37 |
38 |
68 |
69 |
70 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
Abstract
89 |
90 |
91 |
92 | Deep generative models can synthesize photorealistic images of human faces with novel identities.
93 | However, a key challenge to the wide applicability of such techniques is to provide independent control over semantically meaningful parameters: appearance, head pose, face shape, and facial expressions.
94 | In this paper, we propose VariTex - to the best of our knowledge the first method that learns a variational latent feature space of neural face textures, which allows sampling of novel identities.
95 | We combine this generative model with a parametric face model and gain explicit control over head pose and facial expressions.
96 | To generate complete images of human heads, we propose an additive decoder that adds plausible details such as hair.
97 | A novel training scheme enforces a pose-independent latent space and in consequence, allows learning a one-to-many mapping between latent codes and pose-conditioned exterior regions.
98 | The resulting method can generate geometrically consistent images of novel identities under fine-grained control over head pose, face shape, and facial expressions. This facilitates a broad range of downstream tasks, like sampling novel identities, changing the head pose, expression transfer, and more.
99 |
100 |
101 |
102 |
103 |
104 |
105 |
Video
106 |
107 | VIDEO
108 |
109 |
110 |
111 |
112 |
113 |
VariTex Controls
114 |
115 |
116 |
117 |
118 |
119 |
Expressions
120 |
121 |
122 |
123 |
124 |
128 |
Pose
129 |
130 |
131 |
132 |
133 |
137 |
Identity
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
Method
146 |
147 |
148 | The objective of our pipeline is to learn a Generator that can synthesize face images with arbitrary novel
149 | identities whose pose and expressions can be controlled using face model parameters.
150 | During training, we use unlabeled monocular RGB images to learn a smooth latent space
151 | of natural face appearance using a variational encoder.
152 | A latent code sampled from this space is then decoded to a novel face image.
153 | At test time, we use samples drawn from a normal distribution to generate novel face images.
154 | Our variationally generated neural textures can also be stylistically interpolated to generate
155 | intermediate identities.
156 |
157 |
158 |
159 |
160 |
161 |
162 |
Code and Models
163 | Available on
GitHub . Make sure to check out our
demo notebook .
164 |
165 |
166 |
167 |
168 |
Citation
169 |
170 | @inproceedings{buehler2021varitex,
171 | title={VariTex: Variational Neural Face Textures},
172 | author={Marcel C. Buehler and Abhimitra Meka and Gengyan Li and Thabo Beeler and Otmar Hilliges},
173 | booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
174 | year={2021}
175 | }
176 |
BibTeX
177 |
178 |
179 |
180 |
181 |
199 |
 83 |
83 | 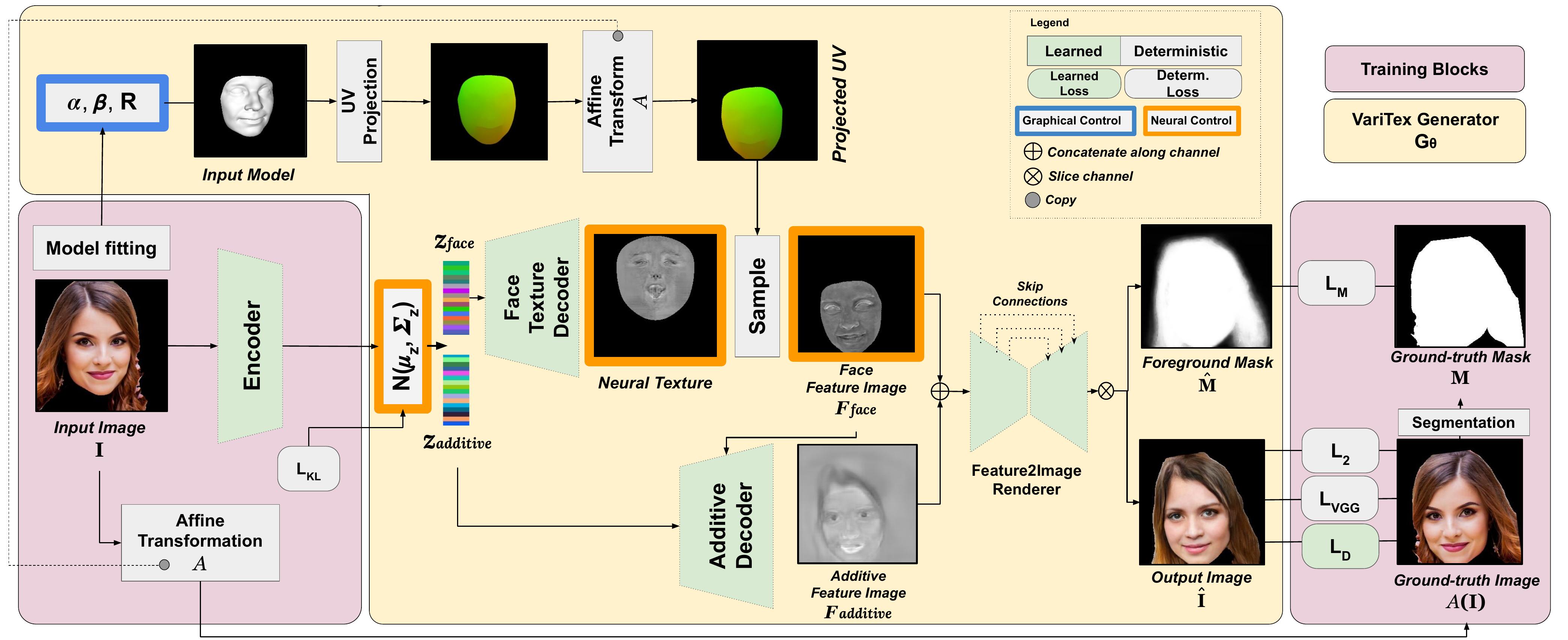 147 |
147 |