├── lightweight_gan
├── version.py
├── __init__.py
├── diff_augment_test.py
├── diff_augment.py
├── cli.py
└── lightweight_gan.py
├── .github
├── FUNDING.yml
└── workflows
│ └── python-publish.yml
├── images
├── pizza-512.jpg
├── sample-256.jpg
└── sample-512.jpg
├── docs
├── aug_test
│ ├── lena.jpg
│ ├── lena_augs.jpg
│ └── lena_augs_default.jpg
├── aug_types
│ ├── lena_augs_color.jpg
│ ├── lena_augs_cutout.jpg
│ ├── lena_augs_offset.jpg
│ ├── lena_augs_offset_h.jpg
│ ├── lena_augs_offset_v.jpg
│ └── lena_augs_translation.jpg
└── show_progress
│ ├── show-progress.gif
│ └── show-progress.mp4
├── LICENSE
├── setup.py
├── .gitignore
└── README.md
/lightweight_gan/version.py:
--------------------------------------------------------------------------------
1 | __version__ = '1.2.1'
2 |
--------------------------------------------------------------------------------
/.github/FUNDING.yml:
--------------------------------------------------------------------------------
1 | # These are supported funding model platforms
2 |
3 | github: [lucidrains]
4 |
--------------------------------------------------------------------------------
/images/pizza-512.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/images/pizza-512.jpg
--------------------------------------------------------------------------------
/docs/aug_test/lena.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/docs/aug_test/lena.jpg
--------------------------------------------------------------------------------
/images/sample-256.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/images/sample-256.jpg
--------------------------------------------------------------------------------
/images/sample-512.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/images/sample-512.jpg
--------------------------------------------------------------------------------
/docs/aug_test/lena_augs.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/docs/aug_test/lena_augs.jpg
--------------------------------------------------------------------------------
/docs/aug_test/lena_augs_default.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/docs/aug_test/lena_augs_default.jpg
--------------------------------------------------------------------------------
/docs/aug_types/lena_augs_color.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/docs/aug_types/lena_augs_color.jpg
--------------------------------------------------------------------------------
/docs/aug_types/lena_augs_cutout.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/docs/aug_types/lena_augs_cutout.jpg
--------------------------------------------------------------------------------
/docs/aug_types/lena_augs_offset.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/docs/aug_types/lena_augs_offset.jpg
--------------------------------------------------------------------------------
/docs/aug_types/lena_augs_offset_h.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/docs/aug_types/lena_augs_offset_h.jpg
--------------------------------------------------------------------------------
/docs/aug_types/lena_augs_offset_v.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/docs/aug_types/lena_augs_offset_v.jpg
--------------------------------------------------------------------------------
/docs/show_progress/show-progress.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/docs/show_progress/show-progress.gif
--------------------------------------------------------------------------------
/docs/show_progress/show-progress.mp4:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/docs/show_progress/show-progress.mp4
--------------------------------------------------------------------------------
/docs/aug_types/lena_augs_translation.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/lightweight-gan/HEAD/docs/aug_types/lena_augs_translation.jpg
--------------------------------------------------------------------------------
/lightweight_gan/__init__.py:
--------------------------------------------------------------------------------
1 | from lightweight_gan.lightweight_gan import LightweightGAN, Generator, Discriminator, Trainer, NanException
2 | from kornia.filters import filter2d
3 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2021 Phil Wang
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/.github/workflows/python-publish.yml:
--------------------------------------------------------------------------------
1 | # This workflow will upload a Python Package using Twine when a release is created
2 | # For more information see: https://help.github.com/en/actions/language-and-framework-guides/using-python-with-github-actions#publishing-to-package-registries
3 |
4 | # This workflow uses actions that are not certified by GitHub.
5 | # They are provided by a third-party and are governed by
6 | # separate terms of service, privacy policy, and support
7 | # documentation.
8 |
9 | name: Upload Python Package
10 |
11 | on:
12 | release:
13 | types: [published]
14 |
15 | jobs:
16 | deploy:
17 |
18 | runs-on: ubuntu-latest
19 |
20 | steps:
21 | - uses: actions/checkout@v2
22 | - name: Set up Python
23 | uses: actions/setup-python@v2
24 | with:
25 | python-version: '3.x'
26 | - name: Install dependencies
27 | run: |
28 | python -m pip install --upgrade pip
29 | pip install build
30 | - name: Build package
31 | run: python -m build
32 | - name: Publish package
33 | uses: pypa/gh-action-pypi-publish@27b31702a0e7fc50959f5ad993c78deac1bdfc29
34 | with:
35 | user: __token__
36 | password: ${{ secrets.PYPI_API_TOKEN }}
37 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | import sys
2 | from setuptools import setup, find_packages
3 |
4 | sys.path[0:0] = ['lightweight_gan']
5 | from version import __version__
6 |
7 | setup(
8 | name = 'lightweight-gan',
9 | packages = find_packages(),
10 | entry_points={
11 | 'console_scripts': [
12 | 'lightweight_gan = lightweight_gan.cli:main',
13 | ],
14 | },
15 | version = __version__,
16 | license='MIT',
17 | description = 'Lightweight GAN',
18 | author = 'Phil Wang',
19 | author_email = 'lucidrains@gmail.com',
20 | url = 'https://github.com/lucidrains/lightweight-gan',
21 | keywords = [
22 | 'artificial intelligence',
23 | 'deep learning',
24 | 'generative adversarial networks'
25 | ],
26 | install_requires=[
27 | 'adabelief-pytorch',
28 | 'einops>=0.8.0',
29 | 'fire',
30 | 'kornia>=0.5.4',
31 | 'numpy',
32 | 'pillow',
33 | 'retry',
34 | 'torch>=2.2',
35 | 'torchvision',
36 | 'tqdm'
37 | ],
38 | classifiers=[
39 | 'Development Status :: 4 - Beta',
40 | 'Intended Audience :: Developers',
41 | 'Topic :: Scientific/Engineering :: Artificial Intelligence',
42 | 'License :: OSI Approved :: MIT License',
43 | 'Programming Language :: Python :: 3.6',
44 | ],
45 | )
--------------------------------------------------------------------------------
/lightweight_gan/diff_augment_test.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tempfile
3 | from pathlib import Path
4 | from shutil import copyfile
5 |
6 | import torch
7 | import torchvision
8 | from torch import nn
9 | from torch.utils.data import DataLoader
10 |
11 | from lightweight_gan.lightweight_gan import AugWrapper, ImageDataset
12 |
13 |
14 | assert torch.cuda.is_available(), 'You need to have an Nvidia GPU with CUDA installed.'
15 |
16 |
17 | class DummyModel(nn.Module):
18 | def __init__(self):
19 | super().__init__()
20 |
21 | def forward(self, x):
22 | return x
23 |
24 |
25 | @torch.no_grad()
26 | def DiffAugmentTest(image_size = 256, data = './data/0.jpg', types = [], batch_size = 10, rank = 0, nrow = 5):
27 | model = DummyModel()
28 | aug_wrapper = AugWrapper(model, image_size)
29 |
30 | with tempfile.TemporaryDirectory() as directory:
31 | file = Path(data)
32 |
33 | if os.path.exists(file):
34 | file_name, ext = os.path.splitext(data)
35 |
36 | for i in range(batch_size):
37 | tmp_file_name = str(i) + ext
38 | copyfile(file, os.path.join(directory, tmp_file_name))
39 |
40 | dataset = ImageDataset(directory, image_size, aug_prob=0)
41 | dataloader = DataLoader(dataset, batch_size=batch_size)
42 |
43 | image_batch = next(iter(dataloader)).cuda(rank)
44 | images_augment = aug_wrapper(images=image_batch, prob=1, types=types, detach=True)
45 |
46 | save_result = file_name + f'_augs{ext}'
47 | torchvision.utils.save_image(images_augment, save_result, nrow=nrow)
48 |
49 | print('Save result to:', save_result)
50 |
51 | else:
52 | print('File not found. File', file)
53 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | pip-wheel-metadata/
24 | share/python-wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 | MANIFEST
29 |
30 | # PyInstaller
31 | # Usually these files are written by a python script from a template
32 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
33 | *.manifest
34 | *.spec
35 |
36 | # Installer logs
37 | pip-log.txt
38 | pip-delete-this-directory.txt
39 |
40 | # Unit test / coverage reports
41 | htmlcov/
42 | .tox/
43 | .nox/
44 | .coverage
45 | .coverage.*
46 | .cache
47 | nosetests.xml
48 | coverage.xml
49 | *.cover
50 | *.py,cover
51 | .hypothesis/
52 | .pytest_cache/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | target/
76 |
77 | # Jupyter Notebook
78 | .ipynb_checkpoints
79 |
80 | # IPython
81 | profile_default/
82 | ipython_config.py
83 |
84 | # pyenv
85 | .python-version
86 |
87 | # pipenv
88 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
89 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
90 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
91 | # install all needed dependencies.
92 | #Pipfile.lock
93 |
94 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
95 | __pypackages__/
96 |
97 | # Celery stuff
98 | celerybeat-schedule
99 | celerybeat.pid
100 |
101 | # SageMath parsed files
102 | *.sage.py
103 |
104 | # Environments
105 | .env
106 | .venv
107 | env/
108 | venv/
109 | ENV/
110 | env.bak/
111 | venv.bak/
112 |
113 | # Spyder project settings
114 | .spyderproject
115 | .spyproject
116 |
117 | # Rope project settings
118 | .ropeproject
119 |
120 | # mkdocs documentation
121 | /site
122 |
123 | # mypy
124 | .mypy_cache/
125 | .dmypy.json
126 | dmypy.json
127 |
128 | # Pyre type checker
129 | .pyre/
130 |
131 | .aim
132 | models/
133 | results/
134 |
--------------------------------------------------------------------------------
/lightweight_gan/diff_augment.py:
--------------------------------------------------------------------------------
1 | import random
2 |
3 | import torch
4 | import torch.nn.functional as F
5 |
6 |
7 | def DiffAugment(x, types=[]):
8 | for p in types:
9 | for f in AUGMENT_FNS[p]:
10 | x = f(x)
11 | return x.contiguous()
12 |
13 |
14 | # """
15 | # Augmentation functions got images as `x`
16 | # where `x` is tensor with this dimensions:
17 | # 0 - count of images
18 | # 1 - channels
19 | # 2 - width
20 | # 3 - height of image
21 | # """
22 |
23 | def rand_brightness(x):
24 | x = x + (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) - 0.5)
25 | return x
26 |
27 | def rand_saturation(x):
28 | x_mean = x.mean(dim=1, keepdim=True)
29 | x = (x - x_mean) * (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) * 2) + x_mean
30 | return x
31 |
32 | def rand_contrast(x):
33 | x_mean = x.mean(dim=[1, 2, 3], keepdim=True)
34 | x = (x - x_mean) * (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) + 0.5) + x_mean
35 | return x
36 |
37 | def rand_translation(x, ratio=0.125):
38 | shift_x, shift_y = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)
39 | translation_x = torch.randint(-shift_x, shift_x + 1, size=[x.size(0), 1, 1], device=x.device)
40 | translation_y = torch.randint(-shift_y, shift_y + 1, size=[x.size(0), 1, 1], device=x.device)
41 | grid_batch, grid_x, grid_y = torch.meshgrid(
42 | torch.arange(x.size(0), dtype=torch.long, device=x.device),
43 | torch.arange(x.size(2), dtype=torch.long, device=x.device),
44 | torch.arange(x.size(3), dtype=torch.long, device=x.device),
45 | indexing = 'ij')
46 | grid_x = torch.clamp(grid_x + translation_x + 1, 0, x.size(2) + 1)
47 | grid_y = torch.clamp(grid_y + translation_y + 1, 0, x.size(3) + 1)
48 | x_pad = F.pad(x, [1, 1, 1, 1, 0, 0, 0, 0])
49 | x = x_pad.permute(0, 2, 3, 1).contiguous()[grid_batch, grid_x, grid_y].permute(0, 3, 1, 2)
50 | return x
51 |
52 | def rand_offset(x, ratio=1, ratio_h=1, ratio_v=1):
53 | w, h = x.size(2), x.size(3)
54 |
55 | imgs = []
56 | for img in x.unbind(dim = 0):
57 | max_h = int(w * ratio * ratio_h)
58 | max_v = int(h * ratio * ratio_v)
59 |
60 | value_h = random.randint(0, max_h) * 2 - max_h
61 | value_v = random.randint(0, max_v) * 2 - max_v
62 |
63 | if abs(value_h) > 0:
64 | img = torch.roll(img, value_h, 2)
65 |
66 | if abs(value_v) > 0:
67 | img = torch.roll(img, value_v, 1)
68 |
69 | imgs.append(img)
70 |
71 | return torch.stack(imgs)
72 |
73 | def rand_offset_h(x, ratio=1):
74 | return rand_offset(x, ratio=1, ratio_h=ratio, ratio_v=0)
75 |
76 | def rand_offset_v(x, ratio=1):
77 | return rand_offset(x, ratio=1, ratio_h=0, ratio_v=ratio)
78 |
79 | def rand_cutout(x, ratio=0.5):
80 | cutout_size = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)
81 | offset_x = torch.randint(0, x.size(2) + (1 - cutout_size[0] % 2), size=[x.size(0), 1, 1], device=x.device)
82 | offset_y = torch.randint(0, x.size(3) + (1 - cutout_size[1] % 2), size=[x.size(0), 1, 1], device=x.device)
83 | grid_batch, grid_x, grid_y = torch.meshgrid(
84 | torch.arange(x.size(0), dtype=torch.long, device=x.device),
85 | torch.arange(cutout_size[0], dtype=torch.long, device=x.device),
86 | torch.arange(cutout_size[1], dtype=torch.long, device=x.device),
87 | indexing = 'ij')
88 | grid_x = torch.clamp(grid_x + offset_x - cutout_size[0] // 2, min=0, max=x.size(2) - 1)
89 | grid_y = torch.clamp(grid_y + offset_y - cutout_size[1] // 2, min=0, max=x.size(3) - 1)
90 | mask = torch.ones(x.size(0), x.size(2), x.size(3), dtype=x.dtype, device=x.device)
91 | mask[grid_batch, grid_x, grid_y] = 0
92 | x = x * mask.unsqueeze(1)
93 | return x
94 |
95 | AUGMENT_FNS = {
96 | 'color': [rand_brightness, rand_saturation, rand_contrast],
97 | 'offset': [rand_offset],
98 | 'offset_h': [rand_offset_h],
99 | 'offset_v': [rand_offset_v],
100 | 'translation': [rand_translation],
101 | 'cutout': [rand_cutout],
102 | }
103 |
--------------------------------------------------------------------------------
/lightweight_gan/cli.py:
--------------------------------------------------------------------------------
1 | import os
2 | import fire
3 | import random
4 | from retry.api import retry_call
5 | from tqdm import tqdm
6 | from datetime import datetime
7 | from functools import wraps
8 | from lightweight_gan import Trainer, NanException
9 | from lightweight_gan.diff_augment_test import DiffAugmentTest
10 |
11 | import torch
12 | import torch.multiprocessing as mp
13 | import torch.distributed as dist
14 |
15 | import numpy as np
16 |
17 | def exists(val):
18 | return val is not None
19 |
20 | def default(val, d):
21 | return val if exists(val) else d
22 |
23 | def cast_list(el):
24 | return el if isinstance(el, list) else [el]
25 |
26 | def timestamped_filename(prefix = 'generated-'):
27 | now = datetime.now()
28 | timestamp = now.strftime("%m-%d-%Y_%H-%M-%S")
29 | return f'{prefix}{timestamp}'
30 |
31 | def set_seed(seed):
32 | torch.manual_seed(seed)
33 | torch.backends.cudnn.deterministic = True
34 | torch.backends.cudnn.benchmark = False
35 | np.random.seed(seed)
36 | random.seed(seed)
37 |
38 | def run_training(rank, world_size, model_args, data, load_from, new, num_train_steps, name, seed, use_aim, aim_repo, aim_run_hash):
39 | is_main = rank == 0
40 | is_ddp = world_size > 1
41 |
42 | if is_ddp:
43 | set_seed(seed)
44 | os.environ['MASTER_ADDR'] = 'localhost'
45 | os.environ['MASTER_PORT'] = '12355'
46 | dist.init_process_group('nccl', rank=rank, world_size=world_size)
47 |
48 | print(f"{rank + 1}/{world_size} process initialized.")
49 |
50 | model_args.update(
51 | is_ddp = is_ddp,
52 | rank = rank,
53 | world_size = world_size
54 | )
55 |
56 | model = Trainer(**model_args, hparams=model_args, use_aim=use_aim, aim_repo=aim_repo, aim_run_hash=aim_run_hash)
57 |
58 | if not new:
59 | model.load(load_from)
60 | else:
61 | model.clear()
62 |
63 | model.set_data_src(data)
64 |
65 | progress_bar = tqdm(initial = model.steps, total = num_train_steps, mininterval=10., desc=f'{name}<{data}>')
66 | while model.steps < num_train_steps:
67 | retry_call(model.train, tries=3, exceptions=NanException)
68 | progress_bar.n = model.steps
69 | progress_bar.refresh()
70 | if is_main and model.steps % 50 == 0:
71 | model.print_log()
72 |
73 | model.save(model.checkpoint_num)
74 |
75 | if is_ddp:
76 | dist.destroy_process_group()
77 |
78 | def train_from_folder(
79 | data = './data',
80 | results_dir = './results',
81 | models_dir = './models',
82 | name = 'default',
83 | new = False,
84 | load_from = -1,
85 | image_size = 256,
86 | optimizer = 'adam',
87 | fmap_max = 512,
88 | transparent = False,
89 | greyscale = False,
90 | batch_size = 10,
91 | gradient_accumulate_every = 4,
92 | num_train_steps = 150000,
93 | learning_rate = 2e-4,
94 | save_every = 1000,
95 | evaluate_every = 1000,
96 | generate = False,
97 | generate_types = ['default', 'ema'],
98 | generate_interpolation = False,
99 | aug_test = False,
100 | aug_prob=None,
101 | aug_types=['cutout', 'translation'],
102 | dataset_aug_prob=0.,
103 | attn_res_layers = [32],
104 | freq_chan_attn = False,
105 | disc_output_size = 1,
106 | dual_contrast_loss = False,
107 | antialias = False,
108 | interpolation_num_steps = 100,
109 | save_frames = False,
110 | num_image_tiles = None,
111 | num_workers = None,
112 | multi_gpus = False,
113 | calculate_fid_every = None,
114 | calculate_fid_num_images = 12800,
115 | clear_fid_cache = False,
116 | seed = 42,
117 | amp = False,
118 | show_progress = False,
119 | use_aim = False,
120 | aim_repo = None,
121 | aim_run_hash = None,
122 | load_strict = True
123 | ):
124 | num_image_tiles = default(num_image_tiles, 4 if image_size > 512 else 8)
125 |
126 | model_args = dict(
127 | name = name,
128 | results_dir = results_dir,
129 | models_dir = models_dir,
130 | batch_size = batch_size,
131 | gradient_accumulate_every = gradient_accumulate_every,
132 | attn_res_layers = cast_list(attn_res_layers),
133 | freq_chan_attn = freq_chan_attn,
134 | disc_output_size = disc_output_size,
135 | dual_contrast_loss = dual_contrast_loss,
136 | antialias = antialias,
137 | image_size = image_size,
138 | num_image_tiles = num_image_tiles,
139 | optimizer = optimizer,
140 | num_workers = num_workers,
141 | fmap_max = fmap_max,
142 | transparent = transparent,
143 | greyscale = greyscale,
144 | lr = learning_rate,
145 | save_every = save_every,
146 | evaluate_every = evaluate_every,
147 | aug_prob = aug_prob,
148 | aug_types = cast_list(aug_types),
149 | dataset_aug_prob = dataset_aug_prob,
150 | calculate_fid_every = calculate_fid_every,
151 | calculate_fid_num_images = calculate_fid_num_images,
152 | clear_fid_cache = clear_fid_cache,
153 | amp = amp,
154 | load_strict = load_strict
155 | )
156 |
157 | if generate:
158 | model = Trainer(**model_args, use_aim = use_aim)
159 | model.load(load_from)
160 | samples_name = timestamped_filename()
161 | checkpoint = model.checkpoint_num
162 | dir_result = model.generate(samples_name, num_image_tiles, checkpoint, generate_types)
163 | print(f'sample images generated at {dir_result}')
164 | return
165 |
166 | if generate_interpolation:
167 | model = Trainer(**model_args, use_aim = use_aim)
168 | model.load(load_from)
169 | samples_name = timestamped_filename()
170 | model.generate_interpolation(samples_name, num_image_tiles, num_steps = interpolation_num_steps, save_frames = save_frames)
171 | print(f'interpolation generated at {results_dir}/{name}/{samples_name}')
172 | return
173 |
174 | if show_progress:
175 | model = Trainer(**model_args, use_aim = use_aim)
176 | model.show_progress(num_images=num_image_tiles, types=generate_types)
177 | return
178 |
179 | if aug_test:
180 | DiffAugmentTest(data=data, image_size=image_size, batch_size=batch_size, types=aug_types, nrow=num_image_tiles)
181 | return
182 |
183 | world_size = torch.cuda.device_count()
184 |
185 | if world_size == 1 or not multi_gpus:
186 | run_training(0, 1, model_args, data, load_from, new, num_train_steps, name, seed, use_aim, aim_repo, aim_run_hash)
187 | return
188 |
189 | mp.spawn(run_training,
190 | args=(world_size, model_args, data, load_from, new, num_train_steps, name, seed, use_aim, aim_repo, aim_run_hash,),
191 | nprocs=world_size,
192 | join=True)
193 |
194 | def main():
195 | fire.Fire(train_from_folder)
196 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |  2 |
3 | *512x512 flowers after 12 hours of training, 1 gpu*
4 |
5 |
2 |
3 | *512x512 flowers after 12 hours of training, 1 gpu*
4 |
5 |  6 |
7 | *256x256 flowers after 12 hours of training, 1 gpu*
8 |
9 |
6 |
7 | *256x256 flowers after 12 hours of training, 1 gpu*
8 |
9 |  10 |
11 | *Pizza*
12 |
13 | ## 'Lightweight' GAN
14 |
15 | [](https://badge.fury.io/py/lightweight-gan)
16 |
17 | Implementation of 'lightweight' GAN proposed in ICLR 2021, in Pytorch. The main contributions of the paper is a skip-layer excitation in the generator, paired with autoencoding self-supervised learning in the discriminator. Quoting the one-line summary "converge on single gpu with few hours' training, on 1024 resolution sub-hundred images".
18 |
19 | ## Install
20 |
21 | ```bash
22 | $ pip install lightweight-gan
23 | ```
24 |
25 | ## Use
26 |
27 | One command
28 |
29 | ```bash
30 | $ lightweight_gan --data ./path/to/images --image-size 512
31 | ```
32 |
33 | Model will be saved to `./models/{name}` every 1000 iterations, and samples from the model saved to `./results/{name}`. `name` will be `default`, by default.
34 |
35 | ## Training settings
36 |
37 | Pretty self explanatory for deep learning practitioners
38 |
39 | ```bash
40 | $ lightweight_gan \
41 | --data ./path/to/images \
42 | --name {name of run} \
43 | --batch-size 16 \
44 | --gradient-accumulate-every 4 \
45 | --num-train-steps 200000
46 | ```
47 |
48 | ## Augmentation
49 |
50 | Augmentation is essential for Lightweight GAN to work effectively in a low data setting
51 |
52 | By default, the augmentation types is set to translation and cutout, with color omitted. You can include color as well with the following.
53 |
54 | ```bash
55 | $ lightweight_gan --data ./path/to/images --aug-prob 0.25 --aug-types [translation,cutout,color]
56 | ```
57 |
58 | ### Test augmentation
59 |
60 | You can test and see how your images will be augmented before it pass into a neural network (if you use augmentation). Let's see how it works on this image:
61 |
62 | 
63 |
64 | #### Basic usage
65 |
66 | Base code to augment your image, define `--aug-test` and put path to your image into `--data`:
67 |
68 | ```bash
69 | lightweight_gan \
70 | --aug-test \
71 | --data ./path/to/lena.jpg
72 | ```
73 |
74 | After this will be created the file lena_augs.jpg that will be look something like this:
75 |
76 | 
77 |
78 |
79 | #### Options
80 |
81 | You can use some options to change result:
82 | - `--image-size 256` to change size of image tiles in the result. Default: `256`.
83 | - `--aug-type [color,cutout,translation]` to combine several augmentations. Default: `[cutout,translation]`.
84 | - `--batch-size 10` to change count of images in the result image. Default: `10`.
85 | - `--num-image-tiles 5` to change count of tiles in the result image. Default: `5`.
86 |
87 | Try this command:
88 | ```bash
89 | lightweight_gan \
90 | --aug-test \
91 | --data ./path/to/lena.jpg \
92 | --batch-size 16 \
93 | --num-image-tiles 4 \
94 | --aug-types [color,translation]
95 | ```
96 |
97 | result wil be something like that:
98 |
99 | 
100 |
101 | ### Types of augmentations
102 |
103 | This library contains several types of embedded augmentations.
104 | Some of these works by default, some of these can be controlled from a command as options in the `--aug-types`:
105 | - Horizontal flip (work by default, not under control, runs in the AugWrapper class);
106 | - `color` randomly change brightness, saturation and contrast;
107 | - `cutout` creates random black boxes on the image;
108 | - `offset` randomly moves image by x and y-axis with repeating image;
109 | - `offset_h` only by an x-axis;
110 | - `offset_v` only by a y-axis;
111 | - `translation` randomly moves image on the canvas with black background;
112 |
113 | Full setup of augmentations is `--aug-types [color,cutout,offset,translation]`.
114 | General recommendation is using suitable augs for your data and as many as possible, then after sometime of training disable most destructive (for image) augs.
115 |
116 | #### Color
117 |
118 | 
119 |
120 | #### Cutout
121 |
122 | 
123 |
124 | #### Offset
125 |
126 | 
127 |
128 | Only x-axis:
129 |
130 | 
131 |
132 | Only y-axis:
133 |
134 | 
135 |
136 | #### Translation
137 |
138 | 
139 |
140 | ## Mixed precision
141 |
142 | You can turn on automatic mixed precision with one flag `--amp`
143 |
144 | You should expect it to be 33% faster and save up to 40% memory
145 |
146 | ## Multiple GPUs
147 |
148 | Also one flag to use `--multi-gpus`
149 |
150 |
151 | ## Visualizing training insights with Aim
152 |
153 | [Aim](https://github.com/aimhubio/aim) is an open-source experiment tracker that logs your training runs, enables a beautiful UI to compare them and an API to query them programmatically.
154 |
155 | First you need to install `aim` with `pip`
156 |
157 | ```bash
158 | $ pip install aim
159 | ```
160 |
161 | Next, you can specify Aim logs directory with `--aim_repo` flag, otherwise logs will be stored in the current directory
162 |
163 | ```bash
164 | $ lightweight_gan --data ./path/to/images --image-size 512 --use-aim --aim_repo ./path/to/logs/
165 | ```
166 |
167 | Execute `aim up --repo ./path/to/logs/` to run Aim UI on your server.
168 |
169 | **View all tracked runs, each metric last tracked values and tracked hyperparameters in Runs Dashboard:**
170 |
171 |
10 |
11 | *Pizza*
12 |
13 | ## 'Lightweight' GAN
14 |
15 | [](https://badge.fury.io/py/lightweight-gan)
16 |
17 | Implementation of 'lightweight' GAN proposed in ICLR 2021, in Pytorch. The main contributions of the paper is a skip-layer excitation in the generator, paired with autoencoding self-supervised learning in the discriminator. Quoting the one-line summary "converge on single gpu with few hours' training, on 1024 resolution sub-hundred images".
18 |
19 | ## Install
20 |
21 | ```bash
22 | $ pip install lightweight-gan
23 | ```
24 |
25 | ## Use
26 |
27 | One command
28 |
29 | ```bash
30 | $ lightweight_gan --data ./path/to/images --image-size 512
31 | ```
32 |
33 | Model will be saved to `./models/{name}` every 1000 iterations, and samples from the model saved to `./results/{name}`. `name` will be `default`, by default.
34 |
35 | ## Training settings
36 |
37 | Pretty self explanatory for deep learning practitioners
38 |
39 | ```bash
40 | $ lightweight_gan \
41 | --data ./path/to/images \
42 | --name {name of run} \
43 | --batch-size 16 \
44 | --gradient-accumulate-every 4 \
45 | --num-train-steps 200000
46 | ```
47 |
48 | ## Augmentation
49 |
50 | Augmentation is essential for Lightweight GAN to work effectively in a low data setting
51 |
52 | By default, the augmentation types is set to translation and cutout, with color omitted. You can include color as well with the following.
53 |
54 | ```bash
55 | $ lightweight_gan --data ./path/to/images --aug-prob 0.25 --aug-types [translation,cutout,color]
56 | ```
57 |
58 | ### Test augmentation
59 |
60 | You can test and see how your images will be augmented before it pass into a neural network (if you use augmentation). Let's see how it works on this image:
61 |
62 | 
63 |
64 | #### Basic usage
65 |
66 | Base code to augment your image, define `--aug-test` and put path to your image into `--data`:
67 |
68 | ```bash
69 | lightweight_gan \
70 | --aug-test \
71 | --data ./path/to/lena.jpg
72 | ```
73 |
74 | After this will be created the file lena_augs.jpg that will be look something like this:
75 |
76 | 
77 |
78 |
79 | #### Options
80 |
81 | You can use some options to change result:
82 | - `--image-size 256` to change size of image tiles in the result. Default: `256`.
83 | - `--aug-type [color,cutout,translation]` to combine several augmentations. Default: `[cutout,translation]`.
84 | - `--batch-size 10` to change count of images in the result image. Default: `10`.
85 | - `--num-image-tiles 5` to change count of tiles in the result image. Default: `5`.
86 |
87 | Try this command:
88 | ```bash
89 | lightweight_gan \
90 | --aug-test \
91 | --data ./path/to/lena.jpg \
92 | --batch-size 16 \
93 | --num-image-tiles 4 \
94 | --aug-types [color,translation]
95 | ```
96 |
97 | result wil be something like that:
98 |
99 | 
100 |
101 | ### Types of augmentations
102 |
103 | This library contains several types of embedded augmentations.
104 | Some of these works by default, some of these can be controlled from a command as options in the `--aug-types`:
105 | - Horizontal flip (work by default, not under control, runs in the AugWrapper class);
106 | - `color` randomly change brightness, saturation and contrast;
107 | - `cutout` creates random black boxes on the image;
108 | - `offset` randomly moves image by x and y-axis with repeating image;
109 | - `offset_h` only by an x-axis;
110 | - `offset_v` only by a y-axis;
111 | - `translation` randomly moves image on the canvas with black background;
112 |
113 | Full setup of augmentations is `--aug-types [color,cutout,offset,translation]`.
114 | General recommendation is using suitable augs for your data and as many as possible, then after sometime of training disable most destructive (for image) augs.
115 |
116 | #### Color
117 |
118 | 
119 |
120 | #### Cutout
121 |
122 | 
123 |
124 | #### Offset
125 |
126 | 
127 |
128 | Only x-axis:
129 |
130 | 
131 |
132 | Only y-axis:
133 |
134 | 
135 |
136 | #### Translation
137 |
138 | 
139 |
140 | ## Mixed precision
141 |
142 | You can turn on automatic mixed precision with one flag `--amp`
143 |
144 | You should expect it to be 33% faster and save up to 40% memory
145 |
146 | ## Multiple GPUs
147 |
148 | Also one flag to use `--multi-gpus`
149 |
150 |
151 | ## Visualizing training insights with Aim
152 |
153 | [Aim](https://github.com/aimhubio/aim) is an open-source experiment tracker that logs your training runs, enables a beautiful UI to compare them and an API to query them programmatically.
154 |
155 | First you need to install `aim` with `pip`
156 |
157 | ```bash
158 | $ pip install aim
159 | ```
160 |
161 | Next, you can specify Aim logs directory with `--aim_repo` flag, otherwise logs will be stored in the current directory
162 |
163 | ```bash
164 | $ lightweight_gan --data ./path/to/images --image-size 512 --use-aim --aim_repo ./path/to/logs/
165 | ```
166 |
167 | Execute `aim up --repo ./path/to/logs/` to run Aim UI on your server.
168 |
169 | **View all tracked runs, each metric last tracked values and tracked hyperparameters in Runs Dashboard:**
170 |
171 | 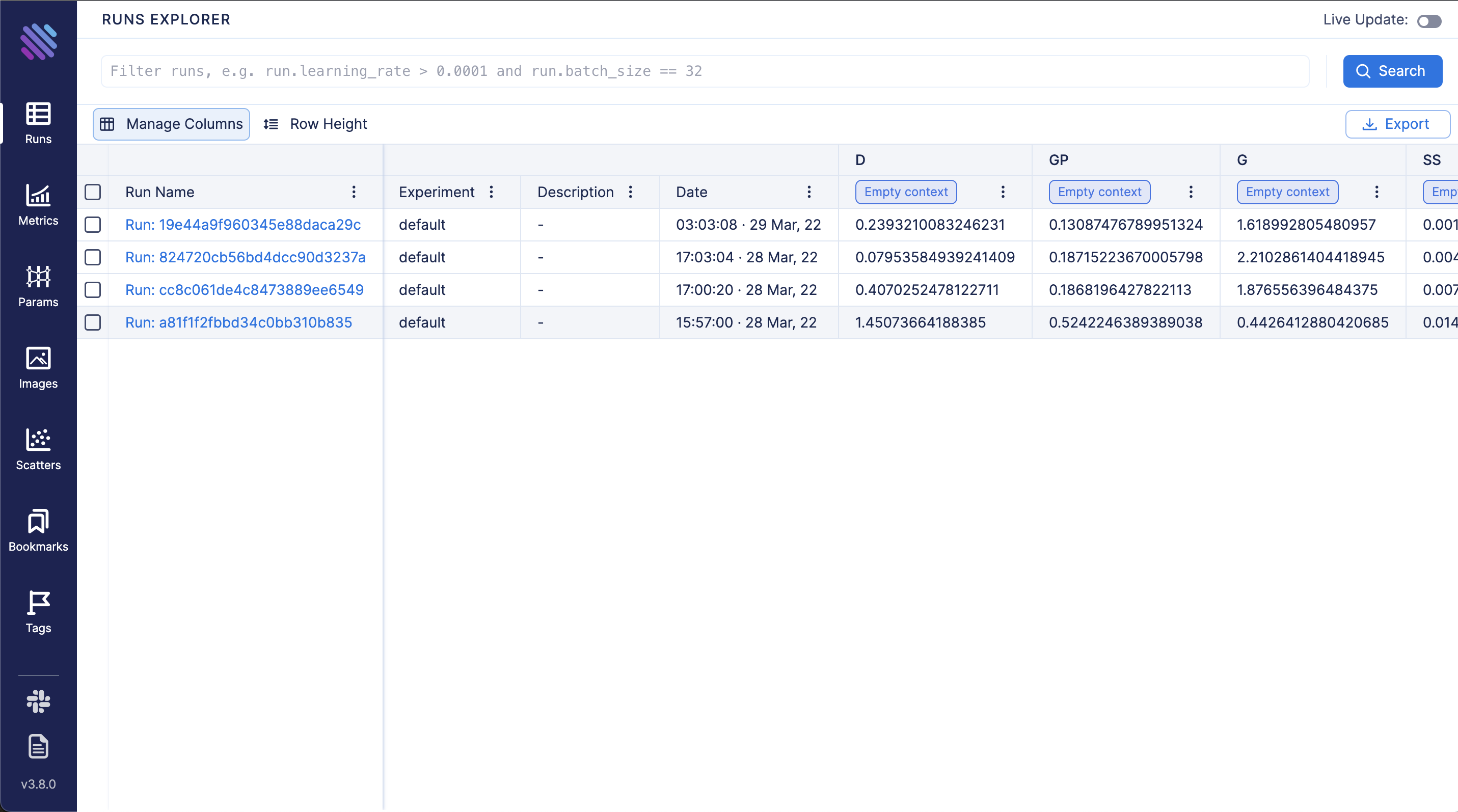 172 |
173 |
174 | **Compare loss curves with Metrics Explorer - group and aggregate by any hyperparameter to easily compare the runs:**
175 |
176 |
172 |
173 |
174 | **Compare loss curves with Metrics Explorer - group and aggregate by any hyperparameter to easily compare the runs:**
175 |
176 | 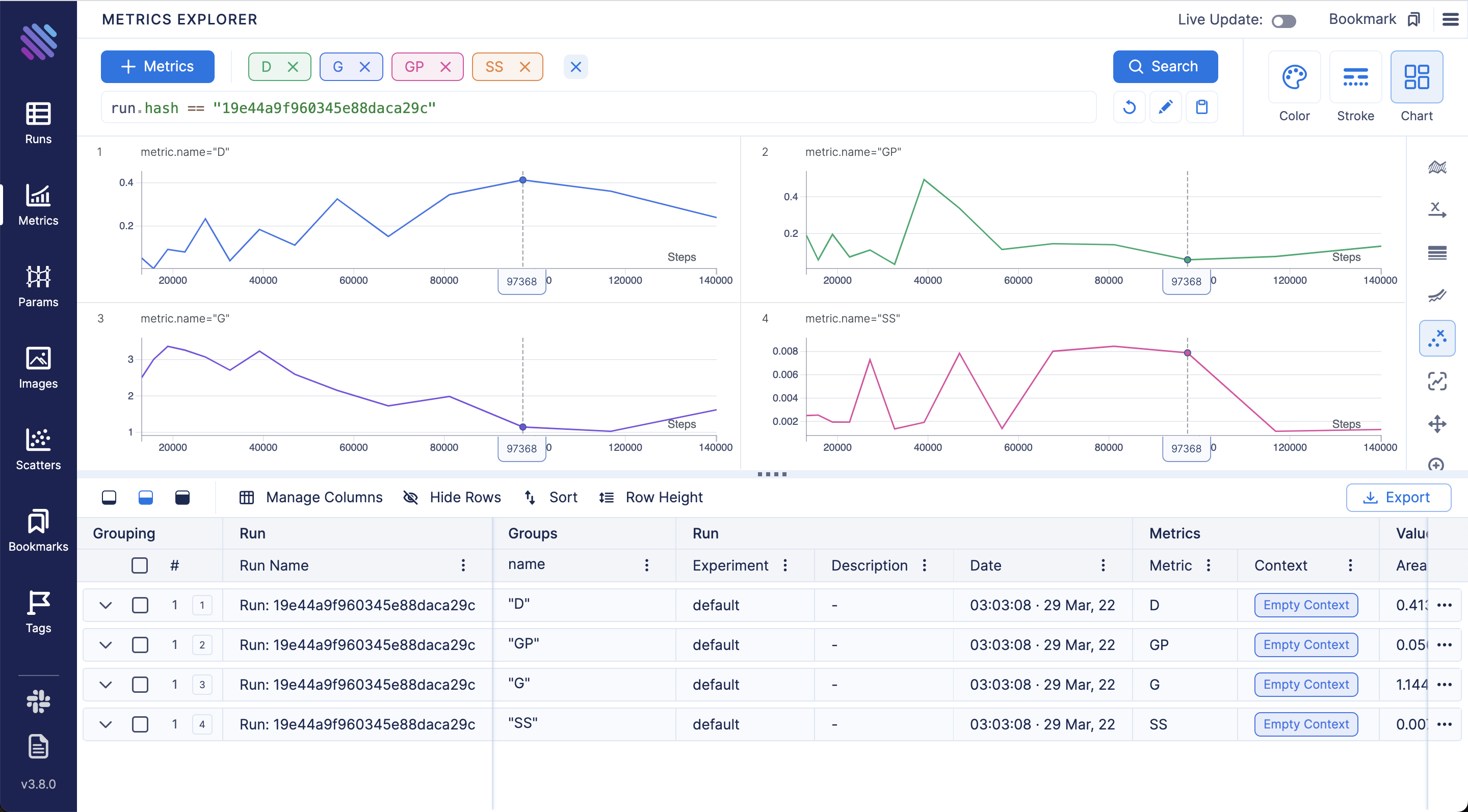 177 |
178 | **Compare and debug generated images across training steps and runs via Images Explorer:**
179 |
180 |
177 |
178 | **Compare and debug generated images across training steps and runs via Images Explorer:**
179 |
180 | 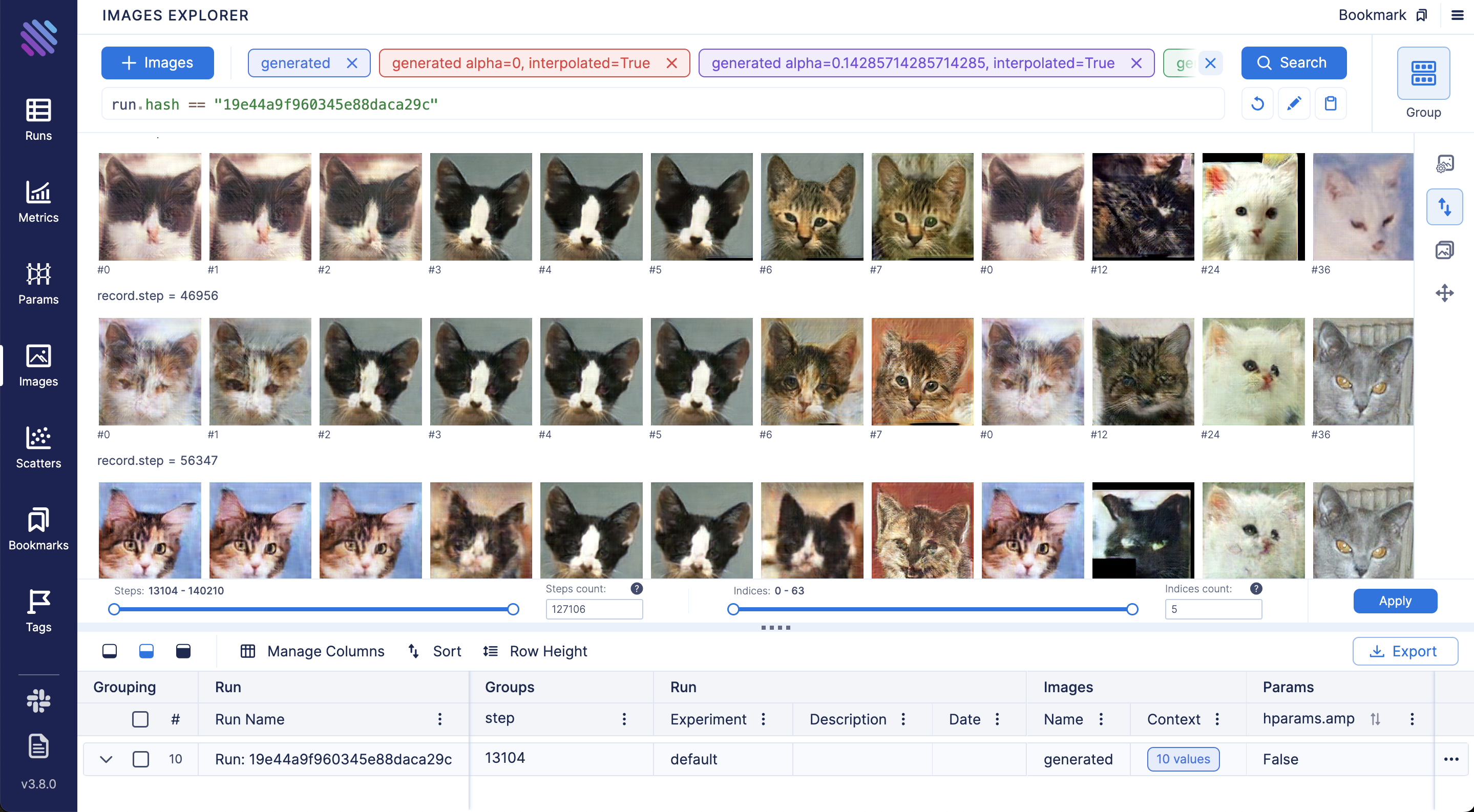 181 |
182 | ## Generating
183 |
184 | Once you have finished training, you can generate samples with one command. You can select which checkpoint number to load from. If `--load-from` is not specified, will default to the latest.
185 |
186 | ```bash
187 | $ lightweight_gan \
188 | --name {name of run} \
189 | --load-from {checkpoint num} \
190 | --generate \
191 | --generate-types {types of result, default: [default,ema]} \
192 | --num-image-tiles {count of image result}
193 | ```
194 |
195 | After run this command you will get folder near results image folder with postfix "-generated-{checkpoint num}".
196 |
197 | You can also generate interpolations
198 |
199 | ```bash
200 | $ lightweight_gan --name {name of run} --generate-interpolation
201 | ```
202 |
203 | ## Show progress
204 |
205 | After creating several checkpoints of model you can generate progress as sequence images by command:
206 |
207 | ```bash
208 | $ lightweight_gan \
209 | --name {name of run} \
210 | --show-progress \
211 | --generate-types {types of result, default: [default,ema]} \
212 | --num-image-tiles {count of image result}
213 | ```
214 |
215 | After running this command you will get a new folder in the results folder, with postfix "-progress". You can convert the images to a video with ffmpeg using the command "ffmpeg -framerate 10 -pattern_type glob -i '*-ema.jpg' out.mp4".
216 |
217 | 
218 |
219 | 
220 |
221 | ## Discriminator output size
222 |
223 | The author has kindly let me know that the discriminator output size (5x5 vs 1x1) leads to different results on different datasets. (5x5 works better for art than for faces, as an example). You can toggle this with a single flag
224 |
225 | ```bash
226 | # disc output size is by default 1x1
227 | $ lightweight_gan --data ./path/to/art --image-size 512 --disc-output-size 5
228 | ```
229 |
230 | ## Attention
231 |
232 | You can add linear + axial attention to specific resolution layers with the following
233 |
234 | ```bash
235 | # make sure there are no spaces between the values within the brackets []
236 | $ lightweight_gan --data ./path/to/images --image-size 512 --attn-res-layers [32,64] --aug-prob 0.25
237 | ```
238 |
239 | ## Dual Contrastive Loss
240 |
241 | A recent paper has proposed that a novel contrastive loss between the real and fake logits can improve quality slightly over the default hinge loss.
242 |
243 | You can use this with one extra flag as follows
244 |
245 | ```bash
246 | $ lightweight_gan --data ./path/to/images --dual-contrast-loss
247 | ```
248 |
249 | ## Bonus
250 |
251 | You can also train with transparent images
252 |
253 | ```bash
254 | $ lightweight_gan --data ./path/to/images --transparent
255 | ```
256 |
257 | Or greyscale
258 |
259 | ```bash
260 | $ lightweight_gan --data ./path/to/images --greyscale
261 | ```
262 |
263 | ## Alternatives
264 |
265 | If you want the current state of the art GAN, you can find it at https://github.com/lucidrains/stylegan2-pytorch
266 |
267 | ## Citations
268 |
269 | ```bibtex
270 | @inproceedings{
271 | anonymous2021towards,
272 | title = {Towards Faster and Stabilized {\{}GAN{\}} Training for High-fidelity Few-shot Image Synthesis},
273 | author = {Anonymous},
274 | booktitle = {Submitted to International Conference on Learning Representations},
275 | year = {2021},
276 | url = {https://openreview.net/forum?id=1Fqg133qRaI},
277 | note = {under review}
278 | }
279 | ```
280 |
281 | ```bibtex
282 | @misc{cao2020global,
283 | title = {Global Context Networks},
284 | author = {Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu},
285 | year = {2020},
286 | eprint = {2012.13375},
287 | archivePrefix = {arXiv},
288 | primaryClass = {cs.CV}
289 | }
290 | ```
291 |
292 | ```bibtex
293 | @misc{qin2020fcanet,
294 | title = {FcaNet: Frequency Channel Attention Networks},
295 | author = {Zequn Qin and Pengyi Zhang and Fei Wu and Xi Li},
296 | year = {2020},
297 | eprint = {2012.11879},
298 | archivePrefix = {arXiv},
299 | primaryClass = {cs.CV}
300 | }
301 | ```
302 |
303 | ```bibtex
304 | @misc{yu2021dual,
305 | title = {Dual Contrastive Loss and Attention for GANs},
306 | author = {Ning Yu and Guilin Liu and Aysegul Dundar and Andrew Tao and Bryan Catanzaro and Larry Davis and Mario Fritz},
307 | year = {2021},
308 | eprint = {2103.16748},
309 | archivePrefix = {arXiv},
310 | primaryClass = {cs.CV}
311 | }
312 | ```
313 |
314 | ```bibtex
315 | @article{Sunkara2022NoMS,
316 | title = {No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects},
317 | author = {Raja Sunkara and Tie Luo},
318 | journal = {ArXiv},
319 | year = {2022},
320 | volume = {abs/2208.03641}
321 | }
322 | ```
323 |
324 | ```bibtex
325 | @inproceedings{Huang2025TheGI,
326 | title = {The GAN is dead; long live the GAN! A Modern GAN Baseline},
327 | author = {Yiwen Huang and Aaron Gokaslan and Volodymyr Kuleshov and James Tompkin},
328 | year = {2025},
329 | url = {https://api.semanticscholar.org/CorpusID:275405495}
330 | }
331 | ```
332 |
333 | *What I cannot create, I do not understand* - Richard Feynman
334 |
--------------------------------------------------------------------------------
/lightweight_gan/lightweight_gan.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import multiprocessing
4 | from random import random
5 | import math
6 | from math import log2, floor
7 | from functools import lru_cache, partial
8 | from contextlib import contextmanager, ExitStack
9 | from pathlib import Path
10 | from shutil import rmtree
11 |
12 | import torch
13 | from torch.amp import autocast, GradScaler
14 | from torch.optim import Adam
15 | from torch import nn, einsum
16 | import torch.nn.functional as F
17 | from torch.utils.data import Dataset, DataLoader
18 | from torch.autograd import grad as torch_grad
19 | from torch.utils.data.distributed import DistributedSampler
20 | from torch.nn.parallel import DistributedDataParallel as DDP
21 |
22 | from PIL import Image
23 | import torchvision
24 | from torchvision import transforms
25 | from kornia.filters import filter2d
26 |
27 | from lightweight_gan.diff_augment import DiffAugment
28 | from lightweight_gan.version import __version__
29 |
30 | from tqdm import tqdm
31 | from einops import rearrange, reduce, repeat
32 | from einops.layers.torch import Rearrange
33 |
34 | from adabelief_pytorch import AdaBelief
35 |
36 | # asserts
37 |
38 | assert torch.cuda.is_available(), 'You need to have an Nvidia GPU with CUDA installed.'
39 |
40 | # constants
41 |
42 | NUM_CORES = multiprocessing.cpu_count()
43 | EXTS = ['jpg', 'jpeg', 'png', 'tiff']
44 |
45 | # helpers
46 |
47 | def exists(val):
48 | return val is not None
49 |
50 | @contextmanager
51 | def null_context():
52 | yield
53 |
54 | def combine_contexts(contexts):
55 | @contextmanager
56 | def multi_contexts():
57 | with ExitStack() as stack:
58 | yield [stack.enter_context(ctx()) for ctx in contexts]
59 | return multi_contexts
60 |
61 | def is_power_of_two(val):
62 | return log2(val).is_integer()
63 |
64 | def default(val, d):
65 | return val if exists(val) else d
66 |
67 | def set_requires_grad(model, bool):
68 | for p in model.parameters():
69 | p.requires_grad = bool
70 |
71 | def cycle(iterable):
72 | while True:
73 | for i in iterable:
74 | yield i
75 |
76 | def raise_if_nan(t):
77 | if torch.isnan(t):
78 | raise NanException
79 |
80 | def gradient_accumulate_contexts(gradient_accumulate_every, is_ddp, ddps):
81 | if is_ddp:
82 | num_no_syncs = gradient_accumulate_every - 1
83 | head = [combine_contexts(map(lambda ddp: ddp.no_sync, ddps))] * num_no_syncs
84 | tail = [null_context]
85 | contexts = head + tail
86 | else:
87 | contexts = [null_context] * gradient_accumulate_every
88 |
89 | for context in contexts:
90 | with context():
91 | yield
92 |
93 | def evaluate_in_chunks(max_batch_size, model, *args):
94 | split_args = list(zip(*list(map(lambda x: x.split(max_batch_size, dim=0), args))))
95 | chunked_outputs = [model(*i) for i in split_args]
96 | if len(chunked_outputs) == 1:
97 | return chunked_outputs[0]
98 | return torch.cat(chunked_outputs, dim=0)
99 |
100 | def slerp(val, low, high):
101 | low_norm = low / torch.norm(low, dim=1, keepdim=True)
102 | high_norm = high / torch.norm(high, dim=1, keepdim=True)
103 | omega = torch.acos((low_norm * high_norm).sum(1))
104 | so = torch.sin(omega)
105 | res = (torch.sin((1.0 - val) * omega) / so).unsqueeze(1) * low + (torch.sin(val * omega) / so).unsqueeze(1) * high
106 | return res
107 |
108 | def safe_div(n, d):
109 | try:
110 | res = n / d
111 | except ZeroDivisionError:
112 | prefix = '' if int(n >= 0) else '-'
113 | res = float(f'{prefix}inf')
114 | return res
115 |
116 | # loss functions
117 |
118 | def gen_hinge_loss(fake, real):
119 | return fake.mean()
120 |
121 | def hinge_loss(real, fake):
122 | return (F.relu(1 + real) + F.relu(1 - fake)).mean()
123 |
124 | def dual_contrastive_loss(real_logits, fake_logits):
125 | device = real_logits.device
126 | real_logits, fake_logits = map(lambda t: rearrange(t, '... -> (...)'), (real_logits, fake_logits))
127 |
128 | def loss_half(t1, t2):
129 | t1 = rearrange(t1, 'i -> i ()')
130 | t2 = repeat(t2, 'j -> i j', i = t1.shape[0])
131 | t = torch.cat((t1, t2), dim = -1)
132 | return F.cross_entropy(t, torch.zeros(t1.shape[0], device = device, dtype = torch.long))
133 |
134 | return loss_half(real_logits, fake_logits) + loss_half(-fake_logits, -real_logits)
135 |
136 | @lru_cache(maxsize=10)
137 | def det_randn(*args):
138 | """
139 | deterministic random to track the same latent vars (and images) across training steps
140 | helps to visualize same image over training steps
141 | """
142 | return torch.randn(*args)
143 |
144 | def interpolate_between(a, b, *, num_samples, dim):
145 | assert num_samples > 2
146 | samples = []
147 | step_size = 0
148 | for _ in range(num_samples):
149 | sample = torch.lerp(a, b, step_size)
150 | samples.append(sample)
151 | step_size += 1 / (num_samples - 1)
152 | return torch.stack(samples, dim=dim)
153 |
154 | # helper classes
155 |
156 | class NanException(Exception):
157 | pass
158 |
159 | class EMA():
160 | def __init__(self, beta):
161 | super().__init__()
162 | self.beta = beta
163 | def update_average(self, old, new):
164 | if not exists(old):
165 | return new
166 | return old * self.beta + (1 - self.beta) * new
167 |
168 | class RandomApply(nn.Module):
169 | def __init__(self, prob, fn, fn_else = lambda x: x):
170 | super().__init__()
171 | self.fn = fn
172 | self.fn_else = fn_else
173 | self.prob = prob
174 | def forward(self, x):
175 | fn = self.fn if random() < self.prob else self.fn_else
176 | return fn(x)
177 |
178 | class ChanNorm(nn.Module):
179 | def __init__(self, dim, eps = 1e-5):
180 | super().__init__()
181 | self.eps = eps
182 | self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
183 | self.b = nn.Parameter(torch.zeros(1, dim, 1, 1))
184 |
185 | def forward(self, x):
186 | var = torch.var(x, dim = 1, unbiased = False, keepdim = True)
187 | mean = torch.mean(x, dim = 1, keepdim = True)
188 | return (x - mean) / (var + self.eps).sqrt() * self.g + self.b
189 |
190 | class PreNorm(nn.Module):
191 | def __init__(self, dim, fn):
192 | super().__init__()
193 | self.fn = fn
194 | self.norm = ChanNorm(dim)
195 |
196 | def forward(self, x):
197 | return self.fn(self.norm(x))
198 |
199 | class Residual(nn.Module):
200 | def __init__(self, fn):
201 | super().__init__()
202 | self.fn = fn
203 |
204 | def forward(self, x):
205 | return self.fn(x) + x
206 |
207 | class SumBranches(nn.Module):
208 | def __init__(self, branches):
209 | super().__init__()
210 | self.branches = nn.ModuleList(branches)
211 | def forward(self, x):
212 | return sum(map(lambda fn: fn(x), self.branches))
213 |
214 | class Blur(nn.Module):
215 | def __init__(self):
216 | super().__init__()
217 | f = torch.Tensor([1, 2, 1])
218 | self.register_buffer('f', f)
219 | def forward(self, x):
220 | f = self.f
221 | f = f[None, None, :] * f [None, :, None]
222 | return filter2d(x, f, normalized=True)
223 |
224 | class Noise(nn.Module):
225 | def __init__(self):
226 | super().__init__()
227 | self.weight = nn.Parameter(torch.zeros(1))
228 |
229 | def forward(self, x, noise = None):
230 | b, _, h, w, device = *x.shape, x.device
231 |
232 | if not exists(noise):
233 | noise = torch.randn(b, 1, h, w, device = device)
234 |
235 | return x + self.weight * noise
236 |
237 | def Conv2dSame(dim_in, dim_out, kernel_size, bias = True):
238 | pad_left = kernel_size // 2
239 | pad_right = (pad_left - 1) if (kernel_size % 2) == 0 else pad_left
240 |
241 | return nn.Sequential(
242 | nn.ZeroPad2d((pad_left, pad_right, pad_left, pad_right)),
243 | nn.Conv2d(dim_in, dim_out, kernel_size, bias = bias)
244 | )
245 |
246 | # attention
247 |
248 | class DepthWiseConv2d(nn.Module):
249 | def __init__(self, dim_in, dim_out, kernel_size, padding = 0, stride = 1, bias = True):
250 | super().__init__()
251 | self.net = nn.Sequential(
252 | nn.Conv2d(dim_in, dim_in, kernel_size = kernel_size, padding = padding, groups = dim_in, stride = stride, bias = bias),
253 | nn.Conv2d(dim_in, dim_out, kernel_size = 1, bias = bias)
254 | )
255 | def forward(self, x):
256 | return self.net(x)
257 |
258 | class LinearAttention(nn.Module):
259 | def __init__(self, dim, dim_head = 64, heads = 8, kernel_size = 3):
260 | super().__init__()
261 | self.scale = dim_head ** -0.5
262 | self.heads = heads
263 | self.dim_head = dim_head
264 | inner_dim = dim_head * heads
265 |
266 | self.kernel_size = kernel_size
267 | self.nonlin = nn.GELU()
268 |
269 | self.to_lin_q = nn.Conv2d(dim, inner_dim, 1, bias = False)
270 | self.to_lin_kv = DepthWiseConv2d(dim, inner_dim * 2, 3, padding = 1, bias = False)
271 |
272 | self.to_q = nn.Conv2d(dim, inner_dim, 1, bias = False)
273 | self.to_kv = nn.Conv2d(dim, inner_dim * 2, 1, bias = False)
274 |
275 | self.to_out = nn.Conv2d(inner_dim * 2, dim, 1)
276 |
277 | def forward(self, fmap):
278 | h, x, y = self.heads, *fmap.shape[-2:]
279 |
280 | # linear attention
281 |
282 | lin_q, lin_k, lin_v = (self.to_lin_q(fmap), *self.to_lin_kv(fmap).chunk(2, dim = 1))
283 | lin_q, lin_k, lin_v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) (x y) c', h = h), (lin_q, lin_k, lin_v))
284 |
285 | lin_q = lin_q.softmax(dim = -1)
286 | lin_k = lin_k.softmax(dim = -2)
287 |
288 | lin_q = lin_q * self.scale
289 |
290 | context = einsum('b n d, b n e -> b d e', lin_k, lin_v)
291 | lin_out = einsum('b n d, b d e -> b n e', lin_q, context)
292 | lin_out = rearrange(lin_out, '(b h) (x y) d -> b (h d) x y', h = h, x = x, y = y)
293 |
294 | # conv-like full attention
295 |
296 | q, k, v = (self.to_q(fmap), *self.to_kv(fmap).chunk(2, dim = 1))
297 | q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) c x y', h = h), (q, k, v))
298 |
299 | k = F.unfold(k, kernel_size = self.kernel_size, padding = self.kernel_size // 2)
300 | v = F.unfold(v, kernel_size = self.kernel_size, padding = self.kernel_size // 2)
301 |
302 | k, v = map(lambda t: rearrange(t, 'b (d j) n -> b n j d', d = self.dim_head), (k, v))
303 |
304 | q = rearrange(q, 'b c ... -> b (...) c') * self.scale
305 |
306 | sim = einsum('b i d, b i j d -> b i j', q, k)
307 | sim = sim - sim.amax(dim = -1, keepdim = True).detach()
308 |
309 | attn = sim.softmax(dim = -1)
310 |
311 | full_out = einsum('b i j, b i j d -> b i d', attn, v)
312 | full_out = rearrange(full_out, '(b h) (x y) d -> b (h d) x y', h = h, x = x, y = y)
313 |
314 | # add outputs of linear attention + conv like full attention
315 |
316 | lin_out = self.nonlin(lin_out)
317 | out = torch.cat((lin_out, full_out), dim = 1)
318 | return self.to_out(out)
319 |
320 | # dataset
321 |
322 | def convert_image_to(img_type, image):
323 | if image.mode != img_type:
324 | return image.convert(img_type)
325 | return image
326 |
327 | class identity(object):
328 | def __call__(self, tensor):
329 | return tensor
330 |
331 | class expand_greyscale(object):
332 | def __init__(self, transparent):
333 | self.transparent = transparent
334 |
335 | def __call__(self, tensor):
336 | channels = tensor.shape[0]
337 | num_target_channels = 4 if self.transparent else 3
338 |
339 | if channels == num_target_channels:
340 | return tensor
341 |
342 | alpha = None
343 | if channels == 1:
344 | color = tensor.expand(3, -1, -1)
345 | elif channels == 2:
346 | color = tensor[:1].expand(3, -1, -1)
347 | alpha = tensor[1:]
348 | else:
349 | raise Exception(f'image with invalid number of channels given {channels}')
350 |
351 | if not exists(alpha) and self.transparent:
352 | alpha = torch.ones(1, *tensor.shape[1:], device=tensor.device)
353 |
354 | return color if not self.transparent else torch.cat((color, alpha))
355 |
356 | def resize_to_minimum_size(min_size, image):
357 | if max(*image.size) < min_size:
358 | return torchvision.transforms.functional.resize(image, min_size)
359 | return image
360 |
361 | class ImageDataset(Dataset):
362 | def __init__(
363 | self,
364 | folder,
365 | image_size,
366 | transparent = False,
367 | greyscale = False,
368 | aug_prob = 0.
369 | ):
370 | super().__init__()
371 | self.folder = folder
372 | self.image_size = image_size
373 | self.paths = [p for ext in EXTS for p in Path(f'{folder}').glob(f'**/*.{ext}')]
374 | assert len(self.paths) > 0, f'No images were found in {folder} for training'
375 |
376 | if transparent:
377 | num_channels = 4
378 | pillow_mode = 'RGBA'
379 | expand_fn = expand_greyscale(transparent)
380 | elif greyscale:
381 | num_channels = 1
382 | pillow_mode = 'L'
383 | expand_fn = identity()
384 | else:
385 | num_channels = 3
386 | pillow_mode = 'RGB'
387 | expand_fn = expand_greyscale(transparent)
388 |
389 | convert_image_fn = partial(convert_image_to, pillow_mode)
390 |
391 | self.transform = transforms.Compose([
392 | transforms.Lambda(convert_image_fn),
393 | transforms.Lambda(partial(resize_to_minimum_size, image_size)),
394 | transforms.Resize(image_size),
395 | RandomApply(aug_prob, transforms.RandomResizedCrop(image_size, scale=(0.5, 1.0), ratio=(0.98, 1.02)), transforms.CenterCrop(image_size)),
396 | transforms.ToTensor(),
397 | transforms.Lambda(expand_fn)
398 | ])
399 |
400 | def __len__(self):
401 | return len(self.paths)
402 |
403 | def __getitem__(self, index):
404 | path = self.paths[index]
405 | img = Image.open(path)
406 | return self.transform(img)
407 |
408 | # augmentations
409 |
410 | def random_hflip(tensor, prob):
411 | if prob > random():
412 | return tensor
413 | return torch.flip(tensor, dims=(3,))
414 |
415 | class AugWrapper(nn.Module):
416 | def __init__(self, D, image_size):
417 | super().__init__()
418 | self.D = D
419 |
420 | def forward(self, images, prob = 0., types = [], detach = False, input_requires_grad = False, return_discr_input = False, **kwargs):
421 | context = torch.no_grad if detach else null_context
422 |
423 | with context():
424 | if random() < prob:
425 | images = random_hflip(images, prob=0.5)
426 | images = DiffAugment(images, types=types)
427 |
428 | discr_input = images
429 |
430 | if input_requires_grad:
431 | discr_input.requires_grad_()
432 |
433 | out = self.D(discr_input, **kwargs)
434 |
435 | if not return_discr_input:
436 | return out
437 |
438 | return discr_input, out
439 |
440 | # modifiable global variables
441 |
442 | norm_class = nn.BatchNorm2d
443 |
444 | class PixelShuffleUpsample(nn.Module):
445 | def __init__(self, dim, dim_out = None):
446 | super().__init__()
447 | dim_out = default(dim_out, dim)
448 | conv = nn.Conv2d(dim, dim_out * 4, 1)
449 |
450 | self.net = nn.Sequential(
451 | conv,
452 | nn.SiLU(),
453 | nn.PixelShuffle(2)
454 | )
455 |
456 | self.init_conv_(conv)
457 |
458 | def init_conv_(self, conv):
459 | o, i, h, w = conv.weight.shape
460 | conv_weight = torch.empty(o // 4, i, h, w)
461 | nn.init.kaiming_uniform_(conv_weight)
462 | conv_weight = repeat(conv_weight, 'o ... -> (o 4) ...')
463 |
464 | conv.weight.data.copy_(conv_weight)
465 | nn.init.zeros_(conv.bias.data)
466 |
467 | def forward(self, x):
468 | return self.net(x)
469 |
470 | def SPConvDownsample(dim, dim_out = None):
471 | # https://arxiv.org/abs/2208.03641 shows this is the most optimal way to downsample
472 | # named SP-conv in the paper, but basically a pixel unshuffle
473 | dim_out = default(dim_out, dim)
474 | return nn.Sequential(
475 | Rearrange('b c (h s1) (w s2) -> b (c s1 s2) h w', s1 = 2, s2 = 2),
476 | nn.Conv2d(dim * 4, dim_out, 1)
477 | )
478 |
479 | # squeeze excitation classes
480 |
481 | # global context network
482 | # https://arxiv.org/abs/2012.13375
483 | # similar to squeeze-excite, but with a simplified attention pooling and a subsequent layer norm
484 |
485 | class GlobalContext(nn.Module):
486 | def __init__(
487 | self,
488 | *,
489 | chan_in,
490 | chan_out
491 | ):
492 | super().__init__()
493 | self.to_k = nn.Conv2d(chan_in, 1, 1)
494 | chan_intermediate = max(3, chan_out // 2)
495 |
496 | self.net = nn.Sequential(
497 | nn.Conv2d(chan_in, chan_intermediate, 1),
498 | nn.LeakyReLU(0.1),
499 | nn.Conv2d(chan_intermediate, chan_out, 1),
500 | nn.Sigmoid()
501 | )
502 | def forward(self, x):
503 | context = self.to_k(x)
504 | context = context.flatten(2).softmax(dim = -1)
505 | out = einsum('b i n, b c n -> b c i', context, x.flatten(2))
506 | out = out.unsqueeze(-1)
507 | return self.net(out)
508 |
509 | # frequency channel attention
510 | # https://arxiv.org/abs/2012.11879
511 |
512 | def get_1d_dct(i, freq, L):
513 | result = math.cos(math.pi * freq * (i + 0.5) / L) / math.sqrt(L)
514 | return result * (1 if freq == 0 else math.sqrt(2))
515 |
516 | def get_dct_weights(width, channel, fidx_u, fidx_v):
517 | dct_weights = torch.zeros(1, channel, width, width)
518 | c_part = channel // len(fidx_u)
519 |
520 | for i, (u_x, v_y) in enumerate(zip(fidx_u, fidx_v)):
521 | for x in range(width):
522 | for y in range(width):
523 | coor_value = get_1d_dct(x, u_x, width) * get_1d_dct(y, v_y, width)
524 | dct_weights[:, i * c_part: (i + 1) * c_part, x, y] = coor_value
525 |
526 | return dct_weights
527 |
528 | class FCANet(nn.Module):
529 | def __init__(
530 | self,
531 | *,
532 | chan_in,
533 | chan_out,
534 | reduction = 4,
535 | width
536 | ):
537 | super().__init__()
538 |
539 | freq_w, freq_h = ([0] * 8), list(range(8)) # in paper, it seems 16 frequencies was ideal
540 | dct_weights = get_dct_weights(width, chan_in, [*freq_w, *freq_h], [*freq_h, *freq_w])
541 | self.register_buffer('dct_weights', dct_weights)
542 |
543 | chan_intermediate = max(3, chan_out // reduction)
544 |
545 | self.net = nn.Sequential(
546 | nn.Conv2d(chan_in, chan_intermediate, 1),
547 | nn.LeakyReLU(0.1),
548 | nn.Conv2d(chan_intermediate, chan_out, 1),
549 | nn.Sigmoid()
550 | )
551 |
552 | def forward(self, x):
553 | x = reduce(x * self.dct_weights, 'b c (h h1) (w w1) -> b c h1 w1', 'sum', h1 = 1, w1 = 1)
554 | return self.net(x)
555 |
556 | # generative adversarial network
557 |
558 | class Generator(nn.Module):
559 | def __init__(
560 | self,
561 | *,
562 | image_size,
563 | latent_dim = 256,
564 | fmap_max = 512,
565 | fmap_inverse_coef = 12,
566 | transparent = False,
567 | greyscale = False,
568 | attn_res_layers = [],
569 | freq_chan_attn = False
570 | ):
571 | super().__init__()
572 | resolution = log2(image_size)
573 | assert is_power_of_two(image_size), 'image size must be a power of 2'
574 |
575 | if transparent:
576 | init_channel = 4
577 | elif greyscale:
578 | init_channel = 1
579 | else:
580 | init_channel = 3
581 |
582 | fmap_max = default(fmap_max, latent_dim)
583 |
584 | self.initial_conv = nn.Sequential(
585 | nn.ConvTranspose2d(latent_dim, latent_dim * 2, 4),
586 | norm_class(latent_dim * 2),
587 | nn.GLU(dim = 1)
588 | )
589 |
590 | num_layers = int(resolution) - 2
591 | features = list(map(lambda n: (n, 2 ** (fmap_inverse_coef - n)), range(2, num_layers + 2)))
592 | features = list(map(lambda n: (n[0], min(n[1], fmap_max)), features))
593 | features = list(map(lambda n: 3 if n[0] >= 8 else n[1], features))
594 | features = [latent_dim, *features]
595 |
596 | in_out_features = list(zip(features[:-1], features[1:]))
597 |
598 | self.res_layers = range(2, num_layers + 2)
599 | self.layers = nn.ModuleList([])
600 | self.res_to_feature_map = dict(zip(self.res_layers, in_out_features))
601 |
602 | self.sle_map = ((3, 7), (4, 8), (5, 9), (6, 10))
603 | self.sle_map = list(filter(lambda t: t[0] <= resolution and t[1] <= resolution, self.sle_map))
604 | self.sle_map = dict(self.sle_map)
605 |
606 | self.num_layers_spatial_res = 1
607 |
608 | for (res, (chan_in, chan_out)) in zip(self.res_layers, in_out_features):
609 | image_width = 2 ** res
610 |
611 | attn = None
612 | if image_width in attn_res_layers:
613 | attn = PreNorm(chan_in, LinearAttention(chan_in))
614 |
615 | sle = None
616 | if res in self.sle_map:
617 | residual_layer = self.sle_map[res]
618 | sle_chan_out = self.res_to_feature_map[residual_layer - 1][-1]
619 |
620 | if freq_chan_attn:
621 | sle = FCANet(
622 | chan_in = chan_out,
623 | chan_out = sle_chan_out,
624 | width = 2 ** (res + 1)
625 | )
626 | else:
627 | sle = GlobalContext(
628 | chan_in = chan_out,
629 | chan_out = sle_chan_out
630 | )
631 |
632 | layer = nn.ModuleList([
633 | nn.Sequential(
634 | PixelShuffleUpsample(chan_in),
635 | Blur(),
636 | Conv2dSame(chan_in, chan_out * 2, 4),
637 | Noise(),
638 | norm_class(chan_out * 2),
639 | nn.GLU(dim = 1)
640 | ),
641 | sle,
642 | attn
643 | ])
644 | self.layers.append(layer)
645 |
646 | self.out_conv = nn.Conv2d(features[-1], init_channel, 3, padding = 1)
647 |
648 | def forward(self, x):
649 | x = rearrange(x, 'b c -> b c () ()')
650 | x = self.initial_conv(x)
651 | x = F.normalize(x, dim = 1)
652 |
653 | residuals = dict()
654 |
655 | for (res, (up, sle, attn)) in zip(self.res_layers, self.layers):
656 | if exists(attn):
657 | x = attn(x) + x
658 |
659 | x = up(x)
660 |
661 | if exists(sle):
662 | out_res = self.sle_map[res]
663 | residual = sle(x)
664 | residuals[out_res] = residual
665 |
666 | next_res = res + 1
667 | if next_res in residuals:
668 | x = x * residuals[next_res]
669 |
670 | return self.out_conv(x)
671 |
672 | class SimpleDecoder(nn.Module):
673 | def __init__(
674 | self,
675 | *,
676 | chan_in,
677 | chan_out = 3,
678 | num_upsamples = 4,
679 | ):
680 | super().__init__()
681 |
682 | self.layers = nn.ModuleList([])
683 | final_chan = chan_out
684 | chans = chan_in
685 |
686 | for ind in range(num_upsamples):
687 | last_layer = ind == (num_upsamples - 1)
688 | chan_out = chans if not last_layer else final_chan * 2
689 | layer = nn.Sequential(
690 | PixelShuffleUpsample(chans),
691 | nn.Conv2d(chans, chan_out, 3, padding = 1),
692 | nn.GLU(dim = 1)
693 | )
694 | self.layers.append(layer)
695 | chans //= 2
696 |
697 | def forward(self, x):
698 | for layer in self.layers:
699 | x = layer(x)
700 | return x
701 |
702 | class Discriminator(nn.Module):
703 | def __init__(
704 | self,
705 | *,
706 | image_size,
707 | fmap_max = 512,
708 | fmap_inverse_coef = 12,
709 | transparent = False,
710 | greyscale = False,
711 | disc_output_size = 5,
712 | attn_res_layers = []
713 | ):
714 | super().__init__()
715 | resolution = log2(image_size)
716 | assert is_power_of_two(image_size), 'image size must be a power of 2'
717 | assert disc_output_size in {1, 5}, 'discriminator output dimensions can only be 5x5 or 1x1'
718 |
719 | resolution = int(resolution)
720 |
721 | if transparent:
722 | init_channel = 4
723 | elif greyscale:
724 | init_channel = 1
725 | else:
726 | init_channel = 3
727 |
728 | num_non_residual_layers = max(0, int(resolution) - 8)
729 | num_residual_layers = 8 - 3
730 |
731 | non_residual_resolutions = range(min(8, resolution), 2, -1)
732 | features = list(map(lambda n: (n, 2 ** (fmap_inverse_coef - n)), non_residual_resolutions))
733 | features = list(map(lambda n: (n[0], min(n[1], fmap_max)), features))
734 |
735 | if num_non_residual_layers == 0:
736 | res, _ = features[0]
737 | features[0] = (res, init_channel)
738 |
739 | chan_in_out = list(zip(features[:-1], features[1:]))
740 |
741 | self.non_residual_layers = nn.ModuleList([])
742 | for ind in range(num_non_residual_layers):
743 | first_layer = ind == 0
744 | last_layer = ind == (num_non_residual_layers - 1)
745 | chan_out = features[0][-1] if last_layer else init_channel
746 |
747 | self.non_residual_layers.append(nn.Sequential(
748 | Blur(),
749 | nn.Conv2d(init_channel, chan_out, 4, stride = 2, padding = 1),
750 | nn.LeakyReLU(0.1)
751 | ))
752 |
753 | self.residual_layers = nn.ModuleList([])
754 |
755 | for (res, ((_, chan_in), (_, chan_out))) in zip(non_residual_resolutions, chan_in_out):
756 | image_width = 2 ** res
757 |
758 | attn = None
759 | if image_width in attn_res_layers:
760 | attn = PreNorm(chan_in, LinearAttention(chan_in))
761 |
762 | self.residual_layers.append(nn.ModuleList([
763 | SumBranches([
764 | nn.Sequential(
765 | Blur(),
766 | SPConvDownsample(chan_in, chan_out),
767 | nn.LeakyReLU(0.1),
768 | nn.Conv2d(chan_out, chan_out, 3, padding = 1),
769 | nn.LeakyReLU(0.1)
770 | ),
771 | nn.Sequential(
772 | Blur(),
773 | nn.AvgPool2d(2),
774 | nn.Conv2d(chan_in, chan_out, 1),
775 | nn.LeakyReLU(0.1),
776 | )
777 | ]),
778 | attn
779 | ]))
780 |
781 | last_chan = features[-1][-1]
782 | if disc_output_size == 5:
783 | self.to_logits = nn.Sequential(
784 | nn.Conv2d(last_chan, last_chan, 1),
785 | nn.LeakyReLU(0.1),
786 | nn.Conv2d(last_chan, 1, 4)
787 | )
788 | elif disc_output_size == 1:
789 | self.to_logits = nn.Sequential(
790 | Blur(),
791 | nn.Conv2d(last_chan, last_chan, 3, stride = 2, padding = 1),
792 | nn.LeakyReLU(0.1),
793 | nn.Conv2d(last_chan, 1, 4)
794 | )
795 |
796 | self.to_shape_disc_out = nn.Sequential(
797 | nn.Conv2d(init_channel, 64, 3, padding = 1),
798 | Residual(PreNorm(64, LinearAttention(64))),
799 | SumBranches([
800 | nn.Sequential(
801 | Blur(),
802 | SPConvDownsample(64, 32),
803 | nn.LeakyReLU(0.1),
804 | nn.Conv2d(32, 32, 3, padding = 1),
805 | nn.LeakyReLU(0.1)
806 | ),
807 | nn.Sequential(
808 | Blur(),
809 | nn.AvgPool2d(2),
810 | nn.Conv2d(64, 32, 1),
811 | nn.LeakyReLU(0.1),
812 | )
813 | ]),
814 | Residual(PreNorm(32, LinearAttention(32))),
815 | nn.AdaptiveAvgPool2d((4, 4)),
816 | nn.Conv2d(32, 1, 4)
817 | )
818 |
819 | self.decoder1 = SimpleDecoder(chan_in = last_chan, chan_out = init_channel)
820 | self.decoder2 = SimpleDecoder(chan_in = features[-2][-1], chan_out = init_channel) if resolution >= 9 else None
821 |
822 | def forward(self, x, calc_aux_loss = False):
823 | orig_img = x
824 |
825 | for layer in self.non_residual_layers:
826 | x = layer(x)
827 |
828 | layer_outputs = []
829 |
830 | for (net, attn) in self.residual_layers:
831 | if exists(attn):
832 | x = attn(x) + x
833 |
834 | x = net(x)
835 | layer_outputs.append(x)
836 |
837 | out = self.to_logits(x).flatten(1)
838 |
839 | img_32x32 = F.interpolate(orig_img, size = (32, 32))
840 | out_32x32 = self.to_shape_disc_out(img_32x32)
841 |
842 | if not calc_aux_loss:
843 | return out, out_32x32, None
844 |
845 | # self-supervised auto-encoding loss
846 |
847 | layer_8x8 = layer_outputs[-1]
848 | layer_16x16 = layer_outputs[-2]
849 |
850 | recon_img_8x8 = self.decoder1(layer_8x8)
851 |
852 | aux_loss = F.mse_loss(
853 | recon_img_8x8,
854 | F.interpolate(orig_img, size = recon_img_8x8.shape[2:])
855 | )
856 |
857 | if exists(self.decoder2):
858 | select_random_quadrant = lambda rand_quadrant, img: rearrange(img, 'b c (m h) (n w) -> (m n) b c h w', m = 2, n = 2)[rand_quadrant]
859 | crop_image_fn = partial(select_random_quadrant, floor(random() * 4))
860 | img_part, layer_16x16_part = map(crop_image_fn, (orig_img, layer_16x16))
861 |
862 | recon_img_16x16 = self.decoder2(layer_16x16_part)
863 |
864 | aux_loss_16x16 = F.mse_loss(
865 | recon_img_16x16,
866 | F.interpolate(img_part, size = recon_img_16x16.shape[2:])
867 | )
868 |
869 | aux_loss = aux_loss + aux_loss_16x16
870 |
871 | return out, out_32x32, aux_loss
872 |
873 | class LightweightGAN(nn.Module):
874 | def __init__(
875 | self,
876 | *,
877 | latent_dim,
878 | image_size,
879 | optimizer = "adam",
880 | fmap_max = 512,
881 | fmap_inverse_coef = 12,
882 | transparent = False,
883 | greyscale = False,
884 | disc_output_size = 5,
885 | attn_res_layers = [],
886 | freq_chan_attn = False,
887 | ttur_mult = 1.,
888 | lr = 2e-4,
889 | rank = 0,
890 | ddp = False
891 | ):
892 | super().__init__()
893 | self.latent_dim = latent_dim
894 | self.image_size = image_size
895 |
896 | G_kwargs = dict(
897 | image_size = image_size,
898 | latent_dim = latent_dim,
899 | fmap_max = fmap_max,
900 | fmap_inverse_coef = fmap_inverse_coef,
901 | transparent = transparent,
902 | greyscale = greyscale,
903 | attn_res_layers = attn_res_layers,
904 | freq_chan_attn = freq_chan_attn
905 | )
906 |
907 | self.G = Generator(**G_kwargs)
908 |
909 | self.D = Discriminator(
910 | image_size = image_size,
911 | fmap_max = fmap_max,
912 | fmap_inverse_coef = fmap_inverse_coef,
913 | transparent = transparent,
914 | greyscale = greyscale,
915 | attn_res_layers = attn_res_layers,
916 | disc_output_size = disc_output_size
917 | )
918 |
919 | self.ema_updater = EMA(0.995)
920 | self.GE = Generator(**G_kwargs)
921 | set_requires_grad(self.GE, False)
922 |
923 |
924 | if optimizer == "adam":
925 | self.G_opt = Adam(self.G.parameters(), lr = lr, betas=(0.5, 0.9))
926 | self.D_opt = Adam(self.D.parameters(), lr = lr * ttur_mult, betas=(0.5, 0.9))
927 | elif optimizer == "adabelief":
928 | self.G_opt = AdaBelief(self.G.parameters(), lr = lr, betas=(0.5, 0.9))
929 | self.D_opt = AdaBelief(self.D.parameters(), lr = lr * ttur_mult, betas=(0.5, 0.9))
930 | else:
931 | assert False, "No valid optimizer is given"
932 |
933 | self.apply(self._init_weights)
934 | self.reset_parameter_averaging()
935 |
936 | self.cuda(rank)
937 | self.D_aug = AugWrapper(self.D, image_size)
938 |
939 | def _init_weights(self, m):
940 | if type(m) in {nn.Conv2d, nn.Linear}:
941 | nn.init.kaiming_normal_(m.weight, a=0, mode='fan_in', nonlinearity='leaky_relu')
942 |
943 | def EMA(self):
944 | def update_moving_average(ma_model, current_model):
945 | for current_params, ma_params in zip(current_model.parameters(), ma_model.parameters()):
946 | old_weight, up_weight = ma_params.data, current_params.data
947 | ma_params.data = self.ema_updater.update_average(old_weight, up_weight)
948 |
949 | for current_buffer, ma_buffer in zip(current_model.buffers(), ma_model.buffers()):
950 | new_buffer_value = self.ema_updater.update_average(ma_buffer, current_buffer)
951 | ma_buffer.copy_(new_buffer_value)
952 |
953 | update_moving_average(self.GE, self.G)
954 |
955 | def reset_parameter_averaging(self):
956 | self.GE.load_state_dict(self.G.state_dict())
957 |
958 | def forward(self, x):
959 | raise NotImplemented
960 |
961 | # trainer
962 |
963 | class Trainer():
964 | def __init__(
965 | self,
966 | name = 'default',
967 | results_dir = 'results',
968 | models_dir = 'models',
969 | base_dir = './',
970 | optimizer = 'adam',
971 | num_workers = None,
972 | latent_dim = 256,
973 | image_size = 128,
974 | num_image_tiles = 8,
975 | fmap_max = 512,
976 | transparent = False,
977 | greyscale = False,
978 | batch_size = 4,
979 | gp_weight = 10,
980 | gradient_accumulate_every = 1,
981 | attn_res_layers = [],
982 | freq_chan_attn = False,
983 | disc_output_size = 5,
984 | dual_contrast_loss = False,
985 | antialias = False,
986 | lr = 2e-4,
987 | lr_mlp = 1.,
988 | ttur_mult = 1.,
989 | save_every = 1000,
990 | evaluate_every = 1000,
991 | aug_prob = None,
992 | aug_types = ['translation', 'cutout'],
993 | dataset_aug_prob = 0.,
994 | calculate_fid_every = None,
995 | calculate_fid_num_images = 12800,
996 | clear_fid_cache = False,
997 | is_ddp = False,
998 | rank = 0,
999 | world_size = 1,
1000 | log = False,
1001 | amp = False,
1002 | hparams = None,
1003 | use_aim = True,
1004 | aim_repo = None,
1005 | aim_run_hash = None,
1006 | load_strict = True,
1007 | *args,
1008 | **kwargs
1009 | ):
1010 | self.GAN_params = [args, kwargs]
1011 | self.GAN = None
1012 |
1013 | self.name = name
1014 |
1015 | base_dir = Path(base_dir)
1016 | self.base_dir = base_dir
1017 | self.results_dir = base_dir / results_dir
1018 | self.models_dir = base_dir / models_dir
1019 | self.fid_dir = base_dir / 'fid' / name
1020 |
1021 | self.config_path = self.models_dir / name / '.config.json'
1022 |
1023 | assert is_power_of_two(image_size), 'image size must be a power of 2 (64, 128, 256, 512, 1024)'
1024 | assert all(map(is_power_of_two, attn_res_layers)), 'resolution layers of attention must all be powers of 2 (16, 32, 64, 128, 256, 512)'
1025 |
1026 | assert not (dual_contrast_loss and disc_output_size > 1), 'discriminator output size cannot be greater than 1 if using dual contrastive loss'
1027 |
1028 | self.image_size = image_size
1029 | self.num_image_tiles = num_image_tiles
1030 |
1031 | self.latent_dim = latent_dim
1032 | self.fmap_max = fmap_max
1033 | self.transparent = transparent
1034 | self.greyscale = greyscale
1035 |
1036 | assert (int(self.transparent) + int(self.greyscale)) < 2, 'you can only set either transparency or greyscale'
1037 |
1038 | self.aug_prob = aug_prob
1039 | self.aug_types = aug_types
1040 |
1041 | self.lr = lr
1042 | self.optimizer = optimizer
1043 | self.num_workers = num_workers
1044 | self.ttur_mult = ttur_mult
1045 | self.batch_size = batch_size
1046 | self.gradient_accumulate_every = gradient_accumulate_every
1047 |
1048 | self.gp_weight = gp_weight
1049 |
1050 | self.evaluate_every = evaluate_every
1051 | self.save_every = save_every
1052 | self.steps = 0
1053 |
1054 | self.attn_res_layers = attn_res_layers
1055 | self.freq_chan_attn = freq_chan_attn
1056 |
1057 | self.disc_output_size = disc_output_size
1058 | self.antialias = antialias
1059 |
1060 | self.dual_contrast_loss = dual_contrast_loss
1061 |
1062 | self.d_loss = 0
1063 | self.g_loss = 0
1064 | self.last_gp_loss = None
1065 | self.last_recon_loss = None
1066 | self.last_fid = None
1067 |
1068 | self.init_folders()
1069 |
1070 | self.loader = None
1071 | self.dataset_aug_prob = dataset_aug_prob
1072 |
1073 | self.calculate_fid_every = calculate_fid_every
1074 | self.calculate_fid_num_images = calculate_fid_num_images
1075 | self.clear_fid_cache = clear_fid_cache
1076 |
1077 | self.is_ddp = is_ddp
1078 | self.is_main = rank == 0
1079 | self.rank = rank
1080 | self.world_size = world_size
1081 |
1082 | self.syncbatchnorm = is_ddp
1083 |
1084 | self.load_strict = load_strict
1085 |
1086 | self.amp = amp
1087 | self.G_scaler = GradScaler(enabled = self.amp)
1088 | self.D_scaler = GradScaler(enabled = self.amp)
1089 |
1090 | self.run = None
1091 | self.hparams = hparams
1092 |
1093 | if self.is_main and use_aim:
1094 | try:
1095 | import aim
1096 | self.aim = aim
1097 | except ImportError:
1098 | print('unable to import aim experiment tracker - please run `pip install aim` first')
1099 |
1100 | self.run = self.aim.Run(run_hash=aim_run_hash, repo=aim_repo)
1101 | self.run['hparams'] = hparams
1102 |
1103 | @property
1104 | def image_extension(self):
1105 | return 'jpg' if not self.transparent else 'png'
1106 |
1107 | @property
1108 | def checkpoint_num(self):
1109 | return floor(self.steps // self.save_every)
1110 |
1111 | def init_GAN(self):
1112 | args, kwargs = self.GAN_params
1113 |
1114 | # set some global variables before instantiating GAN
1115 |
1116 | global norm_class
1117 | global Blur
1118 |
1119 | norm_class = nn.SyncBatchNorm if self.syncbatchnorm else nn.BatchNorm2d
1120 | Blur = nn.Identity if not self.antialias else Blur
1121 |
1122 | # handle bugs when
1123 | # switching from multi-gpu back to single gpu
1124 |
1125 | if self.syncbatchnorm and not self.is_ddp:
1126 | import torch.distributed as dist
1127 | os.environ['MASTER_ADDR'] = 'localhost'
1128 | os.environ['MASTER_PORT'] = '12355'
1129 | dist.init_process_group('nccl', rank=0, world_size=1)
1130 |
1131 | # instantiate GAN
1132 |
1133 | self.GAN = LightweightGAN(
1134 | optimizer=self.optimizer,
1135 | lr = self.lr,
1136 | latent_dim = self.latent_dim,
1137 | attn_res_layers = self.attn_res_layers,
1138 | freq_chan_attn = self.freq_chan_attn,
1139 | image_size = self.image_size,
1140 | ttur_mult = self.ttur_mult,
1141 | fmap_max = self.fmap_max,
1142 | disc_output_size = self.disc_output_size,
1143 | transparent = self.transparent,
1144 | greyscale = self.greyscale,
1145 | rank = self.rank,
1146 | *args,
1147 | **kwargs
1148 | )
1149 |
1150 | if self.is_ddp:
1151 | ddp_kwargs = {'device_ids': [self.rank], 'output_device': self.rank, 'find_unused_parameters': True}
1152 |
1153 | self.G_ddp = DDP(self.GAN.G, **ddp_kwargs)
1154 | self.D_ddp = DDP(self.GAN.D, **ddp_kwargs)
1155 | self.D_aug_ddp = DDP(self.GAN.D_aug, **ddp_kwargs)
1156 |
1157 | def write_config(self):
1158 | self.config_path.write_text(json.dumps(self.config()))
1159 |
1160 | def load_config(self):
1161 | config = self.config() if not self.config_path.exists() else json.loads(self.config_path.read_text())
1162 | self.image_size = config['image_size']
1163 | self.transparent = config['transparent']
1164 | self.syncbatchnorm = config['syncbatchnorm']
1165 | self.disc_output_size = config['disc_output_size']
1166 | self.greyscale = config.pop('greyscale', False)
1167 | self.attn_res_layers = config.pop('attn_res_layers', [])
1168 | self.freq_chan_attn = config.pop('freq_chan_attn', False)
1169 | self.optimizer = config.pop('optimizer', 'adam')
1170 | self.fmap_max = config.pop('fmap_max', 512)
1171 | del self.GAN
1172 | self.init_GAN()
1173 |
1174 | def config(self):
1175 | return {
1176 | 'image_size': self.image_size,
1177 | 'transparent': self.transparent,
1178 | 'greyscale': self.greyscale,
1179 | 'syncbatchnorm': self.syncbatchnorm,
1180 | 'disc_output_size': self.disc_output_size,
1181 | 'optimizer': self.optimizer,
1182 | 'attn_res_layers': self.attn_res_layers,
1183 | 'freq_chan_attn': self.freq_chan_attn
1184 | }
1185 |
1186 | def set_data_src(self, folder):
1187 | num_workers = default(self.num_workers, math.ceil(NUM_CORES / self.world_size))
1188 | self.dataset = ImageDataset(folder, self.image_size, transparent = self.transparent, greyscale = self.greyscale, aug_prob = self.dataset_aug_prob)
1189 | sampler = DistributedSampler(self.dataset, rank=self.rank, num_replicas=self.world_size, shuffle=True) if self.is_ddp else None
1190 | dataloader = DataLoader(self.dataset, num_workers = num_workers, batch_size = math.ceil(self.batch_size / self.world_size), sampler = sampler, shuffle = not self.is_ddp, drop_last = True, pin_memory = True)
1191 | self.loader = cycle(dataloader)
1192 |
1193 | # auto set augmentation prob for user if dataset is detected to be low
1194 | num_samples = len(self.dataset)
1195 | if not exists(self.aug_prob) and num_samples < 1e5:
1196 | self.aug_prob = min(0.5, (1e5 - num_samples) * 3e-6)
1197 | print(f'autosetting augmentation probability to {round(self.aug_prob * 100)}%')
1198 |
1199 | def train(self):
1200 | assert exists(self.loader), 'You must first initialize the data source with `.set_data_src()`'
1201 | device = torch.device(f'cuda:{self.rank}')
1202 |
1203 | if not exists(self.GAN):
1204 | self.init_GAN()
1205 |
1206 | self.GAN.train()
1207 | total_disc_loss = torch.zeros([], device=device)
1208 | total_gen_loss = torch.zeros([], device=device)
1209 |
1210 | batch_size = math.ceil(self.batch_size / self.world_size)
1211 |
1212 | image_size = self.GAN.image_size
1213 | latent_dim = self.GAN.latent_dim
1214 |
1215 | aug_prob = default(self.aug_prob, 0)
1216 | aug_types = self.aug_types
1217 | aug_kwargs = {'prob': aug_prob, 'types': aug_types}
1218 |
1219 | G = self.GAN.G if not self.is_ddp else self.G_ddp
1220 | D = self.GAN.D if not self.is_ddp else self.D_ddp
1221 | D_aug = self.GAN.D_aug if not self.is_ddp else self.D_aug_ddp
1222 |
1223 | apply_gradient_penalty = self.steps % 4 == 0
1224 |
1225 | # amp related contexts and functions
1226 |
1227 | amp_context = partial(autocast, 'cuda') if self.amp else null_context
1228 |
1229 | # discriminator loss fn
1230 |
1231 | if self.dual_contrast_loss:
1232 | D_loss_fn = dual_contrastive_loss
1233 | else:
1234 | D_loss_fn = hinge_loss
1235 |
1236 | # train discriminator
1237 |
1238 | self.GAN.D_opt.zero_grad()
1239 | for i in gradient_accumulate_contexts(self.gradient_accumulate_every, self.is_ddp, ddps=[D_aug, G]):
1240 | latents = torch.randn(batch_size, latent_dim).cuda(self.rank)
1241 | image_batch = next(self.loader).cuda(self.rank)
1242 |
1243 | with amp_context():
1244 | with torch.no_grad():
1245 | generated_images = G(latents)
1246 |
1247 | if apply_gradient_penalty:
1248 | image_batch.requires_grad_()
1249 |
1250 | generated_images, (fake_output, fake_output_32x32, _) = D_aug(generated_images, detach = True, input_requires_grad = apply_gradient_penalty, return_discr_input = True, **aug_kwargs)
1251 |
1252 | real_output, real_output_32x32, real_aux_loss = D_aug(image_batch, calc_aux_loss = True, **aug_kwargs)
1253 |
1254 | real_output_loss = real_output
1255 | fake_output_loss = fake_output
1256 |
1257 | divergence = D_loss_fn(real_output_loss, fake_output_loss)
1258 | divergence_32x32 = D_loss_fn(real_output_32x32, fake_output_32x32)
1259 | disc_loss = divergence + divergence_32x32
1260 |
1261 | aux_loss = real_aux_loss
1262 | disc_loss = disc_loss + aux_loss
1263 |
1264 | if apply_gradient_penalty:
1265 | real_outputs = [real_output, real_output_32x32]
1266 | real_outputs = list(map(self.D_scaler.scale, real_outputs)) if self.amp else real_outputs
1267 |
1268 | fake_outputs = [fake_output, fake_output_32x32]
1269 | fake_outputs = list(map(self.D_scaler.scale, fake_outputs)) if self.amp else fake_outputs
1270 |
1271 | scaled_real_gradients = torch_grad(outputs=real_outputs, inputs=image_batch,
1272 | grad_outputs=[torch.ones_like(t) for t in real_outputs],
1273 | create_graph=True, retain_graph=True, only_inputs=True)[0]
1274 |
1275 | scaled_fake_gradients = torch_grad(outputs=fake_outputs, inputs=generated_images,
1276 | grad_outputs=[torch.ones_like(t) for t in fake_outputs],
1277 | create_graph=True, retain_graph=True, only_inputs=True)[0]
1278 |
1279 | inv_scale = safe_div(1., self.D_scaler.get_scale()) if self.amp else 1.
1280 |
1281 | if inv_scale != float('inf'):
1282 | scaled_gradients = torch.cat((scaled_real_gradients, scaled_fake_gradients))
1283 |
1284 | gradients = scaled_gradients * inv_scale
1285 |
1286 | with amp_context():
1287 | gradients = gradients.reshape(2 * batch_size, -1)
1288 |
1289 | gp = self.gp_weight * (gradients.norm(2, dim = 1) ** 2).mean()
1290 |
1291 | if not torch.isnan(gp):
1292 | disc_loss = disc_loss + gp
1293 | self.last_gp_loss = gp.clone().detach().item()
1294 |
1295 | with amp_context():
1296 | disc_loss = disc_loss / self.gradient_accumulate_every
1297 |
1298 | disc_loss.register_hook(raise_if_nan)
1299 | self.D_scaler.scale(disc_loss).backward()
1300 | total_disc_loss += divergence
1301 |
1302 | self.last_recon_loss = aux_loss.item()
1303 | self.d_loss = float(total_disc_loss.item() / self.gradient_accumulate_every)
1304 | self.D_scaler.step(self.GAN.D_opt)
1305 | self.D_scaler.update()
1306 |
1307 | # generator loss fn
1308 |
1309 | if self.dual_contrast_loss:
1310 | G_loss_fn = dual_contrastive_loss
1311 | G_requires_calc_real = True
1312 | else:
1313 | G_loss_fn = gen_hinge_loss
1314 | G_requires_calc_real = False
1315 |
1316 | # train generator
1317 |
1318 | self.GAN.G_opt.zero_grad()
1319 |
1320 | for i in gradient_accumulate_contexts(self.gradient_accumulate_every, self.is_ddp, ddps=[G, D_aug]):
1321 | latents = torch.randn(batch_size, latent_dim).cuda(self.rank)
1322 |
1323 | if G_requires_calc_real:
1324 | image_batch = next(self.loader).cuda(self.rank)
1325 | image_batch.requires_grad_()
1326 |
1327 | with amp_context():
1328 | generated_images = G(latents)
1329 |
1330 | fake_output, fake_output_32x32, _ = D_aug(generated_images, **aug_kwargs)
1331 | real_output, real_output_32x32, _ = D_aug(image_batch, **aug_kwargs) if G_requires_calc_real else (None, None, None)
1332 |
1333 | loss = G_loss_fn(fake_output, real_output)
1334 | loss_32x32 = G_loss_fn(fake_output_32x32, real_output_32x32)
1335 |
1336 | gen_loss = loss + loss_32x32
1337 |
1338 | gen_loss = gen_loss / self.gradient_accumulate_every
1339 |
1340 | gen_loss.register_hook(raise_if_nan)
1341 | self.G_scaler.scale(gen_loss).backward()
1342 | total_gen_loss += loss
1343 |
1344 | self.g_loss = float(total_gen_loss.item() / self.gradient_accumulate_every)
1345 | self.G_scaler.step(self.GAN.G_opt)
1346 | self.G_scaler.update()
1347 |
1348 | # calculate moving averages
1349 |
1350 | if self.is_main and self.steps % 10 == 0 and self.steps > 20000:
1351 | self.GAN.EMA()
1352 |
1353 | if self.is_main and self.steps <= 25000 and self.steps % 1000 == 2:
1354 | self.GAN.reset_parameter_averaging()
1355 |
1356 | # save from NaN errors
1357 |
1358 | if any(torch.isnan(l) for l in (total_gen_loss, total_disc_loss)):
1359 | print(f'NaN detected for generator or discriminator. Loading from checkpoint #{self.checkpoint_num}')
1360 | self.load(self.checkpoint_num)
1361 | raise NanException
1362 |
1363 | del total_disc_loss
1364 | del total_gen_loss
1365 |
1366 | # periodically save results
1367 |
1368 | if self.is_main:
1369 | if self.steps % self.save_every == 0:
1370 | self.save(self.checkpoint_num)
1371 |
1372 | if self.steps % self.evaluate_every == 0 or (self.steps % 100 == 0 and self.steps < 20000):
1373 | self.evaluate(floor(self.steps / self.evaluate_every), num_image_tiles = self.num_image_tiles)
1374 |
1375 | if exists(self.calculate_fid_every) and self.steps % self.calculate_fid_every == 0 and self.steps != 0:
1376 | num_batches = math.ceil(self.calculate_fid_num_images / self.batch_size)
1377 | fid = self.calculate_fid(num_batches)
1378 | self.last_fid = fid
1379 |
1380 | with open(str(self.results_dir / self.name / f'fid_scores.txt'), 'a') as f:
1381 | f.write(f'{self.steps},{fid}\n')
1382 |
1383 | self.steps += 1
1384 |
1385 | @torch.no_grad()
1386 | def evaluate(self, num = 0, num_image_tiles = 4):
1387 | self.GAN.eval()
1388 |
1389 | ext = self.image_extension
1390 | num_rows = num_image_tiles
1391 |
1392 | latent_dim = self.GAN.latent_dim
1393 | image_size = self.GAN.image_size
1394 |
1395 | # latents and noise
1396 | def image_to_pil(image):
1397 | ndarr = image.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()
1398 | im = Image.fromarray(ndarr)
1399 | return im
1400 |
1401 | latents = det_randn((num_rows ** 2, latent_dim)).cuda(self.rank)
1402 | interpolate_latents = interpolate_between(latents[:num_rows], latents[-num_rows:],
1403 | num_samples=num_rows,
1404 | dim=0).flatten(end_dim=1)
1405 |
1406 | generate_interpolations = self.generate_(self.GAN.G, interpolate_latents)
1407 | if self.run is not None:
1408 | grouped = generate_interpolations.view(num_rows, num_rows, *generate_interpolations.shape[1:])
1409 | for idx, images in enumerate(grouped):
1410 | alpha = idx / (len(grouped) - 1)
1411 | aim_images = []
1412 | for image in images:
1413 | im = image_to_pil(image)
1414 | aim_images.append(self.aim.Image(im, caption=f'#{idx}'))
1415 |
1416 | self.run.track(value=aim_images, name='generated',
1417 | step=self.steps,
1418 | context={'interpolated': True,
1419 | 'alpha': alpha})
1420 | torchvision.utils.save_image(generate_interpolations, str(self.results_dir / self.name / f'{str(num)}-interp.{ext}'), nrow=num_rows)
1421 | # regular
1422 |
1423 | generated_images = self.generate_(self.GAN.G, latents)
1424 |
1425 | if self.run is not None:
1426 | aim_images = []
1427 | for idx, image in enumerate(generated_images):
1428 | im = image_to_pil(image)
1429 | aim_images.append(self.aim.Image(im, caption=f'#{idx}'))
1430 |
1431 | self.run.track(value=aim_images, name='generated',
1432 | step=self.steps,
1433 | context={'ema': False})
1434 | torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}.{ext}'), nrow=num_rows)
1435 |
1436 | # moving averages
1437 |
1438 | generated_images = self.generate_(self.GAN.GE, latents)
1439 | if self.run is not None:
1440 | aim_images = []
1441 | for idx, image in enumerate(generated_images):
1442 | im = image_to_pil(image)
1443 | aim_images.append(self.aim.Image(im, caption=f'EMA #{idx}'))
1444 |
1445 | self.run.track(value=aim_images, name='generated',
1446 | step=self.steps,
1447 | context={'ema': True})
1448 | torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}-ema.{ext}'), nrow=num_rows)
1449 |
1450 | @torch.no_grad()
1451 | def generate(self, num=0, num_image_tiles=4, checkpoint=None, types=['default', 'ema']):
1452 | self.GAN.eval()
1453 |
1454 | latent_dim = self.GAN.latent_dim
1455 | dir_name = self.name + str('-generated-') + str(checkpoint)
1456 | dir_full = Path().absolute() / self.results_dir / dir_name
1457 | ext = self.image_extension
1458 |
1459 | if not dir_full.exists():
1460 | os.mkdir(dir_full)
1461 |
1462 | # regular
1463 | if 'default' in types:
1464 | for i in tqdm(range(num_image_tiles), desc='Saving generated default images'):
1465 | latents = torch.randn((1, latent_dim)).cuda(self.rank)
1466 | generated_image = self.generate_(self.GAN.G, latents)
1467 | path = str(self.results_dir / dir_name / f'{str(num)}-{str(i)}.{ext}')
1468 | torchvision.utils.save_image(generated_image[0], path, nrow=1)
1469 |
1470 | # moving averages
1471 | if 'ema' in types:
1472 | for i in tqdm(range(num_image_tiles), desc='Saving generated EMA images'):
1473 | latents = torch.randn((1, latent_dim)).cuda(self.rank)
1474 | generated_image = self.generate_(self.GAN.GE, latents)
1475 | path = str(self.results_dir / dir_name / f'{str(num)}-{str(i)}-ema.{ext}')
1476 | torchvision.utils.save_image(generated_image[0], path, nrow=1)
1477 |
1478 | return dir_full
1479 |
1480 | @torch.no_grad()
1481 | def show_progress(self, num_images=4, types=['default', 'ema']):
1482 | checkpoints = self.get_checkpoints()
1483 | assert exists(checkpoints), 'cannot find any checkpoints to create a training progress video for'
1484 |
1485 | dir_name = self.name + str('-progress')
1486 | dir_full = Path().absolute() / self.results_dir / dir_name
1487 | ext = self.image_extension
1488 | latents = None
1489 |
1490 | zfill_length = math.ceil(math.log10(len(checkpoints)))
1491 |
1492 | if not dir_full.exists():
1493 | os.mkdir(dir_full)
1494 |
1495 | for checkpoint in tqdm(checkpoints, desc='Generating progress images'):
1496 | self.load(checkpoint, print_version=False)
1497 | self.GAN.eval()
1498 |
1499 | if checkpoint == 0:
1500 | latents = torch.randn((num_images, self.GAN.latent_dim)).cuda(self.rank)
1501 |
1502 | # regular
1503 | if 'default' in types:
1504 | generated_image = self.generate_(self.GAN.G, latents)
1505 | path = str(self.results_dir / dir_name / f'{str(checkpoint).zfill(zfill_length)}.{ext}')
1506 | torchvision.utils.save_image(generated_image, path, nrow=num_images)
1507 |
1508 | # moving averages
1509 | if 'ema' in types:
1510 | generated_image = self.generate_(self.GAN.GE, latents)
1511 | path = str(self.results_dir / dir_name / f'{str(checkpoint).zfill(zfill_length)}-ema.{ext}')
1512 | torchvision.utils.save_image(generated_image, path, nrow=num_images)
1513 |
1514 | @torch.no_grad()
1515 | def calculate_fid(self, num_batches):
1516 | from pytorch_fid import fid_score
1517 | torch.cuda.empty_cache()
1518 |
1519 | real_path = self.fid_dir / 'real'
1520 | fake_path = self.fid_dir / 'fake'
1521 |
1522 | # remove any existing files used for fid calculation and recreate directories
1523 | if not real_path.exists() or self.clear_fid_cache:
1524 | rmtree(real_path, ignore_errors=True)
1525 | os.makedirs(real_path)
1526 |
1527 | for batch_num in tqdm(range(num_batches), desc='calculating FID - saving reals'):
1528 | real_batch = next(self.loader)
1529 | for k, image in enumerate(real_batch.unbind(0)):
1530 | ind = k + batch_num * self.batch_size
1531 | torchvision.utils.save_image(image, real_path / f'{ind}.png')
1532 |
1533 | # generate a bunch of fake images in results / name / fid_fake
1534 |
1535 | rmtree(fake_path, ignore_errors=True)
1536 | os.makedirs(fake_path)
1537 |
1538 | self.GAN.eval()
1539 | ext = self.image_extension
1540 |
1541 | latent_dim = self.GAN.latent_dim
1542 | image_size = self.GAN.image_size
1543 |
1544 | for batch_num in tqdm(range(num_batches), desc='calculating FID - saving generated'):
1545 | # latents and noise
1546 | latents = torch.randn(self.batch_size, latent_dim).cuda(self.rank)
1547 |
1548 | # moving averages
1549 | generated_images = self.generate_(self.GAN.GE, latents)
1550 |
1551 | for j, image in enumerate(generated_images.unbind(0)):
1552 | ind = j + batch_num * self.batch_size
1553 | torchvision.utils.save_image(image, str(fake_path / f'{str(ind)}-ema.{ext}'))
1554 |
1555 | return fid_score.calculate_fid_given_paths([str(real_path), str(fake_path)], 256, latents.device, 2048)
1556 |
1557 | @torch.no_grad()
1558 | def generate_(self, G, style, num_image_tiles = 8):
1559 | generated_images = evaluate_in_chunks(self.batch_size, G, style)
1560 | return generated_images.clamp_(0., 1.)
1561 |
1562 | @torch.no_grad()
1563 | def generate_interpolation(self, num = 0, num_image_tiles = 8, num_steps = 100, save_frames = False):
1564 | self.GAN.eval()
1565 | ext = self.image_extension
1566 | num_rows = num_image_tiles
1567 |
1568 | latent_dim = self.GAN.latent_dim
1569 | image_size = self.GAN.image_size
1570 |
1571 | # latents and noise
1572 |
1573 | latents_low = torch.randn(num_rows ** 2, latent_dim).cuda(self.rank)
1574 | latents_high = torch.randn(num_rows ** 2, latent_dim).cuda(self.rank)
1575 |
1576 | ratios = torch.linspace(0., 8., num_steps)
1577 |
1578 | frames = []
1579 | for ratio in tqdm(ratios):
1580 | interp_latents = slerp(ratio, latents_low, latents_high)
1581 | generated_images = self.generate_(self.GAN.GE, interp_latents)
1582 | images_grid = torchvision.utils.make_grid(generated_images, nrow = num_rows)
1583 | pil_image = transforms.ToPILImage()(images_grid.cpu())
1584 |
1585 | if self.transparent:
1586 | background = Image.new('RGBA', pil_image.size, (255, 255, 255))
1587 | pil_image = Image.alpha_composite(background, pil_image)
1588 |
1589 | frames.append(pil_image)
1590 |
1591 | frames[0].save(str(self.results_dir / self.name / f'{str(num)}.gif'), save_all=True, append_images=frames[1:], duration=80, loop=0, optimize=True)
1592 |
1593 | if save_frames:
1594 | folder_path = (self.results_dir / self.name / f'{str(num)}')
1595 | folder_path.mkdir(parents=True, exist_ok=True)
1596 | for ind, frame in enumerate(frames):
1597 | frame.save(str(folder_path / f'{str(ind)}.{ext}'))
1598 |
1599 | def print_log(self):
1600 | data = [
1601 | ('G', self.g_loss),
1602 | ('D', self.d_loss),
1603 | ('GP', self.last_gp_loss),
1604 | ('SS', self.last_recon_loss),
1605 | ('FID', self.last_fid)
1606 | ]
1607 |
1608 | data = [d for d in data if exists(d[1])]
1609 | log = ' | '.join(map(lambda n: f'{n[0]}: {n[1]:.2f}', data))
1610 | print(log)
1611 |
1612 | if self.run is not None:
1613 | for key, value in data:
1614 | self.run.track(value, key, step=self.steps)
1615 |
1616 | return data
1617 |
1618 | def model_name(self, num):
1619 | return str(self.models_dir / self.name / f'model_{num}.pt')
1620 |
1621 | def init_folders(self):
1622 | (self.results_dir / self.name).mkdir(parents=True, exist_ok=True)
1623 | (self.models_dir / self.name).mkdir(parents=True, exist_ok=True)
1624 |
1625 | def clear(self):
1626 | rmtree(str(self.models_dir / self.name), True)
1627 | rmtree(str(self.results_dir / self.name), True)
1628 | rmtree(str(self.fid_dir), True)
1629 | rmtree(str(self.config_path), True)
1630 | self.init_folders()
1631 |
1632 | def save(self, num):
1633 | save_data = {
1634 | 'GAN': self.GAN.state_dict(),
1635 | 'version': __version__,
1636 | 'G_scaler': self.G_scaler.state_dict(),
1637 | 'D_scaler': self.D_scaler.state_dict()
1638 | }
1639 |
1640 | torch.save(save_data, self.model_name(num))
1641 | self.write_config()
1642 |
1643 | def load(self, num=-1, print_version=True):
1644 | self.load_config()
1645 |
1646 | name = num
1647 | if num == -1:
1648 | checkpoints = self.get_checkpoints()
1649 |
1650 | if not exists(checkpoints):
1651 | return
1652 |
1653 | name = checkpoints[-1]
1654 | print(f'continuing from previous epoch - {name}')
1655 |
1656 | self.steps = name * self.save_every
1657 |
1658 | load_data = torch.load(self.model_name(name), weights_only = True)
1659 |
1660 | if print_version and 'version' in load_data and self.is_main:
1661 | print(f"loading from version {load_data['version']}")
1662 |
1663 | try:
1664 | self.GAN.load_state_dict(load_data['GAN'], strict = self.load_strict)
1665 | except Exception as e:
1666 | saved_version = load_data['version']
1667 | print('unable to load save model. please try downgrading the package to the version specified by the saved model (to do so, just run `pip install lightweight-gan=={saved_version}`')
1668 | raise e
1669 |
1670 | if 'G_scaler' in load_data:
1671 | self.G_scaler.load_state_dict(load_data['G_scaler'])
1672 | if 'D_scaler' in load_data:
1673 | self.D_scaler.load_state_dict(load_data['D_scaler'])
1674 |
1675 | def get_checkpoints(self):
1676 | file_paths = [p for p in Path(self.models_dir / self.name).glob('model_*.pt')]
1677 | saved_nums = sorted(map(lambda x: int(x.stem.split('_')[1]), file_paths))
1678 |
1679 | if len(saved_nums) == 0:
1680 | return None
1681 |
1682 | return saved_nums
1683 |
--------------------------------------------------------------------------------
181 |
182 | ## Generating
183 |
184 | Once you have finished training, you can generate samples with one command. You can select which checkpoint number to load from. If `--load-from` is not specified, will default to the latest.
185 |
186 | ```bash
187 | $ lightweight_gan \
188 | --name {name of run} \
189 | --load-from {checkpoint num} \
190 | --generate \
191 | --generate-types {types of result, default: [default,ema]} \
192 | --num-image-tiles {count of image result}
193 | ```
194 |
195 | After run this command you will get folder near results image folder with postfix "-generated-{checkpoint num}".
196 |
197 | You can also generate interpolations
198 |
199 | ```bash
200 | $ lightweight_gan --name {name of run} --generate-interpolation
201 | ```
202 |
203 | ## Show progress
204 |
205 | After creating several checkpoints of model you can generate progress as sequence images by command:
206 |
207 | ```bash
208 | $ lightweight_gan \
209 | --name {name of run} \
210 | --show-progress \
211 | --generate-types {types of result, default: [default,ema]} \
212 | --num-image-tiles {count of image result}
213 | ```
214 |
215 | After running this command you will get a new folder in the results folder, with postfix "-progress". You can convert the images to a video with ffmpeg using the command "ffmpeg -framerate 10 -pattern_type glob -i '*-ema.jpg' out.mp4".
216 |
217 | 
218 |
219 | 
220 |
221 | ## Discriminator output size
222 |
223 | The author has kindly let me know that the discriminator output size (5x5 vs 1x1) leads to different results on different datasets. (5x5 works better for art than for faces, as an example). You can toggle this with a single flag
224 |
225 | ```bash
226 | # disc output size is by default 1x1
227 | $ lightweight_gan --data ./path/to/art --image-size 512 --disc-output-size 5
228 | ```
229 |
230 | ## Attention
231 |
232 | You can add linear + axial attention to specific resolution layers with the following
233 |
234 | ```bash
235 | # make sure there are no spaces between the values within the brackets []
236 | $ lightweight_gan --data ./path/to/images --image-size 512 --attn-res-layers [32,64] --aug-prob 0.25
237 | ```
238 |
239 | ## Dual Contrastive Loss
240 |
241 | A recent paper has proposed that a novel contrastive loss between the real and fake logits can improve quality slightly over the default hinge loss.
242 |
243 | You can use this with one extra flag as follows
244 |
245 | ```bash
246 | $ lightweight_gan --data ./path/to/images --dual-contrast-loss
247 | ```
248 |
249 | ## Bonus
250 |
251 | You can also train with transparent images
252 |
253 | ```bash
254 | $ lightweight_gan --data ./path/to/images --transparent
255 | ```
256 |
257 | Or greyscale
258 |
259 | ```bash
260 | $ lightweight_gan --data ./path/to/images --greyscale
261 | ```
262 |
263 | ## Alternatives
264 |
265 | If you want the current state of the art GAN, you can find it at https://github.com/lucidrains/stylegan2-pytorch
266 |
267 | ## Citations
268 |
269 | ```bibtex
270 | @inproceedings{
271 | anonymous2021towards,
272 | title = {Towards Faster and Stabilized {\{}GAN{\}} Training for High-fidelity Few-shot Image Synthesis},
273 | author = {Anonymous},
274 | booktitle = {Submitted to International Conference on Learning Representations},
275 | year = {2021},
276 | url = {https://openreview.net/forum?id=1Fqg133qRaI},
277 | note = {under review}
278 | }
279 | ```
280 |
281 | ```bibtex
282 | @misc{cao2020global,
283 | title = {Global Context Networks},
284 | author = {Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu},
285 | year = {2020},
286 | eprint = {2012.13375},
287 | archivePrefix = {arXiv},
288 | primaryClass = {cs.CV}
289 | }
290 | ```
291 |
292 | ```bibtex
293 | @misc{qin2020fcanet,
294 | title = {FcaNet: Frequency Channel Attention Networks},
295 | author = {Zequn Qin and Pengyi Zhang and Fei Wu and Xi Li},
296 | year = {2020},
297 | eprint = {2012.11879},
298 | archivePrefix = {arXiv},
299 | primaryClass = {cs.CV}
300 | }
301 | ```
302 |
303 | ```bibtex
304 | @misc{yu2021dual,
305 | title = {Dual Contrastive Loss and Attention for GANs},
306 | author = {Ning Yu and Guilin Liu and Aysegul Dundar and Andrew Tao and Bryan Catanzaro and Larry Davis and Mario Fritz},
307 | year = {2021},
308 | eprint = {2103.16748},
309 | archivePrefix = {arXiv},
310 | primaryClass = {cs.CV}
311 | }
312 | ```
313 |
314 | ```bibtex
315 | @article{Sunkara2022NoMS,
316 | title = {No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects},
317 | author = {Raja Sunkara and Tie Luo},
318 | journal = {ArXiv},
319 | year = {2022},
320 | volume = {abs/2208.03641}
321 | }
322 | ```
323 |
324 | ```bibtex
325 | @inproceedings{Huang2025TheGI,
326 | title = {The GAN is dead; long live the GAN! A Modern GAN Baseline},
327 | author = {Yiwen Huang and Aaron Gokaslan and Volodymyr Kuleshov and James Tompkin},
328 | year = {2025},
329 | url = {https://api.semanticscholar.org/CorpusID:275405495}
330 | }
331 | ```
332 |
333 | *What I cannot create, I do not understand* - Richard Feynman
334 |
--------------------------------------------------------------------------------
/lightweight_gan/lightweight_gan.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import multiprocessing
4 | from random import random
5 | import math
6 | from math import log2, floor
7 | from functools import lru_cache, partial
8 | from contextlib import contextmanager, ExitStack
9 | from pathlib import Path
10 | from shutil import rmtree
11 |
12 | import torch
13 | from torch.amp import autocast, GradScaler
14 | from torch.optim import Adam
15 | from torch import nn, einsum
16 | import torch.nn.functional as F
17 | from torch.utils.data import Dataset, DataLoader
18 | from torch.autograd import grad as torch_grad
19 | from torch.utils.data.distributed import DistributedSampler
20 | from torch.nn.parallel import DistributedDataParallel as DDP
21 |
22 | from PIL import Image
23 | import torchvision
24 | from torchvision import transforms
25 | from kornia.filters import filter2d
26 |
27 | from lightweight_gan.diff_augment import DiffAugment
28 | from lightweight_gan.version import __version__
29 |
30 | from tqdm import tqdm
31 | from einops import rearrange, reduce, repeat
32 | from einops.layers.torch import Rearrange
33 |
34 | from adabelief_pytorch import AdaBelief
35 |
36 | # asserts
37 |
38 | assert torch.cuda.is_available(), 'You need to have an Nvidia GPU with CUDA installed.'
39 |
40 | # constants
41 |
42 | NUM_CORES = multiprocessing.cpu_count()
43 | EXTS = ['jpg', 'jpeg', 'png', 'tiff']
44 |
45 | # helpers
46 |
47 | def exists(val):
48 | return val is not None
49 |
50 | @contextmanager
51 | def null_context():
52 | yield
53 |
54 | def combine_contexts(contexts):
55 | @contextmanager
56 | def multi_contexts():
57 | with ExitStack() as stack:
58 | yield [stack.enter_context(ctx()) for ctx in contexts]
59 | return multi_contexts
60 |
61 | def is_power_of_two(val):
62 | return log2(val).is_integer()
63 |
64 | def default(val, d):
65 | return val if exists(val) else d
66 |
67 | def set_requires_grad(model, bool):
68 | for p in model.parameters():
69 | p.requires_grad = bool
70 |
71 | def cycle(iterable):
72 | while True:
73 | for i in iterable:
74 | yield i
75 |
76 | def raise_if_nan(t):
77 | if torch.isnan(t):
78 | raise NanException
79 |
80 | def gradient_accumulate_contexts(gradient_accumulate_every, is_ddp, ddps):
81 | if is_ddp:
82 | num_no_syncs = gradient_accumulate_every - 1
83 | head = [combine_contexts(map(lambda ddp: ddp.no_sync, ddps))] * num_no_syncs
84 | tail = [null_context]
85 | contexts = head + tail
86 | else:
87 | contexts = [null_context] * gradient_accumulate_every
88 |
89 | for context in contexts:
90 | with context():
91 | yield
92 |
93 | def evaluate_in_chunks(max_batch_size, model, *args):
94 | split_args = list(zip(*list(map(lambda x: x.split(max_batch_size, dim=0), args))))
95 | chunked_outputs = [model(*i) for i in split_args]
96 | if len(chunked_outputs) == 1:
97 | return chunked_outputs[0]
98 | return torch.cat(chunked_outputs, dim=0)
99 |
100 | def slerp(val, low, high):
101 | low_norm = low / torch.norm(low, dim=1, keepdim=True)
102 | high_norm = high / torch.norm(high, dim=1, keepdim=True)
103 | omega = torch.acos((low_norm * high_norm).sum(1))
104 | so = torch.sin(omega)
105 | res = (torch.sin((1.0 - val) * omega) / so).unsqueeze(1) * low + (torch.sin(val * omega) / so).unsqueeze(1) * high
106 | return res
107 |
108 | def safe_div(n, d):
109 | try:
110 | res = n / d
111 | except ZeroDivisionError:
112 | prefix = '' if int(n >= 0) else '-'
113 | res = float(f'{prefix}inf')
114 | return res
115 |
116 | # loss functions
117 |
118 | def gen_hinge_loss(fake, real):
119 | return fake.mean()
120 |
121 | def hinge_loss(real, fake):
122 | return (F.relu(1 + real) + F.relu(1 - fake)).mean()
123 |
124 | def dual_contrastive_loss(real_logits, fake_logits):
125 | device = real_logits.device
126 | real_logits, fake_logits = map(lambda t: rearrange(t, '... -> (...)'), (real_logits, fake_logits))
127 |
128 | def loss_half(t1, t2):
129 | t1 = rearrange(t1, 'i -> i ()')
130 | t2 = repeat(t2, 'j -> i j', i = t1.shape[0])
131 | t = torch.cat((t1, t2), dim = -1)
132 | return F.cross_entropy(t, torch.zeros(t1.shape[0], device = device, dtype = torch.long))
133 |
134 | return loss_half(real_logits, fake_logits) + loss_half(-fake_logits, -real_logits)
135 |
136 | @lru_cache(maxsize=10)
137 | def det_randn(*args):
138 | """
139 | deterministic random to track the same latent vars (and images) across training steps
140 | helps to visualize same image over training steps
141 | """
142 | return torch.randn(*args)
143 |
144 | def interpolate_between(a, b, *, num_samples, dim):
145 | assert num_samples > 2
146 | samples = []
147 | step_size = 0
148 | for _ in range(num_samples):
149 | sample = torch.lerp(a, b, step_size)
150 | samples.append(sample)
151 | step_size += 1 / (num_samples - 1)
152 | return torch.stack(samples, dim=dim)
153 |
154 | # helper classes
155 |
156 | class NanException(Exception):
157 | pass
158 |
159 | class EMA():
160 | def __init__(self, beta):
161 | super().__init__()
162 | self.beta = beta
163 | def update_average(self, old, new):
164 | if not exists(old):
165 | return new
166 | return old * self.beta + (1 - self.beta) * new
167 |
168 | class RandomApply(nn.Module):
169 | def __init__(self, prob, fn, fn_else = lambda x: x):
170 | super().__init__()
171 | self.fn = fn
172 | self.fn_else = fn_else
173 | self.prob = prob
174 | def forward(self, x):
175 | fn = self.fn if random() < self.prob else self.fn_else
176 | return fn(x)
177 |
178 | class ChanNorm(nn.Module):
179 | def __init__(self, dim, eps = 1e-5):
180 | super().__init__()
181 | self.eps = eps
182 | self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
183 | self.b = nn.Parameter(torch.zeros(1, dim, 1, 1))
184 |
185 | def forward(self, x):
186 | var = torch.var(x, dim = 1, unbiased = False, keepdim = True)
187 | mean = torch.mean(x, dim = 1, keepdim = True)
188 | return (x - mean) / (var + self.eps).sqrt() * self.g + self.b
189 |
190 | class PreNorm(nn.Module):
191 | def __init__(self, dim, fn):
192 | super().__init__()
193 | self.fn = fn
194 | self.norm = ChanNorm(dim)
195 |
196 | def forward(self, x):
197 | return self.fn(self.norm(x))
198 |
199 | class Residual(nn.Module):
200 | def __init__(self, fn):
201 | super().__init__()
202 | self.fn = fn
203 |
204 | def forward(self, x):
205 | return self.fn(x) + x
206 |
207 | class SumBranches(nn.Module):
208 | def __init__(self, branches):
209 | super().__init__()
210 | self.branches = nn.ModuleList(branches)
211 | def forward(self, x):
212 | return sum(map(lambda fn: fn(x), self.branches))
213 |
214 | class Blur(nn.Module):
215 | def __init__(self):
216 | super().__init__()
217 | f = torch.Tensor([1, 2, 1])
218 | self.register_buffer('f', f)
219 | def forward(self, x):
220 | f = self.f
221 | f = f[None, None, :] * f [None, :, None]
222 | return filter2d(x, f, normalized=True)
223 |
224 | class Noise(nn.Module):
225 | def __init__(self):
226 | super().__init__()
227 | self.weight = nn.Parameter(torch.zeros(1))
228 |
229 | def forward(self, x, noise = None):
230 | b, _, h, w, device = *x.shape, x.device
231 |
232 | if not exists(noise):
233 | noise = torch.randn(b, 1, h, w, device = device)
234 |
235 | return x + self.weight * noise
236 |
237 | def Conv2dSame(dim_in, dim_out, kernel_size, bias = True):
238 | pad_left = kernel_size // 2
239 | pad_right = (pad_left - 1) if (kernel_size % 2) == 0 else pad_left
240 |
241 | return nn.Sequential(
242 | nn.ZeroPad2d((pad_left, pad_right, pad_left, pad_right)),
243 | nn.Conv2d(dim_in, dim_out, kernel_size, bias = bias)
244 | )
245 |
246 | # attention
247 |
248 | class DepthWiseConv2d(nn.Module):
249 | def __init__(self, dim_in, dim_out, kernel_size, padding = 0, stride = 1, bias = True):
250 | super().__init__()
251 | self.net = nn.Sequential(
252 | nn.Conv2d(dim_in, dim_in, kernel_size = kernel_size, padding = padding, groups = dim_in, stride = stride, bias = bias),
253 | nn.Conv2d(dim_in, dim_out, kernel_size = 1, bias = bias)
254 | )
255 | def forward(self, x):
256 | return self.net(x)
257 |
258 | class LinearAttention(nn.Module):
259 | def __init__(self, dim, dim_head = 64, heads = 8, kernel_size = 3):
260 | super().__init__()
261 | self.scale = dim_head ** -0.5
262 | self.heads = heads
263 | self.dim_head = dim_head
264 | inner_dim = dim_head * heads
265 |
266 | self.kernel_size = kernel_size
267 | self.nonlin = nn.GELU()
268 |
269 | self.to_lin_q = nn.Conv2d(dim, inner_dim, 1, bias = False)
270 | self.to_lin_kv = DepthWiseConv2d(dim, inner_dim * 2, 3, padding = 1, bias = False)
271 |
272 | self.to_q = nn.Conv2d(dim, inner_dim, 1, bias = False)
273 | self.to_kv = nn.Conv2d(dim, inner_dim * 2, 1, bias = False)
274 |
275 | self.to_out = nn.Conv2d(inner_dim * 2, dim, 1)
276 |
277 | def forward(self, fmap):
278 | h, x, y = self.heads, *fmap.shape[-2:]
279 |
280 | # linear attention
281 |
282 | lin_q, lin_k, lin_v = (self.to_lin_q(fmap), *self.to_lin_kv(fmap).chunk(2, dim = 1))
283 | lin_q, lin_k, lin_v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) (x y) c', h = h), (lin_q, lin_k, lin_v))
284 |
285 | lin_q = lin_q.softmax(dim = -1)
286 | lin_k = lin_k.softmax(dim = -2)
287 |
288 | lin_q = lin_q * self.scale
289 |
290 | context = einsum('b n d, b n e -> b d e', lin_k, lin_v)
291 | lin_out = einsum('b n d, b d e -> b n e', lin_q, context)
292 | lin_out = rearrange(lin_out, '(b h) (x y) d -> b (h d) x y', h = h, x = x, y = y)
293 |
294 | # conv-like full attention
295 |
296 | q, k, v = (self.to_q(fmap), *self.to_kv(fmap).chunk(2, dim = 1))
297 | q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) c x y', h = h), (q, k, v))
298 |
299 | k = F.unfold(k, kernel_size = self.kernel_size, padding = self.kernel_size // 2)
300 | v = F.unfold(v, kernel_size = self.kernel_size, padding = self.kernel_size // 2)
301 |
302 | k, v = map(lambda t: rearrange(t, 'b (d j) n -> b n j d', d = self.dim_head), (k, v))
303 |
304 | q = rearrange(q, 'b c ... -> b (...) c') * self.scale
305 |
306 | sim = einsum('b i d, b i j d -> b i j', q, k)
307 | sim = sim - sim.amax(dim = -1, keepdim = True).detach()
308 |
309 | attn = sim.softmax(dim = -1)
310 |
311 | full_out = einsum('b i j, b i j d -> b i d', attn, v)
312 | full_out = rearrange(full_out, '(b h) (x y) d -> b (h d) x y', h = h, x = x, y = y)
313 |
314 | # add outputs of linear attention + conv like full attention
315 |
316 | lin_out = self.nonlin(lin_out)
317 | out = torch.cat((lin_out, full_out), dim = 1)
318 | return self.to_out(out)
319 |
320 | # dataset
321 |
322 | def convert_image_to(img_type, image):
323 | if image.mode != img_type:
324 | return image.convert(img_type)
325 | return image
326 |
327 | class identity(object):
328 | def __call__(self, tensor):
329 | return tensor
330 |
331 | class expand_greyscale(object):
332 | def __init__(self, transparent):
333 | self.transparent = transparent
334 |
335 | def __call__(self, tensor):
336 | channels = tensor.shape[0]
337 | num_target_channels = 4 if self.transparent else 3
338 |
339 | if channels == num_target_channels:
340 | return tensor
341 |
342 | alpha = None
343 | if channels == 1:
344 | color = tensor.expand(3, -1, -1)
345 | elif channels == 2:
346 | color = tensor[:1].expand(3, -1, -1)
347 | alpha = tensor[1:]
348 | else:
349 | raise Exception(f'image with invalid number of channels given {channels}')
350 |
351 | if not exists(alpha) and self.transparent:
352 | alpha = torch.ones(1, *tensor.shape[1:], device=tensor.device)
353 |
354 | return color if not self.transparent else torch.cat((color, alpha))
355 |
356 | def resize_to_minimum_size(min_size, image):
357 | if max(*image.size) < min_size:
358 | return torchvision.transforms.functional.resize(image, min_size)
359 | return image
360 |
361 | class ImageDataset(Dataset):
362 | def __init__(
363 | self,
364 | folder,
365 | image_size,
366 | transparent = False,
367 | greyscale = False,
368 | aug_prob = 0.
369 | ):
370 | super().__init__()
371 | self.folder = folder
372 | self.image_size = image_size
373 | self.paths = [p for ext in EXTS for p in Path(f'{folder}').glob(f'**/*.{ext}')]
374 | assert len(self.paths) > 0, f'No images were found in {folder} for training'
375 |
376 | if transparent:
377 | num_channels = 4
378 | pillow_mode = 'RGBA'
379 | expand_fn = expand_greyscale(transparent)
380 | elif greyscale:
381 | num_channels = 1
382 | pillow_mode = 'L'
383 | expand_fn = identity()
384 | else:
385 | num_channels = 3
386 | pillow_mode = 'RGB'
387 | expand_fn = expand_greyscale(transparent)
388 |
389 | convert_image_fn = partial(convert_image_to, pillow_mode)
390 |
391 | self.transform = transforms.Compose([
392 | transforms.Lambda(convert_image_fn),
393 | transforms.Lambda(partial(resize_to_minimum_size, image_size)),
394 | transforms.Resize(image_size),
395 | RandomApply(aug_prob, transforms.RandomResizedCrop(image_size, scale=(0.5, 1.0), ratio=(0.98, 1.02)), transforms.CenterCrop(image_size)),
396 | transforms.ToTensor(),
397 | transforms.Lambda(expand_fn)
398 | ])
399 |
400 | def __len__(self):
401 | return len(self.paths)
402 |
403 | def __getitem__(self, index):
404 | path = self.paths[index]
405 | img = Image.open(path)
406 | return self.transform(img)
407 |
408 | # augmentations
409 |
410 | def random_hflip(tensor, prob):
411 | if prob > random():
412 | return tensor
413 | return torch.flip(tensor, dims=(3,))
414 |
415 | class AugWrapper(nn.Module):
416 | def __init__(self, D, image_size):
417 | super().__init__()
418 | self.D = D
419 |
420 | def forward(self, images, prob = 0., types = [], detach = False, input_requires_grad = False, return_discr_input = False, **kwargs):
421 | context = torch.no_grad if detach else null_context
422 |
423 | with context():
424 | if random() < prob:
425 | images = random_hflip(images, prob=0.5)
426 | images = DiffAugment(images, types=types)
427 |
428 | discr_input = images
429 |
430 | if input_requires_grad:
431 | discr_input.requires_grad_()
432 |
433 | out = self.D(discr_input, **kwargs)
434 |
435 | if not return_discr_input:
436 | return out
437 |
438 | return discr_input, out
439 |
440 | # modifiable global variables
441 |
442 | norm_class = nn.BatchNorm2d
443 |
444 | class PixelShuffleUpsample(nn.Module):
445 | def __init__(self, dim, dim_out = None):
446 | super().__init__()
447 | dim_out = default(dim_out, dim)
448 | conv = nn.Conv2d(dim, dim_out * 4, 1)
449 |
450 | self.net = nn.Sequential(
451 | conv,
452 | nn.SiLU(),
453 | nn.PixelShuffle(2)
454 | )
455 |
456 | self.init_conv_(conv)
457 |
458 | def init_conv_(self, conv):
459 | o, i, h, w = conv.weight.shape
460 | conv_weight = torch.empty(o // 4, i, h, w)
461 | nn.init.kaiming_uniform_(conv_weight)
462 | conv_weight = repeat(conv_weight, 'o ... -> (o 4) ...')
463 |
464 | conv.weight.data.copy_(conv_weight)
465 | nn.init.zeros_(conv.bias.data)
466 |
467 | def forward(self, x):
468 | return self.net(x)
469 |
470 | def SPConvDownsample(dim, dim_out = None):
471 | # https://arxiv.org/abs/2208.03641 shows this is the most optimal way to downsample
472 | # named SP-conv in the paper, but basically a pixel unshuffle
473 | dim_out = default(dim_out, dim)
474 | return nn.Sequential(
475 | Rearrange('b c (h s1) (w s2) -> b (c s1 s2) h w', s1 = 2, s2 = 2),
476 | nn.Conv2d(dim * 4, dim_out, 1)
477 | )
478 |
479 | # squeeze excitation classes
480 |
481 | # global context network
482 | # https://arxiv.org/abs/2012.13375
483 | # similar to squeeze-excite, but with a simplified attention pooling and a subsequent layer norm
484 |
485 | class GlobalContext(nn.Module):
486 | def __init__(
487 | self,
488 | *,
489 | chan_in,
490 | chan_out
491 | ):
492 | super().__init__()
493 | self.to_k = nn.Conv2d(chan_in, 1, 1)
494 | chan_intermediate = max(3, chan_out // 2)
495 |
496 | self.net = nn.Sequential(
497 | nn.Conv2d(chan_in, chan_intermediate, 1),
498 | nn.LeakyReLU(0.1),
499 | nn.Conv2d(chan_intermediate, chan_out, 1),
500 | nn.Sigmoid()
501 | )
502 | def forward(self, x):
503 | context = self.to_k(x)
504 | context = context.flatten(2).softmax(dim = -1)
505 | out = einsum('b i n, b c n -> b c i', context, x.flatten(2))
506 | out = out.unsqueeze(-1)
507 | return self.net(out)
508 |
509 | # frequency channel attention
510 | # https://arxiv.org/abs/2012.11879
511 |
512 | def get_1d_dct(i, freq, L):
513 | result = math.cos(math.pi * freq * (i + 0.5) / L) / math.sqrt(L)
514 | return result * (1 if freq == 0 else math.sqrt(2))
515 |
516 | def get_dct_weights(width, channel, fidx_u, fidx_v):
517 | dct_weights = torch.zeros(1, channel, width, width)
518 | c_part = channel // len(fidx_u)
519 |
520 | for i, (u_x, v_y) in enumerate(zip(fidx_u, fidx_v)):
521 | for x in range(width):
522 | for y in range(width):
523 | coor_value = get_1d_dct(x, u_x, width) * get_1d_dct(y, v_y, width)
524 | dct_weights[:, i * c_part: (i + 1) * c_part, x, y] = coor_value
525 |
526 | return dct_weights
527 |
528 | class FCANet(nn.Module):
529 | def __init__(
530 | self,
531 | *,
532 | chan_in,
533 | chan_out,
534 | reduction = 4,
535 | width
536 | ):
537 | super().__init__()
538 |
539 | freq_w, freq_h = ([0] * 8), list(range(8)) # in paper, it seems 16 frequencies was ideal
540 | dct_weights = get_dct_weights(width, chan_in, [*freq_w, *freq_h], [*freq_h, *freq_w])
541 | self.register_buffer('dct_weights', dct_weights)
542 |
543 | chan_intermediate = max(3, chan_out // reduction)
544 |
545 | self.net = nn.Sequential(
546 | nn.Conv2d(chan_in, chan_intermediate, 1),
547 | nn.LeakyReLU(0.1),
548 | nn.Conv2d(chan_intermediate, chan_out, 1),
549 | nn.Sigmoid()
550 | )
551 |
552 | def forward(self, x):
553 | x = reduce(x * self.dct_weights, 'b c (h h1) (w w1) -> b c h1 w1', 'sum', h1 = 1, w1 = 1)
554 | return self.net(x)
555 |
556 | # generative adversarial network
557 |
558 | class Generator(nn.Module):
559 | def __init__(
560 | self,
561 | *,
562 | image_size,
563 | latent_dim = 256,
564 | fmap_max = 512,
565 | fmap_inverse_coef = 12,
566 | transparent = False,
567 | greyscale = False,
568 | attn_res_layers = [],
569 | freq_chan_attn = False
570 | ):
571 | super().__init__()
572 | resolution = log2(image_size)
573 | assert is_power_of_two(image_size), 'image size must be a power of 2'
574 |
575 | if transparent:
576 | init_channel = 4
577 | elif greyscale:
578 | init_channel = 1
579 | else:
580 | init_channel = 3
581 |
582 | fmap_max = default(fmap_max, latent_dim)
583 |
584 | self.initial_conv = nn.Sequential(
585 | nn.ConvTranspose2d(latent_dim, latent_dim * 2, 4),
586 | norm_class(latent_dim * 2),
587 | nn.GLU(dim = 1)
588 | )
589 |
590 | num_layers = int(resolution) - 2
591 | features = list(map(lambda n: (n, 2 ** (fmap_inverse_coef - n)), range(2, num_layers + 2)))
592 | features = list(map(lambda n: (n[0], min(n[1], fmap_max)), features))
593 | features = list(map(lambda n: 3 if n[0] >= 8 else n[1], features))
594 | features = [latent_dim, *features]
595 |
596 | in_out_features = list(zip(features[:-1], features[1:]))
597 |
598 | self.res_layers = range(2, num_layers + 2)
599 | self.layers = nn.ModuleList([])
600 | self.res_to_feature_map = dict(zip(self.res_layers, in_out_features))
601 |
602 | self.sle_map = ((3, 7), (4, 8), (5, 9), (6, 10))
603 | self.sle_map = list(filter(lambda t: t[0] <= resolution and t[1] <= resolution, self.sle_map))
604 | self.sle_map = dict(self.sle_map)
605 |
606 | self.num_layers_spatial_res = 1
607 |
608 | for (res, (chan_in, chan_out)) in zip(self.res_layers, in_out_features):
609 | image_width = 2 ** res
610 |
611 | attn = None
612 | if image_width in attn_res_layers:
613 | attn = PreNorm(chan_in, LinearAttention(chan_in))
614 |
615 | sle = None
616 | if res in self.sle_map:
617 | residual_layer = self.sle_map[res]
618 | sle_chan_out = self.res_to_feature_map[residual_layer - 1][-1]
619 |
620 | if freq_chan_attn:
621 | sle = FCANet(
622 | chan_in = chan_out,
623 | chan_out = sle_chan_out,
624 | width = 2 ** (res + 1)
625 | )
626 | else:
627 | sle = GlobalContext(
628 | chan_in = chan_out,
629 | chan_out = sle_chan_out
630 | )
631 |
632 | layer = nn.ModuleList([
633 | nn.Sequential(
634 | PixelShuffleUpsample(chan_in),
635 | Blur(),
636 | Conv2dSame(chan_in, chan_out * 2, 4),
637 | Noise(),
638 | norm_class(chan_out * 2),
639 | nn.GLU(dim = 1)
640 | ),
641 | sle,
642 | attn
643 | ])
644 | self.layers.append(layer)
645 |
646 | self.out_conv = nn.Conv2d(features[-1], init_channel, 3, padding = 1)
647 |
648 | def forward(self, x):
649 | x = rearrange(x, 'b c -> b c () ()')
650 | x = self.initial_conv(x)
651 | x = F.normalize(x, dim = 1)
652 |
653 | residuals = dict()
654 |
655 | for (res, (up, sle, attn)) in zip(self.res_layers, self.layers):
656 | if exists(attn):
657 | x = attn(x) + x
658 |
659 | x = up(x)
660 |
661 | if exists(sle):
662 | out_res = self.sle_map[res]
663 | residual = sle(x)
664 | residuals[out_res] = residual
665 |
666 | next_res = res + 1
667 | if next_res in residuals:
668 | x = x * residuals[next_res]
669 |
670 | return self.out_conv(x)
671 |
672 | class SimpleDecoder(nn.Module):
673 | def __init__(
674 | self,
675 | *,
676 | chan_in,
677 | chan_out = 3,
678 | num_upsamples = 4,
679 | ):
680 | super().__init__()
681 |
682 | self.layers = nn.ModuleList([])
683 | final_chan = chan_out
684 | chans = chan_in
685 |
686 | for ind in range(num_upsamples):
687 | last_layer = ind == (num_upsamples - 1)
688 | chan_out = chans if not last_layer else final_chan * 2
689 | layer = nn.Sequential(
690 | PixelShuffleUpsample(chans),
691 | nn.Conv2d(chans, chan_out, 3, padding = 1),
692 | nn.GLU(dim = 1)
693 | )
694 | self.layers.append(layer)
695 | chans //= 2
696 |
697 | def forward(self, x):
698 | for layer in self.layers:
699 | x = layer(x)
700 | return x
701 |
702 | class Discriminator(nn.Module):
703 | def __init__(
704 | self,
705 | *,
706 | image_size,
707 | fmap_max = 512,
708 | fmap_inverse_coef = 12,
709 | transparent = False,
710 | greyscale = False,
711 | disc_output_size = 5,
712 | attn_res_layers = []
713 | ):
714 | super().__init__()
715 | resolution = log2(image_size)
716 | assert is_power_of_two(image_size), 'image size must be a power of 2'
717 | assert disc_output_size in {1, 5}, 'discriminator output dimensions can only be 5x5 or 1x1'
718 |
719 | resolution = int(resolution)
720 |
721 | if transparent:
722 | init_channel = 4
723 | elif greyscale:
724 | init_channel = 1
725 | else:
726 | init_channel = 3
727 |
728 | num_non_residual_layers = max(0, int(resolution) - 8)
729 | num_residual_layers = 8 - 3
730 |
731 | non_residual_resolutions = range(min(8, resolution), 2, -1)
732 | features = list(map(lambda n: (n, 2 ** (fmap_inverse_coef - n)), non_residual_resolutions))
733 | features = list(map(lambda n: (n[0], min(n[1], fmap_max)), features))
734 |
735 | if num_non_residual_layers == 0:
736 | res, _ = features[0]
737 | features[0] = (res, init_channel)
738 |
739 | chan_in_out = list(zip(features[:-1], features[1:]))
740 |
741 | self.non_residual_layers = nn.ModuleList([])
742 | for ind in range(num_non_residual_layers):
743 | first_layer = ind == 0
744 | last_layer = ind == (num_non_residual_layers - 1)
745 | chan_out = features[0][-1] if last_layer else init_channel
746 |
747 | self.non_residual_layers.append(nn.Sequential(
748 | Blur(),
749 | nn.Conv2d(init_channel, chan_out, 4, stride = 2, padding = 1),
750 | nn.LeakyReLU(0.1)
751 | ))
752 |
753 | self.residual_layers = nn.ModuleList([])
754 |
755 | for (res, ((_, chan_in), (_, chan_out))) in zip(non_residual_resolutions, chan_in_out):
756 | image_width = 2 ** res
757 |
758 | attn = None
759 | if image_width in attn_res_layers:
760 | attn = PreNorm(chan_in, LinearAttention(chan_in))
761 |
762 | self.residual_layers.append(nn.ModuleList([
763 | SumBranches([
764 | nn.Sequential(
765 | Blur(),
766 | SPConvDownsample(chan_in, chan_out),
767 | nn.LeakyReLU(0.1),
768 | nn.Conv2d(chan_out, chan_out, 3, padding = 1),
769 | nn.LeakyReLU(0.1)
770 | ),
771 | nn.Sequential(
772 | Blur(),
773 | nn.AvgPool2d(2),
774 | nn.Conv2d(chan_in, chan_out, 1),
775 | nn.LeakyReLU(0.1),
776 | )
777 | ]),
778 | attn
779 | ]))
780 |
781 | last_chan = features[-1][-1]
782 | if disc_output_size == 5:
783 | self.to_logits = nn.Sequential(
784 | nn.Conv2d(last_chan, last_chan, 1),
785 | nn.LeakyReLU(0.1),
786 | nn.Conv2d(last_chan, 1, 4)
787 | )
788 | elif disc_output_size == 1:
789 | self.to_logits = nn.Sequential(
790 | Blur(),
791 | nn.Conv2d(last_chan, last_chan, 3, stride = 2, padding = 1),
792 | nn.LeakyReLU(0.1),
793 | nn.Conv2d(last_chan, 1, 4)
794 | )
795 |
796 | self.to_shape_disc_out = nn.Sequential(
797 | nn.Conv2d(init_channel, 64, 3, padding = 1),
798 | Residual(PreNorm(64, LinearAttention(64))),
799 | SumBranches([
800 | nn.Sequential(
801 | Blur(),
802 | SPConvDownsample(64, 32),
803 | nn.LeakyReLU(0.1),
804 | nn.Conv2d(32, 32, 3, padding = 1),
805 | nn.LeakyReLU(0.1)
806 | ),
807 | nn.Sequential(
808 | Blur(),
809 | nn.AvgPool2d(2),
810 | nn.Conv2d(64, 32, 1),
811 | nn.LeakyReLU(0.1),
812 | )
813 | ]),
814 | Residual(PreNorm(32, LinearAttention(32))),
815 | nn.AdaptiveAvgPool2d((4, 4)),
816 | nn.Conv2d(32, 1, 4)
817 | )
818 |
819 | self.decoder1 = SimpleDecoder(chan_in = last_chan, chan_out = init_channel)
820 | self.decoder2 = SimpleDecoder(chan_in = features[-2][-1], chan_out = init_channel) if resolution >= 9 else None
821 |
822 | def forward(self, x, calc_aux_loss = False):
823 | orig_img = x
824 |
825 | for layer in self.non_residual_layers:
826 | x = layer(x)
827 |
828 | layer_outputs = []
829 |
830 | for (net, attn) in self.residual_layers:
831 | if exists(attn):
832 | x = attn(x) + x
833 |
834 | x = net(x)
835 | layer_outputs.append(x)
836 |
837 | out = self.to_logits(x).flatten(1)
838 |
839 | img_32x32 = F.interpolate(orig_img, size = (32, 32))
840 | out_32x32 = self.to_shape_disc_out(img_32x32)
841 |
842 | if not calc_aux_loss:
843 | return out, out_32x32, None
844 |
845 | # self-supervised auto-encoding loss
846 |
847 | layer_8x8 = layer_outputs[-1]
848 | layer_16x16 = layer_outputs[-2]
849 |
850 | recon_img_8x8 = self.decoder1(layer_8x8)
851 |
852 | aux_loss = F.mse_loss(
853 | recon_img_8x8,
854 | F.interpolate(orig_img, size = recon_img_8x8.shape[2:])
855 | )
856 |
857 | if exists(self.decoder2):
858 | select_random_quadrant = lambda rand_quadrant, img: rearrange(img, 'b c (m h) (n w) -> (m n) b c h w', m = 2, n = 2)[rand_quadrant]
859 | crop_image_fn = partial(select_random_quadrant, floor(random() * 4))
860 | img_part, layer_16x16_part = map(crop_image_fn, (orig_img, layer_16x16))
861 |
862 | recon_img_16x16 = self.decoder2(layer_16x16_part)
863 |
864 | aux_loss_16x16 = F.mse_loss(
865 | recon_img_16x16,
866 | F.interpolate(img_part, size = recon_img_16x16.shape[2:])
867 | )
868 |
869 | aux_loss = aux_loss + aux_loss_16x16
870 |
871 | return out, out_32x32, aux_loss
872 |
873 | class LightweightGAN(nn.Module):
874 | def __init__(
875 | self,
876 | *,
877 | latent_dim,
878 | image_size,
879 | optimizer = "adam",
880 | fmap_max = 512,
881 | fmap_inverse_coef = 12,
882 | transparent = False,
883 | greyscale = False,
884 | disc_output_size = 5,
885 | attn_res_layers = [],
886 | freq_chan_attn = False,
887 | ttur_mult = 1.,
888 | lr = 2e-4,
889 | rank = 0,
890 | ddp = False
891 | ):
892 | super().__init__()
893 | self.latent_dim = latent_dim
894 | self.image_size = image_size
895 |
896 | G_kwargs = dict(
897 | image_size = image_size,
898 | latent_dim = latent_dim,
899 | fmap_max = fmap_max,
900 | fmap_inverse_coef = fmap_inverse_coef,
901 | transparent = transparent,
902 | greyscale = greyscale,
903 | attn_res_layers = attn_res_layers,
904 | freq_chan_attn = freq_chan_attn
905 | )
906 |
907 | self.G = Generator(**G_kwargs)
908 |
909 | self.D = Discriminator(
910 | image_size = image_size,
911 | fmap_max = fmap_max,
912 | fmap_inverse_coef = fmap_inverse_coef,
913 | transparent = transparent,
914 | greyscale = greyscale,
915 | attn_res_layers = attn_res_layers,
916 | disc_output_size = disc_output_size
917 | )
918 |
919 | self.ema_updater = EMA(0.995)
920 | self.GE = Generator(**G_kwargs)
921 | set_requires_grad(self.GE, False)
922 |
923 |
924 | if optimizer == "adam":
925 | self.G_opt = Adam(self.G.parameters(), lr = lr, betas=(0.5, 0.9))
926 | self.D_opt = Adam(self.D.parameters(), lr = lr * ttur_mult, betas=(0.5, 0.9))
927 | elif optimizer == "adabelief":
928 | self.G_opt = AdaBelief(self.G.parameters(), lr = lr, betas=(0.5, 0.9))
929 | self.D_opt = AdaBelief(self.D.parameters(), lr = lr * ttur_mult, betas=(0.5, 0.9))
930 | else:
931 | assert False, "No valid optimizer is given"
932 |
933 | self.apply(self._init_weights)
934 | self.reset_parameter_averaging()
935 |
936 | self.cuda(rank)
937 | self.D_aug = AugWrapper(self.D, image_size)
938 |
939 | def _init_weights(self, m):
940 | if type(m) in {nn.Conv2d, nn.Linear}:
941 | nn.init.kaiming_normal_(m.weight, a=0, mode='fan_in', nonlinearity='leaky_relu')
942 |
943 | def EMA(self):
944 | def update_moving_average(ma_model, current_model):
945 | for current_params, ma_params in zip(current_model.parameters(), ma_model.parameters()):
946 | old_weight, up_weight = ma_params.data, current_params.data
947 | ma_params.data = self.ema_updater.update_average(old_weight, up_weight)
948 |
949 | for current_buffer, ma_buffer in zip(current_model.buffers(), ma_model.buffers()):
950 | new_buffer_value = self.ema_updater.update_average(ma_buffer, current_buffer)
951 | ma_buffer.copy_(new_buffer_value)
952 |
953 | update_moving_average(self.GE, self.G)
954 |
955 | def reset_parameter_averaging(self):
956 | self.GE.load_state_dict(self.G.state_dict())
957 |
958 | def forward(self, x):
959 | raise NotImplemented
960 |
961 | # trainer
962 |
963 | class Trainer():
964 | def __init__(
965 | self,
966 | name = 'default',
967 | results_dir = 'results',
968 | models_dir = 'models',
969 | base_dir = './',
970 | optimizer = 'adam',
971 | num_workers = None,
972 | latent_dim = 256,
973 | image_size = 128,
974 | num_image_tiles = 8,
975 | fmap_max = 512,
976 | transparent = False,
977 | greyscale = False,
978 | batch_size = 4,
979 | gp_weight = 10,
980 | gradient_accumulate_every = 1,
981 | attn_res_layers = [],
982 | freq_chan_attn = False,
983 | disc_output_size = 5,
984 | dual_contrast_loss = False,
985 | antialias = False,
986 | lr = 2e-4,
987 | lr_mlp = 1.,
988 | ttur_mult = 1.,
989 | save_every = 1000,
990 | evaluate_every = 1000,
991 | aug_prob = None,
992 | aug_types = ['translation', 'cutout'],
993 | dataset_aug_prob = 0.,
994 | calculate_fid_every = None,
995 | calculate_fid_num_images = 12800,
996 | clear_fid_cache = False,
997 | is_ddp = False,
998 | rank = 0,
999 | world_size = 1,
1000 | log = False,
1001 | amp = False,
1002 | hparams = None,
1003 | use_aim = True,
1004 | aim_repo = None,
1005 | aim_run_hash = None,
1006 | load_strict = True,
1007 | *args,
1008 | **kwargs
1009 | ):
1010 | self.GAN_params = [args, kwargs]
1011 | self.GAN = None
1012 |
1013 | self.name = name
1014 |
1015 | base_dir = Path(base_dir)
1016 | self.base_dir = base_dir
1017 | self.results_dir = base_dir / results_dir
1018 | self.models_dir = base_dir / models_dir
1019 | self.fid_dir = base_dir / 'fid' / name
1020 |
1021 | self.config_path = self.models_dir / name / '.config.json'
1022 |
1023 | assert is_power_of_two(image_size), 'image size must be a power of 2 (64, 128, 256, 512, 1024)'
1024 | assert all(map(is_power_of_two, attn_res_layers)), 'resolution layers of attention must all be powers of 2 (16, 32, 64, 128, 256, 512)'
1025 |
1026 | assert not (dual_contrast_loss and disc_output_size > 1), 'discriminator output size cannot be greater than 1 if using dual contrastive loss'
1027 |
1028 | self.image_size = image_size
1029 | self.num_image_tiles = num_image_tiles
1030 |
1031 | self.latent_dim = latent_dim
1032 | self.fmap_max = fmap_max
1033 | self.transparent = transparent
1034 | self.greyscale = greyscale
1035 |
1036 | assert (int(self.transparent) + int(self.greyscale)) < 2, 'you can only set either transparency or greyscale'
1037 |
1038 | self.aug_prob = aug_prob
1039 | self.aug_types = aug_types
1040 |
1041 | self.lr = lr
1042 | self.optimizer = optimizer
1043 | self.num_workers = num_workers
1044 | self.ttur_mult = ttur_mult
1045 | self.batch_size = batch_size
1046 | self.gradient_accumulate_every = gradient_accumulate_every
1047 |
1048 | self.gp_weight = gp_weight
1049 |
1050 | self.evaluate_every = evaluate_every
1051 | self.save_every = save_every
1052 | self.steps = 0
1053 |
1054 | self.attn_res_layers = attn_res_layers
1055 | self.freq_chan_attn = freq_chan_attn
1056 |
1057 | self.disc_output_size = disc_output_size
1058 | self.antialias = antialias
1059 |
1060 | self.dual_contrast_loss = dual_contrast_loss
1061 |
1062 | self.d_loss = 0
1063 | self.g_loss = 0
1064 | self.last_gp_loss = None
1065 | self.last_recon_loss = None
1066 | self.last_fid = None
1067 |
1068 | self.init_folders()
1069 |
1070 | self.loader = None
1071 | self.dataset_aug_prob = dataset_aug_prob
1072 |
1073 | self.calculate_fid_every = calculate_fid_every
1074 | self.calculate_fid_num_images = calculate_fid_num_images
1075 | self.clear_fid_cache = clear_fid_cache
1076 |
1077 | self.is_ddp = is_ddp
1078 | self.is_main = rank == 0
1079 | self.rank = rank
1080 | self.world_size = world_size
1081 |
1082 | self.syncbatchnorm = is_ddp
1083 |
1084 | self.load_strict = load_strict
1085 |
1086 | self.amp = amp
1087 | self.G_scaler = GradScaler(enabled = self.amp)
1088 | self.D_scaler = GradScaler(enabled = self.amp)
1089 |
1090 | self.run = None
1091 | self.hparams = hparams
1092 |
1093 | if self.is_main and use_aim:
1094 | try:
1095 | import aim
1096 | self.aim = aim
1097 | except ImportError:
1098 | print('unable to import aim experiment tracker - please run `pip install aim` first')
1099 |
1100 | self.run = self.aim.Run(run_hash=aim_run_hash, repo=aim_repo)
1101 | self.run['hparams'] = hparams
1102 |
1103 | @property
1104 | def image_extension(self):
1105 | return 'jpg' if not self.transparent else 'png'
1106 |
1107 | @property
1108 | def checkpoint_num(self):
1109 | return floor(self.steps // self.save_every)
1110 |
1111 | def init_GAN(self):
1112 | args, kwargs = self.GAN_params
1113 |
1114 | # set some global variables before instantiating GAN
1115 |
1116 | global norm_class
1117 | global Blur
1118 |
1119 | norm_class = nn.SyncBatchNorm if self.syncbatchnorm else nn.BatchNorm2d
1120 | Blur = nn.Identity if not self.antialias else Blur
1121 |
1122 | # handle bugs when
1123 | # switching from multi-gpu back to single gpu
1124 |
1125 | if self.syncbatchnorm and not self.is_ddp:
1126 | import torch.distributed as dist
1127 | os.environ['MASTER_ADDR'] = 'localhost'
1128 | os.environ['MASTER_PORT'] = '12355'
1129 | dist.init_process_group('nccl', rank=0, world_size=1)
1130 |
1131 | # instantiate GAN
1132 |
1133 | self.GAN = LightweightGAN(
1134 | optimizer=self.optimizer,
1135 | lr = self.lr,
1136 | latent_dim = self.latent_dim,
1137 | attn_res_layers = self.attn_res_layers,
1138 | freq_chan_attn = self.freq_chan_attn,
1139 | image_size = self.image_size,
1140 | ttur_mult = self.ttur_mult,
1141 | fmap_max = self.fmap_max,
1142 | disc_output_size = self.disc_output_size,
1143 | transparent = self.transparent,
1144 | greyscale = self.greyscale,
1145 | rank = self.rank,
1146 | *args,
1147 | **kwargs
1148 | )
1149 |
1150 | if self.is_ddp:
1151 | ddp_kwargs = {'device_ids': [self.rank], 'output_device': self.rank, 'find_unused_parameters': True}
1152 |
1153 | self.G_ddp = DDP(self.GAN.G, **ddp_kwargs)
1154 | self.D_ddp = DDP(self.GAN.D, **ddp_kwargs)
1155 | self.D_aug_ddp = DDP(self.GAN.D_aug, **ddp_kwargs)
1156 |
1157 | def write_config(self):
1158 | self.config_path.write_text(json.dumps(self.config()))
1159 |
1160 | def load_config(self):
1161 | config = self.config() if not self.config_path.exists() else json.loads(self.config_path.read_text())
1162 | self.image_size = config['image_size']
1163 | self.transparent = config['transparent']
1164 | self.syncbatchnorm = config['syncbatchnorm']
1165 | self.disc_output_size = config['disc_output_size']
1166 | self.greyscale = config.pop('greyscale', False)
1167 | self.attn_res_layers = config.pop('attn_res_layers', [])
1168 | self.freq_chan_attn = config.pop('freq_chan_attn', False)
1169 | self.optimizer = config.pop('optimizer', 'adam')
1170 | self.fmap_max = config.pop('fmap_max', 512)
1171 | del self.GAN
1172 | self.init_GAN()
1173 |
1174 | def config(self):
1175 | return {
1176 | 'image_size': self.image_size,
1177 | 'transparent': self.transparent,
1178 | 'greyscale': self.greyscale,
1179 | 'syncbatchnorm': self.syncbatchnorm,
1180 | 'disc_output_size': self.disc_output_size,
1181 | 'optimizer': self.optimizer,
1182 | 'attn_res_layers': self.attn_res_layers,
1183 | 'freq_chan_attn': self.freq_chan_attn
1184 | }
1185 |
1186 | def set_data_src(self, folder):
1187 | num_workers = default(self.num_workers, math.ceil(NUM_CORES / self.world_size))
1188 | self.dataset = ImageDataset(folder, self.image_size, transparent = self.transparent, greyscale = self.greyscale, aug_prob = self.dataset_aug_prob)
1189 | sampler = DistributedSampler(self.dataset, rank=self.rank, num_replicas=self.world_size, shuffle=True) if self.is_ddp else None
1190 | dataloader = DataLoader(self.dataset, num_workers = num_workers, batch_size = math.ceil(self.batch_size / self.world_size), sampler = sampler, shuffle = not self.is_ddp, drop_last = True, pin_memory = True)
1191 | self.loader = cycle(dataloader)
1192 |
1193 | # auto set augmentation prob for user if dataset is detected to be low
1194 | num_samples = len(self.dataset)
1195 | if not exists(self.aug_prob) and num_samples < 1e5:
1196 | self.aug_prob = min(0.5, (1e5 - num_samples) * 3e-6)
1197 | print(f'autosetting augmentation probability to {round(self.aug_prob * 100)}%')
1198 |
1199 | def train(self):
1200 | assert exists(self.loader), 'You must first initialize the data source with `.set_data_src()`'
1201 | device = torch.device(f'cuda:{self.rank}')
1202 |
1203 | if not exists(self.GAN):
1204 | self.init_GAN()
1205 |
1206 | self.GAN.train()
1207 | total_disc_loss = torch.zeros([], device=device)
1208 | total_gen_loss = torch.zeros([], device=device)
1209 |
1210 | batch_size = math.ceil(self.batch_size / self.world_size)
1211 |
1212 | image_size = self.GAN.image_size
1213 | latent_dim = self.GAN.latent_dim
1214 |
1215 | aug_prob = default(self.aug_prob, 0)
1216 | aug_types = self.aug_types
1217 | aug_kwargs = {'prob': aug_prob, 'types': aug_types}
1218 |
1219 | G = self.GAN.G if not self.is_ddp else self.G_ddp
1220 | D = self.GAN.D if not self.is_ddp else self.D_ddp
1221 | D_aug = self.GAN.D_aug if not self.is_ddp else self.D_aug_ddp
1222 |
1223 | apply_gradient_penalty = self.steps % 4 == 0
1224 |
1225 | # amp related contexts and functions
1226 |
1227 | amp_context = partial(autocast, 'cuda') if self.amp else null_context
1228 |
1229 | # discriminator loss fn
1230 |
1231 | if self.dual_contrast_loss:
1232 | D_loss_fn = dual_contrastive_loss
1233 | else:
1234 | D_loss_fn = hinge_loss
1235 |
1236 | # train discriminator
1237 |
1238 | self.GAN.D_opt.zero_grad()
1239 | for i in gradient_accumulate_contexts(self.gradient_accumulate_every, self.is_ddp, ddps=[D_aug, G]):
1240 | latents = torch.randn(batch_size, latent_dim).cuda(self.rank)
1241 | image_batch = next(self.loader).cuda(self.rank)
1242 |
1243 | with amp_context():
1244 | with torch.no_grad():
1245 | generated_images = G(latents)
1246 |
1247 | if apply_gradient_penalty:
1248 | image_batch.requires_grad_()
1249 |
1250 | generated_images, (fake_output, fake_output_32x32, _) = D_aug(generated_images, detach = True, input_requires_grad = apply_gradient_penalty, return_discr_input = True, **aug_kwargs)
1251 |
1252 | real_output, real_output_32x32, real_aux_loss = D_aug(image_batch, calc_aux_loss = True, **aug_kwargs)
1253 |
1254 | real_output_loss = real_output
1255 | fake_output_loss = fake_output
1256 |
1257 | divergence = D_loss_fn(real_output_loss, fake_output_loss)
1258 | divergence_32x32 = D_loss_fn(real_output_32x32, fake_output_32x32)
1259 | disc_loss = divergence + divergence_32x32
1260 |
1261 | aux_loss = real_aux_loss
1262 | disc_loss = disc_loss + aux_loss
1263 |
1264 | if apply_gradient_penalty:
1265 | real_outputs = [real_output, real_output_32x32]
1266 | real_outputs = list(map(self.D_scaler.scale, real_outputs)) if self.amp else real_outputs
1267 |
1268 | fake_outputs = [fake_output, fake_output_32x32]
1269 | fake_outputs = list(map(self.D_scaler.scale, fake_outputs)) if self.amp else fake_outputs
1270 |
1271 | scaled_real_gradients = torch_grad(outputs=real_outputs, inputs=image_batch,
1272 | grad_outputs=[torch.ones_like(t) for t in real_outputs],
1273 | create_graph=True, retain_graph=True, only_inputs=True)[0]
1274 |
1275 | scaled_fake_gradients = torch_grad(outputs=fake_outputs, inputs=generated_images,
1276 | grad_outputs=[torch.ones_like(t) for t in fake_outputs],
1277 | create_graph=True, retain_graph=True, only_inputs=True)[0]
1278 |
1279 | inv_scale = safe_div(1., self.D_scaler.get_scale()) if self.amp else 1.
1280 |
1281 | if inv_scale != float('inf'):
1282 | scaled_gradients = torch.cat((scaled_real_gradients, scaled_fake_gradients))
1283 |
1284 | gradients = scaled_gradients * inv_scale
1285 |
1286 | with amp_context():
1287 | gradients = gradients.reshape(2 * batch_size, -1)
1288 |
1289 | gp = self.gp_weight * (gradients.norm(2, dim = 1) ** 2).mean()
1290 |
1291 | if not torch.isnan(gp):
1292 | disc_loss = disc_loss + gp
1293 | self.last_gp_loss = gp.clone().detach().item()
1294 |
1295 | with amp_context():
1296 | disc_loss = disc_loss / self.gradient_accumulate_every
1297 |
1298 | disc_loss.register_hook(raise_if_nan)
1299 | self.D_scaler.scale(disc_loss).backward()
1300 | total_disc_loss += divergence
1301 |
1302 | self.last_recon_loss = aux_loss.item()
1303 | self.d_loss = float(total_disc_loss.item() / self.gradient_accumulate_every)
1304 | self.D_scaler.step(self.GAN.D_opt)
1305 | self.D_scaler.update()
1306 |
1307 | # generator loss fn
1308 |
1309 | if self.dual_contrast_loss:
1310 | G_loss_fn = dual_contrastive_loss
1311 | G_requires_calc_real = True
1312 | else:
1313 | G_loss_fn = gen_hinge_loss
1314 | G_requires_calc_real = False
1315 |
1316 | # train generator
1317 |
1318 | self.GAN.G_opt.zero_grad()
1319 |
1320 | for i in gradient_accumulate_contexts(self.gradient_accumulate_every, self.is_ddp, ddps=[G, D_aug]):
1321 | latents = torch.randn(batch_size, latent_dim).cuda(self.rank)
1322 |
1323 | if G_requires_calc_real:
1324 | image_batch = next(self.loader).cuda(self.rank)
1325 | image_batch.requires_grad_()
1326 |
1327 | with amp_context():
1328 | generated_images = G(latents)
1329 |
1330 | fake_output, fake_output_32x32, _ = D_aug(generated_images, **aug_kwargs)
1331 | real_output, real_output_32x32, _ = D_aug(image_batch, **aug_kwargs) if G_requires_calc_real else (None, None, None)
1332 |
1333 | loss = G_loss_fn(fake_output, real_output)
1334 | loss_32x32 = G_loss_fn(fake_output_32x32, real_output_32x32)
1335 |
1336 | gen_loss = loss + loss_32x32
1337 |
1338 | gen_loss = gen_loss / self.gradient_accumulate_every
1339 |
1340 | gen_loss.register_hook(raise_if_nan)
1341 | self.G_scaler.scale(gen_loss).backward()
1342 | total_gen_loss += loss
1343 |
1344 | self.g_loss = float(total_gen_loss.item() / self.gradient_accumulate_every)
1345 | self.G_scaler.step(self.GAN.G_opt)
1346 | self.G_scaler.update()
1347 |
1348 | # calculate moving averages
1349 |
1350 | if self.is_main and self.steps % 10 == 0 and self.steps > 20000:
1351 | self.GAN.EMA()
1352 |
1353 | if self.is_main and self.steps <= 25000 and self.steps % 1000 == 2:
1354 | self.GAN.reset_parameter_averaging()
1355 |
1356 | # save from NaN errors
1357 |
1358 | if any(torch.isnan(l) for l in (total_gen_loss, total_disc_loss)):
1359 | print(f'NaN detected for generator or discriminator. Loading from checkpoint #{self.checkpoint_num}')
1360 | self.load(self.checkpoint_num)
1361 | raise NanException
1362 |
1363 | del total_disc_loss
1364 | del total_gen_loss
1365 |
1366 | # periodically save results
1367 |
1368 | if self.is_main:
1369 | if self.steps % self.save_every == 0:
1370 | self.save(self.checkpoint_num)
1371 |
1372 | if self.steps % self.evaluate_every == 0 or (self.steps % 100 == 0 and self.steps < 20000):
1373 | self.evaluate(floor(self.steps / self.evaluate_every), num_image_tiles = self.num_image_tiles)
1374 |
1375 | if exists(self.calculate_fid_every) and self.steps % self.calculate_fid_every == 0 and self.steps != 0:
1376 | num_batches = math.ceil(self.calculate_fid_num_images / self.batch_size)
1377 | fid = self.calculate_fid(num_batches)
1378 | self.last_fid = fid
1379 |
1380 | with open(str(self.results_dir / self.name / f'fid_scores.txt'), 'a') as f:
1381 | f.write(f'{self.steps},{fid}\n')
1382 |
1383 | self.steps += 1
1384 |
1385 | @torch.no_grad()
1386 | def evaluate(self, num = 0, num_image_tiles = 4):
1387 | self.GAN.eval()
1388 |
1389 | ext = self.image_extension
1390 | num_rows = num_image_tiles
1391 |
1392 | latent_dim = self.GAN.latent_dim
1393 | image_size = self.GAN.image_size
1394 |
1395 | # latents and noise
1396 | def image_to_pil(image):
1397 | ndarr = image.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()
1398 | im = Image.fromarray(ndarr)
1399 | return im
1400 |
1401 | latents = det_randn((num_rows ** 2, latent_dim)).cuda(self.rank)
1402 | interpolate_latents = interpolate_between(latents[:num_rows], latents[-num_rows:],
1403 | num_samples=num_rows,
1404 | dim=0).flatten(end_dim=1)
1405 |
1406 | generate_interpolations = self.generate_(self.GAN.G, interpolate_latents)
1407 | if self.run is not None:
1408 | grouped = generate_interpolations.view(num_rows, num_rows, *generate_interpolations.shape[1:])
1409 | for idx, images in enumerate(grouped):
1410 | alpha = idx / (len(grouped) - 1)
1411 | aim_images = []
1412 | for image in images:
1413 | im = image_to_pil(image)
1414 | aim_images.append(self.aim.Image(im, caption=f'#{idx}'))
1415 |
1416 | self.run.track(value=aim_images, name='generated',
1417 | step=self.steps,
1418 | context={'interpolated': True,
1419 | 'alpha': alpha})
1420 | torchvision.utils.save_image(generate_interpolations, str(self.results_dir / self.name / f'{str(num)}-interp.{ext}'), nrow=num_rows)
1421 | # regular
1422 |
1423 | generated_images = self.generate_(self.GAN.G, latents)
1424 |
1425 | if self.run is not None:
1426 | aim_images = []
1427 | for idx, image in enumerate(generated_images):
1428 | im = image_to_pil(image)
1429 | aim_images.append(self.aim.Image(im, caption=f'#{idx}'))
1430 |
1431 | self.run.track(value=aim_images, name='generated',
1432 | step=self.steps,
1433 | context={'ema': False})
1434 | torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}.{ext}'), nrow=num_rows)
1435 |
1436 | # moving averages
1437 |
1438 | generated_images = self.generate_(self.GAN.GE, latents)
1439 | if self.run is not None:
1440 | aim_images = []
1441 | for idx, image in enumerate(generated_images):
1442 | im = image_to_pil(image)
1443 | aim_images.append(self.aim.Image(im, caption=f'EMA #{idx}'))
1444 |
1445 | self.run.track(value=aim_images, name='generated',
1446 | step=self.steps,
1447 | context={'ema': True})
1448 | torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}-ema.{ext}'), nrow=num_rows)
1449 |
1450 | @torch.no_grad()
1451 | def generate(self, num=0, num_image_tiles=4, checkpoint=None, types=['default', 'ema']):
1452 | self.GAN.eval()
1453 |
1454 | latent_dim = self.GAN.latent_dim
1455 | dir_name = self.name + str('-generated-') + str(checkpoint)
1456 | dir_full = Path().absolute() / self.results_dir / dir_name
1457 | ext = self.image_extension
1458 |
1459 | if not dir_full.exists():
1460 | os.mkdir(dir_full)
1461 |
1462 | # regular
1463 | if 'default' in types:
1464 | for i in tqdm(range(num_image_tiles), desc='Saving generated default images'):
1465 | latents = torch.randn((1, latent_dim)).cuda(self.rank)
1466 | generated_image = self.generate_(self.GAN.G, latents)
1467 | path = str(self.results_dir / dir_name / f'{str(num)}-{str(i)}.{ext}')
1468 | torchvision.utils.save_image(generated_image[0], path, nrow=1)
1469 |
1470 | # moving averages
1471 | if 'ema' in types:
1472 | for i in tqdm(range(num_image_tiles), desc='Saving generated EMA images'):
1473 | latents = torch.randn((1, latent_dim)).cuda(self.rank)
1474 | generated_image = self.generate_(self.GAN.GE, latents)
1475 | path = str(self.results_dir / dir_name / f'{str(num)}-{str(i)}-ema.{ext}')
1476 | torchvision.utils.save_image(generated_image[0], path, nrow=1)
1477 |
1478 | return dir_full
1479 |
1480 | @torch.no_grad()
1481 | def show_progress(self, num_images=4, types=['default', 'ema']):
1482 | checkpoints = self.get_checkpoints()
1483 | assert exists(checkpoints), 'cannot find any checkpoints to create a training progress video for'
1484 |
1485 | dir_name = self.name + str('-progress')
1486 | dir_full = Path().absolute() / self.results_dir / dir_name
1487 | ext = self.image_extension
1488 | latents = None
1489 |
1490 | zfill_length = math.ceil(math.log10(len(checkpoints)))
1491 |
1492 | if not dir_full.exists():
1493 | os.mkdir(dir_full)
1494 |
1495 | for checkpoint in tqdm(checkpoints, desc='Generating progress images'):
1496 | self.load(checkpoint, print_version=False)
1497 | self.GAN.eval()
1498 |
1499 | if checkpoint == 0:
1500 | latents = torch.randn((num_images, self.GAN.latent_dim)).cuda(self.rank)
1501 |
1502 | # regular
1503 | if 'default' in types:
1504 | generated_image = self.generate_(self.GAN.G, latents)
1505 | path = str(self.results_dir / dir_name / f'{str(checkpoint).zfill(zfill_length)}.{ext}')
1506 | torchvision.utils.save_image(generated_image, path, nrow=num_images)
1507 |
1508 | # moving averages
1509 | if 'ema' in types:
1510 | generated_image = self.generate_(self.GAN.GE, latents)
1511 | path = str(self.results_dir / dir_name / f'{str(checkpoint).zfill(zfill_length)}-ema.{ext}')
1512 | torchvision.utils.save_image(generated_image, path, nrow=num_images)
1513 |
1514 | @torch.no_grad()
1515 | def calculate_fid(self, num_batches):
1516 | from pytorch_fid import fid_score
1517 | torch.cuda.empty_cache()
1518 |
1519 | real_path = self.fid_dir / 'real'
1520 | fake_path = self.fid_dir / 'fake'
1521 |
1522 | # remove any existing files used for fid calculation and recreate directories
1523 | if not real_path.exists() or self.clear_fid_cache:
1524 | rmtree(real_path, ignore_errors=True)
1525 | os.makedirs(real_path)
1526 |
1527 | for batch_num in tqdm(range(num_batches), desc='calculating FID - saving reals'):
1528 | real_batch = next(self.loader)
1529 | for k, image in enumerate(real_batch.unbind(0)):
1530 | ind = k + batch_num * self.batch_size
1531 | torchvision.utils.save_image(image, real_path / f'{ind}.png')
1532 |
1533 | # generate a bunch of fake images in results / name / fid_fake
1534 |
1535 | rmtree(fake_path, ignore_errors=True)
1536 | os.makedirs(fake_path)
1537 |
1538 | self.GAN.eval()
1539 | ext = self.image_extension
1540 |
1541 | latent_dim = self.GAN.latent_dim
1542 | image_size = self.GAN.image_size
1543 |
1544 | for batch_num in tqdm(range(num_batches), desc='calculating FID - saving generated'):
1545 | # latents and noise
1546 | latents = torch.randn(self.batch_size, latent_dim).cuda(self.rank)
1547 |
1548 | # moving averages
1549 | generated_images = self.generate_(self.GAN.GE, latents)
1550 |
1551 | for j, image in enumerate(generated_images.unbind(0)):
1552 | ind = j + batch_num * self.batch_size
1553 | torchvision.utils.save_image(image, str(fake_path / f'{str(ind)}-ema.{ext}'))
1554 |
1555 | return fid_score.calculate_fid_given_paths([str(real_path), str(fake_path)], 256, latents.device, 2048)
1556 |
1557 | @torch.no_grad()
1558 | def generate_(self, G, style, num_image_tiles = 8):
1559 | generated_images = evaluate_in_chunks(self.batch_size, G, style)
1560 | return generated_images.clamp_(0., 1.)
1561 |
1562 | @torch.no_grad()
1563 | def generate_interpolation(self, num = 0, num_image_tiles = 8, num_steps = 100, save_frames = False):
1564 | self.GAN.eval()
1565 | ext = self.image_extension
1566 | num_rows = num_image_tiles
1567 |
1568 | latent_dim = self.GAN.latent_dim
1569 | image_size = self.GAN.image_size
1570 |
1571 | # latents and noise
1572 |
1573 | latents_low = torch.randn(num_rows ** 2, latent_dim).cuda(self.rank)
1574 | latents_high = torch.randn(num_rows ** 2, latent_dim).cuda(self.rank)
1575 |
1576 | ratios = torch.linspace(0., 8., num_steps)
1577 |
1578 | frames = []
1579 | for ratio in tqdm(ratios):
1580 | interp_latents = slerp(ratio, latents_low, latents_high)
1581 | generated_images = self.generate_(self.GAN.GE, interp_latents)
1582 | images_grid = torchvision.utils.make_grid(generated_images, nrow = num_rows)
1583 | pil_image = transforms.ToPILImage()(images_grid.cpu())
1584 |
1585 | if self.transparent:
1586 | background = Image.new('RGBA', pil_image.size, (255, 255, 255))
1587 | pil_image = Image.alpha_composite(background, pil_image)
1588 |
1589 | frames.append(pil_image)
1590 |
1591 | frames[0].save(str(self.results_dir / self.name / f'{str(num)}.gif'), save_all=True, append_images=frames[1:], duration=80, loop=0, optimize=True)
1592 |
1593 | if save_frames:
1594 | folder_path = (self.results_dir / self.name / f'{str(num)}')
1595 | folder_path.mkdir(parents=True, exist_ok=True)
1596 | for ind, frame in enumerate(frames):
1597 | frame.save(str(folder_path / f'{str(ind)}.{ext}'))
1598 |
1599 | def print_log(self):
1600 | data = [
1601 | ('G', self.g_loss),
1602 | ('D', self.d_loss),
1603 | ('GP', self.last_gp_loss),
1604 | ('SS', self.last_recon_loss),
1605 | ('FID', self.last_fid)
1606 | ]
1607 |
1608 | data = [d for d in data if exists(d[1])]
1609 | log = ' | '.join(map(lambda n: f'{n[0]}: {n[1]:.2f}', data))
1610 | print(log)
1611 |
1612 | if self.run is not None:
1613 | for key, value in data:
1614 | self.run.track(value, key, step=self.steps)
1615 |
1616 | return data
1617 |
1618 | def model_name(self, num):
1619 | return str(self.models_dir / self.name / f'model_{num}.pt')
1620 |
1621 | def init_folders(self):
1622 | (self.results_dir / self.name).mkdir(parents=True, exist_ok=True)
1623 | (self.models_dir / self.name).mkdir(parents=True, exist_ok=True)
1624 |
1625 | def clear(self):
1626 | rmtree(str(self.models_dir / self.name), True)
1627 | rmtree(str(self.results_dir / self.name), True)
1628 | rmtree(str(self.fid_dir), True)
1629 | rmtree(str(self.config_path), True)
1630 | self.init_folders()
1631 |
1632 | def save(self, num):
1633 | save_data = {
1634 | 'GAN': self.GAN.state_dict(),
1635 | 'version': __version__,
1636 | 'G_scaler': self.G_scaler.state_dict(),
1637 | 'D_scaler': self.D_scaler.state_dict()
1638 | }
1639 |
1640 | torch.save(save_data, self.model_name(num))
1641 | self.write_config()
1642 |
1643 | def load(self, num=-1, print_version=True):
1644 | self.load_config()
1645 |
1646 | name = num
1647 | if num == -1:
1648 | checkpoints = self.get_checkpoints()
1649 |
1650 | if not exists(checkpoints):
1651 | return
1652 |
1653 | name = checkpoints[-1]
1654 | print(f'continuing from previous epoch - {name}')
1655 |
1656 | self.steps = name * self.save_every
1657 |
1658 | load_data = torch.load(self.model_name(name), weights_only = True)
1659 |
1660 | if print_version and 'version' in load_data and self.is_main:
1661 | print(f"loading from version {load_data['version']}")
1662 |
1663 | try:
1664 | self.GAN.load_state_dict(load_data['GAN'], strict = self.load_strict)
1665 | except Exception as e:
1666 | saved_version = load_data['version']
1667 | print('unable to load save model. please try downgrading the package to the version specified by the saved model (to do so, just run `pip install lightweight-gan=={saved_version}`')
1668 | raise e
1669 |
1670 | if 'G_scaler' in load_data:
1671 | self.G_scaler.load_state_dict(load_data['G_scaler'])
1672 | if 'D_scaler' in load_data:
1673 | self.D_scaler.load_state_dict(load_data['D_scaler'])
1674 |
1675 | def get_checkpoints(self):
1676 | file_paths = [p for p in Path(self.models_dir / self.name).glob('model_*.pt')]
1677 | saved_nums = sorted(map(lambda x: int(x.stem.split('_')[1]), file_paths))
1678 |
1679 | if len(saved_nums) == 0:
1680 | return None
1681 |
1682 | return saved_nums
1683 |
--------------------------------------------------------------------------------