├── stylegan2_pytorch
├── version.py
├── __init__.py
├── diff_augment.py
├── cli.py
└── stylegan2_pytorch.py
├── setup.cfg
├── images
└── aim.png
├── samples
├── hands.jpg
├── cities.jpg
├── flowers.jpg
├── flowers-2.jpg
├── celebrities.jpg
└── celebrities-2.jpg
├── LICENSE
├── .github
└── workflows
│ └── python-publish.yml
├── setup.py
├── .gitignore
└── README.md
/stylegan2_pytorch/version.py:
--------------------------------------------------------------------------------
1 | __version__ = '1.9.0'
2 |
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | # Inside of setup.cfg
2 | [metadata]
3 | description-file = README.md
--------------------------------------------------------------------------------
/images/aim.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/stylegan2-pytorch/HEAD/images/aim.png
--------------------------------------------------------------------------------
/samples/hands.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/stylegan2-pytorch/HEAD/samples/hands.jpg
--------------------------------------------------------------------------------
/samples/cities.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/stylegan2-pytorch/HEAD/samples/cities.jpg
--------------------------------------------------------------------------------
/samples/flowers.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/stylegan2-pytorch/HEAD/samples/flowers.jpg
--------------------------------------------------------------------------------
/samples/flowers-2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/stylegan2-pytorch/HEAD/samples/flowers-2.jpg
--------------------------------------------------------------------------------
/samples/celebrities.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/stylegan2-pytorch/HEAD/samples/celebrities.jpg
--------------------------------------------------------------------------------
/samples/celebrities-2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/lucidrains/stylegan2-pytorch/HEAD/samples/celebrities-2.jpg
--------------------------------------------------------------------------------
/stylegan2_pytorch/__init__.py:
--------------------------------------------------------------------------------
1 | from stylegan2_pytorch.stylegan2_pytorch import Trainer, StyleGAN2, NanException, ModelLoader
2 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2020 Phil Wang
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/.github/workflows/python-publish.yml:
--------------------------------------------------------------------------------
1 | # This workflow will upload a Python Package using Twine when a release is created
2 | # For more information see: https://help.github.com/en/actions/language-and-framework-guides/using-python-with-github-actions#publishing-to-package-registries
3 |
4 | # This workflow uses actions that are not certified by GitHub.
5 | # They are provided by a third-party and are governed by
6 | # separate terms of service, privacy policy, and support
7 | # documentation.
8 |
9 | name: Upload Python Package
10 |
11 | on:
12 | release:
13 | types: [published]
14 |
15 | jobs:
16 | deploy:
17 |
18 | runs-on: ubuntu-latest
19 |
20 | steps:
21 | - uses: actions/checkout@v2
22 | - name: Set up Python
23 | uses: actions/setup-python@v2
24 | with:
25 | python-version: '3.x'
26 | - name: Install dependencies
27 | run: |
28 | python -m pip install --upgrade pip
29 | pip install build
30 | - name: Build package
31 | run: python -m build
32 | - name: Publish package
33 | uses: pypa/gh-action-pypi-publish@27b31702a0e7fc50959f5ad993c78deac1bdfc29
34 | with:
35 | user: __token__
36 | password: ${{ secrets.PYPI_API_TOKEN }}
37 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | import sys
2 | from setuptools import setup, find_packages
3 |
4 | sys.path[0:0] = ['stylegan2_pytorch']
5 | from version import __version__
6 |
7 | setup(
8 | name = 'stylegan2_pytorch',
9 | packages = find_packages(),
10 | entry_points={
11 | 'console_scripts': [
12 | 'stylegan2_pytorch = stylegan2_pytorch.cli:main',
13 | ],
14 | },
15 | version = __version__,
16 | license = 'MIT',
17 | description = 'StyleGan2 in Pytorch',
18 | long_description_content_type = 'text/markdown',
19 | author = 'Phil Wang',
20 | author_email = 'lucidrains@gmail.com',
21 | url = 'https://github.com/lucidrains/stylegan2-pytorch',
22 | download_url = 'https://github.com/lucidrains/stylegan2-pytorch/archive/v_036.tar.gz',
23 | keywords = [
24 | 'generative adversarial networks',
25 | 'artificial intelligence'
26 | ],
27 | install_requires=[
28 | 'aim',
29 | 'einops>=0.8.0',
30 | 'contrastive_learner>=0.1.0',
31 | 'fire',
32 | 'kornia>=0.5.4',
33 | 'numpy',
34 | 'retry',
35 | 'tqdm',
36 | 'torch>=2.2',
37 | 'torchvision',
38 | 'pillow',
39 | 'vector-quantize-pytorch==0.1.0'
40 | ],
41 | classifiers=[
42 | 'Development Status :: 4 - Beta',
43 | 'Intended Audience :: Developers',
44 | 'Topic :: Scientific/Engineering :: Artificial Intelligence',
45 | 'License :: OSI Approved :: MIT License',
46 | 'Programming Language :: Python :: 3.6',
47 | ],
48 | )
49 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | pip-wheel-metadata/
24 | share/python-wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 | MANIFEST
29 |
30 | # PyInstaller
31 | # Usually these files are written by a python script from a template
32 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
33 | *.manifest
34 | *.spec
35 |
36 | # Installer logs
37 | pip-log.txt
38 | pip-delete-this-directory.txt
39 |
40 | # Unit test / coverage reports
41 | htmlcov/
42 | .tox/
43 | .nox/
44 | .coverage
45 | .coverage.*
46 | .cache
47 | nosetests.xml
48 | coverage.xml
49 | *.cover
50 | *.py,cover
51 | .hypothesis/
52 | .pytest_cache/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | target/
76 |
77 | # Jupyter Notebook
78 | .ipynb_checkpoints
79 |
80 | # IPython
81 | profile_default/
82 | ipython_config.py
83 |
84 | # pyenv
85 | .python-version
86 |
87 | # pipenv
88 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
89 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
90 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
91 | # install all needed dependencies.
92 | #Pipfile.lock
93 |
94 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
95 | __pypackages__/
96 |
97 | # Celery stuff
98 | celerybeat-schedule
99 | celerybeat.pid
100 |
101 | # SageMath parsed files
102 | *.sage.py
103 |
104 | # Environments
105 | .env
106 | .venv
107 | env/
108 | venv/
109 | ENV/
110 | env.bak/
111 | venv.bak/
112 |
113 | # Spyder project settings
114 | .spyderproject
115 | .spyproject
116 |
117 | # Rope project settings
118 | .ropeproject
119 |
120 | # mkdocs documentation
121 | /site
122 |
123 | # mypy
124 | .mypy_cache/
125 | .dmypy.json
126 | dmypy.json
127 |
128 | # Pyre type checker
129 | .pyre/
130 |
--------------------------------------------------------------------------------
/stylegan2_pytorch/diff_augment.py:
--------------------------------------------------------------------------------
1 | from functools import partial
2 | import random
3 | import torch
4 | import torch.nn.functional as F
5 |
6 |
7 | def DiffAugment(x, types=[]):
8 | for p in types:
9 | for f in AUGMENT_FNS[p]:
10 | x = f(x)
11 | return x.contiguous()
12 |
13 |
14 | # """
15 | # Augmentation functions got images as `x`
16 | # where `x` is tensor with this dimensions:
17 | # 0 - count of images
18 | # 1 - channels
19 | # 2 - width
20 | # 3 - height of image
21 | # """
22 |
23 | def rand_brightness(x, scale):
24 | x = x + (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) - 0.5) * scale
25 | return x
26 |
27 | def rand_saturation(x, scale):
28 | x_mean = x.mean(dim=1, keepdim=True)
29 | x = (x - x_mean) * (((torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) - 0.5) * 2.0 * scale) + 1.0) + x_mean
30 | return x
31 |
32 | def rand_contrast(x, scale):
33 | x_mean = x.mean(dim=[1, 2, 3], keepdim=True)
34 | x = (x - x_mean) * (((torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) - 0.5) * 2.0 * scale) + 1.0) + x_mean
35 | return x
36 |
37 | def rand_translation(x, ratio=0.125):
38 | shift_x, shift_y = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)
39 | translation_x = torch.randint(-shift_x, shift_x + 1, size=[x.size(0), 1, 1], device=x.device)
40 | translation_y = torch.randint(-shift_y, shift_y + 1, size=[x.size(0), 1, 1], device=x.device)
41 | grid_batch, grid_x, grid_y = torch.meshgrid(
42 | torch.arange(x.size(0), dtype=torch.long, device=x.device),
43 | torch.arange(x.size(2), dtype=torch.long, device=x.device),
44 | torch.arange(x.size(3), dtype=torch.long, device=x.device),
45 | )
46 | grid_x = torch.clamp(grid_x + translation_x + 1, 0, x.size(2) + 1)
47 | grid_y = torch.clamp(grid_y + translation_y + 1, 0, x.size(3) + 1)
48 | x_pad = F.pad(x, [1, 1, 1, 1, 0, 0, 0, 0])
49 | x = x_pad.permute(0, 2, 3, 1).contiguous()[grid_batch, grid_x, grid_y].permute(0, 3, 1, 2)
50 | return x
51 |
52 | def rand_offset(x, ratio=1, ratio_h=1, ratio_v=1):
53 | w, h = x.size(2), x.size(3)
54 |
55 | imgs = []
56 | for img in x.unbind(dim = 0):
57 | max_h = int(w * ratio * ratio_h)
58 | max_v = int(h * ratio * ratio_v)
59 |
60 | value_h = random.randint(0, max_h) * 2 - max_h
61 | value_v = random.randint(0, max_v) * 2 - max_v
62 |
63 | if abs(value_h) > 0:
64 | img = torch.roll(img, value_h, 2)
65 |
66 | if abs(value_v) > 0:
67 | img = torch.roll(img, value_v, 1)
68 |
69 | imgs.append(img)
70 |
71 | return torch.stack(imgs)
72 |
73 | def rand_offset_h(x, ratio=1):
74 | return rand_offset(x, ratio=1, ratio_h=ratio, ratio_v=0)
75 |
76 | def rand_offset_v(x, ratio=1):
77 | return rand_offset(x, ratio=1, ratio_h=0, ratio_v=ratio)
78 |
79 | def rand_cutout(x, ratio=0.5):
80 | cutout_size = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)
81 | offset_x = torch.randint(0, x.size(2) + (1 - cutout_size[0] % 2), size=[x.size(0), 1, 1], device=x.device)
82 | offset_y = torch.randint(0, x.size(3) + (1 - cutout_size[1] % 2), size=[x.size(0), 1, 1], device=x.device)
83 | grid_batch, grid_x, grid_y = torch.meshgrid(
84 | torch.arange(x.size(0), dtype=torch.long, device=x.device),
85 | torch.arange(cutout_size[0], dtype=torch.long, device=x.device),
86 | torch.arange(cutout_size[1], dtype=torch.long, device=x.device),
87 | )
88 | grid_x = torch.clamp(grid_x + offset_x - cutout_size[0] // 2, min=0, max=x.size(2) - 1)
89 | grid_y = torch.clamp(grid_y + offset_y - cutout_size[1] // 2, min=0, max=x.size(3) - 1)
90 | mask = torch.ones(x.size(0), x.size(2), x.size(3), dtype=x.dtype, device=x.device)
91 | mask[grid_batch, grid_x, grid_y] = 0
92 | x = x * mask.unsqueeze(1)
93 | return x
94 |
95 | AUGMENT_FNS = {
96 | 'brightness': [partial(rand_brightness, scale=1.)],
97 | 'lightbrightness': [partial(rand_brightness, scale=.65)],
98 | 'contrast': [partial(rand_contrast, scale=.5)],
99 | 'lightcontrast': [partial(rand_contrast, scale=.25)],
100 | 'saturation': [partial(rand_saturation, scale=1.)],
101 | 'lightsaturation': [partial(rand_saturation, scale=.5)],
102 | 'color': [partial(rand_brightness, scale=1.), partial(rand_saturation, scale=1.), partial(rand_contrast, scale=0.5)],
103 | 'lightcolor': [partial(rand_brightness, scale=0.65), partial(rand_saturation, scale=.5), partial(rand_contrast, scale=0.5)],
104 | 'offset': [rand_offset],
105 | 'offset_h': [rand_offset_h],
106 | 'offset_v': [rand_offset_v],
107 | 'translation': [rand_translation],
108 | 'cutout': [rand_cutout],
109 | }
110 |
--------------------------------------------------------------------------------
/stylegan2_pytorch/cli.py:
--------------------------------------------------------------------------------
1 | import os
2 | import fire
3 | import random
4 | from retry.api import retry_call
5 | from tqdm import tqdm
6 | from datetime import datetime
7 | from functools import wraps
8 | from stylegan2_pytorch import Trainer, NanException
9 |
10 | import torch
11 | import torch.multiprocessing as mp
12 | import torch.distributed as dist
13 |
14 | import numpy as np
15 |
16 | def cast_list(el):
17 | return el if isinstance(el, list) else [el]
18 |
19 | def timestamped_filename(prefix = 'generated-'):
20 | now = datetime.now()
21 | timestamp = now.strftime("%m-%d-%Y_%H-%M-%S")
22 | return f'{prefix}{timestamp}'
23 |
24 | def set_seed(seed):
25 | torch.manual_seed(seed)
26 | torch.backends.cudnn.deterministic = True
27 | torch.backends.cudnn.benchmark = False
28 | np.random.seed(seed)
29 | random.seed(seed)
30 |
31 | def run_training(rank, world_size, model_args, data, load_from, new, num_train_steps, name, seed):
32 | is_main = rank == 0
33 | is_ddp = world_size > 1
34 |
35 | if is_ddp:
36 | set_seed(seed)
37 | os.environ['MASTER_ADDR'] = 'localhost'
38 | os.environ['MASTER_PORT'] = '12355'
39 | dist.init_process_group('nccl', rank=rank, world_size=world_size)
40 |
41 | print(f"{rank + 1}/{world_size} process initialized.")
42 |
43 | model_args.update(
44 | is_ddp = is_ddp,
45 | rank = rank,
46 | world_size = world_size
47 | )
48 |
49 | model = Trainer(**model_args)
50 |
51 | if not new:
52 | model.load(load_from)
53 | else:
54 | model.clear()
55 |
56 | model.set_data_src(data)
57 |
58 | progress_bar = tqdm(initial = model.steps, total = num_train_steps, mininterval=10., desc=f'{name}<{data}>')
59 | while model.steps < num_train_steps:
60 | retry_call(model.train, tries=3, exceptions=NanException)
61 | progress_bar.n = model.steps
62 | progress_bar.refresh()
63 | if is_main and model.steps % 50 == 0:
64 | model.print_log()
65 |
66 | model.save(model.checkpoint_num)
67 |
68 | if is_ddp:
69 | dist.destroy_process_group()
70 |
71 | def train_from_folder(
72 | data = './data',
73 | results_dir = './results',
74 | models_dir = './models',
75 | name = 'default',
76 | new = False,
77 | load_from = -1,
78 | image_size = 128,
79 | network_capacity = 16,
80 | fmap_max = 512,
81 | transparent = False,
82 | batch_size = 5,
83 | gradient_accumulate_every = 6,
84 | num_train_steps = 150000,
85 | learning_rate = 2e-4,
86 | lr_mlp = 0.1,
87 | ttur_mult = 1.5,
88 | rel_disc_loss = False,
89 | num_workers = None,
90 | save_every = 1000,
91 | evaluate_every = 1000,
92 | generate = False,
93 | num_generate = 1,
94 | generate_interpolation = False,
95 | interpolation_num_steps = 100,
96 | save_frames = False,
97 | num_image_tiles = 8,
98 | trunc_psi = 0.75,
99 | mixed_prob = 0.9,
100 | fp16 = False,
101 | no_pl_reg = False,
102 | cl_reg = False,
103 | fq_layers = [],
104 | fq_dict_size = 256,
105 | attn_layers = [],
106 | no_const = False,
107 | aug_prob = 0.,
108 | aug_types = ['translation', 'cutout'],
109 | top_k_training = False,
110 | generator_top_k_gamma = 0.99,
111 | generator_top_k_frac = 0.5,
112 | dual_contrast_loss = False,
113 | dataset_aug_prob = 0.,
114 | multi_gpus = False,
115 | calculate_fid_every = None,
116 | calculate_fid_num_images = 12800,
117 | clear_fid_cache = False,
118 | seed = 42,
119 | log = False
120 | ):
121 | model_args = dict(
122 | name = name,
123 | results_dir = results_dir,
124 | models_dir = models_dir,
125 | batch_size = batch_size,
126 | gradient_accumulate_every = gradient_accumulate_every,
127 | image_size = image_size,
128 | network_capacity = network_capacity,
129 | fmap_max = fmap_max,
130 | transparent = transparent,
131 | lr = learning_rate,
132 | lr_mlp = lr_mlp,
133 | ttur_mult = ttur_mult,
134 | rel_disc_loss = rel_disc_loss,
135 | num_workers = num_workers,
136 | save_every = save_every,
137 | evaluate_every = evaluate_every,
138 | num_image_tiles = num_image_tiles,
139 | trunc_psi = trunc_psi,
140 | fp16 = fp16,
141 | no_pl_reg = no_pl_reg,
142 | cl_reg = cl_reg,
143 | fq_layers = fq_layers,
144 | fq_dict_size = fq_dict_size,
145 | attn_layers = attn_layers,
146 | no_const = no_const,
147 | aug_prob = aug_prob,
148 | aug_types = cast_list(aug_types),
149 | top_k_training = top_k_training,
150 | generator_top_k_gamma = generator_top_k_gamma,
151 | generator_top_k_frac = generator_top_k_frac,
152 | dual_contrast_loss = dual_contrast_loss,
153 | dataset_aug_prob = dataset_aug_prob,
154 | calculate_fid_every = calculate_fid_every,
155 | calculate_fid_num_images = calculate_fid_num_images,
156 | clear_fid_cache = clear_fid_cache,
157 | mixed_prob = mixed_prob,
158 | log = log
159 | )
160 |
161 | if generate:
162 | model = Trainer(**model_args)
163 | model.load(load_from)
164 | samples_name = timestamped_filename()
165 | for num in tqdm(range(num_generate)):
166 | model.evaluate(f'{samples_name}-{num}', num_image_tiles)
167 | print(f'sample images generated at {results_dir}/{name}/{samples_name}')
168 | return
169 |
170 | if generate_interpolation:
171 | model = Trainer(**model_args)
172 | model.load(load_from)
173 | samples_name = timestamped_filename()
174 | model.generate_interpolation(samples_name, num_image_tiles, num_steps = interpolation_num_steps, save_frames = save_frames)
175 | print(f'interpolation generated at {results_dir}/{name}/{samples_name}')
176 | return
177 |
178 | world_size = torch.cuda.device_count()
179 |
180 | if world_size == 1 or not multi_gpus:
181 | run_training(0, 1, model_args, data, load_from, new, num_train_steps, name, seed)
182 | return
183 |
184 | mp.spawn(run_training,
185 | args=(world_size, model_args, data, load_from, new, num_train_steps, name, seed),
186 | nprocs=world_size,
187 | join=True)
188 |
189 | def main():
190 | fire.Fire(train_from_folder)
191 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## Simple StyleGan2 for Pytorch
2 | [](https://badge.fury.io/py/stylegan2-pytorch)
3 |
4 | Simple Pytorch implementation of Stylegan2 based on https://arxiv.org/abs/1912.04958 that can be completely trained from the command-line, no coding needed.
5 |
6 | Below are some flowers that do not exist.
7 |
8 |  9 |
10 |
9 |
10 |  11 |
12 | Neither do these hands
13 |
14 |
11 |
12 | Neither do these hands
13 |
14 |  15 |
16 | Nor these cities
17 |
18 |
15 |
16 | Nor these cities
17 |
18 |  19 |
20 | Nor these celebrities (trained by @yoniker)
21 |
22 |
19 |
20 | Nor these celebrities (trained by @yoniker)
21 |
22 |  23 |
24 |
23 |
24 | 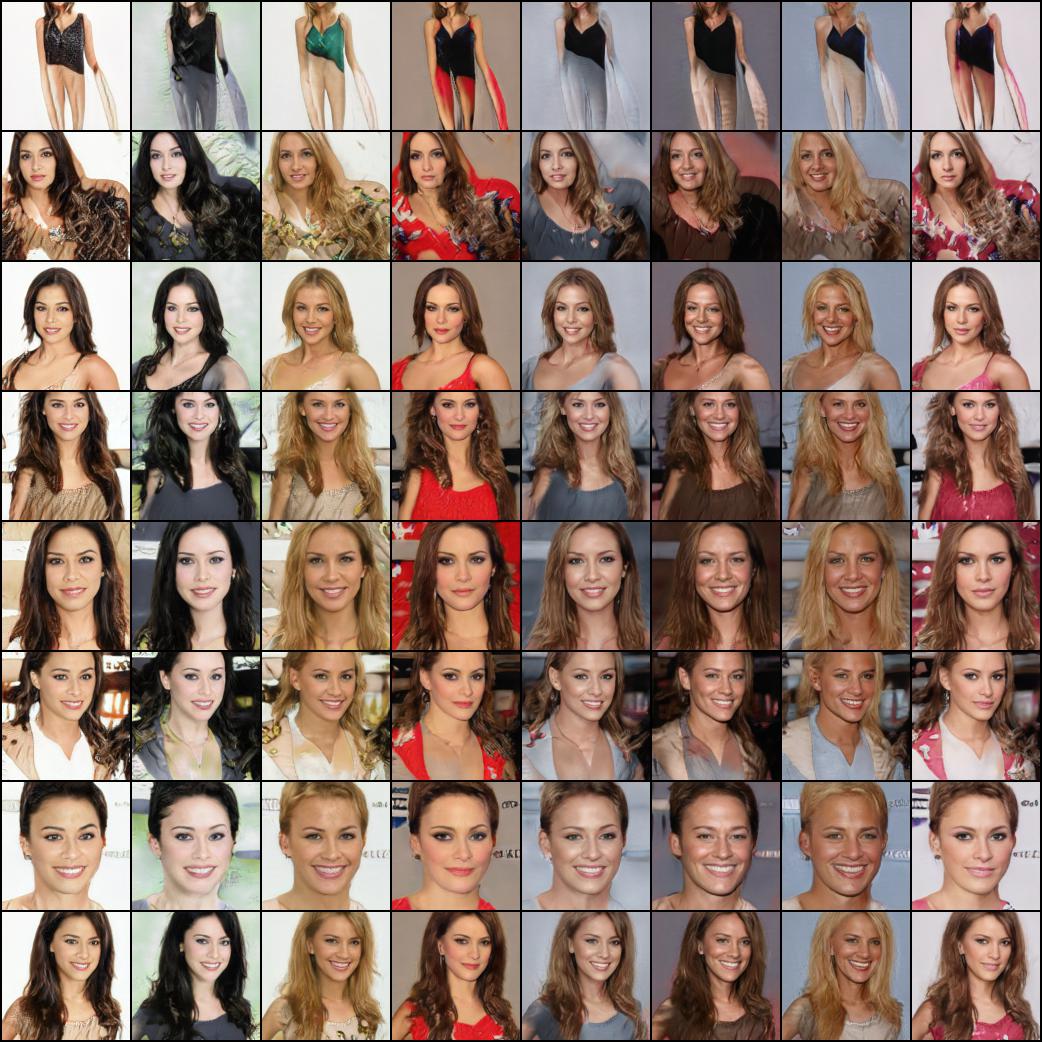 25 |
26 |
27 | ## Install
28 |
29 | You will need a machine with a GPU and CUDA installed. Then pip install the package like this
30 |
31 | ```bash
32 | $ pip install stylegan2_pytorch
33 | ```
34 |
35 | If you are using a windows machine, the following commands reportedly works.
36 |
37 | ```bash
38 | $ conda install pytorch torchvision -c python
39 | $ pip install stylegan2_pytorch
40 | ```
41 |
42 | ## Use
43 |
44 | ```bash
45 | $ stylegan2_pytorch --data /path/to/images
46 | ```
47 |
48 | That's it. Sample images will be saved to `results/default` and models will be saved periodically to `models/default`.
49 |
50 | ## Advanced Use
51 |
52 | You can specify the name of your project with
53 |
54 | ```bash
55 | $ stylegan2_pytorch --data /path/to/images --name my-project-name
56 | ```
57 |
58 | You can also specify the location where intermediate results and model checkpoints should be stored with
59 |
60 | ```bash
61 | $ stylegan2_pytorch --data /path/to/images --name my-project-name --results_dir /path/to/results/dir --models_dir /path/to/models/dir
62 | ```
63 |
64 | You can increase the network capacity (which defaults to `16`) to improve generation results, at the cost of more memory.
65 |
66 | ```bash
67 | $ stylegan2_pytorch --data /path/to/images --network-capacity 256
68 | ```
69 |
70 | By default, if the training gets cut off, it will automatically resume from the last checkpointed file. If you want to restart with new settings, just add a `new` flag
71 |
72 | ```bash
73 | $ stylegan2_pytorch --new --data /path/to/images --name my-project-name --image-size 512 --batch-size 1 --gradient-accumulate-every 16 --network-capacity 10
74 | ```
75 |
76 | Once you have finished training, you can generate images from your latest checkpoint like so.
77 |
78 | ```bash
79 | $ stylegan2_pytorch --generate
80 | ```
81 |
82 | To generate a video of a interpolation through two random points in latent space.
83 |
84 | ```bash
85 | $ stylegan2_pytorch --generate-interpolation --interpolation-num-steps 100
86 | ```
87 |
88 | To save each individual frame of the interpolation
89 |
90 | ```bash
91 | $ stylegan2_pytorch --generate-interpolation --save-frames
92 | ```
93 |
94 | If a previous checkpoint contained a better generator, (which often happens as generators start degrading towards the end of training), you can load from a previous checkpoint with another flag
95 |
96 | ```bash
97 | $ stylegan2_pytorch --generate --load-from {checkpoint number}
98 | ```
99 |
100 | A technique used in both StyleGAN and BigGAN is truncating the latent values so that their values fall close to the mean. The small the truncation value, the better the samples will appear at the cost of sample variety. You can control this with the `--trunc-psi`, where values typically fall between `0.5` and `1`. It is set at `0.75` as default
101 |
102 | ```bash
103 | $ stylegan2_pytorch --generate --trunc-psi 0.5
104 | ```
105 |
106 | ## Multi-GPU training
107 |
108 | If you have one machine with multiple GPUs, the repository offers a way to utilize all of them for training. With multiple GPUs, each batch will be divided evenly amongst the GPUs available. For example, for 2 GPUs, with a batch size of 32, each GPU will see 16 samples.
109 |
110 | You simply have to add a `--multi-gpus` flag, everyting else is taken care of. If you would like to restrict to specific GPUs, you can use the `CUDA_VISIBLE_DEVICES` environment variable to control what devices can be used. (ex. `CUDA_VISIBLE_DEVICES=0,2,3` only devices 0, 2, 3 are available)
111 |
112 | ```bash
113 | $ stylegan2_pytorch --data ./data --multi-gpus --batch-size 32 --gradient-accumulate-every 1
114 | ```
115 |
116 | ## Low amounts of Training Data
117 |
118 | In the past, GANs needed a lot of data to learn how to generate well. The faces model took **70k** high quality images from Flickr, as an example.
119 |
120 | However, in the month of May 2020, researchers all across the world independently converged on a simple technique to reduce that number to as low as **1-2k**. That simple idea was to differentiably augment all images, generated or real, going into the discriminator during training.
121 |
122 | If one were to augment at a low enough probability, the augmentations will not 'leak' into the generations.
123 |
124 | In the setting of low data, you can use the feature with a simple flag.
125 |
126 | ```bash
127 | # find a suitable probability between 0. -> 0.7 at maximum
128 | $ stylegan2_pytorch --data ./data --aug-prob 0.25
129 | ```
130 |
131 | By default, the augmentations used are `translation` and `cutout`. If you would like to add `color`, you can do so with the `--aug-types` argument.
132 |
133 | ```bash
134 | # make sure there are no spaces between items!
135 | $ stylegan2_pytorch --data ./data --aug-prob 0.25 --aug-types [translation,cutout,color]
136 | ```
137 |
138 | You can customize it to any combination of the three you would like. The differentiable augmentation code was copied and slightly modified from here.
139 |
140 | ## When do I stop training?
141 |
142 | For as long as possible until the adversarial game between the two neural nets fall apart (we call this divergence). By default, the number of training steps is set to `150000` for 128x128 images, but you will certainly want this number to be higher if the GAN doesn't diverge by the end of training, or if you are training at a higher resolution.
143 |
144 | ```bash
145 | $ stylegan2_pytorch --data ./data --image-size 512 --num-train-steps 1000000
146 | ```
147 |
148 | ## Attention
149 |
150 | This framework also allows for you to add an efficient form of self-attention to the designated layers of the discriminator (and the symmetric layer of the generator), which will greatly improve results. The more attention you can afford, the better!
151 |
152 | ```python
153 | # add self attention after the output of layer 1
154 | $ stylegan2_pytorch --data ./data --attn-layers 1
155 | ```
156 |
157 | ```python
158 | # add self attention after the output of layers 1 and 2
159 | # do not put a space after the comma in the list!
160 | $ stylegan2_pytorch --data ./data --attn-layers [1,2]
161 | ```
162 |
163 | ## Bonus
164 |
165 | Training on transparent images
166 |
167 | ```bash
168 | $ stylegan2_pytorch --data ./transparent/images/path --transparent
169 | ```
170 |
171 | ## Memory considerations
172 |
173 | The more GPU memory you have, the bigger and better the image generation will be. Nvidia recommended having up to 16GB for training 1024x1024 images. If you have less than that, there are a couple settings you can play with so that the model fits.
174 |
175 | ```bash
176 | $ stylegan2_pytorch --data /path/to/data \
177 | --batch-size 3 \
178 | --gradient-accumulate-every 5 \
179 | --network-capacity 16
180 | ```
181 |
182 | 1. Batch size - You can decrease the `batch-size` down to 1, but you should increase the `gradient-accumulate-every` correspondingly so that the mini-batch the network sees is not too small. This may be confusing to a layperson, so I'll think about how I would automate the choice of `gradient-accumulate-every` going forward.
183 |
184 | 2. Network capacity - You can decrease the neural network capacity to lessen the memory requirements. Just be aware that this has been shown to degrade generation performance.
185 |
186 | If none of this works, you can settle for 'Lightweight' GAN, which will allow you to tradeoff quality to train at greater resolutions in reasonable amount of time.
187 |
188 | ## Deployment on AWS
189 |
190 | Below are some steps which may be helpful for deployment using Amazon Web Services. In order to use this, you will have
191 | to provision a GPU-backed EC2 instance. An appropriate instance type would be from a p2 or p3 series. I (iboates) tried
192 | a p2.xlarge (the cheapest option) and it was quite slow, slower in fact than using Google Colab. More powerful instance
193 | types may be better but they are more expensive. You can read more about them
194 | [here](https://aws.amazon.com/ec2/instance-types/#Accelerated_Computing).
195 |
196 | ### Setup steps
197 |
198 | 1. Archive your training data and upload it to an S3 bucket
199 | 2. Provision your EC2 instance (I used an Ubuntu AMI)
200 | 3. Log into your EC2 instance via SSH
201 | 4. Install the aws CLI client and configure it:
202 |
203 | ```bash
204 | sudo snap install aws-cli --classic
205 | aws configure
206 | ```
207 |
208 | You will then have to enter your AWS access keys, which you can retrieve from the management console under AWS
209 | Management Console > Profile > My Security Credentials > Access Keys
210 |
211 | Then, run these commands, or maybe put them in a shell script and execute that:
212 |
213 | ```bash
214 | mkdir data
215 | curl -O https://bootstrap.pypa.io/get-pip.py
216 | sudo apt-get install python3-distutils
217 | python3 get-pip.py
218 | pip3 install stylegan2_pytorch
219 | export PATH=$PATH:/home/ubuntu/.local/bin
220 | aws s3 sync s3:// ~/data
221 | cd data
222 | tar -xf ../train.tar.gz
223 | ```
224 |
225 | Now you should be able to train by simplying calling `stylegan2_pytorch [args]`.
226 |
227 | Notes:
228 |
229 | * If you have a lot of training data, you may need to provision extra block storage via EBS.
230 | * Also, you may need to spread your data across multiple archives.
231 | * You should run this on a `screen` window so it won't terminate once you log out of the SSH session.
232 |
233 | ## Research
234 |
235 | ### FID Scores
236 |
237 | Thanks to GetsEclectic, you can now calculate the FID score periodically! Again, made super simple with one extra argument, as shown below.
238 |
239 | Firstly, install the `pytorch_fid` package
240 |
241 | ```bash
242 | $ pip install pytorch-fid
243 | ```
244 |
245 | Followed by
246 |
247 | ```bash
248 | $ stylegan2_pytorch --data ./data --calculate-fid-every 5000
249 | ```
250 |
251 | FID results will be logged to `./results/{name}/fid_scores.txt`
252 |
253 | ### Coding
254 |
255 | If you would like to sample images programmatically, you can do so with the following simple `ModelLoader` class.
256 |
257 | ```python
258 | import torch
259 | from torchvision.utils import save_image
260 | from stylegan2_pytorch import ModelLoader
261 |
262 | loader = ModelLoader(
263 | base_dir = '/path/to/directory', # path to where you invoked the command line tool
264 | name = 'default' # the project name, defaults to 'default'
265 | )
266 |
267 | noise = torch.randn(1, 512).cuda() # noise
268 | styles = loader.noise_to_styles(noise, trunc_psi = 0.7) # pass through mapping network
269 | images = loader.styles_to_images(styles) # call the generator on intermediate style vectors
270 |
271 | save_image(images, './sample.jpg') # save your images, or do whatever you desire
272 | ```
273 |
274 | ### Logging to experiment tracker
275 |
276 | To log the losses to an open source experiment tracker (Aim), you simply need to pass an extra flag like so.
277 |
278 | ```bash
279 | $ stylegan2_pytorch --data ./data --log
280 | ```
281 |
282 | Then, you need to make sure you have Docker installed. Following the instructions at Aim, you execute the following in your terminal.
283 |
284 | ```bash
285 | $ aim up
286 | ```
287 |
288 | Then open up your browser to the address and you should see
289 |
290 |
25 |
26 |
27 | ## Install
28 |
29 | You will need a machine with a GPU and CUDA installed. Then pip install the package like this
30 |
31 | ```bash
32 | $ pip install stylegan2_pytorch
33 | ```
34 |
35 | If you are using a windows machine, the following commands reportedly works.
36 |
37 | ```bash
38 | $ conda install pytorch torchvision -c python
39 | $ pip install stylegan2_pytorch
40 | ```
41 |
42 | ## Use
43 |
44 | ```bash
45 | $ stylegan2_pytorch --data /path/to/images
46 | ```
47 |
48 | That's it. Sample images will be saved to `results/default` and models will be saved periodically to `models/default`.
49 |
50 | ## Advanced Use
51 |
52 | You can specify the name of your project with
53 |
54 | ```bash
55 | $ stylegan2_pytorch --data /path/to/images --name my-project-name
56 | ```
57 |
58 | You can also specify the location where intermediate results and model checkpoints should be stored with
59 |
60 | ```bash
61 | $ stylegan2_pytorch --data /path/to/images --name my-project-name --results_dir /path/to/results/dir --models_dir /path/to/models/dir
62 | ```
63 |
64 | You can increase the network capacity (which defaults to `16`) to improve generation results, at the cost of more memory.
65 |
66 | ```bash
67 | $ stylegan2_pytorch --data /path/to/images --network-capacity 256
68 | ```
69 |
70 | By default, if the training gets cut off, it will automatically resume from the last checkpointed file. If you want to restart with new settings, just add a `new` flag
71 |
72 | ```bash
73 | $ stylegan2_pytorch --new --data /path/to/images --name my-project-name --image-size 512 --batch-size 1 --gradient-accumulate-every 16 --network-capacity 10
74 | ```
75 |
76 | Once you have finished training, you can generate images from your latest checkpoint like so.
77 |
78 | ```bash
79 | $ stylegan2_pytorch --generate
80 | ```
81 |
82 | To generate a video of a interpolation through two random points in latent space.
83 |
84 | ```bash
85 | $ stylegan2_pytorch --generate-interpolation --interpolation-num-steps 100
86 | ```
87 |
88 | To save each individual frame of the interpolation
89 |
90 | ```bash
91 | $ stylegan2_pytorch --generate-interpolation --save-frames
92 | ```
93 |
94 | If a previous checkpoint contained a better generator, (which often happens as generators start degrading towards the end of training), you can load from a previous checkpoint with another flag
95 |
96 | ```bash
97 | $ stylegan2_pytorch --generate --load-from {checkpoint number}
98 | ```
99 |
100 | A technique used in both StyleGAN and BigGAN is truncating the latent values so that their values fall close to the mean. The small the truncation value, the better the samples will appear at the cost of sample variety. You can control this with the `--trunc-psi`, where values typically fall between `0.5` and `1`. It is set at `0.75` as default
101 |
102 | ```bash
103 | $ stylegan2_pytorch --generate --trunc-psi 0.5
104 | ```
105 |
106 | ## Multi-GPU training
107 |
108 | If you have one machine with multiple GPUs, the repository offers a way to utilize all of them for training. With multiple GPUs, each batch will be divided evenly amongst the GPUs available. For example, for 2 GPUs, with a batch size of 32, each GPU will see 16 samples.
109 |
110 | You simply have to add a `--multi-gpus` flag, everyting else is taken care of. If you would like to restrict to specific GPUs, you can use the `CUDA_VISIBLE_DEVICES` environment variable to control what devices can be used. (ex. `CUDA_VISIBLE_DEVICES=0,2,3` only devices 0, 2, 3 are available)
111 |
112 | ```bash
113 | $ stylegan2_pytorch --data ./data --multi-gpus --batch-size 32 --gradient-accumulate-every 1
114 | ```
115 |
116 | ## Low amounts of Training Data
117 |
118 | In the past, GANs needed a lot of data to learn how to generate well. The faces model took **70k** high quality images from Flickr, as an example.
119 |
120 | However, in the month of May 2020, researchers all across the world independently converged on a simple technique to reduce that number to as low as **1-2k**. That simple idea was to differentiably augment all images, generated or real, going into the discriminator during training.
121 |
122 | If one were to augment at a low enough probability, the augmentations will not 'leak' into the generations.
123 |
124 | In the setting of low data, you can use the feature with a simple flag.
125 |
126 | ```bash
127 | # find a suitable probability between 0. -> 0.7 at maximum
128 | $ stylegan2_pytorch --data ./data --aug-prob 0.25
129 | ```
130 |
131 | By default, the augmentations used are `translation` and `cutout`. If you would like to add `color`, you can do so with the `--aug-types` argument.
132 |
133 | ```bash
134 | # make sure there are no spaces between items!
135 | $ stylegan2_pytorch --data ./data --aug-prob 0.25 --aug-types [translation,cutout,color]
136 | ```
137 |
138 | You can customize it to any combination of the three you would like. The differentiable augmentation code was copied and slightly modified from here.
139 |
140 | ## When do I stop training?
141 |
142 | For as long as possible until the adversarial game between the two neural nets fall apart (we call this divergence). By default, the number of training steps is set to `150000` for 128x128 images, but you will certainly want this number to be higher if the GAN doesn't diverge by the end of training, or if you are training at a higher resolution.
143 |
144 | ```bash
145 | $ stylegan2_pytorch --data ./data --image-size 512 --num-train-steps 1000000
146 | ```
147 |
148 | ## Attention
149 |
150 | This framework also allows for you to add an efficient form of self-attention to the designated layers of the discriminator (and the symmetric layer of the generator), which will greatly improve results. The more attention you can afford, the better!
151 |
152 | ```python
153 | # add self attention after the output of layer 1
154 | $ stylegan2_pytorch --data ./data --attn-layers 1
155 | ```
156 |
157 | ```python
158 | # add self attention after the output of layers 1 and 2
159 | # do not put a space after the comma in the list!
160 | $ stylegan2_pytorch --data ./data --attn-layers [1,2]
161 | ```
162 |
163 | ## Bonus
164 |
165 | Training on transparent images
166 |
167 | ```bash
168 | $ stylegan2_pytorch --data ./transparent/images/path --transparent
169 | ```
170 |
171 | ## Memory considerations
172 |
173 | The more GPU memory you have, the bigger and better the image generation will be. Nvidia recommended having up to 16GB for training 1024x1024 images. If you have less than that, there are a couple settings you can play with so that the model fits.
174 |
175 | ```bash
176 | $ stylegan2_pytorch --data /path/to/data \
177 | --batch-size 3 \
178 | --gradient-accumulate-every 5 \
179 | --network-capacity 16
180 | ```
181 |
182 | 1. Batch size - You can decrease the `batch-size` down to 1, but you should increase the `gradient-accumulate-every` correspondingly so that the mini-batch the network sees is not too small. This may be confusing to a layperson, so I'll think about how I would automate the choice of `gradient-accumulate-every` going forward.
183 |
184 | 2. Network capacity - You can decrease the neural network capacity to lessen the memory requirements. Just be aware that this has been shown to degrade generation performance.
185 |
186 | If none of this works, you can settle for 'Lightweight' GAN, which will allow you to tradeoff quality to train at greater resolutions in reasonable amount of time.
187 |
188 | ## Deployment on AWS
189 |
190 | Below are some steps which may be helpful for deployment using Amazon Web Services. In order to use this, you will have
191 | to provision a GPU-backed EC2 instance. An appropriate instance type would be from a p2 or p3 series. I (iboates) tried
192 | a p2.xlarge (the cheapest option) and it was quite slow, slower in fact than using Google Colab. More powerful instance
193 | types may be better but they are more expensive. You can read more about them
194 | [here](https://aws.amazon.com/ec2/instance-types/#Accelerated_Computing).
195 |
196 | ### Setup steps
197 |
198 | 1. Archive your training data and upload it to an S3 bucket
199 | 2. Provision your EC2 instance (I used an Ubuntu AMI)
200 | 3. Log into your EC2 instance via SSH
201 | 4. Install the aws CLI client and configure it:
202 |
203 | ```bash
204 | sudo snap install aws-cli --classic
205 | aws configure
206 | ```
207 |
208 | You will then have to enter your AWS access keys, which you can retrieve from the management console under AWS
209 | Management Console > Profile > My Security Credentials > Access Keys
210 |
211 | Then, run these commands, or maybe put them in a shell script and execute that:
212 |
213 | ```bash
214 | mkdir data
215 | curl -O https://bootstrap.pypa.io/get-pip.py
216 | sudo apt-get install python3-distutils
217 | python3 get-pip.py
218 | pip3 install stylegan2_pytorch
219 | export PATH=$PATH:/home/ubuntu/.local/bin
220 | aws s3 sync s3:// ~/data
221 | cd data
222 | tar -xf ../train.tar.gz
223 | ```
224 |
225 | Now you should be able to train by simplying calling `stylegan2_pytorch [args]`.
226 |
227 | Notes:
228 |
229 | * If you have a lot of training data, you may need to provision extra block storage via EBS.
230 | * Also, you may need to spread your data across multiple archives.
231 | * You should run this on a `screen` window so it won't terminate once you log out of the SSH session.
232 |
233 | ## Research
234 |
235 | ### FID Scores
236 |
237 | Thanks to GetsEclectic, you can now calculate the FID score periodically! Again, made super simple with one extra argument, as shown below.
238 |
239 | Firstly, install the `pytorch_fid` package
240 |
241 | ```bash
242 | $ pip install pytorch-fid
243 | ```
244 |
245 | Followed by
246 |
247 | ```bash
248 | $ stylegan2_pytorch --data ./data --calculate-fid-every 5000
249 | ```
250 |
251 | FID results will be logged to `./results/{name}/fid_scores.txt`
252 |
253 | ### Coding
254 |
255 | If you would like to sample images programmatically, you can do so with the following simple `ModelLoader` class.
256 |
257 | ```python
258 | import torch
259 | from torchvision.utils import save_image
260 | from stylegan2_pytorch import ModelLoader
261 |
262 | loader = ModelLoader(
263 | base_dir = '/path/to/directory', # path to where you invoked the command line tool
264 | name = 'default' # the project name, defaults to 'default'
265 | )
266 |
267 | noise = torch.randn(1, 512).cuda() # noise
268 | styles = loader.noise_to_styles(noise, trunc_psi = 0.7) # pass through mapping network
269 | images = loader.styles_to_images(styles) # call the generator on intermediate style vectors
270 |
271 | save_image(images, './sample.jpg') # save your images, or do whatever you desire
272 | ```
273 |
274 | ### Logging to experiment tracker
275 |
276 | To log the losses to an open source experiment tracker (Aim), you simply need to pass an extra flag like so.
277 |
278 | ```bash
279 | $ stylegan2_pytorch --data ./data --log
280 | ```
281 |
282 | Then, you need to make sure you have Docker installed. Following the instructions at Aim, you execute the following in your terminal.
283 |
284 | ```bash
285 | $ aim up
286 | ```
287 |
288 | Then open up your browser to the address and you should see
289 |
290 |  291 |
292 |
293 | ## Experimental
294 |
295 | ### Top-k Training for Generator
296 |
297 | A new paper has produced evidence that by simply zero-ing out the gradient contributions from samples that are deemed fake by the discriminator, the generator learns significantly better, achieving new state of the art.
298 |
299 | ```python
300 | $ stylegan2_pytorch --data ./data --top-k-training
301 | ```
302 |
303 | Gamma is a decay schedule that slowly decreases the topk from the full batch size to the target fraction of 50% (also modifiable hyperparameter).
304 |
305 | ```python
306 | $ stylegan2_pytorch --data ./data --top-k-training --generate-top-k-frac 0.5 --generate-top-k-gamma 0.99
307 | ```
308 |
309 | ### Feature Quantization
310 |
311 | A recent paper reported improved results if intermediate representations of the discriminator are vector quantized. Although I have not noticed any dramatic changes, I have decided to add this as a feature, so other minds out there can investigate. To use, you have to specify which layer(s) you would like to vector quantize. Default dictionary size is `256` and is also tunable.
312 |
313 | ```python
314 | # feature quantize layers 1 and 2, with a dictionary size of 512 each
315 | # do not put a space after the comma in the list!
316 | $ stylegan2_pytorch --data ./data --fq-layers [1,2] --fq-dict-size 512
317 | ```
318 |
319 | ### Contrastive Loss Regularization
320 |
321 | I have tried contrastive learning on the discriminator (in step with the usual GAN training) and possibly observed improved stability and quality of final results. You can turn on this experimental feature with a simple flag as shown below.
322 |
323 | ```python
324 | $ stylegan2_pytorch --data ./data --cl-reg
325 | ```
326 |
327 | ### Relativistic Discriminator Loss
328 |
329 | This was proposed in the Relativistic GAN paper to stabilize training. I have had mixed results, but will include the feature for those who want to experiment with it.
330 |
331 | ```python
332 | $ stylegan2_pytorch --data ./data --rel-disc-loss
333 | ```
334 |
335 | ### Non-constant 4x4 Block
336 |
337 | By default, the StyleGAN architecture styles a constant learned 4x4 block as it is progressively upsampled. This is an experimental feature that makes it so the 4x4 block is learned from the style vector `w` instead.
338 |
339 | ```python
340 | $ stylegan2_pytorch --data ./data --no-const
341 | ```
342 |
343 | ### Dual Contrastive Loss
344 |
345 | A recent paper has proposed that a novel contrastive loss between the real and fake logits can improve quality over other types of losses. (The default in this repository is hinge loss, and the paper shows a slight improvement)
346 |
347 | ```python
348 | $ stylegan2_pytorch --data ./data --dual-contrast-loss
349 | ```
350 |
351 | ## Alternatives
352 |
353 | Stylegan2 + Unet Discriminator
354 |
355 | I have gotten really good results with a unet discriminator, but the architecturally change was too big to fit as an option in this repository. If you are aiming for perfection, feel free to try it.
356 |
357 | If you would like me to give the royal treatment to some other GAN architecture (BigGAN), feel free to reach out at my email. Happy to hear your pitch.
358 |
359 | ## Appreciation
360 |
361 | Thank you to Matthew Mann for his inspiring [simple port](https://github.com/manicman1999/StyleGAN2-Tensorflow-2.0) for Tensorflow 2.0
362 |
363 | ## References
364 |
365 | ```bibtex
366 | @article{Karras2019stylegan2,
367 | title = {Analyzing and Improving the Image Quality of {StyleGAN}},
368 | author = {Tero Karras and Samuli Laine and Miika Aittala and Janne Hellsten and Jaakko Lehtinen and Timo Aila},
369 | journal = {CoRR},
370 | volume = {abs/1912.04958},
371 | year = {2019},
372 | }
373 | ```
374 |
375 | ```bibtex
376 | @misc{zhao2020feature,
377 | title = {Feature Quantization Improves GAN Training},
378 | author = {Yang Zhao and Chunyuan Li and Ping Yu and Jianfeng Gao and Changyou Chen},
379 | year = {2020}
380 | }
381 | ```
382 |
383 | ```bibtex
384 | @misc{chen2020simple,
385 | title = {A Simple Framework for Contrastive Learning of Visual Representations},
386 | author = {Ting Chen and Simon Kornblith and Mohammad Norouzi and Geoffrey Hinton},
387 | year = {2020}
388 | }
389 | ```
390 |
391 | ```bibtex
392 | @article{,
393 | title = {Oxford 102 Flowers},
394 | author = {Nilsback, M-E. and Zisserman, A., 2008},
395 | abstract = {A 102 category dataset consisting of 102 flower categories, commonly occuring in the United Kingdom. Each class consists of 40 to 258 images. The images have large scale, pose and light variations.}
396 | }
397 | ```
398 |
399 | ```bibtex
400 | @article{afifi201911k,
401 | title = {11K Hands: gender recognition and biometric identification using a large dataset of hand images},
402 | author = {Afifi, Mahmoud},
403 | journal = {Multimedia Tools and Applications}
404 | }
405 | ```
406 |
407 | ```bibtex
408 | @misc{zhang2018selfattention,
409 | title = {Self-Attention Generative Adversarial Networks},
410 | author = {Han Zhang and Ian Goodfellow and Dimitris Metaxas and Augustus Odena},
411 | year = {2018},
412 | eprint = {1805.08318},
413 | archivePrefix = {arXiv}
414 | }
415 | ```
416 |
417 | ```bibtex
418 | @article{shen2019efficient,
419 | author = {Zhuoran Shen and
420 | Mingyuan Zhang and
421 | Haiyu Zhao and
422 | Shuai Yi and
423 | Hongsheng Li},
424 | title = {Efficient Attention: Attention with Linear Complexities},
425 | journal = {CoRR},
426 | year = {2018},
427 | url = {http://arxiv.org/abs/1812.01243},
428 | }
429 | ```
430 |
431 | ```bibtex
432 | @article{zhao2020diffaugment,
433 | title = {Differentiable Augmentation for Data-Efficient GAN Training},
434 | author = {Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
435 | journal = {arXiv preprint arXiv:2006.10738},
436 | year = {2020}
437 | }
438 | ```
439 |
440 | ```bibtex
441 | @misc{zhao2020image,
442 | title = {Image Augmentations for GAN Training},
443 | author = {Zhengli Zhao and Zizhao Zhang and Ting Chen and Sameer Singh and Han Zhang},
444 | year = {2020},
445 | eprint = {2006.02595},
446 | archivePrefix = {arXiv}
447 | }
448 | ```
449 |
450 | ```bibtex
451 | @misc{karras2020training,
452 | title = {Training Generative Adversarial Networks with Limited Data},
453 | author = {Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila},
454 | year = {2020},
455 | eprint = {2006.06676},
456 | archivePrefix = {arXiv},
457 | primaryClass = {cs.CV}
458 | }
459 | ```
460 |
461 | ```bibtex
462 | @misc{jolicoeurmartineau2018relativistic,
463 | title = {The relativistic discriminator: a key element missing from standard GAN},
464 | author = {Alexia Jolicoeur-Martineau},
465 | year = {2018},
466 | eprint = {1807.00734},
467 | archivePrefix = {arXiv},
468 | primaryClass = {cs.LG}
469 | }
470 | ```
471 |
472 | ```bibtex
473 | @misc{sinha2020topk,
474 | title = {Top-k Training of GANs: Improving GAN Performance by Throwing Away Bad Samples},
475 | author = {Samarth Sinha and Zhengli Zhao and Anirudh Goyal and Colin Raffel and Augustus Odena},
476 | year = {2020},
477 | eprint = {2002.06224},
478 | archivePrefix = {arXiv},
479 | primaryClass = {stat.ML}
480 | }
481 | ```
482 |
483 | ```bibtex
484 | @misc{yu2021dual,
485 | title = {Dual Contrastive Loss and Attention for GANs},
486 | author = {Ning Yu and Guilin Liu and Aysegul Dundar and Andrew Tao and Bryan Catanzaro and Larry Davis and Mario Fritz},
487 | year = {2021},
488 | eprint = {2103.16748},
489 | archivePrefix = {arXiv},
490 | primaryClass = {cs.CV}
491 | }
492 | ```
493 |
494 | ```bibtex
495 | @inproceedings{Huang2025TheGI,
496 | title = {The GAN is dead; long live the GAN! A Modern GAN Baseline},
497 | author = {Yiwen Huang and Aaron Gokaslan and Volodymyr Kuleshov and James Tompkin},
498 | year = {2025},
499 | url = {https://api.semanticscholar.org/CorpusID:275405495}
500 | }
501 | ```
502 |
--------------------------------------------------------------------------------
/stylegan2_pytorch/stylegan2_pytorch.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import math
4 | import fire
5 | import json
6 |
7 | from tqdm import tqdm
8 | from math import floor, log2
9 | from random import random
10 | from shutil import rmtree
11 | from functools import partial
12 | import multiprocessing
13 | from contextlib import contextmanager, ExitStack
14 |
15 | import numpy as np
16 |
17 | import torch
18 | from torch import nn, einsum
19 | from torch.utils import data
20 | from torch.optim import Adam
21 | import torch.nn.functional as F
22 | from torch.autograd import grad as torch_grad
23 | from torch.utils.data.distributed import DistributedSampler
24 | from torch.nn.parallel import DistributedDataParallel as DDP
25 |
26 | from einops import rearrange, repeat
27 | from kornia.filters import filter2d
28 |
29 | import torchvision
30 | from torchvision import transforms
31 | from stylegan2_pytorch.version import __version__
32 | from stylegan2_pytorch.diff_augment import DiffAugment
33 |
34 | from vector_quantize_pytorch import VectorQuantize
35 |
36 | from PIL import Image
37 | from pathlib import Path
38 |
39 | try:
40 | from apex import amp
41 | APEX_AVAILABLE = True
42 | except:
43 | APEX_AVAILABLE = False
44 |
45 | import aim
46 |
47 | assert torch.cuda.is_available(), 'You need to have an Nvidia GPU with CUDA installed.'
48 |
49 |
50 | # constants
51 |
52 | NUM_CORES = multiprocessing.cpu_count()
53 | EXTS = ['jpg', 'jpeg', 'png']
54 |
55 | # helper classes
56 |
57 | class NanException(Exception):
58 | pass
59 |
60 | class EMA():
61 | def __init__(self, beta):
62 | super().__init__()
63 | self.beta = beta
64 | def update_average(self, old, new):
65 | if not exists(old):
66 | return new
67 | return old * self.beta + (1 - self.beta) * new
68 |
69 | class Flatten(nn.Module):
70 | def forward(self, x):
71 | return x.reshape(x.shape[0], -1)
72 |
73 | class RandomApply(nn.Module):
74 | def __init__(self, prob, fn, fn_else = lambda x: x):
75 | super().__init__()
76 | self.fn = fn
77 | self.fn_else = fn_else
78 | self.prob = prob
79 | def forward(self, x):
80 | fn = self.fn if random() < self.prob else self.fn_else
81 | return fn(x)
82 |
83 | class Residual(nn.Module):
84 | def __init__(self, fn):
85 | super().__init__()
86 | self.fn = fn
87 | def forward(self, x):
88 | return self.fn(x) + x
89 |
90 | class ChanNorm(nn.Module):
91 | def __init__(self, dim, eps = 1e-5):
92 | super().__init__()
93 | self.eps = eps
94 | self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
95 | self.b = nn.Parameter(torch.zeros(1, dim, 1, 1))
96 |
97 | def forward(self, x):
98 | var = torch.var(x, dim = 1, unbiased = False, keepdim = True)
99 | mean = torch.mean(x, dim = 1, keepdim = True)
100 | return (x - mean) / (var + self.eps).sqrt() * self.g + self.b
101 |
102 | class PreNorm(nn.Module):
103 | def __init__(self, dim, fn):
104 | super().__init__()
105 | self.fn = fn
106 | self.norm = ChanNorm(dim)
107 |
108 | def forward(self, x):
109 | return self.fn(self.norm(x))
110 |
111 | class PermuteToFrom(nn.Module):
112 | def __init__(self, fn):
113 | super().__init__()
114 | self.fn = fn
115 | def forward(self, x):
116 | x = x.permute(0, 2, 3, 1)
117 | out, *_, loss = self.fn(x)
118 | out = out.permute(0, 3, 1, 2)
119 | return out, loss
120 |
121 | class Blur(nn.Module):
122 | def __init__(self):
123 | super().__init__()
124 | f = torch.Tensor([1, 2, 1])
125 | self.register_buffer('f', f)
126 | def forward(self, x):
127 | f = self.f
128 | f = f[None, None, :] * f [None, :, None]
129 | return filter2d(x, f, normalized=True)
130 |
131 | # attention
132 |
133 | class DepthWiseConv2d(nn.Module):
134 | def __init__(self, dim_in, dim_out, kernel_size, padding = 0, stride = 1, bias = True):
135 | super().__init__()
136 | self.net = nn.Sequential(
137 | nn.Conv2d(dim_in, dim_in, kernel_size = kernel_size, padding = padding, groups = dim_in, stride = stride, bias = bias),
138 | nn.Conv2d(dim_in, dim_out, kernel_size = 1, bias = bias)
139 | )
140 | def forward(self, x):
141 | return self.net(x)
142 |
143 | class LinearAttention(nn.Module):
144 | def __init__(self, dim, dim_head = 64, heads = 8):
145 | super().__init__()
146 | self.scale = dim_head ** -0.5
147 | self.heads = heads
148 | inner_dim = dim_head * heads
149 |
150 | self.nonlin = nn.GELU()
151 | self.to_q = nn.Conv2d(dim, inner_dim, 1, bias = False)
152 | self.to_kv = DepthWiseConv2d(dim, inner_dim * 2, 3, padding = 1, bias = False)
153 | self.to_out = nn.Conv2d(inner_dim, dim, 1)
154 |
155 | def forward(self, fmap):
156 | h, x, y = self.heads, *fmap.shape[-2:]
157 | q, k, v = (self.to_q(fmap), *self.to_kv(fmap).chunk(2, dim = 1))
158 | q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) (x y) c', h = h), (q, k, v))
159 |
160 | q = q.softmax(dim = -1)
161 | k = k.softmax(dim = -2)
162 |
163 | q = q * self.scale
164 |
165 | context = einsum('b n d, b n e -> b d e', k, v)
166 | out = einsum('b n d, b d e -> b n e', q, context)
167 | out = rearrange(out, '(b h) (x y) d -> b (h d) x y', h = h, x = x, y = y)
168 |
169 | out = self.nonlin(out)
170 | return self.to_out(out)
171 |
172 | # one layer of self-attention and feedforward, for images
173 |
174 | attn_and_ff = lambda chan: nn.Sequential(*[
175 | Residual(PreNorm(chan, LinearAttention(chan))),
176 | Residual(PreNorm(chan, nn.Sequential(nn.Conv2d(chan, chan * 2, 1), leaky_relu(), nn.Conv2d(chan * 2, chan, 1))))
177 | ])
178 |
179 | # helpers
180 |
181 | def exists(val):
182 | return val is not None
183 |
184 | @contextmanager
185 | def null_context():
186 | yield
187 |
188 | def combine_contexts(contexts):
189 | @contextmanager
190 | def multi_contexts():
191 | with ExitStack() as stack:
192 | yield [stack.enter_context(ctx()) for ctx in contexts]
193 | return multi_contexts
194 |
195 | def default(value, d):
196 | return value if exists(value) else d
197 |
198 | def cycle(iterable):
199 | while True:
200 | for i in iterable:
201 | yield i
202 |
203 | def cast_list(el):
204 | return el if isinstance(el, list) else [el]
205 |
206 | def is_empty(t):
207 | if isinstance(t, torch.Tensor):
208 | return t.nelement() == 0
209 | return not exists(t)
210 |
211 | def raise_if_nan(t):
212 | if torch.isnan(t):
213 | raise NanException
214 |
215 | def gradient_accumulate_contexts(gradient_accumulate_every, is_ddp, ddps):
216 | if is_ddp:
217 | num_no_syncs = gradient_accumulate_every - 1
218 | head = [combine_contexts(map(lambda ddp: ddp.no_sync, ddps))] * num_no_syncs
219 | tail = [null_context]
220 | contexts = head + tail
221 | else:
222 | contexts = [null_context] * gradient_accumulate_every
223 |
224 | for context in contexts:
225 | with context():
226 | yield
227 |
228 | def loss_backwards(fp16, loss, optimizer, loss_id, **kwargs):
229 | if fp16:
230 | with amp.scale_loss(loss, optimizer, loss_id) as scaled_loss:
231 | scaled_loss.backward(**kwargs)
232 | else:
233 | loss.backward(**kwargs)
234 |
235 | def gradient_penalty(images, output, weight = 10, center = 0.):
236 | batch_size = images.shape[0]
237 | gradients = torch_grad(outputs=output, inputs=images,
238 | grad_outputs=torch.ones(output.size(), device=images.device),
239 | create_graph=True, retain_graph=True, only_inputs=True)[0]
240 |
241 | gradients = gradients.reshape(batch_size, -1)
242 | return weight * ((gradients.norm(2, dim=1) - center) ** 2).mean()
243 |
244 | def calc_pl_lengths(styles, images):
245 | device = images.device
246 | num_pixels = images.shape[2] * images.shape[3]
247 | pl_noise = torch.randn(images.shape, device=device) / math.sqrt(num_pixels)
248 | outputs = (images * pl_noise).sum()
249 |
250 | pl_grads = torch_grad(outputs=outputs, inputs=styles,
251 | grad_outputs=torch.ones(outputs.shape, device=device),
252 | create_graph=True, retain_graph=True, only_inputs=True)[0]
253 |
254 | return (pl_grads ** 2).sum(dim=2).mean(dim=1).sqrt()
255 |
256 | def noise(n, latent_dim, device):
257 | return torch.randn(n, latent_dim).cuda(device)
258 |
259 | def noise_list(n, layers, latent_dim, device):
260 | return [(noise(n, latent_dim, device), layers)]
261 |
262 | def mixed_list(n, layers, latent_dim, device):
263 | tt = int(torch.rand(()).numpy() * layers)
264 | return noise_list(n, tt, latent_dim, device) + noise_list(n, layers - tt, latent_dim, device)
265 |
266 | def latent_to_w(style_vectorizer, latent_descr):
267 | return [(style_vectorizer(z), num_layers) for z, num_layers in latent_descr]
268 |
269 | def image_noise(n, im_size, device):
270 | return torch.FloatTensor(n, im_size, im_size, 1).uniform_(0., 1.).cuda(device)
271 |
272 | def leaky_relu(p=0.2):
273 | return nn.LeakyReLU(p, inplace=True)
274 |
275 | def evaluate_in_chunks(max_batch_size, model, *args):
276 | split_args = list(zip(*list(map(lambda x: x.split(max_batch_size, dim=0), args))))
277 | chunked_outputs = [model(*i) for i in split_args]
278 | if len(chunked_outputs) == 1:
279 | return chunked_outputs[0]
280 | return torch.cat(chunked_outputs, dim=0)
281 |
282 | def styles_def_to_tensor(styles_def):
283 | return torch.cat([t[:, None, :].expand(-1, n, -1) for t, n in styles_def], dim=1)
284 |
285 | def set_requires_grad(model, bool):
286 | for p in model.parameters():
287 | p.requires_grad = bool
288 |
289 | def slerp(val, low, high):
290 | low_norm = low / torch.norm(low, dim=1, keepdim=True)
291 | high_norm = high / torch.norm(high, dim=1, keepdim=True)
292 | omega = torch.acos((low_norm * high_norm).sum(1))
293 | so = torch.sin(omega)
294 | res = (torch.sin((1.0 - val) * omega) / so).unsqueeze(1) * low + (torch.sin(val * omega) / so).unsqueeze(1) * high
295 | return res
296 |
297 | # losses
298 |
299 | def gen_hinge_loss(fake, real):
300 | return fake.mean()
301 |
302 | def hinge_loss(fake, real):
303 | return (F.relu(1 + real) + F.relu(1 - fake)).mean()
304 |
305 | def dual_contrastive_loss(fake_logits, real_logits):
306 | device = real_logits.device
307 | real_logits, fake_logits = map(lambda t: rearrange(t, '... -> (...)'), (real_logits, fake_logits))
308 |
309 | def loss_half(t1, t2):
310 | t1 = rearrange(t1, 'i -> i 1')
311 | t2 = repeat(t2, 'j -> i j', i = t1.shape[0])
312 | t = torch.cat((t1, t2), dim = -1)
313 | return F.cross_entropy(t, torch.zeros(t1.shape[0], device = device, dtype = torch.long))
314 |
315 | return loss_half(real_logits, fake_logits) + loss_half(-fake_logits, -real_logits)
316 |
317 | # dataset
318 |
319 | def convert_rgb_to_transparent(image):
320 | if image.mode != 'RGBA':
321 | return image.convert('RGBA')
322 | return image
323 |
324 | def convert_transparent_to_rgb(image):
325 | if image.mode != 'RGB':
326 | return image.convert('RGB')
327 | return image
328 |
329 | class expand_greyscale(object):
330 | def __init__(self, transparent):
331 | self.transparent = transparent
332 |
333 | def __call__(self, tensor):
334 | channels = tensor.shape[0]
335 | num_target_channels = 4 if self.transparent else 3
336 |
337 | if channels == num_target_channels:
338 | return tensor
339 |
340 | alpha = None
341 | if channels == 1:
342 | color = tensor.expand(3, -1, -1)
343 | elif channels == 2:
344 | color = tensor[:1].expand(3, -1, -1)
345 | alpha = tensor[1:]
346 | else:
347 | raise Exception(f'image with invalid number of channels given {channels}')
348 |
349 | if not exists(alpha) and self.transparent:
350 | alpha = torch.ones(1, *tensor.shape[1:], device=tensor.device)
351 |
352 | return color if not self.transparent else torch.cat((color, alpha))
353 |
354 | def resize_to_minimum_size(min_size, image):
355 | if max(*image.size) < min_size:
356 | return torchvision.transforms.functional.resize(image, min_size)
357 | return image
358 |
359 | class Dataset(data.Dataset):
360 | def __init__(self, folder, image_size, transparent = False, aug_prob = 0.):
361 | super().__init__()
362 | self.folder = folder
363 | self.image_size = image_size
364 | self.paths = [p for ext in EXTS for p in Path(f'{folder}').glob(f'**/*.{ext}')]
365 | assert len(self.paths) > 0, f'No images were found in {folder} for training'
366 |
367 | convert_image_fn = convert_transparent_to_rgb if not transparent else convert_rgb_to_transparent
368 | num_channels = 3 if not transparent else 4
369 |
370 | self.transform = transforms.Compose([
371 | transforms.Lambda(convert_image_fn),
372 | transforms.Lambda(partial(resize_to_minimum_size, image_size)),
373 | transforms.Resize(image_size),
374 | RandomApply(aug_prob, transforms.RandomResizedCrop(image_size, scale=(0.5, 1.0), ratio=(0.98, 1.02)), transforms.CenterCrop(image_size)),
375 | transforms.ToTensor(),
376 | transforms.Lambda(expand_greyscale(transparent))
377 | ])
378 |
379 | def __len__(self):
380 | return len(self.paths)
381 |
382 | def __getitem__(self, index):
383 | path = self.paths[index]
384 | img = Image.open(path)
385 | return self.transform(img)
386 |
387 | # augmentations
388 |
389 | def random_hflip(tensor, prob):
390 | if prob < random():
391 | return tensor
392 | return torch.flip(tensor, dims=(3,))
393 |
394 | class AugWrapper(nn.Module):
395 | def __init__(self, D, image_size):
396 | super().__init__()
397 | self.D = D
398 |
399 | def forward(self, images, prob = 0., types = [], detach = False, return_aug_images = False, input_requires_grad = False):
400 | if random() < prob:
401 | images = random_hflip(images, prob=0.5)
402 | images = DiffAugment(images, types=types)
403 |
404 | if detach:
405 | images = images.detach()
406 |
407 | if input_requires_grad:
408 | images.requires_grad_()
409 |
410 | logits = self.D(images)
411 |
412 | if not return_aug_images:
413 | return logits
414 |
415 | return images, logits
416 |
417 | # stylegan2 classes
418 |
419 | class EqualLinear(nn.Module):
420 | def __init__(self, in_dim, out_dim, lr_mul = 1, bias = True):
421 | super().__init__()
422 | self.weight = nn.Parameter(torch.randn(out_dim, in_dim))
423 | if bias:
424 | self.bias = nn.Parameter(torch.zeros(out_dim))
425 |
426 | self.lr_mul = lr_mul
427 |
428 | def forward(self, input):
429 | return F.linear(input, self.weight * self.lr_mul, bias=self.bias * self.lr_mul)
430 |
431 | class StyleVectorizer(nn.Module):
432 | def __init__(self, emb, depth, lr_mul = 0.1):
433 | super().__init__()
434 |
435 | layers = []
436 | for i in range(depth):
437 | layers.extend([EqualLinear(emb, emb, lr_mul), leaky_relu()])
438 |
439 | self.net = nn.Sequential(*layers)
440 |
441 | def forward(self, x):
442 | x = F.normalize(x, dim=1)
443 | return self.net(x)
444 |
445 | class RGBBlock(nn.Module):
446 | def __init__(self, latent_dim, input_channel, upsample, rgba = False):
447 | super().__init__()
448 | self.input_channel = input_channel
449 | self.to_style = nn.Linear(latent_dim, input_channel)
450 |
451 | out_filters = 3 if not rgba else 4
452 | self.conv = Conv2DMod(input_channel, out_filters, 1, demod=False)
453 |
454 | self.upsample = nn.Sequential(
455 | nn.Upsample(scale_factor = 2, mode='bilinear', align_corners=False),
456 | Blur()
457 | ) if upsample else None
458 |
459 | def forward(self, x, prev_rgb, istyle):
460 | b, c, h, w = x.shape
461 | style = self.to_style(istyle)
462 | x = self.conv(x, style)
463 |
464 | if exists(prev_rgb):
465 | x = x + prev_rgb
466 |
467 | if exists(self.upsample):
468 | x = self.upsample(x)
469 |
470 | return x
471 |
472 | class Conv2DMod(nn.Module):
473 | def __init__(self, in_chan, out_chan, kernel, demod=True, stride=1, dilation=1, eps = 1e-8, **kwargs):
474 | super().__init__()
475 | self.filters = out_chan
476 | self.demod = demod
477 | self.kernel = kernel
478 | self.stride = stride
479 | self.dilation = dilation
480 | self.weight = nn.Parameter(torch.randn((out_chan, in_chan, kernel, kernel)))
481 | self.eps = eps
482 | nn.init.kaiming_normal_(self.weight, a=0, mode='fan_in', nonlinearity='leaky_relu')
483 |
484 | def _get_same_padding(self, size, kernel, dilation, stride):
485 | return ((size - 1) * (stride - 1) + dilation * (kernel - 1)) // 2
486 |
487 | def forward(self, x, y):
488 | b, c, h, w = x.shape
489 |
490 | w1 = y[:, None, :, None, None]
491 | w2 = self.weight[None, :, :, :, :]
492 | weights = w2 * (w1 + 1)
493 |
494 | if self.demod:
495 | d = torch.rsqrt((weights ** 2).sum(dim=(2, 3, 4), keepdim=True) + self.eps)
496 | weights = weights * d
497 |
498 | x = x.reshape(1, -1, h, w)
499 |
500 | _, _, *ws = weights.shape
501 | weights = weights.reshape(b * self.filters, *ws)
502 |
503 | padding = self._get_same_padding(h, self.kernel, self.dilation, self.stride)
504 | x = F.conv2d(x, weights, padding=padding, groups=b)
505 |
506 | x = x.reshape(-1, self.filters, h, w)
507 | return x
508 |
509 | class GeneratorBlock(nn.Module):
510 | def __init__(self, latent_dim, input_channels, filters, upsample = True, upsample_rgb = True, rgba = False):
511 | super().__init__()
512 | self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False) if upsample else None
513 |
514 | self.to_style1 = nn.Linear(latent_dim, input_channels)
515 | self.to_noise1 = nn.Linear(1, filters)
516 | self.conv1 = Conv2DMod(input_channels, filters, 3)
517 |
518 | self.to_style2 = nn.Linear(latent_dim, filters)
519 | self.to_noise2 = nn.Linear(1, filters)
520 | self.conv2 = Conv2DMod(filters, filters, 3)
521 |
522 | self.activation = leaky_relu()
523 | self.to_rgb = RGBBlock(latent_dim, filters, upsample_rgb, rgba)
524 |
525 | def forward(self, x, prev_rgb, istyle, inoise):
526 | if exists(self.upsample):
527 | x = self.upsample(x)
528 |
529 | inoise = inoise[:, :x.shape[2], :x.shape[3], :]
530 | noise1 = self.to_noise1(inoise).permute((0, 3, 2, 1))
531 | noise2 = self.to_noise2(inoise).permute((0, 3, 2, 1))
532 |
533 | style1 = self.to_style1(istyle)
534 | x = self.conv1(x, style1)
535 | x = self.activation(x + noise1)
536 |
537 | style2 = self.to_style2(istyle)
538 | x = self.conv2(x, style2)
539 | x = self.activation(x + noise2)
540 |
541 | rgb = self.to_rgb(x, prev_rgb, istyle)
542 | return x, rgb
543 |
544 | class DiscriminatorBlock(nn.Module):
545 | def __init__(self, input_channels, filters, downsample=True):
546 | super().__init__()
547 | self.conv_res = nn.Conv2d(input_channels, filters, 1, stride = (2 if downsample else 1))
548 |
549 | self.net = nn.Sequential(
550 | nn.Conv2d(input_channels, filters, 3, padding=1),
551 | leaky_relu(),
552 | nn.Conv2d(filters, filters, 3, padding=1),
553 | leaky_relu()
554 | )
555 |
556 | self.downsample = nn.Sequential(
557 | Blur(),
558 | nn.Conv2d(filters, filters, 3, padding = 1, stride = 2)
559 | ) if downsample else None
560 |
561 | def forward(self, x):
562 | res = self.conv_res(x)
563 | x = self.net(x)
564 | if exists(self.downsample):
565 | x = self.downsample(x)
566 | x = (x + res) * (1 / math.sqrt(2))
567 | return x
568 |
569 | class Generator(nn.Module):
570 | def __init__(self, image_size, latent_dim, network_capacity = 16, transparent = False, attn_layers = [], no_const = False, fmap_max = 512):
571 | super().__init__()
572 | self.image_size = image_size
573 | self.latent_dim = latent_dim
574 | self.num_layers = int(log2(image_size) - 1)
575 |
576 | filters = [network_capacity * (2 ** (i + 1)) for i in range(self.num_layers)][::-1]
577 |
578 | set_fmap_max = partial(min, fmap_max)
579 | filters = list(map(set_fmap_max, filters))
580 | init_channels = filters[0]
581 | filters = [init_channels, *filters]
582 |
583 | in_out_pairs = zip(filters[:-1], filters[1:])
584 | self.no_const = no_const
585 |
586 | if no_const:
587 | self.to_initial_block = nn.ConvTranspose2d(latent_dim, init_channels, 4, 1, 0, bias=False)
588 | else:
589 | self.initial_block = nn.Parameter(torch.randn((1, init_channels, 4, 4)))
590 |
591 | self.initial_conv = nn.Conv2d(filters[0], filters[0], 3, padding=1)
592 | self.blocks = nn.ModuleList([])
593 | self.attns = nn.ModuleList([])
594 |
595 | for ind, (in_chan, out_chan) in enumerate(in_out_pairs):
596 | not_first = ind != 0
597 | not_last = ind != (self.num_layers - 1)
598 | num_layer = self.num_layers - ind
599 |
600 | attn_fn = attn_and_ff(in_chan) if num_layer in attn_layers else None
601 |
602 | self.attns.append(attn_fn)
603 |
604 | block = GeneratorBlock(
605 | latent_dim,
606 | in_chan,
607 | out_chan,
608 | upsample = not_first,
609 | upsample_rgb = not_last,
610 | rgba = transparent
611 | )
612 | self.blocks.append(block)
613 |
614 | def forward(self, styles, input_noise):
615 | batch_size = styles.shape[0]
616 | image_size = self.image_size
617 |
618 | if self.no_const:
619 | avg_style = styles.mean(dim=1)[:, :, None, None]
620 | x = self.to_initial_block(avg_style)
621 | else:
622 | x = self.initial_block.expand(batch_size, -1, -1, -1)
623 |
624 | rgb = None
625 | styles = styles.transpose(0, 1)
626 | x = self.initial_conv(x)
627 |
628 | for style, block, attn in zip(styles, self.blocks, self.attns):
629 | if exists(attn):
630 | x = attn(x)
631 | x, rgb = block(x, rgb, style, input_noise)
632 |
633 | return rgb
634 |
635 | class Discriminator(nn.Module):
636 | def __init__(self, image_size, network_capacity = 16, fq_layers = [], fq_dict_size = 256, attn_layers = [], transparent = False, fmap_max = 512):
637 | super().__init__()
638 | num_layers = int(log2(image_size) - 1)
639 | num_init_filters = 3 if not transparent else 4
640 |
641 | blocks = []
642 | filters = [num_init_filters] + [(network_capacity * 4) * (2 ** i) for i in range(num_layers + 1)]
643 |
644 | set_fmap_max = partial(min, fmap_max)
645 | filters = list(map(set_fmap_max, filters))
646 | chan_in_out = list(zip(filters[:-1], filters[1:]))
647 |
648 | blocks = []
649 | attn_blocks = []
650 | quantize_blocks = []
651 |
652 | for ind, (in_chan, out_chan) in enumerate(chan_in_out):
653 | num_layer = ind + 1
654 | is_not_last = ind != (len(chan_in_out) - 1)
655 |
656 | block = DiscriminatorBlock(in_chan, out_chan, downsample = is_not_last)
657 | blocks.append(block)
658 |
659 | attn_fn = attn_and_ff(out_chan) if num_layer in attn_layers else None
660 |
661 | attn_blocks.append(attn_fn)
662 |
663 | quantize_fn = PermuteToFrom(VectorQuantize(out_chan, fq_dict_size)) if num_layer in fq_layers else None
664 | quantize_blocks.append(quantize_fn)
665 |
666 | self.blocks = nn.ModuleList(blocks)
667 | self.attn_blocks = nn.ModuleList(attn_blocks)
668 | self.quantize_blocks = nn.ModuleList(quantize_blocks)
669 |
670 | chan_last = filters[-1]
671 | latent_dim = 2 * 2 * chan_last
672 |
673 | self.final_conv = nn.Conv2d(chan_last, chan_last, 3, padding=1)
674 | self.flatten = Flatten()
675 | self.to_logit = nn.Linear(latent_dim, 1)
676 |
677 | def forward(self, x):
678 | b, *_ = x.shape
679 |
680 | quantize_loss = torch.zeros(1).to(x)
681 |
682 | for (block, attn_block, q_block) in zip(self.blocks, self.attn_blocks, self.quantize_blocks):
683 | x = block(x)
684 |
685 | if exists(attn_block):
686 | x = attn_block(x)
687 |
688 | if exists(q_block):
689 | x, loss = q_block(x)
690 | quantize_loss += loss
691 |
692 | x = self.final_conv(x)
693 | x = self.flatten(x)
694 | x = self.to_logit(x)
695 | return x.squeeze(), quantize_loss
696 |
697 | class StyleGAN2(nn.Module):
698 | def __init__(self, image_size, latent_dim = 512, fmap_max = 512, style_depth = 8, network_capacity = 16, transparent = False, fp16 = False, cl_reg = False, steps = 1, lr = 1e-4, ttur_mult = 2, fq_layers = [], fq_dict_size = 256, attn_layers = [], no_const = False, lr_mlp = 0.1, rank = 0):
699 | super().__init__()
700 | self.lr = lr
701 | self.steps = steps
702 | self.ema_updater = EMA(0.995)
703 |
704 | self.S = StyleVectorizer(latent_dim, style_depth, lr_mul = lr_mlp)
705 | self.G = Generator(image_size, latent_dim, network_capacity, transparent = transparent, attn_layers = attn_layers, no_const = no_const, fmap_max = fmap_max)
706 | self.D = Discriminator(image_size, network_capacity, fq_layers = fq_layers, fq_dict_size = fq_dict_size, attn_layers = attn_layers, transparent = transparent, fmap_max = fmap_max)
707 |
708 | self.SE = StyleVectorizer(latent_dim, style_depth, lr_mul = lr_mlp)
709 | self.GE = Generator(image_size, latent_dim, network_capacity, transparent = transparent, attn_layers = attn_layers, no_const = no_const)
710 |
711 | self.D_cl = None
712 |
713 | if cl_reg:
714 | from contrastive_learner import ContrastiveLearner
715 | # experimental contrastive loss discriminator regularization
716 | assert not transparent, 'contrastive loss regularization does not work with transparent images yet'
717 | self.D_cl = ContrastiveLearner(self.D, image_size, hidden_layer='flatten')
718 |
719 | # wrapper for augmenting all images going into the discriminator
720 | self.D_aug = AugWrapper(self.D, image_size)
721 |
722 | # turn off grad for exponential moving averages
723 | set_requires_grad(self.SE, False)
724 | set_requires_grad(self.GE, False)
725 |
726 | # init optimizers
727 | generator_params = list(self.G.parameters()) + list(self.S.parameters())
728 | self.G_opt = Adam(generator_params, lr = self.lr, betas=(0.5, 0.9))
729 | self.D_opt = Adam(self.D.parameters(), lr = self.lr * ttur_mult, betas=(0.5, 0.9))
730 |
731 | # init weights
732 | self._init_weights()
733 | self.reset_parameter_averaging()
734 |
735 | self.cuda(rank)
736 |
737 | # startup apex mixed precision
738 | self.fp16 = fp16
739 | if fp16:
740 | (self.S, self.G, self.D, self.SE, self.GE), (self.G_opt, self.D_opt) = amp.initialize([self.S, self.G, self.D, self.SE, self.GE], [self.G_opt, self.D_opt], opt_level='O1', num_losses=3)
741 |
742 | def _init_weights(self):
743 | for m in self.modules():
744 | if type(m) in {nn.Conv2d, nn.Linear}:
745 | nn.init.kaiming_normal_(m.weight, a=0, mode='fan_in', nonlinearity='leaky_relu')
746 |
747 | for block in self.G.blocks:
748 | nn.init.zeros_(block.to_noise1.weight)
749 | nn.init.zeros_(block.to_noise2.weight)
750 | nn.init.zeros_(block.to_noise1.bias)
751 | nn.init.zeros_(block.to_noise2.bias)
752 |
753 | def EMA(self):
754 | def update_moving_average(ma_model, current_model):
755 | for current_params, ma_params in zip(current_model.parameters(), ma_model.parameters()):
756 | old_weight, up_weight = ma_params.data, current_params.data
757 | ma_params.data = self.ema_updater.update_average(old_weight, up_weight)
758 |
759 | update_moving_average(self.SE, self.S)
760 | update_moving_average(self.GE, self.G)
761 |
762 | def reset_parameter_averaging(self):
763 | self.SE.load_state_dict(self.S.state_dict())
764 | self.GE.load_state_dict(self.G.state_dict())
765 |
766 | def forward(self, x):
767 | return x
768 |
769 | class Trainer():
770 | def __init__(
771 | self,
772 | name = 'default',
773 | results_dir = 'results',
774 | models_dir = 'models',
775 | base_dir = './',
776 | image_size = 128,
777 | network_capacity = 16,
778 | fmap_max = 512,
779 | transparent = False,
780 | batch_size = 4,
781 | mixed_prob = 0.9,
782 | gradient_accumulate_every=1,
783 | lr = 2e-4,
784 | lr_mlp = 0.1,
785 | ttur_mult = 2,
786 | rel_disc_loss = False,
787 | num_workers = None,
788 | save_every = 1000,
789 | evaluate_every = 1000,
790 | num_image_tiles = 8,
791 | trunc_psi = 0.6,
792 | fp16 = False,
793 | cl_reg = False,
794 | no_pl_reg = False,
795 | fq_layers = [],
796 | fq_dict_size = 256,
797 | attn_layers = [],
798 | no_const = False,
799 | aug_prob = 0.,
800 | aug_types = ['translation', 'cutout'],
801 | top_k_training = False,
802 | generator_top_k_gamma = 0.99,
803 | generator_top_k_frac = 0.5,
804 | dual_contrast_loss = False,
805 | dataset_aug_prob = 0.,
806 | calculate_fid_every = None,
807 | calculate_fid_num_images = 12800,
808 | clear_fid_cache = False,
809 | is_ddp = False,
810 | rank = 0,
811 | world_size = 1,
812 | log = False,
813 | *args,
814 | **kwargs
815 | ):
816 | self.GAN_params = [args, kwargs]
817 | self.GAN = None
818 |
819 | self.name = name
820 |
821 | base_dir = Path(base_dir)
822 | self.base_dir = base_dir
823 | self.results_dir = base_dir / results_dir
824 | self.models_dir = base_dir / models_dir
825 | self.fid_dir = base_dir / 'fid' / name
826 | self.config_path = self.models_dir / name / '.config.json'
827 |
828 | assert log2(image_size).is_integer(), 'image size must be a power of 2 (64, 128, 256, 512, 1024)'
829 | self.image_size = image_size
830 | self.network_capacity = network_capacity
831 | self.fmap_max = fmap_max
832 | self.transparent = transparent
833 |
834 | self.fq_layers = cast_list(fq_layers)
835 | self.fq_dict_size = fq_dict_size
836 | self.has_fq = len(self.fq_layers) > 0
837 |
838 | self.attn_layers = cast_list(attn_layers)
839 | self.no_const = no_const
840 |
841 | self.aug_prob = aug_prob
842 | self.aug_types = aug_types
843 |
844 | self.lr = lr
845 | self.lr_mlp = lr_mlp
846 | self.ttur_mult = ttur_mult
847 | self.rel_disc_loss = rel_disc_loss
848 | self.batch_size = batch_size
849 | self.num_workers = num_workers
850 | self.mixed_prob = mixed_prob
851 |
852 | self.num_image_tiles = num_image_tiles
853 | self.evaluate_every = evaluate_every
854 | self.save_every = save_every
855 | self.steps = 0
856 |
857 | self.av = None
858 | self.trunc_psi = trunc_psi
859 |
860 | self.no_pl_reg = no_pl_reg
861 | self.pl_mean = None
862 |
863 | self.gradient_accumulate_every = gradient_accumulate_every
864 |
865 | assert not fp16 or fp16 and APEX_AVAILABLE, 'Apex is not available for you to use mixed precision training'
866 | self.fp16 = fp16
867 |
868 | self.cl_reg = cl_reg
869 |
870 | self.d_loss = 0
871 | self.g_loss = 0
872 | self.q_loss = None
873 | self.last_gp_loss = None
874 | self.last_cr_loss = None
875 | self.last_fid = None
876 |
877 | self.pl_length_ma = EMA(0.99)
878 | self.init_folders()
879 |
880 | self.loader = None
881 | self.dataset_aug_prob = dataset_aug_prob
882 |
883 | self.calculate_fid_every = calculate_fid_every
884 | self.calculate_fid_num_images = calculate_fid_num_images
885 | self.clear_fid_cache = clear_fid_cache
886 |
887 | self.top_k_training = top_k_training
888 | self.generator_top_k_gamma = generator_top_k_gamma
889 | self.generator_top_k_frac = generator_top_k_frac
890 |
891 | self.dual_contrast_loss = dual_contrast_loss
892 |
893 | assert not (is_ddp and cl_reg), 'Contrastive loss regularization does not work well with multi GPUs yet'
894 | self.is_ddp = is_ddp
895 | self.is_main = rank == 0
896 | self.rank = rank
897 | self.world_size = world_size
898 |
899 | self.logger = aim.Session(experiment=name) if log else None
900 |
901 | @property
902 | def image_extension(self):
903 | return 'jpg' if not self.transparent else 'png'
904 |
905 | @property
906 | def checkpoint_num(self):
907 | return floor(self.steps // self.save_every)
908 |
909 | @property
910 | def hparams(self):
911 | return {'image_size': self.image_size, 'network_capacity': self.network_capacity}
912 |
913 | def init_GAN(self):
914 | args, kwargs = self.GAN_params
915 | self.GAN = StyleGAN2(lr = self.lr, lr_mlp = self.lr_mlp, ttur_mult = self.ttur_mult, image_size = self.image_size, network_capacity = self.network_capacity, fmap_max = self.fmap_max, transparent = self.transparent, fq_layers = self.fq_layers, fq_dict_size = self.fq_dict_size, attn_layers = self.attn_layers, fp16 = self.fp16, cl_reg = self.cl_reg, no_const = self.no_const, rank = self.rank, *args, **kwargs)
916 |
917 | if self.is_ddp:
918 | ddp_kwargs = {'device_ids': [self.rank]}
919 | self.S_ddp = DDP(self.GAN.S, **ddp_kwargs)
920 | self.G_ddp = DDP(self.GAN.G, **ddp_kwargs)
921 | self.D_ddp = DDP(self.GAN.D, **ddp_kwargs)
922 | self.D_aug_ddp = DDP(self.GAN.D_aug, **ddp_kwargs)
923 |
924 | if exists(self.logger):
925 | self.logger.set_params(self.hparams)
926 |
927 | def write_config(self):
928 | self.config_path.write_text(json.dumps(self.config()))
929 |
930 | def load_config(self):
931 | config = self.config() if not self.config_path.exists() else json.loads(self.config_path.read_text())
932 | self.image_size = config['image_size']
933 | self.network_capacity = config['network_capacity']
934 | self.transparent = config['transparent']
935 | self.fq_layers = config['fq_layers']
936 | self.fq_dict_size = config['fq_dict_size']
937 | self.fmap_max = config.pop('fmap_max', 512)
938 | self.attn_layers = config.pop('attn_layers', [])
939 | self.no_const = config.pop('no_const', False)
940 | self.lr_mlp = config.pop('lr_mlp', 0.1)
941 | del self.GAN
942 | self.init_GAN()
943 |
944 | def config(self):
945 | return {'image_size': self.image_size, 'network_capacity': self.network_capacity, 'lr_mlp': self.lr_mlp, 'transparent': self.transparent, 'fq_layers': self.fq_layers, 'fq_dict_size': self.fq_dict_size, 'attn_layers': self.attn_layers, 'no_const': self.no_const}
946 |
947 | def set_data_src(self, folder):
948 | self.dataset = Dataset(folder, self.image_size, transparent = self.transparent, aug_prob = self.dataset_aug_prob)
949 | num_workers = num_workers = default(self.num_workers, NUM_CORES if not self.is_ddp else 0)
950 | sampler = DistributedSampler(self.dataset, rank=self.rank, num_replicas=self.world_size, shuffle=True) if self.is_ddp else None
951 | dataloader = data.DataLoader(self.dataset, num_workers = num_workers, batch_size = math.ceil(self.batch_size / self.world_size), sampler = sampler, shuffle = not self.is_ddp, drop_last = True, pin_memory = True)
952 | self.loader = cycle(dataloader)
953 |
954 | # auto set augmentation prob for user if dataset is detected to be low
955 | num_samples = len(self.dataset)
956 | if not exists(self.aug_prob) and num_samples < 1e5:
957 | self.aug_prob = min(0.5, (1e5 - num_samples) * 3e-6)
958 | print(f'autosetting augmentation probability to {round(self.aug_prob * 100)}%')
959 |
960 | def train(self):
961 | assert exists(self.loader), 'You must first initialize the data source with `.set_data_src()`'
962 |
963 | if not exists(self.GAN):
964 | self.init_GAN()
965 |
966 | self.GAN.train()
967 | total_disc_loss = torch.tensor(0.).cuda(self.rank)
968 | total_gen_loss = torch.tensor(0.).cuda(self.rank)
969 |
970 | batch_size = math.ceil(self.batch_size / self.world_size)
971 |
972 | image_size = self.GAN.G.image_size
973 | latent_dim = self.GAN.G.latent_dim
974 | num_layers = self.GAN.G.num_layers
975 |
976 | aug_prob = self.aug_prob
977 | aug_types = self.aug_types
978 | aug_kwargs = {'prob': aug_prob, 'types': aug_types}
979 |
980 | apply_gradient_penalty = self.steps % 4 == 0
981 | apply_path_penalty = not self.no_pl_reg and self.steps > 5000 and self.steps % 32 == 0
982 | apply_cl_reg_to_generated = self.steps > 20000
983 |
984 | S = self.GAN.S if not self.is_ddp else self.S_ddp
985 | G = self.GAN.G if not self.is_ddp else self.G_ddp
986 | D = self.GAN.D if not self.is_ddp else self.D_ddp
987 | D_aug = self.GAN.D_aug if not self.is_ddp else self.D_aug_ddp
988 |
989 | backwards = partial(loss_backwards, self.fp16)
990 |
991 | if exists(self.GAN.D_cl):
992 | self.GAN.D_opt.zero_grad()
993 |
994 | if apply_cl_reg_to_generated:
995 | for i in range(self.gradient_accumulate_every):
996 | get_latents_fn = mixed_list if random() < self.mixed_prob else noise_list
997 | style = get_latents_fn(batch_size, num_layers, latent_dim, device=self.rank)
998 | noise = image_noise(batch_size, image_size, device=self.rank)
999 |
1000 | w_space = latent_to_w(self.GAN.S, style)
1001 | w_styles = styles_def_to_tensor(w_space)
1002 |
1003 | generated_images = self.GAN.G(w_styles, noise)
1004 | self.GAN.D_cl(generated_images.clone().detach(), accumulate=True)
1005 |
1006 | for i in range(self.gradient_accumulate_every):
1007 | image_batch = next(self.loader).cuda(self.rank)
1008 | self.GAN.D_cl(image_batch, accumulate=True)
1009 |
1010 | loss = self.GAN.D_cl.calculate_loss()
1011 | self.last_cr_loss = loss.clone().detach().item()
1012 | backwards(loss, self.GAN.D_opt, loss_id = 0)
1013 |
1014 | self.GAN.D_opt.step()
1015 |
1016 | # setup losses
1017 |
1018 | if not self.dual_contrast_loss:
1019 | D_loss_fn = hinge_loss
1020 | G_loss_fn = gen_hinge_loss
1021 | G_requires_reals = False
1022 | else:
1023 | D_loss_fn = dual_contrastive_loss
1024 | G_loss_fn = dual_contrastive_loss
1025 | G_requires_reals = True
1026 |
1027 | # train discriminator
1028 |
1029 | avg_pl_length = self.pl_mean
1030 | self.GAN.D_opt.zero_grad()
1031 |
1032 | for i in gradient_accumulate_contexts(self.gradient_accumulate_every, self.is_ddp, ddps=[D_aug, S, G]):
1033 | get_latents_fn = mixed_list if random() < self.mixed_prob else noise_list
1034 | style = get_latents_fn(batch_size, num_layers, latent_dim, device=self.rank)
1035 | noise = image_noise(batch_size, image_size, device=self.rank)
1036 |
1037 | w_space = latent_to_w(S, style)
1038 | w_styles = styles_def_to_tensor(w_space)
1039 |
1040 | generated_images = G(w_styles, noise)
1041 | generated_images, (fake_output, fake_q_loss) = D_aug(generated_images.clone().detach(), return_aug_images = True, input_requires_grad = apply_gradient_penalty, detach = True, **aug_kwargs)
1042 |
1043 | image_batch = next(self.loader).cuda(self.rank)
1044 |
1045 | if apply_gradient_penalty:
1046 | image_batch.requires_grad_()
1047 |
1048 | real_output, real_q_loss = D_aug(image_batch, **aug_kwargs)
1049 |
1050 | real_output_loss = real_output
1051 | fake_output_loss = fake_output
1052 |
1053 | if self.rel_disc_loss:
1054 | real_output_loss = real_output_loss - fake_output.mean()
1055 | fake_output_loss = fake_output_loss - real_output.mean()
1056 |
1057 | divergence = D_loss_fn(fake_output_loss, real_output_loss)
1058 | disc_loss = divergence
1059 |
1060 | if self.has_fq:
1061 | quantize_loss = (fake_q_loss + real_q_loss).mean()
1062 | self.q_loss = float(quantize_loss.detach().item())
1063 |
1064 | disc_loss = disc_loss + quantize_loss
1065 |
1066 | if apply_gradient_penalty:
1067 | gp = gradient_penalty(image_batch, real_output) + gradient_penalty(generated_images, fake_output)
1068 | self.last_gp_loss = gp.clone().detach().item()
1069 | self.track(self.last_gp_loss, 'GP')
1070 | disc_loss = disc_loss + gp
1071 |
1072 | disc_loss = disc_loss / self.gradient_accumulate_every
1073 | disc_loss.register_hook(raise_if_nan)
1074 | backwards(disc_loss, self.GAN.D_opt, loss_id = 1)
1075 |
1076 | total_disc_loss += divergence.detach().item() / self.gradient_accumulate_every
1077 |
1078 | self.d_loss = float(total_disc_loss)
1079 | self.track(self.d_loss, 'D')
1080 |
1081 | self.GAN.D_opt.step()
1082 |
1083 | # train generator
1084 |
1085 | self.GAN.G_opt.zero_grad()
1086 |
1087 | for i in gradient_accumulate_contexts(self.gradient_accumulate_every, self.is_ddp, ddps=[S, G, D_aug]):
1088 | style = get_latents_fn(batch_size, num_layers, latent_dim, device=self.rank)
1089 | noise = image_noise(batch_size, image_size, device=self.rank)
1090 |
1091 | w_space = latent_to_w(S, style)
1092 | w_styles = styles_def_to_tensor(w_space)
1093 |
1094 | generated_images = G(w_styles, noise)
1095 | fake_output, _ = D_aug(generated_images, **aug_kwargs)
1096 | fake_output_loss = fake_output
1097 |
1098 | real_output = None
1099 | if G_requires_reals:
1100 | image_batch = next(self.loader).cuda(self.rank)
1101 | real_output, _ = D_aug(image_batch, detach = True, **aug_kwargs)
1102 | real_output = real_output.detach()
1103 |
1104 | if self.top_k_training:
1105 | epochs = (self.steps * batch_size * self.gradient_accumulate_every) / len(self.dataset)
1106 | k_frac = max(self.generator_top_k_gamma ** epochs, self.generator_top_k_frac)
1107 | k = math.ceil(batch_size * k_frac)
1108 |
1109 | if k != batch_size:
1110 | fake_output_loss, _ = fake_output_loss.topk(k=k, largest=False)
1111 |
1112 | loss = G_loss_fn(fake_output_loss, real_output)
1113 | gen_loss = loss
1114 |
1115 | if apply_path_penalty:
1116 | pl_lengths = calc_pl_lengths(w_styles, generated_images)
1117 | avg_pl_length = np.mean(pl_lengths.detach().cpu().numpy())
1118 |
1119 | if not is_empty(self.pl_mean):
1120 | pl_loss = ((pl_lengths - self.pl_mean) ** 2).mean()
1121 | if not torch.isnan(pl_loss):
1122 | gen_loss = gen_loss + pl_loss
1123 |
1124 | gen_loss = gen_loss / self.gradient_accumulate_every
1125 | gen_loss.register_hook(raise_if_nan)
1126 | backwards(gen_loss, self.GAN.G_opt, loss_id = 2)
1127 |
1128 | total_gen_loss += loss.detach().item() / self.gradient_accumulate_every
1129 |
1130 | self.g_loss = float(total_gen_loss)
1131 | self.track(self.g_loss, 'G')
1132 |
1133 | self.GAN.G_opt.step()
1134 |
1135 | # calculate moving averages
1136 |
1137 | if apply_path_penalty and not np.isnan(avg_pl_length):
1138 | self.pl_mean = self.pl_length_ma.update_average(self.pl_mean, avg_pl_length)
1139 | self.track(self.pl_mean, 'PL')
1140 |
1141 | if self.is_main and self.steps % 10 == 0 and self.steps > 20000:
1142 | self.GAN.EMA()
1143 |
1144 | if self.is_main and self.steps <= 25000 and self.steps % 1000 == 2:
1145 | self.GAN.reset_parameter_averaging()
1146 |
1147 | # save from NaN errors
1148 |
1149 | if any(torch.isnan(l) for l in (total_gen_loss, total_disc_loss)):
1150 | print(f'NaN detected for generator or discriminator. Loading from checkpoint #{self.checkpoint_num}')
1151 | self.load(self.checkpoint_num)
1152 | raise NanException
1153 |
1154 | # periodically save results
1155 |
1156 | if self.is_main:
1157 | if self.steps % self.save_every == 0:
1158 | self.save(self.checkpoint_num)
1159 |
1160 | if self.steps % self.evaluate_every == 0 or (self.steps % 100 == 0 and self.steps < 2500):
1161 | self.evaluate(floor(self.steps / self.evaluate_every))
1162 |
1163 | if exists(self.calculate_fid_every) and self.steps % self.calculate_fid_every == 0 and self.steps != 0:
1164 | num_batches = math.ceil(self.calculate_fid_num_images / self.batch_size)
1165 | fid = self.calculate_fid(num_batches)
1166 | self.last_fid = fid
1167 |
1168 | with open(str(self.results_dir / self.name / f'fid_scores.txt'), 'a') as f:
1169 | f.write(f'{self.steps},{fid}\n')
1170 |
1171 | self.steps += 1
1172 | self.av = None
1173 |
1174 | @torch.no_grad()
1175 | def evaluate(self, num = 0, trunc = 1.0):
1176 | self.GAN.eval()
1177 | ext = self.image_extension
1178 | num_rows = self.num_image_tiles
1179 |
1180 | latent_dim = self.GAN.G.latent_dim
1181 | image_size = self.GAN.G.image_size
1182 | num_layers = self.GAN.G.num_layers
1183 |
1184 | # latents and noise
1185 |
1186 | latents = noise_list(num_rows ** 2, num_layers, latent_dim, device=self.rank)
1187 | n = image_noise(num_rows ** 2, image_size, device=self.rank)
1188 |
1189 | # regular
1190 |
1191 | generated_images = self.generate_truncated(self.GAN.S, self.GAN.G, latents, n, trunc_psi = self.trunc_psi)
1192 | torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}.{ext}'), nrow=num_rows)
1193 |
1194 | # moving averages
1195 |
1196 | generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, latents, n, trunc_psi = self.trunc_psi)
1197 | torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}-ema.{ext}'), nrow=num_rows)
1198 |
1199 | # mixing regularities
1200 |
1201 | def tile(a, dim, n_tile):
1202 | init_dim = a.size(dim)
1203 | repeat_idx = [1] * a.dim()
1204 | repeat_idx[dim] = n_tile
1205 | a = a.repeat(*(repeat_idx))
1206 | order_index = torch.LongTensor(np.concatenate([init_dim * np.arange(n_tile) + i for i in range(init_dim)])).cuda(self.rank)
1207 | return torch.index_select(a, dim, order_index)
1208 |
1209 | nn = noise(num_rows, latent_dim, device=self.rank)
1210 | tmp1 = tile(nn, 0, num_rows)
1211 | tmp2 = nn.repeat(num_rows, 1)
1212 |
1213 | tt = int(num_layers / 2)
1214 | mixed_latents = [(tmp1, tt), (tmp2, num_layers - tt)]
1215 |
1216 | generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, mixed_latents, n, trunc_psi = self.trunc_psi)
1217 | torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}-mr.{ext}'), nrow=num_rows)
1218 |
1219 | @torch.no_grad()
1220 | def calculate_fid(self, num_batches):
1221 | from pytorch_fid import fid_score
1222 | torch.cuda.empty_cache()
1223 |
1224 | real_path = self.fid_dir / 'real'
1225 | fake_path = self.fid_dir / 'fake'
1226 |
1227 | # remove any existing files used for fid calculation and recreate directories
1228 |
1229 | if not real_path.exists() or self.clear_fid_cache:
1230 | rmtree(real_path, ignore_errors=True)
1231 | os.makedirs(real_path)
1232 |
1233 | for batch_num in tqdm(range(num_batches), desc='calculating FID - saving reals'):
1234 | real_batch = next(self.loader)
1235 | for k, image in enumerate(real_batch.unbind(0)):
1236 | filename = str(k + batch_num * self.batch_size)
1237 | torchvision.utils.save_image(image, str(real_path / f'{filename}.png'))
1238 |
1239 | # generate a bunch of fake images in results / name / fid_fake
1240 |
1241 | rmtree(fake_path, ignore_errors=True)
1242 | os.makedirs(fake_path)
1243 |
1244 | self.GAN.eval()
1245 | ext = self.image_extension
1246 |
1247 | latent_dim = self.GAN.G.latent_dim
1248 | image_size = self.GAN.G.image_size
1249 | num_layers = self.GAN.G.num_layers
1250 |
1251 | for batch_num in tqdm(range(num_batches), desc='calculating FID - saving generated'):
1252 | # latents and noise
1253 | latents = noise_list(self.batch_size, num_layers, latent_dim, device=self.rank)
1254 | noise = image_noise(self.batch_size, image_size, device=self.rank)
1255 |
1256 | # moving averages
1257 | generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, latents, noise, trunc_psi = self.trunc_psi)
1258 |
1259 | for j, image in enumerate(generated_images.unbind(0)):
1260 | torchvision.utils.save_image(image, str(fake_path / f'{str(j + batch_num * self.batch_size)}-ema.{ext}'))
1261 |
1262 | return fid_score.calculate_fid_given_paths([str(real_path), str(fake_path)], 256, noise.device, 2048)
1263 |
1264 | @torch.no_grad()
1265 | def truncate_style(self, tensor, S = None, trunc_psi = 0.75):
1266 | S = default(S, self.GAN.S)
1267 | batch_size = self.batch_size
1268 | latent_dim = self.GAN.G.latent_dim
1269 |
1270 | if not exists(self.av):
1271 | z = noise(2000, latent_dim, device=self.rank)
1272 | samples = evaluate_in_chunks(batch_size, S, z).cpu().numpy()
1273 | self.av = np.mean(samples, axis = 0)
1274 | self.av = np.expand_dims(self.av, axis = 0)
1275 |
1276 | av_torch = torch.from_numpy(self.av).cuda(self.rank)
1277 | tensor = trunc_psi * (tensor - av_torch) + av_torch
1278 | return tensor
1279 |
1280 | @torch.no_grad()
1281 | def truncate_style_defs(self, w, S = None, trunc_psi = 0.75):
1282 | w_space = []
1283 | for tensor, num_layers in w:
1284 | tensor = self.truncate_style(tensor, S = S, trunc_psi = trunc_psi)
1285 | w_space.append((tensor, num_layers))
1286 | return w_space
1287 |
1288 | @torch.no_grad()
1289 | def generate_truncated(self, S, G, style, noi, trunc_psi = 0.75, num_image_tiles = 8):
1290 | w = map(lambda t: (S(t[0]), t[1]), style)
1291 | w_truncated = self.truncate_style_defs(w, S = S, trunc_psi = trunc_psi)
1292 | w_styles = styles_def_to_tensor(w_truncated)
1293 | generated_images = evaluate_in_chunks(self.batch_size, G, w_styles, noi)
1294 | return generated_images.clamp_(0., 1.)
1295 |
1296 | @torch.no_grad()
1297 | def generate_interpolation(self, num = 0, num_image_tiles = 8, trunc = 1.0, num_steps = 100, save_frames = False):
1298 | self.GAN.eval()
1299 | ext = self.image_extension
1300 | num_rows = num_image_tiles
1301 |
1302 | latent_dim = self.GAN.G.latent_dim
1303 | image_size = self.GAN.G.image_size
1304 | num_layers = self.GAN.G.num_layers
1305 |
1306 | # latents and noise
1307 |
1308 | latents_low = noise(num_rows ** 2, latent_dim, device=self.rank)
1309 | latents_high = noise(num_rows ** 2, latent_dim, device=self.rank)
1310 | n = image_noise(num_rows ** 2, image_size, device=self.rank)
1311 |
1312 | ratios = torch.linspace(0., 8., num_steps)
1313 |
1314 | frames = []
1315 | for ratio in tqdm(ratios):
1316 | interp_latents = slerp(ratio, latents_low, latents_high)
1317 | latents = [(interp_latents, num_layers)]
1318 | generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, latents, n, trunc_psi = self.trunc_psi)
1319 | images_grid = torchvision.utils.make_grid(generated_images, nrow = num_rows)
1320 | pil_image = transforms.ToPILImage()(images_grid.cpu())
1321 |
1322 | if self.transparent:
1323 | background = Image.new("RGBA", pil_image.size, (255, 255, 255))
1324 | pil_image = Image.alpha_composite(background, pil_image)
1325 |
1326 | frames.append(pil_image)
1327 |
1328 | frames[0].save(str(self.results_dir / self.name / f'{str(num)}.gif'), save_all=True, append_images=frames[1:], duration=80, loop=0, optimize=True)
1329 |
1330 | if save_frames:
1331 | folder_path = (self.results_dir / self.name / f'{str(num)}')
1332 | folder_path.mkdir(parents=True, exist_ok=True)
1333 | for ind, frame in enumerate(frames):
1334 | frame.save(str(folder_path / f'{str(ind)}.{ext}'))
1335 |
1336 | def print_log(self):
1337 | data = [
1338 | ('G', self.g_loss),
1339 | ('D', self.d_loss),
1340 | ('GP', self.last_gp_loss),
1341 | ('PL', self.pl_mean),
1342 | ('CR', self.last_cr_loss),
1343 | ('Q', self.q_loss),
1344 | ('FID', self.last_fid)
1345 | ]
1346 |
1347 | data = [d for d in data if exists(d[1])]
1348 | log = ' | '.join(map(lambda n: f'{n[0]}: {n[1]:.2f}', data))
1349 | print(log)
1350 |
1351 | def track(self, value, name):
1352 | if not exists(self.logger):
1353 | return
1354 | self.logger.track(value, name = name)
1355 |
1356 | def model_name(self, num):
1357 | return str(self.models_dir / self.name / f'model_{num}.pt')
1358 |
1359 | def init_folders(self):
1360 | (self.results_dir / self.name).mkdir(parents=True, exist_ok=True)
1361 | (self.models_dir / self.name).mkdir(parents=True, exist_ok=True)
1362 |
1363 | def clear(self):
1364 | rmtree(str(self.models_dir / self.name), True)
1365 | rmtree(str(self.results_dir / self.name), True)
1366 | rmtree(str(self.fid_dir), True)
1367 | rmtree(str(self.config_path), True)
1368 | self.init_folders()
1369 |
1370 | def save(self, num):
1371 | save_data = {
1372 | 'GAN': self.GAN.state_dict(),
1373 | 'version': __version__
1374 | }
1375 |
1376 | if self.GAN.fp16:
1377 | save_data['amp'] = amp.state_dict()
1378 |
1379 | torch.save(save_data, self.model_name(num))
1380 | self.write_config()
1381 |
1382 | def load(self, num = -1):
1383 | self.load_config()
1384 |
1385 | name = num
1386 | if num == -1:
1387 | file_paths = [p for p in Path(self.models_dir / self.name).glob('model_*.pt')]
1388 | saved_nums = sorted(map(lambda x: int(x.stem.split('_')[1]), file_paths))
1389 | if len(saved_nums) == 0:
1390 | return
1391 | name = saved_nums[-1]
1392 | print(f'continuing from previous epoch - {name}')
1393 |
1394 | self.steps = name * self.save_every
1395 |
1396 | load_data = torch.load(self.model_name(name), weights_only = True)
1397 |
1398 | if 'version' in load_data:
1399 | print(f"loading from version {load_data['version']}")
1400 |
1401 | try:
1402 | self.GAN.load_state_dict(load_data['GAN'])
1403 | except Exception as e:
1404 | print('unable to load save model. please try downgrading the package to the version specified by the saved model')
1405 | raise e
1406 | if self.GAN.fp16 and 'amp' in load_data:
1407 | amp.load_state_dict(load_data['amp'])
1408 |
1409 | class ModelLoader:
1410 | def __init__(self, *, base_dir, name = 'default', load_from = -1):
1411 | self.model = Trainer(name = name, base_dir = base_dir)
1412 | self.model.load(load_from)
1413 |
1414 | def noise_to_styles(self, noise, trunc_psi = None):
1415 | noise = noise.cuda()
1416 | w = self.model.GAN.SE(noise)
1417 | if exists(trunc_psi):
1418 | w = self.model.truncate_style(w)
1419 | return w
1420 |
1421 | def styles_to_images(self, w):
1422 | batch_size, *_ = w.shape
1423 | num_layers = self.model.GAN.GE.num_layers
1424 | image_size = self.model.image_size
1425 | w_def = [(w, num_layers)]
1426 |
1427 | w_tensors = styles_def_to_tensor(w_def)
1428 | noise = image_noise(batch_size, image_size, device = 0)
1429 |
1430 | images = self.model.GAN.GE(w_tensors, noise)
1431 | images.clamp_(0., 1.)
1432 | return images
1433 |
--------------------------------------------------------------------------------
291 |
292 |
293 | ## Experimental
294 |
295 | ### Top-k Training for Generator
296 |
297 | A new paper has produced evidence that by simply zero-ing out the gradient contributions from samples that are deemed fake by the discriminator, the generator learns significantly better, achieving new state of the art.
298 |
299 | ```python
300 | $ stylegan2_pytorch --data ./data --top-k-training
301 | ```
302 |
303 | Gamma is a decay schedule that slowly decreases the topk from the full batch size to the target fraction of 50% (also modifiable hyperparameter).
304 |
305 | ```python
306 | $ stylegan2_pytorch --data ./data --top-k-training --generate-top-k-frac 0.5 --generate-top-k-gamma 0.99
307 | ```
308 |
309 | ### Feature Quantization
310 |
311 | A recent paper reported improved results if intermediate representations of the discriminator are vector quantized. Although I have not noticed any dramatic changes, I have decided to add this as a feature, so other minds out there can investigate. To use, you have to specify which layer(s) you would like to vector quantize. Default dictionary size is `256` and is also tunable.
312 |
313 | ```python
314 | # feature quantize layers 1 and 2, with a dictionary size of 512 each
315 | # do not put a space after the comma in the list!
316 | $ stylegan2_pytorch --data ./data --fq-layers [1,2] --fq-dict-size 512
317 | ```
318 |
319 | ### Contrastive Loss Regularization
320 |
321 | I have tried contrastive learning on the discriminator (in step with the usual GAN training) and possibly observed improved stability and quality of final results. You can turn on this experimental feature with a simple flag as shown below.
322 |
323 | ```python
324 | $ stylegan2_pytorch --data ./data --cl-reg
325 | ```
326 |
327 | ### Relativistic Discriminator Loss
328 |
329 | This was proposed in the Relativistic GAN paper to stabilize training. I have had mixed results, but will include the feature for those who want to experiment with it.
330 |
331 | ```python
332 | $ stylegan2_pytorch --data ./data --rel-disc-loss
333 | ```
334 |
335 | ### Non-constant 4x4 Block
336 |
337 | By default, the StyleGAN architecture styles a constant learned 4x4 block as it is progressively upsampled. This is an experimental feature that makes it so the 4x4 block is learned from the style vector `w` instead.
338 |
339 | ```python
340 | $ stylegan2_pytorch --data ./data --no-const
341 | ```
342 |
343 | ### Dual Contrastive Loss
344 |
345 | A recent paper has proposed that a novel contrastive loss between the real and fake logits can improve quality over other types of losses. (The default in this repository is hinge loss, and the paper shows a slight improvement)
346 |
347 | ```python
348 | $ stylegan2_pytorch --data ./data --dual-contrast-loss
349 | ```
350 |
351 | ## Alternatives
352 |
353 | Stylegan2 + Unet Discriminator
354 |
355 | I have gotten really good results with a unet discriminator, but the architecturally change was too big to fit as an option in this repository. If you are aiming for perfection, feel free to try it.
356 |
357 | If you would like me to give the royal treatment to some other GAN architecture (BigGAN), feel free to reach out at my email. Happy to hear your pitch.
358 |
359 | ## Appreciation
360 |
361 | Thank you to Matthew Mann for his inspiring [simple port](https://github.com/manicman1999/StyleGAN2-Tensorflow-2.0) for Tensorflow 2.0
362 |
363 | ## References
364 |
365 | ```bibtex
366 | @article{Karras2019stylegan2,
367 | title = {Analyzing and Improving the Image Quality of {StyleGAN}},
368 | author = {Tero Karras and Samuli Laine and Miika Aittala and Janne Hellsten and Jaakko Lehtinen and Timo Aila},
369 | journal = {CoRR},
370 | volume = {abs/1912.04958},
371 | year = {2019},
372 | }
373 | ```
374 |
375 | ```bibtex
376 | @misc{zhao2020feature,
377 | title = {Feature Quantization Improves GAN Training},
378 | author = {Yang Zhao and Chunyuan Li and Ping Yu and Jianfeng Gao and Changyou Chen},
379 | year = {2020}
380 | }
381 | ```
382 |
383 | ```bibtex
384 | @misc{chen2020simple,
385 | title = {A Simple Framework for Contrastive Learning of Visual Representations},
386 | author = {Ting Chen and Simon Kornblith and Mohammad Norouzi and Geoffrey Hinton},
387 | year = {2020}
388 | }
389 | ```
390 |
391 | ```bibtex
392 | @article{,
393 | title = {Oxford 102 Flowers},
394 | author = {Nilsback, M-E. and Zisserman, A., 2008},
395 | abstract = {A 102 category dataset consisting of 102 flower categories, commonly occuring in the United Kingdom. Each class consists of 40 to 258 images. The images have large scale, pose and light variations.}
396 | }
397 | ```
398 |
399 | ```bibtex
400 | @article{afifi201911k,
401 | title = {11K Hands: gender recognition and biometric identification using a large dataset of hand images},
402 | author = {Afifi, Mahmoud},
403 | journal = {Multimedia Tools and Applications}
404 | }
405 | ```
406 |
407 | ```bibtex
408 | @misc{zhang2018selfattention,
409 | title = {Self-Attention Generative Adversarial Networks},
410 | author = {Han Zhang and Ian Goodfellow and Dimitris Metaxas and Augustus Odena},
411 | year = {2018},
412 | eprint = {1805.08318},
413 | archivePrefix = {arXiv}
414 | }
415 | ```
416 |
417 | ```bibtex
418 | @article{shen2019efficient,
419 | author = {Zhuoran Shen and
420 | Mingyuan Zhang and
421 | Haiyu Zhao and
422 | Shuai Yi and
423 | Hongsheng Li},
424 | title = {Efficient Attention: Attention with Linear Complexities},
425 | journal = {CoRR},
426 | year = {2018},
427 | url = {http://arxiv.org/abs/1812.01243},
428 | }
429 | ```
430 |
431 | ```bibtex
432 | @article{zhao2020diffaugment,
433 | title = {Differentiable Augmentation for Data-Efficient GAN Training},
434 | author = {Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
435 | journal = {arXiv preprint arXiv:2006.10738},
436 | year = {2020}
437 | }
438 | ```
439 |
440 | ```bibtex
441 | @misc{zhao2020image,
442 | title = {Image Augmentations for GAN Training},
443 | author = {Zhengli Zhao and Zizhao Zhang and Ting Chen and Sameer Singh and Han Zhang},
444 | year = {2020},
445 | eprint = {2006.02595},
446 | archivePrefix = {arXiv}
447 | }
448 | ```
449 |
450 | ```bibtex
451 | @misc{karras2020training,
452 | title = {Training Generative Adversarial Networks with Limited Data},
453 | author = {Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila},
454 | year = {2020},
455 | eprint = {2006.06676},
456 | archivePrefix = {arXiv},
457 | primaryClass = {cs.CV}
458 | }
459 | ```
460 |
461 | ```bibtex
462 | @misc{jolicoeurmartineau2018relativistic,
463 | title = {The relativistic discriminator: a key element missing from standard GAN},
464 | author = {Alexia Jolicoeur-Martineau},
465 | year = {2018},
466 | eprint = {1807.00734},
467 | archivePrefix = {arXiv},
468 | primaryClass = {cs.LG}
469 | }
470 | ```
471 |
472 | ```bibtex
473 | @misc{sinha2020topk,
474 | title = {Top-k Training of GANs: Improving GAN Performance by Throwing Away Bad Samples},
475 | author = {Samarth Sinha and Zhengli Zhao and Anirudh Goyal and Colin Raffel and Augustus Odena},
476 | year = {2020},
477 | eprint = {2002.06224},
478 | archivePrefix = {arXiv},
479 | primaryClass = {stat.ML}
480 | }
481 | ```
482 |
483 | ```bibtex
484 | @misc{yu2021dual,
485 | title = {Dual Contrastive Loss and Attention for GANs},
486 | author = {Ning Yu and Guilin Liu and Aysegul Dundar and Andrew Tao and Bryan Catanzaro and Larry Davis and Mario Fritz},
487 | year = {2021},
488 | eprint = {2103.16748},
489 | archivePrefix = {arXiv},
490 | primaryClass = {cs.CV}
491 | }
492 | ```
493 |
494 | ```bibtex
495 | @inproceedings{Huang2025TheGI,
496 | title = {The GAN is dead; long live the GAN! A Modern GAN Baseline},
497 | author = {Yiwen Huang and Aaron Gokaslan and Volodymyr Kuleshov and James Tompkin},
498 | year = {2025},
499 | url = {https://api.semanticscholar.org/CorpusID:275405495}
500 | }
501 | ```
502 |
--------------------------------------------------------------------------------
/stylegan2_pytorch/stylegan2_pytorch.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import math
4 | import fire
5 | import json
6 |
7 | from tqdm import tqdm
8 | from math import floor, log2
9 | from random import random
10 | from shutil import rmtree
11 | from functools import partial
12 | import multiprocessing
13 | from contextlib import contextmanager, ExitStack
14 |
15 | import numpy as np
16 |
17 | import torch
18 | from torch import nn, einsum
19 | from torch.utils import data
20 | from torch.optim import Adam
21 | import torch.nn.functional as F
22 | from torch.autograd import grad as torch_grad
23 | from torch.utils.data.distributed import DistributedSampler
24 | from torch.nn.parallel import DistributedDataParallel as DDP
25 |
26 | from einops import rearrange, repeat
27 | from kornia.filters import filter2d
28 |
29 | import torchvision
30 | from torchvision import transforms
31 | from stylegan2_pytorch.version import __version__
32 | from stylegan2_pytorch.diff_augment import DiffAugment
33 |
34 | from vector_quantize_pytorch import VectorQuantize
35 |
36 | from PIL import Image
37 | from pathlib import Path
38 |
39 | try:
40 | from apex import amp
41 | APEX_AVAILABLE = True
42 | except:
43 | APEX_AVAILABLE = False
44 |
45 | import aim
46 |
47 | assert torch.cuda.is_available(), 'You need to have an Nvidia GPU with CUDA installed.'
48 |
49 |
50 | # constants
51 |
52 | NUM_CORES = multiprocessing.cpu_count()
53 | EXTS = ['jpg', 'jpeg', 'png']
54 |
55 | # helper classes
56 |
57 | class NanException(Exception):
58 | pass
59 |
60 | class EMA():
61 | def __init__(self, beta):
62 | super().__init__()
63 | self.beta = beta
64 | def update_average(self, old, new):
65 | if not exists(old):
66 | return new
67 | return old * self.beta + (1 - self.beta) * new
68 |
69 | class Flatten(nn.Module):
70 | def forward(self, x):
71 | return x.reshape(x.shape[0], -1)
72 |
73 | class RandomApply(nn.Module):
74 | def __init__(self, prob, fn, fn_else = lambda x: x):
75 | super().__init__()
76 | self.fn = fn
77 | self.fn_else = fn_else
78 | self.prob = prob
79 | def forward(self, x):
80 | fn = self.fn if random() < self.prob else self.fn_else
81 | return fn(x)
82 |
83 | class Residual(nn.Module):
84 | def __init__(self, fn):
85 | super().__init__()
86 | self.fn = fn
87 | def forward(self, x):
88 | return self.fn(x) + x
89 |
90 | class ChanNorm(nn.Module):
91 | def __init__(self, dim, eps = 1e-5):
92 | super().__init__()
93 | self.eps = eps
94 | self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
95 | self.b = nn.Parameter(torch.zeros(1, dim, 1, 1))
96 |
97 | def forward(self, x):
98 | var = torch.var(x, dim = 1, unbiased = False, keepdim = True)
99 | mean = torch.mean(x, dim = 1, keepdim = True)
100 | return (x - mean) / (var + self.eps).sqrt() * self.g + self.b
101 |
102 | class PreNorm(nn.Module):
103 | def __init__(self, dim, fn):
104 | super().__init__()
105 | self.fn = fn
106 | self.norm = ChanNorm(dim)
107 |
108 | def forward(self, x):
109 | return self.fn(self.norm(x))
110 |
111 | class PermuteToFrom(nn.Module):
112 | def __init__(self, fn):
113 | super().__init__()
114 | self.fn = fn
115 | def forward(self, x):
116 | x = x.permute(0, 2, 3, 1)
117 | out, *_, loss = self.fn(x)
118 | out = out.permute(0, 3, 1, 2)
119 | return out, loss
120 |
121 | class Blur(nn.Module):
122 | def __init__(self):
123 | super().__init__()
124 | f = torch.Tensor([1, 2, 1])
125 | self.register_buffer('f', f)
126 | def forward(self, x):
127 | f = self.f
128 | f = f[None, None, :] * f [None, :, None]
129 | return filter2d(x, f, normalized=True)
130 |
131 | # attention
132 |
133 | class DepthWiseConv2d(nn.Module):
134 | def __init__(self, dim_in, dim_out, kernel_size, padding = 0, stride = 1, bias = True):
135 | super().__init__()
136 | self.net = nn.Sequential(
137 | nn.Conv2d(dim_in, dim_in, kernel_size = kernel_size, padding = padding, groups = dim_in, stride = stride, bias = bias),
138 | nn.Conv2d(dim_in, dim_out, kernel_size = 1, bias = bias)
139 | )
140 | def forward(self, x):
141 | return self.net(x)
142 |
143 | class LinearAttention(nn.Module):
144 | def __init__(self, dim, dim_head = 64, heads = 8):
145 | super().__init__()
146 | self.scale = dim_head ** -0.5
147 | self.heads = heads
148 | inner_dim = dim_head * heads
149 |
150 | self.nonlin = nn.GELU()
151 | self.to_q = nn.Conv2d(dim, inner_dim, 1, bias = False)
152 | self.to_kv = DepthWiseConv2d(dim, inner_dim * 2, 3, padding = 1, bias = False)
153 | self.to_out = nn.Conv2d(inner_dim, dim, 1)
154 |
155 | def forward(self, fmap):
156 | h, x, y = self.heads, *fmap.shape[-2:]
157 | q, k, v = (self.to_q(fmap), *self.to_kv(fmap).chunk(2, dim = 1))
158 | q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) (x y) c', h = h), (q, k, v))
159 |
160 | q = q.softmax(dim = -1)
161 | k = k.softmax(dim = -2)
162 |
163 | q = q * self.scale
164 |
165 | context = einsum('b n d, b n e -> b d e', k, v)
166 | out = einsum('b n d, b d e -> b n e', q, context)
167 | out = rearrange(out, '(b h) (x y) d -> b (h d) x y', h = h, x = x, y = y)
168 |
169 | out = self.nonlin(out)
170 | return self.to_out(out)
171 |
172 | # one layer of self-attention and feedforward, for images
173 |
174 | attn_and_ff = lambda chan: nn.Sequential(*[
175 | Residual(PreNorm(chan, LinearAttention(chan))),
176 | Residual(PreNorm(chan, nn.Sequential(nn.Conv2d(chan, chan * 2, 1), leaky_relu(), nn.Conv2d(chan * 2, chan, 1))))
177 | ])
178 |
179 | # helpers
180 |
181 | def exists(val):
182 | return val is not None
183 |
184 | @contextmanager
185 | def null_context():
186 | yield
187 |
188 | def combine_contexts(contexts):
189 | @contextmanager
190 | def multi_contexts():
191 | with ExitStack() as stack:
192 | yield [stack.enter_context(ctx()) for ctx in contexts]
193 | return multi_contexts
194 |
195 | def default(value, d):
196 | return value if exists(value) else d
197 |
198 | def cycle(iterable):
199 | while True:
200 | for i in iterable:
201 | yield i
202 |
203 | def cast_list(el):
204 | return el if isinstance(el, list) else [el]
205 |
206 | def is_empty(t):
207 | if isinstance(t, torch.Tensor):
208 | return t.nelement() == 0
209 | return not exists(t)
210 |
211 | def raise_if_nan(t):
212 | if torch.isnan(t):
213 | raise NanException
214 |
215 | def gradient_accumulate_contexts(gradient_accumulate_every, is_ddp, ddps):
216 | if is_ddp:
217 | num_no_syncs = gradient_accumulate_every - 1
218 | head = [combine_contexts(map(lambda ddp: ddp.no_sync, ddps))] * num_no_syncs
219 | tail = [null_context]
220 | contexts = head + tail
221 | else:
222 | contexts = [null_context] * gradient_accumulate_every
223 |
224 | for context in contexts:
225 | with context():
226 | yield
227 |
228 | def loss_backwards(fp16, loss, optimizer, loss_id, **kwargs):
229 | if fp16:
230 | with amp.scale_loss(loss, optimizer, loss_id) as scaled_loss:
231 | scaled_loss.backward(**kwargs)
232 | else:
233 | loss.backward(**kwargs)
234 |
235 | def gradient_penalty(images, output, weight = 10, center = 0.):
236 | batch_size = images.shape[0]
237 | gradients = torch_grad(outputs=output, inputs=images,
238 | grad_outputs=torch.ones(output.size(), device=images.device),
239 | create_graph=True, retain_graph=True, only_inputs=True)[0]
240 |
241 | gradients = gradients.reshape(batch_size, -1)
242 | return weight * ((gradients.norm(2, dim=1) - center) ** 2).mean()
243 |
244 | def calc_pl_lengths(styles, images):
245 | device = images.device
246 | num_pixels = images.shape[2] * images.shape[3]
247 | pl_noise = torch.randn(images.shape, device=device) / math.sqrt(num_pixels)
248 | outputs = (images * pl_noise).sum()
249 |
250 | pl_grads = torch_grad(outputs=outputs, inputs=styles,
251 | grad_outputs=torch.ones(outputs.shape, device=device),
252 | create_graph=True, retain_graph=True, only_inputs=True)[0]
253 |
254 | return (pl_grads ** 2).sum(dim=2).mean(dim=1).sqrt()
255 |
256 | def noise(n, latent_dim, device):
257 | return torch.randn(n, latent_dim).cuda(device)
258 |
259 | def noise_list(n, layers, latent_dim, device):
260 | return [(noise(n, latent_dim, device), layers)]
261 |
262 | def mixed_list(n, layers, latent_dim, device):
263 | tt = int(torch.rand(()).numpy() * layers)
264 | return noise_list(n, tt, latent_dim, device) + noise_list(n, layers - tt, latent_dim, device)
265 |
266 | def latent_to_w(style_vectorizer, latent_descr):
267 | return [(style_vectorizer(z), num_layers) for z, num_layers in latent_descr]
268 |
269 | def image_noise(n, im_size, device):
270 | return torch.FloatTensor(n, im_size, im_size, 1).uniform_(0., 1.).cuda(device)
271 |
272 | def leaky_relu(p=0.2):
273 | return nn.LeakyReLU(p, inplace=True)
274 |
275 | def evaluate_in_chunks(max_batch_size, model, *args):
276 | split_args = list(zip(*list(map(lambda x: x.split(max_batch_size, dim=0), args))))
277 | chunked_outputs = [model(*i) for i in split_args]
278 | if len(chunked_outputs) == 1:
279 | return chunked_outputs[0]
280 | return torch.cat(chunked_outputs, dim=0)
281 |
282 | def styles_def_to_tensor(styles_def):
283 | return torch.cat([t[:, None, :].expand(-1, n, -1) for t, n in styles_def], dim=1)
284 |
285 | def set_requires_grad(model, bool):
286 | for p in model.parameters():
287 | p.requires_grad = bool
288 |
289 | def slerp(val, low, high):
290 | low_norm = low / torch.norm(low, dim=1, keepdim=True)
291 | high_norm = high / torch.norm(high, dim=1, keepdim=True)
292 | omega = torch.acos((low_norm * high_norm).sum(1))
293 | so = torch.sin(omega)
294 | res = (torch.sin((1.0 - val) * omega) / so).unsqueeze(1) * low + (torch.sin(val * omega) / so).unsqueeze(1) * high
295 | return res
296 |
297 | # losses
298 |
299 | def gen_hinge_loss(fake, real):
300 | return fake.mean()
301 |
302 | def hinge_loss(fake, real):
303 | return (F.relu(1 + real) + F.relu(1 - fake)).mean()
304 |
305 | def dual_contrastive_loss(fake_logits, real_logits):
306 | device = real_logits.device
307 | real_logits, fake_logits = map(lambda t: rearrange(t, '... -> (...)'), (real_logits, fake_logits))
308 |
309 | def loss_half(t1, t2):
310 | t1 = rearrange(t1, 'i -> i 1')
311 | t2 = repeat(t2, 'j -> i j', i = t1.shape[0])
312 | t = torch.cat((t1, t2), dim = -1)
313 | return F.cross_entropy(t, torch.zeros(t1.shape[0], device = device, dtype = torch.long))
314 |
315 | return loss_half(real_logits, fake_logits) + loss_half(-fake_logits, -real_logits)
316 |
317 | # dataset
318 |
319 | def convert_rgb_to_transparent(image):
320 | if image.mode != 'RGBA':
321 | return image.convert('RGBA')
322 | return image
323 |
324 | def convert_transparent_to_rgb(image):
325 | if image.mode != 'RGB':
326 | return image.convert('RGB')
327 | return image
328 |
329 | class expand_greyscale(object):
330 | def __init__(self, transparent):
331 | self.transparent = transparent
332 |
333 | def __call__(self, tensor):
334 | channels = tensor.shape[0]
335 | num_target_channels = 4 if self.transparent else 3
336 |
337 | if channels == num_target_channels:
338 | return tensor
339 |
340 | alpha = None
341 | if channels == 1:
342 | color = tensor.expand(3, -1, -1)
343 | elif channels == 2:
344 | color = tensor[:1].expand(3, -1, -1)
345 | alpha = tensor[1:]
346 | else:
347 | raise Exception(f'image with invalid number of channels given {channels}')
348 |
349 | if not exists(alpha) and self.transparent:
350 | alpha = torch.ones(1, *tensor.shape[1:], device=tensor.device)
351 |
352 | return color if not self.transparent else torch.cat((color, alpha))
353 |
354 | def resize_to_minimum_size(min_size, image):
355 | if max(*image.size) < min_size:
356 | return torchvision.transforms.functional.resize(image, min_size)
357 | return image
358 |
359 | class Dataset(data.Dataset):
360 | def __init__(self, folder, image_size, transparent = False, aug_prob = 0.):
361 | super().__init__()
362 | self.folder = folder
363 | self.image_size = image_size
364 | self.paths = [p for ext in EXTS for p in Path(f'{folder}').glob(f'**/*.{ext}')]
365 | assert len(self.paths) > 0, f'No images were found in {folder} for training'
366 |
367 | convert_image_fn = convert_transparent_to_rgb if not transparent else convert_rgb_to_transparent
368 | num_channels = 3 if not transparent else 4
369 |
370 | self.transform = transforms.Compose([
371 | transforms.Lambda(convert_image_fn),
372 | transforms.Lambda(partial(resize_to_minimum_size, image_size)),
373 | transforms.Resize(image_size),
374 | RandomApply(aug_prob, transforms.RandomResizedCrop(image_size, scale=(0.5, 1.0), ratio=(0.98, 1.02)), transforms.CenterCrop(image_size)),
375 | transforms.ToTensor(),
376 | transforms.Lambda(expand_greyscale(transparent))
377 | ])
378 |
379 | def __len__(self):
380 | return len(self.paths)
381 |
382 | def __getitem__(self, index):
383 | path = self.paths[index]
384 | img = Image.open(path)
385 | return self.transform(img)
386 |
387 | # augmentations
388 |
389 | def random_hflip(tensor, prob):
390 | if prob < random():
391 | return tensor
392 | return torch.flip(tensor, dims=(3,))
393 |
394 | class AugWrapper(nn.Module):
395 | def __init__(self, D, image_size):
396 | super().__init__()
397 | self.D = D
398 |
399 | def forward(self, images, prob = 0., types = [], detach = False, return_aug_images = False, input_requires_grad = False):
400 | if random() < prob:
401 | images = random_hflip(images, prob=0.5)
402 | images = DiffAugment(images, types=types)
403 |
404 | if detach:
405 | images = images.detach()
406 |
407 | if input_requires_grad:
408 | images.requires_grad_()
409 |
410 | logits = self.D(images)
411 |
412 | if not return_aug_images:
413 | return logits
414 |
415 | return images, logits
416 |
417 | # stylegan2 classes
418 |
419 | class EqualLinear(nn.Module):
420 | def __init__(self, in_dim, out_dim, lr_mul = 1, bias = True):
421 | super().__init__()
422 | self.weight = nn.Parameter(torch.randn(out_dim, in_dim))
423 | if bias:
424 | self.bias = nn.Parameter(torch.zeros(out_dim))
425 |
426 | self.lr_mul = lr_mul
427 |
428 | def forward(self, input):
429 | return F.linear(input, self.weight * self.lr_mul, bias=self.bias * self.lr_mul)
430 |
431 | class StyleVectorizer(nn.Module):
432 | def __init__(self, emb, depth, lr_mul = 0.1):
433 | super().__init__()
434 |
435 | layers = []
436 | for i in range(depth):
437 | layers.extend([EqualLinear(emb, emb, lr_mul), leaky_relu()])
438 |
439 | self.net = nn.Sequential(*layers)
440 |
441 | def forward(self, x):
442 | x = F.normalize(x, dim=1)
443 | return self.net(x)
444 |
445 | class RGBBlock(nn.Module):
446 | def __init__(self, latent_dim, input_channel, upsample, rgba = False):
447 | super().__init__()
448 | self.input_channel = input_channel
449 | self.to_style = nn.Linear(latent_dim, input_channel)
450 |
451 | out_filters = 3 if not rgba else 4
452 | self.conv = Conv2DMod(input_channel, out_filters, 1, demod=False)
453 |
454 | self.upsample = nn.Sequential(
455 | nn.Upsample(scale_factor = 2, mode='bilinear', align_corners=False),
456 | Blur()
457 | ) if upsample else None
458 |
459 | def forward(self, x, prev_rgb, istyle):
460 | b, c, h, w = x.shape
461 | style = self.to_style(istyle)
462 | x = self.conv(x, style)
463 |
464 | if exists(prev_rgb):
465 | x = x + prev_rgb
466 |
467 | if exists(self.upsample):
468 | x = self.upsample(x)
469 |
470 | return x
471 |
472 | class Conv2DMod(nn.Module):
473 | def __init__(self, in_chan, out_chan, kernel, demod=True, stride=1, dilation=1, eps = 1e-8, **kwargs):
474 | super().__init__()
475 | self.filters = out_chan
476 | self.demod = demod
477 | self.kernel = kernel
478 | self.stride = stride
479 | self.dilation = dilation
480 | self.weight = nn.Parameter(torch.randn((out_chan, in_chan, kernel, kernel)))
481 | self.eps = eps
482 | nn.init.kaiming_normal_(self.weight, a=0, mode='fan_in', nonlinearity='leaky_relu')
483 |
484 | def _get_same_padding(self, size, kernel, dilation, stride):
485 | return ((size - 1) * (stride - 1) + dilation * (kernel - 1)) // 2
486 |
487 | def forward(self, x, y):
488 | b, c, h, w = x.shape
489 |
490 | w1 = y[:, None, :, None, None]
491 | w2 = self.weight[None, :, :, :, :]
492 | weights = w2 * (w1 + 1)
493 |
494 | if self.demod:
495 | d = torch.rsqrt((weights ** 2).sum(dim=(2, 3, 4), keepdim=True) + self.eps)
496 | weights = weights * d
497 |
498 | x = x.reshape(1, -1, h, w)
499 |
500 | _, _, *ws = weights.shape
501 | weights = weights.reshape(b * self.filters, *ws)
502 |
503 | padding = self._get_same_padding(h, self.kernel, self.dilation, self.stride)
504 | x = F.conv2d(x, weights, padding=padding, groups=b)
505 |
506 | x = x.reshape(-1, self.filters, h, w)
507 | return x
508 |
509 | class GeneratorBlock(nn.Module):
510 | def __init__(self, latent_dim, input_channels, filters, upsample = True, upsample_rgb = True, rgba = False):
511 | super().__init__()
512 | self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False) if upsample else None
513 |
514 | self.to_style1 = nn.Linear(latent_dim, input_channels)
515 | self.to_noise1 = nn.Linear(1, filters)
516 | self.conv1 = Conv2DMod(input_channels, filters, 3)
517 |
518 | self.to_style2 = nn.Linear(latent_dim, filters)
519 | self.to_noise2 = nn.Linear(1, filters)
520 | self.conv2 = Conv2DMod(filters, filters, 3)
521 |
522 | self.activation = leaky_relu()
523 | self.to_rgb = RGBBlock(latent_dim, filters, upsample_rgb, rgba)
524 |
525 | def forward(self, x, prev_rgb, istyle, inoise):
526 | if exists(self.upsample):
527 | x = self.upsample(x)
528 |
529 | inoise = inoise[:, :x.shape[2], :x.shape[3], :]
530 | noise1 = self.to_noise1(inoise).permute((0, 3, 2, 1))
531 | noise2 = self.to_noise2(inoise).permute((0, 3, 2, 1))
532 |
533 | style1 = self.to_style1(istyle)
534 | x = self.conv1(x, style1)
535 | x = self.activation(x + noise1)
536 |
537 | style2 = self.to_style2(istyle)
538 | x = self.conv2(x, style2)
539 | x = self.activation(x + noise2)
540 |
541 | rgb = self.to_rgb(x, prev_rgb, istyle)
542 | return x, rgb
543 |
544 | class DiscriminatorBlock(nn.Module):
545 | def __init__(self, input_channels, filters, downsample=True):
546 | super().__init__()
547 | self.conv_res = nn.Conv2d(input_channels, filters, 1, stride = (2 if downsample else 1))
548 |
549 | self.net = nn.Sequential(
550 | nn.Conv2d(input_channels, filters, 3, padding=1),
551 | leaky_relu(),
552 | nn.Conv2d(filters, filters, 3, padding=1),
553 | leaky_relu()
554 | )
555 |
556 | self.downsample = nn.Sequential(
557 | Blur(),
558 | nn.Conv2d(filters, filters, 3, padding = 1, stride = 2)
559 | ) if downsample else None
560 |
561 | def forward(self, x):
562 | res = self.conv_res(x)
563 | x = self.net(x)
564 | if exists(self.downsample):
565 | x = self.downsample(x)
566 | x = (x + res) * (1 / math.sqrt(2))
567 | return x
568 |
569 | class Generator(nn.Module):
570 | def __init__(self, image_size, latent_dim, network_capacity = 16, transparent = False, attn_layers = [], no_const = False, fmap_max = 512):
571 | super().__init__()
572 | self.image_size = image_size
573 | self.latent_dim = latent_dim
574 | self.num_layers = int(log2(image_size) - 1)
575 |
576 | filters = [network_capacity * (2 ** (i + 1)) for i in range(self.num_layers)][::-1]
577 |
578 | set_fmap_max = partial(min, fmap_max)
579 | filters = list(map(set_fmap_max, filters))
580 | init_channels = filters[0]
581 | filters = [init_channels, *filters]
582 |
583 | in_out_pairs = zip(filters[:-1], filters[1:])
584 | self.no_const = no_const
585 |
586 | if no_const:
587 | self.to_initial_block = nn.ConvTranspose2d(latent_dim, init_channels, 4, 1, 0, bias=False)
588 | else:
589 | self.initial_block = nn.Parameter(torch.randn((1, init_channels, 4, 4)))
590 |
591 | self.initial_conv = nn.Conv2d(filters[0], filters[0], 3, padding=1)
592 | self.blocks = nn.ModuleList([])
593 | self.attns = nn.ModuleList([])
594 |
595 | for ind, (in_chan, out_chan) in enumerate(in_out_pairs):
596 | not_first = ind != 0
597 | not_last = ind != (self.num_layers - 1)
598 | num_layer = self.num_layers - ind
599 |
600 | attn_fn = attn_and_ff(in_chan) if num_layer in attn_layers else None
601 |
602 | self.attns.append(attn_fn)
603 |
604 | block = GeneratorBlock(
605 | latent_dim,
606 | in_chan,
607 | out_chan,
608 | upsample = not_first,
609 | upsample_rgb = not_last,
610 | rgba = transparent
611 | )
612 | self.blocks.append(block)
613 |
614 | def forward(self, styles, input_noise):
615 | batch_size = styles.shape[0]
616 | image_size = self.image_size
617 |
618 | if self.no_const:
619 | avg_style = styles.mean(dim=1)[:, :, None, None]
620 | x = self.to_initial_block(avg_style)
621 | else:
622 | x = self.initial_block.expand(batch_size, -1, -1, -1)
623 |
624 | rgb = None
625 | styles = styles.transpose(0, 1)
626 | x = self.initial_conv(x)
627 |
628 | for style, block, attn in zip(styles, self.blocks, self.attns):
629 | if exists(attn):
630 | x = attn(x)
631 | x, rgb = block(x, rgb, style, input_noise)
632 |
633 | return rgb
634 |
635 | class Discriminator(nn.Module):
636 | def __init__(self, image_size, network_capacity = 16, fq_layers = [], fq_dict_size = 256, attn_layers = [], transparent = False, fmap_max = 512):
637 | super().__init__()
638 | num_layers = int(log2(image_size) - 1)
639 | num_init_filters = 3 if not transparent else 4
640 |
641 | blocks = []
642 | filters = [num_init_filters] + [(network_capacity * 4) * (2 ** i) for i in range(num_layers + 1)]
643 |
644 | set_fmap_max = partial(min, fmap_max)
645 | filters = list(map(set_fmap_max, filters))
646 | chan_in_out = list(zip(filters[:-1], filters[1:]))
647 |
648 | blocks = []
649 | attn_blocks = []
650 | quantize_blocks = []
651 |
652 | for ind, (in_chan, out_chan) in enumerate(chan_in_out):
653 | num_layer = ind + 1
654 | is_not_last = ind != (len(chan_in_out) - 1)
655 |
656 | block = DiscriminatorBlock(in_chan, out_chan, downsample = is_not_last)
657 | blocks.append(block)
658 |
659 | attn_fn = attn_and_ff(out_chan) if num_layer in attn_layers else None
660 |
661 | attn_blocks.append(attn_fn)
662 |
663 | quantize_fn = PermuteToFrom(VectorQuantize(out_chan, fq_dict_size)) if num_layer in fq_layers else None
664 | quantize_blocks.append(quantize_fn)
665 |
666 | self.blocks = nn.ModuleList(blocks)
667 | self.attn_blocks = nn.ModuleList(attn_blocks)
668 | self.quantize_blocks = nn.ModuleList(quantize_blocks)
669 |
670 | chan_last = filters[-1]
671 | latent_dim = 2 * 2 * chan_last
672 |
673 | self.final_conv = nn.Conv2d(chan_last, chan_last, 3, padding=1)
674 | self.flatten = Flatten()
675 | self.to_logit = nn.Linear(latent_dim, 1)
676 |
677 | def forward(self, x):
678 | b, *_ = x.shape
679 |
680 | quantize_loss = torch.zeros(1).to(x)
681 |
682 | for (block, attn_block, q_block) in zip(self.blocks, self.attn_blocks, self.quantize_blocks):
683 | x = block(x)
684 |
685 | if exists(attn_block):
686 | x = attn_block(x)
687 |
688 | if exists(q_block):
689 | x, loss = q_block(x)
690 | quantize_loss += loss
691 |
692 | x = self.final_conv(x)
693 | x = self.flatten(x)
694 | x = self.to_logit(x)
695 | return x.squeeze(), quantize_loss
696 |
697 | class StyleGAN2(nn.Module):
698 | def __init__(self, image_size, latent_dim = 512, fmap_max = 512, style_depth = 8, network_capacity = 16, transparent = False, fp16 = False, cl_reg = False, steps = 1, lr = 1e-4, ttur_mult = 2, fq_layers = [], fq_dict_size = 256, attn_layers = [], no_const = False, lr_mlp = 0.1, rank = 0):
699 | super().__init__()
700 | self.lr = lr
701 | self.steps = steps
702 | self.ema_updater = EMA(0.995)
703 |
704 | self.S = StyleVectorizer(latent_dim, style_depth, lr_mul = lr_mlp)
705 | self.G = Generator(image_size, latent_dim, network_capacity, transparent = transparent, attn_layers = attn_layers, no_const = no_const, fmap_max = fmap_max)
706 | self.D = Discriminator(image_size, network_capacity, fq_layers = fq_layers, fq_dict_size = fq_dict_size, attn_layers = attn_layers, transparent = transparent, fmap_max = fmap_max)
707 |
708 | self.SE = StyleVectorizer(latent_dim, style_depth, lr_mul = lr_mlp)
709 | self.GE = Generator(image_size, latent_dim, network_capacity, transparent = transparent, attn_layers = attn_layers, no_const = no_const)
710 |
711 | self.D_cl = None
712 |
713 | if cl_reg:
714 | from contrastive_learner import ContrastiveLearner
715 | # experimental contrastive loss discriminator regularization
716 | assert not transparent, 'contrastive loss regularization does not work with transparent images yet'
717 | self.D_cl = ContrastiveLearner(self.D, image_size, hidden_layer='flatten')
718 |
719 | # wrapper for augmenting all images going into the discriminator
720 | self.D_aug = AugWrapper(self.D, image_size)
721 |
722 | # turn off grad for exponential moving averages
723 | set_requires_grad(self.SE, False)
724 | set_requires_grad(self.GE, False)
725 |
726 | # init optimizers
727 | generator_params = list(self.G.parameters()) + list(self.S.parameters())
728 | self.G_opt = Adam(generator_params, lr = self.lr, betas=(0.5, 0.9))
729 | self.D_opt = Adam(self.D.parameters(), lr = self.lr * ttur_mult, betas=(0.5, 0.9))
730 |
731 | # init weights
732 | self._init_weights()
733 | self.reset_parameter_averaging()
734 |
735 | self.cuda(rank)
736 |
737 | # startup apex mixed precision
738 | self.fp16 = fp16
739 | if fp16:
740 | (self.S, self.G, self.D, self.SE, self.GE), (self.G_opt, self.D_opt) = amp.initialize([self.S, self.G, self.D, self.SE, self.GE], [self.G_opt, self.D_opt], opt_level='O1', num_losses=3)
741 |
742 | def _init_weights(self):
743 | for m in self.modules():
744 | if type(m) in {nn.Conv2d, nn.Linear}:
745 | nn.init.kaiming_normal_(m.weight, a=0, mode='fan_in', nonlinearity='leaky_relu')
746 |
747 | for block in self.G.blocks:
748 | nn.init.zeros_(block.to_noise1.weight)
749 | nn.init.zeros_(block.to_noise2.weight)
750 | nn.init.zeros_(block.to_noise1.bias)
751 | nn.init.zeros_(block.to_noise2.bias)
752 |
753 | def EMA(self):
754 | def update_moving_average(ma_model, current_model):
755 | for current_params, ma_params in zip(current_model.parameters(), ma_model.parameters()):
756 | old_weight, up_weight = ma_params.data, current_params.data
757 | ma_params.data = self.ema_updater.update_average(old_weight, up_weight)
758 |
759 | update_moving_average(self.SE, self.S)
760 | update_moving_average(self.GE, self.G)
761 |
762 | def reset_parameter_averaging(self):
763 | self.SE.load_state_dict(self.S.state_dict())
764 | self.GE.load_state_dict(self.G.state_dict())
765 |
766 | def forward(self, x):
767 | return x
768 |
769 | class Trainer():
770 | def __init__(
771 | self,
772 | name = 'default',
773 | results_dir = 'results',
774 | models_dir = 'models',
775 | base_dir = './',
776 | image_size = 128,
777 | network_capacity = 16,
778 | fmap_max = 512,
779 | transparent = False,
780 | batch_size = 4,
781 | mixed_prob = 0.9,
782 | gradient_accumulate_every=1,
783 | lr = 2e-4,
784 | lr_mlp = 0.1,
785 | ttur_mult = 2,
786 | rel_disc_loss = False,
787 | num_workers = None,
788 | save_every = 1000,
789 | evaluate_every = 1000,
790 | num_image_tiles = 8,
791 | trunc_psi = 0.6,
792 | fp16 = False,
793 | cl_reg = False,
794 | no_pl_reg = False,
795 | fq_layers = [],
796 | fq_dict_size = 256,
797 | attn_layers = [],
798 | no_const = False,
799 | aug_prob = 0.,
800 | aug_types = ['translation', 'cutout'],
801 | top_k_training = False,
802 | generator_top_k_gamma = 0.99,
803 | generator_top_k_frac = 0.5,
804 | dual_contrast_loss = False,
805 | dataset_aug_prob = 0.,
806 | calculate_fid_every = None,
807 | calculate_fid_num_images = 12800,
808 | clear_fid_cache = False,
809 | is_ddp = False,
810 | rank = 0,
811 | world_size = 1,
812 | log = False,
813 | *args,
814 | **kwargs
815 | ):
816 | self.GAN_params = [args, kwargs]
817 | self.GAN = None
818 |
819 | self.name = name
820 |
821 | base_dir = Path(base_dir)
822 | self.base_dir = base_dir
823 | self.results_dir = base_dir / results_dir
824 | self.models_dir = base_dir / models_dir
825 | self.fid_dir = base_dir / 'fid' / name
826 | self.config_path = self.models_dir / name / '.config.json'
827 |
828 | assert log2(image_size).is_integer(), 'image size must be a power of 2 (64, 128, 256, 512, 1024)'
829 | self.image_size = image_size
830 | self.network_capacity = network_capacity
831 | self.fmap_max = fmap_max
832 | self.transparent = transparent
833 |
834 | self.fq_layers = cast_list(fq_layers)
835 | self.fq_dict_size = fq_dict_size
836 | self.has_fq = len(self.fq_layers) > 0
837 |
838 | self.attn_layers = cast_list(attn_layers)
839 | self.no_const = no_const
840 |
841 | self.aug_prob = aug_prob
842 | self.aug_types = aug_types
843 |
844 | self.lr = lr
845 | self.lr_mlp = lr_mlp
846 | self.ttur_mult = ttur_mult
847 | self.rel_disc_loss = rel_disc_loss
848 | self.batch_size = batch_size
849 | self.num_workers = num_workers
850 | self.mixed_prob = mixed_prob
851 |
852 | self.num_image_tiles = num_image_tiles
853 | self.evaluate_every = evaluate_every
854 | self.save_every = save_every
855 | self.steps = 0
856 |
857 | self.av = None
858 | self.trunc_psi = trunc_psi
859 |
860 | self.no_pl_reg = no_pl_reg
861 | self.pl_mean = None
862 |
863 | self.gradient_accumulate_every = gradient_accumulate_every
864 |
865 | assert not fp16 or fp16 and APEX_AVAILABLE, 'Apex is not available for you to use mixed precision training'
866 | self.fp16 = fp16
867 |
868 | self.cl_reg = cl_reg
869 |
870 | self.d_loss = 0
871 | self.g_loss = 0
872 | self.q_loss = None
873 | self.last_gp_loss = None
874 | self.last_cr_loss = None
875 | self.last_fid = None
876 |
877 | self.pl_length_ma = EMA(0.99)
878 | self.init_folders()
879 |
880 | self.loader = None
881 | self.dataset_aug_prob = dataset_aug_prob
882 |
883 | self.calculate_fid_every = calculate_fid_every
884 | self.calculate_fid_num_images = calculate_fid_num_images
885 | self.clear_fid_cache = clear_fid_cache
886 |
887 | self.top_k_training = top_k_training
888 | self.generator_top_k_gamma = generator_top_k_gamma
889 | self.generator_top_k_frac = generator_top_k_frac
890 |
891 | self.dual_contrast_loss = dual_contrast_loss
892 |
893 | assert not (is_ddp and cl_reg), 'Contrastive loss regularization does not work well with multi GPUs yet'
894 | self.is_ddp = is_ddp
895 | self.is_main = rank == 0
896 | self.rank = rank
897 | self.world_size = world_size
898 |
899 | self.logger = aim.Session(experiment=name) if log else None
900 |
901 | @property
902 | def image_extension(self):
903 | return 'jpg' if not self.transparent else 'png'
904 |
905 | @property
906 | def checkpoint_num(self):
907 | return floor(self.steps // self.save_every)
908 |
909 | @property
910 | def hparams(self):
911 | return {'image_size': self.image_size, 'network_capacity': self.network_capacity}
912 |
913 | def init_GAN(self):
914 | args, kwargs = self.GAN_params
915 | self.GAN = StyleGAN2(lr = self.lr, lr_mlp = self.lr_mlp, ttur_mult = self.ttur_mult, image_size = self.image_size, network_capacity = self.network_capacity, fmap_max = self.fmap_max, transparent = self.transparent, fq_layers = self.fq_layers, fq_dict_size = self.fq_dict_size, attn_layers = self.attn_layers, fp16 = self.fp16, cl_reg = self.cl_reg, no_const = self.no_const, rank = self.rank, *args, **kwargs)
916 |
917 | if self.is_ddp:
918 | ddp_kwargs = {'device_ids': [self.rank]}
919 | self.S_ddp = DDP(self.GAN.S, **ddp_kwargs)
920 | self.G_ddp = DDP(self.GAN.G, **ddp_kwargs)
921 | self.D_ddp = DDP(self.GAN.D, **ddp_kwargs)
922 | self.D_aug_ddp = DDP(self.GAN.D_aug, **ddp_kwargs)
923 |
924 | if exists(self.logger):
925 | self.logger.set_params(self.hparams)
926 |
927 | def write_config(self):
928 | self.config_path.write_text(json.dumps(self.config()))
929 |
930 | def load_config(self):
931 | config = self.config() if not self.config_path.exists() else json.loads(self.config_path.read_text())
932 | self.image_size = config['image_size']
933 | self.network_capacity = config['network_capacity']
934 | self.transparent = config['transparent']
935 | self.fq_layers = config['fq_layers']
936 | self.fq_dict_size = config['fq_dict_size']
937 | self.fmap_max = config.pop('fmap_max', 512)
938 | self.attn_layers = config.pop('attn_layers', [])
939 | self.no_const = config.pop('no_const', False)
940 | self.lr_mlp = config.pop('lr_mlp', 0.1)
941 | del self.GAN
942 | self.init_GAN()
943 |
944 | def config(self):
945 | return {'image_size': self.image_size, 'network_capacity': self.network_capacity, 'lr_mlp': self.lr_mlp, 'transparent': self.transparent, 'fq_layers': self.fq_layers, 'fq_dict_size': self.fq_dict_size, 'attn_layers': self.attn_layers, 'no_const': self.no_const}
946 |
947 | def set_data_src(self, folder):
948 | self.dataset = Dataset(folder, self.image_size, transparent = self.transparent, aug_prob = self.dataset_aug_prob)
949 | num_workers = num_workers = default(self.num_workers, NUM_CORES if not self.is_ddp else 0)
950 | sampler = DistributedSampler(self.dataset, rank=self.rank, num_replicas=self.world_size, shuffle=True) if self.is_ddp else None
951 | dataloader = data.DataLoader(self.dataset, num_workers = num_workers, batch_size = math.ceil(self.batch_size / self.world_size), sampler = sampler, shuffle = not self.is_ddp, drop_last = True, pin_memory = True)
952 | self.loader = cycle(dataloader)
953 |
954 | # auto set augmentation prob for user if dataset is detected to be low
955 | num_samples = len(self.dataset)
956 | if not exists(self.aug_prob) and num_samples < 1e5:
957 | self.aug_prob = min(0.5, (1e5 - num_samples) * 3e-6)
958 | print(f'autosetting augmentation probability to {round(self.aug_prob * 100)}%')
959 |
960 | def train(self):
961 | assert exists(self.loader), 'You must first initialize the data source with `.set_data_src()`'
962 |
963 | if not exists(self.GAN):
964 | self.init_GAN()
965 |
966 | self.GAN.train()
967 | total_disc_loss = torch.tensor(0.).cuda(self.rank)
968 | total_gen_loss = torch.tensor(0.).cuda(self.rank)
969 |
970 | batch_size = math.ceil(self.batch_size / self.world_size)
971 |
972 | image_size = self.GAN.G.image_size
973 | latent_dim = self.GAN.G.latent_dim
974 | num_layers = self.GAN.G.num_layers
975 |
976 | aug_prob = self.aug_prob
977 | aug_types = self.aug_types
978 | aug_kwargs = {'prob': aug_prob, 'types': aug_types}
979 |
980 | apply_gradient_penalty = self.steps % 4 == 0
981 | apply_path_penalty = not self.no_pl_reg and self.steps > 5000 and self.steps % 32 == 0
982 | apply_cl_reg_to_generated = self.steps > 20000
983 |
984 | S = self.GAN.S if not self.is_ddp else self.S_ddp
985 | G = self.GAN.G if not self.is_ddp else self.G_ddp
986 | D = self.GAN.D if not self.is_ddp else self.D_ddp
987 | D_aug = self.GAN.D_aug if not self.is_ddp else self.D_aug_ddp
988 |
989 | backwards = partial(loss_backwards, self.fp16)
990 |
991 | if exists(self.GAN.D_cl):
992 | self.GAN.D_opt.zero_grad()
993 |
994 | if apply_cl_reg_to_generated:
995 | for i in range(self.gradient_accumulate_every):
996 | get_latents_fn = mixed_list if random() < self.mixed_prob else noise_list
997 | style = get_latents_fn(batch_size, num_layers, latent_dim, device=self.rank)
998 | noise = image_noise(batch_size, image_size, device=self.rank)
999 |
1000 | w_space = latent_to_w(self.GAN.S, style)
1001 | w_styles = styles_def_to_tensor(w_space)
1002 |
1003 | generated_images = self.GAN.G(w_styles, noise)
1004 | self.GAN.D_cl(generated_images.clone().detach(), accumulate=True)
1005 |
1006 | for i in range(self.gradient_accumulate_every):
1007 | image_batch = next(self.loader).cuda(self.rank)
1008 | self.GAN.D_cl(image_batch, accumulate=True)
1009 |
1010 | loss = self.GAN.D_cl.calculate_loss()
1011 | self.last_cr_loss = loss.clone().detach().item()
1012 | backwards(loss, self.GAN.D_opt, loss_id = 0)
1013 |
1014 | self.GAN.D_opt.step()
1015 |
1016 | # setup losses
1017 |
1018 | if not self.dual_contrast_loss:
1019 | D_loss_fn = hinge_loss
1020 | G_loss_fn = gen_hinge_loss
1021 | G_requires_reals = False
1022 | else:
1023 | D_loss_fn = dual_contrastive_loss
1024 | G_loss_fn = dual_contrastive_loss
1025 | G_requires_reals = True
1026 |
1027 | # train discriminator
1028 |
1029 | avg_pl_length = self.pl_mean
1030 | self.GAN.D_opt.zero_grad()
1031 |
1032 | for i in gradient_accumulate_contexts(self.gradient_accumulate_every, self.is_ddp, ddps=[D_aug, S, G]):
1033 | get_latents_fn = mixed_list if random() < self.mixed_prob else noise_list
1034 | style = get_latents_fn(batch_size, num_layers, latent_dim, device=self.rank)
1035 | noise = image_noise(batch_size, image_size, device=self.rank)
1036 |
1037 | w_space = latent_to_w(S, style)
1038 | w_styles = styles_def_to_tensor(w_space)
1039 |
1040 | generated_images = G(w_styles, noise)
1041 | generated_images, (fake_output, fake_q_loss) = D_aug(generated_images.clone().detach(), return_aug_images = True, input_requires_grad = apply_gradient_penalty, detach = True, **aug_kwargs)
1042 |
1043 | image_batch = next(self.loader).cuda(self.rank)
1044 |
1045 | if apply_gradient_penalty:
1046 | image_batch.requires_grad_()
1047 |
1048 | real_output, real_q_loss = D_aug(image_batch, **aug_kwargs)
1049 |
1050 | real_output_loss = real_output
1051 | fake_output_loss = fake_output
1052 |
1053 | if self.rel_disc_loss:
1054 | real_output_loss = real_output_loss - fake_output.mean()
1055 | fake_output_loss = fake_output_loss - real_output.mean()
1056 |
1057 | divergence = D_loss_fn(fake_output_loss, real_output_loss)
1058 | disc_loss = divergence
1059 |
1060 | if self.has_fq:
1061 | quantize_loss = (fake_q_loss + real_q_loss).mean()
1062 | self.q_loss = float(quantize_loss.detach().item())
1063 |
1064 | disc_loss = disc_loss + quantize_loss
1065 |
1066 | if apply_gradient_penalty:
1067 | gp = gradient_penalty(image_batch, real_output) + gradient_penalty(generated_images, fake_output)
1068 | self.last_gp_loss = gp.clone().detach().item()
1069 | self.track(self.last_gp_loss, 'GP')
1070 | disc_loss = disc_loss + gp
1071 |
1072 | disc_loss = disc_loss / self.gradient_accumulate_every
1073 | disc_loss.register_hook(raise_if_nan)
1074 | backwards(disc_loss, self.GAN.D_opt, loss_id = 1)
1075 |
1076 | total_disc_loss += divergence.detach().item() / self.gradient_accumulate_every
1077 |
1078 | self.d_loss = float(total_disc_loss)
1079 | self.track(self.d_loss, 'D')
1080 |
1081 | self.GAN.D_opt.step()
1082 |
1083 | # train generator
1084 |
1085 | self.GAN.G_opt.zero_grad()
1086 |
1087 | for i in gradient_accumulate_contexts(self.gradient_accumulate_every, self.is_ddp, ddps=[S, G, D_aug]):
1088 | style = get_latents_fn(batch_size, num_layers, latent_dim, device=self.rank)
1089 | noise = image_noise(batch_size, image_size, device=self.rank)
1090 |
1091 | w_space = latent_to_w(S, style)
1092 | w_styles = styles_def_to_tensor(w_space)
1093 |
1094 | generated_images = G(w_styles, noise)
1095 | fake_output, _ = D_aug(generated_images, **aug_kwargs)
1096 | fake_output_loss = fake_output
1097 |
1098 | real_output = None
1099 | if G_requires_reals:
1100 | image_batch = next(self.loader).cuda(self.rank)
1101 | real_output, _ = D_aug(image_batch, detach = True, **aug_kwargs)
1102 | real_output = real_output.detach()
1103 |
1104 | if self.top_k_training:
1105 | epochs = (self.steps * batch_size * self.gradient_accumulate_every) / len(self.dataset)
1106 | k_frac = max(self.generator_top_k_gamma ** epochs, self.generator_top_k_frac)
1107 | k = math.ceil(batch_size * k_frac)
1108 |
1109 | if k != batch_size:
1110 | fake_output_loss, _ = fake_output_loss.topk(k=k, largest=False)
1111 |
1112 | loss = G_loss_fn(fake_output_loss, real_output)
1113 | gen_loss = loss
1114 |
1115 | if apply_path_penalty:
1116 | pl_lengths = calc_pl_lengths(w_styles, generated_images)
1117 | avg_pl_length = np.mean(pl_lengths.detach().cpu().numpy())
1118 |
1119 | if not is_empty(self.pl_mean):
1120 | pl_loss = ((pl_lengths - self.pl_mean) ** 2).mean()
1121 | if not torch.isnan(pl_loss):
1122 | gen_loss = gen_loss + pl_loss
1123 |
1124 | gen_loss = gen_loss / self.gradient_accumulate_every
1125 | gen_loss.register_hook(raise_if_nan)
1126 | backwards(gen_loss, self.GAN.G_opt, loss_id = 2)
1127 |
1128 | total_gen_loss += loss.detach().item() / self.gradient_accumulate_every
1129 |
1130 | self.g_loss = float(total_gen_loss)
1131 | self.track(self.g_loss, 'G')
1132 |
1133 | self.GAN.G_opt.step()
1134 |
1135 | # calculate moving averages
1136 |
1137 | if apply_path_penalty and not np.isnan(avg_pl_length):
1138 | self.pl_mean = self.pl_length_ma.update_average(self.pl_mean, avg_pl_length)
1139 | self.track(self.pl_mean, 'PL')
1140 |
1141 | if self.is_main and self.steps % 10 == 0 and self.steps > 20000:
1142 | self.GAN.EMA()
1143 |
1144 | if self.is_main and self.steps <= 25000 and self.steps % 1000 == 2:
1145 | self.GAN.reset_parameter_averaging()
1146 |
1147 | # save from NaN errors
1148 |
1149 | if any(torch.isnan(l) for l in (total_gen_loss, total_disc_loss)):
1150 | print(f'NaN detected for generator or discriminator. Loading from checkpoint #{self.checkpoint_num}')
1151 | self.load(self.checkpoint_num)
1152 | raise NanException
1153 |
1154 | # periodically save results
1155 |
1156 | if self.is_main:
1157 | if self.steps % self.save_every == 0:
1158 | self.save(self.checkpoint_num)
1159 |
1160 | if self.steps % self.evaluate_every == 0 or (self.steps % 100 == 0 and self.steps < 2500):
1161 | self.evaluate(floor(self.steps / self.evaluate_every))
1162 |
1163 | if exists(self.calculate_fid_every) and self.steps % self.calculate_fid_every == 0 and self.steps != 0:
1164 | num_batches = math.ceil(self.calculate_fid_num_images / self.batch_size)
1165 | fid = self.calculate_fid(num_batches)
1166 | self.last_fid = fid
1167 |
1168 | with open(str(self.results_dir / self.name / f'fid_scores.txt'), 'a') as f:
1169 | f.write(f'{self.steps},{fid}\n')
1170 |
1171 | self.steps += 1
1172 | self.av = None
1173 |
1174 | @torch.no_grad()
1175 | def evaluate(self, num = 0, trunc = 1.0):
1176 | self.GAN.eval()
1177 | ext = self.image_extension
1178 | num_rows = self.num_image_tiles
1179 |
1180 | latent_dim = self.GAN.G.latent_dim
1181 | image_size = self.GAN.G.image_size
1182 | num_layers = self.GAN.G.num_layers
1183 |
1184 | # latents and noise
1185 |
1186 | latents = noise_list(num_rows ** 2, num_layers, latent_dim, device=self.rank)
1187 | n = image_noise(num_rows ** 2, image_size, device=self.rank)
1188 |
1189 | # regular
1190 |
1191 | generated_images = self.generate_truncated(self.GAN.S, self.GAN.G, latents, n, trunc_psi = self.trunc_psi)
1192 | torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}.{ext}'), nrow=num_rows)
1193 |
1194 | # moving averages
1195 |
1196 | generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, latents, n, trunc_psi = self.trunc_psi)
1197 | torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}-ema.{ext}'), nrow=num_rows)
1198 |
1199 | # mixing regularities
1200 |
1201 | def tile(a, dim, n_tile):
1202 | init_dim = a.size(dim)
1203 | repeat_idx = [1] * a.dim()
1204 | repeat_idx[dim] = n_tile
1205 | a = a.repeat(*(repeat_idx))
1206 | order_index = torch.LongTensor(np.concatenate([init_dim * np.arange(n_tile) + i for i in range(init_dim)])).cuda(self.rank)
1207 | return torch.index_select(a, dim, order_index)
1208 |
1209 | nn = noise(num_rows, latent_dim, device=self.rank)
1210 | tmp1 = tile(nn, 0, num_rows)
1211 | tmp2 = nn.repeat(num_rows, 1)
1212 |
1213 | tt = int(num_layers / 2)
1214 | mixed_latents = [(tmp1, tt), (tmp2, num_layers - tt)]
1215 |
1216 | generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, mixed_latents, n, trunc_psi = self.trunc_psi)
1217 | torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}-mr.{ext}'), nrow=num_rows)
1218 |
1219 | @torch.no_grad()
1220 | def calculate_fid(self, num_batches):
1221 | from pytorch_fid import fid_score
1222 | torch.cuda.empty_cache()
1223 |
1224 | real_path = self.fid_dir / 'real'
1225 | fake_path = self.fid_dir / 'fake'
1226 |
1227 | # remove any existing files used for fid calculation and recreate directories
1228 |
1229 | if not real_path.exists() or self.clear_fid_cache:
1230 | rmtree(real_path, ignore_errors=True)
1231 | os.makedirs(real_path)
1232 |
1233 | for batch_num in tqdm(range(num_batches), desc='calculating FID - saving reals'):
1234 | real_batch = next(self.loader)
1235 | for k, image in enumerate(real_batch.unbind(0)):
1236 | filename = str(k + batch_num * self.batch_size)
1237 | torchvision.utils.save_image(image, str(real_path / f'{filename}.png'))
1238 |
1239 | # generate a bunch of fake images in results / name / fid_fake
1240 |
1241 | rmtree(fake_path, ignore_errors=True)
1242 | os.makedirs(fake_path)
1243 |
1244 | self.GAN.eval()
1245 | ext = self.image_extension
1246 |
1247 | latent_dim = self.GAN.G.latent_dim
1248 | image_size = self.GAN.G.image_size
1249 | num_layers = self.GAN.G.num_layers
1250 |
1251 | for batch_num in tqdm(range(num_batches), desc='calculating FID - saving generated'):
1252 | # latents and noise
1253 | latents = noise_list(self.batch_size, num_layers, latent_dim, device=self.rank)
1254 | noise = image_noise(self.batch_size, image_size, device=self.rank)
1255 |
1256 | # moving averages
1257 | generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, latents, noise, trunc_psi = self.trunc_psi)
1258 |
1259 | for j, image in enumerate(generated_images.unbind(0)):
1260 | torchvision.utils.save_image(image, str(fake_path / f'{str(j + batch_num * self.batch_size)}-ema.{ext}'))
1261 |
1262 | return fid_score.calculate_fid_given_paths([str(real_path), str(fake_path)], 256, noise.device, 2048)
1263 |
1264 | @torch.no_grad()
1265 | def truncate_style(self, tensor, S = None, trunc_psi = 0.75):
1266 | S = default(S, self.GAN.S)
1267 | batch_size = self.batch_size
1268 | latent_dim = self.GAN.G.latent_dim
1269 |
1270 | if not exists(self.av):
1271 | z = noise(2000, latent_dim, device=self.rank)
1272 | samples = evaluate_in_chunks(batch_size, S, z).cpu().numpy()
1273 | self.av = np.mean(samples, axis = 0)
1274 | self.av = np.expand_dims(self.av, axis = 0)
1275 |
1276 | av_torch = torch.from_numpy(self.av).cuda(self.rank)
1277 | tensor = trunc_psi * (tensor - av_torch) + av_torch
1278 | return tensor
1279 |
1280 | @torch.no_grad()
1281 | def truncate_style_defs(self, w, S = None, trunc_psi = 0.75):
1282 | w_space = []
1283 | for tensor, num_layers in w:
1284 | tensor = self.truncate_style(tensor, S = S, trunc_psi = trunc_psi)
1285 | w_space.append((tensor, num_layers))
1286 | return w_space
1287 |
1288 | @torch.no_grad()
1289 | def generate_truncated(self, S, G, style, noi, trunc_psi = 0.75, num_image_tiles = 8):
1290 | w = map(lambda t: (S(t[0]), t[1]), style)
1291 | w_truncated = self.truncate_style_defs(w, S = S, trunc_psi = trunc_psi)
1292 | w_styles = styles_def_to_tensor(w_truncated)
1293 | generated_images = evaluate_in_chunks(self.batch_size, G, w_styles, noi)
1294 | return generated_images.clamp_(0., 1.)
1295 |
1296 | @torch.no_grad()
1297 | def generate_interpolation(self, num = 0, num_image_tiles = 8, trunc = 1.0, num_steps = 100, save_frames = False):
1298 | self.GAN.eval()
1299 | ext = self.image_extension
1300 | num_rows = num_image_tiles
1301 |
1302 | latent_dim = self.GAN.G.latent_dim
1303 | image_size = self.GAN.G.image_size
1304 | num_layers = self.GAN.G.num_layers
1305 |
1306 | # latents and noise
1307 |
1308 | latents_low = noise(num_rows ** 2, latent_dim, device=self.rank)
1309 | latents_high = noise(num_rows ** 2, latent_dim, device=self.rank)
1310 | n = image_noise(num_rows ** 2, image_size, device=self.rank)
1311 |
1312 | ratios = torch.linspace(0., 8., num_steps)
1313 |
1314 | frames = []
1315 | for ratio in tqdm(ratios):
1316 | interp_latents = slerp(ratio, latents_low, latents_high)
1317 | latents = [(interp_latents, num_layers)]
1318 | generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, latents, n, trunc_psi = self.trunc_psi)
1319 | images_grid = torchvision.utils.make_grid(generated_images, nrow = num_rows)
1320 | pil_image = transforms.ToPILImage()(images_grid.cpu())
1321 |
1322 | if self.transparent:
1323 | background = Image.new("RGBA", pil_image.size, (255, 255, 255))
1324 | pil_image = Image.alpha_composite(background, pil_image)
1325 |
1326 | frames.append(pil_image)
1327 |
1328 | frames[0].save(str(self.results_dir / self.name / f'{str(num)}.gif'), save_all=True, append_images=frames[1:], duration=80, loop=0, optimize=True)
1329 |
1330 | if save_frames:
1331 | folder_path = (self.results_dir / self.name / f'{str(num)}')
1332 | folder_path.mkdir(parents=True, exist_ok=True)
1333 | for ind, frame in enumerate(frames):
1334 | frame.save(str(folder_path / f'{str(ind)}.{ext}'))
1335 |
1336 | def print_log(self):
1337 | data = [
1338 | ('G', self.g_loss),
1339 | ('D', self.d_loss),
1340 | ('GP', self.last_gp_loss),
1341 | ('PL', self.pl_mean),
1342 | ('CR', self.last_cr_loss),
1343 | ('Q', self.q_loss),
1344 | ('FID', self.last_fid)
1345 | ]
1346 |
1347 | data = [d for d in data if exists(d[1])]
1348 | log = ' | '.join(map(lambda n: f'{n[0]}: {n[1]:.2f}', data))
1349 | print(log)
1350 |
1351 | def track(self, value, name):
1352 | if not exists(self.logger):
1353 | return
1354 | self.logger.track(value, name = name)
1355 |
1356 | def model_name(self, num):
1357 | return str(self.models_dir / self.name / f'model_{num}.pt')
1358 |
1359 | def init_folders(self):
1360 | (self.results_dir / self.name).mkdir(parents=True, exist_ok=True)
1361 | (self.models_dir / self.name).mkdir(parents=True, exist_ok=True)
1362 |
1363 | def clear(self):
1364 | rmtree(str(self.models_dir / self.name), True)
1365 | rmtree(str(self.results_dir / self.name), True)
1366 | rmtree(str(self.fid_dir), True)
1367 | rmtree(str(self.config_path), True)
1368 | self.init_folders()
1369 |
1370 | def save(self, num):
1371 | save_data = {
1372 | 'GAN': self.GAN.state_dict(),
1373 | 'version': __version__
1374 | }
1375 |
1376 | if self.GAN.fp16:
1377 | save_data['amp'] = amp.state_dict()
1378 |
1379 | torch.save(save_data, self.model_name(num))
1380 | self.write_config()
1381 |
1382 | def load(self, num = -1):
1383 | self.load_config()
1384 |
1385 | name = num
1386 | if num == -1:
1387 | file_paths = [p for p in Path(self.models_dir / self.name).glob('model_*.pt')]
1388 | saved_nums = sorted(map(lambda x: int(x.stem.split('_')[1]), file_paths))
1389 | if len(saved_nums) == 0:
1390 | return
1391 | name = saved_nums[-1]
1392 | print(f'continuing from previous epoch - {name}')
1393 |
1394 | self.steps = name * self.save_every
1395 |
1396 | load_data = torch.load(self.model_name(name), weights_only = True)
1397 |
1398 | if 'version' in load_data:
1399 | print(f"loading from version {load_data['version']}")
1400 |
1401 | try:
1402 | self.GAN.load_state_dict(load_data['GAN'])
1403 | except Exception as e:
1404 | print('unable to load save model. please try downgrading the package to the version specified by the saved model')
1405 | raise e
1406 | if self.GAN.fp16 and 'amp' in load_data:
1407 | amp.load_state_dict(load_data['amp'])
1408 |
1409 | class ModelLoader:
1410 | def __init__(self, *, base_dir, name = 'default', load_from = -1):
1411 | self.model = Trainer(name = name, base_dir = base_dir)
1412 | self.model.load(load_from)
1413 |
1414 | def noise_to_styles(self, noise, trunc_psi = None):
1415 | noise = noise.cuda()
1416 | w = self.model.GAN.SE(noise)
1417 | if exists(trunc_psi):
1418 | w = self.model.truncate_style(w)
1419 | return w
1420 |
1421 | def styles_to_images(self, w):
1422 | batch_size, *_ = w.shape
1423 | num_layers = self.model.GAN.GE.num_layers
1424 | image_size = self.model.image_size
1425 | w_def = [(w, num_layers)]
1426 |
1427 | w_tensors = styles_def_to_tensor(w_def)
1428 | noise = image_noise(batch_size, image_size, device = 0)
1429 |
1430 | images = self.model.GAN.GE(w_tensors, noise)
1431 | images.clamp_(0., 1.)
1432 | return images
1433 |
--------------------------------------------------------------------------------