8 |
9 | {{
10 | post.summary.title
11 | }}
12 |
13 |
14 | {{ post.summary.date }}
15 |
16 |
17 |
21 |
22 | #{{ tag }}
23 |
24 |
25 | {{ post.date }}
13 |
2 |  3 |
3 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |

Q-Blog - Quicker and Cuter
24 | 25 | Welcome to [my personal blog site](https://blog.liuly.moe) ([subscribe](https://blog.liuly.moe/feed.xml)). 26 | 27 | - Vite5, Vue3, TypeScript, Naive UI 28 | - Responsive Web Design, Dark Mode, PWA 29 | - [WIP] **(Have a look!) Rollup [partial evaluate plugin](./partial-evaluate/)** 30 | 31 | ## Usage 32 | 33 | Installation: 34 | 35 | ```bash 36 | npm install -g pnpm # install pnpm first 37 | pnpm i 38 | ``` 39 | 40 | Development: 41 | 42 | ```bash 43 | pnpm dev # run server at `localhost:3000` 44 | ``` 45 | 46 | Build: 47 | 48 | ```bash 49 | pnpm build # compile to `dist` folder 50 | pnpm preview # preview the production build 51 | ``` 52 | 53 | ## Credits 54 | 55 | - [tov-template](https://github.com/dishait/tov-template) 56 | - [Vite PWA](https://github.com/vite-pwa/vite-plugin-pwa) 57 | -------------------------------------------------------------------------------- /src/composables/usePostData.ts: -------------------------------------------------------------------------------- 1 | import type { AsyncComputedOnCancel } from '@vueuse/core' 2 | 3 | function getPostName(post: string) { 4 | const parts = post.split('/') 5 | const lastPart = parts[parts.length - 1] || parts[parts.length - 2] || '' 6 | return lastPart.split('.')[0] 7 | } 8 | 9 | async function getPostData(postName: string, onCancel?: AsyncComputedOnCancel) { 10 | const abortController = new AbortController() 11 | onCancel && onCancel(() => abortController.abort()) 12 | return fetch(`/posts/${postName}.htm`, { signal: abortController.signal }) 13 | .then(res => res.text()) 14 | } 15 | 16 | function getCachedSeconds(postName: string) { 17 | const now = Date.now() 18 | const cachedTime = sessionStorage.getItem(`${postName}__time`) ?? '0' 19 | return (now - Number(cachedTime)) / 1000 20 | } 21 | 22 | async function getCachedPostData(post: string, onCancel?: AsyncComputedOnCancel) { 23 | const postName = getPostName(post) 24 | const cached = sessionStorage.getItem(postName) 25 | const cachedSeconds = getCachedSeconds(postName) 26 | if (cached && cachedSeconds < 3600) 27 | return cached 28 | 29 | const data = await getPostData(postName, onCancel) 30 | 31 | sessionStorage.setItem(postName, data) 32 | sessionStorage.setItem(`${postName}__time`, Date.now().toString()) 33 | return data 34 | } 35 | 36 | const emptySummary = Object.freeze({ url: '', title: '404 Not Found', tags: [], date: '' }) 37 | 38 | const { summary } = useSummary() 39 | function getCurrentPostSummary(post: string) { 40 | return summary.find(post_ => post.includes(post_.url)) ?? emptySummary 41 | } 42 | 43 | export default () => ({ emptySummary, getCachedPostData, getCurrentPostSummary }) 44 | -------------------------------------------------------------------------------- /src/components/Comment.vue: -------------------------------------------------------------------------------- 1 | 42 | 43 | 44 |49 | 评论加载中... 50 |
51 |lly | undef_baka
19 |愛の形骸
追う絵 覆う手を
23 | POSTS 24 |
25 |{{ summary.length }}
26 |29 | TAGS 30 |
31 |{{ tagCount.length }}
32 |注意:这个 JS 应该放在 head 中加载,如果放在 footer 后加载会导致浅色样式生效后再应用深色模式
73 | 74 | ## git 工作流 75 | 76 | 本次增加夜间模式所进行的修改都是在修改 Hexo 主题基础之上完成的。而一个主题会包含很多文件,有时候很难记住自己所进行的修改,再加上修改一般会很多很杂,这个时候就切实需要一个好用的版本控制工具。于是这里采用了 git。 77 | 78 | ### git 安装及配置 79 | 80 | git 的安装直接在官网下载即可。Ubuntu 则可以直接 `sudo apt-get install git` 来安装 git。 81 | 82 | 此后配置用户名和邮箱: 83 | 84 | ```bash 85 | git config --global user.name "xxx" 86 | git config --global user.email "xxx" 87 | ``` 88 | 89 | 为了搭配 GitHub 使用,可以利用 SSH 验证。 90 | 91 | 输入: 92 | 93 | ```bash 94 | ssh-keygen -C 'you email address@gmail.com' -t rsa 95 | ``` 96 | 97 | 在 `~/.ssh` 中找到公钥文件,打开复制至自己 GitHub 设置中去即可。 98 | 99 | 可以通过 `git init` 初始化仓库,考虑和 GitHub 同步,则可以 `git clone` 来复制已有仓库。GitHub 某一个仓库中点击 clone,选择 SSH,复制后面内容,添加到 `git clone` 后即可。也可以自行指定本地仓库的路径,否则则会 clone 到当前文件夹。 100 | 101 | 此后通过 `git commit -m "这里写注释"` 可以提交当前修改(还是在本地仓库)。最后 `git push origin main` 即可推送到 GitHub。 102 | 103 | vscode 图形界面已经集成了 git 的一些基本操作,可以很方便的完成推送。 104 | 105 | 如果想查看每次 commit 造成的更改,可以使用 `git log`,增加参数 `-p` 会显示每次 commit 造成的变化(增量形式),增加参数 `-num`(num 是自己制定的数字),则可以限制显示的提交次数。 106 | -------------------------------------------------------------------------------- /src/pages/bangumi.vue: -------------------------------------------------------------------------------- 1 | 42 | 43 | 44 |48 | 我在 bangumi 49 | 上对部分看过动画的评分与短评(Optional)。 50 |
51 | = (player: APlayer) => void;
25 | export const APlayerFixedModePlugin: Plugin (plugin: Plugin ): APlayer `,我们会有 `APlayer `(`unknown & P = P` 是顶类型,或者说全集具有的性质)。
121 |
122 | 从集合的角度,我们还可以发现,空集的大小为 0,所以 `never` 没有实例。因此,它可以表示一个函数永远不会返回值(死循环或异常),或者一个变量永远不会被赋值。
123 |
124 | ```typescript
125 | let bar: never = (() => {
126 | throw new Error('Throw my hands in the air like I just dont care');
127 | })();
128 | ```
129 |
130 | 一个函数除了正常情况(有特定返回值)和永远不返回(`never`)之外,还可能我们并不关心它的返回值。通常这可以通过什么都不返回实现(其实是返回 `undefined`)。
131 |
132 | ```typescript
133 | type f = () => void;
134 | let a: f = () => {};
135 | let b: f = () => 1;
136 | ```
137 |
138 | 注意不关心(不使用)返回值不等于没有返回值。这就是 `void` 类型的特殊性,在一个标注为需要返回值 `void` 的函数的地方,我们使用返回值为任意值的函数都是可以的(如上面的 `b`)。
139 |
--------------------------------------------------------------------------------
/posts/digital-lab.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 数电计组实验 Vscode 配置指南
3 | date: 2022-03-19 21:18:29
4 | tags: [笔记]
5 | category: 笔记
6 | tocbot: true
7 | ---
8 |
9 | 本篇博客将带来优雅的 Vscode 编写数字电路实验 / 计算机组成原理实验的 Verilog 一键式配置方案,让你编写代码全程远离 Vivado(~~新建工程还是要见一面的~~)
10 |
11 | 主要还是介绍一些名词和工具,读者看上去了哪些可以自己挑
12 |
13 | 
14 |
15 |
16 |
17 | ## Vscode 插件
18 |
19 | 首先可能需要连接远程的 Vlab 服务器,这个时候需要使用 Vscode-remote 插件
20 |
21 | 
22 |
23 | 这个插件主要作用就是能在本地通过 SSH 连接操作 Vlab 虚拟机
24 |
25 | 具体配置过程不再赘述,配置完之后可以很方便的浏览远程文件
26 |
27 | 
28 |
29 | 这个时候已经能愉快的在 Vscode 上写 Verilog 了,但是仅仅能写肯定不够,我们还需要一个 linter(检查语法) 还有一个 formatter(代码格式化)
30 |
31 | 这里推荐一个插件:Digital IDE
32 |
33 | 
34 |
35 | 插件来自 [ysy-phoenix](https://github.com/ysy-phoenix) 的推荐,在此感谢
36 |
37 | 配置完之后应该已经默认有代码格式化和端口的各种提示信息了,上图的代码就是这个插件格式后的成果
38 |
39 | 但 linter 还需要额外配置,这里我们打开插件的设置:
40 |
41 | 
42 |
43 | 个人感觉 Verilator 更好用,当然 Vlab 虚拟机上默认是没有自带的,不过 Ubuntu 通过包管理器安装还是很方便的:
44 |
45 | ```bash
46 | apt update // 这一步为了确保软件包是最新的
47 | apt install verilator // 安装
48 | ```
49 |
50 | 两下就好了,之后写代码时一保存文件就可以自动帮你检查语法错误了:
51 |
52 | 
53 |
54 | (这里报错会显示在一行上是因为装了另一个插件 Error Lens,很美观,亲测好用)
55 |
56 | ## 干掉 Vivado 之仿真篇
57 |
58 | 仿真需要看波形,这个时候一个推荐是 `gtkwave`,Ubuntu 下同样通过包管理器安装即可
59 |
60 | 因为这个不能在没有图形界面的 Vlab 上运行,所以下文给出的仿真推荐都是配在本地环境的:
61 |
62 | ### Icarus Verilog
63 |
64 | 大名鼎鼎的一个仿真工具,简称 iverilog, 如果你用 Ubuntu 的包管理器装它还会自动帮你装上 gtkwave(~~捆绑消费~~)
65 |
66 | Digital IDE 自带了对于 Icarus Verilog 的快速仿真支持,见 [它的文档](https://zhuanlan.zhihu.com/p/365805011)
67 |
68 | ### Verilator
69 |
70 | 这里还是要安利 Verilator,因为用它做仿真可以 **不写 Verilog** ,Verilator 会生成高层次的 C++ 代码模拟模块的行为,然后你只需要用 C++ 编写 top 模块进行测试就行了
71 |
72 | 很大的好处在于 C++ 作为高级语言很明显比 Verilog 的 testbench 写起来灵活
73 |
74 | Ubuntu 包管理器装的版本比较旧,如果想要最新版可以自己下载它的 GitHub 仓库按照说明编译,不过这样就麻烦一点了
75 |
76 | 具体使用方式可以参考 [这篇文章](http://www.sunnychen.top/2019/07/25/%E8%B7%A8%E8%AF%AD%E8%A8%80%E7%9A%84Verilator%E4%BB%BF%E7%9C%9F%EF%BC%9A%E4%BD%BF%E7%94%A8%E8%BF%9B%E7%A8%8B%E9%97%B4%E9%80%9A%E4%BF%A1/) ,~~对着复制粘贴就行~~
77 |
78 | 如果你发现 Vscode 找不到头文件 `verilated.h` ,那就找到这个设置(直接在 Vscode 的设置里搜索即可),路径添加以下两个中的一个(根据你自己的情况而定,自己看哪个目录能进,如果是包管理器装的应该是下面那个路径)
79 |
80 | 
81 |
82 | 然后就可以愉悦的编写 C++ 代码仿真了,以下是一个对 ALU 模块 100% 覆盖率的测试示例:
83 |
84 | 
85 |
86 | 根据上面那篇链接里教程的步骤,即可判断仿真结果是否正确,并生成波形
87 |
88 | ## 干掉 Vivado 之比特流
89 |
90 | 写完代码我们还需要 Vivado 这个~~工具人~~帮我们生成比特流
91 |
92 | 但每次打开 VNC 操作 Vivado 显然太过笨重,这个时候我们可以利用 Vivado 自带的 TCL 命令行工具来构建项目
93 |
94 | 这里直接贴一个 Vlab 能用的脚本(如果在本地跑可能需要一些修改)[作者链接](https://github.com/WuTianming)
95 |
96 | ```bash
97 | #!/bin/bash
98 |
99 | echo "Initiating project build ..."
100 |
101 | ProjName=$(find . -type f -iname "*.xpr")
102 | if [ -z "$ProjName" ]; then
103 | echo "xpr file not found. Exiting"
104 | exit 1
105 | fi
106 | echo "Found project file ${ProjName}."
107 |
108 | echo "Creating build script ..."
109 | cat - > automation_genbitstream.tcl << EOF
110 | set_param general.maxThreads 2
111 | open_project ${ProjName}
112 |
113 | reset_run synth_1
114 | launch_run synth_1
115 | wait_on_run synth_1
116 | open_run synth_1
117 | # report_timing_summary
118 | launch_run -to_step write_bitstream impl_1
119 | wait_on_run impl_1
120 | # open_run impl_1
121 | # report_timing_summary
122 | # report_utilization > utilization.txt
123 |
124 | quit
125 | EOF
126 |
127 | cat - > wrapper.tcl << EOF
128 | if {[catch {source automation_genbitstream.tcl} errorstring]} {
129 | puts "Error - $errorstring"
130 | exit 1
131 | }
132 | quit
133 | EOF
134 |
135 | cat - > build_remote.sh << EOF
136 | #!/bin/bash
137 |
138 | # source /extra/vivado2016/Vivado/2016.3/settings64.sh
139 | source /opt/vlab/path.sh
140 |
141 | if ! time vivado2019 -mode tcl -source wrapper.tcl; then
142 | grep --color=always "ERROR" vivado.log
143 | fi
144 | rm -f *.log *.jou
145 | printf "\a"
146 | EOF
147 |
148 | echo "Running job ..."
149 | bash build_remote.sh
150 | echo "Build done."
151 |
152 | rm automation_genbitstream.tcl wrapper.tcl build_remote.sh
153 | ```
154 |
155 | 放在和 xpr 文件同一个目录(也就是项目目录下即可)
156 |
157 | 怎么运行脚本这里不再赘述
158 |
159 | 
160 |
161 | 可以很漂亮的在命令行里得到结果并看到各种 report
162 |
163 | 具体设置可以自己看脚本被注释掉的一些部分
164 |
165 | 至此我们成功构建了一套还算趁手的 Verilog 开发工具链
166 |
--------------------------------------------------------------------------------
/posts/github-actions-ci.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: GitHub Actions 持续集成体验
3 | date: 2022-08-23 19:10:20
4 | tags: [笔记]
5 | category: web
6 | ---
7 |
8 | 咕了快小半年,今天更新一期关于 GitHub Actions 在项目部署测试中的应用
9 |
10 | ## 介绍
11 |
12 | 官方介绍:
13 |
14 | > GitHub Actions 是一个持续集成和持续交付 (CI/CD) 平台,可用于自动执行构建、测试和部署管道。您可以创建工作流程来构建和测试存储库的每个拉取请求,或将合并的拉取请求部署到生产环境。
15 | GitHub Actions 不仅仅是 DevOps,还允许您在存储库中发生其他事件时运行工作流程。例如,您可以运行工作流程,以便在有人在您的存储库中创建新问题时自动添加相应的标签。
16 | GitHub 提供 Linux、Windows 和 macOS 虚拟机来运行工作流程,或者您可以在自己的数据中心或云基础架构中托管自己的自托管运行器。
17 |
18 |
19 |
20 | 概括一下其实就是 GitHub 给你送了台虚拟机的免费使用权,你可以利用它在项目有新 push, pull request 时或者定时执行某些构建,测试,部署的任务
21 |
22 | - 构建:如果项目需要构建出 release 版本,可以使用它自动发布
23 | - 测试:运行测试脚本,监测项目的可用性及正确性
24 | - 部署:例如与 GitHub Pages 配合使用,可以自动将静态网页部署到 GitHub Pages 上
25 |
26 | ## 构建与部署
27 |
28 | 首先介绍下 GitHub Actions 的 YAML 格式,需要包含:
29 |
30 | - 触发事件,决定什么时候运行虚拟机,可选 push/pull request/手动运行等
31 | - 运行流程,决定具体虚拟机内执行的程序
32 |
33 | 一个项目可能需要多个 actions,每个 actions 都是 `.github/workflows` 下的一个文件,触发事件和运行流程都彼此独立
34 |
35 | ```yaml
36 | name: build
37 |
38 | on:
39 | push:
40 | branches:
41 | - posts
42 |
43 | jobs:
44 | build:
45 | runs-on: ubuntu-latest
46 |
47 | steps:
48 | - uses: pnpm/action-setup@v2.2.2
49 | with:
50 | version: latest
51 |
52 | - uses: actions/checkout@v2
53 |
54 | - name: Set up Python 3.8
55 | uses: actions/setup-python@v2
56 | with:
57 | python-version: 3.8
58 |
59 | - name: Run build script
60 | run: |
61 | bash build.sh
62 |
63 | - name: Push
64 | uses: s0/git-publish-subdir-action@develop
65 | env:
66 | REPO: self
67 | BRANCH: main
68 | FOLDER: Q-Blog/dist
69 | GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
70 |
71 | ```
72 |
73 | 例如以上是一个 workflow 文件,该 actions 的功能是在仓库内的博客 md 文件更新后,自动构建生成静态网页并 push 到 main 分支(随后这一 push 会由 GitHub Pages 负责自动更新静态网页)
74 |
75 | - 触发事件:posts 分支的 push 请求
76 | - 运行流程:一个 actions 可以由几个 job 组成,这些 job 可以根据需求并行或者串行,这里只有一个 job
77 |
78 | 具体来说,一个 job 由多个 step 串行组成,以下具体分析
79 |
80 | ```yaml
81 | - uses: pnpm/action-setup@v2.2.2
82 | with:
83 | version: latest
84 | ```
85 |
86 | 通过 uses, 可以方便地使用别人编写的用于实现特定功能的 actions
87 |
88 | with 相当于传入需要的参数
89 |
90 | 别人的 actions 可以在 GitHub 提供的 [marketplace](https://github.com/marketplace?type=actions) 找到
91 |
92 | 例如这一 step 是配置 node 和 pnpm 环境
93 |
94 | 同理
95 |
96 | ```yaml
97 | - uses: actions/checkout@v2
98 |
99 | - name: Set up Python 3.8
100 | uses: actions/setup-python@v2
101 | with:
102 | python-version: 3.8
103 | ```
104 |
105 | 分别使得 actions 可以访问本仓库文件以及设置起 python 和 pip 的环境
106 |
107 | 之后的 steps 则是构建出静态文件并 push 到 main 分支
108 |
109 | ## 测试
110 |
111 | GitHub Actions 的另一大常见用途便是用于测试,我们经常能看见别人的开源项目会有一个  的标识,甚至还有测试覆盖率,这都可以通过 GitHub Actions 实现,例如上面的图标表示的就是某个 workflow 上次运行的测试是否通过
112 |
113 | 例如这个暑假摸了一个 QQ 机器人的插件
75 | {{ anime.subject.name_cn || anime.subject.name }}
76 |
78 | {{ anime.subject.short_summary }}……
79 |
85 | {{ anime.comment }}
86 |
67 | 说明:本程序基于 GitHub 项目
68 | lc3web
69 | 修改而来,旨在满足修读 2021 USTC CS1002A 计算系统概论的同学们的可能的需要。
70 | fork 后仓库: lc3web
73 | 请先在本模拟器中载入汇编代码或者机器码(在左侧的 Assemble 和 Raw
74 | 选项中载入),机器码需要 0011 0000 0000 0000 开头。
75 |
77 | 然后即可点击下方选择需要评测的实验,目前支持显示测试点正确性以及总执行指令数。评测要求基本参照助教文档。数据是自己随便给的,尽量全一点
78 |
68 |
82 |
73 |
74 |
81 |
83 |
84 |
94 |
88 |
93 |
65 |
133 | ```
134 |
135 | 按照原来的格式写好组件,然后加点允许用户自由设置的输入框即可。评测分别采用三个函数 `bench1(), bench2(), bench3()`
136 |
137 | 主要是因为一共没几个实验,而且输入输出不固定(直接指定寄存器),所以就直接这样高耦合低内聚的写了()
138 |
139 | #### 脚本逻辑
140 |
141 | 不想破坏原来框架的美感,另开一个 `lc3_bench.js`
142 |
143 | 核心是判题逻辑:
144 |
145 | 在 bench 函数预先处理好寄存器数据后,就要运行判题逻辑了,需要:
146 |
147 | 1. 获取设置的单个 case 最多指令数
148 | 2. pc 归位 x3000
149 | 3. 总执行指令数清零
150 |
151 | 随后就逐条指令执行。终止标志是当前即将执行的指令是 Trap 或者是 x0000(与\_\_\_助教的判题逻辑相同)
152 |
153 | ```javascript
154 | function benchTest(f) {
155 | const limit = document.querySelector("#cycleLimit").value;
156 | lc3.pc = 0x3000;
157 | lc3.totalInstruction = 0;
158 | var cnt = 0;
159 | while (true) {
160 | var op = lc3.decode(lc3.getMemory(lc3.pc));
161 | if ((op.raw >= 61440 && op.raw <= 61695) || op.raw === 0) {
162 | var str = f();
163 | break;
164 | }
165 | cnt++;
166 | if (cnt > limit) {
167 | alert("有测试样例超过单次最高执行指令数,请检查!");
168 | return;
169 | }
170 | lc3.nextInstruction();
171 | }
172 | return str;
173 | }
174 | ```
175 |
176 | 当评测结束时,传入的回调函数用于处理结果(lc-3 模拟器是一个全局变量,回调函数通过读取这些全局变量的值判断结果是否正确)
177 |
178 | 下面是每个题目判题脚本的编写。以 lab2&3 为例:
179 |
180 | ```javascript
181 | function bench2() {
182 | // r0 是给定的 n, 其余寄存器初始化为 0, 结果存在 r7,
183 | // 计算数列:f(0)=1,f(1)=1,f(2)=2,f(n)=f(n-1)+2*f(n-3) 的第 n 项
184 |
185 | // 设置批处理模式,不更新用户显示的界面(见 lc3_ui.js)
186 | window.batchMode = true;
187 |
188 | // 获取正确答案的函数(因为测试样例没有很多,直接每次 O(n) 算了)
189 | function fib(x) {
190 | var arr = [1, 1, 2];
191 | for (var i = 3; i <= x; i++) {
192 | arr[i] = (arr[i - 1] + 2 * arr[i - 3]) % 1024;
193 | }
194 | return arr[x];
195 | }
196 |
197 | // 获取用户填入的测试样例
198 | const testcase = document
199 | .querySelector("#testcase1")
200 | .value.replace(/\s*/g, "")
201 | .split(",")
202 | .map(Number);
203 |
204 | var str = ""; // 最终将显示的结果
205 | var sumInstruction = 0; // 总计命令数(用于计算平均值)
206 |
207 | for (var i = 0; i < testcase.length; i++) {
208 | // 每次测试先初始化寄存器
209 | window.lc3.r = [0, 0, 0, 0, 0, 0, 0, 0];
210 | window.lc3.r[0] = testcase[i];
211 |
212 | var ans = fib(testcase[i]); // 获取正确答案
213 | str += `测试数据 F(${testcase[i]}) = ${ans} `; // 理论答案
214 | str += benchTest(bench_res); // 实际测试
215 | }
216 |
217 | // 所有样例评测完毕
218 | str += "平均指令数 " + sumInstruction / testcase.length; // 显示平均指令
219 | alert(str); // 显示最终将显示的结果
220 | window.gExitBatchMode(); // 刷新界面,退出批处理模式
221 | return;
222 |
223 | // 判断结果正确性的函数
224 | function bench_res() {
225 | // 判断结果
226 | var lc3res = window.lc3.r[7];
227 | sumInstruction += window.lc3.totalInstruction;
228 | if (lc3res == ans) {
229 | return `你的回答正确,指令数 ${window.lc3.totalInstruction} \n`;
230 | } else {
231 | return `你的答案是 ${lc3res} \n`;
232 | }
233 | }
234 | }
235 | ```
236 |
237 | 大概还可以抽象优化一下,摸了
238 |
239 | Have fun playing
240 |
241 | 不知道下一届还需不需要用到这个(希望人没事)
242 |
--------------------------------------------------------------------------------
/posts/csapp-shell.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: CSAPP 之 Shell Lab
3 | date: 2022-03-19 22:27:56
4 | tags: [C/C++, os]
5 | category: 笔记
6 | mathjax: true
7 | tocbot: true
8 | ---
9 |
10 | 博客摘几篇自己做的 CSAPP 发发(自认为可能有点参考价值)
11 |
12 | 全部代码可以见 [GitHub 仓库](https://github.com/liuly0322/CSAPP-LABS)
13 |
14 | 本篇是 Shell Lab
15 |
16 |
17 |
18 | 本次实验的要求是实现一个支持任务控制的 Unix shell 程序
19 |
20 | 程序的框架已经给出,只需要补充一些功能性的函数
21 |
22 | 由于整体是一个编程性质的实验,所以这里只在贴上最后结果后,讲一些实验中值得注意的函数
23 |
24 | ## 评测
25 |
26 | 可能由于每次运行的 pid 都有所不同,并且也无法保证 `/bin/ps` 行为相同,本实验没有给出一键测试 shell 正确性的程序
27 |
28 | 但对于每个评测点,都给出了 `tsh` 和 `tshref` 生成运行结果的程序
29 |
30 | 所以只要批量生成结果后手动比较即可
31 |
32 | `tshref` 的结果已经给出,在 `tshref.out` 文件中,下面我们写一个脚本批量生成 `tsh` 的运行结果 (fish 脚本,语法与 posix 有所不同)
33 |
34 | 
35 |
36 | 然后手动比较文件
37 |
38 | (因为 pid 都在括号内,所以首先用正则表达式把 pid 统一替换成 10000)
39 |
40 | 
41 |
42 | 随后比较:
43 |
44 | ```bash
45 | diff 1.out tshref.out > out.diff
46 | ```
47 |
48 | 查看发现只有 `ps` 运行结果不同,而运行行为达到预期
49 |
50 | 
51 |
52 | 因此实验完成
53 |
54 | ## eval
55 |
56 | 补全如下:
57 |
58 | ```cpp
59 | void eval(char* cmdline) {
60 | char* argv[MAXARGS];
61 | int bg;
62 | pid_t pid;
63 |
64 | bg = parseline(cmdline, argv);
65 | if (argv[0] == NULL)
66 | return;
67 |
68 | if (!builtin_cmd(argv)) {
69 | if ((pid = fork()) == 0) {
70 | setpgid(0, 0);
71 | if (execve(argv[0], argv, environ) < 0) {
72 | printf("%s: Command not found\n", argv[0]);
73 | exit(0);
74 | }
75 | }
76 |
77 | // 此处是父进程
78 | addjob(jobs, pid, (bg == 1 ? BG : FG), cmdline);
79 | if (!bg) {
80 | waitfg(pid);
81 | } else {
82 | printf("[%d] (%d) %s", pid2jid(pid), pid, cmdline);
83 | }
84 | }
85 |
86 | return;
87 | }
88 | ```
89 |
90 | 和书上给出的例程差不多,主要区别如下:
91 |
92 | - `setpgid(0, 0);` 使得能正常接受别的 `shell` 发送的终止信号,否则自己的所有子进程都会被终止
93 | - 前台进程的阻塞用的是 `waitfg`,后面实现 `fg` 命令也需要用到这一函数
94 |
95 | 理论上来说这里需要考虑屏蔽信号,实际上,现代计算机多核 CPU 并行运行各个进程,在进程数小的情况下很难因为并发遇到执行时序的问题,不过严谨考虑还是加锁为好,这里作为一个 toy 程序就没加了
96 |
97 | ## do_bgfg
98 |
99 | 这里的 `do_xx` 似乎是这种解释器程序普遍的命名习惯,代表执行什么什么内置指令
100 |
101 | `bg` 和 `fg` 要实现的是对进程运行状态的转换
102 |
103 | ```cpp
104 | void do_bgfg(char** argv) {
105 | int id;
106 | struct job_t* job;
107 |
108 | // 这里根据参数判断合法性,获取 job
109 | ......
110 |
111 | job->state = (argv[0][0] == 'b' ? BG : FG);
112 | kill(-job->pid, SIGCONT);
113 | if (argv[0][0] == 'b')
114 | printf("[%d] (%d) %s", job->jid, job->pid, job->cmdline);
115 | else
116 | waitfg(job->pid);
117 |
118 | return;
119 | }
120 | ```
121 |
122 | 注意前台进程需要等待即可
123 |
124 | ## waitfg
125 |
126 | 很实用的 `helper` 函数
127 |
128 | ```cpp
129 | void waitfg(pid_t pid) {
130 | struct job_t* job = getjobpid(jobs, pid);
131 | while (job->state == FG) {
132 | sleep(1);
133 | }
134 | return;
135 | }
136 | ```
137 |
138 | 按照实验说明的推荐,采用轮询加上休眠的方式即可,这样对这一进程的负担也比较小
139 |
140 | ## sigint & sigtstp
141 |
142 | 接下来是几个信号处理时的异步回调函数
143 |
144 | ```cpp
145 | void sigint_handler(int sig) {
146 | pid_t f_pid = fgpid(jobs);
147 | if (f_pid) {
148 | kill(-f_pid, sig);
149 | }
150 | return;
151 | }
152 | ```
153 |
154 | ```cpp
155 | void sigtstp_handler(int sig) {
156 | pid_t f_pid = fgpid(jobs);
157 | if (f_pid) {
158 | kill(-f_pid, sig);
159 | }
160 | return;
161 | }
162 | ```
163 |
164 | 这两个函数比较类似,接收到键盘的终止 / 暂停信号后发送给前台进程的进程组,所以用 `-f_pid`
165 |
166 | ## sigchld
167 |
168 | 这一部分用于处理子进程的中断 / 暂停信号
169 |
170 | ```cpp
171 | void sigchld_handler(int sig) {
172 | pid_t pid;
173 | int status;
174 |
175 | while ((pid = waitpid(-1, &status, WNOHANG | WUNTRACED)) > 0) {
176 | if (WIFSTOPPED(status)) { // 暂停信号
177 | printf("Job [%d] (%d) stopped by signal %d\n", pid2jid(pid), pid,
178 | WSTOPSIG(status));
179 | getjobpid(jobs, pid)->state = ST;
180 | } else {
181 | if (WIFSIGNALED(status)) { // 退出信号
182 | printf("Job [%d] (%d) terminated by signal %d\n", pid2jid(pid),
183 | pid, WTERMSIG(status));
184 | }
185 | // 子进程退出信号,以及正常运行结束
186 | deletejob(jobs, pid);
187 | }
188 | }
189 | return;
190 | }
191 | ```
192 |
193 | 注意由于 unix 信号的阻塞机制,这里需要用 `while` 处理所有的僵死进程
194 |
195 | ## debug 细节
196 |
197 | 由于是编程实验,这一部分记录实验过程中遇到的有意思的问题以及解决方案
198 |
199 | ### 信号处理
200 |
201 | 在 `sigchld_handler` 函数中,一开始仿照书本 (注:第二版书),采用的条件是
202 |
203 | ```cpp
204 | while ((pid = waitpid(-1, &status, 0)) > 0) {
205 | ......
206 | }
207 | ```
208 |
209 | 但是会出现奇怪的 bug,终止进程输出的提示均为 `[0] (0)`
210 |
211 | 实际上书本的写法是有些问题的:这样做虽然会回收所有的僵死进程,但是 `waitpid` 的默认行为会不断等待活跃进程,直到活跃进程僵死才会返回
212 |
213 | 而我们虽然希望信号处理函数能够回收所有的进程,但我们也不希望信号处理处理函数会一直阻塞,直到所有进程运行完毕才继续执行,这样的话之后连前台进程都不存在了,自然也就获取不到前台进程的 `pid` 了,故 shell 的显示就会出现问题。理想情况下,应该是一次信号处理函数处理完当前所有僵死进程后就退出
214 |
215 | 换言之,这里的 `waitpid` 应该是一个同步函数而非异步函数
216 |
217 | (吐槽一下,高级语言的同步异步函数写多了再看 C 语言这种面向底层的语言确实有点小头疼)
218 |
219 | 为了修正这一问题,可以通过设置 `waitpid` 的 `options` 参数改变 `waitpid` 的默认行为
220 |
221 | 修改后如下:
222 |
223 | ```cpp
224 | while ((pid = waitpid(-1, &status, WNOHANG | WUNTRACED)) > 0) {
225 | ......
226 | }
227 | ```
228 |
229 | `WNOHANG` 选项使得这一函数变为同步函数,如果没有僵死进程就立刻返回
230 |
231 | `WUNTRACED` 选项使得这一函数能够处理暂停的进程
232 |
233 | ### printf
234 |
235 | 可能在阅读上面代码时,读者会觉得 `sigchld_handler` 的信号处理很不优雅, `printf` 这种根据信号类型来打印的函数为什么不放在具体的信号处理函数里,而是选择放在一个大的回收子进程的函数内呢?
236 |
237 | 从功能上来说,是因为如果 shell 中运行的子进程收到终止 / 暂停信号而终止,我们希望 shell 程序也能提示用户。而信号处理函数只能处理 shell 进程自身收到的信号,适用范围就窄了。如果把打印写在信号处理函数内,信号依旧会得到处理,但是会在 `test16` 中因为没有子进程终止信号的提示,输出与 `tshref` 不一致
238 |
239 | 值得一提的是,这里有一个很有意思的安全问题,由信号处理函数中的 `printf` 引发。我们现在所写的 `sigchld_handler` 事实上也是不安全的,C 语言中信号处理函数中能安全调用的函数是有限的,可以在 [这个网站](https://man7.org/linux/man-pages/man7/signal-safety.7.html) 查阅
240 |
241 | 而 `printf` 函数并不在此列,这是因为 `printf` 为了确保线程安全会在写入到文件(这里是写入到标准输出这一文件描述符)时给文件加一个锁,但是注意:这个 `shell` 程序在主体控制流中也有 `printf` 函数的调用(例如打印进程的提示消息),考虑现在发生了这样的一个调用,并且在从打印提示消息到给文件描述符解锁的过程中,恰好程序收到一个终止信号,于是信号处理函数被调用,进程会阻塞在给文件描述符解锁之前,转而去执行信号处理函数中的 `printf` ,而这次的调用在执行到准备打印时,却会发现标准输出被加锁了(因为还没能成功解锁),故会停下来等候。但信号处理函数已经阻塞了进程执行正常控制流,自然也就一直等不到谁能给标准输出解锁了:这就造成了程序的死锁
242 |
243 | 严格来说,我们这个 "toy shell" 目前还是一个非常不健壮的状态。这种类似的信号处理更合理也更普遍的方式是使用管道来完成,不过这就大大超出了本实验的范畴,故不在此介绍
244 |
245 | 至此,Shell Lab 的实验圆满结束
246 |
--------------------------------------------------------------------------------
/posts/sudoko-iddfs.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 数独的模拟逻辑解法的实现
3 | date: 2021-06-03 23:38:03
4 | tags: [算法, C/C++]
5 | category: 算法
6 | mathjax: true
7 | tocbot: true
8 | ---
9 |
10 | 本文将主要介绍人工解数独时采用的唯余法的算法实现,并给出将其改造成迭代加深算法时,解所在最低层数的确定。
11 |
12 | ## 唯余法
13 |
14 | > 当数独谜题中的某一个宫格,因为所处的列、行及九宫格中,合计已出现过不同的 8 个数字,使得这个宫格所能填入 的数字,就只剩下那个还没出现过的数字时,我们称这个宫格有唯余解。
15 |
16 | 可以看到,唯余法就是利用排除法得出数独某个位置可能的唯一解。但在人工用这种方法解数独时,可能会出现以下问题:
17 |
18 | 1. 只剩唯一解的数独格子难以直接观察得到。采用唯余法观察时,行,列,宫格的重复性都要考虑,~~对人的视力提出了巨大的挑战~~。
19 | 2. 可能,而且很可能不存在能直接确定答案的数独格子。比如可能排除到最后,这个格子还剩 4 和 6 能填,确定不了具体需要填哪一个数。
20 |
21 |
22 |
23 | 但以上两点在计算机算法实现时却可以比较好的解决。对于第一点,计算机可以穷举每一个格子,对于第二点,计算机可以穷举每一个可能性,这就为我们采用唯余法编写程序提供了可行性。
24 |
25 | ## 算法实现
26 |
27 | ### 基本思路
28 |
29 | 采用递归的思路编写程序。这里采用 DFS 遍历所有格子。递归函数 int 类型,有解返回 1,无解返回 0
30 |
31 | 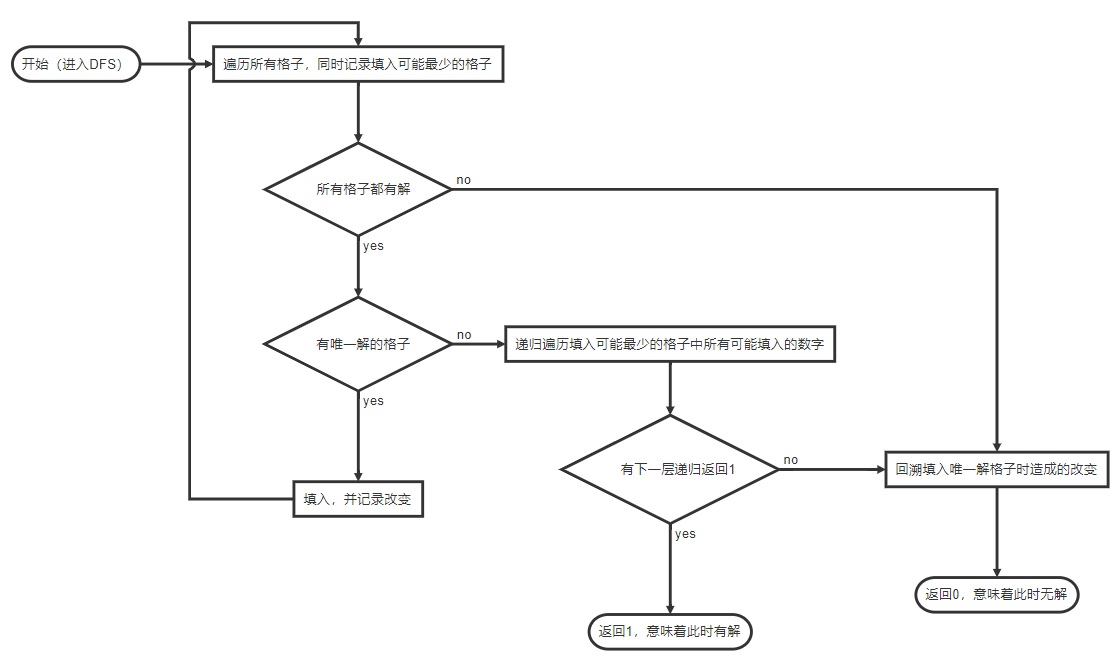
32 |
33 | 此外,内层每次递归时也要对操作进行回溯,此处不表。
34 |
35 | 这里列出流程所必需的变量:
36 |
37 | - `char sudoko_solve[9][9]`:记录着当前的解
38 | - `char num_can_input[81]`:记录着每个格子还可以放多少数字。0 表示无解,取最大值 127 表示格子已经被填入数字
39 | - `bool mark[81][10]`:记录每个格子是否允许放 1 到 9 的数字。0 空出来,是为了代码简洁性。
40 |
41 | 在进入正式流程之前,先要对这些数字预处理。这里略去过程。
42 |
43 | `sudoko_solve[9][9]` 对于已有数字为该数字,否则为 0。
44 |
45 | 可能会注意到,这里存在 $9*9$ 和 81 两种数据记录的方法。这是由笔者别的模块的函数写法决定的。
46 |
47 | 转换关系:对于坐标 $(x,y)$,对应的后者数字为 $9*x+y$。反之,$x = cell / 9, y = cell \% 9$。
48 |
49 | ### 代码实现
50 |
51 | 根据上面的说明写出代码:
52 |
53 | ```cpp
54 | int dfs_ID(bool mark[][10], char* num_can_put, int depth) {
55 | if (depth> 90) {
56 | return 0; //迭代加深,退出递归,目前深度待定
57 | }
58 | struct IDDFS_change* queue[81]; //记录填入唯一解数字时造成的改变
59 | int change_num = 0; //对应上面的 queue,记录有多少唯一解
60 | int min = 127, min_index, flag = 0;
61 | do {
62 | min = 127; flag = 0;
63 | for (int i = 0; i < 81; i++) {
64 | if (num_can_put[i] == 0) { //无解,回溯后退出
65 | solve_res = 1;
66 | for (int i = change_num - 1; i>= 0; i--) {
67 | dfs_ID_recall(mark, num_can_put, queue[i]);
68 | }
69 | return 0;
70 | }
71 | else if (num_can_put[i] == 1) { //唯一解,填入并记录
72 | flag = 1;
73 | queue[change_num] = new IDDFS_change; change_num++;
74 | for (int j = 1; j <= 9; j++) {
75 | if (!mark[i][j]) {
76 | dfs_ID_fill(mark, num_can_put, i, j, queue[change_num - 1]);
77 | break;
78 | }
79 | }
80 | continue; //填入唯一解后,再次进入循环
81 | }
82 | else if (num_can_put[i] < min) { //记录最小值
83 | min = num_can_put[i];
84 | min_index = i;
85 | }
86 | }
87 | } while (flag == 1); //填入了唯一解,需要再搜
88 | if (min == 127) { //最小值是 127,意味着每个格子都是唯一解的,也就是找到了数独的解
89 | solve_res = 2;
90 | return 1;
91 | }
92 | //对 min_index 进入下一层
93 | int cell = min_index;
94 | for (int j = 1; j <= 9; j++) {
95 | if (!mark[cell][j]) {
96 | struct IDDFS_change* nextlay = new struct IDDFS_change; //记录改变
97 | dfs_ID_fill(mark, num_can_put, cell, j, nextlay);
98 | if (dfs_ID(mark, num_can_put, depth + 1)) { //填入
99 | return 1;
100 | }
101 | dfs_ID_recall(mark, num_can_put, nextlay); //无解,回溯
102 | }
103 | }
104 | for (int i = change_num - 1; i>= 0; i--) { //回溯填入的唯一解
105 | dfs_ID_recall(mark, num_can_put, queue[i]);
106 | }
107 | return 0;
108 | }
109 | ```
110 |
111 | 这里用 `flag` 记录是否有只有唯一解的格子。
112 |
113 | 填入和回溯函数借助了一个结构体:`struct IDDFS_change`。
114 |
115 | ```cpp
116 | struct IDDFS_change {
117 | int cell_fill,num_fill;
118 | int cell_num_can_put;
119 | int queue[30], change_num;
120 | };
121 | ```
122 |
123 | 这里仅仅是用于储存需要回溯的一些数据,所以不需要用类,结构体足矣。
124 |
125 | `dfs_ID_fill` 用于填入数字,并记录信息到 p 指针,便于回溯。
126 |
127 | ```cpp
128 | void dfs_ID_fill(bool mark[][10], char* num_can_put, int cell, int num, struct IDDFS_change* p) {
129 | p->cell_fill = cell; p->num_fill = num;
130 | p->cell_num_can_put = num_can_put[cell]; p->change_num = 0; //记录回溯需要信息
131 | int x = cell / 9, y = cell % 9;
132 | sudoko_solve[x][y] = num; //数字填入该格子
133 | num_can_put[cell] = 127;
134 | for (int k = 0; k < 9; k++) {
135 | if (!mark[9 * x + k][num] && !sudoko_solve[x][k]) {
136 | p->queue[p->change_num] = 9 * x + k; p->change_num++; //记录改变
137 | mark[9 * x + k][num] = true;
138 | num_can_put[9 * x + k]--;
139 | }
140 | }
141 | for (int k = 0; k < 9; k++) {
142 | if (!mark[9 * k + y][num] && !sudoko_solve[k][y]) {
143 | p->queue[p->change_num] = 9 * k + y; p->change_num++;
144 | mark[9 * k + y][num] = true;
145 | num_can_put[9 * k + y]--;
146 | }
147 | }
148 | int i_start = x / 3 * 3, j_start = y / 3 * 3;
149 | for (int dx = 0; dx < 3; dx++) {
150 | for (int dy = 0; dy < 3; dy++) {
151 | if (!mark[(i_start + dx) * 9 + (j_start + dy)][num] &&
152 | !sudoko_solve[(i_start + dx)][(j_start + dy)]) {
153 | p->queue[p->change_num] = (i_start + dx) * 9 + (j_start + dy);
154 | p->change_num++;
155 | mark[(i_start + dx) * 9 + (j_start + dy)][num] = true;
156 | num_can_put[(i_start + dx) * 9 + (j_start + dy)]--;
157 | }
158 | }
159 | }
160 | }
161 | ```
162 |
163 | `dfs_ID_recall` 用于回溯。
164 |
165 | ```cpp
166 | void dfs_ID_recall(bool mark[][10], char* num_can_put, struct IDDFS_change* p) {
167 | int x = p->cell_fill / 9, y = p->cell_fill % 9;
168 | num_can_put[9 * x + y] = p->cell_num_can_put;
169 | sudoko_solve[x][y] = 0;
170 | for (int i = 0; i < p->change_num; i++) {
171 | num_can_put[p->queue[i]]++;
172 | mark[p->queue[i]][p->num_fill] = false;
173 | }
174 | delete p;
175 | }
176 | ```
177 |
178 | ## 算法的迭代加深改进
179 |
180 | 这里可以考虑随机生成数独并利用该算法求解,记录:出现解时最低到达深度。
181 |
182 | 随机生成数独是指在 $9*9$ 的格子上随机放入指定数量的数字(确保不矛盾,但未必有解)
183 |
184 | 因此,这里需要更改放入数字数量,反复实验,实验结果如下所示:
185 |
186 | - 初始 17 数字:
187 |
188 | 21,20,20,21,24,20,21,27,21,27,21,24,24,21,19,21,20,23,28,24,25,23。
189 |
190 | - 初始 25 数字:
191 |
192 | 12,10,16,9,12,9,13,6,13,7,12,11,10,8,12,10,5,3,17,7。
193 |
194 | - 初始 30 数字:
195 |
196 | 3,3,5,4,5,3,3,3,3,2,8,11,6,2,10,5,4,4,2,3。
197 |
198 | 可以看出,大部分情况,设置搜索深度为 24 已经能够找到目标,这样的搜索深度并不大。如果没找到目标,全部遍历即可。
199 |
200 | 本算法在复杂度上和朴素 dfs 都是 $O(c^n)$ 级别,$n=81$,但是相比朴素 dfs 大幅降低了 c,所以即便穷举所耗时间也比较优秀。
201 |
202 | 故可以这样将算法改进为迭代加深版本:
203 |
204 | ```cpp
205 | int Sudoko::dfs_ID(bool mark[][10], char* num_can_put, int depth, bool full_search) {
206 | if (depth> 24 && !full_search) {
207 | solve_res = 1;
208 | return 0; //迭代加深,退出递归。
209 | }
210 | ...
211 | }
212 | ```
213 |
214 | 增加了一个参数 `bool full_search` 用于表示当前是否需要全部搜索。至此,就完成了本次实验题关于实现迭代加深 DFS 算法的要求。
215 |
--------------------------------------------------------------------------------
/posts/lifemanual.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 写于 2021 高考前
3 | category:
4 | - 日志
5 | date: 2021-05-21 20:16:47
6 | mathjax: true
7 | tags: [杂谈]
8 | tocbot: true
9 | ---
10 |
11 | ## 前言
12 |
13 | 本文写于 2021 高考临近前,旨在给即将进入大学的各位提供一些微小的帮助。
14 |
15 | 考虑到本人能力,视野有限,故选校 / 学习部分更多是站在一个 985 理工科的视角上,若不符合个人情况,仅供参考。
16 |
17 |
18 |
19 | ---
20 |
21 | ## 选校篇
22 |
23 | 基本原则:
24 |
25 | 1. “兴趣”优于“热门”(前提真的是兴趣
26 |
27 | 2. “择专”优于“择校”
28 |
29 | ### 如何得知专业信息
30 |
31 | ---
32 |
33 | 其实高考后留给各位选专业的时间并不是很多,因此如何在短时间内搜集自己想选择的专业的内容是很重要的。下面提供几个了解专业信息时可以侧重考虑的方面:
34 |
35 | #### 学什么
36 |
37 | “顾名思义”并不总能奏效,比如 USTC 有信息学院和计算机学院两个平行的院系,对于大部分没有搜集过相关信息的同学,如果我问他们这两个学院之间有什么区别,相信大多数人都是答不上来的。
38 |
39 | 此外,就算是学院的名字你很熟悉,比如物理学院,但是大学阶段的物理真的和诸位在中学阶段的物理学到的是一回事吗?这些问题都是很值得思考的。当然,高考后到填报志愿之间的时间并不长,因此到也不必真的需要对每个专业如数家珍,但是对自己感兴趣的专业应该多少做到心里有数。
40 |
41 | 这里提供一些了解专业学习内容的比较好的办法:
42 |
43 | > 在网络上搜索本专业的一些通用介绍,可以参考百度百科、学院官网的介绍(包括师资、培养计划、专业排名等)、官方的各种就业深造统计数据、知乎等问答性网站,但这些内容往往缺少针对性,而且不是可交互的,无法及时针对你的疑问做出相应回答。
44 |
45 | 本部分引用自上海交通大学生存手册,文末可获得详细链接。补充一点,百度搜索“你考虑的学校 + 教务系统”,一般排在前列会出现该学校的教务系统或者教务处界面,在这里通常可以公开查询到不同专业的培养方案(也就是必修什么课)。
46 |
47 | #### 未来发展
48 |
49 | 就业 or 科研?就业前景如何,科研收入如何,辛不辛苦?科研可能并不像大家想象的那么美好,从硕士到博士到博士能顺利毕业到评奖,评教职,以至于更上,每一步都会淘汰不计其数的人,如果没有对科研的真心热爱,这会是一条很辛苦的路。
50 |
51 | ### 新兴专业,交叉学科与强基计划
52 |
53 | ---
54 |
55 | 这一条要单独列出来讲,是因为这些名词看上去很高端很唬人,但大部分这些所谓的名词并不是真的就这么美好:新兴专业,很多时候,连同其他一些热门专业一样,属于是顺应了时代的需求或者被其他因素推动捧成了热门专业(这里点名“21 世纪是生物的世纪”),并不是说这些热门专业就不好,而是说没必要冲着它们的名字就作出选择,还是要想清楚自己喜欢的是什么。
56 |
57 | 此外,对于强基计划,还是要慎重考虑,一方面这些强基计划覆盖的专业多为基础专业,且理论上不允许转强基计划之外的专业;另一方面,对于强基计划对应的特殊培养方案以及可能宣传的教授指导:特殊培养方案未必对你是好事,永远不要太高估自己的抗压能力;而教授辅导这件事情,事实上只要你对该学科有兴趣,哪怕你甚至不是这个专业,在大学你往往也可以通过邮件联系导师进行本科科研等,强基计划只能是提供一个平台,具体个人的发展还是得靠自己的奋斗(((
58 |
59 | 既然说到了这些比较现实的因素,那大家可以看看这份 [清华大学 2021 转专业结果](https://www.zhihu.com/question/455564234),以供参考。
60 |
61 | ### 其他影响择校因素
62 |
63 | ---
64 |
65 | 列举一些以供参考:
66 |
67 | 1. 转专业方便程度
68 |
69 | 2. 宿舍条件:24 小时热水,上床下桌,卫生间条件,晚上是否断网断电,空调是否自行决定开关
70 |
71 | 3. 地理位置:是否方便,离家远近等
72 |
73 | 4. ~~男女比例~~
74 |
75 | 5. 规章制度是否严格,是否自由(比如点不点名)
76 |
77 | 以上信息有条件的可以找认识的问问,没条件的话可以多看看想报的学校的贴吧以及知乎评价。
78 |
79 | ---
80 |
81 | ## 开学过渡篇
82 |
83 | 本篇内容将简要带来大学的生活概要,以便各位提前准备,适应。
84 |
85 | ### 暑假
86 |
87 | ---
88 |
89 | 暑假主要活动当然就是玩,不过如果你**非要**想学习的话,这里推荐几个可以考虑的:
90 |
91 | 1. 数学:数列极限的 $\varepsilon-N$ 语言,函数极限的 $\varepsilon-\delta$ 语言,如果你开学后第一学期要学线性代数,可以提前看一下 3blue1brown 做的 [线性代数的本质](https://www.bilibili.com/video/BV1ys411472E),或者 MIT 的 [线代课程](https://www.bilibili.com/video/BV1zx411g7gq?p=3),国内的线性代数教材普遍忽视了一些几何的东西,可能理解起来有点难受。
92 |
93 | 2. 程序设计:不同学校通修的语言可能不太一样,不过也没必要提前学太多,大概看看 B 站网课有个基本的理解就行了。如果你想对计算机科学,而不仅是编程,有更深的理解,这里推荐一下哈佛的 [CS50](https://www.bilibili.com/video/BV1Rb411378V) 课程,是一门类似于讲座性质的公开课,这视频有点老了,不过还是挺经典。
94 |
95 | ### 军训
96 |
97 | ---
98 |
99 | 这应该是大部分同学与大学的第一次接触了,一般时间也就两周左右,基本内容从晒太阳到练习军体拳到聊天到展示才艺不等,几乎等价于一场大型体育课,以下几点注意一下:
100 |
101 | 1. 军训可能采用的是那种平底鞋,站起军姿属实又麻又累,强烈建议提前准备一次性鞋垫,而且一般一次可以多垫几张,如果没有准备的话,~~反正我校每年都是有男生军训几天受不了去超市买卫生巾的~~
102 |
103 | 2. 防晒:站在大太阳底下两周对皮肤造成的~~荼毒~~和平时完全是不能比的,因此强烈建议提前准备防晒霜之类的,~~男孩子也要爱护好自己的皮肤~~,本人当时头铁,结果袖子内外的皮肤晒出了明显的分界线,过了好几个月才逐渐模糊
104 |
105 | 3. 降温:可选,不是很必要,因为假如训练量大了,教官一般还是比较好心的,会有休息时间的,而且别人都在训练,你一个人贴清凉贴吹电风扇似乎也有点奇怪(((
106 |
107 | 以上主要是提醒一下对自己好一点,相信到时候你们妈妈应该也会跟你们说这些的,这里是稍微再强调一下。
108 |
109 | ### 寝室
110 |
111 | ---
112 |
113 | 大概会成为各位在大学待最久的地方?(不过如果你天天去图书馆卷或者在实验室搞科研那确实例外)宿舍条件这玩意选完学校就已经定下来了,是否有 24h 热水,是否上床下桌,独立卫浴... 本篇主要安利一些(可能有用)小东西。
114 |
115 | 1. 小风扇:推荐选那种可以手持又可以放桌上的那种,风量基本够用,反正可以往近了放。
116 |
117 | 2. 插线板:提醒一下买大一点的,以免不够用。
118 |
119 | 3. 理线器:那种可以粘在桌子后面桌子底下的,建议桌上各种数据线鼠标线电线如果过长了都可以绕到桌子后面走一下线,让桌子整洁一点。
120 |
121 | 4. 键盘鼠标:如果没买的话,建议买无线的,绝对比有线的方便了不少,然后如果不打游戏,对键盘鼠标手感没太高追求的话可以买那种宣传静音的,去图书馆学习时不会打扰别人。
122 |
123 | ---
124 |
125 | ## 开学学习篇
126 |
127 | ### 电子产品选购与使用
128 |
129 | ---
130 |
131 | 这里介绍学习时可能会需要的一些电子产品。由于苹果的产品比较特殊,推荐:
132 |
133 | 1. 要么买全套(iPhone,iPad,MacBook)中的至少两件(但考虑大家有打游戏等需求,可能笔记本更适合买 Windows 系统的),以感受苹果生态带来的联动
134 |
135 | 2. 要么就分开选购:手机平板选择安卓,电脑选择 Windows,或者如果电脑没有打游戏的需求,专业也不需要特别强的电脑配置的话,可以考虑买带有触屏的轻薄本,同时作为电脑和平板。(当然,对于学习而言,平板电脑不是必须的)
136 |
137 | #### 笔记本电脑
138 |
139 | ---
140 |
141 | 由于近来挖矿逐渐盛行的原因,电脑显卡价格暴增,这对笔记本市场也产生了一定的影响。
142 |
143 | 这里建议如果家里有电脑的话就先用着吧,现在买笔记本大部分溢价严重,如果是买轻薄本可以考虑,买一些游戏性能比较好的独显笔记本实在不太值得。
144 |
145 | 考虑到大家选购笔记本的时间可能并不统一,为了保证本文时效性,建议有购买需求的同学可以去 b 站关注 up 主 [笔吧评测室](https://space.bilibili.com/367877)
146 |
147 | #### 平板电脑
148 |
149 | ---
150 |
151 | 平板电脑对于学习不是必选项,如果要买的话建议首先考虑自己手机品牌,苹果就买苹果,华为就买华为,别的随意(((
152 |
153 | 平板电脑如果用来学习,最主要的应用场景大概就是手写记笔记了:iPad 上会有很多好用的笔记软件,goodnotes,notability 等,华为在这方面的软件生态会稍微差一点。
154 |
155 | 其次就是看很多电子书以及论文(pdf),有个平板会方便很多。如果觉得自己是那种学一门科目就一定会去找参考书看的,那买个平板应该很能方便你:对于大部分主课,助教及老师往往都会给出推荐书目,这些书目大部分都是可以在学校图书馆网站或者别的地方找到电子版下载的,或者助教会直接提供电子版。
156 |
157 | 最后再提醒一下,平板电脑对于学习不是必须的,买之前建议考虑清楚你买的平板会不会变成“买前生产力,买后爱奇艺”(((
158 |
159 | ### 学习规划
160 |
161 | ---
162 |
163 | #### 名词介绍
164 |
165 | ---
166 |
167 | **绩点**:
168 |
169 | 你所修读的每一门课程都会按照期末总评(一般参考考试成绩和平时分)给出一个对应的成绩档位,比如采用 95-100 分对应 4.3, 90-94 对应 4.0, 85-89 对应 3.7......
170 |
171 | 那么对于所有你所修读的要计算成绩的课程,按照学分对每门课所取得的成绩档位进行加权平均,即得到你的绩点(GPA)。计算公式:
172 | $$\frac{\sum score_i * credit_i}{\sum credit_i}$$
173 | 对于校内评比,往往 GPA 是很重要的一个因素。或者有的学校会单纯将分数按照学分加权平均(略去转换每门课绩点的过程),以总加权平均分作为校内评比依据。
174 |
175 | **通修课,专业课,选修课**:
176 |
177 | 基本上你要学习的课程可以分为两类,一类是培养计划内的,统称为必修课,另一类是培养计划要求之外的,统称为选修课。顺利毕业除了要求修完必修学分之外,往往还要求选修学分达到一定数目。
178 |
179 | 必修课中有一部分是数理基础课,体育课,英语课,思政课等通修课,还有一部分则是与你专业有关的专业课。
180 |
181 | #### 选课
182 |
183 | ---
184 |
185 | 这里建议第一学期默认置课基本没啥必要再动了,以适应为主,选课往往专业课看讲的怎么样,一些选修课看有没有趣,给分好不好。这些东西怎么判断建议询问对应学校学长学姐经验(进校再问肯定不迟,或者这些东西在学校的一些 qq 大群中询问一般都能得到回答)。
186 |
187 | #### 一些时间节点
188 |
189 | ---
190 |
191 | 一般来说规划是大一大二打好专业基础,大二大三有兴趣可以发邮件找导师做点科研,考虑工作实习的话大三也要开始准备了。
192 |
193 | 以上规划也需要具体专业具体分析,比如数学专业本科学到的内容大概是不足以接触一些前沿的东西的,所以~~主要就是学~~。
194 |
195 | 如果想出国考虑学英语的话,视自己英语水平而定,一般来说这些英语考试(托福,雅思,GRE)证书有效期有 2 年,所以往往稳妥打算,在大二的寒假及春季学期可以考虑针对性学习,考试(因为要申请国外学校的话可能大四一开始甚至更早就要着手申请)。平时的话能多积累点词汇,听听听力自然更好。
196 |
197 | ### 学习心态
198 |
199 | ---
200 |
201 | 诗云:
202 |
203 | > 晚上熬夜冲浪,早上不想起床。
204 | > 完全不敢逃课,前排上网很忙。
205 | > 知乎微博豆瓣,B 站白嫖之王。
206 | > 催利老师营业,建议爽子改行。
207 | > 中午想吃什么,西区芳华食堂。
208 | > 回寝开始游戏,作业完全不慌。
209 | > 三点开始午觉,四点上课匆忙。
210 | > 课上继续游戏,输到头昏脑涨。
211 | > 晚上大物实验,做到直接骂娘。
212 | > 回寝先买夜宵,冰粉不加红糖。
213 | > 抹嘴拿出手机,数据扔在一旁。
214 | > ddl 马上截止,自习室装模作样。
215 | > 微积分学习指导,看懂的不过几行。
216 | > 遇题不会求群友,群友个个是卷王。
217 | > 一般方法就不讲,wolfram 它不香?
218 | > 实验报告不会写,祖传张力帮大忙。
219 | > 凑完作业连诉苦,享受网抑云时光。
220 | > 生而为人很抱歉,失去梦想不应当。
221 | > 复习一天练习生,头脑空空上考场。
222 | > 考完快乐把号上,成绩下来涕泗淌。
223 | > 痛心疾首狂饮醉,愧对自己愧爹娘。
224 | > 明日立志当勤学,闻鸡起舞好儿郎。
225 | > 闹钟六点开始响,愣是九点没起床。
226 | > 和大多数人一样,三十没牵过姑娘。
227 | > 隔壁寝室的兄弟,和 npy 得郭奖。
228 | > 游戏水准直线升,英语能力指数降。
229 | > 能力不如田舍郎,幻想能登天子堂。
230 | > 问我所得有几何?肥西路上划水王。
231 | > 故表情包有云:
232 | > 读书人,混子人,看完忘一半是基本。学到一半群聊见,手机三分钟瞄一眼,装模作样读书人!
233 | > 中国科大学生星云诗社 - 刚体小咸鱼 投稿
234 |
235 | 各位大学的学习生活其实理论上来说是相当自由的:不会有班主任天天盯着你学习,甚至上不上课往往都看你个人意愿(~~本人已经好几节近现代史纲要课没去上了~~)。
236 |
237 | 不过出于种种原因,不管是想获得一个好看的成绩,还是周围同学都付出了许多努力,往往会有很多因素会推动你去“应试性的学习”。然而就算获得一个好成绩,也不代表真正掌握了一门课的内容。且如果这种学习不是出于你的本意,那想必你也不会很快乐。本部分内容主要是希望各位能够不要太应试性的学习。
238 |
239 | 出于不再重复造轮子的原则,这里仅提供一篇文章以供拓展阅读:
240 | [上海交通大学生存手册](https://survivesjtu.gitbook.io/survivesjtumanual/)
241 |
--------------------------------------------------------------------------------
/posts/vue3-fastapi.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: vue3-fastapi 简易开发体验
3 | date: 2022-03-01 14:20:02
4 | tags: [vue, fastapi, 异步]
5 | category: web
6 | mathjax: true
7 | tocbot: true
8 | ---
9 |
10 | 温故而知新,本文将借助比较现代化的开发流程(vue-cli, vue3, fastapi)重构之前的一篇简易备忘系统
11 |
12 |
13 |
14 | ## 前端
15 |
16 | 前端借助 Vue CLI 搭建起 Vue 项目,并对原先内容进行迁移
17 |
18 | ```bash
19 | vue create hello-world
20 | ```
21 |
22 | 后即可修改 Vue 项目
23 |
24 | ### Vue
25 |
26 | 在介绍 Vue3 之前,首先需要介绍一下 Vue 框架的基本思想。
27 |
28 | 原先,DOM (html 文档) 中显示的数据和 JS 中的变量并没有绑定关系,因此,每次变量改变(包括从后端获取数据)都需要重新操作 DOM, 更新数据
29 |
30 | Vue 对此进行了简化,这是怎么做到的呢?
31 |
32 | 从逻辑上来说,设 State 是当前所有应用(网页)中所有数据的集合,View 是用户看到的 ui 界面,它们之间应该具备一个单向的函数关系 $View = f(state)$
33 |
34 | Vue 所做的工作即为自动描述了这一函数关系,使得 HTML 文档中显示的元素可以通过 Vue 提供的模板语法 `{{ }}` 与 State 中的变量进行绑定,比如如果我想在页面某处显示脚本中的值 `x`,那 HTML 对应位置直接写 `{{ x }}` 即可。加上 Vue 提供的 `v-if` 和 `v-for` 之类的模板控制流,使得用户可以专注于数据的操作,而无需担心这些数据怎样更新到页面上
35 |
36 | 具体实现上,Vue2 采用 `data、computed、methods、watch` 等组件,被称为响应式 API:
37 |
38 | - data 即为 $State$ 集合,包含了所有该页面需要用到的数据
39 | - methods 是一些方法(函数)的集合,可以用于处理页面点击事件,更新数据等
40 | - computed 为计算属性,可以理解一个语法糖(当然,具体实现上不是语法糖)。如果页面上一个元素的内容 $a$ 依赖数据 $x$, 具体关系为 $a = f(x)$, $f$ 是一个很复杂的函数,直接写模板 `{{ f(x) }}` 既麻烦又表意不明,这个时候可以设置计算属性 $y = f(x)$,即可通过 `{{ y }}` 达到自己想要的效果
41 | - watch 用于自动检测页面上元素的变化,可以在检测到用户的操作之后调用相应的 methods 中的函数
42 |
43 | ### 组合式 API
44 |
45 | Vue2 在功能上已经很完善,但是一个很大的弊端是如果不注意拆分组件(页面),一个组件文件可能会非常长,甚至上千行。试想一个界面内有很多元素,每个元素都有对应的数据和用户操作界面的方法,那么 `data、computed、methods、watch` 中会有页面里不同模块的内容混杂,一方面可读性较差,另外一方面太长的文件也不方便编辑。
46 |
47 | 对此,Vue3 相对于原先的响应式 API,引入了组合式 API,目的就是为了将操作页面中同一模块的 JS 逻辑整合到一起。
48 |
49 | `data、computed、methods、watch` 在这一改变后被统合到了一个 `setup` 组件。
50 |
51 | 先看一下重构之后的备忘系统前端逻辑:
52 |
53 | ```html
54 |
84 | ```
85 |
86 | 再来逐个部分解析。
87 |
88 | #### 前后端通信
89 |
90 | 首先是三个前后端通信的接口,这里先忽略 `async` 只要知道它们能请求数据即可。
91 |
92 | ```html
93 |
119 | ```
120 |
121 | #### 数据绑定
122 |
123 | 接下来讨论一下 $View = f(state)$ 如何实现。
124 |
125 | 主要实现方法是 `ref`,这是为了给指定的数据创建引用。为什么要创建引用以及引用的使用可以参见官方 [组合式 API 文档](https://v3.cn.vuejs.org/api/composition-api.html), 这里注意组合式 API 是兼容原先响应式 API 的, `
152 | ```
153 |
154 | #### 钩子
155 |
156 | 再来看 `onMounted(getNotes);` 这一行。Vue 提供了一些特殊的钩子,`onMounted` 代表组件加载完毕后会执行的语句。这里我们希望组件加载完成后直接加载所有笔记数据。关于钩子,是 Vue 的一个重要特性,本文不在此讨论。
157 |
158 | ```html
159 |
183 | ```
184 |
185 | #### 页面模板
186 |
187 | 至此,前端的逻辑就基本分析完毕。下面考虑页面模板的编写:
188 |
189 | ```html
190 | lab 评测
66 |
80 |
132 |
81 | 选择测试题目
82 | 限制单次指令数:
116 |
131 |
87 | lab1 乘数数组:
88 |
94 | lab1 被乘数数组:
95 |
101 | lab2&3 测试数据:
102 |
108 | lab5 测试数据:
109 |
115 |
191 |
204 | ```
205 |
206 | 可以看到 `v-if` 和 `v-for` 的方便之处。
207 |
208 | #### 补充:异步
209 |
210 | 异步名字看起来很高大上,但原理没有这么复杂。本质就是因为浏览器对某个接口的请求可能会耗费较长的时间(比如我们用 JS 下载一个文件,可能需要好几秒),这个期间我们希望 JS 能继续执行。因此,我们需要一个 **回调函数** ,在接口请求完成后继续执行这个回调函数,来完成与后端接口通信结束之后的处理。
211 |
212 | 举例来说,逻辑大致是这样:
213 |
214 | ```javascript
215 | func1 = ...
216 | func2 = ...
217 | func3 = ...
218 | func4 = ...
219 |
220 | func1()
221 |
222 | fuc2(请求的 url 和相关参数,func3)
223 |
224 | func4()
225 | ```
226 |
227 | 实际执行中,func1 执行完后来到了一个请求后端接口的函数 func2,func2 在请求后端数据的同时,JS 的运行并不会阻塞,而是会继续从 func4 往后执行。直到请求完成,才会执行 func3(比如用于处理得到的数据)
228 |
229 | async/await 是对以上的异步过程的简化。这里我们不去阐述 JS 的 Promise 机制,而单从使用上理解:对于一个异步函数(比如调用后端接口),我们可以用 await 来 "等待" 这一函数调用完毕。await 之后的内容起到了与回调函数类似的作用,会在异步函数调用完后再执行。
230 |
231 | 比如以下代码(这并不实际生效,下面再解释)
232 |
233 | ```javascript
234 | function foo() {
235 | const resp = await axios.get(url); // GET 请求的结果会被存在 resp 中
236 | // 接下来可以处理 resp
237 | }
238 | ```
239 |
240 | 但注意的是,`foo` 调用了一个异步函数,所以 `foo` 的执行会消耗较长时间,于是它也变成了一个异步函数。为了标识这一点,我们给 `foo` 注明 `async`
241 |
242 | ```javascript
243 | async function foo() {
244 | const resp = await axios.get(url); // GET 请求的结果会被存在 resp 中
245 | // 接下来可以处理 resp
246 | }
247 | ```
248 |
249 | `foo` 是一个异步函数,所以也可以再写一个异步函数处理 `foo` 返回的数据:
250 |
251 | ```javascript
252 | async function bar() {
253 | const res = await foo();
254 | // 接下来处理 res
255 | }
256 | ```
257 |
258 | 若调用 `bar`,实际会依次执行 `axios`, `foo`, `bar` 中的逻辑,但是我们的代码中并没有出现嵌套,使得异步代码看起来与同步代码类似,很清爽
259 |
260 | ## 后端
261 |
262 | 本文采用 uvicorn + fastapi 在服务器上部署。部署具体可以参考 fastapi 文档。
263 |
264 | ```bash
265 | pip install fastapi
266 | pip install uvicorn[standard]
267 | vim main.py
268 | uvicorn main:app --host 0.0.0.0 --port 80 # for example
269 | ```
270 |
271 | fastapi 官方文档的说明非常清楚,直接贴代码:
272 |
273 | ```python
274 | from fastapi import FastAPI
275 | from fastapi.middleware.cors import CORSMiddleware
276 |
277 | from pydantic import BaseModel
278 |
279 |
280 | class Note(BaseModel):
281 | content: str
282 | create_time: str
283 |
284 |
285 | app = FastAPI()
286 | app.add_middleware(CORSMiddleware, allow_origins=["*"], allow_methods=["*"],
287 | allow_headers=["*"],)
288 |
289 | notes = []
290 |
291 |
292 | @app.get("/notes")
293 | def read_notes():
294 | return notes
295 |
296 |
297 | @app.post("/notes")
298 | def append_note(note: Note):
299 | notes.append(note)
300 | return notes[-1]
301 |
302 |
303 | @app.delete("/notes/{id}")
304 | def delete_note(id: int):
305 | return notes.pop(id)
306 |
307 | ```
308 |
309 | 这一行是用来设置跨域
310 |
311 | ```python
312 | app.add_middleware(CORSMiddleware, allow_origins=["*"], allow_methods=["*"],
313 | allow_headers=["*"],)
314 | ```
315 |
316 | `@app.get("/notes")` 代表使用 `GET` 访问 `/notes` 接口时会调用的函数。这里介绍几个常见的访问接口的方式:
317 |
318 | - GET: 获取信息
319 | - POST: 添加信息
320 | - PUT: 添加/更新信息,需要保证调用 n 次和调用 1 次的结果相同,因此常用于更新数据
321 | - DELETE:删除数据
322 |
323 | ## 画饼
324 |
325 | 啥时候用 Vue3 + fastapi 把自己博客重构一遍()
326 |
--------------------------------------------------------------------------------
暂无数据
192 |
201 | 增加备忘:
202 |
203 |