├── 01-kaggle-dataset-download.html
├── 02-extract-transform-load.html
├── 03-data-visualization.html
├── 04-train-model-pipelines.html
├── 05-model-serving.html
├── Architecture-flow.png
├── README.md
└── workflow.html
/Architecture-flow.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mdrakiburrahman/azure-databricks-malware-prediction/b82994c5b74ef93b959b7423be575e90a7dd24ee/Architecture-flow.png
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # azure-databricks-malware-prediction
2 | End-to-end Machine Learning Pipeline demo using Delta Lake, MLflow and AzureML in Azure Databricks
3 |
4 | # The Problem
5 | The problem I set out to solve is this public [Kaggle competition](https://www.kaggle.com/c/microsoft-malware-prediction) hosted my Microsoft earlier this year. Essentially, Microsoft has provided datasets containing Windows telemetry data for a variety of machines; in order words - a dump of various windows features (Os Build, Patch version etc.) for machines like our laptops. The idea is to use the test.csv and train.csv dataset to develop a Machine Learning model that would predict a Windows machine's probability of getting infected with various families of malware.
6 |
7 | ## Architecture
8 | 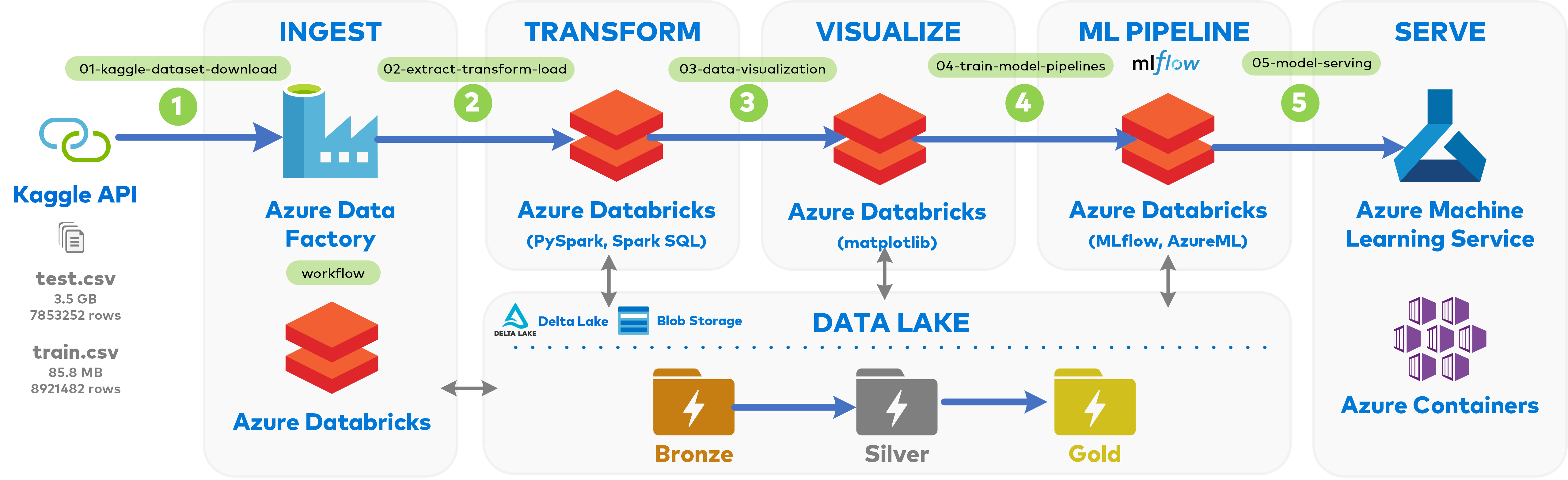.
9 |
10 | # 01-kaggle-dataset-download: Connecting to Kaggle via API and copying competition files to Azure Blob Storage
11 |
12 | The Kaggle API allows us to connect to various competitions and datasets hosted on the platform: [API documentation](https://github.com/Kaggle/kaggle-api).
13 |
14 | **Pre-requisite**: You should have downloaded the _kaggle.json_ containing the API *username* and *key* and localized the notebook below.
15 | In this notebook, we will -
16 | 1. Mount a container called `bronze` in Azure Blob Storage
17 | 2. Import the competition data set in .zip format from Kaggle to the mounted container
18 | 3. Unzip the downloaded data set and remove the zip file
19 |
20 | # 02-extract-transform-load: EXTRACT, TRANSFORM, LOAD from BRONZE to SILVER Zone
21 |
22 | Here is the Data Lake Architecture we are emulating:
23 |
24 | 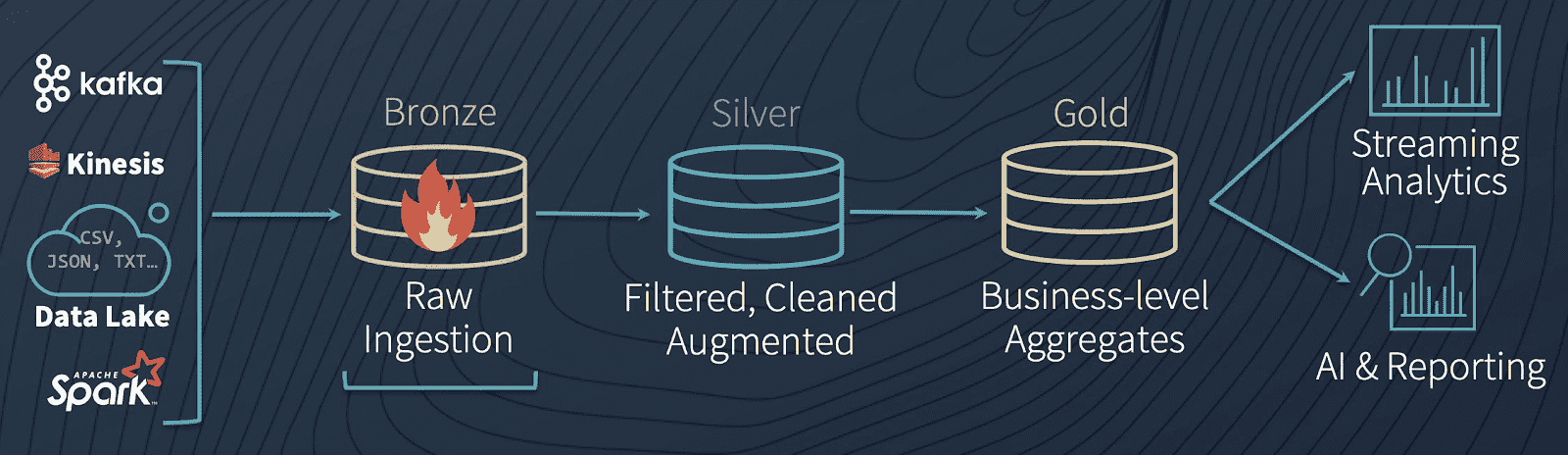.
25 |
26 | **Pre-requisite**: You should have run `01-kaggle-dataset-download` to download the Kaggle dataset to BRONZE Zone.
27 | In this notebook, we will -
28 | 1. **EXTRACT** the downloaded Kaggle `train.csv` dataset from BRONZE Zone into a dataframe
29 | 2. Perform various **TRANSFORMATIONS** on the dataframe to enhance/clean the data
30 | 3. **LOAD** the data into SILVER Zone in Delta Lake format
31 | 4. Repeat the above three steps for `test.csv`
32 | 5. Take the Curated `test.csv` data and enhance it further for ML scoring later on.
33 |
34 | # 03-data-visualization: Data Visualization
35 |
36 | I'm leveraging a lot of the visualization/data exploration done by the brilliant folks over at [Kaggle](https://www.kaggle.com/c/microsoft-malware-prediction/notebooks) that have already spent a lot of time exploring this Dataset.
37 |
38 | **Pre-requisite**: You should have run `02-extract-transform-load` and have the curated data ready to go in SILVER Zone.
39 | In this notebook, we will -
40 | 1. Import the `malware_train_delta` training dataset from SILVER Zone into a dataframe
41 | 2. Explore live visualization capabilities built into Databricks GUI
42 | 3. Explore the top 10 features most correlated with the `HasDetections` column - the column of interest
43 | 4. Generate a correlation heatmap for the top 10 features
44 | 5. Explore top 3 features via various plots to visualize the data
45 |
46 | # 04-train-model-pipelines: Use MLflow to create Machine Learning Pipelines and Track Experiments
47 |
48 | ## Tracking Experiments with MLflow
49 |
50 | MLflow Tracking is one of the three main components of MLflow. It is a logging API specific for machine learning and agnostic to libraries and environments that do the training. It is organized around the concept of **runs**, which are executions of data science code. Runs are aggregated into **experiments** where many runs can be a part of a given experiment and an MLflow server can host many experiments.
51 |
52 | MLflow tracking also serves as a **model registry** so tracked models can easily be stored and, as necessary, deployed into production.
53 |
54 |
55 |
56 | In this notebook, we will -
57 | 1. Load our `train` dataset from SILVER Zone
58 | 2. Use MLflow to create a Logistic Regression ML Pipeline
59 | 3. Explore the run details using MLflow integration in Databricks
60 |
61 | # 05-model-serving: Model Serving - Batch Scoring and REST API
62 |
63 | Operationalizing machine learning models in a consistent and reliable manner is one of the most relevant technical challenges in the industry today.
64 |
65 | [Docker](https://opensource.com/resources/what-docker), a tool designed to make it easier to package, deploy and run applications via containers is almost always involved in the Operationalization/Model serving process. Containers essentially abstract away the underlying Operating System and machine specific dependencies, allowing a developer to package an application with all of it's dependency libraries, and ship it out as one self-contained package.
66 |
67 | By using Dockerized Containers, and a Container hosting tool - such as Kubernetes or Azure Container Instances, our focus shifts to connecting the operationalized ML Pipeline (such as MLflow we discovered earlier) with a robust Model Serving tool to manage and (re)deploy our Models as it matures.
68 |
69 | # Azure Machine Learning Services
70 | We'll be using Azure Machine Learning Service to track experiments and deploy our model as a REST API via [Azure Container Instances](https://docs.microsoft.com/en-us/azure/container-instances/).
71 |
72 | 
73 |
74 | **Pre-requisite**: You should have run `02-extract-transform-load` to have the validation data ready to go in SILVER Zone, and `04-train-model-pipelines` to have the model file stored on the Databricks cluster.
75 | In this notebook, we will -
76 | 1. Batch score `test_validation` SILVER Zone data via our MLflow trained Linear Regression model
77 | 2. Use MLflow and Azure ML services to build and deploy an Azure Container Image for live REST API scoring via HTTP
78 |
--------------------------------------------------------------------------------
/workflow.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | workflow - Databricks
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
21 |
24 |
25 |
26 |
41 |
42 |
43 |
--------------------------------------------------------------------------------