├── book-data
├── 2-4-1-sample_data.csv
├── 3-3-1-fish-species.csv
├── 3-4-1-fish-length.csv
├── 3-5-3-cross2.csv
├── 6-3-1-click_data.csv
├── 3-7-1-lineplot-data.csv
├── 3-3-2-fish-length.csv
├── 3-5-1-cov.csv
├── 3-6-1-fish_multi.csv
├── 6-2-1-paired-t-test.csv
├── 3-5-2-cross.csv
├── 5-6-1-fish_length.csv
├── 9-4-1-poisson-regression.csv
├── 8-1-1-beer.csv
├── 8-4-1-brand-1.csv
├── 6-1-1-junk-food-weight.csv
├── 8-4-2-brand-2.csv
├── 9-2-1-logistic-regression.csv
├── 8-4-3-brand-3.csv
├── 2-2-Jupyter Notebookの基本.ipynb
├── 6-3-分割表の検定.ipynb
├── 6-2-平均値の差の検定.ipynb
├── 6-1-母平均に関する1標本のt検定.ipynb
├── 3-5-多変量データの統計量.ipynb
├── 9-3-一般化線形モデルの評価.ipynb
├── 5-6-区間推定.ipynb
├── 2-3-Pythonによるプログラミングの基本.ipynb
├── 5-4-母分散の推定.ipynb
├── 8-3-分散分析.ipynb
├── 3-4-1変量データの統計量.ipynb
└── 2-4-numpy・pandasの基本.ipynb
└── README.md
/book-data/2-4-1-sample_data.csv:
--------------------------------------------------------------------------------
1 | col1,col2
2 | 1, A
3 | 2, A
4 | 3, B
5 | 4, B
6 | 5, C
7 | 6, C
--------------------------------------------------------------------------------
/book-data/3-3-1-fish-species.csv:
--------------------------------------------------------------------------------
1 | species
2 | A
3 | A
4 | A
5 | B
6 | B
7 | B
8 | B
9 | B
10 | B
11 | B
12 |
--------------------------------------------------------------------------------
/book-data/3-4-1-fish-length.csv:
--------------------------------------------------------------------------------
1 | length
2 | 2
3 | 3
4 | 3
5 | 4
6 | 4
7 | 4
8 | 4
9 | 5
10 | 5
11 | 6
12 |
--------------------------------------------------------------------------------
/book-data/3-5-3-cross2.csv:
--------------------------------------------------------------------------------
1 | store,color,sales
2 | tokyo,blue,10
3 | tokyo,red,15
4 | osaka,blue,13
5 | osaka,red,9
6 |
--------------------------------------------------------------------------------
/book-data/6-3-1-click_data.csv:
--------------------------------------------------------------------------------
1 | color,click,freq
2 | blue,click,20
3 | blue,not,230
4 | red,click,10
5 | red,not,40
6 |
7 |
--------------------------------------------------------------------------------
/book-data/3-7-1-lineplot-data.csv:
--------------------------------------------------------------------------------
1 | x,y
2 | 0,2
3 | 1,3
4 | 2,4
5 | 3,3
6 | 4,5
7 | 5,4
8 | 6,6
9 | 7,7
10 | 8,4
11 | 9,8
12 |
--------------------------------------------------------------------------------
/book-data/3-3-2-fish-length.csv:
--------------------------------------------------------------------------------
1 | length
2 | 1.91
3 | 1.21
4 | 2.28
5 | 1.01
6 | 1.00
7 | 4.50
8 | 1.96
9 | 0.72
10 | 3.67
11 | 2.55
12 |
--------------------------------------------------------------------------------
/book-data/3-5-1-cov.csv:
--------------------------------------------------------------------------------
1 | x,y
2 | 18.5,34
3 | 18.7,39
4 | 19.1,41
5 | 19.7,38
6 | 21.5,45
7 | 21.7,41
8 | 21.8,52
9 | 22,44
10 | 23.4,44
11 | 23.8,49
12 |
--------------------------------------------------------------------------------
/book-data/3-6-1-fish_multi.csv:
--------------------------------------------------------------------------------
1 | species,length
2 | A,2
3 | A,3
4 | A,3
5 | A,4
6 | A,4
7 | A,4
8 | A,4
9 | A,5
10 | A,5
11 | A,6
12 | B,5
13 | B,6
14 | B,6
15 | B,7
16 | B,7
17 | B,7
18 | B,7
19 | B,8
20 | B,8
21 | B,9
22 |
--------------------------------------------------------------------------------
/book-data/6-2-1-paired-t-test.csv:
--------------------------------------------------------------------------------
1 | person,medicine,body_temperature
2 | A,before,36.2
3 | B,before,36.2
4 | C,before,35.3
5 | D,before,36.1
6 | E,before,36.1
7 | A,after,36.8
8 | B,after,36.1
9 | C,after,36.8
10 | D,after,37.1
11 | E,after,36.9
12 |
--------------------------------------------------------------------------------
/book-data/3-5-2-cross.csv:
--------------------------------------------------------------------------------
1 | sunlight,disease
2 | yes,yes
3 | yes,yes
4 | yes,yes
5 | yes,no
6 | yes,no
7 | yes,no
8 | yes,no
9 | yes,no
10 | yes,no
11 | yes,no
12 | no,yes
13 | no,yes
14 | no,yes
15 | no,yes
16 | no,yes
17 | no,yes
18 | no,yes
19 | no,yes
20 | no,no
21 | no,no
22 |
--------------------------------------------------------------------------------
/book-data/5-6-1-fish_length.csv:
--------------------------------------------------------------------------------
1 | length
2 | 4.352981989508033500e+00
3 | 3.735303878484729889e+00
4 | 5.944616949606223777e+00
5 | 3.798326296317538375e+00
6 | 4.087687873262546567e+00
7 | 5.265984893649251042e+00
8 | 3.272614076115006654e+00
9 | 3.526690673655769270e+00
10 | 4.150082580669628207e+00
11 | 3.736104033776512789e+00
12 |
--------------------------------------------------------------------------------
/book-data/9-4-1-poisson-regression.csv:
--------------------------------------------------------------------------------
1 | beer_number,temperature
2 | 6,17.5
3 | 11,26.6
4 | 2,5.0
5 | 4,14.1
6 | 2,9.4
7 | 2,7.8
8 | 3,10.6
9 | 5,15.4
10 | 6,16.9
11 | 7,21.2
12 | 6,17.6
13 | 11,25.6
14 | 4,11.1
15 | 16,31.3
16 | 4,5.8
17 | 13,25.1
18 | 5,17.5
19 | 7,21.8
20 | 3,9.2
21 | 5,10.9
22 | 14,29.0
23 | 22,34.0
24 | 7,14.4
25 | 11,25.8
26 | 18,31.3
27 | 17,31.8
28 | 2,7.6
29 | 2,6.2
30 | 4,10.1
31 | 16,31.3
32 |
--------------------------------------------------------------------------------
/book-data/8-1-1-beer.csv:
--------------------------------------------------------------------------------
1 | beer,temperature
2 | 45.3,20.5
3 | 59.3,25.0
4 | 40.4,10.0
5 | 38.0,26.9
6 | 37.0,15.8
7 | 40.900000000000006,4.2
8 | 60.2,13.5
9 | 63.3,26.0
10 | 51.099999999999994,23.3
11 | 44.9,8.5
12 | 47.0,26.2
13 | 53.2,19.1
14 | 43.5,24.3
15 | 53.199999999999996,23.3
16 | 37.4,8.4
17 | 59.9,23.5
18 | 41.5,13.9
19 | 75.1,35.5
20 | 55.6,27.2
21 | 57.2,20.5
22 | 46.5,10.2
23 | 35.8,20.5
24 | 51.9,21.6
25 | 38.199999999999996,7.9
26 | 66.0,42.2
27 | 55.3,23.9
28 | 55.300000000000004,36.9
29 | 43.3,8.9
30 | 70.5,36.4
31 | 38.8,6.4
32 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Pythonで学ぶあたらしい統計学の教科書 [第2版]
2 | 書籍『Pythonで学ぶあたらしい統計学の教科書 [第2版]』のサンプルコードとデータをここに配置しています。
3 |
4 | 詳細な情報は、下記のサポートページも参照してください。
5 | https://logics-of-blue.com/python-stats-book-2nd-support/
6 |
7 |
8 |
9 |
10 | ## 【ファイルをダウンロードする方法】
11 |
12 | ファイルをダウンロードする場合は、下記画像を参考にして、まずは緑色の「Code▼」をクリックします。
13 | その次に「Download ZIP」をクリックしてください。ZIPファイルとしてダウンロードされます。
14 |
15 | 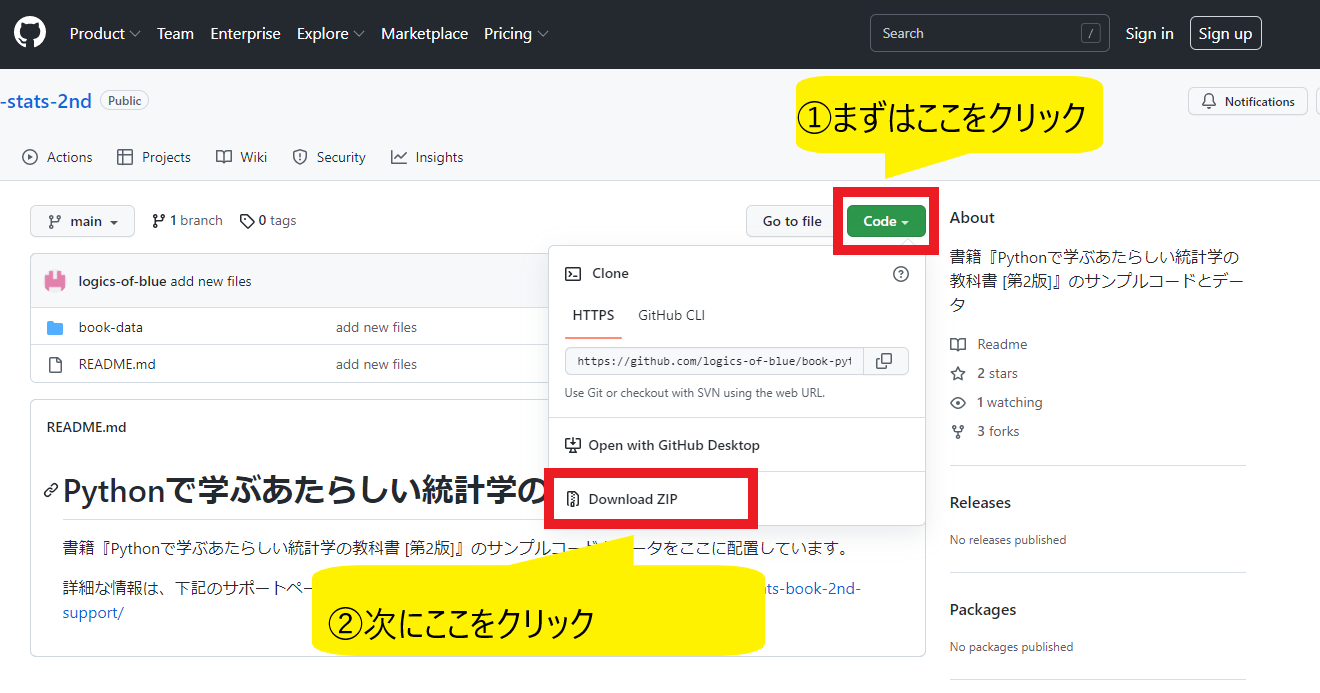 16 |
--------------------------------------------------------------------------------
/book-data/8-4-1-brand-1.csv:
--------------------------------------------------------------------------------
1 | sales,brand,local_population
2 | 348.0,A,215.1
3 | 169.7,A,152.0
4 | 143.7,A,107.7
5 | 295.7,A,371.5
6 | 281.2,A,184.7
7 | 106.2,A,206.2
8 | 412.3,A,296.6
9 | 139.2,A,121.3
10 | 349.9,A,329.6
11 | 470.0,A,550.0
12 | 422.7,A,335.7
13 | 242.3,A,379.9
14 | 179.3,A,140.9
15 | 262.9,A,265.6
16 | 432.5,A,377.8
17 | 331.0,B,424.3
18 | 310.2,B,315.0
19 | 369.9,B,460.8
20 | 451.9,B,499.1
21 | 453.1,B,454.5
22 | 442.3,B,583.4
23 | 501.9,B,476.0
24 | 553.8,B,571.0
25 | 369.0,B,341.2
26 | 259.1,B,150.0
27 | 438.5,B,542.2
28 | 386.1,B,419.3
29 | 288.6,B,349.6
30 | 488.7,B,578.3
31 | 414.8,B,404.3
32 |
--------------------------------------------------------------------------------
/book-data/6-1-1-junk-food-weight.csv:
--------------------------------------------------------------------------------
1 | weight
2 | 5.852981989508032967e+01
3 | 5.235303878484729978e+01
4 | 7.444616949606223955e+01
5 | 5.298326296317538464e+01
6 | 5.587687873262546390e+01
7 | 6.765984893649250864e+01
8 | 4.772614076115006299e+01
9 | 5.026690673655769359e+01
10 | 5.650082580669628385e+01
11 | 5.236104033776512523e+01
12 | 4.545788310062555126e+01
13 | 5.336098791529930452e+01
14 | 5.212936842399005855e+01
15 | 5.982777282087596404e+01
16 | 4.168169176422644284e+01
17 | 4.939856769848039164e+01
18 | 6.421112807589736349e+01
19 | 6.985864805785050180e+01
20 | 4.291056353849307214e+01
21 | 6.015878008714222602e+01
22 |
--------------------------------------------------------------------------------
/book-data/8-4-2-brand-2.csv:
--------------------------------------------------------------------------------
1 | sales,brand,local_population
2 | 385.8,A,265.6
3 | 473.0,A,386.1
4 | 451.6,A,522.7
5 | 556.9,A,530.5
6 | 423.8,A,397.8
7 | 226.1,A,142.3
8 | 410.4,A,398.6
9 | 397.3,A,222.7
10 | 503.1,A,466.3
11 | 454.8,A,547.3
12 | 465.8,A,357.4
13 | 445.6,A,401.8
14 | 341.8,A,132.5
15 | 454.9,A,370.0
16 | 262.9,A,164.6
17 | 474.7,A,407.3
18 | 354.5,A,281.8
19 | 584.8,A,483.9
20 | 355.6,A,124.3
21 | 330.2,A,154.9
22 | 412.0,A,442.0
23 | 431.9,A,357.3
24 | 452.5,A,385.8
25 | 438.4,A,521.9
26 | 555.4,A,343.9
27 | 578.2,B,505.1
28 | 521.1,B,355.1
29 | 540.3,B,563.4
30 | 588.3,B,433.5
31 | 175.3,B,174.4
32 | 315.0,B,282.3
33 | 612.2,B,532.9
34 | 350.5,B,275.1
35 | 133.6,B,194.5
36 | 336.3,B,336.3
37 | 417.0,B,296.4
38 | 593.8,B,409.5
39 | 441.5,B,318.4
40 | 290.9,B,230.5
41 | 423.4,B,306.2
42 | 309.9,B,309.5
43 | 626.7,B,551.2
44 | 550.0,B,589.8
45 | 470.1,B,411.8
46 | 219.6,B,141.6
47 | 568.0,B,466.5
48 | 477.2,B,439.3
49 | 633.8,B,513.0
50 | 334.5,B,273.7
51 | 266.7,B,129.4
52 |
--------------------------------------------------------------------------------
/book-data/9-2-1-logistic-regression.csv:
--------------------------------------------------------------------------------
1 | hours,result
2 | 0,0
3 | 0,0
4 | 0,0
5 | 0,0
6 | 0,0
7 | 0,0
8 | 0,0
9 | 0,0
10 | 0,0
11 | 0,0
12 | 1,0
13 | 1,0
14 | 1,0
15 | 1,0
16 | 1,0
17 | 1,0
18 | 1,0
19 | 1,0
20 | 1,0
21 | 1,0
22 | 2,0
23 | 2,1
24 | 2,0
25 | 2,0
26 | 2,0
27 | 2,0
28 | 2,0
29 | 2,0
30 | 2,0
31 | 2,0
32 | 3,0
33 | 3,0
34 | 3,1
35 | 3,0
36 | 3,0
37 | 3,0
38 | 3,0
39 | 3,0
40 | 3,0
41 | 3,0
42 | 4,1
43 | 4,1
44 | 4,0
45 | 4,1
46 | 4,0
47 | 4,0
48 | 4,1
49 | 4,0
50 | 4,0
51 | 4,0
52 | 5,0
53 | 5,1
54 | 5,0
55 | 5,0
56 | 5,0
57 | 5,0
58 | 5,1
59 | 5,0
60 | 5,1
61 | 5,1
62 | 6,1
63 | 6,1
64 | 6,1
65 | 6,1
66 | 6,1
67 | 6,1
68 | 6,1
69 | 6,1
70 | 6,0
71 | 6,1
72 | 7,0
73 | 7,1
74 | 7,1
75 | 7,1
76 | 7,1
77 | 7,1
78 | 7,0
79 | 7,1
80 | 7,1
81 | 7,1
82 | 8,1
83 | 8,1
84 | 8,1
85 | 8,1
86 | 8,1
87 | 8,1
88 | 8,1
89 | 8,0
90 | 8,1
91 | 8,1
92 | 9,1
93 | 9,1
94 | 9,1
95 | 9,1
96 | 9,1
97 | 9,1
98 | 9,1
99 | 9,1
100 | 9,1
101 | 9,1
102 |
--------------------------------------------------------------------------------
/book-data/8-4-3-brand-3.csv:
--------------------------------------------------------------------------------
1 | sales,brand,local_population
2 | 385.8,0.0,265.6
3 | 473.0,0.0,386.1
4 | 451.6,0.0,522.7
5 | 556.9,0.0,530.5
6 | 423.8,0.0,397.8
7 | 226.1,0.0,142.3
8 | 410.4,0.0,398.6
9 | 397.3,0.0,222.7
10 | 503.1,0.0,466.3
11 | 454.8,0.0,547.3
12 | 465.8,0.0,357.4
13 | 445.6,0.0,401.8
14 | 341.8,0.0,132.5
15 | 454.9,0.0,370.0
16 | 262.9,0.0,164.6
17 | 474.7,0.0,407.3
18 | 354.5,0.0,281.8
19 | 584.8,0.0,483.9
20 | 355.6,0.0,124.3
21 | 330.2,0.0,154.9
22 | 412.0,0.0,442.0
23 | 431.9,0.0,357.3
24 | 452.5,0.0,385.8
25 | 438.4,0.0,521.9
26 | 555.4,0.0,343.9
27 | 578.2,99.0,505.1
28 | 521.1,99.0,355.1
29 | 540.3,99.0,563.4
30 | 588.3,99.0,433.5
31 | 175.3,99.0,174.4
32 | 315.0,99.0,282.3
33 | 612.2,99.0,532.9
34 | 350.5,99.0,275.1
35 | 133.6,99.0,194.5
36 | 336.3,99.0,336.3
37 | 417.0,99.0,296.4
38 | 593.8,99.0,409.5
39 | 441.5,99.0,318.4
40 | 290.9,99.0,230.5
41 | 423.4,99.0,306.2
42 | 309.9,99.0,309.5
43 | 626.7,99.0,551.2
44 | 550.0,99.0,589.8
45 | 470.1,99.0,411.8
46 | 219.6,99.0,141.6
47 | 568.0,99.0,466.5
48 | 477.2,99.0,439.3
49 | 633.8,99.0,513.0
50 | 334.5,99.0,273.7
51 | 266.7,99.0,129.4
52 |
--------------------------------------------------------------------------------
/book-data/2-2-Jupyter Notebookの基本.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第2部 PythonとJupyter Notebookの基本\n",
8 | "\n",
9 | "## 2章 Jupyter Notebookの基本"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 計算の実行方法"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [
24 | {
25 | "data": {
26 | "text/plain": [
27 | "1"
28 | ]
29 | },
30 | "execution_count": 1,
31 | "metadata": {},
32 | "output_type": "execute_result"
33 | }
34 | ],
35 | "source": [
36 | "1"
37 | ]
38 | },
39 | {
40 | "cell_type": "markdown",
41 | "metadata": {},
42 | "source": [
43 | "### Markdownの使い方"
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {
49 | "collapsed": true
50 | },
51 | "source": [
52 | "# 大きな表題\n",
53 | "## 少し小さな表題\n",
54 | "-----------------\n",
55 | "- 箇条書き\n",
56 | "- 箇条書き\n",
57 | "-----------------\n",
58 | "1. 箇条書き\n",
59 | "1. 箇条書き"
60 | ]
61 | }
62 | ],
63 | "metadata": {
64 | "kernelspec": {
65 | "display_name": "Python 3 (ipykernel)",
66 | "language": "python",
67 | "name": "python3"
68 | },
69 | "language_info": {
70 | "codemirror_mode": {
71 | "name": "ipython",
72 | "version": 3
73 | },
74 | "file_extension": ".py",
75 | "mimetype": "text/x-python",
76 | "name": "python",
77 | "nbconvert_exporter": "python",
78 | "pygments_lexer": "ipython3",
79 | "version": "3.9.7"
80 | }
81 | },
82 | "nbformat": 4,
83 | "nbformat_minor": 2
84 | }
85 |
--------------------------------------------------------------------------------
/book-data/6-3-分割表の検定.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第6部 統計的仮説検定\n",
8 | "\n",
9 | "## 3章 分割表の検定"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd\n",
28 | "from scipy import stats"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": 2,
34 | "metadata": {},
35 | "outputs": [],
36 | "source": [
37 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
38 | "np.set_printoptions(linewidth=60)\n",
39 | "pd.set_option('display.width', 60)\n",
40 | "\n",
41 | "from matplotlib.pylab import rcParams\n",
42 | "rcParams['figure.figsize'] = 8, 4"
43 | ]
44 | },
45 | {
46 | "cell_type": "markdown",
47 | "metadata": {},
48 | "source": [
49 | "### 実装:p値の計算"
50 | ]
51 | },
52 | {
53 | "cell_type": "code",
54 | "execution_count": 3,
55 | "metadata": {},
56 | "outputs": [
57 | {
58 | "data": {
59 | "text/plain": [
60 | "0.009821437357809604"
61 | ]
62 | },
63 | "execution_count": 3,
64 | "metadata": {},
65 | "output_type": "execute_result"
66 | }
67 | ],
68 | "source": [
69 | "# p値を求める\n",
70 | "1 - stats.chi2.cdf(x=6.667, df=1)"
71 | ]
72 | },
73 | {
74 | "cell_type": "markdown",
75 | "metadata": {},
76 | "source": [
77 | "### 実装:分割表の検定"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 4,
83 | "metadata": {
84 | "scrolled": true
85 | },
86 | "outputs": [
87 | {
88 | "name": "stdout",
89 | "output_type": "stream",
90 | "text": [
91 | " color click freq\n",
92 | "0 blue click 20\n",
93 | "1 blue not 230\n",
94 | "2 red click 10\n",
95 | "3 red not 40\n"
96 | ]
97 | }
98 | ],
99 | "source": [
100 | "# データの読み込み\n",
101 | "click_data = pd.read_csv('6-3-1-click_data.csv')\n",
102 | "print(click_data)"
103 | ]
104 | },
105 | {
106 | "cell_type": "code",
107 | "execution_count": 5,
108 | "metadata": {},
109 | "outputs": [
110 | {
111 | "name": "stdout",
112 | "output_type": "stream",
113 | "text": [
114 | "click click not\n",
115 | "color \n",
116 | "blue 20 230\n",
117 | "red 10 40\n"
118 | ]
119 | }
120 | ],
121 | "source": [
122 | "# 分割表形式に変換\n",
123 | "cross = pd.pivot_table(\n",
124 | " data=click_data,\n",
125 | " values='freq',\n",
126 | " aggfunc='sum',\n",
127 | " index='color',\n",
128 | " columns='click'\n",
129 | ")\n",
130 | "print(cross)"
131 | ]
132 | },
133 | {
134 | "cell_type": "code",
135 | "execution_count": 6,
136 | "metadata": {},
137 | "outputs": [
138 | {
139 | "data": {
140 | "text/plain": [
141 | "(6.666666666666666,\n",
142 | " 0.009823274507519247,\n",
143 | " 1,\n",
144 | " array([[ 25., 225.],\n",
145 | " [ 5., 45.]]))"
146 | ]
147 | },
148 | "execution_count": 6,
149 | "metadata": {},
150 | "output_type": "execute_result"
151 | }
152 | ],
153 | "source": [
154 | "# 検定の実行\n",
155 | "stats.chi2_contingency(cross, correction=False)"
156 | ]
157 | }
158 | ],
159 | "metadata": {
160 | "kernelspec": {
161 | "display_name": "Python 3 (ipykernel)",
162 | "language": "python",
163 | "name": "python3"
164 | },
165 | "language_info": {
166 | "codemirror_mode": {
167 | "name": "ipython",
168 | "version": 3
169 | },
170 | "file_extension": ".py",
171 | "mimetype": "text/x-python",
172 | "name": "python",
173 | "nbconvert_exporter": "python",
174 | "pygments_lexer": "ipython3",
175 | "version": "3.9.7"
176 | }
177 | },
178 | "nbformat": 4,
179 | "nbformat_minor": 2
180 | }
181 |
--------------------------------------------------------------------------------
/book-data/6-2-平均値の差の検定.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第6部 統計的仮説検定\n",
8 | "\n",
9 | "## 2章 平均値の差の検定"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd\n",
28 | "from scipy import stats"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": 2,
34 | "metadata": {},
35 | "outputs": [],
36 | "source": [
37 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
38 | "np.set_printoptions(linewidth=60)\n",
39 | "pd.set_option('display.width', 60)\n",
40 | "\n",
41 | "from matplotlib.pylab import rcParams\n",
42 | "rcParams['figure.figsize'] = 8, 4"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 3,
48 | "metadata": {
49 | "scrolled": true
50 | },
51 | "outputs": [
52 | {
53 | "name": "stdout",
54 | "output_type": "stream",
55 | "text": [
56 | " person medicine body_temperature\n",
57 | "0 A before 36.2\n",
58 | "1 B before 36.2\n",
59 | "2 C before 35.3\n",
60 | "3 D before 36.1\n",
61 | "4 E before 36.1\n",
62 | "5 A after 36.8\n",
63 | "6 B after 36.1\n",
64 | "7 C after 36.8\n",
65 | "8 D after 37.1\n",
66 | "9 E after 36.9\n"
67 | ]
68 | }
69 | ],
70 | "source": [
71 | "# データの読み込み\n",
72 | "paired_test_data = pd.read_csv('6-2-1-paired-t-test.csv')\n",
73 | "print(paired_test_data)"
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "### 実装:対応のあるt検定"
81 | ]
82 | },
83 | {
84 | "cell_type": "code",
85 | "execution_count": 4,
86 | "metadata": {},
87 | "outputs": [
88 | {
89 | "data": {
90 | "text/plain": [
91 | "array([ 0.6, -0.1, 1.5, 1. , 0.8])"
92 | ]
93 | },
94 | "execution_count": 4,
95 | "metadata": {},
96 | "output_type": "execute_result"
97 | }
98 | ],
99 | "source": [
100 | "# 薬を飲む前と飲んだ後の標本平均\n",
101 | "before = paired_test_data.query(\n",
102 | " 'medicine == \"before\"')['body_temperature']\n",
103 | "after = paired_test_data.query(\n",
104 | " 'medicine == \"after\"')['body_temperature']\n",
105 | "# アレイに変換\n",
106 | "before = np.array(before)\n",
107 | "after = np.array(after)\n",
108 | "# 差を計算\n",
109 | "diff = after - before\n",
110 | "diff"
111 | ]
112 | },
113 | {
114 | "cell_type": "code",
115 | "execution_count": 5,
116 | "metadata": {},
117 | "outputs": [
118 | {
119 | "data": {
120 | "text/plain": [
121 | "Ttest_1sampResult(statistic=2.901693483620596, pvalue=0.044043109730074276)"
122 | ]
123 | },
124 | "execution_count": 5,
125 | "metadata": {},
126 | "output_type": "execute_result"
127 | }
128 | ],
129 | "source": [
130 | "# 平均値が0と異なるか検定\n",
131 | "stats.ttest_1samp(diff, 0)"
132 | ]
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": 6,
137 | "metadata": {},
138 | "outputs": [
139 | {
140 | "data": {
141 | "text/plain": [
142 | "Ttest_relResult(statistic=2.901693483620596, pvalue=0.044043109730074276)"
143 | ]
144 | },
145 | "execution_count": 6,
146 | "metadata": {},
147 | "output_type": "execute_result"
148 | }
149 | ],
150 | "source": [
151 | "# 対応のあるt検定\n",
152 | "stats.ttest_rel(after, before)"
153 | ]
154 | },
155 | {
156 | "cell_type": "markdown",
157 | "metadata": {},
158 | "source": [
159 | "### 実装:対応の無いt検定(不等分散)"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 7,
165 | "metadata": {},
166 | "outputs": [
167 | {
168 | "data": {
169 | "text/plain": [
170 | "3.156"
171 | ]
172 | },
173 | "execution_count": 7,
174 | "metadata": {},
175 | "output_type": "execute_result"
176 | }
177 | ],
178 | "source": [
179 | "# 平均値\n",
180 | "x_bar_bef = np.mean(before)\n",
181 | "x_bar_aft = np.mean(after)\n",
182 | "\n",
183 | "# 分散\n",
184 | "u2_bef = np.var(before, ddof=1)\n",
185 | "u2_aft = np.var(after, ddof=1)\n",
186 | "\n",
187 | "# サンプルサイズ\n",
188 | "m = len(before)\n",
189 | "n = len(after)\n",
190 | "\n",
191 | "# t値\n",
192 | "t_value = (x_bar_aft - x_bar_bef) / \\\n",
193 | " np.sqrt((u2_bef/m + u2_aft/n))\n",
194 | "round(t_value, 3)"
195 | ]
196 | },
197 | {
198 | "cell_type": "code",
199 | "execution_count": 8,
200 | "metadata": {},
201 | "outputs": [
202 | {
203 | "data": {
204 | "text/plain": [
205 | "7.998"
206 | ]
207 | },
208 | "execution_count": 8,
209 | "metadata": {},
210 | "output_type": "execute_result"
211 | }
212 | ],
213 | "source": [
214 | "# 自由度\n",
215 | "df = (u2_bef / m + u2_aft / n)**2 / \\\n",
216 | " ((u2_bef / m)**2 / (m-1) + (u2_aft / n)**2 / (n-1))\n",
217 | "round(df, 3)"
218 | ]
219 | },
220 | {
221 | "cell_type": "code",
222 | "execution_count": 9,
223 | "metadata": {},
224 | "outputs": [
225 | {
226 | "data": {
227 | "text/plain": [
228 | "0.01348"
229 | ]
230 | },
231 | "execution_count": 9,
232 | "metadata": {},
233 | "output_type": "execute_result"
234 | }
235 | ],
236 | "source": [
237 | "# p値\n",
238 | "p_value = stats.t.cdf(-np.abs(t_value), df=df) * 2\n",
239 | "round(p_value, 5)"
240 | ]
241 | },
242 | {
243 | "cell_type": "code",
244 | "execution_count": 10,
245 | "metadata": {},
246 | "outputs": [
247 | {
248 | "data": {
249 | "text/plain": [
250 | "Ttest_indResult(statistic=3.1557282344421034, pvalue=0.013484775682079892)"
251 | ]
252 | },
253 | "execution_count": 10,
254 | "metadata": {},
255 | "output_type": "execute_result"
256 | }
257 | ],
258 | "source": [
259 | "stats.ttest_ind(after, before, equal_var=False)"
260 | ]
261 | }
262 | ],
263 | "metadata": {
264 | "kernelspec": {
265 | "display_name": "Python 3 (ipykernel)",
266 | "language": "python",
267 | "name": "python3"
268 | },
269 | "language_info": {
270 | "codemirror_mode": {
271 | "name": "ipython",
272 | "version": 3
273 | },
274 | "file_extension": ".py",
275 | "mimetype": "text/x-python",
276 | "name": "python",
277 | "nbconvert_exporter": "python",
278 | "pygments_lexer": "ipython3",
279 | "version": "3.9.7"
280 | }
281 | },
282 | "nbformat": 4,
283 | "nbformat_minor": 2
284 | }
285 |
--------------------------------------------------------------------------------
/book-data/6-1-母平均に関する1標本のt検定.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第6部 統計的仮説検定\n",
8 | "\n",
9 | "## 1章 母平均に関する1標本のt検定"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd\n",
28 | "from scipy import stats"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": 2,
34 | "metadata": {},
35 | "outputs": [],
36 | "source": [
37 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
38 | "np.set_printoptions(linewidth=60)\n",
39 | "pd.set_option('display.width', 60)\n",
40 | "\n",
41 | "from matplotlib.pylab import rcParams\n",
42 | "rcParams['figure.figsize'] = 8, 4"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 3,
48 | "metadata": {
49 | "scrolled": true
50 | },
51 | "outputs": [
52 | {
53 | "data": {
54 | "text/plain": [
55 | "0 58.529820\n",
56 | "1 52.353039\n",
57 | "2 74.446169\n",
58 | "3 52.983263\n",
59 | "4 55.876879\n",
60 | "Name: weight, dtype: float64"
61 | ]
62 | },
63 | "execution_count": 3,
64 | "metadata": {},
65 | "output_type": "execute_result"
66 | }
67 | ],
68 | "source": [
69 | "# データの読み込み\n",
70 | "junk_food = pd.read_csv('6-1-1-junk-food-weight.csv')['weight']\n",
71 | "junk_food.head()"
72 | ]
73 | },
74 | {
75 | "cell_type": "markdown",
76 | "metadata": {},
77 | "source": [
78 | "### 実装:t値の計算"
79 | ]
80 | },
81 | {
82 | "cell_type": "code",
83 | "execution_count": 4,
84 | "metadata": {},
85 | "outputs": [
86 | {
87 | "data": {
88 | "text/plain": [
89 | "55.385"
90 | ]
91 | },
92 | "execution_count": 4,
93 | "metadata": {},
94 | "output_type": "execute_result"
95 | }
96 | ],
97 | "source": [
98 | "# 標本平均\n",
99 | "x_bar = np.mean(junk_food)\n",
100 | "round(x_bar, 3)"
101 | ]
102 | },
103 | {
104 | "cell_type": "code",
105 | "execution_count": 5,
106 | "metadata": {},
107 | "outputs": [
108 | {
109 | "data": {
110 | "text/plain": [
111 | "19"
112 | ]
113 | },
114 | "execution_count": 5,
115 | "metadata": {},
116 | "output_type": "execute_result"
117 | }
118 | ],
119 | "source": [
120 | "# 自由度\n",
121 | "n = len(junk_food)\n",
122 | "df = n - 1\n",
123 | "df"
124 | ]
125 | },
126 | {
127 | "cell_type": "code",
128 | "execution_count": 6,
129 | "metadata": {},
130 | "outputs": [
131 | {
132 | "data": {
133 | "text/plain": [
134 | "1.958"
135 | ]
136 | },
137 | "execution_count": 6,
138 | "metadata": {},
139 | "output_type": "execute_result"
140 | }
141 | ],
142 | "source": [
143 | "# 標準誤差\n",
144 | "u = np.std(junk_food, ddof = 1)\n",
145 | "se = u / np.sqrt(n)\n",
146 | "round(se, 3)"
147 | ]
148 | },
149 | {
150 | "cell_type": "code",
151 | "execution_count": 7,
152 | "metadata": {},
153 | "outputs": [
154 | {
155 | "data": {
156 | "text/plain": [
157 | "2.75"
158 | ]
159 | },
160 | "execution_count": 7,
161 | "metadata": {},
162 | "output_type": "execute_result"
163 | }
164 | ],
165 | "source": [
166 | "# t値\n",
167 | "t_sample = (x_bar - 50) / se\n",
168 | "round(t_sample, 3)"
169 | ]
170 | },
171 | {
172 | "cell_type": "markdown",
173 | "metadata": {},
174 | "source": [
175 | "### 実装:棄却域の計算"
176 | ]
177 | },
178 | {
179 | "cell_type": "code",
180 | "execution_count": 8,
181 | "metadata": {},
182 | "outputs": [
183 | {
184 | "data": {
185 | "text/plain": [
186 | "-2.093"
187 | ]
188 | },
189 | "execution_count": 8,
190 | "metadata": {},
191 | "output_type": "execute_result"
192 | }
193 | ],
194 | "source": [
195 | "# t分布の2.5%点\n",
196 | "round(stats.t.ppf(q=0.025, df=df), 3)"
197 | ]
198 | },
199 | {
200 | "cell_type": "markdown",
201 | "metadata": {},
202 | "source": [
203 | "### 実装:p値の計算"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": 9,
209 | "metadata": {},
210 | "outputs": [
211 | {
212 | "data": {
213 | "text/plain": [
214 | "0.013"
215 | ]
216 | },
217 | "execution_count": 9,
218 | "metadata": {},
219 | "output_type": "execute_result"
220 | }
221 | ],
222 | "source": [
223 | "# p値\n",
224 | "p_value = stats.t.cdf(-np.abs(t_sample), df=df) * 2\n",
225 | "round(p_value, 3)"
226 | ]
227 | },
228 | {
229 | "cell_type": "code",
230 | "execution_count": 10,
231 | "metadata": {},
232 | "outputs": [
233 | {
234 | "data": {
235 | "text/plain": [
236 | "Ttest_1sampResult(statistic=2.750339683171343, pvalue=0.012725590012524182)"
237 | ]
238 | },
239 | "execution_count": 10,
240 | "metadata": {},
241 | "output_type": "execute_result"
242 | }
243 | ],
244 | "source": [
245 | "# t検定\n",
246 | "stats.ttest_1samp(junk_food, 50)"
247 | ]
248 | },
249 | {
250 | "cell_type": "markdown",
251 | "metadata": {
252 | "collapsed": true
253 | },
254 | "source": [
255 | "### 実装:シミュレーションによるp値の計算"
256 | ]
257 | },
258 | {
259 | "cell_type": "code",
260 | "execution_count": 11,
261 | "metadata": {},
262 | "outputs": [],
263 | "source": [
264 | "# 標本の情報(一部再掲)\n",
265 | "n = len(junk_food)\n",
266 | "u = np.std(junk_food, ddof=1)"
267 | ]
268 | },
269 | {
270 | "cell_type": "code",
271 | "execution_count": 12,
272 | "metadata": {},
273 | "outputs": [],
274 | "source": [
275 | "# t値を格納する変数\n",
276 | "t_value_array = np.zeros(50000)"
277 | ]
278 | },
279 | {
280 | "cell_type": "code",
281 | "execution_count": 13,
282 | "metadata": {},
283 | "outputs": [],
284 | "source": [
285 | "# 母平均が50(帰無仮説が正しい)と仮定してt値を計算することを50000回繰り返す\n",
286 | "np.random.seed(1)\n",
287 | "norm_dist = stats.norm(loc=50, scale=u)\n",
288 | "for i in range(0, 50000):\n",
289 | " # 標本の抽出\n",
290 | " sample = norm_dist.rvs(size=n)\n",
291 | " # t値の計算\n",
292 | " sample_x_bar = np.mean(sample) # 標本平均\n",
293 | " sample_u = np.std(sample, ddof=1) # 標準偏差\n",
294 | " sample_se = sample_u / np.sqrt(n) # 標準誤差\n",
295 | " t_value_array[i] = (sample_x_bar - 50) / sample_se # t値"
296 | ]
297 | },
298 | {
299 | "cell_type": "code",
300 | "execution_count": 14,
301 | "metadata": {},
302 | "outputs": [
303 | {
304 | "data": {
305 | "text/plain": [
306 | "0.013"
307 | ]
308 | },
309 | "execution_count": 14,
310 | "metadata": {},
311 | "output_type": "execute_result"
312 | }
313 | ],
314 | "source": [
315 | "p_sim = (sum(t_value_array >= t_sample) / 50000) * 2\n",
316 | "round(p_sim, 3)"
317 | ]
318 | }
319 | ],
320 | "metadata": {
321 | "kernelspec": {
322 | "display_name": "Python 3 (ipykernel)",
323 | "language": "python",
324 | "name": "python3"
325 | },
326 | "language_info": {
327 | "codemirror_mode": {
328 | "name": "ipython",
329 | "version": 3
330 | },
331 | "file_extension": ".py",
332 | "mimetype": "text/x-python",
333 | "name": "python",
334 | "nbconvert_exporter": "python",
335 | "pygments_lexer": "ipython3",
336 | "version": "3.9.7"
337 | }
338 | },
339 | "nbformat": 4,
340 | "nbformat_minor": 2
341 | }
342 |
--------------------------------------------------------------------------------
/book-data/3-5-多変量データの統計量.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第3部 記述統計\n",
8 | "\n",
9 | "## 5章 多変量データの統計量"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd"
28 | ]
29 | },
30 | {
31 | "cell_type": "markdown",
32 | "metadata": {},
33 | "source": [
34 | "### 実装:分析対象となるデータの用意"
35 | ]
36 | },
37 | {
38 | "cell_type": "code",
39 | "execution_count": 2,
40 | "metadata": {},
41 | "outputs": [
42 | {
43 | "name": "stdout",
44 | "output_type": "stream",
45 | "text": [
46 | " x y\n",
47 | "0 18.5 34\n",
48 | "1 18.7 39\n",
49 | "2 19.1 41\n",
50 | "3 19.7 38\n",
51 | "4 21.5 45\n",
52 | "5 21.7 41\n",
53 | "6 21.8 52\n",
54 | "7 22.0 44\n",
55 | "8 23.4 44\n",
56 | "9 23.8 49\n"
57 | ]
58 | }
59 | ],
60 | "source": [
61 | "# データの読み込み\n",
62 | "cov_data = pd.read_csv('3-5-1-cov.csv')\n",
63 | "print(cov_data)"
64 | ]
65 | },
66 | {
67 | "cell_type": "markdown",
68 | "metadata": {},
69 | "source": [
70 | "### 実装:共分散"
71 | ]
72 | },
73 | {
74 | "cell_type": "code",
75 | "execution_count": 3,
76 | "metadata": {},
77 | "outputs": [],
78 | "source": [
79 | "# データの取り出し\n",
80 | "x = cov_data['x']\n",
81 | "y = cov_data['y']\n",
82 | "\n",
83 | "# サンプルサイズ\n",
84 | "n = len(cov_data)\n",
85 | "\n",
86 | "# 標本平均\n",
87 | "x_bar = np.mean(x)\n",
88 | "y_bar = np.mean(y)"
89 | ]
90 | },
91 | {
92 | "cell_type": "code",
93 | "execution_count": 4,
94 | "metadata": {},
95 | "outputs": [
96 | {
97 | "data": {
98 | "text/plain": [
99 | "6.906"
100 | ]
101 | },
102 | "execution_count": 4,
103 | "metadata": {},
104 | "output_type": "execute_result"
105 | }
106 | ],
107 | "source": [
108 | "# 共分散\n",
109 | "cov = sum((x - x_bar) * (y - y_bar)) / n\n",
110 | "round(cov, 3)"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {
116 | "collapsed": true
117 | },
118 | "source": [
119 | "### 実装:分散共分散行列"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 5,
125 | "metadata": {},
126 | "outputs": [
127 | {
128 | "name": "stdout",
129 | "output_type": "stream",
130 | "text": [
131 | "xの標本分散: 3.282\n",
132 | "yの標本分散: 25.21\n"
133 | ]
134 | }
135 | ],
136 | "source": [
137 | "# 分散の計算\n",
138 | "s2_x = np.var(x, ddof=0)\n",
139 | "s2_y = np.var(y, ddof=0)\n",
140 | "\n",
141 | "print('xの標本分散:', round(s2_x, 3))\n",
142 | "print('yの標本分散:', round(s2_y, 3))"
143 | ]
144 | },
145 | {
146 | "cell_type": "code",
147 | "execution_count": 6,
148 | "metadata": {},
149 | "outputs": [
150 | {
151 | "data": {
152 | "text/plain": [
153 | "array([[ 3.2816, 6.906 ],\n",
154 | " [ 6.906 , 25.21 ]])"
155 | ]
156 | },
157 | "execution_count": 6,
158 | "metadata": {},
159 | "output_type": "execute_result"
160 | }
161 | ],
162 | "source": [
163 | "# 共分散\n",
164 | "np.cov(x, y, ddof=0)"
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "metadata": {
170 | "collapsed": true
171 | },
172 | "source": [
173 | "### 実装:ピアソンの積率相関係数"
174 | ]
175 | },
176 | {
177 | "cell_type": "code",
178 | "execution_count": 7,
179 | "metadata": {},
180 | "outputs": [
181 | {
182 | "data": {
183 | "text/plain": [
184 | "0.759"
185 | ]
186 | },
187 | "execution_count": 7,
188 | "metadata": {},
189 | "output_type": "execute_result"
190 | }
191 | ],
192 | "source": [
193 | "# 相関係数\n",
194 | "rho = cov / np.sqrt(s2_x * s2_y)\n",
195 | "round(rho, 3)"
196 | ]
197 | },
198 | {
199 | "cell_type": "code",
200 | "execution_count": 8,
201 | "metadata": {},
202 | "outputs": [
203 | {
204 | "data": {
205 | "text/plain": [
206 | "array([[1. , 0.7592719],\n",
207 | " [0.7592719, 1. ]])"
208 | ]
209 | },
210 | "execution_count": 8,
211 | "metadata": {},
212 | "output_type": "execute_result"
213 | }
214 | ],
215 | "source": [
216 | "# 相関行列\n",
217 | "np.corrcoef(x, y)"
218 | ]
219 | },
220 | {
221 | "cell_type": "markdown",
222 | "metadata": {},
223 | "source": [
224 | "### 実装:クロス集計表"
225 | ]
226 | },
227 | {
228 | "cell_type": "markdown",
229 | "metadata": {},
230 | "source": [
231 | "#### 度数をカウントする事例"
232 | ]
233 | },
234 | {
235 | "cell_type": "code",
236 | "execution_count": 9,
237 | "metadata": {
238 | "scrolled": true
239 | },
240 | "outputs": [
241 | {
242 | "name": "stdout",
243 | "output_type": "stream",
244 | "text": [
245 | " sunlight disease\n",
246 | "0 yes yes\n",
247 | "1 yes yes\n",
248 | "2 yes yes\n",
249 | "3 yes no\n",
250 | "4 yes no\n"
251 | ]
252 | }
253 | ],
254 | "source": [
255 | "disease = pd.read_csv('3-5-2-cross.csv')\n",
256 | "print(disease.head())"
257 | ]
258 | },
259 | {
260 | "cell_type": "code",
261 | "execution_count": 10,
262 | "metadata": {},
263 | "outputs": [
264 | {
265 | "name": "stdout",
266 | "output_type": "stream",
267 | "text": [
268 | "disease no yes\n",
269 | "sunlight \n",
270 | "no 2 8\n",
271 | "yes 7 3\n"
272 | ]
273 | }
274 | ],
275 | "source": [
276 | "# クロス集計\n",
277 | "cross_1 = pd.crosstab(\n",
278 | " disease['sunlight'],\n",
279 | " disease['disease']\n",
280 | ")\n",
281 | "print(cross_1)"
282 | ]
283 | },
284 | {
285 | "cell_type": "markdown",
286 | "metadata": {},
287 | "source": [
288 | "#### クロス集計表の作成"
289 | ]
290 | },
291 | {
292 | "cell_type": "code",
293 | "execution_count": 11,
294 | "metadata": {},
295 | "outputs": [
296 | {
297 | "name": "stdout",
298 | "output_type": "stream",
299 | "text": [
300 | " store color sales\n",
301 | "0 tokyo blue 10\n",
302 | "1 tokyo red 15\n",
303 | "2 osaka blue 13\n",
304 | "3 osaka red 9\n"
305 | ]
306 | }
307 | ],
308 | "source": [
309 | "shoes = pd.read_csv('3-5-3-cross2.csv')\n",
310 | "print(shoes)"
311 | ]
312 | },
313 | {
314 | "cell_type": "code",
315 | "execution_count": 12,
316 | "metadata": {},
317 | "outputs": [
318 | {
319 | "name": "stdout",
320 | "output_type": "stream",
321 | "text": [
322 | "color blue red\n",
323 | "store \n",
324 | "osaka 13 9\n",
325 | "tokyo 10 15\n"
326 | ]
327 | }
328 | ],
329 | "source": [
330 | "cross_2 = pd.pivot_table(\n",
331 | " data=shoes,\n",
332 | " values='sales',\n",
333 | " aggfunc='sum',\n",
334 | " index='store',\n",
335 | " columns='color'\n",
336 | ")\n",
337 | "print(cross_2)"
338 | ]
339 | }
340 | ],
341 | "metadata": {
342 | "kernelspec": {
343 | "display_name": "Python 3 (ipykernel)",
344 | "language": "python",
345 | "name": "python3"
346 | },
347 | "language_info": {
348 | "codemirror_mode": {
349 | "name": "ipython",
350 | "version": 3
351 | },
352 | "file_extension": ".py",
353 | "mimetype": "text/x-python",
354 | "name": "python",
355 | "nbconvert_exporter": "python",
356 | "pygments_lexer": "ipython3",
357 | "version": "3.9.7"
358 | }
359 | },
360 | "nbformat": 4,
361 | "nbformat_minor": 2
362 | }
363 |
--------------------------------------------------------------------------------
/book-data/9-3-一般化線形モデルの評価.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第9部 一般化線形モデル\n",
8 | "\n",
9 | "## 3章 一般化線形モデルの評価"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {
23 | "scrolled": true
24 | },
25 | "outputs": [],
26 | "source": [
27 | "# 数値計算に使うライブラリ\n",
28 | "import numpy as np\n",
29 | "import pandas as pd\n",
30 | "from scipy import stats\n",
31 | "# 表示桁数の設定\n",
32 | "pd.set_option('display.precision', 3)\n",
33 | "np.set_printoptions(precision=3)\n",
34 | "\n",
35 | "# 統計モデルを推定するライブラリ\n",
36 | "import statsmodels.formula.api as smf\n",
37 | "import statsmodels.api as sm"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": 2,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
47 | "np.set_printoptions(linewidth=60)\n",
48 | "pd.set_option('display.width', 60)"
49 | ]
50 | },
51 | {
52 | "cell_type": "code",
53 | "execution_count": 3,
54 | "metadata": {},
55 | "outputs": [],
56 | "source": [
57 | "# データの読み込み\n",
58 | "test_result = pd.read_csv('9-2-1-logistic-regression.csv')\n",
59 | "\n",
60 | "# モデル化\n",
61 | "mod_glm = smf.glm(formula = 'result ~ hours', \n",
62 | " data = test_result, \n",
63 | " family=sm.families.Binomial()).fit()"
64 | ]
65 | },
66 | {
67 | "cell_type": "markdown",
68 | "metadata": {
69 | "collapsed": true
70 | },
71 | "source": [
72 | "### 実装:ピアソン残差"
73 | ]
74 | },
75 | {
76 | "cell_type": "code",
77 | "execution_count": 4,
78 | "metadata": {
79 | "scrolled": true
80 | },
81 | "outputs": [
82 | {
83 | "data": {
84 | "text/plain": [
85 | "0 -0.102\n",
86 | "1 -0.102\n",
87 | "2 -0.102\n",
88 | "Name: result, dtype: float64"
89 | ]
90 | },
91 | "execution_count": 4,
92 | "metadata": {},
93 | "output_type": "execute_result"
94 | }
95 | ],
96 | "source": [
97 | "# ピアソン残差の計算\n",
98 | "\n",
99 | "# 予測された成功確率\n",
100 | "pred = mod_glm.predict()\n",
101 | "# 応答変数(テストの合否)\n",
102 | "y = test_result.result\n",
103 | "\n",
104 | "# ピアソン残差\n",
105 | "peason_resid = (y - pred) / np.sqrt(pred * (1 - pred))\n",
106 | "peason_resid.head(3)"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": 5,
112 | "metadata": {
113 | "scrolled": true
114 | },
115 | "outputs": [
116 | {
117 | "data": {
118 | "text/plain": [
119 | "0 -0.102\n",
120 | "1 -0.102\n",
121 | "2 -0.102\n",
122 | "dtype: float64"
123 | ]
124 | },
125 | "execution_count": 5,
126 | "metadata": {},
127 | "output_type": "execute_result"
128 | }
129 | ],
130 | "source": [
131 | "# ピアソン残差の取り出し\n",
132 | "mod_glm.resid_pearson.head(3)"
133 | ]
134 | },
135 | {
136 | "cell_type": "code",
137 | "execution_count": 6,
138 | "metadata": {},
139 | "outputs": [
140 | {
141 | "data": {
142 | "text/plain": [
143 | "84.911"
144 | ]
145 | },
146 | "execution_count": 6,
147 | "metadata": {},
148 | "output_type": "execute_result"
149 | }
150 | ],
151 | "source": [
152 | "# ピアソン残差の2乗和\n",
153 | "round(np.sum(mod_glm.resid_pearson**2), 3)"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": 7,
159 | "metadata": {},
160 | "outputs": [
161 | {
162 | "data": {
163 | "text/plain": [
164 | "84.911"
165 | ]
166 | },
167 | "execution_count": 7,
168 | "metadata": {},
169 | "output_type": "execute_result"
170 | }
171 | ],
172 | "source": [
173 | "# summary関数でも出力されている\n",
174 | "round(mod_glm.pearson_chi2, 3)"
175 | ]
176 | },
177 | {
178 | "cell_type": "markdown",
179 | "metadata": {},
180 | "source": [
181 | "### 実装:deviance残差"
182 | ]
183 | },
184 | {
185 | "cell_type": "markdown",
186 | "metadata": {},
187 | "source": [
188 | "#### deviance残差の計算"
189 | ]
190 | },
191 | {
192 | "cell_type": "code",
193 | "execution_count": 8,
194 | "metadata": {
195 | "scrolled": false
196 | },
197 | "outputs": [
198 | {
199 | "data": {
200 | "text/plain": [
201 | "0 -0.144\n",
202 | "1 -0.144\n",
203 | "2 -0.144\n",
204 | "Name: result, dtype: float64"
205 | ]
206 | },
207 | "execution_count": 8,
208 | "metadata": {},
209 | "output_type": "execute_result"
210 | }
211 | ],
212 | "source": [
213 | "# deviance残差の計算\n",
214 | "\n",
215 | "# 成功確率の当てはめ値\n",
216 | "pred = mod_glm.predict()\n",
217 | "# 応答変数(テストの合否)\n",
218 | "y = test_result.result\n",
219 | "\n",
220 | "# 合否を完全に予測できたときの対数尤度との差異\n",
221 | "resid_tmp = 0 - np.log(stats.binom.pmf(k = y, n = 1, \n",
222 | " p = pred))\n",
223 | "# deviance残差\n",
224 | "deviance_resid = np.sqrt(\n",
225 | " 2 * resid_tmp) * np.sign(y - pred)\n",
226 | "# 結果の確認\n",
227 | "deviance_resid.head(3)"
228 | ]
229 | },
230 | {
231 | "cell_type": "code",
232 | "execution_count": 9,
233 | "metadata": {},
234 | "outputs": [
235 | {
236 | "data": {
237 | "text/plain": [
238 | "0 -0.144\n",
239 | "1 -0.144\n",
240 | "2 -0.144\n",
241 | "dtype: float64"
242 | ]
243 | },
244 | "execution_count": 9,
245 | "metadata": {},
246 | "output_type": "execute_result"
247 | }
248 | ],
249 | "source": [
250 | "mod_glm.resid_deviance.head(3)"
251 | ]
252 | },
253 | {
254 | "cell_type": "markdown",
255 | "metadata": {},
256 | "source": [
257 | "#### devianceの計算"
258 | ]
259 | },
260 | {
261 | "cell_type": "code",
262 | "execution_count": 10,
263 | "metadata": {},
264 | "outputs": [
265 | {
266 | "data": {
267 | "text/plain": [
268 | "68.028"
269 | ]
270 | },
271 | "execution_count": 10,
272 | "metadata": {},
273 | "output_type": "execute_result"
274 | }
275 | ],
276 | "source": [
277 | "# deviance\n",
278 | "deviance = np.sum(mod_glm.resid_deviance ** 2)\n",
279 | "round(deviance, 3)"
280 | ]
281 | },
282 | {
283 | "cell_type": "markdown",
284 | "metadata": {},
285 | "source": [
286 | "#### 最大化対数尤度からdevianceを計算"
287 | ]
288 | },
289 | {
290 | "cell_type": "code",
291 | "execution_count": 11,
292 | "metadata": {},
293 | "outputs": [
294 | {
295 | "data": {
296 | "text/plain": [
297 | "-34.014"
298 | ]
299 | },
300 | "execution_count": 11,
301 | "metadata": {},
302 | "output_type": "execute_result"
303 | }
304 | ],
305 | "source": [
306 | "# 最大化対数尤度の計算\n",
307 | "loglik = sum(np.log(stats.binom.pmf(k=y, n=1, p=pred)))\n",
308 | "round(loglik, 3)"
309 | ]
310 | },
311 | {
312 | "cell_type": "code",
313 | "execution_count": 12,
314 | "metadata": {},
315 | "outputs": [
316 | {
317 | "data": {
318 | "text/plain": [
319 | "-34.014"
320 | ]
321 | },
322 | "execution_count": 12,
323 | "metadata": {},
324 | "output_type": "execute_result"
325 | }
326 | ],
327 | "source": [
328 | "# 最大化対数尤度の取得\n",
329 | "round(mod_glm.llf, 3)"
330 | ]
331 | },
332 | {
333 | "cell_type": "code",
334 | "execution_count": 13,
335 | "metadata": {},
336 | "outputs": [
337 | {
338 | "data": {
339 | "text/plain": [
340 | "68.028"
341 | ]
342 | },
343 | "execution_count": 13,
344 | "metadata": {},
345 | "output_type": "execute_result"
346 | }
347 | ],
348 | "source": [
349 | "# 最大化対数尤度からdevianceを計算\n",
350 | "round(2 * (0 - mod_glm.llf), 3)"
351 | ]
352 | },
353 | {
354 | "cell_type": "code",
355 | "execution_count": 14,
356 | "metadata": {},
357 | "outputs": [
358 | {
359 | "data": {
360 | "text/plain": [
361 | "68.028"
362 | ]
363 | },
364 | "execution_count": 14,
365 | "metadata": {},
366 | "output_type": "execute_result"
367 | }
368 | ],
369 | "source": [
370 | "# devianceの取得\n",
371 | "round(mod_glm.deviance, 3)"
372 | ]
373 | }
374 | ],
375 | "metadata": {
376 | "kernelspec": {
377 | "display_name": "Python 3 (ipykernel)",
378 | "language": "python",
379 | "name": "python3"
380 | },
381 | "language_info": {
382 | "codemirror_mode": {
383 | "name": "ipython",
384 | "version": 3
385 | },
386 | "file_extension": ".py",
387 | "mimetype": "text/x-python",
388 | "name": "python",
389 | "nbconvert_exporter": "python",
390 | "pygments_lexer": "ipython3",
391 | "version": "3.9.7"
392 | }
393 | },
394 | "nbformat": 4,
395 | "nbformat_minor": 2
396 | }
397 |
--------------------------------------------------------------------------------
/book-data/5-6-区間推定.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第5部 統計的推定\n",
8 | "## 6章 区間推定"
9 | ]
10 | },
11 | {
12 | "cell_type": "markdown",
13 | "metadata": {},
14 | "source": [
15 | "### 実装:分析の準備"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 1,
21 | "metadata": {},
22 | "outputs": [],
23 | "source": [
24 | "# 数値計算に使うライブラリ\n",
25 | "import numpy as np\n",
26 | "import pandas as pd\n",
27 | "from scipy import stats\n",
28 | "\n",
29 | "# グラフを描画するライブラリ\n",
30 | "from matplotlib import pyplot as plt\n",
31 | "import seaborn as sns\n",
32 | "sns.set()\n",
33 | "\n",
34 | "# グラフの日本語表記\n",
35 | "from matplotlib import rcParams\n",
36 | "rcParams['font.family'] = 'sans-serif'\n",
37 | "rcParams['font.sans-serif'] = 'Meiryo'"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": 2,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
47 | "np.set_printoptions(linewidth=60)\n",
48 | "pd.set_option('display.width', 60)\n",
49 | "\n",
50 | "from matplotlib.pylab import rcParams\n",
51 | "rcParams['figure.figsize'] = 8, 4"
52 | ]
53 | },
54 | {
55 | "cell_type": "code",
56 | "execution_count": 3,
57 | "metadata": {},
58 | "outputs": [
59 | {
60 | "data": {
61 | "text/plain": [
62 | "0 4.352982\n",
63 | "1 3.735304\n",
64 | "2 5.944617\n",
65 | "3 3.798326\n",
66 | "4 4.087688\n",
67 | "5 5.265985\n",
68 | "6 3.272614\n",
69 | "7 3.526691\n",
70 | "8 4.150083\n",
71 | "9 3.736104\n",
72 | "Name: length, dtype: float64"
73 | ]
74 | },
75 | "execution_count": 3,
76 | "metadata": {},
77 | "output_type": "execute_result"
78 | }
79 | ],
80 | "source": [
81 | "# データの読み込み\n",
82 | "fish = pd.read_csv('5-6-1-fish_length.csv')['length']\n",
83 | "fish"
84 | ]
85 | },
86 | {
87 | "cell_type": "markdown",
88 | "metadata": {},
89 | "source": [
90 | "### 実装:点推定"
91 | ]
92 | },
93 | {
94 | "cell_type": "code",
95 | "execution_count": 4,
96 | "metadata": {},
97 | "outputs": [
98 | {
99 | "name": "stdout",
100 | "output_type": "stream",
101 | "text": [
102 | "標本平均: 4.187\n",
103 | "不偏分散: 0.68\n"
104 | ]
105 | }
106 | ],
107 | "source": [
108 | "# 点推定\n",
109 | "x_bar = np.mean(fish)\n",
110 | "u2 = np.var(fish, ddof=1)\n",
111 | "\n",
112 | "print('標本平均:', round(x_bar, 3))\n",
113 | "print('不偏分散:', round(u2, 3))"
114 | ]
115 | },
116 | {
117 | "cell_type": "markdown",
118 | "metadata": {},
119 | "source": [
120 | "### 実装:母平均の区間推定"
121 | ]
122 | },
123 | {
124 | "cell_type": "markdown",
125 | "metadata": {},
126 | "source": [
127 | "#### 定義通りの実装"
128 | ]
129 | },
130 | {
131 | "cell_type": "code",
132 | "execution_count": 5,
133 | "metadata": {},
134 | "outputs": [
135 | {
136 | "name": "stdout",
137 | "output_type": "stream",
138 | "text": [
139 | "サンプルサイズ: 10\n",
140 | "自由度 : 9\n",
141 | "標準偏差 : 0.825\n",
142 | "標準誤差 : 0.261\n",
143 | "標本平均 : 4.187\n"
144 | ]
145 | }
146 | ],
147 | "source": [
148 | "# 統計量の計算\n",
149 | "n = len(fish) # サンプルサイズ\n",
150 | "df = n - 1 # 自由度\n",
151 | "u = np.std(fish, ddof=1) # 標準偏差\n",
152 | "se = u / np.sqrt(n) # 標準誤差\n",
153 | "\n",
154 | "print('サンプルサイズ:', n)\n",
155 | "print('自由度 :', df)\n",
156 | "print('標準偏差 :', round(u, 3))\n",
157 | "print('標準誤差 :', round(se, 3))\n",
158 | "print('標本平均 :', round(x_bar, 3))"
159 | ]
160 | },
161 | {
162 | "cell_type": "code",
163 | "execution_count": 6,
164 | "metadata": {},
165 | "outputs": [
166 | {
167 | "name": "stdout",
168 | "output_type": "stream",
169 | "text": [
170 | "t分布の 2.5%点: -2.262\n",
171 | "t分布の97.5%点: 2.262\n"
172 | ]
173 | }
174 | ],
175 | "source": [
176 | "# 2.5%点と97.5%点\n",
177 | "t_025 = stats.t.ppf(q=0.025, df=df)\n",
178 | "t_975 = stats.t.ppf(q=0.975, df=df)\n",
179 | "\n",
180 | "print('t分布の 2.5%点:', round(t_025, 3))\n",
181 | "print('t分布の97.5%点:', round(t_975, 3))"
182 | ]
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": 7,
187 | "metadata": {},
188 | "outputs": [
189 | {
190 | "name": "stdout",
191 | "output_type": "stream",
192 | "text": [
193 | "下側信頼限界: 3.597\n",
194 | "上側信頼限界: 4.777\n"
195 | ]
196 | }
197 | ],
198 | "source": [
199 | "# 母平均の区間推定\n",
200 | "lower_mu = x_bar - t_975 * se\n",
201 | "upper_mu = x_bar - t_025 * se\n",
202 | "\n",
203 | "print('下側信頼限界:', round(lower_mu, 3))\n",
204 | "print('上側信頼限界:', round(upper_mu, 3))"
205 | ]
206 | },
207 | {
208 | "cell_type": "markdown",
209 | "metadata": {},
210 | "source": [
211 | "#### 簡単な実装方法"
212 | ]
213 | },
214 | {
215 | "cell_type": "code",
216 | "execution_count": 8,
217 | "metadata": {},
218 | "outputs": [
219 | {
220 | "data": {
221 | "text/plain": [
222 | "array([3.597, 4.777])"
223 | ]
224 | },
225 | "execution_count": 8,
226 | "metadata": {},
227 | "output_type": "execute_result"
228 | }
229 | ],
230 | "source": [
231 | "# 区間推定\n",
232 | "res_1 = stats.t.interval(alpha=0.95, df=df, loc=x_bar, scale=se)\n",
233 | "np.round(res_1, 3)"
234 | ]
235 | },
236 | {
237 | "cell_type": "markdown",
238 | "metadata": {},
239 | "source": [
240 | "### 信頼区間の幅を決める要素"
241 | ]
242 | },
243 | {
244 | "cell_type": "code",
245 | "execution_count": 9,
246 | "metadata": {},
247 | "outputs": [
248 | {
249 | "data": {
250 | "text/plain": [
251 | "array([-1.713, 10.087])"
252 | ]
253 | },
254 | "execution_count": 9,
255 | "metadata": {},
256 | "output_type": "execute_result"
257 | }
258 | ],
259 | "source": [
260 | "# 標準偏差が大きいと、信頼区間は広くなる\n",
261 | "se_2 = (u * 10) / np.sqrt(n)\n",
262 | "res_2 = stats.t.interval(alpha=0.95, df=df, loc=x_bar, scale=se_2)\n",
263 | "np.round(res_2, 3)"
264 | ]
265 | },
266 | {
267 | "cell_type": "code",
268 | "execution_count": 10,
269 | "metadata": {},
270 | "outputs": [
271 | {
272 | "data": {
273 | "text/plain": [
274 | "array([4.023, 4.351])"
275 | ]
276 | },
277 | "execution_count": 10,
278 | "metadata": {},
279 | "output_type": "execute_result"
280 | }
281 | ],
282 | "source": [
283 | "# サンプルサイズが大きいと、信頼区間は狭くなる\n",
284 | "n_2 = n * 10\n",
285 | "df_2 = n_2 - 1\n",
286 | "se_3 = u / np.sqrt(n_2)\n",
287 | "res_3 = stats.t.interval(alpha=0.95, df=df_2, loc=x_bar, scale=se_3)\n",
288 | "np.round(res_3, 3)"
289 | ]
290 | },
291 | {
292 | "cell_type": "code",
293 | "execution_count": 11,
294 | "metadata": {},
295 | "outputs": [
296 | {
297 | "data": {
298 | "text/plain": [
299 | "array([3.339, 5.035])"
300 | ]
301 | },
302 | "execution_count": 11,
303 | "metadata": {},
304 | "output_type": "execute_result"
305 | }
306 | ],
307 | "source": [
308 | "# 99%信頼区間\n",
309 | "res_4 = stats.t.interval(alpha=0.99, df=df, loc=x_bar, scale=se)\n",
310 | "np.round(res_4, 3)"
311 | ]
312 | },
313 | {
314 | "cell_type": "markdown",
315 | "metadata": {},
316 | "source": [
317 | "### 区間推定の結果の解釈"
318 | ]
319 | },
320 | {
321 | "cell_type": "code",
322 | "execution_count": 12,
323 | "metadata": {},
324 | "outputs": [],
325 | "source": [
326 | "# 母集団分布(母平均は4)\n",
327 | "norm_dist = stats.norm(loc=4, scale=0.8)"
328 | ]
329 | },
330 | {
331 | "cell_type": "code",
332 | "execution_count": 13,
333 | "metadata": {},
334 | "outputs": [],
335 | "source": [
336 | "num_trials = 20000 # シミュレーションの繰り返し数\n",
337 | "included_num = 0 # 信頼区間が母平均(4)を含んでいた回数"
338 | ]
339 | },
340 | {
341 | "cell_type": "code",
342 | "execution_count": 14,
343 | "metadata": {},
344 | "outputs": [],
345 | "source": [
346 | "# 「データを10個選んで95%信頼区間を求める」試行を20000回繰り返す\n",
347 | "np.random.seed(1) # 乱数の種\n",
348 | "for i in range(0, num_trials):\n",
349 | " # 標本の抽出\n",
350 | " sample = norm_dist.rvs(size=n)\n",
351 | " # 信頼区間の計算\n",
352 | " df = n - 1 # 自由度\n",
353 | " x_bar = np.mean(sample) # 標本平均\n",
354 | " u = np.std(sample, ddof=1) # 標準偏差\n",
355 | " se = u / np.sqrt(n) # 標準誤差\n",
356 | " interval = stats.t.interval(0.95, df, x_bar, se)\n",
357 | " # 信頼区間が母平均(4)を含んでいた回数をカウント\n",
358 | " if(interval[0] <= 4 <= interval[1]):\n",
359 | " included_num = included_num + 1"
360 | ]
361 | },
362 | {
363 | "cell_type": "code",
364 | "execution_count": 15,
365 | "metadata": {},
366 | "outputs": [
367 | {
368 | "data": {
369 | "text/plain": [
370 | "0.948"
371 | ]
372 | },
373 | "execution_count": 15,
374 | "metadata": {},
375 | "output_type": "execute_result"
376 | }
377 | ],
378 | "source": [
379 | "# 全試行中、信頼区間が母平均(4)を含んでいた割合\n",
380 | "included_num / num_trials"
381 | ]
382 | },
383 | {
384 | "cell_type": "markdown",
385 | "metadata": {},
386 | "source": [
387 | "### 実装:母分散の区間推定"
388 | ]
389 | },
390 | {
391 | "cell_type": "code",
392 | "execution_count": 16,
393 | "metadata": {},
394 | "outputs": [
395 | {
396 | "name": "stdout",
397 | "output_type": "stream",
398 | "text": [
399 | "χ2分布の 2.5%点: 2.7\n",
400 | "χ2分布の97.5%点: 19.023\n"
401 | ]
402 | }
403 | ],
404 | "source": [
405 | "# 2.5%点と97.5%点\n",
406 | "chi2_025 = stats.chi2.ppf(q=0.025, df=df)\n",
407 | "chi2_975 = stats.chi2.ppf(q=0.975, df=df)\n",
408 | "\n",
409 | "print('χ2分布の 2.5%点:', round(chi2_025, 3))\n",
410 | "print('χ2分布の97.5%点:', round(chi2_975, 3))"
411 | ]
412 | },
413 | {
414 | "cell_type": "code",
415 | "execution_count": 17,
416 | "metadata": {},
417 | "outputs": [
418 | {
419 | "name": "stdout",
420 | "output_type": "stream",
421 | "text": [
422 | "下側信頼限界: 0.322\n",
423 | "上側信頼限界: 2.267\n"
424 | ]
425 | }
426 | ],
427 | "source": [
428 | "# 母分散の区間推定\n",
429 | "upper_sigma = (n - 1) * u2 / chi2_025\n",
430 | "lower_sigma = (n - 1) * u2 / chi2_975\n",
431 | "\n",
432 | "print('下側信頼限界:', round(lower_sigma, 3))\n",
433 | "print('上側信頼限界:', round(upper_sigma, 3))"
434 | ]
435 | }
436 | ],
437 | "metadata": {
438 | "kernelspec": {
439 | "display_name": "Python 3 (ipykernel)",
440 | "language": "python",
441 | "name": "python3"
442 | },
443 | "language_info": {
444 | "codemirror_mode": {
445 | "name": "ipython",
446 | "version": 3
447 | },
448 | "file_extension": ".py",
449 | "mimetype": "text/x-python",
450 | "name": "python",
451 | "nbconvert_exporter": "python",
452 | "pygments_lexer": "ipython3",
453 | "version": "3.9.7"
454 | }
455 | },
456 | "nbformat": 4,
457 | "nbformat_minor": 2
458 | }
459 |
--------------------------------------------------------------------------------
/book-data/2-3-Pythonによるプログラミングの基本.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第2部 PythonとJupyter Notebookの基本\n",
8 | "\n",
9 | "## 3章 Pythonによるプログラミングの基本"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:四則演算"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [
24 | {
25 | "data": {
26 | "text/plain": [
27 | "2"
28 | ]
29 | },
30 | "execution_count": 1,
31 | "metadata": {},
32 | "output_type": "execute_result"
33 | }
34 | ],
35 | "source": [
36 | "1 + 1"
37 | ]
38 | },
39 | {
40 | "cell_type": "code",
41 | "execution_count": 2,
42 | "metadata": {},
43 | "outputs": [
44 | {
45 | "data": {
46 | "text/plain": [
47 | "3"
48 | ]
49 | },
50 | "execution_count": 2,
51 | "metadata": {},
52 | "output_type": "execute_result"
53 | }
54 | ],
55 | "source": [
56 | "5 - 2"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 3,
62 | "metadata": {},
63 | "outputs": [
64 | {
65 | "data": {
66 | "text/plain": [
67 | "6"
68 | ]
69 | },
70 | "execution_count": 3,
71 | "metadata": {},
72 | "output_type": "execute_result"
73 | }
74 | ],
75 | "source": [
76 | "2 * 3"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 4,
82 | "metadata": {},
83 | "outputs": [
84 | {
85 | "data": {
86 | "text/plain": [
87 | "2.0"
88 | ]
89 | },
90 | "execution_count": 4,
91 | "metadata": {},
92 | "output_type": "execute_result"
93 | }
94 | ],
95 | "source": [
96 | "6 / 3"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "### 実装:その他の演算"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 5,
109 | "metadata": {},
110 | "outputs": [
111 | {
112 | "data": {
113 | "text/plain": [
114 | "8"
115 | ]
116 | },
117 | "execution_count": 5,
118 | "metadata": {},
119 | "output_type": "execute_result"
120 | }
121 | ],
122 | "source": [
123 | "# 累乗\n",
124 | "2 ** 3"
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": 6,
130 | "metadata": {},
131 | "outputs": [
132 | {
133 | "data": {
134 | "text/plain": [
135 | "2"
136 | ]
137 | },
138 | "execution_count": 6,
139 | "metadata": {},
140 | "output_type": "execute_result"
141 | }
142 | ],
143 | "source": [
144 | "# 整数の商\n",
145 | "7 // 3"
146 | ]
147 | },
148 | {
149 | "cell_type": "code",
150 | "execution_count": 7,
151 | "metadata": {},
152 | "outputs": [
153 | {
154 | "data": {
155 | "text/plain": [
156 | "1"
157 | ]
158 | },
159 | "execution_count": 7,
160 | "metadata": {},
161 | "output_type": "execute_result"
162 | }
163 | ],
164 | "source": [
165 | "# 余り\n",
166 | "7 % 3"
167 | ]
168 | },
169 | {
170 | "cell_type": "markdown",
171 | "metadata": {},
172 | "source": [
173 | "### 実装:コメントの書き方"
174 | ]
175 | },
176 | {
177 | "cell_type": "code",
178 | "execution_count": 8,
179 | "metadata": {},
180 | "outputs": [],
181 | "source": [
182 | "# 1 + 1"
183 | ]
184 | },
185 | {
186 | "cell_type": "markdown",
187 | "metadata": {
188 | "collapsed": true
189 | },
190 | "source": [
191 | "### 実装:データの型"
192 | ]
193 | },
194 | {
195 | "cell_type": "markdown",
196 | "metadata": {},
197 | "source": [
198 | "#### 文字列型"
199 | ]
200 | },
201 | {
202 | "cell_type": "code",
203 | "execution_count": 9,
204 | "metadata": {},
205 | "outputs": [
206 | {
207 | "data": {
208 | "text/plain": [
209 | "'A'"
210 | ]
211 | },
212 | "execution_count": 9,
213 | "metadata": {},
214 | "output_type": "execute_result"
215 | }
216 | ],
217 | "source": [
218 | "\"A\""
219 | ]
220 | },
221 | {
222 | "cell_type": "code",
223 | "execution_count": 10,
224 | "metadata": {},
225 | "outputs": [
226 | {
227 | "data": {
228 | "text/plain": [
229 | "'A'"
230 | ]
231 | },
232 | "execution_count": 10,
233 | "metadata": {},
234 | "output_type": "execute_result"
235 | }
236 | ],
237 | "source": [
238 | "'A'"
239 | ]
240 | },
241 | {
242 | "cell_type": "code",
243 | "execution_count": 11,
244 | "metadata": {},
245 | "outputs": [
246 | {
247 | "data": {
248 | "text/plain": [
249 | "str"
250 | ]
251 | },
252 | "execution_count": 11,
253 | "metadata": {},
254 | "output_type": "execute_result"
255 | }
256 | ],
257 | "source": [
258 | "# 文字列型\n",
259 | "type('A')"
260 | ]
261 | },
262 | {
263 | "cell_type": "code",
264 | "execution_count": 12,
265 | "metadata": {},
266 | "outputs": [
267 | {
268 | "data": {
269 | "text/plain": [
270 | "str"
271 | ]
272 | },
273 | "execution_count": 12,
274 | "metadata": {},
275 | "output_type": "execute_result"
276 | }
277 | ],
278 | "source": [
279 | "# 文字列型\n",
280 | "type(\"A\")"
281 | ]
282 | },
283 | {
284 | "cell_type": "markdown",
285 | "metadata": {},
286 | "source": [
287 | "#### 整数型・浮動小数点型"
288 | ]
289 | },
290 | {
291 | "cell_type": "code",
292 | "execution_count": 13,
293 | "metadata": {},
294 | "outputs": [
295 | {
296 | "data": {
297 | "text/plain": [
298 | "int"
299 | ]
300 | },
301 | "execution_count": 13,
302 | "metadata": {},
303 | "output_type": "execute_result"
304 | }
305 | ],
306 | "source": [
307 | "# 整数型\n",
308 | "type(1)"
309 | ]
310 | },
311 | {
312 | "cell_type": "code",
313 | "execution_count": 14,
314 | "metadata": {},
315 | "outputs": [
316 | {
317 | "data": {
318 | "text/plain": [
319 | "float"
320 | ]
321 | },
322 | "execution_count": 14,
323 | "metadata": {},
324 | "output_type": "execute_result"
325 | }
326 | ],
327 | "source": [
328 | "# 浮動小数点\n",
329 | "type(2.4)"
330 | ]
331 | },
332 | {
333 | "cell_type": "markdown",
334 | "metadata": {},
335 | "source": [
336 | "#### ブール型"
337 | ]
338 | },
339 | {
340 | "cell_type": "code",
341 | "execution_count": 15,
342 | "metadata": {},
343 | "outputs": [
344 | {
345 | "data": {
346 | "text/plain": [
347 | "bool"
348 | ]
349 | },
350 | "execution_count": 15,
351 | "metadata": {},
352 | "output_type": "execute_result"
353 | }
354 | ],
355 | "source": [
356 | "# ブール型\n",
357 | "type(True)"
358 | ]
359 | },
360 | {
361 | "cell_type": "code",
362 | "execution_count": 16,
363 | "metadata": {},
364 | "outputs": [
365 | {
366 | "data": {
367 | "text/plain": [
368 | "bool"
369 | ]
370 | },
371 | "execution_count": 16,
372 | "metadata": {},
373 | "output_type": "execute_result"
374 | }
375 | ],
376 | "source": [
377 | "# ブール型\n",
378 | "type(False)"
379 | ]
380 | },
381 | {
382 | "cell_type": "markdown",
383 | "metadata": {},
384 | "source": [
385 | "#### 異なるデータ型の間での演算"
386 | ]
387 | },
388 | {
389 | "cell_type": "code",
390 | "execution_count": 17,
391 | "metadata": {},
392 | "outputs": [
393 | {
394 | "ename": "TypeError",
395 | "evalue": "can only concatenate str (not \"int\") to str",
396 | "output_type": "error",
397 | "traceback": [
398 | "\u001b[1;31m---------------------------------------------------------------------------\u001b[0m",
399 | "\u001b[1;31mTypeError\u001b[0m Traceback (most recent call last)",
400 | "\u001b[1;32m~\\AppData\\Local\\Temp/ipykernel_3200/2400233845.py\u001b[0m in \u001b[0;36m\u001b[1;34m\u001b[0m\n\u001b[1;32m----> 1\u001b[1;33m \u001b[1;34m'A'\u001b[0m \u001b[1;33m+\u001b[0m \u001b[1;36m1\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0m",
401 | "\u001b[1;31mTypeError\u001b[0m: can only concatenate str (not \"int\") to str"
402 | ]
403 | }
404 | ],
405 | "source": [
406 | "'A' + 1"
407 | ]
408 | },
409 | {
410 | "cell_type": "markdown",
411 | "metadata": {},
412 | "source": [
413 | "### 実装:比較演算"
414 | ]
415 | },
416 | {
417 | "cell_type": "code",
418 | "execution_count": 18,
419 | "metadata": {},
420 | "outputs": [
421 | {
422 | "data": {
423 | "text/plain": [
424 | "True"
425 | ]
426 | },
427 | "execution_count": 18,
428 | "metadata": {},
429 | "output_type": "execute_result"
430 | }
431 | ],
432 | "source": [
433 | "1 > 0.89"
434 | ]
435 | },
436 | {
437 | "cell_type": "code",
438 | "execution_count": 19,
439 | "metadata": {},
440 | "outputs": [
441 | {
442 | "data": {
443 | "text/plain": [
444 | "True"
445 | ]
446 | },
447 | "execution_count": 19,
448 | "metadata": {},
449 | "output_type": "execute_result"
450 | }
451 | ],
452 | "source": [
453 | "3 >= 2"
454 | ]
455 | },
456 | {
457 | "cell_type": "code",
458 | "execution_count": 20,
459 | "metadata": {},
460 | "outputs": [
461 | {
462 | "data": {
463 | "text/plain": [
464 | "False"
465 | ]
466 | },
467 | "execution_count": 20,
468 | "metadata": {},
469 | "output_type": "execute_result"
470 | }
471 | ],
472 | "source": [
473 | "3 < 2"
474 | ]
475 | },
476 | {
477 | "cell_type": "code",
478 | "execution_count": 21,
479 | "metadata": {},
480 | "outputs": [
481 | {
482 | "data": {
483 | "text/plain": [
484 | "False"
485 | ]
486 | },
487 | "execution_count": 21,
488 | "metadata": {},
489 | "output_type": "execute_result"
490 | }
491 | ],
492 | "source": [
493 | "3 <= 2"
494 | ]
495 | },
496 | {
497 | "cell_type": "code",
498 | "execution_count": 22,
499 | "metadata": {},
500 | "outputs": [
501 | {
502 | "data": {
503 | "text/plain": [
504 | "False"
505 | ]
506 | },
507 | "execution_count": 22,
508 | "metadata": {},
509 | "output_type": "execute_result"
510 | }
511 | ],
512 | "source": [
513 | "3 == 2"
514 | ]
515 | },
516 | {
517 | "cell_type": "code",
518 | "execution_count": 23,
519 | "metadata": {},
520 | "outputs": [
521 | {
522 | "data": {
523 | "text/plain": [
524 | "True"
525 | ]
526 | },
527 | "execution_count": 23,
528 | "metadata": {},
529 | "output_type": "execute_result"
530 | }
531 | ],
532 | "source": [
533 | "3 != 2"
534 | ]
535 | },
536 | {
537 | "cell_type": "markdown",
538 | "metadata": {},
539 | "source": [
540 | "### 実装:変数"
541 | ]
542 | },
543 | {
544 | "cell_type": "code",
545 | "execution_count": 24,
546 | "metadata": {},
547 | "outputs": [],
548 | "source": [
549 | "x = 100"
550 | ]
551 | },
552 | {
553 | "cell_type": "code",
554 | "execution_count": 25,
555 | "metadata": {},
556 | "outputs": [
557 | {
558 | "data": {
559 | "text/plain": [
560 | "100"
561 | ]
562 | },
563 | "execution_count": 25,
564 | "metadata": {},
565 | "output_type": "execute_result"
566 | }
567 | ],
568 | "source": [
569 | "x"
570 | ]
571 | },
572 | {
573 | "cell_type": "code",
574 | "execution_count": 26,
575 | "metadata": {},
576 | "outputs": [
577 | {
578 | "data": {
579 | "text/plain": [
580 | "293"
581 | ]
582 | },
583 | "execution_count": 26,
584 | "metadata": {},
585 | "output_type": "execute_result"
586 | }
587 | ],
588 | "source": [
589 | "x = 293\n",
590 | "x"
591 | ]
592 | },
593 | {
594 | "cell_type": "code",
595 | "execution_count": 27,
596 | "metadata": {},
597 | "outputs": [
598 | {
599 | "ename": "SyntaxError",
600 | "evalue": "cannot assign to literal (Temp/ipykernel_3200/3756881235.py, line 2)",
601 | "output_type": "error",
602 | "traceback": [
603 | "\u001b[1;36m File \u001b[1;32m\"C:\\Users\\black\\AppData\\Local\\Temp/ipykernel_3200/3756881235.py\"\u001b[1;36m, line \u001b[1;32m2\u001b[0m\n\u001b[1;33m 100 = 293\u001b[0m\n\u001b[1;37m ^\u001b[0m\n\u001b[1;31mSyntaxError\u001b[0m\u001b[1;31m:\u001b[0m cannot assign to literal\n"
604 | ]
605 | }
606 | ],
607 | "source": [
608 | "# 参考までに、以下のコードはエラーになる\n",
609 | "100 = 293"
610 | ]
611 | },
612 | {
613 | "cell_type": "code",
614 | "execution_count": 28,
615 | "metadata": {},
616 | "outputs": [
617 | {
618 | "ename": "NameError",
619 | "evalue": "name 'y' is not defined",
620 | "output_type": "error",
621 | "traceback": [
622 | "\u001b[1;31m---------------------------------------------------------------------------\u001b[0m",
623 | "\u001b[1;31mNameError\u001b[0m Traceback (most recent call last)",
624 | "\u001b[1;32m~\\AppData\\Local\\Temp/ipykernel_3200/3563912222.py\u001b[0m in \u001b[0;36m\u001b[1;34m\u001b[0m\n\u001b[1;32m----> 1\u001b[1;33m \u001b[0my\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0m",
625 | "\u001b[1;31mNameError\u001b[0m: name 'y' is not defined"
626 | ]
627 | }
628 | ],
629 | "source": [
630 | "y"
631 | ]
632 | },
633 | {
634 | "cell_type": "code",
635 | "execution_count": 29,
636 | "metadata": {},
637 | "outputs": [
638 | {
639 | "data": {
640 | "text/plain": [
641 | "50"
642 | ]
643 | },
644 | "execution_count": 29,
645 | "metadata": {},
646 | "output_type": "execute_result"
647 | }
648 | ],
649 | "source": [
650 | "y = 50\n",
651 | "y"
652 | ]
653 | },
654 | {
655 | "cell_type": "code",
656 | "execution_count": 30,
657 | "metadata": {},
658 | "outputs": [
659 | {
660 | "data": {
661 | "text/plain": [
662 | "343"
663 | ]
664 | },
665 | "execution_count": 30,
666 | "metadata": {},
667 | "output_type": "execute_result"
668 | }
669 | ],
670 | "source": [
671 | "x + y"
672 | ]
673 | },
674 | {
675 | "cell_type": "markdown",
676 | "metadata": {},
677 | "source": [
678 | "### 実装:関数"
679 | ]
680 | },
681 | {
682 | "cell_type": "code",
683 | "execution_count": 31,
684 | "metadata": {},
685 | "outputs": [
686 | {
687 | "data": {
688 | "text/plain": [
689 | "208"
690 | ]
691 | },
692 | "execution_count": 31,
693 | "metadata": {},
694 | "output_type": "execute_result"
695 | }
696 | ],
697 | "source": [
698 | "(y + 2) * 4"
699 | ]
700 | },
701 | {
702 | "cell_type": "code",
703 | "execution_count": 32,
704 | "metadata": {},
705 | "outputs": [],
706 | "source": [
707 | "def sample_function(data):\n",
708 | " return (data + 2) * 4"
709 | ]
710 | },
711 | {
712 | "cell_type": "code",
713 | "execution_count": 33,
714 | "metadata": {},
715 | "outputs": [
716 | {
717 | "data": {
718 | "text/plain": [
719 | "208"
720 | ]
721 | },
722 | "execution_count": 33,
723 | "metadata": {},
724 | "output_type": "execute_result"
725 | }
726 | ],
727 | "source": [
728 | "sample_function(data=y)"
729 | ]
730 | },
731 | {
732 | "cell_type": "code",
733 | "execution_count": 34,
734 | "metadata": {},
735 | "outputs": [
736 | {
737 | "data": {
738 | "text/plain": [
739 | "208"
740 | ]
741 | },
742 | "execution_count": 34,
743 | "metadata": {},
744 | "output_type": "execute_result"
745 | }
746 | ],
747 | "source": [
748 | "# 引数の名前は省略できる\n",
749 | "sample_function(y)"
750 | ]
751 | },
752 | {
753 | "cell_type": "code",
754 | "execution_count": 35,
755 | "metadata": {},
756 | "outputs": [
757 | {
758 | "data": {
759 | "text/plain": [
760 | "20"
761 | ]
762 | },
763 | "execution_count": 35,
764 | "metadata": {},
765 | "output_type": "execute_result"
766 | }
767 | ],
768 | "source": [
769 | "sample_function(3)"
770 | ]
771 | },
772 | {
773 | "cell_type": "code",
774 | "execution_count": 36,
775 | "metadata": {},
776 | "outputs": [
777 | {
778 | "data": {
779 | "text/plain": [
780 | "228"
781 | ]
782 | },
783 | "execution_count": 36,
784 | "metadata": {},
785 | "output_type": "execute_result"
786 | }
787 | ],
788 | "source": [
789 | "sample_function(y) + sample_function(3)"
790 | ]
791 | },
792 | {
793 | "cell_type": "markdown",
794 | "metadata": {},
795 | "source": [
796 | "### 実装:頻繁に使う関数"
797 | ]
798 | },
799 | {
800 | "cell_type": "markdown",
801 | "metadata": {},
802 | "source": [
803 | "#### print関数"
804 | ]
805 | },
806 | {
807 | "cell_type": "code",
808 | "execution_count": 37,
809 | "metadata": {},
810 | "outputs": [
811 | {
812 | "name": "stdout",
813 | "output_type": "stream",
814 | "text": [
815 | "2\n"
816 | ]
817 | }
818 | ],
819 | "source": [
820 | "print(1 + 1)"
821 | ]
822 | },
823 | {
824 | "cell_type": "code",
825 | "execution_count": 38,
826 | "metadata": {},
827 | "outputs": [
828 | {
829 | "name": "stdout",
830 | "output_type": "stream",
831 | "text": [
832 | "今から計算をします:計算結果は 2\n"
833 | ]
834 | }
835 | ],
836 | "source": [
837 | "print('今から計算をします:計算結果は', 1 + 1)"
838 | ]
839 | },
840 | {
841 | "cell_type": "code",
842 | "execution_count": 39,
843 | "metadata": {},
844 | "outputs": [
845 | {
846 | "data": {
847 | "text/plain": [
848 | "4"
849 | ]
850 | },
851 | "execution_count": 39,
852 | "metadata": {},
853 | "output_type": "execute_result"
854 | }
855 | ],
856 | "source": [
857 | "# 最後の数値だけが出力される\n",
858 | "1 + 1\n",
859 | "1 + 3"
860 | ]
861 | },
862 | {
863 | "cell_type": "code",
864 | "execution_count": 40,
865 | "metadata": {},
866 | "outputs": [
867 | {
868 | "name": "stdout",
869 | "output_type": "stream",
870 | "text": [
871 | "2\n",
872 | "4\n"
873 | ]
874 | }
875 | ],
876 | "source": [
877 | "# 両方出力される\n",
878 | "print(1 + 1)\n",
879 | "print(1 + 3)"
880 | ]
881 | },
882 | {
883 | "cell_type": "markdown",
884 | "metadata": {},
885 | "source": [
886 | "#### round関数"
887 | ]
888 | },
889 | {
890 | "cell_type": "code",
891 | "execution_count": 41,
892 | "metadata": {},
893 | "outputs": [
894 | {
895 | "name": "stdout",
896 | "output_type": "stream",
897 | "text": [
898 | "1.234を丸めた結果 1\n",
899 | "1.963を丸めた結果 2\n"
900 | ]
901 | }
902 | ],
903 | "source": [
904 | "print('1.234を丸めた結果', round(1.234))\n",
905 | "print('1.963を丸めた結果', round(1.963))"
906 | ]
907 | },
908 | {
909 | "cell_type": "code",
910 | "execution_count": 42,
911 | "metadata": {},
912 | "outputs": [
913 | {
914 | "data": {
915 | "text/plain": [
916 | "1.23"
917 | ]
918 | },
919 | "execution_count": 42,
920 | "metadata": {},
921 | "output_type": "execute_result"
922 | }
923 | ],
924 | "source": [
925 | "round(1.234, ndigits=2)"
926 | ]
927 | },
928 | {
929 | "cell_type": "code",
930 | "execution_count": 43,
931 | "metadata": {},
932 | "outputs": [
933 | {
934 | "name": "stdout",
935 | "output_type": "stream",
936 | "text": [
937 | "2.5を丸めた結果 2\n",
938 | "3.5を丸めた結果 4\n"
939 | ]
940 | }
941 | ],
942 | "source": [
943 | "# 通常の四捨五入とは異なるので注意\n",
944 | "print('2.5を丸めた結果', round(2.5))\n",
945 | "print('3.5を丸めた結果', round(3.5))"
946 | ]
947 | },
948 | {
949 | "cell_type": "markdown",
950 | "metadata": {
951 | "collapsed": true
952 | },
953 | "source": [
954 | "### 実装:クラスとインスタンス"
955 | ]
956 | },
957 | {
958 | "cell_type": "code",
959 | "execution_count": 44,
960 | "metadata": {},
961 | "outputs": [],
962 | "source": [
963 | "class Sample_Class:\n",
964 | " def __init__(self, data1, data2):\n",
965 | " self.data1 = data1\n",
966 | " self.data2 = data2\n",
967 | " \n",
968 | " def method2(self):\n",
969 | " return self.data1 + self.data2"
970 | ]
971 | },
972 | {
973 | "cell_type": "code",
974 | "execution_count": 45,
975 | "metadata": {},
976 | "outputs": [],
977 | "source": [
978 | "sample_instance = Sample_Class(data1=2, data2=3)"
979 | ]
980 | },
981 | {
982 | "cell_type": "code",
983 | "execution_count": 46,
984 | "metadata": {},
985 | "outputs": [
986 | {
987 | "data": {
988 | "text/plain": [
989 | "2"
990 | ]
991 | },
992 | "execution_count": 46,
993 | "metadata": {},
994 | "output_type": "execute_result"
995 | }
996 | ],
997 | "source": [
998 | "sample_instance.data1"
999 | ]
1000 | },
1001 | {
1002 | "cell_type": "code",
1003 | "execution_count": 47,
1004 | "metadata": {},
1005 | "outputs": [
1006 | {
1007 | "data": {
1008 | "text/plain": [
1009 | "5"
1010 | ]
1011 | },
1012 | "execution_count": 47,
1013 | "metadata": {},
1014 | "output_type": "execute_result"
1015 | }
1016 | ],
1017 | "source": [
1018 | "sample_instance.method2()"
1019 | ]
1020 | },
1021 | {
1022 | "cell_type": "markdown",
1023 | "metadata": {},
1024 | "source": [
1025 | "### 実装:if構文による分岐"
1026 | ]
1027 | },
1028 | {
1029 | "cell_type": "code",
1030 | "execution_count": 48,
1031 | "metadata": {},
1032 | "outputs": [
1033 | {
1034 | "name": "stdout",
1035 | "output_type": "stream",
1036 | "text": [
1037 | "2より小さいデータです\n"
1038 | ]
1039 | }
1040 | ],
1041 | "source": [
1042 | "data = 1\n",
1043 | "if(data < 2):\n",
1044 | " print('2より小さいデータです')\n",
1045 | "else:\n",
1046 | " print('2以上のデータです')"
1047 | ]
1048 | },
1049 | {
1050 | "cell_type": "code",
1051 | "execution_count": 49,
1052 | "metadata": {},
1053 | "outputs": [
1054 | {
1055 | "name": "stdout",
1056 | "output_type": "stream",
1057 | "text": [
1058 | "2以上のデータです\n"
1059 | ]
1060 | }
1061 | ],
1062 | "source": [
1063 | "data = 3\n",
1064 | "if(data < 2):\n",
1065 | " print('2より小さいデータです')\n",
1066 | "else:\n",
1067 | " print('2以上のデータです')"
1068 | ]
1069 | },
1070 | {
1071 | "cell_type": "markdown",
1072 | "metadata": {},
1073 | "source": [
1074 | "### 実装:for構文による繰り返し"
1075 | ]
1076 | },
1077 | {
1078 | "cell_type": "code",
1079 | "execution_count": 50,
1080 | "metadata": {},
1081 | "outputs": [
1082 | {
1083 | "data": {
1084 | "text/plain": [
1085 | "range(0, 3)"
1086 | ]
1087 | },
1088 | "execution_count": 50,
1089 | "metadata": {},
1090 | "output_type": "execute_result"
1091 | }
1092 | ],
1093 | "source": [
1094 | "range(0, 3)"
1095 | ]
1096 | },
1097 | {
1098 | "cell_type": "code",
1099 | "execution_count": 51,
1100 | "metadata": {},
1101 | "outputs": [
1102 | {
1103 | "name": "stdout",
1104 | "output_type": "stream",
1105 | "text": [
1106 | "0\n",
1107 | "1\n",
1108 | "2\n"
1109 | ]
1110 | }
1111 | ],
1112 | "source": [
1113 | "for i in range(0, 3):\n",
1114 | " print(i)"
1115 | ]
1116 | },
1117 | {
1118 | "cell_type": "code",
1119 | "execution_count": 52,
1120 | "metadata": {},
1121 | "outputs": [
1122 | {
1123 | "name": "stdout",
1124 | "output_type": "stream",
1125 | "text": [
1126 | "hello\n",
1127 | "hello\n",
1128 | "hello\n"
1129 | ]
1130 | }
1131 | ],
1132 | "source": [
1133 | "for i in range(0, 3):\n",
1134 | " print('hello')"
1135 | ]
1136 | }
1137 | ],
1138 | "metadata": {
1139 | "kernelspec": {
1140 | "display_name": "Python 3 (ipykernel)",
1141 | "language": "python",
1142 | "name": "python3"
1143 | },
1144 | "language_info": {
1145 | "codemirror_mode": {
1146 | "name": "ipython",
1147 | "version": 3
1148 | },
1149 | "file_extension": ".py",
1150 | "mimetype": "text/x-python",
1151 | "name": "python",
1152 | "nbconvert_exporter": "python",
1153 | "pygments_lexer": "ipython3",
1154 | "version": "3.9.7"
1155 | }
1156 | },
1157 | "nbformat": 4,
1158 | "nbformat_minor": 2
1159 | }
1160 |
--------------------------------------------------------------------------------
/book-data/5-4-母分散の推定.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第5部 統計的推定\n",
8 | "\n",
9 | "## 4章 母分散の推定"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd\n",
28 | "from scipy import stats\n",
29 | "\n",
30 | "# グラフを描画するライブラリ\n",
31 | "from matplotlib import pyplot as plt\n",
32 | "import seaborn as sns\n",
33 | "sns.set()\n",
34 | "\n",
35 | "# グラフの日本語表記\n",
36 | "from matplotlib import rcParams\n",
37 | "rcParams['font.family'] = 'sans-serif'\n",
38 | "rcParams['font.sans-serif'] = 'Meiryo'"
39 | ]
40 | },
41 | {
42 | "cell_type": "code",
43 | "execution_count": 2,
44 | "metadata": {},
45 | "outputs": [],
46 | "source": [
47 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
48 | "np.set_printoptions(linewidth=60)\n",
49 | "pd.set_option('display.width', 60)\n",
50 | "\n",
51 | "from matplotlib.pylab import rcParams\n",
52 | "rcParams['figure.figsize'] = 8, 4"
53 | ]
54 | },
55 | {
56 | "cell_type": "markdown",
57 | "metadata": {},
58 | "source": [
59 | "### 実装:母集団の用意"
60 | ]
61 | },
62 | {
63 | "cell_type": "code",
64 | "execution_count": 3,
65 | "metadata": {},
66 | "outputs": [],
67 | "source": [
68 | "# 平均4、標準偏差0.8の正規分布を使いまわす\n",
69 | "population = stats.norm(loc=4, scale=0.8)"
70 | ]
71 | },
72 | {
73 | "cell_type": "markdown",
74 | "metadata": {},
75 | "source": [
76 | "### 実装:標本分散と不偏分散を計算する"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 4,
82 | "metadata": {},
83 | "outputs": [
84 | {
85 | "data": {
86 | "text/plain": [
87 | "array([3.66659372, 3.95498654, 2.29104312, 5.31221665,\n",
88 | " 2.56525153, 3.32660211, 4.40230513, 3.00376953,\n",
89 | " 3.15363822, 3.27279391])"
90 | ]
91 | },
92 | "execution_count": 4,
93 | "metadata": {},
94 | "output_type": "execute_result"
95 | }
96 | ],
97 | "source": [
98 | "np.random.seed(2)\n",
99 | "sample = population.rvs(size=10)\n",
100 | "sample"
101 | ]
102 | },
103 | {
104 | "cell_type": "code",
105 | "execution_count": 5,
106 | "metadata": {},
107 | "outputs": [
108 | {
109 | "name": "stdout",
110 | "output_type": "stream",
111 | "text": [
112 | "標本分散 0.712\n",
113 | "不偏分散 0.791\n"
114 | ]
115 | }
116 | ],
117 | "source": [
118 | "print('標本分散', round(np.var(sample, ddof=0), 3))\n",
119 | "print('不偏分散', round(np.var(sample, ddof=1), 3))"
120 | ]
121 | },
122 | {
123 | "cell_type": "markdown",
124 | "metadata": {},
125 | "source": [
126 | "### 実装:標本分散の平均値"
127 | ]
128 | },
129 | {
130 | "cell_type": "code",
131 | "execution_count": 6,
132 | "metadata": {},
133 | "outputs": [],
134 | "source": [
135 | "# 「標本分散」を格納する入れ物\n",
136 | "sample_var_array = np.zeros(10000)"
137 | ]
138 | },
139 | {
140 | "cell_type": "code",
141 | "execution_count": 7,
142 | "metadata": {},
143 | "outputs": [],
144 | "source": [
145 | "# 「データを10個選んで標本分散を求める」試行を10000回繰り返す\n",
146 | "np.random.seed(1)\n",
147 | "for i in range(0, 10000):\n",
148 | " sample_loop = population.rvs(size=10)\n",
149 | " sample_var_array[i] = np.var(sample_loop, ddof=0)"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": 8,
155 | "metadata": {},
156 | "outputs": [
157 | {
158 | "data": {
159 | "text/plain": [
160 | "0.575"
161 | ]
162 | },
163 | "execution_count": 8,
164 | "metadata": {},
165 | "output_type": "execute_result"
166 | }
167 | ],
168 | "source": [
169 | "# 標本分散の平均値\n",
170 | "round(np.mean(sample_var_array), 3)"
171 | ]
172 | },
173 | {
174 | "cell_type": "markdown",
175 | "metadata": {},
176 | "source": [
177 | "### 実装:不偏分散の平均値"
178 | ]
179 | },
180 | {
181 | "cell_type": "code",
182 | "execution_count": 9,
183 | "metadata": {},
184 | "outputs": [
185 | {
186 | "data": {
187 | "text/plain": [
188 | "0.639"
189 | ]
190 | },
191 | "execution_count": 9,
192 | "metadata": {},
193 | "output_type": "execute_result"
194 | }
195 | ],
196 | "source": [
197 | "# 「不偏分散」を格納する入れ物\n",
198 | "unbias_var_array = np.zeros(10000)\n",
199 | "# 「データを10個選んで不偏分散を求める」試行を10000回繰り返す\n",
200 | "np.random.seed(1)\n",
201 | "for i in range(0, 10000):\n",
202 | " sample_loop = population.rvs(size=10)\n",
203 | " unbias_var_array[i] = np.var(sample_loop, ddof=1)\n",
204 | "# 不偏分散の平均値\n",
205 | "round(np.mean(unbias_var_array), 3)"
206 | ]
207 | },
208 | {
209 | "cell_type": "markdown",
210 | "metadata": {},
211 | "source": [
212 | "### 実装:サンプルサイズを大きくしたときの不偏分散"
213 | ]
214 | },
215 | {
216 | "cell_type": "code",
217 | "execution_count": 10,
218 | "metadata": {
219 | "scrolled": true
220 | },
221 | "outputs": [
222 | {
223 | "data": {
224 | "text/plain": [
225 | "array([ 10, 110, 210, ..., 99810, 99910, 100010])"
226 | ]
227 | },
228 | "execution_count": 10,
229 | "metadata": {},
230 | "output_type": "execute_result"
231 | }
232 | ],
233 | "source": [
234 | "# サンプルサイズを10~100010までの範囲で100区切りで変化させる\n",
235 | "size_array = np.arange(start=10, stop=100100, step=100)\n",
236 | "size_array"
237 | ]
238 | },
239 | {
240 | "cell_type": "code",
241 | "execution_count": 11,
242 | "metadata": {},
243 | "outputs": [],
244 | "source": [
245 | "# 「不偏分散」を格納する入れ物\n",
246 | "unbias_var_array_size = np.zeros(len(size_array))"
247 | ]
248 | },
249 | {
250 | "cell_type": "code",
251 | "execution_count": 12,
252 | "metadata": {},
253 | "outputs": [],
254 | "source": [
255 | "# 「不偏分散を求める」試行を、サンプルサイズを変えながら何度も実行\n",
256 | "np.random.seed(1)\n",
257 | "for i in range(0, len(size_array)):\n",
258 | " sample_loop = population.rvs(size=size_array[i])\n",
259 | " unbias_var_array_size[i] = np.var(sample_loop, ddof=1)"
260 | ]
261 | },
262 | {
263 | "cell_type": "code",
264 | "execution_count": 13,
265 | "metadata": {},
266 | "outputs": [
267 | {
268 | "name": "stdout",
269 | "output_type": "stream",
270 | "text": [
271 | " sample_size unbias_var\n",
272 | "0 10 1.008526\n",
273 | "1 110 0.460805\n",
274 | "2 210 0.631723\n"
275 | ]
276 | }
277 | ],
278 | "source": [
279 | "# データフレームにまとめる\n",
280 | "size_var_df = pd.DataFrame({\n",
281 | " 'sample_size': size_array,\n",
282 | " 'unbias_var': unbias_var_array_size\n",
283 | "})\n",
284 | "\n",
285 | "print(size_var_df.head(3))"
286 | ]
287 | },
288 | {
289 | "cell_type": "code",
290 | "execution_count": 14,
291 | "metadata": {},
292 | "outputs": [
293 | {
294 | "data": {
295 | "text/plain": [
296 | ""
297 | ]
298 | },
299 | "execution_count": 14,
300 | "metadata": {},
301 | "output_type": "execute_result"
302 | },
303 | {
304 | "data": {
305 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAfgAAAELCAYAAAA1LpTIAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjQuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/MnkTPAAAACXBIWXMAAAsTAAALEwEAmpwYAAA6iklEQVR4nO3dd1hTZ/8G8DsMAQUUEHBSpcNRR1/H66gTWwcOEAVtrRbrelutVqij7oUba611W1etiHtUsTjrFltRWycqQwSCiAwHQvL8/uDHKTEhBEPAxPtzXee6ck7OePIl5D7POScnMiGEABEREZkUs9JuABERERU/BjwREZEJYsATERGZIAY8ERGRCWLAExERmSAGPBERkQliwBMREZkgi9JuQHFKTX0CpbJ4vtbv5GSLlJTMYlnXm4x11B9rqD/WUH+sof6Ku4ZmZjI4OJQr8HmTCnilUhRbwOetj/THOuqPNdQfa6g/1lB/JVlDHqInIiIyQQx4IiIiE8SAJyIiMkEMeCIiIhPEgCciIjJBDHgiIiITVGIBn5aWhk6dOiExMVHj80IILF26FL1790avXr2wdOnSkmqamtjYGLi5uSE+/n6ptYGIiEgfJRLwP//8M3r27Im4uLgC5zl06BCuXLmCrVu3IjQ0FJGRkTh06FBJNE9NTEw04uLiEBsbUyrbJyIi0leJBPwXX3yBo0ePolKlSgXOc+LECXh5ecHc3Bzm5ubw8vLC8ePHS6J5BRKCN3UgIiLj9Nqcg09KSoKzs7M07uLigqSkpFJpi0wmK5XtEhERFZfX5la1mnrLRQ1aJyfbYmlLhQplAQDly9vA2dmuWNb5JmMN9cca6o811B9rqL+SrOFrE/Curq5ITk6WxpOTk+Hi4lKkdaSkZBbLfX7T0p4BAB4/fork5Ay91/cmc3a2Yw31xBrqjzXUH2uov+KuoZmZTGvHtlQP0cfGxiIjI/fFtm7dGvv27YNSqYRSqcT+/fvRtm3b0mwez8ETEZHRKpGADwkJwaBBg/Dw4UOMGTMG8+bNAwD4+/sjPDwcAODp6YlatWrB19cXvr6+qFOnDjp16lQSzVPDc/BERGTsSuQQfd++fdG3b1+16UePHpUey2QyjB49GqNHjy6JJumEPXgiIjJWr81V9K8T9uCJiMjYMeC1YA+eiIiMFQNeA/bgiYjI2DHgtWAPnoiIjBUDXiP24ImIyLgx4LVgD56IiIwVA16DvHPwDHgiIjJWDHgNeJEdEREZOwa8FuzBExGRsWLAa8AOPBERGTsGvFbswRMRkXFiwGvAc/BERGTsGPBa8Bw8EREZKwa8BuzBExGRsWPAa8EePBERGSsGvAbswRMRkbFjwGvBHjwRERkrBrwG7METEZGxY8BrwR48EREZKwa8BuzBExGRsWPAa8EOPBERGSsGvAbswRMRkbFjwGvBc/BERGSsGPAasAdPRETGjgGvBXvwRERkrBjwGuT14BnwRERkrBjwGvEQPRERGTeLktjIpUuXMG/ePCgUCjg4OCAoKAjOzs4q82RmZmLmzJmIjo5GTk4OOnfujCFDhpRE8wrEHjwRERkrg/fgs7KyEBAQgPnz52Pbtm3o3r07Jk+erDbf/Pnz8d5772Hr1q3YsmULzp49i6NHjxq6eRrxIjsiIjJ2Bg/4y5cvw93dHW5ubgAAT09PXLx4ETk5OSrz/fXXX/Dw8AAAlClTBn369EF4eLihm6cVe/BERGSsDB7wSUlJcHFxkcbNzc1hb2+PlJQUlflq1aqF/fv3S6Ganp4OuVxu6OZpxB48EREZO4Ofgy+oF/xyiE6cOBELFixAr1694ODgACcnJ9ja2hZpW05ORZu/II6O5QAA9vbWcHa2K5Z1vslYQ/2xhvpjDfXHGuqvJGto8IB3dXVV6YkrlUqkp6fD0dFRZT5HR0fMmTNHGg8ODoaTk1ORtpWSkgmlUv/D6qmpTwEAaWnPkJycoff63mTOznasoZ5YQ/2xhvpjDfVX3DU0M5Np7dga/BB9w4YNERUVhbi4OABAWFgYGjduDAsLC8TGxiIjQ/3F/vnnnzhy5Ah69epl6OYVgufgiYjIOBm8B29tbY3g4GAEBgZCCIHy5csjKCgIAODv748RI0bAx8cHiYmJGDhwIGxsbFCtWjWsXLkSdnalcziI5+CJiMjYlcj34Js0aYLQ0FC16fm/BlepUiUcPHiwJJqjM15FT0RExop3stOAPXgiIjJ2DHgt2IMnIiJjxYDXgD14IiIydgx4LdiDJyIiY8WA14A9eCIiMnYMeC3YgyciImPFgNeAPXgiIjJ2DHgt2IMnIiJjxYDXIK8Hz4AnIiJjxYDXgEfoiYjI2DHgtWAPnoiIjBUDXgNeZEdERMaOAa8Fe/BERGSsGPAasQdPRETGjQGvBXvwRERkrBjwGvAcPBERGTsGvBbswRMRkbFiwGvAHjwRERk7BrwW7METEZGxYsBrwB48EREZOwY8ERGRCWLAa8AePBERGTsGvBY8B09ERMaKAa8Be/BERGTsdA74y5cvG7IdryX24ImIyFjpHPBfffWVIdvxWmEPnoiIjJ3OAV+jRg08fvzYgE15/bAHT0RExspC1xk/+ugjzJ07F/7+/mrP1a5dW+uyly5dwrx586BQKODg4ICgoCA4OzurzKNUKrFw4UKcO3cOZmZmqFixImbOnKk2X0nI68Ez4ImIyFjpHPCbNm0CAFy4cEFlukwmw5EjRwpcLisrCwEBAdiwYQPc3Nywb98+TJ48GStWrFCZb+/evbh//z527NgBmUyGNWvWYNGiRZgzZ05RXk+x4CF6IiIydjoH/NGjR19pA5cvX4a7uzvc3NwAAJ6enpg+fTpycnJgYfHv5pVKJZ48eQKFQgELCwvY29vDysrqlbZZXNiDJyIiY6VzwAPA06dPER8fD4VCoTJd2yH6pKQkuLi4SOPm5uawt7dHSkoKXF1dpene3t64cOEC+vTpg//+97+4d+8e5s+fX5TmFRv24ImIyNjpHPAHDhzA9OnTkZmZKQWzXC6Hk5MTTpw4UeByBfWCXw7R8+fPw9bWFtu3b8elS5ewcOFCHD9+HD169NC1iXBystV5Xm1evMhdj62tFZyd7YplnW8y1lB/rKH+WEP9sYb6K8ka6hzwy5Ytw+7du+Hr6ysdrt+8eTNSU1O1Lufq6gq5XC6NK5VKpKenw9HRUWW+DRs2oH///pDJZGjUqBEmT56MsWPHFingU1IyoVTqf1j90aMnAICMjOdITs7Qe31vMmdnO9ZQT6yh/lhD/bGG+ivuGpqZybR2bHX+mlx6ejoqV64MGxsbPHmSG4B+fn7Yt2+f1uUaNmyIqKgoxMXFAQDCwsLQuHFjWFhYIDY2FhkZuS/2rbfewu+//y71+CMjI/Huu+/q2jyD4Dl4IiIyVjoHvFKpBAC8/fbbOHbsGADgyZMnhX433traGsHBwQgMDISvry927tyJGTNmAAD8/f0RHh4OABg5ciSysrLg7e2NPn36ICIiApMnT36V16Q3noMnIiJjp/Mh+tatWyMhIQH+/v4YOXIkduzYgejoaPj6+ha6bJMmTRAaGqo2Pf+V+eXKlcPcuXN1bU6JYA+eiIiMlc4BP2HCBNjZ2aFy5crYs2cPrl69ikqVKqFBgwaGbF8pYQ+eiIiMW5HuZOfh4YG+ffuiYcOGqFy5siHb9VpgD56IiIyVzufgw8PDUa9ePUybNg3e3t7YsmWLdLGdqeE5eCIiMnY6B7y9vT369euHXbt2Yfbs2YiKikLXrl0xZcoUQ7avVLEHT0RExkrngM8vNTUVDx8+RFZWFszNzYu7TaWOPXgiIjJ2Op+DT0hIwI4dO7Bz505UrFgRfn5+mDt3LmxsbAzZvlLFHjwRERkrnQPey8sLXbt2xbJlywr9eVhjxx48EREZO50D/sSJE1p76/PmzcO4ceOKpVGvD/bgiYjIOOl8Dr6wQ/GF3bLWmLAHT0RExu6VLrJ7U/AcPBERGSsGvAZ5HXgGPBERGSsGvAY8RE9ERMaOAa8Fe/BERGSsGPAasAdPRETGrtgC3tHRsbhW9dpgD56IiIyVzgEfFhaGEydOAACio6MxdOhQjBo1CklJSQCAvXv3GqaFpYA9eCIiMnY6B/zixYvx1ltvAQDmzp0Ld3d3NGzYEFOnTjVY40obe/BERGSsdL6TXVpaGmrUqAGlUolLly5h8eLFsLa2xsaNGw3ZvlLBHjwRERk7nQPe3t4eKSkpuHfvHqpVqwZra2tkZWXhxYsXhmxfqWIHnoiIjJXOAT9kyBB0794dz549kw7L79+/H/Xr1zdY40oLe/BERGTsdA743r17o3nz5lAoFNK5+Hr16qFly5YGa1xp4zl4IiIyVjoHPADk5OQgOjoaUVFRKtMrV65crI0qbezBExGRsdM54Ddu3IgNGzZALpfjgw8+AABcv34db731Fjp06GCo9pUq9uCJiMhY6Rzwmzdvxs6dO9G1a1ds2rQJAHDgwAFcunTJYI0rPezBExGRcdP5e/DPnj1D+fLlUa5cOaSlpQEAOnfujOPHjxuqbaWOPXgiIjJWOge8EAJKpRJ16tTBnj17AAAPHjxAZmamwRpXWngOnoiIjJ3Oh+h79eqF5ORk/O9//8PgwYPxyy+/IDU1FSNHjjRk+0oVe/BERGSsdA74b775BgDg6uqKI0eOICoqCi4uLnB2di502UuXLmHevHlQKBRwcHBAUFCQ2nKrV69GeHi4NC6EQEpKCo4ePaprE4sNe/BERGTsCg34yMhIfPDBB4iIiFB7Ljo6GtHR0WjatGmBy2dlZSEgIAAbNmyAm5sb9u3bh8mTJ2PFihUq8w0ZMgRDhgyRxvft24dTp04V5bUUO/bgiYjIWBUa8EFBQdi2bRuCgoI0Pi+TybBr164Cl798+TLc3d3h5uYGAPD09MT06dORk5MDCwvNm8/OzsayZcuwatUqXV5Dsfu3B8+AJyIi41RowG/btg0AsHv37lfaQFJSElxcXKRxc3Nz6b72rq6uGpfZunUrmjVrhurVq7/SNvXFQ/RERGTsinQnu0OHDuHYsWN49OgRqlatCl9fX9StW1frMgUd5i4oRJ88eYKff/4ZW7ZsKUrTAABOTrZFXkaT588tAQBly5aBs7NdsazzTcYa6o811B9rqD/WUH8lWUOdA37BggU4ffo0fH194eDggPv372P48OEYM2YMPD09C1zO1dUVcrlcGlcqlUhPT4ejo6PG+detW4dOnToV2LvXJiUlE0ql/ofVs7KyAABPnmQhOTlD7/W9yZyd7VhDPbGG+mMN9cca6q+4a2hmJtPasdU54Pfs2YODBw/Czu7fvY+OHTti2LBhWgO+YcOGiIqKQlxcHKpXr46wsDA0btwYFhYWiI2NhYODg7TOR48eYevWrdL37EsbL7IjIiJjpXPAOzk5wcbGRmVajRo18OTJE63LWVtbIzg4GIGBgRBCoHz58tIFe/7+/hgxYgR8fHwAAMuXL0fv3r0L7N2XFJ6DJyIiY1dowOfdqa5nz5749ddfpTAGgLi4OFSrVq3QjTRp0gShoaFq01/+jvvEiRMLXVdJyuvBP3gQD7k8CR980KiUW0RERKSbQgO+SZMmkMlkUtjNnj0bAKRpptjbzXtNc+bMROXKVTB69AgoFArI5eml3DIiIiLdFBrwN27cKIl2vLZmzpwKhUJR2s0gIiIqEp1/bOZNkv+ohCkeoSAiItOn80V2Fy9exMyZM3H37l3k5OQAgHSI/vr16wZrYGljwBMRkTHSOeAnTJiAwYMHo23btihbtqwh21Tq2IMnIiJjp3PA5+TkwM/Pz5BteS0x4ImIyBjpfA6+efPm+OeffwzZltdG/lA3M/u3RNu3b0VMTHQptIiIiKhodO7BZ2VlYcyYMWjdurXac999912xNup1Eh9/X3r81VdD4Ozsgn/+iSqRbUdH38O9e3fRvn2HEtkeERGZDp0DvmbNmqhZs6Yh2/La0HZYPjlZjmfPnmHw4AGYMWM23n773SKvPzX1EZRKAScnJwC5O085OTkoV66cynytWjXFixcv+P17IiIqMp0DfsSIEYZsh9EwMzPDmTMnER5+CEqlElu27CjyOmrVqgEAUnB/9FFr3Lx5Qy3IX7x4ASD3B3pu3rwBpVKJ99+vp98LICKiN4LOAb906dICnzO18NfWg7e0tJSez/9jNAqFAteu/YP69RsUeXs3b2q/mdCTJ5lo27Y5AOjVm//994NITU1Fnz6fvvI6SktWVhbmz5+Nb74JhJ2dfWk3x+QoFAqYmZnxolIiE6LzRXbp6elqw2+//YZ79+4Zsn2vnaysLCnYlUqlNH3cuEB06NAKe/fuUpk/NHSL3hfmpacXHOrHjh3B5s0bdVrPZ5/1wddf/0+vtugqOzsbEyeOxe3btwudd9y4ABw6dFBt+qZN6/HHH8cBAL/+ugk//vg9liz5vribWiKEELhx4/W9X0Tlyg4YOzagtJtBZJJycnKkI7IlSeeAnzBhgtowb948WFlZGbJ9r6VPPukN4N8efGZmBn79NTdkDx78TZovOzsbI0YMg5dXlwLXlX9+Fxd7/PBDsNo8QUHTpcc7doQiI+PfwO/TpydGj1Y9gpKRkY4tW35Benoa1q1bg+zs7EJf0+nTJ/HnnxEFPn/+/Dls3LgOq1cvh7e3JxYtmq/153SPHAnH6tUrCr0AUwiBdevWoH//Pjh37ozKRY2BgSPRu3cPAEB6ehoAFHjb4NTUR3j+/LnWbb3s8eNU/PXXxSItk59cLke3bh2xevXyQufduHEd2rRphrNnTwMAEhMTMGrUV0hLe/zK2y8ueb8IuWHDWp3mF0IgNjZGr21mZmbg0097Iyqq8B3A150QApMnj9frvfSmuXPnNpRKJRQKhU6fT8aue/eOqFatYolvV69b1TZo0ADnzp0rrrYYHSGAK1cice/ePenufo8fp2LVqmXIzs5GZmYGgNxfo8vKygIAzJ8/O9/yAp9//onKOvOHeZ7t27dKj7/8cjDGjBkNQHXnAMg9BN+wYW0MGPAJRo36CtOmTcK4cQF49103fPnlYK2vpWfPrujS5d+r9YUQKmHavXtHfPvtKEycOA5nzpzC3LmzEBn5l9p6MjMzkZ2djcjIPwEAVlZWUCgU2Lt3l8Zw/vbbUdLjHj064z//qYvAwJEq85w8eUIKgszMDERG/oWmTRtg7dpVCA8Pw6hRX6FWrRrw9fVSaX/+wP/zzwj888/fuH79Gry8uiAzMxM9e3ZD584e0pGYx49Tte4kvPxB9MMPC3HhwjlMnDgO69atQaVKFfDs2TONy/7991UAwLlzZwAAw4Z9gS1bfsGpUycL3J4m8fH31XYKUlJSVO4uqWmn4cCB/di0ab3GdT58mCw9vnnzRqE7HfPnz0aTJvVx8uQJrfPl1UuhUODBg3i19hw+/Dvmzp2Fv/++Kr03lErl/1+EqlRbX56jRw8jLi4WALBv3x5s3LgOT58+xY8/Lsbz58/x9OlTnD59Et9/v0BlZ1gX+d+jGzb8rPX02enTJ3HjxnWkpKRg5cpl8PX1LtK28uzbt1utPsVl2bIf4eJir/K+vHfvLn7//SDOnDllkG3ml5SUqDbt7t07aNGiMRYunIsuXTzw7rvV1ebJzs4u9KfIDenp06f44ov+xbYD+uefpbTzJ3SUkZGhMiQmJoqtW7cKDw8PXVdhcA8fZgi5PL1YBgB6DdOnzxYXL15Vmfby+KFDxzQu27VrDxEXl1zguv/73+ZqbZTL00WDBh+oTOvcuavG5WNikkRSUprG15uUlCYePHgk6tdvKN56q4aQy9NFfHyKxvVMnjxDDB8+Sixe/JPo0qWbuHPnvto8bdu2FT/9tEoAEFOnztK5zklJaa9U97z1jhnznQAg3nnnXXHs2Jl87WkvAIhff90mTbt9O1ZERycKAMLb20fI5eni+vV7Yu/eQ1Kdrly5KQCIYcOGiyNHTokHDx4Jf/9Batt/++13xOXLN8SwYcNFv34DxLVrd4Vcni58fftKf9tNm7ZK88+Zs1ClHteu3RXHj58Vcnm6uHUrRri6VhJOTk4iJGSnGD36WwFAVK1aTVy9ekvI5ekiNlYuAAgvLx+xatU6ERq6WwAQc+cGC7k8Xaxf/6tYsGCxSl3ztpWUlCauXbsr+vcfqPY6Ro4MEPv2/S7i41PEgAFfiCNHToolS5aLyMjr4j//aaTS9piYJHH27J9i06at4sGDR0IuTxe7dx+Q3uPDh48SAMSSJctFhQoVxJ0798W0aUECgGjfvoMAIP73vxEiMfGxtP3WrduK/v0HisTEx0IuTxd378aLe/cSxOrV6wUA4epaSeX9M2HCFAFATJsWJPr27afyWu7ffyiEEGrvvaSkNHHhwmWxePFP4urV2yIwcJwwNzcXR46cUvn/27Rpq9bPiLz/Y0tLS5Xno6MTxbp1m4WHx0eiZctWIiEhVWzdukucOHFOmmfr1l0CgPjkk89Ulj137i/RunU7cfNmtIiJSRIHDx4RgYHjRJ06dcWvv26T5vvnnzuiSpWqYsWKtWrtO38+UmrjsWNnpO3mr825c39J76W8Nr+8nvnzvxchITs01vD48bNixozZQi5PFytX/ixu3oyWpu/b97sAINau3STN37p1O2nbNWrUVPm/vXcvQTg7uwgrKyvh6dldABC//RYu4uNT1Lb7999RYu/eQyI0dLcICdkhBg0aKkJCdohFi34Uw4Z9JQ4f/kOad9GiH8WRI6dEUlKaWLBgsfQ/qW1YtWqdACC6dfMSMTFJYt68RSIhIVXt/ZP3Pzts2FdSe+XydDFp0nQBQPz88y8q7+vs7Oxiyyi5PF08fJihNRN1DvhatWqJ2rVri1q1aolatWqJ999/X3Tr1k2cOXNGj0guXqUd8NWru6mMHz16WmV86dKVKuOVKlUucF3bt+/Vuq2EhFSV8cTEx8LN7S2Vae+9V0tYWVmJtWs3qi3fubOn9Aa9fPmGNN3Ts7vKP+Hduw9E2bLlNLahZctWOtXFyclJety8eUsRHLxEhITsFAcOHC5wmZkz57zS3yApKU0cPvxHgc+3bt220NcREDBWetyhw8di5879YvPmUJV5KlasKNzd39a4jbp166mMnzhxTjRu3LTANi1ZslycOHFOrF27Ubz3Xi3p7/npp/21vtZNm7aq7SR6efkIAKJZsxZa38fDhn0l7XQUNJQrZyuWLFkuAAhHR0e15z/77HOxcWOI2vQrV26KgQMHCwBi0qRpwtnZRe315j1+9933/r+ezqJy5Spq6zpw4LC4ceOexvZVqFBBpa0AxMcfd1Kbz9bWTjg6OorIyOti58794uzZP8WxY2eknaG8euW1Zfbs+WLZstVq76s5cxaKjRtDxNtvvyMmTpwqPZdXxzJlyoiEhFRx58598eDBI7V2eHh8JD2+du2u+OOP86Jp02ZSu/NC4/3360vzFfQeqFjRWcyZs1DaQQAgQkJ2iv37w4VMJhNOTk4qny81a7prXE9emw4f/kPaiZ01a660kxsefkIAEBYWFuLu3bti//5wMXv2fNGgwQdiypSZok6dumrrr1+/oQAgvba897OPT+8C32uNGjUW9vblC3ze3NxcjBs3Uaxdu0n8/PMvKs/Vq9dA4zLdu3tLj52dXaTPhY8+6ih9zl+5clM0a9ZC+Pj4is8/H6SycwrkBnze4x9+WCZ9Nmpra/7PU0A1F2JjY1/PgDcGpR3wbdq0VxlfuPAHlfG8DyFNH1AvD507e2rdVt4/kS7DH3+c1zh99er1Gj+I8g8vB2KvXn5ix459r1Sf12HQdafk5cHGxqbIy3Tp0k1l3M2tRoHzVqxYscjr79ixs9Q7Ll9e/b1UtmxZvWrl6lpJ7aiQLkP+D79GjRqX+t88bzAzMyu2dRX2fijK/2fe0Lt3H+Hg4FAqtfH3HyTGjp0gjQcHLynW9dvZ2auMW1tbl+p74fPPB4kZM2arTW/Vqo3B28mAf0WlHfAv721/+eXXhS5TrVr1Yn3z+Pl9ojbt5T3K/EPeYTRdh4CAsa9cH23DL79sVeslF+fQqVMXAUCtN6nvYGtrV+BzMTFJKuNTp84S/foNkHqKwKuFjpWVlXjnnXel5Xv37qPT32TVqnUqvXZNYeLt7aM2rUqVqirjnp7dC+wRmpub6/XaNA3adoxGjgyQHuc/8pQ3DBs2vEjbsrCweKU2ajpykH+YNi1ItG3bXjp1VNiQ/+8wa9bcIrfH0tLylV6Htk5HYcP48ZOkU0Z5g5WVlcZ5V61aJ0aNCtS5pnmnhV6HoV07D43tdHBwUNmRWb16vfj669Eq837xxRcM+FdVWgHfrZuXuHs3vtBDnpqGjh07q/1DF2Xo2rWHyvjOnftVgmX58jXi7t0HOq3r5b3XvCEkZIf0eOzYCUWqz5AhQ4SHx0fi0KFjWnupZ878KeTydBEZeV3IZDKt6/zkk8/UpmnbmerT51O1w3pVq1YTe/YcLFKtBw0aKj3u1KmL2LJlu4iNlUvnfwGIESO+EVOmzBTdunmp1enAgcNCLk8XV6/eFgDE8OGjREJCqujWzUuYmZlJ55c1DRERV6TH4eEnVK4hiIy8rnZoMf/QvHlLAUA6l3n06GkREXFF5Rxt3nDqVIQ4ePCIyiH5/D07ACI2Vq7y2vr1GyCA3NMD9+8/lOoTE5MkvvpqpDhy5KR45513xfjxk8R3302Wlsu7huGtt2qIFi0+FMuWrRZHj54WX375tTh37pI0n1yeLk6fviiWLFkurl69JYYO/VIAEHfvxgu5PF3akTh+/KxK4A8bNlwEBc1TafvAgYPF/v3h0viiRT+KNWs2CCD3fzA6OlH6kA4N3S3On48UXbv2EK1atRFr124Sp09flI7MyWQy4evbV1SuXEXcvBkt7XSNGPGNqFOnrsrRi7yavfyeKF++gujUqYt0zhnIDcW890ne+fYlS5aLefMWqSzbtGkzqe3Av0dsJk2aJtav/1U6oti0aTNx4sQ5ldcN5B5yXrt2k/jhh2UCyD3sf/t2rPR8s2YtxI0b96SjQ+Hh4dKpi969+0jX3Dg7u4jz5yOl17dhwxZpHdev555esba2Fi1afCitNzHxsYiPT5E+nzZs2CJu344VP/20Snh5+Yi//44SSUlpIiYmSdy//1Bcv35P9O7dR5w795e4ezdeTJo0XURFxYkjR06JyMjrIizsqOje3VvcuXNfxMbKRVjYUZXOS97py0WLfpSmDRjwhdi4MURERl5XqUuHDh+L1q3bSUdhPDw+kj67/ve/EeL27Vjx2Wefi++/Xyq+/Xa8CAnZKYDc60BOnrwghg8fJZo3byn9v0VEXBFz5waLxMTHQgj16xgMGfAyIbR818nIpKRkQqksnpfj4qLbzVTq1HkfJ06cBQB4eLTC339fKdJ2vL19EBS0ADk52WjYsLY0fdWqdXj8+DHGjs29Yj4pKQ3JyclITX2E1q3/K833ySefYcuWXwAAvr59sXTpSshkMqn9Fy9eRfXqbnB1LV9oW0JDd+P27ZvIzs5BZOSf6NWrD+7fj8OgQUMxc+ZU/Pjj95gwYQq++eZbtfrY2tohMzMDTZr8F/36DcDo0SMwalQgFi9eiOTk3G8T3Lp1EwkJD6Sr3d3c3sKXX46Ap2d3VK5cRWV9s2ZNw5Ili9TauHbtRnTv7o1Ll/5Ep07tAQDr1/8KT89uePLkCdasWaH2TYR79xKQmvoIjRq9DwB4++138Ntv4Xjy5AkaN1a/M2Bw8BIEBo6Ei4srPvywFXbt2gEPj4/wyy+hWLhwDlq0aIW2bdtL87948UL6Coz8pRsRNWlSH7GxMVLd8sTFxaJy5SqwsMi919STJ09QtmxZTJnyHdavX4usrCwsXvwTYmLuwc+vF2rUqI3KlR0AALGxclhZWWHDhp/RtGkzlbsb5v1d5PJ06XFk5HU4OjrB2tpapW2ZmZlwd1et+9278bC1tUNExHkMHToQ8fH38fvvx/HwYTL8/fup3Dr5998P4uTJE5g+fTZ++mkJ+vXrD0dHJ6SmPoK1tQ1sbGzUapvbNjnMzMxgY2ODH34IRseOndGkyX9V5smr6fDhozB16kyV53KvsM5EhQq59bh06U9YWpZBvXr1AQAXL16AvX15vPdeLTx+nIrBg/2xZs1KpKU9h5vbW5DJZKha1Qk9evTE8uVrIIRARMQFNG36X8hkMsTFxSI+/j6aN2+psf0AcPbsadSs6Y5KlSpDoVDA3Nwcw4YNxK5dO/DHH+dRu3Yd/PHHcfTu3QOrVq2Dt3cvadk7d27j9OlTuHr1CubOXQhzc3MAuV9vzbuKP++1vSwi4jxiY2NQr14DVK/uhrJlyyIh4QF++ukHxMbGIizsNyxZshx9+/aT/sZlypRBmTJlAABr166Eo6MTevbsLa3z1Kk/4OPTDS1afIg9ew5i9OgRuH37Ftat2wxnZ2ecPn0SEyaMwcWLEcjMzMGuXdvRpUs32NjY4OLFC6hWrToqVaqs0s5p0yahSpUqGDr0K1y9ehk1a7rD1tYO8fH3UaVK1RK7oVL+/4e8qHN1LY/mzVti794wAIAQAqNHj0C9evXRuHFT/Oc/jQEAjx6lYNmyH/HFF7m/QWJmZib9rfITQuDo0XC0besh/T8XxNnZTvo8LA5mZjI4OdkW+DwDvgCFBfzkyTMwc+YU2NnZ486d3O9ub9y4TuVrX3nmzg3G+PGBKtOsrKyQlZWFdu08EBq6G1lZWahe3Vl6Pu9DNP8bFIDafAMHDsa6dWvg4+OLFSv+/R5z3nL37iWgXLly0njFihVx7NhZpKenYezY0Th9+t+vad25c7/Au8QtXfoDZsyYjODgJejf319a361bMThz5jQyMtLx9df/Q/fu3li7dqP0oafpDZ23bFJSWoH/6JmZmViyZBEWL14oTXvnnXdx5syf0vjt27cwduxobNoUAltbO7X150lKyv0OfZUqjlAoFBgw4AssXLgYAHD16hX8889VjBz5pTR/TEwSsrKew87OHmlpj9GzZzesXPkzateuo7Gt+bf5csDnfX2tsH/8/Hr27IrTp08iNHQ32rXzkGrYpYsHYmKice3aXZ3a0bXrx4iIOI8HDx4VuP2AgK9Rr14DnD59Evv27VZrf0ZGuvSeePbsGZ4/fwYHB0edX4s+nj17Bmtr62IJg5ffhzk5OTAzM1P5tUh9ZWZm4PDh31XCvCQdOnTw/+8ncQnu7m/rvFxWVhZGjx6BwMCxWn9bo7jDqSQkJ+d+BdTZ2VllWtmyZdV++6MkMOD1YKiADwnZgb59//2nPX78LBSKHHTokPvLevk/FDXtGOTvTeWpWrUa4uPvo2fPXli5cp00fezY0Xj77XcwbNhwlfUVtI0FCxZjzJhvsGjRj/jss8+l6Q0a1EJiYoK03M8/r8b48YHw9OyO9es3A4DUKwcALy8frF69vsB6ZGdn49dfN+Gzzz6Hubk5du/egUuX/sL06UEAcoPg888/xfz53+Odd/79kND0hvbz88bx40d1uu1uRMR5JCQ8QEZGBtq0aYfq1d0KXebMmVOQy5MwdOhAAP/WLjs7G8HBczF06FdwdHRSWaaggNbVlSuRKF++At56q8YrLZ/f1auXMXZsALZt2wNbW1uphtnZ2VAqlVpvLtWlSwfY2Nhg5879SE9PQ0xMNOrXb1joNrOzs/H8+TOTvQ2wMYbTqxBCGKx3/KbU0JAY8HowVMDfvRsPd/eq0vjVq7dhbm6OunXdARQcvmFhR1GunC1q1aqtFvAffdQRPXr0RKdOXbT2iAoL+KSkNJw8eQKtW7dV+cdOTk7G/fux0uEmIQQ2bVqPrl17SL9il5KSgjp1akqvydXVtbCyFJmmN3R2djZycnIKPIRbXIoS2keO/A65XI5PPvnMoG16Ffxg1R9rqD/WUH8lHfC6Hzd8g9na2iEqKg7vvJN7x6UyZSwLPEeWX6NGTVTWkZmZIR0NUCgU0nmyooqNlcPNzQVA7g/jtGnTTm0eZ2dnlcNSMpkMAwYMVJnHyckJ8fEpiImJNki4F8TS0hKWlpYG305IyA6d70TVoUNHA7eGiKhkMeB1ZG//70VqlpZlIJPJsHjxT2q/HhcWdhQ+Pt3w9dejVaafOnUB0dH3pHFr61fvvVpbW8PFxRVyedIrryOPpaWlyiF1U+Lh8TE8PD4u7WYQEZUKBnwh8l8tnSfvitRPP+2v9lyjRk0QHa1+/+UqVaqiSpWqUCqVGDduIgYM+EKn7R85chLm5up/pnPn/nojfqSBiIheDQO+EKGhu9Wm6XN42czMDIGB43Sev6ALpPJfNU5ERPSy4vuOiInSdEVqSX2Hk4iI6FWVSA/+0qVLmDdvHhQKBRwcHBAUFKRyAVieuLg4LFiwAHFxcXj69CnWrl2LatWqlUQTiYiITIrBAz4rKwsBAQHYsGED3NzcsG/fPkyePBkrVqxQmS8jIwODBw/G1KlT0bJlwXeQIiIiosIZ/BD95cuX4e7uDje33BuUeHp64uLFi9IdvvJs374dHTp0eK3DfevWXQgIGFvazSAiIiqUwXvwSUlJcHFxkcbNzc1hb2+PlJQUle9eX7p0CZaWlhg0aBBSU1NRt25dfPvtt6hQoYLO29L2hf9X5ez878Vsfn7e8PPzLvZtmLr8NaRXwxrqjzXUH2uov5KsocEDvqAb5b18oVpmZiZ69OgBb29vCCGwZMkSzJo1CwsXLtS4vCbFeSe7PLxzk3549yv9sYb6Yw31xxrqr6TvZGfwQ/Surq6Qy+XSuFKpRHp6OhwdHdXmK1u2LIDc8O/evTtu3rxp6OYRERGZJIMHfMOGDREVFYW4uDgAQFhYGBo3bgwLCwvExsYiIyN3b+bjjz9GSEgIXrx4AQA4ceIEGjdubOjmERERmSSDH6K3trZGcHAwAgMDIYRA+fLlERSU+wtk/v7+GDFiBHx8fODh4YE7d+6gb9++sLS0RM2aNTFp0iRDN4+IiMgk8dfkCqDvz4dSLp630x9rqD/WUH+sof5M7hw8ERERlTwGPBERkQliwBMREZkgBjwREZEJYsATERGZIAY8ERGRCWLAExERmSAGPBERkQliwBMREZkgBjwREZEJYsATERGZIAY8ERGRCWLAExERmSAGPBERkQliwBMREZkgBjwREZEJYsATERGZIAY8ERGRCWLAExERmSAGPBERkQliwBMREZkgBjwREZEJYsATERGZIAY8ERGRCWLAExERmSAGPBERkQliwBMREZkgi5LYyKVLlzBv3jwoFAo4ODggKCgIzs7OKvPcv38fXbp0QZ06daRpzZs3R0BAQEk0kYiIyKQYPOCzsrIQEBCADRs2wM3NDfv27cPkyZOxYsUKtXkrVaqE0NBQQzeJiIjI5Bn8EP3ly5fh7u4ONzc3AICnpycuXryInJwcQ2+aiIjojWXwHnxSUhJcXFykcXNzc9jb2yMlJQWurq4q8z58+BB+fn5QKpVo3rw5Ro4ciTJlyui8LScn22Jrdx5nZ7tiX+ebhjXUH2uoP9ZQf6yh/kqyhgYPeCGExukymUxlvEqVKoiIiICFhQWePn2KKVOmYMWKFRg5cqTO20pJyYRSqXl7ryo5OaNY1/emcXa2Yw31xBrqjzXUH2uov+KuoZmZTGvH1uCH6F1dXSGXy6VxpVKJ9PR0ODo6qjbEzAwWFrn7G2XLlkXXrl1x69YtQzePiIjIJBk84Bs2bIioqCjExcUBAMLCwtC4cWNYWFggNjYWGRm5ezM3btxAWloaAEChUODgwYNo0qSJoZtHRERkkgx+iN7a2hrBwcEIDAyEEALly5dHUFAQAMDf3x8jRoyAj48PYmJiMGbMGFhaWgIAWrdujQEDBhi6eURERCZJJgo6SW6EivMcvIuLPQBALk8vlvW9qXjeTn+sof5YQ/2xhvozuXPwREREVPIY8ERERCaIAU9ERGSCGPBEREQmiAFPRERkghjwREREJogBT0REZIIY8ERERCaIAa9F3br1SrsJREREr8Tgt6o1Vk+fPkVq6rPSbgYREdErYQ++ADY2NtJ98YmIiIwNA56IiMgEMeCJiIhMEAOeiIjIBDHgiYiITBADnoiIyAQx4ImIiEyQSX0P3sxM9lqv703FOuqPNdQfa6g/1lB/xVnDwtYlE0KIYtsaERERvRZ4iJ6IiMgEMeCJiIhMEAOeiIjIBDHgiYiITBADnoiIyAQx4ImIiEwQA56IiMgEMeCJiIhMEAOeiIjIBJnUrWqLy6VLlzBv3jwoFAo4ODggKCgIzs7Opd2sUvH1118jOjoa1tbWKFeuHGbMmAE3NzccOXIEy5cvh0wmQ/Xq1TFjxgzY2toCAEJCQrBt2zbIZDI0aNAA3333HSwtLSGEwE8//YTjx49DCIH27dtjxIgRAIDs7GzMmTMHV65cgRACvr6+6Nu3b2m+9GIXFRUFPz8/rFq1Ck2aNGENi0ChUGDFihU4fPgwhBDo1q0bBg8ezBoW0cmTJ7F06VIAQE5ODoYPHw4PDw/WsRBpaWnw8/PDhg0bUKlSJQAo0ZplZmZiypQpiIuLgxACX375JTp06FB4wwWpeP78uWjXrp2IiYkRQgixd+9eMWzYsFJuVek5d+6c9HjXrl1iyJAhIjExUXTo0EGkpKQIIYRYvny5mDFjhhBCiCtXroiePXuKZ8+eCSGEmDRpkli7dq0QQoiDBw+KIUOGiJycHJGTkyMGDRokwsLChBBCrFmzRkyePFkIIcTTp0+Fl5eXuHr1aom9TkNLTU0Vffv2FZ07dxYRERGsYRHNmDFDTJ06Vbx48UKaxhoWzfPnz0WLFi1EUlKSEEKI+Ph40bRpU9axEGvXrhXt27cXderUEQkJCUKIkn/vTZ8+XaxcuVIIIURKSorw8PAQiYmJhbadh+hfcvnyZbi7u8PNzQ0A4OnpiYsXLyInJ6eUW1Y6mjVrJj1+77338OjRI5w5cwYtW7aEo6MjAKBnz544fvw4AODEiRPo3LkzrK2tNT7n5eUFc3NzmJubw8vLS3ru+PHj8PHxAQDY2Nigc+fO0nPGLicnB2PGjMHYsWNRsWJFAGANiyAlJQXHjh3DxIkTYWlpKU1nDYtGoVBAoVDg6dOnAIDy5cvD0tKSdSzEF198gaNHj0o9d6Dk33vHjx9Hz549AQCOjo5o2bIlzp49W2jbGfAvSUpKgouLizRubm4Oe3t7pKSklGKrXg8hISHw8PBQq5GLiwuSkpIA5NYv/+kMXZ+Ty+UFPmfsgoKC4Onpif/85z/SNNZQd1euXIGdnR3GjRuHPn36wN/fHxEREaxhEZUtWxYLFizAwIED8d133yEgIADBwcGs4yso6Zppei4xMbHQdjLgXyIK+HE9mezN/pnErVu34t69exg0aFCBNQIKrl9Bz+XVVdtzxmz79u2wtraW9r7zsIa6y8zMRKVKlRAUFIStW7di/PjxGD16NGtYRE+fPsXmzZuxbds2BAQEwN3dHevXr2cdX8HrUDNd6smAf4mrqyvkcrk0rlQqkZ6eLh2KeROtX78eYWFhWL58OaysrNRqlJycDFdXVwC59UtOTtb5uby9YG3PGbPbt28jIiICfn5+8PPzwz///IOpU6eiTJkyrKGOXF1dIZPJYGNjAwCoXbs2qlatCisrK9awCE6dOgVbW1tUrFgRzs7OGDduHBISEmBtbc06FlFJfwa6uLgUuE5tGPAvadiwIaKiohAXFwcACAsLQ+PGjWFh8eZ94UCpVCIoKAg3b97EqlWrpCtEW7RogTNnziA1NRUAsGfPHrRt2xYA0Lp1a4SFheH58+cAgL1796o8t2/fPiiVSiiVSuzfv1/luT179gAAnj9/jkOHDqFNmzYl+noN4bvvvsP27dsRGhqK0NBQvP/++5g+fTo8PT1ZQx01bNgQd+7cwZ07dwAA8fHxSElJQadOnVjDInBzc8Nff/0lnW5MSkpCWloaOnbsyDoWUUl/BrZq1Qq7d+8GAKSmpuLs2bNo0aJFoe2UCW3HE95QFy9exPz58yGEQPny5REUFKTT3pKpuXHjBnr16oX3339fZfr8+fNx48YNrF69GmZmZqhatSpmzZol7QD88ssv2LVrF2QyGd5//31MnDgRZcqUgRACixcvxqlTpwAAbdq0wciRIyGTyfDixQvMmjUL165dgxACPj4+6NevX4m/ZkPr378/Ro0ahSZNmiAsLIw11NHVq1cxZ84c5OTkoEyZMvj222/xwQcfsIZFtGPHDmzcuBFWVlawsLDA119/jRYtWrCOWoSEhCA8PBwRERFo2LAh6tWrh3HjxpVozTIyMjBp0iQ8ePAAQggMHToUHTt2LLTtDHgiIiITxEP0REREJogBT0REZIIY8ERERCaIAU9ERGSCGPBEREQmiAFPREWyc+dOfPXVVwZZd0JCAj788EODrJvoTcOAJ6LXRuXKlXH69OnSbgaRSWDAExkhhUKB2bNno127dmjWrBl8fX1x69YteHl54cMPP0SbNm3wySef4Nq1awCA+/fvo3Hjxti8eTO6d++ORo0a4fvvv8eBAwfg5eWFpk2bIjAwEEqlEgAwfvx4TJgwAYMGDcKHH36Ifv364cGDBxrbcvToUfTo0QOtWrVC//79ER0drdNrWLlyJTw8PNC8eXN0794d58+fR3p6OmrVqgUAWLp0KT788ENpqFevHubPnw8AuHPnDvz9/dGqVSt4enrixIkTelaUyATp8HO4RPSa2blzpxgwYIB4/vy5UCgU4uzZs+L69esiPj5emicsLEz4+fkJIYSIi4sTderUEZs3bxYvXrwQ165dE7Vq1RITJkwQaWlpIj09XbRv31788ccfQgghxo0bJwYMGCAePHgglEqlWLJkiRgyZIgQQogdO3aIL7/8UgghxN9//y3at28v7t69K7Wrd+/ehbb//PnzokuXLiIjI0MolUpx5coVcf78eZGWlibee+89tfn//vtv0bp1a5GYmCiePHki2rdvL44dOyaEEOLWrVuiZcuW0m9zE1GuN+8G60QmICcnB6mpqYiPj4e7uzuaN28OANiyZQt+++03xMXFISsrS+UXqsqWLYtPP/0UAFCnTh1UrFgRAwYMgL29PQDggw8+QGxsrDR/+/btUblyZQDAwIED0bRpU2RnZ6u0IzQ0FAMGDEDNmjUB5P72dVBQEB49eqT1B5pycnKQkZGBmJgY1K1bF/Xr1wcApKenq8375MkTBAQEYObMmXB1dcWBAwdQq1YttGvXDgDw7rvvokGDBrhw4QI6d+5cpDoSmTIGPJER8vb2RlxcHIYNG4anT5+iQ4cOaNSoEVauXIng4GDUr18fcrkc3t7eBa6jTJky0iH5vPGXAzyPra0tLC0tkZaWpjL9wYMHOHDgAFavXi1NUyqVSElJ0RrwLVu2hL+/P8aNG4fk5GS0bNlSul/3y6ZPnw4PDw/pRzni4+Nx9uxZlYvxXrx4YVI/ZkJUHBjwREbI0tISAQEBCAgIQHJyMkaPHo3du3dj2LBhaNy4cbFvTy6XQyaTwcnJSWW6q6srRo8eLR0ZKIpBgwZh0KBBSEtLw7Rp0/Djjz8iMDBQZZ7du3fj7t27CAoKUtlmu3btsHjx4ld6LURvCl5kR2SEDh48iLNnz0KhUKBChQooX748hg4diqtXryInJwdpaWlYuXKlXttISEhATk4OXrx4gfnz56NXr16QyWQq8/j4+GDdunW4efMmACArKwv79u1DTk6O1nWfPXsW4eHhePHiBezs7ODk5ISyZcuqzBMdHY1Fixbh+++/h6WlpTS9Xbt2iIyMxOHDhyGEgFKpREREBO7du6fX6yUyNQx4IiNUoUIFBAcHo2XLlujYsSNcXV3h7+8PpVIpXc1erVo1vbbx119/oWvXrmjfvj2srKwwZswYtXkaNWqEcePG4bvvvkOrVq3QpUsXXLhwQW1H4GUODg7YuHEj2rRpg/bt2yM1NRXDhw9XmWfNmjVITU1F3759pSvpp0yZAnt7e6xcuRJbtmxBmzZt0LZtW6xbtw4WFjwgSZQffy6WiNSMHz8etWvXhr+/f2k3hYheEXd5iajY7d69GwsWLCjw+V27dsHFxaUEW0T05mHAE1Gx8/b21noFPxEZHg/RExERmSBeZEdERGSCGPBEREQmiAFPRERkghjwREREJogBT0REZIIY8ERERCbo/wCw7hwNqaLnfQAAAABJRU5ErkJggg==\n",
306 | "text/plain": [
307 | "
16 |
--------------------------------------------------------------------------------
/book-data/8-4-1-brand-1.csv:
--------------------------------------------------------------------------------
1 | sales,brand,local_population
2 | 348.0,A,215.1
3 | 169.7,A,152.0
4 | 143.7,A,107.7
5 | 295.7,A,371.5
6 | 281.2,A,184.7
7 | 106.2,A,206.2
8 | 412.3,A,296.6
9 | 139.2,A,121.3
10 | 349.9,A,329.6
11 | 470.0,A,550.0
12 | 422.7,A,335.7
13 | 242.3,A,379.9
14 | 179.3,A,140.9
15 | 262.9,A,265.6
16 | 432.5,A,377.8
17 | 331.0,B,424.3
18 | 310.2,B,315.0
19 | 369.9,B,460.8
20 | 451.9,B,499.1
21 | 453.1,B,454.5
22 | 442.3,B,583.4
23 | 501.9,B,476.0
24 | 553.8,B,571.0
25 | 369.0,B,341.2
26 | 259.1,B,150.0
27 | 438.5,B,542.2
28 | 386.1,B,419.3
29 | 288.6,B,349.6
30 | 488.7,B,578.3
31 | 414.8,B,404.3
32 |
--------------------------------------------------------------------------------
/book-data/6-1-1-junk-food-weight.csv:
--------------------------------------------------------------------------------
1 | weight
2 | 5.852981989508032967e+01
3 | 5.235303878484729978e+01
4 | 7.444616949606223955e+01
5 | 5.298326296317538464e+01
6 | 5.587687873262546390e+01
7 | 6.765984893649250864e+01
8 | 4.772614076115006299e+01
9 | 5.026690673655769359e+01
10 | 5.650082580669628385e+01
11 | 5.236104033776512523e+01
12 | 4.545788310062555126e+01
13 | 5.336098791529930452e+01
14 | 5.212936842399005855e+01
15 | 5.982777282087596404e+01
16 | 4.168169176422644284e+01
17 | 4.939856769848039164e+01
18 | 6.421112807589736349e+01
19 | 6.985864805785050180e+01
20 | 4.291056353849307214e+01
21 | 6.015878008714222602e+01
22 |
--------------------------------------------------------------------------------
/book-data/8-4-2-brand-2.csv:
--------------------------------------------------------------------------------
1 | sales,brand,local_population
2 | 385.8,A,265.6
3 | 473.0,A,386.1
4 | 451.6,A,522.7
5 | 556.9,A,530.5
6 | 423.8,A,397.8
7 | 226.1,A,142.3
8 | 410.4,A,398.6
9 | 397.3,A,222.7
10 | 503.1,A,466.3
11 | 454.8,A,547.3
12 | 465.8,A,357.4
13 | 445.6,A,401.8
14 | 341.8,A,132.5
15 | 454.9,A,370.0
16 | 262.9,A,164.6
17 | 474.7,A,407.3
18 | 354.5,A,281.8
19 | 584.8,A,483.9
20 | 355.6,A,124.3
21 | 330.2,A,154.9
22 | 412.0,A,442.0
23 | 431.9,A,357.3
24 | 452.5,A,385.8
25 | 438.4,A,521.9
26 | 555.4,A,343.9
27 | 578.2,B,505.1
28 | 521.1,B,355.1
29 | 540.3,B,563.4
30 | 588.3,B,433.5
31 | 175.3,B,174.4
32 | 315.0,B,282.3
33 | 612.2,B,532.9
34 | 350.5,B,275.1
35 | 133.6,B,194.5
36 | 336.3,B,336.3
37 | 417.0,B,296.4
38 | 593.8,B,409.5
39 | 441.5,B,318.4
40 | 290.9,B,230.5
41 | 423.4,B,306.2
42 | 309.9,B,309.5
43 | 626.7,B,551.2
44 | 550.0,B,589.8
45 | 470.1,B,411.8
46 | 219.6,B,141.6
47 | 568.0,B,466.5
48 | 477.2,B,439.3
49 | 633.8,B,513.0
50 | 334.5,B,273.7
51 | 266.7,B,129.4
52 |
--------------------------------------------------------------------------------
/book-data/9-2-1-logistic-regression.csv:
--------------------------------------------------------------------------------
1 | hours,result
2 | 0,0
3 | 0,0
4 | 0,0
5 | 0,0
6 | 0,0
7 | 0,0
8 | 0,0
9 | 0,0
10 | 0,0
11 | 0,0
12 | 1,0
13 | 1,0
14 | 1,0
15 | 1,0
16 | 1,0
17 | 1,0
18 | 1,0
19 | 1,0
20 | 1,0
21 | 1,0
22 | 2,0
23 | 2,1
24 | 2,0
25 | 2,0
26 | 2,0
27 | 2,0
28 | 2,0
29 | 2,0
30 | 2,0
31 | 2,0
32 | 3,0
33 | 3,0
34 | 3,1
35 | 3,0
36 | 3,0
37 | 3,0
38 | 3,0
39 | 3,0
40 | 3,0
41 | 3,0
42 | 4,1
43 | 4,1
44 | 4,0
45 | 4,1
46 | 4,0
47 | 4,0
48 | 4,1
49 | 4,0
50 | 4,0
51 | 4,0
52 | 5,0
53 | 5,1
54 | 5,0
55 | 5,0
56 | 5,0
57 | 5,0
58 | 5,1
59 | 5,0
60 | 5,1
61 | 5,1
62 | 6,1
63 | 6,1
64 | 6,1
65 | 6,1
66 | 6,1
67 | 6,1
68 | 6,1
69 | 6,1
70 | 6,0
71 | 6,1
72 | 7,0
73 | 7,1
74 | 7,1
75 | 7,1
76 | 7,1
77 | 7,1
78 | 7,0
79 | 7,1
80 | 7,1
81 | 7,1
82 | 8,1
83 | 8,1
84 | 8,1
85 | 8,1
86 | 8,1
87 | 8,1
88 | 8,1
89 | 8,0
90 | 8,1
91 | 8,1
92 | 9,1
93 | 9,1
94 | 9,1
95 | 9,1
96 | 9,1
97 | 9,1
98 | 9,1
99 | 9,1
100 | 9,1
101 | 9,1
102 |
--------------------------------------------------------------------------------
/book-data/8-4-3-brand-3.csv:
--------------------------------------------------------------------------------
1 | sales,brand,local_population
2 | 385.8,0.0,265.6
3 | 473.0,0.0,386.1
4 | 451.6,0.0,522.7
5 | 556.9,0.0,530.5
6 | 423.8,0.0,397.8
7 | 226.1,0.0,142.3
8 | 410.4,0.0,398.6
9 | 397.3,0.0,222.7
10 | 503.1,0.0,466.3
11 | 454.8,0.0,547.3
12 | 465.8,0.0,357.4
13 | 445.6,0.0,401.8
14 | 341.8,0.0,132.5
15 | 454.9,0.0,370.0
16 | 262.9,0.0,164.6
17 | 474.7,0.0,407.3
18 | 354.5,0.0,281.8
19 | 584.8,0.0,483.9
20 | 355.6,0.0,124.3
21 | 330.2,0.0,154.9
22 | 412.0,0.0,442.0
23 | 431.9,0.0,357.3
24 | 452.5,0.0,385.8
25 | 438.4,0.0,521.9
26 | 555.4,0.0,343.9
27 | 578.2,99.0,505.1
28 | 521.1,99.0,355.1
29 | 540.3,99.0,563.4
30 | 588.3,99.0,433.5
31 | 175.3,99.0,174.4
32 | 315.0,99.0,282.3
33 | 612.2,99.0,532.9
34 | 350.5,99.0,275.1
35 | 133.6,99.0,194.5
36 | 336.3,99.0,336.3
37 | 417.0,99.0,296.4
38 | 593.8,99.0,409.5
39 | 441.5,99.0,318.4
40 | 290.9,99.0,230.5
41 | 423.4,99.0,306.2
42 | 309.9,99.0,309.5
43 | 626.7,99.0,551.2
44 | 550.0,99.0,589.8
45 | 470.1,99.0,411.8
46 | 219.6,99.0,141.6
47 | 568.0,99.0,466.5
48 | 477.2,99.0,439.3
49 | 633.8,99.0,513.0
50 | 334.5,99.0,273.7
51 | 266.7,99.0,129.4
52 |
--------------------------------------------------------------------------------
/book-data/2-2-Jupyter Notebookの基本.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第2部 PythonとJupyter Notebookの基本\n",
8 | "\n",
9 | "## 2章 Jupyter Notebookの基本"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 計算の実行方法"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [
24 | {
25 | "data": {
26 | "text/plain": [
27 | "1"
28 | ]
29 | },
30 | "execution_count": 1,
31 | "metadata": {},
32 | "output_type": "execute_result"
33 | }
34 | ],
35 | "source": [
36 | "1"
37 | ]
38 | },
39 | {
40 | "cell_type": "markdown",
41 | "metadata": {},
42 | "source": [
43 | "### Markdownの使い方"
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {
49 | "collapsed": true
50 | },
51 | "source": [
52 | "# 大きな表題\n",
53 | "## 少し小さな表題\n",
54 | "-----------------\n",
55 | "- 箇条書き\n",
56 | "- 箇条書き\n",
57 | "-----------------\n",
58 | "1. 箇条書き\n",
59 | "1. 箇条書き"
60 | ]
61 | }
62 | ],
63 | "metadata": {
64 | "kernelspec": {
65 | "display_name": "Python 3 (ipykernel)",
66 | "language": "python",
67 | "name": "python3"
68 | },
69 | "language_info": {
70 | "codemirror_mode": {
71 | "name": "ipython",
72 | "version": 3
73 | },
74 | "file_extension": ".py",
75 | "mimetype": "text/x-python",
76 | "name": "python",
77 | "nbconvert_exporter": "python",
78 | "pygments_lexer": "ipython3",
79 | "version": "3.9.7"
80 | }
81 | },
82 | "nbformat": 4,
83 | "nbformat_minor": 2
84 | }
85 |
--------------------------------------------------------------------------------
/book-data/6-3-分割表の検定.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第6部 統計的仮説検定\n",
8 | "\n",
9 | "## 3章 分割表の検定"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd\n",
28 | "from scipy import stats"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": 2,
34 | "metadata": {},
35 | "outputs": [],
36 | "source": [
37 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
38 | "np.set_printoptions(linewidth=60)\n",
39 | "pd.set_option('display.width', 60)\n",
40 | "\n",
41 | "from matplotlib.pylab import rcParams\n",
42 | "rcParams['figure.figsize'] = 8, 4"
43 | ]
44 | },
45 | {
46 | "cell_type": "markdown",
47 | "metadata": {},
48 | "source": [
49 | "### 実装:p値の計算"
50 | ]
51 | },
52 | {
53 | "cell_type": "code",
54 | "execution_count": 3,
55 | "metadata": {},
56 | "outputs": [
57 | {
58 | "data": {
59 | "text/plain": [
60 | "0.009821437357809604"
61 | ]
62 | },
63 | "execution_count": 3,
64 | "metadata": {},
65 | "output_type": "execute_result"
66 | }
67 | ],
68 | "source": [
69 | "# p値を求める\n",
70 | "1 - stats.chi2.cdf(x=6.667, df=1)"
71 | ]
72 | },
73 | {
74 | "cell_type": "markdown",
75 | "metadata": {},
76 | "source": [
77 | "### 実装:分割表の検定"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 4,
83 | "metadata": {
84 | "scrolled": true
85 | },
86 | "outputs": [
87 | {
88 | "name": "stdout",
89 | "output_type": "stream",
90 | "text": [
91 | " color click freq\n",
92 | "0 blue click 20\n",
93 | "1 blue not 230\n",
94 | "2 red click 10\n",
95 | "3 red not 40\n"
96 | ]
97 | }
98 | ],
99 | "source": [
100 | "# データの読み込み\n",
101 | "click_data = pd.read_csv('6-3-1-click_data.csv')\n",
102 | "print(click_data)"
103 | ]
104 | },
105 | {
106 | "cell_type": "code",
107 | "execution_count": 5,
108 | "metadata": {},
109 | "outputs": [
110 | {
111 | "name": "stdout",
112 | "output_type": "stream",
113 | "text": [
114 | "click click not\n",
115 | "color \n",
116 | "blue 20 230\n",
117 | "red 10 40\n"
118 | ]
119 | }
120 | ],
121 | "source": [
122 | "# 分割表形式に変換\n",
123 | "cross = pd.pivot_table(\n",
124 | " data=click_data,\n",
125 | " values='freq',\n",
126 | " aggfunc='sum',\n",
127 | " index='color',\n",
128 | " columns='click'\n",
129 | ")\n",
130 | "print(cross)"
131 | ]
132 | },
133 | {
134 | "cell_type": "code",
135 | "execution_count": 6,
136 | "metadata": {},
137 | "outputs": [
138 | {
139 | "data": {
140 | "text/plain": [
141 | "(6.666666666666666,\n",
142 | " 0.009823274507519247,\n",
143 | " 1,\n",
144 | " array([[ 25., 225.],\n",
145 | " [ 5., 45.]]))"
146 | ]
147 | },
148 | "execution_count": 6,
149 | "metadata": {},
150 | "output_type": "execute_result"
151 | }
152 | ],
153 | "source": [
154 | "# 検定の実行\n",
155 | "stats.chi2_contingency(cross, correction=False)"
156 | ]
157 | }
158 | ],
159 | "metadata": {
160 | "kernelspec": {
161 | "display_name": "Python 3 (ipykernel)",
162 | "language": "python",
163 | "name": "python3"
164 | },
165 | "language_info": {
166 | "codemirror_mode": {
167 | "name": "ipython",
168 | "version": 3
169 | },
170 | "file_extension": ".py",
171 | "mimetype": "text/x-python",
172 | "name": "python",
173 | "nbconvert_exporter": "python",
174 | "pygments_lexer": "ipython3",
175 | "version": "3.9.7"
176 | }
177 | },
178 | "nbformat": 4,
179 | "nbformat_minor": 2
180 | }
181 |
--------------------------------------------------------------------------------
/book-data/6-2-平均値の差の検定.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第6部 統計的仮説検定\n",
8 | "\n",
9 | "## 2章 平均値の差の検定"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd\n",
28 | "from scipy import stats"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": 2,
34 | "metadata": {},
35 | "outputs": [],
36 | "source": [
37 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
38 | "np.set_printoptions(linewidth=60)\n",
39 | "pd.set_option('display.width', 60)\n",
40 | "\n",
41 | "from matplotlib.pylab import rcParams\n",
42 | "rcParams['figure.figsize'] = 8, 4"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 3,
48 | "metadata": {
49 | "scrolled": true
50 | },
51 | "outputs": [
52 | {
53 | "name": "stdout",
54 | "output_type": "stream",
55 | "text": [
56 | " person medicine body_temperature\n",
57 | "0 A before 36.2\n",
58 | "1 B before 36.2\n",
59 | "2 C before 35.3\n",
60 | "3 D before 36.1\n",
61 | "4 E before 36.1\n",
62 | "5 A after 36.8\n",
63 | "6 B after 36.1\n",
64 | "7 C after 36.8\n",
65 | "8 D after 37.1\n",
66 | "9 E after 36.9\n"
67 | ]
68 | }
69 | ],
70 | "source": [
71 | "# データの読み込み\n",
72 | "paired_test_data = pd.read_csv('6-2-1-paired-t-test.csv')\n",
73 | "print(paired_test_data)"
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "### 実装:対応のあるt検定"
81 | ]
82 | },
83 | {
84 | "cell_type": "code",
85 | "execution_count": 4,
86 | "metadata": {},
87 | "outputs": [
88 | {
89 | "data": {
90 | "text/plain": [
91 | "array([ 0.6, -0.1, 1.5, 1. , 0.8])"
92 | ]
93 | },
94 | "execution_count": 4,
95 | "metadata": {},
96 | "output_type": "execute_result"
97 | }
98 | ],
99 | "source": [
100 | "# 薬を飲む前と飲んだ後の標本平均\n",
101 | "before = paired_test_data.query(\n",
102 | " 'medicine == \"before\"')['body_temperature']\n",
103 | "after = paired_test_data.query(\n",
104 | " 'medicine == \"after\"')['body_temperature']\n",
105 | "# アレイに変換\n",
106 | "before = np.array(before)\n",
107 | "after = np.array(after)\n",
108 | "# 差を計算\n",
109 | "diff = after - before\n",
110 | "diff"
111 | ]
112 | },
113 | {
114 | "cell_type": "code",
115 | "execution_count": 5,
116 | "metadata": {},
117 | "outputs": [
118 | {
119 | "data": {
120 | "text/plain": [
121 | "Ttest_1sampResult(statistic=2.901693483620596, pvalue=0.044043109730074276)"
122 | ]
123 | },
124 | "execution_count": 5,
125 | "metadata": {},
126 | "output_type": "execute_result"
127 | }
128 | ],
129 | "source": [
130 | "# 平均値が0と異なるか検定\n",
131 | "stats.ttest_1samp(diff, 0)"
132 | ]
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": 6,
137 | "metadata": {},
138 | "outputs": [
139 | {
140 | "data": {
141 | "text/plain": [
142 | "Ttest_relResult(statistic=2.901693483620596, pvalue=0.044043109730074276)"
143 | ]
144 | },
145 | "execution_count": 6,
146 | "metadata": {},
147 | "output_type": "execute_result"
148 | }
149 | ],
150 | "source": [
151 | "# 対応のあるt検定\n",
152 | "stats.ttest_rel(after, before)"
153 | ]
154 | },
155 | {
156 | "cell_type": "markdown",
157 | "metadata": {},
158 | "source": [
159 | "### 実装:対応の無いt検定(不等分散)"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 7,
165 | "metadata": {},
166 | "outputs": [
167 | {
168 | "data": {
169 | "text/plain": [
170 | "3.156"
171 | ]
172 | },
173 | "execution_count": 7,
174 | "metadata": {},
175 | "output_type": "execute_result"
176 | }
177 | ],
178 | "source": [
179 | "# 平均値\n",
180 | "x_bar_bef = np.mean(before)\n",
181 | "x_bar_aft = np.mean(after)\n",
182 | "\n",
183 | "# 分散\n",
184 | "u2_bef = np.var(before, ddof=1)\n",
185 | "u2_aft = np.var(after, ddof=1)\n",
186 | "\n",
187 | "# サンプルサイズ\n",
188 | "m = len(before)\n",
189 | "n = len(after)\n",
190 | "\n",
191 | "# t値\n",
192 | "t_value = (x_bar_aft - x_bar_bef) / \\\n",
193 | " np.sqrt((u2_bef/m + u2_aft/n))\n",
194 | "round(t_value, 3)"
195 | ]
196 | },
197 | {
198 | "cell_type": "code",
199 | "execution_count": 8,
200 | "metadata": {},
201 | "outputs": [
202 | {
203 | "data": {
204 | "text/plain": [
205 | "7.998"
206 | ]
207 | },
208 | "execution_count": 8,
209 | "metadata": {},
210 | "output_type": "execute_result"
211 | }
212 | ],
213 | "source": [
214 | "# 自由度\n",
215 | "df = (u2_bef / m + u2_aft / n)**2 / \\\n",
216 | " ((u2_bef / m)**2 / (m-1) + (u2_aft / n)**2 / (n-1))\n",
217 | "round(df, 3)"
218 | ]
219 | },
220 | {
221 | "cell_type": "code",
222 | "execution_count": 9,
223 | "metadata": {},
224 | "outputs": [
225 | {
226 | "data": {
227 | "text/plain": [
228 | "0.01348"
229 | ]
230 | },
231 | "execution_count": 9,
232 | "metadata": {},
233 | "output_type": "execute_result"
234 | }
235 | ],
236 | "source": [
237 | "# p値\n",
238 | "p_value = stats.t.cdf(-np.abs(t_value), df=df) * 2\n",
239 | "round(p_value, 5)"
240 | ]
241 | },
242 | {
243 | "cell_type": "code",
244 | "execution_count": 10,
245 | "metadata": {},
246 | "outputs": [
247 | {
248 | "data": {
249 | "text/plain": [
250 | "Ttest_indResult(statistic=3.1557282344421034, pvalue=0.013484775682079892)"
251 | ]
252 | },
253 | "execution_count": 10,
254 | "metadata": {},
255 | "output_type": "execute_result"
256 | }
257 | ],
258 | "source": [
259 | "stats.ttest_ind(after, before, equal_var=False)"
260 | ]
261 | }
262 | ],
263 | "metadata": {
264 | "kernelspec": {
265 | "display_name": "Python 3 (ipykernel)",
266 | "language": "python",
267 | "name": "python3"
268 | },
269 | "language_info": {
270 | "codemirror_mode": {
271 | "name": "ipython",
272 | "version": 3
273 | },
274 | "file_extension": ".py",
275 | "mimetype": "text/x-python",
276 | "name": "python",
277 | "nbconvert_exporter": "python",
278 | "pygments_lexer": "ipython3",
279 | "version": "3.9.7"
280 | }
281 | },
282 | "nbformat": 4,
283 | "nbformat_minor": 2
284 | }
285 |
--------------------------------------------------------------------------------
/book-data/6-1-母平均に関する1標本のt検定.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第6部 統計的仮説検定\n",
8 | "\n",
9 | "## 1章 母平均に関する1標本のt検定"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd\n",
28 | "from scipy import stats"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": 2,
34 | "metadata": {},
35 | "outputs": [],
36 | "source": [
37 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
38 | "np.set_printoptions(linewidth=60)\n",
39 | "pd.set_option('display.width', 60)\n",
40 | "\n",
41 | "from matplotlib.pylab import rcParams\n",
42 | "rcParams['figure.figsize'] = 8, 4"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 3,
48 | "metadata": {
49 | "scrolled": true
50 | },
51 | "outputs": [
52 | {
53 | "data": {
54 | "text/plain": [
55 | "0 58.529820\n",
56 | "1 52.353039\n",
57 | "2 74.446169\n",
58 | "3 52.983263\n",
59 | "4 55.876879\n",
60 | "Name: weight, dtype: float64"
61 | ]
62 | },
63 | "execution_count": 3,
64 | "metadata": {},
65 | "output_type": "execute_result"
66 | }
67 | ],
68 | "source": [
69 | "# データの読み込み\n",
70 | "junk_food = pd.read_csv('6-1-1-junk-food-weight.csv')['weight']\n",
71 | "junk_food.head()"
72 | ]
73 | },
74 | {
75 | "cell_type": "markdown",
76 | "metadata": {},
77 | "source": [
78 | "### 実装:t値の計算"
79 | ]
80 | },
81 | {
82 | "cell_type": "code",
83 | "execution_count": 4,
84 | "metadata": {},
85 | "outputs": [
86 | {
87 | "data": {
88 | "text/plain": [
89 | "55.385"
90 | ]
91 | },
92 | "execution_count": 4,
93 | "metadata": {},
94 | "output_type": "execute_result"
95 | }
96 | ],
97 | "source": [
98 | "# 標本平均\n",
99 | "x_bar = np.mean(junk_food)\n",
100 | "round(x_bar, 3)"
101 | ]
102 | },
103 | {
104 | "cell_type": "code",
105 | "execution_count": 5,
106 | "metadata": {},
107 | "outputs": [
108 | {
109 | "data": {
110 | "text/plain": [
111 | "19"
112 | ]
113 | },
114 | "execution_count": 5,
115 | "metadata": {},
116 | "output_type": "execute_result"
117 | }
118 | ],
119 | "source": [
120 | "# 自由度\n",
121 | "n = len(junk_food)\n",
122 | "df = n - 1\n",
123 | "df"
124 | ]
125 | },
126 | {
127 | "cell_type": "code",
128 | "execution_count": 6,
129 | "metadata": {},
130 | "outputs": [
131 | {
132 | "data": {
133 | "text/plain": [
134 | "1.958"
135 | ]
136 | },
137 | "execution_count": 6,
138 | "metadata": {},
139 | "output_type": "execute_result"
140 | }
141 | ],
142 | "source": [
143 | "# 標準誤差\n",
144 | "u = np.std(junk_food, ddof = 1)\n",
145 | "se = u / np.sqrt(n)\n",
146 | "round(se, 3)"
147 | ]
148 | },
149 | {
150 | "cell_type": "code",
151 | "execution_count": 7,
152 | "metadata": {},
153 | "outputs": [
154 | {
155 | "data": {
156 | "text/plain": [
157 | "2.75"
158 | ]
159 | },
160 | "execution_count": 7,
161 | "metadata": {},
162 | "output_type": "execute_result"
163 | }
164 | ],
165 | "source": [
166 | "# t値\n",
167 | "t_sample = (x_bar - 50) / se\n",
168 | "round(t_sample, 3)"
169 | ]
170 | },
171 | {
172 | "cell_type": "markdown",
173 | "metadata": {},
174 | "source": [
175 | "### 実装:棄却域の計算"
176 | ]
177 | },
178 | {
179 | "cell_type": "code",
180 | "execution_count": 8,
181 | "metadata": {},
182 | "outputs": [
183 | {
184 | "data": {
185 | "text/plain": [
186 | "-2.093"
187 | ]
188 | },
189 | "execution_count": 8,
190 | "metadata": {},
191 | "output_type": "execute_result"
192 | }
193 | ],
194 | "source": [
195 | "# t分布の2.5%点\n",
196 | "round(stats.t.ppf(q=0.025, df=df), 3)"
197 | ]
198 | },
199 | {
200 | "cell_type": "markdown",
201 | "metadata": {},
202 | "source": [
203 | "### 実装:p値の計算"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": 9,
209 | "metadata": {},
210 | "outputs": [
211 | {
212 | "data": {
213 | "text/plain": [
214 | "0.013"
215 | ]
216 | },
217 | "execution_count": 9,
218 | "metadata": {},
219 | "output_type": "execute_result"
220 | }
221 | ],
222 | "source": [
223 | "# p値\n",
224 | "p_value = stats.t.cdf(-np.abs(t_sample), df=df) * 2\n",
225 | "round(p_value, 3)"
226 | ]
227 | },
228 | {
229 | "cell_type": "code",
230 | "execution_count": 10,
231 | "metadata": {},
232 | "outputs": [
233 | {
234 | "data": {
235 | "text/plain": [
236 | "Ttest_1sampResult(statistic=2.750339683171343, pvalue=0.012725590012524182)"
237 | ]
238 | },
239 | "execution_count": 10,
240 | "metadata": {},
241 | "output_type": "execute_result"
242 | }
243 | ],
244 | "source": [
245 | "# t検定\n",
246 | "stats.ttest_1samp(junk_food, 50)"
247 | ]
248 | },
249 | {
250 | "cell_type": "markdown",
251 | "metadata": {
252 | "collapsed": true
253 | },
254 | "source": [
255 | "### 実装:シミュレーションによるp値の計算"
256 | ]
257 | },
258 | {
259 | "cell_type": "code",
260 | "execution_count": 11,
261 | "metadata": {},
262 | "outputs": [],
263 | "source": [
264 | "# 標本の情報(一部再掲)\n",
265 | "n = len(junk_food)\n",
266 | "u = np.std(junk_food, ddof=1)"
267 | ]
268 | },
269 | {
270 | "cell_type": "code",
271 | "execution_count": 12,
272 | "metadata": {},
273 | "outputs": [],
274 | "source": [
275 | "# t値を格納する変数\n",
276 | "t_value_array = np.zeros(50000)"
277 | ]
278 | },
279 | {
280 | "cell_type": "code",
281 | "execution_count": 13,
282 | "metadata": {},
283 | "outputs": [],
284 | "source": [
285 | "# 母平均が50(帰無仮説が正しい)と仮定してt値を計算することを50000回繰り返す\n",
286 | "np.random.seed(1)\n",
287 | "norm_dist = stats.norm(loc=50, scale=u)\n",
288 | "for i in range(0, 50000):\n",
289 | " # 標本の抽出\n",
290 | " sample = norm_dist.rvs(size=n)\n",
291 | " # t値の計算\n",
292 | " sample_x_bar = np.mean(sample) # 標本平均\n",
293 | " sample_u = np.std(sample, ddof=1) # 標準偏差\n",
294 | " sample_se = sample_u / np.sqrt(n) # 標準誤差\n",
295 | " t_value_array[i] = (sample_x_bar - 50) / sample_se # t値"
296 | ]
297 | },
298 | {
299 | "cell_type": "code",
300 | "execution_count": 14,
301 | "metadata": {},
302 | "outputs": [
303 | {
304 | "data": {
305 | "text/plain": [
306 | "0.013"
307 | ]
308 | },
309 | "execution_count": 14,
310 | "metadata": {},
311 | "output_type": "execute_result"
312 | }
313 | ],
314 | "source": [
315 | "p_sim = (sum(t_value_array >= t_sample) / 50000) * 2\n",
316 | "round(p_sim, 3)"
317 | ]
318 | }
319 | ],
320 | "metadata": {
321 | "kernelspec": {
322 | "display_name": "Python 3 (ipykernel)",
323 | "language": "python",
324 | "name": "python3"
325 | },
326 | "language_info": {
327 | "codemirror_mode": {
328 | "name": "ipython",
329 | "version": 3
330 | },
331 | "file_extension": ".py",
332 | "mimetype": "text/x-python",
333 | "name": "python",
334 | "nbconvert_exporter": "python",
335 | "pygments_lexer": "ipython3",
336 | "version": "3.9.7"
337 | }
338 | },
339 | "nbformat": 4,
340 | "nbformat_minor": 2
341 | }
342 |
--------------------------------------------------------------------------------
/book-data/3-5-多変量データの統計量.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第3部 記述統計\n",
8 | "\n",
9 | "## 5章 多変量データの統計量"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd"
28 | ]
29 | },
30 | {
31 | "cell_type": "markdown",
32 | "metadata": {},
33 | "source": [
34 | "### 実装:分析対象となるデータの用意"
35 | ]
36 | },
37 | {
38 | "cell_type": "code",
39 | "execution_count": 2,
40 | "metadata": {},
41 | "outputs": [
42 | {
43 | "name": "stdout",
44 | "output_type": "stream",
45 | "text": [
46 | " x y\n",
47 | "0 18.5 34\n",
48 | "1 18.7 39\n",
49 | "2 19.1 41\n",
50 | "3 19.7 38\n",
51 | "4 21.5 45\n",
52 | "5 21.7 41\n",
53 | "6 21.8 52\n",
54 | "7 22.0 44\n",
55 | "8 23.4 44\n",
56 | "9 23.8 49\n"
57 | ]
58 | }
59 | ],
60 | "source": [
61 | "# データの読み込み\n",
62 | "cov_data = pd.read_csv('3-5-1-cov.csv')\n",
63 | "print(cov_data)"
64 | ]
65 | },
66 | {
67 | "cell_type": "markdown",
68 | "metadata": {},
69 | "source": [
70 | "### 実装:共分散"
71 | ]
72 | },
73 | {
74 | "cell_type": "code",
75 | "execution_count": 3,
76 | "metadata": {},
77 | "outputs": [],
78 | "source": [
79 | "# データの取り出し\n",
80 | "x = cov_data['x']\n",
81 | "y = cov_data['y']\n",
82 | "\n",
83 | "# サンプルサイズ\n",
84 | "n = len(cov_data)\n",
85 | "\n",
86 | "# 標本平均\n",
87 | "x_bar = np.mean(x)\n",
88 | "y_bar = np.mean(y)"
89 | ]
90 | },
91 | {
92 | "cell_type": "code",
93 | "execution_count": 4,
94 | "metadata": {},
95 | "outputs": [
96 | {
97 | "data": {
98 | "text/plain": [
99 | "6.906"
100 | ]
101 | },
102 | "execution_count": 4,
103 | "metadata": {},
104 | "output_type": "execute_result"
105 | }
106 | ],
107 | "source": [
108 | "# 共分散\n",
109 | "cov = sum((x - x_bar) * (y - y_bar)) / n\n",
110 | "round(cov, 3)"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {
116 | "collapsed": true
117 | },
118 | "source": [
119 | "### 実装:分散共分散行列"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 5,
125 | "metadata": {},
126 | "outputs": [
127 | {
128 | "name": "stdout",
129 | "output_type": "stream",
130 | "text": [
131 | "xの標本分散: 3.282\n",
132 | "yの標本分散: 25.21\n"
133 | ]
134 | }
135 | ],
136 | "source": [
137 | "# 分散の計算\n",
138 | "s2_x = np.var(x, ddof=0)\n",
139 | "s2_y = np.var(y, ddof=0)\n",
140 | "\n",
141 | "print('xの標本分散:', round(s2_x, 3))\n",
142 | "print('yの標本分散:', round(s2_y, 3))"
143 | ]
144 | },
145 | {
146 | "cell_type": "code",
147 | "execution_count": 6,
148 | "metadata": {},
149 | "outputs": [
150 | {
151 | "data": {
152 | "text/plain": [
153 | "array([[ 3.2816, 6.906 ],\n",
154 | " [ 6.906 , 25.21 ]])"
155 | ]
156 | },
157 | "execution_count": 6,
158 | "metadata": {},
159 | "output_type": "execute_result"
160 | }
161 | ],
162 | "source": [
163 | "# 共分散\n",
164 | "np.cov(x, y, ddof=0)"
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "metadata": {
170 | "collapsed": true
171 | },
172 | "source": [
173 | "### 実装:ピアソンの積率相関係数"
174 | ]
175 | },
176 | {
177 | "cell_type": "code",
178 | "execution_count": 7,
179 | "metadata": {},
180 | "outputs": [
181 | {
182 | "data": {
183 | "text/plain": [
184 | "0.759"
185 | ]
186 | },
187 | "execution_count": 7,
188 | "metadata": {},
189 | "output_type": "execute_result"
190 | }
191 | ],
192 | "source": [
193 | "# 相関係数\n",
194 | "rho = cov / np.sqrt(s2_x * s2_y)\n",
195 | "round(rho, 3)"
196 | ]
197 | },
198 | {
199 | "cell_type": "code",
200 | "execution_count": 8,
201 | "metadata": {},
202 | "outputs": [
203 | {
204 | "data": {
205 | "text/plain": [
206 | "array([[1. , 0.7592719],\n",
207 | " [0.7592719, 1. ]])"
208 | ]
209 | },
210 | "execution_count": 8,
211 | "metadata": {},
212 | "output_type": "execute_result"
213 | }
214 | ],
215 | "source": [
216 | "# 相関行列\n",
217 | "np.corrcoef(x, y)"
218 | ]
219 | },
220 | {
221 | "cell_type": "markdown",
222 | "metadata": {},
223 | "source": [
224 | "### 実装:クロス集計表"
225 | ]
226 | },
227 | {
228 | "cell_type": "markdown",
229 | "metadata": {},
230 | "source": [
231 | "#### 度数をカウントする事例"
232 | ]
233 | },
234 | {
235 | "cell_type": "code",
236 | "execution_count": 9,
237 | "metadata": {
238 | "scrolled": true
239 | },
240 | "outputs": [
241 | {
242 | "name": "stdout",
243 | "output_type": "stream",
244 | "text": [
245 | " sunlight disease\n",
246 | "0 yes yes\n",
247 | "1 yes yes\n",
248 | "2 yes yes\n",
249 | "3 yes no\n",
250 | "4 yes no\n"
251 | ]
252 | }
253 | ],
254 | "source": [
255 | "disease = pd.read_csv('3-5-2-cross.csv')\n",
256 | "print(disease.head())"
257 | ]
258 | },
259 | {
260 | "cell_type": "code",
261 | "execution_count": 10,
262 | "metadata": {},
263 | "outputs": [
264 | {
265 | "name": "stdout",
266 | "output_type": "stream",
267 | "text": [
268 | "disease no yes\n",
269 | "sunlight \n",
270 | "no 2 8\n",
271 | "yes 7 3\n"
272 | ]
273 | }
274 | ],
275 | "source": [
276 | "# クロス集計\n",
277 | "cross_1 = pd.crosstab(\n",
278 | " disease['sunlight'],\n",
279 | " disease['disease']\n",
280 | ")\n",
281 | "print(cross_1)"
282 | ]
283 | },
284 | {
285 | "cell_type": "markdown",
286 | "metadata": {},
287 | "source": [
288 | "#### クロス集計表の作成"
289 | ]
290 | },
291 | {
292 | "cell_type": "code",
293 | "execution_count": 11,
294 | "metadata": {},
295 | "outputs": [
296 | {
297 | "name": "stdout",
298 | "output_type": "stream",
299 | "text": [
300 | " store color sales\n",
301 | "0 tokyo blue 10\n",
302 | "1 tokyo red 15\n",
303 | "2 osaka blue 13\n",
304 | "3 osaka red 9\n"
305 | ]
306 | }
307 | ],
308 | "source": [
309 | "shoes = pd.read_csv('3-5-3-cross2.csv')\n",
310 | "print(shoes)"
311 | ]
312 | },
313 | {
314 | "cell_type": "code",
315 | "execution_count": 12,
316 | "metadata": {},
317 | "outputs": [
318 | {
319 | "name": "stdout",
320 | "output_type": "stream",
321 | "text": [
322 | "color blue red\n",
323 | "store \n",
324 | "osaka 13 9\n",
325 | "tokyo 10 15\n"
326 | ]
327 | }
328 | ],
329 | "source": [
330 | "cross_2 = pd.pivot_table(\n",
331 | " data=shoes,\n",
332 | " values='sales',\n",
333 | " aggfunc='sum',\n",
334 | " index='store',\n",
335 | " columns='color'\n",
336 | ")\n",
337 | "print(cross_2)"
338 | ]
339 | }
340 | ],
341 | "metadata": {
342 | "kernelspec": {
343 | "display_name": "Python 3 (ipykernel)",
344 | "language": "python",
345 | "name": "python3"
346 | },
347 | "language_info": {
348 | "codemirror_mode": {
349 | "name": "ipython",
350 | "version": 3
351 | },
352 | "file_extension": ".py",
353 | "mimetype": "text/x-python",
354 | "name": "python",
355 | "nbconvert_exporter": "python",
356 | "pygments_lexer": "ipython3",
357 | "version": "3.9.7"
358 | }
359 | },
360 | "nbformat": 4,
361 | "nbformat_minor": 2
362 | }
363 |
--------------------------------------------------------------------------------
/book-data/9-3-一般化線形モデルの評価.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第9部 一般化線形モデル\n",
8 | "\n",
9 | "## 3章 一般化線形モデルの評価"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {
23 | "scrolled": true
24 | },
25 | "outputs": [],
26 | "source": [
27 | "# 数値計算に使うライブラリ\n",
28 | "import numpy as np\n",
29 | "import pandas as pd\n",
30 | "from scipy import stats\n",
31 | "# 表示桁数の設定\n",
32 | "pd.set_option('display.precision', 3)\n",
33 | "np.set_printoptions(precision=3)\n",
34 | "\n",
35 | "# 統計モデルを推定するライブラリ\n",
36 | "import statsmodels.formula.api as smf\n",
37 | "import statsmodels.api as sm"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": 2,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
47 | "np.set_printoptions(linewidth=60)\n",
48 | "pd.set_option('display.width', 60)"
49 | ]
50 | },
51 | {
52 | "cell_type": "code",
53 | "execution_count": 3,
54 | "metadata": {},
55 | "outputs": [],
56 | "source": [
57 | "# データの読み込み\n",
58 | "test_result = pd.read_csv('9-2-1-logistic-regression.csv')\n",
59 | "\n",
60 | "# モデル化\n",
61 | "mod_glm = smf.glm(formula = 'result ~ hours', \n",
62 | " data = test_result, \n",
63 | " family=sm.families.Binomial()).fit()"
64 | ]
65 | },
66 | {
67 | "cell_type": "markdown",
68 | "metadata": {
69 | "collapsed": true
70 | },
71 | "source": [
72 | "### 実装:ピアソン残差"
73 | ]
74 | },
75 | {
76 | "cell_type": "code",
77 | "execution_count": 4,
78 | "metadata": {
79 | "scrolled": true
80 | },
81 | "outputs": [
82 | {
83 | "data": {
84 | "text/plain": [
85 | "0 -0.102\n",
86 | "1 -0.102\n",
87 | "2 -0.102\n",
88 | "Name: result, dtype: float64"
89 | ]
90 | },
91 | "execution_count": 4,
92 | "metadata": {},
93 | "output_type": "execute_result"
94 | }
95 | ],
96 | "source": [
97 | "# ピアソン残差の計算\n",
98 | "\n",
99 | "# 予測された成功確率\n",
100 | "pred = mod_glm.predict()\n",
101 | "# 応答変数(テストの合否)\n",
102 | "y = test_result.result\n",
103 | "\n",
104 | "# ピアソン残差\n",
105 | "peason_resid = (y - pred) / np.sqrt(pred * (1 - pred))\n",
106 | "peason_resid.head(3)"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": 5,
112 | "metadata": {
113 | "scrolled": true
114 | },
115 | "outputs": [
116 | {
117 | "data": {
118 | "text/plain": [
119 | "0 -0.102\n",
120 | "1 -0.102\n",
121 | "2 -0.102\n",
122 | "dtype: float64"
123 | ]
124 | },
125 | "execution_count": 5,
126 | "metadata": {},
127 | "output_type": "execute_result"
128 | }
129 | ],
130 | "source": [
131 | "# ピアソン残差の取り出し\n",
132 | "mod_glm.resid_pearson.head(3)"
133 | ]
134 | },
135 | {
136 | "cell_type": "code",
137 | "execution_count": 6,
138 | "metadata": {},
139 | "outputs": [
140 | {
141 | "data": {
142 | "text/plain": [
143 | "84.911"
144 | ]
145 | },
146 | "execution_count": 6,
147 | "metadata": {},
148 | "output_type": "execute_result"
149 | }
150 | ],
151 | "source": [
152 | "# ピアソン残差の2乗和\n",
153 | "round(np.sum(mod_glm.resid_pearson**2), 3)"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": 7,
159 | "metadata": {},
160 | "outputs": [
161 | {
162 | "data": {
163 | "text/plain": [
164 | "84.911"
165 | ]
166 | },
167 | "execution_count": 7,
168 | "metadata": {},
169 | "output_type": "execute_result"
170 | }
171 | ],
172 | "source": [
173 | "# summary関数でも出力されている\n",
174 | "round(mod_glm.pearson_chi2, 3)"
175 | ]
176 | },
177 | {
178 | "cell_type": "markdown",
179 | "metadata": {},
180 | "source": [
181 | "### 実装:deviance残差"
182 | ]
183 | },
184 | {
185 | "cell_type": "markdown",
186 | "metadata": {},
187 | "source": [
188 | "#### deviance残差の計算"
189 | ]
190 | },
191 | {
192 | "cell_type": "code",
193 | "execution_count": 8,
194 | "metadata": {
195 | "scrolled": false
196 | },
197 | "outputs": [
198 | {
199 | "data": {
200 | "text/plain": [
201 | "0 -0.144\n",
202 | "1 -0.144\n",
203 | "2 -0.144\n",
204 | "Name: result, dtype: float64"
205 | ]
206 | },
207 | "execution_count": 8,
208 | "metadata": {},
209 | "output_type": "execute_result"
210 | }
211 | ],
212 | "source": [
213 | "# deviance残差の計算\n",
214 | "\n",
215 | "# 成功確率の当てはめ値\n",
216 | "pred = mod_glm.predict()\n",
217 | "# 応答変数(テストの合否)\n",
218 | "y = test_result.result\n",
219 | "\n",
220 | "# 合否を完全に予測できたときの対数尤度との差異\n",
221 | "resid_tmp = 0 - np.log(stats.binom.pmf(k = y, n = 1, \n",
222 | " p = pred))\n",
223 | "# deviance残差\n",
224 | "deviance_resid = np.sqrt(\n",
225 | " 2 * resid_tmp) * np.sign(y - pred)\n",
226 | "# 結果の確認\n",
227 | "deviance_resid.head(3)"
228 | ]
229 | },
230 | {
231 | "cell_type": "code",
232 | "execution_count": 9,
233 | "metadata": {},
234 | "outputs": [
235 | {
236 | "data": {
237 | "text/plain": [
238 | "0 -0.144\n",
239 | "1 -0.144\n",
240 | "2 -0.144\n",
241 | "dtype: float64"
242 | ]
243 | },
244 | "execution_count": 9,
245 | "metadata": {},
246 | "output_type": "execute_result"
247 | }
248 | ],
249 | "source": [
250 | "mod_glm.resid_deviance.head(3)"
251 | ]
252 | },
253 | {
254 | "cell_type": "markdown",
255 | "metadata": {},
256 | "source": [
257 | "#### devianceの計算"
258 | ]
259 | },
260 | {
261 | "cell_type": "code",
262 | "execution_count": 10,
263 | "metadata": {},
264 | "outputs": [
265 | {
266 | "data": {
267 | "text/plain": [
268 | "68.028"
269 | ]
270 | },
271 | "execution_count": 10,
272 | "metadata": {},
273 | "output_type": "execute_result"
274 | }
275 | ],
276 | "source": [
277 | "# deviance\n",
278 | "deviance = np.sum(mod_glm.resid_deviance ** 2)\n",
279 | "round(deviance, 3)"
280 | ]
281 | },
282 | {
283 | "cell_type": "markdown",
284 | "metadata": {},
285 | "source": [
286 | "#### 最大化対数尤度からdevianceを計算"
287 | ]
288 | },
289 | {
290 | "cell_type": "code",
291 | "execution_count": 11,
292 | "metadata": {},
293 | "outputs": [
294 | {
295 | "data": {
296 | "text/plain": [
297 | "-34.014"
298 | ]
299 | },
300 | "execution_count": 11,
301 | "metadata": {},
302 | "output_type": "execute_result"
303 | }
304 | ],
305 | "source": [
306 | "# 最大化対数尤度の計算\n",
307 | "loglik = sum(np.log(stats.binom.pmf(k=y, n=1, p=pred)))\n",
308 | "round(loglik, 3)"
309 | ]
310 | },
311 | {
312 | "cell_type": "code",
313 | "execution_count": 12,
314 | "metadata": {},
315 | "outputs": [
316 | {
317 | "data": {
318 | "text/plain": [
319 | "-34.014"
320 | ]
321 | },
322 | "execution_count": 12,
323 | "metadata": {},
324 | "output_type": "execute_result"
325 | }
326 | ],
327 | "source": [
328 | "# 最大化対数尤度の取得\n",
329 | "round(mod_glm.llf, 3)"
330 | ]
331 | },
332 | {
333 | "cell_type": "code",
334 | "execution_count": 13,
335 | "metadata": {},
336 | "outputs": [
337 | {
338 | "data": {
339 | "text/plain": [
340 | "68.028"
341 | ]
342 | },
343 | "execution_count": 13,
344 | "metadata": {},
345 | "output_type": "execute_result"
346 | }
347 | ],
348 | "source": [
349 | "# 最大化対数尤度からdevianceを計算\n",
350 | "round(2 * (0 - mod_glm.llf), 3)"
351 | ]
352 | },
353 | {
354 | "cell_type": "code",
355 | "execution_count": 14,
356 | "metadata": {},
357 | "outputs": [
358 | {
359 | "data": {
360 | "text/plain": [
361 | "68.028"
362 | ]
363 | },
364 | "execution_count": 14,
365 | "metadata": {},
366 | "output_type": "execute_result"
367 | }
368 | ],
369 | "source": [
370 | "# devianceの取得\n",
371 | "round(mod_glm.deviance, 3)"
372 | ]
373 | }
374 | ],
375 | "metadata": {
376 | "kernelspec": {
377 | "display_name": "Python 3 (ipykernel)",
378 | "language": "python",
379 | "name": "python3"
380 | },
381 | "language_info": {
382 | "codemirror_mode": {
383 | "name": "ipython",
384 | "version": 3
385 | },
386 | "file_extension": ".py",
387 | "mimetype": "text/x-python",
388 | "name": "python",
389 | "nbconvert_exporter": "python",
390 | "pygments_lexer": "ipython3",
391 | "version": "3.9.7"
392 | }
393 | },
394 | "nbformat": 4,
395 | "nbformat_minor": 2
396 | }
397 |
--------------------------------------------------------------------------------
/book-data/5-6-区間推定.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第5部 統計的推定\n",
8 | "## 6章 区間推定"
9 | ]
10 | },
11 | {
12 | "cell_type": "markdown",
13 | "metadata": {},
14 | "source": [
15 | "### 実装:分析の準備"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 1,
21 | "metadata": {},
22 | "outputs": [],
23 | "source": [
24 | "# 数値計算に使うライブラリ\n",
25 | "import numpy as np\n",
26 | "import pandas as pd\n",
27 | "from scipy import stats\n",
28 | "\n",
29 | "# グラフを描画するライブラリ\n",
30 | "from matplotlib import pyplot as plt\n",
31 | "import seaborn as sns\n",
32 | "sns.set()\n",
33 | "\n",
34 | "# グラフの日本語表記\n",
35 | "from matplotlib import rcParams\n",
36 | "rcParams['font.family'] = 'sans-serif'\n",
37 | "rcParams['font.sans-serif'] = 'Meiryo'"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": 2,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
47 | "np.set_printoptions(linewidth=60)\n",
48 | "pd.set_option('display.width', 60)\n",
49 | "\n",
50 | "from matplotlib.pylab import rcParams\n",
51 | "rcParams['figure.figsize'] = 8, 4"
52 | ]
53 | },
54 | {
55 | "cell_type": "code",
56 | "execution_count": 3,
57 | "metadata": {},
58 | "outputs": [
59 | {
60 | "data": {
61 | "text/plain": [
62 | "0 4.352982\n",
63 | "1 3.735304\n",
64 | "2 5.944617\n",
65 | "3 3.798326\n",
66 | "4 4.087688\n",
67 | "5 5.265985\n",
68 | "6 3.272614\n",
69 | "7 3.526691\n",
70 | "8 4.150083\n",
71 | "9 3.736104\n",
72 | "Name: length, dtype: float64"
73 | ]
74 | },
75 | "execution_count": 3,
76 | "metadata": {},
77 | "output_type": "execute_result"
78 | }
79 | ],
80 | "source": [
81 | "# データの読み込み\n",
82 | "fish = pd.read_csv('5-6-1-fish_length.csv')['length']\n",
83 | "fish"
84 | ]
85 | },
86 | {
87 | "cell_type": "markdown",
88 | "metadata": {},
89 | "source": [
90 | "### 実装:点推定"
91 | ]
92 | },
93 | {
94 | "cell_type": "code",
95 | "execution_count": 4,
96 | "metadata": {},
97 | "outputs": [
98 | {
99 | "name": "stdout",
100 | "output_type": "stream",
101 | "text": [
102 | "標本平均: 4.187\n",
103 | "不偏分散: 0.68\n"
104 | ]
105 | }
106 | ],
107 | "source": [
108 | "# 点推定\n",
109 | "x_bar = np.mean(fish)\n",
110 | "u2 = np.var(fish, ddof=1)\n",
111 | "\n",
112 | "print('標本平均:', round(x_bar, 3))\n",
113 | "print('不偏分散:', round(u2, 3))"
114 | ]
115 | },
116 | {
117 | "cell_type": "markdown",
118 | "metadata": {},
119 | "source": [
120 | "### 実装:母平均の区間推定"
121 | ]
122 | },
123 | {
124 | "cell_type": "markdown",
125 | "metadata": {},
126 | "source": [
127 | "#### 定義通りの実装"
128 | ]
129 | },
130 | {
131 | "cell_type": "code",
132 | "execution_count": 5,
133 | "metadata": {},
134 | "outputs": [
135 | {
136 | "name": "stdout",
137 | "output_type": "stream",
138 | "text": [
139 | "サンプルサイズ: 10\n",
140 | "自由度 : 9\n",
141 | "標準偏差 : 0.825\n",
142 | "標準誤差 : 0.261\n",
143 | "標本平均 : 4.187\n"
144 | ]
145 | }
146 | ],
147 | "source": [
148 | "# 統計量の計算\n",
149 | "n = len(fish) # サンプルサイズ\n",
150 | "df = n - 1 # 自由度\n",
151 | "u = np.std(fish, ddof=1) # 標準偏差\n",
152 | "se = u / np.sqrt(n) # 標準誤差\n",
153 | "\n",
154 | "print('サンプルサイズ:', n)\n",
155 | "print('自由度 :', df)\n",
156 | "print('標準偏差 :', round(u, 3))\n",
157 | "print('標準誤差 :', round(se, 3))\n",
158 | "print('標本平均 :', round(x_bar, 3))"
159 | ]
160 | },
161 | {
162 | "cell_type": "code",
163 | "execution_count": 6,
164 | "metadata": {},
165 | "outputs": [
166 | {
167 | "name": "stdout",
168 | "output_type": "stream",
169 | "text": [
170 | "t分布の 2.5%点: -2.262\n",
171 | "t分布の97.5%点: 2.262\n"
172 | ]
173 | }
174 | ],
175 | "source": [
176 | "# 2.5%点と97.5%点\n",
177 | "t_025 = stats.t.ppf(q=0.025, df=df)\n",
178 | "t_975 = stats.t.ppf(q=0.975, df=df)\n",
179 | "\n",
180 | "print('t分布の 2.5%点:', round(t_025, 3))\n",
181 | "print('t分布の97.5%点:', round(t_975, 3))"
182 | ]
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": 7,
187 | "metadata": {},
188 | "outputs": [
189 | {
190 | "name": "stdout",
191 | "output_type": "stream",
192 | "text": [
193 | "下側信頼限界: 3.597\n",
194 | "上側信頼限界: 4.777\n"
195 | ]
196 | }
197 | ],
198 | "source": [
199 | "# 母平均の区間推定\n",
200 | "lower_mu = x_bar - t_975 * se\n",
201 | "upper_mu = x_bar - t_025 * se\n",
202 | "\n",
203 | "print('下側信頼限界:', round(lower_mu, 3))\n",
204 | "print('上側信頼限界:', round(upper_mu, 3))"
205 | ]
206 | },
207 | {
208 | "cell_type": "markdown",
209 | "metadata": {},
210 | "source": [
211 | "#### 簡単な実装方法"
212 | ]
213 | },
214 | {
215 | "cell_type": "code",
216 | "execution_count": 8,
217 | "metadata": {},
218 | "outputs": [
219 | {
220 | "data": {
221 | "text/plain": [
222 | "array([3.597, 4.777])"
223 | ]
224 | },
225 | "execution_count": 8,
226 | "metadata": {},
227 | "output_type": "execute_result"
228 | }
229 | ],
230 | "source": [
231 | "# 区間推定\n",
232 | "res_1 = stats.t.interval(alpha=0.95, df=df, loc=x_bar, scale=se)\n",
233 | "np.round(res_1, 3)"
234 | ]
235 | },
236 | {
237 | "cell_type": "markdown",
238 | "metadata": {},
239 | "source": [
240 | "### 信頼区間の幅を決める要素"
241 | ]
242 | },
243 | {
244 | "cell_type": "code",
245 | "execution_count": 9,
246 | "metadata": {},
247 | "outputs": [
248 | {
249 | "data": {
250 | "text/plain": [
251 | "array([-1.713, 10.087])"
252 | ]
253 | },
254 | "execution_count": 9,
255 | "metadata": {},
256 | "output_type": "execute_result"
257 | }
258 | ],
259 | "source": [
260 | "# 標準偏差が大きいと、信頼区間は広くなる\n",
261 | "se_2 = (u * 10) / np.sqrt(n)\n",
262 | "res_2 = stats.t.interval(alpha=0.95, df=df, loc=x_bar, scale=se_2)\n",
263 | "np.round(res_2, 3)"
264 | ]
265 | },
266 | {
267 | "cell_type": "code",
268 | "execution_count": 10,
269 | "metadata": {},
270 | "outputs": [
271 | {
272 | "data": {
273 | "text/plain": [
274 | "array([4.023, 4.351])"
275 | ]
276 | },
277 | "execution_count": 10,
278 | "metadata": {},
279 | "output_type": "execute_result"
280 | }
281 | ],
282 | "source": [
283 | "# サンプルサイズが大きいと、信頼区間は狭くなる\n",
284 | "n_2 = n * 10\n",
285 | "df_2 = n_2 - 1\n",
286 | "se_3 = u / np.sqrt(n_2)\n",
287 | "res_3 = stats.t.interval(alpha=0.95, df=df_2, loc=x_bar, scale=se_3)\n",
288 | "np.round(res_3, 3)"
289 | ]
290 | },
291 | {
292 | "cell_type": "code",
293 | "execution_count": 11,
294 | "metadata": {},
295 | "outputs": [
296 | {
297 | "data": {
298 | "text/plain": [
299 | "array([3.339, 5.035])"
300 | ]
301 | },
302 | "execution_count": 11,
303 | "metadata": {},
304 | "output_type": "execute_result"
305 | }
306 | ],
307 | "source": [
308 | "# 99%信頼区間\n",
309 | "res_4 = stats.t.interval(alpha=0.99, df=df, loc=x_bar, scale=se)\n",
310 | "np.round(res_4, 3)"
311 | ]
312 | },
313 | {
314 | "cell_type": "markdown",
315 | "metadata": {},
316 | "source": [
317 | "### 区間推定の結果の解釈"
318 | ]
319 | },
320 | {
321 | "cell_type": "code",
322 | "execution_count": 12,
323 | "metadata": {},
324 | "outputs": [],
325 | "source": [
326 | "# 母集団分布(母平均は4)\n",
327 | "norm_dist = stats.norm(loc=4, scale=0.8)"
328 | ]
329 | },
330 | {
331 | "cell_type": "code",
332 | "execution_count": 13,
333 | "metadata": {},
334 | "outputs": [],
335 | "source": [
336 | "num_trials = 20000 # シミュレーションの繰り返し数\n",
337 | "included_num = 0 # 信頼区間が母平均(4)を含んでいた回数"
338 | ]
339 | },
340 | {
341 | "cell_type": "code",
342 | "execution_count": 14,
343 | "metadata": {},
344 | "outputs": [],
345 | "source": [
346 | "# 「データを10個選んで95%信頼区間を求める」試行を20000回繰り返す\n",
347 | "np.random.seed(1) # 乱数の種\n",
348 | "for i in range(0, num_trials):\n",
349 | " # 標本の抽出\n",
350 | " sample = norm_dist.rvs(size=n)\n",
351 | " # 信頼区間の計算\n",
352 | " df = n - 1 # 自由度\n",
353 | " x_bar = np.mean(sample) # 標本平均\n",
354 | " u = np.std(sample, ddof=1) # 標準偏差\n",
355 | " se = u / np.sqrt(n) # 標準誤差\n",
356 | " interval = stats.t.interval(0.95, df, x_bar, se)\n",
357 | " # 信頼区間が母平均(4)を含んでいた回数をカウント\n",
358 | " if(interval[0] <= 4 <= interval[1]):\n",
359 | " included_num = included_num + 1"
360 | ]
361 | },
362 | {
363 | "cell_type": "code",
364 | "execution_count": 15,
365 | "metadata": {},
366 | "outputs": [
367 | {
368 | "data": {
369 | "text/plain": [
370 | "0.948"
371 | ]
372 | },
373 | "execution_count": 15,
374 | "metadata": {},
375 | "output_type": "execute_result"
376 | }
377 | ],
378 | "source": [
379 | "# 全試行中、信頼区間が母平均(4)を含んでいた割合\n",
380 | "included_num / num_trials"
381 | ]
382 | },
383 | {
384 | "cell_type": "markdown",
385 | "metadata": {},
386 | "source": [
387 | "### 実装:母分散の区間推定"
388 | ]
389 | },
390 | {
391 | "cell_type": "code",
392 | "execution_count": 16,
393 | "metadata": {},
394 | "outputs": [
395 | {
396 | "name": "stdout",
397 | "output_type": "stream",
398 | "text": [
399 | "χ2分布の 2.5%点: 2.7\n",
400 | "χ2分布の97.5%点: 19.023\n"
401 | ]
402 | }
403 | ],
404 | "source": [
405 | "# 2.5%点と97.5%点\n",
406 | "chi2_025 = stats.chi2.ppf(q=0.025, df=df)\n",
407 | "chi2_975 = stats.chi2.ppf(q=0.975, df=df)\n",
408 | "\n",
409 | "print('χ2分布の 2.5%点:', round(chi2_025, 3))\n",
410 | "print('χ2分布の97.5%点:', round(chi2_975, 3))"
411 | ]
412 | },
413 | {
414 | "cell_type": "code",
415 | "execution_count": 17,
416 | "metadata": {},
417 | "outputs": [
418 | {
419 | "name": "stdout",
420 | "output_type": "stream",
421 | "text": [
422 | "下側信頼限界: 0.322\n",
423 | "上側信頼限界: 2.267\n"
424 | ]
425 | }
426 | ],
427 | "source": [
428 | "# 母分散の区間推定\n",
429 | "upper_sigma = (n - 1) * u2 / chi2_025\n",
430 | "lower_sigma = (n - 1) * u2 / chi2_975\n",
431 | "\n",
432 | "print('下側信頼限界:', round(lower_sigma, 3))\n",
433 | "print('上側信頼限界:', round(upper_sigma, 3))"
434 | ]
435 | }
436 | ],
437 | "metadata": {
438 | "kernelspec": {
439 | "display_name": "Python 3 (ipykernel)",
440 | "language": "python",
441 | "name": "python3"
442 | },
443 | "language_info": {
444 | "codemirror_mode": {
445 | "name": "ipython",
446 | "version": 3
447 | },
448 | "file_extension": ".py",
449 | "mimetype": "text/x-python",
450 | "name": "python",
451 | "nbconvert_exporter": "python",
452 | "pygments_lexer": "ipython3",
453 | "version": "3.9.7"
454 | }
455 | },
456 | "nbformat": 4,
457 | "nbformat_minor": 2
458 | }
459 |
--------------------------------------------------------------------------------
/book-data/2-3-Pythonによるプログラミングの基本.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第2部 PythonとJupyter Notebookの基本\n",
8 | "\n",
9 | "## 3章 Pythonによるプログラミングの基本"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:四則演算"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [
24 | {
25 | "data": {
26 | "text/plain": [
27 | "2"
28 | ]
29 | },
30 | "execution_count": 1,
31 | "metadata": {},
32 | "output_type": "execute_result"
33 | }
34 | ],
35 | "source": [
36 | "1 + 1"
37 | ]
38 | },
39 | {
40 | "cell_type": "code",
41 | "execution_count": 2,
42 | "metadata": {},
43 | "outputs": [
44 | {
45 | "data": {
46 | "text/plain": [
47 | "3"
48 | ]
49 | },
50 | "execution_count": 2,
51 | "metadata": {},
52 | "output_type": "execute_result"
53 | }
54 | ],
55 | "source": [
56 | "5 - 2"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 3,
62 | "metadata": {},
63 | "outputs": [
64 | {
65 | "data": {
66 | "text/plain": [
67 | "6"
68 | ]
69 | },
70 | "execution_count": 3,
71 | "metadata": {},
72 | "output_type": "execute_result"
73 | }
74 | ],
75 | "source": [
76 | "2 * 3"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 4,
82 | "metadata": {},
83 | "outputs": [
84 | {
85 | "data": {
86 | "text/plain": [
87 | "2.0"
88 | ]
89 | },
90 | "execution_count": 4,
91 | "metadata": {},
92 | "output_type": "execute_result"
93 | }
94 | ],
95 | "source": [
96 | "6 / 3"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "### 実装:その他の演算"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 5,
109 | "metadata": {},
110 | "outputs": [
111 | {
112 | "data": {
113 | "text/plain": [
114 | "8"
115 | ]
116 | },
117 | "execution_count": 5,
118 | "metadata": {},
119 | "output_type": "execute_result"
120 | }
121 | ],
122 | "source": [
123 | "# 累乗\n",
124 | "2 ** 3"
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": 6,
130 | "metadata": {},
131 | "outputs": [
132 | {
133 | "data": {
134 | "text/plain": [
135 | "2"
136 | ]
137 | },
138 | "execution_count": 6,
139 | "metadata": {},
140 | "output_type": "execute_result"
141 | }
142 | ],
143 | "source": [
144 | "# 整数の商\n",
145 | "7 // 3"
146 | ]
147 | },
148 | {
149 | "cell_type": "code",
150 | "execution_count": 7,
151 | "metadata": {},
152 | "outputs": [
153 | {
154 | "data": {
155 | "text/plain": [
156 | "1"
157 | ]
158 | },
159 | "execution_count": 7,
160 | "metadata": {},
161 | "output_type": "execute_result"
162 | }
163 | ],
164 | "source": [
165 | "# 余り\n",
166 | "7 % 3"
167 | ]
168 | },
169 | {
170 | "cell_type": "markdown",
171 | "metadata": {},
172 | "source": [
173 | "### 実装:コメントの書き方"
174 | ]
175 | },
176 | {
177 | "cell_type": "code",
178 | "execution_count": 8,
179 | "metadata": {},
180 | "outputs": [],
181 | "source": [
182 | "# 1 + 1"
183 | ]
184 | },
185 | {
186 | "cell_type": "markdown",
187 | "metadata": {
188 | "collapsed": true
189 | },
190 | "source": [
191 | "### 実装:データの型"
192 | ]
193 | },
194 | {
195 | "cell_type": "markdown",
196 | "metadata": {},
197 | "source": [
198 | "#### 文字列型"
199 | ]
200 | },
201 | {
202 | "cell_type": "code",
203 | "execution_count": 9,
204 | "metadata": {},
205 | "outputs": [
206 | {
207 | "data": {
208 | "text/plain": [
209 | "'A'"
210 | ]
211 | },
212 | "execution_count": 9,
213 | "metadata": {},
214 | "output_type": "execute_result"
215 | }
216 | ],
217 | "source": [
218 | "\"A\""
219 | ]
220 | },
221 | {
222 | "cell_type": "code",
223 | "execution_count": 10,
224 | "metadata": {},
225 | "outputs": [
226 | {
227 | "data": {
228 | "text/plain": [
229 | "'A'"
230 | ]
231 | },
232 | "execution_count": 10,
233 | "metadata": {},
234 | "output_type": "execute_result"
235 | }
236 | ],
237 | "source": [
238 | "'A'"
239 | ]
240 | },
241 | {
242 | "cell_type": "code",
243 | "execution_count": 11,
244 | "metadata": {},
245 | "outputs": [
246 | {
247 | "data": {
248 | "text/plain": [
249 | "str"
250 | ]
251 | },
252 | "execution_count": 11,
253 | "metadata": {},
254 | "output_type": "execute_result"
255 | }
256 | ],
257 | "source": [
258 | "# 文字列型\n",
259 | "type('A')"
260 | ]
261 | },
262 | {
263 | "cell_type": "code",
264 | "execution_count": 12,
265 | "metadata": {},
266 | "outputs": [
267 | {
268 | "data": {
269 | "text/plain": [
270 | "str"
271 | ]
272 | },
273 | "execution_count": 12,
274 | "metadata": {},
275 | "output_type": "execute_result"
276 | }
277 | ],
278 | "source": [
279 | "# 文字列型\n",
280 | "type(\"A\")"
281 | ]
282 | },
283 | {
284 | "cell_type": "markdown",
285 | "metadata": {},
286 | "source": [
287 | "#### 整数型・浮動小数点型"
288 | ]
289 | },
290 | {
291 | "cell_type": "code",
292 | "execution_count": 13,
293 | "metadata": {},
294 | "outputs": [
295 | {
296 | "data": {
297 | "text/plain": [
298 | "int"
299 | ]
300 | },
301 | "execution_count": 13,
302 | "metadata": {},
303 | "output_type": "execute_result"
304 | }
305 | ],
306 | "source": [
307 | "# 整数型\n",
308 | "type(1)"
309 | ]
310 | },
311 | {
312 | "cell_type": "code",
313 | "execution_count": 14,
314 | "metadata": {},
315 | "outputs": [
316 | {
317 | "data": {
318 | "text/plain": [
319 | "float"
320 | ]
321 | },
322 | "execution_count": 14,
323 | "metadata": {},
324 | "output_type": "execute_result"
325 | }
326 | ],
327 | "source": [
328 | "# 浮動小数点\n",
329 | "type(2.4)"
330 | ]
331 | },
332 | {
333 | "cell_type": "markdown",
334 | "metadata": {},
335 | "source": [
336 | "#### ブール型"
337 | ]
338 | },
339 | {
340 | "cell_type": "code",
341 | "execution_count": 15,
342 | "metadata": {},
343 | "outputs": [
344 | {
345 | "data": {
346 | "text/plain": [
347 | "bool"
348 | ]
349 | },
350 | "execution_count": 15,
351 | "metadata": {},
352 | "output_type": "execute_result"
353 | }
354 | ],
355 | "source": [
356 | "# ブール型\n",
357 | "type(True)"
358 | ]
359 | },
360 | {
361 | "cell_type": "code",
362 | "execution_count": 16,
363 | "metadata": {},
364 | "outputs": [
365 | {
366 | "data": {
367 | "text/plain": [
368 | "bool"
369 | ]
370 | },
371 | "execution_count": 16,
372 | "metadata": {},
373 | "output_type": "execute_result"
374 | }
375 | ],
376 | "source": [
377 | "# ブール型\n",
378 | "type(False)"
379 | ]
380 | },
381 | {
382 | "cell_type": "markdown",
383 | "metadata": {},
384 | "source": [
385 | "#### 異なるデータ型の間での演算"
386 | ]
387 | },
388 | {
389 | "cell_type": "code",
390 | "execution_count": 17,
391 | "metadata": {},
392 | "outputs": [
393 | {
394 | "ename": "TypeError",
395 | "evalue": "can only concatenate str (not \"int\") to str",
396 | "output_type": "error",
397 | "traceback": [
398 | "\u001b[1;31m---------------------------------------------------------------------------\u001b[0m",
399 | "\u001b[1;31mTypeError\u001b[0m Traceback (most recent call last)",
400 | "\u001b[1;32m~\\AppData\\Local\\Temp/ipykernel_3200/2400233845.py\u001b[0m in \u001b[0;36m\u001b[1;34m\u001b[0m\n\u001b[1;32m----> 1\u001b[1;33m \u001b[1;34m'A'\u001b[0m \u001b[1;33m+\u001b[0m \u001b[1;36m1\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0m",
401 | "\u001b[1;31mTypeError\u001b[0m: can only concatenate str (not \"int\") to str"
402 | ]
403 | }
404 | ],
405 | "source": [
406 | "'A' + 1"
407 | ]
408 | },
409 | {
410 | "cell_type": "markdown",
411 | "metadata": {},
412 | "source": [
413 | "### 実装:比較演算"
414 | ]
415 | },
416 | {
417 | "cell_type": "code",
418 | "execution_count": 18,
419 | "metadata": {},
420 | "outputs": [
421 | {
422 | "data": {
423 | "text/plain": [
424 | "True"
425 | ]
426 | },
427 | "execution_count": 18,
428 | "metadata": {},
429 | "output_type": "execute_result"
430 | }
431 | ],
432 | "source": [
433 | "1 > 0.89"
434 | ]
435 | },
436 | {
437 | "cell_type": "code",
438 | "execution_count": 19,
439 | "metadata": {},
440 | "outputs": [
441 | {
442 | "data": {
443 | "text/plain": [
444 | "True"
445 | ]
446 | },
447 | "execution_count": 19,
448 | "metadata": {},
449 | "output_type": "execute_result"
450 | }
451 | ],
452 | "source": [
453 | "3 >= 2"
454 | ]
455 | },
456 | {
457 | "cell_type": "code",
458 | "execution_count": 20,
459 | "metadata": {},
460 | "outputs": [
461 | {
462 | "data": {
463 | "text/plain": [
464 | "False"
465 | ]
466 | },
467 | "execution_count": 20,
468 | "metadata": {},
469 | "output_type": "execute_result"
470 | }
471 | ],
472 | "source": [
473 | "3 < 2"
474 | ]
475 | },
476 | {
477 | "cell_type": "code",
478 | "execution_count": 21,
479 | "metadata": {},
480 | "outputs": [
481 | {
482 | "data": {
483 | "text/plain": [
484 | "False"
485 | ]
486 | },
487 | "execution_count": 21,
488 | "metadata": {},
489 | "output_type": "execute_result"
490 | }
491 | ],
492 | "source": [
493 | "3 <= 2"
494 | ]
495 | },
496 | {
497 | "cell_type": "code",
498 | "execution_count": 22,
499 | "metadata": {},
500 | "outputs": [
501 | {
502 | "data": {
503 | "text/plain": [
504 | "False"
505 | ]
506 | },
507 | "execution_count": 22,
508 | "metadata": {},
509 | "output_type": "execute_result"
510 | }
511 | ],
512 | "source": [
513 | "3 == 2"
514 | ]
515 | },
516 | {
517 | "cell_type": "code",
518 | "execution_count": 23,
519 | "metadata": {},
520 | "outputs": [
521 | {
522 | "data": {
523 | "text/plain": [
524 | "True"
525 | ]
526 | },
527 | "execution_count": 23,
528 | "metadata": {},
529 | "output_type": "execute_result"
530 | }
531 | ],
532 | "source": [
533 | "3 != 2"
534 | ]
535 | },
536 | {
537 | "cell_type": "markdown",
538 | "metadata": {},
539 | "source": [
540 | "### 実装:変数"
541 | ]
542 | },
543 | {
544 | "cell_type": "code",
545 | "execution_count": 24,
546 | "metadata": {},
547 | "outputs": [],
548 | "source": [
549 | "x = 100"
550 | ]
551 | },
552 | {
553 | "cell_type": "code",
554 | "execution_count": 25,
555 | "metadata": {},
556 | "outputs": [
557 | {
558 | "data": {
559 | "text/plain": [
560 | "100"
561 | ]
562 | },
563 | "execution_count": 25,
564 | "metadata": {},
565 | "output_type": "execute_result"
566 | }
567 | ],
568 | "source": [
569 | "x"
570 | ]
571 | },
572 | {
573 | "cell_type": "code",
574 | "execution_count": 26,
575 | "metadata": {},
576 | "outputs": [
577 | {
578 | "data": {
579 | "text/plain": [
580 | "293"
581 | ]
582 | },
583 | "execution_count": 26,
584 | "metadata": {},
585 | "output_type": "execute_result"
586 | }
587 | ],
588 | "source": [
589 | "x = 293\n",
590 | "x"
591 | ]
592 | },
593 | {
594 | "cell_type": "code",
595 | "execution_count": 27,
596 | "metadata": {},
597 | "outputs": [
598 | {
599 | "ename": "SyntaxError",
600 | "evalue": "cannot assign to literal (Temp/ipykernel_3200/3756881235.py, line 2)",
601 | "output_type": "error",
602 | "traceback": [
603 | "\u001b[1;36m File \u001b[1;32m\"C:\\Users\\black\\AppData\\Local\\Temp/ipykernel_3200/3756881235.py\"\u001b[1;36m, line \u001b[1;32m2\u001b[0m\n\u001b[1;33m 100 = 293\u001b[0m\n\u001b[1;37m ^\u001b[0m\n\u001b[1;31mSyntaxError\u001b[0m\u001b[1;31m:\u001b[0m cannot assign to literal\n"
604 | ]
605 | }
606 | ],
607 | "source": [
608 | "# 参考までに、以下のコードはエラーになる\n",
609 | "100 = 293"
610 | ]
611 | },
612 | {
613 | "cell_type": "code",
614 | "execution_count": 28,
615 | "metadata": {},
616 | "outputs": [
617 | {
618 | "ename": "NameError",
619 | "evalue": "name 'y' is not defined",
620 | "output_type": "error",
621 | "traceback": [
622 | "\u001b[1;31m---------------------------------------------------------------------------\u001b[0m",
623 | "\u001b[1;31mNameError\u001b[0m Traceback (most recent call last)",
624 | "\u001b[1;32m~\\AppData\\Local\\Temp/ipykernel_3200/3563912222.py\u001b[0m in \u001b[0;36m\u001b[1;34m\u001b[0m\n\u001b[1;32m----> 1\u001b[1;33m \u001b[0my\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0m",
625 | "\u001b[1;31mNameError\u001b[0m: name 'y' is not defined"
626 | ]
627 | }
628 | ],
629 | "source": [
630 | "y"
631 | ]
632 | },
633 | {
634 | "cell_type": "code",
635 | "execution_count": 29,
636 | "metadata": {},
637 | "outputs": [
638 | {
639 | "data": {
640 | "text/plain": [
641 | "50"
642 | ]
643 | },
644 | "execution_count": 29,
645 | "metadata": {},
646 | "output_type": "execute_result"
647 | }
648 | ],
649 | "source": [
650 | "y = 50\n",
651 | "y"
652 | ]
653 | },
654 | {
655 | "cell_type": "code",
656 | "execution_count": 30,
657 | "metadata": {},
658 | "outputs": [
659 | {
660 | "data": {
661 | "text/plain": [
662 | "343"
663 | ]
664 | },
665 | "execution_count": 30,
666 | "metadata": {},
667 | "output_type": "execute_result"
668 | }
669 | ],
670 | "source": [
671 | "x + y"
672 | ]
673 | },
674 | {
675 | "cell_type": "markdown",
676 | "metadata": {},
677 | "source": [
678 | "### 実装:関数"
679 | ]
680 | },
681 | {
682 | "cell_type": "code",
683 | "execution_count": 31,
684 | "metadata": {},
685 | "outputs": [
686 | {
687 | "data": {
688 | "text/plain": [
689 | "208"
690 | ]
691 | },
692 | "execution_count": 31,
693 | "metadata": {},
694 | "output_type": "execute_result"
695 | }
696 | ],
697 | "source": [
698 | "(y + 2) * 4"
699 | ]
700 | },
701 | {
702 | "cell_type": "code",
703 | "execution_count": 32,
704 | "metadata": {},
705 | "outputs": [],
706 | "source": [
707 | "def sample_function(data):\n",
708 | " return (data + 2) * 4"
709 | ]
710 | },
711 | {
712 | "cell_type": "code",
713 | "execution_count": 33,
714 | "metadata": {},
715 | "outputs": [
716 | {
717 | "data": {
718 | "text/plain": [
719 | "208"
720 | ]
721 | },
722 | "execution_count": 33,
723 | "metadata": {},
724 | "output_type": "execute_result"
725 | }
726 | ],
727 | "source": [
728 | "sample_function(data=y)"
729 | ]
730 | },
731 | {
732 | "cell_type": "code",
733 | "execution_count": 34,
734 | "metadata": {},
735 | "outputs": [
736 | {
737 | "data": {
738 | "text/plain": [
739 | "208"
740 | ]
741 | },
742 | "execution_count": 34,
743 | "metadata": {},
744 | "output_type": "execute_result"
745 | }
746 | ],
747 | "source": [
748 | "# 引数の名前は省略できる\n",
749 | "sample_function(y)"
750 | ]
751 | },
752 | {
753 | "cell_type": "code",
754 | "execution_count": 35,
755 | "metadata": {},
756 | "outputs": [
757 | {
758 | "data": {
759 | "text/plain": [
760 | "20"
761 | ]
762 | },
763 | "execution_count": 35,
764 | "metadata": {},
765 | "output_type": "execute_result"
766 | }
767 | ],
768 | "source": [
769 | "sample_function(3)"
770 | ]
771 | },
772 | {
773 | "cell_type": "code",
774 | "execution_count": 36,
775 | "metadata": {},
776 | "outputs": [
777 | {
778 | "data": {
779 | "text/plain": [
780 | "228"
781 | ]
782 | },
783 | "execution_count": 36,
784 | "metadata": {},
785 | "output_type": "execute_result"
786 | }
787 | ],
788 | "source": [
789 | "sample_function(y) + sample_function(3)"
790 | ]
791 | },
792 | {
793 | "cell_type": "markdown",
794 | "metadata": {},
795 | "source": [
796 | "### 実装:頻繁に使う関数"
797 | ]
798 | },
799 | {
800 | "cell_type": "markdown",
801 | "metadata": {},
802 | "source": [
803 | "#### print関数"
804 | ]
805 | },
806 | {
807 | "cell_type": "code",
808 | "execution_count": 37,
809 | "metadata": {},
810 | "outputs": [
811 | {
812 | "name": "stdout",
813 | "output_type": "stream",
814 | "text": [
815 | "2\n"
816 | ]
817 | }
818 | ],
819 | "source": [
820 | "print(1 + 1)"
821 | ]
822 | },
823 | {
824 | "cell_type": "code",
825 | "execution_count": 38,
826 | "metadata": {},
827 | "outputs": [
828 | {
829 | "name": "stdout",
830 | "output_type": "stream",
831 | "text": [
832 | "今から計算をします:計算結果は 2\n"
833 | ]
834 | }
835 | ],
836 | "source": [
837 | "print('今から計算をします:計算結果は', 1 + 1)"
838 | ]
839 | },
840 | {
841 | "cell_type": "code",
842 | "execution_count": 39,
843 | "metadata": {},
844 | "outputs": [
845 | {
846 | "data": {
847 | "text/plain": [
848 | "4"
849 | ]
850 | },
851 | "execution_count": 39,
852 | "metadata": {},
853 | "output_type": "execute_result"
854 | }
855 | ],
856 | "source": [
857 | "# 最後の数値だけが出力される\n",
858 | "1 + 1\n",
859 | "1 + 3"
860 | ]
861 | },
862 | {
863 | "cell_type": "code",
864 | "execution_count": 40,
865 | "metadata": {},
866 | "outputs": [
867 | {
868 | "name": "stdout",
869 | "output_type": "stream",
870 | "text": [
871 | "2\n",
872 | "4\n"
873 | ]
874 | }
875 | ],
876 | "source": [
877 | "# 両方出力される\n",
878 | "print(1 + 1)\n",
879 | "print(1 + 3)"
880 | ]
881 | },
882 | {
883 | "cell_type": "markdown",
884 | "metadata": {},
885 | "source": [
886 | "#### round関数"
887 | ]
888 | },
889 | {
890 | "cell_type": "code",
891 | "execution_count": 41,
892 | "metadata": {},
893 | "outputs": [
894 | {
895 | "name": "stdout",
896 | "output_type": "stream",
897 | "text": [
898 | "1.234を丸めた結果 1\n",
899 | "1.963を丸めた結果 2\n"
900 | ]
901 | }
902 | ],
903 | "source": [
904 | "print('1.234を丸めた結果', round(1.234))\n",
905 | "print('1.963を丸めた結果', round(1.963))"
906 | ]
907 | },
908 | {
909 | "cell_type": "code",
910 | "execution_count": 42,
911 | "metadata": {},
912 | "outputs": [
913 | {
914 | "data": {
915 | "text/plain": [
916 | "1.23"
917 | ]
918 | },
919 | "execution_count": 42,
920 | "metadata": {},
921 | "output_type": "execute_result"
922 | }
923 | ],
924 | "source": [
925 | "round(1.234, ndigits=2)"
926 | ]
927 | },
928 | {
929 | "cell_type": "code",
930 | "execution_count": 43,
931 | "metadata": {},
932 | "outputs": [
933 | {
934 | "name": "stdout",
935 | "output_type": "stream",
936 | "text": [
937 | "2.5を丸めた結果 2\n",
938 | "3.5を丸めた結果 4\n"
939 | ]
940 | }
941 | ],
942 | "source": [
943 | "# 通常の四捨五入とは異なるので注意\n",
944 | "print('2.5を丸めた結果', round(2.5))\n",
945 | "print('3.5を丸めた結果', round(3.5))"
946 | ]
947 | },
948 | {
949 | "cell_type": "markdown",
950 | "metadata": {
951 | "collapsed": true
952 | },
953 | "source": [
954 | "### 実装:クラスとインスタンス"
955 | ]
956 | },
957 | {
958 | "cell_type": "code",
959 | "execution_count": 44,
960 | "metadata": {},
961 | "outputs": [],
962 | "source": [
963 | "class Sample_Class:\n",
964 | " def __init__(self, data1, data2):\n",
965 | " self.data1 = data1\n",
966 | " self.data2 = data2\n",
967 | " \n",
968 | " def method2(self):\n",
969 | " return self.data1 + self.data2"
970 | ]
971 | },
972 | {
973 | "cell_type": "code",
974 | "execution_count": 45,
975 | "metadata": {},
976 | "outputs": [],
977 | "source": [
978 | "sample_instance = Sample_Class(data1=2, data2=3)"
979 | ]
980 | },
981 | {
982 | "cell_type": "code",
983 | "execution_count": 46,
984 | "metadata": {},
985 | "outputs": [
986 | {
987 | "data": {
988 | "text/plain": [
989 | "2"
990 | ]
991 | },
992 | "execution_count": 46,
993 | "metadata": {},
994 | "output_type": "execute_result"
995 | }
996 | ],
997 | "source": [
998 | "sample_instance.data1"
999 | ]
1000 | },
1001 | {
1002 | "cell_type": "code",
1003 | "execution_count": 47,
1004 | "metadata": {},
1005 | "outputs": [
1006 | {
1007 | "data": {
1008 | "text/plain": [
1009 | "5"
1010 | ]
1011 | },
1012 | "execution_count": 47,
1013 | "metadata": {},
1014 | "output_type": "execute_result"
1015 | }
1016 | ],
1017 | "source": [
1018 | "sample_instance.method2()"
1019 | ]
1020 | },
1021 | {
1022 | "cell_type": "markdown",
1023 | "metadata": {},
1024 | "source": [
1025 | "### 実装:if構文による分岐"
1026 | ]
1027 | },
1028 | {
1029 | "cell_type": "code",
1030 | "execution_count": 48,
1031 | "metadata": {},
1032 | "outputs": [
1033 | {
1034 | "name": "stdout",
1035 | "output_type": "stream",
1036 | "text": [
1037 | "2より小さいデータです\n"
1038 | ]
1039 | }
1040 | ],
1041 | "source": [
1042 | "data = 1\n",
1043 | "if(data < 2):\n",
1044 | " print('2より小さいデータです')\n",
1045 | "else:\n",
1046 | " print('2以上のデータです')"
1047 | ]
1048 | },
1049 | {
1050 | "cell_type": "code",
1051 | "execution_count": 49,
1052 | "metadata": {},
1053 | "outputs": [
1054 | {
1055 | "name": "stdout",
1056 | "output_type": "stream",
1057 | "text": [
1058 | "2以上のデータです\n"
1059 | ]
1060 | }
1061 | ],
1062 | "source": [
1063 | "data = 3\n",
1064 | "if(data < 2):\n",
1065 | " print('2より小さいデータです')\n",
1066 | "else:\n",
1067 | " print('2以上のデータです')"
1068 | ]
1069 | },
1070 | {
1071 | "cell_type": "markdown",
1072 | "metadata": {},
1073 | "source": [
1074 | "### 実装:for構文による繰り返し"
1075 | ]
1076 | },
1077 | {
1078 | "cell_type": "code",
1079 | "execution_count": 50,
1080 | "metadata": {},
1081 | "outputs": [
1082 | {
1083 | "data": {
1084 | "text/plain": [
1085 | "range(0, 3)"
1086 | ]
1087 | },
1088 | "execution_count": 50,
1089 | "metadata": {},
1090 | "output_type": "execute_result"
1091 | }
1092 | ],
1093 | "source": [
1094 | "range(0, 3)"
1095 | ]
1096 | },
1097 | {
1098 | "cell_type": "code",
1099 | "execution_count": 51,
1100 | "metadata": {},
1101 | "outputs": [
1102 | {
1103 | "name": "stdout",
1104 | "output_type": "stream",
1105 | "text": [
1106 | "0\n",
1107 | "1\n",
1108 | "2\n"
1109 | ]
1110 | }
1111 | ],
1112 | "source": [
1113 | "for i in range(0, 3):\n",
1114 | " print(i)"
1115 | ]
1116 | },
1117 | {
1118 | "cell_type": "code",
1119 | "execution_count": 52,
1120 | "metadata": {},
1121 | "outputs": [
1122 | {
1123 | "name": "stdout",
1124 | "output_type": "stream",
1125 | "text": [
1126 | "hello\n",
1127 | "hello\n",
1128 | "hello\n"
1129 | ]
1130 | }
1131 | ],
1132 | "source": [
1133 | "for i in range(0, 3):\n",
1134 | " print('hello')"
1135 | ]
1136 | }
1137 | ],
1138 | "metadata": {
1139 | "kernelspec": {
1140 | "display_name": "Python 3 (ipykernel)",
1141 | "language": "python",
1142 | "name": "python3"
1143 | },
1144 | "language_info": {
1145 | "codemirror_mode": {
1146 | "name": "ipython",
1147 | "version": 3
1148 | },
1149 | "file_extension": ".py",
1150 | "mimetype": "text/x-python",
1151 | "name": "python",
1152 | "nbconvert_exporter": "python",
1153 | "pygments_lexer": "ipython3",
1154 | "version": "3.9.7"
1155 | }
1156 | },
1157 | "nbformat": 4,
1158 | "nbformat_minor": 2
1159 | }
1160 |
--------------------------------------------------------------------------------
/book-data/5-4-母分散の推定.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第5部 統計的推定\n",
8 | "\n",
9 | "## 4章 母分散の推定"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd\n",
28 | "from scipy import stats\n",
29 | "\n",
30 | "# グラフを描画するライブラリ\n",
31 | "from matplotlib import pyplot as plt\n",
32 | "import seaborn as sns\n",
33 | "sns.set()\n",
34 | "\n",
35 | "# グラフの日本語表記\n",
36 | "from matplotlib import rcParams\n",
37 | "rcParams['font.family'] = 'sans-serif'\n",
38 | "rcParams['font.sans-serif'] = 'Meiryo'"
39 | ]
40 | },
41 | {
42 | "cell_type": "code",
43 | "execution_count": 2,
44 | "metadata": {},
45 | "outputs": [],
46 | "source": [
47 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
48 | "np.set_printoptions(linewidth=60)\n",
49 | "pd.set_option('display.width', 60)\n",
50 | "\n",
51 | "from matplotlib.pylab import rcParams\n",
52 | "rcParams['figure.figsize'] = 8, 4"
53 | ]
54 | },
55 | {
56 | "cell_type": "markdown",
57 | "metadata": {},
58 | "source": [
59 | "### 実装:母集団の用意"
60 | ]
61 | },
62 | {
63 | "cell_type": "code",
64 | "execution_count": 3,
65 | "metadata": {},
66 | "outputs": [],
67 | "source": [
68 | "# 平均4、標準偏差0.8の正規分布を使いまわす\n",
69 | "population = stats.norm(loc=4, scale=0.8)"
70 | ]
71 | },
72 | {
73 | "cell_type": "markdown",
74 | "metadata": {},
75 | "source": [
76 | "### 実装:標本分散と不偏分散を計算する"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 4,
82 | "metadata": {},
83 | "outputs": [
84 | {
85 | "data": {
86 | "text/plain": [
87 | "array([3.66659372, 3.95498654, 2.29104312, 5.31221665,\n",
88 | " 2.56525153, 3.32660211, 4.40230513, 3.00376953,\n",
89 | " 3.15363822, 3.27279391])"
90 | ]
91 | },
92 | "execution_count": 4,
93 | "metadata": {},
94 | "output_type": "execute_result"
95 | }
96 | ],
97 | "source": [
98 | "np.random.seed(2)\n",
99 | "sample = population.rvs(size=10)\n",
100 | "sample"
101 | ]
102 | },
103 | {
104 | "cell_type": "code",
105 | "execution_count": 5,
106 | "metadata": {},
107 | "outputs": [
108 | {
109 | "name": "stdout",
110 | "output_type": "stream",
111 | "text": [
112 | "標本分散 0.712\n",
113 | "不偏分散 0.791\n"
114 | ]
115 | }
116 | ],
117 | "source": [
118 | "print('標本分散', round(np.var(sample, ddof=0), 3))\n",
119 | "print('不偏分散', round(np.var(sample, ddof=1), 3))"
120 | ]
121 | },
122 | {
123 | "cell_type": "markdown",
124 | "metadata": {},
125 | "source": [
126 | "### 実装:標本分散の平均値"
127 | ]
128 | },
129 | {
130 | "cell_type": "code",
131 | "execution_count": 6,
132 | "metadata": {},
133 | "outputs": [],
134 | "source": [
135 | "# 「標本分散」を格納する入れ物\n",
136 | "sample_var_array = np.zeros(10000)"
137 | ]
138 | },
139 | {
140 | "cell_type": "code",
141 | "execution_count": 7,
142 | "metadata": {},
143 | "outputs": [],
144 | "source": [
145 | "# 「データを10個選んで標本分散を求める」試行を10000回繰り返す\n",
146 | "np.random.seed(1)\n",
147 | "for i in range(0, 10000):\n",
148 | " sample_loop = population.rvs(size=10)\n",
149 | " sample_var_array[i] = np.var(sample_loop, ddof=0)"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": 8,
155 | "metadata": {},
156 | "outputs": [
157 | {
158 | "data": {
159 | "text/plain": [
160 | "0.575"
161 | ]
162 | },
163 | "execution_count": 8,
164 | "metadata": {},
165 | "output_type": "execute_result"
166 | }
167 | ],
168 | "source": [
169 | "# 標本分散の平均値\n",
170 | "round(np.mean(sample_var_array), 3)"
171 | ]
172 | },
173 | {
174 | "cell_type": "markdown",
175 | "metadata": {},
176 | "source": [
177 | "### 実装:不偏分散の平均値"
178 | ]
179 | },
180 | {
181 | "cell_type": "code",
182 | "execution_count": 9,
183 | "metadata": {},
184 | "outputs": [
185 | {
186 | "data": {
187 | "text/plain": [
188 | "0.639"
189 | ]
190 | },
191 | "execution_count": 9,
192 | "metadata": {},
193 | "output_type": "execute_result"
194 | }
195 | ],
196 | "source": [
197 | "# 「不偏分散」を格納する入れ物\n",
198 | "unbias_var_array = np.zeros(10000)\n",
199 | "# 「データを10個選んで不偏分散を求める」試行を10000回繰り返す\n",
200 | "np.random.seed(1)\n",
201 | "for i in range(0, 10000):\n",
202 | " sample_loop = population.rvs(size=10)\n",
203 | " unbias_var_array[i] = np.var(sample_loop, ddof=1)\n",
204 | "# 不偏分散の平均値\n",
205 | "round(np.mean(unbias_var_array), 3)"
206 | ]
207 | },
208 | {
209 | "cell_type": "markdown",
210 | "metadata": {},
211 | "source": [
212 | "### 実装:サンプルサイズを大きくしたときの不偏分散"
213 | ]
214 | },
215 | {
216 | "cell_type": "code",
217 | "execution_count": 10,
218 | "metadata": {
219 | "scrolled": true
220 | },
221 | "outputs": [
222 | {
223 | "data": {
224 | "text/plain": [
225 | "array([ 10, 110, 210, ..., 99810, 99910, 100010])"
226 | ]
227 | },
228 | "execution_count": 10,
229 | "metadata": {},
230 | "output_type": "execute_result"
231 | }
232 | ],
233 | "source": [
234 | "# サンプルサイズを10~100010までの範囲で100区切りで変化させる\n",
235 | "size_array = np.arange(start=10, stop=100100, step=100)\n",
236 | "size_array"
237 | ]
238 | },
239 | {
240 | "cell_type": "code",
241 | "execution_count": 11,
242 | "metadata": {},
243 | "outputs": [],
244 | "source": [
245 | "# 「不偏分散」を格納する入れ物\n",
246 | "unbias_var_array_size = np.zeros(len(size_array))"
247 | ]
248 | },
249 | {
250 | "cell_type": "code",
251 | "execution_count": 12,
252 | "metadata": {},
253 | "outputs": [],
254 | "source": [
255 | "# 「不偏分散を求める」試行を、サンプルサイズを変えながら何度も実行\n",
256 | "np.random.seed(1)\n",
257 | "for i in range(0, len(size_array)):\n",
258 | " sample_loop = population.rvs(size=size_array[i])\n",
259 | " unbias_var_array_size[i] = np.var(sample_loop, ddof=1)"
260 | ]
261 | },
262 | {
263 | "cell_type": "code",
264 | "execution_count": 13,
265 | "metadata": {},
266 | "outputs": [
267 | {
268 | "name": "stdout",
269 | "output_type": "stream",
270 | "text": [
271 | " sample_size unbias_var\n",
272 | "0 10 1.008526\n",
273 | "1 110 0.460805\n",
274 | "2 210 0.631723\n"
275 | ]
276 | }
277 | ],
278 | "source": [
279 | "# データフレームにまとめる\n",
280 | "size_var_df = pd.DataFrame({\n",
281 | " 'sample_size': size_array,\n",
282 | " 'unbias_var': unbias_var_array_size\n",
283 | "})\n",
284 | "\n",
285 | "print(size_var_df.head(3))"
286 | ]
287 | },
288 | {
289 | "cell_type": "code",
290 | "execution_count": 14,
291 | "metadata": {},
292 | "outputs": [
293 | {
294 | "data": {
295 | "text/plain": [
296 | ""
297 | ]
298 | },
299 | "execution_count": 14,
300 | "metadata": {},
301 | "output_type": "execute_result"
302 | },
303 | {
304 | "data": {
305 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAfgAAAELCAYAAAA1LpTIAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjQuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/MnkTPAAAACXBIWXMAAAsTAAALEwEAmpwYAAA6iklEQVR4nO3dd1hTZ/8G8DsMAQUUEHBSpcNRR1/H66gTWwcOEAVtrRbrelutVqij7oUba611W1etiHtUsTjrFltRWycqQwSCiAwHQvL8/uDHKTEhBEPAxPtzXee6ck7OePIl5D7POScnMiGEABEREZkUs9JuABERERU/BjwREZEJYsATERGZIAY8ERGRCWLAExERmSAGPBERkQliwBMREZkgi9JuQHFKTX0CpbJ4vtbv5GSLlJTMYlnXm4x11B9rqD/WUH+sof6Ku4ZmZjI4OJQr8HmTCnilUhRbwOetj/THOuqPNdQfa6g/1lB/JVlDHqInIiIyQQx4IiIiE8SAJyIiMkEMeCIiIhPEgCciIjJBDHgiIiITVGIBn5aWhk6dOiExMVHj80IILF26FL1790avXr2wdOnSkmqamtjYGLi5uSE+/n6ptYGIiEgfJRLwP//8M3r27Im4uLgC5zl06BCuXLmCrVu3IjQ0FJGRkTh06FBJNE9NTEw04uLiEBsbUyrbJyIi0leJBPwXX3yBo0ePolKlSgXOc+LECXh5ecHc3Bzm5ubw8vLC8ePHS6J5BRKCN3UgIiLj9Nqcg09KSoKzs7M07uLigqSkpFJpi0wmK5XtEhERFZfX5la1mnrLRQ1aJyfbYmlLhQplAQDly9vA2dmuWNb5JmMN9cca6o811B9rqL+SrOFrE/Curq5ITk6WxpOTk+Hi4lKkdaSkZBbLfX7T0p4BAB4/fork5Ay91/cmc3a2Yw31xBrqjzXUH2uov+KuoZmZTGvHtlQP0cfGxiIjI/fFtm7dGvv27YNSqYRSqcT+/fvRtm3b0mwez8ETEZHRKpGADwkJwaBBg/Dw4UOMGTMG8+bNAwD4+/sjPDwcAODp6YlatWrB19cXvr6+qFOnDjp16lQSzVPDc/BERGTsSuQQfd++fdG3b1+16UePHpUey2QyjB49GqNHjy6JJumEPXgiIjJWr81V9K8T9uCJiMjYMeC1YA+eiIiMFQNeA/bgiYjI2DHgtWAPnoiIjBUDXiP24ImIyLgx4LVgD56IiIwVA16DvHPwDHgiIjJWDHgNeJEdEREZOwa8FuzBExGRsWLAa8AOPBERGTsGvFbswRMRkXFiwGvAc/BERGTsGPBa8Bw8EREZKwa8BuzBExGRsWPAa8EePBERGSsGvAbswRMRkbFjwGvBHjwRERkrBrwG7METEZGxY8BrwR48EREZKwa8BuzBExGRsWPAa8EOPBERGSsGvAbswRMRkbFjwGvBc/BERGSsGPAasAdPRETGjgGvBXvwRERkrBjwGuT14BnwRERkrBjwGvEQPRERGTeLktjIpUuXMG/ePCgUCjg4OCAoKAjOzs4q82RmZmLmzJmIjo5GTk4OOnfujCFDhpRE8wrEHjwRERkrg/fgs7KyEBAQgPnz52Pbtm3o3r07Jk+erDbf/Pnz8d5772Hr1q3YsmULzp49i6NHjxq6eRrxIjsiIjJ2Bg/4y5cvw93dHW5ubgAAT09PXLx4ETk5OSrz/fXXX/Dw8AAAlClTBn369EF4eLihm6cVe/BERGSsDB7wSUlJcHFxkcbNzc1hb2+PlJQUlflq1aqF/fv3S6Ganp4OuVxu6OZpxB48EREZO4Ofgy+oF/xyiE6cOBELFixAr1694ODgACcnJ9ja2hZpW05ORZu/II6O5QAA9vbWcHa2K5Z1vslYQ/2xhvpjDfXHGuqvJGto8IB3dXVV6YkrlUqkp6fD0dFRZT5HR0fMmTNHGg8ODoaTk1ORtpWSkgmlUv/D6qmpTwEAaWnPkJycoff63mTOznasoZ5YQ/2xhvpjDfVX3DU0M5Np7dga/BB9w4YNERUVhbi4OABAWFgYGjduDAsLC8TGxiIjQ/3F/vnnnzhy5Ah69epl6OYVgufgiYjIOBm8B29tbY3g4GAEBgZCCIHy5csjKCgIAODv748RI0bAx8cHiYmJGDhwIGxsbFCtWjWsXLkSdnalcziI5+CJiMjYlcj34Js0aYLQ0FC16fm/BlepUiUcPHiwJJqjM15FT0RExop3stOAPXgiIjJ2DHgt2IMnIiJjxYDXgD14IiIydgx4LdiDJyIiY8WA14A9eCIiMnYMeC3YgyciImPFgNeAPXgiIjJ2DHgt2IMnIiJjxYDXIK8Hz4AnIiJjxYDXgEfoiYjI2DHgtWAPnoiIjBUDXgNeZEdERMaOAa8Fe/BERGSsGPAasQdPRETGjQGvBXvwRERkrBjwGvAcPBERGTsGvBbswRMRkbFiwGvAHjwRERk7BrwW7METEZGxYsBrwB48EREZOwY8ERGRCWLAa8AePBERGTsGvBY8B09ERMaKAa8Be/BERGTsdA74y5cvG7IdryX24ImIyFjpHPBfffWVIdvxWmEPnoiIjJ3OAV+jRg08fvzYgE15/bAHT0RExspC1xk/+ugjzJ07F/7+/mrP1a5dW+uyly5dwrx586BQKODg4ICgoCA4OzurzKNUKrFw4UKcO3cOZmZmqFixImbOnKk2X0nI68Ez4ImIyFjpHPCbNm0CAFy4cEFlukwmw5EjRwpcLisrCwEBAdiwYQPc3Nywb98+TJ48GStWrFCZb+/evbh//z527NgBmUyGNWvWYNGiRZgzZ05RXk+x4CF6IiIydjoH/NGjR19pA5cvX4a7uzvc3NwAAJ6enpg+fTpycnJgYfHv5pVKJZ48eQKFQgELCwvY29vDysrqlbZZXNiDJyIiY6VzwAPA06dPER8fD4VCoTJd2yH6pKQkuLi4SOPm5uawt7dHSkoKXF1dpene3t64cOEC+vTpg//+97+4d+8e5s+fX5TmFRv24ImIyNjpHPAHDhzA9OnTkZmZKQWzXC6Hk5MTTpw4UeByBfWCXw7R8+fPw9bWFtu3b8elS5ewcOFCHD9+HD169NC1iXBystV5Xm1evMhdj62tFZyd7YplnW8y1lB/rKH+WEP9sYb6K8ka6hzwy5Ytw+7du+Hr6ysdrt+8eTNSU1O1Lufq6gq5XC6NK5VKpKenw9HRUWW+DRs2oH///pDJZGjUqBEmT56MsWPHFingU1IyoVTqf1j90aMnAICMjOdITs7Qe31vMmdnO9ZQT6yh/lhD/bGG+ivuGpqZybR2bHX+mlx6ejoqV64MGxsbPHmSG4B+fn7Yt2+f1uUaNmyIqKgoxMXFAQDCwsLQuHFjWFhYIDY2FhkZuS/2rbfewu+//y71+CMjI/Huu+/q2jyD4Dl4IiIyVjoHvFKpBAC8/fbbOHbsGADgyZMnhX433traGsHBwQgMDISvry927tyJGTNmAAD8/f0RHh4OABg5ciSysrLg7e2NPn36ICIiApMnT36V16Q3noMnIiJjp/Mh+tatWyMhIQH+/v4YOXIkduzYgejoaPj6+ha6bJMmTRAaGqo2Pf+V+eXKlcPcuXN1bU6JYA+eiIiMlc4BP2HCBNjZ2aFy5crYs2cPrl69ikqVKqFBgwaGbF8pYQ+eiIiMW5HuZOfh4YG+ffuiYcOGqFy5siHb9VpgD56IiIyVzufgw8PDUa9ePUybNg3e3t7YsmWLdLGdqeE5eCIiMnY6B7y9vT369euHXbt2Yfbs2YiKikLXrl0xZcoUQ7avVLEHT0RExkrngM8vNTUVDx8+RFZWFszNzYu7TaWOPXgiIjJ2Op+DT0hIwI4dO7Bz505UrFgRfn5+mDt3LmxsbAzZvlLFHjwRERkrnQPey8sLXbt2xbJlywr9eVhjxx48EREZO50D/sSJE1p76/PmzcO4ceOKpVGvD/bgiYjIOOl8Dr6wQ/GF3bLWmLAHT0RExu6VLrJ7U/AcPBERGSsGvAZ5HXgGPBERGSsGvAY8RE9ERMaOAa8Fe/BERGSsGPAasAdPRETGrtgC3tHRsbhW9dpgD56IiIyVzgEfFhaGEydOAACio6MxdOhQjBo1CklJSQCAvXv3GqaFpYA9eCIiMnY6B/zixYvx1ltvAQDmzp0Ld3d3NGzYEFOnTjVY40obe/BERGSsdL6TXVpaGmrUqAGlUolLly5h8eLFsLa2xsaNGw3ZvlLBHjwRERk7nQPe3t4eKSkpuHfvHqpVqwZra2tkZWXhxYsXhmxfqWIHnoiIjJXOAT9kyBB0794dz549kw7L79+/H/Xr1zdY40oLe/BERGTsdA743r17o3nz5lAoFNK5+Hr16qFly5YGa1xp4zl4IiIyVjoHPADk5OQgOjoaUVFRKtMrV65crI0qbezBExGRsdM54Ddu3IgNGzZALpfjgw8+AABcv34db731Fjp06GCo9pUq9uCJiMhY6Rzwmzdvxs6dO9G1a1ds2rQJAHDgwAFcunTJYI0rPezBExGRcdP5e/DPnj1D+fLlUa5cOaSlpQEAOnfujOPHjxuqbaWOPXgiIjJWOge8EAJKpRJ16tTBnj17AAAPHjxAZmamwRpXWngOnoiIjJ3Oh+h79eqF5ORk/O9//8PgwYPxyy+/IDU1FSNHjjRk+0oVe/BERGSsdA74b775BgDg6uqKI0eOICoqCi4uLnB2di502UuXLmHevHlQKBRwcHBAUFCQ2nKrV69GeHi4NC6EQEpKCo4ePaprE4sNe/BERGTsCg34yMhIfPDBB4iIiFB7Ljo6GtHR0WjatGmBy2dlZSEgIAAbNmyAm5sb9u3bh8mTJ2PFihUq8w0ZMgRDhgyRxvft24dTp04V5bUUO/bgiYjIWBUa8EFBQdi2bRuCgoI0Pi+TybBr164Cl798+TLc3d3h5uYGAPD09MT06dORk5MDCwvNm8/OzsayZcuwatUqXV5Dsfu3B8+AJyIi41RowG/btg0AsHv37lfaQFJSElxcXKRxc3Nz6b72rq6uGpfZunUrmjVrhurVq7/SNvXFQ/RERGTsinQnu0OHDuHYsWN49OgRqlatCl9fX9StW1frMgUd5i4oRJ88eYKff/4ZW7ZsKUrTAABOTrZFXkaT588tAQBly5aBs7NdsazzTcYa6o811B9rqD/WUH8lWUOdA37BggU4ffo0fH194eDggPv372P48OEYM2YMPD09C1zO1dUVcrlcGlcqlUhPT4ejo6PG+detW4dOnToV2LvXJiUlE0ql/ofVs7KyAABPnmQhOTlD7/W9yZyd7VhDPbGG+mMN9cca6q+4a2hmJtPasdU54Pfs2YODBw/Czu7fvY+OHTti2LBhWgO+YcOGiIqKQlxcHKpXr46wsDA0btwYFhYWiI2NhYODg7TOR48eYevWrdL37EsbL7IjIiJjpXPAOzk5wcbGRmVajRo18OTJE63LWVtbIzg4GIGBgRBCoHz58tIFe/7+/hgxYgR8fHwAAMuXL0fv3r0L7N2XFJ6DJyIiY1dowOfdqa5nz5749ddfpTAGgLi4OFSrVq3QjTRp0gShoaFq01/+jvvEiRMLXVdJyuvBP3gQD7k8CR980KiUW0RERKSbQgO+SZMmkMlkUtjNnj0bAKRpptjbzXtNc+bMROXKVTB69AgoFArI5eml3DIiIiLdFBrwN27cKIl2vLZmzpwKhUJR2s0gIiIqEp1/bOZNkv+ohCkeoSAiItOn80V2Fy9exMyZM3H37l3k5OQAgHSI/vr16wZrYGljwBMRkTHSOeAnTJiAwYMHo23btihbtqwh21Tq2IMnIiJjp3PA5+TkwM/Pz5BteS0x4ImIyBjpfA6+efPm+OeffwzZltdG/lA3M/u3RNu3b0VMTHQptIiIiKhodO7BZ2VlYcyYMWjdurXac999912xNup1Eh9/X3r81VdD4Ozsgn/+iSqRbUdH38O9e3fRvn2HEtkeERGZDp0DvmbNmqhZs6Yh2/La0HZYPjlZjmfPnmHw4AGYMWM23n773SKvPzX1EZRKAScnJwC5O085OTkoV66cynytWjXFixcv+P17IiIqMp0DfsSIEYZsh9EwMzPDmTMnER5+CEqlElu27CjyOmrVqgEAUnB/9FFr3Lx5Qy3IX7x4ASD3B3pu3rwBpVKJ99+vp98LICKiN4LOAb906dICnzO18NfWg7e0tJSez/9jNAqFAteu/YP69RsUeXs3b2q/mdCTJ5lo27Y5AOjVm//994NITU1Fnz6fvvI6SktWVhbmz5+Nb74JhJ2dfWk3x+QoFAqYmZnxolIiE6LzRXbp6elqw2+//YZ79+4Zsn2vnaysLCnYlUqlNH3cuEB06NAKe/fuUpk/NHSL3hfmpacXHOrHjh3B5s0bdVrPZ5/1wddf/0+vtugqOzsbEyeOxe3btwudd9y4ABw6dFBt+qZN6/HHH8cBAL/+ugk//vg9liz5vribWiKEELhx4/W9X0Tlyg4YOzagtJtBZJJycnKkI7IlSeeAnzBhgtowb948WFlZGbJ9r6VPPukN4N8efGZmBn79NTdkDx78TZovOzsbI0YMg5dXlwLXlX9+Fxd7/PBDsNo8QUHTpcc7doQiI+PfwO/TpydGj1Y9gpKRkY4tW35Benoa1q1bg+zs7EJf0+nTJ/HnnxEFPn/+/Dls3LgOq1cvh7e3JxYtmq/153SPHAnH6tUrCr0AUwiBdevWoH//Pjh37ozKRY2BgSPRu3cPAEB6ehoAFHjb4NTUR3j+/LnWbb3s8eNU/PXXxSItk59cLke3bh2xevXyQufduHEd2rRphrNnTwMAEhMTMGrUV0hLe/zK2y8ueb8IuWHDWp3mF0IgNjZGr21mZmbg0097Iyqq8B3A150QApMnj9frvfSmuXPnNpRKJRQKhU6fT8aue/eOqFatYolvV69b1TZo0ADnzp0rrrYYHSGAK1cice/ePenufo8fp2LVqmXIzs5GZmYGgNxfo8vKygIAzJ8/O9/yAp9//onKOvOHeZ7t27dKj7/8cjDGjBkNQHXnAMg9BN+wYW0MGPAJRo36CtOmTcK4cQF49103fPnlYK2vpWfPrujS5d+r9YUQKmHavXtHfPvtKEycOA5nzpzC3LmzEBn5l9p6MjMzkZ2djcjIPwEAVlZWUCgU2Lt3l8Zw/vbbUdLjHj064z//qYvAwJEq85w8eUIKgszMDERG/oWmTRtg7dpVCA8Pw6hRX6FWrRrw9fVSaX/+wP/zzwj888/fuH79Gry8uiAzMxM9e3ZD584e0pGYx49Tte4kvPxB9MMPC3HhwjlMnDgO69atQaVKFfDs2TONy/7991UAwLlzZwAAw4Z9gS1bfsGpUycL3J4m8fH31XYKUlJSVO4uqWmn4cCB/di0ab3GdT58mCw9vnnzRqE7HfPnz0aTJvVx8uQJrfPl1UuhUODBg3i19hw+/Dvmzp2Fv/++Kr03lErl/1+EqlRbX56jRw8jLi4WALBv3x5s3LgOT58+xY8/Lsbz58/x9OlTnD59Et9/v0BlZ1gX+d+jGzb8rPX02enTJ3HjxnWkpKRg5cpl8PX1LtK28uzbt1utPsVl2bIf4eJir/K+vHfvLn7//SDOnDllkG3ml5SUqDbt7t07aNGiMRYunIsuXTzw7rvV1ebJzs4u9KfIDenp06f44ov+xbYD+uefpbTzJ3SUkZGhMiQmJoqtW7cKDw8PXVdhcA8fZgi5PL1YBgB6DdOnzxYXL15Vmfby+KFDxzQu27VrDxEXl1zguv/73+ZqbZTL00WDBh+oTOvcuavG5WNikkRSUprG15uUlCYePHgk6tdvKN56q4aQy9NFfHyKxvVMnjxDDB8+Sixe/JPo0qWbuHPnvto8bdu2FT/9tEoAEFOnztK5zklJaa9U97z1jhnznQAg3nnnXXHs2Jl87WkvAIhff90mTbt9O1ZERycKAMLb20fI5eni+vV7Yu/eQ1Kdrly5KQCIYcOGiyNHTokHDx4Jf/9Batt/++13xOXLN8SwYcNFv34DxLVrd4Vcni58fftKf9tNm7ZK88+Zs1ClHteu3RXHj58Vcnm6uHUrRri6VhJOTk4iJGSnGD36WwFAVK1aTVy9ekvI5ekiNlYuAAgvLx+xatU6ERq6WwAQc+cGC7k8Xaxf/6tYsGCxSl3ztpWUlCauXbsr+vcfqPY6Ro4MEPv2/S7i41PEgAFfiCNHToolS5aLyMjr4j//aaTS9piYJHH27J9i06at4sGDR0IuTxe7dx+Q3uPDh48SAMSSJctFhQoVxJ0798W0aUECgGjfvoMAIP73vxEiMfGxtP3WrduK/v0HisTEx0IuTxd378aLe/cSxOrV6wUA4epaSeX9M2HCFAFATJsWJPr27afyWu7ffyiEEGrvvaSkNHHhwmWxePFP4urV2yIwcJwwNzcXR46cUvn/27Rpq9bPiLz/Y0tLS5Xno6MTxbp1m4WHx0eiZctWIiEhVWzdukucOHFOmmfr1l0CgPjkk89Ulj137i/RunU7cfNmtIiJSRIHDx4RgYHjRJ06dcWvv26T5vvnnzuiSpWqYsWKtWrtO38+UmrjsWNnpO3mr825c39J76W8Nr+8nvnzvxchITs01vD48bNixozZQi5PFytX/ixu3oyWpu/b97sAINau3STN37p1O2nbNWrUVPm/vXcvQTg7uwgrKyvh6dldABC//RYu4uNT1Lb7999RYu/eQyI0dLcICdkhBg0aKkJCdohFi34Uw4Z9JQ4f/kOad9GiH8WRI6dEUlKaWLBgsfQ/qW1YtWqdACC6dfMSMTFJYt68RSIhIVXt/ZP3Pzts2FdSe+XydDFp0nQBQPz88y8q7+vs7Oxiyyi5PF08fJihNRN1DvhatWqJ2rVri1q1aolatWqJ999/X3Tr1k2cOXNGj0guXqUd8NWru6mMHz16WmV86dKVKuOVKlUucF3bt+/Vuq2EhFSV8cTEx8LN7S2Vae+9V0tYWVmJtWs3qi3fubOn9Aa9fPmGNN3Ts7vKP+Hduw9E2bLlNLahZctWOtXFyclJety8eUsRHLxEhITsFAcOHC5wmZkz57zS3yApKU0cPvxHgc+3bt220NcREDBWetyhw8di5879YvPmUJV5KlasKNzd39a4jbp166mMnzhxTjRu3LTANi1ZslycOHFOrF27Ubz3Xi3p7/npp/21vtZNm7aq7SR6efkIAKJZsxZa38fDhn0l7XQUNJQrZyuWLFkuAAhHR0e15z/77HOxcWOI2vQrV26KgQMHCwBi0qRpwtnZRe315j1+9933/r+ezqJy5Spq6zpw4LC4ceOexvZVqFBBpa0AxMcfd1Kbz9bWTjg6OorIyOti58794uzZP8WxY2eknaG8euW1Zfbs+WLZstVq76s5cxaKjRtDxNtvvyMmTpwqPZdXxzJlyoiEhFRx58598eDBI7V2eHh8JD2+du2u+OOP86Jp02ZSu/NC4/3360vzFfQeqFjRWcyZs1DaQQAgQkJ2iv37w4VMJhNOTk4qny81a7prXE9emw4f/kPaiZ01a660kxsefkIAEBYWFuLu3bti//5wMXv2fNGgwQdiypSZok6dumrrr1+/oQAgvba897OPT+8C32uNGjUW9vblC3ze3NxcjBs3Uaxdu0n8/PMvKs/Vq9dA4zLdu3tLj52dXaTPhY8+6ih9zl+5clM0a9ZC+Pj4is8/H6SycwrkBnze4x9+WCZ9Nmpra/7PU0A1F2JjY1/PgDcGpR3wbdq0VxlfuPAHlfG8DyFNH1AvD507e2rdVt4/kS7DH3+c1zh99er1Gj+I8g8vB2KvXn5ix459r1Sf12HQdafk5cHGxqbIy3Tp0k1l3M2tRoHzVqxYscjr79ixs9Q7Ll9e/b1UtmxZvWrl6lpJ7aiQLkP+D79GjRqX+t88bzAzMyu2dRX2fijK/2fe0Lt3H+Hg4FAqtfH3HyTGjp0gjQcHLynW9dvZ2auMW1tbl+p74fPPB4kZM2arTW/Vqo3B28mAf0WlHfAv721/+eXXhS5TrVr1Yn3z+Pl9ojbt5T3K/EPeYTRdh4CAsa9cH23DL79sVeslF+fQqVMXAUCtN6nvYGtrV+BzMTFJKuNTp84S/foNkHqKwKuFjpWVlXjnnXel5Xv37qPT32TVqnUqvXZNYeLt7aM2rUqVqirjnp7dC+wRmpub6/XaNA3adoxGjgyQHuc/8pQ3DBs2vEjbsrCweKU2ajpykH+YNi1ItG3bXjp1VNiQ/+8wa9bcIrfH0tLylV6Htk5HYcP48ZOkU0Z5g5WVlcZ5V61aJ0aNCtS5pnmnhV6HoV07D43tdHBwUNmRWb16vfj669Eq837xxRcM+FdVWgHfrZuXuHs3vtBDnpqGjh07q/1DF2Xo2rWHyvjOnftVgmX58jXi7t0HOq3r5b3XvCEkZIf0eOzYCUWqz5AhQ4SHx0fi0KFjWnupZ878KeTydBEZeV3IZDKt6/zkk8/UpmnbmerT51O1w3pVq1YTe/YcLFKtBw0aKj3u1KmL2LJlu4iNlUvnfwGIESO+EVOmzBTdunmp1enAgcNCLk8XV6/eFgDE8OGjREJCqujWzUuYmZlJ55c1DRERV6TH4eEnVK4hiIy8rnZoMf/QvHlLAUA6l3n06GkREXFF5Rxt3nDqVIQ4ePCIyiH5/D07ACI2Vq7y2vr1GyCA3NMD9+8/lOoTE5MkvvpqpDhy5KR45513xfjxk8R3302Wlsu7huGtt2qIFi0+FMuWrRZHj54WX375tTh37pI0n1yeLk6fviiWLFkurl69JYYO/VIAEHfvxgu5PF3akTh+/KxK4A8bNlwEBc1TafvAgYPF/v3h0viiRT+KNWs2CCD3fzA6OlH6kA4N3S3On48UXbv2EK1atRFr124Sp09flI7MyWQy4evbV1SuXEXcvBkt7XSNGPGNqFOnrsrRi7yavfyeKF++gujUqYt0zhnIDcW890ne+fYlS5aLefMWqSzbtGkzqe3Av0dsJk2aJtav/1U6oti0aTNx4sQ5ldcN5B5yXrt2k/jhh2UCyD3sf/t2rPR8s2YtxI0b96SjQ+Hh4dKpi969+0jX3Dg7u4jz5yOl17dhwxZpHdev555esba2Fi1afCitNzHxsYiPT5E+nzZs2CJu344VP/20Snh5+Yi//44SSUlpIiYmSdy//1Bcv35P9O7dR5w795e4ezdeTJo0XURFxYkjR06JyMjrIizsqOje3VvcuXNfxMbKRVjYUZXOS97py0WLfpSmDRjwhdi4MURERl5XqUuHDh+L1q3bSUdhPDw+kj67/ve/EeL27Vjx2Wefi++/Xyq+/Xa8CAnZKYDc60BOnrwghg8fJZo3byn9v0VEXBFz5waLxMTHQgj16xgMGfAyIbR818nIpKRkQqksnpfj4qLbzVTq1HkfJ06cBQB4eLTC339fKdJ2vL19EBS0ADk52WjYsLY0fdWqdXj8+DHGjs29Yj4pKQ3JyclITX2E1q3/K833ySefYcuWXwAAvr59sXTpSshkMqn9Fy9eRfXqbnB1LV9oW0JDd+P27ZvIzs5BZOSf6NWrD+7fj8OgQUMxc+ZU/Pjj95gwYQq++eZbtfrY2tohMzMDTZr8F/36DcDo0SMwalQgFi9eiOTk3G8T3Lp1EwkJD6Sr3d3c3sKXX46Ap2d3VK5cRWV9s2ZNw5Ili9TauHbtRnTv7o1Ll/5Ep07tAQDr1/8KT89uePLkCdasWaH2TYR79xKQmvoIjRq9DwB4++138Ntv4Xjy5AkaN1a/M2Bw8BIEBo6Ei4srPvywFXbt2gEPj4/wyy+hWLhwDlq0aIW2bdtL87948UL6Coz8pRsRNWlSH7GxMVLd8sTFxaJy5SqwsMi919STJ09QtmxZTJnyHdavX4usrCwsXvwTYmLuwc+vF2rUqI3KlR0AALGxclhZWWHDhp/RtGkzlbsb5v1d5PJ06XFk5HU4OjrB2tpapW2ZmZlwd1et+9278bC1tUNExHkMHToQ8fH38fvvx/HwYTL8/fup3Dr5998P4uTJE5g+fTZ++mkJ+vXrD0dHJ6SmPoK1tQ1sbGzUapvbNjnMzMxgY2ODH34IRseOndGkyX9V5smr6fDhozB16kyV53KvsM5EhQq59bh06U9YWpZBvXr1AQAXL16AvX15vPdeLTx+nIrBg/2xZs1KpKU9h5vbW5DJZKha1Qk9evTE8uVrIIRARMQFNG36X8hkMsTFxSI+/j6aN2+psf0AcPbsadSs6Y5KlSpDoVDA3Nwcw4YNxK5dO/DHH+dRu3Yd/PHHcfTu3QOrVq2Dt3cvadk7d27j9OlTuHr1CubOXQhzc3MAuV9vzbuKP++1vSwi4jxiY2NQr14DVK/uhrJlyyIh4QF++ukHxMbGIizsNyxZshx9+/aT/sZlypRBmTJlAABr166Eo6MTevbsLa3z1Kk/4OPTDS1afIg9ew5i9OgRuH37Ftat2wxnZ2ecPn0SEyaMwcWLEcjMzMGuXdvRpUs32NjY4OLFC6hWrToqVaqs0s5p0yahSpUqGDr0K1y9ehk1a7rD1tYO8fH3UaVK1RK7oVL+/4e8qHN1LY/mzVti794wAIAQAqNHj0C9evXRuHFT/Oc/jQEAjx6lYNmyH/HFF7m/QWJmZib9rfITQuDo0XC0besh/T8XxNnZTvo8LA5mZjI4OdkW+DwDvgCFBfzkyTMwc+YU2NnZ486d3O9ub9y4TuVrX3nmzg3G+PGBKtOsrKyQlZWFdu08EBq6G1lZWahe3Vl6Pu9DNP8bFIDafAMHDsa6dWvg4+OLFSv+/R5z3nL37iWgXLly0njFihVx7NhZpKenYezY0Th9+t+vad25c7/Au8QtXfoDZsyYjODgJejf319a361bMThz5jQyMtLx9df/Q/fu3li7dqP0oafpDZ23bFJSWoH/6JmZmViyZBEWL14oTXvnnXdx5syf0vjt27cwduxobNoUAltbO7X150lKyv0OfZUqjlAoFBgw4AssXLgYAHD16hX8889VjBz5pTR/TEwSsrKew87OHmlpj9GzZzesXPkzateuo7Gt+bf5csDnfX2tsH/8/Hr27IrTp08iNHQ32rXzkGrYpYsHYmKice3aXZ3a0bXrx4iIOI8HDx4VuP2AgK9Rr14DnD59Evv27VZrf0ZGuvSeePbsGZ4/fwYHB0edX4s+nj17Bmtr62IJg5ffhzk5OTAzM1P5tUh9ZWZm4PDh31XCvCQdOnTw/+8ncQnu7m/rvFxWVhZGjx6BwMCxWn9bo7jDqSQkJ+d+BdTZ2VllWtmyZdV++6MkMOD1YKiADwnZgb59//2nPX78LBSKHHTokPvLevk/FDXtGOTvTeWpWrUa4uPvo2fPXli5cp00fezY0Xj77XcwbNhwlfUVtI0FCxZjzJhvsGjRj/jss8+l6Q0a1EJiYoK03M8/r8b48YHw9OyO9es3A4DUKwcALy8frF69vsB6ZGdn49dfN+Gzzz6Hubk5du/egUuX/sL06UEAcoPg888/xfz53+Odd/79kND0hvbz88bx40d1uu1uRMR5JCQ8QEZGBtq0aYfq1d0KXebMmVOQy5MwdOhAAP/WLjs7G8HBczF06FdwdHRSWaaggNbVlSuRKF++At56q8YrLZ/f1auXMXZsALZt2wNbW1uphtnZ2VAqlVpvLtWlSwfY2Nhg5879SE9PQ0xMNOrXb1joNrOzs/H8+TOTvQ2wMYbTqxBCGKx3/KbU0JAY8HowVMDfvRsPd/eq0vjVq7dhbm6OunXdARQcvmFhR1GunC1q1aqtFvAffdQRPXr0RKdOXbT2iAoL+KSkNJw8eQKtW7dV+cdOTk7G/fux0uEmIQQ2bVqPrl17SL9il5KSgjp1akqvydXVtbCyFJmmN3R2djZycnIKPIRbXIoS2keO/A65XI5PPvnMoG16Ffxg1R9rqD/WUH8lHfC6Hzd8g9na2iEqKg7vvJN7x6UyZSwLPEeWX6NGTVTWkZmZIR0NUCgU0nmyooqNlcPNzQVA7g/jtGnTTm0eZ2dnlcNSMpkMAwYMVJnHyckJ8fEpiImJNki4F8TS0hKWlpYG305IyA6d70TVoUNHA7eGiKhkMeB1ZG//70VqlpZlIJPJsHjxT2q/HhcWdhQ+Pt3w9dejVaafOnUB0dH3pHFr61fvvVpbW8PFxRVyedIrryOPpaWlyiF1U+Lh8TE8PD4u7WYQEZUKBnwh8l8tnSfvitRPP+2v9lyjRk0QHa1+/+UqVaqiSpWqUCqVGDduIgYM+EKn7R85chLm5up/pnPn/nojfqSBiIheDQO+EKGhu9Wm6XN42czMDIGB43Sev6ALpPJfNU5ERPSy4vuOiInSdEVqSX2Hk4iI6FWVSA/+0qVLmDdvHhQKBRwcHBAUFKRyAVieuLg4LFiwAHFxcXj69CnWrl2LatWqlUQTiYiITIrBAz4rKwsBAQHYsGED3NzcsG/fPkyePBkrVqxQmS8jIwODBw/G1KlT0bJlwXeQIiIiosIZ/BD95cuX4e7uDje33BuUeHp64uLFi9IdvvJs374dHTp0eK3DfevWXQgIGFvazSAiIiqUwXvwSUlJcHFxkcbNzc1hb2+PlJQUle9eX7p0CZaWlhg0aBBSU1NRt25dfPvtt6hQoYLO29L2hf9X5ez878Vsfn7e8PPzLvZtmLr8NaRXwxrqjzXUH2uov5KsocEDvqAb5b18oVpmZiZ69OgBb29vCCGwZMkSzJo1CwsXLtS4vCbFeSe7PLxzk3549yv9sYb6Yw31xxrqr6TvZGfwQ/Surq6Qy+XSuFKpRHp6OhwdHdXmK1u2LIDc8O/evTtu3rxp6OYRERGZJIMHfMOGDREVFYW4uDgAQFhYGBo3bgwLCwvExsYiIyN3b+bjjz9GSEgIXrx4AQA4ceIEGjdubOjmERERmSSDH6K3trZGcHAwAgMDIYRA+fLlERSU+wtk/v7+GDFiBHx8fODh4YE7d+6gb9++sLS0RM2aNTFp0iRDN4+IiMgk8dfkCqDvz4dSLp630x9rqD/WUH+sof5M7hw8ERERlTwGPBERkQliwBMREZkgBjwREZEJYsATERGZIAY8ERGRCWLAExERmSAGPBERkQliwBMREZkgBjwREZEJYsATERGZIAY8ERGRCWLAExERmSAGPBERkQliwBMREZkgBjwREZEJYsATERGZIAY8ERGRCWLAExERmSAGPBERkQliwBMREZkgBjwREZEJYsATERGZIAY8ERGRCWLAExERmSAGPBERkQliwBMREZkgi5LYyKVLlzBv3jwoFAo4ODggKCgIzs7OKvPcv38fXbp0QZ06daRpzZs3R0BAQEk0kYiIyKQYPOCzsrIQEBCADRs2wM3NDfv27cPkyZOxYsUKtXkrVaqE0NBQQzeJiIjI5Bn8EP3ly5fh7u4ONzc3AICnpycuXryInJwcQ2+aiIjojWXwHnxSUhJcXFykcXNzc9jb2yMlJQWurq4q8z58+BB+fn5QKpVo3rw5Ro4ciTJlyui8LScn22Jrdx5nZ7tiX+ebhjXUH2uoP9ZQf6yh/kqyhgYPeCGExukymUxlvEqVKoiIiICFhQWePn2KKVOmYMWKFRg5cqTO20pJyYRSqXl7ryo5OaNY1/emcXa2Yw31xBrqjzXUH2uov+KuoZmZTGvH1uCH6F1dXSGXy6VxpVKJ9PR0ODo6qjbEzAwWFrn7G2XLlkXXrl1x69YtQzePiIjIJBk84Bs2bIioqCjExcUBAMLCwtC4cWNYWFggNjYWGRm5ezM3btxAWloaAEChUODgwYNo0qSJoZtHRERkkgx+iN7a2hrBwcEIDAyEEALly5dHUFAQAMDf3x8jRoyAj48PYmJiMGbMGFhaWgIAWrdujQEDBhi6eURERCZJJgo6SW6EivMcvIuLPQBALk8vlvW9qXjeTn+sof5YQ/2xhvozuXPwREREVPIY8ERERCaIAU9ERGSCGPBEREQmiAFPRERkghjwREREJogBT0REZIIY8ERERCaIAa9F3br1SrsJREREr8Tgt6o1Vk+fPkVq6rPSbgYREdErYQ++ADY2NtJ98YmIiIwNA56IiMgEMeCJiIhMEAOeiIjIBDHgiYiITBADnoiIyAQx4ImIiEyQSX0P3sxM9lqv703FOuqPNdQfa6g/1lB/xVnDwtYlE0KIYtsaERERvRZ4iJ6IiMgEMeCJiIhMEAOeiIjIBDHgiYiITBADnoiIyAQx4ImIiEwQA56IiMgEMeCJiIhMEAOeiIjIBJnUrWqLy6VLlzBv3jwoFAo4ODggKCgIzs7Opd2sUvH1118jOjoa1tbWKFeuHGbMmAE3NzccOXIEy5cvh0wmQ/Xq1TFjxgzY2toCAEJCQrBt2zbIZDI0aNAA3333HSwtLSGEwE8//YTjx49DCIH27dtjxIgRAIDs7GzMmTMHV65cgRACvr6+6Nu3b2m+9GIXFRUFPz8/rFq1Ck2aNGENi0ChUGDFihU4fPgwhBDo1q0bBg8ezBoW0cmTJ7F06VIAQE5ODoYPHw4PDw/WsRBpaWnw8/PDhg0bUKlSJQAo0ZplZmZiypQpiIuLgxACX375JTp06FB4wwWpeP78uWjXrp2IiYkRQgixd+9eMWzYsFJuVek5d+6c9HjXrl1iyJAhIjExUXTo0EGkpKQIIYRYvny5mDFjhhBCiCtXroiePXuKZ8+eCSGEmDRpkli7dq0QQoiDBw+KIUOGiJycHJGTkyMGDRokwsLChBBCrFmzRkyePFkIIcTTp0+Fl5eXuHr1aom9TkNLTU0Vffv2FZ07dxYRERGsYRHNmDFDTJ06Vbx48UKaxhoWzfPnz0WLFi1EUlKSEEKI+Ph40bRpU9axEGvXrhXt27cXderUEQkJCUKIkn/vTZ8+XaxcuVIIIURKSorw8PAQiYmJhbadh+hfcvnyZbi7u8PNzQ0A4OnpiYsXLyInJ6eUW1Y6mjVrJj1+77338OjRI5w5cwYtW7aEo6MjAKBnz544fvw4AODEiRPo3LkzrK2tNT7n5eUFc3NzmJubw8vLS3ru+PHj8PHxAQDY2Nigc+fO0nPGLicnB2PGjMHYsWNRsWJFAGANiyAlJQXHjh3DxIkTYWlpKU1nDYtGoVBAoVDg6dOnAIDy5cvD0tKSdSzEF198gaNHj0o9d6Dk33vHjx9Hz549AQCOjo5o2bIlzp49W2jbGfAvSUpKgouLizRubm4Oe3t7pKSklGKrXg8hISHw8PBQq5GLiwuSkpIA5NYv/+kMXZ+Ty+UFPmfsgoKC4Onpif/85z/SNNZQd1euXIGdnR3GjRuHPn36wN/fHxEREaxhEZUtWxYLFizAwIED8d133yEgIADBwcGs4yso6Zppei4xMbHQdjLgXyIK+HE9mezN/pnErVu34t69exg0aFCBNQIKrl9Bz+XVVdtzxmz79u2wtraW9r7zsIa6y8zMRKVKlRAUFIStW7di/PjxGD16NGtYRE+fPsXmzZuxbds2BAQEwN3dHevXr2cdX8HrUDNd6smAf4mrqyvkcrk0rlQqkZ6eLh2KeROtX78eYWFhWL58OaysrNRqlJycDFdXVwC59UtOTtb5uby9YG3PGbPbt28jIiICfn5+8PPzwz///IOpU6eiTJkyrKGOXF1dIZPJYGNjAwCoXbs2qlatCisrK9awCE6dOgVbW1tUrFgRzs7OGDduHBISEmBtbc06FlFJfwa6uLgUuE5tGPAvadiwIaKiohAXFwcACAsLQ+PGjWFh8eZ94UCpVCIoKAg3b97EqlWrpCtEW7RogTNnziA1NRUAsGfPHrRt2xYA0Lp1a4SFheH58+cAgL1796o8t2/fPiiVSiiVSuzfv1/luT179gAAnj9/jkOHDqFNmzYl+noN4bvvvsP27dsRGhqK0NBQvP/++5g+fTo8PT1ZQx01bNgQd+7cwZ07dwAA8fHxSElJQadOnVjDInBzc8Nff/0lnW5MSkpCWloaOnbsyDoWUUl/BrZq1Qq7d+8GAKSmpuLs2bNo0aJFoe2UCW3HE95QFy9exPz58yGEQPny5REUFKTT3pKpuXHjBnr16oX3339fZfr8+fNx48YNrF69GmZmZqhatSpmzZol7QD88ssv2LVrF2QyGd5//31MnDgRZcqUgRACixcvxqlTpwAAbdq0wciRIyGTyfDixQvMmjUL165dgxACPj4+6NevX4m/ZkPr378/Ro0ahSZNmiAsLIw11NHVq1cxZ84c5OTkoEyZMvj222/xwQcfsIZFtGPHDmzcuBFWVlawsLDA119/jRYtWrCOWoSEhCA8PBwRERFo2LAh6tWrh3HjxpVozTIyMjBp0iQ8ePAAQggMHToUHTt2LLTtDHgiIiITxEP0REREJogBT0REZIIY8ERERCaIAU9ERGSCGPBEREQmiAFPREWyc+dOfPXVVwZZd0JCAj788EODrJvoTcOAJ6LXRuXKlXH69OnSbgaRSWDAExkhhUKB2bNno127dmjWrBl8fX1x69YteHl54cMPP0SbNm3wySef4Nq1awCA+/fvo3Hjxti8eTO6d++ORo0a4fvvv8eBAwfg5eWFpk2bIjAwEEqlEgAwfvx4TJgwAYMGDcKHH36Ifv364cGDBxrbcvToUfTo0QOtWrVC//79ER0drdNrWLlyJTw8PNC8eXN0794d58+fR3p6OmrVqgUAWLp0KT788ENpqFevHubPnw8AuHPnDvz9/dGqVSt4enrixIkTelaUyATp8HO4RPSa2blzpxgwYIB4/vy5UCgU4uzZs+L69esiPj5emicsLEz4+fkJIYSIi4sTderUEZs3bxYvXrwQ165dE7Vq1RITJkwQaWlpIj09XbRv31788ccfQgghxo0bJwYMGCAePHgglEqlWLJkiRgyZIgQQogdO3aIL7/8UgghxN9//y3at28v7t69K7Wrd+/ehbb//PnzokuXLiIjI0MolUpx5coVcf78eZGWlibee+89tfn//vtv0bp1a5GYmCiePHki2rdvL44dOyaEEOLWrVuiZcuW0m9zE1GuN+8G60QmICcnB6mpqYiPj4e7uzuaN28OANiyZQt+++03xMXFISsrS+UXqsqWLYtPP/0UAFCnTh1UrFgRAwYMgL29PQDggw8+QGxsrDR/+/btUblyZQDAwIED0bRpU2RnZ6u0IzQ0FAMGDEDNmjUB5P72dVBQEB49eqT1B5pycnKQkZGBmJgY1K1bF/Xr1wcApKenq8375MkTBAQEYObMmXB1dcWBAwdQq1YttGvXDgDw7rvvokGDBrhw4QI6d+5cpDoSmTIGPJER8vb2RlxcHIYNG4anT5+iQ4cOaNSoEVauXIng4GDUr18fcrkc3t7eBa6jTJky0iH5vPGXAzyPra0tLC0tkZaWpjL9wYMHOHDgAFavXi1NUyqVSElJ0RrwLVu2hL+/P8aNG4fk5GS0bNlSul/3y6ZPnw4PDw/pRzni4+Nx9uxZlYvxXrx4YVI/ZkJUHBjwREbI0tISAQEBCAgIQHJyMkaPHo3du3dj2LBhaNy4cbFvTy6XQyaTwcnJSWW6q6srRo8eLR0ZKIpBgwZh0KBBSEtLw7Rp0/Djjz8iMDBQZZ7du3fj7t27CAoKUtlmu3btsHjx4ld6LURvCl5kR2SEDh48iLNnz0KhUKBChQooX748hg4diqtXryInJwdpaWlYuXKlXttISEhATk4OXrx4gfnz56NXr16QyWQq8/j4+GDdunW4efMmACArKwv79u1DTk6O1nWfPXsW4eHhePHiBezs7ODk5ISyZcuqzBMdHY1Fixbh+++/h6WlpTS9Xbt2iIyMxOHDhyGEgFKpREREBO7du6fX6yUyNQx4IiNUoUIFBAcHo2XLlujYsSNcXV3h7+8PpVIpXc1erVo1vbbx119/oWvXrmjfvj2srKwwZswYtXkaNWqEcePG4bvvvkOrVq3QpUsXXLhwQW1H4GUODg7YuHEj2rRpg/bt2yM1NRXDhw9XmWfNmjVITU1F3759pSvpp0yZAnt7e6xcuRJbtmxBmzZt0LZtW6xbtw4WFjwgSZQffy6WiNSMHz8etWvXhr+/f2k3hYheEXd5iajY7d69GwsWLCjw+V27dsHFxaUEW0T05mHAE1Gx8/b21noFPxEZHg/RExERmSBeZEdERGSCGPBEREQmiAFPRERkghjwREREJogBT0REZIIY8ERERCbo/wCw7hwNqaLnfQAAAABJRU5ErkJggg==\n",
306 | "text/plain": [
307 | ""
308 | ]
309 | },
310 | "metadata": {},
311 | "output_type": "display_data"
312 | }
313 | ],
314 | "source": [
315 | "sns.lineplot(x='sample_size', y='unbias_var',\n",
316 | " data=size_var_df, color='black')"
317 | ]
318 | }
319 | ],
320 | "metadata": {
321 | "kernelspec": {
322 | "display_name": "Python 3 (ipykernel)",
323 | "language": "python",
324 | "name": "python3"
325 | },
326 | "language_info": {
327 | "codemirror_mode": {
328 | "name": "ipython",
329 | "version": 3
330 | },
331 | "file_extension": ".py",
332 | "mimetype": "text/x-python",
333 | "name": "python",
334 | "nbconvert_exporter": "python",
335 | "pygments_lexer": "ipython3",
336 | "version": "3.9.7"
337 | }
338 | },
339 | "nbformat": 4,
340 | "nbformat_minor": 2
341 | }
342 |
--------------------------------------------------------------------------------
/book-data/8-3-分散分析.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第8部 正規線形モデル\n",
8 | "\n",
9 | "## 3章 分散分析"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd\n",
28 | "from scipy import stats\n",
29 | "# 表示桁数の設定\n",
30 | "pd.set_option('display.precision', 3)\n",
31 | "np.set_printoptions(precision=3)\n",
32 | "\n",
33 | "# グラフを描画するライブラリ\n",
34 | "from matplotlib import pyplot as plt\n",
35 | "import seaborn as sns\n",
36 | "sns.set()\n",
37 | "\n",
38 | "# 統計モデルを推定するライブラリ\n",
39 | "import statsmodels.formula.api as smf\n",
40 | "import statsmodels.api as sm"
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": 2,
46 | "metadata": {},
47 | "outputs": [],
48 | "source": [
49 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
50 | "np.set_printoptions(linewidth=60)\n",
51 | "pd.set_option('display.width', 60)\n",
52 | "\n",
53 | "from matplotlib.pylab import rcParams\n",
54 | "rcParams['figure.figsize'] = 8, 4"
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "metadata": {},
60 | "source": [
61 | "### 実装:データの作成と可視化"
62 | ]
63 | },
64 | {
65 | "cell_type": "code",
66 | "execution_count": 3,
67 | "metadata": {},
68 | "outputs": [
69 | {
70 | "name": "stdout",
71 | "output_type": "stream",
72 | "text": [
73 | " beer weather\n",
74 | "0 6 cloudy\n",
75 | "1 8 cloudy\n",
76 | "2 2 rainy\n",
77 | "3 4 rainy\n",
78 | "4 10 sunny\n",
79 | "5 12 sunny\n"
80 | ]
81 | }
82 | ],
83 | "source": [
84 | "# サンプルデータの作成\n",
85 | "weather = [\n",
86 | " 'cloudy','cloudy',\n",
87 | " 'rainy','rainy',\n",
88 | " 'sunny','sunny'\n",
89 | "]\n",
90 | "beer = [6,8,2,4,10,12]\n",
91 | "\n",
92 | "# データフレームにまとめる\n",
93 | "weather_beer = pd.DataFrame({\n",
94 | " 'beer' : beer,\n",
95 | " 'weather': weather\n",
96 | "})\n",
97 | "print(weather_beer)"
98 | ]
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": 4,
103 | "metadata": {},
104 | "outputs": [
105 | {
106 | "data": {
107 | "text/plain": [
108 | ""
109 | ]
110 | },
111 | "execution_count": 4,
112 | "metadata": {},
113 | "output_type": "execute_result"
114 | },
115 | {
116 | "data": {
117 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAfAAAAEJCAYAAABrMXU3AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjQuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/MnkTPAAAACXBIWXMAAAsTAAALEwEAmpwYAAAZrUlEQVR4nO3de1BU9/3G8WcRFFREBYyWiOloNJ2W0V5sAqIg8a6ogE3FkVQjk6TtpNXoELReZlpNlBiJo402KWao9RrFeLemUQmKsTUaE6vSaBXxEkKwoMiqwO7vD0d+SaNmVfYcvvB+/RVgdz/PiTiP37N7vsfhdrvdAgAARvGxOwAAALh3FDgAAAaiwAEAMBAFDgCAgShwAAAMRIEDAGAgChwAAAP52h3gXv33v1flcnHpOgCgYfPxcahNmxZ3/LlxBe5yuSlwAECjxyl0AAAMRIEDAGAgChwAAAN5tcArKio0bNgwnTt3TpK0Zs0aDRs2TPHx8Zo6dapu3LjhzfEAADRYXivwI0eOKDk5WWfOnJEknT59WllZWVq9erU2bdokl8ullStXems8AAANmtcKfO3atZo1a5batWsnSWratKlmzZqlli1byuFwqGvXrrpw4YK3xgMA0KB57TKyOXPmfO3rsLAwhYWFSZIuXbqkFStW6JVXXvHWeADAt8jPz9PevbmWzy0vL5MkBQW1tnx2dHSMoqJ6Wz7XGyy/Dry4uFipqalKSkrS448/fs/PDw5u6YVUAND4BAb6y8+vieVzL18ulySFhARbPjsw0F+hoYGWz/UGSwv81KlTSk1NVUpKip555pn7eo3S0go2cgGAOhAR0VMRET0tn5uRMVuSNGnSVMtnS1JJyRVb5t4rHx/HXRetlhV4RUWFJkyYoIkTJ2rkyJFWjQUAoEGy7DrwdevW6csvv9Tbb7+tESNGaMSIEVq4cKFV4wEAaFC8vgLftWuXJGncuHEaN26ct8cBANAosBMbAAAGosABADAQBQ4AgIEocAAADORwu91GXVTNdeAAGppVq5arqKjQ7hiWOXv25rGGh3eyOYk1OnbspOTklHt+Xr25DhwAcHtFRYU6efLfCggIsDuKJVyuGknS+fNFNifxPqfT6bXXpsABoB4ICAhQt27d7I6BOlZQUOC11+Y9cAAADESBAwBgIAocAAADUeAAABiIAgcAwEAUOAAABqLAAQAwENeBA4DNysvLVFlZ6dVrhmGPyspKlZeXeeW1WYEDAGAgVuAAYLOgoNaqqLjCTmwNUEFBgYKCWnvltVmBAwBgIAocAAADUeAAABiIAgcAwEAUOAAABqLAAQAwEJeRAUA94HQ6G81GLlVVVZIkPz8/m5N4n9Pp9NprU+AAYLOOHTvZHcFSZ88WSpLCwjranMQa3vrzdbjdbrdXXtlLSksr5HIZFRkA8BUZGbMlSWlp021OUr/5+DgUHNzyzj+3MAsAAKgjFDgAAAaiwAEAMBAFDgCAgShwAAAM5NUCr6io0LBhw3Tu3DlJUn5+vuLj4zVgwABlZmZ6czQAAA2a1wr8yJEjSk5O1pkzZyRJ165d07Rp0/TGG29o27ZtOnr0qHJzc701HgCABs1rG7msXbtWs2bNUlpamiTpk08+UadOndSx480L9+Pj47Vjxw7FxMR4KwIA4C7y8/O0d6/1C6lbG7ncuh7cStHRMYqK6m35XG/wWoHPmTPna19/8cUXCg0Nrf26Xbt2Ki4uvufXvdtF7QAAzwUG+svPr4nlc9u2bSNJtswODPRXaGig5XO9wbKtVF0ulxwOR+3Xbrf7a197ip3YAKBuRET0VERET7tjWK6k5IrdETxSb3Zia9++vUpKSmq/LikpUbt27awaDwBAg2JZgXfv3l2nT59WYWGhampqtGXLFvXp08eq8QAANCiWnUJv1qyZ5s6dqxdeeEHXr19XTEyMBg0aZNV4AAAaFO5GBgBAPVRv3gMHAAB1hwIHAMBAFDgAAAaiwAEAMBAFDgCAgShwAAAMRIEDAGAgChwAAANR4AAAGIgCBwDAQBQ4AAAGosABADAQBQ4AgIEocAAADESBAwBgIAocAAADUeAAABiIAgcAwEAUOAAABqLAAQAwEAUOAICBKHAAAAxEgQMAYCAKHAAAA1HgAAAYiAIHAMBAFDgAAAaiwAEAMBAFDgCAgShwAAAMZEuBb9y4UUOHDtXQoUM1b948OyIAAGA0ywvc6XRqzpw5Wr58uTZu3KiDBw8qPz/f6hgAABjN8gKvqamRy+WS0+lUdXW1qqur1axZM6tjAABgNF+rB7Zs2VK//e1vNXjwYAUEBKhnz5760Y9+ZHUMS+Tn52nv3lxLZ5aXl0mSgoJaWzpXkqKjYxQV1dvyuQDQGFle4CdOnND69eu1e/duBQYGasqUKcrKylJqaqpHzw8ObunlhHUnMNBffn5NLJ15+XK5JCkkJNjSudLN4w0NDbR8LgA0Rg632+22cuCf//xnlZaW6qWXXpIk7dmzRytXrtSbb77p0fNLSyvkclka2SgZGbMlSWlp021OAgB4ED4+jrsuWi1/D/yxxx5Tfn6+Kisr5Xa7tWvXLkVERFgdAwAAo1l+Cj06OlrHjh1TYmKi/Pz8FBERoWeffdbqGAAAGM3yApekZ599ltIGAOABsBMbAAAGosABADAQBQ4AgIEocAAADOTRdeBffvmlQkJCrMjzre7nOvBVq5arqKjQS4nql7Nnbx5neHgnm5NYp2PHTkpOTrE7BgDUqW+7DtyjT6GPHTtWO3bsqLNQVisqKtTJk/9WQECA3VG8zuWqkSSdP19kcxJrOJ1OuyMAgC08KvCwsDAdOnRIPXr0kI+PmWfdAwIC1K1bN7tjoI4VFBTYHQEAbOFRgZ86dUpjxoyRr6+vmjZtKrfbLYfDoUOHDnk7HwAAuA2PCnzFihXezgEAAO6BR+fDw8LC9Omnn2rt2rVq27atDh8+rLCwMG9nAwAAd+BRgb/55ptatWqVduzYoWvXrmnx4sX64x//6O1sAADgDjwq8K1bt+qtt95SQECA2rRpo7Vr12rLli3ezgYAAO7AowK/9eG1W1q1aiVfX1vugwIAAOThh9g6dOigPXv2yOFw6MaNG8rKyuI9cAAAbORRgc+YMUNpaWkqKChQjx491L17d7322mvezlZnysvLVFlZyTXDDVBlZaXKy8vsjgEAlvOowB966CFlZ2fL6XSqpqZGLVveeWs3AADgfR4V+NWrVzV//nz95z//0cKFCzVz5ky99NJLatGihbfz1YmgoNaqqLjCTmwNUEFBgYKCWtsdAwAs59GH2GbPnq1WrVqptLRUzZo1U0VFhWbOnOntbAAA4A48KvDjx49r0qRJ8vX1VUBAgObPn6/jx497OxsAALgDjwr8f29gUlNTY+xNTQAAaAg8eg+8Z8+eevXVV3Xt2jXl5eXpr3/9qx5//HFvZwMAAHfg0TJ6ypQpat68uZo3b67MzEw99thjSktL83Y2AABwBx6twC9cuKDc3FydOHFCDodDLVu21KVLl9ShQwdv5wMAALfh8UYuo0aNqr2t6OrVqzV9+nRlZWV5NVxdcjqdjWIjl6qqKkmSn5+fzUms4XQ67Y4AALbwqMAvX76sp556qvbrlJQUrVu3zmuh6lrHjp3sjmCZs2cLJUlhYR1tTmKdxvTnCwC3eFTg4eHhOnLkiLp37y5JOnHihMLDw70arC4lJ6fYHcEyGRmzJUlpadNtTgIA8Ka7Fnh8fLykmzuxjRkzRt26dZOPj49OnDihzp07WxIQAAB8010LfMaMGVblAAAA9+CuBf7Tn/7UqhwAAOAesJ0aAAAGosABADCQLQW+a9cuJSYmavDgwZo9e7YdEQAAMJrlBV5UVKRZs2bpjTfe0KZNm3Ts2DHl5uZaHQMAAKM53G6328qBy5YtU3FxsaZOnSpJKi4uVrNmzdS6dWuPnl9aWiGXy9LI9y0/P09791r7j5NbG7mEh1u/uUl0dIyionpbPhcAGiIfH4eCg1ve8ecebeRSlwoLC+Xn56fnn39eFy9eVGxsrCZOnOjx8+92MPVNYKC//PyaWDqzbds2kmT5XOnm8YaGBlo+FwAaI8sLvKamRgcPHtTy5cvVvHlz/fKXv9SGDRuUmJjo0fNNWoFHRPRURERPu2NYqqTkit0RAKBB+LYVuOXvgYeEhCgyMlJt27aVv7+/+vXrp08++cTqGAAAGM3yAu/bt6/27t2ry5cvq6amRnl5efr+979vdQwAAIxm+Sn07t27KzU1VWPGjFFVVZV69eqlpKQkq2MAAGA0yz+F/qBMeg8cAID7Ve/eAwcAAA+OAgcAwEAUOAAABqLAAQAwEAUOAICBKHAAAAxEgQMAYCAKHAAAA1HgAAAYiAIHAMBAFDgAAAaiwAEAMBAFDgCAgShwAAAMRIEDAGAgChwAAANR4AAAGIgCBwDAQBQ4AAAGosABADAQBQ4AgIEocAAADESBAwBgIAocAAADUeAAABiIAgcAwEAUOAAABqLAAQAwEAUOAICBKHAAAAxka4HPmzdP6enpdkYAAMBIthX4/v37tWHDBrvGAwBgNFsKvKysTJmZmXr++eftGA8AgPF87Rg6c+ZMTZo0SRcvXrRjPGCk/Pw87d2ba/nc8vIySVJQUGvLZ0dHxygqqrflcwETWF7g77zzjjp06KDIyEjl5OTc8/ODg1t6IRVQ/wUG+svPr4nlcy9fLpckhYQEWz47MNBfoaGBls8FTOBwu91uKweOHz9eJSUlatKkicrLy1VZWamRI0dq2rRpHj2/tLRCLpelkYFGLSNjtiQpLW26zUmAxsXHx3HXRavlK/C333679r9zcnL0j3/8w+PyBgAAN3EdOAAABrLlQ2y3JCYmKjEx0c4IAAAYiRU4AAAGosABADAQBQ4AgIEocAAADGT5deAPiuvAUR+sWrVcRUWFdsewxNmzN48zPLyTzUms07FjJyUnp9gdA41cvbsOHGgIiooKdfLkvxUQEGB3FK9zuWokSefPF9mcxBpOp9PuCIBHKHDgPgUEBKhbt252x0AdKygosDsC4BHeAwcAwEAUOAAABqLAAQAwEAUOAICBKHAAAAxEgQMAYCAKHAAAA3EdOHAfysvLVFlZyTXDDVBlZaXKy8vsjgF8K1bgAAAYiBU4cB+CglqrouIKO7E1QAUFBQoKam13DOBbsQIHAMBAFDgAAAaiwAEAMBAFDgCAgShwAAAMRIEDAGAgChwAAANxHThwn5xOZ6PYia2qqkqS5OfnZ3MSazidTrsjAB6hwIH70LFjJ7sjWObs2UJJUlhYR5uTWKcx/fnCXA632+22O8S9KC2tkMtlVGTAaBkZsyVJaWnTbU4CNC4+Pg4FB7e8888tzAIAAOoIBQ4AgIEocAAADESBAwBgIFs+hb548WJt375dkhQTE6O0tDQ7YgAAYCzLV+D5+fnau3evNmzYoHfffVf/+te/9N5771kdAwAAo1m+Ag8NDVV6erqaNm0qSercubMuXLhgdQzAOPn5edq7N9fyubeuA791OZmVoqNjFBXV2/K5gAksL/BHH3209r/PnDmj7du3a9WqVR4//27XxAENWWCgv/z8mlg+t23bNpJky+zAQH+FhgZaPhcwgW0buXz22Wd67rnn9MILLyghIcHj57GRCwCgMaiXG7l89NFHGjdunCZPnnxP5Q0AAG6y/BT6xYsX9etf/1qZmZmKjIy0ejwAAA2C5QWelZWl69eva+7cubXfGz16tJKTk62OAgCAsbiZCQAA9VC9fA8cAAA8GAocAAADUeAAABjIlr3QH4SPj8PuCAAAeN239Z1xH2IDAACcQgcAwEgUOAAABqLAAQAwEAUOAICBKHAAAAxEgQMAYCAKHAAAA1HgAAAYiAIHAMBAFLhBUlJSdODAgQd+nZycHKWnp9dBIjR077//vhYuXGh3DAC3Ydxe6ACs8+STT+rJJ5+0OwaA22AFXk+53W69+uqrGjhwoIYMGaLs7Oyv/Xzp0qUaMmSI4uPjNXfuXNXU1OjcuXOKi4urfcyiRYu0aNEiSdK7776rgQMHKikpSXv27JEk7d+/X6NHj659fE5OjmbNmuX9g0O9cODAAY0aNUqJiYkaP368JkyYoKeeekqxsbG1q+6vnq2Ji4vT66+/rlGjRmno0KE6evSoCgsLFRsbK5fLVfuaqampth0TrPf5559r7NixSkxM1KhRo/Txxx8rLi5O586dk3TzdyIlJUXSzbOIGRkZ+vnPf67+/fsrNzdXkpSenq7Zs2crOTlZcXFxWr9+vVwul+Li4nT69GlJUmVlpWJiYnT9+nV7DrQeosDrqR07dujQoUPavHmz3nnnHeXk5KikpESSlJubq127dmn9+vXasGGDCgsLtXr16ju+VnFxsebPn68VK1ZozZo1unr1qiTpiSeeUElJic6ePSvpZsknJiZ6/+BQb5w5c0bZ2dmKjo7WsGHDtHbtWm3evFnZ2dm6dOnSNx7funVrrVu3TqNHj9af/vQnderUSQ8//HDtWzv8DjU+69atU2xsrHJycvSb3/xGH3300V0fX1VVpTVr1mjq1Klfe3vm888/18qVK7VkyRJlZGTIx8dHI0eO1KZNmyRJO3fuVGxsrJo1a+bV4zEJBV5P/fOf/9TgwYPVtGlTtWjRQhs3blRoaKgk6cMPP9TQoUMVEBAgX19fJSUlaf/+/Xd8rcOHD+uHP/yhQkJC5Ovrq/j4eEmSw+FQQkKCNm3apAsXLqi0tFTdu3e35PhQP3z3u99VYGCgJkyYoA4dOigrK0tz5sxRVVWVnE7nNx7fu3dvSdKjjz6qsrIySVJSUpI2bdokp9OpDz/8kFPujUxkZKSWLVumyZMnq6ysTGPHjr3r42/3OyRJvXr1ksPhUNeuXWu/n5iYqC1btkiSNmzYwD8O/wfvgddTvr6+cjj+/16w586dU2VlpSTVnq78qurqajkcDn317rDV1dW1r/PV7/v6/v8fe0JCglJTU9W0aVONGDHCG4eCeszf31+SNHfuXBUVFWnYsGHq16+f8vPzdbs7Dd9a/Xz1d3PQoEHKzMzU3/72N/Xp04cVUiPz4x//WFu3btWePXu0bds2bdiwQZJqf3+qq6u/9vjb/Q7d6fsPP/ywvvOd72jnzp0sMG6DFXg91bNnT+3cubN2JZSamqri4mJJN099b926VdeuXVN1dbXWr1+vJ554Qq1atVJZWZkuXbqkGzduKC8vT9LNv2Aff/yxiouL5XK5tG3btto5YWFhat++vVavXk2BN2L79u3ThAkTNHjwYJ0+fbr2d8UTAQEB6tOnjxYsWMAKqRHKyMjQpk2blJCQoJkzZ+rYsWNq06aNTp48KenmlQwPIikpSbNnz9bw4cPrIm6Dwgq8nurfv7+OHj2qxMREuVwuPf3009q+fbskqW/fvjp+/LiSkpJUXV2t6OhojR07Vr6+vkpNTdWoUaPUvn17RURESJJCQkI0ffp0jRs3TgEBAerSpcvXZg0ZMkQ7d+7UQw89ZPlxon547rnnlJaWJn9/f7Vv314/+MEPaj+E5ImhQ4fq0KFDrJAaoZSUFE2ePFk5OTlq0qSJ5s2bJ4fDoT/84Q9avHixoqOjH+j1BwwYoBkzZrDAuA2H+3bnydBoVFdXKy0tTYMGDdKAAQPsjgMD1dTUKDMzU8HBwRo/frzdcdCAuN1uffDBB1q1apWWLl1qd5x6hxV4I+Z2u9W7d29FRUWpX79+dseBoZKSktSmTRstWbLE7ihoYF5++WXt3r1bb731lt1R6iVW4AAAGIgPsQEAYCAKHAAAA1HgAAAYiAIH4JFnnnmmdnvVuLg4ffrppzYnAho3ChyAR/bt22d3BABfQYEDDcyIESNq98bfsmWLIiIidO3aNUnS7373O2VnZ+vll19WQkKChg8frvT0dFVUVEiSdu/erdGjRysxMVGxsbF6/fXXJUlTp06VJP3iF7/QxYsXJUlr1qypfVxmZmbt/F27dulnP/uZRo4cqdGjR+vw4cOSbt4db8KECYqPj9eUKVMs+X8BNGRcBw40MP3799cHH3ygyMhI5eXlKSgoSAcPHlSvXr2Um5urDh06qEmTJsrJyZHD4dCCBQs0f/58zZo1S8uWLdPcuXP1yCOPqLi4WH379tXTTz+tV155RTk5OcrOzlbbtm0l3dy7+tZd8uLi4jR69Ghdv35dmZmZ+stf/qI2bdros88+0/jx47Vz505J0vnz57Vly5av7ccP4P7wtwhoYPr3768XX3xRaWlpOnjwoMaNG6d9+/apRYsWCg8P1549e3TlyhXl5+dLunl7x+DgYDkcDi1dulR79uzRli1bdOrUKbnd7tvelUyShg0bJkkKDQ1VSEiISktLdeTIEX3xxRcaN25c7eMcDkftLWt79OhBeQN1hL9JQAPTrVs3VVVV6f3339cjjzyivn37atKkSfL19dXAgQO1ceNGTZs2TTExMZKkq1ev6vr166qsrFRCQoL69eunn/zkJ0pKStLf//73296VTPr6Xe1u3fHO5XIpMjKy9tS7JF28eFHt2rXTe++9p+bNm3v12IHGhPfAgQaoX79+eu2119SrVy917txZFRUV2rx5swYMGKDo6GitWLFCN27ckMvl0owZM7RgwQIVFhaqoqJCEydOVFxcnA4cOFD7GElq0qTJN24N+b8iIyO1b98+nTp1SpKUm5ur4cOH174HD6DusAIHGqD+/fsrKytLUVFRkqSoqCgVFBSoQ4cO+tWvfqV58+YpISFBNTU1+t73vqf09HQ1b95csbGxGjx4sJo2baquXbuqS5cuKiwsVHh4uAYNGqSUlBQtWrTojnO7dOmi3//+93rxxRfldrvl6+urJUuWqEWLFlYdOtBosBc6AAAG4hQ6AAAGosABADAQBQ4AgIEocAAADESBAwBgIAocAAADUeAAABiIAgcAwED/B2/gRl9IbuXvAAAAAElFTkSuQmCC\n",
118 | "text/plain": [
119 | ""
120 | ]
121 | },
122 | "metadata": {},
123 | "output_type": "display_data"
124 | }
125 | ],
126 | "source": [
127 | "# 箱髭図を描く\n",
128 | "sns.boxplot(x='weather',y='beer',\n",
129 | " data=weather_beer, color='gray')"
130 | ]
131 | },
132 | {
133 | "cell_type": "markdown",
134 | "metadata": {},
135 | "source": [
136 | "### 実装:総平均と水準別平均の計算"
137 | ]
138 | },
139 | {
140 | "cell_type": "code",
141 | "execution_count": 5,
142 | "metadata": {},
143 | "outputs": [
144 | {
145 | "data": {
146 | "text/plain": [
147 | "array([ 6, 8, 2, 4, 10, 12], dtype=int64)"
148 | ]
149 | },
150 | "execution_count": 5,
151 | "metadata": {},
152 | "output_type": "execute_result"
153 | }
154 | ],
155 | "source": [
156 | "# ビールの売り上げデータを扱いやすくするため切り出す\n",
157 | "y = weather_beer.beer.to_numpy()\n",
158 | "y"
159 | ]
160 | },
161 | {
162 | "cell_type": "code",
163 | "execution_count": 6,
164 | "metadata": {},
165 | "outputs": [
166 | {
167 | "data": {
168 | "text/plain": [
169 | "7.0"
170 | ]
171 | },
172 | "execution_count": 6,
173 | "metadata": {},
174 | "output_type": "execute_result"
175 | }
176 | ],
177 | "source": [
178 | "# データの総平均\n",
179 | "y_bar = np.mean(y)\n",
180 | "y_bar"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 7,
186 | "metadata": {},
187 | "outputs": [
188 | {
189 | "name": "stdout",
190 | "output_type": "stream",
191 | "text": [
192 | " beer\n",
193 | "weather \n",
194 | "cloudy 7.0\n",
195 | "rainy 3.0\n",
196 | "sunny 11.0\n"
197 | ]
198 | }
199 | ],
200 | "source": [
201 | "# 各データの平均値\n",
202 | "y_bar_j = weather_beer.groupby('weather').mean()\n",
203 | "print(y_bar_j)"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {},
209 | "source": [
210 | "### 実装:分散分析①群間・群内平方和の計算"
211 | ]
212 | },
213 | {
214 | "cell_type": "code",
215 | "execution_count": 8,
216 | "metadata": {},
217 | "outputs": [
218 | {
219 | "data": {
220 | "text/plain": [
221 | "weather\n",
222 | "cloudy 7.0\n",
223 | "cloudy 7.0\n",
224 | "rainy 3.0\n",
225 | "rainy 3.0\n",
226 | "sunny 11.0\n",
227 | "sunny 11.0\n",
228 | "Name: beer, dtype: float64"
229 | ]
230 | },
231 | "execution_count": 8,
232 | "metadata": {},
233 | "output_type": "execute_result"
234 | }
235 | ],
236 | "source": [
237 | "# 水準ごとのサンプルサイズ\n",
238 | "n_j = 2\n",
239 | "# 天気による影響だけを考えた場合の売り上げ\n",
240 | "effect = np.repeat(y_bar_j.beer, n_j)\n",
241 | "effect"
242 | ]
243 | },
244 | {
245 | "cell_type": "code",
246 | "execution_count": 9,
247 | "metadata": {},
248 | "outputs": [
249 | {
250 | "data": {
251 | "text/plain": [
252 | "64.0"
253 | ]
254 | },
255 | "execution_count": 9,
256 | "metadata": {},
257 | "output_type": "execute_result"
258 | }
259 | ],
260 | "source": [
261 | "# 群間の平方和\n",
262 | "ss_b = np.sum((effect - y_bar) ** 2 )\n",
263 | "ss_b"
264 | ]
265 | },
266 | {
267 | "cell_type": "code",
268 | "execution_count": 10,
269 | "metadata": {},
270 | "outputs": [
271 | {
272 | "data": {
273 | "text/plain": [
274 | "weather\n",
275 | "cloudy -1.0\n",
276 | "cloudy 1.0\n",
277 | "rainy -1.0\n",
278 | "rainy 1.0\n",
279 | "sunny -1.0\n",
280 | "sunny 1.0\n",
281 | "Name: beer, dtype: float64"
282 | ]
283 | },
284 | "execution_count": 10,
285 | "metadata": {},
286 | "output_type": "execute_result"
287 | }
288 | ],
289 | "source": [
290 | "# 天気では説明することができない誤差\n",
291 | "resid = y - effect\n",
292 | "resid"
293 | ]
294 | },
295 | {
296 | "cell_type": "code",
297 | "execution_count": 11,
298 | "metadata": {},
299 | "outputs": [
300 | {
301 | "data": {
302 | "text/plain": [
303 | "6.0"
304 | ]
305 | },
306 | "execution_count": 11,
307 | "metadata": {},
308 | "output_type": "execute_result"
309 | }
310 | ],
311 | "source": [
312 | "# 群内の平方和\n",
313 | "ss_w = np.sum(resid ** 2)\n",
314 | "ss_w"
315 | ]
316 | },
317 | {
318 | "cell_type": "markdown",
319 | "metadata": {},
320 | "source": [
321 | "### 実装:分散分析②群間・群内分散の計算"
322 | ]
323 | },
324 | {
325 | "cell_type": "code",
326 | "execution_count": 12,
327 | "metadata": {},
328 | "outputs": [],
329 | "source": [
330 | "df_b = 2 # 群間変動の自由度\n",
331 | "df_w = 3 # 群内変動の自由度"
332 | ]
333 | },
334 | {
335 | "cell_type": "code",
336 | "execution_count": 13,
337 | "metadata": {},
338 | "outputs": [
339 | {
340 | "data": {
341 | "text/plain": [
342 | "32.0"
343 | ]
344 | },
345 | "execution_count": 13,
346 | "metadata": {},
347 | "output_type": "execute_result"
348 | }
349 | ],
350 | "source": [
351 | "# 群間の平均平方(分散)\n",
352 | "sigma_b = ss_b / df_b\n",
353 | "sigma_b"
354 | ]
355 | },
356 | {
357 | "cell_type": "code",
358 | "execution_count": 14,
359 | "metadata": {},
360 | "outputs": [
361 | {
362 | "data": {
363 | "text/plain": [
364 | "2.0"
365 | ]
366 | },
367 | "execution_count": 14,
368 | "metadata": {},
369 | "output_type": "execute_result"
370 | }
371 | ],
372 | "source": [
373 | "# 群内の平均平方(分散)\n",
374 | "sigma_w = ss_w / df_w\n",
375 | "sigma_w"
376 | ]
377 | },
378 | {
379 | "cell_type": "markdown",
380 | "metadata": {},
381 | "source": [
382 | "### 実装:分散分析③p値の計算"
383 | ]
384 | },
385 | {
386 | "cell_type": "code",
387 | "execution_count": 15,
388 | "metadata": {},
389 | "outputs": [
390 | {
391 | "data": {
392 | "text/plain": [
393 | "16.0"
394 | ]
395 | },
396 | "execution_count": 15,
397 | "metadata": {},
398 | "output_type": "execute_result"
399 | }
400 | ],
401 | "source": [
402 | "# F比\n",
403 | "f_ratio = sigma_b / sigma_w\n",
404 | "f_ratio"
405 | ]
406 | },
407 | {
408 | "cell_type": "code",
409 | "execution_count": 16,
410 | "metadata": {},
411 | "outputs": [
412 | {
413 | "data": {
414 | "text/plain": [
415 | "0.025"
416 | ]
417 | },
418 | "execution_count": 16,
419 | "metadata": {},
420 | "output_type": "execute_result"
421 | }
422 | ],
423 | "source": [
424 | "# p値\n",
425 | "p_value = 1 - stats.f.cdf(x=f_ratio, dfn=df_b, dfd=df_w)\n",
426 | "round(p_value, 3)"
427 | ]
428 | },
429 | {
430 | "cell_type": "markdown",
431 | "metadata": {},
432 | "source": [
433 | "### 実装:statsmodelsによる分散分析"
434 | ]
435 | },
436 | {
437 | "cell_type": "code",
438 | "execution_count": 17,
439 | "metadata": {},
440 | "outputs": [],
441 | "source": [
442 | "# 正規線形モデルの構築\n",
443 | "anova_model = smf.ols(formula='beer ~ weather',\n",
444 | " data = weather_beer).fit()"
445 | ]
446 | },
447 | {
448 | "cell_type": "code",
449 | "execution_count": 18,
450 | "metadata": {},
451 | "outputs": [
452 | {
453 | "name": "stdout",
454 | "output_type": "stream",
455 | "text": [
456 | " sum_sq df F PR(>F)\n",
457 | "weather 64.0 2.0 16.0 0.025\n",
458 | "Residual 6.0 3.0 NaN NaN\n"
459 | ]
460 | }
461 | ],
462 | "source": [
463 | "# 分散分析の結果\n",
464 | "print(sm.stats.anova_lm(anova_model, typ=2))"
465 | ]
466 | },
467 | {
468 | "cell_type": "code",
469 | "execution_count": 19,
470 | "metadata": {},
471 | "outputs": [
472 | {
473 | "data": {
474 | "text/plain": [
475 | "70.0"
476 | ]
477 | },
478 | "execution_count": 19,
479 | "metadata": {},
480 | "output_type": "execute_result"
481 | }
482 | ],
483 | "source": [
484 | "# 総平方和\n",
485 | "np.sum((y - y_bar)**2)"
486 | ]
487 | },
488 | {
489 | "cell_type": "markdown",
490 | "metadata": {},
491 | "source": [
492 | "### モデルの係数の解釈"
493 | ]
494 | },
495 | {
496 | "cell_type": "code",
497 | "execution_count": 20,
498 | "metadata": {},
499 | "outputs": [
500 | {
501 | "data": {
502 | "text/plain": [
503 | "Intercept 7.0\n",
504 | "weather[T.rainy] -4.0\n",
505 | "weather[T.sunny] 4.0\n",
506 | "dtype: float64"
507 | ]
508 | },
509 | "execution_count": 20,
510 | "metadata": {},
511 | "output_type": "execute_result"
512 | }
513 | ],
514 | "source": [
515 | "anova_model.params"
516 | ]
517 | },
518 | {
519 | "cell_type": "markdown",
520 | "metadata": {},
521 | "source": [
522 | "### 実装:モデルを用いて誤差と効果を分離する"
523 | ]
524 | },
525 | {
526 | "cell_type": "code",
527 | "execution_count": 21,
528 | "metadata": {},
529 | "outputs": [
530 | {
531 | "data": {
532 | "text/plain": [
533 | "0 7.0\n",
534 | "1 7.0\n",
535 | "2 3.0\n",
536 | "3 3.0\n",
537 | "4 11.0\n",
538 | "5 11.0\n",
539 | "dtype: float64"
540 | ]
541 | },
542 | "execution_count": 21,
543 | "metadata": {},
544 | "output_type": "execute_result"
545 | }
546 | ],
547 | "source": [
548 | "#当てはめ値\n",
549 | "fitted = anova_model.fittedvalues\n",
550 | "fitted"
551 | ]
552 | },
553 | {
554 | "cell_type": "code",
555 | "execution_count": 22,
556 | "metadata": {},
557 | "outputs": [
558 | {
559 | "data": {
560 | "text/plain": [
561 | "0 -1.0\n",
562 | "1 1.0\n",
563 | "2 -1.0\n",
564 | "3 1.0\n",
565 | "4 -1.0\n",
566 | "5 1.0\n",
567 | "dtype: float64"
568 | ]
569 | },
570 | "execution_count": 22,
571 | "metadata": {},
572 | "output_type": "execute_result"
573 | }
574 | ],
575 | "source": [
576 | "# 残差\n",
577 | "anova_model.resid"
578 | ]
579 | },
580 | {
581 | "cell_type": "markdown",
582 | "metadata": {
583 | "collapsed": true
584 | },
585 | "source": [
586 | "### 実装:回帰モデルにおける分散分析"
587 | ]
588 | },
589 | {
590 | "cell_type": "markdown",
591 | "metadata": {},
592 | "source": [
593 | "#### モデルの推定"
594 | ]
595 | },
596 | {
597 | "cell_type": "code",
598 | "execution_count": 23,
599 | "metadata": {},
600 | "outputs": [],
601 | "source": [
602 | "# データの読み込み\n",
603 | "beer = pd.read_csv('8-1-1-beer.csv')\n",
604 | "\n",
605 | "# モデルの推定\n",
606 | "lm_model = smf.ols(formula='beer ~ temperature', \n",
607 | " data = beer).fit()"
608 | ]
609 | },
610 | {
611 | "cell_type": "markdown",
612 | "metadata": {},
613 | "source": [
614 | "#### F比の計算"
615 | ]
616 | },
617 | {
618 | "cell_type": "code",
619 | "execution_count": 24,
620 | "metadata": {},
621 | "outputs": [
622 | {
623 | "name": "stdout",
624 | "output_type": "stream",
625 | "text": [
626 | "モデルの自由度: 1.0\n",
627 | "残差の自由度 : 28.0\n"
628 | ]
629 | }
630 | ],
631 | "source": [
632 | "print('モデルの自由度:', lm_model.df_model)\n",
633 | "print('残差の自由度 :', lm_model.df_resid)"
634 | ]
635 | },
636 | {
637 | "cell_type": "code",
638 | "execution_count": 25,
639 | "metadata": {},
640 | "outputs": [
641 | {
642 | "data": {
643 | "text/plain": [
644 | "28.447"
645 | ]
646 | },
647 | "execution_count": 25,
648 | "metadata": {},
649 | "output_type": "execute_result"
650 | }
651 | ],
652 | "source": [
653 | "# 応答変数\n",
654 | "y = beer.beer\n",
655 | "# 当てはめ値\n",
656 | "effect = lm_model.fittedvalues\n",
657 | "# 残差\n",
658 | "resid = lm_model.resid\n",
659 | "# 気温の持つ効果の大きさ\n",
660 | "y_bar = np.mean(y)\n",
661 | "ss_model = np.sum((effect - y_bar) ** 2)\n",
662 | "sigma_model = ss_model / lm_model.df_model\n",
663 | "# 残差の大きさ\n",
664 | "ss_resid = np.sum((resid) ** 2)\n",
665 | "sigma_resid = ss_resid / lm_model.df_resid\n",
666 | "# F比\n",
667 | "f_value_lm = sigma_model / sigma_resid\n",
668 | "round(f_value_lm, 3)"
669 | ]
670 | },
671 | {
672 | "cell_type": "code",
673 | "execution_count": 26,
674 | "metadata": {},
675 | "outputs": [
676 | {
677 | "data": {
678 | "text/plain": [
679 | "1.1148907825053733e-05"
680 | ]
681 | },
682 | "execution_count": 26,
683 | "metadata": {},
684 | "output_type": "execute_result"
685 | }
686 | ],
687 | "source": [
688 | "# 参考:p値は桁落ちでほぼ0になる(書籍には載っていないコードです)\n",
689 | "1 - stats.f.cdf(x=f_value_lm, dfn=lm_model.df_model, dfd=lm_model.df_resid)"
690 | ]
691 | },
692 | {
693 | "cell_type": "markdown",
694 | "metadata": {},
695 | "source": [
696 | "#### 分散分析の実行"
697 | ]
698 | },
699 | {
700 | "cell_type": "code",
701 | "execution_count": 27,
702 | "metadata": {},
703 | "outputs": [
704 | {
705 | "name": "stdout",
706 | "output_type": "stream",
707 | "text": [
708 | " sum_sq df F PR(>F)\n",
709 | "temperature 1651.532 1.0 28.447 1.115e-05\n",
710 | "Residual 1625.582 28.0 NaN NaN\n"
711 | ]
712 | }
713 | ],
714 | "source": [
715 | "# 分散分析表\n",
716 | "print(sm.stats.anova_lm(lm_model, typ=2))"
717 | ]
718 | },
719 | {
720 | "cell_type": "code",
721 | "execution_count": 28,
722 | "metadata": {},
723 | "outputs": [
724 | {
725 | "data": {
726 | "text/html": [
727 | "\n",
728 | "OLS Regression Results\n",
729 | "\n",
730 | " | Dep. Variable: | beer | R-squared: | 0.504 | \n",
731 | "
\n",
732 | "\n",
733 | " | Model: | OLS | Adj. R-squared: | 0.486 | \n",
734 | "
\n",
735 | "\n",
736 | " | Method: | Least Squares | F-statistic: | 28.45 | \n",
737 | "
\n",
738 | "\n",
739 | " | Date: | Sun, 22 May 2022 | Prob (F-statistic): | 1.11e-05 | \n",
740 | "
\n",
741 | "\n",
742 | " | Time: | 15:43:38 | Log-Likelihood: | -102.45 | \n",
743 | "
\n",
744 | "\n",
745 | " | No. Observations: | 30 | AIC: | 208.9 | \n",
746 | "
\n",
747 | "\n",
748 | " | Df Residuals: | 28 | BIC: | 211.7 | \n",
749 | "
\n",
750 | "\n",
751 | " | Df Model: | 1 | | | \n",
752 | "
\n",
753 | "\n",
754 | " | Covariance Type: | nonrobust | | | \n",
755 | "
\n",
756 | "
\n",
757 | "\n",
758 | "\n",
759 | " | coef | std err | t | P>|t| | [0.025 | 0.975] | \n",
760 | "
\n",
761 | "\n",
762 | " | Intercept | 34.6102 | 3.235 | 10.699 | 0.000 | 27.984 | 41.237 | \n",
763 | "
\n",
764 | "\n",
765 | " | temperature | 0.7654 | 0.144 | 5.334 | 0.000 | 0.471 | 1.059 | \n",
766 | "
\n",
767 | "
\n",
768 | "\n",
769 | "\n",
770 | " | Omnibus: | 0.587 | Durbin-Watson: | 1.960 | \n",
771 | "
\n",
772 | "\n",
773 | " | Prob(Omnibus): | 0.746 | Jarque-Bera (JB): | 0.290 | \n",
774 | "
\n",
775 | "\n",
776 | " | Skew: | -0.240 | Prob(JB): | 0.865 | \n",
777 | "
\n",
778 | "\n",
779 | " | Kurtosis: | 2.951 | Cond. No. | 52.5 | \n",
780 | "
\n",
781 | "
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified."
782 | ],
783 | "text/plain": [
784 | "\n",
785 | "\"\"\"\n",
786 | " OLS Regression Results \n",
787 | "==============================================================================\n",
788 | "Dep. Variable: beer R-squared: 0.504\n",
789 | "Model: OLS Adj. R-squared: 0.486\n",
790 | "Method: Least Squares F-statistic: 28.45\n",
791 | "Date: Sun, 22 May 2022 Prob (F-statistic): 1.11e-05\n",
792 | "Time: 15:43:38 Log-Likelihood: -102.45\n",
793 | "No. Observations: 30 AIC: 208.9\n",
794 | "Df Residuals: 28 BIC: 211.7\n",
795 | "Df Model: 1 \n",
796 | "Covariance Type: nonrobust \n",
797 | "===============================================================================\n",
798 | " coef std err t P>|t| [0.025 0.975]\n",
799 | "-------------------------------------------------------------------------------\n",
800 | "Intercept 34.6102 3.235 10.699 0.000 27.984 41.237\n",
801 | "temperature 0.7654 0.144 5.334 0.000 0.471 1.059\n",
802 | "==============================================================================\n",
803 | "Omnibus: 0.587 Durbin-Watson: 1.960\n",
804 | "Prob(Omnibus): 0.746 Jarque-Bera (JB): 0.290\n",
805 | "Skew: -0.240 Prob(JB): 0.865\n",
806 | "Kurtosis: 2.951 Cond. No. 52.5\n",
807 | "==============================================================================\n",
808 | "\n",
809 | "Notes:\n",
810 | "[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n",
811 | "\"\"\""
812 | ]
813 | },
814 | "execution_count": 28,
815 | "metadata": {},
816 | "output_type": "execute_result"
817 | }
818 | ],
819 | "source": [
820 | "# モデルのsumamry\n",
821 | "lm_model.summary()"
822 | ]
823 | },
824 | {
825 | "cell_type": "markdown",
826 | "metadata": {},
827 | "source": [
828 | "#### 平方和の分解"
829 | ]
830 | },
831 | {
832 | "cell_type": "code",
833 | "execution_count": 29,
834 | "metadata": {},
835 | "outputs": [
836 | {
837 | "name": "stdout",
838 | "output_type": "stream",
839 | "text": [
840 | "総平方和 : 3277.115\n",
841 | "SS_B + SS_W: 3277.115\n"
842 | ]
843 | }
844 | ],
845 | "source": [
846 | "print('総平方和 :', round(np.sum((y - y_bar)**2), 3))\n",
847 | "print('SS_B + SS_W:', round(ss_model + ss_resid, 3))"
848 | ]
849 | },
850 | {
851 | "cell_type": "code",
852 | "execution_count": 30,
853 | "metadata": {},
854 | "outputs": [
855 | {
856 | "data": {
857 | "text/plain": [
858 | "1651.532"
859 | ]
860 | },
861 | "execution_count": 30,
862 | "metadata": {},
863 | "output_type": "execute_result"
864 | }
865 | ],
866 | "source": [
867 | "# ss_modelの異なる求め方\n",
868 | "round(np.sum((y - y_bar)**2) - np.sum((resid) ** 2), 3)"
869 | ]
870 | }
871 | ],
872 | "metadata": {
873 | "kernelspec": {
874 | "display_name": "Python 3 (ipykernel)",
875 | "language": "python",
876 | "name": "python3"
877 | },
878 | "language_info": {
879 | "codemirror_mode": {
880 | "name": "ipython",
881 | "version": 3
882 | },
883 | "file_extension": ".py",
884 | "mimetype": "text/x-python",
885 | "name": "python",
886 | "nbconvert_exporter": "python",
887 | "pygments_lexer": "ipython3",
888 | "version": "3.9.7"
889 | }
890 | },
891 | "nbformat": 4,
892 | "nbformat_minor": 2
893 | }
894 |
--------------------------------------------------------------------------------
/book-data/3-4-1変量データの統計量.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第3部 記述統計\n",
8 | "\n",
9 | "## 4章 1変量データの統計量"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 実装:分析の準備"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "# 数値計算に使うライブラリ\n",
26 | "import numpy as np\n",
27 | "import pandas as pd\n",
28 | "\n",
29 | "# 複雑な統計処理を行うライブラリ\n",
30 | "from scipy import stats"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": 2,
36 | "metadata": {},
37 | "outputs": [],
38 | "source": [
39 | "# 表示設定(書籍本文のレイアウトと合わせるためであり、必須ではありません)\n",
40 | "np.set_printoptions(linewidth=60)"
41 | ]
42 | },
43 | {
44 | "cell_type": "markdown",
45 | "metadata": {},
46 | "source": [
47 | "### 分析対象となるデータの用意"
48 | ]
49 | },
50 | {
51 | "cell_type": "markdown",
52 | "metadata": {},
53 | "source": [
54 | "#### numpyアレイで用意"
55 | ]
56 | },
57 | {
58 | "cell_type": "code",
59 | "execution_count": 3,
60 | "metadata": {},
61 | "outputs": [
62 | {
63 | "data": {
64 | "text/plain": [
65 | "array([2, 3, 3, 4, 4, 4, 4, 5, 5, 6])"
66 | ]
67 | },
68 | "execution_count": 3,
69 | "metadata": {},
70 | "output_type": "execute_result"
71 | }
72 | ],
73 | "source": [
74 | "fish_length = np.array([2,3,3,4,4,4,4,5,5,6])\n",
75 | "fish_length"
76 | ]
77 | },
78 | {
79 | "cell_type": "markdown",
80 | "metadata": {},
81 | "source": [
82 | "#### CSVファイルから読み込み"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 4,
88 | "metadata": {},
89 | "outputs": [
90 | {
91 | "name": "stdout",
92 | "output_type": "stream",
93 | "text": [
94 | " length\n",
95 | "0 2\n",
96 | "1 3\n",
97 | "2 3\n",
98 | "3 4\n",
99 | "4 4\n",
100 | "5 4\n",
101 | "6 4\n",
102 | "7 5\n",
103 | "8 5\n",
104 | "9 6\n"
105 | ]
106 | }
107 | ],
108 | "source": [
109 | "# データの読み込み\n",
110 | "fish_length_df = pd.read_csv('3-4-1-fish-length.csv')\n",
111 | "print(fish_length_df)"
112 | ]
113 | },
114 | {
115 | "cell_type": "markdown",
116 | "metadata": {},
117 | "source": [
118 | "#### データフレームとアレイの変換"
119 | ]
120 | },
121 | {
122 | "cell_type": "code",
123 | "execution_count": 5,
124 | "metadata": {},
125 | "outputs": [
126 | {
127 | "data": {
128 | "text/plain": [
129 | "array([ True, True, True, True, True, True, True,\n",
130 | " True, True, True])"
131 | ]
132 | },
133 | "execution_count": 5,
134 | "metadata": {},
135 | "output_type": "execute_result"
136 | }
137 | ],
138 | "source": [
139 | "# データフレームもアレイに変換できる\n",
140 | "fish_length_df.length.to_numpy() == fish_length"
141 | ]
142 | },
143 | {
144 | "cell_type": "markdown",
145 | "metadata": {},
146 | "source": [
147 | "### 実装:サンプルサイズ"
148 | ]
149 | },
150 | {
151 | "cell_type": "code",
152 | "execution_count": 6,
153 | "metadata": {},
154 | "outputs": [
155 | {
156 | "data": {
157 | "text/plain": [
158 | "10"
159 | ]
160 | },
161 | "execution_count": 6,
162 | "metadata": {},
163 | "output_type": "execute_result"
164 | }
165 | ],
166 | "source": [
167 | "# サンプルサイズ\n",
168 | "len(fish_length)"
169 | ]
170 | },
171 | {
172 | "cell_type": "code",
173 | "execution_count": 7,
174 | "metadata": {},
175 | "outputs": [
176 | {
177 | "data": {
178 | "text/plain": [
179 | "10"
180 | ]
181 | },
182 | "execution_count": 7,
183 | "metadata": {},
184 | "output_type": "execute_result"
185 | }
186 | ],
187 | "source": [
188 | "# サンプルサイズ(データフレームの行数)\n",
189 | "len(fish_length_df)"
190 | ]
191 | },
192 | {
193 | "cell_type": "markdown",
194 | "metadata": {},
195 | "source": [
196 | "### 実装:合計値"
197 | ]
198 | },
199 | {
200 | "cell_type": "markdown",
201 | "metadata": {},
202 | "source": [
203 | "#### 基本的な計算方法"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": 8,
209 | "metadata": {},
210 | "outputs": [
211 | {
212 | "data": {
213 | "text/plain": [
214 | "40"
215 | ]
216 | },
217 | "execution_count": 8,
218 | "metadata": {},
219 | "output_type": "execute_result"
220 | }
221 | ],
222 | "source": [
223 | "# 合計\n",
224 | "np.sum(fish_length)"
225 | ]
226 | },
227 | {
228 | "cell_type": "code",
229 | "execution_count": 9,
230 | "metadata": {},
231 | "outputs": [
232 | {
233 | "data": {
234 | "text/plain": [
235 | "length 40\n",
236 | "dtype: int64"
237 | ]
238 | },
239 | "execution_count": 9,
240 | "metadata": {},
241 | "output_type": "execute_result"
242 | }
243 | ],
244 | "source": [
245 | "# 合計\n",
246 | "np.sum(fish_length_df)"
247 | ]
248 | },
249 | {
250 | "cell_type": "markdown",
251 | "metadata": {},
252 | "source": [
253 | "#### その他の計算方法"
254 | ]
255 | },
256 | {
257 | "cell_type": "code",
258 | "execution_count": 10,
259 | "metadata": {},
260 | "outputs": [
261 | {
262 | "data": {
263 | "text/plain": [
264 | "40"
265 | ]
266 | },
267 | "execution_count": 10,
268 | "metadata": {},
269 | "output_type": "execute_result"
270 | }
271 | ],
272 | "source": [
273 | "# アレイが持つsum関数を実行\n",
274 | "fish_length.sum()"
275 | ]
276 | },
277 | {
278 | "cell_type": "code",
279 | "execution_count": 11,
280 | "metadata": {},
281 | "outputs": [
282 | {
283 | "data": {
284 | "text/plain": [
285 | "length 40\n",
286 | "dtype: int64"
287 | ]
288 | },
289 | "execution_count": 11,
290 | "metadata": {},
291 | "output_type": "execute_result"
292 | }
293 | ],
294 | "source": [
295 | "# データフレームが持つ関数を実行\n",
296 | "fish_length_df.sum()"
297 | ]
298 | },
299 | {
300 | "cell_type": "markdown",
301 | "metadata": {},
302 | "source": [
303 | "### 実装:標本平均"
304 | ]
305 | },
306 | {
307 | "cell_type": "markdown",
308 | "metadata": {},
309 | "source": [
310 | "#### 計算方法の確認"
311 | ]
312 | },
313 | {
314 | "cell_type": "code",
315 | "execution_count": 12,
316 | "metadata": {},
317 | "outputs": [
318 | {
319 | "data": {
320 | "text/plain": [
321 | "10"
322 | ]
323 | },
324 | "execution_count": 12,
325 | "metadata": {},
326 | "output_type": "execute_result"
327 | }
328 | ],
329 | "source": [
330 | "# サンプルサイズ\n",
331 | "n = len(fish_length)\n",
332 | "n"
333 | ]
334 | },
335 | {
336 | "cell_type": "code",
337 | "execution_count": 13,
338 | "metadata": {},
339 | "outputs": [
340 | {
341 | "data": {
342 | "text/plain": [
343 | "40"
344 | ]
345 | },
346 | "execution_count": 13,
347 | "metadata": {},
348 | "output_type": "execute_result"
349 | }
350 | ],
351 | "source": [
352 | "# 合計値\n",
353 | "sum_value = np.sum(fish_length)\n",
354 | "sum_value"
355 | ]
356 | },
357 | {
358 | "cell_type": "code",
359 | "execution_count": 14,
360 | "metadata": {},
361 | "outputs": [
362 | {
363 | "data": {
364 | "text/plain": [
365 | "4.0"
366 | ]
367 | },
368 | "execution_count": 14,
369 | "metadata": {},
370 | "output_type": "execute_result"
371 | }
372 | ],
373 | "source": [
374 | "# 平均値の計算\n",
375 | "x_bar = sum_value / n\n",
376 | "x_bar"
377 | ]
378 | },
379 | {
380 | "cell_type": "markdown",
381 | "metadata": {},
382 | "source": [
383 | "#### 関数を使った効率的な実装"
384 | ]
385 | },
386 | {
387 | "cell_type": "code",
388 | "execution_count": 15,
389 | "metadata": {},
390 | "outputs": [
391 | {
392 | "data": {
393 | "text/plain": [
394 | "4.0"
395 | ]
396 | },
397 | "execution_count": 15,
398 | "metadata": {},
399 | "output_type": "execute_result"
400 | }
401 | ],
402 | "source": [
403 | "# 関数を使った平均値の計算\n",
404 | "np.mean(fish_length)"
405 | ]
406 | },
407 | {
408 | "cell_type": "markdown",
409 | "metadata": {},
410 | "source": [
411 | "### 実装:標本分散"
412 | ]
413 | },
414 | {
415 | "cell_type": "markdown",
416 | "metadata": {},
417 | "source": [
418 | "#### 計算方法の確認"
419 | ]
420 | },
421 | {
422 | "cell_type": "code",
423 | "execution_count": 16,
424 | "metadata": {},
425 | "outputs": [
426 | {
427 | "data": {
428 | "text/plain": [
429 | "1.2"
430 | ]
431 | },
432 | "execution_count": 16,
433 | "metadata": {},
434 | "output_type": "execute_result"
435 | }
436 | ],
437 | "source": [
438 | "# 標本分散\n",
439 | "s2 = np.sum((fish_length - x_bar) ** 2) / n\n",
440 | "s2"
441 | ]
442 | },
443 | {
444 | "cell_type": "markdown",
445 | "metadata": {},
446 | "source": [
447 | "#### 実装コードの解読"
448 | ]
449 | },
450 | {
451 | "cell_type": "code",
452 | "execution_count": 17,
453 | "metadata": {},
454 | "outputs": [
455 | {
456 | "data": {
457 | "text/plain": [
458 | "array([2, 3, 3, 4, 4, 4, 4, 5, 5, 6])"
459 | ]
460 | },
461 | "execution_count": 17,
462 | "metadata": {},
463 | "output_type": "execute_result"
464 | }
465 | ],
466 | "source": [
467 | "fish_length"
468 | ]
469 | },
470 | {
471 | "cell_type": "code",
472 | "execution_count": 18,
473 | "metadata": {},
474 | "outputs": [
475 | {
476 | "data": {
477 | "text/plain": [
478 | "array([-2., -1., -1., 0., 0., 0., 0., 1., 1., 2.])"
479 | ]
480 | },
481 | "execution_count": 18,
482 | "metadata": {},
483 | "output_type": "execute_result"
484 | }
485 | ],
486 | "source": [
487 | "fish_length - x_bar"
488 | ]
489 | },
490 | {
491 | "cell_type": "code",
492 | "execution_count": 19,
493 | "metadata": {},
494 | "outputs": [
495 | {
496 | "data": {
497 | "text/plain": [
498 | "array([4., 1., 1., 0., 0., 0., 0., 1., 1., 4.])"
499 | ]
500 | },
501 | "execution_count": 19,
502 | "metadata": {},
503 | "output_type": "execute_result"
504 | }
505 | ],
506 | "source": [
507 | "(fish_length - x_bar) ** 2"
508 | ]
509 | },
510 | {
511 | "cell_type": "code",
512 | "execution_count": 20,
513 | "metadata": {},
514 | "outputs": [
515 | {
516 | "data": {
517 | "text/plain": [
518 | "12.0"
519 | ]
520 | },
521 | "execution_count": 20,
522 | "metadata": {},
523 | "output_type": "execute_result"
524 | }
525 | ],
526 | "source": [
527 | "np.sum((fish_length - x_bar) ** 2)"
528 | ]
529 | },
530 | {
531 | "cell_type": "markdown",
532 | "metadata": {},
533 | "source": [
534 | "#### 関数を使った効率的な実装"
535 | ]
536 | },
537 | {
538 | "cell_type": "code",
539 | "execution_count": 21,
540 | "metadata": {},
541 | "outputs": [
542 | {
543 | "data": {
544 | "text/plain": [
545 | "1.2"
546 | ]
547 | },
548 | "execution_count": 21,
549 | "metadata": {},
550 | "output_type": "execute_result"
551 | }
552 | ],
553 | "source": [
554 | "# 関数を使った標本分散\n",
555 | "np.var(fish_length, ddof=0)"
556 | ]
557 | },
558 | {
559 | "cell_type": "markdown",
560 | "metadata": {},
561 | "source": [
562 | "### 実装:不偏分散"
563 | ]
564 | },
565 | {
566 | "cell_type": "markdown",
567 | "metadata": {},
568 | "source": [
569 | "#### 計算方法の確認"
570 | ]
571 | },
572 | {
573 | "cell_type": "code",
574 | "execution_count": 22,
575 | "metadata": {},
576 | "outputs": [
577 | {
578 | "data": {
579 | "text/plain": [
580 | "1.3333333333333333"
581 | ]
582 | },
583 | "execution_count": 22,
584 | "metadata": {},
585 | "output_type": "execute_result"
586 | }
587 | ],
588 | "source": [
589 | "# 不偏分散\n",
590 | "u2 = np.sum((fish_length - x_bar) ** 2) / (n - 1)\n",
591 | "u2"
592 | ]
593 | },
594 | {
595 | "cell_type": "code",
596 | "execution_count": 23,
597 | "metadata": {},
598 | "outputs": [
599 | {
600 | "data": {
601 | "text/plain": [
602 | "1.333"
603 | ]
604 | },
605 | "execution_count": 23,
606 | "metadata": {},
607 | "output_type": "execute_result"
608 | }
609 | ],
610 | "source": [
611 | "# 小数点以下第3位で丸める\n",
612 | "round(u2, 3)"
613 | ]
614 | },
615 | {
616 | "cell_type": "markdown",
617 | "metadata": {},
618 | "source": [
619 | "#### 関数を使った効率的な実装"
620 | ]
621 | },
622 | {
623 | "cell_type": "code",
624 | "execution_count": 24,
625 | "metadata": {},
626 | "outputs": [
627 | {
628 | "data": {
629 | "text/plain": [
630 | "1.333"
631 | ]
632 | },
633 | "execution_count": 24,
634 | "metadata": {},
635 | "output_type": "execute_result"
636 | }
637 | ],
638 | "source": [
639 | "# 不偏分散\n",
640 | "round(np.var(fish_length, ddof=1), 3)"
641 | ]
642 | },
643 | {
644 | "cell_type": "markdown",
645 | "metadata": {},
646 | "source": [
647 | "#### ライブラリの違いに注意"
648 | ]
649 | },
650 | {
651 | "cell_type": "code",
652 | "execution_count": 25,
653 | "metadata": {},
654 | "outputs": [
655 | {
656 | "data": {
657 | "text/plain": [
658 | "length 1.2\n",
659 | "dtype: float64"
660 | ]
661 | },
662 | "execution_count": 25,
663 | "metadata": {},
664 | "output_type": "execute_result"
665 | }
666 | ],
667 | "source": [
668 | "# numpy(標準は標本分散)\n",
669 | "np.var(fish_length_df)"
670 | ]
671 | },
672 | {
673 | "cell_type": "code",
674 | "execution_count": 26,
675 | "metadata": {},
676 | "outputs": [
677 | {
678 | "data": {
679 | "text/plain": [
680 | "length 1.333333\n",
681 | "dtype: float64"
682 | ]
683 | },
684 | "execution_count": 26,
685 | "metadata": {},
686 | "output_type": "execute_result"
687 | }
688 | ],
689 | "source": [
690 | "# pandas(標準は不偏分散)\n",
691 | "fish_length_df.var()"
692 | ]
693 | },
694 | {
695 | "cell_type": "code",
696 | "execution_count": 27,
697 | "metadata": {},
698 | "outputs": [
699 | {
700 | "data": {
701 | "text/plain": [
702 | "length 1.2\n",
703 | "dtype: float64"
704 | ]
705 | },
706 | "execution_count": 27,
707 | "metadata": {},
708 | "output_type": "execute_result"
709 | }
710 | ],
711 | "source": [
712 | "# ddofを指定\n",
713 | "fish_length_df.var(ddof=0)"
714 | ]
715 | },
716 | {
717 | "cell_type": "code",
718 | "execution_count": 28,
719 | "metadata": {},
720 | "outputs": [
721 | {
722 | "name": "stdout",
723 | "output_type": "stream",
724 | "text": [
725 | "numpyのバージョン 1.20.3\n",
726 | "pandasのバージョン 1.3.4\n"
727 | ]
728 | }
729 | ],
730 | "source": [
731 | "# 参考:ライブラリのバージョン(書籍には載っていないコードです)\n",
732 | "print('numpyのバージョン', np.__version__)\n",
733 | "print('pandasのバージョン', pd.__version__)"
734 | ]
735 | },
736 | {
737 | "cell_type": "markdown",
738 | "metadata": {},
739 | "source": [
740 | "### 実装:標準偏差"
741 | ]
742 | },
743 | {
744 | "cell_type": "markdown",
745 | "metadata": {},
746 | "source": [
747 | "#### 計算方法の確認"
748 | ]
749 | },
750 | {
751 | "cell_type": "code",
752 | "execution_count": 29,
753 | "metadata": {},
754 | "outputs": [
755 | {
756 | "data": {
757 | "text/plain": [
758 | "1.095"
759 | ]
760 | },
761 | "execution_count": 29,
762 | "metadata": {},
763 | "output_type": "execute_result"
764 | }
765 | ],
766 | "source": [
767 | "# 標準偏差\n",
768 | "s = np.sqrt(s2)\n",
769 | "round(s, 3)"
770 | ]
771 | },
772 | {
773 | "cell_type": "markdown",
774 | "metadata": {},
775 | "source": [
776 | "#### 関数を使った効率的な実装"
777 | ]
778 | },
779 | {
780 | "cell_type": "code",
781 | "execution_count": 30,
782 | "metadata": {},
783 | "outputs": [
784 | {
785 | "data": {
786 | "text/plain": [
787 | "1.095"
788 | ]
789 | },
790 | "execution_count": 30,
791 | "metadata": {},
792 | "output_type": "execute_result"
793 | }
794 | ],
795 | "source": [
796 | "# 関数を使った標準偏差\n",
797 | "round(np.std(fish_length, ddof=0), 3)"
798 | ]
799 | },
800 | {
801 | "cell_type": "markdown",
802 | "metadata": {},
803 | "source": [
804 | "### 実装:変動係数"
805 | ]
806 | },
807 | {
808 | "cell_type": "markdown",
809 | "metadata": {},
810 | "source": [
811 | "#### 計算方法の確認"
812 | ]
813 | },
814 | {
815 | "cell_type": "code",
816 | "execution_count": 31,
817 | "metadata": {},
818 | "outputs": [
819 | {
820 | "data": {
821 | "text/plain": [
822 | "0.274"
823 | ]
824 | },
825 | "execution_count": 31,
826 | "metadata": {},
827 | "output_type": "execute_result"
828 | }
829 | ],
830 | "source": [
831 | "cv = s / x_bar\n",
832 | "round(cv, 3)"
833 | ]
834 | },
835 | {
836 | "cell_type": "markdown",
837 | "metadata": {},
838 | "source": [
839 | "#### 関数を使った効率的な実装"
840 | ]
841 | },
842 | {
843 | "cell_type": "code",
844 | "execution_count": 32,
845 | "metadata": {},
846 | "outputs": [
847 | {
848 | "data": {
849 | "text/plain": [
850 | "0.274"
851 | ]
852 | },
853 | "execution_count": 32,
854 | "metadata": {},
855 | "output_type": "execute_result"
856 | }
857 | ],
858 | "source": [
859 | "round(stats.variation(fish_length), 3)"
860 | ]
861 | },
862 | {
863 | "cell_type": "code",
864 | "execution_count": 33,
865 | "metadata": {},
866 | "outputs": [
867 | {
868 | "data": {
869 | "text/plain": [
870 | "0.289"
871 | ]
872 | },
873 | "execution_count": 33,
874 | "metadata": {},
875 | "output_type": "execute_result"
876 | }
877 | ],
878 | "source": [
879 | "# 不偏分散を使った変動係数の計算\n",
880 | "round(stats.variation(fish_length, ddof=1), 3)"
881 | ]
882 | },
883 | {
884 | "cell_type": "code",
885 | "execution_count": 34,
886 | "metadata": {},
887 | "outputs": [
888 | {
889 | "data": {
890 | "text/plain": [
891 | "0.289"
892 | ]
893 | },
894 | "execution_count": 34,
895 | "metadata": {},
896 | "output_type": "execute_result"
897 | }
898 | ],
899 | "source": [
900 | "# 参考:不偏分散を使った変動係数の計算(書籍には載っていないコードです)\n",
901 | "round(np.sqrt(u2) / x_bar, 3)"
902 | ]
903 | },
904 | {
905 | "cell_type": "code",
906 | "execution_count": 35,
907 | "metadata": {},
908 | "outputs": [
909 | {
910 | "name": "stdout",
911 | "output_type": "stream",
912 | "text": [
913 | "1.7.1\n"
914 | ]
915 | }
916 | ],
917 | "source": [
918 | "# 参考:ライブラリのバージョン(書籍には載っていないコードです)\n",
919 | "import scipy\n",
920 | "print(scipy.__version__)"
921 | ]
922 | },
923 | {
924 | "cell_type": "markdown",
925 | "metadata": {},
926 | "source": [
927 | "#### 変動係数を使う注意点"
928 | ]
929 | },
930 | {
931 | "cell_type": "code",
932 | "execution_count": 36,
933 | "metadata": {},
934 | "outputs": [],
935 | "source": [
936 | "# 冬の気温と夏の気温\n",
937 | "winter = np.array([1,1,1,2,2,2])\n",
938 | "summer = np.array([29,29,29,30,30,30])"
939 | ]
940 | },
941 | {
942 | "cell_type": "code",
943 | "execution_count": 37,
944 | "metadata": {},
945 | "outputs": [
946 | {
947 | "name": "stdout",
948 | "output_type": "stream",
949 | "text": [
950 | "冬の気温の標準偏差: 0.5\n",
951 | "夏の気温の標準偏差: 0.5\n"
952 | ]
953 | }
954 | ],
955 | "source": [
956 | "# 標準偏差の比較\n",
957 | "print('冬の気温の標準偏差:', np.std(winter, ddof=0))\n",
958 | "print('夏の気温の標準偏差:', np.std(summer, ddof=0))"
959 | ]
960 | },
961 | {
962 | "cell_type": "code",
963 | "execution_count": 38,
964 | "metadata": {},
965 | "outputs": [
966 | {
967 | "name": "stdout",
968 | "output_type": "stream",
969 | "text": [
970 | "冬の気温の変動係数: 0.333\n",
971 | "夏の気温の変動係数: 0.017\n"
972 | ]
973 | }
974 | ],
975 | "source": [
976 | "# 変動係数の比較\n",
977 | "print('冬の気温の変動係数:', round(stats.variation(winter), 3))\n",
978 | "print('夏の気温の変動係数:', round(stats.variation(summer), 3))"
979 | ]
980 | },
981 | {
982 | "cell_type": "markdown",
983 | "metadata": {},
984 | "source": [
985 | "### 実装:標準化"
986 | ]
987 | },
988 | {
989 | "cell_type": "markdown",
990 | "metadata": {},
991 | "source": [
992 | "#### 計算方法の確認"
993 | ]
994 | },
995 | {
996 | "cell_type": "code",
997 | "execution_count": 39,
998 | "metadata": {},
999 | "outputs": [
1000 | {
1001 | "data": {
1002 | "text/plain": [
1003 | "array([-1.826, -0.913, -0.913, 0. , 0. , 0. ,\n",
1004 | " 0. , 0.913, 0.913, 1.826])"
1005 | ]
1006 | },
1007 | "execution_count": 39,
1008 | "metadata": {},
1009 | "output_type": "execute_result"
1010 | }
1011 | ],
1012 | "source": [
1013 | "z = (fish_length - x_bar) / s\n",
1014 | "np.round(z, 3)"
1015 | ]
1016 | },
1017 | {
1018 | "cell_type": "code",
1019 | "execution_count": 40,
1020 | "metadata": {},
1021 | "outputs": [
1022 | {
1023 | "data": {
1024 | "text/plain": [
1025 | "2.2204460492503132e-17"
1026 | ]
1027 | },
1028 | "execution_count": 40,
1029 | "metadata": {},
1030 | "output_type": "execute_result"
1031 | }
1032 | ],
1033 | "source": [
1034 | "# z得点の平均値はほぼ0\n",
1035 | "np.mean(z)"
1036 | ]
1037 | },
1038 | {
1039 | "cell_type": "code",
1040 | "execution_count": 41,
1041 | "metadata": {},
1042 | "outputs": [
1043 | {
1044 | "data": {
1045 | "text/plain": [
1046 | "1.0"
1047 | ]
1048 | },
1049 | "execution_count": 41,
1050 | "metadata": {},
1051 | "output_type": "execute_result"
1052 | }
1053 | ],
1054 | "source": [
1055 | "# z得点の標準偏差はほぼ1\n",
1056 | "np.std(z, ddof=0)"
1057 | ]
1058 | },
1059 | {
1060 | "cell_type": "markdown",
1061 | "metadata": {},
1062 | "source": [
1063 | "#### 関数を使った効率的な実装"
1064 | ]
1065 | },
1066 | {
1067 | "cell_type": "code",
1068 | "execution_count": 42,
1069 | "metadata": {},
1070 | "outputs": [
1071 | {
1072 | "data": {
1073 | "text/plain": [
1074 | "array([-1.826, -0.913, -0.913, 0. , 0. , 0. ,\n",
1075 | " 0. , 0.913, 0.913, 1.826])"
1076 | ]
1077 | },
1078 | "execution_count": 42,
1079 | "metadata": {},
1080 | "output_type": "execute_result"
1081 | }
1082 | ],
1083 | "source": [
1084 | "np.round(stats.zscore(fish_length, ddof=0), 3)"
1085 | ]
1086 | },
1087 | {
1088 | "cell_type": "markdown",
1089 | "metadata": {},
1090 | "source": [
1091 | "### 実装:最大値と最小値"
1092 | ]
1093 | },
1094 | {
1095 | "cell_type": "code",
1096 | "execution_count": 43,
1097 | "metadata": {},
1098 | "outputs": [
1099 | {
1100 | "data": {
1101 | "text/plain": [
1102 | "2"
1103 | ]
1104 | },
1105 | "execution_count": 43,
1106 | "metadata": {},
1107 | "output_type": "execute_result"
1108 | }
1109 | ],
1110 | "source": [
1111 | "# 最小\n",
1112 | "np.amin(fish_length)"
1113 | ]
1114 | },
1115 | {
1116 | "cell_type": "code",
1117 | "execution_count": 44,
1118 | "metadata": {},
1119 | "outputs": [
1120 | {
1121 | "data": {
1122 | "text/plain": [
1123 | "6"
1124 | ]
1125 | },
1126 | "execution_count": 44,
1127 | "metadata": {},
1128 | "output_type": "execute_result"
1129 | }
1130 | ],
1131 | "source": [
1132 | "# 最大\n",
1133 | "np.amax(fish_length)"
1134 | ]
1135 | },
1136 | {
1137 | "cell_type": "markdown",
1138 | "metadata": {},
1139 | "source": [
1140 | "### 実装:中央値"
1141 | ]
1142 | },
1143 | {
1144 | "cell_type": "markdown",
1145 | "metadata": {},
1146 | "source": [
1147 | "#### 中央値の実装"
1148 | ]
1149 | },
1150 | {
1151 | "cell_type": "code",
1152 | "execution_count": 45,
1153 | "metadata": {},
1154 | "outputs": [
1155 | {
1156 | "data": {
1157 | "text/plain": [
1158 | "4.0"
1159 | ]
1160 | },
1161 | "execution_count": 45,
1162 | "metadata": {},
1163 | "output_type": "execute_result"
1164 | }
1165 | ],
1166 | "source": [
1167 | "# 中央値\n",
1168 | "np.median(fish_length)"
1169 | ]
1170 | },
1171 | {
1172 | "cell_type": "markdown",
1173 | "metadata": {},
1174 | "source": [
1175 | "#### 平均値と中央値の違い"
1176 | ]
1177 | },
1178 | {
1179 | "cell_type": "code",
1180 | "execution_count": 46,
1181 | "metadata": {},
1182 | "outputs": [],
1183 | "source": [
1184 | "# 外れ値のあるデータ\n",
1185 | "fish_length_2 = np.array([2,3,3,4,4,4,4,5,5,100])"
1186 | ]
1187 | },
1188 | {
1189 | "cell_type": "code",
1190 | "execution_count": 47,
1191 | "metadata": {},
1192 | "outputs": [
1193 | {
1194 | "name": "stdout",
1195 | "output_type": "stream",
1196 | "text": [
1197 | "平均値: 13.4\n",
1198 | "中央値: 4.0\n"
1199 | ]
1200 | }
1201 | ],
1202 | "source": [
1203 | "# 平均値と中央値の比較\n",
1204 | "print('平均値:', np.mean(fish_length_2))\n",
1205 | "print('中央値:', np.median(fish_length_2))"
1206 | ]
1207 | },
1208 | {
1209 | "cell_type": "markdown",
1210 | "metadata": {},
1211 | "source": [
1212 | "### 実装:四分位点"
1213 | ]
1214 | },
1215 | {
1216 | "cell_type": "code",
1217 | "execution_count": 48,
1218 | "metadata": {},
1219 | "outputs": [
1220 | {
1221 | "name": "stdout",
1222 | "output_type": "stream",
1223 | "text": [
1224 | "第1四分位点 3.25\n",
1225 | "第3四分位点 4.75\n"
1226 | ]
1227 | }
1228 | ],
1229 | "source": [
1230 | "print('第1四分位点', np.quantile(fish_length, q=0.25))\n",
1231 | "print('第3四分位点', np.quantile(fish_length, q=0.75))"
1232 | ]
1233 | },
1234 | {
1235 | "cell_type": "code",
1236 | "execution_count": 49,
1237 | "metadata": {},
1238 | "outputs": [
1239 | {
1240 | "data": {
1241 | "text/plain": [
1242 | "array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,\n",
1243 | " 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,\n",
1244 | " 20, 21, 22, 23, 24, 25, 26, 27, 28, 29,\n",
1245 | " 30, 31, 32, 33, 34, 35, 36, 37, 38, 39,\n",
1246 | " 40, 41, 42, 43, 44, 45, 46, 47, 48, 49,\n",
1247 | " 50, 51, 52, 53, 54, 55, 56, 57, 58, 59,\n",
1248 | " 60, 61, 62, 63, 64, 65, 66, 67, 68, 69,\n",
1249 | " 70, 71, 72, 73, 74, 75, 76, 77, 78, 79,\n",
1250 | " 80, 81, 82, 83, 84, 85, 86, 87, 88, 89,\n",
1251 | " 90, 91, 92, 93, 94, 95, 96, 97, 98, 99,\n",
1252 | " 100])"
1253 | ]
1254 | },
1255 | "execution_count": 49,
1256 | "metadata": {},
1257 | "output_type": "execute_result"
1258 | }
1259 | ],
1260 | "source": [
1261 | "# 別のデータを利用\n",
1262 | "fish_length_3 = np.arange(0, 101, 1)\n",
1263 | "fish_length_3"
1264 | ]
1265 | },
1266 | {
1267 | "cell_type": "code",
1268 | "execution_count": 50,
1269 | "metadata": {},
1270 | "outputs": [
1271 | {
1272 | "data": {
1273 | "text/plain": [
1274 | "101"
1275 | ]
1276 | },
1277 | "execution_count": 50,
1278 | "metadata": {},
1279 | "output_type": "execute_result"
1280 | }
1281 | ],
1282 | "source": [
1283 | "# サンプルサイズ\n",
1284 | "len(fish_length_3)"
1285 | ]
1286 | },
1287 | {
1288 | "cell_type": "code",
1289 | "execution_count": 51,
1290 | "metadata": {},
1291 | "outputs": [
1292 | {
1293 | "name": "stdout",
1294 | "output_type": "stream",
1295 | "text": [
1296 | "第1四分位点 25.0\n",
1297 | "第3四分位点 75.0\n"
1298 | ]
1299 | }
1300 | ],
1301 | "source": [
1302 | "print('第1四分位点', np.quantile(fish_length_3, q=0.25))\n",
1303 | "print('第3四分位点', np.quantile(fish_length_3, q=0.75))"
1304 | ]
1305 | },
1306 | {
1307 | "cell_type": "code",
1308 | "execution_count": 52,
1309 | "metadata": {},
1310 | "outputs": [
1311 | {
1312 | "name": "stdout",
1313 | "output_type": "stream",
1314 | "text": [
1315 | "中央値: 50.0\n",
1316 | "50%点 : 50.0\n"
1317 | ]
1318 | }
1319 | ],
1320 | "source": [
1321 | "# 中央値\n",
1322 | "print('中央値:', np.median(fish_length_3))\n",
1323 | "print('50%点 :', np.quantile(fish_length_3, q=0.5))"
1324 | ]
1325 | },
1326 | {
1327 | "cell_type": "markdown",
1328 | "metadata": {},
1329 | "source": [
1330 | "### 実装:最頻値"
1331 | ]
1332 | },
1333 | {
1334 | "cell_type": "code",
1335 | "execution_count": 53,
1336 | "metadata": {},
1337 | "outputs": [
1338 | {
1339 | "data": {
1340 | "text/plain": [
1341 | "array([2, 3, 3, 4, 4, 4, 4, 5, 5, 6])"
1342 | ]
1343 | },
1344 | "execution_count": 53,
1345 | "metadata": {},
1346 | "output_type": "execute_result"
1347 | }
1348 | ],
1349 | "source": [
1350 | "# 元のデータ\n",
1351 | "fish_length"
1352 | ]
1353 | },
1354 | {
1355 | "cell_type": "code",
1356 | "execution_count": 54,
1357 | "metadata": {},
1358 | "outputs": [
1359 | {
1360 | "data": {
1361 | "text/plain": [
1362 | "ModeResult(mode=array([4]), count=array([4]))"
1363 | ]
1364 | },
1365 | "execution_count": 54,
1366 | "metadata": {},
1367 | "output_type": "execute_result"
1368 | }
1369 | ],
1370 | "source": [
1371 | "# 最頻値\n",
1372 | "stats.mode(fish_length)"
1373 | ]
1374 | },
1375 | {
1376 | "cell_type": "code",
1377 | "execution_count": 55,
1378 | "metadata": {},
1379 | "outputs": [
1380 | {
1381 | "data": {
1382 | "text/plain": [
1383 | "ModeResult(mode=array([1]), count=array([4]))"
1384 | ]
1385 | },
1386 | "execution_count": 55,
1387 | "metadata": {},
1388 | "output_type": "execute_result"
1389 | }
1390 | ],
1391 | "source": [
1392 | "# 度数が同じなら、小さい値が出力される\n",
1393 | "stats.mode(np.array([1,1,1,1,2,3,3,3,3]))"
1394 | ]
1395 | },
1396 | {
1397 | "cell_type": "markdown",
1398 | "metadata": {},
1399 | "source": [
1400 | "### 実装:pandasのdescribe関数の利用"
1401 | ]
1402 | },
1403 | {
1404 | "cell_type": "code",
1405 | "execution_count": 56,
1406 | "metadata": {},
1407 | "outputs": [
1408 | {
1409 | "name": "stdout",
1410 | "output_type": "stream",
1411 | "text": [
1412 | " length\n",
1413 | "count 10.000000\n",
1414 | "mean 4.000000\n",
1415 | "std 1.154701\n",
1416 | "min 2.000000\n",
1417 | "25% 3.250000\n",
1418 | "50% 4.000000\n",
1419 | "75% 4.750000\n",
1420 | "max 6.000000\n"
1421 | ]
1422 | }
1423 | ],
1424 | "source": [
1425 | "# 統計量をまとめて算出\n",
1426 | "print(fish_length_df.describe())"
1427 | ]
1428 | }
1429 | ],
1430 | "metadata": {
1431 | "kernelspec": {
1432 | "display_name": "Python 3 (ipykernel)",
1433 | "language": "python",
1434 | "name": "python3"
1435 | },
1436 | "language_info": {
1437 | "codemirror_mode": {
1438 | "name": "ipython",
1439 | "version": 3
1440 | },
1441 | "file_extension": ".py",
1442 | "mimetype": "text/x-python",
1443 | "name": "python",
1444 | "nbconvert_exporter": "python",
1445 | "pygments_lexer": "ipython3",
1446 | "version": "3.9.7"
1447 | }
1448 | },
1449 | "nbformat": 4,
1450 | "nbformat_minor": 2
1451 | }
1452 |
--------------------------------------------------------------------------------
/book-data/2-4-numpy・pandasの基本.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第2部 PythonとJupyter Notebookの基本\n",
8 | "\n",
9 | "## 4章 numpy・pandasの基本"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### 分析のための追加機能のインポート"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "import numpy as np\n",
26 | "import pandas as pd"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "metadata": {},
32 | "source": [
33 | "### 実装:リスト"
34 | ]
35 | },
36 | {
37 | "cell_type": "code",
38 | "execution_count": 2,
39 | "metadata": {},
40 | "outputs": [
41 | {
42 | "data": {
43 | "text/plain": [
44 | "[1, 2, 3, 4, 5]"
45 | ]
46 | },
47 | "execution_count": 2,
48 | "metadata": {},
49 | "output_type": "execute_result"
50 | }
51 | ],
52 | "source": [
53 | "sample_list = [1,2,3,4,5]\n",
54 | "sample_list"
55 | ]
56 | },
57 | {
58 | "cell_type": "code",
59 | "execution_count": 3,
60 | "metadata": {},
61 | "outputs": [
62 | {
63 | "ename": "TypeError",
64 | "evalue": "can only concatenate list (not \"int\") to list",
65 | "output_type": "error",
66 | "traceback": [
67 | "\u001b[1;31m---------------------------------------------------------------------------\u001b[0m",
68 | "\u001b[1;31mTypeError\u001b[0m Traceback (most recent call last)",
69 | "\u001b[1;32m~\\AppData\\Local\\Temp/ipykernel_7912/94494827.py\u001b[0m in \u001b[0;36m\u001b[1;34m\u001b[0m\n\u001b[0;32m 1\u001b[0m \u001b[1;31m# これはエラー\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[1;32m----> 2\u001b[1;33m \u001b[0msample_list\u001b[0m \u001b[1;33m+\u001b[0m \u001b[1;36m1\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0m",
70 | "\u001b[1;31mTypeError\u001b[0m: can only concatenate list (not \"int\") to list"
71 | ]
72 | }
73 | ],
74 | "source": [
75 | "# これはエラー\n",
76 | "sample_list + 1"
77 | ]
78 | },
79 | {
80 | "cell_type": "markdown",
81 | "metadata": {},
82 | "source": [
83 | "### 実装:アレイ"
84 | ]
85 | },
86 | {
87 | "cell_type": "code",
88 | "execution_count": 4,
89 | "metadata": {},
90 | "outputs": [
91 | {
92 | "data": {
93 | "text/plain": [
94 | "array([1, 2, 3, 4, 5])"
95 | ]
96 | },
97 | "execution_count": 4,
98 | "metadata": {},
99 | "output_type": "execute_result"
100 | }
101 | ],
102 | "source": [
103 | "sample_array = np.array([1, 2, 3, 4, 5])\n",
104 | "sample_array"
105 | ]
106 | },
107 | {
108 | "cell_type": "code",
109 | "execution_count": 5,
110 | "metadata": {},
111 | "outputs": [
112 | {
113 | "data": {
114 | "text/plain": [
115 | "array(['1', '2', 'A'], dtype='\n",
698 | "\n",
711 | "\n",
712 | " \n",
713 | " \n",
714 | " | \n",
715 | " col1 | \n",
716 | " col2 | \n",
717 | " col3 | \n",
718 | "
\n",
719 | " \n",
720 | " \n",
721 | " \n",
722 | " | 0 | \n",
723 | " 1 | \n",
724 | " 2 | \n",
725 | " A | \n",
726 | "
\n",
727 | " \n",
728 | " | 1 | \n",
729 | " 2 | \n",
730 | " 4 | \n",
731 | " B | \n",
732 | "
\n",
733 | " \n",
734 | " | 2 | \n",
735 | " 3 | \n",
736 | " 6 | \n",
737 | " C | \n",
738 | "
\n",
739 | " \n",
740 | " | 3 | \n",
741 | " 4 | \n",
742 | " 8 | \n",
743 | " D | \n",
744 | "
\n",
745 | " \n",
746 | " | 4 | \n",
747 | " 5 | \n",
748 | " 10 | \n",
749 | " E | \n",
750 | "
\n",
751 | " \n",
752 | "
\n",
753 | ""
754 | ],
755 | "text/plain": [
756 | " col1 col2 col3\n",
757 | "0 1 2 A\n",
758 | "1 2 4 B\n",
759 | "2 3 6 C\n",
760 | "3 4 8 D\n",
761 | "4 5 10 E"
762 | ]
763 | },
764 | "execution_count": 29,
765 | "metadata": {},
766 | "output_type": "execute_result"
767 | }
768 | ],
769 | "source": [
770 | "# print関数を使わないで表示\n",
771 | "sample_df"
772 | ]
773 | },
774 | {
775 | "cell_type": "markdown",
776 | "metadata": {},
777 | "source": [
778 | "### 実装:ファイルデータの読み込み"
779 | ]
780 | },
781 | {
782 | "cell_type": "code",
783 | "execution_count": 30,
784 | "metadata": {},
785 | "outputs": [
786 | {
787 | "name": "stdout",
788 | "output_type": "stream",
789 | "text": [
790 | " col1 col2\n",
791 | "0 1 A\n",
792 | "1 2 A\n",
793 | "2 3 B\n",
794 | "3 4 B\n",
795 | "4 5 C\n",
796 | "5 6 C\n"
797 | ]
798 | }
799 | ],
800 | "source": [
801 | "file_data = pd.read_csv('2-4-1-sample_data.csv')\n",
802 | "print(file_data)"
803 | ]
804 | },
805 | {
806 | "cell_type": "markdown",
807 | "metadata": {},
808 | "source": [
809 | "### 実装:データフレームの結合"
810 | ]
811 | },
812 | {
813 | "cell_type": "code",
814 | "execution_count": 31,
815 | "metadata": {},
816 | "outputs": [],
817 | "source": [
818 | "df_1 = pd.DataFrame({\n",
819 | " 'col1' : np.array([1, 2, 3]),\n",
820 | " 'col2' : np.array(['A', 'B', 'C'])\n",
821 | "})\n",
822 | "df_2 = pd.DataFrame({\n",
823 | " 'col1' : np.array([4, 5, 6]),\n",
824 | " 'col2' : np.array(['D', 'E', 'F'])\n",
825 | "})"
826 | ]
827 | },
828 | {
829 | "cell_type": "code",
830 | "execution_count": 32,
831 | "metadata": {},
832 | "outputs": [
833 | {
834 | "name": "stdout",
835 | "output_type": "stream",
836 | "text": [
837 | " col1 col2\n",
838 | "0 1 A\n",
839 | "1 2 B\n",
840 | "2 3 C\n",
841 | "0 4 D\n",
842 | "1 5 E\n",
843 | "2 6 F\n"
844 | ]
845 | }
846 | ],
847 | "source": [
848 | "# 縦に結合\n",
849 | "print(pd.concat([df_1, df_2]))"
850 | ]
851 | },
852 | {
853 | "cell_type": "code",
854 | "execution_count": 33,
855 | "metadata": {},
856 | "outputs": [
857 | {
858 | "name": "stdout",
859 | "output_type": "stream",
860 | "text": [
861 | " col1 col2 col1 col2\n",
862 | "0 1 A 4 D\n",
863 | "1 2 B 5 E\n",
864 | "2 3 C 6 F\n"
865 | ]
866 | }
867 | ],
868 | "source": [
869 | "# 横に結合\n",
870 | "print(pd.concat([df_1, df_2], axis=1))"
871 | ]
872 | },
873 | {
874 | "cell_type": "markdown",
875 | "metadata": {},
876 | "source": [
877 | "### 実装:特定の列の取得"
878 | ]
879 | },
880 | {
881 | "cell_type": "code",
882 | "execution_count": 34,
883 | "metadata": {},
884 | "outputs": [
885 | {
886 | "name": "stdout",
887 | "output_type": "stream",
888 | "text": [
889 | " col1 col2 col3\n",
890 | "0 1 2 A\n",
891 | "1 2 4 B\n",
892 | "2 3 6 C\n",
893 | "3 4 8 D\n",
894 | "4 5 10 E\n"
895 | ]
896 | }
897 | ],
898 | "source": [
899 | "# 対象データ\n",
900 | "print(sample_df)"
901 | ]
902 | },
903 | {
904 | "cell_type": "code",
905 | "execution_count": 35,
906 | "metadata": {},
907 | "outputs": [
908 | {
909 | "name": "stdout",
910 | "output_type": "stream",
911 | "text": [
912 | "0 2\n",
913 | "1 4\n",
914 | "2 6\n",
915 | "3 8\n",
916 | "4 10\n",
917 | "Name: col2, dtype: int32\n"
918 | ]
919 | }
920 | ],
921 | "source": [
922 | "# 列名を指定して抽出\n",
923 | "print(sample_df.col2)"
924 | ]
925 | },
926 | {
927 | "cell_type": "code",
928 | "execution_count": 36,
929 | "metadata": {},
930 | "outputs": [
931 | {
932 | "name": "stdout",
933 | "output_type": "stream",
934 | "text": [
935 | "0 2\n",
936 | "1 4\n",
937 | "2 6\n",
938 | "3 8\n",
939 | "4 10\n",
940 | "Name: col2, dtype: int32\n"
941 | ]
942 | }
943 | ],
944 | "source": [
945 | "print(sample_df['col2'])"
946 | ]
947 | },
948 | {
949 | "cell_type": "code",
950 | "execution_count": 37,
951 | "metadata": {},
952 | "outputs": [
953 | {
954 | "name": "stdout",
955 | "output_type": "stream",
956 | "text": [
957 | " col2 col3\n",
958 | "0 2 A\n",
959 | "1 4 B\n",
960 | "2 6 C\n",
961 | "3 8 D\n",
962 | "4 10 E\n"
963 | ]
964 | }
965 | ],
966 | "source": [
967 | "print(sample_df[['col2', 'col3']])"
968 | ]
969 | },
970 | {
971 | "cell_type": "code",
972 | "execution_count": 38,
973 | "metadata": {},
974 | "outputs": [
975 | {
976 | "name": "stdout",
977 | "output_type": "stream",
978 | "text": [
979 | " col2 col3\n",
980 | "0 2 A\n",
981 | "1 4 B\n",
982 | "2 6 C\n",
983 | "3 8 D\n",
984 | "4 10 E\n"
985 | ]
986 | }
987 | ],
988 | "source": [
989 | "# 列の削除\n",
990 | "print(sample_df.drop('col1', axis=1))"
991 | ]
992 | },
993 | {
994 | "cell_type": "markdown",
995 | "metadata": {},
996 | "source": [
997 | "### 実装:特定の行の取得"
998 | ]
999 | },
1000 | {
1001 | "cell_type": "code",
1002 | "execution_count": 39,
1003 | "metadata": {},
1004 | "outputs": [
1005 | {
1006 | "name": "stdout",
1007 | "output_type": "stream",
1008 | "text": [
1009 | " col1 col2 col3\n",
1010 | "0 1 2 A\n",
1011 | "1 2 4 B\n",
1012 | "2 3 6 C\n"
1013 | ]
1014 | }
1015 | ],
1016 | "source": [
1017 | "# 最初の3行だけを抽出\n",
1018 | "print(sample_df.head(n=3))"
1019 | ]
1020 | },
1021 | {
1022 | "cell_type": "code",
1023 | "execution_count": 40,
1024 | "metadata": {},
1025 | "outputs": [
1026 | {
1027 | "name": "stdout",
1028 | "output_type": "stream",
1029 | "text": [
1030 | " col1 col2 col3\n",
1031 | "0 1 2 A\n"
1032 | ]
1033 | }
1034 | ],
1035 | "source": [
1036 | "# 最初の行を抽出\n",
1037 | "print(sample_df.query('index == 0'))"
1038 | ]
1039 | },
1040 | {
1041 | "cell_type": "code",
1042 | "execution_count": 41,
1043 | "metadata": {},
1044 | "outputs": [
1045 | {
1046 | "name": "stdout",
1047 | "output_type": "stream",
1048 | "text": [
1049 | " col1 col2 col3\n",
1050 | "0 1 2 A\n"
1051 | ]
1052 | }
1053 | ],
1054 | "source": [
1055 | "# さまざまな条件で抽出\n",
1056 | "print(sample_df.query('col3 == \"A\"'))"
1057 | ]
1058 | },
1059 | {
1060 | "cell_type": "code",
1061 | "execution_count": 42,
1062 | "metadata": {},
1063 | "outputs": [
1064 | {
1065 | "name": "stdout",
1066 | "output_type": "stream",
1067 | "text": [
1068 | " col1 col2 col3\n",
1069 | "0 1 2 A\n",
1070 | "3 4 8 D\n"
1071 | ]
1072 | }
1073 | ],
1074 | "source": [
1075 | "# OR条件で抽出\n",
1076 | "print(sample_df.query('col3 == \"A\" | col3 == \"D\"'))"
1077 | ]
1078 | },
1079 | {
1080 | "cell_type": "code",
1081 | "execution_count": 43,
1082 | "metadata": {},
1083 | "outputs": [
1084 | {
1085 | "name": "stdout",
1086 | "output_type": "stream",
1087 | "text": [
1088 | "Empty DataFrame\n",
1089 | "Columns: [col1, col2, col3]\n",
1090 | "Index: []\n"
1091 | ]
1092 | }
1093 | ],
1094 | "source": [
1095 | "# AND条件で抽出\n",
1096 | "print(sample_df.query('col3 == \"A\" & col1 == 3'))"
1097 | ]
1098 | },
1099 | {
1100 | "cell_type": "code",
1101 | "execution_count": 44,
1102 | "metadata": {},
1103 | "outputs": [
1104 | {
1105 | "name": "stdout",
1106 | "output_type": "stream",
1107 | "text": [
1108 | " col2 col3\n",
1109 | "0 2 A\n"
1110 | ]
1111 | }
1112 | ],
1113 | "source": [
1114 | "# 行も列も選択する\n",
1115 | "print(sample_df.query('col3 == \"A\"')[['col2', 'col3']])"
1116 | ]
1117 | },
1118 | {
1119 | "cell_type": "markdown",
1120 | "metadata": {},
1121 | "source": [
1122 | "### 実装:シリーズ"
1123 | ]
1124 | },
1125 | {
1126 | "cell_type": "code",
1127 | "execution_count": 45,
1128 | "metadata": {},
1129 | "outputs": [
1130 | {
1131 | "data": {
1132 | "text/plain": [
1133 | "pandas.core.frame.DataFrame"
1134 | ]
1135 | },
1136 | "execution_count": 45,
1137 | "metadata": {},
1138 | "output_type": "execute_result"
1139 | }
1140 | ],
1141 | "source": [
1142 | "type(sample_df)"
1143 | ]
1144 | },
1145 | {
1146 | "cell_type": "code",
1147 | "execution_count": 46,
1148 | "metadata": {},
1149 | "outputs": [
1150 | {
1151 | "data": {
1152 | "text/plain": [
1153 | "pandas.core.series.Series"
1154 | ]
1155 | },
1156 | "execution_count": 46,
1157 | "metadata": {},
1158 | "output_type": "execute_result"
1159 | }
1160 | ],
1161 | "source": [
1162 | "type(sample_df.col1)"
1163 | ]
1164 | },
1165 | {
1166 | "cell_type": "code",
1167 | "execution_count": 47,
1168 | "metadata": {},
1169 | "outputs": [
1170 | {
1171 | "data": {
1172 | "text/plain": [
1173 | "numpy.ndarray"
1174 | ]
1175 | },
1176 | "execution_count": 47,
1177 | "metadata": {},
1178 | "output_type": "execute_result"
1179 | }
1180 | ],
1181 | "source": [
1182 | "# アレイへの変換\n",
1183 | "type(np.array(sample_df.col1))"
1184 | ]
1185 | },
1186 | {
1187 | "cell_type": "code",
1188 | "execution_count": 48,
1189 | "metadata": {},
1190 | "outputs": [
1191 | {
1192 | "data": {
1193 | "text/plain": [
1194 | "numpy.ndarray"
1195 | ]
1196 | },
1197 | "execution_count": 48,
1198 | "metadata": {},
1199 | "output_type": "execute_result"
1200 | }
1201 | ],
1202 | "source": [
1203 | "# アレイへの変換\n",
1204 | "type(sample_df.col1.to_numpy())"
1205 | ]
1206 | },
1207 | {
1208 | "cell_type": "markdown",
1209 | "metadata": {},
1210 | "source": [
1211 | "### 実装:関数のヘルプ"
1212 | ]
1213 | },
1214 | {
1215 | "cell_type": "code",
1216 | "execution_count": 49,
1217 | "metadata": {
1218 | "scrolled": false
1219 | },
1220 | "outputs": [
1221 | {
1222 | "name": "stdout",
1223 | "output_type": "stream",
1224 | "text": [
1225 | "Help on method query in module pandas.core.frame:\n",
1226 | "\n",
1227 | "query(expr: 'str', inplace: 'bool' = False, **kwargs) method of pandas.core.frame.DataFrame instance\n",
1228 | " Query the columns of a DataFrame with a boolean expression.\n",
1229 | " \n",
1230 | " Parameters\n",
1231 | " ----------\n",
1232 | " expr : str\n",
1233 | " The query string to evaluate.\n",
1234 | " \n",
1235 | " You can refer to variables\n",
1236 | " in the environment by prefixing them with an '@' character like\n",
1237 | " ``@a + b``.\n",
1238 | " \n",
1239 | " You can refer to column names that are not valid Python variable names\n",
1240 | " by surrounding them in backticks. Thus, column names containing spaces\n",
1241 | " or punctuations (besides underscores) or starting with digits must be\n",
1242 | " surrounded by backticks. (For example, a column named \"Area (cm^2)\" would\n",
1243 | " be referenced as ```Area (cm^2)```). Column names which are Python keywords\n",
1244 | " (like \"list\", \"for\", \"import\", etc) cannot be used.\n",
1245 | " \n",
1246 | " For example, if one of your columns is called ``a a`` and you want\n",
1247 | " to sum it with ``b``, your query should be ```a a` + b``.\n",
1248 | " \n",
1249 | " .. versionadded:: 0.25.0\n",
1250 | " Backtick quoting introduced.\n",
1251 | " \n",
1252 | " .. versionadded:: 1.0.0\n",
1253 | " Expanding functionality of backtick quoting for more than only spaces.\n",
1254 | " \n",
1255 | " inplace : bool\n",
1256 | " Whether the query should modify the data in place or return\n",
1257 | " a modified copy.\n",
1258 | " **kwargs\n",
1259 | " See the documentation for :func:`eval` for complete details\n",
1260 | " on the keyword arguments accepted by :meth:`DataFrame.query`.\n",
1261 | " \n",
1262 | " Returns\n",
1263 | " -------\n",
1264 | " DataFrame or None\n",
1265 | " DataFrame resulting from the provided query expression or\n",
1266 | " None if ``inplace=True``.\n",
1267 | " \n",
1268 | " See Also\n",
1269 | " --------\n",
1270 | " eval : Evaluate a string describing operations on\n",
1271 | " DataFrame columns.\n",
1272 | " DataFrame.eval : Evaluate a string describing operations on\n",
1273 | " DataFrame columns.\n",
1274 | " \n",
1275 | " Notes\n",
1276 | " -----\n",
1277 | " The result of the evaluation of this expression is first passed to\n",
1278 | " :attr:`DataFrame.loc` and if that fails because of a\n",
1279 | " multidimensional key (e.g., a DataFrame) then the result will be passed\n",
1280 | " to :meth:`DataFrame.__getitem__`.\n",
1281 | " \n",
1282 | " This method uses the top-level :func:`eval` function to\n",
1283 | " evaluate the passed query.\n",
1284 | " \n",
1285 | " The :meth:`~pandas.DataFrame.query` method uses a slightly\n",
1286 | " modified Python syntax by default. For example, the ``&`` and ``|``\n",
1287 | " (bitwise) operators have the precedence of their boolean cousins,\n",
1288 | " :keyword:`and` and :keyword:`or`. This *is* syntactically valid Python,\n",
1289 | " however the semantics are different.\n",
1290 | " \n",
1291 | " You can change the semantics of the expression by passing the keyword\n",
1292 | " argument ``parser='python'``. This enforces the same semantics as\n",
1293 | " evaluation in Python space. Likewise, you can pass ``engine='python'``\n",
1294 | " to evaluate an expression using Python itself as a backend. This is not\n",
1295 | " recommended as it is inefficient compared to using ``numexpr`` as the\n",
1296 | " engine.\n",
1297 | " \n",
1298 | " The :attr:`DataFrame.index` and\n",
1299 | " :attr:`DataFrame.columns` attributes of the\n",
1300 | " :class:`~pandas.DataFrame` instance are placed in the query namespace\n",
1301 | " by default, which allows you to treat both the index and columns of the\n",
1302 | " frame as a column in the frame.\n",
1303 | " The identifier ``index`` is used for the frame index; you can also\n",
1304 | " use the name of the index to identify it in a query. Please note that\n",
1305 | " Python keywords may not be used as identifiers.\n",
1306 | " \n",
1307 | " For further details and examples see the ``query`` documentation in\n",
1308 | " :ref:`indexing `.\n",
1309 | " \n",
1310 | " *Backtick quoted variables*\n",
1311 | " \n",
1312 | " Backtick quoted variables are parsed as literal Python code and\n",
1313 | " are converted internally to a Python valid identifier.\n",
1314 | " This can lead to the following problems.\n",
1315 | " \n",
1316 | " During parsing a number of disallowed characters inside the backtick\n",
1317 | " quoted string are replaced by strings that are allowed as a Python identifier.\n",
1318 | " These characters include all operators in Python, the space character, the\n",
1319 | " question mark, the exclamation mark, the dollar sign, and the euro sign.\n",
1320 | " For other characters that fall outside the ASCII range (U+0001..U+007F)\n",
1321 | " and those that are not further specified in PEP 3131,\n",
1322 | " the query parser will raise an error.\n",
1323 | " This excludes whitespace different than the space character,\n",
1324 | " but also the hashtag (as it is used for comments) and the backtick\n",
1325 | " itself (backtick can also not be escaped).\n",
1326 | " \n",
1327 | " In a special case, quotes that make a pair around a backtick can\n",
1328 | " confuse the parser.\n",
1329 | " For example, ```it's` > `that's``` will raise an error,\n",
1330 | " as it forms a quoted string (``'s > `that'``) with a backtick inside.\n",
1331 | " \n",
1332 | " See also the Python documentation about lexical analysis\n",
1333 | " (https://docs.python.org/3/reference/lexical_analysis.html)\n",
1334 | " in combination with the source code in :mod:`pandas.core.computation.parsing`.\n",
1335 | " \n",
1336 | " Examples\n",
1337 | " --------\n",
1338 | " >>> df = pd.DataFrame({'A': range(1, 6),\n",
1339 | " ... 'B': range(10, 0, -2),\n",
1340 | " ... 'C C': range(10, 5, -1)})\n",
1341 | " >>> df\n",
1342 | " A B C C\n",
1343 | " 0 1 10 10\n",
1344 | " 1 2 8 9\n",
1345 | " 2 3 6 8\n",
1346 | " 3 4 4 7\n",
1347 | " 4 5 2 6\n",
1348 | " >>> df.query('A > B')\n",
1349 | " A B C C\n",
1350 | " 4 5 2 6\n",
1351 | " \n",
1352 | " The previous expression is equivalent to\n",
1353 | " \n",
1354 | " >>> df[df.A > df.B]\n",
1355 | " A B C C\n",
1356 | " 4 5 2 6\n",
1357 | " \n",
1358 | " For columns with spaces in their name, you can use backtick quoting.\n",
1359 | " \n",
1360 | " >>> df.query('B == `C C`')\n",
1361 | " A B C C\n",
1362 | " 0 1 10 10\n",
1363 | " \n",
1364 | " The previous expression is equivalent to\n",
1365 | " \n",
1366 | " >>> df[df.B == df['C C']]\n",
1367 | " A B C C\n",
1368 | " 0 1 10 10\n",
1369 | "\n"
1370 | ]
1371 | }
1372 | ],
1373 | "source": [
1374 | "help(sample_df.query)"
1375 | ]
1376 | }
1377 | ],
1378 | "metadata": {
1379 | "kernelspec": {
1380 | "display_name": "Python 3 (ipykernel)",
1381 | "language": "python",
1382 | "name": "python3"
1383 | },
1384 | "language_info": {
1385 | "codemirror_mode": {
1386 | "name": "ipython",
1387 | "version": 3
1388 | },
1389 | "file_extension": ".py",
1390 | "mimetype": "text/x-python",
1391 | "name": "python",
1392 | "nbconvert_exporter": "python",
1393 | "pygments_lexer": "ipython3",
1394 | "version": "3.9.7"
1395 | }
1396 | },
1397 | "nbformat": 4,
1398 | "nbformat_minor": 2
1399 | }
1400 |
--------------------------------------------------------------------------------