.
675 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # leetcode-hero
2 | Abstract data types and algorithmic techniques to solve programming interview problems
3 |
4 | ## Topics
5 |
6 | - [Manipulação de bits](https://dev.to/thiagocesarm/manipulacao-de-bits-para-resolucao-de-questoes-de-entrevistas-de-programacao-1kjp)
7 | - Algoritmos gulosos: [Medium](https://medium.com/@alvarofpp/algoritmos-gulosos-937390bb1137), [jupyter notebook](greedy/greedy-algorithms.ipynb).
8 | - [Segment Tree](https://dev.to/curingartur/segment-tree-3hpe)
9 | - [Ordenação topológica]: [Medium](https://medium.com/@mateussfcosta/ordena%C3%A7%C3%A3o-topol%C3%B3gica-para-resolu%C3%A7%C3%A3o-de-quest%C3%B5es-de-entrevistas-de-programa%C3%A7%C3%A3o-23563fbfc80b) - [Jupyter Notebok](topological_sort.ipynb)
10 | - [Fila de prioridade](priority-queue/README.md)
11 | - Programação dinâmica: [Medium](https://medium.com/@andersonsmed/programa%C3%A7%C3%A3o-din%C3%A2mica-c27598898165), [Notebook](dynamic-programming/dynamic-programming.ipynb)
--------------------------------------------------------------------------------
/dynamic-programming/dynamic-programming.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "name": "ProgramaçãoDinâmica.ipynb",
7 | "provenance": [],
8 | "collapsed_sections": [],
9 | "include_colab_link": true
10 | },
11 | "kernelspec": {
12 | "name": "python3",
13 | "display_name": "Python 3"
14 | }
15 | },
16 | "cells": [
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {
20 | "id": "view-in-github",
21 | "colab_type": "text"
22 | },
23 | "source": [
24 | " "
25 | ]
26 | },
27 | {
28 | "cell_type": "markdown",
29 | "metadata": {
30 | "id": "lKPOujAnk9js",
31 | "colab_type": "text"
32 | },
33 | "source": [
34 | "# Programação Dinâmica\n",
35 | "\n",
36 | "Programação dinâmica pode ser descrita como recursão com o apoio de uma tabela. Mais precisamente, ao invés de resolver os subproblemas recursivamente, esses subproblemas são resolvidos sequencialmente e as suas soluções são armazenadas em uma tabela.\n",
37 | "\n",
38 | "O truque para esse tipo de resolução é resolver os problemas na ordem certa, assim, sempre que você precisar de uma solução para um subproblema, ele já estará disponível na tabela.\n",
39 | "\n",
40 | "A utilidade da programação dinâmica é em problemas que a divisão e conquista produz um número exponencial de subproblemas e na verdade o que ocorre é a repetição de um pequeno número de subproblemas com frequência. Logo, nessas situações, calcula-se cada solução na primeira vez e as armazena em uma tabela para uso futuro, em vez sempre recalcular as soluções recursivamente quando for necessário.\n",
41 | "\n",
42 | "Enquanto a divisão e conquista é top-down, a programação dinâmica é bottom-up. Em resumo, com PD resolve-se os problemas de pequena\n",
43 | "dimensão e guarda-se as soluções. A solução de um problema é\n",
44 | "obtida combinando as de problemas de menor dimensão. "
45 | ]
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "metadata": {
50 | "id": "Mf6jUayY69KK",
51 | "colab_type": "text"
52 | },
53 | "source": [
54 | "-----------------------"
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "metadata": {
60 | "id": "13lYtLO9nnJx",
61 | "colab_type": "text"
62 | },
63 | "source": [
64 | "Para exemplificar, vamos a um exemplo básico:"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "metadata": {
70 | "id": "gnit9uI_UPAT",
71 | "colab_type": "code",
72 | "colab": {}
73 | },
74 | "source": [
75 | "def fibonacci (numero):\n",
76 | " \n",
77 | " if numero <= 1:\n",
78 | " return numero\n",
79 | " else:\n",
80 | " return fibonacci(numero - 1) + fibonacci(numero - 2)"
81 | ],
82 | "execution_count": 0,
83 | "outputs": []
84 | },
85 | {
86 | "cell_type": "markdown",
87 | "metadata": {
88 | "id": "tazzPwzkohj0",
89 | "colab_type": "text"
90 | },
91 | "source": [
92 | "Acima nós temos uma implementação clássica do algoritmo de fibonacci, onde você calcula o fibonacci de um número através do fibonacci dos dois números anteriores a ele. Agora vamos a uma implementação com programação dinâmica."
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "metadata": {
98 | "id": "qjFFL2e1owQx",
99 | "colab_type": "code",
100 | "colab": {}
101 | },
102 | "source": [
103 | "def fibonacci_pd (numero):\n",
104 | "\n",
105 | " # Aqui nós definimos nossa estrutura, que trabalhará como uma \"memória\" com o fibonacci dos números já computados\n",
106 | " fib = [0, 1]\n",
107 | "\n",
108 | " for temp_num in range(2, numero + 1):\n",
109 | " \n",
110 | " fib.append(fib[temp_num - 1] + fib[temp_num - 2])\n",
111 | "\n",
112 | " return fib[numero]"
113 | ],
114 | "execution_count": 0,
115 | "outputs": []
116 | },
117 | {
118 | "cell_type": "markdown",
119 | "metadata": {
120 | "id": "rP9pazHOpZdN",
121 | "colab_type": "text"
122 | },
123 | "source": [
124 | "Agora vamos medir o tempo em que cada uma de nossas funções demora para calcular o fibonacci do número 40"
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "metadata": {
130 | "id": "ws97zybgpqC_",
131 | "colab_type": "code",
132 | "outputId": "47220d2c-aaba-4488-e192-13faa79867a1",
133 | "colab": {
134 | "base_uri": "https://localhost:8080/",
135 | "height": 34
136 | }
137 | },
138 | "source": [
139 | "import time\n",
140 | "\n",
141 | "start_time = time.clock()\n",
142 | "fibonacci(40)\n",
143 | "print(\"{} segundos\".format(time.clock() - start_time))"
144 | ],
145 | "execution_count": 0,
146 | "outputs": [
147 | {
148 | "output_type": "stream",
149 | "text": [
150 | "35.759142999999995 segundos\n"
151 | ],
152 | "name": "stdout"
153 | }
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "metadata": {
159 | "id": "-nhCIMm1t3aq",
160 | "colab_type": "code",
161 | "outputId": "4adbde32-485e-42d9-a8bb-5c1f3ba238d6",
162 | "colab": {
163 | "base_uri": "https://localhost:8080/",
164 | "height": 34
165 | }
166 | },
167 | "source": [
168 | "start_time = time.clock()\n",
169 | "fibonacci_pd(40)\n",
170 | "print(\"{} segundos\".format(time.clock() - start_time))"
171 | ],
172 | "execution_count": 0,
173 | "outputs": [
174 | {
175 | "output_type": "stream",
176 | "text": [
177 | "0.00013999999987390765 segundos\n"
178 | ],
179 | "name": "stdout"
180 | }
181 | ]
182 | },
183 | {
184 | "cell_type": "markdown",
185 | "metadata": {
186 | "id": "94mAV71AvJZO",
187 | "colab_type": "text"
188 | },
189 | "source": [
190 | ""
191 | ]
192 | },
193 | {
194 | "cell_type": "markdown",
195 | "metadata": {
196 | "id": "7oNn_QGMvHnp",
197 | "colab_type": "text"
198 | },
199 | "source": [
200 | "Como podemos ver na imagem acima, o que acontece é que, no primeiro exemplo, vários números tem o seu fibonacci calculado repetidamente (veja o caso do número 2 e 3), e o que a programação dinâmica nos entrega é uma forma de armazenar esses dados, afim de melhorar a complexidade assintótica de nosso algoritmo."
201 | ]
202 | },
203 | {
204 | "cell_type": "markdown",
205 | "metadata": {
206 | "id": "S4YkJspc7CVc",
207 | "colab_type": "text"
208 | },
209 | "source": [
210 | "--------------------"
211 | ]
212 | },
213 | {
214 | "cell_type": "markdown",
215 | "metadata": {
216 | "id": "GcPNYtge2Xf_",
217 | "colab_type": "text"
218 | },
219 | "source": [
220 | "##Exemplos"
221 | ]
222 | },
223 | {
224 | "cell_type": "markdown",
225 | "metadata": {
226 | "id": "vCMC8_ZW2cJB",
227 | "colab_type": "text"
228 | },
229 | "source": [
230 | "Agora vamos aos exemplos, começando pela questão 303 do LeetCode, que pode ser encontrada no link a seguir:\n",
231 | "- https://leetcode.com/problems/range-sum-query-immutable/"
232 | ]
233 | },
234 | {
235 | "cell_type": "markdown",
236 | "metadata": {
237 | "id": "ksBVY02K2pvf",
238 | "colab_type": "text"
239 | },
240 | "source": [
241 | "303. Dado um array de números inteiros, encontre a soma dos elementos entre os índices i e j (i ≤ j), de forma inclusiva."
242 | ]
243 | },
244 | {
245 | "cell_type": "code",
246 | "metadata": {
247 | "id": "fO-tQlHO279-",
248 | "colab_type": "code",
249 | "colab": {}
250 | },
251 | "source": [
252 | "class NumArray:\n",
253 | "\n",
254 | " _sum_list = None\n",
255 | " \n",
256 | " def __init__(self, nums: List[int]):\n",
257 | " \n",
258 | " self._sum_list = list()\n",
259 | " \n",
260 | " for index in range(len(nums) + 1):\n",
261 | " num = nums[index - 1] if index > 0 else 0\n",
262 | " \n",
263 | " if index >= 1:\n",
264 | " self._sum_list.append(self._sum_list[index - 1] + num)\n",
265 | " else:\n",
266 | " self._sum_list.append(num)\n",
267 | " \n",
268 | "\n",
269 | " def sumRange(self, i: int, j: int) -> int:\n",
270 | " \n",
271 | " return self._sum_list[j + 1] - self._sum_list[i]\n"
272 | ],
273 | "execution_count": 0,
274 | "outputs": []
275 | },
276 | {
277 | "cell_type": "markdown",
278 | "metadata": {
279 | "id": "uohLTTRm3APt",
280 | "colab_type": "text"
281 | },
282 | "source": [
283 | "O problema dessa questão está no fato que o método sumRange será chamado várias vezes, fazendo com que seja necessário recalcular a soma entre as posições várias vezes, de tal forma que a complexidade assintótica depende da quantidade de vezes que o método sumRange é chamado. Exemplificando:\n",
284 | "- Caso o método seja chamado n vezes, sendo n o tamanho do array de nums, a complexidade desse problema seria de O(n * n), no pior caso."
285 | ]
286 | },
287 | {
288 | "cell_type": "markdown",
289 | "metadata": {
290 | "id": "pJ5xerjV38A1",
291 | "colab_type": "text"
292 | },
293 | "source": [
294 | "Para contornar esse problema, nós fazemos um processamento inicial, calculando a soma de todas as posições em relação aos seus anteriores, totalizando assim uma complexidade assintótica de O(n)."
295 | ]
296 | },
297 | {
298 | "cell_type": "markdown",
299 | "metadata": {
300 | "id": "xphnVzdF43z5",
301 | "colab_type": "text"
302 | },
303 | "source": [
304 | "Esse procedimento é necessário para criar uma \"memória\" das somas, de tal forma que, quando seja necessário calcular a soma entre as posições i e j, esse cálculo seja realizado de forma constante, ou seja, em O(1)."
305 | ]
306 | },
307 | {
308 | "cell_type": "markdown",
309 | "metadata": {
310 | "id": "gJjXfyqD4U2L",
311 | "colab_type": "text"
312 | },
313 | "source": [
314 | "------------"
315 | ]
316 | },
317 | {
318 | "cell_type": "markdown",
319 | "metadata": {
320 | "id": "ivlMoYW95WlY",
321 | "colab_type": "text"
322 | },
323 | "source": [
324 | "Partindo agora para resolução de problemas mais complexos, vamos resolver a questão 62, que pode ser encontrada no link a seguir:\n",
325 | "- https://leetcode.com/problems/unique-paths/"
326 | ]
327 | },
328 | {
329 | "cell_type": "markdown",
330 | "metadata": {
331 | "id": "YEbr0IAn55u3",
332 | "colab_type": "text"
333 | },
334 | "source": [
335 | "62. Um robô está localizado no canto superior esquerdo de uma matriz m x n. Ele só pode se mover ou para baixo ou para direita. O robô está tentando chegar ao canto inferiror direito da matriz. Nós devemos calcular a quantidade de caminhos únicos que o robô pode tomar.\n"
336 | ]
337 | },
338 | {
339 | "cell_type": "code",
340 | "metadata": {
341 | "id": "eIpuxYgm6mRr",
342 | "colab_type": "code",
343 | "colab": {}
344 | },
345 | "source": [
346 | "class Solution:\n",
347 | "\n",
348 | " def uniquePaths(self, m: int, n: int) -> int:\n",
349 | " # Iniciamos os caminhos possíveis com 1, pois em uma matriz de 1 x 1, o robô só possui um caminho a tomar\n",
350 | " possible_paths = [[1 for col in range(m)] for row in range(n)]\n",
351 | " \n",
352 | " for a in range(1, n):\n",
353 | " for b in range(1, m):\n",
354 | " possible_paths[a][b] = possible_paths[a - 1][b] + possible_paths[a][b - 1]\n",
355 | " \n",
356 | " return possible_paths[n - 1][m - 1]"
357 | ],
358 | "execution_count": 0,
359 | "outputs": []
360 | },
361 | {
362 | "cell_type": "markdown",
363 | "metadata": {
364 | "id": "sCK_x0AX64IQ",
365 | "colab_type": "text"
366 | },
367 | "source": [
368 | "Esse problema pode ser considerado como um exemplo clássico do uso de programação dinâmica, uma vez que, pensando na forma recursiva, nós temos que a quantidade de caminhos que o robô pode tomar é igual a quantidade de caminhos tanto a esquerda quanto acima, uma vez que estamos falando de uma matriz em 2D. O que poderia nos levar a seguinte resolução:"
369 | ]
370 | },
371 | {
372 | "cell_type": "code",
373 | "metadata": {
374 | "id": "T-kwDSDw8pnV",
375 | "colab_type": "code",
376 | "colab": {}
377 | },
378 | "source": [
379 | "def caminhosUnicos(m, n):\n",
380 | " if m == 1 and n == 1:\n",
381 | " return 1\n",
382 | " if m == 0 or n == 0:\n",
383 | " return 0\n",
384 | " return caminhosUnicos(m - 1, n) + caminhosUnicos(m, n - 1)"
385 | ],
386 | "execution_count": 0,
387 | "outputs": []
388 | },
389 | {
390 | "cell_type": "markdown",
391 | "metadata": {
392 | "id": "LJxfnZbw9UiG",
393 | "colab_type": "text"
394 | },
395 | "source": [
396 | "Porém, como nós já vimos, essa resolução nos leva ao problema do re-processamento desnecessário, de tal forma que certos elementos no espaço serão recalculados várias vezes, liderando a uma complexidade exponencial."
397 | ]
398 | },
399 | {
400 | "cell_type": "markdown",
401 | "metadata": {
402 | "id": "9wcefjqd9keq",
403 | "colab_type": "text"
404 | },
405 | "source": [
406 | "Para tal, nós chegamos ao código mostrado na primeira célula, onde usamos uma matriz para armazenar os possíveis caminhos, seguindo de forma iterativa até termos preenchido toda a matriz com os possíveis caminhos, diminuindo a complexidade assintótica do problema de exponencial para O(n * m)."
407 | ]
408 | },
409 | {
410 | "cell_type": "markdown",
411 | "metadata": {
412 | "id": "FOYi9gjI64MI",
413 | "colab_type": "text"
414 | },
415 | "source": [
416 | "--------------------"
417 | ]
418 | },
419 | {
420 | "cell_type": "markdown",
421 | "metadata": {
422 | "id": "5we0q2v4VhNe",
423 | "colab_type": "text"
424 | },
425 | "source": [
426 | "Caso tenha interesse, a seguir nós listamos a resolução do problema 123, que é um problema do nível difícil e que usa programação dinâmica, seguem os links para o problema a para a resolução, respectivamente:\n",
427 | "- https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii/description/\n",
428 | "- https://leetcode.com/playground/TVPEFDu8\n",
429 | "- OBS: A resolução foi implementada em C++, então se segure bem na cadeira antes de abrir esse link hahaha."
430 | ]
431 | },
432 | {
433 | "cell_type": "markdown",
434 | "metadata": {
435 | "id": "DBF0WwMEWShr",
436 | "colab_type": "text"
437 | },
438 | "source": [
439 | "---------"
440 | ]
441 | },
442 | {
443 | "cell_type": "markdown",
444 | "metadata": {
445 | "id": "kUUS8-g07IZC",
446 | "colab_type": "text"
447 | },
448 | "source": [
449 | "## Colaboradores"
450 | ]
451 | },
452 | {
453 | "cell_type": "markdown",
454 | "metadata": {
455 | "id": "6SzJUVLQs61C",
456 | "colab_type": "text"
457 | },
458 | "source": [
459 | "* André Winston \n",
460 | "* Camila Duarte\n",
461 | "* Anderson Medeiros\n",
462 | "\n"
463 | ]
464 | }
465 | ]
466 | }
--------------------------------------------------------------------------------
/greedy/greedy-algorithms.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "name": "Programação Gulosa.ipynb",
7 | "provenance": [],
8 | "collapsed_sections": [],
9 | "toc_visible": true
10 | },
11 | "kernelspec": {
12 | "name": "python3",
13 | "display_name": "Python 3"
14 | }
15 | },
16 | "cells": [
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {
20 | "id": "aof5Xlf20n1P",
21 | "colab_type": "text"
22 | },
23 | "source": [
24 | "# Algoritmos Gulosos\n",
25 | "Uma introdução à estratégia de programação 'gulosa'"
26 | ]
27 | },
28 | {
29 | "cell_type": "markdown",
30 | "metadata": {
31 | "id": "kjFOBoPw05pQ",
32 | "colab_type": "text"
33 | },
34 | "source": [
35 | "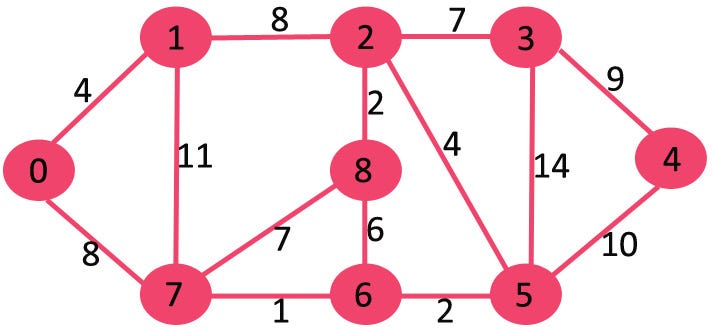"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {
41 | "id": "6cV0V9GF0hUw",
42 | "colab_type": "text"
43 | },
44 | "source": [
45 | "De modo geral, algoritmos gulosos são aqueles que **sempre tomam a melhor decisão** que ele consegue encontrar, no conjunto de decisões possíveis a cada iteração, possuindo como objetivo 'coletar' um conjunto de melhores soluções com base em algum determinado critério, formando assim a solução do problema. Os critérios que definem o que seria a melhor decisão a tomar em certa iteração irão variar para cada problema. \n",
46 | "\n",
47 | "Tomem como exemplo, a situação em que você tem de sair da sua casa até um certo supermercado da sua cidade. Há várias ruas no caminho, todas com certo comprimento e você decide por utilizar uma abordagem gulosa para chegar até lá. A cada vez que você tem que escolher por qual rua seguir, você decide pela rua com menor comprimento, até chegar ao destino final, o supermercado. \n",
48 | "\n",
49 | "No exemplo, cada 'iteração' significa: **Escolha uma rua para seguir**. E a 'decisão gulosa' que foi escolhida foi: **Siga pela rua mais curta**. \n",
50 | "\n",
51 | "Vale reforçar que a tomada de decisão é com base nas informações disponíveis na iteração corrente, sem levar em consideração possíveis consequências futuras da escolha da decisão, ou seja, depois que uma decisão foi tomada, ela não pode ser desfeita.\n",
52 | "\n",
53 | "O algoritmo sempre tenta encontrar a melhor solução local, para no fim obter uma solução que resolva o problema, não necessariamente da melhor forma possível.\n",
54 | "\n"
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "metadata": {
60 | "id": "ReslvGAOHnRR",
61 | "colab_type": "text"
62 | },
63 | "source": [
64 | "O grafo a baixo ilustra a ideia dos algoritmos gulosos, a cada iteração, o critério utilizado para percorrer o gráfo é escolher o filho de maior peso.\n",
65 | "\n",
66 | ""
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {
72 | "id": "bSMxD8K4M6vo",
73 | "colab_type": "text"
74 | },
75 | "source": [
76 | "Mas a ideia do problema seria encontrar o caminhos de maior custos (custo é dado pela soma dos nos), nesse problema o algoritimo guloso, não consegue alcançar a melhor solução."
77 | ]
78 | },
79 | {
80 | "cell_type": "markdown",
81 | "metadata": {
82 | "id": "Qo3jB9lc20x3",
83 | "colab_type": "text"
84 | },
85 | "source": [
86 | "\n",
87 | "# Características\n",
88 | "1. Jamais se arrepende de uma decisão, as escolhas realizadas são definitivas;\n",
89 | "2. Não leva em consideração as consequências de suas decisões;\n",
90 | "3. Podem fazer cálculos repetitivos;\n",
91 | "4. Nem sempre produz a melhor solução final (depende da quantidade de informação fornecida);\n",
92 | "5. Quanto mais informações, maior a chance de produzir uma solução melhor\n",
93 | "\n",
94 | "\n",
95 | "\n",
96 | "\n",
97 | "\n",
98 | "\n",
99 | "\n",
100 | "\n"
101 | ]
102 | },
103 | {
104 | "cell_type": "markdown",
105 | "metadata": {
106 | "id": "Tvx-dqGn5_Ot",
107 | "colab_type": "text"
108 | },
109 | "source": [
110 | "\n",
111 | "# Vantagens\n",
112 | "\n",
113 | "1. Simples e fácil de implementação;\n",
114 | "2. Algoritmos de rápida execução;\n",
115 | "3. Podem fornecer a melhor solução (estado ideal).\n"
116 | ]
117 | },
118 | {
119 | "cell_type": "markdown",
120 | "metadata": {
121 | "id": "DxzDyS8Q6vIG",
122 | "colab_type": "text"
123 | },
124 | "source": [
125 | "#Desvantagens\n",
126 | "1. Nem sempre conduz a soluções ótimas globais. Podem efetuar cálculos repetitivos.\n",
127 | "2. Escolhe o caminho que, à primeira vista, é mais econômico.\n",
128 | "3. Pode entrar em loop se não detectar a expansão de estados repetidos.\n",
129 | "4. Pode tentar desenvolver um caminho infinito."
130 | ]
131 | },
132 | {
133 | "cell_type": "markdown",
134 | "metadata": {
135 | "id": "RvJEyY2LDxnS",
136 | "colab_type": "text"
137 | },
138 | "source": [
139 | "#Exemplos\n",
140 | "\n",
141 | "Os exemplos abaixo são questões provindas do site LeetCode, que possui questões de algoritmos dos mais diversos assuntos e que comumente aparecem em entrevistas de programação"
142 | ]
143 | },
144 | {
145 | "cell_type": "markdown",
146 | "metadata": {
147 | "id": "9jnR3KL1D1Zw",
148 | "colab_type": "text"
149 | },
150 | "source": [
151 | "**EXEMPLO 1**\n",
152 | "[Questão 1221](https://leetcode.com/problems/split-a-string-in-balanced-strings/) do site leetcode\n",
153 | "\n",
154 | "**Separe uma string em strings balanceadas**\n",
155 | "\n",
156 | "String balanceadas são aquelas que possuem quantidades iguais de caracteres 'L' e 'R'.\n",
157 | "\n",
158 | "Dada uma string, divida-a na quantidade máxima de substrings balanceadas. Retorne a quantidade máxima de string balanceadas divididas."
159 | ]
160 | },
161 | {
162 | "cell_type": "markdown",
163 | "metadata": {
164 | "id": "h_a_0fu2W9sX",
165 | "colab_type": "text"
166 | },
167 | "source": [
168 | "O problema pode ser compreendido da seguinte forma:\n",
169 | "\n",
170 | "Para separar a string de maneira correta, temos que iniciar dois contadores, um para \"L\" e um para \"R\".\n",
171 | "\n",
172 | "Depois de iniciar os contadores, vamos interar sobre a string adcionando aos contadores as ocorrencias de \"L\" e \"R\" e sempre que o valor dos contadores de \"R\" e \"L\" forem iguais e maiores que 0 é certo que ali está uma sub string balanceada.\n",
173 | "\n",
174 | "Nesse momento o algoritmo deve separar a string, fazendo uma ação definitiva, caracteristica de programação gulosa.\n",
175 | "\n",
176 | "No fim do laço basta retorna o numero de separações que a string teve ao longo da execução, que foi armazenado em \"output\".\n",
177 | "\n",
178 | "Segue abaixo o codigo da função:"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "metadata": {
184 | "id": "ZQxQek8jCTgh",
185 | "colab_type": "code",
186 | "colab": {}
187 | },
188 | "source": [
189 | "def balanced_strings_split(s):\n",
190 | " count = {\n",
191 | " \"L\" : 0,\n",
192 | " \"R\" : 0,\n",
193 | " }\n",
194 | " output = 0\n",
195 | " for char in s:\n",
196 | " count[char] +=1\n",
197 | " if count[\"L\"] == count[\"R\"]:\n",
198 | " output += 1\n",
199 | " return output"
200 | ],
201 | "execution_count": 0,
202 | "outputs": []
203 | },
204 | {
205 | "cell_type": "markdown",
206 | "metadata": {
207 | "id": "N4Flpk4bXGzt",
208 | "colab_type": "text"
209 | },
210 | "source": [
211 | "Testando o codigo com uma entrada balanceada:"
212 | ]
213 | },
214 | {
215 | "cell_type": "code",
216 | "metadata": {
217 | "id": "MyIKK0g8DGUy",
218 | "colab_type": "code",
219 | "colab": {}
220 | },
221 | "source": [
222 | "print(balanced_strings_split(\"LLLRRLRRLRRRLRLL\"))"
223 | ],
224 | "execution_count": 0,
225 | "outputs": []
226 | },
227 | {
228 | "cell_type": "markdown",
229 | "metadata": {
230 | "id": "cTU0JwDRDTfE",
231 | "colab_type": "text"
232 | },
233 | "source": [
234 | "**EXEMPLO 2**\n",
235 | "[Questão 55](https://leetcode.com/problems/jump-game/). Jump Game do site leetcode\n",
236 | "\n",
237 | "**Dada uma matriz de números inteiros não negativos, você está inicialmente posicionado no primeiro índice da matriz.**\n",
238 | "\n",
239 | "\n",
240 | "Cada elemento da matriz representa seu comprimento máximo de salto nessa posição.\n",
241 | "\n",
242 | "Determine se você consegue alcançar o último índice."
243 | ]
244 | },
245 | {
246 | "cell_type": "markdown",
247 | "metadata": {
248 | "id": "cF_ZwDRCEIxB",
249 | "colab_type": "text"
250 | },
251 | "source": [
252 | "Solução:\n"
253 | ]
254 | },
255 | {
256 | "cell_type": "code",
257 | "metadata": {
258 | "id": "bYUjUMSZGMgu",
259 | "colab_type": "code",
260 | "colab": {}
261 | },
262 | "source": [
263 | "def canJump(self, nums: List[int]) -> bool:\n",
264 | " r=0\n",
265 | " for l in range(len(nums)):\n",
266 | " if l>r:\n",
267 | " return False\n",
268 | " r=max(r,l+nums[l])\n",
269 | " if r>=len(nums)-1:\n",
270 | " return True"
271 | ],
272 | "execution_count": 0,
273 | "outputs": []
274 | },
275 | {
276 | "cell_type": "markdown",
277 | "metadata": {
278 | "id": "bU4EglKMVlMW",
279 | "colab_type": "text"
280 | },
281 | "source": [
282 | "**EXEMPLO 3**\n",
283 | "[763.](https://leetcode.com/problems/partition-labels/). Partition Labels\n",
284 | "\n",
285 | "Uma sequência S de letras minúsculas é fornecida. Queremos particionar essa string em tantas partes quanto possível, para que cada letra apareça em no máximo uma parte e retorne uma lista de números inteiros representando o tamanho dessas partes.\n",
286 | "\n",
287 | "Seja: \n",
288 | "\n",
289 | "Entrada: S = \"ababcbacadefegdehijhklij\"\n",
290 | "\n",
291 | "Saída: [9,7,8]\n",
292 | "\n",
293 | "Explicando a saída:\n",
294 | "\n",
295 | "As partições são \"ababcbaca\", \"defegde\", \"hijhklij\"."
296 | ]
297 | },
298 | {
299 | "cell_type": "markdown",
300 | "metadata": {
301 | "id": "Im-wydjVjxat",
302 | "colab_type": "text"
303 | },
304 | "source": [
305 | "Para entendermos como resolver esse problema, podemos ver a ideia de algortimos gulosos, que sempre vão executar a melhor ação dada as condições atuais. E também não vai mudar seu comportamento perante isso.\n",
306 | "\n",
307 | "\n",
308 | "Temos que percorrer toda a string e verificar se o caractere atual, a sua ultima ocorrencia estoura o limite da partição definida pelo primeiro caractere, se estourar, dizemos que a ultima ocorrencia desse novo caractere é o limite da partição.\n",
309 | "\n",
310 | "Percorremos a string até encontrar o limite da partição com essa limitação sendo verdadeira, se isso ocorrer podemos iniciar uma segunda partição."
311 | ]
312 | },
313 | {
314 | "cell_type": "markdown",
315 | "metadata": {
316 | "id": "5XD1_Rks1oAn",
317 | "colab_type": "text"
318 | },
319 | "source": [
320 | "Abaixo uma solução com as regras corrigidas e citadas."
321 | ]
322 | },
323 | {
324 | "cell_type": "code",
325 | "metadata": {
326 | "id": "c7_NFhVv0gJ0",
327 | "colab_type": "code",
328 | "colab": {}
329 | },
330 | "source": [
331 | "def partition_labels(s):\n",
332 | " last = {c: i for i,c in enumerate(s)}\n",
333 | " j = anchor = 0\n",
334 | " ans = []\n",
335 | " for i,c in enumerate(s):\n",
336 | " j = max(j,last[c])\n",
337 | " if i == j:\n",
338 | " ans.append(i-anchor + 1)\n",
339 | " anchor = i + 1\n",
340 | " return ans"
341 | ],
342 | "execution_count": 0,
343 | "outputs": []
344 | },
345 | {
346 | "cell_type": "markdown",
347 | "metadata": {
348 | "id": "ZiwbAjYS2-2u",
349 | "colab_type": "text"
350 | },
351 | "source": [
352 | "Teste da solução"
353 | ]
354 | },
355 | {
356 | "cell_type": "code",
357 | "metadata": {
358 | "id": "srsyesM01I4m",
359 | "colab_type": "code",
360 | "outputId": "4377cdcc-c1bc-4921-8787-5c6ad9682997",
361 | "colab": {
362 | "base_uri": "https://localhost:8080/",
363 | "height": 34
364 | }
365 | },
366 | "source": [
367 | "partition_labels(\"ababcbacadefegdehijhklij\")"
368 | ],
369 | "execution_count": 0,
370 | "outputs": [
371 | {
372 | "output_type": "execute_result",
373 | "data": {
374 | "text/plain": [
375 | "[9, 7, 8]"
376 | ]
377 | },
378 | "metadata": {
379 | "tags": []
380 | },
381 | "execution_count": 70
382 | }
383 | ]
384 | }
385 | ]
386 | }
--------------------------------------------------------------------------------
/priority-queue/README.md:
--------------------------------------------------------------------------------
1 | # Fila de prioridade
2 |
3 | Veja o no Medium uma explicação detalhada sobre filas de prioridade, e o que você deve ter em mente para quando tentar resolver essas questões, segue o link:
4 | https://medium.com/@wander.alves13/37e39985e302
5 |
6 | ## Questões do leet code resolvidadas
7 |
8 | 1. [Partition List](question86.md)
9 |
10 | + Dificuldade: Média
11 |
12 | 215. [Kth Largest Element in an Array](question215.md)
13 |
14 | + Dificuldade: Média
15 |
16 | 767. [Reorganize String](question767.md)
17 |
18 | + Dificuldade: Média
19 |
20 | ## Implementação:
21 |
22 | + Python 3
23 |
24 | Authors:
25 |
26 | + [Pablo Emanuell](https://github.com/pabloufrn)
27 | + [Graco Silva](https://github.com/gbvsilva)
28 | + [Wanderson Alves](https://github.com/wanderson130)
29 |
30 | <- [BACK TO HOME](../README.md)
--------------------------------------------------------------------------------
/priority-queue/question215.md:
--------------------------------------------------------------------------------
1 | # 215. Kth Largest Element in an Array
2 |
3 | ## Solução
4 |
5 | > Find the kth largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element.
6 | >
7 | > **Example 1:**
8 | >
9 | > ```
10 | > Input: [3,2,1,5,6,4] and k = 2
11 | > Output: 5
12 | > ```
13 | >
14 | > **Example 2:**
15 | >
16 | > ```Input: [3,2,3,1,2,4,5,5,6] and k = 4
17 | > Output: 4
18 | > ```
19 | > **Note:**
20 | > You may assume k is always valid, 1 ≤ k ≤ array's length.
21 |
22 | Para resolver essa questão, podemos ordenar a lista em ordem decrescente e retornar o k-ésimo termo, porém para economizar espaço podemos guardar apenas os cinco maiores elementos em uma fila e retornar o menor.
23 |
24 | ## Implementação
25 |
26 | Como sempre iniciamos declarando a lista, depois, para cada elemento na lista adicionamos ele na fila, e, como queremos guardar apenas os `k` maiores elementos, se o tamanho da fila é maior que `k`, removemos o menor. No final, apenas retornamos o menor elemento da fila. Veja o código:
27 |
28 | ```Python 3
29 | pqueue = []
30 | for el in nums:
31 | heappush(pqueue, el)
32 | if(len(pqueue) > k):
33 | heappop(pqueue)
34 | return pqueue[0]
35 | ```
36 |
37 | + [Código completo](./question215.py)
38 | + [Pratique no LeetCode](https://leetcode.com/problems/kth-largest-element-in-an-array/)
39 |
40 | Viu algum erro? mande um email para pabloemanuell2017@gmail.com
41 |
42 | [<- ANTERIOR](question86.md) | [PRÓXIMA ->](question767.md)
43 |
44 | [VOLTAR PARA O ÍNICIO](README.md)
45 |
--------------------------------------------------------------------------------
/priority-queue/question215.py:
--------------------------------------------------------------------------------
1 | from heapq import *
2 |
3 | class Solution:
4 | def findKthLargest(self, nums: List[int], k: int) -> int:
5 | pqueue = []
6 | for el in nums:
7 | heappush(pqueue, el)
8 | if(len(pqueue) > k):
9 | heappop(pqueue)
10 | return pqueue[0]
11 |
12 |
--------------------------------------------------------------------------------
/priority-queue/question767.md:
--------------------------------------------------------------------------------
1 | # 767. Reorganize String
2 |
3 | ## Solução
4 |
5 | > Given a string `S`, check if the letters can be rearranged so that two characters that are adjacent to each other are not the same.
6 | >
7 | > If possible, output any possible result. If not possible, return the empty string.
8 | >
9 | > **Example 1:**
10 | >
"
25 | ]
26 | },
27 | {
28 | "cell_type": "markdown",
29 | "metadata": {
30 | "id": "lKPOujAnk9js",
31 | "colab_type": "text"
32 | },
33 | "source": [
34 | "# Programação Dinâmica\n",
35 | "\n",
36 | "Programação dinâmica pode ser descrita como recursão com o apoio de uma tabela. Mais precisamente, ao invés de resolver os subproblemas recursivamente, esses subproblemas são resolvidos sequencialmente e as suas soluções são armazenadas em uma tabela.\n",
37 | "\n",
38 | "O truque para esse tipo de resolução é resolver os problemas na ordem certa, assim, sempre que você precisar de uma solução para um subproblema, ele já estará disponível na tabela.\n",
39 | "\n",
40 | "A utilidade da programação dinâmica é em problemas que a divisão e conquista produz um número exponencial de subproblemas e na verdade o que ocorre é a repetição de um pequeno número de subproblemas com frequência. Logo, nessas situações, calcula-se cada solução na primeira vez e as armazena em uma tabela para uso futuro, em vez sempre recalcular as soluções recursivamente quando for necessário.\n",
41 | "\n",
42 | "Enquanto a divisão e conquista é top-down, a programação dinâmica é bottom-up. Em resumo, com PD resolve-se os problemas de pequena\n",
43 | "dimensão e guarda-se as soluções. A solução de um problema é\n",
44 | "obtida combinando as de problemas de menor dimensão. "
45 | ]
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "metadata": {
50 | "id": "Mf6jUayY69KK",
51 | "colab_type": "text"
52 | },
53 | "source": [
54 | "-----------------------"
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "metadata": {
60 | "id": "13lYtLO9nnJx",
61 | "colab_type": "text"
62 | },
63 | "source": [
64 | "Para exemplificar, vamos a um exemplo básico:"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "metadata": {
70 | "id": "gnit9uI_UPAT",
71 | "colab_type": "code",
72 | "colab": {}
73 | },
74 | "source": [
75 | "def fibonacci (numero):\n",
76 | " \n",
77 | " if numero <= 1:\n",
78 | " return numero\n",
79 | " else:\n",
80 | " return fibonacci(numero - 1) + fibonacci(numero - 2)"
81 | ],
82 | "execution_count": 0,
83 | "outputs": []
84 | },
85 | {
86 | "cell_type": "markdown",
87 | "metadata": {
88 | "id": "tazzPwzkohj0",
89 | "colab_type": "text"
90 | },
91 | "source": [
92 | "Acima nós temos uma implementação clássica do algoritmo de fibonacci, onde você calcula o fibonacci de um número através do fibonacci dos dois números anteriores a ele. Agora vamos a uma implementação com programação dinâmica."
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "metadata": {
98 | "id": "qjFFL2e1owQx",
99 | "colab_type": "code",
100 | "colab": {}
101 | },
102 | "source": [
103 | "def fibonacci_pd (numero):\n",
104 | "\n",
105 | " # Aqui nós definimos nossa estrutura, que trabalhará como uma \"memória\" com o fibonacci dos números já computados\n",
106 | " fib = [0, 1]\n",
107 | "\n",
108 | " for temp_num in range(2, numero + 1):\n",
109 | " \n",
110 | " fib.append(fib[temp_num - 1] + fib[temp_num - 2])\n",
111 | "\n",
112 | " return fib[numero]"
113 | ],
114 | "execution_count": 0,
115 | "outputs": []
116 | },
117 | {
118 | "cell_type": "markdown",
119 | "metadata": {
120 | "id": "rP9pazHOpZdN",
121 | "colab_type": "text"
122 | },
123 | "source": [
124 | "Agora vamos medir o tempo em que cada uma de nossas funções demora para calcular o fibonacci do número 40"
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "metadata": {
130 | "id": "ws97zybgpqC_",
131 | "colab_type": "code",
132 | "outputId": "47220d2c-aaba-4488-e192-13faa79867a1",
133 | "colab": {
134 | "base_uri": "https://localhost:8080/",
135 | "height": 34
136 | }
137 | },
138 | "source": [
139 | "import time\n",
140 | "\n",
141 | "start_time = time.clock()\n",
142 | "fibonacci(40)\n",
143 | "print(\"{} segundos\".format(time.clock() - start_time))"
144 | ],
145 | "execution_count": 0,
146 | "outputs": [
147 | {
148 | "output_type": "stream",
149 | "text": [
150 | "35.759142999999995 segundos\n"
151 | ],
152 | "name": "stdout"
153 | }
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "metadata": {
159 | "id": "-nhCIMm1t3aq",
160 | "colab_type": "code",
161 | "outputId": "4adbde32-485e-42d9-a8bb-5c1f3ba238d6",
162 | "colab": {
163 | "base_uri": "https://localhost:8080/",
164 | "height": 34
165 | }
166 | },
167 | "source": [
168 | "start_time = time.clock()\n",
169 | "fibonacci_pd(40)\n",
170 | "print(\"{} segundos\".format(time.clock() - start_time))"
171 | ],
172 | "execution_count": 0,
173 | "outputs": [
174 | {
175 | "output_type": "stream",
176 | "text": [
177 | "0.00013999999987390765 segundos\n"
178 | ],
179 | "name": "stdout"
180 | }
181 | ]
182 | },
183 | {
184 | "cell_type": "markdown",
185 | "metadata": {
186 | "id": "94mAV71AvJZO",
187 | "colab_type": "text"
188 | },
189 | "source": [
190 | ""
191 | ]
192 | },
193 | {
194 | "cell_type": "markdown",
195 | "metadata": {
196 | "id": "7oNn_QGMvHnp",
197 | "colab_type": "text"
198 | },
199 | "source": [
200 | "Como podemos ver na imagem acima, o que acontece é que, no primeiro exemplo, vários números tem o seu fibonacci calculado repetidamente (veja o caso do número 2 e 3), e o que a programação dinâmica nos entrega é uma forma de armazenar esses dados, afim de melhorar a complexidade assintótica de nosso algoritmo."
201 | ]
202 | },
203 | {
204 | "cell_type": "markdown",
205 | "metadata": {
206 | "id": "S4YkJspc7CVc",
207 | "colab_type": "text"
208 | },
209 | "source": [
210 | "--------------------"
211 | ]
212 | },
213 | {
214 | "cell_type": "markdown",
215 | "metadata": {
216 | "id": "GcPNYtge2Xf_",
217 | "colab_type": "text"
218 | },
219 | "source": [
220 | "##Exemplos"
221 | ]
222 | },
223 | {
224 | "cell_type": "markdown",
225 | "metadata": {
226 | "id": "vCMC8_ZW2cJB",
227 | "colab_type": "text"
228 | },
229 | "source": [
230 | "Agora vamos aos exemplos, começando pela questão 303 do LeetCode, que pode ser encontrada no link a seguir:\n",
231 | "- https://leetcode.com/problems/range-sum-query-immutable/"
232 | ]
233 | },
234 | {
235 | "cell_type": "markdown",
236 | "metadata": {
237 | "id": "ksBVY02K2pvf",
238 | "colab_type": "text"
239 | },
240 | "source": [
241 | "303. Dado um array de números inteiros, encontre a soma dos elementos entre os índices i e j (i ≤ j), de forma inclusiva."
242 | ]
243 | },
244 | {
245 | "cell_type": "code",
246 | "metadata": {
247 | "id": "fO-tQlHO279-",
248 | "colab_type": "code",
249 | "colab": {}
250 | },
251 | "source": [
252 | "class NumArray:\n",
253 | "\n",
254 | " _sum_list = None\n",
255 | " \n",
256 | " def __init__(self, nums: List[int]):\n",
257 | " \n",
258 | " self._sum_list = list()\n",
259 | " \n",
260 | " for index in range(len(nums) + 1):\n",
261 | " num = nums[index - 1] if index > 0 else 0\n",
262 | " \n",
263 | " if index >= 1:\n",
264 | " self._sum_list.append(self._sum_list[index - 1] + num)\n",
265 | " else:\n",
266 | " self._sum_list.append(num)\n",
267 | " \n",
268 | "\n",
269 | " def sumRange(self, i: int, j: int) -> int:\n",
270 | " \n",
271 | " return self._sum_list[j + 1] - self._sum_list[i]\n"
272 | ],
273 | "execution_count": 0,
274 | "outputs": []
275 | },
276 | {
277 | "cell_type": "markdown",
278 | "metadata": {
279 | "id": "uohLTTRm3APt",
280 | "colab_type": "text"
281 | },
282 | "source": [
283 | "O problema dessa questão está no fato que o método sumRange será chamado várias vezes, fazendo com que seja necessário recalcular a soma entre as posições várias vezes, de tal forma que a complexidade assintótica depende da quantidade de vezes que o método sumRange é chamado. Exemplificando:\n",
284 | "- Caso o método seja chamado n vezes, sendo n o tamanho do array de nums, a complexidade desse problema seria de O(n * n), no pior caso."
285 | ]
286 | },
287 | {
288 | "cell_type": "markdown",
289 | "metadata": {
290 | "id": "pJ5xerjV38A1",
291 | "colab_type": "text"
292 | },
293 | "source": [
294 | "Para contornar esse problema, nós fazemos um processamento inicial, calculando a soma de todas as posições em relação aos seus anteriores, totalizando assim uma complexidade assintótica de O(n)."
295 | ]
296 | },
297 | {
298 | "cell_type": "markdown",
299 | "metadata": {
300 | "id": "xphnVzdF43z5",
301 | "colab_type": "text"
302 | },
303 | "source": [
304 | "Esse procedimento é necessário para criar uma \"memória\" das somas, de tal forma que, quando seja necessário calcular a soma entre as posições i e j, esse cálculo seja realizado de forma constante, ou seja, em O(1)."
305 | ]
306 | },
307 | {
308 | "cell_type": "markdown",
309 | "metadata": {
310 | "id": "gJjXfyqD4U2L",
311 | "colab_type": "text"
312 | },
313 | "source": [
314 | "------------"
315 | ]
316 | },
317 | {
318 | "cell_type": "markdown",
319 | "metadata": {
320 | "id": "ivlMoYW95WlY",
321 | "colab_type": "text"
322 | },
323 | "source": [
324 | "Partindo agora para resolução de problemas mais complexos, vamos resolver a questão 62, que pode ser encontrada no link a seguir:\n",
325 | "- https://leetcode.com/problems/unique-paths/"
326 | ]
327 | },
328 | {
329 | "cell_type": "markdown",
330 | "metadata": {
331 | "id": "YEbr0IAn55u3",
332 | "colab_type": "text"
333 | },
334 | "source": [
335 | "62. Um robô está localizado no canto superior esquerdo de uma matriz m x n. Ele só pode se mover ou para baixo ou para direita. O robô está tentando chegar ao canto inferiror direito da matriz. Nós devemos calcular a quantidade de caminhos únicos que o robô pode tomar.\n"
336 | ]
337 | },
338 | {
339 | "cell_type": "code",
340 | "metadata": {
341 | "id": "eIpuxYgm6mRr",
342 | "colab_type": "code",
343 | "colab": {}
344 | },
345 | "source": [
346 | "class Solution:\n",
347 | "\n",
348 | " def uniquePaths(self, m: int, n: int) -> int:\n",
349 | " # Iniciamos os caminhos possíveis com 1, pois em uma matriz de 1 x 1, o robô só possui um caminho a tomar\n",
350 | " possible_paths = [[1 for col in range(m)] for row in range(n)]\n",
351 | " \n",
352 | " for a in range(1, n):\n",
353 | " for b in range(1, m):\n",
354 | " possible_paths[a][b] = possible_paths[a - 1][b] + possible_paths[a][b - 1]\n",
355 | " \n",
356 | " return possible_paths[n - 1][m - 1]"
357 | ],
358 | "execution_count": 0,
359 | "outputs": []
360 | },
361 | {
362 | "cell_type": "markdown",
363 | "metadata": {
364 | "id": "sCK_x0AX64IQ",
365 | "colab_type": "text"
366 | },
367 | "source": [
368 | "Esse problema pode ser considerado como um exemplo clássico do uso de programação dinâmica, uma vez que, pensando na forma recursiva, nós temos que a quantidade de caminhos que o robô pode tomar é igual a quantidade de caminhos tanto a esquerda quanto acima, uma vez que estamos falando de uma matriz em 2D. O que poderia nos levar a seguinte resolução:"
369 | ]
370 | },
371 | {
372 | "cell_type": "code",
373 | "metadata": {
374 | "id": "T-kwDSDw8pnV",
375 | "colab_type": "code",
376 | "colab": {}
377 | },
378 | "source": [
379 | "def caminhosUnicos(m, n):\n",
380 | " if m == 1 and n == 1:\n",
381 | " return 1\n",
382 | " if m == 0 or n == 0:\n",
383 | " return 0\n",
384 | " return caminhosUnicos(m - 1, n) + caminhosUnicos(m, n - 1)"
385 | ],
386 | "execution_count": 0,
387 | "outputs": []
388 | },
389 | {
390 | "cell_type": "markdown",
391 | "metadata": {
392 | "id": "LJxfnZbw9UiG",
393 | "colab_type": "text"
394 | },
395 | "source": [
396 | "Porém, como nós já vimos, essa resolução nos leva ao problema do re-processamento desnecessário, de tal forma que certos elementos no espaço serão recalculados várias vezes, liderando a uma complexidade exponencial."
397 | ]
398 | },
399 | {
400 | "cell_type": "markdown",
401 | "metadata": {
402 | "id": "9wcefjqd9keq",
403 | "colab_type": "text"
404 | },
405 | "source": [
406 | "Para tal, nós chegamos ao código mostrado na primeira célula, onde usamos uma matriz para armazenar os possíveis caminhos, seguindo de forma iterativa até termos preenchido toda a matriz com os possíveis caminhos, diminuindo a complexidade assintótica do problema de exponencial para O(n * m)."
407 | ]
408 | },
409 | {
410 | "cell_type": "markdown",
411 | "metadata": {
412 | "id": "FOYi9gjI64MI",
413 | "colab_type": "text"
414 | },
415 | "source": [
416 | "--------------------"
417 | ]
418 | },
419 | {
420 | "cell_type": "markdown",
421 | "metadata": {
422 | "id": "5we0q2v4VhNe",
423 | "colab_type": "text"
424 | },
425 | "source": [
426 | "Caso tenha interesse, a seguir nós listamos a resolução do problema 123, que é um problema do nível difícil e que usa programação dinâmica, seguem os links para o problema a para a resolução, respectivamente:\n",
427 | "- https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii/description/\n",
428 | "- https://leetcode.com/playground/TVPEFDu8\n",
429 | "- OBS: A resolução foi implementada em C++, então se segure bem na cadeira antes de abrir esse link hahaha."
430 | ]
431 | },
432 | {
433 | "cell_type": "markdown",
434 | "metadata": {
435 | "id": "DBF0WwMEWShr",
436 | "colab_type": "text"
437 | },
438 | "source": [
439 | "---------"
440 | ]
441 | },
442 | {
443 | "cell_type": "markdown",
444 | "metadata": {
445 | "id": "kUUS8-g07IZC",
446 | "colab_type": "text"
447 | },
448 | "source": [
449 | "## Colaboradores"
450 | ]
451 | },
452 | {
453 | "cell_type": "markdown",
454 | "metadata": {
455 | "id": "6SzJUVLQs61C",
456 | "colab_type": "text"
457 | },
458 | "source": [
459 | "* André Winston \n",
460 | "* Camila Duarte\n",
461 | "* Anderson Medeiros\n",
462 | "\n"
463 | ]
464 | }
465 | ]
466 | }
--------------------------------------------------------------------------------
/greedy/greedy-algorithms.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "name": "Programação Gulosa.ipynb",
7 | "provenance": [],
8 | "collapsed_sections": [],
9 | "toc_visible": true
10 | },
11 | "kernelspec": {
12 | "name": "python3",
13 | "display_name": "Python 3"
14 | }
15 | },
16 | "cells": [
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {
20 | "id": "aof5Xlf20n1P",
21 | "colab_type": "text"
22 | },
23 | "source": [
24 | "# Algoritmos Gulosos\n",
25 | "Uma introdução à estratégia de programação 'gulosa'"
26 | ]
27 | },
28 | {
29 | "cell_type": "markdown",
30 | "metadata": {
31 | "id": "kjFOBoPw05pQ",
32 | "colab_type": "text"
33 | },
34 | "source": [
35 | ""
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {
41 | "id": "6cV0V9GF0hUw",
42 | "colab_type": "text"
43 | },
44 | "source": [
45 | "De modo geral, algoritmos gulosos são aqueles que **sempre tomam a melhor decisão** que ele consegue encontrar, no conjunto de decisões possíveis a cada iteração, possuindo como objetivo 'coletar' um conjunto de melhores soluções com base em algum determinado critério, formando assim a solução do problema. Os critérios que definem o que seria a melhor decisão a tomar em certa iteração irão variar para cada problema. \n",
46 | "\n",
47 | "Tomem como exemplo, a situação em que você tem de sair da sua casa até um certo supermercado da sua cidade. Há várias ruas no caminho, todas com certo comprimento e você decide por utilizar uma abordagem gulosa para chegar até lá. A cada vez que você tem que escolher por qual rua seguir, você decide pela rua com menor comprimento, até chegar ao destino final, o supermercado. \n",
48 | "\n",
49 | "No exemplo, cada 'iteração' significa: **Escolha uma rua para seguir**. E a 'decisão gulosa' que foi escolhida foi: **Siga pela rua mais curta**. \n",
50 | "\n",
51 | "Vale reforçar que a tomada de decisão é com base nas informações disponíveis na iteração corrente, sem levar em consideração possíveis consequências futuras da escolha da decisão, ou seja, depois que uma decisão foi tomada, ela não pode ser desfeita.\n",
52 | "\n",
53 | "O algoritmo sempre tenta encontrar a melhor solução local, para no fim obter uma solução que resolva o problema, não necessariamente da melhor forma possível.\n",
54 | "\n"
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "metadata": {
60 | "id": "ReslvGAOHnRR",
61 | "colab_type": "text"
62 | },
63 | "source": [
64 | "O grafo a baixo ilustra a ideia dos algoritmos gulosos, a cada iteração, o critério utilizado para percorrer o gráfo é escolher o filho de maior peso.\n",
65 | "\n",
66 | ""
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {
72 | "id": "bSMxD8K4M6vo",
73 | "colab_type": "text"
74 | },
75 | "source": [
76 | "Mas a ideia do problema seria encontrar o caminhos de maior custos (custo é dado pela soma dos nos), nesse problema o algoritimo guloso, não consegue alcançar a melhor solução."
77 | ]
78 | },
79 | {
80 | "cell_type": "markdown",
81 | "metadata": {
82 | "id": "Qo3jB9lc20x3",
83 | "colab_type": "text"
84 | },
85 | "source": [
86 | "\n",
87 | "# Características\n",
88 | "1. Jamais se arrepende de uma decisão, as escolhas realizadas são definitivas;\n",
89 | "2. Não leva em consideração as consequências de suas decisões;\n",
90 | "3. Podem fazer cálculos repetitivos;\n",
91 | "4. Nem sempre produz a melhor solução final (depende da quantidade de informação fornecida);\n",
92 | "5. Quanto mais informações, maior a chance de produzir uma solução melhor\n",
93 | "\n",
94 | "\n",
95 | "\n",
96 | "\n",
97 | "\n",
98 | "\n",
99 | "\n",
100 | "\n"
101 | ]
102 | },
103 | {
104 | "cell_type": "markdown",
105 | "metadata": {
106 | "id": "Tvx-dqGn5_Ot",
107 | "colab_type": "text"
108 | },
109 | "source": [
110 | "\n",
111 | "# Vantagens\n",
112 | "\n",
113 | "1. Simples e fácil de implementação;\n",
114 | "2. Algoritmos de rápida execução;\n",
115 | "3. Podem fornecer a melhor solução (estado ideal).\n"
116 | ]
117 | },
118 | {
119 | "cell_type": "markdown",
120 | "metadata": {
121 | "id": "DxzDyS8Q6vIG",
122 | "colab_type": "text"
123 | },
124 | "source": [
125 | "#Desvantagens\n",
126 | "1. Nem sempre conduz a soluções ótimas globais. Podem efetuar cálculos repetitivos.\n",
127 | "2. Escolhe o caminho que, à primeira vista, é mais econômico.\n",
128 | "3. Pode entrar em loop se não detectar a expansão de estados repetidos.\n",
129 | "4. Pode tentar desenvolver um caminho infinito."
130 | ]
131 | },
132 | {
133 | "cell_type": "markdown",
134 | "metadata": {
135 | "id": "RvJEyY2LDxnS",
136 | "colab_type": "text"
137 | },
138 | "source": [
139 | "#Exemplos\n",
140 | "\n",
141 | "Os exemplos abaixo são questões provindas do site LeetCode, que possui questões de algoritmos dos mais diversos assuntos e que comumente aparecem em entrevistas de programação"
142 | ]
143 | },
144 | {
145 | "cell_type": "markdown",
146 | "metadata": {
147 | "id": "9jnR3KL1D1Zw",
148 | "colab_type": "text"
149 | },
150 | "source": [
151 | "**EXEMPLO 1**\n",
152 | "[Questão 1221](https://leetcode.com/problems/split-a-string-in-balanced-strings/) do site leetcode\n",
153 | "\n",
154 | "**Separe uma string em strings balanceadas**\n",
155 | "\n",
156 | "String balanceadas são aquelas que possuem quantidades iguais de caracteres 'L' e 'R'.\n",
157 | "\n",
158 | "Dada uma string, divida-a na quantidade máxima de substrings balanceadas. Retorne a quantidade máxima de string balanceadas divididas."
159 | ]
160 | },
161 | {
162 | "cell_type": "markdown",
163 | "metadata": {
164 | "id": "h_a_0fu2W9sX",
165 | "colab_type": "text"
166 | },
167 | "source": [
168 | "O problema pode ser compreendido da seguinte forma:\n",
169 | "\n",
170 | "Para separar a string de maneira correta, temos que iniciar dois contadores, um para \"L\" e um para \"R\".\n",
171 | "\n",
172 | "Depois de iniciar os contadores, vamos interar sobre a string adcionando aos contadores as ocorrencias de \"L\" e \"R\" e sempre que o valor dos contadores de \"R\" e \"L\" forem iguais e maiores que 0 é certo que ali está uma sub string balanceada.\n",
173 | "\n",
174 | "Nesse momento o algoritmo deve separar a string, fazendo uma ação definitiva, caracteristica de programação gulosa.\n",
175 | "\n",
176 | "No fim do laço basta retorna o numero de separações que a string teve ao longo da execução, que foi armazenado em \"output\".\n",
177 | "\n",
178 | "Segue abaixo o codigo da função:"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "metadata": {
184 | "id": "ZQxQek8jCTgh",
185 | "colab_type": "code",
186 | "colab": {}
187 | },
188 | "source": [
189 | "def balanced_strings_split(s):\n",
190 | " count = {\n",
191 | " \"L\" : 0,\n",
192 | " \"R\" : 0,\n",
193 | " }\n",
194 | " output = 0\n",
195 | " for char in s:\n",
196 | " count[char] +=1\n",
197 | " if count[\"L\"] == count[\"R\"]:\n",
198 | " output += 1\n",
199 | " return output"
200 | ],
201 | "execution_count": 0,
202 | "outputs": []
203 | },
204 | {
205 | "cell_type": "markdown",
206 | "metadata": {
207 | "id": "N4Flpk4bXGzt",
208 | "colab_type": "text"
209 | },
210 | "source": [
211 | "Testando o codigo com uma entrada balanceada:"
212 | ]
213 | },
214 | {
215 | "cell_type": "code",
216 | "metadata": {
217 | "id": "MyIKK0g8DGUy",
218 | "colab_type": "code",
219 | "colab": {}
220 | },
221 | "source": [
222 | "print(balanced_strings_split(\"LLLRRLRRLRRRLRLL\"))"
223 | ],
224 | "execution_count": 0,
225 | "outputs": []
226 | },
227 | {
228 | "cell_type": "markdown",
229 | "metadata": {
230 | "id": "cTU0JwDRDTfE",
231 | "colab_type": "text"
232 | },
233 | "source": [
234 | "**EXEMPLO 2**\n",
235 | "[Questão 55](https://leetcode.com/problems/jump-game/). Jump Game do site leetcode\n",
236 | "\n",
237 | "**Dada uma matriz de números inteiros não negativos, você está inicialmente posicionado no primeiro índice da matriz.**\n",
238 | "\n",
239 | "\n",
240 | "Cada elemento da matriz representa seu comprimento máximo de salto nessa posição.\n",
241 | "\n",
242 | "Determine se você consegue alcançar o último índice."
243 | ]
244 | },
245 | {
246 | "cell_type": "markdown",
247 | "metadata": {
248 | "id": "cF_ZwDRCEIxB",
249 | "colab_type": "text"
250 | },
251 | "source": [
252 | "Solução:\n"
253 | ]
254 | },
255 | {
256 | "cell_type": "code",
257 | "metadata": {
258 | "id": "bYUjUMSZGMgu",
259 | "colab_type": "code",
260 | "colab": {}
261 | },
262 | "source": [
263 | "def canJump(self, nums: List[int]) -> bool:\n",
264 | " r=0\n",
265 | " for l in range(len(nums)):\n",
266 | " if l>r:\n",
267 | " return False\n",
268 | " r=max(r,l+nums[l])\n",
269 | " if r>=len(nums)-1:\n",
270 | " return True"
271 | ],
272 | "execution_count": 0,
273 | "outputs": []
274 | },
275 | {
276 | "cell_type": "markdown",
277 | "metadata": {
278 | "id": "bU4EglKMVlMW",
279 | "colab_type": "text"
280 | },
281 | "source": [
282 | "**EXEMPLO 3**\n",
283 | "[763.](https://leetcode.com/problems/partition-labels/). Partition Labels\n",
284 | "\n",
285 | "Uma sequência S de letras minúsculas é fornecida. Queremos particionar essa string em tantas partes quanto possível, para que cada letra apareça em no máximo uma parte e retorne uma lista de números inteiros representando o tamanho dessas partes.\n",
286 | "\n",
287 | "Seja: \n",
288 | "\n",
289 | "Entrada: S = \"ababcbacadefegdehijhklij\"\n",
290 | "\n",
291 | "Saída: [9,7,8]\n",
292 | "\n",
293 | "Explicando a saída:\n",
294 | "\n",
295 | "As partições são \"ababcbaca\", \"defegde\", \"hijhklij\"."
296 | ]
297 | },
298 | {
299 | "cell_type": "markdown",
300 | "metadata": {
301 | "id": "Im-wydjVjxat",
302 | "colab_type": "text"
303 | },
304 | "source": [
305 | "Para entendermos como resolver esse problema, podemos ver a ideia de algortimos gulosos, que sempre vão executar a melhor ação dada as condições atuais. E também não vai mudar seu comportamento perante isso.\n",
306 | "\n",
307 | "\n",
308 | "Temos que percorrer toda a string e verificar se o caractere atual, a sua ultima ocorrencia estoura o limite da partição definida pelo primeiro caractere, se estourar, dizemos que a ultima ocorrencia desse novo caractere é o limite da partição.\n",
309 | "\n",
310 | "Percorremos a string até encontrar o limite da partição com essa limitação sendo verdadeira, se isso ocorrer podemos iniciar uma segunda partição."
311 | ]
312 | },
313 | {
314 | "cell_type": "markdown",
315 | "metadata": {
316 | "id": "5XD1_Rks1oAn",
317 | "colab_type": "text"
318 | },
319 | "source": [
320 | "Abaixo uma solução com as regras corrigidas e citadas."
321 | ]
322 | },
323 | {
324 | "cell_type": "code",
325 | "metadata": {
326 | "id": "c7_NFhVv0gJ0",
327 | "colab_type": "code",
328 | "colab": {}
329 | },
330 | "source": [
331 | "def partition_labels(s):\n",
332 | " last = {c: i for i,c in enumerate(s)}\n",
333 | " j = anchor = 0\n",
334 | " ans = []\n",
335 | " for i,c in enumerate(s):\n",
336 | " j = max(j,last[c])\n",
337 | " if i == j:\n",
338 | " ans.append(i-anchor + 1)\n",
339 | " anchor = i + 1\n",
340 | " return ans"
341 | ],
342 | "execution_count": 0,
343 | "outputs": []
344 | },
345 | {
346 | "cell_type": "markdown",
347 | "metadata": {
348 | "id": "ZiwbAjYS2-2u",
349 | "colab_type": "text"
350 | },
351 | "source": [
352 | "Teste da solução"
353 | ]
354 | },
355 | {
356 | "cell_type": "code",
357 | "metadata": {
358 | "id": "srsyesM01I4m",
359 | "colab_type": "code",
360 | "outputId": "4377cdcc-c1bc-4921-8787-5c6ad9682997",
361 | "colab": {
362 | "base_uri": "https://localhost:8080/",
363 | "height": 34
364 | }
365 | },
366 | "source": [
367 | "partition_labels(\"ababcbacadefegdehijhklij\")"
368 | ],
369 | "execution_count": 0,
370 | "outputs": [
371 | {
372 | "output_type": "execute_result",
373 | "data": {
374 | "text/plain": [
375 | "[9, 7, 8]"
376 | ]
377 | },
378 | "metadata": {
379 | "tags": []
380 | },
381 | "execution_count": 70
382 | }
383 | ]
384 | }
385 | ]
386 | }
--------------------------------------------------------------------------------
/priority-queue/README.md:
--------------------------------------------------------------------------------
1 | # Fila de prioridade
2 |
3 | Veja o no Medium uma explicação detalhada sobre filas de prioridade, e o que você deve ter em mente para quando tentar resolver essas questões, segue o link:
4 | https://medium.com/@wander.alves13/37e39985e302
5 |
6 | ## Questões do leet code resolvidadas
7 |
8 | 1. [Partition List](question86.md)
9 |
10 | + Dificuldade: Média
11 |
12 | 215. [Kth Largest Element in an Array](question215.md)
13 |
14 | + Dificuldade: Média
15 |
16 | 767. [Reorganize String](question767.md)
17 |
18 | + Dificuldade: Média
19 |
20 | ## Implementação:
21 |
22 | + Python 3
23 |
24 | Authors:
25 |
26 | + [Pablo Emanuell](https://github.com/pabloufrn)
27 | + [Graco Silva](https://github.com/gbvsilva)
28 | + [Wanderson Alves](https://github.com/wanderson130)
29 |
30 | <- [BACK TO HOME](../README.md)
--------------------------------------------------------------------------------
/priority-queue/question215.md:
--------------------------------------------------------------------------------
1 | # 215. Kth Largest Element in an Array
2 |
3 | ## Solução
4 |
5 | > Find the kth largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element.
6 | >
7 | > **Example 1:**
8 | >
9 | > ```
10 | > Input: [3,2,1,5,6,4] and k = 2
11 | > Output: 5
12 | > ```
13 | >
14 | > **Example 2:**
15 | >
16 | > ```Input: [3,2,3,1,2,4,5,5,6] and k = 4
17 | > Output: 4
18 | > ```
19 | > **Note:**
20 | > You may assume k is always valid, 1 ≤ k ≤ array's length.
21 |
22 | Para resolver essa questão, podemos ordenar a lista em ordem decrescente e retornar o k-ésimo termo, porém para economizar espaço podemos guardar apenas os cinco maiores elementos em uma fila e retornar o menor.
23 |
24 | ## Implementação
25 |
26 | Como sempre iniciamos declarando a lista, depois, para cada elemento na lista adicionamos ele na fila, e, como queremos guardar apenas os `k` maiores elementos, se o tamanho da fila é maior que `k`, removemos o menor. No final, apenas retornamos o menor elemento da fila. Veja o código:
27 |
28 | ```Python 3
29 | pqueue = []
30 | for el in nums:
31 | heappush(pqueue, el)
32 | if(len(pqueue) > k):
33 | heappop(pqueue)
34 | return pqueue[0]
35 | ```
36 |
37 | + [Código completo](./question215.py)
38 | + [Pratique no LeetCode](https://leetcode.com/problems/kth-largest-element-in-an-array/)
39 |
40 | Viu algum erro? mande um email para pabloemanuell2017@gmail.com
41 |
42 | [<- ANTERIOR](question86.md) | [PRÓXIMA ->](question767.md)
43 |
44 | [VOLTAR PARA O ÍNICIO](README.md)
45 |
--------------------------------------------------------------------------------
/priority-queue/question215.py:
--------------------------------------------------------------------------------
1 | from heapq import *
2 |
3 | class Solution:
4 | def findKthLargest(self, nums: List[int], k: int) -> int:
5 | pqueue = []
6 | for el in nums:
7 | heappush(pqueue, el)
8 | if(len(pqueue) > k):
9 | heappop(pqueue)
10 | return pqueue[0]
11 |
12 |
--------------------------------------------------------------------------------
/priority-queue/question767.md:
--------------------------------------------------------------------------------
1 | # 767. Reorganize String
2 |
3 | ## Solução
4 |
5 | > Given a string `S`, check if the letters can be rearranged so that two characters that are adjacent to each other are not the same.
6 | >
7 | > If possible, output any possible result. If not possible, return the empty string.
8 | >
9 | > **Example 1:**
10 | >
11 | > Input: S = "aab"
12 | > Output: = "aba"
13 | >
14 | > **Example 2:**
15 | >
16 | > Input: S = "aaab"
17 | > Output: = ""
18 | >
19 | > **Note:**
20 | > - `S` will consist of lowercase letters and have length in range` [1, 500]`.
21 |
22 | Para resolver essa questão, é necessário seguir uma estrátegia para tentar reorganizar a string. Devemos perceber que as letras que mais ocorrem são as que causam mais problemas. Podemos alternar entre as duas letras com maior número de ocorrências na string das letras que ainda precisam ser organizadas. Como na questão [86](question86.md), precisamos de uma tupla, que nesse caso terá primeiro o número de ocorrências e depois o valor.
23 |
24 | Além disso temos um valor máximo do maior número de ocorrências, imagine que a letra que mais ocorre é um separador, se tivermos `k` separadores, precisamos de, no mínimo `k` letras restantes, se `k` for ímpar e `k-1` letras restantes se `k` for par. Em geral `k` pode ser no máximo `piso(n + 1 / 2)` .
25 |
26 | ## Implementação
27 |
28 | Para fazer a contagem, usamos um dicionário, primeiro precisamos colocar os elementos nele:
29 |
30 | ```Python
31 | C = {}
32 | max_count = (len(S) + 1) // 2
33 | for ch in S:
34 | count = C.get(ch, 0) + 1
35 | if(count > max_count):
36 | return ""
37 | C[ch] = count
38 | ```
39 |
40 | Depois é só ordenar pelos critérios discutidos. Mas como temos uma min-heap, e queremos que os elementos com maior número de ocorrências venham primeiro, utilizamos o valor negativo para as ocorrências.
41 |
42 | ```Python
43 | pq = []
44 | for key, value in C.items():
45 | pq.append((-value, key))
46 | heapify(pq)
47 | ```
48 |
49 | Por fim organizamos a nova string, alternando entre os dois elementos com mais ocorrências (atualmente), sempre diminuindo o número de ocorrências em 1 (ou seja, somando 1 no número negativo de ocorrências), e retornamos o resultado.
50 |
51 | ```Python 3
52 | result = ""
53 | while(len(pq) > 1):
54 | p1, v1 = heappop(pq)
55 | p2, v2 = heappop(pq)
56 | result += v1 + v2
57 | if(p1 != -1):
58 | heappush(pq, (p1 + 1, v1))
59 | if(p2 != -1):
60 | heappush(pq, (p2 + 1, v2))
61 | if(len(pq) == 1):
62 | result += heappop(pq)[1]
63 | return result
64 | ```
65 |
66 | Como pode ser observado, ao pegar os elementos dois a dois, pode ser que sobre um, se sobrar é só concatenar no resultado.
67 |
68 | - [Código completo](./question767.py)
69 |
70 | - [Pratique no LeetCode](https://leetcode.com/problems/reorganize-string/)
71 |
72 | Viu algum erro? mande um email para pabloemanuell2017@gmail.com
73 |
74 | | [<- ANTERIOR](question215.md)
75 | | [<- VOLTAR PARA O ÍNICIO](README.md)
76 |
--------------------------------------------------------------------------------
/priority-queue/question767.py:
--------------------------------------------------------------------------------
1 | from heapq import *
2 |
3 | class Solution:
4 | def reorganizeString(self, S: str) -> str:
5 | C = {}
6 | max_count = (len(S) + 1) // 2
7 | for ch in S:
8 | count = C.get(ch, 0) + 1
9 | if(count > max_count):
10 | return ""
11 | C[ch] = count
12 |
13 | pq = []
14 | for key, value in C.items():
15 | pq.append((-value, key))
16 | heapify(pq)
17 |
18 | result = ""
19 | while(len(pq) > 1):
20 | p1, v1 = heappop(pq)
21 | p2, v2 = heappop(pq)
22 | result += v1 + v2
23 | if(p1 != -1):
24 | heappush(pq, (p1 + 1, v1))
25 | if(p2 != -1):
26 | heappush(pq, (p2 + 1, v2))
27 | if(len(pq) == 1):
28 | result += heappop(pq)[1]
29 | return result
--------------------------------------------------------------------------------
/priority-queue/question86.md:
--------------------------------------------------------------------------------
1 | # 86. Partition List
2 |
3 | ## Solução
4 |
5 | > Given a linked list and a value x, partition it such that all nodes less than x come before nodes greater than or equal to x.
6 | > You should preserve the original relative order of the nodes in each of the two partitions.
7 | > **Example:**
8 | >
9 | > ```None
10 | > Input: head = 1->4->3->2->5->2, x = 3
11 | > Output: 1->2->2->4->3->5
12 | > ```
13 | >
14 | Para resolver a questão, temos que ordenar pelos seguintes críterios, em ordem de prioridade:
15 |
16 | 1. Valores menores que `x` primeiro.
17 | 2. Valores mais à esquerda na lista original primeiro.
18 |
19 | Isso é, precisamos fazer uma lista de prioridade com que armazene tuplas do tipo:
20 | t = (critério 1, critério 2, valor)
21 | Para o critério 1 podemos fazer dois grupos (0 e 1), um para valores menores que `x` e outro para o restante.
22 | Para o critério 2 podemos usar o índice dos elementos na lista original.
23 | Ao final da construção da fila, podemos fazer uma lista encadeada com o terceiro item de cada tupla.
24 |
25 | ## Implementação
26 |
27 | Primeiramente declaramos a fila de prioridade:
28 |
29 | ```Python 3
30 | pqueue = []
31 | ```
32 |
33 | Depois precisamos percorrer a lista de entrada e colocar os elementos na fila, conforme os critérios estabelecidos:
34 |
35 | ```Python 3
36 | current = head
37 | i = 0
38 | while(current != None):
39 | val = current.val
40 | heappush(pqueue, (0 if val < x else 1, i, val))
41 | current = current.next
42 | i += 1
43 | ```
44 |
45 | Agora construímos a nova lista de adjacência e retornamos:
46 |
47 | ```Python 3
48 | newhead = ListNode(heappop(pqueue)[2])
49 | current = newhead
50 | while(len(pqueue) > 0):
51 | current.next = ListNode(heappop(pqueue)[2])
52 | current = current.next
53 | return newhead
54 | ```
55 |
56 | Tomando cuidado, no começo, com o caso da lista vazia:
57 | ```Python 3
58 | if(head == None):
59 | return head
60 | ```
61 |
62 | + [Código completo](./question86.py)
63 | + [Pratique no LeetCode](https://leetcode.com/problems/partition-list/)
64 |
65 | Viu algum erro? mande um email para pabloemanuell2017@gmail.com
66 |
67 | | [-> PRÓXIMA](question215.md)
68 |
69 | | [<- VOLTAR PARA O ÍNICIO](README.md)
70 |
--------------------------------------------------------------------------------
/priority-queue/question86.py:
--------------------------------------------------------------------------------
1 | from heapq import *
2 |
3 | class Solution:
4 | def partition(self, head: ListNode, x: int) -> ListNode:
5 | if(head == None):
6 | return head
7 | pqueue = []
8 | current = head
9 | i = 0
10 | while(current != None):
11 | val = current.val
12 | heappush(pqueue, (0 if val < x else 1, i, val))
13 | current = current.next
14 | i += 1
15 | newhead = ListNode(heappop(pqueue)[2])
16 | current = newhead
17 | while(len(pqueue) > 0):
18 | current.next = ListNode(heappop(pqueue)[2])
19 | current = current.next
20 | return newhead
--------------------------------------------------------------------------------
/sweep-line-algorithm/README.md:
--------------------------------------------------------------------------------
1 | # Sweep Line Algorithm
2 | In computational geometry, a **sweep line algorithm** or **plane sweep algorithm** is an algorithmic paradigm that uses a conceptual sweep line or sweep surface to solve various problems in Euclidean space. It is one of the key techniques in computational geometry.
3 |
4 | The idea behind algorithms of this type is to imagine that a line (often a vertical line) is swept or moved across the plane, stopping at some points. Geometric operations are restricted to geometric objects that either intersect or are in the immediate vicinity of the sweep line whenever it stops, and the complete solution is available once the line has passed over all objects.
5 |
6 | In mathematics, a **[Voronoi diagram](https://en.wikipedia.org/wiki/Voronoi_diagram)** is a partition of a plane into regions close to each of a given set of objects. In the simplest case, these objects are just finitely many points in the plane (called seeds, sites, or generators). For each seed there is a corresponding region consisting of all points of the plane closer to that seed than to any other. These regions are called Voronoi cells. The Voronoi diagram of a set of points is dual to its Delaunay triangulation.
7 |
8 | 
9 | ##### [From Wikipedia, the free encyclopedia](https://en.wikipedia.org/wiki/Sweep_line_algorithm)
10 |
11 | ## Problems
12 | 1. [Maximum Intervals Overlap](geeks-for-geeks/README.md)
13 | + Level: Medium
14 | 2. [Rectangle Area](leetcode/README.md)
15 | + Level: Medium
16 | 3. [Rectangle Overlap](leetcode/README.md)
17 | + Level: Easy
18 |
19 | ## Implementations:
20 | + C++
21 | + Python 3
22 |
23 | ## Disclaimer
24 | > This material was used in the course SPECIAL TOPICS IN COMPUTER XIV - Programming Interviewing Practices of the Digital Metropolis Institute of the Federal University of Rio Grande do Norte.
25 |
26 | Authors:
27 | + [Giovanne Santos](https://github.com/gsdante)
28 | + [Marlus Marcos](https://github.com/marlusmarcos)
29 | + [Thiago Silva](https://github.com/silva-thiago)
30 | + [Yan Carlos](https://github.com/yandl5)
31 |
32 | <- [BACK TO HOME](../README.md)
--------------------------------------------------------------------------------
/sweep-line-algorithm/geeks-for-geeks/README.md:
--------------------------------------------------------------------------------
1 | # Problem 1
2 |
3 | ## Maximum Intervals Overlap
4 | Consider a big party where a log register for guest’s entry and exit times is maintained. Find the time at which there are maximum guests in the party. Note that entries in register are not in any order.
5 |
6 | #### Input:
7 | The first line of input contains an integer T denoting the number of test cases. Then T test cases follow. Each test case contains an integer n denoting the size of the entry and exit array. Then the next two line contains the entry and exit array respectively.
8 |
9 | #### Output:
10 | Print the maximum no of guests and the time at which there are maximum guests in the party.
11 |
12 | #### Constraints:
13 | 1 <= T <= 10^5
14 |
15 | 1 <= N <= 10^5
16 |
17 | 1 <= entry[i], exit[i] <= 10^5
18 |
19 | ### Example:
20 | #### Input:
21 | 2
22 |
23 | 5
24 |
25 | 1 2 10 5 5
26 |
27 | 4 5 12 9 12
28 |
29 | 7
30 |
31 | 13 28 29 14 40 17 3
32 |
33 | 107 95 111 105 70 127 74
34 |
35 | #### Output:
36 | 3 5
37 |
38 | 7 40
39 |
40 | ### Disclaimer
41 | > This material was used in the course SPECIAL TOPICS IN COMPUTER XIV - Programming Interviewing Practices of the Digital Metropolis Institute of the Federal University of Rio Grande do Norte.
42 |
43 | + [C++ problem solution](./maximum-intervals-overlap.cpp)
44 |
45 | + [Very cool technique used to solve problems with geometric solutions.](https://www.youtube.com/watch?v=3ph6V32oja0)
46 |
47 | + [Practice on Geeks for Geeks](https://practice.geeksforgeeks.org/problems/maximum-intervals-overlap/0)
48 |
49 | <- [BACK](../README.md)
--------------------------------------------------------------------------------
/sweep-line-algorithm/geeks-for-geeks/input.txt:
--------------------------------------------------------------------------------
1 | 2
2 | 5
3 | 1 2 10 5 5
4 | 4 5 12 9 12
5 | 7
6 | 13 28 29 14 40 17 3
7 | 107 95 111 105 70 127 74
--------------------------------------------------------------------------------
/sweep-line-algorithm/geeks-for-geeks/maximum-intervals-overlap.cpp:
--------------------------------------------------------------------------------
1 | /// Source: https://practice.geeksforgeeks.org/problems/maximum-intervals-overlap/0#ExpectOP
2 | /// Problem: Maximum Intervals Overlap
3 | /// Data Structure: Sweep Line Algorithm
4 | /// Difficult: Medium
5 | /// Autores: Giovanne Santos, Marlus Marcos, Thiago Silva, Yan Carlos
6 | /// Created on 2019/09/26
7 |
8 | #include
9 | #include
10 | #include
11 | #include
12 |
13 | #define ADD 0 /// Entrada na festa
14 | #define RMV 1 /// Saída da festa
15 |
16 | int main()
17 | {
18 | /** Ler arquivo com as informações de entrada */
19 | std::ifstream ifs("input.txt");
20 |
21 | if (not ifs)
22 | {
23 | /** Feedback em caso de problema para a leitura */
24 | std::perror("input.txt");
25 | }
26 | else
27 | {
28 | /** Ler o número de casos de teste */
29 | int test_case;
30 | //std::cin >> test_case;
31 | ifs >> test_case;
32 |
33 | /** Resposta para todos os casos de teste */
34 | while (test_case--)
35 | {
36 | /**
37 | * Lista de evento e o modo como o evento será modelado
38 | * 'int' é o tempo e o 'bool' é para desenpatar a ordenação (a entrada é preferêncial)
39 | */
40 | std::vector> event;
41 |
42 | /** Ler a quantidade de convidados */
43 | int guests;
44 | //std::cin >> guests;
45 | ifs >> guests;
46 |
47 | /** Registrar o tempo da chegada dos convidados */
48 | for (int i = 0; i < guests; ++i)
49 | {
50 | int entry_time;
51 | //std::cin >> entry_time;
52 | ifs >> entry_time;
53 |
54 | /**
55 | * event: Registra o tempo que o evento acontece.
56 | * entry_time: Tempo em que o evento está acontecendo
57 | * ADD: Tipo do evento quando alguém entra
58 | */
59 | event.emplace_back(entry_time, ADD);
60 | /**
61 | * note: candidate:
62 | * 'void std::vector<_Tp, _Alloc>::push_back(const value_type&) [with _Tp = std::pair;
63 | * _Alloc = std::allocator >;
64 | * std::vector<_Tp, _Alloc>::value_type = std::pair]'
65 | * push_back(const value_type& __x)
66 | */
67 | }
68 |
69 | /** Registrar o tempo da saída dos convidados */
70 | for (int i = 0; i < guests; ++i)
71 | {
72 | int departure_time;
73 | //std::cin >> departure_time;
74 | ifs >> departure_time;
75 |
76 | /**
77 | * event: Registra o tempo que o evento acontece
78 | * departure_time: Tempo em que o evento foi encerrado
79 | * ADD: Tipo do evento quando alguém entra
80 | */
81 | event.emplace_back(departure_time, RMV);
82 | }
83 |
84 | /** Ordenar o vetor para realizar o Line Sweep. Como o vetor é de 'pair', ele já sabe como ordenar */
85 | std::sort(event.begin(), event.end());
86 |
87 | /** Quantidade de convidados na festa */
88 | int guest = 0;
89 | /** Auge da festa, quantidade máxima de convidados */
90 | int max_guests = -1;
91 | /** Tempo em que foi registrado o auge */
92 | int time_max_guests = 0;
93 |
94 | /** Percorrer o vetor de eventos */
95 | for (std::pair ev : event)
96 | {
97 | int event_time = ev.first; /// Tempo em que o evento ocorreu
98 | bool event_type = ev.second; /// Tipo de evento
99 |
100 | /** Se o tipo for de adição, um convidado será colocado na festa */
101 | if (event_type == ADD)
102 | {
103 | guest++; /// Chegou um convidado
104 | }
105 | else
106 | {
107 | guest--; /// Saiu um convidado
108 | }
109 |
110 | /** Atualizar o número de convidados na festa, caso um novo convidado chegue à festa */
111 | if (guest > max_guests)
112 | {
113 | max_guests = guest;
114 | time_max_guests = event_time;
115 | }
116 | }
117 |
118 | /** Imprimir a quantidade máxima de convidados e em que momento isso ocorreu */
119 | std::cout << "The maximum no of guests: " << max_guests << "\nThe time at which there are maximum guests in the party: " << time_max_guests << std::endl;
120 | }
121 | }
122 |
123 | ifs.close();
124 | }
125 |
--------------------------------------------------------------------------------
/sweep-line-algorithm/leetcode/README.md:
--------------------------------------------------------------------------------
1 | # Problem 1
2 |
3 | ## 836. Rectangle Overlap
4 | A rectangle is represented as a list **[x1, y1, x2, y2]**, where **(x1, y1)** are the coordinates of its bottom-left corner, and **(x2, y2)** are the coordinates of its top-right corner.
5 |
6 | Two rectangles overlap if the area of their intersection is positive. To be clear, two rectangles that only touch at the corner or edges do not overlap.
7 |
8 | Given two (axis-aligned) rectangles, return whether they overlap.
9 |
10 | ### Example 1:
11 | #### Input: rec1 = [0,0,2,2], rec2 = [1,1,3,3]
12 | #### Output: true
13 |
14 | ### Example 2:
15 | #### Input: rec1 = [0,0,1,1], rec2 = [1,0,2,1]
16 | #### Output: false
17 |
18 | ### Notes:
19 | 1. Both rectangles rec1 and rec2 are lists of 4 integers.
20 | 2. All coordinates in rectangles will be between -10^9 and 10^9.
21 |
22 | [Python 3 Problem Solution](./rectangle-overlap.py)
23 |
24 | [Practice on Leetcode](https://leetcode.com/problems/rectangle-overlap/)
25 |
26 | # Problem 2
27 |
28 | ## 223. Rectangle Area
29 | Find the total area covered by two rectilinear rectangles in a 2D plane.
30 |
31 | Each rectangle is defined by its bottom left corner and top right corner as shown in the figure.
32 |
33 | 
34 |
35 | ### Example:
36 | #### Input: A = -3, B = 0, C = 3, D = 4, E = 0, F = -1, G = 9, H = 2
37 | #### Output: 45
38 |
39 | ### Note:
40 | Assume that the total area is never beyond the maximum possible value of int.
41 |
42 | ## Disclaimer
43 | > This material was used in the course SPECIAL TOPICS IN COMPUTER XIV - Programming Interviewing Practices of the Digital Metropolis Institute of the Federal University of Rio Grande do Norte.
44 |
45 | + [Python 3 Problem Solution](./rectangle-area.py)
46 |
47 | + [Practice on Leetcode](https://leetcode.com/problems/rectangle-area/)
48 |
49 | <- [BACK](../README.md)
--------------------------------------------------------------------------------
/sweep-line-algorithm/leetcode/rectangle-area.py:
--------------------------------------------------------------------------------
1 | # Source: https://leetcode.com/problems/rectangle-area/
2 | # Problem: 223. Rectangle Area
3 | # Data Structure: Sweep Line Algorithm
4 | # Difficult: Medium
5 | # Autores: Giovanne Santos, Marlus Marcos, Thiago Silva, Yan Carlos
6 | # Created on 2019/09/26
7 |
8 | def isRectangleOverlap(rec1: List[int], rec2: List[int]) -> bool:
9 | horiz_overlap = max(rec1[0], rec2[0]) < min(rec1[2], rec2[2])
10 | vert_overlap = max(rec1[1], rec2[1]) < min(rec1[3], rec2[3])
11 | return horiz_overlap and vert_overlap
12 |
13 | def isRectangleContains(rec1: List[int], rec2: List[int]) -> bool:
14 | horiz_contains = rec1[0] == min(rec1[0], rec2[0]) and rec1[2] == max(rec1[2], rec2[2])
15 | vert_contains = rec1[1] == min(rec1[1], rec2[1]) and rec1[3] == max(rec1[3], rec2[3])
16 | return horiz_contains and vert_contains
17 |
18 |
19 | class Solution:
20 | def computeArea(self, A: int, B: int, C: int, D: int, E: int, F: int, G: int, H: int) -> int:
21 | rec1 = [A,B,C,D]
22 | rec2 = [E,F,G,H]
23 | rec1_area = (C - A) * (D - B)
24 | rec2_area = (G - E) * (H - F)
25 | overlap = isRectangleOverlap(rec1, rec2)
26 | if not overlap:
27 | return rec1_area + rec2_area
28 | else:
29 | if isRectangleContains(rec1, rec2):
30 | return rec1_area
31 | if isRectangleContains(rec2, rec1):
32 | return rec2_area
33 |
34 | return rec1_area + rec2_area - (min(C,G) - max(A,E)) * (min(D,H) - max(B,F))
35 | total = (max(C,G) - min(A,E)) * (max(D,H) - min(B,F))
36 | total -= (max(A,E) - min(A,E)) * (max(B,F) - min(B,F))
37 | total -= (max(C,G) - min(C,G)) * (max(D,H) - min(D,H))
38 | return total
39 |
--------------------------------------------------------------------------------
/sweep-line-algorithm/leetcode/rectangle-overlap.py:
--------------------------------------------------------------------------------
1 | # Source: https://leetcode.com/problems/rectangle-overlap/
2 | # Problem: 836. Rectangle Overlap
3 | # Data Structure: Sweep Line Algorithm
4 | # Difficult: Easy
5 | # Autores: Giovanne Santos, Marlus Marcos, Thiago Silva, Yan Carlos
6 | # Created on 2019/09/26
7 |
8 | class Solution:
9 | def isRectangleOverlap(self, rec1: List[int], rec2: List[int]) -> bool:
10 | horiz_overlap = max(rec1[0], rec2[0]) < min(rec1[2], rec2[2])
11 | vert_overlap = max(rec1[1], rec2[1]) < min(rec1[3], rec2[3])
12 | return horiz_overlap and vert_overlap
13 |
--------------------------------------------------------------------------------
/topological_sort.ipynb:
--------------------------------------------------------------------------------
1 | {"nbformat":4,"nbformat_minor":0,"metadata":{"colab":{"name":"topological_sort.ipynb","provenance":[],"collapsed_sections":[],"toc_visible":true},"kernelspec":{"name":"python3","display_name":"Python 3"}},"cells":[{"cell_type":"markdown","metadata":{"id":"fTARpIj9a0nQ","colab_type":"text"},"source":["# **1. Ordenação Topológica**\n","\n","É comum no cotidiano de todos a realização de atividades que, de certo modo, possuem tarefas agregadas. Desta forma, podemos imaginar uma atividade como um conjunto de sub atividades, onde esta atividade será concluída se, e somente se, suas atividades agregadas e antecedentes forem também. Usando a teoria de grafos, podemos explicar este contexto através da ordenação topológica para o Grafo Direcionado Acíclico - **Directed Acyclic Graph (DAG)**. Essa é uma ordenação linear de vértices de tal modo que, para cada arco direcionado $(u, v)$, o vértice $u$ vem antes de $v$ na ordenação, logo essa abordagem não é possível se o gráfico não for um DAG.\n","\n"," \n","
\n","
Figura 1. Exemplo de um DAG.\n","\n","\n","De maneira bem simples, podemos aplicar essa teoria com um exemplo que se aplica a esta ideia de atividades agregadas: fazer um bolo. Fazer o bolo seria a atividade principal, e desta forma, possui várias outras atividades agregadas. Para se concluir a atividade principal, seria preciso assar o bolo; mas antes, é necessário ter todos os ingredientes misturados. De modo geral, podemos imaginar que atividade de cozinhar um bolo (que iremos chamar de atividade A) possui duas sub atividades: assar o bolo (atividade B) e misturar os ingredientes (atividade C). Mas veja que antes de concluirmos a atividade B, devemos realizar a C. Desta forma, obtemos uma sequência de atividades que, ao serem realizadas na ordem correta, resultam num bolo.\n","\n","No âmbito computacional, podemos aplicar essa ideia em uma variedade de contextos de aplicações, incluindo sistemas operacionais, sistemas de informação e gerenciamento de redes."]},{"cell_type":"markdown","metadata":{"id":"hQwO72iqQFS5","colab_type":"text"},"source":["## **1.1 Aplicações e Casos de uso**\n"]},{"cell_type":"markdown","metadata":{"id":"VxqN9XrQannP","colab_type":"text"},"source":["### **1.1.1 Dependência entre tarefas**\n","Os **vértices** do digrafo podem representar tarefas a serem realizadas, e os **arestas** (arestas) restrições de dependência entre as tarefas.\n","\n","> *Uma ordenação topológica é uma sequência válida de tarefas.*"]},{"cell_type":"markdown","metadata":{"id":"o9XORck1ap6l","colab_type":"text"},"source":["### **1.1.2 Pré-requisitos de disciplinas**\n","Os **vértices** do digrafo podem representar disciplinas de um curso, e os **arcos** (arestas) pré-requisitos entre as disciplinas.\n","\n","> *Uma ordenação topológica é uma sequência válida para se cursar as disciplinas.*\n"]},{"cell_type":"markdown","metadata":{"id":"Y_dr_MUnapqS","colab_type":"text"},"source":["### **1.1.3 Como se vestir**\n","Os **vértices** do digrafo podem representar peças a serem vestidas, e os **arcos** (arestas) as dependência entre as peças.\n","\n","> *Uma ordenação topológica é uma sequência(ideial) de como se vestir*\n",">\n","> *PS: ignore se você for um Supemar da decada de 90*\n","\n"," \n","
\n","
Figura 2. Exemplo de DAG para o problema de como se vestir.\n","\n"]},{"cell_type":"markdown","metadata":{"id":"MVRqu5twfd6C","colab_type":"text"},"source":["## **1.2 Algoritmos e complexidade**\n","\n","Dentre as diversas abordagens conhecidas, uma das mais utilizadas para solucionar o problema da ordenação topológica é utilizando o algoritmo Depth-first search (DFS). Dado um DAG $G = (V,E)$, o algoritmo DFS percorre todos os vértices de $G$ e, para cada um deles, executa os seguintes passos:\n","\n","1. marca o vértice atual como visitado\n","2. imprime o vértice atual\n","3. visita todos os vértices adjacentes que não foram visitados;\n","4. explora tanto quanto possível cada um dos seus ramos, antes de retroceder (backtracking).\n","\n","Vale ressaltar que uma DFS propriamente dita não é capaz de encontrar uma ordenação topológica de um grafo. Para isso, é necessário realizar alguns ajustes no algoritmo para que isso seja possível. Uma maneira é utilizar uma pilha e, depois de percorrer todos os sucessores de um vértice, então, ele é adicionado à pilha. Após percorrer todos os vértices do DAG, a ordenação topológica será o conteúdo da própria pilha.\n","\n","A maioria dos algoritmos, inclusive a abordagem com DFS, que trabalham para encontrar a ordenação topológica de um grafo $G=(V,E)$, tal que $G$ é dirigido e acíclico, conseguem realizar este processo com uma complexidade $O(|V|+|E|)$. Vale ressaltar que esta complexidade se dá para algoritmos que não trabalham de forma dinâmica, isto é, não apresentam a capacidade de atualizar a ordenação topológica ao adicionar ou remover uma aresta.\n","\n","Outra abordagem conhecida é o **Algoritmo de Kahn**. Este algoritmo trabalha escolhendo vértices na mesma ordem da eventual ordenação topológica. Primeiro, encontra uma lista de nós \"íniciais\", que não tem arestas de entrada e os insere em um conjunto S; pelo menos um nó devem existir se o grafo é acíclico. \n","\n","```\n","L ← Lista vazia que irá conter os elementos ordenados\n","S ← Conjunto de todos os nós sem arestas de entrada\n","enquanto S é não-vazio faça\n"," remova um nodo n de S\n"," insira n em L\n"," para cada nodo m com uma aresta e de n até m faça\n"," remova a aresta e do grafo\n"," se m não tem mais arestas de entrada então\n"," insira m em S\n","se o grafo tem arestas então\n"," escrever mensagem de erro (grafo tem pelo menos um ciclo)\n","senão\n"," escrever mensagem (ordenação topológica proposta: L)\n","```\n","\n","Se o grafo é um digrafo acíclico (DAG), a solução está contida na lista L (a solução não é única). Caso contrário, o grafo tem pelo menos um ciclo e, portanto, uma ordenação topológica é impossível."]},{"cell_type":"markdown","metadata":{"id":"BRtnIMDeUI7V","colab_type":"text"},"source":["# **2. Questões do Leet Code**\n","\n","Foram escolhidas duas questões do [LeetCode](https://www.leetcode.com) para serem resolvidas. Elas apresentam soluções bem semelhantes, alterando apenas a forma de retorno de cada função.\n","\n","A primeira questão é a de número 207: **Course Schedule**. Nesta questão, o principal objetivo é verificar se o grafo possui uma ordenação topológica. \n","A segunda questão, de número 210: **Course Schedule II**, diferentemente da primeira, tem como objetivo encontrar a ordenação topológica do grafo proprieamente dita. A descrição das duas questões, seguidas de possíveis soluções, são exibidas nas próximas subseções.\n","\n"]},{"cell_type":"markdown","metadata":{"id":"NSqmV-NqTwxK","colab_type":"text"},"source":["## **[2.1 Course Schedule](https://leetcode.com/problems/course-schedule/)**\n","\n","> *A descrição da questão foi retirada do próprio site do Leet Code e traduzida para o português.*\n","\n","Há um total de n cursos que você deve fazer, rotulados de 0 a n-1.\n","\n","Alguns cursos podem ter pré-requisitos, por exemplo, para o curso 0, você deve primeiro fazer o curso 1, que é expresso como um par: [0,1]\n","\n","Dado o número total de cursos e uma lista de pares de pré-requisitos, é possível concluir todos os cursos?\n","\n","**Exemplo 1:**\n","```\n","Entrada: 2, [[1,0]] \n","Saída: true\n","Explicação: Há um total de 2 cursos para fazer. \n"," Para fazer o curso 1, você deve ter concluído o curso 0. Portanto,\n"," é possível.\n","```\n","\n","**Example 2:**\n","```\n","Entrada: 2, [[1,0],[0,1]]\n","Saída: false\n","Explanation: Há um total de 2 cursos para fazer.\n"," Para fazer o curso 1, você deve ter concluído o curso 0 e, para\n"," fazer o curso 0, também deve ter concluído o curso 1. Portanto, é\n"," impossível.\n","```\n","**Nota:**\n","\n","1. Os pré-requisitos de entrada são um grafo representado por uma lista de arestas, não matrizes de adjacência. Leia mais sobre como um grafo é representado.\n","\n","2. Você pode assumir que não há arestas duplicadas nos pré-requisitos de entrada.\n","\n"]},{"cell_type":"markdown","metadata":{"id":"OGu5kkp7eetL","colab_type":"text"},"source":["### **2.1.1 Solução**\n"]},{"cell_type":"code","metadata":{"id":"LyQBHBpqJ3Ak","colab_type":"code","colab":{}},"source":["from collections import defaultdict\n","\n","class Solution:\n"," def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:\n"," graph = defaultdict(list)\n"," canFinish = True\n"," \n"," for dest, src in prerequisites:\n"," graph[src].append(dest)\n"," \n"," visited = [0]*numCourses\n"," stack = []\n"," \n"," def topologicalSortUtil(v): \n"," nonlocal canFinish\n"," \n"," visited[v] = 2\n"," \n"," for i in graph[v]: \n"," if visited[i] == 0: \n"," topologicalSortUtil(i) \n"," elif visited[i] == 2:\n"," canFinish = False\n"," \n"," visited[v] = 1\n"," stack.insert(0,v)\n"," \n"," for i in range(numCourses): \n"," if visited[i] == 0: \n"," topologicalSortUtil(i)\n"," \n"," if not canFinish:\n"," break\n","\n"," return canFinish\n"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"O1Vt2LaISxn_","colab_type":"text"},"source":["#### **Estatísticas**\n","Esta solução é melhor que 60,09% das submissões para esta questão no LeetCode.\n"]},{"cell_type":"markdown","metadata":{"id":"y8yQXjrwT9Nt","colab_type":"text"},"source":["## **[2.2 Course Schedule II](https://leetcode.com/problems/course-schedule-ii/)**\n","\n","> *A descrição da questão foi retirada do próprio site do Leet Code e traduzida para o português.*\n","\n","Há um total de n cursos que você deve fazer, rotulados de 0 a n-1.\n","\n","Alguns cursos podem ter pré-requisitos, por exemplo, para o curso 0, você deve primeiro fazer o curso 1, que é expresso como um par: [0,1]\n","\n","Dado o número total de cursos e uma lista de pares de pré-requisitos, retorne a ordem dos cursos que você deve fazer para concluir todos os cursos.\n","\n","Pode haver várias ordenações corretas, você só precisa retornar uma delas. Se for impossível concluir todos os cursos, retorne uma lista vazia.\n","\n","**Exemplo 1:**\n","```\n","Entrada: 2, [[1,0]] \n","Saída: [0,1]\n","Explicação: Há um total de 2 cursos para fazer.\n"," Para fazer o curso 1, você deve ter concluído o curso 0. Portanto, a ordem correta dos cursos é [0,1].\n","```\n","**Exemplo 2:**\n","```\n","Entrada: 4, [[1,0],[2,0],[3,1],[3,2]]\n","Saída: [0,1,2,3] ou [0,2,1,3]\n","Explicação: Há um total de 4 cursos a fazer. \n"," Para fazer o curso 3, você deve ter concluído os cursos 1 e 2.\n"," Os cursos 1 e 2 devem ser realizados após o término do curso 0.\n"," Portanto, uma ordem correta do curso é [0,1,2,3]. Outra ordenação\n"," correta é [0,2,1,3].\n","```\n","**Nota:**\n","\n","1. Os pré-requisitos de entrada são um grafo representado por uma lista de arestas, não matrizes de adjacência. Leia mais sobre como um grafo é representado.\n","\n","2. Você pode assumir que não há arestas duplicadas nos pré-requisitos de entrada.\n","\n"]},{"cell_type":"markdown","metadata":{"id":"hzybaHlHeYR7","colab_type":"text"},"source":["### **2.2.1 Solução**"]},{"cell_type":"code","metadata":{"id":"nUkhv_BYUCoQ","colab_type":"code","colab":{}},"source":["from collections import defaultdict\n","\n","class Solution:\n"," def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:\n"," graph = defaultdict(list)\n"," canFinish = True\n"," \n"," for dest, src in prerequisites:\n"," graph[src].append(dest)\n"," \n"," visited = [0]*numCourses\n"," stack = []\n"," \n"," def topologicalSortUtil(v): \n"," nonlocal canFinish\n"," \n"," visited[v] = 2\n"," \n"," for i in graph[v]: \n"," if visited[i] == 0: \n"," topologicalSortUtil(i) \n"," elif visited[i] == 2:\n"," canFinish = False\n"," \n"," visited[v] = 1\n"," stack.insert(0,v)\n"," \n"," for i in range(numCourses): \n"," if visited[i] == 0: \n"," topologicalSortUtil(i)\n"," \n"," if not canFinish:\n"," break\n","\n"," return stack if canFinish else []"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Y1TFt5gkS_bz","colab_type":"text"},"source":["##### **Estatísticas**\n","\n","Esta solução é melhor que 73,02% das submissões para esta questão no LeetCode."]},{"cell_type":"markdown","metadata":{"id":"kU_CRs0uOTB1","colab_type":"text"},"source":["# **Referências**\n","\n","http://wiki.icmc.usp.br/images/9/93/Alg2_05.Grafos_ordenacaotopologica.pdf\n","\n","http://www.codcad.com/lesson/50\n","\n","http://edirlei.3dgb.com.br/aulas/paa/PAA_Aula_07_Ordenacao_Topologica.pdf\n","\n","https://pt.wikipedia.org/wiki/Ordena%C3%A7%C3%A3o_topol%C3%B3gica\n","\n","http://www.ic.unicamp.br/~meidanis/courses/mo417/2003s1/aulas/2003-05-14.html\n","\n","##Colaboradores\n","\n","#####Douglas Alexandre dos Santos <>\n","#####Franklin Matheus da Costa Lima <>\n","#####Mateus Santiago Ferreira Costa <>\n"]}]}
--------------------------------------------------------------------------------