 4 |
5 |
6 | ## 写在前面
7 | - **主要在飞桨的跨镜头跟踪基础上进行改进,主要实现两路rtsp视频流的实时跨镜头跟踪,相较于原来只能跟踪视频数据的工程,主要改动在于```pipline.py```与```mtmct.py```**
8 |
9 | ### 简单介绍
10 | - **相较于视频的mtmct,本质上是对两个视频的人物ID进行重新分配,无需真正的考虑跨境头的问题,不会出现一个人从一个镜头走到另一个,即一个人同时只出现在一个镜头的情况。视频推流的实时跟踪主要的难点在于各个人物的特征数据少,若是同一人出现在两镜头区域还好说,如果是从一个镜头走到另一个镜头,对于实时跟踪就要求存储两镜头中所有出现过的人物,进行对比,这样就会有很大的计算量.不过好歹最终效果有点像样,不管了**
11 |
12 | ### 底层苦劳工的心血展示
13 | 
14 | 
15 |
16 | ### 关于模型
17 | - **模型都是用的最轻量级,原计划部署在npu,因为reid对数据精度要求颇高选择放弃**
18 | ## 🗳 模型库
19 |
20 | ### PP-Human
21 |
22 |
4 |
5 |
6 | ## 写在前面
7 | - **主要在飞桨的跨镜头跟踪基础上进行改进,主要实现两路rtsp视频流的实时跨镜头跟踪,相较于原来只能跟踪视频数据的工程,主要改动在于```pipline.py```与```mtmct.py```**
8 |
9 | ### 简单介绍
10 | - **相较于视频的mtmct,本质上是对两个视频的人物ID进行重新分配,无需真正的考虑跨境头的问题,不会出现一个人从一个镜头走到另一个,即一个人同时只出现在一个镜头的情况。视频推流的实时跟踪主要的难点在于各个人物的特征数据少,若是同一人出现在两镜头区域还好说,如果是从一个镜头走到另一个镜头,对于实时跟踪就要求存储两镜头中所有出现过的人物,进行对比,这样就会有很大的计算量.不过好歹最终效果有点像样,不管了**
11 |
12 | ### 底层苦劳工的心血展示
13 | 
14 | 
15 |
16 | ### 关于模型
17 | - **模型都是用的最轻量级,原计划部署在npu,因为reid对数据精度要求颇高选择放弃**
18 | ## 🗳 模型库
19 |
20 | ### PP-Human
21 |
22 | [车牌字符识别](https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_rec_infer.tar.gz) | 车牌检测:3.9M
车牌字符识别: 12M | 60 | | 车辆属性 | 7.31ms | [车辆属性](https://bj.bcebos.com/v1/paddledet/models/pipeline/vehicle_attribute_model.zip) | 7.2M | 61 | | 车道线检测 | 47ms | [车道线模型](https://bj.bcebos.com/v1/paddledet/models/pipeline/pp_lite_stdc2_bdd100k.zip) | 47M | 62 | 63 | 下载模型后,解压至`./output_inference`文件夹。 64 | 65 | 在配置文件中,模型路径默认为模型的下载路径,如果用户不修改,则在推理时会自动下载对应的模型。 66 | 67 | **注意:** 68 | 69 | - 检测跟踪模型精度为公开数据集BDD100K-MOT和UA-DETRAC整合后的联合数据集PPVehicle的结果,具体参照[ppvehicle](../../../../configs/ppvehicle) 70 | - 预测速度为T4下,开启TensorRT FP16的效果, 模型预测速度包含数据预处理、模型预测、后处理全流程 71 | 72 | ## 配置文件说明 73 | 74 | PP-Vehicle相关配置位于```deploy/pipeline/config/infer_cfg_ppvehicle.yml```中,存放模型路径,完成不同功能需要设置不同的任务类型 75 | 76 | 功能及任务类型对应表单如下: 77 | 78 | | 输入类型 | 功能 | 任务类型 | 配置项 | 79 | |-------|-------|----------|-----| 80 | | 图片 | 属性识别 | 目标检测 属性识别 | DET ATTR | 81 | | 单镜头视频 | 属性识别 | 多目标跟踪 属性识别 | MOT ATTR | 82 | | 单镜头视频 | 车牌识别 | 多目标跟踪 车牌识别 | MOT VEHICLEPLATE | 83 | 84 | 例如基于视频输入的属性识别,任务类型包含多目标跟踪和属性识别,具体配置如下: 85 | 86 | ``` 87 | crop_thresh: 0.5 88 | visual: True 89 | warmup_frame: 50 90 | 91 | MOT: 92 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip 93 | tracker_config: deploy/pipeline/config/tracker_config.yml 94 | batch_size: 1 95 | enable: True 96 | 97 | VEHICLE_ATTR: 98 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/vehicle_attribute_model.zip 99 | batch_size: 8 100 | color_threshold: 0.5 101 | type_threshold: 0.5 102 | enable: True 103 | ``` 104 | 105 | **注意:** 106 | 107 | - 如果用户需要实现不同任务,可以在配置文件对应enable选项设置为True。 108 | - 如果用户仅需要修改模型文件路径,可以在命令行中--config后面紧跟着 `-o MOT.model_dir=ppyoloe/` 进行修改即可,也可以手动修改配置文件中的相应模型路径,详细说明参考下方参数说明文档。 109 | 110 | 111 | ## 预测部署 112 | 113 | 1. 直接使用默认配置或者examples中配置文件,或者直接在`infer_cfg_ppvehicle.yml`中修改配置: 114 | ``` 115 | # 例:车辆检测,指定配置文件路径和测试图片 116 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml --image_file=test_image.jpg --device=gpu 117 | 118 | # 例:车辆车牌识别,指定配置文件路径和测试视频 119 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/examples/infer_cfg_vehicle_plate.yml --video_file=test_video.mp4 --device=gpu 120 | ``` 121 | 122 | 2. 使用命令行进行功能开启,或者模型路径修改: 123 | ``` 124 | # 例:车辆跟踪,指定配置文件路径和测试视频,命令行中开启MOT模型并修改模型路径,命令行中指定的模型路径优先级高于配置文件 125 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml -o MOT.enable=True MOT.model_dir=ppyoloe_infer/ --video_file=test_video.mp4 --device=gpu 126 | 127 | # 例:车辆违章分析,指定配置文件和测试视频,命令行中指定违停区域设置、违停时间判断。 128 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/examples/infer_cfg_illegal_parking.yml \ 129 | --video_file=../car_test.mov \ 130 | --device=gpu \ 131 | --draw_center_traj \ 132 | --illegal_parking_time=3 \ 133 | --region_type=custom \ 134 | --region_polygon 600 300 1300 300 1300 800 600 800 135 | 136 | ``` 137 | 138 | ### 在线视频流 139 | 140 | 在线视频流解码功能基于opencv的capture函数,支持rtsp、rtmp格式。 141 | 142 | - rtsp拉流预测 143 | 144 | 对rtsp拉流的支持,使用--rtsp RTSP [RTSP ...]参数指定一路或者多路rtsp视频流,如果是多路地址中间用空格隔开。(或者video_file后面的视频地址直接更换为rtsp流地址),示例如下: 145 | ``` 146 | # 例:车辆属性识别,单路视频流 147 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/examples/infer_cfg_vehicle_attr.yml -o visual=False --rtsp rtsp://[YOUR_RTSP_SITE] --device=gpu 148 | 149 | # 例:车辆属性识别,多路视频流 150 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/examples/infer_cfg_vehicle_attr.yml -o visual=False --rtsp rtsp://[YOUR_RTSP_SITE1] rtsp://[YOUR_RTSP_SITE2] --device=gpu 151 | ``` 152 | 153 | - 视频结果推流rtsp 154 | 155 | 预测结果进行rtsp推流,使用--pushurl rtsp:[IP] 推流到IP地址端,PC端可以使用[VLC播放器](https://vlc.onl/)打开网络流进行播放,播放地址为 `rtsp:[IP]/videoname`。其中`videoname`是预测的视频文件名,如果视频来源是本地摄像头则`videoname`默认为`output`. 156 | ``` 157 | # 例:车辆属性识别,单路视频流,该示例播放地址为 rtsp://[YOUR_SERVER_IP]:8554/test_video 158 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/examples/infer_cfg_vehicle_attr.yml -o visual=False --video_file=test_video.mp4 --device=gpu --pushurl rtsp://[YOUR_SERVER_IP]:8554 159 | ``` 160 | 注: 161 | 1. rtsp推流服务基于 [rtsp-simple-server](https://github.com/aler9/rtsp-simple-server), 如使用推流功能请先开启该服务. 162 | 使用方法很简单,以linux平台为例:1)下载对应平台release包;2)解压后在命令行执行命令 `./rtsp-simple-server`即可,成功后进入服务开启状态就可以接收视频流了。 163 | 2. rtsp推流如果模型处理速度跟不上会出现很明显的卡顿现象,建议跟踪模型使用ppyoloe_s版本,即修改配置中跟踪模型mot_ppyoloe_l_36e_pipeline.zip替换为mot_ppyoloe_s_36e_pipeline.zip。 164 | 165 | ### Jetson部署说明 166 | 167 | 由于Jetson平台算力相比服务器有较大差距,有如下使用建议: 168 | 169 | 1. 模型选择轻量级版本,我们最新提供了轻量级[PP-YOLOE-Plus Tiny模型](../../../../configs/ppvehicle/README.md),该模型在Jetson AGX上可以实现4路视频流20fps实时跟踪。 170 | 2. 如果需进一步提升速度,建议开启跟踪跳帧功能,推荐使用2或者3: `skip_frame_num: 3`,该功能当前默认关闭。 171 | 172 | 上述修改可以直接修改配置文件(推荐),也可以在命令行中修改(字段较长,不推荐)。 173 | 174 | PP-YOLOE-Plus Tiny模型在AGX平台不同功能开启时的速度如下:(测试视频跟踪车辆为1个) 175 | 176 | | 功能 | 平均每帧耗时(ms) | 运行帧率(fps) | 177 | |:----------|:----------|:----------| 178 | | 跟踪 | 13 | 77 | 179 | | 属性识别 | 20.2 | 49.4 | 180 | | 车牌识别 | - | - | 181 | 182 | 183 | ### 参数说明 184 | 185 | | 参数 | 是否必须|含义 | 186 | |-------|-------|----------| 187 | | --config | Yes | 配置文件路径 | 188 | | -o | Option | 覆盖配置文件中对应的配置 | 189 | | --image_file | Option | 需要预测的图片 | 190 | | --image_dir | Option | 要预测的图片文件夹路径 | 191 | | --video_file | Option | 需要预测的视频,或者rtsp流地址 | 192 | | --rtsp | Option | rtsp视频流地址,支持一路或者多路同时输入 | 193 | | --camera_id | Option | 用来预测的摄像头ID,默认为-1(表示不使用摄像头预测,可设置为:0 - (摄像头数目-1) ),预测过程中在可视化界面按`q`退出输出预测结果到:output/output.mp4| 194 | | --device | Option | 运行时的设备,可选择`CPU/GPU/XPU`,默认为`CPU`| 195 | | --pushurl | Option| 对预测结果视频进行推流的地址,以rtsp://开头,该选项优先级高于视频结果本地存储,打开时不再另外存储本地预测结果视频, 默认为空,表示没有开启| 196 | | --output_dir | Option|可视化结果保存的根目录,默认为output/| 197 | | --run_mode | Option |使用GPU时,默认为paddle, 可选(paddle/trt_fp32/trt_fp16/trt_int8)| 198 | | --enable_mkldnn | Option | CPU预测中是否开启MKLDNN加速,默认为False | 199 | | --cpu_threads | Option| 设置cpu线程数,默认为1 | 200 | | --trt_calib_mode | Option| TensorRT是否使用校准功能,默认为False。使用TensorRT的int8功能时,需设置为True,使用PaddleSlim量化后的模型时需要设置为False | 201 | | --do_entrance_counting | Option | 是否统计出入口流量,默认为False | 202 | | --draw_center_traj | Option | 是否绘制跟踪轨迹,默认为False | 203 | | --region_type | Option | 'horizontal'(默认值)、'vertical':表示流量统计方向选择;'custom':表示设置车辆禁停区域 | 204 | | --region_polygon | Option | 设置禁停区域多边形多点的坐标,无默认值 | 205 | | --illegal_parking_time | Option | 设置禁停时间阈值,单位秒(s),-1(默认值)表示不做检查 | 206 | 207 | ## 方案介绍 208 | 209 | PP-Vehicle 整体方案如下图所示: 210 | 211 |
212 |  213 |
213 |
214 |
215 |
216 | ### 车辆检测
217 | - 采用PP-YOLOE L 作为目标检测模型
218 | - 详细文档参考[PP-YOLOE](../../../../configs/ppyoloe/)和[检测跟踪文档](ppvehicle_mot.md)
219 |
220 | ### 车辆跟踪
221 | - 采用SDE方案完成车辆跟踪
222 | - 检测模型使用PP-YOLOE L(高精度)和S(轻量级)
223 | - 跟踪模块采用OC-SORT方案
224 | - 详细文档参考[OC-SORT](../../../../configs/mot/ocsort)和[检测跟踪文档](ppvehicle_mot.md)
225 |
226 | ### 属性识别
227 | - 使用PaddleClas提供的特色模型PP-LCNet,实现对车辆颜色及车型属性的识别。
228 | - 详细文档参考[属性识别](ppvehicle_attribute.md)
229 |
230 | ### 车牌识别
231 | - 使用PaddleOCR特色模型ch_PP-OCRv3_det+ch_PP-OCRv3_rec模型,识别车牌号码
232 | - 详细文档参考[车牌识别](ppvehicle_plate.md)
233 |
234 | ### 违章停车识别
235 | - 车辆跟踪模型使用高精度模型PP-YOLOE L,根据车辆的跟踪轨迹以及指定的违停区域判断是否违章停车,如果存在则展示违章停车车牌号。
236 | - 详细文档参考[违章停车识别](ppvehicle_illegal_parking.md)
237 |
238 | ### 违法分析-逆行
239 | - 违法分析-逆行,通过使用高精度分割模型PP-Seg,对车道线进行分割拟合,然后与车辆轨迹组合判断车辆行驶方向是否与道路方向一致。
240 | - 详细文档参考[违法分析-逆行](ppvehicle_retrograde.md)
241 |
242 | ### 违法分析-压线
243 | - 违法分析-逆行,通过使用高精度分割模型PP-Seg,对车道线进行分割拟合,然后与车辆区域是否覆盖实线区域,进行压线判断。
244 | - 详细文档参考[违法分析-压线](ppvehicle_press.md)
245 |
--------------------------------------------------------------------------------
/docs/tutorials/pphuman_attribute.md:
--------------------------------------------------------------------------------
1 | [English](pphuman_attribute_en.md) | 简体中文
2 |
3 | # PP-Human属性识别模块
4 |
5 | 行人属性识别在智慧社区,工业巡检,交通监控等方向都具有广泛应用,PP-Human中集成了属性识别模块,属性包含性别、年龄、帽子、眼镜、上衣下衣款式等。我们提供了预训练模型,用户可以直接下载使用。
6 |
7 | | 任务 | 算法 | 精度 | 预测速度(ms) |下载链接 |
8 | |:---------------------|:---------:|:------:|:------:| :---------------------------------------------------------------------------------: |
9 | | 行人检测/跟踪 | PP-YOLOE | mAP: 56.3
213 | MOTA: 72.0 | 检测: 16.2ms
跟踪:22.3ms |[下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.zip) | 10 | | 行人属性高精度模型 | PP-HGNet_small | mA: 95.4 | 单人 1.54ms | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/PPHGNet_small_person_attribute_954_infer.zip) | 11 | | 行人属性轻量级模型 | PP-LCNet_x1_0 | mA: 94.5 | 单人 0.54ms | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/PPLCNet_x1_0_person_attribute_945_infer.zip) | 12 | | 行人属性精度与速度均衡模型 | PP-HGNet_tiny | mA: 95.2 | 单人 1.14ms | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/PPHGNet_tiny_person_attribute_952_infer.zip) | 13 | 14 | 15 | 1. 检测/跟踪模型精度为[MOT17](https://motchallenge.net/),[CrowdHuman](http://www.crowdhuman.org/),[HIEVE](http://humaninevents.org/)和部分业务数据融合训练测试得到。 16 | 2. 行人属性分析精度为[PA100k](https://github.com/xh-liu/HydraPlus-Net#pa-100k-dataset),[RAPv2](http://www.rapdataset.com/rapv2.html),[PETA](http://mmlab.ie.cuhk.edu.hk/projects/PETA.html)和部分业务数据融合训练测试得到 17 | 3. 预测速度为V100 机器上使用TensorRT FP16时的速度, 该处测速速度为模型预测速度 18 | 4. 属性模型应用依赖跟踪模型结果,请在[跟踪模型页面](./pphuman_mot.md)下载跟踪模型,依自身需求选择高精或轻量级下载。 19 | 5. 模型下载后解压放置在PaddleDetection/output_inference/目录下。 20 | 21 | ## 使用方法 22 | 23 | 1. 从上表链接中下载模型并解压到```PaddleDetection/output_inference```路径下,并修改配置文件中模型路径,也可默认自动下载模型。设置```deploy/pipeline/config/infer_cfg_pphuman.yml```中`ATTR`的enable: True 24 | 25 | `infer_cfg_pphuman.yml`中配置项说明: 26 | ``` 27 | ATTR: #模块名称 28 | model_dir: output_inference/PPLCNet_x1_0_person_attribute_945_infer/ #模型路径 29 | batch_size: 8 #推理最大batchsize 30 | enable: False #功能是否开启 31 | ``` 32 | 33 | 2. 图片输入时,启动命令如下(更多命令参数说明,请参考[快速开始-参数说明](./PPHuman_QUICK_STARTED.md#41-参数说明))。 34 | ```python 35 | #单张图片 36 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \ 37 | --image_file=test_image.jpg \ 38 | --device=gpu \ 39 | 40 | #图片文件夹 41 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \ 42 | --image_dir=images/ \ 43 | --device=gpu \ 44 | 45 | ``` 46 | 3. 视频输入时,启动命令如下 47 | ```python 48 | #单个视频文件 49 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \ 50 | --video_file=test_video.mp4 \ 51 | --device=gpu \ 52 | 53 | #视频文件夹 54 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \ 55 | --video_dir=test_videos/ \ 56 | --device=gpu \ 57 | ``` 58 | 59 | 4. 若修改模型路径,有以下两种方式: 60 | 61 | - 方法一:```./deploy/pipeline/config/infer_cfg_pphuman.yml```下可以配置不同模型路径,属性识别模型修改ATTR字段下配置 62 | - 方法二:命令行中--config后面紧跟着增加`-o ATTR.model_dir`修改模型路径: 63 | ```python 64 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml 65 | -o ATTR.model_dir=output_inference/PPLCNet_x1_0_person_attribute_945_infer/\ 66 | --video_file=test_video.mp4 \ 67 | --device=gpu 68 | ``` 69 | 70 | 测试效果如下: 71 | 72 |
73 |  74 |
74 |
75 |
76 | 数据来源及版权归属:天覆科技,感谢提供并开源实际场景数据,仅限学术研究使用
77 |
78 | ## 方案说明
79 |
80 | 1. 目标检测/多目标跟踪获取图片/视频输入中的行人检测框,模型方案为PP-YOLOE,详细文档参考[PP-YOLOE](../../../configs/ppyoloe/README_cn.md)
81 | 2. 通过行人检测框的坐标在输入图像中截取每个行人
82 | 3. 使用属性识别分析每个行人对应属性,属性类型与PA100k数据集相同,具体属性列表如下:
83 | ```
84 | - 性别:男、女
85 | - 年龄:小于18、18-60、大于60
86 | - 朝向:朝前、朝后、侧面
87 | - 配饰:眼镜、帽子、无
88 | - 正面持物:是、否
89 | - 包:双肩包、单肩包、手提包
90 | - 上衣风格:带条纹、带logo、带格子、拼接风格
91 | - 下装风格:带条纹、带图案
92 | - 短袖上衣:是、否
93 | - 长袖上衣:是、否
94 | - 长外套:是、否
95 | - 长裤:是、否
96 | - 短裤:是、否
97 | - 短裙&裙子:是、否
98 | - 穿靴:是、否
99 | ```
100 |
101 | 4. 属性识别模型方案为[StrongBaseline](https://arxiv.org/pdf/2107.03576.pdf),模型结构更改为基于PP-HGNet、PP-LCNet的多分类网络结构,引入Weighted BCE loss提升模型效果。
102 |
103 | ## 参考文献
104 | ```
105 | @article{jia2020rethinking,
106 | title={Rethinking of pedestrian attribute recognition: Realistic datasets with efficient method},
107 | author={Jia, Jian and Huang, Houjing and Yang, Wenjie and Chen, Xiaotang and Huang, Kaiqi},
108 | journal={arXiv preprint arXiv:2005.11909},
109 | year={2020}
110 | }
111 | ```
112 |
--------------------------------------------------------------------------------
/docs/tutorials/pphuman_attribute_en.md:
--------------------------------------------------------------------------------
1 | English | [简体中文](pphuman_attribute.md)
2 |
3 | # Attribute Recognition Modules of PP-Human
4 |
5 | Pedestrian attribute recognition has been widely used in the intelligent community, industrial, and transportation monitoring. Many attribute recognition modules have been gathered in PP-Human, including gender, age, hats, eyes, clothing and up to 26 attributes in total. Also, the pre-trained models are offered here and users can download and use them directly.
6 |
7 | | Task | Algorithm | Precision | Inference Speed(ms) | Download Link |
8 | |:---------------------|:---------:|:------:|:------:| :---------------------------------------------------------------------------------: |
9 | | High-Precision Model | PP-HGNet_small | mA: 95.4 | per person 1.54ms | [Download](https://bj.bcebos.com/v1/paddledet/models/pipeline/PPHGNet_small_person_attribute_954_infer.tar) |
10 | | Fast Model | PP-LCNet_x1_0 | mA: 94.5 | per person 0.54ms | [Download](https://bj.bcebos.com/v1/paddledet/models/pipeline/PPLCNet_x1_0_person_attribute_945_infer.tar) |
11 | | Balanced Model | PP-HGNet_tiny | mA: 95.2 | per person 1.14ms | [Download](https://bj.bcebos.com/v1/paddledet/models/pipeline/PPHGNet_tiny_person_attribute_952_infer.tar) |
12 |
13 | 1. The precision of pedestiran attribute analysis is obtained by training and testing on the dataset consist of [PA100k](https://github.com/xh-liu/HydraPlus-Net#pa-100k-dataset),[RAPv2](http://www.rapdataset.com/rapv2.html),[PETA](http://mmlab.ie.cuhk.edu.hk/projects/PETA.html) and some business data.
14 | 2. The inference speed is V100, the speed of using TensorRT FP16.
15 | 3. This model of Attribute is based on the result of tracking, please download tracking model in the [Page of Mot](./pphuman_mot_en.md). The High precision and Faster model are both available.
16 | 4. You should place the model unziped in the directory of `PaddleDetection/output_inference/`.
17 |
18 | ## Instruction
19 |
20 | 1. Download the model from the link in the above table, and unzip it to```./output_inference```, and set the "enable: True" in ATTR of infer_cfg_pphuman.yml
21 |
22 | The meaning of configs of `infer_cfg_pphuman.yml`:
23 | ```
24 | ATTR: #module name
25 | model_dir: output_inference/PPLCNet_x1_0_person_attribute_945_infer/ #model path
26 | batch_size: 8 #maxmum batchsize when inference
27 | enable: False #whether to enable this model
28 | ```
29 |
30 | 2. When inputting the image, run the command as follows (please refer to [QUICK_STARTED-Parameters](./PPHuman_QUICK_STARTED.md#41-参数说明) for more details):
31 | ```python
32 | #single image
33 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
34 | --image_file=test_image.jpg \
35 | --device=gpu \
36 |
37 | #image directory
38 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
39 | --image_dir=images/ \
40 | --device=gpu \
41 |
42 | ```
43 | 3. When inputting the video, run the command as follows:
44 | ```python
45 | #a single video file
46 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
47 | --video_file=test_video.mp4 \
48 | --device=gpu \
49 |
50 | #directory of videos
51 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
52 | --video_dir=test_videos/ \
53 | --device=gpu \
54 | ```
55 | 4. If you want to change the model path, there are two methods:
56 |
57 | - The first: In ```./deploy/pipeline/config/infer_cfg_pphuman.yml``` you can configurate different model paths. In attribute recognition models, you can modify the configuration in the field of ATTR.
58 | - The second: Add `-o ATTR.model_dir` in the command line following the --config to change the model path:
59 | ```python
60 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
61 | -o ATTR.model_dir=output_inference/PPLCNet_x1_0_person_attribute_945_infer/\
62 | --video_file=test_video.mp4 \
63 | --device=gpu
64 | ```
65 |
66 | The test result is:
67 |
68 |
74 |
69 |  70 |
70 |
71 |
72 | Data Source and Copyright:Skyinfor Technology. Thanks for the provision of actual scenario data, which are only used for academic research here.
73 |
74 | ## Introduction to the Solution
75 |
76 | 1. The PP-YOLOE model is used to handle detection boxs of input images/videos from object detection/ multi-object tracking. For details, please refer to the document [PP-YOLOE](../../../configs/ppyoloe).
77 | 2. Capture every pedestrian in the input images with the help of coordiantes of detection boxes.
78 | 3. Analyze the listed labels of pedestirans through attribute recognition. They are the same as those in the PA100k dataset. The label list is as follows:
79 | ```
80 | - Gender
81 | - Age: Less than 18; 18-60; Over 60
82 | - Orientation: Front; Back; Side
83 | - Accessories: Glasses; Hat; None
84 | - HoldObjectsInFront: Yes; No
85 | - Bag: BackPack; ShoulderBag; HandBag
86 | - TopStyle: UpperStride; UpperLogo; UpperPlaid; UpperSplice
87 | - BottomStyle: LowerStripe; LowerPattern
88 | - ShortSleeve: Yes; No
89 | - LongSleeve: Yes; No
90 | - LongCoat: Yes; No
91 | - Trousers: Yes; No
92 | - Shorts: Yes; No
93 | - Skirt&Dress: Yes; No
94 | - Boots: Yes; No
95 | ```
96 |
97 | 4. The model adopted in the attribute recognition is [StrongBaseline](https://arxiv.org/pdf/2107.03576.pdf), where the structure is the multi-class network structure based on PP-HGNet、PP-LCNet, and Weighted BCE loss is introduced for effect optimization.
98 |
99 | ## Reference
100 | ```
101 | @article{jia2020rethinking,
102 | title={Rethinking of pedestrian attribute recognition: Realistic datasets with efficient method},
103 | author={Jia, Jian and Huang, Houjing and Yang, Wenjie and Chen, Xiaotang and Huang, Kaiqi},
104 | journal={arXiv preprint arXiv:2005.11909},
105 | year={2020}
106 | }
107 | ```
108 |
--------------------------------------------------------------------------------
/docs/tutorials/pphuman_mot.md:
--------------------------------------------------------------------------------
1 | [English](pphuman_mot_en.md) | 简体中文
2 |
3 | # PP-Human检测跟踪模块
4 |
5 | 行人检测与跟踪在智慧社区,工业巡检,交通监控等方向都具有广泛应用,PP-Human中集成了检测跟踪模块,是关键点检测、属性行为识别等任务的基础。我们提供了预训练模型,用户可以直接下载使用。
6 |
7 | | 任务 | 算法 | 精度 | 预测速度(ms) |下载链接 |
8 | |:---------------------|:---------:|:------:|:------:| :---------------------------------------------------------------------------------: |
9 | | 行人检测/跟踪 | PP-YOLOE-l | mAP: 57.8
70 | MOTA: 82.2 | 检测: 25.1ms
跟踪:31.8ms | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.zip) | 10 | | 行人检测/跟踪 | PP-YOLOE-s | mAP: 53.2
MOTA: 73.9 | 检测: 16.2ms
跟踪:21.0ms | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_s_36e_pipeline.zip) | 11 | 12 | 1. 检测/跟踪模型精度为[COCO-Person](http://cocodataset.org/), [CrowdHuman](http://www.crowdhuman.org/), [HIEVE](http://humaninevents.org/) 和部分业务数据融合训练测试得到,验证集为业务数据 13 | 2. 预测速度为T4 机器上使用TensorRT FP16时的速度, 速度包含数据预处理、模型预测、后处理全流程 14 | 15 | ## 使用方法 16 | 17 | 1. 从上表链接中下载模型并解压到```./output_inference```路径下,并修改配置文件中模型路径。默认为自动下载模型,无需做改动。 18 | 2. 图片输入时,是纯检测任务,启动命令如下 19 | ```python 20 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \ 21 | --image_file=test_image.jpg \ 22 | --device=gpu 23 | ``` 24 | 3. 视频输入时,是跟踪任务,注意首先设置infer_cfg_pphuman.yml中的MOT配置的`enable=True`,如果希望跳帧加速检测跟踪流程,可以设置`skip_frame_num: 2`,建议跳帧帧数最大不超过3: 25 | ``` 26 | MOT: 27 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.zip 28 | tracker_config: deploy/pipeline/config/tracker_config.yml 29 | batch_size: 1 30 | skip_frame_num: 2 31 | enable: True 32 | ``` 33 | 然后启动命令如下 34 | ```python 35 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \ 36 | --video_file=test_video.mp4 \ 37 | --device=gpu 38 | ``` 39 | 4. 若修改模型路径,有以下两种方式: 40 | 41 | - ```./deploy/pipeline/config/infer_cfg_pphuman.yml```下可以配置不同模型路径,检测和跟踪模型分别对应`DET`和`MOT`字段,修改对应字段下的路径为实际期望的路径即可。 42 | - 命令行中--config后面紧跟着增加`-o MOT.model_dir`修改模型路径: 43 | ```python 44 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \ 45 | -o MOT.model_dir=ppyoloe/\ 46 | --video_file=test_video.mp4 \ 47 | --device=gpu \ 48 | --region_type=horizontal \ 49 | --do_entrance_counting \ 50 | --draw_center_traj 51 | 52 | ``` 53 | **注意:** 54 | - `--do_entrance_counting`表示是否统计出入口流量,不设置即默认为False。 55 | - `--draw_center_traj`表示是否绘制跟踪轨迹,不设置即默认为False。注意绘制跟踪轨迹的测试视频最好是静止摄像头拍摄的。 56 | - `--region_type`表示流量计数的区域,当设置`--do_entrance_counting`时可选择`horizontal`或者`vertical`,默认是`horizontal`,表示以视频图片的中心水平线为出入口,同一物体框的中心点在相邻两秒内分别在区域中心水平线的两侧,即完成计数加一。 57 | 58 | 测试效果如下: 59 | 60 |
61 |  62 |
62 |
63 |
64 | 数据来源及版权归属:天覆科技,感谢提供并开源实际场景数据,仅限学术研究使用
65 |
66 | 5. 区域闯入判断和计数
67 |
68 | 注意首先设置infer_cfg_pphuman.yml中的MOT配置的enable=True,然后启动命令如下
69 | ```python
70 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
71 | --video_file=test_video.mp4 \
72 | --device=gpu \
73 | --draw_center_traj \
74 | --do_break_in_counting \
75 | --region_type=custom \
76 | --region_polygon 200 200 400 200 300 400 100 400
77 | ```
78 | **注意:**
79 | - 区域闯入的测试视频必须是静止摄像头拍摄的,镜头不能抖动或移动。
80 | - `--do_break_in_counting`表示是否进行区域出入后计数,不设置即默认为False。
81 | - `--region_type`表示流量计数的区域,当设置`--do_break_in_counting`时仅可选择`custom`,默认是`custom`,表示以用户自定义区域为出入口,同一物体框的下边界中点坐标在相邻两秒内从区域外到区域内,即完成计数加一。
82 | - `--region_polygon`表示用户自定义区域的多边形的点坐标序列,每两个为一对点坐标(x,y),**按顺时针顺序**连成一个**封闭区域**,至少需要3对点也即6个整数,默认值是`[]`,需要用户自行设置点坐标,如是四边形区域,坐标顺序是`左上、右上、右下、左下`。用户可以运行[此段代码](../../tools/get_video_info.py)获取所测视频的分辨率帧数,以及可以自定义画出自己想要的多边形区域的可视化并自己调整。
83 | 自定义多边形区域的可视化代码运行如下:
84 | ```python
85 | python get_video_info.py --video_file=demo.mp4 --region_polygon 200 200 400 200 300 400 100 400
86 | ```
87 | 快速画出想要的区域的小技巧:先任意取点得到图片,用画图工具打开,鼠标放到想要的区域点上会显示出坐标,记录下来并取整,作为这段可视化代码的region_polygon参数,并再次运行可视化,微调点坐标参数直至满意。
88 |
89 |
90 | 测试效果如下:
91 |
92 |
62 |
93 |  94 |
94 |
95 |
96 | ## 方案说明
97 |
98 | 1. 使用目标检测/多目标跟踪技术来获取图片/视频输入中的行人检测框,检测模型方案为PP-YOLOE,详细文档参考[PP-YOLOE](../../../../configs/ppyoloe)。
99 | 2. 多目标跟踪模型方案采用[ByteTrack](https://arxiv.org/pdf/2110.06864.pdf)和[OC-SORT](https://arxiv.org/pdf/2203.14360.pdf),采用PP-YOLOE替换原文的YOLOX作为检测器,采用BYTETracker和OCSORTTracker作为跟踪器,详细文档参考[ByteTrack](../../../../configs/mot/bytetrack)和[OC-SORT](../../../../configs/mot/ocsort)。
100 |
101 | ## 参考文献
102 | ```
103 | @article{zhang2021bytetrack,
104 | title={ByteTrack: Multi-Object Tracking by Associating Every Detection Box},
105 | author={Zhang, Yifu and Sun, Peize and Jiang, Yi and Yu, Dongdong and Yuan, Zehuan and Luo, Ping and Liu, Wenyu and Wang, Xinggang},
106 | journal={arXiv preprint arXiv:2110.06864},
107 | year={2021}
108 | }
109 |
110 | @article{cao2022observation,
111 | title={Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking},
112 | author={Cao, Jinkun and Weng, Xinshuo and Khirodkar, Rawal and Pang, Jiangmiao and Kitani, Kris},
113 | journal={arXiv preprint arXiv:2203.14360},
114 | year={2022}
115 | }
116 | ```
117 |
--------------------------------------------------------------------------------
/docs/tutorials/pphuman_mot_en.md:
--------------------------------------------------------------------------------
1 | English | [简体中文](pphuman_mot.md)
2 |
3 | # Detection and Tracking Module of PP-Human
4 |
5 | Pedestrian detection and tracking is widely used in the intelligent community, industrial inspection, transportation monitoring and so on. PP-Human has the detection and tracking module, which is fundamental to keypoint detection, attribute action recognition, etc. Users enjoy easy access to pretrained models here.
6 |
7 | | Task | Algorithm | Precision | Inference Speed(ms) | Download Link |
8 | |:---------------------|:---------:|:------:|:------:| :---------------------------------------------------------------------------------: |
9 | | Pedestrian Detection/ Tracking | PP-YOLOE-l | mAP: 57.8
94 | MOTA: 82.2 | Detection: 25.1ms
Tracking:31.8ms | [Download](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.zip) | 10 | | Pedestrian Detection/ Tracking | PP-YOLOE-s | mAP: 53.2
MOTA: 73.9 | Detection: 16.2ms
Tracking:21.0ms | [Download](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_s_36e_pipeline.zip) | 11 | 12 | 1. The precision of the pedestrian detection/ tracking model is obtained by trainning and testing on [COCO-Person](http://cocodataset.org/), [CrowdHuman](http://www.crowdhuman.org/), [HIEVE](http://humaninevents.org/) and some business data. 13 | 2. The inference speed is the speed of using TensorRT FP16 on T4, the total number of data pre-training, model inference, and post-processing. 14 | 15 | ## How to Use 16 | 17 | 1. Download models from the links of the above table and unizp them to ```./output_inference```. 18 | 2. When use the image as input, it's a detection task, the start command is as follows: 19 | ```python 20 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \ 21 | --image_file=test_image.jpg \ 22 | --device=gpu 23 | ``` 24 | 3. When use the video as input, it's a tracking task, first you should set the "enable: True" in MOT of infer_cfg_pphuman.yml. If you want skip some frames speed up the detection and tracking process, you can set `skip_frame_num: 2`, it is recommended that the maximum number of skip_frame_num should not exceed 3: 25 | ``` 26 | MOT: 27 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.zip 28 | tracker_config: deploy/pipeline/config/tracker_config.yml 29 | batch_size: 1 30 | skip_frame_num: 2 31 | enable: True 32 | ``` 33 | and then the start command is as follows: 34 | ```python 35 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \ 36 | --video_file=test_video.mp4 \ 37 | --device=gpu 38 | ``` 39 | 4. There are two ways to modify the model path: 40 | 41 | - In `./deploy/pipeline/config/infer_cfg_pphuman.yml`, you can configurate different model paths,which is proper only if you match keypoint models and action recognition models with the fields of `DET` and `MOT` respectively, and modify the corresponding path of each field into the expected path. 42 | - Add `-o MOT.model_dir` in the command line following the --config to change the model path: 43 | 44 | ```python 45 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \ 46 | -o MOT.model_dir=ppyoloe/\ 47 | --video_file=test_video.mp4 \ 48 | --device=gpu \ 49 | --region_type=horizontal \ 50 | --do_entrance_counting \ 51 | --draw_center_traj 52 | 53 | ``` 54 | **Note:** 55 | 56 | - `--do_entrance_counting` is whether to calculate flow at the gateway, and the default setting is False. 57 | - `--draw_center_traj` means whether to draw the track, and the default setting is False. It's worth noting that the test video of track drawing should be filmed by the still camera. 58 | - `--region_type` means the region type of flow counting. When set `--do_entrance_counting`, you can select from `horizontal` or `vertical`, the default setting is `horizontal`, means that the central horizontal line of the video picture is used as the entrance and exit, and when the central point of the same object box is on both sides of the central horizontal line of the area in two adjacent seconds, the counting plus one is completed. 59 | 60 | The test result is: 61 | 62 |
63 |
64 |
65 |
66 | Data source and copyright owner:Skyinfor Technology. Thanks for the provision of actual scenario data, which are only used for academic research here.
67 |
68 | 5. Break in and counting
69 |
70 | Please set the "enable: True" in MOT of infer_cfg_pphuman.yml at first, and then the start command is as follows:
71 | ```python
72 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
73 | --video_file=test_video.mp4 \
74 | --device=gpu \
75 | --draw_center_traj \
76 | --do_break_in_counting \
77 | --region_type=custom \
78 | --region_polygon 200 200 400 200 300 400 100 400
79 | ```
80 |
81 | **Note:**
82 | - `--do_break_in_counting` is whether to calculate flow when break in the user-defined region, and the default setting is False.
83 | - `--region_type` means the region type of flow counting. When set `--do_break_in_counting`, only `custom` can be selected, and the default is `custom`, which means that the user-defined region is used as the entrance and exit, and when the midpoint coords of the bottom boundary of the same object moves from outside to inside the region within two adjacent seconds, the counting plus one is completed.
84 | - `--region_polygon` means the point coords sequence of the polygon in the user-defined region. Every two integers are a pair of point coords (x,y), which are connected into a closed area in clockwise order. At least 3 pairs of points, that is, 6 integers, are required. The default value is `[]`, and the user needs to set the point coords by himself. Users can run this [code](../../tools/get_video_info.py) to obtain the resolution and frame number of the measured video, and can customize the visualization of drawing the polygon area they want and adjust it by themselves.
85 | The visualization code of the custom polygon region runs as follows:
86 | ```python
87 | python get_video_info.py --video_file=demo.mp4 --region_polygon 200 200 400 200 300 400 100 400
88 | ```
89 |
90 | The test result is:
91 |
92 |
64 |
93 |
94 |
95 |
96 |
97 | ## Introduction to the Solution
98 |
99 | 1. Get the pedestrian detection box of the image/ video input through object detection and multi-object tracking. The detection model is PP-YOLOE, please refer to [PP-YOLOE](../../../../configs/ppyoloe) for details.
100 |
101 | 2. The multi-object tracking solution is based on [ByteTrack](https://arxiv.org/pdf/2110.06864.pdf) and [OC-SORT](https://arxiv.org/pdf/2203.14360.pdf), and replace the original YOLOX with PP-YOLOE as the detector,and BYTETracker or OC-SORT Tracker as the tracker, please refer to [ByteTrack](../../../../configs/mot/bytetrack) and [OC-SORT](../../../../configs/mot/ocsort).
102 |
103 | ## Reference
104 | ```
105 | @article{zhang2021bytetrack,
106 | title={ByteTrack: Multi-Object Tracking by Associating Every Detection Box},
107 | author={Zhang, Yifu and Sun, Peize and Jiang, Yi and Yu, Dongdong and Yuan, Zehuan and Luo, Ping and Liu, Wenyu and Wang, Xinggang},
108 | journal={arXiv preprint arXiv:2110.06864},
109 | year={2021}
110 | }
111 | ```
112 |
--------------------------------------------------------------------------------
/docs/tutorials/pphuman_mtmct.md:
--------------------------------------------------------------------------------
1 | [English](pphuman_mtmct_en.md) | 简体中文
2 |
3 | # PP-Human跨镜头跟踪模块
4 |
5 | 跨镜头跟踪任务,是在单镜头跟踪的基础上,实现不同摄像头中人员的身份匹配关联。在安放、智慧零售等方向有较多的应用。
6 | PP-Human跨镜头跟踪模块主要目的在于提供一套简洁、高效的跨镜跟踪Pipeline,REID模型完全基于开源数据集训练。
7 |
8 | ## 使用方法
9 |
10 | 1. 下载模型 [行人跟踪](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.zip)和[REID模型](https://bj.bcebos.com/v1/paddledet/models/pipeline/reid_model.zip) 并解压到```./output_inference```路径下,修改配置文件中模型路径。也可简单起见直接用默认配置,自动下载模型。 MOT模型请参考[mot说明](./pphuman_mot.md)文件下载。
11 |
12 | 2. 跨镜头跟踪模式下,要求输入的多个视频放在同一目录下,同时开启infer_cfg_pphuman.yml 中的REID选择中的enable=True, 命令如下:
13 | ```python
14 | python3 deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml --video_dir=[your_video_file_directory] --device=gpu
15 | ```
16 |
17 | 3. 相关配置在`./deploy/pipeline/config/infer_cfg_pphuman.yml`文件中修改:
18 |
19 | ```python
20 | python3 deploy/pipeline/pipeline.py
21 | --config deploy/pipeline/config/infer_cfg_pphuman.yml -o REID.model_dir=reid_best/
22 | --video_dir=[your_video_file_directory]
23 | --device=gpu
24 | ```
25 |
26 | ## 方案说明
27 |
28 | 跨镜头跟踪模块,主要由跨镜头跟踪Pipeline及REID模型两部分组成。
29 | 1. 跨镜头跟踪Pipeline
30 |
31 | ```
32 |
33 | 单镜头跟踪[id+bbox]
34 | │
35 | 根据bbox截取原图中目标——│
36 | │ │
37 | REID模型 质量评估(遮挡、完整度、亮度等)
38 | │ │
39 | [feature] [quality]
40 | │ │
41 | datacollector—————│
42 | │
43 | 特征排序、筛选
44 | │
45 | 多视频各id相似度计算
46 | │
47 | id聚类、重新分配id
48 | ```
49 |
50 | 2. 模型方案为[reid-strong-baseline](https://github.com/michuanhaohao/reid-strong-baseline), Backbone为ResNet50, 主要特色为模型结构简单。
51 | 本跨镜跟踪中所用REID模型在上述基础上,整合多个开源数据集并压缩模型特征到128维以提升泛化性能。大幅提升了在实际应用中的泛化效果。
52 |
53 | ### 其他建议
54 | - 提供的REID模型基于开源数据集训练得到,建议加入自有数据,训练更加强有力的REID模型,将非常明显提升跨镜跟踪效果。
55 | - 质量评估部分基于简单逻辑+OpenCV实现,效果有限,如果有条件建议针对性训练质量判断模型。
56 |
57 |
58 | ### 示例效果
59 |
60 | - camera 1:
61 |
94 |
62 |  63 |
63 |
64 |
65 | - camera 2:
66 |
63 |
67 |  68 |
68 |
69 |
70 |
71 | ## 参考文献
72 | ```
73 | @InProceedings{Luo_2019_CVPR_Workshops,
74 | author = {Luo, Hao and Gu, Youzhi and Liao, Xingyu and Lai, Shenqi and Jiang, Wei},
75 | title = {Bag of Tricks and a Strong Baseline for Deep Person Re-Identification},
76 | booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
77 | month = {June},
78 | year = {2019}
79 | }
80 |
81 | @ARTICLE{Luo_2019_Strong_TMM,
82 | author={H. {Luo} and W. {Jiang} and Y. {Gu} and F. {Liu} and X. {Liao} and S. {Lai} and J. {Gu}},
83 | journal={IEEE Transactions on Multimedia},
84 | title={A Strong Baseline and Batch Normalization Neck for Deep Person Re-identification},
85 | year={2019},
86 | pages={1-1},
87 | doi={10.1109/TMM.2019.2958756},
88 | ISSN={1941-0077},
89 | }
90 | ```
91 |
--------------------------------------------------------------------------------
/docs/tutorials/pphuman_mtmct_en.md:
--------------------------------------------------------------------------------
1 | English | [简体中文](pphuman_mtmct.md)
2 |
3 | # Multi-Target Multi-Camera Tracking Module of PP-Human
4 |
5 | Multi-target multi-camera tracking, or MTMCT, matches the identity of a person in different cameras based on the single-camera tracking. MTMCT is usually applied to the security system and the smart retailing.
6 | The MTMCT module of PP-Human aims to provide a multi-target multi-camera pipleline which is simple, and efficient.
7 |
8 | ## How to Use
9 |
10 | 1. Download [REID model](https://bj.bcebos.com/v1/paddledet/models/pipeline/reid_model.zip) and unzip it to ```./output_inference```. For the MOT model, please refer to [mot description](./pphuman_mot.md).
11 |
12 | 2. In the MTMCT mode, input videos are required to be put in the same directory. set the REID "enable: True" in the infer_cfg_pphuman.yml. The command line is:
13 | ```python
14 | python3 deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml --video_dir=[your_video_file_directory] --device=gpu
15 | ```
16 |
17 | 3. Configuration can be modified in `./deploy/pipeline/config/infer_cfg_pphuman.yml`.
18 |
19 | ```python
20 | python3 deploy/pipeline/pipeline.py
21 | --config deploy/pipeline/config/infer_cfg_pphuman.yml -o REID.model_dir=reid_best/
22 | --video_dir=[your_video_file_directory]
23 | --device=gpu
24 | ```
25 |
26 | ## Intorduction to the Solution
27 |
28 | MTMCT module consists of the multi-target multi-camera tracking pipeline and the REID model.
29 |
30 | 1. Multi-Target Multi-Camera Tracking Pipeline
31 |
32 | ```
33 |
34 | single-camera tracking[id+bbox]
35 | │
36 | capture the target in the original image according to bbox——│
37 | │ │
38 | REID model quality assessment (covered or not, complete or not, brightness, etc.)
39 | │ │
40 | [feature] [quality]
41 | │ │
42 | datacollector—————│
43 | │
44 | sort out and filter features
45 | │
46 | calculate the similarity of IDs in the videos
47 | │
48 | make the IDs cluster together and rearrange them
49 | ```
50 |
51 | 2. The model solution is [reid-strong-baseline](https://github.com/michuanhaohao/reid-strong-baseline), with ResNet50 as the backbone.
52 |
53 | Under the above circumstances, the REID model used in MTMCT integrates open-source datasets and compresses model features to 128-dimensional features to optimize the generalization. In this way, the actual generalization result becomes much better.
54 |
55 | ### Other Suggestions
56 |
57 | - The provided REID model is obtained from open-source dataset training. It is recommended to add your own data to get a more powerful REID model, notably improving the MTMCT effect.
58 | - The quality assessment is based on simple logic +OpenCV, whose effect is limited. If possible, it is advisable to conduct specific training on the quality assessment model.
59 |
60 |
61 | ### Example
62 |
63 | - camera 1:
64 |
68 |
65 |
66 |
67 |
68 | - camera 2:
69 |
66 |
70 |
71 |
72 |
73 |
74 | ## Reference
75 | ```
76 | @InProceedings{Luo_2019_CVPR_Workshops,
77 | author = {Luo, Hao and Gu, Youzhi and Liao, Xingyu and Lai, Shenqi and Jiang, Wei},
78 | title = {Bag of Tricks and a Strong Baseline for Deep Person Re-Identification},
79 | booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
80 | month = {June},
81 | year = {2019}
82 | }
83 |
84 | @ARTICLE{Luo_2019_Strong_TMM,
85 | author={H. {Luo} and W. {Jiang} and Y. {Gu} and F. {Liu} and X. {Liao} and S. {Lai} and J. {Gu}},
86 | journal={IEEE Transactions on Multimedia},
87 | title={A Strong Baseline and Batch Normalization Neck for Deep Person Re-identification},
88 | year={2019},
89 | pages={1-1},
90 | doi={10.1109/TMM.2019.2958756},
91 | ISSN={1941-0077},
92 | }
93 | ```
94 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_attribute.md:
--------------------------------------------------------------------------------
1 | [English](ppvehicle_attribute_en.md) | 简体中文
2 |
3 | # PP-Vehicle属性识别模块
4 |
5 | 车辆属性识别在智慧城市,智慧交通等方向具有广泛应用。在PP-Vehicle中,集成了车辆属性识别模块,可识别车辆颜色及车型属性的识别。
6 |
7 | | 任务 | 算法 | 精度 | 预测速度 | 下载链接|
8 | |-----------|------|-----------|----------|---------------|
9 | | 车辆检测/跟踪 | PP-YOLOE | mAP 63.9 | 38.67ms | [预测部署模型](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) |
10 | | 车辆属性识别 | PPLCNet | 90.81 | 7.31 ms | [预测部署模型](https://bj.bcebos.com/v1/paddledet/models/pipeline/vehicle_attribute_model.zip) |
11 |
12 |
13 | 注意:
14 | 1. 属性模型预测速度是基于NVIDIA T4, 开启TensorRT FP16得到。模型预测速度包含数据预处理、模型预测、后处理部分。
15 | 2. 关于PP-LCNet的介绍可以参考[PP-LCNet](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.4/docs/zh_CN/models/PP-LCNet.md)介绍,相关论文可以查阅[PP-LCNet paper](https://arxiv.org/abs/2109.15099)。
16 | 3. 属性模型的训练和精度测试均基于[VeRi数据集](https://www.v7labs.com/open-datasets/veri-dataset)。
17 |
18 |
19 | - 当前提供的预训练模型支持识别10种车辆颜色及9种车型,同VeRi数据集,具体如下:
20 |
21 | ```yaml
22 | # 车辆颜色
23 | - "yellow"
24 | - "orange"
25 | - "green"
26 | - "gray"
27 | - "red"
28 | - "blue"
29 | - "white"
30 | - "golden"
31 | - "brown"
32 | - "black"
33 |
34 | # 车型
35 | - "sedan"
36 | - "suv"
37 | - "van"
38 | - "hatchback"
39 | - "mpv"
40 | - "pickup"
41 | - "bus"
42 | - "truck"
43 | - "estate"
44 | ```
45 |
46 | ## 使用方法
47 |
48 | ### 配置项说明
49 |
50 | [配置文件](../../config/infer_cfg_ppvehicle.yml)中与属性相关的参数如下:
51 | ```
52 | VEHICLE_ATTR:
53 | model_dir: output_inference/vehicle_attribute_infer/ # 车辆属性模型调用路径
54 | batch_size: 8 # 模型预测时的batch_size大小
55 | color_threshold: 0.5 # 颜色属性阈值,需要置信度达到此阈值才会确定具体颜色,否则为'Unknown‘
56 | type_threshold: 0.5 # 车型属性阈值,需要置信度达到此阈值才会确定具体属性,否则为'Unknown‘
57 | enable: False # 是否开启该功能
58 | ```
59 |
60 | ### 使用命令
61 |
62 | 1. 从模型库下载`车辆检测/跟踪`, `车辆属性识别`两个预测部署模型并解压到`./output_inference`路径下;默认会自动下载模型,如果手动下载,需要修改模型文件夹为模型存放路径。
63 | 2. 修改配置文件中`VEHICLE_ATTR`项的`enable: True`,以启用该功能。
64 | 3. 图片输入时,启动命令如下(更多命令参数说明,请参考[快速开始-参数说明](./PPVehicle_QUICK_STARTED.md)):
65 |
66 | ```bash
67 | # 预测单张图片文件
68 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
69 | --image_file=test_image.jpg \
70 | --device=gpu
71 |
72 | # 预测包含一张或多张图片的文件夹
73 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
74 | --image_dir=images/ \
75 | --device=gpu
76 | ```
77 |
78 | 4. 视频输入时,启动命令如下:
79 |
80 | ```bash
81 | #预测单个视频文件
82 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
83 | --video_file=test_video.mp4 \
84 | --device=gpu
85 |
86 | #预测包含一个或多个视频的文件夹
87 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
88 | --video_dir=test_videos/ \
89 | --device=gpu
90 | ```
91 |
92 | 5. 若修改模型路径,有以下两种方式:
93 |
94 | - 方法一:`./deploy/pipeline/config/infer_cfg_ppvehicle.yml`下可以配置不同模型路径,属性识别模型修改`VEHICLE_ATTR`字段下配置
95 | - 方法二:直接在命令行中增加`-o`,以覆盖配置文件中的默认模型路径:
96 |
97 | ```bash
98 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
99 | --video_file=test_video.mp4 \
100 | --device=gpu \
101 | -o VEHICLE_ATTR.model_dir=output_inference/vehicle_attribute_infer
102 | ```
103 |
104 | 测试效果如下:
105 |
106 |
71 |
107 |  108 |
108 |
109 |
110 | ## 方案说明
111 | 车辆属性识别模型使用了[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) 的超轻量图像分类方案(PULC,Practical Ultra Lightweight image Classification)。关于该模型的数据准备、训练、测试等详细内容,请见[PULC 车辆属性识别模型](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.4/docs/zh_CN/PULC/PULC_vehicle_attribute.md).
112 |
113 | 车辆属性识别模型选用了轻量级、高精度的PPLCNet。并在该模型的基础上,进一步使用了以下优化方案:
114 |
115 | - 使用SSLD预训练模型,在不改变推理速度的前提下,精度可以提升约0.5个百分点
116 | - 融合EDA数据增强策略,精度可以再提升0.52个百分点
117 | - 使用SKL-UGI知识蒸馏, 精度可以继续提升0.23个百分点
118 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_attribute_en.md:
--------------------------------------------------------------------------------
1 | English | [简体中文](ppvehicle_attribute.md)
2 |
3 | # Attribute Recognition Module of PP-Vehicle
4 |
5 | Vehicle attribute recognition is widely used in smart cities, smart transportation and other scenarios. In PP-Vehicle, a vehicle attribute recognition module is integrated, which can identify vehicle color and model.
6 |
7 | | Task | Algorithm | Precision | Inference Speed | Download |
8 | |-----------|------|-----------|----------|---------------------|
9 | | Vehicle Detection/Tracking | PP-YOLOE | mAP 63.9 | 38.67ms | [Inference and Deployment Model](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) |
10 | | Vehicle Attribute Recognition | PPLCNet | 90.81 | 7.31 ms | [Inference and Deployment Model](https://bj.bcebos.com/v1/paddledet/models/pipeline/vehicle_attribute_model.zip) |
11 |
12 |
13 | Note:
14 | 1. The inference speed of the attribute model is obtained from the test on NVIDIA T4, with TensorRT FP16. The time includes data pre-process, model inference and post-process.
15 | 2. For introductions, please refer to [PP-LCNet Series](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.4/docs/en/models/PP-LCNet_en.md). Related paper is available on PP-LCNet paper
16 | 3. The training and test phase of vehicle attribute recognition model are both obtained from [VeRi dataset](https://www.v7labs.com/open-datasets/veri-dataset).
17 |
18 |
19 | - The provided pre-trained model supports 10 colors and 9 models, which is the same with VeRi dataset. The details are as follows:
20 |
21 | ```yaml
22 | # Vehicle Colors
23 | - "yellow"
24 | - "orange"
25 | - "green"
26 | - "gray"
27 | - "red"
28 | - "blue"
29 | - "white"
30 | - "golden"
31 | - "brown"
32 | - "black"
33 |
34 | # Vehicle Models
35 | - "sedan"
36 | - "suv"
37 | - "van"
38 | - "hatchback"
39 | - "mpv"
40 | - "pickup"
41 | - "bus"
42 | - "truck"
43 | - "estate"
44 | ```
45 |
46 | ## Instructions
47 |
48 | ### Description of Configuration
49 |
50 | Parameters related to vehicle attribute recognition in the [config file](../../config/infer_cfg_ppvehicle.yml) are as follows:
51 |
52 | ```yaml
53 | VEHICLE_ATTR:
54 | model_dir: output_inference/vehicle_attribute_infer/ # Path of the model
55 | batch_size: 8 # The size of the inference batch
56 | color_threshold: 0.5 # Threshold of color. Confidence is required to reach this threshold to determine the specific attribute, otherwise it will be 'Unknown‘.
57 | type_threshold: 0.5 # Threshold of vehicle model. Confidence is required to reach this threshold to determine the specific attribute, otherwise it will be 'Unknown‘.
58 | enable: False # Whether to enable this function
59 | ```
60 |
61 | ### How to Use
62 | 1. Download models `Vehicle Detection/Tracking` and `Vehicle Attribute Recognition` from the links in `Model Zoo` and unzip them to ```./output_inference```. The models are automatically downloaded by default. If you download them manually, you need to modify the `model_dir` as the model storage path to use this function.
63 |
64 | 2. Set the "enable: True" of `VEHICLE_ATTR` in infer_cfg_ppvehicle.yml.
65 |
66 | 3. For image input, please run these commands. (Description of more parameters, please refer to [QUICK_STARTED - Parameter_Description](./PPVehicle_QUICK_STARTED.md).
67 |
68 | ```bash
69 | # For single image
70 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
71 | --image_file=test_image.jpg \
72 | --device=gpu
73 |
74 | # For folder contains one or multiple images
75 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
76 | --image_dir=images/ \
77 | --device=gpu
78 | ```
79 |
80 | 4. For video input, please run these commands.
81 |
82 | ```bash
83 | # For single video
84 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
85 | --video_file=test_video.mp4 \
86 | --device=gpu
87 |
88 | # For folder contains one or multiple videos
89 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
90 | --video_dir=test_videos/ \
91 | --device=gpu
92 | ```
93 |
94 | 5. There are two ways to modify the model path:
95 |
96 | - Method 1:Set paths of each model in `./deploy/pipeline/config/infer_cfg_ppvehicle.yml`. For vehicle attribute recognition, the path should be modified under the `VEHICLE_ATTR` field.
97 | - Method 2: Directly add `-o` in command line to override the default model path in the configuration file:
98 |
99 | ```bash
100 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
101 | --video_file=test_video.mp4 \
102 | --device=gpu \
103 | -o VEHICLE_ATTR.model_dir=output_inference/vehicle_attribute_infer
104 | ```
105 |
106 | The result is shown as follow:
107 |
108 |
108 |
109 |
110 |
111 |
112 |
113 | ### Features to the Solution
114 |
115 | The vehicle attribute recognition model adopts PULC, Practical Ultra Lightweight image Classification from [PaddleClas](https://github.com/PaddlePaddle/PaddleClas). For details on data preparation, training, and testing of the model, please refer to [PULC Recognition Model of Vehicle Attribute](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.4/docs/en/PULC/PULC_vehicle_attribute_en.md).
116 |
117 | The vehicle attribute recognition model adopts the lightweight and high-precision PPLCNet. And on top of PPLCNet, our model optimized via::
118 |
119 | - Improved about 0.5 percentage points accuracy by using the SSLD pre-trained model without changing the inference speed.
120 | - Improved 0.52 percentage points accuracy further by integrating EDA data augmentation strategy.
121 | - Improved 0.23 percentage points accuracy by using SKL-UGI knowledge distillation.
122 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_illegal_parking.md:
--------------------------------------------------------------------------------
1 |
2 | # PP-Vehicle违章停车识别模块
3 |
4 | 禁停区域违章停车识别在车辆应用场景中有着非常广泛的应用,借助AI的力量可以减轻人力投入,精准快速识别出违停车辆并进一步采取如广播驱离行为。PP-Vehicle中基于车辆跟踪模型、车牌检测模型和车牌识别模型实现了违章停车识别功能,具体模型信息如下:
5 |
6 | | 任务 | 算法 | 精度 | 预测速度(ms) |预测模型下载链接 |
7 | |:---------------------|:---------:|:------:|:------:| :---------------------------------------------------------------------------------: |
8 | | 车辆检测/跟踪 | PP-YOLOE-l | mAP: 63.9 | - |[下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) |
9 | | 车牌检测模型 | ch_PP-OCRv3_det | hmean: 0.979 | - | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_det_infer.tar.gz) |
10 | | 车牌识别模型 | ch_PP-OCRv3_rec | acc: 0.773 | - | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_rec_infer.tar.gz) |
11 |
12 | 1. 跟踪模型使用PPVehicle数据集(整合了BDD100K-MOT和UA-DETRAC),是将BDD100K-MOT中的car, truck, bus, van和UA-DETRAC中的car, bus, van都合并为1类vehicle(1)后的数据集。
13 | 2. 车牌检测、识别模型使用PP-OCRv3模型在CCPD2019、CCPD2020混合车牌数据集上fine-tune得到。
14 |
15 | ## 使用方法
16 |
17 | 1. 用户可从上表链接中下载模型并解压到```PaddleDetection/output_inference```路径下,并修改配置文件中模型路径,也可默认自动下载模型。在```deploy/pipeline/config/examples/infer_cfg_illegal_parking.yml```中可手动设置三个模型的模型路径。
18 |
19 | `infer_cfg_illegal_parking.yml`中配置项说明:
20 | ```
21 | MOT: # 跟踪模块
22 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip # 跟踪模型路径
23 | tracker_config: deploy/pipeline/config/tracker_config.yml # 跟踪配置文件路径
24 | batch_size: 1 # 跟踪batch size
25 | enable: True # 是否开启跟踪功能
26 |
27 | VEHICLE_PLATE: # 车牌识别模块
28 | det_model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_det_infer.tar.gz # 车牌检测模型路径
29 | det_limit_side_len: 480 # 检测模型单边输入尺寸
30 | det_limit_type: "max" # 检测模型输入尺寸长短边选择,"max"表示长边
31 | rec_model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_rec_infer.tar.gz # 车牌识别模型路径
32 | rec_image_shape: [3, 48, 320] # 车牌识别模型输入尺寸
33 | rec_batch_num: 6 # 车牌识别batch size
34 | word_dict_path: deploy/pipeline/ppvehicle/rec_word_dict.txt # OCR模型查询字典
35 | enable: True # 是否开启车牌识别功能
36 | ```
37 |
38 | 2. 输入视频,启动命令如下
39 | ```python
40 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/examples/infer_cfg_illegal_parking.yml \
41 | --video_file=test_video.mp4 \
42 | --device=gpu \
43 | --draw_center_traj \
44 | --illegal_parking_time=5 \
45 | --region_type=custom \
46 | --region_polygon 100 1000 1000 1000 900 1700 0 1700
47 | ```
48 |
49 | 参数说明如下:
50 | - config:配置文件路径;
51 | - video_file:测试视频路径;
52 | - device:推理设备配置;
53 | - draw_center_traj:画出车辆中心运动轨迹;
54 | - illegal_parking_time:非法停车时间,单位为秒;
55 | - region_type:非法停车区域类型,custom表示自定义;
56 | - region_polygon:自定义非法停车多边形,至少为3个点。
57 |
58 | **注意:**
59 | - 违章停车的测试视频必须是静止摄像头拍摄的,镜头不能抖动或移动。
60 | - 判断车辆是否在违停区域内是**以车辆的中心点**作为参考,车辆擦边而过等场景不算作违章停车。
61 | - `--region_polygon`表示用户自定义区域的多边形的点坐标序列,每两个为一对点坐标(x,y),**按顺时针顺序**连成一个**封闭区域**,至少需要3对点也即6个整数,默认值是`[]`,需要用户自行设置点坐标,如是四边形区域,坐标顺序是`左上、右上、右下、左下`。用户可以运行[此段代码](../../tools/get_video_info.py)获取所测视频的分辨率帧数,以及可以自定义画出自己想要的多边形区域的可视化并自己调整。
62 | 自定义多边形区域的可视化代码运行如下:
63 | ```python
64 | python get_video_info.py --video_file=demo.mp4 --region_polygon 200 200 400 200 300 400 100 400
65 | ```
66 | 快速画出想要的区域的小技巧:先任意取点得到图片,用画图工具打开,鼠标放到想要的区域点上会显示出坐标,记录下来并取整,作为这段可视化代码的region_polygon参数,并再次运行可视化,微调点坐标参数直至满意。
67 |
68 |
69 | 3. 若修改模型路径,有以下两种方式:
70 |
71 | - 方法一:```./deploy/pipeline/config/examples/infer_cfg_illegal_parking.yml```下可以配置不同模型路径;
72 | - 方法二:命令行中--config配置项后面增加`-o VEHICLE_PLATE.det_model_dir=[YOUR_DETMODEL_PATH] VEHICLE_PLATE.rec_model_dir=[YOUR_RECMODEL_PATH]`修改模型路径。
73 |
74 |
75 | 测试效果如下:
76 |
77 |
110 |
78 |  79 |
79 |
80 |
81 | 可视化视频中左上角num后面的数值表示当前帧中车辆的数目;Total count表示画面中出现的车辆的总数,包括出现又消失的车辆。
82 |
83 | ## 方案说明
84 |
85 | 1. 目标检测/多目标跟踪获取图片/视频输入中的车辆检测框,模型方案为PP-YOLOE,详细文档参考[PP-YOLOE](../../../configs/ppyoloe/README_cn.md)
86 | 2. 基于跟踪算法获取每辆车的轨迹,如果车辆中心在违停区域内且在指定时间内未发生移动,则视为违章停车;
87 | 3. 使用车牌识别模型得到违章停车车牌并可视化。
88 |
89 | ## 参考资料
90 |
91 | 1. PaddeDetection特色检测模型[PP-YOLOE](../../../../configs/ppyoloe)。
92 | 2. Paddle字符识别模型库[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)。
93 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_illegal_parking_en.md:
--------------------------------------------------------------------------------
1 |
2 | # PP-Vehicle Illegal Parking Recognition Module
3 |
4 | Illegal parking recognition in no-parking areas has a very wide range of applications in vehicle application scenarios. With the help of AI, human input can be reduced, and illegally parked vehicles can be accurately and quickly identified, and further behaviors such as broadcasting to expel the vehicles can be performed. Based on the vehicle tracking model, license plate detection model and license plate recognition model, the PP-Vehicle realizes the illegal parking recognition function. The specific model information is as follows:
5 |
6 | | Task | Algorithm | Precision | Inference Speed(ms) |Inference Model Download Link |
7 | |:---------------------|:---------:|:------:|:------:| :---------------------------------------------------------------------------------: |
8 | | Vehicle Tracking | PP-YOLOE-l | mAP: 63.9 | - |[Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) |
9 | | Plate Detection | ch_PP-OCRv3_det | hmean: 0.979 | - | [Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_det_infer.tar.gz) |
10 | | Plate Recognition | ch_PP-OCRv3_rec | acc: 0.773 | - | [Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_rec_infer.tar.gz) |
11 |
12 | 1. The tracking model uses the PPVehicle dataset (integrating BDD100K-MOT and UA-DETRAC), which combines car, truck, bus, van in BDD100K-MOT and car, bus, and van in UA-DETRAC into one class which named vehicle (1).
13 | 2. The license plate detection and recognition model is fine-tuned on the CCPD2019 and CCPD2020 using the PP-OCRv3 model.
14 |
15 | ## Instructions
16 |
17 | 1. Users can download the model from the link in the table above and unzip it to the ``PaddleDetection/output_inference``` path, and modify the model path in the configuration file, or download the model automatically by default. The model paths for the three models can be manually set in ``deploy/pipeline/config/examples/infer_cfg_illegal_parking.yml```.
18 |
19 | Description of configuration items in `infer_cfg_illegal_parking.yml`:
20 | ```
21 | MOT: # Tracking Module
22 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip # Path of Tracking Model
23 | tracker_config: deploy/pipeline/config/tracker_config.yml # Config Path of Tracking
24 | batch_size: 1 # Tracking batch size
25 | enable: True # Whether to Enable Tracking Function
26 |
27 | VEHICLE_PLATE: # Plate Recognition Module
28 | det_model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_det_infer.tar.gz # Path of Plate Detection Model
29 | det_limit_side_len: 480 # Single Side Size of Detection Model
30 | det_limit_type: "max" # Detection model Input Size Selection of Long and Short Sides, "max" Represents the Long Side
31 | rec_model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_rec_infer.tar.gz # Path of Plate Recognition Model
32 | rec_image_shape: [3, 48, 320] # The Input Size of Plate Recognition Model
33 | rec_batch_num: 6 # Plate Recognition batch size
34 | word_dict_path: deploy/pipeline/ppvehicle/rec_word_dict.txt # OCR Model Look-up Table
35 | enable: True # Whether to Enable Plate Recognition Function
36 | ```
37 |
38 | 2. Input video, the command is as follows:
39 | ```python
40 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/examples/infer_cfg_illegal_parking.yml \
41 | --video_file=test_video.mp4 \
42 | --device=gpu \
43 | --draw_center_traj \
44 | --illegal_parking_time=5 \
45 | --region_type=custom \
46 | --region_polygon 100 1000 1000 1000 900 1700 0 1700
47 |
48 | The parameter description:
49 | - config: config path;
50 | - video_file: video path to be tested;
51 | - device: device to infe;
52 | - draw_center_traj: draw the trajectory of the center of the vehicle;
53 | - illegal_parking_time: illegal parking time, in seconds;
54 | - region_type: illegal parking region type, 'custom' means the region is customized;
55 | - region_polygon: customized illegal parking region which includes three points at least.
56 |
57 | 3. Methods to modify the path of model:
58 |
59 | - Method 1: Configure different model paths in ```./deploy/pipeline/config/examples/infer_cfg_illegal_parking.yml``` file;
60 | - Method2: In the command line, add `-o VEHICLE_PLATE.det_model_dir=[YOUR_DETMODEL_PATH] VEHICLE_PLATE.rec_model_dir=[YOUR_RECMODEL_PATH]` after the --config configuration item to modify the model path.
61 |
62 |
63 | Test Result:
64 |
65 |
79 |
66 |
67 |
68 |
69 |
70 | ## Method Description
71 |
72 | 1. Target multi-target tracking obtains the vehicle detection frame in the picture/video input. The model scheme is PP-YOLOE. For detailed documentation, refer to [PP-YOLOE](../../../configs/ppyoloe/README_cn. md)
73 | 2. Obtain the trajectory of each vehicle based on the tracking algorithm. If the center of the vehicle is in the illegal parking area and does not move within the specified time, it is considered illegal parking;
74 | 3. Use the license plate recognition model to get the illegal parking license plate and visualize it.
75 |
76 |
77 | ## References
78 |
79 | 1. Detection Model in PaddeDetection:[PP-YOLOE](../../../../configs/ppyoloe).
80 | 2. Character Recognition Model Library in Paddle: [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR).
81 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_mot.md:
--------------------------------------------------------------------------------
1 | [English](ppvehicle_mot_en.md) | 简体中文
2 |
3 | # PP-Vehicle车辆跟踪模块
4 |
5 | 【应用介绍】
6 | 车辆检测与跟踪在交通监控、自动驾驶等方向都具有广泛应用,PP-Vehicle中集成了检测跟踪模块,是车牌检测、车辆属性识别等任务的基础。我们提供了预训练模型,用户可以直接下载使用。
7 |
8 | 【模型下载】
9 | | 任务 | 算法 | 精度 | 预测速度(ms) |下载链接 |
10 | |:---------------------|:---------:|:------:|:------:| :---------------------------------------------------------------------------------: |
11 | | 车辆检测/跟踪 | PP-YOLOE-l | mAP: 63.9
67 | MOTA: 50.1 | 检测: 25.1ms
跟踪:31.8ms | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) | 12 | | 车辆检测/跟踪 | PP-YOLOE-s | mAP: 61.3
MOTA: 46.8 | 检测: 16.2ms
跟踪:21.0ms | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_s_36e_ppvehicle.zip) | 13 | 14 | 1. 检测/跟踪模型精度为PPVehicle数据集训练得到,整合了BDD100K-MOT和UA-DETRAC,是将BDD100K-MOT中的`car, truck, bus, van`和UA-DETRAC中的`car, bus, van`都合并为1类`vehicle(1)`后的数据集,检测精度mAP是PPVehicle的验证集上测得,跟踪精度MOTA是在BDD100K-MOT的验证集上测得(`car, truck, bus, van`合并为1类`vehicle`)。训练具体流程请参照[ppvehicle](../../../../configs/ppvehicle)。 15 | 2. 预测速度为T4 机器上使用TensorRT FP16时的速度, 速度包含数据预处理、模型预测、后处理全流程。 16 | 17 | ## 使用方法 18 | 19 | 【配置项说明】 20 | 21 | 配置文件中与属性相关的参数如下: 22 | ``` 23 | DET: 24 | model_dir: output_inference/mot_ppyoloe_l_36e_ppvehicle/ # 车辆检测模型调用路径 25 | batch_size: 1 # 模型预测时的batch_size大小 26 | 27 | MOT: 28 | model_dir: output_inference/mot_ppyoloe_l_36e_ppvehicle/ # 车辆跟踪模型调用路径 29 | tracker_config: deploy/pipeline/config/tracker_config.yml 30 | batch_size: 1 # 模型预测时的batch_size大小, 跟踪任务只能设置为1 31 | skip_frame_num: -1 # 跳帧预测的帧数,-1表示不进行跳帧,建议跳帧帧数最大不超过3 32 | enable: False # 是否开启该功能,使用跟踪前必须确保设置为True 33 | ``` 34 | 35 | 【使用命令】 36 | 1. 从上表链接中下载模型并解压到```./output_inference```路径下,并修改配置文件中模型路径。默认为自动下载模型,无需做改动。 37 | 2. 图片输入时,是纯检测任务,启动命令如下 38 | ```python 39 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \ 40 | --image_file=test_image.jpg \ 41 | --device=gpu 42 | ``` 43 | 3. 视频输入时,是跟踪任务,注意首先设置infer_cfg_ppvehicle.yml中的MOT配置的`enable=True`,如果希望跳帧加速检测跟踪流程,可以设置`skip_frame_num: 2`,建议跳帧帧数最大不超过3: 44 | ``` 45 | MOT: 46 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip 47 | tracker_config: deploy/pipeline/config/tracker_config.yml 48 | batch_size: 1 49 | skip_frame_num: 2 50 | enable: True 51 | ``` 52 | ```python 53 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \ 54 | --video_file=test_video.mp4 \ 55 | --device=gpu 56 | ``` 57 | 4. 若修改模型路径,有以下两种方式: 58 | - 方法一:```./deploy/pipeline/config/infer_cfg_ppvehicle.yml```下可以配置不同模型路径,检测和跟踪模型分别对应`DET`和`MOT`字段,修改对应字段下的路径为实际期望的路径即可。 59 | - 方法二:命令行中--config配置项后面增加`-o MOT.model_dir=[YOUR_DETMODEL_PATH]`修改模型路径。 60 | ```python 61 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \ 62 | --video_file=test_video.mp4 \ 63 | --device=gpu \ 64 | --region_type=horizontal \ 65 | --do_entrance_counting \ 66 | --draw_center_traj \ 67 | -o MOT.model_dir=ppyoloe/ 68 | 69 | ``` 70 | **注意:** 71 | - `--do_entrance_counting`表示是否统计出入口流量,不设置即默认为False。 72 | - `--draw_center_traj`表示是否绘制跟踪轨迹,不设置即默认为False。注意绘制跟踪轨迹的测试视频最好是静止摄像头拍摄的。 73 | - `--region_type`表示流量计数的区域,当设置`--do_entrance_counting`时可选择`horizontal`或者`vertical`,默认是`horizontal`,表示以视频图片的中心水平线为出入口,同一物体框的中心点在相邻两秒内分别在区域中心水平线的两侧,即完成计数加一。 74 | 75 | 76 | 5. 区域闯入判断和计数 77 | 78 | 注意首先设置infer_cfg_ppvehicle.yml中的MOT配置的enable=True,然后启动命令如下 79 | ```python 80 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \ 81 | --video_file=test_video.mp4 \ 82 | --device=gpu \ 83 | --draw_center_traj \ 84 | --do_break_in_counting \ 85 | --region_type=custom \ 86 | --region_polygon 200 200 400 200 300 400 100 400 87 | ``` 88 | **注意:** 89 | - 区域闯入的测试视频必须是静止摄像头拍摄的,镜头不能抖动或移动。 90 | - `--do_break_in_counting`表示是否进行区域出入后计数,不设置即默认为False。 91 | - `--region_type`表示流量计数的区域,当设置`--do_break_in_counting`时仅可选择`custom`,默认是`custom`,表示以用户自定义区域为出入口,同一物体框的下边界中点坐标在相邻两秒内从区域外到区域内,即完成计数加一。 92 | - `--region_polygon`表示用户自定义区域的多边形的点坐标序列,每两个为一对点坐标(x,y),**按顺时针顺序**连成一个**封闭区域**,至少需要3对点也即6个整数,默认值是`[]`,需要用户自行设置点坐标,如是四边形区域,坐标顺序是`左上、右上、右下、左下`。用户可以运行[此段代码](../../tools/get_video_info.py)获取所测视频的分辨率帧数,以及可以自定义画出自己想要的多边形区域的可视化并自己调整。 93 | 自定义多边形区域的可视化代码运行如下: 94 | ```python 95 | python get_video_info.py --video_file=demo.mp4 --region_polygon 200 200 400 200 300 400 100 400 96 | ``` 97 | 快速画出想要的区域的小技巧:先任意取点得到图片,用画图工具打开,鼠标放到想要的区域点上会显示出坐标,记录下来并取整,作为这段可视化代码的region_polygon参数,并再次运行可视化,微调点坐标参数直至满意。 98 | 99 | 100 | 【效果展示】 101 | 102 |
103 |  104 |
104 |
105 |
106 | ## 方案说明
107 |
108 | 【实现方案及特色】
109 | 1. 使用目标检测/多目标跟踪技术来获取图片/视频输入中的车辆检测框,检测模型方案为PP-YOLOE,详细文档参考[PP-YOLOE](../../../../configs/ppyoloe)和[ppvehicle](../../../../configs/ppvehicle)。
110 | 2. 多目标跟踪模型方案采用[OC-SORT](https://arxiv.org/pdf/2203.14360.pdf),采用PP-YOLOE替换原文的YOLOX作为检测器,采用OCSORTTracker作为跟踪器,详细文档参考[OC-SORT](../../../../configs/mot/ocsort)。
111 |
112 | ## 参考文献
113 | ```
114 | @article{cao2022observation,
115 | title={Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking},
116 | author={Cao, Jinkun and Weng, Xinshuo and Khirodkar, Rawal and Pang, Jiangmiao and Kitani, Kris},
117 | journal={arXiv preprint arXiv:2203.14360},
118 | year={2022}
119 | }
120 | ```
121 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_mot_en.md:
--------------------------------------------------------------------------------
1 | English | [简体中文](ppvehicle_mot.md)
2 |
3 | # PP-Vehicle Vehicle Tracking Module
4 |
5 | 【Application Introduction】
6 |
7 | Vehicle detection and tracking are widely used in traffic monitoring and autonomous driving. The detection and tracking module is integrated in PP-Vehicle, providing a solid foundation for tasks including license plate detection and vehicle attribute recognition. We provide pre-trained models that can be directly used by developers.
8 |
9 | 【Model Download】
10 |
11 | | Task | Algorithm | Accuracy | Inference speed(ms) | Download Link |
12 | | -------------------------- | ---------- | ----------------------- | ------------------------------------ | ------------------------------------------------------------------------------------------ |
13 | | Vehicle Detection/Tracking | PP-YOLOE-l | mAP: 63.9
104 | MOTA: 50.1 | Detection: 25.1ms
Tracking:31.8ms | [Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) | 14 | | Vehicle Detection/Tracking | PP-YOLOE-s | mAP: 61.3
MOTA: 46.8 | Detection: 16.2ms
Tracking:21.0ms | [Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_s_36e_ppvehicle.zip) | 15 | 16 | 1. The detection/tracking model uses the PPVehicle dataset ( which integrates BDD100K-MOT and UA-DETRAC). The dataset merged car, truck, bus, van from BDD100K-MOT and car, bus, van from UA-DETRAC all into 1 class vehicle(1). The detection accuracy mAP was tested on the test set of PPVehicle, and the tracking accuracy MOTA was obtained on the test set of BDD100K-MOT (`car, truck, bus, van` were combined into 1 class `vehicle`). For more details about the training procedure, please refer to [ppvehicle](../../../../configs/ppvehicle). 17 | 2. Inference speed is obtained at T4 with TensorRT FP16 enabled, which includes data pre-processing, model inference and post-processing. 18 | 19 | ## How To Use 20 | 21 | 【Config】 22 | 23 | The parameters associated with the attributes in the configuration file are as follows. 24 | 25 | ``` 26 | DET: 27 | model_dir: output_inference/mot_ppyoloe_l_36e_ppvehicle/ # Vehicle detection model path 28 | batch_size: 1 # Batch_size size for model inference 29 | 30 | MOT: 31 | model_dir: output_inference/mot_ppyoloe_l_36e_ppvehicle/ # Vehicle tracking model path 32 | tracker_config: deploy/pipeline/config/tracker_config.yml 33 | batch_size: 1 # Batch_size size for model inference, 1 only for tracking task. 34 | skip_frame_num: -1 # Number of frames to skip, -1 means no skipping, the maximum skipped frames are recommended to be 3 35 | enable: False # Whether or not to enable this function, please make sure it is set to True before tracking 36 | ``` 37 | 38 | 【Usage】 39 | 40 | 1. Download the model from the link in the table above and unzip it to ``. /output_inference`` and change the model path in the configuration file. The default is to download the model automatically, no changes are needed. 41 | 42 | 2. The image input will start a pure detection task, and the start command is as follows 43 | 44 | ```python 45 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \ 46 | --image_file=test_image.jpg \ 47 | --device=gpu 48 | ``` 49 | 50 | 3. Video input will start a tracking task. Please set `enable=True` for the MOT configuration in infer_cfg_ppvehicle.yml. If skip frames are needed for faster detection and tracking, it is recommended to set `skip_frame_num: 2` the maximum should not exceed 3. 51 | 52 | ``` 53 | MOT: 54 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip 55 | tracker_config: deploy/pipeline/config/tracker_config.yml 56 | batch_size: 1 57 | skip_frame_num: 2 58 | enable: True 59 | ``` 60 | 61 | ```python 62 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \ 63 | --video_file=test_video.mp4 \ 64 | --device=gpu 65 | ``` 66 | 67 | 4. There are two ways to modify the model path 68 | 69 | - Config different model path in```./deploy/pipeline/config/infer_cfg_ppvehicle.yml```. The detection and tracking models correspond to the `DET` and `MOT` fields respectively. Modify the path under the corresponding field to the actual path. 70 | 71 | - **[Recommand]** Add`-o MOT.model_dir=[YOUR_DETMODEL_PATH]` after the config in the command line to modify model path 72 | 73 | ```python 74 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \ 75 | --video_file=test_video.mp4 \ 76 | --device=gpu \ 77 | --region_type=horizontal \ 78 | --do_entrance_counting \ 79 | --draw_center_traj \ 80 | -o MOT.model_dir=ppyoloe/ 81 | ``` 82 | 83 | **Note:** 84 | 85 | - `--do_entrance_counting` : Whether to count entrance/exit traffic flows, the default is False 86 | 87 | - `--draw_center_traj` : Whether to draw center trajectory, the default is False. Its input video is preferably taken from a still camera 88 | 89 | - `--region_type` : The region for traffic counting. When setting `--do_entrance_counting`, there are two options: `horizontal` or `vertical`. The default is `horizontal`, which means the center horizontal line of the video picture is the entrance and exit. When the center point of the same object frame is on both sides of the centre horizontal line of the region in two adjacent seconds, i.e. the count adds 1. 90 | 5. Regional break-in and counting 91 | 92 | Please set the MOT config: enable=True in `infer_cfg_ppvehicle.yml` before running the starting command: 93 | 94 | ``` 95 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \ 96 | --video_file=test_video.mp4 \ 97 | --device=gpu \ 98 | --draw_center_traj \ 99 | --do_break_in_counting \ 100 | --region_type=custom \ 101 | --region_polygon 200 200 400 200 300 400 100 400 102 | ``` 103 | 104 | **Note:** 105 | 106 | - Test video of area break-ins must be taken from a still camera, with no shaky or moving footage. 107 | 108 | - `--do_break_in_counting`Indicates whether or not to count the entrance and exit of the area. The default is False. 109 | 110 | - `--region_type` indicates the region for traffic counting, when setting `--do_break_in_counting` only `custom` can be selected, and the default is `custom`. It means that the customized region is used as the entry and exit. When the coordinates of the lower boundary midpoint of the same object frame goes to the inside of the region within two adjacent seconds, i.e. the count adds one. 111 | 112 | - `--region_polygon` indicates a sequence of point coordinates for a polygon in a customized region. Every two are a pair of point coordinates (x,y). **In clockwise order** they are connected into a **closed region**, at least 3 pairs of points are needed (or 6 integers). The default value is `[]`. Developers need to set the point coordinates manually. If it is a quadrilateral region, the coordinate order is `top left, top right , bottom right, bottom left`. Developers can run [this code](... /... /tools/get_video_info.py) to get the resolution frames of the predicted video. It also supports customizing and adjusting the visualisation of the polygon area. 113 | The code for the visualisation of the customized polygon area runs as follows. 114 | 115 | ```python 116 | python get_video_info.py --video_file=demo.mp4 --region_polygon 200 200 400 200 300 400 100 400 117 | ``` 118 | 119 | A quick tip for drawing customized area: first take any point to get the picture, open it with the drawing tool, mouse over the area point and the coordinates will be displayed, record it and round it up, use it as a region_polygon parameter for this visualisation code and run the visualisation again, and fine-tune the point coordinates parameter. 120 | 121 | 【Showcase】 122 | 123 |
124 |
125 |
126 |
127 | ## Solution
128 |
129 | 【Solution and feature】
130 |
131 | - PP-YOLOE is adopted for vehicle detection frame of object detection, multi-object tracking in the picture/video input. For details, please refer to [PP-YOLOE](... /... /... /configs/ppyoloe/README_cn.md) and [PPVehicle](../../../../configs/ppvehicle)
132 | - [OC-SORT](https://arxiv.org/pdf/2203.14360.pdf) is adopted as multi-object tracking model. PP-YOLOE replaced YOLOX as detector, and OCSORTTracker is the tracker. For more details, please refer to [OC-SORT](../../../../configs/mot/ocsort)
133 |
134 | ## Reference
135 |
136 | ```
137 | @article{cao2022observation,
138 | title={Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking},
139 | author={Cao, Jinkun and Weng, Xinshuo and Khirodkar, Rawal and Pang, Jiangmiao and Kitani, Kris},
140 | journal={arXiv preprint arXiv:2203.14360},
141 | year={2022}
142 | }
143 | ```
144 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_plate.md:
--------------------------------------------------------------------------------
1 | [English](ppvehicle_plate_en.md) | 简体中文
2 |
3 | # PP-Vehicle车牌识别模块
4 |
5 | 车牌识别,在车辆应用场景中有着非常广泛的应用,起到车辆身份识别的作用,比如车辆出入口自动闸机。PP-Vehicle中提供了车辆的跟踪及其车牌识别的功能,并提供模型下载:
6 |
7 | | 任务 | 算法 | 精度 | 预测速度(ms) |预测模型下载链接 |
8 | |:---------------------|:---------:|:------:|:------:| :---------------------------------------------------------------------------------: |
9 | | 车辆检测/跟踪 | PP-YOLOE-l | mAP: 63.9 | - |[下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) |
10 | | 车牌检测模型 | ch_PP-OCRv3_det | hmean: 0.979 | - | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_det_infer.tar.gz) |
11 | | 车牌识别模型 | ch_PP-OCRv3_rec | acc: 0.773 | - | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_rec_infer.tar.gz) |
12 | 1. 跟踪模型使用PPVehicle数据集(整合了BDD100K-MOT和UA-DETRAC),是将BDD100K-MOT中的car, truck, bus, van和UA-DETRAC中的car, bus, van都合并为1类vehicle(1)后的数据集。
13 | 2. 车牌检测、识别模型使用PP-OCRv3模型在CCPD2019、CCPD2020混合车牌数据集上fine-tune得到。
14 |
15 | ## 使用方法
16 |
17 | 1. 从上表链接中下载模型并解压到```PaddleDetection/output_inference```路径下,并修改配置文件中模型路径,也可默认自动下载模型。设置```deploy/pipeline/config/infer_cfg_ppvehicle.yml```中`VEHICLE_PLATE`的enable: True
18 |
19 | `infer_cfg_ppvehicle.yml`中配置项说明:
20 | ```
21 | VEHICLE_PLATE: #模块名称
22 | det_model_dir: output_inference/ch_PP-OCRv3_det_infer/ #车牌检测模型路径
23 | det_limit_side_len: 480 #检测模型单边输入尺寸
24 | det_limit_type: "max" #检测模型输入尺寸长短边选择,"max"表示长边
25 | rec_model_dir: output_inference/ch_PP-OCRv3_rec_infer/ #车牌识别模型路径
26 | rec_image_shape: [3, 48, 320] #车牌识别模型输入尺寸
27 | rec_batch_num: 6 #车牌识别batchsize
28 | word_dict_path: deploy/pipeline/ppvehicle/rec_word_dict.txt #OCR模型查询字典
29 | basemode: "idbased" #流程类型,'idbased'表示基于跟踪模型
30 | enable: False #功能是否开启
31 | ```
32 |
33 | 2. 图片输入时,启动命令如下(更多命令参数说明,请参考[快速开始-参数说明](./PPVehicle_QUICK_STARTED.md#41-参数说明))。
34 | ```python
35 | #单张图片
36 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
37 | --image_file=test_image.jpg \
38 | --device=gpu \
39 |
40 | #图片文件夹
41 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
42 | --image_dir=images/ \
43 | --device=gpu \
44 |
45 | ```
46 |
47 | 3. 视频输入时,启动命令如下
48 | ```python
49 | #单个视频文件
50 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
51 | --video_file=test_video.mp4 \
52 | --device=gpu \
53 |
54 | #视频文件夹
55 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
56 | --video_dir=test_videos/ \
57 | --device=gpu \
58 | ```
59 |
60 | 4. 若修改模型路径,有以下两种方式:
61 |
62 | - 方法一:```./deploy/pipeline/config/infer_cfg_ppvehicle.yml```下可以配置不同模型路径,车牌识别模型修改`VEHICLE_PLATE`字段下配置
63 | - 方法二:命令行中--config配置项后面增加`-o VEHICLE_PLATE.det_model_dir=[YOUR_DETMODEL_PATH] VEHICLE_PLATE.rec_model_dir=[YOUR_RECMODEL_PATH]`修改模型路径。
64 |
65 |
66 | 测试效果如下:
67 |
68 |
125 |
69 |  70 |
70 |
71 |
72 |
73 | ## 方案说明
74 |
75 | 1. 目标检测/多目标跟踪获取图片/视频输入中的车辆检测框,模型方案为PP-YOLOE,详细文档参考[PP-YOLOE](../../../configs/ppyoloe/README_cn.md)
76 | 2. 通过车辆检测框的坐标在输入图像中截取每个车辆
77 | 3. 使用车牌检测模型在每张车辆截图中识别车牌所在位置,同理截取车牌区域,模型方案为PP-OCRv3_det模型,经CCPD数据集在车牌场景fine-tune得到。
78 | 4. 使用字符识别模型识别车牌中的字符。模型方案为PP-OCRv3_rec模型,经CCPD数据集在车牌场景fine-tune得到。
79 |
80 | **性能优化措施:**
81 |
82 | 1. 使用跳帧策略,每10帧做一次车牌检测,避免每帧做车牌检测的算力消耗。
83 | 2. 车牌结果稳定策略,避免单帧结果的波动,利用同一个id的历史所有车牌识别结果进行投票,得到该id最大可能的正确结果。
84 |
85 | ## 参考资料
86 |
87 | 1. PaddeDetection特色检测模型[PP-YOLOE](../../../../configs/ppyoloe)。
88 | 2. Paddle字符识别模型库[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)。
89 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_plate_en.md:
--------------------------------------------------------------------------------
1 | English | [简体中文](ppvehicle_plate.md)
2 |
3 | # PP-Vehicle License Plate Recognition Modules
4 |
5 | License plate recognition has a very wide range of applications with vehicle identification functions, such as automatic vehicle entrance/exit gates.
6 |
7 | PP-Vehicle supports vehicle tracking and license plate recognition. Models are available for download:
8 |
9 | | Task | Algorithm | Accuracy | Inference speed(ms) | Model Download |
10 | |:-------------------------- |:---------------:|:------------:|:-------------------:|:------------------------------------------------------------------------------------------:|
11 | | Vehicle Detection/Tracking | PP-YOLOE-l | mAP: 63.9 | - | [Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) |
12 | | Vehicle Detection Model | ch_PP-OCRv3_det | hmean: 0.979 | - | [Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_det_infer.tar.gz) |
13 | | Vehicle Detection Model | ch_PP-OCRv3_rec | acc: 0.773 | - | [Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/ch_PP-OCRv3_rec_infer.tar.gz) |
14 |
15 | 1. The tracking model uses the PPVehicle dataset ( which integrates BDD100K-MOT and UA-DETRAC). The dataset merged car, truck, bus, van from BDD100K-MOT and car, bus, van from UA-DETRAC all into 1 class vehicle(1).
16 | 2. License plate detection and recognition models were obtained from fine-tuned PP-OCRv3 model on the CCPD2019 and CCPD2020 mixed license plate datasets.
17 |
18 | ## How to Use
19 |
20 | 1. Download models from the above table and unzip it to```PaddleDetection/output_inference```, and modify the model path in the configuration file. Models can also be downloaded automatically by default: Set enable: True of `VEHICLE_PLATE` in `deploy/pipeline/config/infer_cfg_ppvehicle.yml`
21 |
22 | Config Description of `infer_cfg_ppvehicle.yml`:
23 |
24 | ```
25 | VEHICLE_PLATE: #模块名称
26 | det_model_dir: output_inference/ch_PP-OCRv3_det_infer/ #车牌检测模型路径
27 | det_limit_side_len: 480 #检测模型单边输入尺寸
28 | det_limit_type: "max" #检测模型输入尺寸长短边选择,"max"表示长边
29 | rec_model_dir: output_inference/ch_PP-OCRv3_rec_infer/ #车牌识别模型路径
30 | rec_image_shape: [3, 48, 320] #车牌识别模型输入尺寸
31 | rec_batch_num: 6 #车牌识别batchsize
32 | word_dict_path: deploy/pipeline/ppvehicle/rec_word_dict.txt #OCR模型查询字典
33 | basemode: "idbased" #流程类型,'idbased'表示基于跟踪模型
34 | enable: False #功能是否开启
35 | ```
36 |
37 | 2. For picture input, the start command is as follows (for more descriptions of the command parameters, please refer to [Quick Start - Parameter Description](. /PPVehicle_QUICK_STARTED.md#41-parameter description)).
38 |
39 | ```python
40 | #Single image
41 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
42 | --image_file=test_image.jpg \
43 | --device=gpu \
44 | #Image folder
45 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
46 | --image_dir=images/ \
47 | --device=gpu \
48 | ```
49 |
50 | 3. For video input, the start command is as follows
51 |
52 | ```bash
53 | #Single video
54 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
55 | --video_file=test_video.mp4 \
56 | --device=gpu \
57 |
58 | #Video folder
59 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
60 | --video_dir=test_videos/ \
61 | --device=gpu \
62 | ```
63 |
64 | 4. There are two ways to modify the model path
65 |
66 | - Config different model path in ```./deploy/pipeline/config/infer_cfg_ppvehicle.yml```, and modify`VEHICLE_PLATE`field to config license plate recognition model modification
67 | - **[Recommand]** Add`-o VEHICLE_PLATE.det_model_dir=[YOUR_DETMODEL_PATH] VEHICLE_PLATE.rec_model_dir=[YOUR_RECMODEL_PATH]` to config file in command line.
68 |
69 | The test results are as follows:
70 |
71 |
70 |
72 |
73 |
74 |
75 | ## Solutions
76 |
77 | 1. PP-YOLOE is adopted for vehicle detection frame of object detection, multi-object tracking in the picture/video input. For details, please refer to [PP-YOLOE](... /... /... /configs/ppyoloe/README_cn.md)
78 | 2. By using the coordinates of the vehicle detection frame, each vehicle's image is intercepted in the input image
79 | 3. Use the license plate detection model to identify the location of the license plate in each vehicle screenshot as well as the license plate area. The PP-OCRv3_det model is adopted as the solution, obtained from fine-tuned CCPD dataset in terms of number plate.
80 | 4. Use a character recognition model to identify characters in a number plate. The PP-OCRv3_det model is adopted as the solution, obtained from fine-tuned CCPD dataset in terms of number plate.
81 |
82 | **Performance optimization measures:**
83 |
84 | 1. Use a frame skipping strategy to detect license plates every 10 frames to reduce the computing workload.
85 | 2. Use the license plate result stabilization strategy to avoid the volatility of single frame results; use all historical license plate recognition results of the same id to gain the most likely result for that id.
86 |
87 | ## Reference
88 |
89 | 1. PaddeDetection featured detection model PP-YOLOE](../../../../configs/ppyoloe)。
90 | 2. Paddle OCR Model Library [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)。
91 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_press.md:
--------------------------------------------------------------------------------
1 | [English](ppvehicle_press_en.md) | 简体中文
2 |
3 | # PP-Vehicle压实线识别模块
4 |
5 | 车辆压实线识别在智慧城市,智慧交通等方向具有广泛应用。在PP-Vehicle中,集成了车辆压实线识别模块,可识别车辆是否违章压实线。
6 |
7 | | 任务 | 算法 | 精度 | 预测速度 | 下载链接|
8 | |-----------|------|-----------|----------|---------------|
9 | | 车辆检测/跟踪 | PP-YOLOE | mAP 63.9 | 38.67ms | [预测部署模型](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) |
10 | | 车道线识别 | PP-liteseg | mIou 32.69 | 47 ms | [预测部署模型](https://bj.bcebos.com/v1/paddledet/models/pipeline/pp_lite_stdc2_bdd100k.zip) |
11 |
12 |
13 | 注意:
14 | 1. 车辆检测/跟踪模型预测速度是基于NVIDIA T4, 开启TensorRT FP16得到。模型预测速度包含数据预处理、模型预测、后处理部分。
15 | 2. 车辆检测/跟踪模型的训练和精度测试均基于[VeRi数据集](https://www.v7labs.com/open-datasets/veri-dataset)。
16 | 3. 车道线模型预测速度基于Tesla P40,python端预测,模型预测速度包含数据预处理、模型预测、后处理部分。
17 | 4. 车道线模型训练和精度测试均基于[BDD100K-LaneSeg](https://bdd-data.berkeley.edu/portal.html#download)和[Apollo Scape](http://apolloscape.auto/lane_segmentation.html#to_dataset_href),两个数据集车道线分割[标签](https://bj.bcebos.com/v1/paddledet/data/mot/bdd100k/lane_dataset_label.zip)
18 |
19 |
20 | ## 使用方法
21 |
22 | ### 配置项说明
23 |
24 | [配置文件](../../config/infer_cfg_ppvehicle.yml)中与车辆压线相关的参数如下:
25 | ```
26 | VEHICLE_PRESSING:
27 | enable: True #是否开启功能
28 | LANE_SEG:
29 | lane_seg_config: deploy/pipeline/config/lane_seg_config.yml #车道线提取配置文件
30 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/pp_lite_stdc2_bdd100k.zip #模型文件路径
31 | ```
32 | [车道线配置文件](../../config/lane_seg_config.yml)中与车道线提取相关的参数如下:
33 | ```
34 | type: PLSLaneseg #选择分割模型
35 |
36 | PLSLaneseg:
37 | batch_size: 1 #图片batch_size
38 | device: gpu #选择gpu还是cpu
39 | filter_flag: True #是否过滤水平方向道路线
40 | horizontal_filtration_degree: 23 #过滤水平方向车道线阈值,当分割出来的车道线最大倾斜角与
41 | #最小倾斜角差值小于阈值时,不进行过滤
42 | horizontal_filtering_threshold: 0.25 #确定竖直方向与水平方向分开阈值
43 | #thr = (min_degree+max_degree)*0.25
44 | #根据车道线倾斜角与thr的大小比较,将车道线分为垂直方向与水平方向
45 | ```
46 |
47 | ### 使用命令
48 |
49 | 1. 从模型库下载`车辆检测/跟踪`, `车道线识别`两个预测部署模型并解压到`./output_inference`路径下;默认会自动下载模型,如果手动下载,需要修改模型文件夹为模型存放路径。
50 | 2. 修改配置文件中`VEHICLE_PRESSING`项的`enable: True`,以启用该功能。
51 | 3. 图片输入时,启动命令如下(更多命令参数说明,请参考[快速开始-参数说明](./PPVehicle_QUICK_STARTED.md)):
52 |
53 | ```bash
54 | # 预测单张图片文件
55 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
56 | -o VEHICLE_PRESSING.enable=true
57 | --image_file=test_image.jpg \
58 | --device=gpu
59 |
60 | # 预测包含一张或多张图片的文件夹
61 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
62 | -o VEHICLE_PRESSING.enable=true
63 | --image_dir=images/ \
64 | --device=gpu
65 | ```
66 |
67 | 4. 视频输入时,启动命令如下:
68 |
69 | ```bash
70 | #预测单个视频文件
71 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
72 | -o VEHICLE_PRESSING.enable=true
73 | --video_file=test_video.mp4 \
74 | --device=gpu
75 |
76 | #预测包含一个或多个视频的文件夹
77 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
78 | --video_dir=test_videos/ \
79 | -o VEHICLE_PRESSING.enable=true
80 | --device=gpu
81 | ```
82 |
83 | 5. 若修改模型路径,有以下两种方式:
84 |
85 | - 方法一:`./deploy/pipeline/config/infer_cfg_ppvehicle.yml`下可以配置不同模型路径,车道线识别模型修改`LANE_SEG`字段下配置
86 | - 方法二:直接在命令行中增加`-o`,以覆盖配置文件中的默认模型路径:
87 |
88 | ```bash
89 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
90 | --video_file=test_video.mp4 \
91 | --device=gpu \
92 | -o VEHICLE_PRESSING.enable=true
93 | LANE_SEG.model_dir=output_inference
94 | ```
95 |
96 | 测试效果如下:
97 |
98 |
73 |
99 |  100 |
100 |
101 |
102 | ## 方案说明
103 | 1.车道线识别模型使用了[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg) 的超轻量分割方案。训练样本[标签](https://bj.bcebos.com/v1/paddledet/data/mot/bdd100k/lane_dataset_label.zip)分为4类:
104 | 0 背景
105 | 1 双黄线
106 | 2 实线
107 | 3 虚线
108 | 车辆压线分析过滤虚线类;
109 |
110 | 2.车道线通过对分割结果聚类得到,且默认过滤水平方向车道线,若不过滤可在[车道线配置文件](../../config/lane_seg_config.yml)修改`filter_flag`参数;
111 |
112 | 3.车辆压线判断条件:车辆的检测框底边线与车道线是否有交点;
113 |
114 | **性能优化措施**
115 | 1.因摄像头视角原因,可以根据实际情况决定是否过滤水平方向车道线;
116 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_press_en.md:
--------------------------------------------------------------------------------
1 | English | [简体中文](ppvehicle_press.md)
2 |
3 | # PP-Vehicle press line identification module
4 |
5 | Vehicle compaction line recognition is widely used in smart cities, smart transportation and other directions.
6 | In PP-Vehicle, a vehicle compaction line identification module is integrated to identify whether the vehicle is in violation of regulations.
7 |
8 | | task | algorithm | precision | infer speed | download|
9 | |-----------|------|-----------|----------|---------------|
10 | | Vehicle detection/tracking | PP-YOLOE | mAP 63.9 | 38.67ms | [infer deploy model](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) |
11 | | Lane line segmentation | PP-liteseg | mIou 32.69 | 47 ms | [infer deploy model](https://bj.bcebos.com/v1/paddledet/models/pipeline/pp_lite_stdc2_bdd100k.zip) |
12 |
13 |
14 | Notes:
15 | 1. The prediction speed of vehicle detection/tracking model is based on NVIDIA T4 and TensorRT FP16. The model prediction speed includes data preprocessing, model prediction and post-processing.
16 | 2. The training and precision test of vehicle detection/tracking model are based on [VeRi](https://www.v7labs.com/open-datasets/veri-dataset).
17 | 3. The predicted speed of lane line segmentation model is based on Tesla P40 and python prediction. The predicted speed of the model includes data preprocessing, model prediction and post-processing.
18 | 4. Lane line model training and precision testing are based on [BDD100K-LaneSeg](https://bdd-data.berkeley.edu/portal.html#download)and [Apollo Scape](http://apolloscape.auto/lane_segmentation.html#to_dataset_href),The label data of the two data sets is in[Lane_dataset_label](https://bj.bcebos.com/v1/paddledet/data/mot/bdd100k/lane_dataset_label.zip)
19 |
20 |
21 | ## Instructions
22 |
23 | ### Description of Configuration
24 |
25 | The parameters related to vehicle line pressing in [config file](../../config/infer_cfg_ppvehicle.yml) is as follows:
26 | ```
27 | VEHICLE_PRESSING:
28 | enable: True #Whether to enable the funcion
29 | LANE_SEG:
30 | lane_seg_config: deploy/pipeline/config/lane_seg_config.yml #lane line seg config file
31 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/pp_lite_stdc2_bdd100k.zip #model path
32 | ```
33 | The parameters related to Lane line segmentation in [lane line seg config file](../../config/lane_seg_config.yml)is as follows:
34 | ```
35 | type: PLSLaneseg #Select segmentation Model
36 |
37 | PLSLaneseg:
38 | batch_size: 1 #image batch_size
39 | device: gpu #device is gpu or cpu
40 | filter_flag: True #Whether to filter the horizontal direction road route
41 | horizontal_filtration_degree: 23 #Filter the threshold value of the lane line in the horizontal direction. When the difference between the maximum inclination angle and the minimum inclination angle of the segmented lane line is less than the threshold value, no filtering is performed
42 |
43 | horizontal_filtering_threshold: 0.25 #Determine the threshold value for separating the vertical direction from the horizontal direction thr=(min_degree+max_degree) * 0.25 Divide the lane line into vertical direction and horizontal direction according to the comparison between the gradient angle of the lane line and thr
44 | ```
45 | ### How to Use
46 |
47 | 1. Download 'vehicle detection/tracking' and 'lane line recognition' two prediction deployment models from the model base and unzip them to '/ output_ Invitation ` under the path; By default, the model will be downloaded automatically. If you download it manually, you need to modify the model folder as the model storage path.
48 |
49 | 2. Modify Profile ` VEHICLE_PRESSING ' -'enable: True' item to enable this function.
50 |
51 | 3. When inputting a picture, the startup command is as follows (for more command parameter descriptions,please refer to [QUICK_STARTED - Parameter_Description](./PPVehicle_QUICK_STARTED.md)
52 |
53 | ```bash
54 | # For single image
55 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
56 | -o VEHICLE_PRESSING.enable=true
57 | --image_file=test_image.jpg \
58 | --device=gpu
59 |
60 | # For folder contains one or multiple images
61 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
62 | -o VEHICLE_PRESSING.enable=true
63 | --image_dir=images/ \
64 | --device=gpu
65 | ```
66 |
67 | 4. For video input, please run these commands.
68 |
69 | ```bash
70 | #For single video
71 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
72 | -o VEHICLE_PRESSING.enable=true
73 | --video_file=test_video.mp4 \
74 | --device=gpu
75 |
76 | #For folder contains one or multiple videos
77 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
78 | --video_dir=test_videos/ \
79 | -o VEHICLE_PRESSING.enable=true
80 | --device=gpu
81 | ```
82 |
83 | 5. There are two ways to modify the model path:
84 |
85 | - 1.Set paths of each model in `./deploy/pipeline/config/infer_cfg_ppvehicle.yml`,For Lane line segmentation, the path should be modified under the `LANE_SEG`
86 | - 2.Directly add `-o` in command line to override the default model path in the configuration file:
87 |
88 | ```bash
89 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
90 | --video_file=test_video.mp4 \
91 | --device=gpu \
92 | -o VEHICLE_PRESSING.enable=true
93 | LANE_SEG.model_dir=output_inference
94 | ```
95 |
96 | The result is shown as follow:
97 |
98 |
100 |
99 |
100 |
101 |
102 | ## Features to the Solution
103 | 1.Lane line recognition model uses [PaddleSeg]( https://github.com/PaddlePaddle/PaddleSeg )Super lightweight segmentation scheme.Train [lable](https://bj.bcebos.com/v1/paddledet/data/mot/bdd100k/lane_dataset_label.zip)it is divided into four categories:
104 | 0 Background
105 | 1 Double yellow line
106 | 2 Solid line
107 | 3 Dashed line
108 | Lane line recognition filtering Dashed lines;
109 |
110 | 2.Lane lines are obtained by clustering segmentation results, and the horizontal lane lines are filtered by default. If not, you can modify the `filter_flag` in [lane line seg config file](../../config/lane_seg_config.yml);
111 |
112 | 3.Judgment conditions for vehicle line pressing: whether there is intersection between the bottom edge line of vehicle detection frame and lane line;
113 |
114 | **Performance optimization measures:**
115 | 1.Due to the camera angle, it can be decided whether to filter the lane line in the horizontal direction according to the actual situation;
116 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_retrograde.md:
--------------------------------------------------------------------------------
1 | [English](ppvehicle_retrograde_en.md) | 简体中文
2 |
3 | # PP-Vehicle车辆逆行识别模块
4 |
5 | 车辆逆行识别在智慧城市,智慧交通等方向具有广泛应用。在PP-Vehicle中,集成了车辆逆行识别模块,可识别车辆是否逆行。
6 |
7 | | 任务 | 算法 | 精度 | 预测速度 | 下载链接|
8 | |-----------|------|-----------|----------|---------------|
9 | | 车辆检测/跟踪 | PP-YOLOE | mAP 63.9 | 38.67ms | [预测部署模型](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) |
10 | | 车道线识别 | PP-liteseg | mIou 32.69 | 47 ms | [预测部署模型](https://bj.bcebos.com/v1/paddledet/models/pipeline/pp_lite_stdc2_bdd100k.zip) |
11 |
12 |
13 | 注意:
14 | 1. 车辆检测/跟踪模型预测速度是基于NVIDIA T4, 开启TensorRT FP16得到。模型预测速度包含数据预处理、模型预测、后处理部分。
15 | 2. 车辆检测/跟踪模型的训练和精度测试均基于[VeRi数据集](https://www.v7labs.com/open-datasets/veri-dataset)。
16 | 3. 车道线模型预测速度基于Tesla P40,python端预测,模型预测速度包含数据预处理、模型预测、后处理部分。
17 | 4. 车道线模型训练和精度测试均基于[BDD100K-LaneSeg](https://bdd-data.berkeley.edu/portal.html#download.)和[Apollo Scape](http://apolloscape.auto/lane_segmentation.html#to_dataset_href)。两个数据集的标签文件[Lane_dataset_label](https://bj.bcebos.com/v1/paddledet/data/mot/bdd100k/lane_dataset_label.zip)
18 |
19 |
20 | ## 使用方法
21 |
22 | ### 配置项说明
23 |
24 | [配置文件](../../config/infer_cfg_ppvehicle.yml)中与车辆逆行识别模块相关的参数如下:
25 | ```
26 | LANE_SEG:
27 | lane_seg_config: deploy/pipeline/config/lane_seg_config.yml #车道线提取配置文件
28 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/pp_lite_stdc2_bdd100k.zip #模型文件路径
29 |
30 | VEHICLE_RETROGRADE:
31 | frame_len: 8 #采样帧数
32 | sample_freq: 7 #采样频率
33 | enable: True #开启车辆逆行判断功能
34 | filter_horizontal_flag: False #是否过滤水平方向车辆
35 | keep_right_flag: True #按车辆靠右行驶规则,若车辆靠左行驶,则设为False
36 | deviation: 23 #过滤水平方向车辆的角度阈值,如果大于该角度则过滤
37 | move_scale: 0.01 #过滤静止车辆阈值,若车辆移动像素大于图片对角线*move_scale,则认为车辆移动,反之
38 | #车辆静止
39 | fence_line: [] #车道中间线坐标,格式[x1,y1,x2,y2] 且y2>y1。若为空,由程序根据车流方向自动判断
40 | ```
41 | [车道线配置文件](../../config/lane_seg_config.yml)中与车道线提取相关的参数如下:
42 | ```
43 | type: PLSLaneseg #选择分割模型
44 |
45 | PLSLaneseg:
46 | batch_size: 1 #图片batch_size
47 | device: gpu #选择gpu还是cpu
48 | filter_flag: True #是否过滤水平方向道路线
49 | horizontal_filtration_degree: 23 #过滤水平方向车道线阈值,当分割出来的车道线最大倾斜角与
50 | #最小倾斜角差值小于阈值时,不进行过滤
51 | horizontal_filtering_threshold: 0.25 #确定竖直方向与水平方向分开阈值
52 | #thr = (min_degree+max_degree)*0.25
53 | #根据车道线倾斜角与thr的大小比较,将车道线分为垂直方向与水平方向
54 | ```
55 |
56 | ### 使用命令
57 |
58 | 1. 从模型库下载`车辆检测/跟踪`, `车道线识别`两个预测部署模型并解压到`./output_inference`路径下;默认会自动下载模型,如果手动下载,需要修改模型文件夹为模型存放路径。
59 | 2. 修改配置文件中`VEHICLE_RETROGRADE`项的`enable: True`,以启用该功能。
60 |
61 |
62 |
63 | 3. 车辆逆行识别功能需要视频输入时,启动命令如下:
64 |
65 | ```bash
66 | #预测单个视频文件
67 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
68 | -o VEHICLE_RETROGRADE.enable=true \
69 | --video_file=test_video.mp4 \
70 | --device=gpu
71 |
72 | #预测包含一个或多个视频的文件夹
73 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
74 | -o VEHICLE_RETROGRADE.enable=true \
75 | --video_dir=test_video \
76 | --device=gpu
77 | ```
78 |
79 | 5. 若修改模型路径,有以下两种方式:
80 |
81 | - 方法一:`./deploy/pipeline/config/infer_cfg_ppvehicle.yml`下可以配置不同模型路径,车道线识别模型修改`LANE_SEG`字段下配置
82 | - 方法二:直接在命令行中增加`-o`,以覆盖配置文件中的默认模型路径:
83 |
84 | ```bash
85 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
86 | --video_file=test_video.mp4 \
87 | --device=gpu \
88 | -o LANE_SEG.model_dir=output_inference/
89 | VEHICLE_RETROGRADE.enable=true
90 |
91 | ```
92 | 测试效果如下:
93 |
94 |
100 |
95 |  96 |
96 |
97 |
98 | **注意:**
99 | - 车道线中间线自动判断条件:在采样的视频段内同时有两个相反方向的车辆,且判断一次后固定,不再更新;
100 | - 因摄像头角度以及2d视角问题,车道线中间线判断存在不准确情况;
101 | - 可在配置文件手动输入中间线坐标.参考[车辆违章配置文件](../../config/examples/infer_cfg_vehicle_violation.yml)
102 |
103 |
104 | ## 方案说明
105 | 1.车辆在采样视频段内,根据车道中间线的位置与车辆轨迹,判断车辆是否逆行,判断流程图:
106 |
96 |
107 | 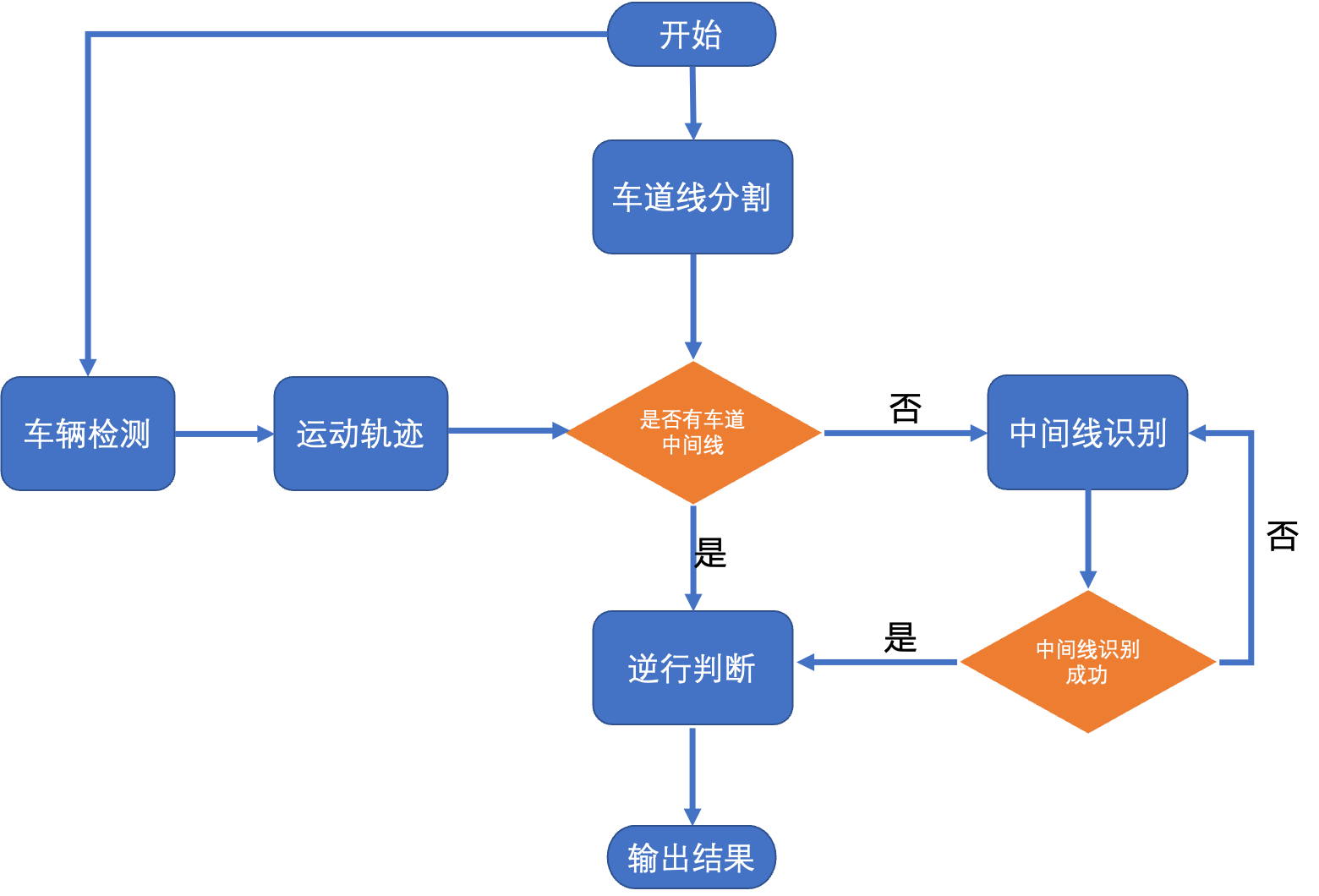 108 |
108 |
109 |
110 | 2.车道线识别模型使用了[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg) 的超轻量分割方案。训练样本[标签](https://bj.bcebos.com/v1/paddledet/data/mot/bdd100k/lane_dataset_label.zip)分为4类:
111 | 0 背景
112 | 1 双黄线
113 | 2 实线
114 | 3 虚线
115 | 车辆逆行分析过滤虚线类;
116 |
117 | 3.车道线通过对分割结果聚类得到,且默认过滤水平方向车道线,若不过滤可在[车道线配置文件](../../config/lane_seg_config.yml)修改`filter_flag`参数;
118 |
119 | 4.车辆逆行判断默认过滤水平方向车辆,若不过滤可在[配置文件](../../config/infer_cfg_ppvehicle.yml)修改`filter_horizontal_flag`参数;
120 |
121 | 5.车辆逆行默认按靠右行驶规则判断,若修改,可在[配置文件](../../config/infer_cfg_ppvehicle.yml)修改`keep_right_flag`参数;
122 |
123 | **性能优化措施**:
124 | 1.因摄像头视角原因,可以根据实际情况决定是否过滤水平方向车道线与水平方向车辆;
125 |
126 | 2.车道中间线可手动输入;
127 |
--------------------------------------------------------------------------------
/docs/tutorials/ppvehicle_retrograde_en.md:
--------------------------------------------------------------------------------
1 | English | [简体中文](ppvehicle_retrograde.md)
2 |
3 | # PP-Vehicle vehicle retrograde identification module
4 |
5 | Vehicle reverse identification is widely used in smart cities, smart transportation and other directions. In PP-Vehicle, a vehicle retrograde identification module is integrated to identify whether the vehicle is retrograde.
6 |
7 | | task | algorithm | precision | infer speed | download|
8 | |-----------|------|-----------|----------|---------------|
9 | | Vehicle detection/tracking | PP-YOLOE | mAP 63.9 | 38.67ms | [infer deploy model](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_ppvehicle.zip) |
10 | | Lane line segmentation | PP-liteseg | mIou 32.69 | 47 ms | [infer deploy model](https://bj.bcebos.com/v1/paddledet/models/pipeline/pp_lite_stdc2_bdd100k.zip) |
11 |
12 |
13 | Notes:
14 | 1. The prediction speed of vehicle detection/tracking model is based on NVIDIA T4 and TensorRT FP16. The model prediction speed includes data preprocessing, model prediction and post-processing.
15 | 2. The training and precision test of vehicle detection/tracking model are based on [VeRi](https://www.v7labs.com/open-datasets/veri-dataset).
16 | 3. The predicted speed of lane line segmentation model is based on Tesla P40 and python prediction. The predicted speed of the model includes data preprocessing, model prediction and post-processing.
17 | 4. Lane line model training and precision testing are based on [BDD100K-LaneSeg](https://bdd-data.berkeley.edu/portal.html#download) and [Apollo Scape](http://apolloscape.auto/lane_segmentation.html#to_dataset_href),The label data of the two data sets is in [Lane_dataset_label](https://bj.bcebos.com/v1/paddledet/data/mot/bdd100k/lane_dataset_label.zip)
18 |
19 |
20 |
21 | ## Instructions
22 |
23 | ### Description of Configuration
24 |
25 | [The parameters related to vehicle retrograde in [config file](../../config/infer_cfg_ppvehicle.yml) is as follows:
26 | ```
27 | LANE_SEG:
28 | lane_seg_config: deploy/pipeline/config/lane_seg_config.yml #lane line seg config file
29 | model_dir: https://bj.bcebos.com/v1/paddledet/models/pipeline/pp_lite_stdc2_bdd100k.zip #model path
30 |
31 | VEHICLE_RETROGRADE:
32 | frame_len: 8 #Number of sampling frames
33 | sample_freq: 7 #sampling frequency
34 | enable: True #Whether to enable the funcion
35 | filter_horizontal_flag: False #Whether to filter vehicles in horizontal direction
36 | keep_right_flag: True #According to the right driving rule, if the vehicle keeps left driving, it is set as False
37 | deviation: 23 #Filter the horizontal angle vehicles threshold. If it is greater than this angle, filter
38 | move_scale: 0.01 #Filter the threshold value of stationary vehicles. If the vehicle moving pixel is greater than the image diagonal * move_scale, the vehicle is considered moving, otherwise, the vehicle is stationary
39 | fence_line: [] #Lane centerline coordinates, format[x1,y1,x2,y2] and y2>y1. If it is empty, the program will automatically judge according to the direction of traffic flow
40 | ```
41 | The parameters related to Lane line segmentation in [lane line seg config file](../../config/lane_seg_config.yml)is as follows:
42 | ```
43 | type: PLSLaneseg #Select segmentation Model
44 |
45 | PLSLaneseg:
46 | batch_size: 1 #image batch_size
47 | device: gpu #device is gpu or cpu
48 | filter_flag: True #Whether to filter the horizontal direction road route
49 | horizontal_filtration_degree: 23 #Filter the threshold value of the lane line in the horizontal direction. When the difference between the maximum inclination angle and the minimum inclination angle of the segmented lane line is less than the threshold value, no filtering is performed
50 |
51 | horizontal_filtering_threshold: 0.25 #Determine the threshold value for separating the vertical direction from the horizontal direction thr=(min_degree+max_degree) * 0.25 Divide the lane line into vertical direction and horizontal direction according to the comparison between the gradient angle of the lane line and thr
52 | ```
53 |
54 | ### How to Use
55 |
56 | 1. Download 'vehicle detection/tracking' and 'lane line recognition' two prediction deployment models from the model base and unzip them to '/ output_ Invitation ` under the path; By default, the model will be downloaded automatically. If you download it manually, you need to modify the model folder as the model storage path.
57 | 2. Modify Profile`VEHICLE_RETROGRADE`-`enable: True`, item to enable this function.
58 |
59 |
60 |
61 | 3. When video input is required for vehicle retrograde recognition function, the starting command is as follows:
62 |
63 | ```bash
64 | #For single video
65 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
66 | -o VEHICLE_RETROGRADE.enable=true \
67 | --video_file=test_video.mp4 \
68 | --device=gpu
69 |
70 | #For folder contains one or multiple videos
71 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
72 | -o VEHICLE_RETROGRADE.enable=true \
73 | --video_dir=test_video \
74 | --device=gpu
75 | ```
76 |
77 | 5. There are two ways to modify the model path:
78 |
79 | - 1.Set paths of each model in `./deploy/pipeline/config/infer_cfg_ppvehicle.yml`,For Lane line segmentation, the path should be modified under the `LANE_SEG`
80 | - 2.Directly add `-o` in command line to override the default model path in the configuration file:
81 |
82 | ```bash
83 | python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_ppvehicle.yml \
84 | --video_file=test_video.mp4 \
85 | --device=gpu \
86 | -o LANE_SEG.model_dir=output_inference/
87 | VEHICLE_RETROGRADE.enable=true
88 |
89 | ```
90 | The result is shown as follow:
91 |
92 |
108 |
93 |
94 |
95 |
96 | **Note:**
97 | - Automatic judgment condition of lane line middle line: there are two vehicles in opposite directions in the sampled video segment, and the judgment is fixed after one time and will not be updated;
98 | - Due to camera angle and 2d visual angle problems, the judgment of lane line middle line is inaccurate.
99 | - You can manually enter the middle line coordinates in the configuration file.Example as [infer_cfg_vehicle_violation.yml](../../config/examples/infer_cfg_vehicle_violation.yml)
100 |
101 |
102 | ## Features to the Solution
103 | 1.In the sampling video segment, judge whether the vehicle is retrograde according to the location of the lane centerline and the vehicle track, and determine the flow chart:
104 |
94 |
105 |  106 |
106 |
107 |
108 | 2.Lane line recognition model uses [PaddleSeg]( https://github.com/PaddlePaddle/PaddleSeg )Super lightweight segmentation scheme.Train [lable](https://bj.bcebos.com/v1/paddledet/data/mot/bdd100k/lane_dataset_label.zip)it is divided into four categories:
109 | 0 Background
110 | 1 Double yellow line
111 | 2 Solid line
112 | 3 Dashed line
113 | Lane line recognition filtering Dashed lines;
114 |
115 | 3.Lane lines are obtained by clustering segmentation results, and the horizontal lane lines are filtered by default. If not, you can modify the `filter_flag` in [lane line seg config file](../../config/lane_seg_config.yml);
116 |
117 | 4.The vehicles in the horizontal direction are filtered by default when judging the vehicles in the reverse direction. If not, you can modify the `filter_horizontal_flag` in [config file](../../config/infer_cfg_ppvehicle.yml);
118 |
119 | 5.The vehicle will be judged according to the right driving rule by default.If not, you can modify the `keep_right_flag` in [config file](../../config/infer_cfg_ppvehicle.yml);
120 |
121 |
122 | **Performance optimization measures:**
123 | 1.Due to the camera's viewing angle, it can be decided whether to filter the lane lines and vehicles in the horizontal direction according to the actual situation;
124 |
125 | 2.The lane middle line can be manually entered;
126 |
--------------------------------------------------------------------------------
/mtmct.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/mtmct.gif
--------------------------------------------------------------------------------
/pipe_utils.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | import time
16 | import os
17 | import ast
18 | import glob
19 | import yaml
20 | import copy
21 | import numpy as np
22 | import subprocess as sp
23 |
24 | from python.keypoint_preprocess import EvalAffine, TopDownEvalAffine, expand_crop
25 |
26 |
27 | class Times(object):
28 | def __init__(self):
29 | self.time = 0.
30 | # start time
31 | self.st = 0.
32 | # end time
33 | self.et = 0.
34 |
35 | def start(self):
36 | self.st = time.time()
37 |
38 | def end(self, repeats=1, accumulative=True):
39 | self.et = time.time()
40 | if accumulative:
41 | self.time += (self.et - self.st) / repeats
42 | else:
43 | self.time = (self.et - self.st) / repeats
44 |
45 | def reset(self):
46 | self.time = 0.
47 | self.st = 0.
48 | self.et = 0.
49 |
50 | def value(self):
51 | return round(self.time, 4)
52 |
53 |
54 | class PipeTimer(Times):
55 | def __init__(self):
56 | super(PipeTimer, self).__init__()
57 | self.total_time = Times()
58 | self.module_time = {
59 | 'det': Times(),
60 | 'mot': Times(),
61 | 'attr': Times(),
62 | 'kpt': Times(),
63 | 'video_action': Times(),
64 | 'skeleton_action': Times(),
65 | 'reid': Times(),
66 | 'det_action': Times(),
67 | 'cls_action': Times(),
68 | 'vehicle_attr': Times(),
69 | 'vehicleplate': Times(),
70 | 'lanes': Times(),
71 | 'vehicle_press': Times(),
72 | 'vehicle_retrograde': Times()
73 | }
74 | self.img_num = 0
75 | self.track_num = 0
76 |
77 | def get_total_time(self):
78 | total_time = self.total_time.value()
79 | total_time = round(total_time, 4)
80 | average_latency = total_time / max(1, self.img_num)
81 | qps = 0
82 | if total_time > 0:
83 | qps = 1 / average_latency
84 | return total_time, average_latency, qps
85 |
86 | def info(self):
87 | total_time, average_latency, qps = self.get_total_time()
88 | print("------------------ Inference Time Info ----------------------")
89 | print("total_time(ms): {}, img_num: {}".format(total_time * 1000,
90 | self.img_num))
91 |
92 | for k, v in self.module_time.items():
93 | v_time = round(v.value(), 4)
94 | if v_time > 0 and k in ['det', 'mot', 'video_action']:
95 | print("{} time(ms): {}; per frame average time(ms): {}".format(
96 | k, v_time * 1000, v_time * 1000 / self.img_num))
97 | elif v_time > 0:
98 | print("{} time(ms): {}; per trackid average time(ms): {}".
99 | format(k, v_time * 1000, v_time * 1000 / self.track_num))
100 |
101 | print("average latency time(ms): {:.2f}, QPS: {:2f}".format(
102 | average_latency * 1000, qps))
103 | return qps
104 |
105 | def report(self, average=False):
106 | dic = {}
107 | dic['total'] = round(self.total_time.value() / max(1, self.img_num),
108 | 4) if average else self.total_time.value()
109 | dic['det'] = round(self.module_time['det'].value() /
110 | max(1, self.img_num),
111 | 4) if average else self.module_time['det'].value()
112 | dic['mot'] = round(self.module_time['mot'].value() /
113 | max(1, self.img_num),
114 | 4) if average else self.module_time['mot'].value()
115 | dic['attr'] = round(self.module_time['attr'].value() /
116 | max(1, self.img_num),
117 | 4) if average else self.module_time['attr'].value()
118 | dic['kpt'] = round(self.module_time['kpt'].value() /
119 | max(1, self.img_num),
120 | 4) if average else self.module_time['kpt'].value()
121 | dic['video_action'] = self.module_time['video_action'].value()
122 | dic['skeleton_action'] = round(
123 | self.module_time['skeleton_action'].value() / max(1, self.img_num),
124 | 4) if average else self.module_time['skeleton_action'].value()
125 |
126 | dic['img_num'] = self.img_num
127 | return dic
128 |
129 |
130 | class PushStream(object):
131 | def __init__(self, pushurl="rtsp://127.0.0.1:8554/"):
132 | self.command = ""
133 | # 自行设置
134 | self.pushurl = pushurl
135 |
136 | def initcmd(self, fps, width, height):
137 | self.command = [
138 | 'ffmpeg', '-y', '-f', 'rawvideo', '-vcodec', 'rawvideo', '-pix_fmt',
139 | 'bgr24', '-s', "{}x{}".format(width, height), '-r', str(fps), '-i',
140 | '-', '-pix_fmt', 'yuv420p', '-f', 'rtsp', self.pushurl
141 | ]
142 | self.pipe = sp.Popen(self.command, stdin=sp.PIPE)
143 |
144 |
145 | def get_test_images(infer_dir, infer_img):
146 | """
147 | Get image path list in TEST mode
148 | """
149 | assert infer_img is not None or infer_dir is not None, \
150 | "--infer_img or --infer_dir should be set"
151 | assert infer_img is None or os.path.isfile(infer_img), \
152 | "{} is not a file".format(infer_img)
153 | assert infer_dir is None or os.path.isdir(infer_dir), \
154 | "{} is not a directory".format(infer_dir)
155 |
156 | # infer_img has a higher priority
157 | if infer_img and os.path.isfile(infer_img):
158 | return [infer_img]
159 |
160 | images = set()
161 | infer_dir = os.path.abspath(infer_dir)
162 | assert os.path.isdir(infer_dir), \
163 | "infer_dir {} is not a directory".format(infer_dir)
164 | exts = ['jpg', 'jpeg', 'png', 'bmp']
165 | exts += [ext.upper() for ext in exts]
166 | for ext in exts:
167 | images.update(glob.glob('{}/*.{}'.format(infer_dir, ext)))
168 | images = list(images)
169 |
170 | assert len(images) > 0, "no image found in {}".format(infer_dir)
171 | print("Found {} inference images in total.".format(len(images)))
172 |
173 | return images
174 |
175 |
176 | def crop_image_with_det(batch_input, det_res, thresh=0.3):
177 | boxes = det_res['boxes']
178 | score = det_res['boxes'][:, 1]
179 | boxes_num = det_res['boxes_num']
180 | start_idx = 0
181 | crop_res = []
182 | for b_id, input in enumerate(batch_input):
183 | boxes_num_i = boxes_num[b_id]
184 | if boxes_num_i == 0:
185 | continue
186 | boxes_i = boxes[start_idx:start_idx + boxes_num_i, :]
187 | score_i = score[start_idx:start_idx + boxes_num_i]
188 | res = []
189 | for box, s in zip(boxes_i, score_i):
190 | if s > thresh:
191 | crop_image, new_box, ori_box = expand_crop(input, box)
192 | if crop_image is not None:
193 | res.append(crop_image)
194 | crop_res.append(res)
195 | return crop_res
196 |
197 |
198 | def normal_crop(image, rect):
199 | imgh, imgw, c = image.shape
200 | label, conf, xmin, ymin, xmax, ymax = [int(x) for x in rect.tolist()]
201 | org_rect = [xmin, ymin, xmax, ymax]
202 | if label != 0:
203 | return None, None, None
204 | xmin = max(0, xmin)
205 | ymin = max(0, ymin)
206 | xmax = min(imgw, xmax)
207 | ymax = min(imgh, ymax)
208 | return image[ymin:ymax, xmin:xmax, :], [xmin, ymin, xmax, ymax], org_rect
209 |
210 |
211 | def crop_image_with_mot(input, mot_res, expand=True):
212 | res = mot_res['boxes']
213 | crop_res = []
214 | new_bboxes = []
215 | ori_bboxes = []
216 | for box in res:
217 | if expand:
218 | crop_image, new_bbox, ori_bbox = expand_crop(input, box[1:])
219 | else:
220 | crop_image, new_bbox, ori_bbox = normal_crop(input, box[1:])
221 | if crop_image is not None:
222 | crop_res.append(crop_image)
223 | new_bboxes.append(new_bbox)
224 | ori_bboxes.append(ori_bbox)
225 | return crop_res, new_bboxes, ori_bboxes
226 |
227 |
228 | def parse_mot_res(input):
229 | mot_res = []
230 | boxes, scores, ids = input[0]
231 | for box, score, i in zip(boxes[0], scores[0], ids[0]):
232 | xmin, ymin, w, h = box
233 | res = [i, 0, score, xmin, ymin, xmin + w, ymin + h]
234 | mot_res.append(res)
235 | return {'boxes': np.array(mot_res)}
236 |
237 |
238 | def refine_keypoint_coordinary(kpts, bbox, coord_size):
239 | """
240 | This function is used to adjust coordinate values to a fixed scale.
241 | """
242 | tl = bbox[:, 0:2]
243 | wh = bbox[:, 2:] - tl
244 | tl = np.expand_dims(np.transpose(tl, (1, 0)), (2, 3))
245 | wh = np.expand_dims(np.transpose(wh, (1, 0)), (2, 3))
246 | target_w, target_h = coord_size
247 | res = (kpts - tl) / wh * np.expand_dims(
248 | np.array([[target_w], [target_h]]), (2, 3))
249 | return res
250 |
251 |
252 | def parse_mot_keypoint(input, coord_size):
253 | parsed_skeleton_with_mot = {}
254 | ids = []
255 | skeleton = []
256 | for tracker_id, kpt_seq in input:
257 | ids.append(tracker_id)
258 | kpts = np.array(kpt_seq.kpts, dtype=np.float32)[:, :, :2]
259 | kpts = np.expand_dims(np.transpose(kpts, [2, 0, 1]),
260 | -1) #T, K, C -> C, T, K, 1
261 | bbox = np.array(kpt_seq.bboxes, dtype=np.float32)
262 | skeleton.append(refine_keypoint_coordinary(kpts, bbox, coord_size))
263 | parsed_skeleton_with_mot["mot_id"] = ids
264 | parsed_skeleton_with_mot["skeleton"] = skeleton
265 | return parsed_skeleton_with_mot
--------------------------------------------------------------------------------
/pphuman/__pycache__/action_infer.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/pphuman/__pycache__/action_infer.cpython-38.pyc
--------------------------------------------------------------------------------
/pphuman/__pycache__/action_utils.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/pphuman/__pycache__/action_utils.cpython-38.pyc
--------------------------------------------------------------------------------
/pphuman/__pycache__/attr_infer.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/pphuman/__pycache__/attr_infer.cpython-38.pyc
--------------------------------------------------------------------------------
/pphuman/__pycache__/mtmct.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/pphuman/__pycache__/mtmct.cpython-38.pyc
--------------------------------------------------------------------------------
/pphuman/__pycache__/reid.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/pphuman/__pycache__/reid.cpython-38.pyc
--------------------------------------------------------------------------------
/pphuman/__pycache__/video_action_infer.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/pphuman/__pycache__/video_action_infer.cpython-38.pyc
--------------------------------------------------------------------------------
/pphuman/__pycache__/video_action_preprocess.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/pphuman/__pycache__/video_action_preprocess.cpython-38.pyc
--------------------------------------------------------------------------------
/pphuman/action_utils.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 |
16 | class KeyPointSequence(object):
17 | def __init__(self, max_size=100):
18 | self.frames = 0
19 | self.kpts = []
20 | self.bboxes = []
21 | self.max_size = max_size
22 |
23 | def save(self, kpt, bbox):
24 | self.kpts.append(kpt)
25 | self.bboxes.append(bbox)
26 | self.frames += 1
27 | if self.frames == self.max_size:
28 | return True
29 | return False
30 |
31 |
32 | class KeyPointBuff(object):
33 | def __init__(self, max_size=100):
34 | self.flag_track_interrupt = False
35 | self.keypoint_saver = dict()
36 | self.max_size = max_size
37 | self.id_to_pop = set()
38 | self.flag_to_pop = False
39 |
40 | def get_state(self):
41 | return self.flag_to_pop
42 |
43 | def update(self, kpt_res, mot_res):
44 | kpts = kpt_res.get('keypoint')[0]
45 | bboxes = kpt_res.get('bbox')
46 | mot_bboxes = mot_res.get('boxes')
47 | updated_id = set()
48 |
49 | for idx in range(len(kpts)):
50 | tracker_id = mot_bboxes[idx, 0]
51 | updated_id.add(tracker_id)
52 |
53 | kpt_seq = self.keypoint_saver.get(tracker_id,
54 | KeyPointSequence(self.max_size))
55 | is_full = kpt_seq.save(kpts[idx], bboxes[idx])
56 | self.keypoint_saver[tracker_id] = kpt_seq
57 |
58 | #Scene1: result should be popped when frames meet max size
59 | if is_full:
60 | self.id_to_pop.add(tracker_id)
61 | self.flag_to_pop = True
62 |
63 | #Scene2: result of a lost tracker should be popped
64 | interrupted_id = set(self.keypoint_saver.keys()) - updated_id
65 | if len(interrupted_id) > 0:
66 | self.flag_to_pop = True
67 | self.id_to_pop.update(interrupted_id)
68 |
69 | def get_collected_keypoint(self):
70 | """
71 | Output (List): List of keypoint results for Skeletonbased Recognition task, where
72 | the format of each element is [tracker_id, KeyPointSequence of tracker_id]
73 | """
74 | output = []
75 | for tracker_id in self.id_to_pop:
76 | output.append([tracker_id, self.keypoint_saver[tracker_id]])
77 | del (self.keypoint_saver[tracker_id])
78 | self.flag_to_pop = False
79 | self.id_to_pop.clear()
80 | return output
81 |
82 |
83 | class ActionVisualHelper(object):
84 | def __init__(self, frame_life=20):
85 | self.frame_life = frame_life
86 | self.action_history = {}
87 |
88 | def get_visualize_ids(self):
89 | id_detected = self.check_detected()
90 | return id_detected
91 |
92 | def check_detected(self):
93 | id_detected = set()
94 | deperate_id = []
95 | for mot_id in self.action_history:
96 | self.action_history[mot_id]["life_remain"] -= 1
97 | if int(self.action_history[mot_id]["class"]) == 0:
98 | id_detected.add(mot_id)
99 | if self.action_history[mot_id]["life_remain"] == 0:
100 | deperate_id.append(mot_id)
101 | for mot_id in deperate_id:
102 | del (self.action_history[mot_id])
103 | return id_detected
104 |
105 | def update(self, action_res_list):
106 | for mot_id, action_res in action_res_list:
107 | if mot_id in self.action_history:
108 | if int(action_res["class"]) != 0 and int(self.action_history[
109 | mot_id]["class"]) == 0:
110 | continue
111 | action_info = self.action_history.get(mot_id, {})
112 | action_info["class"] = action_res["class"]
113 | action_info["life_remain"] = self.frame_life
114 | self.action_history[mot_id] = action_info
115 |
--------------------------------------------------------------------------------
/pphuman/reid.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | import os
16 | import sys
17 | import cv2
18 | import numpy as np
19 | # add deploy path of PaddleDetection to sys.path
20 | parent_path = os.path.abspath(os.path.join(__file__, *(['..'] * 2)))
21 | sys.path.insert(0, parent_path)
22 |
23 | from python.infer import PredictConfig
24 | from pptracking.python.det_infer import load_predictor
25 | from python.utils import Timer
26 |
27 |
28 | class ReID(object):
29 | """
30 | ReID of SDE methods
31 |
32 | Args:
33 | pred_config (object): config of model, defined by `Config(model_dir)`
34 | model_dir (str): root path of model.pdiparams, model.pdmodel and infer_cfg.yml
35 | device (str): Choose the device you want to run, it can be: CPU/GPU/XPU/NPU, default is CPU
36 | run_mode (str): mode of running(paddle/trt_fp32/trt_fp16)
37 | batch_size (int): size of per batch in inference, default 50 means at most
38 | 50 sub images can be made a batch and send into ReID model
39 | trt_min_shape (int): min shape for dynamic shape in trt
40 | trt_max_shape (int): max shape for dynamic shape in trt
41 | trt_opt_shape (int): opt shape for dynamic shape in trt
42 | trt_calib_mode (bool): If the model is produced by TRT offline quantitative
43 | calibration, trt_calib_mode need to set True
44 | cpu_threads (int): cpu threads
45 | enable_mkldnn (bool): whether to open MKLDNN
46 | """
47 |
48 | def __init__(self,
49 | model_dir,
50 | device='CPU',
51 | run_mode='paddle',
52 | batch_size=50,
53 | trt_min_shape=1,
54 | trt_max_shape=1088,
55 | trt_opt_shape=608,
56 | trt_calib_mode=False,
57 | cpu_threads=4,
58 | enable_mkldnn=False):
59 | self.pred_config = self.set_config(model_dir)
60 | self.predictor, self.config = load_predictor(
61 | model_dir,
62 | run_mode=run_mode,
63 | batch_size=batch_size,
64 | min_subgraph_size=self.pred_config.min_subgraph_size,
65 | device=device,
66 | use_dynamic_shape=self.pred_config.use_dynamic_shape,
67 | trt_min_shape=trt_min_shape,
68 | trt_max_shape=trt_max_shape,
69 | trt_opt_shape=trt_opt_shape,
70 | trt_calib_mode=trt_calib_mode,
71 | cpu_threads=cpu_threads,
72 | enable_mkldnn=enable_mkldnn)
73 | self.det_times = Timer()
74 | self.cpu_mem, self.gpu_mem, self.gpu_util = 0, 0, 0
75 | self.batch_size = batch_size
76 | self.input_wh = (128, 256)
77 |
78 | @classmethod
79 | def init_with_cfg(cls, args, cfg):
80 | return cls(model_dir=cfg['model_dir'],
81 | batch_size=cfg['batch_size'],
82 | device=args.device,
83 | run_mode=args.run_mode,
84 | trt_min_shape=args.trt_min_shape,
85 | trt_max_shape=args.trt_max_shape,
86 | trt_opt_shape=args.trt_opt_shape,
87 | trt_calib_mode=args.trt_calib_mode,
88 | cpu_threads=args.cpu_threads,
89 | enable_mkldnn=args.enable_mkldnn)
90 |
91 | def set_config(self, model_dir):
92 | return PredictConfig(model_dir)
93 |
94 | def check_img_quality(self, crop, bbox, xyxy):
95 | if crop is None:
96 | return None
97 | #eclipse
98 | eclipse_quality = 1.0
99 | inner_rect = np.zeros(xyxy.shape)
100 | inner_rect[:, :2] = np.maximum(xyxy[:, :2], bbox[None, :2])
101 | inner_rect[:, 2:] = np.minimum(xyxy[:, 2:], bbox[None, 2:])
102 | wh_array = inner_rect[:, 2:] - inner_rect[:, :2]
103 | filt = np.logical_and(wh_array[:, 0] > 0, wh_array[:, 1] > 0)
104 | wh_array = wh_array[filt]
105 | if wh_array.shape[0] > 1:
106 | eclipse_ratio = wh_array / (bbox[2:] - bbox[:2])
107 | eclipse_area_ratio = eclipse_ratio[:, 0] * eclipse_ratio[:, 1]
108 | ear_lst = eclipse_area_ratio.tolist()
109 | ear_lst.sort(reverse=True)
110 | eclipse_quality = 1.0 - ear_lst[1]
111 | bbox_wh = (bbox[2:] - bbox[:2])
112 | height_quality = bbox_wh[1] / (bbox_wh[0] * 2)
113 | eclipse_quality = min(eclipse_quality, height_quality)
114 |
115 | #definition
116 | cropgray = cv2.cvtColor(crop, cv2.COLOR_BGR2GRAY)
117 | definition = int(cv2.Laplacian(cropgray, cv2.CV_64F, ksize=3).var())
118 | brightness = int(cropgray.mean())
119 | bd_quality = min(1., brightness / 50.)
120 |
121 | eclipse_weight = 0.7
122 | return eclipse_quality * eclipse_weight + bd_quality * (1 -
123 | eclipse_weight)
124 |
125 | def normal_crop(self, image, rect):
126 | imgh, imgw, c = image.shape
127 | label, conf, xmin, ymin, xmax, ymax = [int(x) for x in rect.tolist()]
128 | xmin = max(0, xmin)
129 | ymin = max(0, ymin)
130 | xmax = min(imgw, xmax)
131 | ymax = min(imgh, ymax)
132 | if label != 0 or xmax <= xmin or ymax <= ymin:
133 | print("Warning! label missed!!")
134 | return None, None, None
135 | return image[ymin:ymax, xmin:xmax, :]
136 |
137 | # mot output format: id, class, score, xmin, ymin, xmax, ymax
138 | def crop_image_with_mot(self, image, mot_res):
139 | res = mot_res['boxes']
140 | crop_res = []
141 | img_quality = []
142 | rects = []
143 | for box in res:
144 | crop_image = self.normal_crop(image, box[1:])
145 | quality_item = self.check_img_quality(crop_image, box[3:],
146 | res[:, 3:])
147 | if crop_image is not None:
148 | crop_res.append(crop_image)
149 | img_quality.append(quality_item)
150 | rects.append(box)
151 | return crop_res, img_quality, rects
152 |
153 | def preprocess(self,
154 | imgs,
155 | mean=[0.485, 0.456, 0.406],
156 | std=[0.229, 0.224, 0.225]):
157 | im_batch = []
158 | for img in imgs:
159 | img = cv2.resize(img, self.input_wh)
160 | img = img.astype('float32') / 255.
161 | img -= np.array(mean)
162 | img /= np.array(std)
163 | im_batch.append(img.transpose((2, 0, 1)))
164 | inputs = {}
165 | inputs['x'] = np.array(im_batch).astype('float32')
166 | return inputs
167 |
168 | def predict(self, crops, repeats=1, add_timer=True, seq_name=''):
169 | # preprocess
170 | if add_timer:
171 | self.det_times.preprocess_time_s.start()
172 | inputs = self.preprocess(crops)
173 | input_names = self.predictor.get_input_names()
174 | for i in range(len(input_names)):
175 | input_tensor = self.predictor.get_input_handle(input_names[i])
176 | input_tensor.copy_from_cpu(inputs[input_names[i]])
177 |
178 | if add_timer:
179 | self.det_times.preprocess_time_s.end()
180 | self.det_times.inference_time_s.start()
181 |
182 | # model prediction
183 | for i in range(repeats):
184 | self.predictor.run()
185 | output_names = self.predictor.get_output_names()
186 | feature_tensor = self.predictor.get_output_handle(output_names[0])
187 | pred_embs = feature_tensor.copy_to_cpu()
188 | if add_timer:
189 | self.det_times.inference_time_s.end(repeats=repeats)
190 | self.det_times.postprocess_time_s.start()
191 |
192 | if add_timer:
193 | self.det_times.postprocess_time_s.end()
194 | self.det_times.img_num += 1
195 | return pred_embs
196 |
197 | def predict_batch(self, imgs, batch_size=4):
198 | batch_feat = []
199 | for b in range(0, len(imgs), batch_size):
200 | b_end = min(len(imgs), b + batch_size)
201 | batch_imgs = imgs[b:b_end]
202 | feat = self.predict(batch_imgs)
203 | batch_feat.extend(feat.tolist())
204 |
205 | return batch_feat
206 |
--------------------------------------------------------------------------------
/ppvehicle/__pycache__/lane_seg_infer.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/ppvehicle/__pycache__/lane_seg_infer.cpython-38.pyc
--------------------------------------------------------------------------------
/ppvehicle/__pycache__/vehicle_attr.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/ppvehicle/__pycache__/vehicle_attr.cpython-38.pyc
--------------------------------------------------------------------------------
/ppvehicle/__pycache__/vehicle_plate.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/ppvehicle/__pycache__/vehicle_plate.cpython-38.pyc
--------------------------------------------------------------------------------
/ppvehicle/__pycache__/vehicle_plateutils.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/ppvehicle/__pycache__/vehicle_plateutils.cpython-38.pyc
--------------------------------------------------------------------------------
/ppvehicle/__pycache__/vehicle_pressing.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/ppvehicle/__pycache__/vehicle_pressing.cpython-38.pyc
--------------------------------------------------------------------------------
/ppvehicle/__pycache__/vehicle_retrograde.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/ppvehicle/__pycache__/vehicle_retrograde.cpython-38.pyc
--------------------------------------------------------------------------------
/ppvehicle/__pycache__/vehicleplate_postprocess.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/ppvehicle/__pycache__/vehicleplate_postprocess.cpython-38.pyc
--------------------------------------------------------------------------------
/ppvehicle/lane_seg_infer.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | import argparse
16 | import codecs
17 | import os
18 |
19 | import yaml
20 | import numpy as np
21 | import cv2
22 | from sklearn.cluster import DBSCAN
23 | from pptracking.python.det_infer import load_predictor
24 |
25 |
26 | class LaneSegPredictor:
27 | def __init__(self, lane_seg_config, model_dir):
28 | """
29 | Prepare for prediction.
30 | The usage and docs of paddle inference, please refer to
31 | https://paddleinference.paddlepaddle.org.cn/product_introduction/summary.html
32 | """
33 | if not os.path.exists(lane_seg_config):
34 | raise ValueError("Cannot find : {},".format(lane_seg_config))
35 |
36 | args = yaml.safe_load(open(lane_seg_config))
37 | self.model_dir = model_dir
38 | self.args = args[args['type']]
39 |
40 | self.shape = None
41 | self.filter_horizontal_flag = self.args['filter_horizontal_flag']
42 | self.horizontal_filtration_degree = self.args[
43 | 'horizontal_filtration_degree']
44 | self.horizontal_filtering_threshold = self.args[
45 | 'horizontal_filtering_threshold']
46 |
47 | try:
48 | self.predictor, _ = load_predictor(
49 | model_dir=self.model_dir,
50 | run_mode=self.args['run_mode'],
51 | batch_size=self.args['batch_size'],
52 | device=self.args['device'],
53 | min_subgraph_size=self.args['min_subgraph_size'],
54 | use_dynamic_shape=self.args['use_dynamic_shape'],
55 | trt_min_shape=self.args['trt_min_shape'],
56 | trt_max_shape=self.args['trt_max_shape'],
57 | trt_opt_shape=self.args['trt_opt_shape'],
58 | trt_calib_mode=self.args['trt_calib_mode'],
59 | cpu_threads=self.args['cpu_threads'],
60 | enable_mkldnn=self.args['enable_mkldnn'])
61 | except Exception as e:
62 | print(str(e))
63 | exit()
64 |
65 | def run(self, img):
66 |
67 | input_names = self.predictor.get_input_names()
68 | input_handle = self.predictor.get_input_handle(input_names[0])
69 | output_names = self.predictor.get_output_names()
70 | output_handle = self.predictor.get_output_handle(output_names[0])
71 |
72 | img = np.array(img)
73 | self.shape = img.shape[1:3]
74 | img = self.normalize(img)
75 | img = np.transpose(img, (0, 3, 1, 2))
76 | input_handle.reshape(img.shape)
77 | input_handle.copy_from_cpu(img)
78 |
79 | self.predictor.run()
80 |
81 | results = output_handle.copy_to_cpu()
82 | results = self.postprocess(results)
83 |
84 | return self.get_line(results)
85 |
86 | def normalize(self, im, mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)):
87 | mean = np.array(mean)[np.newaxis, np.newaxis, :]
88 | std = np.array(std)[np.newaxis, np.newaxis, :]
89 | im = im.astype(np.float32, copy=False) / 255.0
90 | im -= mean
91 | im /= std
92 | return im
93 |
94 | def postprocess(self, pred):
95 |
96 | pred = np.argmax(pred, axis=1)
97 | pred[pred == 3] = 0
98 | pred[pred > 0] = 255
99 |
100 | return pred
101 |
102 | def get_line(self, results):
103 | lines = []
104 | directions = []
105 | for i in range(results.shape[0]):
106 | line, direction = self.hough_line(np.uint8(results[i]))
107 | lines.append(line)
108 | directions.append(direction)
109 | return lines, directions
110 |
111 | def get_distance(self, array_1, array_2):
112 | lon_a = array_1[0]
113 | lat_a = array_1[1]
114 | lon_b = array_2[0]
115 | lat_b = array_2[1]
116 |
117 | s = pow(pow((lat_b - lat_a), 2) + pow((lon_b - lon_a), 2), 0.5)
118 | return s
119 |
120 | def get_angle(self, array):
121 | import math
122 | x1, y1, x2, y2 = array
123 | a_x = x2 - x1
124 | a_y = y2 - y1
125 | angle1 = math.atan2(a_y, a_x)
126 | angle1 = int(angle1 * 180 / math.pi)
127 | if angle1 > 90:
128 | angle1 = 180 - angle1
129 | return angle1
130 |
131 | def get_proportion(self, lines):
132 |
133 | proportion = 0.0
134 | h, w = self.shape
135 | for line in lines:
136 | x1, y1, x2, y2 = line
137 | length = abs(y2 - y1) / h + abs(x2 - x1) / w
138 | proportion = proportion + length
139 |
140 | return proportion
141 |
142 | def line_cluster(self, linesP):
143 |
144 | points = []
145 | for i in range(0, len(linesP)):
146 | l = linesP[i]
147 | x_center = (float(
148 | (max(l[2], l[0]) - min(l[2], l[0]))) / 2.0 + min(l[2], l[0]))
149 | y_center = (float(
150 | (max(l[3], l[1]) - min(l[3], l[1]))) / 2.0 + min(l[3], l[1]))
151 | points.append([x_center, y_center])
152 |
153 | dbscan = DBSCAN(
154 | eps=50, min_samples=2, metric=self.get_distance).fit(points)
155 |
156 | labels = dbscan.labels_
157 | n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
158 | cluster_list = list([] for i in range(n_clusters_))
159 | if linesP is not None:
160 | for i in range(0, len(linesP)):
161 | if labels[i] == -1:
162 | continue
163 | l = linesP[i]
164 | x1, y1, x2, y2 = l
165 | if y2 >= y1:
166 | cluster_list[labels[i]].append([x1, y1, x2, y2])
167 | else:
168 | ll = [x2, y2, x1, y1]
169 | cluster_list[labels[i]].append(ll)
170 |
171 | return cluster_list
172 |
173 | def hough_line(self,
174 | binary_img,
175 | min_line=50,
176 | min_line_points=50,
177 | max_line_gap=10):
178 | linesP = cv2.HoughLinesP(binary_img, 1, np.pi / 180, min_line, None,
179 | min_line_points, max_line_gap)
180 | if linesP is None:
181 | return [], None
182 |
183 | coarse_cluster_list = self.line_cluster(linesP[:, 0])
184 | filter_lines_output, direction = self.filter_lines(coarse_cluster_list)
185 |
186 | return filter_lines_output, direction
187 |
188 | def filter_lines(self, coarse_cluster_list):
189 |
190 | lines = []
191 | angles = []
192 | for i in range(len(coarse_cluster_list)):
193 | if len(coarse_cluster_list[i]) == 0:
194 | continue
195 | coarse_cluster_list[i] = np.array(coarse_cluster_list[i])
196 | distance = abs(coarse_cluster_list[i][:, 3] - coarse_cluster_list[i]
197 | [:, 1]) + abs(coarse_cluster_list[i][:, 2] -
198 | coarse_cluster_list[i][:, 0])
199 | l = coarse_cluster_list[i][np.argmax(distance)]
200 | angles.append(self.get_angle(l))
201 | lines.append(l)
202 |
203 | if len(lines) == 0:
204 | return [], None
205 | if not self.filter_horizontal_flag:
206 | return lines, None
207 |
208 | #filter horizontal roads
209 | angles = np.array(angles)
210 |
211 | max_angle, min_angle = np.max(angles), np.min(angles)
212 |
213 | if (max_angle - min_angle) < self.horizontal_filtration_degree:
214 | return lines, np.mean(angles)
215 |
216 | thr_angle = (
217 | max_angle + min_angle) * self.horizontal_filtering_threshold
218 | lines = np.array(lines)
219 |
220 | min_angle_line = lines[np.where(angles < thr_angle)]
221 | max_angle_line = lines[np.where(angles >= thr_angle)]
222 |
223 | max_angle_line_pro = self.get_proportion(max_angle_line)
224 | min_angle_line_pro = self.get_proportion(min_angle_line)
225 |
226 | if max_angle_line_pro >= min_angle_line_pro:
227 | angle_list = angles[np.where(angles >= thr_angle)]
228 | return max_angle_line, np.mean(angle_list)
229 | else:
230 | angle_list = angles[np.where(angles < thr_angle)]
231 | return min_angle_line, np.mean(angle_list)
232 |
--------------------------------------------------------------------------------
/ppvehicle/vehicle_attr.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | import os
16 | import yaml
17 | import glob
18 |
19 | import cv2
20 | import numpy as np
21 | import math
22 | import paddle
23 | import sys
24 | try:
25 | from collections.abc import Sequence
26 | except Exception:
27 | from collections import Sequence
28 |
29 | # add deploy path of PaddleDetection to sys.path
30 | parent_path = os.path.abspath(os.path.join(__file__, *(['..'] * 3)))
31 | sys.path.insert(0, parent_path)
32 |
33 | from paddle.inference import Config, create_predictor
34 | from python.utils import argsparser, Timer, get_current_memory_mb
35 | from python.benchmark_utils import PaddleInferBenchmark
36 | from python.infer import Detector, print_arguments
37 | from pipeline.pphuman.attr_infer import AttrDetector
38 |
39 |
40 | class VehicleAttr(AttrDetector):
41 | """
42 | Args:
43 | model_dir (str): root path of model.pdiparams, model.pdmodel and infer_cfg.yml
44 | device (str): Choose the device you want to run, it can be: CPU/GPU/XPU/NPU, default is CPU
45 | run_mode (str): mode of running(paddle/trt_fp32/trt_fp16)
46 | batch_size (int): size of pre batch in inference
47 | trt_min_shape (int): min shape for dynamic shape in trt
48 | trt_max_shape (int): max shape for dynamic shape in trt
49 | trt_opt_shape (int): opt shape for dynamic shape in trt
50 | trt_calib_mode (bool): If the model is produced by TRT offline quantitative
51 | calibration, trt_calib_mode need to set True
52 | cpu_threads (int): cpu threads
53 | enable_mkldnn (bool): whether to open MKLDNN
54 | type_threshold (float): The threshold of score for vehicle type recognition.
55 | color_threshold (float): The threshold of score for vehicle color recognition.
56 | """
57 |
58 | def __init__(self,
59 | model_dir,
60 | device='CPU',
61 | run_mode='paddle',
62 | batch_size=1,
63 | trt_min_shape=1,
64 | trt_max_shape=1280,
65 | trt_opt_shape=640,
66 | trt_calib_mode=False,
67 | cpu_threads=1,
68 | enable_mkldnn=False,
69 | output_dir='output',
70 | color_threshold=0.5,
71 | type_threshold=0.5):
72 | super(VehicleAttr, self).__init__(
73 | model_dir=model_dir,
74 | device=device,
75 | run_mode=run_mode,
76 | batch_size=batch_size,
77 | trt_min_shape=trt_min_shape,
78 | trt_max_shape=trt_max_shape,
79 | trt_opt_shape=trt_opt_shape,
80 | trt_calib_mode=trt_calib_mode,
81 | cpu_threads=cpu_threads,
82 | enable_mkldnn=enable_mkldnn,
83 | output_dir=output_dir)
84 | self.color_threshold = color_threshold
85 | self.type_threshold = type_threshold
86 | self.result_history = {}
87 | self.color_list = [
88 | "yellow", "orange", "green", "gray", "red", "blue", "white",
89 | "golden", "brown", "black"
90 | ]
91 | self.type_list = [
92 | "sedan", "suv", "van", "hatchback", "mpv", "pickup", "bus", "truck",
93 | "estate"
94 | ]
95 |
96 | @classmethod
97 | def init_with_cfg(cls, args, cfg):
98 | return cls(model_dir=cfg['model_dir'],
99 | batch_size=cfg['batch_size'],
100 | color_threshold=cfg['color_threshold'],
101 | type_threshold=cfg['type_threshold'],
102 | device=args.device,
103 | run_mode=args.run_mode,
104 | trt_min_shape=args.trt_min_shape,
105 | trt_max_shape=args.trt_max_shape,
106 | trt_opt_shape=args.trt_opt_shape,
107 | trt_calib_mode=args.trt_calib_mode,
108 | cpu_threads=args.cpu_threads,
109 | enable_mkldnn=args.enable_mkldnn)
110 |
111 | def postprocess(self, inputs, result):
112 | # postprocess output of predictor
113 | im_results = result['output']
114 | batch_res = []
115 | for res in im_results:
116 | res = res.tolist()
117 | attr_res = []
118 | color_res_str = "Color: "
119 | type_res_str = "Type: "
120 | color_idx = np.argmax(res[:10])
121 | type_idx = np.argmax(res[10:])
122 |
123 | if res[color_idx] >= self.color_threshold:
124 | color_res_str += self.color_list[color_idx]
125 | else:
126 | color_res_str += "Unknown"
127 | attr_res.append(color_res_str)
128 |
129 | if res[type_idx + 10] >= self.type_threshold:
130 | type_res_str += self.type_list[type_idx]
131 | else:
132 | type_res_str += "Unknown"
133 | attr_res.append(type_res_str)
134 |
135 | batch_res.append(attr_res)
136 | result = {'output': batch_res}
137 | return result
138 |
139 |
140 | if __name__ == '__main__':
141 | paddle.enable_static()
142 | parser = argsparser()
143 | FLAGS = parser.parse_args()
144 | print_arguments(FLAGS)
145 | FLAGS.device = FLAGS.device.upper()
146 | assert FLAGS.device in ['CPU', 'GPU', 'XPU', 'NPU'
147 | ], "device should be CPU, GPU, NPU or XPU"
148 | assert not FLAGS.use_gpu, "use_gpu has been deprecated, please use --device"
149 |
150 | main()
151 |
--------------------------------------------------------------------------------
/ppvehicle/vehicle_pressing.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | import os
16 |
17 | import numpy as np
18 | import math
19 |
20 |
21 | class VehiclePressingRecognizer(object):
22 | def __init__(self, cfg):
23 | self.cfg = cfg
24 |
25 | def judge(self, Ax1, Ay1, Ax2, Ay2, Bx1, By1, Bx2, By2):
26 |
27 | if (max(Ax1,Ax2)>=min(Bx1,Bx2) and min(Ax1,Ax2)<=max(Bx1,Bx2)) and \
28 | (max(Ay1,Ay2)>=min(By1,By2) and min(Ay1,Ay2)<=max(By1,By2)):
29 |
30 | if ((Bx1-Ax1)*(Ay2-Ay1)-(By1-Ay1)*(Ax2-Ax1)) * ((Bx2-Ax1)*(Ay2-Ay1)-(By2-Ay1)*(Ax2-Ax1))<=0 \
31 | and ((Ax1-Bx1)*(By2-By1)-(Ay1-By1)*(Bx2-Bx1)) * ((Ax2-Bx1)*(By2-By1)-(Ay2-By1)*(Bx2-Bx1)) <=0:
32 | return True
33 | else:
34 | return False
35 | else:
36 | return False
37 |
38 | def is_intersect(self, line, bbox):
39 | Ax1, Ay1, Ax2, Ay2 = line
40 |
41 | xmin, ymin, xmax, ymax = bbox
42 |
43 | bottom = self.judge(Ax1, Ay1, Ax2, Ay2, xmin, ymax, xmax, ymax)
44 | return bottom
45 |
46 | def run(self, lanes, det_res):
47 | intersect_bbox_list = []
48 | start_idx, boxes_num_i = 0, 0
49 |
50 | for i in range(len(lanes)):
51 | lane = lanes[i]
52 | if det_res is not None:
53 | det_res_i = {}
54 | boxes_num_i = det_res['boxes_num'][i]
55 | det_res_i['boxes'] = det_res['boxes'][start_idx:start_idx +
56 | boxes_num_i, :]
57 | intersect_bbox = []
58 |
59 | for line in lane:
60 | for bbox in det_res_i['boxes']:
61 | if self.is_intersect(line, bbox[2:]):
62 | intersect_bbox.append(bbox)
63 | intersect_bbox_list.append(intersect_bbox)
64 |
65 | start_idx += boxes_num_i
66 |
67 | return intersect_bbox_list
68 |
69 | def mot_run(self, lanes, det_res):
70 |
71 | intersect_bbox_list = []
72 | if det_res is None:
73 | return intersect_bbox_list
74 | lanes_res = lanes['output']
75 | for i in range(len(lanes_res)):
76 | lane = lanes_res[i]
77 | for line in lane:
78 | for bbox in det_res:
79 | if self.is_intersect(line, bbox[3:]):
80 | intersect_bbox_list.append(bbox)
81 | return intersect_bbox_list
--------------------------------------------------------------------------------
/tools/ccpd2ocr_all.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import os
3 | import json
4 | from tqdm import tqdm
5 | import numpy as np
6 |
7 | provinces = [
8 | "皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣",
9 | "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁",
10 | "新", "警", "学", "O"
11 | ]
12 | alphabets = [
13 | 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q',
14 | 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'O'
15 | ]
16 | ads = [
17 | 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q',
18 | 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '0', '1', '2', '3', '4', '5',
19 | '6', '7', '8', '9', 'O'
20 | ]
21 |
22 |
23 | def make_label_2020(img_dir, save_gt_folder, phase):
24 | crop_img_save_dir = os.path.join(save_gt_folder, phase, 'crop_imgs')
25 | os.makedirs(crop_img_save_dir, exist_ok=True)
26 |
27 | f_det = open(
28 | os.path.join(save_gt_folder, phase, 'det.txt'), 'w', encoding='utf-8')
29 | f_rec = open(
30 | os.path.join(save_gt_folder, phase, 'rec.txt'), 'w', encoding='utf-8')
31 |
32 | i = 0
33 | for filename in tqdm(os.listdir(os.path.join(img_dir, phase))):
34 | str_list = filename.split('-')
35 | if len(str_list) < 5:
36 | continue
37 | coord_list = str_list[3].split('_')
38 | txt_list = str_list[4].split('_')
39 | boxes = []
40 | for coord in coord_list:
41 | boxes.append([int(x) for x in coord.split("&")])
42 | boxes = [boxes[2], boxes[3], boxes[0], boxes[1]]
43 | lp_number = provinces[int(txt_list[0])] + alphabets[int(txt_list[
44 | 1])] + ''.join([ads[int(x)] for x in txt_list[2:]])
45 |
46 | # det
47 | det_info = [{'points': boxes, 'transcription': lp_number}]
48 | f_det.write('{}\t{}\n'.format(
49 | os.path.join("CCPD2020/ccpd_green", phase, filename),
50 | json.dumps(
51 | det_info, ensure_ascii=False)))
52 |
53 | # rec
54 | boxes = np.float32(boxes)
55 | img = cv2.imread(os.path.join(img_dir, phase, filename))
56 | # crop_img = img[int(boxes[:,1].min()):int(boxes[:,1].max()),int(boxes[:,0].min()):int(boxes[:,0].max())]
57 | crop_img = get_rotate_crop_image(img, boxes)
58 | crop_img_save_filename = '{}_{}.jpg'.format(i, '_'.join(txt_list))
59 | crop_img_save_path = os.path.join(crop_img_save_dir,
60 | crop_img_save_filename)
61 | cv2.imwrite(crop_img_save_path, crop_img)
62 | f_rec.write('{}/{}/crop_imgs/{}\t{}\n'.format(
63 | "CCPD2020/PPOCR", phase, crop_img_save_filename, lp_number))
64 | i += 1
65 | f_det.close()
66 | f_rec.close()
67 |
68 |
69 | def make_label_2019(list_dir, save_gt_folder, phase):
70 | crop_img_save_dir = os.path.join(save_gt_folder, phase, 'crop_imgs')
71 | os.makedirs(crop_img_save_dir, exist_ok=True)
72 |
73 | f_det = open(
74 | os.path.join(save_gt_folder, phase, 'det.txt'), 'w', encoding='utf-8')
75 | f_rec = open(
76 | os.path.join(save_gt_folder, phase, 'rec.txt'), 'w', encoding='utf-8')
77 |
78 | with open(os.path.join(list_dir, phase + ".txt"), 'r') as rf:
79 | imglist = rf.readlines()
80 |
81 | i = 0
82 | for idx, filename in enumerate(imglist):
83 | if idx % 1000 == 0:
84 | print("{}/{}".format(idx, len(imglist)))
85 | filename = filename.strip()
86 | str_list = filename.split('-')
87 | if len(str_list) < 5:
88 | continue
89 | coord_list = str_list[3].split('_')
90 | txt_list = str_list[4].split('_')
91 | boxes = []
92 | for coord in coord_list:
93 | boxes.append([int(x) for x in coord.split("&")])
94 | boxes = [boxes[2], boxes[3], boxes[0], boxes[1]]
95 | lp_number = provinces[int(txt_list[0])] + alphabets[int(txt_list[
96 | 1])] + ''.join([ads[int(x)] for x in txt_list[2:]])
97 |
98 | # det
99 | det_info = [{'points': boxes, 'transcription': lp_number}]
100 | f_det.write('{}\t{}\n'.format(
101 | os.path.join("CCPD2019", filename),
102 | json.dumps(
103 | det_info, ensure_ascii=False)))
104 |
105 | # rec
106 | boxes = np.float32(boxes)
107 | imgpath = os.path.join(list_dir[:-7], filename)
108 | img = cv2.imread(imgpath)
109 | # crop_img = img[int(boxes[:,1].min()):int(boxes[:,1].max()),int(boxes[:,0].min()):int(boxes[:,0].max())]
110 | crop_img = get_rotate_crop_image(img, boxes)
111 | crop_img_save_filename = '{}_{}.jpg'.format(i, '_'.join(txt_list))
112 | crop_img_save_path = os.path.join(crop_img_save_dir,
113 | crop_img_save_filename)
114 | cv2.imwrite(crop_img_save_path, crop_img)
115 | f_rec.write('{}/{}/crop_imgs/{}\t{}\n'.format(
116 | "CCPD2019/PPOCR", phase, crop_img_save_filename, lp_number))
117 | i += 1
118 | f_det.close()
119 | f_rec.close()
120 |
121 |
122 | def get_rotate_crop_image(img, points):
123 | '''
124 | img_height, img_width = img.shape[0:2]
125 | left = int(np.min(points[:, 0]))
126 | right = int(np.max(points[:, 0]))
127 | top = int(np.min(points[:, 1]))
128 | bottom = int(np.max(points[:, 1]))
129 | img_crop = img[top:bottom, left:right, :].copy()
130 | points[:, 0] = points[:, 0] - left
131 | points[:, 1] = points[:, 1] - top
132 | '''
133 | assert len(points) == 4, "shape of points must be 4*2"
134 | img_crop_width = int(
135 | max(
136 | np.linalg.norm(points[0] - points[1]),
137 | np.linalg.norm(points[2] - points[3])))
138 | img_crop_height = int(
139 | max(
140 | np.linalg.norm(points[0] - points[3]),
141 | np.linalg.norm(points[1] - points[2])))
142 | pts_std = np.float32([[0, 0], [img_crop_width, 0],
143 | [img_crop_width, img_crop_height],
144 | [0, img_crop_height]])
145 | M = cv2.getPerspectiveTransform(points, pts_std)
146 | dst_img = cv2.warpPerspective(
147 | img,
148 | M, (img_crop_width, img_crop_height),
149 | borderMode=cv2.BORDER_REPLICATE,
150 | flags=cv2.INTER_CUBIC)
151 | dst_img_height, dst_img_width = dst_img.shape[0:2]
152 | if dst_img_height * 1.0 / dst_img_width >= 1.5:
153 | dst_img = np.rot90(dst_img)
154 | return dst_img
155 |
156 |
157 | img_dir = './CCPD2020/ccpd_green'
158 | save_gt_folder = './CCPD2020/PPOCR'
159 | # phase = 'train' # change to val and test to make val dataset and test dataset
160 | for phase in ['train', 'val', 'test']:
161 | make_label_2020(img_dir, save_gt_folder, phase)
162 |
163 | list_dir = './CCPD2019/splits/'
164 | save_gt_folder = './CCPD2019/PPOCR'
165 |
166 | for phase in ['train', 'val', 'test']:
167 | make_label_2019(list_dir, save_gt_folder, phase)
168 |
--------------------------------------------------------------------------------
/tools/clip_video.py:
--------------------------------------------------------------------------------
1 | import cv2
2 |
3 |
4 | def cut_video(video_path, frameToStart, frametoStop, saved_video_path):
5 | cap = cv2.VideoCapture(video_path)
6 | FPS = cap.get(cv2.CAP_PROP_FPS)
7 |
8 | TOTAL_FRAME = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数
9 |
10 | size = (cap.get(cv2.CAP_PROP_FRAME_WIDTH),
11 | cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
12 |
13 | videoWriter = cv2.VideoWriter(
14 | saved_video_path,
15 | apiPreference=0,
16 | fourcc=cv2.VideoWriter_fourcc(* 'mp4v'),
17 | fps=FPS,
18 | frameSize=(int(size[0]), int(size[1])))
19 |
20 | COUNT = 0
21 | while True:
22 | success, frame = cap.read()
23 | if success:
24 | COUNT += 1
25 | if COUNT <= frametoStop and COUNT > frameToStart: # 选取起始帧
26 | videoWriter.write(frame)
27 | else:
28 | print("cap.read failed!")
29 | break
30 | if COUNT > frametoStop:
31 | break
32 |
33 | cap.release()
34 | videoWriter.release()
35 |
36 | print(saved_video_path)
37 |
--------------------------------------------------------------------------------
/tools/create_dataset_list.py:
--------------------------------------------------------------------------------
1 | # coding: utf8
2 | # Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserve.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | import glob
17 | import os.path
18 | import argparse
19 | import warnings
20 |
21 |
22 | def parse_args():
23 | parser = argparse.ArgumentParser(
24 | description='PaddleSeg generate file list on cityscapes or your customized dataset.'
25 | )
26 | parser.add_argument('dataset_root', help='dataset root directory', type=str)
27 | parser.add_argument(
28 | '--type',
29 | help='dataset type: \n'
30 | '- cityscapes \n'
31 | '- custom(default)',
32 | default="custom",
33 | type=str)
34 | parser.add_argument(
35 | '--separator',
36 | dest='separator',
37 | help='file list separator',
38 | default=" ",
39 | type=str)
40 | parser.add_argument(
41 | '--folder',
42 | help='the folder names of images and labels',
43 | type=str,
44 | nargs=2,
45 | default=['images', 'labels'])
46 | parser.add_argument(
47 | '--second_folder',
48 | help='the second-level folder names of train set, validation set, test set',
49 | type=str,
50 | nargs='*',
51 | default=['train', 'val', 'test'])
52 | parser.add_argument(
53 | '--format',
54 | help='data format of images and labels, e.g. jpg or png.',
55 | type=str,
56 | nargs=2,
57 | default=['jpg', 'png'])
58 | parser.add_argument(
59 | '--postfix',
60 | help='postfix of images or labels',
61 | type=str,
62 | nargs=2,
63 | default=['', ''])
64 |
65 | return parser.parse_args()
66 |
67 |
68 | def get_files(image_or_label, dataset_split, args):
69 | dataset_root = args.dataset_root
70 | postfix = args.postfix
71 | format = args.format
72 | folder = args.folder
73 |
74 | pattern = '*%s.%s' % (postfix[image_or_label], format[image_or_label])
75 |
76 | search_files = os.path.join(dataset_root, folder[image_or_label],
77 | dataset_split, pattern)
78 | search_files2 = os.path.join(dataset_root, folder[image_or_label],
79 | dataset_split, "*", pattern) # 包含子目录
80 | search_files3 = os.path.join(dataset_root, folder[image_or_label],
81 | dataset_split, "*", "*", pattern) # 包含三级目录
82 | search_files4 = os.path.join(dataset_root, folder[image_or_label],
83 | dataset_split, "*", "*", "*",
84 | pattern) # 包含四级目录
85 | search_files5 = os.path.join(dataset_root, folder[image_or_label],
86 | dataset_split, "*", "*", "*", "*",
87 | pattern) # 包含五级目录
88 |
89 | filenames = glob.glob(search_files)
90 | filenames2 = glob.glob(search_files2)
91 | filenames3 = glob.glob(search_files3)
92 | filenames4 = glob.glob(search_files4)
93 | filenames5 = glob.glob(search_files5)
94 |
95 | filenames = filenames + filenames2 + filenames3 + filenames4 + filenames5
96 |
97 | return sorted(filenames)
98 |
99 |
100 | def generate_list(args):
101 | dataset_root = args.dataset_root
102 | separator = args.separator
103 |
104 | for dataset_split in args.second_folder:
105 | print("Creating {}.txt...".format(dataset_split))
106 | image_files = get_files(0, dataset_split, args)
107 | label_files = get_files(1, dataset_split, args)
108 | if not image_files:
109 | img_dir = os.path.join(dataset_root, args.folder[0], dataset_split)
110 | warnings.warn("No images in {} !!!".format(img_dir))
111 | num_images = len(image_files)
112 |
113 | if not label_files:
114 | label_dir = os.path.join(dataset_root, args.folder[1],
115 | dataset_split)
116 | warnings.warn("No labels in {} !!!".format(label_dir))
117 | num_label = len(label_files)
118 |
119 | if num_images != num_label and num_label > 0:
120 | raise Exception(
121 | "Number of images = {} number of labels = {} \n"
122 | "Either number of images is equal to number of labels, "
123 | "or number of labels is equal to 0.\n"
124 | "Please check your dataset!".format(num_images, num_label))
125 |
126 | file_list = os.path.join(dataset_root, dataset_split + '.txt')
127 | with open(file_list, "w") as f:
128 | for item in range(num_images):
129 | left = image_files[item].replace(dataset_root, '', 1)
130 | if left[0] == os.path.sep:
131 | left = left.lstrip(os.path.sep)
132 |
133 | try:
134 | right = label_files[item].replace(dataset_root, '', 1)
135 | if right[0] == os.path.sep:
136 | right = right.lstrip(os.path.sep)
137 | line = left + separator + right + '\n'
138 | except:
139 | line = left + '\n'
140 |
141 | f.write(line)
142 | print(line)
143 |
144 |
145 | if __name__ == '__main__':
146 | args = parse_args()
147 | generate_list(args)
148 |
--------------------------------------------------------------------------------
/tools/get_video_info.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import cv2
4 | import numpy as np
5 | import argparse
6 |
7 |
8 | def argsparser():
9 | parser = argparse.ArgumentParser(description=__doc__)
10 | parser.add_argument(
11 | "--video_file",
12 | type=str,
13 | default=None,
14 | help="Path of video file, `video_file` or `camera_id` has a highest priority."
15 | )
16 | parser.add_argument(
17 | '--region_polygon',
18 | nargs='+',
19 | type=int,
20 | default=[],
21 | help="Clockwise point coords (x0,y0,x1,y1...) of polygon of area when "
22 | "do_break_in_counting. Note that only support single-class MOT and "
23 | "the video should be taken by a static camera.")
24 | return parser
25 |
26 |
27 | def get_video_info(video_file, region_polygon):
28 | entrance = []
29 | assert len(region_polygon
30 | ) % 2 == 0, "region_polygon should be pairs of coords points."
31 | for i in range(0, len(region_polygon), 2):
32 | entrance.append([region_polygon[i], region_polygon[i + 1]])
33 |
34 | if not os.path.exists(video_file):
35 | print("video path '{}' not exists".format(video_file))
36 | sys.exit(-1)
37 | capture = cv2.VideoCapture(video_file)
38 | width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))
39 | height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
40 | print("video width: %d, height: %d" % (width, height))
41 | np_masks = np.zeros((height, width, 1), np.uint8)
42 |
43 | entrance = np.array(entrance)
44 | cv2.fillPoly(np_masks, [entrance], 255)
45 |
46 | fps = int(capture.get(cv2.CAP_PROP_FPS))
47 | frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))
48 | print("video fps: %d, frame_count: %d" % (fps, frame_count))
49 | cnt = 0
50 | while (1):
51 | ret, frame = capture.read()
52 | cnt += 1
53 | if cnt == 3: break
54 |
55 | alpha = 0.3
56 | img = np.array(frame).astype('float32')
57 | mask = np_masks[:, :, 0]
58 | color_mask = [0, 0, 255]
59 | idx = np.nonzero(mask)
60 | color_mask = np.array(color_mask)
61 | img[idx[0], idx[1], :] *= 1.0 - alpha
62 | img[idx[0], idx[1], :] += alpha * color_mask
63 | cv2.imwrite('region_vis.jpg', img)
64 |
65 |
66 | if __name__ == "__main__":
67 | parser = argsparser()
68 | FLAGS = parser.parse_args()
69 | get_video_info(FLAGS.video_file, FLAGS.region_polygon)
70 |
71 | # python get_video_info.py --video_file=demo.mp4 --region_polygon 200 200 400 200 300 400 100 400
72 |
--------------------------------------------------------------------------------
/tools/split_fight_train_test_dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import glob
3 | import random
4 | import fnmatch
5 | import re
6 | import sys
7 |
8 | class_id = {"nofight": 0, "fight": 1}
9 |
10 |
11 | def get_list(path, key_func=lambda x: x[-11:], rgb_prefix='img_', level=1):
12 | if level == 1:
13 | frame_folders = glob.glob(os.path.join(path, '*'))
14 | elif level == 2:
15 | frame_folders = glob.glob(os.path.join(path, '*', '*'))
16 | else:
17 | raise ValueError('level can be only 1 or 2')
18 |
19 | def count_files(directory):
20 | lst = os.listdir(directory)
21 | cnt = len(fnmatch.filter(lst, rgb_prefix + '*'))
22 | return cnt
23 |
24 | # check RGB
25 | video_dict = {}
26 | for f in frame_folders:
27 | cnt = count_files(f)
28 | k = key_func(f)
29 | if level == 2:
30 | k = k.split("/")[0]
31 |
32 | video_dict[f] = str(cnt) + " " + str(class_id[k])
33 |
34 | return video_dict
35 |
36 |
37 | def fight_splits(video_dict, train_percent=0.8):
38 | videos = list(video_dict.keys())
39 |
40 | train_num = int(len(videos) * train_percent)
41 |
42 | train_list = []
43 | val_list = []
44 |
45 | random.shuffle(videos)
46 |
47 | for i in range(train_num):
48 | train_list.append(videos[i] + " " + str(video_dict[videos[i]]))
49 | for i in range(train_num, len(videos)):
50 | val_list.append(videos[i] + " " + str(video_dict[videos[i]]))
51 |
52 | print("train:", len(train_list), ",val:", len(val_list))
53 |
54 | with open("fight_train_list.txt", "w") as f:
55 | for item in train_list:
56 | f.write(item + "\n")
57 |
58 | with open("fight_val_list.txt", "w") as f:
59 | for item in val_list:
60 | f.write(item + "\n")
61 |
62 |
63 | if __name__ == "__main__":
64 | frame_dir = sys.argv[1] # "rawframes"
65 | level = sys.argv[2] # 2
66 | train_percent = sys.argv[3] # 0.8
67 |
68 | if level == 2:
69 |
70 | def key_func(x):
71 | return '/'.join(x.split('/')[-2:])
72 | else:
73 |
74 | def key_func(x):
75 | return x.split('/')[-1]
76 |
77 | video_dict = get_list(frame_dir, key_func=key_func, level=level)
78 | print("number:", len(video_dict))
79 |
80 | fight_splits(video_dict, train_percent)
81 |
--------------------------------------------------------------------------------
/录屏 2023年07月26日 10时13 -big-original.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mianfeng/paddle_MTMCT/3577ed115fe191053b5955c11746389cd85e35b0/录屏 2023年07月26日 10时13 -big-original.gif
--------------------------------------------------------------------------------
106 |