├── 1.PostgreSQL 学习系列
├── PostgreSQL.md
├── PostgreSQL中文文档
│ ├── 8.数据类型(一).md
│ ├── 8.数据类型(二).md
│ └── 附录:PostgreSQL限制.md
├── PostgreSQL学习记录
│ ├── PostgreSQL简介(一)—— Getting Started.md
│ ├── PostgreSQL简介(三)—— Managing Databases.md
│ ├── PostgreSQL简介(二)—— Database Roles.md
│ └── PostgreSQL简介(四)—— Client Authentication.md
├── PostgreSQL系统表详解.md
├── 不睡觉的怪叔叔PgRouting教程
│ ├── 1.pgRouting官方教程:介绍.md
│ ├── 10.pgRouting教程十:使用OpenLayers调用pgRouting的存储过程.md
│ ├── 2.pgRouting官方教程:关于教程.md
│ ├── 3.pgRouting教程三:安装pgRouting.md
│ ├── 4.pgRouting教程四:准备数据.md
│ ├── 5.pgRouting教程五:pgRouting算法.md
│ ├── 6.pgRouting教程六:高级路径查询.md
│ ├── 7.pgRouting教程七:使用SQL存储过程.md
│ ├── 8.pgRouting教程八:使用plpgsql写存储过程.md
│ ├── 9.pgRouting教程九:使用GeoServer发布WMSWFS接口.md
│ └── pgRouting官方文档:简单数据.md
└── 教程系列
│ ├── 1.PostgreSQL基础.md
│ ├── 10.PostgreSQL别名.md
│ ├── 11.PostgreSQL 触发器 .md
│ ├── 12.PostgreSQL索引.md
│ ├── 13.PostgreSQL Alter,Truncate Table.md
│ ├── 14.PostgreSQL视图、事务、锁.md
│ ├── 15.PostgreSQL子查询,Auto Increment.md
│ ├── 16.PostgreSQL权限Privileges.md
│ ├── 17.PostgreSQL时间日期函数和操作符 .md
│ ├── 18.PostgreSQL常用函数.md
│ ├── 19.PostgreSQL的模式、表、空间、用户间的关系.md
│ ├── 2.PostgreSQL语法.md
│ ├── 3.PostgreSQL数据类型.md
│ ├── 4.PostgreSQL数据库操作.md
│ ├── 5.PostgreSQL表格操作.md
│ ├── 6.PostgreSQL模式Schema.md
│ ├── 7.PostgreSQL操作语句.md
│ ├── 8.PostgreSQL约束.md
│ └── 9.PostgreSQL的Join,Union,Null.md
├── 10.PostgreSQL 配置文件
└── PostgreSQL 11 postgresql.conf 参数模板.md
├── 11.PostgreSQL PDF资料文档
├── OLAP 在互联网公司的实践与思考.md
├── OLAP-practice-.pdf
├── PG(PostgreSQL)的社会价值.pdf
├── Postgresql思维导图.xmind
├── SaaS行业需要什么样的数据库.pdf
└── 开发者PG TOP 18问.pdf
├── 12.PostgreSQL 安装与部署
├── 1. 集群部署
│ └── 基于pgpool搭建postgressql集群部署.md
├── Linux中PostgreSQL和PostGIS的安装和使用.md
├── PostgreSQL 持续稳定使用的小技巧 - 最佳实践、规约、规范.md
├── PostgreSQL+PostGIS安装部署.md
└── PostgreSQL的Docker安装与部署.md
├── 13.PostgreSQL 开发与使用
├── Geotools连接PostgreSQL数据库.md
├── JDBC与PostgreSQL(一).md
├── JDBC与PostgreSQL(三):存储过程和函数.md
├── PG SQL记录
│ ├── PG查询字段注释,表注释.md
│ └── postgresql兼容mysql last_insert_id().md
├── PgSQL批量插入测试数据.md
├── PostGresql 实现四舍五入、小数转换、百分比的用法说明.md
├── PostgreSQL 如何快速构建 海量 逼真 测试数据.md
├── PostgreSQL三种自增列sequence,serial,identity的用法区别.md
├── PostgreSQL与MySQL
│ ├── PostgreSQL 新增数据返回自增ID.md
│ ├── PostgreSQL和mysql数据类型对比兼容.md
│ ├── PostgreSQL(MySQL)插入操作传入值为空则设置默认值.md
│ └── PostgreSQL(MySQL)插入操作遇到唯一值重复时更新.md
├── PostgreSQL常用SQL.md
├── PostgreSQL数据库中如何保证LIKE语句的效率(推荐).md
├── PostgreSQL自动更新时间戳.md
├── PostgreSQL表分区的三种方式.md
├── Postgresql 查看SQL语句执行效率的操作.md
├── postgresql 中的to_char()常用操作.md
├── postgresql 删除重复数据的几种方法小结.md
├── postgresql 自动类型转换.md
├── postgresql数据库连接数和状态查询操作.md
├── sql语句中“!=”与“”的区别.md
├── 函数
│ ├── ST_Transform.md
│ └── pg函数(function).md
├── 字符串相关操作
│ └── PostGreSql 判断字符串中是否有中文的案例.md
├── 数据备份
│ ├── 备份 PostgreSQL特定schema或table数据.md
│ └── 逻辑备份和物理备份实战.md
├── 时间相关操作
│ ├── PGSQL 实现查询今天,昨天的数据,一个月之内的数据.md
│ ├── PostgreSQL 字符串处理与日期处理操作.md
│ ├── postgresql 中的时间处理小技巧(推荐).md
│ └── postgresql数据库使用说明_实现时间范围查询.md
├── 索引相关
│ ├── PostgreSQL索引介绍.md
│ ├── PostgreSQL索引详解5——Gist索引.md
│ └── PostgreSql 索引简明教程.md
├── 详解PostgreSQL提升批量数据导入性能的n种方法.md
└── 调优相关
│ └── PostgreSQL 内存参数调优.md
├── 14.PostgreSQL 监控
├── PostgreSQL监控实战.md
└── 金融级PostgreSQL监控与优化.md
├── 15.PostgreSQL 与SpringBoot
├── Mybatis-plus读取和保存Postgis geometry数据.md
├── Mybatis处理数据库geometry字段.md
└── Postgresql+Springboot yml基本使用.md
├── 16.PostgreSQL 架构与设计
├── MySQL和PostgreSQL设计规范.md
├── PG实例的架构设计与踩坑经验.md
├── PostgreSQL规范
│ ├── 1.PostgreSQL 命名规范.md
│ ├── 2.PostgreSQL 设计规范.md
│ ├── 3.PostgreSQL QUERY规范.md
│ ├── 4.PostgreSQL 管理规范.md
│ ├── 5.PostgreSQL 稳定性与性能规范.md
│ ├── 6.PostgreSQL 阿里云RDS PostgreSQL 使用规范.md
│ └── 7. PostgreSQL 索引规范.md
├── 平安Postgresql架构实践.md
└── 数据模型设计.md
├── 2.PostgreSQL 优势
├── PG和Mysql哪个更加适合企业.md
├── PostgreSQL 与 MySQL 的区别.md
├── PostgreSQL 与 MySQL 相比,优势何在?.md
├── PostgreSQL 和 MySQL 在用途、好处、特性和特点上的异同.md
├── 【干货总结】可能是史上最全的MySQL和PGSQL的对比材料.md
├── 为什么数据库选型和找对象一样重要.md
├── 为什么选择开源数据库、如何选择、需要做哪些准备.md
├── 企业数据库选型规则 .md
├── 全方位比较PostgreSQL和MySQL.md
└── 学生为什么应该学PG, PG与其他数据库有哪些独特性, 为什么PG是数据库的未来 .md
├── 20.环境部署
└── 10.pgAdmin.md
├── 3.PostgreSQL 笔记
├── POSTGRES 数据类型 JAVA类型对照.md
├── PostgreSQL 删除重复数据.md
├── PostgreSQL 系列
│ ├── 6 index链表跳跳糖 (CTE recursive 递归的详细用例) .md
│ ├── 7 垂帘听政 异步消息 .md
│ ├── 9 面向多值列的倒排索引GINRUM .md
│ ├── OKR 和 KPI的区别与实践.md
│ ├── PostgreSQL + MySQL 如何互补.md
│ ├── PostgreSQL AB表切换最佳实践 - 提高切换成功率.md
│ ├── PostgreSQL DBA 日常管理 SQL .md
│ ├── PostgreSQL DBA最常用SQL.md
│ ├── PostgreSQL IoT,车联网 - 实时轨迹、行程实践 1.md
│ ├── PostgreSQL OpenStreeMap PBF 地理数据文件外部表 , 支持 NODE, WAY, RELATION 类型, GIS地理信息,地图类数据应用 .md
│ ├── PostgreSQL hash分区表扩容、缩容(增加分区、减少分区、分区重分布、拆分区、合并分区), hash算法 hash_any, 混合hash MODULUS 分区 - attach , detach .md
│ ├── PostgreSQL permission 权限查询与统计.md
│ ├── PostgreSQL prefix 插件 - 身份证、手机号、路由、区号等编码前缀搜索 .md
│ ├── PostgreSQL ssl 证书配置 - 防止中间攻击者 - 以及如何使用证书无密码登录配置cert .md
│ ├── PostgreSQL 三种心跳(keepalive)指标的应用 - 时间戳、redo(wal)位点、事务号 .md
│ ├── PostgreSQL 任意字段组合查询.md
│ ├── PostgreSQL 国内外信息获取渠道网站 - 新闻、研发、软件、用户组、FAQ、博客、会议、相关项目、开源代码、JOB、安全信息、技能评估、培训等 .md
│ ├── PostgreSQL 基于PG内置流复制的,靠谱的PostgreSQL高可用方案(Patroni stolon).md
│ ├── PostgreSQL 多维、图像 欧式距离、向量距离、向量相似 查询优化 - cube,imgsmlr - 压缩、分段、异步并行 .md
│ ├── PostgreSQL 大量IO扫描、计算浪费的优化 - 推荐模块, 过滤已推荐. (热点用户、已推荐列表超大) .md
│ ├── PostgreSQL 实时健康监控 大屏 - 低频指标.md
│ ├── PostgreSQL 实时健康监控 大屏 - 高频指标(服务器).md
│ ├── PostgreSQL 并行计算解说 汇总 .md
│ ├── PostgreSQL 懒人快速(无堵塞、或短暂堵塞DML)创建一大堆分区索引 .md
│ ├── PostgreSQL 持续稳定使用的小技巧 - 最佳实践、规约、规范.md
│ ├── PostgreSQL 数组里面的元素,模糊搜索,模糊查询,like,前后百分号,正则查询,倒排索引 .md
│ ├── PostgreSQL 生成随机数据方法大汇总 .md
│ ├── PostgreSQL 知识图谱 (xmind, png格式) .md
│ ├── PostgreSQL 社区建设思考 .md
│ ├── PostgreSQL 跟踪记录(row,tuple)的插入、更新时间.md
│ └── batch insert in PostgreSQL.md
├── PostgreSQL 表空间(TABLESPACE).md
├── PostgreSQL常用SQL语句.md
├── PostgreSQL组合唯一约束空值问题.md
├── Postgresql实现动态SQL语句.md
├── postgresql 自动类型转换.md
├── postgresql 身份证、手机号、营业执照验证脚本.md
├── postgresql数据库使用遇到的问题及解决方案.md
└── 查看PostgreSQL 表结构及权限列表.md
├── 4.PostgreSQL 课程
├── 36.md
├── Benchmark.md
├── HTAP.md
├── Oracle兼容性.md
├── README.md
├── 安全与审计.md
├── 应用开发.md
├── 思维精进.md
├── 招聘与求职信息.md
├── 数据库选型.md
├── 时序、时空、对象多维处理.md
├── 最佳实践.md
├── 标准化(规约、制度、流程).md
├── 沙龙、会议、培训.md
├── 流式计算.md
├── 版本新特性.md
├── 监控.md
├── 系列课程.md
├── 经典案例.md
└── 问题诊断与性能优化.md
├── 5.PostgreSQL 案例
├── 时间、空间、业务多维数据实时透视
│ ├── 1.数据透视 - 商场(如沃尔玛)选址应用.md
│ ├── 2.奔跑吧,大屏 - 时间+空间 实时四维数据透视.md
│ └── 3.(新零售)商户网格化(基于位置GIS)运营 - 阿里云RDS PostgreSQL、HybridDB for PostgreSQL最佳实践.md
├── 流式数据实时处理案例
│ ├── 1.物联网流式处理应用 - 用PostgreSQL实时处理(万亿每天).md
│ ├── 2.基于PostgreSQL的流式PipelineDB, 1000万s实时统计不是梦.md
│ ├── 3.流计算风云再起 - PostgreSQL携PipelineDB力挺IoT.md
│ └── 4.(流式、lambda、触发器)实时处理大比拼 - 物联网(IoT)金融,时序处理最佳实践.md
├── 物联网案例
│ ├── 1.车联网案例,轨迹清洗 - 阿里云RDS PostgreSQL最佳实践 - 窗口函数.md
│ ├── 2.PostgreSQL 黑科技 range 类型及 gist index 助力物联网(IoT).md
│ └── 3.旋转门数据压缩算法在PostgreSQL中的实现 - 流式压缩在物联网、监控、传感器等场景的应用.md
├── 空间数据应用案例
│ ├── 1.菜鸟末端轨迹 - 电子围栏(解密支撑每天251亿个包裹的数据库) - 阿里云RDS PostgreSQL最佳实践.md
│ ├── 2.PostgreSQL 物流轨迹系统数据库需求分析与设计 - 包裹侠实时跟踪与召回 .md
│ ├── 3.无人驾驶背后的技术 - PostGIS点云(pointcloud)应用 - 1.md
│ ├── 4.无人驾驶背后的技术 - PostGIS点云(pointcloud)应用 - 2.md
│ ├── 5.多点最优路径规划 - (商旅问题,拼车,餐饮配送,包裹配送,包裹取件,回程单).md
│ ├── 6.PostgreSQL数据库应用:基于GIS的实时车辆位置查询.md
│ ├── 7.PostgreSQL 百亿地理位置数据 近邻查询性能.md
│ ├── GIS 近邻查询优化
│ │ ├── 1.PostGIS空间索引(GiST、BRIN、R-Tree)选择、优化 - 阿里云RDS PostgreSQL最佳实践.md
│ │ └── 2.SRID (空间引用识别号, 坐标系).md
│ ├── 时空调度系统
│ │ ├── 1.网约车打车派单系统思考 数据库设计与实现 - 每月投入6140元, 1天最多可盈利117亿 -_-!.md
│ │ ├── 2.PostgreSQL 网约车打车派单 高峰区域集中打车冲突优化1 - 宇宙大爆炸理论与PostgreSQL实践.md
│ │ └── 3.为什么geometry+GIST 比 geohash+BTREE更适合空间搜索 - 多出的不仅仅是20倍性能提升.md
│ ├── 电子围栏
│ │ ├── PostgreSQL 3D City 应用.md
│ │ └── PostgreSQL 电子围栏的应用场景和性能(大疆、共享设备、菜鸟。。。).md
│ ├── 空间包含查询原理、优化
│ │ ├── PostgreSQL + PostGIS + SFCGAL 优雅的处理3D数据.md
│ │ └── PostgreSQL 空间切割(st_split, ST_Subdivide)功能扩展 - 空间对象网格化 (多边形GiST优化).md
│ └── 空间投影
│ │ ├── PostGIS 距离计算建议 - 投影 与 球 坐标系, geometry 与 geography 类型.md
│ │ └── PostgreSQL 实时位置跟踪+轨迹分析系统实践 - 单机顶千亿轨迹天.md
├── 轨迹系列
│ └── PostgreSQL 实时位置跟踪+轨迹分析系统实践 - 单机顶千亿轨迹天.md
├── 阿里云PostgreSQL案例精选1 - 实时精准营销、人群圈选 .md
└── 阿里云PostgreSQL案例精选2 - 图像识别、人脸识别、相似特征检索、相似人群圈选 .md
├── 6.PostgreSQL PostGIS GIST
├── 00.德哥GIS相关笔记
│ ├── 8 轨迹业务IO杀手克星index include(覆盖索引) .md
│ ├── GIS 完整开源解决方案.md
│ ├── Greenplum 轨迹相似(伴随分析) .md
│ ├── PostGIS 3 瓦片提取函数 ST_TileEnvelope .md
│ ├── PostGIS空间索引(GiST、BRIN、R-Tree)选择、优化 - 2 .md
│ ├── PostgreSQL + PostGIS 时态分析 .md
│ ├── PostgreSQL 12 + PostGIS 3 - 让空间并行计算更加智能 .md
│ ├── PostgreSQL 12 + PostGIS 3 实现FULL PARALLEL - GIS计算智能并行 .md
│ ├── PostgreSQL GiST 索引原理 - 1 .md
│ ├── PostgreSQL GiST 索引原理 - 2.md
│ ├── PostgreSQL GiST 索引原理 - 3.md
│ ├── PostgreSQL GiST 索引原理 - 4 .md
│ ├── PostgreSQL PostGIS 3 - 从min(x) 到 z-order 到 Hilbert Geometry Sorting - PostGIS空间排序算法优化 .md
│ ├── PostgreSQL PostGIS 3 ST_AsGeoJSON(record) - early only ST_AsGeoJSON(geo) .md
│ ├── PostgreSQL PostGIS ST_AsMVT Performance 提升 - SQL提取地图矢量瓦片(Mapbox Vector Tile) .md
│ ├── PostgreSQL PostGIS overlap .md
│ ├── PostgreSQL PostGIS point join polygon (by ST_xxxx) - pglz_decompress 性能优化.md
│ ├── PostgreSQL PostGIS 坐标转换项目 - 百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换.md
│ ├── PostgreSQL PostGIS 的5种空间距离排序(knn)算法 .md
│ ├── PostgreSQL 多维空间几何对象 相交、包含 高效率检索实践 - cube.md
│ ├── PostgreSQL 如何将空间数据导入PostGIS .md
│ ├── PostgreSQL 生成空间热力图 .md
│ ├── PostgreSQL 空间位置(geometry 经纬、点、线、面...)、行政地址(门牌、商圈、行政区...) 相互转换方法 .md
│ ├── PostgreSQL 空间聚合性能 - 行政区、电子围栏 空间聚合 - 时间、空间热力图 .md
│ ├── 基于GIS位置、群众热点、人为热点的内容推荐服务 - 挑战和策略.md
│ └── 时空轨迹系统 新冠&刑侦&预测 .md
├── 01.不睡觉的怪叔叔PostGIS教程
│ ├── 1.PostGIS教程:PostGIS介绍.md
│ ├── 10.PostGIS教程:空间连接.md
│ ├── 11.PostGIS教程:空间索引.md
│ ├── 12.PostGIS教程:投影数据.md
│ ├── 13.PostGIS教程:地理.md
│ ├── 14.PostGIS教程:几何图形创建函数.md
│ ├── 15.PostGIS教程:更多的空间连接.md
│ ├── 16.PostGIS教程:几何图形的有效性.md
│ ├── 17.PostGIS教程:相等.md
│ ├── 18.PostGIS教程:线性参考.md
│ ├── 19.PostGIS教程:维数扩展的9交集模型.md
│ ├── 2.PostGIS教程:PostGIS的安装.md
│ ├── 20.PostGIS教程:索引集群.md
│ ├── 21.PostGIS教程:3-D.md
│ ├── 22.PostGIS教程:最近邻域搜索.md
│ ├── 3.PostGIS教程:创建空间数据库.md
│ ├── 4.PostGIS教程:加载空间数据.md
│ ├── 5.PostGIS教程:数据.md
│ ├── 6.PostGIS教程:简单的SQL语句.md
│ ├── 7.PostGIS教程:几何图形(Geometry).md
│ ├── 8.PostGIS教程:关于几何图形的练习.md
│ ├── 9.PostGIS教程:空间关系.md
│ └── PostGIS官方教程汇总目录.md
├── 03.PostGIS参考笔记
│ ├── GIS术语 - POI、AOI、LOI、路径、轨迹.md
│ ├── PostGIS 常用函数.md
│ ├── PostGIS中geometry与geography的区别.md
│ ├── PostGIS中几何图形的有效性与简单性.md
│ ├── PostGIS使用2:如何利用PostGIS正确计算距离和面积.md
│ ├── PostGIS使用3:PostGIS功能简介(1.概要+空间数据类型).md
│ ├── PostGIS总结.md
│ ├── PostGIS的geometry类型及使用方法.md
│ ├── PostGIS相关数据类型及内置函数介绍 .md
│ ├── PostGIS空间数据类型的组织与表达(geography数据类型).md
│ ├── PostGIS空间数据类型的组织与表达(geometry数据类型).md
│ ├── PostGIS管网连通性分析.md
│ ├── PostGis基本操作-新建空间数据库与shp数据的导入.md
│ ├── PostgreSQL + PostGIS 时态分析 .md
│ ├── PostgreSQL 生成空间热力图.md
│ ├── PostgreSQL存储地理信息数据的注意点.md
│ ├── 地理信息系统PostGis.md
│ └── 基于PG与PostGIS搭建实时矢量瓦片服务.md
├── 04.PostgreSQL与PostGIS基础
│ ├── PostGIS基本使用.md
│ ├── PostGIS导入shp文件.md
│ ├── PostGIS导入导出ESRI Shapefile数据.md
│ ├── PostgreSQL+PostGIS 的使用.md
│ ├── PostgreSQL与PostGIS的基础入门.md
│ ├── PostgreSql对空间数据的操作函数.md
│ ├── Postgres空间地理类型POINT POLYGON实现附近的定位和电子围栏功能.md
│ └── postgresql 创建gis空间数据库,shp数据入库.md
├── 10.PostGIS操作
│ ├── Geometry——PostgreSQL+PostGIS的使用.md
│ ├── PostGIS 测试 - 基本类型(WKT & WKB).md
│ ├── PostGIS 测试 - 线(LINESTRING).md
│ ├── PostGIS中geometry与geography的区别.md
│ ├── PostGIS测试 - geometry_columns.md
│ ├── PostGIS的geometry类型及使用方法.md
│ ├── postgresql 计算两点距离的2种方法小结.md
│ ├── postgresql更改geometry类型列的srid.md
│ ├── 三维坐标转换为二维坐标.md
│ ├── 使用PG处理地图数据偏移问题.md
│ └── 基于PostGIS的轨迹数据修复.md
├── 11.PostGIS函数说明
│ ├── AddGeometryColumn.md
│ ├── DropGeometryColumn.md
│ └── postgis添加geometry类型字段.md
├── 12.Java PostgreSQL Geometry应用
│ ├── Java Geometry空间几何数据的处理应用.md
│ ├── Java 操作gis geometry类型数据.md
│ └── Postgis中geometry字段在mybatis generator插件中成果转换对照的解决方案.md
└── 20.PgRouting
│ ├── PgRouting-AStar
│ ├── PGRouting导航规划-AStar算法.md
│ ├── PostGIS路径规划-AStar.md
│ └── 使用pgrouting和geotools实现最短路径,服务区分析.md
│ ├── PgRouting求解大数据量最短路径.md
│ ├── PgRouting系列教程
│ ├── pgRouting官方文档:pgr_dijkstra.md
│ ├── pgRouting官方文档:pgr_dijkstraCost.md
│ ├── pgRouting官方文档:简单数据.md
│ ├── pgRouting教程一:介绍.md
│ ├── pgRouting教程七:使用SQL存储过程.md
│ ├── pgRouting教程三:安装pgRouting.md
│ ├── pgRouting教程二:关于教程.md
│ ├── pgRouting教程五:pgRouting算法.md
│ ├── pgRouting教程八:使用plpgsql写存储过程.md
│ ├── pgRouting教程六:高级路径查询.md
│ └── pgRouting教程四:准备数据.md
│ ├── PostGIS拓扑:pgRouting最短路径分析.md
│ ├── PostGis+GeoServer+OpenLayers最短路径分析.md
│ ├── pgRouting最短路径查询.md
│ ├── pgRouting路径规划.md
│ ├── pgr_createTopology.md
│ ├── pgr_createVerticesTable.md
│ ├── pgrouting最优路径规划之一.md
│ └── 基于pgrouting的路径规划处理.md
├── 7.PostgreSQL 推荐系统
├── PostgreSQL 推荐系统优化总计.md
├── PostgreSQL 相似人群圈选,人群扩选,向量相似 使用实践 - cube .md
├── 推荐系统, 已阅读过滤, 大量CPU和IO浪费的优化思路2.md
├── 用户喜好推荐系统 - PostgreSQL 近似计算应用.md
└── 社交、电商、游戏等 推荐系统 (相似推荐).md
├── 8.PostgreSQL 应用开发解决方案
├── PostgreSQL 应用开发解决方案最佳实践系列课程 - 1. 中文分词与模糊查询 .md
├── PostgreSQL 应用开发解决方案最佳实践系列课程 - 2. 短视频业务实时推荐 .md
├── PostgreSQL 应用开发解决方案最佳实践系列课程 - 3. 人脸识别和向量相似搜索 .md
├── PostgreSQL 应用开发解决方案最佳实践系列课程 - 4. 出行相关调度系统 .md
├── PostgreSQL 应用开发解决方案最佳实践系列课程 - 5. 配送相关调度系统 .md
├── PostgreSQL 应用开发解决方案最佳实践系列课程 - 6. 时空、时态、时序、日志等轨迹系统.md
├── PostgreSQL 应用开发解决方案最佳实践系列课程 - 8. 树状图谱关系系统.md
├── PostgreSQL 应用开发解决方案最佳实践系列课程 - 9. 数据存储冷热分离 .md
└── 数据库案例集锦 - 开发者的《如来神掌》.md
├── 9.PostgreSQL 插件与工具
├── Pgadmin4.md
├── Pigsty 图形化PostgreSQL.md
├── PostgreSQL 最常用的插件.md
├── PostgreSQL 有价值的插件、可改进功能.md
├── PostgreSQL 用户最喜爱的扩展插件功能 .md
└── PostgreSQL工具.md
├── DBA职能.md
├── LICENSE
├── README.md
├── 德哥系列
└── 德哥直播课程.md
└── 自动化脚本.bat
/1.PostgreSQL 学习系列/PostgreSQL中文文档/附录:PostgreSQL限制.md:
--------------------------------------------------------------------------------
1 | **表 K.1. PostgreSQL限制**
2 |
3 | | 项目 | 上限值 | 说明 |
4 | | -------------------- | ----------------------------------------- | ------------------------------------------------------ |
5 | | 数据库大小 | 不限 | |
6 | | 数据库数量 | 4,294,950,911 | |
7 | | 每个数据库的关系数量 | 1,431,650,303 | |
8 | | 关系大小 | 32 TB | 基于`BLCKSZ`为缺省的8192字节 |
9 | | 每个表的记录数 | 受限于可以放到4,294,967,295个页中的元组数 | |
10 | | 每个表的列数 | 1600 | 同时受限于元组大小,需要能放到单个页中; 参考下面的说明 |
11 | | 字段大小 | 1 GB | |
12 | | 标识符长度 | 63字节 | 可以通过重新编译PostgreSQL增大 |
13 | | 每个表的索引数 | 不限 | 受每个数据库最大关系数的约束 |
14 | | 每个索引的列数 | 32 | 可以通过重新编译PostgreSQL增大 |
15 | | 分区键数量 | 32 | 可以通过重新编译PostgreSQL增大 |
16 |
17 |
18 |
19 | 由于要存储的元组必须适合单个8192字节的堆页面,因此表的最大列数进一步减少。 例如,除元组头外,由1600个`int`列组成的元组将占用6400字节并可以存储在堆页面中, 而一个包含1600个`bigint`列的元组将消耗12800字节,因此无法放入单个堆页面。 当类型为比如`text`,`varchar`和`char`的可变长度字段时, 如果值的长度足够大,它们的值可以存储在行外的TOAST表中。 表堆中的元组中只保留18个字节的指针。 对于较短长度的可变长度字段,使用4字节或1字节的字段头,并且该值存储在堆元组内部。
20 |
21 | 从表中删除的列也会影响最大列限制。此外,尽管在元组的空位图中将新创建的元组的删除列值内部标记为空,但空位图也占用空间。
--------------------------------------------------------------------------------
/1.PostgreSQL 学习系列/不睡觉的怪叔叔PgRouting教程/1.pgRouting官方教程:介绍.md:
--------------------------------------------------------------------------------
1 | # pgRouting官方教程一:介绍
2 |
3 | # 一、概述
4 |
5 | **pgRouting**向PostGIS添加了路由功能,这个教程将向你展示:使用[OpenStreetMap](http://www.openstreetmap.org/)道路网数据的示例,包括如何准备数据,进行路由查询,编写一个自定义的'plpgsql'函数来在web地图应用程序中绘制你的路由。换句话说,将pgRouting和其他FOSS4G工具集成到一起。
6 |
7 | 道路网路的导航需要复杂的路径选择算法,这些算法支持转弯限制,甚至支持依赖时间的属性。pgRouting是一个可扩展的开源库,它作为PostgreSQL和PostGIS的扩展为最短路径搜索提供了多种工具。
8 |
9 | 本教程的重点是在实际道路网络中使用pgRouting进行最短路径搜索。它将涵盖以下主题:
10 |
11 | - 安装pgRouting
12 | - 创建路由拓扑
13 | - 使用pgRouting算法
14 | - 导入OpenStreetMap道路网数据
15 | - 编写高级查询
16 | - 在'plpgsql'中编写自定义PostgreSQL存储过程
17 | - 构建一个简单的浏览器应用程序
18 | - 使用OpenLayers构建基本的地图界面
19 |
20 |
21 |
22 | # 二、先决条件
23 |
24 | - 教程等级:中级
25 | - 需要的先前知识:SQL(PostgreSQL,PostGIS),JavaScript,HTML
26 | - 设备:本教程使用[OSGeo Live](http://live.osgeo.org/)(Version 12.0)
--------------------------------------------------------------------------------
/1.PostgreSQL 学习系列/不睡觉的怪叔叔PgRouting教程/2.pgRouting官方教程:关于教程.md:
--------------------------------------------------------------------------------
1 | # pgRouting官方教程二:关于教程
2 |
3 | 本教程使用了多个[FOSS4G](http://www.osgeo.org/)工具,大多数FOSS4G软件都与其他开放源代码项目相关,这里就不一一列出来了。
4 |
5 | # 一、pgRouting概览
6 |
7 | pgRouting扩展了PostGIS/PostgreSQL地理空间数据库,以提供地理空间路由功能。
8 |
9 | 数据库路由方法的优点是:
10 |
11 | - 数据和属性可以由许多客户机修改,比如QGIS和uDig可以通过JDBC、ODBC进行修改,或者直接使用Pl/pgSQL进行修改。客户端可以是PC,也可以是移动设备。
12 | - 数据更改可以通过路由引擎即时反映,不需要预先计算。
13 | - 可以通过SQL动态计算"cost"参数,其值可以来自多个字段或表。
14 |
15 | pgRouting库包含以下核心功能:
16 |
17 | - [Dijkstra算法](https://en.wikipedia.org/wiki/Dijkstra' rel=)
18 | - [约翰逊算法(Johnson's Algorithm)](https://en.wikipedia.org/wiki/Johnson' rel=)
19 | - [弗洛伊德-沃沙尔算法(Floyd-Warshall Algorithm)](https://en.wikipedia.org/wiki/Floyd–Warshall_algorithm)
20 | - [A*算法](https://en.wikipedia.org/wiki/A*_search_algorithm)
21 | - [双向算法*双向Dijkstra](https://en.wikipedia.org/wiki/Bidirectional_search)*双向A*(Bi-directional Algorithms*Bi-directional Dijkstra*Bi-directional A*)
22 | - [旅行商(Traveling Sales Person)](https://en.wikipedia.org/wiki/Travelling_salesman_problem)
23 | - Driving Distance
24 | - 转弯限制最短路径(TRSP)
25 | - 更多!
26 |
27 | pgRouting是开放源代码的,在GPLv2许可下提供,受[Georepublic](http://georepublic.info/)、[iMaptools](http://imaptools.com/)和广大用户社区的支持和维护。
28 |
29 | pgRouting是[OSGeo Foundation](http://osgeo.org/)的[OSGeo Community Projects](http://wiki.osgeo.org/wiki/OSGeo_Community_Projects)项目,包含在[OSGeoLive](http://live.osgeo.org/)中。
30 |
31 | 网站:[http://www.pgrouting.org](http://www.pgrouting.org/)
32 |
33 | OSGeoLive: https://live.osgeo.org/en/overview/pgrouting_overview.html
34 |
35 |
36 |
37 | # 二、osm2pgrouting概览
38 |
39 | osm2pgrouting是一个命令行工具,用于将OpenStreetMap数据导入pgRouting数据库。它会自动构建路由网络拓扑,并为要素类型和道路类别创建表。osm2pgrouting主要是由Daniel Wendt编写,现在托管在[pgRouting项目站点](https://github.com/pgRouting/osm2pgrouting)上。
40 |
41 | 基于GPLv2许可,可以使用osm2pgrouting。
42 |
43 | 维基:https://github.com/pgRouting/osm2pgrouting/wiki
44 |
45 |
46 |
47 | # 三、OpenStreetMap概览
48 |
49 | "OpenStreetMap是一个旨在创建并向任何需要的人提供免费地理数据(如街道地图)的项目,启动该项目的目的是因为大多数你认为免费的地图在使用时实际上都有法律或技术的限制,阻碍了人们以创造性、生产性或奇特的方式使用它们。"
50 |
51 | (来源: http://wiki.openstreetmap.org/index.php/Press)
52 |
53 | 对于pgRouting来说,OpenStreetMap是一个丰富的数据源,因为在处理数据方面没有技术限制。各国的数据可获取性仍然不尽相同,但是世界范围的覆盖性正在日益改善。
54 |
55 | OpenStreetMap使用拓扑数据结构:
56 |
57 | - 节点(Nodes)是具有地理位置的点。
58 | - 道路(Ways)是节点的序列,被表示为折线(Poly Line)或者多边形
59 | - 关系是指可以被赋予为确定属性的一组节点、道路和其他地理要素之间的关系
60 | - 属性可以指定给节点、道路或者关系并由name=value对组成
61 |
62 | OpenStreetMap网站:[http://www.openstreetmap.org](http://www.openstreetmap.org/)
--------------------------------------------------------------------------------
/1.PostgreSQL 学习系列/教程系列/1.PostgreSQL基础.md:
--------------------------------------------------------------------------------
1 | # 一、架构基础
2 |
3 | PostgreSQL使用一种客户端/服务器的模型。一次PostgreSQL会话由下列相关的进程(程序)组成:
4 |
5 | - 一个服务器进程,它管理数据库文件、接受来自客户端应用与数据库的联接并且代表客户端在数据库上执行操作。 该数据库服务器程序叫做`postgres`。
6 | - 那些需要执行数据库操作的用户的客户端(前端)应用。 客户端应用可能本身就是多种多样的:可以是一个面向文本的工具, 也可以是一个图形界面的应用,或者是一个通过访问数据库来显示网页的网页服务器,或者是一个特制的数据库管理工具。 一些客户端应用是和 PostgreSQL发布一起提供的,但绝大部分是用户开发的。
7 |
8 |
9 |
10 | 和典型的客户端/服务器应用(C/S应用)一样,这些客户端和服务器可以在不同的主机上。 这时它们通过 TCP/IP 网络联接通讯。 你应该记住的是,在客户机上可以访问的文件未必能够在数据库服务器机器上访问(或者只能用不同的文件名进行访问)。
11 |
12 | PostgreSQL服务器可以处理来自客户端的多个并发请求。 因此,它为每个连接启动(“forks”)一个新的进程。 从这个时候开始,客户端和新服务器进程就不再经过最初的 `postgres`进程的干涉进行通讯。 因此,主服务器进程总是在运行并等待着客户端联接, 而客户端和相关联的服务器进程则是起起停停。
13 |
14 |
15 |
16 | # 二、创建示例数据库
17 |
18 | 一台运行着的PostgreSQL服务器可以管理许多数据库。 通常我们会为每个项目和每个用户单独使用一个数据库。
19 |
20 | 要创建一个新的数据库,在我们这个例子里叫`mydb`,你可以使用下面的命令:
21 |
22 | ```sql
23 | $ createdb mydb
24 | ```
25 |
26 | 如果不产生任何响应则表示该步骤成功。
27 |
28 | 如果你看到类似下面这样的信息:
29 |
30 | ```sql
31 | createdb: command not found
32 | ```
33 |
34 | 那么就是PostgreSQL没有安装好。或者是根本没安装, 或者是你的shell搜索路径没有设置正确。尝试用绝对路径调用该命令试试:
35 |
36 | ```sqlite
37 | $ /usr/local/pgsql/bin/createdb mydb
38 | ```
39 |
40 | PostgreSQL允许你在一个站点上创建任意数量的数据库。 数据库名必须是以字母开头并且小于 63 个字符长。 一个方便的做法是创建和你当前用户名同名的数据库。 许多工具假设该数据库名为缺省数据库名,所以这样可以节省你的敲键。 要创建这样的数据库,只需要键入:
41 |
42 | ```sql
43 | $ createdb
44 | ```
45 |
46 | 如果你再也不想使用你的数据库了,那么你可以删除它。 比如,如果你是数据库`mydb`的所有人(创建人), 那么你就可以用下面的命令删除它:
47 |
48 | ```sql
49 | $ dropdb mydb
50 | ```
51 |
52 | # 三、访问数据库
53 |
54 | 一旦你创建了数据库,你就可以通过以下方式访问它:
55 |
56 | - 运行PostgreSQL的交互式终端程序,它被称为*psql*, 它允许你交互地输入、编辑和执行SQL命令。
57 | - 使用一种已有的图形化前端工具,比如pgAdmin或者带ODBC或JDBC支持的办公套件来创建和管理数据库。这种方法在这份教程中没有介绍。
58 | - 使用多种绑定发行的语言中的一种写一个自定义的应用。
59 |
60 | 启动`psql`来试验本教程中的例子。 你可以用下面的命令为`mydb`数据库激活它:
61 |
62 | ```
63 | $ psql mydb
64 | ```
65 |
66 | 如果你不提供数据库名字,那么它的缺省值就是你的用户账号名字。
--------------------------------------------------------------------------------
/1.PostgreSQL 学习系列/教程系列/10.PostgreSQL别名.md:
--------------------------------------------------------------------------------
1 | # 一、PostgreSQL 别名
2 |
3 | 我们可以用 SQL 重命名一张表或者一个字段的名称,这个名称就叫着该表或该字段的别名。
4 |
5 | 创建别名是为了让表名或列名的可读性更强。
6 |
7 | SQL 中 使用 **AS** 来创建别名。
8 |
9 | ## 1.1 语法
10 |
11 | 表的别名语法:
12 |
13 | ```plsql
14 | SELECT column1, column2....
15 | FROM table_name AS alias_name
16 | WHERE [condition];
17 | ```
18 |
19 | 列的别名语法:
20 |
21 | ```plsql
22 | SELECT column_name AS alias_name
23 | FROM table_name
24 | WHERE [condition];
25 | ```
26 |
27 | ### 1.1.1 实例
28 |
29 | 创建 COMPANY 表([下载 COMPANY SQL 文件](https://static.runoob.com/download/company.sql) ),数据内容如下:
30 |
31 | ```plsql
32 | runoobdb# select * from COMPANY;
33 | id | name | age | address | salary
34 | ----+-------+-----+-----------+--------
35 | 1 | Paul | 32 | California| 20000
36 | 2 | Allen | 25 | Texas | 15000
37 | 3 | Teddy | 23 | Norway | 20000
38 | 4 | Mark | 25 | Rich-Mond | 65000
39 | 5 | David | 27 | Texas | 85000
40 | 6 | Kim | 22 | South-Hall| 45000
41 | 7 | James | 24 | Houston | 10000
42 | (7 rows)
43 | ```
44 |
45 | 创建 DEPARTMENT 表([下载 COMPANY SQL 文件](https://static.runoob.com/download/department.sql) ),数据内容如下:
46 |
47 | ```plsql
48 | runoobdb=# SELECT * from DEPARTMENT;
49 | id | dept | emp_id
50 | ----+-------------+--------
51 | 1 | IT Billing | 1
52 | 2 | Engineering | 2
53 | 3 | Finance | 7
54 | 4 | Engineering | 3
55 | 5 | Finance | 4
56 | 6 | Engineering | 5
57 | 7 | Finance | 6
58 | (7 rows)
59 | ```
60 |
61 | 下面我们分别用 C 和 D 表示 COMPANY 表和 DEPAERMENT 表的别名:
62 |
63 | ```plsql
64 | runoobdb=# SELECT C.ID, C.NAME, C.AGE, D.DEPT FROM COMPANY AS C, DEPARTMENT AS D WHERE C.ID = D.EMP_ID;
65 | ```
66 |
67 | 得到结果如下:
68 |
69 | ```plsql
70 | id | name | age | dept
71 | ----+-------+-----+------------
72 | 1 | Paul | 32 | IT Billing
73 | 2 | Allen | 25 | Engineering
74 | 7 | James | 24 | Finance
75 | 3 | Teddy | 23 | Engineering
76 | 4 | Mark | 25 | Finance
77 | 5 | David | 27 | Engineering
78 | 6 | Kim | 22 | Finance
79 | (7 rows)
80 | ```
81 |
82 | 下面,我们用 COMPANY_ID 表示 ID 列,COMPANY_NAME 表示 NAME 列,来展示列别名的用法:
83 |
84 | ```plsql
85 | runoobdb=# SELECT C.ID AS COMPANY_ID, C.NAME AS COMPANY_NAME, C.AGE, D.DEPT FROM COMPANY AS C, DEPARTMENT AS D WHERE C.ID = D.EMP_ID;
86 | ```
87 |
88 | 得到结果如下:
89 |
90 | ```plsql
91 | company_id | company_name | age | dept
92 | ------------+--------------+-----+------------
93 | 1 | Paul | 32 | IT Billing
94 | 2 | Allen | 25 | Engineering
95 | 7 | James | 24 | Finance
96 | 3 | Teddy | 23 | Engineering
97 | 4 | Mark | 25 | Finance
98 | 5 | David | 27 | Engineering
99 | 6 | Kim | 22 | Finance
100 | (7 rows)
101 | ```
--------------------------------------------------------------------------------
/1.PostgreSQL 学习系列/教程系列/11.PostgreSQL 触发器 .md:
--------------------------------------------------------------------------------
1 | # 一、PostgreSQL 触发器
2 |
3 | PostgreSQL 触发器是数据库的回调函数,它会在指定的数据库事件发生时自动执行/调用。
4 |
5 | 下面是关于 PostgreSQL 触发器几个比较重要的点:
6 |
7 | - PostgreSQL 触发器可以在下面几种情况下触发:
8 | - 在执行操作之前(在检查约束并尝试插入、更新或删除之前)。
9 | - 在执行操作之后(在检查约束并插入、更新或删除完成之后)。
10 | - 更新操作(在对一个视图进行插入、更新、删除时)。
11 | - 触发器的 FOR EACH ROW 属性是可选的,如果选中,当操作修改时每行调用一次;相反,选中 FOR EACH STATEMENT,不管修改了多少行,每个语句标记的触发器执行一次。
12 | - WHEN 子句和触发器操作在引用 NEW.column-name 和 OLD.column-name 表单插入、删除或更新时可以访问每一行元素。其中 column-name 是与触发器关联的表中的列的名称。
13 | - 如果存在 WHEN 子句,PostgreSQL 语句只会执行 WHEN 子句成立的那一行,如果没有 WHEN 子句,PostgreSQL 语句会在每一行执行。
14 | - BEFORE 或 AFTER 关键字决定何时执行触发器动作,决定是在关联行的插入、修改或删除之前或者之后执行触发器动作。
15 | - 要修改的表必须存在于同一数据库中,作为触发器被附加的表或视图,且必须只使用 tablename,而不是 database.tablename。
16 | - 当创建约束触发器时会指定约束选项。这与常规触发器相同,只是可以使用这种约束来调整触发器触发的时间。当约束触发器实现的约束被违反时,它将抛出异常。
17 |
18 | ## 1.1 语法
19 |
20 | 创建触发器时的基础语法如下:
21 |
22 | ```plsql
23 | CREATE TRIGGER trigger_name [BEFORE|AFTER|INSTEAD OF] event_name
24 | ON table_name
25 | [
26 | -- 触发器逻辑....
27 | ];
28 | ```
29 |
30 | 在这里,event_name 可以是在所提到的表 table_name 上的 INSERT、DELETE 和 UPDATE 数据库操作。您可以在表名后选择指定 FOR EACH ROW。
31 |
32 | 以下是在 UPDATE 操作上在表的一个或多个指定列上创建触发器的语法:
33 |
34 | ```plsql
35 | CREATE TRIGGER trigger_name [BEFORE|AFTER] UPDATE OF column_name
36 | ON table_name
37 | [
38 | -- 触发器逻辑....
39 | ];
40 | ```
41 |
42 | ### 1.1.1 实例
43 |
44 | 让我们假设一个情况,我们要为被插入到新创建的 COMPANY 表(如果已经存在,则删除重新创建)中的每一个记录保持审计试验:
45 |
46 | ```plsql
47 | runoobdb=# CREATE TABLE COMPANY(
48 | ID INT PRIMARY KEY NOT NULL,
49 | NAME TEXT NOT NULL,
50 | AGE INT NOT NULL,
51 | ADDRESS CHAR(50),
52 | SALARY REAL
53 | );
54 | ```
55 |
56 | 为了保持审计试验,我们将创建一个名为 AUDIT 的新表。每当 COMPANY 表中有一个新的记录项时,日志消息将被插入其中:
57 |
58 | ```plsql
59 | runoobdb=# CREATE TABLE AUDIT(
60 | EMP_ID INT NOT NULL,
61 | ENTRY_DATE TEXT NOT NULL
62 | );
63 | ```
64 |
65 | 在这里,ID 是 AUDIT 记录的 ID,EMP_ID 是来自 COMPANY 表的 ID,DATE 将保持 COMPANY 中记录被创建时的时间戳。所以,现在让我们在 COMPANY 表上创建一个触发器,如下所示:
66 |
67 | ```plsql
68 | runoobdb=# CREATE TRIGGER example_trigger AFTER INSERT ON COMPANY FOR EACH ROW EXECUTE PROCEDURE auditlogfunc();
69 | ```
70 |
71 | auditlogfunc() 是 PostgreSQL 一个程序,其定义如下:
72 |
73 | ```plsql
74 | CREATE OR REPLACE FUNCTION auditlogfunc() RETURNS TRIGGER AS $example_table$
75 | BEGIN
76 | INSERT INTO AUDIT(EMP_ID, ENTRY_DATE) VALUES (new.ID, current_timestamp);
77 | RETURN NEW;
78 | END;
79 | $example_table$ LANGUAGE plpgsql;
80 | ```
81 |
82 | 现在,我们开始往 COMPANY 表中插入数据:
83 |
84 | ```plsql
85 | runoobdb=# INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Paul', 32, 'California', 20000.00 );
86 | ```
87 |
88 | 这时,COMPANY 表中插入了一条记录:
89 |
90 | 同时, AUDIT 表中也插入了一条记录,因为我们在插入 COMPANY 表时创建了一个触发器。相似的,我们也可以根据需求在更新和删除时创建触发器:
91 |
92 | ```plsql
93 | emp_id | entry_date
94 | --------+-------------------------------
95 | 1 | 2013-05-05 15:49:59.968+05:30
96 | (1 row)
97 | ```
98 |
99 | ## 1.2 列出触发器
100 |
101 | 你可以把从 pg_trigger 表中把当前数据库所有触发器列举出来:
102 |
103 | ```plsql
104 | runoobdb=# SELECT * FROM pg_trigger;
105 | ```
106 |
107 | 如果,你想列举出特定表的触发器,语法如下:
108 |
109 | ```plsql
110 | runoobdb=# SELECT tgname FROM pg_trigger, pg_class WHERE tgrelid=pg_class.oid AND relname='company';
111 | ```
112 |
113 | 得到结果如下:
114 |
115 | ```plsql
116 | tgname
117 | -----------------
118 | example_trigger
119 | (1 row)
120 | ```
121 |
122 | ## 1.3 删除触发器
123 |
124 | 删除触发器基础语法如下:
125 |
126 | ```plsql
127 | drop trigger ${trigger_name} on ${table_of_trigger_dependent};
128 | ```
129 |
130 | 删除本文上表 company 上的触发器 example_trigger 的指令为:
131 |
132 | ```plsql
133 | drop trigger example_trigger on company;
134 | ```
--------------------------------------------------------------------------------
/1.PostgreSQL 学习系列/教程系列/12.PostgreSQL索引.md:
--------------------------------------------------------------------------------
1 | # 一、PostgreSQL 索引
2 |
3 | 索引是加速搜索引擎检索数据的一种特殊表查询。简单地说,索引是一个指向表中数据的指针。一个数据库中的索引与一本书的索引目录是非常相似的。
4 |
5 | 拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。
6 |
7 | 索引有助于加快 SELECT 查询和 WHERE 子句,但它会减慢使用 UPDATE 和 INSERT 语句时的数据输入。索引可以创建或删除,但不会影响数据。
8 |
9 | 使用 CREATE INDEX 语句创建索引,它允许命名索引,指定表及要索引的一列或多列,并指示索引是升序排列还是降序排列。
10 |
11 | 索引也可以是唯一的,与 UNIQUE 约束类似,在列上或列组合上防止重复条目。
12 |
13 | ## 1.1 CREATE INDEX 命令
14 |
15 | CREATE INDEX (创建索引)的语法如下:
16 |
17 | ```plsql
18 | CREATE INDEX index_name ON table_name;
19 | ```
20 |
21 | ## 1.2 索引类型
22 |
23 | ### 1.2.1 单列索引
24 |
25 | 单列索引是一个只基于表的一个列上创建的索引,基本语法如下:
26 |
27 | ```plsql
28 | CREATE INDEX index_name
29 | ON table_name (column_name);
30 | ```
31 |
32 | ### 1.2.2 组合索
33 |
34 | 组合索引是基于表的多列上创建的索引,基本语法如下:
35 |
36 | ```plsql
37 | CREATE INDEX index_name
38 | ON table_name (column1_name, column2_name);
39 | ```
40 |
41 | 不管是单列索引还是组合索引,该索引必须是在 WHEHE 子句的过滤条件中使用非常频繁的列。
42 |
43 | 如果只有一列被使用到,就选择单列索引,如果有多列就使用组合索引。
44 |
45 | ### 1.2.3 唯一索引
46 |
47 | 使用唯一索引不仅是为了性能,同时也为了数据的完整性。唯一索引不允许任何重复的值插入到表中。基本语法如下:
48 |
49 | ```plsql
50 | CREATE UNIQUE INDEX index_name
51 | on table_name (column_name);
52 | ```
53 |
54 | ### 1.2.4 局部索引
55 |
56 | 局部索引 是在表的子集上构建的索引;子集由一个条件表达式上定义。索引只包含满足条件的行。基础语法如下:
57 |
58 | ```plsql
59 | CREATE INDEX index_name
60 | on table_name (conditional_expression);
61 | ```
62 |
63 | ### 1.2.5 隐式索引
64 |
65 | 隐式索引 是在创建对象时,由数据库服务器自动创建的索引。索引自动创建为主键约束和唯一约束。
66 |
67 | ## 1.3 实例
68 |
69 | 下面实例将在 COMPANY 表的 SALARY 列上创建索引:
70 |
71 | ```plsql
72 | # CREATE INDEX salary_index ON COMPANY (salary);
73 | ```
74 |
75 | 现在,用 **\d company** 命令列出 COMPANY 表的所有索引:
76 |
77 | ```plsql
78 | # \d company
79 | ```
80 |
81 | 得到的结果如下,company_pkey 是隐式索引 ,是表创建表时创建的:
82 |
83 | ```plsql
84 | runoobdb=# \d company
85 | Table "public.company"
86 | Column | Type | Collation | Nullable | Default
87 | ---------+---------------+-----------+----------+---------
88 | id | integer | | not null |
89 | name | text | | not null |
90 | age | integer | | not null |
91 | address | character(50) | | |
92 | salary | real | | |
93 | Indexes:
94 | "company_pkey" PRIMARY KEY, btree (id)
95 | "salary_index" btree (salary)
96 | ```
97 |
98 | 你可以使用 \di 命令列出数据库中所有索引:
99 |
100 | ```plsql
101 | runoobdb=# \di
102 | List of relations
103 | Schema | Name | Type | Owner | Table
104 | --------+-----------------+-------+----------+------------
105 | public | company_pkey | index | postgres | company
106 | public | department_pkey | index | postgres | department
107 | public | salary_index | index | postgres | company
108 | (3 rows)
109 | ```
110 |
111 | ## 1.4 DROP INDEX (删除索引)
112 |
113 | 一个索引可以使用 PostgreSQL 的 DROP 命令删除。
114 |
115 | ```plsql
116 | DROP INDEX index_name;
117 | ```
118 |
119 | 您可以使用下面的语句来删除之前创建的索引:
120 |
121 | ```plsql
122 | # DROP INDEX salary_index;
123 | ```
124 |
125 | 删除后,可以看到 salary_index 已经在索引的列表中被删除:
126 |
127 | ```plsql
128 | runoobdb=# \di
129 | List of relations
130 | Schema | Name | Type | Owner | Table
131 | --------+-----------------+-------+----------+------------
132 | public | company_pkey | index | postgres | company
133 | public | department_pkey | index | postgres | department
134 | (2 rows)
135 | ```
136 |
137 | ## 1.5 什么情况下要避免使用索引?
138 |
139 | 虽然索引的目的在于提高数据库的性能,但这里有几个情况需要避免使用索引。
140 |
141 | 使用索引时,需要考虑下列准则:
142 |
143 | - 索引不应该使用在较小的表上。
144 | - 索引不应该使用在有频繁的大批量的更新或插入操作的表上。
145 | - 索引不应该使用在含有大量的 NULL 值的列上。
146 | - 索引不应该使用在频繁操作的列上。
--------------------------------------------------------------------------------
/1.PostgreSQL 学习系列/教程系列/16.PostgreSQL权限Privileges.md:
--------------------------------------------------------------------------------
1 | # 一、PostgreSQL PRIVILEGES(权限)
2 |
3 | 无论何时创建数据库对象,都会为其分配一个所有者,所有者通常是执行 create 语句的人。
4 |
5 | 对于大多数类型的对象,初始状态是只有所有者(或超级用户)才能修改或删除对象。要允许其他角色或用户使用它,必须为该用户设置权限。
6 |
7 | 在 PostgreSQL 中,权限分为以下几种:
8 |
9 | - SELECT
10 | - INSERT
11 | - UPDATE
12 | - DELETE
13 | - TRUNCATE
14 | - REFERENCES
15 | - TRIGGER
16 | - CREATE
17 | - CONNECT
18 | - TEMPORARY
19 | - EXECUTE
20 | - USAGE
21 |
22 | 根据对象的类型(表、函数等),将指定权限应用于该对象。
23 |
24 | 要向用户分配权限,可以使用 GRANT 命令。
25 |
26 | ## 1.1 GRANT 语法
27 |
28 | GRANT 命令的基本语法如下:
29 |
30 | ```plsql
31 | GRANT privilege [, ...]
32 | ON object [, ...]
33 | TO { PUBLIC | GROUP group | username }
34 | ```
35 |
36 | - privilege − 值可以为:SELECT,INSERT,UPDATE,DELETE, RULE,ALL。
37 | - object − 要授予访问权限的对象名称。可能的对象有: table, view,sequence。
38 | - PUBLIC − 表示所有用户。
39 | - GROUP group − 为用户组授予权限。
40 | - username − 要授予权限的用户名。PUBLIC 是代表所有用户的简短形式。
41 |
42 | 另外,我们可以使用 REVOKE 命令取消权限,REVOKE 语法:
43 |
44 | ```plsql
45 | REVOKE privilege [, ...]
46 | ON object [, ...]
47 | FROM { PUBLIC | GROUP groupname | username }
48 | ```
49 |
50 | ### 1.1.1 实例
51 |
52 | 为了理解权限,创建一个用户:
53 |
54 | ```plsql
55 | runoobdb=# CREATE USER runoob WITH PASSWORD 'password';
56 | CREATE ROLE
57 | ```
58 |
59 | 信息 CREATE ROLE 表示创建了一个用户 "runoob"。
60 |
61 | ## 1.2 实例
62 |
63 | 创建 COMPANY 表([下载 COMPANY SQL 文件](https://static.runoob.com/download/company.sql) ),数据内容如下:
64 |
65 | ```plsql
66 | runoobdb# select * from COMPANY;
67 | id | name | age | address | salary
68 | ----+-------+-----+-----------+--------
69 | 1 | Paul | 32 | California| 20000
70 | 2 | Allen | 25 | Texas | 15000
71 | 3 | Teddy | 23 | Norway | 20000
72 | 4 | Mark | 25 | Rich-Mond | 65000
73 | 5 | David | 27 | Texas | 85000
74 | 6 | Kim | 22 | South-Hall| 45000
75 | 7 | James | 24 | Houston | 10000
76 | (7 rows)
77 | ```
78 |
79 | 现在给用户 "runoob" 分配权限:
80 |
81 | ```plsql
82 | runoobdb=# GRANT ALL ON COMPANY TO runoob;
83 | GRANT
84 | ```
85 |
86 | 信息 GRANT 表示所有权限已经分配给了 "runoob"。
87 |
88 | 下面撤销用户 "runoob" 的权限:
89 |
90 | ```plsql
91 | runoobdb=# REVOKE ALL ON COMPANY FROM runoob;
92 | REVOKE
93 | ```
94 |
95 | 信息 REVOKE 表示已经将用户的权限撤销。
96 |
97 | 你也可以删除用户:
98 |
99 | ```plsql
100 | runoobdb=# DROP USER runoob;
101 | DROP ROLE
102 | ```
103 |
104 | 信息 DROP ROLE 表示用户 "runoob" 已经从数据库中删除。
--------------------------------------------------------------------------------
/1.PostgreSQL 学习系列/教程系列/5.PostgreSQL表格操作.md:
--------------------------------------------------------------------------------
1 | # 一、PostgreSQL 创建表格
2 |
3 | PostgreSQL 使用 CREATE TABLE 语句来创建数据库表格。
4 |
5 | ## 1.1 语法
6 |
7 | **CREATE TABLE** 语法格式如下:
8 |
9 | ```sql
10 | CREATE TABLE table_name(
11 | column1 datatype,
12 | column2 datatype,
13 | column3 datatype,
14 | .....
15 | columnN datatype,
16 | PRIMARY KEY( 一个或多个列 )
17 | );
18 | ```
19 |
20 | **CREATE TABLE** 是一个关键词,用于告诉数据库系统将创建一个数据表。
21 |
22 | 表名字必需在同一模式中的其它表、 序列、索引、视图或外部表名字中唯一。
23 |
24 | **CREATE TABLE** 在当前数据库创建一个新的空白表,该表将由发出此命令的用户所拥有。
25 |
26 | 表格中的每个字段都会定义数据类型,如下:
27 |
28 | ## 1.2 实例
29 |
30 | 以下创建了一个表,表名为 **COMPANY** 表格,主键为 **ID**,**NOT NULL** 表示字段不允许包含 **NULL** 值:
31 |
32 | ```sql
33 | CREATE TABLE COMPANY(
34 | ID INT PRIMARY KEY NOT NULL,
35 | NAME TEXT NOT NULL,
36 | AGE INT NOT NULL,
37 | ADDRESS CHAR(50),
38 | SALARY REAL
39 | );
40 | ```
41 |
42 | 接下来我们再创建一个表格,在后面章节会用到:
43 |
44 | ```sql
45 | CREATE TABLE DEPARTMENT(
46 | ID INT PRIMARY KEY NOT NULL,
47 | DEPT CHAR(50) NOT NULL,
48 | EMP_ID INT NOT NULL
49 | );
50 | ```
51 |
52 | 我们可以使用 \d 命令来查看表格是否创建成功:
53 |
54 | ```sql
55 | runoobdb=# \d
56 | List of relations
57 | Schema | Name | Type | Owner
58 | --------+------------+-------+----------
59 | public | company | table | postgres
60 | public | department | table | postgres
61 | (2 rows)
62 | ```
63 |
64 | \d tablename 查看表格信息:
65 |
66 | ```sql
67 | runoobdb=# \d company
68 | Table "public.company"
69 | Column | Type | Collation | Nullable | Default
70 | ---------+---------------+-----------+----------+---------
71 | id | integer | | not null |
72 | name | text | | not null |
73 | age | integer | | not null |
74 | address | character(50) | | |
75 | salary | real | | |
76 | Indexes:
77 | "company_pkey" PRIMARY KEY, btree (id)
78 | ```
79 |
80 | # 二、PostgreSQL 删除表格
81 |
82 | PostgreSQL 使用 DROP TABLE 语句来删除表格,包含表格数据、规则、触发器等,所以删除表格要慎重,删除后所有信息就消失了。
83 |
84 | ## 2.1 语法
85 |
86 | **DROP TABLE** 语法格式如下:
87 |
88 | ```sql
89 | DROP TABLE table_name;
90 | ```
91 |
92 | ## 2.2 实例
93 |
94 | 上一章节中我们创建了 COMPANY 和 DEPARTMENT 两个表格,我们可以先使用 \d 命令来查看表格是否创建成功:
95 |
96 | ```sql
97 | runoobdb=# \d
98 | List of relations
99 | Schema | Name | Type | Owner
100 | --------+------------+-------+----------
101 | public | company | table | postgres
102 | public | department | table | postgres
103 | (2 rows)
104 | ```
105 |
106 | 从以上结果可以看出,我们表格已经创建成功,接下来我们删除这两个表格:
107 |
108 | ```sql
109 | runoobdb=# drop table department, company;
110 | DROP TABLE
111 | ```
112 |
113 | 再使用 \d 命令来查看就找不到表格了:
114 |
115 | ```sql
116 | testdb=# \d
117 | Did not find any relations.
118 | ```
--------------------------------------------------------------------------------
/1.PostgreSQL 学习系列/教程系列/6.PostgreSQL模式Schema.md:
--------------------------------------------------------------------------------
1 | # 一、PostgreSQL 模式(SCHEMA)
2 |
3 | PostgreSQL 模式(SCHEMA)可以看着是一个表的集合。
4 |
5 | 一个模式可以包含视图、索引、数据类型、函数和操作符等。
6 |
7 | 相同的对象名称可以被用于不同的模式中而不会出现冲突,例如 schema1 和 myschema 都可以包含名为 mytable 的表。
8 |
9 | 使用模式的优势:
10 |
11 | - 允许多个用户使用一个数据库并且不会互相干扰。
12 | - 将数据库对象组织成逻辑组以便更容易管理。
13 | - 第三方应用的对象可以放在独立的模式中,这样它们就不会与其他对象的名称发生冲突。
14 |
15 | 模式类似于操作系统层的目录,但是模式不能嵌套。
16 |
17 | ## 1.1 语法
18 |
19 | 我们可以使用 **CREATE SCHEMA** 语句来创建模式,语法格式如下:
20 |
21 | ```sql
22 | CREATE SCHEMA myschema.mytable (
23 | ...
24 | );
25 | ```
26 |
27 | ## 1.2 实例
28 |
29 | 接下来我们连接到 runoobdb 来创建模式 myschema:
30 |
31 | ```sql
32 | runoobdb=# create schema myschema;
33 | CREATE SCHEMA
34 | ```
35 |
36 | 输出结果 "CREATE SCHEMA" 就代表模式创建成功。
37 |
38 | 接下来我们再创建一个表格:
39 |
40 | ```sql
41 | runoobdb=# create table myschema.company(
42 | ID INT NOT NULL,
43 | NAME VARCHAR (20) NOT NULL,
44 | AGE INT NOT NULL,
45 | ADDRESS CHAR (25),
46 | SALARY DECIMAL (18, 2),
47 | PRIMARY KEY (ID)
48 | );
49 | ```
50 |
51 | 以上命令创建了一个空的表格,我们使用以下 SQL 来查看表格是否创建:
52 |
53 | ```sql
54 | runoobdb=# select * from myschema.company;
55 | id | name | age | address | salary
56 | ----+------+-----+---------+--------
57 | (0 rows)
58 | ```
59 |
60 | ## 1.3 删除模式
61 |
62 | 删除一个为空的模式(其中的所有对象已经被删除):
63 |
64 | ```sql
65 | DROP SCHEMA myschema;
66 | ```
67 |
68 | 删除一个模式以及其中包含的所有对象:
69 |
70 | ```sql
71 | DROP SCHEMA myschema CASCADE;
72 | ```
--------------------------------------------------------------------------------
/11.PostgreSQL PDF资料文档/OLAP 在互联网公司的实践与思考.md:
--------------------------------------------------------------------------------
1 | 参考文件夹内的PDF文件
2 |
3 | PDF文件地址:https://cn.greenplum.org/wp-content/uploads/2020/08/OLAP-practice-.pdf
4 |
5 |
--------------------------------------------------------------------------------
/11.PostgreSQL PDF资料文档/OLAP-practice-.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lovebetterworld/postgres/2cfdc43e2ed7a5d12c0d9aece4774c1b1794981e/11.PostgreSQL PDF资料文档/OLAP-practice-.pdf
--------------------------------------------------------------------------------
/11.PostgreSQL PDF资料文档/PG(PostgreSQL)的社会价值.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lovebetterworld/postgres/2cfdc43e2ed7a5d12c0d9aece4774c1b1794981e/11.PostgreSQL PDF资料文档/PG(PostgreSQL)的社会价值.pdf
--------------------------------------------------------------------------------
/11.PostgreSQL PDF资料文档/Postgresql思维导图.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lovebetterworld/postgres/2cfdc43e2ed7a5d12c0d9aece4774c1b1794981e/11.PostgreSQL PDF资料文档/Postgresql思维导图.xmind
--------------------------------------------------------------------------------
/11.PostgreSQL PDF资料文档/SaaS行业需要什么样的数据库.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lovebetterworld/postgres/2cfdc43e2ed7a5d12c0d9aece4774c1b1794981e/11.PostgreSQL PDF资料文档/SaaS行业需要什么样的数据库.pdf
--------------------------------------------------------------------------------
/11.PostgreSQL PDF资料文档/开发者PG TOP 18问.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lovebetterworld/postgres/2cfdc43e2ed7a5d12c0d9aece4774c1b1794981e/11.PostgreSQL PDF资料文档/开发者PG TOP 18问.pdf
--------------------------------------------------------------------------------
/12.PostgreSQL 安装与部署/PostgreSQL+PostGIS安装部署.md:
--------------------------------------------------------------------------------
1 | - [如何安装PostgreSQL + PostGIS请点击](http://mp.weixin.qq.com/s?__biz=MzU3MTc1NzU0Mg==&mid=2247484008&idx=1&sn=789825cfd234bd5b664304d110b0b4e2&chksm=fcda04e1cbad8df78d0f95ce9322858180064652411d13ef2595b72fba37193fde6ae561d863&scene=21#wechat_redirect)
2 |
3 | PostgreSQL与PostGIS版本的依赖关系可点击:http://trac.osgeo.org/postgis/wiki/UsersWikiPostgreSQLPostGIS
4 |
5 | # 一、在线安装
6 |
7 | 通过下载外部repo源的安装方式,我这里暂且称之为在线安装。
8 |
9 | 我们首先要使用在线安装的方式,成功安装postgresql + postgis,然后再考虑如何获取相关依赖rpm包的问题。请看具体命令:
10 |
11 | ```bash
12 | # 安装postgresql依赖的rpm包
13 | rpm -ivh https://download.postgresql.org/pub/repos/yum/9.6/redhat/rhel-7-x86_64/pgdg-centos96-9.6-3.noarch.rpm
14 | # 安装postgis的依赖包
15 | rpm -ivh https://mirrors.aliyun.com/epel/epel-release-latest-7.noarch.rpm
16 | ```
17 |
18 | 通过执行上述命令,在/etc/yum.repos.d/目录下会有以下几个文件:
19 |
20 | - pgdg-96-centos.repo
21 | - epel.repo
22 | - epel-testing.repo
23 |
24 | 三个文件含有postgresql + postgis的外部下载源。通过yum的方式来安装:
25 |
26 | ```bash
27 | # 安装postgresql
28 | yum install postgresql96 postgresql96-server postgresql96-libs postgresql96-contrib postgresql96-devel
29 | # 安装postGIS
30 | yum install postgis24_96
31 | ```
32 |
33 | 安装成功。接下来就是要将postgresql + postgis依赖的rpm包收集起来,然后做一个yum本地源,就可以进行离线安装了。
34 |
35 | # 而、收集依赖的rpm包
36 |
37 | 我们可以使用yum命令的--downloaddir参数及--downloadonly参数来将依赖的rpm包下载到本地。具体步骤如下:
38 |
39 | 1. 首先需要将postgresql + postgis相关的包进行yum卸载,然后我们再install到本地
40 |
41 | ```bash
42 | yum remove postgresql96 postgresql96-server postgresql96-libs postgresql96-contrib postgresql96-devel postgis24_96
43 | ```
44 |
45 | 1. 创建目录,指定rpm依赖包的存储目录。我们后续会用到httpd,所以我们先安装httpd服务。
46 |
47 | ```bash
48 | yum install -y httpd
49 | # httpd安装成功后,会自动创建/var/www/html/目录,我们将要下载的rpm依赖包放置到该目录下
50 | mkdir /var/www/html/postgres
51 | ```
52 |
53 | 1. 下载rpm依赖包
54 |
55 | ```bash
56 | yum install --downloaddir=/var/www/html/postgres --downloadonly postgresql96 postgresql96-server postgresql96-libs postgresql96-contrib postgresql96-devel postgis24_96
57 | ```
58 |
59 | 等下载完毕之后,rpm依赖包如下图所示:
60 |
61 | 
62 |
63 | 然后我们再搭建yum本地源。
64 |
65 | # 三、搭建yum本地源
66 |
67 | 1. 下载createrepo工具
68 |
69 | ```bash
70 | yum install -y createrepo
71 | ```
72 |
73 | 1. 生成repodata目录
74 |
75 | ```bash
76 | cd /var/www/html/postgres
77 | createrepo .
78 | ll repodata
79 | ```
80 |
81 | 1. 删除之前在线安装时的repo文件
82 |
83 | ```bash
84 | cd /etc/yum.repos.d
85 | # 删除之前在线安装时的repo文件,以测试yum本地源是否搭建成功
86 | rm -rf epel.repo epel-testing.repo pgdg-96-centos.repo
87 | ```
88 |
89 | 1. 启动httpd服务
90 |
91 | ```bash
92 | service httpd start
93 | ```
94 |
95 | 1. 制作.repo文件
96 |
97 | 新建postgres.repo文件,并将其放入到/etc/yum.repos.d目录下。文件内容如下:
98 |
99 | ```bash
100 | [postgres]
101 | name=postgresql and postgis
102 | baseurl=http://liuyzh2.xdata/postgres/
103 | gpgcheck=0
104 | enabled=1
105 | ```
106 |
107 | 
108 |
109 | # 四、yum安装
110 |
111 | ```bash
112 | # 先卸载postgresql相关包
113 | yum remove postgresql*
114 | # 安装postgresql9.6 + postgis2.4
115 | yum install -y postgresql96 postgresql96-server postgresql96-libs postgresql96-contrib postgresql96-devel postgis24_96
116 | ```
117 |
118 | 安装成功,如下图所示;
119 |
120 | 
121 |
122 | # 五、总结
123 |
124 | 总结一下:
125 |
126 | - 我们首先下载了外部repo源,然后通过yum install的方式将需要的服务成功安装。
127 | - 然后执行`yum install --downloaddir=/var/www/html/postgres --downloadonly postgresql96 postgis24_96 …`命令,这样就将`postgresql96 postgis24_96 …`等所依赖的rpm包下载到了`/var/www/html/postgres`目录下了。
128 | - 有了依赖的rpm包,就简单多啦。直接制作yum本地源,生成repo文件就行了。
--------------------------------------------------------------------------------
/12.PostgreSQL 安装与部署/PostgreSQL的Docker安装与部署.md:
--------------------------------------------------------------------------------
1 | - [docker安装并持久化postgresql数据库](https://www.cnblogs.com/mingfan/p/11863509.html)
2 |
3 | # 一、docker安装并持久化postgresql数据库
4 |
5 | ## 1.1 拉取postgresql镜像
6 |
7 | ```bash
8 | docker pull postgresql
9 | ```
10 |
11 | ## 1.2 创建本地卷,数据卷可以在容器之间共享和重用, 默认会一直存在,即使容器被删除(`docker volume inspect `pgdata可查看数据卷的本地位置)
12 |
13 | ```bash
14 | docker volume create pgdata
15 | ```
16 |
17 | ## 1.3 启动容器
18 |
19 | ```bash
20 | docker run --name postgres2 -e POSTGRES_PASSWORD=password -p 5432:5432 -v pgdata:/var/lib/postgresql/data -d postgres:9.6
21 | ```
22 |
23 | 
24 |
25 | ## 1.4 进入postgres容器执行sql
26 |
27 | ```bash
28 | docker exec -it postgres2 bash
29 |
30 | psql -h localhost -p 5432 -U postgres --password
31 | ```
32 |
33 | 
34 |
35 |
36 |
37 | 至此,postgresql安装成功。
38 |
39 | # 二、docker 部署带postgis扩展的postgresql
40 |
41 | - [hey laosha](https://blog.csdn.net/geol200709)
42 |
43 | - [docker 部署带postgis扩展的postgresql](https://blog.csdn.net/geol200709/article/details/89481194)
44 |
45 | 拉取 postgresql 9.6 版本以及postgis 2.4 版本
46 |
47 | ```bash
48 | docker pull kartoza/postgis:9.6-2.4
49 |
50 | docker run -d --name postgresql9.6 -e ALLOW_IP_RANGE=0.0.0.0/0 -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres -v /var/minio/postgresql/data:/var/lib/postgresql/data -p 5432:5432 kartoza/postgis:9.6-2.4
51 | ```
52 |
53 | - -e ALLOW_IP_RANGE=0.0.0.0/0,这个表示允许所有ip访问,如果不加,则非本机 ip 访问不了
54 | - -e POSTGRES_USER=postgres 用户名
55 | - -e POSTGRES_PASS=‘postgres’ 指定密码
56 |
57 |
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/PG SQL记录/PG查询字段注释,表注释.md:
--------------------------------------------------------------------------------
1 | - [PG查询字段注释,表注释](https://www.cnblogs.com/yugege9213/p/15798077.html)
2 |
3 | ```plsql
4 | select a.attnum AS 序号,
5 | c.relname AS 表名,
6 | cast(obj_description(c.oid) as varchar) AS 表描述,
7 | a.attname AS 列名,
8 | concat_ws('',t.typname,SUBSTRING(format_type(a.atttypid,a.atttypmod) from '\(.*\)')) as 字段类型,
9 | d.description AS 备注
10 | from pg_attribute a
11 | left join pg_class c on c.oid=a.attrelid
12 | LEFT JOIN pg_type t on t.oid=a.atttypid
13 | left join pg_description d on d.objoid=a.attrelid and d.objsubid=a.attnum
14 | where c.relname='表名' and a.attnum>0 order by c.relname desc ,a.attnum asc;
15 | ```
16 |
17 |
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/PG SQL记录/postgresql兼容mysql last_insert_id().md:
--------------------------------------------------------------------------------
1 | - [postgresql兼容mysql last_insert_id()_Ruby-PGer的博客-CSDN博客](https://blog.csdn.net/qq_32935175/article/details/122296941)
2 |
3 | PG 中有类似的用法,[INSERT](https://so.csdn.net/so/search?q=INSERT&spm=1001.2101.3001.7020) INTO student1() VALUES () RETURNING id;就像这样。
4 |
5 | 如果不想改代码,可以直接在PG 数据库封装一个同名函数,使用lastval()实现:
6 |
7 | lastval() bigint 返回最近一次用 nextval 获取任何序列的数值。
8 |
9 | [自定义函数](https://so.csdn.net/so/search?q=自定义函数&spm=1001.2101.3001.7020):
10 |
11 | ```sql
12 | create or replace function last_insert_id() returns int4 as
13 |
14 | $$
15 |
16 | begin
17 |
18 | return lastval();
19 |
20 | end ;
21 |
22 | $$
23 |
24 | language plpgsql;
25 | ```
26 |
27 | 一个差异就是,如果一次插入多行的话,MySQL是返回第一个值, PG是返回最后一个值。
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/PostGresql 实现四舍五入、小数转换、百分比的用法说明.md:
--------------------------------------------------------------------------------
1 | # PostGresql 实现四舍五入、小数转换、百分比的用法说明
2 |
3 | 需求:两个整数相除,保留两位小数并四舍五入,完了转成百分比形式,即4/5=0.80=80%
4 |
5 | ### 1.两个整数相除:
6 |
7 | ```plsql
8 | idn_dw=> select 4/5;
9 | ?column?
10 | ----------
11 | 0
12 | (1 row)
13 | ```
14 |
15 | 在sql运算中,"/"意思是相除取整,这样小数部分就会被舍去。
16 |
17 | ### 2.用cast将被除数转成小数
18 |
19 | ```plsql
20 | idn_dw=> select cast(4 as numeric)/5;
21 | ?column?
22 | ------------------------
23 | 0.80000000000000000000
24 | (1 row)
25 | ```
26 |
27 | 也可以简化:pg中"::"是转换的意思
28 |
29 | ```plsql
30 | idn_dw=> select 4::numeric/5;
31 | ?column?
32 | ------------------------
33 | 0.80000000000000000000
34 | (1 row)
35 | ```
36 |
37 | ### 3.四舍五入,保留两位小数
38 |
39 | ```plsql
40 | idn_dw=> select round(cast(4 as numeric)/5,2);
41 | round
42 | -------
43 | 0.80
44 | (1 row)
45 | ```
46 |
47 | ### 4.放大100,转成百分比形式
48 |
49 | ```plsql
50 | idn_dw=> select concat(round(4::numeric/5,2)*100,'%');
51 | concat
52 | --------
53 | 80.00%
54 | (1 row)
55 | ```
56 |
57 | 但是,小数部分不需要,调整一下顺序
58 |
59 | ```plsql
60 | idn_dw=> select concat(round(4::numeric/5*100),'%');
61 | concat
62 | --------
63 | 80%
64 | (1 row)
65 | ```
66 |
67 | 完事。
68 |
69 | **补充:使用postgresql的round()四舍五入函数报错**
70 |
71 | ### 需求:
72 |
73 | 使用postgresql的round()四舍五入保留两位小数
74 |
75 | 报错:
76 |
77 | ```plsql
78 | HINT: No function matches the given name and argument types. You might
79 | ```
80 |
81 | ### 解决方案:
82 |
83 | 使用cast函数将需要四舍五入的值转为 numeric,转为其他的类型可能会报错
84 |
85 | 示例:
86 |
87 | ```plsql
88 | round(cast(计算结果) as numeric), ``2``)
89 | ```
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/PostgreSQL与MySQL/PostgreSQL 新增数据返回自增ID.md:
--------------------------------------------------------------------------------
1 | - [PostgreSQL 新增数据返回自增ID_张志翔 ̮的博客-CSDN博客_postgresql 获取自增id](https://vegetable-chicken.blog.csdn.net/article/details/104901750)
2 |
3 | 最近在项目中需要[Postgresql](https://so.csdn.net/so/search?q=Postgresql&spm=1001.2101.3001.7020)在新增数据后返回自增的ID,特此记录便于日后查阅。
4 |
5 | ```plsql
6 |
7 |
8 | SELECT currval('training_group_id_seq'::regclass) AS id
9 |
10 | INSERT INTO t_teaching_training_group(
11 | outline_id,
12 | total_student,
13 | max_count,
14 | group_no,
15 | parent_id,
16 | status,
17 | type,
18 | min_gpu_cores,
19 | gpu_specs,
20 | min_cpu_cores,
21 | min_memory,
22 | min_store,
23 | plan_training_start_date,
24 | plan_training_end_date,
25 | create_date,
26 | modify_date,
27 | create_user,
28 | is_delete,
29 | issue_training_date
30 | )
31 | VALUES
32 | (
33 | #{outlineId},
34 | #{totalStudent},
35 | #{maxCount},
36 | #{groupNo},
37 | #{id},
38 | #{status},
39 | #{type},
40 | #{minGpuCores},
41 | #{gpuSpecs},
42 | #{minCpuCores},
43 | #{minMemory},
44 | #{minStore},
45 | #{retrainingStartDate},
46 | #{retrainingEndDate},
47 | now(),
48 | now(),
49 | #{createUser},
50 | #{isDelete},
51 | #{issueTrainingDate}
52 | )
53 |
54 | ```
55 |
56 | 上述代码重点关注这一代码段,代码如下:
57 |
58 | ```plsql
59 |
60 | SELECT currval('training_group_id_seq'::regclass) AS id
61 |
62 | ```
63 |
64 | 上述代码的作用是,在数据插入完成后返回主键ID。
65 |
66 | **注意:这里有个坑,keyProperty="id,这里指的是将主键id返回给传入实体的哪一个字段中,这里就是自增的主键id会放到传入TrainingGroupBO中的id属性中,如果要获取自增的id的话通过 trainingGroupBO.getId() 获取(我在这里吃了亏,以为Mybatis INSERT返回值就是自增后的id,结果调试了一个小时不管怎么修改返回的都是1)。**
67 |
68 | 到此 Postgresql 插入数据返回自增ID介绍完成。
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/PostgreSQL与MySQL/PostgreSQL(MySQL)插入操作传入值为空则设置默认值.md:
--------------------------------------------------------------------------------
1 | - [PostgreSQL(MySQL)插入操作传入值为空则设置默认值_张志翔 ̮的博客-CSDN博客](https://vegetable-chicken.blog.csdn.net/article/details/103740673)
2 |
3 | **1、mysql写法**
4 |
5 | IFNULL(p1,p2),如果p1有值就是p1,如果p1是空,则值为p2
6 |
7 | ```lua
8 |
9 | insert into user_message
10 | ( skip_id )
11 | values
12 |
13 | ( ifnull(#{userMessage.skipId},"0") )
14 |
15 |
16 | ```
17 |
18 | **2、postgresql写法**
19 |
20 | COALESCE函数是返回参数中的第一个非null的值,它要求参数中至少有一个是非null的,如果参数都是null会报错
21 |
22 | ```sql
23 | select COALESCE(null,null); //报错
24 | select COALESCE(null,null,now(),''); //结果会得到当前的时间
25 | select COALESCE(null,null,'',now()); //结果会得到''
26 |
27 | //可以和其他函数配合来实现一些复杂点的功能:查询学生姓名,如果学生名字为null或''则显示“姓名为空”
28 | select case when coalesce(name,'') = '' then '姓名为空' else name end from student;
29 | ```
30 |
31 | 问题到此解决。
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/PostgreSQL与MySQL/PostgreSQL(MySQL)插入操作遇到唯一值重复时更新.md:
--------------------------------------------------------------------------------
1 | - [PostgreSQL(MySQL)插入操作遇到唯一值重复时更新_张志翔 ̮的博客-CSDN博客](https://vegetable-chicken.blog.csdn.net/article/details/103733927)
2 |
3 | **1、mysql写法(on duplicate key update 语法必须配合唯一索引)**
4 |
5 | ```csharp
6 |
7 | insert into test
8 | (a,b,c)
9 | values
10 | (#{a},#{b},#{c})
11 | on duplicate key update
12 | c = values(c)
13 |
14 |
15 |
16 | insert into test
17 | (a,b,c)
18 | values
19 |
20 | (#{l.a},#{l.b},#{l.c})
21 |
22 | on duplicate key update
23 | c = values(c)
24 |
25 | ```
26 |
27 | **2、postgresql写法(on conflict 语法必须配合主键或唯一索引)**
28 |
29 | ```csharp
30 |
31 | insert into test
32 | (a,b,c)
33 | values
34 | (#{a},#{b},#{c})
35 | on conflict(a,b)
36 | do update set
37 | c = #{c}
38 |
39 |
40 |
41 | insert into test
42 | (a,b,c)
43 | values
44 |
45 | (#{l.a},#{l.b},#{l.c})
46 |
47 | on conflict(a,b) do nothing
48 |
49 |
50 | 推荐下面:
51 |
52 | insert into test
53 | (a,b,c)
54 | values
55 | (#{a},#{b},#{c})
56 | on conflict(a,b) do update set c = excluded.c
57 |
58 | ```
59 |
60 | **注:1、PostgreSQL单条插入更新的时候三种写法都可以用,但是!!!批量插入更新的时候只能用第三种写法!!!**
61 |
62 | **2、PostgreSQL的conflict语法只在PostgreSQL-9.5以上才可生效,9.5以下版本直接报错。**
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/PostgreSQL自动更新时间戳.md:
--------------------------------------------------------------------------------
1 | - [PostgreSQL如何自动更新时间戳? ](https://juejin.cn/post/7033762606175223839)
2 |
3 | # 一、需求描述
4 | 对于很多业务表,我们大多数需要记录以下几个字段:
5 |
6 | - create_at 创建时间
7 | - update_at 更新时间
8 | - create_by 创建人
9 | - update_by 更新人
10 |
11 | 为了给这些字段赋值,我们需要在repository层为entity赋值,创建时间和更新时间就取当前系统时间LocalDateTime,创建人和更新人需要用系统用户去赋值。对于创建时间和更新时间,这种与当前业务无关的字段,有没有可能不在repository上每次去手动赋值。
12 | 当然,肯定是有的,创建时间无非就是数据新插入行的时间,更新时间就是行数据更新的时间,理解了这一层的含义,那就有解决办法了。
13 | 对于Mysql来说,其内部提供的函数对于创建时间和更新时间的字段的自动更新是相当容易的,但对于PostgreSQL事情会稍稍复杂一点。
14 |
15 | # 二、如何做
16 |
17 | 要在插入数据的时候自动填充 create_at列的值,我们可以使用DEFAULT值,如下面所示。
18 | ```sql
19 | CREATE TABLE users (
20 | ...
21 | create_at timestamp(6) default current_timestamp
22 | )
23 | ```
24 |
25 | 为create_at字段设置一个默认值current_timestamp当前时间戳,这样达到了通过在 INSERT 语句中提供值来显式地覆盖该列的值。
26 | 但上面的这种方式只是对于insert行数据的时候管用,如果对行更新的时候,我们需要使用到数据库的触发器trigger。
27 | 首先我们编写一个触发器update_modified_column如下面的代码所示,含义是更新表的字段update_at为当前时间戳。
28 | ```sql
29 | CREATE OR REPLACE FUNCTION update_modified_column()
30 | RETURNS TRIGGER AS $$
31 | BEGIN
32 | NEW.update_at = now();
33 | RETURN NEW;
34 | END;
35 | $$ language 'plpgsql';
36 | ```
37 |
38 | 然后我们应用这个触发器,如何应用呢?当然是为这个触发器设置触发条件。
39 | ```sql
40 | CREATE TRIGGER update_table_name_update_at BEFORE UPDATE ON table_name FOR EACH ROW EXECUTE PROCEDURE update_modified_column();
41 | ```
42 |
43 | 即代表的含义是更新表table_name行数据的时候,执行这个触发器,我们需要为每一个表设置应用这个触发器!至此,达到目的。
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/Postgresql 查看SQL语句执行效率的操作.md:
--------------------------------------------------------------------------------
1 | # Postgresql 查看SQL语句执行效率的操作
2 |
3 | Explain命令在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决,Explain可以用来查看 SQL 语句的执行效 果,可以帮助选择更好的索引和优化查询语句,写出更好的优化语句。
4 |
5 | ## Explain语法:
6 |
7 | ```plsql
8 | explain select … from … [where ...]
9 | ```
10 |
11 | ### 例如:
12 |
13 | ```plsql
14 | explain select * from dual;
15 | ```
16 |
17 | ## 这里有一个简单的例子,如下:
18 |
19 | ```plsql
20 | EXPLAIN SELECT * FROM tenk1;
21 | QUERY PLAN
22 | ----------------------------------------------------------------
23 | Seq Scan on tenk1 (cost=0.00..458.00 rows=10000 width=244)
24 | ```
25 |
26 | ### EXPLAIN引用的数据是:
27 |
28 | 1). 预计的启动开销(在输出扫描开始之前消耗的时间,比如在一个排序节点里做排续的时间)。
29 |
30 | 2). 预计的总开销。
31 |
32 | 3). 预计的该规划节点输出的行数。
33 |
34 | 4). 预计的该规划节点的行平均宽度(单位:字节)。
35 |
36 | 这里开销(cost)的计算单位是磁盘页面的存取数量,如1.0将表示一次顺序的磁盘页面读取。其中上层节点的开销将包括其所有子节点的开销。这里的输出行数(rows)并不是规划节点处理/扫描的行数,通常会更少一些。一般而言,顶层的行预计数量会更接近于查询实际返回的行数。
37 |
38 | ### 现在我们执行下面基于系统表的查询:
39 |
40 | ```
41 | SELECT relpages, reltuples FROM pg_class WHERE relname = 'tenk1';
42 | ```
43 |
44 | 从查询结果中可以看出tenk1表占有358个磁盘页面和10000条记录,然而为了计算cost的值,我们仍然需要知道另外一个系统参数值。
45 |
46 | ```plsql
47 | postgres=# show cpu_tuple_cost;
48 | cpu_tuple_cost
49 | ----------------
50 | 0.01
51 | (1 row)
52 | cost = 458(磁盘页面数) + 10000(行数) * 0.01(cpu_tuple_cost系统参数值
53 | ```
54 |
55 | **补充:postgresql SQL COUNT(DISTNCT FIELD) 优化**
56 |
57 | ## 背景
58 |
59 | 统计某时段关键词的所有总数,也包含null (statistics 有400w+的数据,表大小为 600M),故
60 |
61 | 写出sql:
62 |
63 | ```plsql
64 | select count(distinct keyword) +1 as count from statistics;
65 | ```
66 |
67 | ## 问题
68 |
69 | 虽然是后台查询,但是太慢了,执行时间为为 38.6s,那怎么优化呢?
70 |
71 | ## 解决
72 |
73 | ### 方法1(治标)
74 |
75 | 把这个定时执行,然后把sql结果缓存下,然后程序访问缓存结果,页面访问是快了些,但是本质上还没有解决sql执行慢的问题。
76 |
77 | ### 方法2(治本)
78 |
79 | 优化sql,首先说说 count( distinct FIELD) 为啥这么慢,此处不再赘述了,请看这篇:https://www.jb51.net/article/65680.htm
80 |
81 | 优化内容:
82 |
83 | ```plsql
84 | select count( distinct FIELD ) from table
85 | ```
86 |
87 | 修改为
88 |
89 | ```plsql
90 | select count(1) from (select distinct FIELD from table) as foo;
91 | ```
92 |
93 | ### 比较
94 |
95 | 执行过程比对,可以使用 explian anaylze sql语句 查看
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/postgresql 中的to_char()常用操作.md:
--------------------------------------------------------------------------------
1 | # postgresql 中的to_char()常用操作
2 |
3 | postgresql中的to_char()用法和Oracle相比,多了一个参数。
4 |
5 | 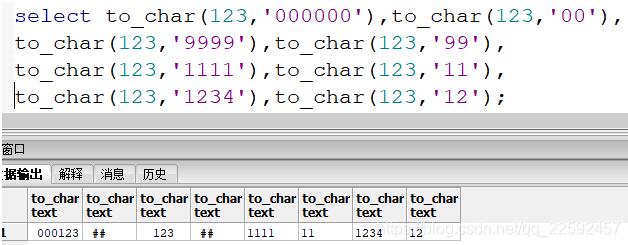
6 |
7 | to_char(待转换值,转换格式);
8 |
9 | ### 常用转换格式有2种:
10 |
11 | 一个是写若干个0,如果待转换的值位数少于于你定义的转换格式位数,输出值会自动在左边补0,位数补齐到转换格式的长度;如果待转换的值位数多于你定义的转换格式位数,输出值为:##(长度跟你定义的转换格式一样);
12 |
13 | 另一个是写若干个9,如果待转换的值位数少于你定义的转换格式位数,正常输出;
14 |
15 | 如果待转换的值位数多于于你定义的转换格式位数,输出值为:##(长度跟你定义的转换格式一样);
16 |
17 | 转换格式如果写其他数字,输出结果为转换格式的值。
18 |
19 | **补充:Postgresql中使用to_char进行yyyy-MM-dd HH:mm:ss转换时要注意的问题**
20 |
21 | 在java和一些常用的数据中(mysql/sqlsever)中进行年月日分秒转换的时候,都是用
22 |
23 | ```plsql
24 | SELECT to_char(CURRENT_DATE,'yyyy-MM-dd hh:MM:ss')
25 | ```
26 |
27 | 但是在Postgresql中这样用就会出现问题,在pg中执行上面的语句返回的结果为
28 |
29 | 2015-05-06 12:05:00
30 |
31 | 看到了,这并不是我们想要的,那怎么处理呢?在pg中要用下面的方法
32 |
33 | ```plsql
34 | SELECT to_char(CURRENT_DATE,'yyyy-MM-dd hh24:MI:ss')
35 | ```
36 |
37 | 结果如下
38 |
39 | 2015-05-06 00:00:00
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/postgresql数据库连接数和状态查询操作.md:
--------------------------------------------------------------------------------
1 | # postgresql数据库连接数和状态查询操作
2 |
3 | ### 查看数据库的当前连接数和状态的几种方式:
4 |
5 | 只是能看出数据库服务是否正在运行和启动路径
6 |
7 | ```plsql
8 | pg_ctl status
9 | ```
10 |
11 | 统计当前postgresql相关进程数,在大体上可以估算数据库的连接数,非精准,但是目前最常用的
12 |
13 | ```plsql
14 | ps -ef |grep postgres |wc -l
15 | ```
16 |
17 | 包含本窗口的所有数据库连接数
18 |
19 | ```plsql
20 | SELECT count(*) FROM pg_stat_activity;
21 | ```
22 |
23 | 不包含本窗口的所有数据库连接数,其中pg_backend_pid()函数的意思是当前进程相关的后台进程ID
24 |
25 | ```plsql
26 | SELECT count(*) FROM pg_stat_activity WHERE NOT pid=pg_backend_pid();
27 | ```
28 |
29 | 数据库状态查询(类似于
30 |
31 | Oracle 的 select open_mode from v$database;
32 |
33 | ```plsql
34 | select state from pg_stat_activity where datname = 'highgo';
35 | ```
36 |
37 | **补充:postgres数据库最大连接数**
38 |
39 | –当前总共正在使用的连接数
40 |
41 | ```plsql
42 | postgres=# select count(1) from pg_stat_activity;
43 | ```
44 |
45 | –显示系统允许的最大连接数
46 |
47 | ```plsql
48 | postgres=# show max_connections;
49 | ```
50 |
51 | –显示系统保留的用户数
52 |
53 | ```plsql
54 | postgres=# show superuser_reserved_connections ;
55 | ```
56 |
57 | –按照用户分组查看
58 |
59 | ```plsql
60 | select usename, count(*) from pg_stat_activity group by usename order by count(*) desc;
61 | ```
62 |
63 |
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/sql语句中“!=”与“”的区别.md:
--------------------------------------------------------------------------------
1 | - [sql语句中“!=”与“<>”的区别 - 奋斗中的菜鸟程序猿 - 博客园 (cnblogs.com)](https://www.cnblogs.com/wushuo-1992/p/8364828.html)
2 |
3 | ANSI标准中是用<>(所以建议用<>),但为了跟大部分数据库保持一致,数据库中一般都提供了 !=(高级语言一般用来表示不等于) 与 <> 来表示不等于:
4 |
5 | - MySQL 5.1: 支持 `!=` 和 `<>`
6 | - PostgreSQL 8.3: 支持 `!=` 和 `<>`
7 | - SQLite: 支持 `!=` 和 `<>`
8 | - Oracle 10g: 支持 `!=` 和 `<>`
9 | - Microsoft SQL Server 2000/2005/2008: 支持 `!=` 和 `<>`
10 | - IBM Informix Dynamic Server 10: 支持 `!=` 和 `<>`
11 | - InterBase/Firebird: 支持 `!=` 和 `<>`
12 |
13 | 最后两个只支持ANSI标准的数据库:
14 |
15 | - IBM DB2 UDB 9.5:仅支持 `<>`
16 | - Apache Derby:仅支持 `<>`
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/函数/ST_Transform.md:
--------------------------------------------------------------------------------
1 | - [ST_Transform (postgis.net)](https://postgis.net/docs/ST_Transform.html)
2 |
3 | ## Synopsis
4 |
5 | `geometry ST_Transform(`geometry g1, integer srid`)`;
6 |
7 | `geometry ST_Transform(`geometry geom, text to_proj`)`;
8 |
9 | `geometry ST_Transform(`geometry geom, text from_proj, text to_proj`)`;
10 |
11 | `geometry ST_Transform(`geometry geom, text from_proj, integer to_srid`)`;
12 |
13 | ## Description
14 |
15 | 返回一个新的几何图形,其坐标转换为不同的空间参考系统。指向_srid的目标空间引用可以通过一个有效的SRID整数参数来标识(即它必须存在于spatial_ref_sys表中)。或者,定义为project .4字符串的空间引用可以用于to_proj和/或from_proj,但是这些方法没有优化。如果目标空间引用系统用project .4字符串而不是SRID表示,那么输出几何图形的SRID将被设为零。除了使用from_proj的函数外,输入几何图形必须有一个定义好的SRID。
16 |
17 | ST_Transform经常与ST_SetSRID混淆。**ST_Transform实际上是将几何图形的坐标从一个空间引用系统更改为另一个空间引用系统**,而ST_SetSRID()只是更改几何图形的SRID标识符。
18 |
19 | - 需要PROJ支持PostGIS编译。使用PostGIS_Full_Version来确认你已经编译了PROJ支持。
20 | - 如果使用不止一个转换,在常用转换上有一个函数索引是很有用的,以便利用索引的使用。
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/函数/pg函数(function).md:
--------------------------------------------------------------------------------
1 | - [pg函数(function)_进无止尽-如履平地的博客-CSDN博客_pg 函数](https://blog.csdn.net/weixin_40245601/article/details/108196727)
2 |
3 | # 函数的格式
4 |
5 | ```sql
6 | Create or replace function 过程名(参数名 参数类型,…..) returns 返回值类型 as
7 | $body$
8 | //声明变量
9 | Declare
10 | 变量名变量类型;
11 | 如:
12 | flag Boolean;
13 | 变量赋值方式(变量名类型 :=值;)
14 | 如:
15 | str text :=值; / str text; str :=值;
16 | Begin
17 | 函数体;
18 | return 变量名; //存储过程中的返回语句
19 | End;
20 | $body$
21 | Language plpgsql;
22 | ```
23 |
24 | 1. 存储过程(FUNCITON)变量可以直接用 || 拼接。
25 | 2. 存储过程的对象不可以直接用变量,要用 quote_ident(objVar)
26 | 3. $1 $2是 FUNCTION 参数的顺序
27 | 4. SQL语句中的大写全部会变成小写,要想大写存大,必须要用双引号。
28 |
29 | # 函数
30 |
31 | ## 例子
32 |
33 | ```sql
34 | create or replace function intobatch() returns integer as
35 |
36 | $body$
37 |
38 | declare
39 |
40 | skyid integer;
41 | lot float;
42 | lat float;
43 | sex varchar;
44 | level integer;
45 | ctime int := 1325404914;
46 | num integer := 0;
47 | total integer := 0;
48 |
49 | begin
50 | lot = '73.6666666';
51 | lat = '3.8666666';
52 | FOR skyid IN 404499817 ..404953416
53 | loop
54 | if (lot > 135.0416666) then
55 | lot = 73.6666666;
56 | end if;
57 | if (lat > 53.5500000) then
58 | lat = 3.8666666;
59 | end if;
60 | if (skyid % 2 <> 0) then
61 | sex = '1';
62 | level = 0;
63 | else
64 | sex = '2';
65 | level = 1;
66 | end if;
67 | /*INSERT INTO user_last_location(user_id, app_id, lonlat, sex, accurate_level, lonlat_point, create_time)
68 | VALUES (skyid, 2934, ST_GeomFromText('POINT(' || lot || ' ' || lat || ')', 4326), sex, level,
69 | POINT(lot, lat), to_timestamp(ctime));*/
70 | INSERT INTO department(id, d_code, d_name,d_parentid,d_sex,d_level) VALUES (5,'1010','success',3,sex,level);
71 | lot = lot + 0.1;
72 | lat = lat + 0.1;
73 | skyid = skyid + 1;
74 | end loop;
75 | return skyid;
76 | end
77 | $body$
78 | language plpgsql;
79 | ```
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/字符串相关操作/PostGreSql 判断字符串中是否有中文的案例.md:
--------------------------------------------------------------------------------
1 | # PostGreSql 判断字符串中是否有中文的案例
2 |
3 | ## 实例
4 |
5 | ```plsql
6 | imos=# select 'hello' ~ '[\u2e80-\ua4cf]|[\uf900-\ufaff]|[\ufe30-\ufe4f]';
7 | ?column?
8 | ----------
9 | f
10 | (1 row)
11 | imos=#
12 | imos=# select 'hello中国' ~ '[\u2e80-\ua4cf]|[\uf900-\ufaff]|[\ufe30-\ufe4f]';
13 | ?column?
14 | ----------
15 | t
16 | (1 row)
17 | ```
18 |
19 | **补充:PostgreSQL 判断字符串包含的几种方法**
20 |
21 | ## 判断字符串包含的几种方法:
22 |
23 | ### 1. position(substring in string):
24 |
25 | ```plsql
26 | postgres=# select position('aa' in 'abcd');
27 | position
28 | ----------
29 | 0
30 | (1 row)
31 | postgres=# select position('ab' in 'abcd');
32 | position
33 | ----------
34 | 1
35 | (1 row)
36 | postgres=# select position('ab' in 'abcdab');
37 | position
38 | ----------
39 | 1
40 | (1 row)
41 | ```
42 |
43 | 可以看出,如果包含目标字符串,会返回目标字符串笫一次出现的位置,可以根据返回值是否大于0来判断是否包含目标字符串。
44 |
45 | ### 2. strpos(string, substring):
46 |
47 | 该函数的作用是声明子串的位置。
48 |
49 | ```plsql
50 | postgres=# select strpos('abcd','aa');
51 | strpos
52 | --------
53 | 0
54 | (1 row)
55 | postgres=# select strpos('abcd','ab');
56 | strpos
57 | --------
58 | 1
59 | (1 row)
60 | postgres=# select strpos('abcdab','ab');
61 | strpos
62 | --------
63 | 1
64 | (1 row)
65 | ```
66 |
67 | 作用与position函数一致。
68 |
69 | ### 3. 使用正则表达式:
70 |
71 | ```plsql
72 | postgres=# select 'abcd' ~ 'aa';
73 | ?column?
74 | ----------
75 | f
76 | (1 row)
77 | postgres=# select 'abcd' ~ 'ab';
78 | ?column?
79 | ----------
80 | t
81 | (1 row)
82 | postgres=# select 'abcdab' ~ 'ab';
83 | ?column?
84 | ----------
85 | t
86 | (1 row)
87 | ```
88 |
89 | ### 4. 使用数组的@>操作符(不能准确判断是否包含):
90 |
91 | ```plsql
92 | postgres=# select regexp_split_to_array('abcd','') @> array['b','e'];
93 | ?column?
94 | ----------
95 | f
96 | (1 row)
97 | postgres=# select regexp_split_to_array('abcd','') @> array['a','b'];
98 | ?column?
99 | ----------
100 | t
101 | (1 row)
102 | ```
103 |
104 | ## 注意下面这些例子:
105 |
106 | ```plsql
107 | postgres=# select regexp_split_to_array('abcd','') @> array['a','a'];
108 | ?column?
109 | ----------
110 | t
111 | (1 row)
112 | postgres=# select regexp_split_to_array('abcd','') @> array['a','c'];
113 | ?column?
114 | ----------
115 | t
116 | (1 row)
117 | postgres=# select regexp_split_to_array('abcd','') @> array['a','c','a','c'];
118 | ?column?
119 | ----------
120 | t
121 | (1 row)
122 | ```
123 |
124 | 可以看出,数组的包含操作符判断的时候不管顺序、重复,只要包含了就返回true,在真正使用的时候注意。
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/数据备份/备份 PostgreSQL特定schema或table数据.md:
--------------------------------------------------------------------------------
1 | - [备份 PostgreSQL特定schema或table数据](https://blog.csdn.net/neweastsun/article/details/119887298)
2 |
3 | 除了创建独立数据库,PostgreSQL DBA 通常建议创建schema,因为PostgreSQL不支持跨库进行查询。在当前数据库中,你不能选择当前数据库服务器上的任何其他数据库的数据,如果要实现需要配置DB link。
4 |
5 | 因此大多数数据库用户会为不同应用场景创建不同的schema,本文针对这种应用场景介绍如何备份特定schema及表。
6 |
7 | ## 备份特定范围数据
8 |
9 | ### 备份schema
10 |
11 | ```sql
12 | pg_dump -U postgres -d postgres --schema=public > back1.sql
13 | ```
14 |
15 | ### 备份指定表
16 |
17 | ```sql
18 | pg_dump -U postgres -d postgres -t public.t_oil >t_oil.sql
19 | ```
20 |
21 | 另外还有其他几个常用参数:
22 |
23 | ```sql
24 | pg_dump -U postgres -W -F t dvdrental > c:\pgbackup\dvdrental.tar
25 | -U postgres` 指定用户连接数据库服务器,这里是 `postgres
26 | ```
27 |
28 | `-W` 强制 pg_dump 在连接数据库服务器之前提示密码
29 |
30 | `-F` 指定输入文件格式:
31 |
32 | - `c`: 自定义归档文件格式
33 | - `d`: 目录方式归档,创建目录包括每个表对应一个文件
34 | - `t`: tar压缩文件格式
35 | - `p`: 普通SQL文本
36 |
37 | ## 备份其他数据库对象
38 |
39 | 我们知道可以通过 pg_dumpall 命令备份全部数据库对象:
40 |
41 | ```sql
42 | pg_dumpall -U postgres > c:\pgbackup\all.sql
43 | ```
44 |
45 | 我们也可以备份其他数据库特定对象,如角色、表空间、数据库、schema、table、索引等。下面给几个典型示例。
46 |
47 | 仅备份scheam定义:
48 |
49 | ```
50 | pg_dumpall --schema-only > c:\pgdump\definitiononly.sql
51 | ```
52 |
53 | 仅备份角色定义:
54 |
55 | ```sql
56 | pg_dumpall --roles-only > c:\pgdump\allroles.sql
57 | ```
58 |
59 | 仅备份表空间定义:
60 |
61 | ```sql
62 | pg_dumpall --tablespaces-only > c:\pgdump\allroles.sql
63 | ```
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/数据备份/逻辑备份和物理备份实战.md:
--------------------------------------------------------------------------------
1 | - [PG运维篇--逻辑备份和物理备份实战 _MySQL DBA攻坚之路的技术博客_51CTO博客](https://blog.51cto.com/u_13874232/5481943)
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/时间相关操作/PGSQL 实现查询今天,昨天的数据,一个月之内的数据.md:
--------------------------------------------------------------------------------
1 | # PGSQL 实现查询今天,昨天的数据,一个月之内的数据
2 |
3 | ### PGSQL查询今天的数据
4 |
5 | ```plsql
6 | select *
7 | from 表名 as n
8 | where n.create_date>=current_date;
9 | ```
10 |
11 | ### PG查询昨天的数据
12 |
13 | **方法1:**
14 |
15 | ```plsql
16 | select *
17 | from 表名 as n
18 | where
19 | age(
20 | current_date,to_timestamp(substring(to_char(n.create_date, 'yyyy-MM-dd hh24 : MI : ss' ) FROM 1 FOR 10),'yyyy-MM-dd')) ='1 days';
21 | ```
22 |
23 | **方法2:**
24 |
25 | ```plsql
26 | select *
27 | from 表名 as n
28 | where n.create_date>=current_date-1 and n.create_date =to_timestamp(substring(to_char(now(),'yyyy-MM-dd hh24:MI:ss') FROM 1 FOR 10),'yyyy-MM-dd')- interval '30 day';
49 | ```
50 |
51 | **补充:postgresql 查询当前时间**
52 |
53 | 需求:PostgreSQL中有四种获取当前时间的方式。
54 |
55 | ### 解决方案:
56 |
57 | **1.now()**
58 |
59 | 
60 |
61 | 返回值:当前年月日、时分秒,且秒保留6位小数。
62 |
63 | **2.current_timestamp**
64 |
65 | 
66 |
67 | 返回值:当前年月日、时分秒,且秒保留6位小数。(同上)
68 |
69 | 申明:now和current_timestamp几乎没区别,返回值相同,建议用now。
70 |
71 | **3.current_time**
72 |
73 | 
74 |
75 | 返回值:时分秒,秒最高精确到6位
76 |
77 | **4.current_date**
78 |
79 | 
80 |
81 | 返回值:年月日
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/时间相关操作/PostgreSQL 字符串处理与日期处理操作.md:
--------------------------------------------------------------------------------
1 | # PostgreSQL 字符串处理与日期处理操作
2 |
3 | ### 字符串长度、大小写
4 |
5 | ```plsql
6 | SELECT CHAR_LENGTH('test') -- 字符串长度
7 | SELECT LENGTH('test')
8 | LENGTH(string,encoding name)
9 | SELECT LENGTH('测试','UTF-8');
10 | LOWER(string) 或者 UPPER(string) -- 大小写
11 | ASCII(string)
12 | SELECT ASCII('abc') -- 结果是'a'的ascii码
13 | ```
14 |
15 | ### 字符串格式化
16 |
17 | ```plsql
18 | FORMAT(formatstr text [,formatarg "any" [, ...] ]) -- 类似于printf
19 | ```
20 |
21 | ### 字符串拼接
22 |
23 | ```plsql
24 | SELECT 'number' || 123 --字符串连接
25 | CONCAT(str "any" [, str "any" [, ...] ])
26 | CONCAT_WS(sep text, str "any" [,str "any" [, ...] ])
27 | SELECT * FROM CONCAT_WS('#','hello','world')
28 | ```
29 |
30 | ### 字符串剪切与截取
31 |
32 | ```plsql
33 | LPAD(string text, length int [,fill text])
34 | RPAD(string text, length int [,fill text])
35 | SELECT LPAD('12345', 10,'0') -- 结果 "0000012345"
36 | TRIM([leading | trailing | both] [characters] from string)
37 | SELECT TRIM(both ' ' from ' hello world') -- 结果是'hello world'
38 | BTRIM(string text [, characters text])
39 | RTRIM(string text [, characterstext])
40 | LTRIM(string text [, characterstext])
41 | SELECT BTRIM('yyhello worldyyyy','y') -- 结果是'hello world'
42 | LEFT(str text, n int) -- 返回字符串前n个字符,n为负数时返回除最后|n|个字符以外的所有字符
43 | RIGHT(str text, n int)
44 | SUBSTRING(string from int [for int])
45 | SELECT SUBSTRING('hello world' from 7 for 5) -- 结果是'world'
46 | ```
47 |
48 | ### 字符串加引号
49 |
50 | ```plsql
51 | QUOTE_IDENT(string text)
52 | QUOTE_LITERAL(STRING TEXT)
53 | QUOTE_LITERAL(value anyelement)
54 | SELECT 'l''host"' -- 结果是'l'host"'
55 | SELECT QUOTE_LITERAL('l''host"') -- 结果是'l''host"'
56 | ```
57 |
58 | ### 字符串分割
59 |
60 | ```plsql
61 | SPLIT_PART(string text,delimiter text, field int)
62 | REGEXP_SPLIT_TO_ARRAY(stringtext, pattern text [, flags text])
63 | REGEXP_SPLIT_TO_TABLE(stringtext, pattern text [, flagstext])
64 | SELECT SPLIT_PART('hello#world','#',2) -- 结果是'world'
65 | SELECT REGEXP_SPLIT_TO_ARRAY('hello#world','#') -- 结果是{hello,world}
66 | SELECT REGEXP_SPLIT_TO_TABLE('hello#world','#') as split_res -- 结果是两行,第一行hello,第二行world
67 | ```
68 |
69 | ### 字符串查找、反转与替换
70 |
71 | ```plsql
72 | POSITION(substring in string) -- 查找
73 | SELECT POSITION('h' in 'hello world') -- 结果是1,这里从1开始计数
74 | REVERSE(str)
75 | REPEAT(string text, number int)
76 | REPLACE(string,string,string)
77 | SELECT REPLACE('hello world',' ','#')
78 | REGEXP_MATCHES(string text,pattern text [, flags text])
79 | REGEXP_REPLACE(string text,pattern text,replacement text[, flags text])
80 | SELECT REGEXP_MATCHES('hello world','.o.','g') -- 返回两行,第一行是'lo ',第二行是'wor'
81 | SELECT REGEXP_MATCHES('hello world','.o.') -- 返回第一个匹配,'lo '
82 | ```
83 |
84 | ### 时间处理
85 |
86 | ```plsql
87 | SELECT TO_CHAR(TO_TIMESTAMP(CREATE_TIME),'YYYY-MM-DD HH24:MI:SS')
88 | SELECT EXTRACT(YEAR FROM NOW());
89 | ```
90 |
91 | **补充:postgresql处理时间函数 截取hh:mm/yyyy-mm-dd**
92 |
93 | ### 1.to_timestamp:
94 |
95 | ```plsql
96 | AND to_timestamp(a.upload_time,'yyyy-MM-dd')>='"+startTime+"' and to_timestamp(a.upload_time,'yyyy-MM-dd') <= '"+endTime+"'
97 | ```
98 |
99 | ### 2.substring:
100 |
101 | ```plsql
102 | substring('2019-04-08 14:18:09',index,k):
103 | ```
104 |
105 | 数值代表含义 index:代表从index开始截取数据,k代表从index开始截取到第k个数据
106 |
107 | 处理对象:时间为字符串格式的数据
108 |
109 | **eg:**
110 |
111 | ### 截取时间到 年-月-日:
112 |
113 | ```plsql
114 | SELECT substring(upload_time,1,10) from table WHERE upload_time='2019-04-08 14:18:09'
115 | ```
116 |
117 | 结果:2019-04-08
118 |
119 | ### 截取时间到 时:分:
120 |
121 | ```plsql
122 | SELECT substring(upload_time,12,5) from table WHERE upload_time='2019-04-08 14:18:09'
123 | ```
124 |
125 | 结果:14:18
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/时间相关操作/postgresql 中的时间处理小技巧(推荐).md:
--------------------------------------------------------------------------------
1 | # postgresql 中的时间处理小技巧
2 |
3 | ## 时间格式处理
4 |
5 | 按照给定格式返回:to_char(timestamp,format)
6 |
7 | 
8 |
9 | 返回相差的天数:(date(time1) - current_date)
10 |
11 | 
12 |
13 | 返回时间戳对应的的日期[yyyy-MM-dd]:date(timestamp)
14 |
15 | 
16 |
17 | 计算结果取两位小数(方便条件筛选):round((ABS(a-b)::numeric / a), 2) * 100 < 10
18 |
19 | 
20 |
21 | ## 时间运算
22 |
23 | 加减运算
24 |
25 | '-' :前x天/月/年
26 |
27 | '+' :后x天/月/年
28 |
29 | current_timestamp - interval 'x day/month/year...' 返回时间戳
30 |
31 | 
32 |
33 | date_part('day', current_timestamp - time1) 两个时间相差的天数
34 |
35 | 
36 |
37 | 返回时间间隔的秒数
38 |
39 | 两个timestamp 直接相减返回的是 interval类型,而不是毫秒数
40 |
41 | extract(epoch from (time1- time2)) * 1000
42 |
43 | 
44 |
45 | 如果在sql 中使用long类型的 timestamp,需要包裹 to_timestamp() 函数
46 |
47 | 
48 |
49 | **参考资料:**
50 |
51 | 1. https://www.yiibai.com/manual/postgresql/functions-formatting.html
52 |
53 | 2. http://www.postgres.cn/docs/9.4/functions-datetime.html
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/时间相关操作/postgresql数据库使用说明_实现时间范围查询.md:
--------------------------------------------------------------------------------
1 | # postgresql数据库使用说明_实现时间范围查询
2 |
3 | ## 按照日期查询通常有好几种方法:
4 |
5 | 按照日期范围查询有好几种方法,日期字段类型一般为:
6 |
7 | ```plsql
8 | Timestamp without timezone
9 | ```
10 |
11 | ### 方法一:
12 |
13 | ```plsql
14 | select * from user_info where create_date
15 | >= '2015-07-01' and create_date < '2015-08-15';
16 | ```
17 |
18 | ### 方法二:
19 |
20 | ```plsql
21 | select * from user_info where create_date
22 | between '2015-07-01' and '2015-08-15';
23 | ```
24 |
25 | ### 方法三:
26 |
27 | ```plsql
28 | select * from user_info where create_date
29 | >= '2015-07-01'::timestamp and create_date < '2015-08-15'::timestamp;
30 | ```
31 |
32 | ### 方法四:
33 |
34 | ```plsql
35 | select * from user_info where create_date
36 | between to_date('2015-07-01','YYYY-MM-DD') and to_date('2015-08-15','YYYY-MM-DD');
37 | ```
38 |
39 | pandas.to_sql 遇到主键重复的,怎么能够跳过继续执行呢,其实很简单,就一条一条的插入就可以了,因为to_sql还没有很好的解决办法。
40 |
41 | **具体的代码如下所示:**
42 |
43 | ```plsql
44 | for exchange in exchange_list.items():
45 | if exchange[1]==True:
46 | pass
47 | else:
48 | continue
49 | sql = """ SELECT * FROM %s WHERE "time" BETWEEN '2019-07-05 18:48' AND '2019-07-09' """ % (exchange[0])
50 | data = pd.read_sql(sql=sql, con=conn)
51 | print(data.head())
52 | for i in range(len(data)):
53 | #sql = "SELECT * FROM `%s` WHERE `key` = '{}'"%(exchange).format(row.Key)
54 | #found = pd.read_sql(sql, con=conn2)
55 | #if len(found) == 0:
56 | try:
57 | data.iloc[i:i + 1].to_sql(name=exchange[0], index=False,if_exists='append', con=conn2)
58 | except Exception as e:
59 | print(e)
60 | pass
61 | ```
62 |
63 | pandas.to_sql 无法设置主键,这个是肯定的,能做的办法就是在to_sql之前先使用创建表的方法,创建一张表
64 |
65 | **建表的代码如下所示:**
66 |
67 | ```plsql
68 | /*
69 | Create SEQUENCE for table
70 | */
71 | DROP SEQUENCE IF EXISTS @exchangeName_id_seq;
72 | CREATE SEQUENCE @exchangeName_id_seq
73 | START WITH 1
74 | INCREMENT BY 1
75 | NO MINVALUE
76 | NO MAXVALUE
77 | CACHE 1;
78 |
79 | /*
80 | Create Table structure for table
81 | */
82 | DROP TABLE IF EXISTS "public"."@exchangeName";
83 | CREATE TABLE "public"."@exchangeName" (
84 | "id" int4 NOT NULL DEFAULT nextval('@exchangeName_id_seq'::regclass),
85 | "time" timestamp(6) NOT NULL,
86 | "open" float8,
87 | "high" float8,
88 | "low" float8,
89 | "close" float8,
90 | "volume" float8,
91 | "info" varchar COLLATE "pg_catalog"."default" NOT NULL
92 | )
93 | ;
94 |
95 | /*
96 | Create Primary Key structure for table
97 | */
98 | ALTER TABLE "public"."@exchangeName" DROP CONSTRAINT IF EXISTS "@exchangeName_pkey";
99 | ALTER TABLE "public"."@exchangeName" ADD CONSTRAINT "@exchangeName_pkey" PRIMARY KEY ("time", "info");
100 | ```
101 |
102 | **补充:postgresql 数据库时间间隔数据查询**
103 |
104 | 当前时间向前推一天:
105 |
106 | ```plsql
107 | SELECT current_timestamp - interval '1 day'
108 | ```
109 |
110 | 当前时间向前推一个月:
111 |
112 | ```plsql
113 | SELECT current_timestamp - interval '1 month'
114 | ```
115 |
116 | 当前时间向前推一年:
117 |
118 | ```plsql
119 | SELECT current_timestamp - interval '1 year'
120 | ```
121 |
122 | 当前时间向前推一小时:
123 |
124 | ```plsql
125 | SELECT current_timestamp - interval '1 hour'
126 | ```
127 |
128 | 当前时间向前推一分钟:
129 |
130 | ```plsql
131 | SELECT current_timestamp - interval '1 min'
132 | ```
133 |
134 | 当前时间向前推60秒:
135 |
136 | ```plsql
137 | SELECT current_timestamp - interval '60 second'
138 | ```
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/详解PostgreSQL提升批量数据导入性能的n种方法.md:
--------------------------------------------------------------------------------
1 | # 详解PostgreSQL提升批量数据导入性能的n种方法
2 |
3 | 关键字:批量数据导入,数据加载,大量插入,加快,提升速度
4 | 多元化选择时代,人生里很多事物都是如此,凡事都没有一成不变的方式和方法。不管白猫黑猫,能抓老鼠的就是好猫,适合自己的就是最好的。
5 | 提升批量数据导入的方法亦是如此,没有何种方法是最优的,应用任何方法前根据自己的实际情况权衡利弊,做出选择。
6 | 批量导入数据之前,无论采取何种方式,务必做好相应的备份。
7 | 导入完成后亦需对相应对象进行ANALYZE操作,这样查询优化器才会按照最新的统计信息生成正确的执行计划。
8 |
9 | 下面正式介绍提升批量数据导入性能的n种方法。
10 |
11 | # 方法1:禁用自动提交。
12 |
13 | ```plsql
14 | psql
15 | \set AUTOCOMMIT off
16 |
17 | 其他
18 | BEGIN;
19 | 执行批量数据导入
20 | COMMIT;
21 | ```
22 |
23 | # 方法2:设置表为UNLOGGED。
24 |
25 | 导入数据之前先把表改成UNLOGGED模式,导入完成后改回LOGGED模式。
26 |
27 | ```plsql
28 | ALTER TABLE tablename SET UNLOGGED;
29 | 执行批量数据导入
30 | ALTER TABLE tablename LOGGED;
31 | ```
32 |
33 | 优点:
34 | 导入信息不记录WAL日志,极大减少io,提升导入速度。
35 | 缺点:
36 | 1.在replication环境下,表无法设置为UNLOGGED模式。
37 | 2.导入过程一旦出现停电死机等会导致数据库不能干净关库的情况,数据库中所有UNLOGGED表的数据将丢失。
38 |
39 | # 方法3:重建索引。
40 |
41 | 导入数据之前先删除相关表上的索引,导入完成后重新创建之。
42 |
43 | ```plsql
44 | DROP INDEX indexname;
45 | 执行批量数据导入
46 | CREATE INDEX ...;
47 | ```
48 |
49 | 查询表上索引定义的方法
50 |
51 | ```plsql
52 | select * from pg_indexes where tablename ='tablename' and schemaname = 'schemaname';
53 | ```
54 |
55 | # 方法4:重建外键。
56 |
57 | 导入数据之前先删除相关表上的外键,导入完成后重新创建之。
58 |
59 | ```plsql
60 | select * from pg_indexes where tablename ='tablename' and schemaname = 'schemaname';
61 | ```
62 |
63 | 相关信息可查询pg_constraint。
64 |
65 | # 方法5:停用触发器
66 |
67 | 导入数据之前先DISABLE掉相关表上的触发器,导入完成后重新ENABLE之。
68 |
69 | ```plsql
70 | ALTER TABLE tablename DISABLE TRIGGER ALL;
71 | 执行批量数据导入
72 | ALTER TABLE tablename ENABLE TRIGGER ALL;
73 | ```
74 |
75 | 相关信息可查询pg_trigger。
76 |
77 | # 方法6:insert改copy
78 |
79 | COPY针对批量数据加载进行了优化。
80 |
81 | ```plsql
82 | COPY ... FROM 'xxx';
83 | ```
84 |
85 | # 方法7:单值insert改多值insert
86 |
87 | 减少sql解析的时间。
88 |
89 | # 方法8:insert改PREPARE
90 |
91 | 通过使用PREPARE预备语句,降低解析消耗。
92 |
93 | ```plsql
94 | PREPARE fooplan (int, text, bool, numeric) AS
95 | INSERT INTO foo VALUES($1, $2, $3, $4);
96 | EXECUTE fooplan(1, 'Hunter Valley', 't', 200.00);
97 | ```
98 |
99 | 方法9:修改参数
100 |
101 | 增大maintenance_work_mem,增大max_wal_size。
102 |
103 | 方法10:关闭归档模式,降低wal日志级别。
104 |
105 | 修改archive_mode参数控制归档开启和关闭。降低wal_level值为minimal来减少日志信息记录。
106 | 此法需要重启数据库,需要规划停机时间。此外如有replication备库,还需考虑对其影响。
--------------------------------------------------------------------------------
/13.PostgreSQL 开发与使用/调优相关/PostgreSQL 内存参数调优.md:
--------------------------------------------------------------------------------
1 | - [PostgreSQL 内存参数调优](https://blog.csdn.net/neweastsun/article/details/111768840)
2 |
3 | 本文讨论PostgreSQL中一些管理内存参数,并对每个参数提供参考值建议。
4 |
5 | ## 1. 概述
6 |
7 | GUC: Grand Unified Configuration 是postgreSQL对数据库参数进行管理的机制。通常理解是对postgresql.conf文件中变量进行修改,或通过set命令对参数进行设置。本文对GUC参数中内存管理相关参数进行说明,用于提升数据库服务器的性能。所有这些参数位于数据库服务器配置管理文件postgresql.conf中($PDATA目录中)。主要包括下面四个参数。
8 |
9 | - Shared_buffers (integer)
10 | - Work_mem (integer)
11 | - Maintenance_work_mem (integer)
12 | - Effective_cache_size (integer)
13 |
14 | ## 2. 内存参数说明
15 |
16 | ### 2.1 shared_buffers (integer)
17 |
18 | shared_buffers 参数决定多少内存用于数据库服务器缓存数据。在postgresql.conf的缺省值是128M。
19 |
20 | ```
21 | #shared_buffers = 128MB
22 | ```
23 |
24 | 该值应该被设为整个机器内存的 15% ~ 25%。举例:如果机器RAM为32 GB,那么建议设置shared_buffers 为 8 GB。注意,调整该参数需要重启数据库服务器。
25 |
26 | ### 2.2 Work_mem (integer)
27 |
28 | work_mem 参数设置提供内部排序和写入临时磁盘文件的hash操作的内存数。排序操作用在 order by, distinct以及merge join 场景. Hash表操作用于hash joins 和 hash 聚集。 postgresql.conf中参数缺省值:
29 |
30 | ```
31 | #work_mem = 4MB
32 | ```
33 |
34 | 正确设置work_mem参数值可避免磁盘交换从而加快查询速度。可以通过下面公式计算最优值:
35 |
36 | ```
37 | Total RAM * 0.25 / max_connections
38 | ```
39 |
40 | max_connections是一个GUC 参数,用于指定数据库服务器的最大并发连接数,缺省为 100 。
41 |
42 | 也可以直接给角色设置work_mem参数值:
43 |
44 | ```
45 | postgres=# alter user test set work_mem='4GB';
46 |
47 | ALTER ROLE
48 | ```
49 |
50 | ### 2.3 Maintenance_work_mem (integer)
51 |
52 | maintenance_work_mem 参数设置维护操作的最大内存数,如 vacuum, create index, alter table add foreign key 操作。
53 | 在postgresql.conf缺省值为:
54 |
55 | ```
56 | #maintenance_work_mem = 64MB
57 | ```
58 |
59 | 建议设置值比work_mem值大,可以提升vacuum性能。通常设置为:
60 |
61 | ```
62 | Total RAM * 0.05
63 | ```
64 |
65 | ### 2.4 Effective_cache_size (integer)
66 |
67 | effective_cache_size参数有操作系统和数据库评估多少内存可用磁盘缓存,PostgreSQL查询计划决定它是否固定在RAM中。索引扫描最有可能用于较高的值;如果该值为低将使用顺序扫描。建议将effecve_cache_size设置为机器总RAM的50%。
68 |
69 | 跟多其他参数请参考 PostgreSQL 官方文档: https://www.postgresql.org/docs/12/runtime-config-resource.html。
70 |
71 | ## 3. 总结
72 |
73 | 本文介绍了PostgreSQL常用内存参数,并提供参考计算公式。
--------------------------------------------------------------------------------
/14.PostgreSQL 监控/PostgreSQL监控实战.md:
--------------------------------------------------------------------------------
1 | - [PostgreSQL技术周刊第21期:PostgreSQL监控实战](https://developer.aliyun.com/article/696652?spm=a2c6h.14164896.0.0.76342bde1mVVRD)
2 |
3 |
4 |
5 |
--------------------------------------------------------------------------------
/14.PostgreSQL 监控/金融级PostgreSQL监控与优化.md:
--------------------------------------------------------------------------------
1 | # 金融级PostgreSQL监控与优化
2 |
3 | PDF文档地址:http://www.postgres.cn/downfiles/pg2016conf_day1_s3_pm2.pdf
4 |
5 | 平安科技(深圳)有限公司
6 |
7 | # 一、监控实现
8 |
9 | 
10 |
11 | 
12 |
13 | 
14 |
15 | 
16 |
17 | 
18 |
19 | 
20 |
21 | 
22 |
23 | # 二、性能快照
24 |
25 | 
26 |
27 | 
28 |
29 | 
30 |
31 | 
32 |
33 | # 三、运维优化
34 |
35 | 
36 |
37 | 
38 |
39 | 
40 |
41 | 
42 |
43 | 
44 |
45 | 
46 |
47 | # 四、其他
48 |
49 | 
50 |
51 | 
52 |
53 | 
54 |
55 | 
56 |
57 | 
--------------------------------------------------------------------------------
/15.PostgreSQL 与SpringBoot/Mybatis-plus读取和保存Postgis geometry数据.md:
--------------------------------------------------------------------------------
1 | - [Mybatis-plus读取和保存Postgis geometry数据 - 简书 (jianshu.com)](https://www.jianshu.com/p/e27e28996ad1)
2 | - [mybatis 处理 数据库geometry字段_PigZHU'的博客-CSDN博客](https://blog.csdn.net/u010667710/article/details/103807117?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-5-103807117-blog-104626105.pc_relevant_antiscanv2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-5-103807117-blog-104626105.pc_relevant_antiscanv2&utm_relevant_index=6)
3 |
4 | ## 1 Maven依赖
5 |
6 | ```xml
7 |
8 | net.postgis
9 | postgis-jdbc
10 | 2.5.0
11 |
12 |
13 | org.postgresql
14 | postgresql
15 | 42.2.6
16 |
17 | ```
18 |
19 | ## 2 创建类型转换类GeometryTypeHandler
20 |
21 | ```java
22 | import org.apache.ibatis.type.BaseTypeHandler;
23 | import org.apache.ibatis.type.JdbcType;
24 | import org.apache.ibatis.type.MappedTypes;
25 | import org.postgis.PGgeometry;
26 |
27 | import java.sql.CallableStatement;
28 | import java.sql.PreparedStatement;
29 | import java.sql.ResultSet;
30 | import java.sql.SQLException;
31 |
32 | @MappedTypes({String.class})
33 | public class MyGeometryTypeHandler extends BaseTypeHandler {
34 | @Override
35 | public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException {
36 | PGgeometry pGgeometry = new PGgeometry(parameter);
37 | ps.setObject(i, pGgeometry);
38 | }
39 |
40 | @Override
41 | public String getNullableResult(ResultSet rs, String columnName) throws SQLException {
42 | PGgeometry pGgeometry = new PGgeometry(rs.getString(columnName));
43 | if (pGgeometry == null) {
44 | return null;
45 | }
46 | return pGgeometry.toString();
47 | }
48 |
49 | @Override
50 | public String getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
51 | PGgeometry pGgeometry = new PGgeometry(rs.getString(columnIndex));
52 | if (pGgeometry == null) {
53 | return null;
54 | }
55 | return pGgeometry.toString();
56 | }
57 |
58 | @Override
59 | public String getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
60 |
61 | PGgeometry pGgeometry = new PGgeometry(cs.getString(columnIndex));
62 | if (pGgeometry == null) {
63 | return null;
64 | }
65 | return pGgeometry.toString();
66 | }
67 | }
68 | ```
69 |
70 | ## 3 在实体类配置typeHandler
71 |
72 | ```java
73 | @TableField(typeHandler = GeometryTypeHandler.class)
74 | private String wkb;
75 | ```
76 |
77 |
--------------------------------------------------------------------------------
/16.PostgreSQL 架构与设计/PostgreSQL规范/1.PostgreSQL 命名规范.md:
--------------------------------------------------------------------------------
1 | 文章来源:[diagoal德哥PostgreSQL数据库开发规范]
2 |
3 | # 一、命名规范
4 |
5 | 【强制】库名、表名限制命名长度,建议表名及字段名字符总长度小于等于63。
6 |
7 | 【强制】对象名(表名、列名、函数名、视图名、序列名、等对象名称)规范,对象名务必只使用小写字母,下划线,数字。不要以pg开头,不要以数字开头,不要使用保留字。
8 | 保留字参考
9 | https://www.postgresql.org/docs/9.5/static/sql-keywords-appendix.html
10 |
11 | 【强制】query中的别名不要使用 "小写字母,下划线,数字" 以外的字符,例如中文。
12 |
13 | 【推荐】主键索引应以 pk_ 开头, 唯一索引要以 uk_ 开头,普通索引要以 idx_ 打头。
14 |
15 | 【推荐】临时表以 tmp_ 开头,子表以规则结尾,例如按年分区的主表如果为tbl, 则子表为tbl_2016,tbl_2017,。。。
16 |
17 | 【推荐】库名最好以部门名字开头 + 功能,如 xxx_yyy,xxx_zzz,便于辨识, 。。。
18 |
19 | 【推荐】库名最好与应用名称一致,或便于辨识。
20 |
21 | 【推荐】不建议使用public schema(不同业务共享的对象可以使用public schema),应该为每个应用分配对应的schema,schema_name最好与user name一致。
22 |
23 | 【推荐】comment不要使用中文,因为编码可能不一样,如果存进去和读取时的编码不一致,导致可读性不强。 pg_dump时也必须与comment时的编码一致,否则可能乱码。
24 |
25 |
26 |
27 | # 二、PostgreSQL开发规约
28 |
29 | 本规则适用于所有对象名,包括:库名、表名、表名、列名、函数名、视图名、序列号名、别名等。
30 |
31 | 对象名务必只使用小写字母,下划线,数字,但首字母必须为小写字母,常规表禁止以打头。
32 |
33 | 对象名长度不超过63个字符,命名统一采用。
34 |
35 | 禁止使用SQL保留字,使用获取保留关键字列表。
36 |
37 | 禁止出现美元符号,禁止使用中文,不要以开头。
38 |
39 | 提高用词品味,做到信达雅;不要使用拼音,不要使用生僻冷词,不要使用小众缩写。
40 |
41 | ## 2.1 【强制】库命名规则
42 |
43 | 库名最好与应用或服务保持一致,必须为具有高区分度的英文单词。
44 |
45 | 命名必须以开头,为具体业务线名称,如果是分片库必须以结尾。
46 |
47 | 多个部分使用连接。例如:,等,总共不超过三段。
48 |
49 | ## 2.2 【强制】角色命名规范
50 |
51 | 数据库有且仅有一个:,用于流复制的用户命名为。
52 |
53 | 生产用户命名使用作为前缀,具体功能作为后缀。
54 |
55 | 所有数据库默认有三个基础角色:,,,分别拥有所有表的只读,只写,函数的执行权限。
56 |
57 | 生产用户,ETL用户,个人用户通过继承相应的基础角色获取权限。
58 |
59 | 更为精细的权限控制使用独立的角色与用户,依业务而异。
60 |
61 | ## 2.3 【强制】模式命名规则
62 |
63 | 业务统一使用作为模式名,为业务定义的名称,必须设置为首位元素。
64 |
65 | ,,为保留模式名。
66 |
67 | 分片模式命名规则采用:。
68 |
69 | 无特殊理由不应在其他模式中创建对象。
70 |
71 | ## 2.4 【推荐】关系命名规则
72 |
73 | 关系命名以表意清晰为第一要义,不要使用含混的缩写,也不应过分冗长,遵循通用命名规则。
74 |
75 | 表名应当使用复数名词,与历史惯例保持一致,但应尽量避免带有不规则复数形式的单词。
76 |
77 | 视图以作为命名前缀,物化视图使用作为命名前缀,临时表以作为命名前缀。
78 |
79 | 继承或分区表应当以父表表名作为前缀,并以子表特性(规则,分片范围等)作为后缀。
80 |
81 | ## 2.5 【推荐】索引命名规则
82 |
83 | 创建索引时如**有条件**应当指定索引名称,并与PostgreSQL默认命名规则保持一致,避免重复执行时建立重复索引。
84 |
85 | 用于主键的索引以结尾,唯一索引以结尾,用于约束的索引以结尾,普通索引以结尾。
86 |
87 | ## 2.6 【推荐】函数命名规则
88 |
89 | 以,,,,打头,表示动作类型。
90 |
91 | 重要参数可以通过,的后缀在函数名中体现。
92 |
93 | 避免函数重载,同名函数尽量只保留一个。
94 |
95 | 禁止通过等整型进行重载,调用时可能产生歧义。
96 |
97 | ## 2.7 【推荐】字段命名规则
98 |
99 | 不得使用系统列保留字段名:,,,,,等。
100 |
101 | 主键列通常命名为,或以作为后缀。
102 |
103 | 创建时间通常命名为,修改时间通常命名为
104 |
105 | 布尔型字段建议使用,等作为前缀。
106 |
107 | 其余各字段名需与已有表命名惯例保持一致。
108 |
109 | ## 2.8 【推荐】**变量命名规则**
110 |
111 | 存储过程与函数中的变量使用命名参数,而非位置参数。
112 |
113 | 如果参数名与对象名出现冲突,在参数后添加,例如。
114 |
115 | ## 2.9 【推荐】**注释规范**
116 |
117 | 尽量为对象提供注释(),注释使用英文,言简意赅,一行为宜。
118 |
119 | 对象的模式或内容语义发生变更时,务必一并更新注释,与实际情况保持同步。
120 |
--------------------------------------------------------------------------------
/16.PostgreSQL 架构与设计/PostgreSQL规范/3.PostgreSQL QUERY规范.md:
--------------------------------------------------------------------------------
1 | 文章来源:[diagoal德哥PostgreSQL数据库开发规范]
2 |
3 | # 一、QUERY 规范
4 |
5 | 【强制】不要使用count(列名)或count(常量)来替代count(`*`),count(`*`)就是SQL92定义的标准统计行数的语法,跟数据库无关,跟NULL和非NULL无关。
6 | 说明:count(`*`)会统计NULL值(真实行数),而count(列名)不会统计。
7 |
8 | 【强制】count(多列列名)时,多列列名必须使用括号,例如count( (col1,col2,col3) )。注意多列的count,即使所有列都为NULL,该行也被计数,所以效果与count(`*`)一致。
9 | 例如
10 |
11 | ```plsql
12 | postgres=# create table t123(c1 int,c2 int,c3 int);
13 | CREATE TABLE
14 | postgres=# insert into t123 values (null,null,null),(null,null,null),(1,null,null),(2,null,null),(null,1,null),(null,2,null);
15 | INSERT 0 6
16 | postgres=# select count((c1,c2)) from t123;
17 | count
18 | -------
19 | 6
20 | (1 row)
21 | postgres=# select count((c1)) from t123;
22 | count
23 | -------
24 | 2
25 | (1 row)
26 | ```
27 |
28 | 【强制】count(distinct col) 计算该列的非NULL不重复数量,NULL不被计数。
29 | 例如
30 |
31 | ```plsql
32 | postgres=# select count(distinct (c1)) from t123;
33 | count
34 | -------
35 | 2
36 | (1 row)
37 | ```
38 |
39 | 【强制】count(distinct (col1,col2,...) ) 计算多列的唯一值时,NULL会被计数,同时NULL与NULL会被认为是想同的。
40 | 例如
41 |
42 | ```plsql
43 | postgres=# select count(distinct (c1,c2)) from t123;
44 | count
45 | -------
46 | 5
47 | (1 row)
48 | postgres=# select count(distinct (c1,c2,c3)) from t123;
49 | count
50 | -------
51 | 5
52 | (1 row)
53 | ```
54 |
55 | 【强制】count(col)对 "是NULL的col列" 返回为0,而sum(col)则为NULL。
56 | 例如
57 |
58 | ```plsql
59 | postgres=# select count(c1),sum(c1) from t123 where c1 is null;
60 | count | sum
61 | -------+-----
62 | 0 |
63 | (1 row)
64 | ```
65 |
66 | 因此注意sum(col)的NPE问题,如果你的期望是当SUM返回NULL时要得到0,可以这样实现
67 |
68 | ```plsql
69 | SELECT coalesce( SUM(g)), 0, SUM(g) ) FROM table;
70 | ```
71 |
72 | 【强制】NULL是UNKNOWN的意思,也就是不知道是什么。 因此NULL与任意值的逻辑判断都返回NULL。
73 | 例如
74 | NULL<>NULL 的返回结果是NULL,不是false。
75 | NULL=NULL的返回结果也是NULL,不是true。
76 | NULL值与任何值的比较都为NULL,即NULL<>1,返回的是NULL,而不是true。
77 |
78 | 【强制】除非是ETL程序,否则应该尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
79 |
80 | 【强制】任何地方都不要使用 select `*` from t ,用具体的字段列表代替`*`,不要返回用不到的任何字段。另外表结构发生变化也容易出现问题。
81 |
82 |
83 |
84 |
--------------------------------------------------------------------------------
/16.PostgreSQL 架构与设计/PostgreSQL规范/4.PostgreSQL 管理规范.md:
--------------------------------------------------------------------------------
1 | 文章来源:[diagoal德哥PostgreSQL数据库开发规范]
2 |
3 | # 一、管理规范
4 |
5 | 【强制】数据订正时,删除和修改记录时,要先select,避免出现误删除,确认无误才能提交执行。
6 |
7 | 【强制】DDL操作(以及类似的可能获取大锁的操作,譬如vacuum full, create index等)必须设置锁等待,可以防止堵塞所有其他与该DDL锁对象相关的QUERY。
8 | 例如
9 |
10 | ```plsql
11 | begin;
12 | set local lock_timeout = '10s';
13 | -- DDL query;
14 | end;
15 | ```
16 |
17 | 【强制】用户可以使用explain analyze查看实际的执行计划,但是如果需要查看的执行计划设计数据的变更,必须在事务中执行explain analyze,然后回滚。
18 | 例如
19 |
20 | ```plsql
21 | begin;
22 | explain analyze query;
23 | rollback;
24 | ```
25 |
26 | 【强制】如何并行创建索引,不堵塞表的DML,创建索引时加CONCURRENTLY关键字,就可以并行创建,不会堵塞DML操作,否则会堵塞DML操作。
27 | 例如
28 |
29 | ```plsql
30 | create index CONCURRENTLY idx on tbl(id);
31 | ```
32 |
33 | 【强制】为数据库访问账号设置复杂密码。
34 | 说明:密码由小写字母,数字、下划线组成、字母开头,字母或数字结尾,禁止123456,hello123等简单密码。
35 |
36 | 【强制】业务系统,开发测试账号,不要使用数据库超级用户。非常危险。
37 |
38 | 【强制】如果数据库开启了archive_mode,一定要设置archive_command,同时监控pg_xlog的空间使用情况,避免因为归档失败,导致xlog不断堆积,甚至导致空间占满。
39 |
40 | 【强制】如果数据库配置了standby,并且使用了slot,必须监控备机的延迟,监控slot的状态(延迟),否则可能导致主库XLOG文件堆积的问题,甚至导致空间占满。
41 |
42 | 【推荐】多个业务共用一个PG集群时,建议为每个业务创建一个数据库。 如果业务之间有数据交集,或者事务相关的处理,强烈建议在程序层处理数据的交互。
43 | 不能在程序中处理时,可以将多个业务合并到一个库,但是使用不同的schema将多个业务的对象分开来。
44 |
45 | 【推荐】应该为每个业务分配不同的数据库账号,禁止多个业务共用一个数据库账号。
46 |
47 | 【推荐】在发生主备切换后,新的主库在开放给应用程序使用前,建议使用pg_prewarm预热之前的主库shared buffer里的热数据。
48 |
49 | 【推荐】快速的装载数据的方法,关闭autovacuum, 删除索引,数据导入后,对表进行analyze同时创建索引。
50 |
51 | 【推荐】如何加快创建索引的速度,调大maintenance_work_mem,可以提升创建索引的速度,但是需要考虑实际的可用内存。
52 | 例如
53 |
54 | ```plsql
55 | begin;
56 | set local maintenance_work_mem='2GB';
57 | create index idx on tbl(id);
58 | end;
59 | ```
60 |
61 | 【推荐】如何防止长连接,占用过多的relcache, syscache。
62 | 当系统中有很多张表时,元数据会比较庞大,例如1万张表可能有上百MB的元数据,如果一个长连接的会话,访问到了所有的对象,则可能会长期占用这些syscache和relcache。
63 | 建议遇到这种情况时,定期释放长连接,重新建立连接,例如每个小时释放一次长连接。
64 |
65 | PS
66 | 阿里云的RDS PGSQL版本提供了主动释放syscache和 relcache的接口,不需要断开连接。
67 |
68 | 【推荐】大批量数据入库的优化,如果有大批量的数据入库,建议使用copy语法,或者 insert into table values (),(),...(); 的方式。 提高写入速度。
69 |
70 | 【推荐】大批量数据入库、大批量数据更新、大批量数据删除后,如果没有开启autovacuum进程,或者表级层面关闭了autovacuum,那么建议人为执行一下vacuum verbose analyze table;
71 |
72 | 【推荐】大批量删除和更新数据时,不建议一个事务中完成,建议分批次操作,以免一次产生较多垃圾。当然如果一定要大批量操作的话,在操作完后,建议使用pg_repack重组表。 建议操作前检查膨胀率。
73 |
74 |
--------------------------------------------------------------------------------
/16.PostgreSQL 架构与设计/PostgreSQL规范/6.PostgreSQL 阿里云RDS PostgreSQL 使用规范.md:
--------------------------------------------------------------------------------
1 | - 文章来源:[diagoal德哥PostgreSQL数据库开发规范]
2 |
3 | # 一、阿里云RDS PostgreSQL 使用规范
4 |
5 | 如果你是阿里云RDS PGSQL的用户,推荐你参考一下规范,阿里云RDS PGSQL提供了很多有趣的特性帮助用户解决社区版本不能解决的问题。
6 |
7 | 【推荐】冷热数据分离
8 | 当数据库非常庞大(例如超过2TB)时,建议使用阿里云PGSQL的OSS_EXT外部表插件,将冷数据存入OSS。
9 | 通过建立OSS外部表,实现对OSS数据的透明访问。
10 | 参考
11 | https://help.aliyun.com/document_detail/35457.html
12 |
13 | 【推荐】对RT要求高的业务,请使用SLB链路 或 PROXY透传模式连接数据库。
14 |
15 | 【推荐】RDS的地域选择与应用保持一致。
16 | 说明:比如应用上海环境,数据库选择上海region,避免应用和数据库出现跨区域访问。
17 |
18 | 【推荐】为RDS报警设置多位接收人,并设置合适的报警阀值。
19 |
20 | 【推荐】为RDS设置合适的白名单,加固数据访问的安全性。
21 |
22 | 【推荐】尽量禁止数据库被公网访问,如果真的要访问,一定要设置白名单。
23 |
24 | 【推荐】如果数据用户的查询中,使用索引的列,数据倾斜较为严重,即某些值很多记录,某些值很少记录,则查询某些列时可能不走索引,而查询另外一些列可能走索引。
25 | 特别是这种情况,可能造成绑定变量执行计划倾斜的问题,如果用户使用了绑定变量,同时出现了执行计划的倾斜,建议使用pg_hint_plan绑定执行计划,避免倾斜。
26 | 例如
27 |
28 | ```plsql
29 | test=> create extension pg_hint_plan;
30 | CREATE EXTENSION
31 | test=> alter role all set session_preload_libraries='pg_hint_plan';
32 | ALTER ROLE
33 | test=> create table test(id int primary key, info text);
34 | CREATE TABLE
35 | test=> insert into test select generate_series(1,100000);
36 | INSERT 0 100000
37 | test=> explain select * from test where id=1;
38 | QUERY PLAN
39 | -----------------------------------------------------------------------
40 | Index Scan using test_pkey on test (cost=0.29..8.31 rows=1 width=36)
41 | Index Cond: (id = 1)
42 | (2 rows)
43 | test=> /*+ seqscan(test) */ explain select * from test where id=1;
44 | QUERY PLAN
45 | ----------------------------------------------------------
46 | Seq Scan on test (cost=0.00..1124.11 rows=272 width=36)
47 | Filter: (id = 1)
48 | (2 rows)
49 | test=> /*+ bitmapscan(test) */ explain select * from test where id=1;
50 | QUERY PLAN
51 | ------------------------------------------------------------------------
52 | Bitmap Heap Scan on test (cost=4.30..8.31 rows=1 width=36)
53 | Recheck Cond: (id = 1)
54 | -> Bitmap Index Scan on test_pkey (cost=0.00..4.30 rows=1 width=0)
55 | Index Cond: (id = 1)
56 | (4 rows)
57 | ```
58 |
59 |
--------------------------------------------------------------------------------
/16.PostgreSQL 架构与设计/PostgreSQL规范/7. PostgreSQL 索引规范.md:
--------------------------------------------------------------------------------
1 | # 一、索引规范
2 |
3 | Wer Ordnung hält, ist nur zu faul zum Suchen.—German proverb
4 |
5 | ## 1.1【强制】在线查询必须有配套索引
6 |
7 | 所有在线查询必须针对其访问模式设计相应索引,除极个别小表外不允许全表扫描。
8 |
9 | 索引有代价,不允许创建不使用的索引。
10 |
11 | ## 1.2【强制】禁止在大字段上建立索引
12 |
13 | 被索引字段大小无法超过2KB(1/3的页容量),原则上禁止超过64个字符。
14 |
15 | 如有大字段索引需求,可以考虑对大字段取哈希,并建立函数索引。或使用其他类型的索引(GIN)。
16 |
17 | ## 1.3【强制】明确空值排序规则
18 |
19 | 如在可空列上有排序需求,需要在查询与索引中明确指定还是。
20 |
21 | 注意,排序的默认规则是,即空值会出现在排序的最前面,通常这不是期望行为。
22 |
23 | 索引的排序条件必须与查询匹配,如:
24 |
25 | ## 1.4【强制】利用GiST索引应对近邻查询问题
26 |
27 | 传统B树索引无法提供对KNN问题的良好支持,应当使用GiST索引。
28 |
29 | ## 1.5【推荐】利用函数索引
30 |
31 | 任何可以由同一行其他字段推断得出的冗余字段,可以使用函数索引替代。
32 |
33 | 对于经常使用表达式作为查询条件的语句,可以使用表达式或函数索引加速查询。
34 |
35 | 典型场景:建立大字段上的哈希函数索引,为需要左模糊查询的文本列建立reverse函数索引。
36 |
37 | ## 1.6【推荐】利用部分索引
38 |
39 | 查询中查询条件固定的部分,可以使用部分索引,减小索引大小并提升查询效率。
40 |
41 | 查询中某待索引字段若只有有限几种取值,也可以建立几个相应的部分索引。
42 |
43 | ## 1.7【推荐】利用范围索引
44 |
45 | 对于值与堆表的存储顺序线性相关的数据,如果通常的查询为范围查询,建议使用BRIN索引。
46 |
47 | 最典型场景如仅追加写入的时序数据,BRIN索引更为高效。
--------------------------------------------------------------------------------
/16.PostgreSQL 架构与设计/平安Postgresql架构实践.md:
--------------------------------------------------------------------------------
1 | # 平安Postgresql架构实践
2 |
3 | PDF文档地址:https://itdks.su.bcebos.com/31dd4832b2764d7f8a0b7841624f0fb8.pdf
4 |
5 | ## 私有云和金融行业云架构差异
6 |
7 | 
8 |
9 | ## 首个RDS为何选择PG
10 |
11 | 
12 |
13 | # 私有云架构
14 |
15 | 
16 |
17 | # 金融行业云
18 |
19 | 
--------------------------------------------------------------------------------
/20.环境部署/10.pgAdmin.md:
--------------------------------------------------------------------------------
1 | ## 1.创建文件
2 |
3 | ```shell
4 | mkdir -p /data/docker/pgadmin/{data, logs}
5 | ```
6 |
7 | ## 2.给文件夹授权
8 |
9 | ```shell
10 | cd /data/docker/pgadmin
11 | chown -R 5050:5050 pgadmin/
12 | ```
13 |
14 | ## 3.运行pgadmin
15 |
16 | ```shell
17 | docker run -d --name pgadmin -p 5434:80 \
18 | -e "PGADMIN_DEFAULT_EMAIL=admin@venny.cn" \
19 | -e "PGADMIN_DEFAULT_PASSWORD=123456" \
20 | -v /data/docker/pgadmin/data:/var/lib/pgadmin \
21 | -v /data/docker/pgadmin/logs:/var/log/pgadmin \
22 | dpage/pgadmin4
23 | ```
24 |
25 | ## 4.使用
26 |
27 | 浏览器打开http://ip:5434/,输入账号admin@venny.cn 密码: 123456
--------------------------------------------------------------------------------
/3.PostgreSQL 笔记/POSTGRES 数据类型 JAVA类型对照.md:
--------------------------------------------------------------------------------
1 | - [POSTGRES 数据类型 JAVA类型对照_bzy_4331的博客-CSDN博客](https://blog.csdn.net/bzy_4331/article/details/83259441)
2 | - [PostgreSQL数据类型与Java8数据类型对照_林深时见鹿v的博客-CSDN博客_网易云音乐](https://blog.csdn.net/weixin_51833408/article/details/119705720)
3 |
4 | | 编号 | 数据库类型 | JAVA类型 | JDBC索引 |
5 | | ---- | ---------- | -------------------- | -------- |
6 | | 1 | varchar | java.lang.String | 12 |
7 | | 2 | char | java.lang.String | 1 |
8 | | 2 | text | java.lang.String | 12 |
9 | | 3 | int2 | java.lang.Integer | 5 |
10 | | 4 | int4 | java.lang.Integer | 4 |
11 | | 5 | int8 | java.lang.Long | -5 |
12 | | 6 | numeric | java.math.BigDecimal | 2 |
13 | | 7 | float4 | java.lang.Float | 7 |
14 | | 8 | float8 | java.lang.Double | 8 |
15 | | 9 | money | java.lang.Double | 8 |
16 | | 10 | bit | java.lang.Boolean | -7 |
17 | | 11 | bool | java.lang.Boolean | -7 |
18 | | 12 | time | java.sql.Time | 92 |
19 | | 13 | timestamp | java.sql.Timestamp | 93 |
20 |
21 |
--------------------------------------------------------------------------------
/3.PostgreSQL 笔记/PostgreSQL 删除重复数据.md:
--------------------------------------------------------------------------------
1 | - [PostgreSQL 删除重复数据](https://blog.csdn.net/neweastsun/article/details/119566977)
2 |
3 | ## 准备数据
4 |
5 | 创建 `basket` 表:
6 |
7 | ```sql
8 | CREATE TABLE basket(
9 | id SERIAL PRIMARY KEY,
10 | fruit VARCHAR(50) NOT NULL
11 | );
12 | ```
13 |
14 | 插入示例数据:
15 |
16 | ```sql
17 | INSERT INTO basket(fruit) values('apple');
18 | INSERT INTO basket(fruit) values('apple');
19 |
20 | INSERT INTO basket(fruit) values('orange');
21 | INSERT INTO basket(fruit) values('orange');
22 | INSERT INTO basket(fruit) values('orange');
23 |
24 | INSERT INTO basket(fruit) values('banana');
25 |
26 | select * from basket; -- 查询示例数据
27 | ```
28 |
29 | 返回结果:
30 |
31 | | id | fruit |
32 | | ---- | ------ |
33 | | 1 | apple |
34 | | 2 | apple |
35 | | 3 | orange |
36 | | 4 | orange |
37 | | 5 | orange |
38 | | 6 | banana |
39 |
40 | 我们看到有两条 `apple` 和 三条 `orange` 记录,下面我们的目标是删除重复数据。
41 |
42 | ### 查询重复数据
43 |
44 | ```sql
45 | SELECT fruit, COUNT(fruit)
46 | FROM basket
47 | GROUP BY fruit
48 | HAVING COUNT(fruit) > 1
49 | ORDER BY fruit;
50 | ```
51 |
52 | 返回结果:
53 |
54 | | fruit | count |
55 | | ------ | ----- |
56 | | apple | 2 |
57 | | orange | 3 |
58 |
59 | ## 删除重复数据
60 |
61 | ### 使用DELETE USING 语句
62 |
63 | ```sql
64 | DELETE FROM basket a
65 | USING basket b
66 | WHERE a.id < b.id
67 | AND a.fruit = b.fruit;
68 | ```
69 |
70 | 我们连接 basket 表 和 它自身,然后检查不同行满足条件为 (a.id < b.id) 和 fruit 相同(a.fruit = b.fruit); 结果符合我们预期,重复数据被删除。
71 |
72 | 我们发现最小ID 值对应记录被删除而保留了ID值最大的记录。如果我们选哟保留最小的记录:
73 |
74 | ```sql
75 | DELETE FROM basket a
76 | USING basket b
77 | WHERE a.id > b.id
78 | AND a.fruit = b.fruit;
79 | ```
80 |
81 | 结果是最小ID值记录保留。
82 |
83 | ### 使用子查询删除重复记录
84 |
85 | ```sql
86 | DELETE FROM basket
87 | WHERE id IN
88 | (SELECT id
89 | FROM (
90 | SELECT id, ROW_NUMBER() OVER( PARTITION BY fruit ORDER BY id ) AS row_num
91 | FROM basket
92 | ) t
93 | WHERE t.row_num > 1 );
94 | ```
95 |
96 | 子查询返回重复行,除了重复记录的第一行;然后外部DELETE 根据子查询删除对应记录。
97 |
98 | 如果你想保留最高ID记录,需要修改排序条件:
99 |
100 | ```sql
101 | DELETE FROM basket
102 | WHERE id IN
103 | (SELECT id
104 | FROM (
105 | SELECT id, ROW_NUMBER() OVER( PARTITION BY fruit ORDER BY id DESC ) AS row_num
106 | FROM basket
107 | ) t
108 | WHERE t.row_num > 1 );
109 | ```
110 |
111 | 如果基于多个列确定重复记录,则查询模板为:
112 |
113 | ```sql
114 | DELETE FROM table_name
115 | WHERE id IN
116 | (SELECT id
117 | FROM (
118 | SELECT id,
119 | ROW_NUMBER() OVER( PARTITION BY column_1, column_2 ORDER BY id ) AS row_num
120 | FROM table_name
121 | ) t
122 | WHERE t.row_num > 1 );
123 | ```
124 |
125 | 如果数据量较大情况下,利用窗口函数的子查询方式效率应该会更优。因为不是每条记录和全部进行比较,而是在窗口内比较。
126 |
127 | ### 使用中间表删除数据
128 |
129 | 利用中间表需要下面几个步骤:
130 |
131 | 1. 创建相同表结构的新表,用于存储无重复记录
132 | 2. 插入无重复记录至新表
133 | 3. 删除原表
134 | 4. 重命名新表
135 |
136 | 实现如下:
137 |
138 | ```sql
139 | -- step 1
140 | CREATE TABLE basket_temp (LIKE basket);
141 |
142 | -- step 2
143 | INSERT INTO basket_temp(fruit, id)
144 | SELECT
145 | DISTINCT ON (fruit) fruit,
146 | id
147 | FROM basket;
148 |
149 | -- step 3
150 | DROP TABLE basket;
151 |
152 | -- step 4
153 | ALTER TABLE basket_temp
154 | RENAME TO basket;
155 | ```
156 |
157 | ## 总结
158 |
159 | 本文介绍不同方式删除重复记录,使用 `delete using` 、利用窗口函数的子查询方式,最后是利用中间表方式。
--------------------------------------------------------------------------------
/3.PostgreSQL 笔记/PostgreSQL 系列/PostgreSQL + MySQL 如何互补.md:
--------------------------------------------------------------------------------
1 | ## PostgreSQL + MySQL 如何互补
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2020-01-08
8 |
9 | ### 标签
10 | PostgreSQL , MySQL , 联合解决方案 , 互补
11 |
12 | ----
13 |
14 | ## 背景
15 |
16 | ## PG好在哪里?
17 | - License友好,无商业化公司控制,允许用户分发、修改、商用
18 | - 功能更丰富,各种插件
19 | - 和Oracle兼容性更好
20 | - 支持并行计算,LLVM,GPU加速,向量计算,MPP(citus插件),行列混合存储(zedstore)等功能,分析能力更强。
21 | - 优化器更强,应对复杂SQL处理效率更高,适合更复杂的业务场景。
22 | - 服务端编程能力更强,更适合金融、政府、企业ERP等对数据库存储过程强需求的传统行业或领域。
23 | - 内核扩展能力更强,可以根据垂直领域的需求定制化数据库,提升行业生产力。
24 | - GIS功能更强更专业,支持平面、球面几何,栅格,时空轨迹,点云,拓扑网络模型。
25 | - 多模能力更强,其表现在索引更丰富,除了btree,hash还支持gin,gist,spgist,brin,bloom,rum等索引接口,适合更加丰富的数据处理模型,例如模糊搜索,全文检索,多维任意搜索,时空搜索,高维向量(广泛应用于图像识别、相似特征扩选,阿里云rds pg增加pase支持512维,PG社区内置最高100维cube,开源imgsmlr最高16维),时序搜索,用户画像,化学分析,DNA检索等。
26 | - 类型更加丰富,同时支持扩展类型,除了基本类型以外,支持网络、全文检索、数组、xml、JSON、范围、域、树、多维、分子、GIS等类型。支持更丰富的应用场景。
27 | - 更加严谨,支持强制约束。
28 | - 适合场景更广泛,例如oltp和olap,时序,多模类混合场景。
29 |
30 | ## MySQL好在哪?
31 | - 简单,学习成本低,会MySQL的人多
32 | - 虽然数据库功能偏弱无法处理复杂业务,但是分布式框架多,可以很容易的拆分,开发生态完善
33 |
--------------------------------------------------------------------------------
/3.PostgreSQL 笔记/PostgreSQL 系列/PostgreSQL IoT,车联网 - 实时轨迹、行程实践 1.md:
--------------------------------------------------------------------------------
1 | ## PostgreSQL IoT,车联网 - 实时轨迹、行程实践 1
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2018-12-07
8 |
9 | ### 标签
10 | PostgreSQL , 实时轨迹 , IoT , 车联网 , GIS
11 |
12 | ----
13 |
14 | ## 背景
15 | 车联网,IoT场景中,终端为传感器,采集各个指标的数据(同时包括时间、GIS位置信息,速度,油耗,温度,EDU采集指标),在运动过程中,通过GPS准实时上报到服务端。
16 |
17 | 服务端则通常根据设备(比如车辆)、时间范围,查询指定设备在某个时间区间的行程。
18 |
19 | 例如:
20 |
21 | 1、设备轨迹点表
22 |
23 | ``` plsql
24 | create table tbl (
25 | id int primary key, -- 主键
26 | sid int, -- 传感器(车辆)ID
27 | xxx int, -- 行程ID
28 | geo geometry, -- 位置
29 | att jsonb, -- 属性
30 | crt_time timestamp -- 时间
31 | );
32 | ```
33 |
34 | 2、查询
35 |
36 | ``` plsql
37 | select * from tbl where sid=? and crt_time between x and y;
38 | ```
39 |
40 | 这种方法的问题(一个点一条记录):
41 |
42 | 1、查询性能问题,有IO放大(因为传感器都活跃),一个行程的每个点都落在不同的BLOCK里面,查询有IO放大。
43 |
44 | 2、空间占用,一个点一条记录,压缩比低。
45 |
46 | 3、行程运算,行程的所有点没有合并,运算效率差。
47 |
48 | ## 行程合并问题
49 |
50 | 为了解决以上问题,可以新建行程表,并将点的数据合并到行程。
51 |
52 | ``` plsql
53 | create table tbl_agg (
54 | xxx int, -- 行程ID
55 | geo 轨迹类型, -- 轨迹
56 | agg jsonb[] -- 其他属性聚合
57 | )
58 | ```
59 |
60 | 例如,每隔N秒,将点表的数据,按行程ID为主键更新到行程表。
61 |
62 | ``` plsql
63 | insert into tbl_agg on conflict (geo) do ?
64 | select xxx,geo_agg(geo),jsonb_agg(jsonb) from tbl where crt_time between ? and ?;
65 | ```
66 |
67 | 这种做法有性能问题:
68 |
69 | 1、锁
70 |
71 | 如果并发聚合的话,很显然可能多个会话中会出现同样的xxx行程ID字段,所以会有锁冲突。
72 |
73 | 2、IO放大
74 |
75 | 如果要解决锁的问题,我们可以用HASH,每个会话算其中的一个HASH value,但是这样就会导致扫描时IO放大,例如8个并行,则有效数据仅八分之一。相当于IO多扫描了7次。
76 |
77 | 3、CPU只能用一核
78 |
79 | 为了解决第一个问题,也可以使用串行方法,串行就只能用一核。
80 |
81 | 4、GAP,由于时间差的问题(例如INSERT到达的数据有错乱,那么可能导致中间出现GAP,聚合的行程缺少一些点)
82 |
83 | 5、实时性,异步合并到行程表,显然,查询行程表时,可能还有一些POINT没有合并进来,那么就会导致即刻查询行程缺少最近没有合并的点(延迟)。
84 |
85 | ## 行程合并优化
86 | 为了解决前面提到的5个问题。行程合并的流程可以优化。
87 |
88 | 1、点表分区,对点表进行分区。按行程ID HASH。
89 |
90 | ``` plsql
91 | create table tbl (like old_tbl including defaults) partition by list (abs(mod(hashtext(行程字段),16)));
92 |
93 | do language plpgsql $$
94 | declare
95 | begin
96 | for i in 0..15 loop
97 | execute 'create table tbl_'||i||' partition of tbl for values in ('||i||')';
98 | execute 'create index idx_tbl_'||i||'_1 on tbl_'||i||' (id)';
99 | execute 'create index idx_tbl_'||i||'_2 on tbl_'||i||' (crt_time)';
100 | end loop;
101 | end;
102 | $$;
103 | ```
104 |
105 | 2、由于点表分区了,而且行程ID HASH分区,每个分区一个行程合并处理进程(没有锁的问题),总共就可以开多个并行来提高合并行程的处理并行度。提高整体合并行程的性能。
106 |
107 | 3、行程表,分区。解决行程表垃圾回收的问题。
108 |
109 | 行程是UPDATE(APPEND POINT到行程类型中)的形式,所以UPDATE会很多,会经常需要对行程表进行VACUUM。
110 |
111 | 如果行程表不分区,行程表就会很大,目前PG的VACUUM,对于单个表来说,同一时间只能一个核来进行垃圾回收,还没有支持单表并行VACUUM。
112 |
113 | 所以行程表如果很大,并且需要频繁垃圾回收时,为了避免垃圾回收速度赶不上垃圾产生速度,同样也可以使用分区。
114 |
115 | ```
116 | 与点表分区类似,最好使用一样的分区键。
117 | ```
118 |
119 |
120 | ## 参考
121 | [《PostgreSQL pipelinedb 流计算插件 - IoT应用 - 实时轨迹聚合》](../201811/20181101_02.md)
122 |
123 | [《PostgreSQL 时序最佳实践 - 证券交易系统数据库设计 - 阿里云RDS PostgreSQL最佳实践》](../201704/20170417_01.md)
--------------------------------------------------------------------------------
/3.PostgreSQL 笔记/PostgreSQL 系列/PostgreSQL 基于PG内置流复制的,靠谱的PostgreSQL高可用方案(Patroni stolon).md:
--------------------------------------------------------------------------------
1 | ## PostgreSQL 基于PG内置流复制的,靠谱的PostgreSQL高可用方案(Patroni \ stolon) - 珍藏级
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2018-07-25
8 |
9 | ### 标签
10 | PostgreSQL , etcd , raft , 高可用 , Patroni
11 |
12 | ----
13 |
14 | ## 背景
15 |
16 | 可能是目前除“基于共享存储的数据库高可用方案”以外,基于PG内置流复制的,最靠谱的PostgreSQL高可用方案。
17 |
18 | [《Patroni: PostgreSQL High Availability made easy 2018》](20180725_03_pdf_003.pdf)
19 |
20 | [《Patroni: PostgreSQL High Availability made easy 2016》](20180725_03_pdf_001.pdf)
21 |
22 | 看完下面这个PPT,你会发现Zalando和探探类似,把PG用得比较狠的一家公司。
23 |
24 | [《Why Zalando trusts in PostgreSQL》](20180725_03_pdf_002.pdf)
25 |
26 | https://github.com/zalando-stups/java-sproc-wrapper
27 |
28 |
29 |
30 | ## 参考
31 |
32 | https://github.com/Zalando
33 |
34 | https://www.opsdash.com/blog/postgres-getting-started-patroni.html
35 |
36 | https://media.readthedocs.org/pdf/patroni/latest/patroni.pdf
37 |
38 | https://pypi.org/project/patroni/
39 |
40 | https://postgresconf.org/system/events/document/000/000/228/Patroni_tutorial_4x3-2.pdf
41 |
42 | https://www.linode.com/docs/databases/postgresql/create-a-highly-available-postgresql-cluster-using-patroni-and-haproxy/#what-is-postgresql
43 |
44 | https://www.cybertec-postgresql.com/en/services/postgresql-replication/clustering-failover/
45 |
46 | 与patroni类似的,GO实现的PG HA管理软件。
47 |
48 | https://github.com/sorintlab/stolon
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 | #### [PostgreSQL 许愿链接](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216")
123 | 您的愿望将传达给PG kernel hacker、数据库厂商等, 帮助提高数据库产品质量和功能, 说不定下一个PG版本就有您提出的功能点. 针对非常好的提议,奖励限量版PG文化衫、纪念品、贴纸、PG热门书籍等,奖品丰富,快来许愿。[开不开森](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216").
124 |
125 |
126 | #### [9.9元购买3个月阿里云RDS PostgreSQL实例](https://www.aliyun.com/database/postgresqlactivity "57258f76c37864c6e6d23383d05714ea")
127 |
128 |
129 | #### [PostgreSQL 解决方案集合](https://yq.aliyun.com/topic/118 "40cff096e9ed7122c512b35d8561d9c8")
130 |
131 |
132 | #### [德哥 / digoal's github - 公益是一辈子的事.](https://github.com/digoal/blog/blob/master/README.md "22709685feb7cab07d30f30387f0a9ae")
133 |
134 |
135 | 
136 |
137 |
--------------------------------------------------------------------------------
/3.PostgreSQL 笔记/PostgreSQL 系列/PostgreSQL 知识图谱 (xmind, png格式) .md:
--------------------------------------------------------------------------------
1 | ## PostgreSQL 知识图谱 (xmind, png格式)
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2019-03-03
8 |
9 | ### 标签
10 | PostgreSQL , 知识图谱 , xmind , png
11 |
12 | ----
13 |
14 | ## 背景
15 | 周末整理的PostgreSQL知识图谱。
16 |
17 | ## 1 对应的培训文档(培训PDF文件后续上传),参见
18 |
19 | [《PostgreSQL 2天培训大纲》](../201901/20190105_01.md)
20 |
21 | ## 2 对应培训视频参见
22 |
23 | ### PostgreSQL, Greenplum 学习视频1
24 |
25 | 下载链接: http://pan.baidu.com/s/1pKVCgHX (如果链接失效请通知我, 谢谢)
26 |
27 | 1、PostgreSQL 9.3 数据库管理与优化 视频4天
28 | 2、PostgreSQL 9.3 数据库管理与优化 视频5天
29 | 3、PostgreSQL 9.1 数据库管理与开发 视频1天
30 | 4、PostgreSQL 9.3 数据库优化 视频3天
31 | 5、PostgreSQL 专题讲座 视频
32 |
33 | ### PostgreSQL, Greenplum 学习视频2
34 |
35 | [《PostgreSQL 生态、案例、开发实践、管理实践、原理、日常维护、诊断、排错、优化、资料。 含学习视频》](../201801/20180121_01.md)
36 |
37 | ## 3 其他参考文档见
38 | [《PostgreSQL、Greenplum 《如来神掌》》](../201706/20170601_02.md)
39 |
40 | [《Oracle DBA 转型 PostgreSQL,Greenplum 学习规划》](../201804/20180425_01.md)
41 |
42 | [《PostgreSQL 多场景 沙箱实验》](../201805/20180524_02.md)
43 |
44 | ## 4 知识图谱
45 | 
46 |
47 | [PostgreSQL 知识图谱 xmind](20190303_01_doc_001.xmind)
48 |
49 | 其他详见我GIT。
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 | #### [PostgreSQL 许愿链接](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216")
122 | 您的愿望将传达给PG kernel hacker、数据库厂商等, 帮助提高数据库产品质量和功能, 说不定下一个PG版本就有您提出的功能点. 针对非常好的提议,奖励限量版PG文化衫、纪念品、贴纸、PG热门书籍等,奖品丰富,快来许愿。[开不开森](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216").
123 |
124 |
125 | #### [9.9元购买3个月阿里云RDS PostgreSQL实例](https://www.aliyun.com/database/postgresqlactivity "57258f76c37864c6e6d23383d05714ea")
126 |
127 |
128 | #### [PostgreSQL 解决方案集合](https://yq.aliyun.com/topic/118 "40cff096e9ed7122c512b35d8561d9c8")
129 |
130 |
131 | #### [德哥 / digoal's github - 公益是一辈子的事.](https://github.com/digoal/blog/blob/master/README.md "22709685feb7cab07d30f30387f0a9ae")
132 |
133 |
134 | 
135 |
136 |
--------------------------------------------------------------------------------
/3.PostgreSQL 笔记/PostgreSQL 表空间(TABLESPACE).md:
--------------------------------------------------------------------------------
1 | - [PostgreSQL 表空间(TABLESPACE)](https://blog.csdn.net/neweastsun/article/details/113784173)
2 |
3 | ## 1. 表空间介绍
4 |
5 | 表空间即PostgreSQL存储数据文件的位置,其中包括数据库对象。如,索引、表等。
6 | PostgreSQL使用表空间映射逻辑名称和磁盘物理位置。默认提供了两个表空间:
7 |
8 | - pg_default 表空间存储用户数据.
9 | - pg_global 表空间存储全局数据.
10 |
11 | 利用表空间可以控制PostgreSQL的磁盘布局,它有两方面的优势:
12 |
13 | 首先,如果集群中的某个分区超出初始空间,可以在另一个分区上创建新的表空间并使用。后期可以重新配置系统。
14 |
15 | 其次,可以使用统计优化数据库性能。举例,可以把频繁访问的索引或表放在高性能的磁盘上,如固态硬盘;把归档数据放在较慢的设备上。
16 |
17 | ## 2. 创建表空间
18 |
19 | 下面介绍如何创建表空间,并通过示例进行学习。
20 |
21 | ### 2.1 创建表空间语句
22 |
23 | 使用`CREATE TABLESPACE`语句创建表空间,语法如下:
24 |
25 | ```plsql
26 | CREATE TABLESPACE tablespace_name
27 | OWNER user_name
28 | LOCATION directory_path;
29 | ```
30 |
31 | 表空间名称不能以`pg`开头,因为这些名称为系统表空间保留。默认执行`CREATE TABLESPACE`语句的用户是表空间的拥有者。如果需要给其他用户赋权,可以值后面指定`owner`关键词。
32 |
33 | `directory_path`是表空间使用空目录的绝对路径,PostgreSQL的用户必须拥有该目录的权限可以进行读写操作。
34 |
35 | 一旦创建好表空间,可以在CREATE DATABASE, CREATE TABLE 和 CREATE INDEX 语句中使用。
36 |
37 | ### 2.2 示例
38 |
39 | 下面语句创建新的表空间`ts_primary`:
40 |
41 | ```plsql
42 | CREATE TABLESPACE ts_primary
43 | LOCATION 'e:\pg-data\primary';
44 | ```
45 |
46 | 上面示例使用unix风格斜杠作为目录路径,该目录必须要存在。列出所有表空间使用`\db`:
47 |
48 | ```plsql
49 | postgres=# \db
50 | 表空间列表
51 | 名称 | 拥有者 | 所在地
52 | ------------+----------+--------------------
53 | pg_default | postgres |
54 | pg_global | postgres |
55 | ts_primary | postgres | E:\pg-data\primary
56 | (3 行记录)
57 | ```
58 |
59 | 读者可以使用`\db+`查看更详细的表空间信息。
60 |
61 | ```plsql
62 | postgres=# \db+
63 | 表空间列表
64 | 名称 | 拥有者 | 所在地 | 存取权限 | 选项 | 大小 | 描述
65 | ------------+----------+--------------------+----------+------+---------+------
66 | pg_default | postgres | | | | 6558 MB |
67 | pg_global | postgres | | | | 575 kB |
68 | ts_primary | postgres | E:\pg-data\primary | | | 7513 kB |
69 | (3 行记录)
70 | ```
71 |
72 | 下面语句创建`logistics`数据库并使用`ts_primary`表空间:
73 |
74 | ```plsql
75 | CREATE DATABASE logistics
76 | TABLESPACE ts_primary;
77 | ```
78 |
79 | TABLESPACE子句指定要使用的表空间。
80 |
81 | 下面在logistics数据库中创建表并插入一行数据:
82 |
83 | ```plsql
84 | CREATE TABLE deliveries (
85 | delivery_id INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
86 | order_date DATE,
87 | customer_id INT
88 | );
89 |
90 | INSERT INTO deliveries(order_date, customer_id)
91 | VALUES('2020-08-01',1);
92 | ```
93 |
94 | 既然`ts_primary`表空间上已经有了数据,我们进行查看并验证:
95 |
96 | ```plsql
97 | \db+ ts_primary
98 | ```
99 |
100 | 输出结果:
101 |
102 | ```plsql
103 | postgres=# \db+ ts_primary
104 | 表空间列表
105 | 名称 | 拥有者 | 所在地 | 存取权限 | 选项 | 大小 | 描述
106 | ------------+----------+--------------------+----------+------+---------+------
107 | ts_primary | postgres | E:\pg-data\primary | | | 7513 kB |
108 | (1 行记录)
109 | ```
110 |
111 | ## 3. 总结
112 |
113 | 本文介绍了如何创建表空间。表空间是存储设备的具体位置,PostgreSQL用其实际存储数据文件。
--------------------------------------------------------------------------------
/3.PostgreSQL 笔记/PostgreSQL组合唯一约束空值问题.md:
--------------------------------------------------------------------------------
1 | - [PostgreSQL组合唯一约束空值问题](https://blog.csdn.net/neweastsun/article/details/119649930)
2 |
3 | > 因为 `PostgreSQL`唯一约束并考虑空值的唯一性,我们虽然在列上定义了唯一约束,但仍然会存在重复数据。`PostgreSQL`唯一约束的规则是,唯一键的列值可以为NULL。
4 |
5 | ## 问题描述
6 |
7 | 在多个列上定义组合唯一键,那么当其中一个值为空而其他值不为空时约束不起作用,下面看详细过程。
8 |
9 | - 创建表
10 |
11 | ```sql
12 | CREATE TABLE TestUniqueNull
13 | (
14 | ID INTEGER
15 | ,NoA INTEGER
16 | ,NoB INTEGER
17 | ,NoC INTEGER
18 | ,CONSTRAINT pk_tbl_TestUniqueNull_ID PRIMARY KEY(ID)
19 | ,CONSTRAINT uk_tbl_TestUniqueNull_NoA_NoB_NoC unique (NoA,NoB,NoC)
20 | );
21 | ```
22 |
23 | - 插入示例数据
24 |
25 | ```sql
26 | INSERT INTO TestUniqueNull VALUES (1,1,2,NULL);
27 | INSERT INTO TestUniqueNull VALUES (2,1,2,NULL);
28 | INSERT INTO TestUniqueNull VALUES (3,1,5,NULL);
29 | INSERT INTO TestUniqueNull VALUES (4,3,NULL,1);
30 | INSERT INTO TestUniqueNull VALUES (5,3,NULL,1);
31 | ```
32 |
33 | - 查看数据
34 |
35 | | id | noa | nob | noc |
36 | | ---- | ---- | ---- | ---- |
37 | | 1 | 1 | 2 | |
38 | | 2 | 1 | 2 | |
39 | | 3 | 1 | 5 | |
40 | | 4 | 3 | | 1 |
41 | | 5 | 3 | | 1 |
42 |
43 | 我们看到当列值为空时,存在重复记录,违背了定义唯一约束的需求。
44 |
45 | ## 使用唯一索引
46 |
47 | 针对上面的问题,我们使用唯一索引代替组合唯一约束:
48 |
49 | ```sql
50 | CREATE TABLE TestUniqueNull
51 | (
52 | ID INTEGER
53 | ,NoA INTEGER
54 | ,NoB INTEGER
55 | ,NoC INTEGER
56 | ,CONSTRAINT pk_tbl_TestUniqueNull_ID PRIMARY KEY(ID)
57 | );
58 |
59 | CREATE UNIQUE INDEX UIdx_NoA_NoB_NoC
60 | ON TestUniqueNull(coalesce(NoA,-1),coalesce(NoB,-1),coalesce(NoC,-1));
61 | ```
62 |
63 | 再次插入示例会报错:
64 |
65 | > SQL 错误 [23505]: 错误: 重复键违反唯一约束 “uidx_noa_nob_noc”
66 | > Detail: 键值"(COALESCE(noa, ‘-1’::integer), COALESCE(nob, ‘-1’::integer), COALESCE(noc, ‘-1’::integer))=(1, 2, -1)" 已经存在
67 |
68 | ## 总结
69 |
70 | 本文描述`PostgreSQL` 组合唯一约束空值问题,并给出使用唯一索引代替约束的解决方法。
--------------------------------------------------------------------------------
/3.PostgreSQL 笔记/Postgresql实现动态SQL语句.md:
--------------------------------------------------------------------------------
1 | - [Postgresql实现动态SQL语句](https://blog.csdn.net/neweastsun/article/details/113773212)
2 |
3 | 本文介绍Postgresql如何实现动态SQL语句。
4 |
5 | ## 1. 动态SQL
6 |
7 | 动态SQL在程序启动时会根据输入参数替换相应变量。使用动态SQL可以创建更强大和灵活的应用程序,但在编译时SQL语句的全文不确定,因此运行时编译会牺牲一些性能。动态SQL可以是代码或SQL语句的一部分,动态部分要么由开发人员输入,要么由程序本身创建。
8 |
9 | ### 1.1 动态SQL使用场景
10 |
11 | 在PL/pgSQL函数或过程中有时需要生成动态命令,因为命令涉及不同表或数据类型,仅在运行时才能确定具体对象或值。这时比较适合使用动态SQL。
12 |
13 | 另外,在特定情况下,如果静态SQL语句无法执行,或者您真的不知道函数或过程要执行的确切SQL语句,那么您必须使用动态SQL。
14 |
15 | ### 1.2 动态SQL VS 静态SQL
16 |
17 | | 动态SQL | 静态SQL |
18 | | ------------------------------------------------------------ | ------------------------------------------------------------ |
19 | | SQL语句在编译时编译 | SQL语句在运行时编译 |
20 | | SQL语句在编译时进行解析,有效性检查表、视图和过程。编译时优化并生成应用程序执行计划 | SQL语句在运行时进行编译解析SQL语句,有效性检查表、视图和过程,优化并生成应用程序执行计划 |
21 | | 性能好,速度快 | 与静态SQL相比较性能不好 |
22 | | 不够灵活 | 非常灵活 |
23 |
24 | ## 2. 生成动态SQL
25 |
26 | 共有三种方式实现动态SQL。使用format函数,使用quote_ident 和 quote_literal函数,使用连接操作符`||`(发音pipe),我最喜欢使用第一种,下面分别进行说明。
27 |
28 | 注意:构建查询时插入的动态值需要仔细处理,因为可能需要包含引号。
29 |
30 | ### 2.1 使用format函数
31 |
32 | 首先我们介绍下format函数的形式参数:
33 |
34 | %s s格式化参数值作为简单字符串.
35 | %I I 处理参数值作为SQL 标识符,有必要增加双引号.
36 | %L L 引用参数作为SQL字面值.
37 |
38 | 这里先要区分两个概念:SQL标识符和SQL字面值。
39 |
40 | SQL标识符表示数据库名称、表名、索引名、schema名、约束名、游标名、触发器、列、视图名称。在动态SQL中,I%会按照SQL标识符进行解析。
41 |
42 | SQL字面值表示显示值,数值、字符、字符串、布尔值,不代表SQL标识符。有不同类型的字面值:
43 |
44 | | 类型 | 举例 |
45 | | -------------- | ---------------------------------------------- |
46 | | 字符串 String | ‘Hello! everyone’ |
47 | | 整数 Integer | 45, 78, +89 , -465,6E5 |
48 | | 数值 Decimal | 45.56 |
49 | | 日期 DateTime | ‘5/20/2020’ , TIMESTAMP ‘2020-05-20 12:01:01’; |
50 | | 字符 Character | A’ ‘%’ ‘9’ ’ ’ ‘z’ ‘(’ |
51 | | 布尔 Boolean | true, false, null |
52 |
53 | 下面举例说明:
54 |
55 | ```
56 | SELECT format('Hello! Welcome to my %s!', 'Blog') as msg;
57 | ```
58 |
59 | 返回:`Hello! Welcome to my Blog!`
60 |
61 | ```
62 | SELECT format('%s! Welcome to my %s! - %s','Hi','Blog','Ourtechroom') as msg;
63 | ```
64 |
65 | 返回 :`Hi! Welcome to my Blog! - Ourtechroom`
66 |
67 | ```
68 | SELECT format('INSERT INTO %I VALUES(%L)', 'tbl_test', 'test');
69 | ```
70 |
71 | 返回:`INSERT INTO tbl_test VALUES('test')`
72 |
73 | 这里%I 被替换为`tbl_test`,%L被替换为`'test'`
74 |
75 | ### 2.2 使用quote_indent 函数
76 |
77 | PostgreSQL 的quote_indent 函数
78 |
79 | ```
80 | quote_ident('Hello World'); // "Hello World" 字面量增加引号
81 |
82 | quote_ident('mytable'); // mytable 表名称自动去掉引号
83 |
84 | quote_ident('MyTable'); // MyTable 区分大小写,表名称自动去掉引号
85 | ```
86 |
87 | 除此之外还有几个类似函数。 QUOTE_LITERAL(string text), QUOTE_LITERAL(value anyelement), QUOTE_NULLABLE(value anyelement);
88 |
89 | QUOTE_LITERAL函数返回值自动增加引号。QUOTE_NULLABLE对于非空参数增加引号,否则返回null。
90 |
91 | ### 2.3 使用连接操作符`||`
92 |
93 | 举例:
94 |
95 | ```
96 | select ' be.id from ' || tbl_name || ' t where m.commodity_id = ' || sorttype || ' order by t.amount ' || test_id ||;
97 | ```
98 |
99 | 这种方式对于需要增加单引号比较麻烦,且容易造成SQL注入。
100 |
101 | ## 3. 总结
102 |
103 | 本文介绍Postgresql三种方式实现动态SQL语句,并通过示例对比不同方式的差异。相比使用format方式更简单高效。
--------------------------------------------------------------------------------
/3.PostgreSQL 笔记/postgresql 身份证、手机号、营业执照验证脚本.md:
--------------------------------------------------------------------------------
1 | - [postgresql 身份证、手机号、营业执照验证脚本](https://hanbo.blog.csdn.net/article/details/114115204)
2 |
3 | # 验证18位身份证号码
4 |
5 | ```plsql
6 | CREATE OR REPLACE FUNCTION "public"."check_idcard"("a_sfz" varchar)
7 | RETURNS "pg_catalog"."bool" AS $BODY$DECLARE
8 | v_sfz varchar;
9 | v_i integer;
10 | v_sum integer;
11 | v_array1 integer[];
12 | v_array2 varchar[];
13 | v_s varchar;
14 | BEGIN
15 | v_sfz:=upper(trim(a_sfz));
16 | raise notice '检测身份证号%',v_sfz;
17 | if length(v_sfz)=18 and v_sfz ~ '^[123456789]\d{5}(19|20)\d{2}(0\d|10|11|12)(0\d|1\d|2\d|30|31)\d{3}[\dX]' then
18 | v_array1:=array[7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2];
19 | v_array2:=array['1','0','X','9','8','7','6','5','4','3','2'];
20 | v_i:=1;
21 | v_sum:=0;
22 | loop
23 | v_s:=substr(v_sfz,v_i,1);
24 | v_sum:=v_sum + cast(v_s as integer)*v_array1[v_i];
25 | v_i:=v_i + 1;
26 | if v_i>17 then
27 | exit;
28 | end if;
29 | end loop;
30 | v_sum:=mod(v_sum,11) + 1;
31 | v_s:=v_array2[v_sum];
32 | if v_s=substr(v_sfz,18,1) then
33 | return true;
34 | else
35 | return false;
36 | end if;
37 | else
38 | return false;
39 | end if;
40 | END
41 | $BODY$
42 | LANGUAGE plpgsql VOLATILE
43 | COST 100
44 | ```
45 |
46 | # 验证手机号
47 |
48 | ```plsql
49 | CREATE OR REPLACE FUNCTION "public"."check_phone"("name_per" text)
50 | RETURNS "pg_catalog"."bool" AS $BODY$
51 | ---------------------------------------------
52 | -- 1.长度,2-11
53 | -- 2.无特殊符号及数字、字母,·除外,^[\u4e00-\u9fa5]{0,}$
54 | ---------------------------------------------
55 |
56 | declare
57 | begin
58 |
59 | if length(name_per) !=11 then
60 | return false;
61 | else
62 | if replace(name_per,'·','') ~* '^1[3|4|5|6|7|8|9][0-9]\d{8}$' then
63 | return true;
64 | else
65 | return false;
66 | end if;
67 | end if;
68 | end;
69 | $BODY$
70 | LANGUAGE plpgsql VOLATILE
71 | COST 100
72 | ```
73 |
74 | # 验证营业执照
75 |
76 | ```plsql
77 | CREATE OR REPLACE FUNCTION "public"."check_phone"("name_per" text)
78 | RETURNS "pg_catalog"."bool" AS $BODY$
79 | ---------------------------------------------
80 | -- 1.长度,2-11
81 | -- 2.无特殊符号及数字、字母,·除外,^[\u4e00-\u9fa5]{0,}$
82 | ---------------------------------------------
83 |
84 | declare
85 | begin
86 |
87 | if length(name_per) =0 then
88 | return false;
89 | else
90 | if replace(name_per,'·','') ~* '^[0-9A-HJ-NPQRTUWXY]{2}\d{6}[0-9A-HJ-NPQRTUWXY]{10}' then
91 | return true;
92 | else
93 | return false;
94 | end if;
95 | end if;
96 | end;
97 | $BODY$
98 | LANGUAGE plpgsql VOLATILE
99 | COST 100
100 | ```
--------------------------------------------------------------------------------
/4.PostgreSQL 课程/HTAP.md:
--------------------------------------------------------------------------------
1 | # 16 HTAP
2 | ##### 201612/20161216_01.md [《分析加速引擎黑科技 - LLVM、列存、多核并行、算子复用 大联姻 - 一起来开启PostgreSQL的百宝箱》](../201612/20161216_01.md)
3 | ##### 201702/20170225_01.md [《PostgreSQL 向量化执行插件(瓦片式实现) 10x提速OLAP》](../201702/20170225_01.md)
4 | ##### 201703/20170312_05.md [《PostgreSQL 10.0 preview 多核并行增强 - tuplesort 多核并行创建索引》](../201703/20170312_05.md)
5 | ##### 201703/20170312_07.md [《PostgreSQL 10.0 preview sharding增强 - postgres_fdw 多节点异步并行执行》](../201703/20170312_07.md)
6 | ##### 201703/20170312_08.md [《PostgreSQL 10.0 preview 多核并行增强 - 并行hash join支持shared hashdata, 节约哈希表内存提高效率》](../201703/20170312_08.md)
7 | ##### 201703/20170312_11.md [《PostgreSQL 10.0 preview sharding增强 - 支持Append节点并行》](../201703/20170312_11.md)
8 | ##### 201703/20170312_14.md [《PostgreSQL 10.0 preview 性能增强 - OLAP提速框架, Faster Expression Evaluation Framework(含JIT)》](../201703/20170312_14.md)
9 | ##### 201703/20170313_06.md [《PostgreSQL 10.0 preview 功能增强 - OLAP增强 向量聚集索引(列存储扩展)》](../201703/20170313_06.md)
10 | ##### 201703/20170313_08.md [《PostgreSQL 10.0 preview 多核并行增强 - 索引扫描、子查询、VACUUM、fdw/csp钩子》](../201703/20170313_08.md)
11 | ##### 201703/20170313_09.md [《PostgreSQL 10.0 preview 性能增强 - mergesort(Gather merge)》](../201703/20170313_09.md)
12 | ##### 201703/20170313_12.md [《PostgreSQL 10.0 preview 多核并行增强 - 控制集群并行度》](../201703/20170313_12.md)
13 | ##### 201703/20170330_02.md [《PostgreSQL 10.0 preview 性能增强 - 推出JIT开发框架(朝着HTAP迈进)》](../201703/20170330_02.md)
14 | ##### 201703/20170331_03.md [《PostgreSQL 10.0 preview sharding增强 - 支持分布式事务》](../201703/20170331_03.md)
15 |
--------------------------------------------------------------------------------
/4.PostgreSQL 课程/README.md:
--------------------------------------------------------------------------------
1 |
2 | digoal's|PostgreSQL|文章|归类
3 | ---|---|---|---
4 | **[1 应用开发](1.md)** | **[2 日常维护](2.md)** | **[3 监控](3.md)** | **[4 备份,恢复,容灾](4.md)**
5 | **[5 高可用](5.md)** | **[6 安全与审计](6.md)** | **[7 问题诊断与性能优化](7.md)** | **[8 流式复制](8.md)**
6 | **[9 读写分离](9.md)** | **[10 水平分库](10.md)** | **[11 OLAP(MPP...)](11.md)** | **[12 数据库扩展插件](12.md)**
7 | **[13 版本新特性](13.md)** | **[14 内核原理与开发](14.md)** | **[15 经典案例](15.md)** | **[16 HTAP](16.md)**
8 | **[17 流式计算](17.md)** | **[18 时序、时空、对象多维处理](18.md)** | **[19 图式搜索](19.md)** | **[20 GIS](20.md)**
9 | **[21 Oracle兼容性](21.md)** | **[22 数据库选型](22.md)** | **[23 Benchmark](23.md)** | **[24 最佳实践](24.md)**
10 | **[25 DaaS](25.md)** | **[26 垂直行业应用](26.md)** | **[27 标准化(规约、制度、流程)](27.md)** | **[28 版本升级](28.md)**
11 | **[29 同、异构数据同步](29.md)** | **[30 数据分析](30.md)** | **[31 系列课程](31.md)** | **[32 其他](32.md)**
12 | **[33 招聘与求职信息](33.md)** | **[34 沙龙、会议、培训](34.md)** | **[35 思维精进](35.md)** | **[36 视频回放](36.md)**
13 |
14 |
--------------------------------------------------------------------------------
/4.PostgreSQL 课程/招聘与求职信息.md:
--------------------------------------------------------------------------------
1 | # 33 招聘与求职信息
2 | #### 所有和PostgreSQL,Greenplum有关的企业招聘或求职信息,欢迎发送邮件(digoal@126.com)或ISSUE给我。
3 | 
4 | ##### 202009/20200906_01.md [《[商业智能-杭州正马软件 招聘]PostgreSQL DBA》](../202009/20200906_01.md)
5 | ##### 202009/20200904_02.md [《[HelloBike 招聘]PostgreSQL DBA》](../202009/20200904_02.md)
6 | ##### 202003/20200305_01.md [《[招聘] [外企、体育行业] [上海] 高级PG DBA》](../202003/20200305_01.md)
7 | ##### 202003/20200304_01.md [《[招聘] [Airwallex] [上海、西安]高级PG DBA》](../202003/20200304_01.md)
8 | ##### 202002/20200218_01.md [《[招聘] [阿里云] [北京、杭州、深圳]运营专家、高级产品专家、项目管理专家、文档写作专家、解决方案架构师、后端研发》](../202002/20200218_01.md)
9 | ##### 201906/20190604_02.md [《[招聘] [沃趣] 招聘PostgreSQL全栈工程师》](../201906/20190604_02.md)
10 | ##### 201905/20190517_03.md [《[招聘] [国家电网旗下 - 许继] 招聘PostgreSQL 数据库DBA》](../201905/20190517_03.md)
11 | ##### 201905/20190517_02.md [《[招聘] [阿里巴巴] 招聘PostgreSQL 数据库DBA》](../201905/20190517_02.md)
12 | ##### 201905/20190517_01.md [《[招聘] [上海光源-国家级应用物理研究所] 招聘PostgreSQL 数据库DBA》](../201905/20190517_01.md)
13 | ##### 201811/20181127_02.md [《[招聘] [神州飞象] 招聘PostgreSQL 数据库内核研发、DBA》](../201811/20181127_02.md)
14 | ##### 201811/20181127_01.md [《[招聘] [亚信] 招聘PostgreSQL 数据库内核研发》](../201811/20181127_01.md)
15 | ##### 201811/20181126_01.md [《[招聘] [千寻位置] 招聘PostgreSQL DBA与PG背景的服务端研发》](../201811/20181126_01.md)
16 | ##### 201811/20181107_01.md [《[招聘] [恩墨] 招聘PostgreSQL 高级DBA》](../201811/20181107_01.md)
17 | ##### 201805/20180524_04.md [《[招聘] [杭州米雅] PostgreSQL 开发 DBA》](../201805/20180524_04.md)
18 | ##### 201805/20180524_03.md [《[招聘] [招商仁和人寿] PostgreSQL 开发 DBA》](../201805/20180524_03.md)
19 | ##### 201708/20170804_02.md [《[招聘] [探探] PostgreSQL DBA》](../201708/20170804_02.md)
20 | ##### 201708/20170801_03.md [《[招聘] [鲁邦通] PostgreSQL DBA》](../201708/20170801_03.md)
21 | ##### 201708/20170801_02.md [《[招聘] [HelloBike] PostgreSQL DBA》](../201708/20170801_02.md)
22 |
--------------------------------------------------------------------------------
/4.PostgreSQL 课程/数据库选型.md:
--------------------------------------------------------------------------------
1 | # 22 数据库选型
2 | ##### 201609/20160929_02.md [《PostgreSQL 前世今生》](../201609/20160929_02.md)
3 | ##### 201701/20170120_01.md [《PostgreSQL 特性故事会》](../201701/20170120_01.md)
4 | ##### 201702/20170208_03.md [《数据库选型思考》](../201702/20170208_03.md)
5 | ##### 201702/20170209_01.md [《数据库选型之 - 大象十八摸 - 致 架构师、开发者》](../201702/20170209_01.md)
6 | ##### 201703/20170322_01.md [《数据库三十六计 - PostgreSQL 三十六计(上)》](../201703/20170322_01.md)
7 | ##### 201703/20170322_02.md [《数据库三十六计 - PostgreSQL 三十六计(中)》](../201703/20170322_02.md)
8 | ##### 201703/20170322_03.md [《数据库三十六计 - PostgreSQL 三十六计(下)》](../201703/20170322_03.md)
9 | ##### 201703/20170322_04.md [《MySQL不适合去O(Oracle)的原因分析》](../201703/20170322_04.md)
10 | ##### 201703/20170328_05.md [《一张图读懂RDBMS的历史和基因》](../201703/20170328_05.md)
11 | ##### 201709/20170921_01.md [《PostgreSQL 规格评估 - 微观、宏观、精准 多视角估算数据库性能(选型、做预算不求人)》](../201709/20170921_01.md)
12 | ##### 197001/20190214_01.md [《企业数据库选型规则》](../197001/20190214_01.md)
13 | ##### 202003/20200322_01.md [《为什么数据库选型和找对象一样重要》](../202003/20200322_01.md)
14 | ##### 202003/20200326_26.md [《IoT 数据库选型》](../202003/20200326_26.md)
15 | ##### 202005/20200527_06.md [《未来数据库方向》](../202005/20200527_06.md)
16 | ##### 202007/20200727_04.md [《云、商业、开源数据库终局之战 - 商业角度解读PG如何破局 - openapi 、 扩展能力、插件开源协议》](../202007/20200727_04.md)
17 | ##### 202009/20200926_03.md [《[直播]大话数据库终局之战》](../202009/20200926_03.md)
18 | ##### 202101/20210117_04.md [《理性 - 企业CxO数据库选型应该回答清楚的 15 个问题》](../202101/20210117_04.md)
19 | ##### 202101/20210120_02.md [《开源数据库全球化协作浪潮 思考 - 24问》](../202101/20210120_02.md)
20 |
--------------------------------------------------------------------------------
/4.PostgreSQL 课程/时序、时空、对象多维处理.md:
--------------------------------------------------------------------------------
1 | # 18 时序、时空、对象多维处理
2 | ##### 201611/20161128_01.md [《时序数据合并场景加速分析和实现 - 复合索引,窗口分组查询加速,变态递归加速》](../201611/20161128_01.md)
3 | ##### 201702/20170219_01.md [《高并发行为、轨迹类大吞吐数据查询场景解说 - PostgreSQL 聚集存储 与 BRIN索引》](../201702/20170219_01.md)
4 | ##### 201702/20170221_01.md [《PostgreSQL GIN 单列聚集索引 应用》](../201702/20170221_01.md)
5 | ##### 201703/20170321_02.md [《PostgreSQL 数据rotate用法介绍 - 按时间覆盖历史数据》](../201703/20170321_02.md)
6 | ##### 201704/20170409_05.md [《时序数据库有哪些特点? TimescaleDB时序数据库介绍》](../201704/20170409_05.md)
7 | ##### 201704/20170413_02.md [《奔跑吧,大屏 - 时间+空间 实时四维数据透视》](../201704/20170413_02.md)
8 | ##### 201704/20170417_01.md [《PostgreSQL 时序最佳实践 - 证券交易数据库需求分析与应用 》](../201704/20170417_01.md)
9 | ##### 201705/20170518_01.md [《(流式、lambda、触发器)实时处理大比拼 - 物联网(IoT)\金融,时序处理最佳实践》](../201705/20170518_01.md)
10 | ##### 201706/20170611_02.md [《PostgreSQL 并行写入堆表,如何保证时序线性存储 - BRIN索引优化》](../201706/20170611_02.md)
11 | ##### 201706/20170612_03.md [《数据保留时间窗口的使用》](../201706/20170612_03.md)
12 | ##### 201706/20170629_01.md [《PostgreSQL\GPDB 毫秒级海量时空数据透视 典型案例分享》](../201706/20170629_01.md)
13 | ##### 201707/20170702_01.md [《PostgreSQL FDW 伪列实现 时序数据存储自动分区 - FUNCTION pushdown》](../201707/20170702_01.md)
14 | ##### 201707/20170705_01.md [《PostgreSQL 海量时序数据(任意滑动窗口实时统计分析) - 传感器、人群、物体等对象跟踪》](../201707/20170705_01.md)
15 | ##### 201707/20170705_02.md [《PostgreSQL 金融类账务流水数据快照分析 案例分享》](../201707/20170705_02.md)
16 | ##### 201707/20170722_01.md [《时间、空间、对象多维属性 海量数据任意多维 高效检索 - 阿里云RDS PostgreSQL最佳实践》](../201707/20170722_01.md)
17 |
--------------------------------------------------------------------------------
/4.PostgreSQL 课程/标准化(规约、制度、流程).md:
--------------------------------------------------------------------------------
1 | # 27 标准化(规约、制度、流程)
2 | ##### 201410/20141009_01.md [《PostgreSQL 密码安全指南》](../201410/20141009_01.md)
3 | ##### 201506/20150601_01.md [《PostgreSQL 数据库安全指南》](../201506/20150601_01.md)
4 | ##### 201609/20160926_01.md [《PostgreSQL 数据库开发规范》](../201609/20160926_01.md)
5 | ##### 201612/20161224_01.md [《DBA专供 冈本003系列 - 数据库安全第一,过个好年》](../201612/20161224_01.md)
6 | ##### 201701/20170120_02.md [《DBA一族九阳神功秘籍,标准和制度(含重大节日)》](../201701/20170120_02.md)
7 |
--------------------------------------------------------------------------------
/4.PostgreSQL 课程/流式计算.md:
--------------------------------------------------------------------------------
1 | # 17 流式计算
2 | ##### 201612/20161220_01.md [《流计算风云再起 - PostgreSQL携PipelineDB力挺IoT》](../201612/20161220_01.md)
3 |
--------------------------------------------------------------------------------
/4.PostgreSQL 课程/系列课程.md:
--------------------------------------------------------------------------------
1 | # 31 系列课程
2 | ##### 201704/20170411_01.md [《快速入门PostgreSQL应用开发与管理 - 1 如何搭建一套学习、开发PostgreSQL的环境》](../201704/20170411_01.md)
3 | ##### 201704/20170411_02.md [《快速入门PostgreSQL应用开发与管理 - 2 Linux基本操作》](../201704/20170411_02.md)
4 | ##### 201704/20170411_03.md [《快速入门PostgreSQL应用开发与管理 - 3 访问数据》](../201704/20170411_03.md)
5 | ##### 201704/20170411_04.md [《快速入门PostgreSQL应用开发与管理 - 4 高级SQL用法》](../201704/20170411_04.md)
6 | ##### 201704/20170411_05.md [《快速入门PostgreSQL应用开发与管理 - 5 数据定义》](../201704/20170411_05.md)
7 | ##### 201704/20170412_01.md [《快速入门PostgreSQL应用开发与管理 - 6 事务和锁》](../201704/20170412_01.md)
8 | ##### 201704/20170412_02.md [《快速入门PostgreSQL应用开发与管理 - 7 函数、存储过程和触发器》](../201704/20170412_02.md)
9 | ##### 201704/20170412_04.md [《快速入门PostgreSQL应用开发与管理 - 8 PostgreSQL 管理》](../201704/20170412_04.md)
10 |
--------------------------------------------------------------------------------
/5.PostgreSQL 案例/空间数据应用案例/电子围栏/PostgreSQL 电子围栏的应用场景和性能(大疆、共享设备、菜鸟。。。).md:
--------------------------------------------------------------------------------
1 | # PostgreSQL 电子围栏的应用场景和性能(大疆、共享设备、菜鸟)
2 |
3 | **作者**
4 |
5 | digoal
6 |
7 | **日期**
8 |
9 | 2017-10-31
10 |
11 | **标签**
12 |
13 | PostgreSQL , 电子围栏 , 共享自行车 , 共享充电宝 , 共享xxx , 菜鸟 , 航空管制 , 无人飞行器 , pipelinedb , 流式计算
14 |
15 | # 背景
16 |
17 | 电子围栏,这个在GIS应用中非常常见的词。在很多业务场景中都可以使用:
18 |
19 | 电子围栏的常见手段是圈出一块,或者一些多边形。当被监控对象在多边形内或者多边形外时(根据业务模型),作为一个判断条件,触发一些业务规则。
20 |
21 | 1、禁飞区
22 |
23 | 玩大疆无人机的话,你一定要知道哪里是禁飞区,否则可能违法被抓,但是你可能并不知道哪里是禁飞区,还有飞行高度的限制。
24 |
25 | 有了电子围栏,可以在飞行器内置这样的功能,你就可以放心的飞了。比如到达了禁飞区后,飞行器可以发出告警,禁止飞行。
26 |
27 | 2、共享单车还车点
28 |
29 | 共享单车乱摆放是个问题,原因是什么地方都能还车。使用电子围栏,可以约束用户的还车点,只允许用户将自行车停在某个空间内,或不在某个空间内才能还车。
30 |
31 | 3、汽车禁行区
32 |
33 | 例如,某些汽车,在某个时间段不允许出现在某个区域内。
34 |
35 | 例如限行车辆,例如危化品车辆、黄沙车、货车等的行驶范围。以往,我们只能靠摄像头、或者靠警力来管理。加入电子围栏,一切都变得更简单。
36 |
37 | 4、国界线
38 |
39 | 这个是有非常鲜明的地理属性的,电子围栏,结合流式计算,可以非常实时的发现异常。
40 |
41 | 5、山头线
42 |
43 | 我记得小时候,我们那里的班车线路都是承包的,谁要是敢乱拉客,车子可能是会被砸掉的。实际上这个也是一些商业边界的问题,如果商业边界涉及到地理信息,通过电子围栏,可以更加方便的实现边界控制和管理。
44 |
45 | 6、远程打卡,当你进入了办公区域附近(电子围栏)时,才允许打卡。
46 |
47 | 7、远程办公管理,公司可以划定一些可以办公的常用地的多边形,当员工出了这个区域时,触发事件。
48 |
49 | 8、公务用车、商用车辆的行驶区域管理,出了区域,可以触发事件。
50 |
51 | 9、放牧管理,例如在大草原放养的动物,可以挂上GPS跟踪器,划定电子围栏,出了区域,触发事件。
52 |
53 | 10、假释人员的管理,不在需要投入大量警力跟踪假释人员。当然人的管理更加复杂,因为跟踪器可能更换。
54 |
55 | 11、... ...
56 |
57 | 试想一下,当每个对象都带上空间属性后,还有很多很多很多场景,可以设置电子围栏。
58 |
59 | 空间数据的处理,将会是一片巨大的蓝海。
60 |
61 | 围栏除了空间属性,还可以有其他属性,PostgreSQL提供了btree_gist接口,可以对空间、标量字段建立联合索引,提高性能。
62 |
63 | https://www.postgresql.org/docs/10/static/btree-gist.html
64 |
65 | 同时PostgreSQL还支持空间独立排他约束,可以防止围栏重叠。
66 |
67 | https://www.postgresql.org/docs/10/static/ddl-constraints.html#ddl-constraints-exclusion
68 |
69 | PostgreSQL 深耕空间数据管理数十年,一定能服务好这片业务,一起来为人类发展做出贡献。
70 |
71 | # 电子围栏性能
72 |
73 | 电子围栏中,最常用的手段是点面判断,对于共享单车业务,我们为了防止自行车乱停放,可以圈定可以换车、或者不能换车的点(视业务需求),创建很多的多边形区域,当用户还车时,上报车辆位置,同时判断是不是落在可以换车的点,或者不能换车的点内。决定用户是否可以在当地还车。
74 |
75 | 可能有千万、甚至更多的多边形面。
76 |
77 | 这个需求和菜鸟的配送调度类似,也有点面判断的需求,下面是一个设计和性能测试
78 |
79 | [《菜鸟末端轨迹 - 电子围栏(解密支撑每天251亿个包裹的数据库) - 阿里云RDS PostgreSQL最佳实践》](https://github.com/digoal/blog/blob/master/201708/20170803_01.md)
80 |
81 | 1000万个多边形,根据位置查询这个位置在哪个面里面,或者有没有面包含了这个点。
82 |
83 | PostgreSQL单机可以达到`251亿次/天`的点面判断请求的性能。
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/00.德哥GIS相关笔记/PostGIS 3 瓦片提取函数 ST_TileEnvelope .md:
--------------------------------------------------------------------------------
1 | ## PostGIS 3 瓦片提取函数 ST_TileEnvelope
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2019-08-19
8 |
9 | ### 标签
10 | PostgreSQL , PostGIS , 瓦片
11 |
12 | ----
13 |
14 | ## 背景
15 | 原文
16 |
17 | https://info.crunchydata.com/blog/waiting-for-postgis-3-st_tileenvelopezxy
18 |
19 | With the availability of MVT tile format in PostGIS via ST_AsMVT(), 越来越多用户使用PostGIS存储并直接产生地图瓦片。
20 |
21 | Tile coordinates consist of three values:
22 |
23 | - zoom, the level of the tile pyramid the tile is from
24 | - x, the coordinate of the tile at that zoom, counting from the left, starting at zero
25 | - y, the coordinate of the tile at that zoom, counting from the top, starting at zero
26 |
27 |
28 | PostGIS 3提供了提取瓦片的函数ST_TileEnvelope,输入参数为金字塔图层的层级、x轴编号、y轴编号,瓦片空间。输出为指定x,y位置的瓦片(一个瓦片的像素为256\*256)
29 |
30 | https://en.wikipedia.org/wiki/Tiled_web_map
31 |
32 | ```
33 | geometry ST_TileEnvelope(integer tileZoom, integer tileX, integer tileY, geometry bounds=SRID=3857;LINESTRING(-20037508.342789 -20037508.342789,20037508.342789 20037508.342789));
34 | ```
35 |
36 | 这个函数默认使用Spherical Mercator坐标,https://en.wikipedia.org/wiki/Web_Mercator_projection
37 |
38 | ## 例子
39 | 1、使用默认坐标
40 |
41 | ```
42 | SELECT ST_AsText( ST_TileEnvelope(2, 1, 1) );
43 |
44 | st_astext
45 | ------------------------------
46 | POLYGON((-10018754.1713945 0,-10018754.1713945 10018754.1713945,0 10018754.1713945,0 0,-10018754.1713945 0))
47 | ```
48 |
49 | 2、使用非默认坐标
50 |
51 | ```
52 | SELECT ST_AsText( ST_TileEnvelope(3, 1, 1, ST_MakeEnvelope(-180, -90, 180, 90, 4326) ) );
53 |
54 | st_astext
55 | ------------------------------------------------------
56 | POLYGON((-135 45,-135 67.5,-90 67.5,-90 45,-135 45))
57 | ```
58 |
59 | 3、创建非默认坐标
60 |
61 | ```
62 | geometry ST_MakeEnvelope(float xmin, float ymin, float xmax, float ymax, integer srid=unknown);
63 | ```
64 |
65 |
66 | ## 参考
67 | https://postgis.net/docs/manual-dev/ST_TileEnvelope.html
68 |
69 | https://info.crunchydata.com/blog/waiting-for-postgis-3-st_tileenvelopezxy
70 |
71 | https://postgis.net/docs/manual-dev/ST_MakeEnvelope.html
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 | #### [PostgreSQL 许愿链接](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216")
143 | 您的愿望将传达给PG kernel hacker、数据库厂商等, 帮助提高数据库产品质量和功能, 说不定下一个PG版本就有您提出的功能点. 针对非常好的提议,奖励限量版PG文化衫、纪念品、贴纸、PG热门书籍等,奖品丰富,快来许愿。[开不开森](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216").
144 |
145 |
146 | #### [9.9元购买3个月阿里云RDS PostgreSQL实例](https://www.aliyun.com/database/postgresqlactivity "57258f76c37864c6e6d23383d05714ea")
147 |
148 |
149 | #### [PostgreSQL 解决方案集合](https://yq.aliyun.com/topic/118 "40cff096e9ed7122c512b35d8561d9c8")
150 |
151 |
152 | #### [德哥 / digoal's github - 公益是一辈子的事.](https://github.com/digoal/blog/blob/master/README.md "22709685feb7cab07d30f30387f0a9ae")
153 |
154 |
155 | 
156 |
157 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/00.德哥GIS相关笔记/PostgreSQL PostGIS 坐标转换项目 - 百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换.md:
--------------------------------------------------------------------------------
1 | ## PostgreSQL PostGIS 坐标转换项目 - 百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2019-08-14
8 |
9 | ### 标签
10 | PostgreSQL , PostGIS , 百度坐标(BD09), 国测局坐标(火星坐标,GCJ02), WGS84坐标系
11 |
12 | ----
13 |
14 | ## 背景
15 | 分享几个社区小伙伴开源的坐标转换项目。感谢他们。
16 |
17 | 1、批量对数据进行加偏到百度坐标,高德谷歌的火星坐标,或者逆向纠偏
18 |
19 | https://github.com/FreeGIS/Postgis_Coordinate_Transform
20 |
21 | 2、基于PostgreSQL+PostGIS的坐标转换函数,支持点、线、面的WGS84、GCJ02、BD09坐标互转
22 |
23 | https://github.com/geocompass/pg-coordtransform
24 |
25 | 3、一个提供了百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换的工具模块。
26 |
27 | https://github.com/wandergis/coordTransform
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 | #### [PostgreSQL 许愿链接](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216")
99 | 您的愿望将传达给PG kernel hacker、数据库厂商等, 帮助提高数据库产品质量和功能, 说不定下一个PG版本就有您提出的功能点. 针对非常好的提议,奖励限量版PG文化衫、纪念品、贴纸、PG热门书籍等,奖品丰富,快来许愿。[开不开森](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216").
100 |
101 |
102 | #### [9.9元购买3个月阿里云RDS PostgreSQL实例](https://www.aliyun.com/database/postgresqlactivity "57258f76c37864c6e6d23383d05714ea")
103 |
104 |
105 | #### [PostgreSQL 解决方案集合](https://yq.aliyun.com/topic/118 "40cff096e9ed7122c512b35d8561d9c8")
106 |
107 |
108 | #### [德哥 / digoal's github - 公益是一辈子的事.](https://github.com/digoal/blog/blob/master/README.md "22709685feb7cab07d30f30387f0a9ae")
109 |
110 |
111 | 
112 |
113 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/00.德哥GIS相关笔记/基于GIS位置、群众热点、人为热点的内容推荐服务 - 挑战和策略.md:
--------------------------------------------------------------------------------
1 | ## 基于GIS位置、群众热点、人为热点的内容推荐服务 - 挑战和策略
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2020-02-26
8 |
9 | ### 标签
10 | PostgreSQL , gis , 表达式索引 , 空间索引 , 只读实例 , copy
11 |
12 | ----
13 |
14 | ## 背景
15 | 带有位置、群众热点、人为热点属性的内容推荐服务.
16 | 内容数量可控, 有淘汰机制, 数据量不会太大.
17 | 最终用户上报位置, 推荐服务则结合用户的位置、内容的位置、内容的时效(付费权重、阶段性热议标签权重)|动态权重等条件推荐相应的内容给用户.
18 | 让所有的内容都有机会在全国曝光, 同时让平台可以基于流量变现.
19 |
20 | ## 推荐内容
21 | 呈现给最终用户的内容分为两部分:
22 | - 本地属性内容推荐 占比xxx
23 | - 全国属性内容推荐 占比xxx
24 |
25 | ### 1本地推荐条件
26 | 地域属性: 可以用来查询在用户附近的内容
27 |
28 | 时效权重: 付费时效权重、标签时效权重. 例如:
29 | - 由运营负责维护的标签权重, 近期热点话题标签, 热度随时可能发生变化.
30 | - 付费则是为流量变现准备的权重, 付费的内容权重提升. 这些都是有时效的.
31 |
32 |
33 | 动态权重: 内容的下载、点击、赞等计数, 越热的内容越容易被推荐
34 |
35 | ### 2全国推荐条件
36 | 时效权重: 付费时效权重、标签时效权重. 例如:
37 | - 由运营负责维护的标签权重, 近期热点话题标签, 热度随时可能发生变化.
38 | - 付费则是为流量变现准备的权重, 付费的内容权重提升. 这些都是有时效的.
39 |
40 |
41 | 动态权重: 内容的下载、点击、赞等计数
42 |
43 | ## 核心数据结构指标
44 | 内容属性表:
45 | - 内容id, 付费时效权重, 标签id, 经纬度, 赞, 点击, 下载计数
46 |
47 |
48 | 标签属性(运营调整)表:
49 | - 标签id, 标签权重
50 |
51 | ## 业务指标
52 | xxx亿用户数级别
53 | xxx亿级别内容数
54 |
55 | ## 挑战点和应对策略
56 | 1、作为群众热点的内容有大量更新(动态权重更新:赞, 点击, 下载计数)
57 | 策略: 合并update
58 |
59 | 2、本地内容推荐算法: 地域 + (时效权重 + 动态权重)排序 , 挑战: 无法完全用索引筛选.
60 | 策略:
61 |
62 | 分级过滤, 数据库过滤第一道, 应用过滤第二道
63 |
64 | batch get: 使用postgis, 采用空间索引, 仅按空间排序get 指定记录数(走空间索引), 返回记录数万级别.
65 |
66 | (根据数据库压力, 选择是否将 时效+动态权重排序 下移到应用层计算.)
67 |
68 | 缓存, 应用层根据时效+动态权重排序后筛选并写入缓存, 缓存分批次老化,
69 |
70 | 3、全国内容推荐算法: (时效权重 + 动态权重)排序 , 时效权重在另一张表, 挑战: 无法完全用索引筛选.
71 | 策略1:
72 |
73 | batch get1:
74 | 按动态权重排序取出第1批结果(采用表达式索引, 无需额外计算), 输出时同时关联出标签表的权重, 记录数万级别.
75 |
76 | batch get2:
77 | 从标签表按权重取出top n时效标签, 基于这些时效标签查询内容表, 按动态权重排序取出第2批结果(采用表达式索引, 无需额外计算), 输出时同时关联出标签表的权重, 记录数万级别.
78 |
79 | 缓存, 应用层根据时效+动态权重排序后筛选并写入缓存, 缓存分批次老化,
80 |
81 | 缺陷: 结果可能不精确, 某些(时效权重 + 动态权重高)的内容可能永远取不出来.
82 |
83 | 策略2:
84 |
85 | 硬算: JOIN后计算综合权重排名, 并写入缓存. 由于是全国热点, 全国共享, 查询量不大, 可以定期更新缓存.
86 |
87 | 4、人口密集处可能有大量缓存重复
88 |
89 | 缓存: 按geohash box(可根据实际情况缩放hash精度) 映射到 固定内容集ID , 落在同一个geohash的用户, 都取同一个映射的内容集.
90 |
91 | 取的时候: 取1个格子的映射内容集, 或取相邻的9个格子的映射内容集, 或取若干相邻格子的映射内容集.
92 |
93 | 5、单次数据库batch查询返回记录量大
94 |
95 | 使用PG只读实例
96 |
97 | 用copy接口返回记录, 并发情况下每秒能返回数千万行记录
98 |
99 | ## 结论
100 | 数据库挑战: 大量大结果集的JOIN查询查询|GIS空间排序查询、网络带宽、频繁更新.
101 |
102 | 策略: 空间索引、表达式索引、合并更新、加只读节点、copy接口.
103 |
104 | 应用挑战: 排序计算(第二道过滤).
105 |
106 | 策略: 横向扩容
107 |
108 | 缓存挑战: 缓存重复、读、更新.
109 |
110 | 策略: geohash 映射降低重复、横向扩容
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/01.不睡觉的怪叔叔PostGIS教程/17.PostGIS教程:相等.md:
--------------------------------------------------------------------------------
1 | # PostGIS教程十七:相等
2 |
3 | 在处理几何图形时确定相等可能很困难。PostGIS支持三种不同的函数,可以用来确定不同级别的相等。为了说明这些函数,我们将使用以下多边形。
4 |
5 | 
6 |
7 | 使用以下命令加载这些多边形:
8 |
9 | ```sql
10 | CREATE TABLE polygons (id integer, name varchar, poly geometry);
11 | INSERT INTO polygons VALUES
12 | (1, 'Polygon 1', 'POLYGON((-1 1.732,1 1.732,2 0,1 -1.732,
13 | -1 -1.732,-2 0,-1 1.732))'),
14 | (2, 'Polygon 2', 'POLYGON((-1 1.732,-2 0,-1 -1.732,1 -1.732,
15 | 2 0,1 1.732,-1 1.732))'),
16 | (3, 'Polygon 3', 'POLYGON((1 -1.732,2 0,1 1.732,-1 1.732,
17 | -2 0,-1 -1.732,1 -1.732))'),
18 | (4, 'Polygon 4', 'POLYGON((-1 1.732,0 1.732, 1 1.732,1.5 0.866,
19 | 2 0,1.5 -0.866,1 -1.732,0 -1.732,-1 -1.732,-1.5 -0.866,
20 | -2 0,-1.5 0.866,-1 1.732))'),
21 | (5, 'Polygon 5', 'POLYGON((-2 -1.732,2 -1.732,2 1.732,
22 | -2 1.732,-2 -1.732))');
23 | ```
24 |
25 | 
26 |
27 | # 一、精确相等
28 |
29 | 精确相等是通过按顺序逐个比较两个几何图形的顶点来确定的,以确保它们在位置上是相同的。下面的例子说明了这种方法的有效性是如何受到限制的。
30 |
31 | ```sql
32 | SELECT a.name, b.name, CASE WHEN ST_OrderingEquals(a.poly, b.poly)
33 | THEN 'Exactly Equal' ELSE 'Not Exactly Equal' end
34 | FROM polygons as a, polygons as b;
35 | ```
36 |
37 | 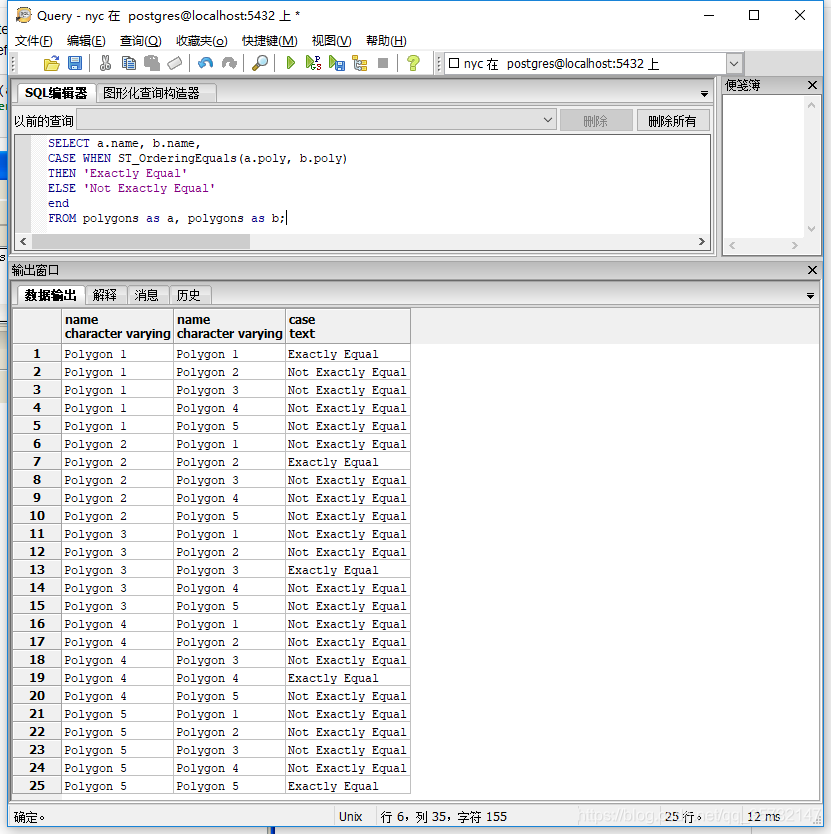
38 |
39 | 在此示例中,多边形仅与自身相等,而不等于其他看似相等的多边形(如在多边形1到3的情况下)。对于多边形1、2和3,顶点处于相同的位置,但定义顺序不同。多边形4在六边形边上有共线(因此是冗余的)顶点,导致与多边形1不相等。
40 |
41 |
42 |
43 | # 二、空间相等
44 |
45 | 正如我们在上面看到的,精确的相等并没有考虑到几何图形的空间性质。有一个名为**ST_Equals**的函数,可用于测试几何图形的空间相等性或等价性。
46 |
47 | ```sql
48 | SELECT a.name, b.name, CASE WHEN ST_Equals(a.poly, b.poly)
49 | THEN 'Spatially Equal' ELSE 'Not Equal' end
50 | FROM polygons as a, polygons as b;
51 | ```
52 |
53 | 
54 |
55 | 这些结果更符合我们对相等的直觉理解。多边形1到4被认为是相等的,因为它们包含相同的区域。请注意,无论是绘制多边形的方向、定义多边形的起点,还是使用的点的个数的差异在这里都不重要。重要的是多边形包含相同的空间区域。
56 |
57 |
58 |
59 | # 三、等边界框
60 |
61 | 在最坏的情况下,需要精确相等来比较几何图形中的每个顶点以确定相等。这可能会比较慢,并且可能不适合数量大的几何图形。为了更快地进行比较,提供了等边界运算符 ' **=** ' 。这仅在边界框(矩形)上操作,确保几何图形占用相同的二维范围,但不一定占用相同的空间。
62 |
63 | ```sql
64 | SELECT a.name, b.name, CASE WHEN a.poly = b.poly
65 | THEN 'Equal Bounds' ELSE 'Non-equal Bounds' end
66 | FROM polygons as a, polygons as b;
67 | ```
68 |
69 | 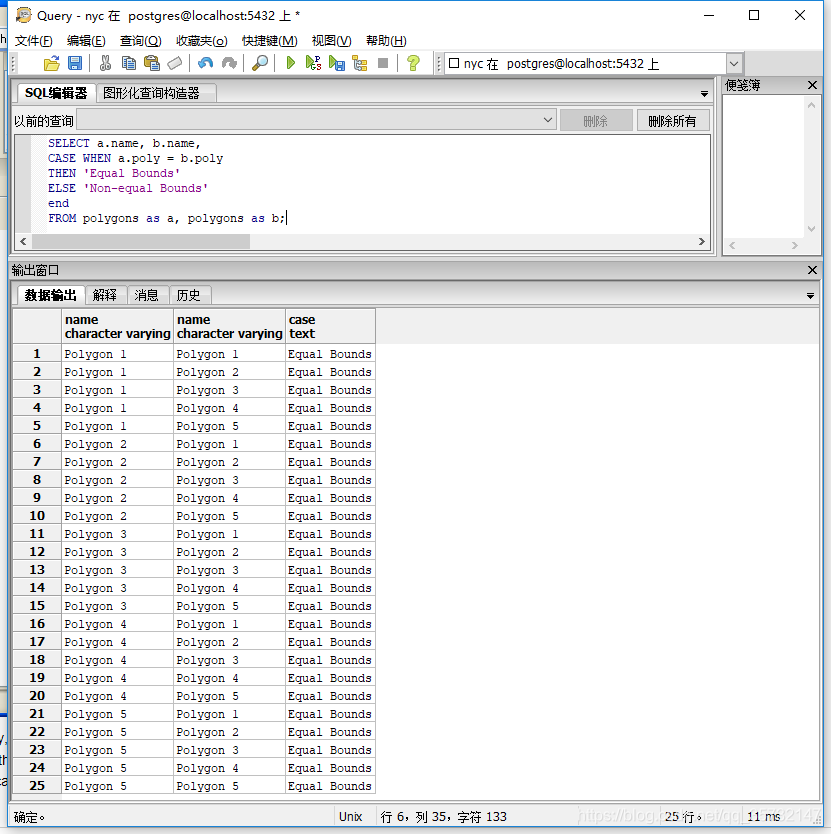
70 |
71 | 如你所见,我们所有在空间上相等的几何图形也有相等的边界框。不幸的是,在此测试中返回的多边形5也是相等的,因为它与其他几何图形一样具有相同的边界框。那这有什么用呢?虽然这将在稍后详细介绍,但简短的答案是,这允许使用空间索引,在连接或筛选数据时,可以将大量的比较集快速减少为更易于处理的子集。
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/01.不睡觉的怪叔叔PostGIS教程/2.PostGIS教程:PostGIS的安装.md:
--------------------------------------------------------------------------------
1 | - [PostGIS教程二:PostGIS的安装](https://blog.csdn.net/qq_35732147/article/details/86299060)
2 |
3 |
4 |
5 | # 一、下载安装程序
6 |
7 | 在安装PostGIS前首先必须安装**PostgreSQL**,然后在安装好的**Stack Builder**中选择安装PostGIS组件。
8 |
9 | PostgreSQL安装文件下载地址是https://www.enterprisedb.com/downloads/postgres-postgresql-downloads
10 |
11 | 这里使用的PostgreSQL版本是9.6。
12 |
13 | # 二、安装PostgreSQL
14 |
15 | 双击下载的文件,所有设置都使用默认设置即可,只是需要设置超级用户postgres的密码。
16 |
17 | # 三、安装PostGIS
18 |
19 | 安装PostgreSQL安装完成后,提示运行**Stack Builder**。通过该工具安装PostGIS。
20 |
21 | Stack Builder运行后,选择安装目标软件为PostgreSQL 9.6 on port 5432。然后在安装程序选择对话框中选择PostGIS 2.3。
22 |
23 | 
24 |
25 | 
26 |
27 | 然后Stack Builder会下载PostGIS 2.3的安装程序。下载后就会安装,在设置安装组件时,最好选择"**Create spatial database**",以便在创建数据库时可以以此作为模板。对于其他步骤的设置都选择默认值即可。
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/01.不睡觉的怪叔叔PostGIS教程/20.PostGIS教程:索引集群.md:
--------------------------------------------------------------------------------
1 | # PostGIS教程二十:索引集群
2 |
3 | 数据库只能以从磁盘获取信息的速度检索信息。小型数据库将完全浮动于RAM缓存,并摆脱物理磁盘限制。但是对于大型数据库,对物理磁盘的访问将限制信息检索速度。
4 |
5 | 数据是偶尔写入磁盘的,因此存储在磁盘上的有序数据与应用程序访问或组织该数据的方式之间不需要存在任何关联。
6 |
7 | 
8 |
9 | 加速数据访问的一种方法是确保可能在同一结果集中一起检索的记录位于硬盘上的相似物理位置。这就是所谓的"**集群**(**clustering**)"。
10 |
11 | 要使用正确的集群方案可能很棘手,但可以遵循一条一般规则:索引定义了数据的自然排序方案,该方案类似于检索数据的访问模式。
12 |
13 | 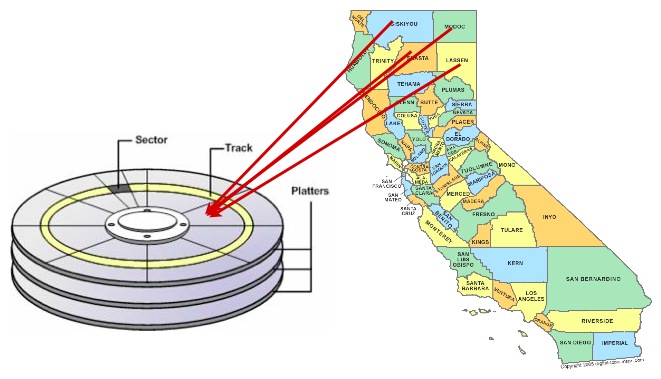
14 |
15 | 正因为如此,在某些情况下,以与索引相同的顺序对磁盘上的数据进行排序可以加速数据访问速度。
16 |
17 | # 一、R-Tree上的集群
18 |
19 | 空间数据倾向于在客户端的窗口中访问:想想Web应用程序或桌面应用程序中的地图窗口。窗口中的所有数据都具有相似的位置信息(否则它们将不在相同的窗口中!)。
20 |
21 | 因此,基于空间索引的集群对于将通过空间查询访问的空间数据是有意义的:相似的事物往往具有相似的位置(**地理学第一定律**)。
22 |
23 | 让我们根据nyc_census_blocks的空间索引对该表数据进行集群:
24 |
25 | ```sql
26 | -- Cluster the blocks based on their spatial index
27 | CLUSTER nyc_census_blocks USING nyc_census_blocks_geom_idx;
28 | ```
29 |
30 | 
31 |
32 | 该命令按照空间索引nyc_census_blocks_geom_idx所定义的顺序重新写入nyc_census_blocks。你能感觉到访问数据的速度的差异吗?可能不会,因为表很小,很容易装入内存,所以磁盘访问开销不会影响性能。
33 |
34 | R-Tree的一个令人惊讶的地方是,基于空间数据而递增构建的R-Tree可能没有很高的**叶节点**(每个叶节点对应一个区域和一个磁盘页)的空间协调性(spatial coherence)。例如,请参见不列颠哥伦比亚省道路索引的空间索引**叶节点**的可视化。
35 |
36 | 
37 |
38 | 我们更喜欢使用空间更均衡紧凑、排列合理的R-tree索引结构进行集群,比如这种平衡的R-Tree(balanced R-Tree)。
39 |
40 | 
41 |
42 | 我们在PostGIS中没有**平衡R-Tree的**算法,但我们有一个有用的代替方法,可以将空间数据进行空间自相关顺序排列,即**ST_GeoHash()**函数。
43 |
44 | # 二、GeoHash上的集群
45 |
46 | 要使用ST_GeoHash()函数进行集群,首先需要在数据上有一个**geohash索引**。幸运的是,它们很容易构建。
47 |
48 | geohash算法仅适用于地理(经度/纬度)坐标中的数据,因此我们需要在对其进行哈希操作之前先转换几何图形(转换为EPSG:4326,即经度/纬度)。
49 |
50 | ```sql
51 | CREATE INDEX nyc_census_blocks_geohash ON nyc_census_blocks (ST_GeoHash(ST_Transform(geom,4326)));
52 | ```
53 |
54 | 
55 |
56 | 一旦有了geohash索引,就可以使用和R-Tree集群相同的语法进行集群。
57 |
58 | ```sql
59 | CLUSTER nyc_census_blocks USING nyc_census_blocks_geohash;
60 | ```
61 |
62 | 
63 |
64 | 现在,数据就很好地以空间相关的顺序排列!
65 |
66 | # 三、函数列表
67 |
68 | 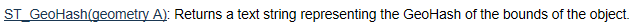
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/01.不睡觉的怪叔叔PostGIS教程/3.PostGIS教程:创建空间数据库.md:
--------------------------------------------------------------------------------
1 | # 一、PgAdmin
2 |
3 | PostgreSQL有许多管理工具,主要的一个是**psql**,一个输入SQL命令查询的命令行工具。
4 |
5 | 另一个流行的PostgreSQL工具是免费的开源图形工具**pgAdmin**,在pgAdmin中完成的所有查询都可以使用psql完成。
6 |
7 | ## **1.1、**找到pgAdmin并启动它
8 |
9 | 
10 |
11 | 
12 |
13 | ## 1.2、如果是第一次运行pgAdmin,应该有一个已在pgAdmin中配置的PostGIS服务器条目(localhost:5432)。双击该条目,并在密码框中输入密码,以连接到数据库。
14 |
15 | 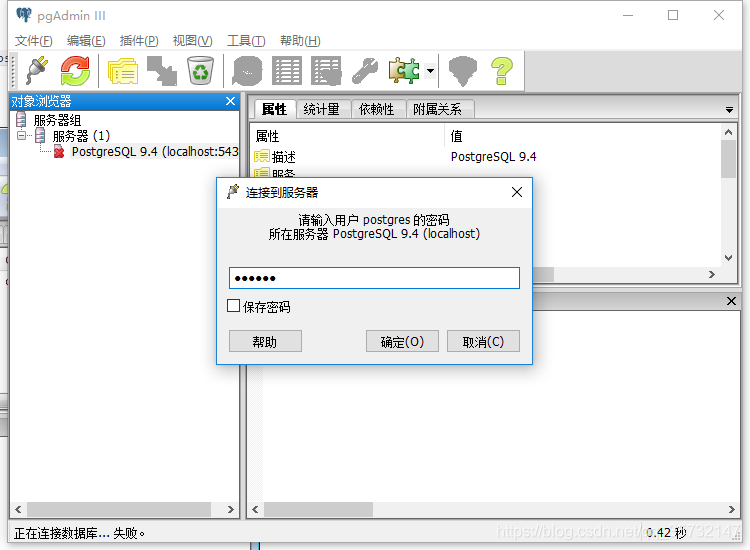
16 |
17 | # 二、创建一个数据库
18 |
19 | ## **2.1、**打开数据库的树结构选项,查看可用的数据库。postgres数据库是默认的postgres用户所属的用户数据库,我们不对该数据库感兴趣。
20 |
21 | 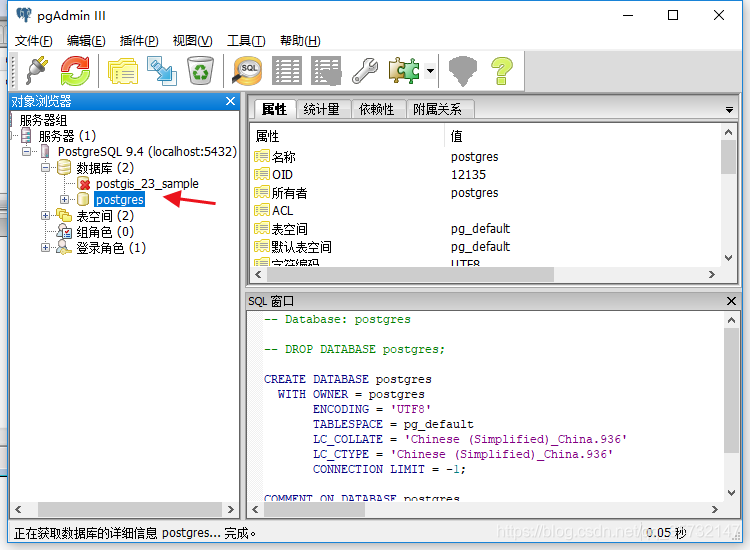
22 |
23 | ## **2.2、**鼠标右击数据库**选项并选择**新建数据库:
24 |
25 | 
26 |
27 | ## **2.3、**如下图所示,填写“**新建数据库**”表单,然后单击“**确定**”:
28 |
29 | 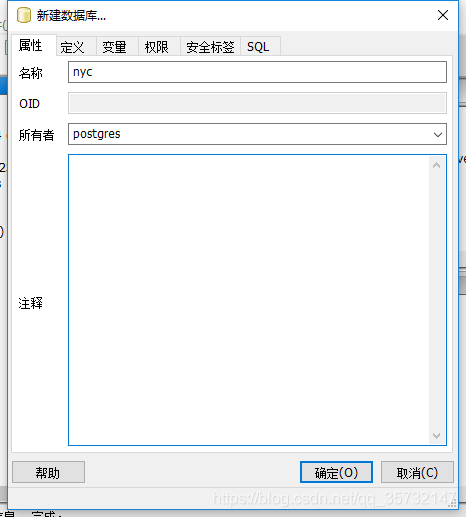
30 |
31 | ## 2.4、选择nyc这个新建的数据库,并打开它以显示对象树,将会看到public架构(schema):
32 |
33 | 
34 |
35 | ## **2.5、**单击下面所示的SQL查询按钮(或转到**工具** > **查询工具**)。
36 |
37 | 
38 |
39 | ## **2.6、**在查询文本区域中输入以下查询语句以加载**PostGIS空间扩展**:
40 |
41 | ```sql
42 | CREATE EXTENSION postgis;
43 | ```
44 |
45 | 
46 |
47 | ## **2.7、**单击工具栏中的**执行查询**按钮(或按F5)以"执行查询"。
48 |
49 | 
50 |
51 | ## **2.8、**现在,通过运行PostGIS函数来确认是否安装了PostGIS:
52 |
53 | ```sql
54 | SELECT postgis_full_version();
55 | ```
56 |
57 | 
58 |
59 | 至此,已经成功地创建了PostGIS空间数据库!
60 |
61 | # 三、函数列表
62 |
63 | **PostGIS_Full_Version()** —— 返回完整的PostGIS版本信息和配置信息。
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/01.不睡觉的怪叔叔PostGIS教程/5.PostGIS教程:数据.md:
--------------------------------------------------------------------------------
1 | # PostGIS教程五:数据
2 |
3 | 教程的数据是有关**纽约市**的四个shapefile文件和一个包含社会人口经济数据的数据表。在前面一节我们已经将shapefile加载为PostGIS表,在后面我们将添加社会人口经济数据。
4 |
5 | 下面描述了每个数据集的记录数量和表属性。这些属性值和关系是我们以后分析的基础。
6 |
7 | 要在pgAdmin中浏览表的性质或属性,请在高亮显示的表上单击鼠标右键,然后选择**属性**(property)。
8 |
9 | # 一、nyc_census_blocks
10 |
11 | **人口普查块**(census block)是报告人口普查数据的最小地理单位。
12 |
13 | 所有更高级别的人口普查的地理单位(块组-block groups、区域-tracts、市区-metro areas、县-counties等)都可以通过对人口普查块的联合(Union)而建立起来。
14 |
15 | 我们已经附加了一些人口统计数据到我们的nyc_census_blocks表里。
16 |
17 | 记录的数目:36592
18 |
19 | 
20 |
21 | 
22 |
23 | 黑人人口占总人口的百分比
24 |
25 | **注意**:要制作这样的GIS数据,需要连接两部分信息:实际社会人口数据(text)和几何信息数据(spatial)。获取数据的方法很多,比如可以从美国人口普查局的[American FactFinder](http://factfinder.census.gov/)下载数据。
26 |
27 | # 二、nyc_neighborhoods
28 |
29 | 纽约有丰富的社区名称和社区范围变更的历史。社区是不遵循政府规定的界限的的社会地理结构。
30 |
31 | 例如,**布鲁克林区**(Brooklyn)的**卡罗尔花园**(Carroll Gardens)、**红钩区**(Red Hook)和**克布尔山**(Cobble Hill)曾被统称为“**南布鲁克林**(South Brooklyn)"。
32 |
33 | 而现在,以前被同时称为红钩的四个街区现在可以被分别称为**哥伦比亚高地**(Columbia Heights)、**西卡罗尔花园**(Carroll Gardens)或**红钩**(Red Hook)。
34 |
35 | 记录数目:129
36 |
37 | 
38 |
39 | 
40 |
41 | 纽约市的街区分布
42 |
43 | # 三、nyc_streets
44 |
45 | 街道线构成了这个城市的交通网络。为了区分主干道、高速公路和较小的街道,这些街道被标记为不同的类型(type)。适宜居住的地方可能位于住宅区街道附近,而不是在高速公路旁。
46 |
47 | 记录数量:19091
48 |
49 | 
50 |
51 | 
52 |
53 | 纽约市街道分布
54 |
55 | # 四、nyc_subway_stations
56 |
57 | 地铁站将人们居住的地铁世界与地下看不见的地铁网络连接起来。
58 |
59 | 作为公共交通系统的入口,车站位置决定了处于不同位置的市民使用地铁交通的难易程度。
60 |
61 | 记录数目:491
62 |
63 | 
64 |
65 | 
66 |
67 | 纽约市地铁站的位置分布
68 |
69 | # 五、nyc_census_sociodata
70 |
71 | 在普查过程中收集了大量的社会人口经济数据,但仅限于普查区域较大的地理层面。
72 |
73 | **人口普查块**(census blocks)组合在一起形成**人口普查区域**(census tracts)(和**块组**-block groups)。
74 |
75 | 我们收集了一些与**人口普查区域**对应的社会人口经济数据,来回答更多关于纽约市的有趣问题。
76 |
77 | 注意:nyc_census_sociodata是一个**数据表**。在进行任何空间分析之前,我们需要将其与人口普查的地理信息联系起来。
78 |
79 | 
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/01.不睡觉的怪叔叔PostGIS教程/PostGIS官方教程汇总目录.md:
--------------------------------------------------------------------------------
1 | # PostGIS官方教程汇总目录
2 |
3 | 一、[PostGIS介绍](https://blog.csdn.net/qq_35732147/article/details/85158177)
4 |
5 | 二、[PostGIS安装](https://blog.csdn.net/qq_35732147/article/details/86299060)
6 |
7 | 三、[创建空间数据库](https://blog.csdn.net/qq_35732147/article/details/85226864)
8 |
9 | 四、[加载空间数据](https://blog.csdn.net/qq_35732147/article/details/85228444)
10 |
11 | 五、[数据](https://blog.csdn.net/qq_35732147/article/details/85242296)
12 |
13 | 六、[简单的SQL语句](https://blog.csdn.net/qq_35732147/article/details/85243978)
14 |
15 | 七、[几何图形(Geometry)](https://blog.csdn.net/qq_35732147/article/details/85258273)
16 |
17 | 八、[关于几何图形的练习](https://blog.csdn.net/qq_35732147/article/details/85338695)
18 |
19 | 九、[空间关系](https://blog.csdn.net/qq_35732147/article/details/85615057)
20 |
21 | 十、[空间连接](https://blog.csdn.net/qq_35732147/article/details/85676670)
22 |
23 | 十一、[空间索引](https://blog.csdn.net/qq_35732147/article/details/86212840)
24 |
25 | 十二、[投影数据](https://blog.csdn.net/qq_35732147/article/details/86301242)
26 |
27 | 十三:[地理](https://blog.csdn.net/qq_35732147/article/details/86489918)
28 |
29 | 十四:[几何图形创建函数](https://blog.csdn.net/qq_35732147/article/details/86576507)
30 |
31 | 十五:[更多的空间连接](https://blog.csdn.net/qq_35732147/article/details/86606486)
32 |
33 | 十六:[有效性](https://blog.csdn.net/qq_35732147/article/details/86620358)
34 |
35 | 十七:[相等](https://blog.csdn.net/qq_35732147/article/details/87343551)
36 |
37 | 十八:[线性参考](https://blog.csdn.net/qq_35732147/article/details/87450027)
38 |
39 | 十九:[维数扩展的9交集模型](https://blog.csdn.net/qq_35732147/article/details/87709276)
40 |
41 | 二十:[索引集群](https://blog.csdn.net/qq_35732147/article/details/88048758)
42 |
43 | 二十一:[3-D](https://blog.csdn.net/qq_35732147/article/details/88099418)
44 |
45 | 二十二:[最近邻域搜索](https://blog.csdn.net/qq_35732147/article/details/88219928)
46 |
47 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/03.PostGIS参考笔记/GIS术语 - POI、AOI、LOI、路径、轨迹.md:
--------------------------------------------------------------------------------
1 | # GIS术语 - POI、AOI、LOI、路径、轨迹
2 |
3 | **作者**
4 |
5 | digoal
6 |
7 | **日期**
8 |
9 | 2017-12-04
10 |
11 | **标签**
12 |
13 | PostgreSQL , PostGIS , 空间数据库 , POI , AOI , LOI , 轨迹 , 路径 , pgrouting , ltree , geojson , geoarray , 全文检索
14 |
15 | # 背景
16 |
17 | # 一、poi
18 |
19 | Point of interesting. 可以翻译为兴趣点,就是在地图上任何非地理意义的有意义的点:比如商店,酒吧,加油站,医院,车站等。不属于poi的是有地理意义的坐标:城市,河流,山峰
20 |
21 | 兴趣点(POI,Point of interest),兴趣点是我们就是导航软件商收录的信息点,比如说XX大厦,XX餐厅等特定的为位置,通过POI我们可以直接在导航软件上查找相应的目的地。
22 |
23 | 在导航软件上如果收录的POI不完整、不准确或者说未收录,那么我们就会发现我们很难开始导航,因为我们无法在导航软件上找到我们想要去的地方。所以说POI是我们在操作导航仪时首先会遇到的数据库,就好比在字典中查找一个我们未知的词语一样,对于能否得到答案起着至关重要的作用。
24 |
25 | 在实际应用的过程中,我们一般是直接输入一个地名,然后进行查找,在得到了目的地的具体位置的时候,用导航仪对我们的行车方向进行指引,然后完成导航的全部过程。
26 |
27 | # 二、aoi
28 |
29 | area of interest (AOI)
30 |
31 | the geographic bounds of the map sheet
32 |
33 | 可以理解为AOI个多边形。
34 |
35 | # 三、loi
36 |
37 | location of interest (LOI)
38 |
39 | 兴趣位置(LOI)。LOI可以是多边形、点或多点要素、或者是多个多边形。
40 |
41 | # 四、路径
42 |
43 | 这个很好理解,指规划好的有先后顺序的路径。常见于导航。
44 |
45 | # 五、轨迹
46 |
47 | 实际走过的路径。由多个有时序的点组成。
48 |
49 | # 六、对应PostgreSQL中的空间特性
50 |
51 | 1、POI,指中文描述+经纬度。正反都可以查询。使用空间数据库PostGIS存储经纬度,使用全文检索、模糊查询、拼音检索、首字母检索等 PostgreSQL 技术,搜索中文描述。
52 |
53 | [《HTAP数据库 PostgreSQL 场景与性能测试之 6 - (OLTP) 空间应用 - KNN查询(搜索附近对象,由近到远排序输出)》](https://github.com/digoal/blog/blob/master/201711/20171107_07.md)
54 |
55 | [《HTAP数据库 PostgreSQL 场景与性能测试之 5 - (OLTP) 空间应用 - 空间包含查询》](https://github.com/digoal/blog/blob/master/201711/20171107_06.md)
56 |
57 | [《在PostgreSQL中实现按拼音、汉字、拼音首字母搜索的例子》](https://github.com/digoal/blog/blob/master/201611/20161109_01.md)
58 |
59 | [《HTAP数据库 PostgreSQL 场景与性能测试之 14 - (OLTP) 字符串搜索 - 全文检索》](https://github.com/digoal/blog/blob/master/201711/20171107_15.md)
60 |
61 | [《HTAP数据库 PostgreSQL 场景与性能测试之 7 - (OLTP) 全文检索 - 含索引实时写入》](https://github.com/digoal/blog/blob/master/201711/20171107_08.md)
62 |
63 | [《多国语言字符串的加密、全文检索、模糊查询的支持》](https://github.com/digoal/blog/blob/master/201710/20171020_01.md)
64 |
65 | [《PostgreSQL 模糊查询最佳实践》](https://github.com/digoal/blog/blob/master/201704/20170426_01.md)
66 |
67 | [《PostgreSQL 全表 全字段 模糊查询的毫秒级高效实现 - 搜索引擎颤抖了》](https://github.com/digoal/blog/blob/master/201701/20170106_04.md)
68 |
69 | [《从难缠的模糊查询聊开 - PostgreSQL独门绝招之一 GIN , GiST , SP-GiST , RUM 索引原理与技术背景》](https://github.com/digoal/blog/blob/master/201612/20161231_01.md)
70 |
71 | 2、AOI
72 |
73 | PostGIS中的geometry类型,可以存储2d, 3d, 4d点、线、线段、面、集合。
74 |
75 | http://postgis.net/docs/manual-2.4/reference.html
76 |
77 | 3、LOI
78 |
79 | PostGIS中的geometry类型,可以存储2d, 3d, 4d点、线、线段、面、集合。
80 |
81 | http://postgis.net/docs/manual-2.4/reference.html
82 |
83 | 4、路径,可以使用pgrouting生成,根据内置的图搜索算法。
84 |
85 | http://pgrouting.org/
86 |
87 | 5、轨迹,指实际运行生成的轨迹,可以存储为多条记录,也可以存储为一个 线段、GEO 数组、GEO JSON、HSTORE(K-V)、文本等。
88 |
89 | http://postgis.net/docs/manual-2.4/ST_LinestringFromWKB.html
90 |
91 | # 参考
92 |
93 | http://gps.zol.com.cn/243/2436644.html
94 |
95 | https://en.wikipedia.org/wiki/Point_of_interest
96 |
97 | https://pro.arcgis.com/en/pro-app/help/workflow-manager/specifying-an-area-of-interest-aoi.htm
98 |
99 | http://webhelp.esri.com/arcgisdesktop/9.3/index.cfm?TopicName=The_Area_of_Interest_(AOI)_tool
100 |
101 | http://zhihu.esrichina.com.cn/article/562
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/03.PostGIS参考笔记/PostGIS空间数据类型的组织与表达(geography数据类型).md:
--------------------------------------------------------------------------------
1 | # PostGIS空间数据类型的组织与表达(geography数据类型)
2 |
3 | 作者:不睡觉的怪叔叔
4 |
5 | 地址:https://zhuanlan.zhihu.com/p/105909086
6 |
7 |
8 |
9 | 在PostGIS中还有另一种数据类型**Geography**,它们的最大不同之处是对空间数据的计算方式不同。
10 |
11 | 例如,计算两个坐标点的距离,Geometry数据类型的数据是基于平面坐标来计算的,也就是将两个坐标点看作是处于同一个平面,计算它们之间的平面距离。而Geography数据类型的数据是基于球面坐标来计算的,也就是将两个坐标点看作地球参考椭球体上的两个坐标点,计算它们之间的[大圆航线](https://link.zhihu.com/?target=https%3A//baike.baidu.com/item/%E5%A4%A7%E5%9C%86%E8%88%AA%E7%BA%BF/8760252%3Ffr%3Daladdin)的距离。
12 |
13 | 我们都知道,在球面上的计算比在平面上的计算更复杂,代价更高,所以Geography数据类型支持的空间函数比Geometry数据类型支持的空间函数少。不过,Geography数据类型与Geometry数据类型可以相互转换。
14 |
15 | 另外,Geography数据类型早期只支持WGS84地理坐标系,但是现在Geography数据类型可以支持**spatial_ref_sys**表中定义的所有地理坐标系(注意!是所有地理坐标系,而不是投影坐标系,因为它是基于地球参考椭球体的)。
16 |
17 | # 一、Geography基础
18 |
19 | Geography数据类型除了不支持CURE、TIN、POLYHEDRALSURFACE类型,它支持所有Geometry中的类型:
20 |
21 | - POINT
22 | - LINESTRING
23 | - POLYGON
24 | - MULTIPOINT
25 | - MULTILINESTRING
26 | - MULTIPOLYGON
27 | - GEOMETRYCOLLECTION
28 | - 还有其他的多维数据类型。。。
29 |
30 | 可以采用以下语法创建一张基于Geography数据类型的POINT(点类型)的表:
31 |
32 | ```sql
33 | CREATE TABLE global_points (
34 | id SERIAL PRIMARY KEY,
35 | name VARCHAR(64),
36 | geog GEOGRAPHY(POINT,4326)
37 | );
38 | ```
39 |
40 | 然后就可以往该表插入数据:
41 |
42 | ```sql
43 | INSERT INTO global_points (name, geog) VALUES ('Town', 'SRID=4326;POINT(-110 30)');
44 | INSERT INTO global_points (name, geog) VALUES ('Forest', 'SRID=4326;POINT(-109 29)');
45 | INSERT INTO global_points (name, geog) VALUES ('London', 'SRID=4326;POINT(0 49)');
46 | ```
47 |
48 | 还可以对geog列建立空间索引:
49 |
50 | ```sql
51 | CREATE INDEX global_points_gix ON global_points USING GIST ( geog );
52 | ```
53 |
54 | 虽然语法和geometry类型建立索引一样,但是geometry类型建立的是基于平面索引,而这里建立的是基于球面的索引。
55 |
56 | # 二、Geometry与Geography的比较
57 |
58 | 可以通过以下链接查看Geometry与Geography的详细比较:
59 |
60 | [Geometry与Geography的详细比较](http://postgis.net/docs/manual-3.0/PostGIS_Special_Functions_Index.html#PostGIS_TypeFunctionMatrix)
61 |
62 | # 三、Geography支持的空间函数
63 |
64 | 可以查看通过以下链接查看Geography支持的空间函数:
65 |
66 | [Geography支持的空间函数](http://postgis.net/docs/manual-3.0/PostGIS_Special_Functions_Index.html#PostGIS_GeographyFunctions)
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/03.PostGIS参考笔记/PostGIS管网连通性分析.md:
--------------------------------------------------------------------------------
1 | - [PostGIS管网连通性分析 ](https://juejin.cn/post/6955670546038128677)
2 |
3 |
4 |
5 | GIS在管网数据中的很重要的一个应用方向就是”管网空间分析“,其中包括连通性分析、上下游分析、爆管分析等等。下面是我使用`postgis`来实现该“管网连通性分析”的解决方案,分享给大家,以便相互学习。
6 |
7 | 使用该分析之前确保已添加扩展`postgis`、`pgrouting`
8 |
9 | ```sql
10 | CREATE EXTENSION postgis;
11 | CREATE EXTENSION pgrouting;
12 | ```
13 |
14 | # 导入数据
15 |
16 | 将数据导入到`postgreSQL`数据库,我是从`ArcGIS`直接导入的,导入方式参考[blog.csdn.net/eternity_xy…](https://link.juejin.cn?target=https%3A%2F%2Fblog.csdn.net%2Feternity_xyf%2Farticle%2Fdetails%2F80168029)
17 |
18 | # 创建拓扑
19 |
20 | 这里我用的管网数据表名为`pipe`
21 |
22 | 创建拓扑,生成`pipe_vertices_pgr`,该操作类似于`ArcGIS`中创建路网数据。
23 |
24 | 为`pipe`添加管段起始编号`pgr_source`、结束编号`pgr_target`、管段长度`pgr_length`三个字段,其中管段长度是用于分析的权重值。
25 |
26 | ```sql
27 | --添加起点id
28 | ALTER TABLE postgres.pipe ADD COLUMN IF NOT EXISTS pgr_source integer;
29 |
30 | --添加终点id
31 | ALTER TABLE postgres.pipe ADD COLUMN IF NOT EXISTS pgr_target integer;
32 |
33 | --添加权重值
34 | ALTER TABLE postgres.pipe ADD COLUMN IF NOT EXISTS pgr_length double precision;
35 | ```
36 |
37 | 为`pgr_source`、`pgr_target`创建索引
38 |
39 | ```sql
40 | --为pgr_source字段创建索引
41 | CREATE INDEX IF NOT EXISTS pgr_source_idx ON postgres.pipe("pgr_source")
42 |
43 | --为pgr_target字段创建索引
44 | CREATE INDEX IF NOT EXISTS pgr_target_idx ON postgres.pipe("pgr_target")
45 | ```
46 |
47 | 为权重字段`pgr_length`赋值
48 |
49 | ```sql
50 | --为pgr_length赋值,shape为几何类型的字段,可能为shape、the_geom,通过ArcGIS导入的时候字段为"shape",其他方式导入时一般为"the_geom"
51 | update postgres.pipe set pgr_length = public.st_length(shape)
52 | ```
53 |
54 | 调用`pgr_createTopology`方法,创建拓扑,这个步骤会为`pgr_source`和`pgr_target`字段赋值,同时生成节点表`pipe_vertices_pgr`
55 |
56 | ```sql
57 | --为目标表创建拓扑布局,即为pgr_source和pgr_target字段赋值
58 | select public.pgr_createTopology('postgres.pipe',0.000001,'shape','objectid','pgr_source','pgr_target')
59 | ```
60 |
61 | # 计算联通性
62 |
63 | 根据起点坐标、终点坐标从`pipe_vertices_pgr`查询最近的起点、终点标识
64 |
65 | 
66 |
67 | 调用`pgr_kdijkstraPath`函数,查询出起点、终点联通的线。
68 |
69 | 
70 |
71 | 通过这里我们可以看出,该分析的核心是调用了`pgrouting`扩展中的求最短路径的函数`pgr_kdijkstraPath`,该函数用的是是[Dijkstra](https://link.juejin.cn?target=https%3A%2F%2Fblog.csdn.net%2Flbperfect123%2Farticle%2Fdetails%2F84281300)算法,通过已添加的索引`pgr_source`和`pgr_target`以及权重值`pgr_length`,计算出两点之间的最短路径,如果有最短路径,证明两点联通。
72 |
73 | 该分析可用于计算给水管网、排水管网、输油管道等管网数据的两节点的连通性,当然也可用于路网的最短路径分析。
74 |
75 | # 函数脚本
76 |
77 | 上面为整体分析思路,现在将上述思路整理成函数,方便使用
78 |
79 | 1. 创建拓扑函数:[analysis_updatetopology()](https://link.juejin.cn?target=http%3A%2F%2Fgisarmory.xyz%2Fblog%2Findex.html%3Fsource%3DPostGISUpdateTopology)
80 | 2. 计算连通性函数:[analysis_connect()](https://link.juejin.cn?target=http%3A%2F%2Fgisarmory.xyz%2Fblog%2Findex.html%3Fsource%3DPostGISConnect)
81 |
82 | # 如何使用
83 |
84 | 1. 调用`analysis_updatetopology()`函数,完成拓扑创建
85 |
86 | ```sql
87 | -- 传入表名pipe,创建拓扑
88 | select * from analysis_updatetopology('pipe')
89 | ```
90 |
91 | 2. 从地图选择起点、终点,然后调用`analysis_connect()`函数,得到分析结果
92 |
93 | ```sql
94 | -- 传入表名、起点坐标、终点坐标、容差值
95 | select * from analysis_connect('pipe',103.90893393,30.789659886,103.911700936,30.787850094,0.00001)
96 | ```
97 |
98 | ------
99 |
100 | 原文地址:[gisarmory.xyz/blog/index.…](https://link.juejin.cn?target=http%3A%2F%2Fgisarmory.xyz%2Fblog%2Findex.html%3Fblog%3DPostGISConnect)
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/03.PostGIS参考笔记/PostGis基本操作-新建空间数据库与shp数据的导入.md:
--------------------------------------------------------------------------------
1 | - [PostGis基本操作-新建空间数据库与shp数据的导入_霸道流氓气质的博客-CSDN博客](https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/114790636)
2 |
3 | # 场景
4 |
5 | PostGresSQL简介与Windows上的安装教程:
6 |
7 | https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/113981563
8 |
9 | 在上面介绍了PostGreSql的安装,安装完成后可选择安装postgis扩展。
10 |
11 | 那么怎么使用PostGis新建空间数据库以及shp地图数据的导入。
12 |
13 | # 实现
14 |
15 | ## 空间数据库的创建
16 |
17 | 首先在电脑中打开pgAdmin,输入密码连接成功之后,点击数据库-新建-数据库
18 |
19 |
20 |
21 | 
22 |
23 | 这里取名叫demo,然后再demo数据库上右键-查询工具
24 |
25 |
26 |
27 | 
28 |
29 | 然后输入
30 |
31 | ```
32 | CREATE EXTENSION postgis;
33 | ```
34 |
35 | 并点击上面三角形的运行按钮
36 |
37 |
38 |
39 | 
40 |
41 | 然后在扩展里面就有postgis了,并且可以继续在查询工具中执行
42 |
43 | ```
44 | SELECT postgis_full_version();
45 | ```
46 |
47 | 验证是否安装成功
48 |
49 |
50 |
51 | 
52 |
53 | ## shp数据的导入
54 |
55 | 安装完postgresql以及postgis的扩展后,就可以在电脑中搜索
56 |
57 | PostGis Shapefile and DBF Loader Exporter工具来进行shp文件的导入
58 |
59 |
60 |
61 | 
62 |
63 | 注意:
64 |
65 | 首先你要有一个shp文件,这里提供一个中国省级行政区划_shp地图数据文件:
66 |
67 | https://download.csdn.net/download/BADAO_LIUMANG_QIZHI/15785012
68 |
69 | 将其下载之后,注意两点,一是shp文件名不能有中文,而是shp的路径中不能有中文。
70 |
71 | 打开工具后,点击View connection details
72 |
73 | 然后输入要连接的用户名和密码以及ip端口和数据库
74 |
75 |
76 |
77 | 
78 |
79 | 点击ok后会提示连接成功。
80 |
81 | 然后为了兼容不同版本的兼容问题,这里的Options下的Import Options中的编码修改为GBK
82 |
83 |
84 |
85 | 
86 |
87 | 然后点击import按钮,选择上面下载的或者要导入的shp文件的路径
88 |
89 | 
90 |
91 | 这里不能只有shp文件,还需要dbf文件,不然会导入失败
92 |
93 | 导入成功之后会有成功的提示
94 |
95 |
96 |
97 | 
98 |
99 | 查看数据是在架构下public下表下面就可以找到新导入的表,然后右键查看/编辑数据-前100行,就可以看到数据了。
100 |
101 | 
102 |
103 |
104 |
105 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/03.PostGIS参考笔记/PostgreSQL存储地理信息数据的注意点.md:
--------------------------------------------------------------------------------
1 | - [PostgreSQL存储地理信息数据的注意点](https://blog.csdn.net/qq_35241223/article/details/107734044)
2 |
3 |
4 |
5 | 矢量数据分为点、线、面三种,实际存储过程中还有多点、多线、多面,并且数据还要包含坐标系信息。PostgreSQL安装PostGIS扩展后可以存储以上信息。实际使用过程中对于geometry类型的字段会区分类型,具体是点,是线,还是面,以及还要区分是WGS84(4326)坐标系的,是CGCS2000(4490)坐标系,还是Web墨卡托(3857)坐标系。但实际情况下,某些时候在存储过程中发现没有限制了,以下介绍一下该情况。
6 |
7 | # 一、正常情况
8 |
9 | 正常情况下使用AddGeometryColumn方法创建字段时,会指定该字段的数据类型(点、线、面、多点……)以及该字段的坐标系,创建完成后插入其它类型数据时会报错,即不允许存储规定外的数据类型。该情况也是我们预期的,示例如下:
10 |
11 | 示例表名为test1,类型为点,坐标系为4326(WGS84坐标系)
12 |
13 | 查看字段类型与坐标系信息:
14 |
15 | 使用ST_GeometryType与ST_SRID查看行数据中类型与坐标系,但实际限制未在这
16 |
17 | 
18 |
19 | - 查看`geometry_columns`表中记录的信息,实际限制在此
20 |
21 | 
22 |
23 | 更新`test1`表的字段为线,实际情况插入不进去:
24 |
25 | - 坐标系为4326,但类型不符,插入失败
26 | 
27 |
28 | - 坐标系不符,插入失败
29 |
30 | 
31 |
32 | # 二、非正常情况
33 |
34 | 将`test1`表使用navicat复制数据复制一份,此时查看数据类型时会发现类型变为`GEOMETRY`,`srid`变为0,此时不再有限制,字段可以存储任何类型与任何坐标系的数据。
35 |
36 | 
37 | 查看类型:
38 |
39 | 
40 |
41 | 更新为线以及其他坐标系,不再有限制,结果如下:
42 |
43 | 更新id为2的数据,将点更新为线,同时坐标系设置为4490
44 |
45 | 
46 |
47 | # 三、建议
48 |
49 | 1. 新增字段时使用AddGeometryColumn,指定类型、坐标系等信息
50 | 2. 新增字段时使用Alter Table test add column aa geometry('point', 4326)要指定类型、坐标系等信息
51 | 3. 迁移数据后,记得要使用geometry_column查看类型与坐标系,防止信息丢失,不再有限制,导致一张表中存储不同类型的数据
52 |
53 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/03.PostGIS参考笔记/基于PG与PostGIS搭建实时矢量瓦片服务.md:
--------------------------------------------------------------------------------
1 | - [基于PG与PostGIS搭建实时矢量瓦片服务](https://blog.csdn.net/qq_35241223/article/details/106439268)
2 |
3 |
4 |
5 | # 一、矢量瓦片(MVT)
6 |
7 | 本文中提到的矢量瓦片为Mapbox Vector Tile格式,简称MVT。
8 |
9 | ## 1.1 MVT标准
10 |
11 | MVT标准参考Mapbox官方文档。
12 |
13 | [传送门链接](https://github.com/mapbox/vector-tile-spec)
14 |
15 | ## 1.2 矢量瓦片优势
16 |
17 | - 可以支持高分辨率屏幕的显示
18 | - 地图渲染在前端,可以支持一套数据随意更改配图方案,解决传统栅格瓦片动态样式上的问题
19 | - 要素查询可以在前端进行
20 | - 保持了矢量数据的优势,同时采用切片方式又提高了传输上的效率
21 |
22 | ## 1.3 实时矢量瓦片
23 |
24 | 顾明思议,矢量瓦片不在使用工具线下进行预先切片,采用即时浏览即时传输矢量瓦片。
25 |
26 |
27 |
28 | ### 1.3.1 为什么要有实时的矢量瓦片
29 |
30 | 采用实时切的矢量瓦片可以做到数据编辑功能。如果采用预先切片方式,那么在数据编辑后,浏览的数据还是旧的数据,做到实时的矢量瓦片后,编辑数据之后浏览到的矢量瓦片就是最新数据。这样就可以解决数据编辑后瓦片不是最新的问题。
31 |
32 |
33 |
34 | # 二、PostGIS中矢量切片相关函数
35 |
36 | 本文介绍使用PG+PostGIS来做到实时的矢量瓦片,在实战之前先介绍几个用到的矢量瓦片相关的函数。
37 |
38 | ## 2.1 主要函数:
39 |
40 | - ST_AsMvtGeom 将Geom转化为MVT的geom
41 | - ST_AsMVT 将geom转换为MVT数据
42 | - ST_TileEnvelope(3.0以上支持) 根据行列号获取Envelope
43 |
44 | ## 2.2 辅助函数:
45 |
46 | - ST_Transform 坐标转换函数,用它可以做到支持任何坐标系的矢量瓦片
47 | - ST_Simplify 简化,用它来做线或者面的简化
48 | - ST_SimplifyPreserveTopology 与简化类似
49 |
50 | # 三、实战
51 |
52 | 思路:
53 |
54 | - 前端地图库浏览时,将请求URL传到后台
55 | - 后端实现URL的服务,根据x、y、z获取对应范围数据,使用sql查询到数据返回给前端
56 |
57 | ## 3.1 只有点层的SQL语句
58 |
59 | 
60 |
61 | 
62 |
63 |
64 | ## 3.2 点、线、面层在一起的SQL
65 |
66 | 
67 |
68 | 
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/04.PostgreSQL与PostGIS基础/PostGIS基本使用.md:
--------------------------------------------------------------------------------
1 | - [PostGIS的基础入门](https://cloud.tencent.com/developer/article/1414516?from=article.detail.1722171)
2 |
3 | ## 一、PostGIS
4 |
5 | PostgreSQL数据库安装PostGIS扩展,数据库将可以进行空间数据管理、数量测量与几何拓扑分析。
6 |
7 | ### 1.1 在testdb数据库下安装PostGIS扩展
8 |
9 | 安装PostGIS扩展:
10 |
11 | ```plsql
12 | CREATE EXTENSION postgis;
13 | ```
14 |
15 | 验证PostGIS扩展是否安装成功:
16 |
17 | ```plsql
18 | SELECT postgis_full_version();
19 | ```
20 |
21 | 还可以安装其它的一些扩展:
22 |
23 | ```plsql
24 | -- Enable Topology
25 | CREATE EXTENSION postgis_topology;
26 | -- Enable PostGIS Advanced 3D-- and other geoprocessing algorithms
27 | -- sfcgal not available with all distributions
28 | CREATE EXTENSION postgis_sfcgal;
29 | -- fuzzy matching needed for Tiger
30 | CREATE EXTENSION fuzzystrmatch;
31 | -- rule based standardizer
32 | CREATE EXTENSION address_standardizer;
33 | -- example rule data set
34 | CREATE EXTENSION address_standardizer_data_us;
35 | -- Enable US Tiger Geocoder
36 | CREATE EXTENSION postgis_tiger_geocoder;
37 | ```
38 |
39 | 可使用`\dx`命令查看已安装的扩展。
40 |
41 | ### 1.2 创建空间数据表
42 |
43 | - 先建立一个常规的表存储
44 |
45 | ```plsql
46 | CREATE TABLE cities(id smallint,name varchar(50));
47 | ```
48 |
49 | - 添加一个空间列,用于存储城市的位置。 习惯上这个列叫做 “the_geom”。它记录了数据的类型(点、线、面)、有几维(这里是二维)以及空间坐标系统。这里使用 EPSG:4326 坐标系统: SELECT AddGeometryColumn ('cities', 'the_geom', 4326, 'POINT', 2);
50 |
51 | ### 1.3 插入数据到空间表
52 |
53 | 批量插入三条数据:
54 |
55 | ```plsql
56 | INSERT INTO cities(id, the_geom, name) VALUES (1,ST_GeomFromText('POINT(-0.1257 51.508)',4326),'London, England'), (2,ST_GeomFromText('POINT(-81.233 42.983)',4326),'London, Ontario'), (3,ST_GeomFromText('POINT(27.91162491 -33.01529)',4326),'East London,SA');
57 | ```
58 |
59 | ### 1.4 简单查询
60 |
61 | 标准的PostgreSQL语句都可以用于PostGIS,这里我们查询cities表数据:
62 |
63 | ```plsql
64 | SELECT * FROM cities;
65 | ```
66 |
67 | 这里的坐标是无法阅读的 16 进制格式。要以WKT文本显示,使用ST_AsText(the_geom)或ST_AsEwkt(the_geom)函数。也可以使用ST_X(the_geom)和ST_Y(the_geom)显示一个维度的坐标:
68 |
69 | ```plsql
70 | SELECT id, ST_AsText(the_geom), ST_AsEwkt(the_geom), ST_X(the_geom), ST_Y(the_geom) FROM cities;
71 | ```
72 |
73 | ### 1.5 空间查询
74 |
75 | 以米为单位并假设地球是完美椭球,上面三个城市相互的距离是多少?
76 |
77 | 执行以下代码计算距离:
78 |
79 | ```plsql
80 | SELECT p1.name,p2.name,ST_Distance_Sphere(p1.the_geom,p2.the_geom) FROM cities AS p1, cities AS p2 WHERE p1.id > p2.id;
81 | ```
82 |
83 | ## 二、总结
84 |
85 | 关于PostgreSQL的一些官方学习资料如下,请参考:
86 |
87 | - https://www.postgresql.org/files/documentation/pdf/9.6/postgresql-9.6-A4.pdf
88 | - https://wiki.postgresql.org/wiki/9.1%E7%AC%AC%E4%BA%8C%E7%AB%A0
89 | - https://wiki.postgresql.org/wiki/Main_Page
90 | - 易百教程:https://www.yiibai.com/postgresql/postgresql-datatypes.html
91 | - 中文手册:http://www.postgres.cn/docs/9.6/index.html
92 | - Postgres中文社区:http://www.postgres.cn/v2/home
93 |
94 | 关于PostGIS的官方学习资料如下,请参考:
95 |
96 | - 英文官方资料:http://www.postgis.net/stuff/postgis-2.4.pdf
97 | - 中文社区资料:http://www.postgres.cn/docs/PostGis-2.2.0dev_Manual.pdf
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/04.PostgreSQL与PostGIS基础/PostGIS导入shp文件.md:
--------------------------------------------------------------------------------
1 | - [Geoserver+Postgresql+PostGIS 进行数据发布](https://www.cnblogs.com/CityLcf/p/10054927.html)
2 |
3 |
4 |
5 | # 一、数据库创建
6 |
7 | ## 1.1 进行数据库创建 暂时命名为test
8 |
9 | 
10 |
11 | 
12 |
13 | 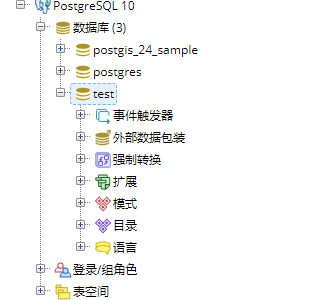
14 |
15 | ## 1.2 进行postgis插件添加
16 |
17 | 
18 |
19 | 
20 |
21 | 
22 |
23 | ## 1.3 进行空间数据导入
24 |
25 | 我们用postgis插件中的功能来进行数据导入
26 |
27 | 
28 |
29 |
30 |
31 | 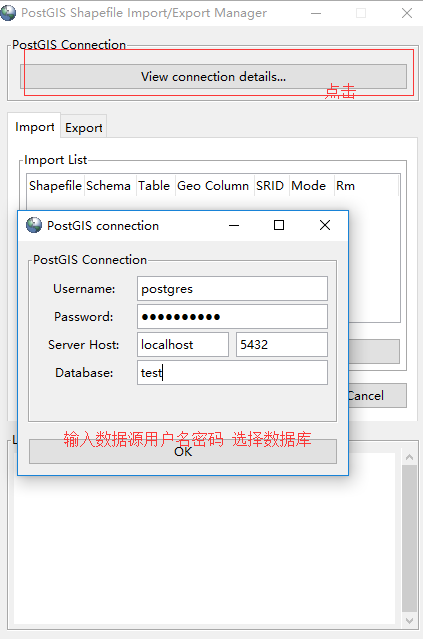
32 |
33 | 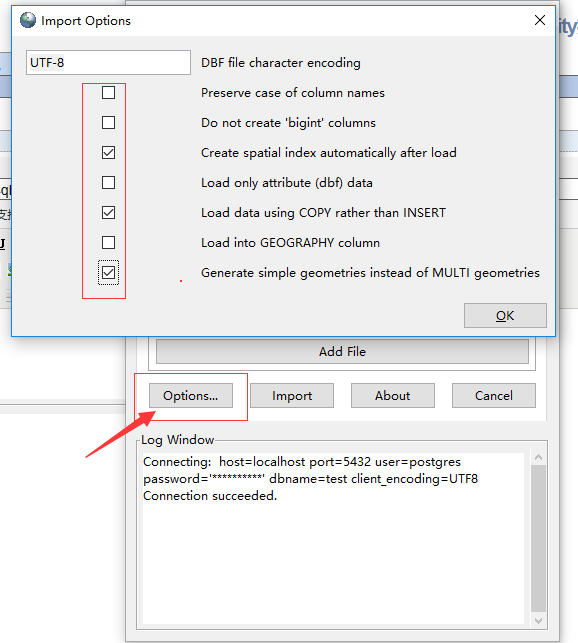
34 |
35 | 
36 |
37 | 文件选择完,修改SRID(坐标系)4326是经纬度的WGS-84坐标系,也可以选择墨卡托坐标系(3857)
38 |
39 | 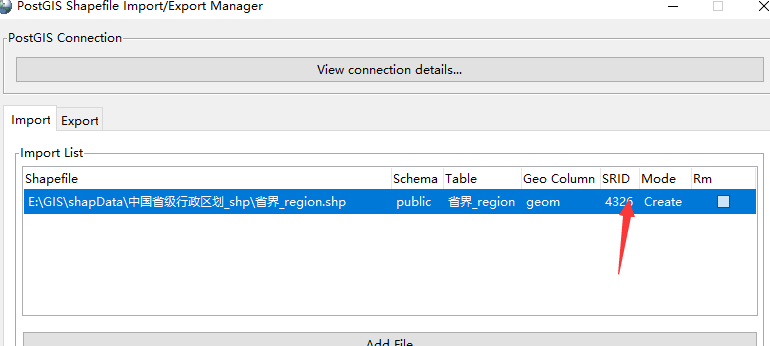
40 |
41 | 突然发现报错了 报错如下
42 |
43 | 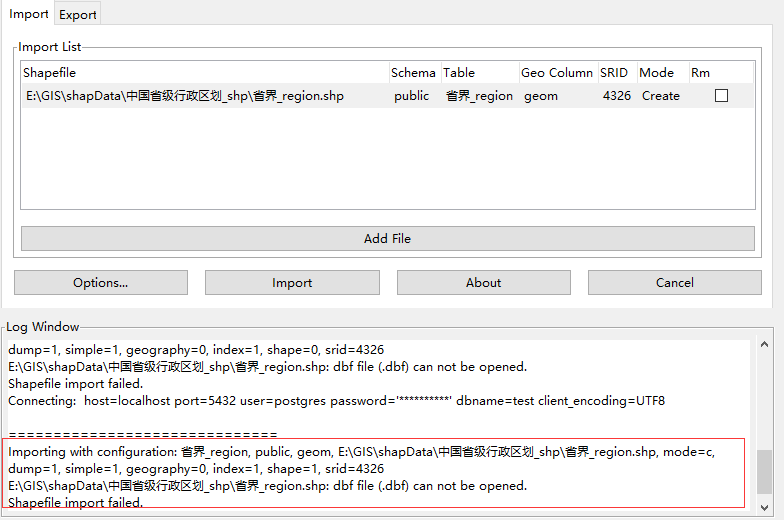
44 |
45 | 经查询是由于路径中有中文导致的
46 |
47 | 
48 |
49 | 路径替换后导入成功,这个时候在pgadmin下能看见当导入的数据,如下图所示
50 |
51 | 
52 |
53 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/04.PostgreSQL与PostGIS基础/PostgreSQL与PostGIS的基础入门.md:
--------------------------------------------------------------------------------
1 | # PostgreSQL与PostGIS的基础入门
2 |
3 | 原文地址:https://cloud.tencent.com/developer/article/1414516?from=article.detail.1379951
4 |
5 | 关于PostgreSQL的一些官方学习资料如下,请参考:
6 |
7 | - https://www.postgresql.org/files/documentation/pdf/9.6/postgresql-9.6-A4.pdf
8 | - https://wiki.postgresql.org/wiki/9.1%E7%AC%AC%E4%BA%8C%E7%AB%A0
9 | - https://wiki.postgresql.org/wiki/Main_Page
10 | - 易百教程:https://www.yiibai.com/postgresql/postgresql-datatypes.html
11 | - 中文手册:http://www.postgres.cn/docs/9.6/index.html
12 | - Postgres中文社区:http://www.postgres.cn/v2/home
13 |
14 | 关于PostGIS的官方学习资料如下,请参考:
15 |
16 | - 英文官方资料:http://www.postgis.net/stuff/postgis-2.4.pdf
17 | - 中文社区资料:http://www.postgres.cn/docs/PostGis-2.2.0dev_Manual.pdf
18 |
19 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/04.PostgreSQL与PostGIS基础/PostgreSql对空间数据的操作函数.md:
--------------------------------------------------------------------------------
1 | ## 一、PostgreSql对空间数据的操作函数
2 |
3 | - [PostgreSql对空间数据的操作函数](https://blog.csdn.net/fengyao1995/article/details/53730417)
4 |
5 | ### 1.1 空间数据
6 |
7 | 介绍这些函数之前,先了解一下什么是空间数据。空间数据是指用来表示空间实体的位置、形状、大小及其分布特征诸多方面信息的数据,它可以用来描述来自现实世界的目标,它具有定位、定性、时间和空间关系等特性。空间数据是一种用点、线、面以及实体等基本空间数据结构来表示人们赖以生存的自然世界的数据。简单来说,操作空间数据主要是对点、线、面等基本结构的操作。
8 |
9 | 地图上的图层有面图层、点图层和线图层之分,就拿一个城市的地图来说,该城市的公园图层就相当于面图层,因为可能需要表示公园有多大;一个城市医院或者银行的分布可以看做是点图层;城市的道路交通可以认为是线图层。
10 |
11 | 这些空间数据可以在数据库中存储,存储时可以是geometry格式;也可以以文件的形式存储,存储成shape文件。在数据库中存储时,geometry是以十六进制串组成的,表示的是几何形状。shape文件存储时,对应点线面分别由三种类型,point、line、polygon,这是单一的类型,对应联合的类型又有multipoint、multiline、multipolygon,所以说,shape文件存储的是wkt类型的数据。本篇博客暂且把空间数据分为这两种类型:geometry和wkt。
12 |
13 | ### 1.2 函数操作
14 |
15 | 在系统中我们用的地图插件是Openlayer,它对地图的操作是操作wkt数据,所以就涉及到geometry和wkt的转换。
16 |
17 | st_geomfromtext(wkt,坐标系参数):该方法是把wkt格式数据转换成geometry类型,参数有两个,第一个是wkt类型的数据,第二个是坐标系参数。
18 |
19 | st_astext(geometry):该方法是把geometry类型数据转换成wkt格式数据,参数只有一个,是geometry类型的数据。
20 |
21 | 图层是由各个图斑构成的,如果要在地图上定位某个图斑,就需要获取这个图斑的中心点坐标。
22 |
23 | st_centroid(geometry):这个方法是获取这个geometry的中心点,参数是要获取中心点的geometry。
24 |
25 | st_x(point):该方法是获取点的x坐标,它操作的对象是一个点。
26 |
27 | st_y(point):该方法是获取点的y坐标,它操作的对象也是一个点。
28 |
29 | 有时我们需要实现两个图斑相交,也可以用函数执行。
30 |
31 | st_intersects(geometry,geometry):该方法是实现两个图斑相交,传入的参数是两个图斑的geometry。
32 |
33 | 跟这个方法类似的还有好多函数,比如判断两个图斑是否相交,返回一个布尔值;或者获取两个图斑相交的geometry和不相交的geometry。
34 |
35 | 如果要使图斑联合,则需要union函数。
36 |
37 | st_union(geometry):如果一个图层表中存储好多图斑,其中有一列名为geom,存储的是各个图斑的geometry,那么st_union(geom)就是将该图层的所有图斑联合成一个,得到的结果就是multi类型的数据。
38 |
39 | 如果要查看某个图斑方圆多少米之内的情况,就要对该图斑进行缓冲。
40 |
41 | st_buffer(geometry,长度):该方法是对某个图斑进行缓冲,传入要缓冲的geometry,在传入缓冲的距离即可。
42 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/10.PostGIS操作/PostGIS 测试 - 线(LINESTRING).md:
--------------------------------------------------------------------------------
1 | - [PostGIS 测试 - 线(LINESTRING)_万里归来少年心的博客-CSDN博客_postgis 线](https://blog.csdn.net/liyazhen2011/article/details/88995716)
2 |
3 | ### 1.建表
4 |
5 | ```sql
6 | CREATE TABLE linetable (
7 | id SERIAL PRIMARY KEY,
8 | name VARCHAR(128),
9 | geom GEOMETRY(LINESTRING, 26910)
10 | );
11 | ```
12 |
13 | ### 2.添加GIST索引
14 |
15 | ```sql
16 | CREATE INDEX linetable_gix ON linetable USING GIST (geom);
17 | ```
18 |
19 | ### 3.插入数据
20 |
21 | ```sql
22 | INSERT INTO linetable (name, geom) VALUES ('L1',
23 | ST_GeomFromText('LINESTRING(0 0,1 1,1 2)', 26910)
24 | );
25 |
26 | INSERT INTO linetable (name, geom) VALUES ('L2',
27 | ST_GeomFromText('LINESTRING(1 0,2 1,2 2)', 26910)
28 | );
29 | ```
30 |
31 | ### 4.QGIS中显示几何数据
32 |
33 | 
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/10.PostGIS操作/PostGIS测试 - geometry_columns.md:
--------------------------------------------------------------------------------
1 | - [PostGIS测试 - geometry_columns_万里归来少年心的博客-CSDN博客_geometry_columns](https://blog.csdn.net/liyazhen2011/article/details/89101902)
2 |
3 | 创建空间数据库后,会默认生成数据表geometry_columns表,它存放了当前数据库中所有表的几何字段信息。用工具pgAdmin查看该表。
4 |
5 | 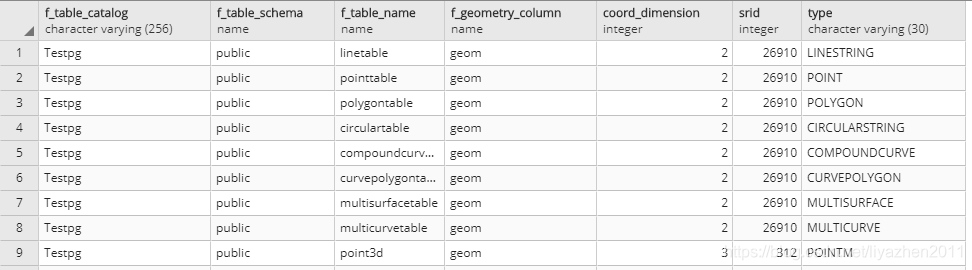
6 |
7 | 该表各列的含义如下:
8 |
9 | - f_table_catalog表示数据库名。
10 | - f_table_schema表示空间表所在的模式。
11 | - f_table_name表示空间表的表名。
12 | - f_geometry_column表示空间表中几何字段的名称。
13 | - coord_dimension表示几何字段维数。
14 | - srid表示空间表的空间参考。
15 | - type表示几何字段的类型。
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/10.PostGIS操作/postgresql 计算两点距离的2种方法小结.md:
--------------------------------------------------------------------------------
1 | # 1 PostGIS 如何计算两个经纬度之间的距离
2 |
3 | ```sql
4 | SELECT ST_Distance(ST_GeomFromText('POINT(120.30 30.06)')::geography, ST_GeomFromText('POINT(120.36 30.16)')::geography));
5 | ```
6 |
7 | 注意:如果POINT是3857坐标系的,就需要转一下,转成4326坐标系的再进行计算,如下所示
8 |
9 | ```sql
10 | SELECT ST_Distance(ST_GeomFromText('POINT(lon1 lat1)', 4326)::geography, ST_GeomFromText('POINT(lon2 lat2)', 4326)::geography);
11 | ```
12 |
13 | # 2 算两点距离的2种方法小结
14 |
15 | postgresql计算两点距离
16 |
17 | ### 2.1 下面两种方法:
18 |
19 | ```plsql
20 | select
21 | ST_Distance(
22 | ST_SetSRID(ST_MakePoint(115.97166453999147,28.716493914230423),4326)::geography,
23 | ST_SetSRID(ST_MakePoint(106.00231199774656,29.719258550486572),4326)::geography
24 | ),
25 | ST_Length(
26 | ST_MakeLine(
27 | ST_MakePoint(115.97166453999147,28.716493914230423),
28 | ST_MakePoint(106.00231199774656,29.719258550486572)
29 | )::geography
30 | )
31 | ```
32 |
33 | 备注:
34 |
35 | ```plsql
36 | create or replace function getdistance
37 | (
38 | lon1 numeric,
39 | lat1 numeric,
40 | lon2 numeric,
41 | lat2 numeric
42 | )
43 | returns int
44 | as
45 | $body$
46 | declare
47 | v_distance numeric;
48 | v_earth_radius numeric;
49 | radLat1 numeric;
50 | radLat2 numeric;
51 | v_radlatdiff numeric;
52 | v_radlngdiff numeric;
53 | begin
54 | --地球半径
55 | v_earth_radius:=6378137;
56 |
57 | radLat1 := lat1 * pi()/180.0;
58 | radLat2 := lat2 * pi()/180.0;
59 | v_radlatdiff := radLat1 - radLat2;
60 | v_radlngdiff := lon1 * pi()/180.0 - lon2 * pi()/180.0;
61 | v_distance := 2 * asin(sqrt(power(sin(v_radlatdiff / 2), 2) + cos(radLat1) * cos(radLat2) * power(sin(v_radlngdiff/2),2)));
62 | v_distance := round(v_distance * v_earth_radius);
63 | return v_distance;
64 | end;
65 | $body$
66 | language 'plpgsql' volatile;
67 | ```
68 |
69 | **补充:postgresql计算两点欧式距离(经纬度地理位置)**
70 |
71 | 我就废话不多说了,大家还是直接看代码吧~
72 |
73 | ```plsql
74 | create or replace function getdistance
75 | (
76 | i_lngbegin real,
77 | i_latbegin real,
78 | i_lngend real,
79 | i_latend real
80 | )
81 | returns float
82 | as
83 | $body$
84 | /*
85 | *
86 | * select getdistance_bygispoint(116.281524,39.957202,117.648673,38.42584) as distance;
87 | * */
88 | declare
89 | v_distance real;
90 | v_earth_radius real;
91 | v_radlatbegin real;
92 | v_radlatend real;
93 | v_radlatdiff real;
94 | v_radlngdiff real;
95 | begin
96 | --地球半径
97 | v_earth_radius:=6378.137;
98 |
99 | v_radlatbegin := i_latbegin * pi()/180.0;
100 | v_radlatend := i_latend * pi()/180.0;
101 | v_radlatdiff := v_radlatbegin - v_radlatend;
102 | v_radlngdiff := i_lngbegin * pi()/180.0 - i_lngend * pi()/180.0;
103 | v_distance := 2 * asin(sqrt(power(sin(v_radlatdiff / 2), 2) + cos(v_radlatbegin) * cos(v_radlatend) * power(sin(v_radlngdiff/2),2)));
104 | v_distance := v_distance * v_earth_radius*1000;
105 | return v_distance;
106 | end;
107 | $body$
108 | language 'plpgsql' volatile;
109 | ```
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/10.PostGIS操作/postgresql更改geometry类型列的srid.md:
--------------------------------------------------------------------------------
1 | - [postgresql更改geometry类型列的srid_lwdbcy的博客-CSDN博客](https://blog.csdn.net/lwd18175239125/article/details/126283586)
2 |
3 | ## 1 问题描述
4 |
5 | 有一张表包含空间信息列`geom` ,它是地理坐标系(`WGS84` ),srid为4326,现在我不小心向其中插入了一批投影坐标系(CGCS2000)的数据,我要如何修正呢?
6 |
7 | ## 2 主要使用函数
8 |
9 | ### 2.1 ST_SetSRID(geom,srid)
10 |
11 | > 该函数返回一个与输入几何体相同的几何体,只不过使用空间参考系统标识符 (SRID) 的输入值进行了更新。
12 |
13 | 就是说对几何体**geom** 设置了空间参考
14 |
15 | ### 2.2 ST_Transform(geom, srid)
16 |
17 | > ST_Transform 返回一个新的几何体,坐标在由输入空间参考系统标识符(SRID)定义的空间参考系统中转换。
18 |
19 | 看名字就知道是转换,将**geom**转换成指定空间参考下的几何体
20 |
21 | ## 3 解决步骤
22 |
23 | 解决这个问题关键就是知道上面的两个函数,其他挺简单的
24 |
25 | 1. 查询`CGCS2000 / 3-degree Gauss-Kruger CM 120E` 的EPSG代码为**4549**
26 | 2. 更新数据
27 |
28 | ```sql
29 | UPDATE table_name SET geom=ST_TRANSFORM(ST_SETSRID(geom, 4549), 4326)
30 | WHERE xxxxx
31 | ```
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/10.PostGIS操作/三维坐标转换为二维坐标.md:
--------------------------------------------------------------------------------
1 | ```sql
2 | ALTER TABLE "Road"
3 | ALTER COLUMN geom TYPE geometry(multilinestring)
4 | USING st_force2d(geom)
5 | ```
6 |
7 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/11.PostGIS函数说明/DropGeometryColumn.md:
--------------------------------------------------------------------------------
1 | # DropGeometryColumn
2 |
3 | ```plsql
4 | boolean DropGeometryTable(varchar table_name);
5 |
6 | boolean DropGeometryTable(varchar schema_name, varchar table_name);
7 |
8 | boolean DropGeometryTable(varchar catalog_name, varchar schema_name, varchar table_name);
9 | ```
10 |
11 | ## 描述
12 |
13 | 删除一个表及其在geometry_columns中的所有引用。
14 |
15 | **注意:**如果没有提供模式,则在支持模式的pgsql安装上使用current_schema()。
16 |
17 |
18 |
19 | **更改:**2.0.0提供此函数是为了向后兼容。既然geometry_columns现在是针对系统编目的视图,那么您可以像使用drop table一样删除具有几何列的表。
20 |
21 | ## 示例
22 |
23 | ```plsql
24 | SELECT DropGeometryTable ('my_schema','my_spatial_table');
25 | ----RESULT output ---
26 | my_schema.my_spatial_table dropped.
27 |
28 | -- The above is now equivalent to --
29 | DROP TABLE my_schema.my_spatial_table;
30 | ```
31 |
32 | # DropGeometryColumn
33 |
34 | ```plsql
35 | text DropGeometryColumn(varchar table_name, varchar column_name);
36 |
37 | text DropGeometryColumn(varchar schema_name, varchar table_name, varchar column_name);
38 |
39 | text DropGeometryColumn(varchar catalog_name, varchar schema_name, varchar table_name, varchar column_name);
40 | ```
41 |
42 | ## 描述
43 |
44 | 从空间表中删除几何列。注意,schema_name将需要匹配几何列表中表行的f_table_schema字段。
45 |
46 | **更改:**2.0.0提供此函数是为了向后兼容。既然geometry_columns现在是系统编目的一个视图,那么您可以使用ALTER TABLE删除一个几何列,就像删除任何其他表列一样
47 |
48 | ## 示例
49 |
50 | ```plsql
51 | SELECT DropGeometryColumn ('my_schema','my_spatial_table','geom');
52 | ----RESULT output ---
53 | dropgeometrycolumn
54 | ------------------------------------------------------
55 | my_schema.my_spatial_table.geom effectively removed.
56 |
57 | -- In PostGIS 2.0+ the above is also equivalent to the standard
58 | -- the standard alter table. Both will deregister from geometry_columns
59 | ALTER TABLE my_schema.my_spatial_table DROP column geom;
60 | ```
61 |
62 |
63 |
64 |
65 |
66 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/11.PostGIS函数说明/postgis添加geometry类型字段.md:
--------------------------------------------------------------------------------
1 | ## 1 postgis添加geometry类型字段
2 |
3 | 创建一张测试表
4 |
5 | ```plsql
6 | CREATE TABLE test1(
7 | id int4,
8 | name varchar(255)
9 | )
10 |
11 | > NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'id' as the Greenplum Database data distribution key for this table.
12 | > HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
13 |
14 |
15 | > 时间: 0.246s
16 | ```
17 |
18 | 增加geometry类型字段
19 |
20 | ```plsql
21 | SELECT AddGeometryColumn ('test1', 'the_geom', 4326, 'POINT', 2);
22 | ```
23 |
24 | 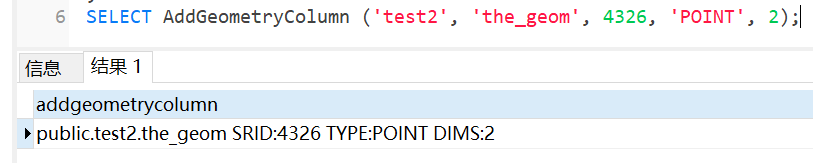
25 |
26 | 插入数据
27 |
28 | ```plsql
29 | INSERT INTO test1 (id, the_geom, name) VALUES (1,ST_GeomFromText('POINT(-0.1257 51.508)',4326),'London, England');
30 | INSERT INTO test1 (id, the_geom, name) VALUES (2,ST_GeomFromText('POINT(-81.233 42.983)',4326),'London, Ontario');
31 | INSERT INTO test1 (id, the_geom, name) VALUES (3,ST_GeomFromText('POINT(27.91162491 -33.01529)',4326),'East London,SA');
32 | ```
33 |
34 | 
35 |
36 | ## 2 Postgresql存储Geometry对象类型
37 |
38 | - [Postgresql存储Geometry对象类型](https://www.bianchengquan.com/article/366575.html)
39 |
40 | ### 2.1 查询Geometry
41 |
42 | ```sql
43 | select ST_GeomFromText('Polygon((117.357442 30.231278,119.235188 30.231278,119.235188 32.614617,117.357442 32.614617,117.357442 30.231278))');
44 | ```
45 |
46 | ### 2.2 设计Geometry字段表
47 |
48 | #### 2.2.1 政区表:Geometry=Polygon
49 |
50 | ```sql
51 | drop table if EXISTS aggregate_state;
52 | /***创建政区表***/
53 | create table aggregate_state(
54 | pk_uid serial primary key,
55 | code CHARACTER VARYING(20) NOT NULL,
56 | "name" CHARACTER VARYING(100) NOT NULL,
57 | zoom INTEGER NOT NULL,
58 | geom geometry(Polygon,4326) NOT NULL ,/*geom public.geometry(Polygon,4490),*/
59 | longitude double precision ,
60 | latitude double precision
61 | );
62 | ```
63 |
64 | #### 2.2.2 空间业务表:Geometry=Point
65 |
66 | ```plsql
67 | drop table if EXISTS aggregate_spatial;
68 | /***创建空间业务表***/
69 | create table aggregate_spatial(
70 | pk_uid serial primary key,
71 | sheng CHARACTER VARYING(20),
72 | shi CHARACTER VARYING(20),
73 | xian CHARACTER VARYING(20),
74 | xiang CHARACTER VARYING(20),
75 | cun CHARACTER VARYING(20),
76 | mzguid CHARACTER VARYING(255),
77 | zoom INTEGER,
78 | geom geometry(Point,4326) ,/*geom public.geometry(Point,4490),*/
79 | longitude double precision,
80 | latitude double precision
81 | );
82 | ```
83 |
84 | ### 2.3 保存Geometry的类型
85 |
86 | 
87 |
88 | 用得比较多的就是point、path、Polygon、text。下面是保存示例:
89 |
90 | ```sql
91 | insert into aggregate_state(code,name,zoom,geom,longitude,latitude) VALUES('21','上海',7,ST_GeomFromText('SRID=4326;Polygon((117.357442 30.231278,119.235188 30.231278,119.235188 32.614617,117.357442 32.614617,117.357442 30.231278))'),
92 | ST_X(st_centroid(ST_GeomFromText('SRID=4326;Polygon((117.357442 30.231278,119.235188 30.231278,119.235188 32.614617,117.357442 32.614617,117.357442 30.231278))'))),
93 | ST_Y(st_centroid(ST_GeomFromText('SRID=4326;Polygon((117.357442 30.231278,119.235188 30.231278,119.235188 32.614617,117.357442 32.614617,117.357442 30.231278))')))
94 | );
95 | ```
96 |
97 | 注意:SRID必须与设计的表对应,且Geometry的类型要对应,insert into示例还计算了面的中心展示位置方便聚合数据输出到地图显示。
98 |
99 | #### 2.3.1 Multipoint多点保存
100 |
101 | ```sql
102 | CREATE TABLE xh_yw.xh_point_tb
103 | (
104 | id bigint NOT NULL,
105 | track_point geometry(MultiPoint,4326),
106 | CONSTRAINT xh_point_tb_pkey PRIMARY KEY (id)
107 | )
108 |
109 | INSERT INTO xh_yw.xh_point_tb (id,track_point) VALUES (1,
110 | ST_GeomFromText('MULTIPOINT((0 0),(5 0),(0 10))', 4326)
111 | );
112 | ```
113 |
114 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/12.Java PostgreSQL Geometry应用/Java 操作gis geometry类型数据.md:
--------------------------------------------------------------------------------
1 | # Java 操作Gis geometry类型数据
2 |
3 | **geolatte-geom** 和**geolatte-geojson**。用于操作geometry和String以及json的互相转化。而json和geojson个人理解就是输出格式不同。多了一些geometry特有的属性。
4 |
5 | pom.xml文件如下:
6 |
7 | ```xml
8 |
9 |
10 | org.geolatte
11 | geolatte-geom
12 | 1.6.0
13 |
14 |
15 |
16 |
17 | org.geolatte
18 | geolatte-geojson
19 | 1.6.0
20 |
21 | ```
22 | ```java
23 | public static void main(String[] args) {
24 |
25 | // 模拟数据库中直接取出的geometry对象值(他是二进制的)
26 | // WKT 是字符串形式,类似"POINT(1 2)"的形式
27 | // 所以WKT转 geometry,相当于是字符串转geometry
28 | // WKB转 geometry,相当于是字节转geometry
29 | String s="01020000800200000097E5880801845C404D064F3AF4AE36400000000000000000290A915F01845C40DC90B1A051AE36400000000000000000";
30 | Geometry geo = Wkb.fromWkb(ByteBuffer.from(s));
31 |
32 | // geometry对象和WKT输出一致
33 |
34 | // Geometry geometry1 = Wkt.fromWkt(wkt);
35 | System.out.println("-----Geometry------"+geo.getPositionN(1));
36 | System.out.println("-----wkt------"+ Wkt.toWkt(geo));
37 | System.out.println("-----wkb------"+Wkb.toWkb(geo));
38 | }
39 | ```
40 |
41 |
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/20.PgRouting/PgRouting系列教程/pgRouting官方文档:pgr_dijkstraCost.md:
--------------------------------------------------------------------------------
1 | - [pgRouting官方文档:pgr_dijkstraCost - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/86539197)
2 |
3 | 原文地址: [pgr_dijkstraCost - pgRouting Manual (3.0-alpha)](https://link.zhihu.com/?target=http%3A//docs.pgrouting.org/latest/en/pgr_dijkstraCost.html)
4 |
5 | pgr_dijkstraCost是基于Boost Graph实现的Dijkstra算法,它只提取找出的最短路径消耗的总代价(Cost)。
6 |
7 | ## 一、描述
8 |
9 | pgr_dijkstraCost函数是用于计算图中节点对最短路径的代价之和。它的时间复杂度为:O(VlogV+E)。
10 |
11 | 该函数的特征为:
12 |
13 | ①它不返回最短路径,它返回的是找到的最短路径的代价之和。
14 |
15 | ②只有路径边的cost为正值,才能将该路径边包含在计算之中。
16 |
17 | ③值在有路径时返回:
18 |
19 | - 返回的值是一组(start_vid, end_vid, agg_cost)的形式*。*
20 | - 当起始节点和结束节点是相同的,则最短路径不存在。此时agg_cost为0。
21 | - 当起始节点和结束节点是不同的,但是找不到最短路径,则agg_cost为∞。
22 |
23 | ④假设返回的值存储在表中,因此唯一的主键索引将是属性对: (start_vid, end_vid)。
24 |
25 | ⑤对于无向图来说,结果是对称的。即顶点对(u, v)和顶点对(v, u)将得到相同的结果。
26 |
27 | ⑥start_vid或end_vid中的任何重复值都将被忽略。
28 |
29 | ⑦返回的值可以如下排序:
30 |
31 | - 从start_vid上升排序
32 | - 从end_vid上升排序
33 |
34 | ⑧运行时间:O(|start_vids|∗(VlogV+E))
35 |
36 | ## 二、函数签名
37 |
38 | **签名摘要**
39 |
40 | 
41 |
42 | **使用默认值**
43 |
44 | 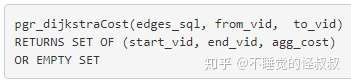
45 |
46 | 示例:在**有向图**中从顶点2到顶点3
47 |
48 | 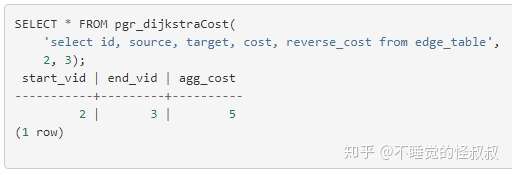
49 |
50 | ## 2.1、一到一
51 |
52 | 
53 |
54 | 示例:在**无向图**中从顶点2到顶点3
55 |
56 | 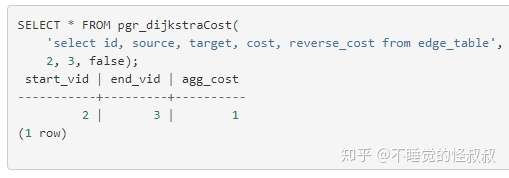
57 |
58 | ## 2.2、一到多
59 |
60 | 
61 |
62 | 示例:在**有向图**中从顶点2到两个顶点{3, 11}
63 |
64 | 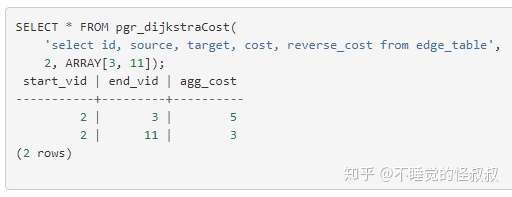
65 |
66 | ## 2.3、多到一
67 |
68 | 
69 |
70 | 示例:在**有向图**中从两个顶点{2, 7}到顶点3
71 |
72 | 
73 |
74 | ## 2.4、多到多
75 |
76 | 
77 |
78 | 示例:在有向图中从两个顶点{2, 7}到两个顶点{3, 11}
79 |
80 | 
81 |
82 | ## 三、其他示例
83 |
84 | 示例1:忽略重复值,并对结果进行排序
85 |
86 | 
87 |
88 | 示例2:使start_vids与end_vids相同
89 |
90 | 
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/20.PgRouting/PgRouting系列教程/pgRouting教程一:介绍.md:
--------------------------------------------------------------------------------
1 | - [pgRouting教程一:介绍 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/82225790)
2 |
3 | ## 一、概述
4 |
5 | **pgRouting**向PostGIS添加了路由功能,这个教程将向你展示:使用[OpenStreetMap](https://link.zhihu.com/?target=http%3A//www.openstreetmap.org/)道路网数据的示例,包括如何准备数据,进行路径查询,编写一个自定义的**'PL/PGSQL'(PostgreSQL的过程化语言-Process Language)**函数来在web地图应用程序中绘制你的路径。换句话说,将pgRouting和其他FOSS4G(Free and Open Source Software For GIS)工具集成到一起。
6 |
7 | 道路网的导航需要复杂的图论算法,这些算法支持考虑**转弯限制(Turn Restriction)**,甚至支持考虑**依赖时间的属性**。pgRouting是一个可扩展的开源库,它作为PostgreSQL和PostGIS的扩展为最短路径搜索提供了多种工具。
8 |
9 | 本教程的重点是在实际道路网络中使用pgRouting进行最短路径搜索。它将涵盖以下主题:
10 |
11 | - 安装pgRouting
12 | - 创建路由拓扑(topology)
13 | - 使用pgRouting算法
14 | - 导入Open Street Map道路网数据
15 | - 编写高级查询
16 | - 使用PL/PGSQL编写自定义PostgreSQL存储过程(函数)
17 | - 构建一个简单的浏览器应用程序
18 | - 使用OpenLayers构建基本的地图界面
19 |
20 | ## 二、先决条件
21 |
22 | - 教程等级:中级
23 | - 需要的预备知识:SQL(PostgreSQL,PostGIS),JavaScript,HTML
24 | - 设备:原教程使用[OSGeo Live](https://link.zhihu.com/?target=http%3A//live.osgeo.org/)(Version 12.0),我这里不用OSGeo Live这个软件集合,而是直接一步步在Linux中安装相关软件
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/20.PgRouting/PgRouting系列教程/pgRouting教程三:安装pgRouting.md:
--------------------------------------------------------------------------------
1 | - [pgRouting教程三:安装pgRouting - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/82408769)
2 |
3 | 官方教程使用OSGeo Live这个软件集合,为了更贴近开发过程,我这里自己手动来安装pgRouting。
4 |
5 | 本文分别介绍pgRouting在Windows中的安装与在Linux(centos)中的安装。
6 |
7 | 推荐在Linux中安装pgRouting,因为生产环境中也大多是将pgRouting安装在Linux中。当然,在windows中安装pgRouting来学习本教程也是可以的。
8 |
9 | ### 一、在Windows中安装pgRouting
10 |
11 | 在Windows中安装pgRouting比较简单。因为PostGIS的Windows安装包里集成了pgRouting,只要安装了PostGIS也就同时安装了pgRouting。
12 |
13 | 要安装PostGIS,可以参考我的文章:
14 |
15 | [不睡觉的怪叔叔:PostGIS教程二:PostGIS安装和创建空间数据库42 赞同 · 15 评论文章](https://zhuanlan.zhihu.com/p/62157728)
16 |
17 | 安装了PostGIS后(我这里安装的是2.5.3版的PostGIS),使用pgAdmin(我这里使用的pgAdmin4)连接PostgreSQL数据库,然后新建一个测试数据库test:
18 |
19 | 
20 |
21 | 在该数据库下执行SQL语句:**CREATE EXTENSION postgis**,创建PostGIS:
22 |
23 | 
24 |
25 | 成功创建postgis插件,接下来继续在test数据库中执行SQL语句:**CREATE EXTENSION pgRouting**,创建pgRouting:
26 |
27 | 
28 |
29 | 查看pgRouting版本:
30 |
31 | 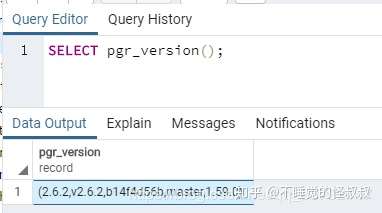
32 |
33 | 至此,就在Windows操作系统中成功安装了pgRouting插件!
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/20.PgRouting/PgRouting系列教程/pgRouting教程二:关于教程.md:
--------------------------------------------------------------------------------
1 | - [pgRouting教程二:关于教程 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/82227139)
2 |
3 | 本教程使用了多个[FOSS4G](https://link.zhihu.com/?target=http%3A//www.osgeo.org/)(Free and Open Source Software For Geo)工具,大多数FOSS4G软件都与其他开放源代码项目相关,这里就不一一列出来了。
4 |
5 | ## 一、pgRouting概览
6 |
7 | pgRouting扩展了PostgreSQL/PostGIS地理空间数据库的功能,以提供地理空间路由功能。pgRouting就是PostgreSQL中的一个插件。
8 |
9 | 数据库的路由功能的优点是:
10 |
11 | - 数据和属性可以在许多客户端修改,比如**QGIS**和**uDig**可以通过**JDBC**、**ODBC**进行修改,或者直接使用**PL/pgSQL**进行修改。客户端可以是PC,也可以是移动设备。
12 | - 数据更改可以通过路由引擎即时反映(实时计算),不需要预先计算。
13 | - 可以通过SQL动态计算"**cost**"(成本、代价)参数,其值可以来自多个字段或表。
14 |
15 | pgRouting库包含以下核心功能:
16 |
17 | - [Dijkstra Algorithm](https://link.zhihu.com/?target=https%3A//docs.pgrouting.org/latest/en/pgr_dijkstra.html)
18 | - [Johnson’s Algorithm](https://link.zhihu.com/?target=https%3A//docs.pgrouting.org/latest/en/pgr_johnson.html)
19 | - [Floyd-Warshall Algorithm](https://link.zhihu.com/?target=https%3A//docs.pgrouting.org/latest/en/pgr_floydWarshall.html)
20 | - [A* Search Algorithm](https://link.zhihu.com/?target=https%3A//docs.pgrouting.org/latest/en/pgr_aStar.html)
21 | - [Bi-directional Dijkstra](https://link.zhihu.com/?target=https%3A//docs.pgrouting.org/latest/en/pgr_bdDijkstra.html)
22 | - [Bi-directional A*](https://link.zhihu.com/?target=https%3A//docs.pgrouting.org/latest/en/pgr_bdAstar.html)
23 | - [Traveling Salesperson Problem](https://link.zhihu.com/?target=https%3A//docs.pgrouting.org/latest/en/pgr_TSP.html)
24 | - [Driving Distance](https://link.zhihu.com/?target=https%3A//docs.pgrouting.org/latest/en/pgr_drivingDistance.html)
25 | - Turn Restriction Shortest Path(TRSP)
26 | - 更多!
27 |
28 | pgRouting是开放源代码的,基于GPLv2许可,受[Georepublic](https://link.zhihu.com/?target=http%3A//georepublic.info/)、[iMaptools](https://link.zhihu.com/?target=http%3A//imaptools.com/)和广大用户社区的支持和维护。
29 |
30 | pgRouting是[OSGeo Foundation](https://link.zhihu.com/?target=http%3A//osgeo.org/)的[OSGeo Community Projects](https://link.zhihu.com/?target=http%3A//wiki.osgeo.org/wiki/OSGeo_Community_Projects)项目,[OSGeoLive](https://link.zhihu.com/?target=http%3A//live.osgeo.org/)里也包含了它。
31 |
32 | pgRouting官网:[http://www.pgrouting.org](https://link.zhihu.com/?target=http%3A//www.pgrouting.org/)
33 |
34 | OSGeoLive: [https://live.osgeo.org/en/overview/pgrouting_overview.html](https://link.zhihu.com/?target=https%3A//live.osgeo.org/en/overview/pgrouting_overview.html)
35 |
36 | ## 二、osm2pgrouting概览
37 |
38 | 
39 |
40 | **osm2pgrouting(Open Street Map To PgRouting)**是一个命令行工具,用于将OpenStreetMap数据导入pgRouting数据库。它会自动构建路由网络拓扑,并为要素类型和道路类别创建表。osm2pgrouting主要是由Daniel Wendt编写,现在托管在[pgRouting项目站点](https://link.zhihu.com/?target=https%3A//github.com/pgRouting/osm2pgrouting)上。
41 |
42 | osm2pgrouting也是基于GPLv2许可。
43 |
44 | 维基:[https://github.com/pgRouting/osm2pgrouting/wiki](https://link.zhihu.com/?target=https%3A//github.com/pgRouting/osm2pgrouting/wiki)
45 |
46 | ## 三、OpenStreetMap概览
47 |
48 | 
49 |
50 | "OpenStreetMap是一个旨在创建并向任何需要的人提供免费地理数据(如街道地图)的项目,启动该项目的目的是因为大多数你认为免费的地图在使用时实际上都有法律或技术的限制,阻碍了人们以创造性、生产性或奇特的方式自由使用它们。"
51 |
52 | (来源: [http://wiki.openstreetmap.org/index.php/Press](https://link.zhihu.com/?target=http%3A//wiki.openstreetmap.org/index.php/Press))
53 |
54 | 对于pgRouting来说,OpenStreetMap是一个丰富的数据源,因为在处理数据方面没有技术限制。各国的数据可获取性仍然不尽相同,但是数据的世界范围覆盖性正在日益改善。
55 |
56 | OpenStreetMap使用一种拓扑数据结构:
57 |
58 | - 节点(Nodes) —— 具有地理位置的点。
59 | - 道路(Ways) —— 节点的序列,被表示为折线(Poly Line)或者多边形
60 | - 关系(Relations) —— 指可以被赋予为确定属性的一组节点、道路和其他地理要素之间的关系
61 | - 属性(Properties) —— 可以指定给节点、道路或者关系,由name=value对组成
62 |
63 | OpenStreetMap网站:[http://www.openstreetmap.org](https://link.zhihu.com/?target=http%3A//www.openstreetmap.org/)
--------------------------------------------------------------------------------
/6.PostgreSQL PostGIS GIST/20.PgRouting/pgr_createVerticesTable.md:
--------------------------------------------------------------------------------
1 | - [pgr_createVerticesTable — pgRouting Manual (2.2)](https://docs.pgrouting.org/2.2/en/src/topology/doc/pgr_createVerticesTable.html)
2 |
3 | 基于源和目标信息重新构建顶点表。
4 |
5 | ```sql
6 | varchar pgr_createVerticesTable(text edge_table, text the_geom:='the_geom'
7 | text source:='source',text target:='target',text rows_where:='true')
8 | ```
9 |
10 | 顶点表函数的重建接受以下参数:
11 |
12 | | edge_table: | `text` 表名 (may contain the schema name as well) |
13 | | :---------- | ------------------------------------------------------------ |
14 | | the_geom: | `text` Geometry column name of the network table. Default value is `the_geom`. |
15 | | source: | `text` Source column name of the network table. Default value is `source`. |
16 | | target: | `text` Target column name of the network table. Default value is `target`. |
17 | | rows_where: | `text` Condition to SELECT a subset or rows. Default value is `true` to indicate all rows. |
18 |
19 | The `edge_table` will be affected
20 |
21 | > - An index will be created, if it doesn’t exists, to speed up the process to the following columns:
22 | >
23 | > > - `the_geom`
24 | > > - `source`
25 | > > - `target`
26 |
27 | The function returns:
28 |
29 | 成功:
30 |
31 | - after the vertices table has been reconstructed.
32 |
33 | - Creates a vertices table: _vertices_pgr.
34 |
35 | - Fills `id` and `the_geom` columns of the vertices table based on the source and target columns of the edge table.
36 |
37 | 失败:
38 |
39 | - when the vertices table was not reconstructed due to an error.
40 |
41 | - A required column of the Network table is not found or is not of the appropriate type.
42 |
43 | - The condition is not well formed.
44 |
45 | - The names of source, target are the same.
46 |
47 | - The SRID of the geometry could not be determined.
48 |
49 | 顶点表的结构是:
50 |
51 | | id: | `bigint` Identifier of the vertex. |
52 | | :-------- | ------------------------------------------------------------ |
53 | | cnt: | `integer` Number of vertices in the edge_table that reference this vertex. See [*pgr_analyzeGraph*](https://docs.pgrouting.org/2.2/en/src/topology/doc/pgr_analyzeGraph.html#pgr-analyze-graph). |
54 | | chk: | `integer` Indicator that the vertex might have a problem. See [*pgr_analyzeGraph*](https://docs.pgrouting.org/2.2/en/src/topology/doc/pgr_analyzeGraph.html#pgr-analyze-graph). |
55 | | ein: | `integer` Number of vertices in the edge_table that reference this vertex as incoming. See [*pgr_analyzeOneway*](https://docs.pgrouting.org/2.2/en/src/topology/doc/pgr_analyzeOneWay.html#pgr-analyze-oneway). |
56 | | eout: | `integer` Number of vertices in the edge_table that reference this vertex as outgoing. See [*pgr_analyzeOneway*](https://docs.pgrouting.org/2.2/en/src/topology/doc/pgr_analyzeOneWay.html#pgr-analyze-oneway). |
57 | | the_geom: | `geometry` Point geometry of the vertex. |
--------------------------------------------------------------------------------
/7.PostgreSQL 推荐系统/推荐系统, 已阅读过滤, 大量CPU和IO浪费的优化思路2.md:
--------------------------------------------------------------------------------
1 | ## 推荐系统, 已阅读过滤, 大量CPU和IO浪费的优化思路2 - partial index - hash 分片, 降低过滤量
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2020-06-10
8 |
9 | ### 标签
10 | PostgreSQL , 推荐系统 , offset , 浪费
11 |
12 | ----
13 |
14 | ## 背景
15 | 推荐系统.
16 |
17 | User 10亿级别
18 | video 10亿级别
19 |
20 | 给 User 推送 video, 按weight权重排序选择vids, 并且过滤已读(获取后到客户端已读表示已读), 采用HLL记录vid hash, 通过hash判断是否已读. hll_val || vid_hash <> hll_val 表示未读.
21 |
22 | ```
23 | create table t (vid int8, weight float4, ts timestamp);
24 | insert into t select generate_series(1,10000000), random();
25 | create index idx_t_1 on t (weight);
26 | ```
27 |
28 | 随着已读列表越来越大, 每次按weight倒排查出来的记录有大量是已读的, 浪费了大量的时间在hll运算上. 使用offset可以模拟hll计算, 例如offset过滤20万条
29 |
30 | ```
31 | select * from t order by weight desc offset 200000 limit 100;
32 | ```
33 |
34 | 耗费 Time: 147.740 ms
35 |
36 | 视频权重会因为大赏、观看等情况不断变化, 所以没有办法使用记录weight 位点来加速offset. 也没有办法使用ts结合weight来跟踪offset位点, 因为热vid会越来越热.
37 |
38 | 每个人观看、喜好的vid都不一样, 所以没有办法统一处理加速.
39 |
40 | ## 优化思路:
41 |
42 | 降低每次hll计算已读的量, 将table强行进行随机索引分区, 每次只查询一个分区, 这样与业务可能有一丝丝不符, 因为查询到的记录是部分记录.
43 |
44 | 但是从整体拉平来看, 只要用户请求次数足够多, 随机能覆盖到所有的记录.
45 |
46 | 例如按20个分区索引来进行随机选择.
47 |
48 | ```
49 | do language plpgsql $$
50 | declare
51 | sql text;
52 | begin
53 | for i in 0..19 loop
54 | sql := format($_$
55 | create index idx_t_p_%s on t (weight) where mod(abs(hashint8(vid)),20)=%s;
56 | $_$, i, i);
57 | execute sql;
58 | end loop;
59 | end;
60 | $$;
61 | ```
62 |
63 | 那么查询的范围将缩小到20分之一, 因为用户已读列表的总量不变, 所以在这个分区中的已读量也会变成20分之一. 那么offset量就会降低20倍. 性能明显提升.
64 |
65 | ```
66 | select * from t
67 | where mod(abs(hashint8(vid)),20) = 0
68 | order by weight desc offset 10000 limit 100;
69 | ```
70 |
71 | 耗费 Time: 12.139 ms
72 |
73 | ## 参考
74 | [《PostgreSQL 大量IO扫描、计算浪费的优化 - 推荐模块, 过滤已推荐. (热点用户、已推荐列表超大)》](../202006/20200601_01.md)
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 | #### [PostgreSQL 许愿链接](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216")
130 | 您的愿望将传达给PG kernel hacker、数据库厂商等, 帮助提高数据库产品质量和功能, 说不定下一个PG版本就有您提出的功能点. 针对非常好的提议,奖励限量版PG文化衫、纪念品、贴纸、PG热门书籍等,奖品丰富,快来许愿。[开不开森](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216").
131 |
132 |
133 | #### [9.9元购买3个月阿里云RDS PostgreSQL实例](https://www.aliyun.com/database/postgresqlactivity "57258f76c37864c6e6d23383d05714ea")
134 |
135 |
136 | #### [PostgreSQL 解决方案集合](https://yq.aliyun.com/topic/118 "40cff096e9ed7122c512b35d8561d9c8")
137 |
138 |
139 | #### [德哥 / digoal's github - 公益是一辈子的事.](https://github.com/digoal/blog/blob/master/README.md "22709685feb7cab07d30f30387f0a9ae")
140 |
141 |
142 | 
143 |
144 |
--------------------------------------------------------------------------------
/8.PostgreSQL 应用开发解决方案/PostgreSQL 应用开发解决方案最佳实践系列课程 - 2. 短视频业务实时推荐 .md:
--------------------------------------------------------------------------------
1 | ## PostgreSQL 应用开发解决方案最佳实践系列课程 - 2. 短视频业务实时推荐
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2021-05-03
8 |
9 | ### 标签
10 | PostgreSQL , 解决方案 , 最佳实践 , 课程
11 |
12 | ----
13 |
14 | ## 背景
15 |
16 | 短视频实时推荐算法
17 | 随机采样
18 | HLL
19 | roaringbitmap
20 | 短视频业务实时推荐 demo
21 |
22 | PostgreSQL 应用开发解决方案最佳实践系列课程 - 2. 短视频业务实时推荐
23 |
24 | [视频回放](xx)
25 |
26 | ## 课程对象
27 | 数据库架构师, 应用开发者, DBA.
28 |
29 | ## 1、应用场景
30 |
31 | 1、短视频
32 | 实时推荐
33 |
34 | ## 2、业界解决方案
35 | 1、随机
36 |
37 | ## 3、业界解决方案的挑战或痛点
38 |
39 | 成本
40 | 实时性差
41 | 随机无喜好关系
42 | 重复播放现象
43 | 过滤已读需要存储大量数据
44 | 过滤扫描代价极大 (not in 百万级)
45 | 视频标签权重实时变化
46 | 池(大、地理位置、热搜)
47 | 交互次数
48 |
49 | ## 4、PG的解决方案
50 |
51 | HLL或roaringbitmap 少量空间存储已读
52 | partial index解决大量过滤已读的无用消耗
53 | sub 单次交互
54 | 异步刷新权重
55 |
56 | ## 5、PG的解决方案原理
57 | Hyperloglog
58 | roaring bitmap
59 | partial index
60 |
61 | ## 6、PG的解决方案 VS 业界解决方案
62 |
63 | ## 7、DEMO
64 |
65 | 准备工作
66 | ECS , Linux + PostgreSQL 客户端软件
67 | 阿里云 RDS PostgreSQL 12 (由于RDS PG 13暂时只支持hll, 不支持pg_roaringbitmap)
68 |
69 | ### 7.1、实时随机采样推荐
70 | 建表
71 | 生成数据
72 | 随机采样查询
73 | 性能
74 |
75 | ### 7.2、实时精准喜好推荐
76 |
77 | 建表
78 | 生成数据
79 | 创建索引
80 | 精准喜好推荐查询
81 |
82 |
83 | ### 7.3、性能
84 | 大量已读过滤查询
85 | 优化大量已读过滤查询
86 |
87 | ### 7.4、扩展性
88 | 垂直扩展
89 | 水平扩展
90 | 只读实例
91 | partial index
92 |
93 | ## 8、知识点回顾
94 |
95 | 随机采样
96 | sub
97 | HLL
98 | roaringbitmap
99 | partial index
100 |
101 | ## 9、参考文档
102 | [《PostgreSQL 15大惊奇应用场景实践 - 直播预告》](../202009/20200903_02.md)
103 |
104 | https://help.aliyun.com/document_detail/164024.html
105 |
106 | https://help.aliyun.com/document_detail/154079.htm
107 |
108 | https://help.aliyun.com/document_detail/183124.html
109 |
110 | [《PostgreSQL 推荐系统优化总计 - 空间、时间、标量等混合多模查询场景, 大量已读过滤导致CPU IO剧增(类挖矿概率下降优化)》](../202006/20200612_01.md)
111 |
112 | [《推荐系统, 已阅读过滤, 大量CPU和IO浪费的优化思路2 - partial index - hash 分片, 降低过滤量》](../202006/20200610_02.md)
113 |
114 | [《PostgreSQL 大量IO扫描、计算浪费的优化 - 推荐模块, 过滤已推荐. (热点用户、已推荐列表超大)》](../202006/20200601_01.md)
115 |
116 | [《PostgreSQL 随机采样应用 - table sample, tsm_system_rows, tsm_system_time》](../202005/20200509_01.md)
117 |
118 | [《社交、电商、游戏等 推荐系统 (相似推荐) - 阿里云pase smlar索引方案对比》](../202004/20200421_01.md)
119 |
120 | [《PostgreSQL 向量相似推荐设计 - pase》](../202004/20200424_01.md)
121 |
122 | [《用户喜好推荐系统 - PostgreSQL 近似计算应用》](../202002/20200228_02.md)
123 |
124 | [《基于GIS位置、群众热点、人为热点的内容推荐服务 - 挑战和策略》](../202002/20200226_01.md)
125 |
126 | [《[视频直播]亿级用户量的实时推荐数据库到底要几毛钱?》](../202009/20200910_02.md)
127 |
128 |
129 |
130 |
131 | #### [PostgreSQL 许愿链接](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216")
132 | 您的愿望将传达给PG kernel hacker、数据库厂商等, 帮助提高数据库产品质量和功能, 说不定下一个PG版本就有您提出的功能点. 针对非常好的提议,奖励限量版PG文化衫、纪念品、贴纸、PG热门书籍等,奖品丰富,快来许愿。[开不开森](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216").
133 |
134 |
135 | #### [9.9元购买3个月阿里云RDS PostgreSQL实例](https://www.aliyun.com/database/postgresqlactivity "57258f76c37864c6e6d23383d05714ea")
136 |
137 |
138 | #### [PostgreSQL 解决方案集合](https://yq.aliyun.com/topic/118 "40cff096e9ed7122c512b35d8561d9c8")
139 |
140 |
141 | #### [德哥 / digoal's github - 公益是一辈子的事.](https://github.com/digoal/blog/blob/master/README.md "22709685feb7cab07d30f30387f0a9ae")
142 |
143 |
144 | 
145 |
146 |
--------------------------------------------------------------------------------
/8.PostgreSQL 应用开发解决方案/PostgreSQL 应用开发解决方案最佳实践系列课程 - 3. 人脸识别和向量相似搜索 .md:
--------------------------------------------------------------------------------
1 | ## PostgreSQL 应用开发解决方案最佳实践系列课程 - 3. 人脸识别和向量相似搜索
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2021-05-06
8 |
9 | ### 标签
10 | PostgreSQL , 解决方案 , 最佳实践 , 课程
11 |
12 | ----
13 |
14 | ## 背景
15 |
16 |
17 | PostgreSQL 应用开发解决方案最佳实践系列课程 - 3. 人脸识别和向量相似搜索
18 |
19 | [视频回放](xx)
20 |
21 | ## 课程对象
22 | 数据库架构师, 应用开发者, DBA.
23 |
24 | ## 1、应用场景
25 |
26 | 1、新零售、酒店、餐饮、会所等, 会员到店提醒和营销系统
27 | 2、公共场所安全
28 | 3、刷脸打卡、支付等场景
29 |
30 | ## 2、业界解决方案
31 | 1、暴力计算
32 | 2、应用程序自行实现向量搜索加速
33 |
34 | ## 3、业界解决方案的挑战或痛点
35 | 采用暴力计算搜索效率低
36 | 应用实现加速的弊端1: 数据加载时间久, 每次应用启动需要全量加载数据并构建加速结构
37 | 应用实现加速的弊端2: 数据维护非常麻烦, 更新后要通知所有应用, 并且应用需要重构加速结构, 无法实现全局一致性.
38 | 应用实现加速的弊端3: 实现效率取决于技术团队, 掌握在少数企业, 甲方的议价能力弱同时风险高.
39 |
40 |
41 | ## 4、PG的解决方案
42 |
43 | pase 向量加速索引.
44 | 将图片特征转换为高维浮点数组, 对浮点数组创建向量索引, 按向量距离排序返回. 实现高效率相似搜索.
45 |
46 | ## 5、PG的解决方案原理
47 | pase插件
48 | ivfflat
49 | hnsw
50 |
51 | ## 6、PG的解决方案 VS 业界解决方案
52 | PG 优势:
53 | 效率高
54 | 无需提前加载数据
55 | 保证数据一致性
56 | 扩展方便, 增加只读实例即可
57 | 采用蚂蚁的人脸识别算法, 效率非常高, 精度有保障, 有大规模应用实践. 方案具有通用性, 不依赖开发商技术能力.
58 |
59 |
60 | ## 7、DEMO
61 |
62 | 准备工作
63 | ECS , Linux + PostgreSQL 客户端软件
64 | 阿里云 RDS PostgreSQL 11 (目前只有RDS PG 11 支持pase 插件)
65 |
66 |
67 | ### 7.1、ivfflat 向量搜索
68 | 创建pase插件
69 | 建表
70 | 生成数据
71 | ivfflat 索引
72 | 使用 ivfflat 索引进行向量搜索
73 | 性能
74 |
75 | ### 7.2、hnsw 向量搜索
76 | 创建pase插件
77 | 建表
78 | 生成数据
79 | hnsw 索引
80 | 使用 hnsw 索引进行向量搜索
81 | 性能
82 |
83 |
84 |
85 | ## 8、知识点回顾
86 |
87 | pase插件
88 | ivfflat索引
89 | hnsw索引
90 |
91 | ## 9、参考文档
92 | [《PostgreSQL 15大惊奇应用场景实践 - 直播预告》](../202009/20200903_02.md)
93 |
94 | https://help.aliyun.com/document_detail/147837.html
95 |
96 | [有个开源插件, 根据PASE提供的论文, 实现了ivfflat向量索引, 有兴趣的用户也可以看看](https://pgxn.org/dist/vector/0.1.2/)
97 |
98 | [《阿里云PostgreSQL案例精选2 - 图像识别、人脸识别、相似特征检索、相似人群圈选》](202002/20200227_01.md)
99 |
100 | [《PostgreSQL 阿里云rds pg发布高维向量索引,支持图像识别、人脸识别 - pase 插件》](201912/20191219_02.md)
101 |
102 | [《[直播]刷脸支付会不会刷到别人的钱包?》](202009/20200919_01.md)
103 |
104 |
105 | #### [PostgreSQL 许愿链接](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216")
106 | 您的愿望将传达给PG kernel hacker、数据库厂商等, 帮助提高数据库产品质量和功能, 说不定下一个PG版本就有您提出的功能点. 针对非常好的提议,奖励限量版PG文化衫、纪念品、贴纸、PG热门书籍等,奖品丰富,快来许愿。[开不开森](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216").
107 |
108 |
109 | #### [9.9元购买3个月阿里云RDS PostgreSQL实例](https://www.aliyun.com/database/postgresqlactivity "57258f76c37864c6e6d23383d05714ea")
110 |
111 |
112 | #### [PostgreSQL 解决方案集合](https://yq.aliyun.com/topic/118 "40cff096e9ed7122c512b35d8561d9c8")
113 |
114 |
115 | #### [德哥 / digoal's github - 公益是一辈子的事.](https://github.com/digoal/blog/blob/master/README.md "22709685feb7cab07d30f30387f0a9ae")
116 |
117 |
118 | 
119 |
120 |
--------------------------------------------------------------------------------
/8.PostgreSQL 应用开发解决方案/PostgreSQL 应用开发解决方案最佳实践系列课程 - 4. 出行相关调度系统 .md:
--------------------------------------------------------------------------------
1 | ## PostgreSQL 应用开发解决方案最佳实践系列课程 - 4. 出行相关调度系统
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2021-05-07
8 |
9 | ### 标签
10 | PostgreSQL , 解决方案 , 最佳实践 , 课程
11 |
12 | ----
13 |
14 | ## 背景
15 |
16 | PostgreSQL 应用开发解决方案最佳实践系列课程 - 4. 出行相关调度系统
17 |
18 | [视频回放](xx)
19 |
20 | ## 课程对象
21 | 数据库架构师, 应用开发者, DBA.
22 |
23 | ## 1、应用场景
24 |
25 | 网约车
26 |
27 | ## 2、业界解决方案
28 |
29 | geohash
30 |
31 | ## 3、业界解决方案的挑战或痛点
32 |
33 | 1、编码精度和边界问题. geohash是地球球面平面化的编码方式, 编码有边界问题, 在编码接缝处的国家和地域无法有效支持.
34 | geohash 长度决定了精度, 但是车辆稀少和车辆密集的地方无法调和.
35 | 高密集地域: 精度低会导致圈选车辆过多导致性能差. 精度高则会导致更新代价巨大, 位置稍为变化都会导致geohash value变化.
36 | 2、不支持距离排序, 只支持geohash范围搜索. 导致问题:
37 | 按人车距离近远、司机评分高低等多重条件筛选的效率问题.
38 | 按geohash方圆圈选, 导致查询效率极其不稳定, 车辆稀少和车辆密集的地方无法调和. 密集地域方圆500米可能就有几十辆车, 而非密集地域方圆5公里都可能没车. 导致SQL没法写.
39 | 3、车辆位置更新实时性问题. 更新量大, 性能问题.
40 | 4、下班高峰期的打车难问题. 争抢严重, 锁的开销巨大.
41 | 5、拼车算法优化难题. 典型的商旅问题, 需要图式理论来解决.
42 |
43 |
44 | ## 4、PG的解决方案
45 |
46 | 1、Ganos & PostGIS.
47 | geometry类型, 规避了编码边界问题. 存储为经纬度value, 精度完全有客户掌握.
48 |
49 | 2、GiST index
50 | 搜索采用GiST索引, 索引层面支持"order by 距离 limit N"返回, 完全规避了这个问题: "按geohash方圆圈选, 导致查询效率极其不稳定, 车辆稀少和车辆密集的地方无法调和. 密集地域方圆500米可能就有几十辆车, 而非密集地域方圆5公里都可能没车. 导致SQL没法写."
51 | 支持高性能实时更新.
52 |
53 | 3、pgrouting
54 | 支持图算法, 解决TSP商旅问题, 可以高效匹配最佳拼车单.
55 |
56 | 4、位置漂移减少热点 、 skip locks
57 | 解决高峰期打车争抢严重, 锁开销巨大的问题.
58 |
59 | ## 5、PG的解决方案原理
60 |
61 |
62 | ## 6、PG的解决方案 VS 业界解决方案
63 |
64 |
65 |
66 | ## 7、DEMO
67 |
68 | 准备工作
69 | ECS , Linux + PostgreSQL 客户端软件
70 | 阿里云 RDS PostgreSQL 13
71 |
72 |
73 | ### 7.1、出行相关调度系统
74 |
75 | 1、创建插件
76 | 2、建表
77 | 3、索引
78 | 4、模拟网约车数据
79 | 5、更新压测
80 | 6、按距离、司机评分等多重条件快速检索匹配网约车测试
81 | 7、写字楼, 高峰期, 密集打车压测
82 | 8、拼车测试
83 |
84 |
85 | ## 8、知识点回顾
86 |
87 | ganos
88 | postgis
89 | GiST 索引
90 | pgrouting 商旅优化
91 | 位置漂移减少热点
92 | skip locks
93 |
94 | ## 9、参考文档
95 | [《PostgreSQL 15大惊奇应用场景实践 - 直播预告》](../202009/20200903_02.md)
96 |
97 | https://help.aliyun.com/document_detail/95580.html
98 |
99 | [《[直播]为什么打车和宇宙大爆炸有关?》](../202009/20200926_02.md)
100 |
101 | [《PostgreSQL 网约车打车派单 高峰区域集中打车冲突优化1 - 宇宙大爆炸理论与PostgreSQL实践》](../201804/20180416_02.md)
102 |
103 | [《网约车打车派单系统思考 数据库设计与实现 - 每月投入6140元, 1天最多可盈利117亿 -_-!》](../201804/20180414_03.md)
104 |
105 | [《多点最优路径规划 - (商旅问题,拼车,餐饮配送,包裹配送,包裹取件,回程单)》](../201704/20170409_01.md)
106 |
107 |
108 | #### [PostgreSQL 许愿链接](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216")
109 | 您的愿望将传达给PG kernel hacker、数据库厂商等, 帮助提高数据库产品质量和功能, 说不定下一个PG版本就有您提出的功能点. 针对非常好的提议,奖励限量版PG文化衫、纪念品、贴纸、PG热门书籍等,奖品丰富,快来许愿。[开不开森](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216").
110 |
111 |
112 | #### [9.9元购买3个月阿里云RDS PostgreSQL实例](https://www.aliyun.com/database/postgresqlactivity "57258f76c37864c6e6d23383d05714ea")
113 |
114 |
115 | #### [PostgreSQL 解决方案集合](https://yq.aliyun.com/topic/118 "40cff096e9ed7122c512b35d8561d9c8")
116 |
117 |
118 | #### [德哥 / digoal's github - 公益是一辈子的事.](https://github.com/digoal/blog/blob/master/README.md "22709685feb7cab07d30f30387f0a9ae")
119 |
120 |
121 | 
122 |
123 |
--------------------------------------------------------------------------------
/9.PostgreSQL 插件与工具/Pgadmin4.md:
--------------------------------------------------------------------------------
1 | # 打开pgadmin4 进行界面汉化
2 |
3 | 打开是一个英文的管理界面 如下
4 |
5 | 
6 |
7 |
8 |
9 | 这个是可以汉化的 按照下面步骤来进行汉化
10 |
11 | 
12 |
13 | 
14 |
15 | 点击OK后重新进入即可
16 |
17 | 
18 |
19 |
--------------------------------------------------------------------------------
/9.PostgreSQL 插件与工具/PostgreSQL 用户最喜爱的扩展插件功能 .md:
--------------------------------------------------------------------------------
1 | ## PostgreSQL 用户最喜爱的扩展插件功能
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2021-02-22
8 |
9 | ### 标签
10 | PostgreSQL , 插件
11 |
12 | ----
13 |
14 | ## 背景
15 | - 存储过程
16 | - GIS
17 | - 全文检索
18 | - 正则查询、模糊查询索引
19 | - btree, gin, gist 混合搜索
20 | - 加密
21 | - uuid
22 | - 忽略大小写文本类型
23 | - 行列转换
24 | - NoSQL (json, hstore)
25 | - 外部表
26 | - 冷热分离存储
27 | - dblink
28 | - 高维向量
29 | - plan hint
30 | - top sql
31 | - 垃圾分析
32 |
33 |
34 |
35 | #### [PostgreSQL 许愿链接](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216")
36 | 您的愿望将传达给PG kernel hacker、数据库厂商等, 帮助提高数据库产品质量和功能, 说不定下一个PG版本就有您提出的功能点. 针对非常好的提议,奖励限量版PG文化衫、纪念品、贴纸、PG热门书籍等,奖品丰富,快来许愿。[开不开森](https://github.com/digoal/blog/issues/76 "269ac3d1c492e938c0191101c7238216").
37 |
38 |
39 | #### [9.9元购买3个月阿里云RDS PostgreSQL实例](https://www.aliyun.com/database/postgresqlactivity "57258f76c37864c6e6d23383d05714ea")
40 |
41 |
42 | #### [PostgreSQL 解决方案集合](https://yq.aliyun.com/topic/118 "40cff096e9ed7122c512b35d8561d9c8")
43 |
44 |
45 | #### [德哥 / digoal's github - 公益是一辈子的事.](https://github.com/digoal/blog/blob/master/README.md "22709685feb7cab07d30f30387f0a9ae")
46 |
47 |
48 | 
49 |
50 |
--------------------------------------------------------------------------------
/DBA职能.md:
--------------------------------------------------------------------------------
1 | ## DBA职能(持续补充)
2 |
3 | ### 作者
4 | digoal
5 |
6 | ### 日期
7 | 2010-05-11
8 |
9 | ### 标签
10 | DBA
11 |
12 | ----
13 |
14 | ## 背景
15 | 如何能够最大的发挥DBA在企业中的作用,首先要搞清楚DBA的职能。DBA能干什么?DBA怎么干好这些?
16 |
17 | 首先DBA能干的事情(未包含测试):
18 |
19 | 1\. 需求调研
20 |
21 | 2\. 设计数据库
22 |
23 | 3\. 创建数据库
24 |
25 | 4\. 维护数据库
26 |
27 | 5\. 归档并销毁数据库
28 |
29 | 如何来干好这些事情:
30 |
31 | 1\. 需求调研
32 |
33 | 首先要搞清楚调研的目的,所谓磨刀不误砍柴功,每个项目都应该有需求调研的阶段。
34 |
35 | 必须搞清楚项目需要来自何方,将要达成的目标是什么,项目经理、项目成员的详细信息,与开发人员沟通如何实现,把控开发人员对数据库的使用是否合理,评估业务量的发展对数据库的要求,评估数据库平台对硬件的要求,确定数据库型号,增加一个与其他项目的衔接(如数据仓库)等。
36 |
37 | 2\. 设计数据库
38 |
39 | 设计数据库、输出文档。
40 |
41 | 逻辑设计:
42 |
43 | 设计ER图,数据字典(表,索引,约束,同义词,视图,过程,函数等),设计SQL,输出SQL详细PLAN报告等。
44 |
45 | 还有很重要的一点是资源限制或资源管理设计(可以通过数据库自身或中间件来实现)。
46 |
47 | benchmark输出
48 |
49 | 物理设计:
50 |
51 | 设计物理运行平台:存储环境,操作系统,网络环境,数据库平台,表空间,参数配置,等。
52 |
53 | 测试方案设计:
54 |
55 | 输出测试方案,测试条目及目标,功能测试,压力测试。
56 |
57 | 3\. 创建数据库
58 |
59 | 高可用设计:数据库集群,容灾设计,等。
60 |
61 | 剩下的这个不用多说了,就是部署。
62 |
63 | 4\. 维护数据库
64 |
65 | 输出维护方案,维护目标,维护手册(日,周,月,季度,年,特殊维护等)
66 |
67 | 监控数据库,(benchmark)
68 |
69 | 包含开发支持(部署),维护,等
70 |
71 | 5\. 归档并销毁数据库
72 |
73 | 在接到数据库可以销毁的指令后,归档并销毁之。
74 |
75 | 辅助职能:
76 |
77 | 1\. 降低成本
78 |
79 | 2\. 提高团队凝聚力
80 |
81 | 3\. 提高团队战斗力
82 |
83 | 4\. 降低风险(外部风险与内部风险)
84 |
85 | 同时还要做好各个职能之间的衔接和协调,提高响应速度。
86 |
87 | 先写到这,其他的以后再补充.
88 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | PostgreSQL学习仓库:https://gitee.com/AiShiYuShiJiePingXing/postgres
2 |
3 | ## 1 仓库说明
4 |
5 | 因为一直在交通相关行业工作,多多少少对GIS有些熟悉,数据大多都离不开GIS得分析和处理,于是开始研究了PostGis得相关内容,发现了PostgreSQL数据库得很多优秀特性,便开始慢慢总结学习。
6 |
7 | 最初,是整理得德哥得PG仓库,筛选了一些优秀得内容,后来,开始自己慢慢积攒记录相关得学习笔记
8 |
9 | 同时,也将该仓库作为自己学习和研究PostgreSQL的仓库,会不断积累和分享有关PostgreSQL的内容。
10 |
11 | 德哥PostgreSQL仓库地址:https://github.com/digoal/blog
12 |
13 | ## 2 最佳阅读方式
14 |
15 | 因为文章全部是md格式的,所以建议采用Typora阅读。
16 |
17 | 1. `git clone https://gitee.com/AiShiYuShiJiePingXing/postgres.git`
18 | 2. 使用Typora打开克隆后的项目
19 |
20 | 3. 阅读学习
21 |
22 | ## 3 批评指正
23 |
24 | 因大部分资料都是互联网资源,如有侵权,请联系删除。
25 |
26 | 对于错误或者不当之处,劳烦及时指正,会尽快更改。
27 |
28 | 再次多谢PG大佬们的辛勤付出!!!
--------------------------------------------------------------------------------
/德哥系列/德哥直播课程.md:
--------------------------------------------------------------------------------
1 | **德哥直播课程**
2 |
3 | **系列二**
4 | [PostgreSQL培训系列直播—第三章:PG实例初始化、基本配置-第一节](https://yq.aliyun.com/live/946)
5 | [PostgreSQL培训系列直播—第三章:PG实例初始化、基本配置-第二节](https://yq.aliyun.com/live/966)
6 | [PostgreSQL培训系列直播—第二章:PG安装](https://yq.aliyun.com/live/931)
7 | [PostgreSQL培训系列直播—第一章:掀开 PostgreSQL 的盖头](https://yq.aliyun.com/live/919)
8 |
9 | **系列一**
10 | [PostgreSQL多场景阿里云沙箱实验(第15讲):PostgreSQL 新类型提高开发生产力](https://yq.aliyun.com/live/909)
11 | [PostgreSQL多场景阿里云沙箱实验(第14讲):PostgreSQL 数据清洗、采样、脱敏、批处理、合并](https://yq.aliyun.com/live/885)
12 | [PostgreSQL多场景阿里云沙箱实验(第13讲):PostgreSQL 图式关系数据应用实践](https://yq.aliyun.com/live/869)
13 | [PostgreSQL多场景阿里云沙箱实验(第12讲):PostgreSQL 物联网最佳实践](https://yq.aliyun.com/live/846)
14 | [PostgreSQL多场景阿里云沙箱实验(第11讲):PostgreSQL 在社交应用领域的最佳实践](https://yq.aliyun.com/live/824)
15 | [PostgreSQL多场景阿里云沙箱实验(第10讲):PostgreSQL 时空调度数据库实践](https://yq.aliyun.com/live/807)
16 | [PostgreSQL多场景阿里云沙箱实验(第9讲):PostgreSQL 时空业务实践](https://yq.aliyun.com/live/794)
17 | [PostgreSQL多场景阿里云沙箱实验(第8讲):PostgreSQL 简单空间应用实践](https://yq.aliyun.com/live/783)
18 | [PostgreSQL多场景阿里云沙箱实验(第7讲):PostgreSQL 并行计算](https://yq.aliyun.com/live/733)
19 | [PostgreSQL多场景阿里云沙箱实验(第6讲):PostgreSQL 用户画像系统实践](https://yq.aliyun.com/live/710)
20 | [PostgreSQL多场景阿里云沙箱实验(第5讲):PostgreSQL 估值、概率计算](https://yq.aliyun.com/live/691)
21 | [PostgreSQL多场景阿里云沙箱实验(第4讲):PostgreSQL 实时多维分析](https://yq.aliyun.com/live/659?spm=a2c6h.12873639.0.0.10591305AER8HX)
22 | [PostgreSQL多场景阿里云沙箱实验(第3讲):PostgreSQL 实时搜索实践](https://yq.aliyun.com/live/647?spm=a2c6h.12873639.0.0.10591305AER8HX)
23 | [PostgreSQL多场景阿里云沙箱实验(第2讲):PG秒杀场景实践](https://yq.aliyun.com/live/615)
24 | [PostgreSQL多场景阿里云沙箱实验(第1讲):如何快速构建海量逼真测试数据](https://yq.aliyun.com/live/594)
--------------------------------------------------------------------------------
/自动化脚本.bat:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lovebetterworld/postgres/2cfdc43e2ed7a5d12c0d9aece4774c1b1794981e/自动化脚本.bat
--------------------------------------------------------------------------------