├── .github
├── ISSUE_TEMPLATE
│ └── example_request.yaml
├── PULL_REQUEST_TEMPLATE.md
└── workflows
│ └── test.yaml
├── .gitignore
├── .pre-commit-config.yaml
├── LICENSE
├── README.md
├── assets
├── explore_high_dimensional_data.gif
└── youtube_summary.png
├── explore_high_dimensional_data
├── README.md
└── explore_high_dimensional_data.py
├── nlp_span_comparison
├── README.md
└── nlp_span_comparison.py
├── pyproject.toml
├── tests
└── test_examples_without_error.py
└── youtube_summary
├── README.md
└── youtube_summary.py
/.github/ISSUE_TEMPLATE/example_request.yaml:
--------------------------------------------------------------------------------
1 | # yaml-language-server: $schema=https://raw.githubusercontent.com/SchemaStore/schemastore/refs/heads/master/src/schemas/json/github-issue-forms.json
2 | name: '🚀 Example request'
3 | description: Request a new example
4 | type: Example
5 | body:
6 | - type: markdown
7 | attributes:
8 | value: |
9 | Let us know what example you'd like to see added!
10 | - type: textarea
11 | id: example-description
12 | attributes:
13 | label: Description
14 | description: 'Description of the example to add. Please make the reason and usecases as detailed as possible. If you intend to submit a PR for this issue, tell us in the description. Thanks!'
15 | placeholder: I would like an example notebook on ...
16 | validations:
17 | required: true
18 |
--------------------------------------------------------------------------------
/.github/PULL_REQUEST_TEMPLATE.md:
--------------------------------------------------------------------------------
1 | ## 📝 Summary
2 |
3 |
8 |
9 | ## 🔍 Description of example
10 |
11 |
12 |
13 |
14 | ## 📋 Checklist
15 |
16 | - [ ] I have included package dependencies in the notebook file [using `--sandbox`](https://docs.marimo.io/guides/package_reproducibility/)
17 | - [ ] I have included a short README.md describing my example and how to run it.
18 | - [ ] I have included instructions on how to adapt the notebook to custom data and models
19 | - [ ] I have included an ["Open in marimo" badge](https://docs.marimo.io/guides/publishing/playground/#open-notebooks-hosted-on-github) in the README if my example works in [WASM](https://docs.marimo.io/guides/wasm/).
20 | - [ ] If my notebook accesses local files, I used [`mo.notebook_directory()`](https://docs.marimo.io/api/miscellaneous/?h=notebook_directory#marimo.notebook_directory) to construct notebook paths
21 |
--------------------------------------------------------------------------------
/.github/workflows/test.yaml:
--------------------------------------------------------------------------------
1 | name: Tests
2 |
3 | on:
4 | push:
5 | branches: [main]
6 | pull_request: {}
7 |
8 | jobs:
9 | test:
10 | name: Test notebooks
11 | runs-on: ubuntu-latest
12 | steps:
13 | - name: 🛑 Cancel Previous Runs
14 | uses: styfle/cancel-workflow-action@0.12.1
15 | - name: Checkout the repository
16 | uses: actions/checkout@main
17 | - name: 🐍 Setup uv
18 | uses: astral-sh/setup-uv@v5
19 | - name: Run tests
20 | run: |
21 | uvx --with marimo pytest -v
22 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | share/python-wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 | MANIFEST
28 |
29 | # PyInstaller
30 | # Usually these files are written by a python script from a template
31 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
32 | *.manifest
33 | *.spec
34 |
35 | # Installer logs
36 | pip-log.txt
37 | pip-delete-this-directory.txt
38 |
39 | # Unit test / coverage reports
40 | htmlcov/
41 | .tox/
42 | .nox/
43 | .coverage
44 | .coverage.*
45 | .cache
46 | nosetests.xml
47 | coverage.xml
48 | *.cover
49 | *.py,cover
50 | .hypothesis/
51 | .pytest_cache/
52 | cover/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | .pybuilder/
76 | target/
77 |
78 | # Jupyter Notebook
79 | .ipynb_checkpoints
80 |
81 | # IPython
82 | profile_default/
83 | ipython_config.py
84 |
85 | # pyenv
86 | # For a library or package, you might want to ignore these files since the code is
87 | # intended to run in multiple environments; otherwise, check them in:
88 | # .python-version
89 |
90 | # pipenv
91 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
92 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
93 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
94 | # install all needed dependencies.
95 | #Pipfile.lock
96 |
97 | # poetry
98 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
99 | # This is especially recommended for binary packages to ensure reproducibility, and is more
100 | # commonly ignored for libraries.
101 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
102 | #poetry.lock
103 |
104 | # pdm
105 | # Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
106 | #pdm.lock
107 | # pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
108 | # in version control.
109 | # https://pdm.fming.dev/#use-with-ide
110 | .pdm.toml
111 |
112 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
113 | __pypackages__/
114 |
115 | # Celery stuff
116 | celerybeat-schedule
117 | celerybeat.pid
118 |
119 | # SageMath parsed files
120 | *.sage.py
121 |
122 | # Environments
123 | .env
124 | .venv
125 | env/
126 | venv/
127 | ENV/
128 | env.bak/
129 | venv.bak/
130 |
131 | # Spyder project settings
132 | .spyderproject
133 | .spyproject
134 |
135 | # Rope project settings
136 | .ropeproject
137 |
138 | # mkdocs documentation
139 | /site
140 |
141 | # mypy
142 | .mypy_cache/
143 | .dmypy.json
144 | dmypy.json
145 |
146 | # Pyre type checker
147 | .pyre/
148 |
149 | # pytype static type analyzer
150 | .pytype/
151 |
152 | # Cython debug symbols
153 | cython_debug/
154 |
155 | # PyCharm
156 | # JetBrains specific template is maintained in a separate JetBrains.gitignore that can
157 | # be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
158 | # and can be added to the global gitignore or merged into this file. For a more nuclear
159 | # option (not recommended) you can uncomment the following to ignore the entire idea folder.
160 | #.idea/
161 |
--------------------------------------------------------------------------------
/.pre-commit-config.yaml:
--------------------------------------------------------------------------------
1 | fail_fast: false
2 |
3 | repos:
4 | - repo: https://github.com/pre-commit/pre-commit-hooks
5 | rev: v5.0.0
6 | hooks:
7 | - id: check-yaml
8 |
9 | - repo: https://github.com/rhysd/actionlint
10 | rev: v1.7.7
11 | hooks:
12 | - id: actionlint
13 | args: [-ignore, SC]
14 |
15 | - repo: https://github.com/igorshubovych/markdownlint-cli
16 | rev: v0.44.0
17 | hooks:
18 | - id: markdownlint-fix
19 | args: [-c, configs/.markdownlint.yaml, --fix, --disable, MD028]
20 |
21 | - repo: https://github.com/crate-ci/typos
22 | rev: typos-dict-v0.12.4
23 | hooks:
24 | - id: typos
25 |
26 | - repo: https://github.com/astral-sh/ruff-pre-commit
27 | rev: v0.9.6
28 | hooks:
29 | # Run the formatter
30 | - id: ruff-format
31 |
32 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 marimo
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 | A curated collection of example marimo notebooks.
7 |
8 |
9 | This repository contains a curated collection of example
10 | [marimo](https://github.com/marimo-team/marimo) notebooks. Use these notebooks
11 | as starting points for your own data exploration, experimentation, workflows,
12 | and apps.
13 |
14 | ## Running examples
15 |
16 | Each example has a README that tells you how to run it locally. Most examples
17 | can also be opened in marimo's [online
18 | playground](https://docs.marimo.io/guides/publishing/playground/) by clicking
19 | the "open in marimo" badge in its README.
20 |
21 | ## Adding new examples
22 |
23 | We welcome community contributions of examples!
24 |
25 | Open a pull request to contribute a new example. Ideally, examples are easy for
26 | others to adapt to their own data and models. Here's a contribution checklist:
27 |
28 | - [ ] Place the example in its own folder
29 | - [ ] Include package dependencies in notebook files [using
30 | `--sandbox`](https://docs.marimo.io/guides/package_reproducibility/)
31 | - [ ] Include a short README.md describing your example and how to run it.
32 | - [ ] Include instructions on how to adapt the notebook to custom data and models
33 |
34 | If you aren't comfortable adding a new example, you can also request new
35 | examples by filing an issue.
36 |
37 | ## Community
38 |
39 | We're building a community. Come hang out with us!
40 |
41 | - 🌟 [Star us on GitHub](https://github.com/marimo-team/examples)
42 | - 💬 [Chat with us on Discord](https://marimo.io/discord?ref=readme)
43 | - 📧 [Subscribe to our Newsletter](https://marimo.io/newsletter)
44 | - ☁️ [Join our Cloud Waitlist](https://marimo.io/cloud)
45 | - ✏️ [Start a GitHub Discussion](https://github.com/marimo-team/marimo/discussions)
46 | - 🦋 [Follow us on Bluesky](https://bsky.app/profile/marimo.io)
47 | - 🐦 [Follow us on Twitter](https://twitter.com/marimo_io)
48 | - 🕴️ [Follow us on LinkedIn](https://www.linkedin.com/company/marimo-io)
49 |
50 |
51 |
52 |
53 |
54 |
--------------------------------------------------------------------------------
/assets/explore_high_dimensional_data.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marimo-team/examples/dc02cc00df77d06fb1d5581c47759be8b6ace50b/assets/explore_high_dimensional_data.gif
--------------------------------------------------------------------------------
/assets/youtube_summary.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/marimo-team/examples/dc02cc00df77d06fb1d5581c47759be8b6ace50b/assets/youtube_summary.png
--------------------------------------------------------------------------------
/explore_high_dimensional_data/README.md:
--------------------------------------------------------------------------------
1 | # Explore high dimensional data
2 |
3 | [](https://marimo.app/github.com/marimo-team/examples/blob/main/explore_high_dimensional_data/explore_high_dimensional_data.py)
4 |
5 | **This template lets you visualize and interactively explore high dimensional
6 | data.** The starter code uses PCA to embed and plot numerical digits, seeing
7 | how they cluster together — when you select points in the plot, the notebook
8 | shows you the underlying images!
9 |
10 | To use this notebook on your own data, just replace the implementations
11 | of the following four functions:
12 |
13 | * `load_data`
14 | * `embed_data`
15 | * `scatter_data`
16 | * `show_selection`
17 |
18 |
19 |
20 | ## Running this notebook
21 |
22 | Open this notebook in [our online
23 | playground](https://marimo.app/github.com/marimo-team/examples/blob/main/explore_high_dimensional_data/explore_high_dimensional_data.py)
24 | or run it locally.
25 |
26 | ### Running locally
27 |
28 | The requirements of each notebook are serialized in them as a top-level
29 | comment. Here are the steps to run the notebook:
30 |
31 | 1. [Install `uv`](https://github.com/astral-sh/uv/?tab=readme-ov-file#installation)
32 | 2. Open an example with `uvx marimo edit --sandbox `
33 |
34 | > [!TIP]
35 | > The [`--sandbox`
36 | > flag](https://docs.marimo.io/guides/package_reproducibility/) opens the
37 | > notebook in an isolated virtual environment, automatically installing the
38 | > notebook's dependencies 📦
39 |
40 | You can also open notebooks without `uv`, in which case you'll need to
41 | manually [install marimo](https://docs.marimo.io/getting_started/index.html#installation)
42 | first. Then run `marimo edit `; however, you'll also need to
43 | install the requirements yourself.
44 |
--------------------------------------------------------------------------------
/explore_high_dimensional_data/explore_high_dimensional_data.py:
--------------------------------------------------------------------------------
1 | # /// script
2 | # requires-python = ">=3.12"
3 | # dependencies = [
4 | # "altair==5.5.0",
5 | # "marimo",
6 | # "matplotlib==3.10.0",
7 | # "pandas==2.2.3",
8 | # "polars==1.20.0",
9 | # "scikit-learn==1.6.1",
10 | # ]
11 | # ///
12 |
13 | import marimo
14 |
15 | __generated_with = "0.10.16"
16 | app = marimo.App(width="columns")
17 |
18 |
19 | @app.cell(column=0, hide_code=True)
20 | def _(mo):
21 | mo.md(
22 | """
23 | **This template lets you visualize and interactively explore high dimensional data.** The starter code uses PCA to embed and plot numerical
24 | digits, seeing how they cluster together — when you select points in the plot, the notebook shows you the underlying images.
25 |
26 | The left-hand column implements the core logic; the right-hand column executes the dimensionality reduction and shows the outputs.
27 |
28 | **To customize this template to your own data, just implement the functions in
29 | this column.**
30 | """
31 | )
32 | return
33 |
34 |
35 | @app.cell
36 | def _():
37 | def load_data():
38 | """
39 | Return a tuple of your data:
40 |
41 | * The dataset, with each row a different item in the dataset
42 | * A label for each data point.
43 |
44 | If your data doesn't have labels, just return a list of all ones
45 | with the same length as the number of items in your dataset.
46 | """
47 | import sklearn.datasets
48 |
49 | data, labels = sklearn.datasets.load_digits(return_X_y=True)
50 | return data, labels
51 |
52 | return (load_data,)
53 |
54 |
55 | @app.cell
56 | def _():
57 | def embed_data(data):
58 | """
59 | Embed the data into two dimensions. The default implementation
60 | uses PCA, but you can also use UMAP, tSNE, or any other dimensionality
61 | reduction algorithm you like.
62 |
63 | The starter implementation here uses PCA, and assumes the data is a NumPy
64 | array.
65 | """
66 | import sklearn
67 | import sklearn.decomposition
68 |
69 | return sklearn.decomposition.PCA(n_components=2, whiten=True).fit_transform(
70 | data
71 | )
72 |
73 | return (embed_data,)
74 |
75 |
76 | @app.cell
77 | def _(pl):
78 | def scatter_data(df: pl.DataFrame) -> alt.Chart:
79 | """
80 | Visualize the embedded data using an Altair scatterplot.
81 |
82 | - df is a Polars dataframe with the following columns:
83 | * x: the first coordinate of the embedding
84 | * y: the second coordinate of the embedding
85 | * label: a label identifying each item, for coloring
86 |
87 | Modify the starter implementation to suit your needs, but make sure
88 | to return an altair chart.
89 | """
90 | import altair as alt
91 |
92 | return (
93 | alt.Chart(df)
94 | .mark_circle()
95 | .encode(
96 | x=alt.X("x:Q").scale(domain=(-2.5, 2.5)),
97 | y=alt.Y("y:Q").scale(domain=(-2.5, 2.5)),
98 | color=alt.Color("label:N"),
99 | )
100 | .properties(width=500, height=500)
101 | )
102 |
103 | return (scatter_data,)
104 |
105 |
106 | @app.cell
107 | def _():
108 | def show_selection(data, rows, max_rows=10):
109 | """
110 | Visualize selected rows of the data.
111 |
112 | - `data` is the data returned from `load_data`
113 | - `rows` is a list or array of row indices
114 | - `max_rows` is the maximum number of rows to display
115 | """
116 | import matplotlib.pyplot as plt
117 |
118 | # show 10 images: either the first 10 from the selection, or the first ten
119 | # selected in the table
120 | rows = rows[:max_rows]
121 | images = data.reshape((-1, 8, 8))[rows]
122 | fig, axes = plt.subplots(1, len(rows))
123 | fig.set_size_inches(12.5, 1.5)
124 | if len(rows) > 1:
125 | for im, ax in zip(images, axes.flat):
126 | ax.imshow(im, cmap="gray")
127 | ax.set_yticks([])
128 | ax.set_xticks([])
129 | else:
130 | axes.imshow(images[0], cmap="gray")
131 | axes.set_yticks([])
132 | axes.set_xticks([])
133 | plt.tight_layout()
134 | return fig
135 |
136 | return (show_selection,)
137 |
138 |
139 | @app.cell(column=1, hide_code=True)
140 | def _(mo):
141 | mo.md("""# Explore high dimensional data""")
142 | return
143 |
144 |
145 | @app.cell(hide_code=True)
146 | def _(mo):
147 | mo.md(
148 | """
149 | Here's an **embedding** of your data, with similar points close to each other.
150 |
151 | This notebook will automatically drill down into points you **select with
152 | your mouse**; try it!
153 | """
154 | )
155 | return
156 |
157 |
158 | @app.cell
159 | def _(load_data):
160 | data, labels = load_data()
161 | return data, labels
162 |
163 |
164 | @app.cell
165 | def _():
166 | import polars as pl
167 |
168 | return (pl,)
169 |
170 |
171 | @app.cell
172 | def _(data, embed_data, labels, pl):
173 | X_embedded = embed_data(data)
174 |
175 | embedding = pl.DataFrame(
176 | {
177 | "x": X_embedded[:, 0],
178 | "y": X_embedded[:, 1],
179 | "label": labels,
180 | "index": list(range(X_embedded.shape[0])),
181 | }
182 | )
183 | return X_embedded, embedding
184 |
185 |
186 | @app.cell
187 | def _(embedding, mo, scatter_data):
188 | chart = mo.ui.altair_chart(scatter_data(embedding))
189 | chart
190 | return (chart,)
191 |
192 |
193 | @app.cell
194 | def _(chart, mo):
195 | table = mo.ui.table(chart.value)
196 | return (table,)
197 |
198 |
199 | @app.cell
200 | def _(chart, data, mo, show_selection, table):
201 | mo.stop(not len(chart.value))
202 |
203 | selected_rows = (
204 | show_selection(data, list(chart.value["index"]))
205 | if table.value.is_empty()
206 | else show_selection(data, list(table.value["index"]))
207 | )
208 |
209 | mo.md(
210 | f"""
211 | **Here's a preview of the items you've selected**:
212 |
213 | {mo.as_html(selected_rows)}
214 |
215 | Here's all the data you've selected.
216 |
217 | {table}
218 | """
219 | )
220 | return (selected_rows,)
221 |
222 |
223 | @app.cell
224 | def _():
225 | import marimo as mo
226 |
227 | return (mo,)
228 |
229 |
230 | if __name__ == "__main__":
231 | app.run()
232 |
--------------------------------------------------------------------------------
/nlp_span_comparison/README.md:
--------------------------------------------------------------------------------
1 | # NLP Span Comparison
2 |
3 | [](https://marimo.app/github.com/marimo-team/examples/blob/main/nlp_span_comparison/nlp_span_comparison.py)
4 |
5 | This notebook can be used as a template for comparing NLP models that predict
6 | spans. Given two models and a sequence of text examples from which to extract
7 | spans, the notebook presents the model predictions on each example and
8 | lets you indicate which model yielded the better prediction. Your preferences
9 | are saved (and loaded) from storage, letting you use this as a real tool.
10 |
11 | To use this notebook for your own data, just replace the implementations
12 | of the following three functions:
13 |
14 | * `load_examples`: Load your own examples (strings) from a file or database.
15 | * `model_a_predictor`: Predict a span for a given example using model A.
16 | * `model_b_predictor`: Predict a span for a given example using model B.
17 |
18 | The notebook keeps track of your preferences in a JSON file. To track
19 | preferences in a different way, such as in a database, replace the implementations
20 | of the following two functions:
21 |
22 | * `load_choices`
23 | * `save_choices`
24 |
25 |
26 |
27 | ## Running this notebook
28 |
29 | Open this notebook in [our online
30 | playground](https://marimo.app/github.com/marimo-team/examples/blob/main/examples/nlp_span_comparison/nlp_span_comparison.py)
31 | or run it locally.
32 |
33 | ### Running locally
34 |
35 | The requirements of each notebook are serialized in them as a top-level
36 | comment. Here are the steps to run the notebook:
37 |
38 | 1. [Install `uv`](https://github.com/astral-sh/uv/?tab=readme-ov-file#installation)
39 | 2. Open an example with `uvx marimo edit --sandbox `
40 |
41 | > [!TIP]
42 | > The [`--sandbox`
43 | > flag](https://docs.marimo.io/guides/package_reproducibility/) opens the
44 | > notebook in an isolated virtual environment, automatically installing the
45 | > notebook's dependencies 📦
46 |
47 | You can also open notebooks without `uv`, in which case you'll need to
48 | manually [install marimo](https://docs.marimo.io/getting_started/index.html#installation)
49 | first. Then run `marimo edit `; however, you'll also need to
50 | install the requirements yourself.
51 |
--------------------------------------------------------------------------------
/nlp_span_comparison/nlp_span_comparison.py:
--------------------------------------------------------------------------------
1 | # /// script
2 | # requires-python = ">=3.9"
3 | # dependencies = [
4 | # "marimo",
5 | # ]
6 | # ///
7 |
8 | import marimo
9 |
10 | __generated_with = "0.10.13"
11 | app = marimo.App()
12 |
13 |
14 | @app.cell(hide_code=True)
15 | def _(mo):
16 | mo.md("""# Span Comparison""")
17 | return
18 |
19 |
20 | @app.cell
21 | def _(textwrap, urllib):
22 | # Modify this function to load your own examples
23 | def load_examples():
24 | hamlet_url = "https://gist.githubusercontent.com/provpup/2fc41686eab7400b796b/raw/b575bd01a58494dfddc1d6429ef0167e709abf9b/hamlet.txt"
25 |
26 | with urllib.request.urlopen(hamlet_url) as f:
27 | HAMLET = f.read().decode("utf-8")
28 |
29 | return [
30 | textwrap.dedent(block).strip()[:1000]
31 | for block in HAMLET.split("\n\n")
32 | if block
33 | ]
34 |
35 | return (load_examples,)
36 |
37 |
38 | @app.cell
39 | def _(random):
40 | # Replace with your predictor for model A
41 | def model_a_predictor(text: str) -> tuple[int, int]:
42 | random.seed(len(text))
43 | start = random.randint(0, len(text) - 2)
44 | end = random.randint(start + 1, len(text) - 1)
45 | return start, end
46 |
47 | return (model_a_predictor,)
48 |
49 |
50 | @app.cell
51 | def _(random):
52 | # Replace with your predictor for model B
53 | def model_b_predictor(text: str) -> tuple[int, int]:
54 | random.seed(len(text) / 2)
55 | start = random.randint(0, len(text) - 2)
56 | end = random.randint(start + 1, len(text) - 1)
57 | return start, end
58 |
59 | return (model_b_predictor,)
60 |
61 |
62 | @app.cell(hide_code=True)
63 | def _(mo):
64 | mo.md(
65 | r"""
66 | !!! tip "This notebook is best viewed as an app."
67 | Hit `Cmd/Ctrl+.` or click the "app view" button in the bottom right.
68 | """
69 | )
70 | return
71 |
72 |
73 | @app.cell
74 | def _(load_examples):
75 | EXAMPLES = load_examples()
76 | return (EXAMPLES,)
77 |
78 |
79 | @app.cell
80 | def _(NUMBER_OF_EXAMPLES, mo):
81 | index = mo.ui.number(
82 | 0,
83 | NUMBER_OF_EXAMPLES - 1,
84 | value=0,
85 | step=1,
86 | debounce=True,
87 | label="example number",
88 | )
89 | return (index,)
90 |
91 |
92 | @app.cell(hide_code=True)
93 | def _(mo):
94 | mo.md("""_Models A and B both predict spans. Which do you prefer?_""")
95 | return
96 |
97 |
98 | @app.cell
99 | def _(NUMBER_OF_EXAMPLES, mo, num_a_preferred, num_b_preferred):
100 | mo.ui.table(
101 | [
102 | {"Model": "A", "Score": f"{num_a_preferred}/{NUMBER_OF_EXAMPLES}"},
103 | {"Model": "B", "Score": f"{num_b_preferred}/{NUMBER_OF_EXAMPLES}"},
104 | ],
105 | selection=None,
106 | )
107 | return
108 |
109 |
110 | @app.cell
111 | def _(get_choices, mo):
112 | mo.accordion({"All preferences": mo.ui.table(get_choices(), selection=None)})
113 | return
114 |
115 |
116 | @app.cell
117 | def _(index):
118 | index.center()
119 | return
120 |
121 |
122 | @app.cell
123 | def _(CHOICES_PATH, get_choices, index, mo, write_choices):
124 | def _():
125 | preference = get_choices()[index.value]["model"]
126 | mo.stop(preference is None, mo.md("**Choose the better model**.").center())
127 |
128 | write_choices(get_choices(), CHOICES_PATH)
129 | return mo.md(f"You prefer **model {preference}**.").center()
130 |
131 | _()
132 | return
133 |
134 |
135 | @app.cell
136 | def _(annotate, mo):
137 | mo.hstack(
138 | [
139 | annotate("Model A", [0, len("Model A")], "yellow"),
140 | annotate("Model B", [0, len("Model B")], "lightblue"),
141 | ],
142 | justify="space-around",
143 | )
144 | return
145 |
146 |
147 | @app.cell
148 | def _(CHOICES_PATH, EXAMPLES, load_choices, mo):
149 | get_choices, set_choices = mo.state(load_choices(CHOICES_PATH, len(EXAMPLES)))
150 | return get_choices, set_choices
151 |
152 |
153 | @app.cell
154 | def _(index, mo, set_choices):
155 | model_A = mo.ui.button(
156 | label="Model A",
157 | on_change=lambda _: set_choices(
158 | lambda v: v[: index.value]
159 | + [{"index": index.value, "model": "A"}]
160 | + v[index.value + 1 :]
161 | ),
162 | )
163 |
164 | model_B = mo.ui.button(
165 | label="Model B",
166 | on_change=lambda _: set_choices(
167 | lambda v: v[: index.value]
168 | + [{"index": index.value, "model": "B"}]
169 | + v[index.value + 1 :]
170 | ),
171 | )
172 | mo.hstack([model_A, model_B], justify="space-around")
173 | return model_A, model_B
174 |
175 |
176 | @app.cell
177 | def _(EXAMPLES, annotate, index, model_a_predictor, model_b_predictor):
178 | _example = EXAMPLES[index.value]
179 |
180 | model_A_prediction = annotate(_example, model_a_predictor(_example), color="yellow")
181 |
182 | model_B_prediction = annotate(
183 | _example, model_b_predictor(_example), color="lightblue"
184 | )
185 | return model_A_prediction, model_B_prediction
186 |
187 |
188 | @app.cell
189 | def _(mo, model_A_prediction, model_B_prediction):
190 | mo.hstack([model_A_prediction, model_B_prediction], gap=2, justify="space-around")
191 | return
192 |
193 |
194 | @app.cell
195 | def _(get_choices):
196 | num_a_preferred = sum(1 for c in get_choices() if c["model"] == "A")
197 | num_b_preferred = sum(1 for c in get_choices() if c["model"] == "B")
198 | return num_a_preferred, num_b_preferred
199 |
200 |
201 | @app.cell
202 | def _(mo):
203 | CHOICES_PATH = str(mo.notebook_dir() / "choices.json")
204 | return (CHOICES_PATH,)
205 |
206 |
207 | @app.cell
208 | def _(json, os):
209 | # This template gets and saves labels to a local JSON file, but you
210 | # can readily change this to point to a database or anything else.
211 | def load_choices(path, number_of_examples):
212 | if not os.path.exists(path):
213 | return [{"index": i, "model": None} for i in range(number_of_examples)]
214 |
215 | with open(path, "r") as f:
216 | choices = json.loads(f.read())
217 | assert len(choices) == number_of_examples
218 | return choices
219 |
220 | def write_choices(choices, path):
221 | # Trunacate notes
222 | with open(path, "w") as f:
223 | f.write(json.dumps(choices))
224 |
225 | return load_choices, write_choices
226 |
227 |
228 | @app.cell
229 | def _(mo):
230 | def annotate(text, span, color):
231 | mark_start = f""
232 | return mo.md(
233 | text[: span[0]]
234 | + mark_start
235 | + text[span[0] : span[1]]
236 | + ""
237 | + text[span[1] :]
238 | )
239 |
240 | return (annotate,)
241 |
242 |
243 | @app.cell
244 | def _(EXAMPLES):
245 | NUMBER_OF_EXAMPLES = len(EXAMPLES)
246 | return (NUMBER_OF_EXAMPLES,)
247 |
248 |
249 | @app.cell
250 | def _():
251 | import marimo as mo
252 |
253 | return (mo,)
254 |
255 |
256 | @app.cell
257 | def _():
258 | import json
259 | import os
260 | import random
261 | import textwrap
262 | import urllib
263 |
264 | return json, os, random, textwrap, urllib
265 |
266 |
267 | if __name__ == "__main__":
268 | app.run()
269 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.pytest.ini_options]
2 | pythonpath = ["."]
3 |
--------------------------------------------------------------------------------
/tests/test_examples_without_error.py:
--------------------------------------------------------------------------------
1 | """Smoke tests that check notebooks don't have syntax errors."""
2 |
3 |
4 | def test_nlp_span_comparison() -> None:
5 | from nlp_span_comparison import nlp_span_comparison
6 |
7 | assert not nlp_span_comparison.app._unparsable
8 |
9 |
10 | def test_explore_high_dimensional_data() -> None:
11 | from explore_high_dimensional_data import explore_high_dimensional_data
12 |
13 | assert not explore_high_dimensional_data.app._unparsable
14 |
--------------------------------------------------------------------------------
/youtube_summary/README.md:
--------------------------------------------------------------------------------
1 | # Youtube Summary
2 |
3 | This notebook can be used as a template to summarise YouTube videos. It was originally
4 | used to fetch summaries for some [keyboard reviews](https://www.youtube.com/playlist?list=PLGj5nRqy15j93TD0iReqfLL9lU1lZFEs6) but the notebook itself can be adapted
5 | for many other use-cases too.
6 |
7 | 
8 |
9 | ## Running this notebook
10 |
11 | The only want to run this notebook is to run it locally. This demo uses Claude as
12 | an LLM backend which requires a `ANTHROPIC_API_KEY` set in a `.env` file. Finally,
13 | this notebook also assumes that `ffmpeg` is available on your system ([details](https://github.com/openai/whisper/blob/main/README.md#setup)).
14 |
15 | Once that's taken care of you can run this notebook in a sandbox. The requirements of each notebook are serialized in them as a top-level
16 | comment. Here are the steps to run the notebook:
17 |
18 | 1. [Install `uv`](https://github.com/astral-sh/uv/?tab=readme-ov-file#installation)
19 | 2. Open an example with `uvx marimo edit --sandbox `
20 |
21 | > [!TIP]
22 | > The [`--sandbox`
23 | > flag](https://docs.marimo.io/guides/package_reproducibility/) opens the
24 | > notebook in an isolated virtual environment, automatically installing the
25 | > notebook's dependencies 📦
26 |
27 | You can also open notebooks without `uv`, in which case you'll need to
28 | manually [install marimo](https://docs.marimo.io/getting_started/index.html#installation)
29 | first. Then run `marimo edit `; however, you'll also need to
30 | install the requirements yourself.
31 |
--------------------------------------------------------------------------------
/youtube_summary/youtube_summary.py:
--------------------------------------------------------------------------------
1 | # /// script
2 | # requires-python = ">=3.12"
3 | # dependencies = [
4 | # "anthropic==0.45.2",
5 | # "instructor==1.7.2",
6 | # "jinja2==3.1.5",
7 | # "marimo",
8 | # "matplotlib==3.10.0",
9 | # "mohtml==0.1.2",
10 | # "openai-whisper",
11 | # "opencv-python==4.11.0.86",
12 | # "pydantic==2.10.6",
13 | # "python-dotenv==1.0.1",
14 | # "wigglystuff==0.1.9",
15 | # "yt-dlp==2025.1.26",
16 | # ]
17 | # ///
18 |
19 | import marimo
20 |
21 | __generated_with = "0.10.19"
22 | app = marimo.App()
23 |
24 |
25 | @app.cell
26 | def _():
27 | import matplotlib.pylab as plt
28 | import cv2
29 | from yt_dlp import YoutubeDL
30 | from pathlib import Path
31 |
32 | def download_yt(yt_url: str):
33 | yt_id = yt_url[-11:]
34 | video_path = f"{yt_id}.m4a"
35 |
36 | ydl_opts = {
37 | "format": "m4a/bestaudio/best",
38 | "postprocessors": [
39 | {
40 | "key": "FFmpegExtractAudio",
41 | "preferredcodec": "m4a",
42 | }
43 | ],
44 | }
45 |
46 | if not Path(video_path).exists():
47 | URLS = [yt_url]
48 | with YoutubeDL(ydl_opts) as ydl:
49 | ydl.download(URLS)
50 | for vid in Path().glob("*.m4a"):
51 | if yt_id in str(vid):
52 | vid.rename(video_path)
53 | else:
54 | print("Video has been downloaded already")
55 |
56 | return Path, YoutubeDL, cv2, download_yt, plt
57 |
58 |
59 | @app.cell
60 | def _():
61 | import marimo as mo
62 |
63 | return (mo,)
64 |
65 |
66 | @app.cell
67 | def _(mo):
68 | text_input = mo.ui.text(label="YouTube URL")
69 |
70 | mo.md(f"""
71 | Fill in the YouTube URL or pass the video id here:
72 |
73 | {text_input}
74 |
75 | In our experience sofar it can help to make sure that you are downloading a video that is set to "public". Unlisted videos caused download errors in the past.
76 | """).batch(text_input=text_input).form()
77 | return (text_input,)
78 |
79 |
80 | @app.cell
81 | def _(download_yt, mo, text_input):
82 | with mo.status.spinner(subtitle="Downloading ...") as _spinner:
83 | if text_input.value:
84 | download_yt(text_input.value)
85 | return
86 |
87 |
88 | @app.cell
89 | def _(mo, text_input):
90 | import whisper
91 |
92 | with mo.status.spinner(subtitle="Running Whisper ...") as _spinner:
93 | model = whisper.load_model("base")
94 | result = model.transcribe(f"{text_input.value[-11:]}.m4a")
95 | return model, result, whisper
96 |
97 |
98 | @app.cell
99 | def _(YoutubeDL, text_input):
100 | with YoutubeDL() as ydl:
101 | info = ydl.extract_info(text_input.value, download=False)
102 | return info, ydl
103 |
104 |
105 | @app.cell
106 | def _():
107 | from typing import List
108 | import instructor
109 | from pydantic import BaseModel
110 |
111 | class YouTubeOutput(BaseModel):
112 | """
113 | Output of a YouTube video that reviews ergonomic keyboards.
114 |
115 | Make sure that you have a clear summary that highlights some of the findings. Refer to the reviewer as "me" and write as if it was written by the reviewer. But not in the present tense, it needs to be past tense. Avoid a formal style, write as if it was written on an informal tech-blog. Also make sure that you create a sequences of pros and cons of the keyboard. No more than 4 pros and 4 cons. Also add a oneliner tldr for the review, typically you can just copy what is in the title. The name of the keyboard should also include the brand if there is one.
116 | """
117 |
118 | summary: str
119 | pros: List[str]
120 | cons: List[str]
121 | tldr: str
122 | keyboard_name: str
123 |
124 | return BaseModel, List, YouTubeOutput, instructor
125 |
126 |
127 | @app.cell
128 | def _(instructor):
129 | from instructor import Instructor, Mode, patch
130 | from anthropic import Anthropic
131 | from dotenv import load_dotenv
132 | import os
133 |
134 | load_dotenv(".env")
135 |
136 | client = instructor.from_anthropic(
137 | Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"]),
138 | )
139 | return Anthropic, Instructor, Mode, client, load_dotenv, os, patch
140 |
141 |
142 | @app.cell
143 | def _(mo):
144 | mo.md(
145 | "Once the downloading/parsing/generating is done, you can see the results below together with a 'copy to clipboard' button."
146 | )
147 | return
148 |
149 |
150 | @app.cell
151 | def _(
152 | CopyToClipboard,
153 | YouTubeOutput,
154 | client,
155 | info,
156 | mo,
157 | result,
158 | text_input,
159 | ):
160 | from mohtml import pre, p, code, div
161 | from jinja2 import Template
162 |
163 | template = Template("""
164 | ---
165 | hide:
166 | - toc
167 | - navigation
168 | title: {{keyboard_name}}
169 | ---
170 |
171 | ## {{tldr}}
172 |
173 |
174 |
175 |
176 |
177 | {{summary}}
178 |
179 | ## Pros
180 | {% for pro in pros %}
181 | - {{ pro }}
182 | {% endfor %}
183 |
184 | ## Cons
185 | {% for con in cons %}
186 | - {{ con }}
187 | {% endfor %}
188 |
189 | """)
190 |
191 | with mo.status.spinner(subtitle="Running LLM ...") as _spinner:
192 | response = client.chat.completions.create(
193 | model="claude-3-5-sonnet-20241022",
194 | messages=[
195 | {
196 | "role": "user",
197 | "content": f"Create a proper summary of the following keyboard review. This is the title: {info['title']}. This is the text for the full review: {result['text']}",
198 | }
199 | ],
200 | max_tokens=1500,
201 | response_model=YouTubeOutput,
202 | )
203 | rendered = template.render(
204 | summary=response.summary,
205 | pros=response.pros,
206 | cons=response.cons,
207 | title=info["title"],
208 | thumbnail=info["thumbnail"],
209 | keyboard_name=response.keyboard_name,
210 | tldr=response.tldr,
211 | video_idx=f"{text_input.value[-11:]}",
212 | )
213 | clipboard_btn = CopyToClipboard(rendered)
214 |
215 | rendered
216 | return (
217 | Template,
218 | clipboard_btn,
219 | code,
220 | div,
221 | p,
222 | pre,
223 | rendered,
224 | response,
225 | template,
226 | )
227 |
228 |
229 | @app.cell
230 | def _():
231 | from wigglystuff import CopyToClipboard
232 |
233 | return (CopyToClipboard,)
234 |
235 |
236 | @app.cell
237 | def _(clipboard_btn):
238 | clipboard_btn
239 | return
240 |
241 |
242 | if __name__ == "__main__":
243 | app.run()
244 |
--------------------------------------------------------------------------------
 3 |
3 |  53 |
53 | 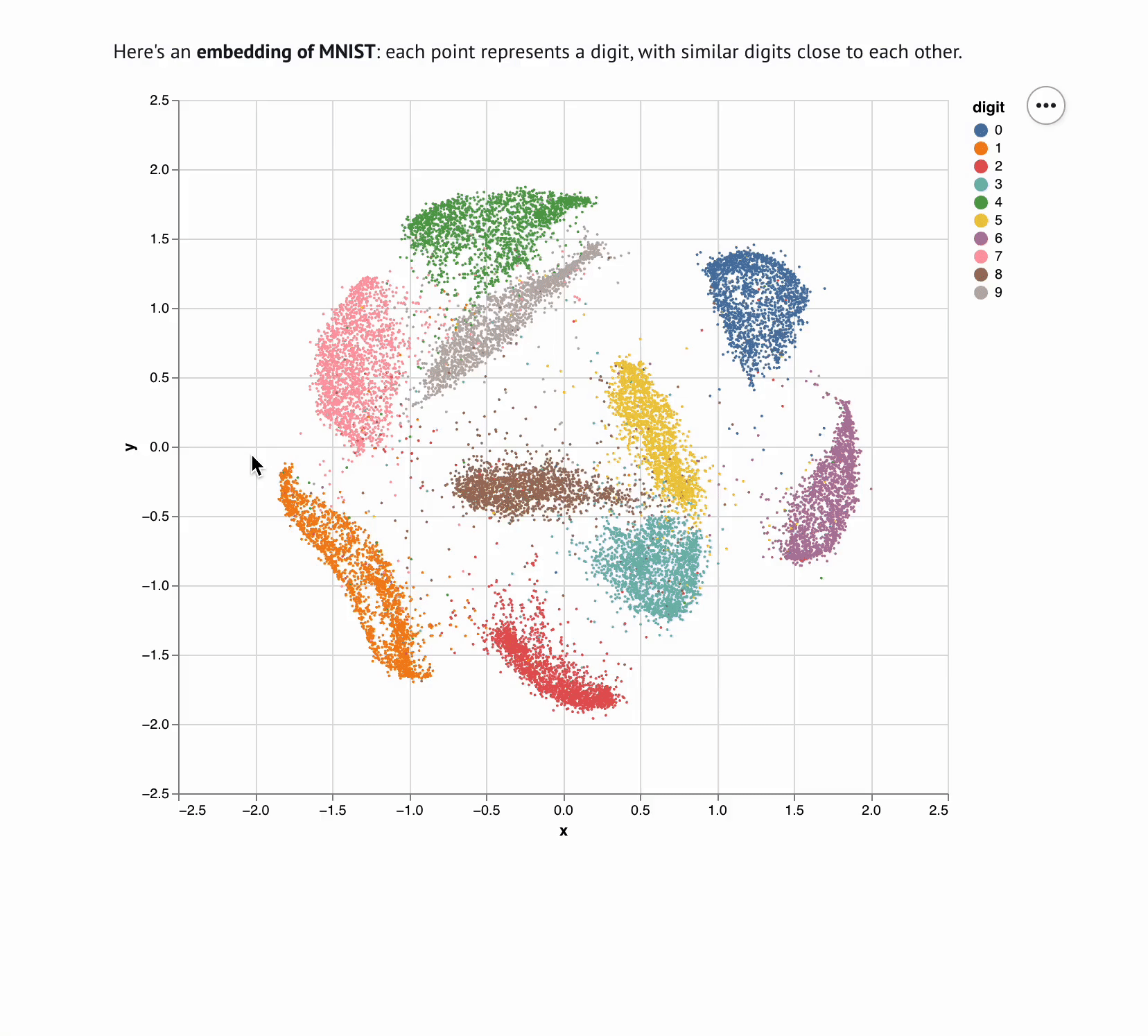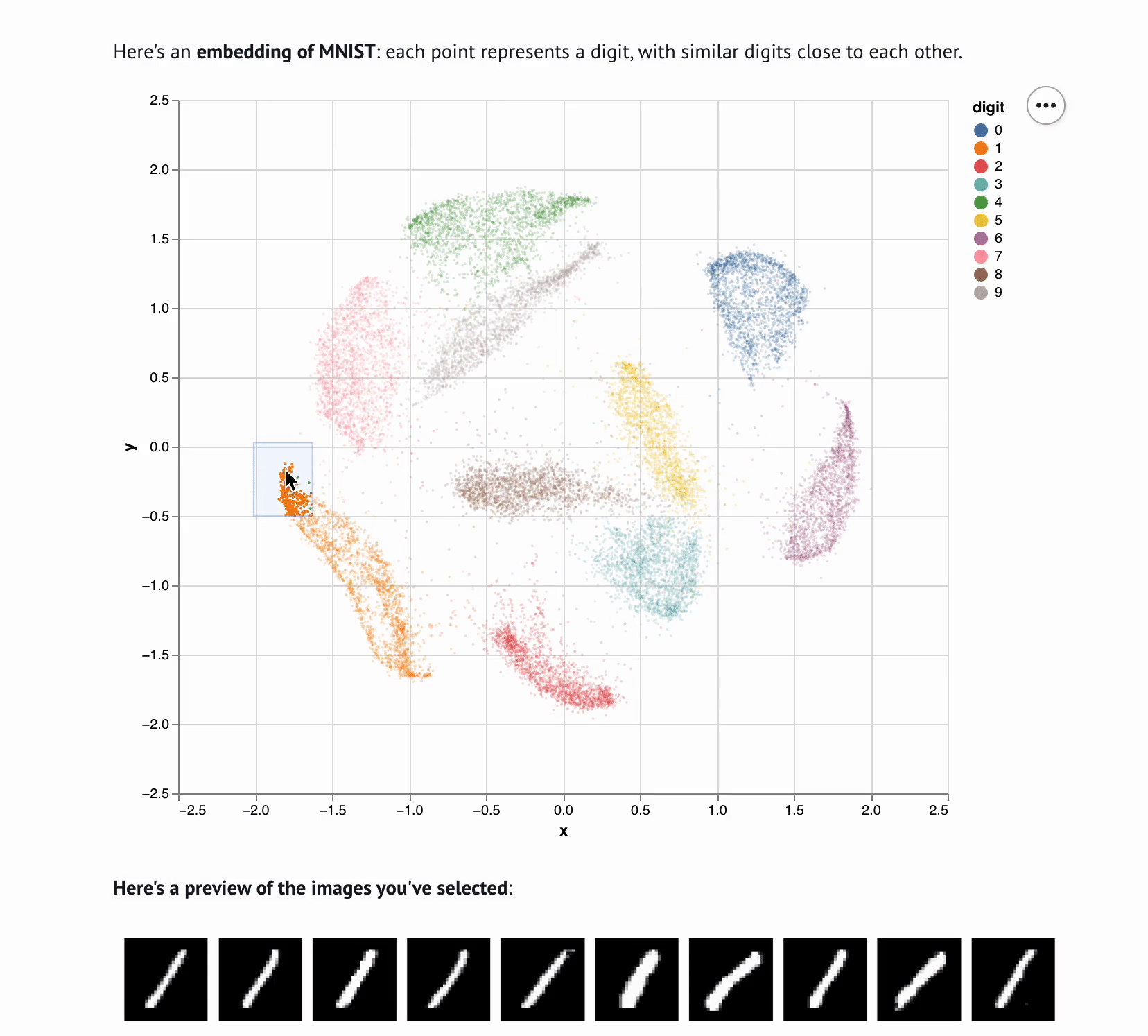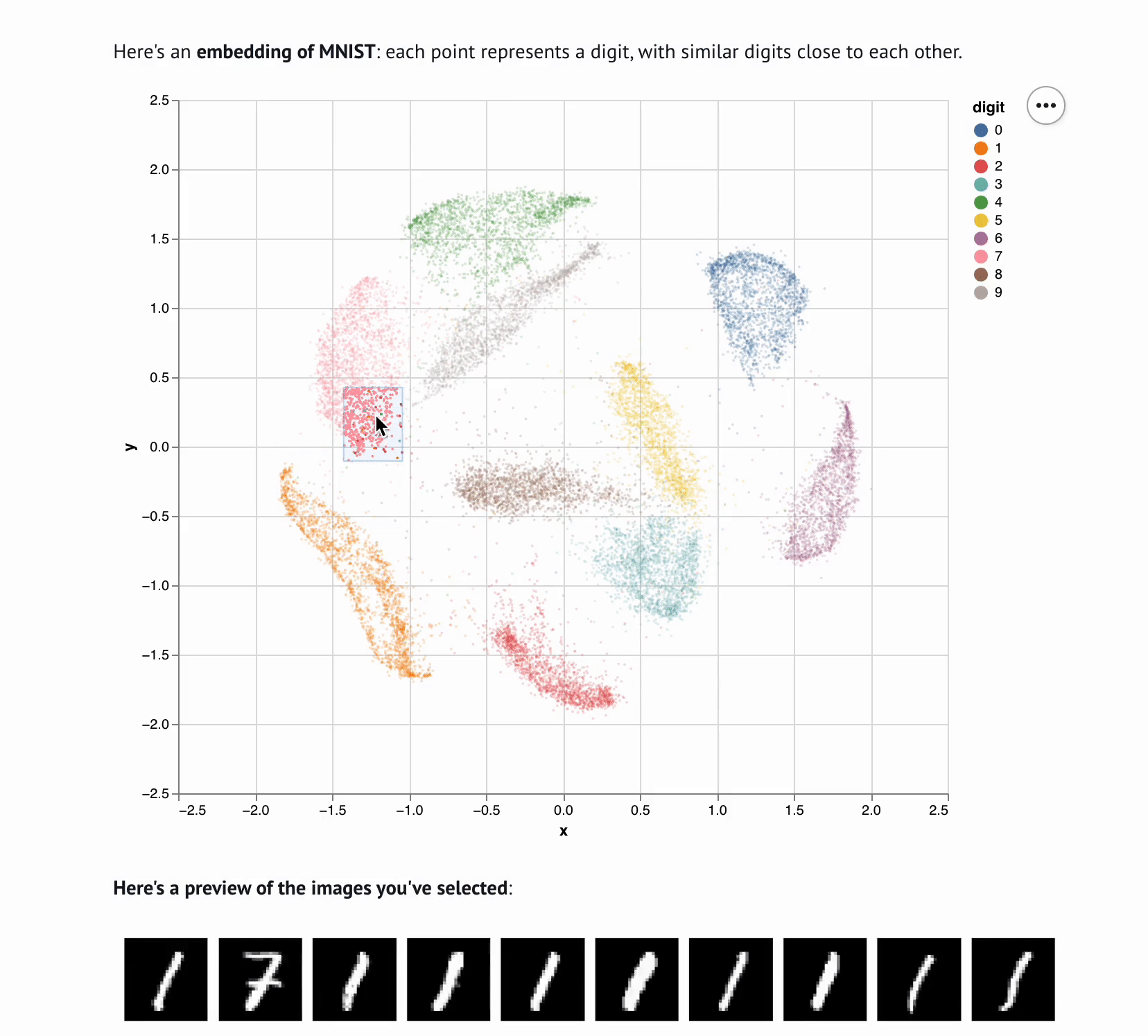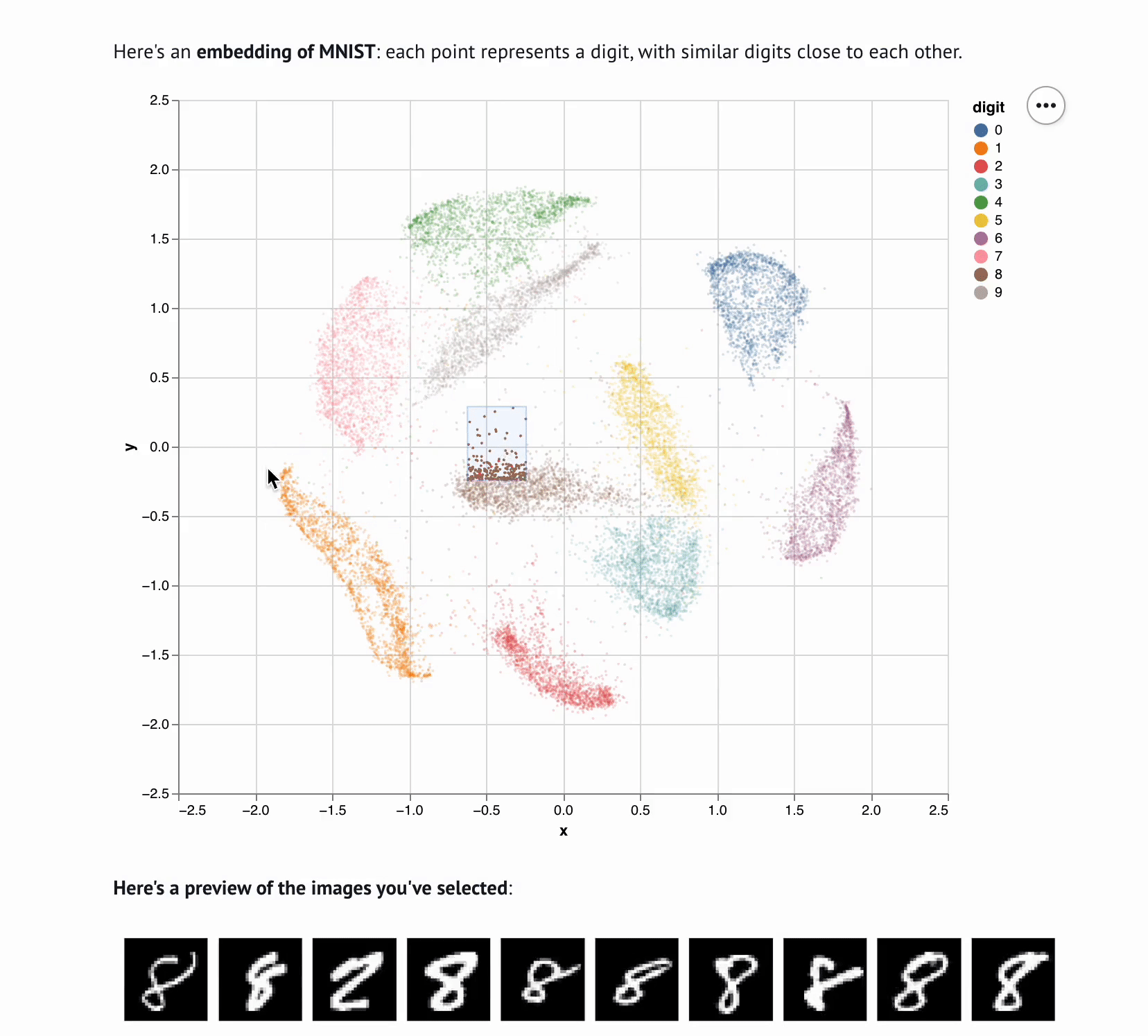 19 |
20 | ## Running this notebook
21 |
22 | Open this notebook in [our online
23 | playground](https://marimo.app/github.com/marimo-team/examples/blob/main/explore_high_dimensional_data/explore_high_dimensional_data.py)
24 | or run it locally.
25 |
26 | ### Running locally
27 |
28 | The requirements of each notebook are serialized in them as a top-level
29 | comment. Here are the steps to run the notebook:
30 |
31 | 1. [Install `uv`](https://github.com/astral-sh/uv/?tab=readme-ov-file#installation)
32 | 2. Open an example with `uvx marimo edit --sandbox
19 |
20 | ## Running this notebook
21 |
22 | Open this notebook in [our online
23 | playground](https://marimo.app/github.com/marimo-team/examples/blob/main/explore_high_dimensional_data/explore_high_dimensional_data.py)
24 | or run it locally.
25 |
26 | ### Running locally
27 |
28 | The requirements of each notebook are serialized in them as a top-level
29 | comment. Here are the steps to run the notebook:
30 |
31 | 1. [Install `uv`](https://github.com/astral-sh/uv/?tab=readme-ov-file#installation)
32 | 2. Open an example with `uvx marimo edit --sandbox 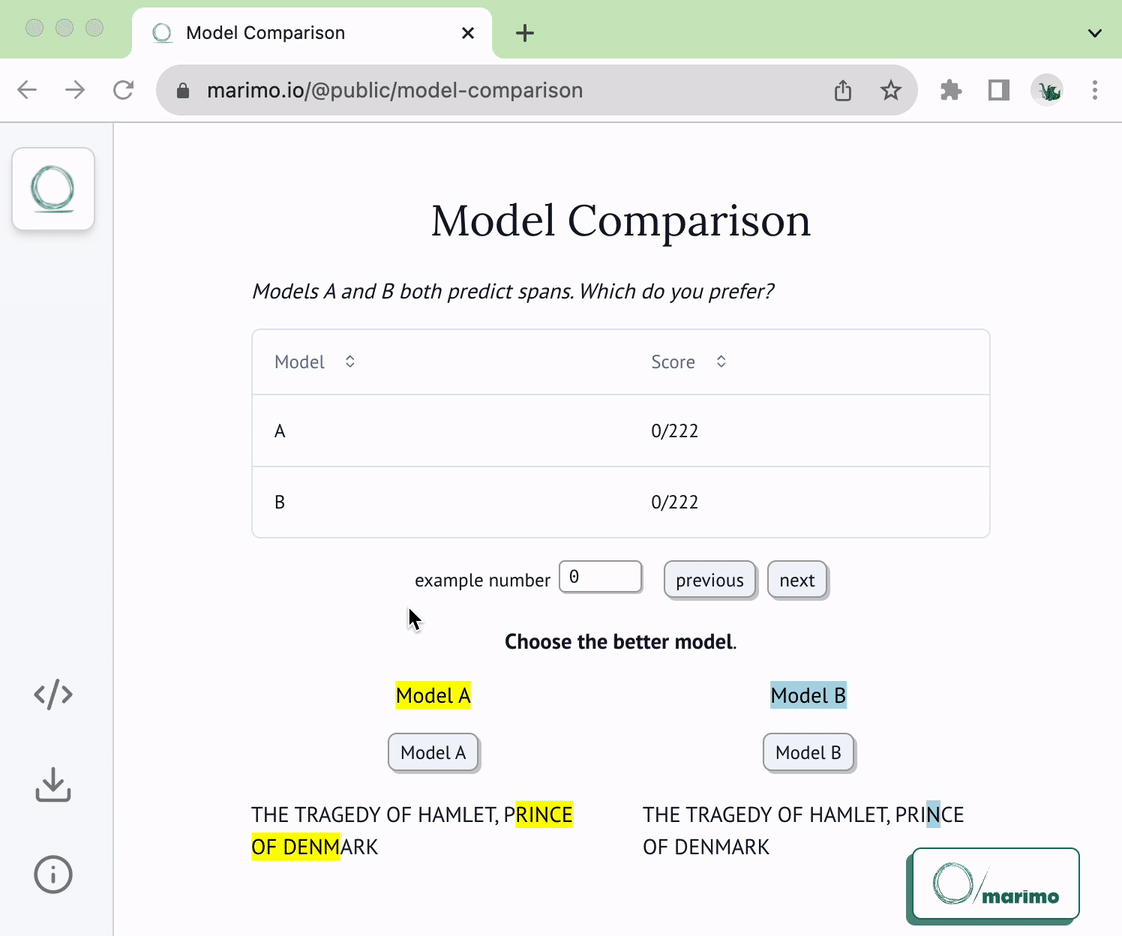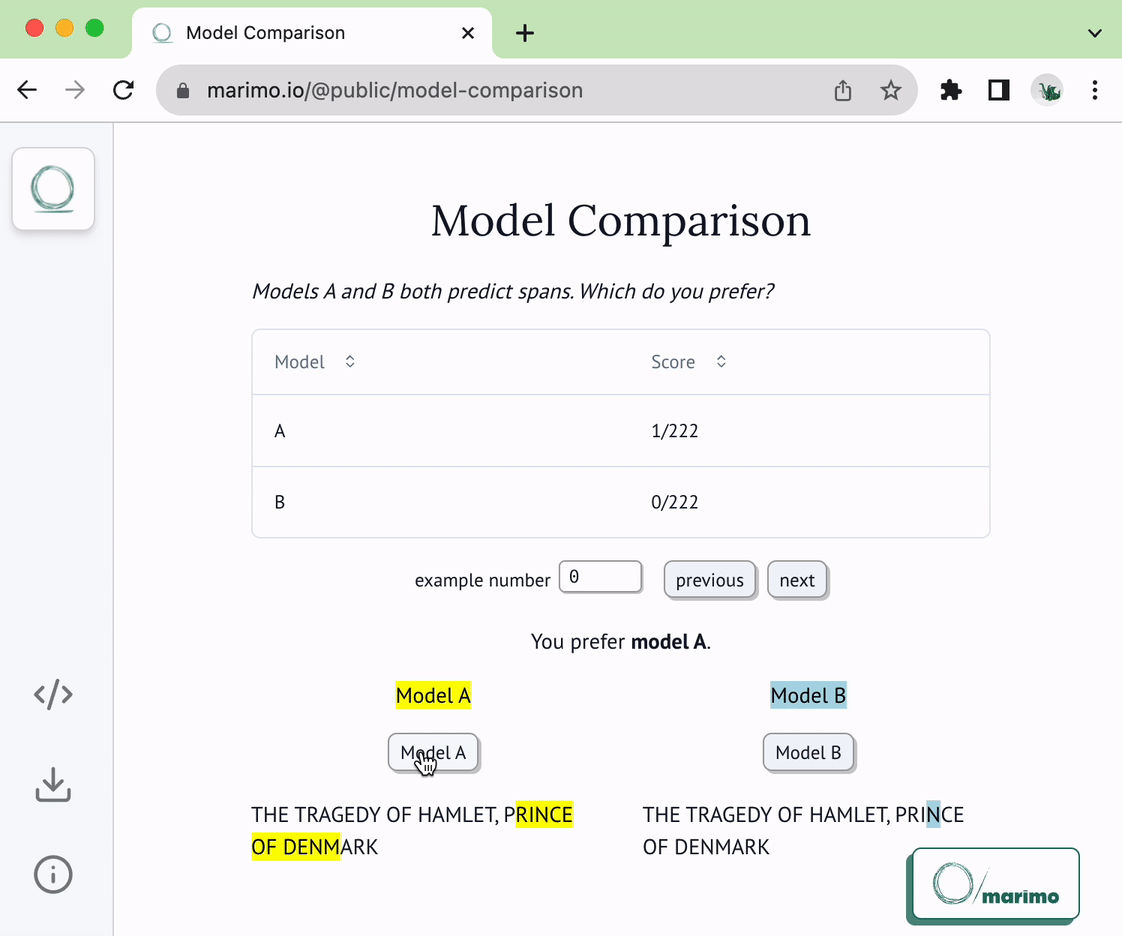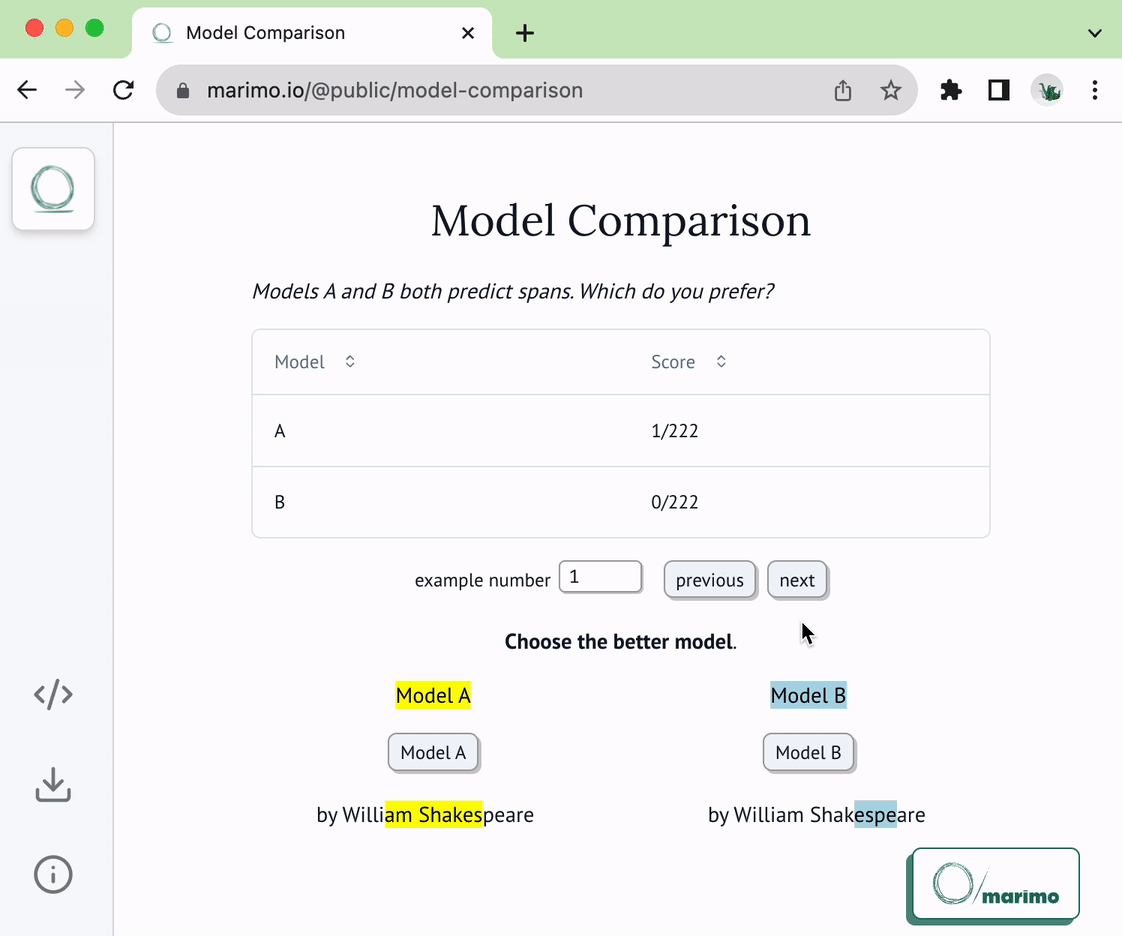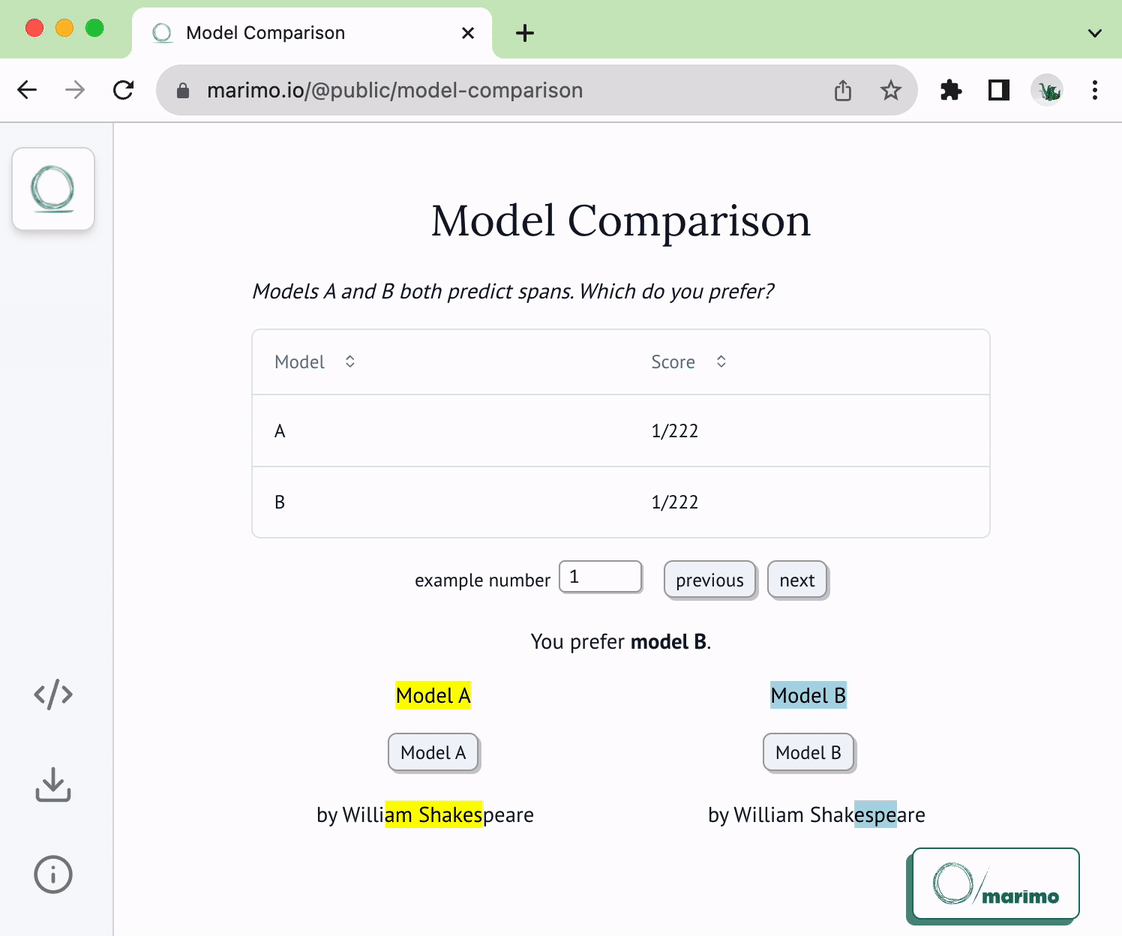 26 |
27 | ## Running this notebook
28 |
29 | Open this notebook in [our online
30 | playground](https://marimo.app/github.com/marimo-team/examples/blob/main/examples/nlp_span_comparison/nlp_span_comparison.py)
31 | or run it locally.
32 |
33 | ### Running locally
34 |
35 | The requirements of each notebook are serialized in them as a top-level
36 | comment. Here are the steps to run the notebook:
37 |
38 | 1. [Install `uv`](https://github.com/astral-sh/uv/?tab=readme-ov-file#installation)
39 | 2. Open an example with `uvx marimo edit --sandbox
26 |
27 | ## Running this notebook
28 |
29 | Open this notebook in [our online
30 | playground](https://marimo.app/github.com/marimo-team/examples/blob/main/examples/nlp_span_comparison/nlp_span_comparison.py)
31 | or run it locally.
32 |
33 | ### Running locally
34 |
35 | The requirements of each notebook are serialized in them as a top-level
36 | comment. Here are the steps to run the notebook:
37 |
38 | 1. [Install `uv`](https://github.com/astral-sh/uv/?tab=readme-ov-file#installation)
39 | 2. Open an example with `uvx marimo edit --sandbox