├── .gitignore
├── LICENSE
├── README.md
├── conf.sample.ini
├── requirements.txt
├── run.py
└── utils
├── __init__.py
├── feed2toot.py
├── feed_parser.py
├── get_config.py
├── media_downloader.py
├── toot_poster.py
└── tweet_decoder.py
/.gitignore:
--------------------------------------------------------------------------------
1 | temp
2 | ffmpeg.exe
3 | conf.ini
4 | db.txt
5 | __pycache__
6 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2020 Mashiro / tweet2toot contributors
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # tweet2toot
2 |
3 | A simple script that transport tweets from twitter to Mastodon. Based on the Twitter RSS feed powered by [RSSHub](https://rsshub.app).
4 |
5 | ```
6 | pip3 install -r requirements.txt
7 | cp conf.sample.ini conf.ini
8 | nano conf.ini
9 | python3 run.py
10 | ```
11 |
12 | Please install FFmpeg if you need support for twitter's GIFs.
13 |
14 | ```
15 | sudo apt install ffmpeg
16 | ```
17 |
18 | crontab job setting:
19 | ```
20 | crontab -e
21 | ```
22 | or (Ubuntu 18.04)
23 | ```
24 | nano /etc/crontab
25 | /etc/init.d/cron restart
26 | ```
27 |
28 | Recommand do job hourly:
29 | ```
30 | #m h dom mon dow user command
31 | 13 * * * * root cd /tweet2toot && python3 run.py
32 | ```
33 |
34 | 一个将推特搬运到长毛象的脚本——基于[RSSHub](https://rsshub.app)生成的推特RSS。
35 |
36 | 推特的开发者账号很长时间没有申请到,所以只能暂时用RSSHub作为数据源了。😢
--------------------------------------------------------------------------------
/conf.sample.ini:
--------------------------------------------------------------------------------
1 | [PROXY]
2 | ProxyOn = false
3 | HttpProxy = http://127.0.0.1:7890
4 | HttpsProxy = https://127.0.0.1:7890
5 |
6 | [MASTODON]
7 | BaseUrl = https://hello.2heng.xin/
8 | # register your application here: https://hello.2heng.xin/settings/applications
9 | AccessToken = your_app_token
10 | # add your custom filter here, only accept one regular expression, see: https://docs.python.org/3/library/re.html
11 | Filter = None
12 | # 'direct' - post will be visible only to mentioned users
13 | # 'private' - post will be visible only to followers
14 | # 'unlisted' - post will be public but not appear on the public timeline
15 | # 'public' - post will be public
16 | TootVisibility = unlisted
17 | ShowSource = true
18 | # Icon/prefix shows before tweet's source link
19 | TweetSourcePrefix = :sys_twitter:
20 | # Also transport video?
21 | IncludeVideo = true
22 | # Below is necessary even you've filled in 'false' above
23 | VideoSourcePrefix = :sys_video:
24 |
25 | [TWITTER]
26 | TwitterRss = https://rss.zeka.cloud/twitter/user/ruanyf
27 | BackupRss = https://rsshub.app/twitter/user/ruanyf
28 | # you can also use a Nginx like reverse proxy
29 | ImageProxy = https://pbs.twimg.com/
30 | VideoProxy = https://video.twimg.com/
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | beautifulsoup4==4.9.1
2 | Pillow==9.0.1
3 | ffmpy==0.2.3
4 | feedparser==5.2.1
5 | Mastodon.py==1.5.1
6 | filetype==1.0.7
--------------------------------------------------------------------------------
/run.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python3
2 | # -*- coding: utf-8 -*-
3 | """
4 | Created on May 29, 2020
5 | Desc: Twitter feed to toot (based on RSSHub's feed)
6 | Author: Mashiro
7 | URL: https://2heng.xin
8 | License: MIT
9 | """
10 | from utils.feed_parser import FeedParaser
11 | from utils.feed2toot import Feed2Toot
12 | from utils.get_config import GetConfig
13 | import os
14 |
15 | config = GetConfig()
16 |
17 | if __name__ == '__main__':
18 | if config['PROXY']['ProxyOn'] == 'true':
19 | os.environ['HTTP_PROXY'] = config['PROXY']['HttpProxy']
20 | os.environ['HTTPS_PROXY'] = config['PROXY']['HttpsProxy']
21 | rss_url = config['TWITTER']['TwitterRss']
22 | try:
23 | RSS_dict = FeedParaser(rss_url)
24 | except Exception:
25 | backup_rss = config['TWITTER'].get('BackupRss', None)
26 | print('WARN: source {} seems unavailable, switch to {}'.format(rss_url, backup_rss))
27 | if backup_rss:
28 | RSS_dict = FeedParaser(backup_rss)
29 | else:
30 | print('ERROR: no backup source found, exit')
31 | exit(-1)
32 | Feed2Toot(RSS_dict)
33 |
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
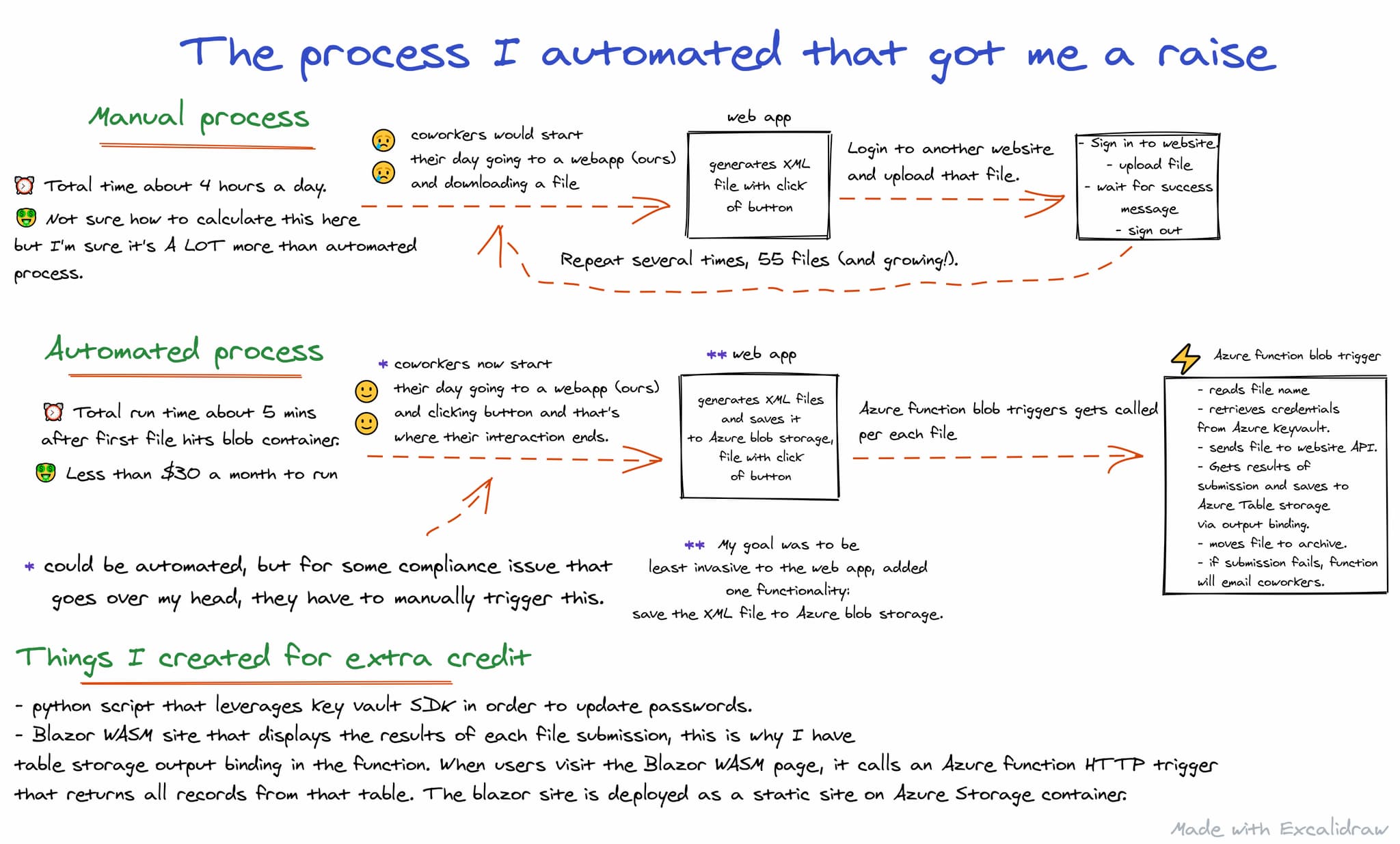
https://raw.githubusercontent.com/mashirozx/tweet2toot/636e7133f611deac5a259b5949ae33f20391e03a/utils/__init__.py
--------------------------------------------------------------------------------
/utils/feed2toot.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python3
2 | # -*- coding: utf-8 -*-
3 | """
4 | Created on May 29, 2020
5 | Desc: feed to toot
6 | Author: Mashiro
7 | URL: https://2heng.xin
8 | License: MIT
9 | """
10 | from os import path, makedirs
11 | import re
12 | import shutil
13 | from .tweet_decoder import TweetDecoder
14 | from .media_downloader import MediaDownloader
15 | from .toot_poster import TootPoster
16 | from .get_config import GetConfig
17 |
18 | config = GetConfig()
19 |
20 |
21 | def TwitterFilter(feed_data):
22 | if config['TWITTER'] is None:
23 | return feed_data
24 | try:
25 | twitter_filter = config['TWITTER']['Filter']
26 | except KeyError:
27 | twitter_filter = None
28 | if (twitter_filter is None) or (twitter_filter == 'False') or (twitter_filter == 'None'):
29 | return feed_data
30 | pat = re.compile(twitter_filter)
31 | result = []
32 | for feed in feed_data:
33 | if pat.match(feed['summary']):
34 | result.append(feed)
35 | return result
36 |
37 |
38 | def Feed2Toot(feed_data):
39 | feed_data = TwitterFilter(feed_data)
40 | if path.exists('db.txt'):
41 | historyList = [line.rstrip('\n') for line in open('db.txt')]
42 | else:
43 | historyList = []
44 |
45 | for tweet in reversed(feed_data):
46 | if not path.exists('temp'):
47 | makedirs('temp')
48 |
49 | if tweet['id'] not in historyList:
50 | print('INFO: decode ' + tweet['id'])
51 | tweet_decoded = TweetDecoder(tweet)
52 | print('INFO: download ' + tweet['id'])
53 | try:
54 | toot_content = MediaDownloader(tweet_decoded)
55 | print('INFO: download succeed ' + tweet['id'])
56 | except Exception:
57 | print('ERRO: download failed ' + tweet['id'])
58 | print('INFO: post toot ' + tweet['id'])
59 | try:
60 | TootPoster(toot_content)
61 | print('INFO: post succeed ' + tweet['id'])
62 | except Exception:
63 | print('ERRO: post failed ' + tweet['id'])
64 | historyList.append(tweet['id'])
65 |
66 | if path.exists('temp'):
67 | shutil.rmtree('temp')
68 |
69 | print('INFO: save to db ' + tweet['id'])
70 | with open('db.txt', 'w+') as db:
71 | for row in historyList:
72 | db.write(str(row) + '\n')
73 |
74 | if __name__ == '__main__':
75 | test_feed = [{
76 | 'title': "content",
77 | 'summary': 'content
',
78 | 'id': 'https://twitter.com/zlj517/status/1266540485973180416',
79 | 'link': 'https://twitter.com/zlj517/status/1266540485973180416',
80 | }]
81 | Feed2Toot(test_feed)
--------------------------------------------------------------------------------
/utils/feed_parser.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python3
2 | # -*- coding: utf-8 -*-
3 | """
4 | Created on May 29, 2020
5 | Desc: RSS feed parser
6 | Author: Mashiro
7 | URL: https://2heng.xin
8 | License: MIT
9 | """
10 | import feedparser
11 |
12 | def FeedParaser(rss_link):
13 | """
14 | :param str: RSS URL
15 | :return object: rss object
16 | """
17 | RssHubFeed = feedparser.parse(rss_link)
18 |
19 | rss = []
20 |
21 | for item in RssHubFeed.entries:
22 | data={}
23 | # for detail in item.keys():
24 | # data[detail]=item[detail]
25 | data['title']=item['title']
26 | data['summary']=item['summary']
27 | data['id']=item['id']
28 | data['link']=item['link']
29 | rss.append(data)
30 |
31 | # print(rss)
32 | return rss
33 |
34 | if __name__ == '__main__':
35 | print(str(FeedParaser("https://rsshub.app/twitter/user/jk_rowling")))
--------------------------------------------------------------------------------
/utils/get_config.py:
--------------------------------------------------------------------------------
1 | import configparser
2 |
3 | config = configparser.ConfigParser()
4 | config.read('conf.ini')
5 |
6 | def GetConfig():
7 | for i in config:
8 | for t in i:
9 | t = str(t)
10 | return config
--------------------------------------------------------------------------------
/utils/media_downloader.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python3
2 | # -*- coding: utf-8 -*-
3 | """
4 | Created on May 29, 2020
5 | Desc: Media file downloader
6 | Author: Mashiro
7 | URL: https://2heng.xin
8 | License: MIT
9 | """
10 | import urllib.request
11 | import ffmpy
12 | from .get_config import GetConfig
13 |
14 | config = GetConfig()
15 |
16 | def MediaDownloader(data):
17 | """
18 | :param object: Data return from TweetDecoder
19 | :return {'gif_count': (max+1)gif_id, 'video_count': video_id, 'image_count': img_id, 'plain': str}
20 | """
21 | # set header
22 | opener = urllib.request.build_opener()
23 | opener.addheaders = opener.addheaders = [
24 | ('User-agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36')]
25 | urllib.request.install_opener(opener)
26 |
27 | res = {'gif_count': None, 'video_count': None, 'image_count': None, 'plain': None, 'video_link': None}
28 |
29 | if data['image']:
30 | img_id = 1
31 | for url in data['image']:
32 | if (img_id <= 4):
33 | try:
34 | urllib.request.urlretrieve(url.replace('https://pbs.twimg.com/',config['TWITTER']['ImageProxy']), 'temp/img'+str(img_id)+'.png')
35 | img_id = img_id+1
36 | except Exception:
37 | print(f'ERRO: failed[img]: {url}')
38 | # for e in Exception:
39 | # print(e)
40 |
41 | res['image_count']=img_id
42 |
43 | if data['gif']:
44 | gif_id = 1
45 | for url in data['gif']:
46 | if (gif_id <= 4):
47 | try:
48 | urllib.request.urlretrieve(url.replace('https://video.twimg.com/',config['TWITTER']['VideoProxy']), 'temp/gif'+str(gif_id)+'.mp4')
49 | ff = ffmpy.FFmpeg(
50 | inputs={'temp/gif'+str(gif_id)+'.mp4': None},
51 | outputs={'temp/gif'+str(gif_id)+'.gif': ['-vf', 'fps=10,scale=\'min(600,iw)\':-1:flags=lanczos', '-y']}
52 | )
53 | ff.run()
54 | gif_id = gif_id+1
55 | except Exception:
56 | print(f'ERRO: failed[gif]: {url}')
57 | try:
58 | urllib.request.urlretrieve(data['gif_poster'][gif_id-1].replace('https://pbs.twimg.com/',config['TWITTER']['ImageProxy']), 'temp/gif'+str(gif_id)+'.gif')
59 | gif_id = gif_id+1
60 | except Exception:
61 | print(f'ERRO: failed[gif]: {url}')
62 | # for e in Exception:
63 | # print(e)
64 |
65 | res['gif_count']=gif_id
66 |
67 | if data['video']:
68 | video_id = 1
69 | for url in data['video']:
70 | if (video_id <= 1):
71 | try:
72 | if config['MASTODON']['IncludeVideo'] != 'false':
73 | urllib.request.urlretrieve(url.replace('https://video.twimg.com/',config['TWITTER']['VideoProxy']), 'temp/video'+str(video_id)+'.mp4')
74 |
75 | urllib.request.urlretrieve(data['video_poster'][video_id-1].replace('https://pbs.twimg.com/',config['TWITTER']['ImageProxy']), 'temp/video'+str(video_id)+'.png')
76 | res['video_link']=url
77 | video_id = video_id+1
78 | except Exception:
79 | print(f'ERRO: failed[vid]: {url}')
80 | # for e in Exception:
81 | # print(e)
82 |
83 | res['video_count']=video_id
84 |
85 | res['plain']=data['plain']
86 |
87 | return res
88 |
89 | if __name__ == '__main__':
90 | test_data = {'gif': ['https://video.twimg.com/tweet_video/EZLxKmTUMAARbSa.mp4'], 'gif_poster': ['https://pbs.twimg.com/tweet_video_thumb/EZLxKmTUMAARbSa.jpg'], 'video': ['https://video.twimg.com/ext_tw_video/1265470079203827712/pu/vid/1280x720/B-BRCBM0djUAqJl0.mp4?tag=10'], 'video_poster': ['https://pbs.twimg.com/ext_tw_video_thumb/1265470079203827712/pu/img/VujsmqbQORfHDeCP.jpg'], 'image': ['https://pbs.twimg.com/media/EZJh5RPUMAEz4aS?format=jpg&name=orig','https://s3-view.2heng.xin/aws_cached/2019/07/14/53c2adbc381e3aa17968d5d36feee002.md.png', 'https://s3-view.2heng.xin/aws_cached/2020/05/19/b1a7d8ff391616ad152f9958c6302ba0.md.jpg', 'https://s3-view.2heng.xin/aws_cached/2020/05/18/671a82563dfe40885196166683bf6f0b.md.jpg'], 'plain': '流程图工具 Excalidraw 可以做出下面这样的图示效果,可惜中文没有手写效果。 https://excalidraw.com/ '}
91 | MediaDownloader(test_data)
--------------------------------------------------------------------------------
/utils/toot_poster.py:
--------------------------------------------------------------------------------
1 | from mastodon import Mastodon
2 | import filetype
3 | from .get_config import GetConfig
4 |
5 | config = GetConfig()
6 |
7 | mastodon = Mastodon(
8 | access_token = config['MASTODON']['AccessToken'],
9 | api_base_url = config['MASTODON']['BaseUrl']
10 | )
11 |
12 | def media_post(file):
13 | kind = filetype.guess(file)
14 | # print('File extension: %s' % kind.extension)
15 | # print('File MIME type: %s' % kind.mime)
16 | return mastodon.media_post(file, kind.mime)
17 |
18 | def TootPoster(data):
19 | """
20 | :data object: Return from media_downloader
21 | :return void
22 | """
23 | media_ids_arr = []
24 |
25 | if data['video_count'] is not None:
26 | id=1
27 | if config['MASTODON']['IncludeVideo'] == 'false':
28 | media_ids_arr.append(media_post('temp/video%d.png' % id))
29 | data['plain'] = data['plain'] + '\n'+config['MASTODON']['VideoSourcePrefix']+' ' + data['video_link']
30 | else:
31 | try:
32 | media_ids_arr.append(media_post('temp/video%d.mp4' % id))
33 | except Exception:
34 | media_ids_arr.append(media_post('temp/video%d.png' % id))
35 | data['plain'] = data['plain'] + '\n'+config['MASTODON']['VideoSourcePrefix']+' ' + data['video_link']
36 |
37 | else:
38 | if data['image_count'] is not None:
39 | for id in range(1, data['image_count']):
40 | media_ids_arr.append(media_post('temp/img%d.png' % id))
41 |
42 | if data['gif_count'] is not None:
43 | for id in range(1, data['gif_count']):
44 | media_ids_arr.append(media_post('temp/gif%d.gif' % id))
45 |
46 | while len(media_ids_arr) > 4:
47 | media_ids_arr.pop()
48 |
49 | mastodon.status_post(status=data['plain'], media_ids=media_ids_arr, visibility=config['MASTODON']['TootVisibility'])
50 |
51 | if __name__ == '__main__':
52 | test_data = {'gif_count': 1, 'video_count': None, 'image_count': 3, 'plain': 'Tooting from python using `status_post` #mastodonpy !'}
53 | TootPoster(test_data)
--------------------------------------------------------------------------------
/utils/tweet_decoder.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python3
2 | # -*- coding: utf-8 -*-
3 | """
4 | Created on May 29, 2020
5 | Desc: Twitter HTML parser
6 | Author: Mashiro
7 | URL: https://2heng.xin
8 | License: MIT
9 | """
10 | from bs4 import BeautifulSoup
11 | from html import unescape
12 | from .get_config import GetConfig
13 |
14 | config = GetConfig()
15 |
16 | def TweetDecoder(rss_data):
17 | """
18 | :params object: Summary from FeedParaser
19 | :return object
20 | """
21 | soup = BeautifulSoup(rss_data['summary'], features='html.parser')
22 |
23 | data = {
24 | 'gif': [],
25 | 'gif_poster': [],
26 | 'video': [],
27 | 'video_poster': [],
28 | 'image': [],
29 | 'plain': None
30 | }
31 |
32 | for link in soup.find_all('a'):
33 | link.replace_with(' ' + link.get('href') + ' ')
34 |
35 | for video in soup.find_all('video'):
36 | # print(video.get('src'))
37 | if ('https://video.twimg.com/tweet_video' in video.get('src')):
38 | data['gif'].append(video.get('src'))
39 | data['gif_poster'].append(video.get('poster'))
40 | video.replace_with('')
41 | if ('https://video.twimg.com/ext_tw_video' in video.get('src')):
42 | data['video'].append(video.get('src'))
43 | data['video_poster'].append(video.get('poster'))
44 | video.replace_with('')
45 | if ('https://video.twimg.com/amplify_video' in video.get('src')):
46 | data['video'].append(video.get('src'))
47 | data['video_poster'].append(video.get('poster'))
48 | video.replace_with('')
49 |
50 | for image in soup.find_all('img'):
51 | # print(video.get('src'))
52 | data['image'].append(image.get('src'))
53 | image.replace_with('')
54 |
55 | for br in soup.find_all('br'):
56 | br.replace_with('\n')
57 |
58 | # print(soup.prettify())
59 | # print(str(data))
60 | if config['MASTODON']['ShowSource'] == 'true':
61 | data['plain'] = unescape(soup.prettify()) + '\n'+config['MASTODON']['TweetSourcePrefix']+' ' + rss_data['link']
62 | else:
63 | data['plain'] = unescape(soup.prettify())
64 | return data
65 |
66 | if __name__ == '__main__':
67 | test_normal = """
68 | 流程图工具 Excalidraw 可以做出下面这样的图示效果,可惜中文没有手写效果。https://excalidraw.com/https://2heng.xin/


 69 | """
70 |
71 | test_gif = """
72 | 【Vitafield Rewilder Series - Wilted Cypress - Firewatch】
69 | """
70 |
71 | test_gif = """
72 | 【Vitafield Rewilder Series - Wilted Cypress - Firewatch】
Now available at the Store until June 10, 03:59(UTC-7)!
#Arknights #Yostar
73 | """
74 |
75 | test_video = """
76 | Arknights Official Trailer – Code of Brawl
"Doctor, relying on me isn't a very wise decision"
HD version:
#Arknights #Yostar http://youtu.be/SJ1qvqEmkVQ
77 | """
78 | print(TweetDecoder(test_video))
--------------------------------------------------------------------------------