并不能被直接调用,而是由这些指令触发的: new , getstatic , putstatic or invokestatic。
206 |
207 | ## 4.3 栈内存操作指令
208 |
209 | 有很多指令可以操作方法栈。 前面也提到过一些基本的栈操作指令: 他们将值压入栈,或者从栈中获取值。 除了这些基础操作之外也还有一些指令可以操作栈内存; 比如 swap 指令用来交换栈顶两个元素的值。下面是一些示例:
210 |
211 | 最基础的是 dup 和 pop 指令。
212 |
213 | - dup 指令复制栈顶元素的值。
214 | - pop 指令则从栈中删除最顶部的值。
215 |
216 | 还有复杂一点的指令:比如, swap , dup_x1 和 dup2_x1 。
217 |
218 | - 顾名思义, swap 指令可交换栈顶两个元素的值,例如A和B交换位置(图中示例 4);
219 | - dup_x1 将复制栈顶元素的值,并在插入在最上面两个值后(图中示例5);
220 | - dup2_x1 则复制栈顶两个元素的值,并插入最上面三个值后(图中示例6)。
221 |
222 | 
223 |
224 | dup , dup_x1 , dup2_x1 指令补充说明 :
225 |
226 | - dup 指令:官方说明是,复制栈顶的值, 并将复制的值压入栈.
227 | - dup_x1 指令 : 官方说明是,复制栈顶的值, 并将复制的值插入到最上面2个值的下方。
228 | - dup2_x1 指令: 官方说明是,复制栈顶 1个64位/或2个32位的值, 并将复制的值按照原始顺序,插入原始值下面一个32位值的下方。
229 |
230 | # 5. 算术运算指令与类型转换指令
231 |
232 | Java字节码中有许多指令可以执行算术运算。实际上,指令集中有很大一部分表示都是关于数学运算的。对于所有数值类型( int , long , double , float ),都有加, 减,乘,除,取反的指令。 那么 byte 和 char , boolean 呢? JVM 是当做 int 来处理的。另外还有部分指令用于数据类型之间的转换。
233 |
234 | 
235 |
236 | 当我们想将 int 类型的值赋值给 long 类型的变量时,就会发生类型转换。
237 |
238 | 
239 |
240 |
241 |
242 | # 6. 方法调用指令和参数传递
243 |
244 | - invokestatic ,顾名思义,这个指令用于调用某个类的静态方法,这也是方法调用指令中最快的一个。
245 | - invokespecial , 我们已经学过了, invokespecial 指令用来调用构造函数, 但也可以用于调用同一个类中的 private 方法, 以及可见的超类方法。
246 | - invokevirtual ,如果是具体类型的目标对象, invokevirtual 用于调用公共,受保护和打包私有方法。
247 | - invokeinterface ,当要调用的方法属于某个接口时,将使用invokeinterface 指令。
248 |
249 | > 那么 invokevirtual 和 invokeinterface 有什么区别呢?这确实是个好问 题。 为什么需要 invokevirtual 和 invokeinterface 这两种指令呢? 毕竟 所有的接口方法都是公共方法, 直接使用 invokevirtual 不就可以了吗? 这么做是源于对方法调用的优化。JVM必须先解析该方法,然后才能调用它
250 |
251 | - 使用 invokestatic 指令,JVM就确切地知道要调用的是哪个方法:因为调用的是静态方法,只能属于一个类。
252 | - 使用 invokespecial 时, 查找的数量也很少, 解析也更加容易,那么运行时就能更快地找到所需的方法。
253 | - ava虚拟机的字节码指令集在JDK7之前一直就只有前面提到的4种指令 (invokestatic,invokespecial,invokevirtual,invokeinterface)。随着JDK 7的发 布,字节码指令集新增了 invokedynamic 指令。这条新增加的指令是实现“动态类型 语言”(Dynamically Typed Language)支持而进行的改进之一,同时也是JDK 8以后 支持的lambda表达式的实现基础。
254 |
255 | # 7. Java类加载器
256 |
257 | ## 7.1 类的生命周期和加载过程
258 |
259 | 
260 |
261 | 一个类在JVM里的生命周期有7个阶段,分别是加载(Loading)、验证 (Verification)、准备(Preparation)、解析(Resolution)、初始化 (Initialization)、使用(Using)、卸载(Unloading)。 其中前五个部分(加载,验证,准备,解析,初始化)统称为类加载,下面我们就分 别来说一下这五个过程。
262 |
263 | ### 7.1.1 加载
264 |
265 | 加载阶段也可以称为“装载”阶段。 这个阶段主要的操作是: 根据明确知道的class完全限定名, 来获取二进制classfile格式的字节流,简单点说就是 找到文件系统中/jar包中/或存在于任何地方的“ class文件 ”。 如果找不到二进制表示形式,则会抛出NoClassDefFound 错误。装载阶段并不会检查 classfile 的语法和格式。类加载的整个过程主要由JVM和Java 的类加载系统共同完成, 当然具体到loading 阶 段则是由JVM与具体的某一个类加载器(java.lang.classLoader)协作完成的。
266 |
267 | ### 7.1.2 校验
268 |
269 | 链接过程的第一个阶段是校验 ,确保class文件里的字节流信息符合当前虚拟机的要求,不会危害虚拟机的安全。校验过程检classfile 的语义,判断常量池中的符号,并执行类型检查, 主要目的是判断字节码的合法性,比如 magic number, 对版本号进行验证。 这些检查 过程中可能会抛出 VerifyError , ClassFormatError 或 UnsupportedClassVersionError 。 因为classfile的验证属是链接阶段的一部分,所以这个过程中可能需要加载其他类, 在某个类的加载过程中,JVM必须加载其所有的超类和接口。 如果类层次结构有问题(例如,该类是自己的超类或接口,死循环了),则JVM将抛出 ClassCircularityError 。 而如果实现的接口并不是一个 interface,或者声明的超类是一个 interface,也会抛出 IncompatibleClassChangeError 。
270 |
271 | ### 7.1.3 准备
272 |
273 | 然后进入准备阶段,这个阶段将会创建静态字段, 并将其初始化为标准默认值(比如 null 或者 0值 ),并分配方法表,即在方法区中分配这些变量所使用的内存空间。 请注意,准备阶段并未执行任何Java代码。
274 |
275 | 例如:
276 |
277 | ```
278 | public static int i = 1;
279 | ```
280 |
281 | 在准备阶段 i 的值会被初始化为0,后面在类初始化阶段才会执行赋值为1; 但是下面如果使用final作为静态常量,某些JVM的行为就不一样了:
282 |
283 | ```
284 | public static final int i = 1;
285 | ```
286 |
287 | 对应常量i,在准备阶段就会被赋值1,其实这样还是比较puzzle,例如其他语言 (C#)有直接的常量关键字const,让告诉编译器在编译阶段就替换成常量,类似 于宏指令,更简单。
288 |
289 | ### 7.1.4 解析
290 |
291 | 然后进入可选的解析符号引用阶段。 也就是解析常量池,主要有以下四种:类或接口的解析、字段解析、类方法解析、接 口方法解析。
292 |
293 | 简单的来说就是我们编写的代码中,当一个变量引用某个对象的时候,这个引用在 .class 文件中是以符号引用来存储的(相当于做了一个索引记录)。 在解析阶段就需要将其解析并链接为直接引用(相当于指向实际对象)。如果有了直 接引用,那引用的目标必定在堆中存在。加载一个class时, 需要加载所有的super类和super接口。
294 |
295 | ### 7.1.5 初始化
296 |
297 | JVM规范明确规定, 必须在类的首次“主动使用”时才能执行类初始化。 初始化的过程包括执行:
298 |
299 | - 类构造器方法
300 | - static静态变量赋值语句
301 | - static静态代码块
302 |
303 | 如果是一个子类进行初始化会先对其父类进行初始化,保证其父类在子类之前进行初 始化。所以其实在java中初始化一个类,那么必然先初始化过 java.lang.Object 类,因为所有的java类都继承自java.lang.Object。
304 |
305 | ## 7.2 类加载时机
306 |
307 | 了解了类的加载过程,我们再看看类的初始化何时会被触发呢?JVM 规范枚举了下述多种触发情况:
308 |
309 | - 当虚拟机启动时,初始化用户指定的主类,就是启动执行的 main方法所在的类;
310 | - 当遇到用以新建目标类实例的 new 指令时,初始化 new 指令的目标类,就是 new一个类的时候要初始化
311 | - 当遇到调用静态方法的指令时,初始化该静态方法所在的类;
312 | - 当遇到访问静态字段的指令时,初始化该静态字段所在的类;
313 | - 子类的初始化会触发父类的初始化;
314 | - 如果一个接口定义了 default 方法,那么直接实现或者间接实现该接口的类的初始化,会触发该接口的初始化;
315 | - 使用反射 API 对某个类进行反射调用时,初始化这个类,其实跟前面一样,反射调用要么是已经有实例了,要么是静态方法,都需要初始化;
316 | - 当初次调用 MethodHandle 实例时,初始化该 MethodHandle 指向的方法所在的类。
317 |
318 | 同时以下几种情况不会执行类初始化:
319 |
320 | - 通过子类引用父类的静态字段,只会触发父类的初始化,而不会触发子类的初始化。
321 | - 定义对象数组,不会触发该类的初始化。
322 | - 常量在编译期间会存入调用类的常量池中,本质上并没有直接引用定义常量的类,不会触发定义常量所在的类。
323 | - 通过类名获取Class对象,不会触发类的初始化,Hello.class不会让Hello类初始化。
324 | - 通过Class.forName加载指定类时,如果指定参数initialize为false时,也不会触发类初始化,其实这个参数是告诉虚拟机,是否要对类进行初始化。 Class.forName(“jvm.Hello”)默认会加载Hello类。
325 | - 通过ClassLoader默认的loadClass方法,也不会触发初始化动作(加载了,但是不初始化)。
326 |
327 | ### 7.3 类加载机制
328 |
329 | 类加载过程可以描述为“通过一个类的全限定名a.b.c.XXClass来获取描述此类的Class 对象”,这个过程由“类加载器(ClassLoader)”来完成。这样的好处在于,子类加载器可以复用父加载器加载的类。系统自带的类加载器分为三种 :
330 |
331 | 
332 |
333 |
334 |
335 | - 启动类加载器(BootstrapClassLoader)
336 |
337 | 启动类加载器(bootstrap class loader): 它用来加载 Java 的核心类,是用原生 C++代码来实现的,并不继承自
338 |
339 | java.lang.ClassLoader(负责加载JDK中 jre/lib/rt.jar里所有的class)。它可以看做是JVM自带的,我们再代码层面无法直接获取到
340 |
341 | 启动类加载器的引用,所以不允许直接操作它, 如果打印出来就是个 null 。举例来说,java.lang.String是由启动类加载器加载
342 |
343 | 的,所以 String.class.getClassLoader()就会返回null。但是后面可以看到可以通过命令行 参数影响它加载什么。
344 |
345 | - 扩展类加载器(ExtClassLoader)
346 |
347 | - 扩展类加载器(extensions class loader):它负责加载JRE的扩展目录,lib/ext 或者由java.ext.dirs系统属性指定的目录中的JAR包的类,代码里直接获取它的父 类加载器为null(因为无法拿到启动类加载器)。
348 |
349 | - 应用类加载器(AppClassLoader)
350 |
351 | - 应用类加载器(app class loader):它负责在JVM启动时加载来自Java命令的classpath或者cp选项、java.class.path系统属性指定的jar包和类路径。在应用程序代码里可以通过ClassLoader的静态方法getSystemClassLoader()来获取应用类加载器。如果没有特别指定,则在没有使用自定义类加载器情况下,用户自定义的类都由此加载器加载。
352 |
353 | **类加载机制有三个特点:**
354 |
355 | - 双亲委托:当一个自定义类加载器需要加载一个类,比如java.lang.String,它很懒,不会一上来就直接试图加载它,而是先委托自己的父加载器去加载,父加载 器如果发现自己还有父加载器,会一直往前找,这样只要上级加载器,比如启动类加载器已经加载了某个类比如java.lang.String,所有的子加载器都不需要自己加载了。如果几个类加载器都没有加载到指定名称的类,那么会抛出 ClassNotFountException异常。
356 | - 负责依赖:如果一个加载器在加载某个类的时候,发现这个类依赖于另外几个类或接口,也会去尝试加载这些依赖项。
357 | - 缓存加载:为了提升加载效率,消除重复加载,一旦某个类被一个类加载器加载,那么它会缓存这个加载结果,不会重复加载。
358 |
359 | 
--------------------------------------------------------------------------------
/docs/notes/java/Java集合总结.md:
--------------------------------------------------------------------------------
1 | # 集合
2 |
3 | # ArrayList
4 |
5 | ArrayList 实现于 List、RandomAccess 接口。可以插入空数据,也支持随机访问。其中最重要的两个属性分别是: elementData 数组,以及 size 大小。 默认初始化容量为10,每次扩容会扩容1.5倍(新容量=旧容量+旧容量>>1)。有序、非线程安全的。
6 |
7 | **执行add(E)方法:**
8 |
9 | ```java
10 | /**
11 | * Appends the specified element to the end of this list.
12 | *
13 | * @param e element to be appended to this list
14 | * @return {@code true} (as specified by {@link Collection#add})
15 | */
16 | public boolean add(E e) {
17 | modCount++;
18 | add(e, elementData, size);
19 | return true;
20 | }
21 |
22 | /**
23 | * This helper method split out from add(E) to keep method
24 | * bytecode size under 35 (the -XX:MaxInlineSize default value),
25 | * which helps when add(E) is called in a C1-compiled loop.
26 | */
27 | private void add(E e, Object[] elementData, int s) {
28 | if (s == elementData.length)
29 | elementData = grow();
30 | elementData[s] = e;
31 | size = s + 1;
32 | }
33 | ```
34 |
35 | - 首先记录对该列表进行结构修改的次数
36 | - 然后执行添加元素,默认添加到末尾
37 | - 判断数组的容量是否满了,如果是就先进行扩容
38 | - 将元素添加到指定位置,修改size大小
39 |
40 | **执行add(index,e)方法,添加元素到指定位置:**
41 |
42 | ```java
43 | /**
44 | * Inserts the specified element at the specified position in this
45 | * list. Shifts the element currently at that position (if any) and
46 | * any subsequent elements to the right (adds one to their indices).
47 | *
48 | * @param index index at which the specified element is to be inserted
49 | * @param element element to be inserted
50 | * @throws IndexOutOfBoundsException {@inheritDoc}
51 | */
52 | public void add(int index, E element) {
53 | rangeCheckForAdd(index);
54 | modCount++;
55 | final int s;
56 | Object[] elementData;
57 | if ((s = size) == (elementData = this.elementData).length)
58 | elementData = grow();
59 | System.arraycopy(elementData, index,
60 | elementData, index + 1,
61 | s - index);
62 | elementData[index] = element;
63 | size = s + 1;
64 | }
65 | ```
66 |
67 | - check下标是否越界,并记录列表结构修改次数
68 | - 判断数组是否需要扩容
69 | - 通过System.arraycopy方法复制指定的元素向后移动
70 | - 将添加的元素赋值给指定的下标 ,修改size大小
71 |
72 | **扩容方法grow():**
73 |
74 | ```java
75 | private Object[] grow() {
76 | return grow(size + 1);
77 | }
78 | /**
79 | * Increases the capacity to ensure that it can hold at least the
80 | * number of elements specified by the minimum capacity argument.
81 | *
82 | * @param minCapacity the desired minimum capacity
83 | * @throws OutOfMemoryError if minCapacity is less than zero
84 | */
85 | private Object[] grow(int minCapacity) {
86 | return elementData = Arrays.copyOf(elementData,
87 | newCapacity(minCapacity));
88 | }
89 |
90 | /**
91 | * Returns a capacity at least as large as the given minimum capacity.
92 | * Returns the current capacity increased by 50% if that suffices.
93 | * Will not return a capacity greater than MAX_ARRAY_SIZE unless
94 | * the given minimum capacity is greater than MAX_ARRAY_SIZE.
95 | *
96 | * @param minCapacity the desired minimum capacity
97 | * @throws OutOfMemoryError if minCapacity is less than zero
98 | */
99 | private int newCapacity(int minCapacity) {
100 | // overflow-conscious code
101 | int oldCapacity = elementData.length;
102 | int newCapacity = oldCapacity + (oldCapacity >> 1);
103 | if (newCapacity - minCapacity <= 0) {
104 | if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
105 | return Math.max(DEFAULT_CAPACITY, minCapacity);
106 | if (minCapacity < 0) // overflow
107 | throw new OutOfMemoryError();
108 | return minCapacity;
109 | }
110 | return (newCapacity - MAX_ARRAY_SIZE <= 0)
111 | ? newCapacity
112 | : hugeCapacity(minCapacity);
113 | }
114 |
115 | private static int hugeCapacity(int minCapacity) {
116 | if (minCapacity < 0) // overflow
117 | throw new OutOfMemoryError();
118 | return (minCapacity > MAX_ARRAY_SIZE)
119 | ? Integer.MAX_VALUE
120 | : MAX_ARRAY_SIZE;
121 | }
122 | ```
123 |
124 | - 主要是通过旧的容量+旧的容量,然后右位移1位来计算新的容量
125 | - 通过容量创建一个新的数组,进行数组复制。
126 |
127 | # Vector
128 |
129 | 底层使用数组实现,扩容方式与List不同,如果初始化Vector时没有指定容量增量,那么会默认扩容2倍(新容量=旧容量+旧容量),如果指定了容量增量,那么扩容的容量就是(新容量=旧容量+容量增量),使用synchronized包装了类的方法,所以是线程安全的。并且有序。
130 |
131 | **执行add(E e)方法:**
132 |
133 | ```java
134 | /**
135 | * Appends the specified element to the end of this Vector.
136 | *
137 | * @param e element to be appended to this Vector
138 | * @return {@code true} (as specified by {@link Collection#add})
139 | * @since 1.2
140 | */
141 | public synchronized boolean add(E e) {
142 | modCount++;
143 | add(e, elementData, elementCount);
144 | return true;
145 | }
146 | /**
147 | * This helper method split out from add(E) to keep method
148 | * bytecode size under 35 (the -XX:MaxInlineSize default value),
149 | * which helps when add(E) is called in a C1-compiled loop.
150 | */
151 | private void add(E e, Object[] elementData, int s) {
152 | if (s == elementData.length)
153 | elementData = grow();
154 | elementData[s] = e;
155 | elementCount = s + 1;
156 | }
157 | ```
158 |
159 | - 判断是否需要扩容
160 | - 赋值元素到指定的下标
161 | - 修改容器大小
162 |
163 | # LinkedList
164 |
165 | 采用双向链表实现,get指定索引的值会先对链表的大小进行右位移1,来判断获取的索引值在链表的上半部分还是下半部分,如果是上半部分会从头部节点开始遍历查找,如果是下半部分会从尾部节点开始遍历查找,有序、非线程安全。
166 |
167 | **执行add(E e)方法:**
168 |
169 | ```java
170 | /**
171 | * Appends the specified element to the end of this list.
172 | *
173 | * This method is equivalent to {@link #addLast}.
174 | *
175 | * @param e element to be appended to this list
176 | * @return {@code true} (as specified by {@link Collection#add})
177 | */
178 | public boolean add(E e) {
179 | linkLast(e);
180 | return true;
181 | }
182 | /**
183 | * Links e as last element.
184 | */
185 | void linkLast(E e) {
186 | final Node l = last;
187 | final Node newNode = new Node<>(l, e, null);
188 | last = newNode;
189 | if (l == null)
190 | first = newNode;
191 | else
192 | l.next = newNode;
193 | size++;
194 | modCount++;
195 | }
196 | ```
197 |
198 | - 默认添加到链表的最后面,先取出lastNode的一个临时变量。
199 | - 将要添加的元素包装成一个newNode节点,将newNode节点的前置节点设置为当前链表的最后一个节点
200 | - 将newNode设置为新的last节点
201 | - 判断lastNode是否为空,如果为空,那么此时添加的是链表的第一个节点,那么直接设置firstNode等于newNode。如果不是就将newNode链接到lastNode后边
202 | - 修改改链表大小及结构修改次数
203 |
204 | **执行get(int index)方法:**
205 |
206 | ```java
207 | /**
208 | * Returns the element at the specified position in this list.
209 | *
210 | * @param index index of the element to return
211 | * @return the element at the specified position in this list
212 | * @throws IndexOutOfBoundsException {@inheritDoc}
213 | */
214 | public E get(int index) {
215 | checkElementIndex(index);
216 | return node(index).item;
217 | }
218 | /**
219 | * Returns the (non-null) Node at the specified element index.
220 | */
221 | Node node(int index) {
222 | // assert isElementIndex(index);
223 |
224 | if (index < (size >> 1)) {
225 | Node x = first;
226 | for (int i = 0; i < index; i++)
227 | x = x.next;
228 | return x;
229 | } else {
230 | Node x = last;
231 | for (int i = size - 1; i > index; i--)
232 | x = x.prev;
233 | return x;
234 | }
235 | }
236 | ```
237 |
238 | - 先判断要获取的索引是否超出链表大小
239 | - 通过将size左位移一位来判断index是在链表的上半部分还是下半部分
240 | - 如果在上半部分则通过头节点开始遍历查找
241 | - 如果在下半部分则通过尾节点开始遍历查找
242 |
243 | # HashSet
244 |
245 | 底层使用HashMap实现,所有添加到set中的元素最终都会添加到map的key中,value用一个final的object对象填充。无序不重复,非线程安全
246 |
247 | # TreeSet
248 |
249 | 底层使用NavigableMap实现,所有添加到set中的元素最终都会添加到map的key中,value用一个final的object对象填充。有序不重复,非线程安全
250 |
251 | # HashMap
252 |
253 | HashMap初始容量为16的Note数组,数组内的链表容量大于8时会自动转换为红黑树,只有当这个数大于2并值至少有8个才能满足树的假设,当这个值缩小到6的时候就会转换为链表。
254 |
255 | **在hashMap中get操作:**
256 |
257 | ```java
258 | public V get(Object key) {
259 | Node e;
260 | return (e = getNode(hash(key), key)) == null ? null : e.value;
261 | }
262 |
263 | /**
264 | * Implements Map.get and related methods.
265 | *
266 | * @param hash hash for key
267 | * @param key the key
268 | * @return the node, or null if none
269 | */
270 | final Node getNode(int hash, Object key) {
271 | Node[] tab; Node first, e; int n; K k;
272 | if ((tab = table) != null && (n = tab.length) > 0 &&
273 | (first = tab[(n - 1) & hash]) != null) {
274 | if (first.hash == hash && // always check first node
275 | ((k = first.key) == key || (key != null && key.equals(k))))
276 | return first;
277 | if ((e = first.next) != null) {
278 | if (first instanceof TreeNode)
279 | return ((TreeNode)first).getTreeNode(hash, key);
280 | do {
281 | if (e.hash == hash &&
282 | ((k = e.key) == key || (key != null && key.equals(k))))
283 | return e;
284 | } while ((e = e.next) != null);
285 | }
286 | }
287 | return null;
288 | }
289 | ```
290 |
291 | - 计算key的hash值,判断get的元素是不是firstNoe,如果直接返回
292 | - 如果不是firstNode,那么判断是否是树,如果是的话通过遍历树查找。
293 | - 否则遍历链表找到key相等的值。
294 |
295 | **在hashMap中put操作:**
296 |
297 | ```java
298 | public V put(K key, V value) {
299 | return putVal(hash(key), key, value, false, true);
300 | }
301 |
302 | /**
303 | * Implements Map.put and related methods.
304 | *
305 | * @param hash hash for key
306 | * @param key the key
307 | * @param value the value to put
308 | * @param onlyIfAbsent if true, don't change existing value
309 | * @param evict if false, the table is in creation mode.
310 | * @return previous value, or null if none
311 | */
312 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
313 | boolean evict) {
314 | Node[] tab; Node p; int n, i;
315 | if ((tab = table) == null || (n = tab.length) == 0)
316 | n = (tab = resize()).length;
317 | if ((p = tab[i = (n - 1) & hash]) == null)
318 | tab[i] = newNode(hash, key, value, null);
319 | else {
320 | Node e; K k;
321 | if (p.hash == hash &&
322 | ((k = p.key) == key || (key != null && key.equals(k))))
323 | e = p;
324 | else if (p instanceof TreeNode)
325 | e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
326 | else {
327 | for (int binCount = 0; ; ++binCount) {
328 | if ((e = p.next) == null) {
329 | p.next = newNode(hash, key, value, null);
330 | if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
331 | treeifyBin(tab, hash);
332 | break;
333 | }
334 | if (e.hash == hash &&
335 | ((k = e.key) == key || (key != null && key.equals(k))))
336 | break;
337 | p = e;
338 | }
339 | }
340 | if (e != null) { // existing mapping for key
341 | V oldValue = e.value;
342 | if (!onlyIfAbsent || oldValue == null)
343 | e.value = value;
344 | afterNodeAccess(e);
345 | return oldValue;
346 | }
347 | }
348 | ++modCount;
349 | if (++size > threshold)
350 | resize();
351 | afterNodeInsertion(evict);
352 | return null;
353 | }
354 | ```
355 |
356 | - 计算key的hash值,算出元素在底层数组中的下标位置。如果下标位置为空,直接插入。
357 | - 通过下标位置定位到底层数组里的元素(也有可能是链表也有可能是树)。
358 | - 取到元素,判断放入元素的key是否==或equals当前位置的key,成立则替换value值,返回旧值。
359 | - 如果是树,循环树中的节点,判断放入元素的key是否==或equals节点的key,成立则替换树里的value,并返回旧值,不成立就添加到树里。
360 | - 否则就顺着元素的链表结构循环节点,判断放入元素的key是否==或equals节点的key,成立则替换链表里value,并返回旧值,找不到就添加到链表的最后。
361 | - 精简一下,判断放入HashMap中的元素要不要替换当前节点的元素,key满足以下两个条件即可替换:
362 | - **hash值相等。**
363 | - **==或equals的结果为true。**
364 |
365 | # LinkedHashMap
366 |
367 | 主体的实现都是借助于 HashMap 来完成的,只是对其中的 recordAccess(), addEntry(), createEntry() 进行了重写。
368 |
369 | 总的来说 `LinkedHashMap` 其实就是对 `HashMap` 进行了拓展,使用了双向链表来保证了顺序性。因为是继承与 `HashMap` 的,所以一些 `HashMap` 存在的问题 `LinkedHashMap` 也会存在,比如不支持并发等。
370 |
371 | `LinkedHashMap` 的排序方式有两种:
372 |
373 | - 根据写入顺序排序。
374 | - 根据访问顺序排序。
375 |
376 | # ConcurrentHashMap
377 |
378 | ## jdk1.7实现
379 |
380 | 
381 |
382 | 如图所示,是由 `Segment` 数组、`HashEntry` 数组组成,和 `HashMap` 一样,仍然是数组加链表组成。
383 |
384 | `ConcurrentHashMap` 采用了分段锁技术,其中 `Segment` 继承于 `ReentrantLock`。不会像 `HashTable` 那样不管是 `put` 还是 `get` 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 `CurrencyLevel` (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 `Segment` 时,不会影响到其他的 `Segment`。
385 |
386 | ### get方法
387 |
388 | `ConcurrentHashMap` 的 `get` 方法是非常高效的,因为整个过程都不需要加锁。
389 |
390 | 只需要将 `Key` 通过 `Hash` 之后定位到具体的 `Segment` ,再通过一次 `Hash` 定位到具体的元素上。由于 `HashEntry` 中的 `value` 属性是用 `volatile` 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值(**[volatile 相关知识点](https://github.com/crossoverJie/Java-Interview/blob/master/MD/Threadcore.md#%E5%8F%AF%E8%A7%81%E6%80%A7)**)。
391 |
392 | ### put 方法
393 |
394 | 内部利用HashEntry类存储数据。
395 |
396 | 虽然 HashEntry 中的 value 是用 `volatile` 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理。
397 |
398 | 首先也是通过 Key 的 Hash 定位到具体的 Segment,在 put 之前会进行一次扩容校验。这里比 HashMap 要好的一点是:HashMap 是插入元素之后再看是否需要扩容,有可能扩容之后后续就没有插入就浪费了本次扩容(扩容非常消耗性能)。
399 |
400 | 而 ConcurrentHashMap 不一样,它是在将数据插入之前检查是否需要扩容,之后再做插入操作。
401 |
402 | ## JDK1.8 实现
403 |
404 | 
405 |
406 | 1.8 中的 ConcurrentHashMap 数据结构和实现与 1.7 还是有着明显的差异。其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。也将 1.7 中存放数据的 HashEntry 改为 Node,但作用都是相同的。其中的 val和next 字段都用了 volatile 修饰,保证了可见性。
407 |
408 | ### put方法
409 |
410 | 
411 |
412 | - 根据 key 计算出 hashcode 。
413 | - 判断是否需要进行初始化。
414 | - `f` 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
415 | - 如果当前位置的 `hashcode == MOVED == -1`,则需要进行扩容。
416 | - 如果都不满足,则利用 synchronized 锁写入数据。
417 | - 如果数量大于 `TREEIFY_THRESHOLD` 则要转换为红黑树
418 |
419 | ### get方法
420 |
421 | 
422 |
423 | - 根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
424 | - 如果是红黑树那就按照树的方式获取值。
425 | - 都不满足那就按照链表的方式遍历获取值。
--------------------------------------------------------------------------------
/docs/notes/java/Java11都有哪些特性.md:
--------------------------------------------------------------------------------
1 | ### 为什么选择Java11
2 |
3 | - 容器环境支持,GC等领域的增强。
4 | - 进行了瘦身,更轻量级,安装包体积小。
5 | - JDK11 是一个长期支持版。
6 |
7 | ### 特性介绍
8 |
9 | #### Jshell @since 9
10 |
11 | Jshell在Java9中就被提出来了,可以直接在终端写Java程序,回车就可以执行。Jshell默认会导入下面的一些包,所以在Jshell环境中这些包的内容都是可以使用的。
12 |
13 | ```
14 | import java.lang.*;
15 | import java.io.*;
16 | import java.math.*;
17 | import java.net.*;
18 | import java.nio.file.*;
19 | import java.util.*;
20 | import java.util.concurrent.*;
21 | import java.util.function.*;
22 | import java.util.prefs.*;
23 | import java.util.regex.*;
24 | import java.util.stream.*;
25 | ```
26 |
27 |
28 |
29 | ##### 1.什么是Jshell?
30 |
31 | Jshell是在 Java 9 中引入的。它提供了一个交互式 shell,用于快速原型、调试、学习 Java 及 Java API,所有这些都不需要 public static void main 方法,也不需要在执行之前编译代码。
32 |
33 | ##### 2.Jshell的使用
34 |
35 | 打开终端,键入jshell进入jshell环境,然后输入/help intro可以查看Jshell的介绍。
36 |
37 | ```
38 | lixiaoshuang@localhost ~ jshell
39 | | 欢迎使用 JShell -- 版本 11.0.2
40 | | 要大致了解该版本, 请键入: /help intro
41 |
42 | jshell> /help intro
43 | |
44 | | intro
45 | | =====
46 | |
47 | | 使用 jshell 工具可以执行 Java 代码,从而立即获取结果。
48 | | 您可以输入 Java 定义(变量、方法、类等等),例如:int x = 8
49 | | 或 Java 表达式,例如:x + x
50 | | 或 Java 语句或导入。
51 | | 这些小块的 Java 代码称为“片段”。
52 | |
53 | | 这些 jshell 工具命令还可以让您了解和
54 | | 控制您正在执行的操作,例如:/list
55 | |
56 | | 有关命令的列表,请执行:/help
57 |
58 | jshell>
59 | ```
60 |
61 | Jshell确实是一个好用的小工具,这里不做过多介绍,我就举一个例子,剩下的大家自己体会。比如我们现在就想随机生成一个UUID,以前需要这么做:
62 |
63 | - 创建一个类。
64 | - 创建一个main方法。
65 | - 然后写一个生成UUID的逻辑,执行。
66 |
67 | 现在只需要,进入打开终端键入jshell,然后直接输入`var uuid = UUID.randomUUID()`回车。就可以看到uuid的回显,这样我们就得到了一个uuid。并不需要public static void main(String[] args);
68 |
69 | ```
70 | lixiaoshuang@localhost ~ jshell
71 | | 欢迎使用 JShell -- 版本 11.0.2
72 | | 要大致了解该版本, 请键入: /help intro
73 |
74 | jshell> var uuid = UUID.randomUUID();
75 | uuid ==> 9dac239e-c572-494f-b06d-84576212e012
76 | jshell>
77 | ```
78 |
79 | ##### 3.怎么退出Jshell?
80 |
81 | 在Jshell环境中键入`/exit`就可以退出。
82 |
83 | ```
84 | lixiaoshuang@localhost ~
85 | lixiaoshuang@localhost ~ jshell
86 | | 欢迎使用 JShell -- 版本 11.0.2
87 | | 要大致了解该版本, 请键入: /help intro
88 |
89 | jshell> var uuid = UUID.randomUUID();
90 | uuid ==> 9dac239e-c572-494f-b06d-84576212e012
91 |
92 | jshell> /exit
93 | | 再见
94 | lixiaoshuang@localhost ~
95 | ```
96 |
97 |
98 |
99 | #### 模块化(Module)@since 9
100 |
101 | ##### 1.什么是模块化?
102 |
103 | 模块化就是增加了更高级别的聚合,是Package的封装体。Package是一些类路径名字的约定,而模块是一个或多个Package组成的封装体。
104 |
105 | java9以前 :package => class/interface。
106 |
107 | java9以后 :module => package => class/interface。
108 |
109 | 那么JDK被拆为了哪些模块呢?打开终端执行`java --list-modules`查看。
110 |
111 | ```
112 | lixiaoshuang@localhost ~ java --list-modules
113 | java.base@11.0.2
114 | java.compiler@11.0.2
115 | java.datatransfer@11.0.2
116 | java.desktop@11.0.2
117 | java.instrument@11.0.2
118 | java.logging@11.0.2
119 | java.management@11.0.2
120 | java.management.rmi@11.0.2
121 | java.naming@11.0.2
122 | java.net.http@11.0.2
123 | java.prefs@11.0.2
124 | java.rmi@11.0.2
125 | java.scripting@11.0.2
126 | java.se@11.0.2
127 | java.security.jgss@11.0.2
128 | java.security.sasl@11.0.2
129 | java.smartcardio@11.0.2
130 | java.sql@11.0.2
131 | java.sql.rowset@11.0.2
132 | java.transaction.xa@11.0.2
133 | java.xml@11.0.2
134 | java.xml.crypto@11.0.2
135 | jdk.accessibility@11.0.2
136 | jdk.aot@11.0.2
137 | jdk.attach@11.0.2
138 | jdk.charsets@11.0.2
139 | jdk.compiler@11.0.2
140 | jdk.crypto.cryptoki@11.0.2
141 | jdk.crypto.ec@11.0.2
142 | jdk.dynalink@11.0.2
143 | jdk.editpad@11.0.2
144 | jdk.hotspot.agent@11.0.2
145 | jdk.httpserver@11.0.2
146 | jdk.internal.ed@11.0.2
147 | jdk.internal.jvmstat@11.0.2
148 | jdk.internal.le@11.0.2
149 | jdk.internal.opt@11.0.2
150 | jdk.internal.vm.ci@11.0.2
151 | jdk.internal.vm.compiler@11.0.2
152 | jdk.internal.vm.compiler.management@11.0.2
153 | jdk.jartool@11.0.2
154 | jdk.javadoc@11.0.2
155 | jdk.jcmd@11.0.2
156 | jdk.jconsole@11.0.2
157 | jdk.jdeps@11.0.2
158 | jdk.jdi@11.0.2
159 | jdk.jdwp.agent@11.0.2
160 | jdk.jfr@11.0.2
161 | jdk.jlink@11.0.2
162 | jdk.jshell@11.0.2
163 | jdk.jsobject@11.0.2
164 | jdk.jstatd@11.0.2
165 | jdk.localedata@11.0.2
166 | jdk.management@11.0.2
167 | jdk.management.agent@11.0.2
168 | jdk.management.jfr@11.0.2
169 | jdk.naming.dns@11.0.2
170 | jdk.naming.rmi@11.0.2
171 | jdk.net@11.0.2
172 | jdk.pack@11.0.2
173 | jdk.rmic@11.0.2
174 | jdk.scripting.nashorn@11.0.2
175 | jdk.scripting.nashorn.shell@11.0.2
176 | jdk.sctp@11.0.2
177 | jdk.security.auth@11.0.2
178 | jdk.security.jgss@11.0.2
179 | jdk.unsupported@11.0.2
180 | jdk.unsupported.desktop@11.0.2
181 | jdk.xml.dom@11.0.2
182 | jdk.zipfs@11.0.2
183 | ```
184 |
185 |
186 |
187 | ##### 2.为什么这么做?
188 |
189 | 大家都知道JRE中有一个超级大的rt.jar(60多M),tools.jar也有几十兆,以前运行一个hello world也需要上百兆的环境。
190 |
191 | - 让Java SE程序更加容易轻量级部署。
192 | - 强大的封装能力。
193 | - 改进组件间的依赖管理,引入比jar粒度更大的Module。
194 | - 改进性能和安全性。
195 |
196 | ##### 3.怎么定义模块?
197 |
198 | 模块的是通过module-info.java进行定义,编译后打包后,就成为一个模块的实体。下面来看下最简单的模块定义。
199 |
200 | 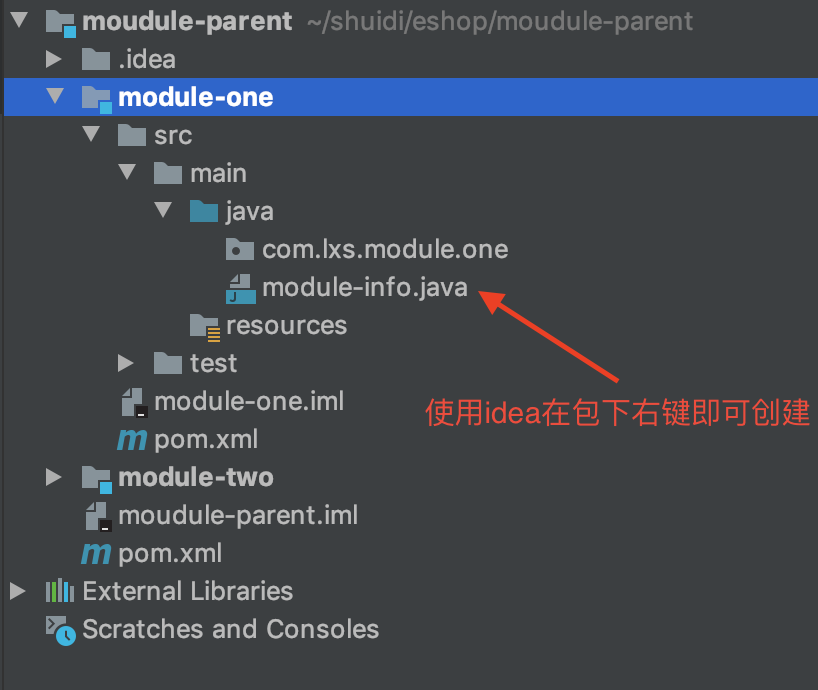
201 |
202 | 
203 |
204 | ##### 4.模块的关键字
205 |
206 | - open
207 |
208 | 用来指定开放模块,开放模块的所有包都是公开的,public的可以直接引用使用,其他类型可以通过反射得到。
209 |
210 | ```
211 | open module module.one {
212 | //导入日志包
213 | requires java.logging;
214 |
215 | }
216 | ```
217 |
218 | - opens
219 |
220 | opens 用来指定开放的包,其中public类型是可以直接访问的,其他类型可以通过反射得到。
221 |
222 | ```
223 | module module.one {
224 |
225 | opens ;
226 | }
227 | ```
228 |
229 | - exports
230 |
231 | exports用于指定模块下的哪些包可以被其他模块访问。
232 |
233 | ```
234 | module module.one {
235 |
236 | exports ;
237 |
238 | exports to , ...;
239 | }
240 | ```
241 |
242 | - requires
243 |
244 | 该关键字声明当前模块与另一个模块的依赖关系。
245 |
246 | ```
247 | module module.one {
248 |
249 | requires ;
250 |
251 | }
252 | ```
253 |
254 | - uses、provides…with…
255 |
256 | uses语句使用服务接口的名字,当前模块就会发现它,使用java.util.ServiceLoader类进行加载,必须是本模块中的,不能是其他模块中的.其实现类可以由其他模块提供。
257 |
258 | ```
259 | module module.one {
260 |
261 | //对外提供的接口服务 ,下面指定的接口以及提供服务的impl,如果有多个实现类,用用逗号隔开
262 | uses <接口名>;
263 |
264 | provides <接口名> with <接口实现类>,<接口实现类>;
265 |
266 | }
267 | ```
268 |
269 |
270 |
271 | #### var关键字 @since 10
272 |
273 | ##### 1.var是什么?
274 |
275 | var是Java10中新增的局部类型变量推断。它会根据后面的值来推断变量的类型,所以var必须要初始化。
276 |
277 | 例:
278 |
279 | ```
280 | var a; ❌
281 | var a = 1; ✅
282 | ```
283 |
284 | ##### 2.var使用示例
285 |
286 | - var定义局部变量
287 |
288 | ```
289 | var a = 1;
290 | 等于
291 | int a = 1;
292 | ```
293 |
294 | - var接收方法返回时
295 |
296 | ```
297 | var result = this.getResult();
298 | 等于
299 | String result = this.getResult();
300 | ```
301 |
302 | - var循环中定义局部变量
303 |
304 | ```
305 | for (var i = 0; i < 5; i++) {
306 | System.out.println(i);
307 | }
308 | 等于
309 | for (int i = 0; i < 5; i++) {
310 | System.out.println(i);
311 | }
312 | ```
313 |
314 | - var结合泛型
315 |
316 | ```
317 | var list1 = new ArrayList(); //在<>中指定了list类型为String
318 | 等于
319 | List list1 = new ArrayList<>();
320 |
321 | var list2 = new ArrayList<>(); //<>里默认会是Object
322 | ```
323 |
324 | - var在Lambda中使用(java11才可以使用)
325 |
326 | ```
327 | Consumer Consumer = (var i) -> System.out.println(i);
328 | 等于
329 | Consumer Consumer = (String i) -> System.out.println(i);
330 | ```
331 |
332 | ##### 3.var不能再哪里使用?
333 |
334 | - 类成员变量类型。
335 | - 方法返回值类型。
336 | - Java10中Lambda不能使用var,Java11中可以使用。
337 |
338 | #### 增强api
339 |
340 | ##### 1.字符串增强 @since 11
341 |
342 | ```
343 | // 判断字符串是否为空白
344 | " ".isBlank(); // true
345 |
346 | // 去除首尾空格
347 | " Hello Java11 ".strip(); // "Hello Java11"
348 |
349 | // 去除尾部空格
350 | " Hello Java11 ".stripTrailing(); // " Hello Java11"
351 |
352 | // 去除首部空格
353 | " Hello Java11 ".stripLeading(); // "Hello Java11 "
354 |
355 | // 复制字符串
356 | "Java11".repeat(3); // "Java11Java11Java11"
357 |
358 | // 行数统计
359 | "A\nB\nC".lines().count(); // 3
360 | ```
361 |
362 |
363 |
364 | ##### 2.集合增强
365 |
366 | 从Java 9 开始,jdk里面就为集合(List、Set、Map)增加了of和copyOf方法。它们用来创建不可变集合。
367 |
368 | - of() @since 9
369 | - copyOf() @since 10
370 |
371 | 示例一:
372 |
373 | ```
374 | var list = List.of("Java", "Python", "C"); //不可变集合
375 | var copy = List.copyOf(list); //copyOf判断是否是不可变集合类型,如果是直接返回
376 | System.out.println(list == copy); // true
377 |
378 | var list = new ArrayList(); // 这里返回正常的集合
379 | var copy = List.copyOf(list); // 这里返回一个不可变集合
380 | System.out.println(list == copy); // false
381 | ```
382 |
383 | 示例二:
384 |
385 | ```
386 | var set = Set.of("Java", "Python", "C");
387 | var copy = Set.copyOf(set);
388 | System.out.println(set == copy); // true
389 |
390 | var set1 = new HashSet();
391 | var copy1 = List.copyOf(set1);
392 | System.out.println(set1 == copy1); // false
393 | ```
394 |
395 | 示例三:
396 |
397 | ```
398 | var map = Map.of("Java", 1, "Python", 2, "C", 3);
399 | var copy = Map.copyOf(map);
400 | System.out.println(map == copy); // true
401 |
402 | var map1 = new HashMap();
403 | var copy1 = Map.copyOf(map1);
404 | System.out.println(map1 == copy1); // false
405 | ```
406 |
407 | `注意:使用 of 和 copyOf 创建的集合为不可变集合,不能进行添加、删除、替换、排序等操作,不然会报java.lang.UnsupportedOperationException异常,使用Set.of()不能出现重复元素、Map.of()不能出现重复key,否则回报java.lang.IllegalArgumentException。`。
408 |
409 | ##### 3.Stream增强 @since 9
410 |
411 | Stream是Java 8 中的特性,在Java 9 中为其新增了4个方法:
412 |
413 | - ofNullable(T t)
414 |
415 | 此方法可以接收null来创建一个空流
416 |
417 | ```
418 | 以前
419 | Stream.of(null); //报错
420 | 现在
421 | Stream.ofNullable(null);
422 | ```
423 |
424 | - takeWhile(Predicate predicate)
425 |
426 | 此方法根据Predicate接口来判断如果为true就 `取出` 来生成一个新的流,只要碰到false就终止,不管后边的元素是否符合条件。
427 |
428 | ```
429 | Stream integerStream = Stream.of(6, 10, 11, 15, 20);
430 | Stream takeWhile = integerStream.takeWhile(t -> t % 2 == 0);
431 | takeWhile.forEach(System.out::println); // 6,10
432 | ```
433 |
434 | - dropWhile(Predicate predicate)
435 |
436 | 此方法根据Predicate接口来判断如果为true就 `丢弃` 来生成一个新的流,只要碰到false就终止,不管后边的元素是否符合条件。
437 |
438 | ```
439 | Stream integerStream = Stream.of(6, 10, 11, 15, 20);
440 | Stream takeWhile = integerStream.dropWhile(t -> t % 2 == 0);
441 | takeWhile.forEach(System.out::println); //11,15,20
442 | ```
443 |
444 | - iterate重载
445 |
446 | 以前使用iterate方法生成无限流需要配合limit进行截断
447 |
448 | ```
449 | Stream limit = Stream.iterate(1, i -> i + 1).limit(5);
450 | limit.forEach(System.out::println); //1,2,3,4,5
451 | ```
452 |
453 | 现在重载后这个方法增加了个判断参数
454 |
455 | ```
456 | Stream iterate = Stream.iterate(1, i -> i <= 5, i -> i + 1);
457 | iterate.forEach(System.out::println); //1,2,3,4,5
458 | ```
459 |
460 | ##### 4.Optional增强 @since 9
461 |
462 | - stream()
463 |
464 | 如果为空返回一个空流,如果不为空将Optional的值转成一个流。
465 |
466 | ```
467 | //返回Optional值的流
468 | Stream stream = Optional.of("Java 11").stream();
469 | stream.forEach(System.out::println); // Java 11
470 |
471 | //返回空流
472 | Stream
 2 |
3 |
4 | - 此项目是利用业余时间,对一些技术知识点进行整理,用来记录个人学习笔记。这个项目和 [study](https://github.com/xiaoshuanglee/study) 项目的不同在于 [study](https://github.com/xiaoshuanglee/study) 是用来动手实践,对于一些技术的实际搭建和造轮子的项目,正所谓实践出真知。相关的源码都会在上边。两个项目结合就是理论+实践。欢迎大家Star和follow!
5 |
6 |
7 |
8 | [](https://github.com/CodeGeekLee/RoadToGrowth)
9 | [](https://github.com/CodeGeekLee/RoadToGrowth)
10 |
11 | [开始阅读](README.md)
--------------------------------------------------------------------------------
/docs/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
2 |
3 |
4 | - 此项目是利用业余时间,对一些技术知识点进行整理,用来记录个人学习笔记。这个项目和 [study](https://github.com/xiaoshuanglee/study) 项目的不同在于 [study](https://github.com/xiaoshuanglee/study) 是用来动手实践,对于一些技术的实际搭建和造轮子的项目,正所谓实践出真知。相关的源码都会在上边。两个项目结合就是理论+实践。欢迎大家Star和follow!
5 |
6 |
7 |
8 | [](https://github.com/CodeGeekLee/RoadToGrowth)
9 | [](https://github.com/CodeGeekLee/RoadToGrowth)
10 |
11 | [开始阅读](README.md)
--------------------------------------------------------------------------------
/docs/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |