├── .editorconfig
├── .gitattributes
├── .gitignore
├── .travis.yml
├── LICENSE
├── README.md
├── docs
├── .markdownlint.json
├── .vuepress
│ ├── config.js
│ ├── enhanceApp.js
│ └── public
│ │ ├── favicon.ico
│ │ └── images
│ │ └── javaTKBJ-1.jpeg
├── README.md
├── mysql
│ ├── README.md
│ ├── mysql-index-1.md
│ ├── mysql-index-2.md
│ └── mysql-index-3.md
├── package.json
└── test
│ ├── README.md
│ ├── experiment-md.md
│ └── jmh-tutorial.md
├── package.json
└── scripts
└── deploy.sh
/.editorconfig:
--------------------------------------------------------------------------------
1 | # EditorConfig 用于在 IDE 中检查代码的基本 Code Style
2 | # @see: https://editorconfig.org/
3 |
4 | # 配置说明:
5 | # 所有文件换行使用 Unix 风格(LF),*.bat 文件使用 Windows 风格(CRLF)
6 | # java / sh 文件缩进 4 个空格,其他所有文件缩进 2 个空格
7 |
8 | root = true
9 |
10 | [*]
11 | end_of_line = lf
12 | indent_size = 2
13 | indent_style = space
14 | max_line_length = 120
15 | charset = utf-8
16 | trim_trailing_whitespace = true
17 | insert_final_newline = true
18 |
19 | [*.{bat, cmd}]
20 | end_of_line = crlf
21 |
22 | [*.{java, gradle, groovy, kt, sh}]
23 | indent_size = 4
24 |
25 | [*.md]
26 | max_line_length = 0
27 | trim_trailing_whitespace = false
28 |
--------------------------------------------------------------------------------
/.gitattributes:
--------------------------------------------------------------------------------
1 | * text=auto eol=lf
2 |
3 | # plan text
4 | *.txt text
5 | *.java text
6 | *.scala text
7 | *.groovy text
8 | *.gradle text
9 | *.xml text
10 | *.xsd text
11 | *.tld text
12 | *.yaml text
13 | *.yml text
14 | *.wsdd text
15 | *.wsdl text
16 | *.jsp text
17 | *.jspf text
18 | *.js text
19 | *.jsx text
20 | *.json text
21 | *.css text
22 | *.less text
23 | *.sql text
24 | *.properties text
25 |
26 | # unix style
27 | *.sh text eol=lf
28 |
29 | # win style
30 | *.bat text eol=crlf
31 |
32 | # don't handle
33 | *.der -text
34 | *.jks -text
35 | *.pfx -text
36 | *.map -text
37 | *.patch -text
38 | *.dat -text
39 | *.data -text
40 | *.db -text
41 |
42 | # binary
43 | *.jar binary
44 | *.war binary
45 | *.zip binary
46 | *.tar binary
47 | *.tar.gz binary
48 | *.gz binary
49 | *.apk binary
50 | *.bin binary
51 | *.exe binary
52 |
53 | # images
54 | *.png binary
55 | *.jpg binary
56 | *.ico binary
57 | *.gif binary
58 |
59 | # medias
60 | *.mp3 binary
61 | *.swf binary
62 |
63 | # fonts
64 | *.eot binary
65 | *.svg binary
66 | *.ttf binary
67 | *.woff binary
68 |
69 | # others
70 | *.pdf binary
71 | *.doc binary
72 | *.docx binary
73 | *.ppt binary
74 | *.pptx binary
75 | *.xls binary
76 | *.xlsx binary
77 | *.xmind binary
78 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # ---------------------------------------------------------------------
2 | # more gitignore templates see https://github.com/github/gitignore
3 | # ---------------------------------------------------------------------
4 |
5 | # ------------------------------- java -------------------------------
6 | # compiled folders
7 | classes
8 | target
9 | logs
10 | .mtj.tmp/
11 |
12 | # compiled files
13 | *.class
14 |
15 | # bluej files
16 | *.ctxt
17 |
18 | # package files #
19 | *.jar
20 | *.war
21 | *.nar
22 | *.ear
23 | *.zip
24 | *.tar.gz
25 | *.rar
26 |
27 | # virtual machine crash logs
28 | hs_err_pid*
29 |
30 | # maven plugin temp files
31 | .flattened-pom.xml
32 | package-lock.json
33 |
34 |
35 | # ------------------------------- javascript -------------------------------
36 | # dependencies
37 | node_modules
38 |
39 | # temp folders
40 | .temp
41 | dist
42 | _book
43 | _jsdoc
44 |
45 | # temp files
46 | *.log
47 | npm-debug.log*
48 | yarn-debug.log*
49 | yarn-error.log*
50 | bundle*.js
51 | book.pdf
52 |
53 |
54 | # ------------------------------- intellij -------------------------------
55 | .idea
56 | *.iml
57 |
58 |
59 | # ------------------------------- eclipse -------------------------------
60 | .classpath
61 | .project
62 |
--------------------------------------------------------------------------------
/.travis.yml:
--------------------------------------------------------------------------------
1 | # 持续集成 CI
2 | # @see https://docs.travis-ci.com/user/tutorial/
3 |
4 | language: node_js
5 |
6 | sudo: required
7 |
8 | node_js: stable
9 |
10 | branches:
11 | only:
12 | - master
13 |
14 | before_install:
15 | - export TZ=Asia/Shanghai
16 |
17 | script: bash ./scripts/deploy.sh
18 |
19 | notifications:
20 | email:
21 | recipients:
22 | - liqiang1chnk@163.com
23 | on_success: change
24 | on_failure: always
25 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Attribution-ShareAlike 4.0 International
2 |
3 | =======================================================================
4 |
5 | Creative Commons Corporation ("Creative Commons") is not a law firm and
6 | does not provide legal services or legal advice. Distribution of
7 | Creative Commons public licenses does not create a lawyer-client or
8 | other relationship. Creative Commons makes its licenses and related
9 | information available on an "as-is" basis. Creative Commons gives no
10 | warranties regarding its licenses, any material licensed under their
11 | terms and conditions, or any related information. Creative Commons
12 | disclaims all liability for damages resulting from their use to the
13 | fullest extent possible.
14 |
15 | Using Creative Commons Public Licenses
16 |
17 | Creative Commons public licenses provide a standard set of terms and
18 | conditions that creators and other rights holders may use to share
19 | original works of authorship and other material subject to copyright
20 | and certain other rights specified in the public license below. The
21 | following considerations are for informational purposes only, are not
22 | exhaustive, and do not form part of our licenses.
23 |
24 | Considerations for licensors: Our public licenses are
25 | intended for use by those authorized to give the public
26 | permission to use material in ways otherwise restricted by
27 | copyright and certain other rights. Our licenses are
28 | irrevocable. Licensors should read and understand the terms
29 | and conditions of the license they choose before applying it.
30 | Licensors should also secure all rights necessary before
31 | applying our licenses so that the public can reuse the
32 | material as expected. Licensors should clearly mark any
33 | material not subject to the license. This includes other CC-
34 | licensed material, or material used under an exception or
35 | limitation to copyright. More considerations for licensors:
36 | wiki.creativecommons.org/Considerations_for_licensors
37 |
38 | Considerations for the public: By using one of our public
39 | licenses, a licensor grants the public permission to use the
40 | licensed material under specified terms and conditions. If
41 | the licensor's permission is not necessary for any reason--for
42 | example, because of any applicable exception or limitation to
43 | copyright--then that use is not regulated by the license. Our
44 | licenses grant only permissions under copyright and certain
45 | other rights that a licensor has authority to grant. Use of
46 | the licensed material may still be restricted for other
47 | reasons, including because others have copyright or other
48 | rights in the material. A licensor may make special requests,
49 | such as asking that all changes be marked or described.
50 | Although not required by our licenses, you are encouraged to
51 | respect those requests where reasonable. More_considerations
52 | for the public:
53 | wiki.creativecommons.org/Considerations_for_licensees
54 |
55 | =======================================================================
56 |
57 | Creative Commons Attribution-ShareAlike 4.0 International Public
58 | License
59 |
60 | By exercising the Licensed Rights (defined below), You accept and agree
61 | to be bound by the terms and conditions of this Creative Commons
62 | Attribution-ShareAlike 4.0 International Public License ("Public
63 | License"). To the extent this Public License may be interpreted as a
64 | contract, You are granted the Licensed Rights in consideration of Your
65 | acceptance of these terms and conditions, and the Licensor grants You
66 | such rights in consideration of benefits the Licensor receives from
67 | making the Licensed Material available under these terms and
68 | conditions.
69 |
70 |
71 | Section 1 -- Definitions.
72 |
73 | a. Adapted Material means material subject to Copyright and Similar
74 | Rights that is derived from or based upon the Licensed Material
75 | and in which the Licensed Material is translated, altered,
76 | arranged, transformed, or otherwise modified in a manner requiring
77 | permission under the Copyright and Similar Rights held by the
78 | Licensor. For purposes of this Public License, where the Licensed
79 | Material is a musical work, performance, or sound recording,
80 | Adapted Material is always produced where the Licensed Material is
81 | synched in timed relation with a moving image.
82 |
83 | b. Adapter's License means the license You apply to Your Copyright
84 | and Similar Rights in Your contributions to Adapted Material in
85 | accordance with the terms and conditions of this Public License.
86 |
87 | c. BY-SA Compatible License means a license listed at
88 | creativecommons.org/compatiblelicenses, approved by Creative
89 | Commons as essentially the equivalent of this Public License.
90 |
91 | d. Copyright and Similar Rights means copyright and/or similar rights
92 | closely related to copyright including, without limitation,
93 | performance, broadcast, sound recording, and Sui Generis Database
94 | Rights, without regard to how the rights are labeled or
95 | categorized. For purposes of this Public License, the rights
96 | specified in Section 2(b)(1)-(2) are not Copyright and Similar
97 | Rights.
98 |
99 | e. Effective Technological Measures means those measures that, in the
100 | absence of proper authority, may not be circumvented under laws
101 | fulfilling obligations under Article 11 of the WIPO Copyright
102 | Treaty adopted on December 20, 1996, and/or similar international
103 | agreements.
104 |
105 | f. Exceptions and Limitations means fair use, fair dealing, and/or
106 | any other exception or limitation to Copyright and Similar Rights
107 | that applies to Your use of the Licensed Material.
108 |
109 | g. License Elements means the license attributes listed in the name
110 | of a Creative Commons Public License. The License Elements of this
111 | Public License are Attribution and ShareAlike.
112 |
113 | h. Licensed Material means the artistic or literary work, database,
114 | or other material to which the Licensor applied this Public
115 | License.
116 |
117 | i. Licensed Rights means the rights granted to You subject to the
118 | terms and conditions of this Public License, which are limited to
119 | all Copyright and Similar Rights that apply to Your use of the
120 | Licensed Material and that the Licensor has authority to license.
121 |
122 | j. Licensor means the individual(s) or entity(ies) granting rights
123 | under this Public License.
124 |
125 | k. Share means to provide material to the public by any means or
126 | process that requires permission under the Licensed Rights, such
127 | as reproduction, public display, public performance, distribution,
128 | dissemination, communication, or importation, and to make material
129 | available to the public including in ways that members of the
130 | public may access the material from a place and at a time
131 | individually chosen by them.
132 |
133 | l. Sui Generis Database Rights means rights other than copyright
134 | resulting from Directive 96/9/EC of the European Parliament and of
135 | the Council of 11 March 1996 on the legal protection of databases,
136 | as amended and/or succeeded, as well as other essentially
137 | equivalent rights anywhere in the world.
138 |
139 | m. You means the individual or entity exercising the Licensed Rights
140 | under this Public License. Your has a corresponding meaning.
141 |
142 |
143 | Section 2 -- Scope.
144 |
145 | a. License grant.
146 |
147 | 1. Subject to the terms and conditions of this Public License,
148 | the Licensor hereby grants You a worldwide, royalty-free,
149 | non-sublicensable, non-exclusive, irrevocable license to
150 | exercise the Licensed Rights in the Licensed Material to:
151 |
152 | a. reproduce and Share the Licensed Material, in whole or
153 | in part; and
154 |
155 | b. produce, reproduce, and Share Adapted Material.
156 |
157 | 2. Exceptions and Limitations. For the avoidance of doubt, where
158 | Exceptions and Limitations apply to Your use, this Public
159 | License does not apply, and You do not need to comply with
160 | its terms and conditions.
161 |
162 | 3. Term. The term of this Public License is specified in Section
163 | 6(a).
164 |
165 | 4. Media and formats; technical modifications allowed. The
166 | Licensor authorizes You to exercise the Licensed Rights in
167 | all media and formats whether now known or hereafter created,
168 | and to make technical modifications necessary to do so. The
169 | Licensor waives and/or agrees not to assert any right or
170 | authority to forbid You from making technical modifications
171 | necessary to exercise the Licensed Rights, including
172 | technical modifications necessary to circumvent Effective
173 | Technological Measures. For purposes of this Public License,
174 | simply making modifications authorized by this Section 2(a)
175 | (4) never produces Adapted Material.
176 |
177 | 5. Downstream recipients.
178 |
179 | a. Offer from the Licensor -- Licensed Material. Every
180 | recipient of the Licensed Material automatically
181 | receives an offer from the Licensor to exercise the
182 | Licensed Rights under the terms and conditions of this
183 | Public License.
184 |
185 | b. Additional offer from the Licensor -- Adapted Material.
186 | Every recipient of Adapted Material from You
187 | automatically receives an offer from the Licensor to
188 | exercise the Licensed Rights in the Adapted Material
189 | under the conditions of the Adapter's License You apply.
190 |
191 | c. No downstream restrictions. You may not offer or impose
192 | any additional or different terms or conditions on, or
193 | apply any Effective Technological Measures to, the
194 | Licensed Material if doing so restricts exercise of the
195 | Licensed Rights by any recipient of the Licensed
196 | Material.
197 |
198 | 6. No endorsement. Nothing in this Public License constitutes or
199 | may be construed as permission to assert or imply that You
200 | are, or that Your use of the Licensed Material is, connected
201 | with, or sponsored, endorsed, or granted official status by,
202 | the Licensor or others designated to receive attribution as
203 | provided in Section 3(a)(1)(A)(i).
204 |
205 | b. Other rights.
206 |
207 | 1. Moral rights, such as the right of integrity, are not
208 | licensed under this Public License, nor are publicity,
209 | privacy, and/or other similar personality rights; however, to
210 | the extent possible, the Licensor waives and/or agrees not to
211 | assert any such rights held by the Licensor to the limited
212 | extent necessary to allow You to exercise the Licensed
213 | Rights, but not otherwise.
214 |
215 | 2. Patent and trademark rights are not licensed under this
216 | Public License.
217 |
218 | 3. To the extent possible, the Licensor waives any right to
219 | collect royalties from You for the exercise of the Licensed
220 | Rights, whether directly or through a collecting society
221 | under any voluntary or waivable statutory or compulsory
222 | licensing scheme. In all other cases the Licensor expressly
223 | reserves any right to collect such royalties.
224 |
225 |
226 | Section 3 -- License Conditions.
227 |
228 | Your exercise of the Licensed Rights is expressly made subject to the
229 | following conditions.
230 |
231 | a. Attribution.
232 |
233 | 1. If You Share the Licensed Material (including in modified
234 | form), You must:
235 |
236 | a. retain the following if it is supplied by the Licensor
237 | with the Licensed Material:
238 |
239 | i. identification of the creator(s) of the Licensed
240 | Material and any others designated to receive
241 | attribution, in any reasonable manner requested by
242 | the Licensor (including by pseudonym if
243 | designated);
244 |
245 | ii. a copyright notice;
246 |
247 | iii. a notice that refers to this Public License;
248 |
249 | iv. a notice that refers to the disclaimer of
250 | warranties;
251 |
252 | v. a URI or hyperlink to the Licensed Material to the
253 | extent reasonably practicable;
254 |
255 | b. indicate if You modified the Licensed Material and
256 | retain an indication of any previous modifications; and
257 |
258 | c. indicate the Licensed Material is licensed under this
259 | Public License, and include the text of, or the URI or
260 | hyperlink to, this Public License.
261 |
262 | 2. You may satisfy the conditions in Section 3(a)(1) in any
263 | reasonable manner based on the medium, means, and context in
264 | which You Share the Licensed Material. For example, it may be
265 | reasonable to satisfy the conditions by providing a URI or
266 | hyperlink to a resource that includes the required
267 | information.
268 |
269 | 3. If requested by the Licensor, You must remove any of the
270 | information required by Section 3(a)(1)(A) to the extent
271 | reasonably practicable.
272 |
273 | b. ShareAlike.
274 |
275 | In addition to the conditions in Section 3(a), if You Share
276 | Adapted Material You produce, the following conditions also apply.
277 |
278 | 1. The Adapter's License You apply must be a Creative Commons
279 | license with the same License Elements, this version or
280 | later, or a BY-SA Compatible License.
281 |
282 | 2. You must include the text of, or the URI or hyperlink to, the
283 | Adapter's License You apply. You may satisfy this condition
284 | in any reasonable manner based on the medium, means, and
285 | context in which You Share Adapted Material.
286 |
287 | 3. You may not offer or impose any additional or different terms
288 | or conditions on, or apply any Effective Technological
289 | Measures to, Adapted Material that restrict exercise of the
290 | rights granted under the Adapter's License You apply.
291 |
292 |
293 | Section 4 -- Sui Generis Database Rights.
294 |
295 | Where the Licensed Rights include Sui Generis Database Rights that
296 | apply to Your use of the Licensed Material:
297 |
298 | a. for the avoidance of doubt, Section 2(a)(1) grants You the right
299 | to extract, reuse, reproduce, and Share all or a substantial
300 | portion of the contents of the database;
301 |
302 | b. if You include all or a substantial portion of the database
303 | contents in a database in which You have Sui Generis Database
304 | Rights, then the database in which You have Sui Generis Database
305 | Rights (but not its individual contents) is Adapted Material,
306 |
307 | including for purposes of Section 3(b); and
308 | c. You must comply with the conditions in Section 3(a) if You Share
309 | all or a substantial portion of the contents of the database.
310 |
311 | For the avoidance of doubt, this Section 4 supplements and does not
312 | replace Your obligations under this Public License where the Licensed
313 | Rights include other Copyright and Similar Rights.
314 |
315 |
316 | Section 5 -- Disclaimer of Warranties and Limitation of Liability.
317 |
318 | a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
319 | EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
320 | AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
321 | ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
322 | IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
323 | WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
324 | PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
325 | ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
326 | KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
327 | ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
328 |
329 | b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
330 | TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
331 | NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
332 | INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
333 | COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
334 | USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
335 | ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
336 | DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
337 | IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
338 |
339 | c. The disclaimer of warranties and limitation of liability provided
340 | above shall be interpreted in a manner that, to the extent
341 | possible, most closely approximates an absolute disclaimer and
342 | waiver of all liability.
343 |
344 |
345 | Section 6 -- Term and Termination.
346 |
347 | a. This Public License applies for the term of the Copyright and
348 | Similar Rights licensed here. However, if You fail to comply with
349 | this Public License, then Your rights under this Public License
350 | terminate automatically.
351 |
352 | b. Where Your right to use the Licensed Material has terminated under
353 | Section 6(a), it reinstates:
354 |
355 | 1. automatically as of the date the violation is cured, provided
356 | it is cured within 30 days of Your discovery of the
357 | violation; or
358 |
359 | 2. upon express reinstatement by the Licensor.
360 |
361 | For the avoidance of doubt, this Section 6(b) does not affect any
362 | right the Licensor may have to seek remedies for Your violations
363 | of this Public License.
364 |
365 | c. For the avoidance of doubt, the Licensor may also offer the
366 | Licensed Material under separate terms or conditions or stop
367 | distributing the Licensed Material at any time; however, doing so
368 | will not terminate this Public License.
369 |
370 | d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
371 | License.
372 |
373 |
374 | Section 7 -- Other Terms and Conditions.
375 |
376 | a. The Licensor shall not be bound by any additional or different
377 | terms or conditions communicated by You unless expressly agreed.
378 |
379 | b. Any arrangements, understandings, or agreements regarding the
380 | Licensed Material not stated herein are separate from and
381 | independent of the terms and conditions of this Public License.
382 |
383 |
384 | Section 8 -- Interpretation.
385 |
386 | a. For the avoidance of doubt, this Public License does not, and
387 | shall not be interpreted to, reduce, limit, restrict, or impose
388 | conditions on any use of the Licensed Material that could lawfully
389 | be made without permission under this Public License.
390 |
391 | b. To the extent possible, if any provision of this Public License is
392 | deemed unenforceable, it shall be automatically reformed to the
393 | minimum extent necessary to make it enforceable. If the provision
394 | cannot be reformed, it shall be severed from this Public License
395 | without affecting the enforceability of the remaining terms and
396 | conditions.
397 |
398 | c. No term or condition of this Public License will be waived and no
399 | failure to comply consented to unless expressly agreed to by the
400 | Licensor.
401 |
402 | d. Nothing in this Public License constitutes or may be interpreted
403 | as a limitation upon, or waiver of, any privileges and immunities
404 | that apply to the Licensor or You, including from the legal
405 | processes of any jurisdiction or authority.
406 |
407 |
408 | =======================================================================
409 |
410 | Creative Commons is not a party to its public
411 | licenses. Notwithstanding, Creative Commons may elect to apply one of
412 | its public licenses to material it publishes and in those instances
413 | will be considered the “Licensor.” The text of the Creative Commons
414 | public licenses is dedicated to the public domain under the CC0 Public
415 | Domain Dedication. Except for the limited purpose of indicating that
416 | material is shared under a Creative Commons public license or as
417 | otherwise permitted by the Creative Commons policies published at
418 | creativecommons.org/policies, Creative Commons does not authorize the
419 | use of the trademark "Creative Commons" or any other trademark or logo
420 | of Creative Commons without its prior written consent including,
421 | without limitation, in connection with any unauthorized modifications
422 | to any of its public licenses or any other arrangements,
423 | understandings, or agreements concerning use of licensed material. For
424 | the avoidance of doubt, this paragraph does not form part of the
425 | public licenses.
426 |
427 | Creative Commons may be contacted at creativecommons.org.
428 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## 一、Jann Lee|李强的个人博客
2 | mycookies
3 |
--------------------------------------------------------------------------------
/docs/.markdownlint.json:
--------------------------------------------------------------------------------
1 | {
2 | "default": true,
3 | "MD002": false,
4 | "MD004": { "style": "dash" },
5 | "ul-indent": { "indent": 2 },
6 | "MD013": { "line_length": 600 },
7 | "MD024": false,
8 | "MD025": false,
9 | "MD026": false,
10 | "MD029": { "style": "ordered" },
11 | "MD033": false,
12 | "MD034": false,
13 | "MD036": false,
14 | "fenced-code-language": false,
15 | "no-hard-tabs": false,
16 | "whitespace": false,
17 | "emphasis-style": { "style": "consistent" }
18 | }
19 |
--------------------------------------------------------------------------------
/docs/.vuepress/config.js:
--------------------------------------------------------------------------------
1 | /**
2 | * @see https://vuepress.vuejs.org/zh/
3 | */
4 | module.exports = {
5 | port: '4000',
6 | dest: 'dist',
7 | base: '/',
8 | title: 'Java填坑笔记',
9 | description: 'Java 填坑记录',
10 | head: [['link', { rel: 'icon', href: `/favicon.ico` }]],
11 | markdown: {
12 | code: {
13 | lineNumbers: true,
14 | },
15 | externalLinks: {
16 | target: '_blank',
17 | rel: 'noopener noreferrer',
18 | },
19 | },
20 | themeConfig: {
21 | logo: 'https://source.mycookies.cn/3f4fb78ab4aec2948d6c40584c235b9e.jpeg',
22 | repo: 'liqianggh/blog',
23 | repoLabel: 'Github',
24 | docsDir: 'docs',
25 | docsBranch: 'master',
26 | editLinks: true,
27 | smoothScroll: true,
28 | locales: {
29 | '/': {
30 | label: '简体中文',
31 | selectText: 'Languages',
32 | editLinkText: '帮助我们改善此页面!',
33 | lastUpdated: '上次更新',
34 | nav: [
35 | {
36 | text: 'MySQL',
37 | link: '/mysql/',
38 | },
39 | {
40 | text: 'Test',
41 | link: '/test/',
42 | },
43 | ],
44 | sidebar: 'auto',
45 | sidebarDepth: 2,
46 | },
47 | },
48 | },
49 | plugins: [
50 | [
51 | '@vuepress/container',
52 | ],
53 | [
54 | '@vuepress/active-header-links',
55 | {
56 | sidebarLinkSelector: '.sidebar-link',
57 | headerAnchorSelector: '.header-anchor',
58 | },
59 | ],
60 | [
61 | '@vuepress/pwa',
62 | {
63 | serviceWorker: true,
64 | updatePopup: true,
65 | },
66 | ],
67 | [
68 | '@vuepress/last-updated',
69 | {
70 | transformer: (timestamp, lang) => {
71 | // 不要忘了安装 moment
72 | const moment = require('moment')
73 | moment.locale(lang)
74 | return moment(timestamp).fromNow()
75 | },
76 | },
77 | ],
78 | ['@vuepress/medium-zoom', true],
79 | [
80 | 'container',
81 | {
82 | type: 'vue',
83 | before: '',
84 | after: '
',
85 | },
86 | ],
87 | [
88 | 'container',
89 | {
90 | type: 'upgrade',
91 | before: (info) => ``,
92 | after: '',
93 | },
94 | ],
95 | ['flowchart'],
96 | [
97 | 'vuepress-plugin-mygitalk',{
98 | // 是否启用(关闭请设置为false)(default: true)
99 | enable: true,
100 | // 是否开启首页评论(default: true)
101 | home: true,
102 | // Gitalk配置
103 | gitalk: {
104 | // GitHub Application Client ID.
105 | clientID: '556b3313997ea5ab29a0',
106 | // GitHub Application Client Secret.
107 | clientSecret: '49271bf6819717c6c1bd10fb83190d2c0442d9d6',
108 | // GitHub repository. 存储评论的 repo
109 | repo: 'blog',
110 | // GitHub repository 所有者,可以是个人或者组织。
111 | owner: 'liqianggh',
112 | // GitHub repository 的所有者和合作者 (对这个 repository 有写权限的用户)。(不配置默认是owner配置)
113 | admin: ['liqianggh'],
114 | // 设置语言(default: zh-CN)
115 | language: 'zh-CN',
116 | }
117 | }
118 | ],
119 | ],
120 | }
121 |
--------------------------------------------------------------------------------
/docs/.vuepress/enhanceApp.js:
--------------------------------------------------------------------------------
1 | export default ({ Vue, isServer }) => {
2 | if (!isServer) {
3 | import('vue-toasted' /* webpackChunkName: "notification" */).then(module => {
4 | Vue.use(module.default)
5 | })
6 | }
7 | }
8 |
--------------------------------------------------------------------------------
/docs/.vuepress/public/favicon.ico:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/liqianggh/blog/89556c3f7fa8556edd4b622d96d46b9302095f45/docs/.vuepress/public/favicon.ico
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/javaTKBJ-1.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/liqianggh/blog/89556c3f7fa8556edd4b622d96d46b9302095f45/docs/.vuepress/public/images/javaTKBJ-1.jpeg
--------------------------------------------------------------------------------
/docs/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | home: true
3 | heroImage:
4 | heroText: Java填坑笔记
5 | tagline: ☕ Hello world
6 | actionLink: /
7 | footer: CC-BY-SA-4.0 Licensed | Copyright © liqiang|备案号:皖ICP备17014740号-1
8 | ---
9 |
10 | ## Hello Index
11 | > 📚
12 |
13 |
14 |
15 |
--------------------------------------------------------------------------------
/docs/mysql/README.md:
--------------------------------------------------------------------------------
1 | # MySQL
2 | ## 📖 内容
3 | - [MySQL索引分类](mysql-index-1.md)
4 | - [为什么使用B+Tree](mysql-index-2.md)
5 | - [索引实战](mysql-index-3.md)
6 | ## 📚 资料
7 |
8 | ## 🚪 传送
9 |
10 |
--------------------------------------------------------------------------------
/docs/mysql/mysql-index-1.md:
--------------------------------------------------------------------------------
1 | # MySQL索引分类
2 |
3 | 关于MySQL索引相关的内容,一直是一个让人头疼的问题,尤其是对于初学者来说。笔者曾在很长一段时间内深陷其中,无法分清**“覆盖索引,辅助索引,唯一索引,Hash索引,B-Tree索引......”到底是些什么东西**,导致在面试过程中进入比较尴尬的局面。
4 |
5 | 很多人可能会抱怨”**面试造火箭,工作拧螺丝,很多知识都是为了面试学的,工作中根本用不到!**“。庆幸的是,MySQL中索引不仅是面试必考知识,还是工作中用到最为频繁的必备技能,在笔者看来,索引是**MySQL中性价比最高的一部分内容**。
6 |
7 | 由于MySQL中支持多种存储引擎,在不同的存储引擎中实现略微有所差距,索引下文中如果没有特殊声明,默认指的都是InnoDB存储引擎。
8 |
9 | ## 一、底层数据结构
10 |
11 | 首先,**索引是高效获取数据的数据结构**。就像书中的目录一样,我们可以通过它快速定位到数据所在的位置,从而提高数据查询的效率。
12 |
13 | 在MySQL中有许多关于索引的名词和概念,对于初学者来说很容易被迷惑。为了方便理解,我建立了一张表,从具体的案例中尝试说清楚这些概念到底是什么。
14 |
15 | > Hash索引
16 |
17 | 正如上文中说到,索引是提高查询效率的数据结构,而能够提高查询效率的数据结构有很多,如二叉搜索树,红黑树,跳表,哈希表(散列表)等,而MySQL中用到了B+Tree和散列表(Hash表)作为索引的底层数据结构。
18 |
19 | 需要注意的是,MySQL**并没有显式支持Hash索引,而是作为内部的一种优化,对于热点的数据会自动生成Hash索引,也叫自适应Hash索引**。
20 |
21 | Hash索引在等值查询中,可以O(1)时间复杂度定位到数据,效率非常高,但是不支持范围查询。在许多编程语言以及数据库中都会用到这个数据结构,如Redis支持的Hash数据结构。具体结构如下:
22 |
23 | 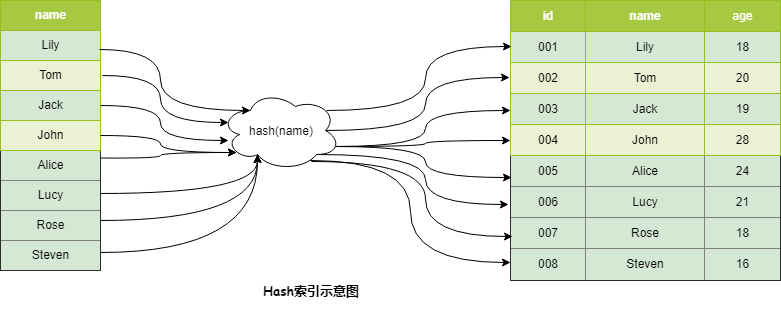
24 |
25 | > B+Tree索引
26 |
27 | 提到B+Tree首先不得不提**B-Tree**,B-Tree(多路搜索树,并不是二叉的)是一种常见的数据结构。使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。
28 |
29 | 
30 |
31 | **B+ 树**是基于B-Tree升级后的一种树数据结构,通常用于数据库和操作系统的文件系统中。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入,这与二叉树恰好相反。
32 |
33 | MySQL索引的实现也是基于这种高效的数据结构。具体数据结构如下:
34 |
35 | 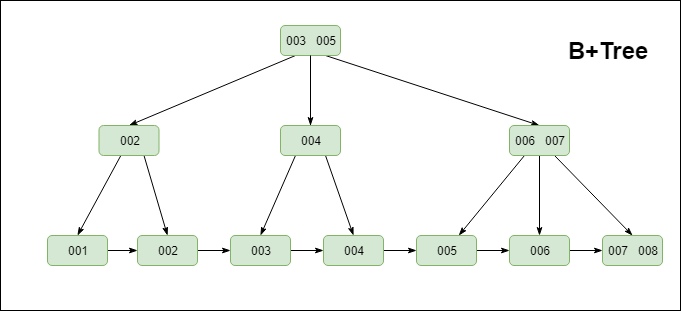
36 |
37 | 笔者首先要声明一下,不要将**B树,B-Tree以及B+Tree**弄混淆。首先,B-Tree就是B树,中间的“-”是一个中划线,而不是减号,并不存在"B减树"这种数据结构。其次,就是B+Tree和B-Tree实现索引时有两个区别,具体可见下图
38 |
39 | ①B+Tree只在叶子节点存储数据,而B-Tree的数据存储在各个节点中
40 |
41 | 
42 |
43 | ②B+Tree的叶子节点间通过指针链接,可以通过遍历叶子节点即可获取所有数据。
44 |
45 | 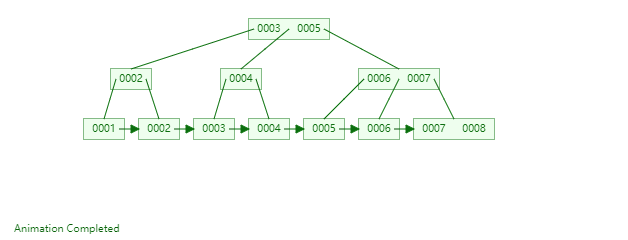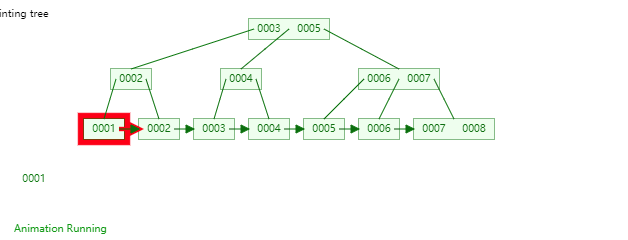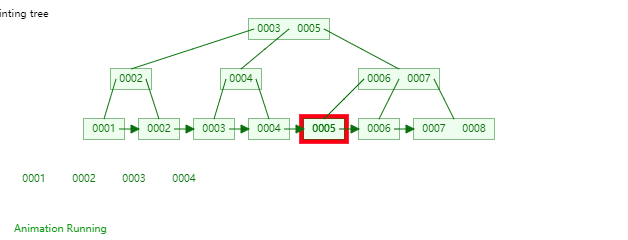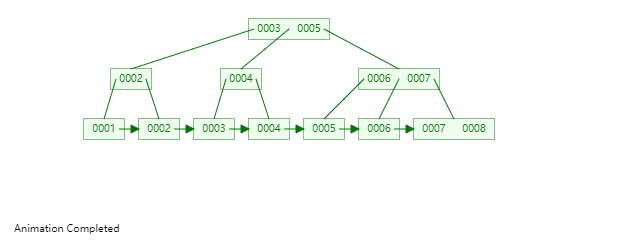
46 |
47 | B+Tree是一种神奇的数据结构,如果用语言来讲可能会有点费劲,感兴趣的同学可以点击文末数据结构可视化工具,操作一番后想必会有所收获,下图是笔者演示B+Tree的数据插入方式(自下而上)。
48 |
49 | 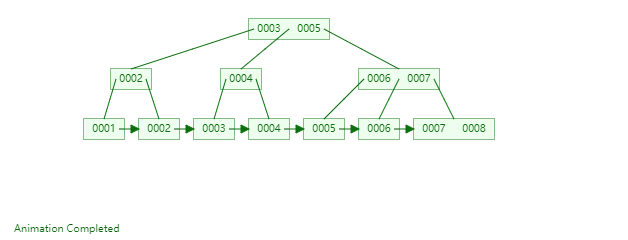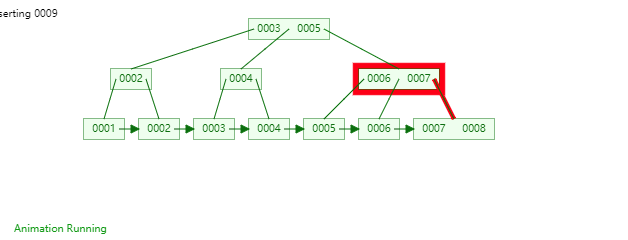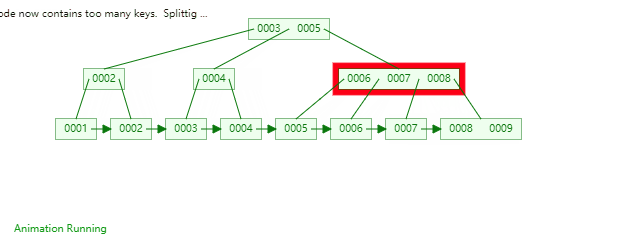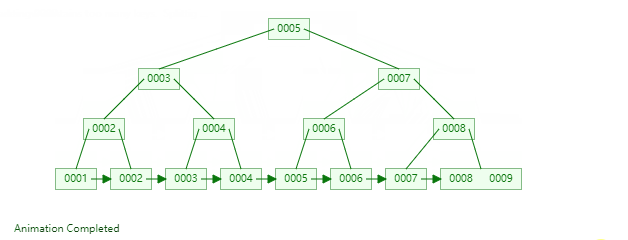
50 |
51 | ## 二,数据组织方式
52 |
53 | 根据数据的组织方式,可以分为聚簇索引和非聚簇索引(也叫聚集索引和非聚集索引)。聚簇索引就是按照每张表的主键构造一棵B+Tree,同时**叶子节点存放了整张表的行记录数据**。
54 |
55 | 在InnoDB中**聚簇索引和主键索引**概念等价,MySQL中规定所以每张表都必须有主键索引,**主键索引只能有一个,不能为null同时必须保证唯一性**。建表时如果没有指定主键索引,则会自动生成一个隐藏的字段作为主键索引。
56 |
57 | 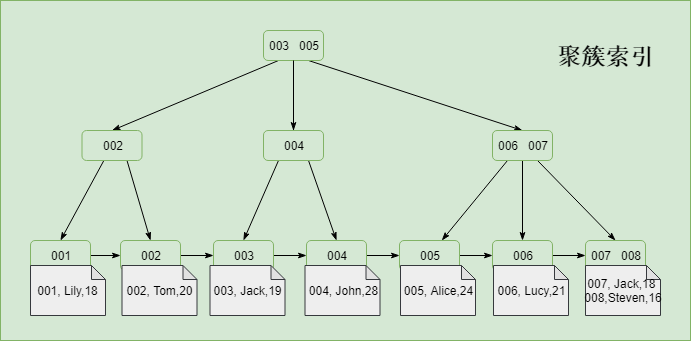
58 |
59 | 与之对应的则是非聚集索引,**非聚集索引又可以称之为为非主键索引,辅助索引,二级索引**。主键索引的叶子节点存储了完整的数据行,而**非主键索引的叶子节点存储的则是主键索引值**,通过非主键索引查询数据时,会先查找到主键索引,然后再到主键索引上去查找对应的数据,这个过程叫做**回表**(下文中会再次提到)。
60 |
61 | 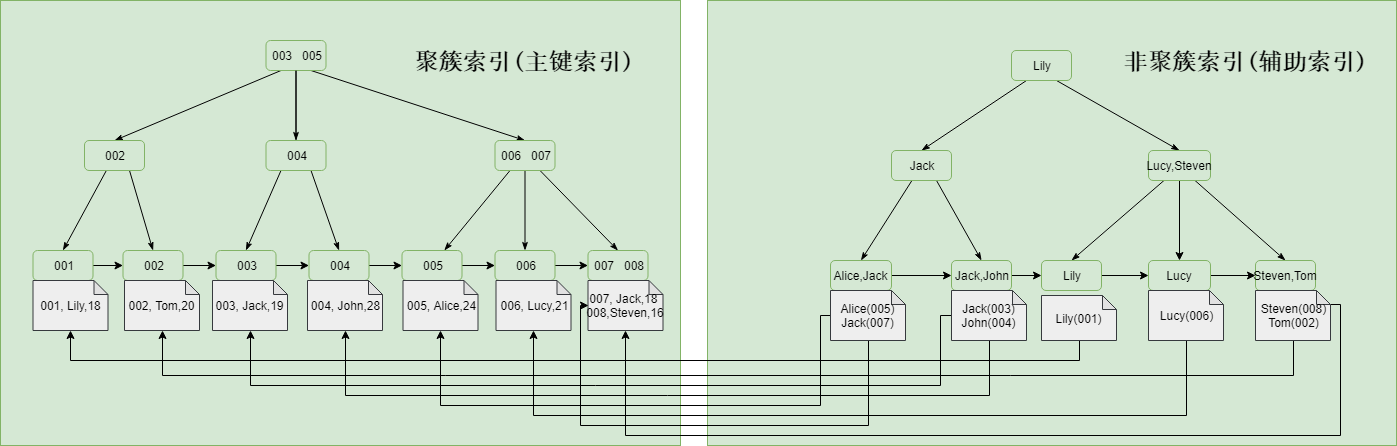
62 |
63 | 需要补充的是MyISAM中索引和数据文件分开存储,所有的索引都是非聚簇索引。B+Tree的叶子节点存储的是**数据存放的地址**,而不是具体的数据 。
64 |
65 | 
66 |
67 |
68 |
69 | ## 三,包含字段个数
70 |
71 | 为了能应对不同的数据检索需求,索引即可以仅包含一个字段,也可以同时包含多个字段。单个字段组成的索引可以称为单值索引,否则称之为复合索引(或者称为组合索引或多值索引)。上文中演示的都是单值索引,所以接下来展示一下复合索引作为对比。
72 |
73 | 复合索引的索引的数据顺序跟字段的顺序相关,包含多个值的索引中,如果当前面字段的值重复时,将会按照其后面的值进行排序。
74 |
75 | 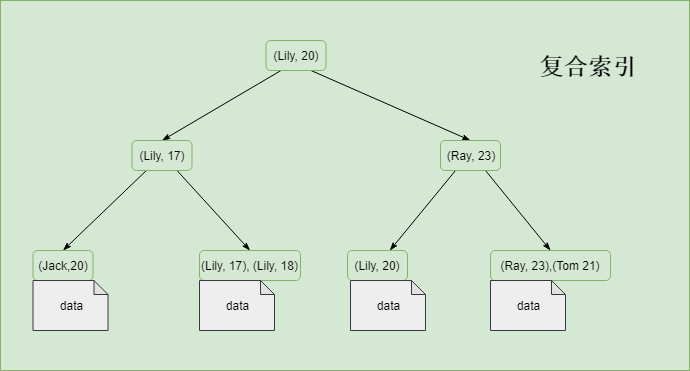
76 |
77 |
78 |
79 | ## 四,其他分类
80 |
81 | > 唯一索引
82 |
83 | 唯一索引,不允许具有索引值相同的行,从而禁止重复的索引或键值。系统在创建该索引时检查是否有重复的键值,并在每次使用 INSERT 或 UPDATE 语句添加数据时进行检查, 如果有重复的值,则会操作失败,抛出异常。
84 |
85 | 需要注意的是,主键索引一定是唯一索引,而唯一索引不一定是主键索引。**唯一索引可以理解为仅仅是将索引设置一个唯一性的属性**。
86 |
87 | > 覆盖索引
88 |
89 | 上文提到了一个回表的概念,既如果通过非主键索引查询数据时,会先查询到主键索引的值,然后再去主键索引中查询具体的数据,整个查询流程需要扫描两次索引,显然回表是一个耗时的操作。
90 |
91 | 为了减少回表次数,在设计索引时我们可以**让索引中包含要查询的结果**,在辅助索引中检索到数据后直接返回,而不需要进行回表操作。
92 |
93 | 但是需要注意的是,使用覆盖索引的前提是字段长度比较短,对于值长度较长的字段则不适合使用覆盖索引,原因有很多,比如索引一般存储在内存中,如果占用空间较大,则可能会从磁盘中加载,影响性能。当然还有其他原因,具体情况将会在下一篇文章中介绍。
94 |
95 | ## 六,总结
96 |
97 | 本文从不同维度介绍了MySQL中的索引,索引从不同维度划分可以有很多种名称,但是需要明确一个问题就是,**索引的本质是一种数据结构**,其他索引的划分则是针对实际应用而言。具体分类如下图所示:
98 |
99 | 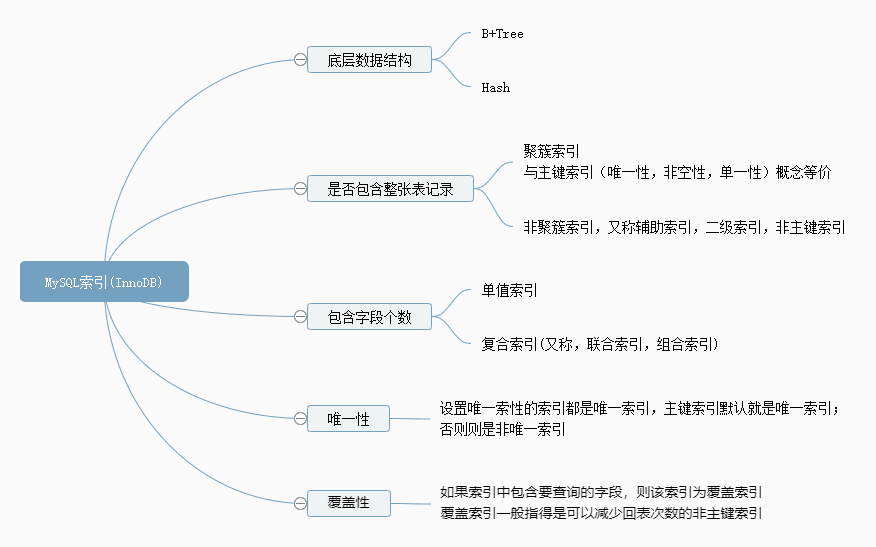
100 |
101 | 目的是让大家对于索引有个初步且清晰的认识,解决**What**的问题。后续将会针对**Why**以及**How**,进行深入探讨,当然,首先应当能区分本章文章中讲述的概念性问题。
102 |
103 | 数据结构可视化工具: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
104 |
105 | ## 七、Q&A
106 |
107 | **1. 为什么MySQL索引使用B+Tree实现,而不是搜索二叉树,红黑树或者跳表?**
108 |
109 | 这是一个综合性问题,远不止看起来那么简单,小伙伴们可以**把答案写在留言区**我们一起探讨,同样笔者将会在下一篇文章中重点介绍为什么,以及如何正确使用索引。
110 |
111 | 
112 |
113 |
--------------------------------------------------------------------------------
/docs/mysql/mysql-index-2.md:
--------------------------------------------------------------------------------
1 | # 为什么使用B+Tree
2 |
3 | 索引是一种支持快速查询的数据结构,同时索引优化也是后端工程师的必会知识点。各个公司都有所谓的MySQL”军规“,其实这些所谓的优化和规定,并不是什么高深的技术,只是要求大家正确建立和使用索引而已。工欲善其事必先利其器,想要正确运用索引,需要了解其底层实现原理,本文将探索关于索引的“是什么”以及”为什么“。
4 |
5 | MySQL中关于索引的概念有很多,为了避免混淆,在上一篇文章中关于索引在不同维度分类设计到的一些名词进行了解释,如辅助索引,唯一索引,覆盖索引,B+Tree索引…., 墙裂建议不明白的小伙伴可以先去看看[图解MySQL索引(上)—聊聊索引的分类](https://mp.weixin.qq.com/s?__biz=MzI4MTA0OTIxMg==&mid=2247483703&idx=1&sn=8f186c5e1f09440b539594ece0a311eb&chksm=ebae6024dcd9e932e32c4468f0eb1fb8c148bed73ae0c33d06cb05314f2e12e07c977a144002&token=1212138108&lang=zh_CN#rd),本文中关于索引类型的各种定义不再复述。
6 |
7 | ## 一,磁盘IO问题
8 |
9 | > 1.1 磁盘IO
10 |
11 | 所谓磁盘IO,简单来讲就是就是将磁盘中的数据读取到内存或者是从内存写入磁盘。在系统开发与设计过程中,磁盘IO的瓶颈往往不可忽略,因为这是一个相对比较耗时的操作。
12 |
13 | 
14 |
15 | 上图是一个机械硬盘,虽然速度不如SSD,但是由于价格低廉,目前仍是主流的存储介质。它的IO操作通常需要**寻道,旋转和传输**三个步骤。
16 |
17 | 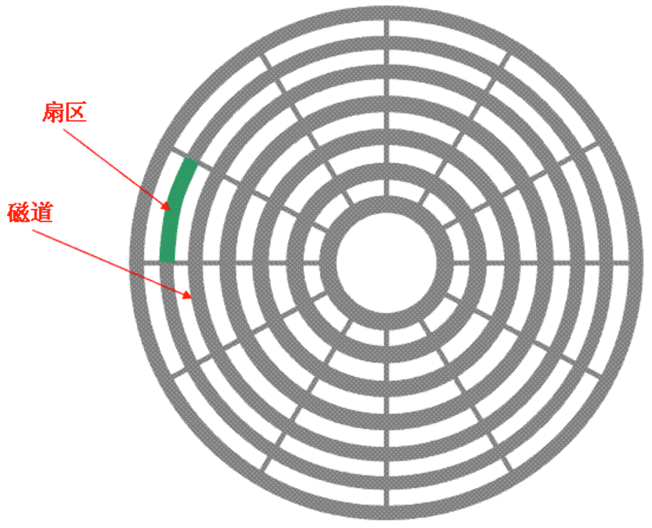
18 |
19 | 寻道,是指将读写磁头移动到正确的磁道,寻道时间越短,IO操作越快,目前磁盘的平均寻道时间一般在3-15ms左右。
20 |
21 | 旋转,是指将盘片旋转到请求数据所在的扇区,这部分所需要的时间由硬盘的配置所决定。旋转延迟由磁盘转速所决定,也就是常说的7200转和5400转等。
22 |
23 | 例如,7200转是指每分钟可以旋转7200圈,那么旋转一圈所需要的时间就是60*1000/7200 ≈ 8.33ms,而旋转延迟通常取旋转一周时间的1/2,也就是大约4.17ms。
24 |
25 | 传输,磁盘传输的速度通常在几十到上百M每秒,假设速度为20M/s,要传输的数据为64kb,则传输时间则是 64 / 1024 / 20 * 1000 = 3.125ms。不过目前流行的SSD传输速度大幅度提升,SATA Ⅱ可以达到300M/s,传输速度往往远小于前两步操作所以传输时间往往可以忽略不记。
26 |
27 | 机械硬盘的连续读写性能很好,但随机读写性能很差,这主要是因为磁头移动到正确的磁道上需要时间,随机读写时,磁头需要不停的移动,时间都浪费在了磁头寻址上,所以性能不高。
28 |
29 | 上述过程是对传统机械磁盘IO延迟的粗略介绍,目的是告诉大家磁盘IO过程是个耗时的过程,内存操作往往与之速度不在同一个数量级。即使是目前比较流行的SSD,想必内存中数据读取性能也差之千里。
30 |
31 | > 1.2 局部性原理
32 |
33 | 由于磁盘IO是一个比较耗时的操作,而操作系统在设计时则定义一个空间局部性原则,局部性原理是指CPU访问存储器时,**无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中**。
34 |
35 | 在操作系统的文件系统中,数据也是按照page划分的,一般为4k或8k。**当计算机访问一个地址数据时,不仅会加载当前数据所在的数据页,还会将当前数据页相邻的数据页一同加载到内存**。而这个过程实际上只发生了1次磁盘IO,这个理论对于索引的数据结构设计非常有帮助。
36 |
37 | ## 二,索引数据结构演进
38 |
39 | 索引是一种**支持快速查找的数据结构**,在运用中往往还要求能够支持**顺序查询**,而常见的数据结构有很多,比如数组,链表,二叉树,散列表,二叉搜索树,平衡搜索二叉树,红黑树,跳表等。仅仅从数据结构那么为什么选择B+Tree呢?
40 |
41 | 首先对于数组,链表这种线性表来说,适合存储数据,而不是查找数据,同样,对于普通二叉树来说,数据存储没有特定规律,所以也不适合。
42 |
43 | > 2.1 哈希索引不能满足业务需求
44 |
45 | 哈希(Hash)是一种非常快的查找方法,在一般情况下这种查找的时间复杂度为O(1),即一般仅需要一次查找就能定位到数据。在各种编程语言和数据库中应用广泛,如Java,Python,Redis中都有使用。
46 |
47 | 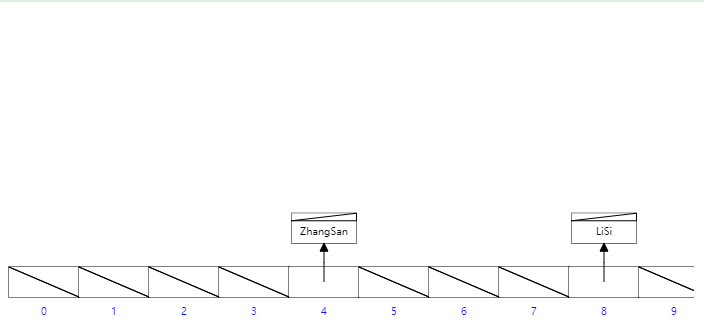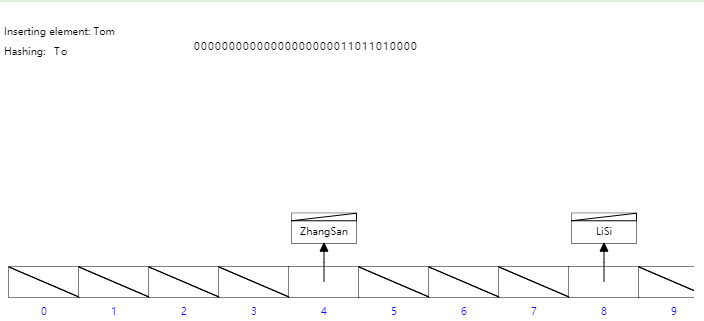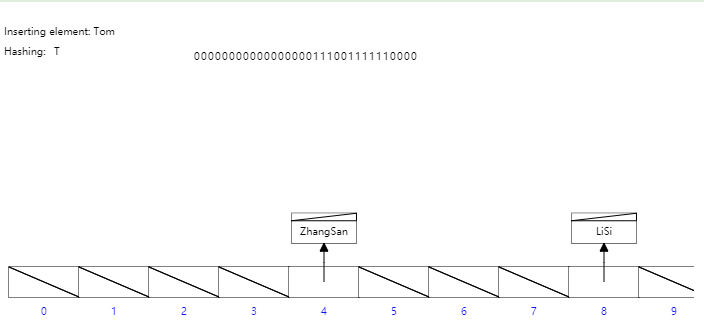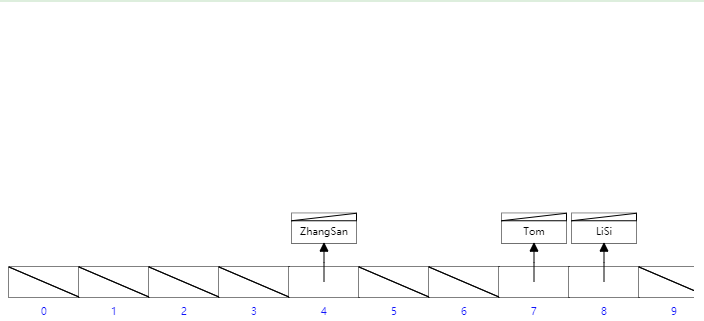
48 |
49 | 哈希结构在单条数据的等值查询是性能非常优秀,但是**只能用来搜索等值的查询**, 对于范围查询,模糊查询(最左前缀原则)都不支持,所以不能很好的支持业务需求;所以MySQL并没有显式支持Hash索引,而是根据数据的访问频次和模式自动的为热点数据页建立哈希索引,称之为自适应哈希索引。
50 |
51 | 并且由于哈希函数的随机性,Hash索引通常都是**随机的内存访问,对于缓存不友好**,会造成频繁的磁盘IO。
52 |
53 | > 2.2 二叉搜索树退化成链表
54 |
55 | 二叉搜索树,如果左子树不为空,则左子树上所有节点均小于根节点,右子树节点均大于根节点;由其属性不难看出,这种树非常适合数据查找。不过有个致命的缺点是**二叉搜索树的树型取决于数据的输入顺序**,极端情况下会退化成链表。
56 |
57 | 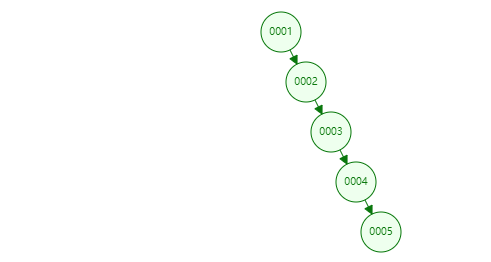
58 |
59 | > 2.3 平衡二叉搜索树过于严格
60 |
61 | 为了解决上述问题,平衡二叉搜索树就诞生了。在保证数据顺序的基础上,又能维持树型,保证每个节点的左右子树高度相差不超过1。
62 |
63 | 不过由于要维持树的平衡,**在插入数据时可能要进行大量的数据移动**。平衡搜索二叉树过于严格的平衡要求,导致几乎每次插入和删除节点都会破坏树的平衡性,使得树的性能大打折扣。
64 |
65 | 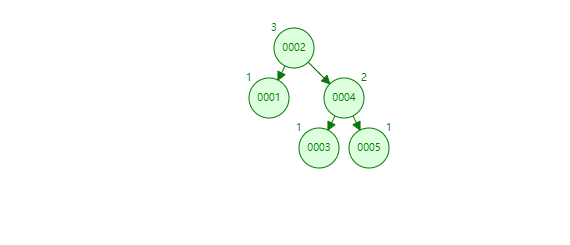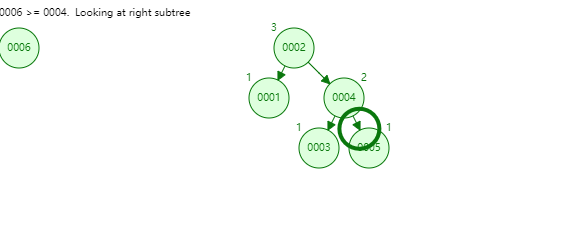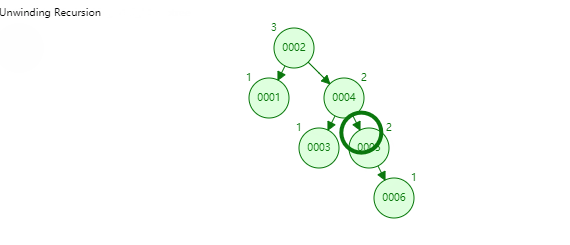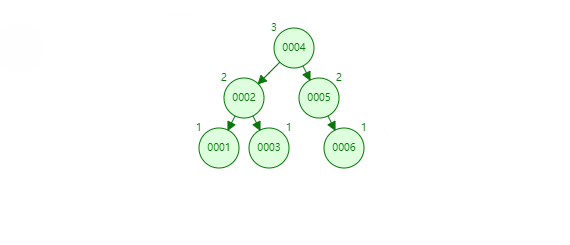
66 |
67 | > 2.4 红黑树高度过高,磁盘IO次数频繁
68 |
69 | 有没有一种数据结构,即能够快速查找数据,又不需要频繁的调整以维持平衡呢?这时红黑树就闪亮登场了。
70 |
71 | 红黑树和其他二叉搜索树类似, 都是在进行插入和删除操作时通过特定操作保持二叉查找树的性质,从而获得较高的查找性能。与之不同的是,红黑树的平衡性并不像平衡搜索二叉树一样严格的同时,又能保证在, O(log n) 时间复杂度内做查找和删除。
72 |
73 | 红黑树通过改变节点的颜色,可以有效减少节点的移动次数,由于红黑树的实现比较复杂,本文不再展开,感兴趣的小伙伴可以去深入学习。
74 |
75 | 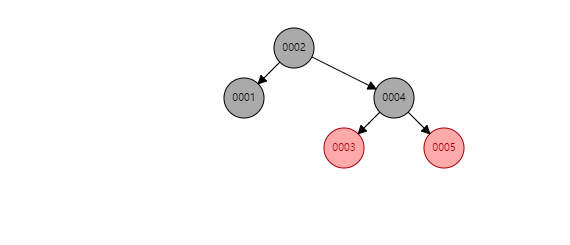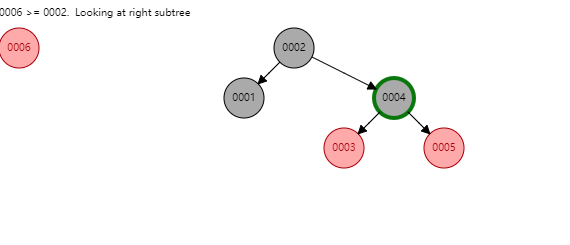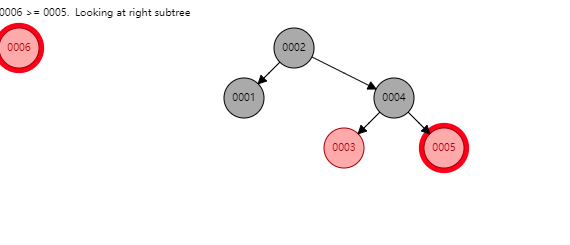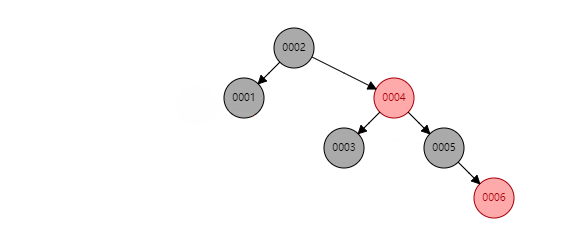
76 |
77 | 看似红黑树是一种完美的数据结构,能够胜任索引的工作。但MySQL并未使用其作为索引的实现,主要原因在于**红黑树的深度过大,数据检索时造成磁盘IO频繁**,假设一个每个节点存储在一个page中,树的高度为10,则每次检索可能就需要进行10次磁盘IO。
78 |
79 | > 2.5 B-Tree不支持顺序查询
80 |
81 | B-Tree是一种自平衡的多叉搜索树,一个节点可以拥有两个以上的子节点。适合读写相对大的数据块的存储系统,例如磁盘。
82 |
83 | 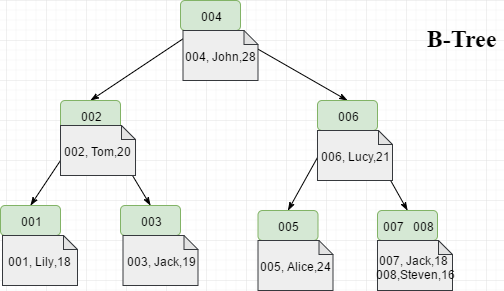
84 |
85 | 由于MySQL索引一般都存储在内存中,如果使用B-Tree作为索引的话,索引和数据存储在一块,分布在各个节点中;而内存资源往往比较宝贵,**一定内存的情况下可以存储的索引数量相对有限**,毕竟每条数据的大小一般远大于索引列的大小,导致内存使用率不高。
86 |
87 | 数据查询过程中往往会有顺序查询,而**B-Tree和红黑树对于顺序查询并不友好**。
88 |
89 | > 2.6 为什么选B+Tree
90 |
91 | B+Tree是在B-Tree基础上演进而来的。与之不同的是B+Tree的数据页只存储在叶子节点中,并且叶子节点之间通过指针相连,为双向链表结构。
92 |
93 | 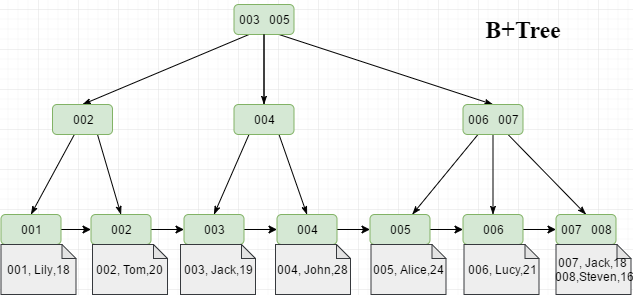
94 |
95 | B+Tree的优点可以分为以四个:
96 |
97 | 1. 充分利用空间局部性原理,适合磁盘存储。
98 | 2. 树的高度很低,能够在存储大量数据情况下,进行较少的磁盘IO【见下文介绍】。
99 | 3. 能够很好支持单值,范围查询,有序性查询。
100 | 4. 索引和数据分开存储,让更多的索引存储在内存中。
101 |
102 | ## 三,MySQL中索引实现
103 |
104 | > 3.1 巧妙利用B+Tree
105 |
106 | MySQL中的数据存储通常以Page为单位,俗称数据页,每个Page对应B+Tree的一个节点。页是InnoDB磁盘管理的最小单位,默认每个数据页的大小为16kb,也可以通过参数innodb_page_size将页的大小设置成其他值。
107 |
108 | 数据库的页大小和操作系统类似,是指存放数据时,每一块连续区域数据的大小。比如一个1M的数据存放在数据库中时, 需要大概64个页来存放(1024=64*16)。如果是在操作系统上安装的数据库,最好将数据库页大小设置为操作系统页大小的倍数,才是最佳设置。
109 |
110 | 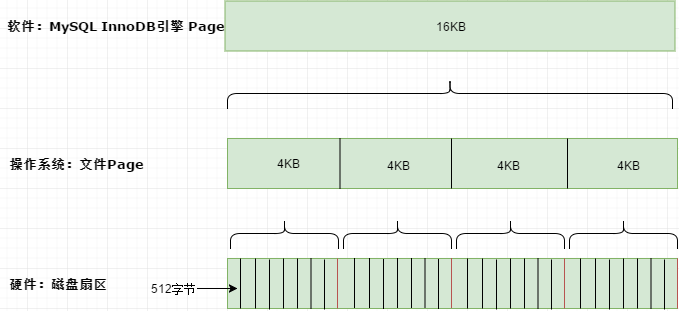
111 |
112 | > 3.2 树的高度-有效减少磁盘IO次数
113 |
114 | 通常情况下,一张MySQL表中有成千上万条数据,而磁盘IO次数往往与数的高度成正比。默认情况下一个Page的大小为16kb,由于每个Page中数据通过指针相连,且每个指针大小为6字节。
115 |
116 | 在工作中,我们通常使用长度为8个字节的bigint类型作为主键id的类型。已知,每一条数据都会包含一个6字节的指针(数据页中每条记录都有指向下一条记录的指针,但是没有指向上一条记录的指针);所以一条索引数据大约占用8+6=14个字节,一个Page中能存储16 * 1024 / 14 ≈ 1170条索引数据。高度为2的B+Tree大约能存储1170*16 = 18720条这样的记录。同理,高度为3的B+Tree的B+Tree大约能存储1170 * 1170 * 16 = 21902400,大约两千万条数据。 (每个节点大约能存储1170条记录,可以理解为此时B+Tree为1170叉树)
117 |
118 | 例如,要检索id=008的数据,则需要进行三次磁盘IO找到对应的数据页(最多三次,因为Page可能在缓存中),然后在数据页中进行二分查找,定位到对应的记录。
119 |
120 | 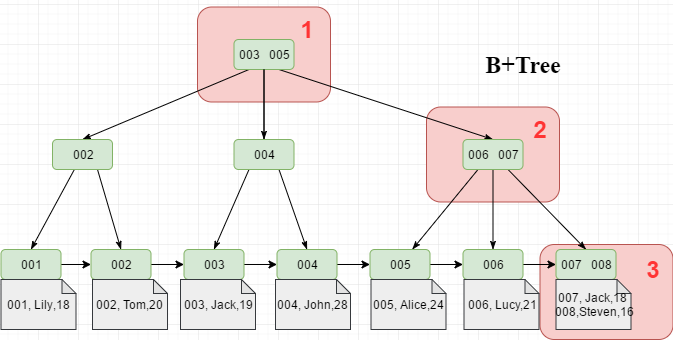
121 |
122 | ## 四,总结
123 |
124 | 大家耳熟能详的B+Tree索引是一种非常优秀的数据结构,也是面试热点问题。本文从数据结构和磁盘IO两个方面分析了为什么使用B+Tree,以及MySQL的InnoDB存储引擎的索引实现。在笔者面试过程中,被问到MySQL索引时通常也是从**底层数据结构特点以及结合磁盘IO**两个角度去分析,屡试不爽。
125 |
126 | 学习一门技术时,我们不仅要知道其优点更要了解其缺点和瓶颈。在分析MySQL索引的实现时,不妨试试从其他数据结构的缺点入手!在Redis中使用跳表实现了有序集合Zset,同样支持高效的顺序查询,对比MySQL索引实现,**跳表能否替换B+Tree**?如果不行,是因为什么呢?
127 |
128 | 
129 |
--------------------------------------------------------------------------------
/docs/mysql/mysql-index-3.md:
--------------------------------------------------------------------------------
1 | # 索引实战
2 |
3 | MySQL使用了B+Tree作为底层数据结构,能够实现快速高效的数据查询功能。工作中可怕的是没有建立索引,比这更可怕的是建好了索引又没有使用到。
4 | 本文将围绕着如何优雅的使用索引,图文并茂地和大家一起探讨索引的正确打开姿势,不谈底层原理,只求工作实战。
5 |
6 | ## 1. 索引的特点
7 |
8 | page之间是双链表形式,而每个page内部的数据则是单链表形式存在。当进行数据查询时,会限定位到具体的page,然后在page中通过二分查找具体的记录。
9 |
10 | 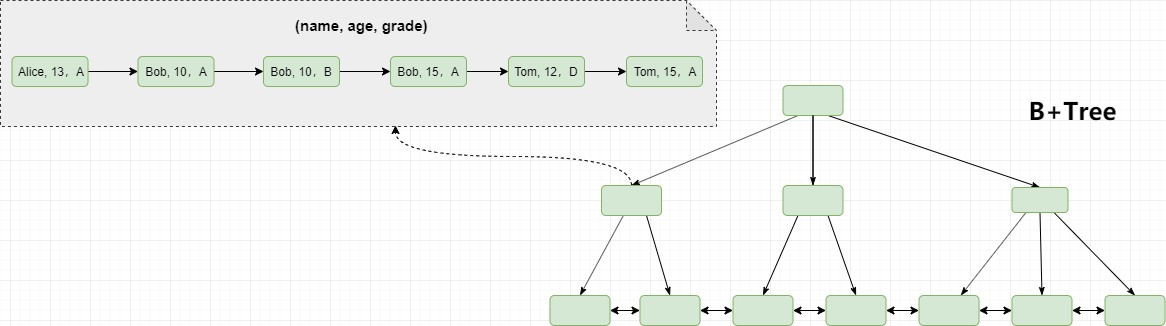
11 |
12 | 并且索引的顺序不同,数据的存储顺序则也不同。所以在开发过程中,一定要注意索引字段的先后顺序。
13 |
14 | 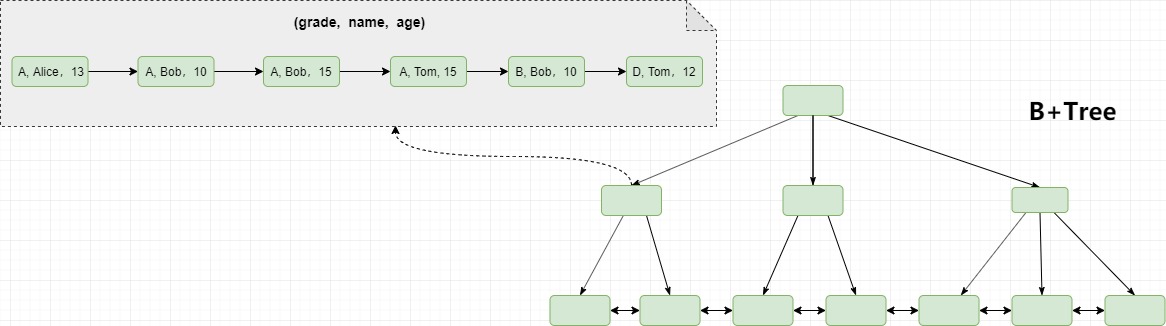
15 |
16 | > 最左匹配原则
17 |
18 | 当一个索引中包含多个字段时,可以称之为组合索引。MySQL中有个很重要的规则,即最左匹配原则用来定义组合索引的命中规则,它是指在检索数据时从联合索引的最左边开始匹配。假设对用户表建立一个联合索引(a,b,c),那么条件a,(a,b),(a,b,c)都会用到索引。
19 |
20 | 在匹配过程中会优先根据最左前面的字段a进行匹配,然后再判断是否用到了索引字段b,直到无法找到对应的索引字段,或者对应的索引被”破坏“(下文中会介绍)。
21 |
22 | 以下是本文中操作实践用到的初始化语句,有条件的同学可以再本地执行,建议使用MySQL5.6+版本,毕竟实操才是学习的最佳途径。
23 |
24 | ```sql
25 | SET NAMES utf8mb4;
26 | -- ----------------------------
27 | -- Table structure for test_table
28 | -- ----------------------------
29 | DROP TABLE IF EXISTS `test_table`;
30 | CREATE TABLE `test_table` (
31 | `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
32 | `a` varchar(255) COLLATE utf8mb4_bin NOT NULL,
33 | `b` varchar(255) COLLATE utf8mb4_bin NOT NULL,
34 | `c` varchar(255) COLLATE utf8mb4_bin NOT NULL,
35 | `d` varchar(255) COLLATE utf8mb4_bin NOT NULL,
36 | PRIMARY KEY (`id`),
37 | KEY `idx_a_b_c` (`a`,`b`,`c`)
38 | ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
39 |
40 | -- ----------------------------
41 | -- Records of test_table
42 | -- ----------------------------
43 | BEGIN;
44 | INSERT INTO `test_table` VALUES
45 | (1, 'zhangsan', '12222222222', '23', 'aafasd'),
46 | (2, 'lisi', '13333333333', '21', 'cxvcxv'),
47 | (3, 'wanger', '14444444444', '24', 'dfdf'),
48 | (4, 'liqiang', '18888888888', '18', 'ccsdf');
49 | COMMIT;
50 | ```
51 |
52 | ## 2. 正确创建索引
53 |
54 | > 尽量使用自增长主键
55 |
56 | 使用自增长主键的原因笔者认为有两个。首先能有效减少页分裂,MySQL中数据是以页为单位存储的且每个页的大小是固定的(默认16kb),如果一个数据页的数据满了,则需要分成两个页来存储,这个过程就叫做页分裂。
57 |
58 | 如果使用了自增主键的话,新插入的数据都会尽量的往一个数据页中写,写满了之后再申请一个新的数据页写即可(大多数情况下不需要分裂,除非父节点的容量也满了)。
59 |
60 | 自增主键
61 |
62 | 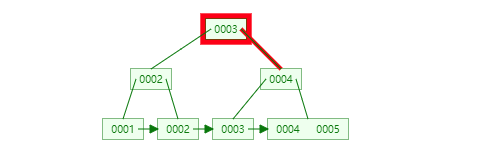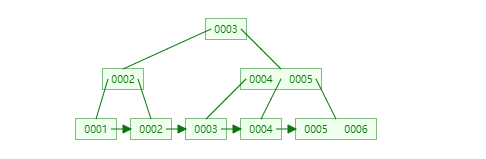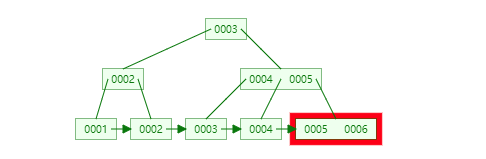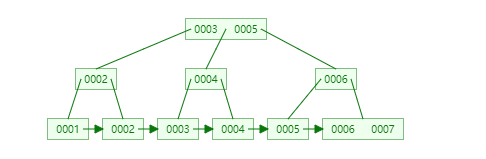
63 |
64 | 非自增主键
65 |
66 | 
67 |
68 | 其次,对于缓存友好。系统分配给MySQL的内存有限,对于数据量比较多的数据库来说,通常只有一小部分数据在内存中,而大多数数据都在磁盘中。如果使用无序的主键,则会造成随机的磁盘IO,影响系统性能。
69 |
70 | > 选择性高的列优先
71 |
72 | 关注索引的选择性。索引的选择性,也可称为数据的熵。在创建索引的时候通常要求将选择性高的列放在最前面,对于选择性不高的列甚至可以不创建索引。如果选择性不高,极端性情况下可能会扫描全部或者大多数索引,然后再回表,这个过程可能不如直接走主键索引性能高。
73 |
74 | 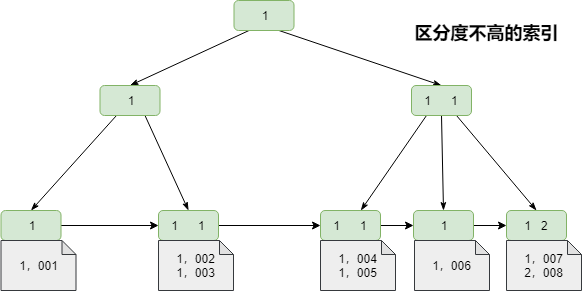
75 |
76 | 索引列的选择往往需要根据具体的业务场景来选择,但是需要注意的是索引的区分度越高则价值就越高,意味着对于检索的性价比就高。索引的区分度等于count(distinct 具体的列) / count(*),表示字段不重复的比例。
77 |
78 | 唯一键的区分度是1,而对于一些状态值,性别等字段区分度往往比较低,在数据量比较大的情况下,甚至有无限接近0。假设一张表中用data_status来表示数据的状态,1-有效,2-删除,则数据的区分度为 1/500000。如果100万条数据中只有1条被删除,并且在查询数据时查找data_status = 0 的数据时,需要进行全表扫描。由于索引也是需要占用内存的,所以在内存较为有限的环境下,区分度不高的索引几乎没有意义。
79 |
80 | > 联合索引优先于多列独立索引
81 |
82 | 联合索引优先于多列独立索引, 假设有三个字段a,b,c, 索引(a)(a,b),(a,b,c)可以使用(a,b,c)代替。MySQL中的索引并不是越多越好,各个公司的规定中往往会限制单表中的索引的个数。原因在于,索引本身也会占用一定的空间,并且维护一个索引时有一定的代码的,所以在满足需求的情况下一定要尽可能创建更少的索引。
83 |
84 | 执行语句:
85 |
86 | ```sql
87 | explain select * from test_table where a = "zhangsan";
88 | explain select * from test_table where a = "zhangsan" and b = "188466668888";
89 | explain select * from test_table where a = "zhangsan" and b = "188466668888" and c = "23";
90 | ```
91 |
92 | 执行结果分析:
93 |
94 | 
95 |
96 | 
97 |
98 | 
99 |
100 | 实际上建立(a, b, c)联合索引时,其作用相当于(a), (a, b), (a, b, c) 三个索引。所以以上三种查询方式均会命中索引。
101 |
102 | > 覆盖索引避免回表
103 |
104 | 覆盖索引如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引 k 已经“覆盖了”我们的查询需求,我们称为覆盖索引。由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
105 |
106 | 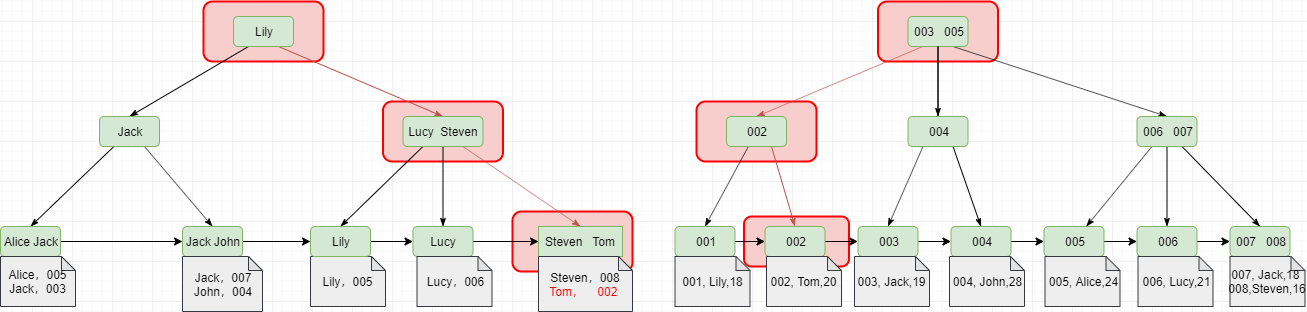
107 |
108 | 
109 |
110 | **覆盖索引的查询优化**
111 |
112 | 覆盖索引同时还会影响索引的选择,对于(a,b,c)索引来说,理论上来说不满足最左匹配原则,但是实际上也会走索引。原因在于,优化器认为(a,b,c)索引的性能会高于全表扫描,实际情况也是这样的,感兴趣的小伙伴不妨分析一下上文中介绍的数据结构。
113 |
114 | ```sql
115 | explain select a,b,c from test_table where b = "188466668888" and c = "23";
116 | ```
117 |
118 | 执行结果:
119 |
120 | 
121 |
122 |
123 | > 满足查询和排序
124 |
125 | 索引要满足查询和排序。大部分同学在创建索引时,通常第一反应是查询条件来选择索引列,需要注意的是查询和排序同样重要,我们建立的索引要同时满足查询和排序的需求.
126 |
127 | **包含要排序的列**
128 |
129 | ```sql
130 | select c, d from test_table where a = 1 and b = 2 order by c;
131 | ```
132 |
133 | 虽然查询条件只使用了a,b两个字段,但是由于排序用到了c字段,我们能可以建立(a,b,c)联合索引来进行优化。
134 |
135 | **保证索引字段顺序**
136 |
137 | 如上文中的介绍,索引的字段顺序决定了索引数据的组织顺序。要想更高性能的检索数据,一定要尽可能的借助底层数据结构的特点来进行。如,索引(a, b)的默认组织形式就是先根据a排序,在a相同的情况下再根据b排序。
138 |
139 | > 考虑索引的大小
140 |
141 | 内存中的空间十分宝贵,而索引往往又需要在内存中。为了在有限的内存中存储更多的索引,在设计索引时往往要考虑索引的大小。比如我们常用的邮箱,xxxx@xx.com, 假设都是abc公司的,则邮箱后缀完全一致为@abc.com, 索引的区分度完全取决于@前面的字符串。
142 |
143 | 针对上述情况,MySQL 是支持**前缀索引**的,也就是说,你可以定义字符串的一部分作为索引。默认地,如果你创建索引的语句不指定前缀长度,那么索引就会包含整个字符串。
144 |
145 | 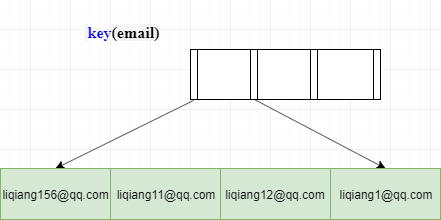
146 |
147 | 如果使用的 email 整个字符串的索引结构执行顺序是这样的:从 index1 索引树找到满足索引值是’liqiang156@11.com’的这条记录,取得 id (主键)的值ID2;到主键上查到主键值是ID2的行,将这行记录加入结果集;
148 |
149 | 取 email 索引树上刚刚查到的位置的下一条记录,发现已经不满足 email='liqiang156@qq.com’的条件了,循环结束。这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。但是它的问题就是索引的后半部分都是重复的,浪费内存。
150 |
151 | 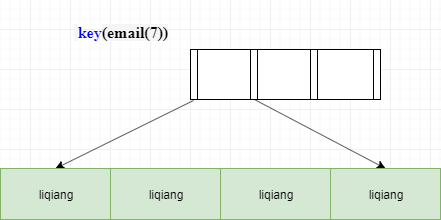
152 |
153 | 这时我们可以考虑使用前缀索引,如果使用的是 index2 (email(7) 索引结构),执行顺序是这样的:从 index2 索引树找到满足索引值是’liqiang’的记录,找到的第一个是 ID1,到主键上查到主键值是 ID1 的行,判断出 email 的值是’liqiang156@xxx.com’,加入结果集。
154 |
155 | 取 index2 上刚刚查到的位置的下一条记录,发现仍然是’liqiang’,取出 ID2,再到 ID 索引上取整行然后判断,这次值仍然不对,则丢弃继续往下取。
156 | 重复上一步,直到在 index2 上取到的值不是’liqiang’或者索引搜索完毕之后,循环结束。在这个过程中,要回主键索引取 4 次数据,也就是扫描了 4 行。通过这个对比,你很容易就可以发现,使用前缀索引后,可能会导致查询语句读数据的次数变多。
157 |
158 | 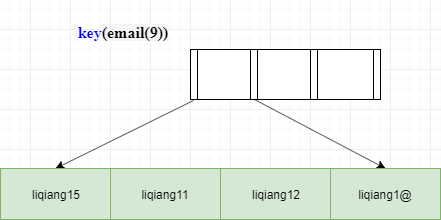
159 |
160 | 不过方法总比困难多,我们在建立索引时可以先通过语句查看一下索引的区分度,或者提前预估余下前缀长度,对于上述问题我们可以将前缀长度调整为9即可达到效果。索引,在使用前缀索引时,一定要充分考虑数据的特征,选择合适的
161 |
162 | 对于一些比较长的字段的等值查询,我们也可以采用其他方式来缩短索引的长度。比如url一般都是比较长,我们可以冗余一列**存储其Hash值**。
163 |
164 | ```sql
165 | select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
166 | ```
167 |
168 | 对于我们国家的身份证号,一共 18 位,其中前 6 位是地址码,所以同一个县的人的身份证号前 6 位一般会是相同的。为了提高区分度,我们可以将身份证号码**倒序存储**。
169 |
170 | ```sql
171 | select field_list from t where id_card = reverse('input_id_card_string');
172 | ```
173 |
174 | ## 3. 正确使用索引
175 |
176 | 建立合适的索引是前提,想要取得理想的查询性能,还应保证能够用到索引。避免索引失效即是优化。
177 |
178 | > 不在索引上进行任何操作
179 |
180 | 索引上进行**计算,函数,类型转换**等操作都会导致索引从当前位置(联合索引多个字段,不影响前面字段的匹配)失效,可能会进行全表扫描。
181 |
182 | ```sql
183 | explain select * from test_table where upper(a) = "ZHANGSAN"
184 | ```
185 |
186 | 
187 |
188 | 对于需要计算的字段,则一定要将计算方法放在“=”后面,否则会破坏索引的匹配,目前来说MySQL优化器不能对此进行优化。
189 |
190 | ```sql
191 | explain select * from test_table where a = lower("ZHANGSAN")
192 | ```
193 |
194 | 
195 |
196 | **隐式类型转换**
197 |
198 | 需要注意的是,在查询时一定要注意字段类型问题,比如a字段时字符串类型的,而匹配参数用的是int类型,此时就会发生隐式类型转换,相当于相当于在索引上使用函数。
199 |
200 | ```sql
201 | explain select * from test_table where a = 1;
202 |
203 | ```
204 |
205 | 
206 | `a是字符串类型,然后使用int类型的1进行匹配`,此时就发生了隐式类型转换,破坏索引的使用。
207 |
208 | > 只查询需要的列
209 |
210 | 在日常开发中很多同学习惯使用 select * ... 来构建查询语句,这种做法也是极不推荐的。主要原因有两个,首先查询无用的列在数据传输和解析绑定过程中会增加网络IO,以及CPU的开销,尽管往往这些消耗可以被忽略,但是我们也要避免埋坑。
211 |
212 | ```sql
213 | explain select a,b,c from test_table where a="zhangsan" and b = "188466668888" and c = "23";
214 | ```
215 |
216 | 
217 |
218 | 其次就是会使得覆盖索引"失效", 这里的失效并非真正的不走索引。覆盖索引的本质就是在索引中包含所要查询的字段,而 select * 将使覆盖索引失去意义,仍然需要进行回表操作,毕竟索引通常不会包含所有的字段,这一点很重要。
219 |
220 | ```sql
221 | explain select * from test_table where a="zhangsan" and b = "188466668888" and c = "23";
222 | ```
223 |
224 | 
225 |
226 | > 不等式条件
227 |
228 | 查询语句中只要包含不等式,负向查询一般都不会走索引,如 !=, <>, not in, not like等。
229 |
230 | ```sql
231 | explain select * from test_table where a !="1222" and b="12222222222" and c = 23;
232 | explain select * from test_table where a <>"1222" and b="12222222222" and c = 23;
233 | ```
234 |
235 | 
236 |
237 | ```sql
238 | explain select * from test_table where a not in ("xxxx");
239 | ```
240 |
241 | 
242 |
243 | > 模糊匹配查询
244 |
245 | 最左前缀在进行模糊匹配时,一般禁止使用%前导的查询,如like “%zhangsan”。
246 |
247 | ```sql
248 | explain select * from test_table where a like "zhangsan";
249 | explain select * from test_table where a like "%zhangsan";
250 | explain select * from test_table where a like "zhangsan%";
251 | ```
252 |
253 | 
254 |
255 | 
256 |
257 | 
258 |
259 | > 最左匹配原则
260 |
261 | 索引是有顺序的,查询条件中缺失索引列之后的其他条件都不会走索引。比如(a, b, c)索引,只使用b, c索引,就不会走索引。
262 |
263 | ```sql
264 | explain select * from test_table where b = "188466668888" and c = "23";
265 |
266 | ```
267 |
268 | 
269 |
270 | 如果索引从中间断开,索引会部分失效。这里的断开指的是缺失该字段的查询条件,或者说满足上述索引失效情况的任意一个。不过这里的仍然会使用到索引,只不过只能使用到索引的前半部分。
271 |
272 | ```sql
273 | explain select * from test_table where a="zhangsan" and b != 1 and c = "23"
274 |
275 | ```
276 |
277 | 
278 |
279 | 值得注意的是,如果使用了不等式查询条件,会导致索引完全失效。而上一个例子中即使用了不等式条件,也使用了隐式类型转换却能用到索引。
280 |
281 | 
282 |
283 | 同理,根据最左前缀匹配原则,以下如果使用b,c作为查询条件则不会使用(a, b, c)索引。
284 |
285 | 执行语句:
286 |
287 | ```sql
288 | explain select * from test_table where b = "188466668888" and c = "23";
289 |
290 | ```
291 |
292 | 执行结果:
293 |
294 | 
295 |
296 | **索引下推**
297 |
298 | 在说索引下推之前,我们先执行一下SQL。
299 |
300 | 执行语句:
301 |
302 | ```sql
303 | explain select * from test_table where a = "zhangsan" and c = "23";
304 |
305 | ```
306 |
307 | 
308 |
309 | 上述的最左前缀匹配原则相信大家都能很容易的理解,那么使用(a, c)条件查询能够利用(a, b, c)吗?答案是肯定的,正如上图所示。即使没有索引下推也会会根据最左匹配原则,使用到索引中的a字段。有了索引下推之后会增加查询的效率。
310 |
311 | 在面试中通常会问到这样一个问题,已知有索引(a,b,c)则根据条件(a,c)查询时会不会走索引呢?答案是肯定的,但是是有版本限制的。
312 |
313 | 而 MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数,是对查询的一种优化,感兴趣的同学可以看一下官方说明https://dev.mysql.com/doc/refman/8.0/en/index-condition-pushdown-optimization.html。
314 |
315 | 
316 |
317 | 上述是没有索引下推,每次查询完之后都会回表,取到对应的字段进行匹配。
318 |
319 | 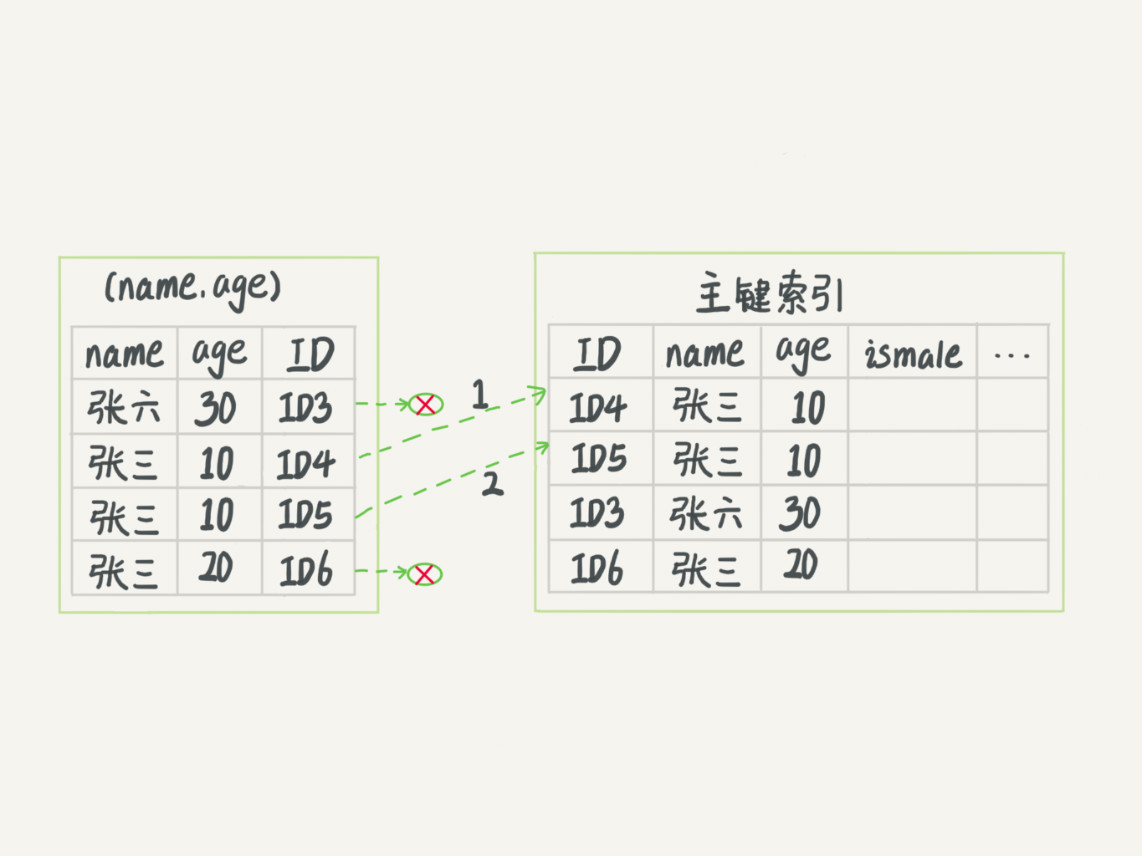
320 | 利用索引下推,每次尽可能在辅助索引中将不符合条件数据过滤掉。比如,索引中已经包含了name和age,索引不妨暂且忽略破坏索引匹配的条件直接匹配。
321 |
322 | **查询优化-自适应索引顺序**
323 |
324 | 查询时,mysql的优化器会优化sql的执行,即使查询条件的顺序没有按照定义顺序来使用,也是可以使用索引的。但是需要注意的是优化本身也会消耗一定的性能,所以还是推荐按照索引的定义来书写sql。
325 |
326 | ```sql
327 | explain select * from test_table where b="12222222222" and a="zhangsan" and c = 23;
328 | explain select * from test_table where a="zhangsan" and b="12222222222" and c = 23;
329 |
330 | ```
331 |
332 | 
333 |
334 | ## 4. 总结
335 |
336 | 索引并不是什么高深的技术,从底层来看,不过是一个数据结构罢了。要想使用好索引,一定要先将B+Tree理解透彻,在此基础上对于日常使用和面试则是信手拈来。
337 |
338 | 脱离业务的设计都是耍流氓,技术的意义在于服务业务。所以,索引的设计需要充分考虑业务的需求与设计原则之间做一些取舍,满足需求是基础。
339 |
340 | 在工作中,各个公司的版本可能大不相同,会存在一些奇奇怪怪,不确定的问题。所以为了验证索引的有效性,强烈推荐把主要的查询sql都通过explain查看一下执行计划,是否会用到索引。
341 |
342 | ## 参考资料:
343 | 1.《MySQL 45讲》—极客时间
344 | 2.《InnoDB存储引擎》
345 | 3.《高性能MySQL》
346 | 4. https://dev.mysql.com/doc/refman/8.0/en/
347 |
--------------------------------------------------------------------------------
/docs/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "JavaTKBJ",
3 | "version": "1.0.0",
4 | "private": true,
5 | "scripts": {
6 | "clean": "rimraf dist && rimraf .temp",
7 | "build": "npm run clean && vuepress build",
8 | "start": "vuepress dev ./",
9 | "lint": "markdownlint -r markdownlint-rule-emphasis-style -c ./.markdownlint.json **/*.md -i node_modules",
10 | "lint:fix": "markdownlint -f -r markdownlint-rule-emphasis-style -c ./.markdownlint.json **/*.md -i node_modules",
11 | "show-help": "vuepress --help",
12 | "view-info": "vuepress view-info ./ --temp .temp"
13 | },
14 | "devDependencies": {
15 | "@vuepress/plugin-active-header-links": "^1.8.2",
16 | "@vuepress/plugin-back-to-top": "^1.8.2",
17 | "@vuepress/plugin-medium-zoom": "^1.8.2",
18 | "@vuepress/plugin-pwa": "^1.4.0",
19 | "@vuepress/theme-vue": "^1.8.2",
20 | "markdownlint-cli": "^0.25.0",
21 | "markdownlint-rule-emphasis-style": "^1.0.1",
22 | "rimraf": "^3.0.1",
23 | "vue-toasted": "^1.1.25",
24 | "vuepress": "^1.8.2",
25 | "vuepress-plugin-flowchart": "^1.4.0"
26 | },
27 | "dependencies": {
28 | "moment": "^2.29.1",
29 | "vssue": "^1.4.8",
30 | "vuepress-plugin-mygitalk": "^1.0.5"
31 | }
32 | }
33 |
--------------------------------------------------------------------------------
/docs/test/README.md:
--------------------------------------------------------------------------------
1 | # Test
2 | ## 📖 内容
3 | - [JMH使用教程](jmh-tutorial.md)
4 | ## 📚 资料
5 |
6 | ## 🚪 传送
7 |
8 |
--------------------------------------------------------------------------------
/docs/test/experiment-md.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "我的VuePress试验田"
3 | date: "2021-07-13"
4 | description: "VuePress测试"
5 | ---
6 | ## 扩展语法
7 | ### 链接
8 | 代码:
9 | ```md
10 | [首页](/)
11 | [JMH使用教程](./jmh-tutorial.md)
12 | [MySQL](../mysql/)
13 | [MySQL-1](../mysql/mysql-index-1.md)
14 | [外部链接](http://www.baidu.com)
15 | ```
16 | 示例:
17 | [首页](/)
18 |
[JMH使用教程](./jmh-tutorial.md)
19 |
[MySQL](../mysql/)
20 |
[MySQL-1](../mysql/mysql-index-1.md)
21 |
[外部链接](http://www.baidu.com)
22 |
23 | ### 目录
24 | 代码:
25 | ```md
26 | [[toc]]
27 | ```
28 | 示例:
29 | [[toc]]
30 |
31 | ### 自定义容器
32 | ```md
33 | ::: tip
34 | 这是一个提示
35 | :::
36 |
37 | ::: warning
38 | 这是一个警告
39 | :::
40 |
41 | ::: danger
42 | 这是一个危险警告
43 | :::
44 |
45 | ::: details
46 | 这是一个详情块,在 IE / Edge 中不生效
47 | :::
48 | ```
49 | 示例:
50 |
51 | ::: tip 温馨提示
52 | 这是一个提示
53 | :::
54 |
55 | ::: warning 注意事项
56 | 这是一个警告
57 | :::
58 |
59 | ::: danger 危险告警
60 | 这是一个危险警告
61 | :::
62 |
63 | ::: details
64 | 这是一个详情块,在 IE / Edge 中不生效
65 | :::
66 |
67 | ::: details 点击查看代码
68 | ```js
69 | console.log('你好,VuePress!')
70 | ```
71 | :::
72 |
73 | ### 代码中的亮行
74 | 代码:
75 | ```md
76 | ``` js {4}
77 | export default {
78 | data () {
79 | return {
80 | msg: 'Highlighted!'
81 | }
82 | }
83 | }
84 | ```
85 | ```
86 | 示例:
87 | ``` js {4}
88 | export default {
89 | data () {
90 | return {
91 | msg: 'Highlighted!'
92 | }
93 | }
94 | }
95 | ```
96 | ### 标题主题
97 | 代码:
98 | ```md
99 | ## 标题主题
100 | ```
101 |
102 | 属性:
103 | * `text`-string
104 | * `type`-string, 可选值 "tip"|"warning"|"error",默认值是: "tip"
105 | * `veritcal`-string, 可选值: "top"|"middle",默认值是: "top"
106 |
107 | 示例
108 |
109 | ```md
110 | ## 标题主题
111 | ```
112 |
113 | # 一级标题
114 |
115 | ## 二级标题
116 |
117 | ### 三级标题
118 |
119 | #### 四级标题
120 | ```md
121 | # 一级标题
122 |
123 | ## 二级标题
124 |
125 | ### 三级标题
126 |
127 | #### 四级标题
128 | ```
129 |
130 | ```java
131 | public class JMHSample_01_HelloWorld {
132 |
133 | @Benchmark
134 | public void wellHelloThere() {
135 | }
136 |
137 | public static void main(String[] args) throws RunnerException {
138 | Options opt = new OptionsBuilder()
139 | .include(JMHSample_01_HelloWorld.class.getSimpleName())
140 | .forks(1)
141 | .build();
142 |
143 | new Runner(opt).run();
144 | }
145 | ```
--------------------------------------------------------------------------------
/docs/test/jmh-tutorial.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "JMH使用教程"
3 | date: "2021-07-13"
4 | description: "基准测试,JMH教程,JMH用法,微基准测试"
5 | footer: CC-BY-SA-4.0 Licensed | Copyright © liqiang
6 | ---
7 |
8 | ## 概述
9 | * ArrayList 和 LinkedList谁更快?
10 | * 二维数组行优先和列优先哪种方式遍历更优?
11 | * StringBuilder 和 StringBuffer性能差异多少?
12 |
13 | 在工作中我们有很多性能对比测试的需求,为了能得出正确的结论,避免受到不必要的挑战,我们需要给出量化的测试结果。
14 |
15 | 所以掌握一种科学的,量化对比测试方法很有必要,尤其是对于从事底层开发来说,这是一项必会的技能。
16 |
17 | ### 基准测试
18 | 基准测试(Benckmarking)是指通过设计科学的测试方法、测试工具和测试系统,实现对一类测试对象的某项性能指标进行定量的和可对比的测试。
19 |
20 | 例如,对计算机CPU进行浮点运算、数据访问的带宽和延迟等指标的基准测试,可以使用户清楚地了解每一款CPU的运算性能及作业吞吐能力是否满足应用程序的要求.
21 |
22 | ### JMH 是什么
23 | JMH(Java Microbenchmark Harness)是一个用来构建,执行和分析 Java 和其他面向 JVM 的语言的微基准测试工具包。
24 |
25 | 所谓微基准指的是其测试精读最高可达**纳秒**级别,使得应用场景更广,测试结果更加精准;而Harness则就表明了其不仅能够进行测试,还集成了生成测试报告的能力,当代码执行完毕后,可以轻而易举地生成图片和报表。
26 |
27 | TODO: 图片
28 |
29 | JMH 与 JVM 是同一团队开发的,所以针对虚拟机的各种优化 JMH 也会考虑在内。是比较靠谱的一个基准测试工具,在很多开源框架中也使用JMH做性能测试。
30 |
31 | ## QuickStart
32 | ### 命令行中构建
33 |
34 | 在测试大型项目时,通常将基准测试保存在单独的子项目(模块)中,通过构建依赖关系来依赖测试模块。通常不建议在IDE中运行基准测试,因为基准测试运行的环境通常不受控制。
35 |
36 | 虽推荐使用命令行的方式,但是很多人仍然你喜欢使用IDE。IDE的具体使用教程请移步[JMH官方文档]( https://github.com/openjdk/jmh)。此处介绍命令行的方式构建基准测试程序。
37 |
38 | **Step 1**:配置基准测试项目。使用以下命令,可以基于 maven 模板,在test文件夹下生成一个 JMH 驱动的项目。
39 |
40 | ```shell
41 | $ mvn archetype:generate \
42 | -DinteractiveMode=false \
43 | -DarchetypeGroupId=org.openjdk.jmh \
44 | -DarchetypeArtifactId=jmh-java-benchmark-archetype \
45 | -DgroupId=org.sample \
46 | -DartifactId=test \
47 | -Dversion=1.0
48 | ```
49 | 如果您想要对其他的JVM语言进行基准测试,只需要将DarchetypeArtifactId参数值改成即可,具体可选项参考已有的[模板列表](https://repo.maven.apache.org/maven2/org/openjdk/jmh/)。
50 |
51 | **Step 2**:构建基准测试。在项目生成后,可以通过一下命令进行构建项目。
52 |
53 | ```shell
54 | cd test/
55 | mvn clean verify
56 | ```
57 |
58 | **Step 3**:运行基准测试。当项目构建完成后,你会得到包含所有的JMH基础代码以及你的基准测试代码的可执行jar包。运行它即可。
59 |
60 | ```
61 | java -jar target/benchmarks.jar
62 | ```
63 |
64 | ## JMH 注意事项
65 | 想要获得准确的测试结果,我们必须模拟程序的真实执行场景,排除JVM优化和其他无关操作对执行结果的影响。
66 | ### JVM,操作系统优化
67 | **无效代码消除(Dead Code Elimination)**,在运行时不是所有代码都会执行。当JVM认为一段逻辑执行后没有结果输出或者外部影响,就会将当前代码判定为DeadCode,从而不会执行这段代码。
68 |
69 | ::: details 代码示例
70 | ```java
71 | @Benchmark
72 | public void measureWrong() {
73 | // 这是错误的:结果没有被使用,整个计算将会被编译器优化。
74 | Math.log(x);
75 | }
76 | ```
77 | :::
78 | **常量折叠(Constant Folding)**,是通过对编译时常量或常量表达式进行计算来简化代码。它是无效代码消除的另一种形式。
79 |
80 | ::: details 代码示例
81 | ```java
82 | @Benchmark
83 | public void measureWrong() {
84 | // 常量折叠
85 | int x = 7 * 8 / 2;
86 | int y = 4;
87 | // 常量传播(也属于常量折叠)
88 | return x + y;
89 | }
90 | ```
91 | :::
92 | 以上代码经过编译器的常量折叠优化后,会直接返回一个数值,无需额外计算,具体代码如下:
93 | ::: details 代码示例
94 | ```java
95 | @Benchmark
96 | public void measureWrong() {
97 | return 32;
98 | }
99 | ```
100 | :::
101 |
102 | JVM是解释执行语言,Java代码会先编译成二进制码(.class文件),然后加载到JVM中,在运行时时在转换成机器码执行。HotSpot自适应优化器在执行期间收集有关程序热点的信息,会将热点编译为机器码以提高程序的秩序速度。
103 |
104 | **方法内联(Inlining)**是JVM非常重要的一个优化,内联是一种优化已编译源源码的方式,通常将最常执行的方法调用(也称之为热点),在运行时替换为方法主体,以便减少调用成本。比如 A 方法内调用 B 方法,则编译器可能会将 B 方法的代码编译进 A 方法体中,以提高 A 方法的执行速度。
105 | ::: details 代码示例
106 | ```java
107 | private int addFour(int x1 , int x2 , int x3 , int x4) {
108 | return addTwo(x1 , x2) + addTwo(x3, x4);
109 | }
110 |
111 | private int addTwo(int x1 , int x2) {
112 | return x1 + x2;
113 | }
114 |
115 | // 内联后
116 | private int addFour(int x1 , int x2 , int x3 , int x4) {
117 | // return addTwo(x1 , x2) + addTwo(x3, x4);
118 | return x1 + x2 + x3 + x4;
119 | }
120 | ```
121 | :::
122 | ### 资源释放与销毁
123 | 测试时往往会依赖于一些参数和外部资源,这些和测试目标无关的操作,不应当计入测试报告中。
124 | 比如测试文件随机访问性能时,我们要在每次此时执行之前生成测试文件;测试HashMap和ConcurrentHashmap的性能区别时,我们要预先构建出相应的测试数据。
125 | ::: details 代码示例
126 | ```java
127 | // 错误代码示例
128 |
129 | ```
130 | :::
131 |
132 | ### 注意事项
133 |
134 | 1. 用户可以通过注解选择默认的执行模式,也可以通过运行时选择其他的模式。
135 |
136 | 2. 在测试过程中我们的代码可能会因为性能抛出异常,此时需要声明将它们抛出去即可。如果代码抛出了实际的异常,此次测试将会因为报错而立马终止。
137 |
138 | 3. 当你对代码执行行为或结果感到疑惑时,需要检查生成的代码是否和你的预期相符。准确的测试结果往往需要正确得试验配置,所以交叉检查生成的代码对试验的成功至关重要。
139 | 生成的代码位置一般在/target/generated-sources/annotations/.../XXXX.java。
140 |
141 | ## @Benchmark:Hello world
142 |
143 | Benchmark注解用于基准方法之上。JMH会在编译时为该方法生成生成的benchmark代码,将该方法注册到及注册时方法列表中,从注解中读出默认值,然后为benchmark准备运行环境。
144 |
145 | 测试可以使存粹的性能测试,也可以是对比测试,所以一个基准测试类中可以包含多个被@Benchmark注释的代码,表示将进行多组基准测试。
146 |
147 | 需要注意的是,org.openjdk.jmh.annotations包中的大多数注解都可以放在Benchmark方法中,也可以放在类上由类中的所有Benchmark方法继承。
148 |
149 | ### 使用限制
150 | 1. 修饰的方法应该是public的
151 | 2. 方法入参只能包括调用方法时注入的@State对象(下文有介绍),或者@Blackhole对象
152 | 3. 只有在相关的State放在封闭类上时,方法才能同步
153 |
154 | 如果要对破坏这些属性的方法进行基准测试,则必须将它们写成不同的方法并从Benchmark方法中调用它们。
155 | Benchmark 方法可以声明要抛出的异常和 Throwable,任何实际引发和抛出的异常都将被视为基准测试失败
156 | ### 代码示例
157 | ::: details 代码示例
158 | ```java
159 | public class JMHSample_01_HelloWorld {
160 |
161 | @Benchmark
162 | public void wellHelloThere() {
163 | }
164 |
165 | public static void main(String[] args) throws RunnerException {
166 | Options opt = new OptionsBuilder()
167 | .include(JMHSample_01_HelloWorld.class.getSimpleName())
168 | .forks(1)
169 | .build();
170 |
171 | new Runner(opt).run();
172 | }
173 | ```
174 | :::
175 | ### 让程序跑起来
176 | 构建JMH程序的执行方式分为两种,即命令行和IDE。对于基准测试方法的执行,我们还有很多可选的配置参数,比如程序的执行时间,执行次数,预热次数等,这些在下文将会进行详细介绍。
177 | 假设是通过命令行构建的程序,我们通过以下命令执行程序。
178 | ```
179 | :::shell
180 | # a) Via command-line:
181 | $ mvn clean install
182 | $ java -jar target/benchmarks.jar JMHSample_01
183 | ```
184 | :::
185 | 也可以通过JavaAPI方式运行程序,我们需要在main方法中执行,将执行所需要的参数设置到Options对象中,然后通过Runner方法的run方法启动程序即可。
186 | ::: details 代码示例
187 | ```java
188 | public static void main(String[] args) throws RunnerException {
189 | Options opt = new OptionsBuilder()
190 | .include(JMHSample_01_HelloWorld.class.getSimpleName())
191 | .forks(1)
192 | .build();
193 |
194 | new Runner(opt).run();
195 | }
196 | ```
197 | :::
198 | ### 参数设置原则
199 | 对于配置参数,我们可以通过三种方式进行设置,即 注解,Java API/命令行。
200 |
201 | 命令行/JavaAPI模式统称为命令行选项,如果是命令行模式,我们可以在命令行中指定对应的参数即可;如果是在IDE通过main方法执行,则可以通过在Options配置JMH的执行参数。
202 |
203 | 除了运行时所有的命令行选项外,我们还可以通过注解给一些基准测试提供默认值。在你处理大量基准测试时这个很有用,因为其中一些基准方法需要特殊处理。
204 |
205 | 注解可以放在class上,来影响这个class中所有的基准测试方法。规则是,靠近作用域的注解有优先权:比如,方法上的注解可以覆盖类上的注解;命令行优先级最高。
206 |
207 | #### 代码示例
208 | ::: details 代码示例
209 | ```java
210 | @State(Scope.Thread)
211 | @OutputTimeUnit(TimeUnit.MICROSECONDS)
212 | public class JMHSample4ParamsSetup {
213 |
214 | double x1 = Math.PI;
215 |
216 | /*
217 | * 方法上的@Measurement覆盖类上的设置
218 | */
219 | @Benchmark
220 | @OutputTimeUnit(TimeUnit.MICROSECONDS)
221 | public double measure() {
222 | return Math.log(x1);
223 | }
224 |
225 | public static void main(String[] args) throws RunnerException {
226 | Options opt = new OptionsBuilder()
227 | .include(JMHSample_20_Annotations.class.getSimpleName())
228 | .timeUnit(TimeUnit.SECONDS)
229 | .build();
230 | new Runner(opt).run();
231 | }
232 |
233 | }
234 | ```
235 | :::
236 | 如果在IDE中执行以上案例,测试报告中的单位应该是秒,因为命令行选项的优先级最高。
237 |
238 | ## @OutputTimeUnit:结果时间单位
239 | 我们可以在方法或者类上加@OutputTimeUnit注解,来设置执行结果测试报告中的时间单位,JMH支持的精读范围是 纳秒 到 天。
240 |
241 | ::: tip 时间单位换算
242 | 1000纳秒= 1 微秒,1000微秒=1毫秒 ,1秒=1000毫秒
243 | :::
244 | ## @BenchmarkMode: 明确测量指标
245 | 进行基准测试之前,我们首先要根据测试目的设定一些指标。是吞吐量还是执行时间?
246 | 这时可以通过@BenckmarkMode设置,可以传入1个或者多个Mode枚举值设置测量指标。
247 |
248 | ### Mode可选参数
249 | 吞吐量(Throughput),表示在单位时间内的执行次数。通过在一段时间内(time)不断调用基准方法,统计该方法(ops)的执行次数进而计算吞吐量,即throughput = ops/time。
250 |
251 | 平均时间(AverageTime), AverageTime= time/ops, 表示每次执行所需要的平均时间。和Throughput类似,此模式是基于时间的,通过在一段时间内(time)不断调用基准方法,统计该方法(ops)的执行次数,即AverageTime = time/ops。
252 |
253 | 取样时间(SampleTime), 采样统计方法执行时间。此模式也是基于时间的,通过在一段时间内不断调用基准方法,然后对方法的执行进行采样统计,以方便我们可以推算出**分布、百分位数**等。JMH会尝试自动调整采样频率,如果方法执行时间足够长,最终将会采集所有的样本。
254 |
255 | 单次调用时间(SingleShotTime), 测试方法执行一次所需要的时间。此模式是基于调用次数的,测试时,只会调用一次 @Benchmark 方法,并记录执行时间。这种模式通常用来测试冷启动时的性能。
256 |
257 | 所有模式(ALL),相当于传入以上所有的参数数组。
258 | ### 代码示例
259 | 当然我们也可以一次选择多个模式,只需要将参数换成数组即可;也可以通过Mode.All来选择全部模式。
260 | ::: details 代码示例
261 | ```java
262 | @Benchmark
263 | @BenchmarkMode(Mode.Throughput)
264 | @OutputTimeUnit(TimeUnit.MICROSECONDS)
265 | public void measureMultiple() throws InterruptedException {
266 | TimeUnit.MILLISECONDS.sleep(100);
267 | }
268 |
269 | @Benchmark
270 | @BenchmarkMode({Mode.Throughput, Mode.AverageTime, Mode.SampleTime, Mode.SingleShotTime})
271 | @OutputTimeUnit(TimeUnit.MICROSECONDS)
272 | public void measureMultiple() throws InterruptedException {
273 | TimeUnit.MILLISECONDS.sleep(100);
274 | }
275 |
276 | @Benchmark
277 | @BenchmarkMode(Mode.All)
278 | @OutputTimeUnit(TimeUnit.MICROSECONDS)
279 | public void measureAll() throws InterruptedException {
280 | TimeUnit.MILLISECONDS.sleep(100);
281 | }
282 | ```
283 | :::
284 |
285 | ## @State:多线程测试必备
286 |
287 | ### 什么是状态变量
288 | 基准测试有时需要依赖一些变量或者外部资源,但是又不想这些变量或资源成为基准测试代码的一部分。
289 |
290 | 比如在测试文件随机读取性能时,我们要先生成不同的测试文件;测试HashMap和ConcurrentHashMap的读取性能时,我们需要先创建相应的对象并设置初始值;或者说我们需要将基准测试过程中的某个结果记录到一个变量中。
291 |
292 | 这一类数据在JMH中统称为“状态”变量。状态变量需要再特定的状态类(@State注解修饰)中声明,然后可以将该状态类的实例作为参数提供给基准测试方法。这些类的实例会在需要时初始化,,并在整个基准测试过程中重复使用。
293 |
294 | 以下是两个是两个状态类,可以忽略类名,只需要在对应类上加上@State即可。
295 |
296 | ::: details 代码示例
297 | ```java
298 | @State(Scope.Benchmark)
299 | public static class BenchmarkState {
300 | volatile double x = Math.PI;
301 | }
302 |
303 | @State(Scope.Thread)
304 | public static class ThreadState {
305 | volatile double x = Math.PI;
306 | }
307 | ```
308 | :::
309 |
310 | 基准方法可以引用这些状态变量,JMH将在调用这些方法时注入适当的状态。可以完全没有状态变量,或者只有一个状态变量,或者引用多个状态变量。状态的引入使得我们进行多线程并发基准测试更加简单。
311 |
312 | ::: details 代码示例
313 | ```java
314 | // 所有的基准测试方法都会调用这个方法,因为Scope是Thread,所以每个线程都会有一个独立的状态对象,这种case通常用于保存非共享数据。
315 | @Benchmark
316 | public void measureUnshared(ThreadState state) {
317 | // All benchmark threads will call in this method.
318 | //
319 | // However, since ThreadState is the Scope.Thread, each thread
320 | // will have it's own copy of the state, and this benchmark
321 | // will measure unshared case.
322 | state.x++;
323 | }
324 | // 所有的基准测试方法都会调用这个方法,因为Scope为Benchmark,所以所有线程都共享一个状态实例,这种case通常用于保存多线程共享数据
325 | @Benchmark
326 | public void measureShared(BenchmarkState state) {
327 | // All benchmark threads will call in this method.
328 | //
329 | // Since BenchmarkState is the Scope.Benchmark, all threads
330 | // will share the state instance, and we will end up measuring
331 | // shared case.
332 | state.x++;
333 | }
334 | ```
335 | :::
336 | ### 状态类的限制
337 | 1. 类的作用域必须是public
338 | 2. 如果是内部类,则必须声明为静态内部类(public static class ...)
339 | 3. 必须包含无参构造函数
340 |
341 | ### State Scope
342 | State 对象在整个基准测试过程中可以被重复使用,可以通过Scope枚举指定 State 的作用域。State作用域一共有三种:
343 |
344 | Benchmark:同一类型的State对象将会在所有线程之间共享,即只会创建一个全局状态对象。
345 | Thread::同一类型的State对象,每个线程都会创建一个,即线程间不同享。
346 | Group:同一类型的所有State对象将会在同一执行组内的所有线程共享,即每个执行组都会创建一个状态对象。
347 |
348 | ### Default State
349 | 幸运的是,大多数情况我们只需要使用一个状态对象,这是我们可以直接基准测试类所在的类加上@State注解,将状态信息定义在当前类中,在基准测试方法中直接引用即可。
350 |
351 | ::: details 代码示例
352 | ```java
353 | @State(Scope.Thread)
354 | public class JMHSample_04_DefaultState {
355 |
356 | double x = Math.PI;
357 |
358 | @Benchmark
359 | public void measure() {
360 | x++;
361 | }
362 | }
363 | ```
364 | :::
365 |
366 | 当然,你可以选择单独定义一个状态对象。
367 | ::: details 代码示例
368 | ```java
369 | @State(Scope.Thread)
370 | public class JMHSample_04_DefaultState {
371 |
372 | @Benchmark
373 | public void measure(CountState state) {
374 | state.addOne();
375 | }
376 | }
377 | @State(Scope.Thread)
378 | public class CountState {
379 |
380 | double x = 0;
381 |
382 | public void addOne() {
383 | x++;
384 | }
385 | }
386 | ```
387 | :::
388 |
389 | ### State Fixtures:状态设置和销毁
390 |
391 | 大多数的基准测试都会执行很多次基准方法,而状态对象会伴随着在整个基准测试生命周期,我们需要再特定时机对状态值进行初始化和重置动作。
392 |
393 | JMH提供了两个状态管理的注解,@Setup, 表示被该注解标记的方法会在基准测试方法执行之前执行,而被@Teardown标记的方法则会在方法执行之后执行。与Junit中的Before和Teardown的语义是类似的。**fixture方法的耗时不会被统计进性能指标,所以可以用它来做一些比较重的操作。**
394 |
395 | JUnit和TestNG中的也有类似的方法,比如JUnit中@Before和@After与之语义相似。
396 | ::: warn 注意事项
397 | 这些状态管理的方法只能在对状态对象起作用, 否则编译时会报错!
398 | :::
399 | 和State对象一样,这些固定的方法只会被使用State对象的基准测试线程调用。也就是说,你可以在ThreadLocal上下文中操作,不用对这些方法加锁同步。
400 |
401 | 注意:这些固定方法也能够操作静态字段,尽管这些操作语意已经超过了状态对象的范畴,但是这仍然符合Java的语法规则。(比如,每个类中都定义一个静态字段)
402 |
403 | ::: details 代码示例
404 | ```java
405 | @State(Scope.Thread)
406 | public class JMHSample_05_StateFixtures {
407 |
408 | double x;
409 | /* 默认每个@Benchmark前执行:基准测试测试前的准备工作
410 | */
411 |
412 | @Setup
413 | public void prepare() {
414 | x = Math.PI;
415 | }
416 |
417 | /* 默认每个@Benchmark执行之后执行:检查基准测是否执行成功 ???
418 | */
419 |
420 | @TearDown
421 | public void check() {
422 | assert x > Math.PI : "Nothing changed?";
423 | }
424 |
425 | /* 这个方法显然是正确的,每次基准测试方法执行时,都是操作State对象的x字段。check()永远不会失败,因为我们总是保证每轮测试至少调用一次基准测试方法。
426 | */
427 |
428 | @Benchmark
429 | public void measureRight() {
430 | x++;
431 | }
432 |
433 | /* 这个方法执行到check()时一定会报错,因为每轮测试时我们修改的都是局部变量x。
434 | */
435 |
436 | @Benchmark
437 | public void measureWrong() {
438 | double x = 0;
439 | x++;
440 | }
441 |
442 | public static void main(String[] args) throws RunnerException {
443 | Options opt = new OptionsBuilder()
444 | .include(JMHSample_05_StateFixtures.class.getSimpleName())
445 | .forks(1)
446 | .jvmArgs("-ea")
447 | .build();
448 | new Runner(opt).run();
449 | }
450 | }
451 | ```
452 | :::
453 |
454 | ### FixureLevel:状态生命周期方法被执行多少次?
455 |
456 | 上一节讲到了@Setup和@Teardown,被它们标记的方法分别会在基准测试方法执行前和执行后执行。但是无论是基于时间还是次数的基准测试,往往都会执行很多次才能统计出一个较为准确的结果。
457 |
458 | 那么这些 Fixtures 方法究竟何时执行,执行多少次呢?我们可以通过 FixureLevel 来进行配置,Fixure方法在运行时一共可以分为三个等级:
459 |
460 | 1. Level.Trial:整个基准测试(一个@Benchmark注解为一个基准测试)运行之前或之后(多个迭代)
461 | 2. Level.Iteration:在基准测试迭代之前或之后(每一轮迭代)
462 | 3. Level.Invocation:在每次基准测试方法调用之前或之后。(每一次调用调用)
463 |
464 | ::: details 代码示例
465 | ```java
466 | @State(Scope.Thread)
467 | public class JMHSample_06_FixtureLevel {
468 |
469 | double x;
470 |
471 | @TearDown(Level.Iteration)
472 | public void check() {
473 | assert x > Math.PI : "Nothing changed?";
474 | }
475 |
476 | @Benchmark
477 | public void measureRight() {
478 | x++;
479 | }
480 |
481 | @Benchmark
482 | public void measureWrong() {
483 | double x = 0;
484 | x++;
485 | }
486 |
487 | public static void main(String[] args) throws RunnerException {
488 | Options opt = new OptionsBuilder()
489 | .include(JMHSample_06_FixtureLevel.class.getSimpleName())
490 | .forks(1)
491 | .jvmArgs("-ea")
492 | .shouldFailOnError(false) // switch to "true" to fail the complete run
493 | .build();
494 |
495 | new Runner(opt).run();
496 | }
497 | }
498 | ```
499 | :::
500 |
501 | ### FixureLevel: 慎用Invocation
502 |
503 | 需要注意的是 对于 Leavel.Invocation 等级下的**时间戳**和**方法同步调用**可能会明显影响测试报告结果值,一定要谨慎使用。
504 |
505 | 这个等级只适用于每次benchmark方法执行时间超过1ms的场景, 在特别的基础上验证对您的案例的影响也是一个好主意???
506 |
507 | 1. 由于我们必须从基准测试时间中减去setup和teardown方法的耗时,在这个级别上,我们必须为每次基准测试方法调用设置时间戳。如果基准测试方法耗时很短,那么大量的时间戳请求会使系统饱和,这将引入虚假的延迟、吞吐量和可伸缩性瓶颈。
508 |
509 | 2. 由于我们使用此级别测量单个调用时间,因此我们可能会为(协调的)遗漏做好准备。这意味着测量中的小问题可以从时序测量中隐藏起来,并可能带来令人惊讶的结果。例如,当我们使用时序来理解基准吞吐量时,省略的时序测量将导致较低的聚合时间,并虚构更大的吞吐量。
510 |
511 | 3. 为了维持与其他级别相同的共享行为,我们有时必须同步的方式对{@link State}对象的访问。其他级别下这样做可能对测量结果影响不大,但是在这个级别,我们必须在关键方法上同步,增加同步等待时间,使得测量结果偏差很大。
512 |
513 | 4. 目前的实现允许在这个级别的辅助方法执行与基准调用本身重叠,在多线程基准测试中,当一个执行{@link Benchmark}方法的工作线程执行时,可能会得到的是状态数据被其他线程执行了{@link TearDown}方法。
514 |
515 |
516 | ::: details 代码示例
517 | ```java
518 | /**
519 | * Fixtures have different Levels to control when they are about to run.
520 | * Level.Invocation is useful sometimes to do some per-invocation work
521 | * which should not count as payload (e.g. sleep for some time to emulate
522 | * think time)
523 | */
524 | @OutputTimeUnit(TimeUnit.MICROSECONDS)
525 | public class JMHSample_07_FixtureLevelInvocation {
526 |
527 | /*
528 | * Fixtures have different Levels to control when they are about to run.
529 | * Level.Invocation is useful sometimes to do some per-invocation work,
530 | * which should not count as payload. PLEASE NOTE the timestamping and
531 | * synchronization for Level.Invocation helpers might significantly offset
532 | * the measurement, use with care. See Level.Invocation javadoc for further
533 | * discussion.
534 | *
535 | * Consider this sample:
536 | */
537 |
538 | /*
539 | * This state handles the executor.
540 | * Note we create and shutdown executor with Level.Trial, so
541 | * it is kept around the same across all iterations.
542 | */
543 |
544 | @State(Scope.Benchmark)
545 | public static class NormalState {
546 | ExecutorService service;
547 |
548 | @Setup(Level.Trial)
549 | public void up() {
550 | service = Executors.newCachedThreadPool();
551 | }
552 |
553 | @TearDown(Level.Trial)
554 | public void down() {
555 | service.shutdown();
556 | }
557 |
558 | }
559 |
560 | /*
561 | * This is the *extension* of the basic state, which also
562 | * has the Level.Invocation fixture method, sleeping for some time.
563 | */
564 |
565 | public static class LaggingState extends NormalState {
566 | public static final int SLEEP_TIME = Integer.getInteger("sleepTime", 10);
567 |
568 | @Setup(Level.Invocation)
569 | public void lag() throws InterruptedException {
570 | TimeUnit.MILLISECONDS.sleep(SLEEP_TIME);
571 | }
572 | }
573 |
574 | /*
575 | * This allows us to formulate the task: measure the task turnaround in
576 | * "hot" mode when we are not sleeping between the submits, and "cold" mode,
577 | * when we are sleeping.
578 | */
579 |
580 | @Benchmark
581 | @BenchmarkMode(Mode.AverageTime)
582 | public double measureHot(NormalState e, final Scratch s) throws ExecutionException, InterruptedException {
583 | return e.service.submit(new Task(s)).get();
584 | }
585 |
586 | @Benchmark
587 | @BenchmarkMode(Mode.AverageTime)
588 | public double measureCold(LaggingState e, final Scratch s) throws ExecutionException, InterruptedException {
589 | return e.service.submit(new Task(s)).get();
590 | }
591 |
592 | /*
593 | * This is our scratch state which will handle the work.
594 | */
595 |
596 | @State(Scope.Thread)
597 | public static class Scratch {
598 | private double p;
599 | public double doWork() {
600 | p = Math.log(p);
601 | return p;
602 | }
603 | }
604 |
605 | public static class Task implements Callable {
606 | private Scratch s;
607 |
608 | public Task(Scratch s) {
609 | this.s = s;
610 | }
611 |
612 | @Override
613 | public Double call() {
614 | return s.doWork();
615 | }
616 | }
617 |
618 | /*
619 | * ============================== HOW TO RUN THIS TEST: ====================================
620 | *
621 | * You can see the cold scenario is running longer, because we pay for
622 | * thread wakeups.
623 | *
624 | * You can run this test:
625 | *
626 | * a) Via the command line:
627 | * $ mvn clean install
628 | * $ java -jar target/benchmarks.jar JMHSample_07 -f 1
629 | * (we requested single fork; there are also other options, see -h)
630 | *
631 | * b) Via the Java API:
632 | * (see the JMH homepage for possible caveats when running from IDE:
633 | * http://openjdk.java.net/projects/code-tools/jmh/)
634 | */
635 |
636 | public static void main(String[] args) throws RunnerException {
637 | Options opt = new OptionsBuilder()
638 | .include(JMHSample_07_FixtureLevelInvocation.class.getSimpleName())
639 | .forks(1)
640 | .build();
641 |
642 | new Runner(opt).run();
643 | }
644 |
645 | }
646 |
647 | ```
648 | :::
649 | ## 避免 JVM 优化
650 | 很多情况下基准测试的失败,都是由JVM优化导致的。所以在进行基准测试时,我们必须要考虑JVM优化对我们测试方法的影响。
651 | ### @Forking
652 | 众所周知,JVM 擅长配置 profile-guided 的化。但是这对进准测试并不友好,因为不同的测试可以将它们配置混合在一起, 然后为每个测试呈现一致的异常的结果。
653 |
654 | forking(运行在不同的进程中)每个测试都可以帮助规避这个问题。
655 |
656 | ::: warning
657 | 使用non-forked运行仅用于调试目的,而不是用于实际基准测试,JMH默认会fork所有的test。
658 | :::
659 |
660 | ::: details 代码示例
661 | ```java
662 | @State(Scope.Thread)
663 | @BenchmarkMode(Mode.AverageTime)
664 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
665 | public class JMHSample_12_Forking {
666 |
667 | /*
668 | * JVMs are notoriously good at profile-guided optimizations. This is bad
669 | * for benchmarks, because different tests can mix their profiles together,
670 | * and then render the "uniformly bad" code for every test. Forking (running
671 | * in a separate process) each test can help to evade this issue.
672 | *
673 | * JMH will fork the tests by default.
674 | *
675 | * JMH默认fork所有test。
676 | */
677 |
678 | /*
679 | * Suppose we have this simple counter interface, and two implementations.
680 | * Even though those are semantically the same, from the JVM standpoint,
681 | * those are distinct classes.
682 | *
683 | * 假设我们又一个简单的统计接口,并且有两个实现。
684 | * 即使他们逻辑相同,站在JVM角度看他们是不同的类。
685 | */
686 |
687 | public interface Counter {
688 | int inc();
689 | }
690 |
691 | public class Counter1 implements Counter {
692 | private int x;
693 |
694 | @Override
695 | public int inc() {
696 | return x++;
697 | }
698 | }
699 |
700 | public class Counter2 implements Counter {
701 | private int x;
702 |
703 | @Override
704 | public int inc() {
705 | return x++;
706 | }
707 | }
708 |
709 | /*
710 | * And this is how we measure it.
711 | * Note this is susceptible for same issue with loops we mention in previous examples.
712 | */
713 |
714 | public int measure(Counter c) {
715 | int s = 0;
716 | for (int i = 0; i < 10; i++) {
717 | s += c.inc();
718 | }
719 | return s;
720 | }
721 |
722 | /*
723 | * These are two counters.
724 | */
725 |
726 | Counter c1 = new Counter1();
727 | Counter c2 = new Counter2();
728 |
729 | /*
730 | * We first measure the Counter1 alone...
731 | * Fork(0) helps to run in the same JVM.
732 | */
733 |
734 | @Benchmark
735 | @Fork(0)
736 | public int measure_1_c1() {
737 | return measure(c1);
738 | }
739 |
740 | /*
741 | * Then Counter2...
742 | */
743 |
744 | @Benchmark
745 | @Fork(0)
746 | public int measure_2_c2() {
747 | return measure(c2);
748 | }
749 |
750 | /*
751 | * Then Counter1 again...
752 | */
753 |
754 | @Benchmark
755 | @Fork(0)
756 | public int measure_3_c1_again() {
757 | return measure(c1);
758 | }
759 |
760 | /*
761 | * These two tests have explicit @Fork annotation.
762 | * JMH takes this annotation as the request to run the test in the forked JVM.
763 | * It's even simpler to force this behavior for all the tests via the command
764 | * line option "-f". The forking is default, but we still use the annotation
765 | * for the consistency.
766 | *
767 | * This is the test for Counter1.
768 | */
769 |
770 | @Benchmark
771 | @Fork(1)
772 | public int measure_4_forked_c1() {
773 | return measure(c1);
774 | }
775 |
776 | /*
777 | * ...and this is the test for Counter2.
778 | */
779 |
780 | @Benchmark
781 | @Fork(1)
782 | public int measure_5_forked_c2() {
783 | return measure(c2);
784 | }
785 |
786 | /*
787 | * ============================== HOW TO RUN THIS TEST: ====================================
788 | *
789 | * Note that C1 is faster, C2 is slower, but the C1 is slow again! This is because
790 | * the profiles for C1 and C2 had merged together.
791 | *
792 | */
793 |
794 | public static void main(String[] args) throws RunnerException {
795 | Options opt = new OptionsBuilder()
796 | .include(JMHSample_12_Forking.class.getSimpleName())
797 | .output("JMHSample_12_Forking.sampleLog")
798 | .build();
799 |
800 | new Runner(opt).run();
801 | }
802 |
803 | }
804 | ```
805 | :::
806 |
807 | ### RunToRun
808 | Forking 还允许预估每次运行之间的的差异。毕竟 JVM 是个非常复杂的系统,所以它包含了很多不确定性。
809 |
810 | 这就要求我们始终将运行间的差异的视为我们实验中的影响之一,幸运的是,foking 模式下聚合了多个 JVM 运行的结果。
811 |
812 | 为了引入易于量化的运行间差异,我们建立了工作负载(同时运行多个进程),其性能在运行间有所不同。请注意,许多工作负载会有类似的行为,但我们人为地这样做是为了说明一个问题。
813 |
814 | ::: details 代码示例
815 | ```java
816 |
817 | @State(Scope.Thread)
818 | @BenchmarkMode(Mode.AverageTime)
819 | @OutputTimeUnit(TimeUnit.MILLISECONDS)
820 | public class JMHSample_13_RunToRun {
821 |
822 | /*
823 | * Forking also allows to estimate run-to-run variance.
824 | *
825 | * JVMs are complex systems, and the non-determinism is inherent for them.
826 | * This requires us to always account the run-to-run variance as the one
827 | * of the effects in our experiments.
828 | *
829 | * Luckily, forking aggregates the results across several JVM launches.
830 | */
831 |
832 | /*
833 | * In order to introduce readily measurable run-to-run variance, we build
834 | * the workload which performance differs from run to run. Note that many workloads
835 | * will have the similar behavior, but we do that artificially to make a point.
836 | */
837 |
838 | @State(Scope.Thread)
839 | public static class SleepyState {
840 | public long sleepTime;
841 |
842 | @Setup
843 | public void setup() {
844 | sleepTime = (long) (Math.random() * 1000);
845 | }
846 | }
847 |
848 | /*
849 | * Now, we will run this different number of times.
850 | */
851 |
852 | @Benchmark
853 | @Fork(1)
854 | public void baseline(SleepyState s) throws InterruptedException {
855 | TimeUnit.MILLISECONDS.sleep(s.sleepTime);
856 | }
857 |
858 | @Benchmark
859 | @Fork(5)
860 | public void fork_1(SleepyState s) throws InterruptedException {
861 | TimeUnit.MILLISECONDS.sleep(s.sleepTime);
862 | }
863 |
864 | @Benchmark
865 | @Fork(20)
866 | public void fork_2(SleepyState s) throws InterruptedException {
867 | TimeUnit.MILLISECONDS.sleep(s.sleepTime);
868 | }
869 |
870 | /*
871 | * ============================== HOW TO RUN THIS TEST: ====================================
872 | *
873 | * Note the baseline is random within [0..1000] msec; and both forked runs
874 | * are estimating the average 500 msec with some confidence.
875 | *
876 | * You can run this test:
877 | *
878 | * a) Via the command line:
879 | * $ mvn clean install
880 | * $ java -jar target/benchmarks.jar JMHSample_13 -wi 0 -i 3
881 | * (we requested no warmup, 3 measurement iterations; there are also other options, see -h)
882 | *
883 | * b) Via the Java API:
884 | * (see the JMH homepage for possible caveats when running from IDE:
885 | * http://openjdk.java.net/projects/code-tools/jmh/)
886 | */
887 |
888 | public static void main(String[] args) throws RunnerException {
889 | Options opt = new OptionsBuilder()
890 | .include(JMHSample_13_RunToRun.class.getSimpleName())
891 | .warmupIterations(0)
892 | .measurementIterations(3)
893 | .build();
894 |
895 | new Runner(opt).run();
896 | }
897 |
898 | }
899 | ```
900 | :::
901 |
902 | ### DeadCode:编译器优化
903 | 许多基准测试的失败是因为Dead-Code的消除:编译器非常智能可以推断出一些冗余的计算并彻底消除。如果被消除的部分是我们的基准测试代码,我们的基准测试将是无效的。
904 |
905 | 如下示例代码,
906 | ::: details 代码示例
907 | ```java
908 | package org.openjdk.jmh.samples;
909 |
910 | import org.openjdk.jmh.annotations.*;
911 | import org.openjdk.jmh.runner.Runner;
912 | import org.openjdk.jmh.runner.RunnerException;
913 | import org.openjdk.jmh.runner.options.Options;
914 | import org.openjdk.jmh.runner.options.OptionsBuilder;
915 |
916 | import java.util.concurrent.TimeUnit;
917 |
918 | @State(Scope.Thread)
919 | @BenchmarkMode(Mode.AverageTime)
920 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
921 | public class JMHSample_08_DeadCode {
922 |
923 | /*
924 | * The downfall of many benchmarks is Dead-Code Elimination (DCE): compilers
925 | * are smart enough to deduce some computations are redundant and eliminate
926 | * them completely. If the eliminated part was our benchmarked code, we are
927 | * in trouble.
928 | *
929 | * Fortunately, JMH provides the essential infrastructure to fight this
930 | * where appropriate: returning the result of the computation will ask JMH
931 | * to deal with the result to limit dead-code elimination (returned results
932 | * are implicitly consumed by Blackholes, see JMHSample_09_Blackholes).
933 | */
934 |
935 | private double x = Math.PI;
936 |
937 | @Benchmark
938 | public void baseline() {
939 | // do nothing, this is a baseline
940 | }
941 | // 错误示例:由于计算结果没有被使用,所以整个计算过程被优化(忽略),执行效果和baseLine()方法一样
942 | @Benchmark
943 | public void measureWrong() {
944 | // This is wrong: result is not used and the entire computation is optimized away.
945 | Math.log(x);
946 | }
947 |
948 | @Benchmark
949 | public double measureRight() {
950 | // This is correct: the result is being used.
951 | return Math.log(x);
952 | }
953 |
954 | /*
955 | * ============================== HOW TO RUN THIS TEST: ====================================
956 | *
957 | * You can see the unrealistically fast calculation in with measureWrong(),
958 | * while realistic measurement with measureRight().
959 | *
960 | * You can run this test:
961 | *
962 | * a) Via the command line:
963 | * $ mvn clean install
964 | * $ java -jar target/benchmarks.jar JMHSample_08 -f 1
965 | * (we requested single fork; there are also other options, see -h)
966 | *
967 | * b) Via the Java API:
968 | * (see the JMH homepage for possible caveats when running from IDE:
969 | * http://openjdk.java.net/projects/code-tools/jmh/)
970 | */
971 |
972 | public static void main(String[] args) throws RunnerException {
973 | Options opt = new OptionsBuilder()
974 | .include(JMHSample_08_DeadCode.class.getSimpleName())
975 | .forks(1)
976 | .build();
977 |
978 | new Runner(opt).run();
979 | }
980 |
981 | }
982 | ```
983 | :::
984 |
985 | ### BlackHole:防止DeadCode被优化
986 | 幸运的是,JMH提供了必要的基础设施来应对这一情况,返回计算结果将要求JMH处理结果以限制死代码消除。
987 |
988 | 首选需要确认的是你的基准测试是否返回多个结果,如果你只会产生一个结果,应该使用更易读的明确return,就像JMHSample_08_DeadCode。不要使用明确的Blackholes来降低您的基准代码的可读性!
989 |
990 | ::: details 代码示例
991 | ```java
992 | @BenchmarkMode(Mode.AverageTime)
993 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
994 | @State(Scope.Thread)
995 | public class JMHSample_09_Blackholes {
996 |
997 | double x1 = Math.PI;
998 | double x2 = Math.PI * 2;
999 |
1000 | /*
1001 | * Baseline measurement: how much single Math.sampleLog costs.
1002 | */
1003 |
1004 | @Benchmark
1005 | public double baseline() {
1006 | return Math.log(x1);
1007 | }
1008 |
1009 | /*
1010 | * 虽然Math.log(x2)计算是完整的,但Math.log(x1)是冗余的,并被优化了。
1011 | */
1012 |
1013 | @Benchmark
1014 | public double measureWrong() {
1015 | Math.log(x1);
1016 | return Math.log(x2);
1017 | }
1018 |
1019 | /*
1020 | * 选择一: 合并多个结果并返回,这在Math.log()方法计算量比较大的情况下是可以的,合并结果不会对结果产生太大影响。
1021 | */
1022 |
1023 | @Benchmark
1024 | public double measureRight_1() {
1025 | return Math.log(x1) + Math.log(x2);
1026 | }
1027 |
1028 | /*
1029 | * 选择二: 显示使用Blackhole对象,并将结果值传入Blackhole.consume方法中。
1030 | * (Blackhole就像@State对象的一种特殊实现,JMH自动绑定)
1031 | */
1032 |
1033 | @Benchmark
1034 | public void measureRight_2(Blackhole bh) {
1035 | bh.consume(Math.log(x1));
1036 | bh.consume(Math.log(x2));
1037 | }
1038 |
1039 | public static void main(String[] args) throws RunnerException {
1040 | Options opt = new OptionsBuilder()
1041 | .include(JMHSample_09_Blackholes.class.getSimpleName())
1042 | .forks(1)
1043 | .build();
1044 |
1045 | new Runner(opt).run();
1046 | }
1047 | }
1048 | ```
1049 | :::
1050 | ### BlackHole#ConsumeCPU:消耗CPU的时钟周期
1051 | 有时我们可能仅仅需要测试消耗CPU资源,这时也可以通过 Blackhole.consumeCPU方法实现。
1052 |
1053 | ::: details 代码示例
1054 | ```java
1055 | @BenchmarkMode(Mode.AverageTime)
1056 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
1057 | public class JMHSample_21_ConsumeCPU {
1058 |
1059 | /*
1060 | * At times you require the test to burn some of the cycles doing nothing.
1061 | * In many cases, you *do* want to burn the cycles instead of waiting.
1062 | *
1063 | * For these occasions, we have the infrastructure support. Blackholes
1064 | * can not only consume the values, but also the time! Run this test
1065 | * to get familiar with this part of JMH.
1066 | *
1067 | * (Note we use static method because most of the use cases are deep
1068 | * within the testing code, and propagating blackholes is tedious).
1069 | */
1070 |
1071 | @Benchmark
1072 | public void consume_0000() {
1073 | Blackhole.consumeCPU(0);
1074 | }
1075 |
1076 | @Benchmark
1077 | public void consume_0001() {
1078 | Blackhole.consumeCPU(1);
1079 | }
1080 |
1081 | @Benchmark
1082 | public void consume_0002() {
1083 | Blackhole.consumeCPU(2);
1084 | }
1085 |
1086 | @Benchmark
1087 | public void consume_0004() {
1088 | Blackhole.consumeCPU(4);
1089 | }
1090 |
1091 | @Benchmark
1092 | public void consume_0008() {
1093 | Blackhole.consumeCPU(8);
1094 | }
1095 |
1096 | @Benchmark
1097 | public void consume_0016() {
1098 | Blackhole.consumeCPU(16);
1099 | }
1100 |
1101 | @Benchmark
1102 | public void consume_0032() {
1103 | Blackhole.consumeCPU(32);
1104 | }
1105 |
1106 | @Benchmark
1107 | public void consume_0064() {
1108 | Blackhole.consumeCPU(64);
1109 | }
1110 |
1111 | @Benchmark
1112 | public void consume_0128() {
1113 | Blackhole.consumeCPU(128);
1114 | }
1115 |
1116 | @Benchmark
1117 | public void consume_0256() {
1118 | Blackhole.consumeCPU(256);
1119 | }
1120 |
1121 | @Benchmark
1122 | public void consume_0512() {
1123 | Blackhole.consumeCPU(512);
1124 | }
1125 |
1126 | @Benchmark
1127 | public void consume_1024() {
1128 | Blackhole.consumeCPU(1024);
1129 | }
1130 | public static void main(String[] args) throws RunnerException {
1131 | Options opt = new OptionsBuilder()
1132 | .include(JMHSample_21_ConsumeCPU.class.getSimpleName())
1133 | .forks(1)
1134 | .build();
1135 |
1136 | new Runner(opt).run();
1137 | }
1138 |
1139 | }
1140 | ```
1141 | :::
1142 |
1143 | ### ConstantFold 常量折叠
1144 | 死代码消除的另一种形式是常量折叠。
1145 |
1146 | 如果JVM发现不管怎么计算,计算结果都是不变的,它可以巧妙地优化它。在我们的case中,这就意味着我们可以把计算移到JMH之外。
1147 |
1148 | 可以通过@State对象的非final类型的字段读取输入,根据这些值计算结果,遵守这些规则就能防止DeadCode。
1149 |
1150 | ::: details 代码示例
1151 | ```java
1152 | @State(Scope.Thread)
1153 | @BenchmarkMode(Mode.AverageTime)
1154 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
1155 | public class JMHSample_10_ConstantFold {
1156 |
1157 |
1158 | private double x = Math.PI;
1159 |
1160 | private final double wrongX = Math.PI;
1161 |
1162 | @Benchmark
1163 | public double baseline() {
1164 | // 基础case:简单返回一个常量结果
1165 | return Math.PI;
1166 | }
1167 |
1168 | @Benchmark
1169 | public double measureWrong_1() {
1170 | // 错误示例: 结果可预测,计算会被折叠 「参数为常量」
1171 | return Math.log(Math.PI);
1172 | }
1173 |
1174 | @Benchmark
1175 | public double measureWrong_2() {
1176 | // 错误示例: 结果可预测,计算会被折叠 「参数为常量」
1177 | return Math.log(wrongX);
1178 | }
1179 |
1180 | @Benchmark
1181 | public double measureRight() {
1182 | // 正确示例: 结果不可预测,参数作为变量传入
1183 | return Math.log(x);
1184 | }
1185 |
1186 | public static void main(String[] args) throws RunnerException {
1187 | Options opt = new OptionsBuilder()
1188 | .include(JMHSample_10_ConstantFold.class.getSimpleName())
1189 | .forks(1)
1190 | .output("JMHSample_10_ConstantFold.sampleLog")
1191 | .build();
1192 | new Runner(opt).run();
1193 | }
1194 | }
1195 | ```
1196 | :::
1197 |
1198 | ### CompilerController: 编译控制
1199 | 方法内联(Method Inlining),是JVM对代码的编译优化,常见的编译优化可以从参考http://www.importnew.com/2009.html
1200 | Java编程语言中虚拟方法调用的频率是一个重要的优化瓶颈。一旦Java HotSpot自适应优化器在执行期间收集有关程序热点的信息,它不仅将热点编译为本机代码,而且还对该代码执行大量方法内联。
1201 | 内联有很多好处。 它大大降低了方法调用的动态频率,从而节省了执行这些方法调用所需的时间。但更重要的是,内联会产生更大的代码块供优化器处理,这就大大提高了传统编译器优化的效率,克服了提高Java编程语言性能的主要障碍。
1202 | 内联与其他代码优化是协同的,因为它使它们更有效。随着Java HotSpot编译器的成熟,对大型内联代码块进行操作的能力将为未来一系列更高级的优化打开大门。
1203 |
1204 | 关于编译控制,JMH提供了三个选项供我们选择:TODO
1205 | 1. CompilerControl.Mode.DONT_INLINE:
1206 | 2. CompilerControl.Mode.INLINE:
1207 | 3. CompilerControl.Mode.EXCLUDE:
1208 | 我们使用HotSpot特定的功能来告诉编译器我们想对特定的方法做什么, 为了演示效果,我们在这个例子中写了三个测试方法。
1209 | ::: details 代码示例
1210 | ```java
1211 | @State(Scope.Thread)
1212 | @BenchmarkMode(Mode.AverageTime)
1213 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
1214 | public class JMHSample_16_CompilerControl {
1215 |
1216 | /*
1217 | * We can use HotSpot-specific functionality to tell the compiler what
1218 | * do we want to do with particular methods. To demonstrate the effects,
1219 | * we end up with 3 methods in this sample.
1220 | *
1221 | * 我们使用HotSpot特定的功能来告诉编译器我们想对特定的方法做怎么。
1222 | * 为了证明这种效果,我们在这个例子中写了三个测试方法。
1223 | */
1224 |
1225 | /**
1226 | *
1227 | * 这是我们的目标:
1228 | * - 第一个方法禁止内敛
1229 | * - 第二个方法强制内敛
1230 | * - 第三个方法禁止编译
1231 | *
1232 | * 我们甚至可以将注释直接放在基准测试方法中,但这更清楚地表达了意图。
1233 | */
1234 |
1235 | public void target_blank() {
1236 | // this method was intentionally left blank
1237 | // 方法故意留空
1238 | }
1239 |
1240 | @CompilerControl(CompilerControl.Mode.DONT_INLINE)
1241 | public void target_dontInline() {
1242 | // this method was intentionally left blank
1243 | }
1244 |
1245 | @CompilerControl(CompilerControl.Mode.INLINE)
1246 | public void target_inline() {
1247 | // this method was intentionally left blank
1248 | }
1249 |
1250 | /**
1251 | * Exclude the method from the compilation.
1252 | */
1253 | @CompilerControl(CompilerControl.Mode.EXCLUDE)
1254 | public void target_exclude() {
1255 | // this method was intentionally left blank
1256 | }
1257 |
1258 | /*
1259 | * These method measures the calls performance.
1260 | * 这些方法来测量调用性能。
1261 | */
1262 |
1263 | @Benchmark
1264 | public void baseline() {
1265 | // this method was intentionally left blank
1266 | }
1267 |
1268 | @Benchmark
1269 | public void blank() {
1270 | target_blank();
1271 | }
1272 |
1273 | @Benchmark
1274 | public void dontinline() {
1275 | target_dontInline();
1276 | }
1277 |
1278 | @Benchmark
1279 | public void inline() {
1280 | target_inline();
1281 | }
1282 |
1283 | @Benchmark
1284 | public void exclude() {
1285 | target_exclude();
1286 | }
1287 | }
1288 | ```
1289 | :::
1290 |
1291 | ## Loops 循环
1292 | 把你的基准代码放在你的基准方法中的一个循环里是很诱人的,以便在每次调用基准方法时重复更多的次数(以减少基准方法调用的开销)。然而,JVM非常善于优化循环,所以你最终得到的结果可能与你预期的不同。一般来说,你应该避免基准方法中的循环,除非它们是你想测量的代码的一部分(而不是在你想测量的代码周围)。
1293 | ::: details 代码示例
1294 | ```java
1295 | @State(Scope.Thread)
1296 | @BenchmarkMode(Mode.AverageTime)
1297 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
1298 | public class JMHSample_11_Loops {
1299 |
1300 | /*
1301 | * 假设我们要测试两个整数相加的性能
1302 | */
1303 |
1304 | int x = 1;
1305 | int y = 2;
1306 |
1307 | /*
1308 | * This is what you do with JMH.
1309 | */
1310 |
1311 | @Benchmark
1312 | public int measureRight() {
1313 | return (x + y);
1314 | }
1315 |
1316 | /*
1317 | * The following tests emulate the naive looping.
1318 | * This is the Caliper-style benchmark.
1319 | *
1320 | * Caliper风格的基准测试
1321 | */
1322 |
1323 | private int reps(int reps) {
1324 | int s = 0;
1325 | for (int i = 0; i < reps; i++) {
1326 | s += (x + y);
1327 | }
1328 | return s;
1329 | }
1330 |
1331 | /*
1332 | * We would like to measure this with different repetitions count.
1333 | * Special annotation is used to get the individual operation cost.
1334 | */
1335 |
1336 | @Benchmark
1337 | @OperationsPerInvocation(1)
1338 | public int measureWrong_1() {
1339 | return reps(1);
1340 | }
1341 |
1342 | @Benchmark
1343 | @OperationsPerInvocation(10)
1344 | public int measureWrong_10() {
1345 | return reps(10);
1346 | }
1347 |
1348 | @Benchmark
1349 | @OperationsPerInvocation(100)
1350 | public int measureWrong_100() {
1351 | return reps(100);
1352 | }
1353 |
1354 | @Benchmark
1355 | @OperationsPerInvocation(1000)
1356 | public int measureWrong_1000() {
1357 | return reps(1000);
1358 | }
1359 |
1360 | @Benchmark
1361 | @OperationsPerInvocation(10000)
1362 | public int measureWrong_10000() {
1363 | return reps(10000);
1364 | }
1365 |
1366 | @Benchmark
1367 | @OperationsPerInvocation(100000)
1368 | public int measureWrong_100000() {
1369 | return reps(100000);
1370 | }
1371 |
1372 | /*
1373 | *
1374 | * 你可能已经注意到,循环次数越多,统计出来的时间越短。到目前为止,每次操作的时间已经是1/20 ns,远远超过硬件的实际能力。
1375 | *
1376 | * 发生这种情况是因为循环被大量展开。所以:不要过度使用循环,依靠JMH来正确测量。
1377 | */
1378 |
1379 | public static void main(String[] args) throws RunnerException {
1380 | Options opt = new OptionsBuilder()
1381 | .include(JMHSample_11_Loops.class.getSimpleName())
1382 | .forks(1)
1383 | .output("JMHSample_11_Loops.sampleLog")
1384 | .build();
1385 |
1386 | new Runner(opt).run();
1387 | }
1388 |
1389 | }
1390 | ```
1391 | :::
1392 |
1393 | ### @OperationsPerInvocation
1394 | OperationsPerInvocation注解可以让基准测试进行不止一个操作,并让JMH适当地调整结果。
1395 |
1396 | 例如,一个使用内部循环的基准方法有多个操作,需要想测量单个操作的性能。通常OperationsPerInvocation设置值一般和for循环的次数一致。
1397 |
1398 | ```java
1399 | @Benchmark
1400 | @OperationsPerInvocation(10)
1401 | public void test() {
1402 | for (int i = 0; i < 10; i++) {
1403 | // do something
1404 | }
1405 | }
1406 | ```
1407 | ### BadCase:循环展开
1408 | 循环展开能够降低循环开销,为具有多个功能单元的处理器提供指令级并行,也有利于指令流水线的调度。例如:
1409 | 原始代码:
1410 | ```java
1411 | for (i = 1; i <= 60; i++) {
1412 | a[i] = a[i] * b + c;
1413 | }
1414 | ```
1415 | 展开后实际执行的代码:
1416 | ```java
1417 | for (i = 1; i <= 60; i+=3) {
1418 | a[i] = a[i] * b + c;
1419 | a[i+1] = a[i+1] * b + c;
1420 | a[i+2] = a[i+2] * b + c;
1421 | }
1422 | ```
1423 |
1424 | ### SafeLooping
1425 | JMHSample_11_Loops 示例介绍了我们在 @Benchmark 方法中使用循环的危险性。然而,有时需要遍历数据集中的多个元素。没有循环就很难做到这一点,因此我们需要设计一个方案安全循环。
1426 |
1427 | 如何在基准测试中安全地循环?我们只需要进行简单地控制,通过检查基准成本随着任务规模的增加而线性增长,如果不是,那么就说明发生了"错误"。
1428 |
1429 | 假设我们要测试在不同的参数下,work()方法执行耗时情况。这里模拟了一个常见的用例,使用不同的参数调对同相同的方法实现进行测试。
1430 | ::: details 代码示例
1431 |
1432 | ```java
1433 | @State(Scope.Thread)
1434 | @Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
1435 | @Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
1436 | @Fork(3)
1437 | @BenchmarkMode(Mode.AverageTime)
1438 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
1439 | public class JMHSample_34_SafeLooping {
1440 |
1441 | /*
1442 | * JMHSample_11_Loops warns about the dangers of using loops in @Benchmark methods.
1443 | * Sometimes, however, one needs to traverse through several elements in a dataset.
1444 | * This is hard to do without loops, and therefore we need to devise a scheme for
1445 | * safe looping.
1446 | */
1447 |
1448 | /*
1449 | * Suppose we want to measure how much it takes to execute work() with different
1450 | * arguments. This mimics a frequent use case when multiple instances with the same
1451 | * implementation, but different data, is measured.
1452 | */
1453 |
1454 | static final int BASE = 42;
1455 |
1456 | static int work(int x) {
1457 | return BASE + x;
1458 | }
1459 |
1460 | /*
1461 | * Every benchmark requires control. We do a trivial control for our benchmarks
1462 | * by checking the benchmark costs are growing linearly with increased task size.
1463 | * If it doesn't, then something wrong is happening.
1464 | */
1465 |
1466 | @Param({"1", "10", "100", "1000"})
1467 | int size;
1468 |
1469 | int[] xs;
1470 |
1471 | @Setup
1472 | public void setup() {
1473 | xs = new int[size];
1474 | for (int c = 0; c < size; c++) {
1475 | xs[c] = c;
1476 | }
1477 | }
1478 |
1479 | /*
1480 | * First, the obviously wrong way: "saving" the result into a local variable would not
1481 | * work. A sufficiently smart compiler will inline work(), and figure out only the last
1482 | * work() call needs to be evaluated. Indeed, if you run it with varying $size, the score
1483 | * will stay the same!
1484 | *
1485 | * 首先,明显错误的方式:将结果“保存”到局部变量中是行不通的。
1486 | * 一个足够聪明的编译器将内联 work()方法,只需要测试最后一次 work() 调用即可。事实上,如果你用不同的 $size 运行它,结果都是一样的!
1487 | */
1488 |
1489 | @Benchmark
1490 | public int measureWrong_1() {
1491 | int acc = 0;
1492 | for (int x : xs) {
1493 | acc = work(x);
1494 | }
1495 | return acc;
1496 | }
1497 |
1498 | /*
1499 | * Second, another wrong way: "accumulating" the result into a local variable. While
1500 | * it would force the computation of each work() method, there are software pipelining
1501 | * effects in action, that can merge the operations between two otherwise distinct work()
1502 | * bodies. This will obliterate the benchmark setup.
1503 | *
1504 | * In this example, HotSpot does the unrolled loop, merges the $BASE operands into a single
1505 | * addition to $acc, and then does a bunch of very tight stores of $x-s. The final performance
1506 | * depends on how much of the loop unrolling happened *and* how much data is available to make
1507 | * the large strides.
1508 | *
1509 | * 另外一种错误方式就是将结果累加到一个局部变量中。虽然他会强制计算每一个work()方法,但是由于软件流水线的作用,可以合并两个原本不同的的work()之间的不同操作。这将使得基准测试的设置失效。
1510 | *
1511 | * 这个例子中,HotSpot 执行展开循环,将 $BASE操作数合并一个操作加到$acc中,然后对$x-s做了一些非常紧凑的压缩。
1512 | * 最终的性能取决于有多少循环被展开以及有多少数据可以用来做大跨度。张开的原理示意可以见上一小节「循环展开」
1513 | */
1514 |
1515 | @Benchmark
1516 | public int measureWrong_2() {
1517 | int acc = 0;
1518 | for (int x : xs) {
1519 | acc += work(x);
1520 | }
1521 | return acc;
1522 | }
1523 |
1524 | /*
1525 | * Now, let's see how to measure these things properly. A very straight-forward way to
1526 | * break the merging is to sink each result to Blackhole. This will force runtime to compute
1527 | * every work() call in full. (We would normally like to care about several concurrent work()
1528 | * computations at once, but the memory effects from Blackhole.consume() prevent those optimization
1529 | * on most runtimes).
1530 | *
1531 | * 现在,让我们看看如何正确测量这些东西。打破合并的一个非常直接的方法是将每个结果下沉到黑洞。
1532 | * 这将迫使运行时完整地计算每个work()调用。我们通常希望同时关注多个并发 work() 计算,但是 Blackhole.consume() 的内存效应阻止了大多数运行时的优化)。
1533 | */
1534 |
1535 | @Benchmark
1536 | public void measureRight_1(Blackhole bh) {
1537 | for (int x : xs) {
1538 | bh.consume(work(x));
1539 | }
1540 | }
1541 |
1542 | /*
1543 | * 注意事项:DANGEROUS AREA, PLEASE READ THE DESCRIPTION BELOW.
1544 | *
1545 | * Sometimes, the cost of sinking the value into a Blackhole is dominating the nano-benchmark score.
1546 | * In these cases, one may try to do a make-shift "sinker" with non-inlineable method. This trick is
1547 | * *very* VM-specific, and can only be used if you are verifying the generated code (that's a good
1548 | * strategy when dealing with nano-benchmarks anyway).
1549 | *
1550 | * You SHOULD NOT use this trick in most cases. Apply only where needed.
1551 | *
1552 | * 有时,将值放入 Blackhole 的成本在**纳秒级别的基准测试**中占比很高,会影响测试结果。
1553 | * 在这些情况下,人们可能会尝试使用不可内联的方法来做一个临时的“sinker” 。这个技巧是针对虚拟机的,只有在你验证生成的代码时才能使用(无论如何,在处理纳米基准时这是一个好的策略)。
1554 | *
1555 | * 注意:在大多数情况下,你不应该使用这个技巧。只在需要的时候使用。
1556 | */
1557 |
1558 | @Benchmark
1559 | public void measureRight_2() {
1560 | for (int x : xs) {
1561 | sink(work(x));
1562 | }
1563 | }
1564 |
1565 | @CompilerControl(CompilerControl.Mode.DONT_INLINE)
1566 | public static void sink(int v) {
1567 | // IT IS VERY IMPORTANT TO MATCH THE SIGNATURE TO AVOID AUTOBOXING.
1568 | // The method intentionally does nothing.
1569 | }
1570 |
1571 |
1572 | /*
1573 | * ============================== HOW TO RUN THIS TEST: ====================================
1574 | *
1575 | * You might notice measureWrong_1 does not depend on $size, measureWrong_2 has troubles with
1576 | * linearity, and otherwise much faster than both measureRight_*. You can also see measureRight_2
1577 | * is marginally faster than measureRight_1.
1578 | *
1579 | * 从执行结果中可以发现,measureWrong_1的执行结果不依赖于 $size参数,而measureWrong_2 的执行性能不是增长,否则比 measureRight_ 快得多。
1580 | * 您还可以看到 measureRight_2 略快于 measureRight_1。
1581 | *
1582 | * You can run this test:
1583 | *
1584 | * a) Via the command line:
1585 | * $ mvn clean install
1586 | * $ java -jar target/benchmarks.jar JMHSample_34
1587 | *
1588 | * b) Via the Java API:
1589 | * (see the JMH homepage for possible caveats when running from IDE:
1590 | * http://openjdk.java.net/projects/code-tools/jmh/)
1591 | */
1592 |
1593 | public static void main(String[] args) throws RunnerException {
1594 | Options opt = new OptionsBuilder()
1595 | .include(JMHSample_34_SafeLooping.class.getSimpleName())
1596 | .forks(3)
1597 | .build();
1598 |
1599 | new Runner(opt).run();
1600 | }
1601 |
1602 | }
1603 | ```
1604 | :::
1605 | ::: tip Tips
1606 | 1. 观察测量结果是否随测量数据规模线性增长?如果不是,则可能有问题
1607 | 2. 使用 BlackHole 防止JVM循环展开优化
1608 | 3. 对于`纳秒`级的基准测试,可以会尝试使用不可内联的方法来做一个临时的“sinker",必要时可以这样做!
1609 | :::
1610 | ## @Params:不同参数组合测试
1611 | 在很多场景下,一个基准测试需要再不同的配置下运行。这些需要额外的控制,或者需要验证在不同参数下程序的性能变化。
1612 | ::: tips 多个参数组合
1613 | 如果多个参数的情况,JMH会计算参数的笛卡尔积,在针对每种情况进行测试。
1614 | :::
1615 |
1616 | ::: details 代码示例
1617 | ```java
1618 | @BenchmarkMode(Mode.AverageTime)
1619 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
1620 | @Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
1621 | @Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
1622 | @Fork(1)
1623 | @State(Scope.Benchmark)
1624 | public class JMHSample_27_Params {
1625 |
1626 | /**
1627 | * In many cases, the experiments require walking the configuration space
1628 | * for a benchmark. This is needed for additional control, or investigating
1629 | * how the workload performance changes with different settings.
1630 | */
1631 |
1632 | @Param({"1", "31", "65", "101", "103"})
1633 | public int arg;
1634 |
1635 | @Param({"0", "1", "2", "4", "8", "16", "32"})
1636 | public int certainty;
1637 |
1638 | @Benchmark
1639 | public boolean bench() {
1640 | return BigInteger.valueOf(arg).isProbablePrime(certainty);
1641 | }
1642 |
1643 | /*
1644 | * ============================== HOW TO RUN THIS TEST: ====================================
1645 | *
1646 | * Note the performance is different with different parameters.
1647 | *
1648 | * You can run this test:
1649 | *
1650 | * a) Via the command line:
1651 | * $ mvn clean install
1652 | * $ java -jar target/benchmarks.jar JMHSample_27
1653 | *
1654 | * You can juggle parameters through the command line, e.g. with "-p arg=41,42"
1655 | *
1656 | * b) Via the Java API:
1657 | * (see the JMH homepage for possible caveats when running from IDE:
1658 | * http://openjdk.java.net/projects/code-tools/jmh/)
1659 | */
1660 |
1661 | public static void main(String[] args) throws RunnerException {
1662 | Options opt = new OptionsBuilder()
1663 | .include(JMHSample_27_Params.class.getSimpleName())
1664 | // .param("arg", "41", "42") // Use this to selectively constrain/override parameters
1665 | .build();
1666 |
1667 | new Runner(opt).run();
1668 | }
1669 |
1670 | }
1671 | ```
1672 | :::
1673 |
1674 | ## Asymmetric:非对称试验
1675 | 目前为止,我们的测试都是对称的:所有的线程都运行相同的代码。接下来我们一起学习一下非对称测试。
1676 |
1677 | JMH引入了Group的概念,并提供了@Group注解来把几个方法绑定到一起,所有线程都分布在测试方法中。
1678 |
1679 | 每个执行组包含一个或者多个线程。特定执行组中的每个线程执行一个@Group标记的 benchmark方法,多个执行组可以参与运行时,运行中的总线程数将四舍五入为执行组大小,这将保证所有执行组都是完整的。
1680 |
1681 | 注意那两个状态的作用域:Scope.Benchmark 和 Scope.Thread没有在这个用例中覆盖,表明你要么在状态中共享每个东西,要么不共享。我们使用Scope.Group状态用来表明在执行组内共享,而不在组间共享。
1682 |
1683 | ::: details 代码示例
1684 | ```java
1685 | @State(Scope.Group)
1686 | @BenchmarkMode(Mode.AverageTime)
1687 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
1688 | public class JMHSample_15_Asymmetric {
1689 |
1690 | /*
1691 | * So far all the tests were symmetric: the same code was executed in all the threads.
1692 | * At times, you need the asymmetric test. JMH provides this with the notion of @Group,
1693 | * which can bind several methods together, and all the threads are distributed among
1694 | * the test methods.
1695 | *
1696 | * Each execution group contains of one or more threads. Each thread within a particular
1697 | * execution group executes one of @Group-annotated @Benchmark methods. Multiple execution
1698 | * groups may participate in the run. The total thread count in the run is rounded to the
1699 | * execution group size, which will only allow the full execution groups.
1700 | *
1701 | * Note that two state scopes: Scope.Benchmark and Scope.Thread are not covering all
1702 | * the use cases here -- you either share everything in the state, or share nothing.
1703 | * To break this, we have the middle ground Scope.Group, which marks the state to be
1704 | * shared within the execution group, but not among the execution groups.
1705 | *
1706 | * Putting this all together, the example below means:
1707 | * a) define the execution group "g", with 3 threads executing inc(), and 1 thread
1708 | * executing get(), 4 threads per group in total;
1709 | * b) if we run this test case with 4 threads, then we will have a single execution
1710 | * group. Generally, running with 4*N threads will create N execution groups, etc.;
1711 | * c) each execution group has one @State instance to share: that is, execution groups
1712 | * share the counter within the group, but not across the groups.
1713 | *
1714 | * 到目前位置,我们的测试都是对称的:所有的线程都运行相同的代码。
1715 | * 是时候了解非对称测试了。JMH提供了@Group注解来把几个方法绑定到一起,所有线程都分布在测试方法中。
1716 | *
1717 | * 每个执行组包含一个或者多个线程。特定执行组中的每个线程执行一个@Group标记的 benchmark方法
1718 | * 多个执行组可以参与运行时,运行中的总线程数将四舍五入为执行组大小,这将保证所有执行组都是完整的。
1719 | *
1720 | * 注意那两个状态的作用域:Scope.Benchmark 和 Scope.Thread没有在这个用例中覆盖,表明你要么在状态中共享每个东西,要么不共享。我们使用Scope.Group状态用来表明在执行组内共享,而不在组间共享。
1721 | *
1722 | * 以下事例含义:
1723 | * a)定义执行组"g",它有3个线程来执行inc(),1个线程来执行get(),每个分组共有4个线程;
1724 | * b)如果我们用4个线程来运行这个测试用例,我们将会有一个单独的执行组。通常,用4*N个线程来创建N个执行组。
1725 | * c)每个执行组内共享一个@State实例:也就是执行组内共享counter,而不是跨组共享。
1726 | */
1727 |
1728 | private AtomicInteger counter;
1729 |
1730 | @Setup
1731 | public void up() {
1732 | counter = new AtomicInteger();
1733 | }
1734 |
1735 | @Benchmark
1736 | @Group("g")
1737 | @GroupThreads(3)
1738 | public int inc() {
1739 | return counter.incrementAndGet();
1740 | }
1741 |
1742 | @Benchmark
1743 | @Group("g")
1744 | @GroupThreads(1)
1745 | public int get() {
1746 | return counter.get();
1747 | }
1748 |
1749 | /*
1750 | * ============================== HOW TO RUN THIS TEST: ====================================
1751 | *
1752 | * You will have the distinct metrics for inc() and get() from this run.
1753 | *
1754 | * 在此次运行中我们讲分别获得inc()和get()的指标。
1755 | *
1756 | * You can run this test:
1757 | *
1758 | * a) Via the command line:
1759 | * $ mvn clean install
1760 | * $ java -jar target/benchmarks.jar JMHSample_15 -f 1
1761 | * (we requested single fork; there are also other options, see -h)
1762 | *
1763 | * b) Via the Java API:
1764 | * (see the JMH homepage for possible caveats when running from IDE:
1765 | * http://openjdk.java.net/projects/code-tools/jmh/)
1766 | */
1767 |
1768 | public static void main(String[] args) throws RunnerException {
1769 | Options opt = new OptionsBuilder()
1770 | .include(JMHSample_15_Asymmetric.class.getSimpleName())
1771 | .forks(1)
1772 | .output("JMHSample_15_Asymmetric.sampleLog")
1773 | .build();
1774 |
1775 | new Runner(opt).run();
1776 | }
1777 |
1778 | }
1779 | ```
1780 | :::
1781 |
1782 |
1783 | ## SyncIterations
1784 | 事实证明如果你用多线程来跑benchmark,你启动和停止工作线程的方式会严重影响性能。
1785 |
1786 | 通常的做法是,让所有的线程都挂起在一些有序的屏障上,然后让他们一起开始。
1787 | 然而,这种做法是不奏效的:没有谁能够保证工作线程在同一时间开始,这就意味着其他工作线程在更好的条件下运行,从而扭曲了结果。
1788 |
1789 | 更好的解决方案是引入虚假迭代,增加执行迭代的线程,然后将系统自动切换为测试任务。在减速期间可以做同样的事情,这听起来很复杂,但是JMH已经帮你处理好了。
1790 |
1791 | syncIterations设置为true时,先让线程池预热,都预热完成后让所有线程同时进行基准测试,测试完等待所有线程都结束再关闭线程池。这样能够更加真实的模拟线上多线程并发执行的情况。
1792 | ::: details 代码示例
1793 |
1794 | ```java
1795 | @State(Scope.Thread)
1796 | @OutputTimeUnit(TimeUnit.MILLISECONDS)
1797 | public class JMHSample_17_SyncIterations {
1798 |
1799 | /*
1800 | * This is the another thing that is enabled in JMH by default.
1801 | *
1802 | * Suppose we have this simple benchmark.
1803 | */
1804 |
1805 | private double src;
1806 |
1807 | @Benchmark
1808 | public double test() {
1809 | double s = src;
1810 | for (int i = 0; i < 1000; i++) {
1811 | s = Math.sin(s);
1812 | }
1813 | return s;
1814 | }
1815 |
1816 | /*
1817 | * It turns out if you run the benchmark with multiple threads,
1818 | * the way you start and stop the worker threads seriously affects
1819 | * performance.
1820 | *
1821 | * The natural way would be to park all the threads on some sort
1822 | * of barrier, and the let them go "at once". However, that does
1823 | * not work: there are no guarantees the worker threads will start
1824 | * at the same time, meaning other worker threads are working
1825 | * in better conditions, skewing the result.
1826 | *
1827 | * The better solution would be to introduce bogus iterations,
1828 | * ramp up the threads executing the iterations, and then atomically
1829 | * shift the system to measuring stuff. The same thing can be done
1830 | * during the rampdown. This sounds complicated, but JMH already
1831 | * handles that for you.
1832 | *
1833 | */
1834 |
1835 | /*
1836 | * ============================== HOW TO RUN THIS TEST: ====================================
1837 | *
1838 | * You will need to oversubscribe the system to make this effect
1839 | * clearly visible; however, this effect can also be shown on the
1840 | * unsaturated systems.*
1841 | *
1842 | * Note the performance of -si false version is more flaky, even
1843 | * though it is "better". This is the false improvement, granted by
1844 | * some of the threads executing in solo. The -si true version more stable
1845 | * and coherent.
1846 | *
1847 | * -si true is enabled by default.
1848 | *
1849 | * Say, $CPU is the number of CPUs on your machine.
1850 | *
1851 | * You can run this test with:
1852 | *
1853 | * a) Via the command line:
1854 | * $ mvn clean install
1855 | * $ java -jar target/benchmarks.jar JMHSample_17 \
1856 | * -w 1s -r 1s -f 1 -t ${CPU*16} -si {true|false}
1857 | * (we requested shorter warmup/measurement iterations, single fork,
1858 | * lots of threads, and changeable "synchronize iterations" option)
1859 | *
1860 | * b) Via the Java API:
1861 | * (see the JMH homepage for possible caveats when running from IDE:
1862 | * http://openjdk.java.net/projects/code-tools/jmh/)
1863 | */
1864 |
1865 | public static void main(String[] args) throws RunnerException {
1866 | Options opt = new OptionsBuilder()
1867 | .include(JMHSample_17_SyncIterations.class.getSimpleName())
1868 | .warmupTime(TimeValue.seconds(1))
1869 | .measurementTime(TimeValue.seconds(1))
1870 | .threads(Runtime.getRuntime().availableProcessors()*16)
1871 | .forks(1)
1872 | .syncIterations(true) // try to switch to "false"
1873 | .build();
1874 |
1875 | new Runner(opt).run();
1876 | }
1877 |
1878 | }
1879 | ```
1880 | :::
1881 |
1882 | ## Annotations:注解 or API
1883 |
1884 | 除了运行时所有的命令行选项外,我们还可以通过注解给一些基准测试提供默认值。在你处理大量基准测试时这个很有用,其中一些需要特别处理。
1885 |
1886 | 注解可以放在class上,来影响这个class中所有的基准测试方法。规则是,靠近作用域的注解有优先权:比如,方法上的注解可以覆盖类上的注解;命令行优先级最高。
1887 |
1888 | ::: details 代码示例
1889 | ```java
1890 | @State(Scope.Thread)
1891 | @OutputTimeUnit(TimeUnit.MICROSECONDS)
1892 | @Fork(1)
1893 | public class JMHSample_20_Annotations {
1894 |
1895 | double x1 = Math.PI;
1896 |
1897 | /*
1898 | * In addition to all the command line options usable at run time,
1899 | * we have the annotations which can provide the reasonable defaults
1900 | * for the some of the benchmarks. This is very useful when you are
1901 | * dealing with lots of benchmarks, and some of them require
1902 | * special treatment.
1903 | *
1904 | * Annotation can also be placed on class, to have the effect over
1905 | * all the benchmark methods in the same class. The rule is, the
1906 | * annotation in the closest scope takes the precedence: i.e.
1907 | * the method-based annotation overrides class-based annotation,
1908 | * etc.
1909 | */
1910 |
1911 | @Benchmark
1912 | @Warmup(iterations = 5, time = 100, timeUnit = TimeUnit.MILLISECONDS)
1913 | @Measurement(iterations = 5, time = 100, timeUnit = TimeUnit.MILLISECONDS)
1914 | public double measure() {
1915 | return Math.log(x1);
1916 | }
1917 |
1918 | /*
1919 | * ============================== HOW TO RUN THIS TEST: ====================================
1920 | *
1921 | * Note JMH honors the default annotation settings. You can always override
1922 | * the defaults via the command line or API.
1923 | *
1924 | * You can run this test:
1925 | *
1926 | * a) Via the command line:
1927 | * $ mvn clean install
1928 | * $ java -jar target/benchmarks.jar JMHSample_20
1929 | *
1930 | * b) Via the Java API:
1931 | * (see the JMH homepage for possible caveats when running from IDE:
1932 | * http://openjdk.java.net/projects/code-tools/jmh/)
1933 | */
1934 |
1935 | public static void main(String[] args) throws RunnerException {
1936 | Options opt = new OptionsBuilder()
1937 | .include(JMHSample_20_Annotations.class.getSimpleName())
1938 | .build();
1939 |
1940 | new Runner(opt).run();
1941 | }
1942 |
1943 | }
1944 | ```
1945 | :::
1946 |
1947 |
1948 | ## FalseSharing :消除伪共享
1949 |
1950 | 伪共享引发的错误可能让你大吃一惊。若干两个线程访问内存中两个相邻的值,它们很可能修改的是同一缓存行上的值,这就导致程序的执行明显变慢。
1951 |
1952 | JMH能够使用@State自动填充解决这个问题。但是这种填充没有在@State内部实现,需要开发手动处理。
1953 |
1954 |
1955 | ::: details 代码示例
1956 | ```java
1957 | @BenchmarkMode(Mode.Throughput)
1958 | @OutputTimeUnit(TimeUnit.MICROSECONDS)
1959 | @Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
1960 | @Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
1961 | @Fork(5)
1962 | public class JMHSample_22_FalseSharing {
1963 |
1964 | /*
1965 | * Suppose we have two threads:
1966 | * a) innocuous reader which blindly reads its own field
1967 | * b) furious writer which updates its own field
1968 | */
1969 |
1970 | /*
1971 | * BASELINE EXPERIMENT:
1972 | * Because of the false sharing, both reader and writer will experience
1973 | * penalties.
1974 | */
1975 |
1976 | @State(Scope.Group)
1977 | public static class StateBaseline {
1978 | int readOnly;
1979 | int writeOnly;
1980 | }
1981 |
1982 | @Benchmark
1983 | @Group("baseline")
1984 | public int reader(StateBaseline s) {
1985 | return s.readOnly;
1986 | }
1987 |
1988 | @Benchmark
1989 | @Group("baseline")
1990 | public void writer(StateBaseline s) {
1991 | s.writeOnly++;
1992 | }
1993 |
1994 | /*
1995 | * APPROACH 1: PADDING
1996 | *
1997 | * We can try to alleviate some of the effects with padding.
1998 | * This is not versatile because JVMs can freely rearrange the
1999 | * field order, even of the same type.
2000 | */
2001 |
2002 | @State(Scope.Group)
2003 | public static class StatePadded {
2004 | int readOnly;
2005 | int p01, p02, p03, p04, p05, p06, p07, p08;
2006 | int p11, p12, p13, p14, p15, p16, p17, p18;
2007 | int writeOnly;
2008 | int q01, q02, q03, q04, q05, q06, q07, q08;
2009 | int q11, q12, q13, q14, q15, q16, q17, q18;
2010 | }
2011 |
2012 | @Benchmark
2013 | @Group("padded")
2014 | public int reader(StatePadded s) {
2015 | return s.readOnly;
2016 | }
2017 |
2018 | @Benchmark
2019 | @Group("padded")
2020 | public void writer(StatePadded s) {
2021 | s.writeOnly++;
2022 | }
2023 |
2024 | /*
2025 | * APPROACH 2: CLASS HIERARCHY TRICK
2026 | *
2027 | * We can alleviate false sharing with this convoluted hierarchy trick,
2028 | * using the fact that superclass fields are usually laid out first.
2029 | * In this construction, the protected field will be squashed between
2030 | * paddings.
2031 | * It is important to use the smallest data type, so that layouter would
2032 | * not generate any gaps that can be taken by later protected subclasses
2033 | * fields. Depending on the actual field layout of classes that bear the
2034 | * protected fields, we might need more padding to account for "lost"
2035 | * padding fields pulled into in their superclass gaps.
2036 | */
2037 |
2038 | public static class StateHierarchy_1 {
2039 | int readOnly;
2040 | }
2041 |
2042 | public static class StateHierarchy_2 extends StateHierarchy_1 {
2043 | byte p01, p02, p03, p04, p05, p06, p07, p08;
2044 | byte p11, p12, p13, p14, p15, p16, p17, p18;
2045 | byte p21, p22, p23, p24, p25, p26, p27, p28;
2046 | byte p31, p32, p33, p34, p35, p36, p37, p38;
2047 | byte p41, p42, p43, p44, p45, p46, p47, p48;
2048 | byte p51, p52, p53, p54, p55, p56, p57, p58;
2049 | byte p61, p62, p63, p64, p65, p66, p67, p68;
2050 | byte p71, p72, p73, p74, p75, p76, p77, p78;
2051 | }
2052 |
2053 | public static class StateHierarchy_3 extends StateHierarchy_2 {
2054 | int writeOnly;
2055 | }
2056 |
2057 | public static class StateHierarchy_4 extends StateHierarchy_3 {
2058 | byte q01, q02, q03, q04, q05, q06, q07, q08;
2059 | byte q11, q12, q13, q14, q15, q16, q17, q18;
2060 | byte q21, q22, q23, q24, q25, q26, q27, q28;
2061 | byte q31, q32, q33, q34, q35, q36, q37, q38;
2062 | byte q41, q42, q43, q44, q45, q46, q47, q48;
2063 | byte q51, q52, q53, q54, q55, q56, q57, q58;
2064 | byte q61, q62, q63, q64, q65, q66, q67, q68;
2065 | byte q71, q72, q73, q74, q75, q76, q77, q78;
2066 | }
2067 |
2068 | @State(Scope.Group)
2069 | public static class StateHierarchy extends StateHierarchy_4 {
2070 | }
2071 |
2072 | @Benchmark
2073 | @Group("hierarchy")
2074 | public int reader(StateHierarchy s) {
2075 | return s.readOnly;
2076 | }
2077 |
2078 | @Benchmark
2079 | @Group("hierarchy")
2080 | public void writer(StateHierarchy s) {
2081 | s.writeOnly++;
2082 | }
2083 |
2084 | /*
2085 | * APPROACH 3: ARRAY TRICK
2086 | *
2087 | * This trick relies on the contiguous allocation of an array.
2088 | * Instead of placing the fields in the class, we mangle them
2089 | * into the array at very sparse offsets.
2090 | */
2091 |
2092 | @State(Scope.Group)
2093 | public static class StateArray {
2094 | int[] arr = new int[128];
2095 | }
2096 |
2097 | @Benchmark
2098 | @Group("sparse")
2099 | public int reader(StateArray s) {
2100 | return s.arr[0];
2101 | }
2102 |
2103 | @Benchmark
2104 | @Group("sparse")
2105 | public void writer(StateArray s) {
2106 | s.arr[64]++;
2107 | }
2108 |
2109 | /*
2110 | * APPROACH 4:
2111 | *
2112 | * @Contended (since JDK 8):
2113 | * Uncomment the annotation if building with JDK 8.
2114 | * Remember to flip -XX:-RestrictContended to enable.
2115 | */
2116 |
2117 | @State(Scope.Group)
2118 | public static class StateContended {
2119 | int readOnly;
2120 |
2121 | // @sun.misc.Contended
2122 | int writeOnly;
2123 | }
2124 |
2125 | @Benchmark
2126 | @Group("contended")
2127 | public int reader(StateContended s) {
2128 | return s.readOnly;
2129 | }
2130 |
2131 | @Benchmark
2132 | @Group("contended")
2133 | public void writer(StateContended s) {
2134 | s.writeOnly++;
2135 | }
2136 |
2137 | public static void main(String[] args) throws RunnerException {
2138 | Options opt = new OptionsBuilder()
2139 | .include(JMHSample_22_FalseSharing.class.getSimpleName())
2140 | .threads(Runtime.getRuntime().availableProcessors())
2141 | .build();
2142 |
2143 | new Runner(opt).run();
2144 | }
2145 |
2146 | }
2147 |
2148 | ```
2149 | :::
2150 | ## 最佳实践:
2151 | ### Inheritance: 模板方法
2152 | 在有些场景下下,我们可以使用模版模式通过抽象方法来分离实现。
2153 | 经验法则是:如果一些类有@Benchmark方法,那么它所有的子类都继承@Benchmark方法。 注意,因为我们只知道编译期间的类型层次结构,所以只能在同一个编译会话期间使用。也就是说,在JMH编译之后混合扩展benchmark类的子类将不起作用。
2154 | 注释现在有两个可能的地方,这时采用**就近原则**,离得近的生效。
2155 | ::: details 代码示例
2156 | ```java
2157 | public class JMHSample_24_Inheritance {
2158 |
2159 | /*
2160 | * In very special circumstances, you might want to provide the benchmark
2161 | * body in the (abstract) superclass, and specialize it with the concrete
2162 | * pieces in the subclasses.
2163 | *
2164 | * The rule of thumb is: if some class has @Benchmark method, then all the subclasses
2165 | * are also having the "synthetic" @Benchmark method. The caveat is, because we only
2166 | * know the type hierarchy during the compilation, it is only possible during
2167 | * the same compilation session. That is, mixing in the subclass extending your
2168 | * benchmark class *after* the JMH compilation would have no effect.
2169 | *
2170 | * Note how annotations now have two possible places. The closest annotation
2171 | * in the hierarchy wins.
2172 | */
2173 |
2174 | @BenchmarkMode(Mode.AverageTime)
2175 | @Fork(1)
2176 | @State(Scope.Thread)
2177 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
2178 | public static abstract class AbstractBenchmark {
2179 | int x;
2180 |
2181 | @Setup
2182 | public void setup() {
2183 | x = 42;
2184 | }
2185 |
2186 | @Benchmark
2187 | @Warmup(iterations = 5, time = 100, timeUnit = TimeUnit.MILLISECONDS)
2188 | @Measurement(iterations = 5, time = 100, timeUnit = TimeUnit.MILLISECONDS)
2189 | public double bench() {
2190 | return doWork() * doWork();
2191 | }
2192 |
2193 | protected abstract double doWork();
2194 | }
2195 |
2196 | public static class BenchmarkLog extends AbstractBenchmark {
2197 | @Override
2198 | protected double doWork() {
2199 | return Math.log(x);
2200 | }
2201 | }
2202 |
2203 | public static class BenchmarkSin extends AbstractBenchmark {
2204 | @Override
2205 | protected double doWork() {
2206 | return Math.sin(x);
2207 | }
2208 | }
2209 |
2210 | public static class BenchmarkCos extends AbstractBenchmark {
2211 | @Override
2212 | protected double doWork() {
2213 | return Math.cos(x);
2214 | }
2215 | }
2216 |
2217 | /*
2218 | * ============================== HOW TO RUN THIS TEST: ====================================
2219 | *
2220 | * You can run this test, and observe the three distinct benchmarks running the squares
2221 | * of Math.log, Math.sin, and Math.cos, accordingly.
2222 | *
2223 | * a) Via the command line:
2224 | * $ mvn clean install
2225 | * $ java -jar target/benchmarks.jar JMHSample_24
2226 | *
2227 | * b) Via the Java API:
2228 | * (see the JMH homepage for possible caveats when running from IDE:
2229 | * http://openjdk.java.net/projects/code-tools/jmh/)
2230 | */
2231 |
2232 | public static void main(String[] args) throws RunnerException {
2233 | Options opt = new OptionsBuilder()
2234 | .include(JMHSample_24_Inheritance.class.getSimpleName())
2235 | .build();
2236 |
2237 | new Runner(opt).run();
2238 | }
2239 |
2240 | }
2241 | ```
2242 | :::
2243 |
2244 | ### API_GA:API方式开发
2245 | 上文中大部分案例都是基于注解方式开发JMH程序,这个例子展示了在复杂场景中利用 JMH API 的一种相当复杂但有趣的方式。不过笔者认为注解方式更简单和灵活!
2246 | ::: details 代码示例
2247 | ```java
2248 |
2249 | @State(Scope.Thread)
2250 | public class JMHSample_25_API_GA {
2251 |
2252 | /**
2253 | * This example shows the rather convoluted, but fun way to exploit
2254 | * JMH API in complex scenarios. Up to this point, we haven't consumed
2255 | * the results programmatically, and hence we are missing all the fun.
2256 | *
2257 | * Let's consider this naive code, which obviously suffers from the
2258 | * performance anomalies, since current HotSpot is resistant to make
2259 | * the tail-call optimizations.
2260 | */
2261 |
2262 | private int v;
2263 |
2264 | @Benchmark
2265 | public int test() {
2266 | return veryImportantCode(1000, v);
2267 | }
2268 |
2269 | public int veryImportantCode(int d, int v) {
2270 | if (d == 0) {
2271 | return v;
2272 | } else {
2273 | return veryImportantCode(d - 1, v);
2274 | }
2275 | }
2276 |
2277 | /*
2278 | * We could probably make up for the absence of TCO with better inlining
2279 | * policy. But hand-tuning the policy requires knowing a lot about VM
2280 | * internals. Let's instead construct the layman's genetic algorithm
2281 | * which sifts through inlining settings trying to find the better policy.
2282 | *
2283 | * If you are not familiar with the concept of Genetic Algorithms,
2284 | * read the Wikipedia article first:
2285 | * http://en.wikipedia.org/wiki/Genetic_algorithm
2286 | *
2287 | * VM experts can guess which option should be tuned to get the max
2288 | * performance. Try to run the sample and see if it improves performance.
2289 | */
2290 |
2291 | public static void main(String[] args) throws RunnerException {
2292 | // These are our base options. We will mix these options into the
2293 | // measurement runs. That is, all measurement runs will inherit these,
2294 | // see how it's done below.
2295 | Options baseOpts = new OptionsBuilder()
2296 | .include(JMHSample_25_API_GA.class.getName())
2297 | .warmupTime(TimeValue.milliseconds(200))
2298 | .measurementTime(TimeValue.milliseconds(200))
2299 | .warmupIterations(5)
2300 | .measurementIterations(5)
2301 | .forks(1)
2302 | .verbosity(VerboseMode.SILENT)
2303 | .build();
2304 |
2305 | // Initial population
2306 | Population pop = new Population();
2307 | final int POPULATION = 10;
2308 | for (int c = 0; c < POPULATION; c++) {
2309 | pop.addChromosome(new Chromosome(baseOpts));
2310 | }
2311 |
2312 | // Make a few rounds of optimization:
2313 | final int GENERATIONS = 100;
2314 | for (int g = 0; g < GENERATIONS; g++) {
2315 | System.out.println("Entering generation " + g);
2316 |
2317 | // Get the baseline score.
2318 | // We opt to remeasure it in order to get reliable current estimate.
2319 | RunResult runner = new Runner(baseOpts).runSingle();
2320 | Result baseResult = runner.getPrimaryResult();
2321 |
2322 | // Printing a nice table...
2323 | System.out.println("---------------------------------------");
2324 | System.out.printf("Baseline score: %10.2f %s%n",
2325 | baseResult.getScore(),
2326 | baseResult.getScoreUnit()
2327 | );
2328 |
2329 | for (Chromosome c : pop.getAll()) {
2330 | System.out.printf("%10.2f %s (%+10.2f%%) %s%n",
2331 | c.getScore(),
2332 | baseResult.getScoreUnit(),
2333 | (c.getScore() / baseResult.getScore() - 1) * 100,
2334 | c.toString()
2335 | );
2336 | }
2337 | System.out.println();
2338 |
2339 | Population newPop = new Population();
2340 |
2341 | // Copy out elite solutions
2342 | final int ELITE = 2;
2343 | for (Chromosome c : pop.getAll().subList(0, ELITE)) {
2344 | newPop.addChromosome(c);
2345 | }
2346 |
2347 | // Cross-breed the rest of new population
2348 | while (newPop.size() < pop.size()) {
2349 | Chromosome p1 = pop.selectToBreed();
2350 | Chromosome p2 = pop.selectToBreed();
2351 |
2352 | newPop.addChromosome(p1.crossover(p2).mutate());
2353 | newPop.addChromosome(p2.crossover(p1).mutate());
2354 | }
2355 |
2356 | pop = newPop;
2357 | }
2358 |
2359 | }
2360 |
2361 | /**
2362 | * Population.
2363 | */
2364 | public static class Population {
2365 | private final List list = new ArrayList<>();
2366 |
2367 | public void addChromosome(Chromosome c) {
2368 | list.add(c);
2369 | Collections.sort(list);
2370 | }
2371 |
2372 | /**
2373 | * Select the breeding material.
2374 | * Solutions with better score have better chance to be selected.
2375 | * @return breed
2376 | */
2377 | public Chromosome selectToBreed() {
2378 | double totalScore = 0D;
2379 | for (Chromosome c : list) {
2380 | totalScore += c.score();
2381 | }
2382 |
2383 | double thresh = Math.random() * totalScore;
2384 | for (Chromosome c : list) {
2385 | if (thresh >= 0) {
2386 | thresh -= c.score();
2387 | } else {
2388 | return c;
2389 | }
2390 | }
2391 |
2392 | // Return the last
2393 | return list.get(list.size() - 1);
2394 | }
2395 |
2396 | public int size() {
2397 | return list.size();
2398 | }
2399 |
2400 | public List getAll() {
2401 | return list;
2402 | }
2403 | }
2404 |
2405 | /**
2406 | * Chromosome: encodes solution.
2407 | */
2408 | public static class Chromosome implements Comparable {
2409 |
2410 | // Current score is not yet computed.
2411 | double score = Double.NEGATIVE_INFINITY;
2412 |
2413 | // Base options to mix in
2414 | final Options baseOpts;
2415 |
2416 | // These are current HotSpot defaults.
2417 | int freqInlineSize = 325;
2418 | int inlineSmallCode = 1000;
2419 | int maxInlineLevel = 9;
2420 | int maxInlineSize = 35;
2421 | int maxRecursiveInlineLevel = 1;
2422 | int minInliningThreshold = 250;
2423 |
2424 | public Chromosome(Options baseOpts) {
2425 | this.baseOpts = baseOpts;
2426 | }
2427 |
2428 | public double score() {
2429 | if (score != Double.NEGATIVE_INFINITY) {
2430 | // Already got the score, shortcutting
2431 | return score;
2432 | }
2433 |
2434 | try {
2435 | // Add the options encoded by this solution:
2436 | // a) Mix in base options.
2437 | // b) Add JVM arguments: we opt to parse the
2438 | // stringly representation to make the example
2439 | // shorter. There are, of course, cleaner ways
2440 | // to do this.
2441 | Options theseOpts = new OptionsBuilder()
2442 | .parent(baseOpts)
2443 | .jvmArgs(toString().split("[ ]"))
2444 | .build();
2445 |
2446 | // Run through JMH and get the result back.
2447 | RunResult runResult = new Runner(theseOpts).runSingle();
2448 | score = runResult.getPrimaryResult().getScore();
2449 | } catch (RunnerException e) {
2450 | // Something went wrong, the solution is defective
2451 | score = Double.MIN_VALUE;
2452 | }
2453 |
2454 | return score;
2455 | }
2456 |
2457 | @Override
2458 | public int compareTo(Chromosome o) {
2459 | // Order by score, descending.
2460 | return -Double.compare(score(), o.score());
2461 | }
2462 |
2463 | @Override
2464 | public String toString() {
2465 | return "-XX:FreqInlineSize=" + freqInlineSize +
2466 | " -XX:InlineSmallCode=" + inlineSmallCode +
2467 | " -XX:MaxInlineLevel=" + maxInlineLevel +
2468 | " -XX:MaxInlineSize=" + maxInlineSize +
2469 | " -XX:MaxRecursiveInlineLevel=" + maxRecursiveInlineLevel +
2470 | " -XX:MinInliningThreshold=" + minInliningThreshold;
2471 | }
2472 |
2473 | public Chromosome crossover(Chromosome other) {
2474 | // Perform crossover:
2475 | // While this is a very naive way to perform crossover, it still works.
2476 |
2477 | final double CROSSOVER_PROB = 0.1;
2478 |
2479 | Chromosome result = new Chromosome(baseOpts);
2480 |
2481 | result.freqInlineSize = (Math.random() < CROSSOVER_PROB) ?
2482 | this.freqInlineSize : other.freqInlineSize;
2483 |
2484 | result.inlineSmallCode = (Math.random() < CROSSOVER_PROB) ?
2485 | this.inlineSmallCode : other.inlineSmallCode;
2486 |
2487 | result.maxInlineLevel = (Math.random() < CROSSOVER_PROB) ?
2488 | this.maxInlineLevel : other.maxInlineLevel;
2489 |
2490 | result.maxInlineSize = (Math.random() < CROSSOVER_PROB) ?
2491 | this.maxInlineSize : other.maxInlineSize;
2492 |
2493 | result.maxRecursiveInlineLevel = (Math.random() < CROSSOVER_PROB) ?
2494 | this.maxRecursiveInlineLevel : other.maxRecursiveInlineLevel;
2495 |
2496 | result.minInliningThreshold = (Math.random() < CROSSOVER_PROB) ?
2497 | this.minInliningThreshold : other.minInliningThreshold;
2498 |
2499 | return result;
2500 | }
2501 |
2502 | public Chromosome mutate() {
2503 | // Perform mutation:
2504 | // Again, this is a naive way to do mutation, but it still works.
2505 |
2506 | Chromosome result = new Chromosome(baseOpts);
2507 |
2508 | result.freqInlineSize = (int) randomChange(freqInlineSize);
2509 | result.inlineSmallCode = (int) randomChange(inlineSmallCode);
2510 | result.maxInlineLevel = (int) randomChange(maxInlineLevel);
2511 | result.maxInlineSize = (int) randomChange(maxInlineSize);
2512 | result.maxRecursiveInlineLevel = (int) randomChange(maxRecursiveInlineLevel);
2513 | result.minInliningThreshold = (int) randomChange(minInliningThreshold);
2514 |
2515 | return result;
2516 | }
2517 |
2518 | private double randomChange(double v) {
2519 | final double MUTATE_PROB = 0.5;
2520 | if (Math.random() < MUTATE_PROB) {
2521 | if (Math.random() < 0.5) {
2522 | return v / (Math.random() * 2);
2523 | } else {
2524 | return v * (Math.random() * 2);
2525 | }
2526 | } else {
2527 | return v;
2528 | }
2529 | }
2530 |
2531 | public double getScore() {
2532 | return score;
2533 | }
2534 | }
2535 |
2536 | }
2537 | ```
2538 | :::
2539 |
2540 | ### BlackholeHelper
2541 | 有时我们不需要将BlackHole注入到每个基准测试方法中。而是使用增加辅助类(方法),在辅助方法中直接使用Blackhole对象即可。这适用于@Setup和@TearDown方法,也适用于其他JMH基础设施对象,如Control。
2542 | 以下是{@link com.cxd.benchmark.JMHSample_08_DeadCode}的变种,但是他被包装在匿名类中。
2543 | ::: details 代码示例
2544 | ```java
2545 | @BenchmarkMode(Mode.AverageTime)
2546 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
2547 | @Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
2548 | @Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
2549 | @Fork(1)
2550 | @State(Scope.Thread)
2551 | public class JMHSample_28_BlackholeHelpers {
2552 |
2553 | /**
2554 | * Sometimes you need the black hole not in @Benchmark method, but in
2555 | * helper methods, because you want to pass it through to the concrete
2556 | * implementation which is instantiated in helper methods. In this case,
2557 | * you can request the black hole straight in the helper method signature.
2558 | * This applies to both @Setup and @TearDown methods, and also to other
2559 | * JMH infrastructure objects, like Control.
2560 | *
2561 | * Below is the variant of {@link org.openjdk.jmh.samples.JMHSample_08_DeadCode}
2562 | * test, but wrapped in the anonymous classes.
2563 | */
2564 |
2565 | public interface Worker {
2566 | void work();
2567 | }
2568 |
2569 | private Worker workerBaseline;
2570 | private Worker workerRight;
2571 | private Worker workerWrong;
2572 |
2573 | @Setup
2574 | public void setup(final Blackhole bh) {
2575 | workerBaseline = new Worker() {
2576 | double x;
2577 |
2578 | @Override
2579 | public void work() {
2580 | // do nothing
2581 | }
2582 | };
2583 |
2584 | workerWrong = new Worker() {
2585 | double x;
2586 |
2587 | @Override
2588 | public void work() {
2589 | Math.log(x);
2590 | }
2591 | };
2592 |
2593 | workerRight = new Worker() {
2594 | double x;
2595 |
2596 | @Override
2597 | public void work() {
2598 | bh.consume(Math.log(x));
2599 | }
2600 | };
2601 |
2602 | }
2603 |
2604 | @Benchmark
2605 | public void baseline() {
2606 | workerBaseline.work();
2607 | }
2608 |
2609 | @Benchmark
2610 | public void measureWrong() {
2611 | workerWrong.work();
2612 | }
2613 |
2614 | @Benchmark
2615 | public void measureRight() {
2616 | workerRight.work();
2617 | }
2618 |
2619 | /*
2620 | * ============================== HOW TO RUN THIS TEST: ====================================
2621 | *
2622 | * You will see measureWrong() running on-par with baseline().
2623 | * Both measureRight() are measuring twice the baseline, so the logs are intact.
2624 | *
2625 | * You can run this test:
2626 | *
2627 | * a) Via the command line:
2628 | * $ mvn clean install
2629 | * $ java -jar target/benchmarks.jar JMHSample_28
2630 | *
2631 | * b) Via the Java API:
2632 | * (see the JMH homepage for possible caveats when running from IDE:
2633 | * http://openjdk.java.net/projects/code-tools/jmh/)
2634 | */
2635 |
2636 | public static void main(String[] args) throws RunnerException {
2637 | Options opt = new OptionsBuilder()
2638 | .include(JMHSample_28_BlackholeHelpers.class.getSimpleName())
2639 | .build();
2640 |
2641 | new Runner(opt).run();
2642 | }
2643 |
2644 | }
2645 | ```
2646 | :::
2647 |
2648 | ### BatchSize:Single Shot + BatchSize
2649 | 有时你需要评估不具备稳定状态的操作。一个基准操作的成本在不同的调用中可能有很大的不同。在这种情况下,使用定时测量并不是一个好主意,唯一可以接受的基准模式是 Single shot。
2650 |
2651 | 另一方面,操作时间/吞吐量可能太小,无法进行可靠的单次测量。我们可以使用 "BatchSize" 参数来描述每一次调用所要做的基准调用的数量,将多个小的操作合并成一个,而不需要手动循环该方法,这样可以避免JMHSample_11_Loops中描述的问题。
2652 |
2653 | 即使用 @BenchmarkMode(Mode.SingleShotTime) + @Measurement(iterations = 5, batchSize = 5000) 模式。
2654 |
2655 | ::: details 代码示例
2656 | ```java
2657 | public class JMHSample_26_BatchSize {
2658 |
2659 | List list = new LinkedList<>();
2660 |
2661 | @Benchmark
2662 | @Warmup(iterations = 5, time = 1)
2663 | @Measurement(iterations = 5, time = 1)
2664 | @BenchmarkMode(Mode.AverageTime)
2665 | public List measureWrong_1() {
2666 | list.add(list.size() / 2, "something");
2667 | return list;
2668 | }
2669 |
2670 | @Benchmark
2671 | @Warmup(iterations = 5, time = 5)
2672 | @Measurement(iterations = 5, time = 5)
2673 | @BenchmarkMode(Mode.AverageTime)
2674 | public List measureWrong_5() {
2675 | list.add(list.size() / 2, "something");
2676 | return list;
2677 | }
2678 |
2679 | /*
2680 | * This is what you do with JMH.
2681 | */
2682 |
2683 | @Benchmark
2684 | @Warmup(iterations = 5, batchSize = 5000)
2685 | @Measurement(iterations = 5, batchSize = 5000)
2686 | @BenchmarkMode(Mode.SingleShotTime)
2687 | public List measureRight() {
2688 | list.add(list.size() / 2, "something");
2689 | return list;
2690 | }
2691 |
2692 | @Setup(Level.Iteration)
2693 | public void setup(){
2694 | list.clear();
2695 | }
2696 |
2697 | /*
2698 | * ============================== HOW TO RUN THIS TEST: ====================================
2699 | *
2700 | * You can see completely different results for measureWrong_1 and measureWrong_5; this
2701 | * is because the workload has no steady state. The result of the workload is dependent
2702 | * on the measurement time. measureRight does not have this drawback, because it measures
2703 | * the N invocations of the test method and measures it's time.
2704 | *
2705 | * We measure batch of 5000 invocations and consider the batch as the single operation.
2706 | *
2707 | * 您可以看到measureWrong_1和measureWrong_5的完全不同的结果;这是因为工作负载没有稳定状态。工作量的结果取决于测量时间。
2708 | * measureRight没有这个缺点,因为它测量测试方法的N次调用并测量它的时间。
2709 | *
2710 | * 我们测量5000次调用批次并将批次视为单个操作。
2711 | *
2712 | * You can run this test:
2713 | *
2714 | * a) Via the command line:
2715 | * $ mvn clean install
2716 | * $ java -jar target/benchmarks.jar JMHSample_26 -f 1
2717 | *
2718 | * b) Via the Java API:
2719 | * (see the JMH homepage for possible caveats when running from IDE:
2720 | * http://openjdk.java.net/projects/code-tools/jmh/)
2721 | */
2722 |
2723 | public static void main(String[] args) throws RunnerException {
2724 | Options opt = new OptionsBuilder()
2725 | .include(JMHSample_26_BatchSize.class.getSimpleName())
2726 | .forks(1)
2727 | .output("JMHSample_26_BatchSize.sampleLog")
2728 | .build();
2729 |
2730 | new Runner(opt).run();
2731 | }
2732 |
2733 | }
2734 | ```
2735 | :::
2736 | ## StatesDAG
2737 |
2738 | > THIS IS AN EXPERIMENTAL FEATURE, BE READY FOR IT BECOME REMOVED WITHOUT NOTICE!
2739 |
2740 | 当基准状态由一组@States 更清晰地描述时,存在一些奇怪的情况,并且这些@States 相互引用。 JMH 允许通过在辅助方法签名中引用 @States 来链接有向无环图 (DAG) 中的 @States。 (请注意, org.openjdk.jmh.samples.JMHSample_28_BlackholeHelpers只是其中的一个特例。遵循@Benchmark 调用的接口,所有引用@State-s 的@Setups 在当前@State 可以访问之前都会被触发。类似地,在完成当前@State 之前,不会为引用的@State 触发@TearDown 方法。
2741 | ::: details 代码示例
2742 | ```java
2743 | @BenchmarkMode(Mode.AverageTime)
2744 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
2745 | @Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
2746 | @Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
2747 | @Fork(1)
2748 | @State(Scope.Thread)
2749 | public class JMHSample_29_StatesDAG {
2750 |
2751 | /**
2752 | * WARNING:
2753 | * THIS IS AN EXPERIMENTAL FEATURE, BE READY FOR IT BECOME REMOVED WITHOUT NOTICE!
2754 | */
2755 |
2756 | /**
2757 | * There are weird cases when the benchmark state is more cleanly described
2758 | * by the set of @States, and those @States reference each other. JMH allows
2759 | * linking @States in directed acyclic graphs (DAGs) by referencing @States
2760 | * in helper method signatures. (Note that {@link org.openjdk.jmh.samples.JMHSample_28_BlackholeHelpers}
2761 | * is just a special case of that.
2762 | *
2763 | * Following the interface for @Benchmark calls, all @Setups for
2764 | * referenced @State-s are fired before it becomes accessible to current @State.
2765 | * Similarly, no @TearDown methods are fired for referenced @State before
2766 | * current @State is done with it.
2767 | */
2768 |
2769 | /*
2770 | * This is a model case, and it might not be a good benchmark.
2771 | * // TODO: Replace it with the benchmark which does something useful.
2772 | */
2773 |
2774 | public static class Counter {
2775 | int x;
2776 |
2777 | public int inc() {
2778 | return x++;
2779 | }
2780 |
2781 | public void dispose() {
2782 | // pretend this is something really useful
2783 | }
2784 | }
2785 |
2786 | /*
2787 | * Shared state maintains the set of Counters, and worker threads should
2788 | * poll their own instances of Counter to work with. However, it should only
2789 | * be done once, and therefore, Local state caches it after requesting the
2790 | * counter from Shared state.
2791 | * 共享状态维护计数器集,工作线程应该轮询自己的计数器实例来使用。 但是,它应该只执行一次,因此,本地状态在从共享状态请求计数器后缓存它。
2792 | */
2793 |
2794 | @State(Scope.Benchmark)
2795 | public static class Shared {
2796 | List all;
2797 | Queue available;
2798 |
2799 | @Setup
2800 | public synchronized void setup() {
2801 | all = new ArrayList<>();
2802 | for (int c = 0; c < 10; c++) {
2803 | all.add(new Counter());
2804 | }
2805 |
2806 | available = new LinkedList<>();
2807 | available.addAll(all);
2808 | }
2809 |
2810 | @TearDown
2811 | public synchronized void tearDown() {
2812 | for (Counter c : all) {
2813 | c.dispose();
2814 | }
2815 | }
2816 |
2817 | public synchronized Counter getMine() {
2818 | return available.poll();
2819 | }
2820 | }
2821 |
2822 | @State(Scope.Thread)
2823 | public static class Local {
2824 | Counter cnt;
2825 |
2826 | @Setup
2827 | public void setup(Shared shared) {
2828 | cnt = shared.getMine();
2829 | }
2830 | }
2831 |
2832 | @Benchmark
2833 | public int test(Local local) {
2834 | return local.cnt.inc();
2835 | }
2836 |
2837 | /*
2838 | * ============================== HOW TO RUN THIS TEST: ====================================
2839 | *
2840 | * You can run this test:
2841 | *
2842 | * a) Via the command line:
2843 | * $ mvn clean install
2844 | * $ java -jar target/benchmarks.jar JMHSample_29
2845 | *
2846 | * b) Via the Java API:
2847 | * (see the JMH homepage for possible caveats when running from IDE:
2848 | * http://openjdk.java.net/projects/code-tools/jmh/)
2849 | */
2850 |
2851 | public static void main(String[] args) throws RunnerException {
2852 | Options opt = new OptionsBuilder()
2853 | .include(JMHSample_29_StatesDAG.class.getSimpleName())
2854 | .build();
2855 |
2856 | new Runner(opt).run();
2857 | }
2858 |
2859 |
2860 | }
2861 | ```
2862 | :::
2863 |
2864 | ## Interrupts
2865 | JMH还可以检测线程何时卡在基准测试中,并尝试强制中断基准线程。 在可以确定它不会影响测量时,JMH会尝试这样做。
2866 |
2867 | 在这个例子中,我们想测量ArrayBlockingQueue的简单性能特征。 不幸的是,在没有工具支持的情况下执行此操作会使其中一个线程死锁,因为take / put的执行不能完美配对。
2868 |
2869 | 幸运的是,这两种方法都能很好地应对中断,因此我们可以依赖JMH来中断测量。 JMH将通知用户有关中断操作的信息,因此用户可以查看这些中断是否会影响测量。
2870 | 在达到默认或用户指定的超时后,JMH将开始发出中断。这是 {@link com.cxd.benchmark.JMHSample_18_Control}的一个变种,但是没有明确的控制对象。
2871 | 这个例子很适合那些需要优雅应对中断的方法。
2872 |
2873 |
2874 | ::: details 代码示例
2875 | ```java
2876 | @BenchmarkMode(Mode.AverageTime)
2877 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
2878 | @State(Scope.Group)
2879 | @Timeout(time = 10)
2880 | public class JMHSample_30_Interrupts {
2881 |
2882 | /*
2883 | * JMH can also detect when threads are stuck in the benchmarks, and try
2884 | * to forcefully interrupt the benchmark thread. JMH tries to do that
2885 | * when it is arguably sure it would not affect the measurement.
2886 | *
2887 | * JMH还可以检测线程何时卡在基准测试中,并尝试强制中断基准线程。
2888 | * 在可以确定它不会影响测量时,JMH会尝试这样做。
2889 | */
2890 |
2891 | /*
2892 | * In this example, we want to measure the simple performance characteristics
2893 | * of the ArrayBlockingQueue. Unfortunately, doing that without a harness
2894 | * support will deadlock one of the threads, because the executions of
2895 | * take/put are not paired perfectly. Fortunately for us, both methods react
2896 | * to interrupts well, and therefore we can rely on JMH to terminate the
2897 | * measurement for us. JMH will notify users about the interrupt actions
2898 | * nevertheless, so users can see if those interrupts affected the measurement.
2899 | * JMH will start issuing interrupts after the default or user-specified timeout
2900 | * had been reached.
2901 | *
2902 | * This is a variant of org.openjdk.jmh.samples.JMHSample_18_Control, but without
2903 | * the explicit control objects. This example is suitable for the methods which
2904 | * react to interrupts gracefully.
2905 | */
2906 |
2907 | private BlockingQueue q;
2908 |
2909 | @Setup
2910 | public void setup() {
2911 | q = new ArrayBlockingQueue<>(1);
2912 | }
2913 |
2914 | @Group("Q")
2915 | @Benchmark
2916 | public Integer take() throws InterruptedException {
2917 | return q.take();
2918 | }
2919 |
2920 | @Group("Q")
2921 | @Benchmark
2922 | public void put() throws InterruptedException {
2923 | q.put(42);
2924 | }
2925 |
2926 | /*
2927 | * ============================== HOW TO RUN THIS TEST: ====================================
2928 | *
2929 | * You can run this test:
2930 | *
2931 | * a) Via the command line:
2932 | * $ mvn clean install
2933 | * $ java -jar target/benchmarks.jar JMHSample_30 -t 2 -f 5 -to 10
2934 | * (we requested 2 threads, 5 forks, and 10 sec timeout)
2935 | *
2936 | * b) Via the Java API:
2937 | * (see the JMH homepage for possible caveats when running from IDE:
2938 | * http://openjdk.java.net/projects/code-tools/jmh/)
2939 | */
2940 |
2941 | public static void main(String[] args) throws RunnerException {
2942 | Options opt = new OptionsBuilder()
2943 | .include(JMHSample_30_Interrupts.class.getSimpleName())
2944 | .threads(2)
2945 | .forks(5)
2946 | // .timeout(TimeValue.seconds(10))
2947 | .output("JMHSample_30_Interrupts_annotation.sampleLog")
2948 | .build();
2949 |
2950 | new Runner(opt).run();
2951 | }
2952 |
2953 | }
2954 | ```
2955 | :::
2956 | ## InfraParams
2957 | 通过JMH提供的脚手架获取JMH的一些运行信息
2958 |
2959 | 有一种方式用来查JMH并发运行的模型。通过请求注入以下三个脚手架对象我们就可以做到:
2960 |
2961 | - BenchmarkParams: 涵盖了benchmark的全局配置
2962 | - IterationParams: 涵盖了当前迭代的配置
2963 | - ThreadParams: 涵盖了指定线程的配置
2964 |
2965 | 假设我们想检查ConcurrentHashMap如何在不同的并行级别下差异。我们可以可以把并发级别通过@Param传入, 但有时不方便,比如,我们想让他和@Threads一致。以下是我们如何查询JMH关于当前运行请求的线程数, 并将其放入ConcurrentHashMap构造函数的concurrencyLevel参数中。
2966 |
2967 | ::: details 代码示例
2968 | ```java
2969 | @BenchmarkMode(Mode.Throughput)
2970 | @OutputTimeUnit(TimeUnit.SECONDS)
2971 | @State(Scope.Benchmark)
2972 | public class JMHSample_31_InfraParams {
2973 |
2974 | /**
2975 | * There is a way to query JMH about the current running mode. This is
2976 | * possible with three infrastructure objects we can request to be injected:
2977 | * - BenchmarkParams: covers the benchmark-global configuration
2978 | * - IterationParams: covers the current iteration configuration
2979 | * - ThreadParams: covers the specifics about threading
2980 | *
2981 | * Suppose we want to check how the ConcurrentHashMap scales under different
2982 | * parallelism levels. We can put concurrencyLevel in @Param, but it sometimes
2983 | * inconvenient if, say, we want it to follow the @Threads count. Here is
2984 | * how we can query JMH about how many threads was requested for the current run,
2985 | * and put that into concurrencyLevel argument for CHM constructor.
2986 | *
2987 | * 有一种方式用来查JMH并发运行的模型。通过请求注入以下三个脚手架对象我们就可以做到:
2988 | * - BenchmarkParams: 涵盖了benchmark的全局配置
2989 | * - IterationParams: 涵盖了当前迭代的配置
2990 | * - ThreadParams: 涵盖了指定线程的配置
2991 | *
2992 | * 假设我们想检查ConcurrentHashMap如何在不同的并行级别下扩展。我们可以可以把concurrencyLevel通过@Param传入,
2993 | * 但有时不方便,比如,我们想让他和@Threads一致。以下是我们如何查询JMH关于当前运行请求的线程数,
2994 | * 并将其放入ConcurrentHashMap构造函数的concurrencyLevel参数中。
2995 | */
2996 |
2997 | static final int THREAD_SLICE = 1000;
2998 |
2999 | private ConcurrentHashMap mapSingle;
3000 | private ConcurrentHashMap mapFollowThreads;
3001 |
3002 | @Setup
3003 | public void setup(BenchmarkParams params) {
3004 | int capacity = 16 * THREAD_SLICE * params.getThreads();
3005 | // 并发级别数量似乎只会影响initcapacity(仅在initcapacity小于并发数量时)。这么测试好像没什么意义。
3006 | mapSingle = new ConcurrentHashMap<>(capacity, 0.75f, 1);
3007 | mapFollowThreads = new ConcurrentHashMap<>(capacity, 0.75f, params.getThreads());
3008 | }
3009 |
3010 | /*
3011 | * Here is another neat trick. Generate the distinct set of keys for all threads:
3012 | *
3013 | * 这是另一个巧妙的伎俩。为所有线程生成不同的密钥集:
3014 | */
3015 |
3016 | @State(Scope.Thread)
3017 | public static class Ids {
3018 | private List ids;
3019 |
3020 | @Setup
3021 | public void setup(ThreadParams threads) {
3022 | ids = new ArrayList<>();
3023 | for (int c = 0; c < THREAD_SLICE; c++) {
3024 | ids.add("ID" + (THREAD_SLICE * threads.getThreadIndex() + c));
3025 | }
3026 | }
3027 | }
3028 |
3029 | @Benchmark
3030 | public void measureDefault(Ids ids) {
3031 | for (String s : ids.ids) {
3032 | mapSingle.remove(s);
3033 | mapSingle.put(s, s);
3034 | }
3035 | }
3036 |
3037 | @Benchmark
3038 | public void measureFollowThreads(Ids ids) {
3039 | for (String s : ids.ids) {
3040 | mapFollowThreads.remove(s);
3041 | mapFollowThreads.put(s, s);
3042 | }
3043 | }
3044 |
3045 | /*
3046 | * ============================== HOW TO RUN THIS TEST: ====================================
3047 | *
3048 | * You can run this test:
3049 | *
3050 | * a) Via the command line:
3051 | * $ mvn clean install
3052 | * $ java -jar target/benchmarks.jar JMHSample_31 -t 4 -f 5
3053 | * (we requested 4 threads, and 5 forks; there are also other options, see -h)
3054 | *
3055 | * b) Via the Java API:
3056 | * (see the JMH homepage for possible caveats when running from IDE:
3057 | * http://openjdk.java.net/projects/code-tools/jmh/)
3058 | */
3059 |
3060 | public static void main(String[] args) throws RunnerException {
3061 | Options opt = new OptionsBuilder()
3062 | .include(JMHSample_31_InfraParams.class.getSimpleName())
3063 | .threads(4)
3064 | .forks(5)
3065 | .output("JMHSample_31_InfraParams.sampleLog")
3066 | .build();
3067 |
3068 | new Runner(opt).run();
3069 | }
3070 |
3071 | }
3072 | ```
3073 | :::
3074 | ## BulkWarmup
3075 | 这是JMHSample_12_Forking测试的补充。
3076 |
3077 | 预热方式不同测量的结果大不一样。
3078 |
3079 | 有时你想要一个相反的配置:您可以将它们混合在一起以测试最坏情况,而不是分离不同基准的配置文件。
3080 |
3081 | JMH有一个批量预热特性:它首先预热所有测试,然后测量他们。JMH仍然为每个测试fork出一个JVM,但当新的JVM启动,所有的预热在测量开始前都会执行。
3082 | 这有助于避免类型配置文件偏差,因为每个测试仍然在不同的JVM中执行,我们只“混合”我们想要的预热代码。
3083 |
3084 | ::: details 代码示例
3085 |
3086 | ```java
3087 | @State(Scope.Thread)
3088 | @BenchmarkMode(Mode.AverageTime)
3089 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
3090 | public class JMHSample_32_BulkWarmup {
3091 |
3092 | /*
3093 | * This is an addendum to JMHSample_12_Forking test.
3094 | *
3095 | * Sometimes you want an opposite configuration: instead of separating the profiles
3096 | * for different benchmarks, you want to mix them together to test the worst-case
3097 | * scenario.
3098 | *
3099 | * JMH has a bulk warmup feature for that: it does the warmups for all the tests
3100 | * first, and then measures them. JMH still forks the JVM for each test, but once the
3101 | * new JVM has started, all the warmups are being run there, before running the
3102 | * measurement. This helps to dodge the type profile skews, as each test is still
3103 | * executed in a different JVM, and we only "mix" the warmup code we want.
3104 | *
3105 | * 这是JMHSample_12_Forking测试的附录。
3106 | *
3107 | * 有时你想要一个相反的配置:您可以将它们混合在一起以测试最坏情况,而不是分离不同基准的配置文件。
3108 | *
3109 | * JMH有一个批量预热特性:它首先预热所有测试,然后测量他们。JMH仍然为每个测试fork出一个JVM,但当新的JVM启动,
3110 | * 所有的预热在测量开始前都会执行。
3111 | * 这有助于避免类型配置文件偏差???,因为每个测试仍然在不同的JVM中执行,我们只“混合”我们想要的预热代码。
3112 | */
3113 |
3114 | /*
3115 | * These test classes are borrowed verbatim from JMHSample_12_Forking.
3116 | */
3117 |
3118 | public interface Counter {
3119 | int inc();
3120 | }
3121 |
3122 | public class Counter1 implements Counter {
3123 | private int x;
3124 |
3125 | @Override
3126 | public int inc() {
3127 | return x++;
3128 | }
3129 | }
3130 |
3131 | public class Counter2 implements Counter {
3132 | private int x;
3133 |
3134 | @Override
3135 | public int inc() {
3136 | return x++;
3137 | }
3138 | }
3139 |
3140 | Counter c1 = new Counter1();
3141 | Counter c2 = new Counter2();
3142 |
3143 | /*
3144 | * And this is our test payload. Notice we have to break the inlining of the payload,
3145 | * so that in could not be inlined in either measure_c1() or measure_c2() below, and
3146 | * specialized for that only call.
3147 | */
3148 |
3149 | @CompilerControl(CompilerControl.Mode.DONT_INLINE)
3150 | public int measure(Counter c) {
3151 | int s = 0;
3152 | for (int i = 0; i < 10; i++) {
3153 | s += c.inc();
3154 | }
3155 | return s;
3156 | }
3157 |
3158 | @Benchmark
3159 | public int measure_c1() {
3160 | return measure(c1);
3161 | }
3162 |
3163 | @Benchmark
3164 | public int measure_c2() {
3165 | return measure(c2);
3166 | }
3167 |
3168 | /*
3169 | * ============================== HOW TO RUN THIS TEST: ====================================
3170 | *
3171 | * Note how JMH runs the warmups first, and only then a given test. Note how JMH re-warmups
3172 | * the JVM for each test. The scores for C1 and C2 cases are equally bad, compare them to
3173 | * the scores from JMHSample_12_Forking.
3174 | *
3175 | * You can run this test:
3176 | *
3177 | * a) Via the command line:
3178 | * $ mvn clean install
3179 | * $ java -jar target/benchmarks.jar JMHSample_32 -f 1 -wm BULK
3180 | * (we requested a single fork, and bulk warmup mode; there are also other options, see -h)
3181 | *
3182 | * b) Via the Java API:
3183 | * (see the JMH homepage for possible caveats when running from IDE:
3184 | * http://openjdk.java.net/projects/code-tools/jmh/)
3185 | */
3186 |
3187 | public static void main(String[] args) throws RunnerException {
3188 | Options opt = new OptionsBuilder()
3189 | .include(JMHSample_32_BulkWarmup.class.getSimpleName())
3190 | // .includeWarmup(...) <-- this may include other benchmarks into warmup
3191 | // .warmupMode(WarmupMode.BULK) // see other WarmupMode.* as well
3192 | .warmupMode(WarmupMode.INDI) // see other WarmupMode.* as well
3193 | .forks(1)
3194 | .output("JMHSample_32_BulkWarmup_indi.sampleLog")
3195 | .build();
3196 |
3197 | new Runner(opt).run();
3198 | }
3199 |
3200 | }
3201 | ```
3202 | :::
3203 |
3204 | ## SecurityManager
3205 |
3206 | 一些有针对性的测试可能会关心是否安装了 SecurityManager。由于 JMH 本身需要执行特权操作,因此盲目安装 SecurityManager 是不够的,因为 JMH 基础架构会失败。
3207 |
3208 | 在这个例子中,我们想要测量 System.getProperty 在安装 SecurityManager 的情况下的性能。为此,我们有两个带有辅助方法的状态类。一种读取默认的 JMH 安全策略(我们随 JMH 提供一种),并安装安全管理器;另一个确保未安装 SecurityManager。
3209 |
3210 | 如果您需要测试的受限安全策略,建议您获取 /jmh-security-minimal.policy,其中包含运行 JMH 基准测试所需的最低权限,在那里合并新权限,在临时生成新策略文件位置,并改为加载该策略文件。还有 /jmh-security-minimal-runner.policy,它包含运行 JMH 工具的最小权限,如果你想使用 JVM 参数来装备 SecurityManager。
3211 |
3212 | ::: details 代码示例
3213 | ```java
3214 | @BenchmarkMode(Mode.AverageTime)
3215 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
3216 | public class JMHSample_33_SecurityManager {
3217 |
3218 | /*
3219 | * Some targeted tests may care about SecurityManager being installed.
3220 | * Since JMH itself needs to do privileged actions, it is not enough
3221 | * to blindly install the SecurityManager, as JMH infrastructure will fail.
3222 | */
3223 |
3224 | /*
3225 | * In this example, we want to measure the performance of System.getProperty
3226 | * with SecurityManager installed or not. To do this, we have two state classes
3227 | * with helper methods. One that reads the default JMH security policy (we ship one
3228 | * with JMH), and installs the security manager; another one that makes sure
3229 | * the SecurityManager is not installed.
3230 | *
3231 | * If you need a restricted security policy for the tests, you are advised to
3232 | * get /jmh-security-minimal.policy, that contains the minimal permissions
3233 | * required for JMH benchmark to run, merge the new permissions there, produce new
3234 | * policy file in a temporary location, and load that policy file instead.
3235 | * There is also /jmh-security-minimal-runner.policy, that contains the minimal
3236 | * permissions for the JMH harness to run, if you want to use JVM args to arm
3237 | * the SecurityManager.
3238 | */
3239 |
3240 | @State(Scope.Benchmark)
3241 | public static class SecurityManagerInstalled {
3242 | @Setup
3243 | public void setup() throws IOException, NoSuchAlgorithmException, URISyntaxException {
3244 | URI policyFile = JMHSample_33_SecurityManager.class.getResource("/jmh-security.policy").toURI();
3245 | Policy.setPolicy(Policy.getInstance("JavaPolicy", new URIParameter(policyFile)));
3246 | System.setSecurityManager(new SecurityManager());
3247 | }
3248 |
3249 | @TearDown
3250 | public void tearDown() {
3251 | System.setSecurityManager(null);
3252 | }
3253 | }
3254 |
3255 | @State(Scope.Benchmark)
3256 | public static class SecurityManagerEmpty {
3257 | @Setup
3258 | public void setup() throws IOException, NoSuchAlgorithmException, URISyntaxException {
3259 | System.setSecurityManager(null);
3260 | }
3261 | }
3262 |
3263 | @Benchmark
3264 | public String testWithSM(SecurityManagerInstalled s) throws InterruptedException {
3265 | return System.getProperty("java.home");
3266 | }
3267 |
3268 | @Benchmark
3269 | public String testWithoutSM(SecurityManagerEmpty s) throws InterruptedException {
3270 | return System.getProperty("java.home");
3271 | }
3272 |
3273 | /*
3274 | * ============================== HOW TO RUN THIS TEST: ====================================
3275 | *
3276 | * You can run this test:
3277 | *
3278 | * a) Via the command line:
3279 | * $ mvn clean install
3280 | * $ java -jar target/benchmarks.jar JMHSample_33 -f 1
3281 | * (we requested 5 warmup iterations, 5 forks; there are also other options, see -h))
3282 | *
3283 | * b) Via the Java API:
3284 | * (see the JMH homepage for possible caveats when running from IDE:
3285 | * http://openjdk.java.net/projects/code-tools/jmh/)
3286 | */
3287 |
3288 | public static void main(String[] args) throws RunnerException {
3289 | Options opt = new OptionsBuilder()
3290 | .include(JMHSample_33_SecurityManager.class.getSimpleName())
3291 | .warmupIterations(5)
3292 | .measurementIterations(5)
3293 | .forks(1)
3294 | .build();
3295 |
3296 | new Runner(opt).run();
3297 | }
3298 |
3299 | }
3300 | ```
3301 | :::
3302 |
3303 | ## Profilers
3304 | 这个例子是profiler(分析器)的概览。
3305 |
3306 | JMH有一些很便利的profiler来帮助我们理解benchmark。虽然这些分析器不能替代成熟的外部分析器,但在许多情况下,这些分析器很容易快速发现基准测试行为。
3307 |
3308 | 当你正在对基准代码本身进行多次调整时,快速获得结果非常重要。
3309 |
3310 | 可以使用-lprof列出所有profiler。本例中只展示常用的一些。许多profiler有他们自己的选项,通过-prof `:help`获取。
3311 |
3312 | 因为不同的profiler做不同的事情,很难在一个基准测试中展示所有profiler的行为。因为有好几个例子。
3313 |
3314 | ## BranchPrediction: 分支预测
3315 |
3316 | ## What is ?
3317 | xxx运行优化
3318 |
3319 | 此示例用作针对常规数据集的警告。
3320 |
3321 | 由于简单的生成策略,或者只是因为对常规数据集感觉更好,因此很容易将常规数据集用于基准测试。
3322 |
3323 | 不幸的是,它经常事与愿违:已知常规数据集可以通过软件和硬件很好地进行优化。
3324 |
3325 | 这个例子来展示分支预测优化。
3326 |
3327 | 想象一下我们的基准测试根据数组内容选择分支,因为我们正在通过它进行流式传输。
3328 |
3329 | ::: details 代码示例
3330 | ```java
3331 | @BenchmarkMode(Mode.AverageTime)
3332 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
3333 | @Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
3334 | @Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
3335 | @Fork(5)
3336 | @State(Scope.Benchmark)
3337 | public class JMHSample_36_BranchPrediction {
3338 |
3339 | /*
3340 | * This sample serves as a warning against regular data sets.
3341 | *
3342 | * It is very tempting to present a regular data set to benchmark, either due to
3343 | * naive generation strategy, or just from feeling better about regular data sets.
3344 | * Unfortunately, it frequently backfires: the regular datasets are known to be
3345 | * optimized well by software and hardware. This example exploits one of these
3346 | * optimizations: branch prediction.
3347 | *
3348 | * Imagine our benchmark selects the branch based on the array contents, as
3349 | * we are streaming through it:
3350 | */
3351 |
3352 | private static final int COUNT = 1024 * 1024;
3353 |
3354 | private byte[] sorted;
3355 | private byte[] unsorted;
3356 |
3357 | @Setup
3358 | public void setup() {
3359 | sorted = new byte[COUNT];
3360 | unsorted = new byte[COUNT];
3361 | Random random = new Random(1234);
3362 | random.nextBytes(sorted);
3363 | random.nextBytes(unsorted);
3364 | Arrays.sort(sorted);
3365 | }
3366 |
3367 | @Benchmark
3368 | @OperationsPerInvocation(COUNT)
3369 | public void sorted(Blackhole bh1, Blackhole bh2) {
3370 | for (byte v : sorted) {
3371 | if (v > 0) {
3372 | bh1.consume(v);
3373 | } else {
3374 | bh2.consume(v);
3375 | }
3376 | }
3377 | }
3378 |
3379 | @Benchmark
3380 | @OperationsPerInvocation(COUNT)
3381 | public void unsorted(Blackhole bh1, Blackhole bh2) {
3382 | for (byte v : unsorted) {
3383 | if (v > 0) {
3384 | bh1.consume(v);
3385 | } else {
3386 | bh2.consume(v);
3387 | }
3388 | }
3389 | }
3390 |
3391 | /*
3392 | There is a substantial difference in performance for these benchmarks!
3393 | It is explained by good branch prediction in "sorted" case, and branch mispredicts in "unsorted"
3394 | case. -prof perfnorm conveniently highlights that, with larger "branch-misses", and larger "CPI"
3395 | for "unsorted" case:
3396 |
3397 | 这些基准测试的性能存在显着差异!
3398 | 它可以通过“已排序”情况下的良好分支预测和“未排序”情况下的分支预测错误来解释。 -prof perfnorm 可以明显看出,具有更多的“分支未命中”和更多的“CPI”对于“未分类”的情况:
3399 | Benchmark Mode Cnt Score Error Units
3400 | JMHSample_36_BranchPrediction.sorted avgt 25 2.160 ± 0.049 ns/op
3401 | JMHSample_36_BranchPrediction.sorted:·CPI avgt 5 0.286 ± 0.025 #/op
3402 | JMHSample_36_BranchPrediction.sorted:·branch-misses avgt 5 ≈ 10⁻⁴ #/op
3403 | JMHSample_36_BranchPrediction.sorted:·branches avgt 5 7.606 ± 1.742 #/op
3404 | JMHSample_36_BranchPrediction.sorted:·cycles avgt 5 8.998 ± 1.081 #/op
3405 | JMHSample_36_BranchPrediction.sorted:·instructions avgt 5 31.442 ± 4.899 #/op
3406 | JMHSample_36_BranchPrediction.unsorted avgt 25 5.943 ± 0.018 ns/op
3407 | JMHSample_36_BranchPrediction.unsorted:·CPI avgt 5 0.775 ± 0.052 #/op
3408 | JMHSample_36_BranchPrediction.unsorted:·branch-misses avgt 5 0.529 ± 0.026 #/op <--- OOPS
3409 | JMHSample_36_BranchPrediction.unsorted:·branches avgt 5 7.841 ± 0.046 #/op
3410 | JMHSample_36_BranchPrediction.unsorted:·cycles avgt 5 24.793 ± 0.434 #/op
3411 | JMHSample_36_BranchPrediction.unsorted:·instructions avgt 5 31.994 ± 2.342 #/op
3412 | It is an open question if you want to measure only one of these tests. In many cases, you have to measure
3413 | both to get the proper best-case and worst-case estimate!
3414 | */
3415 |
3416 |
3417 | /*
3418 | * ============================== HOW TO RUN THIS TEST: ====================================
3419 | *
3420 | * You can run this test:
3421 | *
3422 | * a) Via the command line:
3423 | * $ mvn clean install
3424 | * $ java -jar target/benchmarks.jar JMHSample_36
3425 | *
3426 | * b) Via the Java API:
3427 | * (see the JMH homepage for possible caveats when running from IDE:
3428 | * http://openjdk.java.net/projects/code-tools/jmh/)
3429 | */
3430 | public static void main(String[] args) throws RunnerException {
3431 | Options opt = new OptionsBuilder()
3432 | .include(".*" + JMHSample_36_BranchPrediction.class.getSimpleName() + ".*")
3433 | .build();
3434 | new Runner(opt).run();
3435 | }
3436 |
3437 | }
3438 | ```
3439 | :::
3440 | ## CacheAccess
3441 |
3442 | 此示例用作来提醒缓存访问模式中的细微差异。 许多性能差异可以通过测试访问内存的方式来解释。 在下面的示例中,我们以行优先或列优先遍历矩阵:
3443 |
3444 | ::: details 代码示例
3445 | ```java
3446 | @BenchmarkMode(Mode.AverageTime)
3447 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
3448 | @Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
3449 | @Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
3450 | @Fork(5)
3451 | @State(Scope.Benchmark)
3452 | public class JMHSample_37_CacheAccess {
3453 |
3454 | /*
3455 | * This sample serves as a warning against subtle differences in cache access patterns.
3456 | *
3457 | * Many performance differences may be explained by the way tests are accessing memory.
3458 | * In the example below, we walk the matrix either row-first, or col-first:
3459 | */
3460 |
3461 | private final static int COUNT = 4096;
3462 | private final static int MATRIX_SIZE = COUNT * COUNT;
3463 |
3464 | private int[][] matrix;
3465 |
3466 | @Setup
3467 | public void setup() {
3468 | matrix = new int[COUNT][COUNT];
3469 | Random random = new Random(1234);
3470 | for (int i = 0; i < COUNT; i++) {
3471 | for (int j = 0; j < COUNT; j++) {
3472 | matrix[i][j] = random.nextInt();
3473 | }
3474 | }
3475 | }
3476 |
3477 | @Benchmark
3478 | @OperationsPerInvocation(MATRIX_SIZE)
3479 | public void colFirst(Blackhole bh) {
3480 | for (int c = 0; c < COUNT; c++) {
3481 | for (int r = 0; r < COUNT; r++) {
3482 | bh.consume(matrix[r][c]);
3483 | }
3484 | }
3485 | }
3486 |
3487 | @Benchmark
3488 | @OperationsPerInvocation(MATRIX_SIZE)
3489 | public void rowFirst(Blackhole bh) {
3490 | for (int r = 0; r < COUNT; r++) {
3491 | for (int c = 0; c < COUNT; c++) {
3492 | bh.consume(matrix[r][c]);
3493 | }
3494 | }
3495 | }
3496 |
3497 | /*
3498 | Notably, colFirst accesses are much slower, and that's not a surprise: Java's multidimensional
3499 | arrays are actually rigged, being one-dimensional arrays of one-dimensional arrays. Therefore,
3500 | pulling n-th element from each of the inner array induces more cache misses, when matrix is large.
3501 | -prof perfnorm conveniently highlights that, with >2 cache misses per one benchmark op:
3502 | Benchmark Mode Cnt Score Error Units
3503 | JMHSample_37_MatrixCopy.colFirst avgt 25 5.306 ± 0.020 ns/op
3504 | JMHSample_37_MatrixCopy.colFirst:·CPI avgt 5 0.621 ± 0.011 #/op
3505 | JMHSample_37_MatrixCopy.colFirst:·L1-dcache-load-misses avgt 5 2.177 ± 0.044 #/op <-- OOPS
3506 | JMHSample_37_MatrixCopy.colFirst:·L1-dcache-loads avgt 5 14.804 ± 0.261 #/op
3507 | JMHSample_37_MatrixCopy.colFirst:·LLC-loads avgt 5 2.165 ± 0.091 #/op
3508 | JMHSample_37_MatrixCopy.colFirst:·cycles avgt 5 22.272 ± 0.372 #/op
3509 | JMHSample_37_MatrixCopy.colFirst:·instructions avgt 5 35.888 ± 1.215 #/op
3510 | JMHSample_37_MatrixCopy.rowFirst avgt 25 2.662 ± 0.003 ns/op
3511 | JMHSample_37_MatrixCopy.rowFirst:·CPI avgt 5 0.312 ± 0.003 #/op
3512 | JMHSample_37_MatrixCopy.rowFirst:·L1-dcache-load-misses avgt 5 0.066 ± 0.001 #/op
3513 | JMHSample_37_MatrixCopy.rowFirst:·L1-dcache-loads avgt 5 14.570 ± 0.400 #/op
3514 | JMHSample_37_MatrixCopy.rowFirst:·LLC-loads avgt 5 0.002 ± 0.001 #/op
3515 | JMHSample_37_MatrixCopy.rowFirst:·cycles avgt 5 11.046 ± 0.343 #/op
3516 | JMHSample_37_MatrixCopy.rowFirst:·instructions avgt 5 35.416 ± 1.248 #/op
3517 | So, when comparing two different benchmarks, you have to follow up if the difference is caused
3518 | by the memory locality issues.
3519 | */
3520 |
3521 | /*
3522 | * ============================== HOW TO RUN THIS TEST: ====================================
3523 | *
3524 | * You can run this test:
3525 | *
3526 | * a) Via the command line:
3527 | * $ mvn clean install
3528 | * $ java -jar target/benchmarks.jar JMHSample_37
3529 | *
3530 | * b) Via the Java API:
3531 | * (see the JMH homepage for possible caveats when running from IDE:
3532 | * http://openjdk.java.net/projects/code-tools/jmh/)
3533 | */
3534 | public static void main(String[] args) throws RunnerException {
3535 | Options opt = new OptionsBuilder()
3536 | .include(".*" + JMHSample_37_CacheAccess.class.getSimpleName() + ".*")
3537 | .build();
3538 |
3539 | new Runner(opt).run();
3540 | }
3541 |
3542 | }
3543 | ```
3544 | :::
3545 | ## PerInvokeSetup
3546 | 这个例子突出了非稳态基准测试中的常见错误。
3547 |
3548 | 假设我们要测试对数组进行冒泡排序的耗时。
3549 | 我们天真地认为可以使用随机(未排序)值填充数组,并一遍又一遍地调用sort测试:
3550 |
3551 | ::: details 代码示例
3552 | ```java
3553 | @BenchmarkMode(Mode.AverageTime)
3554 | @OutputTimeUnit(TimeUnit.NANOSECONDS)
3555 | @Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
3556 | @Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
3557 | @Fork(5)
3558 | public class JMHSample_38_PerInvokeSetup {
3559 |
3560 | /*
3561 | * This example highlights the usual mistake in non-steady-state benchmarks.
3562 | *
3563 | * Suppose we want to test how long it takes to bubble sort an array. Naively,
3564 | * we could make the test that populates an array with random (unsorted) values,
3565 | * and calls sort on it over and over again:
3566 | *
3567 | * 此示例突显非稳态基准测试(non-steady-state benchmarks)中的常见错误。
3568 | *
3569 | * 假设我们要测试对数组进行冒泡排序的耗时。
3570 | * 天真地,我们可以使用随机(未排序)值填充数组,并一遍又一遍地调用sort测试:
3571 | */
3572 |
3573 | private void bubbleSort(byte[] b) {
3574 | boolean changed = true;
3575 | while (changed) {
3576 | changed = false;
3577 | for (int c = 0; c < b.length - 1; c++) {
3578 | if (b[c] > b[c + 1]) {
3579 | byte t = b[c];
3580 | b[c] = b[c + 1];
3581 | b[c + 1] = t;
3582 | changed = true;
3583 | }
3584 | }
3585 | }
3586 | }
3587 |
3588 | // Could be an implicit State instead, but we are going to use it
3589 | // as the dependency in one of the tests below
3590 | // 可能是一个隐式状态,但我们将在下面的一个测试中依赖它
3591 |
3592 | @State(Scope.Benchmark)
3593 | public static class Data {
3594 |
3595 | @Param({"1", "16", "256"})
3596 | int count;
3597 |
3598 | byte[] arr;
3599 |
3600 | @Setup
3601 | public void setup() {
3602 | arr = new byte[count];
3603 | Random random = new Random(1234);
3604 | random.nextBytes(arr);
3605 | }
3606 | }
3607 |
3608 | @Benchmark
3609 | public byte[] measureWrong(Data d) {
3610 | bubbleSort(d.arr);
3611 | return d.arr;
3612 | }
3613 |
3614 | /*
3615 | * The method above is subtly wrong: it sorts the random array on the first invocation
3616 | * only. Every subsequent call will "sort" the already sorted array. With bubble sort,
3617 | * that operation would be significantly faster!
3618 | *
3619 | * This is how we might *try* to measure it right by making a copy in Level.Invocation
3620 | * setup. However, this is susceptible to the problems described in Level.Invocation
3621 | * Javadocs, READ AND UNDERSTAND THOSE DOCS BEFORE USING THIS APPROACH.
3622 | *
3623 | * 上面的方法是巧妙的错误:它只在第一次调用时对随机数组进行排序。
3624 | * 后续每个调用都将"排序"已排序的数组。
3625 | * 通过冒泡排序,操作速度会明显加快!
3626 | *
3627 | * 我们可以尝试通过在Level.Invocation中制作数组的副本来正确测量它。
3628 | * 在使用Level.Invocation这些方法之前请阅读并理解这些文档。
3629 | */
3630 |
3631 | @State(Scope.Thread)
3632 | public static class DataCopy {
3633 | byte[] copy;
3634 |
3635 | @Setup(Level.Invocation)
3636 | public void setup2(Data d) {
3637 | copy = Arrays.copyOf(d.arr, d.arr.length);
3638 | }
3639 | }
3640 |
3641 | @Benchmark
3642 | public byte[] measureNeutral(DataCopy d) {
3643 | bubbleSort(d.copy);
3644 | return d.copy;
3645 | }
3646 |
3647 | /*
3648 | * In an overwhelming majority of cases, the only sensible thing to do is to suck up
3649 | * the per-invocation setup costs into a benchmark itself. This work well in practice,
3650 | * especially when the payload costs dominate the setup costs.
3651 | *
3652 | * 在绝大多数情况下,唯一明智的做法是将每次调用设置成本吸收到基准测试本身。
3653 | *
3654 | * 这在实践中很有效,特别是当有效载荷成本主导设置成本时
3655 | * (即:测试本身耗时远远大于准备数据时,准备数据时间对测试本身的影响可以忽略)。
3656 | */
3657 |
3658 | @Benchmark
3659 | public byte[] measureRight(Data d) {
3660 | byte[] c = Arrays.copyOf(d.arr, d.arr.length);
3661 | bubbleSort(c);
3662 | return c;
3663 | }
3664 |
3665 | /*
3666 | Benchmark (count) Mode Cnt Score Error Units
3667 |
3668 | JMHSample_38_PerInvokeSetup.measureWrong 1 avgt 25 2.408 ± 0.011 ns/op
3669 | JMHSample_38_PerInvokeSetup.measureWrong 16 avgt 25 8.286 ± 0.023 ns/op
3670 | JMHSample_38_PerInvokeSetup.measureWrong 256 avgt 25 73.405 ± 0.018 ns/op
3671 |
3672 | JMHSample_38_PerInvokeSetup.measureNeutral 1 avgt 25 15.835 ± 0.470 ns/op
3673 | JMHSample_38_PerInvokeSetup.measureNeutral 16 avgt 25 112.552 ± 0.787 ns/op
3674 | JMHSample_38_PerInvokeSetup.measureNeutral 256 avgt 25 58343.848 ± 991.202 ns/op
3675 |
3676 | JMHSample_38_PerInvokeSetup.measureRight 1 avgt 25 6.075 ± 0.018 ns/op
3677 | JMHSample_38_PerInvokeSetup.measureRight 16 avgt 25 102.390 ± 0.676 ns/op
3678 | JMHSample_38_PerInvokeSetup.measureRight 256 avgt 25 58812.411 ± 997.951 ns/op
3679 |
3680 | We can clearly see that "measureWrong" provides a very weird result: it "sorts" way too fast.
3681 | "measureNeutral" is neither good or bad: while it prepares the data for each invocation correctly,
3682 | the timing overheads are clearly visible. These overheads can be overwhelming, depending on
3683 | the thread count and/or OS flavor.
3684 |
3685 | 明显可以看出"measureWrong"跑出来一个奇怪的结果:它的排序太快了。
3686 | "measureNeutral"一般般:它正确地为每个调用准备数据,时间开销清晰可见。在不同的线程数 和/或 OS风格下,这些开销可能会非常大。
3687 | */
3688 |
3689 | /*
3690 | * ============================== HOW TO RUN THIS TEST: ====================================
3691 | *
3692 | * You can run this test:
3693 | *
3694 | * a) Via the command line:
3695 | * $ mvn clean install
3696 | * $ java -jar target/benchmarks.jar JMHSample_38
3697 | *
3698 | * b) Via the Java API:
3699 | * (see the JMH homepage for possible caveats when running from IDE:
3700 | * http://openjdk.java.net/projects/code-tools/jmh/)
3701 | */
3702 | public static void main(String[] args) throws RunnerException {
3703 | Options opt = new OptionsBuilder()
3704 | .include(".*" + JMHSample_38_PerInvokeSetup.class.getSimpleName() + ".*")
3705 | .output("JMHSample_38_PerInvokeSetup.sampleLog")
3706 | .build();
3707 |
3708 | new Runner(opt).run();
3709 | }
3710 |
3711 | }
3712 | ```
3713 | :::
3714 |
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "dependencies": {
3 | "@vssue/api-github-v3": "^1.4.7",
4 | "@vssue/vuepress-plugin-vssue": "^1.4.8"
5 | },
6 | "devDependencies": {
7 | "@vuepress/plugin-google-analytics": "^1.8.2",
8 | "vuepress": "^2.0.0-beta.22"
9 | }
10 | }
11 |
--------------------------------------------------------------------------------
/scripts/deploy.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 |
3 |
4 | # 装载其它库
5 | ROOT_DIR=$(cd `dirname $0`/..; pwd)
6 |
7 | # 确保脚本抛出遇到的错误
8 | set -e
9 |
10 | cd "${ROOT_DIR}/docs"
11 | sudo rm -rf ./dist
12 | echo "删除目录:$(pwd)/dist"
13 |
14 |
15 | # 生成静态文件
16 | npm install
17 | npm run build
18 |
19 | # 进入生成的文件夹
20 | cd dist
21 | echo "当前目录:$(pwd)"
22 |
23 | # 如果是发布到自定义域名
24 | echo 'www.mycookies.cn' > CNAME
25 |
26 | echo "执行命令:git init"
27 | git init
28 |
29 | echo "执行命令:git checkout -b gh-pages && git add ."
30 | git checkout -b gh-pages && git add .
31 |
32 | echo "git commit -m 'deploy'"
33 | git commit -m 'deploy'
34 |
35 | # 如果发布到 https://.github.io/
36 | if [[ ${GITHUB_TOKEN} ]] && [[ ${GITEE_TOKEN} ]]; then
37 | echo "使用 token 公钥部署 gh-pages"
38 | # ${GITHUB_TOKEN} 是 Github 私人令牌;${GITEE_TOKEN} 是 Gitee 私人令牌
39 | # ${GITHUB_TOKEN} 和 ${GITEE_TOKEN} 都是环境变量;travis-ci 构建时会传入变量
40 | git push --force --quiet "https://liqianggh:${GITHUB_TOKEN}@github.com/blog.git" gh-pages
41 | else
42 | echo "执行命令:git push -f git@github.com:liqianggh/blog.git gh-pages"
43 | git push -f git@github.com:liqianggh/blog.git gh-pages
44 | fi
45 | cd "${ROOT_DIR}"
46 |
--------------------------------------------------------------------------------