├── .editorconfig
├── .gitignore
├── CODE_OF_CONDUCT.md
├── LICENSE
├── README.md
├── SECURITY.md
├── SUPPORT.md
├── configs
├── captioning
│ └── m4c_textcaps
│ │ ├── tap_base_pretrain.yml
│ │ └── tap_refine.yml
└── vqa
│ ├── m4c_stvqa
│ ├── tap_base_pretrain.yml
│ └── tap_refine.yml
│ └── m4c_textvqa
│ ├── tap_base_pretrain.yml
│ └── tap_refine.yml
├── data
└── README.md
├── projects
├── M4C_Captioner
│ └── scripts
│ │ └── textcaps_eval.py
├── TAP_Caption
│ └── README.md
└── TAP_QA
│ └── README.md
├── pythia
├── common
│ ├── __init__.py
│ ├── batch_collator.py
│ ├── constants.py
│ ├── dataset_loader.py
│ ├── defaults
│ │ ├── __init__.py
│ │ └── configs
│ │ │ ├── base.yml
│ │ │ └── datasets
│ │ │ ├── captioning
│ │ │ ├── coco.yml
│ │ │ ├── m4c_textcaps.yml
│ │ │ └── m4c_textcaps_ocr100.yml
│ │ │ ├── dialog
│ │ │ └── visual_dialog.yml
│ │ │ └── vqa
│ │ │ ├── clevr.yml
│ │ │ ├── m4c_ocrvqa.yml
│ │ │ ├── m4c_stvqa.yml
│ │ │ ├── m4c_stvqa_ocr100.yml
│ │ │ ├── m4c_textvqa.yml
│ │ │ ├── m4c_textvqa_ocr100.yml
│ │ │ ├── textvqa.yml
│ │ │ ├── visual_genome.yml
│ │ │ ├── vizwiz.yml
│ │ │ └── vqa2.yml
│ ├── meter.py
│ ├── registry.py
│ ├── report.py
│ ├── sample.py
│ └── test_reporter.py
├── datasets
│ ├── __init__.py
│ ├── base_dataset.py
│ ├── base_dataset_builder.py
│ ├── captioning
│ │ ├── __init__.py
│ │ ├── coco
│ │ │ ├── __init__.py
│ │ │ ├── builder.py
│ │ │ └── dataset.py
│ │ └── m4c_textcaps
│ │ │ ├── __init__.py
│ │ │ ├── builder.py
│ │ │ └── dataset.py
│ ├── concat_dataset.py
│ ├── dialog
│ │ ├── __init__.py
│ │ ├── original.py
│ │ └── visual_dialog
│ │ │ ├── config.yml
│ │ │ └── scripts
│ │ │ ├── build_imdb.py
│ │ │ └── extract_vocabulary.py
│ ├── feature_readers.py
│ ├── features_dataset.py
│ ├── image_database.py
│ ├── multi_dataset.py
│ ├── processors.py
│ ├── samplers.py
│ ├── scene_graph_database.py
│ └── vqa
│ │ ├── __init__.py
│ │ ├── clevr
│ │ ├── __init__.py
│ │ ├── builder.py
│ │ └── dataset.py
│ │ ├── m4c_ocrvqa
│ │ ├── __init__.py
│ │ ├── builder.py
│ │ └── dataset.py
│ │ ├── m4c_stvqa
│ │ ├── __init__.py
│ │ ├── builder.py
│ │ └── dataset.py
│ │ ├── m4c_textvqa
│ │ ├── __init__.py
│ │ ├── builder.py
│ │ └── dataset.py
│ │ ├── textvqa
│ │ ├── __init__.py
│ │ ├── builder.py
│ │ └── dataset.py
│ │ ├── visual_genome
│ │ ├── builder.py
│ │ └── dataset.py
│ │ ├── vizwiz
│ │ ├── __init__.py
│ │ ├── builder.py
│ │ └── dataset.py
│ │ └── vqa2
│ │ ├── __init__.py
│ │ ├── builder.py
│ │ ├── dataset.py
│ │ ├── ocr_builder.py
│ │ └── ocr_dataset.py
├── models
│ ├── __init__.py
│ ├── ban.py
│ ├── base_model.py
│ ├── butd.py
│ ├── cnn_lstm.py
│ ├── lorra.py
│ ├── m4c.py
│ ├── m4c_captioner.py
│ ├── pythia.py
│ ├── tap.py
│ ├── top_down_bottom_up.py
│ └── visdial_multi_modal.py
├── modules
│ ├── __init__.py
│ ├── attention.py
│ ├── decoders.py
│ ├── embeddings.py
│ ├── encoders.py
│ ├── layers.py
│ ├── losses.py
│ └── metrics.py
├── trainers
│ ├── __init__.py
│ └── base_trainer.py
└── utils
│ ├── __init__.py
│ ├── build_utils.py
│ ├── checkpoint.py
│ ├── configuration.py
│ ├── dataset_utils.py
│ ├── distributed_utils.py
│ ├── early_stopping.py
│ ├── flags.py
│ ├── general.py
│ ├── logger.py
│ ├── m4c_evaluators.py
│ ├── objects_to_byte_tensor.py
│ ├── phoc
│ ├── __init__.py
│ ├── build_phoc.py
│ └── src
│ │ └── cphoc.c
│ ├── process_answers.py
│ ├── text_utils.py
│ ├── timer.py
│ └── vocab.py
├── requirements.txt
├── setup.py
└── tools
└── run.py
/.editorconfig:
--------------------------------------------------------------------------------
1 | root = true
2 |
3 | [*.py]
4 | charset = utf-8
5 | trim_trailing_whitespace = true
6 | end_of_line = lf
7 | insert_final_newline = true
8 | indent_style = space
9 | indent_size = 4
10 |
11 | [*.md]
12 | trim_trailing_whitespace = false
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | *.log
2 | *.err
3 | *.pyc
4 | *.swp
5 | .idea/*
6 | **/__pycache__/*
7 | **/output/*
8 | data/.DS_Store
9 | docs/build
10 | results/*
11 | build
12 | dist
13 | boards/*
14 | *.egg-info/
15 | checkpoint
16 | *.pth
17 | *.ckpt
18 | *_cache
19 | .cache
20 | save
21 | .eggs
22 | eggs/
23 | *.egg
24 | .DS_Store
25 | .vscode/*
26 | *.so
27 | *-checkpoint.ipynb
28 |
--------------------------------------------------------------------------------
/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | # Microsoft Open Source Code of Conduct
2 |
3 | This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
4 |
5 | Resources:
6 |
7 | - [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/)
8 | - [Microsoft Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/)
9 | - Contact [opencode@microsoft.com](mailto:opencode@microsoft.com) with questions or concerns
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) Microsoft Corporation.
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # TAP: Text-Aware Pre-training
2 | [TAP: Text-Aware Pre-training for Text-VQA and Text-Caption](https://arxiv.org/pdf/2012.04638.pdf)
3 |
4 | by [Zhengyuan Yang](https://zyang-ur.github.io/), [Yijuan Lu](https://scholar.google.com/citations?user=cpkrT44AAAAJ&hl=en), [Jianfeng Wang](https://scholar.google.com/citations?user=vJWEw_8AAAAJ&hl=en), [Xi Yin](https://xiyinmsu.github.io/), [Dinei Florencio](https://www.microsoft.com/en-us/research/people/dinei/), [Lijuan Wang](https://www.microsoft.com/en-us/research/people/lijuanw/), [Cha Zhang](https://www.microsoft.com/en-us/research/people/chazhang/), [Lei Zhang](https://www.microsoft.com/en-us/research/people/leizhang/), and [Jiebo Luo](http://cs.rochester.edu/u/jluo)
5 |
6 | IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, Oral
7 |
8 |
9 | ### Introduction
10 | We propose Text-Aware Pre-training (TAP) for Text-VQA and Text-Caption tasks.
11 | For more details, please refer to our
12 | [paper](https://arxiv.org/pdf/2012.04638.pdf).
13 |
14 |
15 |
16 |
17 | 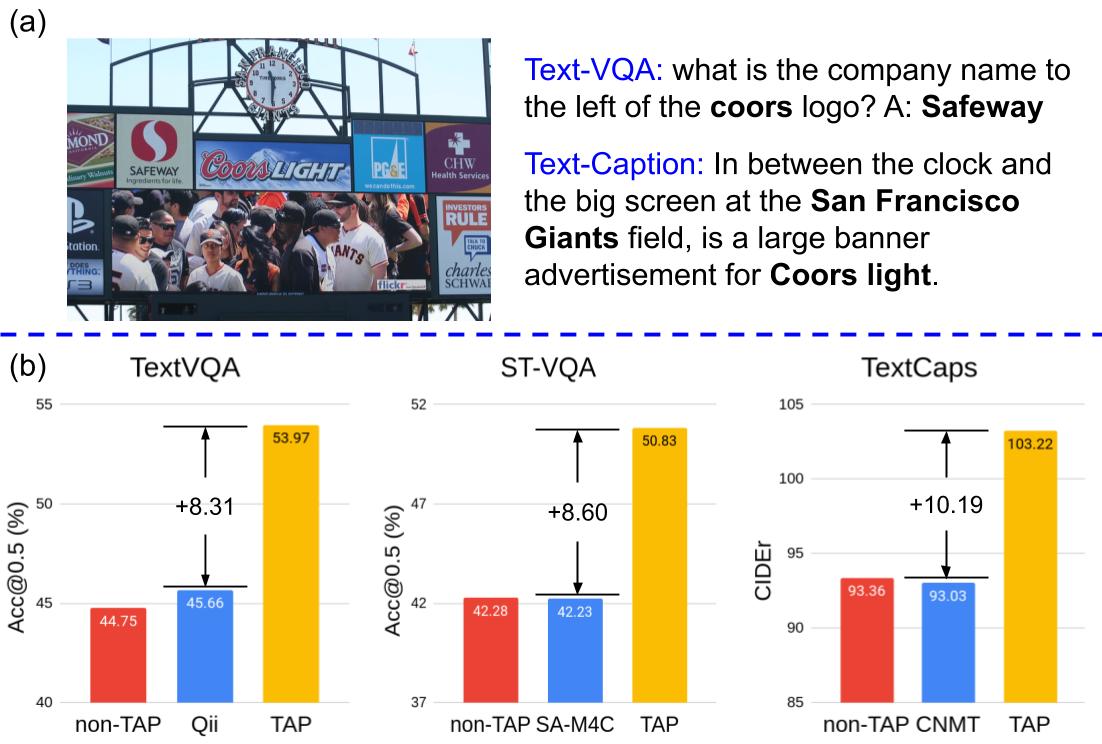 18 |
18 |
19 |
20 | ### Citation
21 |
22 | @inproceedings{yang2021tap,
23 | title={TAP: Text-Aware Pre-training for Text-VQA and Text-Caption},
24 | author={Yang, Zhengyuan and Lu, Yijuan and Wang, Jianfeng and Yin, Xi and Florencio, Dinei and Wang, Lijuan and Zhang, Cha and Zhang, Lei and Luo, Jiebo},
25 | booktitle={CVPR},
26 | year={2021}
27 | }
28 |
29 | ### Prerequisites
30 | * Python 3.6
31 | * Pytorch 1.4.0
32 | * Please refer to ``requirements.txt``. Or using
33 |
34 | ```
35 | python setup.py develop
36 | ```
37 |
38 | ## Installation
39 |
40 | 1. Clone the repository
41 |
42 | ```
43 | git clone https://github.com/microsoft/TAP.git
44 | cd TAP
45 | python setup.py develop
46 | ```
47 |
48 | 2. Data
49 |
50 | * Please refer to the Readme in the ``data`` folder.
51 |
52 |
53 | ### Training
54 | 3. Train the model, run the code under main folder.
55 | Using flag ``--pretrain`` to access the pre-training mode, otherwise the main QA/Captioning losses are used to optimize the model. Example yml files are in ``configs`` folder. Detailed configs are in [released models](https://github.com/microsoft/TAP/tree/main/data).
56 |
57 | Pre-training:
58 | ```
59 | python -m torch.distributed.launch --nproc_per_node $num_gpu tools/run.py --pretrain --tasks vqa --datasets $dataset --model $model --seed $seed --config configs/vqa/$dataset/"$pretrain_yml".yml --save_dir save/$pretrain_savedir training_parameters.distributed True
60 |
61 | # for example
62 | python -m torch.distributed.launch --nproc_per_node 4 tools/run.py --pretrain --tasks vqa --datasets m4c_textvqa --model m4c_split --seed 13 --config configs/vqa/m4c_textvqa/tap_base_pretrain.yml --save_dir save/m4c_split_pretrain_test training_parameters.distributed True
63 | ```
64 |
65 | Fine-tuning:
66 | ```
67 | python -m torch.distributed.launch --nproc_per_node $num_gpu tools/run.py --tasks vqa --datasets $dataset --model $model --seed $seed --config configs/vqa/$dataset/"$refine_yml".yml --save_dir save/$refine_savedir --resume_file save/$pretrain_savedir/$savename/best.ckpt training_parameters.distributed True
68 |
69 | # for example
70 | python -m torch.distributed.launch --nproc_per_node 4 tools/run.py --tasks vqa --datasets m4c_textvqa --model m4c_split --seed 13 --config configs/vqa/m4c_textvqa/tap_refine.yml --save_dir save/m4c_split_refine_test --resume_file save/pretrained/textvqa_tap_base_pretrain.ckpt training_parameters.distributed True
71 | ```
72 |
73 | 4. Evaluate the model, run the code under main folder.
74 | Set up val or test set by ``--run_type``.
75 |
76 | ```
77 | python -m torch.distributed.launch --nproc_per_node $num_gpu tools/run.py --tasks vqa --datasets $dataset --model $model --config configs/vqa/$dataset/"$refine_yml".yml --save_dir save/$refine_savedir --run_type val --resume_file save/$refine_savedir/$savename/best.ckpt training_parameters.distributed True
78 |
79 | # for example
80 | python -m torch.distributed.launch --nproc_per_node 4 tools/run.py --tasks vqa --datasets m4c_textvqa --model m4c_split --config configs/vqa/m4c_textvqa/tap_refine.yml --save_dir save/m4c_split_refine_test --run_type val --resume_file save/finetuned/textvqa_tap_base_best.ckpt training_parameters.distributed True
81 | ```
82 |
83 | 5. Captioning evaluation.
84 | ```
85 | python projects/M4C_Captioner/scripts/textcaps_eval.py --set val --pred_file YOUR_VAL_PREDICTION_FILE
86 | ```
87 |
88 | ## Performance and Pre-trained Models
89 | Please check the detailed experiment settings in our [paper](https://arxiv.org/pdf/2012.04638.pdf).
90 |
91 | [Model checkpoints (~17G)](https://tapvqacaption.blob.core.windows.net/data/save).
92 |
93 | ```
94 | path/to/azcopy copy https://tapvqacaption.blob.core.windows.net/data/save /save --recursive
95 | ```
96 |
97 | Please refer to the Readme in the ``data`` folder for the detailed instructions on azcopy downloading.
98 |
99 |
100 |
101 | | Text-VQA |
102 | TAP |
103 | TAP** (with extra data) |
104 |
105 |
106 |
107 |
108 | | TextVQA |
109 | 49.91 |
110 | 54.71 |
111 |
112 |
113 | | STVQA |
114 | 45.29 |
115 | 50.83 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 | | Text-Captioning |
124 | TAP |
125 | TAP** (with extra data) |
126 |
127 |
128 |
129 |
130 | | TextCaps |
131 | 105.05 |
132 | 109.16 |
133 |
134 |
135 |
136 |
137 | ### Credits
138 | The project is built based on the following repository:
139 | * [MMF: A multimodal framework for vision and language research](https://github.com/facebookresearch/mmf/).
--------------------------------------------------------------------------------
/SECURITY.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Security
4 |
5 | Microsoft takes the security of our software products and services seriously, which includes all source code repositories managed through our GitHub organizations, which include [Microsoft](https://github.com/Microsoft), [Azure](https://github.com/Azure), [DotNet](https://github.com/dotnet), [AspNet](https://github.com/aspnet), [Xamarin](https://github.com/xamarin), and [our GitHub organizations](https://opensource.microsoft.com/).
6 |
7 | If you believe you have found a security vulnerability in any Microsoft-owned repository that meets [Microsoft's definition of a security vulnerability](https://docs.microsoft.com/en-us/previous-versions/tn-archive/cc751383(v=technet.10)), please report it to us as described below.
8 |
9 | ## Reporting Security Issues
10 |
11 | **Please do not report security vulnerabilities through public GitHub issues.**
12 |
13 | Instead, please report them to the Microsoft Security Response Center (MSRC) at [https://msrc.microsoft.com/create-report](https://msrc.microsoft.com/create-report).
14 |
15 | If you prefer to submit without logging in, send email to [secure@microsoft.com](mailto:secure@microsoft.com). If possible, encrypt your message with our PGP key; please download it from the [Microsoft Security Response Center PGP Key page](https://www.microsoft.com/en-us/msrc/pgp-key-msrc).
16 |
17 | You should receive a response within 24 hours. If for some reason you do not, please follow up via email to ensure we received your original message. Additional information can be found at [microsoft.com/msrc](https://www.microsoft.com/msrc).
18 |
19 | Please include the requested information listed below (as much as you can provide) to help us better understand the nature and scope of the possible issue:
20 |
21 | * Type of issue (e.g. buffer overflow, SQL injection, cross-site scripting, etc.)
22 | * Full paths of source file(s) related to the manifestation of the issue
23 | * The location of the affected source code (tag/branch/commit or direct URL)
24 | * Any special configuration required to reproduce the issue
25 | * Step-by-step instructions to reproduce the issue
26 | * Proof-of-concept or exploit code (if possible)
27 | * Impact of the issue, including how an attacker might exploit the issue
28 |
29 | This information will help us triage your report more quickly.
30 |
31 | If you are reporting for a bug bounty, more complete reports can contribute to a higher bounty award. Please visit our [Microsoft Bug Bounty Program](https://microsoft.com/msrc/bounty) page for more details about our active programs.
32 |
33 | ## Preferred Languages
34 |
35 | We prefer all communications to be in English.
36 |
37 | ## Policy
38 |
39 | Microsoft follows the principle of [Coordinated Vulnerability Disclosure](https://www.microsoft.com/en-us/msrc/cvd).
40 |
41 |
--------------------------------------------------------------------------------
/SUPPORT.md:
--------------------------------------------------------------------------------
1 | # TODO: The maintainer of this repo has not yet edited this file
2 |
3 | **REPO OWNER**: Do you want Customer Service & Support (CSS) support for this product/project?
4 |
5 | - **No CSS support:** Fill out this template with information about how to file issues and get help.
6 | - **Yes CSS support:** Fill out an intake form at [aka.ms/spot](https://aka.ms/spot). CSS will work with/help you to determine next steps. More details also available at [aka.ms/onboardsupport](https://aka.ms/onboardsupport).
7 | - **Not sure?** Fill out a SPOT intake as though the answer were "Yes". CSS will help you decide.
8 |
9 | *Then remove this first heading from this SUPPORT.MD file before publishing your repo.*
10 |
11 | # Support
12 |
13 | ## How to file issues and get help
14 |
15 | This project uses GitHub Issues to track bugs and feature requests. Please search the existing
16 | issues before filing new issues to avoid duplicates. For new issues, file your bug or
17 | feature request as a new Issue.
18 |
19 | For help and questions about using this project, please **REPO MAINTAINER: INSERT INSTRUCTIONS HERE
20 | FOR HOW TO ENGAGE REPO OWNERS OR COMMUNITY FOR HELP. COULD BE A STACK OVERFLOW TAG OR OTHER
21 | CHANNEL. WHERE WILL YOU HELP PEOPLE?**.
22 |
23 | ## Microsoft Support Policy
24 |
25 | Support for this **PROJECT or PRODUCT** is limited to the resources listed above.
--------------------------------------------------------------------------------
/configs/captioning/m4c_textcaps/tap_base_pretrain.yml:
--------------------------------------------------------------------------------
1 | includes:
2 | - common/defaults/configs/datasets/captioning/m4c_textcaps_ocr100.yml
3 | # Use soft copy
4 | dataset_attributes:
5 | m4c_textcaps:
6 | image_features:
7 | train:
8 | - feat_resx/train,ocr_feat_resx/textvqa_conf/train_images
9 | val:
10 | - feat_resx/train,ocr_feat_resx/textvqa_conf/train_images
11 | test:
12 | - feat_resx/test,ocr_feat_resx/textvqa_conf/test_images
13 | imdb_files:
14 | train:
15 | - imdb/m4c_textcaps/imdb_train.npy
16 | val:
17 | - imdb/m4c_textcaps/imdb_val_filtered_by_image_id.npy # only one sample per image_id
18 | test:
19 | - imdb/m4c_textcaps/imdb_test_filtered_by_image_id.npy # only one sample per image_id
20 | processors:
21 | text_processor:
22 | type: bert_tokenizer
23 | params:
24 | # max_length: 1
25 | max_length: 20
26 | answer_processor:
27 | type: m4c_caption
28 | params:
29 | vocab_file: m4c_captioner_vocabs/textcaps/vocab_textcap_threshold_10.txt
30 | preprocessor:
31 | type: simple_word
32 | params: {}
33 | context_preprocessor:
34 | type: simple_word
35 | params: {}
36 | max_length: 100
37 | max_copy_steps: 30
38 | num_answers: 1
39 | copy_processor:
40 | type: copy
41 | params:
42 | obj_max_length: 100
43 | max_length: 100
44 | phoc_processor:
45 | type: phoc
46 | params:
47 | max_length: 100
48 | model_attributes:
49 | m4c_captioner:
50 | lr_scale_frcn: 0.1
51 | lr_scale_text_bert: 0.1
52 | lr_scale_mmt: 1.0 # no scaling
53 | text_bert_init_from_bert_base: true
54 | text_bert:
55 | num_hidden_layers: 3
56 | obj:
57 | mmt_in_dim: 2048
58 | dropout_prob: 0.1
59 | ocr:
60 | mmt_in_dim: 3052 # 300 (FastText) + 604 (PHOC) + 2048 (Faster R-CNN) + 100 (all zeros; legacy)
61 | dropout_prob: 0.1
62 | mmt:
63 | hidden_size: 768
64 | num_hidden_layers: 4
65 | classifier:
66 | type: linear
67 | ocr_max_num: 100
68 | ocr_ptr_net:
69 | hidden_size: 768
70 | query_key_size: 768
71 | params: {}
72 | model_data_dir: ../data
73 | metrics:
74 | - type: maskpred_accuracy
75 | losses:
76 | - type: pretrainonly_m4c_decoding_bce_with_mask
77 | remove_unk_in_pred: true
78 | optimizer_attributes:
79 | params:
80 | eps: 1.0e-08
81 | lr: 1e-4
82 | weight_decay: 0
83 | type: Adam
84 | training_parameters:
85 | clip_norm_mode: all
86 | clip_gradients: true
87 | max_grad_l2_norm: 0.25
88 | lr_scheduler: true
89 | lr_steps:
90 | - 10000
91 | - 11000
92 | lr_ratio: 0.1
93 | use_warmup: true
94 | warmup_factor: 0.2
95 | warmup_iterations: 1000
96 | max_iterations: 12000
97 | batch_size: 128
98 | num_workers: 8
99 | task_size_proportional_sampling: true
100 | monitored_metric: m4c_textcaps/maskpred_accuracy
101 | metric_minimize: false
102 |
--------------------------------------------------------------------------------
/configs/captioning/m4c_textcaps/tap_refine.yml:
--------------------------------------------------------------------------------
1 | includes:
2 | - common/defaults/configs/datasets/captioning/m4c_textcaps_ocr100.yml
3 | # Use soft copy
4 | dataset_attributes:
5 | m4c_textcaps:
6 | image_features:
7 | train:
8 | - feat_resx/train,ocr_feat_resx/textvqa_conf/train_images
9 | val:
10 | - feat_resx/train,ocr_feat_resx/textvqa_conf/train_images
11 | test:
12 | - feat_resx/test,ocr_feat_resx/textvqa_conf/test_images
13 | imdb_files:
14 | train:
15 | - imdb/m4c_textcaps/imdb_train.npy
16 | val:
17 | - imdb/m4c_textcaps/imdb_val_filtered_by_image_id.npy # only one sample per image_id
18 | test:
19 | - imdb/m4c_textcaps/imdb_test_filtered_by_image_id.npy # only one sample per image_id
20 | processors:
21 | text_processor:
22 | type: bert_tokenizer
23 | params:
24 | # max_length: 1
25 | max_length: 20
26 | answer_processor:
27 | type: m4c_caption
28 | params:
29 | vocab_file: m4c_captioner_vocabs/textcaps/vocab_textcap_threshold_10.txt
30 | preprocessor:
31 | type: simple_word
32 | params: {}
33 | context_preprocessor:
34 | type: simple_word
35 | params: {}
36 | max_length: 100
37 | max_copy_steps: 30
38 | num_answers: 1
39 | copy_processor:
40 | type: copy
41 | params:
42 | obj_max_length: 100
43 | max_length: 100
44 | phoc_processor:
45 | type: phoc
46 | params:
47 | max_length: 100
48 | model_attributes:
49 | m4c_captioner:
50 | lr_scale_frcn: 0.1
51 | lr_scale_text_bert: 0.1
52 | lr_scale_mmt: 1.0 # no scaling
53 | text_bert_init_from_bert_base: true
54 | text_bert:
55 | num_hidden_layers: 3
56 | obj:
57 | mmt_in_dim: 2048
58 | dropout_prob: 0.1
59 | ocr:
60 | mmt_in_dim: 3052 # 300 (FastText) + 604 (PHOC) + 2048 (Faster R-CNN) + 100 (all zeros; legacy)
61 | dropout_prob: 0.1
62 | mmt:
63 | hidden_size: 768
64 | num_hidden_layers: 4
65 | classifier:
66 | type: linear
67 | ocr_max_num: 100
68 | ocr_ptr_net:
69 | hidden_size: 768
70 | query_key_size: 768
71 | params: {}
72 | model_data_dir: ../data
73 | metrics:
74 | - type: textcaps_bleu4
75 | losses:
76 | - type: m4c_decoding_bce_with_mask
77 | remove_unk_in_pred: true
78 | optimizer_attributes:
79 | params:
80 | eps: 1.0e-08
81 | lr: 1e-4
82 | weight_decay: 0
83 | type: Adam
84 | training_parameters:
85 | clip_norm_mode: all
86 | clip_gradients: true
87 | max_grad_l2_norm: 0.25
88 | lr_scheduler: true
89 | lr_steps:
90 | - 10000
91 | - 11000
92 | lr_ratio: 0.1
93 | use_warmup: true
94 | warmup_factor: 0.2
95 | warmup_iterations: 1000
96 | max_iterations: 12000
97 | batch_size: 128
98 | num_workers: 8
99 | task_size_proportional_sampling: true
100 | monitored_metric: m4c_textcaps/textcaps_bleu4
101 | metric_minimize: false
102 |
--------------------------------------------------------------------------------
/configs/vqa/m4c_stvqa/tap_base_pretrain.yml:
--------------------------------------------------------------------------------
1 | includes:
2 | - common/defaults/configs/datasets/vqa/m4c_stvqa_ocr100.yml
3 | # Use soft copy
4 | dataset_attributes:
5 | m4c_textvqa:
6 | image_features:
7 | train:
8 | - feat_resx/stvqa/train,ocr_feat_resx/stvqa_conf
9 | val:
10 | - feat_resx/stvqa/train,ocr_feat_resx/stvqa_conf
11 | test:
12 | - feat_resx/stvqa/test_task3,ocr_feat_resx/stvqa_conf/test_task3
13 | imdb_files:
14 | train:
15 | - original_dl/ST-VQA/m4c_stvqa/imdb_subtrain.npy
16 | val:
17 | - original_dl/ST-VQA/m4c_stvqa/imdb_subval.npy
18 | test:
19 | - original_dl/ST-VQA/m4c_stvqa/imdb_test_task3.npy
20 | processors:
21 | text_processor:
22 | type: bert_tokenizer
23 | params:
24 | max_length: 20
25 | context_processor:
26 | params:
27 | max_length: 100
28 | answer_processor:
29 | type: m4c_answer
30 | params:
31 | vocab_file: m4c_vocabs/stvqa/fixed_answer_vocab_stvqa_5k.txt
32 | preprocessor:
33 | type: simple_word
34 | params: {}
35 | context_preprocessor:
36 | type: simple_word
37 | params: {}
38 | max_length: 100
39 | max_copy_steps: 12
40 | num_answers: 10
41 | copy_processor:
42 | type: copy
43 | params:
44 | obj_max_length: 100
45 | max_length: 100
46 | phoc_processor:
47 | type: phoc
48 | params:
49 | max_length: 100
50 | model_attributes:
51 | m4c_split:
52 | lr_scale_frcn: 0.1
53 | lr_scale_text_bert: 0.1
54 | lr_scale_mmt: 1.0 # no scaling
55 | text_bert_init_from_bert_base: true
56 | text_bert:
57 | num_hidden_layers: 3
58 | obj:
59 | mmt_in_dim: 2048
60 | dropout_prob: 0.1
61 | ocr:
62 | mmt_in_dim: 3052 # 300 (FastText) + 604 (PHOC) + 2048 (Faster R-CNN) + 100 (all zeros; legacy)
63 | dropout_prob: 0.1
64 | mmt:
65 | hidden_size: 768
66 | num_hidden_layers: 4
67 | classifier:
68 | type: linear
69 | ocr_max_num: 100
70 | ocr_ptr_net:
71 | hidden_size: 768
72 | query_key_size: 768
73 | params: {}
74 | model_data_dir: ../data
75 | metrics:
76 | - type: maskpred_accuracy
77 | losses:
78 | - type: pretrainonly_m4c_decoding_bce_with_mask
79 | optimizer_attributes:
80 | params:
81 | eps: 1.0e-08
82 | lr: 1e-4
83 | weight_decay: 0
84 | type: Adam
85 | training_parameters:
86 | clip_norm_mode: all
87 | clip_gradients: true
88 | max_grad_l2_norm: 0.25
89 | lr_scheduler: true
90 | lr_steps:
91 | - 14000
92 | - 19000
93 | lr_ratio: 0.1
94 | use_warmup: true
95 | warmup_factor: 0.2
96 | warmup_iterations: 1000
97 | max_iterations: 24000
98 | batch_size: 128
99 | num_workers: 8
100 | task_size_proportional_sampling: true
101 | monitored_metric: m4c_stvqa/maskpred_accuracy
102 | metric_minimize: false
--------------------------------------------------------------------------------
/configs/vqa/m4c_stvqa/tap_refine.yml:
--------------------------------------------------------------------------------
1 | includes:
2 | - common/defaults/configs/datasets/vqa/m4c_stvqa_ocr100.yml
3 | # Use soft copy
4 | dataset_attributes:
5 | m4c_textvqa:
6 | image_features:
7 | train:
8 | - feat_resx/stvqa/train,ocr_feat_resx/stvqa_conf
9 | val:
10 | - feat_resx/stvqa/train,ocr_feat_resx/stvqa_conf
11 | test:
12 | - feat_resx/stvqa/test_task3,ocr_feat_resx/stvqa_conf/test_task3
13 | imdb_files:
14 | train:
15 | - original_dl/ST-VQA/m4c_stvqa/imdb_subtrain.npy
16 | val:
17 | - original_dl/ST-VQA/m4c_stvqa/imdb_subval.npy
18 | test:
19 | - original_dl/ST-VQA/m4c_stvqa/imdb_test_task3.npy
20 | processors:
21 | text_processor:
22 | type: bert_tokenizer
23 | params:
24 | max_length: 20
25 | context_processor:
26 | params:
27 | max_length: 100
28 | answer_processor:
29 | type: m4c_answer
30 | params:
31 | vocab_file: m4c_vocabs/stvqa/fixed_answer_vocab_stvqa_5k.txt
32 | preprocessor:
33 | type: simple_word
34 | params: {}
35 | context_preprocessor:
36 | type: simple_word
37 | params: {}
38 | max_length: 100
39 | max_copy_steps: 12
40 | num_answers: 10
41 | copy_processor:
42 | type: copy
43 | params:
44 | obj_max_length: 100
45 | max_length: 100
46 | phoc_processor:
47 | type: phoc
48 | params:
49 | max_length: 100
50 | model_attributes:
51 | m4c_split:
52 | lr_scale_frcn: 0.1
53 | lr_scale_text_bert: 0.1
54 | lr_scale_mmt: 1.0 # no scaling
55 | text_bert_init_from_bert_base: true
56 | text_bert:
57 | num_hidden_layers: 3
58 | obj:
59 | mmt_in_dim: 2048
60 | dropout_prob: 0.1
61 | ocr:
62 | mmt_in_dim: 3052 # 300 (FastText) + 604 (PHOC) + 2048 (Faster R-CNN) + 100 (all zeros; legacy)
63 | dropout_prob: 0.1
64 | mmt:
65 | hidden_size: 768
66 | num_hidden_layers: 4
67 | classifier:
68 | type: linear
69 | ocr_max_num: 100
70 | ocr_ptr_net:
71 | hidden_size: 768
72 | query_key_size: 768
73 | params: {}
74 | model_data_dir: ../data
75 | metrics:
76 | - type: stvqa_accuracy
77 | - type: stvqa_anls
78 | losses:
79 | - type: m4c_decoding_bce_with_mask
80 | optimizer_attributes:
81 | params:
82 | eps: 1.0e-08
83 | lr: 1e-4
84 | weight_decay: 0
85 | type: Adam
86 | training_parameters:
87 | clip_norm_mode: all
88 | clip_gradients: true
89 | max_grad_l2_norm: 0.25
90 | lr_scheduler: true
91 | lr_steps:
92 | - 14000
93 | - 19000
94 | lr_ratio: 0.1
95 | use_warmup: true
96 | warmup_factor: 0.2
97 | warmup_iterations: 1000
98 | max_iterations: 24000
99 | batch_size: 128
100 | num_workers: 8
101 | task_size_proportional_sampling: true
102 | monitored_metric: m4c_stvqa/stvqa_accuracy
103 | metric_minimize: false
--------------------------------------------------------------------------------
/configs/vqa/m4c_textvqa/tap_base_pretrain.yml:
--------------------------------------------------------------------------------
1 | includes:
2 | - common/defaults/configs/datasets/vqa/m4c_textvqa_ocr100.yml
3 | # Use soft copy
4 | dataset_attributes:
5 | m4c_textvqa:
6 | image_features:
7 | train:
8 | - feat_resx/train,ocr_feat_resx/textvqa_conf/train_images
9 | val:
10 | - feat_resx/train,ocr_feat_resx/textvqa_conf/train_images
11 | test:
12 | - feat_resx/test,ocr_feat_resx/textvqa_conf/test_images
13 | imdb_files:
14 | train:
15 | - imdb/m4c_textvqa/imdb_train_ocr_en.npy
16 | val:
17 | - imdb/m4c_textvqa/imdb_val_ocr_en.npy
18 | test:
19 | - imdb/m4c_textvqa/imdb_test_ocr_en.npy
20 | processors:
21 | text_processor:
22 | type: bert_tokenizer
23 | params:
24 | max_length: 20
25 | context_processor:
26 | params:
27 | max_length: 100
28 | answer_processor:
29 | type: m4c_answer
30 | params:
31 | vocab_file: m4c_vocabs/textvqa/fixed_answer_vocab_textvqa_5k.txt
32 | preprocessor:
33 | type: simple_word
34 | params: {}
35 | context_preprocessor:
36 | type: simple_word
37 | params: {}
38 | max_length: 100
39 | max_copy_steps: 12
40 | num_answers: 10
41 | copy_processor:
42 | type: copy
43 | params:
44 | obj_max_length: 100
45 | max_length: 100
46 | phoc_processor:
47 | type: phoc
48 | params:
49 | max_length: 100
50 | model_attributes:
51 | m4c_split:
52 | lr_scale_frcn: 0.1
53 | lr_scale_text_bert: 0.1
54 | lr_scale_mmt: 1.0 # no scaling
55 | text_bert_init_from_bert_base: true
56 | text_bert:
57 | num_hidden_layers: 3
58 | obj:
59 | mmt_in_dim: 2048
60 | dropout_prob: 0.1
61 | ocr:
62 | mmt_in_dim: 3052 # 300 (FastText) + 604 (PHOC) + 2048 (Faster R-CNN) + 100 (all zeros; legacy)
63 | dropout_prob: 0.1
64 | mmt:
65 | hidden_size: 768
66 | num_hidden_layers: 4
67 | classifier:
68 | type: linear
69 | ocr_max_num: 100
70 | ocr_ptr_net:
71 | hidden_size: 768
72 | query_key_size: 768
73 | params: {}
74 | model_data_dir: ../data
75 | metrics:
76 | - type: maskpred_accuracy
77 | losses:
78 | - type: pretrainonly_m4c_decoding_bce_with_mask
79 | optimizer_attributes:
80 | params:
81 | eps: 1.0e-08
82 | lr: 1e-4
83 | weight_decay: 0
84 | type: Adam
85 | training_parameters:
86 | clip_norm_mode: all
87 | clip_gradients: true
88 | max_grad_l2_norm: 0.25
89 | lr_scheduler: true
90 | lr_steps:
91 | - 14000
92 | - 19000
93 | lr_ratio: 0.1
94 | use_warmup: true
95 | warmup_factor: 0.2
96 | warmup_iterations: 1000
97 | max_iterations: 24000
98 | batch_size: 128
99 | num_workers: 8
100 | task_size_proportional_sampling: true
101 | monitored_metric: m4c_textvqa/maskpred_accuracy
102 | metric_minimize: false
--------------------------------------------------------------------------------
/configs/vqa/m4c_textvqa/tap_refine.yml:
--------------------------------------------------------------------------------
1 | includes:
2 | - common/defaults/configs/datasets/vqa/m4c_textvqa_ocr100.yml
3 | # Use soft copy
4 | dataset_attributes:
5 | m4c_textvqa:
6 | image_features:
7 | train:
8 | - feat_resx/train,ocr_feat_resx/textvqa_conf/train_images
9 | val:
10 | - feat_resx/train,ocr_feat_resx/textvqa_conf/train_images
11 | test:
12 | - feat_resx/test,ocr_feat_resx/textvqa_conf/test_images
13 | imdb_files:
14 | train:
15 | - imdb/m4c_textvqa/imdb_train_ocr_en.npy
16 | val:
17 | - imdb/m4c_textvqa/imdb_val_ocr_en.npy
18 | test:
19 | - imdb/m4c_textvqa/imdb_test_ocr_en.npy
20 | processors:
21 | text_processor:
22 | type: bert_tokenizer
23 | params:
24 | max_length: 20
25 | context_processor:
26 | params:
27 | max_length: 100
28 | answer_processor:
29 | type: m4c_answer
30 | params:
31 | vocab_file: m4c_vocabs/textvqa/fixed_answer_vocab_textvqa_5k.txt
32 | preprocessor:
33 | type: simple_word
34 | params: {}
35 | context_preprocessor:
36 | type: simple_word
37 | params: {}
38 | max_length: 100
39 | max_copy_steps: 12
40 | num_answers: 10
41 | copy_processor:
42 | type: copy
43 | params:
44 | obj_max_length: 100
45 | max_length: 100
46 | phoc_processor:
47 | type: phoc
48 | params:
49 | max_length: 100
50 | model_attributes:
51 | m4c_split:
52 | lr_scale_frcn: 0.1
53 | lr_scale_text_bert: 0.1
54 | lr_scale_mmt: 1.0 # no scaling
55 | text_bert_init_from_bert_base: true
56 | text_bert:
57 | num_hidden_layers: 3
58 | obj:
59 | mmt_in_dim: 2048
60 | dropout_prob: 0.1
61 | ocr:
62 | mmt_in_dim: 3052 # 300 (FastText) + 604 (PHOC) + 2048 (Faster R-CNN) + 100 (all zeros; legacy)
63 | dropout_prob: 0.1
64 | mmt:
65 | hidden_size: 768
66 | num_hidden_layers: 4
67 | classifier:
68 | type: linear
69 | ocr_max_num: 100
70 | ocr_ptr_net:
71 | hidden_size: 768
72 | query_key_size: 768
73 | params: {}
74 | model_data_dir: ../data
75 | metrics:
76 | - type: textvqa_accuracy
77 | losses:
78 | - type: m4c_decoding_bce_with_mask
79 | optimizer_attributes:
80 | params:
81 | eps: 1.0e-08
82 | lr: 1e-4
83 | weight_decay: 0
84 | type: Adam
85 | training_parameters:
86 | clip_norm_mode: all
87 | clip_gradients: true
88 | max_grad_l2_norm: 0.25
89 | lr_scheduler: true
90 | lr_steps:
91 | - 14000
92 | - 19000
93 | lr_ratio: 0.1
94 | use_warmup: true
95 | warmup_factor: 0.2
96 | warmup_iterations: 1000
97 | max_iterations: 24000
98 | batch_size: 128
99 | num_workers: 8
100 | task_size_proportional_sampling: true
101 | monitored_metric: m4c_textvqa/textvqa_accuracy
102 | metric_minimize: false
--------------------------------------------------------------------------------
/data/README.md:
--------------------------------------------------------------------------------
1 | ## Data Organization
2 | We recommend using the following AzCopy command to download.
3 | AzCopy executable tools can be downloaded [here](https://docs.microsoft.com/en-us/azure/storage/common/storage-use-azcopy-v10#download-azcopy).
4 | Move ``GoogleCC`` folder under ``data`` to match the default paths.
5 |
6 | [TextVQA/Caps/STVQA Data (~62G)](https://tapvqacaption.blob.core.windows.net/data/data).
7 |
8 | [OCR-CC Data (Huge, ~1.3T)](https://tapvqacaption.blob.core.windows.net/data/GoogleCC).
9 |
10 | [Model checkpoints (~17G)](https://tapvqacaption.blob.core.windows.net/data/save).
11 |
12 | A subset of OCR-CC with around 400K samples is availble in imdb ``data/imdb/cc/imdb_train_ocr_subset.npy``. The subset is faster to train with a small drop in performance, compared with the full set ``data/imdb/cc/imdb_train_ocr.npy``.
13 |
14 | ```
15 | path/to/azcopy copy --resursive"
16 |
17 | # for example, downloading TextVQA/Caps/STVQA Data
18 | path/to/azcopy copy https://tapvqacaption.blob.core.windows.net/data/data /data --recursive
19 |
20 | # for example, downloading OCR-CC Data
21 | path/to/azcopy copy https://tapvqacaption.blob.core.windows.net/data/GoogleCC /data/GoogleCC --recursive
22 |
23 | # for example, downloading model checkpoints
24 | path/to/azcopy copy https://tapvqacaption.blob.core.windows.net/data/save /save --recursive
25 | ```
26 |
--------------------------------------------------------------------------------
/projects/M4C_Captioner/scripts/textcaps_eval.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import json
3 | import numpy as np
4 | import os
5 |
6 | sys.path.append(
7 | os.path.join(os.path.dirname(__file__), '../../../pythia/scripts/coco/')
8 | )
9 | import coco_caption_eval # NoQA
10 |
11 |
12 | def print_metrics(res_metrics):
13 | print(res_metrics)
14 | keys = ['Bleu_1', 'Bleu_2', 'Bleu_3', 'Bleu_4', 'METEOR', 'ROUGE_L', 'SPICE', 'CIDEr']
15 | print('\n\n**********\nFinal model performance:\n**********')
16 | for k in keys:
17 | print(k, ': %.1f' % (res_metrics[k] * 100))
18 |
19 |
20 | if __name__ == '__main__':
21 | import argparse
22 | parser = argparse.ArgumentParser()
23 | parser.add_argument('--pred_file', type=str, required=True)
24 | parser.add_argument('--set', type=str, default='val')
25 | args = parser.parse_args()
26 |
27 | if args.set not in ['train', 'val']:
28 | raise Exception(
29 | 'this script only supports TextCaps train and val set. '
30 | 'Please use the EvalAI server for test set evaluation'
31 | )
32 |
33 | with open(args.pred_file) as f:
34 | preds = json.load(f)
35 | imdb_file = os.path.join(
36 | os.path.dirname(__file__),
37 | '../../../data/imdb/m4c_textcaps/imdb_{}.npy'.format(args.set)
38 | )
39 | imdb = np.load(imdb_file, allow_pickle=True)
40 | imdb = imdb[1:]
41 |
42 | gts = [
43 | {'image_id': info['image_id'], 'caption': info['caption_str']}
44 | for info in imdb
45 | ]
46 | preds = [
47 | {'image_id': p['image_id'], 'caption': p['caption']}
48 | for p in preds
49 | ]
50 | imgids = list(set(g['image_id'] for g in gts))
51 |
52 | metrics = coco_caption_eval.calculate_metrics(
53 | imgids, {'annotations': gts}, {'annotations': preds}
54 | )
55 |
56 | print_metrics(metrics)
57 |
--------------------------------------------------------------------------------
/projects/TAP_Caption/README.md:
--------------------------------------------------------------------------------
1 | TAP
2 |
--------------------------------------------------------------------------------
/projects/TAP_QA/README.md:
--------------------------------------------------------------------------------
1 | TAP
2 |
--------------------------------------------------------------------------------
/pythia/common/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
--------------------------------------------------------------------------------
/pythia/common/batch_collator.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.common.sample import SampleList
3 | import random
4 | import torch
5 |
6 | def combine_seq(texta, textlena, textmaska, textb, textlenb, textmaskb, texta_maxlen=None):
7 | if textmaska is None: textmaska = torch.ones(texta.shape).long()*-1
8 | if textmaskb is None: textmaskb = torch.ones(textb.shape).long()*-1
9 | textb[0] = 102
10 | cmb_text, cmb_textmask = torch.cat([texta,textb],0), torch.cat([textmaska,textmaskb],0)
11 | cmb_textlen = textlena + textlenb
12 | return cmb_text, cmb_textlen, cmb_textmask
13 |
14 | def combine_seq_pollute(batch):
15 | batch_size = len(batch)
16 | for ii in range(batch_size):
17 | assert(batch_size!=0)
18 | if batch_size!=1:
19 | pollute = random.choice([i for i in range(batch_size) if i!=ii])
20 | else:
21 | pollute = ii
22 | qidx, ocridx, objidx = ii, ii, ii
23 | if 'langtag_pollute' in batch[ii]:
24 | if int(batch[ii].langtag_pollute)==1: qidx = pollute
25 | if 'ocrtag_pollute' in batch[ii]:
26 | if int(batch[ii].ocrtag_pollute)==1: ocridx = pollute
27 | if 'objtag_pollute' in batch[ii]:
28 | if int(batch[ii].objtag_pollute)==1: objidx = pollute
29 | qocr_text, qocr_text_len, qocr_text_mask_label = combine_seq(\
30 | batch[qidx].text, batch[qidx].text_len, batch[qidx].text_mask_label, \
31 | batch[ocridx].ocr_text, batch[ocridx].ocr_text_len, batch[ocridx].ocrtext_mask_label, texta_maxlen=batch[qidx].text.shape[0])
32 |
33 | batch[ii].cmb_text, batch[ii].cmb_text_len, batch[ii].cmb_text_mask_label = combine_seq(\
34 | qocr_text, qocr_text_len, qocr_text_mask_label, \
35 | batch[objidx].obj_text, batch[objidx].obj_text_len, batch[objidx].objtext_mask_label, texta_maxlen=qocr_text.shape[0])
36 | return batch
37 |
38 | class BatchCollator:
39 | # TODO: Think more if there is a better way to do this
40 | _IDENTICAL_VALUE_KEYS = ["dataset_type", "dataset_name"]
41 |
42 | def __call__(self, batch):
43 | batch = combine_seq_pollute(batch)
44 | sample_list = SampleList(batch)
45 | for key in self._IDENTICAL_VALUE_KEYS:
46 | sample_list[key + "_"] = sample_list[key]
47 | sample_list[key] = sample_list[key][0]
48 |
49 | return sample_list
--------------------------------------------------------------------------------
/pythia/common/constants.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import os
3 |
4 |
5 | imdb_version = 1
6 | FASTTEXT_WIKI_URL = (
7 | "https://dl.fbaipublicfiles.com/pythia/pretrained_models/fasttext/wiki.en.bin"
8 | )
9 |
10 | CLEVR_DOWNLOAD_URL = (
11 | "https://dl.fbaipublicfiles.com/clevr/CLEVR_v1.0.zip"
12 | )
13 |
14 | VISUAL_GENOME_CONSTS = {
15 | "imdb_url": "https://dl.fbaipublicfiles.com/pythia/data/imdb/visual_genome.tar.gz",
16 | "features_url": "https://dl.fbaipublicfiles.com/pythia/features/visual_genome.tar.gz",
17 | "synset_file": "vg_synsets.txt",
18 | "vocabs": "https://dl.fbaipublicfiles.com/pythia/data/vocab.tar.gz"
19 | }
20 |
21 | VISUAL_DIALOG_CONSTS = {
22 | "imdb_url": {
23 | "train": "https://www.dropbox.com/s/ix8keeudqrd8hn8/visdial_1.0_train.zip?dl=1",
24 | "val": "https://www.dropbox.com/s/ibs3a0zhw74zisc/visdial_1.0_val.zip?dl=1",
25 | "test": "https://www.dropbox.com/s/ibs3a0zhw74zisc/visdial_1.0_test.zip?dl=1"
26 | },
27 | "features_url": {
28 | "visual_dialog": "https://dl.fbaipublicfiles.com/pythia/features/visual_dialog.tar.gz",
29 | "coco": "https://dl.fbaipublicfiles.com/pythia/features/coco.tar.gz"
30 | },
31 | "vocabs": "https://dl.fbaipublicfiles.com/pythia/data/vocab.tar.gz"
32 | }
33 |
34 | DOWNLOAD_CHUNK_SIZE = 1024 * 1024
35 |
--------------------------------------------------------------------------------
/pythia/common/dataset_loader.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import os
3 |
4 | import yaml
5 | from torch.utils.data import DataLoader
6 |
7 | from pythia.common.batch_collator import BatchCollator
8 | from pythia.common.test_reporter import TestReporter
9 | from pythia.datasets.multi_dataset import MultiDataset
10 | from pythia.datasets.samplers import DistributedSampler
11 | from pythia.utils.general import get_batch_size
12 |
13 |
14 | class DatasetLoader:
15 | def __init__(self, config):
16 | self.config = config
17 |
18 | def load_datasets(self):
19 | self.train_dataset = MultiDataset("train")
20 | self.val_dataset = MultiDataset("val")
21 | self.test_dataset = MultiDataset("test")
22 |
23 | self.train_dataset.load(**self.config)
24 | self.val_dataset.load(**self.config)
25 | self.test_dataset.load(**self.config)
26 |
27 | if self.train_dataset.num_datasets == 1:
28 | self.train_loader = self.train_dataset.first_loader
29 | self.val_loader = self.val_dataset.first_loader
30 | self.test_loader = self.test_dataset.first_loader
31 | else:
32 | self.train_loader = self.train_dataset
33 | self.val_loader = self.val_dataset
34 | self.test_loader = self.test_dataset
35 |
36 | self.mapping = {
37 | "train": self.train_dataset,
38 | "val": self.val_dataset,
39 | "test": self.test_dataset,
40 | }
41 |
42 | self.test_reporter = None
43 | self.should_not_log = self.config.training_parameters.should_not_log
44 |
45 | @property
46 | def dataset_config(self):
47 | return self._dataset_config
48 |
49 | @dataset_config.setter
50 | def dataset_config(self, config):
51 | self._dataset_config = config
52 |
53 | def get_config(self):
54 | return self._dataset_config
55 |
56 | def get_test_reporter(self, dataset_type):
57 | dataset = getattr(self, "{}_dataset".format(dataset_type))
58 | return TestReporter(dataset)
59 |
60 | def update_registry_for_model(self, config):
61 | self.train_dataset.update_registry_for_model(config)
62 | self.val_dataset.update_registry_for_model(config)
63 | self.test_dataset.update_registry_for_model(config)
64 |
65 | def clean_config(self, config):
66 | self.train_dataset.clean_config(config)
67 | self.val_dataset.clean_config(config)
68 | self.test_dataset.clean_config(config)
69 |
70 | def prepare_batch(self, batch, *args, **kwargs):
71 | return self.mapping[batch.dataset_type].prepare_batch(batch)
72 |
73 | def verbose_dump(self, report, *args, **kwargs):
74 | if self.config.training_parameters.verbose_dump:
75 | dataset_type = report.dataset_type
76 | self.mapping[dataset_type].verbose_dump(report, *args, **kwargs)
77 |
78 | def seed_sampler(self, dataset_type, seed):
79 | dataset = getattr(self, "{}_dataset".format(dataset_type))
80 | dataset.seed_sampler(seed)
81 |
--------------------------------------------------------------------------------
/pythia/common/defaults/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/microsoft/TAP/352891f93c75ac5d6b9ba141bbe831477dcdd807/pythia/common/defaults/__init__.py
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/base.yml:
--------------------------------------------------------------------------------
1 | # Configuration for training
2 | training_parameters:
3 | # Name of the trainer class used to define the training/evalution loop
4 | trainer: 'base_trainer'
5 | # Name of the experiment, will be used while saving checkpoints
6 | # and generating reports
7 | experiment_name: run
8 | # Maximum number of iterations the training will run
9 | max_iterations: 22000
10 | # Maximum epochs in case you don't want to use iterations
11 | # Can be mixed with max iterations, so it will stop whichever is
12 | # completed first. Default: null means epochs won't be used
13 | max_epochs: null
14 | # After `log_interval` iterations, current iteration's training loss and
15 | # metrics will be reported. This will also report validation
16 | # loss and metrics on a single batch from validation set
17 | # to provide an estimate on validation side
18 | log_interval: 100
19 | # After `snapshot_interval` iterations, pythia will make a snapshot
20 | # which will involve creating a checkpoint for current training scenarios
21 | # This will also evaluate validation metrics on whole validation set
22 | # TODO: Change this to checkpoint_interval and create a new
23 | # `validation_interval` for evaluating on validation set
24 | snapshot_interval: 1000
25 | # Whether gradients should be clipped
26 | clip_gradients: false
27 | # Mode for clip norm
28 | clip_norm_mode: all
29 | # Device to be used, if cuda then GPUs will be used
30 | device: cuda
31 | # Seed to be used for training. -1 means random seed.
32 | # Either pass fixed through your config or command line arguments
33 | seed: null
34 | # Size of each batch. If distributed or data_parallel
35 | # is used, this will be divided equally among GPUs
36 | batch_size: 512
37 | # Number of workers to be used in dataloaders
38 | num_workers: 4
39 |
40 | # Whether to use early stopping, (Default: false)
41 | should_early_stop: false
42 | # Patience for early stopping
43 | patience: 4000
44 | # Metric to be monitored for early stopping
45 | # loss will monitor combined loss from all of the tasks
46 | # Usually, it will be of the form `dataset_metric`
47 | # for e.g. vqa2_vqa_accuracy
48 | monitored_metric: total_loss
49 | # Whether the monitored metric should be minimized for early stopping
50 | # or not, for e.g. you would want to minimize loss but maximize accuracy
51 | metric_minimize: true
52 |
53 | # Should a lr scheduler be used
54 | lr_scheduler: false
55 | # Steps for LR scheduler, will be an array of iteration count
56 | # when lr should be decreased
57 | lr_steps: []
58 | # Ratio for each lr step
59 | lr_ratio: 0.1
60 |
61 | # Should use warmup for lr
62 | use_warmup: false
63 | # Warmup factor learning rate warmup
64 | warmup_factor: 0.2
65 | # Iteration until which warnup should be done
66 | warmup_iterations: 1000
67 |
68 | # Type of run, train+inference by default means both training and inference
69 | # (test) stage will be run, if run_type contains 'val',
70 | # inference will be run on val set also.
71 | run_type: train+inference
72 | # Level of logging, only logs which are >= to current level will be logged
73 | logger_level: info
74 | # Whether to use distributed training, mutually exclusive with respected
75 | # to `data_parallel` flag
76 | distributed: false
77 | # Local rank of the GPU device
78 | local_rank: null
79 |
80 | # Whether to use data parallel, mutually exclusive with respect to
81 | # `distributed` flag
82 | data_parallel: false
83 | # Whether JSON files for evalai evaluation should be generated
84 | evalai_inference: false
85 | # Use to load specific modules from checkpoint to your model,
86 | # this is helpful in finetuning. for e.g. you can specify
87 | # text_embeddings: text_embedding_pythia
88 | # for loading `text_embedding` module of your model
89 | # from `text_embedding_pythia`
90 | pretrained_mapping: {}
91 | # Whether the above mentioned pretrained mapping should be loaded or not
92 | load_pretrained: false
93 |
94 | # Directory for saving checkpoints and other metadata
95 | save_dir: "./save"
96 | # Directory for saving logs
97 | log_dir: "./logs"
98 | # Whether Pythia should log or not, Default: False, which means
99 | # pythia will log by default
100 | should_not_log: false
101 |
102 | # If verbose dump is active, pythia will dump dataset, model specific
103 | # information which can be useful in debugging
104 | verbose_dump: false
105 | # If resume is true, pythia will try to load automatically load
106 | # last of same parameters from save_dir
107 | resume: false
108 | # `resume_file` can be used to load a specific checkpoint from a file
109 | resume_file: null
110 | # Whether to pin memory in dataloader
111 | pin_memory: false
112 |
113 | # Use in multi-tasking, when you want to sample tasks proportional to their sizes
114 | dataset_size_proportional_sampling: true
115 |
116 | # Attributes for model, default configuration files for various models
117 | # included in pythia can be found under configs directory in root folder
118 | model_attributes: {}
119 |
120 | # Attributes for datasets. Separate configuration
121 | # for different datasets included in pythia are included in dataset folder
122 | # which can be mixed and matched to train multiple datasets together
123 | # An example for mixing all vqa datasets is present under vqa folder
124 | dataset_attributes: {}
125 |
126 | # Defines which datasets from the above tasks you want to train on
127 | datasets: []
128 |
129 | # Defines which model you want to train on
130 | model: null
131 |
132 | # Attributes for optimizer, examples can be found in models' configs in
133 | # configs folder
134 | optimizer_attributes: {}
135 |
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/captioning/coco.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | coco:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | image_features:
7 | train:
8 | - coco/detectron_fix_100/fc6/train_val_2014
9 | val:
10 | - coco/detectron_fix_100/fc6/train_val_2014
11 | test:
12 | - coco/detectron_fix_100/fc6/train_val_2014
13 | imdb_files:
14 | train:
15 | - imdb/coco_captions/imdb_karpathy_train.npy
16 | val:
17 | - imdb/coco_captions/imdb_karpathy_val.npy
18 | test:
19 | - imdb/coco_captions/imdb_karpathy_test.npy
20 | features_max_len: 100
21 | processors:
22 | text_processor:
23 | type: vocab
24 | params:
25 | max_length: 52
26 | vocab:
27 | type: intersected
28 | embedding_name: glove.6B.300d
29 | vocab_file: vocabs/vocabulary_captioning_thresh5.txt
30 | preprocessor:
31 | type: simple_sentence
32 | params: {}
33 | caption_processor:
34 | type: caption
35 | params:
36 | vocab:
37 | type: intersected
38 | embedding_name: glove.6B.300d
39 | vocab_file: vocabs/vocabulary_captioning_thresh5.txt
40 | min_captions_per_img: 5
41 | return_info: false
42 | # Return OCR information
43 | use_ocr: false
44 | # Return spatial information of OCR tokens if present
45 | use_ocr_info: false
46 | training_parameters:
47 | monitored_metric: coco/caption_bleu4
48 | metric_minimize: false
49 |
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/captioning/m4c_textcaps.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | m4c_textcaps:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | features_max_len: 100
7 | processors:
8 | context_processor:
9 | type: fasttext
10 | params:
11 | max_length: 50
12 | model_file: .vector_cache/wiki.en.bin
13 | ocr_token_processor:
14 | type: simple_word
15 | params: {}
16 | bbox_processor:
17 | type: bbox
18 | params:
19 | max_length: 50
20 | return_info: true
21 | use_ocr: true
22 | use_ocr_info: true
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/captioning/m4c_textcaps_ocr100.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | m4c_textcaps:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | features_max_len: 100
7 | processors:
8 | context_processor:
9 | type: fasttext
10 | params:
11 | max_length: 100
12 | model_file: .vector_cache/wiki.en.bin
13 | ocr_token_processor:
14 | type: simple_word
15 | params: {}
16 | bbox_processor:
17 | type: bbox
18 | params:
19 | max_length: 100
20 | return_info: true
21 | use_ocr: true
22 | use_ocr_info: true
23 |
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/dialog/visual_dialog.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | visual_genome:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | image_features:
7 | train:
8 | - coco/detectron_fix_100/fc6/train_val_2014,coco/resnet152/train_val_2014
9 | val:
10 | - visual_dialog/detectron_fix_100/fc6/val2018,visual_dialog/resnet152/
11 | test:
12 | - visual_dialog/detectron_fix_100/fc6/test2018,visual_dialog/resnet152/
13 | imdb_files:
14 | train:
15 | - imdb/visual_dialog/visdial_1.0_train.json
16 | val:
17 | - imdb/visual_dialog/visdial_1.0_val.json
18 | test:
19 | - imdb/visual_dialog/visdial_1.0_test.json
20 | features_max_len: 100
21 | processors:
22 | text_processor:
23 | type: vocab
24 | params:
25 | max_length: 14
26 | vocab:
27 | type: intersected
28 | embedding_name: glove.6B.300d
29 | vocab_file: vocabs/vocabulary_100k.txt
30 | preprocessor:
31 | type: simple_sentence
32 | params: {}
33 | answer_processor:
34 | type: vqa_answer
35 | params:
36 | num_answers: 1
37 | vocab_file: vocabs/answers_vqa.txt
38 | preprocessor:
39 | type: simple_word
40 | params: {}
41 | discriminative_answer_processor:
42 | type: vocab
43 | params:
44 | max_length: 1
45 | vocab:
46 | type: random
47 | vocab_file: vocabs/vocabulary_100k.txt
48 | vg_answer_preprocessor:
49 | type: simple_word
50 | params: {}
51 | history_processor:
52 | type: vocab
53 | params:
54 | max_length: 100
55 | vocab:
56 | type: intersected
57 | embedding_name: glove.6B.300d
58 | vocab_file: vocabs/vocabulary_100k.txt
59 | preprocessor:
60 | type: simple_sentence
61 | params: {}
62 | bbox_processor:
63 | type: bbox
64 | params:
65 | max_length: 50
66 | return_history: true
67 | # Means you have to rank 100 candidate answers
68 | discriminative:
69 | enabled: true
70 | # Only return answer indices, otherwise it will return
71 | # glove embeddings
72 | return_indices: true
73 | no_unk: false
74 | # Return OCR information
75 | use_ocr: false
76 | # Return spatial information of OCR tokens if present
77 | use_ocr_info: false
78 | training_parameters:
79 | monitored_metric: visual_dialog/r@1
80 | metric_minimize: false
81 |
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/vqa/clevr.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | clevr:
3 | data_root_dir: ../data
4 | data_folder: CLEVR_v1.0
5 | build_attributes:
6 | min_count: 1
7 | split_regex: " "
8 | keep:
9 | - ";"
10 | - ","
11 | remove:
12 | - "?"
13 | - "."
14 | processors:
15 | text_processor:
16 | type: vocab
17 | params:
18 | max_length: 10
19 | vocab:
20 | type: random
21 | vocab_file: vocabs/clevr_question_vocab.txt
22 | preprocessor:
23 | type: simple_sentence
24 | params: {}
25 | answer_processor:
26 | type: multi_hot_answer_from_vocab
27 | params:
28 | num_answers: 1
29 | # Vocab file is relative to [data_root_dir]/[data_folder]
30 | vocab_file: vocabs/clevr_answer_vocab.txt
31 | preprocessor:
32 | type: simple_word
33 | params: {}
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/vqa/m4c_ocrvqa.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | m4c_ocrvqa:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | features_max_len: 100
7 | processors:
8 | context_processor:
9 | type: fasttext
10 | params:
11 | max_length: 50
12 | model_file: .vector_cache/wiki.en.bin
13 | ocr_token_processor:
14 | type: simple_word
15 | params: {}
16 | bbox_processor:
17 | type: bbox
18 | params:
19 | max_length: 50
20 | return_info: true
21 | use_ocr: true
22 | use_ocr_info: true
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/vqa/m4c_stvqa.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | m4c_stvqa:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | features_max_len: 100
7 | processors:
8 | context_processor:
9 | type: fasttext
10 | params:
11 | max_length: 50
12 | model_file: .vector_cache/wiki.en.bin
13 | ocr_token_processor:
14 | type: simple_word
15 | params: {}
16 | bbox_processor:
17 | type: bbox
18 | params:
19 | max_length: 50
20 | return_info: true
21 | use_ocr: true
22 | use_ocr_info: true
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/vqa/m4c_stvqa_ocr100.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | m4c_stvqa:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | features_max_len: 100
7 | processors:
8 | context_processor:
9 | type: fasttext
10 | params:
11 | max_length: 100
12 | model_file: .vector_cache/wiki.en.bin
13 | ocr_token_processor:
14 | type: simple_word
15 | params: {}
16 | bbox_processor:
17 | type: bbox
18 | params:
19 | max_length: 100
20 | return_info: true
21 | use_ocr: true
22 | use_ocr_info: true
23 |
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/vqa/m4c_textvqa.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | m4c_textvqa:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | features_max_len: 100
7 | processors:
8 | context_processor:
9 | type: fasttext
10 | params:
11 | max_length: 50
12 | model_file: .vector_cache/wiki.en.bin
13 | ocr_token_processor:
14 | type: simple_word
15 | params: {}
16 | bbox_processor:
17 | type: bbox
18 | params:
19 | max_length: 50
20 | return_info: true
21 | use_ocr: true
22 | use_ocr_info: true
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/vqa/m4c_textvqa_ocr100.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | m4c_textvqa:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | features_max_len: 100
7 | processors:
8 | context_processor:
9 | type: fasttext
10 | params:
11 | max_length: 100
12 | model_file: .vector_cache/wiki.en.bin
13 | ocr_token_processor:
14 | type: simple_word
15 | params: {}
16 | bbox_processor:
17 | type: bbox
18 | params:
19 | max_length: 100
20 | return_info: true
21 | use_ocr: true
22 | use_ocr_info: true
23 |
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/vqa/textvqa.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | textvqa:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | image_features:
7 | train:
8 | - open_images/detectron_fix_100/fc6/train,open_images/resnet152/train
9 | val:
10 | - open_images/detectron_fix_100/fc6/train,open_images/resnet152/train
11 | test:
12 | - open_images/detectron_fix_100/fc6/test,open_images/resnet152/test
13 | imdb_files:
14 | train:
15 | - imdb/textvqa_0.5/imdb_textvqa_train.npy
16 | val:
17 | - imdb/textvqa_0.5/imdb_textvqa_val.npy
18 | test:
19 | - imdb/textvqa_0.5/imdb_textvqa_test.npy
20 | features_max_len: 137
21 | processors:
22 | text_processor:
23 | type: vocab
24 | params:
25 | max_length: 14
26 | vocab:
27 | type: intersected
28 | embedding_name: glove.6B.300d
29 | vocab_file: vocabs/vocabulary_100k.txt
30 | preprocessor:
31 | type: simple_sentence
32 | params: {}
33 | answer_processor:
34 | type: vqa_answer
35 | params:
36 | vocab_file: vocabs/answers_textvqa_8k.txt
37 | preprocessor:
38 | type: simple_word
39 | params: {}
40 | num_answers: 10
41 | context_processor:
42 | type: fasttext
43 | params:
44 | max_length: 50
45 | model_file: .vector_cache/wiki.en.bin
46 | ocr_token_processor:
47 | type: simple_word
48 | params: {}
49 | bbox_processor:
50 | type: bbox
51 | params:
52 | max_length: 50
53 | return_info: true
54 | # Return OCR information
55 | use_ocr: true
56 | # Return spatial information of OCR tokens if present
57 | use_ocr_info: false
58 | training_parameters:
59 | monitored_metric: textvqa/vqa_accuracy
60 | metric_minimize: false
61 |
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/vqa/visual_genome.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | visual_genome:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | image_features:
7 | train:
8 | - visual_genome/detectron_fix_100/fc6/,visual_genome/resnet152/
9 | val:
10 | - visual_genome/detectron_fix_100/fc6/,visual_genome/resnet152/
11 | test:
12 | - visual_genome/detectron_fix_100/fc6/,visual_genome/resnet152/
13 | imdb_files:
14 | train:
15 | - imdb/visual_genome/vg_question_answers.jsonl
16 | val:
17 | - imdb/visual_genome/vg_question_answers_placeholder.jsonl
18 | test:
19 | - imdb/visual_genome/vg_question_answers_placeholder.jsonl
20 | scene_graph_files:
21 | train:
22 | - imdb/visual_genome/vg_scene_graphs.jsonl
23 | val:
24 | - imdb/visual_genome/vg_scene_graphs_placeholder.jsonl
25 | test:
26 | - imdb/visual_genome/vg_scene_graphs_placeholder.jsonl
27 | features_max_len: 100
28 | processors:
29 | text_processor:
30 | type: vocab
31 | params:
32 | max_length: 14
33 | vocab:
34 | type: intersected
35 | embedding_name: glove.6B.300d
36 | vocab_file: vocabs/vocabulary_100k.txt
37 | preprocessor:
38 | type: simple_sentence
39 | params: {}
40 | answer_processor:
41 | type: vqa_answer
42 | params:
43 | num_answers: 1
44 | vocab_file: vocabs/answers_vqa.txt
45 | preprocessor:
46 | type: simple_word
47 | params: {}
48 | vg_answer_preprocessor:
49 | type: simple_word
50 | params: {}
51 | attribute_processor:
52 | type: vocab
53 | params:
54 | max_length: 2
55 | vocab:
56 | type: random
57 | vocab_file: vocabs/vocabulary_100k.txt
58 | name_processor:
59 | type: vocab
60 | params:
61 | max_length: 1
62 | vocab:
63 | type: random
64 | vocab_file: vocabs/vocabulary_100k.txt
65 | predicate_processor:
66 | type: vocab
67 | params:
68 | max_length: 2
69 | vocab:
70 | type: random
71 | vocab_file: vocabs/vocabulary_100k.txt
72 | synset_processor:
73 | type: vocab
74 | params:
75 | max_length: 1
76 | vocab:
77 | type: random
78 | vocab_file: vocabs/vg_synsets.txt
79 | bbox_processor:
80 | type: bbox
81 | params:
82 | max_length: 50
83 | return_scene_graph: true
84 | return_objects: true
85 | return_relationships: true
86 | return_info: true
87 | no_unk: false
88 | # Return OCR information
89 | use_ocr: false
90 | # Return spatial information of OCR tokens if present
91 | use_ocr_info: false
92 | training_parameters:
93 | monitored_metric: visual_genome/vqa_accuracy
94 | metric_minimize: false
95 |
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/vqa/vizwiz.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | vizwiz:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | image_features:
7 | train:
8 | - vizwiz/detectron_fix_100/fc6/train,vizwiz/resnet152/train
9 | val:
10 | - vizwiz/detectron_fix_100/fc6/val,vizwiz/resnet152/val
11 | test:
12 | - vizwiz/detectron_fix_100/fc6/test,vizwiz/resnet152/test
13 | imdb_files:
14 | train:
15 | - imdb/vizwiz/imdb_vizwiz_train.npy
16 | val:
17 | - imdb/vizwiz/imdb_vizwiz_val.npy
18 | test:
19 | - imdb/vizwiz/imdb_vizwiz_test.npy
20 | features_max_len: 100
21 | processors:
22 | text_processor:
23 | type: vocab
24 | params:
25 | max_length: 14
26 | vocab:
27 | type: intersected
28 | embedding_name: glove.6B.300d
29 | vocab_file: vocabs/vocabulary_100k.txt
30 | preprocessor:
31 | type: simple_sentence
32 | params: {}
33 | answer_processor:
34 | type: vqa_answer
35 | params:
36 | vocab_file: vocabs/answers_vizwiz_7k.txt
37 | preprocessor:
38 | type: simple_word
39 | params: {}
40 | num_answers: 10
41 | context_processor:
42 | type: fasttext
43 | params:
44 | max_length: 50
45 | model_file: .vector_cache/wiki.en.bin
46 | ocr_token_processor:
47 | type: simple_word
48 | params: {}
49 | bbox_processor:
50 | type: bbox
51 | params:
52 | max_length: 50
53 | return_info: true
54 | # Return OCR information
55 | use_ocr: false
56 | # Return spatial information of OCR tokens if present
57 | use_ocr_info: false
58 | training_parameters:
59 | monitored_metric: vizwiz/vqa_accuracy
60 | metric_minimize: false
61 |
--------------------------------------------------------------------------------
/pythia/common/defaults/configs/datasets/vqa/vqa2.yml:
--------------------------------------------------------------------------------
1 | dataset_attributes:
2 | vqa2:
3 | data_root_dir: ../data
4 | image_depth_first: false
5 | fast_read: false
6 | image_features:
7 | train:
8 | - coco/detectron_fix_100/fc6/train_val_2014,coco/resnet152/train_val_2014
9 | val:
10 | - coco/detectron_fix_100/fc6/train_val_2014,coco/resnet152/train_val_2014
11 | test:
12 | - coco/detectron_fix_100/fc6/test2015,coco/resnet152/test2015
13 | imdb_files:
14 | train:
15 | - imdb/vqa/imdb_train2014.npy
16 | val:
17 | - imdb/vqa/imdb_val2014.npy
18 | test:
19 | - imdb/vqa/imdb_test2015.npy
20 | features_max_len: 100
21 | processors:
22 | text_processor:
23 | type: vocab
24 | params:
25 | max_length: 14
26 | vocab:
27 | type: intersected
28 | embedding_name: glove.6B.300d
29 | vocab_file: vocabs/vocabulary_100k.txt
30 | preprocessor:
31 | type: simple_sentence
32 | params: {}
33 | answer_processor:
34 | type: vqa_answer
35 | params:
36 | num_answers: 10
37 | vocab_file: vocabs/answers_vqa.txt
38 | preprocessor:
39 | type: simple_word
40 | params: {}
41 | context_processor:
42 | type: fasttext
43 | params:
44 | download_initially: false
45 | max_length: 50
46 | model_file: .vector_cache/wiki.en.bin
47 | ocr_token_processor:
48 | type: simple_word
49 | params: {}
50 | bbox_processor:
51 | type: bbox
52 | params:
53 | max_length: 50
54 | return_info: true
55 | # Return OCR information
56 | use_ocr: false
57 | # Return spatial information of OCR tokens if present
58 | use_ocr_info: false
59 | training_parameters:
60 | monitored_metric: vqa2/vqa_accuracy
61 | metric_minimize: false
62 |
--------------------------------------------------------------------------------
/pythia/common/meter.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | # Inspired from maskrcnn benchmark
3 | from collections import defaultdict, deque
4 |
5 | import torch
6 |
7 |
8 | class SmoothedValue:
9 | """Track a series of values and provide access to smoothed values over a
10 | window or the global series average.
11 | """
12 |
13 | def __init__(self, window_size=20):
14 | self.window_size = window_size
15 | self.reset()
16 |
17 | def reset(self):
18 | self.deque = deque(maxlen=self.window_size)
19 | self.series = []
20 | self.total = 0.0
21 | self.count = 0
22 |
23 | def update(self, value):
24 | self.deque.append(value)
25 | self.series.append(value)
26 | self.count += 1
27 | self.total += value
28 |
29 | @property
30 | def median(self):
31 | d = torch.tensor(list(self.deque))
32 | return d.median().item()
33 |
34 | @property
35 | def avg(self):
36 | d = torch.tensor(list(self.deque))
37 | return d.mean().item()
38 |
39 | @property
40 | def global_avg(self):
41 | return self.total / self.count
42 |
43 | def get_latest(self):
44 | return self.deque[-1]
45 |
46 |
47 | class Meter:
48 | def __init__(self, delimiter=", "):
49 | self.meters = defaultdict(SmoothedValue)
50 | self.delimiter = delimiter
51 |
52 | def update(self, update_dict):
53 | for k, v in update_dict.items():
54 | if isinstance(v, torch.Tensor):
55 | if v.dim() != 0:
56 | v = v.mean()
57 | v = v.item()
58 | assert isinstance(v, (float, int))
59 | self.meters[k].update(v)
60 |
61 | def update_from_meter(self, meter):
62 | for key, value in meter.meters.items():
63 | assert isinstance(value, SmoothedValue)
64 | self.meters[key] = value
65 |
66 | def __getattr__(self, attr):
67 | if attr in self.meters:
68 | return self.meters[attr]
69 | if attr in self.__dict__:
70 | return self.__dict__[attr]
71 | raise AttributeError(
72 | "'{}' object has no attribute '{}'".format(type(self).__name__, attr)
73 | )
74 |
75 | def get_scalar_dict(self):
76 | scalar_dict = {}
77 | for k, v in self.meters.items():
78 | scalar_dict[k] = v.get_latest()
79 |
80 | return scalar_dict
81 |
82 | def __str__(self):
83 | loss_str = []
84 | for name, meter in self.meters.items():
85 | if "train" in name:
86 | loss_str.append(
87 | "{}: {:.4f} ({:.4f})".format(name, meter.median, meter.global_avg)
88 | )
89 | else:
90 | # In case of val print global avg
91 | loss_str.append("{}: {:.4f}".format(name, meter.global_avg))
92 |
93 | return self.delimiter.join(loss_str)
94 |
--------------------------------------------------------------------------------
/pythia/common/report.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import collections
3 | import warnings
4 | from collections import OrderedDict
5 |
6 | from pythia.common.registry import registry
7 |
8 |
9 | class Report(OrderedDict):
10 | def __init__(self, batch, model_output={}, *args):
11 | super().__init__(self)
12 | if self._check_and_load_tuple(batch):
13 | return
14 |
15 | all_args = [batch, model_output] + [*args]
16 | for idx, arg in enumerate(all_args):
17 | if not isinstance(arg, collections.abc.Mapping):
18 | raise TypeError(
19 | "Argument {:d}, {} must be of instance of "
20 | "collections.abc.Mapping".format(idx, arg)
21 | )
22 |
23 | self.writer = registry.get("writer")
24 |
25 | self.warning_string = (
26 | "Updating forward report with key {}"
27 | "{}, but it already exists in {}. "
28 | "Please consider using a different key, "
29 | "as this can cause issues during loss and "
30 | "metric calculations."
31 | )
32 |
33 | for idx, arg in enumerate(all_args):
34 | for key, item in arg.items():
35 | if key in self and idx >= 2:
36 | log = self.warning_string.format(
37 | key, "", "in previous arguments to report"
38 | )
39 | warnings.warn(log)
40 | self[key] = item
41 |
42 | def _check_and_load_tuple(self, batch):
43 | if isinstance(batch, collections.abc.Mapping):
44 | return False
45 |
46 | if isinstance(batch[0], (tuple, list)) and isinstance(batch[0][0], str):
47 | for kv_pair in batch:
48 | self[kv_pair[0]] = kv_pair[1]
49 | return True
50 | else:
51 | return False
52 |
53 | def __setattr__(self, key, value):
54 | self[key] = value
55 |
56 | def __getattr__(self, key):
57 | try:
58 | return self[key]
59 | except KeyError:
60 | raise AttributeError(key)
61 |
62 | def fields(self):
63 | return list(self.keys())
64 |
--------------------------------------------------------------------------------
/pythia/common/test_reporter.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import json
3 | import os
4 |
5 | import torch
6 | from torch.utils.data import DataLoader, Dataset
7 | from torch.utils.data.distributed import DistributedSampler
8 |
9 | from pythia.common.batch_collator import BatchCollator
10 | from pythia.common.registry import registry
11 | from pythia.utils.distributed_utils import (gather_tensor, get_world_size,
12 | is_main_process)
13 | from pythia.utils.general import (ckpt_name_from_core_args,
14 | foldername_from_config_override)
15 | from pythia.utils.timer import Timer
16 |
17 |
18 | class TestReporter(Dataset):
19 | def __init__(self, multi_task_instance):
20 | self.test_task = multi_task_instance
21 | self.task_type = multi_task_instance.dataset_type
22 | self.config = registry.get("config")
23 | self.writer = registry.get("writer")
24 | self.report = []
25 | self.timer = Timer()
26 | self.training_parameters = self.config["training_parameters"]
27 | self.num_workers = self.training_parameters["num_workers"]
28 | self.batch_size = self.training_parameters["batch_size"]
29 | self.report_folder_arg = self.config.get("report_folder", None)
30 | self.experiment_name = self.training_parameters.get("experiment_name", "")
31 |
32 | self.datasets = []
33 |
34 | for dataset in self.test_task.get_datasets():
35 | self.datasets.append(dataset)
36 |
37 | self.current_dataset_idx = -1
38 | self.current_dataset = self.datasets[self.current_dataset_idx]
39 |
40 | self.save_dir = self.config.training_parameters.save_dir
41 | self.report_folder = ckpt_name_from_core_args(self.config)
42 | self.report_folder += foldername_from_config_override(self.config)
43 |
44 | self.report_folder = os.path.join(self.save_dir, self.report_folder)
45 | self.report_folder = os.path.join(self.report_folder, "reports")
46 |
47 | if self.report_folder_arg is not None:
48 | self.report_folder = self.report_folder_arg
49 |
50 | if not os.path.exists(self.report_folder):
51 | os.makedirs(self.report_folder)
52 |
53 | def next_dataset(self):
54 | if self.current_dataset_idx >= 0:
55 | self.flush_report()
56 |
57 | self.current_dataset_idx += 1
58 |
59 | if self.current_dataset_idx == len(self.datasets):
60 | return False
61 | else:
62 | self.current_dataset = self.datasets[self.current_dataset_idx]
63 | self.writer.write("Predicting for " + self.current_dataset._name)
64 | return True
65 |
66 | def flush_report(self):
67 | if not is_main_process():
68 | return
69 |
70 | name = self.current_dataset._name
71 | time_format = "%Y-%m-%dT%H:%M:%S"
72 | time = self.timer.get_time_hhmmss(None, format=time_format)
73 |
74 | filename = name + "_"
75 |
76 | if len(self.experiment_name) > 0:
77 | filename += self.experiment_name + "_"
78 |
79 | filename += self.task_type + "_"
80 |
81 | filename += time + ".json"
82 | filepath = os.path.join(self.report_folder, filename)
83 |
84 | with open(filepath, "w") as f:
85 | json.dump(self.report, f)
86 |
87 | self.writer.write(
88 | "Wrote evalai predictions for %s to %s" % (name, os.path.abspath(filepath))
89 | )
90 | self.report = []
91 |
92 | def get_dataloader(self):
93 | other_args = self._add_extra_args_for_dataloader()
94 | return DataLoader(
95 | dataset=self.current_dataset,
96 | collate_fn=BatchCollator(),
97 | num_workers=self.num_workers,
98 | pin_memory=self.config.training_parameters.pin_memory,
99 | **other_args
100 | )
101 |
102 | def _add_extra_args_for_dataloader(self, other_args={}):
103 | training_parameters = self.config.training_parameters
104 |
105 | if (
106 | training_parameters.local_rank is not None
107 | and training_parameters.distributed
108 | ):
109 | other_args["sampler"] = DistributedSampler(self.current_dataset)
110 | else:
111 | other_args["shuffle"] = True
112 |
113 | batch_size = training_parameters.batch_size
114 |
115 | world_size = get_world_size()
116 |
117 | if batch_size % world_size != 0:
118 | raise RuntimeError(
119 | "Batch size {} must be divisible by number "
120 | "of GPUs {} used.".format(batch_size, world_size)
121 | )
122 |
123 | other_args["batch_size"] = batch_size // world_size
124 |
125 | return other_args
126 |
127 | def prepare_batch(self, batch):
128 | return self.current_dataset.prepare_batch(batch)
129 |
130 | def __len__(self):
131 | return len(self.current_dataset)
132 |
133 | def __getitem__(self, idx):
134 | return self.current_dataset[idx]
135 |
136 | def add_to_report(self, report):
137 | # TODO: Later gather whole report for no opinions
138 | if self.current_dataset._name == "coco":
139 | report.captions = gather_tensor(report.captions)
140 | if isinstance(report.image_id, torch.Tensor):
141 | report.image_id = gather_tensor(report.image_id).view(-1)
142 | else:
143 | report.scores = gather_tensor(report.scores).view(-1, report.scores.size(-1))
144 | report.question_id = gather_tensor(report.question_id).view(-1)
145 |
146 | if not is_main_process():
147 | return
148 |
149 | results = self.current_dataset.format_for_evalai(report)
150 |
151 | self.report = self.report + results
152 |
--------------------------------------------------------------------------------
/pythia/datasets/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from .base_dataset_builder import BaseDatasetBuilder
3 | from .multi_dataset import MultiDataset
4 | from .base_dataset import BaseDataset
5 |
6 | __all__ = ["BaseDataset", "BaseDatasetBuilder", "MultiDataset"]
7 |
--------------------------------------------------------------------------------
/pythia/datasets/base_dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from torch.utils.data.dataset import Dataset
3 |
4 | from pythia.common.registry import registry
5 | from pythia.common.sample import SampleList
6 | from pythia.datasets.processors import Processor
7 |
8 |
9 | class BaseDataset(Dataset):
10 | """Base class for implementing a dataset. Inherits from PyTorch's Dataset class
11 | but adds some custom functionality on top. Instead of ``__getitem__`` you have to implement
12 | ``get_item`` here. Processors mentioned in the configuration are automatically initialized for
13 | the end user.
14 |
15 | Args:
16 | name (str): Name of your dataset to be used a representative in text strings
17 | dataset_type (str): Type of your dataset. Normally, train|val|test
18 | config (ConfigNode): Configuration for the current dataset
19 | """
20 | def __init__(self, name, dataset_type, config={}):
21 | super(BaseDataset, self).__init__()
22 | self.config = config
23 | self._name = name
24 | self._dataset_type = dataset_type
25 | self.writer = registry.get("writer")
26 | self._global_config = registry.get("config")
27 | self._device = registry.get("current_device")
28 | self.use_cuda = "cuda" in str(self._device)
29 |
30 | def load_item(self, idx):
31 | """
32 | Implement if you need to separately load the item and cache it.
33 |
34 | Args:
35 | idx (int): Index of the sample to be loaded.
36 | """
37 | return
38 |
39 | def get_item(self, idx):
40 | """
41 | Basically, __getitem__ of a torch dataset.
42 |
43 | Args:
44 | idx (int): Index of the sample to be loaded.
45 | """
46 |
47 | raise NotImplementedError
48 |
49 | def init_processors(self):
50 | if not hasattr(self.config, "processors"):
51 | return
52 | extra_params = {"data_root_dir": self.config.data_root_dir}
53 | for processor_key, processor_params in self.config.processors.items():
54 | reg_key = "{}_{}".format(self._name, processor_key)
55 | reg_check = registry.get(reg_key, no_warning=True)
56 |
57 | if reg_check is None:
58 | processor_object = Processor(processor_params, **extra_params)
59 | setattr(self, processor_key, processor_object)
60 | registry.register(reg_key, processor_object)
61 | else:
62 | setattr(self, processor_key, reg_check)
63 |
64 | def try_fast_read(self):
65 | return
66 |
67 | def __getitem__(self, idx):
68 | # TODO: Add warning about overriding
69 | """
70 | Internal __getitem__. Don't override, instead override ``get_item`` for your usecase.
71 |
72 | .. warning::
73 |
74 | DO NOT OVERRIDE in child class. Instead override ``get_item``.
75 | """
76 | sample = self.get_item(idx)
77 | sample.dataset_type = self._dataset_type
78 | sample.dataset_name = self._name
79 | return sample
80 |
81 | def prepare_batch(self, batch):
82 | """
83 | Can be possibly overriden in your child class
84 |
85 | Prepare batch for passing to model. Whatever returned from here will
86 | be directly passed to model's forward function. Currently moves the batch to
87 | proper device.
88 |
89 | Args:
90 | batch (SampleList): sample list containing the currently loaded batch
91 |
92 | Returns:
93 | sample_list (SampleList): Returns a sample representing current batch loaded
94 | """
95 | # Should be a SampleList
96 | if not isinstance(batch, SampleList):
97 | # Try converting to SampleList
98 | batch = SampleList(batch)
99 | batch = batch.to(self._device)
100 | return batch
101 |
102 | def format_for_evalai(self, report):
103 | return []
104 |
105 | def verbose_dump(self, *args, **kwargs):
106 | return
107 |
--------------------------------------------------------------------------------
/pythia/datasets/base_dataset_builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | """
3 | In Pythia, for adding new datasets, dataset builder for datasets need to be
4 | added. A new dataset builder must inherit ``BaseDatasetBuilder`` class and
5 | implement ``_load`` and ``_build`` functions.
6 |
7 | ``_build`` is used to build a dataset when it is not available. For e.g.
8 | downloading the ImDBs for a dataset. In future, we plan to add a ``_build``
9 | to add dataset builder to ease setup of Pythia.
10 |
11 | ``_load`` is used to load a dataset from specific path. ``_load`` needs to return
12 | an instance of subclass of ``pythia.datasets.base_dataset.BaseDataset``.
13 |
14 | See complete example for ``VQA2DatasetBuilder`` here_.
15 |
16 | Example::
17 |
18 | from torch.utils.data import Dataset
19 |
20 | from pythia.datasets.base_dataset_builder import BaseDatasetBuilder
21 | from pythia.common.registry import registry
22 |
23 | @registry.register_builder("my")
24 | class MyBuilder(BaseDatasetBuilder):
25 | def __init__(self):
26 | super().__init__("my")
27 |
28 | def _load(self, dataset_type, config, *args, **kwargs):
29 | ...
30 | return Dataset()
31 |
32 | def _build(self, dataset_type, config, *args, **kwargs):
33 | ...
34 |
35 | .. _here: https://github.com/facebookresearch/pythia/blob/master/pythia/datasets/vqa/vqa2/builder.py
36 | """
37 |
38 | from pythia.utils.distributed_utils import is_main_process, synchronize
39 |
40 |
41 | class BaseDatasetBuilder:
42 | """Base class for implementing dataset builders. See more information
43 | on top. Child class needs to implement ``_build`` and ``_load``.
44 |
45 | Args:
46 | dataset_name (str): Name of the dataset passed from child.
47 | """
48 |
49 | def __init__(self, dataset_name):
50 | self.dataset_name = dataset_name
51 |
52 | def load(self, dataset_type, config, *args, **kwargs):
53 | """Main load function use by Pythia. This will internally call ``_load``
54 | function. Calls ``init_processors`` and ``try_fast_read`` on the
55 | dataset returned from ``_load``
56 |
57 | Args:
58 | dataset_type (str): Type of dataset, train|val|test
59 | config (ConfigNode): Configuration of this dataset loaded from config.
60 |
61 | Returns:
62 | dataset (BaseDataset): Dataset containing data to be trained on
63 |
64 | .. warning::
65 |
66 | DO NOT OVERRIDE in child class. Instead override ``_load``.
67 | """
68 | dataset = self._load(dataset_type, config, *args, **kwargs)
69 | if dataset is not None:
70 | dataset.init_processors()
71 | dataset.try_fast_read()
72 | return dataset
73 |
74 | def _load(self, dataset_type, config, *args, **kwargs):
75 | """
76 | This is used to prepare the dataset and load it from a path.
77 | Override this method in your child dataset builder class.
78 |
79 | Args:
80 | dataset_type (str): Type of dataset, train|val|test
81 | config (ConfigNode): Configuration of this dataset loaded from config.
82 |
83 | Returns:
84 | dataset (BaseDataset): Dataset containing data to be trained on
85 | """
86 | raise NotImplementedError(
87 | "This dataset builder doesn't implement a load method"
88 | )
89 |
90 | def build(self, dataset_type, config, *args, **kwargs):
91 | """
92 | Similar to load function, used by Pythia to build a dataset for first
93 | time when it is not available. This internally calls '_build' function.
94 | Override that function in your child class.
95 |
96 | Args:
97 | dataset_type (str): Type of dataset, train|val|test
98 | config (ConfigNode): Configuration of this dataset loaded from
99 | config.
100 |
101 | .. warning::
102 |
103 | DO NOT OVERRIDE in child class. Instead override ``_build``.
104 | """
105 | # Only build in main process, so none of the others have to build
106 | if is_main_process():
107 | self._build(dataset_type, config, *args, **kwargs)
108 | synchronize()
109 |
110 | def _build(self, dataset_type, config, *args, **kwargs):
111 | """
112 | This is used to build a dataset first time.
113 | Implement this method in your child dataset builder class.
114 |
115 | Args:
116 | dataset_type (str): Type of dataset, train|val|test
117 | config (ConfigNode): Configuration of this dataset loaded from
118 | config.
119 | """
120 | raise NotImplementedError(
121 | "This dataset builder doesn't implement a build method"
122 | )
123 |
--------------------------------------------------------------------------------
/pythia/datasets/captioning/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
--------------------------------------------------------------------------------
/pythia/datasets/captioning/coco/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | __all__ = ["COCOBuilder", "COCODataset"]
3 |
4 | from .builder import COCOBuilder
5 | from .dataset import COCODataset
6 |
--------------------------------------------------------------------------------
/pythia/datasets/captioning/coco/builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | # All rights reserved.
3 | #
4 | # This source code is licensed under the license found in the
5 | # LICENSE file in the root directory of this source tree.
6 | #
7 |
8 | from pythia.common.registry import registry
9 | from pythia.datasets.vqa.vqa2 import VQA2Builder
10 |
11 | from .dataset import COCODataset
12 |
13 |
14 | @registry.register_builder("coco")
15 | class COCOBuilder(VQA2Builder):
16 | def __init__(self):
17 | super().__init__()
18 | self.dataset_name = "coco"
19 | self.set_dataset_class(COCODataset)
20 |
21 | def update_registry_for_model(self, config):
22 | registry.register(
23 | self.dataset_name + "_text_vocab_size",
24 | self.dataset.text_processor.get_vocab_size(),
25 | )
26 |
--------------------------------------------------------------------------------
/pythia/datasets/captioning/coco/dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import torch
3 |
4 | from pythia.common.sample import Sample
5 | from pythia.datasets.vqa.vqa2 import VQA2Dataset
6 |
7 |
8 | class COCODataset(VQA2Dataset):
9 | def __init__(self, dataset_type, imdb_file_index, config, *args, **kwargs):
10 | super().__init__(dataset_type, imdb_file_index, config, *args, **kwargs)
11 | self._name = "coco"
12 |
13 | def load_item(self, idx):
14 | sample_info = self.imdb[idx]
15 | current_sample = Sample()
16 |
17 | if self._dataset_type != "test":
18 | text_processor_argument = {"tokens": sample_info["caption_tokens"]}
19 | processed_caption = self.text_processor(text_processor_argument)
20 | current_sample.text = processed_caption["text"]
21 | current_sample.caption_id = torch.tensor(
22 | sample_info["caption_id"], dtype=torch.int
23 | )
24 | current_sample.caption_len = torch.tensor(
25 | len(sample_info["caption_tokens"]), dtype=torch.int
26 | )
27 |
28 | if isinstance(sample_info["image_id"], int):
29 | current_sample.image_id = torch.tensor(
30 | sample_info["image_id"], dtype=torch.int
31 | )
32 | else:
33 | current_sample.image_id = sample_info["image_id"]
34 |
35 | if self._use_features is True:
36 | features = self.features_db[idx]
37 | current_sample.update(features)
38 |
39 | # Add reference captions to sample
40 | current_sample = self.add_reference_caption(sample_info, current_sample)
41 |
42 | return current_sample
43 |
44 | def add_reference_caption(self, sample_info, sample):
45 | reference_list = []
46 | for reference in sample_info["reference_tokens"]:
47 | text_processor_argument = {"tokens": reference}
48 | processed_reference = self.text_processor(text_processor_argument)
49 | reference_list.append(processed_reference["text"])
50 |
51 | # Restrict to minimum reference captions available per image
52 | sample.answers = torch.stack(reference_list)[: self.config.min_captions_per_img]
53 |
54 | return sample
55 |
56 | def format_for_evalai(self, report):
57 | captions = report.captions.tolist()
58 | predictions = []
59 | remove_unk_from_caption_prediction = getattr(
60 | self.config, 'remove_unk_from_caption_prediction', False
61 | )
62 | for idx, image_id in enumerate(report.image_id):
63 | caption = self.caption_processor(captions[idx])["caption"]
64 | if remove_unk_from_caption_prediction:
65 | caption = caption.replace('', '')
66 | caption = caption.replace(' ', ' ').strip()
67 | if isinstance(image_id, torch.Tensor):
68 | image_id = image_id.item()
69 | predictions.append({"image_id": image_id, "caption": caption})
70 |
71 | return predictions
72 |
--------------------------------------------------------------------------------
/pythia/datasets/captioning/m4c_textcaps/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
--------------------------------------------------------------------------------
/pythia/datasets/captioning/m4c_textcaps/builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.common.registry import Registry
3 | from pythia.datasets.captioning.m4c_textcaps.dataset import M4CTextCapsDataset
4 | from pythia.datasets.vqa.m4c_textvqa.builder import M4CTextVQABuilder
5 |
6 |
7 | @Registry.register_builder("m4c_textcaps")
8 | class M4CTextCapsBuilder(M4CTextVQABuilder):
9 | def __init__(self):
10 | super().__init__()
11 | self.dataset_name = "m4c_textcaps"
12 | self.set_dataset_class(M4CTextCapsDataset)
13 |
--------------------------------------------------------------------------------
/pythia/datasets/captioning/m4c_textcaps/dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.datasets.vqa.m4c_textvqa.dataset import M4CTextVQADataset
3 | from pythia.utils.objects_to_byte_tensor import enc_obj2bytes
4 |
5 |
6 | class M4CTextCapsDataset(M4CTextVQADataset):
7 | def __init__(self, dataset_type, imdb_file_index, config, *args, **kwargs):
8 | super().__init__(
9 | dataset_type, imdb_file_index, config, *args, **kwargs
10 | )
11 | self._name = "m4c_textcaps"
12 |
13 | def preprocess_sample_info(self, sample_info):
14 | # add dummy questions to train with M4C (for TextVQA)
15 | sample_info['question_str'] = '' # empty question
16 | # sample_info['question_id'] = sample_info['caption_id']
17 | if 'caption_id' in sample_info:
18 | sample_info['question_id'] = sample_info['caption_id'] ## added for qa dataset joint train
19 | return sample_info
20 |
21 | def postprocess_evalai_entry(self, entry):
22 | new_entry = {
23 | 'caption_id': entry['question_id'],
24 | 'image_id': entry['image_id'],
25 | 'caption': entry['answer'],
26 | 'pred_source': entry['pred_source'],
27 | }
28 | return new_entry
29 |
30 | def add_answer_info(self, sample_info, sample):
31 | sample_has_caption = ('caption_str' in sample_info)
32 | if sample_has_caption:
33 | sample_info['answers'] = [sample_info['caption_str']]
34 | elif self._dataset_type!='test': ## added for qa dataset joint train
35 | sample_info['answers'] = [sample_info['answers'][0]]
36 | sample = super().add_answer_info(sample_info, sample)
37 |
38 | if sample_has_caption:
39 | sample.caption_str = enc_obj2bytes(sample_info['caption_str'])
40 | sample.ref_strs = enc_obj2bytes(sample_info['reference_strs'])
41 | sample.pop('gt_answers_enc')
42 | elif self._dataset_type!='test': ## added for qa dataset joint train; only in pretrain, not used anyway, just match the format
43 | sample.caption_str = enc_obj2bytes(sample_info['answers'])
44 | sample.ref_strs = enc_obj2bytes([sample_info['answers']])
45 | sample.pop('gt_answers_enc')
46 |
47 | return sample
48 |
--------------------------------------------------------------------------------
/pythia/datasets/concat_dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import functools
3 | import types
4 |
5 | from torch.utils.data import ConcatDataset
6 |
7 |
8 | class PythiaConcatDataset(ConcatDataset):
9 | # These functions should only be called once even if they return nothing
10 | _SINGLE_CALL_FUNCS = []
11 |
12 | def __init__(self, datasets):
13 | super().__init__(datasets)
14 | self._dir_representation = dir(self)
15 |
16 | def __getattr__(self, name):
17 | if name in self._dir_representation:
18 | return getattr(self, name)
19 | elif hasattr(self.datasets[0], name):
20 | attr = getattr(self.datasets[0], name)
21 | # Check if the current attribute is class method function
22 | if isinstance(attr, types.MethodType):
23 | # if it is the, we to call this function for
24 | # each of the child datasets
25 | attr = functools.partial(self._call_all_datasets_func, name)
26 | return attr
27 | else:
28 | raise AttributeError(name)
29 |
30 | def _get_single_call_funcs(self):
31 | return PythiaConcatDataset._SINGLE_CALL_FUNCS
32 |
33 | def _call_all_datasets_func(self, name, *args, **kwargs):
34 | for dataset in self.datasets:
35 | value = getattr(dataset, name)(*args, **kwargs)
36 | if value is not None:
37 | # TODO: Log a warning here
38 | return value
39 | # raise RuntimeError("Functions returning values can't be "
40 | # "called through PythiaConcatDataset")
41 | if (
42 | hasattr(dataset, "get_single_call_funcs")
43 | and name in dataset.get_single_call_funcs()
44 | ):
45 | return
46 |
--------------------------------------------------------------------------------
/pythia/datasets/dialog/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
--------------------------------------------------------------------------------
/pythia/datasets/dialog/original.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import os
3 |
4 | import torch
5 | from torch.autograd import Variable
6 | from torch.utils.data import ConcatDataset
7 |
8 | from pythia.datasets.vqa2.task import VQA2Task
9 |
10 | from .dataset import VisualDialogDataset
11 |
12 |
13 | class VisualDialogTask(VQA2Task):
14 | def __init__(self, dataset_type):
15 | super(VisualDialogTask, self).__init__(dataset_type)
16 | self.task_name = "VisualDialog"
17 |
18 | def prepare_data_set(self, imdb_file_label, image_feature_dir_label, **data_config):
19 | data_root_dir = data_config["data_root_dir"]
20 |
21 | vocab_file = os.path.join(data_root_dir, data_config["vocab_file"])
22 | embedding_name = data_config["embedding_name"]
23 | max_seq_len = data_config["max_seq_len"]
24 | max_history_len = data_config["max_history_len"]
25 | image_depth_first = data_config["image_depth_first"]
26 | image_fast_reader = data_config["image_fast_reader"]
27 |
28 | if "verbose" in data_config:
29 | verbose = data_config["verbose"]
30 | else:
31 | verbose = False
32 |
33 | if "test_mode" in data_config:
34 | test_mode = data_config["test_mode"]
35 | else:
36 | test_mode = False
37 |
38 | if "image_max_loc" in data_config:
39 | image_max_loc = data_config["image_max_loc"]
40 | else:
41 | image_max_loc = False
42 |
43 | imdb_files = data_config[imdb_file_label]
44 | image_feat_dirs = data_config[image_feature_dir_label]
45 |
46 | condition = len(imdb_files) == len(image_feat_dirs)
47 | error = imdb_file_label + "length != " + image_feature_dir_label
48 | error += "length"
49 | assert condition, error
50 |
51 | datasets = []
52 |
53 | for imdb_file, image_feature_dir in zip(imdb_files, image_feat_dirs):
54 | imdb_file = os.path.join(data_root_dir, imdb_file)
55 | image_feat_dirs = [
56 | os.path.join(data_root_dir, d) for d in image_feature_dir.split(",")
57 | ]
58 | args = {
59 | "imdb_file": imdb_file,
60 | "image_feat_directories": image_feat_dirs,
61 | "max_seq_len": max_seq_len,
62 | "max_history_len": max_history_len,
63 | "vocab_file": vocab_file,
64 | "image_depth_first": image_depth_first,
65 | "fast_read": image_fast_reader,
66 | "verbose": verbose,
67 | "test_mode": test_mode,
68 | "image_max_loc": image_max_loc,
69 | "embedding_name": embedding_name,
70 | }
71 |
72 | train_dataset = VisualDialogDataset(**args)
73 | datasets.append(train_dataset)
74 |
75 | return VisualDialogConcatDataset(datasets)
76 |
77 | def prepare_batch(self, batch, use_cuda):
78 | questions = batch["questions"]
79 | input_image_features = batch["image_feat_batch"]
80 | answer_options = batch["answer_options"]
81 | histories = batch["histories"]
82 |
83 | questions = Variable(questions.type(torch.LongTensor))
84 | histories = Variable(histories.type(torch.LongTensor))
85 | answer_options = Variable(answer_options.type(torch.LongTensor))
86 | input_image_features = Variable(input_image_features)
87 |
88 | if use_cuda:
89 | questions = questions.cuda()
90 | histories = histories.cuda()
91 | answer_options = answer_options.cuda()
92 | input_image_features = input_image_features.cuda()
93 |
94 | image_feature_variables = [input_image_features]
95 | image_dim_variable = None
96 |
97 | if "image_dim" in batch:
98 | image_dims = batch["image_dim"]
99 | image_dim_variable = Variable(
100 | image_dims, requires_grad=False, volatile=False
101 | )
102 |
103 | if use_cuda:
104 | image_dim_variable = image_dim_variable.cuda()
105 |
106 | # check if more than 1 image_feat_batch
107 | i = 1
108 | image_feat_key = "image_feat_batch_%s"
109 | while image_feat_key % str(i) in batch:
110 | tmp_image_variable = Variable(batch[image_feat_key % str(i)])
111 | if use_cuda:
112 | tmp_image_variable = tmp_image_variable.cuda()
113 | image_feature_variables.append(tmp_image_variable)
114 | i += 1
115 |
116 | y = batch["expected"]
117 | y = Variable(y.type(torch.FloatTensor))
118 | y = y.view(-1, y.size(-1))
119 | if use_cuda:
120 | y = y.cuda()
121 |
122 | out = {
123 | "texts": questions,
124 | "answer_options": answer_options,
125 | "histories": histories,
126 | "image_features": image_feature_variables,
127 | "image_dims": image_dim_variable,
128 | "texts_len": batch["questions_len"],
129 | "answer_options_len": batch["answer_options_len"],
130 | "histories_len": batch["histories_len"],
131 | }
132 |
133 | return out, y
134 |
135 | def update_registry_for_model(self, config):
136 | config["num_vocab_txt"] = self.dataset.vocab.get_size()
137 | config["vocab_size"] = self.dataset.vocab.get_size()
138 | config["num_image_features"] = self.num_image_features
139 | config["embedding_vectors"] = self.dataset.vocab.vectors
140 |
141 | def clean_config(self, config):
142 | config.pop("embedding_vectors", None)
143 |
144 |
145 | class VisualDialogConcatDataset(ConcatDataset):
146 | def __init__(self, datasets):
147 | super(VisualDialogConcatDataset, self).__init__(datasets)
148 | self.vocab = datasets[0].vocab
149 |
--------------------------------------------------------------------------------
/pythia/datasets/dialog/visual_dialog/config.yml:
--------------------------------------------------------------------------------
1 | task_attributes:
2 | data_root_dir: data
3 | batch_size: 10
4 | vocab_file: visdial/visdial_vocabulary.txt
5 | max_seq_len: 20
6 | max_history_len: 300
7 | embedding_name: glove.6B.300d
8 | image_depth_first: false
9 | image_fast_reader: false
10 | image_feat_test:
11 | - /checkpoint02/tinayujiang/features/visdial/detectron_23/fc6/
12 | image_feat_train:
13 | - detec/detectron/fc6/vqa/train+val2014
14 | image_feat_val:
15 | - /checkpoint02/tinayujiang/features/visdial/detectron_23/fc6/
16 | image_max_loc: 100
17 | imdb_file_test:
18 | - visdial/visdial_1.0_val_imdb.json
19 | imdb_file_train:
20 | - visdial/visdial_1.0_train_imdb.json
21 | imdb_file_val:
22 | - visdial/visdial_1.0_val_imdb.json
23 | num_workers: 12
24 | enforce_slow_reader: false
25 | metrics:
26 | - r@1
27 | - r@5
28 | - r@10
29 | - mean_r
30 | - mean_rr
31 | monitored_metric: 0
32 | metric_minimize: False
33 | should_early_stop: True
34 | exp_name: baseline
35 | loss: logit_bce
36 | lr_scheduler: true
37 | model_attributes:
38 | visdial_top_down_bottom_up:
39 | classifier:
40 | type: logit
41 | params:
42 | img_hidden_dim: 5000
43 | text_hidden_dim: 300
44 | image_embeddings:
45 | - modal_combine:
46 | type: non_linear_element_multiply
47 | params:
48 | dropout: 0
49 | hidden_dim: 5000
50 | normalization: softmax
51 | transform:
52 | type: linear
53 | params:
54 | out_dim: 1
55 | image_feature_dim: 2048
56 | image_feature_encodings:
57 | - type: finetune_faster_rcnn_fpn_fc7
58 | params:
59 | bias_file: detec/detectron/fc6/fc7_b.pkl
60 | weights_file: detec/detectron/fc6/fc7_w.pkl
61 | modal_combine:
62 | type: non_linear_element_multiply
63 | params:
64 | dropout: 0
65 | hidden_dim: 5000
66 | text_embeddings:
67 | - type: attention
68 | params:
69 | hidden_dim: 1024
70 | num_layers: 1
71 | conv1_out: 512
72 | conv2_out: 2
73 | dropout: 0
74 | embedding_dim: 300
75 | embedding_init_file: vqa2.0_glove.6B.300d.txt.npy
76 | kernel_size: 1
77 | padding: 0
78 | optimizer_attributes:
79 | type: Adamax
80 | params:
81 | eps: 1.0e-08
82 | lr: 0.01
83 | weight_decay: 0
84 | run: train+predict
85 | training_parameters:
86 | clip_norm_mode: all
87 | clip_gradients: true
88 | lr_ratio: 0.1
89 | lr_steps:
90 | - 15000
91 | - 18000
92 | - 20000
93 | - 21000
94 | max_grad_l2_norm: 0.25
95 | max_iterations: 22000
96 | log_interval: 100
97 | snapshot_interval: 3000
98 | wu_factor: 0.2
99 | wu_iters: 1000
100 | patience: 3500
101 |
--------------------------------------------------------------------------------
/pythia/datasets/dialog/visual_dialog/scripts/build_imdb.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import argparse
3 | import glob
4 | import json
5 | import os
6 |
7 | from pythia.utils.preprocessing import text_tokenize
8 |
9 |
10 | class IMDBBuilder:
11 | def __init__(self):
12 | self.args = self.get_args()
13 |
14 | def get_args(self):
15 | parser = argparse.ArgumentParser("Build IMDB for VisDial")
16 | parser.add_argument(
17 | "-o",
18 | "--out_file",
19 | type=str,
20 | default="./imdb.npy",
21 | help="Output file for IMDB",
22 | )
23 | parser.add_argument(
24 | "-i",
25 | "--image_root",
26 | type=str,
27 | default="./COCO",
28 | help="Image directory for COCO",
29 | )
30 | parser.add_argument(
31 | "-v", "--version", type=float, default=0.9, help="Visdial version"
32 | )
33 | parser.add_argument(
34 | "-d",
35 | "--data_dir",
36 | type=str,
37 | default="./visdial",
38 | help="Directory which contains visdial jsons",
39 | )
40 | parser.add_argument(
41 | "-s",
42 | "--set_type",
43 | type=str,
44 | default="train",
45 | help="Dataset type train|val|test",
46 | )
47 |
48 | return parser.parse_args()
49 |
50 | def get_id_to_path_dict(self):
51 | id2path = {}
52 | globs = glob.iglob(os.path.join(self.args.image_root, "*", "*.npy"))
53 | # NOTE: based on assumption that image_id is unique across all splits
54 | for image_path in globs:
55 | path = "/".join(image_path.split("/")[-2:])
56 | image_id = int(image_path[-16:-4])
57 | id2path[image_id] = path
58 |
59 | return id2path
60 |
61 | def build(self):
62 | visdial_json_file = os.path.join(
63 | self.args.data_dir,
64 | "visdial_%.1f_%s.json" % (self.args.version, self.args.set_type),
65 | )
66 | data = None
67 |
68 | with open(visdial_json_file, "r") as f:
69 | data = json.load(f)["data"]
70 |
71 | final_questions = self.get_tokens(data["questions"])
72 | final_answers = self.get_tokens(data["answers"])
73 | dialogs = data["dialogs"]
74 |
75 | dialogs_with_features = self.parse_dialogs(dialogs)
76 |
77 | imdb = {
78 | "questions": final_questions,
79 | "answers": final_answers,
80 | "dialogs": dialogs_with_features,
81 | }
82 |
83 | self.save_imdb(imdb)
84 |
85 | def save_imdb(self, imdb):
86 | with open(self.args.out_file, "w") as f:
87 | json.dump(imdb, f)
88 |
89 | def get_tokens(self, sentences):
90 | if not isinstance(sentences, list):
91 | sentences = [sentences]
92 | final_sentences = []
93 | for idx, sentence in enumerate(sentences):
94 | tokens = text_tokenize(sentence)
95 | final_sentences.append(tokens)
96 |
97 | return final_sentences
98 |
99 | def parse_dialogs(self, dialogs):
100 | id2path = self.get_id_to_path_dict()
101 |
102 | for dialog in dialogs:
103 | image_id = dialog["image_id"]
104 | image_feature_path = id2path[image_id]
105 | dialog["image_feature_path"] = image_feature_path
106 | dialog["caption"] = self.get_tokens(dialog["caption"])
107 |
108 | return dialogs
109 |
110 |
111 | if __name__ == "__main__":
112 | imdb_builder = IMDBBuilder()
113 | imdb_builder.build()
114 |
--------------------------------------------------------------------------------
/pythia/datasets/dialog/visual_dialog/scripts/extract_vocabulary.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import json
3 |
4 | from pythia.scripts.extract_vocabulary import ExtractVocabulary
5 |
6 |
7 | class ExtractVisdialVocabulary(ExtractVocabulary):
8 | def __init__(self):
9 | super(ExtractVisdialVocabulary, self).__init__()
10 |
11 | def get_text(self):
12 | text = []
13 |
14 | for input_file in self.input_files:
15 | with open(input_file, "r") as f:
16 | f_json = json.load(f)
17 | # Add 'questions' from visdial
18 | text += f_json["data"]["questions"]
19 | # Add 'answers' from visdial
20 | text += f_json["data"]["answers"]
21 |
22 | for dialog in f_json["data"]["dialogs"]:
23 | text += [dialog["caption"]]
24 | return text
25 |
26 |
27 | if __name__ == "__main__":
28 | extractor = ExtractVisdialVocabulary()
29 | extractor.extract()
30 |
--------------------------------------------------------------------------------
/pythia/datasets/feature_readers.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import os
3 |
4 | import numpy as np
5 | import torch
6 |
7 |
8 | class FeatureReader:
9 | def __init__(self, base_path, depth_first, max_features=None):
10 | """Feature Reader class for reading features.
11 |
12 | Note: Deprecation: ndim and image_feature will be deprecated later
13 | and the format will be standardize using features from detectron.
14 |
15 | Parameters
16 | ----------
17 | ndim : int
18 | Number of expected dimensions in features
19 | depth_first : bool
20 | CHW vs HWC
21 | max_features : int
22 | Number of maximum bboxes to keep
23 |
24 | Returns
25 | -------
26 | type
27 | Description of returned object.
28 |
29 | """
30 | self.base_path = base_path
31 | ndim = None
32 | self.feat_reader = None
33 | self.depth_first = depth_first
34 | self.max_features = max_features
35 | self.ndim = ndim
36 |
37 | def _init_reader(self):
38 | if self.ndim == 2 or self.ndim == 0:
39 | if self.max_features is None:
40 | self.feat_reader = FasterRCNNFeatureReader()
41 | else:
42 | # TODO: Fix later when we move to proper standardized features
43 | # if isinstance(self.image_feature.item(0), dict):
44 | # self.feat_reader = \
45 | # PaddedFeatureRCNNWithBBoxesFeatureReader(
46 | # self.max_features
47 | # )
48 | # else:
49 | self.feat_reader = PaddedFasterRCNNFeatureReader(self.max_features)
50 | elif self.ndim == 3 and not self.depth_first:
51 | self.feat_reader = Dim3FeatureReader()
52 | elif self.ndim == 4 and self.depth_first:
53 | self.feat_reader = CHWFeatureReader()
54 | elif self.ndim == 4 and not self.depth_first:
55 | self.feat_reader = HWCFeatureReader()
56 | else:
57 | raise TypeError("unkown image feature format")
58 |
59 | def read(self, image_feat_path):
60 | if not image_feat_path.endswith("npy"):
61 | return None
62 | image_feat_path = os.path.join(self.base_path, image_feat_path)
63 |
64 | if self.feat_reader is None:
65 | if self.ndim is None:
66 | feat = np.load(image_feat_path)
67 | self.ndim = feat.ndim
68 | self._init_reader()
69 |
70 | return self.feat_reader.read(image_feat_path)
71 |
72 |
73 | class FasterRCNNFeatureReader:
74 | def read(self, image_feat_path):
75 | return torch.from_numpy(np.load(image_feat_path)), None
76 |
77 |
78 | class CHWFeatureReader:
79 | def read(self, image_feat_path):
80 | feat = np.load(image_feat_path)
81 | assert feat.shape[0] == 1, "batch is not 1"
82 | feat = torch.from_numpy(feat.squeeze(0))
83 | return feat, None
84 |
85 |
86 | class Dim3FeatureReader:
87 | def read(self, image_feat_path):
88 | tmp = np.load(image_feat_path)
89 | _, _, c_dim = tmp.shape
90 | image_feature = torch.from_numpy(np.reshape(tmp, (-1, c_dim)))
91 | return image_feature, None
92 |
93 |
94 | class HWCFeatureReader:
95 | def read(self, image_feat_path):
96 | tmp = np.load(image_feat_path)
97 | assert tmp.shape[0] == 1, "batch is not 1"
98 | _, _, _, c_dim = tmp.shape
99 | image_feature = torch.from_numpy(np.reshape(tmp, (-1, c_dim)))
100 | return image_feature, None
101 |
102 |
103 | class PaddedFasterRCNNFeatureReader:
104 | def __init__(self, max_loc):
105 | self.max_loc = max_loc
106 | self.first = True
107 | self.take_item = False
108 |
109 | def read(self, image_feat_path):
110 | content = np.load(image_feat_path, allow_pickle=True)
111 | info_path = "{}_info.npy".format(image_feat_path.split(".npy")[0])
112 | image_info = {}
113 |
114 | if os.path.exists(info_path):
115 | ## new resx feat extracted with py2, default encoding changed from py2 to py3
116 | image_info.update(np.load(info_path, allow_pickle=True, encoding='latin1').item())
117 |
118 | if self.first:
119 | self.first = False
120 | if content.size == 1 and "image_feat" in content.item():
121 | self.take_item = True
122 | image_feature = content
123 |
124 | if self.take_item:
125 | item = content.item()
126 | if "image_text" in item:
127 | image_info["image_text"] = item["image_text"]
128 | image_info["is_ocr"] = item["image_bbox_source"]
129 | image_feature = item["image_feat"]
130 |
131 | if "info" in item:
132 | if "image_text" in item["info"]:
133 | image_info.update(item["info"])
134 | image_feature = item["feature"]
135 |
136 | image_loc, image_dim = image_feature.shape
137 | tmp_image_feat = np.zeros((self.max_loc, image_dim), dtype=np.float32)
138 | tmp_image_feat[0:image_loc,] = image_feature[:self.max_loc, :]
139 | image_feature = torch.from_numpy(tmp_image_feat)
140 |
141 | image_info["max_features"] = torch.tensor(image_loc, dtype=torch.long)
142 | return image_feature, image_info
143 |
144 |
145 | class PaddedFeatureRCNNWithBBoxesFeatureReader:
146 | def __init__(self, max_loc):
147 | self.max_loc = max_loc
148 |
149 | def read(self, image_feat_path):
150 | image_feat_bbox = np.load(image_feat_path)
151 | image_boxes = image_feat_bbox.item().get("image_bboxes")
152 | tmp_image_feat = image_feat_bbox.item().get("image_feature")
153 | image_loc, image_dim = tmp_image_feat.shape
154 | tmp_image_feat_2 = np.zeros((self.max_loc, image_dim), dtype=np.float32)
155 | tmp_image_feat_2[0:image_loc,] = tmp_image_feat
156 | tmp_image_feat_2 = torch.from_numpy(tmp_image_feat_2)
157 | tmp_image_box = np.zeros((self.max_loc, 4), dtype=np.int32)
158 | tmp_image_box[0:image_loc] = image_boxes
159 | tmp_image_box = torch.from_numpy(tmp_image_box)
160 | image_info = {
161 | "image_bbox": tmp_image_box,
162 | "max_features": torch.tensor(image_loc, dtype=torch.int),
163 | }
164 |
165 | return tmp_image_feat_2, image_info
166 |
--------------------------------------------------------------------------------
/pythia/datasets/features_dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from multiprocessing.pool import ThreadPool
3 |
4 | import torch
5 | import tqdm
6 |
7 | from pythia.common.registry import registry
8 | from pythia.datasets.feature_readers import FeatureReader
9 | from pythia.utils.distributed_utils import is_main_process
10 |
11 |
12 | class FeaturesDataset:
13 | def __init__(self, features_type, *args, **kwargs):
14 | self.features_db = None
15 | if features_type == "coco":
16 | self.features_db = COCOFeaturesDataset(*args, **kwargs)
17 | else:
18 | raise ValueError("Unknown features' type {}".format(features_type))
19 |
20 | def __getattr__(self, name):
21 | if hasattr(self.features_db, name):
22 | return getattr(self.features_db, name)
23 | elif name in dir(self):
24 | return getattr(self, name)
25 | else:
26 | raise AttributeError(name)
27 |
28 | def __getitem__(self, idx):
29 | return self.features_db[idx]
30 |
31 | def __len__(self):
32 | return len(self.features_db)
33 |
34 |
35 | class BaseFeaturesDataset(torch.utils.data.Dataset):
36 | def __init__(self):
37 | super(BaseFeaturesDataset, self).__init__()
38 |
39 |
40 | class COCOFeaturesDataset(BaseFeaturesDataset):
41 | def __init__(self, *args, **kwargs):
42 | super(COCOFeaturesDataset, self).__init__()
43 | self.feature_readers = []
44 | self.feature_dict = {}
45 |
46 | self.fast_read = kwargs["fast_read"]
47 | self.writer = registry.get("writer")
48 |
49 | for image_feature_dir in kwargs["directories"]:
50 | feature_reader = FeatureReader(
51 | base_path=image_feature_dir,
52 | depth_first=kwargs["depth_first"],
53 | max_features=kwargs["max_features"],
54 | )
55 | self.feature_readers.append(feature_reader)
56 |
57 | self.imdb = kwargs["imdb"]
58 | self.kwargs = kwargs
59 | self.should_return_info = kwargs.get("return_info", True)
60 |
61 | if self.fast_read:
62 | self.writer.write(
63 | "Fast reading features from %s" % (", ".join(kwargs["directories"]))
64 | )
65 | self.writer.write("Hold tight, this may take a while...")
66 | self._threaded_read()
67 |
68 | def _threaded_read(self):
69 | elements = [idx for idx in range(1, len(self.imdb))]
70 | pool = ThreadPool(processes=4)
71 |
72 | with tqdm.tqdm(total=len(elements), disable=not is_main_process()) as pbar:
73 | for i, _ in enumerate(pool.imap_unordered(self._fill_cache, elements)):
74 | if i % 100 == 0:
75 | pbar.update(100)
76 | pool.close()
77 |
78 | def _fill_cache(self, idx):
79 | feat_file = self.imdb[idx]["feature_path"]
80 | features, info = self._read_features_and_info(feat_file)
81 | self.feature_dict[feat_file] = (features, info)
82 |
83 | def _read_features_and_info(self, feat_file):
84 | features = []
85 | infos = []
86 | for feature_reader in self.feature_readers:
87 | feature, info = feature_reader.read(feat_file)
88 | # feature = torch.from_numpy(feature).share_memory_()
89 |
90 | features.append(feature)
91 | infos.append(info)
92 |
93 | if not self.should_return_info:
94 | infos = None
95 | return features, infos
96 |
97 | def _get_image_features_and_info(self, feat_file):
98 | image_feats, infos = self.feature_dict.get(feat_file, (None, None))
99 |
100 | if image_feats is None:
101 | image_feats, infos = self._read_features_and_info(feat_file)
102 |
103 | # TODO: Remove after standardization
104 | # https://github.com/facebookresearch/pythia/blob/master/dataset_utils/dataSet.py#L226
105 | return image_feats, infos
106 |
107 | def __len__(self):
108 | return len(self.imdb) - 1
109 |
110 | def __getitem__(self, idx):
111 | image_info = self.imdb[idx]
112 | image_file_name = image_info.get("feature_path", None)
113 |
114 | if image_file_name is None:
115 | image_file_name = "{}.npy".format(image_info["image_id"])
116 |
117 | image_features, infos = self._get_image_features_and_info(image_file_name)
118 |
119 | item = {}
120 | for idx, image_feature in enumerate(image_features):
121 | item["image_feature_%s" % idx] = image_feature
122 | if infos is not None:
123 | item["image_info_%s" % idx] = infos[idx]
124 |
125 | return item
126 |
--------------------------------------------------------------------------------
/pythia/datasets/image_database.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import numpy as np
3 | import torch
4 | import json
5 |
6 |
7 | class ImageDatabase(torch.utils.data.Dataset):
8 | """
9 | Dataset for IMDB used in Pythia
10 | General format that we have standardize follows:
11 | {
12 | metadata: {
13 | 'version': x
14 | },
15 | data: [
16 | {
17 | 'id': DATASET_SET_ID,
18 | 'set_folder': ,
19 | 'feature_path': ,
20 | 'info': {
21 | // Extra information
22 | 'questions_tokens': [],
23 | 'answer_tokens': []
24 | }
25 | }
26 | ]
27 | }
28 | """
29 |
30 | def __init__(self, imdb_path):
31 | super().__init__()
32 | self.metadata = {}
33 | self._load_imdb(imdb_path)
34 |
35 | def _load_imdb(self, imdb_path):
36 | if imdb_path.endswith(".npy"):
37 | self._load_npy(imdb_path)
38 | elif imdb_path.endswith(".jsonl"):
39 | self._load_jsonl(imdb_path)
40 | elif imdb_path.contains("visdial") or imdb_path.contains("visual_dialog"):
41 | self._load_visual_dialog(imdb_path)
42 | else:
43 | raise ValueError("Unknown file format for imdb")
44 |
45 | def _load_jsonl(self, imdb_path):
46 | with open(imdb_path, "r") as f:
47 | db = f.readlines()
48 | for idx, line in enumerate(db):
49 | db[idx] = json.loads(line.strip("\n"))
50 | self.data = db
51 | self.start_idx = 0
52 |
53 | def _load_npy(self, imdb_path):
54 | self.db = np.load(imdb_path, allow_pickle=True)
55 | self.start_idx = 0
56 |
57 | if type(self.db) == dict:
58 | self.metadata = self.db.get("metadata", {})
59 | self.data = self.db.get("data", [])
60 | else:
61 | # TODO: Deprecate support for this
62 | self.metadata = {"version": 1}
63 | self.data = self.db
64 | # Handle old imdb support
65 | if "image_id" not in self.data[0]:
66 | self.start_idx = 1
67 |
68 | if len(self.data) == 0:
69 | self.data = self.db
70 |
71 | def _load_visual_dialog(self, imdb_path):
72 | from pythia.datasets.dialog.visual_dialog.database import VisualDialogDatabase
73 | self.data = VisualDialogDatabase(imdb_path)
74 | self.metadata = self.data.metadata
75 | self.start_idx = 0
76 |
77 | def __len__(self):
78 | return len(self.data) - self.start_idx
79 |
80 | def __getitem__(self, idx):
81 | data = self.data[idx + self.start_idx]
82 |
83 | # Hacks for older IMDBs
84 | if "answers" not in data:
85 | if "all_answers" in data and "valid_answers" not in data:
86 | data["answers"] = data["all_answers"]
87 | if "valid_answers" in data:
88 | data["answers"] = data["valid_answers"]
89 |
90 | # TODO: Later clean up VizWIz IMDB from copy tokens
91 | if "answers" in data and data["answers"][-1] == "":
92 | data["answers"] = data["answers"][:-1]
93 |
94 | return data
95 |
96 | def get_version(self):
97 | return self.metadata.get("version", None)
98 |
--------------------------------------------------------------------------------
/pythia/datasets/samplers.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
2 | # Code is copy-pasted exactly as in torch.utils.data.distributed.
3 | # FIXME remove this once c10d fixes the bug it has
4 | import math
5 | import torch
6 | import torch.distributed as dist
7 | from torch.utils.data.sampler import Sampler
8 |
9 |
10 | class DistributedSampler(Sampler):
11 | """Sampler that restricts data loading to a subset of the dataset.
12 | It is especially useful in conjunction with
13 | :class:`torch.nn.parallel.DistributedDataParallel`. In such case, each
14 | process can pass a DistributedSampler instance as a DataLoader sampler,
15 | and load a subset of the original dataset that is exclusive to it.
16 | .. note::
17 | Dataset is assumed to be of constant size.
18 | Arguments:
19 | dataset: Dataset used for sampling.
20 | num_replicas (optional): Number of processes participating in
21 | distributed training.
22 | rank (optional): Rank of the current process within num_replicas.
23 | """
24 |
25 | def __init__(self, dataset, num_replicas=None, rank=None, shuffle=True):
26 | if num_replicas is None:
27 | if not dist.is_available():
28 | raise RuntimeError("Requires distributed package to be available")
29 | num_replicas = dist.get_world_size()
30 | if rank is None:
31 | if not dist.is_available():
32 | raise RuntimeError("Requires distributed package to be available")
33 | rank = dist.get_rank()
34 | self.dataset = dataset
35 | self.num_replicas = num_replicas
36 | self.rank = rank
37 | self.epoch = 0
38 | self.num_samples = int(math.ceil(len(self.dataset) * 1.0 / self.num_replicas))
39 | self.total_size = self.num_samples * self.num_replicas
40 | self.shuffle = shuffle
41 |
42 | def __iter__(self):
43 | if self.shuffle:
44 | # deterministically shuffle based on epoch
45 | g = torch.Generator()
46 | g.manual_seed(self.epoch)
47 | indices = torch.randperm(len(self.dataset), generator=g).tolist()
48 | else:
49 | indices = torch.arange(len(self.dataset)).tolist()
50 |
51 | # add extra samples to make it evenly divisible
52 | indices += indices[: (self.total_size - len(indices))]
53 | assert len(indices) == self.total_size
54 |
55 | # subsample
56 | offset = self.num_samples * self.rank
57 | indices = indices[offset : offset + self.num_samples]
58 | assert len(indices) == self.num_samples
59 |
60 | return iter(indices)
61 |
62 | def __len__(self):
63 | return self.num_samples
64 |
65 | def set_epoch(self, epoch):
66 | self.epoch = epoch
67 |
--------------------------------------------------------------------------------
/pythia/datasets/scene_graph_database.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.datasets.image_database import ImageDatabase
3 |
4 |
5 | class SceneGraphDatabase(ImageDatabase):
6 | def __init__(self, scene_graph_path):
7 | super().__init__(scene_graph_path)
8 | self.data_dict = {}
9 | for item in self.data:
10 | self.data_dict[item["image_id"]] = item
11 |
12 | def __getitem__(self, idx):
13 | return self.data_dict[idx]
14 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/clevr/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/microsoft/TAP/352891f93c75ac5d6b9ba141bbe831477dcdd807/pythia/datasets/vqa/clevr/__init__.py
--------------------------------------------------------------------------------
/pythia/datasets/vqa/clevr/builder.py:
--------------------------------------------------------------------------------
1 | import json
2 | import math
3 | import os
4 | import zipfile
5 | from collections import Counter
6 |
7 | from pythia.common.registry import registry
8 | from pythia.common.constants import CLEVR_DOWNLOAD_URL
9 | from pythia.datasets.base_dataset_builder import BaseDatasetBuilder
10 | from pythia.datasets.vqa.clevr.dataset import CLEVRDataset
11 | from pythia.utils.general import download_file, get_pythia_root
12 |
13 |
14 | @registry.register_builder("clevr")
15 | class CLEVRBuilder(BaseDatasetBuilder):
16 | def __init__(self):
17 | super().__init__("clevr")
18 | self.writer = registry.get("writer")
19 | self.dataset_class = CLEVRDataset
20 |
21 | def _build(self, dataset_type, config):
22 | download_folder = os.path.join(get_pythia_root(), config.data_root_dir, config.data_folder)
23 |
24 | file_name = CLEVR_DOWNLOAD_URL.split("/")[-1]
25 | local_filename = os.path.join(download_folder, file_name)
26 |
27 | extraction_folder = os.path.join(download_folder, ".".join(file_name.split(".")[:-1]))
28 | self.data_folder = extraction_folder
29 |
30 | # Either if the zip file is already present or if there are some
31 | # files inside the folder we don't continue download process
32 | if os.path.exists(local_filename):
33 | self.writer.write("CLEVR dataset is already present. Skipping download.")
34 | return
35 |
36 | if os.path.exists(extraction_folder) and \
37 | len(os.listdir(extraction_folder)) != 0:
38 | return
39 |
40 | self.writer.write("Downloading the CLEVR dataset now")
41 | download_file(CLEVR_DOWNLOAD_URL, output_dir=download_folder)
42 |
43 | self.writer.write("Downloaded. Extracting now. This can take time.")
44 | with zipfile.ZipFile(local_filename, "r") as zip_ref:
45 | zip_ref.extractall(download_folder)
46 |
47 |
48 | def _load(self, dataset_type, config, *args, **kwargs):
49 | self.dataset = CLEVRDataset(
50 | dataset_type, config, data_folder=self.data_folder
51 | )
52 | return self.dataset
53 |
54 | def update_registry_for_model(self, config):
55 | registry.register(
56 | self.dataset_name + "_text_vocab_size",
57 | self.dataset.text_processor.get_vocab_size(),
58 | )
59 | registry.register(
60 | self.dataset_name + "_num_final_outputs",
61 | self.dataset.answer_processor.get_vocab_size(),
62 | )
63 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/clevr/dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 |
4 | import numpy as np
5 | import torch
6 |
7 | from PIL import Image
8 |
9 | from pythia.common.registry import registry
10 | from pythia.common.sample import Sample
11 | from pythia.datasets.base_dataset import BaseDataset
12 | from pythia.utils.general import get_pythia_root
13 | from pythia.utils.text_utils import VocabFromText, tokenize
14 | from pythia.utils.distributed_utils import is_main_process, synchronize
15 |
16 |
17 | _CONSTANTS = {
18 | "questions_folder": "questions",
19 | "dataset_key": "clevr",
20 | "empty_folder_error": "CLEVR dataset folder is empty.",
21 | "questions_key": "questions",
22 | "question_key": "question",
23 | "answer_key": "answer",
24 | "train_dataset_key": "train",
25 | "images_folder": "images",
26 | "vocabs_folder": "vocabs"
27 | }
28 |
29 | _TEMPLATES = {
30 | "data_folder_missing_error": "Data folder {} for CLEVR is not present.",
31 | "question_json_file": "CLEVR_{}_questions.json",
32 | "vocab_file_template": "{}_{}_vocab.txt"
33 | }
34 |
35 |
36 | class CLEVRDataset(BaseDataset):
37 | """Dataset for CLEVR. CLEVR is a reasoning task where given an image with some
38 | 3D shapes you have to answer basic questions.
39 |
40 | Args:
41 | dataset_type (str): type of dataset, train|val|test
42 | config (ConfigNode): Configuration Node representing all of the data necessary
43 | to initialize CLEVR dataset class
44 | data_folder: Root folder in which all of the data will be present if passed
45 | replaces default based on data_root_dir and data_folder in config.
46 |
47 | """
48 | def __init__(self, dataset_type, config, data_folder=None, *args, **kwargs):
49 | super().__init__(_CONSTANTS["dataset_key"], dataset_type, config)
50 | self._data_folder = data_folder
51 | self._data_root_dir = os.path.join(get_pythia_root(), config.data_root_dir)
52 |
53 | if not self._data_folder:
54 | self._data_folder = os.path.join(self._data_root_dir, config.data_folder)
55 |
56 | if not os.path.exists(self._data_folder):
57 | raise RuntimeError(_TEMPLATES["data_folder_missing_error"].format(self._data_folder))
58 |
59 | # Check if the folder was actually extracted in the subfolder
60 | if config.data_folder in os.listdir(self._data_folder):
61 | self._data_folder = os.path.join(self._data_folder, config.data_folder)
62 |
63 | if len(os.listdir(self._data_folder)) == 0:
64 | raise FileNotFoundError(_CONSTANTS["empty_folder_error"])
65 |
66 | self._load()
67 |
68 | def _load(self):
69 | self.image_path = os.path.join(self._data_folder, _CONSTANTS["images_folder"], self._dataset_type)
70 |
71 | with open(
72 | os.path.join(
73 | self._data_folder,
74 | _CONSTANTS["questions_folder"],
75 | _TEMPLATES["question_json_file"].format(self._dataset_type),
76 | )
77 | ) as f:
78 | self.questions = json.load(f)[_CONSTANTS["questions_key"]]
79 |
80 | # Vocab should only be built in main process, as it will repetition of same task
81 | if is_main_process():
82 | self._build_vocab(self.questions, _CONSTANTS["question_key"])
83 | self._build_vocab(self.questions, _CONSTANTS["answer_key"])
84 | synchronize()
85 |
86 | def __len__(self):
87 | return len(self.questions)
88 |
89 | def _get_vocab_path(self, attribute):
90 | return os.path.join(
91 | self._data_root_dir, _CONSTANTS["vocabs_folder"],
92 | _TEMPLATES["vocab_file_template"].format(self._name, attribute)
93 | )
94 |
95 | def _build_vocab(self, questions, attribute):
96 | # Vocab should only be built from "train" as val and test are not observed in training
97 | if self._dataset_type != _CONSTANTS["train_dataset_key"]:
98 | return
99 |
100 | vocab_file = self._get_vocab_path(attribute)
101 |
102 | # Already exists, no need to recreate
103 | if os.path.exists(vocab_file):
104 | return
105 |
106 | # Create necessary dirs if not present
107 | os.makedirs(os.path.dirname(vocab_file), exist_ok=True)
108 |
109 | sentences = [question[attribute] for question in questions]
110 | build_attributes = self.config.build_attributes
111 |
112 | # Regex is default one in tokenize i.e. space
113 | kwargs = {
114 | "min_count": build_attributes.get("min_count", 1),
115 | "keep": build_attributes.get("keep", [";", ","]),
116 | "remove": build_attributes.get("remove", ["?", "."])
117 | }
118 |
119 | if attribute == _CONSTANTS["answer_key"]:
120 | kwargs["only_unk_extra"] = False
121 |
122 | vocab = VocabFromText(sentences, **kwargs)
123 |
124 | with open(vocab_file,"w") as f:
125 | f.write("\n".join(vocab.word_list))
126 |
127 | def get_item(self, idx):
128 | data = self.questions[idx]
129 |
130 | # Each call to get_item from dataloader returns a Sample class object which
131 | # collated by our special batch collator to a SampleList which is basically
132 | # a attribute based batch in layman terms
133 | current_sample = Sample()
134 |
135 | question = data["question"]
136 | tokens = tokenize(question, keep=[";", ","], remove=["?", "."])
137 | processed = self.text_processor({"tokens": tokens})
138 | current_sample.text = processed["text"]
139 |
140 | processed = self.answer_processor({"answers": [data["answer"]]})
141 | current_sample.answers = processed["answers"]
142 | current_sample.targets = processed["answers_scores"]
143 |
144 | image_path = os.path.join(self.image_path, data["image_filename"])
145 | image = np.true_divide(Image.open(image_path).convert("RGB"), 255)
146 | image = image.astype(np.float32)
147 | current_sample.image = torch.from_numpy(image.transpose(2, 0, 1))
148 |
149 | return current_sample
150 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/m4c_ocrvqa/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/m4c_ocrvqa/builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.common.registry import Registry
3 | from pythia.datasets.vqa.m4c_ocrvqa.dataset import M4COCRVQADataset
4 | from pythia.datasets.vqa.m4c_textvqa.builder import M4CTextVQABuilder
5 |
6 |
7 | @Registry.register_builder("m4c_ocrvqa")
8 | class M4COCRVQABuilder(M4CTextVQABuilder):
9 | def __init__(self):
10 | super().__init__()
11 | self.dataset_name = "m4c_ocrvqa"
12 | self.set_dataset_class(M4COCRVQADataset)
13 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/m4c_ocrvqa/dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.datasets.vqa.m4c_textvqa.dataset import M4CTextVQADataset
3 |
4 |
5 | class M4COCRVQADataset(M4CTextVQADataset):
6 | def __init__(self, dataset_type, imdb_file_index, config, *args, **kwargs):
7 | super().__init__(
8 | dataset_type, imdb_file_index, config, *args, **kwargs
9 | )
10 | self._name = "m4c_ocrvqa"
11 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/m4c_stvqa/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/m4c_stvqa/builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.common.registry import Registry
3 | from pythia.datasets.vqa.m4c_stvqa.dataset import M4CSTVQADataset
4 | from pythia.datasets.vqa.m4c_textvqa.builder import M4CTextVQABuilder
5 |
6 |
7 | @Registry.register_builder("m4c_stvqa")
8 | class M4CSTVQABuilder(M4CTextVQABuilder):
9 | def __init__(self):
10 | super().__init__()
11 | self.dataset_name = "m4c_stvqa"
12 | self.set_dataset_class(M4CSTVQADataset)
13 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/m4c_stvqa/dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.datasets.vqa.m4c_textvqa.dataset import M4CTextVQADataset
3 |
4 |
5 | class M4CSTVQADataset(M4CTextVQADataset):
6 | def __init__(self, dataset_type, imdb_file_index, config, *args, **kwargs):
7 | super().__init__(
8 | dataset_type, imdb_file_index, config, *args, **kwargs
9 | )
10 | self._name = "m4c_stvqa"
11 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/m4c_textvqa/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/m4c_textvqa/builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.common.registry import Registry
3 | from pythia.datasets.vqa.m4c_textvqa.dataset import M4CTextVQADataset
4 | from pythia.datasets.vqa.textvqa.builder import TextVQABuilder
5 |
6 |
7 | @Registry.register_builder("m4c_textvqa")
8 | class M4CTextVQABuilder(TextVQABuilder):
9 | def __init__(self):
10 | super().__init__()
11 | self.dataset_name = "m4c_textvqa"
12 | self.set_dataset_class(M4CTextVQADataset)
13 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/textvqa/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/textvqa/builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.common.registry import Registry
3 | from pythia.datasets.vqa.textvqa.dataset import TextVQADataset
4 | from pythia.datasets.vqa.vizwiz import VizWizBuilder
5 |
6 |
7 | @Registry.register_builder("textvqa")
8 | class TextVQABuilder(VizWizBuilder):
9 | def __init__(self):
10 | super().__init__()
11 | self.dataset_name = "textvqa"
12 | self.set_dataset_class(TextVQADataset)
13 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/textvqa/dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.datasets.vqa.vizwiz import VizWizDataset
3 | from pythia.utils.text_utils import word_tokenize
4 |
5 |
6 | class TextVQADataset(VizWizDataset):
7 | def __init__(self, dataset_type, imdb_file_index, config, *args, **kwargs):
8 | super().__init__(dataset_type, imdb_file_index, config, *args, **kwargs)
9 | self._name = "textvqa"
10 |
11 | def format_for_evalai(self, report):
12 | answers = report.scores.argmax(dim=1)
13 |
14 | predictions = []
15 | answer_space_size = self.answer_processor.get_true_vocab_size()
16 |
17 | for idx, question_id in enumerate(report.question_id):
18 | answer_id = answers[idx].item()
19 | print(answer_id, idx, len(answers), len(report.question_id), len(report.context_tokens))
20 | if answer_id >= answer_space_size:
21 | answer_id -= answer_space_size
22 | answer = word_tokenize(report.context_tokens[idx][answer_id])
23 | else:
24 | answer = self.answer_processor.idx2word(answer_id)
25 |
26 | predictions.append({"question_id": question_id.item(), "answer": answer})
27 | return predictions
28 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/visual_genome/builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import os
3 | import shutil
4 |
5 | from pythia.common.registry import registry
6 | from pythia.datasets.vqa.vqa2.builder import VQA2Builder
7 | from pythia.datasets.vqa.visual_genome.dataset import VisualGenomeDataset
8 | from pythia.utils.general import download_file, extract_file, get_pythia_root
9 | from pythia.common.constants import VISUAL_GENOME_CONSTS
10 |
11 |
12 | @registry.register_builder("visual_genome")
13 | class VisualGenomeBuilder(VQA2Builder):
14 | def __init__(self):
15 | super().__init__()
16 | self.dataset_name = "visual_genome"
17 | self.dataset_proper_name = "Visual Genome"
18 | self.dataset_class = VisualGenomeDataset
19 | self.writer = registry.get("writer")
20 |
21 | def _build(self, dataset_type, config):
22 | self._dataset_type = dataset_type
23 | self._config = config
24 | data_folder = os.path.join(get_pythia_root(), self._config.data_root_dir)
25 |
26 | # Since the imdb tar file contains all of the sets, we won't download them
27 | # except in case of train
28 | if self._dataset_type != "train":
29 | return
30 |
31 | self._download_and_extract_imdb(data_folder)
32 | self._download_and_extract_features(data_folder)
33 |
34 | def _download_and_extract_imdb(self, data_folder):
35 | download_folder = os.path.join(data_folder, "imdb")
36 | vocab_folder = os.path.join(data_folder, "vocabs")
37 | vocab_file = os.path.join(vocab_folder, VISUAL_GENOME_CONSTS["synset_file"])
38 | os.makedirs(vocab_folder, exist_ok=True)
39 |
40 | self._download_and_extract(
41 | "vocabs", VISUAL_GENOME_CONSTS["vocabs"], data_folder
42 | )
43 | extraction_folder = self._download_and_extract(
44 | "imdb_url", VISUAL_GENOME_CONSTS["imdb_url"], download_folder
45 | )
46 |
47 | if not os.path.exists(vocab_file):
48 | shutil.move(
49 | os.path.join(extraction_folder, VISUAL_GENOME_CONSTS["synset_file"]),
50 | vocab_file
51 | )
52 |
53 | def _download_and_extract_features(self, data_folder):
54 | self._download_and_extract(
55 | "features_url", VISUAL_GENOME_CONSTS["features_url"], data_folder
56 | )
57 |
58 | def _download_and_extract(self, key, url, download_folder):
59 | file_type = key.split("_")[0]
60 | os.makedirs(download_folder, exist_ok=True)
61 | local_filename = url.split("/")[-1]
62 | extraction_folder = os.path.join(download_folder, local_filename.split(".")[0])
63 | local_filename = os.path.join(download_folder, local_filename)
64 |
65 | if os.path.exists(local_filename) or \
66 | (os.path.exists(extraction_folder) and len(os.listdir(extraction_folder))) != 0:
67 | self.writer.write(
68 | "{} {} already present. Skipping download.".format(
69 | self.dataset_proper_name, file_type
70 | )
71 | )
72 | return extraction_folder
73 |
74 |
75 | self.writer.write("Downloading the {} {} now.".format(
76 | self.dataset_proper_name, file_type)
77 | )
78 | download_file(url, output_dir=download_folder)
79 |
80 | self.writer.write(
81 | "Extracting the {} {} now. This may take time".format(
82 | self.dataset_proper_name, file_type
83 | )
84 | )
85 | extract_file(local_filename, output_dir=download_folder)
86 |
87 | return extraction_folder
88 |
89 |
90 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/vizwiz/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from .builder import VizWizBuilder
3 | from .dataset import VizWizDataset
4 |
5 |
6 | __all__ = ["VizWizBuilder", "VizWizDataset"]
7 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/vizwiz/builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.common.registry import registry
3 | from pythia.datasets.vqa.vizwiz.dataset import VizWizDataset
4 | from pythia.datasets.vqa.vqa2 import VQA2Builder
5 |
6 |
7 | @registry.register_builder("vizwiz")
8 | class VizWizBuilder(VQA2Builder):
9 | def __init__(self):
10 | super().__init__()
11 | self.dataset_name = "vizwiz"
12 | self.set_dataset_class(VizWizDataset)
13 |
14 | def update_registry_for_model(self, config):
15 | super().update_registry_for_model(config)
16 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/vizwiz/dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import torch
3 |
4 | from pythia.common.sample import Sample
5 | from pythia.datasets.vqa.vqa2 import VQA2Dataset
6 |
7 |
8 | class VizWizDataset(VQA2Dataset):
9 | def __init__(self, dataset_type, imdb_file_index, config, *args, **kwargs):
10 | super().__init__(dataset_type, imdb_file_index, config, *args, **kwargs)
11 |
12 | # Update name as default would be 'vqa2' due to inheritance
13 | self._name = "vizwiz"
14 |
15 | def load_item(self, idx):
16 | sample = super().load_item(idx)
17 |
18 | sample_info = self.imdb[idx]
19 |
20 | if "image_name" in sample_info:
21 | sample.image_id = sample_info["image_name"]
22 |
23 | return sample
24 |
25 | def format_for_evalai(self, report):
26 | answers = report.scores.argmax(dim=1)
27 |
28 | predictions = []
29 | answer_space_size = self.answer_processor.get_true_vocab_size()
30 |
31 | for idx, image_id in enumerate(report.image_id):
32 | answer_id = answers[idx].item()
33 |
34 | if answer_id >= answer_space_size:
35 | answer_id -= answer_space_size
36 | answer = report.context_tokens[idx][answer_id]
37 | else:
38 | answer = self.answer_processor.idx2word(answer_id)
39 | if answer == self.context_processor.PAD_TOKEN:
40 | answer = "unanswerable"
41 | predictions.append(
42 | {
43 | "image": "_".join(["VizWiz"] + image_id.split("_")[2:]) + ".jpg",
44 | "answer": answer,
45 | }
46 | )
47 |
48 | return predictions
49 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/vqa2/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | __all__ = ["VQA2Builder", "VQA2Dataset"]
3 |
4 | from .builder import VQA2Builder
5 | from .dataset import VQA2Dataset
6 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/vqa2/builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | # All rights reserved.
3 | #
4 | # This source code is licensed under the license found in the
5 | # LICENSE file in the root directory of this source tree.
6 | #
7 |
8 |
9 | import os
10 | import warnings
11 |
12 | from pythia.common.registry import registry
13 | from pythia.datasets.base_dataset_builder import BaseDatasetBuilder
14 | from pythia.datasets.concat_dataset import PythiaConcatDataset
15 | from pythia.datasets.vqa.vqa2.dataset import VQA2Dataset
16 |
17 |
18 | @registry.register_builder("vqa2")
19 | class VQA2Builder(BaseDatasetBuilder):
20 | def __init__(self):
21 | super().__init__("vqa2")
22 | self.dataset_class = VQA2Dataset
23 |
24 | def _load(self, dataset_type, config, *args, **kwargs):
25 | self.config = config
26 |
27 | image_features = config["image_features"]["train"][0].split(",")
28 | self.num_image_features = len(image_features)
29 |
30 | registry.register("num_image_features", self.num_image_features)
31 |
32 | self.dataset = self.prepare_data_set(dataset_type, config)
33 |
34 | return self.dataset
35 |
36 | def _build(self, dataset_type, config):
37 | # TODO: Build actually here
38 | return
39 |
40 | def update_registry_for_model(self, config):
41 | registry.register(
42 | self.dataset_name + "_text_vocab_size",
43 | self.dataset.text_processor.get_vocab_size(),
44 | )
45 | registry.register(
46 | self.dataset_name + "_num_final_outputs",
47 | self.dataset.answer_processor.get_vocab_size(),
48 | )
49 |
50 | def init_args(self, parser):
51 | parser.add_argument_group("VQA2 task specific arguments")
52 | parser.add_argument(
53 | "--data_root_dir",
54 | type=str,
55 | default="../data",
56 | help="Root directory for data",
57 | )
58 | parser.add_argument(
59 | "-nfr",
60 | "--fast_read",
61 | type=bool,
62 | default=None,
63 | help="Disable fast read and load features on fly",
64 | )
65 |
66 | def set_dataset_class(self, cls):
67 | self.dataset_class = cls
68 |
69 | def prepare_data_set(self, dataset_type, config):
70 | if dataset_type not in config.imdb_files:
71 | warnings.warn(
72 | "Dataset type {} is not present in "
73 | "imdb_files of dataset config. Returning None. "
74 | "This dataset won't be used.".format(dataset_type)
75 | )
76 | return None
77 |
78 | imdb_files = config["imdb_files"][dataset_type]
79 |
80 | datasets = []
81 |
82 | for imdb_idx in range(len(imdb_files)):
83 | cls = self.dataset_class
84 | dataset = cls(dataset_type, imdb_idx, config)
85 | datasets.append(dataset)
86 |
87 | dataset = PythiaConcatDataset(datasets)
88 |
89 | return dataset
90 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/vqa2/ocr_builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.common.registry import Registry
3 | from pythia.datasets.vqa.vizwiz import VizWizBuilder
4 | from pythia.datasets.vqa.vqa2.ocr_dataset import VQA2OCRDataset
5 |
6 |
7 | @Registry.register_builder("vqa2_ocr")
8 | class TextVQABuilder(VizWizBuilder):
9 | def __init__(self):
10 | super().__init__()
11 | self.dataset_name = "VQA2_OCR"
12 | self.set_dataset_class(VQA2OCRDataset)
13 |
--------------------------------------------------------------------------------
/pythia/datasets/vqa/vqa2/ocr_dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.datasets.vqa.vizwiz import VizWizDataset
3 | from pythia.utils.text_utils import word_tokenize
4 |
5 |
6 | class VQA2OCRDataset(VizWizDataset):
7 | def __init__(self, imdb_file, image_feat_directories, verbose=False, **data_params):
8 | super(VQA2OCRDataset, self).__init__(
9 | imdb_file, image_feat_directories, verbose, **data_params
10 | )
11 | self.name = "vqa2_ocr"
12 |
13 | def format_for_evalai(self, batch, answers):
14 | answers = answers.argmax(dim=1)
15 |
16 | predictions = []
17 | for idx, question_id in enumerate(batch["question_id"]):
18 | answer_id = answers[idx]
19 |
20 | if answer_id >= self.answer_space_size:
21 | answer_id -= self.answer_space_size
22 | answer = word_tokenize(batch["ocr_tokens"][answer_id][idx])
23 | else:
24 | answer = self.answer_dict.idx2word(answer_id)
25 | predictions.append({"question_id": question_id.item(), "answer": answer})
26 |
27 | return predictions
28 |
29 | def __getitem__(self, idx):
30 | sample = super(VQA2OCRDataset, self).__getitem__(idx)
31 |
32 | if sample["question_id"] is None:
33 | sample["question_id"] = -1
34 | return sample
35 |
--------------------------------------------------------------------------------
/pythia/models/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | __all__ = ["TopDownBottomUp", "Pythia", "LoRRA", "BAN"]
3 |
4 | from .top_down_bottom_up import TopDownBottomUp
5 | from .ban import BAN
6 | from .pythia import Pythia
7 | from .lorra import LoRRA
8 |
--------------------------------------------------------------------------------
/pythia/models/ban.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import torch
3 | from torch import nn
4 |
5 | from pythia.common.registry import registry
6 | from pythia.models.base_model import BaseModel
7 | from pythia.modules.embeddings import BiLSTMTextEmbedding
8 | from pythia.modules.layers import (BCNet, BiAttention, FCNet,
9 | WeightNormClassifier)
10 |
11 |
12 | @registry.register_model("ban")
13 | class BAN(BaseModel):
14 | def __init__(self, config):
15 | super(BAN, self).__init__(config)
16 | self.config = config
17 | self._global_config = registry.get("config")
18 | self._datasets = self._global_config.datasets.split(",")
19 |
20 | def build(self):
21 | self._build_word_embedding()
22 | self._init_text_embedding()
23 | self._init_classifier()
24 | self._init_bilinear_attention()
25 |
26 | def _build_word_embedding(self):
27 | text_processor = registry.get(self._datasets[0] + "_text_processor")
28 | vocab = text_processor.vocab
29 | self.word_embedding = vocab.get_embedding(torch.nn.Embedding, embedding_dim=300)
30 |
31 | def _init_text_embedding(self):
32 | module_config = self.config["text_embedding"]
33 | q_mod = BiLSTMTextEmbedding(
34 | module_config["num_hidden"],
35 | module_config["emb_size"],
36 | module_config["num_layers"],
37 | module_config["dropout"],
38 | module_config["bidirectional"],
39 | module_config["rnn_type"],
40 | )
41 | self.q_emb = q_mod
42 |
43 | def _init_bilinear_attention(self):
44 | module_config = self.config["bilinear_attention"]
45 | num_hidden = self.config["text_embedding"]["num_hidden"]
46 | v_dim = module_config["visual_feat_dim"]
47 |
48 | v_att = BiAttention(v_dim, num_hidden, num_hidden, module_config["gamma"])
49 |
50 | b_net = []
51 | q_prj = []
52 |
53 | for i in range(module_config["gamma"]):
54 | b_net.append(
55 | BCNet(
56 | v_dim, num_hidden, num_hidden, None, k=module_config["bc_net"]["k"]
57 | )
58 | )
59 |
60 | q_prj.append(
61 | FCNet(
62 | dims=[num_hidden, num_hidden],
63 | act=module_config["fc_net"]["activation"],
64 | dropout=module_config["fc_net"]["dropout"],
65 | )
66 | )
67 |
68 | self.b_net = nn.ModuleList(b_net)
69 | self.q_prj = nn.ModuleList(q_prj)
70 | self.v_att = v_att
71 |
72 | def _init_classifier(self):
73 | num_hidden = self.config["text_embedding"]["num_hidden"]
74 | num_choices = registry.get(self._datasets[0] + "_num_final_outputs")
75 | dropout = self.config["classifier"]["dropout"]
76 | self.classifier = WeightNormClassifier(
77 | num_hidden, num_choices, num_hidden * 2, dropout
78 | )
79 |
80 | def forward(self, sample_list):
81 |
82 | v = sample_list.image_feature_0
83 | q = self.word_embedding(sample_list.text)
84 |
85 | q_emb = self.q_emb.forward_all(q)
86 |
87 | b_emb = [0] * self.config["bilinear_attention"]["gamma"]
88 | att, logits = self.v_att.forward_all(v, q_emb)
89 |
90 | for g in range(self.config["bilinear_attention"]["gamma"]):
91 | g_att = att[:, g, :, :]
92 | b_emb[g] = self.b_net[g].forward_with_weights(v, q_emb, g_att)
93 | q_emb = self.q_prj[g](b_emb[g].unsqueeze(1)) + q_emb
94 |
95 | logits = self.classifier(q_emb.sum(1))
96 |
97 | return {"scores": logits}
98 |
--------------------------------------------------------------------------------
/pythia/models/base_model.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | """
3 | Models built on top of Pythia need to inherit ``BaseModel`` class and adhere to
4 | some format. To create a model for Pythia, follow this quick cheatsheet.
5 |
6 | 1. Inherit ``BaseModel`` class, make sure to call ``super().__init__()`` in your
7 | class's ``__init__`` function.
8 | 2. Implement `build` function for your model. If you build everything in ``__init__``,
9 | you can just return in this function.
10 | 3. Write a `forward` function which takes in a ``SampleList`` as an argument and
11 | returns a dict.
12 | 4. Register using ``@registry.register_model("key")`` decorator on top of the
13 | class.
14 |
15 | If you are doing logits based predictions, the dict you return from your model
16 | should contain a `scores` field. Losses and Metrics are automatically
17 | calculated by the ``BaseModel`` class and added to this dict if not present.
18 |
19 | Example::
20 |
21 | import torch
22 |
23 | from pythia.common.registry import registry
24 | from pythia.models.base_model import BaseModel
25 |
26 |
27 | @registry.register("pythia")
28 | class Pythia(BaseModel):
29 | # config is model_attributes from global config
30 | def __init__(self, config):
31 | super().__init__(config)
32 |
33 | def build(self):
34 | ....
35 |
36 | def forward(self, sample_list):
37 | scores = torch.rand(sample_list.get_batch_size(), 3127)
38 | return {"scores": scores}
39 | """
40 |
41 |
42 | import collections
43 | import warnings
44 |
45 | from torch import nn
46 |
47 | from pythia.common.registry import registry
48 | from pythia.common.report import Report
49 | from pythia.modules.losses import Losses
50 | from pythia.modules.metrics import Metrics
51 |
52 |
53 | class BaseModel(nn.Module):
54 | """For integration with Pythia's trainer, datasets and other feautures,
55 | models needs to inherit this class, call `super`, write a build function,
56 | write a forward function taking a ``SampleList`` as input and returning a
57 | dict as output and finally, register it using ``@registry.register_model``
58 |
59 | Args:
60 | config (ConfigNode): ``model_attributes`` configuration from global config.
61 |
62 | """
63 |
64 | def __init__(self, config):
65 | super().__init__()
66 | self.config = config
67 | self.writer = registry.get("writer")
68 |
69 | def build(self):
70 | """Function to be implemented by the child class, in case they need to
71 | build their model separately than ``__init__``. All model related
72 | downloads should also happen here.
73 | """
74 | raise NotImplementedError(
75 | "Build method not implemented in the child model class."
76 | )
77 |
78 | def init_losses_and_metrics(self):
79 | """Initializes loss and metrics for the model based ``losses`` key
80 | and ``metrics`` keys. Automatically called by Pythia internally after
81 | building the model.
82 | """
83 | losses = self.config.get("losses", [])
84 | metrics = self.config.get("metrics", [])
85 | if len(losses) == 0:
86 | warnings.warn(
87 | "No losses are defined in model configuration. You are expected "
88 | "to return loss in your return dict from forward."
89 | )
90 |
91 | if len(metrics) == 0:
92 | warnings.warn(
93 | "No metrics are defined in model configuration. You are expected "
94 | "to return metrics in your return dict from forward."
95 | )
96 | self.losses = Losses(losses)
97 | self.metrics = Metrics(metrics)
98 |
99 | @classmethod
100 | def init_args(cls, parser):
101 | return parser
102 |
103 | def forward(self, sample_list, *args, **kwargs):
104 | """To be implemented by child class. Takes in a ``SampleList`` and
105 | returns back a dict.
106 |
107 | Args:
108 | sample_list (SampleList): SampleList returned by the DataLoader for
109 | current iteration
110 |
111 | Returns:
112 | Dict: Dict containing scores object.
113 |
114 | """
115 | raise NotImplementedError(
116 | "Forward of the child model class needs to be implemented."
117 | )
118 |
119 | def __call__(self, sample_list, *args, **kwargs):
120 | model_output = super().__call__(sample_list, *args, **kwargs)
121 |
122 | # Make sure theat the output from the model is a Mapping
123 | assert isinstance(model_output, collections.abc.Mapping), (
124 | "A dict must be returned from the forward of the model."
125 | )
126 |
127 | if "losses" in model_output:
128 | warnings.warn(
129 | "'losses' already present in model output. "
130 | "No calculation will be done in base model."
131 | )
132 | assert isinstance(
133 | model_output["losses"], collections.abc.Mapping
134 | ), "'losses' must be a dict."
135 | else:
136 | model_output["losses"] = self.losses(sample_list, model_output)
137 |
138 | if "metrics" in model_output:
139 | warnings.warn(
140 | "'metrics' already present in model output. "
141 | "No calculation will be done in base model."
142 | )
143 | assert isinstance(
144 | model_output["metrics"], collections.abc.Mapping
145 | ), "'metrics' must be a dict."
146 | else:
147 | model_output["metrics"] = self.metrics(sample_list, model_output)
148 |
149 | return model_output
150 |
--------------------------------------------------------------------------------
/pythia/models/cnn_lstm.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from torch import nn
4 |
5 | from pythia.common.registry import registry
6 | from pythia.models.base_model import BaseModel
7 | from pythia.modules.layers import ConvNet, Flatten
8 |
9 |
10 | _TEMPLATES = {
11 | "question_vocab_size": "{}_text_vocab_size",
12 | "number_of_answers": "{}_num_final_outputs"
13 | }
14 |
15 | _CONSTANTS = {
16 | "hidden_state_warning": "hidden state (final) should have 1st dim as 2"
17 | }
18 |
19 |
20 | @registry.register_model("cnn_lstm")
21 | class CNNLSTM(BaseModel):
22 | """CNNLSTM is a simple model for vision and language tasks. CNNLSTM is supposed to act
23 | as a baseline to test out your stuff without any complex functionality. Passes image
24 | through a CNN, and text through an LSTM and fuses them using concatenation. Then, it finally
25 | passes the fused representation from a MLP to generate scores for each of the possible answers.
26 |
27 | Args:
28 | config (ConfigNode): Configuration node containing all of the necessary config required
29 | to initialize CNNLSTM.
30 |
31 | Inputs: sample_list (SampleList)
32 | - **sample_list** should contain image attribute for image, text for question split into
33 | word indices, targets for answer scores
34 | """
35 | def __init__(self, config):
36 | super().__init__(config)
37 | self._global_config = registry.get("config")
38 | self._datasets = self._global_config.datasets.split(",")
39 |
40 | def build(self):
41 | assert len(self._datasets) > 0
42 | num_question_choices = registry.get(
43 | _TEMPLATES["question_vocab_size"].format(self._datasets[0])
44 | )
45 | num_answer_choices = registry.get(
46 | _TEMPLATES["number_of_answers"].format(self._datasets[0])
47 | )
48 |
49 | self.text_embedding = nn.Embedding(
50 | num_question_choices, self.config.text_embedding.embedding_dim
51 | )
52 | self.lstm = nn.LSTM(**self.config.lstm)
53 |
54 | layers_config = self.config.cnn.layers
55 | conv_layers = []
56 | for i in range(len(layers_config.input_dims)):
57 | conv_layers.append(
58 | ConvNet(
59 | layers_config.input_dims[i],
60 | layers_config.output_dims[i],
61 | kernel_size=layers_config.kernel_sizes[i]
62 | )
63 | )
64 | conv_layers.append(Flatten())
65 | self.cnn = nn.Sequential(*conv_layers)
66 |
67 | self.classifier = nn.Linear(self.config.classifier.input_dim, num_answer_choices)
68 |
69 | def forward(self, sample_list):
70 | self.lstm.flatten_parameters()
71 |
72 | question = sample_list.text
73 | image = sample_list.image
74 |
75 | # Get (h_n, c_n), last hidden and cell state
76 | _, hidden = self.lstm(self.text_embedding(question))
77 | # X x B x H => B x X x H where X = num_layers * num_directions
78 | hidden = hidden[0].transpose(0, 1)
79 |
80 | # X should be 2 so we can merge in that dimension
81 | assert hidden.size(1) == 2, _CONSTANTS["hidden_state_warning"]
82 |
83 | hidden = torch.cat([hidden[:, 0, :], hidden[:, 1, :]], dim=-1)
84 | image = self.cnn(image)
85 |
86 | # Fuse into single dimension
87 | fused = torch.cat([hidden, image], dim=-1)
88 | scores = self.classifier(fused)
89 |
90 |
91 | return {"scores": scores}
92 |
--------------------------------------------------------------------------------
/pythia/models/lorra.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import torch
3 |
4 | from pythia.common.registry import registry
5 | from pythia.models.pythia import Pythia
6 | from pythia.modules.layers import ClassifierLayer
7 |
8 |
9 | @registry.register_model("lorra")
10 | class LoRRA(Pythia):
11 | def __init__(self, config):
12 | super().__init__(config)
13 |
14 | def build(self):
15 | self._init_text_embeddings("text")
16 | # For LoRRA context feature and text embeddings would be identity
17 | # but to keep a unified API, we will init them also
18 | # and we need to build them first before building pythia's other
19 | # modules as some of the modules require context attributes to be set
20 | self._init_text_embeddings("context")
21 | self._init_feature_encoders("context")
22 | self._init_feature_embeddings("context")
23 | super().build()
24 |
25 | def get_optimizer_parameters(self, config):
26 | params = super().get_optimizer_parameters(config)
27 | params += [
28 | {"params": self.context_feature_embeddings_list.parameters()},
29 | {"params": self.context_embeddings.parameters()},
30 | {"params": self.context_feature_encoders.parameters()},
31 | ]
32 |
33 | return params
34 |
35 | def _get_classifier_input_dim(self):
36 | # Now, the classifier's input will be cat of image and context based
37 | # features
38 | return 2 * super()._get_classifier_input_dim()
39 |
40 | def forward(self, sample_list):
41 | sample_list.text = self.word_embedding(sample_list.text)
42 | text_embedding_total = self.process_text_embedding(sample_list)
43 |
44 | image_embedding_total, _ = self.process_feature_embedding(
45 | "image", sample_list, text_embedding_total
46 | )
47 |
48 | context_embedding_total, _ = self.process_feature_embedding(
49 | "context", sample_list, text_embedding_total, ["order_vectors"]
50 | )
51 |
52 | if self.inter_model is not None:
53 | image_embedding_total = self.inter_model(image_embedding_total)
54 |
55 | joint_embedding = self.combine_embeddings(
56 | ["image", "text"],
57 | [image_embedding_total, text_embedding_total, context_embedding_total],
58 | )
59 |
60 | scores = self.calculate_logits(joint_embedding)
61 |
62 | return {"scores": scores}
63 |
--------------------------------------------------------------------------------
/pythia/models/m4c_captioner.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | from pythia.common.registry import registry
3 | from pythia.models.tap import M4C
4 |
5 |
6 | @registry.register_model("m4c_captioner")
7 | class M4CCaptioner(M4C):
8 | def __init__(self, config):
9 | super().__init__(config)
10 | self.remove_unk_in_pred = self.config.remove_unk_in_pred
11 |
12 | def _forward_output(self, sample_list, fwd_results):
13 | super()._forward_output(sample_list, fwd_results)
14 |
15 | if self.remove_unk_in_pred:
16 | # avoid outputting in the generated captions
17 | fwd_results["scores"][..., self.answer_processor.UNK_IDX] = -1e10
18 |
19 | return fwd_results
20 |
--------------------------------------------------------------------------------
/pythia/models/top_down_bottom_up.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import torch
3 | from torch import nn
4 |
5 | from pythia.common.registry import registry
6 | from pythia.models.base_model import BaseModel
7 | from pythia.modules.embeddings import (ImageEmbedding, PreExtractedEmbedding,
8 | TextEmbedding)
9 | from pythia.modules.encoders import ImageEncoder
10 | from pythia.modules.layers import (ClassifierLayer, Identity,
11 | ModalCombineLayer, ReLUWithWeightNormFC)
12 |
13 |
14 | # Note: Doesn't work currently. Needs to be migrated to new API
15 | @registry.register_model("top_down_bottom_up")
16 | class TopDownBottomUp(BaseModel):
17 | def __init__(self, image_attention_model, text_embedding_models, classifier):
18 | super().__init__()
19 | self.image_attention_model = image_attention_model
20 | self.text_embedding_models = text_embedding_models
21 | self.classifier = classifier
22 | text_lstm_dim = sum([q.text_out_dim for q in text_embedding_models])
23 | joint_embedding_out_dim = classifier.input_dim
24 | image_feat_dim = image_attention_model.image_feat_dim
25 | self.non_linear_text = ReLUWithWeightNormFC(
26 | text_lstm_dim, joint_embedding_out_dim
27 | )
28 | self.non_linear_image = ReLUWithWeightNormFC(
29 | image_feat_dim, joint_embedding_out_dim
30 | )
31 |
32 | def build(self):
33 | return
34 |
35 | def forward(
36 | self, image_feat_variable, input_text_variable, input_answers=None, **kwargs
37 | ):
38 | text_embeddings = []
39 | for q_model in self.text_embedding_models:
40 | q_embedding = q_model(input_text_variable)
41 | text_embeddings.append(q_embedding)
42 | text_embedding = torch.cat(text_embeddings, dim=1)
43 |
44 | if isinstance(image_feat_variable, list):
45 | image_embeddings = []
46 | for idx, image_feat in enumerate(image_feat_variable):
47 | ques_embedding_each = torch.unsqueeze(text_embedding[idx, :], 0)
48 | image_feat_each = torch.unsqueeze(image_feat, dim=0)
49 | attention_each = self.image_attention_model(
50 | image_feat_each, ques_embedding_each
51 | )
52 | image_embedding_each = torch.sum(attention_each * image_feat, dim=1)
53 | image_embeddings.append(image_embedding_each)
54 | image_embedding = torch.cat(image_embeddings, dim=0)
55 | else:
56 | attention = self.image_attention_model(image_feat_variable, text_embedding)
57 | image_embedding = torch.sum(attention * image_feat_variable, dim=1)
58 |
59 | joint_embedding = self.non_linear_text(text_embedding) * self.non_linear_image(
60 | image_embedding
61 | )
62 | logit_res = self.classifier(joint_embedding)
63 |
64 | return logit_res
65 |
--------------------------------------------------------------------------------
/pythia/models/visdial_multi_modal.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import torch
3 |
4 | from pythia.models.pythia import Pythia
5 | from pythia.modules.decoders import VisDialDiscriminator
6 |
7 |
8 | class VisDialMultiModalModel(Pythia):
9 | def __init__(self, config):
10 | super().__init__(config)
11 |
12 | def build(self):
13 | self._init_text_embedding()
14 | self._init_image_encoders()
15 | self._init_image_embeddings()
16 | self._init_combine_layer()
17 | self._init_decoder()
18 | self._init_extras()
19 |
20 | def _init_text_embedding(self):
21 | parent = super(VisDialMultiModalModel, self)
22 | parent._init_text_embedding("text_embeddings", False)
23 | parent._init_text_embedding("history_embeddings", True)
24 |
25 | def get_optimizer_parameters(self, config):
26 | # TODO: Update after implementing decoder
27 | params = [
28 | {"params": self.img_embeddings_list.parameters()},
29 | {"params": self.text_embeddings.parameters()},
30 | {"params": self.multi_modal_combine_layer.parameters()},
31 | {"params": self.decoder.projection_layer.parameters()},
32 | {
33 | "params": self.img_feat_encoders.parameters(),
34 | "lr": (config["optimizer_attributes"]["params"]["lr"] * 0.1),
35 | },
36 | ]
37 |
38 | return params
39 |
40 | def _update_text_embedding_args(self, args):
41 | parent = super(VisDialMultiModalModel, self)
42 | parent._update_text_embedding_args(args)
43 | # Add embedding vectors to args
44 | args["embedding_vectors"] = self.config["embedding_vectors"]
45 |
46 | def _init_decoder(self):
47 | embedding = self.text_embeddings[0].module
48 | embedding_dim = self.text_embeddings[0].embedding_dim
49 | hidden_dim = self.multi_modal_combine_layer.out_dim
50 |
51 | self.decoder = VisDialDiscriminator(
52 | {"embedding_dim": embedding_dim, "hidden_dim": hidden_dim}, embedding
53 | )
54 |
55 | def combine_embeddings(self, *args):
56 | return self.multi_modal_combine_layer(*args)
57 |
58 | def calculate_logits(self, joint_embedding, **kwargs):
59 | return self.decoder(joint_embedding, kwargs)
60 |
61 | def forward(
62 | self, texts, answer_options, histories, image_features, image_dims, **kwargs
63 | ):
64 |
65 | texts = texts.view(-1, texts.size(2))
66 | histories = histories.view(-1, histories.size(2))
67 | text_embedding_total = self.process_text_embedding(texts)
68 | histories_total = self.process_text_embedding(histories, "history_embeddings")
69 |
70 | for idx, image_feature in enumerate(image_features):
71 | feature_size = image_feature.size()[2:]
72 | image_features[idx] = image_feature.view(-1, *feature_size)
73 |
74 | size = image_dims.size()[2:]
75 | image_dims = image_dims.view(-1, *size)
76 |
77 | assert len(image_features) == len(
78 | self.img_feat_encoders
79 | ), "number of image feature model doesnot equal \
80 | to number of image features"
81 |
82 | image_embedding_total = self.process_image_embedding(
83 | image_features, image_dims, text_embedding_total
84 | )
85 |
86 | if self.inter_model is not None:
87 | image_embedding_total = self.inter_model(image_embedding_total)
88 |
89 | joint_embedding = self.combine_embeddings(
90 | image_embedding_total, text_embedding_total, histories_total
91 | )
92 |
93 | decoder_info = {
94 | "answer_options": answer_options,
95 | "answer_options_len": kwargs["answer_options_len"],
96 | }
97 | return self.calculate_logits(joint_embedding, **decoder_info)
98 |
--------------------------------------------------------------------------------
/pythia/modules/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
--------------------------------------------------------------------------------
/pythia/modules/attention.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import torch
3 | from torch import nn
4 |
5 | from pythia.modules.layers import GatedTanh, ModalCombineLayer, TransformLayer
6 |
7 |
8 | class AttentionLayer(nn.Module):
9 | def __init__(self, image_dim, question_dim, **kwargs):
10 | super(AttentionLayer, self).__init__()
11 |
12 | combine_type = kwargs["modal_combine"]["type"]
13 | combine_params = kwargs["modal_combine"]["params"]
14 | modal_combine_layer = ModalCombineLayer(
15 | combine_type, image_dim, question_dim, **combine_params
16 | )
17 |
18 | transform_type = kwargs["transform"]["type"]
19 | transform_params = kwargs["transform"]["params"]
20 | transform_layer = TransformLayer(
21 | transform_type, modal_combine_layer.out_dim, **transform_params
22 | )
23 |
24 | normalization = kwargs["normalization"]
25 |
26 | self.module = TopDownAttention(
27 | modal_combine_layer, transform_layer, normalization
28 | )
29 |
30 | if getattr(self.module, "out_dim"):
31 | self.out_dim = self.module.out_dim
32 |
33 | def forward(self, *args, **kwargs):
34 | return self.module(*args, **kwargs)
35 |
36 |
37 | class ConcatenationAttention(nn.Module):
38 | def __init__(self, image_feat_dim, txt_rnn_embeding_dim, hidden_size):
39 | super(ConcatenationAttention, self).__init__()
40 | self.image_feat_dim = image_feat_dim
41 | self.txt_embeding_dim = txt_rnn_embeding_dim
42 | self.fa = GatedTanh(image_feat_dim + txt_rnn_embeding_dim, hidden_size)
43 | self.lc = nn.Linear(hidden_size, 1)
44 |
45 | def forward(self, image_feat, question_embedding):
46 | _, num_location, _ = image_feat.shape
47 | question_embedding_expand = torch.unsqueeze(question_embedding, 1).expand(
48 | -1, num_location, -1
49 | )
50 | concat_feature = torch.cat((image_feat, question_embedding_expand), dim=2)
51 | raw_attention = self.lc(self.fa(concat_feature))
52 | # softmax across locations
53 | attention_weights = nn.functional.softmax(raw_attention, dim=1)
54 | attention_weights = attention_weights.expand_as(image_feat)
55 | return attention_weights
56 |
57 |
58 | class ProjectAttention(nn.Module):
59 | def __init__(self, image_feat_dim, txt_rnn_embeding_dim, hidden_size, dropout=0.2):
60 | super(ProjectAttention, self).__init__()
61 | self.image_feat_dim = image_feat_dim
62 | self.txt_embeding_dim = txt_rnn_embeding_dim
63 | self.fa_image = GatedTanh(image_feat_dim, hidden_size)
64 | self.fa_txt = GatedTanh(txt_rnn_embeding_dim, hidden_size)
65 | self.dropout = nn.Dropout(dropout)
66 | self.lc = nn.Linear(hidden_size, 1)
67 |
68 | def compute_raw_att(self, image_feat, question_embedding):
69 | num_location = image_feat.shape[1]
70 | image_fa = self.fa_image(image_feat)
71 | question_fa = self.fa_txt(question_embedding)
72 | question_fa_expand = torch.unsqueeze(question_fa, 1).expand(
73 | -1, num_location, -1
74 | )
75 | joint_feature = image_fa * question_fa_expand
76 | joint_feature = self.dropout(joint_feature)
77 | raw_attention = self.lc(joint_feature)
78 | return raw_attention
79 |
80 | def forward(self, image_feat, question_embedding):
81 | raw_attention = self.compute_raw_att(image_feat, question_embedding)
82 | # softmax across locations
83 | attention_weights = nn.functional.softmax(raw_attention, dim=1)
84 | attention_weights = attention_weights.expand_as(image_feat)
85 | return attention_weights
86 |
87 |
88 | class DoubleProjectAttention(nn.Module):
89 | def __init__(self, image_feat_dim, txt_rnn_embeding_dim, hidden_size, dropout=0.2):
90 | super(DoubleProjectAttention, self).__init__()
91 | self.att1 = ProjectAttention(
92 | image_feat_dim, txt_rnn_embeding_dim, hidden_size, dropout
93 | )
94 | self.att2 = ProjectAttention(
95 | image_feat_dim, txt_rnn_embeding_dim, hidden_size, dropout
96 | )
97 | self.image_feat_dim = image_feat_dim
98 | self.txt_embeding_dim = txt_rnn_embeding_dim
99 |
100 | def forward(self, image_feat, question_embedding):
101 | att1 = self.att1.compute_raw_att(image_feat, question_embedding)
102 | att2 = self.att2.compute_raw_att(image_feat, question_embedding)
103 | raw_attn_weights = att1 + att2
104 | # softmax across locations
105 | attention_weights = nn.functional.softmax(raw_attn_weights, dim=1)
106 | attention_weights = attention_weights.expand_as(image_feat)
107 | return attention_weights
108 |
109 |
110 | class TopDownAttention(nn.Module):
111 | EPS = 1.0e-08
112 |
113 | def __init__(self, combination_layer, transform_module, normalization):
114 | super(TopDownAttention, self).__init__()
115 | self.combination_layer = combination_layer
116 | self.normalization = normalization
117 | self.transform = transform_module
118 | self.out_dim = self.transform.out_dim
119 |
120 | @staticmethod
121 | def _mask_attentions(attention, image_locs):
122 | batch_size, num_loc, n_att = attention.size()
123 | tmp1 = attention.new_zeros(num_loc)
124 | tmp1[:num_loc] = torch.arange(0, num_loc, dtype=attention.dtype).unsqueeze(
125 | dim=0
126 | )
127 |
128 | tmp1 = tmp1.expand(batch_size, num_loc)
129 | tmp2 = image_locs.type(tmp1.type())
130 | tmp2 = tmp2.unsqueeze(dim=1).expand(batch_size, num_loc)
131 | mask = torch.ge(tmp1, tmp2)
132 | mask = mask.unsqueeze(dim=2).expand_as(attention)
133 | attention = attention.masked_fill(mask, 0)
134 | return attention
135 |
136 | def forward(self, image_feat, question_embedding, image_locs=None):
137 | # N x K x joint_dim
138 | joint_feature = self.combination_layer(image_feat, question_embedding)
139 | # N x K x n_att
140 | raw_attn = self.transform(joint_feature)
141 |
142 | if self.normalization.lower() == "softmax":
143 | attention = nn.functional.softmax(raw_attn, dim=1)
144 | if image_locs is not None:
145 | masked_attention = self._mask_attentions(attention, image_locs)
146 | masked_attention_sum = torch.sum(masked_attention, dim=1, keepdim=True)
147 | masked_attention_sum += masked_attention_sum.eq(0).float() + self.EPS
148 | masked_attention = masked_attention / masked_attention_sum
149 | else:
150 | masked_attention = attention
151 |
152 | elif self.normalization.lower() == "sigmoid":
153 | attention = torch.sigmoid(raw_attn)
154 | masked_attention = attention
155 | if image_locs is not None:
156 | masked_attention = self._mask_attentions(attention, image_locs)
157 |
158 | return masked_attention
159 |
--------------------------------------------------------------------------------
/pythia/modules/decoders.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import torch
3 | from torch import nn
4 | from torch.nn.utils.weight_norm import weight_norm
5 | from pythia.common.registry import registry
6 |
7 |
8 | class VisDialDiscriminator(nn.Module):
9 | def __init__(self, config, embedding):
10 | super(VisDialDiscriminator, self).__init__()
11 | self.config = config
12 | self.embedding = embedding
13 |
14 | self.emb_out_dim = embedding.text_out_dim
15 | self.hidden_dim = self.config["hidden_dim"]
16 |
17 | self.projection_layer = nn.Linear(self.emb_out_dim, self.hidden_dim)
18 |
19 | def forward(self, encoder_output, batch):
20 | answer_options_len = batch["answer_options_len"]
21 |
22 | # BATCH_SIZE X DIALOGUES X 100 X SEQ_LEN
23 | answer_options = batch["answer_options"]
24 |
25 | max_seq_len = answer_options.size(-1)
26 |
27 | batch_size, ndialogues, noptions, seq_len = answer_options.size()
28 |
29 | # (B X D X 100) X SEQ_LEN
30 | answer_options = answer_options.view(-1, max_seq_len)
31 | answer_options_len = answer_options_len.view(-1)
32 |
33 | # (B x D x 100) x EMB_OUT_DIM
34 | answer_options = self.embedding(answer_options)
35 |
36 | # (B x D x 100) x HIDDEN_DIM
37 | answer_options = self.projection_layer(answer_options)
38 |
39 | # (B x D) x 100 x HIDDEN_DIM
40 | answer_options = answer_options.view(
41 | batch_size * ndialogues, noptions, self.hidden_dim
42 | )
43 |
44 | # (B x D) x HIDDEN_DIM => (B x D) x 100 x HIDDEN_DIM
45 | encoder_output = encoder_output.unsqueeze(1).expand(-1, noptions, -1)
46 |
47 | # (B x D) x 100 x HIDDEN_DIM * (B x D) x 100 x HIDDEN_DIM = SAME THING
48 | # SUM => (B x D) x 100
49 | scores = torch.sum(answer_options * encoder_output, dim=2)
50 |
51 | return scores
52 |
53 |
54 | class LanguageDecoder(nn.Module):
55 | def __init__(self, in_dim, out_dim, **kwargs):
56 | super().__init__()
57 |
58 | self.language_lstm = nn.LSTMCell(
59 | in_dim + kwargs["hidden_dim"], kwargs["hidden_dim"], bias=True
60 | )
61 | self.fc = weight_norm(nn.Linear(kwargs["hidden_dim"], out_dim))
62 | self.dropout = nn.Dropout(p=kwargs["dropout"])
63 | self.init_weights(kwargs["fc_bias_init"])
64 |
65 | def init_weights(self, fc_bias_init):
66 | self.fc.bias.data.fill_(fc_bias_init)
67 | self.fc.weight.data.uniform_(-0.1, 0.1)
68 |
69 | def forward(self, weighted_attn):
70 | # Get LSTM state
71 | state = registry.get("{}_lstm_state".format(weighted_attn.device))
72 | h1, c1 = state["td_hidden"]
73 | h2, c2 = state["lm_hidden"]
74 |
75 | # Language LSTM
76 | h2, c2 = self.language_lstm(torch.cat([weighted_attn, h1], dim=1), (h2, c2))
77 | predictions = self.fc(self.dropout(h2))
78 |
79 | # Update hidden state for t+1
80 | state["lm_hidden"] = (h2, c2)
81 |
82 | return predictions
83 |
--------------------------------------------------------------------------------
/pythia/modules/encoders.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import os
3 | import pickle
4 |
5 | import torch
6 | from torch import nn
7 |
8 | from pythia.modules.layers import Identity
9 | from pythia.utils.general import get_pythia_root
10 |
11 |
12 | class ImageEncoder(nn.Module):
13 | def __init__(self, encoder_type, in_dim, **kwargs):
14 | super(ImageEncoder, self).__init__()
15 |
16 | if encoder_type == "default":
17 | self.module = Identity()
18 | self.module.in_dim = in_dim
19 | self.module.out_dim = in_dim
20 | elif encoder_type == "finetune_faster_rcnn_fpn_fc7":
21 | self.module = FinetuneFasterRcnnFpnFc7(in_dim, **kwargs)
22 | else:
23 | raise NotImplementedError("Unknown Image Encoder: %s" % encoder_type)
24 |
25 | self.out_dim = self.module.out_dim
26 |
27 | def forward(self, *args, **kwargs):
28 | return self.module(*args, **kwargs)
29 |
30 |
31 | class FinetuneFasterRcnnFpnFc7(nn.Module):
32 | def __init__(self, in_dim, weights_file, bias_file, model_data_dir):
33 | super(FinetuneFasterRcnnFpnFc7, self).__init__()
34 | pythia_root = get_pythia_root()
35 | model_data_dir = os.path.join(pythia_root, model_data_dir)
36 |
37 | if not os.path.isabs(weights_file):
38 | weights_file = os.path.join(model_data_dir, weights_file)
39 | if not os.path.isabs(bias_file):
40 | bias_file = os.path.join(model_data_dir, bias_file)
41 | with open(weights_file, "rb") as w:
42 | weights = pickle.load(w)
43 | with open(bias_file, "rb") as b:
44 | bias = pickle.load(b)
45 | out_dim = bias.shape[0]
46 |
47 | self.lc = nn.Linear(in_dim, out_dim)
48 | self.lc.weight.data.copy_(torch.from_numpy(weights))
49 | self.lc.bias.data.copy_(torch.from_numpy(bias))
50 | self.out_dim = out_dim
51 |
52 | def forward(self, image):
53 | i2 = self.lc(image)
54 | i3 = nn.functional.relu(i2)
55 | return i3
56 |
--------------------------------------------------------------------------------
/pythia/trainers/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | __all__ = ["BaseTrainer"]
3 |
4 | from .base_trainer import BaseTrainer
5 |
--------------------------------------------------------------------------------
/pythia/utils/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
--------------------------------------------------------------------------------
/pythia/utils/build_utils.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import torch
3 | import warnings
4 |
5 | from pythia.utils.configuration import Configuration
6 | from pythia.common.registry import registry
7 | from pythia.utils.general import get_optimizer_parameters
8 |
9 |
10 | def build_trainer(args, *rest, **kwargs):
11 | configuration = Configuration(args.config)
12 |
13 | # Update with the config override if passed
14 | configuration.override_with_cmd_config(args.config_override)
15 |
16 | # Now, update with opts args that were passed
17 | configuration.override_with_cmd_opts(args.opts)
18 |
19 | # Finally, update with args that were specifically passed
20 | # as arguments
21 | configuration.update_with_args(args)
22 | configuration.config['model_attributes'][configuration.config['model']]['pretrain']= args.pretrain
23 | configuration.config['dataset_attributes'][configuration.config['datasets']]['pretrain']= args.pretrain
24 | configuration.freeze()
25 |
26 | config = configuration.get_config()
27 | registry.register("config", config)
28 | registry.register("configuration", configuration)
29 |
30 | trainer_type = config.training_parameters.trainer
31 | trainer_cls = registry.get_trainer_class(trainer_type)
32 | trainer_obj = trainer_cls(config)
33 |
34 | # Set args as an attribute for future use
35 | setattr(trainer_obj, 'args', args)
36 |
37 | return trainer_obj
38 |
39 |
40 | def build_model(config):
41 | model_name = config.model
42 |
43 | model_class = registry.get_model_class(model_name)
44 |
45 | if model_class is None:
46 | registry.get("writer").write("No model registered for name: %s" % model_name)
47 | model = model_class(config)
48 |
49 | if hasattr(model, "build"):
50 | model.build()
51 | model.init_losses_and_metrics()
52 |
53 | return model
54 |
55 |
56 | def build_optimizer(model, config):
57 | optimizer_config = config.optimizer_attributes
58 | if not hasattr(optimizer_config, "type"):
59 | raise ValueError(
60 | "Optimizer attributes must have a 'type' key "
61 | "specifying the type of optimizer. "
62 | "(Custom or PyTorch)"
63 | )
64 | optimizer_type = optimizer_config.type
65 |
66 | if not hasattr(optimizer_config, "params"):
67 | warnings.warn(
68 | "optimizer attributes has no params defined, defaulting to {}."
69 | )
70 |
71 | params = getattr(optimizer_config, "params", {})
72 |
73 | if hasattr(torch.optim, optimizer_type):
74 | optimizer_class = getattr(torch.optim, optimizer_type)
75 | else:
76 | optimizer_class = registry.get_optimizer_class(optimizer_type)
77 | if optimizer_class is None:
78 | raise ValueError(
79 | "No optimizer class of type {} present in "
80 | "either torch or registered to registry"
81 | )
82 |
83 | parameters = get_optimizer_parameters(model, config)
84 | optimizer = optimizer_class(parameters, **params)
85 | return optimizer
86 |
--------------------------------------------------------------------------------
/pythia/utils/dataset_utils.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import torch
3 |
4 | from pythia.common.sample import Sample
5 |
6 |
7 | def build_bbox_tensors(infos, max_length):
8 | num_bbox = min(max_length, len(infos))
9 |
10 | # After num_bbox, everything else should be zero
11 | coord_tensor = torch.zeros((max_length, 4), dtype=torch.float)
12 | width_tensor = torch.zeros(max_length, dtype=torch.float)
13 | height_tensor = torch.zeros(max_length, dtype=torch.float)
14 | bbox_types = ["xyxy"] * max_length
15 |
16 | infos = infos[:num_bbox]
17 | sample = Sample()
18 |
19 | for idx, info in enumerate(infos):
20 | bbox = info["bounding_box"]
21 | x = bbox["top_left_x"]
22 | y = bbox["top_left_y"]
23 | width = bbox["width"]
24 | height = bbox["height"]
25 |
26 | coord_tensor[idx][0] = x
27 | coord_tensor[idx][1] = y
28 | coord_tensor[idx][2] = x + width
29 | coord_tensor[idx][3] = y + height
30 |
31 | width_tensor[idx] = width
32 | height_tensor[idx] = height
33 | sample.coordinates = coord_tensor
34 | sample.width = width_tensor
35 | sample.height = height_tensor
36 | sample.bbox_types = bbox_types
37 |
38 | return sample
39 |
--------------------------------------------------------------------------------
/pythia/utils/distributed_utils.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | # Inspired from maskrcnn_benchmark
3 | import torch
4 | from torch import distributed as dist
5 |
6 |
7 | def synchronize():
8 | if not dist.is_nccl_available():
9 | return
10 | if not dist.is_initialized():
11 | return
12 |
13 | world_size = dist.get_world_size()
14 |
15 | if world_size == 1:
16 | return
17 |
18 | dist.barrier()
19 |
20 |
21 | def get_rank():
22 | if not dist.is_nccl_available():
23 | return 0
24 | if not dist.is_initialized():
25 | return 0
26 | return dist.get_rank()
27 |
28 |
29 | def is_main_process():
30 | return get_rank() == 0
31 |
32 |
33 | def get_world_size():
34 | if not dist.is_nccl_available():
35 | return 1
36 | if not dist.is_initialized():
37 | return 1
38 | return dist.get_world_size()
39 |
40 |
41 | def broadcast_tensor(tensor, src=0):
42 | world_size = get_world_size()
43 | if world_size < 2:
44 | return tensor
45 |
46 | with torch.no_grad():
47 | dist.broadcast(tensor, src=0)
48 |
49 | return tensor
50 |
51 |
52 | def broadcast_scalar(scalar, src=0, device="cpu"):
53 | if get_world_size() < 2:
54 | return scalar
55 | scalar_tensor = torch.tensor(scalar).long().to(device)
56 | scalar_tensor = broadcast_tensor(scalar_tensor, src)
57 | return scalar_tensor.item()
58 |
59 |
60 | def reduce_tensor(tensor):
61 | world_size = get_world_size()
62 |
63 | if world_size < 2:
64 | return tensor
65 |
66 | with torch.no_grad():
67 | dist.reduce(tensor, dst=0)
68 | if dist.get_rank() == 0:
69 | tensor = tensor.div(world_size)
70 |
71 | return tensor
72 |
73 |
74 | def gather_tensor(tensor):
75 | world_size = get_world_size()
76 |
77 | if world_size < 2:
78 | return tensor
79 |
80 | with torch.no_grad():
81 | tensor_list = []
82 |
83 | for _ in range(world_size):
84 | tensor_list.append(torch.zeros_like(tensor))
85 |
86 | dist.all_gather(tensor_list, tensor)
87 | tensor_list = torch.stack(tensor_list, dim=0)
88 | return tensor_list
89 |
90 |
91 | def reduce_dict(dictionary):
92 | world_size = get_world_size()
93 | if world_size < 2:
94 | return dictionary
95 |
96 | with torch.no_grad():
97 | if len(dictionary) == 0:
98 | return dictionary
99 |
100 | keys, values = zip(*sorted(dictionary.items()))
101 | values = torch.stack(values, dim=0)
102 |
103 | dist.reduce(values, dst=0)
104 |
105 | if dist.get_rank() == 0:
106 | # only main process gets accumulated, so only divide by
107 | # world_size in this case
108 | values /= world_size
109 | reduced_dict = {k: v for k, v in zip(keys, values)}
110 | return reduced_dict
111 |
112 |
113 | def print_only_main(string):
114 | if is_main_process():
115 | print(string)
116 |
--------------------------------------------------------------------------------
/pythia/utils/early_stopping.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import numpy as np
3 | import torch
4 |
5 | from pythia.common.registry import registry
6 | from pythia.utils.distributed_utils import is_main_process
7 |
8 |
9 | class EarlyStopping:
10 | """
11 | Provides early stopping functionality. Keeps track of model metrics,
12 | and if it doesn't improve over time restores last best performing
13 | parameters.
14 | """
15 |
16 | def __init__(
17 | self,
18 | model,
19 | checkpoint_instance,
20 | monitored_metric="total_loss",
21 | patience=1000,
22 | minimize=False,
23 | should_stop=True,
24 | ):
25 | self.minimize = minimize
26 | self.patience = patience
27 | self.model = model
28 | self.checkpoint = checkpoint_instance
29 | self.monitored_metric = monitored_metric
30 |
31 | if "val" not in self.monitored_metric:
32 | self.monitored_metric = "val/{}".format(self.monitored_metric)
33 |
34 | self.best_monitored_value = -np.inf if not minimize else np.inf
35 | self.best_monitored_iteration = 0
36 | self.should_stop = should_stop
37 | self.activated = False
38 | self.metric = self.monitored_metric
39 |
40 | def __call__(self, iteration, meter):
41 | """
42 | Method to be called everytime you need to check whether to
43 | early stop or not
44 | Arguments:
45 | iteration {number}: Current iteration number
46 | Returns:
47 | bool -- Tells whether early stopping occurred or not
48 | """
49 | if not is_main_process():
50 | return False
51 |
52 | value = meter.meters.get(self.monitored_metric, None)
53 | if value is None:
54 | raise ValueError(
55 | "Metric used for early stopping ({}) is not "
56 | "present in meter.".format(self.monitored_metric)
57 | )
58 |
59 | value = value.global_avg
60 |
61 | if isinstance(value, torch.Tensor):
62 | value = value.item()
63 |
64 | if (self.minimize and value < self.best_monitored_value) or (
65 | not self.minimize and value > self.best_monitored_value
66 | ):
67 | self.best_monitored_value = value
68 | self.best_monitored_iteration = iteration
69 | self.checkpoint.save(iteration, update_best=True)
70 |
71 | elif self.best_monitored_iteration + self.patience < iteration:
72 | self.activated = True
73 | if self.should_stop is True:
74 | self.checkpoint.restore()
75 | self.checkpoint.finalize()
76 | return True
77 | else:
78 | return False
79 | else:
80 | self.checkpoint.save(iteration, update_best=False)
81 |
82 | return False
83 |
84 | def is_activated(self):
85 | return self.activated
86 |
87 | def init_from_checkpoint(self, load):
88 | if "best_iteration" in load:
89 | self.best_monitored_iteration = load["best_iteration"]
90 |
91 | if "best_metric_value" in load:
92 | self.best_monitored_value = load["best_metric_value"]
93 |
94 | def get_info(self):
95 | return {
96 | "best iteration": self.best_monitored_iteration,
97 | "best {}".format(self.metric): "{:.6f}".format(self.best_monitored_value),
98 | }
99 |
--------------------------------------------------------------------------------
/pythia/utils/logger.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import base64
3 | import logging
4 | import os
5 | import sys
6 |
7 | from tensorboardX import SummaryWriter
8 |
9 | from pythia.utils.distributed_utils import is_main_process
10 | from pythia.utils.general import (ckpt_name_from_core_args,
11 | foldername_from_config_override)
12 | from pythia.utils.timer import Timer
13 |
14 |
15 | class Logger:
16 | def __init__(self, config):
17 | self.logger = None
18 | self.summary_writer = None
19 | self._is_main_process = is_main_process()
20 |
21 | self.timer = Timer()
22 | self.config = config
23 | self.save_dir = config.training_parameters.save_dir
24 | self.log_folder = ckpt_name_from_core_args(config)
25 | self.log_folder += foldername_from_config_override(config)
26 | time_format = "%Y-%m-%dT%H:%M:%S"
27 | self.log_filename = ckpt_name_from_core_args(config) + "_"
28 | self.log_filename += self.timer.get_time_hhmmss(None, format=time_format)
29 | self.log_filename += ".log"
30 |
31 | self.log_folder = os.path.join(self.save_dir, self.log_folder, "logs")
32 |
33 | arg_log_dir = self.config.get("log_dir", None)
34 | if arg_log_dir:
35 | self.log_folder = arg_log_dir
36 |
37 | if not os.path.exists(self.log_folder):
38 | os.makedirs(self.log_folder, exist_ok=True)
39 |
40 |
41 | self.log_filename = os.path.join(self.log_folder, self.log_filename)
42 |
43 | if self._is_main_process:
44 | tensorboard_folder = os.path.join(self.log_folder, "tensorboard")
45 | self.summary_writer = SummaryWriter(tensorboard_folder)
46 | print("Logging to:", self.log_filename)
47 |
48 | logging.captureWarnings(True)
49 |
50 | self.logger = logging.getLogger(__name__)
51 | self._file_only_logger = logging.getLogger(__name__)
52 | warnings_logger = logging.getLogger("py.warnings")
53 |
54 | # Set level
55 | level = config["training_parameters"].get("logger_level", "info")
56 | self.logger.setLevel(getattr(logging, level.upper()))
57 | self._file_only_logger.setLevel(getattr(logging, level.upper()))
58 |
59 | formatter = logging.Formatter(
60 | "%(asctime)s %(levelname)s: %(message)s", datefmt="%Y-%m-%dT%H:%M:%S"
61 | )
62 |
63 | # Add handler to file
64 | channel = logging.FileHandler(filename=self.log_filename, mode="a")
65 | channel.setFormatter(formatter)
66 |
67 | self.logger.addHandler(channel)
68 | self._file_only_logger.addHandler(channel)
69 | warnings_logger.addHandler(channel)
70 |
71 | # Add handler to stdout
72 | channel = logging.StreamHandler(sys.stdout)
73 | channel.setFormatter(formatter)
74 |
75 | self.logger.addHandler(channel)
76 | warnings_logger.addHandler(channel)
77 |
78 | should_not_log = self.config["training_parameters"]["should_not_log"]
79 | self.should_log = not should_not_log
80 |
81 | # Single log wrapper map
82 | self._single_log_map = set()
83 |
84 | def __del__(self):
85 | if getattr(self, "summary_writer", None) is not None:
86 | self.summary_writer.close()
87 |
88 | def write(self, x, level="info", donot_print=False, log_all=False):
89 | if self.logger is None:
90 | return
91 |
92 | if log_all is False and not self._is_main_process:
93 | return
94 |
95 | # if it should not log then just print it
96 | if self.should_log:
97 | if hasattr(self.logger, level):
98 | if donot_print:
99 | getattr(self._file_only_logger, level)(str(x))
100 | else:
101 | getattr(self.logger, level)(str(x))
102 | else:
103 | self.logger.error("Unknown log level type: %s" % level)
104 | else:
105 | print(str(x) + "\n")
106 |
107 | def single_write(self, x, level="info"):
108 | if x + "_" + level in self._single_log_map:
109 | return
110 | else:
111 | self.write(x, level)
112 |
113 | def _should_log_tensorboard(self):
114 | if self.summary_writer is None:
115 | return False
116 |
117 | if not self._is_main_process:
118 | return False
119 |
120 | return True
121 |
122 | def add_scalar(self, key, value, iteration):
123 | if not self._should_log_tensorboard():
124 | return
125 |
126 | self.summary_writer.add_scalar(key, value, iteration)
127 |
128 | def add_scalars(self, scalar_dict, iteration):
129 | if not self._should_log_tensorboard():
130 | return
131 |
132 | for key, val in scalar_dict.items():
133 | self.summary_writer.add_scalar(key, val, iteration)
134 |
135 | def add_histogram_for_model(self, model, iteration):
136 | if not self._should_log_tensorboard():
137 | return
138 |
139 | for name, param in model.named_parameters():
140 | np_param = param.clone().cpu().data.numpy()
141 | self.summary_writer.add_histogram(name, np_param, iteration)
142 |
--------------------------------------------------------------------------------
/pythia/utils/objects_to_byte_tensor.py:
--------------------------------------------------------------------------------
1 |
2 | # Adopted from
3 | # https://github.com/pytorch/fairseq/blob/master/fairseq/distributed_utils.py
4 |
5 | import pickle
6 | import torch
7 |
8 | MAX_SIZE_LIMIT = 65533
9 | BYTE_SIZE = 256
10 |
11 |
12 | def enc_obj2bytes(obj, max_size=4094):
13 | """
14 | Encode Python objects to PyTorch byte tensors
15 | """
16 | assert max_size <= MAX_SIZE_LIMIT
17 | byte_tensor = torch.zeros(max_size, dtype=torch.uint8)
18 |
19 | obj_enc = pickle.dumps(obj)
20 | obj_size = len(obj_enc)
21 | if obj_size > max_size:
22 | raise Exception(
23 | 'objects too large: object size {}, max size {}'.format(
24 | obj_size, max_size
25 | )
26 | )
27 |
28 | byte_tensor[0] = obj_size // 256
29 | byte_tensor[1] = obj_size % 256
30 | byte_tensor[2:2+obj_size] = torch.ByteTensor(list(obj_enc))
31 | return byte_tensor
32 |
33 |
34 | def dec_bytes2obj(byte_tensor, max_size=4094):
35 | """
36 | Decode PyTorch byte tensors to Python objects
37 | """
38 | assert max_size <= MAX_SIZE_LIMIT
39 |
40 | obj_size = byte_tensor[0].item() * 256 + byte_tensor[1].item()
41 | obj_enc = bytes(byte_tensor[2:2+obj_size].tolist())
42 | obj = pickle.loads(obj_enc)
43 | return obj
44 |
45 |
46 | if __name__ == '__main__':
47 | test_obj = [1, '2', {3: 4}, [5]]
48 | test_obj_bytes = enc_obj2bytes(test_obj)
49 | test_obj_dec = dec_bytes2obj(test_obj_bytes)
50 | print(test_obj_dec == test_obj)
51 |
--------------------------------------------------------------------------------
/pythia/utils/phoc/__init__.py:
--------------------------------------------------------------------------------
1 | from .build_phoc import build_phoc # NoQA
2 |
--------------------------------------------------------------------------------
/pythia/utils/phoc/build_phoc.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | from .cphoc import build_phoc as _build_phoc_raw
4 |
5 |
6 | _alphabet = {"a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z","0","1","2","3","4","5","6","7","8","9"} # NoQA
7 |
8 |
9 | def build_phoc(token):
10 | token = token.lower().strip()
11 | token = ''.join([c for c in token if c in _alphabet])
12 | phoc = _build_phoc_raw(token)
13 | phoc = np.array(phoc, dtype=np.float32)
14 | return phoc
15 |
--------------------------------------------------------------------------------
/pythia/utils/phoc/src/cphoc.c:
--------------------------------------------------------------------------------
1 | // C implementation of the PHOC respresentation. Converts a string into a PHOC feature vector
2 | // from https://github.com/lluisgomez/single-shot-str/blob/master/cphoc/cphoc.c
3 |
4 | #include
5 | #include
6 | #include
7 |
8 | #define min(X,Y) (((X) < (Y)) ? (X) : (Y))
9 | #define max(X,Y) (((X) > (Y)) ? (X) : (Y))
10 |
11 |
12 | static PyObject* build_phoc(PyObject* self, PyObject* args)
13 | {
14 | char* word = NULL;
15 | int ok;
16 | ok = PyArg_ParseTuple(args, "s", &word);
17 | if (!ok) {
18 | return PyErr_Format(
19 | PyExc_RuntimeError,
20 | "Failed to parse arguments in build_phoc. Call build_phoc with a single str parameter."
21 | );
22 | }
23 |
24 | float phoc[604] = {.0};
25 |
26 | int index,level,region,i,k,l;
27 |
28 | char *unigrams[36] = {"a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z","0","1","2","3","4","5","6","7","8","9"};
29 | char *bigrams[50] = {"th","he","in","er","an","re","es","on","st","nt","en","at","ed","nd","to","or","ea","ti","ar","te","ng","al","it","as","is","ha","et","se","ou","of","le","sa","ve","ro","ra","ri","hi","ne","me","de","co","ta","ec","si","ll","so","na","li","la","el"};
30 |
31 | int n = strlen(word);
32 | for (index=0; index < n; index++)
33 | {
34 | float char_occ0 = (float)index / (float)n;
35 | float char_occ1 = (float)(index + 1) / (float)n;
36 | int char_index = -1;
37 | for (k=0; k<36; k++)
38 | {
39 | if (memcmp(unigrams[k], word+index, 1) == 0)
40 | {
41 | char_index = k;
42 | break;
43 | }
44 | }
45 | if (char_index == -1)
46 | {
47 | char error_msg[50];
48 | sprintf(error_msg, "Error: unigram %c is unknown", *(word+index));
49 | return PyErr_Format(PyExc_RuntimeError, error_msg);
50 | }
51 | // check unigram levels
52 | for (level=2; level<6; level++)
53 | {
54 | for (region=0; region= (float)0.5 )
62 | {
63 | int sum=0;
64 | for (l=2; l<6; l++) if (l= 0.5 )
99 | {
100 | phoc[ngram_offset + region * 50 + ngram_index] = 1;
101 | }
102 | }
103 | }
104 |
105 |
106 |
107 | PyObject *dlist = PyList_New(604);
108 |
109 | for (i=0; i<604; i++)
110 | PyList_SetItem(dlist, i, PyFloat_FromDouble((double)phoc[i]));
111 |
112 | return dlist;
113 | }
114 |
115 | static PyObject* getList(PyObject* self, PyObject* args)
116 | {
117 | PyObject *dlist = PyList_New(2);
118 | PyList_SetItem(dlist, 0, PyFloat_FromDouble(0.00001));
119 | PyList_SetItem(dlist, 1, PyFloat_FromDouble(42.0));
120 |
121 | return dlist;
122 | }
123 |
124 | // Our Module's Function Definition struct
125 | // We require this `NULL` to signal the end of our method
126 | // definition
127 | static PyMethodDef myMethods[] = {
128 | { "build_phoc", build_phoc, METH_VARARGS, "" },
129 | { "getList", getList, METH_NOARGS, "" },
130 | { NULL, NULL, 0, NULL }
131 | };
132 |
133 | // Our Module Definition struct
134 | static struct PyModuleDef cphoc = {
135 | PyModuleDef_HEAD_INIT,
136 | "cphoc",
137 | "cphoc Module",
138 | -1,
139 | myMethods
140 | };
141 |
142 | // Initializes our module using our above struct
143 | PyMODINIT_FUNC PyInit_cphoc(void)
144 | {
145 | return PyModule_Create(&cphoc);
146 | }
147 |
--------------------------------------------------------------------------------
/pythia/utils/timer.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import time
3 |
4 |
5 | class Timer:
6 | DEFAULT_TIME_FORMAT_DATE_TIME = "%Y/%m/%d %H:%M:%S"
7 | DEFAULT_TIME_FORMAT = ["%03dms", "%02ds", "%02dm", "%02dh"]
8 |
9 | def __init__(self):
10 | self.start = time.time() * 1000
11 |
12 | def get_current(self):
13 | return self.get_time_hhmmss(self.start)
14 |
15 | def reset(self):
16 | self.start = time.time() * 1000
17 |
18 | def get_time_since_start(self, format=None):
19 | return self.get_time_hhmmss(self.start, format)
20 |
21 | def get_time_hhmmss(self, start=None, end=None, gap=None, format=None):
22 | """
23 | Calculates time since `start` and formats as a string.
24 | """
25 | if start is None and gap is None:
26 |
27 | if format is None:
28 | format = self.DEFAULT_TIME_FORMAT_DATE_TIME
29 |
30 | return time.strftime(format)
31 |
32 | if end is None:
33 | end = time.time() * 1000
34 | if gap is None:
35 | gap = end - start
36 |
37 | s, ms = divmod(gap, 1000)
38 | m, s = divmod(s, 60)
39 | h, m = divmod(m, 60)
40 |
41 | if format is None:
42 | format = self.DEFAULT_TIME_FORMAT
43 |
44 | items = [ms, s, m, h]
45 | assert len(items) == len(format), "Format length should be same as items"
46 |
47 | time_str = ""
48 | for idx, item in enumerate(items):
49 | if item != 0:
50 | time_str = format[idx] % item + " " + time_str
51 |
52 | return time_str.strip()
53 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=1.4
2 | torchvision>0.2
3 | tensorboardX>=1.2
4 | numpy>=1.14
5 | tqdm>=4.19
6 | demjson>=2.2
7 | torchtext==0.6
8 | GitPython>=2.1
9 | PyYAML>=3.11
10 | pytest==5.2.0
11 | requests==2.21.0
12 | fastText==0.9.1
13 | nltk==3.4.5
14 | pytorch-transformers==1.2.0
15 | editdistance
16 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 |
3 | # Copyright (c) Facebook, Inc. and its affiliates.
4 | import os.path
5 | import shutil
6 | from glob import glob
7 | import sys
8 |
9 | import setuptools
10 | from setuptools import Extension
11 | from setuptools.command.build_ext import build_ext
12 |
13 | sys.path.insert(0, os.path.join(os.path.dirname(__file__), "pythia"))
14 |
15 | with open("README.md", encoding="utf8") as f:
16 | readme = f.read()
17 |
18 | with open("LICENSE") as f:
19 | license = f.read()
20 |
21 | with open("requirements.txt") as f:
22 | reqs = f.read()
23 |
24 | DISTNAME = "pythia"
25 | DESCRIPTION = "pythia: a modular framework for vision and language multimodal \
26 | research."
27 | LONG_DESCRIPTION = readme
28 | AUTHOR = "Facebook AI Research"
29 | LICENSE = license
30 | REQUIREMENTS = (reqs.strip().split("\n"),)
31 |
32 | ext_modules = [
33 | Extension(
34 | 'cphoc',
35 | sources=['pythia/utils/phoc/src/cphoc.c'],
36 | language='c',
37 | libraries=["pthread", "dl", "util", "rt", "m"],
38 | extra_compile_args=["-O3"],
39 | ),
40 | ]
41 |
42 |
43 | class BuildExt(build_ext):
44 | def run(self):
45 | build_ext.run(self)
46 | cphoc_lib = glob('build/lib.*/cphoc.*.so')[0]
47 | shutil.copy(cphoc_lib, 'pythia/utils/phoc/cphoc.so')
48 |
49 |
50 | if __name__ == "__main__":
51 | setuptools.setup(
52 | name=DISTNAME,
53 | install_requires=REQUIREMENTS,
54 | packages=setuptools.find_packages(),
55 | ext_modules=ext_modules,
56 | cmdclass={'build_ext': BuildExt},
57 | version="0.3",
58 | description=DESCRIPTION,
59 | long_description=LONG_DESCRIPTION,
60 | author=AUTHOR,
61 | license=LICENSE,
62 | setup_requires=["pytest-runner"],
63 | tests_require=["flake8", "pytest"],
64 | )
65 |
--------------------------------------------------------------------------------
/tools/run.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import glob
3 | import importlib
4 | import os
5 |
6 | from pythia.common.registry import registry
7 | from pythia.utils.build_utils import build_trainer
8 | from pythia.utils.distributed_utils import is_main_process
9 | from pythia.utils.flags import flags
10 |
11 |
12 | def setup_imports():
13 | # Automatically load all of the modules, so that
14 | # they register with registry
15 | root_folder = registry.get("pythia_root", no_warning=True)
16 |
17 | if root_folder is None:
18 | root_folder = os.path.dirname(os.path.abspath(__file__))
19 | root_folder = os.path.join(root_folder, "..")
20 |
21 | environment_pythia_path = os.environ.get("PYTHIA_PATH")
22 |
23 | if environment_pythia_path is not None:
24 | root_folder = environment_pythia_path
25 |
26 | root_folder = os.path.join(root_folder, "pythia")
27 | registry.register("pythia_path", root_folder)
28 |
29 | trainer_folder = os.path.join(root_folder, "trainers")
30 | trainer_pattern = os.path.join(trainer_folder, "**", "*.py")
31 | datasets_folder = os.path.join(root_folder, "datasets")
32 | datasets_pattern = os.path.join(datasets_folder, "**", "*.py")
33 | model_folder = os.path.join(root_folder, "models")
34 | model_pattern = os.path.join(model_folder, "**", "*.py")
35 |
36 | importlib.import_module("pythia.common.meter")
37 |
38 | files = glob.glob(datasets_pattern, recursive=True) + \
39 | glob.glob(model_pattern, recursive=True) + \
40 | glob.glob(trainer_pattern, recursive=True)
41 |
42 | for f in files:
43 | if f.find("models") != -1:
44 | splits = f.split(os.sep)
45 | file_name = splits[-1]
46 | module_name = file_name[: file_name.find(".py")]
47 | importlib.import_module("pythia.models." + module_name)
48 | elif f.find("trainer") != -1:
49 | splits = f.split(os.sep)
50 | file_name = splits[-1]
51 | module_name = file_name[: file_name.find(".py")]
52 | importlib.import_module("pythia.trainers." + module_name)
53 | elif f.endswith("builder.py"):
54 | splits = f.split(os.sep)
55 | task_name = splits[-3]
56 | dataset_name = splits[-2]
57 | if task_name == "datasets" or dataset_name == "datasets":
58 | continue
59 | file_name = splits[-1]
60 | module_name = file_name[: file_name.find(".py")]
61 | importlib.import_module(
62 | "pythia.datasets." + task_name + "." + dataset_name + "." + module_name
63 | )
64 |
65 |
66 | def run():
67 | setup_imports()
68 | parser = flags.get_parser()
69 | args = parser.parse_args()
70 | os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
71 | os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
72 | #os.environ['MASTER_ADDR'] = '127.0.0.1'
73 | os.environ['MASTER_PORT'] = args.MASTER_PORT
74 |
75 | trainer = build_trainer(args)
76 |
77 |
78 | # Log any errors that occur to log file
79 | try:
80 | trainer.load()
81 | trainer.train()
82 | except Exception as e:
83 | writer = getattr(trainer, "writer", None)
84 |
85 | if writer is not None:
86 | writer.write(e, "error", donot_print=True)
87 | if is_main_process():
88 | raise
89 |
90 |
91 | if __name__ == "__main__":
92 | run()
93 |
--------------------------------------------------------------------------------