├── .gitignore
├── .travis.yml
├── CONTRIBUTING.md
├── LICENSE
├── MANIFEST.in
├── README.md
├── benchmark
├── __init__.py
├── table_perf.py
└── text_perf.py
├── binder
└── environment.yml
├── citation.bib
├── doc
├── blog_post.md
├── conf.py
├── images
│ ├── image_from_paper.png
│ ├── images.png
│ ├── lime.png
│ ├── multiclass.png
│ ├── tabular.png
│ ├── twoclass.png
│ └── video_screenshot.png
├── index.rst
├── lime.rst
└── notebooks
│ ├── Latin Hypercube Sampling.ipynb
│ ├── Lime - basic usage, two class case.ipynb
│ ├── Lime - multiclass.ipynb
│ ├── Lime with Recurrent Neural Networks.ipynb
│ ├── Submodular Pick examples.ipynb
│ ├── Tutorial - Faces and GradBoost.ipynb
│ ├── Tutorial - Image Classification Keras.ipynb
│ ├── Tutorial - MNIST and RF.ipynb
│ ├── Tutorial - continuous and categorical features.ipynb
│ ├── Tutorial - images - Pytorch.ipynb
│ ├── Tutorial - images.ipynb
│ ├── Tutorial_H2O_continuous_and_cat.ipynb
│ ├── Using lime for regression.ipynb
│ └── data
│ ├── adult.csv
│ ├── cat_mouse.jpg
│ ├── co2_data.csv
│ ├── dogs.png
│ ├── imagenet_class_index.json
│ └── mushroom_data.csv
├── lime
├── __init__.py
├── bundle.js
├── bundle.js.map
├── discretize.py
├── exceptions.py
├── explanation.py
├── js
│ ├── bar_chart.js
│ ├── explanation.js
│ ├── main.js
│ ├── predict_proba.js
│ └── predicted_value.js
├── lime_base.py
├── lime_image.py
├── lime_tabular.py
├── lime_text.py
├── package.json
├── style.css
├── submodular_pick.py
├── test_table.html
├── tests
│ ├── __init__.py
│ ├── test_discretize.py
│ ├── test_generic_utils.py
│ ├── test_lime_tabular.py
│ ├── test_lime_text.py
│ └── test_scikit_image.py
├── utils
│ ├── __init__.py
│ └── generic_utils.py
├── webpack.config.js
└── wrappers
│ ├── __init__.py
│ └── scikit_image.py
├── setup.cfg
└── setup.py
/.gitignore:
--------------------------------------------------------------------------------
1 | # Compiled python modules.
2 | *.pyc
3 |
4 | # Setuptools distribution folder.
5 | /dist/
6 |
7 | /lime/node_modules
8 |
9 | # Python egg metadata, regenerated from source files by setuptools.
10 | /*.egg-info
11 |
12 | # Unit test / coverage reports
13 | .cache
14 |
15 | # Created by https://www.gitignore.io/api/pycharm
16 |
17 | ### PyCharm ###
18 | # Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and Webstorm
19 | # Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
20 |
21 | # User-specific stuff:
22 | .idea/workspace.xml
23 | .idea/tasks.xml
24 | .idea/dictionaries
25 | .idea/vcs.xml
26 | .idea/jsLibraryMappings.xml
27 |
28 | # Sensitive or high-churn files:
29 | .idea/dataSources.ids
30 | .idea/dataSources.xml
31 | .idea/dataSources.local.xml
32 | .idea/sqlDataSources.xml
33 | .idea/dynamic.xml
34 | .idea/uiDesigner.xml
35 |
36 | # Gradle:
37 | .idea/gradle.xml
38 | .idea/libraries
39 |
40 | # Mongo Explorer plugin:
41 | .idea/mongoSettings.xml
42 |
43 | ## File-based project format:
44 | *.iws
45 |
46 | ## Plugin-specific files:
47 |
48 | # IntelliJ
49 | /out/
50 |
51 | # mpeltonen/sbt-idea plugin
52 | .idea_modules/
53 |
54 | # JIRA plugin
55 | atlassian-ide-plugin.xml
56 |
57 | # Crashlytics plugin (for Android Studio and IntelliJ)
58 | com_crashlytics_export_strings.xml
59 | crashlytics.properties
60 | crashlytics-build.properties
61 | fabric.properties
62 |
63 | ### PyCharm Patch ###
64 | # Comment Reason: https://github.com/joeblau/gitignore.io/issues/186#issuecomment-215987721
65 |
66 | # *.iml
67 | # modules.xml
68 | # .idea/misc.xml
69 | # *.ipr
70 |
71 | # Pycharm
72 | .idea
73 |
--------------------------------------------------------------------------------
/.travis.yml:
--------------------------------------------------------------------------------
1 | dist: xenial
2 | sudo: false
3 | language: python
4 | cache: pip
5 | python:
6 | - "3.6"
7 | - "3.7"
8 | # command to install dependencies
9 | install:
10 | - python -m pip install -U pip
11 | - python -m pip install -e .[dev]
12 | # command to run tests
13 | script:
14 | - pytest lime
15 | - flake8 lime
16 |
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | ## Contributing
2 | I am delighted when people want to contribute to LIME. Here are a few things to keep in mind before sending in a pull request:
3 | * We are now using flake8 as a style guide enforcer (I plan on adding eslint for javascript soon). Make sure your code passes the default flake8 execution.
4 | * There must be a really good reason to change the external interfaces - I want to avoid breaking previous code as much as possible.
5 | * If you are adding a new feature, please let me know the use case and the rationale behind how you did it (unless it's obvious)
6 |
7 | If you want to contribute but don't know where to start, take a look at the [issues page](https://github.com/marcotcr/lime/issues), or at the list below.
8 |
9 | # Roadmap
10 | Here are a few high level features I want to incorporate in LIME. If you want to work incrementally in any of these, feel free to start a branch.
11 |
12 | 1. Creating meaningful tests that we can run before merging things. Right now I run the example notebooks and the few tests we have.
13 | 2. Creating a wrapper that computes explanations for a particular dataset, and suggests instances for the user to look at (similar to what we did in [the paper](http://arxiv.org/abs/1602.04938))
14 | 3. Making LIME work with images in a reasonable time. The explanations we used in the paper took a few minutes, which is too slow.
15 | 4. Thinking through what is needed to use LIME in regression problems. An obvious problem is that features with different scales make it really hard to interpret.
16 | 5. Figuring out better alternatives to discretizing the data for tabular data. Discretizing is definitely more interpretable, but we may just want to treat features as continuous.
17 | 6. Figuring out better ways to sample around a data point for tabular data. One example is sampling columns from the training set assuming independence, or some form of conditional sampling.
18 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Copyright (c) 2016, Marco Tulio Correia Ribeiro
2 | All rights reserved.
3 |
4 | Redistribution and use in source and binary forms, with or without
5 | modification, are permitted provided that the following conditions are met:
6 |
7 | * Redistributions of source code must retain the above copyright notice, this
8 | list of conditions and the following disclaimer.
9 |
10 | * Redistributions in binary form must reproduce the above copyright notice,
11 | this list of conditions and the following disclaimer in the documentation
12 | and/or other materials provided with the distribution.
13 |
14 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
15 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
16 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
17 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
18 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
19 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
20 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
21 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
22 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
23 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
24 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include lime/*.js
2 | include LICENSE
3 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # lime
2 |
3 | [](https://travis-ci.org/marcotcr/lime)
4 | [](https://mybinder.org/v2/gh/marcotcr/lime/master)
5 |
6 | This project is about explaining what machine learning classifiers (or models) are doing.
7 | At the moment, we support explaining individual predictions for text classifiers or classifiers that act on tables (numpy arrays of numerical or categorical data) or images, with a package called lime (short for local interpretable model-agnostic explanations).
8 | Lime is based on the work presented in [this paper](https://arxiv.org/abs/1602.04938) ([bibtex here for citation](https://github.com/marcotcr/lime/blob/master/citation.bib)). Here is a link to the promo video:
9 |
10 |  11 |
12 | Our plan is to add more packages that help users understand and interact meaningfully with machine learning.
13 |
14 | Lime is able to explain any black box classifier, with two or more classes. All we require is that the classifier implements a function that takes in raw text or a numpy array and outputs a probability for each class. Support for scikit-learn classifiers is built-in.
15 |
16 | ## Installation
17 |
18 | The lime package is on [PyPI](https://pypi.python.org/pypi/lime). Simply run:
19 |
20 | ```sh
21 | pip install lime
22 | ```
23 |
24 | Or clone the repository and run:
25 |
26 | ```sh
27 | pip install .
28 | ```
29 |
30 | We dropped python2 support in `0.2.0`, `0.1.1.37` was the last version before that.
31 |
32 | ## Screenshots
33 |
34 | Below are some screenshots of lime explanations. These are generated in html, and can be easily produced and embedded in ipython notebooks. We also support visualizations using matplotlib, although they don't look as nice as these ones.
35 |
36 | #### Two class case, text
37 |
38 | Negative (blue) words indicate atheism, while positive (orange) words indicate christian. The way to interpret the weights by applying them to the prediction probabilities. For example, if we remove the words Host and NNTP from the document, we expect the classifier to predict atheism with probability 0.58 - 0.14 - 0.11 = 0.31.
39 |
40 | 
41 |
42 | #### Multiclass case
43 |
44 | 
45 |
46 | #### Tabular data
47 |
48 | 
49 |
50 | #### Images (explaining prediction of 'Cat' in pros and cons)
51 |
52 |
11 |
12 | Our plan is to add more packages that help users understand and interact meaningfully with machine learning.
13 |
14 | Lime is able to explain any black box classifier, with two or more classes. All we require is that the classifier implements a function that takes in raw text or a numpy array and outputs a probability for each class. Support for scikit-learn classifiers is built-in.
15 |
16 | ## Installation
17 |
18 | The lime package is on [PyPI](https://pypi.python.org/pypi/lime). Simply run:
19 |
20 | ```sh
21 | pip install lime
22 | ```
23 |
24 | Or clone the repository and run:
25 |
26 | ```sh
27 | pip install .
28 | ```
29 |
30 | We dropped python2 support in `0.2.0`, `0.1.1.37` was the last version before that.
31 |
32 | ## Screenshots
33 |
34 | Below are some screenshots of lime explanations. These are generated in html, and can be easily produced and embedded in ipython notebooks. We also support visualizations using matplotlib, although they don't look as nice as these ones.
35 |
36 | #### Two class case, text
37 |
38 | Negative (blue) words indicate atheism, while positive (orange) words indicate christian. The way to interpret the weights by applying them to the prediction probabilities. For example, if we remove the words Host and NNTP from the document, we expect the classifier to predict atheism with probability 0.58 - 0.14 - 0.11 = 0.31.
39 |
40 | 
41 |
42 | #### Multiclass case
43 |
44 | 
45 |
46 | #### Tabular data
47 |
48 | 
49 |
50 | #### Images (explaining prediction of 'Cat' in pros and cons)
51 |
52 |  53 |
54 | ## Tutorials and API
55 |
56 | For example usage for text classifiers, take a look at the following two tutorials (generated from ipython notebooks):
57 |
58 | - [Basic usage, two class. We explain random forest classifiers.](https://marcotcr.github.io/lime/tutorials/Lime%20-%20basic%20usage%2C%20two%20class%20case.html)
59 | - [Multiclass case](https://marcotcr.github.io/lime/tutorials/Lime%20-%20multiclass.html)
60 |
61 | For classifiers that use numerical or categorical data, take a look at the following tutorial (this is newer, so please let me know if you find something wrong):
62 |
63 | - [Tabular data](https://marcotcr.github.io/lime/tutorials/Tutorial%20-%20continuous%20and%20categorical%20features.html)
64 | - [Tabular data with H2O models](https://marcotcr.github.io/lime/tutorials/Tutorial_H2O_continuous_and_cat.html)
65 | - [Latin Hypercube Sampling](doc/notebooks/Latin%20Hypercube%20Sampling.ipynb)
66 |
67 | For image classifiers:
68 |
69 | - [Images - basic](https://marcotcr.github.io/lime/tutorials/Tutorial%20-%20images.html)
70 | - [Images - Faces](https://github.com/marcotcr/lime/blob/master/doc/notebooks/Tutorial%20-%20Faces%20and%20GradBoost.ipynb)
71 | - [Images with Keras](https://github.com/marcotcr/lime/blob/master/doc/notebooks/Tutorial%20-%20Image%20Classification%20Keras.ipynb)
72 | - [MNIST with random forests](https://github.com/marcotcr/lime/blob/master/doc/notebooks/Tutorial%20-%20MNIST%20and%20RF.ipynb)
73 | - [Images with PyTorch](https://github.com/marcotcr/lime/blob/master/doc/notebooks/Tutorial%20-%20images%20-%20Pytorch.ipynb)
74 |
75 | For regression:
76 |
77 | - [Simple regression](https://marcotcr.github.io/lime/tutorials/Using%2Blime%2Bfor%2Bregression.html)
78 |
79 | Submodular Pick:
80 |
81 | - [Submodular Pick](https://github.com/marcotcr/lime/tree/master/doc/notebooks/Submodular%20Pick%20examples.ipynb)
82 |
83 | The raw (non-html) notebooks for these tutorials are available [here](https://github.com/marcotcr/lime/tree/master/doc/notebooks).
84 |
85 | The API reference is available [here](https://lime-ml.readthedocs.io/en/latest/).
86 |
87 | ## What are explanations?
88 |
89 | Intuitively, an explanation is a local linear approximation of the model's behaviour.
90 | While the model may be very complex globally, it is easier to approximate it around the vicinity of a particular instance.
91 | While treating the model as a black box, we perturb the instance we want to explain and learn a sparse linear model around it, as an explanation.
92 | The figure below illustrates the intuition for this procedure. The model's decision function is represented by the blue/pink background, and is clearly nonlinear.
93 | The bright red cross is the instance being explained (let's call it X).
94 | We sample instances around X, and weight them according to their proximity to X (weight here is indicated by size).
95 | We then learn a linear model (dashed line) that approximates the model well in the vicinity of X, but not necessarily globally. For more information, [read our paper](https://arxiv.org/abs/1602.04938), or take a look at [this blog post](https://www.oreilly.com/learning/introduction-to-local-interpretable-model-agnostic-explanations-lime).
96 |
97 |
53 |
54 | ## Tutorials and API
55 |
56 | For example usage for text classifiers, take a look at the following two tutorials (generated from ipython notebooks):
57 |
58 | - [Basic usage, two class. We explain random forest classifiers.](https://marcotcr.github.io/lime/tutorials/Lime%20-%20basic%20usage%2C%20two%20class%20case.html)
59 | - [Multiclass case](https://marcotcr.github.io/lime/tutorials/Lime%20-%20multiclass.html)
60 |
61 | For classifiers that use numerical or categorical data, take a look at the following tutorial (this is newer, so please let me know if you find something wrong):
62 |
63 | - [Tabular data](https://marcotcr.github.io/lime/tutorials/Tutorial%20-%20continuous%20and%20categorical%20features.html)
64 | - [Tabular data with H2O models](https://marcotcr.github.io/lime/tutorials/Tutorial_H2O_continuous_and_cat.html)
65 | - [Latin Hypercube Sampling](doc/notebooks/Latin%20Hypercube%20Sampling.ipynb)
66 |
67 | For image classifiers:
68 |
69 | - [Images - basic](https://marcotcr.github.io/lime/tutorials/Tutorial%20-%20images.html)
70 | - [Images - Faces](https://github.com/marcotcr/lime/blob/master/doc/notebooks/Tutorial%20-%20Faces%20and%20GradBoost.ipynb)
71 | - [Images with Keras](https://github.com/marcotcr/lime/blob/master/doc/notebooks/Tutorial%20-%20Image%20Classification%20Keras.ipynb)
72 | - [MNIST with random forests](https://github.com/marcotcr/lime/blob/master/doc/notebooks/Tutorial%20-%20MNIST%20and%20RF.ipynb)
73 | - [Images with PyTorch](https://github.com/marcotcr/lime/blob/master/doc/notebooks/Tutorial%20-%20images%20-%20Pytorch.ipynb)
74 |
75 | For regression:
76 |
77 | - [Simple regression](https://marcotcr.github.io/lime/tutorials/Using%2Blime%2Bfor%2Bregression.html)
78 |
79 | Submodular Pick:
80 |
81 | - [Submodular Pick](https://github.com/marcotcr/lime/tree/master/doc/notebooks/Submodular%20Pick%20examples.ipynb)
82 |
83 | The raw (non-html) notebooks for these tutorials are available [here](https://github.com/marcotcr/lime/tree/master/doc/notebooks).
84 |
85 | The API reference is available [here](https://lime-ml.readthedocs.io/en/latest/).
86 |
87 | ## What are explanations?
88 |
89 | Intuitively, an explanation is a local linear approximation of the model's behaviour.
90 | While the model may be very complex globally, it is easier to approximate it around the vicinity of a particular instance.
91 | While treating the model as a black box, we perturb the instance we want to explain and learn a sparse linear model around it, as an explanation.
92 | The figure below illustrates the intuition for this procedure. The model's decision function is represented by the blue/pink background, and is clearly nonlinear.
93 | The bright red cross is the instance being explained (let's call it X).
94 | We sample instances around X, and weight them according to their proximity to X (weight here is indicated by size).
95 | We then learn a linear model (dashed line) that approximates the model well in the vicinity of X, but not necessarily globally. For more information, [read our paper](https://arxiv.org/abs/1602.04938), or take a look at [this blog post](https://www.oreilly.com/learning/introduction-to-local-interpretable-model-agnostic-explanations-lime).
96 |
97 | 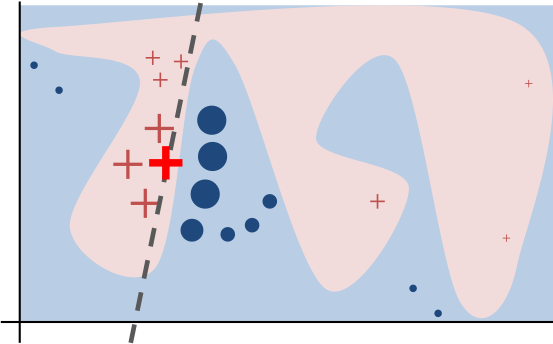 98 |
99 | ## Contributing
100 |
101 | Please read [this](CONTRIBUTING.md).
102 |
--------------------------------------------------------------------------------
/benchmark/__init__.py:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/benchmark/table_perf.py:
--------------------------------------------------------------------------------
1 | """
2 | A helper script for evaluating performance of changes to the tabular explainer, in this case different
3 | implementations and methods for distance calculation.
4 | """
5 |
6 | import time
7 | from sklearn.ensemble import RandomForestClassifier
8 | from sklearn.datasets import make_classification
9 | from lime.lime_tabular import LimeTabularExplainer
10 |
11 |
12 | def interpret_data(X, y, func):
13 | explainer = LimeTabularExplainer(X, discretize_continuous=False, kernel_width=3)
14 | times, scores = [], []
15 | for r_idx in range(100):
16 | start_time = time.time()
17 | explanation = explainer.explain_instance(X[r_idx, :], func)
18 | times.append(time.time() - start_time)
19 | scores.append(explanation.score)
20 | print('...')
21 |
22 | return times, scores
23 |
24 |
25 | if __name__ == '__main__':
26 | X_raw, y_raw = make_classification(n_classes=2, n_features=1000, n_samples=1000)
27 | clf = RandomForestClassifier()
28 | clf.fit(X_raw, y_raw)
29 | y_hat = clf.predict_proba(X_raw)
30 |
31 | times, scores = interpret_data(X_raw, y_hat, clf.predict_proba)
32 | print('%9.4fs %9.4fs %9.4fs' % (min(times), sum(times) / len(times), max(times)))
33 | print('%9.4f %9.4f% 9.4f' % (min(scores), sum(scores) / len(scores), max(scores)))
--------------------------------------------------------------------------------
/benchmark/text_perf.py:
--------------------------------------------------------------------------------
1 | import time
2 | import sklearn
3 | import sklearn.ensemble
4 | import sklearn.metrics
5 | from sklearn.datasets import fetch_20newsgroups
6 | from sklearn.pipeline import make_pipeline
7 | from lime.lime_text import LimeTextExplainer
8 |
9 |
10 | def interpret_data(X, y, func, class_names):
11 | explainer = LimeTextExplainer(class_names=class_names)
12 | times, scores = [], []
13 | for r_idx in range(10):
14 | start_time = time.time()
15 | exp = explainer.explain_instance(newsgroups_test.data[r_idx], func, num_features=6)
16 | times.append(time.time() - start_time)
17 | scores.append(exp.score)
18 | print('...')
19 |
20 | return times, scores
21 |
22 | if __name__ == '__main__':
23 | categories = ['alt.atheism', 'soc.religion.christian']
24 | newsgroups_train = fetch_20newsgroups(subset='train', categories=categories)
25 | newsgroups_test = fetch_20newsgroups(subset='test', categories=categories)
26 | class_names = ['atheism', 'christian']
27 |
28 | vectorizer = sklearn.feature_extraction.text.TfidfVectorizer(lowercase=False)
29 | train_vectors = vectorizer.fit_transform(newsgroups_train.data)
30 | test_vectors = vectorizer.transform(newsgroups_test.data)
31 | rf = sklearn.ensemble.RandomForestClassifier(n_estimators=500)
32 | rf.fit(train_vectors, newsgroups_train.target)
33 | pred = rf.predict(test_vectors)
34 | sklearn.metrics.f1_score(newsgroups_test.target, pred, average='binary')
35 | c = make_pipeline(vectorizer, rf)
36 |
37 | interpret_data(train_vectors, newsgroups_train.target, c.predict_proba, class_names)
--------------------------------------------------------------------------------
/binder/environment.yml:
--------------------------------------------------------------------------------
1 |
2 | name: lime-dev
3 | channels:
4 | - conda-forge
5 | dependencies:
6 | - python=3.7.*
7 | # lime install dependencies
8 | - matplotlib
9 | - numpy
10 | - scipy
11 | - scikit-learn
12 | - scikit-image
13 | - pyDOE2
14 | # for testing
15 | - flake8
16 | - pytest
17 | # for examples
18 | - jupyter
19 | - pandas
20 | - keras
21 | - pytorch::pytorch-cpu
22 | - tensorflow
23 | - h2oai::h2o
24 | - py-xgboost
25 | - pip:
26 | # lime source code
27 | - -e ..
28 |
--------------------------------------------------------------------------------
/citation.bib:
--------------------------------------------------------------------------------
1 | @inproceedings{lime,
2 | author = {Marco Tulio Ribeiro and
3 | Sameer Singh and
4 | Carlos Guestrin},
5 | title = {"Why Should {I} Trust You?": Explaining the Predictions of Any Classifier},
6 | booktitle = {Proceedings of the 22nd {ACM} {SIGKDD} International Conference on
7 | Knowledge Discovery and Data Mining, San Francisco, CA, USA, August
8 | 13-17, 2016},
9 | pages = {1135--1144},
10 | year = {2016},
11 | }
12 |
--------------------------------------------------------------------------------
/doc/blog_post.md:
--------------------------------------------------------------------------------
1 | # LIME - Local Interpretable Model-Agnostic Explanations
2 | In this post, we'll talk about the method for explaining the predictions of any classifier described in [this paper](http://arxiv.org/pdf/1602.04938v1.pdf), and implemented in [this open source package](https://github.com/marcotcr/lime).
3 | # Motivation: why do we want to understand predictions?
4 | Machine learning is a buzzword these days. With computers beating professionals in games like [Go](https://deepmind.com/alpha-go.html), many people have started asking if machines would also make for better [drivers](https://www.google.com/selfdrivingcar/), or even doctors.
5 |
6 | Many of the state of the art machine learning models are functionally black boxes, as it is nearly impossible to get a feeling for its inner workings. This brings us to a question of trust: do I trust that a certain prediction from the model is correct? Or do I even trust that the model is making reasonable predictions in general?
7 | While the stakes are low in a Go game, they are much higher if a computer is replacing my doctor, or deciding if I am a suspect of terrorism ([Person of Interest](http://www.imdb.com/title/tt1839578/), anyone?). Perhaps more commonly, if a company is replacing some system with one based on machine learning, it has to trust that the machine learning model will behave reasonably well.
8 |
9 | It seems intuitive that explaining the rationale behind individual predictions would make us better positioned to trust or mistrust the prediction, or the classifier as a whole. Even if we can't necesseraly understand how the model behaves on all cases, it may be possible (and indeed it is in most cases) to understand how it behaves in particular cases.
10 |
11 | Finally, a word on accuracy. If you have had experience with machine learning, I bet you are thinking something along the lines of: "of course I know my model is going to perform well in the real world, I have really high cross validation accuracy! Why do I need to understand it's predictions when I know it gets it right 99% of the time?". As anyone who has used machine learning in the real world (not only in a static dataset) can attest, accuracy on cross validation can be very misleading. Sometimes data that shouldn't be available leaks into the training data accidentaly. Sometimes the way you gather data introduces correlations that will not exist in the real world, which the model exploits. Many other tricky problems can give us a false understanding of performance, even in [doing A/B tests](http://www.exp-platform.com/documents/puzzlingoutcomesincontrolledexperiments.pdf). I am not saying you shouldn't measure accuracy, but simply that it should not be your only metric for assessing trust.
12 |
13 | # Lime: A couple of examples.
14 | First, we give an example from text classification. The famous [20 newsgroups dataset](http://qwone.com/~jason/20Newsgroups/) is a benchmark in the field, and has been used to compare different models in several papers. We take two classes that are suposedly harder to distinguish, due to the fact that they share many words: Christianity and Atheism. Training a random forest with 500 trees, we get a test set accuracy of 92.4%, which is surprisingly high. If accuracy was our only measure of trust, we would definitely trust this algorithm.
15 |
16 | Below is an explanation for an arbitrary instance in the test set, generated using [the lime package](https://github.com/marcotcr/lime).
17 | 
18 | This is a case where the classifier predicts the instance correctly, but for the wrong reasons. A little further exploration shows us that the word "Posting" (part of the email header) appears in 21.6% of the examples in the training set, only two times in the class 'Christianity'. This is repeated on the test set, where it appears in almost 20% of the examples, only twice in 'Christianity'. This kind of quirk in the dataset makes the problem much easier than it is in the real world, where this classifier would **not** be able to distinguish between christianity and atheism documents. This is hard to see just by looking at accuracy or raw data, but easy once explanations are provided. Such insights become common once you understand what models are actually doing, leading to models that generalize much better.
19 |
20 | Note further how interpretable the explanations are: they correspond to a very sparse linear model (with only 6 features). Even though the underlying classifier is a complicated random forest, in the neighborhood of this example it behaves roughly as a linear model. Sure nenough, if we remove the words "Host" and "NNTP" from the example, the "atheism" prediction probability becomes close to 0.57 - 0.14 - 0.12 = 0.31.
21 |
22 | Below is an image from our paper, where we explain Google's [Inception neural network](https://github.com/google/inception) on some arbitary images. In this case, we keep as explanations the parts of the image that are most positive towards a certain class. In this case, the classifier predicts Electric Guitar even though the image contains an acoustic guitar. The explanation reveals why it would confuse the two: the fretboard is very similar. Getting explanations for image classifiers is something that is not yet available in the lime package, but we are working on it.
23 | 
24 |
25 | # Lime: how we get explanations
26 | Lime is short for Local Interpretable Model-Agnostic Explanations. Each part of the name reflects something that we desire in explanations. **Local** refers to local fidelity - i.e., we want the explanation to really reflect the behaviour of the classifier "around" the instance being predicted. This explanation is useless unless it is **interpretable** - that is, unless a human can make sense of it. Lime is able to explain any model without needing to 'peak' into it, so it is **model-agnostic**. We now give a high level overview of how lime works. For more details, check out our [pre-print](http://arxiv.org/pdf/1602.04938v1.pdf).
27 |
28 | First, a word about **interpretability**. Some classifiers use representations that are not intuitive to users at all (e.g. word embeddings). Lime explains those classifiers in terms of interpretable representations (words), even if that is not the representation actually used by the classifier. Further, lime takes human limitations into account: i.e. the explanations are not too long. Right now, our package supports explanations that are sparse linear models (as presented before), although we are working on other representations.
29 |
30 | In order to be **model-agnostic**, lime can't peak into the model. In order to figure out what parts of the interpretable input are contributing to the prediction, we perturb the input around its neighborhood and see how the model's predictions behave. We then weight these perturbed data points by their proximity to the original example, and learn an interpretable model on those and the associated predictions. For example, if we are trying to explain the prediction for the sentence "I hate this movie", we will perturb the sentence and get predictions on sentences such as "I hate movie", "I this movie", "I movie", "I hate", etc. Even if the original classifier takes many more words into account globally, it is reasonable to expect that around this example only the word "hate" will be relevant. Note that if the classifier uses some uninterpretable representation such as word embeddings, this still works: we just represent the perturbed sentences with word embeddings, and the explanation will still be in terms of words such as "hate" or "movie".
31 |
32 | An illustration of this process is given below. The original model's decision function is represented by the blue/pink background, and is clearly nonlinear.
33 | The bright red cross is the instance being explained (let's call it X).
34 | We sample perturbed instances around X, and weight them according to their proximity to X (weight here is represented by size). We get original model's prediction on these perturbed instances, and then learn a linear model (dashed line) that approximates the model well in the vicinity of X. Note that the explanation in this case is not faithful globally, but it is faithful locally around X.
35 | 
36 |
37 | # Conclusion
38 | I hope I've convinced you that understanding individual predictions from classifiers is an important problem. Having explanations lets you make an informed decision about how much you trust the prediction or the model as a whole, and provides insights that can be used to improve the model.
39 |
40 | If you're interested in going more in-depth into how lime works, and the kinds of experiments we did to validate the usefulness of such explanations, [here is a link to our pre-print paper](http://arxiv.org/pdf/1602.04938v1.pdf).
41 |
42 | If you are interested in trying lime for text classifiers, make sure you check out our [python package](https://github.com/marcotcr/lime/). Installation is as simple as typing:
43 | ```pip install lime```
44 | The package is very easy to use. It is particulary easy to explain scikit-learn classifiers. In the github page we also link to a few tutorials, such as [this one](http://marcotcr.github.io/lime/tutorials/Lime%20-%20basic%20usage%2C%20two%20class%20case.html), with examples from scikit-learn.
45 |
46 |
47 |
--------------------------------------------------------------------------------
/doc/conf.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | #
3 | # lime documentation build configuration file, created by
4 | # sphinx-quickstart on Fri Mar 18 16:20:40 2016.
5 | #
6 | # This file is execfile()d with the current directory set to its
7 | # containing dir.
8 | #
9 | # Note that not all possible configuration values are present in this
10 | # autogenerated file.
11 | #
12 | # All configuration values have a default; values that are commented out
13 | # serve to show the default.
14 |
15 | import sys
16 | import os
17 |
18 | # If extensions (or modules to document with autodoc) are in another directory,
19 | # add these directories to sys.path here. If the directory is relative to the
20 | # documentation root, use os.path.abspath to make it absolute, like shown here.
21 | #sys.path.insert(0, os.path.abspath('.'))
22 | curr_path = os.path.dirname(os.path.abspath(os.path.expanduser(__file__)))
23 | libpath = os.path.join(curr_path, '../')
24 | sys.path.insert(0, libpath)
25 | sys.path.insert(0, curr_path)
26 |
27 | import mock
28 | MOCK_MODULES = ['numpy', 'scipy', 'scipy.sparse', 'scipy.special',
29 | 'scipy.stats', 'scipy.stats.distributions', 'sklearn', 'sklearn.preprocessing',
30 | 'sklearn.linear_model', 'matplotlib',
31 | 'sklearn.datasets', 'sklearn.ensemble', 'sklearn.cross_validation',
32 | 'sklearn.feature_extraction', 'sklearn.feature_extraction.text',
33 | 'sklearn.metrics', 'sklearn.naive_bayes', 'sklearn.pipeline',
34 | 'sklearn.utils', 'pyDOE2',]
35 | # for mod_name in MOCK_MODULES:
36 | # sys.modules[mod_name] = mock.Mock()
37 |
38 | import scipy
39 | import scipy.stats
40 | import scipy.stats.distributions
41 | import lime
42 | import lime.lime_text
43 |
44 | import lime.lime_tabular
45 | import lime.explanation
46 | import lime.lime_base
47 | import lime.submodular_pick
48 |
49 | # -- General configuration ------------------------------------------------
50 |
51 | # If your documentation needs a minimal Sphinx version, state it here.
52 | #needs_sphinx = '1.0'
53 |
54 | # Add any Sphinx extension module names here, as strings. They can be
55 | # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
56 | # ones.
57 | extensions = [
58 | 'sphinx.ext.autodoc',
59 | 'sphinx.ext.mathjax',
60 | 'sphinx.ext.napoleon',
61 | ]
62 |
63 | # Add any paths that contain templates here, relative to this directory.
64 | templates_path = ['_templates']
65 |
66 | # The suffix(es) of source filenames.
67 | # You can specify multiple suffix as a list of string:
68 | # source_suffix = ['.rst', '.md']
69 | source_suffix = '.rst'
70 |
71 | # The encoding of source files.
72 | #source_encoding = 'utf-8-sig'
73 |
74 | # The master toctree document.
75 | master_doc = 'index'
76 |
77 | # General information about the project.
78 | project = u'lime'
79 | copyright = u'2016, Marco Tulio Ribeiro'
80 | author = u'Marco Tulio Ribeiro'
81 |
82 | # The version info for the project you're documenting, acts as replacement for
83 | # |version| and |release|, also used in various other places throughout the
84 | # built documents.
85 | #
86 | # The short X.Y version.
87 | version = u'0.1'
88 | # The full version, including alpha/beta/rc tags.
89 | release = u'0.1'
90 |
91 | # The language for content autogenerated by Sphinx. Refer to documentation
92 | # for a list of supported languages.
93 | #
94 | # This is also used if you do content translation via gettext catalogs.
95 | # Usually you set "language" from the command line for these cases.
96 | language = None
97 |
98 | # There are two options for replacing |today|: either, you set today to some
99 | # non-false value, then it is used:
100 | #today = ''
101 | # Else, today_fmt is used as the format for a strftime call.
102 | #today_fmt = '%B %d, %Y'
103 |
104 | # List of patterns, relative to source directory, that match files and
105 | # directories to ignore when looking for source files.
106 | exclude_patterns = ['_build']
107 |
108 | # The reST default role (used for this markup: `text`) to use for all
109 | # documents.
110 | #default_role = None
111 |
112 | # If true, '()' will be appended to :func: etc. cross-reference text.
113 | #add_function_parentheses = True
114 |
115 | # If true, the current module name will be prepended to all description
116 | # unit titles (such as .. function::).
117 | #add_module_names = True
118 |
119 | # If true, sectionauthor and moduleauthor directives will be shown in the
120 | # output. They are ignored by default.
121 | #show_authors = False
122 |
123 | # The name of the Pygments (syntax highlighting) style to use.
124 | pygments_style = 'sphinx'
125 |
126 | # A list of ignored prefixes for module index sorting.
127 | #modindex_common_prefix = []
128 |
129 | # If true, keep warnings as "system message" paragraphs in the built documents.
130 | #keep_warnings = False
131 |
132 | # If true, `todo` and `todoList` produce output, else they produce nothing.
133 | todo_include_todos = False
134 |
135 |
136 | # -- Options for HTML output ----------------------------------------------
137 |
138 | # The theme to use for HTML and HTML Help pages. See the documentation for
139 | # a list of builtin themes.
140 | html_theme = 'default'
141 |
142 | # Theme options are theme-specific and customize the look and feel of a theme
143 | # further. For a list of options available for each theme, see the
144 | # documentation.
145 | #html_theme_options = {}
146 |
147 | # Add any paths that contain custom themes here, relative to this directory.
148 | #html_theme_path = []
149 |
150 | # The name for this set of Sphinx documents. If None, it defaults to
151 | # " v documentation".
152 | #html_title = None
153 |
154 | # A shorter title for the navigation bar. Default is the same as html_title.
155 | #html_short_title = None
156 |
157 | # The name of an image file (relative to this directory) to place at the top
158 | # of the sidebar.
159 | #html_logo = None
160 |
161 | # The name of an image file (relative to this directory) to use as a favicon of
162 | # the docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
163 | # pixels large.
164 | #html_favicon = None
165 |
166 | # Add any paths that contain custom static files (such as style sheets) here,
167 | # relative to this directory. They are copied after the builtin static files,
168 | # so a file named "default.css" will overwrite the builtin "default.css".
169 | html_static_path = ['_static']
170 |
171 | # Add any extra paths that contain custom files (such as robots.txt or
172 | # .htaccess) here, relative to this directory. These files are copied
173 | # directly to the root of the documentation.
174 | #html_extra_path = []
175 |
176 | # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
177 | # using the given strftime format.
178 | #html_last_updated_fmt = '%b %d, %Y'
179 |
180 | # If true, SmartyPants will be used to convert quotes and dashes to
181 | # typographically correct entities.
182 | #html_use_smartypants = True
183 |
184 | # Custom sidebar templates, maps document names to template names.
185 | #html_sidebars = {}
186 |
187 | # Additional templates that should be rendered to pages, maps page names to
188 | # template names.
189 | #html_additional_pages = {}
190 |
191 | # If false, no module index is generated.
192 | #html_domain_indices = True
193 |
194 | # If false, no index is generated.
195 | #html_use_index = True
196 |
197 | # If true, the index is split into individual pages for each letter.
198 | #html_split_index = False
199 |
200 | # If true, links to the reST sources are added to the pages.
201 | #html_show_sourcelink = True
202 |
203 | # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
204 | #html_show_sphinx = True
205 |
206 | # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
207 | #html_show_copyright = True
208 |
209 | # If true, an OpenSearch description file will be output, and all pages will
210 | # contain a tag referring to it. The value of this option must be the
211 | # base URL from which the finished HTML is served.
212 | #html_use_opensearch = ''
213 |
214 | # This is the file name suffix for HTML files (e.g. ".xhtml").
215 | #html_file_suffix = None
216 |
217 | # Language to be used for generating the HTML full-text search index.
218 | # Sphinx supports the following languages:
219 | # 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'
220 | # 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'
221 | #html_search_language = 'en'
222 |
223 | # A dictionary with options for the search language support, empty by default.
224 | # Now only 'ja' uses this config value
225 | #html_search_options = {'type': 'default'}
226 |
227 | # The name of a javascript file (relative to the configuration directory) that
228 | # implements a search results scorer. If empty, the default will be used.
229 | #html_search_scorer = 'scorer.js'
230 |
231 | # Output file base name for HTML help builder.
232 | htmlhelp_basename = 'limedoc'
233 |
234 | # -- Options for LaTeX output ---------------------------------------------
235 |
236 | latex_elements = {
237 | # The paper size ('letterpaper' or 'a4paper').
238 | #'papersize': 'letterpaper',
239 |
240 | # The font size ('10pt', '11pt' or '12pt').
241 | #'pointsize': '10pt',
242 |
243 | # Additional stuff for the LaTeX preamble.
244 | #'preamble': '',
245 |
246 | # Latex figure (float) alignment
247 | #'figure_align': 'htbp',
248 | }
249 |
250 | # Grouping the document tree into LaTeX files. List of tuples
251 | # (source start file, target name, title,
252 | # author, documentclass [howto, manual, or own class]).
253 | latex_documents = [
254 | (master_doc, 'lime.tex', u'lime Documentation',
255 | u'Marco Tulio Ribeiro', 'manual'),
256 | ]
257 |
258 | # The name of an image file (relative to this directory) to place at the top of
259 | # the title page.
260 | #latex_logo = None
261 |
262 | # For "manual" documents, if this is true, then toplevel headings are parts,
263 | # not chapters.
264 | #latex_use_parts = False
265 |
266 | # If true, show page references after internal links.
267 | #latex_show_pagerefs = False
268 |
269 | # If true, show URL addresses after external links.
270 | #latex_show_urls = False
271 |
272 | # Documents to append as an appendix to all manuals.
273 | #latex_appendices = []
274 |
275 | # If false, no module index is generated.
276 | #latex_domain_indices = True
277 |
278 |
279 | # -- Options for manual page output ---------------------------------------
280 |
281 | # One entry per manual page. List of tuples
282 | # (source start file, name, description, authors, manual section).
283 | man_pages = [
284 | (master_doc, 'lime', u'lime Documentation',
285 | [author], 1)
286 | ]
287 |
288 | # If true, show URL addresses after external links.
289 | #man_show_urls = False
290 |
291 |
292 | # -- Options for Texinfo output -------------------------------------------
293 |
294 | # Grouping the document tree into Texinfo files. List of tuples
295 | # (source start file, target name, title, author,
296 | # dir menu entry, description, category)
297 | texinfo_documents = [
298 | (master_doc, 'lime', u'lime Documentation',
299 | author, 'lime', 'One line description of project.',
300 | 'Miscellaneous'),
301 | ]
302 |
303 | autoclass_content = 'both'
304 | # Documents to append as an appendix to all manuals.
305 | #texinfo_appendices = []
306 |
307 | # If false, no module index is generated.
308 | #texinfo_domain_indices = True
309 |
310 | # How to display URL addresses: 'footnote', 'no', or 'inline'.
311 | #texinfo_show_urls = 'footnote'
312 |
313 | # If true, do not generate a @detailmenu in the "Top" node's menu.
314 | #texinfo_no_detailmenu = False
315 |
--------------------------------------------------------------------------------
/doc/images/image_from_paper.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/image_from_paper.png
--------------------------------------------------------------------------------
/doc/images/images.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/images.png
--------------------------------------------------------------------------------
/doc/images/lime.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/lime.png
--------------------------------------------------------------------------------
/doc/images/multiclass.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/multiclass.png
--------------------------------------------------------------------------------
/doc/images/tabular.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/tabular.png
--------------------------------------------------------------------------------
/doc/images/twoclass.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/twoclass.png
--------------------------------------------------------------------------------
/doc/images/video_screenshot.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/video_screenshot.png
--------------------------------------------------------------------------------
/doc/index.rst:
--------------------------------------------------------------------------------
1 | .. lime documentation master file, created by
2 | sphinx-quickstart on Fri Mar 18 16:20:40 2016.
3 | You can adapt this file completely to your liking, but it should at least
4 | contain the root `toctree` directive.
5 |
6 | Local Interpretable Model-Agnostic Explanations (lime)
7 | ================================
8 | In this page, you can find the Python API reference for the lime package (local interpretable model-agnostic explanations).
9 | For tutorials and more information, visit `the github page `_.
10 |
11 |
12 | .. toctree::
13 | :maxdepth: 2
14 |
15 | lime
16 |
17 |
18 |
19 | Indices and tables
20 | ==================
21 |
22 | * :ref:`genindex`
23 | * :ref:`modindex`
24 | * :ref:`search`
25 |
26 |
--------------------------------------------------------------------------------
/doc/lime.rst:
--------------------------------------------------------------------------------
1 | lime package
2 | ============
3 |
4 | Subpackages
5 | -----------
6 |
7 | .. toctree::
8 |
9 | lime.tests
10 |
11 | Submodules
12 | ----------
13 |
14 | lime\.discretize module
15 | -----------------------
16 |
17 | .. automodule:: lime.discretize
18 | :members:
19 | :undoc-members:
20 | :show-inheritance:
21 |
22 | lime\.exceptions module
23 | -----------------------
24 |
25 | .. automodule:: lime.exceptions
26 | :members:
27 | :undoc-members:
28 | :show-inheritance:
29 |
30 | lime\.explanation module
31 | ------------------------
32 |
33 | .. automodule:: lime.explanation
34 | :members:
35 | :undoc-members:
36 | :show-inheritance:
37 |
38 | lime\.lime\_base module
39 | -----------------------
40 |
41 | .. automodule:: lime.lime_base
42 | :members:
43 | :undoc-members:
44 | :show-inheritance:
45 |
46 | lime\.lime\_image module
47 | ------------------------
48 |
49 | .. automodule:: lime.lime_image
50 | :members:
51 | :undoc-members:
52 | :show-inheritance:
53 |
54 | lime\.lime\_tabular module
55 | --------------------------
56 |
57 | .. automodule:: lime.lime_tabular
58 | :members:
59 | :undoc-members:
60 | :show-inheritance:
61 |
62 | lime\.lime\_text module
63 | -----------------------
64 |
65 | .. automodule:: lime.lime_text
66 | :members:
67 | :undoc-members:
68 | :show-inheritance:
69 |
70 |
71 | lime\.submodular\_pick module
72 | -----------------------
73 |
74 | .. automodule:: lime.submodular_pick
75 | :members:
76 | :undoc-members:
77 | :show-inheritance:
78 |
79 |
80 | Module contents
81 | ---------------
82 |
83 | .. automodule:: lime
84 | :members:
85 | :undoc-members:
86 | :show-inheritance:
87 |
--------------------------------------------------------------------------------
/doc/notebooks/data/cat_mouse.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/notebooks/data/cat_mouse.jpg
--------------------------------------------------------------------------------
/doc/notebooks/data/dogs.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/notebooks/data/dogs.png
--------------------------------------------------------------------------------
/doc/notebooks/data/imagenet_class_index.json:
--------------------------------------------------------------------------------
1 | {"0": ["n01440764", "tench"], "1": ["n01443537", "goldfish"], "2": ["n01484850", "great_white_shark"], "3": ["n01491361", "tiger_shark"], "4": ["n01494475", "hammerhead"], "5": ["n01496331", "electric_ray"], "6": ["n01498041", "stingray"], "7": ["n01514668", "cock"], "8": ["n01514859", "hen"], "9": ["n01518878", "ostrich"], "10": ["n01530575", "brambling"], "11": ["n01531178", "goldfinch"], "12": ["n01532829", "house_finch"], "13": ["n01534433", "junco"], "14": ["n01537544", "indigo_bunting"], "15": ["n01558993", "robin"], "16": ["n01560419", "bulbul"], "17": ["n01580077", "jay"], "18": ["n01582220", "magpie"], "19": ["n01592084", "chickadee"], "20": ["n01601694", "water_ouzel"], "21": ["n01608432", "kite"], "22": ["n01614925", "bald_eagle"], "23": ["n01616318", "vulture"], "24": ["n01622779", "great_grey_owl"], "25": ["n01629819", "European_fire_salamander"], "26": ["n01630670", "common_newt"], "27": ["n01631663", "eft"], "28": ["n01632458", "spotted_salamander"], "29": ["n01632777", "axolotl"], "30": ["n01641577", "bullfrog"], "31": ["n01644373", "tree_frog"], "32": ["n01644900", "tailed_frog"], "33": ["n01664065", "loggerhead"], "34": ["n01665541", "leatherback_turtle"], "35": ["n01667114", "mud_turtle"], "36": ["n01667778", "terrapin"], "37": ["n01669191", "box_turtle"], "38": ["n01675722", "banded_gecko"], "39": ["n01677366", "common_iguana"], "40": ["n01682714", "American_chameleon"], "41": ["n01685808", "whiptail"], "42": ["n01687978", "agama"], "43": ["n01688243", "frilled_lizard"], "44": ["n01689811", "alligator_lizard"], "45": ["n01692333", "Gila_monster"], "46": ["n01693334", "green_lizard"], "47": ["n01694178", "African_chameleon"], "48": ["n01695060", "Komodo_dragon"], "49": ["n01697457", "African_crocodile"], "50": ["n01698640", "American_alligator"], "51": ["n01704323", "triceratops"], "52": ["n01728572", "thunder_snake"], "53": ["n01728920", "ringneck_snake"], "54": ["n01729322", "hognose_snake"], "55": ["n01729977", "green_snake"], "56": ["n01734418", "king_snake"], "57": ["n01735189", "garter_snake"], "58": ["n01737021", "water_snake"], "59": ["n01739381", "vine_snake"], "60": ["n01740131", "night_snake"], "61": ["n01742172", "boa_constrictor"], "62": ["n01744401", "rock_python"], "63": ["n01748264", "Indian_cobra"], "64": ["n01749939", "green_mamba"], "65": ["n01751748", "sea_snake"], "66": ["n01753488", "horned_viper"], "67": ["n01755581", "diamondback"], "68": ["n01756291", "sidewinder"], "69": ["n01768244", "trilobite"], "70": ["n01770081", "harvestman"], "71": ["n01770393", "scorpion"], "72": ["n01773157", "black_and_gold_garden_spider"], "73": ["n01773549", "barn_spider"], "74": ["n01773797", "garden_spider"], "75": ["n01774384", "black_widow"], "76": ["n01774750", "tarantula"], "77": ["n01775062", "wolf_spider"], "78": ["n01776313", "tick"], "79": ["n01784675", "centipede"], "80": ["n01795545", "black_grouse"], "81": ["n01796340", "ptarmigan"], "82": ["n01797886", "ruffed_grouse"], "83": ["n01798484", "prairie_chicken"], "84": ["n01806143", "peacock"], "85": ["n01806567", "quail"], "86": ["n01807496", "partridge"], "87": ["n01817953", "African_grey"], "88": ["n01818515", "macaw"], "89": ["n01819313", "sulphur-crested_cockatoo"], "90": ["n01820546", "lorikeet"], "91": ["n01824575", "coucal"], "92": ["n01828970", "bee_eater"], "93": ["n01829413", "hornbill"], "94": ["n01833805", "hummingbird"], "95": ["n01843065", "jacamar"], "96": ["n01843383", "toucan"], "97": ["n01847000", "drake"], "98": ["n01855032", "red-breasted_merganser"], "99": ["n01855672", "goose"], "100": ["n01860187", "black_swan"], "101": ["n01871265", "tusker"], "102": ["n01872401", "echidna"], "103": ["n01873310", "platypus"], "104": ["n01877812", "wallaby"], "105": ["n01882714", "koala"], "106": ["n01883070", "wombat"], "107": ["n01910747", "jellyfish"], "108": ["n01914609", "sea_anemone"], "109": ["n01917289", "brain_coral"], "110": ["n01924916", "flatworm"], "111": ["n01930112", "nematode"], "112": ["n01943899", "conch"], "113": ["n01944390", "snail"], "114": ["n01945685", "slug"], "115": ["n01950731", "sea_slug"], "116": ["n01955084", "chiton"], "117": ["n01968897", "chambered_nautilus"], "118": ["n01978287", "Dungeness_crab"], "119": ["n01978455", "rock_crab"], "120": ["n01980166", "fiddler_crab"], "121": ["n01981276", "king_crab"], "122": ["n01983481", "American_lobster"], "123": ["n01984695", "spiny_lobster"], "124": ["n01985128", "crayfish"], "125": ["n01986214", "hermit_crab"], "126": ["n01990800", "isopod"], "127": ["n02002556", "white_stork"], "128": ["n02002724", "black_stork"], "129": ["n02006656", "spoonbill"], "130": ["n02007558", "flamingo"], "131": ["n02009229", "little_blue_heron"], "132": ["n02009912", "American_egret"], "133": ["n02011460", "bittern"], "134": ["n02012849", "crane"], "135": ["n02013706", "limpkin"], "136": ["n02017213", "European_gallinule"], "137": ["n02018207", "American_coot"], "138": ["n02018795", "bustard"], "139": ["n02025239", "ruddy_turnstone"], "140": ["n02027492", "red-backed_sandpiper"], "141": ["n02028035", "redshank"], "142": ["n02033041", "dowitcher"], "143": ["n02037110", "oystercatcher"], "144": ["n02051845", "pelican"], "145": ["n02056570", "king_penguin"], "146": ["n02058221", "albatross"], "147": ["n02066245", "grey_whale"], "148": ["n02071294", "killer_whale"], "149": ["n02074367", "dugong"], "150": ["n02077923", "sea_lion"], "151": ["n02085620", "Chihuahua"], "152": ["n02085782", "Japanese_spaniel"], "153": ["n02085936", "Maltese_dog"], "154": ["n02086079", "Pekinese"], "155": ["n02086240", "Shih-Tzu"], "156": ["n02086646", "Blenheim_spaniel"], "157": ["n02086910", "papillon"], "158": ["n02087046", "toy_terrier"], "159": ["n02087394", "Rhodesian_ridgeback"], "160": ["n02088094", "Afghan_hound"], "161": ["n02088238", "basset"], "162": ["n02088364", "beagle"], "163": ["n02088466", "bloodhound"], "164": ["n02088632", "bluetick"], "165": ["n02089078", "black-and-tan_coonhound"], "166": ["n02089867", "Walker_hound"], "167": ["n02089973", "English_foxhound"], "168": ["n02090379", "redbone"], "169": ["n02090622", "borzoi"], "170": ["n02090721", "Irish_wolfhound"], "171": ["n02091032", "Italian_greyhound"], "172": ["n02091134", "whippet"], "173": ["n02091244", "Ibizan_hound"], "174": ["n02091467", "Norwegian_elkhound"], "175": ["n02091635", "otterhound"], "176": ["n02091831", "Saluki"], "177": ["n02092002", "Scottish_deerhound"], "178": ["n02092339", "Weimaraner"], "179": ["n02093256", "Staffordshire_bullterrier"], "180": ["n02093428", "American_Staffordshire_terrier"], "181": ["n02093647", "Bedlington_terrier"], "182": ["n02093754", "Border_terrier"], "183": ["n02093859", "Kerry_blue_terrier"], "184": ["n02093991", "Irish_terrier"], "185": ["n02094114", "Norfolk_terrier"], "186": ["n02094258", "Norwich_terrier"], "187": ["n02094433", "Yorkshire_terrier"], "188": ["n02095314", "wire-haired_fox_terrier"], "189": ["n02095570", "Lakeland_terrier"], "190": ["n02095889", "Sealyham_terrier"], "191": ["n02096051", "Airedale"], "192": ["n02096177", "cairn"], "193": ["n02096294", "Australian_terrier"], "194": ["n02096437", "Dandie_Dinmont"], "195": ["n02096585", "Boston_bull"], "196": ["n02097047", "miniature_schnauzer"], "197": ["n02097130", "giant_schnauzer"], "198": ["n02097209", "standard_schnauzer"], "199": ["n02097298", "Scotch_terrier"], "200": ["n02097474", "Tibetan_terrier"], "201": ["n02097658", "silky_terrier"], "202": ["n02098105", "soft-coated_wheaten_terrier"], "203": ["n02098286", "West_Highland_white_terrier"], "204": ["n02098413", "Lhasa"], "205": ["n02099267", "flat-coated_retriever"], "206": ["n02099429", "curly-coated_retriever"], "207": ["n02099601", "golden_retriever"], "208": ["n02099712", "Labrador_retriever"], "209": ["n02099849", "Chesapeake_Bay_retriever"], "210": ["n02100236", "German_short-haired_pointer"], "211": ["n02100583", "vizsla"], "212": ["n02100735", "English_setter"], "213": ["n02100877", "Irish_setter"], "214": ["n02101006", "Gordon_setter"], "215": ["n02101388", "Brittany_spaniel"], "216": ["n02101556", "clumber"], "217": ["n02102040", "English_springer"], "218": ["n02102177", "Welsh_springer_spaniel"], "219": ["n02102318", "cocker_spaniel"], "220": ["n02102480", "Sussex_spaniel"], "221": ["n02102973", "Irish_water_spaniel"], "222": ["n02104029", "kuvasz"], "223": ["n02104365", "schipperke"], "224": ["n02105056", "groenendael"], "225": ["n02105162", "malinois"], "226": ["n02105251", "briard"], "227": ["n02105412", "kelpie"], "228": ["n02105505", "komondor"], "229": ["n02105641", "Old_English_sheepdog"], "230": ["n02105855", "Shetland_sheepdog"], "231": ["n02106030", "collie"], "232": ["n02106166", "Border_collie"], "233": ["n02106382", "Bouvier_des_Flandres"], "234": ["n02106550", "Rottweiler"], "235": ["n02106662", "German_shepherd"], "236": ["n02107142", "Doberman"], "237": ["n02107312", "miniature_pinscher"], "238": ["n02107574", "Greater_Swiss_Mountain_dog"], "239": ["n02107683", "Bernese_mountain_dog"], "240": ["n02107908", "Appenzeller"], "241": ["n02108000", "EntleBucher"], "242": ["n02108089", "boxer"], "243": ["n02108422", "bull_mastiff"], "244": ["n02108551", "Tibetan_mastiff"], "245": ["n02108915", "French_bulldog"], "246": ["n02109047", "Great_Dane"], "247": ["n02109525", "Saint_Bernard"], "248": ["n02109961", "Eskimo_dog"], "249": ["n02110063", "malamute"], "250": ["n02110185", "Siberian_husky"], "251": ["n02110341", "dalmatian"], "252": ["n02110627", "affenpinscher"], "253": ["n02110806", "basenji"], "254": ["n02110958", "pug"], "255": ["n02111129", "Leonberg"], "256": ["n02111277", "Newfoundland"], "257": ["n02111500", "Great_Pyrenees"], "258": ["n02111889", "Samoyed"], "259": ["n02112018", "Pomeranian"], "260": ["n02112137", "chow"], "261": ["n02112350", "keeshond"], "262": ["n02112706", "Brabancon_griffon"], "263": ["n02113023", "Pembroke"], "264": ["n02113186", "Cardigan"], "265": ["n02113624", "toy_poodle"], "266": ["n02113712", "miniature_poodle"], "267": ["n02113799", "standard_poodle"], "268": ["n02113978", "Mexican_hairless"], "269": ["n02114367", "timber_wolf"], "270": ["n02114548", "white_wolf"], "271": ["n02114712", "red_wolf"], "272": ["n02114855", "coyote"], "273": ["n02115641", "dingo"], "274": ["n02115913", "dhole"], "275": ["n02116738", "African_hunting_dog"], "276": ["n02117135", "hyena"], "277": ["n02119022", "red_fox"], "278": ["n02119789", "kit_fox"], "279": ["n02120079", "Arctic_fox"], "280": ["n02120505", "grey_fox"], "281": ["n02123045", "tabby"], "282": ["n02123159", "tiger_cat"], "283": ["n02123394", "Persian_cat"], "284": ["n02123597", "Siamese_cat"], "285": ["n02124075", "Egyptian_cat"], "286": ["n02125311", "cougar"], "287": ["n02127052", "lynx"], "288": ["n02128385", "leopard"], "289": ["n02128757", "snow_leopard"], "290": ["n02128925", "jaguar"], "291": ["n02129165", "lion"], "292": ["n02129604", "tiger"], "293": ["n02130308", "cheetah"], "294": ["n02132136", "brown_bear"], "295": ["n02133161", "American_black_bear"], "296": ["n02134084", "ice_bear"], "297": ["n02134418", "sloth_bear"], "298": ["n02137549", "mongoose"], "299": ["n02138441", "meerkat"], "300": ["n02165105", "tiger_beetle"], "301": ["n02165456", "ladybug"], "302": ["n02167151", "ground_beetle"], "303": ["n02168699", "long-horned_beetle"], "304": ["n02169497", "leaf_beetle"], "305": ["n02172182", "dung_beetle"], "306": ["n02174001", "rhinoceros_beetle"], "307": ["n02177972", "weevil"], "308": ["n02190166", "fly"], "309": ["n02206856", "bee"], "310": ["n02219486", "ant"], "311": ["n02226429", "grasshopper"], "312": ["n02229544", "cricket"], "313": ["n02231487", "walking_stick"], "314": ["n02233338", "cockroach"], "315": ["n02236044", "mantis"], "316": ["n02256656", "cicada"], "317": ["n02259212", "leafhopper"], "318": ["n02264363", "lacewing"], "319": ["n02268443", "dragonfly"], "320": ["n02268853", "damselfly"], "321": ["n02276258", "admiral"], "322": ["n02277742", "ringlet"], "323": ["n02279972", "monarch"], "324": ["n02280649", "cabbage_butterfly"], "325": ["n02281406", "sulphur_butterfly"], "326": ["n02281787", "lycaenid"], "327": ["n02317335", "starfish"], "328": ["n02319095", "sea_urchin"], "329": ["n02321529", "sea_cucumber"], "330": ["n02325366", "wood_rabbit"], "331": ["n02326432", "hare"], "332": ["n02328150", "Angora"], "333": ["n02342885", "hamster"], "334": ["n02346627", "porcupine"], "335": ["n02356798", "fox_squirrel"], "336": ["n02361337", "marmot"], "337": ["n02363005", "beaver"], "338": ["n02364673", "guinea_pig"], "339": ["n02389026", "sorrel"], "340": ["n02391049", "zebra"], "341": ["n02395406", "hog"], "342": ["n02396427", "wild_boar"], "343": ["n02397096", "warthog"], "344": ["n02398521", "hippopotamus"], "345": ["n02403003", "ox"], "346": ["n02408429", "water_buffalo"], "347": ["n02410509", "bison"], "348": ["n02412080", "ram"], "349": ["n02415577", "bighorn"], "350": ["n02417914", "ibex"], "351": ["n02422106", "hartebeest"], "352": ["n02422699", "impala"], "353": ["n02423022", "gazelle"], "354": ["n02437312", "Arabian_camel"], "355": ["n02437616", "llama"], "356": ["n02441942", "weasel"], "357": ["n02442845", "mink"], "358": ["n02443114", "polecat"], "359": ["n02443484", "black-footed_ferret"], "360": ["n02444819", "otter"], "361": ["n02445715", "skunk"], "362": ["n02447366", "badger"], "363": ["n02454379", "armadillo"], "364": ["n02457408", "three-toed_sloth"], "365": ["n02480495", "orangutan"], "366": ["n02480855", "gorilla"], "367": ["n02481823", "chimpanzee"], "368": ["n02483362", "gibbon"], "369": ["n02483708", "siamang"], "370": ["n02484975", "guenon"], "371": ["n02486261", "patas"], "372": ["n02486410", "baboon"], "373": ["n02487347", "macaque"], "374": ["n02488291", "langur"], "375": ["n02488702", "colobus"], "376": ["n02489166", "proboscis_monkey"], "377": ["n02490219", "marmoset"], "378": ["n02492035", "capuchin"], "379": ["n02492660", "howler_monkey"], "380": ["n02493509", "titi"], "381": ["n02493793", "spider_monkey"], "382": ["n02494079", "squirrel_monkey"], "383": ["n02497673", "Madagascar_cat"], "384": ["n02500267", "indri"], "385": ["n02504013", "Indian_elephant"], "386": ["n02504458", "African_elephant"], "387": ["n02509815", "lesser_panda"], "388": ["n02510455", "giant_panda"], "389": ["n02514041", "barracouta"], "390": ["n02526121", "eel"], "391": ["n02536864", "coho"], "392": ["n02606052", "rock_beauty"], "393": ["n02607072", "anemone_fish"], "394": ["n02640242", "sturgeon"], "395": ["n02641379", "gar"], "396": ["n02643566", "lionfish"], "397": ["n02655020", "puffer"], "398": ["n02666196", "abacus"], "399": ["n02667093", "abaya"], "400": ["n02669723", "academic_gown"], "401": ["n02672831", "accordion"], "402": ["n02676566", "acoustic_guitar"], "403": ["n02687172", "aircraft_carrier"], "404": ["n02690373", "airliner"], "405": ["n02692877", "airship"], "406": ["n02699494", "altar"], "407": ["n02701002", "ambulance"], "408": ["n02704792", "amphibian"], "409": ["n02708093", "analog_clock"], "410": ["n02727426", "apiary"], "411": ["n02730930", "apron"], "412": ["n02747177", "ashcan"], "413": ["n02749479", "assault_rifle"], "414": ["n02769748", "backpack"], "415": ["n02776631", "bakery"], "416": ["n02777292", "balance_beam"], "417": ["n02782093", "balloon"], "418": ["n02783161", "ballpoint"], "419": ["n02786058", "Band_Aid"], "420": ["n02787622", "banjo"], "421": ["n02788148", "bannister"], "422": ["n02790996", "barbell"], "423": ["n02791124", "barber_chair"], "424": ["n02791270", "barbershop"], "425": ["n02793495", "barn"], "426": ["n02794156", "barometer"], "427": ["n02795169", "barrel"], "428": ["n02797295", "barrow"], "429": ["n02799071", "baseball"], "430": ["n02802426", "basketball"], "431": ["n02804414", "bassinet"], "432": ["n02804610", "bassoon"], "433": ["n02807133", "bathing_cap"], "434": ["n02808304", "bath_towel"], "435": ["n02808440", "bathtub"], "436": ["n02814533", "beach_wagon"], "437": ["n02814860", "beacon"], "438": ["n02815834", "beaker"], "439": ["n02817516", "bearskin"], "440": ["n02823428", "beer_bottle"], "441": ["n02823750", "beer_glass"], "442": ["n02825657", "bell_cote"], "443": ["n02834397", "bib"], "444": ["n02835271", "bicycle-built-for-two"], "445": ["n02837789", "bikini"], "446": ["n02840245", "binder"], "447": ["n02841315", "binoculars"], "448": ["n02843684", "birdhouse"], "449": ["n02859443", "boathouse"], "450": ["n02860847", "bobsled"], "451": ["n02865351", "bolo_tie"], "452": ["n02869837", "bonnet"], "453": ["n02870880", "bookcase"], "454": ["n02871525", "bookshop"], "455": ["n02877765", "bottlecap"], "456": ["n02879718", "bow"], "457": ["n02883205", "bow_tie"], "458": ["n02892201", "brass"], "459": ["n02892767", "brassiere"], "460": ["n02894605", "breakwater"], "461": ["n02895154", "breastplate"], "462": ["n02906734", "broom"], "463": ["n02909870", "bucket"], "464": ["n02910353", "buckle"], "465": ["n02916936", "bulletproof_vest"], "466": ["n02917067", "bullet_train"], "467": ["n02927161", "butcher_shop"], "468": ["n02930766", "cab"], "469": ["n02939185", "caldron"], "470": ["n02948072", "candle"], "471": ["n02950826", "cannon"], "472": ["n02951358", "canoe"], "473": ["n02951585", "can_opener"], "474": ["n02963159", "cardigan"], "475": ["n02965783", "car_mirror"], "476": ["n02966193", "carousel"], "477": ["n02966687", "carpenter's_kit"], "478": ["n02971356", "carton"], "479": ["n02974003", "car_wheel"], "480": ["n02977058", "cash_machine"], "481": ["n02978881", "cassette"], "482": ["n02979186", "cassette_player"], "483": ["n02980441", "castle"], "484": ["n02981792", "catamaran"], "485": ["n02988304", "CD_player"], "486": ["n02992211", "cello"], "487": ["n02992529", "cellular_telephone"], "488": ["n02999410", "chain"], "489": ["n03000134", "chainlink_fence"], "490": ["n03000247", "chain_mail"], "491": ["n03000684", "chain_saw"], "492": ["n03014705", "chest"], "493": ["n03016953", "chiffonier"], "494": ["n03017168", "chime"], "495": ["n03018349", "china_cabinet"], "496": ["n03026506", "Christmas_stocking"], "497": ["n03028079", "church"], "498": ["n03032252", "cinema"], "499": ["n03041632", "cleaver"], "500": ["n03042490", "cliff_dwelling"], "501": ["n03045698", "cloak"], "502": ["n03047690", "clog"], "503": ["n03062245", "cocktail_shaker"], "504": ["n03063599", "coffee_mug"], "505": ["n03063689", "coffeepot"], "506": ["n03065424", "coil"], "507": ["n03075370", "combination_lock"], "508": ["n03085013", "computer_keyboard"], "509": ["n03089624", "confectionery"], "510": ["n03095699", "container_ship"], "511": ["n03100240", "convertible"], "512": ["n03109150", "corkscrew"], "513": ["n03110669", "cornet"], "514": ["n03124043", "cowboy_boot"], "515": ["n03124170", "cowboy_hat"], "516": ["n03125729", "cradle"], "517": ["n03126707", "crane"], "518": ["n03127747", "crash_helmet"], "519": ["n03127925", "crate"], "520": ["n03131574", "crib"], "521": ["n03133878", "Crock_Pot"], "522": ["n03134739", "croquet_ball"], "523": ["n03141823", "crutch"], "524": ["n03146219", "cuirass"], "525": ["n03160309", "dam"], "526": ["n03179701", "desk"], "527": ["n03180011", "desktop_computer"], "528": ["n03187595", "dial_telephone"], "529": ["n03188531", "diaper"], "530": ["n03196217", "digital_clock"], "531": ["n03197337", "digital_watch"], "532": ["n03201208", "dining_table"], "533": ["n03207743", "dishrag"], "534": ["n03207941", "dishwasher"], "535": ["n03208938", "disk_brake"], "536": ["n03216828", "dock"], "537": ["n03218198", "dogsled"], "538": ["n03220513", "dome"], "539": ["n03223299", "doormat"], "540": ["n03240683", "drilling_platform"], "541": ["n03249569", "drum"], "542": ["n03250847", "drumstick"], "543": ["n03255030", "dumbbell"], "544": ["n03259280", "Dutch_oven"], "545": ["n03271574", "electric_fan"], "546": ["n03272010", "electric_guitar"], "547": ["n03272562", "electric_locomotive"], "548": ["n03290653", "entertainment_center"], "549": ["n03291819", "envelope"], "550": ["n03297495", "espresso_maker"], "551": ["n03314780", "face_powder"], "552": ["n03325584", "feather_boa"], "553": ["n03337140", "file"], "554": ["n03344393", "fireboat"], "555": ["n03345487", "fire_engine"], "556": ["n03347037", "fire_screen"], "557": ["n03355925", "flagpole"], "558": ["n03372029", "flute"], "559": ["n03376595", "folding_chair"], "560": ["n03379051", "football_helmet"], "561": ["n03384352", "forklift"], "562": ["n03388043", "fountain"], "563": ["n03388183", "fountain_pen"], "564": ["n03388549", "four-poster"], "565": ["n03393912", "freight_car"], "566": ["n03394916", "French_horn"], "567": ["n03400231", "frying_pan"], "568": ["n03404251", "fur_coat"], "569": ["n03417042", "garbage_truck"], "570": ["n03424325", "gasmask"], "571": ["n03425413", "gas_pump"], "572": ["n03443371", "goblet"], "573": ["n03444034", "go-kart"], "574": ["n03445777", "golf_ball"], "575": ["n03445924", "golfcart"], "576": ["n03447447", "gondola"], "577": ["n03447721", "gong"], "578": ["n03450230", "gown"], "579": ["n03452741", "grand_piano"], "580": ["n03457902", "greenhouse"], "581": ["n03459775", "grille"], "582": ["n03461385", "grocery_store"], "583": ["n03467068", "guillotine"], "584": ["n03476684", "hair_slide"], "585": ["n03476991", "hair_spray"], "586": ["n03478589", "half_track"], "587": ["n03481172", "hammer"], "588": ["n03482405", "hamper"], "589": ["n03483316", "hand_blower"], "590": ["n03485407", "hand-held_computer"], "591": ["n03485794", "handkerchief"], "592": ["n03492542", "hard_disc"], "593": ["n03494278", "harmonica"], "594": ["n03495258", "harp"], "595": ["n03496892", "harvester"], "596": ["n03498962", "hatchet"], "597": ["n03527444", "holster"], "598": ["n03529860", "home_theater"], "599": ["n03530642", "honeycomb"], "600": ["n03532672", "hook"], "601": ["n03534580", "hoopskirt"], "602": ["n03535780", "horizontal_bar"], "603": ["n03538406", "horse_cart"], "604": ["n03544143", "hourglass"], "605": ["n03584254", "iPod"], "606": ["n03584829", "iron"], "607": ["n03590841", "jack-o'-lantern"], "608": ["n03594734", "jean"], "609": ["n03594945", "jeep"], "610": ["n03595614", "jersey"], "611": ["n03598930", "jigsaw_puzzle"], "612": ["n03599486", "jinrikisha"], "613": ["n03602883", "joystick"], "614": ["n03617480", "kimono"], "615": ["n03623198", "knee_pad"], "616": ["n03627232", "knot"], "617": ["n03630383", "lab_coat"], "618": ["n03633091", "ladle"], "619": ["n03637318", "lampshade"], "620": ["n03642806", "laptop"], "621": ["n03649909", "lawn_mower"], "622": ["n03657121", "lens_cap"], "623": ["n03658185", "letter_opener"], "624": ["n03661043", "library"], "625": ["n03662601", "lifeboat"], "626": ["n03666591", "lighter"], "627": ["n03670208", "limousine"], "628": ["n03673027", "liner"], "629": ["n03676483", "lipstick"], "630": ["n03680355", "Loafer"], "631": ["n03690938", "lotion"], "632": ["n03691459", "loudspeaker"], "633": ["n03692522", "loupe"], "634": ["n03697007", "lumbermill"], "635": ["n03706229", "magnetic_compass"], "636": ["n03709823", "mailbag"], "637": ["n03710193", "mailbox"], "638": ["n03710637", "maillot"], "639": ["n03710721", "maillot"], "640": ["n03717622", "manhole_cover"], "641": ["n03720891", "maraca"], "642": ["n03721384", "marimba"], "643": ["n03724870", "mask"], "644": ["n03729826", "matchstick"], "645": ["n03733131", "maypole"], "646": ["n03733281", "maze"], "647": ["n03733805", "measuring_cup"], "648": ["n03742115", "medicine_chest"], "649": ["n03743016", "megalith"], "650": ["n03759954", "microphone"], "651": ["n03761084", "microwave"], "652": ["n03763968", "military_uniform"], "653": ["n03764736", "milk_can"], "654": ["n03769881", "minibus"], "655": ["n03770439", "miniskirt"], "656": ["n03770679", "minivan"], "657": ["n03773504", "missile"], "658": ["n03775071", "mitten"], "659": ["n03775546", "mixing_bowl"], "660": ["n03776460", "mobile_home"], "661": ["n03777568", "Model_T"], "662": ["n03777754", "modem"], "663": ["n03781244", "monastery"], "664": ["n03782006", "monitor"], "665": ["n03785016", "moped"], "666": ["n03786901", "mortar"], "667": ["n03787032", "mortarboard"], "668": ["n03788195", "mosque"], "669": ["n03788365", "mosquito_net"], "670": ["n03791053", "motor_scooter"], "671": ["n03792782", "mountain_bike"], "672": ["n03792972", "mountain_tent"], "673": ["n03793489", "mouse"], "674": ["n03794056", "mousetrap"], "675": ["n03796401", "moving_van"], "676": ["n03803284", "muzzle"], "677": ["n03804744", "nail"], "678": ["n03814639", "neck_brace"], "679": ["n03814906", "necklace"], "680": ["n03825788", "nipple"], "681": ["n03832673", "notebook"], "682": ["n03837869", "obelisk"], "683": ["n03838899", "oboe"], "684": ["n03840681", "ocarina"], "685": ["n03841143", "odometer"], "686": ["n03843555", "oil_filter"], "687": ["n03854065", "organ"], "688": ["n03857828", "oscilloscope"], "689": ["n03866082", "overskirt"], "690": ["n03868242", "oxcart"], "691": ["n03868863", "oxygen_mask"], "692": ["n03871628", "packet"], "693": ["n03873416", "paddle"], "694": ["n03874293", "paddlewheel"], "695": ["n03874599", "padlock"], "696": ["n03876231", "paintbrush"], "697": ["n03877472", "pajama"], "698": ["n03877845", "palace"], "699": ["n03884397", "panpipe"], "700": ["n03887697", "paper_towel"], "701": ["n03888257", "parachute"], "702": ["n03888605", "parallel_bars"], "703": ["n03891251", "park_bench"], "704": ["n03891332", "parking_meter"], "705": ["n03895866", "passenger_car"], "706": ["n03899768", "patio"], "707": ["n03902125", "pay-phone"], "708": ["n03903868", "pedestal"], "709": ["n03908618", "pencil_box"], "710": ["n03908714", "pencil_sharpener"], "711": ["n03916031", "perfume"], "712": ["n03920288", "Petri_dish"], "713": ["n03924679", "photocopier"], "714": ["n03929660", "pick"], "715": ["n03929855", "pickelhaube"], "716": ["n03930313", "picket_fence"], "717": ["n03930630", "pickup"], "718": ["n03933933", "pier"], "719": ["n03935335", "piggy_bank"], "720": ["n03937543", "pill_bottle"], "721": ["n03938244", "pillow"], "722": ["n03942813", "ping-pong_ball"], "723": ["n03944341", "pinwheel"], "724": ["n03947888", "pirate"], "725": ["n03950228", "pitcher"], "726": ["n03954731", "plane"], "727": ["n03956157", "planetarium"], "728": ["n03958227", "plastic_bag"], "729": ["n03961711", "plate_rack"], "730": ["n03967562", "plow"], "731": ["n03970156", "plunger"], "732": ["n03976467", "Polaroid_camera"], "733": ["n03976657", "pole"], "734": ["n03977966", "police_van"], "735": ["n03980874", "poncho"], "736": ["n03982430", "pool_table"], "737": ["n03983396", "pop_bottle"], "738": ["n03991062", "pot"], "739": ["n03992509", "potter's_wheel"], "740": ["n03995372", "power_drill"], "741": ["n03998194", "prayer_rug"], "742": ["n04004767", "printer"], "743": ["n04005630", "prison"], "744": ["n04008634", "projectile"], "745": ["n04009552", "projector"], "746": ["n04019541", "puck"], "747": ["n04023962", "punching_bag"], "748": ["n04026417", "purse"], "749": ["n04033901", "quill"], "750": ["n04033995", "quilt"], "751": ["n04037443", "racer"], "752": ["n04039381", "racket"], "753": ["n04040759", "radiator"], "754": ["n04041544", "radio"], "755": ["n04044716", "radio_telescope"], "756": ["n04049303", "rain_barrel"], "757": ["n04065272", "recreational_vehicle"], "758": ["n04067472", "reel"], "759": ["n04069434", "reflex_camera"], "760": ["n04070727", "refrigerator"], "761": ["n04074963", "remote_control"], "762": ["n04081281", "restaurant"], "763": ["n04086273", "revolver"], "764": ["n04090263", "rifle"], "765": ["n04099969", "rocking_chair"], "766": ["n04111531", "rotisserie"], "767": ["n04116512", "rubber_eraser"], "768": ["n04118538", "rugby_ball"], "769": ["n04118776", "rule"], "770": ["n04120489", "running_shoe"], "771": ["n04125021", "safe"], "772": ["n04127249", "safety_pin"], "773": ["n04131690", "saltshaker"], "774": ["n04133789", "sandal"], "775": ["n04136333", "sarong"], "776": ["n04141076", "sax"], "777": ["n04141327", "scabbard"], "778": ["n04141975", "scale"], "779": ["n04146614", "school_bus"], "780": ["n04147183", "schooner"], "781": ["n04149813", "scoreboard"], "782": ["n04152593", "screen"], "783": ["n04153751", "screw"], "784": ["n04154565", "screwdriver"], "785": ["n04162706", "seat_belt"], "786": ["n04179913", "sewing_machine"], "787": ["n04192698", "shield"], "788": ["n04200800", "shoe_shop"], "789": ["n04201297", "shoji"], "790": ["n04204238", "shopping_basket"], "791": ["n04204347", "shopping_cart"], "792": ["n04208210", "shovel"], "793": ["n04209133", "shower_cap"], "794": ["n04209239", "shower_curtain"], "795": ["n04228054", "ski"], "796": ["n04229816", "ski_mask"], "797": ["n04235860", "sleeping_bag"], "798": ["n04238763", "slide_rule"], "799": ["n04239074", "sliding_door"], "800": ["n04243546", "slot"], "801": ["n04251144", "snorkel"], "802": ["n04252077", "snowmobile"], "803": ["n04252225", "snowplow"], "804": ["n04254120", "soap_dispenser"], "805": ["n04254680", "soccer_ball"], "806": ["n04254777", "sock"], "807": ["n04258138", "solar_dish"], "808": ["n04259630", "sombrero"], "809": ["n04263257", "soup_bowl"], "810": ["n04264628", "space_bar"], "811": ["n04265275", "space_heater"], "812": ["n04266014", "space_shuttle"], "813": ["n04270147", "spatula"], "814": ["n04273569", "speedboat"], "815": ["n04275548", "spider_web"], "816": ["n04277352", "spindle"], "817": ["n04285008", "sports_car"], "818": ["n04286575", "spotlight"], "819": ["n04296562", "stage"], "820": ["n04310018", "steam_locomotive"], "821": ["n04311004", "steel_arch_bridge"], "822": ["n04311174", "steel_drum"], "823": ["n04317175", "stethoscope"], "824": ["n04325704", "stole"], "825": ["n04326547", "stone_wall"], "826": ["n04328186", "stopwatch"], "827": ["n04330267", "stove"], "828": ["n04332243", "strainer"], "829": ["n04335435", "streetcar"], "830": ["n04336792", "stretcher"], "831": ["n04344873", "studio_couch"], "832": ["n04346328", "stupa"], "833": ["n04347754", "submarine"], "834": ["n04350905", "suit"], "835": ["n04355338", "sundial"], "836": ["n04355933", "sunglass"], "837": ["n04356056", "sunglasses"], "838": ["n04357314", "sunscreen"], "839": ["n04366367", "suspension_bridge"], "840": ["n04367480", "swab"], "841": ["n04370456", "sweatshirt"], "842": ["n04371430", "swimming_trunks"], "843": ["n04371774", "swing"], "844": ["n04372370", "switch"], "845": ["n04376876", "syringe"], "846": ["n04380533", "table_lamp"], "847": ["n04389033", "tank"], "848": ["n04392985", "tape_player"], "849": ["n04398044", "teapot"], "850": ["n04399382", "teddy"], "851": ["n04404412", "television"], "852": ["n04409515", "tennis_ball"], "853": ["n04417672", "thatch"], "854": ["n04418357", "theater_curtain"], "855": ["n04423845", "thimble"], "856": ["n04428191", "thresher"], "857": ["n04429376", "throne"], "858": ["n04435653", "tile_roof"], "859": ["n04442312", "toaster"], "860": ["n04443257", "tobacco_shop"], "861": ["n04447861", "toilet_seat"], "862": ["n04456115", "torch"], "863": ["n04458633", "totem_pole"], "864": ["n04461696", "tow_truck"], "865": ["n04462240", "toyshop"], "866": ["n04465501", "tractor"], "867": ["n04467665", "trailer_truck"], "868": ["n04476259", "tray"], "869": ["n04479046", "trench_coat"], "870": ["n04482393", "tricycle"], "871": ["n04483307", "trimaran"], "872": ["n04485082", "tripod"], "873": ["n04486054", "triumphal_arch"], "874": ["n04487081", "trolleybus"], "875": ["n04487394", "trombone"], "876": ["n04493381", "tub"], "877": ["n04501370", "turnstile"], "878": ["n04505470", "typewriter_keyboard"], "879": ["n04507155", "umbrella"], "880": ["n04509417", "unicycle"], "881": ["n04515003", "upright"], "882": ["n04517823", "vacuum"], "883": ["n04522168", "vase"], "884": ["n04523525", "vault"], "885": ["n04525038", "velvet"], "886": ["n04525305", "vending_machine"], "887": ["n04532106", "vestment"], "888": ["n04532670", "viaduct"], "889": ["n04536866", "violin"], "890": ["n04540053", "volleyball"], "891": ["n04542943", "waffle_iron"], "892": ["n04548280", "wall_clock"], "893": ["n04548362", "wallet"], "894": ["n04550184", "wardrobe"], "895": ["n04552348", "warplane"], "896": ["n04553703", "washbasin"], "897": ["n04554684", "washer"], "898": ["n04557648", "water_bottle"], "899": ["n04560804", "water_jug"], "900": ["n04562935", "water_tower"], "901": ["n04579145", "whiskey_jug"], "902": ["n04579432", "whistle"], "903": ["n04584207", "wig"], "904": ["n04589890", "window_screen"], "905": ["n04590129", "window_shade"], "906": ["n04591157", "Windsor_tie"], "907": ["n04591713", "wine_bottle"], "908": ["n04592741", "wing"], "909": ["n04596742", "wok"], "910": ["n04597913", "wooden_spoon"], "911": ["n04599235", "wool"], "912": ["n04604644", "worm_fence"], "913": ["n04606251", "wreck"], "914": ["n04612504", "yawl"], "915": ["n04613696", "yurt"], "916": ["n06359193", "web_site"], "917": ["n06596364", "comic_book"], "918": ["n06785654", "crossword_puzzle"], "919": ["n06794110", "street_sign"], "920": ["n06874185", "traffic_light"], "921": ["n07248320", "book_jacket"], "922": ["n07565083", "menu"], "923": ["n07579787", "plate"], "924": ["n07583066", "guacamole"], "925": ["n07584110", "consomme"], "926": ["n07590611", "hot_pot"], "927": ["n07613480", "trifle"], "928": ["n07614500", "ice_cream"], "929": ["n07615774", "ice_lolly"], "930": ["n07684084", "French_loaf"], "931": ["n07693725", "bagel"], "932": ["n07695742", "pretzel"], "933": ["n07697313", "cheeseburger"], "934": ["n07697537", "hotdog"], "935": ["n07711569", "mashed_potato"], "936": ["n07714571", "head_cabbage"], "937": ["n07714990", "broccoli"], "938": ["n07715103", "cauliflower"], "939": ["n07716358", "zucchini"], "940": ["n07716906", "spaghetti_squash"], "941": ["n07717410", "acorn_squash"], "942": ["n07717556", "butternut_squash"], "943": ["n07718472", "cucumber"], "944": ["n07718747", "artichoke"], "945": ["n07720875", "bell_pepper"], "946": ["n07730033", "cardoon"], "947": ["n07734744", "mushroom"], "948": ["n07742313", "Granny_Smith"], "949": ["n07745940", "strawberry"], "950": ["n07747607", "orange"], "951": ["n07749582", "lemon"], "952": ["n07753113", "fig"], "953": ["n07753275", "pineapple"], "954": ["n07753592", "banana"], "955": ["n07754684", "jackfruit"], "956": ["n07760859", "custard_apple"], "957": ["n07768694", "pomegranate"], "958": ["n07802026", "hay"], "959": ["n07831146", "carbonara"], "960": ["n07836838", "chocolate_sauce"], "961": ["n07860988", "dough"], "962": ["n07871810", "meat_loaf"], "963": ["n07873807", "pizza"], "964": ["n07875152", "potpie"], "965": ["n07880968", "burrito"], "966": ["n07892512", "red_wine"], "967": ["n07920052", "espresso"], "968": ["n07930864", "cup"], "969": ["n07932039", "eggnog"], "970": ["n09193705", "alp"], "971": ["n09229709", "bubble"], "972": ["n09246464", "cliff"], "973": ["n09256479", "coral_reef"], "974": ["n09288635", "geyser"], "975": ["n09332890", "lakeside"], "976": ["n09399592", "promontory"], "977": ["n09421951", "sandbar"], "978": ["n09428293", "seashore"], "979": ["n09468604", "valley"], "980": ["n09472597", "volcano"], "981": ["n09835506", "ballplayer"], "982": ["n10148035", "groom"], "983": ["n10565667", "scuba_diver"], "984": ["n11879895", "rapeseed"], "985": ["n11939491", "daisy"], "986": ["n12057211", "yellow_lady's_slipper"], "987": ["n12144580", "corn"], "988": ["n12267677", "acorn"], "989": ["n12620546", "hip"], "990": ["n12768682", "buckeye"], "991": ["n12985857", "coral_fungus"], "992": ["n12998815", "agaric"], "993": ["n13037406", "gyromitra"], "994": ["n13040303", "stinkhorn"], "995": ["n13044778", "earthstar"], "996": ["n13052670", "hen-of-the-woods"], "997": ["n13054560", "bolete"], "998": ["n13133613", "ear"], "999": ["n15075141", "toilet_tissue"]}
--------------------------------------------------------------------------------
/lime/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/lime/__init__.py
--------------------------------------------------------------------------------
/lime/discretize.py:
--------------------------------------------------------------------------------
1 | """
2 | Discretizers classes, to be used in lime_tabular
3 | """
4 | import numpy as np
5 | import sklearn
6 | import sklearn.tree
7 | import scipy
8 | from sklearn.utils import check_random_state
9 | from abc import ABCMeta, abstractmethod
10 |
11 |
12 | class BaseDiscretizer():
13 | """
14 | Abstract class - Build a class that inherits from this class to implement
15 | a custom discretizer.
16 | Method bins() is to be redefined in the child class, as it is the actual
17 | custom part of the discretizer.
18 | """
19 |
20 | __metaclass__ = ABCMeta # abstract class
21 |
22 | def __init__(self, data, categorical_features, feature_names, labels=None, random_state=None,
23 | data_stats=None):
24 | """Initializer
25 | Args:
26 | data: numpy 2d array
27 | categorical_features: list of indices (ints) corresponding to the
28 | categorical columns. These features will not be discretized.
29 | Everything else will be considered continuous, and will be
30 | discretized.
31 | categorical_names: map from int to list of names, where
32 | categorical_names[x][y] represents the name of the yth value of
33 | column x.
34 | feature_names: list of names (strings) corresponding to the columns
35 | in the training data.
36 | data_stats: must have 'means', 'stds', 'mins' and 'maxs', use this
37 | if you don't want these values to be computed from data
38 | """
39 | self.to_discretize = ([x for x in range(data.shape[1])
40 | if x not in categorical_features])
41 | self.data_stats = data_stats
42 | self.names = {}
43 | self.lambdas = {}
44 | self.means = {}
45 | self.stds = {}
46 | self.mins = {}
47 | self.maxs = {}
48 | self.random_state = check_random_state(random_state)
49 |
50 | # To override when implementing a custom binning
51 | bins = self.bins(data, labels)
52 | bins = [np.unique(x) for x in bins]
53 |
54 | # Read the stats from data_stats if exists
55 | if data_stats:
56 | self.means = self.data_stats.get("means")
57 | self.stds = self.data_stats.get("stds")
58 | self.mins = self.data_stats.get("mins")
59 | self.maxs = self.data_stats.get("maxs")
60 |
61 | for feature, qts in zip(self.to_discretize, bins):
62 | n_bins = qts.shape[0] # Actually number of borders (= #bins-1)
63 | boundaries = np.min(data[:, feature]), np.max(data[:, feature])
64 | name = feature_names[feature]
65 |
66 | self.names[feature] = ['%s <= %.2f' % (name, qts[0])]
67 | for i in range(n_bins - 1):
68 | self.names[feature].append('%.2f < %s <= %.2f' %
69 | (qts[i], name, qts[i + 1]))
70 | self.names[feature].append('%s > %.2f' % (name, qts[n_bins - 1]))
71 |
72 | self.lambdas[feature] = lambda x, qts=qts: np.searchsorted(qts, x)
73 | discretized = self.lambdas[feature](data[:, feature])
74 |
75 | # If data stats are provided no need to compute the below set of details
76 | if data_stats:
77 | continue
78 |
79 | self.means[feature] = []
80 | self.stds[feature] = []
81 | for x in range(n_bins + 1):
82 | selection = data[discretized == x, feature]
83 | mean = 0 if len(selection) == 0 else np.mean(selection)
84 | self.means[feature].append(mean)
85 | std = 0 if len(selection) == 0 else np.std(selection)
86 | std += 0.00000000001
87 | self.stds[feature].append(std)
88 | self.mins[feature] = [boundaries[0]] + qts.tolist()
89 | self.maxs[feature] = qts.tolist() + [boundaries[1]]
90 |
91 | @abstractmethod
92 | def bins(self, data, labels):
93 | """
94 | To be overridden
95 | Returns for each feature to discretize the boundaries
96 | that form each bin of the discretizer
97 | """
98 | raise NotImplementedError("Must override bins() method")
99 |
100 | def discretize(self, data):
101 | """Discretizes the data.
102 | Args:
103 | data: numpy 2d or 1d array
104 | Returns:
105 | numpy array of same dimension, discretized.
106 | """
107 | ret = data.copy()
108 | for feature in self.lambdas:
109 | if len(data.shape) == 1:
110 | ret[feature] = int(self.lambdas[feature](ret[feature]))
111 | else:
112 | ret[:, feature] = self.lambdas[feature](
113 | ret[:, feature]).astype(int)
114 | return ret
115 |
116 | def get_undiscretize_values(self, feature, values):
117 | mins = np.array(self.mins[feature])[values]
118 | maxs = np.array(self.maxs[feature])[values]
119 |
120 | means = np.array(self.means[feature])[values]
121 | stds = np.array(self.stds[feature])[values]
122 | minz = (mins - means) / stds
123 | maxz = (maxs - means) / stds
124 | min_max_unequal = (minz != maxz)
125 |
126 | ret = minz
127 | ret[np.where(min_max_unequal)] = scipy.stats.truncnorm.rvs(
128 | minz[min_max_unequal],
129 | maxz[min_max_unequal],
130 | loc=means[min_max_unequal],
131 | scale=stds[min_max_unequal],
132 | random_state=self.random_state
133 | )
134 | return ret
135 |
136 | def undiscretize(self, data):
137 | ret = data.copy()
138 | for feature in self.means:
139 | if len(data.shape) == 1:
140 | ret[feature] = self.get_undiscretize_values(
141 | feature, ret[feature].astype(int).reshape(-1, 1)
142 | )
143 | else:
144 | ret[:, feature] = self.get_undiscretize_values(
145 | feature, ret[:, feature].astype(int)
146 | )
147 | return ret
148 |
149 |
150 | class StatsDiscretizer(BaseDiscretizer):
151 | """
152 | Class to be used to supply the data stats info when discretize_continuous is true
153 | """
154 |
155 | def __init__(self, data, categorical_features, feature_names, labels=None, random_state=None,
156 | data_stats=None):
157 |
158 | BaseDiscretizer.__init__(self, data, categorical_features,
159 | feature_names, labels=labels,
160 | random_state=random_state,
161 | data_stats=data_stats)
162 |
163 | def bins(self, data, labels):
164 | bins_from_stats = self.data_stats.get("bins")
165 | bins = []
166 | if bins_from_stats is not None:
167 | for feature in self.to_discretize:
168 | bins_from_stats_feature = bins_from_stats.get(feature)
169 | if bins_from_stats_feature is not None:
170 | qts = np.array(bins_from_stats_feature)
171 | bins.append(qts)
172 | return bins
173 |
174 |
175 | class QuartileDiscretizer(BaseDiscretizer):
176 | def __init__(self, data, categorical_features, feature_names, labels=None, random_state=None):
177 |
178 | BaseDiscretizer.__init__(self, data, categorical_features,
179 | feature_names, labels=labels,
180 | random_state=random_state)
181 |
182 | def bins(self, data, labels):
183 | bins = []
184 | for feature in self.to_discretize:
185 | qts = np.array(np.percentile(data[:, feature], [25, 50, 75]))
186 | bins.append(qts)
187 | return bins
188 |
189 |
190 | class DecileDiscretizer(BaseDiscretizer):
191 | def __init__(self, data, categorical_features, feature_names, labels=None, random_state=None):
192 | BaseDiscretizer.__init__(self, data, categorical_features,
193 | feature_names, labels=labels,
194 | random_state=random_state)
195 |
196 | def bins(self, data, labels):
197 | bins = []
198 | for feature in self.to_discretize:
199 | qts = np.array(np.percentile(data[:, feature],
200 | [10, 20, 30, 40, 50, 60, 70, 80, 90]))
201 | bins.append(qts)
202 | return bins
203 |
204 |
205 | class EntropyDiscretizer(BaseDiscretizer):
206 | def __init__(self, data, categorical_features, feature_names, labels=None, random_state=None):
207 | if(labels is None):
208 | raise ValueError('Labels must be not None when using \
209 | EntropyDiscretizer')
210 | BaseDiscretizer.__init__(self, data, categorical_features,
211 | feature_names, labels=labels,
212 | random_state=random_state)
213 |
214 | def bins(self, data, labels):
215 | bins = []
216 | for feature in self.to_discretize:
217 | # Entropy splitting / at most 8 bins so max_depth=3
218 | dt = sklearn.tree.DecisionTreeClassifier(criterion='entropy',
219 | max_depth=3,
220 | random_state=self.random_state)
221 | x = np.reshape(data[:, feature], (-1, 1))
222 | dt.fit(x, labels)
223 | qts = dt.tree_.threshold[np.where(dt.tree_.children_left > -1)]
224 |
225 | if qts.shape[0] == 0:
226 | qts = np.array([np.median(data[:, feature])])
227 | else:
228 | qts = np.sort(qts)
229 |
230 | bins.append(qts)
231 |
232 | return bins
233 |
--------------------------------------------------------------------------------
/lime/exceptions.py:
--------------------------------------------------------------------------------
1 | class LimeError(Exception):
2 | """Raise for errors"""
3 |
--------------------------------------------------------------------------------
/lime/explanation.py:
--------------------------------------------------------------------------------
1 | """
2 | Explanation class, with visualization functions.
3 | """
4 | from io import open
5 | import os
6 | import os.path
7 | import json
8 | import string
9 | import numpy as np
10 |
11 | from .exceptions import LimeError
12 |
13 | from sklearn.utils import check_random_state
14 |
15 |
16 | def id_generator(size=15, random_state=None):
17 | """Helper function to generate random div ids. This is useful for embedding
18 | HTML into ipython notebooks."""
19 | chars = list(string.ascii_uppercase + string.digits)
20 | return ''.join(random_state.choice(chars, size, replace=True))
21 |
22 |
23 | class DomainMapper(object):
24 | """Class for mapping features to the specific domain.
25 |
26 | The idea is that there would be a subclass for each domain (text, tables,
27 | images, etc), so that we can have a general Explanation class, and separate
28 | out the specifics of visualizing features in here.
29 | """
30 |
31 | def __init__(self):
32 | pass
33 |
34 | def map_exp_ids(self, exp, **kwargs):
35 | """Maps the feature ids to concrete names.
36 |
37 | Default behaviour is the identity function. Subclasses can implement
38 | this as they see fit.
39 |
40 | Args:
41 | exp: list of tuples [(id, weight), (id,weight)]
42 | kwargs: optional keyword arguments
43 |
44 | Returns:
45 | exp: list of tuples [(name, weight), (name, weight)...]
46 | """
47 | return exp
48 |
49 | def visualize_instance_html(self,
50 | exp,
51 | label,
52 | div_name,
53 | exp_object_name,
54 | **kwargs):
55 | """Produces html for visualizing the instance.
56 |
57 | Default behaviour does nothing. Subclasses can implement this as they
58 | see fit.
59 |
60 | Args:
61 | exp: list of tuples [(id, weight), (id,weight)]
62 | label: label id (integer)
63 | div_name: name of div object to be used for rendering(in js)
64 | exp_object_name: name of js explanation object
65 | kwargs: optional keyword arguments
66 |
67 | Returns:
68 | js code for visualizing the instance
69 | """
70 | return ''
71 |
72 |
73 | class Explanation(object):
74 | """Object returned by explainers."""
75 |
76 | def __init__(self,
77 | domain_mapper,
78 | mode='classification',
79 | class_names=None,
80 | random_state=None):
81 | """
82 |
83 | Initializer.
84 |
85 | Args:
86 | domain_mapper: must inherit from DomainMapper class
87 | type: "classification" or "regression"
88 | class_names: list of class names (only used for classification)
89 | random_state: an integer or numpy.RandomState that will be used to
90 | generate random numbers. If None, the random state will be
91 | initialized using the internal numpy seed.
92 | """
93 | self.random_state = random_state
94 | self.mode = mode
95 | self.domain_mapper = domain_mapper
96 | self.local_exp = {}
97 | self.intercept = {}
98 | self.score = {}
99 | self.local_pred = {}
100 | if mode == 'classification':
101 | self.class_names = class_names
102 | self.top_labels = None
103 | self.predict_proba = None
104 | elif mode == 'regression':
105 | self.class_names = ['negative', 'positive']
106 | self.predicted_value = None
107 | self.min_value = 0.0
108 | self.max_value = 1.0
109 | self.dummy_label = 1
110 | else:
111 | raise LimeError('Invalid explanation mode "{}". '
112 | 'Should be either "classification" '
113 | 'or "regression".'.format(mode))
114 |
115 | def available_labels(self):
116 | """
117 | Returns the list of classification labels for which we have any explanations.
118 | """
119 | try:
120 | assert self.mode == "classification"
121 | except AssertionError:
122 | raise NotImplementedError('Not supported for regression explanations.')
123 | else:
124 | ans = self.top_labels if self.top_labels else self.local_exp.keys()
125 | return list(ans)
126 |
127 | def as_list(self, label=1, **kwargs):
128 | """Returns the explanation as a list.
129 |
130 | Args:
131 | label: desired label. If you ask for a label for which an
132 | explanation wasn't computed, will throw an exception.
133 | Will be ignored for regression explanations.
134 | kwargs: keyword arguments, passed to domain_mapper
135 |
136 | Returns:
137 | list of tuples (representation, weight), where representation is
138 | given by domain_mapper. Weight is a float.
139 | """
140 | label_to_use = label if self.mode == "classification" else self.dummy_label
141 | ans = self.domain_mapper.map_exp_ids(self.local_exp[label_to_use], **kwargs)
142 | ans = [(x[0], float(x[1])) for x in ans]
143 | return ans
144 |
145 | def as_map(self):
146 | """Returns the map of explanations.
147 |
148 | Returns:
149 | Map from label to list of tuples (feature_id, weight).
150 | """
151 | return self.local_exp
152 |
153 | def as_pyplot_figure(self, label=1, figsize=(4,4), **kwargs):
154 | """Returns the explanation as a pyplot figure.
155 |
156 | Will throw an error if you don't have matplotlib installed
157 | Args:
158 | label: desired label. If you ask for a label for which an
159 | explanation wasn't computed, will throw an exception.
160 | Will be ignored for regression explanations.
161 | figsize: desired size of pyplot in tuple format, defaults to (4,4).
162 | kwargs: keyword arguments, passed to domain_mapper
163 |
164 | Returns:
165 | pyplot figure (barchart).
166 | """
167 | import matplotlib.pyplot as plt
168 | exp = self.as_list(label=label, **kwargs)
169 | fig = plt.figure(figsize=figsize)
170 | vals = [x[1] for x in exp]
171 | names = [x[0] for x in exp]
172 | vals.reverse()
173 | names.reverse()
174 | colors = ['green' if x > 0 else 'red' for x in vals]
175 | pos = np.arange(len(exp)) + .5
176 | plt.barh(pos, vals, align='center', color=colors)
177 | plt.yticks(pos, names)
178 | if self.mode == "classification":
179 | title = 'Local explanation for class %s' % self.class_names[label]
180 | else:
181 | title = 'Local explanation'
182 | plt.title(title)
183 | return fig
184 |
185 | def show_in_notebook(self,
186 | labels=None,
187 | predict_proba=True,
188 | show_predicted_value=True,
189 | **kwargs):
190 | """Shows html explanation in ipython notebook.
191 |
192 | See as_html() for parameters.
193 | This will throw an error if you don't have IPython installed"""
194 |
195 | from IPython.core.display import display, HTML
196 | display(HTML(self.as_html(labels=labels,
197 | predict_proba=predict_proba,
198 | show_predicted_value=show_predicted_value,
199 | **kwargs)))
200 |
201 | def save_to_file(self,
202 | file_path,
203 | labels=None,
204 | predict_proba=True,
205 | show_predicted_value=True,
206 | **kwargs):
207 | """Saves html explanation to file. .
208 |
209 | Params:
210 | file_path: file to save explanations to
211 |
212 | See as_html() for additional parameters.
213 |
214 | """
215 | file_ = open(file_path, 'w', encoding='utf8')
216 | file_.write(self.as_html(labels=labels,
217 | predict_proba=predict_proba,
218 | show_predicted_value=show_predicted_value,
219 | **kwargs))
220 | file_.close()
221 |
222 | def as_html(self,
223 | labels=None,
224 | predict_proba=True,
225 | show_predicted_value=True,
226 | **kwargs):
227 | """Returns the explanation as an html page.
228 |
229 | Args:
230 | labels: desired labels to show explanations for (as barcharts).
231 | If you ask for a label for which an explanation wasn't
232 | computed, will throw an exception. If None, will show
233 | explanations for all available labels. (only used for classification)
234 | predict_proba: if true, add barchart with prediction probabilities
235 | for the top classes. (only used for classification)
236 | show_predicted_value: if true, add barchart with expected value
237 | (only used for regression)
238 | kwargs: keyword arguments, passed to domain_mapper
239 |
240 | Returns:
241 | code for an html page, including javascript includes.
242 | """
243 |
244 | def jsonize(x):
245 | return json.dumps(x, ensure_ascii=False)
246 |
247 | if labels is None and self.mode == "classification":
248 | labels = self.available_labels()
249 |
250 | this_dir, _ = os.path.split(__file__)
251 | bundle = open(os.path.join(this_dir, 'bundle.js'),
252 | encoding="utf8").read()
253 |
254 | out = u'''
255 |
256 | ''' % bundle
257 | random_id = id_generator(size=15, random_state=check_random_state(self.random_state))
258 | out += u'''
259 |
260 | ''' % random_id
261 |
262 | predict_proba_js = ''
263 | if self.mode == "classification" and predict_proba:
264 | predict_proba_js = u'''
265 | var pp_div = top_div.append('div')
266 | .classed('lime predict_proba', true);
267 | var pp_svg = pp_div.append('svg').style('width', '100%%');
268 | var pp = new lime.PredictProba(pp_svg, %s, %s);
269 | ''' % (jsonize([str(x) for x in self.class_names]),
270 | jsonize(list(self.predict_proba.astype(float))))
271 |
272 | predict_value_js = ''
273 | if self.mode == "regression" and show_predicted_value:
274 | # reference self.predicted_value
275 | # (svg, predicted_value, min_value, max_value)
276 | predict_value_js = u'''
277 | var pp_div = top_div.append('div')
278 | .classed('lime predicted_value', true);
279 | var pp_svg = pp_div.append('svg').style('width', '100%%');
280 | var pp = new lime.PredictedValue(pp_svg, %s, %s, %s);
281 | ''' % (jsonize(float(self.predicted_value)),
282 | jsonize(float(self.min_value)),
283 | jsonize(float(self.max_value)))
284 |
285 | exp_js = '''var exp_div;
286 | var exp = new lime.Explanation(%s);
287 | ''' % (jsonize([str(x) for x in self.class_names]))
288 |
289 | if self.mode == "classification":
290 | for label in labels:
291 | exp = jsonize(self.as_list(label))
292 | exp_js += u'''
293 | exp_div = top_div.append('div').classed('lime explanation', true);
294 | exp.show(%s, %d, exp_div);
295 | ''' % (exp, label)
296 | else:
297 | exp = jsonize(self.as_list())
298 | exp_js += u'''
299 | exp_div = top_div.append('div').classed('lime explanation', true);
300 | exp.show(%s, %s, exp_div);
301 | ''' % (exp, self.dummy_label)
302 |
303 | raw_js = '''var raw_div = top_div.append('div');'''
304 |
305 | if self.mode == "classification":
306 | html_data = self.local_exp[labels[0]]
307 | else:
308 | html_data = self.local_exp[self.dummy_label]
309 |
310 | raw_js += self.domain_mapper.visualize_instance_html(
311 | html_data,
312 | labels[0] if self.mode == "classification" else self.dummy_label,
313 | 'raw_div',
314 | 'exp',
315 | **kwargs)
316 | out += u'''
317 |
324 | ''' % (random_id, predict_proba_js, predict_value_js, exp_js, raw_js)
325 | out += u''
326 |
327 | return out
328 |
--------------------------------------------------------------------------------
/lime/js/bar_chart.js:
--------------------------------------------------------------------------------
1 | import d3 from 'd3';
2 | class Barchart {
3 | // svg: d3 object with the svg in question
4 | // exp_array: list of (feature_name, weight)
5 | constructor(svg, exp_array, two_sided=true, titles=undefined, colors=['red', 'green'], show_numbers=false, bar_height=5) {
6 | let svg_width = Math.min(600, parseInt(svg.style('width')));
7 | let bar_width = two_sided ? svg_width / 2 : svg_width;
8 | if (titles === undefined) {
9 | titles = two_sided ? ['Cons', 'Pros'] : 'Pros';
10 | }
11 | if (show_numbers) {
12 | bar_width = bar_width - 30;
13 | }
14 | let x_offset = two_sided ? svg_width / 2 : 10;
15 | // 13.1 is +- the width of W, the widest letter.
16 | if (two_sided && titles.length == 2) {
17 | svg.append('text')
18 | .attr('x', svg_width / 4)
19 | .attr('y', 15)
20 | .attr('font-size', '20')
21 | .attr('text-anchor', 'middle')
22 | .style('fill', colors[0])
23 | .text(titles[0]);
24 |
25 | svg.append('text')
26 | .attr('x', svg_width / 4 * 3)
27 | .attr('y', 15)
28 | .attr('font-size', '20')
29 | .attr('text-anchor', 'middle')
30 | .style('fill', colors[1])
31 | .text(titles[1]);
32 | }
33 | else {
34 | let pos = two_sided ? svg_width / 2 : x_offset;
35 | let anchor = two_sided ? 'middle' : 'begin';
36 | svg.append('text')
37 | .attr('x', pos)
38 | .attr('y', 15)
39 | .attr('font-size', '20')
40 | .attr('text-anchor', anchor)
41 | .text(titles);
42 | }
43 | let yshift = 20;
44 | let space_between_bars = 0;
45 | let text_height = 16;
46 | let space_between_bar_and_text = 3;
47 | let total_bar_height = text_height + space_between_bar_and_text + bar_height + space_between_bars;
48 | let total_height = (total_bar_height) * exp_array.length;
49 | this.svg_height = total_height + yshift;
50 | let yscale = d3.scale.linear()
51 | .domain([0, exp_array.length])
52 | .range([yshift, yshift + total_height])
53 | let names = exp_array.map(v => v[0]);
54 | let weights = exp_array.map(v => v[1]);
55 | let max_weight = Math.max(...(weights.map(v=>Math.abs(v))));
56 | let xscale = d3.scale.linear()
57 | .domain([0,Math.max(1, max_weight)])
58 | .range([0, bar_width]);
59 |
60 | for (var i = 0; i < exp_array.length; ++i) {
61 | let name = names[i];
62 | let weight = weights[i];
63 | var size = xscale(Math.abs(weight));
64 | let to_the_right = (weight > 0 || !two_sided)
65 | let text = svg.append('text')
66 | .attr('x', to_the_right ? x_offset + 2 : x_offset - 2)
67 | .attr('y', yscale(i) + text_height)
68 | .attr('text-anchor', to_the_right ? 'begin' : 'end')
69 | .attr('font-size', '14')
70 | .text(name);
71 | while (text.node().getBBox()['width'] + 1 > bar_width) {
72 | let cur_text = text.text().slice(0, text.text().length - 5);
73 | text.text(cur_text + '...');
74 | if (text === '...') {
75 | break;
76 | }
77 | }
78 | let bar = svg.append('rect')
79 | .attr('height', bar_height)
80 | .attr('x', to_the_right ? x_offset : x_offset - size)
81 | .attr('y', text_height + yscale(i) + space_between_bar_and_text)// + bar_height)
82 | .attr('width', size)
83 | .style('fill', weight > 0 ? colors[1] : colors[0]);
84 | if (show_numbers) {
85 | let bartext = svg.append('text')
86 | .attr('x', to_the_right ? x_offset + size + 1 : x_offset - size - 1)
87 | .attr('text-anchor', (weight > 0 || !two_sided) ? 'begin' : 'end')
88 | .attr('y', bar_height + yscale(i) + text_height + space_between_bar_and_text)
89 | .attr('font-size', '10')
90 | .text(Math.abs(weight).toFixed(2));
91 | }
92 | }
93 | let line = svg.append("line")
94 | .attr("x1", x_offset)
95 | .attr("x2", x_offset)
96 | .attr("y1", bar_height + yshift)
97 | .attr("y2", Math.max(bar_height, yscale(exp_array.length)))
98 | .style("stroke-width",2)
99 | .style("stroke", "black");
100 | }
101 |
102 | }
103 | export default Barchart;
104 |
--------------------------------------------------------------------------------
/lime/js/explanation.js:
--------------------------------------------------------------------------------
1 | import d3 from 'd3';
2 | import Barchart from './bar_chart.js';
3 | import {range, sortBy} from 'lodash';
4 | class Explanation {
5 | constructor(class_names) {
6 | this.names = class_names;
7 | if (class_names.length < 10) {
8 | this.colors = d3.scale.category10().domain(this.names);
9 | this.colors_i = d3.scale.category10().domain(range(this.names.length));
10 | }
11 | else {
12 | this.colors = d3.scale.category20().domain(this.names);
13 | this.colors_i = d3.scale.category20().domain(range(this.names.length));
14 | }
15 | }
16 | // exp: [(feature-name, weight), ...]
17 | // label: int
18 | // div: d3 selection
19 | show(exp, label, div) {
20 | let svg = div.append('svg').style('width', '100%');
21 | let colors=['#5F9EA0', this.colors_i(label)];
22 | let names = [`NOT ${this.names[label]}`, this.names[label]];
23 | if (this.names.length == 2) {
24 | colors=[this.colors_i(0), this.colors_i(1)];
25 | names = this.names;
26 | }
27 | let plot = new Barchart(svg, exp, true, names, colors, true, 10);
28 | svg.style('height', plot.svg_height + 'px');
29 | }
30 | // exp has all ocurrences of words, with start index and weight:
31 | // exp = [('word', 132, -0.13), ('word3', 111, 1.3)
32 | show_raw_text(exp, label, raw, div, opacity=true) {
33 | //let colors=['#5F9EA0', this.colors(this.exp['class'])];
34 | let colors=['#5F9EA0', this.colors_i(label)];
35 | if (this.names.length == 2) {
36 | colors=[this.colors_i(0), this.colors_i(1)];
37 | }
38 | let word_lists = [[], []];
39 | let max_weight = -1;
40 | for (let [word, start, weight] of exp) {
41 | if (weight > 0) {
42 | word_lists[1].push([start, start + word.length, weight]);
43 | }
44 | else {
45 | word_lists[0].push([start, start + word.length, -weight]);
46 | }
47 | max_weight = Math.max(max_weight, Math.abs(weight));
48 | }
49 | if (!opacity) {
50 | max_weight = 0;
51 | }
52 | this.display_raw_text(div, raw, word_lists, colors, max_weight, true);
53 | }
54 | // exp is list of (feature_name, value, weight)
55 | show_raw_tabular(exp, label, div) {
56 | div.classed('lime', true).classed('table_div', true);
57 | let colors=['#5F9EA0', this.colors_i(label)];
58 | if (this.names.length == 2) {
59 | colors=[this.colors_i(0), this.colors_i(1)];
60 | }
61 | const table = div.append('table');
62 | const thead = table.append('tr');
63 | thead.append('td').text('Feature');
64 | thead.append('td').text('Value');
65 | thead.style('color', 'black')
66 | .style('font-size', '20px');
67 | for (let [fname, value, weight] of exp) {
68 | const tr = table.append('tr');
69 | tr.style('border-style', 'hidden');
70 | tr.append('td').text(fname);
71 | tr.append('td').text(value);
72 | if (weight > 0) {
73 | tr.style('background-color', colors[1]);
74 | }
75 | else if (weight < 0) {
76 | tr.style('background-color', colors[0]);
77 | }
78 | else {
79 | tr.style('color', 'black');
80 | }
81 | }
82 | }
83 | hexToRgb(hex) {
84 | let result = /^#?([a-f\d]{2})([a-f\d]{2})([a-f\d]{2})$/i.exec(hex);
85 | return result ? {
86 | r: parseInt(result[1], 16),
87 | g: parseInt(result[2], 16),
88 | b: parseInt(result[3], 16)
89 | } : null;
90 | }
91 | applyAlpha(hex, alpha) {
92 | let components = this.hexToRgb(hex);
93 | return 'rgba(' + components.r + "," + components.g + "," + components.b + "," + alpha.toFixed(3) + ")"
94 | }
95 | // sord_lists is an array of arrays, of length (colors). if with_positions is true,
96 | // word_lists is an array of [start,end] positions instead
97 | display_raw_text(div, raw_text, word_lists=[], colors=[], max_weight=1, positions=false) {
98 | div.classed('lime', true).classed('text_div', true);
99 | div.append('h3').text('Text with highlighted words');
100 | let highlight_tag = 'span';
101 | let text_span = div.append('span').style('white-space', 'pre-wrap').text(raw_text);
102 | let position_lists = word_lists;
103 | if (!positions) {
104 | position_lists = this.wordlists_to_positions(word_lists, raw_text);
105 | }
106 | let objects = []
107 | for (let i of range(position_lists.length)) {
108 | position_lists[i].map(x => objects.push({'label' : i, 'start': x[0], 'end': x[1], 'alpha': max_weight === 0 ? 1: x[2] / max_weight}));
109 | }
110 | objects = sortBy(objects, x=>x['start']);
111 | let node = text_span.node().childNodes[0];
112 | let subtract = 0;
113 | for (let obj of objects) {
114 | let word = raw_text.slice(obj.start, obj.end);
115 | let start = obj.start - subtract;
116 | let end = obj.end - subtract;
117 | let match = document.createElement(highlight_tag);
118 | match.appendChild(document.createTextNode(word));
119 | match.style.backgroundColor = this.applyAlpha(colors[obj.label], obj.alpha);
120 | let after = node.splitText(start);
121 | after.nodeValue = after.nodeValue.substring(word.length);
122 | node.parentNode.insertBefore(match, after);
123 | subtract += end;
124 | node = after;
125 | }
126 | }
127 | wordlists_to_positions(word_lists, raw_text) {
128 | let ret = []
129 | for(let words of word_lists) {
130 | if (words.length === 0) {
131 | ret.push([]);
132 | continue;
133 | }
134 | let re = new RegExp("\\b(" + words.join('|') + ")\\b",'gm')
135 | let temp;
136 | let list = [];
137 | while ((temp = re.exec(raw_text)) !== null) {
138 | list.push([temp.index, temp.index + temp[0].length]);
139 | }
140 | ret.push(list);
141 | }
142 | return ret;
143 | }
144 |
145 | }
146 | export default Explanation;
147 |
--------------------------------------------------------------------------------
/lime/js/main.js:
--------------------------------------------------------------------------------
1 | if (!global._babelPolyfill) {
2 | require('babel-polyfill')
3 | }
4 |
5 |
6 | import Explanation from './explanation.js';
7 | import Barchart from './bar_chart.js';
8 | import PredictProba from './predict_proba.js';
9 | import PredictedValue from './predicted_value.js';
10 | require('../style.css');
11 |
12 | export {Explanation, Barchart, PredictProba, PredictedValue};
13 | //require('style-loader');
14 |
15 |
16 |
--------------------------------------------------------------------------------
/lime/js/predict_proba.js:
--------------------------------------------------------------------------------
1 | import d3 from 'd3';
2 | import {range, sortBy} from 'lodash';
3 |
4 | class PredictProba {
5 | // svg: d3 object with the svg in question
6 | // class_names: array of class names
7 | // predict_probas: array of prediction probabilities
8 | constructor(svg, class_names, predict_probas, title='Prediction probabilities') {
9 | let width = parseInt(svg.style('width'));
10 | this.names = class_names;
11 | this.names.push('Other');
12 | if (class_names.length < 10) {
13 | this.colors = d3.scale.category10().domain(this.names);
14 | this.colors_i = d3.scale.category10().domain(range(this.names.length));
15 | }
16 | else {
17 | this.colors = d3.scale.category20().domain(this.names);
18 | this.colors_i = d3.scale.category20().domain(range(this.names.length));
19 | }
20 | let [names, data] = this.map_classes(this.names, predict_probas);
21 | let bar_x = width - 125;
22 | let class_names_width = bar_x;
23 | let bar_width = width - bar_x - 32;
24 | let x_scale = d3.scale.linear().range([0, bar_width]);
25 | let bar_height = 17;
26 | let space_between_bars = 5;
27 | let bar_yshift= title === '' ? 0 : 35;
28 | let n_bars = Math.min(5, data.length);
29 | this.svg_height = n_bars * (bar_height + space_between_bars) + bar_yshift;
30 | svg.style('height', this.svg_height + 'px');
31 | let this_object = this;
32 | if (title !== '') {
33 | svg.append('text')
34 | .text(title)
35 | .attr('x', 20)
36 | .attr('y', 20);
37 | }
38 | let bar_y = i => (bar_height + space_between_bars) * i + bar_yshift;
39 | let bar = svg.append("g");
40 |
41 | for (let i of range(data.length)) {
42 | var color = this.colors(names[i]);
43 | if (names[i] == 'Other' && this.names.length > 20) {
44 | color = '#5F9EA0';
45 | }
46 | let rect = bar.append("rect");
47 | rect.attr("x", bar_x)
48 | .attr("y", bar_y(i))
49 | .attr("height", bar_height)
50 | .attr("width", x_scale(data[i]))
51 | .style("fill", color);
52 | bar.append("rect").attr("x", bar_x)
53 | .attr("y", bar_y(i))
54 | .attr("height", bar_height)
55 | .attr("width", bar_width - 1)
56 | .attr("fill-opacity", 0)
57 | .attr("stroke", "black");
58 | let text = bar.append("text");
59 | text.classed("prob_text", true);
60 | text.attr("y", bar_y(i) + bar_height - 3).attr("fill", "black").style("font", "14px tahoma, sans-serif");
61 | text = bar.append("text");
62 | text.attr("x", bar_x + x_scale(data[i]) + 5)
63 | .attr("y", bar_y(i) + bar_height - 3)
64 | .attr("fill", "black")
65 | .style("font", "14px tahoma, sans-serif")
66 | .text(data[i].toFixed(2));
67 | text = bar.append("text");
68 | text.attr("x", bar_x - 10)
69 | .attr("y", bar_y(i) + bar_height - 3)
70 | .attr("fill", "black")
71 | .attr("text-anchor", "end")
72 | .style("font", "14px tahoma, sans-serif")
73 | .text(names[i]);
74 | while (text.node().getBBox()['width'] + 1 > (class_names_width - 10)) {
75 | // TODO: ta mostrando só dois, e talvez quando hover mostrar o texto
76 | // todo
77 | let cur_text = text.text().slice(0, text.text().length - 5);
78 | text.text(cur_text + '...');
79 | if (cur_text.length <= 3) {
80 | break
81 | }
82 | }
83 | }
84 | }
85 | map_classes(class_names, predict_proba) {
86 | if (class_names.length <= 6) {
87 | return [class_names, predict_proba];
88 | }
89 | let class_dict = range(predict_proba.length).map(i => ({'name': class_names[i], 'prob': predict_proba[i], 'i' : i}));
90 | let sorted = sortBy(class_dict, d => -d.prob);
91 | let other = new Set();
92 | range(4, sorted.length).map(d => other.add(sorted[d].name));
93 | let other_prob = 0;
94 | let ret_probs = [];
95 | let ret_names = [];
96 | for (let d of range(sorted.length)) {
97 | if (other.has(sorted[d].name)) {
98 | other_prob += sorted[d].prob;
99 | }
100 | else {
101 | ret_probs.push(sorted[d].prob);
102 | ret_names.push(sorted[d].name);
103 | }
104 | };
105 | ret_names.push("Other");
106 | ret_probs.push(other_prob);
107 | return [ret_names, ret_probs];
108 | }
109 |
110 | }
111 | export default PredictProba;
112 |
113 |
114 |
--------------------------------------------------------------------------------
/lime/js/predicted_value.js:
--------------------------------------------------------------------------------
1 | import d3 from 'd3';
2 | import {range, sortBy} from 'lodash';
3 |
4 | class PredictedValue {
5 | // svg: d3 object with the svg in question
6 | // class_names: array of class names
7 | // predict_probas: array of prediction probabilities
8 | constructor(svg, predicted_value, min_value, max_value, title='Predicted value', log_coords = false) {
9 |
10 | if (min_value == max_value){
11 | var width_proportion = 1.0;
12 | } else {
13 | var width_proportion = (predicted_value - min_value) / (max_value - min_value);
14 | }
15 |
16 |
17 | let width = parseInt(svg.style('width'))
18 |
19 | this.color = d3.scale.category10()
20 | this.color('predicted_value')
21 | // + 2 is due to it being a float
22 | let num_digits = Math.floor(Math.max(Math.log10(Math.abs(min_value)), Math.log10(Math.abs(max_value)))) + 2
23 | num_digits = Math.max(num_digits, 3)
24 |
25 | let corner_width = 12 * num_digits;
26 | let corner_padding = 5.5 * num_digits;
27 | let bar_x = corner_width + corner_padding;
28 | let bar_width = width - corner_width * 2 - corner_padding * 2;
29 | let x_scale = d3.scale.linear().range([0, bar_width]);
30 | let bar_height = 17;
31 | let bar_yshift= title === '' ? 0 : 35;
32 | let n_bars = 1;
33 | let this_object = this;
34 | if (title !== '') {
35 | svg.append('text')
36 | .text(title)
37 | .attr('x', 20)
38 | .attr('y', 20);
39 | }
40 | let bar_y = bar_yshift;
41 | let bar = svg.append("g");
42 |
43 | //filled in bar representing predicted value in range
44 | let rect = bar.append("rect");
45 | rect.attr("x", bar_x)
46 | .attr("y", bar_y)
47 | .attr("height", bar_height)
48 | .attr("width", x_scale(width_proportion))
49 | .style("fill", this.color);
50 |
51 | //empty box representing range
52 | bar.append("rect").attr("x", bar_x)
53 | .attr("y", bar_y)
54 | .attr("height", bar_height)
55 | .attr("width",x_scale(1))
56 | .attr("fill-opacity", 0)
57 | .attr("stroke", "black");
58 | let text = bar.append("text");
59 | text.classed("prob_text", true);
60 | text.attr("y", bar_y + bar_height - 3).attr("fill", "black").style("font", "14px tahoma, sans-serif");
61 |
62 |
63 | //text for min value
64 | text = bar.append("text");
65 | text.attr("x", bar_x - corner_padding)
66 | .attr("y", bar_y + bar_height - 3)
67 | .attr("fill", "black")
68 | .attr("text-anchor", "end")
69 | .style("font", "14px tahoma, sans-serif")
70 | .text(min_value.toFixed(2));
71 |
72 | //text for range min annotation
73 | let v_adjust_min_value_annotation = text.node().getBBox().height;
74 | text = bar.append("text");
75 | text.attr("x", bar_x - corner_padding)
76 | .attr("y", bar_y + bar_height - 3 + v_adjust_min_value_annotation)
77 | .attr("fill", "black")
78 | .attr("text-anchor", "end")
79 | .style("font", "14px tahoma, sans-serif")
80 | .text("(min)");
81 |
82 |
83 | //text for predicted value
84 | // console.log('bar height: ' + bar_height)
85 | text = bar.append("text");
86 | text.text(predicted_value.toFixed(2));
87 | // let h_adjust_predicted_value_text = text.node().getBBox().width / 2;
88 | let v_adjust_predicted_value_text = text.node().getBBox().height;
89 | text.attr("x", bar_x + x_scale(width_proportion))
90 | .attr("y", bar_y + bar_height + v_adjust_predicted_value_text)
91 | .attr("fill", "black")
92 | .attr("text-anchor", "middle")
93 | .style("font", "14px tahoma, sans-serif")
94 |
95 |
96 |
97 |
98 |
99 | //text for max value
100 | text = bar.append("text");
101 | text.text(max_value.toFixed(2));
102 | // let h_adjust = text.node().getBBox().width;
103 | text.attr("x", bar_x + bar_width + corner_padding)
104 | .attr("y", bar_y + bar_height - 3)
105 | .attr("fill", "black")
106 | .attr("text-anchor", "begin")
107 | .style("font", "14px tahoma, sans-serif");
108 |
109 |
110 | //text for range max annotation
111 | let v_adjust_max_value_annotation = text.node().getBBox().height;
112 | text = bar.append("text");
113 | text.attr("x", bar_x + bar_width + corner_padding)
114 | .attr("y", bar_y + bar_height - 3 + v_adjust_min_value_annotation)
115 | .attr("fill", "black")
116 | .attr("text-anchor", "begin")
117 | .style("font", "14px tahoma, sans-serif")
118 | .text("(max)");
119 |
120 |
121 | //readjust svg size
122 | // let svg_width = width + 1 * h_adjust;
123 | // svg.style('width', svg_width + 'px');
124 |
125 | this.svg_height = n_bars * (bar_height) + bar_yshift + (2 * text.node().getBBox().height) + 10;
126 | svg.style('height', this.svg_height + 'px');
127 | if (log_coords) {
128 | console.log("svg width: " + svg_width);
129 | console.log("svg height: " + this.svg_height);
130 | console.log("bar_y: " + bar_y);
131 | console.log("bar_x: " + bar_x);
132 | console.log("Min value: " + min_value);
133 | console.log("Max value: " + max_value);
134 | console.log("Pred value: " + predicted_value);
135 | }
136 | }
137 | }
138 |
139 |
140 | export default PredictedValue;
141 |
--------------------------------------------------------------------------------
/lime/lime_base.py:
--------------------------------------------------------------------------------
1 | """
2 | Contains abstract functionality for learning locally linear sparse model.
3 | """
4 | import numpy as np
5 | import scipy as sp
6 | from sklearn.linear_model import Ridge, lars_path
7 | from sklearn.utils import check_random_state
8 |
9 |
10 | class LimeBase(object):
11 | """Class for learning a locally linear sparse model from perturbed data"""
12 | def __init__(self,
13 | kernel_fn,
14 | verbose=False,
15 | random_state=None):
16 | """Init function
17 |
18 | Args:
19 | kernel_fn: function that transforms an array of distances into an
20 | array of proximity values (floats).
21 | verbose: if true, print local prediction values from linear model.
22 | random_state: an integer or numpy.RandomState that will be used to
23 | generate random numbers. If None, the random state will be
24 | initialized using the internal numpy seed.
25 | """
26 | self.kernel_fn = kernel_fn
27 | self.verbose = verbose
28 | self.random_state = check_random_state(random_state)
29 |
30 | @staticmethod
31 | def generate_lars_path(weighted_data, weighted_labels):
32 | """Generates the lars path for weighted data.
33 |
34 | Args:
35 | weighted_data: data that has been weighted by kernel
36 | weighted_label: labels, weighted by kernel
37 |
38 | Returns:
39 | (alphas, coefs), both are arrays corresponding to the
40 | regularization parameter and coefficients, respectively
41 | """
42 | x_vector = weighted_data
43 | alphas, _, coefs = lars_path(x_vector,
44 | weighted_labels,
45 | method='lasso',
46 | verbose=False)
47 | return alphas, coefs
48 |
49 | def forward_selection(self, data, labels, weights, num_features):
50 | """Iteratively adds features to the model"""
51 | clf = Ridge(alpha=0, fit_intercept=True, random_state=self.random_state)
52 | used_features = []
53 | for _ in range(min(num_features, data.shape[1])):
54 | max_ = -100000000
55 | best = 0
56 | for feature in range(data.shape[1]):
57 | if feature in used_features:
58 | continue
59 | clf.fit(data[:, used_features + [feature]], labels,
60 | sample_weight=weights)
61 | score = clf.score(data[:, used_features + [feature]],
62 | labels,
63 | sample_weight=weights)
64 | if score > max_:
65 | best = feature
66 | max_ = score
67 | used_features.append(best)
68 | return np.array(used_features)
69 |
70 | def feature_selection(self, data, labels, weights, num_features, method):
71 | """Selects features for the model. see explain_instance_with_data to
72 | understand the parameters."""
73 | if method == 'none':
74 | return np.array(range(data.shape[1]))
75 | elif method == 'forward_selection':
76 | return self.forward_selection(data, labels, weights, num_features)
77 | elif method == 'highest_weights':
78 | clf = Ridge(alpha=0.01, fit_intercept=True,
79 | random_state=self.random_state)
80 | clf.fit(data, labels, sample_weight=weights)
81 |
82 | coef = clf.coef_
83 | if sp.sparse.issparse(data):
84 | coef = sp.sparse.csr_matrix(clf.coef_)
85 | weighted_data = coef.multiply(data[0])
86 | # Note: most efficient to slice the data before reversing
87 | sdata = len(weighted_data.data)
88 | argsort_data = np.abs(weighted_data.data).argsort()
89 | # Edge case where data is more sparse than requested number of feature importances
90 | # In that case, we just pad with zero-valued features
91 | if sdata < num_features:
92 | nnz_indexes = argsort_data[::-1]
93 | indices = weighted_data.indices[nnz_indexes]
94 | num_to_pad = num_features - sdata
95 | indices = np.concatenate((indices, np.zeros(num_to_pad, dtype=indices.dtype)))
96 | indices_set = set(indices)
97 | pad_counter = 0
98 | for i in range(data.shape[1]):
99 | if i not in indices_set:
100 | indices[pad_counter + sdata] = i
101 | pad_counter += 1
102 | if pad_counter >= num_to_pad:
103 | break
104 | else:
105 | nnz_indexes = argsort_data[sdata - num_features:sdata][::-1]
106 | indices = weighted_data.indices[nnz_indexes]
107 | return indices
108 | else:
109 | weighted_data = coef * data[0]
110 | feature_weights = sorted(
111 | zip(range(data.shape[1]), weighted_data),
112 | key=lambda x: np.abs(x[1]),
113 | reverse=True)
114 | return np.array([x[0] for x in feature_weights[:num_features]])
115 | elif method == 'lasso_path':
116 | weighted_data = ((data - np.average(data, axis=0, weights=weights))
117 | * np.sqrt(weights[:, np.newaxis]))
118 | weighted_labels = ((labels - np.average(labels, weights=weights))
119 | * np.sqrt(weights))
120 | nonzero = range(weighted_data.shape[1])
121 | _, coefs = self.generate_lars_path(weighted_data,
122 | weighted_labels)
123 | for i in range(len(coefs.T) - 1, 0, -1):
124 | nonzero = coefs.T[i].nonzero()[0]
125 | if len(nonzero) <= num_features:
126 | break
127 | used_features = nonzero
128 | return used_features
129 | elif method == 'auto':
130 | if num_features <= 6:
131 | n_method = 'forward_selection'
132 | else:
133 | n_method = 'highest_weights'
134 | return self.feature_selection(data, labels, weights,
135 | num_features, n_method)
136 |
137 | def explain_instance_with_data(self,
138 | neighborhood_data,
139 | neighborhood_labels,
140 | distances,
141 | label,
142 | num_features,
143 | feature_selection='auto',
144 | model_regressor=None):
145 | """Takes perturbed data, labels and distances, returns explanation.
146 |
147 | Args:
148 | neighborhood_data: perturbed data, 2d array. first element is
149 | assumed to be the original data point.
150 | neighborhood_labels: corresponding perturbed labels. should have as
151 | many columns as the number of possible labels.
152 | distances: distances to original data point.
153 | label: label for which we want an explanation
154 | num_features: maximum number of features in explanation
155 | feature_selection: how to select num_features. options are:
156 | 'forward_selection': iteratively add features to the model.
157 | This is costly when num_features is high
158 | 'highest_weights': selects the features that have the highest
159 | product of absolute weight * original data point when
160 | learning with all the features
161 | 'lasso_path': chooses features based on the lasso
162 | regularization path
163 | 'none': uses all features, ignores num_features
164 | 'auto': uses forward_selection if num_features <= 6, and
165 | 'highest_weights' otherwise.
166 | model_regressor: sklearn regressor to use in explanation.
167 | Defaults to Ridge regression if None. Must have
168 | model_regressor.coef_ and 'sample_weight' as a parameter
169 | to model_regressor.fit()
170 |
171 | Returns:
172 | (intercept, exp, score, local_pred):
173 | intercept is a float.
174 | exp is a sorted list of tuples, where each tuple (x,y) corresponds
175 | to the feature id (x) and the local weight (y). The list is sorted
176 | by decreasing absolute value of y.
177 | score is the R^2 value of the returned explanation
178 | local_pred is the prediction of the explanation model on the original instance
179 | """
180 |
181 | weights = self.kernel_fn(distances)
182 | labels_column = neighborhood_labels[:, label]
183 | used_features = self.feature_selection(neighborhood_data,
184 | labels_column,
185 | weights,
186 | num_features,
187 | feature_selection)
188 | if model_regressor is None:
189 | model_regressor = Ridge(alpha=1, fit_intercept=True,
190 | random_state=self.random_state)
191 | easy_model = model_regressor
192 | easy_model.fit(neighborhood_data[:, used_features],
193 | labels_column, sample_weight=weights)
194 | prediction_score = easy_model.score(
195 | neighborhood_data[:, used_features],
196 | labels_column, sample_weight=weights)
197 |
198 | local_pred = easy_model.predict(neighborhood_data[0, used_features].reshape(1, -1))
199 |
200 | if self.verbose:
201 | print('Intercept', easy_model.intercept_)
202 | print('Prediction_local', local_pred,)
203 | print('Right:', neighborhood_labels[0, label])
204 | return (easy_model.intercept_,
205 | sorted(zip(used_features, easy_model.coef_),
206 | key=lambda x: np.abs(x[1]), reverse=True),
207 | prediction_score, local_pred)
208 |
--------------------------------------------------------------------------------
/lime/lime_image.py:
--------------------------------------------------------------------------------
1 | """
2 | Functions for explaining classifiers that use Image data.
3 | """
4 | import copy
5 | from functools import partial
6 |
7 | import numpy as np
8 | import sklearn
9 | from sklearn.utils import check_random_state
10 | from skimage.color import gray2rgb
11 | from tqdm.auto import tqdm
12 |
13 |
14 | from . import lime_base
15 | from .wrappers.scikit_image import SegmentationAlgorithm
16 |
17 |
18 | class ImageExplanation(object):
19 | def __init__(self, image, segments):
20 | """Init function.
21 |
22 | Args:
23 | image: 3d numpy array
24 | segments: 2d numpy array, with the output from skimage.segmentation
25 | """
26 | self.image = image
27 | self.segments = segments
28 | self.intercept = {}
29 | self.local_exp = {}
30 | self.local_pred = {}
31 | self.score = {}
32 |
33 | def get_image_and_mask(self, label, positive_only=True, negative_only=False, hide_rest=False,
34 | num_features=5, min_weight=0.):
35 | """Init function.
36 |
37 | Args:
38 | label: label to explain
39 | positive_only: if True, only take superpixels that positively contribute to
40 | the prediction of the label.
41 | negative_only: if True, only take superpixels that negatively contribute to
42 | the prediction of the label. If false, and so is positive_only, then both
43 | negativey and positively contributions will be taken.
44 | Both can't be True at the same time
45 | hide_rest: if True, make the non-explanation part of the return
46 | image gray
47 | num_features: number of superpixels to include in explanation
48 | min_weight: minimum weight of the superpixels to include in explanation
49 |
50 | Returns:
51 | (image, mask), where image is a 3d numpy array and mask is a 2d
52 | numpy array that can be used with
53 | skimage.segmentation.mark_boundaries
54 | """
55 | if label not in self.local_exp:
56 | raise KeyError('Label not in explanation')
57 | if positive_only & negative_only:
58 | raise ValueError("Positive_only and negative_only cannot be true at the same time.")
59 | segments = self.segments
60 | image = self.image
61 | exp = self.local_exp[label]
62 | mask = np.zeros(segments.shape, segments.dtype)
63 | if hide_rest:
64 | temp = np.zeros(self.image.shape)
65 | else:
66 | temp = self.image.copy()
67 | if positive_only:
68 | fs = [x[0] for x in exp
69 | if x[1] > 0 and x[1] > min_weight][:num_features]
70 | if negative_only:
71 | fs = [x[0] for x in exp
72 | if x[1] < 0 and abs(x[1]) > min_weight][:num_features]
73 | if positive_only or negative_only:
74 | for f in fs:
75 | temp[segments == f] = image[segments == f].copy()
76 | mask[segments == f] = 1
77 | return temp, mask
78 | else:
79 | for f, w in exp[:num_features]:
80 | if np.abs(w) < min_weight:
81 | continue
82 | c = 0 if w < 0 else 1
83 | mask[segments == f] = -1 if w < 0 else 1
84 | temp[segments == f] = image[segments == f].copy()
85 | temp[segments == f, c] = np.max(image)
86 | return temp, mask
87 |
88 |
89 | class LimeImageExplainer(object):
90 | """Explains predictions on Image (i.e. matrix) data.
91 | For numerical features, perturb them by sampling from a Normal(0,1) and
92 | doing the inverse operation of mean-centering and scaling, according to the
93 | means and stds in the training data. For categorical features, perturb by
94 | sampling according to the training distribution, and making a binary
95 | feature that is 1 when the value is the same as the instance being
96 | explained."""
97 |
98 | def __init__(self, kernel_width=.25, kernel=None, verbose=False,
99 | feature_selection='auto', random_state=None):
100 | """Init function.
101 |
102 | Args:
103 | kernel_width: kernel width for the exponential kernel.
104 | If None, defaults to sqrt(number of columns) * 0.75.
105 | kernel: similarity kernel that takes euclidean distances and kernel
106 | width as input and outputs weights in (0,1). If None, defaults to
107 | an exponential kernel.
108 | verbose: if true, print local prediction values from linear model
109 | feature_selection: feature selection method. can be
110 | 'forward_selection', 'lasso_path', 'none' or 'auto'.
111 | See function 'explain_instance_with_data' in lime_base.py for
112 | details on what each of the options does.
113 | random_state: an integer or numpy.RandomState that will be used to
114 | generate random numbers. If None, the random state will be
115 | initialized using the internal numpy seed.
116 | """
117 | kernel_width = float(kernel_width)
118 |
119 | if kernel is None:
120 | def kernel(d, kernel_width):
121 | return np.sqrt(np.exp(-(d ** 2) / kernel_width ** 2))
122 |
123 | kernel_fn = partial(kernel, kernel_width=kernel_width)
124 |
125 | self.random_state = check_random_state(random_state)
126 | self.feature_selection = feature_selection
127 | self.base = lime_base.LimeBase(kernel_fn, verbose, random_state=self.random_state)
128 |
129 | def explain_instance(self, image, classifier_fn, labels=(1,),
130 | hide_color=None,
131 | top_labels=5, num_features=100000, num_samples=1000,
132 | batch_size=10,
133 | segmentation_fn=None,
134 | distance_metric='cosine',
135 | model_regressor=None,
136 | random_seed=None,
137 | progress_bar=True):
138 | """Generates explanations for a prediction.
139 |
140 | First, we generate neighborhood data by randomly perturbing features
141 | from the instance (see __data_inverse). We then learn locally weighted
142 | linear models on this neighborhood data to explain each of the classes
143 | in an interpretable way (see lime_base.py).
144 |
145 | Args:
146 | image: 3 dimension RGB image. If this is only two dimensional,
147 | we will assume it's a grayscale image and call gray2rgb.
148 | classifier_fn: classifier prediction probability function, which
149 | takes a numpy array and outputs prediction probabilities. For
150 | ScikitClassifiers , this is classifier.predict_proba.
151 | labels: iterable with labels to be explained.
152 | hide_color: If not None, will hide superpixels with this color.
153 | Otherwise, use the mean pixel color of the image.
154 | top_labels: if not None, ignore labels and produce explanations for
155 | the K labels with highest prediction probabilities, where K is
156 | this parameter.
157 | num_features: maximum number of features present in explanation
158 | num_samples: size of the neighborhood to learn the linear model
159 | batch_size: batch size for model predictions
160 | distance_metric: the distance metric to use for weights.
161 | model_regressor: sklearn regressor to use in explanation. Defaults
162 | to Ridge regression in LimeBase. Must have model_regressor.coef_
163 | and 'sample_weight' as a parameter to model_regressor.fit()
164 | segmentation_fn: SegmentationAlgorithm, wrapped skimage
165 | segmentation function
166 | random_seed: integer used as random seed for the segmentation
167 | algorithm. If None, a random integer, between 0 and 1000,
168 | will be generated using the internal random number generator.
169 | progress_bar: if True, show tqdm progress bar.
170 |
171 | Returns:
172 | An ImageExplanation object (see lime_image.py) with the corresponding
173 | explanations.
174 | """
175 | if len(image.shape) == 2:
176 | image = gray2rgb(image)
177 | if random_seed is None:
178 | random_seed = self.random_state.randint(0, high=1000)
179 |
180 | if segmentation_fn is None:
181 | segmentation_fn = SegmentationAlgorithm('quickshift', kernel_size=4,
182 | max_dist=200, ratio=0.2,
183 | random_seed=random_seed)
184 | segments = segmentation_fn(image)
185 |
186 | fudged_image = image.copy()
187 | if hide_color is None:
188 | for x in np.unique(segments):
189 | fudged_image[segments == x] = (
190 | np.mean(image[segments == x][:, 0]),
191 | np.mean(image[segments == x][:, 1]),
192 | np.mean(image[segments == x][:, 2]))
193 | else:
194 | fudged_image[:] = hide_color
195 |
196 | top = labels
197 |
198 | data, labels = self.data_labels(image, fudged_image, segments,
199 | classifier_fn, num_samples,
200 | batch_size=batch_size,
201 | progress_bar=progress_bar)
202 |
203 | distances = sklearn.metrics.pairwise_distances(
204 | data,
205 | data[0].reshape(1, -1),
206 | metric=distance_metric
207 | ).ravel()
208 |
209 | ret_exp = ImageExplanation(image, segments)
210 | if top_labels:
211 | top = np.argsort(labels[0])[-top_labels:]
212 | ret_exp.top_labels = list(top)
213 | ret_exp.top_labels.reverse()
214 | for label in top:
215 | (ret_exp.intercept[label],
216 | ret_exp.local_exp[label],
217 | ret_exp.score[label],
218 | ret_exp.local_pred[label]) = self.base.explain_instance_with_data(
219 | data, labels, distances, label, num_features,
220 | model_regressor=model_regressor,
221 | feature_selection=self.feature_selection)
222 | return ret_exp
223 |
224 | def data_labels(self,
225 | image,
226 | fudged_image,
227 | segments,
228 | classifier_fn,
229 | num_samples,
230 | batch_size=10,
231 | progress_bar=True):
232 | """Generates images and predictions in the neighborhood of this image.
233 |
234 | Args:
235 | image: 3d numpy array, the image
236 | fudged_image: 3d numpy array, image to replace original image when
237 | superpixel is turned off
238 | segments: segmentation of the image
239 | classifier_fn: function that takes a list of images and returns a
240 | matrix of prediction probabilities
241 | num_samples: size of the neighborhood to learn the linear model
242 | batch_size: classifier_fn will be called on batches of this size.
243 | progress_bar: if True, show tqdm progress bar.
244 |
245 | Returns:
246 | A tuple (data, labels), where:
247 | data: dense num_samples * num_superpixels
248 | labels: prediction probabilities matrix
249 | """
250 | n_features = np.unique(segments).shape[0]
251 | data = self.random_state.randint(0, 2, num_samples * n_features)\
252 | .reshape((num_samples, n_features))
253 | labels = []
254 | data[0, :] = 1
255 | imgs = []
256 | rows = tqdm(data) if progress_bar else data
257 | for row in rows:
258 | temp = copy.deepcopy(image)
259 | zeros = np.where(row == 0)[0]
260 | mask = np.zeros(segments.shape).astype(bool)
261 | for z in zeros:
262 | mask[segments == z] = True
263 | temp[mask] = fudged_image[mask]
264 | imgs.append(temp)
265 | if len(imgs) == batch_size:
266 | preds = classifier_fn(np.array(imgs))
267 | labels.extend(preds)
268 | imgs = []
269 | if len(imgs) > 0:
270 | preds = classifier_fn(np.array(imgs))
271 | labels.extend(preds)
272 | return data, np.array(labels)
273 |
--------------------------------------------------------------------------------
/lime/lime_text.py:
--------------------------------------------------------------------------------
1 | """
2 | Functions for explaining text classifiers.
3 | """
4 | from functools import partial
5 | import itertools
6 | import json
7 | import re
8 |
9 | import numpy as np
10 | import scipy as sp
11 | import sklearn
12 | from sklearn.utils import check_random_state
13 |
14 | from . import explanation
15 | from . import lime_base
16 |
17 |
18 | class TextDomainMapper(explanation.DomainMapper):
19 | """Maps feature ids to words or word-positions"""
20 |
21 | def __init__(self, indexed_string):
22 | """Initializer.
23 |
24 | Args:
25 | indexed_string: lime_text.IndexedString, original string
26 | """
27 | self.indexed_string = indexed_string
28 |
29 | def map_exp_ids(self, exp, positions=False):
30 | """Maps ids to words or word-position strings.
31 |
32 | Args:
33 | exp: list of tuples [(id, weight), (id,weight)]
34 | positions: if True, also return word positions
35 |
36 | Returns:
37 | list of tuples (word, weight), or (word_positions, weight) if
38 | examples: ('bad', 1) or ('bad_3-6-12', 1)
39 | """
40 | if positions:
41 | exp = [('%s_%s' % (
42 | self.indexed_string.word(x[0]),
43 | '-'.join(
44 | map(str,
45 | self.indexed_string.string_position(x[0])))), x[1])
46 | for x in exp]
47 | else:
48 | exp = [(self.indexed_string.word(x[0]), x[1]) for x in exp]
49 | return exp
50 |
51 | def visualize_instance_html(self, exp, label, div_name, exp_object_name,
52 | text=True, opacity=True):
53 | """Adds text with highlighted words to visualization.
54 |
55 | Args:
56 | exp: list of tuples [(id, weight), (id,weight)]
57 | label: label id (integer)
58 | div_name: name of div object to be used for rendering(in js)
59 | exp_object_name: name of js explanation object
60 | text: if False, return empty
61 | opacity: if True, fade colors according to weight
62 | """
63 | if not text:
64 | return u''
65 | text = (self.indexed_string.raw_string()
66 | .encode('utf-8', 'xmlcharrefreplace').decode('utf-8'))
67 | text = re.sub(r'[<>&]', '|', text)
68 | exp = [(self.indexed_string.word(x[0]),
69 | self.indexed_string.string_position(x[0]),
70 | x[1]) for x in exp]
71 | all_occurrences = list(itertools.chain.from_iterable(
72 | [itertools.product([x[0]], x[1], [x[2]]) for x in exp]))
73 | all_occurrences = [(x[0], int(x[1]), x[2]) for x in all_occurrences]
74 | ret = '''
75 | %s.show_raw_text(%s, %d, %s, %s, %s);
76 | ''' % (exp_object_name, json.dumps(all_occurrences), label,
77 | json.dumps(text), div_name, json.dumps(opacity))
78 | return ret
79 |
80 |
81 | class IndexedString(object):
82 | """String with various indexes."""
83 |
84 | def __init__(self, raw_string, split_expression=r'\W+', bow=True,
85 | mask_string=None):
86 | """Initializer.
87 |
88 | Args:
89 | raw_string: string with raw text in it
90 | split_expression: Regex string or callable. If regex string, will be used with re.split.
91 | If callable, the function should return a list of tokens.
92 | bow: if True, a word is the same everywhere in the text - i.e. we
93 | will index multiple occurrences of the same word. If False,
94 | order matters, so that the same word will have different ids
95 | according to position.
96 | mask_string: If not None, replace words with this if bow=False
97 | if None, default value is UNKWORDZ
98 | """
99 | self.raw = raw_string
100 | self.mask_string = 'UNKWORDZ' if mask_string is None else mask_string
101 |
102 | if callable(split_expression):
103 | tokens = split_expression(self.raw)
104 | self.as_list = self._segment_with_tokens(self.raw, tokens)
105 | tokens = set(tokens)
106 |
107 | def non_word(string):
108 | return string not in tokens
109 |
110 | else:
111 | # with the split_expression as a non-capturing group (?:), we don't need to filter out
112 | # the separator character from the split results.
113 | splitter = re.compile(r'(%s)|$' % split_expression)
114 | self.as_list = [s for s in splitter.split(self.raw) if s]
115 | non_word = splitter.match
116 |
117 | self.as_np = np.array(self.as_list)
118 | self.string_start = np.hstack(
119 | ([0], np.cumsum([len(x) for x in self.as_np[:-1]])))
120 | vocab = {}
121 | self.inverse_vocab = []
122 | self.positions = []
123 | self.bow = bow
124 | non_vocab = set()
125 | for i, word in enumerate(self.as_np):
126 | if word in non_vocab:
127 | continue
128 | if non_word(word):
129 | non_vocab.add(word)
130 | continue
131 | if bow:
132 | if word not in vocab:
133 | vocab[word] = len(vocab)
134 | self.inverse_vocab.append(word)
135 | self.positions.append([])
136 | idx_word = vocab[word]
137 | self.positions[idx_word].append(i)
138 | else:
139 | self.inverse_vocab.append(word)
140 | self.positions.append(i)
141 | if not bow:
142 | self.positions = np.array(self.positions)
143 |
144 | def raw_string(self):
145 | """Returns the original raw string"""
146 | return self.raw
147 |
148 | def num_words(self):
149 | """Returns the number of tokens in the vocabulary for this document."""
150 | return len(self.inverse_vocab)
151 |
152 | def word(self, id_):
153 | """Returns the word that corresponds to id_ (int)"""
154 | return self.inverse_vocab[id_]
155 |
156 | def string_position(self, id_):
157 | """Returns a np array with indices to id_ (int) occurrences"""
158 | if self.bow:
159 | return self.string_start[self.positions[id_]]
160 | else:
161 | return self.string_start[[self.positions[id_]]]
162 |
163 | def inverse_removing(self, words_to_remove):
164 | """Returns a string after removing the appropriate words.
165 |
166 | If self.bow is false, replaces word with UNKWORDZ instead of removing
167 | it.
168 |
169 | Args:
170 | words_to_remove: list of ids (ints) to remove
171 |
172 | Returns:
173 | original raw string with appropriate words removed.
174 | """
175 | mask = np.ones(self.as_np.shape[0], dtype='bool')
176 | mask[self.__get_idxs(words_to_remove)] = False
177 | if not self.bow:
178 | return ''.join(
179 | [self.as_list[i] if mask[i] else self.mask_string
180 | for i in range(mask.shape[0])])
181 | return ''.join([self.as_list[v] for v in mask.nonzero()[0]])
182 |
183 | @staticmethod
184 | def _segment_with_tokens(text, tokens):
185 | """Segment a string around the tokens created by a passed-in tokenizer"""
186 | list_form = []
187 | text_ptr = 0
188 | for token in tokens:
189 | inter_token_string = []
190 | while not text[text_ptr:].startswith(token):
191 | inter_token_string.append(text[text_ptr])
192 | text_ptr += 1
193 | if text_ptr >= len(text):
194 | raise ValueError("Tokenization produced tokens that do not belong in string!")
195 | text_ptr += len(token)
196 | if inter_token_string:
197 | list_form.append(''.join(inter_token_string))
198 | list_form.append(token)
199 | if text_ptr < len(text):
200 | list_form.append(text[text_ptr:])
201 | return list_form
202 |
203 | def __get_idxs(self, words):
204 | """Returns indexes to appropriate words."""
205 | if self.bow:
206 | return list(itertools.chain.from_iterable(
207 | [self.positions[z] for z in words]))
208 | else:
209 | return self.positions[words]
210 |
211 |
212 | class IndexedCharacters(object):
213 | """String with various indexes."""
214 |
215 | def __init__(self, raw_string, bow=True, mask_string=None):
216 | """Initializer.
217 |
218 | Args:
219 | raw_string: string with raw text in it
220 | bow: if True, a char is the same everywhere in the text - i.e. we
221 | will index multiple occurrences of the same character. If False,
222 | order matters, so that the same word will have different ids
223 | according to position.
224 | mask_string: If not None, replace characters with this if bow=False
225 | if None, default value is chr(0)
226 | """
227 | self.raw = raw_string
228 | self.as_list = list(self.raw)
229 | self.as_np = np.array(self.as_list)
230 | self.mask_string = chr(0) if mask_string is None else mask_string
231 | self.string_start = np.arange(len(self.raw))
232 | vocab = {}
233 | self.inverse_vocab = []
234 | self.positions = []
235 | self.bow = bow
236 | non_vocab = set()
237 | for i, char in enumerate(self.as_np):
238 | if char in non_vocab:
239 | continue
240 | if bow:
241 | if char not in vocab:
242 | vocab[char] = len(vocab)
243 | self.inverse_vocab.append(char)
244 | self.positions.append([])
245 | idx_char = vocab[char]
246 | self.positions[idx_char].append(i)
247 | else:
248 | self.inverse_vocab.append(char)
249 | self.positions.append(i)
250 | if not bow:
251 | self.positions = np.array(self.positions)
252 |
253 | def raw_string(self):
254 | """Returns the original raw string"""
255 | return self.raw
256 |
257 | def num_words(self):
258 | """Returns the number of tokens in the vocabulary for this document."""
259 | return len(self.inverse_vocab)
260 |
261 | def word(self, id_):
262 | """Returns the word that corresponds to id_ (int)"""
263 | return self.inverse_vocab[id_]
264 |
265 | def string_position(self, id_):
266 | """Returns a np array with indices to id_ (int) occurrences"""
267 | if self.bow:
268 | return self.string_start[self.positions[id_]]
269 | else:
270 | return self.string_start[[self.positions[id_]]]
271 |
272 | def inverse_removing(self, words_to_remove):
273 | """Returns a string after removing the appropriate words.
274 |
275 | If self.bow is false, replaces word with UNKWORDZ instead of removing
276 | it.
277 |
278 | Args:
279 | words_to_remove: list of ids (ints) to remove
280 |
281 | Returns:
282 | original raw string with appropriate words removed.
283 | """
284 | mask = np.ones(self.as_np.shape[0], dtype='bool')
285 | mask[self.__get_idxs(words_to_remove)] = False
286 | if not self.bow:
287 | return ''.join(
288 | [self.as_list[i] if mask[i] else self.mask_string
289 | for i in range(mask.shape[0])])
290 | return ''.join([self.as_list[v] for v in mask.nonzero()[0]])
291 |
292 | def __get_idxs(self, words):
293 | """Returns indexes to appropriate words."""
294 | if self.bow:
295 | return list(itertools.chain.from_iterable(
296 | [self.positions[z] for z in words]))
297 | else:
298 | return self.positions[words]
299 |
300 |
301 | class LimeTextExplainer(object):
302 | """Explains text classifiers.
303 | Currently, we are using an exponential kernel on cosine distance, and
304 | restricting explanations to words that are present in documents."""
305 |
306 | def __init__(self,
307 | kernel_width=25,
308 | kernel=None,
309 | verbose=False,
310 | class_names=None,
311 | feature_selection='auto',
312 | split_expression=r'\W+',
313 | bow=True,
314 | mask_string=None,
315 | random_state=None,
316 | char_level=False):
317 | """Init function.
318 |
319 | Args:
320 | kernel_width: kernel width for the exponential kernel.
321 | kernel: similarity kernel that takes euclidean distances and kernel
322 | width as input and outputs weights in (0,1). If None, defaults to
323 | an exponential kernel.
324 | verbose: if true, print local prediction values from linear model
325 | class_names: list of class names, ordered according to whatever the
326 | classifier is using. If not present, class names will be '0',
327 | '1', ...
328 | feature_selection: feature selection method. can be
329 | 'forward_selection', 'lasso_path', 'none' or 'auto'.
330 | See function 'explain_instance_with_data' in lime_base.py for
331 | details on what each of the options does.
332 | split_expression: Regex string or callable. If regex string, will be used with re.split.
333 | If callable, the function should return a list of tokens.
334 | bow: if True (bag of words), will perturb input data by removing
335 | all occurrences of individual words or characters.
336 | Explanations will be in terms of these words. Otherwise, will
337 | explain in terms of word-positions, so that a word may be
338 | important the first time it appears and unimportant the second.
339 | Only set to false if the classifier uses word order in some way
340 | (bigrams, etc), or if you set char_level=True.
341 | mask_string: String used to mask tokens or characters if bow=False
342 | if None, will be 'UNKWORDZ' if char_level=False, chr(0)
343 | otherwise.
344 | random_state: an integer or numpy.RandomState that will be used to
345 | generate random numbers. If None, the random state will be
346 | initialized using the internal numpy seed.
347 | char_level: an boolean identifying that we treat each character
348 | as an independent occurence in the string
349 | """
350 |
351 | if kernel is None:
352 | def kernel(d, kernel_width):
353 | return np.sqrt(np.exp(-(d ** 2) / kernel_width ** 2))
354 |
355 | kernel_fn = partial(kernel, kernel_width=kernel_width)
356 |
357 | self.random_state = check_random_state(random_state)
358 | self.base = lime_base.LimeBase(kernel_fn, verbose,
359 | random_state=self.random_state)
360 | self.class_names = class_names
361 | self.vocabulary = None
362 | self.feature_selection = feature_selection
363 | self.bow = bow
364 | self.mask_string = mask_string
365 | self.split_expression = split_expression
366 | self.char_level = char_level
367 |
368 | def explain_instance(self,
369 | text_instance,
370 | classifier_fn,
371 | labels=(1,),
372 | top_labels=None,
373 | num_features=10,
374 | num_samples=5000,
375 | distance_metric='cosine',
376 | model_regressor=None):
377 | """Generates explanations for a prediction.
378 |
379 | First, we generate neighborhood data by randomly hiding features from
380 | the instance (see __data_labels_distance_mapping). We then learn
381 | locally weighted linear models on this neighborhood data to explain
382 | each of the classes in an interpretable way (see lime_base.py).
383 |
384 | Args:
385 | text_instance: raw text string to be explained.
386 | classifier_fn: classifier prediction probability function, which
387 | takes a list of d strings and outputs a (d, k) numpy array with
388 | prediction probabilities, where k is the number of classes.
389 | For ScikitClassifiers , this is classifier.predict_proba.
390 | labels: iterable with labels to be explained.
391 | top_labels: if not None, ignore labels and produce explanations for
392 | the K labels with highest prediction probabilities, where K is
393 | this parameter.
394 | num_features: maximum number of features present in explanation
395 | num_samples: size of the neighborhood to learn the linear model
396 | distance_metric: the distance metric to use for sample weighting,
397 | defaults to cosine similarity
398 | model_regressor: sklearn regressor to use in explanation. Defaults
399 | to Ridge regression in LimeBase. Must have model_regressor.coef_
400 | and 'sample_weight' as a parameter to model_regressor.fit()
401 | Returns:
402 | An Explanation object (see explanation.py) with the corresponding
403 | explanations.
404 | """
405 |
406 | indexed_string = (IndexedCharacters(
407 | text_instance, bow=self.bow, mask_string=self.mask_string)
408 | if self.char_level else
409 | IndexedString(text_instance, bow=self.bow,
410 | split_expression=self.split_expression,
411 | mask_string=self.mask_string))
412 | domain_mapper = TextDomainMapper(indexed_string)
413 | data, yss, distances = self.__data_labels_distances(
414 | indexed_string, classifier_fn, num_samples,
415 | distance_metric=distance_metric)
416 | if self.class_names is None:
417 | self.class_names = [str(x) for x in range(yss[0].shape[0])]
418 | ret_exp = explanation.Explanation(domain_mapper=domain_mapper,
419 | class_names=self.class_names,
420 | random_state=self.random_state)
421 | ret_exp.predict_proba = yss[0]
422 | if top_labels:
423 | labels = np.argsort(yss[0])[-top_labels:]
424 | ret_exp.top_labels = list(labels)
425 | ret_exp.top_labels.reverse()
426 | for label in labels:
427 | (ret_exp.intercept[label],
428 | ret_exp.local_exp[label],
429 | ret_exp.score[label],
430 | ret_exp.local_pred[label]) = self.base.explain_instance_with_data(
431 | data, yss, distances, label, num_features,
432 | model_regressor=model_regressor,
433 | feature_selection=self.feature_selection)
434 | return ret_exp
435 |
436 | def __data_labels_distances(self,
437 | indexed_string,
438 | classifier_fn,
439 | num_samples,
440 | distance_metric='cosine'):
441 | """Generates a neighborhood around a prediction.
442 |
443 | Generates neighborhood data by randomly removing words from
444 | the instance, and predicting with the classifier. Uses cosine distance
445 | to compute distances between original and perturbed instances.
446 | Args:
447 | indexed_string: document (IndexedString) to be explained,
448 | classifier_fn: classifier prediction probability function, which
449 | takes a string and outputs prediction probabilities. For
450 | ScikitClassifier, this is classifier.predict_proba.
451 | num_samples: size of the neighborhood to learn the linear model
452 | distance_metric: the distance metric to use for sample weighting,
453 | defaults to cosine similarity.
454 |
455 |
456 | Returns:
457 | A tuple (data, labels, distances), where:
458 | data: dense num_samples * K binary matrix, where K is the
459 | number of tokens in indexed_string. The first row is the
460 | original instance, and thus a row of ones.
461 | labels: num_samples * L matrix, where L is the number of target
462 | labels
463 | distances: cosine distance between the original instance and
464 | each perturbed instance (computed in the binary 'data'
465 | matrix), times 100.
466 | """
467 |
468 | def distance_fn(x):
469 | return sklearn.metrics.pairwise.pairwise_distances(
470 | x, x[0], metric=distance_metric).ravel() * 100
471 |
472 | doc_size = indexed_string.num_words()
473 | sample = self.random_state.randint(1, doc_size + 1, num_samples - 1)
474 | data = np.ones((num_samples, doc_size))
475 | data[0] = np.ones(doc_size)
476 | features_range = range(doc_size)
477 | inverse_data = [indexed_string.raw_string()]
478 | for i, size in enumerate(sample, start=1):
479 | inactive = self.random_state.choice(features_range, size,
480 | replace=False)
481 | data[i, inactive] = 0
482 | inverse_data.append(indexed_string.inverse_removing(inactive))
483 | labels = classifier_fn(inverse_data)
484 | distances = distance_fn(sp.sparse.csr_matrix(data))
485 | return data, labels, distances
486 |
--------------------------------------------------------------------------------
/lime/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "lime",
3 | "version": "1.0.0",
4 | "description": "",
5 | "main": "main.js",
6 | "scripts": {
7 | "build": "webpack",
8 | "watch": "webpack --watch",
9 | "start": "webpack-dev-server --hot --inline",
10 | "lint": "eslint js"
11 | },
12 | "repository": {
13 | "type": "git",
14 | "url": "git+https://github.com/marcotcr/lime.git"
15 | },
16 | "author": "Marco Tulio Ribeiro ",
17 | "license": "TODO",
18 | "bugs": {
19 | "url": "https://github.com/marcotcr/lime/issues"
20 | },
21 | "homepage": "https://github.com/marcotcr/lime#readme",
22 | "devDependencies": {
23 | "babel-cli": "^6.8.0",
24 | "babel-core": "^6.17.0",
25 | "babel-eslint": "^6.1.0",
26 | "babel-loader": "^6.2.4",
27 | "babel-polyfill": "^6.16.0",
28 | "babel-preset-es2015": "^6.0.15",
29 | "babel-preset-es2015-ie": "^6.6.2",
30 | "css-loader": "^0.23.1",
31 | "eslint": "^6.6.0",
32 | "node-libs-browser": "^0.5.3",
33 | "style-loader": "^0.13.1",
34 | "webpack": "^1.13.0",
35 | "webpack-dev-server": "^1.14.1"
36 | },
37 | "dependencies": {
38 | "d3": "^3.5.17",
39 | "lodash": "^4.11.2"
40 | },
41 | "eslintConfig": {
42 | "parser": "babel-eslint",
43 | "parserOptions": {
44 | "ecmaVersion": 6,
45 | "sourceType": "module",
46 | "ecmaFeatures": {
47 | "jsx": true
48 | }
49 | },
50 | "extends": "eslint:recommended"
51 | }
52 | }
53 |
--------------------------------------------------------------------------------
/lime/style.css:
--------------------------------------------------------------------------------
1 | .lime {
2 | all: initial;
3 | }
4 | .lime.top_div {
5 | display: flex;
6 | flex-wrap: wrap;
7 | }
8 | .lime.predict_proba {
9 | width: 245px;
10 | }
11 | .lime.predicted_value {
12 | width: 245px;
13 | }
14 | .lime.explanation {
15 | width: 350px;
16 | }
17 |
18 | .lime.text_div {
19 | max-height:300px;
20 | flex: 1 0 300px;
21 | overflow:scroll;
22 | }
23 | .lime.table_div {
24 | max-height:300px;
25 | flex: 1 0 300px;
26 | overflow:scroll;
27 | }
28 | .lime.table_div table {
29 | border-collapse: collapse;
30 | color: white;
31 | border-style: hidden;
32 | margin: 0 auto;
33 | }
34 |
--------------------------------------------------------------------------------
/lime/submodular_pick.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import warnings
3 |
4 |
5 | class SubmodularPick(object):
6 | """Class for submodular pick
7 |
8 | Saves a representative sample of explanation objects using SP-LIME,
9 | as well as saving all generated explanations
10 |
11 | First, a collection of candidate explanations are generated
12 | (see explain_instance). From these candidates, num_exps_desired are
13 | chosen using submodular pick. (see marcotcr et al paper)."""
14 |
15 | def __init__(self,
16 | explainer,
17 | data,
18 | predict_fn,
19 | method='sample',
20 | sample_size=1000,
21 | num_exps_desired=5,
22 | num_features=10,
23 | **kwargs):
24 |
25 | """
26 | Args:
27 | data: a numpy array where each row is a single input into predict_fn
28 | predict_fn: prediction function. For classifiers, this should be a
29 | function that takes a numpy array and outputs prediction
30 | probabilities. For regressors, this takes a numpy array and
31 | returns the predictions. For ScikitClassifiers, this is
32 | `classifier.predict_proba()`. For ScikitRegressors, this
33 | is `regressor.predict()`. The prediction function needs to work
34 | on multiple feature vectors (the vectors randomly perturbed
35 | from the data_row).
36 | method: The method to use to generate candidate explanations
37 | method == 'sample' will sample the data uniformly at
38 | random. The sample size is given by sample_size. Otherwise
39 | if method == 'full' then explanations will be generated for the
40 | entire data. l
41 | sample_size: The number of instances to explain if method == 'sample'
42 | num_exps_desired: The number of explanation objects returned
43 | num_features: maximum number of features present in explanation
44 |
45 |
46 | Sets value:
47 | sp_explanations: A list of explanation objects that has a high coverage
48 | explanations: All the candidate explanations saved for potential future use.
49 | """
50 |
51 | top_labels = kwargs.get('top_labels', 1)
52 | if 'top_labels' in kwargs:
53 | del kwargs['top_labels']
54 | # Parse args
55 | if method == 'sample':
56 | if sample_size > len(data):
57 | warnings.warn("""Requested sample size larger than
58 | size of input data. Using all data""")
59 | sample_size = len(data)
60 | all_indices = np.arange(len(data))
61 | np.random.shuffle(all_indices)
62 | sample_indices = all_indices[:sample_size]
63 | elif method == 'full':
64 | sample_indices = np.arange(len(data))
65 | else:
66 | raise ValueError('Method must be \'sample\' or \'full\'')
67 |
68 | # Generate Explanations
69 | self.explanations = []
70 | for i in sample_indices:
71 | self.explanations.append(
72 | explainer.explain_instance(
73 | data[i], predict_fn, num_features=num_features,
74 | top_labels=top_labels,
75 | **kwargs))
76 | # Error handling
77 | try:
78 | num_exps_desired = int(num_exps_desired)
79 | except TypeError:
80 | return("Requested number of explanations should be an integer")
81 | if num_exps_desired > len(self.explanations):
82 | warnings.warn("""Requested number of explanations larger than
83 | total number of explanations, returning all
84 | explanations instead.""")
85 | num_exps_desired = min(num_exps_desired, len(self.explanations))
86 |
87 | # Find all the explanation model features used. Defines the dimension d'
88 | features_dict = {}
89 | feature_iter = 0
90 | for exp in self.explanations:
91 | labels = exp.available_labels() if exp.mode == 'classification' else [1]
92 | for label in labels:
93 | for feature, _ in exp.as_list(label=label):
94 | if feature not in features_dict.keys():
95 | features_dict[feature] = (feature_iter)
96 | feature_iter += 1
97 | d_prime = len(features_dict.keys())
98 |
99 | # Create the n x d' dimensional 'explanation matrix', W
100 | W = np.zeros((len(self.explanations), d_prime))
101 | for i, exp in enumerate(self.explanations):
102 | labels = exp.available_labels() if exp.mode == 'classification' else [1]
103 | for label in labels:
104 | for feature, value in exp.as_list(label):
105 | W[i, features_dict[feature]] += value
106 |
107 | # Create the global importance vector, I_j described in the paper
108 | importance = np.sum(abs(W), axis=0)**.5
109 |
110 | # Now run the SP-LIME greedy algorithm
111 | remaining_indices = set(range(len(self.explanations)))
112 | V = []
113 | for _ in range(num_exps_desired):
114 | best = 0
115 | best_ind = None
116 | current = 0
117 | for i in remaining_indices:
118 | current = np.dot(
119 | (np.sum(abs(W)[V + [i]], axis=0) > 0), importance
120 | ) # coverage function
121 | if current >= best:
122 | best = current
123 | best_ind = i
124 | V.append(best_ind)
125 | remaining_indices -= {best_ind}
126 |
127 | self.sp_explanations = [self.explanations[i] for i in V]
128 | self.V = V
129 |
--------------------------------------------------------------------------------
/lime/test_table.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
14 |
15 |
16 |
--------------------------------------------------------------------------------
/lime/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/lime/tests/__init__.py
--------------------------------------------------------------------------------
/lime/tests/test_discretize.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from unittest import TestCase
3 |
4 | import numpy as np
5 |
6 | from sklearn.datasets import load_iris
7 |
8 | from lime.discretize import QuartileDiscretizer, DecileDiscretizer, EntropyDiscretizer
9 |
10 |
11 | class TestDiscretize(TestCase):
12 |
13 | def setUp(self):
14 | iris = load_iris()
15 |
16 | self.feature_names = iris.feature_names
17 | self.x = iris.data
18 | self.y = iris.target
19 |
20 | def check_random_state_for_discretizer_class(self, DiscretizerClass):
21 | # ----------------------------------------------------------------------
22 | # -----------Check if the same random_state produces the same-----------
23 | # -------------results for different discretizer instances.-------------
24 | # ----------------------------------------------------------------------
25 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
26 | random_state=10)
27 | x_1 = discretizer.undiscretize(discretizer.discretize(self.x))
28 |
29 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
30 | random_state=10)
31 | x_2 = discretizer.undiscretize(discretizer.discretize(self.x))
32 |
33 | self.assertEqual((x_1 == x_2).sum(), x_1.shape[0] * x_1.shape[1])
34 |
35 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
36 | random_state=np.random.RandomState(10))
37 | x_1 = discretizer.undiscretize(discretizer.discretize(self.x))
38 |
39 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
40 | random_state=np.random.RandomState(10))
41 | x_2 = discretizer.undiscretize(discretizer.discretize(self.x))
42 |
43 | self.assertEqual((x_1 == x_2).sum(), x_1.shape[0] * x_1.shape[1])
44 |
45 | # ----------------------------------------------------------------------
46 | # ---------Check if two different random_state values produces----------
47 | # -------different results for different discretizers instances.--------
48 | # ----------------------------------------------------------------------
49 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
50 | random_state=10)
51 | x_1 = discretizer.undiscretize(discretizer.discretize(self.x))
52 |
53 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
54 | random_state=20)
55 | x_2 = discretizer.undiscretize(discretizer.discretize(self.x))
56 |
57 | self.assertFalse((x_1 == x_2).sum() == x_1.shape[0] * x_1.shape[1])
58 |
59 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
60 | random_state=np.random.RandomState(10))
61 | x_1 = discretizer.undiscretize(discretizer.discretize(self.x))
62 |
63 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
64 | random_state=np.random.RandomState(20))
65 | x_2 = discretizer.undiscretize(discretizer.discretize(self.x))
66 |
67 | self.assertFalse((x_1 == x_2).sum() == x_1.shape[0] * x_1.shape[1])
68 |
69 | def test_random_state(self):
70 | self.check_random_state_for_discretizer_class(QuartileDiscretizer)
71 |
72 | self.check_random_state_for_discretizer_class(DecileDiscretizer)
73 |
74 | self.check_random_state_for_discretizer_class(EntropyDiscretizer)
75 |
76 | def test_feature_names_1(self):
77 | self.maxDiff = None
78 | discretizer = QuartileDiscretizer(self.x, [], self.feature_names,
79 | self.y, random_state=10)
80 | self.assertDictEqual(
81 | {0: ['sepal length (cm) <= 5.10',
82 | '5.10 < sepal length (cm) <= 5.80',
83 | '5.80 < sepal length (cm) <= 6.40',
84 | 'sepal length (cm) > 6.40'],
85 | 1: ['sepal width (cm) <= 2.80',
86 | '2.80 < sepal width (cm) <= 3.00',
87 | '3.00 < sepal width (cm) <= 3.30',
88 | 'sepal width (cm) > 3.30'],
89 | 2: ['petal length (cm) <= 1.60',
90 | '1.60 < petal length (cm) <= 4.35',
91 | '4.35 < petal length (cm) <= 5.10',
92 | 'petal length (cm) > 5.10'],
93 | 3: ['petal width (cm) <= 0.30',
94 | '0.30 < petal width (cm) <= 1.30',
95 | '1.30 < petal width (cm) <= 1.80',
96 | 'petal width (cm) > 1.80']},
97 | discretizer.names)
98 |
99 | def test_feature_names_2(self):
100 | self.maxDiff = None
101 | discretizer = DecileDiscretizer(self.x, [], self.feature_names, self.y,
102 | random_state=10)
103 | self.assertDictEqual(
104 | {0: ['sepal length (cm) <= 4.80',
105 | '4.80 < sepal length (cm) <= 5.00',
106 | '5.00 < sepal length (cm) <= 5.27',
107 | '5.27 < sepal length (cm) <= 5.60',
108 | '5.60 < sepal length (cm) <= 5.80',
109 | '5.80 < sepal length (cm) <= 6.10',
110 | '6.10 < sepal length (cm) <= 6.30',
111 | '6.30 < sepal length (cm) <= 6.52',
112 | '6.52 < sepal length (cm) <= 6.90',
113 | 'sepal length (cm) > 6.90'],
114 | 1: ['sepal width (cm) <= 2.50',
115 | '2.50 < sepal width (cm) <= 2.70',
116 | '2.70 < sepal width (cm) <= 2.80',
117 | '2.80 < sepal width (cm) <= 3.00',
118 | '3.00 < sepal width (cm) <= 3.10',
119 | '3.10 < sepal width (cm) <= 3.20',
120 | '3.20 < sepal width (cm) <= 3.40',
121 | '3.40 < sepal width (cm) <= 3.61',
122 | 'sepal width (cm) > 3.61'],
123 | 2: ['petal length (cm) <= 1.40',
124 | '1.40 < petal length (cm) <= 1.50',
125 | '1.50 < petal length (cm) <= 1.70',
126 | '1.70 < petal length (cm) <= 3.90',
127 | '3.90 < petal length (cm) <= 4.35',
128 | '4.35 < petal length (cm) <= 4.64',
129 | '4.64 < petal length (cm) <= 5.00',
130 | '5.00 < petal length (cm) <= 5.32',
131 | '5.32 < petal length (cm) <= 5.80',
132 | 'petal length (cm) > 5.80'],
133 | 3: ['petal width (cm) <= 0.20',
134 | '0.20 < petal width (cm) <= 0.40',
135 | '0.40 < petal width (cm) <= 1.16',
136 | '1.16 < petal width (cm) <= 1.30',
137 | '1.30 < petal width (cm) <= 1.50',
138 | '1.50 < petal width (cm) <= 1.80',
139 | '1.80 < petal width (cm) <= 1.90',
140 | '1.90 < petal width (cm) <= 2.20',
141 | 'petal width (cm) > 2.20']},
142 | discretizer.names)
143 |
144 | def test_feature_names_3(self):
145 | self.maxDiff = None
146 | discretizer = EntropyDiscretizer(self.x, [], self.feature_names,
147 | self.y, random_state=10)
148 | self.assertDictEqual(
149 | {0: ['sepal length (cm) <= 4.85',
150 | '4.85 < sepal length (cm) <= 5.45',
151 | '5.45 < sepal length (cm) <= 5.55',
152 | '5.55 < sepal length (cm) <= 5.85',
153 | '5.85 < sepal length (cm) <= 6.15',
154 | '6.15 < sepal length (cm) <= 7.05',
155 | 'sepal length (cm) > 7.05'],
156 | 1: ['sepal width (cm) <= 2.45',
157 | '2.45 < sepal width (cm) <= 2.95',
158 | '2.95 < sepal width (cm) <= 3.05',
159 | '3.05 < sepal width (cm) <= 3.35',
160 | '3.35 < sepal width (cm) <= 3.45',
161 | '3.45 < sepal width (cm) <= 3.55',
162 | 'sepal width (cm) > 3.55'],
163 | 2: ['petal length (cm) <= 2.45',
164 | '2.45 < petal length (cm) <= 4.45',
165 | '4.45 < petal length (cm) <= 4.75',
166 | '4.75 < petal length (cm) <= 5.15',
167 | 'petal length (cm) > 5.15'],
168 | 3: ['petal width (cm) <= 0.80',
169 | '0.80 < petal width (cm) <= 1.35',
170 | '1.35 < petal width (cm) <= 1.75',
171 | '1.75 < petal width (cm) <= 1.85',
172 | 'petal width (cm) > 1.85']},
173 | discretizer.names)
174 |
175 |
176 | if __name__ == '__main__':
177 | unittest.main()
178 |
--------------------------------------------------------------------------------
/lime/tests/test_generic_utils.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | import sys
3 | from lime.utils.generic_utils import has_arg
4 |
5 |
6 | class TestGenericUtils(unittest.TestCase):
7 |
8 | def test_has_arg(self):
9 | # fn is callable / is not callable
10 |
11 | class FooNotCallable:
12 |
13 | def __init__(self, word):
14 | self.message = word
15 |
16 | class FooCallable:
17 |
18 | def __init__(self, word):
19 | self.message = word
20 |
21 | def __call__(self, message):
22 | return message
23 |
24 | def positional_argument_call(self, arg1):
25 | return self.message
26 |
27 | def multiple_positional_arguments_call(self, *args):
28 | res = []
29 | for a in args:
30 | res.append(a)
31 | return res
32 |
33 | def keyword_argument_call(self, filter_=True):
34 | res = self.message
35 | if filter_:
36 | res = 'KO'
37 | return res
38 |
39 | def multiple_keyword_arguments_call(self, arg1='1', arg2='2'):
40 | return self.message + arg1 + arg2
41 |
42 | def undefined_keyword_arguments_call(self, **kwargs):
43 | res = self.message
44 | for a in kwargs:
45 | res = res + a
46 | return a
47 |
48 | foo_callable = FooCallable('OK')
49 | self.assertTrue(has_arg(foo_callable, 'message'))
50 |
51 | if sys.version_info < (3,):
52 | foo_not_callable = FooNotCallable('KO')
53 | self.assertFalse(has_arg(foo_not_callable, 'message'))
54 | elif sys.version_info < (3, 6):
55 | with self.assertRaises(TypeError):
56 | foo_not_callable = FooNotCallable('KO')
57 | has_arg(foo_not_callable, 'message')
58 |
59 | # Python 2, argument in / not in valid arguments / keyword arguments
60 | if sys.version_info < (3,):
61 | self.assertFalse(has_arg(foo_callable, 'invalid_arg'))
62 | self.assertTrue(has_arg(foo_callable.positional_argument_call, 'arg1'))
63 | self.assertFalse(has_arg(foo_callable.multiple_positional_arguments_call, 'argX'))
64 | self.assertFalse(has_arg(foo_callable.keyword_argument_call, 'argX'))
65 | self.assertTrue(has_arg(foo_callable.keyword_argument_call, 'filter_'))
66 | self.assertTrue(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg2'))
67 | self.assertFalse(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg3'))
68 | self.assertFalse(has_arg(foo_callable.undefined_keyword_arguments_call, 'argX'))
69 | # Python 3, argument in / not in valid arguments / keyword arguments
70 | elif sys.version_info < (3, 6):
71 | self.assertFalse(has_arg(foo_callable, 'invalid_arg'))
72 | self.assertTrue(has_arg(foo_callable.positional_argument_call, 'arg1'))
73 | self.assertFalse(has_arg(foo_callable.multiple_positional_arguments_call, 'argX'))
74 | self.assertFalse(has_arg(foo_callable.keyword_argument_call, 'argX'))
75 | self.assertTrue(has_arg(foo_callable.keyword_argument_call, 'filter_'))
76 | self.assertTrue(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg2'))
77 | self.assertFalse(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg3'))
78 | self.assertFalse(has_arg(foo_callable.undefined_keyword_arguments_call, 'argX'))
79 | else:
80 | self.assertFalse(has_arg(foo_callable, 'invalid_arg'))
81 | self.assertTrue(has_arg(foo_callable.positional_argument_call, 'arg1'))
82 | self.assertFalse(has_arg(foo_callable.multiple_positional_arguments_call, 'argX'))
83 | self.assertFalse(has_arg(foo_callable.keyword_argument_call, 'argX'))
84 | self.assertTrue(has_arg(foo_callable.keyword_argument_call, 'filter_'))
85 | self.assertTrue(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg2'))
86 | self.assertFalse(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg3'))
87 | self.assertFalse(has_arg(foo_callable.undefined_keyword_arguments_call, 'argX'))
88 | # argname is None
89 | self.assertFalse(has_arg(foo_callable, None))
90 |
91 |
92 | if __name__ == '__main__':
93 | unittest.main()
94 |
--------------------------------------------------------------------------------
/lime/tests/test_lime_text.py:
--------------------------------------------------------------------------------
1 | import re
2 | import unittest
3 |
4 | import sklearn # noqa
5 | from sklearn.datasets import fetch_20newsgroups
6 | from sklearn.feature_extraction.text import TfidfVectorizer
7 | from sklearn.metrics import f1_score
8 | from sklearn.naive_bayes import MultinomialNB
9 | from sklearn.pipeline import make_pipeline
10 |
11 | import numpy as np
12 |
13 | from lime.lime_text import LimeTextExplainer
14 | from lime.lime_text import IndexedCharacters, IndexedString
15 |
16 |
17 | class TestLimeText(unittest.TestCase):
18 |
19 | def test_lime_text_explainer_good_regressor(self):
20 | categories = ['alt.atheism', 'soc.religion.christian']
21 | newsgroups_train = fetch_20newsgroups(subset='train',
22 | categories=categories)
23 | newsgroups_test = fetch_20newsgroups(subset='test',
24 | categories=categories)
25 | class_names = ['atheism', 'christian']
26 | vectorizer = TfidfVectorizer(lowercase=False)
27 | train_vectors = vectorizer.fit_transform(newsgroups_train.data)
28 | test_vectors = vectorizer.transform(newsgroups_test.data)
29 | nb = MultinomialNB(alpha=.01)
30 | nb.fit(train_vectors, newsgroups_train.target)
31 | pred = nb.predict(test_vectors)
32 | f1_score(newsgroups_test.target, pred, average='weighted')
33 | c = make_pipeline(vectorizer, nb)
34 | explainer = LimeTextExplainer(class_names=class_names)
35 | idx = 83
36 | exp = explainer.explain_instance(newsgroups_test.data[idx],
37 | c.predict_proba, num_features=6)
38 | self.assertIsNotNone(exp)
39 | self.assertEqual(6, len(exp.as_list()))
40 |
41 | def test_lime_text_tabular_equal_random_state(self):
42 | categories = ['alt.atheism', 'soc.religion.christian']
43 | newsgroups_train = fetch_20newsgroups(subset='train',
44 | categories=categories)
45 | newsgroups_test = fetch_20newsgroups(subset='test',
46 | categories=categories)
47 | class_names = ['atheism', 'christian']
48 | vectorizer = TfidfVectorizer(lowercase=False)
49 | train_vectors = vectorizer.fit_transform(newsgroups_train.data)
50 | test_vectors = vectorizer.transform(newsgroups_test.data)
51 | nb = MultinomialNB(alpha=.01)
52 | nb.fit(train_vectors, newsgroups_train.target)
53 | pred = nb.predict(test_vectors)
54 | f1_score(newsgroups_test.target, pred, average='weighted')
55 | c = make_pipeline(vectorizer, nb)
56 |
57 | explainer = LimeTextExplainer(class_names=class_names, random_state=10)
58 | exp_1 = explainer.explain_instance(newsgroups_test.data[83],
59 | c.predict_proba, num_features=6)
60 |
61 | explainer = LimeTextExplainer(class_names=class_names, random_state=10)
62 | exp_2 = explainer.explain_instance(newsgroups_test.data[83],
63 | c.predict_proba, num_features=6)
64 |
65 | self.assertTrue(exp_1.as_map() == exp_2.as_map())
66 |
67 | def test_lime_text_tabular_not_equal_random_state(self):
68 | categories = ['alt.atheism', 'soc.religion.christian']
69 | newsgroups_train = fetch_20newsgroups(subset='train',
70 | categories=categories)
71 | newsgroups_test = fetch_20newsgroups(subset='test',
72 | categories=categories)
73 | class_names = ['atheism', 'christian']
74 | vectorizer = TfidfVectorizer(lowercase=False)
75 | train_vectors = vectorizer.fit_transform(newsgroups_train.data)
76 | test_vectors = vectorizer.transform(newsgroups_test.data)
77 | nb = MultinomialNB(alpha=.01)
78 | nb.fit(train_vectors, newsgroups_train.target)
79 | pred = nb.predict(test_vectors)
80 | f1_score(newsgroups_test.target, pred, average='weighted')
81 | c = make_pipeline(vectorizer, nb)
82 |
83 | explainer = LimeTextExplainer(
84 | class_names=class_names, random_state=10)
85 | exp_1 = explainer.explain_instance(newsgroups_test.data[83],
86 | c.predict_proba, num_features=6)
87 |
88 | explainer = LimeTextExplainer(
89 | class_names=class_names, random_state=20)
90 | exp_2 = explainer.explain_instance(newsgroups_test.data[83],
91 | c.predict_proba, num_features=6)
92 |
93 | self.assertFalse(exp_1.as_map() == exp_2.as_map())
94 |
95 | def test_indexed_characters_bow(self):
96 | s = 'Please, take your time'
97 | inverse_vocab = ['P', 'l', 'e', 'a', 's', ',', ' ', 't', 'k', 'y', 'o', 'u', 'r', 'i', 'm']
98 | positions = [[0], [1], [2, 5, 11, 21], [3, 9],
99 | [4], [6], [7, 12, 17], [8, 18], [10],
100 | [13], [14], [15], [16], [19], [20]]
101 | ic = IndexedCharacters(s)
102 |
103 | self.assertTrue(np.array_equal(ic.as_np, np.array(list(s))))
104 | self.assertTrue(np.array_equal(ic.string_start, np.arange(len(s))))
105 | self.assertTrue(ic.inverse_vocab == inverse_vocab)
106 | self.assertTrue(ic.positions == positions)
107 |
108 | def test_indexed_characters_not_bow(self):
109 | s = 'Please, take your time'
110 |
111 | ic = IndexedCharacters(s, bow=False)
112 |
113 | self.assertTrue(np.array_equal(ic.as_np, np.array(list(s))))
114 | self.assertTrue(np.array_equal(ic.string_start, np.arange(len(s))))
115 | self.assertTrue(ic.inverse_vocab == list(s))
116 | self.assertTrue(np.array_equal(ic.positions, np.arange(len(s))))
117 |
118 | def test_indexed_string_regex(self):
119 | s = 'Please, take your time. Please'
120 | tokenized_string = np.array(
121 | ['Please', ', ', 'take', ' ', 'your', ' ', 'time', '. ', 'Please'])
122 | inverse_vocab = ['Please', 'take', 'your', 'time']
123 | start_positions = [0, 6, 8, 12, 13, 17, 18, 22, 24]
124 | positions = [[0, 8], [2], [4], [6]]
125 | indexed_string = IndexedString(s)
126 |
127 | self.assertTrue(np.array_equal(indexed_string.as_np, tokenized_string))
128 | self.assertTrue(np.array_equal(indexed_string.string_start, start_positions))
129 | self.assertTrue(indexed_string.inverse_vocab == inverse_vocab)
130 | self.assertTrue(np.array_equal(indexed_string.positions, positions))
131 |
132 | def test_indexed_string_callable(self):
133 | s = 'aabbccddaa'
134 |
135 | def tokenizer(string):
136 | return [string[i] + string[i + 1] for i in range(0, len(string) - 1, 2)]
137 |
138 | tokenized_string = np.array(['aa', 'bb', 'cc', 'dd', 'aa'])
139 | inverse_vocab = ['aa', 'bb', 'cc', 'dd']
140 | start_positions = [0, 2, 4, 6, 8]
141 | positions = [[0, 4], [1], [2], [3]]
142 | indexed_string = IndexedString(s, tokenizer)
143 |
144 | self.assertTrue(np.array_equal(indexed_string.as_np, tokenized_string))
145 | self.assertTrue(np.array_equal(indexed_string.string_start, start_positions))
146 | self.assertTrue(indexed_string.inverse_vocab == inverse_vocab)
147 | self.assertTrue(np.array_equal(indexed_string.positions, positions))
148 |
149 | def test_indexed_string_inverse_removing_tokenizer(self):
150 | s = 'This is a good movie. This, it is a great movie.'
151 |
152 | def tokenizer(string):
153 | return re.split(r'(?:\W+)|$', string)
154 |
155 | indexed_string = IndexedString(s, tokenizer)
156 |
157 | self.assertEqual(s, indexed_string.inverse_removing([]))
158 |
159 | def test_indexed_string_inverse_removing_regex(self):
160 | s = 'This is a good movie. This is a great movie'
161 | indexed_string = IndexedString(s)
162 |
163 | self.assertEqual(s, indexed_string.inverse_removing([]))
164 |
165 |
166 | if __name__ == '__main__':
167 | unittest.main()
168 |
--------------------------------------------------------------------------------
/lime/tests/test_scikit_image.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from lime.wrappers.scikit_image import BaseWrapper
3 | from lime.wrappers.scikit_image import SegmentationAlgorithm
4 | from skimage.segmentation import quickshift
5 | from skimage.data import chelsea
6 | from skimage.util import img_as_float
7 | import numpy as np
8 |
9 |
10 | class TestBaseWrapper(unittest.TestCase):
11 |
12 | def test_base_wrapper(self):
13 |
14 | obj_with_params = BaseWrapper(a=10, b='message')
15 | obj_without_params = BaseWrapper()
16 |
17 | def foo_fn():
18 | return 'bar'
19 |
20 | obj_with_fn = BaseWrapper(foo_fn)
21 | self.assertEqual(obj_with_params.target_params, {'a': 10, 'b': 'message'})
22 | self.assertEqual(obj_without_params.target_params, {})
23 | self.assertEqual(obj_with_fn.target_fn(), 'bar')
24 |
25 | def test__check_params(self):
26 |
27 | def bar_fn(a):
28 | return str(a)
29 |
30 | class Pipo():
31 |
32 | def __init__(self):
33 | self.name = 'pipo'
34 |
35 | def __call__(self, message):
36 | return message
37 |
38 | pipo = Pipo()
39 | obj_with_valid_fn = BaseWrapper(bar_fn, a=10, b='message')
40 | obj_with_valid_callable_fn = BaseWrapper(pipo, c=10, d='message')
41 | obj_with_invalid_fn = BaseWrapper([1, 2, 3], fn_name='invalid')
42 |
43 | # target_fn is not a callable or function/method
44 | with self.assertRaises(AttributeError):
45 | obj_with_invalid_fn._check_params('fn_name')
46 |
47 | # parameters is not in target_fn args
48 | with self.assertRaises(ValueError):
49 | obj_with_valid_fn._check_params(['c'])
50 | obj_with_valid_callable_fn._check_params(['e'])
51 |
52 | # params is in target_fn args
53 | try:
54 | obj_with_valid_fn._check_params(['a'])
55 | obj_with_valid_callable_fn._check_params(['message'])
56 | except Exception:
57 | self.fail("_check_params() raised an unexpected exception")
58 |
59 | # params is not a dict or list
60 | with self.assertRaises(TypeError):
61 | obj_with_valid_fn._check_params(None)
62 | with self.assertRaises(TypeError):
63 | obj_with_valid_fn._check_params('param_name')
64 |
65 | def test_set_params(self):
66 |
67 | class Pipo():
68 |
69 | def __init__(self):
70 | self.name = 'pipo'
71 |
72 | def __call__(self, message):
73 | return message
74 | pipo = Pipo()
75 | obj = BaseWrapper(pipo)
76 |
77 | # argument is set accordingly
78 | obj.set_params(message='OK')
79 | self.assertEqual(obj.target_params, {'message': 'OK'})
80 | self.assertEqual(obj.target_fn(**obj.target_params), 'OK')
81 |
82 | # invalid argument is passed
83 | try:
84 | obj = BaseWrapper(Pipo())
85 | obj.set_params(invalid='KO')
86 | except Exception:
87 | self.assertEqual(obj.target_params, {})
88 |
89 | def test_filter_params(self):
90 |
91 | # right arguments are kept and wrong dismmissed
92 | def baz_fn(a, b, c=True):
93 | if c:
94 | return a + b
95 | else:
96 | return a
97 | obj_ = BaseWrapper(baz_fn, a=10, b=100, d=1000)
98 | self.assertEqual(obj_.filter_params(baz_fn), {'a': 10, 'b': 100})
99 |
100 | # target_params is overriden using 'override' argument
101 | self.assertEqual(obj_.filter_params(baz_fn, override={'c': False}),
102 | {'a': 10, 'b': 100, 'c': False})
103 |
104 |
105 | class TestSegmentationAlgorithm(unittest.TestCase):
106 |
107 | def test_instanciate_segmentation_algorithm(self):
108 | img = img_as_float(chelsea()[::2, ::2])
109 |
110 | # wrapped functions provide the same result
111 | fn = SegmentationAlgorithm('quickshift', kernel_size=3, max_dist=6,
112 | ratio=0.5, random_seed=133)
113 | fn_result = fn(img)
114 | original_result = quickshift(img, kernel_size=3, max_dist=6, ratio=0.5,
115 | random_seed=133)
116 |
117 | # same segments
118 | self.assertTrue(np.array_equal(fn_result, original_result))
119 |
120 | def test_instanciate_slic(self):
121 | pass
122 |
123 | def test_instanciate_felzenszwalb(self):
124 | pass
125 |
126 |
127 | if __name__ == '__main__':
128 | unittest.main()
129 |
--------------------------------------------------------------------------------
/lime/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/lime/utils/__init__.py
--------------------------------------------------------------------------------
/lime/utils/generic_utils.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import inspect
3 | import types
4 |
5 |
6 | def has_arg(fn, arg_name):
7 | """Checks if a callable accepts a given keyword argument.
8 |
9 | Args:
10 | fn: callable to inspect
11 | arg_name: string, keyword argument name to check
12 |
13 | Returns:
14 | bool, whether `fn` accepts a `arg_name` keyword argument.
15 | """
16 | if sys.version_info < (3,):
17 | if isinstance(fn, types.FunctionType) or isinstance(fn, types.MethodType):
18 | arg_spec = inspect.getargspec(fn)
19 | else:
20 | try:
21 | arg_spec = inspect.getargspec(fn.__call__)
22 | except AttributeError:
23 | return False
24 | return (arg_name in arg_spec.args)
25 | elif sys.version_info < (3, 6):
26 | arg_spec = inspect.getfullargspec(fn)
27 | return (arg_name in arg_spec.args or
28 | arg_name in arg_spec.kwonlyargs)
29 | else:
30 | try:
31 | signature = inspect.signature(fn)
32 | except ValueError:
33 | # handling Cython
34 | signature = inspect.signature(fn.__call__)
35 | parameter = signature.parameters.get(arg_name)
36 | if parameter is None:
37 | return False
38 | return (parameter.kind in (inspect.Parameter.POSITIONAL_OR_KEYWORD,
39 | inspect.Parameter.KEYWORD_ONLY))
40 |
--------------------------------------------------------------------------------
/lime/webpack.config.js:
--------------------------------------------------------------------------------
1 | var path = require('path');
2 | var webpack = require('webpack');
3 |
4 | module.exports = {
5 | entry: './js/main.js',
6 | output: {
7 | path: __dirname,
8 | filename: 'bundle.js',
9 | library: 'lime'
10 | },
11 | module: {
12 | loaders: [
13 | {
14 | loader: 'babel-loader',
15 | test: path.join(__dirname, 'js'),
16 | query: {
17 | presets: 'es2015-ie',
18 | },
19 |
20 | },
21 | {
22 | test: /\.css$/,
23 | loaders: ['style-loader', 'css-loader'],
24 |
25 | }
26 |
27 | ]
28 | },
29 | plugins: [
30 | // Avoid publishing files when compilation fails
31 | new webpack.NoErrorsPlugin()
32 | ],
33 | stats: {
34 | // Nice colored output
35 | colors: true
36 | },
37 | // Create Sourcemaps for the bundle
38 | devtool: 'source-map',
39 | };
40 |
41 |
--------------------------------------------------------------------------------
/lime/wrappers/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/lime/wrappers/__init__.py
--------------------------------------------------------------------------------
/lime/wrappers/scikit_image.py:
--------------------------------------------------------------------------------
1 | import types
2 | from lime.utils.generic_utils import has_arg
3 | from skimage.segmentation import felzenszwalb, slic, quickshift
4 |
5 |
6 | class BaseWrapper(object):
7 | """Base class for LIME Scikit-Image wrapper
8 |
9 |
10 | Args:
11 | target_fn: callable function or class instance
12 | target_params: dict, parameters to pass to the target_fn
13 |
14 |
15 | 'target_params' takes parameters required to instanciate the
16 | desired Scikit-Image class/model
17 | """
18 |
19 | def __init__(self, target_fn=None, **target_params):
20 | self.target_fn = target_fn
21 | self.target_params = target_params
22 |
23 | def _check_params(self, parameters):
24 | """Checks for mistakes in 'parameters'
25 |
26 | Args :
27 | parameters: dict, parameters to be checked
28 |
29 | Raises :
30 | ValueError: if any parameter is not a valid argument for the target function
31 | or the target function is not defined
32 | TypeError: if argument parameters is not iterable
33 | """
34 | a_valid_fn = []
35 | if self.target_fn is None:
36 | if callable(self):
37 | a_valid_fn.append(self.__call__)
38 | else:
39 | raise TypeError('invalid argument: tested object is not callable,\
40 | please provide a valid target_fn')
41 | elif isinstance(self.target_fn, types.FunctionType) \
42 | or isinstance(self.target_fn, types.MethodType):
43 | a_valid_fn.append(self.target_fn)
44 | else:
45 | a_valid_fn.append(self.target_fn.__call__)
46 |
47 | if not isinstance(parameters, str):
48 | for p in parameters:
49 | for fn in a_valid_fn:
50 | if has_arg(fn, p):
51 | pass
52 | else:
53 | raise ValueError('{} is not a valid parameter'.format(p))
54 | else:
55 | raise TypeError('invalid argument: list or dictionnary expected')
56 |
57 | def set_params(self, **params):
58 | """Sets the parameters of this estimator.
59 | Args:
60 | **params: Dictionary of parameter names mapped to their values.
61 |
62 | Raises :
63 | ValueError: if any parameter is not a valid argument
64 | for the target function
65 | """
66 | self._check_params(params)
67 | self.target_params = params
68 |
69 | def filter_params(self, fn, override=None):
70 | """Filters `target_params` and return those in `fn`'s arguments.
71 | Args:
72 | fn : arbitrary function
73 | override: dict, values to override target_params
74 | Returns:
75 | result : dict, dictionary containing variables
76 | in both target_params and fn's arguments.
77 | """
78 | override = override or {}
79 | result = {}
80 | for name, value in self.target_params.items():
81 | if has_arg(fn, name):
82 | result.update({name: value})
83 | result.update(override)
84 | return result
85 |
86 |
87 | class SegmentationAlgorithm(BaseWrapper):
88 | """ Define the image segmentation function based on Scikit-Image
89 | implementation and a set of provided parameters
90 |
91 | Args:
92 | algo_type: string, segmentation algorithm among the following:
93 | 'quickshift', 'slic', 'felzenszwalb'
94 | target_params: dict, algorithm parameters (valid model paramters
95 | as define in Scikit-Image documentation)
96 | """
97 |
98 | def __init__(self, algo_type, **target_params):
99 | self.algo_type = algo_type
100 | if (self.algo_type == 'quickshift'):
101 | BaseWrapper.__init__(self, quickshift, **target_params)
102 | kwargs = self.filter_params(quickshift)
103 | self.set_params(**kwargs)
104 | elif (self.algo_type == 'felzenszwalb'):
105 | BaseWrapper.__init__(self, felzenszwalb, **target_params)
106 | kwargs = self.filter_params(felzenszwalb)
107 | self.set_params(**kwargs)
108 | elif (self.algo_type == 'slic'):
109 | BaseWrapper.__init__(self, slic, **target_params)
110 | kwargs = self.filter_params(slic)
111 | self.set_params(**kwargs)
112 |
113 | def __call__(self, *args):
114 | return self.target_fn(args[0], **self.target_params)
115 |
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [flake8]
2 | max-line-length = 100
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 |
3 | setup(name='lime',
4 | version='0.2.0.1',
5 | description='Local Interpretable Model-Agnostic Explanations for machine learning classifiers',
6 | url='http://github.com/marcotcr/lime',
7 | author='Marco Tulio Ribeiro',
8 | author_email='marcotcr@gmail.com',
9 | license='BSD',
10 | packages=find_packages(exclude=['js', 'node_modules', 'tests']),
11 | python_requires='>=3.5',
12 | install_requires=[
13 | 'matplotlib',
14 | 'numpy',
15 | 'scipy',
16 | 'tqdm >= 4.29.1',
17 | 'scikit-learn>=0.18',
18 | 'scikit-image>=0.12',
19 | 'pyDOE2==1.3.0'
20 | ],
21 | extras_require={
22 | 'dev': ['pytest', 'flake8'],
23 | },
24 | include_package_data=True,
25 | zip_safe=False)
26 |
--------------------------------------------------------------------------------
98 |
99 | ## Contributing
100 |
101 | Please read [this](CONTRIBUTING.md).
102 |
--------------------------------------------------------------------------------
/benchmark/__init__.py:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/benchmark/table_perf.py:
--------------------------------------------------------------------------------
1 | """
2 | A helper script for evaluating performance of changes to the tabular explainer, in this case different
3 | implementations and methods for distance calculation.
4 | """
5 |
6 | import time
7 | from sklearn.ensemble import RandomForestClassifier
8 | from sklearn.datasets import make_classification
9 | from lime.lime_tabular import LimeTabularExplainer
10 |
11 |
12 | def interpret_data(X, y, func):
13 | explainer = LimeTabularExplainer(X, discretize_continuous=False, kernel_width=3)
14 | times, scores = [], []
15 | for r_idx in range(100):
16 | start_time = time.time()
17 | explanation = explainer.explain_instance(X[r_idx, :], func)
18 | times.append(time.time() - start_time)
19 | scores.append(explanation.score)
20 | print('...')
21 |
22 | return times, scores
23 |
24 |
25 | if __name__ == '__main__':
26 | X_raw, y_raw = make_classification(n_classes=2, n_features=1000, n_samples=1000)
27 | clf = RandomForestClassifier()
28 | clf.fit(X_raw, y_raw)
29 | y_hat = clf.predict_proba(X_raw)
30 |
31 | times, scores = interpret_data(X_raw, y_hat, clf.predict_proba)
32 | print('%9.4fs %9.4fs %9.4fs' % (min(times), sum(times) / len(times), max(times)))
33 | print('%9.4f %9.4f% 9.4f' % (min(scores), sum(scores) / len(scores), max(scores)))
--------------------------------------------------------------------------------
/benchmark/text_perf.py:
--------------------------------------------------------------------------------
1 | import time
2 | import sklearn
3 | import sklearn.ensemble
4 | import sklearn.metrics
5 | from sklearn.datasets import fetch_20newsgroups
6 | from sklearn.pipeline import make_pipeline
7 | from lime.lime_text import LimeTextExplainer
8 |
9 |
10 | def interpret_data(X, y, func, class_names):
11 | explainer = LimeTextExplainer(class_names=class_names)
12 | times, scores = [], []
13 | for r_idx in range(10):
14 | start_time = time.time()
15 | exp = explainer.explain_instance(newsgroups_test.data[r_idx], func, num_features=6)
16 | times.append(time.time() - start_time)
17 | scores.append(exp.score)
18 | print('...')
19 |
20 | return times, scores
21 |
22 | if __name__ == '__main__':
23 | categories = ['alt.atheism', 'soc.religion.christian']
24 | newsgroups_train = fetch_20newsgroups(subset='train', categories=categories)
25 | newsgroups_test = fetch_20newsgroups(subset='test', categories=categories)
26 | class_names = ['atheism', 'christian']
27 |
28 | vectorizer = sklearn.feature_extraction.text.TfidfVectorizer(lowercase=False)
29 | train_vectors = vectorizer.fit_transform(newsgroups_train.data)
30 | test_vectors = vectorizer.transform(newsgroups_test.data)
31 | rf = sklearn.ensemble.RandomForestClassifier(n_estimators=500)
32 | rf.fit(train_vectors, newsgroups_train.target)
33 | pred = rf.predict(test_vectors)
34 | sklearn.metrics.f1_score(newsgroups_test.target, pred, average='binary')
35 | c = make_pipeline(vectorizer, rf)
36 |
37 | interpret_data(train_vectors, newsgroups_train.target, c.predict_proba, class_names)
--------------------------------------------------------------------------------
/binder/environment.yml:
--------------------------------------------------------------------------------
1 |
2 | name: lime-dev
3 | channels:
4 | - conda-forge
5 | dependencies:
6 | - python=3.7.*
7 | # lime install dependencies
8 | - matplotlib
9 | - numpy
10 | - scipy
11 | - scikit-learn
12 | - scikit-image
13 | - pyDOE2
14 | # for testing
15 | - flake8
16 | - pytest
17 | # for examples
18 | - jupyter
19 | - pandas
20 | - keras
21 | - pytorch::pytorch-cpu
22 | - tensorflow
23 | - h2oai::h2o
24 | - py-xgboost
25 | - pip:
26 | # lime source code
27 | - -e ..
28 |
--------------------------------------------------------------------------------
/citation.bib:
--------------------------------------------------------------------------------
1 | @inproceedings{lime,
2 | author = {Marco Tulio Ribeiro and
3 | Sameer Singh and
4 | Carlos Guestrin},
5 | title = {"Why Should {I} Trust You?": Explaining the Predictions of Any Classifier},
6 | booktitle = {Proceedings of the 22nd {ACM} {SIGKDD} International Conference on
7 | Knowledge Discovery and Data Mining, San Francisco, CA, USA, August
8 | 13-17, 2016},
9 | pages = {1135--1144},
10 | year = {2016},
11 | }
12 |
--------------------------------------------------------------------------------
/doc/blog_post.md:
--------------------------------------------------------------------------------
1 | # LIME - Local Interpretable Model-Agnostic Explanations
2 | In this post, we'll talk about the method for explaining the predictions of any classifier described in [this paper](http://arxiv.org/pdf/1602.04938v1.pdf), and implemented in [this open source package](https://github.com/marcotcr/lime).
3 | # Motivation: why do we want to understand predictions?
4 | Machine learning is a buzzword these days. With computers beating professionals in games like [Go](https://deepmind.com/alpha-go.html), many people have started asking if machines would also make for better [drivers](https://www.google.com/selfdrivingcar/), or even doctors.
5 |
6 | Many of the state of the art machine learning models are functionally black boxes, as it is nearly impossible to get a feeling for its inner workings. This brings us to a question of trust: do I trust that a certain prediction from the model is correct? Or do I even trust that the model is making reasonable predictions in general?
7 | While the stakes are low in a Go game, they are much higher if a computer is replacing my doctor, or deciding if I am a suspect of terrorism ([Person of Interest](http://www.imdb.com/title/tt1839578/), anyone?). Perhaps more commonly, if a company is replacing some system with one based on machine learning, it has to trust that the machine learning model will behave reasonably well.
8 |
9 | It seems intuitive that explaining the rationale behind individual predictions would make us better positioned to trust or mistrust the prediction, or the classifier as a whole. Even if we can't necesseraly understand how the model behaves on all cases, it may be possible (and indeed it is in most cases) to understand how it behaves in particular cases.
10 |
11 | Finally, a word on accuracy. If you have had experience with machine learning, I bet you are thinking something along the lines of: "of course I know my model is going to perform well in the real world, I have really high cross validation accuracy! Why do I need to understand it's predictions when I know it gets it right 99% of the time?". As anyone who has used machine learning in the real world (not only in a static dataset) can attest, accuracy on cross validation can be very misleading. Sometimes data that shouldn't be available leaks into the training data accidentaly. Sometimes the way you gather data introduces correlations that will not exist in the real world, which the model exploits. Many other tricky problems can give us a false understanding of performance, even in [doing A/B tests](http://www.exp-platform.com/documents/puzzlingoutcomesincontrolledexperiments.pdf). I am not saying you shouldn't measure accuracy, but simply that it should not be your only metric for assessing trust.
12 |
13 | # Lime: A couple of examples.
14 | First, we give an example from text classification. The famous [20 newsgroups dataset](http://qwone.com/~jason/20Newsgroups/) is a benchmark in the field, and has been used to compare different models in several papers. We take two classes that are suposedly harder to distinguish, due to the fact that they share many words: Christianity and Atheism. Training a random forest with 500 trees, we get a test set accuracy of 92.4%, which is surprisingly high. If accuracy was our only measure of trust, we would definitely trust this algorithm.
15 |
16 | Below is an explanation for an arbitrary instance in the test set, generated using [the lime package](https://github.com/marcotcr/lime).
17 | 
18 | This is a case where the classifier predicts the instance correctly, but for the wrong reasons. A little further exploration shows us that the word "Posting" (part of the email header) appears in 21.6% of the examples in the training set, only two times in the class 'Christianity'. This is repeated on the test set, where it appears in almost 20% of the examples, only twice in 'Christianity'. This kind of quirk in the dataset makes the problem much easier than it is in the real world, where this classifier would **not** be able to distinguish between christianity and atheism documents. This is hard to see just by looking at accuracy or raw data, but easy once explanations are provided. Such insights become common once you understand what models are actually doing, leading to models that generalize much better.
19 |
20 | Note further how interpretable the explanations are: they correspond to a very sparse linear model (with only 6 features). Even though the underlying classifier is a complicated random forest, in the neighborhood of this example it behaves roughly as a linear model. Sure nenough, if we remove the words "Host" and "NNTP" from the example, the "atheism" prediction probability becomes close to 0.57 - 0.14 - 0.12 = 0.31.
21 |
22 | Below is an image from our paper, where we explain Google's [Inception neural network](https://github.com/google/inception) on some arbitary images. In this case, we keep as explanations the parts of the image that are most positive towards a certain class. In this case, the classifier predicts Electric Guitar even though the image contains an acoustic guitar. The explanation reveals why it would confuse the two: the fretboard is very similar. Getting explanations for image classifiers is something that is not yet available in the lime package, but we are working on it.
23 | 
24 |
25 | # Lime: how we get explanations
26 | Lime is short for Local Interpretable Model-Agnostic Explanations. Each part of the name reflects something that we desire in explanations. **Local** refers to local fidelity - i.e., we want the explanation to really reflect the behaviour of the classifier "around" the instance being predicted. This explanation is useless unless it is **interpretable** - that is, unless a human can make sense of it. Lime is able to explain any model without needing to 'peak' into it, so it is **model-agnostic**. We now give a high level overview of how lime works. For more details, check out our [pre-print](http://arxiv.org/pdf/1602.04938v1.pdf).
27 |
28 | First, a word about **interpretability**. Some classifiers use representations that are not intuitive to users at all (e.g. word embeddings). Lime explains those classifiers in terms of interpretable representations (words), even if that is not the representation actually used by the classifier. Further, lime takes human limitations into account: i.e. the explanations are not too long. Right now, our package supports explanations that are sparse linear models (as presented before), although we are working on other representations.
29 |
30 | In order to be **model-agnostic**, lime can't peak into the model. In order to figure out what parts of the interpretable input are contributing to the prediction, we perturb the input around its neighborhood and see how the model's predictions behave. We then weight these perturbed data points by their proximity to the original example, and learn an interpretable model on those and the associated predictions. For example, if we are trying to explain the prediction for the sentence "I hate this movie", we will perturb the sentence and get predictions on sentences such as "I hate movie", "I this movie", "I movie", "I hate", etc. Even if the original classifier takes many more words into account globally, it is reasonable to expect that around this example only the word "hate" will be relevant. Note that if the classifier uses some uninterpretable representation such as word embeddings, this still works: we just represent the perturbed sentences with word embeddings, and the explanation will still be in terms of words such as "hate" or "movie".
31 |
32 | An illustration of this process is given below. The original model's decision function is represented by the blue/pink background, and is clearly nonlinear.
33 | The bright red cross is the instance being explained (let's call it X).
34 | We sample perturbed instances around X, and weight them according to their proximity to X (weight here is represented by size). We get original model's prediction on these perturbed instances, and then learn a linear model (dashed line) that approximates the model well in the vicinity of X. Note that the explanation in this case is not faithful globally, but it is faithful locally around X.
35 | 
36 |
37 | # Conclusion
38 | I hope I've convinced you that understanding individual predictions from classifiers is an important problem. Having explanations lets you make an informed decision about how much you trust the prediction or the model as a whole, and provides insights that can be used to improve the model.
39 |
40 | If you're interested in going more in-depth into how lime works, and the kinds of experiments we did to validate the usefulness of such explanations, [here is a link to our pre-print paper](http://arxiv.org/pdf/1602.04938v1.pdf).
41 |
42 | If you are interested in trying lime for text classifiers, make sure you check out our [python package](https://github.com/marcotcr/lime/). Installation is as simple as typing:
43 | ```pip install lime```
44 | The package is very easy to use. It is particulary easy to explain scikit-learn classifiers. In the github page we also link to a few tutorials, such as [this one](http://marcotcr.github.io/lime/tutorials/Lime%20-%20basic%20usage%2C%20two%20class%20case.html), with examples from scikit-learn.
45 |
46 |
47 |
--------------------------------------------------------------------------------
/doc/conf.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | #
3 | # lime documentation build configuration file, created by
4 | # sphinx-quickstart on Fri Mar 18 16:20:40 2016.
5 | #
6 | # This file is execfile()d with the current directory set to its
7 | # containing dir.
8 | #
9 | # Note that not all possible configuration values are present in this
10 | # autogenerated file.
11 | #
12 | # All configuration values have a default; values that are commented out
13 | # serve to show the default.
14 |
15 | import sys
16 | import os
17 |
18 | # If extensions (or modules to document with autodoc) are in another directory,
19 | # add these directories to sys.path here. If the directory is relative to the
20 | # documentation root, use os.path.abspath to make it absolute, like shown here.
21 | #sys.path.insert(0, os.path.abspath('.'))
22 | curr_path = os.path.dirname(os.path.abspath(os.path.expanduser(__file__)))
23 | libpath = os.path.join(curr_path, '../')
24 | sys.path.insert(0, libpath)
25 | sys.path.insert(0, curr_path)
26 |
27 | import mock
28 | MOCK_MODULES = ['numpy', 'scipy', 'scipy.sparse', 'scipy.special',
29 | 'scipy.stats', 'scipy.stats.distributions', 'sklearn', 'sklearn.preprocessing',
30 | 'sklearn.linear_model', 'matplotlib',
31 | 'sklearn.datasets', 'sklearn.ensemble', 'sklearn.cross_validation',
32 | 'sklearn.feature_extraction', 'sklearn.feature_extraction.text',
33 | 'sklearn.metrics', 'sklearn.naive_bayes', 'sklearn.pipeline',
34 | 'sklearn.utils', 'pyDOE2',]
35 | # for mod_name in MOCK_MODULES:
36 | # sys.modules[mod_name] = mock.Mock()
37 |
38 | import scipy
39 | import scipy.stats
40 | import scipy.stats.distributions
41 | import lime
42 | import lime.lime_text
43 |
44 | import lime.lime_tabular
45 | import lime.explanation
46 | import lime.lime_base
47 | import lime.submodular_pick
48 |
49 | # -- General configuration ------------------------------------------------
50 |
51 | # If your documentation needs a minimal Sphinx version, state it here.
52 | #needs_sphinx = '1.0'
53 |
54 | # Add any Sphinx extension module names here, as strings. They can be
55 | # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
56 | # ones.
57 | extensions = [
58 | 'sphinx.ext.autodoc',
59 | 'sphinx.ext.mathjax',
60 | 'sphinx.ext.napoleon',
61 | ]
62 |
63 | # Add any paths that contain templates here, relative to this directory.
64 | templates_path = ['_templates']
65 |
66 | # The suffix(es) of source filenames.
67 | # You can specify multiple suffix as a list of string:
68 | # source_suffix = ['.rst', '.md']
69 | source_suffix = '.rst'
70 |
71 | # The encoding of source files.
72 | #source_encoding = 'utf-8-sig'
73 |
74 | # The master toctree document.
75 | master_doc = 'index'
76 |
77 | # General information about the project.
78 | project = u'lime'
79 | copyright = u'2016, Marco Tulio Ribeiro'
80 | author = u'Marco Tulio Ribeiro'
81 |
82 | # The version info for the project you're documenting, acts as replacement for
83 | # |version| and |release|, also used in various other places throughout the
84 | # built documents.
85 | #
86 | # The short X.Y version.
87 | version = u'0.1'
88 | # The full version, including alpha/beta/rc tags.
89 | release = u'0.1'
90 |
91 | # The language for content autogenerated by Sphinx. Refer to documentation
92 | # for a list of supported languages.
93 | #
94 | # This is also used if you do content translation via gettext catalogs.
95 | # Usually you set "language" from the command line for these cases.
96 | language = None
97 |
98 | # There are two options for replacing |today|: either, you set today to some
99 | # non-false value, then it is used:
100 | #today = ''
101 | # Else, today_fmt is used as the format for a strftime call.
102 | #today_fmt = '%B %d, %Y'
103 |
104 | # List of patterns, relative to source directory, that match files and
105 | # directories to ignore when looking for source files.
106 | exclude_patterns = ['_build']
107 |
108 | # The reST default role (used for this markup: `text`) to use for all
109 | # documents.
110 | #default_role = None
111 |
112 | # If true, '()' will be appended to :func: etc. cross-reference text.
113 | #add_function_parentheses = True
114 |
115 | # If true, the current module name will be prepended to all description
116 | # unit titles (such as .. function::).
117 | #add_module_names = True
118 |
119 | # If true, sectionauthor and moduleauthor directives will be shown in the
120 | # output. They are ignored by default.
121 | #show_authors = False
122 |
123 | # The name of the Pygments (syntax highlighting) style to use.
124 | pygments_style = 'sphinx'
125 |
126 | # A list of ignored prefixes for module index sorting.
127 | #modindex_common_prefix = []
128 |
129 | # If true, keep warnings as "system message" paragraphs in the built documents.
130 | #keep_warnings = False
131 |
132 | # If true, `todo` and `todoList` produce output, else they produce nothing.
133 | todo_include_todos = False
134 |
135 |
136 | # -- Options for HTML output ----------------------------------------------
137 |
138 | # The theme to use for HTML and HTML Help pages. See the documentation for
139 | # a list of builtin themes.
140 | html_theme = 'default'
141 |
142 | # Theme options are theme-specific and customize the look and feel of a theme
143 | # further. For a list of options available for each theme, see the
144 | # documentation.
145 | #html_theme_options = {}
146 |
147 | # Add any paths that contain custom themes here, relative to this directory.
148 | #html_theme_path = []
149 |
150 | # The name for this set of Sphinx documents. If None, it defaults to
151 | # " v documentation".
152 | #html_title = None
153 |
154 | # A shorter title for the navigation bar. Default is the same as html_title.
155 | #html_short_title = None
156 |
157 | # The name of an image file (relative to this directory) to place at the top
158 | # of the sidebar.
159 | #html_logo = None
160 |
161 | # The name of an image file (relative to this directory) to use as a favicon of
162 | # the docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
163 | # pixels large.
164 | #html_favicon = None
165 |
166 | # Add any paths that contain custom static files (such as style sheets) here,
167 | # relative to this directory. They are copied after the builtin static files,
168 | # so a file named "default.css" will overwrite the builtin "default.css".
169 | html_static_path = ['_static']
170 |
171 | # Add any extra paths that contain custom files (such as robots.txt or
172 | # .htaccess) here, relative to this directory. These files are copied
173 | # directly to the root of the documentation.
174 | #html_extra_path = []
175 |
176 | # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
177 | # using the given strftime format.
178 | #html_last_updated_fmt = '%b %d, %Y'
179 |
180 | # If true, SmartyPants will be used to convert quotes and dashes to
181 | # typographically correct entities.
182 | #html_use_smartypants = True
183 |
184 | # Custom sidebar templates, maps document names to template names.
185 | #html_sidebars = {}
186 |
187 | # Additional templates that should be rendered to pages, maps page names to
188 | # template names.
189 | #html_additional_pages = {}
190 |
191 | # If false, no module index is generated.
192 | #html_domain_indices = True
193 |
194 | # If false, no index is generated.
195 | #html_use_index = True
196 |
197 | # If true, the index is split into individual pages for each letter.
198 | #html_split_index = False
199 |
200 | # If true, links to the reST sources are added to the pages.
201 | #html_show_sourcelink = True
202 |
203 | # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
204 | #html_show_sphinx = True
205 |
206 | # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
207 | #html_show_copyright = True
208 |
209 | # If true, an OpenSearch description file will be output, and all pages will
210 | # contain a tag referring to it. The value of this option must be the
211 | # base URL from which the finished HTML is served.
212 | #html_use_opensearch = ''
213 |
214 | # This is the file name suffix for HTML files (e.g. ".xhtml").
215 | #html_file_suffix = None
216 |
217 | # Language to be used for generating the HTML full-text search index.
218 | # Sphinx supports the following languages:
219 | # 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'
220 | # 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'
221 | #html_search_language = 'en'
222 |
223 | # A dictionary with options for the search language support, empty by default.
224 | # Now only 'ja' uses this config value
225 | #html_search_options = {'type': 'default'}
226 |
227 | # The name of a javascript file (relative to the configuration directory) that
228 | # implements a search results scorer. If empty, the default will be used.
229 | #html_search_scorer = 'scorer.js'
230 |
231 | # Output file base name for HTML help builder.
232 | htmlhelp_basename = 'limedoc'
233 |
234 | # -- Options for LaTeX output ---------------------------------------------
235 |
236 | latex_elements = {
237 | # The paper size ('letterpaper' or 'a4paper').
238 | #'papersize': 'letterpaper',
239 |
240 | # The font size ('10pt', '11pt' or '12pt').
241 | #'pointsize': '10pt',
242 |
243 | # Additional stuff for the LaTeX preamble.
244 | #'preamble': '',
245 |
246 | # Latex figure (float) alignment
247 | #'figure_align': 'htbp',
248 | }
249 |
250 | # Grouping the document tree into LaTeX files. List of tuples
251 | # (source start file, target name, title,
252 | # author, documentclass [howto, manual, or own class]).
253 | latex_documents = [
254 | (master_doc, 'lime.tex', u'lime Documentation',
255 | u'Marco Tulio Ribeiro', 'manual'),
256 | ]
257 |
258 | # The name of an image file (relative to this directory) to place at the top of
259 | # the title page.
260 | #latex_logo = None
261 |
262 | # For "manual" documents, if this is true, then toplevel headings are parts,
263 | # not chapters.
264 | #latex_use_parts = False
265 |
266 | # If true, show page references after internal links.
267 | #latex_show_pagerefs = False
268 |
269 | # If true, show URL addresses after external links.
270 | #latex_show_urls = False
271 |
272 | # Documents to append as an appendix to all manuals.
273 | #latex_appendices = []
274 |
275 | # If false, no module index is generated.
276 | #latex_domain_indices = True
277 |
278 |
279 | # -- Options for manual page output ---------------------------------------
280 |
281 | # One entry per manual page. List of tuples
282 | # (source start file, name, description, authors, manual section).
283 | man_pages = [
284 | (master_doc, 'lime', u'lime Documentation',
285 | [author], 1)
286 | ]
287 |
288 | # If true, show URL addresses after external links.
289 | #man_show_urls = False
290 |
291 |
292 | # -- Options for Texinfo output -------------------------------------------
293 |
294 | # Grouping the document tree into Texinfo files. List of tuples
295 | # (source start file, target name, title, author,
296 | # dir menu entry, description, category)
297 | texinfo_documents = [
298 | (master_doc, 'lime', u'lime Documentation',
299 | author, 'lime', 'One line description of project.',
300 | 'Miscellaneous'),
301 | ]
302 |
303 | autoclass_content = 'both'
304 | # Documents to append as an appendix to all manuals.
305 | #texinfo_appendices = []
306 |
307 | # If false, no module index is generated.
308 | #texinfo_domain_indices = True
309 |
310 | # How to display URL addresses: 'footnote', 'no', or 'inline'.
311 | #texinfo_show_urls = 'footnote'
312 |
313 | # If true, do not generate a @detailmenu in the "Top" node's menu.
314 | #texinfo_no_detailmenu = False
315 |
--------------------------------------------------------------------------------
/doc/images/image_from_paper.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/image_from_paper.png
--------------------------------------------------------------------------------
/doc/images/images.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/images.png
--------------------------------------------------------------------------------
/doc/images/lime.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/lime.png
--------------------------------------------------------------------------------
/doc/images/multiclass.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/multiclass.png
--------------------------------------------------------------------------------
/doc/images/tabular.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/tabular.png
--------------------------------------------------------------------------------
/doc/images/twoclass.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/twoclass.png
--------------------------------------------------------------------------------
/doc/images/video_screenshot.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/images/video_screenshot.png
--------------------------------------------------------------------------------
/doc/index.rst:
--------------------------------------------------------------------------------
1 | .. lime documentation master file, created by
2 | sphinx-quickstart on Fri Mar 18 16:20:40 2016.
3 | You can adapt this file completely to your liking, but it should at least
4 | contain the root `toctree` directive.
5 |
6 | Local Interpretable Model-Agnostic Explanations (lime)
7 | ================================
8 | In this page, you can find the Python API reference for the lime package (local interpretable model-agnostic explanations).
9 | For tutorials and more information, visit `the github page `_.
10 |
11 |
12 | .. toctree::
13 | :maxdepth: 2
14 |
15 | lime
16 |
17 |
18 |
19 | Indices and tables
20 | ==================
21 |
22 | * :ref:`genindex`
23 | * :ref:`modindex`
24 | * :ref:`search`
25 |
26 |
--------------------------------------------------------------------------------
/doc/lime.rst:
--------------------------------------------------------------------------------
1 | lime package
2 | ============
3 |
4 | Subpackages
5 | -----------
6 |
7 | .. toctree::
8 |
9 | lime.tests
10 |
11 | Submodules
12 | ----------
13 |
14 | lime\.discretize module
15 | -----------------------
16 |
17 | .. automodule:: lime.discretize
18 | :members:
19 | :undoc-members:
20 | :show-inheritance:
21 |
22 | lime\.exceptions module
23 | -----------------------
24 |
25 | .. automodule:: lime.exceptions
26 | :members:
27 | :undoc-members:
28 | :show-inheritance:
29 |
30 | lime\.explanation module
31 | ------------------------
32 |
33 | .. automodule:: lime.explanation
34 | :members:
35 | :undoc-members:
36 | :show-inheritance:
37 |
38 | lime\.lime\_base module
39 | -----------------------
40 |
41 | .. automodule:: lime.lime_base
42 | :members:
43 | :undoc-members:
44 | :show-inheritance:
45 |
46 | lime\.lime\_image module
47 | ------------------------
48 |
49 | .. automodule:: lime.lime_image
50 | :members:
51 | :undoc-members:
52 | :show-inheritance:
53 |
54 | lime\.lime\_tabular module
55 | --------------------------
56 |
57 | .. automodule:: lime.lime_tabular
58 | :members:
59 | :undoc-members:
60 | :show-inheritance:
61 |
62 | lime\.lime\_text module
63 | -----------------------
64 |
65 | .. automodule:: lime.lime_text
66 | :members:
67 | :undoc-members:
68 | :show-inheritance:
69 |
70 |
71 | lime\.submodular\_pick module
72 | -----------------------
73 |
74 | .. automodule:: lime.submodular_pick
75 | :members:
76 | :undoc-members:
77 | :show-inheritance:
78 |
79 |
80 | Module contents
81 | ---------------
82 |
83 | .. automodule:: lime
84 | :members:
85 | :undoc-members:
86 | :show-inheritance:
87 |
--------------------------------------------------------------------------------
/doc/notebooks/data/cat_mouse.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/notebooks/data/cat_mouse.jpg
--------------------------------------------------------------------------------
/doc/notebooks/data/dogs.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/doc/notebooks/data/dogs.png
--------------------------------------------------------------------------------
/doc/notebooks/data/imagenet_class_index.json:
--------------------------------------------------------------------------------
1 | {"0": ["n01440764", "tench"], "1": ["n01443537", "goldfish"], "2": ["n01484850", "great_white_shark"], "3": ["n01491361", "tiger_shark"], "4": ["n01494475", "hammerhead"], "5": ["n01496331", "electric_ray"], "6": ["n01498041", "stingray"], "7": ["n01514668", "cock"], "8": ["n01514859", "hen"], "9": ["n01518878", "ostrich"], "10": ["n01530575", "brambling"], "11": ["n01531178", "goldfinch"], "12": ["n01532829", "house_finch"], "13": ["n01534433", "junco"], "14": ["n01537544", "indigo_bunting"], "15": ["n01558993", "robin"], "16": ["n01560419", "bulbul"], "17": ["n01580077", "jay"], "18": ["n01582220", "magpie"], "19": ["n01592084", "chickadee"], "20": ["n01601694", "water_ouzel"], "21": ["n01608432", "kite"], "22": ["n01614925", "bald_eagle"], "23": ["n01616318", "vulture"], "24": ["n01622779", "great_grey_owl"], "25": ["n01629819", "European_fire_salamander"], "26": ["n01630670", "common_newt"], "27": ["n01631663", "eft"], "28": ["n01632458", "spotted_salamander"], "29": ["n01632777", "axolotl"], "30": ["n01641577", "bullfrog"], "31": ["n01644373", "tree_frog"], "32": ["n01644900", "tailed_frog"], "33": ["n01664065", "loggerhead"], "34": ["n01665541", "leatherback_turtle"], "35": ["n01667114", "mud_turtle"], "36": ["n01667778", "terrapin"], "37": ["n01669191", "box_turtle"], "38": ["n01675722", "banded_gecko"], "39": ["n01677366", "common_iguana"], "40": ["n01682714", "American_chameleon"], "41": ["n01685808", "whiptail"], "42": ["n01687978", "agama"], "43": ["n01688243", "frilled_lizard"], "44": ["n01689811", "alligator_lizard"], "45": ["n01692333", "Gila_monster"], "46": ["n01693334", "green_lizard"], "47": ["n01694178", "African_chameleon"], "48": ["n01695060", "Komodo_dragon"], "49": ["n01697457", "African_crocodile"], "50": ["n01698640", "American_alligator"], "51": ["n01704323", "triceratops"], "52": ["n01728572", "thunder_snake"], "53": ["n01728920", "ringneck_snake"], "54": ["n01729322", "hognose_snake"], "55": ["n01729977", "green_snake"], "56": ["n01734418", "king_snake"], "57": ["n01735189", "garter_snake"], "58": ["n01737021", "water_snake"], "59": ["n01739381", "vine_snake"], "60": ["n01740131", "night_snake"], "61": ["n01742172", "boa_constrictor"], "62": ["n01744401", "rock_python"], "63": ["n01748264", "Indian_cobra"], "64": ["n01749939", "green_mamba"], "65": ["n01751748", "sea_snake"], "66": ["n01753488", "horned_viper"], "67": ["n01755581", "diamondback"], "68": ["n01756291", "sidewinder"], "69": ["n01768244", "trilobite"], "70": ["n01770081", "harvestman"], "71": ["n01770393", "scorpion"], "72": ["n01773157", "black_and_gold_garden_spider"], "73": ["n01773549", "barn_spider"], "74": ["n01773797", "garden_spider"], "75": ["n01774384", "black_widow"], "76": ["n01774750", "tarantula"], "77": ["n01775062", "wolf_spider"], "78": ["n01776313", "tick"], "79": ["n01784675", "centipede"], "80": ["n01795545", "black_grouse"], "81": ["n01796340", "ptarmigan"], "82": ["n01797886", "ruffed_grouse"], "83": ["n01798484", "prairie_chicken"], "84": ["n01806143", "peacock"], "85": ["n01806567", "quail"], "86": ["n01807496", "partridge"], "87": ["n01817953", "African_grey"], "88": ["n01818515", "macaw"], "89": ["n01819313", "sulphur-crested_cockatoo"], "90": ["n01820546", "lorikeet"], "91": ["n01824575", "coucal"], "92": ["n01828970", "bee_eater"], "93": ["n01829413", "hornbill"], "94": ["n01833805", "hummingbird"], "95": ["n01843065", "jacamar"], "96": ["n01843383", "toucan"], "97": ["n01847000", "drake"], "98": ["n01855032", "red-breasted_merganser"], "99": ["n01855672", "goose"], "100": ["n01860187", "black_swan"], "101": ["n01871265", "tusker"], "102": ["n01872401", "echidna"], "103": ["n01873310", "platypus"], "104": ["n01877812", "wallaby"], "105": ["n01882714", "koala"], "106": ["n01883070", "wombat"], "107": ["n01910747", "jellyfish"], "108": ["n01914609", "sea_anemone"], "109": ["n01917289", "brain_coral"], "110": ["n01924916", "flatworm"], "111": ["n01930112", "nematode"], "112": ["n01943899", "conch"], "113": ["n01944390", "snail"], "114": ["n01945685", "slug"], "115": ["n01950731", "sea_slug"], "116": ["n01955084", "chiton"], "117": ["n01968897", "chambered_nautilus"], "118": ["n01978287", "Dungeness_crab"], "119": ["n01978455", "rock_crab"], "120": ["n01980166", "fiddler_crab"], "121": ["n01981276", "king_crab"], "122": ["n01983481", "American_lobster"], "123": ["n01984695", "spiny_lobster"], "124": ["n01985128", "crayfish"], "125": ["n01986214", "hermit_crab"], "126": ["n01990800", "isopod"], "127": ["n02002556", "white_stork"], "128": ["n02002724", "black_stork"], "129": ["n02006656", "spoonbill"], "130": ["n02007558", "flamingo"], "131": ["n02009229", "little_blue_heron"], "132": ["n02009912", "American_egret"], "133": ["n02011460", "bittern"], "134": ["n02012849", "crane"], "135": ["n02013706", "limpkin"], "136": ["n02017213", "European_gallinule"], "137": ["n02018207", "American_coot"], "138": ["n02018795", "bustard"], "139": ["n02025239", "ruddy_turnstone"], "140": ["n02027492", "red-backed_sandpiper"], "141": ["n02028035", "redshank"], "142": ["n02033041", "dowitcher"], "143": ["n02037110", "oystercatcher"], "144": ["n02051845", "pelican"], "145": ["n02056570", "king_penguin"], "146": ["n02058221", "albatross"], "147": ["n02066245", "grey_whale"], "148": ["n02071294", "killer_whale"], "149": ["n02074367", "dugong"], "150": ["n02077923", "sea_lion"], "151": ["n02085620", "Chihuahua"], "152": ["n02085782", "Japanese_spaniel"], "153": ["n02085936", "Maltese_dog"], "154": ["n02086079", "Pekinese"], "155": ["n02086240", "Shih-Tzu"], "156": ["n02086646", "Blenheim_spaniel"], "157": ["n02086910", "papillon"], "158": ["n02087046", "toy_terrier"], "159": ["n02087394", "Rhodesian_ridgeback"], "160": ["n02088094", "Afghan_hound"], "161": ["n02088238", "basset"], "162": ["n02088364", "beagle"], "163": ["n02088466", "bloodhound"], "164": ["n02088632", "bluetick"], "165": ["n02089078", "black-and-tan_coonhound"], "166": ["n02089867", "Walker_hound"], "167": ["n02089973", "English_foxhound"], "168": ["n02090379", "redbone"], "169": ["n02090622", "borzoi"], "170": ["n02090721", "Irish_wolfhound"], "171": ["n02091032", "Italian_greyhound"], "172": ["n02091134", "whippet"], "173": ["n02091244", "Ibizan_hound"], "174": ["n02091467", "Norwegian_elkhound"], "175": ["n02091635", "otterhound"], "176": ["n02091831", "Saluki"], "177": ["n02092002", "Scottish_deerhound"], "178": ["n02092339", "Weimaraner"], "179": ["n02093256", "Staffordshire_bullterrier"], "180": ["n02093428", "American_Staffordshire_terrier"], "181": ["n02093647", "Bedlington_terrier"], "182": ["n02093754", "Border_terrier"], "183": ["n02093859", "Kerry_blue_terrier"], "184": ["n02093991", "Irish_terrier"], "185": ["n02094114", "Norfolk_terrier"], "186": ["n02094258", "Norwich_terrier"], "187": ["n02094433", "Yorkshire_terrier"], "188": ["n02095314", "wire-haired_fox_terrier"], "189": ["n02095570", "Lakeland_terrier"], "190": ["n02095889", "Sealyham_terrier"], "191": ["n02096051", "Airedale"], "192": ["n02096177", "cairn"], "193": ["n02096294", "Australian_terrier"], "194": ["n02096437", "Dandie_Dinmont"], "195": ["n02096585", "Boston_bull"], "196": ["n02097047", "miniature_schnauzer"], "197": ["n02097130", "giant_schnauzer"], "198": ["n02097209", "standard_schnauzer"], "199": ["n02097298", "Scotch_terrier"], "200": ["n02097474", "Tibetan_terrier"], "201": ["n02097658", "silky_terrier"], "202": ["n02098105", "soft-coated_wheaten_terrier"], "203": ["n02098286", "West_Highland_white_terrier"], "204": ["n02098413", "Lhasa"], "205": ["n02099267", "flat-coated_retriever"], "206": ["n02099429", "curly-coated_retriever"], "207": ["n02099601", "golden_retriever"], "208": ["n02099712", "Labrador_retriever"], "209": ["n02099849", "Chesapeake_Bay_retriever"], "210": ["n02100236", "German_short-haired_pointer"], "211": ["n02100583", "vizsla"], "212": ["n02100735", "English_setter"], "213": ["n02100877", "Irish_setter"], "214": ["n02101006", "Gordon_setter"], "215": ["n02101388", "Brittany_spaniel"], "216": ["n02101556", "clumber"], "217": ["n02102040", "English_springer"], "218": ["n02102177", "Welsh_springer_spaniel"], "219": ["n02102318", "cocker_spaniel"], "220": ["n02102480", "Sussex_spaniel"], "221": ["n02102973", "Irish_water_spaniel"], "222": ["n02104029", "kuvasz"], "223": ["n02104365", "schipperke"], "224": ["n02105056", "groenendael"], "225": ["n02105162", "malinois"], "226": ["n02105251", "briard"], "227": ["n02105412", "kelpie"], "228": ["n02105505", "komondor"], "229": ["n02105641", "Old_English_sheepdog"], "230": ["n02105855", "Shetland_sheepdog"], "231": ["n02106030", "collie"], "232": ["n02106166", "Border_collie"], "233": ["n02106382", "Bouvier_des_Flandres"], "234": ["n02106550", "Rottweiler"], "235": ["n02106662", "German_shepherd"], "236": ["n02107142", "Doberman"], "237": ["n02107312", "miniature_pinscher"], "238": ["n02107574", "Greater_Swiss_Mountain_dog"], "239": ["n02107683", "Bernese_mountain_dog"], "240": ["n02107908", "Appenzeller"], "241": ["n02108000", "EntleBucher"], "242": ["n02108089", "boxer"], "243": ["n02108422", "bull_mastiff"], "244": ["n02108551", "Tibetan_mastiff"], "245": ["n02108915", "French_bulldog"], "246": ["n02109047", "Great_Dane"], "247": ["n02109525", "Saint_Bernard"], "248": ["n02109961", "Eskimo_dog"], "249": ["n02110063", "malamute"], "250": ["n02110185", "Siberian_husky"], "251": ["n02110341", "dalmatian"], "252": ["n02110627", "affenpinscher"], "253": ["n02110806", "basenji"], "254": ["n02110958", "pug"], "255": ["n02111129", "Leonberg"], "256": ["n02111277", "Newfoundland"], "257": ["n02111500", "Great_Pyrenees"], "258": ["n02111889", "Samoyed"], "259": ["n02112018", "Pomeranian"], "260": ["n02112137", "chow"], "261": ["n02112350", "keeshond"], "262": ["n02112706", "Brabancon_griffon"], "263": ["n02113023", "Pembroke"], "264": ["n02113186", "Cardigan"], "265": ["n02113624", "toy_poodle"], "266": ["n02113712", "miniature_poodle"], "267": ["n02113799", "standard_poodle"], "268": ["n02113978", "Mexican_hairless"], "269": ["n02114367", "timber_wolf"], "270": ["n02114548", "white_wolf"], "271": ["n02114712", "red_wolf"], "272": ["n02114855", "coyote"], "273": ["n02115641", "dingo"], "274": ["n02115913", "dhole"], "275": ["n02116738", "African_hunting_dog"], "276": ["n02117135", "hyena"], "277": ["n02119022", "red_fox"], "278": ["n02119789", "kit_fox"], "279": ["n02120079", "Arctic_fox"], "280": ["n02120505", "grey_fox"], "281": ["n02123045", "tabby"], "282": ["n02123159", "tiger_cat"], "283": ["n02123394", "Persian_cat"], "284": ["n02123597", "Siamese_cat"], "285": ["n02124075", "Egyptian_cat"], "286": ["n02125311", "cougar"], "287": ["n02127052", "lynx"], "288": ["n02128385", "leopard"], "289": ["n02128757", "snow_leopard"], "290": ["n02128925", "jaguar"], "291": ["n02129165", "lion"], "292": ["n02129604", "tiger"], "293": ["n02130308", "cheetah"], "294": ["n02132136", "brown_bear"], "295": ["n02133161", "American_black_bear"], "296": ["n02134084", "ice_bear"], "297": ["n02134418", "sloth_bear"], "298": ["n02137549", "mongoose"], "299": ["n02138441", "meerkat"], "300": ["n02165105", "tiger_beetle"], "301": ["n02165456", "ladybug"], "302": ["n02167151", "ground_beetle"], "303": ["n02168699", "long-horned_beetle"], "304": ["n02169497", "leaf_beetle"], "305": ["n02172182", "dung_beetle"], "306": ["n02174001", "rhinoceros_beetle"], "307": ["n02177972", "weevil"], "308": ["n02190166", "fly"], "309": ["n02206856", "bee"], "310": ["n02219486", "ant"], "311": ["n02226429", "grasshopper"], "312": ["n02229544", "cricket"], "313": ["n02231487", "walking_stick"], "314": ["n02233338", "cockroach"], "315": ["n02236044", "mantis"], "316": ["n02256656", "cicada"], "317": ["n02259212", "leafhopper"], "318": ["n02264363", "lacewing"], "319": ["n02268443", "dragonfly"], "320": ["n02268853", "damselfly"], "321": ["n02276258", "admiral"], "322": ["n02277742", "ringlet"], "323": ["n02279972", "monarch"], "324": ["n02280649", "cabbage_butterfly"], "325": ["n02281406", "sulphur_butterfly"], "326": ["n02281787", "lycaenid"], "327": ["n02317335", "starfish"], "328": ["n02319095", "sea_urchin"], "329": ["n02321529", "sea_cucumber"], "330": ["n02325366", "wood_rabbit"], "331": ["n02326432", "hare"], "332": ["n02328150", "Angora"], "333": ["n02342885", "hamster"], "334": ["n02346627", "porcupine"], "335": ["n02356798", "fox_squirrel"], "336": ["n02361337", "marmot"], "337": ["n02363005", "beaver"], "338": ["n02364673", "guinea_pig"], "339": ["n02389026", "sorrel"], "340": ["n02391049", "zebra"], "341": ["n02395406", "hog"], "342": ["n02396427", "wild_boar"], "343": ["n02397096", "warthog"], "344": ["n02398521", "hippopotamus"], "345": ["n02403003", "ox"], "346": ["n02408429", "water_buffalo"], "347": ["n02410509", "bison"], "348": ["n02412080", "ram"], "349": ["n02415577", "bighorn"], "350": ["n02417914", "ibex"], "351": ["n02422106", "hartebeest"], "352": ["n02422699", "impala"], "353": ["n02423022", "gazelle"], "354": ["n02437312", "Arabian_camel"], "355": ["n02437616", "llama"], "356": ["n02441942", "weasel"], "357": ["n02442845", "mink"], "358": ["n02443114", "polecat"], "359": ["n02443484", "black-footed_ferret"], "360": ["n02444819", "otter"], "361": ["n02445715", "skunk"], "362": ["n02447366", "badger"], "363": ["n02454379", "armadillo"], "364": ["n02457408", "three-toed_sloth"], "365": ["n02480495", "orangutan"], "366": ["n02480855", "gorilla"], "367": ["n02481823", "chimpanzee"], "368": ["n02483362", "gibbon"], "369": ["n02483708", "siamang"], "370": ["n02484975", "guenon"], "371": ["n02486261", "patas"], "372": ["n02486410", "baboon"], "373": ["n02487347", "macaque"], "374": ["n02488291", "langur"], "375": ["n02488702", "colobus"], "376": ["n02489166", "proboscis_monkey"], "377": ["n02490219", "marmoset"], "378": ["n02492035", "capuchin"], "379": ["n02492660", "howler_monkey"], "380": ["n02493509", "titi"], "381": ["n02493793", "spider_monkey"], "382": ["n02494079", "squirrel_monkey"], "383": ["n02497673", "Madagascar_cat"], "384": ["n02500267", "indri"], "385": ["n02504013", "Indian_elephant"], "386": ["n02504458", "African_elephant"], "387": ["n02509815", "lesser_panda"], "388": ["n02510455", "giant_panda"], "389": ["n02514041", "barracouta"], "390": ["n02526121", "eel"], "391": ["n02536864", "coho"], "392": ["n02606052", "rock_beauty"], "393": ["n02607072", "anemone_fish"], "394": ["n02640242", "sturgeon"], "395": ["n02641379", "gar"], "396": ["n02643566", "lionfish"], "397": ["n02655020", "puffer"], "398": ["n02666196", "abacus"], "399": ["n02667093", "abaya"], "400": ["n02669723", "academic_gown"], "401": ["n02672831", "accordion"], "402": ["n02676566", "acoustic_guitar"], "403": ["n02687172", "aircraft_carrier"], "404": ["n02690373", "airliner"], "405": ["n02692877", "airship"], "406": ["n02699494", "altar"], "407": ["n02701002", "ambulance"], "408": ["n02704792", "amphibian"], "409": ["n02708093", "analog_clock"], "410": ["n02727426", "apiary"], "411": ["n02730930", "apron"], "412": ["n02747177", "ashcan"], "413": ["n02749479", "assault_rifle"], "414": ["n02769748", "backpack"], "415": ["n02776631", "bakery"], "416": ["n02777292", "balance_beam"], "417": ["n02782093", "balloon"], "418": ["n02783161", "ballpoint"], "419": ["n02786058", "Band_Aid"], "420": ["n02787622", "banjo"], "421": ["n02788148", "bannister"], "422": ["n02790996", "barbell"], "423": ["n02791124", "barber_chair"], "424": ["n02791270", "barbershop"], "425": ["n02793495", "barn"], "426": ["n02794156", "barometer"], "427": ["n02795169", "barrel"], "428": ["n02797295", "barrow"], "429": ["n02799071", "baseball"], "430": ["n02802426", "basketball"], "431": ["n02804414", "bassinet"], "432": ["n02804610", "bassoon"], "433": ["n02807133", "bathing_cap"], "434": ["n02808304", "bath_towel"], "435": ["n02808440", "bathtub"], "436": ["n02814533", "beach_wagon"], "437": ["n02814860", "beacon"], "438": ["n02815834", "beaker"], "439": ["n02817516", "bearskin"], "440": ["n02823428", "beer_bottle"], "441": ["n02823750", "beer_glass"], "442": ["n02825657", "bell_cote"], "443": ["n02834397", "bib"], "444": ["n02835271", "bicycle-built-for-two"], "445": ["n02837789", "bikini"], "446": ["n02840245", "binder"], "447": ["n02841315", "binoculars"], "448": ["n02843684", "birdhouse"], "449": ["n02859443", "boathouse"], "450": ["n02860847", "bobsled"], "451": ["n02865351", "bolo_tie"], "452": ["n02869837", "bonnet"], "453": ["n02870880", "bookcase"], "454": ["n02871525", "bookshop"], "455": ["n02877765", "bottlecap"], "456": ["n02879718", "bow"], "457": ["n02883205", "bow_tie"], "458": ["n02892201", "brass"], "459": ["n02892767", "brassiere"], "460": ["n02894605", "breakwater"], "461": ["n02895154", "breastplate"], "462": ["n02906734", "broom"], "463": ["n02909870", "bucket"], "464": ["n02910353", "buckle"], "465": ["n02916936", "bulletproof_vest"], "466": ["n02917067", "bullet_train"], "467": ["n02927161", "butcher_shop"], "468": ["n02930766", "cab"], "469": ["n02939185", "caldron"], "470": ["n02948072", "candle"], "471": ["n02950826", "cannon"], "472": ["n02951358", "canoe"], "473": ["n02951585", "can_opener"], "474": ["n02963159", "cardigan"], "475": ["n02965783", "car_mirror"], "476": ["n02966193", "carousel"], "477": ["n02966687", "carpenter's_kit"], "478": ["n02971356", "carton"], "479": ["n02974003", "car_wheel"], "480": ["n02977058", "cash_machine"], "481": ["n02978881", "cassette"], "482": ["n02979186", "cassette_player"], "483": ["n02980441", "castle"], "484": ["n02981792", "catamaran"], "485": ["n02988304", "CD_player"], "486": ["n02992211", "cello"], "487": ["n02992529", "cellular_telephone"], "488": ["n02999410", "chain"], "489": ["n03000134", "chainlink_fence"], "490": ["n03000247", "chain_mail"], "491": ["n03000684", "chain_saw"], "492": ["n03014705", "chest"], "493": ["n03016953", "chiffonier"], "494": ["n03017168", "chime"], "495": ["n03018349", "china_cabinet"], "496": ["n03026506", "Christmas_stocking"], "497": ["n03028079", "church"], "498": ["n03032252", "cinema"], "499": ["n03041632", "cleaver"], "500": ["n03042490", "cliff_dwelling"], "501": ["n03045698", "cloak"], "502": ["n03047690", "clog"], "503": ["n03062245", "cocktail_shaker"], "504": ["n03063599", "coffee_mug"], "505": ["n03063689", "coffeepot"], "506": ["n03065424", "coil"], "507": ["n03075370", "combination_lock"], "508": ["n03085013", "computer_keyboard"], "509": ["n03089624", "confectionery"], "510": ["n03095699", "container_ship"], "511": ["n03100240", "convertible"], "512": ["n03109150", "corkscrew"], "513": ["n03110669", "cornet"], "514": ["n03124043", "cowboy_boot"], "515": ["n03124170", "cowboy_hat"], "516": ["n03125729", "cradle"], "517": ["n03126707", "crane"], "518": ["n03127747", "crash_helmet"], "519": ["n03127925", "crate"], "520": ["n03131574", "crib"], "521": ["n03133878", "Crock_Pot"], "522": ["n03134739", "croquet_ball"], "523": ["n03141823", "crutch"], "524": ["n03146219", "cuirass"], "525": ["n03160309", "dam"], "526": ["n03179701", "desk"], "527": ["n03180011", "desktop_computer"], "528": ["n03187595", "dial_telephone"], "529": ["n03188531", "diaper"], "530": ["n03196217", "digital_clock"], "531": ["n03197337", "digital_watch"], "532": ["n03201208", "dining_table"], "533": ["n03207743", "dishrag"], "534": ["n03207941", "dishwasher"], "535": ["n03208938", "disk_brake"], "536": ["n03216828", "dock"], "537": ["n03218198", "dogsled"], "538": ["n03220513", "dome"], "539": ["n03223299", "doormat"], "540": ["n03240683", "drilling_platform"], "541": ["n03249569", "drum"], "542": ["n03250847", "drumstick"], "543": ["n03255030", "dumbbell"], "544": ["n03259280", "Dutch_oven"], "545": ["n03271574", "electric_fan"], "546": ["n03272010", "electric_guitar"], "547": ["n03272562", "electric_locomotive"], "548": ["n03290653", "entertainment_center"], "549": ["n03291819", "envelope"], "550": ["n03297495", "espresso_maker"], "551": ["n03314780", "face_powder"], "552": ["n03325584", "feather_boa"], "553": ["n03337140", "file"], "554": ["n03344393", "fireboat"], "555": ["n03345487", "fire_engine"], "556": ["n03347037", "fire_screen"], "557": ["n03355925", "flagpole"], "558": ["n03372029", "flute"], "559": ["n03376595", "folding_chair"], "560": ["n03379051", "football_helmet"], "561": ["n03384352", "forklift"], "562": ["n03388043", "fountain"], "563": ["n03388183", "fountain_pen"], "564": ["n03388549", "four-poster"], "565": ["n03393912", "freight_car"], "566": ["n03394916", "French_horn"], "567": ["n03400231", "frying_pan"], "568": ["n03404251", "fur_coat"], "569": ["n03417042", "garbage_truck"], "570": ["n03424325", "gasmask"], "571": ["n03425413", "gas_pump"], "572": ["n03443371", "goblet"], "573": ["n03444034", "go-kart"], "574": ["n03445777", "golf_ball"], "575": ["n03445924", "golfcart"], "576": ["n03447447", "gondola"], "577": ["n03447721", "gong"], "578": ["n03450230", "gown"], "579": ["n03452741", "grand_piano"], "580": ["n03457902", "greenhouse"], "581": ["n03459775", "grille"], "582": ["n03461385", "grocery_store"], "583": ["n03467068", "guillotine"], "584": ["n03476684", "hair_slide"], "585": ["n03476991", "hair_spray"], "586": ["n03478589", "half_track"], "587": ["n03481172", "hammer"], "588": ["n03482405", "hamper"], "589": ["n03483316", "hand_blower"], "590": ["n03485407", "hand-held_computer"], "591": ["n03485794", "handkerchief"], "592": ["n03492542", "hard_disc"], "593": ["n03494278", "harmonica"], "594": ["n03495258", "harp"], "595": ["n03496892", "harvester"], "596": ["n03498962", "hatchet"], "597": ["n03527444", "holster"], "598": ["n03529860", "home_theater"], "599": ["n03530642", "honeycomb"], "600": ["n03532672", "hook"], "601": ["n03534580", "hoopskirt"], "602": ["n03535780", "horizontal_bar"], "603": ["n03538406", "horse_cart"], "604": ["n03544143", "hourglass"], "605": ["n03584254", "iPod"], "606": ["n03584829", "iron"], "607": ["n03590841", "jack-o'-lantern"], "608": ["n03594734", "jean"], "609": ["n03594945", "jeep"], "610": ["n03595614", "jersey"], "611": ["n03598930", "jigsaw_puzzle"], "612": ["n03599486", "jinrikisha"], "613": ["n03602883", "joystick"], "614": ["n03617480", "kimono"], "615": ["n03623198", "knee_pad"], "616": ["n03627232", "knot"], "617": ["n03630383", "lab_coat"], "618": ["n03633091", "ladle"], "619": ["n03637318", "lampshade"], "620": ["n03642806", "laptop"], "621": ["n03649909", "lawn_mower"], "622": ["n03657121", "lens_cap"], "623": ["n03658185", "letter_opener"], "624": ["n03661043", "library"], "625": ["n03662601", "lifeboat"], "626": ["n03666591", "lighter"], "627": ["n03670208", "limousine"], "628": ["n03673027", "liner"], "629": ["n03676483", "lipstick"], "630": ["n03680355", "Loafer"], "631": ["n03690938", "lotion"], "632": ["n03691459", "loudspeaker"], "633": ["n03692522", "loupe"], "634": ["n03697007", "lumbermill"], "635": ["n03706229", "magnetic_compass"], "636": ["n03709823", "mailbag"], "637": ["n03710193", "mailbox"], "638": ["n03710637", "maillot"], "639": ["n03710721", "maillot"], "640": ["n03717622", "manhole_cover"], "641": ["n03720891", "maraca"], "642": ["n03721384", "marimba"], "643": ["n03724870", "mask"], "644": ["n03729826", "matchstick"], "645": ["n03733131", "maypole"], "646": ["n03733281", "maze"], "647": ["n03733805", "measuring_cup"], "648": ["n03742115", "medicine_chest"], "649": ["n03743016", "megalith"], "650": ["n03759954", "microphone"], "651": ["n03761084", "microwave"], "652": ["n03763968", "military_uniform"], "653": ["n03764736", "milk_can"], "654": ["n03769881", "minibus"], "655": ["n03770439", "miniskirt"], "656": ["n03770679", "minivan"], "657": ["n03773504", "missile"], "658": ["n03775071", "mitten"], "659": ["n03775546", "mixing_bowl"], "660": ["n03776460", "mobile_home"], "661": ["n03777568", "Model_T"], "662": ["n03777754", "modem"], "663": ["n03781244", "monastery"], "664": ["n03782006", "monitor"], "665": ["n03785016", "moped"], "666": ["n03786901", "mortar"], "667": ["n03787032", "mortarboard"], "668": ["n03788195", "mosque"], "669": ["n03788365", "mosquito_net"], "670": ["n03791053", "motor_scooter"], "671": ["n03792782", "mountain_bike"], "672": ["n03792972", "mountain_tent"], "673": ["n03793489", "mouse"], "674": ["n03794056", "mousetrap"], "675": ["n03796401", "moving_van"], "676": ["n03803284", "muzzle"], "677": ["n03804744", "nail"], "678": ["n03814639", "neck_brace"], "679": ["n03814906", "necklace"], "680": ["n03825788", "nipple"], "681": ["n03832673", "notebook"], "682": ["n03837869", "obelisk"], "683": ["n03838899", "oboe"], "684": ["n03840681", "ocarina"], "685": ["n03841143", "odometer"], "686": ["n03843555", "oil_filter"], "687": ["n03854065", "organ"], "688": ["n03857828", "oscilloscope"], "689": ["n03866082", "overskirt"], "690": ["n03868242", "oxcart"], "691": ["n03868863", "oxygen_mask"], "692": ["n03871628", "packet"], "693": ["n03873416", "paddle"], "694": ["n03874293", "paddlewheel"], "695": ["n03874599", "padlock"], "696": ["n03876231", "paintbrush"], "697": ["n03877472", "pajama"], "698": ["n03877845", "palace"], "699": ["n03884397", "panpipe"], "700": ["n03887697", "paper_towel"], "701": ["n03888257", "parachute"], "702": ["n03888605", "parallel_bars"], "703": ["n03891251", "park_bench"], "704": ["n03891332", "parking_meter"], "705": ["n03895866", "passenger_car"], "706": ["n03899768", "patio"], "707": ["n03902125", "pay-phone"], "708": ["n03903868", "pedestal"], "709": ["n03908618", "pencil_box"], "710": ["n03908714", "pencil_sharpener"], "711": ["n03916031", "perfume"], "712": ["n03920288", "Petri_dish"], "713": ["n03924679", "photocopier"], "714": ["n03929660", "pick"], "715": ["n03929855", "pickelhaube"], "716": ["n03930313", "picket_fence"], "717": ["n03930630", "pickup"], "718": ["n03933933", "pier"], "719": ["n03935335", "piggy_bank"], "720": ["n03937543", "pill_bottle"], "721": ["n03938244", "pillow"], "722": ["n03942813", "ping-pong_ball"], "723": ["n03944341", "pinwheel"], "724": ["n03947888", "pirate"], "725": ["n03950228", "pitcher"], "726": ["n03954731", "plane"], "727": ["n03956157", "planetarium"], "728": ["n03958227", "plastic_bag"], "729": ["n03961711", "plate_rack"], "730": ["n03967562", "plow"], "731": ["n03970156", "plunger"], "732": ["n03976467", "Polaroid_camera"], "733": ["n03976657", "pole"], "734": ["n03977966", "police_van"], "735": ["n03980874", "poncho"], "736": ["n03982430", "pool_table"], "737": ["n03983396", "pop_bottle"], "738": ["n03991062", "pot"], "739": ["n03992509", "potter's_wheel"], "740": ["n03995372", "power_drill"], "741": ["n03998194", "prayer_rug"], "742": ["n04004767", "printer"], "743": ["n04005630", "prison"], "744": ["n04008634", "projectile"], "745": ["n04009552", "projector"], "746": ["n04019541", "puck"], "747": ["n04023962", "punching_bag"], "748": ["n04026417", "purse"], "749": ["n04033901", "quill"], "750": ["n04033995", "quilt"], "751": ["n04037443", "racer"], "752": ["n04039381", "racket"], "753": ["n04040759", "radiator"], "754": ["n04041544", "radio"], "755": ["n04044716", "radio_telescope"], "756": ["n04049303", "rain_barrel"], "757": ["n04065272", "recreational_vehicle"], "758": ["n04067472", "reel"], "759": ["n04069434", "reflex_camera"], "760": ["n04070727", "refrigerator"], "761": ["n04074963", "remote_control"], "762": ["n04081281", "restaurant"], "763": ["n04086273", "revolver"], "764": ["n04090263", "rifle"], "765": ["n04099969", "rocking_chair"], "766": ["n04111531", "rotisserie"], "767": ["n04116512", "rubber_eraser"], "768": ["n04118538", "rugby_ball"], "769": ["n04118776", "rule"], "770": ["n04120489", "running_shoe"], "771": ["n04125021", "safe"], "772": ["n04127249", "safety_pin"], "773": ["n04131690", "saltshaker"], "774": ["n04133789", "sandal"], "775": ["n04136333", "sarong"], "776": ["n04141076", "sax"], "777": ["n04141327", "scabbard"], "778": ["n04141975", "scale"], "779": ["n04146614", "school_bus"], "780": ["n04147183", "schooner"], "781": ["n04149813", "scoreboard"], "782": ["n04152593", "screen"], "783": ["n04153751", "screw"], "784": ["n04154565", "screwdriver"], "785": ["n04162706", "seat_belt"], "786": ["n04179913", "sewing_machine"], "787": ["n04192698", "shield"], "788": ["n04200800", "shoe_shop"], "789": ["n04201297", "shoji"], "790": ["n04204238", "shopping_basket"], "791": ["n04204347", "shopping_cart"], "792": ["n04208210", "shovel"], "793": ["n04209133", "shower_cap"], "794": ["n04209239", "shower_curtain"], "795": ["n04228054", "ski"], "796": ["n04229816", "ski_mask"], "797": ["n04235860", "sleeping_bag"], "798": ["n04238763", "slide_rule"], "799": ["n04239074", "sliding_door"], "800": ["n04243546", "slot"], "801": ["n04251144", "snorkel"], "802": ["n04252077", "snowmobile"], "803": ["n04252225", "snowplow"], "804": ["n04254120", "soap_dispenser"], "805": ["n04254680", "soccer_ball"], "806": ["n04254777", "sock"], "807": ["n04258138", "solar_dish"], "808": ["n04259630", "sombrero"], "809": ["n04263257", "soup_bowl"], "810": ["n04264628", "space_bar"], "811": ["n04265275", "space_heater"], "812": ["n04266014", "space_shuttle"], "813": ["n04270147", "spatula"], "814": ["n04273569", "speedboat"], "815": ["n04275548", "spider_web"], "816": ["n04277352", "spindle"], "817": ["n04285008", "sports_car"], "818": ["n04286575", "spotlight"], "819": ["n04296562", "stage"], "820": ["n04310018", "steam_locomotive"], "821": ["n04311004", "steel_arch_bridge"], "822": ["n04311174", "steel_drum"], "823": ["n04317175", "stethoscope"], "824": ["n04325704", "stole"], "825": ["n04326547", "stone_wall"], "826": ["n04328186", "stopwatch"], "827": ["n04330267", "stove"], "828": ["n04332243", "strainer"], "829": ["n04335435", "streetcar"], "830": ["n04336792", "stretcher"], "831": ["n04344873", "studio_couch"], "832": ["n04346328", "stupa"], "833": ["n04347754", "submarine"], "834": ["n04350905", "suit"], "835": ["n04355338", "sundial"], "836": ["n04355933", "sunglass"], "837": ["n04356056", "sunglasses"], "838": ["n04357314", "sunscreen"], "839": ["n04366367", "suspension_bridge"], "840": ["n04367480", "swab"], "841": ["n04370456", "sweatshirt"], "842": ["n04371430", "swimming_trunks"], "843": ["n04371774", "swing"], "844": ["n04372370", "switch"], "845": ["n04376876", "syringe"], "846": ["n04380533", "table_lamp"], "847": ["n04389033", "tank"], "848": ["n04392985", "tape_player"], "849": ["n04398044", "teapot"], "850": ["n04399382", "teddy"], "851": ["n04404412", "television"], "852": ["n04409515", "tennis_ball"], "853": ["n04417672", "thatch"], "854": ["n04418357", "theater_curtain"], "855": ["n04423845", "thimble"], "856": ["n04428191", "thresher"], "857": ["n04429376", "throne"], "858": ["n04435653", "tile_roof"], "859": ["n04442312", "toaster"], "860": ["n04443257", "tobacco_shop"], "861": ["n04447861", "toilet_seat"], "862": ["n04456115", "torch"], "863": ["n04458633", "totem_pole"], "864": ["n04461696", "tow_truck"], "865": ["n04462240", "toyshop"], "866": ["n04465501", "tractor"], "867": ["n04467665", "trailer_truck"], "868": ["n04476259", "tray"], "869": ["n04479046", "trench_coat"], "870": ["n04482393", "tricycle"], "871": ["n04483307", "trimaran"], "872": ["n04485082", "tripod"], "873": ["n04486054", "triumphal_arch"], "874": ["n04487081", "trolleybus"], "875": ["n04487394", "trombone"], "876": ["n04493381", "tub"], "877": ["n04501370", "turnstile"], "878": ["n04505470", "typewriter_keyboard"], "879": ["n04507155", "umbrella"], "880": ["n04509417", "unicycle"], "881": ["n04515003", "upright"], "882": ["n04517823", "vacuum"], "883": ["n04522168", "vase"], "884": ["n04523525", "vault"], "885": ["n04525038", "velvet"], "886": ["n04525305", "vending_machine"], "887": ["n04532106", "vestment"], "888": ["n04532670", "viaduct"], "889": ["n04536866", "violin"], "890": ["n04540053", "volleyball"], "891": ["n04542943", "waffle_iron"], "892": ["n04548280", "wall_clock"], "893": ["n04548362", "wallet"], "894": ["n04550184", "wardrobe"], "895": ["n04552348", "warplane"], "896": ["n04553703", "washbasin"], "897": ["n04554684", "washer"], "898": ["n04557648", "water_bottle"], "899": ["n04560804", "water_jug"], "900": ["n04562935", "water_tower"], "901": ["n04579145", "whiskey_jug"], "902": ["n04579432", "whistle"], "903": ["n04584207", "wig"], "904": ["n04589890", "window_screen"], "905": ["n04590129", "window_shade"], "906": ["n04591157", "Windsor_tie"], "907": ["n04591713", "wine_bottle"], "908": ["n04592741", "wing"], "909": ["n04596742", "wok"], "910": ["n04597913", "wooden_spoon"], "911": ["n04599235", "wool"], "912": ["n04604644", "worm_fence"], "913": ["n04606251", "wreck"], "914": ["n04612504", "yawl"], "915": ["n04613696", "yurt"], "916": ["n06359193", "web_site"], "917": ["n06596364", "comic_book"], "918": ["n06785654", "crossword_puzzle"], "919": ["n06794110", "street_sign"], "920": ["n06874185", "traffic_light"], "921": ["n07248320", "book_jacket"], "922": ["n07565083", "menu"], "923": ["n07579787", "plate"], "924": ["n07583066", "guacamole"], "925": ["n07584110", "consomme"], "926": ["n07590611", "hot_pot"], "927": ["n07613480", "trifle"], "928": ["n07614500", "ice_cream"], "929": ["n07615774", "ice_lolly"], "930": ["n07684084", "French_loaf"], "931": ["n07693725", "bagel"], "932": ["n07695742", "pretzel"], "933": ["n07697313", "cheeseburger"], "934": ["n07697537", "hotdog"], "935": ["n07711569", "mashed_potato"], "936": ["n07714571", "head_cabbage"], "937": ["n07714990", "broccoli"], "938": ["n07715103", "cauliflower"], "939": ["n07716358", "zucchini"], "940": ["n07716906", "spaghetti_squash"], "941": ["n07717410", "acorn_squash"], "942": ["n07717556", "butternut_squash"], "943": ["n07718472", "cucumber"], "944": ["n07718747", "artichoke"], "945": ["n07720875", "bell_pepper"], "946": ["n07730033", "cardoon"], "947": ["n07734744", "mushroom"], "948": ["n07742313", "Granny_Smith"], "949": ["n07745940", "strawberry"], "950": ["n07747607", "orange"], "951": ["n07749582", "lemon"], "952": ["n07753113", "fig"], "953": ["n07753275", "pineapple"], "954": ["n07753592", "banana"], "955": ["n07754684", "jackfruit"], "956": ["n07760859", "custard_apple"], "957": ["n07768694", "pomegranate"], "958": ["n07802026", "hay"], "959": ["n07831146", "carbonara"], "960": ["n07836838", "chocolate_sauce"], "961": ["n07860988", "dough"], "962": ["n07871810", "meat_loaf"], "963": ["n07873807", "pizza"], "964": ["n07875152", "potpie"], "965": ["n07880968", "burrito"], "966": ["n07892512", "red_wine"], "967": ["n07920052", "espresso"], "968": ["n07930864", "cup"], "969": ["n07932039", "eggnog"], "970": ["n09193705", "alp"], "971": ["n09229709", "bubble"], "972": ["n09246464", "cliff"], "973": ["n09256479", "coral_reef"], "974": ["n09288635", "geyser"], "975": ["n09332890", "lakeside"], "976": ["n09399592", "promontory"], "977": ["n09421951", "sandbar"], "978": ["n09428293", "seashore"], "979": ["n09468604", "valley"], "980": ["n09472597", "volcano"], "981": ["n09835506", "ballplayer"], "982": ["n10148035", "groom"], "983": ["n10565667", "scuba_diver"], "984": ["n11879895", "rapeseed"], "985": ["n11939491", "daisy"], "986": ["n12057211", "yellow_lady's_slipper"], "987": ["n12144580", "corn"], "988": ["n12267677", "acorn"], "989": ["n12620546", "hip"], "990": ["n12768682", "buckeye"], "991": ["n12985857", "coral_fungus"], "992": ["n12998815", "agaric"], "993": ["n13037406", "gyromitra"], "994": ["n13040303", "stinkhorn"], "995": ["n13044778", "earthstar"], "996": ["n13052670", "hen-of-the-woods"], "997": ["n13054560", "bolete"], "998": ["n13133613", "ear"], "999": ["n15075141", "toilet_tissue"]}
--------------------------------------------------------------------------------
/lime/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/lime/__init__.py
--------------------------------------------------------------------------------
/lime/discretize.py:
--------------------------------------------------------------------------------
1 | """
2 | Discretizers classes, to be used in lime_tabular
3 | """
4 | import numpy as np
5 | import sklearn
6 | import sklearn.tree
7 | import scipy
8 | from sklearn.utils import check_random_state
9 | from abc import ABCMeta, abstractmethod
10 |
11 |
12 | class BaseDiscretizer():
13 | """
14 | Abstract class - Build a class that inherits from this class to implement
15 | a custom discretizer.
16 | Method bins() is to be redefined in the child class, as it is the actual
17 | custom part of the discretizer.
18 | """
19 |
20 | __metaclass__ = ABCMeta # abstract class
21 |
22 | def __init__(self, data, categorical_features, feature_names, labels=None, random_state=None,
23 | data_stats=None):
24 | """Initializer
25 | Args:
26 | data: numpy 2d array
27 | categorical_features: list of indices (ints) corresponding to the
28 | categorical columns. These features will not be discretized.
29 | Everything else will be considered continuous, and will be
30 | discretized.
31 | categorical_names: map from int to list of names, where
32 | categorical_names[x][y] represents the name of the yth value of
33 | column x.
34 | feature_names: list of names (strings) corresponding to the columns
35 | in the training data.
36 | data_stats: must have 'means', 'stds', 'mins' and 'maxs', use this
37 | if you don't want these values to be computed from data
38 | """
39 | self.to_discretize = ([x for x in range(data.shape[1])
40 | if x not in categorical_features])
41 | self.data_stats = data_stats
42 | self.names = {}
43 | self.lambdas = {}
44 | self.means = {}
45 | self.stds = {}
46 | self.mins = {}
47 | self.maxs = {}
48 | self.random_state = check_random_state(random_state)
49 |
50 | # To override when implementing a custom binning
51 | bins = self.bins(data, labels)
52 | bins = [np.unique(x) for x in bins]
53 |
54 | # Read the stats from data_stats if exists
55 | if data_stats:
56 | self.means = self.data_stats.get("means")
57 | self.stds = self.data_stats.get("stds")
58 | self.mins = self.data_stats.get("mins")
59 | self.maxs = self.data_stats.get("maxs")
60 |
61 | for feature, qts in zip(self.to_discretize, bins):
62 | n_bins = qts.shape[0] # Actually number of borders (= #bins-1)
63 | boundaries = np.min(data[:, feature]), np.max(data[:, feature])
64 | name = feature_names[feature]
65 |
66 | self.names[feature] = ['%s <= %.2f' % (name, qts[0])]
67 | for i in range(n_bins - 1):
68 | self.names[feature].append('%.2f < %s <= %.2f' %
69 | (qts[i], name, qts[i + 1]))
70 | self.names[feature].append('%s > %.2f' % (name, qts[n_bins - 1]))
71 |
72 | self.lambdas[feature] = lambda x, qts=qts: np.searchsorted(qts, x)
73 | discretized = self.lambdas[feature](data[:, feature])
74 |
75 | # If data stats are provided no need to compute the below set of details
76 | if data_stats:
77 | continue
78 |
79 | self.means[feature] = []
80 | self.stds[feature] = []
81 | for x in range(n_bins + 1):
82 | selection = data[discretized == x, feature]
83 | mean = 0 if len(selection) == 0 else np.mean(selection)
84 | self.means[feature].append(mean)
85 | std = 0 if len(selection) == 0 else np.std(selection)
86 | std += 0.00000000001
87 | self.stds[feature].append(std)
88 | self.mins[feature] = [boundaries[0]] + qts.tolist()
89 | self.maxs[feature] = qts.tolist() + [boundaries[1]]
90 |
91 | @abstractmethod
92 | def bins(self, data, labels):
93 | """
94 | To be overridden
95 | Returns for each feature to discretize the boundaries
96 | that form each bin of the discretizer
97 | """
98 | raise NotImplementedError("Must override bins() method")
99 |
100 | def discretize(self, data):
101 | """Discretizes the data.
102 | Args:
103 | data: numpy 2d or 1d array
104 | Returns:
105 | numpy array of same dimension, discretized.
106 | """
107 | ret = data.copy()
108 | for feature in self.lambdas:
109 | if len(data.shape) == 1:
110 | ret[feature] = int(self.lambdas[feature](ret[feature]))
111 | else:
112 | ret[:, feature] = self.lambdas[feature](
113 | ret[:, feature]).astype(int)
114 | return ret
115 |
116 | def get_undiscretize_values(self, feature, values):
117 | mins = np.array(self.mins[feature])[values]
118 | maxs = np.array(self.maxs[feature])[values]
119 |
120 | means = np.array(self.means[feature])[values]
121 | stds = np.array(self.stds[feature])[values]
122 | minz = (mins - means) / stds
123 | maxz = (maxs - means) / stds
124 | min_max_unequal = (minz != maxz)
125 |
126 | ret = minz
127 | ret[np.where(min_max_unequal)] = scipy.stats.truncnorm.rvs(
128 | minz[min_max_unequal],
129 | maxz[min_max_unequal],
130 | loc=means[min_max_unequal],
131 | scale=stds[min_max_unequal],
132 | random_state=self.random_state
133 | )
134 | return ret
135 |
136 | def undiscretize(self, data):
137 | ret = data.copy()
138 | for feature in self.means:
139 | if len(data.shape) == 1:
140 | ret[feature] = self.get_undiscretize_values(
141 | feature, ret[feature].astype(int).reshape(-1, 1)
142 | )
143 | else:
144 | ret[:, feature] = self.get_undiscretize_values(
145 | feature, ret[:, feature].astype(int)
146 | )
147 | return ret
148 |
149 |
150 | class StatsDiscretizer(BaseDiscretizer):
151 | """
152 | Class to be used to supply the data stats info when discretize_continuous is true
153 | """
154 |
155 | def __init__(self, data, categorical_features, feature_names, labels=None, random_state=None,
156 | data_stats=None):
157 |
158 | BaseDiscretizer.__init__(self, data, categorical_features,
159 | feature_names, labels=labels,
160 | random_state=random_state,
161 | data_stats=data_stats)
162 |
163 | def bins(self, data, labels):
164 | bins_from_stats = self.data_stats.get("bins")
165 | bins = []
166 | if bins_from_stats is not None:
167 | for feature in self.to_discretize:
168 | bins_from_stats_feature = bins_from_stats.get(feature)
169 | if bins_from_stats_feature is not None:
170 | qts = np.array(bins_from_stats_feature)
171 | bins.append(qts)
172 | return bins
173 |
174 |
175 | class QuartileDiscretizer(BaseDiscretizer):
176 | def __init__(self, data, categorical_features, feature_names, labels=None, random_state=None):
177 |
178 | BaseDiscretizer.__init__(self, data, categorical_features,
179 | feature_names, labels=labels,
180 | random_state=random_state)
181 |
182 | def bins(self, data, labels):
183 | bins = []
184 | for feature in self.to_discretize:
185 | qts = np.array(np.percentile(data[:, feature], [25, 50, 75]))
186 | bins.append(qts)
187 | return bins
188 |
189 |
190 | class DecileDiscretizer(BaseDiscretizer):
191 | def __init__(self, data, categorical_features, feature_names, labels=None, random_state=None):
192 | BaseDiscretizer.__init__(self, data, categorical_features,
193 | feature_names, labels=labels,
194 | random_state=random_state)
195 |
196 | def bins(self, data, labels):
197 | bins = []
198 | for feature in self.to_discretize:
199 | qts = np.array(np.percentile(data[:, feature],
200 | [10, 20, 30, 40, 50, 60, 70, 80, 90]))
201 | bins.append(qts)
202 | return bins
203 |
204 |
205 | class EntropyDiscretizer(BaseDiscretizer):
206 | def __init__(self, data, categorical_features, feature_names, labels=None, random_state=None):
207 | if(labels is None):
208 | raise ValueError('Labels must be not None when using \
209 | EntropyDiscretizer')
210 | BaseDiscretizer.__init__(self, data, categorical_features,
211 | feature_names, labels=labels,
212 | random_state=random_state)
213 |
214 | def bins(self, data, labels):
215 | bins = []
216 | for feature in self.to_discretize:
217 | # Entropy splitting / at most 8 bins so max_depth=3
218 | dt = sklearn.tree.DecisionTreeClassifier(criterion='entropy',
219 | max_depth=3,
220 | random_state=self.random_state)
221 | x = np.reshape(data[:, feature], (-1, 1))
222 | dt.fit(x, labels)
223 | qts = dt.tree_.threshold[np.where(dt.tree_.children_left > -1)]
224 |
225 | if qts.shape[0] == 0:
226 | qts = np.array([np.median(data[:, feature])])
227 | else:
228 | qts = np.sort(qts)
229 |
230 | bins.append(qts)
231 |
232 | return bins
233 |
--------------------------------------------------------------------------------
/lime/exceptions.py:
--------------------------------------------------------------------------------
1 | class LimeError(Exception):
2 | """Raise for errors"""
3 |
--------------------------------------------------------------------------------
/lime/explanation.py:
--------------------------------------------------------------------------------
1 | """
2 | Explanation class, with visualization functions.
3 | """
4 | from io import open
5 | import os
6 | import os.path
7 | import json
8 | import string
9 | import numpy as np
10 |
11 | from .exceptions import LimeError
12 |
13 | from sklearn.utils import check_random_state
14 |
15 |
16 | def id_generator(size=15, random_state=None):
17 | """Helper function to generate random div ids. This is useful for embedding
18 | HTML into ipython notebooks."""
19 | chars = list(string.ascii_uppercase + string.digits)
20 | return ''.join(random_state.choice(chars, size, replace=True))
21 |
22 |
23 | class DomainMapper(object):
24 | """Class for mapping features to the specific domain.
25 |
26 | The idea is that there would be a subclass for each domain (text, tables,
27 | images, etc), so that we can have a general Explanation class, and separate
28 | out the specifics of visualizing features in here.
29 | """
30 |
31 | def __init__(self):
32 | pass
33 |
34 | def map_exp_ids(self, exp, **kwargs):
35 | """Maps the feature ids to concrete names.
36 |
37 | Default behaviour is the identity function. Subclasses can implement
38 | this as they see fit.
39 |
40 | Args:
41 | exp: list of tuples [(id, weight), (id,weight)]
42 | kwargs: optional keyword arguments
43 |
44 | Returns:
45 | exp: list of tuples [(name, weight), (name, weight)...]
46 | """
47 | return exp
48 |
49 | def visualize_instance_html(self,
50 | exp,
51 | label,
52 | div_name,
53 | exp_object_name,
54 | **kwargs):
55 | """Produces html for visualizing the instance.
56 |
57 | Default behaviour does nothing. Subclasses can implement this as they
58 | see fit.
59 |
60 | Args:
61 | exp: list of tuples [(id, weight), (id,weight)]
62 | label: label id (integer)
63 | div_name: name of div object to be used for rendering(in js)
64 | exp_object_name: name of js explanation object
65 | kwargs: optional keyword arguments
66 |
67 | Returns:
68 | js code for visualizing the instance
69 | """
70 | return ''
71 |
72 |
73 | class Explanation(object):
74 | """Object returned by explainers."""
75 |
76 | def __init__(self,
77 | domain_mapper,
78 | mode='classification',
79 | class_names=None,
80 | random_state=None):
81 | """
82 |
83 | Initializer.
84 |
85 | Args:
86 | domain_mapper: must inherit from DomainMapper class
87 | type: "classification" or "regression"
88 | class_names: list of class names (only used for classification)
89 | random_state: an integer or numpy.RandomState that will be used to
90 | generate random numbers. If None, the random state will be
91 | initialized using the internal numpy seed.
92 | """
93 | self.random_state = random_state
94 | self.mode = mode
95 | self.domain_mapper = domain_mapper
96 | self.local_exp = {}
97 | self.intercept = {}
98 | self.score = {}
99 | self.local_pred = {}
100 | if mode == 'classification':
101 | self.class_names = class_names
102 | self.top_labels = None
103 | self.predict_proba = None
104 | elif mode == 'regression':
105 | self.class_names = ['negative', 'positive']
106 | self.predicted_value = None
107 | self.min_value = 0.0
108 | self.max_value = 1.0
109 | self.dummy_label = 1
110 | else:
111 | raise LimeError('Invalid explanation mode "{}". '
112 | 'Should be either "classification" '
113 | 'or "regression".'.format(mode))
114 |
115 | def available_labels(self):
116 | """
117 | Returns the list of classification labels for which we have any explanations.
118 | """
119 | try:
120 | assert self.mode == "classification"
121 | except AssertionError:
122 | raise NotImplementedError('Not supported for regression explanations.')
123 | else:
124 | ans = self.top_labels if self.top_labels else self.local_exp.keys()
125 | return list(ans)
126 |
127 | def as_list(self, label=1, **kwargs):
128 | """Returns the explanation as a list.
129 |
130 | Args:
131 | label: desired label. If you ask for a label for which an
132 | explanation wasn't computed, will throw an exception.
133 | Will be ignored for regression explanations.
134 | kwargs: keyword arguments, passed to domain_mapper
135 |
136 | Returns:
137 | list of tuples (representation, weight), where representation is
138 | given by domain_mapper. Weight is a float.
139 | """
140 | label_to_use = label if self.mode == "classification" else self.dummy_label
141 | ans = self.domain_mapper.map_exp_ids(self.local_exp[label_to_use], **kwargs)
142 | ans = [(x[0], float(x[1])) for x in ans]
143 | return ans
144 |
145 | def as_map(self):
146 | """Returns the map of explanations.
147 |
148 | Returns:
149 | Map from label to list of tuples (feature_id, weight).
150 | """
151 | return self.local_exp
152 |
153 | def as_pyplot_figure(self, label=1, figsize=(4,4), **kwargs):
154 | """Returns the explanation as a pyplot figure.
155 |
156 | Will throw an error if you don't have matplotlib installed
157 | Args:
158 | label: desired label. If you ask for a label for which an
159 | explanation wasn't computed, will throw an exception.
160 | Will be ignored for regression explanations.
161 | figsize: desired size of pyplot in tuple format, defaults to (4,4).
162 | kwargs: keyword arguments, passed to domain_mapper
163 |
164 | Returns:
165 | pyplot figure (barchart).
166 | """
167 | import matplotlib.pyplot as plt
168 | exp = self.as_list(label=label, **kwargs)
169 | fig = plt.figure(figsize=figsize)
170 | vals = [x[1] for x in exp]
171 | names = [x[0] for x in exp]
172 | vals.reverse()
173 | names.reverse()
174 | colors = ['green' if x > 0 else 'red' for x in vals]
175 | pos = np.arange(len(exp)) + .5
176 | plt.barh(pos, vals, align='center', color=colors)
177 | plt.yticks(pos, names)
178 | if self.mode == "classification":
179 | title = 'Local explanation for class %s' % self.class_names[label]
180 | else:
181 | title = 'Local explanation'
182 | plt.title(title)
183 | return fig
184 |
185 | def show_in_notebook(self,
186 | labels=None,
187 | predict_proba=True,
188 | show_predicted_value=True,
189 | **kwargs):
190 | """Shows html explanation in ipython notebook.
191 |
192 | See as_html() for parameters.
193 | This will throw an error if you don't have IPython installed"""
194 |
195 | from IPython.core.display import display, HTML
196 | display(HTML(self.as_html(labels=labels,
197 | predict_proba=predict_proba,
198 | show_predicted_value=show_predicted_value,
199 | **kwargs)))
200 |
201 | def save_to_file(self,
202 | file_path,
203 | labels=None,
204 | predict_proba=True,
205 | show_predicted_value=True,
206 | **kwargs):
207 | """Saves html explanation to file. .
208 |
209 | Params:
210 | file_path: file to save explanations to
211 |
212 | See as_html() for additional parameters.
213 |
214 | """
215 | file_ = open(file_path, 'w', encoding='utf8')
216 | file_.write(self.as_html(labels=labels,
217 | predict_proba=predict_proba,
218 | show_predicted_value=show_predicted_value,
219 | **kwargs))
220 | file_.close()
221 |
222 | def as_html(self,
223 | labels=None,
224 | predict_proba=True,
225 | show_predicted_value=True,
226 | **kwargs):
227 | """Returns the explanation as an html page.
228 |
229 | Args:
230 | labels: desired labels to show explanations for (as barcharts).
231 | If you ask for a label for which an explanation wasn't
232 | computed, will throw an exception. If None, will show
233 | explanations for all available labels. (only used for classification)
234 | predict_proba: if true, add barchart with prediction probabilities
235 | for the top classes. (only used for classification)
236 | show_predicted_value: if true, add barchart with expected value
237 | (only used for regression)
238 | kwargs: keyword arguments, passed to domain_mapper
239 |
240 | Returns:
241 | code for an html page, including javascript includes.
242 | """
243 |
244 | def jsonize(x):
245 | return json.dumps(x, ensure_ascii=False)
246 |
247 | if labels is None and self.mode == "classification":
248 | labels = self.available_labels()
249 |
250 | this_dir, _ = os.path.split(__file__)
251 | bundle = open(os.path.join(this_dir, 'bundle.js'),
252 | encoding="utf8").read()
253 |
254 | out = u'''
255 |
256 | ''' % bundle
257 | random_id = id_generator(size=15, random_state=check_random_state(self.random_state))
258 | out += u'''
259 |
260 | ''' % random_id
261 |
262 | predict_proba_js = ''
263 | if self.mode == "classification" and predict_proba:
264 | predict_proba_js = u'''
265 | var pp_div = top_div.append('div')
266 | .classed('lime predict_proba', true);
267 | var pp_svg = pp_div.append('svg').style('width', '100%%');
268 | var pp = new lime.PredictProba(pp_svg, %s, %s);
269 | ''' % (jsonize([str(x) for x in self.class_names]),
270 | jsonize(list(self.predict_proba.astype(float))))
271 |
272 | predict_value_js = ''
273 | if self.mode == "regression" and show_predicted_value:
274 | # reference self.predicted_value
275 | # (svg, predicted_value, min_value, max_value)
276 | predict_value_js = u'''
277 | var pp_div = top_div.append('div')
278 | .classed('lime predicted_value', true);
279 | var pp_svg = pp_div.append('svg').style('width', '100%%');
280 | var pp = new lime.PredictedValue(pp_svg, %s, %s, %s);
281 | ''' % (jsonize(float(self.predicted_value)),
282 | jsonize(float(self.min_value)),
283 | jsonize(float(self.max_value)))
284 |
285 | exp_js = '''var exp_div;
286 | var exp = new lime.Explanation(%s);
287 | ''' % (jsonize([str(x) for x in self.class_names]))
288 |
289 | if self.mode == "classification":
290 | for label in labels:
291 | exp = jsonize(self.as_list(label))
292 | exp_js += u'''
293 | exp_div = top_div.append('div').classed('lime explanation', true);
294 | exp.show(%s, %d, exp_div);
295 | ''' % (exp, label)
296 | else:
297 | exp = jsonize(self.as_list())
298 | exp_js += u'''
299 | exp_div = top_div.append('div').classed('lime explanation', true);
300 | exp.show(%s, %s, exp_div);
301 | ''' % (exp, self.dummy_label)
302 |
303 | raw_js = '''var raw_div = top_div.append('div');'''
304 |
305 | if self.mode == "classification":
306 | html_data = self.local_exp[labels[0]]
307 | else:
308 | html_data = self.local_exp[self.dummy_label]
309 |
310 | raw_js += self.domain_mapper.visualize_instance_html(
311 | html_data,
312 | labels[0] if self.mode == "classification" else self.dummy_label,
313 | 'raw_div',
314 | 'exp',
315 | **kwargs)
316 | out += u'''
317 |
324 | ''' % (random_id, predict_proba_js, predict_value_js, exp_js, raw_js)
325 | out += u''
326 |
327 | return out
328 |
--------------------------------------------------------------------------------
/lime/js/bar_chart.js:
--------------------------------------------------------------------------------
1 | import d3 from 'd3';
2 | class Barchart {
3 | // svg: d3 object with the svg in question
4 | // exp_array: list of (feature_name, weight)
5 | constructor(svg, exp_array, two_sided=true, titles=undefined, colors=['red', 'green'], show_numbers=false, bar_height=5) {
6 | let svg_width = Math.min(600, parseInt(svg.style('width')));
7 | let bar_width = two_sided ? svg_width / 2 : svg_width;
8 | if (titles === undefined) {
9 | titles = two_sided ? ['Cons', 'Pros'] : 'Pros';
10 | }
11 | if (show_numbers) {
12 | bar_width = bar_width - 30;
13 | }
14 | let x_offset = two_sided ? svg_width / 2 : 10;
15 | // 13.1 is +- the width of W, the widest letter.
16 | if (two_sided && titles.length == 2) {
17 | svg.append('text')
18 | .attr('x', svg_width / 4)
19 | .attr('y', 15)
20 | .attr('font-size', '20')
21 | .attr('text-anchor', 'middle')
22 | .style('fill', colors[0])
23 | .text(titles[0]);
24 |
25 | svg.append('text')
26 | .attr('x', svg_width / 4 * 3)
27 | .attr('y', 15)
28 | .attr('font-size', '20')
29 | .attr('text-anchor', 'middle')
30 | .style('fill', colors[1])
31 | .text(titles[1]);
32 | }
33 | else {
34 | let pos = two_sided ? svg_width / 2 : x_offset;
35 | let anchor = two_sided ? 'middle' : 'begin';
36 | svg.append('text')
37 | .attr('x', pos)
38 | .attr('y', 15)
39 | .attr('font-size', '20')
40 | .attr('text-anchor', anchor)
41 | .text(titles);
42 | }
43 | let yshift = 20;
44 | let space_between_bars = 0;
45 | let text_height = 16;
46 | let space_between_bar_and_text = 3;
47 | let total_bar_height = text_height + space_between_bar_and_text + bar_height + space_between_bars;
48 | let total_height = (total_bar_height) * exp_array.length;
49 | this.svg_height = total_height + yshift;
50 | let yscale = d3.scale.linear()
51 | .domain([0, exp_array.length])
52 | .range([yshift, yshift + total_height])
53 | let names = exp_array.map(v => v[0]);
54 | let weights = exp_array.map(v => v[1]);
55 | let max_weight = Math.max(...(weights.map(v=>Math.abs(v))));
56 | let xscale = d3.scale.linear()
57 | .domain([0,Math.max(1, max_weight)])
58 | .range([0, bar_width]);
59 |
60 | for (var i = 0; i < exp_array.length; ++i) {
61 | let name = names[i];
62 | let weight = weights[i];
63 | var size = xscale(Math.abs(weight));
64 | let to_the_right = (weight > 0 || !two_sided)
65 | let text = svg.append('text')
66 | .attr('x', to_the_right ? x_offset + 2 : x_offset - 2)
67 | .attr('y', yscale(i) + text_height)
68 | .attr('text-anchor', to_the_right ? 'begin' : 'end')
69 | .attr('font-size', '14')
70 | .text(name);
71 | while (text.node().getBBox()['width'] + 1 > bar_width) {
72 | let cur_text = text.text().slice(0, text.text().length - 5);
73 | text.text(cur_text + '...');
74 | if (text === '...') {
75 | break;
76 | }
77 | }
78 | let bar = svg.append('rect')
79 | .attr('height', bar_height)
80 | .attr('x', to_the_right ? x_offset : x_offset - size)
81 | .attr('y', text_height + yscale(i) + space_between_bar_and_text)// + bar_height)
82 | .attr('width', size)
83 | .style('fill', weight > 0 ? colors[1] : colors[0]);
84 | if (show_numbers) {
85 | let bartext = svg.append('text')
86 | .attr('x', to_the_right ? x_offset + size + 1 : x_offset - size - 1)
87 | .attr('text-anchor', (weight > 0 || !two_sided) ? 'begin' : 'end')
88 | .attr('y', bar_height + yscale(i) + text_height + space_between_bar_and_text)
89 | .attr('font-size', '10')
90 | .text(Math.abs(weight).toFixed(2));
91 | }
92 | }
93 | let line = svg.append("line")
94 | .attr("x1", x_offset)
95 | .attr("x2", x_offset)
96 | .attr("y1", bar_height + yshift)
97 | .attr("y2", Math.max(bar_height, yscale(exp_array.length)))
98 | .style("stroke-width",2)
99 | .style("stroke", "black");
100 | }
101 |
102 | }
103 | export default Barchart;
104 |
--------------------------------------------------------------------------------
/lime/js/explanation.js:
--------------------------------------------------------------------------------
1 | import d3 from 'd3';
2 | import Barchart from './bar_chart.js';
3 | import {range, sortBy} from 'lodash';
4 | class Explanation {
5 | constructor(class_names) {
6 | this.names = class_names;
7 | if (class_names.length < 10) {
8 | this.colors = d3.scale.category10().domain(this.names);
9 | this.colors_i = d3.scale.category10().domain(range(this.names.length));
10 | }
11 | else {
12 | this.colors = d3.scale.category20().domain(this.names);
13 | this.colors_i = d3.scale.category20().domain(range(this.names.length));
14 | }
15 | }
16 | // exp: [(feature-name, weight), ...]
17 | // label: int
18 | // div: d3 selection
19 | show(exp, label, div) {
20 | let svg = div.append('svg').style('width', '100%');
21 | let colors=['#5F9EA0', this.colors_i(label)];
22 | let names = [`NOT ${this.names[label]}`, this.names[label]];
23 | if (this.names.length == 2) {
24 | colors=[this.colors_i(0), this.colors_i(1)];
25 | names = this.names;
26 | }
27 | let plot = new Barchart(svg, exp, true, names, colors, true, 10);
28 | svg.style('height', plot.svg_height + 'px');
29 | }
30 | // exp has all ocurrences of words, with start index and weight:
31 | // exp = [('word', 132, -0.13), ('word3', 111, 1.3)
32 | show_raw_text(exp, label, raw, div, opacity=true) {
33 | //let colors=['#5F9EA0', this.colors(this.exp['class'])];
34 | let colors=['#5F9EA0', this.colors_i(label)];
35 | if (this.names.length == 2) {
36 | colors=[this.colors_i(0), this.colors_i(1)];
37 | }
38 | let word_lists = [[], []];
39 | let max_weight = -1;
40 | for (let [word, start, weight] of exp) {
41 | if (weight > 0) {
42 | word_lists[1].push([start, start + word.length, weight]);
43 | }
44 | else {
45 | word_lists[0].push([start, start + word.length, -weight]);
46 | }
47 | max_weight = Math.max(max_weight, Math.abs(weight));
48 | }
49 | if (!opacity) {
50 | max_weight = 0;
51 | }
52 | this.display_raw_text(div, raw, word_lists, colors, max_weight, true);
53 | }
54 | // exp is list of (feature_name, value, weight)
55 | show_raw_tabular(exp, label, div) {
56 | div.classed('lime', true).classed('table_div', true);
57 | let colors=['#5F9EA0', this.colors_i(label)];
58 | if (this.names.length == 2) {
59 | colors=[this.colors_i(0), this.colors_i(1)];
60 | }
61 | const table = div.append('table');
62 | const thead = table.append('tr');
63 | thead.append('td').text('Feature');
64 | thead.append('td').text('Value');
65 | thead.style('color', 'black')
66 | .style('font-size', '20px');
67 | for (let [fname, value, weight] of exp) {
68 | const tr = table.append('tr');
69 | tr.style('border-style', 'hidden');
70 | tr.append('td').text(fname);
71 | tr.append('td').text(value);
72 | if (weight > 0) {
73 | tr.style('background-color', colors[1]);
74 | }
75 | else if (weight < 0) {
76 | tr.style('background-color', colors[0]);
77 | }
78 | else {
79 | tr.style('color', 'black');
80 | }
81 | }
82 | }
83 | hexToRgb(hex) {
84 | let result = /^#?([a-f\d]{2})([a-f\d]{2})([a-f\d]{2})$/i.exec(hex);
85 | return result ? {
86 | r: parseInt(result[1], 16),
87 | g: parseInt(result[2], 16),
88 | b: parseInt(result[3], 16)
89 | } : null;
90 | }
91 | applyAlpha(hex, alpha) {
92 | let components = this.hexToRgb(hex);
93 | return 'rgba(' + components.r + "," + components.g + "," + components.b + "," + alpha.toFixed(3) + ")"
94 | }
95 | // sord_lists is an array of arrays, of length (colors). if with_positions is true,
96 | // word_lists is an array of [start,end] positions instead
97 | display_raw_text(div, raw_text, word_lists=[], colors=[], max_weight=1, positions=false) {
98 | div.classed('lime', true).classed('text_div', true);
99 | div.append('h3').text('Text with highlighted words');
100 | let highlight_tag = 'span';
101 | let text_span = div.append('span').style('white-space', 'pre-wrap').text(raw_text);
102 | let position_lists = word_lists;
103 | if (!positions) {
104 | position_lists = this.wordlists_to_positions(word_lists, raw_text);
105 | }
106 | let objects = []
107 | for (let i of range(position_lists.length)) {
108 | position_lists[i].map(x => objects.push({'label' : i, 'start': x[0], 'end': x[1], 'alpha': max_weight === 0 ? 1: x[2] / max_weight}));
109 | }
110 | objects = sortBy(objects, x=>x['start']);
111 | let node = text_span.node().childNodes[0];
112 | let subtract = 0;
113 | for (let obj of objects) {
114 | let word = raw_text.slice(obj.start, obj.end);
115 | let start = obj.start - subtract;
116 | let end = obj.end - subtract;
117 | let match = document.createElement(highlight_tag);
118 | match.appendChild(document.createTextNode(word));
119 | match.style.backgroundColor = this.applyAlpha(colors[obj.label], obj.alpha);
120 | let after = node.splitText(start);
121 | after.nodeValue = after.nodeValue.substring(word.length);
122 | node.parentNode.insertBefore(match, after);
123 | subtract += end;
124 | node = after;
125 | }
126 | }
127 | wordlists_to_positions(word_lists, raw_text) {
128 | let ret = []
129 | for(let words of word_lists) {
130 | if (words.length === 0) {
131 | ret.push([]);
132 | continue;
133 | }
134 | let re = new RegExp("\\b(" + words.join('|') + ")\\b",'gm')
135 | let temp;
136 | let list = [];
137 | while ((temp = re.exec(raw_text)) !== null) {
138 | list.push([temp.index, temp.index + temp[0].length]);
139 | }
140 | ret.push(list);
141 | }
142 | return ret;
143 | }
144 |
145 | }
146 | export default Explanation;
147 |
--------------------------------------------------------------------------------
/lime/js/main.js:
--------------------------------------------------------------------------------
1 | if (!global._babelPolyfill) {
2 | require('babel-polyfill')
3 | }
4 |
5 |
6 | import Explanation from './explanation.js';
7 | import Barchart from './bar_chart.js';
8 | import PredictProba from './predict_proba.js';
9 | import PredictedValue from './predicted_value.js';
10 | require('../style.css');
11 |
12 | export {Explanation, Barchart, PredictProba, PredictedValue};
13 | //require('style-loader');
14 |
15 |
16 |
--------------------------------------------------------------------------------
/lime/js/predict_proba.js:
--------------------------------------------------------------------------------
1 | import d3 from 'd3';
2 | import {range, sortBy} from 'lodash';
3 |
4 | class PredictProba {
5 | // svg: d3 object with the svg in question
6 | // class_names: array of class names
7 | // predict_probas: array of prediction probabilities
8 | constructor(svg, class_names, predict_probas, title='Prediction probabilities') {
9 | let width = parseInt(svg.style('width'));
10 | this.names = class_names;
11 | this.names.push('Other');
12 | if (class_names.length < 10) {
13 | this.colors = d3.scale.category10().domain(this.names);
14 | this.colors_i = d3.scale.category10().domain(range(this.names.length));
15 | }
16 | else {
17 | this.colors = d3.scale.category20().domain(this.names);
18 | this.colors_i = d3.scale.category20().domain(range(this.names.length));
19 | }
20 | let [names, data] = this.map_classes(this.names, predict_probas);
21 | let bar_x = width - 125;
22 | let class_names_width = bar_x;
23 | let bar_width = width - bar_x - 32;
24 | let x_scale = d3.scale.linear().range([0, bar_width]);
25 | let bar_height = 17;
26 | let space_between_bars = 5;
27 | let bar_yshift= title === '' ? 0 : 35;
28 | let n_bars = Math.min(5, data.length);
29 | this.svg_height = n_bars * (bar_height + space_between_bars) + bar_yshift;
30 | svg.style('height', this.svg_height + 'px');
31 | let this_object = this;
32 | if (title !== '') {
33 | svg.append('text')
34 | .text(title)
35 | .attr('x', 20)
36 | .attr('y', 20);
37 | }
38 | let bar_y = i => (bar_height + space_between_bars) * i + bar_yshift;
39 | let bar = svg.append("g");
40 |
41 | for (let i of range(data.length)) {
42 | var color = this.colors(names[i]);
43 | if (names[i] == 'Other' && this.names.length > 20) {
44 | color = '#5F9EA0';
45 | }
46 | let rect = bar.append("rect");
47 | rect.attr("x", bar_x)
48 | .attr("y", bar_y(i))
49 | .attr("height", bar_height)
50 | .attr("width", x_scale(data[i]))
51 | .style("fill", color);
52 | bar.append("rect").attr("x", bar_x)
53 | .attr("y", bar_y(i))
54 | .attr("height", bar_height)
55 | .attr("width", bar_width - 1)
56 | .attr("fill-opacity", 0)
57 | .attr("stroke", "black");
58 | let text = bar.append("text");
59 | text.classed("prob_text", true);
60 | text.attr("y", bar_y(i) + bar_height - 3).attr("fill", "black").style("font", "14px tahoma, sans-serif");
61 | text = bar.append("text");
62 | text.attr("x", bar_x + x_scale(data[i]) + 5)
63 | .attr("y", bar_y(i) + bar_height - 3)
64 | .attr("fill", "black")
65 | .style("font", "14px tahoma, sans-serif")
66 | .text(data[i].toFixed(2));
67 | text = bar.append("text");
68 | text.attr("x", bar_x - 10)
69 | .attr("y", bar_y(i) + bar_height - 3)
70 | .attr("fill", "black")
71 | .attr("text-anchor", "end")
72 | .style("font", "14px tahoma, sans-serif")
73 | .text(names[i]);
74 | while (text.node().getBBox()['width'] + 1 > (class_names_width - 10)) {
75 | // TODO: ta mostrando só dois, e talvez quando hover mostrar o texto
76 | // todo
77 | let cur_text = text.text().slice(0, text.text().length - 5);
78 | text.text(cur_text + '...');
79 | if (cur_text.length <= 3) {
80 | break
81 | }
82 | }
83 | }
84 | }
85 | map_classes(class_names, predict_proba) {
86 | if (class_names.length <= 6) {
87 | return [class_names, predict_proba];
88 | }
89 | let class_dict = range(predict_proba.length).map(i => ({'name': class_names[i], 'prob': predict_proba[i], 'i' : i}));
90 | let sorted = sortBy(class_dict, d => -d.prob);
91 | let other = new Set();
92 | range(4, sorted.length).map(d => other.add(sorted[d].name));
93 | let other_prob = 0;
94 | let ret_probs = [];
95 | let ret_names = [];
96 | for (let d of range(sorted.length)) {
97 | if (other.has(sorted[d].name)) {
98 | other_prob += sorted[d].prob;
99 | }
100 | else {
101 | ret_probs.push(sorted[d].prob);
102 | ret_names.push(sorted[d].name);
103 | }
104 | };
105 | ret_names.push("Other");
106 | ret_probs.push(other_prob);
107 | return [ret_names, ret_probs];
108 | }
109 |
110 | }
111 | export default PredictProba;
112 |
113 |
114 |
--------------------------------------------------------------------------------
/lime/js/predicted_value.js:
--------------------------------------------------------------------------------
1 | import d3 from 'd3';
2 | import {range, sortBy} from 'lodash';
3 |
4 | class PredictedValue {
5 | // svg: d3 object with the svg in question
6 | // class_names: array of class names
7 | // predict_probas: array of prediction probabilities
8 | constructor(svg, predicted_value, min_value, max_value, title='Predicted value', log_coords = false) {
9 |
10 | if (min_value == max_value){
11 | var width_proportion = 1.0;
12 | } else {
13 | var width_proportion = (predicted_value - min_value) / (max_value - min_value);
14 | }
15 |
16 |
17 | let width = parseInt(svg.style('width'))
18 |
19 | this.color = d3.scale.category10()
20 | this.color('predicted_value')
21 | // + 2 is due to it being a float
22 | let num_digits = Math.floor(Math.max(Math.log10(Math.abs(min_value)), Math.log10(Math.abs(max_value)))) + 2
23 | num_digits = Math.max(num_digits, 3)
24 |
25 | let corner_width = 12 * num_digits;
26 | let corner_padding = 5.5 * num_digits;
27 | let bar_x = corner_width + corner_padding;
28 | let bar_width = width - corner_width * 2 - corner_padding * 2;
29 | let x_scale = d3.scale.linear().range([0, bar_width]);
30 | let bar_height = 17;
31 | let bar_yshift= title === '' ? 0 : 35;
32 | let n_bars = 1;
33 | let this_object = this;
34 | if (title !== '') {
35 | svg.append('text')
36 | .text(title)
37 | .attr('x', 20)
38 | .attr('y', 20);
39 | }
40 | let bar_y = bar_yshift;
41 | let bar = svg.append("g");
42 |
43 | //filled in bar representing predicted value in range
44 | let rect = bar.append("rect");
45 | rect.attr("x", bar_x)
46 | .attr("y", bar_y)
47 | .attr("height", bar_height)
48 | .attr("width", x_scale(width_proportion))
49 | .style("fill", this.color);
50 |
51 | //empty box representing range
52 | bar.append("rect").attr("x", bar_x)
53 | .attr("y", bar_y)
54 | .attr("height", bar_height)
55 | .attr("width",x_scale(1))
56 | .attr("fill-opacity", 0)
57 | .attr("stroke", "black");
58 | let text = bar.append("text");
59 | text.classed("prob_text", true);
60 | text.attr("y", bar_y + bar_height - 3).attr("fill", "black").style("font", "14px tahoma, sans-serif");
61 |
62 |
63 | //text for min value
64 | text = bar.append("text");
65 | text.attr("x", bar_x - corner_padding)
66 | .attr("y", bar_y + bar_height - 3)
67 | .attr("fill", "black")
68 | .attr("text-anchor", "end")
69 | .style("font", "14px tahoma, sans-serif")
70 | .text(min_value.toFixed(2));
71 |
72 | //text for range min annotation
73 | let v_adjust_min_value_annotation = text.node().getBBox().height;
74 | text = bar.append("text");
75 | text.attr("x", bar_x - corner_padding)
76 | .attr("y", bar_y + bar_height - 3 + v_adjust_min_value_annotation)
77 | .attr("fill", "black")
78 | .attr("text-anchor", "end")
79 | .style("font", "14px tahoma, sans-serif")
80 | .text("(min)");
81 |
82 |
83 | //text for predicted value
84 | // console.log('bar height: ' + bar_height)
85 | text = bar.append("text");
86 | text.text(predicted_value.toFixed(2));
87 | // let h_adjust_predicted_value_text = text.node().getBBox().width / 2;
88 | let v_adjust_predicted_value_text = text.node().getBBox().height;
89 | text.attr("x", bar_x + x_scale(width_proportion))
90 | .attr("y", bar_y + bar_height + v_adjust_predicted_value_text)
91 | .attr("fill", "black")
92 | .attr("text-anchor", "middle")
93 | .style("font", "14px tahoma, sans-serif")
94 |
95 |
96 |
97 |
98 |
99 | //text for max value
100 | text = bar.append("text");
101 | text.text(max_value.toFixed(2));
102 | // let h_adjust = text.node().getBBox().width;
103 | text.attr("x", bar_x + bar_width + corner_padding)
104 | .attr("y", bar_y + bar_height - 3)
105 | .attr("fill", "black")
106 | .attr("text-anchor", "begin")
107 | .style("font", "14px tahoma, sans-serif");
108 |
109 |
110 | //text for range max annotation
111 | let v_adjust_max_value_annotation = text.node().getBBox().height;
112 | text = bar.append("text");
113 | text.attr("x", bar_x + bar_width + corner_padding)
114 | .attr("y", bar_y + bar_height - 3 + v_adjust_min_value_annotation)
115 | .attr("fill", "black")
116 | .attr("text-anchor", "begin")
117 | .style("font", "14px tahoma, sans-serif")
118 | .text("(max)");
119 |
120 |
121 | //readjust svg size
122 | // let svg_width = width + 1 * h_adjust;
123 | // svg.style('width', svg_width + 'px');
124 |
125 | this.svg_height = n_bars * (bar_height) + bar_yshift + (2 * text.node().getBBox().height) + 10;
126 | svg.style('height', this.svg_height + 'px');
127 | if (log_coords) {
128 | console.log("svg width: " + svg_width);
129 | console.log("svg height: " + this.svg_height);
130 | console.log("bar_y: " + bar_y);
131 | console.log("bar_x: " + bar_x);
132 | console.log("Min value: " + min_value);
133 | console.log("Max value: " + max_value);
134 | console.log("Pred value: " + predicted_value);
135 | }
136 | }
137 | }
138 |
139 |
140 | export default PredictedValue;
141 |
--------------------------------------------------------------------------------
/lime/lime_base.py:
--------------------------------------------------------------------------------
1 | """
2 | Contains abstract functionality for learning locally linear sparse model.
3 | """
4 | import numpy as np
5 | import scipy as sp
6 | from sklearn.linear_model import Ridge, lars_path
7 | from sklearn.utils import check_random_state
8 |
9 |
10 | class LimeBase(object):
11 | """Class for learning a locally linear sparse model from perturbed data"""
12 | def __init__(self,
13 | kernel_fn,
14 | verbose=False,
15 | random_state=None):
16 | """Init function
17 |
18 | Args:
19 | kernel_fn: function that transforms an array of distances into an
20 | array of proximity values (floats).
21 | verbose: if true, print local prediction values from linear model.
22 | random_state: an integer or numpy.RandomState that will be used to
23 | generate random numbers. If None, the random state will be
24 | initialized using the internal numpy seed.
25 | """
26 | self.kernel_fn = kernel_fn
27 | self.verbose = verbose
28 | self.random_state = check_random_state(random_state)
29 |
30 | @staticmethod
31 | def generate_lars_path(weighted_data, weighted_labels):
32 | """Generates the lars path for weighted data.
33 |
34 | Args:
35 | weighted_data: data that has been weighted by kernel
36 | weighted_label: labels, weighted by kernel
37 |
38 | Returns:
39 | (alphas, coefs), both are arrays corresponding to the
40 | regularization parameter and coefficients, respectively
41 | """
42 | x_vector = weighted_data
43 | alphas, _, coefs = lars_path(x_vector,
44 | weighted_labels,
45 | method='lasso',
46 | verbose=False)
47 | return alphas, coefs
48 |
49 | def forward_selection(self, data, labels, weights, num_features):
50 | """Iteratively adds features to the model"""
51 | clf = Ridge(alpha=0, fit_intercept=True, random_state=self.random_state)
52 | used_features = []
53 | for _ in range(min(num_features, data.shape[1])):
54 | max_ = -100000000
55 | best = 0
56 | for feature in range(data.shape[1]):
57 | if feature in used_features:
58 | continue
59 | clf.fit(data[:, used_features + [feature]], labels,
60 | sample_weight=weights)
61 | score = clf.score(data[:, used_features + [feature]],
62 | labels,
63 | sample_weight=weights)
64 | if score > max_:
65 | best = feature
66 | max_ = score
67 | used_features.append(best)
68 | return np.array(used_features)
69 |
70 | def feature_selection(self, data, labels, weights, num_features, method):
71 | """Selects features for the model. see explain_instance_with_data to
72 | understand the parameters."""
73 | if method == 'none':
74 | return np.array(range(data.shape[1]))
75 | elif method == 'forward_selection':
76 | return self.forward_selection(data, labels, weights, num_features)
77 | elif method == 'highest_weights':
78 | clf = Ridge(alpha=0.01, fit_intercept=True,
79 | random_state=self.random_state)
80 | clf.fit(data, labels, sample_weight=weights)
81 |
82 | coef = clf.coef_
83 | if sp.sparse.issparse(data):
84 | coef = sp.sparse.csr_matrix(clf.coef_)
85 | weighted_data = coef.multiply(data[0])
86 | # Note: most efficient to slice the data before reversing
87 | sdata = len(weighted_data.data)
88 | argsort_data = np.abs(weighted_data.data).argsort()
89 | # Edge case where data is more sparse than requested number of feature importances
90 | # In that case, we just pad with zero-valued features
91 | if sdata < num_features:
92 | nnz_indexes = argsort_data[::-1]
93 | indices = weighted_data.indices[nnz_indexes]
94 | num_to_pad = num_features - sdata
95 | indices = np.concatenate((indices, np.zeros(num_to_pad, dtype=indices.dtype)))
96 | indices_set = set(indices)
97 | pad_counter = 0
98 | for i in range(data.shape[1]):
99 | if i not in indices_set:
100 | indices[pad_counter + sdata] = i
101 | pad_counter += 1
102 | if pad_counter >= num_to_pad:
103 | break
104 | else:
105 | nnz_indexes = argsort_data[sdata - num_features:sdata][::-1]
106 | indices = weighted_data.indices[nnz_indexes]
107 | return indices
108 | else:
109 | weighted_data = coef * data[0]
110 | feature_weights = sorted(
111 | zip(range(data.shape[1]), weighted_data),
112 | key=lambda x: np.abs(x[1]),
113 | reverse=True)
114 | return np.array([x[0] for x in feature_weights[:num_features]])
115 | elif method == 'lasso_path':
116 | weighted_data = ((data - np.average(data, axis=0, weights=weights))
117 | * np.sqrt(weights[:, np.newaxis]))
118 | weighted_labels = ((labels - np.average(labels, weights=weights))
119 | * np.sqrt(weights))
120 | nonzero = range(weighted_data.shape[1])
121 | _, coefs = self.generate_lars_path(weighted_data,
122 | weighted_labels)
123 | for i in range(len(coefs.T) - 1, 0, -1):
124 | nonzero = coefs.T[i].nonzero()[0]
125 | if len(nonzero) <= num_features:
126 | break
127 | used_features = nonzero
128 | return used_features
129 | elif method == 'auto':
130 | if num_features <= 6:
131 | n_method = 'forward_selection'
132 | else:
133 | n_method = 'highest_weights'
134 | return self.feature_selection(data, labels, weights,
135 | num_features, n_method)
136 |
137 | def explain_instance_with_data(self,
138 | neighborhood_data,
139 | neighborhood_labels,
140 | distances,
141 | label,
142 | num_features,
143 | feature_selection='auto',
144 | model_regressor=None):
145 | """Takes perturbed data, labels and distances, returns explanation.
146 |
147 | Args:
148 | neighborhood_data: perturbed data, 2d array. first element is
149 | assumed to be the original data point.
150 | neighborhood_labels: corresponding perturbed labels. should have as
151 | many columns as the number of possible labels.
152 | distances: distances to original data point.
153 | label: label for which we want an explanation
154 | num_features: maximum number of features in explanation
155 | feature_selection: how to select num_features. options are:
156 | 'forward_selection': iteratively add features to the model.
157 | This is costly when num_features is high
158 | 'highest_weights': selects the features that have the highest
159 | product of absolute weight * original data point when
160 | learning with all the features
161 | 'lasso_path': chooses features based on the lasso
162 | regularization path
163 | 'none': uses all features, ignores num_features
164 | 'auto': uses forward_selection if num_features <= 6, and
165 | 'highest_weights' otherwise.
166 | model_regressor: sklearn regressor to use in explanation.
167 | Defaults to Ridge regression if None. Must have
168 | model_regressor.coef_ and 'sample_weight' as a parameter
169 | to model_regressor.fit()
170 |
171 | Returns:
172 | (intercept, exp, score, local_pred):
173 | intercept is a float.
174 | exp is a sorted list of tuples, where each tuple (x,y) corresponds
175 | to the feature id (x) and the local weight (y). The list is sorted
176 | by decreasing absolute value of y.
177 | score is the R^2 value of the returned explanation
178 | local_pred is the prediction of the explanation model on the original instance
179 | """
180 |
181 | weights = self.kernel_fn(distances)
182 | labels_column = neighborhood_labels[:, label]
183 | used_features = self.feature_selection(neighborhood_data,
184 | labels_column,
185 | weights,
186 | num_features,
187 | feature_selection)
188 | if model_regressor is None:
189 | model_regressor = Ridge(alpha=1, fit_intercept=True,
190 | random_state=self.random_state)
191 | easy_model = model_regressor
192 | easy_model.fit(neighborhood_data[:, used_features],
193 | labels_column, sample_weight=weights)
194 | prediction_score = easy_model.score(
195 | neighborhood_data[:, used_features],
196 | labels_column, sample_weight=weights)
197 |
198 | local_pred = easy_model.predict(neighborhood_data[0, used_features].reshape(1, -1))
199 |
200 | if self.verbose:
201 | print('Intercept', easy_model.intercept_)
202 | print('Prediction_local', local_pred,)
203 | print('Right:', neighborhood_labels[0, label])
204 | return (easy_model.intercept_,
205 | sorted(zip(used_features, easy_model.coef_),
206 | key=lambda x: np.abs(x[1]), reverse=True),
207 | prediction_score, local_pred)
208 |
--------------------------------------------------------------------------------
/lime/lime_image.py:
--------------------------------------------------------------------------------
1 | """
2 | Functions for explaining classifiers that use Image data.
3 | """
4 | import copy
5 | from functools import partial
6 |
7 | import numpy as np
8 | import sklearn
9 | from sklearn.utils import check_random_state
10 | from skimage.color import gray2rgb
11 | from tqdm.auto import tqdm
12 |
13 |
14 | from . import lime_base
15 | from .wrappers.scikit_image import SegmentationAlgorithm
16 |
17 |
18 | class ImageExplanation(object):
19 | def __init__(self, image, segments):
20 | """Init function.
21 |
22 | Args:
23 | image: 3d numpy array
24 | segments: 2d numpy array, with the output from skimage.segmentation
25 | """
26 | self.image = image
27 | self.segments = segments
28 | self.intercept = {}
29 | self.local_exp = {}
30 | self.local_pred = {}
31 | self.score = {}
32 |
33 | def get_image_and_mask(self, label, positive_only=True, negative_only=False, hide_rest=False,
34 | num_features=5, min_weight=0.):
35 | """Init function.
36 |
37 | Args:
38 | label: label to explain
39 | positive_only: if True, only take superpixels that positively contribute to
40 | the prediction of the label.
41 | negative_only: if True, only take superpixels that negatively contribute to
42 | the prediction of the label. If false, and so is positive_only, then both
43 | negativey and positively contributions will be taken.
44 | Both can't be True at the same time
45 | hide_rest: if True, make the non-explanation part of the return
46 | image gray
47 | num_features: number of superpixels to include in explanation
48 | min_weight: minimum weight of the superpixels to include in explanation
49 |
50 | Returns:
51 | (image, mask), where image is a 3d numpy array and mask is a 2d
52 | numpy array that can be used with
53 | skimage.segmentation.mark_boundaries
54 | """
55 | if label not in self.local_exp:
56 | raise KeyError('Label not in explanation')
57 | if positive_only & negative_only:
58 | raise ValueError("Positive_only and negative_only cannot be true at the same time.")
59 | segments = self.segments
60 | image = self.image
61 | exp = self.local_exp[label]
62 | mask = np.zeros(segments.shape, segments.dtype)
63 | if hide_rest:
64 | temp = np.zeros(self.image.shape)
65 | else:
66 | temp = self.image.copy()
67 | if positive_only:
68 | fs = [x[0] for x in exp
69 | if x[1] > 0 and x[1] > min_weight][:num_features]
70 | if negative_only:
71 | fs = [x[0] for x in exp
72 | if x[1] < 0 and abs(x[1]) > min_weight][:num_features]
73 | if positive_only or negative_only:
74 | for f in fs:
75 | temp[segments == f] = image[segments == f].copy()
76 | mask[segments == f] = 1
77 | return temp, mask
78 | else:
79 | for f, w in exp[:num_features]:
80 | if np.abs(w) < min_weight:
81 | continue
82 | c = 0 if w < 0 else 1
83 | mask[segments == f] = -1 if w < 0 else 1
84 | temp[segments == f] = image[segments == f].copy()
85 | temp[segments == f, c] = np.max(image)
86 | return temp, mask
87 |
88 |
89 | class LimeImageExplainer(object):
90 | """Explains predictions on Image (i.e. matrix) data.
91 | For numerical features, perturb them by sampling from a Normal(0,1) and
92 | doing the inverse operation of mean-centering and scaling, according to the
93 | means and stds in the training data. For categorical features, perturb by
94 | sampling according to the training distribution, and making a binary
95 | feature that is 1 when the value is the same as the instance being
96 | explained."""
97 |
98 | def __init__(self, kernel_width=.25, kernel=None, verbose=False,
99 | feature_selection='auto', random_state=None):
100 | """Init function.
101 |
102 | Args:
103 | kernel_width: kernel width for the exponential kernel.
104 | If None, defaults to sqrt(number of columns) * 0.75.
105 | kernel: similarity kernel that takes euclidean distances and kernel
106 | width as input and outputs weights in (0,1). If None, defaults to
107 | an exponential kernel.
108 | verbose: if true, print local prediction values from linear model
109 | feature_selection: feature selection method. can be
110 | 'forward_selection', 'lasso_path', 'none' or 'auto'.
111 | See function 'explain_instance_with_data' in lime_base.py for
112 | details on what each of the options does.
113 | random_state: an integer or numpy.RandomState that will be used to
114 | generate random numbers. If None, the random state will be
115 | initialized using the internal numpy seed.
116 | """
117 | kernel_width = float(kernel_width)
118 |
119 | if kernel is None:
120 | def kernel(d, kernel_width):
121 | return np.sqrt(np.exp(-(d ** 2) / kernel_width ** 2))
122 |
123 | kernel_fn = partial(kernel, kernel_width=kernel_width)
124 |
125 | self.random_state = check_random_state(random_state)
126 | self.feature_selection = feature_selection
127 | self.base = lime_base.LimeBase(kernel_fn, verbose, random_state=self.random_state)
128 |
129 | def explain_instance(self, image, classifier_fn, labels=(1,),
130 | hide_color=None,
131 | top_labels=5, num_features=100000, num_samples=1000,
132 | batch_size=10,
133 | segmentation_fn=None,
134 | distance_metric='cosine',
135 | model_regressor=None,
136 | random_seed=None,
137 | progress_bar=True):
138 | """Generates explanations for a prediction.
139 |
140 | First, we generate neighborhood data by randomly perturbing features
141 | from the instance (see __data_inverse). We then learn locally weighted
142 | linear models on this neighborhood data to explain each of the classes
143 | in an interpretable way (see lime_base.py).
144 |
145 | Args:
146 | image: 3 dimension RGB image. If this is only two dimensional,
147 | we will assume it's a grayscale image and call gray2rgb.
148 | classifier_fn: classifier prediction probability function, which
149 | takes a numpy array and outputs prediction probabilities. For
150 | ScikitClassifiers , this is classifier.predict_proba.
151 | labels: iterable with labels to be explained.
152 | hide_color: If not None, will hide superpixels with this color.
153 | Otherwise, use the mean pixel color of the image.
154 | top_labels: if not None, ignore labels and produce explanations for
155 | the K labels with highest prediction probabilities, where K is
156 | this parameter.
157 | num_features: maximum number of features present in explanation
158 | num_samples: size of the neighborhood to learn the linear model
159 | batch_size: batch size for model predictions
160 | distance_metric: the distance metric to use for weights.
161 | model_regressor: sklearn regressor to use in explanation. Defaults
162 | to Ridge regression in LimeBase. Must have model_regressor.coef_
163 | and 'sample_weight' as a parameter to model_regressor.fit()
164 | segmentation_fn: SegmentationAlgorithm, wrapped skimage
165 | segmentation function
166 | random_seed: integer used as random seed for the segmentation
167 | algorithm. If None, a random integer, between 0 and 1000,
168 | will be generated using the internal random number generator.
169 | progress_bar: if True, show tqdm progress bar.
170 |
171 | Returns:
172 | An ImageExplanation object (see lime_image.py) with the corresponding
173 | explanations.
174 | """
175 | if len(image.shape) == 2:
176 | image = gray2rgb(image)
177 | if random_seed is None:
178 | random_seed = self.random_state.randint(0, high=1000)
179 |
180 | if segmentation_fn is None:
181 | segmentation_fn = SegmentationAlgorithm('quickshift', kernel_size=4,
182 | max_dist=200, ratio=0.2,
183 | random_seed=random_seed)
184 | segments = segmentation_fn(image)
185 |
186 | fudged_image = image.copy()
187 | if hide_color is None:
188 | for x in np.unique(segments):
189 | fudged_image[segments == x] = (
190 | np.mean(image[segments == x][:, 0]),
191 | np.mean(image[segments == x][:, 1]),
192 | np.mean(image[segments == x][:, 2]))
193 | else:
194 | fudged_image[:] = hide_color
195 |
196 | top = labels
197 |
198 | data, labels = self.data_labels(image, fudged_image, segments,
199 | classifier_fn, num_samples,
200 | batch_size=batch_size,
201 | progress_bar=progress_bar)
202 |
203 | distances = sklearn.metrics.pairwise_distances(
204 | data,
205 | data[0].reshape(1, -1),
206 | metric=distance_metric
207 | ).ravel()
208 |
209 | ret_exp = ImageExplanation(image, segments)
210 | if top_labels:
211 | top = np.argsort(labels[0])[-top_labels:]
212 | ret_exp.top_labels = list(top)
213 | ret_exp.top_labels.reverse()
214 | for label in top:
215 | (ret_exp.intercept[label],
216 | ret_exp.local_exp[label],
217 | ret_exp.score[label],
218 | ret_exp.local_pred[label]) = self.base.explain_instance_with_data(
219 | data, labels, distances, label, num_features,
220 | model_regressor=model_regressor,
221 | feature_selection=self.feature_selection)
222 | return ret_exp
223 |
224 | def data_labels(self,
225 | image,
226 | fudged_image,
227 | segments,
228 | classifier_fn,
229 | num_samples,
230 | batch_size=10,
231 | progress_bar=True):
232 | """Generates images and predictions in the neighborhood of this image.
233 |
234 | Args:
235 | image: 3d numpy array, the image
236 | fudged_image: 3d numpy array, image to replace original image when
237 | superpixel is turned off
238 | segments: segmentation of the image
239 | classifier_fn: function that takes a list of images and returns a
240 | matrix of prediction probabilities
241 | num_samples: size of the neighborhood to learn the linear model
242 | batch_size: classifier_fn will be called on batches of this size.
243 | progress_bar: if True, show tqdm progress bar.
244 |
245 | Returns:
246 | A tuple (data, labels), where:
247 | data: dense num_samples * num_superpixels
248 | labels: prediction probabilities matrix
249 | """
250 | n_features = np.unique(segments).shape[0]
251 | data = self.random_state.randint(0, 2, num_samples * n_features)\
252 | .reshape((num_samples, n_features))
253 | labels = []
254 | data[0, :] = 1
255 | imgs = []
256 | rows = tqdm(data) if progress_bar else data
257 | for row in rows:
258 | temp = copy.deepcopy(image)
259 | zeros = np.where(row == 0)[0]
260 | mask = np.zeros(segments.shape).astype(bool)
261 | for z in zeros:
262 | mask[segments == z] = True
263 | temp[mask] = fudged_image[mask]
264 | imgs.append(temp)
265 | if len(imgs) == batch_size:
266 | preds = classifier_fn(np.array(imgs))
267 | labels.extend(preds)
268 | imgs = []
269 | if len(imgs) > 0:
270 | preds = classifier_fn(np.array(imgs))
271 | labels.extend(preds)
272 | return data, np.array(labels)
273 |
--------------------------------------------------------------------------------
/lime/lime_text.py:
--------------------------------------------------------------------------------
1 | """
2 | Functions for explaining text classifiers.
3 | """
4 | from functools import partial
5 | import itertools
6 | import json
7 | import re
8 |
9 | import numpy as np
10 | import scipy as sp
11 | import sklearn
12 | from sklearn.utils import check_random_state
13 |
14 | from . import explanation
15 | from . import lime_base
16 |
17 |
18 | class TextDomainMapper(explanation.DomainMapper):
19 | """Maps feature ids to words or word-positions"""
20 |
21 | def __init__(self, indexed_string):
22 | """Initializer.
23 |
24 | Args:
25 | indexed_string: lime_text.IndexedString, original string
26 | """
27 | self.indexed_string = indexed_string
28 |
29 | def map_exp_ids(self, exp, positions=False):
30 | """Maps ids to words or word-position strings.
31 |
32 | Args:
33 | exp: list of tuples [(id, weight), (id,weight)]
34 | positions: if True, also return word positions
35 |
36 | Returns:
37 | list of tuples (word, weight), or (word_positions, weight) if
38 | examples: ('bad', 1) or ('bad_3-6-12', 1)
39 | """
40 | if positions:
41 | exp = [('%s_%s' % (
42 | self.indexed_string.word(x[0]),
43 | '-'.join(
44 | map(str,
45 | self.indexed_string.string_position(x[0])))), x[1])
46 | for x in exp]
47 | else:
48 | exp = [(self.indexed_string.word(x[0]), x[1]) for x in exp]
49 | return exp
50 |
51 | def visualize_instance_html(self, exp, label, div_name, exp_object_name,
52 | text=True, opacity=True):
53 | """Adds text with highlighted words to visualization.
54 |
55 | Args:
56 | exp: list of tuples [(id, weight), (id,weight)]
57 | label: label id (integer)
58 | div_name: name of div object to be used for rendering(in js)
59 | exp_object_name: name of js explanation object
60 | text: if False, return empty
61 | opacity: if True, fade colors according to weight
62 | """
63 | if not text:
64 | return u''
65 | text = (self.indexed_string.raw_string()
66 | .encode('utf-8', 'xmlcharrefreplace').decode('utf-8'))
67 | text = re.sub(r'[<>&]', '|', text)
68 | exp = [(self.indexed_string.word(x[0]),
69 | self.indexed_string.string_position(x[0]),
70 | x[1]) for x in exp]
71 | all_occurrences = list(itertools.chain.from_iterable(
72 | [itertools.product([x[0]], x[1], [x[2]]) for x in exp]))
73 | all_occurrences = [(x[0], int(x[1]), x[2]) for x in all_occurrences]
74 | ret = '''
75 | %s.show_raw_text(%s, %d, %s, %s, %s);
76 | ''' % (exp_object_name, json.dumps(all_occurrences), label,
77 | json.dumps(text), div_name, json.dumps(opacity))
78 | return ret
79 |
80 |
81 | class IndexedString(object):
82 | """String with various indexes."""
83 |
84 | def __init__(self, raw_string, split_expression=r'\W+', bow=True,
85 | mask_string=None):
86 | """Initializer.
87 |
88 | Args:
89 | raw_string: string with raw text in it
90 | split_expression: Regex string or callable. If regex string, will be used with re.split.
91 | If callable, the function should return a list of tokens.
92 | bow: if True, a word is the same everywhere in the text - i.e. we
93 | will index multiple occurrences of the same word. If False,
94 | order matters, so that the same word will have different ids
95 | according to position.
96 | mask_string: If not None, replace words with this if bow=False
97 | if None, default value is UNKWORDZ
98 | """
99 | self.raw = raw_string
100 | self.mask_string = 'UNKWORDZ' if mask_string is None else mask_string
101 |
102 | if callable(split_expression):
103 | tokens = split_expression(self.raw)
104 | self.as_list = self._segment_with_tokens(self.raw, tokens)
105 | tokens = set(tokens)
106 |
107 | def non_word(string):
108 | return string not in tokens
109 |
110 | else:
111 | # with the split_expression as a non-capturing group (?:), we don't need to filter out
112 | # the separator character from the split results.
113 | splitter = re.compile(r'(%s)|$' % split_expression)
114 | self.as_list = [s for s in splitter.split(self.raw) if s]
115 | non_word = splitter.match
116 |
117 | self.as_np = np.array(self.as_list)
118 | self.string_start = np.hstack(
119 | ([0], np.cumsum([len(x) for x in self.as_np[:-1]])))
120 | vocab = {}
121 | self.inverse_vocab = []
122 | self.positions = []
123 | self.bow = bow
124 | non_vocab = set()
125 | for i, word in enumerate(self.as_np):
126 | if word in non_vocab:
127 | continue
128 | if non_word(word):
129 | non_vocab.add(word)
130 | continue
131 | if bow:
132 | if word not in vocab:
133 | vocab[word] = len(vocab)
134 | self.inverse_vocab.append(word)
135 | self.positions.append([])
136 | idx_word = vocab[word]
137 | self.positions[idx_word].append(i)
138 | else:
139 | self.inverse_vocab.append(word)
140 | self.positions.append(i)
141 | if not bow:
142 | self.positions = np.array(self.positions)
143 |
144 | def raw_string(self):
145 | """Returns the original raw string"""
146 | return self.raw
147 |
148 | def num_words(self):
149 | """Returns the number of tokens in the vocabulary for this document."""
150 | return len(self.inverse_vocab)
151 |
152 | def word(self, id_):
153 | """Returns the word that corresponds to id_ (int)"""
154 | return self.inverse_vocab[id_]
155 |
156 | def string_position(self, id_):
157 | """Returns a np array with indices to id_ (int) occurrences"""
158 | if self.bow:
159 | return self.string_start[self.positions[id_]]
160 | else:
161 | return self.string_start[[self.positions[id_]]]
162 |
163 | def inverse_removing(self, words_to_remove):
164 | """Returns a string after removing the appropriate words.
165 |
166 | If self.bow is false, replaces word with UNKWORDZ instead of removing
167 | it.
168 |
169 | Args:
170 | words_to_remove: list of ids (ints) to remove
171 |
172 | Returns:
173 | original raw string with appropriate words removed.
174 | """
175 | mask = np.ones(self.as_np.shape[0], dtype='bool')
176 | mask[self.__get_idxs(words_to_remove)] = False
177 | if not self.bow:
178 | return ''.join(
179 | [self.as_list[i] if mask[i] else self.mask_string
180 | for i in range(mask.shape[0])])
181 | return ''.join([self.as_list[v] for v in mask.nonzero()[0]])
182 |
183 | @staticmethod
184 | def _segment_with_tokens(text, tokens):
185 | """Segment a string around the tokens created by a passed-in tokenizer"""
186 | list_form = []
187 | text_ptr = 0
188 | for token in tokens:
189 | inter_token_string = []
190 | while not text[text_ptr:].startswith(token):
191 | inter_token_string.append(text[text_ptr])
192 | text_ptr += 1
193 | if text_ptr >= len(text):
194 | raise ValueError("Tokenization produced tokens that do not belong in string!")
195 | text_ptr += len(token)
196 | if inter_token_string:
197 | list_form.append(''.join(inter_token_string))
198 | list_form.append(token)
199 | if text_ptr < len(text):
200 | list_form.append(text[text_ptr:])
201 | return list_form
202 |
203 | def __get_idxs(self, words):
204 | """Returns indexes to appropriate words."""
205 | if self.bow:
206 | return list(itertools.chain.from_iterable(
207 | [self.positions[z] for z in words]))
208 | else:
209 | return self.positions[words]
210 |
211 |
212 | class IndexedCharacters(object):
213 | """String with various indexes."""
214 |
215 | def __init__(self, raw_string, bow=True, mask_string=None):
216 | """Initializer.
217 |
218 | Args:
219 | raw_string: string with raw text in it
220 | bow: if True, a char is the same everywhere in the text - i.e. we
221 | will index multiple occurrences of the same character. If False,
222 | order matters, so that the same word will have different ids
223 | according to position.
224 | mask_string: If not None, replace characters with this if bow=False
225 | if None, default value is chr(0)
226 | """
227 | self.raw = raw_string
228 | self.as_list = list(self.raw)
229 | self.as_np = np.array(self.as_list)
230 | self.mask_string = chr(0) if mask_string is None else mask_string
231 | self.string_start = np.arange(len(self.raw))
232 | vocab = {}
233 | self.inverse_vocab = []
234 | self.positions = []
235 | self.bow = bow
236 | non_vocab = set()
237 | for i, char in enumerate(self.as_np):
238 | if char in non_vocab:
239 | continue
240 | if bow:
241 | if char not in vocab:
242 | vocab[char] = len(vocab)
243 | self.inverse_vocab.append(char)
244 | self.positions.append([])
245 | idx_char = vocab[char]
246 | self.positions[idx_char].append(i)
247 | else:
248 | self.inverse_vocab.append(char)
249 | self.positions.append(i)
250 | if not bow:
251 | self.positions = np.array(self.positions)
252 |
253 | def raw_string(self):
254 | """Returns the original raw string"""
255 | return self.raw
256 |
257 | def num_words(self):
258 | """Returns the number of tokens in the vocabulary for this document."""
259 | return len(self.inverse_vocab)
260 |
261 | def word(self, id_):
262 | """Returns the word that corresponds to id_ (int)"""
263 | return self.inverse_vocab[id_]
264 |
265 | def string_position(self, id_):
266 | """Returns a np array with indices to id_ (int) occurrences"""
267 | if self.bow:
268 | return self.string_start[self.positions[id_]]
269 | else:
270 | return self.string_start[[self.positions[id_]]]
271 |
272 | def inverse_removing(self, words_to_remove):
273 | """Returns a string after removing the appropriate words.
274 |
275 | If self.bow is false, replaces word with UNKWORDZ instead of removing
276 | it.
277 |
278 | Args:
279 | words_to_remove: list of ids (ints) to remove
280 |
281 | Returns:
282 | original raw string with appropriate words removed.
283 | """
284 | mask = np.ones(self.as_np.shape[0], dtype='bool')
285 | mask[self.__get_idxs(words_to_remove)] = False
286 | if not self.bow:
287 | return ''.join(
288 | [self.as_list[i] if mask[i] else self.mask_string
289 | for i in range(mask.shape[0])])
290 | return ''.join([self.as_list[v] for v in mask.nonzero()[0]])
291 |
292 | def __get_idxs(self, words):
293 | """Returns indexes to appropriate words."""
294 | if self.bow:
295 | return list(itertools.chain.from_iterable(
296 | [self.positions[z] for z in words]))
297 | else:
298 | return self.positions[words]
299 |
300 |
301 | class LimeTextExplainer(object):
302 | """Explains text classifiers.
303 | Currently, we are using an exponential kernel on cosine distance, and
304 | restricting explanations to words that are present in documents."""
305 |
306 | def __init__(self,
307 | kernel_width=25,
308 | kernel=None,
309 | verbose=False,
310 | class_names=None,
311 | feature_selection='auto',
312 | split_expression=r'\W+',
313 | bow=True,
314 | mask_string=None,
315 | random_state=None,
316 | char_level=False):
317 | """Init function.
318 |
319 | Args:
320 | kernel_width: kernel width for the exponential kernel.
321 | kernel: similarity kernel that takes euclidean distances and kernel
322 | width as input and outputs weights in (0,1). If None, defaults to
323 | an exponential kernel.
324 | verbose: if true, print local prediction values from linear model
325 | class_names: list of class names, ordered according to whatever the
326 | classifier is using. If not present, class names will be '0',
327 | '1', ...
328 | feature_selection: feature selection method. can be
329 | 'forward_selection', 'lasso_path', 'none' or 'auto'.
330 | See function 'explain_instance_with_data' in lime_base.py for
331 | details on what each of the options does.
332 | split_expression: Regex string or callable. If regex string, will be used with re.split.
333 | If callable, the function should return a list of tokens.
334 | bow: if True (bag of words), will perturb input data by removing
335 | all occurrences of individual words or characters.
336 | Explanations will be in terms of these words. Otherwise, will
337 | explain in terms of word-positions, so that a word may be
338 | important the first time it appears and unimportant the second.
339 | Only set to false if the classifier uses word order in some way
340 | (bigrams, etc), or if you set char_level=True.
341 | mask_string: String used to mask tokens or characters if bow=False
342 | if None, will be 'UNKWORDZ' if char_level=False, chr(0)
343 | otherwise.
344 | random_state: an integer or numpy.RandomState that will be used to
345 | generate random numbers. If None, the random state will be
346 | initialized using the internal numpy seed.
347 | char_level: an boolean identifying that we treat each character
348 | as an independent occurence in the string
349 | """
350 |
351 | if kernel is None:
352 | def kernel(d, kernel_width):
353 | return np.sqrt(np.exp(-(d ** 2) / kernel_width ** 2))
354 |
355 | kernel_fn = partial(kernel, kernel_width=kernel_width)
356 |
357 | self.random_state = check_random_state(random_state)
358 | self.base = lime_base.LimeBase(kernel_fn, verbose,
359 | random_state=self.random_state)
360 | self.class_names = class_names
361 | self.vocabulary = None
362 | self.feature_selection = feature_selection
363 | self.bow = bow
364 | self.mask_string = mask_string
365 | self.split_expression = split_expression
366 | self.char_level = char_level
367 |
368 | def explain_instance(self,
369 | text_instance,
370 | classifier_fn,
371 | labels=(1,),
372 | top_labels=None,
373 | num_features=10,
374 | num_samples=5000,
375 | distance_metric='cosine',
376 | model_regressor=None):
377 | """Generates explanations for a prediction.
378 |
379 | First, we generate neighborhood data by randomly hiding features from
380 | the instance (see __data_labels_distance_mapping). We then learn
381 | locally weighted linear models on this neighborhood data to explain
382 | each of the classes in an interpretable way (see lime_base.py).
383 |
384 | Args:
385 | text_instance: raw text string to be explained.
386 | classifier_fn: classifier prediction probability function, which
387 | takes a list of d strings and outputs a (d, k) numpy array with
388 | prediction probabilities, where k is the number of classes.
389 | For ScikitClassifiers , this is classifier.predict_proba.
390 | labels: iterable with labels to be explained.
391 | top_labels: if not None, ignore labels and produce explanations for
392 | the K labels with highest prediction probabilities, where K is
393 | this parameter.
394 | num_features: maximum number of features present in explanation
395 | num_samples: size of the neighborhood to learn the linear model
396 | distance_metric: the distance metric to use for sample weighting,
397 | defaults to cosine similarity
398 | model_regressor: sklearn regressor to use in explanation. Defaults
399 | to Ridge regression in LimeBase. Must have model_regressor.coef_
400 | and 'sample_weight' as a parameter to model_regressor.fit()
401 | Returns:
402 | An Explanation object (see explanation.py) with the corresponding
403 | explanations.
404 | """
405 |
406 | indexed_string = (IndexedCharacters(
407 | text_instance, bow=self.bow, mask_string=self.mask_string)
408 | if self.char_level else
409 | IndexedString(text_instance, bow=self.bow,
410 | split_expression=self.split_expression,
411 | mask_string=self.mask_string))
412 | domain_mapper = TextDomainMapper(indexed_string)
413 | data, yss, distances = self.__data_labels_distances(
414 | indexed_string, classifier_fn, num_samples,
415 | distance_metric=distance_metric)
416 | if self.class_names is None:
417 | self.class_names = [str(x) for x in range(yss[0].shape[0])]
418 | ret_exp = explanation.Explanation(domain_mapper=domain_mapper,
419 | class_names=self.class_names,
420 | random_state=self.random_state)
421 | ret_exp.predict_proba = yss[0]
422 | if top_labels:
423 | labels = np.argsort(yss[0])[-top_labels:]
424 | ret_exp.top_labels = list(labels)
425 | ret_exp.top_labels.reverse()
426 | for label in labels:
427 | (ret_exp.intercept[label],
428 | ret_exp.local_exp[label],
429 | ret_exp.score[label],
430 | ret_exp.local_pred[label]) = self.base.explain_instance_with_data(
431 | data, yss, distances, label, num_features,
432 | model_regressor=model_regressor,
433 | feature_selection=self.feature_selection)
434 | return ret_exp
435 |
436 | def __data_labels_distances(self,
437 | indexed_string,
438 | classifier_fn,
439 | num_samples,
440 | distance_metric='cosine'):
441 | """Generates a neighborhood around a prediction.
442 |
443 | Generates neighborhood data by randomly removing words from
444 | the instance, and predicting with the classifier. Uses cosine distance
445 | to compute distances between original and perturbed instances.
446 | Args:
447 | indexed_string: document (IndexedString) to be explained,
448 | classifier_fn: classifier prediction probability function, which
449 | takes a string and outputs prediction probabilities. For
450 | ScikitClassifier, this is classifier.predict_proba.
451 | num_samples: size of the neighborhood to learn the linear model
452 | distance_metric: the distance metric to use for sample weighting,
453 | defaults to cosine similarity.
454 |
455 |
456 | Returns:
457 | A tuple (data, labels, distances), where:
458 | data: dense num_samples * K binary matrix, where K is the
459 | number of tokens in indexed_string. The first row is the
460 | original instance, and thus a row of ones.
461 | labels: num_samples * L matrix, where L is the number of target
462 | labels
463 | distances: cosine distance between the original instance and
464 | each perturbed instance (computed in the binary 'data'
465 | matrix), times 100.
466 | """
467 |
468 | def distance_fn(x):
469 | return sklearn.metrics.pairwise.pairwise_distances(
470 | x, x[0], metric=distance_metric).ravel() * 100
471 |
472 | doc_size = indexed_string.num_words()
473 | sample = self.random_state.randint(1, doc_size + 1, num_samples - 1)
474 | data = np.ones((num_samples, doc_size))
475 | data[0] = np.ones(doc_size)
476 | features_range = range(doc_size)
477 | inverse_data = [indexed_string.raw_string()]
478 | for i, size in enumerate(sample, start=1):
479 | inactive = self.random_state.choice(features_range, size,
480 | replace=False)
481 | data[i, inactive] = 0
482 | inverse_data.append(indexed_string.inverse_removing(inactive))
483 | labels = classifier_fn(inverse_data)
484 | distances = distance_fn(sp.sparse.csr_matrix(data))
485 | return data, labels, distances
486 |
--------------------------------------------------------------------------------
/lime/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "lime",
3 | "version": "1.0.0",
4 | "description": "",
5 | "main": "main.js",
6 | "scripts": {
7 | "build": "webpack",
8 | "watch": "webpack --watch",
9 | "start": "webpack-dev-server --hot --inline",
10 | "lint": "eslint js"
11 | },
12 | "repository": {
13 | "type": "git",
14 | "url": "git+https://github.com/marcotcr/lime.git"
15 | },
16 | "author": "Marco Tulio Ribeiro ",
17 | "license": "TODO",
18 | "bugs": {
19 | "url": "https://github.com/marcotcr/lime/issues"
20 | },
21 | "homepage": "https://github.com/marcotcr/lime#readme",
22 | "devDependencies": {
23 | "babel-cli": "^6.8.0",
24 | "babel-core": "^6.17.0",
25 | "babel-eslint": "^6.1.0",
26 | "babel-loader": "^6.2.4",
27 | "babel-polyfill": "^6.16.0",
28 | "babel-preset-es2015": "^6.0.15",
29 | "babel-preset-es2015-ie": "^6.6.2",
30 | "css-loader": "^0.23.1",
31 | "eslint": "^6.6.0",
32 | "node-libs-browser": "^0.5.3",
33 | "style-loader": "^0.13.1",
34 | "webpack": "^1.13.0",
35 | "webpack-dev-server": "^1.14.1"
36 | },
37 | "dependencies": {
38 | "d3": "^3.5.17",
39 | "lodash": "^4.11.2"
40 | },
41 | "eslintConfig": {
42 | "parser": "babel-eslint",
43 | "parserOptions": {
44 | "ecmaVersion": 6,
45 | "sourceType": "module",
46 | "ecmaFeatures": {
47 | "jsx": true
48 | }
49 | },
50 | "extends": "eslint:recommended"
51 | }
52 | }
53 |
--------------------------------------------------------------------------------
/lime/style.css:
--------------------------------------------------------------------------------
1 | .lime {
2 | all: initial;
3 | }
4 | .lime.top_div {
5 | display: flex;
6 | flex-wrap: wrap;
7 | }
8 | .lime.predict_proba {
9 | width: 245px;
10 | }
11 | .lime.predicted_value {
12 | width: 245px;
13 | }
14 | .lime.explanation {
15 | width: 350px;
16 | }
17 |
18 | .lime.text_div {
19 | max-height:300px;
20 | flex: 1 0 300px;
21 | overflow:scroll;
22 | }
23 | .lime.table_div {
24 | max-height:300px;
25 | flex: 1 0 300px;
26 | overflow:scroll;
27 | }
28 | .lime.table_div table {
29 | border-collapse: collapse;
30 | color: white;
31 | border-style: hidden;
32 | margin: 0 auto;
33 | }
34 |
--------------------------------------------------------------------------------
/lime/submodular_pick.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import warnings
3 |
4 |
5 | class SubmodularPick(object):
6 | """Class for submodular pick
7 |
8 | Saves a representative sample of explanation objects using SP-LIME,
9 | as well as saving all generated explanations
10 |
11 | First, a collection of candidate explanations are generated
12 | (see explain_instance). From these candidates, num_exps_desired are
13 | chosen using submodular pick. (see marcotcr et al paper)."""
14 |
15 | def __init__(self,
16 | explainer,
17 | data,
18 | predict_fn,
19 | method='sample',
20 | sample_size=1000,
21 | num_exps_desired=5,
22 | num_features=10,
23 | **kwargs):
24 |
25 | """
26 | Args:
27 | data: a numpy array where each row is a single input into predict_fn
28 | predict_fn: prediction function. For classifiers, this should be a
29 | function that takes a numpy array and outputs prediction
30 | probabilities. For regressors, this takes a numpy array and
31 | returns the predictions. For ScikitClassifiers, this is
32 | `classifier.predict_proba()`. For ScikitRegressors, this
33 | is `regressor.predict()`. The prediction function needs to work
34 | on multiple feature vectors (the vectors randomly perturbed
35 | from the data_row).
36 | method: The method to use to generate candidate explanations
37 | method == 'sample' will sample the data uniformly at
38 | random. The sample size is given by sample_size. Otherwise
39 | if method == 'full' then explanations will be generated for the
40 | entire data. l
41 | sample_size: The number of instances to explain if method == 'sample'
42 | num_exps_desired: The number of explanation objects returned
43 | num_features: maximum number of features present in explanation
44 |
45 |
46 | Sets value:
47 | sp_explanations: A list of explanation objects that has a high coverage
48 | explanations: All the candidate explanations saved for potential future use.
49 | """
50 |
51 | top_labels = kwargs.get('top_labels', 1)
52 | if 'top_labels' in kwargs:
53 | del kwargs['top_labels']
54 | # Parse args
55 | if method == 'sample':
56 | if sample_size > len(data):
57 | warnings.warn("""Requested sample size larger than
58 | size of input data. Using all data""")
59 | sample_size = len(data)
60 | all_indices = np.arange(len(data))
61 | np.random.shuffle(all_indices)
62 | sample_indices = all_indices[:sample_size]
63 | elif method == 'full':
64 | sample_indices = np.arange(len(data))
65 | else:
66 | raise ValueError('Method must be \'sample\' or \'full\'')
67 |
68 | # Generate Explanations
69 | self.explanations = []
70 | for i in sample_indices:
71 | self.explanations.append(
72 | explainer.explain_instance(
73 | data[i], predict_fn, num_features=num_features,
74 | top_labels=top_labels,
75 | **kwargs))
76 | # Error handling
77 | try:
78 | num_exps_desired = int(num_exps_desired)
79 | except TypeError:
80 | return("Requested number of explanations should be an integer")
81 | if num_exps_desired > len(self.explanations):
82 | warnings.warn("""Requested number of explanations larger than
83 | total number of explanations, returning all
84 | explanations instead.""")
85 | num_exps_desired = min(num_exps_desired, len(self.explanations))
86 |
87 | # Find all the explanation model features used. Defines the dimension d'
88 | features_dict = {}
89 | feature_iter = 0
90 | for exp in self.explanations:
91 | labels = exp.available_labels() if exp.mode == 'classification' else [1]
92 | for label in labels:
93 | for feature, _ in exp.as_list(label=label):
94 | if feature not in features_dict.keys():
95 | features_dict[feature] = (feature_iter)
96 | feature_iter += 1
97 | d_prime = len(features_dict.keys())
98 |
99 | # Create the n x d' dimensional 'explanation matrix', W
100 | W = np.zeros((len(self.explanations), d_prime))
101 | for i, exp in enumerate(self.explanations):
102 | labels = exp.available_labels() if exp.mode == 'classification' else [1]
103 | for label in labels:
104 | for feature, value in exp.as_list(label):
105 | W[i, features_dict[feature]] += value
106 |
107 | # Create the global importance vector, I_j described in the paper
108 | importance = np.sum(abs(W), axis=0)**.5
109 |
110 | # Now run the SP-LIME greedy algorithm
111 | remaining_indices = set(range(len(self.explanations)))
112 | V = []
113 | for _ in range(num_exps_desired):
114 | best = 0
115 | best_ind = None
116 | current = 0
117 | for i in remaining_indices:
118 | current = np.dot(
119 | (np.sum(abs(W)[V + [i]], axis=0) > 0), importance
120 | ) # coverage function
121 | if current >= best:
122 | best = current
123 | best_ind = i
124 | V.append(best_ind)
125 | remaining_indices -= {best_ind}
126 |
127 | self.sp_explanations = [self.explanations[i] for i in V]
128 | self.V = V
129 |
--------------------------------------------------------------------------------
/lime/test_table.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
14 |
15 |
16 |
--------------------------------------------------------------------------------
/lime/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/lime/tests/__init__.py
--------------------------------------------------------------------------------
/lime/tests/test_discretize.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from unittest import TestCase
3 |
4 | import numpy as np
5 |
6 | from sklearn.datasets import load_iris
7 |
8 | from lime.discretize import QuartileDiscretizer, DecileDiscretizer, EntropyDiscretizer
9 |
10 |
11 | class TestDiscretize(TestCase):
12 |
13 | def setUp(self):
14 | iris = load_iris()
15 |
16 | self.feature_names = iris.feature_names
17 | self.x = iris.data
18 | self.y = iris.target
19 |
20 | def check_random_state_for_discretizer_class(self, DiscretizerClass):
21 | # ----------------------------------------------------------------------
22 | # -----------Check if the same random_state produces the same-----------
23 | # -------------results for different discretizer instances.-------------
24 | # ----------------------------------------------------------------------
25 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
26 | random_state=10)
27 | x_1 = discretizer.undiscretize(discretizer.discretize(self.x))
28 |
29 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
30 | random_state=10)
31 | x_2 = discretizer.undiscretize(discretizer.discretize(self.x))
32 |
33 | self.assertEqual((x_1 == x_2).sum(), x_1.shape[0] * x_1.shape[1])
34 |
35 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
36 | random_state=np.random.RandomState(10))
37 | x_1 = discretizer.undiscretize(discretizer.discretize(self.x))
38 |
39 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
40 | random_state=np.random.RandomState(10))
41 | x_2 = discretizer.undiscretize(discretizer.discretize(self.x))
42 |
43 | self.assertEqual((x_1 == x_2).sum(), x_1.shape[0] * x_1.shape[1])
44 |
45 | # ----------------------------------------------------------------------
46 | # ---------Check if two different random_state values produces----------
47 | # -------different results for different discretizers instances.--------
48 | # ----------------------------------------------------------------------
49 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
50 | random_state=10)
51 | x_1 = discretizer.undiscretize(discretizer.discretize(self.x))
52 |
53 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
54 | random_state=20)
55 | x_2 = discretizer.undiscretize(discretizer.discretize(self.x))
56 |
57 | self.assertFalse((x_1 == x_2).sum() == x_1.shape[0] * x_1.shape[1])
58 |
59 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
60 | random_state=np.random.RandomState(10))
61 | x_1 = discretizer.undiscretize(discretizer.discretize(self.x))
62 |
63 | discretizer = DiscretizerClass(self.x, [], self.feature_names, self.y,
64 | random_state=np.random.RandomState(20))
65 | x_2 = discretizer.undiscretize(discretizer.discretize(self.x))
66 |
67 | self.assertFalse((x_1 == x_2).sum() == x_1.shape[0] * x_1.shape[1])
68 |
69 | def test_random_state(self):
70 | self.check_random_state_for_discretizer_class(QuartileDiscretizer)
71 |
72 | self.check_random_state_for_discretizer_class(DecileDiscretizer)
73 |
74 | self.check_random_state_for_discretizer_class(EntropyDiscretizer)
75 |
76 | def test_feature_names_1(self):
77 | self.maxDiff = None
78 | discretizer = QuartileDiscretizer(self.x, [], self.feature_names,
79 | self.y, random_state=10)
80 | self.assertDictEqual(
81 | {0: ['sepal length (cm) <= 5.10',
82 | '5.10 < sepal length (cm) <= 5.80',
83 | '5.80 < sepal length (cm) <= 6.40',
84 | 'sepal length (cm) > 6.40'],
85 | 1: ['sepal width (cm) <= 2.80',
86 | '2.80 < sepal width (cm) <= 3.00',
87 | '3.00 < sepal width (cm) <= 3.30',
88 | 'sepal width (cm) > 3.30'],
89 | 2: ['petal length (cm) <= 1.60',
90 | '1.60 < petal length (cm) <= 4.35',
91 | '4.35 < petal length (cm) <= 5.10',
92 | 'petal length (cm) > 5.10'],
93 | 3: ['petal width (cm) <= 0.30',
94 | '0.30 < petal width (cm) <= 1.30',
95 | '1.30 < petal width (cm) <= 1.80',
96 | 'petal width (cm) > 1.80']},
97 | discretizer.names)
98 |
99 | def test_feature_names_2(self):
100 | self.maxDiff = None
101 | discretizer = DecileDiscretizer(self.x, [], self.feature_names, self.y,
102 | random_state=10)
103 | self.assertDictEqual(
104 | {0: ['sepal length (cm) <= 4.80',
105 | '4.80 < sepal length (cm) <= 5.00',
106 | '5.00 < sepal length (cm) <= 5.27',
107 | '5.27 < sepal length (cm) <= 5.60',
108 | '5.60 < sepal length (cm) <= 5.80',
109 | '5.80 < sepal length (cm) <= 6.10',
110 | '6.10 < sepal length (cm) <= 6.30',
111 | '6.30 < sepal length (cm) <= 6.52',
112 | '6.52 < sepal length (cm) <= 6.90',
113 | 'sepal length (cm) > 6.90'],
114 | 1: ['sepal width (cm) <= 2.50',
115 | '2.50 < sepal width (cm) <= 2.70',
116 | '2.70 < sepal width (cm) <= 2.80',
117 | '2.80 < sepal width (cm) <= 3.00',
118 | '3.00 < sepal width (cm) <= 3.10',
119 | '3.10 < sepal width (cm) <= 3.20',
120 | '3.20 < sepal width (cm) <= 3.40',
121 | '3.40 < sepal width (cm) <= 3.61',
122 | 'sepal width (cm) > 3.61'],
123 | 2: ['petal length (cm) <= 1.40',
124 | '1.40 < petal length (cm) <= 1.50',
125 | '1.50 < petal length (cm) <= 1.70',
126 | '1.70 < petal length (cm) <= 3.90',
127 | '3.90 < petal length (cm) <= 4.35',
128 | '4.35 < petal length (cm) <= 4.64',
129 | '4.64 < petal length (cm) <= 5.00',
130 | '5.00 < petal length (cm) <= 5.32',
131 | '5.32 < petal length (cm) <= 5.80',
132 | 'petal length (cm) > 5.80'],
133 | 3: ['petal width (cm) <= 0.20',
134 | '0.20 < petal width (cm) <= 0.40',
135 | '0.40 < petal width (cm) <= 1.16',
136 | '1.16 < petal width (cm) <= 1.30',
137 | '1.30 < petal width (cm) <= 1.50',
138 | '1.50 < petal width (cm) <= 1.80',
139 | '1.80 < petal width (cm) <= 1.90',
140 | '1.90 < petal width (cm) <= 2.20',
141 | 'petal width (cm) > 2.20']},
142 | discretizer.names)
143 |
144 | def test_feature_names_3(self):
145 | self.maxDiff = None
146 | discretizer = EntropyDiscretizer(self.x, [], self.feature_names,
147 | self.y, random_state=10)
148 | self.assertDictEqual(
149 | {0: ['sepal length (cm) <= 4.85',
150 | '4.85 < sepal length (cm) <= 5.45',
151 | '5.45 < sepal length (cm) <= 5.55',
152 | '5.55 < sepal length (cm) <= 5.85',
153 | '5.85 < sepal length (cm) <= 6.15',
154 | '6.15 < sepal length (cm) <= 7.05',
155 | 'sepal length (cm) > 7.05'],
156 | 1: ['sepal width (cm) <= 2.45',
157 | '2.45 < sepal width (cm) <= 2.95',
158 | '2.95 < sepal width (cm) <= 3.05',
159 | '3.05 < sepal width (cm) <= 3.35',
160 | '3.35 < sepal width (cm) <= 3.45',
161 | '3.45 < sepal width (cm) <= 3.55',
162 | 'sepal width (cm) > 3.55'],
163 | 2: ['petal length (cm) <= 2.45',
164 | '2.45 < petal length (cm) <= 4.45',
165 | '4.45 < petal length (cm) <= 4.75',
166 | '4.75 < petal length (cm) <= 5.15',
167 | 'petal length (cm) > 5.15'],
168 | 3: ['petal width (cm) <= 0.80',
169 | '0.80 < petal width (cm) <= 1.35',
170 | '1.35 < petal width (cm) <= 1.75',
171 | '1.75 < petal width (cm) <= 1.85',
172 | 'petal width (cm) > 1.85']},
173 | discretizer.names)
174 |
175 |
176 | if __name__ == '__main__':
177 | unittest.main()
178 |
--------------------------------------------------------------------------------
/lime/tests/test_generic_utils.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | import sys
3 | from lime.utils.generic_utils import has_arg
4 |
5 |
6 | class TestGenericUtils(unittest.TestCase):
7 |
8 | def test_has_arg(self):
9 | # fn is callable / is not callable
10 |
11 | class FooNotCallable:
12 |
13 | def __init__(self, word):
14 | self.message = word
15 |
16 | class FooCallable:
17 |
18 | def __init__(self, word):
19 | self.message = word
20 |
21 | def __call__(self, message):
22 | return message
23 |
24 | def positional_argument_call(self, arg1):
25 | return self.message
26 |
27 | def multiple_positional_arguments_call(self, *args):
28 | res = []
29 | for a in args:
30 | res.append(a)
31 | return res
32 |
33 | def keyword_argument_call(self, filter_=True):
34 | res = self.message
35 | if filter_:
36 | res = 'KO'
37 | return res
38 |
39 | def multiple_keyword_arguments_call(self, arg1='1', arg2='2'):
40 | return self.message + arg1 + arg2
41 |
42 | def undefined_keyword_arguments_call(self, **kwargs):
43 | res = self.message
44 | for a in kwargs:
45 | res = res + a
46 | return a
47 |
48 | foo_callable = FooCallable('OK')
49 | self.assertTrue(has_arg(foo_callable, 'message'))
50 |
51 | if sys.version_info < (3,):
52 | foo_not_callable = FooNotCallable('KO')
53 | self.assertFalse(has_arg(foo_not_callable, 'message'))
54 | elif sys.version_info < (3, 6):
55 | with self.assertRaises(TypeError):
56 | foo_not_callable = FooNotCallable('KO')
57 | has_arg(foo_not_callable, 'message')
58 |
59 | # Python 2, argument in / not in valid arguments / keyword arguments
60 | if sys.version_info < (3,):
61 | self.assertFalse(has_arg(foo_callable, 'invalid_arg'))
62 | self.assertTrue(has_arg(foo_callable.positional_argument_call, 'arg1'))
63 | self.assertFalse(has_arg(foo_callable.multiple_positional_arguments_call, 'argX'))
64 | self.assertFalse(has_arg(foo_callable.keyword_argument_call, 'argX'))
65 | self.assertTrue(has_arg(foo_callable.keyword_argument_call, 'filter_'))
66 | self.assertTrue(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg2'))
67 | self.assertFalse(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg3'))
68 | self.assertFalse(has_arg(foo_callable.undefined_keyword_arguments_call, 'argX'))
69 | # Python 3, argument in / not in valid arguments / keyword arguments
70 | elif sys.version_info < (3, 6):
71 | self.assertFalse(has_arg(foo_callable, 'invalid_arg'))
72 | self.assertTrue(has_arg(foo_callable.positional_argument_call, 'arg1'))
73 | self.assertFalse(has_arg(foo_callable.multiple_positional_arguments_call, 'argX'))
74 | self.assertFalse(has_arg(foo_callable.keyword_argument_call, 'argX'))
75 | self.assertTrue(has_arg(foo_callable.keyword_argument_call, 'filter_'))
76 | self.assertTrue(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg2'))
77 | self.assertFalse(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg3'))
78 | self.assertFalse(has_arg(foo_callable.undefined_keyword_arguments_call, 'argX'))
79 | else:
80 | self.assertFalse(has_arg(foo_callable, 'invalid_arg'))
81 | self.assertTrue(has_arg(foo_callable.positional_argument_call, 'arg1'))
82 | self.assertFalse(has_arg(foo_callable.multiple_positional_arguments_call, 'argX'))
83 | self.assertFalse(has_arg(foo_callable.keyword_argument_call, 'argX'))
84 | self.assertTrue(has_arg(foo_callable.keyword_argument_call, 'filter_'))
85 | self.assertTrue(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg2'))
86 | self.assertFalse(has_arg(foo_callable.multiple_keyword_arguments_call, 'arg3'))
87 | self.assertFalse(has_arg(foo_callable.undefined_keyword_arguments_call, 'argX'))
88 | # argname is None
89 | self.assertFalse(has_arg(foo_callable, None))
90 |
91 |
92 | if __name__ == '__main__':
93 | unittest.main()
94 |
--------------------------------------------------------------------------------
/lime/tests/test_lime_text.py:
--------------------------------------------------------------------------------
1 | import re
2 | import unittest
3 |
4 | import sklearn # noqa
5 | from sklearn.datasets import fetch_20newsgroups
6 | from sklearn.feature_extraction.text import TfidfVectorizer
7 | from sklearn.metrics import f1_score
8 | from sklearn.naive_bayes import MultinomialNB
9 | from sklearn.pipeline import make_pipeline
10 |
11 | import numpy as np
12 |
13 | from lime.lime_text import LimeTextExplainer
14 | from lime.lime_text import IndexedCharacters, IndexedString
15 |
16 |
17 | class TestLimeText(unittest.TestCase):
18 |
19 | def test_lime_text_explainer_good_regressor(self):
20 | categories = ['alt.atheism', 'soc.religion.christian']
21 | newsgroups_train = fetch_20newsgroups(subset='train',
22 | categories=categories)
23 | newsgroups_test = fetch_20newsgroups(subset='test',
24 | categories=categories)
25 | class_names = ['atheism', 'christian']
26 | vectorizer = TfidfVectorizer(lowercase=False)
27 | train_vectors = vectorizer.fit_transform(newsgroups_train.data)
28 | test_vectors = vectorizer.transform(newsgroups_test.data)
29 | nb = MultinomialNB(alpha=.01)
30 | nb.fit(train_vectors, newsgroups_train.target)
31 | pred = nb.predict(test_vectors)
32 | f1_score(newsgroups_test.target, pred, average='weighted')
33 | c = make_pipeline(vectorizer, nb)
34 | explainer = LimeTextExplainer(class_names=class_names)
35 | idx = 83
36 | exp = explainer.explain_instance(newsgroups_test.data[idx],
37 | c.predict_proba, num_features=6)
38 | self.assertIsNotNone(exp)
39 | self.assertEqual(6, len(exp.as_list()))
40 |
41 | def test_lime_text_tabular_equal_random_state(self):
42 | categories = ['alt.atheism', 'soc.religion.christian']
43 | newsgroups_train = fetch_20newsgroups(subset='train',
44 | categories=categories)
45 | newsgroups_test = fetch_20newsgroups(subset='test',
46 | categories=categories)
47 | class_names = ['atheism', 'christian']
48 | vectorizer = TfidfVectorizer(lowercase=False)
49 | train_vectors = vectorizer.fit_transform(newsgroups_train.data)
50 | test_vectors = vectorizer.transform(newsgroups_test.data)
51 | nb = MultinomialNB(alpha=.01)
52 | nb.fit(train_vectors, newsgroups_train.target)
53 | pred = nb.predict(test_vectors)
54 | f1_score(newsgroups_test.target, pred, average='weighted')
55 | c = make_pipeline(vectorizer, nb)
56 |
57 | explainer = LimeTextExplainer(class_names=class_names, random_state=10)
58 | exp_1 = explainer.explain_instance(newsgroups_test.data[83],
59 | c.predict_proba, num_features=6)
60 |
61 | explainer = LimeTextExplainer(class_names=class_names, random_state=10)
62 | exp_2 = explainer.explain_instance(newsgroups_test.data[83],
63 | c.predict_proba, num_features=6)
64 |
65 | self.assertTrue(exp_1.as_map() == exp_2.as_map())
66 |
67 | def test_lime_text_tabular_not_equal_random_state(self):
68 | categories = ['alt.atheism', 'soc.religion.christian']
69 | newsgroups_train = fetch_20newsgroups(subset='train',
70 | categories=categories)
71 | newsgroups_test = fetch_20newsgroups(subset='test',
72 | categories=categories)
73 | class_names = ['atheism', 'christian']
74 | vectorizer = TfidfVectorizer(lowercase=False)
75 | train_vectors = vectorizer.fit_transform(newsgroups_train.data)
76 | test_vectors = vectorizer.transform(newsgroups_test.data)
77 | nb = MultinomialNB(alpha=.01)
78 | nb.fit(train_vectors, newsgroups_train.target)
79 | pred = nb.predict(test_vectors)
80 | f1_score(newsgroups_test.target, pred, average='weighted')
81 | c = make_pipeline(vectorizer, nb)
82 |
83 | explainer = LimeTextExplainer(
84 | class_names=class_names, random_state=10)
85 | exp_1 = explainer.explain_instance(newsgroups_test.data[83],
86 | c.predict_proba, num_features=6)
87 |
88 | explainer = LimeTextExplainer(
89 | class_names=class_names, random_state=20)
90 | exp_2 = explainer.explain_instance(newsgroups_test.data[83],
91 | c.predict_proba, num_features=6)
92 |
93 | self.assertFalse(exp_1.as_map() == exp_2.as_map())
94 |
95 | def test_indexed_characters_bow(self):
96 | s = 'Please, take your time'
97 | inverse_vocab = ['P', 'l', 'e', 'a', 's', ',', ' ', 't', 'k', 'y', 'o', 'u', 'r', 'i', 'm']
98 | positions = [[0], [1], [2, 5, 11, 21], [3, 9],
99 | [4], [6], [7, 12, 17], [8, 18], [10],
100 | [13], [14], [15], [16], [19], [20]]
101 | ic = IndexedCharacters(s)
102 |
103 | self.assertTrue(np.array_equal(ic.as_np, np.array(list(s))))
104 | self.assertTrue(np.array_equal(ic.string_start, np.arange(len(s))))
105 | self.assertTrue(ic.inverse_vocab == inverse_vocab)
106 | self.assertTrue(ic.positions == positions)
107 |
108 | def test_indexed_characters_not_bow(self):
109 | s = 'Please, take your time'
110 |
111 | ic = IndexedCharacters(s, bow=False)
112 |
113 | self.assertTrue(np.array_equal(ic.as_np, np.array(list(s))))
114 | self.assertTrue(np.array_equal(ic.string_start, np.arange(len(s))))
115 | self.assertTrue(ic.inverse_vocab == list(s))
116 | self.assertTrue(np.array_equal(ic.positions, np.arange(len(s))))
117 |
118 | def test_indexed_string_regex(self):
119 | s = 'Please, take your time. Please'
120 | tokenized_string = np.array(
121 | ['Please', ', ', 'take', ' ', 'your', ' ', 'time', '. ', 'Please'])
122 | inverse_vocab = ['Please', 'take', 'your', 'time']
123 | start_positions = [0, 6, 8, 12, 13, 17, 18, 22, 24]
124 | positions = [[0, 8], [2], [4], [6]]
125 | indexed_string = IndexedString(s)
126 |
127 | self.assertTrue(np.array_equal(indexed_string.as_np, tokenized_string))
128 | self.assertTrue(np.array_equal(indexed_string.string_start, start_positions))
129 | self.assertTrue(indexed_string.inverse_vocab == inverse_vocab)
130 | self.assertTrue(np.array_equal(indexed_string.positions, positions))
131 |
132 | def test_indexed_string_callable(self):
133 | s = 'aabbccddaa'
134 |
135 | def tokenizer(string):
136 | return [string[i] + string[i + 1] for i in range(0, len(string) - 1, 2)]
137 |
138 | tokenized_string = np.array(['aa', 'bb', 'cc', 'dd', 'aa'])
139 | inverse_vocab = ['aa', 'bb', 'cc', 'dd']
140 | start_positions = [0, 2, 4, 6, 8]
141 | positions = [[0, 4], [1], [2], [3]]
142 | indexed_string = IndexedString(s, tokenizer)
143 |
144 | self.assertTrue(np.array_equal(indexed_string.as_np, tokenized_string))
145 | self.assertTrue(np.array_equal(indexed_string.string_start, start_positions))
146 | self.assertTrue(indexed_string.inverse_vocab == inverse_vocab)
147 | self.assertTrue(np.array_equal(indexed_string.positions, positions))
148 |
149 | def test_indexed_string_inverse_removing_tokenizer(self):
150 | s = 'This is a good movie. This, it is a great movie.'
151 |
152 | def tokenizer(string):
153 | return re.split(r'(?:\W+)|$', string)
154 |
155 | indexed_string = IndexedString(s, tokenizer)
156 |
157 | self.assertEqual(s, indexed_string.inverse_removing([]))
158 |
159 | def test_indexed_string_inverse_removing_regex(self):
160 | s = 'This is a good movie. This is a great movie'
161 | indexed_string = IndexedString(s)
162 |
163 | self.assertEqual(s, indexed_string.inverse_removing([]))
164 |
165 |
166 | if __name__ == '__main__':
167 | unittest.main()
168 |
--------------------------------------------------------------------------------
/lime/tests/test_scikit_image.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from lime.wrappers.scikit_image import BaseWrapper
3 | from lime.wrappers.scikit_image import SegmentationAlgorithm
4 | from skimage.segmentation import quickshift
5 | from skimage.data import chelsea
6 | from skimage.util import img_as_float
7 | import numpy as np
8 |
9 |
10 | class TestBaseWrapper(unittest.TestCase):
11 |
12 | def test_base_wrapper(self):
13 |
14 | obj_with_params = BaseWrapper(a=10, b='message')
15 | obj_without_params = BaseWrapper()
16 |
17 | def foo_fn():
18 | return 'bar'
19 |
20 | obj_with_fn = BaseWrapper(foo_fn)
21 | self.assertEqual(obj_with_params.target_params, {'a': 10, 'b': 'message'})
22 | self.assertEqual(obj_without_params.target_params, {})
23 | self.assertEqual(obj_with_fn.target_fn(), 'bar')
24 |
25 | def test__check_params(self):
26 |
27 | def bar_fn(a):
28 | return str(a)
29 |
30 | class Pipo():
31 |
32 | def __init__(self):
33 | self.name = 'pipo'
34 |
35 | def __call__(self, message):
36 | return message
37 |
38 | pipo = Pipo()
39 | obj_with_valid_fn = BaseWrapper(bar_fn, a=10, b='message')
40 | obj_with_valid_callable_fn = BaseWrapper(pipo, c=10, d='message')
41 | obj_with_invalid_fn = BaseWrapper([1, 2, 3], fn_name='invalid')
42 |
43 | # target_fn is not a callable or function/method
44 | with self.assertRaises(AttributeError):
45 | obj_with_invalid_fn._check_params('fn_name')
46 |
47 | # parameters is not in target_fn args
48 | with self.assertRaises(ValueError):
49 | obj_with_valid_fn._check_params(['c'])
50 | obj_with_valid_callable_fn._check_params(['e'])
51 |
52 | # params is in target_fn args
53 | try:
54 | obj_with_valid_fn._check_params(['a'])
55 | obj_with_valid_callable_fn._check_params(['message'])
56 | except Exception:
57 | self.fail("_check_params() raised an unexpected exception")
58 |
59 | # params is not a dict or list
60 | with self.assertRaises(TypeError):
61 | obj_with_valid_fn._check_params(None)
62 | with self.assertRaises(TypeError):
63 | obj_with_valid_fn._check_params('param_name')
64 |
65 | def test_set_params(self):
66 |
67 | class Pipo():
68 |
69 | def __init__(self):
70 | self.name = 'pipo'
71 |
72 | def __call__(self, message):
73 | return message
74 | pipo = Pipo()
75 | obj = BaseWrapper(pipo)
76 |
77 | # argument is set accordingly
78 | obj.set_params(message='OK')
79 | self.assertEqual(obj.target_params, {'message': 'OK'})
80 | self.assertEqual(obj.target_fn(**obj.target_params), 'OK')
81 |
82 | # invalid argument is passed
83 | try:
84 | obj = BaseWrapper(Pipo())
85 | obj.set_params(invalid='KO')
86 | except Exception:
87 | self.assertEqual(obj.target_params, {})
88 |
89 | def test_filter_params(self):
90 |
91 | # right arguments are kept and wrong dismmissed
92 | def baz_fn(a, b, c=True):
93 | if c:
94 | return a + b
95 | else:
96 | return a
97 | obj_ = BaseWrapper(baz_fn, a=10, b=100, d=1000)
98 | self.assertEqual(obj_.filter_params(baz_fn), {'a': 10, 'b': 100})
99 |
100 | # target_params is overriden using 'override' argument
101 | self.assertEqual(obj_.filter_params(baz_fn, override={'c': False}),
102 | {'a': 10, 'b': 100, 'c': False})
103 |
104 |
105 | class TestSegmentationAlgorithm(unittest.TestCase):
106 |
107 | def test_instanciate_segmentation_algorithm(self):
108 | img = img_as_float(chelsea()[::2, ::2])
109 |
110 | # wrapped functions provide the same result
111 | fn = SegmentationAlgorithm('quickshift', kernel_size=3, max_dist=6,
112 | ratio=0.5, random_seed=133)
113 | fn_result = fn(img)
114 | original_result = quickshift(img, kernel_size=3, max_dist=6, ratio=0.5,
115 | random_seed=133)
116 |
117 | # same segments
118 | self.assertTrue(np.array_equal(fn_result, original_result))
119 |
120 | def test_instanciate_slic(self):
121 | pass
122 |
123 | def test_instanciate_felzenszwalb(self):
124 | pass
125 |
126 |
127 | if __name__ == '__main__':
128 | unittest.main()
129 |
--------------------------------------------------------------------------------
/lime/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/lime/utils/__init__.py
--------------------------------------------------------------------------------
/lime/utils/generic_utils.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import inspect
3 | import types
4 |
5 |
6 | def has_arg(fn, arg_name):
7 | """Checks if a callable accepts a given keyword argument.
8 |
9 | Args:
10 | fn: callable to inspect
11 | arg_name: string, keyword argument name to check
12 |
13 | Returns:
14 | bool, whether `fn` accepts a `arg_name` keyword argument.
15 | """
16 | if sys.version_info < (3,):
17 | if isinstance(fn, types.FunctionType) or isinstance(fn, types.MethodType):
18 | arg_spec = inspect.getargspec(fn)
19 | else:
20 | try:
21 | arg_spec = inspect.getargspec(fn.__call__)
22 | except AttributeError:
23 | return False
24 | return (arg_name in arg_spec.args)
25 | elif sys.version_info < (3, 6):
26 | arg_spec = inspect.getfullargspec(fn)
27 | return (arg_name in arg_spec.args or
28 | arg_name in arg_spec.kwonlyargs)
29 | else:
30 | try:
31 | signature = inspect.signature(fn)
32 | except ValueError:
33 | # handling Cython
34 | signature = inspect.signature(fn.__call__)
35 | parameter = signature.parameters.get(arg_name)
36 | if parameter is None:
37 | return False
38 | return (parameter.kind in (inspect.Parameter.POSITIONAL_OR_KEYWORD,
39 | inspect.Parameter.KEYWORD_ONLY))
40 |
--------------------------------------------------------------------------------
/lime/webpack.config.js:
--------------------------------------------------------------------------------
1 | var path = require('path');
2 | var webpack = require('webpack');
3 |
4 | module.exports = {
5 | entry: './js/main.js',
6 | output: {
7 | path: __dirname,
8 | filename: 'bundle.js',
9 | library: 'lime'
10 | },
11 | module: {
12 | loaders: [
13 | {
14 | loader: 'babel-loader',
15 | test: path.join(__dirname, 'js'),
16 | query: {
17 | presets: 'es2015-ie',
18 | },
19 |
20 | },
21 | {
22 | test: /\.css$/,
23 | loaders: ['style-loader', 'css-loader'],
24 |
25 | }
26 |
27 | ]
28 | },
29 | plugins: [
30 | // Avoid publishing files when compilation fails
31 | new webpack.NoErrorsPlugin()
32 | ],
33 | stats: {
34 | // Nice colored output
35 | colors: true
36 | },
37 | // Create Sourcemaps for the bundle
38 | devtool: 'source-map',
39 | };
40 |
41 |
--------------------------------------------------------------------------------
/lime/wrappers/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marcotcr/lime/fd7eb2e6f760619c29fca0187c07b82157601b32/lime/wrappers/__init__.py
--------------------------------------------------------------------------------
/lime/wrappers/scikit_image.py:
--------------------------------------------------------------------------------
1 | import types
2 | from lime.utils.generic_utils import has_arg
3 | from skimage.segmentation import felzenszwalb, slic, quickshift
4 |
5 |
6 | class BaseWrapper(object):
7 | """Base class for LIME Scikit-Image wrapper
8 |
9 |
10 | Args:
11 | target_fn: callable function or class instance
12 | target_params: dict, parameters to pass to the target_fn
13 |
14 |
15 | 'target_params' takes parameters required to instanciate the
16 | desired Scikit-Image class/model
17 | """
18 |
19 | def __init__(self, target_fn=None, **target_params):
20 | self.target_fn = target_fn
21 | self.target_params = target_params
22 |
23 | def _check_params(self, parameters):
24 | """Checks for mistakes in 'parameters'
25 |
26 | Args :
27 | parameters: dict, parameters to be checked
28 |
29 | Raises :
30 | ValueError: if any parameter is not a valid argument for the target function
31 | or the target function is not defined
32 | TypeError: if argument parameters is not iterable
33 | """
34 | a_valid_fn = []
35 | if self.target_fn is None:
36 | if callable(self):
37 | a_valid_fn.append(self.__call__)
38 | else:
39 | raise TypeError('invalid argument: tested object is not callable,\
40 | please provide a valid target_fn')
41 | elif isinstance(self.target_fn, types.FunctionType) \
42 | or isinstance(self.target_fn, types.MethodType):
43 | a_valid_fn.append(self.target_fn)
44 | else:
45 | a_valid_fn.append(self.target_fn.__call__)
46 |
47 | if not isinstance(parameters, str):
48 | for p in parameters:
49 | for fn in a_valid_fn:
50 | if has_arg(fn, p):
51 | pass
52 | else:
53 | raise ValueError('{} is not a valid parameter'.format(p))
54 | else:
55 | raise TypeError('invalid argument: list or dictionnary expected')
56 |
57 | def set_params(self, **params):
58 | """Sets the parameters of this estimator.
59 | Args:
60 | **params: Dictionary of parameter names mapped to their values.
61 |
62 | Raises :
63 | ValueError: if any parameter is not a valid argument
64 | for the target function
65 | """
66 | self._check_params(params)
67 | self.target_params = params
68 |
69 | def filter_params(self, fn, override=None):
70 | """Filters `target_params` and return those in `fn`'s arguments.
71 | Args:
72 | fn : arbitrary function
73 | override: dict, values to override target_params
74 | Returns:
75 | result : dict, dictionary containing variables
76 | in both target_params and fn's arguments.
77 | """
78 | override = override or {}
79 | result = {}
80 | for name, value in self.target_params.items():
81 | if has_arg(fn, name):
82 | result.update({name: value})
83 | result.update(override)
84 | return result
85 |
86 |
87 | class SegmentationAlgorithm(BaseWrapper):
88 | """ Define the image segmentation function based on Scikit-Image
89 | implementation and a set of provided parameters
90 |
91 | Args:
92 | algo_type: string, segmentation algorithm among the following:
93 | 'quickshift', 'slic', 'felzenszwalb'
94 | target_params: dict, algorithm parameters (valid model paramters
95 | as define in Scikit-Image documentation)
96 | """
97 |
98 | def __init__(self, algo_type, **target_params):
99 | self.algo_type = algo_type
100 | if (self.algo_type == 'quickshift'):
101 | BaseWrapper.__init__(self, quickshift, **target_params)
102 | kwargs = self.filter_params(quickshift)
103 | self.set_params(**kwargs)
104 | elif (self.algo_type == 'felzenszwalb'):
105 | BaseWrapper.__init__(self, felzenszwalb, **target_params)
106 | kwargs = self.filter_params(felzenszwalb)
107 | self.set_params(**kwargs)
108 | elif (self.algo_type == 'slic'):
109 | BaseWrapper.__init__(self, slic, **target_params)
110 | kwargs = self.filter_params(slic)
111 | self.set_params(**kwargs)
112 |
113 | def __call__(self, *args):
114 | return self.target_fn(args[0], **self.target_params)
115 |
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [flake8]
2 | max-line-length = 100
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 |
3 | setup(name='lime',
4 | version='0.2.0.1',
5 | description='Local Interpretable Model-Agnostic Explanations for machine learning classifiers',
6 | url='http://github.com/marcotcr/lime',
7 | author='Marco Tulio Ribeiro',
8 | author_email='marcotcr@gmail.com',
9 | license='BSD',
10 | packages=find_packages(exclude=['js', 'node_modules', 'tests']),
11 | python_requires='>=3.5',
12 | install_requires=[
13 | 'matplotlib',
14 | 'numpy',
15 | 'scipy',
16 | 'tqdm >= 4.29.1',
17 | 'scikit-learn>=0.18',
18 | 'scikit-image>=0.12',
19 | 'pyDOE2==1.3.0'
20 | ],
21 | extras_require={
22 | 'dev': ['pytest', 'flake8'],
23 | },
24 | include_package_data=True,
25 | zip_safe=False)
26 |
--------------------------------------------------------------------------------