├── .github
└── workflows
│ └── build.yml
├── CONTRIBUTING.md
├── LICENSE
├── README.md
├── ddsp
├── __init__.py
├── colab
│ ├── README.md
│ ├── __init__.py
│ ├── colab_utils.py
│ ├── demos
│ │ ├── README.md
│ │ ├── Train_VST.ipynb
│ │ ├── pitch_detection.ipynb
│ │ ├── timbre_transfer.ipynb
│ │ └── train_autoencoder.ipynb
│ └── tutorials
│ │ ├── 0_processor.ipynb
│ │ ├── 1_synths_and_effects.ipynb
│ │ ├── 2_processor_group.ipynb
│ │ ├── 3_training.ipynb
│ │ ├── 4_core_functions.ipynb
│ │ └── README.md
├── core.py
├── core_test.py
├── dags.py
├── dags_test.py
├── effects.py
├── effects_test.py
├── losses.py
├── losses_test.py
├── processors.py
├── processors_test.py
├── spectral_ops.py
├── spectral_ops_test.py
├── synths.py
├── synths_test.py
├── test_util.py
├── training
│ ├── README.md
│ ├── __init__.py
│ ├── cloud.py
│ ├── cloud_test.py
│ ├── data.py
│ ├── data_preparation
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── ddsp_generate_synthetic_dataset.py
│ │ ├── ddsp_prepare_tfrecord.py
│ │ ├── prepare_tfrecord_lib.py
│ │ ├── prepare_tfrecord_lib_test.py
│ │ └── synthetic_data.py
│ ├── ddsp_export.py
│ ├── ddsp_run.py
│ ├── decoders.py
│ ├── decoders_test.py
│ ├── docker
│ │ ├── Dockerfile
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── config_hypertune.yaml
│ │ ├── config_multiple_vms.yaml
│ │ ├── config_single_vm.yaml
│ │ ├── ddsp_ai_platform.py
│ │ ├── task.py
│ │ └── task_test.py
│ ├── encoders.py
│ ├── eval_util.py
│ ├── evaluators.py
│ ├── gin
│ │ ├── __init__.py
│ │ ├── datasets
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── base.gin
│ │ │ ├── nsynth.gin
│ │ │ ├── tfrecord.gin
│ │ │ └── urmp
│ │ │ │ ├── README.md
│ │ │ │ ├── all.gin
│ │ │ │ ├── all_midi.gin
│ │ │ │ ├── base.gin
│ │ │ │ └── midi_base.gin
│ │ ├── eval
│ │ │ ├── __init__.py
│ │ │ ├── basic.gin
│ │ │ ├── basic_f0_ld.gin
│ │ │ ├── basic_f0_ld_twm.gin
│ │ │ ├── heuristic.gin
│ │ │ ├── heuristic_power.gin
│ │ │ └── midi_ae.gin
│ │ ├── models
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── ae.gin
│ │ │ ├── midiae
│ │ │ │ ├── README.md
│ │ │ │ ├── midiae.gin
│ │ │ │ ├── mixins
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── _.gin
│ │ │ │ │ ├── hmm_prior.gin
│ │ │ │ │ ├── midi_encoder.gin
│ │ │ │ │ └── recon_lossgroup.gin
│ │ │ │ └── z_midiae.gin
│ │ │ ├── solo_instrument.gin
│ │ │ └── vst
│ │ │ │ ├── __init__.py
│ │ │ │ ├── vst.gin
│ │ │ │ ├── vst_32k.gin
│ │ │ │ └── vst_48k.gin
│ │ ├── optimization
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── base.gin
│ │ │ └── base_tpu.gin
│ │ └── papers
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── iclr2020
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── nsynth_ae.gin
│ │ │ ├── solo_instrument.gin
│ │ │ └── tiny_instrument.gin
│ │ │ └── icml2020
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── finetune_dataset.gin
│ │ │ ├── finetune_model.gin
│ │ │ ├── pretrain_dataset.gin
│ │ │ └── pretrain_model.gin
│ ├── heuristics.py
│ ├── heuristics_test.py
│ ├── inference.py
│ ├── metrics.py
│ ├── metrics_test.py
│ ├── models
│ │ ├── __init__.py
│ │ ├── autoencoder.py
│ │ ├── autoencoder_test.py
│ │ ├── inverse_synthesis.py
│ │ ├── midi_autoencoder.py
│ │ └── model.py
│ ├── nn.py
│ ├── nn_test.py
│ ├── plotting.py
│ ├── postprocessing.py
│ ├── preprocessing.py
│ ├── preprocessing_test.py
│ ├── summaries.py
│ ├── train_util.py
│ └── trainers.py
└── version.py
├── pylintrc
├── setup.cfg
├── setup.py
├── update_gin_config.py
└── update_pip.sh
/.github/workflows/build.yml:
--------------------------------------------------------------------------------
1 | name: build
2 |
3 | on: [push]
4 |
5 | jobs:
6 | build:
7 | runs-on: ubuntu-latest
8 | steps:
9 | - uses: actions/checkout@v2
10 | - name: Set up Python
11 | uses: actions/setup-python@v2
12 | with:
13 | python-version: '3.8'
14 | - name: Install dependencies
15 | # TODO(jesseengel): Remove `legacy-resolver` when pip dependency resolution
16 | # is no longer broken. Currently stalls (backtracking), only on GitHub, not
17 | # locally.
18 | run: |
19 | sudo apt update
20 | sudo apt-get -y install ffmpeg
21 | pip install -U pip
22 | pip install -e .[data_preparation,test] --use-deprecated=legacy-resolver
23 | - name: Test with pytest
24 | run: pytest
25 | - name: Lint with pylint
26 | run: pylint ddsp
27 | # The below step just reports the success or failure of tests as a "commit status".
28 | # This is needed for copybara integration.
29 | - name: Report success or failure as github status
30 | if: always()
31 | shell: bash
32 | run: |
33 | status="${{ job.status }}"
34 | lowercase_status=$(echo $status | tr '[:upper:]' '[:lower:]')
35 | curl -sS --request POST \
36 | --url https://api.github.com/repos/${{ github.repository }}/statuses/${{ github.sha }} \
37 | --header 'authorization: Bearer ${{ secrets.GITHUB_TOKEN }}' \
38 | --header 'content-type: application/json' \
39 | --data '{
40 | "state": "'$lowercase_status'",
41 | "target_url": "https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}",
42 | "description": "'$status'",
43 | "context": "github-actions/build"
44 | }'
45 |
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # How to Contribute
2 |
3 | We'd love to accept your patches and contributions to this project.
4 | DSP can be subtle to get completely right, so we particularly appreciate the
5 | contributions of those with expertise in signal processing to help fix any
6 | mistakes we may have made 😄.
7 |
8 | # Versioning
9 |
10 | We'll do our best to keep the version updated. This repo contains two code bases
11 | which makes versioning a bit tricky. The core code base `ddsp/` and a more
12 | experimental training code base `ddsp/training/` that is used for active
13 | research. We will thus adopt the following scheme for incrementing version:
14 |
15 | `vMajor.Minor.Revision`
16 |
17 | * Major: Breaking change in `ddsp/`
18 | * Minor: New feature in `ddsp/`, breaking change in `training/`
19 | * Revision: New feature in `training/`, minor bug fix anywhere
20 |
21 | ## Code Design Goals
22 | As much as we can, we would like the DDSP library to be approachable,
23 | well-tested, well-documented, and full of useful examples. Thus, PRs that add
24 | new functionality should be accompanined with ample documentation and tests to
25 | help newcomers understand a typical use case, and guard against silent failures
26 | from breaking changes in the future. Please follow the existing doc/testing
27 | style when you can.
28 |
29 | To ensure a consistent style, new code should follow the [Google's Python Style Guide](https://google.github.io/styleguide/pyguide.html)
30 | and will need to pass a google style linter before acceptance. While this can
31 | add a little work up front, and occasionally make things more verbose, it helps
32 | reduce mental overhead and makes the code more readable.
33 |
34 | ## Code reviews
35 |
36 | All submissions, including submissions by project members, require review. We
37 | use GitHub pull requests for this purpose. Consult
38 | [GitHub Help](https://help.github.com/articles/about-pull-requests/) for more
39 | information on using pull requests.
40 |
41 | Please be sure to test your code by running `pytest` and `pylint` before
42 | submitting a pull request for review. Note that code cannot be merged until
43 | these tests pass on [GitHub Actions](https://github.com/magenta/ddsp/actions?query=workflow%3Abuild).
44 |
45 |
46 | ## Getting Started
47 |
48 | If you're looking for a way to contribute, but not sure where to start, you
49 | could:
50 |
51 | * Add some documentation to an existing function.
52 | * Add a missing test to improve coverage.
53 | * Add type hints to functions in a new file.
54 | * Add a new colab tutorial or demo, covering a typical use case or showing something cool.
55 | * Respond to a bug or feature request in the github [Issues](github.com/magenta/ddsp/issues).
56 | * Add a new signal `Processor` and corresponding test.
57 |
58 | ## Contributor License Agreement
59 |
60 | Contributions to this project must be accompanied by a Contributor License
61 | Agreement. You (or your employer) retain the copyright to your contribution;
62 | this simply gives us permission to use and redistribute your contributions as
63 | part of the project. Head over to to see
64 | your current agreements on file or to sign a new one.
65 |
66 | You generally only need to submit a CLA once, so if you've already submitted one
67 | (even if it was for a different project), you probably don't need to do it
68 | again.
69 |
70 |
71 | ## Community Guidelines
72 |
73 | This project follows
74 | [Google's Open Source Community Guidelines](https://opensource.google/conduct/).
75 |
--------------------------------------------------------------------------------
/ddsp/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 The DDSP Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """Base module for the differentiable digital signal processing library."""
16 |
17 | # Module imports.
18 | from ddsp import core
19 | from ddsp import dags
20 | from ddsp import effects
21 | from ddsp import losses
22 | from ddsp import processors
23 | from ddsp import spectral_ops
24 | from ddsp import synths
25 |
26 | # Version number.
27 | from ddsp.version import __version__
28 |
--------------------------------------------------------------------------------
/ddsp/colab/README.md:
--------------------------------------------------------------------------------
1 | # Colab Notebooks
2 |
3 | Interactive notebooks to demonstrate DDSP.
4 |
5 | * [demos](./demos/): Self-contained demonstrations for training models and showing them in action.
6 |
7 | * [tutorials](./tutorials/): Interactive walkthroughs of the DDSP functions and APIs.
8 |
9 |
--------------------------------------------------------------------------------
/ddsp/colab/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 The DDSP Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 |
--------------------------------------------------------------------------------
/ddsp/colab/demos/README.md:
--------------------------------------------------------------------------------
1 | # Demos
2 |
3 | Here are colab notebooks for demonstrating neat things you can do with DDSP.
4 |
5 | * [timbre_transfer](https://colab.research.google.com/github/magenta/ddsp/blob/main/ddsp/colab/demos/timbre_transfer.ipynb):
6 | Convert audio between sound sources with pretrained models. Try turning your voice into a violin, or scratching your laptop and seeing how it sounds as a flute :). Pick from a selection of pretrained models or upload your own that you can train with the `train_autoencoder` demo.
7 |
8 | * [train_autoencoder](https://colab.research.google.com/github/magenta/ddsp/blob/main/ddsp/colab/demos/train_autoencoder.ipynb):
9 | Takes you through all the steps to convert audio files into a dataset and train your own DDSP autoencoder model. You can transfer data and models to/from google drive, and download a .zip file of your trained model to be used with the `timbre_transfer` demo.
10 |
11 | * [pitch_detection](https://colab.research.google.com/github/magenta/ddsp/blob/main/ddsp/colab/demos/pitch_detection.ipynb):
12 | Demonstration of self-supervised pitch detection models from [2020 ICML Workshop paper](https://openreview.net/forum?id=RlVTYWhsky7).
13 |
14 | * [Train_VST](https://colab.research.google.com/github/magenta/ddsp/blob/main/ddsp/colab/demos/Train_VST.ipynb):
15 | Simplified training colab for the real-time audio plugin (WIP).
16 |
--------------------------------------------------------------------------------
/ddsp/colab/tutorials/README.md:
--------------------------------------------------------------------------------
1 | # Tutorials
2 |
3 | This is the best place to start is the step-by-step tutorials for all the major library components.
4 |
5 | * [0_processor](https://colab.research.google.com/github/magenta/ddsp/blob/main/ddsp/colab/tutorials/0_processor.ipynb):
6 | Introduction to the Processor class.
7 |
8 | * [1_synths_and_effects](https://colab.research.google.com/github/magenta/ddsp/blob/main/ddsp/colab/tutorials/1_synths_and_effects.ipynb):
9 | Example usage of processors.
10 |
11 | * [2_processor_group](https://colab.research.google.com/github/magenta/ddsp/blob/main/ddsp/colab/tutorials/2_processor_group.ipynb):
12 | Stringing processors together in a ProcessorGroup.
13 |
14 | * [3_training](https://colab.research.google.com/github/magenta/ddsp/blob/main/ddsp/colab/tutorials/3_training.ipynb):
15 | Example of training on a single sound.
16 |
17 | * [4_core_functions](https://colab.research.google.com/github/magenta/ddsp/blob/main/ddsp/colab/tutorials/4_core_functions.ipynb):
18 | Extensive examples for most of the core DDSP functions.
19 |
--------------------------------------------------------------------------------
/ddsp/dags.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 The DDSP Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """Library of functions and layers of Directed Acyclical Graphs.
16 |
17 | DAGLayer exists as an alternative to manually specifying the forward pass in
18 | python. The advantage is that a variety of configurations can be
19 | programmatically specified via external dependency injection, such as with the
20 | `gin` library.
21 | """
22 |
23 | from typing import Dict, Sequence, Tuple, Text, TypeVar
24 |
25 | from absl import logging
26 | from ddsp import core
27 | import gin
28 | import tensorflow.compat.v2 as tf
29 |
30 | tfkl = tf.keras.layers
31 |
32 | # Define Types.
33 | TensorDict = Dict[Text, tf.Tensor]
34 | KeyOrModule = TypeVar('KeyOrModule', Text, tf.Module)
35 | Node = Tuple[KeyOrModule, Sequence[Text], Sequence[Text]]
36 | DAG = Sequence[Node]
37 |
38 | # Helper Functions for DAGs ---------------------------------------------------
39 | filter_by_value = lambda d, cond: dict(filter(lambda e: cond(e[1]), d.items()))
40 | is_module = lambda v: isinstance(v, tf.Module)
41 |
42 | # Duck typing.
43 | is_loss = lambda v: hasattr(v, 'get_losses_dict')
44 | is_processor = lambda v: hasattr(v, 'get_signal') and hasattr(v, 'get_controls')
45 |
46 |
47 | def split_keras_kwargs(kwargs):
48 | """Strip keras specific kwargs."""
49 | keras_kwargs = {}
50 | for key in ['training', 'mask', 'name']:
51 | if kwargs.get(key) is not None:
52 | keras_kwargs[key] = kwargs.pop(key)
53 | return keras_kwargs, kwargs
54 |
55 |
56 | # DAG and ProcessorGroup Classes -----------------------------------------------
57 | @gin.register
58 | class DAGLayer(tfkl.Layer):
59 | """String modules together."""
60 |
61 | def __init__(self, dag: DAG, **kwarg_modules):
62 | """Constructor.
63 |
64 | Args:
65 | dag: A directed acyclical graph in the form of a list of nodes. Each node
66 | has the form
67 |
68 | ['module', ['input_key', ...], ['output_key', ...]]
69 |
70 | 'module': Module instance or string name of module. For example,
71 | 'encoder' woud access the attribute `dag_layer.encoder`.
72 | 'input_key': List of strings, nested keys in dictionary of dag outputs.
73 | For example, 'inputs/f0_hz' would access `outputs[inputs]['f0_hz']`.
74 | Inputs to the dag are wrapped in a `inputs` dict as shown in the
75 | example. This list is ordered and has one key per a module input
76 | argument. Each node's outputs are prefixed by their module name.
77 | 'output_key': List of strings, keys for each return value of the module.
78 | For example, ['amps', 'freqs'] would have the module return a dict
79 | {'module_name': {'amps': return_value_0, 'freqs': return_value_1}}.
80 | If the module returns a dictionary, the keys of the dictionary will be
81 | used and these values (if provided) will be ignored.
82 |
83 | The graph is read sequentially and must be topologically sorted. This
84 | means that all inputs for a module must already be generated by earlier
85 | modules (or in the input dictionary).
86 | **kwarg_modules: A series of modules to add to DAGLayer. Each kwarg that
87 | is a tf.Module will be added as a property of the layer, so that it will
88 | be accessible as `dag_layer.kwarg`. Also, other keras kwargs such as
89 | 'name' are split off before adding modules.
90 | """
91 | keras_kwargs, kwarg_modules = split_keras_kwargs(kwarg_modules)
92 | super().__init__(**keras_kwargs)
93 |
94 | # Create properties/submodules from other kwargs.
95 | modules = filter_by_value(kwarg_modules, is_module)
96 |
97 | # Remove modules from the dag, make properties of dag_layer.
98 | dag, dag_modules = self.format_dag(dag)
99 | # DAG is now just strings.
100 | self.dag = dag
101 | modules.update(dag_modules)
102 |
103 | # Make as propreties of DAGLayer to keep track of variables in checkpoints.
104 | self.module_names = list(modules.keys())
105 | for module_name, module in modules.items():
106 | setattr(self, module_name, module)
107 |
108 | @property
109 | def modules(self):
110 | """Module getter."""
111 | return [getattr(self, name) for name in self.module_names]
112 |
113 | @staticmethod
114 | def format_dag(dag):
115 | """Remove modules from dag, and replace with module names."""
116 | modules = {}
117 | dag = list(dag) # Make mutable in case it's a tuple.
118 | for i, node in enumerate(dag):
119 | node = list(node) # Make mutable in case it's a tuple.
120 | module = node[0]
121 | if is_module(module):
122 | # Strip module from the dag.
123 | modules[module.name] = module
124 | # Replace with module name.
125 | node[0] = module.name
126 | dag[i] = node
127 | return dag, modules
128 |
129 | def call(self, inputs: TensorDict, **kwargs) -> tf.Tensor:
130 | """Run dag for an input dictionary."""
131 | return self.run_dag(inputs, **kwargs)
132 |
133 | @gin.configurable(allowlist=['verbose']) # For debugging.
134 | def run_dag(self,
135 | inputs: TensorDict,
136 | verbose: bool = False,
137 | **kwargs) -> TensorDict:
138 | """Connects and runs submodules of dag.
139 |
140 | Args:
141 | inputs: A dictionary of input tensors fed to the dag.
142 | verbose: Print out dag routing when running.
143 | **kwargs: Other kwargs to pass to submodules, such as keras kwargs.
144 |
145 | Returns:
146 | A nested dictionary of all the output tensors.
147 | """
148 | # Initialize the outputs with inputs to the dag.
149 | outputs = {'inputs': inputs}
150 | # TODO(jesseengel): Remove this cluttering of the base namespace. Only there
151 | # for backwards compatability.
152 | outputs.update(inputs)
153 |
154 | # Run through the DAG nodes in sequential order.
155 | for node in self.dag:
156 | # The first element of the node can be either a module or module_key.
157 | module_key, input_keys = node[0], node[1]
158 | module = getattr(self, module_key)
159 | # Optionally specify output keys if module does not return dict.
160 | output_keys = node[2] if len(node) > 2 else None
161 |
162 | # Get the inputs to the node.
163 | inputs = [core.nested_lookup(key, outputs) for key in input_keys]
164 |
165 | if verbose:
166 | shape = lambda d: tf.nest.map_structure(lambda x: list(x.shape), d)
167 | logging.info('Input to Module: %s\nKeys: %s\nIn: %s\n',
168 | module_key, input_keys, shape(inputs))
169 |
170 | # Duck typing to avoid dealing with multiple inheritance of Group modules.
171 | if is_processor(module):
172 | # Processor modules.
173 | module_outputs = module(*inputs, return_outputs_dict=True, **kwargs)
174 | elif is_loss(module):
175 | # Loss modules.
176 | module_outputs = module.get_losses_dict(*inputs, **kwargs)
177 | else:
178 | # Network modules.
179 | module_outputs = module(*inputs, **kwargs)
180 |
181 | if not isinstance(module_outputs, dict):
182 | module_outputs = core.to_dict(module_outputs, output_keys)
183 |
184 | if verbose:
185 | logging.info('Output from Module: %s\nOut: %s\n',
186 | module_key, shape(module_outputs))
187 |
188 | # Add module outputs to the dictionary.
189 | outputs[module_key] = module_outputs
190 |
191 | # Alias final module output as dag output.
192 | # 'out' is a reserved key for final dag output.
193 | outputs['out'] = module_outputs
194 |
195 | return outputs
196 |
--------------------------------------------------------------------------------
/ddsp/dags_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 The DDSP Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """Tests for ddsp.dags.py."""
16 |
17 | from absl.testing import parameterized
18 | from ddsp import dags
19 | import gin
20 | import tensorflow as tf
21 |
22 | # Make dense layers configurable for this test.
23 | gin.external_configurable(tf.keras.layers.Dense, 'tf.keras.layers.Dense')
24 |
25 |
26 | @gin.configurable
27 | class ConfigurableDAGLayer(dags.DAGLayer):
28 | """Configurable wrapper DAGLayer encapsulated for this test."""
29 | pass
30 |
31 |
32 | class DAGLayerTest(parameterized.TestCase, tf.test.TestCase):
33 |
34 | def setUp(self):
35 | """Create some dummy input data for the chain."""
36 | super().setUp()
37 | # Create inputs.
38 | self.n_batch = 4
39 | self.x_dims = 5
40 | self.z_dims = 2
41 | self.x = tf.ones([self.n_batch, self.x_dims])
42 | self.inputs = {'test_data': self.x}
43 | self.gin_config_kwarg_modules = f"""
44 | import ddsp
45 |
46 | ### Modules
47 | ConfigurableDAGLayer.dag = [
48 | ('encoder', ['inputs/test_data'], ['z']),
49 | ('bottleneck', ['encoder/z'], ['z_bottleneck']),
50 | ('decoder', ['bottleneck/z_bottleneck'], ['reconstruction']),
51 | ]
52 | ConfigurableDAGLayer.encoder = @encoder/layers.Dense()
53 | encoder/layers.Dense.units = {self.x_dims}
54 |
55 | ConfigurableDAGLayer.bottleneck = @bottleneck/layers.Dense()
56 | bottleneck/layers.Dense.units = {self.z_dims}
57 |
58 | ConfigurableDAGLayer.decoder = @decoder/layers.Dense()
59 | decoder/layers.Dense.units = {self.x_dims}
60 | """
61 | self.gin_config_dag_modules = f"""
62 | import ddsp
63 |
64 | ### Modules
65 | ConfigurableDAGLayer.dag = [
66 | (@encoder/layers.Dense(), ['inputs/test_data'], ['z']),
67 | (@bottleneck/layers.Dense(), ['encoder/z'], ['z_bottleneck']),
68 | (@decoder/layers.Dense(), ['bottleneck/z_bottleneck'], ['reconstruction']),
69 | ]
70 | encoder/layers.Dense.name = 'encoder'
71 | encoder/layers.Dense.units = {self.x_dims}
72 |
73 | bottleneck/layers.Dense.name = 'bottleneck'
74 | bottleneck/layers.Dense.units = {self.z_dims}
75 |
76 | decoder/layers.Dense.name = 'decoder'
77 | decoder/layers.Dense.units = {self.x_dims}
78 | """
79 |
80 | @parameterized.named_parameters(
81 | ('kwarg_modules', True),
82 | ('dag_modules', False),
83 | )
84 | def test_build_layer(self, kwarg_modules):
85 | """Tests if layer builds properly and produces outputs of correct shape."""
86 | gin_config = (self.gin_config_kwarg_modules if kwarg_modules else
87 | self.gin_config_dag_modules)
88 | with gin.unlock_config():
89 | gin.clear_config()
90 | gin.parse_config(gin_config)
91 |
92 | dag_layer = ConfigurableDAGLayer()
93 | outputs = dag_layer(self.inputs)
94 | self.assertIsInstance(outputs, dict)
95 |
96 | z = outputs['bottleneck']['z_bottleneck']
97 | x_rec = outputs['decoder']['reconstruction']
98 | x_rec2 = outputs['out']['reconstruction']
99 |
100 | # Confirm that layer generates correctly sized tensors.
101 | self.assertEqual(outputs['test_data'].shape, self.x.shape)
102 | self.assertEqual(outputs['inputs']['test_data'].shape, self.x.shape)
103 | self.assertEqual(x_rec.shape, self.x.shape)
104 | self.assertEqual(z.shape[-1], self.z_dims)
105 | self.assertAllClose(x_rec, x_rec2)
106 |
107 | # Confirm that variables are inherited by DAGLayer.
108 | self.assertLen(dag_layer.trainable_variables, 6) # 3 weights, 3 biases.
109 |
110 | if __name__ == '__main__':
111 | tf.test.main()
112 |
--------------------------------------------------------------------------------
/ddsp/effects_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 The DDSP Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """Tests for ddsp.effects."""
16 |
17 | from absl.testing import parameterized
18 | from ddsp import effects
19 | import tensorflow.compat.v2 as tf
20 |
21 |
22 | class ReverbTest(parameterized.TestCase, tf.test.TestCase):
23 |
24 | def setUp(self):
25 | """Creates some test specific attributes."""
26 | super().setUp()
27 | self.reverb_class = effects.Reverb
28 | self.audio = tf.zeros((3, 16000))
29 | self.construct_args = {'reverb_length': 100}
30 | self.call_args = {'ir': tf.zeros((3, 100, 1))}
31 | self.controls_keys = ['audio', 'ir']
32 |
33 | @parameterized.named_parameters(
34 | ('trainable', True),
35 | ('not_trainable', False),
36 | )
37 | def test_output_shape_and_variables_are_correct(self, trainable):
38 | reverb = self.reverb_class(trainable=trainable, **self.construct_args)
39 | if trainable:
40 | output = reverb(self.audio)
41 | else:
42 | output = reverb(self.audio, **self.call_args)
43 |
44 | self.assertListEqual(list(self.audio.shape), output.shape.as_list())
45 | self.assertEqual(reverb.trainable, trainable)
46 | self.assertEmpty(reverb.non_trainable_variables)
47 | assert_variables = self.assertNotEmpty if trainable else self.assertEmpty
48 | assert_variables(reverb.trainable_variables)
49 |
50 | def test_non_trainable_raises_value_error(self):
51 | reverb = self.reverb_class(trainable=False, **self.construct_args)
52 | with self.assertRaises(ValueError):
53 | _ = reverb(self.audio)
54 |
55 | @parameterized.named_parameters(
56 | ('trainable', True),
57 | ('not_trainable', False),
58 | )
59 | def test_get_controls_returns_correct_keys(self, trainable):
60 | reverb = self.reverb_class(trainable=trainable, **self.construct_args)
61 | reverb.build(self.audio.shape)
62 | if trainable:
63 | controls = reverb.get_controls(self.audio)
64 | else:
65 | controls = reverb.get_controls(self.audio, **self.call_args)
66 |
67 | self.assertListEqual(list(controls.keys()), self.controls_keys)
68 |
69 |
70 | class ExpDecayReverbTest(ReverbTest):
71 |
72 | def setUp(self):
73 | """Creates some test specific attributes."""
74 | super().setUp()
75 | self.reverb_class = effects.ExpDecayReverb
76 | self.audio = tf.zeros((3, 16000))
77 | self.construct_args = {'reverb_length': 100}
78 | self.call_args = {'gain': tf.zeros((3, 1)),
79 | 'decay': tf.zeros((3, 1))}
80 |
81 |
82 | class FilteredNoiseReverbTest(ReverbTest):
83 |
84 | def setUp(self):
85 | """Creates some test specific attributes."""
86 | super().setUp()
87 | self.reverb_class = effects.FilteredNoiseReverb
88 | self.audio = tf.zeros((3, 16000))
89 | self.construct_args = {'reverb_length': 100,
90 | 'n_frames': 10,
91 | 'n_filter_banks': 20}
92 | self.call_args = {'magnitudes': tf.zeros((3, 10, 20))}
93 |
94 |
95 | class FIRFilterTest(tf.test.TestCase):
96 |
97 | def test_output_shape_is_correct(self):
98 | processor = effects.FIRFilter()
99 |
100 | audio = tf.zeros((3, 16000))
101 | magnitudes = tf.zeros((3, 100, 30))
102 | output = processor(audio, magnitudes)
103 |
104 | self.assertListEqual([3, 16000], output.shape.as_list())
105 |
106 |
107 | class ModDelayTest(tf.test.TestCase):
108 |
109 | def test_output_shape_is_correct(self):
110 | processor = effects.ModDelay()
111 |
112 | audio = tf.zeros((3, 16000))
113 | gain = tf.zeros((3, 16000, 1))
114 | phase = tf.zeros((3, 16000, 1))
115 | output = processor(audio, gain, phase)
116 |
117 | self.assertListEqual([3, 16000], output.shape.as_list())
118 |
119 |
120 | if __name__ == '__main__':
121 | tf.test.main()
122 |
--------------------------------------------------------------------------------
/ddsp/losses_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 The DDSP Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """Tests for ddsp.losses."""
16 |
17 | from ddsp import core
18 | from ddsp import losses
19 | import numpy as np
20 | import tensorflow as tf
21 |
22 |
23 | class LossGroupTest(tf.test.TestCase):
24 |
25 | def setUp(self):
26 | """Create some dummy input data for the chain."""
27 | super().setUp()
28 |
29 | # Create a network output dictionary.
30 | self.nn_outputs = {
31 | 'audio': tf.ones((3, 8000), dtype=tf.float32),
32 | 'audio_synth': tf.ones((3, 8000), dtype=tf.float32),
33 | 'magnitudes': tf.ones((3, 200, 2), dtype=tf.float32),
34 | 'f0_hz': 200 + tf.ones((3, 200, 1), dtype=tf.float32),
35 | }
36 |
37 | # Create Processors.
38 | spectral_loss = losses.SpectralLoss()
39 | crepe_loss = losses.PretrainedCREPEEmbeddingLoss(name='crepe_loss')
40 |
41 | # Create DAG for testing.
42 | self.dag = [
43 | (spectral_loss, ['audio', 'audio_synth']),
44 | (crepe_loss, ['audio', 'audio_synth']),
45 | ]
46 | self.expected_outputs = [
47 | 'spectral_loss',
48 | 'crepe_loss'
49 | ]
50 |
51 | def _check_tensor_outputs(self, strings_to_check, outputs):
52 | for tensor_string in strings_to_check:
53 | tensor = core.nested_lookup(tensor_string, outputs)
54 | self.assertIsInstance(tensor, (np.ndarray, tf.Tensor))
55 |
56 | def test_dag_construction(self):
57 | """Tests if DAG is built properly and runs.
58 | """
59 | loss_group = losses.LossGroup(dag=self.dag)
60 | print('!!!!!!!!!!!', loss_group.dag, loss_group.loss_names, self.dag)
61 | loss_outputs = loss_group(self.nn_outputs)
62 | self.assertIsInstance(loss_outputs, dict)
63 | self._check_tensor_outputs(self.expected_outputs, loss_outputs)
64 |
65 |
66 | class SpectralLossTest(tf.test.TestCase):
67 |
68 | def test_output_shape_is_correct(self):
69 | """Test correct shape with all losses active."""
70 | loss_obj = losses.SpectralLoss(
71 | mag_weight=1.0,
72 | delta_time_weight=1.0,
73 | delta_freq_weight=1.0,
74 | cumsum_freq_weight=1.0,
75 | logmag_weight=1.0,
76 | loudness_weight=1.0,
77 | )
78 |
79 | input_audio = tf.ones((3, 8000), dtype=tf.float32)
80 | target_audio = tf.ones((3, 8000), dtype=tf.float32)
81 |
82 | loss = loss_obj(input_audio, target_audio)
83 |
84 | self.assertListEqual([], loss.shape.as_list())
85 | self.assertTrue(np.isfinite(loss))
86 |
87 |
88 |
89 |
90 | class PretrainedCREPEEmbeddingLossTest(tf.test.TestCase):
91 |
92 | def test_output_shape_is_correct(self):
93 | loss_obj = losses.PretrainedCREPEEmbeddingLoss()
94 |
95 | input_audio = tf.ones((3, 16000), dtype=tf.float32)
96 | target_audio = tf.ones((3, 16000), dtype=tf.float32)
97 |
98 | loss = loss_obj(input_audio, target_audio)
99 |
100 | self.assertListEqual([], loss.shape.as_list())
101 | self.assertTrue(np.isfinite(loss))
102 |
103 |
104 | if __name__ == '__main__':
105 | tf.test.main()
106 |
--------------------------------------------------------------------------------
/ddsp/processors_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 The DDSP Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """Tests for ddsp.processors."""
16 |
17 | from absl.testing import parameterized
18 | from ddsp import core
19 | from ddsp import effects
20 | from ddsp import processors
21 | from ddsp import synths
22 | import numpy as np
23 | import tensorflow.compat.v2 as tf
24 |
25 |
26 | class ProcessorGroupTest(parameterized.TestCase, tf.test.TestCase):
27 |
28 | def setUp(self):
29 | """Create some dummy input data for the chain."""
30 | super().setUp()
31 | # Create inputs.
32 | self.n_batch = 4
33 | self.n_frames = 1000
34 | self.n_time = 64000
35 | rand_signal = lambda ch: np.random.randn(self.n_batch, self.n_frames, ch)
36 | self.nn_outputs = {
37 | 'amps': rand_signal(1),
38 | 'harmonic_distribution': rand_signal(99),
39 | 'magnitudes': rand_signal(256),
40 | 'f0_hz': 200 + rand_signal(1),
41 | 'target_audio': np.random.randn(self.n_batch, self.n_time)
42 | }
43 |
44 | # Create Processors.
45 | harmonic = synths.Harmonic(name='harmonic')
46 | noise = synths.FilteredNoise(name='noise')
47 | add = processors.Add(name='add')
48 | reverb = effects.Reverb(trainable=True, name='reverb')
49 |
50 | # Create DAG for testing.
51 | self.dag = [
52 | (harmonic, ['amps', 'harmonic_distribution', 'f0_hz']),
53 | (noise, ['magnitudes']),
54 | (add, ['noise/signal', 'harmonic/signal']),
55 | (reverb, ['add/signal']),
56 | ]
57 | self.expected_outputs = [
58 | 'amps',
59 | 'harmonic_distribution',
60 | 'magnitudes',
61 | 'f0_hz',
62 | 'target_audio',
63 | 'harmonic/signal',
64 | 'harmonic/controls/amplitudes',
65 | 'harmonic/controls/harmonic_distribution',
66 | 'harmonic/controls/f0_hz',
67 | 'noise/signal',
68 | 'noise/controls/magnitudes',
69 | 'add/signal',
70 | 'reverb/signal',
71 | 'reverb/controls/ir',
72 | 'out/signal',
73 | ]
74 |
75 | def _check_tensor_outputs(self, strings_to_check, outputs):
76 | for tensor_string in strings_to_check:
77 | tensor = core.nested_lookup(tensor_string, outputs)
78 | self.assertIsInstance(tensor, (np.ndarray, tf.Tensor))
79 |
80 | def test_dag_construction(self):
81 | """Tests if DAG is built properly and runs.
82 | """
83 | processor_group = processors.ProcessorGroup(dag=self.dag,
84 | name='processor_group')
85 | outputs = processor_group.get_controls(self.nn_outputs)
86 | self.assertIsInstance(outputs, dict)
87 | self._check_tensor_outputs(self.expected_outputs, outputs)
88 |
89 |
90 | class AddTest(tf.test.TestCase):
91 |
92 | def test_output_is_correct(self):
93 | processor = processors.Add(name='add')
94 | x = tf.zeros((2, 3), dtype=tf.float32) + 1.0
95 | y = tf.zeros((2, 3), dtype=tf.float32) + 2.0
96 |
97 | output = processor(x, y)
98 |
99 | expected = np.zeros((2, 3), dtype=np.float32) + 3.0
100 | self.assertAllEqual(expected, output)
101 |
102 |
103 | class MixTest(tf.test.TestCase):
104 |
105 | def test_output_shape_is_correct(self):
106 | processor = processors.Mix(name='mix')
107 | x1 = np.zeros((2, 100, 3), dtype=np.float32) + 1.0
108 | x2 = np.zeros((2, 100, 3), dtype=np.float32) + 2.0
109 | mix_level = np.zeros(
110 | (2, 100, 1), dtype=np.float32) + 0.1 # will be passed to sigmoid
111 |
112 | output = processor(x1, x2, mix_level)
113 |
114 | self.assertListEqual([2, 100, 3], output.shape.as_list())
115 |
116 |
117 | if __name__ == '__main__':
118 | tf.test.main()
119 |
--------------------------------------------------------------------------------
/ddsp/synths_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 The DDSP Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """Tests for ddsp.synths."""
16 |
17 | from ddsp import core
18 | from ddsp import synths
19 | import numpy as np
20 | import tensorflow.compat.v2 as tf
21 |
22 |
23 | class HarmonicTest(tf.test.TestCase):
24 |
25 | def test_output_shape_is_correct(self):
26 | synthesizer = synths.Harmonic(
27 | n_samples=64000,
28 | sample_rate=16000,
29 | scale_fn=None,
30 | normalize_below_nyquist=True)
31 | batch_size = 3
32 | num_frames = 1000
33 | amp = tf.zeros((batch_size, num_frames, 1), dtype=tf.float32) + 1.0
34 | harmonic_distribution = tf.zeros(
35 | (batch_size, num_frames, 16), dtype=tf.float32) + 1.0 / 16
36 | f0_hz = tf.zeros((batch_size, num_frames, 1), dtype=tf.float32) + 16000
37 |
38 | output = synthesizer(amp, harmonic_distribution, f0_hz)
39 |
40 | self.assertAllEqual([batch_size, 64000], output.shape.as_list())
41 |
42 |
43 | class FilteredNoiseTest(tf.test.TestCase):
44 |
45 | def test_output_shape_is_correct(self):
46 | synthesizer = synths.FilteredNoise(n_samples=16000)
47 | filter_bank_magnitudes = tf.zeros((3, 16000, 100), dtype=tf.float32) + 3.0
48 | output = synthesizer(filter_bank_magnitudes)
49 |
50 | self.assertAllEqual([3, 16000], output.shape.as_list())
51 |
52 |
53 | class WavetableTest(tf.test.TestCase):
54 |
55 | def test_output_shape_is_correct(self):
56 | synthesizer = synths.Wavetable(
57 | n_samples=64000,
58 | sample_rate=16000,
59 | scale_fn=None)
60 | batch_size = 3
61 | num_frames = 1000
62 | n_wavetable = 1024
63 | amp = tf.zeros((batch_size, num_frames, 1), dtype=tf.float32) + 1.0
64 | wavetables = tf.zeros(
65 | (batch_size, num_frames, n_wavetable), dtype=tf.float32)
66 | f0_hz = tf.zeros((batch_size, num_frames, 1), dtype=tf.float32) + 440
67 |
68 | output = synthesizer(amp, wavetables, f0_hz)
69 |
70 | self.assertAllEqual([batch_size, 64000], output.shape.as_list())
71 |
72 |
73 | class SinusoidalTest(tf.test.TestCase):
74 |
75 | def test_output_shape_is_correct(self):
76 | synthesizer = synths.Sinusoidal(n_samples=32000, sample_rate=16000)
77 | batch_size = 3
78 | num_frames = 1000
79 | n_partials = 10
80 | amps = tf.zeros((batch_size, num_frames, n_partials),
81 | dtype=tf.float32)
82 | freqs = tf.zeros((batch_size, num_frames, n_partials),
83 | dtype=tf.float32)
84 |
85 | output = synthesizer(amps, freqs)
86 |
87 | self.assertAllEqual([batch_size, 32000], output.shape.as_list())
88 |
89 | def test_frequencies_controls_are_bounded(self):
90 | depth = 10
91 | def freq_scale_fn(x):
92 | return core.frequencies_sigmoid(x, depth=depth, hz_min=0.0, hz_max=8000.0)
93 |
94 | synthesizer = synths.Sinusoidal(
95 | n_samples=32000, sample_rate=16000, freq_scale_fn=freq_scale_fn)
96 | batch_size = 3
97 | num_frames = 10
98 | n_partials = 100
99 | amps = tf.zeros((batch_size, num_frames, n_partials), dtype=tf.float32)
100 | freqs = tf.linspace(-100.0, 100.0, n_partials)
101 | freqs = tf.tile(freqs[tf.newaxis, tf.newaxis, :, tf.newaxis],
102 | [batch_size, num_frames, 1, depth])
103 |
104 | controls = synthesizer.get_controls(amps, freqs)
105 | freqs = controls['frequencies']
106 | lt_nyquist = (freqs <= 8000.0)
107 | gt_zero = (freqs >= 0.0)
108 | both_conditions = np.logical_and(lt_nyquist, gt_zero)
109 |
110 | self.assertTrue(np.all(both_conditions))
111 |
112 |
113 | if __name__ == '__main__':
114 | tf.test.main()
115 |
--------------------------------------------------------------------------------
/ddsp/test_util.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 The DDSP Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """Library of helper functions for testing."""
16 |
17 | import numpy as np
18 |
19 |
20 | def gen_np_sinusoid(frequency, amp, sample_rate, audio_len_sec):
21 | x = np.linspace(0, audio_len_sec, int(audio_len_sec * sample_rate))
22 | audio_sin = amp * (np.sin(2 * np.pi * frequency * x))
23 | return audio_sin
24 |
25 |
26 | def gen_np_batched_sinusoids(frequency, amp, sample_rate, audio_len_sec,
27 | batch_size):
28 | batch_sinusoids = [
29 | gen_np_sinusoid(frequency, amp, sample_rate, audio_len_sec)
30 | for _ in range(batch_size)
31 | ]
32 | return np.array(batch_sinusoids)
33 |
34 |
--------------------------------------------------------------------------------
/ddsp/training/README.md:
--------------------------------------------------------------------------------
1 | # DDSP Training
2 |
3 |
4 | This directory contains the code for training models using DDSP modules.
5 | The current supported models are variants of an audio autoencoder.
6 |
7 |
8 |
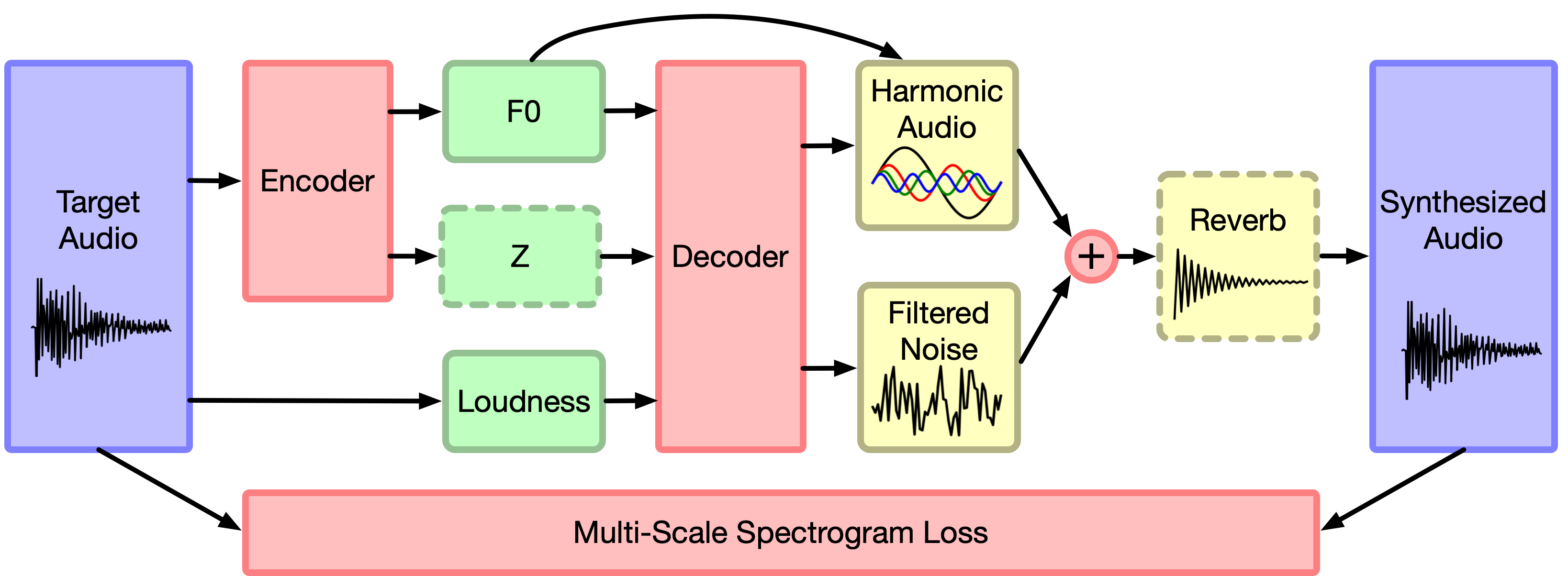
9 |