├── __init__.py
├── LLNL-CODE-802426
├── export
├── scripts_for_testing
├── demo_very-simple_fast-cam.py
├── demo_simple_fast-cam.py
├── nif_fast-cam.py
└── demo_fast-cam.py
├── images
├── snake.jpg
├── spider.png
├── IMG_1382.jpg
├── IMG_2470.jpg
├── IMG_2730.jpg
├── cat_dog.png
├── collies.JPG
├── dd_tree.jpg
├── elephant.png
├── water-bird.JPEG
├── multiple_dogs.jpg
├── 00.00230.03456.105.png
├── 00.00384.02880.105.png
├── 01.13104.08462.000.png
├── 02.08404.03657.090.png
├── 05.11065.01451.105.png
├── 07.06436.09583.135.png
├── 09.08931.05768.075.png
├── 11.02691.07335.030.png
├── 15.11213.10090.030.png
├── ILSVRC2012_val_00049169.JPEG
├── ILSVRC2012_val_00049273.JPEG
├── ILSVRC2012_val_00049702.JPEG
├── ILSVRC2012_val_00049929.JPEG
├── ILSVRC2012_val_00049931.JPEG
├── ILSVRC2012_val_00049937.JPEG
├── ILSVRC2012_val_00049965.JPEG
└── ILSVRC2012_val_00049934.224x224.png
├── mdimg
├── option.jpg
├── SMOE-v-STD.jpg
├── roar_kar.png
├── LOVI_Layers_web.jpg
├── histogram_values.jpg
├── ResNet_w_Salmaps_2.jpg
├── layer_map_examples_2.jpg
├── many_fastcam_examples.jpg
└── fast-cam.ILSVRC2012_val_00049934.jpg
├── example_outputs
├── IMG_1382_CAM_PP.jpg
├── IMG_2470_CAM_PP.jpg
├── IMG_2730_CAM_PP.jpg
├── collies_CAM_PP.jpg
├── water-bird_CAM_PP.jpg
├── multiple_dogs_CAM_PP.jpg
├── ILSVRC2012_val_00049169_CAM_PP.jpg
├── ILSVRC2012_val_00049273_CAM_PP.jpg
├── ILSVRC2012_val_00049702_CAM_PP.jpg
├── ILSVRC2012_val_00049929_CAM_PP.jpg
├── ILSVRC2012_val_00049931_CAM_PP.jpg
├── ILSVRC2012_val_00049937_CAM_PP.jpg
├── ILSVRC2012_val_00049965_CAM_PP.jpg
└── ILSVRC2012_val_00049934.224x224_CAM_PP.jpg
├── requirements.txt
├── .github
└── ISSUE_TEMPLATE
│ ├── custom.md
│ ├── feature_request.md
│ └── bug_report.md
├── LICENSE
├── .gitignore
├── CODE_OF_CONDUCT.md
├── conditional.py
├── README.md
├── scripts
└── create_many_comparison.py
├── mask.py
├── draw.py
├── bidicam.py
├── norm.py
├── resnet.py
├── misc.py
└── maps.py
/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/LLNL-CODE-802426:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/export/scripts_for_testing:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/images/snake.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/snake.jpg
--------------------------------------------------------------------------------
/images/spider.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/spider.png
--------------------------------------------------------------------------------
/mdimg/option.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/mdimg/option.jpg
--------------------------------------------------------------------------------
/images/IMG_1382.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/IMG_1382.jpg
--------------------------------------------------------------------------------
/images/IMG_2470.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/IMG_2470.jpg
--------------------------------------------------------------------------------
/images/IMG_2730.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/IMG_2730.jpg
--------------------------------------------------------------------------------
/images/cat_dog.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/cat_dog.png
--------------------------------------------------------------------------------
/images/collies.JPG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/collies.JPG
--------------------------------------------------------------------------------
/images/dd_tree.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/dd_tree.jpg
--------------------------------------------------------------------------------
/images/elephant.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/elephant.png
--------------------------------------------------------------------------------
/mdimg/SMOE-v-STD.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/mdimg/SMOE-v-STD.jpg
--------------------------------------------------------------------------------
/mdimg/roar_kar.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/mdimg/roar_kar.png
--------------------------------------------------------------------------------
/images/water-bird.JPEG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/water-bird.JPEG
--------------------------------------------------------------------------------
/images/multiple_dogs.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/multiple_dogs.jpg
--------------------------------------------------------------------------------
/mdimg/LOVI_Layers_web.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/mdimg/LOVI_Layers_web.jpg
--------------------------------------------------------------------------------
/mdimg/histogram_values.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/mdimg/histogram_values.jpg
--------------------------------------------------------------------------------
/images/00.00230.03456.105.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/00.00230.03456.105.png
--------------------------------------------------------------------------------
/images/00.00384.02880.105.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/00.00384.02880.105.png
--------------------------------------------------------------------------------
/images/01.13104.08462.000.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/01.13104.08462.000.png
--------------------------------------------------------------------------------
/images/02.08404.03657.090.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/02.08404.03657.090.png
--------------------------------------------------------------------------------
/images/05.11065.01451.105.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/05.11065.01451.105.png
--------------------------------------------------------------------------------
/images/07.06436.09583.135.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/07.06436.09583.135.png
--------------------------------------------------------------------------------
/images/09.08931.05768.075.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/09.08931.05768.075.png
--------------------------------------------------------------------------------
/images/11.02691.07335.030.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/11.02691.07335.030.png
--------------------------------------------------------------------------------
/images/15.11213.10090.030.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/15.11213.10090.030.png
--------------------------------------------------------------------------------
/mdimg/ResNet_w_Salmaps_2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/mdimg/ResNet_w_Salmaps_2.jpg
--------------------------------------------------------------------------------
/mdimg/layer_map_examples_2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/mdimg/layer_map_examples_2.jpg
--------------------------------------------------------------------------------
/mdimg/many_fastcam_examples.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/mdimg/many_fastcam_examples.jpg
--------------------------------------------------------------------------------
/example_outputs/IMG_1382_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/IMG_1382_CAM_PP.jpg
--------------------------------------------------------------------------------
/example_outputs/IMG_2470_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/IMG_2470_CAM_PP.jpg
--------------------------------------------------------------------------------
/example_outputs/IMG_2730_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/IMG_2730_CAM_PP.jpg
--------------------------------------------------------------------------------
/example_outputs/collies_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/collies_CAM_PP.jpg
--------------------------------------------------------------------------------
/images/ILSVRC2012_val_00049169.JPEG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/ILSVRC2012_val_00049169.JPEG
--------------------------------------------------------------------------------
/images/ILSVRC2012_val_00049273.JPEG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/ILSVRC2012_val_00049273.JPEG
--------------------------------------------------------------------------------
/images/ILSVRC2012_val_00049702.JPEG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/ILSVRC2012_val_00049702.JPEG
--------------------------------------------------------------------------------
/images/ILSVRC2012_val_00049929.JPEG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/ILSVRC2012_val_00049929.JPEG
--------------------------------------------------------------------------------
/images/ILSVRC2012_val_00049931.JPEG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/ILSVRC2012_val_00049931.JPEG
--------------------------------------------------------------------------------
/images/ILSVRC2012_val_00049937.JPEG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/ILSVRC2012_val_00049937.JPEG
--------------------------------------------------------------------------------
/images/ILSVRC2012_val_00049965.JPEG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/ILSVRC2012_val_00049965.JPEG
--------------------------------------------------------------------------------
/example_outputs/water-bird_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/water-bird_CAM_PP.jpg
--------------------------------------------------------------------------------
/example_outputs/multiple_dogs_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/multiple_dogs_CAM_PP.jpg
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | numpy
2 | jupyterlab
3 | notebook
4 | torch
5 | torchvision
6 | opencv-python-nonfree
7 | pytorch_gradcam
8 |
--------------------------------------------------------------------------------
/images/ILSVRC2012_val_00049934.224x224.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/images/ILSVRC2012_val_00049934.224x224.png
--------------------------------------------------------------------------------
/mdimg/fast-cam.ILSVRC2012_val_00049934.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/mdimg/fast-cam.ILSVRC2012_val_00049934.jpg
--------------------------------------------------------------------------------
/example_outputs/ILSVRC2012_val_00049169_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/ILSVRC2012_val_00049169_CAM_PP.jpg
--------------------------------------------------------------------------------
/example_outputs/ILSVRC2012_val_00049273_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/ILSVRC2012_val_00049273_CAM_PP.jpg
--------------------------------------------------------------------------------
/example_outputs/ILSVRC2012_val_00049702_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/ILSVRC2012_val_00049702_CAM_PP.jpg
--------------------------------------------------------------------------------
/example_outputs/ILSVRC2012_val_00049929_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/ILSVRC2012_val_00049929_CAM_PP.jpg
--------------------------------------------------------------------------------
/example_outputs/ILSVRC2012_val_00049931_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/ILSVRC2012_val_00049931_CAM_PP.jpg
--------------------------------------------------------------------------------
/example_outputs/ILSVRC2012_val_00049937_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/ILSVRC2012_val_00049937_CAM_PP.jpg
--------------------------------------------------------------------------------
/example_outputs/ILSVRC2012_val_00049965_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/ILSVRC2012_val_00049965_CAM_PP.jpg
--------------------------------------------------------------------------------
/example_outputs/ILSVRC2012_val_00049934.224x224_CAM_PP.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/llnl/fastcam/HEAD/example_outputs/ILSVRC2012_val_00049934.224x224_CAM_PP.jpg
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/custom.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Custom issue template
3 | about: Describe this issue template's purpose here.
4 | title: ''
5 | labels: ''
6 | assignees: ''
7 |
8 | ---
9 |
10 |
11 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/feature_request.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Feature request
3 | about: Suggest an idea for this project
4 | title: ''
5 | labels: ''
6 | assignees: ''
7 |
8 | ---
9 |
10 | **Is your feature request related to a problem? Please describe.**
11 | A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
12 |
13 | **Describe the solution you'd like**
14 | A clear and concise description of what you want to happen.
15 |
16 | **Describe alternatives you've considered**
17 | A clear and concise description of any alternative solutions or features you've considered.
18 |
19 | **Additional context**
20 | Add any other context or screenshots about the feature request here.
21 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/bug_report.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Bug report
3 | about: Create a report to help us improve
4 | title: ''
5 | labels: ''
6 | assignees: ''
7 |
8 | ---
9 |
10 | **Describe the bug**
11 | A clear and concise description of what the bug is.
12 |
13 | **To Reproduce**
14 | Steps to reproduce the behavior:
15 | 1. Go to '...'
16 | 2. Click on '....'
17 | 3. Scroll down to '....'
18 | 4. See error
19 |
20 | **Expected behavior**
21 | A clear and concise description of what you expected to happen.
22 |
23 | **Screenshots**
24 | If applicable, add screenshots to help explain your problem.
25 |
26 | **Desktop (please complete the following information):**
27 | - OS: [e.g. iOS]
28 | - Browser [e.g. chrome, safari]
29 | - Version [e.g. 22]
30 |
31 | **Smartphone (please complete the following information):**
32 | - Device: [e.g. iPhone6]
33 | - OS: [e.g. iOS8.1]
34 | - Browser [e.g. stock browser, safari]
35 | - Version [e.g. 22]
36 |
37 | **Additional context**
38 | Add any other context about the problem here.
39 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | BSD 3-Clause License
2 |
3 | Copyright (c) 2020, Lawrence Livermore National Laboratory
4 | All rights reserved.
5 |
6 | Redistribution and use in source and binary forms, with or without
7 | modification, are permitted provided that the following conditions are met:
8 |
9 | 1. Redistributions of source code must retain the above copyright notice, this
10 | list of conditions and the following disclaimer.
11 |
12 | 2. Redistributions in binary form must reproduce the above copyright notice,
13 | this list of conditions and the following disclaimer in the documentation
14 | and/or other materials provided with the distribution.
15 |
16 | 3. Neither the name of the copyright holder nor the names of its
17 | contributors may be used to endorse or promote products derived from
18 | this software without specific prior written permission.
19 |
20 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | pip-wheel-metadata/
24 | share/python-wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 | MANIFEST
29 |
30 | # PyInstaller
31 | # Usually these files are written by a python script from a template
32 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
33 | *.manifest
34 | *.spec
35 |
36 | # Installer logs
37 | pip-log.txt
38 | pip-delete-this-directory.txt
39 |
40 | # Unit test / coverage reports
41 | htmlcov/
42 | .tox/
43 | .nox/
44 | .coverage
45 | .coverage.*
46 | .cache
47 | nosetests.xml
48 | coverage.xml
49 | *.cover
50 | *.py,cover
51 | .hypothesis/
52 | .pytest_cache/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | target/
76 |
77 | # Jupyter Notebook
78 | .ipynb_checkpoints
79 |
80 | # IPython
81 | profile_default/
82 | ipython_config.py
83 |
84 | # pyenv
85 | .python-version
86 |
87 | # pipenv
88 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
89 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
90 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
91 | # install all needed dependencies.
92 | #Pipfile.lock
93 |
94 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
95 | __pypackages__/
96 |
97 | # Celery stuff
98 | celerybeat-schedule
99 | celerybeat.pid
100 |
101 | # SageMath parsed files
102 | *.sage.py
103 |
104 | # Environments
105 | .env
106 | .venv
107 | env/
108 | venv/
109 | ENV/
110 | env.bak/
111 | venv.bak/
112 |
113 | # Spyder project settings
114 | .spyderproject
115 | .spyproject
116 |
117 | # Rope project settings
118 | .ropeproject
119 |
120 | # mkdocs documentation
121 | /site
122 |
123 | # mypy
124 | .mypy_cache/
125 | .dmypy.json
126 | dmypy.json
127 |
128 | # Pyre type checker
129 | .pyre/
130 |
--------------------------------------------------------------------------------
/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | # Contributor Covenant Code of Conduct
2 |
3 | ## Our Pledge
4 |
5 | In the interest of fostering an open and welcoming environment, we as
6 | contributors and maintainers pledge to making participation in our project and
7 | our community a harassment-free experience for everyone, regardless of age, body
8 | size, disability, ethnicity, sex characteristics, gender identity and expression,
9 | level of experience, education, socio-economic status, nationality, personal
10 | appearance, race, religion, or sexual identity and orientation.
11 |
12 | ## Our Standards
13 |
14 | Examples of behavior that contributes to creating a positive environment
15 | include:
16 |
17 | * Using welcoming and inclusive language
18 | * Being respectful of differing viewpoints and experiences
19 | * Gracefully accepting constructive criticism
20 | * Focusing on what is best for the community
21 | * Showing empathy towards other community members
22 |
23 | Examples of unacceptable behavior by participants include:
24 |
25 | * The use of sexualized language or imagery and unwelcome sexual attention or
26 | advances
27 | * Trolling, insulting/derogatory comments, and personal or political attacks
28 | * Public or private harassment
29 | * Publishing others' private information, such as a physical or electronic
30 | address, without explicit permission
31 | * Other conduct which could reasonably be considered inappropriate in a
32 | professional setting
33 |
34 | ## Our Responsibilities
35 |
36 | Project maintainers are responsible for clarifying the standards of acceptable
37 | behavior and are expected to take appropriate and fair corrective action in
38 | response to any instances of unacceptable behavior.
39 |
40 | Project maintainers have the right and responsibility to remove, edit, or
41 | reject comments, commits, code, wiki edits, issues, and other contributions
42 | that are not aligned to this Code of Conduct, or to ban temporarily or
43 | permanently any contributor for other behaviors that they deem inappropriate,
44 | threatening, offensive, or harmful.
45 |
46 | ## Scope
47 |
48 | This Code of Conduct applies both within project spaces and in public spaces
49 | when an individual is representing the project or its community. Examples of
50 | representing a project or community include using an official project e-mail
51 | address, posting via an official social media account, or acting as an appointed
52 | representative at an online or offline event. Representation of a project may be
53 | further defined and clarified by project maintainers.
54 |
55 | ## Enforcement
56 |
57 | Instances of abusive, harassing, or otherwise unacceptable behavior may be
58 | reported by contacting the project team at github-admin@llnl.gov. All
59 | complaints will be reviewed and investigated and will result in a response that
60 | is deemed necessary and appropriate to the circumstances. The project team is
61 | obligated to maintain confidentiality with regard to the reporter of an incident.
62 | Further details of specific enforcement policies may be posted separately.
63 |
64 | Project maintainers who do not follow or enforce the Code of Conduct in good
65 | faith may face temporary or permanent repercussions as determined by other
66 | members of the project's leadership.
67 |
68 | ## Attribution
69 |
70 | This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
71 | available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
72 |
73 | [homepage]: https://www.contributor-covenant.org
74 |
75 | For answers to common questions about this code of conduct, see
76 | https://www.contributor-covenant.org/faq
77 |
--------------------------------------------------------------------------------
/conditional.py:
--------------------------------------------------------------------------------
1 | '''
2 | BSD 3-Clause License
3 |
4 | Copyright (c) 2020, Lawrence Livermore National Laboratory
5 | All rights reserved.
6 |
7 | Redistribution and use in source and binary forms, with or without
8 | modification, are permitted provided that the following conditions are met:
9 |
10 | 1. Redistributions of source code must retain the above copyright notice, this
11 | list of conditions and the following disclaimer.
12 |
13 | 2. Redistributions in binary form must reproduce the above copyright notice,
14 | this list of conditions and the following disclaimer in the documentation
15 | and/or other materials provided with the distribution.
16 |
17 | 3. Neither the name of the copyright holder nor the names of its
18 | contributors may be used to endorse or promote products derived from
19 | this software without specific prior written permission.
20 |
21 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
31 | '''
32 | '''
33 | https://github.com/LLNL/fastcam
34 |
35 | A toolkit for efficent computation of saliency maps for explainable
36 | AI attribution.
37 |
38 | This work was performed under the auspices of the U.S. Department of Energy
39 | by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344
40 | and was supported by the LLNL-LDRD Program under Project 18-ERD-021 and
41 | Project 17-SI-003.
42 |
43 | Software released as LLNL-CODE-802426.
44 |
45 | See also: https://arxiv.org/abs/1911.11293
46 | '''
47 | import torch
48 | import torch.nn as nn
49 | import torch.nn.functional as F
50 |
51 | try:
52 | from . import maps
53 | except ImportError:
54 | import maps
55 |
56 |
57 |
58 | class ConditionalSaliencyMaps(maps.CombineSaliencyMaps):
59 | r'''
60 | This will combine saliency maps into a single weighted saliency map.
61 |
62 | Input is a list of 3D tensors or various sizes.
63 | Output is a 3D tensor of size output_size
64 |
65 | num_maps specifies how many maps we will combine
66 | weights is an optional list of weights for each layer e.g. [1, 2, 3, 4, 5]
67 | '''
68 |
69 | def __init__(self, **kwargs):
70 |
71 | super(ConditionalSaliencyMaps, self).__init__(**kwargs)
72 |
73 | def forward(self, xmap, ymaps, reverse=False):
74 |
75 | r'''
76 | Input shapes are something like [64,7,7] i.e. [batch size x layer_height x layer_width]
77 | Output shape is something like [64,224,244] i.e. [batch size x image_height x image_width]
78 | '''
79 |
80 | assert(isinstance(xmap,list))
81 | assert(len(xmap) == self.map_num)
82 | assert(len(xmap[0].size()) == 3)
83 |
84 | bn = xmap[0].size()[0]
85 | cm = torch.zeros((bn, 1, self.output_size[0], self.output_size[1]), dtype=xmap[0].dtype, device=xmap[0].device)
86 | ww = []
87 |
88 | r'''
89 | Now get each saliency map and resize it. Then store it and also create a combined saliency map.
90 | '''
91 | for i in range(len(xmap)):
92 | assert(torch.is_tensor(xmap[i]))
93 | wsz = xmap[i].size()
94 | wx = xmap[i].reshape(wsz[0], 1, wsz[1], wsz[2]) + 0.0000001
95 | w = torch.zeros_like(wx)
96 |
97 | if reverse:
98 | for j in range(len(ymaps)):
99 | wy = ymaps[j][i].reshape(wsz[0], 1, wsz[1], wsz[2]) + 0.0000001
100 |
101 | w -= wx*torch.log2(wx/wy)
102 | else:
103 | for j in range(len(ymaps)):
104 | wy = ymaps[j][i].reshape(wsz[0], 1, wsz[1], wsz[2]) + 0.0000001
105 |
106 | w -= wy*torch.log2(wy/wx)
107 |
108 | w = torch.clamp(w,0.0000001,1)
109 | w = nn.functional.interpolate(w, size=self.output_size, mode=self.resize_mode, align_corners=False)
110 |
111 | ww.append(w)
112 | cm += (w * self.weights[i])
113 |
114 | cm = cm / self.weight_sum
115 | cm = cm.reshape(bn, self.output_size[0], self.output_size[1])
116 |
117 | ww = torch.stack(ww,dim=1)
118 | ww = ww.reshape(bn, self.map_num, self.output_size[0], self.output_size[1])
119 |
120 | return cm, ww
121 |
122 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Efficient Saliency and FastCAM
2 |
3 | FastCAM creates a saliency map using SMOE Scale saliency maps as described in our paper on
4 | [ArXiv:1911.11293](https://arxiv.org/abs/1911.11293). We obtain a highly significant speed-up by replacing
5 | the Guided Backprop component typically used alongside GradCAM with our SMOE Scale saliency map.
6 | Additionally, the expected accuracy of the saliency map is increased slightly. Thus, **FastCAM is three orders of magnitude faster and a little bit more accurate than GradCAM+Guided Backprop with SmoothGrad.**
7 |
8 | 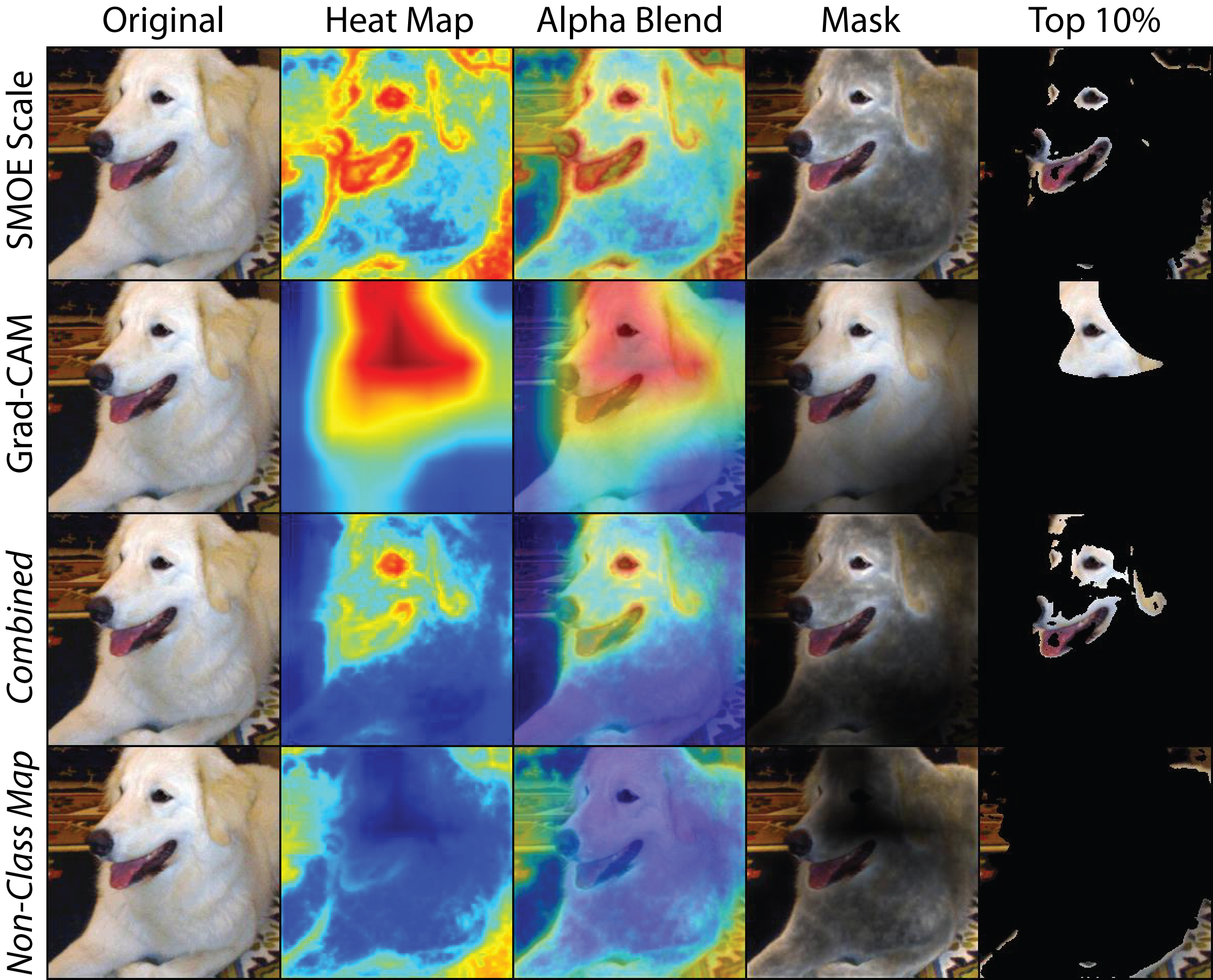
9 |
10 | ## Performance
11 |
12 | FastCAM is not only fast, but it is more accurate than most methods. The following is a list of [ROAR/KAR](https://arxiv.org/abs/1806.10758) ImageNet scores for different methods along with notes about performance. In gray is the total ROAR/KAR score. Higher is better. The last line is the score for the combined map you see here.
13 |
14 | 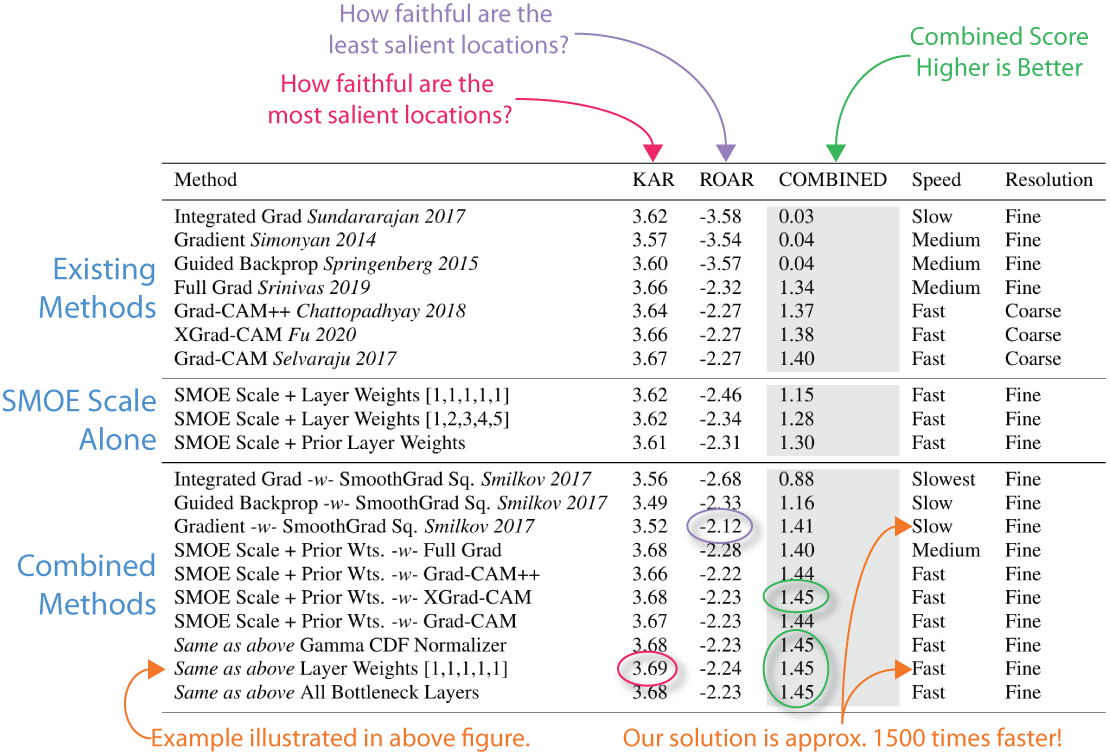
15 |
16 | ## How Does it Work?
17 |
18 | 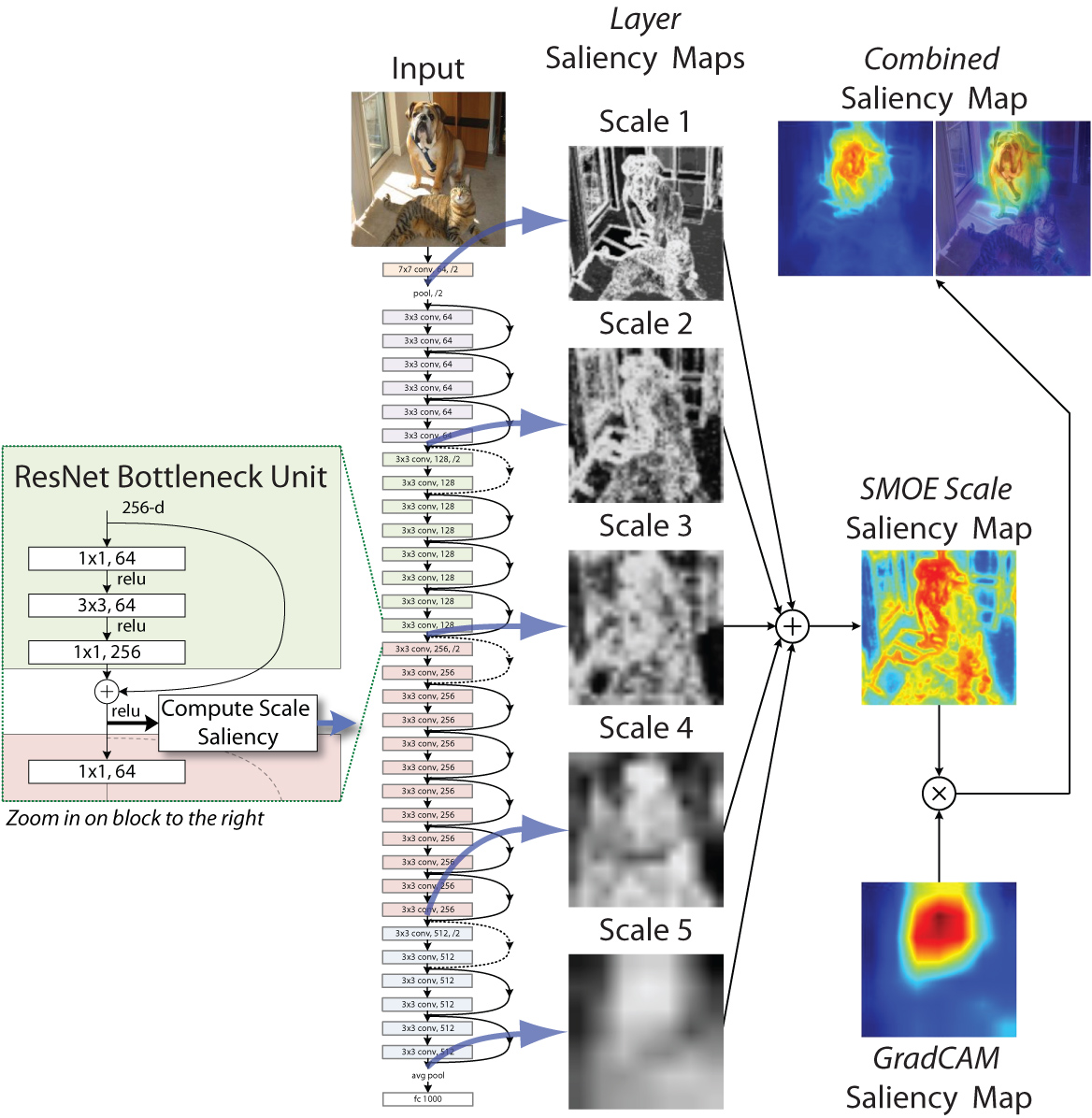
19 |
20 | We compute the saliency map by computing the *conditional entropy* between the mean activation in a layer and the individual values. This gives us the **SMOE Scale** for a given layer. We apply this to the layer at the end of each spatial scale in the network and then take a weighted average. Finally, we combine it with GradCAM by multiplying the combined SMOE Scale saliency map with the GradCAM saliency map.
21 |
22 |
23 | ## Installation
24 |
25 | The FastCAM package runs on **Python 3.x**. The package should run on **Python 2.x**. However, since
26 | the end of product life for 2.x has been announced, we will not actively support it going forward.
27 | All extra requirements are available through *pip* installation. On *IBM Power* based architecture,
28 | some packages may have to be hand installed, but it's totally doable. We have tested on Linux, MacOS and Windows.
29 | Let us know if you have any issues.
30 |
31 | The primary functionality is demonstrated using a **Jupyter notebook**. By following it, you should be
32 | able to see how to use FastCAM on your own deep network.
33 |
34 | ### Required Packages
35 |
36 | When you run the installation, these packages should automatically install for you.
37 |
38 | numpy
39 | jupyterlab
40 | notebook
41 | torch
42 | torchvision
43 | opencv-python
44 | pytorch_gradcam
45 |
46 | ### Install and Run the Demo!
47 |
48 | 
49 |
50 | This will run our [Jupyter Notebook](https://github.com/LLNL/fastcam/blob/master/demo_fast-cam.ipynb) on your local computer.
51 |
52 | **Optionally** if you don't care how it runs and just want to run it, use our [simplified notebook](https://github.com/LLNL/fastcam/blob/master/demo_simple_fast-cam.ipynb).
53 |
54 | **Double Optionally** if you just want to run it and really really really don't care about how it works, use our [notebook for the exceptionally impatient](https://github.com/LLNL/fastcam/blob/master/demo_very-simple_fast-cam.ipynb).
55 |
56 | **Experimentally** we have a [PyTorch Captum framework version of FastCAM](https://github.com/LLNL/fastcam/blob/master/demo-captum.ipynb).
57 |
58 | These are our recommended installation steps:
59 |
60 | git clone git@github.com:LLNL/fastcam.git
61 |
62 | or
63 |
64 | git clone https://github.com/LLNL/fastcam.git
65 |
66 | then do:
67 |
68 | cd fastcam
69 | python3 -m venv venv3
70 | source venv3/bin/activate
71 | pip install -r requirements.txt
72 |
73 | Next you will need to start the jupyter notebook:
74 |
75 | jupyter notebook
76 |
77 | It should start the jupyter web service and create a notebook instance in your browser. You can then click on
78 |
79 | demo_fast-cam.ipynb
80 |
81 | To run the notebook, click on the double arrow (fast forward) button at the top of the web page.
82 |
83 | 
84 |
85 | ### Installation Notes
86 |
87 | **1. You don't need a GPU**
88 |
89 | Because FastCAM is ... well ... fast, you can install and run the demo on a five-year-old MacBook without GPU support. You just need to make sure you have enough RAM to run a forward pass of ResNet 50.
90 |
91 | **2. Pillow Version Issue**
92 |
93 | If you get:
94 |
95 | cannot import name ‘PILLOW_VERSION’
96 |
97 | This is a known weird issue between Pillow and Torchvision, install an older version as such:
98 |
99 | pip install pillow=6.2.1
100 |
101 | **3. PyTorch GradCAM Path Issue**
102 |
103 | The library does not seem to set the python path for you. You may have to set it manually. For example in Bash,
104 | we can set it as such:
105 |
106 | export PYTHONPATH=$PYTHONPATH:/path/to/my/python/lib/python3.7/site-packages/
107 |
108 | If you want to know where that is, try:
109 |
110 | which python
111 |
112 | you will see:
113 |
114 | /path/to/my/python/bin/python
115 |
116 | ## Many More Examples
117 |
118 | 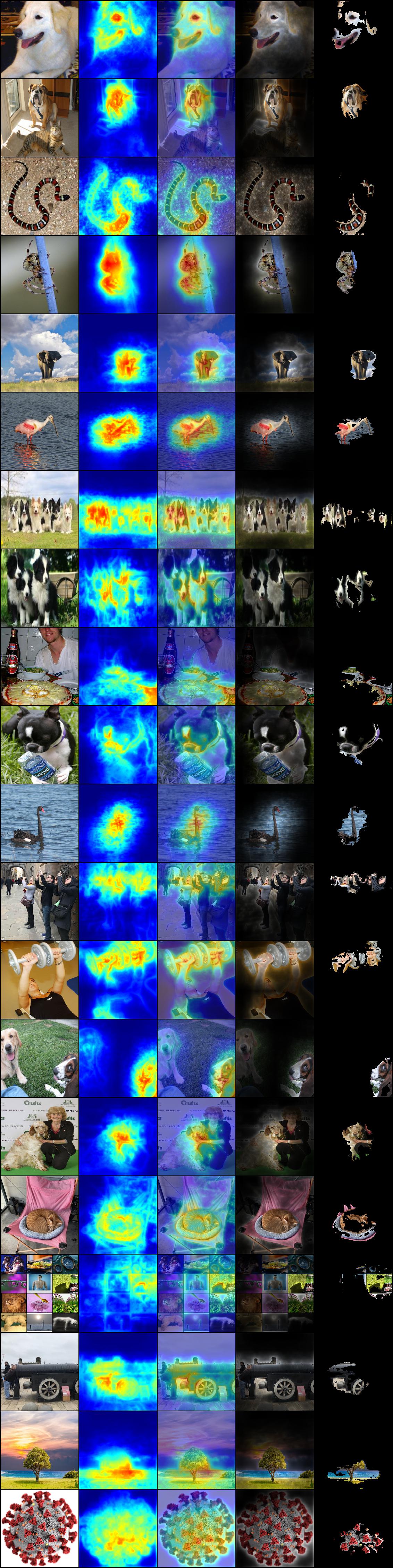
119 |
120 | ## Contact
121 |
122 | Questions, concerns and friendly banter can be addressed to:
123 |
124 | T. Nathan Mundhenk [mundhenk1@llnl.gov](mundhenk1@llnl.gov)
125 |
126 | ## License
127 |
128 | FastCAM is distributed under the [BSD 3-Clause License](https://github.com/LLNL/fastcam/blob/master/LICENSE).
129 |
130 | LLNL-CODE-802426
131 |
132 |
133 |
134 |
--------------------------------------------------------------------------------
/export/demo_very-simple_fast-cam.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | # # DEMO: Running FastCAM for the Exceptionally Impatient
5 |
6 | # ### Import Libs
7 |
8 | # In[1]:
9 |
10 |
11 | import os
12 | from IPython.display import Image
13 |
14 |
15 | # Lets load the **PyTorch** Stuff.
16 |
17 | # In[2]:
18 |
19 |
20 | import torch
21 | import torch.nn.functional as F
22 | from torchvision.utils import make_grid, save_image
23 |
24 | import warnings
25 | warnings.filterwarnings('ignore')
26 |
27 |
28 | # Now we import the saliency libs for **this package**.
29 |
30 | # In[3]:
31 |
32 |
33 | import maps
34 | import misc
35 | import mask
36 | import norm
37 | import resnet
38 |
39 |
40 | # ### Set Adjustable Parameters
41 | # This is where we can set some parameters like the image name and the layer weights.
42 |
43 | # In[4]:
44 |
45 |
46 | input_image_name = "ILSVRC2012_val_00049934.224x224.png" # Our input image to process
47 | output_dir = 'outputs' # Where to save our output images
48 | input_dir = 'images' # Where to load our inputs from
49 | in_height = 224 # Size to scale input image to
50 | in_width = 224 # Size to scale input image to
51 |
52 |
53 | # Now we set up what layers we want to sample from and what weights to give each layer. We specify the layer block name within ResNet were we will pull the forward SMOE Scale results from. The results will be from the end of each layer block.
54 |
55 | # In[5]:
56 |
57 |
58 | weights = [1.0, 1.0, 1.0, 1.0, 1.0] # Equal Weights work best
59 | # when using with GradCAM
60 | layers = ['relu','layer1','layer2','layer3','layer4']
61 |
62 |
63 | # **OPTIONAL:** We can auto compute which layers to run over by setting them to *None*. **This has not yet been quantitatively tested on ROAR/KARR.**
64 |
65 | # In[6]:
66 |
67 |
68 | #weights = None
69 | #layers = None
70 |
71 |
72 | # ### Set Up Loading and Saving File Names
73 | # Lets touch up where to save output and what name to use for output files.
74 |
75 | # In[7]:
76 |
77 |
78 | save_prefix = os.path.split(os.path.splitext(input_image_name)[0])[-1] # Chop the file extension and path
79 | load_image_name = os.path.join(input_dir, input_image_name)
80 |
81 | os.makedirs(output_dir, exist_ok=True)
82 |
83 |
84 | # Take a look at the input image ...
85 | # Good Doggy!
86 |
87 | # In[8]:
88 |
89 |
90 | Image(filename=load_image_name)
91 |
92 |
93 | # ### Set Up Usual PyTorch Network Stuff
94 | # Go ahead and create a standard PyTorch device. It can use the CPU if no GPU is present. This demo works pretty well on just CPU.
95 |
96 | # In[9]:
97 |
98 |
99 | device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
100 |
101 |
102 | # Now we will create a model. Here we have a slightly customized ResNet that will only propagate backwards the last few layers. The customization is just a wrapper around the stock ResNet that comes with PyTorch. SMOE Scale computation does not need any gradients and GradCAM variants only need the last few layers. This will really speed things up, but don't try to train this network. You can train the regular ResNet if you need to do that. Since this network is just a wrapper, it will load any standard PyTorch ResNet training weights.
103 |
104 | # In[10]:
105 |
106 |
107 | model = resnet.resnet50(pretrained=True)
108 | model = model.to(device)
109 |
110 |
111 | # ### Load Images
112 | # Lets load in our image into standard torch tensors. We will do a simple resize on it.
113 |
114 | # In[11]:
115 |
116 |
117 | in_tensor = misc.LoadImageToTensor(load_image_name, device)
118 | in_tensor = F.interpolate(in_tensor, size=(in_height, in_width), mode='bilinear', align_corners=False)
119 |
120 |
121 | # For illustration purposes, Lets also load a non-normalized version of the input.
122 |
123 | # In[12]:
124 |
125 |
126 | raw_tensor = misc.LoadImageToTensor(load_image_name, device, norm=False)
127 | raw_tensor = F.interpolate(raw_tensor, size=(in_height, in_width), mode='bilinear', align_corners=False)
128 |
129 |
130 | # ### Set Up Saliency Objects
131 |
132 | # Choose our layer normalization method.
133 |
134 | # In[13]:
135 |
136 |
137 | #norm_method = norm.GaussNorm2D
138 | norm_method = norm.GammaNorm2D # A little more accurate, but much slower
139 |
140 |
141 | # We create an object to create the saliency map given the model and layers we have selected.
142 |
143 | # In[14]:
144 |
145 |
146 | getSalmap = maps.SaliencyModel(model, layers, output_size=[in_height,in_width], weights=weights,
147 | norm_method=norm_method)
148 |
149 |
150 | # Now we set up our masking object to create a nice mask image of the %10 most salient locations. You will see the results below when it is run.
151 |
152 | # In[15]:
153 |
154 |
155 | getMask = mask.SaliencyMaskDropout(keep_percent = 0.1, scale_map=False)
156 |
157 |
158 | # ### Run Saliency
159 | # Now lets run our input tensor image through the net and get the 2D saliency map back.
160 |
161 | # In[16]:
162 |
163 |
164 | cam_map,_,_ = getSalmap(in_tensor)
165 |
166 |
167 | # ### Visualize It
168 | # Take the images and create a nice tiled image to look at. This will created a tiled image of:
169 | #
170 | # (1) The input image.
171 | # (2) The saliency map.
172 | # (3) The saliency map overlaid on the input image.
173 | # (4) The raw image enhanced with the most salient locations.
174 | # (5) The top 10% most salient locations.
175 |
176 | # In[17]:
177 |
178 |
179 | images = misc.TileOutput(raw_tensor, cam_map, getMask)
180 |
181 |
182 | # We now put all the images into a nice grid for display.
183 |
184 | # In[18]:
185 |
186 |
187 | images = make_grid(torch.cat(images,0), nrow=5)
188 |
189 |
190 | # ... save and look at it.
191 |
192 | # In[19]:
193 |
194 |
195 | output_name = "{}.FASTCAM.jpg".format(save_prefix)
196 | output_path = os.path.join(output_dir, output_name)
197 |
198 | save_image(images, output_path)
199 | Image(filename=output_path)
200 |
201 |
202 | # This image should look **exactly** like the one on the README.md on Github minus the text.
203 |
204 | # In[ ]:
205 |
206 |
207 |
208 |
209 |
--------------------------------------------------------------------------------
/scripts/create_many_comparison.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | import os
5 | import torch
6 | from torchvision import models
7 |
8 | # Lets load things we need for **Grad-CAM**
9 | from torchvision.utils import make_grid, save_image
10 | import torch.nn.functional as F
11 |
12 | #from gradcam.utils import visualize_cam
13 | from gradcam import GradCAM
14 |
15 | # The GradCAM kit throws a warning we don't need to see for this demo.
16 | import warnings
17 | warnings.filterwarnings('ignore')
18 |
19 | # Now we import the code for **this package**.
20 | import maps
21 | import misc
22 | import mask
23 | import norm
24 | import resnet
25 |
26 | # This is where we can set some parameters like the image name and the layer weights.
27 | files = [ "ILSVRC2012_val_00049169.JPEG",
28 | "ILSVRC2012_val_00049273.JPEG",
29 | "ILSVRC2012_val_00049702.JPEG",
30 | "ILSVRC2012_val_00049929.JPEG",
31 | "ILSVRC2012_val_00049931.JPEG",
32 | "ILSVRC2012_val_00049937.JPEG",
33 | "ILSVRC2012_val_00049965.JPEG",
34 | "ILSVRC2012_val_00049934.224x224.png",
35 | "IMG_1382.jpg",
36 | "IMG_2470.jpg",
37 | "IMG_2730.jpg",
38 | "Nate_Face.png",
39 | "brant.png",
40 | "cat_dog.png",
41 | "collies.JPG",
42 | "dd_tree.jpg",
43 | "elephant.png",
44 | "multiple_dogs.jpg",
45 | "sanity.jpg",
46 | "snake.jpg",
47 | "spider.png",
48 | "swan_image.png",
49 | "water-bird.JPEG"]
50 |
51 |
52 | # Lets set up where to save output and what name to use.
53 | output_dir = 'outputs' # Where to save our output images
54 | input_dir = 'images' # Where to load our inputs from
55 |
56 | weights = [1.0, 1.0, 1.0, 1.0, 1.0] # Equal Weights work best
57 | # when using with GradCAM
58 |
59 | #weights = [0.18, 0.15, 0.37, 0.4, 0.72] # Our saliency layer weights
60 | # From paper:
61 | # https://arxiv.org/abs/1911.11293
62 |
63 | in_height = 224 # Size to scale input image to
64 | in_width = 224 # Size to scale input image to
65 |
66 | # Choose how we want to normalize each map.
67 | #norm_method = norm.GaussNorm2D
68 | norm_method = norm.GammaNorm2D # A little more accurate, but much slower
69 |
70 | # You will need to pick out which layers to process. Here we grab the end of each group of layers by scale.
71 | layers = ['relu','layer1','layer2','layer3','layer4']
72 |
73 | # Now we create a model in PyTorch and send it to our device.
74 | device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
75 | model = models.resnet50(pretrained=True)
76 | model = model.to(device)
77 |
78 | many_image = []
79 |
80 |
81 | for f in files:
82 | model.eval()
83 |
84 | print("Image {}".format(f))
85 |
86 | input_image_name = f # Our input image to process
87 |
88 | save_prefix = os.path.split(os.path.splitext(input_image_name)[0])[-1] # Chop the file extension and path
89 | load_image_name = os.path.join(input_dir, input_image_name)
90 |
91 | os.makedirs(output_dir, exist_ok=True)
92 |
93 | # Lets load in our image. We will do a simple resize on it.
94 | in_tensor = misc.LoadImageToTensor(load_image_name, device)
95 | in_tensor = F.interpolate(in_tensor, size=(in_height, in_width), mode='bilinear', align_corners=False)
96 |
97 | # Now, lets get the Grad-CAM++ saliency map only.
98 | resnet_gradcam = GradCAM.from_config(model_type='resnet', arch=model, layer_name='layer4')
99 | cam_map, logit = resnet_gradcam(in_tensor)
100 |
101 | # Create our saliency map object. We hand it our Torch model and names for the layers we want to tap.
102 | get_salmap = maps.SaliencyModel(model, layers, output_size=[in_height,in_width], weights=weights,
103 | norm_method=norm_method)
104 |
105 |
106 | # Get Forward sal map
107 | csmap,smaps,_ = get_salmap(in_tensor)
108 |
109 |
110 | # Let's get our original input image back. We will just use this one for visualization.
111 | raw_tensor = misc.LoadImageToTensor(load_image_name, device, norm=False)
112 | raw_tensor = F.interpolate(raw_tensor, size=(in_height, in_width), mode='bilinear', align_corners=False)
113 |
114 |
115 | # We create an object to get back the mask of the saliency map
116 | getMask = mask.SaliencyMaskDropout(keep_percent = 0.1, scale_map=False)
117 |
118 |
119 | # Now we will create illustrations of the combined saliency map.
120 | images = []
121 | images = misc.TileOutput(raw_tensor,csmap,getMask,images)
122 |
123 | # Let's double check and make sure it's picking the correct class
124 | too_logit = logit.max(1)
125 | print("Network Class Output: {} : Value {} ".format(too_logit[1][0],too_logit[0][0]))
126 |
127 |
128 | # Now visualize the results
129 | images = misc.TileOutput(raw_tensor, cam_map.squeeze(0), getMask, images)
130 |
131 |
132 | # ### Combined CAM and SMOE Scale Maps
133 | # Now we combine the Grad-CAM map and the SMOE Scale saliency maps in the same way we would combine Grad-CAM with Guided Backprop.
134 | fastcam_map = csmap*cam_map
135 |
136 |
137 | # Now let's visualize the combined saliency map from SMOE Scale and GradCAM++.
138 | images = misc.TileOutput(raw_tensor, fastcam_map.squeeze(0), getMask, images)
139 |
140 |
141 | # ### Get Non-class map
142 | # Now we combine the Grad-CAM map and the SMOE Scale saliency maps but create a map of the **non-class** objects. These are salient locations that the network found interesting, but are not part of the object class.
143 | nonclass_map = csmap*(1.0 - cam_map)
144 |
145 |
146 | # Now let's visualize the combined non-class saliency map from SMOE Scale and GradCAM++.
147 | images = misc.TileOutput(raw_tensor, nonclass_map.squeeze(0), getMask, images)
148 |
149 | many_image = misc.TileMaps(raw_tensor, csmap, cam_map.squeeze(0), fastcam_map.squeeze(0), many_image)
150 |
151 |
152 | # ### Visualize this....
153 | # We now put all the images into a nice grid for display.
154 | images = make_grid(torch.cat(images,0), nrow=5)
155 |
156 | # ... save and look at it.
157 | output_name = "{}.CAM.jpg".format(save_prefix)
158 | output_path = os.path.join(output_dir, output_name)
159 |
160 | save_image(images, output_path)
161 |
162 | del in_tensor
163 | del raw_tensor
164 |
165 | many_image = make_grid(torch.cat(many_image,0), nrow=4)
166 | output_name = "many.CAM.jpg".format(save_prefix)
167 | output_path = os.path.join(output_dir, output_name)
168 |
169 | save_image(many_image, output_path)
170 |
--------------------------------------------------------------------------------
/export/demo_simple_fast-cam.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | # # DEMO: Running FastCAM using SMOE Scale Saliency Maps
5 |
6 | # ## Initial code setup
7 |
8 | # In[1]:
9 |
10 |
11 | import os
12 | import torch
13 | from torchvision import models
14 | from IPython.display import Image
15 |
16 |
17 | # Lets load things we need for **Grad-CAM**
18 |
19 | # In[2]:
20 |
21 |
22 | from torchvision.utils import make_grid, save_image
23 | import torch.nn.functional as F
24 |
25 | #from gradcam.utils import visualize_cam
26 | from gradcam import GradCAMpp, GradCAM
27 |
28 | # The GradCAM kit throws a warning we don't need to see for this demo.
29 | import warnings
30 | warnings.filterwarnings('ignore')
31 |
32 |
33 | # Now we import the code for **this package**.
34 |
35 | # In[3]:
36 |
37 |
38 | import maps
39 | import misc
40 | import mask
41 | import norm
42 | import resnet
43 |
44 |
45 | # This is where we can set some parameters like the image name and the layer weights.
46 |
47 | # In[4]:
48 |
49 |
50 | input_image_name = "ILSVRC2012_val_00049934.224x224.png" # Our input image to process
51 | output_dir = 'outputs' # Where to save our output images
52 | input_dir = 'images' # Where to load our inputs from
53 |
54 | weights = [1.0, 1.0, 1.0, 1.0, 1.0] # Equal Weights work best
55 | # when using with GradCAM
56 |
57 | #weights = [0.18, 0.15, 0.37, 0.4, 0.72] # Our saliency layer weights
58 | # From paper:
59 | # https://arxiv.org/abs/1911.11293
60 |
61 | in_height = 224 # Size to scale input image to
62 | in_width = 224 # Size to scale input image to
63 |
64 |
65 | # Lets set up where to save output and what name to use.
66 |
67 | # In[5]:
68 |
69 |
70 | save_prefix = os.path.split(os.path.splitext(input_image_name)[0])[-1] # Chop the file extension and path
71 | load_image_name = os.path.join(input_dir, input_image_name)
72 |
73 | os.makedirs(output_dir, exist_ok=True)
74 |
75 |
76 | # Good Doggy!
77 |
78 | # In[6]:
79 |
80 |
81 | Image(filename=load_image_name)
82 |
83 |
84 | # Now we create a model in PyTorch and send it to our device.
85 |
86 | # In[7]:
87 |
88 |
89 | device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
90 | model = models.resnet50(pretrained=True)
91 | model = model.to(device)
92 |
93 |
94 | # You will need to pick out which layers to process. Here we grab the end of each group of layers by scale.
95 |
96 | # In[8]:
97 |
98 |
99 | layers = ['relu','layer1','layer2','layer3','layer4']
100 |
101 | # It will auto select each bottle neck layer if we instead set to None.
102 | #layers = None
103 |
104 |
105 | # Choose how we want to normalize each map.
106 |
107 | # In[9]:
108 |
109 |
110 | #norm_method = norm.GaussNorm2D
111 | norm_method = norm.GammaNorm2D # A little more accurate, but much slower
112 |
113 |
114 | # Lets load in our image. We will do a simple resize on it.
115 |
116 | # In[10]:
117 |
118 |
119 | in_tensor = misc.LoadImageToTensor(load_image_name, device)
120 | in_tensor = F.interpolate(in_tensor, size=(in_height, in_width), mode='bilinear', align_corners=False)
121 |
122 |
123 | # Create our saliency map object. We hand it our Torch model and names for the layers we want to tap.
124 |
125 | # In[11]:
126 |
127 |
128 | get_salmap = maps.SaliencyModel(model, layers, output_size=[in_height,in_width], weights=weights,
129 | norm_method=norm_method)
130 |
131 |
132 | # Lets got ahead and run the network and get back the saliency map
133 |
134 | # In[12]:
135 |
136 |
137 | csmap,smaps,_ = get_salmap(in_tensor)
138 |
139 |
140 | # ## Run With Grad-CAM or Grad-CAM++
141 |
142 | # Let's go ahead and push our network model into the Grad-CAM library.
143 | #
144 | # **NOTE** much of this code is borrowed from the Pytorch GradCAM package.
145 |
146 | # In[13]:
147 |
148 |
149 | resnet_gradcampp4 = GradCAMpp.from_config(model_type='resnet', arch=model, layer_name='layer4')
150 |
151 |
152 | # Let's get our original input image back. We will just use this one for visualization.
153 |
154 | # In[14]:
155 |
156 |
157 | raw_tensor = misc.LoadImageToTensor(load_image_name, device, norm=False)
158 | raw_tensor = F.interpolate(raw_tensor, size=(in_height, in_width), mode='bilinear', align_corners=False)
159 |
160 |
161 | # We create an object to get back the mask of the saliency map
162 |
163 | # In[15]:
164 |
165 |
166 | getMask = mask.SaliencyMaskDropout(keep_percent = 0.1, scale_map=False)
167 |
168 |
169 | # Now we will create illustrations of the combined saliency map.
170 |
171 | # In[16]:
172 |
173 |
174 | images = misc.TileOutput(raw_tensor,csmap,getMask)
175 |
176 |
177 | # Now, lets get the Grad-CAM++ saliency map only.
178 |
179 | # In[17]:
180 |
181 |
182 | cam_map, logit = resnet_gradcampp4(in_tensor)
183 |
184 |
185 | # Let's double check and make sure it's picking the correct class
186 |
187 | # In[18]:
188 |
189 |
190 | too_logit = logit.max(1)
191 | print("Network Class Output: {} : Value {} ".format(too_logit[1][0],too_logit[0][0]))
192 |
193 |
194 | # Now visualize the results
195 |
196 | # In[19]:
197 |
198 |
199 | images = misc.TileOutput(raw_tensor, cam_map.squeeze(0), getMask, images)
200 |
201 |
202 | # ### Combined CAM and SMOE Scale Maps
203 | # Now we combine the Grad-CAM map and the SMOE Scale saliency maps in the same way we would combine Grad-CAM with Guided Backprop.
204 |
205 | # In[20]:
206 |
207 |
208 | fastcam_map = csmap*cam_map
209 |
210 |
211 | # Now let's visualize the combined saliency map from SMOE Scale and GradCAM++.
212 |
213 | # In[21]:
214 |
215 |
216 | images = misc.TileOutput(raw_tensor, fastcam_map.squeeze(0), getMask, images)
217 |
218 |
219 | # ### Get Non-class map
220 | # Now we combine the Grad-CAM map and the SMOE Scale saliency maps but create a map of the **non-class** objects. These are salient locations that the network found interesting, but are not part of the object class.
221 |
222 | # In[22]:
223 |
224 |
225 | nonclass_map = csmap*(1.0 - cam_map)
226 |
227 |
228 | # Now let's visualize the combined non-class saliency map from SMOE Scale and GradCAM++.
229 |
230 | # In[23]:
231 |
232 |
233 | images = misc.TileOutput(raw_tensor, nonclass_map.squeeze(0), getMask, images)
234 |
235 |
236 | # ### Visualize this....
237 | # We now put all the images into a nice grid for display.
238 |
239 | # In[24]:
240 |
241 |
242 | images = make_grid(torch.cat(images,0), nrow=5)
243 |
244 |
245 | # ... save and look at it.
246 |
247 | # In[25]:
248 |
249 |
250 | output_name = "{}.CAM_PP.jpg".format(save_prefix)
251 | output_path = os.path.join(output_dir, output_name)
252 |
253 | save_image(images, output_path)
254 | Image(filename=output_path)
255 |
256 |
257 | # The top row is the SMOE Scale based saliency map. The second row is GradCAM++ only. Next we have the FastCAM output from combining the two. The last row is the non-class map showing salient regions that are not associated with the output class.
258 | #
259 | # This image should look **exactly** like the one on the README.md on Github minus the text.
260 |
261 | # In[ ]:
262 |
263 |
264 |
265 |
266 |
267 | # In[ ]:
268 |
269 |
270 |
271 |
272 |
--------------------------------------------------------------------------------
/mask.py:
--------------------------------------------------------------------------------
1 | '''
2 | BSD 3-Clause License
3 |
4 | Copyright (c) 2020, Lawrence Livermore National Laboratory
5 | All rights reserved.
6 |
7 | Redistribution and use in source and binary forms, with or without
8 | modification, are permitted provided that the following conditions are met:
9 |
10 | 1. Redistributions of source code must retain the above copyright notice, this
11 | list of conditions and the following disclaimer.
12 |
13 | 2. Redistributions in binary form must reproduce the above copyright notice,
14 | this list of conditions and the following disclaimer in the documentation
15 | and/or other materials provided with the distribution.
16 |
17 | 3. Neither the name of the copyright holder nor the names of its
18 | contributors may be used to endorse or promote products derived from
19 | this software without specific prior written permission.
20 |
21 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
31 | '''
32 | '''
33 | https://github.com/LLNL/fastcam
34 |
35 | A toolkit for efficent computation of saliency maps for explainable
36 | AI attribution.
37 |
38 | This work was performed under the auspices of the U.S. Department of Energy
39 | by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344
40 | and was supported by the LLNL-LDRD Program under Project 18-ERD-021 and
41 | Project 17-SI-003.
42 |
43 | Software released as LLNL-CODE-802426.
44 |
45 | See also: https://arxiv.org/abs/1911.11293
46 | '''
47 | import torch
48 | import torch.nn as nn
49 | import torch.nn.functional as F
50 | import torch.autograd
51 |
52 | # *******************************************************************************************************************
53 | class DropMap(torch.autograd.Function):
54 | r'''
55 | When we created this, the torch.gt function did not seem to propagate gradients.
56 | It might now, but we have not checked. This autograd function provides that.
57 | '''
58 |
59 | @staticmethod
60 | def forward(ctx, p_map, k):
61 |
62 | drop_map_byte = torch.gt(p_map,k)
63 | drop_map = torch.as_tensor(drop_map_byte, dtype=p_map.dtype, device=p_map.device)
64 | ctx.save_for_backward(drop_map)
65 | return drop_map
66 |
67 | @staticmethod
68 | def backward(ctx, grad_output):
69 |
70 | drop_map = ctx.saved_tensors
71 | g_pmap = grad_output * drop_map[0]
72 |
73 | r'''
74 | Just return empty since we don't have use for this gradient.
75 | '''
76 | sz = g_pmap.size()
77 | g_k = torch.empty((sz[0],1), dtype=g_pmap.dtype, device=g_pmap.device)
78 |
79 | return g_pmap, g_k
80 |
81 | # *******************************************************************************************************************
82 | class SaliencyMaskDropout(nn.Module):
83 | r'''
84 | This will mask out an input tensor that can have arbitrary channels. It can also return the
85 | binary mask it created from the saliency map. If it is used inline in a network, scale_map
86 | should be set to True.
87 |
88 | Parameters
89 |
90 | keep_percent: A scalar from 0 to 1. This represents what percent of the image to keep.
91 | return_layer_only: Tells us to just return the masked tensor only. Useful for putting layer into an nn.sequental.
92 | scale_map: Scale the output like we would a dropout layer?
93 |
94 | Will return
95 |
96 | (1) The maksed tensor.
97 | (2) The mask by itself.
98 | '''
99 |
100 | def __init__(self, keep_percent = 0.1, return_layer_only=False, scale_map=True):
101 |
102 | super(SaliencyMaskDropout, self).__init__()
103 |
104 | assert isinstance(keep_percent,float), "keep_percent should be a floating point value from 0 to 1"
105 | assert keep_percent > 0, "keep_percent should be a floating point value from 0 to 1"
106 | assert keep_percent <= 1.0, "keep_percent should be a floating point value from 0 to 1"
107 |
108 | self.keep_percent = keep_percent
109 | if scale_map:
110 | self.scale = 1.0/keep_percent
111 | else:
112 | self.scale = 1.0
113 | self.drop_percent = 1.0-self.keep_percent
114 | self.return_layer_only = return_layer_only
115 |
116 | def forward(self, x, sal_map):
117 |
118 | assert torch.is_tensor(x), "Input x should be a Torch Tensor"
119 | assert torch.is_tensor(sal_map), "Input sal_map should be a Torch Tensor"
120 |
121 | sal_map_size = sal_map.size()
122 | x_size = x.size()
123 |
124 | assert len(x.size()) == 4, "Input x should have 4 dimensions [batch size x chans x height x width]"
125 | assert len(sal_map.size()) == 3, "Input sal_map should be 3D [batch size x height x width]"
126 |
127 | assert x_size[0] == sal_map_size[0], "x and sal_map should have same batch size"
128 | assert x_size[2] == sal_map_size[1], "x and sal_map should have same height"
129 | assert x_size[3] == sal_map_size[2], "x and sal_map should have same width"
130 |
131 | sal_map = sal_map.reshape(sal_map_size[0], sal_map_size[1]*sal_map_size[2])
132 |
133 | r'''
134 | Using basically the same method we would to find the median, we find what value is
135 | at n% in each saliency map.
136 | '''
137 | num_samples = int((sal_map_size[1]*sal_map_size[2])*self.drop_percent)
138 | s = torch.sort(sal_map, dim=1)[0]
139 |
140 | r'''
141 | Here we can check that the saliency map has valid values between 0 to 1 since we
142 | have sorted the image. It's cheap now.
143 | '''
144 | assert s[:,0] >= 0.0, "Saliency map should contain values within the range of 0 to 1"
145 | assert s[:,-1] <= 1.0, "Saliency map should contain values within the range of 0 to 1"
146 |
147 | r'''
148 | Get the kth value for each image in the batch.
149 | '''
150 | k = s[:,num_samples]
151 | k = k.reshape(sal_map_size[0], 1)
152 |
153 | r'''
154 | We will create the saliency mask but we use torch.autograd so that we can optionally
155 | propagate the gradients backwards through the mask. k is assumed to be a dead-end, so
156 | no gradients go to it.
157 | '''
158 | drop_map = DropMap.apply(sal_map, k)
159 |
160 | drop_map = drop_map.reshape(sal_map_size[0], 1, sal_map_size[1]*sal_map_size[2])
161 | x = x.reshape(x_size[0], x_size[1], x_size[2]*x_size[3])
162 |
163 | r'''
164 | Multiply the input by the mask, but optionally scale it like we would a dropout layer.
165 | '''
166 | x = x*drop_map*self.scale
167 |
168 | x = x.reshape(x_size[0], x_size[1], x_size[2], x_size[3])
169 |
170 | if self.return_layer_only:
171 | return x
172 | else:
173 | return x, drop_map.reshape(sal_map_size[0], sal_map_size[1], sal_map_size[2])
174 |
175 |
176 |
--------------------------------------------------------------------------------
/export/nif_fast-cam.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | # # DEMO: Running FastCAM for the Exceptionally Impatient
5 |
6 | # ### Import Libs
7 |
8 | # In[1]:
9 |
10 |
11 | import os
12 | from IPython.display import Image
13 | import cv2
14 | import numpy as np
15 |
16 |
17 | # Lets load the **PyTorch** Stuff.
18 |
19 | # In[2]:
20 |
21 |
22 | import torch
23 | import torch.nn.functional as F
24 | from torchvision.utils import make_grid, save_image
25 |
26 | import warnings
27 | warnings.filterwarnings('ignore')
28 |
29 |
30 | # Now we import the saliency libs for **this package**.
31 |
32 | # In[3]:
33 |
34 |
35 | import maps
36 | import misc
37 | import mask
38 | import norm
39 | import draw
40 | import resnet
41 |
42 |
43 | # ### Set Adjustable Parameters
44 | # This is where we can set some parameters like the image name and the layer weights.
45 |
46 | # In[4]:
47 |
48 |
49 | input_image_names = ["OMF2_715165_45972761_POST_160_267_EXIT_RB_191025_072939.jpg",
50 | "OMF2_715165_45723294_POST_144_306_EXIT_RB_191024_174606.jpg",
51 | "OMF2_715165_47391944_POST_85_273_EXIT_RB_191024_203453.jpg",
52 | "OMF2_715165_48284471_POST_362_243_EXIT_RB_191024_204748.jpg",
53 | "OMF2_715165_48286090_POST_105_340_EXIT_RB_191024_220021.jpg",
54 | "OMF2_715165_49772491_POST_142_332_EXIT_RB_191025_075343.jpg",
55 | "OMF2_715165_48738510_POST_82_283_EXIT_RB_191024_220953.jpg",
56 | "OMF2_715165_48286273_POST_67_288_INPUT_RB_191024_194155.jpg"
57 | ]
58 |
59 |
60 | # In[5]:
61 |
62 |
63 | input_image_name = input_image_names[0] # Pick which image you want from the list
64 | output_dir = 'outputs' # Where to save our output images
65 | input_dir = 'images' # Where to load our inputs from
66 | # Assumes input image size 1392x1040
67 | in_height = 524 # Size to scale input image to
68 | in_width = 696 # Size to scale input image to
69 | in_patch = 480
70 | view_height = 1040
71 | view_width = 1392
72 | view_patch = 952
73 |
74 |
75 | # Now we set up what layers we want to sample from and what weights to give each layer. We specify the layer block name within ResNet were we will pull the forward SMOE Scale results from. The results will be from the end of each layer block.
76 |
77 | # In[6]:
78 |
79 |
80 | weights = [0.18, 0.15, 0.37, 0.4, 0.72] # Our saliency layer weights
81 | # From paper:
82 | # https://arxiv.org/abs/1911.11293
83 | layers = ['relu','layer1','layer2','layer3','layer4']
84 |
85 |
86 | # **OPTIONAL:** We can auto compute which layers to run over by setting them to *None*. **This has not yet been quantitatively tested on ROAR/KARR.**
87 |
88 | # In[7]:
89 |
90 |
91 | #weights = None
92 | #layers = None
93 |
94 |
95 | # ### Set Up Loading and Saving File Names
96 | # Lets touch up where to save output and what name to use for output files.
97 |
98 | # In[8]:
99 |
100 |
101 | save_prefix = os.path.split(os.path.splitext(input_image_name)[0])[-1] # Chop the file extension and path
102 | load_image_name = os.path.join(input_dir, input_image_name)
103 |
104 | os.makedirs(output_dir, exist_ok=True)
105 |
106 |
107 | # Take a look at the input image ...
108 | # Good Doggy!
109 |
110 | # In[9]:
111 |
112 |
113 | Image(filename=load_image_name)
114 |
115 |
116 | # ### Set Up Usual PyTorch Network Stuff
117 | # Go ahead and create a standard PyTorch device. It can use the CPU if no GPU is present. This demo works pretty well on just CPU.
118 |
119 | # In[10]:
120 |
121 |
122 | device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
123 |
124 |
125 | # Now we will create a model. Here we have a slightly customized ResNet that will only propagate backwards the last few layers. The customization is just a wrapper around the stock ResNet that comes with PyTorch. SMOE Scale computation does not need any gradients and GradCAM variants only need the last few layers. This will really speed things up, but don't try to train this network. You can train the regular ResNet if you need to do that. Since this network is just a wrapper, it will load any standard PyTorch ResNet training weights.
126 |
127 | # In[11]:
128 |
129 |
130 | model = resnet.resnet50(pretrained=True)
131 | checkpoint = torch.load("models/NIF_resnet50.random_rotate4.model.pth.tar")
132 | model.load_state_dict(checkpoint,strict=True)
133 | model = model.to(device)
134 |
135 |
136 | # ### Load Images
137 | # Lets load in our image into standard torch tensors. We will do a simple resize on it.
138 |
139 | # In[12]:
140 |
141 |
142 | h_offset = int((in_height-in_patch)/2)
143 | w_offset = int((in_width -in_patch)/2)
144 |
145 |
146 | # In[13]:
147 |
148 |
149 | in_tensor = misc.LoadImageToTensor(load_image_name, device)
150 | in_tensor = F.interpolate(in_tensor, size=(in_height, in_width), mode='bilinear', align_corners=False)
151 | in_tensor = in_tensor[:,:,h_offset:in_patch+h_offset, w_offset:in_patch+w_offset] # Crop
152 |
153 |
154 | # For illustration purposes, Lets also load a non-normalized version of the input.
155 |
156 | # In[14]:
157 |
158 |
159 | h_offset = int((view_height-view_patch)/2)
160 | w_offset = int((view_width -view_patch)/2)
161 |
162 |
163 | # In[15]:
164 |
165 |
166 | raw_tensor = misc.LoadImageToTensor(load_image_name, device, norm=False)
167 | raw_tensor = raw_tensor[:,:,h_offset:view_patch+h_offset,w_offset:view_patch+w_offset] # Crop
168 |
169 |
170 | # ### Set Up Saliency Objects
171 |
172 | # We create an object to create the saliency map given the model and layers we have selected.
173 |
174 | # In[16]:
175 |
176 |
177 | getSalmap = maps.SaliencyMap(model, layers, output_size=[in_patch,in_patch],weights=weights,
178 | norm_method=norm.GammaNorm2D, cam_each_map=True)
179 |
180 |
181 | # Now we set up our masking object to create a nice mask image of the %10 most salient locations. You will see the results below when it is run.
182 |
183 | # In[17]:
184 |
185 |
186 | getMask = mask.SaliencyMaskDropout(keep_percent = 0.1, scale_map=False)
187 |
188 |
189 | # ### Run Saliency
190 | # Now lets run our input tensor image through the net and get the 2D saliency map back.
191 |
192 | # In[18]:
193 |
194 |
195 | cam_map,sal_maps,logit = getSalmap(in_tensor)
196 | cam_map = F.interpolate(cam_map.unsqueeze(0), size=(view_patch, view_patch),
197 | mode='bilinear', align_corners=False)
198 | cam_map = cam_map.squeeze(0)
199 |
200 |
201 | # ### Display Network Classification
202 |
203 | # In[19]:
204 |
205 |
206 | print("Class Likelihood Bad: {} Good: {}".format(logit[0,0],logit[0,1]))
207 |
208 |
209 | # ### Visualize It
210 | # Take the images and create a nice tiled image to look at. This will created a tiled image of:
211 | #
212 | # (1) The input image.
213 | # (2) The saliency map.
214 | # (3) The saliency map overlaid on the input image.
215 | # (4) The raw image enhanced with the most salient locations.
216 | # (5) The top 10% most salient locations.
217 |
218 | # In[20]:
219 |
220 |
221 | images = misc.TileOutput(raw_tensor, cam_map, getMask)
222 |
223 |
224 | # We now put all the images into a nice grid for display.
225 |
226 | # In[21]:
227 |
228 |
229 | images = make_grid(torch.cat(images,0), nrow=5)
230 |
231 |
232 | # ... save and look at it.
233 |
234 | # In[22]:
235 |
236 |
237 | output_name = "{}.FASTCAM.jpg".format(save_prefix)
238 | output_path = os.path.join(output_dir, output_name)
239 |
240 | save_image(images, output_path)
241 | Image(filename=output_path)
242 |
243 |
244 | # This image should look **exactly** like the one on the README.md on Github minus the text.
245 |
246 | # ### Alternative Visualizations
247 |
248 | # In[23]:
249 |
250 |
251 | sal_maps = sal_maps.squeeze(0)
252 |
253 | SHM = draw.HeatMap(shape=sal_maps.size, weights=weights) # Create our heat map drawer
254 | LOVI = draw.LOVI(shape=sal_maps.size, weights=None) # Create out LOVI drawer
255 |
256 | shm_im = SHM.make(sal_maps, raw_tensor) # Combine the saliency maps
257 | # into one heat map
258 | lovi_im = LOVI.make(sal_maps, raw_tensor) # Combine the saliency maps
259 | # into one LOVI image
260 |
261 |
262 | # ### Overlay with Difference Pallet
263 |
264 | # In[24]:
265 |
266 |
267 | output_name = "{}.HEAT.jpg".format(save_prefix)
268 | output_path = os.path.join(output_dir, output_name)
269 | cv2.imwrite(output_path, (shm_im*255.0).astype(np.uint8))
270 |
271 | Image(filename=output_path)
272 |
273 |
274 | # ### LOVI Layer Map
275 |
276 | # In[25]:
277 |
278 |
279 | output_name = "{}.LOVI.jpg".format(save_prefix)
280 | output_path = os.path.join(output_dir, output_name)
281 | cv2.imwrite(output_path, (lovi_im*255.0).astype(np.uint8))
282 |
283 | Image(filename=output_path)
284 |
285 |
286 | # ### Each Layer Saliency Map by Itself
287 |
288 | # In[26]:
289 |
290 |
291 | # We will range normalize each saliency map from 0 to 1
292 | getNorm = norm.RangeNorm2D()
293 |
294 | # Put each saliency map into the figure
295 | il = [getNorm(sal_maps[i,:,:].unsqueeze(0)).squeeze(0) for i in range(sal_maps.size()[0])]
296 |
297 | images = [torch.stack(il, 0)]
298 | images = make_grid(torch.cat(images, 0), nrow=5)
299 | output_name = "{}.SAL_MAPS.jpg".format(save_prefix)
300 | sal_img_file = os.path.join(output_dir, output_name)
301 |
302 | save_image(images.unsqueeze(1), sal_img_file)
303 |
304 | Image(filename=sal_img_file)
305 |
306 |
307 | # In[ ]:
308 |
309 |
310 |
311 |
312 |
313 | # In[ ]:
314 |
315 |
316 |
317 |
318 |
--------------------------------------------------------------------------------
/draw.py:
--------------------------------------------------------------------------------
1 | '''
2 | BSD 3-Clause License
3 |
4 | Copyright (c) 2020, Lawrence Livermore National Laboratory
5 | All rights reserved.
6 |
7 | Redistribution and use in source and binary forms, with or without
8 | modification, are permitted provided that the following conditions are met:
9 |
10 | 1. Redistributions of source code must retain the above copyright notice, this
11 | list of conditions and the following disclaimer.
12 |
13 | 2. Redistributions in binary form must reproduce the above copyright notice,
14 | this list of conditions and the following disclaimer in the documentation
15 | and/or other materials provided with the distribution.
16 |
17 | 3. Neither the name of the copyright holder nor the names of its
18 | contributors may be used to endorse or promote products derived from
19 | this software without specific prior written permission.
20 |
21 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
31 | '''
32 | '''
33 | https://github.com/LLNL/fastcam
34 |
35 | A toolkit for efficent computation of saliency maps for explainable
36 | AI attribution.
37 |
38 | This work was performed under the auspices of the U.S. Department of Energy
39 | by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344
40 | and was supported by the LLNL-LDRD Program under Project 18-ERD-021 and
41 | Project 17-SI-003.
42 |
43 | Software released as LLNL-CODE-802426.
44 |
45 | See also: https://arxiv.org/abs/1911.11293
46 | '''
47 | import cv2
48 | import numpy as np
49 | import math
50 | import torch
51 |
52 | try:
53 | from . import misc
54 | except ImportError:
55 | import misc
56 |
57 | # *******************************************************************************************************************
58 | class _Draw(object):
59 | r'''
60 | This is a base class for drawing different representations of saliency maps.
61 |
62 | See the derived classes below for descriptions of parameters.
63 | '''
64 |
65 | def __init__(self, shape, weights, color):
66 |
67 | # torch tensor will be callable
68 | if callable(shape):
69 | shape = [shape()[1], shape()[2], shape()[0]]
70 |
71 | assert isinstance(shape,tuple) or isinstance(shape,list), "Output shape should be a list or tuple"
72 | assert len(shape) == 3, "Output shape should be height x width x chan"
73 | assert isinstance(color,int), "Color should be an OpenCV defined integer" # How openCV treats this
74 |
75 | self.height = shape[0]
76 | self.width = shape[1]
77 | self.chans = shape[2]
78 |
79 | self.color = color
80 |
81 | assert self.height > 0, "Height should be greater than 0"
82 | assert self.width > 0, "Width should be greater than 0"
83 | assert self.chans > 0, "Chans should be greater than 0"
84 |
85 | if weights is None:
86 | self.weights = np.array([1.0 for _ in range(self.chans)]).astype(np.float32)
87 | elif len(weights) == 1:
88 | assert weights[0] > 0, "is specified, single weight should be greater than 0"
89 | self.weights = np.array([weights[0] for _ in range(self.chans)]).astype(np.float32)
90 | else:
91 | assert len(weights) == self.chans, "List of weights should be the same size as output channels"
92 | self.weights = np.array(weights).astype(np.float32)
93 |
94 | self.fc = float(self.chans)
95 | self.frac = 1.0/self.fc
96 | self.HSV_img = np.empty((self.height,self.width,3), dtype=np.float32)
97 |
98 | self.sum_weights = np.sum(self.weights)
99 |
100 | def _range_normalize(self, data):
101 |
102 | norm = data.max() - data.min()
103 | if norm != 0:
104 | data = (data - data.min()) / norm
105 |
106 | return data
107 |
108 | def __call__(self, input_patches):
109 |
110 | return self.make(input_patches)
111 |
112 | # *******************************************************************************************************************
113 | class HeatMap(_Draw):
114 | r'''
115 | This will create a heat map from a stack of saliency maps. in a H x W x C numpy array.
116 |
117 | Parameters
118 |
119 | shape: This is a list (H,W,C) of the expected size of the saliency map.
120 | weights: This is a list of length C of weight for each channel.
121 | color: The color conversion method to use. Default: cv2.COLOR_HSV2BGR
122 |
123 | Returns:
124 |
125 | An openCV compatible numpy array sized H x W x 3
126 | '''
127 |
128 | def __init__(self, shape, weights=None, color=cv2.COLOR_HSV2BGR):
129 |
130 | super(HeatMap, self).__init__(shape=shape, weights=weights, color=color)
131 |
132 | self.Cexp = 1.0/math.exp(1.0)
133 |
134 | def make(self, input_patches, blend_img=None):
135 | r'''
136 | Input:
137 | input_patches: A numpy array. It should be sized [height x width x channels]. Here channels is each saliency map.
138 | Returns:
139 | A numpy array sized [height x width x 3].
140 | '''
141 | if torch.is_tensor(input_patches):
142 | input_patches = misc.TensorToNumpyImages(input_patches)
143 | if torch.is_tensor(blend_img):
144 | blend_img = misc.TensorToNumpyImages(blend_img)
145 |
146 | assert blend_img is None or isinstance(blend_img, np.ndarray), "Blend Image should be a numpy array or torch tensor"
147 | assert isinstance(input_patches, np.ndarray), "Input should be a numpy array"
148 | assert len(input_patches.shape) == 3, "Input should be height x width x chan"
149 | assert input_patches.shape[0] == self.height, "Input should be height x width x chan"
150 | assert input_patches.shape[1] == self.width, "Input should be height x width x chan"
151 | assert input_patches.shape[2] == self.chans, "Input should be height x width x chan"
152 |
153 | patches = self._range_normalize(input_patches.astype(np.float32)) * self.weights
154 |
155 | r'''
156 | Set intensity to be the weighted average
157 | '''
158 | V = np.sum(patches, 2) / self.sum_weights
159 | V /= V.max()
160 |
161 | r'''
162 | Use the standard integral method for saturation, but give it a boost.
163 | '''
164 | if self.frac != 1.0:
165 | S = 1.0 - (np.sum(patches,2)/(self.fc*np.amax(patches,2)) - self.frac)*(1.0/(1.0 - self.frac))
166 | else:
167 | S = V
168 |
169 | S = pow(S,self.Cexp)
170 |
171 | r'''
172 | Set H,S and V in that order.
173 | '''
174 | self.HSV_img[:,:,0] = (1.0 - V) * 240.0
175 | self.HSV_img[:,:,1] = S
176 | self.HSV_img[:,:,2] = V
177 |
178 | img = cv2.cvtColor(self.HSV_img, self.color)
179 |
180 | if blend_img is not None:
181 | img = cv2.resize(img, (blend_img.shape[0],blend_img.shape[1]))
182 | return misc.AlphaBlend(img, blend_img)
183 | else:
184 | return img
185 |
186 | # *******************************************************************************************************************
187 | class LOVI(_Draw):
188 | r'''
189 | This will create a LOVI map from a stack of saliency maps. in a H x W x C numpy array.
190 |
191 | Parameters
192 |
193 | shape: This is a list (H,W,C) of the expected size of the saliency map.
194 | weights: This is a list of length C of weight for each channel.
195 | color: The color conversion method to use. Default: cv2.COLOR_HSV2BGR
196 |
197 | Returns:
198 |
199 | An openCV compatible numpy array sized H x W x 3
200 | '''
201 | def __init__(self, shape, weights=None, color=cv2.COLOR_HSV2BGR):
202 |
203 | super(LOVI, self).__init__(shape=shape, weights=weights, color=color)
204 |
205 | self.pos_img = np.empty((self.height,self.width,self.chans), dtype=np.float32)
206 |
207 | y = 1.0/((self.fc - 1.0)/self.fc)
208 |
209 | for c_i in range(self.chans):
210 | self.pos_img[:,:,c_i] = 1.0 - (float(c_i)/(self.fc))*y
211 |
212 | def make(self, input_patches, blend_img=None):
213 | r'''
214 | Input:
215 | input_patches: A numpy array. It should be sized [height x width x channels]. Here channels is each saliency map.
216 | Returns:
217 | A numpy array sized [height x width x 3].
218 | '''
219 | if torch.is_tensor(input_patches):
220 | input_patches = misc.TensorToNumpyImages(input_patches)
221 | if torch.is_tensor(blend_img):
222 | blend_img = misc.TensorToNumpyImages(blend_img)
223 |
224 | assert blend_img is None or isinstance(blend_img, np.ndarray), "Blend Image should be a numpy array or torch tensor"
225 | assert isinstance(input_patches, np.ndarray), "Input should be a numpy array or torch tensor"
226 | assert len(input_patches.shape) == 3, "Input should be height x width x chan"
227 | assert input_patches.shape[0] == self.height, "Input should be height x width x chan"
228 | assert input_patches.shape[1] == self.width, "Input should be height x width x chan"
229 | assert input_patches.shape[2] == self.chans, "Input should be height x width x chan"
230 |
231 | patches = self._range_normalize(input_patches.astype(np.float32)) * self.weights
232 |
233 | r'''
234 | Compute position
235 | '''
236 | pos = patches * self.pos_img
237 |
238 | r'''
239 | Get Mean
240 | '''
241 | m = np.sum(pos,2) / np.sum(patches,2)
242 |
243 | r'''
244 | Set H,S and V in that order.
245 | '''
246 | self.HSV_img[:,:,0] = m*300
247 | self.HSV_img[:,:,1] = 1.0 - (np.sum(patches,2)/(self.fc*np.amax(patches,2)) - self.frac)*(1.0/(1.0 - self.frac))
248 | self.HSV_img[:,:,2] = np.amax(patches, 2)
249 |
250 | img = cv2.cvtColor(self.HSV_img, self.color)
251 |
252 | if blend_img is not None:
253 | img = cv2.resize(img, (blend_img.shape[0],blend_img.shape[1]))
254 | return misc.AlphaBlend(img, blend_img)
255 | else:
256 | return img
257 |
258 |
259 |
--------------------------------------------------------------------------------
/bidicam.py:
--------------------------------------------------------------------------------
1 | '''
2 | BSD 3-Clause License
3 |
4 | Copyright (c) 2020, Lawrence Livermore National Laboratory
5 | All rights reserved.
6 |
7 | Redistribution and use in source and binary forms, with or without
8 | modification, are permitted provided that the following conditions are met:
9 |
10 | 1. Redistributions of source code must retain the above copyright notice, this
11 | list of conditions and the following disclaimer.
12 |
13 | 2. Redistributions in binary form must reproduce the above copyright notice,
14 | this list of conditions and the following disclaimer in the documentation
15 | and/or other materials provided with the distribution.
16 |
17 | 3. Neither the name of the copyright holder nor the names of its
18 | contributors may be used to endorse or promote products derived from
19 | this software without specific prior written permission.
20 |
21 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
31 | '''
32 |
33 | '''
34 | https://github.com/LLNL/fastcam
35 |
36 | A toolkit for efficent computation of saliency maps for explainable
37 | AI attribution.
38 |
39 | This work was performed under the auspices of the U.S. Department of Energy
40 | by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344
41 | and was supported by the LLNL-LDRD Program under Project 18-ERD-021 and
42 | Project 17-SI-003.
43 |
44 | Software released as LLNL-CODE-802426.
45 |
46 | See also: https://arxiv.org/abs/1911.11293
47 | '''
48 | import torch
49 | import torch.nn as nn
50 | import torch.nn.functional as F
51 |
52 | from collections import OrderedDict
53 | import math
54 | import numpy as np
55 |
56 | try:
57 | from . import maps
58 | from . import misc
59 | from . import norm
60 | from . import misc
61 | from . import resnet
62 | except ImportError:
63 | import maps
64 | import misc
65 | import norm
66 | import misc
67 | import resnet
68 |
69 | # *******************************************************************************************************************
70 | class ScoreMap(torch.autograd.Function):
71 |
72 | @staticmethod
73 | def forward(ctx, scores):
74 |
75 | ctx.save_for_backward(scores)
76 | return torch.tensor(1.0)
77 |
78 | @staticmethod
79 | def backward(ctx, grad):
80 |
81 | saved = ctx.saved_tensors
82 | g_scores = torch.ones_like(saved[0])
83 |
84 | return g_scores
85 |
86 | # *******************************************************************************************************************
87 | class BiDiCAM(nn.Module):
88 | r"""
89 | Bi Di Bi Di Bi Di Nice shootin' Buck!
90 | """
91 | def __init__(self, model, layers=None, actv_method=maps.SMOEScaleMap, grad_method=maps.SMOEScaleMap, grad_pooling='mag', interp_pooling='nearest',
92 | use_GradCAM=False, do_first_forward=False, num_classes=1000):
93 |
94 | super(BiDiCAM, self).__init__()
95 |
96 | assert isinstance(layers, list) or layers is None
97 | assert isinstance(grad_pooling, str) or grad_pooling is None
98 | assert callable(actv_method)
99 | assert callable(grad_method)
100 | #assert not(use_GradCAM and do_first_forward)
101 |
102 |
103 | self.getActvSmap = actv_method()
104 | self.getGradSmap = grad_method()
105 | self.layers = layers
106 | self.model = model
107 | self.grad_pooling = grad_pooling
108 | self.num_classes = num_classes
109 | self.use_GradCAM = use_GradCAM
110 | self.interp_pooling = interp_pooling
111 | self.do_first_forward = do_first_forward
112 | self.auto_layer = 'BatchNorm2d'
113 | self.getNorm = norm.GaussNorm2D() #norm.GammaNorm2D()
114 |
115 | if layers is None:
116 | self.auto_layers = True
117 | else:
118 | self.auto_layers = False
119 |
120 | if self.auto_layers:
121 | self.layers = []
122 |
123 | for m in self.model.modules():
124 | if self.auto_layer in str(type(m)):
125 | self.layers.append(None)
126 |
127 | def _forward(self, class_idx, logit, retain_graph):
128 |
129 | if class_idx is None:
130 |
131 | sz = logit.size()
132 |
133 | lm = logit.max(1)[1]
134 | r'''
135 | This gets the logits into a form usable when we run a batch. This seems suboptimal.
136 | Open to ideas about how to make this better/faster.
137 | '''
138 | lm = torch.stack([i*self.num_classes + v for i,v in enumerate(lm)])
139 |
140 | logit = logit.reshape(sz[0]*sz[1])
141 |
142 | score = logit[lm]
143 |
144 | logit = logit.reshape(sz[0],sz[1])
145 | score = score.reshape(sz[0],1,1,1)
146 | else:
147 | score = logit[:, class_idx].squeeze()
148 |
149 | r'''
150 | Pass through layer to make auto grad happy
151 | '''
152 | score_end = ScoreMap.apply(score)
153 |
154 | r'''
155 | Zero out grads and then run backwards.
156 | '''
157 | self.model.zero_grad()
158 | score_end.backward(retain_graph=retain_graph)
159 |
160 | def _magnitude_pool2d(self, x, kernel_size=2, stride=2, padding=0, pos_max=False):
161 | r'''
162 | Pick the max magnitude gradient in the pool, the one with the highest absolute value.
163 |
164 | This is an optional method.
165 | '''
166 |
167 | b, k, u, v = x.size()
168 |
169 | p1 = F.max_pool2d(x, kernel_size=kernel_size, stride=stride, padding=padding, ceil_mode=True)
170 | p2 = F.max_pool2d(-1*x, kernel_size=kernel_size, stride=stride, padding=padding, ceil_mode=True) * -1
171 |
172 | d = p1 + p2
173 |
174 | if pos_max:
175 | m = torch.where(d >= 0.0, p1, torch.zeros_like(d))
176 | else:
177 | m = torch.where(d >= 0.0, p1, p2)
178 |
179 | m = nn.functional.interpolate(m, size=[u,v], mode=self.interp_pooling)
180 |
181 | return m
182 |
183 | def _proc_salmap(self, saliency_map, map_method, b, u, v):
184 | r'''
185 | Derive the saliency map from the input layer and then normalize it.
186 | '''
187 |
188 | saliency_map = F.relu(saliency_map)
189 | saliency_map = self.getNorm(map_method(saliency_map)).view(b, u, v)
190 |
191 | return saliency_map
192 |
193 | def __call__(self, input, class_idx=None, retain_graph=False):
194 | """
195 | Args:
196 | input: input image with shape of (1, 3, H, W)
197 | class_idx (int): class index for calculating CAM.
198 | If not specified, the class index that makes the highest model prediction score will be used.
199 | Return:
200 | mask: saliency map of the same spatial dimension with input
201 | logit: model output
202 | """
203 |
204 | self.activation_hooks = []
205 | self.gradient_hooks = []
206 |
207 | if self.auto_layers:
208 | r'''
209 | Auto defined layers. Here we will process all layers of a certain type as defined by the use.
210 | This might commonly be all ReLUs or all Conv layers.
211 | '''
212 | for i,m in enumerate(self.model.modules()):
213 | if self.auto_layer in str(type(m)):
214 | m._forward_hooks = OrderedDict() # PyTorch bug work around, patch is available, but not everyone may be patched
215 | m._backward_hooks = OrderedDict()
216 |
217 | if self.do_first_forward and len(self.activation_hooks) > 0 and not self.use_GradCAM:
218 | pass
219 | else:
220 | h = misc.CaptureLayerOutput(post_process=None, device=input.device)
221 | _ = m.register_forward_hook(h)
222 | self.activation_hooks.append(h)
223 |
224 | h = misc.CaptureGradInput(post_process=None, device=input.device) # The gradient information leaving the layer
225 | _ = m.register_backward_hook(h)
226 | self.gradient_hooks.append(h)
227 | else:
228 | for i,l in enumerate(self.layers):
229 | self.model._modules[l]._forward_hooks = OrderedDict()
230 | self.model._modules[l]._backward_hooks = OrderedDict()
231 |
232 | if self.do_first_forward and i>0 and not self.use_GradCAM:
233 | pass
234 | else:
235 | h = misc.CaptureLayerOutput(post_process=None, device=input.device)
236 | _ = self.model._modules[l].register_forward_hook(h)
237 | self.activation_hooks.append(h)
238 |
239 | h = misc.CaptureGradInput(post_process=None, device=input.device) # The gradient information leaving the layer
240 | _ = self.model._modules[l].register_backward_hook(h)
241 | self.gradient_hooks.append(h)
242 |
243 | r'''
244 | Force to compute grads since we always need them.
245 | '''
246 | with torch.set_grad_enabled(True):
247 |
248 | b, c, h, w = input.size()
249 |
250 | self.model.eval()
251 |
252 | logit = self.model(input)
253 |
254 | self._forward(class_idx, logit, retain_graph)
255 |
256 | backward_saliency_maps = []
257 | forward_saliency_maps = []
258 |
259 | r'''
260 | For each layer, get its activation and gradients. We might pool the gradient layers.
261 |
262 | Finally, processes the activations and return.
263 | '''
264 | for i,l in enumerate(self.layers):
265 |
266 | gradients = self.gradient_hooks[i].data
267 | gb, gk, gu, gv = gradients.size()
268 |
269 | if self.do_first_forward and i>0 and not self.use_GradCAM:
270 | pass
271 | else:
272 | activations = self.activation_hooks[i].data
273 | ab, ak, au, av = activations.size()
274 |
275 | if self.use_GradCAM:
276 | alpha = gradients.view(gb, gk, -1).mean(2)
277 | weights = alpha.view(gb, gk, 1, 1)
278 | cam_map = (weights*activations).sum(1, keepdim=True)
279 | cam_map = cam_map.reshape(gb, gu, gv)
280 | cam_map = self.getNorm(cam_map)
281 |
282 | if self.grad_pooling == 'avg':
283 | gradients = F.avg_pool2d(gradients, kernel_size=2, stride=2, padding=0, ceil_mode=True)
284 | gradients = nn.functional.interpolate(gradients, size=[gu,gv], mode=self.interp_pooling)
285 | elif self.grad_pooling == 'max':
286 | gradients = F.max_pool2d(gradients, kernel_size=2, stride=2, padding=0, ceil_mode=True)
287 | gradients = nn.functional.interpolate(gradients, size=[gu,gv], mode=self.interp_pooling)
288 | elif self.grad_pooling == 'mag':
289 | gradients = self._magnitude_pool2d(gradients, kernel_size=2, stride=2, padding=0)
290 | elif self.grad_pooling is None:
291 | gradients = gradients
292 |
293 | r'''
294 | Optionally, we can meld with GradCAM Method.
295 | '''
296 | if self.use_GradCAM:
297 | l = float(len(self.layers)) - float(i)
298 | n = math.log2(l)
299 | d = math.log2(float(len(self.layers)))
300 | ratio = 1.0 - n/d
301 | grad_map = self._proc_salmap(gradients, self.getGradSmap, gb, gu, gv)
302 | gradients = ratio*cam_map + (1.0 - ratio)*grad_map
303 | else:
304 | gradients = self._proc_salmap(gradients, self.getGradSmap, gb, gu, gv)
305 |
306 | backward_saliency_maps.append(gradients)
307 |
308 | if self.do_first_forward and i>0:
309 | pass
310 | else:
311 | forward_saliency_maps.append(self._proc_salmap(activations, self.getActvSmap, ab, au, av))
312 |
313 | return forward_saliency_maps, backward_saliency_maps, logit
314 |
315 | # *******************************************************************************************************************
316 | class BiDiCAMModel(nn.Module):
317 | r"""
318 | Bi Di Bi Di Bi Di Nice shootin' Buck!
319 | """
320 | def __init__(self, model, layers, output_size=[224,224], weights=None, resize_mode='bilinear', do_relu=False, do_first_forward=False, **kwargs):
321 |
322 | super(BiDiCAMModel, self).__init__()
323 |
324 | self.do_first_forward = do_first_forward
325 |
326 | self.bidicam = BiDiCAM(model, layers, do_first_forward=do_first_forward, **kwargs)
327 |
328 | if self.do_first_forward:
329 | self.combine_maps_act = maps.CombineSaliencyMaps(output_size=output_size, map_num=1, weights=weights,
330 | resize_mode=resize_mode, do_relu=do_relu)
331 | else:
332 | self.combine_maps_act = maps.CombineSaliencyMaps(output_size=output_size, map_num=len(self.bidicam.layers), weights=weights,
333 | resize_mode=resize_mode, do_relu=do_relu)
334 |
335 | self.combine_maps_grad = maps.CombineSaliencyMaps(output_size=output_size, map_num=len(self.bidicam.layers), weights=weights,
336 | resize_mode=resize_mode, do_relu=do_relu)
337 |
338 |
339 |
340 | def __call__(self, input, **kwargs):
341 |
342 |
343 | forward_saliency_maps, backward_saliency_maps, logit = self.bidicam(input, **kwargs)
344 |
345 | with torch.set_grad_enabled(False):
346 |
347 | forward_combined_map, _ = self.combine_maps_act(forward_saliency_maps)
348 | backward_combined_map, _ = self.combine_maps_grad(backward_saliency_maps)
349 |
350 | backward_combined_map = misc.RangeNormalize(backward_combined_map)
351 |
352 | combined_map = forward_combined_map*backward_combined_map
353 |
354 | saliency_maps = torch.ones_like(combined_map)
355 |
356 | return combined_map, saliency_maps, logit
357 |
358 |
359 |
--------------------------------------------------------------------------------
/norm.py:
--------------------------------------------------------------------------------
1 | '''
2 | BSD 3-Clause License
3 |
4 | Copyright (c) 2020, Lawrence Livermore National Laboratory
5 | All rights reserved.
6 |
7 | Redistribution and use in source and binary forms, with or without
8 | modification, are permitted provided that the following conditions are met:
9 |
10 | 1. Redistributions of source code must retain the above copyright notice, this
11 | list of conditions and the following disclaimer.
12 |
13 | 2. Redistributions in binary form must reproduce the above copyright notice,
14 | this list of conditions and the following disclaimer in the documentation
15 | and/or other materials provided with the distribution.
16 |
17 | 3. Neither the name of the copyright holder nor the names of its
18 | contributors may be used to endorse or promote products derived from
19 | this software without specific prior written permission.
20 |
21 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
31 | '''
32 |
33 | '''
34 | https://github.com/LLNL/fastcam
35 |
36 | A toolkit for efficent computation of saliency maps for explainable
37 | AI attribution.
38 |
39 | This work was performed under the auspices of the U.S. Department of Energy
40 | by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344
41 | and was supported by the LLNL-LDRD Program under Project 18-ERD-021 and
42 | Project 17-SI-003.
43 |
44 | Software released as LLNL-CODE-802426.
45 |
46 | See also: https://arxiv.org/abs/1911.11293
47 | '''
48 |
49 | import math
50 |
51 | import torch
52 | import torch.nn as nn
53 | import torch.nn.functional as F
54 |
55 | class GaussNorm2D(nn.Module):
56 | r'''
57 | This will normalize a saliency map to range from 0 to 1 via normal cumulative distribution function.
58 |
59 | Input and output will be a 3D tensor of size [batch size x height x width].
60 |
61 | Input can be any real valued number (supported by hardware)
62 | Output will range from 0 to 1
63 |
64 | Notes:
65 |
66 | (1) GammaNorm2D will produce slightly better results
67 | The sum ROAR/KAR will improve from 1.44 to 1.45 for FastCAM using GradCAM.
68 | (2) This method is a bit less expensive than GammaNorm2D.
69 | '''
70 |
71 | def __init__(self, const_mean=None, const_std=None):
72 |
73 | super(GaussNorm2D, self).__init__()
74 |
75 | assert isinstance(const_mean,float) or const_mean is None
76 | assert isinstance(const_std,float) or const_std is None
77 |
78 | self.const_mean = const_mean
79 | self.const_std = const_std
80 |
81 | def forward(self, x):
82 | r'''
83 | Input:
84 | x: A Torch Tensor image with shape [batch size x height x width] e.g. [64,7,7]
85 | Return:
86 | x: x Normalized by computing mean and std over each individual batch item and squashed with a
87 | Normal/Gaussian CDF.
88 | '''
89 | assert torch.is_tensor(x), "Input must be a Torch Tensor"
90 | assert len(x.size()) == 3, "Input should be sizes [batch size x height x width]"
91 |
92 | s0 = x.size()[0]
93 | s1 = x.size()[1]
94 | s2 = x.size()[2]
95 |
96 | x = x.reshape(s0,s1*s2)
97 |
98 | r'''
99 | Compute Mean
100 | '''
101 | if self.const_mean is None:
102 | m = x.mean(dim=1)
103 | m = m.reshape(m.size()[0],1)
104 | else:
105 | m = self.const_mean
106 |
107 | r'''
108 | Compute Standard Deviation
109 | '''
110 | if self.const_std is None:
111 | s = x.std(dim=1)
112 | s = s.reshape(s.size()[0],1)
113 | else:
114 | s = self.const_std
115 |
116 | r'''
117 | The normal cumulative distribution function is used to squash the values from within the range of 0 to 1
118 | '''
119 | x = 0.5*(1.0 + torch.erf((x-m)/(s*torch.sqrt(torch.tensor(2.0)))))
120 |
121 | x = x.reshape(s0,s1,s2)
122 |
123 | return x
124 |
125 | # *******************************************************************************************************************
126 | # *******************************************************************************************************************
127 | class GammaNorm2D(nn.Module):
128 | r'''
129 | This will normalize a saliency map to range from 0 to 1 via gamma cumulative distribution function.
130 |
131 | Input and output will be a 3D tensor of size [batch size x height x width].
132 |
133 | Input can be any positive real valued number (supported by hardware)
134 | Output will range from 0 to 1
135 |
136 | Notes:
137 |
138 | (1) When applied to each saliency map, this method produces slightly better results than GaussNorm2D.
139 | The sum ROAR/KAR will improve from 1.44 to 1.45 for FastCAM using GradCAM.
140 | (2) This method is a bit more expensive than GaussNorm2D.
141 | '''
142 |
143 | def __init__(self):
144 |
145 | super(GammaNorm2D, self).__init__()
146 |
147 | r'''
148 | Chebyshev polynomials for Gamma Function
149 | '''
150 | self.cheb = torch.tensor([676.5203681218851,
151 | -1259.1392167224028,
152 | 771.32342877765313,
153 | -176.61502916214059,
154 | 12.507343278686905,
155 | -0.13857109526572012,
156 | 9.9843695780195716e-6,
157 | 1.5056327351493116e-7
158 | ])
159 |
160 | self.two_pi = torch.tensor(math.sqrt(2.0*3.141592653589793))
161 |
162 | def _gamma(self,z):
163 | r'''
164 | Gamma Function:
165 |
166 | http://mathworld.wolfram.com/GammaFunction.html
167 |
168 | https://en.wikipedia.org/wiki/Gamma_function#Weierstrass's_definition
169 |
170 | https://en.wikipedia.org/wiki/Lanczos_approximation#Simple_implementation
171 |
172 | gives us gamma(z + 1)
173 | Our version makes some slight changes and is more stable.
174 |
175 | Notes:
176 |
177 | (1) gamma(z) = gamma(z+1)/z
178 | (2) The gamma function is essentially a factorial function that supports real numbers
179 | so it grows very quickly. If z = 18 the result is 355687428096000.0
180 |
181 | Input is an array of positive real values. Zero is undefined.
182 | Output is an array of real postive values.
183 | '''
184 |
185 | x = torch.ones_like(z) * 0.99999999999980993
186 |
187 | for i in range(8):
188 | i1 = torch.tensor(i + 1.0)
189 | x = x + self.cheb[i] / (z + i1)
190 |
191 | t = z + 8.0 - 0.5
192 | y = self.two_pi * t.pow(z+0.5) * torch.exp(-t) * x
193 |
194 | y = y / z
195 |
196 | return y
197 |
198 | def _lower_incl_gamma(self,s,x, iter=8):
199 | r'''
200 | Lower Incomplete Gamma Function:
201 |
202 | This has been optimized to call _gamma and pow only once
203 | The gamma function is very expensive to call over all pixels, as we might do here.
204 |
205 | See: https://en.wikipedia.org/wiki/Incomplete_gamma_function#Holomorphic_extension
206 | '''
207 | iter = iter - 2
208 |
209 | gs = self._gamma(s)
210 |
211 | L = x.pow(s) * gs * torch.exp(-x)
212 |
213 | r'''
214 | For the gamma function: f(x + 1) = x * f(x)
215 | '''
216 | gs *= s # Gamma(s + 1)
217 | R = torch.reciprocal(gs) * torch.ones_like(x)
218 | X = x # x.pow(1)
219 |
220 | for k in range(iter):
221 | gs *= s + k + 1.0 # Gamma(s + k + 2)
222 | R += X / gs
223 | X = X*x # x.pow(k+1)
224 |
225 | gs *= s + iter + 1.0 # Gamma(s + iter + 2)
226 | R += X / gs
227 |
228 | return L * R
229 |
230 | def _trigamma(self,x):
231 | r'''
232 | Trigamma function:
233 |
234 | https://en.wikipedia.org/wiki/Trigamma_function
235 |
236 | We need the first line since recursion is not good for x < 1.0
237 | Note that we take + torch.reciprocal(x.pow(2)) at the end because:
238 |
239 | trigamma(z) = trigamma(z + 1) + 1/z^2
240 | '''
241 |
242 | z = x + 1.0
243 |
244 | zz = z.pow(2.0)
245 | a = 0.2 - torch.reciprocal(7.0*zz)
246 | b = 1.0 - a/zz
247 | c = 1.0 + b/(3.0 * z)
248 | d = 1.0 + c/(2.0 * z)
249 | e = d/z
250 |
251 | e = e + torch.reciprocal(x.pow(2.0))
252 |
253 | return e
254 |
255 | def _k_update(self,k,s):
256 |
257 | nm = torch.log(k) - torch.digamma(k) - s
258 | dn = torch.reciprocal(k) - self._trigamma(k)
259 | k2 = k - nm/dn
260 |
261 | return k2
262 |
263 | def _compute_ml_est(self, x, i=10, eps=0.0000001):
264 | r'''
265 | Compute k and th parameters for the Gamma Probability Distribution.
266 |
267 | This uses maximum likelihood estimation per Choi, S. C.; Wette, R. (1969)
268 |
269 | See: https://en.wikipedia.org/wiki/Gamma_distribution#Parameter_estimation
270 |
271 | Input is an array of real positive values. Zero is undefined, but we handle it.
272 | Output is a single value (per image) for k and th
273 | '''
274 |
275 | r'''
276 | avoid log(0)
277 | '''
278 | x = x + eps
279 |
280 | r'''
281 | Calculate s
282 | This is somewhat akin to computing a log standard deviation.
283 | '''
284 | s = torch.log(torch.mean(x,dim=1)) - torch.mean(torch.log(x),dim=1)
285 |
286 | r'''
287 | Get estimate of k to within 1.5%
288 |
289 | NOTE: K gets smaller as log variance s increases.
290 | '''
291 | s3 = s - 3.0
292 | rt = torch.sqrt(s3.pow(2.0) + 24.0 * s)
293 | nm = 3.0 - s + rt
294 | dn = 12.0 * s
295 | k = nm / dn + eps
296 |
297 | r'''
298 | Do i Newton-Raphson steps to get closer than 1.5%
299 | For i=5 gets us within 4 or 5 decimal places
300 | '''
301 | for _ in range(i):
302 | k = self._k_update(k,s)
303 |
304 | r'''
305 | prevent gamma(k) from being silly big or zero
306 | With k=18, gamma(k) is still 355687428096000.0
307 | This is because the Gamma function is a factorial function with support
308 | for positive natural numbers (here we only support reals).
309 | '''
310 | k = torch.clamp(k, eps, 18.0)
311 |
312 | th = torch.reciprocal(k) * torch.mean(x,dim=1)
313 |
314 | return k, th
315 |
316 | def forward(self, x):
317 | r'''
318 | Input:
319 | x: A Torch Tensor image with shape [batch size x height x width] e.g. [64,7,7]
320 | All values should be real positive (i.e. >= 0).
321 | Return:
322 | x: x Normalized by computing shape and scale over each individual batch item and squashed with a
323 | Gamma CDF.
324 | '''
325 |
326 | assert torch.is_tensor(x), "Input must be a Torch Tensor"
327 | assert len(x.size()) == 3, "Input should be sizes [batch size x height x width]"
328 |
329 | s0 = x.size()[0]
330 | s1 = x.size()[1]
331 | s2 = x.size()[2]
332 |
333 | x = x.reshape(s0,s1*s2)
334 |
335 | r'''
336 | offset from just a little more than 0, keeps k sane.
337 | '''
338 | x = x - torch.min(x,dim=1)[0].reshape(s0,1) + 0.0000001
339 |
340 | k,th = self._compute_ml_est(x)
341 |
342 | k = k.reshape(s0,1)
343 | th = th.reshape(s0,1)
344 |
345 | '''
346 | Squash with a Gamma CDF for range within 0 to 1.
347 | '''
348 | x = (1.0/self._gamma(k)) * self._lower_incl_gamma(k, x/th)
349 |
350 | r'''
351 | There are weird edge cases (e.g. all numbers are equal), prevent NaN
352 | '''
353 | x = torch.where(torch.isfinite(x), x, torch.zeros_like(x))
354 |
355 | x = x.reshape(s0,s1,s2)
356 |
357 | return x
358 |
359 | # *******************************************************************************************************************
360 | # *******************************************************************************************************************
361 | class RangeNorm2D(nn.Module):
362 | r'''
363 | This will normalize a saliency map to range from 0 to 1 via linear range function.
364 |
365 | Input and output will be a 3D tensor of size [batch size x height x width].
366 |
367 | Input can be any real valued number (supported by hardware)
368 | Output will range from 0 to 1
369 |
370 | Parameters:
371 | full_norm: This forces the values to range completely from 0 to 1.
372 | '''
373 |
374 | def __init__(self, full_norm=True, eps=10e-10):
375 |
376 | super(RangeNorm2D, self).__init__()
377 | self.full_norm = full_norm
378 | self.eps = eps
379 |
380 | def forward(self, x):
381 | r'''
382 | Input:
383 | x: A Torch Tensor image with shape [batch size x height x width] e.g. [64,7,7]
384 | All values should be real positive (i.e. >= 0).
385 | Return:
386 | x: x Normalized by dividing by either the min value or the range between max and min.
387 | Each max/min is computed for each batch item.
388 | '''
389 | assert torch.is_tensor(x), "Input must be a Torch Tensor"
390 | assert len(x.size()) == 3, "Input should be sizes [batch size x height x width]"
391 |
392 | s0 = x.size()[0]
393 | s1 = x.size()[1]
394 | s2 = x.size()[2]
395 |
396 | x = x.reshape(s0,s1*s2)
397 |
398 | xmax = x.max(dim=1)[0].reshape(s0,1)
399 |
400 | if self.full_norm:
401 | xmin = x.min(dim=1)[0].reshape(s0,1)
402 |
403 | nval = x - xmin
404 | range = xmax - xmin
405 | else:
406 | nval = x
407 | range = xmax
408 |
409 | r'''
410 | prevent divide by zero by setting zero to a small number
411 |
412 | Simply adding eps does not work will in this case. So we use torch.where to set a minimum value.
413 | '''
414 | eps_mat = torch.zeros_like(range) + self.eps
415 | range = torch.where(range > self.eps, range, eps_mat)
416 |
417 | x = nval / range
418 |
419 | x = x.reshape(s0,s1,s2)
420 |
421 | return x
422 |
--------------------------------------------------------------------------------
/export/demo_fast-cam.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | # # DEMO: Running FastCAM using SMOE Scale Saliency Maps
5 |
6 | # ## Initial code setup
7 |
8 | # In[1]:
9 |
10 |
11 | import os
12 | import cv2
13 | import numpy as np
14 | import torch
15 | from torchvision import models
16 | from IPython.display import Image
17 |
18 |
19 | # Lets load things we need for **Grad-CAM**
20 |
21 | # In[2]:
22 |
23 |
24 | from torchvision.utils import make_grid, save_image
25 | import torch.nn.functional as F
26 |
27 | from gradcam.utils import visualize_cam
28 | from gradcam import GradCAMpp, GradCAM
29 |
30 | # The GradCAM kit throws a warning we don't need to see for this demo.
31 | import warnings
32 | warnings.filterwarnings('ignore')
33 |
34 |
35 | # Now we import the code for **this package**.
36 |
37 | # In[3]:
38 |
39 |
40 | import maps
41 | import mask
42 | import draw
43 | import norm
44 | import misc
45 |
46 |
47 | # This is where we can set some parameters like the image name and the layer weights.
48 |
49 | # In[4]:
50 |
51 |
52 | input_image_name = "ILSVRC2012_val_00049934.224x224.png" # Our input image to process
53 | output_dir = 'outputs' # Where to save our output images
54 | input_dir = 'images' # Where to load our inputs from
55 |
56 | weights = [1.0, 1.0, 1.0, 1.0, 1.0] # Equal Weights work best
57 | # when using with GradCAM
58 |
59 | #weights = [0.18, 0.15, 0.37, 0.4, 0.72] # Our saliency layer weights
60 | # From paper:
61 | # https://arxiv.org/abs/1911.11293
62 |
63 | save_prefix = input_image_name[:-4].split('/')[-1] # Chop the file extension and path
64 | load_image_name = os.path.join(input_dir, input_image_name)
65 |
66 | os.makedirs(output_dir, exist_ok=True)
67 |
68 |
69 | # Good Doggy!
70 |
71 | # In[5]:
72 |
73 |
74 | Image(filename=load_image_name)
75 |
76 |
77 | # Now we create a model in PyTorch and send it to our device.
78 |
79 | # In[6]:
80 |
81 |
82 | device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
83 | model = models.resnet50(pretrained=True)
84 | model = model.to(device)
85 |
86 |
87 | # ## Setting up Hooks
88 | # Now we will set up our layer hooks as callback methods. This will keep a copy of a layers output data from a forward pass. This is how we will get the data out of the network's layers.
89 | #
90 | # So, lets look at the second spatial scale of ResNet-50 which has three bottleneck layers. We want that very last ReLU at the very end.
91 |
92 | # In[7]:
93 |
94 |
95 | print("{}".format(model.layer1))
96 |
97 |
98 | #
99 | #
100 | # **So...** we would select
101 | #
102 | # model.layer1[2].relu
103 | #
104 | # with a command like
105 | #
106 | # model.layer1[2].relu.register_forward_hook(hooks[1])
107 | #
108 | # This attaches a callback which will store this layers output, when the network is run.
109 | #
110 | # Below we attach a hook at the end of each spatial scale.
111 |
112 | # In[8]:
113 |
114 |
115 | hooks = [misc.CaptureLayerOutput() for i in range(5)] # Create 5 callback hooks in a liszt
116 | map_num = len(hooks) # Store size for later use
117 |
118 | # Chopin off the "_ =" is fine. We technically don't
119 | # need anything bach but the handel to each hook.
120 | _ = model.relu.register_forward_hook(hooks[0])
121 | _ = model.layer1[2].relu.register_forward_hook(hooks[1])
122 | _ = model.layer2[3].relu.register_forward_hook(hooks[2])
123 | _ = model.layer3[5].relu.register_forward_hook(hooks[3])
124 | _ = model.layer4[2].relu.register_forward_hook(hooks[4])
125 |
126 |
127 | # Notice that the layers we access are the same as in the resnet50 python model layers specificiation which is **[3, 4, 6, 3]**, we just subtract 1 from each.
128 | #
129 | # OK, now let's load in our image and set it to the standard *ImageNet* size: 224x224.
130 |
131 | # In[9]:
132 |
133 |
134 | in_tensor = misc.LoadImageToTensor(load_image_name, device)
135 | in_tensor = F.interpolate(in_tensor, size=(224, 224), mode='bilinear', align_corners=False)
136 |
137 | in_height = in_tensor.size()[2]
138 | in_width = in_tensor.size()[3]
139 |
140 |
141 | # OK, let's run our ResNet network *forward only*. The callbacks will then contain the layer data afterwards. Since we are only doing a forward computation, this sails on a CPU.
142 |
143 | # In[10]:
144 |
145 |
146 | model.eval()
147 | with torch.set_grad_enabled(False):
148 | _ = model(in_tensor)
149 |
150 |
151 | # ## Running saliency on our network data
152 | #
153 | # Now that the network has run, we can finally do some work. First we create objects for our saliency layers. These are *PyTorch nn layers*, but we can talk to them even if they are not inside a network.
154 |
155 | # All three objects here are technically layers. So, they can be used inside your network as well.
156 | #
157 | # If you want to use these **inside your network**:
158 | #
159 | # example, in your __init__ something like:
160 | #
161 | # self.salmap_layer = maps.SMOEScaleMap()
162 | #
163 | # then in forward(x) something like:
164 | #
165 | # x = self.relu(x)
166 | # x = self.salmap_layer(x)
167 |
168 | # First, we create an object to get each saliency map given the data stored in the hooks. This will run SMOE Scale on each of the layer hook outputs and produce raw a saliency map. This package also includes code for using *Standard Deviation* or *Truncated Normal Entropy*.
169 |
170 | # In[11]:
171 |
172 |
173 | getSmap = maps.SMOEScaleMap()
174 |
175 |
176 | # This next object will normalize the saliency maps from 0 to 1 using a Gaussian CDF squashing function.
177 |
178 | # In[12]:
179 |
180 |
181 | #getNorm = norm.GaussNorm2D()
182 | getNorm = norm.GammaNorm2D() # A little more accurate, but much slower
183 |
184 |
185 | # Now we will create an object to combine the five saliency maps from each scale into one.
186 |
187 | # In[13]:
188 |
189 |
190 | getCsmap = maps.CombineSaliencyMaps(output_size=[in_height,in_width],
191 | map_num=map_num, weights=weights, resize_mode='bilinear')
192 |
193 |
194 | # Once we have our objects, we will run SMOE Scale on each of the output hooks and then normalize the output.
195 |
196 | # In[14]:
197 |
198 |
199 | smaps = [ getNorm(getSmap(x.data)) for x in hooks ]
200 |
201 |
202 | # Now, we combine the different saliency maps into a single combined saliency map. Notice that we also get back each saliency map in *smaps* rescaled by the method.
203 |
204 | # In[15]:
205 |
206 |
207 | csmap,smaps = getCsmap(smaps)
208 |
209 |
210 | # Then we save and view it.
211 |
212 | # In[16]:
213 |
214 |
215 | output_name = "{}.MAP_COMBINED.jpg".format(save_prefix)
216 | output_path = os.path.join(output_dir, output_name)
217 | misc.SaveGrayTensorToImage(csmap, output_path)
218 | np_smaps = misc.TensorToNumpyImages(smaps) # For later use, keep the Numpy version
219 | # of the saliency maps.
220 |
221 | Image(filename=output_path)
222 |
223 |
224 | # Now lets get our individual saliency maps for each of the five layers and look at them.
225 |
226 | # In[17]:
227 |
228 |
229 | il = [smaps[0,i,:,:] for i in range(map_num)] # Put each saliency map into the figure
230 |
231 | il.append(csmap[0,:,:]) # add in the combined map at the end of the figure
232 |
233 | images = [torch.stack(il, 0)]
234 | images = make_grid(torch.cat(images, 0), nrow=5)
235 | output_name = "{}.SAL_MAPS.jpg".format(save_prefix)
236 | sal_img_file = os.path.join(output_dir, output_name)
237 |
238 | save_image(images.unsqueeze(1), sal_img_file)
239 |
240 | Image(filename=sal_img_file)
241 |
242 |
243 | # ## LOVI and Heat Maps
244 | # Now we will take our saliency maps and create the LOVI and Heat Map versions.
245 |
246 | # In[18]:
247 |
248 |
249 | SHM = draw.HeatMap(shape=np_smaps.shape, weights=weights ) # Create our heat map drawer
250 | LOVI = draw.LOVI(shape=np_smaps.shape, weights=None) # Create out LOVI drawer
251 |
252 | shm_im = SHM.make(np_smaps) # Combine the saliency maps
253 | # into one heat map
254 | lovi_im = LOVI.make(np_smaps) # Combine the saliency maps
255 | # into one LOVI image
256 |
257 |
258 | # Next, save and display our images.
259 |
260 | # In[19]:
261 |
262 |
263 | output_name = "{}.HEAT.jpg".format(save_prefix)
264 | output_path = os.path.join(output_dir, output_name)
265 | cv2.imwrite(output_path, (shm_im*255.0).astype(np.uint8))
266 |
267 | Image(filename=output_path)
268 |
269 |
270 | # Let's create on overlay with our original image by alpha blending.
271 |
272 | # In[20]:
273 |
274 |
275 | cv_im = cv2.imread(load_image_name).astype(np.float32) / 255.0
276 | cv_im = cv2.resize(cv_im, (224,224))
277 | ab_shm = misc.AlphaBlend(shm_im, cv_im) # Blend the heat map and the original image
278 |
279 | output_name = "{}.ALPHA_HEAT.jpg".format(save_prefix)
280 | output_path = os.path.join(output_dir, output_name)
281 | cv2.imwrite(output_path, (ab_shm*255.0).astype(np.uint8))
282 |
283 | Image(filename=output_path)
284 |
285 |
286 | # Now we view our LOVI map with and without alpha blending of the original image. The LOVI image tells us which parts of the network are most active by layer. We range like a rainbow with violet/blue representing early layers and yellow/red representing later layers. White areas are active over all layers.
287 |
288 | # In[21]:
289 |
290 |
291 | output_name = "{}.LOVI.jpg".format(save_prefix)
292 | output_path = os.path.join(output_dir, output_name)
293 | cv2.imwrite(output_path, (lovi_im*255.0).astype(np.uint8))
294 |
295 | Image(filename=output_path)
296 |
297 |
298 | # You can see how this image is composed by looking again at all the individual saliency maps...
299 |
300 | # In[22]:
301 |
302 |
303 | Image(filename=sal_img_file)
304 |
305 |
306 | # In[23]:
307 |
308 |
309 | ab_lovi = misc.AlphaBlend(lovi_im, cv_im) # Blend original image and LOVI image
310 |
311 | output_name = "{}.ALPHA_LOVI.jpg".format(save_prefix)
312 | output_path = os.path.join(output_dir, output_name)
313 | cv2.imwrite(output_path, (ab_lovi*255.0).astype(np.uint8))
314 |
315 | Image(filename=output_path)
316 |
317 |
318 | # ## The Masked Image
319 | # From the combined saliency map, we can extract the masked out input image. This illustrates What parts of the image are the top xx% most salient.
320 | #
321 | # First we set up objects to create the mask from the input tensor version of the image and the combined saliency map.
322 |
323 | # In[24]:
324 |
325 |
326 | getMask = mask.SaliencyMaskDropout(keep_percent = 0.1, scale_map=False)
327 |
328 |
329 | # We define a denormalization object to get things back to normal image pixel values.
330 |
331 | # In[25]:
332 |
333 |
334 | denorm = misc.DeNormalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
335 |
336 |
337 | # Next we process the tensor and saliency map to create the masked image.
338 |
339 | # In[26]:
340 |
341 |
342 | masked_tensor,drop_map = getMask(in_tensor, csmap)
343 |
344 |
345 | # Finally, we denormalize the tensor image, save and display it. This shows us the **top 10% most salient parts** of the images.
346 |
347 | # In[27]:
348 |
349 |
350 | masked_tensor = denorm(masked_tensor)
351 |
352 | output_name = "{}.MASK.jpg".format(save_prefix)
353 | output_path = os.path.join(output_dir, output_name)
354 | misc.SaveColorTensorToImage(masked_tensor, output_path)
355 | Image(filename=output_path)
356 |
357 |
358 | # ## Run With Grad-CAM++
359 |
360 | # Let's go ahead and push our network model into the Grad-CAM library.
361 | #
362 | # **NOTE** much of this code is borrowed from the Pytorch GradCAM package.
363 |
364 | # In[28]:
365 |
366 |
367 | resnet_gradcampp4 = GradCAMpp.from_config(model_type='resnet', arch=model, layer_name='layer4')
368 |
369 |
370 | # Let's get our original input image back.
371 |
372 | # In[29]:
373 |
374 |
375 | raw_tensor = misc.LoadImageToTensor(load_image_name, device, norm=False)
376 | raw_tensor = F.interpolate(raw_tensor, size=(224, 224), mode='bilinear', align_corners=False)
377 |
378 |
379 | # Now we will create illustrations of the combined saliency map.
380 |
381 | # In[30]:
382 |
383 |
384 | masked_tensor_raw,drop_map = getMask(raw_tensor, csmap)
385 |
386 | cs_heatmap, cs_result = visualize_cam(csmap, raw_tensor)
387 | cs_masked = misc.AlphaMask(raw_tensor, csmap).squeeze(0)
388 | cs_masked = misc.RangeNormalize(cs_masked)
389 |
390 | images = []
391 | images.append(torch.stack([raw_tensor.squeeze().cpu(), cs_heatmap.cpu(),
392 | cs_result.cpu(), cs_masked.cpu(), masked_tensor_raw[0,].cpu()], 0))
393 |
394 |
395 | # Now, lets get the Grad-CAM++ saliency map only.
396 |
397 | # In[31]:
398 |
399 |
400 | mask_pp1, logit = resnet_gradcampp4(in_tensor)
401 |
402 |
403 | # Let's double check and make sure it's picking the correct class
404 |
405 | # In[32]:
406 |
407 |
408 | too_logit = logit.max(1)
409 | print("Network Class Output: {} : Value {} ".format(too_logit[1][0],too_logit[0][0]))
410 |
411 |
412 | # Now visualize the results
413 |
414 | # In[33]:
415 |
416 |
417 | heatmap_pp1, result_pp1 = visualize_cam(mask_pp1, raw_tensor)
418 |
419 | hard_masked_pp1,_ = getMask(raw_tensor, mask_pp1.squeeze(0))
420 | hard_masked_pp1 = hard_masked_pp1.squeeze(0)
421 | masked_pp1 = misc.AlphaMask(raw_tensor, mask_pp1.squeeze(0)).squeeze(0)
422 | masked_pp1 = misc.RangeNormalize(masked_pp1)
423 |
424 | images.append(torch.stack([raw_tensor.squeeze().cpu(), heatmap_pp1.cpu(),
425 | result_pp1.cpu(), masked_pp1.cpu(), hard_masked_pp1.cpu()], 0))
426 |
427 |
428 | # **Now we combine the Grad-CAM map and the SMOE Scale saliency maps** in the same way we would combine Grad-CAM with Guided Backprop.
429 |
430 | # In[34]:
431 |
432 |
433 | mask_pp2 = csmap*mask_pp1
434 |
435 |
436 | # Now let's visualize the combined saliency map from SMOE Scale and GradCAM++.
437 |
438 | # In[35]:
439 |
440 |
441 | heatmap_pp2, result_pp2 = visualize_cam(mask_pp2, raw_tensor)
442 |
443 | hard_masked_pp2,_ = getMask(raw_tensor,mask_pp2.squeeze(0))
444 | hard_masked_pp2 = hard_masked_pp2.squeeze(0)
445 | masked_pp2 = misc.AlphaMask(raw_tensor, mask_pp2.squeeze(0)).squeeze(0)
446 | masked_pp2 = misc.RangeNormalize(masked_pp2)
447 |
448 | images.append(torch.stack([raw_tensor.squeeze().cpu(), heatmap_pp2.cpu(),
449 | result_pp2.cpu(), masked_pp2.cpu(), hard_masked_pp2.cpu()], 0))
450 |
451 |
452 | # Now we combine the Grad-CAM map and the SMOE Scale saliency maps but create a map of the **non-class** objects. These are salient locations that the network found interesting, but are not part of the object class.
453 |
454 | # In[36]:
455 |
456 |
457 | mask_pp3 = csmap*(1.0 - mask_pp1)
458 |
459 |
460 | # Now let's visualize the combined non-class saliency map from SMOE Scale and GradCAM++.
461 |
462 | # In[37]:
463 |
464 |
465 | heatmap_pp3, result_pp3 = visualize_cam(mask_pp3, raw_tensor)
466 |
467 | hard_masked_pp3,_ = getMask(raw_tensor,mask_pp3.squeeze(0))
468 | hard_masked_pp3 = hard_masked_pp3.squeeze(0)
469 | masked_pp3 = misc.AlphaMask(raw_tensor, mask_pp3.squeeze(0)).squeeze(0)
470 | masked_pp3 = misc.RangeNormalize(masked_pp3)
471 |
472 | images.append(torch.stack([raw_tensor.squeeze().cpu(), heatmap_pp3.cpu(),
473 | result_pp3.cpu(), masked_pp3.cpu(), hard_masked_pp3.cpu()], 0))
474 |
475 |
476 | # We now put all the images into a nice grid for display.
477 |
478 | # In[38]:
479 |
480 |
481 | images = make_grid(torch.cat(images,0), nrow=5)
482 |
483 |
484 | # ... save and look at it.
485 |
486 | # In[39]:
487 |
488 |
489 | output_name = "{}.CAM_PP.jpg".format(save_prefix)
490 | output_path = os.path.join(output_dir, output_name)
491 |
492 | save_image(images, output_path)
493 | Image(filename=output_path)
494 |
495 |
496 | # The top row is the SMOE Scale based saliency map. The second row is GradCAM++ only. Next we have the FastCAM output from combining the two. The last row is the non-class map showing salient regions that are not associated with the output class.
497 | #
498 | # This image should look **exactly** like the one on the README.md on Github minus the text.
499 |
500 | # In[ ]:
501 |
502 |
503 |
504 |
505 |
506 | # In[ ]:
507 |
508 |
509 |
510 |
511 |
--------------------------------------------------------------------------------
/resnet.py:
--------------------------------------------------------------------------------
1 | '''
2 | BSD 3-Clause License
3 |
4 | Copyright (c) 2020, Lawrence Livermore National Laboratory
5 | All rights reserved.
6 |
7 | Redistribution and use in source and binary forms, with or without
8 | modification, are permitted provided that the following conditions are met:
9 |
10 | 1. Redistributions of source code must retain the above copyright notice, this
11 | list of conditions and the following disclaimer.
12 |
13 | 2. Redistributions in binary form must reproduce the above copyright notice,
14 | this list of conditions and the following disclaimer in the documentation
15 | and/or other materials provided with the distribution.
16 |
17 | 3. Neither the name of the copyright holder nor the names of its
18 | contributors may be used to endorse or promote products derived from
19 | this software without specific prior written permission.
20 |
21 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
31 | '''
32 |
33 | '''
34 | https://github.com/LLNL/fastcam
35 |
36 | A toolkit for efficent computation of saliency maps for explainable
37 | AI attribution.
38 |
39 | This work was performed under the auspices of the U.S. Department of Energy
40 | by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344
41 | and was supported by the LLNL-LDRD Program under Project 18-ERD-021 and
42 | Project 17-SI-003.
43 |
44 | Software released as LLNL-CODE-802426.
45 |
46 | See also: https://arxiv.org/abs/1911.11293
47 | '''
48 |
49 | from torchvision import models
50 | from torchvision.models.utils import load_state_dict_from_url
51 | import torch.nn.functional as F
52 | import torch
53 |
54 | try:
55 | from . import norm
56 | except ImportError:
57 | import norm
58 |
59 | # *******************************************************************************************************************
60 | class ScoreMap(torch.autograd.Function):
61 |
62 | @staticmethod
63 | def forward(ctx, scores):
64 |
65 | ctx.save_for_backward(scores)
66 | return torch.tensor(1.0)
67 |
68 | @staticmethod
69 | def backward(ctx, grad):
70 |
71 | saved = ctx.saved_tensors
72 | g_scores = torch.ones_like(saved[0])
73 |
74 | return g_scores
75 |
76 | # *******************************************************************************************************************
77 | class ResNet_FastCAM(models.ResNet):
78 | r'''
79 | Some of the code here is borrowed from the PyTorch source code.
80 |
81 | This is just a wrapper around PyTorch's own ResNet. We use it so we can only compute
82 | gradents over the last few layers and speed things up. Otherwise, ResNet will
83 | compute the usual gradients all the way through the network.
84 |
85 | It is declared the usual way, but returns a saliency map in addition to the logits.
86 |
87 | See: torchvision/models/resnet.py in the torchvision package.
88 |
89 | Parameters:
90 |
91 | block: This is the ResNet block pattern in a list. Something like [3, 4, 23, 3]
92 | layers: What kind of blocks are we using. For instance models.resnet.Bottleneck . This should be callable.
93 | num_classes: How many classes will this network use? Should be an integer. Default: 1000
94 |
95 | Will Return:
96 |
97 | logit: The standard ResNet logits.
98 | saliency_map: This is the combined, normalized saliency map which will resized to be the same
99 | as the input [batch size x height x width].
100 |
101 | '''
102 | def __init__(self, block, layers, num_classes=1000, **kwargs):
103 |
104 | assert callable(block)
105 | assert isinstance(layers,list)
106 | assert isinstance(num_classes,int)
107 |
108 | super(ResNet_FastCAM, self).__init__(block, layers, num_classes=num_classes, **kwargs)
109 |
110 | self.get_norm = norm.RangeNorm2D() # Hard range normalization between 0 to 1
111 | self.num_classes = num_classes # We need this to define the max logits for the CAM map
112 | self.layer = None # This is a dummy layer to stash activations and gradients prior to average pooling
113 |
114 | def _forward_impl(self, x):
115 |
116 | r'''
117 | Turn off gradients so we don't prop all the way back. We only want to
118 | go back a few layers. Saves time and memory.
119 | '''
120 | with torch.set_grad_enabled(False):
121 | x = self.conv1(x)
122 | x = self.bn1(x)
123 | x = self.relu(x)
124 | x = self.maxpool(x)
125 |
126 | x = self.layer1(x)
127 | x = self.layer2(x)
128 | x = self.layer3(x)
129 | x = self.layer4(x)
130 |
131 | r'''
132 | To do:
133 | combine layer4 output with the SaliencyMap final layer
134 | '''
135 |
136 | r'''
137 | Turn on gradients and then get them into a container for usage by CAM
138 | '''
139 | with torch.set_grad_enabled(True):
140 | r'''
141 | Here we save out the layer so we can process it later
142 | '''
143 | x.requires_grad = True
144 | self.layer = x
145 | self.layer.retain_grad()
146 |
147 | r'''
148 | Now run the rest of the network with gradients on
149 | '''
150 | x = self.avgpool(self.layer)
151 | x = torch.flatten(x, 1)
152 | x = self.fc(x)
153 |
154 | return x
155 |
156 | def forward(self, x, class_idx=None, method='gradcam', retain_graph=False):
157 | r'''
158 | Call forward on the input x and return saliency map and logits.
159 |
160 | Args:
161 |
162 | x: A standard Torch Tensor of size [Batch x 3 x Height x Width]
163 | class_idx: For CAM, what class should we propagate from. If None, use the max logit.
164 | method: A string, either 'gradcam' or 'gradcampp'. both yeild the same ROAR/KARR score.
165 | retain_graph: If you don't know what this means, leave it alone.
166 |
167 | Return:
168 |
169 | logit: The standard ResNet logits.
170 | saliency_map: This is the combined, normalized saliency map which will resized to be the same
171 | as the input [batch size x height x width].
172 |
173 | NOTE:
174 |
175 | Some of this code is borrowed from pytorch gradcam:
176 | https://github.com/vickyliin/gradcam_plus_plus-pytorch
177 | '''
178 |
179 | assert torch.is_tensor(x), "Input x must be a Torch Tensor"
180 | assert len(x.size()) == 4, "Input x must have for dims [Batch x 3 x Height x Width]"
181 | assert class_idx is None or (isinstance(class_idx,int) and class_idx >=0 and class_idx < self.num_classes), "class_idx should not be silly"
182 | assert isinstance(retain_graph,bool), "retain_graph must be a bool."
183 | assert isinstance(method,str), "method must be a string"
184 |
185 | b, c, h, w = x.size()
186 |
187 | r'''
188 | Run network forward on input x. Grads will only be kept on the last few layers.
189 | '''
190 | logit = self._forward_impl(x)
191 |
192 | r'''
193 | Torch will need to keep grads for these things.
194 | '''
195 | with torch.set_grad_enabled(True):
196 |
197 | if class_idx is None:
198 |
199 | sz = logit.size()
200 |
201 | lm = logit.max(1)[1]
202 | r'''
203 | This gets the logits into a form usable when we run a batch. This seems suboptimal.
204 | Open to ideas about how to make this better/faster.
205 | '''
206 | lm = torch.stack([i*self.num_classes + v for i,v in enumerate(lm)])
207 |
208 | logit = logit.reshape(sz[0]*sz[1])
209 |
210 | score = logit[lm]
211 |
212 | logit = logit.reshape(sz[0],sz[1])
213 | score = score.reshape(sz[0],1,1,1)
214 | else:
215 | score = logit[:, class_idx].squeeze()
216 |
217 | r'''
218 | Pass through layer to make auto grad happy
219 | '''
220 | score_end = ScoreMap.apply(score)
221 |
222 | r'''
223 | Zero out grads and then run backwards.
224 |
225 | NOTE: This will only run backwards to the average pool layer then stop.
226 | This is because we have set torch.set_grad_enabled(False) for all other layers.
227 | '''
228 | self.zero_grad()
229 | score_end.backward(retain_graph=retain_graph)
230 |
231 | r'''
232 | Make naming clearer for next parts
233 | '''
234 | gradients = self.layer.grad
235 | activations = self.layer
236 |
237 | r'''
238 | Make sure torch doesn't keep grads for all this stuff since it will not be
239 | needed.
240 | '''
241 | with torch.set_grad_enabled(False):
242 |
243 | b, k, u, v = gradients.size()
244 |
245 | if method=='gradcampp':
246 | r'''
247 | GradCAM++ Computation
248 | '''
249 | alpha_num = gradients.pow(2)
250 | alpha_denom = gradients.pow(2).mul(2) + \
251 | activations.mul(gradients.pow(3)).view(b, k, u*v).sum(-1, keepdim=True).view(b, k, 1, 1)
252 | alpha_denom = torch.where(alpha_denom != 0.0, alpha_denom, torch.ones_like(alpha_denom))
253 |
254 | alpha = alpha_num.div(alpha_denom+1e-7)
255 | positive_gradients = F.relu(score.exp()*gradients) # ReLU(dY/dA) == ReLU(exp(S)*dS/dA))
256 | weights = (alpha*positive_gradients).view(b, k, u*v).sum(-1).view(b, k, 1, 1)
257 |
258 | elif method=='gradcam':
259 | r'''
260 | Standard GradCAM Computation
261 | '''
262 | alpha = gradients.view(b, k, -1).mean(2)
263 | weights = alpha.view(b, k, 1, 1)
264 | elif method=='xgradcam':
265 | r'''
266 | XGradCAM Computation
267 | '''
268 | alpha = (gradients*activations).view(b, k, -1).sum(2)
269 | alpha = alpha / (activations.view(b, k, -1).sum(2) + 1e-6)
270 | weights = alpha.view(b, k, 1, 1)
271 | else:
272 | r'''
273 | Just GradCAM++ and original GradCAM
274 | '''
275 | raise ValueError("Unknown CAM type: \"{}\"".format(method))
276 |
277 | saliency_map = (weights*activations).sum(1, keepdim=True)
278 |
279 | r'''
280 | Lets just deal with positive gradients
281 | '''
282 | saliency_map = F.relu(saliency_map)
283 |
284 | r'''
285 | Get back to input image size
286 | '''
287 | saliency_map = F.upsample(saliency_map, size=(h, w), mode='bilinear', align_corners=False)
288 |
289 | r'''
290 | Hard range normalization
291 | '''
292 | saliency_map = self.get_norm(saliency_map.squeeze(1))
293 |
294 | return logit, saliency_map
295 |
296 | # *******************************************************************************************************************
297 | def _resnet(arch, block, layers, pretrained, progress, **kwargs):
298 |
299 | assert isinstance(pretrained, bool)
300 | assert isinstance(progress, bool)
301 |
302 | model = ResNet_FastCAM(block, layers, **kwargs)
303 |
304 | if pretrained:
305 | state_dict = load_state_dict_from_url(models.resnet.model_urls[arch],
306 | progress=progress)
307 | model.load_state_dict(state_dict)
308 |
309 | return model
310 |
311 | # *******************************************************************************************************************
312 | r'''
313 | Everything from here on down is just copied verbatum from torchvision.
314 |
315 | Let me know if there is a better way to do this.
316 | '''
317 |
318 | def resnet18(pretrained=False, progress=True, **kwargs):
319 | r"""ResNet-18 model from
320 | `"Deep Residual Learning for Image Recognition" `_
321 |
322 | Args:
323 | pretrained (bool): If True, returns a model pre-trained on ImageNet
324 | progress (bool): If True, displays a progress bar of the download to stderr
325 | """
326 | return _resnet('resnet18', models.resnet.BasicBlock, [2, 2, 2, 2], pretrained, progress,
327 | **kwargs)
328 |
329 |
330 | def resnet34(pretrained=False, progress=True, **kwargs):
331 | r"""ResNet-34 model from
332 | `"Deep Residual Learning for Image Recognition" `_
333 |
334 | Args:
335 | pretrained (bool): If True, returns a model pre-trained on ImageNet
336 | progress (bool): If True, displays a progress bar of the download to stderr
337 | """
338 | return _resnet('resnet34', models.resnet.BasicBlock, [3, 4, 6, 3], pretrained, progress,
339 | **kwargs)
340 |
341 |
342 | def resnet50(pretrained=False, progress=True, **kwargs):
343 | r"""ResNet-50 model from
344 | `"Deep Residual Learning for Image Recognition" `_
345 |
346 | Args:
347 | pretrained (bool): If True, returns a model pre-trained on ImageNet
348 | progress (bool): If True, displays a progress bar of the download to stderr
349 | """
350 | return _resnet('resnet50', models.resnet.Bottleneck, [3, 4, 6, 3], pretrained, progress,
351 | **kwargs)
352 |
353 |
354 | def resnet101(pretrained=False, progress=True, **kwargs):
355 | r"""ResNet-101 model from
356 | `"Deep Residual Learning for Image Recognition" `_
357 |
358 | Args:
359 | pretrained (bool): If True, returns a model pre-trained on ImageNet
360 | progress (bool): If True, displays a progress bar of the download to stderr
361 | """
362 | return _resnet('resnet101', models.resnet.Bottleneck, [3, 4, 23, 3], pretrained, progress,
363 | **kwargs)
364 |
365 |
366 | def resnet152(pretrained=False, progress=True, **kwargs):
367 | r"""ResNet-152 model from
368 | `"Deep Residual Learning for Image Recognition" `_
369 |
370 | Args:
371 | pretrained (bool): If True, returns a model pre-trained on ImageNet
372 | progress (bool): If True, displays a progress bar of the download to stderr
373 | """
374 | return _resnet('resnet152', models.resnet.Bottleneck, [3, 8, 36, 3], pretrained, progress,
375 | **kwargs)
376 |
377 |
378 | def resnext50_32x4d(pretrained=False, progress=True, **kwargs):
379 | r"""ResNeXt-50 32x4d model from
380 | `"Aggregated Residual Transformation for Deep Neural Networks" `_
381 |
382 | Args:
383 | pretrained (bool): If True, returns a model pre-trained on ImageNet
384 | progress (bool): If True, displays a progress bar of the download to stderr
385 | """
386 | kwargs['groups'] = 32
387 | kwargs['width_per_group'] = 4
388 | return _resnet('resnext50_32x4d', models.resnet.Bottleneck, [3, 4, 6, 3],
389 | pretrained, progress, **kwargs)
390 |
391 |
392 | def resnext101_32x8d(pretrained=False, progress=True, **kwargs):
393 | r"""ResNeXt-101 32x8d model from
394 | `"Aggregated Residual Transformation for Deep Neural Networks" `_
395 |
396 | Args:
397 | pretrained (bool): If True, returns a model pre-trained on ImageNet
398 | progress (bool): If True, displays a progress bar of the download to stderr
399 | """
400 | kwargs['groups'] = 32
401 | kwargs['width_per_group'] = 8
402 | return _resnet('resnext101_32x8d', models.resnet.Bottleneck, [3, 4, 23, 3],
403 | pretrained, progress, **kwargs)
404 |
405 |
406 | def wide_resnet50_2(pretrained=False, progress=True, **kwargs):
407 | r"""Wide ResNet-50-2 model from
408 | `"Wide Residual Networks" `_
409 |
410 | The model is the same as ResNet except for the models.resnet.Bottleneck number of channels
411 | which is twice larger in every block. The number of channels in outer 1x1
412 | convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
413 | channels, and in Wide ResNet-50-2 has 2048-1024-2048.
414 |
415 | Args:
416 | pretrained (bool): If True, returns a model pre-trained on ImageNet
417 | progress (bool): If True, displays a progress bar of the download to stderr
418 | """
419 | kwargs['width_per_group'] = 64 * 2
420 | return _resnet('wide_resnet50_2', models.resnet.Bottleneck, [3, 4, 6, 3],
421 | pretrained, progress, **kwargs)
422 |
423 |
424 | def wide_resnet101_2(pretrained=False, progress=True, **kwargs):
425 | r"""Wide ResNet-101-2 model from
426 | `"Wide Residual Networks" `_
427 |
428 | The model is the same as ResNet except for the models.resnet.Bottleneck number of channels
429 | which is twice larger in every block. The number of channels in outer 1x1
430 | convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
431 | channels, and in Wide ResNet-50-2 has 2048-1024-2048.
432 |
433 | Args:
434 | pretrained (bool): If True, returns a model pre-trained on ImageNet
435 | progress (bool): If True, displays a progress bar of the download to stderr
436 | """
437 | kwargs['width_per_group'] = 64 * 2
438 | return _resnet('wide_resnet101_2', models.resnet.Bottleneck, [3, 4, 23, 3],
439 | pretrained, progress, **kwargs)
440 |
441 |
--------------------------------------------------------------------------------
/misc.py:
--------------------------------------------------------------------------------
1 | '''
2 | BSD 3-Clause License
3 |
4 | Copyright (c) 2020, Lawrence Livermore National Laboratory
5 | All rights reserved.
6 |
7 | Redistribution and use in source and binary forms, with or without
8 | modification, are permitted provided that the following conditions are met:
9 |
10 | 1. Redistributions of source code must retain the above copyright notice, this
11 | list of conditions and the following disclaimer.
12 |
13 | 2. Redistributions in binary form must reproduce the above copyright notice,
14 | this list of conditions and the following disclaimer in the documentation
15 | and/or other materials provided with the distribution.
16 |
17 | 3. Neither the name of the copyright holder nor the names of its
18 | contributors may be used to endorse or promote products derived from
19 | this software without specific prior written permission.
20 |
21 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
31 | '''
32 | '''
33 | https://github.com/LLNL/fastcam
34 |
35 | A toolkit for efficent computation of saliency maps for explainable
36 | AI attribution.
37 |
38 | This work was performed under the auspices of the U.S. Department of Energy
39 | by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344
40 | and was supported by the LLNL-LDRD Program under Project 18-ERD-021 and
41 | Project 17-SI-003.
42 |
43 | Software released as LLNL-CODE-802426.
44 |
45 | See also: https://arxiv.org/abs/1911.11293
46 | '''
47 |
48 | import cv2
49 | import torch
50 | import torch.nn.functional as F
51 | import numpy as np
52 |
53 | try:
54 | from . import maps
55 | except ImportError:
56 | import maps
57 |
58 | from torchvision import models, transforms
59 | from statistics import stdev # Built-in
60 | from gradcam import GradCAM
61 | from gradcam.utils import visualize_cam
62 | from matplotlib import pyplot as plt
63 |
64 | # *******************************************************************************************************************
65 | def from_gpu(data):
66 |
67 | return data.cpu().detach().numpy()
68 |
69 | # *******************************************************************************************************************
70 | def detach(data):
71 |
72 | return data.detach()
73 |
74 | # *******************************************************************************************************************
75 | def no_proc(data):
76 |
77 | return data
78 |
79 | # *******************************************************************************************************************
80 | # *******************************************************************************************************************
81 | class CaptureLayerData(object):
82 | r"""
83 | This is a helper class to get layer data such as network activations from
84 | the network. PyTorch hides this away. To get it, we attach on object of this
85 | type to a layer. This tells PyTorch to give us a copy when it runs a forward
86 | pass.
87 | """
88 |
89 | def __init__(self, device, post_process=no_proc):
90 | self.data = None
91 | self.post_process = post_process
92 |
93 | if device is not None:
94 | self.device = torch.device(device)
95 | else:
96 | self.device = None
97 |
98 | assert(callable(self.post_process) or self.post_process is None)
99 |
100 | # *******************************************************************************************************************
101 | class CaptureLayerOutput(CaptureLayerData):
102 |
103 | def __init__(self, device=None, post_process=detach):
104 |
105 | super(CaptureLayerOutput, self).__init__(device, post_process)
106 |
107 | def __call__(self, m, i, o):
108 |
109 | if self.device is None or self.device == o.device:
110 |
111 | if self.post_process is None:
112 | self.data = o.data
113 | else:
114 | self.data = self.post_process(o.data)
115 |
116 | # *******************************************************************************************************************
117 | class CaptureGradOutput(CaptureLayerData):
118 |
119 | def __init__(self, device=None, post_process=detach):
120 |
121 | super(CaptureGradOutput, self).__init__(device, post_process)
122 |
123 | def __call__(self, m, i, o):
124 |
125 | if self.device is None or self.device == o[0].device:
126 |
127 | # o seems to usualy be size 1
128 |
129 | if self.post_process is None:
130 | self.data = o[0]
131 | else:
132 | self.data = self.post_process(o[0])
133 |
134 | # *******************************************************************************************************************
135 | class CaptureLayerInput(CaptureLayerData):
136 |
137 | def __init__(self, device=None, array_item=None):
138 |
139 | assert(isinstance(array_item, int) or array_item is None)
140 |
141 | if isinstance(array_item, int):
142 | assert array_item >= 0
143 |
144 | self.array_item = array_item
145 |
146 | super(CaptureLayerInput, self).__init__(device, post_process=None)
147 |
148 | def __call__(self, m, i, o):
149 |
150 | if self.device is None or self.device == o.device:
151 |
152 | if self.array_item is None:
153 | self.data = [n.data for n in i]
154 | else:
155 | self.data = i.data[self.array_item]
156 |
157 | # *******************************************************************************************************************
158 | class CaptureLayerPreInput(CaptureLayerData):
159 |
160 | def __init__(self, device=None, array_item=None):
161 |
162 | assert(isinstance(array_item, int) or array_item is None)
163 |
164 | if isinstance(array_item, int):
165 | assert array_item >= 0
166 |
167 | self.array_item = array_item
168 |
169 | super(CaptureLayerPreInput, self).__init__(device, post_process=None)
170 |
171 | def __call__(self, m, i):
172 |
173 | if self.device is None or self.device == o.device:
174 |
175 | if self.array_item is None:
176 | self.data = [n.data for n in i]
177 | else:
178 | self.data = i.data[self.array_item]
179 |
180 | # *******************************************************************************************************************
181 | class CaptureGradInput(CaptureLayerData):
182 |
183 | def __init__(self, device=None, post_process=detach):
184 |
185 | super(CaptureGradInput, self).__init__(device, post_process)
186 |
187 | def __call__(self, m, i, o):
188 |
189 | if self.device is None or self.device == i[0].device:
190 |
191 | # i seems to usualy be size 1
192 |
193 | if self.post_process is None:
194 | self.data = i[0]
195 | else:
196 | self.data = self.post_process(i[0])
197 |
198 | # *******************************************************************************************************************
199 | # *******************************************************************************************************************
200 | def LoadImageToTensor(file_name, device, norm=True, conv=cv2.COLOR_BGR2RGB,
201 | mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225],
202 | cv_process_list=[],pt_process_list=[]):
203 |
204 | assert isinstance(file_name,str)
205 | assert isinstance(device,torch.device)
206 |
207 | toTensor = transforms.ToTensor()
208 | toNorm = transforms.Normalize(mean,std)
209 |
210 | cv_im = cv2.imread(file_name)
211 | assert(cv_im is not None)
212 |
213 | for l in cv_process_list:
214 | cv_im = l(cv_im)
215 |
216 | cv_im = (cv2.cvtColor(cv_im, conv) / 255.0).astype(np.float32) # Put in a float image and range from 0 to 1
217 | pt_im = toTensor(cv_im)
218 |
219 | for l in pt_process_list:
220 | pt_im = l(pt_im)
221 |
222 | if norm:
223 | pt_im = toNorm(pt_im) # Do mean subtraction and divide by std. Then convert to Tensor object.
224 |
225 | pt_im = pt_im.reshape(1, 3, pt_im.size()[1], pt_im.size()[2]) # Add an extra dimension so now its 4D
226 | pt_im = pt_im.to(device) # Send to the GPU
227 |
228 | return pt_im
229 |
230 | # *******************************************************************************************************************
231 | def SaveGrayTensorToImage(tens, file_name):
232 |
233 | assert isinstance(file_name,str)
234 | assert torch.is_tensor(tens)
235 | assert len(tens.size()) == 3 or len(tens.size()) == 4
236 |
237 | if len(tens.size()) == 4:
238 | sz = tens.size()
239 | assert(sz[0] == 1)
240 | assert(sz[1] == 1)
241 | tens = tens.reshape(sz[1],sz[2],sz[3])
242 |
243 | np_tens = tens.cpu().detach().numpy() # Put the tensor into a cpu numpy
244 | np_tens = np_tens.transpose(1, 2, 0) # Transpose to [height x width x channels]
245 | np_tens = cv2.cvtColor(np_tens, cv2.COLOR_GRAY2BGR) # Convert gray to BGR color
246 | np_tens = (np_tens*255.0).astype(np.uint8) # Make it range from 0 to 255 and convert to byte
247 |
248 | cv2.imwrite(file_name,np_tens)
249 |
250 | # *******************************************************************************************************************
251 | def SaveColorTensorToImage(tens, file_name):
252 |
253 | assert isinstance(file_name,str)
254 | assert torch.is_tensor(tens)
255 | assert len(tens.size()) == 3 or len(tens.size()) == 4
256 |
257 | if len(tens.size()) == 4:
258 | sz = tens.size()
259 | assert sz[0] == 1
260 | assert sz[1] == 3
261 | tens = tens.reshape(sz[1],sz[2],sz[3])
262 |
263 | np_tens = tens.cpu().detach().numpy() # Put the tensor into a cpu numpy
264 | np_tens = np_tens.transpose(1, 2, 0) # Transpose to [height x width x channels]
265 | np_tens = cv2.cvtColor(np_tens, cv2.COLOR_RGB2BGR) # Convert gray to BGR color
266 | np_tens = (np_tens*255.0).astype(np.uint8) # Make it range from 0 to 255 and convert to byte
267 |
268 | cv2.imwrite(file_name,np_tens)
269 |
270 | # *******************************************************************************************************************
271 | def SaveGrayNumpyToImage(np_im, file_name):
272 |
273 | assert isinstance(file_name,str)
274 | assert isinstance(np_im, np.ndarray)
275 | assert len(np_im.shape) == 2
276 |
277 | np_im = cv2.cvtColor(np_im, cv2.COLOR_GRAY2BGR) # Convert gray to BGR color
278 | np_im = (np_im*255.0).astype(np.uint8) # Make it range from 0 to 255 and convert to byte
279 |
280 | cv2.imwrite(file_name, np_im) # Save the image
281 |
282 | # *******************************************************************************************************************
283 | def TensorToNumpyImages(tens):
284 |
285 | assert torch.is_tensor(tens)
286 | assert len(tens.size()) == 3 or len(tens.size()) == 4
287 |
288 | np_im = tens.cpu().detach().numpy() # Now we get the individual saliency maps to save
289 |
290 | if len(tens.size()) == 4:
291 | assert(tens.size()[0] == 1)
292 | np_im = np_im.transpose(0, 2, 3, 1) # Transpose to [batch x height x width x channels]
293 | np_im = np_im.reshape(np_im.shape[1],np_im.shape[2],np_im.shape[3]) # Chop off the extra dimension since our batch size is 1
294 | else:
295 | np_im = np_im.transpose(1, 2, 0)
296 |
297 | return np_im
298 |
299 | # *******************************************************************************************************************
300 | def NumpyToTensorImages(np_im, device='cpu'):
301 |
302 | assert isinstance(np_im, np.ndarray)
303 | assert len(np_im.shape) == 3 or len(np_im.shape) == 4
304 |
305 | toTensor = transforms.ToTensor()
306 |
307 | pt_im = toTensor(np_im)
308 | pt_im = pt_im.to(device) # Send to the device
309 |
310 | return pt_im
311 |
312 | # *******************************************************************************************************************
313 | def AlphaBlend(im1, im2, alpha=0.75):
314 |
315 | assert isinstance(im1,np.ndarray) or torch.is_tensor(im1)
316 | assert isinstance(im2,np.ndarray) or torch.is_tensor(im2)
317 | assert type(im1) == type(im2)
318 | assert isinstance(alpha,float)
319 |
320 | t_alpha = alpha
321 | r_alpha = 1.0
322 | norm = t_alpha + r_alpha*(1.0 - t_alpha)
323 |
324 | return (im1*t_alpha + im2*r_alpha*(1.0 - t_alpha))/norm
325 |
326 | # *******************************************************************************************************************
327 | def AlphaMask(im1, mask, alpha=1.0):
328 |
329 | assert isinstance(im1,np.ndarray) or torch.is_tensor(im1)
330 | assert isinstance(mask,np.ndarray) or torch.is_tensor(mask)
331 | assert type(im1) == type(mask)
332 | assert isinstance(alpha,float)
333 |
334 | if isinstance(im1,np.ndarray):
335 | im2 = np.zeros_like(im1)
336 | else:
337 | im2 = torch.zeros_like(im1)
338 |
339 | t_alpha = mask
340 | r_alpha = alpha
341 | norm = t_alpha + r_alpha*(1.0 - t_alpha)
342 |
343 | return (im1*t_alpha + im2*r_alpha*(1.0 - t_alpha))/norm
344 |
345 |
346 | # *******************************************************************************************************************
347 | def AttenuateBorders(im, ammount=[0.333,0.666]):
348 |
349 | assert isinstance(im,np.ndarray) or torch.is_tensor(im)
350 | assert isinstance(ammount,list)
351 |
352 | im[:,0,:] = im[:,0,:] * ammount[0]
353 | im[:,:,0] = im[:,:,0] * ammount[0]
354 | im[:,-1,:] = im[:,-1,:] * ammount[0]
355 | im[:,:,-1] = im[:,:,-1] * ammount[0]
356 |
357 | im[:,1,1:-2] = im[:,1,1:-2] * ammount[1]
358 | im[:,1:-2,1] = im[:,1:-2,1] * ammount[1]
359 | im[:,-2,1:-2] = im[:,-2,1:-2] * ammount[1]
360 | im[:,1:-2,-2] = im[:,1:-2,-2] * ammount[1]
361 |
362 | return im
363 |
364 | # *******************************************************************************************************************
365 | def RangeNormalize(im):
366 |
367 | assert torch.is_tensor(im)
368 |
369 | imax = torch.max(im)
370 | imin = torch.min(im)
371 | rng = imax - imin
372 |
373 | if rng != 0:
374 | return (im - imin)/rng
375 | else:
376 | return im
377 |
378 | # *******************************************************************************************************************
379 | def TileOutput(tensor, mask, mask_func, image_list = []):
380 |
381 | assert torch.is_tensor(tensor)
382 | assert torch.is_tensor(mask)
383 | assert isinstance(image_list,list)
384 | assert callable(mask_func)
385 |
386 | heatmap, result = visualize_cam(mask, tensor)
387 |
388 | hard_masked,_ = mask_func(tensor, mask)
389 | hard_masked = hard_masked.squeeze(0)
390 | masked = AlphaMask(tensor, mask).squeeze(0)
391 | masked = RangeNormalize(masked)
392 |
393 | image_list.append(torch.stack([tensor.squeeze().cpu(), heatmap.cpu(),
394 | result.cpu(), masked.cpu(), hard_masked.cpu()], 0))
395 |
396 | return image_list
397 |
398 | # *******************************************************************************************************************
399 | def TileMaps(tensor, mask_1, mask_2, mask_3, image_list = []):
400 |
401 | assert torch.is_tensor(tensor)
402 | assert torch.is_tensor(mask_1)
403 | assert torch.is_tensor(mask_2)
404 | assert torch.is_tensor(mask_3)
405 |
406 | heatmap_1, _ = visualize_cam(mask_1, tensor)
407 | heatmap_2, _ = visualize_cam(mask_2, tensor)
408 | heatmap_3, _ = visualize_cam(mask_3, tensor)
409 |
410 | image_list.append(torch.stack([tensor.squeeze().cpu(), heatmap_1.cpu(),
411 | heatmap_2.cpu(), heatmap_3.cpu()], 0))
412 |
413 | return image_list
414 |
415 | # *******************************************************************************************************************
416 | def show_hist(tens,file_name=None, max_range=256):
417 |
418 |
419 | '''
420 | Create histogram of pixel values and display.
421 | '''
422 |
423 | tens = RangeNormalize(tens) * float(max_range)
424 |
425 | img = tens.cpu().detach().numpy()
426 |
427 | hist,bins = np.histogram(img.flatten(),max_range,[0,max_range])
428 | cdf = hist.cumsum()
429 | cdf_normalized = cdf * float(hist.max()) / cdf.max()
430 | plt.plot(cdf_normalized, color = 'b')
431 | plt.hist(img.flatten(),max_range,[0,max_range], color = 'r')
432 | plt.xlim([0,max_range])
433 | plt.legend(('cdf','histogram'), loc = 'upper left')
434 |
435 | if file_name is not None:
436 | plt.savefig(file_name)
437 |
438 | plt.show()
439 |
440 | # *******************************************************************************************************************
441 | class DeNormalize:
442 |
443 | def __init__(self,mean,std):
444 |
445 | assert isinstance(mean,list)
446 | assert isinstance(std,list)
447 |
448 | assert len(mean) == 3
449 | assert len(std) == 3
450 |
451 | self.mean = torch.tensor(mean).reshape(1,len(mean),1)
452 | self.std = torch.tensor(std).reshape(1,len(std),1)
453 |
454 |
455 | def __call__(self, tens):
456 |
457 | assert torch.is_tensor(tens)
458 | assert len(tens.size()) == 4
459 |
460 | if tens.device != self.std.device:
461 | self.std = self.std.to(tens.device)
462 |
463 | if tens.device != self.mean.device:
464 | self.mean = self.mean.to(tens.device)
465 |
466 | sz = tens.size()
467 |
468 | tens = tens.reshape(sz[0],sz[1],sz[2]*sz[3])
469 | tens = tens*self.std + self.mean
470 | tens = tens.reshape(sz[0],sz[1],sz[2],sz[3])
471 |
472 | return tens
473 |
474 | # *******************************************************************************************************************
475 | class SmoothGrad:
476 |
477 | def __init__(self, iters=15, magnitude=True, stdev_spread=.15, maps_magnitude=False):
478 |
479 | self.iters = iters
480 | self.magnitude = magnitude
481 | self.stdev_spread = stdev_spread
482 |
483 | self.getSmap = maps.SMOEScaleMap()
484 | self.getNorm = maps.GaussNorm2D()
485 | self.maps_magnitude = maps_magnitude
486 |
487 |
488 | def __call__(self, in_tensor, model, hooks, weights, debug=False):
489 |
490 | in_height = in_tensor.size()[2]
491 | in_width = in_tensor.size()[3]
492 | map_num = len(hooks)
493 |
494 | getCsmap = maps.CombineSaliencyMaps(output_size=[in_height,in_width],
495 | map_num=map_num, weights=weights, resize_mode='bilinear',magnitude=self.maps_magnitude)
496 |
497 | stdev = self.stdev_spread * (torch.max(in_tensor) - torch.min(in_tensor))
498 |
499 | ret_image = []
500 |
501 | if debug:
502 | out_csmap = []
503 | out_smaps = []
504 | else:
505 | out_csmap = torch.zeros((1, in_height, in_width), dtype=in_tensor.dtype, device=in_tensor.device)
506 | out_smaps = torch.zeros((1, map_num, in_height, in_width), dtype=in_tensor.dtype, device=in_tensor.device)
507 |
508 | for i in range(self.iters):
509 |
510 | noise = torch.normal(mean=0, std=stdev, size=in_tensor.size())
511 | in_tensor_noise = in_tensor + noise
512 |
513 | model.eval()
514 |
515 | with torch.set_grad_enabled(False):
516 | _ = model(in_tensor_noise)
517 |
518 | smaps = [ self.getNorm(self.getSmap(x.data)) for x in hooks ]
519 | csmap,smaps = getCsmap(smaps)
520 |
521 | if debug:
522 | out_csmap.append(csmap)
523 | out_smaps.append(smaps)
524 | ret_image.append(in_tensor_noise)
525 | else:
526 | if self.magnitude:
527 | out_csmap += (csmap * csmap)
528 | out_smaps += (smaps * smaps)
529 | else:
530 | out_csmap += csmap
531 | out_smaps += smaps
532 |
533 | if not debug:
534 | out_csmap /= self.iters
535 | out_smaps /= self.iters
536 |
537 | return out_csmap, out_smaps, ret_image
538 |
--------------------------------------------------------------------------------
/maps.py:
--------------------------------------------------------------------------------
1 | '''
2 | BSD 3-Clause License
3 |
4 | Copyright (c) 2020, Lawrence Livermore National Laboratory
5 | All rights reserved.
6 |
7 | Redistribution and use in source and binary forms, with or without
8 | modification, are permitted provided that the following conditions are met:
9 |
10 | 1. Redistributions of source code must retain the above copyright notice, this
11 | list of conditions and the following disclaimer.
12 |
13 | 2. Redistributions in binary form must reproduce the above copyright notice,
14 | this list of conditions and the following disclaimer in the documentation
15 | and/or other materials provided with the distribution.
16 |
17 | 3. Neither the name of the copyright holder nor the names of its
18 | contributors may be used to endorse or promote products derived from
19 | this software without specific prior written permission.
20 |
21 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
31 | '''
32 |
33 | '''
34 | https://github.com/LLNL/fastcam
35 |
36 | A toolkit for efficent computation of saliency maps for explainable
37 | AI attribution.
38 |
39 | This work was performed under the auspices of the U.S. Department of Energy
40 | by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344
41 | and was supported by the LLNL-LDRD Program under Project 18-ERD-021 and
42 | Project 17-SI-003.
43 |
44 | Software released as LLNL-CODE-802426.
45 |
46 | See also: https://arxiv.org/abs/1911.11293
47 | '''
48 |
49 | from collections import OrderedDict
50 | import math
51 |
52 | import torch
53 | import torch.nn as nn
54 | import torch.nn.functional as F
55 |
56 | # A little hacky but this fixes something special
57 | try:
58 | from . import norm
59 | from . import misc
60 | from . import resnet
61 | except ImportError:
62 | import norm
63 | import misc
64 | import resnet
65 |
66 |
67 |
68 | # *******************************************************************************************************************
69 | class SMOEScaleMap(nn.Module):
70 | r'''
71 | Compute SMOE Scale on a 4D tensor. This acts as a standard PyTorch layer.
72 |
73 | SMOE Scale is computed independantly for each batch item at each location x,y
74 |
75 | Input should be:
76 |
77 | (1) A tensor of size [batch x channels x height x width]
78 | (2) A tensor with only positive values. (After a ReLU)
79 |
80 | Output is a 3D tensor of size [batch x height x width]
81 | '''
82 | def __init__(self, run_relu=False):
83 |
84 | super(SMOEScaleMap, self).__init__()
85 |
86 | r'''
87 | SMOE Scale must take in values > 0. Optionally, we can run a ReLU to do that.
88 | '''
89 | if run_relu:
90 | self.relu = nn.ReLU(inplace=False)
91 | else:
92 | self.relu = None
93 |
94 | def forward(self, x):
95 |
96 | assert torch.is_tensor(x), "input must be a Torch Tensor"
97 | assert len(x.size()) > 2, "input must have at least three dims"
98 |
99 |
100 | r'''
101 | If we do not have a convenient ReLU to pluck from, we can do it here
102 | '''
103 | if self.relu is not None:
104 | x = self.relu(x)
105 |
106 | r'''
107 | avoid log(0)
108 | '''
109 | x = x + 0.0000001
110 |
111 | r'''
112 | This is one form. We can also use the log only form.
113 | '''
114 | m = torch.mean(x,dim=1)
115 | k = torch.log2(m) - torch.mean(torch.log2(x), dim=1)
116 |
117 | th = k * m
118 |
119 | return th
120 |
121 | # *******************************************************************************************************************
122 | class StdMap(nn.Module):
123 | r'''
124 | Compute vanilla standard deviation on a 4D tensor. This acts as a standard PyTorch layer.
125 |
126 | Standard Deviation is computed independantly for each batch item at each location x,y
127 |
128 | Input should be:
129 |
130 | (1) A tensor of size [batch x channels x height x width]
131 | (2) Recommend a tensor with only positive values. (After a ReLU)
132 | Any real value will work.
133 |
134 | Output is a 3D tensor of size [batch x height x width]
135 | '''
136 | def __init__(self):
137 |
138 | super(StdMap, self).__init__()
139 |
140 | def forward(self, x):
141 |
142 | assert torch.is_tensor(x), "input must be a Torch Tensor"
143 | assert len(x.size()) > 2, "input must have at least three dims"
144 |
145 | x = torch.std(x,dim=1)
146 |
147 | return x
148 |
149 | # *******************************************************************************************************************
150 | class MeanMap(nn.Module):
151 | r'''
152 | Compute vanilla mean on a 4D tensor. This acts as a standard PyTorch layer.
153 |
154 | The Mean is computed independantly for each batch item at each location x,y
155 |
156 | Input should be:
157 |
158 | (1) A tensor of size [batch x channels x height x width]
159 | (2) Recommend a tensor with only positive values. (After a ReLU)
160 | Any real value will work.
161 |
162 | Output is a 3D tensor of size [batch x height x width]
163 | '''
164 | def __init__(self):
165 |
166 | super(MeanMap, self).__init__()
167 |
168 | def forward(self, x):
169 |
170 | assert torch.is_tensor(x), "input must be a Torch Tensor"
171 | assert len(x.size()) > 2, "input must have at least three dims"
172 |
173 | x = torch.mean(x,dim=1)
174 |
175 | return x
176 |
177 | # *******************************************************************************************************************
178 | class MaxMap(nn.Module):
179 | r'''
180 | Compute vanilla mean on a 4D tensor. This acts as a standard PyTorch layer.
181 |
182 | The Max is computed independantly for each batch item at each location x,y
183 |
184 | Input should be:
185 |
186 | (1) A tensor of size [batch x channels x height x width]
187 | (2) Recommend a tensor with only positive values. (After a ReLU)
188 | Any real value will work.
189 |
190 | Output is a 3D tensor of size [batch x height x width]
191 | '''
192 | def __init__(self):
193 |
194 | super(MaxMap, self).__init__()
195 |
196 | def forward(self, x):
197 |
198 | assert torch.is_tensor(x), "input must be a Torch Tensor"
199 | assert len(x.size()) > 2, "input must have at least three dims"
200 |
201 | x = torch.max(x,dim=1)[0]
202 |
203 | return x
204 |
205 | # *******************************************************************************************************************
206 | class TruncNormalEntMap(nn.Module):
207 | r'''
208 | Compute truncated normal entropy on a 4D tensor. This acts as a standard PyTorch layer.
209 |
210 | Truncated Normal Entropy is computed independantly for each batch item at each location x,y
211 |
212 | Input should be:
213 |
214 | (1) A tensor of size [batch x channels x height x width]
215 | (2) This should come BEFORE a ReLU and can range over any real value.
216 | Ideally it should have both positive and negative values.
217 |
218 | Output is a 3D tensor of size [batch x height x width]
219 | '''
220 | def __init__(self):
221 |
222 | super(TruncNormalEntMap, self).__init__()
223 |
224 | self.c1 = torch.tensor(0.3989422804014327) # 1.0/math.sqrt(2.0*math.pi)
225 | self.c2 = torch.tensor(1.4142135623730951) # math.sqrt(2.0)
226 | self.c3 = torch.tensor(4.1327313541224930) # math.sqrt(2.0*math.pi*math.exp(1))
227 |
228 | def _compute_alpha(self, mean, std, a=0):
229 |
230 | alpha = (a - mean)/std
231 |
232 | return alpha
233 |
234 | def _compute_pdf(self, eta):
235 |
236 | pdf = self.c1 * torch.exp(-0.5*eta.pow(2.0))
237 |
238 | return pdf
239 |
240 | def _compute_cdf(self, eta):
241 |
242 | e = torch.erf(eta/self.c2)
243 | cdf = 0.5 * (1.0 + e)
244 |
245 | return cdf
246 |
247 | def forward(self, x):
248 |
249 | assert torch.is_tensor(x), "input must be a Torch Tensor"
250 | assert len(x.size()) > 2, "input must have at least three dims"
251 |
252 | m = torch.mean(x, dim=1)
253 | s = torch.std(x, dim=1)
254 | a = self._compute_alpha(m, s)
255 | pdf = self._compute_pdf(a)
256 | cdf = self._compute_cdf(a) + 0.0000001 # Prevent log AND division by zero by adding a very small number
257 | Z = 1.0 - cdf
258 | T1 = torch.log(self.c3*s*Z)
259 | T2 = (a*pdf)/(2.0*Z)
260 | ent = T1 + T2
261 |
262 | return ent
263 |
264 | # *******************************************************************************************************************
265 | class GammaScaleMap(nn.Module):
266 | r'''
267 | Compute Gamma Scale on a 4D tensor (The hard way). This acts as a standard PyTorch layer.
268 |
269 | Gamma Scale is computed independantly for each batch item at each location x,y
270 |
271 | Input should be:
272 |
273 | (1) A tensor of size [batch x channels x height x width]
274 | (2) A tensor with only positive values. (After a ReLU)
275 |
276 | Output is a 3D tensor of size [batch x height x width]
277 | '''
278 | def __init__(self, run_relu=False):
279 |
280 | super(GammaScaleMap, self).__init__()
281 |
282 | r'''
283 | SMOE Scale must take in values > 0. Optionally, we can run a ReLU to do that.
284 | '''
285 | if run_relu:
286 | self.relu = nn.ReLU(inplace=False)
287 | else:
288 | self.relu = None
289 |
290 | def _trigamma(self, x):
291 |
292 | r'''
293 | We need this line since recursion is not good for x < 1.0
294 | Note that we take + torch.reciprocal(x.pow(2)) at the end because:
295 |
296 | trigamma(z) = trigamma(z + 1) + 1/z^2
297 |
298 | '''
299 | z = x + 1.0
300 |
301 | zz = z.pow(2)
302 | a = 0.2 - torch.reciprocal(7.0*zz)
303 | b = 1.0 - a/zz
304 | c = 1.0 + b/(3.0 * z)
305 | d = 1.0 + c/(2.0 * z)
306 | e = d/z
307 |
308 | e = e + torch.reciprocal(x.pow(2.0))
309 |
310 | return e
311 |
312 | def _k_update(self,k,s):
313 |
314 | nm = torch.log(k) - torch.digamma(k) - s
315 | dn = torch.reciprocal(k) - self._trigamma(k)
316 | k2 = k - nm/dn
317 |
318 | return k2
319 |
320 | def _compute_k_est(self, x, i=10, dim=1):
321 |
322 | r'''
323 | Calculate s
324 | '''
325 | s = torch.log(torch.mean(x,dim=dim)) - torch.mean(torch.log(x),dim=dim)
326 |
327 | r'''
328 | Get estimate of k to within 1.5%
329 |
330 | NOTE: K gets smaller as log variance s increases
331 | '''
332 | s3 = s - 3.0
333 | rt = torch.sqrt(s3.pow(2) + 24.0 * s)
334 | nm = 3.0 - s + rt
335 | dn = 12.0 * s
336 | k = nm / dn + 0.0000001
337 |
338 | r'''
339 | Do i Newton-Raphson steps to get closer than 1.5%
340 | For i=5 gets us within 4 or 5 decimal places
341 | '''
342 | for _ in range(i):
343 | k = self._k_update(k,s)
344 |
345 | return k
346 |
347 | def forward(self, x):
348 |
349 | assert torch.is_tensor(x), "input must be a Torch Tensor"
350 | assert len(x.size()) > 2, "input must have at least three dims"
351 |
352 | r'''
353 | If we do not have a convenient ReLU to pluck from, we can do it here
354 | '''
355 | if self.relu is not None:
356 | x = self.relu(x)
357 |
358 | r'''
359 | avoid log(0)
360 | '''
361 | x = x + 0.0000001
362 |
363 | k = self._compute_k_est(x)
364 |
365 | th = torch.reciprocal(k) * torch.mean(x,dim=1)
366 |
367 | return th
368 |
369 | # *******************************************************************************************************************
370 | # *******************************************************************************************************************
371 | class CombineSaliencyMaps(nn.Module):
372 | r'''
373 | This will combine saliency maps into a single weighted saliency map.
374 |
375 | Input will be a list of 3D tensors or various sizes.
376 | Output is a 3D tensor of size batch size x output_size. We also return the individual saliency maps resized. to output_size
377 |
378 | Parameters:
379 |
380 | output_size: A list that contains the height and width of the output saliency maps.
381 | num_maps: Specifies how many maps we will combine.
382 | weights: Is an optional list of weights for each layer e.g. [1, 2, 3, 4, 5].
383 | resize_mode: Is given to Torch nn.functional.interpolate. Whatever it supports will work here.
384 | do_relu: Should we do a final clamp on values to set all negative values to 0?
385 |
386 | Will Return:
387 |
388 | cm: The combined saliency map over all layers sized batch size x output_size
389 | ww: Each individual saliency maps sized output_size. Note that we do not weight these outputs.
390 | '''
391 |
392 | def __init__(self, output_size=[224,224], map_num=5, weights=None, resize_mode='bilinear', do_relu=False):
393 |
394 | super(CombineSaliencyMaps, self).__init__()
395 |
396 | assert isinstance(output_size,list), "Output size should be a list (e.g. [224,224])."
397 | assert isinstance(map_num,int), "Number of maps should be a positive integer > 0"
398 | assert isinstance(resize_mode,str), "Resize mode is a string recognized by Torch nn.functional.interpolate (e.g. 'bilinear')."
399 | assert len(output_size) == 2, "Output size should be a list (e.g. [224,224])."
400 | assert output_size[0] > 0, "Output size should be a list (e.g. [224,224])."
401 | assert output_size[1] > 0, "Output size should be a list (e.g. [224,224])."
402 | assert map_num > 0, "Number of maps should be a positive integer > 0"
403 |
404 | r'''
405 | We support weights being None, a scaler or a list.
406 |
407 | Depending on which one, we create a list or just point to one.
408 | '''
409 | if weights is None:
410 | self.weights = [1.0 for _ in range(map_num)]
411 | elif len(weights) == 1:
412 | assert weights > 0
413 | self.weights = [weights for _ in range(map_num)]
414 | else:
415 | assert len(weights) == map_num
416 | self.weights = weights
417 |
418 | self.weight_sum = 0
419 |
420 | for w in self.weights:
421 | self.weight_sum += w
422 |
423 | self.map_num = map_num
424 | self.output_size = output_size
425 | self.resize_mode = resize_mode
426 | self.do_relu = do_relu
427 |
428 | def forward(self, smaps):
429 |
430 | r'''
431 | Input shapes are something like [64,7,7] i.e. [batch size x layer_height x layer_width]
432 | Output shape is something like [64,224,244] i.e. [batch size x image_height x image_width]
433 | '''
434 |
435 | assert isinstance(smaps,list), "Saliency maps must be in a list"
436 | assert len(smaps) == self.map_num, "List length is not the same as predefined length"
437 | assert len(smaps[0].size()) == 3, "Each saliency map must be 3D, [batch size x layer_height x layer_width]"
438 |
439 | bn = smaps[0].size()[0]
440 | cm = torch.zeros((bn, 1, self.output_size[0], self.output_size[1]), dtype=smaps[0].dtype, device=smaps[0].device)
441 | ww = []
442 |
443 | r'''
444 | Now get each saliency map and resize it. Then store it and also create a combined saliency map.
445 | '''
446 | for i in range(len(smaps)):
447 | assert torch.is_tensor(smaps[i]), "Each saliency map must be a Torch Tensor."
448 | wsz = smaps[i].size()
449 | w = smaps[i].reshape(wsz[0], 1, wsz[1], wsz[2])
450 | w = nn.functional.interpolate(w, size=self.output_size, mode=self.resize_mode, align_corners=False)
451 |
452 | ww.append(w) # should we weight the raw maps ... hmmm
453 | cm += (w * self.weights[i])
454 |
455 | r'''
456 | Finish the combined saliency map to make it a weighted average.
457 | '''
458 | cm = cm / self.weight_sum
459 |
460 | cm = cm.reshape(bn, self.output_size[0], self.output_size[1])
461 |
462 | ww = torch.stack(ww,dim=1)
463 | ww = ww.reshape(bn, self.map_num, self.output_size[0], self.output_size[1])
464 |
465 | if self.do_relu:
466 | cm = F.relu(cm)
467 | ww = F.relu(ww)
468 |
469 | return cm, ww
470 |
471 | # *******************************************************************************************************************
472 | class SaliencyMap(object):
473 | r'''
474 | >>>Depricated<<<
475 |
476 | Given an input model and parameters, run the neural network and compute saliency maps for given images.
477 |
478 | input: input image with shape of (batch size, 3, H, W)
479 |
480 | Parameters:
481 |
482 | model: This should be a valid Torch neural network such as a ResNet.
483 | layers: A list of layers you wish to process given by name. If none, we can auto compute a selection.
484 | maps_method: How do we compute saliency for each activation map? Default: SMOEScaleMap
485 | norm_method: How do we post process normalize each saliency map? Default: norm.GaussNorm2D
486 | This can also be norm.GammaNorm2D or norm.RangeNorm2D.
487 | output_size: This is the standard 2D size for the saliency maps. Torch nn.functional.interpolate
488 | will be used to make each saliency map this size. Default [224,224]
489 | weights: The weight for each layer in the combined saliency map's weighted average.
490 | It should either be a list of floats or None.
491 | resize_mode: Is given to Torch nn.functional.interpolate. Whatever it supports will work here.
492 | do_relu: Should we do a final clamp on values to set all negative values to 0?
493 |
494 | Will Return:
495 |
496 | combined_map: [Batch x output height x output width] set of 2D saliency maps combined from each layer
497 | we compute from and combined with a CAM if we computed one.
498 | saliency_maps: A list [number of layers size] containing each saliency map [Batch x output height x output width].
499 | These will have been resized from their orginal layer size.
500 | logit: The output neural network logits.
501 |
502 | '''
503 | def __init__(self, model, layers, maps_method=SMOEScaleMap, norm_method=norm.GaussNorm2D,
504 | output_size=[224,224], weights=None, resize_mode='bilinear', do_relu=False, cam_method='gradcam',
505 | module_layer=None, expl_do_fast_cam=False, do_nonclass_map=False, cam_each_map=False):
506 |
507 | assert isinstance(layers, list) or layers is None, "Layers must be a list of layers or None"
508 | assert callable(maps_method), "Saliency map method must be a callable function or method."
509 | assert callable(norm_method), "Normalization method must be a callable function or method."
510 |
511 | self.get_smap = maps_method()
512 | self.get_norm = norm_method()
513 | self.model = model
514 |
515 | r'''
516 | This gives us access to more complex network modules than a standard ResNet if we need it.
517 | '''
518 | self.module_layer = model if module_layer is None else module_layer
519 |
520 | self.activation_hooks = []
521 |
522 | r'''
523 | Optionally, we can either define the layers we want or we can
524 | automatically pick all the ReLU layers.
525 | '''
526 | if layers is None:
527 | assert weights is None, "If we auto select layers, we should auto compute weights too."
528 | r'''
529 | Pick all the ReLU layers. Set weights to 1 since the number of ReLUs is proportional
530 | to how high up we are in the resulotion pyramid.
531 |
532 | For each we attach a hook to get the layer activations back after the
533 | network runs the data.
534 |
535 | NOTE: This is quantitativly untested. There are no ROAR/KARR scores yet.
536 | '''
537 | self.layers = []
538 | weights = []
539 | for m in self.module_layer.modules():
540 | if isinstance(m, nn.ReLU): # Maybe allow a user defined layer (e.g. nn.Conv)
541 | h = misc.CaptureLayerOutput(post_process=None)
542 | _ = m.register_forward_hook(h)
543 | self.activation_hooks.append(h)
544 | weights.append(1.0) # Maybe replace with a weight function
545 | self.layers.append(None)
546 | else:
547 | r'''
548 | User defined layers.
549 |
550 | For each we attach a hook to get the layer activations back after the
551 | network runs the data.
552 | '''
553 | self.layers = layers
554 | for i,l in enumerate(layers):
555 | h = misc.CaptureLayerOutput(post_process=None)
556 | _ = self.module_layer._modules[l].register_forward_hook(h)
557 | self.activation_hooks.append(h)
558 |
559 | r'''
560 | This object will be used to combine all the saliency maps together after we compute them.
561 | '''
562 | self.combine_maps = CombineSaliencyMaps(output_size=output_size, map_num=len(weights), weights=weights,
563 | resize_mode=resize_mode, do_relu=do_relu)
564 |
565 | r'''
566 | Are we also computing the CAM map?
567 | '''
568 | if isinstance(model,resnet.ResNet_FastCAM) or expl_do_fast_cam:
569 | self.do_fast_cam = True
570 | self.do_nonclass_map = do_nonclass_map
571 | self.cam_method = cam_method
572 | self.cam_each_map = cam_each_map
573 | else:
574 | self.do_fast_cam = False
575 | self.do_nonclass_map = None
576 | self.cam_method = None
577 | self.cam_each_map = None
578 |
579 | def __call__(self, input, grad_enabled=False):
580 | """
581 | Args:
582 | input: input image with shape of (B, 3, H, W)
583 | grad_enabled: Set this to true if you need to compute grads when running the network. For instance, while training.
584 |
585 | Return:
586 | combined_map: [Batch x output height x output width] set of 2D saliency maps combined from each layer
587 | we compute from and combined with a CAM if we computed one.
588 | saliency_maps: A list [number of layers size] containing each saliency map [Batch x output height x output width].
589 | These will have been resized from their orginal layer size.
590 | logit: The output neural network logits.
591 | """
592 |
593 | r'''
594 | Don't compute grads if we do not need them. Cuts network compute time way down.
595 | '''
596 | with torch.set_grad_enabled(grad_enabled):
597 |
598 | r'''
599 | Get the size, but we support lists here for certain special cases.
600 | '''
601 | b, c, h, w = input[0].size() if isinstance(input,list) else input.size()
602 |
603 |
604 | self.model.eval()
605 |
606 | if self.do_fast_cam:
607 | logit,cam_map = self.model(input,method=self.cam_method)
608 | else:
609 | logit = self.model(input)
610 |
611 | saliency_maps = []
612 |
613 | r'''
614 | Get the activation for each layer in our list. Then compute saliency and normalize.
615 | '''
616 | for i,l in enumerate(self.layers):
617 |
618 | activations = self.activation_hooks[i].data
619 | b, k, u, v = activations.size()
620 | activations = F.relu(activations)
621 | saliency_map = self.get_norm(self.get_smap(activations)).view(b, u, v)
622 |
623 | saliency_maps.append(saliency_map)
624 |
625 | r'''
626 | Combine each saliency map together into a single 2D saliency map.
627 | '''
628 | combined_map, saliency_maps = self.combine_maps(saliency_maps)
629 |
630 | r'''
631 | If we computed a CAM, combine it with the forward only saliency map.
632 | '''
633 | if self.do_fast_cam:
634 | if self.do_nonclass_map:
635 | combined_map = combined_map*(1.0 - cam_map)
636 | if self.cam_each_map:
637 | saliency_maps = saliency_maps.squeeze(0)
638 | saliency_maps = saliency_maps*(1.0 - cam_map)
639 | saliency_maps = saliency_maps.unsqueeze(0)
640 | else:
641 | combined_map = combined_map * cam_map
642 |
643 | if self.cam_each_map:
644 | saliency_maps = saliency_maps.squeeze(0)
645 | saliency_maps = saliency_maps*cam_map
646 | saliency_maps = saliency_maps.unsqueeze(0)
647 |
648 |
649 | return combined_map, saliency_maps, logit
650 |
651 | # *******************************************************************************************************************
652 | # *******************************************************************************************************************
653 | class SaliencyVector(SaliencyMap):
654 | r'''
655 | Given an input model and parameters, run the neural network and compute saliency maps for given images.
656 |
657 | input: input image with shape of (batch size, 3, H, W)
658 |
659 | Parameters:
660 |
661 | model: This should be a valid Torch neural network such as a ResNet.
662 | layers: A list of layers you wish to process given by name. If none, we can auto compute a selection.
663 | maps_method: How do we compute saliency for each activation map? Default: SMOEScaleMap
664 | norm_method: How do we post process normalize each saliency map? Default: norm.GaussNorm2D
665 | This can also be norm.GammaNorm2D or norm.RangeNorm2D.
666 | output_size: This is the standard 2D size for the saliency maps. Torch nn.functional.interpolate
667 | will be used to make each saliency map this size. Default [224,224]
668 | weights: The weight for each layer in the combined saliency map's weighted average.
669 | It should either be a list of floats or None.
670 | resize_mode: Is given to Torch nn.functional.interpolate. Whatever it supports will work here.
671 | do_relu: Should we do a final clamp on values to set all negative values to 0?
672 |
673 | Will Return:
674 |
675 | combined_map: [Batch x output height x output width] set of 2D saliency maps combined from each layer
676 | we compute from and combined with a CAM if we computed one.
677 | saliency_maps: A list [number of layers size] containing each saliency map [Batch x output height x output width].
678 | These will have been resized from their orginal layer size.
679 | logit: The output neural network logits.
680 | sal_location: A tuple of x,y locations which are the most salienct in each image.
681 | feature_vecs: List of salient feature vectors. Each list item is assocaited with each layer in the layers argument.
682 |
683 | '''
684 | def __init__(self, model, layers, **kwargs):
685 |
686 | super(SaliencyVector, self).__init__(model, layers, **kwargs)
687 |
688 | def __call__(self, input, grad_enabled=False):
689 |
690 | """
691 | Args:
692 | input: input image with shape of (B, 3, H, W)
693 | grad_enabled: Set this to true if you need to compute grads when running the network. For instance, while training.
694 |
695 | Return:
696 | combined_map: [Batch x output height x output width] set of 2D saliency maps combined from each layer
697 | we compute from and combined with a CAM if we computed one.
698 | saliency_maps: A list [number of layers size] containing each saliency map [Batch x output height x output width].
699 | These will have been resized from their orginal layer size.
700 | logit: The output neural network logits.
701 | sal_location: A tuple of x,y locations which are the most salienct in each image.
702 | feature_vecs: List of salient feature vectors. Each list item is assocaited with each layer in the layers argument.
703 | """
704 |
705 | r'''
706 | Call the base __call__ method from the base class first to get saliency maps.
707 | '''
708 | combined_map, saliency_maps, logit = super(SaliencyVector, self).__call__(input, grad_enabled)
709 |
710 | sz = combined_map.size()
711 |
712 | combined_map = combined_map.reshape(sz[0],sz[1]*sz[2])
713 |
714 | r'''
715 | Get the location x,y expressed as one vector.
716 | '''
717 | sal_loc = torch.argmax(combined_map,dim=1)
718 |
719 | r'''
720 | Get the actual location by offseting the y place size.
721 | '''
722 | sal_y = sal_loc//sz[1]
723 | sal_x = sal_loc%sz[1]
724 |
725 | r'''
726 | Get each activation layer again from the layer hooks.
727 | '''
728 | feature_vecs = []
729 | for i,l in enumerate(self.layers):
730 |
731 | activations = self.activation_hooks[i].data
732 | b, k, v, u = activations.size() # Note: v->y and u->x
733 |
734 | r'''
735 | Compute new x,y location based on the layers size.
736 | '''
737 | loc_x = math.floor((v/sz[2])*float(sal_x))
738 | loc_y = math.floor((u/sz[1])*float(sal_y))
739 | loc = loc_y*u + loc_x
740 |
741 | r'''
742 | Get feature vectors k at location loc from all batches b.
743 | '''
744 | feature_vecs.append(activations.permute(0,2,3,1).reshape(b,v*u,k)[:,loc,:])
745 |
746 | combined_map = combined_map.reshape(sz[0],sz[1],sz[2])
747 | sal_location = (sal_x,sal_y)
748 |
749 | return combined_map, saliency_maps, logit, sal_location, feature_vecs
750 |
751 | # *******************************************************************************************************************
752 | # *******************************************************************************************************************
753 | class SaliencyModel(nn.Module):
754 | r'''
755 | Given an input model and parameters, run the neural network and compute saliency maps for given images.
756 |
757 | This version will run as a regular batch on a mutli-GPU machine. It will eventually replace SaliencyMap.
758 |
759 | input: input image with shape of (batch size, 3, H, W)
760 |
761 | Parameters:
762 |
763 | model: This should be a valid Torch neural network such as a ResNet.
764 | layers: A list of layers you wish to process given by name. If none, we can auto compute a selection.
765 | maps_method: How do we compute saliency for each activation map? Default: SMOEScaleMap
766 | norm_method: How do we post process normalize each saliency map? Default: norm.GaussNorm2D
767 | This can also be norm.GammaNorm2D or norm.RangeNorm2D.
768 | output_size: This is the standard 2D size for the saliency maps. Torch nn.functional.interpolate
769 | will be used to make each saliency map this size. Default [224,224]
770 | resize_mode: Is given to Torch nn.functional.interpolate. Whatever it supports will work here.
771 | do_relu: Should we do a final clamp on values to set all negative values to 0?
772 | cam_method: A string with the method for running CAM. Can be:
773 | gradcam - Default, Standard GradCAM from Selvaraju 2017
774 | gradcampp - GradCAM++ from from Chattopadhyay 2018
775 | xgradcam - XGradCAM from Fu 2020
776 |
777 | Will Return:
778 |
779 | combined_map: [Batch x output height x output width] set of 2D saliency maps combined from each layer
780 | we compute from and combined with a CAM if we computed one.
781 | saliency_maps: A list [number of layers size] containing each saliency map [Batch x output height x output width].
782 | These will have been resized from their orginal layer size.
783 | logit: The output neural network logits.
784 |
785 | '''
786 | def __init__(self, model, layers=None, maps_method=SMOEScaleMap, norm_method=norm.GammaNorm2D,
787 | output_size=[224,224], weights=None, auto_layer=nn.ReLU, resize_mode='bilinear',
788 | do_relu=False, cam_method='gradcam', module_layer=None, expl_do_fast_cam=False,
789 | do_nonclass_map=False, cam_each_map=False):
790 |
791 | assert isinstance(model, nn.Module), "model must be a valid PyTorch module"
792 | assert isinstance(layers, list) or layers is None, "Layers must be a list of layers or None"
793 | assert callable(maps_method), "Saliency map method must be a callable function or method."
794 | assert callable(norm_method), "Normalization method must be a callable function or method."
795 | assert isinstance(auto_layer(), nn.Module), "Auto layer if used must be a type for nn.Module such as nn.ReLU."
796 |
797 | super(SaliencyModel, self).__init__()
798 |
799 | self.get_smap = maps_method()
800 | self.get_norm = norm_method()
801 | self.model = model
802 | self.layers = layers
803 | self.auto_layer = auto_layer
804 |
805 | r'''
806 | If we are auto selecting layers, count how many we have and create an empty layer list of the right size.
807 | Later, this will make us compatible with enumerate(self.layers)
808 | '''
809 | if self.layers is None:
810 | self.auto_layers = True
811 | map_num = 0
812 | weights = None
813 | self.layers = []
814 | for m in self.model.modules():
815 | if isinstance(m, self.auto_layer):
816 | map_num += 1
817 | self.layers.append(None)
818 | else:
819 | map_num = len(self.layers)
820 | self.auto_layers = False
821 |
822 | r'''
823 | This object will be used to combine all the saliency maps together after we compute them.
824 | '''
825 | self.combine_maps = CombineSaliencyMaps(output_size=output_size, map_num=map_num, weights=None,
826 | resize_mode=resize_mode, do_relu=do_relu)
827 |
828 | r'''
829 | Are we also computing the CAM map?
830 | '''
831 | if isinstance(model, resnet.ResNet_FastCAM) or expl_do_fast_cam:
832 | self.do_fast_cam = True
833 | self.do_nonclass_map = do_nonclass_map
834 | self.cam_method = cam_method
835 | self.cam_each_map = cam_each_map
836 | else:
837 | self.do_fast_cam = False
838 | self.do_nonclass_map = None
839 | self.cam_method = None
840 | self.cam_each_map = None
841 |
842 | def __call__(self, input, grad_enabled=False):
843 | """
844 | Args:
845 | input: input image with shape of (B, 3, H, W)
846 | grad_enabled: Set this to true if you need to compute grads when running the network. For instance, while training.
847 |
848 | Return:
849 | combined_map: [Batch x output height x output width] set of 2D saliency maps combined from each layer
850 | we compute from and combined with a CAM if we computed one.
851 | saliency_maps: A list [number of layers size] containing each saliency map [Batch x output height x output width].
852 | These will have been resized from their orginal layer size.
853 | logit: The output neural network logits.
854 | """
855 |
856 | r'''
857 | We set up the hooks each iteration. This is needed when running in a multi GPU version where this module is split out
858 | post __init__.
859 | '''
860 | self.activation_hooks = []
861 |
862 | if self.auto_layers:
863 | r'''
864 | Auto defined layers. Here we will process all layers of a certain type as defined by the use.
865 | This might commonly be all ReLUs or all Conv layers.
866 | '''
867 | for m in self.model.modules():
868 | if isinstance(m, self.auto_layer):
869 | m._forward_hooks = OrderedDict() # PyTorch bug work around, patch is available, but not everyone may be patched
870 | h = misc.CaptureLayerOutput(post_process=None, device=input.device)
871 | _ = m.register_forward_hook(h)
872 | self.activation_hooks.append(h)
873 |
874 | else:
875 | r'''
876 | User defined layers.
877 |
878 | For each we attach a hook to get the layer activations back after the
879 | network runs the data.
880 | '''
881 |
882 | for i,l in enumerate(self.layers):
883 | self.model._modules[l]._forward_hooks = OrderedDict() # PyTorch bug work around, patch is available, but not everyone may be patched
884 | h = misc.CaptureLayerOutput(post_process=None, device=input.device)
885 | _ = self.model._modules[l].register_forward_hook(h)
886 | self.activation_hooks.append(h)
887 |
888 | r'''
889 | Don't compute grads if we do not need them. Cuts network compute time way down.
890 | '''
891 | with torch.set_grad_enabled(grad_enabled):
892 |
893 | r'''
894 | Get the size, but we support lists here for certain special cases.
895 | '''
896 | b, c, h, w = input[0].size() if isinstance(input,list) else input.size()
897 |
898 | self.model.eval()
899 |
900 | if self.do_fast_cam:
901 | logit,cam_map = self.model(input, method=self.cam_method)
902 | else:
903 | logit = self.model(input)
904 |
905 | saliency_maps = []
906 |
907 | r'''
908 | Get the activation for each layer in our list. Then compute saliency and normalize.
909 | '''
910 | for i,l in enumerate(self.layers):
911 |
912 | activations = self.activation_hooks[i].data
913 | b, k, u, v = activations.size()
914 | activations = F.relu(activations)
915 | saliency_map = self.get_norm(self.get_smap(activations)).view(b, u, v)
916 |
917 | saliency_maps.append(saliency_map)
918 |
919 | r'''
920 | Combine each saliency map together into a single 2D saliency map. This is outside the
921 | set_grad_enabled loop since it might need grads if doing FastCAM.
922 | '''
923 | combined_map, saliency_maps = self.combine_maps(saliency_maps)
924 |
925 | r'''
926 | If we computed a CAM, combine it with the forward only saliency map.
927 | '''
928 | if self.do_fast_cam:
929 | if self.do_nonclass_map:
930 | combined_map = combined_map*(1.0 - cam_map)
931 | if self.cam_each_map:
932 | saliency_maps = saliency_maps.squeeze(0)
933 | saliency_maps = saliency_maps*(1.0 - cam_map)
934 | saliency_maps = saliency_maps.unsqueeze(0)
935 | else:
936 | combined_map = combined_map * cam_map
937 | if self.cam_each_map:
938 | saliency_maps = saliency_maps.squeeze(0)
939 | saliency_maps = saliency_maps*cam_map
940 | saliency_maps = saliency_maps.unsqueeze(0)
941 |
942 | return combined_map, saliency_maps, logit
943 |
944 |
945 |
--------------------------------------------------------------------------------