├── weights.h5
├── README.md
├── console.py
├── conversion.py
├── data.py
└── acapellabot.py
/weights.h5:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/madebyollin/acapellabot/HEAD/weights.h5
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # AcapellaBot
2 |
3 | **Update [2020-05-20]:** For better, modern acapella extraction / source separation, I would recommend [Demucs](https://github.com/facebookresearch/demucs), [Spleeter](https://github.com/deezer/spleeter), or PhonicMind (commercial product). This project worked reasonably well when I wrote it in 2017, but the current state of the art is much better :)
4 |
5 | Original README continues below.
6 |
7 | ---
8 |
9 | Isolating vocals from music with a Convolutional Neural Network. Blog post is [here](http://www.madebyollin.com/posts/cnn_acapella_extraction/).
10 |
11 | 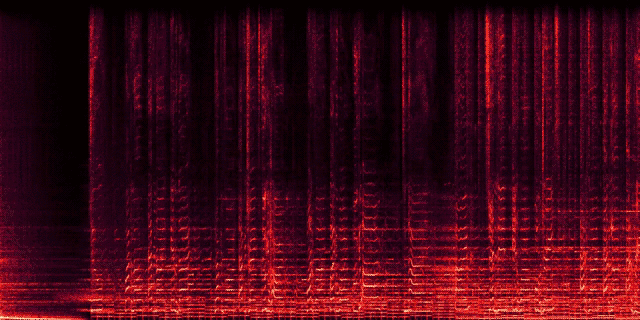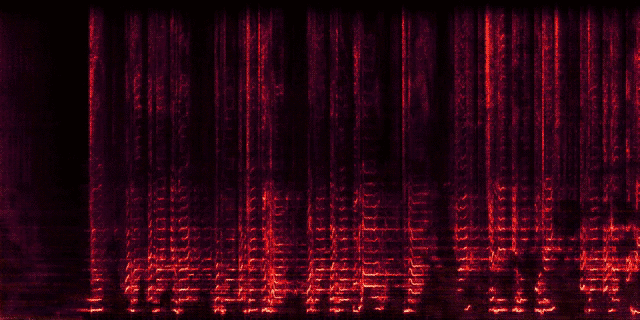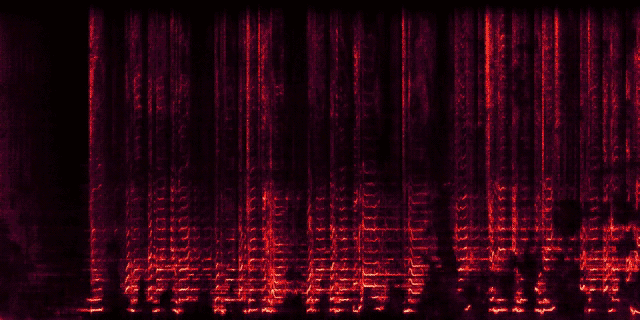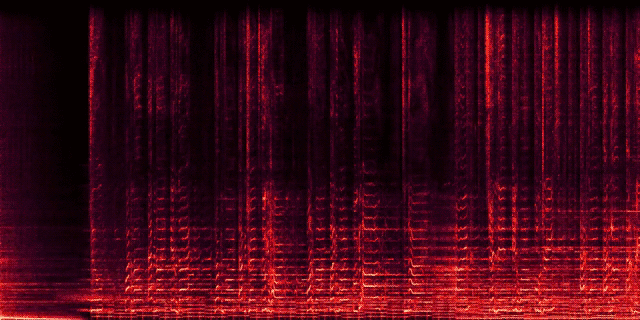
12 |
13 | To Use:
14 |
15 |
16 | - Download the repo
17 | - Install the latest versions of Theano, Keras, librosa, and h5py on Python 3.
18 | - Set your dimension ordering to
tf in ~/keras/keras.json:
19 |
20 | ```
21 | {
22 | "backend": "theano",
23 | "image_dim_ordering": "tf"
24 | }
25 | ```
26 |
27 |
28 | - Run
python acapellabot.py song.mp3
29 |
30 |
31 | Enjoy ❤
32 |
--------------------------------------------------------------------------------
/console.py:
--------------------------------------------------------------------------------
1 | """
2 | Various utilities for pretty console output
3 | Ported nigh-verbatim from a similar file I use for node
4 | """
5 | import os
6 | import time as sysTime
7 |
8 | class colors:
9 | END = "\033[0m"
10 | BRIGHT = "\033[1m"
11 | DIM = "\033[2m"
12 | UNDERSCORE = "\033[4m"
13 | BLINK = "\033[5m"
14 |
15 | RED = "\033[31m"
16 | GREEN = "\033[32m"
17 | YELLOW = "\033[33m"
18 | BLUE = "\033[34m"
19 | MAGENTA = "\033[35m"
20 | CYAN = "\033[36m"
21 | WHITE = "\033[37m"
22 |
23 | DK_RED = "\033[41m"
24 | DK_GREEN = "\033[42m"
25 | DK_YELLOW = "\033[43m"
26 | DK_BLUE = "\033[44m"
27 | DK_MAGENTA = "\033[45m"
28 | DK_CYAN = "\033[46m"
29 | DK_WHITE = "\033[47m"
30 |
31 | timers = {}
32 |
33 | def fmt(iterable):
34 | return " ".join(str(i) for i in iterable)
35 | def h1(*args):
36 | print(colors.BRIGHT, fmt(args), colors.END)
37 | def wait(*args):
38 | input(colors.BLUE + fmt(args) + colors.END)
39 | def log(*args):
40 | print(colors.YELLOW, fmt(args), colors.END)
41 | def info(*args):
42 | print(colors.DIM + "\t", fmt(args), colors.END)
43 | def debug(*args):
44 | print(colors.DK_BLUE + "\t", fmt(args), colors.END)
45 | def warn(*args):
46 | print(colors.DK_CYAN + "WARN:\t" + colors.END + colors.CYAN, fmt(args), colors.END)
47 | def error(*args):
48 | print(colors.DK_RED + colors.BLINK + "ERROR:\t" + colors.END + colors.RED, fmt(args), colors.END)
49 | def time(key):
50 | timers[key] = sysTime.time()
51 | def timeEnd(key):
52 | if key in timers:
53 | t = sysTime.time() - timers[key]
54 | print("\t" + str(t) + colors.DIM + " s \t" + key + colors.END)
55 | del timers[key]
56 | def notify(*args):
57 | # Play bell
58 | print('\a')
59 | # Attempt to send a notification (will fail, but not crash, if not on macOS)
60 | os.system("""
61 | osascript -e 'display notification "{}" with title "{}"'
62 | """.format(args[0], fmt(args[1:])))
63 |
--------------------------------------------------------------------------------
/conversion.py:
--------------------------------------------------------------------------------
1 | import librosa
2 | import numpy as np
3 | import scipy
4 | import warnings
5 | import skimage.io as io
6 | from os.path import basename
7 | from math import ceil
8 | import argparse
9 | import console
10 |
11 | def loadAudioFile(filePath):
12 | audio, sampleRate = librosa.load(filePath)
13 | return audio, sampleRate
14 |
15 | def saveAudioFile(audioFile, filePath, sampleRate):
16 | librosa.output.write_wav(filePath, audioFile, sampleRate, norm=True)
17 | console.info("Wrote audio file to", filePath)
18 |
19 | def expandToGrid(spectrogram, gridSize):
20 | # crop along both axes
21 | newY = ceil(spectrogram.shape[1] / gridSize) * gridSize
22 | newX = ceil(spectrogram.shape[0] / gridSize) * gridSize
23 | newSpectrogram = np.zeros((newX, newY))
24 | newSpectrogram[:spectrogram.shape[0], :spectrogram.shape[1]] = spectrogram
25 | return newSpectrogram
26 |
27 | # Return a 2d numpy array of the spectrogram
28 | def audioFileToSpectrogram(audioFile, fftWindowSize):
29 | spectrogram = librosa.stft(audioFile, fftWindowSize)
30 | phase = np.imag(spectrogram)
31 | amplitude = np.log1p(np.abs(spectrogram))
32 | return amplitude, phase
33 |
34 | # This is the nutty one
35 | def spectrogramToAudioFile(spectrogram, fftWindowSize, phaseIterations=10, phase=None):
36 | if phase is not None:
37 | # reconstructing the new complex matrix
38 | squaredAmplitudeAndSquaredPhase = np.power(spectrogram, 2)
39 | squaredPhase = np.power(phase, 2)
40 | unexpd = np.sqrt(np.max(squaredAmplitudeAndSquaredPhase - squaredPhase, 0))
41 | amplitude = np.expm1(unexpd)
42 | stftMatrix = amplitude + phase * 1j
43 | audio = librosa.istft(stftMatrix)
44 | else:
45 | # phase reconstruction with successive approximation
46 | # credit to https://dsp.stackexchange.com/questions/3406/reconstruction-of-audio-signal-from-its-absolute-spectrogram/3410#3410
47 | # for the algorithm used
48 | amplitude = np.exp(spectrogram) - 1
49 | for i in range(phaseIterations):
50 | if i == 0:
51 | reconstruction = np.random.random_sample(amplitude.shape) + 1j * (2 * np.pi * np.random.random_sample(amplitude.shape) - np.pi)
52 | else:
53 | reconstruction = librosa.stft(audio, fftWindowSize)
54 | spectrum = amplitude * np.exp(1j * np.angle(reconstruction))
55 | audio = librosa.istft(spectrum)
56 | return audio
57 |
58 | def loadSpectrogram(filePath):
59 | fileName = basename(filePath)
60 | if filePath.index("sampleRate") < 0:
61 | console.warn("Sample rate should be specified in file name", filePath)
62 | sampleRate == 22050
63 | else:
64 | sampleRate = int(fileName[fileName.index("sampleRate=") + 11:fileName.index(").png")])
65 | console.info("Using sample rate : " + str(sampleRate))
66 | image = io.imread(filePath, as_grey=True)
67 | return image / np.max(image), sampleRate
68 |
69 | def saveSpectrogram(spectrogram, filePath):
70 | spectrum = spectrogram
71 | console.info("Range of spectrum is " + str(np.min(spectrum)) + " -> " + str(np.max(spectrum)))
72 | image = np.clip((spectrum - np.min(spectrum)) / (np.max(spectrum) - np.min(spectrum)), 0, 1)
73 | console.info("Shape of spectrum is", image.shape)
74 | # Low-contrast image warnings are not helpful, tyvm
75 | with warnings.catch_warnings():
76 | warnings.simplefilter("ignore")
77 | io.imsave(filePath, image)
78 | console.log("Saved image to", filePath)
79 |
80 | def fileSuffix(title, **kwargs):
81 | return " (" + title + "".join(sorted([", " + i + "=" + str(kwargs[i]) for i in kwargs])) + ")"
82 |
83 | def handleAudio(filePath, args):
84 | console.h1("Creating Spectrogram")
85 | INPUT_FILE = filePath
86 | INPUT_FILENAME = basename(INPUT_FILE)
87 |
88 | console.info("Attempting to read from " + INPUT_FILE)
89 | audio, sampleRate = loadAudioFile(INPUT_FILE)
90 | console.info("Max of audio file is " + str(np.max(audio)))
91 | spectrogram, phase = audioFileToSpectrogram(audio, fftWindowSize=args.fft)
92 | SPECTROGRAM_FILENAME = INPUT_FILENAME + fileSuffix("Input Spectrogram", fft=args.fft, iter=args.iter, sampleRate=sampleRate) + ".png"
93 |
94 | saveSpectrogram(spectrogram, SPECTROGRAM_FILENAME)
95 |
96 | print()
97 | console.wait("Saved Spectrogram; press Enter to continue...")
98 | print()
99 |
100 | handleImage(SPECTROGRAM_FILENAME, args, phase)
101 |
102 |
103 | def handleImage(fileName, args, phase=None):
104 | console.h1("Reconstructing Audio from Spectrogram")
105 |
106 | spectrogram, sampleRate = loadSpectrogram(fileName)
107 | audio = spectrogramToAudioFile(spectrogram, fftWindowSize=args.fft, phaseIterations=args.iter)
108 |
109 | sanityCheck, phase = audioFileToSpectrogram(audio, fftWindowSize=args.fft)
110 | saveSpectrogram(sanityCheck, fileName + fileSuffix("Output Spectrogram", fft=args.fft, iter=args.iter, sampleRate=sampleRate) + ".png")
111 |
112 | saveAudioFile(audio, fileName + fileSuffix("Output", fft=args.fft, iter=args.iter) + ".wav", sampleRate)
113 |
114 | if __name__ == "__main__":
115 | # Test code for experimenting with modifying acapellas in image processors (and generally testing the reconstruction pipeline)
116 | parser = argparse.ArgumentParser(description="Convert image files to audio and audio files to images")
117 | parser.add_argument("--fft", default=1536, type=int, help="Size of FFT windows")
118 | parser.add_argument("--iter", default=10, type=int, help="Number of iterations to use for phase reconstruction")
119 | parser.add_argument("files", nargs="*", default=[])
120 |
121 | args = parser.parse_args()
122 |
123 | for f in args.files:
124 | if (f.endswith(".mp3") or f.endswith(".wav")):
125 | handleAudio(f, args)
126 | elif (f.endswith(".png")):
127 | handleImage(f, args)
128 |
--------------------------------------------------------------------------------
/data.py:
--------------------------------------------------------------------------------
1 | """
2 | Loads and stores mashup data given a folder full of acapellas and instrumentals
3 | Assumes that all audio clips (wav, mp3) in the folder
4 | a) have their Camelot key as the first token in the filename
5 | b) are in the same BPM
6 | c) have "acapella" somewhere in the filename if they're an acapella, and are otherwise instrumental
7 | d) all have identical arrangements
8 | e) have the same sample rate
9 | """
10 | import sys
11 | import os
12 | import numpy as np
13 | import h5py
14 |
15 | import console
16 | import conversion
17 |
18 | # Modify these functions if your data is in a different format
19 | def keyOfFile(fileName):
20 | firstToken = int(fileName.split()[0])
21 | if 0 < firstToken <= NUMBER_OF_KEYS:
22 | return firstToken
23 | console.warn("File", fileName, "doesn't specify its key, ignoring..")
24 | return None
25 |
26 | def fileIsAcapella(fileName):
27 | return "acapella" in fileName.lower()
28 |
29 |
30 | NUMBER_OF_KEYS = 12 # number of keys to iterate over
31 | SLICE_SIZE = 128 # size of spectrogram slices to use
32 |
33 | # Slice up matrices into squares so the neural net gets a consistent size for training (doesn't matter for inference)
34 | def chop(matrix, scale):
35 | slices = []
36 | for time in range(0, matrix.shape[1] // scale):
37 | for freq in range(0, matrix.shape[0] // scale):
38 | s = matrix[freq * scale : (freq + 1) * scale,
39 | time * scale : (time + 1) * scale]
40 | slices.append(s)
41 | return slices
42 |
43 | class Data:
44 | def __init__(self, inPath, fftWindowSize=1536, trainingSplit=0.9):
45 | self.inPath = inPath
46 | self.fftWindowSize = fftWindowSize
47 | self.trainingSplit = trainingSplit
48 | self.x = []
49 | self.y = []
50 | self.load()
51 | def train(self):
52 | return (self.x[:int(len(self.x) * self.trainingSplit)], self.y[:int(len(self.y) * self.trainingSplit)])
53 | def valid(self):
54 | return (self.x[int(len(self.x) * self.trainingSplit):], self.y[int(len(self.y) * self.trainingSplit):])
55 | def load(self, saveDataAsH5=False):
56 | h5Path = os.path.join(self.inPath, "data.h5")
57 | if os.path.isfile(h5Path):
58 | h5f = h5py.File(h5Path, "r")
59 | self.x = h5f["x"][:]
60 | self.y = h5f["y"][:]
61 | else:
62 | acapellas = {}
63 | instrumentals = {}
64 | # Hash bins for each camelot key so we can merge
65 | # in the future, this should be a generator w/ yields in order to eat less memory
66 | for i in range(NUMBER_OF_KEYS):
67 | key = i + 1
68 | acapellas[key] = []
69 | instrumentals[key] = []
70 | for dirPath, dirNames, fileNames in os.walk(self.inPath):
71 | for fileName in filter(lambda f : (f.endswith(".mp3") or f.endswith(".wav")) and not f.startswith("."), fileNames):
72 | key = keyOfFile(fileName)
73 | if key:
74 | targetPathMap = acapellas if fileIsAcapella(fileName) else instrumentals
75 | tag = "[Acapella]" if fileIsAcapella(fileName) else "[Instrumental]"
76 | audio, sampleRate = conversion.loadAudioFile(os.path.join(self.inPath, fileName))
77 | spectrogram, phase = conversion.audioFileToSpectrogram(audio, self.fftWindowSize)
78 | targetPathMap[key].append(spectrogram)
79 | console.info(tag, "Created spectrogram for", fileName, "in key", key, "with shape", spectrogram.shape)
80 | # Merge mashups
81 | for k in range(NUMBER_OF_KEYS):
82 | acapellasInKey = acapellas[k + 1]
83 | instrumentalsInKey = instrumentals[k + 1]
84 | count = 0
85 | for acapella in acapellasInKey:
86 | for instrumental in instrumentalsInKey:
87 | # Pad if smaller
88 | if (instrumental.shape[1] < acapella.shape[1]):
89 | newInstrumental = np.zeros(acapella.shape)
90 | newInstrumental[:instrumental.shape[0], :instrumental.shape[1]] = instrumental
91 | instrumental = newInstrumental
92 | elif (acapella.shape[1] < instrumental.shape[1]):
93 | newAcapella = np.zeros(instrumental.shape)
94 | newAcapella[:acapella.shape[0], :acapella.shape[1]] = acapella
95 | acapella = newAcapella
96 | # simulate a limiter/low mixing (loses info, but that's the point)
97 | # I've tested this against making the same mashups in Logic and it's pretty close
98 | mashup = np.maximum(acapella, instrumental)
99 | # chop into slices so everything's the same size in a batch
100 | dim = SLICE_SIZE
101 | mashupSlices = chop(mashup, dim)
102 | acapellaSlices = chop(acapella, dim)
103 | count += 1
104 | self.x.extend(mashupSlices)
105 | self.y.extend(acapellaSlices)
106 | console.info("Created", count, "mashups for key", k, "with", len(self.x), "total slices so far")
107 | # Add a "channels" channel to please the network
108 | self.x = np.array(self.x)[:, :, :, np.newaxis]
109 | self.y = np.array(self.y)[:, :, :, np.newaxis]
110 | # Save to file if asked
111 | if saveDataAsH5:
112 | h5f = h5py.File(h5Path, "w")
113 | h5f.create_dataset("x", data=self.x)
114 | h5f.create_dataset("y", data=self.y)
115 | h5f.close()
116 |
117 | if __name__ == "__main__":
118 | # Simple testing code to use while developing
119 | console.h1("Loading Data")
120 | d = Data(sys.argv[1], 1536)
121 | console.h1("Writing Sample Data")
122 | conversion.saveSpectrogram(d.x[0], "x_sample_0.png")
123 | conversion.saveSpectrogram(d.y[0], "y_sample_0.png")
124 | audio = conversion.spectrogramToAudioFile(d.x[0], 1536)
125 | conversion.saveAudioFile(audio, "x_sample.wav", 22050)
126 |
--------------------------------------------------------------------------------
/acapellabot.py:
--------------------------------------------------------------------------------
1 | """
2 | Acapella extraction with a CNN
3 |
4 | Typical usage:
5 | python acapellabot.py song.wav
6 | => Extracts acapella from to using default weights
7 |
8 | python acapellabot.py --data input_folder --batch 32 --weights new_model_iteration.h5
9 | => Trains a new model based on song/acapella pairs in the folder
10 | and saves weights to once complete.
11 | See data.py for data specifications.
12 | """
13 |
14 | import argparse
15 | import random, string
16 | import os
17 |
18 | import numpy as np
19 | from keras.layers import Input, Conv2D, MaxPooling2D, BatchNormalization, UpSampling2D, Concatenate
20 | from keras.models import Model
21 |
22 | import console
23 | import conversion
24 | from data import Data
25 |
26 |
27 | class AcapellaBot:
28 | def __init__(self):
29 | mashup = Input(shape=(None, None, 1), name='input')
30 | convA = Conv2D(64, 3, activation='relu', padding='same')(mashup)
31 | conv = Conv2D(64, 4, strides=2, activation='relu', padding='same', use_bias=False)(convA)
32 | conv = BatchNormalization()(conv)
33 |
34 | convB = Conv2D(64, 3, activation='relu', padding='same')(conv)
35 | conv = Conv2D(64, 4, strides=2, activation='relu', padding='same', use_bias=False)(convB)
36 | conv = BatchNormalization()(conv)
37 |
38 | conv = Conv2D(128, 3, activation='relu', padding='same')(conv)
39 | conv = Conv2D(128, 3, activation='relu', padding='same', use_bias=False)(conv)
40 | conv = BatchNormalization()(conv)
41 | conv = UpSampling2D((2, 2))(conv)
42 |
43 | conv = Concatenate()([conv, convB])
44 | conv = Conv2D(64, 3, activation='relu', padding='same')(conv)
45 | conv = Conv2D(64, 3, activation='relu', padding='same', use_bias=False)(conv)
46 | conv = BatchNormalization()(conv)
47 | conv = UpSampling2D((2, 2))(conv)
48 |
49 | conv = Concatenate()([conv, convA])
50 | conv = Conv2D(64, 3, activation='relu', padding='same')(conv)
51 | conv = Conv2D(64, 3, activation='relu', padding='same')(conv)
52 | conv = Conv2D(32, 3, activation='relu', padding='same')(conv)
53 | conv = Conv2D(1, 3, activation='relu', padding='same')(conv)
54 | acapella = conv
55 | m = Model(inputs=mashup, outputs=acapella)
56 | console.log("Model has", m.count_params(), "params")
57 | m.compile(loss='mean_squared_error', optimizer='adam')
58 | self.model = m
59 | # need to know so that we can avoid rounding errors with spectrogram
60 | # this should represent how much the input gets downscaled
61 | # in the middle of the network
62 | self.peakDownscaleFactor = 4
63 |
64 | def train(self, data, epochs, batch=8):
65 | xTrain, yTrain = data.train()
66 | xValid, yValid = data.valid()
67 | while epochs > 0:
68 | console.log("Training for", epochs, "epochs on", len(xTrain), "examples")
69 | self.model.fit(xTrain, yTrain, batch_size=batch, epochs=epochs, validation_data=(xValid, yValid))
70 | console.notify(str(epochs) + " Epochs Complete!", "Training on", data.inPath, "with size", batch)
71 | while True:
72 | try:
73 | epochs = int(input("How many more epochs should we train for? "))
74 | break
75 | except ValueError:
76 | console.warn("Oops, number parse failed. Try again, I guess?")
77 | if epochs > 0:
78 | save = input("Should we save intermediate weights [y/n]? ")
79 | if not save.lower().startswith("n"):
80 | weightPath = ''.join(random.choice(string.digits) for _ in range(16)) + ".h5"
81 | console.log("Saving intermediate weights to", weightPath)
82 | self.saveWeights(weightPath)
83 |
84 |
85 | def saveWeights(self, path):
86 | self.model.save_weights(path, overwrite=True)
87 | def loadWeights(self, path):
88 | self.model.load_weights(path)
89 | def isolateVocals(self, path, fftWindowSize, phaseIterations=10):
90 | console.log("Attempting to isolate vocals from", path)
91 | audio, sampleRate = conversion.loadAudioFile(path)
92 | spectrogram, phase = conversion.audioFileToSpectrogram(audio, fftWindowSize=fftWindowSize)
93 | console.log("Retrieved spectrogram; processing...")
94 |
95 | # newSpectrogram = self.model.predict(conversion.expandToGrid(spectrogram, self.peakDownscaleFactor)[np.newaxis, :, :, np.newaxis])[0][:spectrogram.shape[0], :spectrogram.shape[1]]
96 | expandedSpectrogram = conversion.expandToGrid(spectrogram, self.peakDownscaleFactor)
97 | expandedSpectrogramWithBatchAndChannels = expandedSpectrogram[np.newaxis, :, :, np.newaxis]
98 | predictedSpectrogramWithBatchAndChannels = self.model.predict(expandedSpectrogramWithBatchAndChannels)
99 | predictedSpectrogram = predictedSpectrogramWithBatchAndChannels[0, :, :, 0] # o /// o
100 | newSpectrogram = predictedSpectrogram[:spectrogram.shape[0], :spectrogram.shape[1]]
101 | console.log("Processed spectrogram; reconverting to audio")
102 |
103 | newAudio = conversion.spectrogramToAudioFile(newSpectrogram, fftWindowSize=fftWindowSize, phaseIterations=phaseIterations)
104 | pathParts = os.path.split(path)
105 | fileNameParts = os.path.splitext(pathParts[1])
106 | outputFileNameBase = os.path.join(pathParts[0], fileNameParts[0] + "_acapella")
107 | console.log("Converted to audio; writing to", outputFileNameBase)
108 |
109 | conversion.saveAudioFile(newAudio, outputFileNameBase + ".wav", sampleRate)
110 | conversion.saveSpectrogram(newSpectrogram, outputFileNameBase + ".png")
111 | conversion.saveSpectrogram(spectrogram, os.path.join(pathParts[0], fileNameParts[0]) + ".png")
112 | console.log("Vocal isolation complete 👌")
113 |
114 | if __name__ == "__main__":
115 | # if data folder is specified, create a new data object and train on the data
116 | # if input audio is specified, infer on the input
117 | parser = argparse.ArgumentParser(description="Acapella extraction with a convolutional neural network")
118 | parser.add_argument("--fft", default=1536, type=int, help="Size of FFT windows")
119 | parser.add_argument("--data", default=None, type=str, help="Path containing training data")
120 | parser.add_argument("--split", default=0.9, type=float, help="Proportion of the data to train on")
121 | parser.add_argument("--epochs", default=10, type=int, help="Number of epochs to train.")
122 | parser.add_argument("--weights", default="weights.h5", type=str, help="h5 file to read/write weights to")
123 | parser.add_argument("--batch", default=8, type=int, help="Batch size for training")
124 | parser.add_argument("--phase", default=10, type=int, help="Phase iterations for reconstruction")
125 | parser.add_argument("--load", action='store_true', help="Load previous weights file before starting")
126 | parser.add_argument("files", nargs="*", default=[])
127 |
128 | args = parser.parse_args()
129 |
130 | acapellabot = AcapellaBot()
131 |
132 | if len(args.files) == 0 and args.data:
133 | console.log("No files provided; attempting to train on " + args.data + "...")
134 | if args.load:
135 | console.h1("Loading Weights")
136 | acapellabot.loadWeights(args.weights)
137 | console.h1("Loading Data")
138 | data = Data(args.data, args.fft, args.split)
139 | console.h1("Training Model")
140 | acapellabot.train(data, args.epochs, args.batch)
141 | acapellabot.saveWeights(args.weights)
142 | elif len(args.files) > 0:
143 | console.log("Weights provided; performing inference on " + str(args.files) + "...")
144 | console.h1("Loading weights")
145 | acapellabot.loadWeights(args.weights)
146 | for f in args.files:
147 | acapellabot.isolateVocals(f, args.fft, args.phase)
148 | else:
149 | console.error("Please provide data to train on (--data) or files to infer on")
150 |
--------------------------------------------------------------------------------