├── .gitignore
├── LICENSE
├── README.md
├── configuration
├── __init__.py
├── config.json
└── config.py
├── index.html
├── main.py
├── models
├── __init__.py
├── columns.py
├── db_model.py
├── entities.py
├── matcher.py
├── relationships.py
├── sql_model.py
├── sql_scripts
│ ├── columns.sql
│ ├── foreign_keys.sql
│ ├── primary_keys.sql
│ └── tables.sql
├── synonyms.py
└── type_converter.py
├── requirements.txt
├── sql_scripts
├── data_feed.sql
├── metadata_sql_queries.sql
└── sql_schema.sql
├── ss.jpg
├── static
└── sql-formatter.min.js
└── stopwords.txt
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 | .idea/
6 | # C extensions
7 | *.so
8 |
9 | # Blazor
10 | .vs/
11 | bin/
12 | obj/
13 | *.user
14 | artifacts/
15 | .vscode/
16 | .dotnet/
17 | *.binlog
18 |
19 | # Distribution / packaging
20 | .Python
21 | build/
22 | develop-eggs/
23 | dist/
24 | downloads/
25 | eggs/
26 | .eggs/
27 | lib/
28 | lib64/
29 | parts/
30 | sdist/
31 | var/
32 | wheels/
33 | pip-wheel-metadata/
34 | share/python-wheels/
35 | *.egg-info/
36 | .installed.cfg
37 | *.egg
38 | MANIFEST
39 |
40 | # PyInstaller
41 | # Usually these files are written by a python script from a template
42 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
43 | *.manifest
44 | *.spec
45 |
46 | # Installer logs
47 | pip-log.txt
48 | pip-delete-this-directory.txt
49 |
50 | # Unit test / coverage reports
51 | htmlcov/
52 | .tox/
53 | .nox/
54 | .coverage
55 | .coverage.*
56 | .cache
57 | nosetests.xml
58 | coverage.xml
59 | *.cover
60 | .hypothesis/
61 | .pytest_cache/
62 |
63 | # Translations
64 | *.mo
65 | *.pot
66 |
67 | # Django stuff:
68 | *.log
69 | local_settings.py
70 | db.sqlite3
71 | db.sqlite3-journal
72 |
73 | # Flask stuff:
74 | instance/
75 | .webassets-cache
76 |
77 | # Scrapy stuff:
78 | .scrapy
79 |
80 | # Sphinx documentation
81 | docs/_build/
82 |
83 | # PyBuilder
84 | target/
85 |
86 | # Jupyter Notebook
87 | .ipynb_checkpoints
88 |
89 | # IPython
90 | profile_default/
91 | ipython_config.py
92 |
93 | # pyenv
94 | .python-version
95 |
96 | # pipenv
97 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
98 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
99 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
100 | # install all needed dependencies.
101 | #Pipfile.lock
102 |
103 | # celery beat schedule file
104 | celerybeat-schedule
105 |
106 | # SageMath parsed files
107 | *.sage.py
108 |
109 | # Environments
110 | .env
111 | .venv
112 | env/
113 | venv/
114 | ENV/
115 | env.bak/
116 | venv.bak/
117 |
118 | # Spyder project settings
119 | .spyderproject
120 | .spyproject
121 |
122 | # Rope project settings
123 | .ropeproject
124 |
125 | # mkdocs documentation
126 | /site
127 |
128 | # mypy
129 | .mypy_cache/
130 | .dmypy.json
131 | dmypy.json
132 |
133 | # Pyre type checker
134 | .pyre/
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2019 Lokesh Lal
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # TextToSql
2 | An attempt to convert natural language to sql statement
3 |
4 |
5 | ### Approach
6 | ```
7 | Input text -> Text processing will entirely depends upon the targeted domain or customer
8 | Replace key words, such as total number with count or total with sum etc.
9 | Remove stop words
10 | Identify the text from pre-loaded entites
11 | Input string processing using spacy
12 | Identify noun chunks
13 | Identify named entities
14 | Create lemmatized string
15 | Match the processed sentence with the existing columns and tables as well as synonyms defined in the configuration
16 | Split the processed string using phrase splitter configuration (this again has to be domain specific)
17 | Create spacy nlp documents for the splitted phrases
18 | Find entities and columns
19 | Find if any aggregation requires to be run on the entities and columns
20 | Use Named entities identified earlier to correct the values
21 | Buid the dictionary and pass the dictionary to SQL Generator
22 | SQL generator (as of now is for SQL server only) will generate the query based on the entity-column dictionary
23 | Push the query to database and fetch the result
24 | ```
25 |
26 | ### Configuration
27 | Important part to focus here is configuration
28 |
29 | ```
30 | {
31 | "sql": {
32 | "connection_string":""
33 | },
34 | "phrase_splitter": " in |in | in| and |and | and| with |with | with",
35 | "default_columns": {
36 | "entities": {
37 | "student":"name",
38 | "subject":"name",
39 | "student_mark":"id"
40 | }
41 | },
42 | "entities_to_load": [
43 | {
44 | "entity": "subject",
45 | "column": "name"
46 | },
47 | {
48 | "entity": "student",
49 | "column": "name"
50 | }
51 | ],
52 | "synonyms": {
53 | "column": [
54 | {
55 | "original": "class",
56 | "synonyms": [ "standard" ]
57 | }
58 | ],
59 | "table": [
60 | {
61 | "original": "student",
62 | "synonyms": [ "children", "child" ]
63 | }
64 | ]
65 | }
66 | }
67 | ```
68 |
69 | **connection_string**: connection string for the sql server
70 | **phrase_splitter**: phrase splitter for the domain. Customer should know what sort of queries user generally ask and how these can be splitted
71 | **default_columns**: define default columns for the tables. this will be helpful to identify the default column to select when entity is mentioned in the question
72 | **entities_to_load**: which all entities to pre-load. These entities should refer to the master data or data which needs to be looked up without any context
73 | **synonyms**: synonyms for table names and column names
74 |
75 | ### What all is supported as of now
76 | Only sql server is supported as of now.
77 | Following SQL functions - min, max, avg, sum, count
78 | Multiple values for a filter is not supported.
79 |
80 | ### How to run
81 |
82 | ```
83 | python -B main.py
84 | ```
85 |
86 | Go to browser and launch http://127.0.0.1:5000/
87 |
88 | #### Install pyodbc driver from following link
89 | https://docs.microsoft.com/en-us/sql/connect/odbc/linux-mac/installing-the-microsoft-odbc-driver-for-sql-server?view=sql-server-ver15
90 |
91 |
92 | ### Schema tested on
93 | Tested on [test schema](https://github.com/lokeshlal/TextToSql/blob/master/sql_scripts/sql_schema.sql)
94 |
95 | The schema basically consists of three tables Student, Subject and student_mark with relationship among them.
96 |
97 | Test data is populated using [data feed](https://github.com/lokeshlal/TextToSql/blob/master/sql_scripts/data_feed.sql)
98 |
99 | Queries which are tested on the above schema
100 |
101 | ```
102 | students in class 12 and mark 30 in english subject
103 | Show all students with marks greater than 30
104 | students in class 12 and marks less than 50 in english subject in year greater than 2018
105 | students in class 12 and marks less than 50 in english subject
106 | average marks of students in english subject in class 12
107 | average marks in english subject in class 12
108 | student with maximum marks in english subject in class 12
109 | minimum marks in english subject in class 12
110 | total marks of students in class 12 in year 2019
111 | students in class 12 with marks less than 60 in english subject
112 | total marks in class 12 in year 2019
113 | maximum marks in class 12 in year 2019
114 | students in class 12 and 69 marks in english subject
115 | students in class 12 and marks less than 50 in english subject
116 | marks of Manoj Garg student in english subject
117 | student with biology in class 12
118 | marks of Lokesh Lal in english in class 12
119 | maximum marks of vishal gupta in all subject
120 | students with less than 50 marks in class 12
121 | ```
122 |
123 | ### Video
124 |
125 | [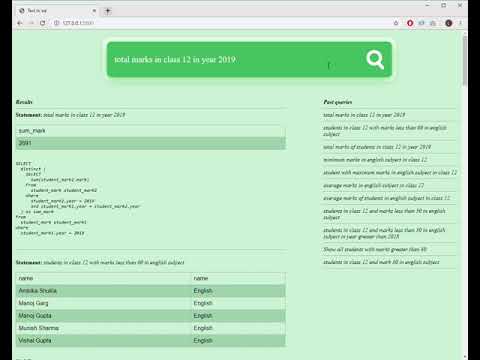](https://www.youtube.com/watch?v=h8J-u_51ADw)
126 |
127 |
128 | ### Things to do
129 |
130 | Define a process to incoperate the ML based learning for various scenarios.
131 |
132 | For example, "students with average marks less than average marks".
133 |
134 | In the above query, we have to find all students with average marks less than the average marks of all students. This can be coded as well. However, there could be many scenarios and based on these scenarios we might not want to change the sql adaptor every time. So best is to leverage the ML model to enhance the dictionary which is being passed to the SQL adaptor and let SQL adaptor build the SQL based on the available sql functions.
135 |
--------------------------------------------------------------------------------
/configuration/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lokeshlal/TextToSql/f5d80a73f455452ddc3c851e499d501fd0613ef6/configuration/__init__.py
--------------------------------------------------------------------------------
/configuration/config.json:
--------------------------------------------------------------------------------
1 | {
2 | "sql": {
3 | "connection_string":""
4 | },
5 | "phrase_splitter": " in |in | in| and |and | and| with |with | with| of |of | of",
6 | "default_columns": {
7 | "entities": {
8 | "student":"name",
9 | "subject":"name",
10 | "student_mark":"id"
11 | }
12 | },
13 | "entities_to_load": [
14 | {
15 | "entity": "subject",
16 | "column": "name"
17 | },
18 | {
19 | "entity": "student",
20 | "column": "name"
21 | }
22 | ],
23 | "synonyms": {
24 | "column": [
25 | {
26 | "original": "class",
27 | "synonyms": [ "standard" ]
28 | }
29 | ],
30 | "table": [
31 | {
32 | "original": "student",
33 | "synonyms": [ "children", "child" ]
34 | }
35 | ]
36 | }
37 | }
--------------------------------------------------------------------------------
/configuration/config.py:
--------------------------------------------------------------------------------
1 | import json
2 | import os
3 |
4 |
5 | class Singleton(type):
6 | """
7 | Define an Instance operation that lets clients access its unique
8 | instance.
9 | """
10 |
11 | def __init__(cls, name, bases, attrs, **kwargs):
12 | super().__init__(name, bases, attrs)
13 | cls._instance = None
14 |
15 | def __call__(cls, *args, **kwargs):
16 | if cls._instance is None:
17 | cls._instance = super().__call__(*args, **kwargs)
18 | return cls._instance
19 |
20 |
21 | class Configuration(metaclass=Singleton):
22 | def __init__(self):
23 | with open(os.path.join(os.path.dirname(__file__), 'config.json')) as json_configuration:
24 | self.data = json.load(json_configuration)
25 |
26 | # sql starts
27 | def get_sql_connection_string(self):
28 | return self.data["sql"]["connection_string"]
29 |
30 | def get_tables_sql_query(self):
31 | with open(os.path.abspath(
32 | os.path.join(os.path.dirname(__file__), '..', 'models', 'sql_scripts', 'tables.sql'))) as query:
33 | return query.read()
34 |
35 | def get_columns_sql_query(self):
36 | with open(os.path.abspath(
37 | os.path.join(os.path.dirname(__file__), '..', 'models', 'sql_scripts', 'columns.sql'))) as query:
38 | return query.read()
39 |
40 | def get_FK_sql_query(self):
41 | with open(os.path.abspath(
42 | os.path.join(os.path.dirname(__file__), '..', 'models', 'sql_scripts', 'foreign_keys.sql'))) as query:
43 | return query.read()
44 |
45 | def get_PK_sql_query(self):
46 | with open(os.path.abspath(
47 | os.path.join(os.path.dirname(__file__), '..', 'models', 'sql_scripts', 'primary_keys.sql'))) as query:
48 | return query.read()
49 |
50 | def get_synonyms(self):
51 | return self.data["synonyms"]
52 |
53 | def get_phrase_splitter(self):
54 | return self.data["phrase_splitter"]
55 |
56 | def get_entitites_to_load(self):
57 | return self.data["entities_to_load"]
58 |
59 | # sql ends
60 |
61 | def get_default_column(self, table_name):
62 | return self.data["default_columns"]["entities"][table_name]
63 |
--------------------------------------------------------------------------------
/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 | Text to sql
4 |
204 |
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
216 |
217 |
218 |
219 |
220 |
221 | Results
222 |
223 |
224 |
225 | Past queries
226 |
227 |
228 |
229 |
296 |
297 |
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | # import libraries
2 | import spacy
3 | import itertools
4 | import re
5 | import flask
6 | import json
7 |
8 | from spacy import displacy
9 | from spacy.matcher import PhraseMatcher
10 | from models.columns import Columns
11 | from models.entities import Entities
12 | from models.db_model import DBModel
13 | from models.type_converter import get_value, get_token_child_len, get_neighbour_tokens, get_type, replace_string, replace_entities
14 | from models.sql_model import SQLGenerator
15 | from models.matcher import Matcher
16 | from configuration.config import Configuration
17 |
18 | #load the configuration
19 | config = Configuration()
20 | # load the DB Model
21 | db_model = DBModel()
22 | # remove unneccesary words
23 | stan_stop_words = [line.rstrip('\n') for line in open("stopwords.txt")]
24 | # load spacy's english model
25 | nlp = spacy.load('en_core_web_sm')
26 | # exceptions
27 | exceptions = ["between", "more", "than"]
28 | lemma_exceptions = ["greater", "less", "than", "more"]
29 | # creating phrase matcher to get the entities and columns
30 | # build this using above entities and columns list
31 | # also add option to get the synonyms in declarative way
32 | custom_matcher = Matcher()
33 | custom_matcher = db_model.get_custom_matcher(custom_matcher, nlp)
34 |
35 | # test sentence
36 | # sentence = u'Show all students with marks greater than 30'
37 | # sentence = u'students in class 12 and mark 30 in english subject'
38 | # sentence = u'students in class 12 and marks less than 50 in english subject in year greater than 2018'
39 | # sentence = u'students in class 12 and marks less than 50 in english subject'
40 | # sentence = u'average marks of students in english subject in class 12'
41 | # sentence = u'average marks in english subject in class 12'
42 | # sentence = u'student with maximum marks in english subject in class 12'
43 | # sentence = u'minimum marks in english subject in class 12'
44 | # sentence = u'total marks of students in class 12 in year 2019'
45 | # sentence = u'students in class 12 with marks less than 60 in english subject'
46 | # sentence = u'total marks in class 12 in year 2019'
47 | # sentence = u'maximum marks in class 12 in year 2019'
48 | # sentence = u'students in class 12 and 69 marks in english subject'
49 | # sentence = u'students in class 12 and marks less than 50 in english subject'
50 | # sentence = u'marks of Manoj Garg student in english subject'
51 |
52 | # main method to process the incoming sentence
53 | def process_sentence(sentence):
54 |
55 | # basic string replacements for count and sum
56 | sentence = sentence.replace("total number", "count")
57 | sentence = sentence.replace("total", "sum")
58 |
59 | # remove the stop words
60 | new_sentence = ""
61 | for word in sentence.split():
62 | if word not in stan_stop_words:
63 | new_sentence += word + " "
64 | sentence = new_sentence.lstrip()
65 |
66 | for loaded_entity in db_model.loaded_entities:
67 | for loaded_entity_value in loaded_entity[1]:
68 | if loaded_entity_value.lower() in sentence:
69 | sentence = replace_entities(sentence, loaded_entity_value, loaded_entity_value)
70 |
71 | # run nlp on sentence
72 | doc = nlp(sentence)
73 |
74 | identified_spans = []
75 | identified_entities = []
76 |
77 | for chunk in doc.noun_chunks:
78 | identified_spans.append(chunk.text)
79 | # print(chunk.text, " -- ", chunk.root.text, " -- ", chunk.root.dep_, " -- ", chunk.root.head.text)
80 | for ent in doc.ents:
81 | identified_entities.append(ent.text)
82 | # print(ent.text, ent.start_char, ent.end_char, ent.label_)
83 |
84 | # build the lemma sentence
85 | lemmatizedSentence = ''
86 | for token in doc:
87 | lemmatizedSentence = lemmatizedSentence + (token.text if token.text in lemma_exceptions else token.lemma_) + " "
88 | lemmatizedSentence = lemmatizedSentence.lstrip()
89 |
90 | # stop word removal
91 | spacy_stopwords = spacy.lang.en.stop_words.STOP_WORDS
92 |
93 | # for chunk in docLemmatized.noun_chunks:
94 | # print(chunk.text, chunk.root.text, chunk.root.dep_,
95 | # chunk.root.head.text)
96 |
97 | # get all tables and columns in the question
98 | # matches = matcher(docLemmatized)
99 | matches = custom_matcher.find(lemmatizedSentence)
100 | matched_entities = []
101 | matched_columns = []
102 | for match in matches:
103 | if match[0].endswith("TABLE"):
104 | matched_entities.append(Entities(match[0].replace("_TABLE","")))
105 | lemmatizedSentence = replace_string(lemmatizedSentence, str(match[1]), match[0].replace("_TABLE",""))
106 | if match[0].endswith("COLUMN"):
107 | columnType = [c.type_ for c in db_model.columns if c.name == match[0].replace("_COLUMN","").lower()]
108 | if len(columnType) > 0:
109 | columnType = columnType[0]
110 | matched_columns.append(Columns(match[0].replace("_COLUMN",""), columnType))
111 | lemmatizedSentence = replace_string(lemmatizedSentence, str(match[1]), match[0].replace("_COLUMN",""))
112 |
113 | docLemmatized = nlp(lemmatizedSentence)
114 |
115 | # print("####################")
116 | # print(lemmatizedSentence)
117 | # print([(m[0], m[1]) for m in custom_matcher.matcher])
118 | # print([(m[0], m[1]) for m in matches])
119 | # print([m.name for m in matched_entities])
120 | # print([m.name for m in matched_columns])
121 | # print("####################")
122 |
123 | # get values for the captured columns in the above use case
124 | for token in docLemmatized:
125 |
126 | # check of token matches any of the matched entities
127 | if token.text.upper() in [m.name for m in matched_entities]:
128 | matched_entity = next(me for me in matched_entities if me.name == token.text.upper())
129 |
130 | contextual_span = get_neighbour_tokens(token)
131 | span_ranges = re.split(config.get_phrase_splitter(), contextual_span)
132 | for span in span_ranges:
133 | if matched_entity.name.lower() in span:
134 | matched_entity.condition = "="
135 | if "average" in span:
136 | matched_entity.isAverage = True
137 | if "avg" in span:
138 | matched_entity.isAverage = True
139 | if "maximum" in span:
140 | matched_entity.isMax = True
141 | if "max" in span:
142 | matched_entity.isMax = True
143 | if "minimum" in span:
144 | matched_entity.isMin = True
145 | if "min" in span:
146 | matched_entity.isMin = True
147 | if "count" in span:
148 | matched_entity.isCount = True
149 | if "sum" in span:
150 | matched_entity.isSum = True
151 | if "total" in span:
152 | matched_entity.isSum = True
153 |
154 | trimmed_span = span \
155 | .replace("average", "") \
156 | .replace("maximum", "") \
157 | .replace("minimum", "") \
158 | .replace("greater than", "") \
159 | .replace("less than", "") \
160 | .replace("more than", "") \
161 | .replace("min", "") \
162 | .replace("max", "") \
163 | .replace("count", "") \
164 | .replace("sum", "")
165 | trimmed_span = ' '.join(trimmed_span.split())
166 | doc_span = nlp(trimmed_span)
167 |
168 | for span_token in doc_span:
169 |
170 | if span_token.text.lower() == matched_entity.name.lower():
171 |
172 | if get_token_child_len(span_token) > 0:
173 | span_token_child = next(itertools.islice(span_token.children, 1))
174 | ent = next(en for en in db_model.entities if en.name.lower() == matched_entity.name.lower())
175 | default_column = next(col for col in ent.columns if col.name.lower() == ent.defaultColumn.lower())
176 | value = get_value(span_token_child.text, default_column.type_)
177 |
178 | identified_entity_exists = False
179 | for identified_entity in identified_entities:
180 | if identified_entity in trimmed_span and str(value) in identified_entity:
181 | identified_entity_exists = True
182 | value = identified_entity
183 | matched_entity.value_ = value
184 |
185 |
186 |
187 | matched_entities = [me for me in matched_entities if me.name != token.text.upper()]
188 | matched_entities.append(matched_entity)
189 |
190 |
191 | # check of token matches any of the matched column
192 | if token.text.upper() in [m.name for m in matched_columns]:
193 | matched_column = next(mc for mc in matched_columns if mc.name == token.text.upper())
194 |
195 | contextual_span = get_neighbour_tokens(token)
196 | span_ranges = re.split(config.get_phrase_splitter(), contextual_span)
197 | for span in span_ranges:
198 | # print("column : ", span)
199 | if matched_column.name.lower() in span:
200 | matched_column.condition = "="
201 | if "average" in span:
202 | matched_column.isAverage = True
203 | if "avg" in span:
204 | matched_column.isAverage = True
205 | if "maximum" in span:
206 | matched_column.isMax = True
207 | if "max" in span:
208 | matched_column.isMax = True
209 | if "minimum" in span:
210 | matched_column.isMin = True
211 | if "min" in span:
212 | matched_column.isMin = True
213 | if "greater than" in span:
214 | matched_column.condition = ">"
215 | if "more than" in span:
216 | matched_column.condition = ">"
217 | if "less than" in span:
218 | matched_column.condition = "<"
219 | if "count" in span:
220 | matched_column.isCount = True
221 | if "sum" in span:
222 | matched_column.isSum = True
223 | if "total" in span:
224 | matched_column.isSum = True
225 |
226 | trimmed_span = span \
227 | .replace("average", "") \
228 | .replace("maximum", "") \
229 | .replace("minimum", "") \
230 | .replace("greater than", "") \
231 | .replace("less than", "") \
232 | .replace("more than", "") \
233 | .replace("min", "") \
234 | .replace("max", "") \
235 | .replace("count", "") \
236 | .replace("sum", "")
237 | trimmed_span = ' '.join(trimmed_span.split())
238 |
239 | doc_span = nlp(trimmed_span)
240 |
241 | for span_token in doc_span:
242 | if span_token.text.lower() == matched_column.name.lower():
243 | if get_token_child_len(span_token) > 0:
244 | span_token_child = next(itertools.islice(span_token.children, 1))
245 | value = get_value(span_token_child.text, matched_column.type_)
246 |
247 | identified_entity_exists = False
248 | for identified_entity in identified_entities:
249 | if identified_entity in trimmed_span and str(value) in identified_entity and get_value(identified_entity, matched_column.type_) != "NoValue":
250 | identified_entity_exists = True
251 | value = identified_entity
252 | matched_column.value_ = value
253 |
254 |
255 | matched_columns = [mc for mc in matched_columns if mc.name != token.text.upper()]
256 | matched_columns.append(matched_column)
257 |
258 | for loaded_entity in db_model.loaded_entities:
259 | entity_name = loaded_entity[0]
260 | for loaded_entity_value in loaded_entity[1]:
261 | if loaded_entity_value.lower() in lemmatizedSentence.lower():
262 | if entity_name.lower() in [me.name.lower() for me in matched_entities]:
263 | # already exists
264 | # no In operator support as of now
265 | print("entity already processed")
266 | else:
267 | en_def_col = next(col for en in db_model.entities if en.name.lower() == entity_name.lower() for col in en.columns if col.name.lower() == en.defaultColumn.lower())
268 | if get_value(loaded_entity_value, en_def_col.type_) != "NoValue":
269 | ent = Entities(entity_name.upper())
270 | ent.condition = "="
271 | ent.value_ = get_value(loaded_entity_value, en_def_col.type_)
272 | matched_entities.append(ent)
273 |
274 | # final representation of columns (matched_columns) and entities (matched_entities), including max, min, average, conditions
275 | # now next is to build the SQL query generator
276 | # matched entities
277 | # print("####################")
278 | # print("\n".join([(mc.name + " -- " + str(mc.value_) + " -- " + " condition : " + str(mc.condition) + " -- " + " isMax : " + str(mc.isMax) + " -- " + " isMin : " + str(mc.isMin) + " -- " + " isAverage : " + str(mc.isAverage) + " -- " + " isSum : " + str(mc.isSum) + " -- " + " isCount : " + str(mc.isCount)) for mc in matched_entities]))
279 | # print("####################")
280 | # matched columns
281 | # print("\n".join([(mc.name + " -- " + str(mc.value_) + " -- " + " condition : " + str(mc.condition) + " -- " + " isMax : " + str(mc.isMax) + " -- " + " isMin : " + str(mc.isMin) + " -- " + " isAverage : " + str(mc.isAverage)) for mc in matched_columns]))
282 | # print("####################")
283 |
284 | sql_generator = SQLGenerator(matched_entities, matched_columns, db_model)
285 | print("=================================================================================")
286 | result = sql_generator.get_sql()
287 | # print(sql_generator.query)
288 | # print("=================================================================================")
289 | # print(result)
290 | # print("=================================================================================")
291 | response = {}
292 | response['sql'] = sql_generator.query
293 | response['result'] = result[0]
294 | response['columns'] = result[1]
295 | return response
296 |
297 |
298 | app = flask.Flask(__name__)
299 | @app.route('/request', methods=['POST'])
300 | def home():
301 | content = flask.request.get_json()
302 | return flask.jsonify(process_sentence(content['sentence']))
303 |
304 | @app.route('/')
305 | def root():
306 | return flask.send_from_directory('','index.html') # serve root index.html
307 |
308 | app.run()
309 |
310 |
311 |
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lokeshlal/TextToSql/f5d80a73f455452ddc3c851e499d501fd0613ef6/models/__init__.py
--------------------------------------------------------------------------------
/models/columns.py:
--------------------------------------------------------------------------------
1 | class Columns(object):
2 | def __init__(self, name=None, type_=None, isAverage=None, isMax=None, isMin=None, isCount=None, value_=None, condition=None, isSum=None):
3 | self.name = name
4 | self.type_ = type_
5 | self.isAverage = isAverage
6 | self.isMax = isMax
7 | self.isMin = isMin
8 | self.isCount = isCount
9 | self.value_ = value_
10 | self.condition = condition
11 | self.isSum = isSum
--------------------------------------------------------------------------------
/models/db_model.py:
--------------------------------------------------------------------------------
1 | import pyodbc
2 |
3 | from configuration.config import Configuration
4 | from models.entities import Entities
5 | from models.columns import Columns
6 | from models.relationships import Relationship
7 | from models.synonyms import Synonyms
8 |
9 | from spacy.lemmatizer import Lemmatizer
10 | from spacy.lookups import Lookups
11 |
12 |
13 | class DBModel(object):
14 | def __init__(self):
15 | self.entities = []
16 | self.columns = []
17 | self.relationships = []
18 | self.synonyms_col = []
19 | self.synonyms_tab = []
20 | self.entity_graph = []
21 | self.loaded_entities = []
22 | self.config = Configuration()
23 | self.conn = pyodbc.connect(self.config.get_sql_connection_string())
24 | lookups = Lookups()
25 | self.lemmatizer = Lemmatizer(lookups)
26 | self.load_db_model()
27 |
28 | def load_db_model(self):
29 | # loading the database from sql server
30 | cursor = self.conn.cursor()
31 | cursor.execute(self.config.get_tables_sql_query())
32 | for row in cursor:
33 | self.entities.append(Entities(row.table_name, self.config.get_default_column(row.table_name)))
34 |
35 | cursor.execute(self.config.get_columns_sql_query())
36 | current_entity = None
37 | current_entity_name = ""
38 | for row in cursor:
39 | if current_entity_name != row.table_name:
40 | current_entity_name = row.table_name
41 | current_entity = next(en for en in self.entities if en.name == current_entity_name)
42 |
43 | col_type = row.type_name
44 | if col_type == "varchar" or col_type == "nvarchar":
45 | col_type = "string"
46 | current_entity.columns.append(Columns(row.column_name, col_type))
47 |
48 | current_entity = None
49 | current_entity_name = ""
50 | cursor.execute(self.config.get_FK_sql_query())
51 | for row in cursor:
52 | self.relationships.append(Relationship(row.parent_table, row.refrenced_table, row.parent_table_col, row.referenced_table_col))
53 | if len([en for en in self.entity_graph if en[0] == row.parent_table]) > 0:
54 | current_entity = next(en for en in self.entity_graph if en[0] == row.parent_table)
55 | current_entity[1].append(row.refrenced_table)
56 | else:
57 | self.entity_graph.append((row.parent_table, [row.refrenced_table]))
58 |
59 | if len([en for en in self.entity_graph if en[0] == row.refrenced_table]) > 0:
60 | current_entity = next(en for en in self.entity_graph if en[0] == row.refrenced_table)
61 | current_entity[1].append(row.parent_table)
62 | else:
63 | self.entity_graph.append((row.refrenced_table, [row.parent_table]))
64 |
65 | current_entity = None
66 | current_entity_name = ""
67 | cursor.execute(self.config.get_PK_sql_query())
68 | for row in cursor:
69 | if len([en for en in self.entity_graph if en[0] == row.table_name]) == 1:
70 | current_entity = next(en for en in self.entities if en.name == row.table_name)
71 | current_entity.primaryKey = row.primary_key
72 |
73 | for entity_to_load in self.config.get_entitites_to_load():
74 | entity_load_query = "select distinct " + entity_to_load["column"] + " from " + entity_to_load["entity"]
75 | cursor.execute(entity_load_query)
76 | entity_data = (entity_to_load["entity"], [])
77 | for row in cursor:
78 | entity_data[1].append(row[0])
79 | # add lemma strings
80 | lemmas = self.lemmatizer(str(row[0]), u'NOUN')
81 | for lemma in lemmas:
82 | entity_data[1].append(str(lemma))
83 | self.loaded_entities.append(entity_data)
84 |
85 | # load synonyms from declarative file
86 | # table sysnonyms
87 | for table_synonym in self.config.get_synonyms()["table"]:
88 | orginal_val = table_synonym["original"]
89 | synonyms_vals = table_synonym["synonyms"]
90 | for synonyms_val in synonyms_vals:
91 | self.synonyms_tab.append(Synonyms(orginal_val, synonyms_val))
92 |
93 | # column sysnonyms
94 | for column_synonym in self.config.get_synonyms()["column"]:
95 | orginal_val = column_synonym["original"]
96 | synonyms_vals = column_synonym["synonyms"]
97 | for synonyms_val in synonyms_vals:
98 | self.synonyms_col.append(Synonyms(orginal_val, synonyms_val))
99 |
100 |
101 | # make a single array
102 | self.columns = [column for entity in self.entities for column in entity.columns]
103 |
104 |
105 | # might have to write a custom matcher TODO
106 | # build the matcher based upon the original value and domain synonyms defined
107 | def get_matcher(self, matcher, nlp):
108 | for entity in self.entities:
109 | matcher.add(entity.name.upper() + "_TABLE", None, nlp(entity.name.lower()))
110 | for column in entity.columns:
111 | matcher.add(column.name.upper() + "_COLUMN", None, nlp(column.name.lower()))
112 |
113 | # add table synonyms to matcher
114 | for synonym in self.synonyms_tab:
115 | for entity in self.entities:
116 | if synonym.column.lower() == entity.name.lower():
117 | matcher.add(entity.name.upper() + "_TABLE", None, nlp(synonym.synonym.lower()))
118 |
119 | # add column synonyms to matcher
120 | for synonym in self.synonyms_col:
121 | for column in self.columns:
122 | if synonym.column.lower() == column.name.lower():
123 | matcher.add(column.name.upper() + "_COLUMN", None, nlp(synonym.synonym.lower()))
124 |
125 |
126 | return matcher
127 |
128 | def get_custom_matcher(self, matcher, nlp):
129 | for entity in self.entities:
130 | matcher.add(entity.name.upper() + "_TABLE", nlp(entity.name.lower()))
131 | for column in entity.columns:
132 | matcher.add(column.name.upper() + "_COLUMN", nlp(column.name.lower()))
133 |
134 | # add table synonyms to matcher
135 | for synonym in self.synonyms_tab:
136 | for entity in self.entities:
137 | if synonym.column.lower() == entity.name.lower():
138 | matcher.add(entity.name.upper() + "_TABLE", nlp(synonym.synonym.lower()))
139 |
140 | # add column synonyms to matcher
141 | for synonym in self.synonyms_col:
142 | for column in self.columns:
143 | if synonym.column.lower() == column.name.lower():
144 | matcher.add(column.name.upper() + "_COLUMN", nlp(synonym.synonym.lower()))
145 |
146 |
147 | return matcher
148 |
--------------------------------------------------------------------------------
/models/entities.py:
--------------------------------------------------------------------------------
1 | class Entities(object):
2 | def __init__(self, name=None, defaultColumn=None, primaryKey=None, isAverage=None, isMax=None, isMin=None, isCount=None, columns=None, condition=None, value_=None, isSum=None):
3 | self.name = name
4 | self.isAverage = isAverage
5 | self.isMax = isMax
6 | self.isMin = isMin
7 | self.isCount = isCount
8 | self.columns = []
9 | self.value_ = value_
10 | self.condition = condition
11 | self.defaultColumn = defaultColumn
12 | self.primaryKey = primaryKey
13 | self.isSum = isSum
14 |
--------------------------------------------------------------------------------
/models/matcher.py:
--------------------------------------------------------------------------------
1 | import copy
2 |
3 |
4 | class Matcher(object):
5 | def __init__(self):
6 | self.matcher = []
7 | return super().__init__()
8 |
9 | def add(self, key, value):
10 | self.matcher.append((key, value))
11 |
12 | def find(self, phrase):
13 | matches = []
14 | for match in self.matcher:
15 | if " " + str(match[1]) + " " in phrase \
16 | or phrase.startswith(str(match[1]) + " ") \
17 | or phrase.endswith(" " + str(match[1])):
18 | matches.append(copy.copy(match))
19 | return matches
20 |
--------------------------------------------------------------------------------
/models/relationships.py:
--------------------------------------------------------------------------------
1 | class Relationship(object):
2 | def __init__(self, entity1, entity2, column1, column2):
3 | self.entity1 = entity1
4 | self.entity2 = entity2
5 | self.column1 = column1
6 | self.column2 = column2
7 |
8 |
--------------------------------------------------------------------------------
/models/sql_model.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import pyodbc
3 |
4 | from configuration.config import Configuration
5 | from models.columns import Columns
6 |
7 |
8 | class SQLGenerator(object):
9 | def __init__(self, entities, columns, db_model):
10 | self.columns = columns
11 | self.entities = entities
12 | self.db_model = db_model
13 | self.entity_column_mapping = []
14 | self.joins = []
15 | self.conditions = []
16 | self.select = []
17 | self.query = ""
18 | self.entities_parsed = []
19 | self.isMaxRequired = ""
20 | self.isMaxRequiredEntity = ""
21 | self.isMinRequired = ""
22 | self.isMinRequiredEntity = ""
23 | self.isAverage = ""
24 | self.isAverageEntity = ""
25 | self.isCount = ""
26 | self.isCountEntity = ""
27 | self.isSum = ""
28 | self.isSumEntity = ""
29 | self.config = Configuration()
30 | self.conn = pyodbc.connect(self.config.get_sql_connection_string())
31 |
32 | def run_query(self):
33 | cursor = self.conn.cursor()
34 | cursor.execute(self.query)
35 | result = []
36 | columns = []
37 | for row in cursor:
38 | result.append([col for col in row])
39 |
40 | columns = [column[0] for column in cursor.description]
41 | return [result, columns]
42 |
43 |
44 | def sortSecond(self, join_comb):
45 | return join_comb[0]
46 |
47 | def get_from_clause(self, level):
48 | # build the from_clause
49 | from_clause = ""
50 | if len(self.entity_column_mapping) == 1:
51 | from_clause = self.entity_column_mapping[0][0] + " " + self.entity_column_mapping[0][0] + level
52 | elif len(self.entity_column_mapping) > 1:
53 | from_clause = ""
54 | join_index = 0
55 | entity_included_in_join = []
56 | for join in self.joins:
57 | if join_index == 0:
58 | from_clause = from_clause + join[0] + " " + join[0] + level + " JOIN " + join[1] + " " + join[1] + level + " ON " + join[0] + level + "." + join[2] + "=" + join[1] + level + "." + join[3]
59 | entity_included_in_join.append(join[0])
60 | entity_included_in_join.append(join[1])
61 | else:
62 | if join[0] in entity_included_in_join:
63 | from_clause = from_clause + " " + " JOIN " + join[1] + " " + join[1] + level + " ON " + join[0]+ level + "." + join[2] + " = " + join[1] + level + "." + join[3]
64 | else:
65 | from_clause = from_clause + " JOIN " + join[0] + " " + join[0] + level + " ON " + join[0] + level + "." + join[2] + " = " + join[1] + level + "." + join[3]
66 | join_index = join_index + 1
67 | return from_clause
68 |
69 | def get_where_clause(self, level):
70 | return " and ".join([cond[0] + level + "." + cond[1] + " " + cond[2] + " " + cond[3] for cond in self.conditions])
71 |
72 | def get_select_clause(self, level):
73 | return ", ".join([col[0] + level + "." + col[1] for col in self.select])
74 |
75 | def correlated_sub_query_in_where(self,
76 | column,
77 | entity,
78 | type_): # type = min, max
79 | # from clause
80 | from_clause = self.get_from_clause("1")
81 | # select clause
82 | select_clause = self.get_select_clause("1")
83 | # where clause
84 | where_clause = self.get_where_clause("1")
85 |
86 | type_sub_query_where_clause = self.get_where_clause("2")
87 | type_sub_query_from_clause = self.get_from_clause("2")
88 |
89 | if type_sub_query_where_clause != "":
90 | type_sub_query_where_clause = " Where " + type_sub_query_where_clause
91 |
92 | typeQuery = "SELECT " + \
93 | type_ + "(" + entity + "2." + column + ") " + \
94 | " From " + \
95 | type_sub_query_from_clause + \
96 | type_sub_query_where_clause
97 | if select_clause != "":
98 | select_clause = select_clause + ", "
99 | if where_clause != "":
100 | where_clause = where_clause + " and "
101 | self.query = "SELECT " + \
102 | select_clause + entity + "1." + column + " " + \
103 | " From " + \
104 | from_clause + \
105 | " Where " + \
106 | where_clause + \
107 | entity + "1." + column + " = (" + typeQuery + ")"
108 |
109 | def correlated_sub_query_in_select(self,
110 | column,
111 | entity,
112 | type_): # type = avg, sum, count
113 | # from clause
114 | from_clause = self.get_from_clause("1")
115 | # select clause
116 | select_clause = self.get_select_clause("1")
117 | # where clause
118 | where_clause = self.get_where_clause("1")
119 |
120 | type_sub_query_where_clause = self.get_where_clause("2")
121 | type_sub_query_from_clause = self.get_from_clause("2")
122 |
123 | # find the identifier column of the entity in parameter
124 | db_model_ent = next(e for e in self.db_model.entities if e.name.lower() == entity.lower())
125 | # db_model_ent.primaryKey
126 | # correlation
127 |
128 | # find where this table is being referenced
129 | entity_relationships = [(rel.entity1, rel.column1) for rel in self.db_model.relationships if (rel.entity2 == entity)]
130 |
131 | correlation_entity = entity
132 | correlation_entity_column = db_model_ent.primaryKey
133 | parent_entity_exists = False
134 | parent_entries = []
135 | if len(self.entity_column_mapping) > 1:
136 | for ecm in self.entity_column_mapping:
137 | if ecm[0] != entity:
138 | if ecm[0] in [ent[0] for ent in entity_relationships]:
139 | parent_entry = next(ent for ent in entity_relationships if ent[0] == ecm[0])
140 | parent_entity_exists = True
141 | parent_entries.append(parent_entry)
142 | elif len(self.entity_column_mapping) == 1:
143 | # only one entity, use where filters
144 | correlation = " and ".join([cond[0] + "1" + "." + cond[1] + " = " + cond[0] + "2" + "." + cond[1] for cond in self.conditions])
145 |
146 | if len(self.entity_column_mapping) > 1:
147 | if parent_entity_exists == True and len(parent_entry) > 0:
148 | correlations = []
149 | for parent_entry in parent_entries:
150 | correlations.append(parent_entry[0] + "2." + parent_entry[1] + "=" + parent_entry[0] + "1." + parent_entry[1])
151 | correlation = " and ".join(correlations)
152 | else:
153 | correlation = entity + "2." + db_model_ent.primaryKey + "=" + entity + "1." + db_model_ent.primaryKey
154 |
155 | if type_sub_query_where_clause == "":
156 | type_sub_query_where_clause = correlation
157 | else:
158 | type_sub_query_where_clause = type_sub_query_where_clause + " and " + correlation
159 |
160 | if type_sub_query_where_clause != "":
161 | type_sub_query_where_clause = " Where " + type_sub_query_where_clause
162 |
163 | type_sub_query = "SELECT " + \
164 | type_ + "(" + entity + "2." + column + ") " + \
165 | " From " + \
166 | type_sub_query_from_clause + \
167 | type_sub_query_where_clause
168 |
169 | if select_clause != "":
170 | select_clause = select_clause + ", "
171 |
172 | if where_clause != "":
173 | where_clause = " Where " + where_clause
174 |
175 | self.query = "SELECT distinct " + \
176 | select_clause + "(" + type_sub_query + ") as " + type_ + "_" + column + " " + \
177 | " From " + \
178 | from_clause + \
179 | where_clause
180 |
181 |
182 | def build_query(self):
183 |
184 | # maximum case
185 | if self.isMaxRequired != "":
186 | self.correlated_sub_query_in_where(self.isMaxRequired, self.isMaxRequiredEntity,"max")
187 | # minimum case
188 | elif self.isMinRequired != "":
189 | self.correlated_sub_query_in_where(self.isMinRequired, self.isMinRequiredEntity,"min")
190 | # average case
191 | elif self.isAverage != "":
192 | self.correlated_sub_query_in_select(self.isAverage, self.isAverageEntity, "avg")
193 | # count
194 | elif self.isCount != "":
195 | self.correlated_sub_query_in_select(self.isCount, self.isCountEntity, "count")
196 | # sum
197 | elif self.isSum != "":
198 | self.correlated_sub_query_in_select(self.isSum, self.isSumEntity, "sum")
199 | # regular
200 | else:
201 | # from clause
202 | from_clause = self.get_from_clause("1")
203 | # select clause
204 | select_clause = self.get_select_clause("1")
205 | # where clause
206 | where_clause = self.get_where_clause("1")
207 |
208 | if where_clause != "":
209 | where_clause = " Where " + where_clause
210 | self.query = "SELECT distinct " + \
211 | select_clause + " " + \
212 | " From " + \
213 | from_clause + \
214 | where_clause
215 |
216 | def find_select(self):
217 | for ecm in self.entity_column_mapping:
218 | # column mapping within entity
219 | for cm in ecm[1]:
220 | # if cm.condition is None and cm.value_ is None:
221 | if cm.value_ is None or cm.value_ == "NoValue":
222 | # entity, column name, [Avg, Min, Max, Sum, Count]
223 | # add the where clause here for min, max and sum conditions
224 | if cm.isMax == True:
225 | self.isMaxRequired = cm.name.lower()
226 | self.isMaxRequiredEntity = ecm[0]
227 | elif cm.isMin == True:
228 | self.isMinRequired = cm.name.lower()
229 | self.isMinRequiredEntity = ecm[0]
230 | elif cm.isAverage == True:
231 | self.isAverage = cm.name.lower()
232 | self.isAverageEntity = ecm[0]
233 | elif cm.isCount == True:
234 | self.isCount = cm.name.lower()
235 | self.isCountEntity = ecm[0]
236 | elif cm.isSum == True:
237 | self.isSum = cm.name.lower()
238 | self.isSumEntity = ecm[0]
239 | else:
240 | # check for duplicates
241 | if len([sel for sel in self.select if sel[0].lower() == ecm[0].lower() and sel[1].lower() == cm.name.lower()]) == 0:
242 | self.select.append((ecm[0], cm.name.lower(), None))
243 |
244 |
245 |
246 | for ent in self.entities:
247 | # TODO... add max, min..etc case
248 | # get default column from db_model
249 | db_model_ent = next(e for e in self.db_model.entities if e.name.lower() == ent.name.lower())
250 | # check for duplicates
251 | if len([sel for sel in self.select if sel[0].lower() == ent.name.lower() and sel[1].lower() == db_model_ent.defaultColumn.lower()]) == 0:
252 | self.select.append((ent.name.lower(), db_model_ent.defaultColumn, None))
253 |
254 | def find_conditions(self):
255 | # entity column mapping
256 | for ecm in self.entity_column_mapping:
257 | # column mapping within entity
258 | for cm in ecm[1]:
259 | if cm.condition is not None and cm.value_ is not None and cm.value_ != "NoValue":
260 | val = cm.value_
261 | if cm.type_ == "string":
262 | val = "'" + val + "'"
263 | self.conditions.append((ecm[0], cm.name.lower(), cm.condition, str(val)))
264 |
265 | def find_relationships(self):
266 | i = 0
267 | j = 0
268 | while i < len(self.entity_column_mapping):
269 | j = i + 1
270 | base_entity = self.entity_column_mapping[i][0]
271 | while j < len(self.entity_column_mapping):
272 | join_entity = self.entity_column_mapping[j][0]
273 | if len([rel for rel in self.db_model.relationships if ((rel.entity1 == base_entity and rel.entity2 == join_entity) or (rel.entity2 == base_entity and rel.entity1 == join_entity))]) == 1:
274 | rel = next(rel for rel in self.db_model.relationships if ((rel.entity1 == base_entity and rel.entity2 == join_entity) or (rel.entity2 == base_entity and rel.entity1 == join_entity)))
275 |
276 | if rel.entity1 == base_entity:
277 | self.joins.append((base_entity, join_entity, rel.column1, rel.column2))
278 | else:
279 | self.joins.append((join_entity, base_entity, rel.column1, rel.column2))
280 | j = j + 1
281 | i = i + 1
282 |
283 | if len(self.joins) == 0 and len(self.entity_column_mapping) > 1:
284 | # try to find the relationship using db model's entity_graph
285 | i = 0
286 | entities_mapped = []
287 | while i < (len(self.entity_column_mapping) - 1):
288 | base_entity = self.entity_column_mapping[i]
289 | join_entity = self.entity_column_mapping[i + 1]
290 | if base_entity[0] not in entities_mapped:
291 | entities_mapped.append(entities_mapped)
292 | found, entities_mapped = self.find_entities_relationship(base_entity, join_entity, entities_mapped)
293 | i = i + 1
294 |
295 | i = 0
296 | j = 0
297 | while i < len(entities_mapped):
298 | j = i + 1
299 | base_entity = entities_mapped[i]
300 | while j < len(entities_mapped):
301 | join_entity = entities_mapped[j]
302 | if len([rel for rel in self.db_model.relationships if ((rel.entity1 == base_entity and rel.entity2 == join_entity) or (rel.entity2 == base_entity and rel.entity1 == join_entity))]) == 1:
303 | rel = next(rel for rel in self.db_model.relationships if ((rel.entity1 == base_entity and rel.entity2 == join_entity) or (rel.entity2 == base_entity and rel.entity1 == join_entity)))
304 |
305 | if rel.entity1 == base_entity:
306 | self.joins.append((base_entity, join_entity, rel.column1, rel.column2))
307 | else:
308 | self.joins.append((join_entity, base_entity, rel.column1, rel.column2))
309 | j = j + 1
310 | i = i + 1
311 |
312 | def find_entities_relationship(self, base_entity, join_entity, entities_mapped):
313 |
314 | entities_to_be_included = copy.copy(entities_mapped)
315 | found = False
316 | base_entity_graph = next(eg for eg in self.db_model.entity_graph if eg[0].lower() == base_entity[0].lower())
317 | for child_entity_in_graph in base_entity_graph[1]:
318 | if child_entity_in_graph == join_entity[0]:
319 | entities_to_be_included.append(child_entity_in_graph)
320 | found = True
321 | break;
322 | child_entity_graph = next(eg for eg in self.db_model.entity_graph if eg[0].lower() == child_entity_in_graph.lower())
323 | entities_to_be_included_temp = copy.copy(entities_to_be_included)
324 | if child_entity_in_graph not in entities_to_be_included_temp:
325 | entities_to_be_included_temp.append(child_entity_in_graph)
326 | found, entities_to_be_included = self.find_entities_relationship(child_entity_graph, join_entity, entities_to_be_included_temp)
327 | if found:
328 | break;
329 |
330 | if found:
331 | for entity_to_be_included in entities_to_be_included:
332 | if entity_to_be_included not in entities_mapped:
333 | entities_mapped.append(entity_to_be_included)
334 |
335 | return (found, entities_to_be_included)
336 |
337 |
338 | def find_column(self, column, entityName):
339 | column_parent_entity_found = False
340 | # get the db model for entity
341 | db_model_entity = next(model_entity for model_entity in self.db_model.entities if model_entity.name == entityName.lower())
342 |
343 | # add entity into parsed collection
344 | self.entities_parsed.append(entityName)
345 |
346 | # check if the column exists in the db_model
347 | if column.name.lower() in [db_model_column.name for db_model_column in db_model_entity.columns]:
348 | # column parent found, break the loop
349 | column_parent_entity_found = True
350 | return (column_parent_entity_found, db_model_entity.name, column)
351 |
352 | # if column does not exists in db_model_entity
353 | # then look for the related entities
354 | if column_parent_entity_found == False:
355 | # look for related entities
356 | for model_entity in [model_entity for model_entities in self.db_model.entity_graph if model_entities[0].lower() == entityName.lower() for model_entity in model_entities[1]]:
357 |
358 | # only process, if not processed before
359 | if len([ep for ep in self.entities_parsed if ep.lower() == model_entity]) == 0:
360 | column_parent_entity_found, model_name, columnName = self.find_column(column, model_entity)
361 | # column found, return entity with column
362 | if column_parent_entity_found == True:
363 | return (column_parent_entity_found, model_name, columnName)
364 |
365 | # column not found
366 | return (column_parent_entity_found, None, None)
367 |
368 | def find_entity(self, column):
369 | column_parent_entity_found = False
370 | for entity in self.entities:
371 | column_parent_entity_found, model_name, columnName = self.find_column(column, entity.name)
372 | # column found, return entity with column
373 | if column_parent_entity_found == True:
374 | return (column_parent_entity_found, model_name, columnName)
375 |
376 | return (column_parent_entity_found, None, None)
377 |
378 |
379 | def get_sql(self):
380 | if len(self.entities) > 0:
381 | for column in self.columns:
382 | # reset the entities_parsed array for new column
383 | self.entities_parsed = []
384 | column_parent_entity_found, model_name, columnName = self.find_entity(column)
385 |
386 | if column_parent_entity_found == True:
387 | if len([ecm for ecm in self.entity_column_mapping if ecm[0] == model_name]) == 1:
388 | ecm = next(ecm for ecm in self.entity_column_mapping if ecm[0] == model_name)
389 | ecm[1].append(columnName)
390 | else:
391 | self.entity_column_mapping.append((model_name, [columnName]))
392 | else:
393 | print("Column " + column.name + " not found.. ignoring column")
394 |
395 | for entity in self.entities:
396 | if entity.condition is not None and entity.value_ is not None:
397 | # reset the entities_parsed array for new column
398 | model_name = entity.name
399 |
400 | ent = next(en for en in self.db_model.entities if en.name.lower() == entity.name.lower())
401 | default_column = next(col for col in ent.columns if col.name.lower() == ent.defaultColumn.lower())
402 | copy_default_column = copy.copy(default_column)
403 | copy_default_column.condition = entity.condition
404 | copy_default_column.value_ = entity.value_
405 | copy_default_column.isSum = entity.isSum
406 | copy_default_column.isAverage = entity.isAverage
407 | copy_default_column.isCount = entity.isCount
408 | copy_default_column.isMin = entity.isMin
409 | copy_default_column.isMax = entity.isMax
410 |
411 | if len([ecm for ecm in self.entity_column_mapping if ecm[0].lower() == model_name.lower()]) == 1:
412 | ecm = next(ecm for ecm in self.entity_column_mapping if ecm[0].lower() == model_name.lower())
413 | ecm[1].append(copy_default_column)
414 | else:
415 | self.entity_column_mapping.append((model_name.lower(), [copy_default_column]))
416 | else:
417 | if len([ecm for ecm in self.entity_column_mapping if ecm[0].lower() == entity.name.lower()]) == 0:
418 | self.entity_column_mapping.append((entity.name.lower(), []))
419 | else:
420 | ecm = next(ecm for ecm in self.entity_column_mapping if ecm[0].lower() == entity.name.lower())
421 |
422 | ent = next(en for en in self.db_model.entities if en.name.lower() == entity.name.lower())
423 | default_column = next(col for col in ent.columns if col.name.lower() == ent.defaultColumn.lower())
424 | copy_default_column = copy.copy(default_column)
425 | copy_default_column.condition = entity.condition
426 | copy_default_column.value_ = entity.value_
427 | copy_default_column.isSum = entity.isSum
428 | copy_default_column.isAverage = entity.isAverage
429 | copy_default_column.isCount = entity.isCount
430 | copy_default_column.isMin = entity.isMin
431 | copy_default_column.isMax = entity.isMax
432 | ecm[1].append(copy_default_column)
433 |
434 | elif len(self.columns) > 0:
435 | # No entities identified in the phrase
436 | # Finding...entities as per the columns identified in the phrase
437 | for col in self.columns:
438 | max_col_found_count = 0
439 | max_col_found_count_entity = ""
440 | # look for columns and find max column in an entity and related entities"
441 | for entity in self.db_model.entities:
442 | column_found_count = 0
443 | if col.name.lower() in [col.name.lower() for col in entity.columns]:
444 | column_found_count = column_found_count + 1
445 | if max_col_found_count < column_found_count:
446 | max_col_found_count = column_found_count
447 | max_col_found_count_entity = entity.name
448 |
449 | if max_col_found_count_entity != "":
450 | if len([ecm for ecm in self.entity_column_mapping if ecm[0] == max_col_found_count_entity]) == 1:
451 | ecm = next(ecm for ecm in self.entity_column_mapping if ecm[0] == max_col_found_count_entity)
452 | ecm[1].append(col)
453 | else:
454 | self.entity_column_mapping.append((max_col_found_count_entity, [col]))
455 | else:
456 | # no column and entity identified
457 | return []
458 |
459 | # print([(e[0], [ec.name for ec in e[1]]) for e in self.entity_column_mapping])
460 | # build the sql
461 | self.find_relationships()
462 | self.find_conditions()
463 | self.find_select()
464 | self.build_query()
465 | print(self.query)
466 | return self.run_query()
467 |
468 |
--------------------------------------------------------------------------------
/models/sql_scripts/columns.sql:
--------------------------------------------------------------------------------
1 | select
2 | t.object_id as table_id,
3 | t.[name] as table_name,
4 | c.[name] as column_name,
5 | c.[column_id] as column_id,
6 | c.[system_type_id],
7 | ty.[name] as type_name
8 | from
9 | sys.columns c
10 | join sys.tables t
11 | on c.object_id = t.object_id
12 | join sys.types ty
13 | on c.system_type_id = ty.user_type_id
14 | where
15 | t.type = 'U'
16 | order by
17 | t.[name], c.[column_id]
18 |
--------------------------------------------------------------------------------
/models/sql_scripts/foreign_keys.sql:
--------------------------------------------------------------------------------
1 | SELECT
2 | tr.name 'parent_table',
3 | cr.name 'parent_table_col', cr.column_id,
4 | tp.name 'refrenced_table',
5 | cp.name as 'referenced_table_col', cp.column_id
6 | FROM
7 | sys.foreign_keys fk
8 | INNER JOIN
9 | sys.tables tp ON fk.parent_object_id = tp.object_id
10 | INNER JOIN
11 | sys.tables tr ON fk.referenced_object_id = tr.object_id
12 | INNER JOIN
13 | sys.foreign_key_columns fkc ON fkc.constraint_object_id = fk.object_id
14 | INNER JOIN
15 | sys.columns cp ON fkc.parent_column_id = cp.column_id AND fkc.parent_object_id = cp.object_id
16 | INNER JOIN
17 | sys.columns cr ON fkc.referenced_column_id = cr.column_id AND fkc.referenced_object_id = cr.object_id
18 | where
19 | tr.type = 'U'
20 | ORDER BY
21 | tp.name, cp.column_id
22 |
--------------------------------------------------------------------------------
/models/sql_scripts/primary_keys.sql:
--------------------------------------------------------------------------------
1 | SELECT OBJECT_NAME(ic.OBJECT_ID) AS table_name,
2 | COL_NAME(ic.OBJECT_ID,ic.column_id) AS primary_key
3 | FROM sys.indexes AS i INNER JOIN
4 | sys.index_columns AS ic ON i.OBJECT_ID = ic.OBJECT_ID
5 | AND i.index_id = ic.index_id
6 | WHERE i.is_primary_key = 1
--------------------------------------------------------------------------------
/models/sql_scripts/tables.sql:
--------------------------------------------------------------------------------
1 | select
2 | object_id as table_id,
3 | [name] as table_name
4 | from
5 | sys.tables
6 | where
7 | type = 'U';
--------------------------------------------------------------------------------
/models/synonyms.py:
--------------------------------------------------------------------------------
1 | class Synonyms(object):
2 | def __init__(self, column, synonym):
3 | self.column = column
4 | self.synonym = synonym
--------------------------------------------------------------------------------
/models/type_converter.py:
--------------------------------------------------------------------------------
1 | def get_value(value, type):
2 | if type == "string":
3 | return str(value)
4 | elif type == "int":
5 | try:
6 | return int(value)
7 | except ValueError:
8 | return "NoValue"
9 | elif type == "float":
10 | try:
11 | return float(value)
12 | except ValueError:
13 | return "NoValue"
14 | return "NoValue"
15 |
16 | def get_type(value, type):
17 | if type == "string":
18 | type = "str"
19 | if type(value).__name__ == type:
20 | return True
21 | else:
22 | return False
23 |
24 | def replace_string(phrase, original, replacement):
25 | result = phrase.lower().find(original.lower())
26 | new_replacement = replacement
27 | if result != -1:
28 | if phrase[result].isupper():
29 | new_replacement = new_replacement[0].upper() + new_replacement[1:].lower()
30 | if phrase[result].islower():
31 | new_replacement = new_replacement.lower()
32 | string_to_replace = phrase[result:(result + len(original))]
33 | phrase = phrase.replace(string_to_replace, new_replacement)
34 | return phrase
35 |
36 | def replace_entities(phrase, original, replacement):
37 | result = phrase.lower().find(original.lower())
38 | if result != -1:
39 | string_to_replace = phrase[result:(result + len(original))]
40 | phrase = phrase.replace(string_to_replace, replacement)
41 | return phrase
42 |
43 |
44 | def get_token_child_len(token):
45 | children_length = len([child.text for child in token.children])
46 | return children_length
47 |
48 | def get_neighbour_tokens(token):
49 | span = ""
50 | for i in range(-4, 6):
51 | try:
52 | span += token.nbor(i).text + " "
53 | except IndexError:
54 | span = span
55 |
56 | return span.lstrip()
57 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | pyodbc
2 | spacy
3 | flask
4 |
--------------------------------------------------------------------------------
/sql_scripts/data_feed.sql:
--------------------------------------------------------------------------------
1 | -- delete any existing data
2 | delete from [student_mark]
3 | delete from [student]
4 | delete from [subject]
5 | -- reseed the identity column
6 | DBCC CHECKIDENT ('student', RESEED, 1)
7 | DBCC CHECKIDENT ('subject', RESEED, 1)
8 | DBCC CHECKIDENT ('student_mark', RESEED, 1)
9 | -- insert student
10 | insert into [student] ([name], [age], [class]) values ('Lokesh Lal', 17, 12)
11 | insert into [student] ([name], [age], [class]) values ('Munish Sharma', 18, 12)
12 | insert into [student] ([name], [age], [class]) values ('Sumit Chharia', 18, 12)
13 | insert into [student] ([name], [age], [class]) values ('Manoj Gupta', 17, 12)
14 | insert into [student] ([name], [age], [class]) values ('Vishal Gupta', 19, 12)
15 | insert into [student] ([name], [age], [class]) values ('Ambika Shukla', 20, 12)
16 | insert into [student] ([name], [age], [class]) values ('Manoj Garg', 18, 12)
17 | insert into [student] ([name], [age], [class]) values ('Gagandeep sampat', 19, 12)
18 | -- insert subject
19 | insert into [subject] ([name], [class]) values ('English', 12)
20 | insert into [subject] ([name], [class]) values ('Maths', 12)
21 | insert into [subject] ([name], [class]) values ('Physics', 12)
22 | insert into [subject] ([name], [class]) values ('Chemistry', 12)
23 | insert into [subject] ([name], [class]) values ('Computer', 12)
24 | insert into [subject] ([name], [class]) values ('Biology', 12)
25 | -- insert student mark
26 | declare @student_id INT = 1
27 | declare @subject_id INT = 1
28 | declare @max_student_id INT
29 | declare @max_subject_id INT
30 | select @max_student_id = count(1) from [student]
31 | select @max_subject_id = count(1) from [subject]
32 |
33 | WHILE @student_id <= @max_student_id
34 | BEGIN
35 | set @subject_id = 1
36 | while @subject_id <= @max_subject_id
37 | BEGIN
38 | insert into [student_mark] ([student_id], [subject_id], [mark], [year])
39 | select @student_id, @subject_id, FLOOR(RAND()*(70-40+1)+40), 2019
40 | set @subject_id = @subject_id + 1
41 | END
42 | set @student_id = @student_id + 1
43 | END
44 |
45 |
46 |
--------------------------------------------------------------------------------
/sql_scripts/metadata_sql_queries.sql:
--------------------------------------------------------------------------------
1 | select
2 | object_id as table_id,
3 | [name] as table_name
4 | from
5 | sys.tables
6 | where
7 | type = 'U';
8 |
9 | select
10 | t.object_id as table_id,
11 | t.[name] as table_name,
12 | c.[name] as column_name,
13 | c.[column_id] as column_id,
14 | c.[system_type_id],
15 | ty.[name] as type_name
16 | from
17 | sys.columns c
18 | join sys.tables t
19 | on c.object_id = t.object_id
20 | join sys.types ty
21 | on c.system_type_id = ty.user_type_id
22 | where
23 | t.type = 'U';
24 |
25 | SELECT
26 | tp.name 'Parent table',
27 | cp.name, cp.column_id,
28 | tr.name 'Refrenced table',
29 | cr.name, cr.column_id
30 | FROM
31 | sys.foreign_keys fk
32 | INNER JOIN
33 | sys.tables tp ON fk.parent_object_id = tp.object_id
34 | INNER JOIN
35 | sys.tables tr ON fk.referenced_object_id = tr.object_id
36 | INNER JOIN
37 | sys.foreign_key_columns fkc ON fkc.constraint_object_id = fk.object_id
38 | INNER JOIN
39 | sys.columns cp ON fkc.parent_column_id = cp.column_id AND fkc.parent_object_id = cp.object_id
40 | INNER JOIN
41 | sys.columns cr ON fkc.referenced_column_id = cr.column_id AND fkc.referenced_object_id = cr.object_id
42 | where
43 | tr.type = 'U'
44 | ORDER BY
45 | tp.name, cp.column_id
46 |
47 | SELECT OBJECT_NAME(ic.OBJECT_ID) AS TableName,
48 | COL_NAME(ic.OBJECT_ID,ic.column_id) AS ColumnName
49 | FROM sys.indexes AS i INNER JOIN
50 | sys.index_columns AS ic ON i.OBJECT_ID = ic.OBJECT_ID
51 | AND i.index_id = ic.index_id
52 | WHERE i.is_primary_key = 1
53 |
--------------------------------------------------------------------------------
/sql_scripts/sql_schema.sql:
--------------------------------------------------------------------------------
1 | drop table [student_mark]
2 | drop table [student]
3 | drop table [subject]
4 |
5 | create table student
6 | (
7 | [id] int not null identity(1,1) primary key,
8 | [name] nvarchar(50) not null,
9 | [age] int not null,
10 | [class] int not null
11 | )
12 |
13 | create table [subject]
14 | (
15 | [id] int not null identity(1,1) primary key,
16 | [name] nvarchar(50) not null,
17 | [class] int not null
18 | )
19 |
20 | create table [student_mark]
21 | (
22 | [id] int not null identity(1,1) primary key,
23 | [student_id] int not null,
24 | [subject_id] int not null,
25 | [mark] int not null,
26 | [year] int not null,
27 | FOREIGN KEY ([student_id]) REFERENCES [student]([id]),
28 | FOREIGN KEY ([subject_id]) REFERENCES [subject]([id])
29 | )
--------------------------------------------------------------------------------
/ss.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lokeshlal/TextToSql/f5d80a73f455452ddc3c851e499d501fd0613ef6/ss.jpg
--------------------------------------------------------------------------------
/static/sql-formatter.min.js:
--------------------------------------------------------------------------------
1 | !function(e,t){"object"==typeof exports&&"object"==typeof module?module.exports=t():"function"==typeof define&&define.amd?define([],t):"object"==typeof exports?exports.sqlFormatter=t():e.sqlFormatter=t()}(this,function(){return function(e){function t(n){if(E[n])return E[n].exports;var r=E[n]={exports:{},id:n,loaded:!1};return e[n].call(r.exports,r,r.exports,t),r.loaded=!0,r.exports}var E={};return t.m=e,t.c=E,t.p="",t(0)}([function(e,t,E){"use strict";function n(e){return e&&e.__esModule?e:{default:e}}t.__esModule=!0;var r=E(24),o=n(r),T=E(25),R=n(T),N=E(26),i=n(N),A=E(27),I=n(A);t.default={format:function(e,t){switch(t=t||{},t.language){case"db2":return new o.default(t).format(e);case"n1ql":return new R.default(t).format(e);case"pl/sql":return new i.default(t).format(e);case"sql":case void 0:return new I.default(t).format(e);default:throw Error("Unsupported SQL dialect: "+t.language)}}},e.exports=t.default},function(e,t,E){var n=E(12),r="object"==typeof self&&self&&self.Object===Object&&self,o=n||r||Function("return this")();e.exports=o},function(e,t,E){function n(e){return null==e?void 0===e?N:R:i&&i in Object(e)?o(e):T(e)}var r=E(9),o=E(48),T=E(57),R="[object Null]",N="[object Undefined]",i=r?r.toStringTag:void 0;e.exports=n},function(e,t,E){function n(e,t){var E=o(e,t);return r(E)?E:void 0}var r=E(39),o=E(50);e.exports=n},function(e,t,E){"use strict";function n(e){return e&&e.__esModule?e:{default:e}}function r(e,t){if(!(e instanceof t))throw new TypeError("Cannot call a class as a function")}t.__esModule=!0;var o=E(74),T=n(o),R=E(8),N=n(R),i=E(21),A=n(i),I=E(22),O=n(I),u=E(23),S=n(u),a=function(){function e(t,E){r(this,e),this.cfg=t||{},this.indentation=new A.default(this.cfg.indent),this.inlineBlock=new O.default,this.params=new S.default(this.cfg.params),this.tokenizer=E,this.previousReservedWord={},this.tokens=[],this.index=0}return e.prototype.format=function(e){this.tokens=this.tokenizer.tokenize(e);var t=this.getFormattedQueryFromTokens();return t.trim()},e.prototype.getFormattedQueryFromTokens=function(){var e=this,t="";return this.tokens.forEach(function(E,n){e.index=n,E.type===N.default.WHITESPACE||(E.type===N.default.LINE_COMMENT?t=e.formatLineComment(E,t):E.type===N.default.BLOCK_COMMENT?t=e.formatBlockComment(E,t):E.type===N.default.RESERVED_TOPLEVEL?(t=e.formatToplevelReservedWord(E,t),e.previousReservedWord=E):E.type===N.default.RESERVED_NEWLINE?(t=e.formatNewlineReservedWord(E,t),e.previousReservedWord=E):E.type===N.default.RESERVED?(t=e.formatWithSpaces(E,t),e.previousReservedWord=E):t=E.type===N.default.OPEN_PAREN?e.formatOpeningParentheses(E,t):E.type===N.default.CLOSE_PAREN?e.formatClosingParentheses(E,t):E.type===N.default.PLACEHOLDER?e.formatPlaceholder(E,t):","===E.value?e.formatComma(E,t):":"===E.value?e.formatWithSpaceAfter(E,t):"."===E.value?e.formatWithoutSpaces(E,t):";"===E.value?e.formatQuerySeparator(E,t):e.formatWithSpaces(E,t))}),t},e.prototype.formatLineComment=function(e,t){return this.addNewline(t+e.value)},e.prototype.formatBlockComment=function(e,t){return this.addNewline(this.addNewline(t)+this.indentComment(e.value))},e.prototype.indentComment=function(e){return e.replace(/\n/g,"\n"+this.indentation.getIndent())},e.prototype.formatToplevelReservedWord=function(e,t){return this.indentation.decreaseTopLevel(),t=this.addNewline(t),this.indentation.increaseToplevel(),t+=this.equalizeWhitespace(e.value),this.addNewline(t)},e.prototype.formatNewlineReservedWord=function(e,t){return this.addNewline(t)+this.equalizeWhitespace(e.value)+" "},e.prototype.equalizeWhitespace=function(e){return e.replace(/\s+/g," ")},e.prototype.formatOpeningParentheses=function(e,t){var E=[N.default.WHITESPACE,N.default.OPEN_PAREN,N.default.LINE_COMMENT];return E.includes(this.previousToken().type)||(t=(0,T.default)(t)),t+=e.value,this.inlineBlock.beginIfPossible(this.tokens,this.index),this.inlineBlock.isActive()||(this.indentation.increaseBlockLevel(),t=this.addNewline(t)),t},e.prototype.formatClosingParentheses=function(e,t){return this.inlineBlock.isActive()?(this.inlineBlock.end(),this.formatWithSpaceAfter(e,t)):(this.indentation.decreaseBlockLevel(),this.formatWithSpaces(e,this.addNewline(t)))},e.prototype.formatPlaceholder=function(e,t){return t+this.params.get(e)+" "},e.prototype.formatComma=function(e,t){return t=this.trimTrailingWhitespace(t)+e.value+" ",this.inlineBlock.isActive()?t:/^LIMIT$/i.test(this.previousReservedWord.value)?t:this.addNewline(t)},e.prototype.formatWithSpaceAfter=function(e,t){return this.trimTrailingWhitespace(t)+e.value+" "},e.prototype.formatWithoutSpaces=function(e,t){return this.trimTrailingWhitespace(t)+e.value},e.prototype.formatWithSpaces=function(e,t){return t+e.value+" "},e.prototype.formatQuerySeparator=function(e,t){return this.trimTrailingWhitespace(t)+e.value+"\n"},e.prototype.addNewline=function(e){return(0,T.default)(e)+"\n"+this.indentation.getIndent()},e.prototype.trimTrailingWhitespace=function(e){return this.previousNonWhitespaceToken().type===N.default.LINE_COMMENT?(0,T.default)(e)+"\n":(0,T.default)(e)},e.prototype.previousNonWhitespaceToken=function(){for(var e=1;this.previousToken(e).type===N.default.WHITESPACE;)e++;return this.previousToken(e)},e.prototype.previousToken=function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:1;return this.tokens[this.index-e]||{}},e}();t.default=a,e.exports=t.default},function(e,t,E){"use strict";function n(e){return e&&e.__esModule?e:{default:e}}function r(e,t){if(!(e instanceof t))throw new TypeError("Cannot call a class as a function")}t.__esModule=!0;var o=E(66),T=n(o),R=E(63),N=n(R),i=E(8),A=n(i),I=function(){function e(t){r(this,e),this.WHITESPACE_REGEX=/^(\s+)/,this.NUMBER_REGEX=/^((-\s*)?[0-9]+(\.[0-9]+)?|0x[0-9a-fA-F]+|0b[01]+)\b/,this.OPERATOR_REGEX=/^(!=|<>|==|<=|>=|!<|!>|\|\||::|->>|->|~~\*|~~|!~~\*|!~~|~\*|!~\*|!~|.)/,this.BLOCK_COMMENT_REGEX=/^(\/\*[^]*?(?:\*\/|$))/,this.LINE_COMMENT_REGEX=this.createLineCommentRegex(t.lineCommentTypes),this.RESERVED_TOPLEVEL_REGEX=this.createReservedWordRegex(t.reservedToplevelWords),this.RESERVED_NEWLINE_REGEX=this.createReservedWordRegex(t.reservedNewlineWords),this.RESERVED_PLAIN_REGEX=this.createReservedWordRegex(t.reservedWords),this.WORD_REGEX=this.createWordRegex(t.specialWordChars),this.STRING_REGEX=this.createStringRegex(t.stringTypes),this.OPEN_PAREN_REGEX=this.createParenRegex(t.openParens),this.CLOSE_PAREN_REGEX=this.createParenRegex(t.closeParens),this.INDEXED_PLACEHOLDER_REGEX=this.createPlaceholderRegex(t.indexedPlaceholderTypes,"[0-9]*"),this.IDENT_NAMED_PLACEHOLDER_REGEX=this.createPlaceholderRegex(t.namedPlaceholderTypes,"[a-zA-Z0-9._$]+"),this.STRING_NAMED_PLACEHOLDER_REGEX=this.createPlaceholderRegex(t.namedPlaceholderTypes,this.createStringPattern(t.stringTypes))}return e.prototype.createLineCommentRegex=function(e){return RegExp("^((?:"+e.map(function(e){return(0,N.default)(e)}).join("|")+").*?(?:\n|$))")},e.prototype.createReservedWordRegex=function(e){var t=e.join("|").replace(/ /g,"\\s+");return RegExp("^("+t+")\\b","i")},e.prototype.createWordRegex=function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:[];return RegExp("^([\\w"+e.join("")+"]+)")},e.prototype.createStringRegex=function(e){return RegExp("^("+this.createStringPattern(e)+")")},e.prototype.createStringPattern=function(e){var t={"``":"((`[^`]*($|`))+)","[]":"((\\[[^\\]]*($|\\]))(\\][^\\]]*($|\\]))*)",'""':'(("[^"\\\\]*(?:\\\\.[^"\\\\]*)*("|$))+)',"''":"(('[^'\\\\]*(?:\\\\.[^'\\\\]*)*('|$))+)","N''":"((N'[^N'\\\\]*(?:\\\\.[^N'\\\\]*)*('|$))+)"};return e.map(function(e){return t[e]}).join("|")},e.prototype.createParenRegex=function(e){var t=this;return RegExp("^("+e.map(function(e){return t.escapeParen(e)}).join("|")+")","i")},e.prototype.escapeParen=function(e){return 1===e.length?(0,N.default)(e):"\\b"+e+"\\b"},e.prototype.createPlaceholderRegex=function(e,t){if((0,T.default)(e))return!1;var E=e.map(N.default).join("|");return RegExp("^((?:"+E+")(?:"+t+"))")},e.prototype.tokenize=function(e){for(var t=[],E=void 0;e.length;)E=this.getNextToken(e,E),e=e.substring(E.value.length),t.push(E);return t},e.prototype.getNextToken=function(e,t){return this.getWhitespaceToken(e)||this.getCommentToken(e)||this.getStringToken(e)||this.getOpenParenToken(e)||this.getCloseParenToken(e)||this.getPlaceholderToken(e)||this.getNumberToken(e)||this.getReservedWordToken(e,t)||this.getWordToken(e)||this.getOperatorToken(e)},e.prototype.getWhitespaceToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.WHITESPACE,regex:this.WHITESPACE_REGEX})},e.prototype.getCommentToken=function(e){return this.getLineCommentToken(e)||this.getBlockCommentToken(e)},e.prototype.getLineCommentToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.LINE_COMMENT,regex:this.LINE_COMMENT_REGEX})},e.prototype.getBlockCommentToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.BLOCK_COMMENT,regex:this.BLOCK_COMMENT_REGEX})},e.prototype.getStringToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.STRING,regex:this.STRING_REGEX})},e.prototype.getOpenParenToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.OPEN_PAREN,regex:this.OPEN_PAREN_REGEX})},e.prototype.getCloseParenToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.CLOSE_PAREN,regex:this.CLOSE_PAREN_REGEX})},e.prototype.getPlaceholderToken=function(e){return this.getIdentNamedPlaceholderToken(e)||this.getStringNamedPlaceholderToken(e)||this.getIndexedPlaceholderToken(e)},e.prototype.getIdentNamedPlaceholderToken=function(e){return this.getPlaceholderTokenWithKey({input:e,regex:this.IDENT_NAMED_PLACEHOLDER_REGEX,parseKey:function(e){return e.slice(1)}})},e.prototype.getStringNamedPlaceholderToken=function(e){var t=this;return this.getPlaceholderTokenWithKey({input:e,regex:this.STRING_NAMED_PLACEHOLDER_REGEX,parseKey:function(e){return t.getEscapedPlaceholderKey({key:e.slice(2,-1),quoteChar:e.slice(-1)})}})},e.prototype.getIndexedPlaceholderToken=function(e){return this.getPlaceholderTokenWithKey({input:e,regex:this.INDEXED_PLACEHOLDER_REGEX,parseKey:function(e){return e.slice(1)}})},e.prototype.getPlaceholderTokenWithKey=function(e){var t=e.input,E=e.regex,n=e.parseKey,r=this.getTokenOnFirstMatch({input:t,regex:E,type:A.default.PLACEHOLDER});return r&&(r.key=n(r.value)),r},e.prototype.getEscapedPlaceholderKey=function(e){var t=e.key,E=e.quoteChar;return t.replace(RegExp((0,N.default)("\\")+E,"g"),E)},e.prototype.getNumberToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.NUMBER,regex:this.NUMBER_REGEX})},e.prototype.getOperatorToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.OPERATOR,regex:this.OPERATOR_REGEX})},e.prototype.getReservedWordToken=function(e,t){if(!t||!t.value||"."!==t.value)return this.getToplevelReservedToken(e)||this.getNewlineReservedToken(e)||this.getPlainReservedToken(e)},e.prototype.getToplevelReservedToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.RESERVED_TOPLEVEL,regex:this.RESERVED_TOPLEVEL_REGEX})},e.prototype.getNewlineReservedToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.RESERVED_NEWLINE,regex:this.RESERVED_NEWLINE_REGEX})},e.prototype.getPlainReservedToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.RESERVED,regex:this.RESERVED_PLAIN_REGEX})},e.prototype.getWordToken=function(e){return this.getTokenOnFirstMatch({input:e,type:A.default.WORD,regex:this.WORD_REGEX})},e.prototype.getTokenOnFirstMatch=function(e){var t=e.input,E=e.type,n=e.regex,r=t.match(n);if(r)return{type:E,value:r[1]}},e}();t.default=I,e.exports=t.default},function(e,t){function E(e){var t=typeof e;return null!=e&&("object"==t||"function"==t)}e.exports=E},function(e,t){function E(e){return null!=e&&"object"==typeof e}e.exports=E},function(e,t){"use strict";t.__esModule=!0,t.default={WHITESPACE:"whitespace",WORD:"word",STRING:"string",RESERVED:"reserved",RESERVED_TOPLEVEL:"reserved-toplevel",RESERVED_NEWLINE:"reserved-newline",OPERATOR:"operator",OPEN_PAREN:"open-paren",CLOSE_PAREN:"close-paren",LINE_COMMENT:"line-comment",BLOCK_COMMENT:"block-comment",NUMBER:"number",PLACEHOLDER:"placeholder"},e.exports=t.default},function(e,t,E){var n=E(1),r=n.Symbol;e.exports=r},function(e,t,E){function n(e){return null==e?"":r(e)}var r=E(11);e.exports=n},function(e,t,E){function n(e){if("string"==typeof e)return e;if(T(e))return o(e,n)+"";if(R(e))return A?A.call(e):"";var t=e+"";return"0"==t&&1/e==-N?"-0":t}var r=E(9),o=E(33),T=E(15),R=E(19),N=1/0,i=r?r.prototype:void 0,A=i?i.toString:void 0;e.exports=n},function(e,t){(function(t){var E="object"==typeof t&&t&&t.Object===Object&&t;e.exports=E}).call(t,function(){return this}())},function(e,t){function E(e){var t=e&&e.constructor,E="function"==typeof t&&t.prototype||n;return e===E}var n=Object.prototype;e.exports=E},function(e,t){function E(e){if(null!=e){try{return r.call(e)}catch(e){}try{return e+""}catch(e){}}return""}var n=Function.prototype,r=n.toString;e.exports=E},function(e,t){var E=Array.isArray;e.exports=E},function(e,t,E){function n(e){return null!=e&&o(e.length)&&!r(e)}var r=E(17),o=E(18);e.exports=n},function(e,t,E){function n(e){if(!o(e))return!1;var t=r(e);return t==R||t==N||t==T||t==i}var r=E(2),o=E(6),T="[object AsyncFunction]",R="[object Function]",N="[object GeneratorFunction]",i="[object Proxy]";e.exports=n},function(e,t){function E(e){return"number"==typeof e&&e>-1&&e%1==0&&n>=e}var n=9007199254740991;e.exports=E},function(e,t,E){function n(e){return"symbol"==typeof e||o(e)&&r(e)==T}var r=E(2),o=E(7),T="[object Symbol]";e.exports=n},function(e,t){e.exports=function(e){return e.webpackPolyfill||(e.deprecate=function(){},e.paths=[],e.children=[],e.webpackPolyfill=1),e}},function(e,t,E){"use strict";function n(e){return e&&e.__esModule?e:{default:e}}function r(e,t){if(!(e instanceof t))throw new TypeError("Cannot call a class as a function")}t.__esModule=!0;var o=E(69),T=n(o),R=E(68),N=n(R),i="top-level",A="block-level",I=function(){function e(t){r(this,e),this.indent=t||" ",this.indentTypes=[]}return e.prototype.getIndent=function(){return(0,T.default)(this.indent,this.indentTypes.length)},e.prototype.increaseToplevel=function(){this.indentTypes.push(i)},e.prototype.increaseBlockLevel=function(){this.indentTypes.push(A)},e.prototype.decreaseTopLevel=function(){(0,N.default)(this.indentTypes)===i&&this.indentTypes.pop()},e.prototype.decreaseBlockLevel=function(){for(;this.indentTypes.length>0;){var e=this.indentTypes.pop();if(e!==i)break}},e}();t.default=I,e.exports=t.default},function(e,t,E){"use strict";function n(e){return e&&e.__esModule?e:{default:e}}function r(e,t){if(!(e instanceof t))throw new TypeError("Cannot call a class as a function")}t.__esModule=!0;var o=E(8),T=n(o),R=50,N=function(){function e(){r(this,e),this.level=0}return e.prototype.beginIfPossible=function(e,t){0===this.level&&this.isInlineBlock(e,t)?this.level=1:this.level>0?this.level++:this.level=0},e.prototype.end=function(){this.level--},e.prototype.isActive=function(){return this.level>0},e.prototype.isInlineBlock=function(e,t){for(var E=0,n=0,r=t;e.length>r;r++){var o=e[r];if(E+=o.value.length,E>R)return!1;if(o.type===T.default.OPEN_PAREN)n++;else if(o.type===T.default.CLOSE_PAREN&&(n--,0===n))return!0;if(this.isForbiddenToken(o))return!1}return!1},e.prototype.isForbiddenToken=function(e){var t=e.type,E=e.value;return t===T.default.RESERVED_TOPLEVEL||t===T.default.RESERVED_NEWLINE||t===T.default.COMMENT||t===T.default.BLOCK_COMMENT||";"===E},e}();t.default=N,e.exports=t.default},function(e,t){"use strict";function E(e,t){if(!(e instanceof t))throw new TypeError("Cannot call a class as a function")}t.__esModule=!0;var n=function(){function e(t){E(this,e),this.params=t,this.index=0}return e.prototype.get=function(e){var t=e.key,E=e.value;return this.params?t?this.params[t]:this.params[this.index++]:E},e}();t.default=n,e.exports=t.default},function(e,t,E){"use strict";function n(e){return e&&e.__esModule?e:{default:e}}function r(e,t){if(!(e instanceof t))throw new TypeError("Cannot call a class as a function")}t.__esModule=!0;var o=E(4),T=n(o),R=E(5),N=n(R),i=["ABS","ACTIVATE","ALIAS","ALL","ALLOCATE","ALLOW","ALTER","ANY","ARE","ARRAY","AS","ASC","ASENSITIVE","ASSOCIATE","ASUTIME","ASYMMETRIC","AT","ATOMIC","ATTRIBUTES","AUDIT","AUTHORIZATION","AUX","AUXILIARY","AVG","BEFORE","BEGIN","BETWEEN","BIGINT","BINARY","BLOB","BOOLEAN","BOTH","BUFFERPOOL","BY","CACHE","CALL","CALLED","CAPTURE","CARDINALITY","CASCADED","CASE","CAST","CCSID","CEIL","CEILING","CHAR","CHARACTER","CHARACTER_LENGTH","CHAR_LENGTH","CHECK","CLOB","CLONE","CLOSE","CLUSTER","COALESCE","COLLATE","COLLECT","COLLECTION","COLLID","COLUMN","COMMENT","COMMIT","CONCAT","CONDITION","CONNECT","CONNECTION","CONSTRAINT","CONTAINS","CONTINUE","CONVERT","CORR","CORRESPONDING","COUNT","COUNT_BIG","COVAR_POP","COVAR_SAMP","CREATE","CROSS","CUBE","CUME_DIST","CURRENT","CURRENT_DATE","CURRENT_DEFAULT_TRANSFORM_GROUP","CURRENT_LC_CTYPE","CURRENT_PATH","CURRENT_ROLE","CURRENT_SCHEMA","CURRENT_SERVER","CURRENT_TIME","CURRENT_TIMESTAMP","CURRENT_TIMEZONE","CURRENT_TRANSFORM_GROUP_FOR_TYPE","CURRENT_USER","CURSOR","CYCLE","DATA","DATABASE","DATAPARTITIONNAME","DATAPARTITIONNUM","DATE","DAY","DAYS","DB2GENERAL","DB2GENRL","DB2SQL","DBINFO","DBPARTITIONNAME","DBPARTITIONNUM","DEALLOCATE","DEC","DECIMAL","DECLARE","DEFAULT","DEFAULTS","DEFINITION","DELETE","DENSERANK","DENSE_RANK","DEREF","DESCRIBE","DESCRIPTOR","DETERMINISTIC","DIAGNOSTICS","DISABLE","DISALLOW","DISCONNECT","DISTINCT","DO","DOCUMENT","DOUBLE","DROP","DSSIZE","DYNAMIC","EACH","EDITPROC","ELEMENT","ELSE","ELSEIF","ENABLE","ENCODING","ENCRYPTION","END","END-EXEC","ENDING","ERASE","ESCAPE","EVERY","EXCEPTION","EXCLUDING","EXCLUSIVE","EXEC","EXECUTE","EXISTS","EXIT","EXP","EXPLAIN","EXTENDED","EXTERNAL","EXTRACT","FALSE","FENCED","FETCH","FIELDPROC","FILE","FILTER","FINAL","FIRST","FLOAT","FLOOR","FOR","FOREIGN","FREE","FULL","FUNCTION","FUSION","GENERAL","GENERATED","GET","GLOBAL","GOTO","GRANT","GRAPHIC","GROUP","GROUPING","HANDLER","HASH","HASHED_VALUE","HINT","HOLD","HOUR","HOURS","IDENTITY","IF","IMMEDIATE","IN","INCLUDING","INCLUSIVE","INCREMENT","INDEX","INDICATOR","INDICATORS","INF","INFINITY","INHERIT","INNER","INOUT","INSENSITIVE","INSERT","INT","INTEGER","INTEGRITY","INTERSECTION","INTERVAL","INTO","IS","ISOBID","ISOLATION","ITERATE","JAR","JAVA","KEEP","KEY","LABEL","LANGUAGE","LARGE","LATERAL","LC_CTYPE","LEADING","LEAVE","LEFT","LIKE","LINKTYPE","LN","LOCAL","LOCALDATE","LOCALE","LOCALTIME","LOCALTIMESTAMP","LOCATOR","LOCATORS","LOCK","LOCKMAX","LOCKSIZE","LONG","LOOP","LOWER","MAINTAINED","MATCH","MATERIALIZED","MAX","MAXVALUE","MEMBER","MERGE","METHOD","MICROSECOND","MICROSECONDS","MIN","MINUTE","MINUTES","MINVALUE","MOD","MODE","MODIFIES","MODULE","MONTH","MONTHS","MULTISET","NAN","NATIONAL","NATURAL","NCHAR","NCLOB","NEW","NEW_TABLE","NEXTVAL","NO","NOCACHE","NOCYCLE","NODENAME","NODENUMBER","NOMAXVALUE","NOMINVALUE","NONE","NOORDER","NORMALIZE","NORMALIZED","NOT","NULL","NULLIF","NULLS","NUMERIC","NUMPARTS","OBID","OCTET_LENGTH","OF","OFFSET","OLD","OLD_TABLE","ON","ONLY","OPEN","OPTIMIZATION","OPTIMIZE","OPTION","ORDER","OUT","OUTER","OVER","OVERLAPS","OVERLAY","OVERRIDING","PACKAGE","PADDED","PAGESIZE","PARAMETER","PART","PARTITION","PARTITIONED","PARTITIONING","PARTITIONS","PASSWORD","PATH","PERCENTILE_CONT","PERCENTILE_DISC","PERCENT_RANK","PIECESIZE","PLAN","POSITION","POWER","PRECISION","PREPARE","PREVVAL","PRIMARY","PRIQTY","PRIVILEGES","PROCEDURE","PROGRAM","PSID","PUBLIC","QUERY","QUERYNO","RANGE","RANK","READ","READS","REAL","RECOVERY","RECURSIVE","REF","REFERENCES","REFERENCING","REFRESH","REGR_AVGX","REGR_AVGY","REGR_COUNT","REGR_INTERCEPT","REGR_R2","REGR_SLOPE","REGR_SXX","REGR_SXY","REGR_SYY","RELEASE","RENAME","REPEAT","RESET","RESIGNAL","RESTART","RESTRICT","RESULT","RESULT_SET_LOCATOR","RETURN","RETURNS","REVOKE","RIGHT","ROLE","ROLLBACK","ROLLUP","ROUND_CEILING","ROUND_DOWN","ROUND_FLOOR","ROUND_HALF_DOWN","ROUND_HALF_EVEN","ROUND_HALF_UP","ROUND_UP","ROUTINE","ROW","ROWNUMBER","ROWS","ROWSET","ROW_NUMBER","RRN","RUN","SAVEPOINT","SCHEMA","SCOPE","SCRATCHPAD","SCROLL","SEARCH","SECOND","SECONDS","SECQTY","SECURITY","SENSITIVE","SEQUENCE","SESSION","SESSION_USER","SIGNAL","SIMILAR","SIMPLE","SMALLINT","SNAN","SOME","SOURCE","SPECIFIC","SPECIFICTYPE","SQL","SQLEXCEPTION","SQLID","SQLSTATE","SQLWARNING","SQRT","STACKED","STANDARD","START","STARTING","STATEMENT","STATIC","STATMENT","STAY","STDDEV_POP","STDDEV_SAMP","STOGROUP","STORES","STYLE","SUBMULTISET","SUBSTRING","SUM","SUMMARY","SYMMETRIC","SYNONYM","SYSFUN","SYSIBM","SYSPROC","SYSTEM","SYSTEM_USER","TABLE","TABLESAMPLE","TABLESPACE","THEN","TIME","TIMESTAMP","TIMEZONE_HOUR","TIMEZONE_MINUTE","TO","TRAILING","TRANSACTION","TRANSLATE","TRANSLATION","TREAT","TRIGGER","TRIM","TRUE","TRUNCATE","TYPE","UESCAPE","UNDO","UNIQUE","UNKNOWN","UNNEST","UNTIL","UPPER","USAGE","USER","USING","VALIDPROC","VALUE","VARCHAR","VARIABLE","VARIANT","VARYING","VAR_POP","VAR_SAMP","VCAT","VERSION","VIEW","VOLATILE","VOLUMES","WHEN","WHENEVER","WHILE","WIDTH_BUCKET","WINDOW","WITH","WITHIN","WITHOUT","WLM","WRITE","XMLELEMENT","XMLEXISTS","XMLNAMESPACES","YEAR","YEARS"],A=["ADD","AFTER","ALTER COLUMN","ALTER TABLE","DELETE FROM","EXCEPT","FETCH FIRST","FROM","GROUP BY","GO","HAVING","INSERT INTO","INTERSECT","LIMIT","ORDER BY","SELECT","SET CURRENT SCHEMA","SET SCHEMA","SET","UNION ALL","UPDATE","VALUES","WHERE"],I=["AND","CROSS JOIN","INNER JOIN","JOIN","LEFT JOIN","LEFT OUTER JOIN","OR","OUTER JOIN","RIGHT JOIN","RIGHT OUTER JOIN"],O=void 0,u=function(){function e(t){r(this,e),this.cfg=t}return e.prototype.format=function(e){return O||(O=new N.default({reservedWords:i,reservedToplevelWords:A,reservedNewlineWords:I,stringTypes:['""',"''","``","[]"],openParens:["("],closeParens:[")"],indexedPlaceholderTypes:["?"],namedPlaceholderTypes:[":"],lineCommentTypes:["--"],specialWordChars:["#","@"]})),new T.default(this.cfg,O).format(e)},e}();t.default=u,e.exports=t.default},function(e,t,E){"use strict";function n(e){return e&&e.__esModule?e:{default:e}}function r(e,t){if(!(e instanceof t))throw new TypeError("Cannot call a class as a function")}t.__esModule=!0;var o=E(4),T=n(o),R=E(5),N=n(R),i=["ALL","ALTER","ANALYZE","AND","ANY","ARRAY","AS","ASC","BEGIN","BETWEEN","BINARY","BOOLEAN","BREAK","BUCKET","BUILD","BY","CALL","CASE","CAST","CLUSTER","COLLATE","COLLECTION","COMMIT","CONNECT","CONTINUE","CORRELATE","COVER","CREATE","DATABASE","DATASET","DATASTORE","DECLARE","DECREMENT","DELETE","DERIVED","DESC","DESCRIBE","DISTINCT","DO","DROP","EACH","ELEMENT","ELSE","END","EVERY","EXCEPT","EXCLUDE","EXECUTE","EXISTS","EXPLAIN","FALSE","FETCH","FIRST","FLATTEN","FOR","FORCE","FROM","FUNCTION","GRANT","GROUP","GSI","HAVING","IF","IGNORE","ILIKE","IN","INCLUDE","INCREMENT","INDEX","INFER","INLINE","INNER","INSERT","INTERSECT","INTO","IS","JOIN","KEY","KEYS","KEYSPACE","KNOWN","LAST","LEFT","LET","LETTING","LIKE","LIMIT","LSM","MAP","MAPPING","MATCHED","MATERIALIZED","MERGE","MINUS","MISSING","NAMESPACE","NEST","NOT","NULL","NUMBER","OBJECT","OFFSET","ON","OPTION","OR","ORDER","OUTER","OVER","PARSE","PARTITION","PASSWORD","PATH","POOL","PREPARE","PRIMARY","PRIVATE","PRIVILEGE","PROCEDURE","PUBLIC","RAW","REALM","REDUCE","RENAME","RETURN","RETURNING","REVOKE","RIGHT","ROLE","ROLLBACK","SATISFIES","SCHEMA","SELECT","SELF","SEMI","SET","SHOW","SOME","START","STATISTICS","STRING","SYSTEM","THEN","TO","TRANSACTION","TRIGGER","TRUE","TRUNCATE","UNDER","UNION","UNIQUE","UNKNOWN","UNNEST","UNSET","UPDATE","UPSERT","USE","USER","USING","VALIDATE","VALUE","VALUED","VALUES","VIA","VIEW","WHEN","WHERE","WHILE","WITH","WITHIN","WORK","XOR"],A=["DELETE FROM","EXCEPT ALL","EXCEPT","EXPLAIN DELETE FROM","EXPLAIN UPDATE","EXPLAIN UPSERT","FROM","GROUP BY","HAVING","INFER","INSERT INTO","INTERSECT ALL","INTERSECT","LET","LIMIT","MERGE","NEST","ORDER BY","PREPARE","SELECT","SET CURRENT SCHEMA","SET SCHEMA","SET","UNION ALL","UNION","UNNEST","UPDATE","UPSERT","USE KEYS","VALUES","WHERE"],I=["AND","INNER JOIN","JOIN","LEFT JOIN","LEFT OUTER JOIN","OR","OUTER JOIN","RIGHT JOIN","RIGHT OUTER JOIN","XOR"],O=void 0,u=function(){function e(t){r(this,e),this.cfg=t}return e.prototype.format=function(e){return O||(O=new N.default({reservedWords:i,reservedToplevelWords:A,reservedNewlineWords:I,stringTypes:['""',"''","``"],openParens:["(","[","{"],closeParens:[")","]","}"],namedPlaceholderTypes:["$"],lineCommentTypes:["#","--"]})),new T.default(this.cfg,O).format(e)},e}();t.default=u,e.exports=t.default},function(e,t,E){"use strict";function n(e){return e&&e.__esModule?e:{default:e}}function r(e,t){if(!(e instanceof t))throw new TypeError("Cannot call a class as a function")}t.__esModule=!0;var o=E(4),T=n(o),R=E(5),N=n(R),i=["A","ACCESSIBLE","AGENT","AGGREGATE","ALL","ALTER","ANY","ARRAY","AS","ASC","AT","ATTRIBUTE","AUTHID","AVG","BETWEEN","BFILE_BASE","BINARY_INTEGER","BINARY","BLOB_BASE","BLOCK","BODY","BOOLEAN","BOTH","BOUND","BULK","BY","BYTE","C","CALL","CALLING","CASCADE","CASE","CHAR_BASE","CHAR","CHARACTER","CHARSET","CHARSETFORM","CHARSETID","CHECK","CLOB_BASE","CLONE","CLOSE","CLUSTER","CLUSTERS","COALESCE","COLAUTH","COLLECT","COLUMNS","COMMENT","COMMIT","COMMITTED","COMPILED","COMPRESS","CONNECT","CONSTANT","CONSTRUCTOR","CONTEXT","CONTINUE","CONVERT","COUNT","CRASH","CREATE","CREDENTIAL","CURRENT","CURRVAL","CURSOR","CUSTOMDATUM","DANGLING","DATA","DATE_BASE","DATE","DAY","DECIMAL","DEFAULT","DEFINE","DELETE","DESC","DETERMINISTIC","DIRECTORY","DISTINCT","DO","DOUBLE","DROP","DURATION","ELEMENT","ELSIF","EMPTY","ESCAPE","EXCEPTIONS","EXCLUSIVE","EXECUTE","EXISTS","EXIT","EXTENDS","EXTERNAL","EXTRACT","FALSE","FETCH","FINAL","FIRST","FIXED","FLOAT","FOR","FORALL","FORCE","FROM","FUNCTION","GENERAL","GOTO","GRANT","GROUP","HASH","HEAP","HIDDEN","HOUR","IDENTIFIED","IF","IMMEDIATE","IN","INCLUDING","INDEX","INDEXES","INDICATOR","INDICES","INFINITE","INSTANTIABLE","INT","INTEGER","INTERFACE","INTERVAL","INTO","INVALIDATE","IS","ISOLATION","JAVA","LANGUAGE","LARGE","LEADING","LENGTH","LEVEL","LIBRARY","LIKE","LIKE2","LIKE4","LIKEC","LIMITED","LOCAL","LOCK","LONG","MAP","MAX","MAXLEN","MEMBER","MERGE","MIN","MINUS","MINUTE","MLSLABEL","MOD","MODE","MONTH","MULTISET","NAME","NAN","NATIONAL","NATIVE","NATURAL","NATURALN","NCHAR","NEW","NEXTVAL","NOCOMPRESS","NOCOPY","NOT","NOWAIT","NULL","NULLIF","NUMBER_BASE","NUMBER","OBJECT","OCICOLL","OCIDATE","OCIDATETIME","OCIDURATION","OCIINTERVAL","OCILOBLOCATOR","OCINUMBER","OCIRAW","OCIREF","OCIREFCURSOR","OCIROWID","OCISTRING","OCITYPE","OF","OLD","ON","ONLY","OPAQUE","OPEN","OPERATOR","OPTION","ORACLE","ORADATA","ORDER","ORGANIZATION","ORLANY","ORLVARY","OTHERS","OUT","OVERLAPS","OVERRIDING","PACKAGE","PARALLEL_ENABLE","PARAMETER","PARAMETERS","PARENT","PARTITION","PASCAL","PCTFREE","PIPE","PIPELINED","PLS_INTEGER","PLUGGABLE","POSITIVE","POSITIVEN","PRAGMA","PRECISION","PRIOR","PRIVATE","PROCEDURE","PUBLIC","RAISE","RANGE","RAW","READ","REAL","RECORD","REF","REFERENCE","RELEASE","RELIES_ON","REM","REMAINDER","RENAME","RESOURCE","RESULT_CACHE","RESULT","RETURN","RETURNING","REVERSE","REVOKE","ROLLBACK","ROW","ROWID","ROWNUM","ROWTYPE","SAMPLE","SAVE","SAVEPOINT","SB1","SB2","SB4","SECOND","SEGMENT","SELF","SEPARATE","SEQUENCE","SERIALIZABLE","SHARE","SHORT","SIZE_T","SIZE","SMALLINT","SOME","SPACE","SPARSE","SQL","SQLCODE","SQLDATA","SQLERRM","SQLNAME","SQLSTATE","STANDARD","START","STATIC","STDDEV","STORED","STRING","STRUCT","STYLE","SUBMULTISET","SUBPARTITION","SUBSTITUTABLE","SUBTYPE","SUCCESSFUL","SUM","SYNONYM","SYSDATE","TABAUTH","TABLE","TDO","THE","THEN","TIME","TIMESTAMP","TIMEZONE_ABBR","TIMEZONE_HOUR","TIMEZONE_MINUTE","TIMEZONE_REGION","TO","TRAILING","TRANSACTION","TRANSACTIONAL","TRIGGER","TRUE","TRUSTED","TYPE","UB1","UB2","UB4","UID","UNDER","UNIQUE","UNPLUG","UNSIGNED","UNTRUSTED","USE","USER","USING","VALIDATE","VALIST","VALUE","VARCHAR","VARCHAR2","VARIABLE","VARIANCE","VARRAY","VARYING","VIEW","VIEWS","VOID","WHENEVER","WHILE","WITH","WORK","WRAPPED","WRITE","YEAR","ZONE"],A=["ADD","ALTER COLUMN","ALTER TABLE","BEGIN","CONNECT BY","DECLARE","DELETE FROM","DELETE","END","EXCEPT","EXCEPTION","FETCH FIRST","FROM","GROUP BY","HAVING","INSERT INTO","INSERT","INTERSECT","LIMIT","LOOP","MODIFY","ORDER BY","SELECT","SET CURRENT SCHEMA","SET SCHEMA","SET","START WITH","UNION ALL","UNION","UPDATE","VALUES","WHERE"],I=["AND","CROSS APPLY","CROSS JOIN","ELSE","END","INNER JOIN","JOIN","LEFT JOIN","LEFT OUTER JOIN","OR","OUTER APPLY","OUTER JOIN","RIGHT JOIN","RIGHT OUTER JOIN","WHEN","XOR"],O=void 0,u=function(){function e(t){r(this,e),this.cfg=t}return e.prototype.format=function(e){return O||(O=new N.default({reservedWords:i,reservedToplevelWords:A,reservedNewlineWords:I,stringTypes:['""',"N''","''","``"],openParens:["(","CASE"],closeParens:[")","END"],indexedPlaceholderTypes:["?"],namedPlaceholderTypes:[":"],lineCommentTypes:["--"],specialWordChars:["_","$","#",".","@"]})),new T.default(this.cfg,O).format(e)},e}();t.default=u,e.exports=t.default},function(e,t,E){"use strict";function n(e){return e&&e.__esModule?e:{default:e}}function r(e,t){if(!(e instanceof t))throw new TypeError("Cannot call a class as a function")}t.__esModule=!0;var o=E(4),T=n(o),R=E(5),N=n(R),i=["ACCESSIBLE","ACTION","AGAINST","AGGREGATE","ALGORITHM","ALL","ALTER","ANALYSE","ANALYZE","AS","ASC","AUTOCOMMIT","AUTO_INCREMENT","BACKUP","BEGIN","BETWEEN","BINLOG","BOTH","CASCADE","CASE","CHANGE","CHANGED","CHARACTER SET","CHARSET","CHECK","CHECKSUM","COLLATE","COLLATION","COLUMN","COLUMNS","COMMENT","COMMIT","COMMITTED","COMPRESSED","CONCURRENT","CONSTRAINT","CONTAINS","CONVERT","CREATE","CROSS","CURRENT_TIMESTAMP","DATABASE","DATABASES","DAY","DAY_HOUR","DAY_MINUTE","DAY_SECOND","DEFAULT","DEFINER","DELAYED","DELETE","DESC","DESCRIBE","DETERMINISTIC","DISTINCT","DISTINCTROW","DIV","DO","DROP","DUMPFILE","DUPLICATE","DYNAMIC","ELSE","ENCLOSED","END","ENGINE","ENGINES","ENGINE_TYPE","ESCAPE","ESCAPED","EVENTS","EXEC","EXECUTE","EXISTS","EXPLAIN","EXTENDED","FAST","FETCH","FIELDS","FILE","FIRST","FIXED","FLUSH","FOR","FORCE","FOREIGN","FULL","FULLTEXT","FUNCTION","GLOBAL","GRANT","GRANTS","GROUP_CONCAT","HEAP","HIGH_PRIORITY","HOSTS","HOUR","HOUR_MINUTE","HOUR_SECOND","IDENTIFIED","IF","IFNULL","IGNORE","IN","INDEX","INDEXES","INFILE","INSERT","INSERT_ID","INSERT_METHOD","INTERVAL","INTO","INVOKER","IS","ISOLATION","KEY","KEYS","KILL","LAST_INSERT_ID","LEADING","LEVEL","LIKE","LINEAR","LINES","LOAD","LOCAL","LOCK","LOCKS","LOGS","LOW_PRIORITY","MARIA","MASTER","MASTER_CONNECT_RETRY","MASTER_HOST","MASTER_LOG_FILE","MATCH","MAX_CONNECTIONS_PER_HOUR","MAX_QUERIES_PER_HOUR","MAX_ROWS","MAX_UPDATES_PER_HOUR","MAX_USER_CONNECTIONS","MEDIUM","MERGE","MINUTE","MINUTE_SECOND","MIN_ROWS","MODE","MODIFY","MONTH","MRG_MYISAM","MYISAM","NAMES","NATURAL","NOT","NOW()","NULL","OFFSET","ON DELETE","ON UPDATE","ON","ONLY","OPEN","OPTIMIZE","OPTION","OPTIONALLY","OUTFILE","PACK_KEYS","PAGE","PARTIAL","PARTITION","PARTITIONS","PASSWORD","PRIMARY","PRIVILEGES","PROCEDURE","PROCESS","PROCESSLIST","PURGE","QUICK","RAID0","RAID_CHUNKS","RAID_CHUNKSIZE","RAID_TYPE","RANGE","READ","READ_ONLY","READ_WRITE","REFERENCES","REGEXP","RELOAD","RENAME","REPAIR","REPEATABLE","REPLACE","REPLICATION","RESET","RESTORE","RESTRICT","RETURN","RETURNS","REVOKE","RLIKE","ROLLBACK","ROW","ROWS","ROW_FORMAT","SECOND","SECURITY","SEPARATOR","SERIALIZABLE","SESSION","SHARE","SHOW","SHUTDOWN","SLAVE","SONAME","SOUNDS","SQL","SQL_AUTO_IS_NULL","SQL_BIG_RESULT","SQL_BIG_SELECTS","SQL_BIG_TABLES","SQL_BUFFER_RESULT","SQL_CACHE","SQL_CALC_FOUND_ROWS","SQL_LOG_BIN","SQL_LOG_OFF","SQL_LOG_UPDATE","SQL_LOW_PRIORITY_UPDATES","SQL_MAX_JOIN_SIZE","SQL_NO_CACHE","SQL_QUOTE_SHOW_CREATE","SQL_SAFE_UPDATES","SQL_SELECT_LIMIT","SQL_SLAVE_SKIP_COUNTER","SQL_SMALL_RESULT","SQL_WARNINGS","START","STARTING","STATUS","STOP","STORAGE","STRAIGHT_JOIN","STRING","STRIPED","SUPER","TABLE","TABLES","TEMPORARY","TERMINATED","THEN","TO","TRAILING","TRANSACTIONAL","TRUE","TRUNCATE","TYPE","TYPES","UNCOMMITTED","UNIQUE","UNLOCK","UNSIGNED","USAGE","USE","USING","VARIABLES","VIEW","WHEN","WITH","WORK","WRITE","YEAR_MONTH"],A=["ADD","AFTER","ALTER COLUMN","ALTER TABLE","DELETE FROM","EXCEPT","FETCH FIRST","FROM","GROUP BY","GO","HAVING","INSERT INTO","INSERT","INTERSECT","LIMIT","MODIFY","ORDER BY","SELECT","SET CURRENT SCHEMA","SET SCHEMA","SET","UNION ALL","UNION","UPDATE","VALUES","WHERE"],I=["AND","CROSS APPLY","CROSS JOIN","ELSE","INNER JOIN","JOIN","LEFT JOIN","LEFT OUTER JOIN","OR","OUTER APPLY","OUTER JOIN","RIGHT JOIN","RIGHT OUTER JOIN","WHEN","XOR"],O=void 0,u=function(){
2 | function e(t){r(this,e),this.cfg=t}return e.prototype.format=function(e){return O||(O=new N.default({reservedWords:i,reservedToplevelWords:A,reservedNewlineWords:I,stringTypes:['""',"N''","''","``","[]"],openParens:["(","CASE"],closeParens:[")","END"],indexedPlaceholderTypes:["?"],namedPlaceholderTypes:["@",":"],lineCommentTypes:["#","--"]})),new T.default(this.cfg,O).format(e)},e}();t.default=u,e.exports=t.default},function(e,t,E){var n=E(3),r=E(1),o=n(r,"DataView");e.exports=o},function(e,t,E){var n=E(3),r=E(1),o=n(r,"Map");e.exports=o},function(e,t,E){var n=E(3),r=E(1),o=n(r,"Promise");e.exports=o},function(e,t,E){var n=E(3),r=E(1),o=n(r,"Set");e.exports=o},function(e,t,E){var n=E(3),r=E(1),o=n(r,"WeakMap");e.exports=o},function(e,t){function E(e,t){for(var E=-1,n=null==e?0:e.length,r=Array(n);++Et||t>n)return E;do t%2&&(E+=e),t=r(t/2),t&&(e+=e);while(t);return E}var n=9007199254740991,r=Math.floor;e.exports=E},function(e,t){function E(e,t,E){var n=-1,r=e.length;0>t&&(t=-t>r?0:r+t),E=E>r?r:E,0>E&&(E+=r),r=t>E?0:E-t>>>0,t>>>=0;for(var o=Array(r);++nE?r(e,t,E):e}var r=E(43);e.exports=n},function(e,t,E){function n(e,t){for(var E=e.length;E--&&r(t,e[E],0)>-1;);return E}var r=E(36);e.exports=n},function(e,t,E){var n=E(1),r=n["__core-js_shared__"];e.exports=r},function(e,t,E){function n(e){var t=T.call(e,N),E=e[N];try{e[N]=void 0;var n=!0}catch(e){}var r=R.call(e);return n&&(t?e[N]=E:delete e[N]),r}var r=E(9),o=Object.prototype,T=o.hasOwnProperty,R=o.toString,N=r?r.toStringTag:void 0;e.exports=n},function(e,t,E){var n=E(28),r=E(29),o=E(30),T=E(31),R=E(32),N=E(2),i=E(14),A="[object Map]",I="[object Object]",O="[object Promise]",u="[object Set]",S="[object WeakMap]",a="[object DataView]",s=i(n),L=i(r),c=i(o),C=i(T),f=i(R),p=N;(n&&p(new n(new ArrayBuffer(1)))!=a||r&&p(new r)!=A||o&&p(o.resolve())!=O||T&&p(new T)!=u||R&&p(new R)!=S)&&(p=function(e){var t=N(e),E=t==I?e.constructor:void 0,n=E?i(E):"";if(n)switch(n){case s:return a;case L:return A;case c:return O;case C:return u;case f:return S}return t}),e.exports=p},function(e,t){function E(e,t){return null==e?void 0:e[t]}e.exports=E},function(e,t){function E(e){return A.test(e)}var n="\\ud800-\\udfff",r="\\u0300-\\u036f",o="\\ufe20-\\ufe2f",T="\\u20d0-\\u20ff",R=r+o+T,N="\\ufe0e\\ufe0f",i="\\u200d",A=RegExp("["+i+n+R+N+"]");e.exports=E},function(e,t){function E(e,t){var E=typeof e;return t=null==t?n:t,!!t&&("number"==E||"symbol"!=E&&r.test(e))&&e>-1&&e%1==0&&t>e}var n=9007199254740991,r=/^(?:0|[1-9]\d*)$/;e.exports=E},function(e,t,E){function n(e,t,E){if(!R(E))return!1;var n=typeof t;return!!("number"==n?o(E)&&T(t,E.length):"string"==n&&t in E)&&r(E[t],e)}var r=E(62),o=E(16),T=E(52),R=E(6);e.exports=n},function(e,t,E){function n(e){return!!o&&o in e}var r=E(47),o=function(){var e=/[^.]+$/.exec(r&&r.keys&&r.keys.IE_PROTO||"");return e?"Symbol(src)_1."+e:""}();e.exports=n},function(e,t,E){var n=E(58),r=n(Object.keys,Object);e.exports=r},function(e,t,E){(function(e){var n=E(12),r="object"==typeof t&&t&&!t.nodeType&&t,o=r&&"object"==typeof e&&e&&!e.nodeType&&e,T=o&&o.exports===r,R=T&&n.process,N=function(){try{var e=o&&o.require&&o.require("util").types;return e?e:R&&R.binding&&R.binding("util")}catch(e){}}();e.exports=N}).call(t,E(20)(e))},function(e,t){function E(e){return r.call(e)}var n=Object.prototype,r=n.toString;e.exports=E},function(e,t){function E(e,t){return function(E){return e(t(E))}}e.exports=E},function(e,t){function E(e,t,E){for(var n=E-1,r=e.length;++ne?-1:1;return t*T}return e===e?e:0}var r=E(73),o=1/0,T=1.7976931348623157e308;e.exports=n},function(e,t,E){function n(e){var t=r(e),E=t%1;return t===t?E?t-E:t:0}var r=E(71);e.exports=n},function(e,t,E){function n(e){if("number"==typeof e)return e;if(o(e))return T;if(r(e)){var t="function"==typeof e.valueOf?e.valueOf():e;e=r(t)?t+"":t}if("string"!=typeof e)return 0===e?e:+e;e=e.replace(R,"");var E=i.test(e);return E||A.test(e)?I(e.slice(2),E?2:8):N.test(e)?T:+e}var r=E(6),o=E(19),T=NaN,R=/^\s+|\s+$/g,N=/^[-+]0x[0-9a-f]+$/i,i=/^0b[01]+$/i,A=/^0o[0-7]+$/i,I=parseInt;e.exports=n},function(e,t,E){function n(e,t,E){if(e=N(e),e&&(E||void 0===t))return e.replace(i,"");if(!e||!(t=r(t)))return e;var n=R(e),A=T(n,R(t))+1;return o(n,0,A).join("")}var r=E(11),o=E(45),T=E(46),R=E(60),N=E(10),i=/\s+$/;e.exports=n}])});
--------------------------------------------------------------------------------
/stopwords.txt:
--------------------------------------------------------------------------------
1 | a
2 | about
3 | above
4 | after
5 | again
6 | against
7 | all
8 | am
9 | an
10 | #and
11 | any
12 | are
13 | aren't
14 | as
15 | at
16 | be
17 | because
18 | been
19 | before
20 | being
21 | below
22 | between
23 | both
24 | but
25 | by
26 | can't
27 | cannot
28 | could
29 | couldn't
30 | did
31 | didn't
32 | do
33 | does
34 | doesn't
35 | doing
36 | don't
37 | down
38 | during
39 | each
40 | few
41 | for
42 | from
43 | further
44 | had
45 | hadn't
46 | has
47 | hasn't
48 | have
49 | haven't
50 | having
51 | he
52 | he'd
53 | he'll
54 | he's
55 | her
56 | here
57 | here's
58 | hers
59 | herself
60 | him
61 | himself
62 | his
63 | how
64 | how's
65 | i
66 | i'd
67 | i'll
68 | i'm
69 | i've
70 | if
71 | #in
72 | into
73 | is
74 | isn't
75 | it
76 | it's
77 | its
78 | itself
79 | let's
80 | me
81 | #more
82 | most
83 | mustn't
84 | my
85 | myself
86 | no
87 | nor
88 | not
89 | #of
90 | off
91 | on
92 | once
93 | only
94 | or
95 | other
96 | ought
97 | our
98 | ours ourselves
99 | out
100 | over
101 | own
102 | same
103 | shan't
104 | she
105 | she'd
106 | she'll
107 | she's
108 | should
109 | shouldn't
110 | so
111 | some
112 | such
113 | #than
114 | that
115 | that's
116 | the
117 | their
118 | theirs
119 | them
120 | themselves
121 | then
122 | there
123 | there's
124 | these
125 | they
126 | they'd
127 | they'll
128 | they're
129 | they've
130 | this
131 | those
132 | through
133 | to
134 | too
135 | under
136 | until
137 | up
138 | very
139 | was
140 | wasn't
141 | we
142 | we'd
143 | we'll
144 | we're
145 | we've
146 | were
147 | weren't
148 | what
149 | what's
150 | when
151 | when's
152 | where
153 | where's
154 | which
155 | while
156 | who
157 | who's
158 | whom
159 | why
160 | why's
161 | #with
162 | won't
163 | would
164 | wouldn't
165 | you
166 | you'd
167 | you'll
168 | you're
169 | you've
170 | your
171 | yours
172 | yourself
173 | yourselves
--------------------------------------------------------------------------------