 106 |
106 |  107 |
108 |
109 | ```
110 |
111 | 代码中有三张图片,这三张图片在代码中由上而下分别是:
112 |
113 | * prefetch 的 russian-girl
114 | * preload 的 dog
115 | * img 标签的 cat
116 | * img 标签的 dog。
117 |
118 | 再看下图中三张照片的加载顺序:
119 |
120 | * 代码中最上面的 prefetch russian-girl 反而是最后被加载,并且在另外两张图片加载就绪之前始终处于 pending 状态,等另外两张图片加载完成后才加载,表明优先级最低,并且不会占用页面资源
121 | * 处于最后的 img dog 反而是最先被加载的,然后 img cat 次之,因为 dog.png 通过 preload 做了预加载,表明 preload 的资源会优先被加载
122 |
123 | **备注:** 为了观看加载效果,所以故意把网络调成了 fast 3G,所以图片加载时间比较长。
124 |
125 |
107 |
108 |
109 | ```
110 |
111 | 代码中有三张图片,这三张图片在代码中由上而下分别是:
112 |
113 | * prefetch 的 russian-girl
114 | * preload 的 dog
115 | * img 标签的 cat
116 | * img 标签的 dog。
117 |
118 | 再看下图中三张照片的加载顺序:
119 |
120 | * 代码中最上面的 prefetch russian-girl 反而是最后被加载,并且在另外两张图片加载就绪之前始终处于 pending 状态,等另外两张图片加载完成后才加载,表明优先级最低,并且不会占用页面资源
121 | * 处于最后的 img dog 反而是最先被加载的,然后 img cat 次之,因为 dog.png 通过 preload 做了预加载,表明 preload 的资源会优先被加载
122 |
123 | **备注:** 为了观看加载效果,所以故意把网络调成了 fast 3G,所以图片加载时间比较长。
124 |
125 |  126 |
127 | # 总结
128 |
129 | prefetch 和 preload 是两种非常有用的资源预加载技术,可以显著提高网站性能并优化用户体验。使用 prefetch 可以帮助浏览器预取将来可能会被用户访问到的资源,而使用 preload 可以预加载即将被使用的资源。在使用这些技术时,我们需要注意谨慎使用,确保只预加载可能会被用户使用的资源,从而并避免过度预加载导致性能问题。
130 |
131 |
126 |
127 | # 总结
128 |
129 | prefetch 和 preload 是两种非常有用的资源预加载技术,可以显著提高网站性能并优化用户体验。使用 prefetch 可以帮助浏览器预取将来可能会被用户访问到的资源,而使用 preload 可以预加载即将被使用的资源。在使用这些技术时,我们需要注意谨慎使用,确保只预加载可能会被用户使用的资源,从而并避免过度预加载导致性能问题。
130 |
131 | 132 | 133 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 134 | 135 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 136 | 137 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 138 | 139 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)** 140 | -------------------------------------------------------------------------------- /PDF 生成/PDF 生成(1)— 开篇.md: -------------------------------------------------------------------------------- 1 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 2 | 3 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 4 | 5 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 6 | 7 | # 封面 8 |  9 | # 简介 10 | 本系列旨在介绍纯前端技术方案下的 PDF 生成最佳实践。内容涵盖业务背景、选型思路和实践历程,从简单的 PDF 文件生成到复杂的配置化与服务化。 11 | 12 | 整个实践过程以技术为驱动,同时也展示了如何打造技术产品的过程。是一份适合任何人实践的教程。 13 | 14 | # 背景 15 | 需求来自业务对公司战略的拆解 — **安全运维托管服务**,为用户提供全日制的数字化资产安全运维、监控、告警、专家分析等服务。一句话总结就是,用户付钱找我们为用户提供全方位的资产运维服务。 16 | 17 | 在这个服务中我们为用户做了很多事情,我们需要让用户看到我们的价值,所以会以日报、周报的形式为用户推送**运维报告**,而这份报告就是以 **PDF 文件**的形式呈现。 18 | 19 | 所以,这份报告承载了产品能力和价值的传递,业务对 PDF 文件内容的展现提出了明确的要求:**需要呈现出色彩鲜明、精美的设计,简单描述就是好看 + 酷炫**。 20 | 21 | 于是,设计同学的设计稿就来了 22 | 23 | > **本系列出现的所有和托管服务相关的配图版权均归 360 企业安全云所有** 24 | 25 |  26 | 27 | 看到设计稿的瞬间,就在想,这效果用 PDF 能呈现?最后会不会是这结果? 28 | 29 |  30 | 31 | **因此,业务需求可以归纳为一份出色、惊艳的 PDF 文件**。 32 | 33 | # 技术调研 34 | 讲了业务背景,接下来就该技术调研了,经过调研,PDF 文件生成可以总结为两大类:原生方案和转化方案。 35 | ## 原生方案 36 | 利用开源工具库直接操作 PDF 文件,在文件内绘制内容,比如 iText、PDFKit、pdf-lib。 37 | 38 | - **优点**,性能高,适用于内容简单的场景 39 | - **缺点**,难以处理具有复杂排版和样式的场景 40 | ## 转化方案 41 | 将内容通过中间媒介转化成 PDF 文件,主要包括:Word 转 PDF、HTML/CSS 转 PDF。 42 | 43 | **Word 转 PDF** 的缺点和原生方案一样,在复杂排版和样式场景上有心无力。大概原理是通过 Word 提供的 API 操作编写 Word 文档,然后 Word 转换成 PDF 文件。 44 | 45 | **HTML/CSS 转 PDF**,主要有如下三种方案: 46 | 47 | - **模版引擎**,利用模版引擎生成 HTML/CSS,然后结合下面的两个方案生成 PDF 文件,一般后端同学会用这个方案 48 | - **Canvas**,前端常用的方案,例如 html2canvas + jsPDF,但在 PDF 分页、内容截断问题上难以解决,PDF 目录页不支持页面跳转和展示页码 49 | - **浏览器打印系统**,利用浏览器的布局、渲染、打印能力,通过 DevTools 协议控制 Chrome/Chromiun,实现 PDF 文件的打印,即 chrome 浏览器**右键 -> 打印**的自动化版本 50 | # 技术决策 51 | 经过调研和众多方案的分析,最终我们选择了**浏览器打印系统**方案,具体的实现上我们选择了 [Puppeteer](https://pptr.dev/) 框架,它是一个 Node.js 库,提供高级 API 控制 Chrome/Chromiun 浏览器,我们在浏览器中手动执行的大多数操作它都可以完成,例如执行 **page.pdf** 方法即可将当前渲染的页面打印成 PDF 文件,简单易用。 52 | 53 | **为什么选择基于浏览器打印系统的 puppeteer 方案?** 54 | 55 | - 经过方案调研之后的综合对比,基于浏览器打印系统的方案更符合业务的诉求 56 | - 我们是前端团队,这套方案更符合团队的技术栈 57 | - 人力和时间成本,其他几个方案基本上就是只能服务端同学自己做,前端很难参与进去,对服务端团队的研发资源造成压力,影响部分业务的吞吐率 58 | 59 | 这套方案前后端同学各司其职、通力合作,分别做自己擅长的事。服务端同学开发页面接口供前端同学调用,前端同学负责开发酷炫的页面,PDF 生成服务将前后端同学开发的页面转成 PDF 文件 60 | 61 | 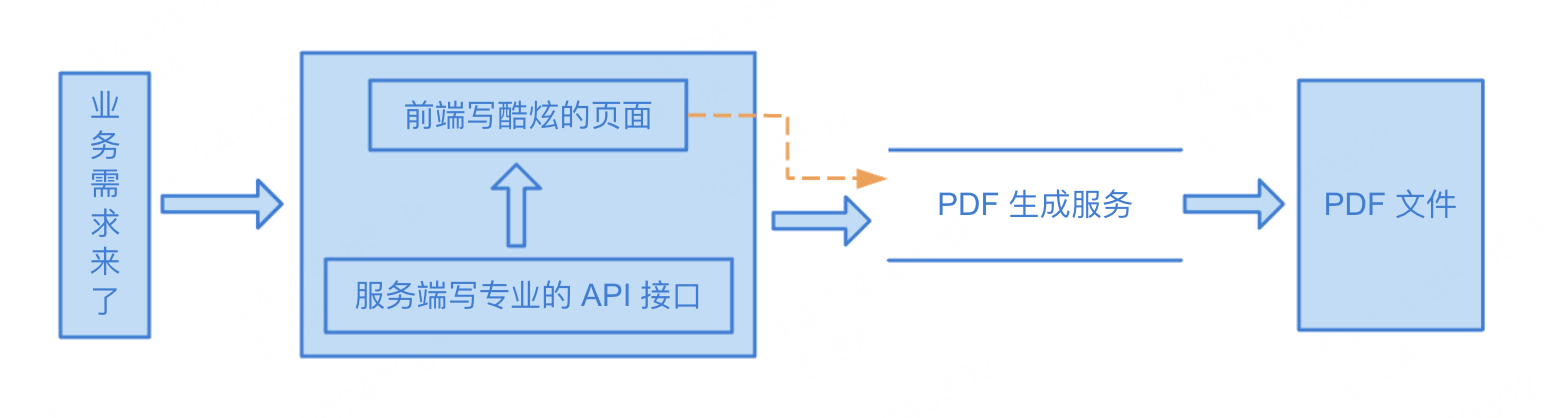 62 | 63 | 于是,产品和设计同学就可以在这张静态的 A4 纸上尽情发挥,不受技术限制。 64 | 65 | # 技术架构 66 | 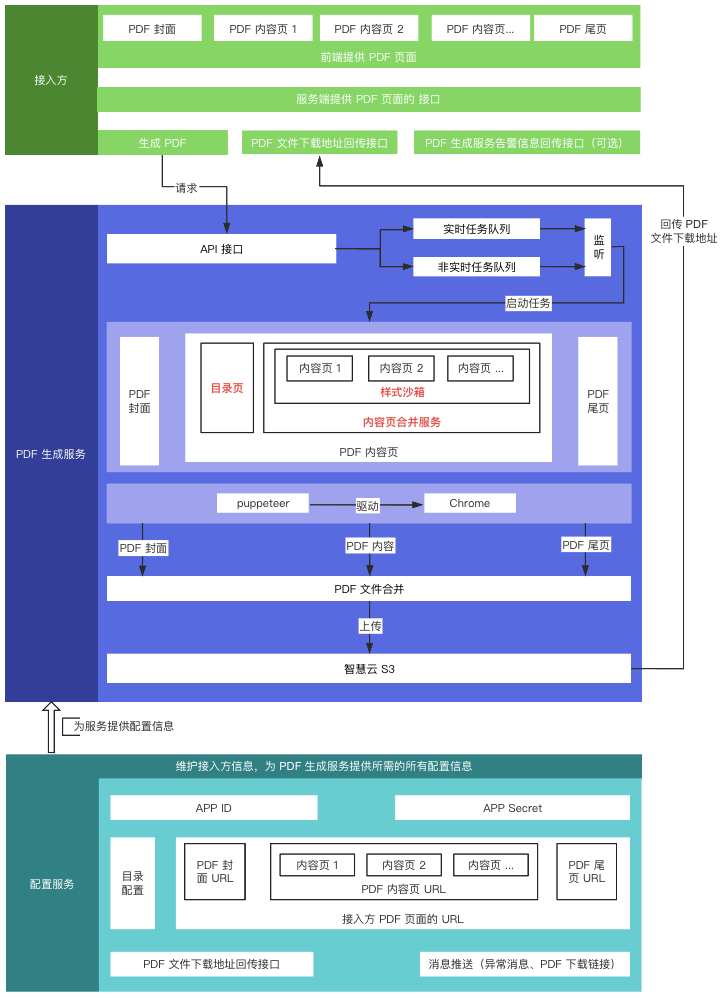 67 | 68 | 方案的技术架构,分为三大块,分别是: 69 | 70 | - **接入方**,即 PDF 生成服务的调用方,就是一个普通的 Web 项目(前端 + 后端) 71 | - **PDF 生成服务**,对外暴露 API,一次 API 调用,产出一份 PDF 文件的下载地址 72 | - **配置服务**,维护接入方的信息,为 PDF 生成服务提供必要的配置信息,比如接入方 Web 项目的页面地址,PDF 生成服务会负责将这些页面生成 PDF 文件 73 | 74 | 整体执行流程如下: 75 | 76 | 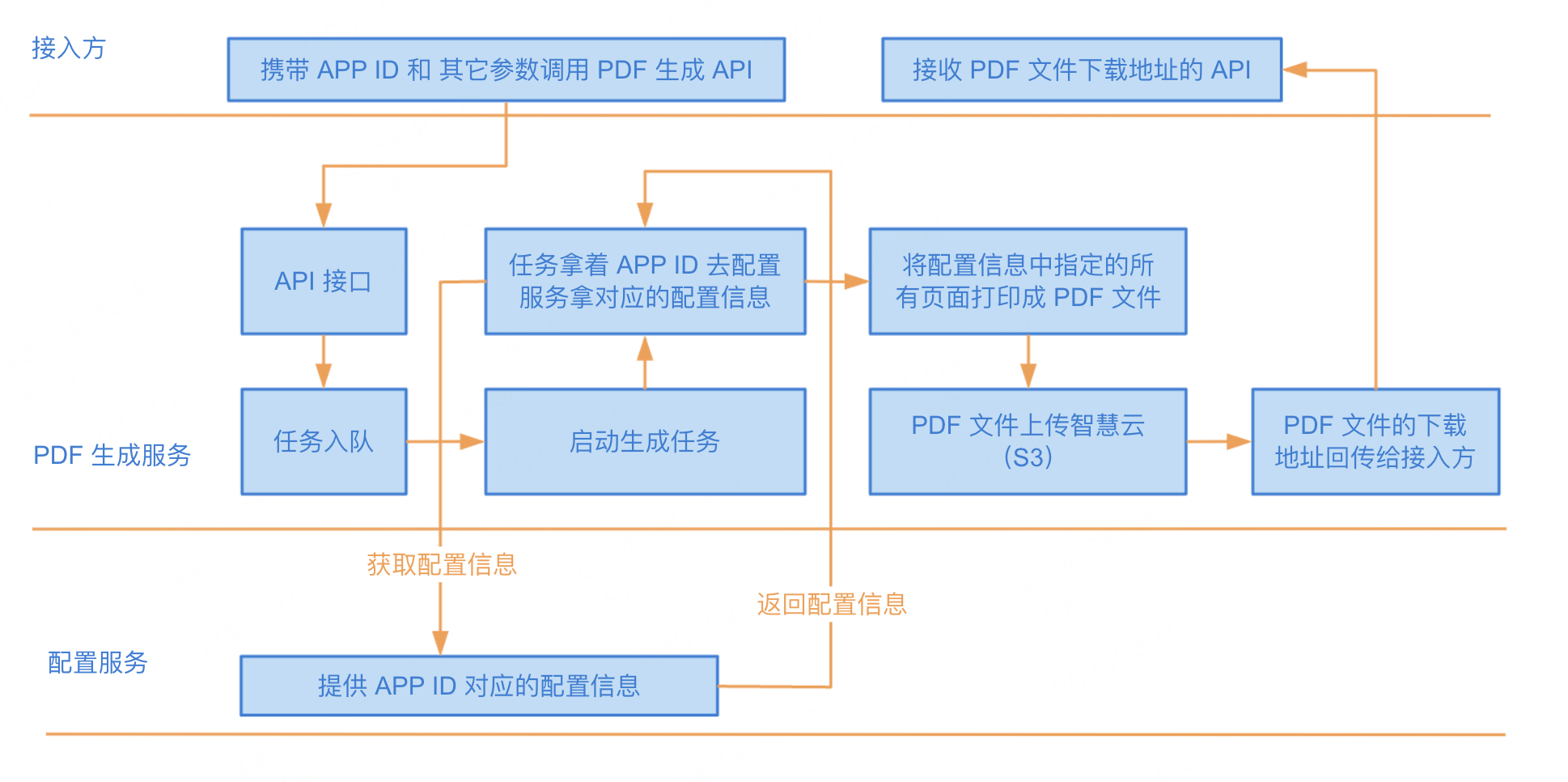 77 | 78 | - **接入方**,带着分配的 APP ID 和 其它参数调用生成 PDF 服务的 API 接口,**其它参数**是接入方前后端自己需要用到的参数,调用时提供的所有参数会原封不动的通过 URL 查询参数带到接入方的前端页面地址上 79 | - **PDF 生成服务** 80 | - 接收到请求后,将请求放入队列 81 | - 监听到队列有内容进入,通知生成 PDF 文件的模块,启动 PDF 生成任务 82 | - 任务拿着 APP ID 请求**配置服务**,获取到对应的配置信息 83 | - 任务将配置信息中指定的所有页面打印成 PDF 文件 84 | - 将 PDF 文件上传到智慧云(S3)上,并将 PDF 文件的下载地址通过回调接口回传给接入方 85 | # 总结 86 | 到这里本文就结束了,本文主要讲了如下内容: 87 | 88 | - 业务背景,要求技术能够产出一份**漂亮 + 酷炫**的 PDF 文件 89 | - 技术调研,主要分为原生方案和转化方案 90 | - 技术决策,结合业务诉求、各个方案的优缺点、团队技术栈和部门人力、时间成本,最终选择**基于浏览器打印系统的 puppeteer 方案** 91 | - 整个方案的技术架构设计 92 | 93 | 一个完善的技术架构是随着业务持续迭代而产生的,接下来我们将从零开始逐步实现整套架构,因此这是一份适合任何人实践的教程 94 | # 链接 95 | 96 | - [PDF 生成(1)— 开篇](https://github.com/liyongning/blog/issues/42) 中讲解了 PDF 生成的技术背景、方案选型和决策,以及整个方案的技术架构图,所以后面的几篇一直都是在实现整套技术架构 97 | - [PDF 生成(2)— 生成 PDF 文件](https://github.com/liyongning/blog/issues/43) 中我们通过 puppeteer 来生成 PDF 文件,并讲了自定义页眉、页脚的使用和其中的**坑**。本文结束之后 puppeteer 在 PDF 文件生成场景下的能力也基本到头了,所以,接下来的内容就全是基于 puppeteer 的增量开发了,也是整套架构的**核心**和**难点** 98 | - [PDF 生成(3)— 封面、尾页](https://github.com/liyongning/blog/issues/44) 通过 PDF 文件合并技术让一份 PDF 文件包含封面、内容页和尾页三部分。 99 | - [PDF 生成(4)— 目录页](https://github.com/liyongning/blog/issues/45) 通过在内容页的开始位置动态插入 HTML 锚点、页面缩放、锚点元素高度计算、换页高度补偿等技术让 PDF 文件拥有了包含准确页码 + 页面跳转能力的目录页 100 | - [PDF 生成(5)— 内容页支持由多页面组成](https://github.com/liyongning/blog/issues/46) 通过多页面合并技术 + 样式沙箱解决了用户在复杂 PDF 场景下前端代码维护问题,让用户的开发更自由、更符合业务逻辑 101 | - [PDF 生成(6)— 服务化、配置化](https://github.com/liyongning/blog/issues/47) 就是本文了,本系列的最后一篇,以服务化的方式对外提供 PDF 生成能力,通过配置服务来维护接入方的信息,通过队列来做并发控制和任务分类 102 | - [代码仓库](https://github.com/liyongning/generate-pdf) **欢迎 Star** 103 | 104 | --- 105 | 106 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 107 | 108 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 109 | 110 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 111 | -------------------------------------------------------------------------------- /其它/AI 编辑器 + MCP 轻松实现设计稿生成前端代码.md: -------------------------------------------------------------------------------- 1 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 2 | 3 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 4 | 5 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 6 | 7 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)** 8 | 9 |
10 | 11 | # 简介 12 | 13 | 今天给大家介绍一款前端生产力提效工具:MasterGo Magic MCP,它是一项独立的 MCP 服务,旨在将 MasterGo 设计工具与 AI 模型链接起来。它使 AI 驱动的工具能够直接从 MasterGo 文件中检索、处理和使用设计数据,从而弥合设计资产和代码生成之间的差距 14 | 15 | # 使用效果 16 | 17 | 第一张图是设计稿,第二张是转换后的效果,还原度是非常高的。 18 | 19 |  20 | 21 | # 基本使用 22 | 23 | 在正式开始配置之前,需要从 [MasterGo](https://mastergo.com/files/account?tab=security) 获取个人访问令牌(token),因为后面的 MCP Server 配置中需要用到。 24 | 25 |  26 | 27 | 接下来配置 AI 编辑器,这里以字节的 Trae 为例,其它编辑器(包括插件)可以查看后面的 **其它工具** 章节。 28 | 29 | ## Trae 30 | 31 | 以 v1.4.3 版本为例。 32 | 33 | **重点:** 模型能力很重要,我的编辑器是用的海外版本,模型选的是 Claude-3.7-Sonnet。国内版本的编辑器,由于各种限制,没什么好的模型,所以效果非常差(可以说没有效果)。 34 | 35 | * 点击右上角的头像 -> AI 功能管理 -> MCP 36 | 37 | 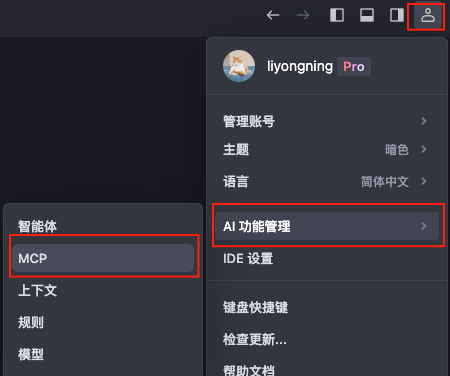 38 | 39 | * 由于 Trae 的插件市场还没有该插件,需要点击 “添加” -> “手动添加” 40 | 41 | * 在弹框中粘贴以下内容: 42 | 43 | ```json 44 | { 45 | "mcpServers": { 46 | "mastergo-magic-mcp": { 47 | "command": "npx", 48 | "args": [ 49 | "-y", 50 | "@mastergo/magic-mcp", 51 | "--token=mg_31e0294a883044cda42be218a0887477", 52 | "--url=https://mastergo.com", 53 | "--rule=Use TypeScript for all components with strict type definitions", 54 | "--rule=Use the method of SCSS combined with CSS modules for style design", 55 | "--rule=Follow Ant Design component patterns and design tokens", 56 | "--rule=Generate components with proper ESLint and Prettier formatting", 57 | "--rule=Create reusable, single-responsibility components", 58 | "--rule=Include proper TypeScript interfaces for all props", 59 | "--rule=Replace icons and images with placeholders. There is no need to implement it with code" 60 | ], 61 | "env": {} 62 | } 63 | } 64 | } 65 | ``` 66 | 67 | > 这里添加了很多自定义规则(--rule),是为了约束 AI,生成符合项目技术栈的代码。这些规则会和 MCP 内部的规则做合并,一起提供给 AI。大家可以根据自己的情况灵活调配。 68 | 69 | 这是添加成功后的界面,需要注意这个提示信息,意思是只有在智能体模式下才能使用,所以在使用时需要先在智能体模式中选中 `Builder with MCP` 。 70 | 71 | 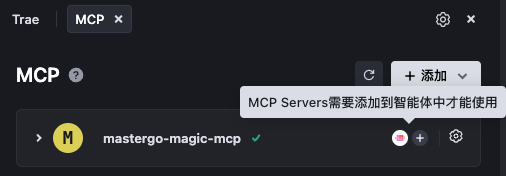 72 | 73 | 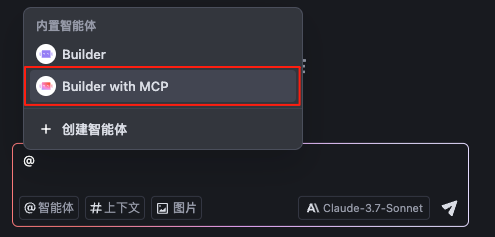 74 | 75 | 接下来打开设计稿选中对应的图层,然后复制地址栏中的 url 到聊天框,比如: 76 | 77 | 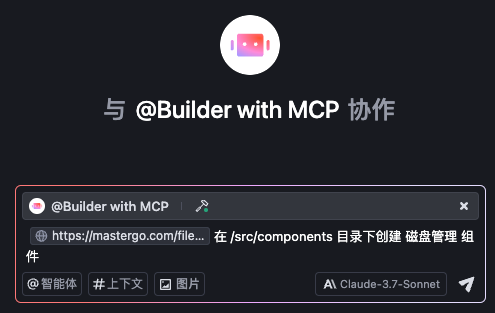 78 | 79 | 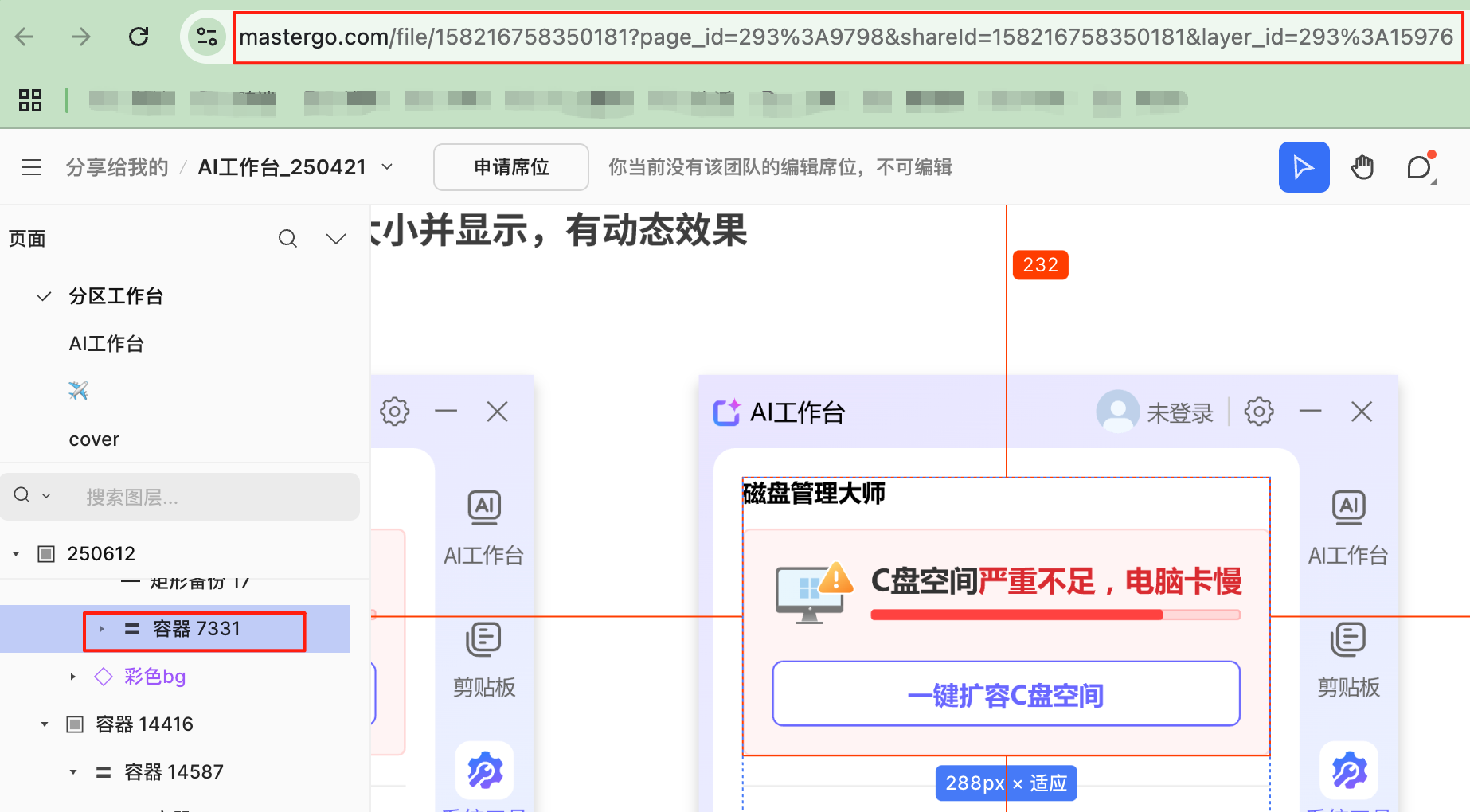 80 | 81 | **重点:** 这里选择图层的时候,和日常开发一样,一定要以组件为单位进行选择,这么做有两个目的: 82 | 83 | * 组件化的方式,AI 生成的代码还原度会更高 84 | * 生成的前端代码可维护性也更好,二次改动的复杂度也更低 85 | 86 | 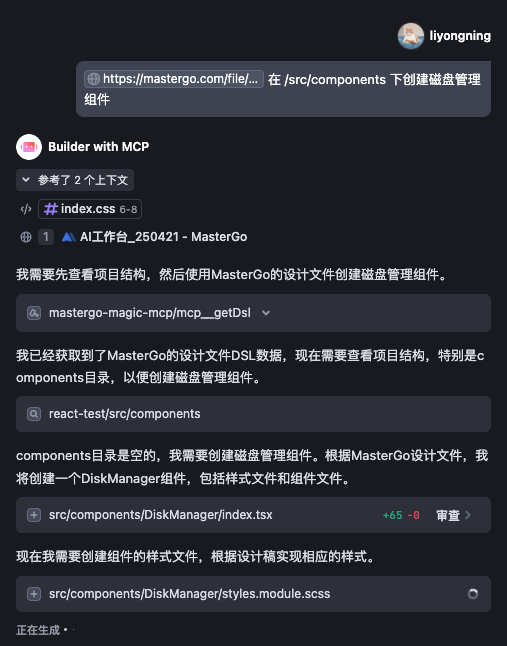 87 | 88 | ## 其它工具 89 | 90 | 其它工具可参考 [官方配置](https://mastergo.com/file/155675508499265?page_id=12549%3A4448&devMode=true),像主流的 cursor、vscode + Lingma、vscode + cline 都支持。但使用时需要注意关于 agent 模式的提示,比如 vscode + Lingma 的方案。 91 | 92 | # 深入理解 93 | 94 | 这是 MasterGo Magic MCP 的架构图,分为上中下三部分。最上面的是 AI 模型的宿主环境,比如 Trae、Cursor 等,中间的则是 MCP 本身,负责串联 AI 模型和 MasterGo 平台,最下面的则是 MasterGo 平台服务,负责为 MCP 提供数据。 95 | 96 | 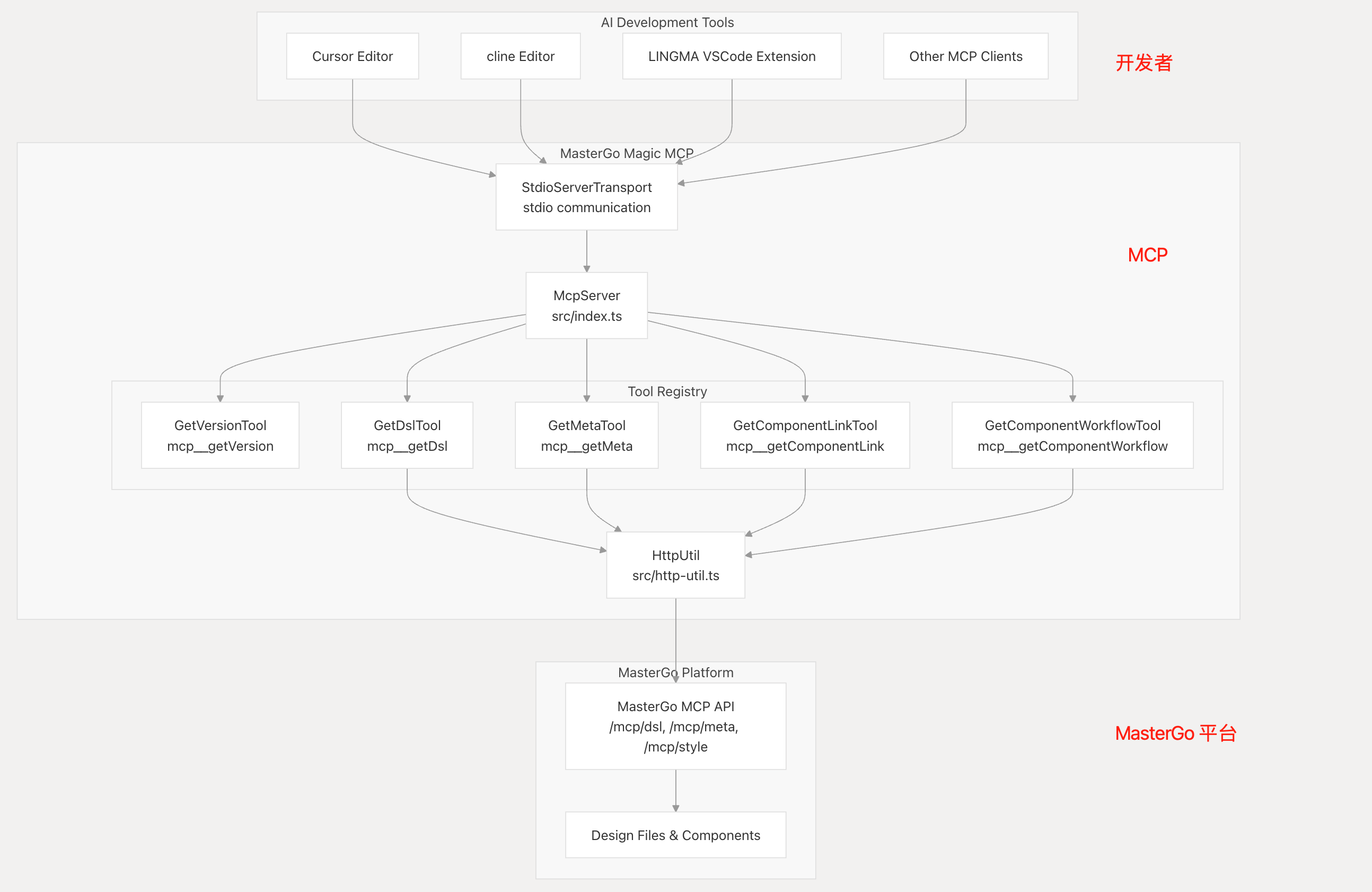 97 | 98 | MCP 目前提供了四个核心的工具,分别是:GetDSLTool、GetMetaTool、GetComponentLinkTool、GetComponentWorkflowTool。 99 | 100 | ## GetDSLTool 101 | 102 | DSL 是 MasterGo Magic MCP(模型上下文协议)系统的核心组件,用于从 MasterGo 设计文件中检索设计规范语言(DSL)数据。该工具充当 MasterGo 设计元素和代码生成过程之间的桥梁,使 AI 工具能够理解和解释设计结构。 103 | 104 | DSL 工具提供对详细设计信息(包括组件层次结构、属性、样式和关系)的访问。这些数据对于以下方面至关重要: 105 | 106 | * 分析 MasterGo 设计的结构 107 | * 了解组件层次结构和关系 108 | * 提取设计属性和约束 109 | * 促进基于设计规范的代码生成 110 | 111 | 该工具还返回在根据检索到的 DSL 数据生成代码时必须遵循的规则。 112 | 113 | ## GetMetaTool 114 | 115 | 元数据工具是 MasterGo Magic MCP 系统中的一个专用组件,用于从 MasterGo 设计文件中检索高级站点配置信息。该工具通过提供有关设计的结构化元数据来充当设计规范和开发之间的桥梁,这些元数据可用于为 AI 辅助代码生成提供信息。 116 | 117 | 元数据工具旨在从 MasterGo 设计文件中检索高级站点配置信息和元数据。它在以下情况下特别有用: 118 | 119 | - 从设计规范构建完整的网站 120 | - 获取高级站点配置信息 121 | - 了解设计元素的结构和属性 122 | - 检索实施过程中应遵循的规则 123 | 124 | 该工具返回元数据结果和一组规则(如 markdown),这些规则指导应如何解释和使用元数据。 125 | 126 | ## GetComponentLinkTool 127 | 128 | 是一个专用的 MCP 工具,用于从额外的 URL 获取组件文档,以帮助 AI 模型生成准确的前端代码实现。 129 | 130 | 如果当前 UI 在设计时使用了组件库,比如 Ant Design,那这个 UI 的 DSL 数据中就可能会包含非空的 `componentDocumentLinks` 数组,这个数组中存放的是依赖的组件的文档链接,AI 随后会使用 `mcp__getComponentLink` 工具循环获取这些文档内容,基于获取的组件文档,AI 能够理解如何正确使用这些组件并生成符合规范的代码。 131 | 132 | 这个机制确保了从设计到代码的转换过程中,AI 能够获得准确的组件使用指南,从而生成符合组件库规范的前端代码。 133 | 134 | ## GetComponentWorkflowTool 135 | 136 | 该工具是 MasterGo Magic MCP 系统中专门用于组件开发场景的工具,与其他工具(如 `GetDslTool`、`GetComponentLinkTool`)协同工作,形成完整的设计到代码转换流程。 137 | 138 | 这个工具不直接生成组件代码,而是为组件开发提供"脚手架"和"指导手册",确保开发者(AI)按照标准化流程开发出符合设计规范的组件。所以,`GetComponentWorkflowTool` 的核心作用就是:**在将设计稿中的指定 UI 的 DSL 数据生成前端组件代码时,提供组件开发的规范、流程以及处理设计资源,即提供完整的组件开发工作流**。 139 | 140 | # 总结 141 | 142 | 本文讲解了 MasterGo Magic MCP 的基础使用和核心工具的介绍,有了该 MCP 前端 UI 研发效率至少提升一倍以上。 143 | 144 | Magic MCP 实现设计稿生成前端代码的原理简单总结就是:通过图层的 layerId 和 fileId 去 MasterGo 平台获取到对应的 DSL 数据,并将数据交给模型,然后模型根据数据以及数据中的约束生成符合要求的前端代码。 145 | 146 |
147 | 148 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 149 | 150 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 151 | 152 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 153 | 154 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)** 155 | -------------------------------------------------------------------------------- /精通 Vue 技术栈的源码原理/手写 Vue2 系列 之 异步更新队列.md: -------------------------------------------------------------------------------- 1 | # 手写 Vue2 系列 之 异步更新队列 2 | 3 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 4 | 5 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 6 | 7 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 8 | 9 | ## 封面 10 | 11 |  12 | 13 | ## 前言 14 | 15 | 上一篇文章 [手写 Vue 系列 之 computed](https://mp.weixin.qq.com/s?__biz=MzA3NTk4NjQ1OQ==&mid=2247485354&idx=1&sn=5e7f0d88192c9119012c49f131327fee&chksm=9f6964dea81eedc8a84d4b214f9e0675ac5bc869d718b3583d94086498c1d0752f1cd7634dc8#rd) 实现了 Vue 的 computed 计算属性。 16 | 17 | ## 目标 18 | 19 | 本篇文章是 `手写 Vue 系列` 的最后一篇,实现 Vue 的异步更新队列。 20 | 21 | 读过源码,相信大家都知道 Vue 异步更新的大概流程:依赖收集结束之后,当响应式数据发生变化 -> 触发 setter 执行 dep.notify -> 让 dep 通知 自己收集的所有 watcher 执行 update 方法 -> watch.update 调用 queueWatcher 将自己放到 watcher 队列 -> 接下来调用 nextTick 方法将刷新 watcher 队列的方法放到 callbacks 数组 -> 然后将刷新 callbacks 数组的方法放到浏览器的异步任务队列 -> 待将来执行时最终触发 watcher.run 方法,执行 watcher.get 方法。 22 | 23 | ## 实现 24 | 25 | 接下来会完整实现 Vue 的异步更新队列,让你彻底理解 Vue 的异步更新过程都发生了什么。 26 | 27 | ### Watcher 28 | 29 | > /src/watcher.js 30 | 31 | ```javascript 32 | // 用来标记 watcher 33 | let uid = 0 34 | 35 | ** 36 | * @param {*} cb 回调函数,负责更新 DOM 的回调函数 37 | * @param {*} options watcher 的配置项 38 | */ 39 | export default function Watcher(cb, options = {}, vm = null) { 40 | // 标识 watcher 41 | this.uid = uid++ 42 | // ... 43 | } 44 | 45 | ``` 46 | 47 | ### watcher.update 48 | 49 | > /src/watcher.js 50 | 51 | ```javascript 52 | /** 53 | * 响应式数据更新时,dep 通知 watcher 执行 update 方法, 54 | * 让 update 方法执行 this._cb 函数更新 DOM 55 | */ 56 | Watcher.prototype.update = function () { 57 | if (this.options.lazy) { // 懒执行,比如 computed 计算属性 58 | // 将 dirty 置为 true,当页面重新渲染获取计算属性时就可以执行 evalute 方法获取最新的值了 59 | this.dirty = true 60 | } else { 61 | // 将 watcher 放入异步 watcher 队列 62 | queueWatcher(this) 63 | } 64 | } 65 | 66 | ``` 67 | 68 | ### watcher.run 69 | 70 | > /src/watcher.js 71 | 72 | ```javascript 73 | /** 74 | * 由刷新 watcher 队列的函数调用,负责执行 watcher.get 方法 75 | */ 76 | Watcher.prototype.run = function () { 77 | this.get() 78 | } 79 | 80 | ``` 81 | 82 | ### 异步更新队列 83 | 84 | > /src/asyncUpdateQueue.js 85 | 86 | ```javascript 87 | /** 88 | * 异步更新队列 89 | */ 90 | 91 | // 存储本次更新的所有 watcher 92 | const queue = [] 93 | 94 | // 标识现在是否正在刷新 watcher 队列 95 | let flushing = false 96 | // 标识,保证 callbacks 数组中只会有一个刷新 watcher 队列的函数 97 | let waiting = false 98 | // 存放刷新 watcher 队列的函数,或者用户调用 Vue.nextTick 方法传递的回调函数 99 | const callbacks = [] 100 | // 标识浏览器当前任务队列中是否存在刷新 callbacks 数组的函数 101 | let pending = false 102 | 103 | ``` 104 | 105 | #### queueWatcher 106 | 107 | > /src/asyncUpdateQueue.js 108 | 109 | ```javascript 110 | /** 111 | * 将 watcher 放入队列 112 | * @param {*} watcher 待会儿需要被执行的 watcher,包括渲染 watcher、用户 watcher、computed 113 | */ 114 | export function queueWatcher(watcher) { 115 | if (!queue.includes(watcher)) { // 防止重复入队 116 | if (!flushing) { // 现在没有在刷新 watcher 队列 117 | queue.push(watcher) 118 | } else { // 正在刷新 watcher 队列,比如用户 watcher 的回调函数中更改了某个响应式数据 119 | // 标记当前 watcher 在 for 中是否已经完成入队操作 120 | let flag = false 121 | // 这时的 watcher 队列时有序的(uid 由小到大),需要保证当前 watcher 插入进去后仍然有序 122 | for (let i = queue.length - 1; i >= 0; i--) { 123 | if (queue[i].uid < watcher.uid) { // 找到了刚好比当前 watcher.uid 小的那个 watcher 的位置 124 | // 将当前 watcher 插入到该位置的后面 125 | queue.splice(i + 1, 0, watcher) 126 | flag = true 127 | break; 128 | } 129 | } 130 | if (!flag) { // 说明上面的 for 循环在队列中没找到比当前 watcher.uid 小的 watcher 131 | // 将当前 watcher 插入到队首 132 | queue.unshift(watcher) 133 | } 134 | } 135 | if (!waiting) { // 表示当前 callbacks 数组中还没有刷新 watcher 队列的函数 136 | // 保证 callbacks 数组中只会有一个刷新 watcher 队列的函数 137 | // 因为如果有多个,没有任何意义,第二个执行的时候 watcher 队列已经为空了 138 | waiting = true 139 | nextTick(flushSchedulerQueue) 140 | } 141 | } 142 | } 143 | 144 | ``` 145 | 146 | #### flushSchedulerQueue 147 | 148 | > /src/asyncUpdateQueue.js 149 | 150 | ```javascript 151 | /** 152 | * 负责刷新 watcher 队列的函数,由 flushCallbacks 函数调用 153 | */ 154 | function flushSchedulerQueue() { 155 | // 表示正在刷新 watcher 队列 156 | flushing = true 157 | // 给 watcher 队列排序,根据 uid 由小到大排序 158 | queue.sort((a, b) => a.uid - b.uid) 159 | // 遍历队列,依次执行其中每个 watcher 的 run 方法 160 | while (queue.length) { 161 | // 取出队首的 watcher 162 | const watcher = queue.shift() 163 | // 执行 run 方法 164 | watcher.run() 165 | } 166 | // 到这里 watcher 队列刷新完毕 167 | flushing = waiting = false 168 | } 169 | 170 | ``` 171 | 172 | #### nextTick 173 | 174 | > /src/asyncUpdateQueue.js 175 | 176 | ```javascript 177 | /** 178 | * 将刷新 watcher 队列的函数或者用户调用 Vue.nextTick 方法传递的回调函数放入 callbacks 数组 179 | * 如果当前的浏览器任务队列中没有刷新 callbacks 的函数,则将 flushCallbacks 函数放入任务队列 180 | */ 181 | function nextTick(cb) { 182 | callbacks.push(cb) 183 | if (!pending) { // 表明浏览器当前任务队列中没有刷新 callbacks 数组的函数 184 | // 将 flushCallbacks 函数放入浏览器的微任务队列 185 | Promise.resolve().then(flushCallbacks) 186 | // 标识浏览器的微任务队列中已经存在 刷新 callbacks 数组的函数了 187 | pending = true 188 | } 189 | } 190 | 191 | ``` 192 | 193 | #### flushCallbacks 194 | 195 | > /src/asyncUpdateQueue.js 196 | 197 | ```javascript 198 | /** 199 | * 负责刷新 callbacks 数组的函数,执行 callbacks 数组中的所有函数 200 | */ 201 | function flushCallbacks() { 202 | // 表示浏览器任务队列中的 flushCallbacks 函数已经被拿到执行栈执行了 203 | // 新的 flushCallbacks 函数可以进入浏览器的任务队列了 204 | pending = false 205 | while(callbacks.length) { 206 | // 拿出最头上的回调函数 207 | const cb = callbacks.shift() 208 | // 执行回调函数 209 | cb() 210 | } 211 | } 212 | 213 | ``` 214 | 215 | ## 总结 216 | 217 | 到这里 `精通 Vue 系列` 就要结束了,现在我们再回头看下整个系列:从 `Vue 源码解读` 开始到现在的 `手写 Vue`,总共 20 篇文章。如果你是从头到尾跟下来的,相信我们最初定的目标早已实现,这会儿你是否可以在自己的简历上写上:精通 Vue 源码原理。 218 | 219 | ## 链接 220 | 221 | * [配套视频,微信公众号回复](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg):"精通 Vue 技术栈源码原理视频版" 获取 222 | * [精通 Vue 技术栈源码原理 专栏](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzA3NTk4NjQ1OQ==&action=getalbum&album_id=2273541436891693065#wechat_redirect) 223 | * [github 仓库 liyongning/Vue](https://github.com/liyongning/Vue) 欢迎 Star 224 | * [github 仓库 liyongning/Lyn-Vue-DOM](https://github.com/liyongning/Lyn-Vue-DOM) 欢迎 Star 225 | * [github 仓库 liyongning/Lyn-Vue-Template](https://github.com/liyongning/Lyn-Vue-Template) 欢迎 Star 226 | 227 | 228 | 229 | 感谢各位的:**关注**、**点赞**、**收藏**和**评论**,我们下期见。 230 | 231 | *** 232 | 233 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、 **点赞**、**收藏**和**评论**。 234 | 235 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 236 | 237 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 -------------------------------------------------------------------------------- /精通 Vue 技术栈的源码原理/Vue 源码解读(1)—— 前言.md: -------------------------------------------------------------------------------- 1 | # Vue 源码解读(1)—— 前言 2 | 3 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **点赞**、**收藏**和**评论**。 4 | 5 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 6 | 7 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 8 | 9 | ## 封面 10 | 11 |  12 | 13 | ## 简介 14 | 15 | 专栏的第一篇,主要介绍专栏的目的、规划、适用人群,以及准备工作和扫盲的基础知识。 16 | 17 | ## 前言 18 | 19 | 最近在准备一些 Vue 系列的文章和视频,之前 Vue 的源码也读过好几遍,但是一直没写相关的文章,所以最近就计划写一写。 20 | 21 | ## 目标 22 | 23 | 精通 Vue 技术栈的源码原理,这是这系列的文章最终目的。 24 | 25 | 首先会从 Vue 源码解读开,会产出一系列的文章和视频,从详细刨析源码,再到 `手写 Vue 1.0` 和 `Vue 2.0`。之后会产出周边生态相关库的源码分析和手写系列,比如:vuex、vue-router、vue-cli 等。 26 | 27 | 相信经过这一系列的认真学习,大家都可以在自己的简历上写上这么一条:**精通 Vue 技术栈的源码原理**。 28 | 29 | ## 适合人群 30 | 31 | * 熟练使用 Vue 技术栈进行日常开发(增删改查) 32 | 33 | * 想深入了解框架实现原理 34 | 35 | * 想跳槽 或 跟老板提涨薪的同学(增删改查不值钱) 36 | 37 | ## 如何学习 38 | 39 | 对于系列文章,顺序学习自然最好,但如果你本身对源码有一些了解或者对某一部分特别感兴趣,也可以直接看相应对应的文章。 40 | 41 | 很多人习惯利用碎片化时间去学习,对于快餐类的文章当然没有问题,但是如果你想深入学习,还是建议坐在电脑前用整块的时间对照着文章亲自动手去学。 42 | 43 | **记住**:光看不练假把式,所以在学习过程中一定要勤动手,不动笔墨不读书,像笔记、思维导图、示例代码、为源码编写注释、debug 调试等,该上就上,绝对不能偷懒。 44 | 45 | 如果你觉得该系列文章对你有帮助,欢迎大家 **点赞**、**关注**,也欢迎将它分享给你身边的小伙伴。 46 | 47 | ## 准备 48 | 49 | 现在最新的 Vue 2 的版本号是 `2.6.12`,所以我就以当前版本的代码进行分析和学习。 50 | 51 | ### 下载 Vue 源码 52 | 53 | * git 命令 54 | 55 | ```shell 56 | git clone https://github.com/vuejs/vue.git 57 | ``` 58 | 59 | * 去 [github](https://github.com/vuejs/vue/tree/dev) 手动下载然后解压 60 | 61 | ### 装包 62 | 63 | 执行 `npm i` 安装依赖,待装到端到端测试工具时可直接 `ctrl + c` 掉,不影响后续源码的研读。 64 | 65 |  66 | 67 | ### source map 68 | 69 | 在 package.json -> scripts 中的 dev 命令中添加 `--sourcemap`,这样就可以在浏览器中调试源码时查看当前代码在源码中的位置。 70 | 71 | ```json 72 | { 73 | "scripts": { 74 | "dev": "rollup -w -c scripts/config.js --sourcemap --environment TARGET:web-full-dev" 75 | } 76 | } 77 | ``` 78 | 79 | ### 开发调试 80 | 81 | 执行以下命令,启动开发环境: 82 | 83 | ```shell 84 | npm run dev 85 | ``` 86 | 87 | 看到如下效果,并在 `dist` 目录下生成 `vue.js.map` 文件,则表示成功。到这里所有的准备工作均已完成,但是不要将当前命令行 `ctrl + c` 掉,因为你在阅读源码时会需要向源码中添加注释,甚至改动源码,当前命令可以监测源码的改动,如果发现改动会自动进行打包;如果关闭当前命令行,你会发现,随着你注释代码的编写,在浏览器中调试源码时会出现和源码映射的偏差。所以为了更好的调试体验就别关闭它。 88 | 89 |  90 | 91 | ## 扫盲 92 | 93 | 执行 `npm run build` 命令之后会发现在 `dist` 目录下生成一堆特殊命名的 `vue.*.js` 文件,这些特殊的命名分别是什么意思呢? 94 | 95 | ### 构建文件分类 96 | 97 | | | UMD | CommonJS | ES Module | 98 | | ----------------------------- | ------------------ | -------------------------- | ------------------ | 99 | | **Full** | vue.js | vue.common.js | vue.esm.js | 100 | | **Runtime-only** | vue.runtime.js | vue.runtime.common.js | vue.runtime.esm.js | 101 | | **Full (production)** | vue.min.js | vue.common.prod.js | | 102 | | **Runtime-only (production)** | vue.runtime.min.js | vue.runtime.common.prod.js | | 103 | 104 | ### 名词解释 105 | 106 | * **Full**:这是一个全量的包,包含编译器(`compiler`)和运行时(`runtime`)。 107 | 108 | * **Compiler**:编译器,负责将模版字符串(即你编写的类 html 语法的模版代码)编译为 JavaScript 语法的 render 函数。 109 | 110 | * **Runtime**:负责创建 Vue 实例、渲染函数、patch 虚拟 DOM 等代码,基本上除了编译器之外的代码都属于运行时代码。 111 | 112 | * **UMD**:兼容 CommonJS 和 AMD 规范,通过 CDN 引入的 vue.js 就是 UMD 规范的代码,包含编译器和运行时。 113 | 114 | * **CommonJS**:典型的应用比如 nodeJS,CommonsJS 规范的包是为了给 browserify 和 webpack 1 这样旧的打包器使用的。他们默认的入口文件为 `vue.runtime.common.js`。 115 | 116 | * **ES Module**:现代 JavaScript 规范,ES Module 规范的包是给像 webpack 2 和 rollup 这样的现代打包器使用的。这些打包器默认使用仅包含运行时的 `vue.runtime.esm.js` 文件。 117 | 118 | ### 运行时(Runtime)+ 编译器(Compiler) vs. 只包含运行时(Runtime-only) 119 | 120 | 如果你需要动态编译模版(比如:将字符串模版传递给 `template` 选项,或者通过提供一个挂载元素的方式编写 html 模版),你将需要编译器,因此需要一个完整的构建包。 121 | 122 | 当你使用 `vue-loader` 或者 `vueify` 时,`*.vue` 文件中的模版在构建时会被编译为 JavaScript 的渲染函数。因此你不需要包含编译器的全量包,只需使用只包含运行时的包即可。 123 | 124 | 只包含运行时的包体积要比全量包的体积小 30%。因此尽量使用只包含运行时的包,如果你需要使用全量包,那么你需要进行如下配置: 125 | 126 | #### webpack 127 | 128 | ```javascript 129 | module.exports = { 130 | // ... 131 | resolve: { 132 | alias: { 133 | 'vue$': 'vue/dist/vue.esm.js' 134 | } 135 | } 136 | } 137 | 138 | ``` 139 | 140 | #### Rollup 141 | 142 | ``` js 143 | const alias = require('rollup-plugin-alias') 144 | 145 | rollup({ 146 | // ... 147 | plugins: [ 148 | alias({ 149 | 'vue': 'vue/dist/vue.esm.js' 150 | }) 151 | ] 152 | }) 153 | ``` 154 | 155 | #### Browserify 156 | 157 | Add to your project's `package.json`: 158 | 159 | ``` js 160 | { 161 | // ... 162 | "browser": { 163 | "vue": "vue/dist/vue.common.js" 164 | } 165 | } 166 | ``` 167 | 168 | ## 源码目录结构 169 | 170 | 通过目录结构的阅读,对源码有一个大致的了解,知道哪些东西需要去哪看。 171 | 172 | ``` 173 | ├── benchmarks 性能、基准测试 174 | ├── dist 构建打包的输出目录 175 | ├── examples 案例目录 176 | ├── flow flow 语法的类型声明 177 | ├── packages 一些额外的包,比如:负责服务端渲染的包 vue-server-renderer、配合 vue-loader 使用的的 vue-template-compiler,还有 weex 相关的 178 | │ ├── vue-server-renderer 179 | │ ├── vue-template-compiler 180 | │ ├── weex-template-compiler 181 | │ └── weex-vue-framework 182 | ├── scripts 所有的配置文件的存放位置,比如 rollup 的配置文件 183 | ├── src vue 源码目录 184 | │ ├── compiler 编译器 185 | │ ├── core 运行时的核心包 186 | │ │ ├── components 全局组件,比如 keep-alive 187 | │ │ ├── config.js 一些默认配置项 188 | │ │ ├── global-api 全局 API,比如熟悉的:Vue.use()、Vue.component() 等 189 | │ │ ├── instance Vue 实例相关的,比如 Vue 构造函数就在这个目录下 190 | │ │ ├── observer 响应式原理 191 | │ │ ├── util 工具方法 192 | │ │ └── vdom 虚拟 DOM 相关,比如熟悉的 patch 算法就在这儿 193 | │ ├── platforms 平台相关的编译器代码 194 | │ │ ├── web 195 | │ │ └── weex 196 | │ ├── server 服务端渲染相关 197 | ├── test 测试目录 198 | ├── types TS 类型声明 199 | ``` 200 | 201 | ## 链接 202 | 203 | * [配套视频,关注微信公众号回复](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg):"精通 Vue 技术栈源码原理视频版" 获取 204 | * [精通 Vue 技术栈源码原理 专栏](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzA3NTk4NjQ1OQ==&action=getalbum&album_id=2273541436891693065#wechat_redirect) 205 | * [github 仓库 liyongning/Vue](https://github.com/liyongning/Vue) 欢迎 Star 206 | 207 | 208 | 209 | 感谢各位的:**点赞**、**收藏**和**评论**,我们下期见。 210 | 211 | *** 212 | 213 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **点赞**、**收藏**和**评论**。 214 | 215 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 216 | 217 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 -------------------------------------------------------------------------------- /精通 Vue 技术栈的源码原理/手写 Vue2 系列 之 patch —— diff.md: -------------------------------------------------------------------------------- 1 | # 手写 Vue2 系列 之 patch —— diff 2 | 3 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 4 | 5 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 6 | 7 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 8 | 9 | ## 封面 10 | 11 |  12 | 13 | ## 前言 14 | 15 | 上一篇文章 [手写 Vue2 系列 之 初始渲染](https://mp.weixin.qq.com/s?__biz=MzA3NTk4NjQ1OQ==&mid=2247485327&idx=1&sn=62d8c7e821a22c8591aa347e84ea8630&chksm=9f6964fba81eeded7cdc07a547a2643e3844c1010e43f82380094a3c2f3df0acf7d680f664e8#rd) 中完成了原始标签、自定义组件、插槽的的初始渲染,当然其中也涉及到 v-bind、v-model、v-on 指令的原理。完成首次渲染之后,接下来就该进行后续的更新了: 16 | 17 | 响应式数据发生更新 -> setter 拦截到更新操作 -> dep 通知 watcher 执行 update 方法 -> 进而执行 updateComponent 方法更新组件 -> 执行 render 生成新的 vnode -> 将 vnode 传递给 vm._update 方法 -> 调用 patch 方法 -> 执行 patchVnode 进行 DOM diff 操作 -> 完成更新 18 | 19 | ## 目标 20 | 21 | 所以,本篇的目标就是实现 DOM diff,完成后续更新。涉及知识点只有一个:DOM diff。 22 | 23 | ## 实现 24 | 25 | 接下来就开始实现 DOM diff,完成响应式数据的后续更新。 26 | 27 | ### patch 28 | 29 | > /src/compiler/patch.js 30 | 31 | ```javascript 32 | /** 33 | * 负责组件的首次渲染和后续更新 34 | * @param {VNode} oldVnode 老的 VNode 35 | * @param {VNode} vnode 新的 VNode 36 | */ 37 | export default function patch(oldVnode, vnode) { 38 | if (oldVnode && !vnode) { 39 | // 老节点存在,新节点不存在,则销毁组件 40 | return 41 | } 42 | 43 | if (!oldVnode) { // oldVnode 不存在,说明是子组件首次渲染 44 | } else { 45 | if (oldVnode.nodeType) { // 真实节点,则表示首次渲染根组件 46 | } else { 47 | // 后续的更新 48 | patchVnode(oldVnode, vnode) 49 | } 50 | } 51 | } 52 | 53 | ``` 54 | 55 | ### patchVnode 56 | 57 | > /src/compiler/patch.js 58 | 59 | ```javascript 60 | /** 61 | * 对比新老节点,找出其中的不同,然后更新老节点 62 | * @param {*} oldVnode 老节点的 vnode 63 | * @param {*} vnode 新节点的 vnode 64 | */ 65 | function patchVnode(oldVnode, vnode) { 66 | // 如果新老节点相同,则直接结束 67 | if (oldVnode === vnode) return 68 | 69 | // 将老 vnode 上的真实节点同步到新的 vnode 上,否则,后续更新的时候会出现 vnode.elm 为空的现象 70 | vnode.elm = oldVnode.elm 71 | 72 | // 走到这里说明新老节点不一样,则获取它们的孩子节点,比较孩子节点 73 | const ch = vnode.children 74 | const oldCh = oldVnode.children 75 | 76 | if (!vnode.text) { // 新节点不存在文本节点 77 | if (ch && oldCh) { // 说明新老节点都有孩子 78 | // diff 79 | updateChildren(ch, oldCh) 80 | } else if (ch) { // 老节点没孩子,新节点有孩子 81 | // 增加孩子节点 82 | } else { // 新节点没孩子,老节点有孩子 83 | // 删除这些孩子节点 84 | } 85 | } else { // 新节点存在文本节点 86 | if (vnode.text.expression) { // 说明存在表达式 87 | // 获取表达式的新值 88 | const value = JSON.stringify(vnode.context[vnode.text.expression]) 89 | // 旧值 90 | try { 91 | const oldValue = oldVnode.elm.textContent 92 | if (value !== oldValue) { // 新老值不一样,则更新 93 | oldVnode.elm.textContent = value 94 | } 95 | } catch { 96 | // 防止更新时遇到插槽,导致报错 97 | // 目前不处理插槽数据的响应式更新 98 | } 99 | } 100 | } 101 | } 102 | 103 | ``` 104 | 105 | ### updateChildren 106 | 107 | > /src/compiler/patch.js 108 | 109 | ```javascript 110 | /** 111 | * diff,比对孩子节点,找出不同点,然后将不同点更新到老节点上 112 | * @param {*} ch 新 vnode 的所有孩子节点 113 | * @param {*} oldCh 老 vnode 的所有孩子节点 114 | */ 115 | function updateChildren(ch, oldCh) { 116 | // 四个游标 117 | // 新孩子节点的开始索引,叫 新开始 118 | let newStartIdx = 0 119 | // 新结束 120 | let newEndIdx = ch.length - 1 121 | // 老开始 122 | let oldStartIdx = 0 123 | // 老结束 124 | let oldEndIdx = oldCh.length - 1 125 | // 循环遍历新老节点,找出节点中不一样的地方,然后更新 126 | while (newStartIdx <= newEndIdx && oldStartIdx <= oldEndIdx) { // 根为 web 中的 DOM 操作特点,做了四种假设,降低时间复杂度 127 | // 新开始节点 128 | const newStartNode = ch[newStartIdx] 129 | // 新结束节点 130 | const newEndNode = ch[newEndIdx] 131 | // 老开始节点 132 | const oldStartNode = oldCh[oldStartIdx] 133 | // 老结束节点 134 | const oldEndNode = oldCh[oldEndIdx] 135 | if (sameVNode(newStartNode, oldStartNode)) { // 假设新开始和老开始是同一个节点 136 | // 对比这两个节点,找出不同然后更新 137 | patchVnode(oldStartNode, newStartNode) 138 | // 移动游标 139 | oldStartIdx++ 140 | newStartIdx++ 141 | } else if (sameVNode(newStartNode, oldEndNode)) { // 假设新开始和老结束是同一个节点 142 | patchVnode(oldEndNode, newStartNode) 143 | // 将老结束移动到新开始的位置 144 | oldEndNode.elm.parentNode.insertBefore(oldEndNode.elm, oldCh[newStartIdx].elm) 145 | // 移动游标 146 | newStartIdx++ 147 | oldEndIdx-- 148 | } else if (sameVNode(newEndNode, oldStartNode)) { // 假设新结束和老开始是同一个节点 149 | patchVnode(oldStartNode, newEndNode) 150 | // 将老开始移动到新结束的位置 151 | oldStartNode.elm.parentNode.insertBefore(oldStartNode.elm, oldCh[newEndIdx].elm.nextSibling) 152 | // 移动游标 153 | newEndIdx-- 154 | oldStartIdx++ 155 | } else if (sameVNode(newEndNode, oldEndNode)) { // 假设新结束和老结束是同一个节点 156 | patchVnode(oldEndNode, newEndNode) 157 | // 移动游标 158 | newEndIdx-- 159 | oldEndIdx-- 160 | } else { 161 | // 上面几种假设都没命中,则老老实的遍历,找到那个相同元素 162 | } 163 | } 164 | // 跳出循环,说明有一个节点首先遍历结束了 165 | if (newStartIdx < newEndIdx) { // 说明老节点先遍历结束,则将剩余的新节点添加到 DOM 中 166 | 167 | } 168 | if (oldStartIdx < oldEndIdx) { // 说明新节点先遍历结束,则将剩余的这些老节点从 DOM 中删掉 169 | 170 | } 171 | } 172 | 173 | ``` 174 | 175 | ### sameVNode 176 | 177 | > /src/compiler/patch.js 178 | 179 | ```javascript 180 | /** 181 | * 判断两个节点是否相同 182 | * 这里的判读比较简单,只做了 key 和 标签的比较 183 | */ 184 | function sameVNode(n1, n2) { 185 | return n1.key == n2.key && n1.tag === n2.tag 186 | } 187 | 188 | ``` 189 | 190 | ## 结果 191 | 192 | 好了,到这里,虚拟 DOM 的 diff 过程就完成了,如果你能看到如下效果图,则说明一切正常。 193 | 194 | 动图地址:https://gitee.com/liyongning/typora-image-bed/raw/master/202203151929235.image 195 | 196 |  197 | 198 | 可以看到,页面已经完全做到响应式数据的初始渲染和后续更新。其中关于 Computed 计算属性的内容仍然没有正确的显示出来,这很正常,因为还没实现这个功能,所以接下来就会去实现 conputed 计算属性,也就是下一篇内容 **手写 Vue2 系列 之 computed**。 199 | 200 | ## 链接 201 | 202 | * [配套视频,微信公众号回复](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg):"精通 Vue 技术栈源码原理视频版" 获取 203 | * [精通 Vue 技术栈源码原理 专栏](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzA3NTk4NjQ1OQ==&action=getalbum&album_id=2273541436891693065#wechat_redirect) 204 | * [github 仓库 liyongning/Vue](https://github.com/liyongning/Vue) 欢迎 Star 205 | * [github 仓库 liyongning/Lyn-Vue-DOM](https://github.com/liyongning/Lyn-Vue-DOM) 欢迎 Star 206 | * [github 仓库 liyongning/Lyn-Vue-Template](https://github.com/liyongning/Lyn-Vue-Template) 欢迎 Star 207 | 208 | 209 | 210 | 感谢各位的:**关注**、**点赞**、**收藏**和**评论**,我们下期见。 211 | 212 | *** 213 | 214 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、 **点赞**、**收藏**和**评论**。 215 | 216 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 217 | 218 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 -------------------------------------------------------------------------------- /精通 Vue 技术栈的源码原理/手写 Vue2 系列 之 computed.md: -------------------------------------------------------------------------------- 1 | # 手写 Vue2 系列 之 computed 2 | 3 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 4 | 5 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 6 | 7 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 8 | 9 | ## 封面 10 | 11 |  12 | 13 | ## 前言 14 | 15 | 上一篇文章 [手写 Vue2 系列 之 patch —— diff](https://mp.weixin.qq.com/s?__biz=MzA3NTk4NjQ1OQ==&mid=2247485338&idx=1&sn=c063df25b963f5db797e2a34402ec7ac&chksm=9f6964eea81eedf85e39ba0e32e579c2b4613fb63cabbb141e1d06b0155dd63fd363c08c3b43#rd) 实现了 DOM diff 过程,完成页面响应式数据的更新。 16 | 17 | ## 目标 18 | 19 | 本篇的目标是实现 computed 计算属性,完成模版中计算属性的展示。涉及的知识点: 20 | 21 | * 计算属性的本质 22 | 23 | * 计算属性的缓存原理 24 | 25 | ## 实现 26 | 27 | 接下来就开始实现 computed 计算属性,。 28 | 29 | ### _init 30 | 31 | > /src/index.js 32 | 33 | ```javascript 34 | /** 35 | * 初始化配置对象 36 | * @param {*} options 37 | */ 38 | Vue.prototype._init = function (options) { 39 | // ... 40 | // 初始化 options.data 41 | // 代理 data 对象上的各个属性到 Vue 实例 42 | // 给 data 对象上的各个属性设置响应式能力 43 | initData(this) 44 | // 初始化 computed 选项,并将计算属性代理到 Vue 实例上 45 | // 结合 watcher 实现缓存 46 | initComputed(this) 47 | // 安装运行时的渲染工具函数 48 | renderHelper(this) 49 | // ... 50 | } 51 | 52 | ``` 53 | 54 | ### initComputed 55 | 56 | > /src/initComputed.js 57 | 58 | ```javascript 59 | /** 60 | * 初始化 computed 配置项 61 | * 为每一项实例化一个 Watcher,并将其 computed 属性代理到 Vue 实例上 62 | * 结合 watcher.dirty 和 watcher.evalute 实现 computed 缓存 63 | * @param {*} vm Vue 实例 64 | */ 65 | export default function initComputed(vm) { 66 | // 获取 computed 配置项 67 | const computed = vm.$options.computed 68 | // 记录 watcher 69 | const watcher = vm._watcher = Object.create(null) 70 | // 遍历 computed 对象 71 | for (let key in computed) { 72 | // 实例化 Watcher,回调函数默认懒执行 73 | watcher[key] = new Watcher(computed[key], { lazy: true }, vm) 74 | // 将 computed 的属性 key 代理到 Vue 实例上 75 | defineComputed(vm, key) 76 | } 77 | } 78 | 79 | ``` 80 | 81 | ### defineComputed 82 | 83 | > /src/initComputed.js 84 | 85 | ```javascript 86 | /** 87 | * 将计算属性代理到 Vue 实例上 88 | * @param {*} vm Vue 实例 89 | * @param {*} key computed 的计算属性 90 | */ 91 | function defineComputed(vm, key) { 92 | // 属性描述符 93 | const descriptor = { 94 | get: function () { 95 | const watcher = vm._watcher[key] 96 | if (watcher.dirty) { // 说明当前 computed 回调函数在本次渲染周期内没有被执行过 97 | // 执行 evalute,通知 watcher 执行 computed 回调函数,得到回调函数返回值 98 | watcher.evalute() 99 | } 100 | return watcher.value 101 | }, 102 | set: function () { 103 | console.log('no setter') 104 | } 105 | } 106 | // 将计算属性代理到 Vue 实例上 107 | Object.defineProperty(vm, key, descriptor) 108 | } 109 | 110 | ``` 111 | 112 | ### Watcher 113 | 114 | > /src/watcher.js 115 | 116 | ```javascript 117 | /** 118 | * @param {*} cb 回调函数,负责更新 DOM 的回调函数 119 | * @param {*} options watcher 的配置项 120 | */ 121 | export default function Watcher(cb, options = {}, vm = null) { 122 | // 备份 cb 函数 123 | this._cb = cb 124 | // 回调函数执行后的值 125 | this.value = null 126 | // computed 计算属性实现缓存的原理,标记当前回调函数在本次渲染周期内是否已经被执行过 127 | this.dirty = !!options.lazy 128 | // Vue 实例 129 | this.vm = vm 130 | // 非懒执行时,直接执行 cb 函数,cb 函数中会发生 vm.xx 的属性读取,从而进行依赖收集 131 | !options.lazy && this.get() 132 | } 133 | 134 | ``` 135 | 136 | #### watcher.get 137 | 138 | > /src/watcher.js 139 | 140 | ```javascript 141 | /** 142 | * 负责执行 Watcher 的 cb 函数 143 | * 执行时进行依赖收集 144 | */ 145 | Watcher.prototype.get = function () { 146 | pushTarget(this) 147 | this.value = this._cb.apply(this.vm) 148 | popTarget() 149 | } 150 | 151 | ``` 152 | 153 | #### watcher.update 154 | 155 | > /src/watcher.js 156 | 157 | ```javascript 158 | /** 159 | * 响应式数据更新时,dep 通知 watcher 执行 update 方法, 160 | * 让 update 方法执行 this._cb 函数更新 DOM 161 | */ 162 | Watcher.prototype.update = function () { 163 | // 通过 Promise,将 this._cb 的执行放到 this.dirty = true 的后面 164 | // 否则,在点击按钮时,computed 属性的第一次计算会无法执行, 165 | // 因为 this._cb 执行的时候,会更新组件,获取计算属性的值的时候 this.dirty 依然是 166 | // 上一次的 false,导致无法得到最新的的计算属性的值 167 | // 不过这个在有了异步更新队列之后就不需要了,当然,毕竟异步更新对象的本质也是 Promise 168 | Promise.resolve().then(() => { 169 | this._cb() 170 | }) 171 | // 执行完 _cb 函数,DOM 更新完毕,进入下一个渲染周期,所以将 dirty 置为 false 172 | // 当再次获取 计算属性 时就可以重新执行 evalute 方法获取最新的值了 173 | this.dirty = true 174 | } 175 | 176 | ``` 177 | 178 | #### watcher.evalute 179 | 180 | > /src/watcher.js 181 | 182 | ```javascript 183 | Watcher.prototype.evalute = function () { 184 | // 执行 get,触发计算函数 (cb) 的执行 185 | this.get() 186 | // 将 dirty 置为 false,实现一次刷新周期内 computed 实现缓存 187 | this.dirty = false 188 | } 189 | 190 | ``` 191 | 192 | ### pushTarget 193 | 194 | > /src/dep.js 195 | 196 | ```javascript 197 | // 存储所有的 Dep.target 198 | // 为什么会有多个 Dep.target? 199 | // 组件会产生一个渲染 Watcher,在渲染的过程中如果处理到用户 Watcher, 200 | // 比如 computed 计算属性,这时候会执行 evalute -> get 201 | // 假如直接赋值 Dep.target,那 Dep.target 的上一个值 —— 渲染 Watcher 就会丢失 202 | // 造成在 computed 计算属性之后渲染的响应式数据无法完成依赖收集 203 | const targetStack = [] 204 | 205 | /** 206 | * 备份本次传递进来的 Watcher,并将其赋值给 Dep.target 207 | * @param {*} target Watcher 实例 208 | */ 209 | export function pushTarget(target) { 210 | // 备份传递进来的 Watcher 211 | targetStack.push(target) 212 | Dep.target = target 213 | } 214 | 215 | ``` 216 | 217 | ### popTarget 218 | 219 | > /src/dep.js 220 | 221 | ```javascript 222 | /** 223 | * 将 Dep.target 重置为上一个 Watcher 或者 null 224 | */ 225 | export function popTarget() { 226 | targetStack.pop() 227 | Dep.target = targetStack[targetStack.length - 1] 228 | } 229 | 230 | ``` 231 | 232 | ## 结果 233 | 234 | 好了,到这里,Vue computed 属性实现就完成了,如果你能看到如下效果图,则说明一切正常。 235 | 236 | 动图地址:https://gitee.com/liyongning/typora-image-bed/raw/master/202203161832189.image 237 | 238 |  239 | 240 | 可以看到,页面中的计算属性已经正常显示,而且也可以做到响应式更新,且具有缓存的能力(通过控制台查看 computed 输出)。 241 | 242 | 到这里,手写 Vue 系列就剩最后一部分内容了 —— **手写 Vue 系列 之 异步更新队列**。 243 | 244 | ## 链接 245 | 246 | * [配套视频,微信公众号回复](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg):"精通 Vue 技术栈源码原理视频版" 获取 247 | * [精通 Vue 技术栈源码原理 专栏](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzA3NTk4NjQ1OQ==&action=getalbum&album_id=2273541436891693065#wechat_redirect) 248 | * [github 仓库 liyongning/Vue](https://github.com/liyongning/Vue) 欢迎 Star 249 | * [github 仓库 liyongning/Lyn-Vue-DOM](https://github.com/liyongning/Lyn-Vue-DOM) 欢迎 Star 250 | * [github 仓库 liyongning/Lyn-Vue-Template](https://github.com/liyongning/Lyn-Vue-Template) 欢迎 Star 251 | 252 | 253 | 254 | 感谢各位的:**关注**、**点赞**、**收藏**和**评论**,我们下期见。 255 | 256 | *** 257 | 258 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、 **点赞**、**收藏**和**评论**。 259 | 260 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 261 | 262 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 -------------------------------------------------------------------------------- /精通 Vue 技术栈的源码原理/Vue 源码解读(7)—— Hook Event.md: -------------------------------------------------------------------------------- 1 | # Vue 源码解读(7)—— Hook Event 2 | 3 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 4 | 5 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 6 | 7 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 8 | 9 | ## 封面 10 | 11 |  12 | 13 | ## 前言 14 | 15 | `Hook Event`(钩子事件)相信很多 Vue 开发者都没有使用过,甚至没听过,毕竟 Vue 官方文档中也没有提及。 16 | 17 | Vue 提供了一些生命周期钩子函数,供开发者在特定的逻辑点添加额外的处理逻辑,比如:在组件挂载阶段提供了 `beforeMount` 和 `mounted` 两个生命周期钩子,供开发者在组件挂载阶段执行额外的逻辑处理,比如为组件准备渲染所需的数据。 18 | 19 | 那这个 Hook Event —— 钩子事件,其中也有钩子的意思,和 Vue 的生命周期钩子函数有什么关系呢?它又有什么用呢?这就是这边文章要解答的问题。 20 | 21 | ## 目标 22 | 23 | * 理解什么是 Hook Event ?明白其使用场景 24 | 25 | * 深入理解 Hook Event 的实现原理 26 | 27 | ## 什么是 Hook Event ? 28 | 29 | Hook Event 是 Vue 的自定义事件结合生命周期钩子实现的一种从组件外部为组件注入额外生命周期方法的功能。 30 | 31 | ### 使用场景 32 | 33 | 假设现在有这么一个第三方的业务组件,逻辑很简单,就在 mounted 生命周期中调用接口获取数据,然后将数据渲染到页面上。 34 | 35 | ```html 36 | 37 |
38 |
44 |
45 |
46 |
60 |
61 | ```
62 |
63 | 然后在使用的发现这个组件有些瑕疵,比如最简单的,接口等待时间可能比较长,我想在 mounted 生命周期开始执行的时候在控制台输出一个 `loading ...` 字符串,增强用户体验。
64 |
65 | 这个需求该怎么实现呢?
66 |
67 | 有两个办法:第一个比较麻烦,修改源码;而第二种方式则简单多了,就是我们今天介绍的 Hook Event,从组件外面为组件注入额外的生命周期方法。
68 |
69 | ```html
70 |
71 | -
39 |
- 40 | {{ item }} 41 | 42 |
72 |
74 |
75 |
76 |
91 |
92 | ```
93 |
94 | 这时候你再刷新页面就会发现业务组件在请求数据的时候,会在控制台输出一个 `loading ...` 字符串。
95 |
96 | ### 作用
97 |
98 | Hook Event 有什么作用?
99 |
100 | 通过 Hook Event 可以从组件外部为组件注入额外的生命周期方法。
101 |
102 | ## 实现原理
103 |
104 | 知道了 Hook Event 的使用场景和作用,接下来就从源码去找它的实现原理,做到 “知其然,亦知其所以然”。
105 |
106 | 前面说过,Hook Event 是 Vue 的自定义事件结合生命周期钩子函数实现的一种功能,所以我们就去看生命周期相关的代码,比如:我们知道,Vue 的生命周期函数是通过一个叫 `callHook` 的方法来执行的
107 |
108 | ### callHook
109 |
110 | > /src/core/instance/lifecycle.js
111 |
112 | ```javascript
113 | /**
114 | * callHook(vm, 'mounted')
115 | * 执行实例指定的生命周期钩子函数
116 | * 如果实例设置有对应的 Hook Event,比如:222 | 223 | * **面试官 问**:Hook Event 是如果实现的? 224 | 225 | **答**: 226 | 227 | ```html 228 |
10 | 11 | # 背景介绍 12 | 13 | 在现代前端开发中,单页应用(SPA)已经成为主流。不同的前端框架(如 React Router、Vue Router)都有自己的路由实现方式。有时候,我们需要监听这些路由的变化来实现一些特定功能,比如页面访问统计、权限控制等。 14 | 15 | # 技术实现 16 | 17 | 这个路由拦截器的核心思想是通过一个统一的方式来监听各种路由变化。它主要覆盖了以下三种场景: 18 | 19 | 1. History API 的路由变化(pushState、replaceState) 20 | 2. 浏览器的前进、后退操作(popstate 事件) 21 | 3. Hash 路由变化(hashchange 事件) 22 | 23 | ## 核心实现 24 | 25 | ### 1. 拦截 History API 26 | 27 | ```typescript 28 | // 保存原始的方法,用于后续恢复 29 | const originalPushState = history.pushState; 30 | const originalReplaceState = history.replaceState; 31 | 32 | // 创建自定义事件 33 | function createCustomEvent(from: string, to: string): CustomEvent
256 | 257 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 258 | 259 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 260 | 261 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 262 | 263 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)** -------------------------------------------------------------------------------- /精通 uni-app/ucharts 图表 H5 打包后无法渲染.md: -------------------------------------------------------------------------------- 1 | # uni-app、Vue3 + ucharts 图表 H5 无法渲染 2 | 3 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 4 | 5 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 6 | 7 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 8 | 9 | ## 封面 10 | 11 |  12 | 13 | ## 简介 14 | 15 | 从问题定位开始,到给框架(uni-app)提 issue、出解决方案(PR),再到最后的思考,详细记录了整个过程。 16 | 17 | ## 前序 18 | 19 | 当你在业务中不幸踩了开源框架的某些坑,这是你的不幸,但这同时也是你的幸运,因为这是你给自己简历中增加亮点的绝佳机会。 20 | 21 | 而给开源社区贡献 PR 是你证明自己技术侧拥有 P7 实力的绝佳方式,P7 的评判标准无非是业务和技术,业务上有收益,技术上有深度和广度(别人有的你能做的更好,别人没有的你能有)。 22 | 23 | 这次整个过程历时 3-4 天,在此之前我也没读过 uni-app 和 ucharts 的源码,所以这里把整个过程分享出来也是给大家一个解决问题的思路。 24 | 25 | ## 环境 26 | 27 | - uni-app cli 版本 3.0.0-alpha-3030820220114011 28 | - hbuilder 版本 3.3.8.20220114-alpha 29 | - ucharts 版本 uni-modules 2.3.7-20220122 30 | ## 现象 31 | 32 | uni-app、vue3 + ucharts 绘制图表,开发环境正常,但是打包上线后,H5 无法绘制图表,也不报任何错误。 33 | 34 | | | 开发 | 线上 | 35 | | --- | --- | --- | 36 | | APP | 正常 | 正常 | 37 | | H5 | 正常 | 无法绘制 | 38 | 39 | ## 问题定位 40 | 给 ucharts 的社区提 issue,经过交流,维护者 “怀疑“ 是 uni-app 的 vue3 的 renderjs 有问题,但是他也给不了一个肯定的答复,让去 uni-app 的社区提 issue 而且示例中不能用 ucharts。个人对于该回答持怀疑态度,于是决定自己去定位问题。 41 | ### 怀疑是 ucharts 的 bug 42 | 43 | - ucharts 视图部分的关键代码 44 | ```vue 45 |
240 | 241 | * **面试官**:详细说一下静态标记的过程 242 | 243 | **答**: 244 | 245 | * 标记静态节点 246 | 247 | * 通过递归的方式标记所有的元素节点 248 | 249 | * 如果节点本身是静态节点,但是存在非静态的子节点,则将节点修改为非静态节点 250 | 251 | * 标记静态根节点,基于静态节点,进一步标记静态根节点 252 | 253 | * 如果节点本身是静态节点 && 而且有子节点 && 子节点不全是文本节点,则标记为静态根节点 254 | 255 | * 如果节点本身不是静态根节点,则递归的遍历所有子节点,在子节点中标记静态根 256 | 257 |
258 | 259 | * **面试官**:什么样的节点才可以被标记为静态节点? 260 | 261 | **答**: 262 | 263 | * 文本节点 264 | 265 | * 节点上没有 v-bind、v-for、v-if 等指令 266 | 267 | * 非组件 268 | 269 | ## 链接 270 | 271 | * [配套视频,微信公众号回复](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg):"精通 Vue 技术栈源码原理视频版" 获取 272 | * [精通 Vue 技术栈源码原理 专栏](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzA3NTk4NjQ1OQ==&action=getalbum&album_id=2273541436891693065#wechat_redirect) 273 | * [github 仓库 liyongning/Vue](https://github.com/liyongning/Vue) 欢迎 Star 274 | 275 | 276 | 277 | 感谢各位的:**关注**、**点赞**、**收藏**和**评论**,我们下期见。 278 | 279 | *** 280 | 281 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、 **点赞**、**收藏**和**评论**。 282 | 283 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 284 | 285 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 -------------------------------------------------------------------------------- /PDF 生成/PDF 生成(3)— 封面、尾页.md: -------------------------------------------------------------------------------- 1 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 2 | 3 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 4 | 5 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 6 | 7 | # 封面 8 |  9 | # 回顾 10 | [PDF 生成(2)— 生成 PDF 文件](https://github.com/liyongning/blog/issues/43) 我们以百度新闻页为例为大家展示了 puppeteer 的基本使用: 11 | 12 | - 通过短短的 10行 代码将百度新闻页打印成一份 PDF 文件 13 | - 通过 puppeteer 的 page.evaluate 方法为浏览器注入一段 JS 代码,用代码来模拟页面滚动,以解决懒加载的问题,从而保证 PDF 文件内容的完整性 14 | - 通过自定义页眉、页脚的方式讲解了 puppeteer 中关于页眉、页脚相关选项的基本使用和其中的**坑** 15 | 16 | 文章最后也提到了 **puppeteer 在 PDF 文件生成场景下的能力基本到头了**,但现有内容在我们的技术架构中只是九牛一毛,所以,接下来的内容就全是基于 puppeteer 的增量开发了,也是整套架构的**核心**和**难点**。 17 | # 问题 18 | 一份专业的 PDF 文件都会有自己的**封面**和**尾页**。在本文开始之前,大家先想想,基于现状如何为我们之前生成的 PDF 文件增加封面和尾页呢?比如 19 | 20 |  21 | 22 | 所以,本文的内容就是为我们在上文中生成的 PDF 文件增加封面和尾页。 23 | 24 | # 分析 25 | 不知道大家是否还记得在 [PDF 生成(1)— 开篇](https://github.com/liyongning/blog/issues/42) 中的技术架构图,为什么架构图中的 PDF 生成服务会产出 3份 PDF 文件?带着问题接着往下看。 26 | 27 |  28 | 29 | 假设前文中我们用的**百度新闻页**就是我们自己开发的一个页面,那在页面的开始和结束位置分别加上封面和尾页的 DOM,然后直接生成 PDF 文件,是不是就可以了?想想,这样做最简单了,一个页面搞定所有内容,比如: 30 | 31 |  32 | 但稍微一分析,就发现不行,因为我们我们在 `page.pdf` 方法中设置的 margin 属性和页眉、页脚是针对整个 PDF 文件的,但封面和尾页不需要边距和页眉、页脚。 33 | 34 | **一个页面(URL)对应一份 PDF 文件,这是大方向,是由技术方案本身的特性所决定的**,因此封面和尾页不能和内容页放一起。 35 | 36 | 经过分析,结合架构图的指引,我们的实现思路是**一份完整的 PDF 文件至少应该包括三个页面 —— 封面页、内容页、尾页,每个页面对应一份 PDF 文件,最后将三份 PDF 合并成一份 PDF**,接下来就进入实战。 37 | 38 | # 实战 39 | 前端页面的开发不是重点,所以这里我们就简单写了。 40 | ## 封面页 — /fe/cover.html 41 | ```html 42 | 43 | 44 | 45 | 46 | 47 |
我是封面
61 | 62 | 63 | ``` 64 | ## 尾页 — **/fe/last-page.html** 65 | ```html 66 | 67 | 68 | 69 | 70 | 71 |我是尾页
85 | 86 | 87 | ``` 88 | ## PDF 生成服务 — **/server/index.mjs** 89 | 在 **/server/index.mjs** 中增加如下代码,用来生成封面和尾页的 PDF 文件 90 | 91 | 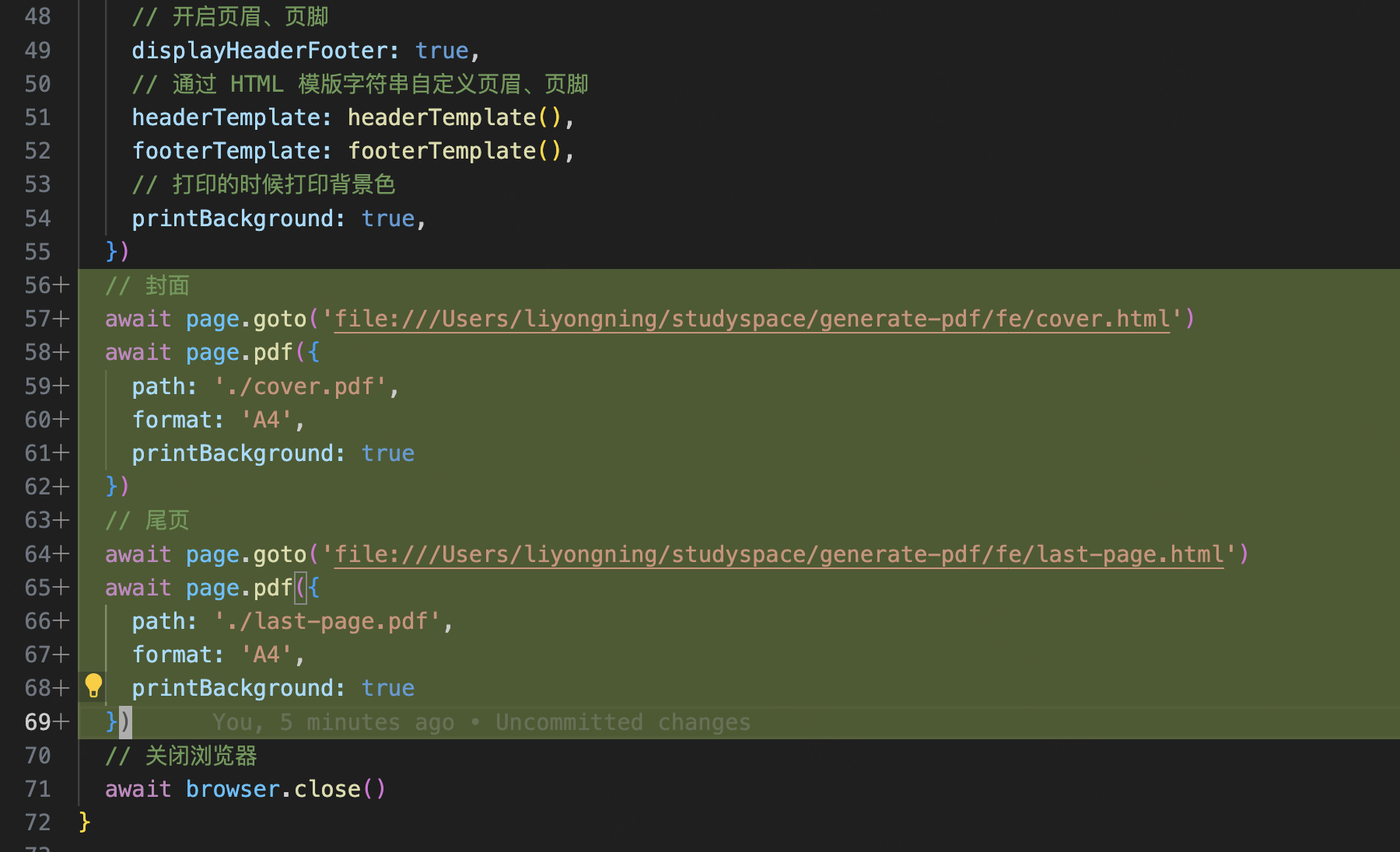 92 | 93 | 截图中对应的代码如下: 94 | 95 | ```javascript 96 | /* 省略之前的代码... */ 97 | // 封面 98 | await page.goto('file:///Users/liyongning/studyspace/generate-pdf/fe/cover.html') 99 | await page.pdf({ 100 | path: './cover.pdf', 101 | format: 'A4', 102 | printBackground: true 103 | }) 104 | // 尾页 105 | await page.goto('file:///Users/liyongning/studyspace/generate-pdf/fe/last-page.html') 106 | await page.pdf({ 107 | path: './last-page.pdf', 108 | format: 'A4', 109 | printBackground: true 110 | }) 111 | /* 省略之后的代码... */ 112 | ``` 113 | 生成的 PDF 效果如下: 114 | 115 |  116 |  117 | 118 | 解析来就是本文的重点了 — **PDF 文件合并**,因为我们最终交付的是一份 PDF 文件,而不是三份。 119 | 120 | ## PDF 文件合并 121 | 我们借助第三方库 `pdf-lib` 来完成 PDF 文件的合并。 122 | 123 | - 首先安装 pdf-lib —— `npm i pdf-lib` 124 | - 新建 `/server/merge-pdf.mjs` 文件来编写文件合并的代码 125 | 126 | 实现如下: 127 | ### /server/index.mjs: 128 |  129 | 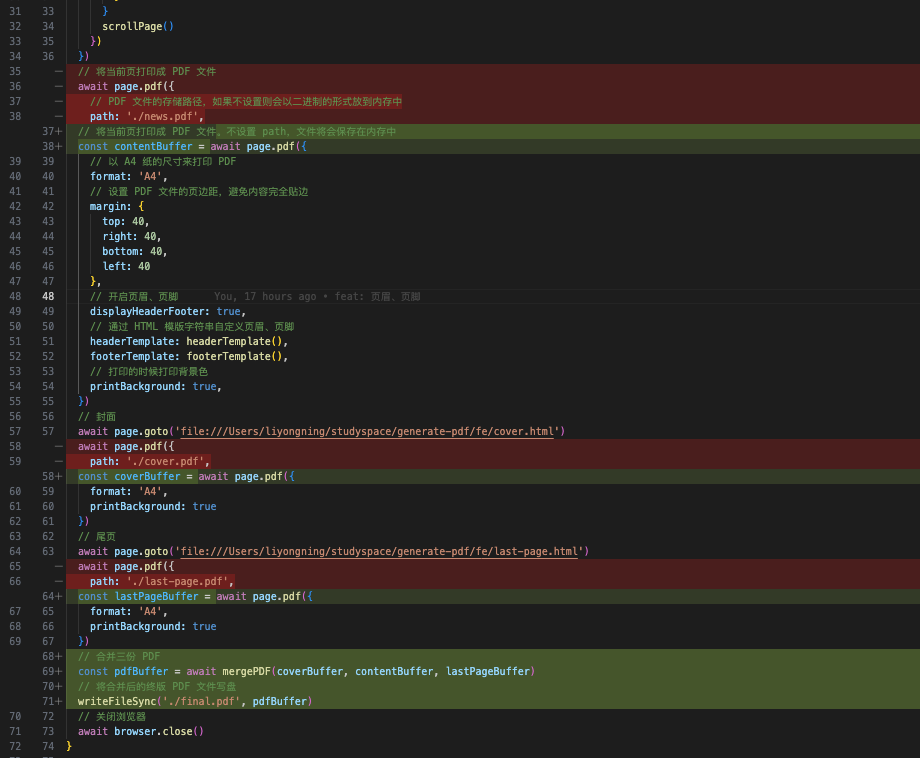 130 | 131 | ### **/server/merge-pdf.mjs:** 132 | 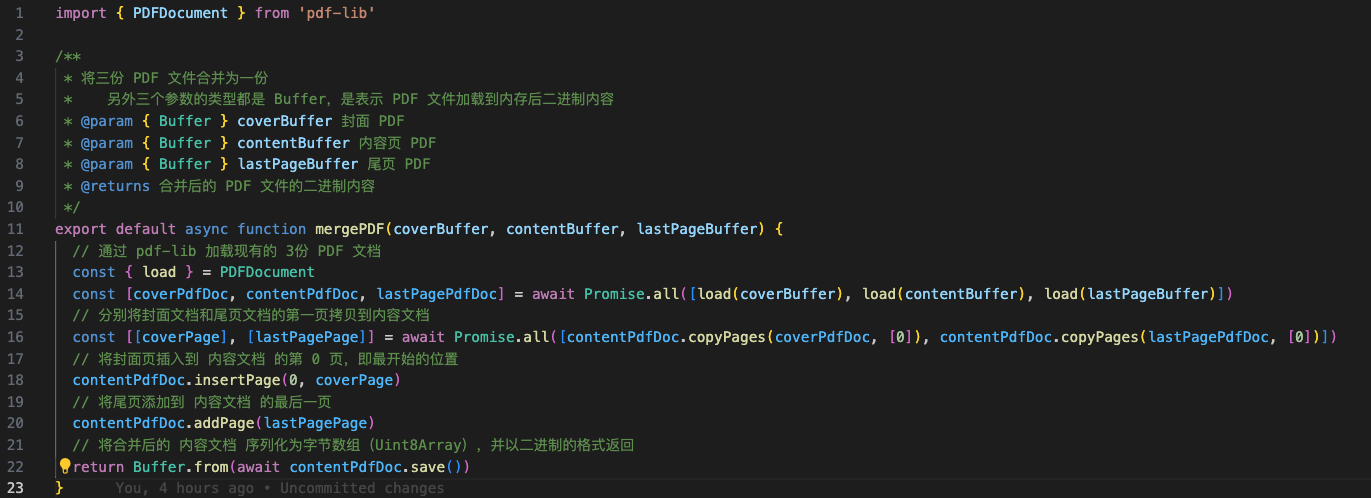 133 | 134 | 这里大家可能会有两个疑问点: 135 | 136 | - 为什么不直接通过 Buffer.concat 合并内容,然后直接写盘,而是要通过 第三方库 先合并再写盘(page.pdf 的返回值是一个 Buffer 类型的数据) 137 | - 为什么不新创建一份 PDF 文件,然后将三个文件合并到一起,或者是将内容页 PDF 的各个页面和尾页 PDF 的页面添加到封面 PDF 中,而是分别将封面 PDF 的页面和尾页 PDF 的页面插到内容 PDF 的对应位置 138 | 139 | 第一个问题的答案是:**数据格式问题**,虽然都是保存在内存中的二进制内容,但是 PDF 文件的二进制内容格式有点特殊,如果直接通过 `Buffer.concat` 将内容拼接,会发现拼接的内容就丢了,所以这里需要借助专门操作 PDF 文件的第三方库。当然了,如果是一个普通的文本文件,通过 `Buffer.concat` 完全没问题,有兴趣的话大家可以自己写个简单的 Demo。 140 | 141 | 至于第二个问题,答案是:不行,简单解释就是 —— 在当前的技术架构下,会导致目录页中目录项的页面跳转能力失效,目录页会用到 HTML 锚点,这些锚点被 pdf-lib 处理之后就失效了。具体内容在后面 [PDF 生成(4)— 目录页](https://github.com/liyongning/blog/issues/45) 详细讲解。 142 | 143 | 最终效果图如下: 144 | 145 | 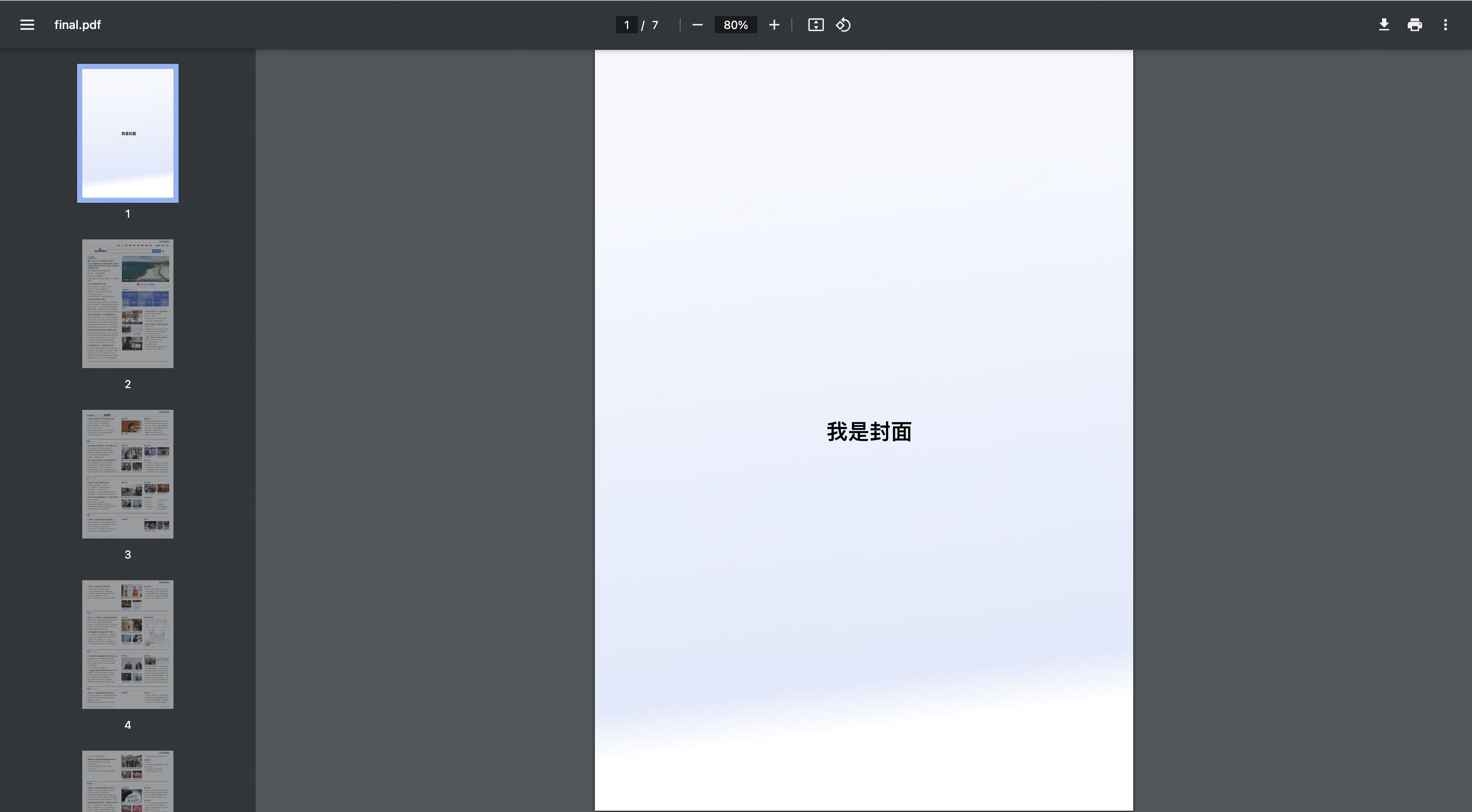 146 | 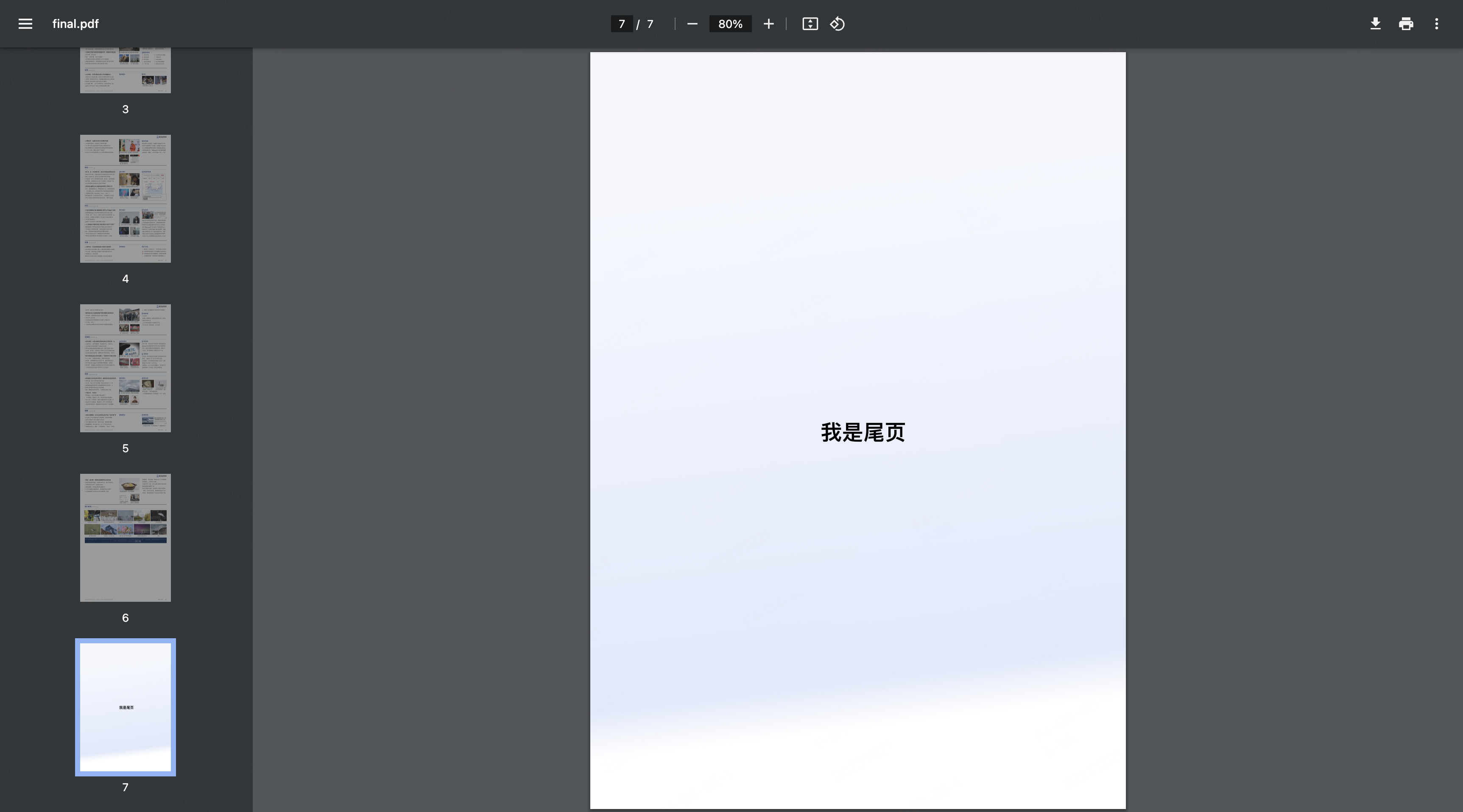 147 | 148 | PDF 文件合并(`/server/merge-pdf.mjs`)的完整代码如下: 149 | 150 | ```javascript 151 | import { PDFDocument } from 'pdf-lib' 152 | 153 | /** 154 | * 将三份 PDF 文件合并为一份 155 | * 另外三个参数的类型都是 Buffer,是表示 PDF 文件加载到内存后二进制内容 156 | * @param { Buffer } coverBuffer 封面 PDF 157 | * @param { Buffer } contentBuffer 内容页 PDF 158 | * @param { Buffer } lastPageBuffer 尾页 PDF 159 | * @returns 合并后的 PDF 文件的二进制内容 160 | */ 161 | export default async function mergePDF(coverBuffer, contentBuffer, lastPageBuffer) { 162 | // 通过 pdf-lib 加载现有的 3份 PDF 文档 163 | const { load } = PDFDocument 164 | const [coverPdfDoc, contentPdfDoc, lastPagePdfDoc] = await Promise.all([load(coverBuffer), load(contentBuffer), load(lastPageBuffer)]) 165 | // 分别将封面文档和尾页文档的第一页拷贝到内容文档 166 | const [[coverPage], [lastPagePage]] = await Promise.all([contentPdfDoc.copyPages(coverPdfDoc, [0]), contentPdfDoc.copyPages(lastPagePdfDoc, [0])]) 167 | // 将封面页插入到 内容文档 的第 0 页,即最开始的位置 168 | contentPdfDoc.insertPage(0, coverPage) 169 | // 将尾页添加到 内容文档 的最后一页 170 | contentPdfDoc.addPage(lastPagePage) 171 | // 将合并后的 内容文档 序列化为字节数组(Uint8Array),并以二进制的格式返回 172 | return Buffer.from(await contentPdfDoc.save()) 173 | } 174 | ``` 175 | # 总结 176 | 本文介绍了如何为通过 Puppeteer 生成的 PDF 文件添加封面和尾页,现在再来整体回顾一下: 177 | 178 | - 首先,技术方案决定了一个页面对应一份 PDF 文件,这是大前提,因为 page.xx 方法的所有配置都是针对当前页的 179 | - 在大前提下,我们通过 PDF 文件合并方案(pdf-lib),分别将封面 PDF、内容页 PDF 和尾页 PDF 三份文件合并为一份报告包含封面、内容页和尾页的完整 PDF 180 | 181 | 到这里,PDF 文件的整体框架已经基本形成(包括封面、内容页、尾页),但还有一点不完整,比如缺少**目录页**,一份完整的文件或文章怎么能没有目录呢?所以,接下来我们就讲 [PDF 生成(4)— 目录页](https://github.com/liyongning/blog/issues/45)。 182 | # 链接 183 | 184 | - [PDF 生成(1)— 开篇](https://github.com/liyongning/blog/issues/42) 中讲解了 PDF 生成的技术背景、方案选型和决策,以及整个方案的技术架构图,所以后面的几篇一直都是在实现整套技术架构 185 | - [PDF 生成(2)— 生成 PDF 文件](https://github.com/liyongning/blog/issues/43) 中我们通过 puppeteer 来生成 PDF 文件,并讲了自定义页眉、页脚的使用和其中的**坑**。本文结束之后 puppeteer 在 PDF 文件生成场景下的能力也基本到头了,所以,接下来的内容就全是基于 puppeteer 的增量开发了,也是整套架构的**核心**和**难点** 186 | - [PDF 生成(3)— 封面、尾页](https://github.com/liyongning/blog/issues/44) 通过 PDF 文件合并技术让一份 PDF 文件包含封面、内容页和尾页三部分。 187 | - [PDF 生成(4)— 目录页](https://github.com/liyongning/blog/issues/45) 通过在内容页的开始位置动态插入 HTML 锚点、页面缩放、锚点元素高度计算、换页高度补偿等技术让 PDF 文件拥有了包含准确页码 + 页面跳转能力的目录页 188 | - [PDF 生成(5)— 内容页支持由多页面组成](https://github.com/liyongning/blog/issues/46) 通过多页面合并技术 + 样式沙箱解决了用户在复杂 PDF 场景下前端代码维护问题,让用户的开发更自由、更符合业务逻辑 189 | - [PDF 生成(6)— 服务化、配置化](https://github.com/liyongning/blog/issues/47) 就是本文了,本系列的最后一篇,以服务化的方式对外提供 PDF 生成能力,通过配置服务来维护接入方的信息,通过队列来做并发控制和任务分类 190 | - [代码仓库](https://github.com/liyongning/generate-pdf) **欢迎 Star** 191 | 192 | --- 193 | 194 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 195 | 196 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 197 | 198 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 199 | -------------------------------------------------------------------------------- /精通 Vue 技术栈的源码原理/手写 Vue 系列 之 从 Vue1 升级到 Vue2.md: -------------------------------------------------------------------------------- 1 | # 手写 Vue 系列 之 从 Vue1 升级到 Vue2 2 | 3 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 4 | 5 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 6 | 7 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 8 | 9 | ## 封面 10 | 11 |  12 | 13 | ## 前言 14 | 15 | 上一篇文章 [手写 Vue 系列 之 Vue1.x](https://mp.weixin.qq.com/s?__biz=MzA3NTk4NjQ1OQ==&mid=2247485261&idx=1&sn=63c8469dc639dac6c7a9395f42045087&chksm=9f696439a81eed2f9327625b09a9b3efaacbca41835ca616833a24c7cdd88a23c71d4f37f5f2#rd) 带大家从零开始实现了 Vue1 的核心原理,包括如下功能: 16 | 17 | * 数据响应式拦截 18 | 19 | * 普通对象 20 | 21 | * 数组 22 | 23 | * 数据响应式更新 24 | 25 | * 依赖收集 26 | 27 | * Dep 28 | 29 | * Watcher 30 | 31 | * 编译器 32 | 33 | * 文本节点 34 | 35 | * v-on:click 36 | 37 | * v-bind 38 | 39 | * v-model 40 | 41 | 42 | 在最后也详细讲解了 Vue1 的诞生以及存在的问题:Vue1.x 在中小型系统中性能会很好,定向更新 DOM 节点,但是大型系统由于 Watcher 太多,导致资源占用过多,性能下降。于是 Vue2 中通过引入 VNode 和 Diff 的来解决这个问题, 43 | 44 | 所以接下来的系列内容就是升级上一篇文章编写的 `lyn-vue` 框架,将它从 Vue1 升级到 Vue2。所以建议整个系列大家按顺序去阅读学习,如若强行阅读,可能会产生云里雾里的感觉,事倍功半。 45 | 46 | 另外欢迎 **关注** 以防迷路,同时系列文章都会收录到 [精通 Vue 技术栈的源码原理](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzA3NTk4NjQ1OQ==&action=getalbum&album_id=2273541436891693065#wechat_redirect) 专栏,也欢迎关注该专栏。 47 | 48 | ## 目标 49 | 50 | 升级后的框架需要将如下示例代码跑起来 51 | 52 | ### 示例 53 | 54 | ```html 55 | 56 | 57 | 58 | 59 | 60 |
65 |
102 |
103 |
106 |
107 |
230 |
231 |
232 |
233 |
234 | ```
235 |
236 | ### 知识点
237 |
238 | 示例代码涉及的知识点包括:
239 |
240 | * 基于模版解析的编译器
241 |
242 | * 解析模版得到 AST
243 |
244 | * 基于 AST 生成渲染函数
245 |
246 | * render helper
247 |
248 | * _c,创建指定标签的 VNode
249 |
250 | * _v,创建文本节点的 VNode
251 |
252 | * _t,创建插槽节点的 VNode
253 |
254 | * VNode
255 |
256 | * patch
257 |
258 | * 原生标签和组件的初始渲染
259 |
260 | * v-model
261 |
262 | * v-bind
263 |
264 | * v-on
265 |
266 | * diff
267 |
268 | * 插槽原理
269 |
270 | * computed
271 |
272 | * 异步更新队列
273 |
274 | ### 效果
275 |
276 | 示例代码最终的运行效果如下:
277 |
278 | 
279 |
280 | ## 说明
281 |
282 | 该框架只为讲解 Vue 的核心原理,没有什么健壮性可言,说不定你换个示例代码可能就会报错、跑不起来,但是用来学习是完全足够了,基本上把 Vue 的核心原理(知识点)都实现了一遍。
283 |
284 | 所以接下来就开始正式的学习之旅吧,加油!!
285 |
286 | ## 链接
287 |
288 | * [配套视频,微信公众号回复](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg):"精通 Vue 技术栈源码原理视频版" 获取
289 | * [精通 Vue 技术栈源码原理 专栏](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzA3NTk4NjQ1OQ==&action=getalbum&album_id=2273541436891693065#wechat_redirect)
290 | * [github 仓库 liyongning/Vue](https://github.com/liyongning/Vue) 欢迎 Star
291 | * [github 仓库 liyongning/Lyn-Vue-DOM](https://github.com/liyongning/Lyn-Vue-DOM) 欢迎 Star
292 | * [github 仓库 liyongning/Lyn-Vue-Template](https://github.com/liyongning/Lyn-Vue-Template) 欢迎 Star
293 |
294 |
295 |
296 | 感谢各位的:**关注**、**点赞**、**收藏**和**评论**,我们下期见。
297 |
298 | ***
299 |
300 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、 **点赞**、**收藏**和**评论**。
301 |
302 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg)
303 |
304 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。
--------------------------------------------------------------------------------
/其它/听说你面试想作弊?浏览器做切屏检测.md:
--------------------------------------------------------------------------------
1 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。
2 |
3 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg)
4 |
5 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。
6 |
7 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)**
8 |
9 | 数据响应式更新 原理
66 |{{ t }}
67 | {{ t1 }}
68 | {{ arr }}
69 | methods + computed + 异步更新队列 原理
70 |
71 |
78 | {{ counter }}
72 |{{ doubleCounter }}
73 | {{ doubleCounter }}
74 | {{ doubleCounter }}
75 |
76 |
77 | v-bind
79 | 右键审查元素查看我的 title 属性 80 |v-model 原理
81 |
82 |
83 |
85 | {{ inputVal }}
84 |
86 |
87 |
89 | {{ isChecked }}
88 |
90 |
95 |
97 | {{ selectValue }}
96 | 组件 原理
98 |插槽 原理
100 |{{ scopeSlot }}
104 |
105 | 10 | 11 | **提前说明**:请大家抱着学习知识的心态来阅读本篇内容。 12 | 13 | # 应用场景 14 | 15 | 浏览器切屏检测的应用场景,一句话总结就是行为监控 + 行为优化,比如: 16 | 17 | * **面试(考试)系统**:需要防止面试者在面试过程中切屏搜索答案,即作弊 18 | * **网课**:教师端需要监测上课时间学生是在用电脑认证听课而不是干其它事情 19 | * **代码行为优化**:有时候我们会通过接口轮询的方式为用户始终提供最新的内容,但如果用户的注意力已经不在该窗口了,这时其实可以停止轮询,以节约用户流量和降低服务压力 20 | 21 | # 读者 和 价值 22 | 23 | * 试图在在线面试中作弊的同学,让你知道,你的所有动作面试官都能看到 24 | * 试图在上网课时,用电脑玩游戏、不认真听课的同学,老师也知道,你有没有在认证听课 25 | * 专业的开发人员,让你的系统行为更合理、更强大,比如补齐考试系统的监测能力、优化系统的轮询机制等 26 | 27 | # 检测方案 28 | 29 | ## 页面是否进入后台 30 | 31 | 可以通过监听`visibilitychange`事件来监测,该事件 [MDN](https://developer.mozilla.org/zh-CN/docs/Web/API/Document/visibilitychange_event) 介绍比较复杂,一句话总结就是:页面进入后台(离开视眼)或者从后台进入前台(回到视眼)都会触发该事件。 32 | 33 | **注意**:如果是双屏显示器,或者一块儿屏幕分成两个部分(比如 Mac 分屏),鼠标光标离开和回到当前页面,是不会触发该事件的。 34 | 35 | 检测代码实现如下:visibilitychange + document.visibilityState 就能监测出页面是否进入了后台 36 | 37 | ```javascript 38 | document.addEventListener('visibilitychange', function () { 39 | if (document.visibilityState === 'hidden') { 40 | console.log(`页面进入了后台,document.hidden = ${document.hidden},document.visibilityState = ${document.visibilityState}`) 41 | } else if (document.visibilityState === 'visible') { 42 | console.log(`页面进入了前台,document.hidden = ${document.hidden},document.visibilityState = ${document.visibilityState}`) 43 | } 44 | }) 45 | ``` 46 | 47 | ## 鼠标离开窗口监测 48 | 49 | `visibilitychange`事件的局限性上面也提到了,即它在双显示器或分屏场景下,是无法监测到用户是否可能在查资料的。所以,这里我们需要引入`mouseleave`和`mouseenter`两个事件,并将其注册到`document`对象上,`mouseleave`在鼠标离开监测对象时(比如这里是整个页面 —— document)触发,而`mouseenter`则是鼠标回到监测对象时触发。 50 | 51 | 代码实现如下: 52 | 53 | ```javascript 54 | document.addEventListener('mouseleave', function () { 55 | console.log('mouseleave,鼠标离开了窗口') 56 | }) 57 | document.addEventListener('mouseenter', function () { 58 | console.log('mouseenter,鼠标进入了窗口') 59 | }) 60 | ``` 61 | 62 | 这里用了`mouseenter`和`mouseleave`来监测,但其实还有其它事件,比如`focus`和`blur`事件,这两个事件监测的灵敏度相比`mouseenter`和`mouseleave`来说稍微低点,它们只在焦点发生变化后才触发,比如你鼠标移出了窗口,但是没有发生任何点击(即窗口没有失去焦点),就不会触发`blur`事件,代码如下: 63 | 64 | ```javascript 65 | window.addEventListener('blur', function () { 66 | console.log('blur,窗口失去了光标') 67 | }) 68 | window.addEventListener('focus', function () { 69 | console.log('focus,光标回到了窗口') 70 | }) 71 | ``` 72 | 73 | 其实还有其它可使用的鼠标事件,比如`mouseout`和`mouseover`也能达到和`mouseleave`、`mouseenter`一样的效果,在实际应用中往往会采用多种监测方式共存的方式,以增加破解难度。 74 | 75 | 以上就是浏览器中常用的检测方案,通过监测浏览器状态和鼠标行为来判断和猜测用户行为,并以此来判断你是否存在作弊行为。 76 | 77 | # 用技术打败技术 78 | 79 | 用魔法打败魔法,上面讲了如何监测,接下来就是讲怎么防御、破解了(防止你做坏事被发现),万一你就是想作弊呢? 80 | 81 | 俗话说,办法总比困难多、上有政策下有对策,但找办法的过程也是要付出代讲的,就看值不值的了。这里讲几种方法,但一句话总结就是:难度大、风险高(万一你的破解方案覆盖不完全呢),正所谓常在河边走,哪有不湿鞋。所以,大家还是**以学习知识为主**吧。 82 | 83 | ## 阻止上报 84 | 85 | 远端如何知道你的行为,肯定是你的行为数据被上报到远端了,所以你可以选择阻止上报数据,该方法需要你分析浏览器中发生的网络请求,比如如下图所示,上报了一条`页面在前台,但鼠标光标离开页面`的数据。 86 | 87 | 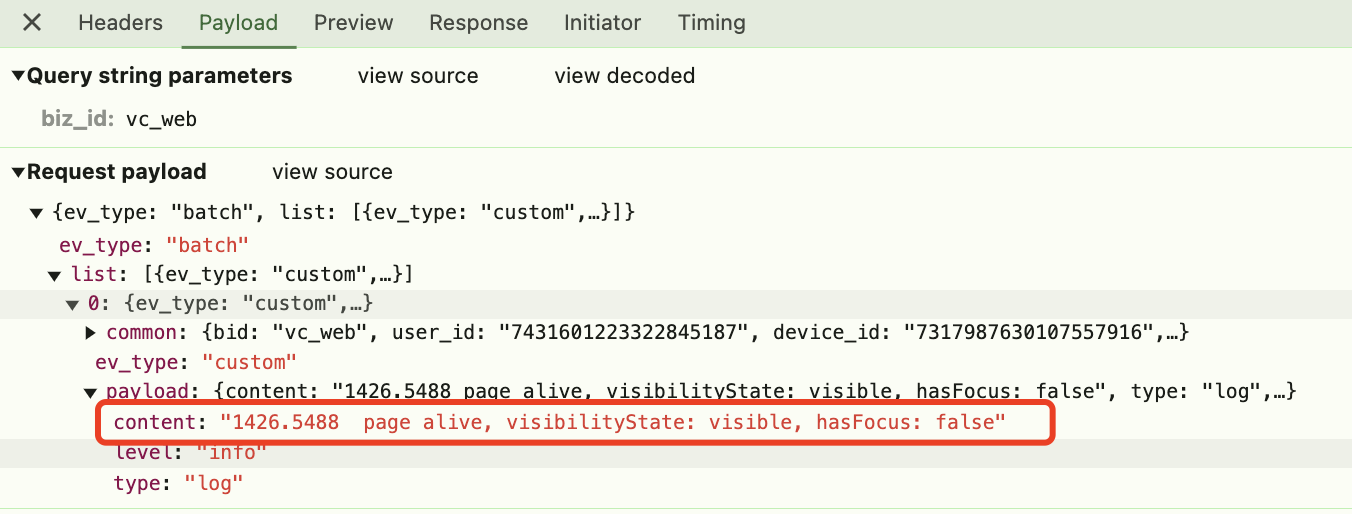 88 | 89 | 这时你就可以在浏览器中利用开发者工具的去阻止该请求的发出,操作方法和结果如下图所示,你可以选择阻止整个域名的请求,也可以阻止该 URL 的请求。 90 | 91 | 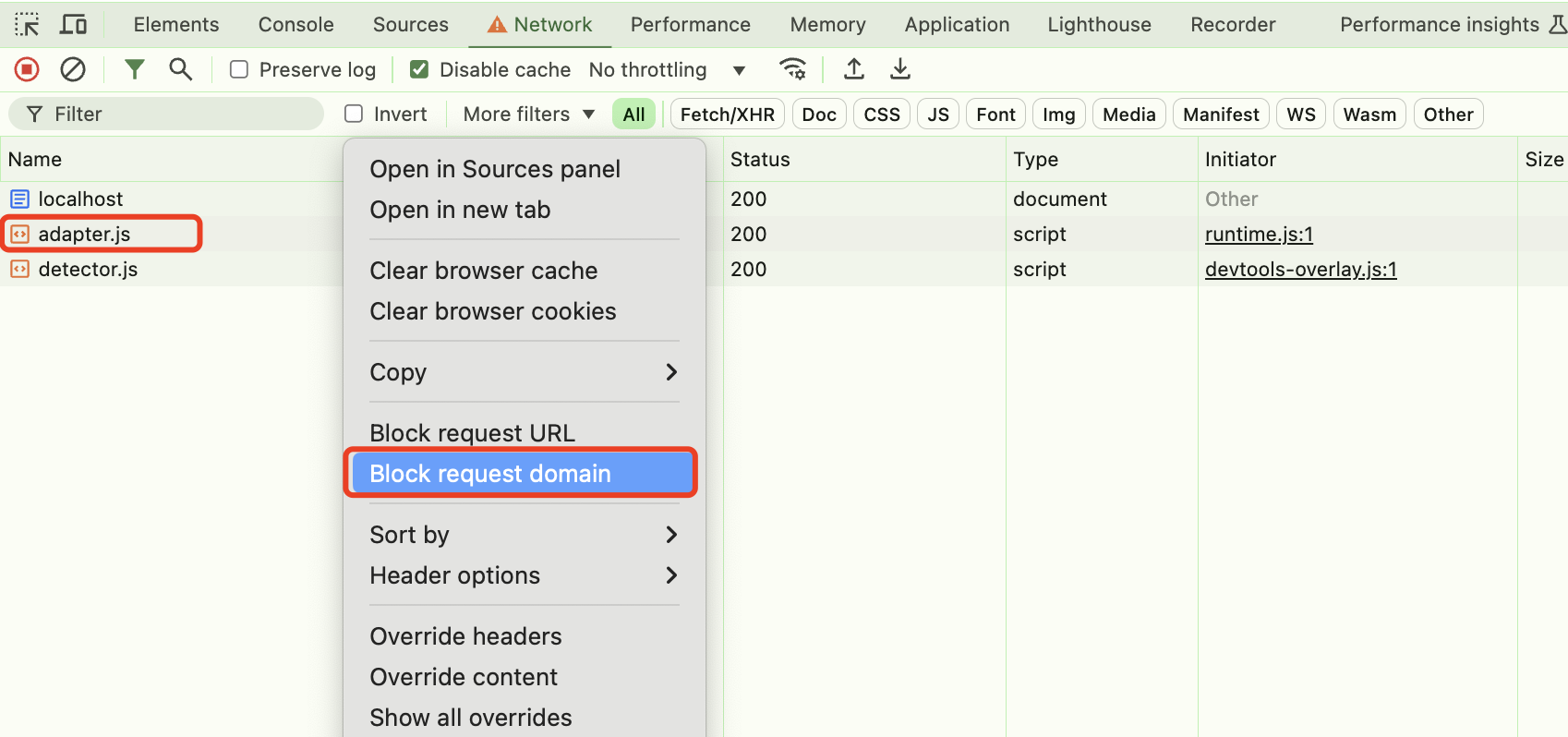 92 | 93 | 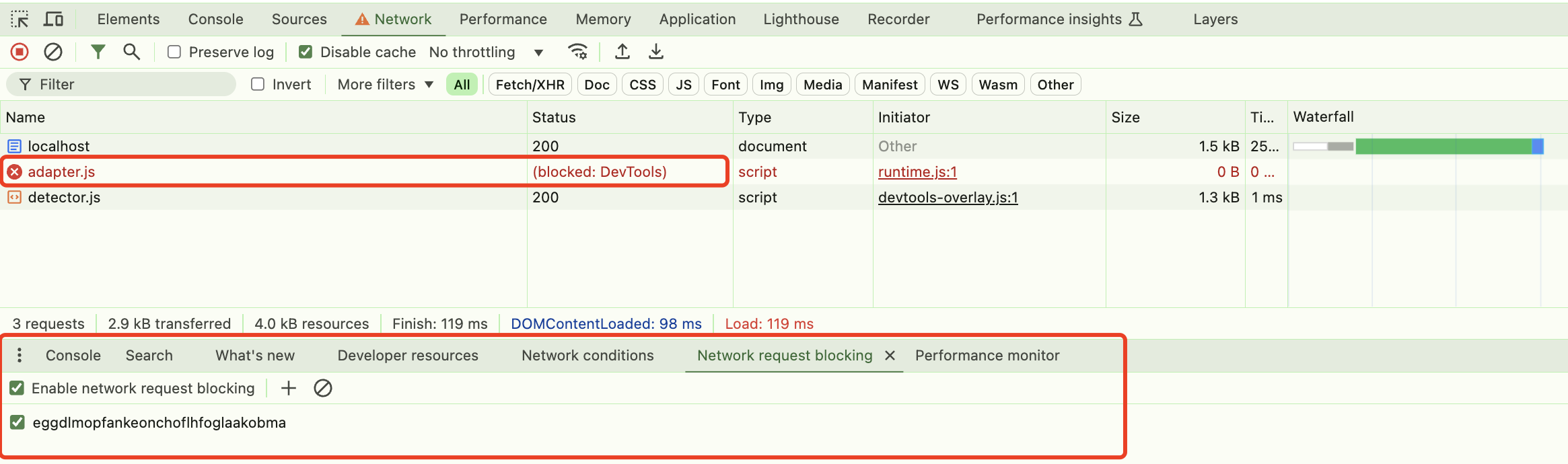 94 | 95 | 当然,除了阻止网络请求,也可以通过一些抓包工具来修改上报数据,比如一个不合适的例子:charles 的端点功能。当然你也可以自己写一个客户端工具,实现拦截本机的所有流量并篡改数据。 96 | 97 | ## 修改代码 98 | 99 | 还是浏览器的开发者工具,你可以如图所示,找到页面中用到的所有事件,点击某个会进入该事件所对应的代码。 100 | 101 | 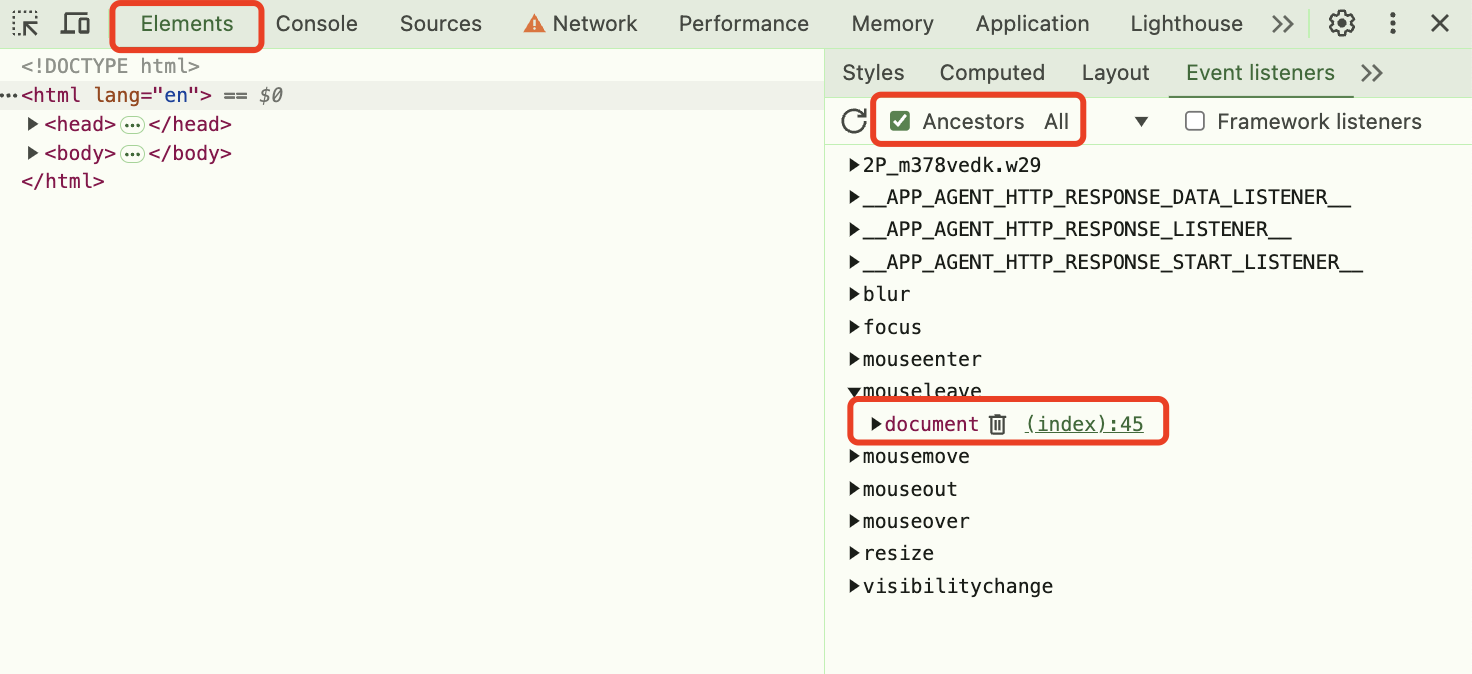 102 | 103 | 上一步点击之后,会进入 source 面板,可以在代码段右键,选择 override content,这时候会将该文件保存到本地,你可以修改其中的内容,并刷新页面,这时候浏览器针对该文件会走本地请求。 104 | 105 |  106 | 107 | 修改如下,并需要注意左侧 overrides 面板的状态,如果你第一次使用,你需要新建一个目录,用来存放浏览器中所有 override content 存放的文件。 108 | 109 |  110 | 111 | 该方法,看着比较高级,但实际操作时,你会发现难度极大,并实际的代码会复杂很多,而且代码也会做混淆,比如: 112 | 113 |  114 | 115 | 这是点 window 上的 visibilitychange 事件进来的截图: 116 | 117 |  118 | 119 | 看了上面这两个截图,你觉得你需要改哪个事件对应的代码?在什么位置改?改完以后是全部都改了吗?有没有漏掉? 120 | 121 | 上面两个方法,都需要一定前端知识,并对浏览器的调试工具有所了解,而且实际的可行性都很低,存在极大的遗漏概率。 122 | 123 | ## 浏览器外部手段 124 | 125 | 上面的两个方法都是在浏览器内部操作,还可以通过浏览器插件(比如油猴)、客户端抓包工具(比如 charles)来做,甚至自己开发一个客户端工具,原理其实一致,要么修改代码,要么修改网络请求,只是在什么位置、通过什么工具去完成这些事。 126 | 127 | ## 风险提示 128 | 129 | 上面提到的方法,都存在同一个问题,你很难完全防止被监测,因为在实际编码时会做很多的冗余、降级策略,你很难做到全面修改或拦截,而且成本会很高,除非你专业做这个事,所以,这里就需要衡量一下突入产出比,以及你能否承担潜在的风险。 130 | 131 | # 辟谣 132 | 133 | 网上有一种终极解决方案——虚拟化系统,即用一个虚拟机,比如阿里云的虚拟机、vmware 的虚拟机。 134 | 135 | **结论**:相比上面讲到的各种方法,这个方法确实是最靠谱的方式,但浏览器或各种软件是可以发现自己运行在虚拟机里面的。 136 | 137 | 靠谱的原因:上面讲到的所有行为监测手段都是发生在浏览器或者操作系统内部,但虚拟机和远程虚拟机的终端是两套独立的操作系统,你可以简单理解为两台设备,所以,你用虚拟机面试,用另外一台机器做其他事,虚拟机是不可能监测到的。 138 | 139 | 但是,设备上运行的应用是能检测到自己是否在虚拟环境中运行的,本质上是通过检测硬件属性来识别的,因为虚拟机里面的所有设备都是通过虚拟化手段模拟出来的,这样应用就可以通过检查一些设备属性来识别自己所处环境,因为虚拟化软件或多或少都会携带一些自己的特征,这里以浏览器和 vmware 虚拟机为例,通过如下代码可以检测摄像头的名称(前提是你已经允许程序使用你的摄像头) 140 | 141 | ```javascript 142 | navigator.mediaDevices.enumerateDevices() 143 | .then((devices) => { 144 | devices.forEach((device) => { 145 | if (device.kind === 'videoinput') { 146 | console.log('摄像头名称: ', device.label); 147 | } 148 | }); 149 | }) 150 | .catch((err) => { 151 | console.log('获取设备信息出错: ', err); 152 | }); 153 | ``` 154 | 155 | 效果如下: 156 | 157 | 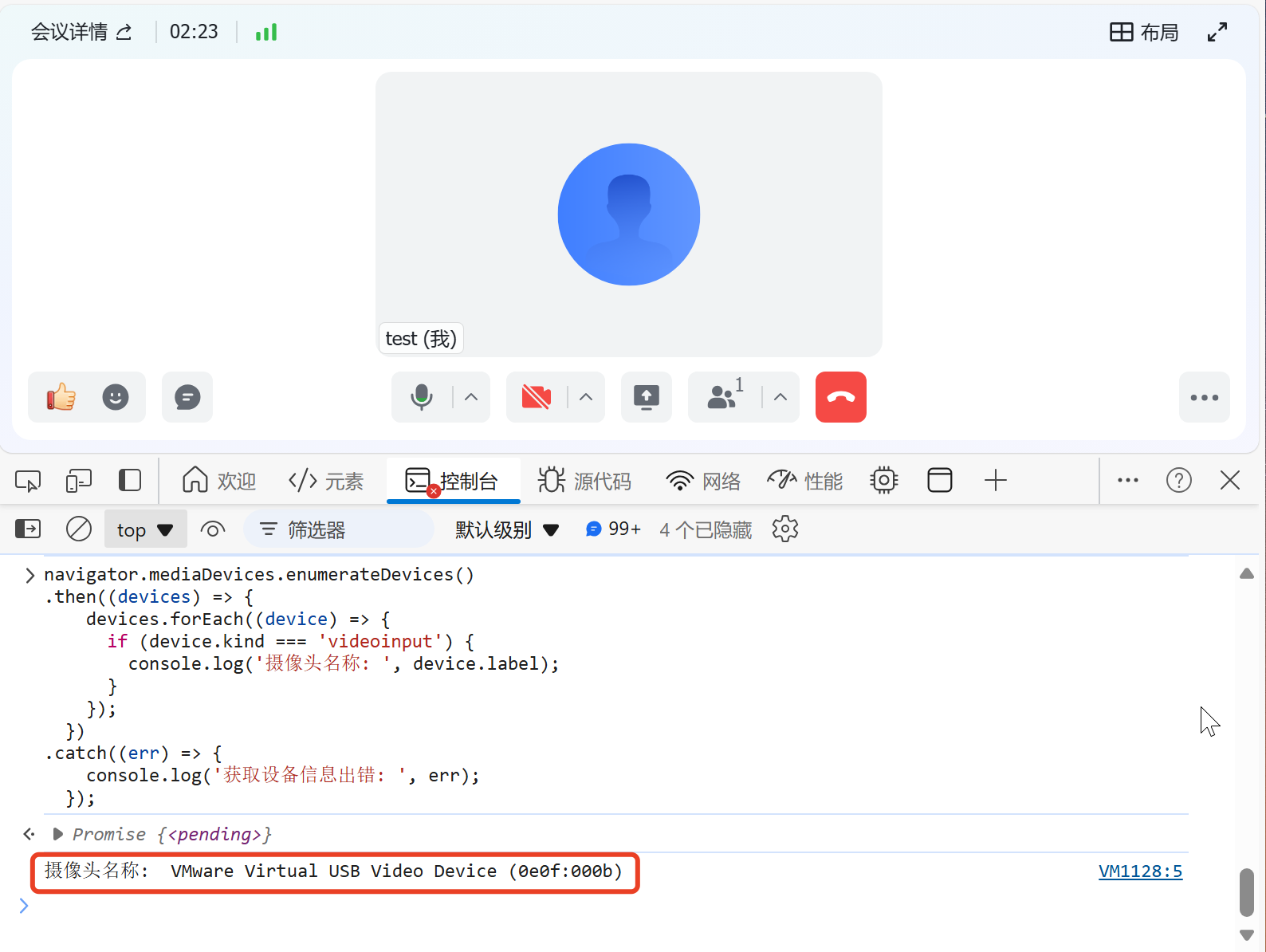 158 | 159 | 所以,这就看双方怎么解释这个事情了,因为确实有很多团队,日常办公用的就是虚拟机,当然面试官也可以要求你不用虚拟机面试,而一些面试系统也是具备这个检测能力的。 160 | 161 | # 总结 162 | 163 | 再次提醒,相信大家是**抱着学习知识的心态**来阅读文章的。 164 | 165 | 文章前半部分讲了浏览器中常见的切屏检测的手段,可以通过 visibilitychange、mouseenter、mouseleave 等事件来检测浏览器状态和鼠标行为,从而辅助判断用户是否正在发生不好的行为。 166 | 167 | 后半部分讲了各种对抗检测的手段,主要是通过修改检测代码、拦截网络请求或借助虚拟化系统隔离的手段来对抗检测。 168 | 169 |
170 | 171 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 172 | 173 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 174 | 175 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 176 | 177 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)** 178 | 179 | # 代码 180 | 181 | 文章中讲到的完整代码,大家可以直接复制执行,以验证效果: 182 | 183 | ```html 184 | 185 | 186 | 187 | 188 | 189 | 190 |
切屏检测
195 |
230 |
231 |
232 |
233 | ```
234 |
--------------------------------------------------------------------------------
/React/源码调试环境.md:
--------------------------------------------------------------------------------
1 | # 调试环境
2 |
3 | https://legacy.reactjs.org/docs/how-to-contribute.html#development-workflow
4 |
5 | * 拉取项目并执行 yarn 安装包
6 | * 首先得执行一遍 yarn build,时间会很长
7 |
8 | 
9 |
10 | 
11 |
12 | * 可以用 fixtures/packaging/babel-standalone/dev.html 做开发调试,这个文件加载的就是构建后的核心文件 —— react、react-dom
13 | * 后续可以执行 执行 yarn build react/index,react-dom/index --type=UMD
14 |
15 |
16 |
17 |
18 |
19 | # Fiber 架构的核心目的
20 |
21 | 我们已经建立了 Fiber 的主要目标是使 React 能够利用调度。具体来说,我们需要能够:
22 |
23 | - 暂停工作并稍后再回来完成。
24 | - 为不同类型的工作分配优先级。
25 | - 重用先前完成的工作。
26 | - 如果工作不再需要,则中止工作。
27 |
28 | 在 React@16 之前是没有调度的概念的,因为 diff 开始后就开始了,整个递归的过程你没办法参与管理。
29 |
30 |
31 |
32 | ```shell
33 | npx create-react-app react-debug-version
34 | ```
35 |
36 | ```shell
37 | cd src && git clone https://github.com/facebook/react.git
38 | ```
39 |
40 | 
41 |
42 | ```shell
43 | rm -rf .git ./src/react/.git && git init
44 | ```
45 |
46 | ```shell
47 | git add .
48 | ```
49 |
50 | ```shell
51 | git commit -m "feat: cra 创建的 React 项目集成 React@18.3.1 源码"
52 | ```
53 |
54 | 
55 |
56 | 是因为 react-script 包在执行一次之后就被删掉了,重新 `npm i` 一下就可以了
57 |
58 | ```shell
59 | npm run eject
60 | ```
61 |
62 | 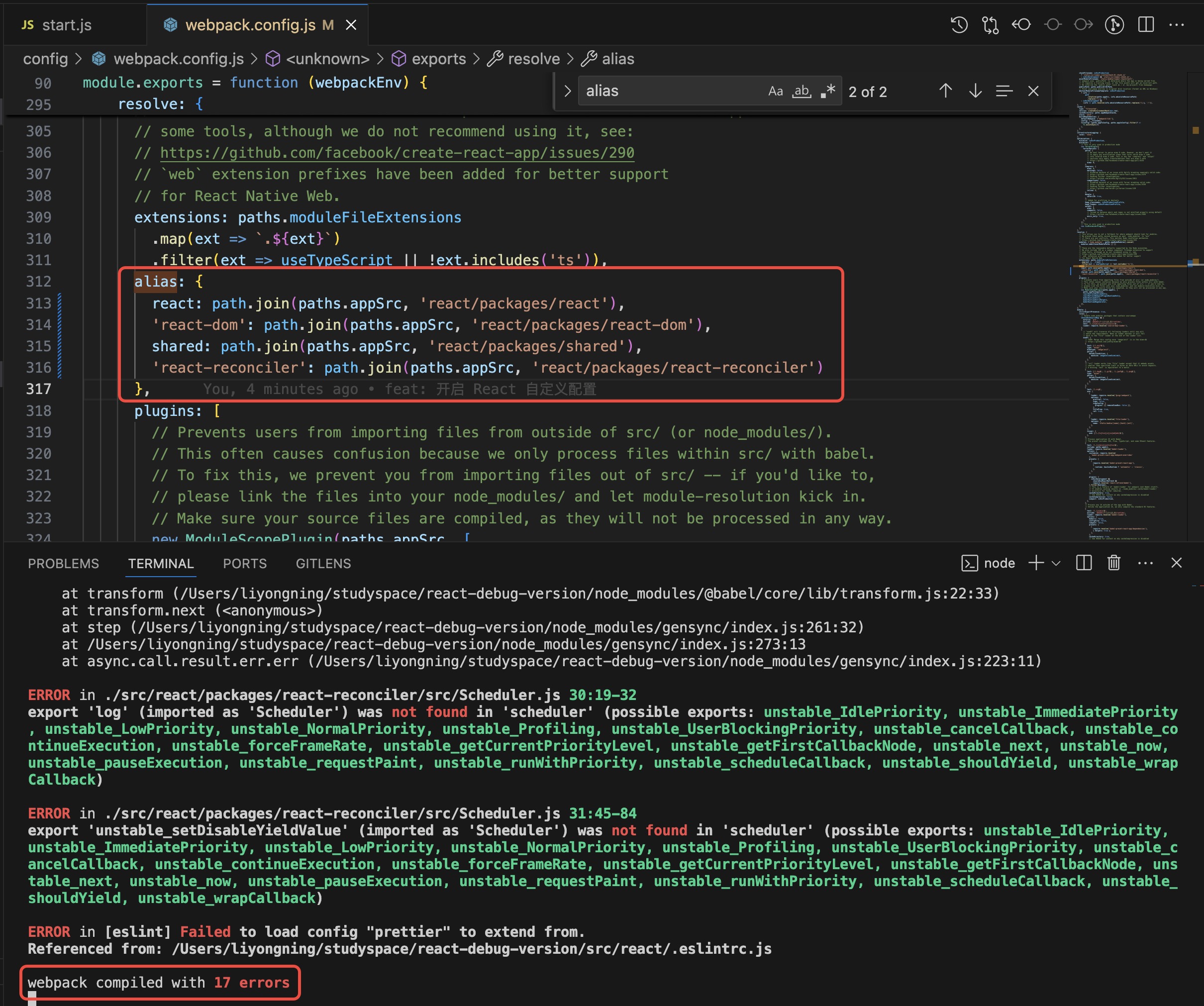
63 |
64 | 引入方式问题,打开源码可以看到都是 export 的具名导出的方式,没有 export default 的默认导出
65 |
66 | 
67 |
68 | React 源码中包找不到的问题
69 |
70 | 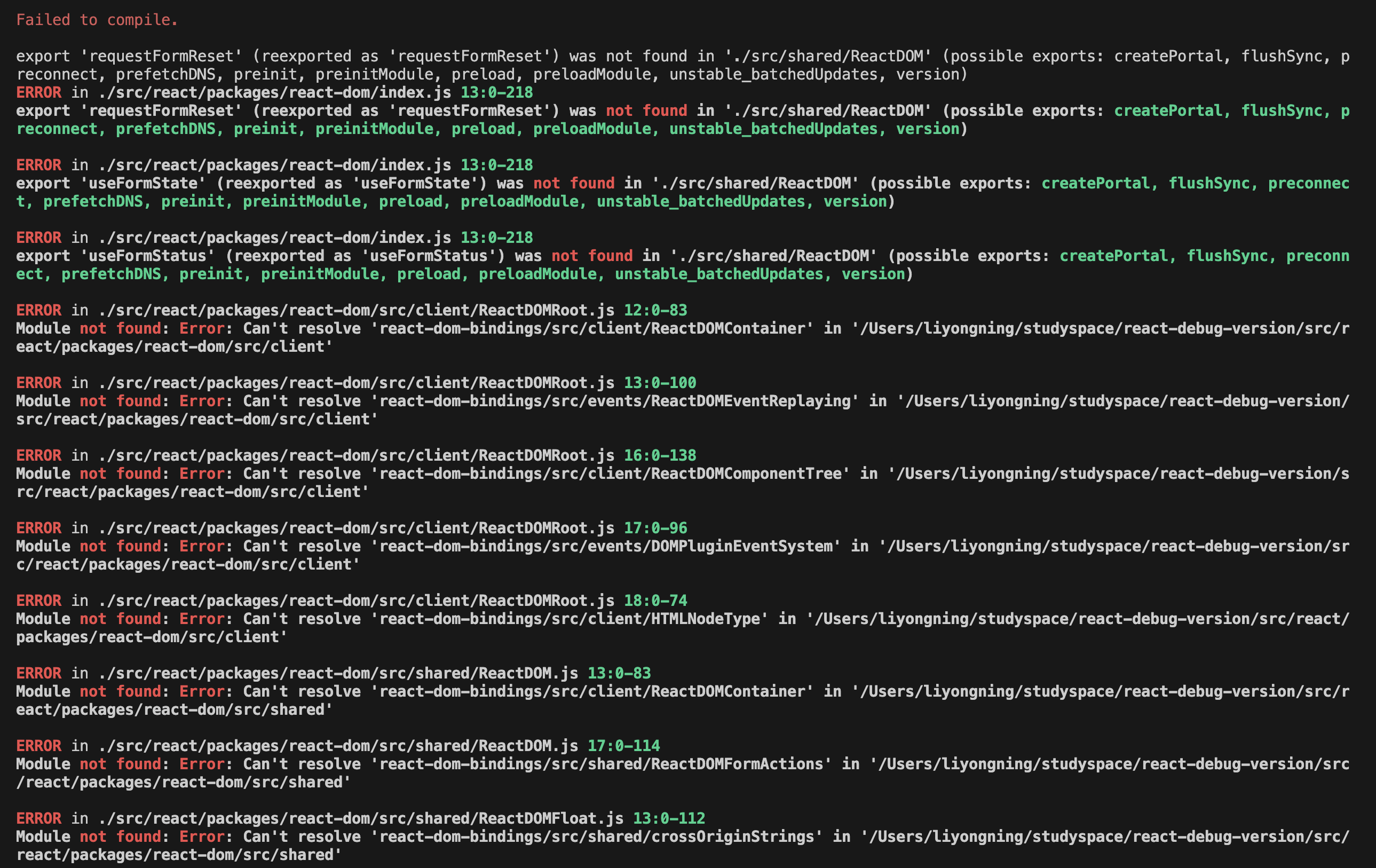
71 |
72 | 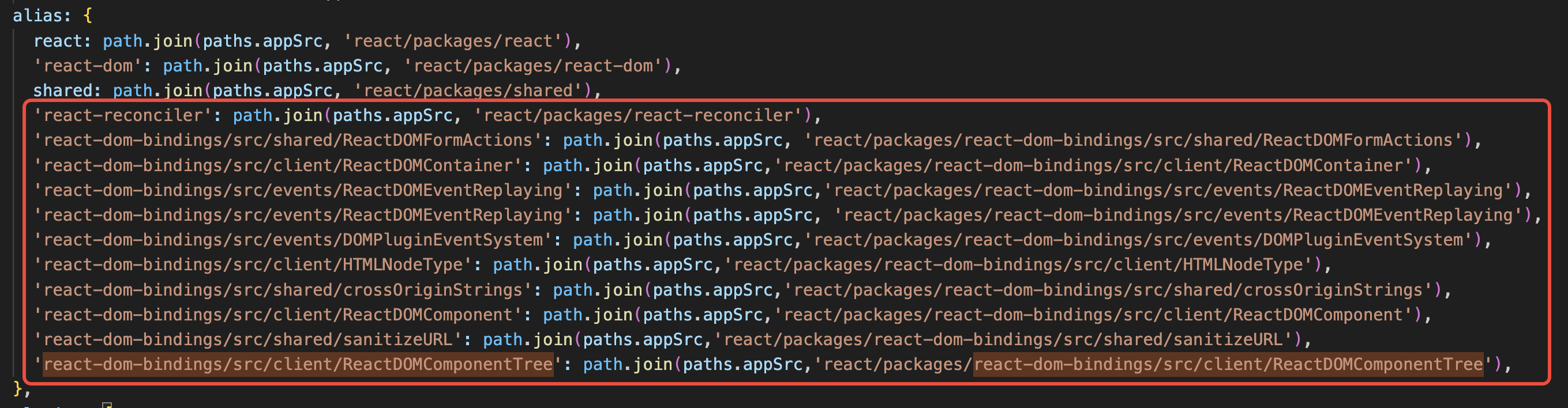
73 |
74 | ```json
75 | {
76 | alias: {
77 | react: path.join(paths.appSrc, 'react/packages/react'),
78 | 'react-dom': path.join(paths.appSrc, 'react/packages/react-dom'),
79 | shared: path.join(paths.appSrc, 'react/packages/shared'),
80 | 'react-reconciler': path.join(paths.appSrc, 'react/packages/react-reconciler'),
81 | 'react-dom-bindings/src/shared/ReactDOMFormActions': path.join(paths.appSrc, 'react/packages/react-dom-bindings/src/shared/ReactDOMFormActions'),
82 | 'react-dom-bindings/src/client/ReactDOMContainer': path.join(paths.appSrc,'react/packages/react-dom-bindings/src/client/ReactDOMContainer'),
83 | 'react-dom-bindings/src/events/ReactDOMEventReplaying': path.join(paths.appSrc,'react/packages/react-dom-bindings/src/events/ReactDOMEventReplaying'),
84 | 'react-dom-bindings/src/events/ReactDOMEventReplaying': path.join(paths.appSrc, 'react/packages/react-dom-bindings/src/events/ReactDOMEventReplaying'),
85 | 'react-dom-bindings/src/events/DOMPluginEventSystem': path.join(paths.appSrc,'react/packages/react-dom-bindings/src/events/DOMPluginEventSystem'),
86 | 'react-dom-bindings/src/client/HTMLNodeType': path.join(paths.appSrc,'react/packages/react-dom-bindings/src/client/HTMLNodeType'),
87 | 'react-dom-bindings/src/shared/crossOriginStrings': path.join(paths.appSrc,'react/packages/react-dom-bindings/src/shared/crossOriginStrings'),
88 | 'react-dom-bindings/src/client/ReactDOMComponent': path.join(paths.appSrc,'react/packages/react-dom-bindings/src/client/ReactDOMComponent'),
89 | 'react-dom-bindings/src/shared/sanitizeURL': path.join(paths.appSrc,'react/packages/react-dom-bindings/src/shared/sanitizeURL'),
90 | 'react-dom-bindings/src/client/ReactDOMComponentTree': path.join(paths.appSrc,'react/packages/react-dom-bindings/src/client/ReactDOMComponentTree'),
91 | },
92 | }
93 | ```
94 |
95 | 语法错误
96 |
97 | 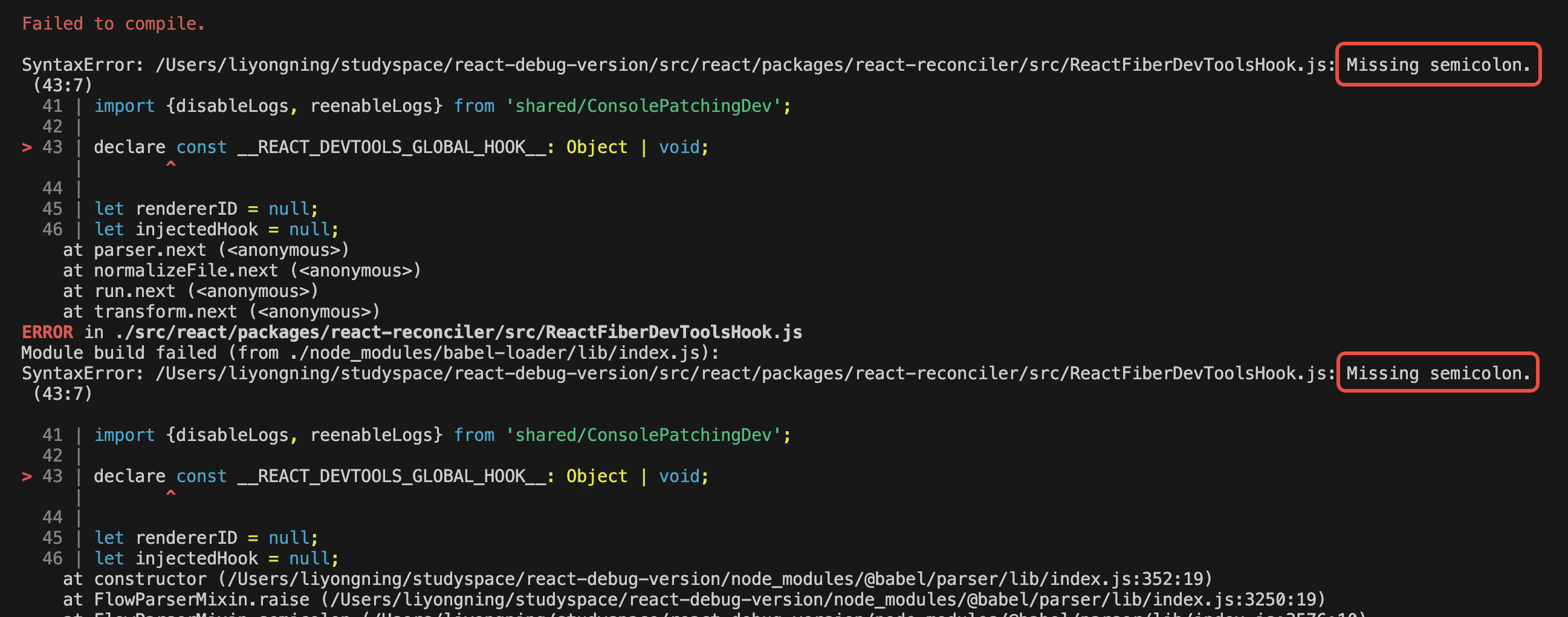
98 |
99 | 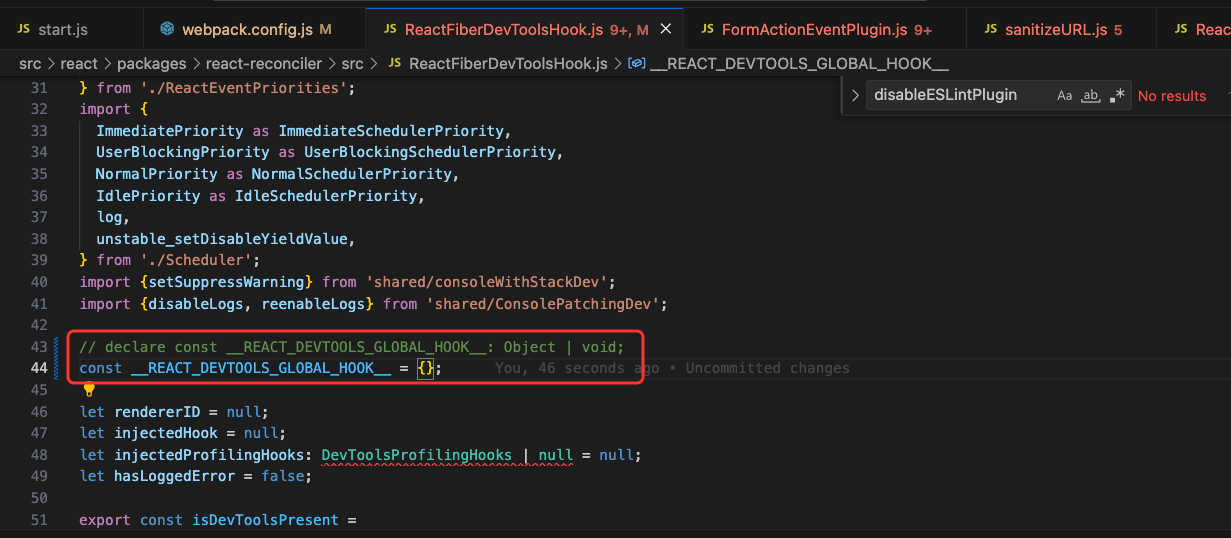
100 |
101 | scheduler
102 |
103 | 找到报错的位置,最终定位到 `src/react/packages/scheduler/src/forks/Scheduler.js`,发现确实没有导出这两个方法,搜索 `unstable_setDisableYieldValue`找到这两个方法是在 `src/react/packages/scheduler/src/forks/SchedulerMock.js` 中定义的,在添加如下代码:
104 |
105 | ```javascript
106 | export * from './SchedulerMock'
107 | ```
108 |
109 | 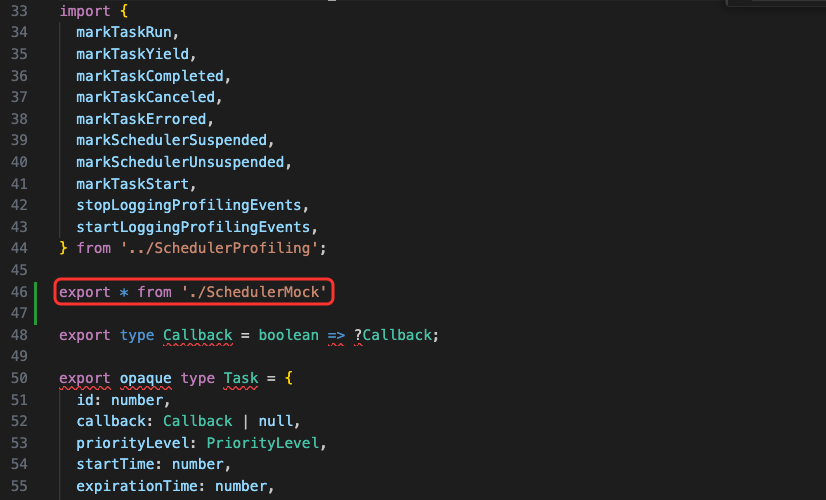
110 |
111 | 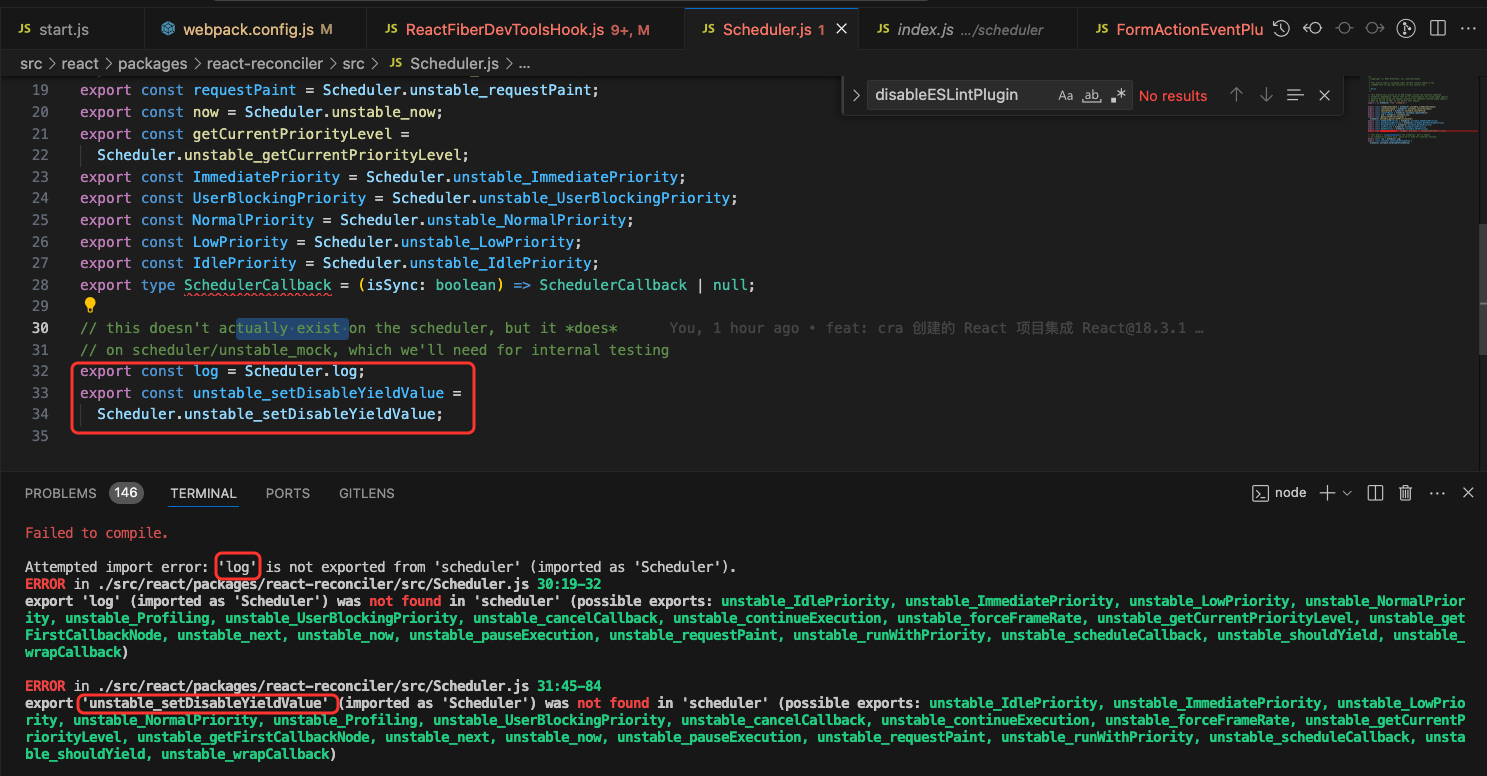
112 |
113 | eslint 报错,关闭 eslint 检查
114 |
115 | 
116 |
117 | 
118 |
119 | 重新编译,终于没有报错了
120 |
121 | 
122 |
123 | 但发现页面白屏,打开 DevTools 发现如下报错:
124 |
125 | 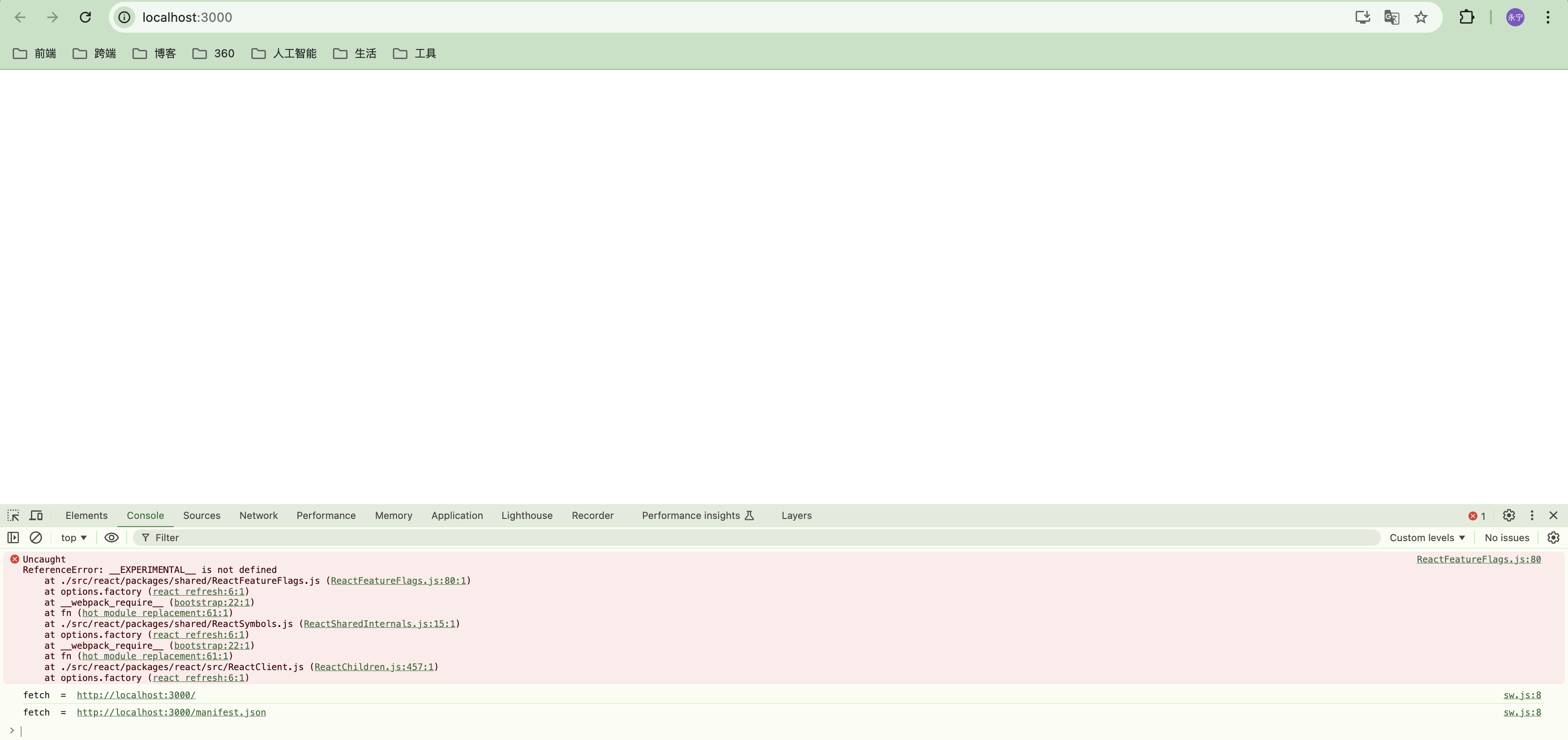
126 |
127 | 
128 |
129 | React 源码中使用了一些环境变量,我们需要将其替换掉,打开 config/env.js
130 |
131 | 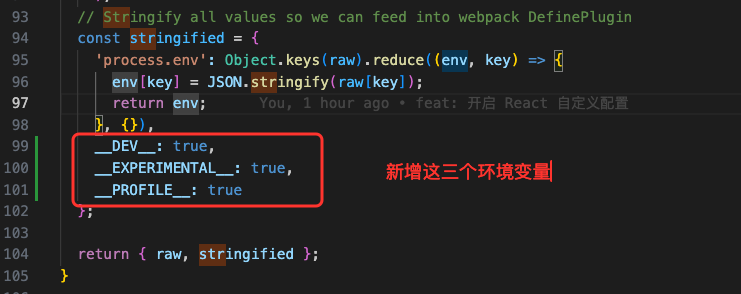
132 |
133 | 再次重新编译,DevTools 出现如下错误:
134 |
135 | 找到报错的文件:src/react/packages/shared/ReactSharedInternals.js
136 |
137 | 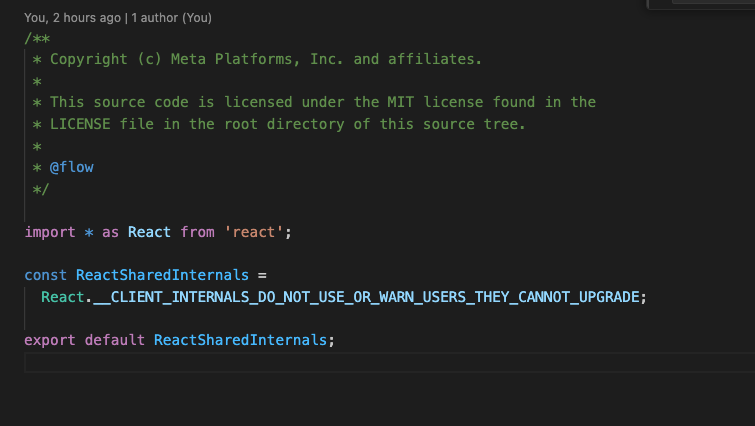
138 |
139 | 发现 __CLIENT_INTERNALS_DO_NOT_USE_OR_WARN_USERS_THEY_CANNOT_UPGRADE 是从 React 包中导出来的,从 React 包中搜索,发现是 src/react/packages/react/src/ReactSharedInternalsClient.js 中的 ReactSharedInternals 对象,直接导入到目标文件,修改如下:
140 |
141 | 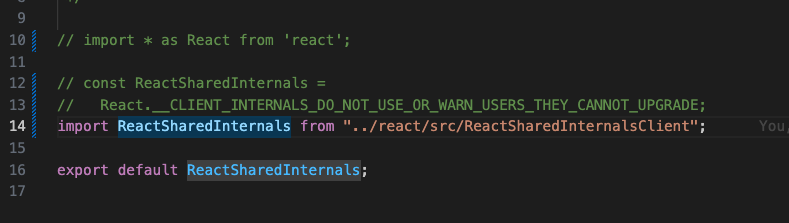
142 |
143 | 
144 |
145 | 打开报错位置:src/react/packages/react-reconciler/src/ReactFiberConfig.js
146 |
147 | 查看文件注释,可以发现,这个文件会在编译时替换为对应宿主环境的配置,正常情况下代码是解析不到这个文件的,但现在我们的方式处于非正常情况,所以文件中的 throw 出了异常,现在我们手动替换内容为浏览器环境的 FiberConfig,即:
148 |
149 | 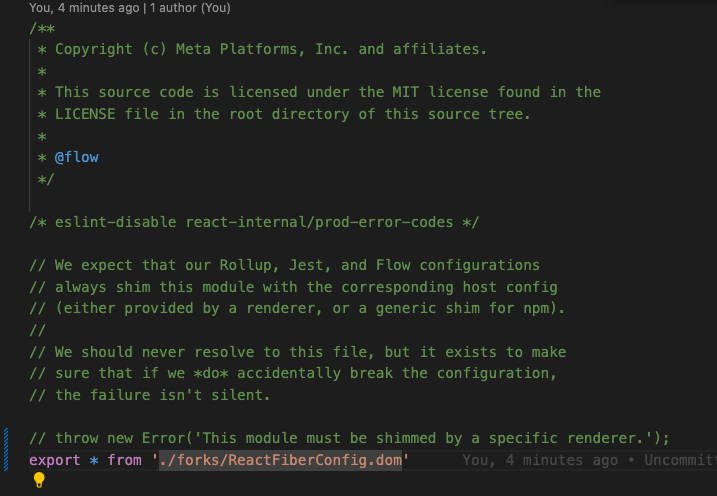
150 |
151 | 可以看到这个文件是会在编译的时候被替换成对应的 host config,我们直接修改如下
152 |
153 | - 版权所有 (c) Meta Platforms, Inc. 及其附属公司。
154 | -
155 | - 此源代码依据在本源代码树的根目录中找到的 MIT 许可证获得许可。
156 | -
157 | - @flow
158 | */
159 |
160 | /* eslint-disable react-internal/prod-error-codes */
161 |
162 | // 我们期望我们的 Rollup、Jest 和 Flow 配置
163 | // 始终使用相应的主机配置来填充此模块
164 | // (要么由渲染器提供,要么是针对 npm 的通用填充)。
165 | //
166 | // 我们永远不应解析到此文件,但它的存在是为了确保
167 | // 如果我们*确实*意外破坏了配置,
168 | // 失败不会是无声的。
169 |
170 | // 抛出新错误('此模块必须由特定的渲染器填充。');
171 |
172 | 
173 |
174 | 重新编译后,会发现一大波错误(总计奖金 300个 error),不要着急,很容易解决,这些问题都是因为找不到模块的问题,即刚引入的 src/react/packages/react-reconciler/src/forks/ReactFiberConfig.dom.js 中引入的模块找不到
175 |
176 | 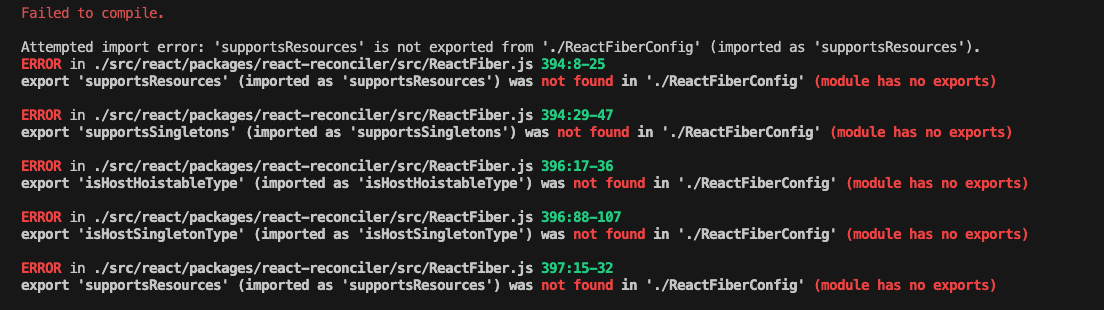
177 |
178 | 
179 |
180 | 
181 |
182 | 只需配置 alias 即可
183 |
184 | 
185 |
186 | 
187 |
188 | 在 src/react/packages/react/index.js 中加入一行代码,比如:
189 |
190 | ```javascript
191 | console.log('react debug version')
192 | console.log('https://github.com/liyongning/blog', '一个能让你升 P7 的仓库,框架源码原理分析(比如 Vue、React、微前端、组件库等)、业界最佳实践等')
193 | ```
194 |
195 | 刷新浏览器,可以发现
196 |
197 | 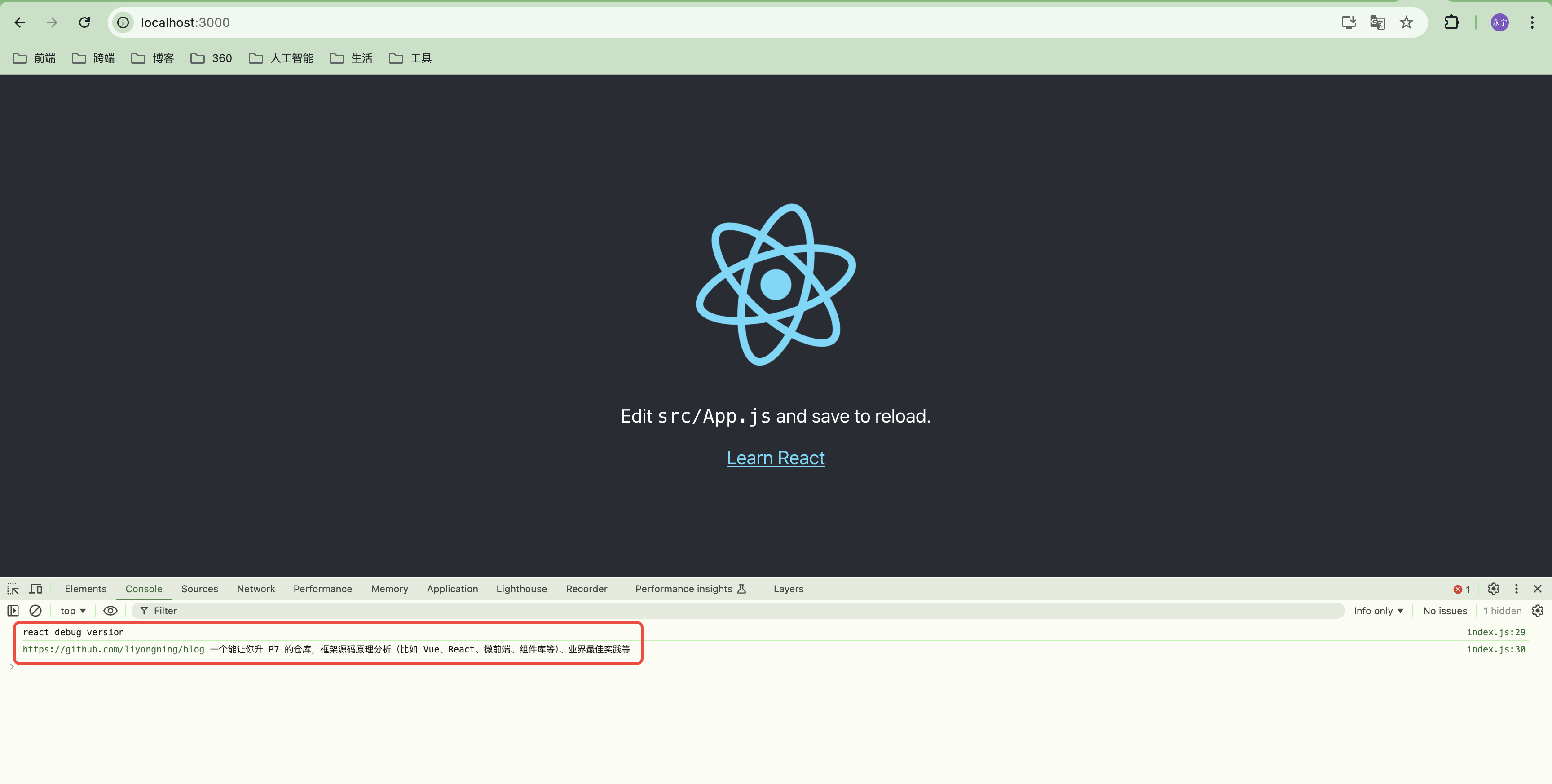
--------------------------------------------------------------------------------
/组件库/从 0 到 1 搭建组件库.md:
--------------------------------------------------------------------------------
1 | # 从 0 到 1 搭建组件库
2 |
3 | **当学习成为了习惯,知识也就变成了常识。**感谢各位的 **点赞**、**收藏**和**评论**。
4 |
5 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg)
6 |
7 | 文章已收录到 [github](https://github.com/liyongning/blog),欢迎 Watch 和 Star。
8 |
9 | ## 封面
10 |
11 | 
12 |
13 | ## 简介
14 |
15 | 从实现项目基本架构 -> 支持多规范打包 -> 实现按需加载 -> 发布 npm 包,带你从 0 到 1 搭建组件库。
16 |
17 | ## 搭建项目
18 |
19 | * 初始化项目目录
20 |
21 | ```shell
22 | mkdir lyn-comp-lib && cd lyn-comp-lib && npm init -y
23 | ```
24 |
25 | * 新建 packages 目录
26 |
27 | packages 目录为组件目录,组件一个文件夹为单位,一个文件夹为一个组件
28 |
29 | ```shell
30 | mkdir packages
31 | ```
32 |
33 | * 新建 /src/index.js
34 |
35 | /src/index.js 作为 commonjs 规范的打包入口
36 |
37 | ```shell
38 | mkdir src && cd src && touch index.js
39 | ```
40 |
41 | * 新建 webpack.common.js
42 |
43 | commonjs 规范的 webpack 配置文件
44 |
45 | ```shell
46 | touch webpack.common.js
47 | ```
48 |
49 | * 新建 webpack.umd.js
50 |
51 | umd 规范的 webpack 配置文件
52 |
53 | ```shell
54 | touch webpack.umd.js
55 | ```
56 |
57 | * 新建 publish.sh
58 |
59 | 负责构建项目 和 发布 npm 包
60 |
61 | ```shell
62 | touch publish.sh
63 | ```
64 |
65 | * 安装 webpack、webpack-cli
66 |
67 | ```shell
68 | npm i webpack webpack-cli -D
69 | ```
70 |
71 | **项目目录结构**
72 |
73 | 
74 |
75 | ## 开始编码
76 |
77 | 目前我们只是为了验证架构设计,所以只会写一些简单的 demo
78 |
79 | ### 组件
80 |
81 | 在 packages 目录中新建两个目录,作为组件目录
82 |
83 | 
84 |
85 | 其实这个目录结构参考了 element-ui 组件库,为支持 按需加载 做准备
86 |
87 | * /packages/hello/src/index.js
88 |
89 | ```javascript
90 | // hello function
91 | export default function hello (msg) {
92 | console.log('hello ', msg)
93 | }
94 | ```
95 |
96 | * /packages/log/src/index.js
97 |
98 | ```javascript
99 | // log function
100 | export default function log (str) {
101 | console.log('log: ', str)
102 | }
103 | ```
104 |
105 | ### 引入并导出组件
106 |
107 | 在 /src/index.js 中统一引入项目中的组件并导出
108 |
109 | ```javascript
110 | // 当组件变得庞大时这部分可自动生成,element-ui 就是采用自动生成的方式
111 | import hello from '../packages/hello/src/index'
112 | import log from '../packages/log/src/index'
113 |
114 | export default {
115 | hello,
116 | log
117 | }
118 | ```
119 |
120 | ### 编写 webpack 配置文件
121 |
122 | * /webpack.common.js
123 |
124 | ```javascript
125 | const path = require('path')
126 |
127 | module.exports = {
128 | entry: './src/index.js',
129 | // 使用 开发者 模式,目的是为了一会儿的调试,实际开发中可改为 production
130 | mode: 'development',
131 | output: {
132 | path: path.join(__dirname, './lib'),
133 | filename: 'lyn-comp-lib.common.js',
134 | // commonjs2 规范
135 | libraryTarget: 'commonjs2',
136 | // 将 bundle 中的 window 对象替换为 this,不然会报 window is not defined
137 | globalObject: 'this',
138 | // 没有该配置项,组件会挂载到 default 属性下,需要 comp.default.xxx 这样使用,不方便
139 | libraryExport: 'default'
140 | }
141 | }
142 | ```
143 |
144 | * /webpack.umd.js
145 |
146 | ```javascript
147 | const path = require('path')
148 |
149 | module.exports = {
150 | // 实际开发时这部分可以自动生成,可采用 element-ui 的方式
151 | // 按需加载 需要将入口配置为多入口模式,一个组件 一个入口
152 | entry: {
153 | log: './packages/log/src/index.js',
154 | hello: './packages/hello/src/index.js'
155 | },
156 | mode: 'development',
157 | output: {
158 | path: path.join(__dirname, './lib'),
159 | filename: '[name].js',
160 | // umd 规范
161 | libraryTarget: 'umd',
162 | globalObject: 'this',
163 | // 组件库暴露出来的 全局变量,比如 通过 script 方式引入 bundle 时就可以使用
164 | library: 'lyn-comp-lib',
165 | libraryExport: 'default'
166 | }
167 | }
168 | ```
169 |
170 | ### package.json
171 |
172 | ```json
173 | {
174 | "name": "@liyongning/lyn-comp-lib",
175 | "version": "1.0.0",
176 | "description": "从 0 到 1 搭建组件库",
177 | "main": "lib/lyn-comp-lib.common.js",
178 | "scripts": {
179 | "build:commonjs2": "webpack --config webpack.common.js",
180 | "build:umd": "webpack --config webpack.umd.js",
181 | "build": "npm run build:commonjs2 && npm run build:umd"
182 | },
183 | "keywords": ["组件库", "0 到 1"],
184 | "author": "Li Yong Ning",
185 | "files": [
186 | "lib",
187 | "package.json"
188 | ],
189 | "repository": {
190 | "type": "git",
191 | "url": "https://github.com/liyongning/lyn-comp-lib.git"
192 | },
193 | ...
194 | }
195 | ```
196 |
197 | #### 解释
198 |
199 | * name
200 |
201 | > 在 包 名称前加自己的 npm 账户名,采用 npm scope 的方式,包目录的组织方式和普通包不一样,而且可以有效的避免和他人的包名冲突
202 |
203 | * main
204 |
205 | > 告诉使用程序 ( import hello from '@liyongning/lyn-comp-lib' ) 去哪里加载组件库
206 |
207 | * script
208 |
209 | > 构建命令
210 |
211 | * files
212 |
213 | > 发布 npm 包时告诉发布程序只将 files 中指定的 文件 和 目录 上传到 npm 服务器
214 |
215 | * repository
216 |
217 | > 代码仓库地址,选项不强制,可以没有,不过一般都会提供,和他人共享
218 |
219 | ### 构建发布脚本 publish.sh
220 |
221 | shell 脚本,负责构建组件库和发布组件库到 npm
222 |
223 | ```shell
224 | #!/bin/bash
225 |
226 | echo '开始构建组件库'
227 |
228 | npm run build
229 |
230 | echo '组件库构建完成,现在发布'
231 |
232 | npm publish --access public
233 | ```
234 |
235 | ### README.md
236 |
237 | 一个项目必可少的文件,readme.md,负责告诉别人,如何使用我们的组件库
238 |
239 | ## 构建、发布
240 |
241 | 到这一步,不出意外,开篇定的目标就要完成了,接下来执行脚本,构建和发布组件库,当然发布之前你应该有一个自己的 npm 账户
242 |
243 | ```shell
244 | sh publish.sh
245 | ```
246 |
247 | 执行脚本过程中没有报错,并最后出现以下内容,则表示发布 npm 包成功,也可以去 [npm 官网](https://www.npmjs.com/) 查看
248 |
249 | ```
250 | ...
251 | npm notice total files: 5
252 | npm notice
253 | + @liyongning/lyn-comp-lib@1.0.0
254 | ```
255 |
256 | ## 测试
257 |
258 | 接下来我们新建一个测试项目去实际使用刚才发布的组件库,去验证其是否可用以及是否达到我们的预期目标
259 |
260 | ### 新建项目
261 |
262 | * 初始化项目目录
263 |
264 | ```shell
265 | mkdir test && cd test && npm init -y && npm i webpack webpack-cli -D && npm i @liyongning/lyn-comp-lib -S
266 | ```
267 |
268 | 查看 日志 或者 package.json 会发现 组件库 已经安装成功,接下来就是使用了
269 |
270 | * 新建 /src/index.js
271 |
272 | ```javascript
273 | import { hello } from '@liyongning/lyn-comp-lib'
274 | console.log(hello('lyn comp lib'))
275 | ```
276 |
277 | * 构建
278 |
279 | ```shell
280 | npx webpack-cli --mode development
281 | ```
282 |
283 | 在 /dist 目录会生成打包后的文件 mian.js,然后在 /dist 目录新建 index.html 文件并引入 main.js,然后在浏览器打开,打开控制台,会发现输出如下内容:
284 |
285 | 
286 |
287 | * 是否按需加载
288 |
289 | 我们在 /src/index.js 中只引入和使用了 hello 方法,在 main.js 中搜索 `hello function` 和 `log function` 会发现都能搜到,说明现在是全量引入,接下来根据 使用文档(README.md) 配置按需加载
290 |
291 | 
292 |
293 | 从这张图上也能看出,引入是 commonjs 的包,而不是 "./node_modules/@liyongning/lyn-comp-lib/lib/hello.js
294 |
295 | * 根据组件库的使用文档配置按需加载
296 |
297 | 安装 `babel-plugin-component`
298 |
299 | 安装 `babel-loader、@babel/core`
300 |
301 | ```shell
302 | npm install --save-dev babel-loader @babel/core
303 | ```
304 |
305 | ```javascript
306 | // webpack.config.js
307 | const path = require('path')
308 |
309 | module.exports = {
310 | entry: './src/index.js',
311 | mode: 'development',
312 | output: {
313 | path: path.resolve(__dirname, './dist'),
314 | filename: 'main.js'
315 | },
316 | module: {
317 | rules: [
318 | {
319 | test: /\.js$/,
320 | exclude: /node_modules/,
321 | loader: 'babel-loader'
322 | }
323 | ]
324 | }
325 | }
326 | ```
327 |
328 | 安装 `@babel/preset-env`
329 |
330 | ```
331 | {
332 | "presets": ["@babel/preset-env"],
333 | "plugins": [
334 | [
335 | "component",
336 | {
337 | "libraryName": "@liyongning/lyn-comp-lib",
338 | "style": false
339 | }
340 | ]
341 | ]
342 | }
343 | ```
344 |
345 | * 配置 package.json 的 script
346 |
347 | ```json
348 | ```json
349 | {
350 | ...
351 | scripts: {
352 | "build": "webpack --config webpack.config.js"
353 | }
354 | ...
355 | }
356 | ```
357 | * 执行构建命令
358 |
359 | ```shell
360 | npm run build
361 | ```
362 |
363 | * 重复上面的第 4 步,会发现打包后的文件只有 `hello function`,没有 `log function`
364 |
365 | 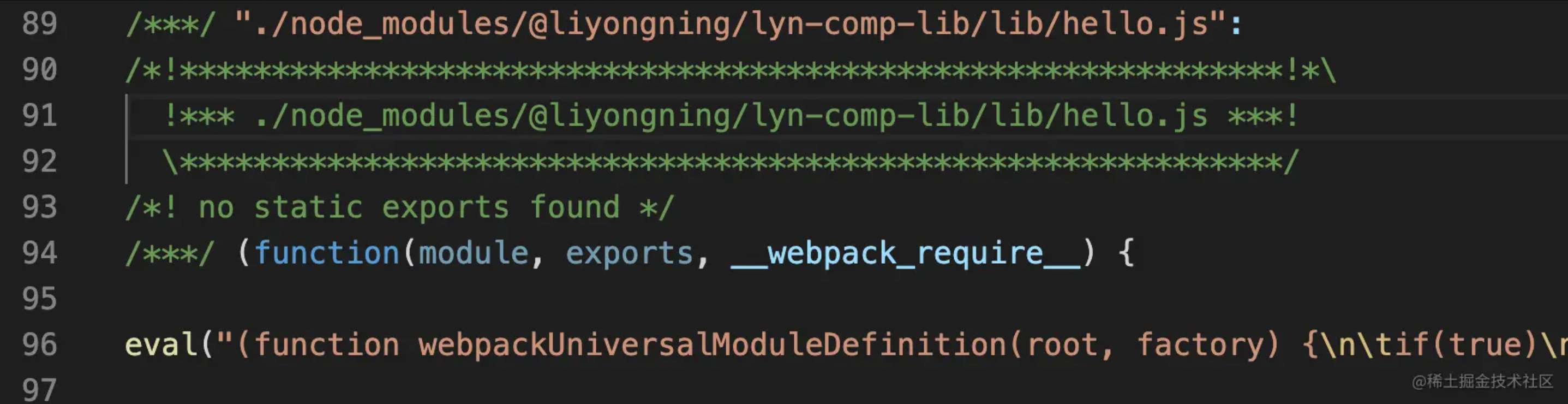
366 |
367 | 而且实际的包体积也小了
368 |
369 | **OK,目标完成!!如有疑问欢迎提问,共同进步**
370 |
371 | ## 链接
372 |
373 | * [组件库专栏](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzA3NTk4NjQ1OQ==&action=getalbum&album_id=2259813235891863559#wechat_redirect)
374 |
375 | - [github](https://github.com/liyongning/lyn-comp-lib.git)
376 |
377 |
378 |
379 | 感谢各位的:**点赞**、**收藏**和**评论**,我们下期见。
380 |
381 | ---
382 |
383 | **当学习成为了习惯,知识也就变成了常识。**感谢各位的 **点赞**、**收藏**和**评论**。
384 |
385 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg)
386 |
387 | 文章已收录到 [github](https://github.com/liyongning/blog),欢迎 Watch 和 Star。
--------------------------------------------------------------------------------
/其它/在线主题切换.md:
--------------------------------------------------------------------------------
1 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。
2 |
3 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg)
4 |
5 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star
6 |
7 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)**
8 |
9 | 10 | 11 | # 在线主题切换 12 | 13 | 在线主题切换的本质就是通过 JS 替换主题 link 标签的 href 属性,加载对应主题的样式包。 14 | 15 | 样式包可以是多套 CSS 样式,也可以是由 CSS 变量组成的主题包。 16 | 17 | ## 多套 CSS 样式 18 | 19 | **优点** 是简单、易于理解,**缺点** 也很明显,可维护性差、扩展性差、开发工作量大(需要研发同学为系统开发多套样式)。可阅读下面的示例代码感受一下 20 | 21 | **index.html** 22 | 23 | ```html 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
38 | multi theme
39 |
40 |
41 |
42 |
43 |
54 |
55 |
56 | ```
57 |
58 | **blue.css**
59 |
60 | ```css
61 | /* 蓝色主题 */
62 | .div-ele {
63 | width: 200px;
64 | height: 200px;
65 | line-height: 200px;
66 | text-align: center;
67 | color: #fff;
68 | margin-bottom: 20px;
69 | background-color: blue;
70 | }
71 | ```
72 |
73 | **red.css**
74 |
75 | ```css
76 | /* 红色主题 */
77 | .theme {
78 | width: 200px;
79 | height: 200px;
80 | line-height: 200px;
81 | text-align: center;
82 | color: #fff;
83 | margin-bottom: 20px;
84 | background-color: red;
85 | }
86 | ```
87 |
88 | 当有一天你接手了类似的一个老旧系统,产品过来跟你说,我们现在需要给系统新增一套样式,全新的 UI 设计稿已经出来了,你抽时间做一下吧。这里大家要搞清楚的是,这不是一个抽时间就能完成的简单需求,这意味着你需要为系统重写一套新的样式,比如叫 `yellow.css`。
89 |
90 | 首先你需要复制已有样式,然后在浏览器中对照设计稿挨个去修改相关样式代码,并将修改同步到代码文件中,对于一个大型系统来说,这个工作量真的是......
91 |
92 | 针对上面的问题,有没有什么优化办法呢?一个呼之欲出的答案就是样式抽离。
93 |
94 | 当你新增或修改已有 UI 样式时,其实修改的只是部分样式,比如背景色、字体颜色、边框色等,这部分经常被修改的样式我们称为主题样式,你需要将这些样式找出来。这里难在寻找样式,就像大海捞针,那能否把相关样式抽出来呢?就像写代码一样,将公共逻辑抽离,然后在各个地方复用。
95 |
96 | ## Sass 变量
97 |
98 | 这里我们需要借助 CSS 预编译语言去实现,比如 Sass。将多套 CSS 样式中的公共样式(主题样式)抽离,通过 Sass 变量维护公共样式,每次新增或修改主题时,只需要修改主题变量文件,然后重新编译生成新的 CSS 样式。也就是说这里的样式需要通过 Sass 或 Less 语言编写,然后编译成 CSS,因为浏览器只认识 CSS。
99 |
100 | 这样就进一步提升了系统的可维护性和扩展性,也降低了主题样式的开发工作量。
101 |
102 | **index.html**
103 |
104 | ```html
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
119 | multi theme
120 |
121 |
122 |
123 |
124 |
135 |
136 |
137 |
138 | ```
139 |
140 | **var.scss**
141 |
142 | ```scss
143 | // blue theme
144 | $backgroundColor: blue;
145 |
146 | // red theme
147 | // $backgroundColor: red;
148 | ```
149 |
150 | **index.scss**
151 |
152 | ```scss
153 | @import './var.scss';
154 |
155 | .div-ele {
156 | width: 200px;
157 | height: 200px;
158 | line-height: 200px;
159 | text-align: center;
160 | color: #fff;
161 | margin-bottom: 20px;
162 | background-color: $backgroundColor
163 | }
164 | ```
165 |
166 | 将 `index.scss` 编译后生成如下两套样式
167 |
168 | **blue.css**
169 |
170 | ```css
171 | /* 蓝色主题 */
172 | .div-ele {
173 | width: 200px;
174 | height: 200px;
175 | line-height: 200px;
176 | text-align: center;
177 | color: #fff;
178 | margin-bottom: 20px;
179 | background-color: blue;
180 | }
181 | ```
182 |
183 | **red.css**
184 |
185 | ```css
186 | /* 红色主题 */
187 | .div-ele {
188 | width: 200px;
189 | height: 200px;
190 | line-height: 200px;
191 | text-align: center;
192 | color: #fff;
193 | margin-bottom: 20px;
194 | background-color: red;
195 | }
196 | ```
197 |
198 | 这时候当产品说新增一套黄色样式的时候,我只需要在 `var.scss` 文件中修改对应的主题样式,然后编译生成 `yellow.css` 样式文件即可。
199 |
200 | 像 ElementUI、Ant Design 就是这样的思路,样式包中内置主题样式变量文件,比如 `var.scss`,文件中维护了大量的样式变量,如果你需要定制自己的主题样式,只需要修改这个变量文件,然后重新编译组件库,发版就可以了。
201 |
202 | 当然了,这里抛开技术之外,有一个跨团队合作的问题(研发、设计、产品),你需要协调三个团队的资源去完成这件事,让产品和设计同学合作,根据业务和产品特点为团队出一套 UI 规范,研发同学根据 UI 规范完成多主题样式的研发。
203 |
204 | 但这里存在一个**问题**,组件库都支持按需打包,只打包使用到的组件和组件的样式。但是当业务系统需要支持多主题时,组件库就没办法再提供样式的按需打包了。
205 |
206 | 首先,组件库多主题需要配置不同的样式变量(var.scss)文件,然后编译生成多套样式,将样式包独立发布。
207 |
208 | 业务系统在使用组件库时,手动引入样式包,不能再使用组件库的样式按需打包能力,因为业务系统切换主题样式是发生在运行时,而按需打包是发生在编译时。
209 |
210 | 运行时切换主题的方式和 `多套 CSS 样式` 一样,也是通过 JavaScript 操作 link 标签,完成样式的替换,所以该方案算是第一个方案的一个优化。
211 |
212 | ## CSS 变量
213 |
214 | Sass 变量的方案虽然提升了可维护性和可扩展性,但是却导致另外一个问题,组件库丢失了样式按需打包的能力。
215 |
216 | 而丢失的原因是因为主题切换发生在运行时,但是组件库的样式却需要在编译期将 Sass 编译为 CSS,两者具有不同的运行时段,所以结合起来使用就导致无法使用组件库样式按需打包的能力。
217 |
218 | 这时候就需要想有没有什么办法能让两者发生在同一时刻,比如都发生在运行时或编译时,可惜编译时暂时还没什么好的方案,但是运行时可以使用 CSS 变量的方式。
219 |
220 | CSS 变量是 CSS 的新功能,可以简单理解为原生支持像 Sass、Less 语言的变量能力,从 2017 年 3 月份之后,所有主要浏览器已经都支持了 CSS 变量。
221 |
222 | 所以这里的方案就是 CSS 变量,将所有主题样式抽离到独立的主题样式文件中,然后在运行时通过 JavaScript 动态替换 link 标签。
223 |
224 | ### CSS 变量基本使用
225 |
226 | ```css
227 | /* 最佳实践是将样式变量定义在根伪类 :root 下,这样就可以在 HTML 文档的任何地方访问到定义的样式变量了,相当于全局作用域 */
228 | :root {
229 | --backgroundColor: red;
230 | }
231 |
232 | .div-ele {
233 | /* 通过 var 函数来获取指定变量的值 */
234 | background-color: var(--backgroundColor);
235 | }
236 | ```
237 |
238 | **index.html**
239 |
240 | ```html
241 |
242 |
243 |
244 |
245 |
246 |
247 |
248 |
257 | multi theme
258 |
259 |
260 |
261 |
262 |
273 |
274 |
275 |
276 | ```
277 |
278 | **index.css**
279 |
280 | ```css
281 | /* 系统样式,其中的主题样式使用 CSS 变量 */
282 | .div-ele {
283 | width: 200px;
284 | height: 200px;
285 | line-height: 200px;
286 | text-align: center;
287 | color: #fff;
288 | margin-bottom: 20px;
289 | /* 使用 CSS 变量声明的主题样式 */
290 | background-color: var(--backgroundColor);
291 | }
292 | ```
293 |
294 | **red.css**
295 |
296 | ```css
297 | /* 红色主题 */
298 | :root {
299 | --backgroundColor: red;
300 | }
301 | ```
302 |
303 | **blue.css**
304 |
305 | ```css
306 | /* 蓝色主题 */
307 | :root {
308 | --backgroundColor: blue;
309 | }
310 | ```
311 |
312 | 所以,当产品需要为系统新增一套黄色主题时,只需要增加一个 `yellow.css` 文件即可
313 |
314 | **yellow.css**
315 |
316 | ```css
317 | /* 黄色主题 */
318 | :root {
319 | --backgroundColor: yellow;
320 | }
321 | ```
322 |
323 | ## 总结
324 |
325 | 以上就是常见的在线主题切换方案:开发多套 CSS 样式、基于 Sass 变量的多套 CSS 样式、CSS 变量。其本质就是在切换主题时通过 JS 替换主题 link 标签的 href 属性,加载对应主题的样式包。
326 |
327 | * 多套 CSS 样式
328 | * **优点:**简单、易理解,就是写多套主题
329 | * **缺点:**开发工作量大、维护难度大、扩展性差
330 | * 基于 Sass 变量优化后的多套 CSS 样式
331 | * **优点:**通过主题样式的抽离,开发工作量小,维护难度中等,扩展性好
332 | * **缺点:**组件库样式丢失了按需打包的能力,因为在线切换的整个主题包,维护难度中等,后期每次新增和修改主题样式都需要重新编译生成对应的主题样式
333 | * CSS 变量
334 | * **优点:**开发工作量小、易维护、扩展性好,浏览器原生支持
335 | * **缺点:**虽然主流浏览器都支持了,单相对上面两个方案来说是劣势,性能稍微优点没那么优秀
336 |
337 | 所以如果你的业务复杂度没那么高(一个页面有上万个 DOM 节点),浏览器兼容性也还好,CSS 变量可以成为你的首选方案,结合 Sass 等预编译语言去实现在线主题切换。
338 |
339 | ## 拓展
340 |
341 | 虽然现在有了多主题方案,但是在团队内如何很好的落地呢?
342 |
343 | 看到这个问题,你可能会想这还不简单?主题肯定是内置到组件库啊。嗯,没问题,这是一种应用场景,但这只是冰山一角。
344 |
345 | 大家要知道 CSS 主题样式的应用场景不止是组件库(基础 UI 库、业务组件库、物料库),更多的其实是在你的业务代码中,可以仔细想想,你平时开发时是不是需要写很多 CSS 代码,这些 CSS 代码中也会包含很多主题相关的样式。
346 |
347 | 你如果将相关样式直接写死成设计稿上给定的数据,在主题切换时,这部分写死的样式就无法被切换,这是切换的只是组件库中相关 UI 的样式。你的业务代码怎么办?
348 |
349 | 1. 原始方案,将主题变量全部通过文档记录,要求每个开发同学熟记这些主题变量,并在业务代码中使用。这个方法一听就很变态(变量那么多)
350 | 2. vscode 插件,将主题变量封装成 vscode 插件,或者代码片段,拿代码片段举例来说,比如背景主题色,输入 `background-color` 直接生成 `background-color: var(--backgroundColor);`。这里只给大家提供一个思路,具体实现可以自己探索探索,有好的实现可以在评论区和大家的分享分享
351 |
352 | ## 链接
353 |
354 | [多主题切换的示例代码:liyongning/multi-theme](https://github.com/liyongning/multi-theme)
355 |
356 |
357 |
358 | 359 | 360 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 361 | 362 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 363 | 364 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star 365 | 366 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)** 367 | -------------------------------------------------------------------------------- /其它/如何使用 axios 实现前端并发限制和重试机制.md: -------------------------------------------------------------------------------- 1 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 2 | 3 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 4 | 5 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star 6 | 7 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)** 8 | 9 |
10 | 11 | # 简介 12 | 13 | 在 Web 开发中,我们经常需要向后端发送多个异步请求以获取数据,然而过多的请求可能会对服务器造成过大的压力,影响系统的性能。因此,我们需要对并发请求进行限制。同时,由于网络环境的不稳定性,发送请求时也需要考虑添加重试机制,以提高请求的成功率和可靠性。 14 | 15 | 本篇博客将介绍如何使用 axios 实现前端并发限制和重试机制。axios 是一款基于 Promise 的 HTTP 客户端,可以用于浏览器和 Node.js 环境下发送 HTTP 请求。 16 | 17 | # 前端并发限制的实现 18 | 19 | 我们可以使用一个请求队列来限制并发请求的数量,每次发送请求时,将请求加入到队列中,并检查当前队列的长度是否小于最大并发请求数量,如果是,就从队列中取出一个请求并发送;如果不是,就等待前面的请求完成后再发送下一个请求。 20 | 21 | 以下是一个使用 axios 实现前端并发限制的示例代码: 22 | 23 | ```javascript 24 | const axios = require('axios'); 25 | 26 | // 最大并发请求数 27 | const MAX_CONCURRENT_REQUESTS = 5; 28 | 29 | // 请求队列 30 | const requestQueue = []; 31 | // 当前正在进行中的请求数 32 | let activeRequests = 0; 33 | 34 | /** 35 | * 处理请求队列中的请求 36 | */ 37 | function processQueue() { 38 | // 如果当前进行中的请求数没达到最大并发数 && 请求队列不为空 39 | if (activeRequests < MAX_CONCURRENT_REQUESTS && requestQueue.length > 0) { 40 | // 从请求队列中取出队头的请求 41 | const { url, config, resolve, reject } = requestQueue.shift(); 42 | // 进行中的请求数 +1 43 | activeRequests++; 44 | // 通过 Axios 发送请求 45 | axios(url, config) 46 | .then((response) => { 47 | // 请求成功,将 外层 Promise 的状态更新为 fulfilled,并返回请求结果 48 | resolve(response); 49 | }) 50 | .catch((error) => { 51 | // 请求失败,将 外层 Promise 的状态更新为 rejected,并返回错误信息 52 | reject(error); 53 | }) 54 | .finally(() => { 55 | // 不论成功还是失败都会执行 finally,表示本次请求结束,将进行中的请求数 -1 56 | activeRequests--; 57 | // 再处理请求队列中的下一个请求 58 | processQueue(); 59 | }); 60 | } 61 | } 62 | 63 | /** 64 | * 并发请求方法 65 | * @param { string } url 请求的 url 66 | * @param { AxiosRequestConfig } config Axios 的请求配置 67 | */ 68 | function limitConcurrentRequests(url, config) { 69 | // 这里很关键,将用户发起的每个请求都变成一个 Promise,而 Promise 的状态会在 processQueue 中根据 Axios 的执行结果来更新 70 | return new Promise((resolve, reject) => { 71 | // 将请求的配置信息 和 更新 Promise 状态的两个方法变成一个对象推入请求队列中 72 | requestQueue.push({ url, config, resolve, reject }); 73 | // 执行 processQueue 方法处理请求队列中的每个请求 74 | processQueue(); 75 | }); 76 | } 77 | 78 | module.exports = { limitConcurrentRequests }; 79 | 80 | ``` 81 | 82 | 在以上代码中,我们设置了一个 `MAX_CONCURRENT_REQUESTS` 常量,表示最大并发请求数量,同时维护了一个请求队列 `requestQueue` 和一个变量 `activeRequests`,分别用于存储请求队列和正在处理的请求数量。我们通过定义 `processQueue` 方法来处理请求队列中的请求,它会检查当前正在处理的请求数量是否小于最大并发请求数量,并从队列中取出一个请求并发送。在发送请求的过程中,我们通过 Promise 的 `then` 和 `catch` 方法来处理成功和失败的情况,并在最后通过 `finally` 方法将正在处理的请求数量减一,并再次调用 `processQueue` 方法,以处理下一个请求。 83 | 84 | 使用时,我们可以通过以下代码来进行测试和梳理上述逻辑: 85 | 86 | ```javascript 87 | const { limitConcurrentRequests } = require('./concurrency'); 88 | 89 | // 定义了 20个 URL 90 | const urls = ['https://jsonplaceholder.typicode.com/posts/1', 'https://jsonplaceholder.typicode.com/posts/2', 'https://jsonplaceholder.typicode.com/posts/3', 'https://jsonplaceholder.typicode.com/posts/4', 'https://jsonplaceholder.typicode.com/posts/5', 'https://jsonplaceholder.typicode.com/posts/6', 'https://jsonplaceholder.typicode.com/posts/7', 'https://jsonplaceholder.typicode.com/posts/8', 'https://jsonplaceholder.typicode.com/posts/9', 'https://jsonplaceholder.typicode.com/posts/10', 'https://jsonplaceholder.typicode.com/posts/11', 'https://jsonplaceholder.typicode.com/posts/12', 'https://jsonplaceholder.typicode.com/posts/13', 'https://jsonplaceholder.typicode.com/posts/14', 'https://jsonplaceholder.typicode.com/posts/15', 'https://jsonplaceholder.typicode.com/posts/16', 'https://jsonplaceholder.typicode.com/posts/17', 'https://jsonplaceholder.typicode.com/posts/18', 'https://jsonplaceholder.typicode.com/posts/19', 'https://jsonplaceholder.typicode.com/posts/20']; 91 | 92 | // 通过循环,同时发起 20 个请求 93 | urls.forEach(url => limitConcurrentRequests(url) 94 | .then(responses => console.log(responses.data)) 95 | .catch(error => console.error(error))); 96 | ``` 97 | 98 | 在以上代码中,我们定义了一个包含 20 个 URL 的数组 `urls`,通过循环同时发送 20个请求。最后,我们通过 `then` 和 `catch` 方法分别处理请求成功和失败的情况,并打印出结果。 99 | 100 | # 前端重试机制的实现 101 | 102 | 有时,由于网络环境的不稳定性,发送的请求可能会失败,因此我们需要对请求添加重试机制。在实现重试机制时,我们需要注意以下几点: 103 | 104 | - 需要限制重试的次数,避免无限重试; 105 | - 在重试过程中,需要添加一定的延迟时间,以避免过于频繁地发送请求; 106 | - 重试时需要保证请求的幂等性,即多次重试的结果应该与单次请求的结果一致。 107 | 108 | 以下是一个使用 axios 实现前端重试机制的示例代码: 109 | 110 | ```javascript 111 | const axios = require('axios'); 112 | 113 | // 最大重试次数,避免无限重试 114 | const MAX_RETRY_TIMES = 3; 115 | // 重试延时,避免频繁发送请求 116 | const RETRY_DELAY = 1000; 117 | 118 | /** 119 | * 支持重试机制的请求方法,整体方案是通过 Promise 包裹 Axios【这点和并发请求 limitConcurrentRequests 思路一样】 + 递归的逻辑来实现 120 | * @param { string } url 请求地址 121 | * @param { AxiosRequestConfig } config Axios 的请求配置 122 | * @param { number } retryTimes 请求最大重试次数 123 | * @returns Promise 124 | */ 125 | function retryableRequest(url, config, retryTimes = MAX_RETRY_TIMES) { 126 | return new Promise((resolve, reject) => { 127 | // 通过 Axios 发送请求 128 | axios(url, config) 129 | .then((response) => { 130 | // 请求成功,直接将 Promise 状态变为 fulfilled 131 | resolve(response); 132 | }) 133 | .catch((error) => { 134 | // 请求失败 135 | if (retryTimes === 0) { 136 | // 剩余重试次数为 0,表示本次请求失败,将 Promise 状态从 pending 更新为 rejected 137 | reject(error); 138 | } else { 139 | // 还能继续重试,RETRY_DELAY 秒之后,递归调用 retryableRequest 方法,重新发送请求 140 | setTimeout(() => { 141 | // 递归逻辑,通过递归来实现重试,每次递归重试次数 -1;根据下层 retryableRequest 方法的 Promise 结果更新当前 Promise 的状态 142 | retryableRequest(url, config, retryTimes - 1) 143 | .then((response) => { 144 | // 请求成功,将 Promise 状态从 pending 更新为 fulfilled 145 | resolve(response); 146 | }) 147 | .catch((error) => { 148 | // 请求失败,表示本次请求失败,将 Promise 状态从 pending 更新为 rejected 149 | reject(error); 150 | }); 151 | }, RETRY_DELAY); 152 | } 153 | }); 154 | }); 155 | } 156 | 157 | module.exports = { retryableRequest }; 158 | 159 | ``` 160 | 161 | 在以上代码中,我们设置了一个 MAX_RETRY_TIMES 常量,表示最大重试次数,同时定义了一个 RETRY_DELAY 常量,表示重试的延迟时间。我们通过定义 retryableRequest 方法来实现重试机制,它会通过递归调用自身来重试请求,同时在每次重试前会添加一定的延迟时间以避免频繁发送请求。如果重试次数超过了最大重试次数,就会抛出错误。 162 | 163 | 以下是一个使用重试机制的示例代码: 164 | 165 | ```javascript 166 | const { retryableRequest } = require('./retry'); 167 | 168 | retryableRequest('https://jsonplaceholder.typicode.com/posts/1', { method: 'get' }) 169 | .then((response) => { 170 | console.log(response.data); 171 | }) 172 | .catch((error) => { 173 | console.error(error); 174 | }); 175 | 176 | ``` 177 | 178 | 在以上代码中,我们使用了 retryableRequest 方法来发送请求,并在 then 和 catch 方法中处理请求成功和失败的情况。如果请求失败,重试机制会自动尝试重新发送请求,直到达到最大重试次数或请求成功为止。 179 | 180 | # 并发限制 + 请求重试 181 | 182 | 上面分别讲述了 `前端并发限制` 和 `前端重试机制` 的实现,但两者逻辑独立,接下来会将两者结合,整体思路是在 并发限制 的基础上增加 请求重试。 183 | 184 | ```javascript 185 | const axios = require('axios'); 186 | 187 | // 最大并发请求数 188 | const MAX_CONCURRENT_REQUESTS = 5; 189 | 190 | // 请求队列 191 | const requestQueue = []; 192 | // 当前正在进行中的请求数 193 | let activeRequests = 0; 194 | 195 | /** 196 | * 处理请求队列中的请求 197 | */ 198 | function processQueue() { 199 | // 如果当前进行中的请求数没达到最大并发数 && 请求队列不为空 200 | if (activeRequests < MAX_CONCURRENT_REQUESTS && requestQueue.length > 0) { 201 | // 从请求队列中取出队头的请求 202 | const { url, config, retryTimes, retryDelay, resolve, reject } = requestQueue.shift(); 203 | // 进行中的请求数 +1 204 | activeRequests++; 205 | // 通过 Axios 发送请求 206 | axios(url, config) 207 | .then((response) => { 208 | // 请求成功,将 外层 Promise 的状态更新为 fulfilled,并返回请求结果 209 | resolve(response); 210 | }) 211 | .catch((error) => { 212 | // 请求失败 213 | if (retryTimes === 0) { 214 | // 剩余重试次数为 0,表示本次请求失败,将 外层 Promise 的状态更新为 rejected,并返回错误信息 215 | reject(error); 216 | } else { 217 | // 还能继续重试,将请求重新入队 218 | setTimeout(() => { 219 | requestQueue.push({ url, config, retryTimes: retryTimes - 1, retryDelay, resolve, reject }); 220 | }, retryDelay); 221 | } 222 | }) 223 | .finally(() => { 224 | // 不论成功还是失败都会执行 finally,表示本次请求结束,将进行中的请求数 -1 225 | activeRequests--; 226 | // 再处理请求队列中的下一个请求 227 | processQueue(); 228 | }); 229 | } 230 | } 231 | 232 | /** 233 | * 请求方法 234 | * @param { string } url 请求的 url 235 | * @param { AxiosRequestConfig } config Axios 的请求配置 236 | * @param { number } retryTimes 最大重试次数,避免无限重试 237 | * @param { number } retryDelay 试延时,避免频繁发送请求 238 | */ 239 | function request(url, config, retryTimes = 3, retryDelay = 1000) { 240 | // 这里很关键,将用户发起的每个请求都变成一个 Promise,而 Promise 的状态会在 processQueue 中根据 Axios 的执行结果来更新 241 | return new Promise((resolve, reject) => { 242 | // 将请求的配置信息 和 更新 Promise 状态的两个方法变成一个对象推入请求队列中 243 | requestQueue.push({ url, config, retryTimes, retryDelay, resolve, reject }); 244 | // 执行 processQueue 方法处理请求队列中的每个请求 245 | processQueue(); 246 | }); 247 | } 248 | 249 | module.exports = { request }; 250 | 251 | ``` 252 | 253 | # 总结 254 | 255 | 并发控制 + 请求重试整体思路还是比较简单的,Promise + 队列是关键。大家可以基于文中的代码扩充自己的业务逻辑。 256 | 257 | 这套思路可使用的场景有很多,比如 通过 refreshToken 刷新 token、URL 携带 ticket 实现免登录 等。 258 | 259 | 通过使用并发限制和重试机制,我们可以更好地控制前端请求的发送和处理。在实际开发中,我们需要根据具体的业务场景来选择合适的并发限制和重试机制,以确保请求的成功率和性能。 260 | 261 |
262 | 263 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 264 | 265 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 266 | 267 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star 268 | 269 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)** 270 | -------------------------------------------------------------------------------- /PDF 生成/PDF 生成(6)— 服务化、配置化.md: -------------------------------------------------------------------------------- 1 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 2 | 3 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 4 | 5 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 6 | 7 | # 封面 8 | 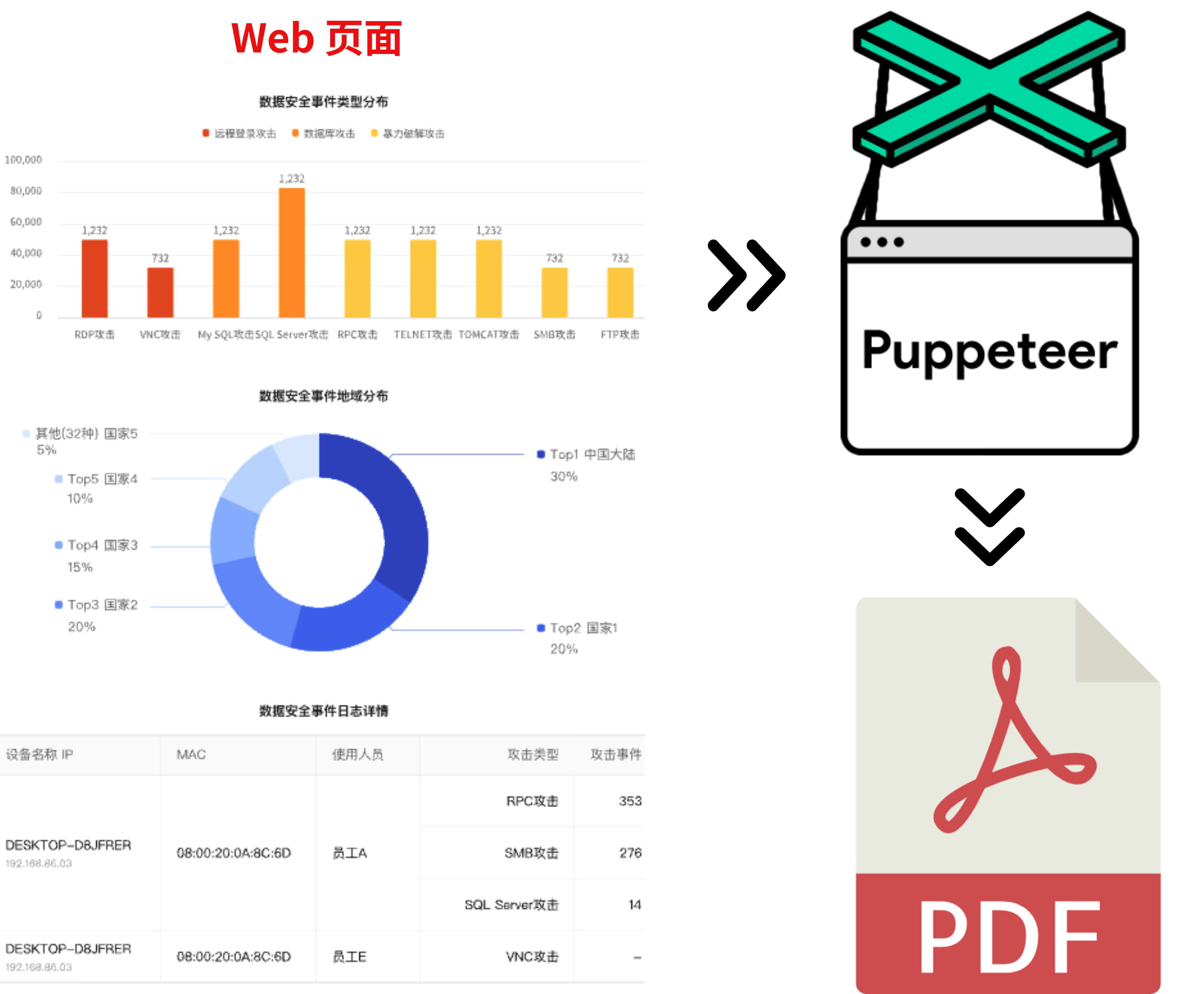 9 | # 回顾 10 | 前面我们分别通过 [PDF 生成(1)— 开篇](https://github.com/liyongning/blog/issues/42)、[PDF 生成(2)— 生成 PDF 文件](https://github.com/liyongning/blog/issues/43)、[PDF 生成(3)— 封面、尾页](https://github.com/liyongning/blog/issues/44)、[PDF 生成(4)— 目录页](https://github.com/liyongning/blog/issues/45)、[PDF 生成(5)— 内容页支持由多页面组成](https://github.com/liyongning/blog/issues/46) 五篇来讲解 PDF 生成的整个方案,到目前为止,整套方案基本完成了: 11 | 12 | - 我们通过 PDF 文件合并技术让一份 PDF 文件包含封面、内容页和尾页三部分 13 | - 通过在内容页的开始位置动态插入 HTML 锚点、页面缩放、锚点元素高度计算、换页高度补偿等技术让 PDF 文件拥有了包含准确页码 + 页面跳转能力的目录页 14 | - 通过多页面合并技术 + 样式沙箱解决了用户在复杂 PDF 场景下前端代码维护问题,让用户的开发更自由、更符合业务逻辑 15 | 16 | 至此,PDF 生成的能力齐了,但怎么给用户使用呢?这就是本文要解决的问题了。 17 | # 简介 18 | 前面我们花了大量的精力来完善整个 PDF 生成方案,现在从 PDF 生成角度来说,能力已经齐备,但整个服务以及相关配置都运行在本地,没办法直接给用户使用。 19 | 20 | 所以本文我们就将 PDF 生成能力通过**服务化**暴露给用户,相关资源**配置化**来适配不同的用户。 21 | 22 | # 服务化 23 | 通过为项目引入 Koa 框架来对外提供服务。 24 | 25 | - 安装 koa 和 @koa/router,`npm i koa @koa/router` 26 | - 新建`/server/koa-server.mjs`文件 27 | 28 | **/server/koa-server.mjs:** 29 | ```javascript 30 | import Koa from 'koa' 31 | import KoaRouter from '@koa/router' 32 | import { generatePDF } from './index.mjs' 33 | 34 | const app = new Koa() 35 | const router = new KoaRouter() 36 | 37 | // 当用户请求 http://localhost:3000 时,触发 generatePDF() 函数生成 PDF 文件 38 | router.get('/', function(ctx) { 39 | generatePDF() 40 | 41 | ctx.body = { 42 | errno: 0, 43 | data: [], 44 | msg: '正在生成 PDF 文件' 45 | } 46 | }) 47 | 48 | app.use(router.routes()) 49 | 50 | app.listen(3000, () => { 51 | console.log('koa-server start at 3000 port') 52 | }) 53 | ``` 54 | **/server/index.mjs** 导出 generatePDF 方法 55 | 56 | 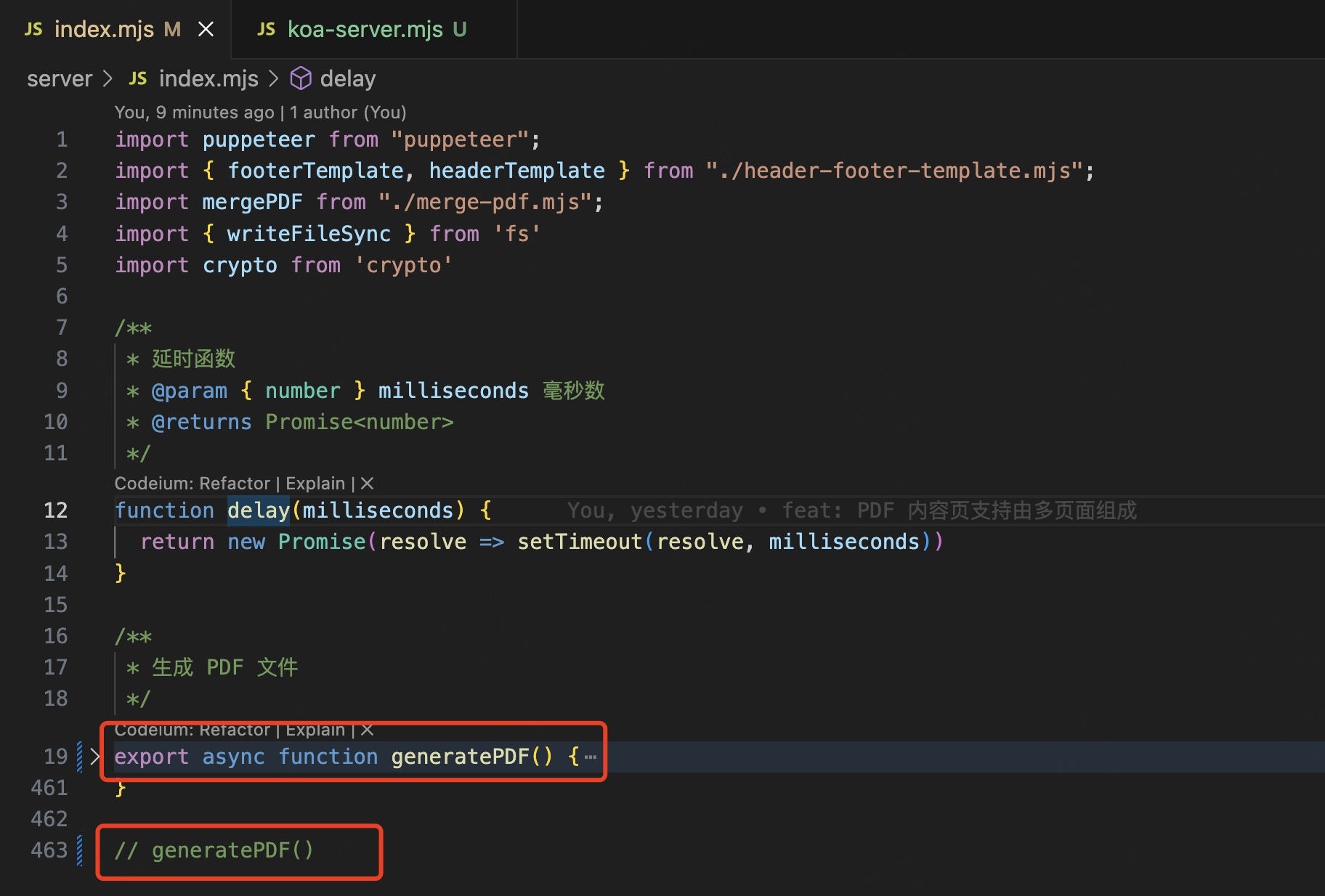 57 | 58 | 通过 node 或 nodemon 执行 **/server/koa-server.mjs**,然后在浏览器直接访问`http://localhost:3000`会看到 PDF 生成服务开始运行,并生成 PDF 文件。这样,我们的 PDF 生成能力就实现了对外的**服务化**。 59 | 60 | # 配置化 61 | 目前可以发现,PDF 文件的目录页配置、前端页面的 URL 等信息都是写死在代码中的,我们需要将这些信息以接入方为维度进行统一维护,并以服务的形式暴露给 PDF 生成服务。 62 | 63 | - 安装 axios,用来请求**配置服务**,`npm i axios` 64 | - 分别对`/server/koa-server.mjs`和`/server/index.mjs`进行如下改造 65 | 66 | **/server/koa-server.mjs** 67 | ```javascript 68 | import Koa from 'koa' 69 | import KoaRouter from '@koa/router' 70 | import { generatePDF } from './index.mjs' 71 | import axios from 'axios' 72 | 73 | const app = new Koa() 74 | const router = new KoaRouter() 75 | 76 | // 当用户请求 http://localhost:3000 时,触发 generatePDF() 函数生成 PDF 文件 77 | router.get('/', async function (ctx) { 78 | const appId = ctx.query.appId 79 | const { data: configData } = await axios.get(`http://localhost:3000/get-pdf-config?appId=${appId}`) 80 | // 异常情况 81 | if (configData.errno) { 82 | ctx.body = configData 83 | return 84 | } 85 | 86 | const { data } = configData 87 | generatePDF(data) 88 | 89 | ctx.body = { 90 | errno: 0, 91 | data: [], 92 | msg: '正在生成 PDF 文件' 93 | } 94 | }) 95 | 96 | // 获取指定 appId 所对应的配置信息 97 | router.get('/get-pdf-config', function (ctx) { 98 | const pdfConfig = { 99 | // 为接入方分配唯一的 uuid 100 | '59edaf80-ca75-8699-7ca7-b8121d01d136': { 101 | name: 'PDF 生成服务测试', 102 | // 目录页配置 103 | dir: [ 104 | { title: '锚点 1', id: 'anchor1' }, 105 | { title: '锚点 2', id: 'anchor2' }, 106 | { title: '第二个内容页 —— 锚点 1', id: 'second-content-page-anchor1' }, 107 | { title: '第二个内容页 —— 锚点 2', id: 'second-content-page-anchor2' }, 108 | ], 109 | // 接入方的前端页面链接 110 | pageInfo: { 111 | // 封面 112 | "cover": "file:///Users/liyongning/studyspace/generate-pdf/fe/cover.html", 113 | // 内容页 114 | "content": [ 115 | "file:///Users/liyongning/studyspace/generate-pdf/fe/exact-page-num.html", 116 | "file:///Users/liyongning/studyspace/generate-pdf/fe/second-content-page.html" 117 | ], 118 | // 尾页 119 | "lastPage": "file:///Users/liyongning/studyspace/generate-pdf/fe/last-page.html" 120 | }, 121 | // ... 还可以增加其他配置 122 | } 123 | } 124 | 125 | const appId = ctx.query.appId || '' 126 | if (!pdfConfig[appId]) { 127 | ctx.body = { 128 | errno: 100, 129 | data: [], 130 | msg: '无效的 appId,请联系服务提供方申请接入' 131 | } 132 | return 133 | } 134 | 135 | ctx.body = { 136 | errno: 0, 137 | data: pdfConfig[appId], 138 | msg: 'success' 139 | } 140 | }) 141 | 142 | app.use(router.routes()) 143 | 144 | app.listen(3000, () => { 145 | console.log('koa-server start at 3000 port') 146 | }) 147 | ``` 148 | 增加了配置服务`/get-pdf-config`,并在 PDF 生成服务中调用,获取配置内容,并将配置内容传递给了`generatePDF`方法。 149 | 150 | **/server/index.mjs** 151 | 152 |  153 |  154 | 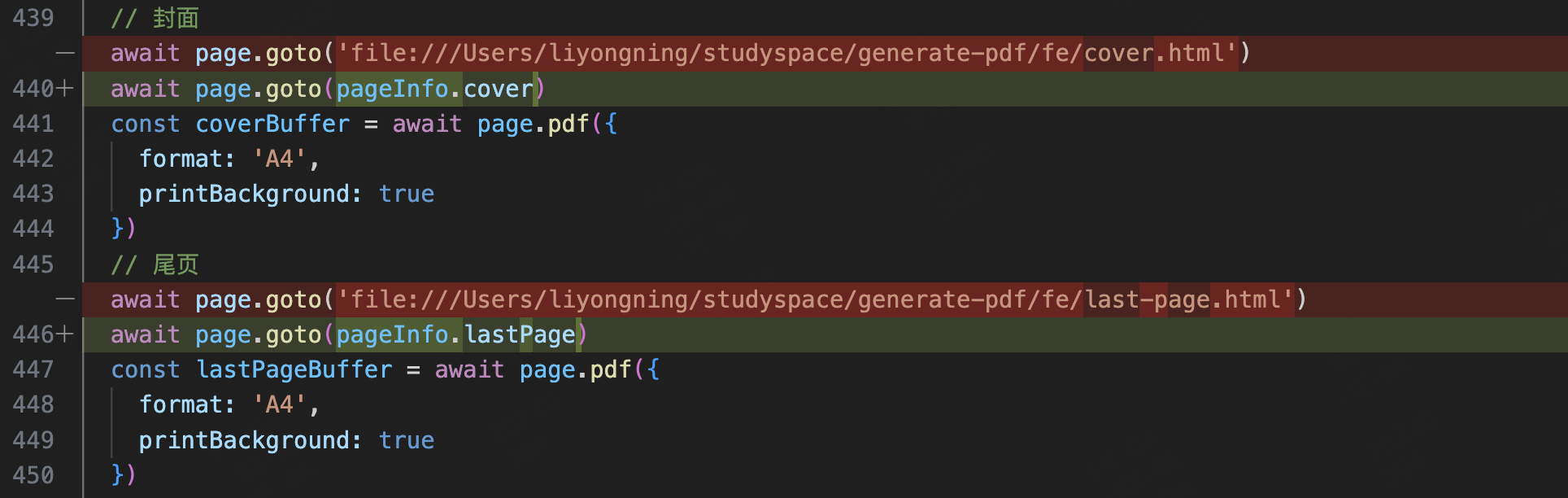 155 | 156 | PDF 的目录页配置、封面、内容页、尾页均改成了使用配置服务传递过来的数据,我们在浏览器访问`http://localhost:3000/?appId=59edaf80-ca75-8699-7ca7-b8121d01d136`即可生成 PDF 文件,如果访问时没有传 appId 会收到异常提示: 157 | 158 |  159 | 160 | 好了,配置化就讲到这里了,就像代码中提到的一样,所有和配置相关的信息都可以通过配置服务来维护,可根据自己的需求来进行扩充。 161 | 162 | # 并发控制(队列) 163 | 现在我们的 PDF 生成能力以服务的形式对外提供,并通过配置服务来维护接入方信息。经过一段时间的推广后,接入的用户越来越多,服务的调用量越来越大,这时候就会遇到服务稳定性的问题。 164 | 165 | 每个请求我们都会启动一个浏览器,一台 2核 4G内存的机器,三四个并发基本上就超负荷运行了,如果同时有更多的请求过来,直接就宕机了。所以,我们需要为服务增加一个并发控制。思路如下: 166 | 167 | - 给服务增加一个任务队列,这个队列可以通过 kafka 实现,也可以通过 redis 来实现,最差也可以程序自己维护一个单机版的内存队列(不推荐) 168 | - 每个请求进来时,先入队 169 | - 当队列中监听到有任务存在时,从队列中取出一个任务然后执行,这个取任务的频率可以由程序自己控制 170 | 171 | 这样,程序就不会因为请求量过大,而导致机器宕机。基于队列我们也可以做任务失败重试。 172 | ## 任务分类 173 | 服务又稳定的运行了一段时间,有天又收到了一个接入申请,这个接入方的使用场景是不定期的生成几千几万份报告,然后将这些报告打包发给销售,让销售进一步跟进用户。 174 | 175 | 这个需求很合理,但是会对我们现有的服务造成影响,试想,如果这个任务一旦启动,短时间就会在队列中堆积几万个待执行的任务,要消费完这些任务可能需要好几个小时甚至一整天,这会影响其他任务的执行,后入队的任务一直排在队尾,迟迟得不到执行。 176 | 177 | 这时候,我们就需要对任务进行分类,将任务分为实时和非实时,实时任务进入实时队列,非实时任务进入非实时队列,程序有优先消费实时队列中的任务,当实时队列为空时去消费非实时队列的任务,当两个队列都为空时,程序停止。 178 | 179 | # 其他优化 180 | 本系列的重点是演示 PDF 生成的核心思路和逻辑,所以有些地方的代码写的比较简单,比如没有做很好的模块化拆分、异常处理等,但这些完全不影响对整体架构的理解。 181 | 182 | 技术架构中我们还有一些能力没有实现,比如: 183 | 184 | - PDF 文件上传 S3,并将下载地址回传给接入方 185 | - 服务的安全校验,可以设置复杂的校验,也可以通过简单的参数签名来做,根据使用场景来决定 186 | - 告警推送,比如 PDF 文件生成异常告警、PDF 文件下载链接推送入群或发给个人等 187 | 188 | 剩下的这些功能都依赖一些内网服务,所以这里就没有一一演示了,只提供一些思路,大家可以根据自己的实际情况有选择性的学习和迭代。 189 | 190 | # 部署问题 191 | 192 | 项目开发结束后,一般都需要部署到服务器上,这时候你可能会遇到一些困难,比如: 193 | 194 | * 启动项目后,会发现有如下报错,其原因是服务器上缺少相关安装包,具体可查看 [鼓掌排除](https://pptr.nodejs.cn/troubleshooting) 下的 **Chrome 无法在 linux 上启动** 195 | 196 |  197 | 198 | * 如果遇到如下错误,是因为 nss 库版本过低,可通过 `rpm -q nss` 命令查看已安装的库信息,然后使用 `yum update nss` 进行升级 199 | 200 |  201 | 202 | * 这会儿,服务应该起来了,但执行的时候发现又报错了,这时候需要禁用沙箱,可以查看 [鼓掌排除](https://pptr.nodejs.cn/troubleshooting) 的 **设置 Chrome Linux 沙箱** 203 | 204 |  205 | 206 | * 这时候 PDF 终于生成了,但可能会发现 — **乱码了**,这是字符集问题,即服务器上没有对应的字体库,具体操作参考下面的**字体库**章节 207 | 208 |  209 | 210 | ## 字体库 211 | 212 | 如果生成的 PDF 文件出现了乱码问题,是因为服务器缺少字体库文件,我们需要为服务器增加相应的字体。比如我们使用的是 PingFang 和思源黑体,去找设计同学要一份字体文件,然后拷贝到 `/usr/share/fonts` 目录下,其中涉及到如下命令: 213 | 214 | * `fc-list | grep 'PingFang SC'` 查看是否有该字体库 215 | * 字体库配置文件 `/etc/fonts/fonts.config`,打开后发现,这就是为什么把新增字体文件放 `/usr/share/fonts` 目录的原因 216 | 217 |  218 | 219 | * 新增字体文件后执行 `fc-cache -f -v` 清空字体缓存,并会生成新的字体缓存 220 | 221 | # 总结 222 | 到这里,本文就结束了,我们来简单总结一些: 223 | 224 | - 我们通过 Koa 框架,将 PDF 生成能力以服务的形式对外暴露 225 | - 通过配置化服务来维护接入方的一些信息,比如业务名称、目录页的配置、PDF 文件封面、内容页、尾页对应的 URL 等,配置化服务配置的内容有很多,根据场景自行扩充 226 | - 通过队列来做并发控制,保证服务的稳定性 227 | - 通过对任务进行分类(实时和非实时),来保证实时任务的及时消费,非实时任务的稳定消费 228 | - 最后给大家提了一些其他可迭代的点,比如文件上传、下载地址回传、服务安全校验、告警推送等 229 | # 系列总结 230 | 如果你完整的阅读了整个系列,那么首先应该为自己鼓掌,毕竟又是成长的一段时间,另外一定要进行实操,光看不实践,学习效果还是会打一定的折扣。接下来我们就对本系列进行一个简单的回顾总结: 231 | 232 | - 首先我们在 [PDF 生成(1)— 开篇](https://github.com/liyongning/blog/issues/42) 中讲解了 PDF 生成的技术背景、方案选型和决策,以及整个方案的技术架构图,所以后面的几篇一直都是在实现整套技术架构 233 | - [PDF 生成(2)— 生成 PDF 文件](https://github.com/liyongning/blog/issues/43) 中我们通过 puppeteer 来生成 PDF 文件,并讲了自定义页眉、页脚的使用和其中的**坑**。本文结束之后 puppeteer 在 PDF 文件生成场景下的能力也基本到头了,所以,接下来的内容就全是基于 puppeteer 的增量开发了,也是整套架构的**核心**和**难点** 234 | - [PDF 生成(3)— 封面、尾页](https://github.com/liyongning/blog/issues/44) 通过 PDF 文件合并技术让一份 PDF 文件包含封面、内容页和尾页三部分。 235 | - [PDF 生成(4)— 目录页](https://github.com/liyongning/blog/issues/45) 通过在内容页的开始位置动态插入 HTML 锚点、页面缩放、锚点元素高度计算、换页高度补偿等技术让 PDF 文件拥有了包含准确页码 + 页面跳转能力的目录页 236 | - [PDF 生成(5)— 内容页支持由多页面组成](https://github.com/liyongning/blog/issues/46) 通过多页面合并技术 + 样式沙箱解决了用户在复杂 PDF 场景下前端代码维护问题,让用户的开发更自由、更符合业务逻辑 237 | - [PDF 生成(6)— 服务化、配置化](https://github.com/liyongning/blog/issues/47) 就是本文了,本系列的最后一篇,以服务化的方式对外提供 PDF 生成能力,通过配置服务来维护接入方的信息,通过队列来做并发控制和任务分类 238 | - [代码仓库](https://github.com/liyongning/generate-pdf) **欢迎 Star** 239 | 240 | 感谢大家花时间阅读,希望大家能从本系列学到对自己有用的知识,不论是 PDF 生成本身,还是整个思考迭代过程,亦或者是其中的某些点。 241 | 242 | --- 243 | 244 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 245 | 246 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 247 | 248 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 249 | 250 | -------------------------------------------------------------------------------- /浏览器工作原理/浏览器工作原理(1)— 多进程架构.md: -------------------------------------------------------------------------------- 1 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 2 | 3 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 4 | 5 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 6 | 7 | # 序 8 | 9 | 作为一名前端开发人员,我们要有一种认知:浏览器是未来。去操作系统和云化是两个大的方向,当它们达成目标时,浏览器将成为与用户接触的唯一渠道。研究浏览器,其本质就时研究交互和表现,这是前端的“终极私活”,因此无论是想设计高性能的 Web 应用,还是要优化现有的 Web 应用,我们都需要了解浏览器的工作原理,比如网络请求、页面渲染、JavaScript 执行流程,甚至是一些安全方面的理论知识,因此,了解浏览器是必要的。 10 | 11 | 但市面上对于浏览器的介绍一直都是零零散散的知识,自己也是一直希望能够深入了解浏览器,因此就有了本专栏。 12 | 13 | 专栏中所有的分析都是基于 Chrome 浏览器的,因为 Chrome、Edge 和国内大部分主流浏览器都是基于 Chromium 二次开发而来,而 Chrome 是 Google 的官方发行版,特性和 Chromium 基本一样,只存在一些产品层面的差异;再加上 Chrome 是目前世界上使用率最高的浏览器,所以 Chrome 最具代表性。 14 | 15 | > 根据市场调查机构 Statcounter 公布的最新报告,2024年2月份 Chrome 浏览器以 65.38% 的市场份额稳居全球浏览器份额第一,苹果的 Safari 浏览器以 18.31% 位居第二,微软 Edge 则以 5.07% 位居第三,可以发现 Chrome 的份额遥遥领先。在互联网 IT 从业者中,Chrome 浏览器的所占份额想必会更夸张,毕竟专业的程序员都用 Chrome。 16 | 17 | 我们以一个问题作为本系列的开始:**Chrome 打开一个页面需要启动多少个进程**?以[我的 Github 博客首页](https://github.com/liyongning/blog)为例,如图所示: 18 | 19 |  20 | 21 | 任务管理器可通过右上角的 `三个点(选项菜单)` -> 更多工具 -> 任务管理器 来打开。通过任务管理器我们发现一个页面打开了 6个进程。第一感觉:这有点夸张,我只是在浏览器中打开了一个页面而已,怎么产生了这么多进程?带着问题继续往下看。 22 | 23 | # 浏览器的发展 24 | 25 | 浏览器架构的发展大概有这么几个关键阶段:**单进程浏览器**、**多进程浏览器**、**沙箱技术的应用**、**WebAssembly** 技术的兴起。多进程浏览器 + 沙箱技术的应用解决了单进程浏览器时代的稳定性、安全性和性能问题。而 WebAssembly 技术的出现,则是为前端带来了太多新的可能性。 26 | 27 | ## 单进程浏览器 28 | 29 | 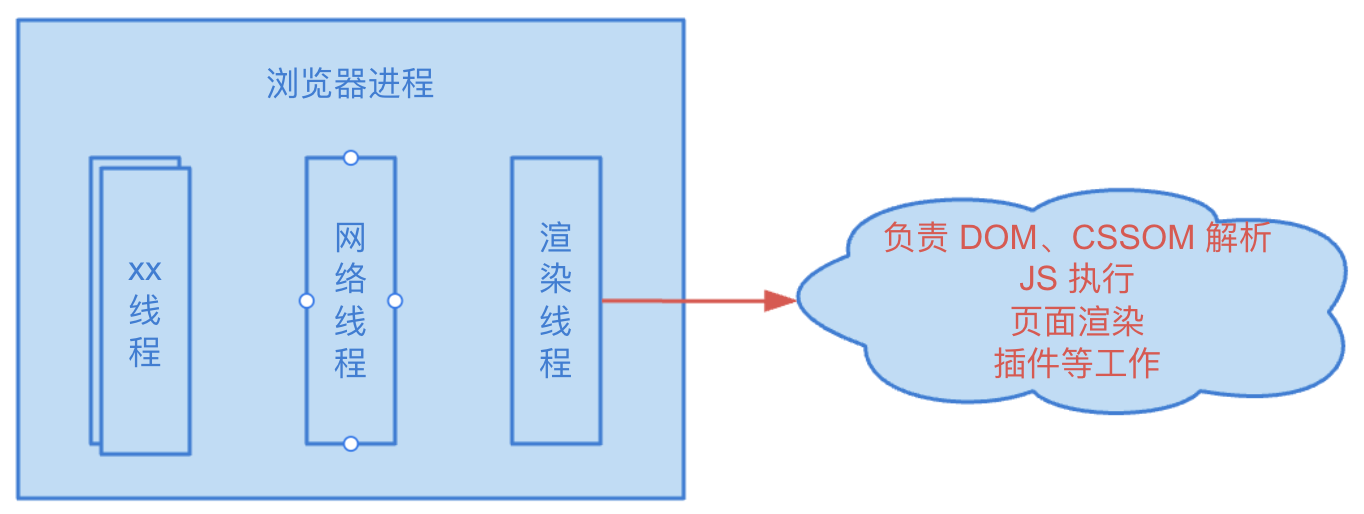 30 | 31 | 最早期的浏览器都是单进程架构,顾名思义,我们在浏览器看到的所有模块(比如工具栏、页面、插件、网络请求、JS 等)都运行在一个进程中。这些功能模块或通过进程来执行,或以线程的方式来运行,这就导致了如下问题 32 | 33 | ### 不稳定 34 | 35 | 一个进程中运行了如此多的线程,任何一个线程崩溃都可能会导致整个进程崩溃,会想一下早先年我们是不是经常碰到如下场景: 36 | 37 | **插件导致浏览器崩溃**:我们在浏览器中安装了一个稳定性较差的插件,或者早先年我们需要借助插件来实现 Web 视频播放或游戏等强大功能,但插件是最容易出现问题的模块,插件模块是作为一个线程运行在浏览器进程中的,一旦插件出现问题,就可能会导致整个浏览器崩溃。 38 | 39 | **渲染线程导致浏览器崩溃**:渲染线程负责执行用户代码完成页面渲染,如果某段用户代码出现异常,比如无限循环或复杂的 JS 代码,导致线程卡死,就会出现所有页面卡死,甚至浏览器崩溃的场景,而且那么多页面运行在一个线程中,没人能保证打开的页面都是稳定的。 40 | 41 | ### 不安全 42 | 43 | 页面脚本可以通过浏览器漏洞来获取系统权限,从而直接操作你的电脑,对电脑做一些恶意的事情。 44 | 45 | 插件可以使用 C 或 C++ 来编写,通过插件可以获取到系统的任意资源,这就意味着,页面上运行的插件可以操作你的电脑,从而释放一些病毒文件、执行一些病毒程序等,从而导致电脑出现安全问题。 46 | 47 | ### 不流畅 48 | 49 | 一个浏览器,只有一个进程,一个进程下只有一个渲染线程,浏览器中打开的所有页面都运行在这一个线程上。如果某个页面有一段这样的 JS 代码: 50 | 51 | ```javascript 52 | function loop() { 53 | console.log('loop function running') 54 | loop(); 55 | } 56 | loop(); 57 | ``` 58 | 59 | 这是一段循环调用的代码,执行后会出现什么样的报错,大家都很清楚。但在单进程架构的浏览器下,这样一段代码带来的问题就很严重了:这段代码一旦开始执行后,它就会一直占用线程,直到爆栈,在这期间,其他页面一直无法得到响应(因为线程被当前代码占用),就会出现假死甚至真卡死的情况,直到爆栈导致线程崩溃,从而导致整个浏览器崩溃。 60 | 61 | 以上三个现象,在早期的浏览器中,相信大家经常会遇到,特别是在浏览器中给老板写邮件期间,打开了某个页面,查询个什么信息,出现了上述三种情况,直接崩溃。。 62 | 63 | ------ 64 | 65 | 读到这里,相信可能会有人有这样一个疑问:**单进程浏览器开多个页面,渲染线程只有一个吗?一个页面配一个渲染线程不是更合理吗**? 66 | 67 | 这个问题需要从 IE6 讲起,IE6 浏览器是单进程的,一个窗口配一个标签页。当时国产浏览器基于 IE6 二次开发,但它们需要一个窗口配多个标签页,这就意味着所有页面都共享同一套 JS 运行环境,所以一个标签页的卡顿会影响整个浏览器。 68 | 69 | 所以国产浏览器开始尝试支持页面多线程,也就是让每个页面运行在单独的线程中,意味着每个线程拥有单独的 JS 执行环境和 Cookie 环境,但这时候发现个问题,比如:A 站点登录了一个网站,保存了一些 Cookie 到磁盘上,并且在当前线程中保存了一些 Session 数据,但由于 Seesion 不存盘,所以 Session 只会存在当前的线程环境中,这时候在另外一个 Tab 页打开 A 站点,就会发现获取不到 Session 数据。所以,需要实现一个 Session 同步能力,但由于 IE 并没有暴露源码,所以实现起来非常困难,国内花了很长时间才解决这个问题。 70 | 71 | Session 问题虽然解决了,但页面假死问题依然存在,因为进程内使用了一个窗口,这个窗口依附到浏览器主窗口之上,所以它们共用一套消息循环机制,这就意味着如果一个窗口卡死,也会导致整个浏览器卡死。于是国产浏览器就把页面做成一个单独的窗口,如果这个页面卡死了,就把这个窗口隐藏掉。但 Chrome 为什么不会出现页面假死影响到主窗口的问题呢?这是因为 Chrome 输出的内容是图像,浏览器把图像贴到自己的窗口上,在 Chrome 的渲染进程内,并没有一个渲染窗口,输出的只有图像,如果卡住了,最多图像不更新。 72 | 73 | 国产浏览器这套技术花了四五年时间,等整套技术差不多成熟时,Chrome 发布了...... 74 | 75 | ## 早期的多进程架构 76 | 77 | 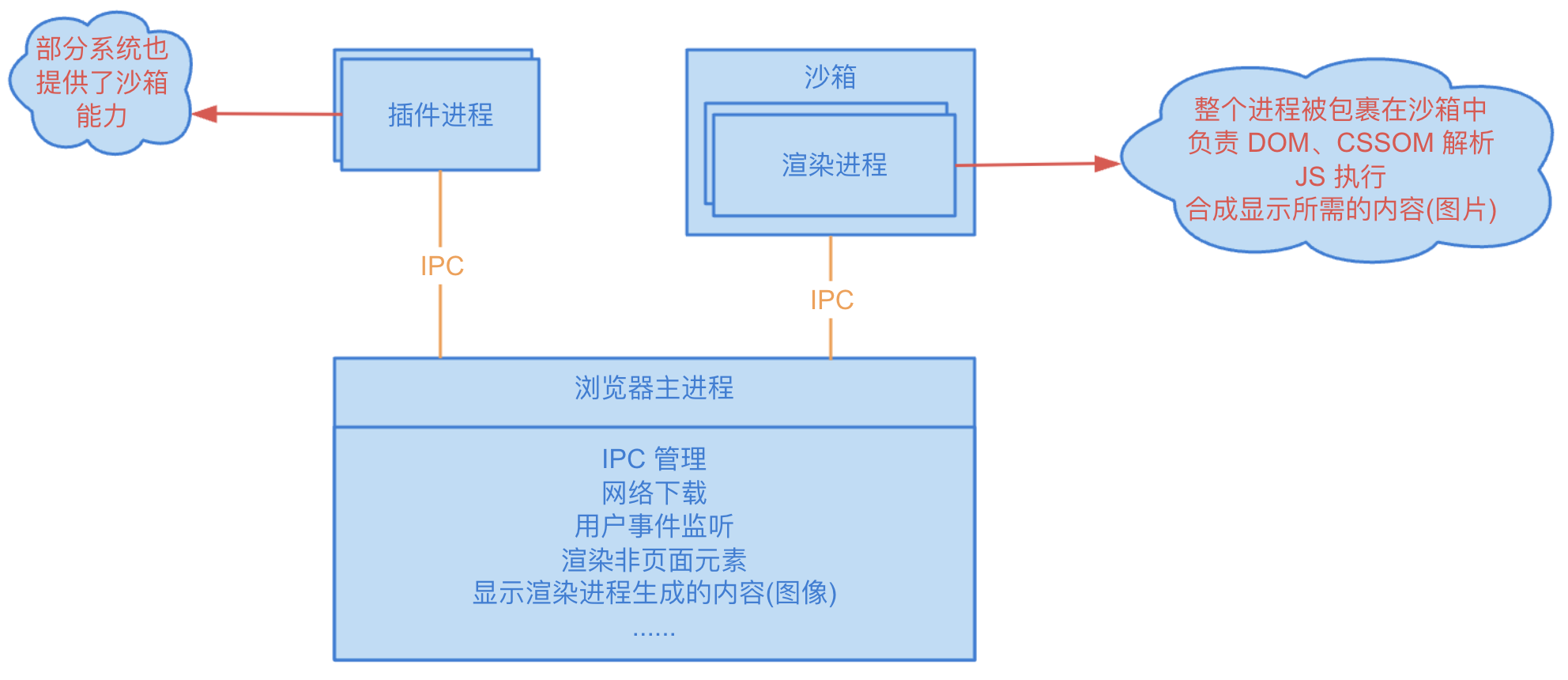 78 | 79 | 2008 年,Chrome 多进程架构发布了,可以看到页面渲染和插件从主进程中独立出来了,每个页面运行在独立的渲染进程中,插件则运行在插件进程中,进程之间通过 IPC 机制进行通信。现在再来看看多进程架构是如何解决单进程架构的问题的。 80 | 81 | ### 不稳定 82 | 83 | **进程之间是相互隔离的**,所以个别插件和页面的崩溃只会影响各自的插件进程和渲染进程,而不会影响到其他插件进程和渲染进程,更不会影响到浏览器主进程。 84 | 85 | ### 不安全 86 | 87 | 安全性问题是通过**沙箱**来解决。可以看到在渲染进程和插件进程外面套了一层沙箱,通过沙箱来限制渲染进程的操作权限,比如禁止对磁盘进行读写,和系统的交互都是借助主进程来完成的。沙箱的应用是得益于多进程架构,因为在单进程中不能直接给整个浏览器套一层沙箱,浏览器主进程的权限相对来说还是比较高的(非 root 权限)。 88 | 89 | ### 不流畅 90 | 91 | 还是**进程之间是相互隔离的**,JS 执行、页面渲染影响的只有当前渲染进程,而不会影响到其他页面所在的渲染进程。另外,内存是在进程中管理的,即使出现内存泄漏,把当前页面关了,渲染进程也就被释放了,内存泄漏的问题自然也就没了。 92 | 93 | ## 当前的多进程架构 94 | 95 | 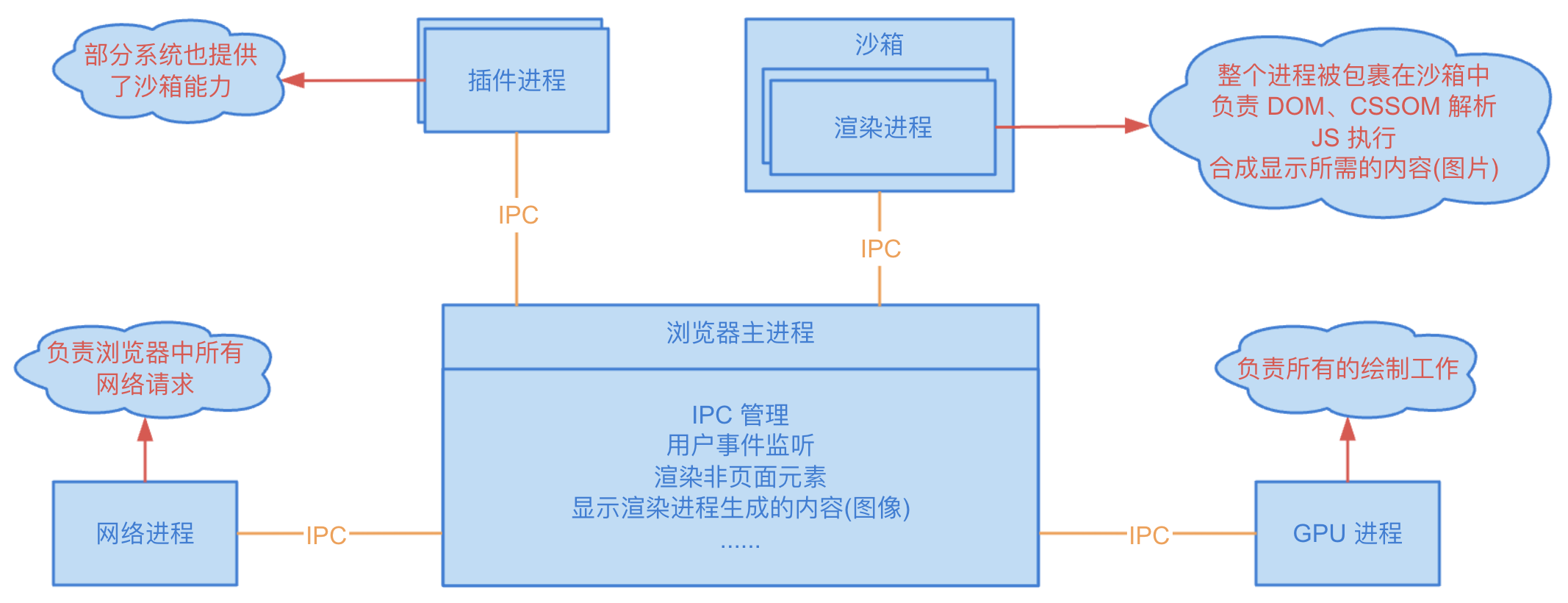 96 | 97 | Chrome 浏览器的迭代从未停止,可以看到进程分离做的越来越极致,相比于最初的多进程架构,现在将网络进程和 GPU 进程也从主进程中独立出来了。所以目前,浏览器的包括:一个主进程、一个网络进程、一个 GPU 进程、多个插件进程和多个渲染进程。 98 | 99 | **主进程**:负责浏览器主框架(浏览器窗口、地址栏、书签栏等非用户界面)的管理、用户交互、子进程管理、存储管理、系统交互等。 100 | 101 | **网络进程**:负责浏览器中所有网络资源的加载。 102 | 103 | **GPU 进程**:早期是为了满足 CSS 3D 渲染的需求,但后来 UI 页面也采用 GPU 来绘制,所以 GPU 就成为了浏览器的普遍需求。 104 | 105 | **插件进程**:负责运行插件,插件易崩溃,所以将插件隔离在独立的进程内,即使崩溃也不会影响到浏览器和用户页面。 106 | 107 | **渲染进程**:负责将 HTML、CSS、JS 转换为用户可以与之交互的界面。排版引擎 Blink 和 JS 引擎 V8 都运行在该进程下。浏览器会为每个 Tab 页创建一个渲染进程,处于安全考虑,每个渲染进程都运行在沙箱里。 108 | 109 | ### 多进程架构的缺陷 110 | 111 | 凡事都有利弊,多进程架构虽然提升了浏览器的稳定性、安全性和流畅性,但也带来了一些额外的问题: 112 | 113 | **更高的资源占用**,每个进程都包含了一些公共基础模块,这就意味着浏览器会消耗更多的内存资源。 114 | 115 | **更复杂的架构设计**,浏览器各模块之间耦合性高、扩展性差,导致现在的架构已经很难适应新的需求了。 116 | 117 | ## 模块服务化 118 | 119 | 针对现有问题,Chrome 团队使用**面向服务的架构**思想设计了新的 Chrome 架构,一句话简单总结就是:代码重构、拆分,让代码组织更合理,一些基础能力以服务的形式对外提供,而不再耦合在进程中。到目前为止有些能力已经发布了,但有些模块还在持续开发中,这是一项任重而道远的工作。 120 | 121 | 另外,Chrome 提供了一种弹性架构,当性能强大的宿主机上会以多进程的模式进程,但在资源受限的机器上,则会将部分服务整个到一个进程中,从而节省资源。 122 | 123 | # 进程计算 124 | 125 | 看完 Chrome 整个架构发展的历程,现在我们再回头看开头提到的那个问题:**Chrome 打开一个页面需要启动多少个进程**?以[我的 Github 博客首页](https://github.com/liyongning/blog)为例。 126 | 127 | 直接回答应该是:一个浏览器进程、一个 GPU 进程、一个网络进程、一个渲染进程,所以 Chrome 打开一个页面至少需要启动 4个进程。 128 | 129 | 实际答案如图所示: 130 | 131 |  132 | 133 | 会发现有些和预期不一样的地方: 134 | 135 | * **网络服务**:不是预期中的网络进程,这个就是 Chrome 最新的**面向服务的架构**,将一些基础的公共能力以服务的形式对外提供,比如图中所示的网络服务和存储服务。 136 | * **存储服务**:是因为当前页面用了浏览器的存储,比如 localStorage 和 sessionStorage 137 | * **备用渲染程序**:在主渲染进程发生故障时,Chrome 会尝试重启该进程或启动一个备用渲染程序,以保持用户当前打开页面的稳定性和可用性,这样可以避免页面崩溃或者导致用户数据丢失的情况发生 138 | 139 | 读到这里,是否有这样一个疑问:**如何计算 Chrome 中渲染进程的个数**? 140 | 141 | ## 如何计算 Chrome 中渲染进程的个数 142 | 143 | ### 正常情况,一个页面至少需要一个渲染进程 144 | 145 | 比如有如下代码,打开后只有一个渲染进程 146 | 147 | ```html 148 | 149 | 150 | 151 | 152 | 153 |
157 | 主页面
158 |
159 |
160 |
161 | ```
162 |
163 | 
164 |
165 | 基于这个正常情况下的结论我们再来看特殊情况
166 |
167 | ### 浏览上下文组中同一站点的页面共用一个渲染进程
168 |
169 | 比如,对主页面进行简单的改动,通过 window.open 打开同站点的另一个页面,如下代码
170 |
171 | ```html
172 |
173 |
174 |
175 |
176 |
177 |
181 | 主页面
182 |
183 |
184 |
185 | page2
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
198 |
199 |
200 | ```
201 |
202 | 发现 page2 并没有新开渲染进程,而是和主页面共用一个渲染进程
203 |
204 | 
205 |
206 | #### 浏览上下文组
207 |
208 | 我们把一个标签页所包含的内容,比如 window 对象、历史记录、滚动条位置等信息称为浏览上下文,而通过脚本相互连接的浏览上下文就是**浏览上下文组**。一般通过以下方式打开的页面或弹窗和父页面同属一个上下文组:
209 |
210 | * 通过`window.open`方法打开页面
211 | * 通过 a 标签在当前标签页打开一个同站点的页面
212 | * form 表单提交后的结果页在当前页打开
213 | * alert、confirm、promt 打开的弹窗
214 | * 当前页中内嵌的 iframe 页面,和父页面同属一个浏览上下文组
215 |
216 | 如果不想让 window.open 和 a 标签打开的页面和父页面产生关联,可以使用 **noopener**、**noreferrer** 属性,意思是让新页面的 window.opener 为 null 并且和父页面不产生关联,这时候会发现两个页面各占一个渲染进程。
217 |
218 | ```javascript
219 | // 可以通过 newWindow 来操作新页面,但会受跨域的限制
220 | const newWindow = window.open('xxx')
221 | ```
222 |
223 | #### 什么是跨站、跨域
224 |
225 | * **是否跨站**:当协议和二级域名相同,即为同站,否则为跨站。
226 |
227 | > 以 https://baidu.com 为例,https 为协议,.com 为根域(顶级域名、一级域名),baidu.com 为二级域名
228 |
229 | * **是否跨域**:当协议、域名和端口号相同,即为同域,否则为跨域。
230 |
231 | #### 如何判断一个请求是同站、同域还是跨站?
232 |
233 | 所有的新型浏览器发送请求时,都会携带 **Sec-Fetch-Site** HTTP 标头,标头的值为:cross-site、same-site、same-origin、none。
234 |
235 | 通过检查 Sec-Fetch-Site 的值,可以确定请求是 same-site、same-origin 还是 cross-site,比如:
236 |
237 | * 同站,都是 https + 360.cn
238 |
239 | 
240 |
241 | * 跨站,二级域名不同,一个是 360.cn,一个是 qihoo.net
242 |
243 | 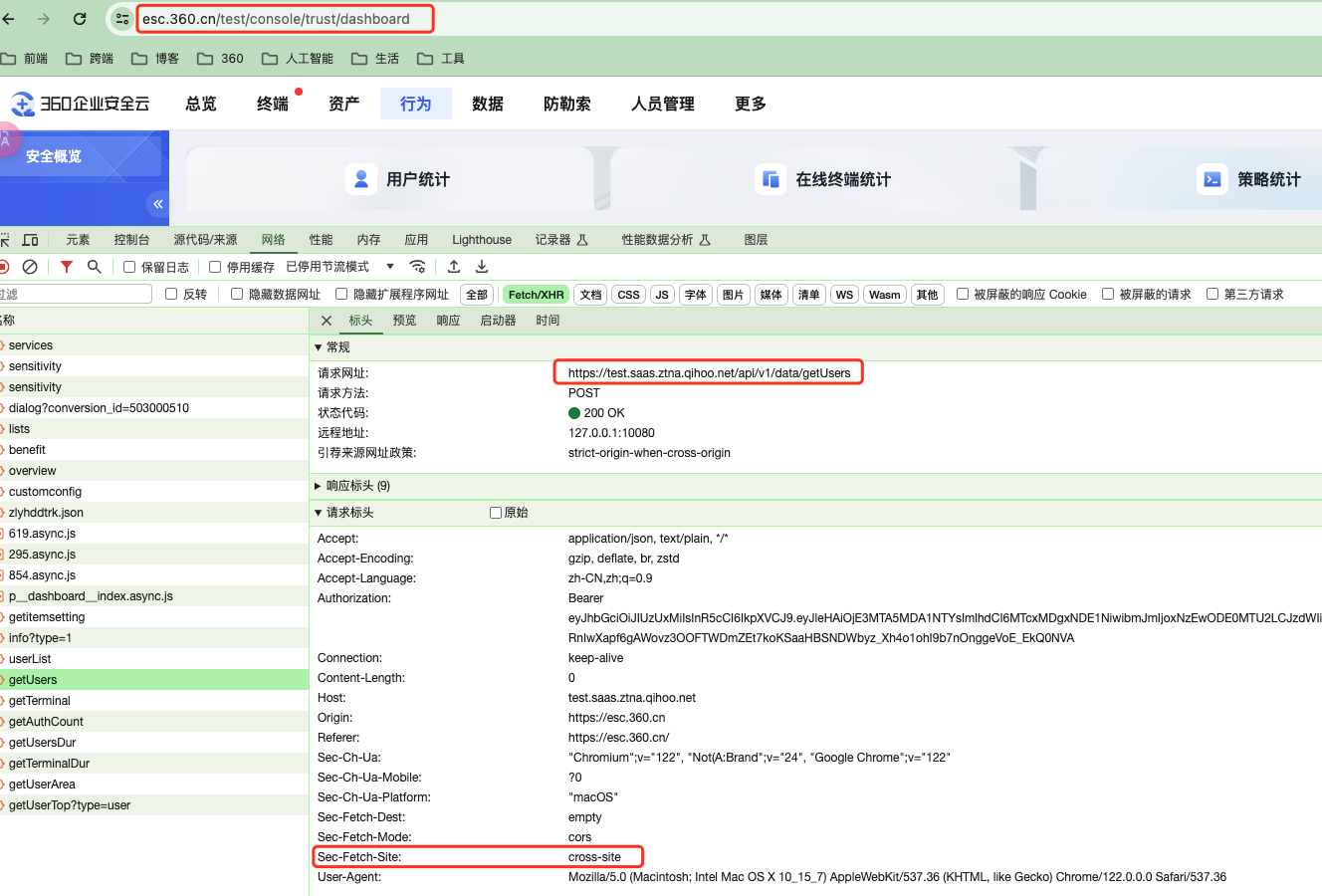
244 |
245 | * 同域,协议、域名、端口号一样,都是 https://sentry.esc.360.cn,端口号为默认端口 —— 443
246 |
247 | 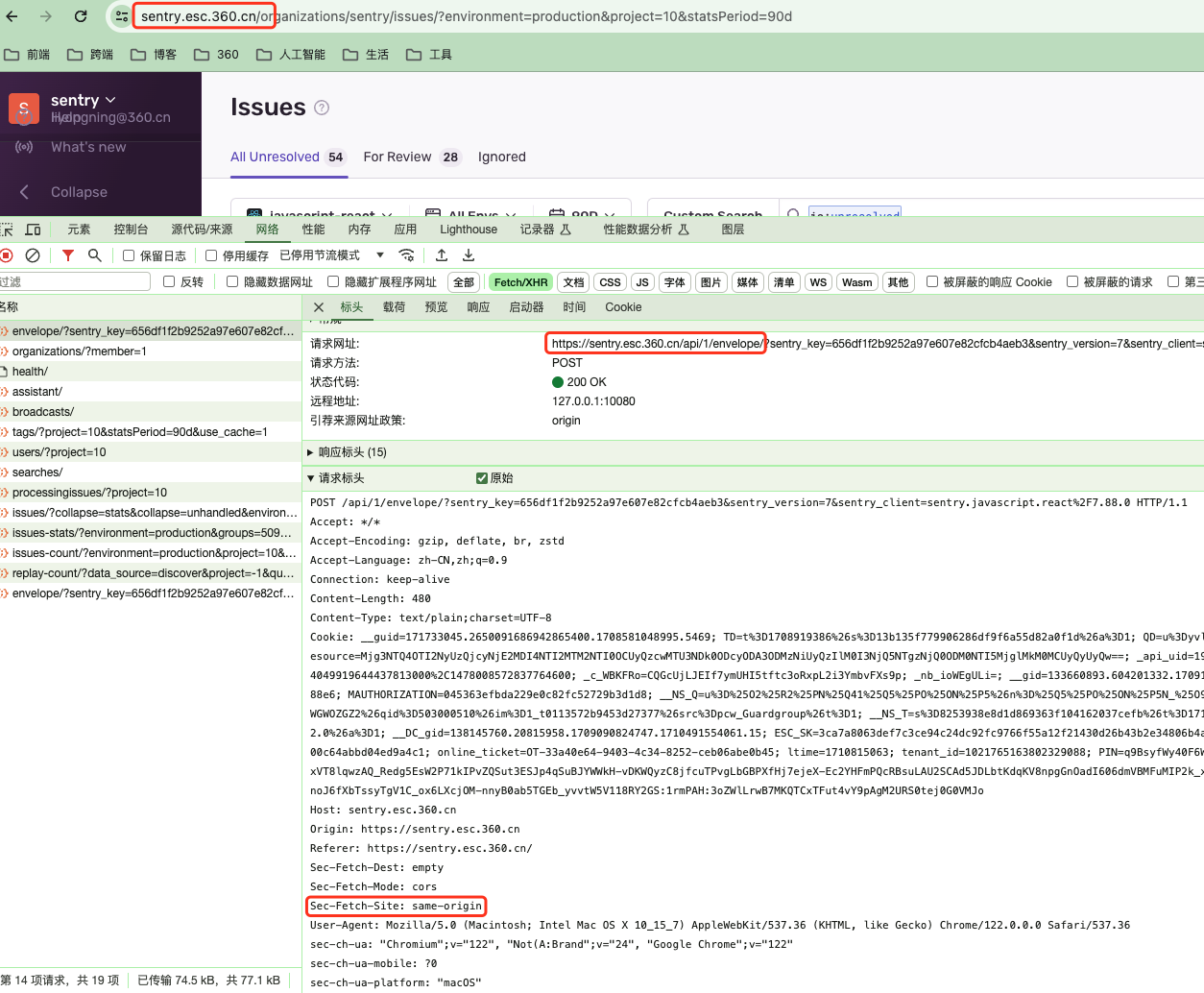
248 |
249 | 你可以合理信任 Sec-Fetch-Site 标头的值,原因如下:
250 |
251 | * JavaScript 无法修改以 Sec- 开头的 HTTP 标头
252 | * 这些标头使用由浏览器设置
253 |
254 | 即使服务器收到了被客户端篡改的 Sec-Fetch-Site 标头,页不会因违反同源策略而对用户或浏览器造成危害。
255 |
256 | ## Chrome 打开一个页面需要启动多少个进程?
257 |
258 | 到这里,我们就可以完整的回答文章开头提到的问题了:
259 |
260 | * 首先,打开一个面至少需要启动 4个进程,分别是一个浏览器进程、一个网络进程(服务)、一个 GPU 进程、一个渲染进程。
261 |
262 | * 如果页面中使用了浏览器存储,还会再打开一个存储进程(服务)。
263 |
264 | * 如果页面运行了 x 个插件,则还会有 x 个插件进程。
265 |
266 | * 如果页面中内嵌了 x 个跨站的页面,则会额外再启动 x 个渲染进程。
267 |
268 | # 总结
269 |
270 | 到这里,本文就结束了,作为本系列的开篇,文章主要讲解了如下内容:
271 |
272 | * 开头,讲了为什么会有本系列。一是为什么要深入了解浏览器?二是浏览器方面的知识都是零零散散的,三是本系列也相当于自己学习的一个记录(笔记)
273 | * 第二部分讲了浏览器的四个发展阶段,从单进程架构 -> 早期多进程架构 -> 成熟的多进程架构 -> 多进程架构 + 模块服务化。每一次迭代都是为了解决特定的问题,让用户体验更好
274 | * 基于问题 —— **Chrome 打开一个页面需要启动多少个进程**,讲了如何计算浏览器中的进程数。顺带讲了浏览上下文组、跨站、跨域的相关概念
275 |
276 | 宏观层面的浏览器架构相关知识到这里就结束了,但后面的页面**导航过程**和**渲染过程**会有更细节的讲解,下篇我们将讲解**浏览器中的网络知识**。
277 |
278 | ---
279 |
280 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。
281 |
282 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg)
283 |
284 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。
285 |
--------------------------------------------------------------------------------
/其它/开发环境配置安全的 HTTPS 协议.md:
--------------------------------------------------------------------------------
1 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。
2 |
3 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg)
4 |
5 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。
6 |
7 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)**
8 |
9 | 10 | 11 | # 简介 12 | 13 | 本文采用实战 + 原理的方式来讲述,目的是为了在开发环境使用安全的 https 协议,并了解其背后涉及的原理。 14 | 15 | 其中的**安全**是指浏览器不报安全提醒,比如: 16 | 17 | 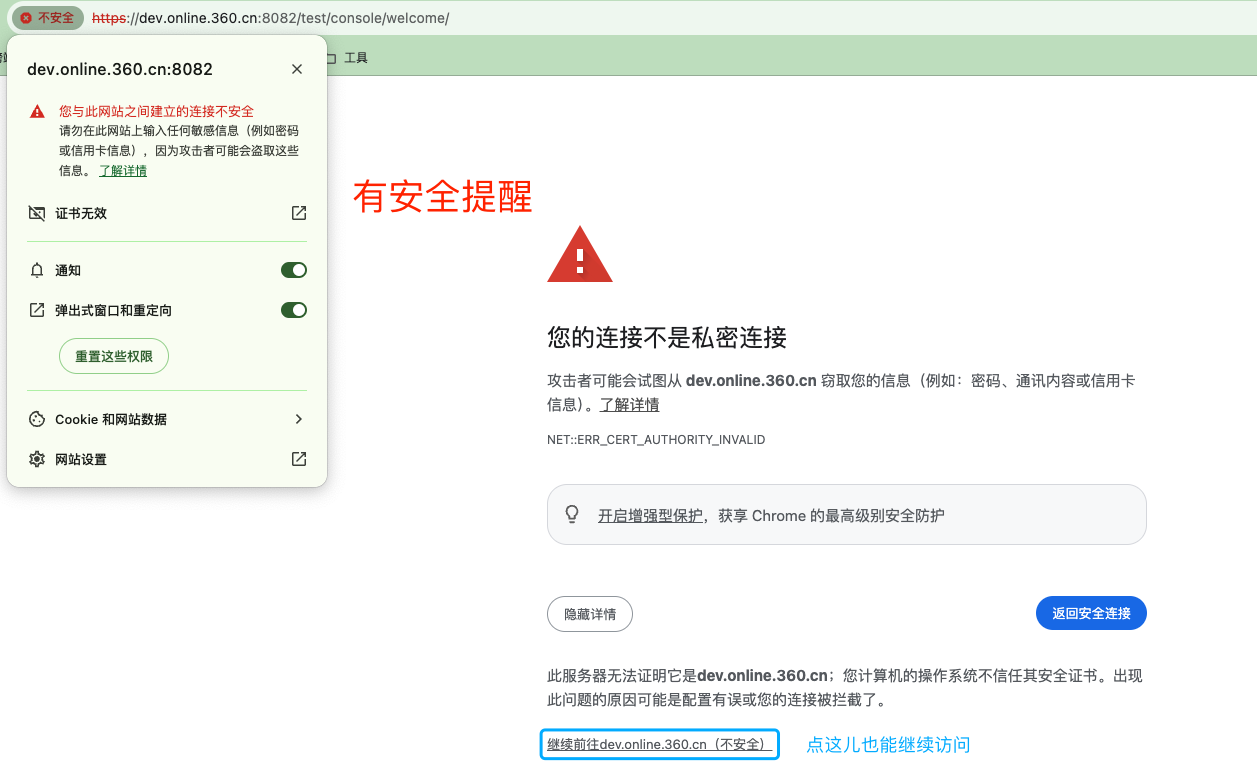 18 | 19 | 在上图所示中,可以通过点击`继续前往`从而忽略浏览器的提示,但我们知道,在陌生网站上这么操作就意味着你离被攻击不远了。但我更希望是这样的效果: 20 | 21 |  22 | 23 | **不安全的 https 有什么问题??** 24 | 25 | 上图可以通过点击`继续前往`来解决,但有一些场景你绕不过去,比如: 26 | 27 | * service worker 场景 28 | * service worker 只能在安全的 https 协议下注册,但 localhost 除外,localhost 上下文被认为是安全的 29 | * service worker 中的 fetch 请求的目标 server 如果是不安全的 https 服务,请求也会失败 30 | 31 | * 浏览器的 AJAX 请求场景,比如通过 fetch API,请求不安全的 server 会失败,比如 qiankun 主应用加载不安全的子应用,需要先在浏览器中访问子应用,让浏览器忽略子应用的不安全,qiankun 才能正常加载 32 | 33 | # 开发环境如何配置安全的 https 协议 34 | 35 | 照例,先上结论,后讲原理。主要分为三步: 36 | 37 | * 生成自签名证书 38 | * 将证书加入系统根证书列表,并选择始终信任 39 | * 项目(https server)集成证书 + 私钥 40 | 41 | ## 生成自签名证书 42 | 43 | 假设以下操作均在`/Users/liyongning/studyspace/ssl`目录完成 44 | 45 | 新建 openssl.cnf 文件,内容如下 46 | 47 | ```cnf[req] 48 | [req] 49 | prompt = no 50 | default_bits = 4096 51 | default_md = sha512 52 | distinguished_name = dn 53 | x509_extensions = v3_req 54 | 55 | [dn] 56 | C=CN 57 | ST=BeiJing 58 | L=BeiJing 59 | O=Development 60 | OU=Fe 61 | CN=self-signed-certificate 62 | emailAddress=test@example.com 63 | 64 | [v3_req] 65 | keyUsage = nonRepudiation, digitalSignature, keyEncipherment 66 | subjectAltName=@alt_names 67 | 68 | [alt_names] 69 | DNS.1 = localhost 70 | DNS.2 = dev.online.360.cn 71 | IP.1 = 127.0.0.1 72 | IP.2 = 0.0.0.0 73 | ``` 74 | 75 | 其中有几个需要注意的字段 76 | 77 | * [alt_names] 下的配置,表示证书的生效范围,即哪些域名或 IP 78 | * 通过 DNS.x 来配置域名,假设你的证书想在多个域名上生效,你就分别配置多个 DNS.x 即可,比如 DNS.1 和 DNS.2 79 | * IP.x 和 DNS.x 同理,只不过是针对 IP 地址的 80 | * CN 字段的值是证书放到`系统 —— 证书`中的名字,比如 81 | *  82 | 83 | 大家使用时只需更改 DNS.x 或 IP.x 即可。 84 | 85 | 接下来,执行如下命令生成密钥和证书文件 86 | 87 | ```shell 88 | openssl req -newkey rsa:2048 -new -nodes -x509 -days 3650 -config openssl.cnf -keyout key.pem -out cert.pem 89 | ``` 90 | 91 | 效果如下,其中 key.pem 是私钥,cert.pem 是证书 92 | 93 |  94 | 95 | ## 信任根证书 96 | 97 | 将上一步生成的 cert.pem 放到根证书列表中,操作如下 98 | 99 | ### Mac 100 | 101 | * Command + 空格,搜索`钥匙串访问`,并打开 102 | 103 | * 找到系统钥匙串 -> 系统 -> 证书 104 | 105 | * 将 cert.pem 文件拖进来,在列表中能看到一条名为 self-signed-certificate 的记录 106 | 107 | * 右键这条记录 -> 显示简介,得到如下界面,将`使用此证书时`的选项更换为`始终信任`,然后关闭当前窗口(**一定要关闭,关闭才能保存**) 108 | 109 | 110 |  111 | 112 | 上述所有 Mac 步骤也可以通过如下命令直接搞定: 113 | 114 | ```shell 115 | sudo security add-trusted-cert -d -r trustRoot -k /Library/Keychains/System.keychain cert.pem 116 | ``` 117 | 118 | ### Windows 119 | 120 | Cmd 命令行输入 121 | 122 | ```shell 123 | certutil -addstore -f "Root" "cert.pem 的路径(文件直接拖进去就可以出路径)" 124 | ``` 125 | 126 | 也可以采用双击 cert.pem 文件进行安装 127 | 128 | ## 项目集成 129 | 130 | ### Vite 项目 131 | 132 | 配置 vite.config.js 133 | 134 | ```javascript 135 | import { defineConfig } from 'vite' 136 | import vue from '@vitejs/plugin-vue' 137 | import fs from 'fs' 138 | 139 | // https://vitejs.dev/config/ 140 | export default defineConfig({ 141 | plugins: [vue()], 142 | server: { 143 | host: 'dev.online.360.cn', 144 | https: { 145 | key: fs.readFileSync('/Users/liyongning/studyspace/ssl/key.pem'), 146 | cert: fs.readFileSync('/Users/liyongning/studyspace/ssl/cert.pem') 147 | } 148 | } 149 | }) 150 | ``` 151 | 152 | 效果如下: 153 | 154 |  155 | 156 | ### Webpack 项目 157 | 158 | 以 vue-cli 为例,配置 vue.config.js 159 | 160 | ```javascript 161 | const { defineConfig } = require('@vue/cli-service'); 162 | const fs = require('fs') 163 | 164 | module.exports = defineConfig({ 165 | devServer: { 166 | https: { 167 | key: fs.readFileSync('/Users/liyongning/studyspace/ssl/key.pem'), 168 | cert: fs.readFileSync('/Users/liyongning/studyspace/ssl/cert.pem') 169 | } 170 | } 171 | }) 172 | ``` 173 | 174 | 效果如下 175 | 176 |  177 | 178 | ### Node 项目 179 | 180 | ```javascript 181 | const express = require('express'); 182 | const https = require('https'); 183 | const fs = require('fs'); 184 | const path = require('path'); 185 | 186 | const app = express(); 187 | 188 | const sslOptions = { 189 | key: fs.readFileSync(path.resolve('/Users/liyongning/studyspace/ssl', 'key.pem')), 190 | cert: fs.readFileSync(path.resolve('/Users/liyongning/studyspace/ssl', 'cert.pem')) 191 | }; 192 | 193 | app.use((_, res, __) => { 194 | res.send('hello https') 195 | }) 196 | 197 | https.createServer(sslOptions, app).listen(8083, () => { 198 | console.log('HTTPS server is running on port 8083'); 199 | }); 200 | ``` 201 | 202 | 效果如下 203 | 204 |  205 | 206 | 至此,自签名证书制作和实际应用都讲完了,接下来的内容就是其中涉及的原理了。 207 | 208 | # HTTPS 发展史 209 | 210 | http 协议最开始的设计目的很简单,就是传输超文本文件(HTML),没有什么加密的需求,所有数据都是明文传输,这就意味数据在传输过程的每个环节都可能被窃取和篡改。 211 | 212 | 这个情况严重制约了业务的发展,比如在线购物、支付转账,毫无安全可言,于是在协议栈中引入了安全层,负责数据的加解密,让数据传输更安全。 213 | 214 | 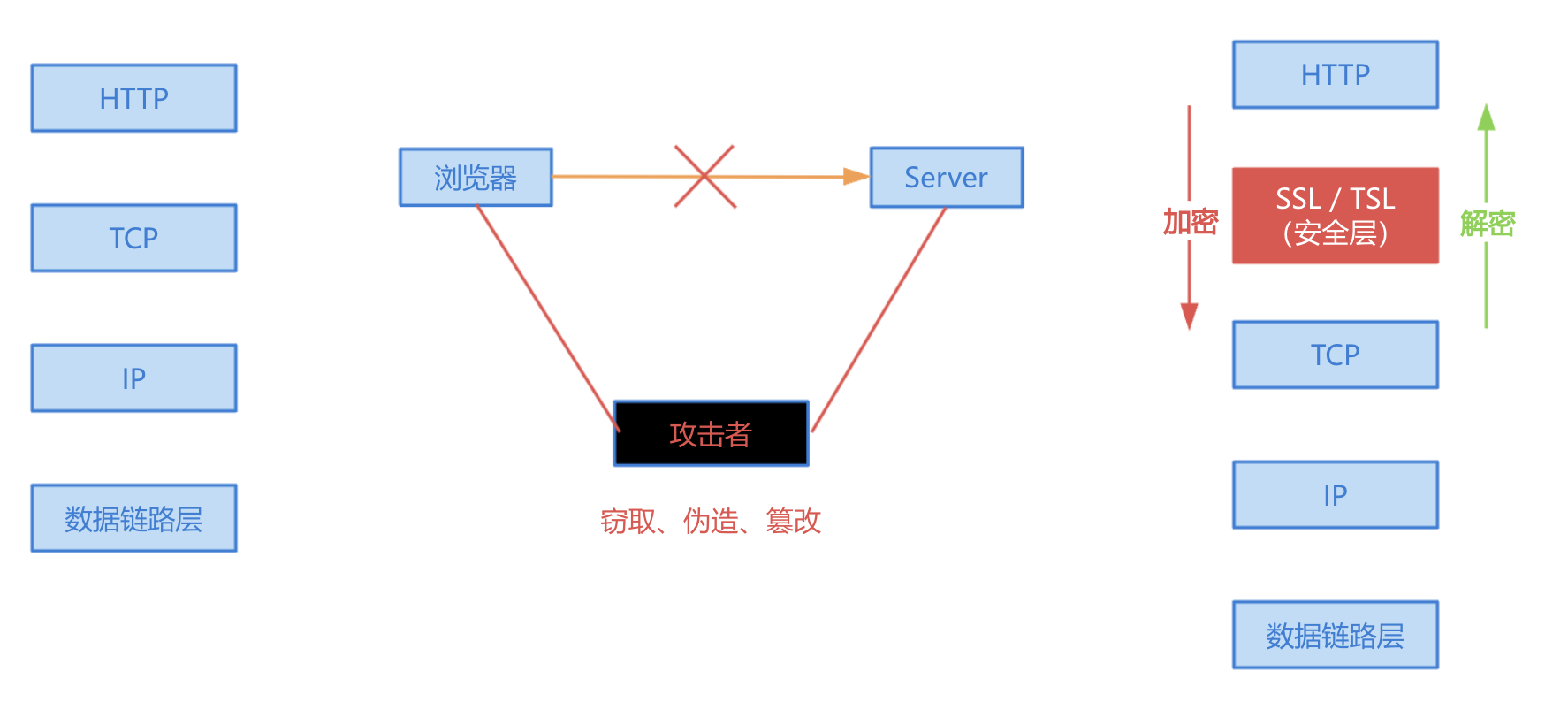 215 | 216 | 可以看到,HTTPS 并不是一个新的协议,只是在 HTTP 层和 TCP 之间加入了一层加解密的逻辑,以前是 HTTP 直接和 TCP 通信,现在是 HTTP -> TSL(SSL 早已废弃)-> TCP,安全层负责对经过的数据进行加解密。所以,HTTPS 的发展史就是安全层逻辑的迭代史。 217 | 218 | ## 对称加密 219 | 220 | 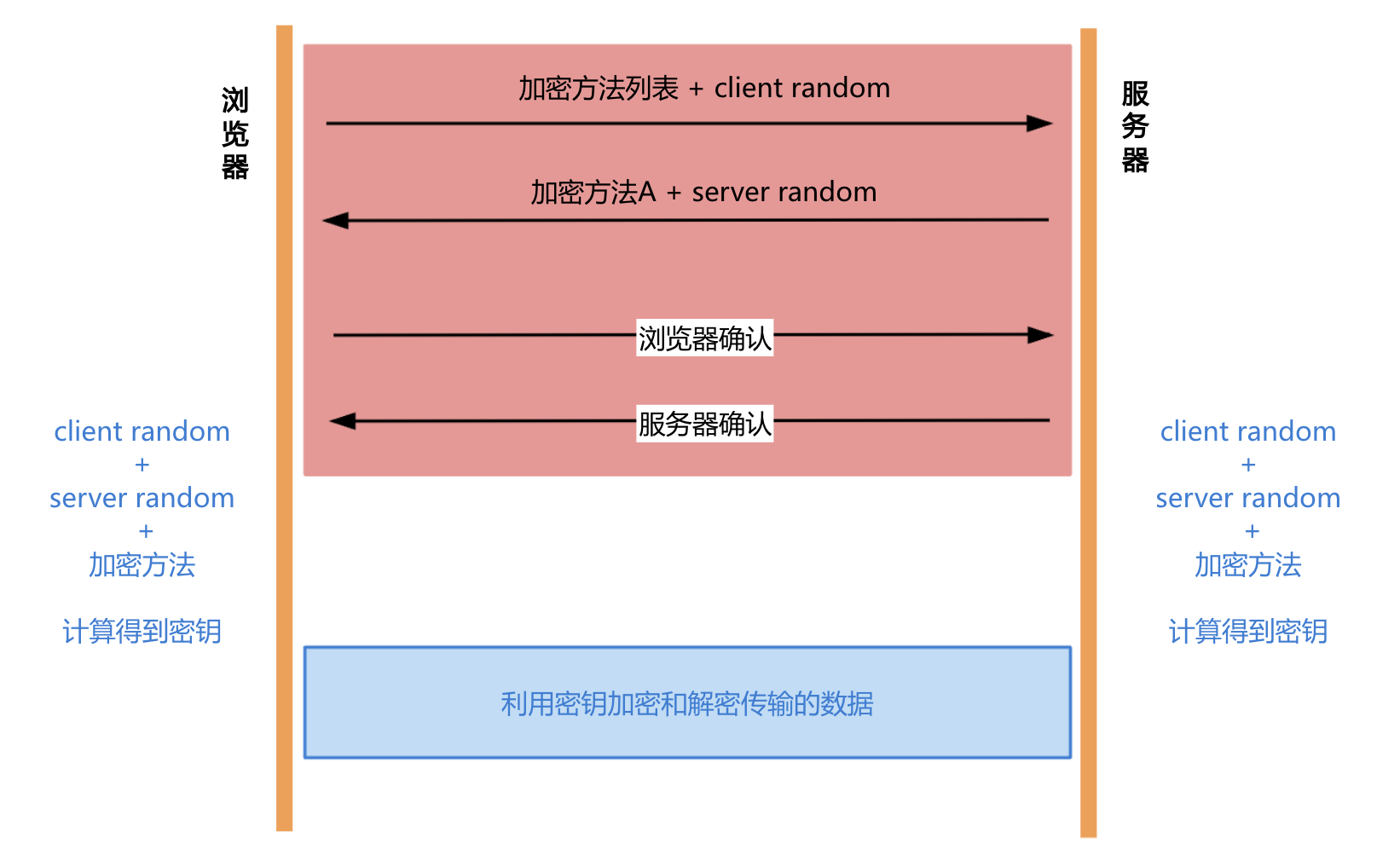 221 | 222 | 对称加密,就是客户端和服务端使用同一个密钥来进行加解密。那么,问题来了,这个密钥怎么来?答案是:由服务端和客户端使用相同的加密方法、key(随机数)计算得到,在正式传输数据之前,浏览器和服务器之间会有一个协商加解密方式的过程,这个过程就是 HTTPS 建立安全连接的过程: 223 | 224 | * 浏览器带着自己支持的加密方案列表和一个随机数,请求服务器 225 | * 服务器收到之后,选择其中的一个加密方法,比如 A,并且也生成一个随机数,返回给浏览器 226 | * 然后浏览器和服务器之间分别相互确认收到了对方的消息,这时浏览器和服务器就有了相同的加密方法和两个随机数 227 | * 于是,浏览器和服务器使用 **加密方法 A + client random + server random** 生成密钥 228 | * 然后,双发利用得到的密钥对传输的数据进行加解密 229 | 230 | 但这时你会发现,虽然,最终的数据全是通过密钥加密传输的,但是生成密钥时使用的加密方法、随机数都是明文传输的,中间人使用相同的方法和随机数同样可以生成相同的密钥,进而解密 -> 窃取、篡改、伪造 -> 加密数据,所以,一样不安全。 231 | 232 | 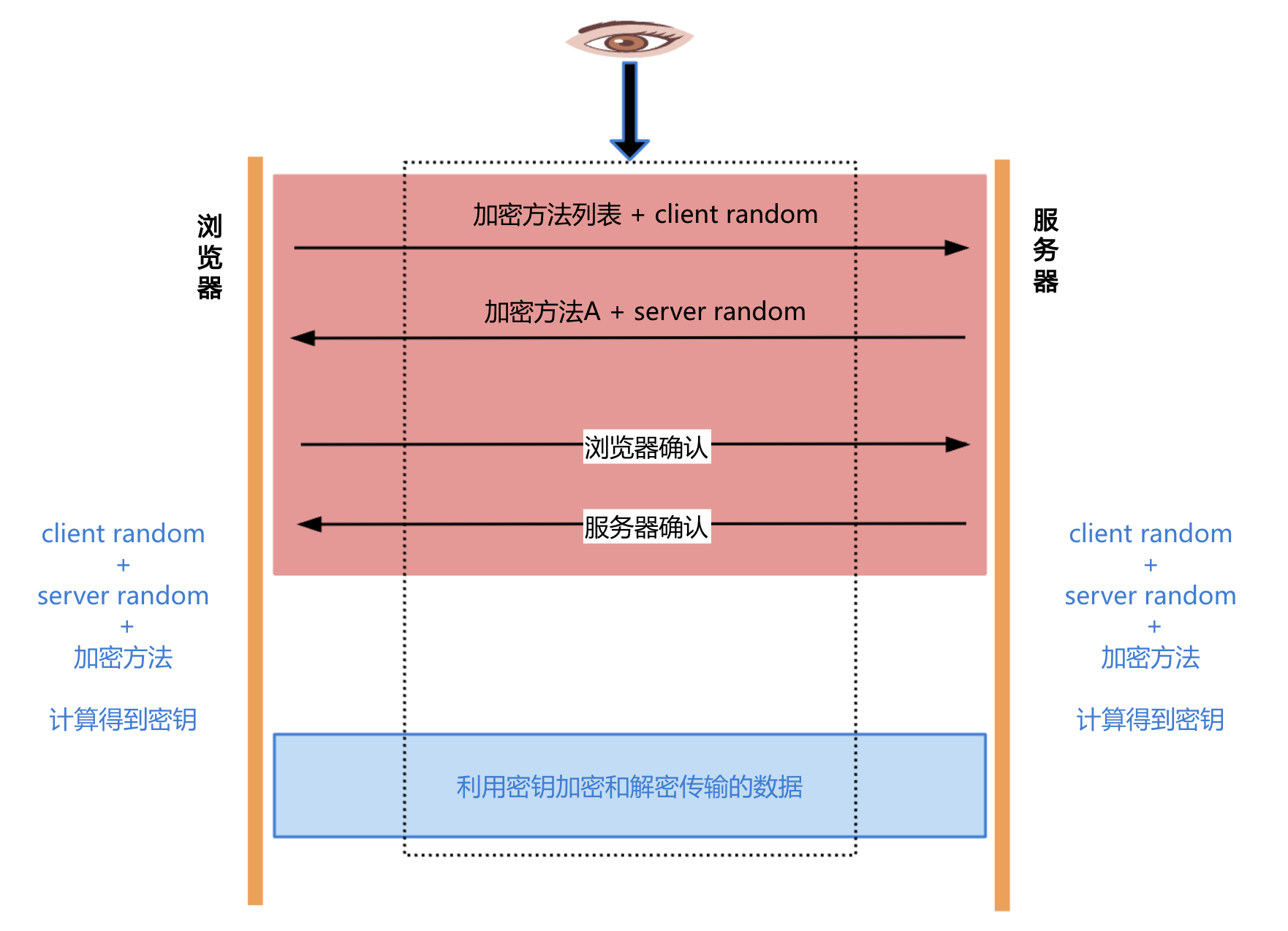 233 | 234 | ## 非对称加密 235 | 236 | 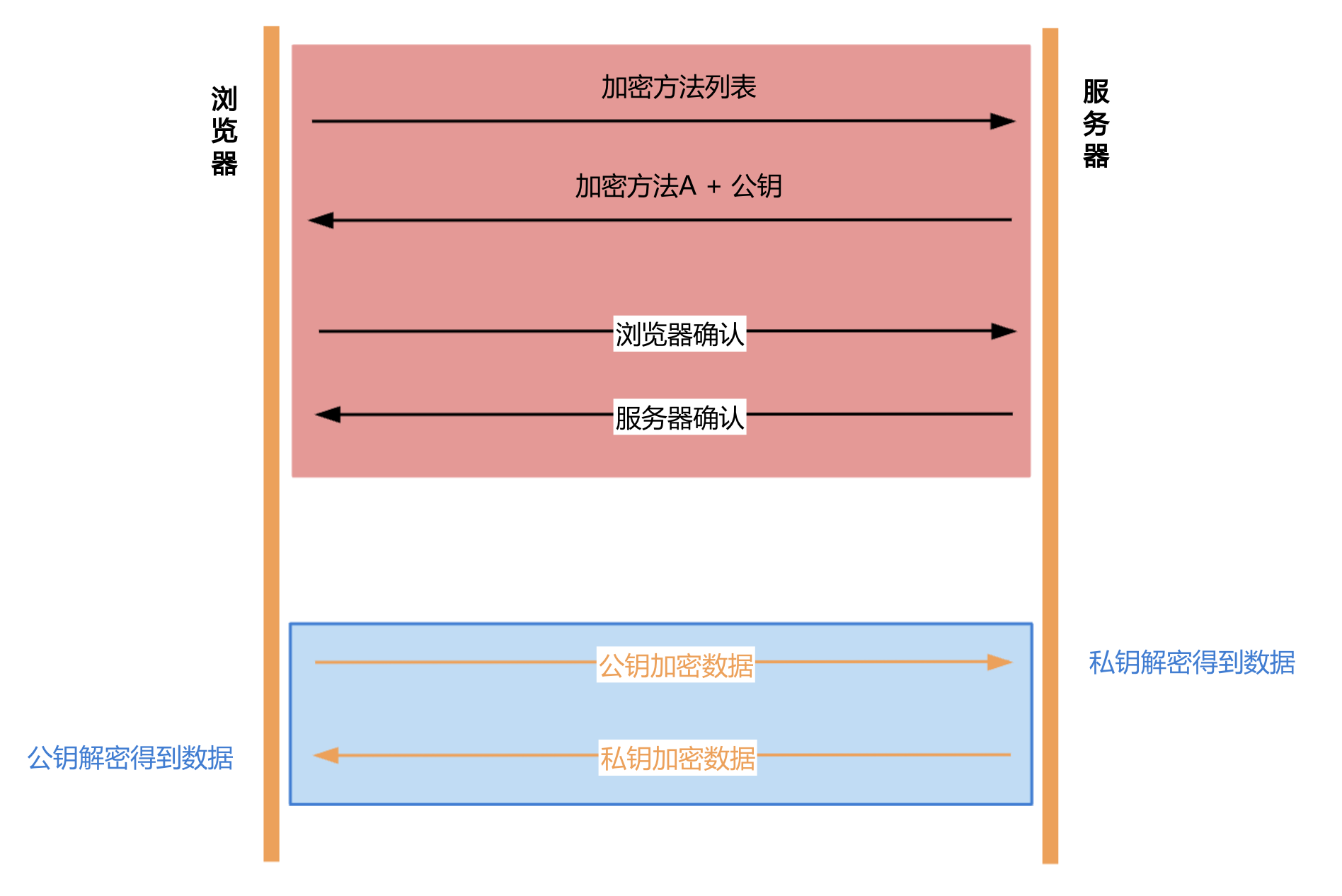 237 | 238 | 非对称加密和对称加密相对,分为私钥和公钥两个密钥,加解密使用的是两个不同的密钥,公钥加密的数据只能使用私钥解密,私钥加密的数据同样只能使用公钥解密。 239 | 240 | * 浏览器携带着自己支持的加密方法列表向服务器发起请求 241 | * 服务器从加密列表中选择一个加密方法,比如 A,并加上自己生成的公钥一起返回给浏览器 242 | 243 | > 服务器会生成一对密钥(公钥 + 私钥),私钥留在自己手里(绝不可泄漏),公钥分发给各个客户端 244 | 245 | * 浏览器和服务器相互确认收到信息,从而建立连接 246 | * 浏览器使用公钥加密数据,然后将数据发送给服务端,服务端使用私钥解密数据 247 | * 服务器使用私钥加密数据,然后将数据发送给浏览器,浏览器使用公钥解密数据 248 | 249 | 接下来,我们分析下整个流程中的数据安全性: 250 | 251 | * 由于公钥加密的数据只能由私钥解密,所以,浏览器发送给服务器的数据,是安全的 252 | * 由于公钥是服务器通过明文的方式发放给浏览器,所以,和对称加密存在一样的问题,中间人一样可以窃取公钥和加密方法,所以,服务器发送给浏览器的数据,中间人同样也可以获取到,因此,服务器发送给浏览器的数据,不安全 253 | * 另外,非对称加密相比对称加密在性能上会有数量级级别的差异,所以,全程采用非对称加密算法,性能会差很多 254 | 255 | 所以,性能差还不能绝对安全。 256 | 257 | ## 非对称加密 + 对称加密 258 | 259 | 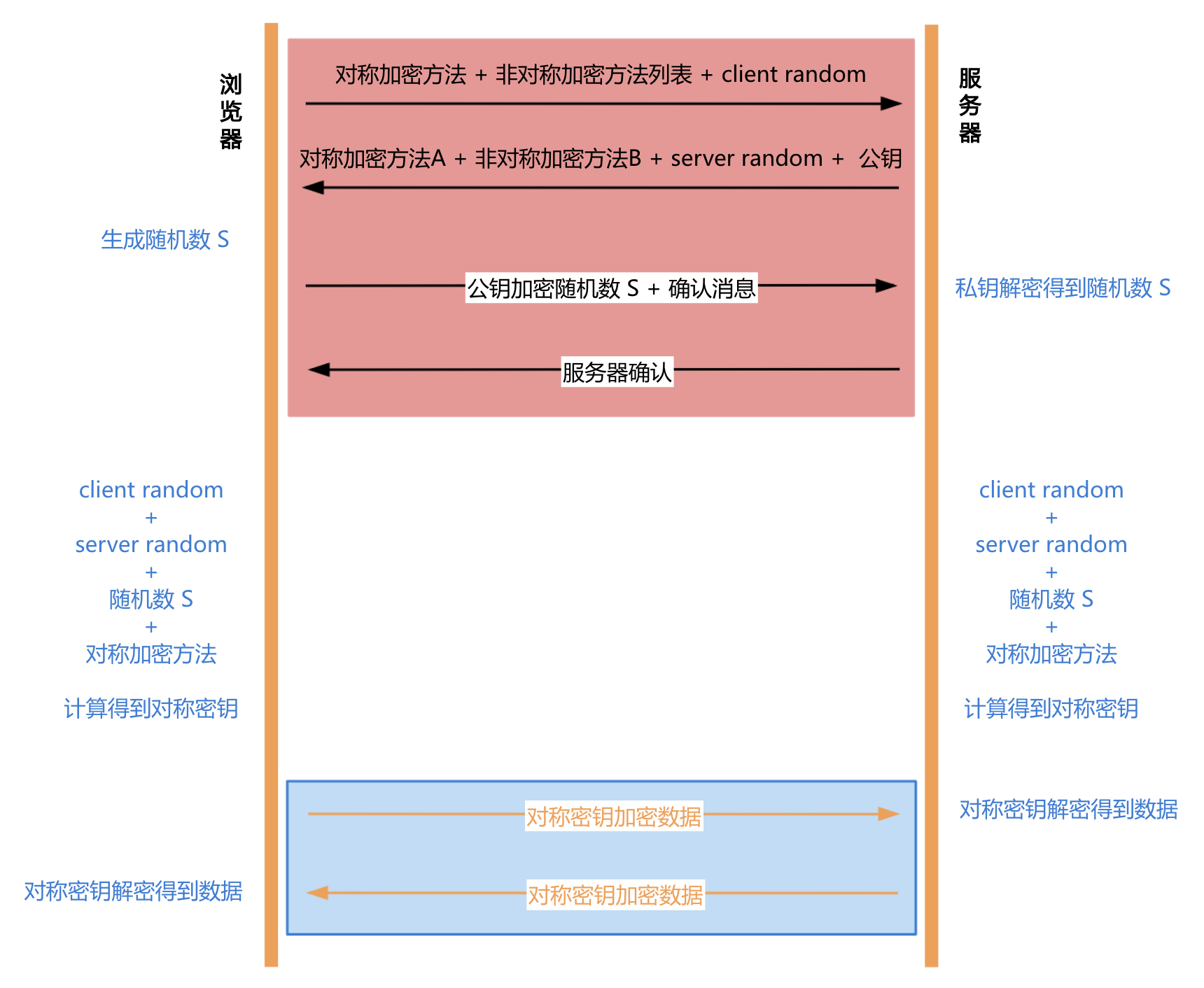 260 | 261 | 意思是,同时采用两种加密方式来保证数据的安全性。协商阶段采用非对称加密的方式,数据传输阶段使用对称加密的方式,通过这样的方式来保证数据传输性能和对称密钥的安全性,即前两种方式的结合版。 262 | 263 | * 浏览器带着自己支持的对称加密方法列表、非对称加密方法列表和随机数请求服务器 264 | * 服务器给浏览器返回它从两个加密列表中选择的加密方法、服务器生成的随机数,以及服务器的公钥 265 | * 浏览器收到服务器返回后,另外再生成一个随机数 S,并通过公钥加密后,发送给服务器 266 | * 服务器使用私钥解密后得到浏览器发送的随机数 S,并向浏览器返回确认收到信息 267 | * 这时,浏览器和服务器同时拥有 client random、server random、随机数 S,然后使用相同的加密方法,计算得到相同的密钥作为对称密钥。这里相比对称加密方案的变化是,随机数 S 的传递是加密的形式,所以生成的对称密钥只有通信双方知道 268 | * 后续使用对称密钥对传递的数据进行加解密 269 | 270 | 这个方案的关键在于非对称密钥 + 双随机数的方式,保证了对称密钥的安全,进而解决了数据安全问题。 271 | 272 | ## 数字证书 273 | 274 | 通过非对称加密 + 对称加密结合的方式,我们实现了数据的加密传输。但是,这套方案还存在一个漏洞 —— 中间人攻击。 275 | 276 | **浏览器访问的服务器,一定是真的目标服务器吗?**比如,你访问 `baidu.com`,如果你的 DNS 解析被人改了,baidu 的流量被解析到了攻击者的服务器上,上述整体流程就变成了:浏览器 -> 黑客服务器 -> 目标服务器,这三者之间的通信了,即浏览器和目标服务器之间的所有通信都是通过黑客服务器来完成中转的,包括随机数和密钥的传输,即: 277 | 278 | * 浏览器看到的 baidu 是黑客的服务器 279 | * 服务器看到的浏览器是黑客的服务器 280 | 281 | 那有什么方案,可以让浏览器知道自己现在访问的服务器是真正的目标服务器吗?这里我们需要引入一个第三方机构。 282 | 283 | 以买房为例,你怎么证明你现在居住的房子是你自己的房子?我们可以通过房管局发放的**房产证**来证明。这里引入具有权威的房管局,以及房管局颁发的房产证,大众信任房管局,所以当你出示房产证的时候,就可以证明这个房子确实是你的房子。 284 | 285 | 同理,在 HTTP 通信的过程里,我们引入权威机构 —— **CA**(Certificate Authority),CA 颁发的证书就是**数字证书**。 286 | 287 | 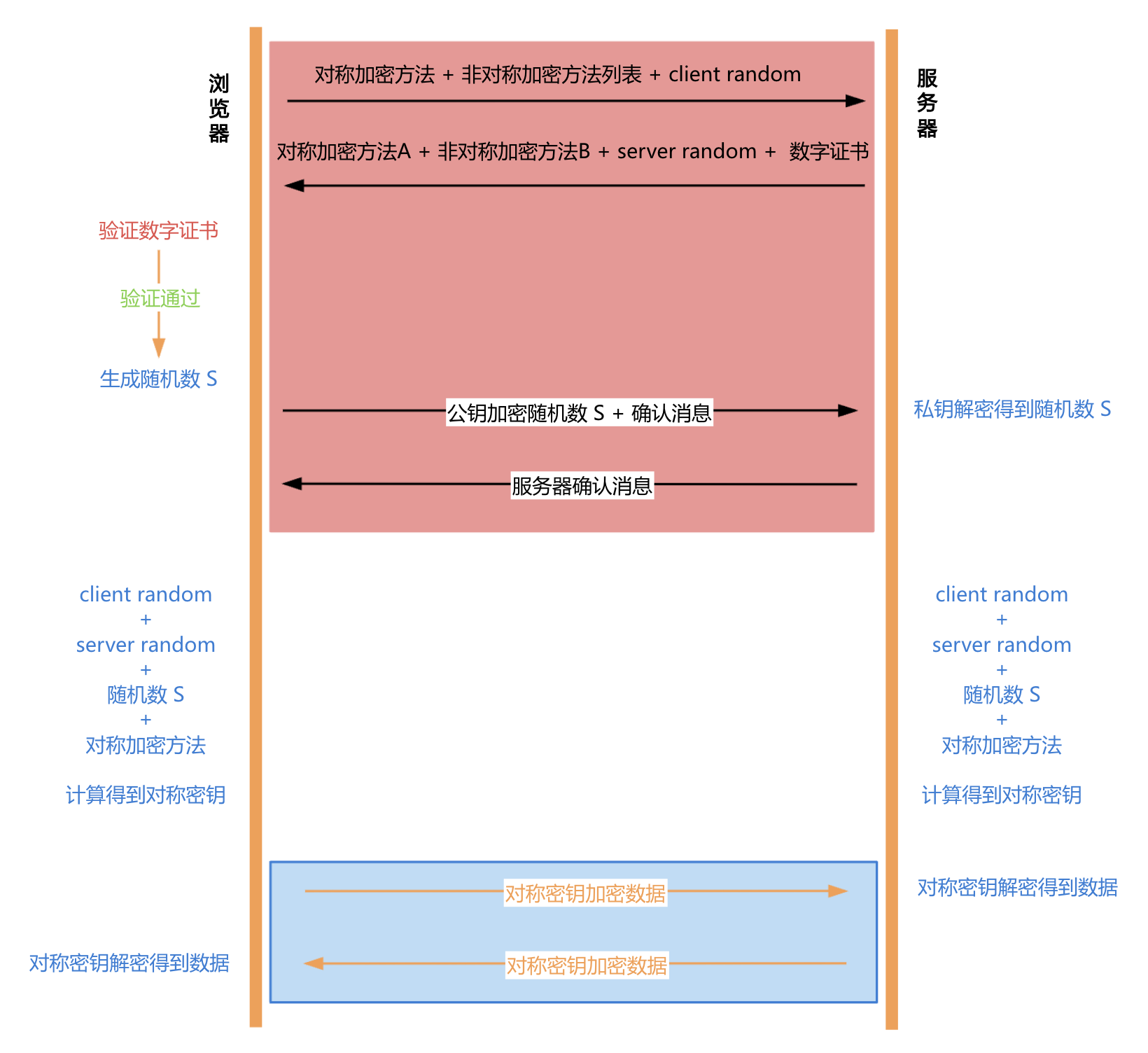 288 | 289 | 相较于上一个方案,这里引入了数字证书的概念,数字证书有两个作用: 290 | 291 | * 让浏览器有机会验证自己访问的服务器是正确的目标服务器,而不是冒名顶起的黑客服务器 292 | * 证书中包含了服务提供商的基础信息以及公钥,所以这套方案中没有专门下发公钥 293 | 294 | 可以看到,流程中多了一步验证数字证书的流程。 295 | 296 | ### 数字证书的申请 297 | 298 | * 公司准备一对私钥和公钥(私钥绝对保密) 299 | * 公司将自己的公钥、公司信息、站点信息提交给 CA 机构 300 | * CA 机构验证公司和站点信息的有效性,验证通过后 301 | * CA 对公司提交的信息做 hash 运算得到信息摘要,并通过 CA 自己的私钥(CA 机构也有一对自己的非对称密钥)对摘要加密,得到一串数字签名,这个签名会放到证书上,然后将证书颁发给公司 302 | * 公司将证书部署到自己的服务器上 303 | 304 | ### 浏览器数字证书 305 | 306 | 浏览器通过验证数字证书,从而得到自己访问的服务器是否为正确的目标服务器。 307 | 308 | 浏览器从服务器拿到数字证书后: 309 | 310 | * 对数字证书上的相关信息做 hash 运算,得到信息摘要 311 | * 通过 CA 机构的公钥解密证书上的数字签名,得到信息摘要 312 | * 对比两个信息摘要,如果内容一致,则说明当前访问的服务器是目标服务器 313 | 314 | 这里有个问题,**CA 机构的公钥怎么来的?**这个证书有两种获取途径,一是从目标服务器返回,另一个是从网络下载(你从浏览器的请求列表中看不到对应的请求)。 315 | 316 | ### 会不会有人冒充 CA 机构 ?? 317 | 318 | 首先,答案是不会。逻辑是这样的: 319 | 320 | CA 结构分为根 CA 和 中间 CA,大家都是去中间 CA 去申请证书,而根 CA 是负责给中间 CA 做认证的,而这些中间 CA 又可以去给其他 CA 做认证,这些每个根 CA 都维护了一棵 CA 树,比如: 321 | 322 |  323 | 324 | admin.saas.360 的证书是由 WoTrus DV Server CA 颁发的,而这个中间 CA 又是由 USERTrust RSA Certification Authority 来负责认证的。 325 | 326 | 所以,这里有一个证书链,浏览器会首先验证 admin.saas.360.cn 的证书是否合法,如果验证通过,再去验 WoTrus DV Server CA 的合法性,如果也合法,再去验证 USERTrust RSA Certification Authority 根 CA 的合法性。 327 | 328 | 那么问题来,最终的**根 CA 合法性如何验证?**很简单,只需要判断这个根证书在不在操作系统中即可,这些根证书是内置在每个操作系统中的,如果系统中存在,则认为合法,否则就是不合法的。 329 | 330 | 相信读到这里,你就能理解本文 **开发环境配置安全的 HTTPS 协议** 的背后原理了。 331 | 332 | 如果某个机构想要成为根 CA,并让它的根证书内置到操作系统中,那么这个机构首先要通过 WebTrust 国际安全审计认证。 333 | 334 | ## HTTPS 就绝对安全吗?? 335 | 336 | 这是 HTTPS 认证流程面试题结束时必问的一个问题。答案是:否,HTTPS 不是绝对安全。 337 | 338 | 相信,读完本文,你就能很清晰的说出来其中的不安全点了: 339 | 340 | * 用户自身行为造成的不安全,浏览器会负责验证站点的安全性,如果有风险,会给用户安全提醒,但用户可以选择忽略并继续访问 341 | * 如果用户设备本身遭遇攻击,将非法的证书内置到用户的操作系统中,就像本文开发环境的配置一样,那浏览器也检测不出来 342 | 343 | 344 | 345 | 好了,到这里就结束了,相信阅读完本文之后: 346 | 347 | * 学到了如何在开发环境配置安全的 HTTPS 协议 348 | * 明白了 HTTPS 安全传输背后的原理,也明白了 HTTPS 并非绝对安全 349 | 350 | # 总结 351 | 352 | 本文从实用角度开始讲,讲了在日常的开发环境中如何配置安全的 HTTPS 协议,即浏览器中没有安全提示 353 | 354 | * 一条命令生成自签名证书 355 | * 在系统根证书列表信任自签名证明 356 | * 然后在项目中集成 357 | 358 | 接下来讲了 HTTPS 的发展史,对称加密、非对称加密、非对称加密 + 对称加密,再到数字证书,从而理解其中的整个原理。 359 | 360 | 最后讲了一道面试题:**HTTPS 就绝对安全吗?**从而验证对原理的理解程度。 361 | 362 |
363 | 364 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 365 | 366 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 367 | 368 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 369 | 370 | **[更多精彩内容](https://github.com/liyongning/blog/blob/main/README.md)** 371 | -------------------------------------------------------------------------------- /PDF 生成/PDF 生成(5)— 内容页支持由多页面组成.md: -------------------------------------------------------------------------------- 1 | **当学习成为了习惯,知识也就变成了常识。** 感谢各位的 **关注**、**点赞**、**收藏**和**评论**。 2 | 3 | 新视频和文章会第一时间在微信公众号发送,欢迎关注:[李永宁lyn](https://gitee.com/liyongning/typora-image-bed/raw/master/202202171742614.jpg) 4 | 5 | 文章已收录到 [github 仓库 liyongning/blog](https://github.com/liyongning/blog),欢迎 Watch 和 Star。 6 | 7 | # 封面 8 | 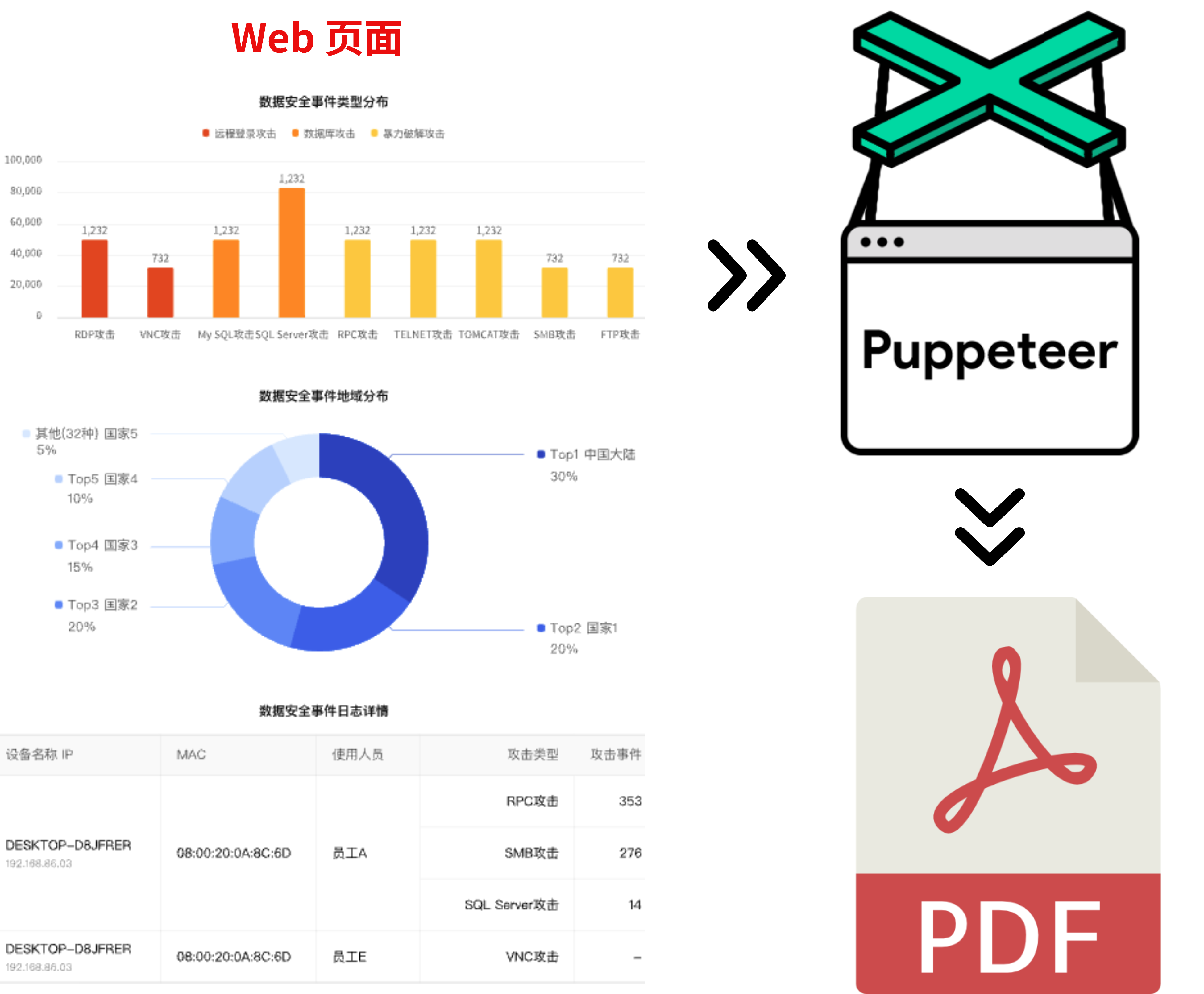 9 | # 回顾 10 | 在本篇开始之前,我们先来回顾一下上篇 [PDF 生成(4)— 目录页](https://github.com/liyongning/blog/issues/45) 的内容: 11 | 12 | - 开头,我们通过 `page.evaluate` 方法为浏览器注入 JS 代码,通过这段 JS 在 PDF 内容页的开始位置(body 的第一个子元素)插入由 a 标签和对应的样式组成的目录页 DOM,从而通过 HTML 锚点实现目录项的页面跳转能力 13 | - 接下来,我们通过为目录页的容器元素设置`break-after: page`样式实现目录页自成一页的效果(和内容页分别两页) 14 | - 然后剩下的所有篇幅都是在讲如何生成带有准确页码的目录项 15 | - 首先,页码是按照**锚点元素在页面中的高度 / PDF 一页的高度**来计算的 16 | - 后来,我们通过下面三步来保证目录页中目录项对应页码的准确性 17 | - 规范化设计稿尺寸(按照 A4 纸对应的 2 倍图尺寸设计) 18 | - 通过页面缩放解决设计稿 DPI 和实际生成 PDF 时 DPI 的差异问题(彻底统一计算时 PDF 一页的像素高度) 19 | - 通过页面高度补充的方案解决章节标题换页引起目录项页码计算错误的问题 20 | 21 | 上篇结束之后,PDF 文件的整体框架已完全成型,包括封面、目录页、内容页和尾页四部分。但系列还没结束,接下来我们会通过本文来提升接入方的使用体验和前端代码可维护性。 22 | 23 | 开始之前,上篇给大家留了一个问题:回顾一下现在 PDF 文件内容页的生成,站在接入方的角度看,是否存在问题?假设一个场景,接入方的 PDF 文件呈现的内容量非常大,比如拥有几十甚至几百页的内容,那接入方的这个前端页面的代码该怎么维护?页面性能又该怎么保证呢? 24 | 25 | # 简介 26 | 本系列的 [PDF 生成(1)— 开篇](https://github.com/liyongning/blog/issues/42)、[PDF 生成(2)— 生成 PDF 文件](https://github.com/liyongning/blog/issues/43)、[PDF 生成(3)— 封面、尾页](https://github.com/liyongning/blog/issues/44)、[PDF 生成(4)— 目录页](https://github.com/liyongning/blog/issues/45) 都是在一步步完善 PDF 文件的整体框架,包括封面、目录页、内容页和尾页四部分,截止上篇,PDF 文件的整体框架已完全成型。 27 | 28 | 本篇是站在用户角度(接入方)来进行的一次技术迭代。目的是为了解决用户前端代码的可维护性问题。 29 | 30 | # 问题 31 | **问题 1**:到目前为止,我们的 PDF 文件内容页是怎么生成的? 32 | 33 | **答**:关键代码之一 `await page.goto('https://content.cn', { waitUntil: ['load', 'networkidle0'] })`,也就是说,PDF 文件的内部部分都是由该链接背后的前端页面提供的。 34 | 35 | --- 36 | 37 | **问题 2**:如果一份 PDF 文件由几十、几百页组成,其中包含几十个模块,这份 PDF 背后的前端页面的代码该怎么维护?页面性能怎么保障? 38 | 39 | **答**:首先,这么庞大的一个页面的前端代码,基本上是非常难维护的;至于性能问题,可以通过滚动懒加载的方案来解决,但这个优化本来是没必要的,完全是由于现有的 PDF 生成服务能力不足导致的。 40 | 41 | # 分析 42 | 我们在做架构设计时,不论是一个系统,还是一个项目,亦或是一个页面甚至一个组件一个方法,都会尽量去避免模块过于复杂,导致难以维护,所以为了更好的可维护性,会尽量将内容进行拆分,比如微服务、组件化。 43 | 44 | 一个包含几十个模块的页面,不论你怎么去组件化,都避免不了这个页面的庞大,做的再极致,一个由几十个组件组成的页面都是难以维护的,而且如果不做滚动懒加载,这个页面首屏的性能会非常差。当下我们的用户就面临这样的问题,因为我们的 PDF 内容页必须是由一个前端页面构成。 45 | 46 | 所以,就在想,怎么才能让我们的用户不这么难受呢?开发 PDF 需求,就像开发普通的 Web 项目一样(这句话我们 [PDF 生成(1)— 开篇](https://github.com/liyongning/blog/issues/42) 的技术选型中就提过),代码可以按照业务逻辑进行合理的划分,而不是全部模块堆叠在一个页面上。 47 | 48 | 其实,经过上面的问题和分析之后,解决方向很明确:**PDF 生成服务不应该限制用户对于项目的设计和编码,所以,PDF 的内容页应该支持多页面**。但怎么支持呢? 49 | 50 | ## 方案限制 51 | 52 | - puppeteer 生成 PDF 文件,只能是一个页面对应一份 PDF 文件,这是最底层的限制。`page.goto`和`page.pdf`都是针对当前页面的(浏览器的打印功能,只能打印当前渲染的页面) 53 | - 目录页方案的限制 54 | - 页面跳转能力是基于 HTML 锚点实现的,意味着相关 DOM 必须在一个页面中 55 | - 目录项对应的页码是通过 DOM 节点在页面中的位置(高度)来计算的,所以如果 DOM 位于不同的页面就意味着没办法计算了 56 | 57 | 这两个既是限制,也是进一步迭代的大前提。也就是说,我们现有的能力(大框架)不能动,也没办法动。**PDF 内容页必须只能对应一个前端页面,至少在 puppeteer 层面是这样的**。 58 | ## 怎么做? 59 | PDF 生成服务是基于 puppeteer 来实现的,也就是说 puppeteer 和用户之间还隔着一个 **PDF 生成服务**。那**如果在 PDF 生成服务上增加一个胶水层呢**?即 PDF 生成服务将用户提供的众多内容页合并成一个,然后将合并后的页面提供给 puppeteer。这是在现有技术架构上做加法,完全不影响现有技术方案和效果。 60 | 61 | 简单来讲就是: 62 | 63 | - 首先,通过 page.goto 方法依次打开用户提供的众多内容页,并拿到这些内容页的 HTML 信息 64 | - 然后,通过 page.gogo 打开 PDF 生成服务提供的容器页面,将上一步拿到的所有 HTML 信息都填充到该容器页中 65 | - 最后,通过 page.pdf 方法打印填充后的容器页得到 PDF 内容页 66 | 67 | 这方案可行,但有问题,这就遇到了整套方案中**第二个难点**了。 68 | ## 难点(问题) 69 | **问题**:我们将用户提供的所有页面的 HTML 都塞到了一个页面中渲染,**怎么解决可能会出现的样式和 JS 冲突?** 70 | 71 | **答**:首先,冲突问题很有可能会出现,用户有义务保证自己的页面内部不出现冲突,但她没有义务确保不同的页面不出现冲突。解决问题的关键是**沙箱**,PDF 生成服务需要提供一套**沙箱**来确保容器页中各个页面的隔离性。 72 | 73 | ## 沙箱 74 | 浏览器中的沙箱包括样式沙箱和 JS 沙箱,实现沙箱方式一般有以下几种: 75 | 76 | - JS 沙箱 77 | - iframe 78 | - 代理,比如微前端框架 qiankun 的 JS 沙箱实现方案之一就是 Proxy 79 | - 样式沙箱 80 | - iframe 81 | - Web Component,通过 shadow dom 将不同页面的 HTML 和 CSS 包裹起来,以实现和外部环境的隔离 82 | - scoped,比如 Vue 组件中的 scoped 属性,qiankun 的样式沙箱方案之一 83 | ### JS 沙箱 84 | 首先,**我们不需要 JS 沙箱**,因为我们获取的是已经渲染好的 HTML 页面,所以会剔除掉 script 标签(打印成 PDF 文件也用不上 JS),JS 的存在反而会带来不确定性和复杂性。 85 | ### 样式沙箱 86 | iframe 最简单,但浏览器的 Web 安全策略会导致我们计算页码时存在问题,因为,跨域场景下没办法操作 iframe 中的 DOM。 87 | 88 | Web Component,其整体实现思路是: 89 | 90 | - 利用 Web Component 的隔离特性作为各个页面的容器,来实现页面的样式隔离 91 | - 通过 JS 给目录项增加点击事件,借用 JS 的能力取到 Web Component 内的目标节点,通过 scrollIntoView 滚动到对应的位置 92 | - 最后,在容器页面中,拼接目录、各个页面对应的 Web Component 组件。 93 | 94 | 这套方案在浏览器场景中没有任何问题,而且也比较简单,但生成 PDF 就有问题了,因为生成 PDF 文件后,JS 的能力就丢了,之前的目录跳转是依靠原生的 HTML 锚点能力,现在有了 Web Component 的隔离,a 标签的 href 就取不到 Web Component 内部的元素了。但是,Web Component 实在是一个不错的样式沙箱方案,其实现思路如下,以后有机会可以在浏览器中使用: 95 | ```javascript 96 | /** 97 | * 生成 PDF 内容页 98 | * @param { Array
205 |
207 | 第二个内容页 —— 锚点 1
206 |
208 |
210 |
211 |
212 | ```
213 |
214 | - 新建 PDF 内容页的容器页面 **/fe/pdf-content.html**,来承载目录和众多 PDF 内容页的 HTML + CSS
215 | ```html
216 |
217 |
218 |
219 |
220 |
221 |