10 | ![]() 11 |
11 |
19 |  20 |
20 |
41 |  42 |
42 |
56 |  57 |
57 |
21 |  22 |
22 |
35 |  36 |
36 |
47 |  48 |
48 |
59 |  60 |
60 |
67 |  68 |
68 |
71 |  72 |
72 |
107 |
108 |
121 |  122 |
122 |
86 |  87 |
87 |
151 | 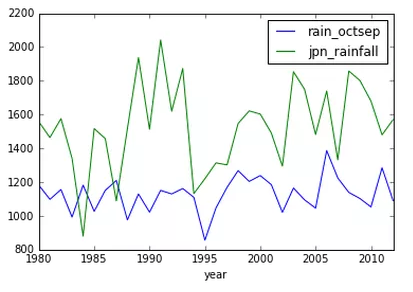 152 |
152 |
99 | 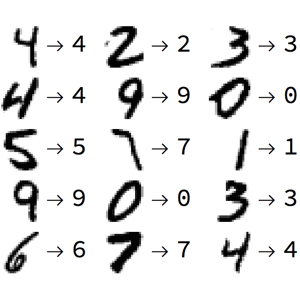 100 |
100 |
108 | 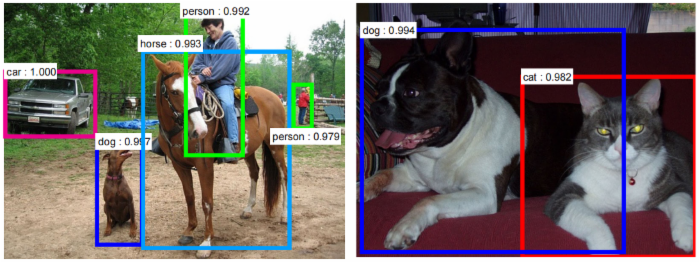 109 |
109 |
116 | 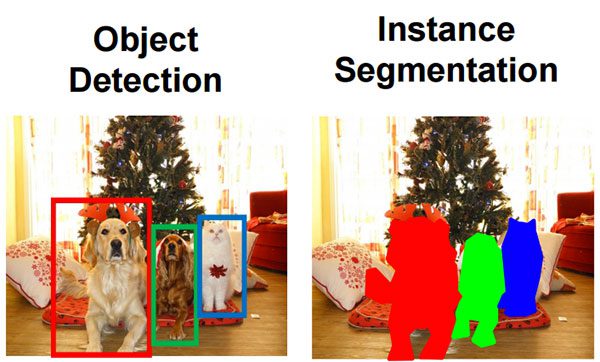 117 |
117 |
122 |  123 |
123 |
25 |  26 |
26 |
34 |
35 |
41 |
42 |
50 |  51 |
51 |
63 |
64 |
84 |  85 |
85 |
100 |  101 |
101 |
143 |  144 |
144 |
26 |  27 |
27 |
32 |  33 |
33 |
42 |  43 |
43 |
47 |  48 |
48 |
59 |  60 |
60 |
69 |  70 |
70 |
85 |
86 |
90 |
91 |
108 |  109 |
109 |
120 | xapprox=Ureduce z 121 |
122 | 123 | 因为从 _x_ 得到 _z_ 的过程可以看做是 _x_ 在空间 _UTreduce_ 上的映射。 124 | 而从 _z_ 得到 _xapprox_ 的过程可以看做反向的映射,也就是在空间 _(UTreduce)-1 = Ureduce_ (A的逆矩阵)上的映射。 125 | 126 | 下图中为一个恢复的例子: 127 |
128 |  129 |
129 |
137 |
138 |
142 |
143 |
147 |
148 |
161 |  162 |
162 |
166 |
167 |
171 |
172 |
35 |  36 |
36 |
40 |  41 |
41 |
45 |  46 |
46 |
72 |
73 |
89 |  90 |
90 |
107 |  108 |
108 |
135 |  136 |
136 |
178 |  179 |
179 |
186 |
187 |
192 |
193 |
199 |
200 |
205 |
206 |
74 |  75 |
75 |
242 | 
243 | 
244 | 
245 |  246 |
246 |
341 |  342 |
342 |
279 |
Converted formulas:
291 | 292 |295 | 296 | 297 |
298 | 299 |``torch.Size`` is in fact a tuple, so it supports all tuple operations.
Any operation that mutates a tensor in-place is post-fixed with an ``_``.\n", 245 | " For example: ``x.copy_(y)``, ``x.t_()``, will change ``x``.
``torch.nn`` only supports mini-batches. The entire ``torch.nn``\n package only supports inputs that are a mini-batch of samples, and not\n a single sample.\n\n For example, ``nn.Conv2d`` will take in a 4D Tensor of\n ``nSamples x nChannels x Height x Width``.\n\n If you have a single sample, just use ``input.unsqueeze(0)`` to add\n a fake batch dimension.

59 |
60 |
67 |
68 |

93 |
94 |
![]()
101 |
102 |

124 |
125 |
128 |
129 |
![]()
146 |
147 |
153 |
154 |


172 |
173 |
179 |
180 |

187 |
188 |