md
│ ├── using_jupyter
│ ├── atom.md
│ ├── console.md
│ ├── intro.md
│ ├── lab.md
│ ├── notebook.md
│ ├── nteract.md
│ ├── qtconsole.md
│ └── remote.md
│ └── using_stata_kernel
│ ├── configuration.md
│ ├── intro.md
│ ├── limitations.md
│ ├── magics.md
│ └── troubleshooting.md
├── examples
└── Example.ipynb
├── poetry.lock
├── poetry.toml
├── pyproject.toml
├── setup.cfg
├── stata_kernel
├── __init__.py
├── __main__.py
├── ado
│ ├── _StataKernelCompletions.ado
│ ├── _StataKernelHead.ado
│ ├── _StataKernelLog.ado
│ ├── _StataKernelResetRC.ado
│ └── _StataKernelTail.ado
├── code_manager.py
├── codemirror
│ └── stata.js
├── completions.py
├── config.py
├── css
│ └── _StataKernelHelpDefault.css
├── docs
│ ├── css
│ │ └── pandoc.css
│ ├── index.html
│ ├── index.txt
│ ├── logo-64x64.png
│ ├── make.sh
│ ├── make_href
│ └── using_stata_kernel
│ │ ├── magics.html
│ │ └── magics.txt
├── install.py
├── kernel.py
├── pygments
│ ├── _mata_builtins.py
│ └── stata.py
├── stata_lexer.py
├── stata_magics.py
├── stata_session.py
└── utils.py
└── tests
├── test_data
└── auto.dta
├── test_kernel_completions.py
├── test_kernel_display_data.py
├── test_kernel_stdout.py
├── test_mata_lexer.py
├── test_stata_lexer.py
└── utils.py
/.editorconfig:
--------------------------------------------------------------------------------
1 | # EditorConfig is awesome: https://EditorConfig.org
2 |
3 | # top-most EditorConfig file
4 | root = true
5 |
6 | # Defaults for all files
7 | [*]
8 | end_of_line = lf
9 | insert_final_newline = true
10 | charset = utf-8
11 | trim_trailing_whitespace = true
12 | indent_style = space
13 | indent_size = 4
14 |
15 | # 2 space indentation
16 | [*.{js,R,r,yml,json}]
17 | indent_size = 2
18 |
19 | # Tab indentation (no size specified)
20 | [Makefile]
21 | indent_style = tab
22 | trim_trailing_whitespace = false
23 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/bug_report.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Bug report
3 | about: Create a report to help us improve
4 |
5 | ---
6 |
7 | #### Problem description
8 |
9 | - This should explain **why** the current behavior is a problem and why the expected output is a better solution.
10 | - **Note**: Many problems can be resolved by simply upgrading `stata_kernel` to the latest version. Before submitting, please try:
11 |
12 | ```
13 | pip install stata_kernel --upgrade
14 | ```
15 | and check if your issue is fixed.
16 |
17 | #### Debugging log
18 |
19 | If possible, attach the text file located at
20 |
21 | ```
22 | $HOME/.stata_kernel_cache/console_debug.log
23 | ```
24 | where `$HOME` is your home directory. This will help us debug your problem quicker.
25 |
26 | **NOTE: This file includes a history of your session. If you work with restricted data, do not include this file.**
27 |
28 | #### Code Sample
29 |
30 | Especially if you cannot attach the debugging log, please include a [minimal, complete, and verifiable example.](https://stackoverflow.com/help/mcve)
31 |
32 | ```stata
33 | // Your code here
34 |
35 | ```
36 |
37 | #### Expected Output
38 |
39 | #### Other information
40 |
41 | If you didn't attach the debugging log, please provide:
42 |
43 | - Operating System
44 | - Stata version
45 | - Package version (You can find this by running `pip show stata_kernel` in your terminal.)
46 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/feature_request.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Feature request
3 | about: Suggest an idea for this project
4 |
5 | ---
6 |
7 | **Is your feature request related to a problem? Please describe.**
8 | A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
9 |
10 | **Describe the solution you'd like**
11 | A clear and concise description of what you want to happen.
12 |
13 | **Describe alternatives you've considered**
14 | A clear and concise description of any alternative solutions or features you've considered.
15 |
16 | **Additional context**
17 | Add any other context or screenshots about the feature request here.
18 |
--------------------------------------------------------------------------------
/.github/PULL_REQUEST_TEMPLATE.md:
--------------------------------------------------------------------------------
1 | - [ ] closes #xxxx
2 | - [ ] tests added / passed
3 | - [ ] passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
4 | - [ ] whatsnew entry
5 |
--------------------------------------------------------------------------------
/.github/workflows/docs.yml:
--------------------------------------------------------------------------------
1 | name: Docs
2 |
3 | on:
4 | push:
5 | branches:
6 | - master
7 |
8 | jobs:
9 | docs:
10 | runs-on: ubuntu-latest
11 | steps:
12 | - uses: actions/checkout@v2
13 | - uses: actions/setup-python@v2
14 | with:
15 | python-version: 3.x
16 | - run: pip install mkdocs mkdocs-material
17 | - run: cd docs && mkdocs gh-deploy --force
18 |
--------------------------------------------------------------------------------
/.github/workflows/test.yml:
--------------------------------------------------------------------------------
1 | name: Test
2 |
3 | # On every pull request, but only on push to master
4 | on:
5 | push:
6 | branches:
7 | - master
8 | tags:
9 | - "*"
10 | pull_request:
11 |
12 | jobs:
13 | tests:
14 | runs-on: ubuntu-20.04
15 | strategy:
16 | matrix:
17 | python-version: [3.6, 3.7, 3.8, 3.9]
18 |
19 | steps:
20 | - uses: actions/checkout@v2
21 |
22 | - name: Set up Python ${{ matrix.python-version }}
23 | uses: actions/setup-python@v2
24 | with:
25 | python-version: ${{ matrix.python-version }}
26 |
27 | - name: Set up Poetry
28 | uses: snok/install-poetry@v1
29 | with:
30 | version: 1.1.10
31 |
32 | - name: Install dependencies
33 | run: |
34 | poetry install
35 | poetry run python -m stata_kernel.install
36 |
37 | - name: Run tests
38 | # TODO: We should be running other tests and not just these two files
39 | run: |
40 | poetry run pytest tests/test_mata_lexer.py tests/test_stata_lexer.py
41 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .DS_Store
2 | .stata_kernel_images
3 | docs/html/mkdocs/
4 |
5 | # Byte-compiled / optimized / DLL files
6 | __pycache__/
7 | *.py[cod]
8 | *$py.class
9 |
10 | # C extensions
11 | *.so
12 |
13 | # Distribution / packaging
14 | .Python
15 | build/
16 | develop-eggs/
17 | dist/
18 | downloads/
19 | eggs/
20 | .eggs/
21 | lib/
22 | lib64/
23 | parts/
24 | sdist/
25 | var/
26 | wheels/
27 | *.egg-info/
28 | .installed.cfg
29 | *.egg
30 | MANIFEST
31 |
32 | # PyInstaller
33 | # Usually these files are written by a python script from a template
34 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
35 | *.manifest
36 | *.spec
37 |
38 | # Installer logs
39 | pip-log.txt
40 | pip-delete-this-directory.txt
41 |
42 | # Unit test / coverage reports
43 | htmlcov/
44 | .tox/
45 | .coverage
46 | .coverage.*
47 | .cache
48 | nosetests.xml
49 | coverage.xml
50 | *.cover
51 | .hypothesis/
52 | .pytest_cache/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 |
63 | # Flask stuff:
64 | instance/
65 | .webassets-cache
66 |
67 | # Scrapy stuff:
68 | .scrapy
69 |
70 | # Sphinx documentation
71 | docs/_build/
72 |
73 | # PyBuilder
74 | target/
75 |
76 | # Jupyter Notebook
77 | .ipynb_checkpoints
78 |
79 | # pyenv
80 | .python-version
81 |
82 | # celery beat schedule file
83 | celerybeat-schedule
84 |
85 | # SageMath parsed files
86 | *.sage.py
87 |
88 | # Environments
89 | .env
90 | .venv
91 | env/
92 | venv/
93 | ENV/
94 | env.bak/
95 | venv.bak/
96 |
97 | # Spyder project settings
98 | .spyderproject
99 | .spyproject
100 |
101 | # Rope project settings
102 | .ropeproject
103 |
104 | # mkdocs documentation
105 | /site
106 |
107 | # mypy
108 | .mypy_cache/
109 |
--------------------------------------------------------------------------------
/CHANGELOG.md:
--------------------------------------------------------------------------------
1 | # Changelog
2 |
3 | ## [1.12.3] - 2021-02-25
4 |
5 | - Simplify kernel installation for conda environments
6 |
7 | ## [1.12.2] - 2020-11-30
8 |
9 | - File spaces in cache dir for graph export (#371)
10 | - spacing in cache dir for head/tail magics (#369)
11 |
12 | ## [1.12.1] - 2020-10-19
13 |
14 | - Fix install on linux when unable to find stata path (#363)
15 |
16 | ## [1.12.0] - 2020-09-21
17 |
18 | - Fix including spaces in filename (#356)
19 | - Add environmental variable option for config global and user locations (#353)
20 | - Support eps graphics via user-specified convert program (#346)
21 |
22 | ## [1.11.2] - 2020-02-21
23 |
24 | - Fix bug where `pdf_dup` was not defined when `graph_format` was not `svg` or `png`. #332
25 |
26 | ## [1.11.1] - 2020-02-10
27 |
28 | - Update search path to find Stata 16 path automatically on Windows. #330
29 |
30 | ## [1.11.0] - 2020-02-10
31 |
32 | - Allow for a global configuration file on Linux. #327
33 | - Fix bug with spaces in log file. #318
34 | - Fix deprecation notice. #324
35 |
36 | ## [1.10.5] - 2019-01-30
37 |
38 | - Fix bug where the return code (`_rc`) was reset by internal code after every user command. #288
39 |
40 | ## [1.10.4] - 2019-01-29
41 |
42 | - _Actually_ fix bug that prevented long commands on Windows from working. #284
43 |
44 | ## [1.10.3] - 2019-01-28
45 |
46 | - Fix "Code editor out of sync" Jupyterlab message. #270
47 |
48 | ## [1.10.2] - 2019-01-28
49 |
50 | - Fix bug that prevented long commands on Windows from working. #284
51 | - Make sure to always find correct Stata path on Mac when using Automation.
52 | - Several documentation updates
53 |
54 | ## [1.10.1] - 2019-01-08
55 |
56 | - Fix bug that prevented from working on Windows. #281
57 |
58 | ## [1.10.0] - 2019-01-04
59 |
60 | - Fix `%help` magic in JupyterLab. #273
61 | - Added example Jupyter Notebook file to documentation. #275
62 | - Throws custom error if the Automation type library isn't registered on Windows. #276
63 | - Adds program names to autocompletion. #280
64 | - Don't sort file paths before variable names. #261
65 |
66 | ## [1.9.0] - 2018-12-19
67 |
68 | - Add `%html` and `%latex` magics for displaying formatted output. #267
69 | - `r()` is no longer cleared between commands. #266
70 | - Add tests
71 |
72 | ## [1.8.1] - 2018-12-17
73 |
74 | - Fix log cleaning for programs and for loops with > 10 lines. #257
75 | - Fix autocomplete to show globals upon typing `${`. #253
76 | - Add kernel tests. #254
77 | - JupyterLab syntax highlighting now exists. Run `jupyter labextension install jupyterlab-stata-highlight`
78 | - Fix bug where incorrect files were suggested. #262
79 | - Allow use of bracketed globals in file path autocompletion
80 |
81 | ## [1.8.0] - 2018-11-28
82 |
83 | - Don't launch Stata with WinExec on Windows. This should have the benefit that 1) a new Stata window isn't created unless it needs to be, and 2) graphs don't show up unnecessarily. #249
84 | - Add magics to show and hide the Stata GUI. #251
85 | - Fix displaying image in QtConsole. #246
86 | - Fix completions bug. #247
87 |
88 | ## [1.7.4] - 2018-11-21
89 |
90 | - Fix finding Stata path on Windows when key not in registry. #242
91 |
92 | ## [1.7.3] - 2018-11-20
93 |
94 | - Fix log cleaning on Windows. #241
95 |
96 | ## [1.7.2] - 2018-11-20
97 |
98 | - Fix install. Add _mata_builtins to MANIFEST.in. #239
99 |
100 | ## [1.7.1] - 2018-11-19
101 |
102 | - Fix `%browse`, `%head`, `%tail` display issues. #237
103 |
104 | ## [1.7.0] - 2018-11-19
105 |
106 | - Add Mata mode. #116
107 | - Allow program to function without a configuration file. #222
108 | - Fixed Ctrl+C behavior.
109 | - Hide most Stata kernel output from user logs #228
110 | - Add completions on word boundaries. #229
111 | - Wrap SVGs in iframe tags to prevent cross-image issues. #235
112 | - Don't overwrite configuration file if it already exists.
113 |
114 | ## [1.6.2] - 2018-10-25
115 |
116 | - Revert closing graph window automatically. #219
117 | - Refactor `%browse` to use the same code as `%head` internally. #217
118 |
119 | ## [1.6.1] - 2018-10-24
120 |
121 | - Remove `regex` package as a dependency. #212
122 | - Fix `cap`/`noi`/`qui` completions with scalars and matrices. #213
123 | - Close Stata graph window after saving graph. #214
124 | - Fix regex to hide "note: graph.svg not found"
125 |
126 | ## [1.6.0] - 2018-10-24
127 |
128 | - File path autocompletions. Currently only works when files have no spaces in them. #195
129 | - Only export graph after successful command. #210
130 | - Display `--more--` in frontend when it stops the display. #198
131 | - Fix `scatter` in graph regex. Only `sc` and `scatter` produce plots when not
132 | preceded by `twoway`. #205
133 | - Give matrix and scalar autocompletions when using shortened command names.
134 | #206
135 |
136 | ## [1.5.9] - 2018-10-16
137 |
138 | - Fix bugs with Python 3.5. #203
139 |
140 | ## [1.5.8] - 2018-10-11
141 |
142 | - Fix incorrect regex escaping. #201
143 |
144 | ## [1.5.7] - 2018-10-11
145 |
146 | - Fix bug that parsed multiple `///` on a single line incorrectly. #200
147 |
148 | ## [1.5.6] - 2018-10-09
149 |
150 | - Fix bug that prevented `set rmsg on` from working. #199
151 |
152 | ## [1.5.5] - 2018-10-05
153 |
154 | - Add `user_graph_keywords` setting to allow graphs to be displayed for third-party commands.
155 |
156 | ## [1.5.4] - 2018-09-21
157 |
158 | - Force utf-8 encoding when writing `include` code to file. #196
159 | - Catch `EOF` when waiting for the PDF copy of graph. #192
160 |
161 | ## [1.5.3] - 2018-09-20
162 |
163 | - Set pexpect terminal size to 255 columns. #190
164 |
165 | ## [1.5.2] - 2018-09-19
166 |
167 | - Add pywin32 as a pip dependency on Windows, thus making installation easier.
168 | - Add jupyter 1.0.0 metapackage as a dependency, so that installs from Miniconda also install all of Jupyter.
169 |
170 | ## [1.5.1] - 2018-09-17
171 |
172 | - Fix issues with `--more--`. #103
173 | - PDF Graph redundancy. This improves ease of export to PDF via LaTeX.
174 | - Catch PermissionsError when copying syntax highlighting files
175 | - Add Stata logo for Jupyter Notebook
176 | - Autoclose local macro quotes in Jupyter Notebook
177 | - Highlight /// as comments in Jupyter Notebook
178 | - Highlight macros in Jupyter Notebook
179 | - Check latest PyPi package version and add alert to banner if newer
180 | - Simplify `%set` magic
181 | - Set default linesize to 255 for now to improve image handling. #177
182 |
183 | ## [1.5.0] - 2018-09-14
184 |
185 | - Add CodeMirror syntax highlighting for Jupyter Notebook
186 | - Improve Pygments syntax highlighting for highlighting of Jupyter QtConsole, Jupyter Console, and Notebook outputs in HTML and PDF format.
187 | - Restore PDF graph support. Although it doesn't display within the Jupyter Notebook for security (or maybe just practical) reasons, it's helpful when exporting a Notebook to a PDF via LaTeX.
188 | - Temporarily fix encoding error from CJK characters being split by a line break. #167
189 |
190 | ## [1.4.8] - 2018-09-12
191 |
192 | - Fix use of `which` in install script
193 | - Redirect `xstata` to `stata` on Linux. #149
194 | - Fix hiding code lines when there are hard tab characters (`\t`). #153
195 | - Make HTML help links open in new tab. #158
196 | - Open log files with utf-8 encoding. https://github.com/kylebarron/language-stata/issues/98
197 |
198 | ## [1.4.7] - 2018-09-08
199 |
200 | - Fix pypi upload. Need to use `python setup.py sdist bdist_wheel` and not `python setup.py sdist bdist`. The latter creates two source packages, and only one source package can ever be uploaded to Pypi per release.
201 |
202 | ## [1.4.6] - 2018-09-08
203 |
204 | - Fix `install.py`; previously it had unmatched `{` and `}`
205 | - Fix display of whitespace when entire result is whitespace. #111
206 |
207 | ## [1.4.5] - 2018-09-07
208 |
209 | - Don't embed images in HTML help; link to them. #140
210 | - Fix blocking for line continuation when string is before `{` #139
211 | - Fix hiding of code lines with leading whitespace. #120
212 | - Remove `stata_kernel_graph_counter` from globals suggestions. #109
213 | - Always use UTF-8 encoding when loading SVGs. #130
214 | - Add download count and Atom gif to README. Try to fix images for Pypi page.
215 |
216 | ## [1.4.4] - 2018-09-06
217 |
218 | - Fully hide Stata GUI on Windows. Always export log file, even on Windows and Mac Automation.
219 | - Set more off within ado files. Should fix #132.
220 | - Use bumpversion for easy version number updating.
221 | - Add `%help kernel` and `%help magics` options
222 | - Add general debugging information (like OS/Stata version/package version) to log
223 | - Add help links to Jupyter Notebook's Help dropdown UI
224 | - Various docs fixes
225 |
226 | ## [1.4.3] - 2018-09-04
227 |
228 | - Release to pypi again because 1.4.2 didn't upload correctly. Apparently only a
229 | Mac version was uploaded, and even that didn't work.
230 |
231 | ## [1.4.2] - 2018-08-21
232 |
233 | - Fix line cleaning for loops/programs of more than 9 lines
234 | - Remove pexpect timeout
235 | - Provide error message upon incomplete input sent to `do_execute`
236 |
237 | ## [1.4.1] - 2018-08-21
238 |
239 | - Add `%head` and `%tail` magics
240 | - Change `%set plot` to `%set graph`
241 |
242 | ## [1.4.0] - 2018-08-21
243 |
244 | - Return results as Stata returns them, not when command finishes
245 | - More stable method of knowing when a command finishes by looking for the text's MD5 hash
246 | - Finds Stata executable during install
247 | - Automatically show graphs after graph commands
248 | - Add %help and %browse magics
249 | - Allow for graph scaling factors
250 | - Fix Windows locals issue
251 | - Fix image spacing
252 |
253 | ## [1.3.1] - 2018-08-13
254 |
255 | - Fix pip installation by adding CHANGELOG and requirements files to `MANIFEST.in`.
256 |
257 | ## [1.3.0] - 2018-08-13
258 |
259 | - Context-aware autocompletions
260 | - Support for #delimit; blocks interactively
261 | - Better parsing for when a user-provided block is complete or not. Typing `2 + ///` will prompt for the next line.
262 | - Split lexer into two lexers. This is helpful to first remove comments and convert #delimit; blocks to cr-delimited blocks.
263 | - Fix svg aspect ratio
264 | - Magics for plotting, retrieving locals and globals, timing commands, seeing current delimiter.
265 | - Add documentation website
266 |
267 | ## [1.2.0] - 2018-08-11
268 |
269 | - Support for `if`, `else`, `else if`, `cap`, `qui`, `noi`, `program`, `input` blocks #28, #27, #30
270 | - Support different graph formats #21
271 | - Heavily refactor codebase into hopefully more stable API #32
272 | - Correctly parse long, text wrapped lines from log file or console #41
273 | - Use a single cache directory, configurable by the user #43
274 | - Correctly remove comments, using a tokenizer #38, #25, #29
275 |
276 |
277 | ## [1.1.0] - 2018-08-06
278 |
279 | **Initial release!** This would ordinarily be something like version 0.1.0, but the Echo kernel framework that I made this from was marked as 1.1 internally, and I forgot to change that before people started downloading this. I don't want to move my number down to 0.1 and have people who already installed not be able to upgrade.
280 |
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing
2 |
3 | All types of contributions are welcome. You can:
4 |
5 | - [Submit a bug report](#bug-reports)
6 | - [Update or add new documentation or examples](#updating-the-docs)
7 | - [Add automated tests](#tests)
8 | - Submit a pull request for a new feature
9 |
10 | ## Bug reports
11 |
12 | The best way to get your issue solved is to provide a [minimal, complete, verifiable example.](https://stackoverflow.com/help/mcve) In order to submit a bug report, [click here](https://github.com/kylebarron/stata_kernel/issues/new/choose) and fill out the template.
13 |
14 | ## Debugging
15 |
16 | The following seems to be the easiest way to debug internals:
17 |
18 | ```py
19 | from stata_kernel.kernel import StataKernel
20 | from stata_kernel.code_manager import CodeManager
21 |
22 | kernel = StataKernel()
23 | session = kernel.stata
24 |
25 | # If on windows, may be helpful
26 | session.show_gui()
27 |
28 | code = 'sysuse auto, clear'
29 | cm = CodeManager(code)
30 | text_to_run, md5, text_to_exclude = cm.get_text(kernel.conf, session)
31 | rc, res = session.do(
32 | text_to_run, md5, text_to_exclude=text_to_exclude, display=False)
33 | ```
34 |
35 | ## Tests
36 |
37 | ### Adding tests
38 |
39 | Tests are contained in the Python files in the `tests/` folder. The `test_stata_lexer.py` and `test_mata_lexer.py` files run automated tests on the code Stata kernel uses to parse user input.
40 |
41 | ### Running tests
42 |
43 | To run the tests, you need to install `pytest` and `jupyter_kernel_test`:
44 | ```
45 | pip install pytest jupyter_kernel_test
46 | ```
47 |
48 | From the project root, to run all tests, run
49 |
50 | ```
51 | pytest tests/
52 | ```
53 |
54 | To run just the non-automated tests that depend on having Stata available locally, run
55 |
56 | ```
57 | pytest tests/test_kernel.py
58 | ```
59 |
60 | For each of the above, if you get a `ModuleNotFound` error, you may need to use `python -m pytest tests/`.
61 |
62 | ## Updating the docs
63 |
64 | First install `mkdocs`:
65 |
66 | ```
67 | pip install mkdocs mkdocs-material
68 | ```
69 |
70 | Then `cd` to the docs folder:
71 | ```
72 | cd docs/
73 | ```
74 |
75 | Then to serve the documentation website in real time, run
76 | ```
77 | mkdocs serve
78 | ```
79 | This starts a web server on localhost, usually on port 8000. So you can open your web browser and type in `localhost:8000`, click Enter, and you should see the website. This will update in real time as you write more documentation.
80 |
81 | To create a static website, run:
82 | ```
83 | mkdocs build
84 | ```
85 |
86 | To publish the website to the documentation website (if you have repository push access) run:
87 | ```
88 | mkdocs gh-deploy
89 | ```
90 |
91 |
92 | ## Releasing new versions
93 |
94 | To increment version numbers, run one of:
95 | ```
96 | bumpversion major
97 | bumpversion minor
98 | bumpversion patch
99 | ```
100 | in the project's root directory. This will also automatically create a git commit and tag of the version. Then push with:
101 |
102 | ```
103 | git push origin master --tags
104 | ```
105 |
106 | so that Github sees the newest tag.
107 |
108 | Then to release:
109 |
110 | ```
111 | python setup.py sdist bdist_wheel
112 | python -m twine upload dist/stata_kernel-VERSION*
113 | ```
114 | and put in the PyPI username and password.
115 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include README.md
2 | include CHANGELOG.md
3 | include requirements.txt
4 | include requirements_dev.txt
5 | include LICENSE
6 | include stata_kernel/ado/*.ado
7 | include stata_kernel/css/*.css
8 | include stata_kernel/docs/logo-64x64.png
9 | include stata_kernel/docs/*html
10 | include stata_kernel/docs/*txt
11 | include stata_kernel/docs/using_stata_kernel/*html
12 | include stata_kernel/docs/using_stata_kernel/*txt
13 | include stata_kernel/codemirror/stata.js
14 | include stata_kernel/pygments/stata.py
15 | include stata_kernel/pygments/_mata_builtins.py
16 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # stata_kernel
2 |
3 | [](https://travis-ci.org/kylebarron/stata_kernel) [](https://pepy.tech/project/stata-kernel) [](https://pepy.tech/project/stata-kernel)
4 |
5 | `stata_kernel` is a Jupyter kernel for Stata; It works on Windows, macOS, and
6 | Linux.
7 |
8 | To see an example Jupyter Notebook, [click here.](https://nbviewer.jupyter.org/github/kylebarron/stata_kernel/blob/master/examples/Example.ipynb)
9 |
10 | For documentation and more information, see: [https://kylebarron.dev/stata_kernel](https://kylebarron.dev/stata_kernel)
11 |
12 | #### Jupyter Notebook
13 | 
14 |
15 | #### Atom
16 | 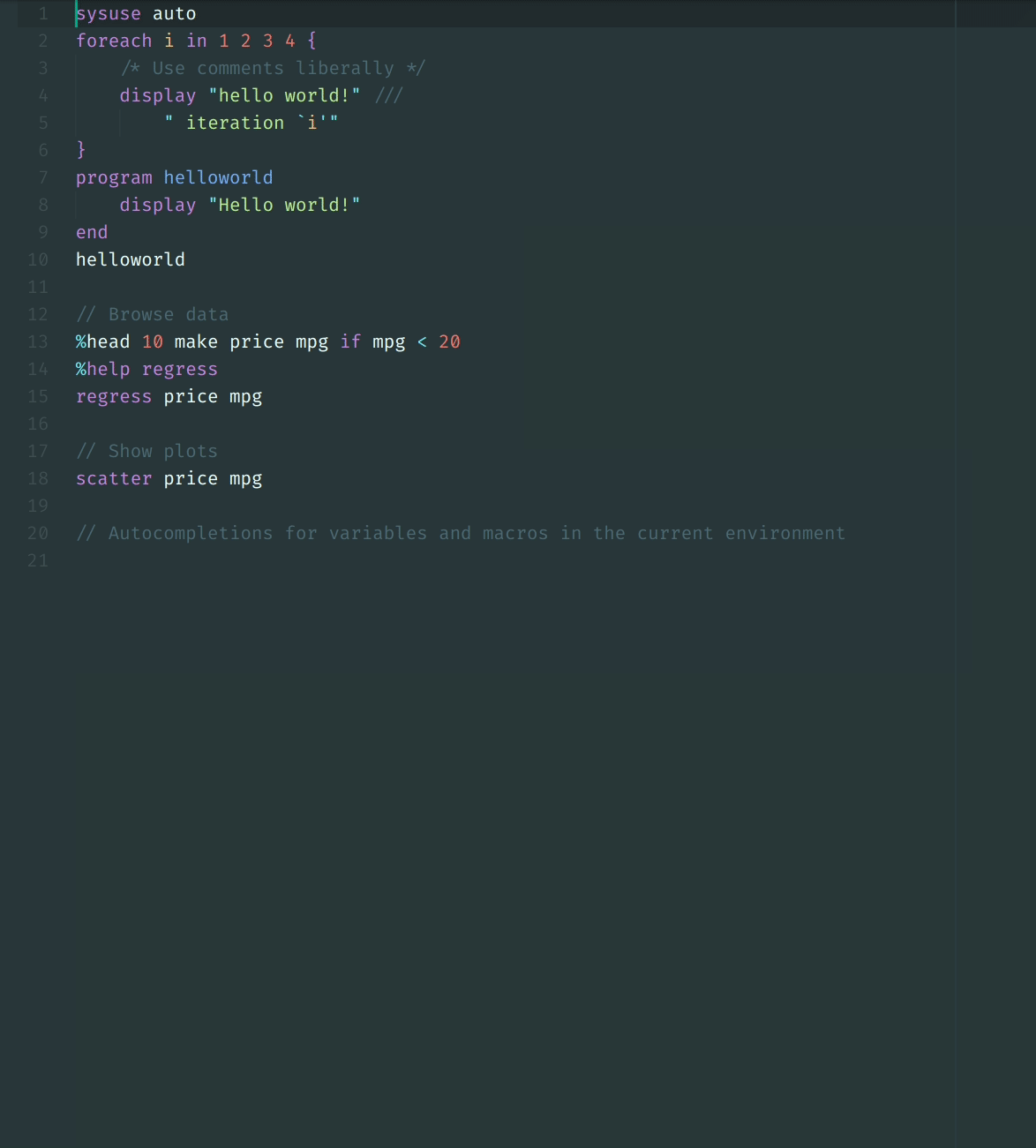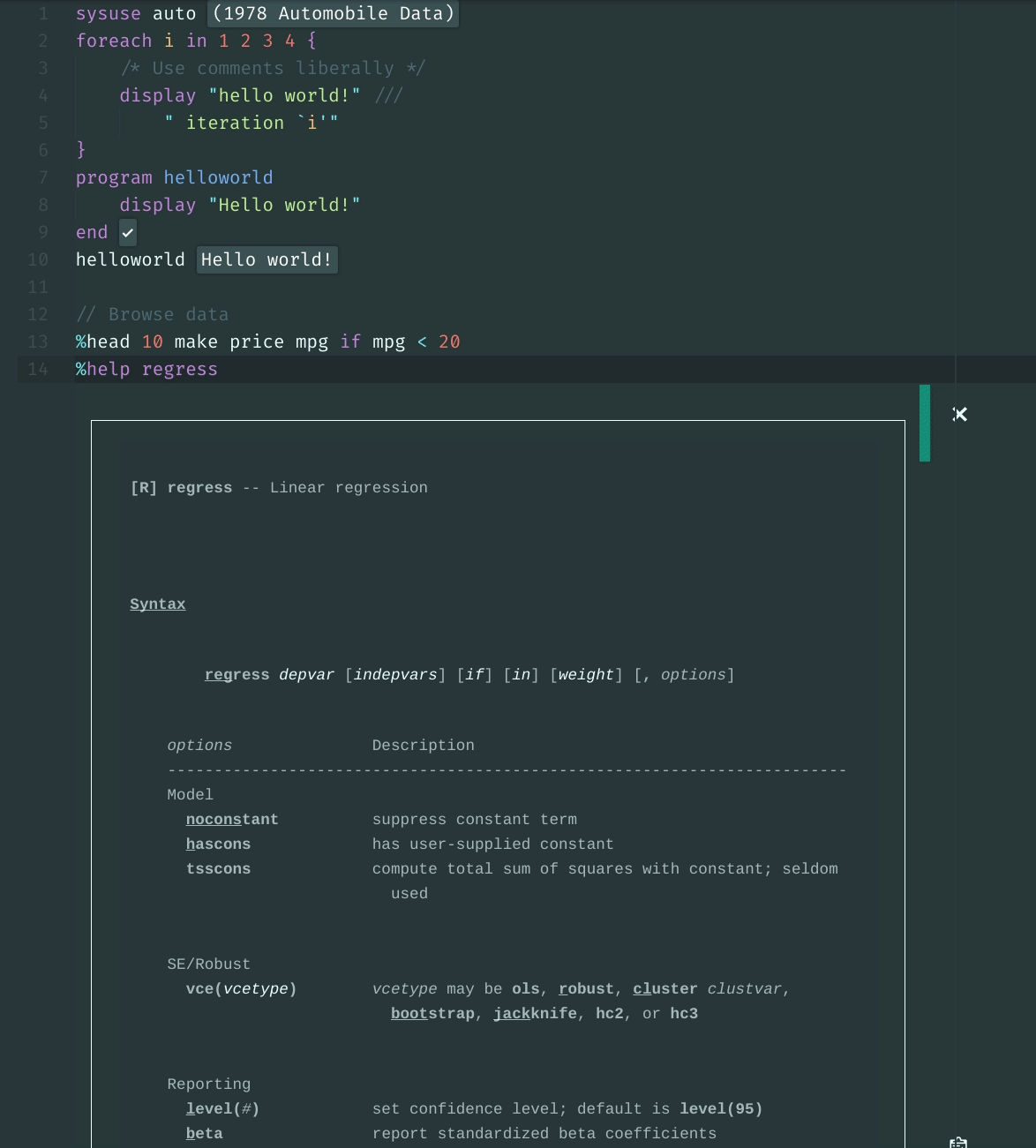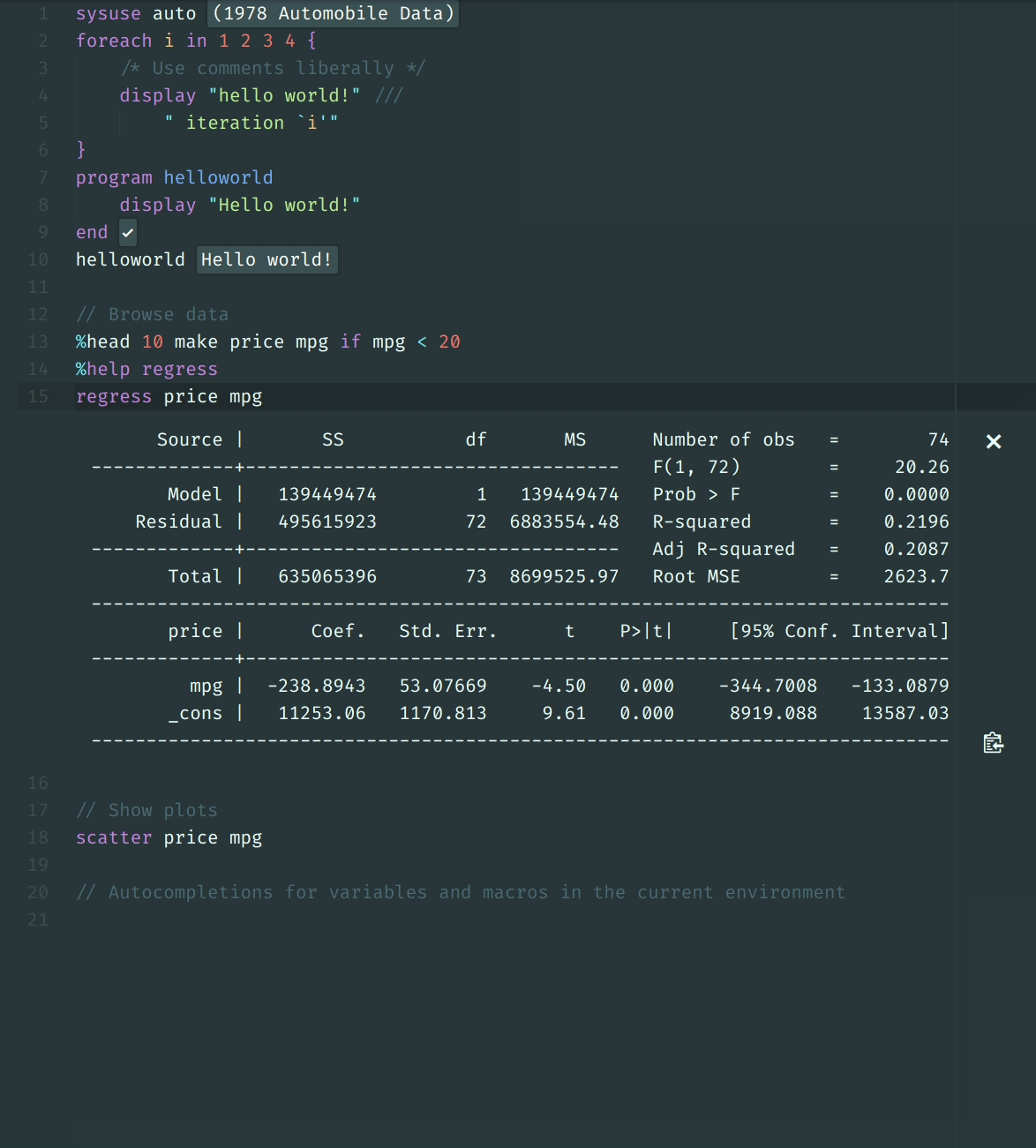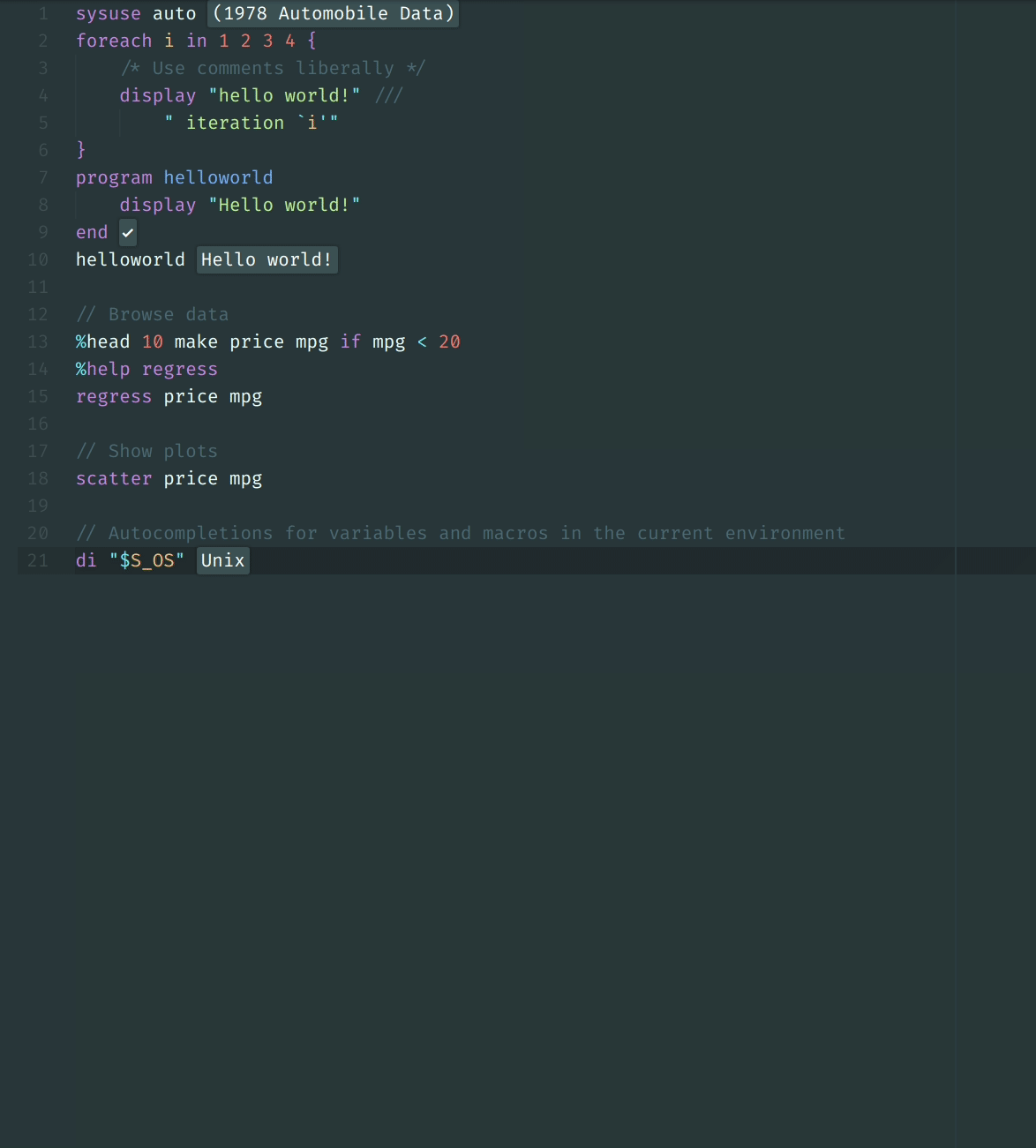
17 |
--------------------------------------------------------------------------------
/docs/mkdocs.yml:
--------------------------------------------------------------------------------
1 | # Project Information
2 | site_name: 'stata_kernel'
3 | site_description: 'A Jupyter Kernel for Stata. Works with Windows, macOS, and Linux.'
4 | site_author: 'Kyle Barron'
5 |
6 | docs_dir: 'src'
7 | site_dir: 'html/mkdocs'
8 |
9 | # Repository
10 | repo_name: 'kylebarron/stata_kernel'
11 | repo_url: 'https://github.com/kylebarron/stata_kernel'
12 | edit_uri: 'blob/master/docs/src/'
13 | site_url: 'https://kylebarron.dev/stata_kernel/'
14 |
15 | # Social links
16 | extra:
17 | social:
18 | - icon: 'fontawesome/brands/github'
19 | link: 'https://github.com/kylebarron'
20 | - icon: 'fontawesome/brands/twitter'
21 | link: 'https://twitter.com/kylebarron2'
22 |
23 | # Layout
24 | nav:
25 | - Home: 'index.md'
26 | - Getting Started: 'getting_started.md'
27 | - Jupyter Notebook Example: 'https://nbviewer.jupyter.org/github/kylebarron/stata_kernel/blob/master/examples/Example.ipynb'
28 | - Using Jupyter:
29 | - Introduction: 'using_jupyter/intro.md'
30 | - JupyterLab: 'using_jupyter/lab.md'
31 | - Hydrogen in Atom: 'using_jupyter/atom.md'
32 | - Jupyter Notebook: 'using_jupyter/notebook.md'
33 | - Nteract: 'using_jupyter/nteract.md'
34 | - Jupyter QtConsole: 'using_jupyter/qtconsole.md'
35 | - Jupyter Console: 'using_jupyter/console.md'
36 | - Remote Servers: 'using_jupyter/remote.md'
37 | - Using the Stata Kernel:
38 | - Introduction: 'using_stata_kernel/intro.md'
39 | - Configuration: 'using_stata_kernel/configuration.md'
40 | - Magics: 'using_stata_kernel/magics.md'
41 | - Limitations: 'using_stata_kernel/limitations.md'
42 | - Troubleshooting: 'using_stata_kernel/troubleshooting.md'
43 | - Comparison with IPyStata: 'comparison_with_ipystata.md'
44 | - Contributing: 'CONTRIBUTING.md'
45 | - Addendum: 'addendum.md'
46 | - License: 'license.md'
47 |
48 | google_analytics:
49 | - 'UA-125422577-1'
50 | - 'auto'
51 |
52 | # Theme
53 | theme:
54 | feature:
55 | tabs: false
56 | icon:
57 | logo: 'material/home'
58 | repo: 'fontawesome/brands/github'
59 | name: 'material'
60 | language: 'en'
61 | palette:
62 | primary: 'blue'
63 | accent: 'light blue'
64 | font:
65 | text: 'Nunito Sans'
66 | code: 'Fira Code'
67 |
68 | # Uncomment if I use math in the docs in the future
69 | # extra_javascript:
70 | # - helpers/helpers.js
71 | # - https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.4/MathJax.js?config=TeX-AMS-MML_HTMLorMML
72 |
73 | # These extensions are chosen to be a superset of Pandoc's Markdown.
74 | # This way, I can write in Pandoc's Markdown and have it be supported here.
75 | # https://pandoc.org/MANUAL.html
76 | markdown_extensions:
77 | - admonition
78 | - attr_list
79 | - codehilite:
80 | guess_lang: false
81 | - def_list
82 | - footnotes
83 | - pymdownx.arithmatex
84 | - pymdownx.betterem
85 | - pymdownx.caret:
86 | insert: false
87 | - pymdownx.details
88 | - pymdownx.emoji
89 | - pymdownx.escapeall:
90 | hardbreak: true
91 | nbsp: true
92 | - pymdownx.magiclink:
93 | hide_protocol: true
94 | repo_url_shortener: true
95 | - pymdownx.smartsymbols
96 | - pymdownx.superfences
97 | - pymdownx.tasklist:
98 | custom_checkbox: true
99 | - pymdownx.tilde
100 | - toc:
101 | permalink: true
102 |
--------------------------------------------------------------------------------
/docs/src/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | ../../CONTRIBUTING.md
--------------------------------------------------------------------------------
/docs/src/addendum.md:
--------------------------------------------------------------------------------
1 | # Addendum
2 |
3 | As an ardent open-source advocate and someone who actively dislikes using Stata,
4 | it somewhat pains me that my work creates value for a proprietary, closed-source
5 | program. I hope that this program improves research in a utilitarian way, and
6 | shows to new users the scope of the open-source tools that have existed for
7 | upwards of a _decade_.
8 |
9 | ## Contributors
10 |
11 | - [Kyle Barron](https://github.com/kylebarron)
12 | - [Mauricio Cáceres](https://github.com/mcaceresb)
13 | - [Full list of contributors](https://github.com/kylebarron/stata_kernel/graphs/contributors)
14 |
--------------------------------------------------------------------------------
/docs/src/comparison_with_ipystata.md:
--------------------------------------------------------------------------------
1 | # Comparison with [IPyStata](https://github.com/TiesdeKok/ipystata)
2 |
3 | ## `stata_kernel` is faster with larger datasets
4 |
5 | `stata_kernel` takes a different approach to communication with Stata. With `IPyStata` on macOS and Linux, to run each segment of code
6 |
7 | 1. Your data has to be moved from Python to Stata
8 | 2. Run the commands in Stata
9 | 3. Return the data to Python to save it for the next command
10 |
11 | This process is prohibitive with larger amounts of data. In contrast, `stata_kernel` controls Stata directly, so it generally is no slower than using the Stata program itself.
12 |
13 | ## `stata_kernel` provides more features
14 |
15 | `stata_kernel` is a pure Jupyter kernel, whereas IPyStata is a Jupyter _magic_ within the Python kernel. This means that with `stata_kernel`
16 |
17 | - You don't have to include `%%stata` at the beginning of every cell.
18 | - You get features like autocompletion and being able to use `;` as a delimiter.
19 | - You see intermediate results of long-running commands without waiting for the entire command to have finished.
20 | - You can create multiple graphs in the same cell without having to name each of them individually. (Order of the graphs is also guaranteed).
21 | - You don't have to have any knowledge whatsoever of Python [^1].
22 |
23 | [^1]: Python is amazing language, and if you want to move on to bigger data, I highly recommend learning Python. Now that `stata_kernel` is installed, if you want to start a Python notebook instead of a Stata notebook, just choose New > Python 3 in the dropdown menu.
24 |
--------------------------------------------------------------------------------
/docs/src/getting_started.md:
--------------------------------------------------------------------------------
1 | # Getting Started
2 |
3 | It doesn't take much to get `stata_kernel` up and running. Here's how:
4 |
5 | ## Prerequisites
6 |
7 | - **Stata**. A currently-licensed version of Stata must already be installed. `stata_kernel` has been reported to work with at least Stata 13+, and may work with Stata 12.
8 | - **Python**. In order to install the kernel, Python 3.5, 3.6, or 3.7 needs to be installed on the computer on which Stata is running.
9 |
10 | I suggest installing the [Anaconda
11 | distribution](https://www.anaconda.com/download/). This doesn't require
12 | administrator privileges, and is the simplest way to install Python and many of the most popular scientific packages.
13 |
14 | The full Anaconda installation is quite large, and includes many libraries for Python that
15 | `stata_kernel` doesn't use. If you don't plan to use Python and want to use
16 | less disk space, install [Miniconda](https://conda.io/miniconda.html), a bare-bones version of Anaconda. Then when [installing the package](#package-install) any other necessary dependencies will be
17 | downloaded automatically.
18 |
19 | ???+ note "Windows-specific steps"
20 |
21 | In order to let `stata_kernel` talk to Stata, you need to [link the Stata Automation library](https://www.stata.com/automation/#install):
22 |
23 | 1. In the installation directory (most likely `C:\Program Files (x86)\Stata15` or similar), right-click on the Stata executable, for example, `StataSE.exe`. Choose `Create Shortcut`. Placing it on the Desktop is fine.
24 | 2. Right-click on the newly created `Shortcut to StataSE.exe`, choose `Property`, and append `/Register` to the end of the Target field. So if the target is currently `"C:\Program Files\Stata15\StataSE.exe"`, change it to `"C:\Program Files\Stata15\StataSE.exe" /Register`. Click `OK`.
25 | 3. Right-click on the updated `Shortcut to StataSE.exe`; choose `Run as administrator`.
26 |
27 | ## Package Install
28 |
29 | If you use Anaconda or Miniconda, from the Anaconda Prompt run:
30 |
31 | ```bash
32 | conda install -c conda-forge stata_kernel
33 | python -m stata_kernel.install
34 | ```
35 |
36 | If you do not use Anaconda/Miniconda, from a terminal or command prompt run:
37 |
38 | ```bash
39 | pip install stata_kernel
40 | python -m stata_kernel.install
41 | ```
42 |
43 | If Python 2 is the default version of Python on your system, you may need to use
44 | `python3` instead of `python` for the `python3 -m stata_kernel.install` step.
45 |
46 | ### Jupyter
47 |
48 | If you chose to install Anaconda you already have [Jupyter Notebook](https://jupyter-notebook.readthedocs.io/en/stable/notebook.html) and [Jupyter Lab](https://jupyterlab.readthedocs.io/en/stable/getting_started/overview.html) installed.
49 |
50 | Otherwise, you need to install Jupyter Notebook or Jupyter Lab. I recommend the latter as it is a similar but more modern environment. If you have Miniconda, open the Anaconda Prompt and run:
51 |
52 | ```bash
53 | conda install jupyterlab
54 | ```
55 |
56 | If you use pip, you can install it via:
57 |
58 | ```bash
59 | pip install jupyterlab
60 | ```
61 |
62 | If you would not like to install Jupyter Lab and only need the Notebook, you can install it by running
63 |
64 | ```bash
65 | conda install notebook
66 | ```
67 |
68 | or
69 |
70 | ```bash
71 | pip install notebook
72 | ```
73 |
74 | depending on your package manager.
75 |
76 | In order to get syntax highlighting in Jupyter Lab, run:
77 | ```bash
78 | conda install -c conda-forge nodejs -y
79 | jupyter labextension install jupyterlab-stata-highlight
80 | ```
81 |
82 | If you didn't install Python from Anaconda/Miniconda, the `conda` command won't work and you'll need to install [Node.js](https://nodejs.org/en/download/) directly before running `jupyter labextension install`.
83 |
84 | ### Upgrading
85 |
86 | To upgrade from a previous version of `stata_kernel`, from a terminal or command prompt run
87 |
88 | ```bash
89 | conda update stata_kernel -y
90 | ```
91 | in the case of Anaconda/Miniconda or
92 |
93 | ```bash
94 | pip install stata_kernel --upgrade
95 | ```
96 | otherwise.
97 |
98 | When upgrading, you don't have to run `python -m stata_kernel.install` again.
99 |
100 | ## Using
101 |
102 | Next, read more about [Jupyter and its different
103 | interfaces](using_jupyter/intro.md) or about [how to use the Stata
104 | kernel](using_stata_kernel/intro.md), specifically.
105 |
--------------------------------------------------------------------------------
/docs/src/helpers/helpers.js:
--------------------------------------------------------------------------------
1 | MathJax.Hub.Config({
2 | TeX: {
3 | equationNumbers: {
4 | autoNumber: "AMS"
5 | }
6 | },
7 | tex2jax: {
8 | inlineMath: [ ['$','$'], ['\\(', '\\)'] ],
9 | displayMath: [ ['$$','$$'] ],
10 | processEscapes: true,
11 | }
12 | });
13 |
--------------------------------------------------------------------------------
/docs/src/img/atom.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/atom.png
--------------------------------------------------------------------------------
/docs/src/img/atom_help_magic.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/atom_help_magic.png
--------------------------------------------------------------------------------
/docs/src/img/browse_atom.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/browse_atom.png
--------------------------------------------------------------------------------
/docs/src/img/browse_notebook.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/browse_notebook.png
--------------------------------------------------------------------------------
/docs/src/img/esttab-html-file.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/esttab-html-file.png
--------------------------------------------------------------------------------
/docs/src/img/esttab-html-jupyterlab.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/esttab-html-jupyterlab.png
--------------------------------------------------------------------------------
/docs/src/img/esttab-latex-jupyterlab.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/esttab-latex-jupyterlab.png
--------------------------------------------------------------------------------
/docs/src/img/esttab-latex-pdf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/esttab-latex-pdf.png
--------------------------------------------------------------------------------
/docs/src/img/hydrogen-watch-browse.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/hydrogen-watch-browse.gif
--------------------------------------------------------------------------------
/docs/src/img/hydrogen-watch-graph.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/hydrogen-watch-graph.gif
--------------------------------------------------------------------------------
/docs/src/img/jupyter_console.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/jupyter_console.png
--------------------------------------------------------------------------------
/docs/src/img/jupyter_notebook.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/jupyter_notebook.png
--------------------------------------------------------------------------------
/docs/src/img/jupyter_notebook_example.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/jupyter_notebook_example.gif
--------------------------------------------------------------------------------
/docs/src/img/jupyterlab_autocompletion.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/jupyterlab_autocompletion.png
--------------------------------------------------------------------------------
/docs/src/img/mobaxterm-local-port-forwarding.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/mobaxterm-local-port-forwarding.png
--------------------------------------------------------------------------------
/docs/src/img/notebook_help_magic.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/notebook_help_magic.png
--------------------------------------------------------------------------------
/docs/src/img/nteract.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/nteract.pdf
--------------------------------------------------------------------------------
/docs/src/img/nteract.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/nteract.png
--------------------------------------------------------------------------------
/docs/src/img/starting_jupyter_notebook.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/starting_jupyter_notebook.gif
--------------------------------------------------------------------------------
/docs/src/img/stata_kernel_example.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/stata_kernel_example.gif
--------------------------------------------------------------------------------
/docs/src/img/subscribe-to-releases.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/kylebarron/stata_kernel/f7be69b81ff83ca9cde27ed1a85f2a93d386d616/docs/src/img/subscribe-to-releases.png
--------------------------------------------------------------------------------
/docs/src/index.md:
--------------------------------------------------------------------------------
1 | # stata_kernel
2 |
3 | `stata_kernel` is a Jupyter kernel for Stata. It works on Windows, macOS, and
4 | Linux.
5 |
6 | ## What is Jupyter?
7 |
8 | Jupyter is an open-source ecosystem for interactive data science. Originally
9 | developed around the Python programming language, Jupyter has grown to interface
10 | with dozens of programming languages.
11 |
12 | `stata_kernel` is the bridge that interactively connects Stata to all the
13 | elements in the ecosystem.
14 |
15 | - [**JupyterLab**](using_jupyter/lab.md) is a web-based interactive editor that allows for interweaving of code, text, and results.
16 |
17 | - Splice models in LaTeX math mode with the code that implements them and the graphs depicting their output.
18 | - [Click here](https://nbviewer.jupyter.org/github/kylebarron/stata_kernel/blob/master/examples/Example.ipynb) to see an example Jupyter Notebook file using `stata_kernel`.
19 | - Jupyter Notebooks can be exported as PDFs or HTML, and are as good for teaching new students as they are for displaying research results.
20 |
21 | 
22 |
23 | - [**Hydrogen**](using_jupyter/atom.md) is a package for the [Atom text editor](https://atom.io) that connects with Jupyter kernels to display results interactively in your text editor.
24 | - The [**Jupyter console**](using_jupyter/console.md) is an enhanced interactive console. Its features include enhanced autocompletion, better searching of history, syntax highlighting, among others. The similar [QtConsole](using_jupyter/qtconsole.md) even allows displaying plots within the terminal.
25 | - [Enhanced remote work](using_jupyter/remote.md). You can set up Jupyter to run computations remotely but to show results locally. Since the only data passing over the network are the text inputs and outputs from Stata, communcation happens much faster than loading `xstata`, especially on slower networks. Being able to use Jupyter Notebook or Hydrogen vastly enhances productivity compared to working with the Stata console through a remote terminal.
26 |
27 | ## `stata_kernel` Features
28 |
29 | - [x] Supports Windows, macOS, and Linux.
30 | - [x] Use any type of comments in your code, not just `*`.
31 | - [x] [Autocompletions](using_stata_kernel/intro#autocompletion) as you type based on the variables, macros, scalars, and matrices currently in memory. As of version 1.6.0 it also suggests file paths for autocompletion.
32 | - [x] [Display graphs](using_stata_kernel/intro/#displaying-graphs).
33 | - [x] Receive results as they appear, not after the entire command finishes.
34 | - [x] [Pull up interactive help files within the kernel](using_stata_kernel/magics#help).
35 | - [x] [Browse data interactively](using_stata_kernel/magics#browse).
36 | - [x] [`#delimit ;` interactive support](using_stata_kernel/intro#delimit-mode)
37 | - [x] Work with a [remote session of Stata](using_jupyter/remote).
38 | - [x] Mata interactive support
39 | - [ ] Cross-session history file
40 |
41 | ## Screenshots
42 |
43 | **Atom**
44 |
45 | 
46 |
--------------------------------------------------------------------------------
/docs/src/using_jupyter/atom.md:
--------------------------------------------------------------------------------
1 | # Hydrogen in Atom
2 |
3 | Hydrogen is a package for the Atom text editor that connects with Jupyter kernels, such as `stata_kernel`, to display results interactively inside the text editor.
4 |
5 | I'll go over how to install Atom and Hydrogen, and then provide a quick overview of Hydrogen's capabilities. For more information on how to use Hydrogen, see [Hydrogen's documentation](https://nteract.gitbooks.io/hydrogen/docs/Usage/GettingStarted.html).
6 |
7 | ## Installation
8 |
9 | Atom and Hydrogen are both free and open source software, just like `stata_kernel`. The download and install is free and easy.
10 |
11 | ### Atom
12 |
13 | Go to [atom.io](https://atom.io), choose the installer for your operating system, then double click the downloaded file.
14 |
15 | ### Hydrogen
16 |
17 | Next you'll need to install a couple add-on packages:
18 |
19 | - [Hydrogen](https://atom.io/packages/hydrogen): this connects to Jupyter kernels and allows you to view results in-line next to your code. You can use it with Python, R, and Julia, as well as Stata.
20 | - [language-stata](https://atom.io/packages/language-stata): this provides syntax highlighting for Stata code and is necessary so that Hydrogen knows that a file with extension `.do` is a Stata file.
21 |
22 | To install these, go to the Atom Settings. You can get there by clicking Preferences > Settings in the menus or by using the keyboard shortcut Ctrl+, (Cmd-, on macOS). Then click _Install_ on the menu in the left, and type in `Hydrogen`, and `language-stata`, and click `Install`.
23 |
24 | Once those are installed, open a do-file and run Ctrl-Enter (Cmd-Enter on macOS) to start the Stata kernel.
25 |
26 | ## Using Atom
27 |
28 | If you've never used Atom before, you're in luck, because it's quite simple and intuitive to use.
29 | [Read here](https://flight-manual.atom.io/getting-started/sections/atom-basics/) for some basics about how to use Atom.
30 |
31 | The most important thing to know is that you can access every command available to you in Atom by using the keyboard shortcut Ctrl+Shift+P (Cmd+Shift+P on macOS). This brings up a menu, called the _Command Palette_, where you can find any command that any package provides.
32 |
33 | ## Running code
34 |
35 | There are three main ways to run code using Hydrogen:
36 |
37 | - Selection. Manually select/highlight the lines you want to send to Stata and then run `Hydrogen: Run`, which is usually bound to Ctrl-Enter.
38 | - Cursor block. When `Hydrogen: Run` is called and no code is selected, Hydrogen runs the current line. If code following the present line is more indented than the current line, Hydrogen will run the entire indented block.
39 | - Cell. A cell is a block of lines to be executed at once. They are defined using `%%` inside comments. See [here](https://nteract.gitbooks.io/hydrogen/docs/Usage/GettingStarted.html#hydrogen-run-cell) for more information.
40 |
41 | ### Output
42 |
43 | Output will display directly beside or beneath the block of code that was
44 | selected to be run. Code that does not produce any output will show a check mark
45 | when completed.
46 |
47 | ### Watch Expressions
48 |
49 | Hydrogen allows for [_watch expressions_](https://nteract.gitbooks.io/hydrogen/docs/Usage/GettingStarted.html#watch-expressions). These are expressions that are automatically re-run after every command sent to the kernel. This is convenient for viewing regression output, graphs, or the data set after changing a parameter.
50 |
51 | Note that since the watch expression is run after _every_ command, it shouldn't be something that changes the state of the data. For example, `replace mpg = mpg * 2` would be unwise to set as a watch expression because that would change the column's data after every command.
52 |
53 | Using watch expressions with a graph:
54 | 
55 |
56 | Using watch expressions to browse data:
57 | 
58 |
59 | ## Indentation and for loops
60 |
61 | Stata `foreach` loops and programs must be sent as a whole to the kernel. If you
62 | send only part of a loop, you'll receive a reply that insufficient input was
63 | provided.
64 |
65 | The easiest way to make sure that this happens is to indent all code pertaining
66 | to a block. This will ensure all lines of the block are sent to `stata_kernel`,
67 | even if the ending `}` has the same indentation as the initial line.
68 |
69 | If the cursor is anywhere on the first line in the segment below, and you run
70 | Ctrl-Enter or Shift-Enter (which
71 | moves your cursor to the next line), it will include the final `}`.
72 |
73 | ```stata
74 | foreach i in 1 2 3 4 {
75 | display "`i'"
76 | }
77 | ```
78 |
--------------------------------------------------------------------------------
/docs/src/using_jupyter/console.md:
--------------------------------------------------------------------------------
1 | # Jupyter Console
2 |
3 | To use it as a console, in your terminal or command prompt run:
4 | ```
5 | jupyter console --kernel stata
6 | ```
7 |
8 | Example:
9 |
10 | 
11 |
--------------------------------------------------------------------------------
/docs/src/using_jupyter/intro.md:
--------------------------------------------------------------------------------
1 | # Introduction to Jupyter
2 |
3 | There are many different ways to use Jupyter. I'll briefly explain several ways of using Jupyter and provide links to more documentation. The information in this section is common to all languages Jupyter supports. [Using the Stata Kernel](../using_stata_kernel/magics.md) has information specific to using Stata with Jupyter.
4 |
5 | If you're unsure which to use, choose [JupyterLab](lab.md).
6 |
7 | - [JupyterLab](lab.md): This is an interactive web-based editor that improves upon the classic Notebook by making it easy to work with several files at the same time in the same window. Users familiar with RStudio may like this.
8 | - [Hydrogen for Atom](atom.md): This is a plugin for the Atom text editor that displays results in line with your code. It's my personal favorite.
9 | - [Jupyter Notebook](notebook.md): This is the classic interactive web-based editor.
10 | - [Nteract](nteract.md): This is a desktop application to work with Jupyter Notebook files. Some may prefer it to the classic web interface of Jupyter Notebooks.
11 | - [Jupyter Console](console.md): This is an enhanced REPL that lives in the console.
12 | - [Jupyter QtConsole](qtconsole.md): An enhanced console that additionally supports graphs and other rich-text displays.
13 | - [Working remotely](remote.md): Any of these tools can be used to edit code on your local computer and have the code run on a remote Unix/Linux server.
14 |
--------------------------------------------------------------------------------
/docs/src/using_jupyter/lab.md:
--------------------------------------------------------------------------------
1 | # JupyterLab
2 |
3 | Jupyter Lab is the successor to [Jupyter Notebook](notebook.md), and allows for having multiple documents side-by-side.
4 |
5 | ### Starting JupyterLab
6 |
7 | You can start JupyterLab by running:
8 |
9 | ```
10 | jupyter lab
11 | ```
12 |
13 | in your terminal or command prompt. Just like the Notebook, this should open up a page in your browser, where you can open a new Stata notebook or console.
14 |
15 | ### Syntax highlighting
16 |
17 | To enable syntax highlighting for Stata with JupyterLab, you need to run (only once):
18 |
19 | ```bash
20 | conda install -c conda-forge nodejs -y
21 | jupyter labextension install jupyterlab-stata-highlight
22 | ```
23 |
24 | If you didn't install Python from Anaconda, the `conda` command won't work and you'll need to install [Node.js](https://nodejs.org/en/download/) directly before running `jupyter labextension install`.
25 |
26 | ### Plugins
27 |
28 | One of the benefits of JupyterLab over the Notebook is that it was designed for extensibility. There's a growing list of plugins that can be used with JupyterLab. Here's an unofficial list:
29 |
30 | ### More info
31 |
32 | Project documentation website:
33 |
34 |
35 | 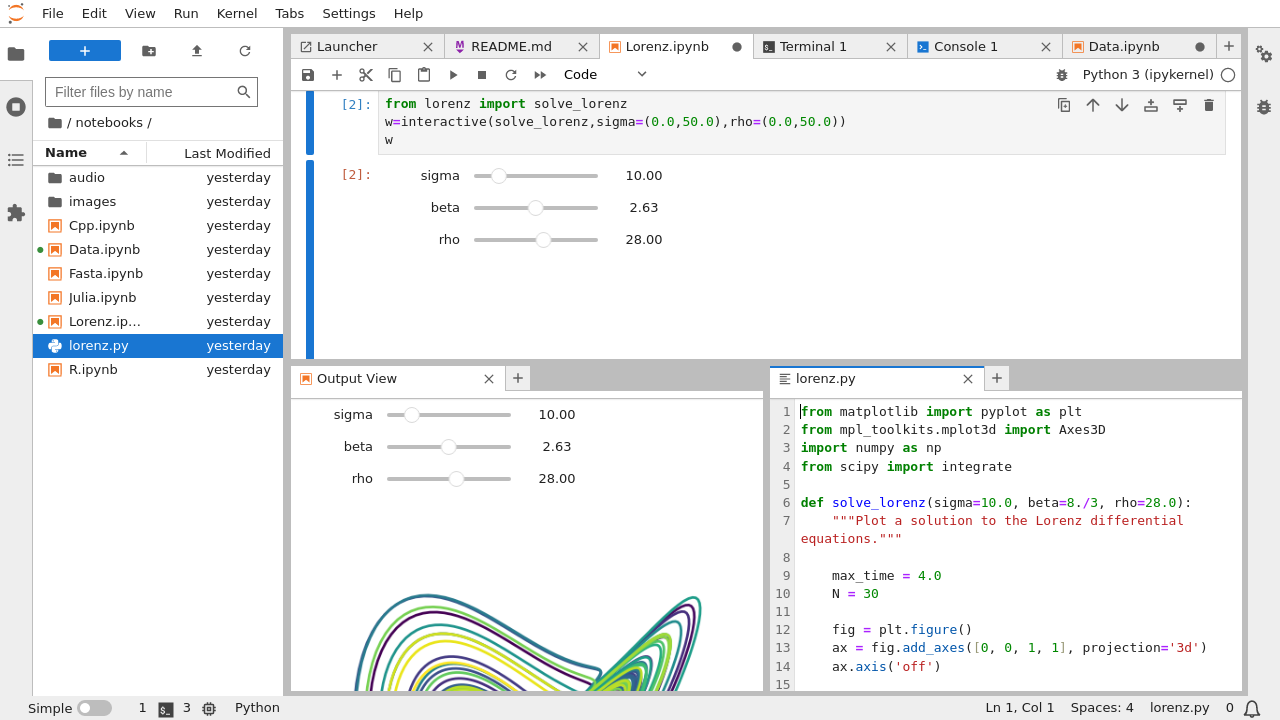
36 |
--------------------------------------------------------------------------------
/docs/src/using_jupyter/notebook.md:
--------------------------------------------------------------------------------
1 | # Jupyter Notebook
2 |
3 | You can start the Jupyter Notebook server by running
4 |
5 | ```
6 | jupyter notebook
7 | ```
8 |
9 | in your terminal or command prompt. That should open up your browser to the
10 | Jupyter home screen. Click the *New* drop down menu in the top right and choose
11 | `Stata` from the list to start a new notebook using Stata as your default
12 | kernel.
13 |
14 | Below is a gif that shows each step of this process.
15 |
16 | [Click here for more documentation.](https://jupyter-notebook.readthedocs.io/en/stable/notebook.html)
17 |
18 | 
19 |
--------------------------------------------------------------------------------
/docs/src/using_jupyter/nteract.md:
--------------------------------------------------------------------------------
1 | # Nteract
2 |
3 | Nteract is a desktop-based computing environment to work with Jupyter Notebook files. It can load and save Jupyter Notebook files and export to PDFs, including output.
4 |
5 | You can download the software from .
6 |
7 | (It's helpful to know that you can use Ctrl+Space to trigger autocompletions in Nteract.)
8 |
9 | Below is an example screenshot of using Nteract, followed by its PDF output.
10 |
11 | 
12 |
13 |