├── .gitignore
├── CODE_OF_CONDUCT.md
├── LICENSE
├── README.md
├── SECURITY.md
├── SUPPORT.md
├── figures
└── concept.gif
├── react_customization
├── .gitignore
├── CITATION.cff
├── HISTORY.md
├── LICENSE
├── MANIFEST.in
├── Makefile
├── README.md
├── pytest.ini
├── requirements-test.txt
├── requirements-training.txt
├── requirements.txt
├── setup.py
└── src
│ ├── open_clip
│ ├── __init__.py
│ ├── bpe_simple_vocab_16e6.txt.gz
│ ├── coca_model.py
│ ├── constants.py
│ ├── factory.py
│ ├── generation_utils.py
│ ├── hf_configs.py
│ ├── hf_model.py
│ ├── loss.py
│ ├── model.py
│ ├── model_configs
│ │ ├── RN101-quickgelu.json
│ │ ├── RN101.json
│ │ ├── RN50-quickgelu.json
│ │ ├── RN50.json
│ │ ├── RN50x16.json
│ │ ├── RN50x4.json
│ │ ├── RN50x64.json
│ │ ├── ViT-B-16-plus-240.json
│ │ ├── ViT-B-16-plus.json
│ │ ├── ViT-B-16.json
│ │ ├── ViT-B-32-plus-256.json
│ │ ├── ViT-B-32-quickgelu.json
│ │ ├── ViT-B-32.json
│ │ ├── ViT-H-14.json
│ │ ├── ViT-H-16.json
│ │ ├── ViT-L-14-280.json
│ │ ├── ViT-L-14-336.json
│ │ ├── ViT-L-14.json
│ │ ├── ViT-L-16-320.json
│ │ ├── ViT-L-16.json
│ │ ├── ViT-M-16-alt.json
│ │ ├── ViT-M-16.json
│ │ ├── ViT-M-32-alt.json
│ │ ├── ViT-M-32.json
│ │ ├── ViT-S-16-alt.json
│ │ ├── ViT-S-16.json
│ │ ├── ViT-S-32-alt.json
│ │ ├── ViT-S-32.json
│ │ ├── ViT-bigG-14.json
│ │ ├── ViT-e-14.json
│ │ ├── ViT-g-14.json
│ │ ├── coca_ViT-B-32.json
│ │ ├── coca_ViT-L-14.json
│ │ ├── coca_base.json
│ │ ├── coca_roberta-ViT-B-32.json
│ │ ├── convnext_base.json
│ │ ├── convnext_base_w.json
│ │ ├── convnext_base_w_320.json
│ │ ├── convnext_large.json
│ │ ├── convnext_large_d.json
│ │ ├── convnext_large_d_320.json
│ │ ├── convnext_small.json
│ │ ├── convnext_tiny.json
│ │ ├── convnext_xlarge.json
│ │ ├── convnext_xxlarge.json
│ │ ├── convnext_xxlarge_320.json
│ │ ├── mt5-base-ViT-B-32.json
│ │ ├── mt5-xl-ViT-H-14.json
│ │ ├── react_ViT-B-16.json
│ │ ├── react_ViT-B-32-quickgelu.json
│ │ ├── react_ViT-B-32.json
│ │ ├── react_ViT-L-14.json
│ │ ├── react_ViT-bigG-14.json
│ │ ├── roberta-ViT-B-32.json
│ │ ├── swin_base_patch4_window7_224.json
│ │ ├── vit_medium_patch16_gap_256.json
│ │ ├── vit_relpos_medium_patch16_cls_224.json
│ │ ├── xlm-roberta-base-ViT-B-32.json
│ │ └── xlm-roberta-large-ViT-H-14.json
│ ├── modified_resnet.py
│ ├── openai.py
│ ├── pretrained.py
│ ├── push_to_hf_hub.py
│ ├── timm_model.py
│ ├── tokenizer.py
│ ├── transform.py
│ ├── transformer.py
│ ├── utils.py
│ └── version.py
│ └── training
│ ├── .gitignore
│ ├── __init__.py
│ ├── calculate_data_size.py
│ ├── data.py
│ ├── distributed.py
│ ├── file_utils.py
│ ├── imagenet_zeroshot_data.py
│ ├── logger.py
│ ├── main.py
│ ├── params.py
│ ├── precision.py
│ ├── profile.py
│ ├── scheduler.py
│ ├── train.py
│ └── zero_shot.py
└── react_retrieval
├── .gitignore
├── README.MD
├── commands
├── create_filelist_webdataset.py
├── extract_feature_pairs.py
├── extract_webdataset_scattered.py
├── retrieve_pairs.py
├── retrieve_pairs_sep_prompts.py
└── train_index.py
├── notebook
└── retrieve_pairs.ipynb
├── react_retrieval
├── data
│ ├── datasets.py
│ ├── filelist_controller.py
│ └── tsv.py
├── index
│ ├── index_factory.py
│ └── index_utils.py
└── utils
│ └── prompts.py
├── requirements.txt
└── setup.py
/.gitignore:
--------------------------------------------------------------------------------
1 | ## Ignore Visual Studio temporary files, build results, and
2 | ## files generated by popular Visual Studio add-ons.
3 | ##
4 | ## Get latest from https://github.com/github/gitignore/blob/master/VisualStudio.gitignore
5 |
6 | # User-specific files
7 | *.rsuser
8 | *.suo
9 | *.user
10 | *.userosscache
11 | *.sln.docstates
12 |
13 | # User-specific files (MonoDevelop/Xamarin Studio)
14 | *.userprefs
15 |
16 | # Mono auto generated files
17 | mono_crash.*
18 |
19 | # Build results
20 | [Dd]ebug/
21 | [Dd]ebugPublic/
22 | [Rr]elease/
23 | [Rr]eleases/
24 | x64/
25 | x86/
26 | [Aa][Rr][Mm]/
27 | [Aa][Rr][Mm]64/
28 | bld/
29 | [Bb]in/
30 | [Oo]bj/
31 | [Ll]og/
32 | [Ll]ogs/
33 |
34 | # Visual Studio 2015/2017 cache/options directory
35 | .vs/
36 | # Uncomment if you have tasks that create the project's static files in wwwroot
37 | #wwwroot/
38 |
39 | # Visual Studio 2017 auto generated files
40 | Generated\ Files/
41 |
42 | # MSTest test Results
43 | [Tt]est[Rr]esult*/
44 | [Bb]uild[Ll]og.*
45 |
46 | # NUnit
47 | *.VisualState.xml
48 | TestResult.xml
49 | nunit-*.xml
50 |
51 | # Build Results of an ATL Project
52 | [Dd]ebugPS/
53 | [Rr]eleasePS/
54 | dlldata.c
55 |
56 | # Benchmark Results
57 | BenchmarkDotNet.Artifacts/
58 |
59 | # .NET Core
60 | project.lock.json
61 | project.fragment.lock.json
62 | artifacts/
63 |
64 | # StyleCop
65 | StyleCopReport.xml
66 |
67 | # Files built by Visual Studio
68 | *_i.c
69 | *_p.c
70 | *_h.h
71 | *.ilk
72 | *.meta
73 | *.obj
74 | *.iobj
75 | *.pch
76 | *.pdb
77 | *.ipdb
78 | *.pgc
79 | *.pgd
80 | *.rsp
81 | *.sbr
82 | *.tlb
83 | *.tli
84 | *.tlh
85 | *.tmp
86 | *.tmp_proj
87 | *_wpftmp.csproj
88 | *.log
89 | *.vspscc
90 | *.vssscc
91 | .builds
92 | *.pidb
93 | *.svclog
94 | *.scc
95 |
96 | # Chutzpah Test files
97 | _Chutzpah*
98 |
99 | # Visual C++ cache files
100 | ipch/
101 | *.aps
102 | *.ncb
103 | *.opendb
104 | *.opensdf
105 | *.sdf
106 | *.cachefile
107 | *.VC.db
108 | *.VC.VC.opendb
109 |
110 | # Visual Studio profiler
111 | *.psess
112 | *.vsp
113 | *.vspx
114 | *.sap
115 |
116 | # Visual Studio Trace Files
117 | *.e2e
118 |
119 | # TFS 2012 Local Workspace
120 | $tf/
121 |
122 | # Guidance Automation Toolkit
123 | *.gpState
124 |
125 | # ReSharper is a .NET coding add-in
126 | _ReSharper*/
127 | *.[Rr]e[Ss]harper
128 | *.DotSettings.user
129 |
130 | # TeamCity is a build add-in
131 | _TeamCity*
132 |
133 | # DotCover is a Code Coverage Tool
134 | *.dotCover
135 |
136 | # AxoCover is a Code Coverage Tool
137 | .axoCover/*
138 | !.axoCover/settings.json
139 |
140 | # Visual Studio code coverage results
141 | *.coverage
142 | *.coveragexml
143 |
144 | # NCrunch
145 | _NCrunch_*
146 | .*crunch*.local.xml
147 | nCrunchTemp_*
148 |
149 | # MightyMoose
150 | *.mm.*
151 | AutoTest.Net/
152 |
153 | # Web workbench (sass)
154 | .sass-cache/
155 |
156 | # Installshield output folder
157 | [Ee]xpress/
158 |
159 | # DocProject is a documentation generator add-in
160 | DocProject/buildhelp/
161 | DocProject/Help/*.HxT
162 | DocProject/Help/*.HxC
163 | DocProject/Help/*.hhc
164 | DocProject/Help/*.hhk
165 | DocProject/Help/*.hhp
166 | DocProject/Help/Html2
167 | DocProject/Help/html
168 |
169 | # Click-Once directory
170 | publish/
171 |
172 | # Publish Web Output
173 | *.[Pp]ublish.xml
174 | *.azurePubxml
175 | # Note: Comment the next line if you want to checkin your web deploy settings,
176 | # but database connection strings (with potential passwords) will be unencrypted
177 | *.pubxml
178 | *.publishproj
179 |
180 | # Microsoft Azure Web App publish settings. Comment the next line if you want to
181 | # checkin your Azure Web App publish settings, but sensitive information contained
182 | # in these scripts will be unencrypted
183 | PublishScripts/
184 |
185 | # NuGet Packages
186 | *.nupkg
187 | # NuGet Symbol Packages
188 | *.snupkg
189 | # The packages folder can be ignored because of Package Restore
190 | **/[Pp]ackages/*
191 | # except build/, which is used as an MSBuild target.
192 | !**/[Pp]ackages/build/
193 | # Uncomment if necessary however generally it will be regenerated when needed
194 | #!**/[Pp]ackages/repositories.config
195 | # NuGet v3's project.json files produces more ignorable files
196 | *.nuget.props
197 | *.nuget.targets
198 |
199 | # Microsoft Azure Build Output
200 | csx/
201 | *.build.csdef
202 |
203 | # Microsoft Azure Emulator
204 | ecf/
205 | rcf/
206 |
207 | # Windows Store app package directories and files
208 | AppPackages/
209 | BundleArtifacts/
210 | Package.StoreAssociation.xml
211 | _pkginfo.txt
212 | *.appx
213 | *.appxbundle
214 | *.appxupload
215 |
216 | # Visual Studio cache files
217 | # files ending in .cache can be ignored
218 | *.[Cc]ache
219 | # but keep track of directories ending in .cache
220 | !?*.[Cc]ache/
221 |
222 | # Others
223 | ClientBin/
224 | ~$*
225 | *~
226 | *.dbmdl
227 | *.dbproj.schemaview
228 | *.jfm
229 | *.pfx
230 | *.publishsettings
231 | orleans.codegen.cs
232 |
233 | # Including strong name files can present a security risk
234 | # (https://github.com/github/gitignore/pull/2483#issue-259490424)
235 | #*.snk
236 |
237 | # Since there are multiple workflows, uncomment next line to ignore bower_components
238 | # (https://github.com/github/gitignore/pull/1529#issuecomment-104372622)
239 | #bower_components/
240 |
241 | # RIA/Silverlight projects
242 | Generated_Code/
243 |
244 | # Backup & report files from converting an old project file
245 | # to a newer Visual Studio version. Backup files are not needed,
246 | # because we have git ;-)
247 | _UpgradeReport_Files/
248 | Backup*/
249 | UpgradeLog*.XML
250 | UpgradeLog*.htm
251 | ServiceFabricBackup/
252 | *.rptproj.bak
253 |
254 | # SQL Server files
255 | *.mdf
256 | *.ldf
257 | *.ndf
258 |
259 | # Business Intelligence projects
260 | *.rdl.data
261 | *.bim.layout
262 | *.bim_*.settings
263 | *.rptproj.rsuser
264 | *- [Bb]ackup.rdl
265 | *- [Bb]ackup ([0-9]).rdl
266 | *- [Bb]ackup ([0-9][0-9]).rdl
267 |
268 | # Microsoft Fakes
269 | FakesAssemblies/
270 |
271 | # GhostDoc plugin setting file
272 | *.GhostDoc.xml
273 |
274 | # Node.js Tools for Visual Studio
275 | .ntvs_analysis.dat
276 | node_modules/
277 |
278 | # Visual Studio 6 build log
279 | *.plg
280 |
281 | # Visual Studio 6 workspace options file
282 | *.opt
283 |
284 | # Visual Studio 6 auto-generated workspace file (contains which files were open etc.)
285 | *.vbw
286 |
287 | # Visual Studio LightSwitch build output
288 | **/*.HTMLClient/GeneratedArtifacts
289 | **/*.DesktopClient/GeneratedArtifacts
290 | **/*.DesktopClient/ModelManifest.xml
291 | **/*.Server/GeneratedArtifacts
292 | **/*.Server/ModelManifest.xml
293 | _Pvt_Extensions
294 |
295 | # Paket dependency manager
296 | .paket/paket.exe
297 | paket-files/
298 |
299 | # FAKE - F# Make
300 | .fake/
301 |
302 | # CodeRush personal settings
303 | .cr/personal
304 |
305 | # Python Tools for Visual Studio (PTVS)
306 | __pycache__/
307 | *.pyc
308 |
309 | # Cake - Uncomment if you are using it
310 | # tools/**
311 | # !tools/packages.config
312 |
313 | # Tabs Studio
314 | *.tss
315 |
316 | # Telerik's JustMock configuration file
317 | *.jmconfig
318 |
319 | # BizTalk build output
320 | *.btp.cs
321 | *.btm.cs
322 | *.odx.cs
323 | *.xsd.cs
324 |
325 | # OpenCover UI analysis results
326 | OpenCover/
327 |
328 | # Azure Stream Analytics local run output
329 | ASALocalRun/
330 |
331 | # MSBuild Binary and Structured Log
332 | *.binlog
333 |
334 | # NVidia Nsight GPU debugger configuration file
335 | *.nvuser
336 |
337 | # MFractors (Xamarin productivity tool) working folder
338 | .mfractor/
339 |
340 | # Local History for Visual Studio
341 | .localhistory/
342 |
343 | # BeatPulse healthcheck temp database
344 | healthchecksdb
345 |
346 | # Backup folder for Package Reference Convert tool in Visual Studio 2017
347 | MigrationBackup/
348 |
349 | # Ionide (cross platform F# VS Code tools) working folder
350 | .ionide/
351 |
--------------------------------------------------------------------------------
/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | # Microsoft Open Source Code of Conduct
2 |
3 | This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
4 |
5 | Resources:
6 |
7 | - [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/)
8 | - [Microsoft Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/)
9 | - Contact [opencode@microsoft.com](mailto:opencode@microsoft.com) with questions or concerns
10 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) Microsoft Corporation.
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | [](https://paperswithcode.com/sota/semi-supervised-image-classification-on-1?p=learning-customized-visual-models-with)
3 | [](https://paperswithcode.com/sota/semi-supervised-image-classification-on-2?p=learning-customized-visual-models-with)
4 |
5 | ## REACT: Learning Customized Visual Models with Retrieval-Augmented Knowledge (CVPR 2023, Highlight 2.5%)
6 |
7 | [Haotian Liu](https://hliu.cc), [Kilho Son](#), [Jianwei Yang](https://jwyang.github.io/), [Ce Liu](#), [Jianfeng Gao](https://www.microsoft.com/en-us/research/people/jfgao/), [Yong Jae Lee*](https://pages.cs.wisc.edu/~yongjaelee/), [Chunyuan Li*](https://chunyuan.li/)
8 |
9 | [[Project Page](https://react-vl.github.io/)] [[Paper](https://arxiv.org/abs/2301.07094)]
10 |
11 | 
12 |
13 | - Introducing a customization stage to the lifecycle of foundation models!
14 | - REACT customizes foundation models to downstream tasks without the need of any labeled data.
15 |
16 | ## :fire: News
17 |
18 | * **[2023.03.29]** Code base and checkpoints are released.
19 | * **[2023.03.25]** Our research paper is selected as highlight (2.5% acceptance rate)!
20 | * **[2023.03.24]** Our new checkpoint based on OpenCLIP-G/14 achieves 81.0% zero-shot on ImageNet, the new SOTA among public checkpoints!
21 | * **[2023.02.28]** Paper is accepted to CVPR 2023.
22 | * **[2023.01.17]** REACT paper is released.
23 |
24 | ## Code
25 |
26 | ### [:globe_with_meridians: Stage 1: Retrieval](./react_retrieval)
27 | REACT provides a pipeline that supports building index on a large dataset, and efficiently queries and retrieves relevant data for downstream tasks with information as simple as class names. See [`react_retrieval`](./react_retrieval) for details.
28 |
29 | You may skip this step if you want to focus on building customized models on standard benchmarks like ImageNet-1K and ELEVATER, by directly using our retrieved indices.
30 |
31 | ### [:art: Stage 2: Customization](./react_customization)
32 |
33 | REACT proposes the efficient and effective *locked-text gated-image tuning* for tuning customized model on the retrieved dataset, with a performance improvement of up to 5.4% improvements on ImageNet. See [`react_customization`](./react_customization) for details.
34 |
35 | 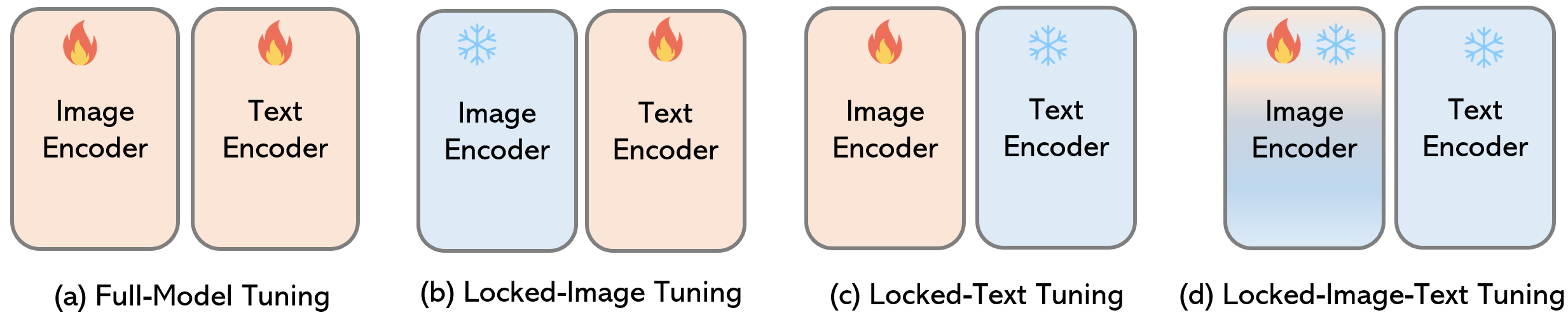
36 |
37 | ## Pretrained Models
38 |
39 | ### ImageNet-1K
40 |
41 | | | Baseline | REACT
(Locked-Text)
LAION-400M | REACT
(Gated-Image)
LAION-400M | REACT
(Gated-Image)
LAION-2B |
42 | |------------------------|------|-----------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------|
43 | | CLIP (B32, WIT-400M) | 63.2 | 66.9 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/clip-vit-base-32-locked-text.pt)) | 68.6 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/clip-vit-base-32-gated-image.pt)) | -- |
44 | | OpenCLIP (B32, L-400M) | 62.9 | 65.7 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/openclip-vit-base-32-locked-text.pt)) | 66.4 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/openclip-vit-base-32-gated-image.pt)) | -- |
45 | | OpenCLIP (B32, L-2B) | 66.6 | 67.5 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/openclip-laion2b-vit-base-32-locked-text.pt)) | 69.5 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/openclip-laion2b-vit-base-32-gated-image.pt)) | -- |
46 | | CLIP (B16, WIT-400M) | 68.6 | 71.6 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/clip-vit-base-16-locked-text.pt)) | 73.4 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/clip-vit-base-16-gated-image.pt)) | -- |
47 | | CLIP (L14, WIT-400M) | 75.3 | -- | 78.1 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/clip-vit-large-14-gated-image.pt)) | 79.8 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/clip-vit-large-14-gated-image-laion2b.pt)) |
48 | | OpenCLIP (L14, L-2B) | 75.3 | -- | 76.4 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/openclip-vit-large-14-gated-image.pt)) | 78.6 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/openclip-vit-large-14-gated-image-laion2b.pt)) |
49 | | OpenCLIP (G14, L-2B) | 80.1 | -- | -- | 81.0 ([hf](https://huggingface.co/react-vl/react-in1k/blob/main/openclip-vit-bigG-14-gated-image-laion2b.pt)) |
50 |
51 | ## Citation
52 | ```
53 | @article{liu2023react,
54 | author = {Liu, Haotian and Son, Kilho and Yang, Jianwei and Liu, Ce and Gao, Jianfeng and Lee, Yong Jae and Li, Chunyuan},
55 | title = {Learning Customized Visual Models with Retrieval-Augmented Knowledge},
56 | publisher = {CVPR},
57 | year = {2023},
58 | }
59 | ```
60 |
61 | ## Acknowledgement
62 |
63 | We are grateful for the contributions of several open-source projects, including [CLIP](https://github.com/openai/CLIP), [OpenCLIP](https://github.com/mlfoundations/open_clip), [LAION.AI](https://laion.ai/), [FAISS](https://github.com/facebookresearch/faiss), [Autofaiss](https://github.com/criteo/autofaiss), [img2dataset](https://github.com/rom1504/img2dataset), and [ELEVATER](https://github.com/Computer-Vision-in-the-Wild/Elevater_Toolkit_IC).
64 |
65 | ## Contributing
66 |
67 | This project welcomes contributions and suggestions. Most contributions require you to agree to a
68 | Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us
69 | the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
70 |
71 | When you submit a pull request, a CLA bot will automatically determine whether you need to provide
72 | a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions
73 | provided by the bot. You will only need to do this once across all repos using our CLA.
74 |
75 | This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
76 | For more information see the [Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/) or
77 | contact [opencode@microsoft.com](mailto:opencode@microsoft.com) with any additional questions or comments.
78 |
79 | ## Trademarks
80 |
81 | This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft
82 | trademarks or logos is subject to and must follow
83 | [Microsoft's Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks/usage/general).
84 | Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship.
85 | Any use of third-party trademarks or logos are subject to those third-party's policies.
86 |
--------------------------------------------------------------------------------
/SECURITY.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Security
4 |
5 | Microsoft takes the security of our software products and services seriously, which includes all source code repositories managed through our GitHub organizations, which include [Microsoft](https://github.com/microsoft), [Azure](https://github.com/Azure), [DotNet](https://github.com/dotnet), [AspNet](https://github.com/aspnet), [Xamarin](https://github.com/xamarin), and [our GitHub organizations](https://opensource.microsoft.com/).
6 |
7 | If you believe you have found a security vulnerability in any Microsoft-owned repository that meets [Microsoft's definition of a security vulnerability](https://aka.ms/opensource/security/definition), please report it to us as described below.
8 |
9 | ## Reporting Security Issues
10 |
11 | **Please do not report security vulnerabilities through public GitHub issues.**
12 |
13 | Instead, please report them to the Microsoft Security Response Center (MSRC) at [https://msrc.microsoft.com/create-report](https://aka.ms/opensource/security/create-report).
14 |
15 | If you prefer to submit without logging in, send email to [secure@microsoft.com](mailto:secure@microsoft.com). If possible, encrypt your message with our PGP key; please download it from the [Microsoft Security Response Center PGP Key page](https://aka.ms/opensource/security/pgpkey).
16 |
17 | You should receive a response within 24 hours. If for some reason you do not, please follow up via email to ensure we received your original message. Additional information can be found at [microsoft.com/msrc](https://aka.ms/opensource/security/msrc).
18 |
19 | Please include the requested information listed below (as much as you can provide) to help us better understand the nature and scope of the possible issue:
20 |
21 | * Type of issue (e.g. buffer overflow, SQL injection, cross-site scripting, etc.)
22 | * Full paths of source file(s) related to the manifestation of the issue
23 | * The location of the affected source code (tag/branch/commit or direct URL)
24 | * Any special configuration required to reproduce the issue
25 | * Step-by-step instructions to reproduce the issue
26 | * Proof-of-concept or exploit code (if possible)
27 | * Impact of the issue, including how an attacker might exploit the issue
28 |
29 | This information will help us triage your report more quickly.
30 |
31 | If you are reporting for a bug bounty, more complete reports can contribute to a higher bounty award. Please visit our [Microsoft Bug Bounty Program](https://aka.ms/opensource/security/bounty) page for more details about our active programs.
32 |
33 | ## Preferred Languages
34 |
35 | We prefer all communications to be in English.
36 |
37 | ## Policy
38 |
39 | Microsoft follows the principle of [Coordinated Vulnerability Disclosure](https://aka.ms/opensource/security/cvd).
40 |
41 |
42 |
--------------------------------------------------------------------------------
/SUPPORT.md:
--------------------------------------------------------------------------------
1 | # Support
2 |
3 | ## How to file issues and get help
4 |
5 | This project uses GitHub Issues to track bugs and feature requests. Please search the existing
6 | issues before filing new issues to avoid duplicates. For new issues, file your bug or
7 | feature request as a new Issue.
8 |
9 | ## Microsoft Support Policy
10 |
11 | Support for this **PROJECT or PRODUCT** is limited to the resources listed above.
12 |
--------------------------------------------------------------------------------
/figures/concept.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/microsoft/react/a1a796fbcd61838042dff43902007af2408959cb/figures/concept.gif
--------------------------------------------------------------------------------
/react_customization/.gitignore:
--------------------------------------------------------------------------------
1 | logs/
2 | wandb/
3 | models/
4 | features/
5 | results/
6 | /data/
7 |
8 | tests/data/
9 | *.pt
10 |
11 | # Byte-compiled / optimized / DLL files
12 | __pycache__/
13 | *.py[cod]
14 | *$py.class
15 |
16 | # C extensions
17 | *.so
18 |
19 | # Distribution / packaging
20 | .Python
21 | build/
22 | develop-eggs/
23 | dist/
24 | downloads/
25 | eggs/
26 | .eggs/
27 | lib/
28 | lib64/
29 | parts/
30 | sdist/
31 | var/
32 | wheels/
33 | pip-wheel-metadata/
34 | share/python-wheels/
35 | *.egg-info/
36 | .installed.cfg
37 | *.egg
38 | MANIFEST
39 |
40 | # PyInstaller
41 | # Usually these files are written by a python script from a template
42 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
43 | *.manifest
44 | *.spec
45 |
46 | # Installer logs
47 | pip-log.txt
48 | pip-delete-this-directory.txt
49 |
50 | # Unit test / coverage reports
51 | htmlcov/
52 | .tox/
53 | .nox/
54 | .coverage
55 | .coverage.*
56 | .cache
57 | nosetests.xml
58 | coverage.xml
59 | *.cover
60 | *.py,cover
61 | .hypothesis/
62 | .pytest_cache/
63 |
64 | # Translations
65 | *.mo
66 | *.pot
67 |
68 | # Django stuff:
69 | *.log
70 | local_settings.py
71 | db.sqlite3
72 | db.sqlite3-journal
73 |
74 | # Flask stuff:
75 | instance/
76 | .webassets-cache
77 |
78 | # Scrapy stuff:
79 | .scrapy
80 |
81 | # Sphinx documentation
82 | docs/_build/
83 |
84 | # PyBuilder
85 | target/
86 |
87 | # Jupyter Notebook
88 | .ipynb_checkpoints
89 |
90 | # IPython
91 | profile_default/
92 | ipython_config.py
93 |
94 | # pyenv
95 | .python-version
96 |
97 | # pipenv
98 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
99 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
100 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
101 | # install all needed dependencies.
102 | #Pipfile.lock
103 |
104 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
105 | __pypackages__/
106 |
107 | # Celery stuff
108 | celerybeat-schedule
109 | celerybeat.pid
110 |
111 | # SageMath parsed files
112 | *.sage.py
113 |
114 | # Environments
115 | .env
116 | .venv
117 | env/
118 | venv/
119 | ENV/
120 | env.bak/
121 | venv.bak/
122 |
123 | # Spyder project settings
124 | .spyderproject
125 | .spyproject
126 |
127 | # Rope project settings
128 | .ropeproject
129 |
130 | # mkdocs documentation
131 | /site
132 |
133 | # mypy
134 | .mypy_cache/
135 | .dmypy.json
136 | dmypy.json
137 |
138 | # Pyre type checker
139 | .pyre/
140 | sync.sh
141 | gpu1sync.sh
142 | .idea
143 | *.pdf
144 | **/._*
145 | **/*DS_*
146 | **.jsonl
147 | src/sbatch
148 | src/misc
149 | .vscode
150 | src/debug
151 | core.*
152 |
153 | # Allow
154 | !src/evaluation/misc/results_dbs/*
--------------------------------------------------------------------------------
/react_customization/CITATION.cff:
--------------------------------------------------------------------------------
1 | cff-version: 1.1.0
2 | message: If you use this software, please cite it as below.
3 | authors:
4 | - family-names: Ilharco
5 | given-names: Gabriel
6 | - family-names: Wortsman
7 | given-names: Mitchell
8 | - family-names: Wightman
9 | given-names: Ross
10 | - family-names: Gordon
11 | given-names: Cade
12 | - family-names: Carlini
13 | given-names: Nicholas
14 | - family-names: Taori
15 | given-names: Rohan
16 | - family-names: Dave
17 | given-names: Achal
18 | - family-names: Shankar
19 | given-names: Vaishaal
20 | - family-names: Namkoong
21 | given-names: Hongseok
22 | - family-names: Miller
23 | given-names: John
24 | - family-names: Hajishirzi
25 | given-names: Hannaneh
26 | - family-names: Farhadi
27 | given-names: Ali
28 | - family-names: Schmidt
29 | given-names: Ludwig
30 | title: OpenCLIP
31 | version: v0.1
32 | doi: 10.5281/zenodo.5143773
33 | date-released: 2021-07-28
34 |
--------------------------------------------------------------------------------
/react_customization/HISTORY.md:
--------------------------------------------------------------------------------
1 | ## 2.14.0
2 |
3 | * Move dataset mixtures logic to shard level
4 | * Fix CoCa accum-grad training
5 | * Safer transformers import guard
6 | * get_labels refactoring
7 |
8 | ## 2.13.0
9 |
10 | * Add support for dataset mixtures with different sampling weights
11 | * Make transformers optional again
12 |
13 | ## 2.12.0
14 |
15 | * Updated convnext configs for consistency
16 | * Added input_patchnorm option
17 | * Clean and improve CoCa generation
18 | * Support model distillation
19 | * Add ConvNeXt-Large 320x320 fine-tune weights
20 |
21 | ## 2.11.1
22 |
23 | * Make transformers optional
24 | * Add MSCOCO CoCa finetunes to pretrained models
25 |
26 | ## 2.11.0
27 |
28 | * coca support and weights
29 | * ConvNeXt-Large weights
30 |
31 | ## 2.10.1
32 |
33 | * `hf-hub:org/model_id` support for loading models w/ config and weights in Hugging Face Hub
34 |
35 | ## 2.10.0
36 |
37 | * Added a ViT-bigG-14 model.
38 | * Added an up-to-date example slurm script for large training jobs.
39 | * Added a option to sync logs and checkpoints to S3 during training.
40 | * New options for LR schedulers, constant and constant with cooldown
41 | * Fix wandb autoresuming when resume is not set
42 | * ConvNeXt `base` & `base_w` pretrained models added
43 | * `timm-` model prefix removed from configs
44 | * `timm` augmentation + regularization (dropout / drop-path) supported
45 |
46 | ## 2.9.3
47 |
48 | * Fix wandb collapsing multiple parallel runs into a single one
49 |
50 | ## 2.9.2
51 |
52 | * Fix braceexpand memory explosion for complex webdataset urls
53 |
54 | ## 2.9.1
55 |
56 | * Fix release
57 |
58 | ## 2.9.0
59 |
60 | * Add training feature to auto-resume from the latest checkpoint on restart via `--resume latest`
61 | * Allow webp in webdataset
62 | * Fix logging for number of samples when using gradient accumulation
63 | * Add model configs for convnext xxlarge
64 |
65 | ## 2.8.2
66 |
67 | * wrapped patchdropout in a torch.nn.Module
68 |
69 | ## 2.8.1
70 |
71 | * relax protobuf dependency
72 | * override the default patch dropout value in 'vision_cfg'
73 |
74 | ## 2.8.0
75 |
76 | * better support for HF models
77 | * add support for gradient accumulation
78 | * CI fixes
79 | * add support for patch dropout
80 | * add convnext configs
81 |
82 |
83 | ## 2.7.0
84 |
85 | * add multilingual H/14 xlm roberta large
86 |
87 | ## 2.6.1
88 |
89 | * fix setup.py _read_reqs
90 |
91 | ## 2.6.0
92 |
93 | * Make openclip training usable from pypi.
94 | * Add xlm roberta large vit h 14 config.
95 |
96 | ## 2.5.0
97 |
98 | * pretrained B/32 xlm roberta base: first multilingual clip trained on laion5B
99 | * pretrained B/32 roberta base: first clip trained using an HF text encoder
100 |
101 | ## 2.4.1
102 |
103 | * Add missing hf_tokenizer_name in CLIPTextCfg.
104 |
105 | ## 2.4.0
106 |
107 | * Fix #211, missing RN50x64 config. Fix type of dropout param for ResNet models
108 | * Bring back LayerNorm impl that casts to input for non bf16/fp16
109 | * zero_shot.py: set correct tokenizer based on args
110 | * training/params.py: remove hf params and get them from model config
111 |
112 | ## 2.3.1
113 |
114 | * Implement grad checkpointing for hf model.
115 | * custom_text: True if hf_model_name is set
116 | * Disable hf tokenizer parallelism
117 |
118 | ## 2.3.0
119 |
120 | * Generalizable Text Transformer with HuggingFace Models (@iejMac)
121 |
122 | ## 2.2.0
123 |
124 | * Support for custom text tower
125 | * Add checksum verification for pretrained model weights
126 |
127 | ## 2.1.0
128 |
129 | * lot including sota models, bfloat16 option, better loading, better metrics
130 |
131 | ## 1.2.0
132 |
133 | * ViT-B/32 trained on Laion2B-en
134 | * add missing openai RN50x64 model
135 |
136 | ## 1.1.1
137 |
138 | * ViT-B/16+
139 | * Add grad checkpointing support
140 | * more robust data loader
141 |
--------------------------------------------------------------------------------
/react_customization/LICENSE:
--------------------------------------------------------------------------------
1 | Copyright (c) 2012-2021 Gabriel Ilharco, Mitchell Wortsman,
2 | Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar,
3 | John Miller, Hongseok Namkoong, Hannaneh Hajishirzi, Ali Farhadi,
4 | Ludwig Schmidt
5 |
6 | Permission is hereby granted, free of charge, to any person obtaining
7 | a copy of this software and associated documentation files (the
8 | "Software"), to deal in the Software without restriction, including
9 | without limitation the rights to use, copy, modify, merge, publish,
10 | distribute, sublicense, and/or sell copies of the Software, and to
11 | permit persons to whom the Software is furnished to do so, subject to
12 | the following conditions:
13 |
14 | The above copyright notice and this permission notice shall be
15 | included in all copies or substantial portions of the Software.
16 |
17 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
18 | EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
19 | MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
20 | NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
21 | LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
22 | OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
23 | WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
24 |
--------------------------------------------------------------------------------
/react_customization/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include src/open_clip/bpe_simple_vocab_16e6.txt.gz
2 | include src/open_clip/model_configs/*.json
3 |
4 |
--------------------------------------------------------------------------------
/react_customization/Makefile:
--------------------------------------------------------------------------------
1 | install: ## [Local development] Upgrade pip, install requirements, install package.
2 | python -m pip install -U pip
3 | python -m pip install -e .
4 |
5 | install-training:
6 | python -m pip install -r requirements-training.txt
7 |
8 | install-test: ## [Local development] Install test requirements
9 | python -m pip install -r requirements-test.txt
10 |
11 | test: ## [Local development] Run unit tests
12 | python -m pytest -x -s -v tests
13 |
--------------------------------------------------------------------------------
/react_customization/README.md:
--------------------------------------------------------------------------------
1 | # :art: REACT: Customization Stage
2 |
3 | **Disclaimer**: *The initial development of REACT customization originated from an internal code base at Microsoft. For public release, we adapted our work to the open-source OpenCLIP code base. Although there might be subtle differences in implementation and training, we have confirmed that the final results are comparable when using the CLIP ViT-B/32 backbone (68.4 this implementation vs 68.6 in paper). See [below](#details-in-the-adaptation-to-openclip-codebase) for details.*
4 |
5 | - [Evaluation](#evaluation)
6 | - [Evaluating ImageNet-1K on OpenCLIP](#evaluating-imagenet-1k-on-openclip)
7 | - [Evaluating ImageNet-1K and ELEVATER benchmark using ELEVATER Toolkit](#evaluating-imagenet-1k-and-elevater-benchmark-using-elevater-toolkit)
8 | - [Training](#training)
9 | - [Download Retrieved Pairs](#download-retrieved-pairs)
10 | - [Gated-image Locked-text Tuning](#gated-image-locked-text-tuning-on-8x-v100s)
11 | - [Locked-text Tuning](#locked-text-tuning-on-8x-v100s)
12 | - [Details in the adaptation to OpenCLIP codebase](#details-in-the-adaptation-to-openclip-codebase)
13 |
14 |
15 | ## Installation
16 | ```
17 | conda create -n react python=3.9 -y
18 | conda activate react
19 | conda install -y pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
20 | make install-training
21 | make install
22 | pip install tensorboard future wandb
23 | ```
24 |
25 | ## Evaluation
26 |
27 | We support evaluation of ImageNet-1K both *directly* using OpenCLIP and using the official toolkit of ELEVATER benchmark. We have verified that there are no significant differences in performance when using OpenCLIP or ELEVATER for evaluation(<0.1% for almost all cases).
28 |
29 | For paper's results, we used the official toolkit of ELEVATER benchmark for evaluating on both ImageNet-1K and ELEVATER 20 datasets.
30 |
31 | ### Evaluating ImageNet-1K on OpenCLIP
32 |
33 | We support evaluation of ImageNet-1K *directly* using OpenCLIP.
34 |
35 | Specifying the pretrained checkpoints with `--model` and `--pretrained` allows automatically downloading the pretrained checkpoints from Hugging Face Hub.
36 |
37 | `--model` can be one of the following:
38 | - Locked-Text Tuning: `ViT-B-32`, `ViT-B-16`, `ViT-L-14`, `ViT-G-14`
39 | - Gated-Image Tuning: `react_ViT-B-32`, `react_ViT-B-16`, `react_ViT-L-14`, `react_ViT-G-14`
40 |
41 | `--pretrained` follows the following format: `react_{base_ckpt}_ret_{retrieval_set}`:
42 | - `base_ckpt` should be one of the following: `clip`, `openclip_laion400m`, and `openclip_laion2b`;
43 | - `retrieval_set`should be one of the following: `laion400m`, `laion2b`.
44 |
45 | See valid combinations from our [list of pretrained checkpoints](../#pretrained-models).
46 |
47 | An example of evaluating **CLIP ViT-B/32** checkpoint customized with REACT on **LAION-400M** using gated-image tuning is provided below.
48 |
49 | ```Shell
50 | python -m training.main \
51 | --zeroshot-frequency 1 \
52 | --imagenet-val=/path/to/imagenet/val/ \
53 | --batch-size=256 \
54 | --workers=16 \
55 | --model react_ViT-B-32 \
56 | --pretrained react_clip_ret_laion400m
57 | ```
58 |
59 | ### Evaluating ImageNet-1K and ELEVATER benchmark using ELEVATER Toolkit
60 |
61 | We used the official toolkit of ELEVATER benchmark for evaluating on both ImageNet-1K and ELEVATER 20 datasets. Please refer to the official documentation of ELEVATER for [installation](https://github.com/Computer-Vision-in-the-Wild/Elevater_Toolkit_IC#installation) and [evaluation](https://github.com/Computer-Vision-in-the-Wild/Elevater_Toolkit_IC#evaluation).
62 |
63 | We provide a sample script for zero-shot evaluation on ImageNet-1K with CLIP ViT-B/32 customized with REACT using gated-image tuning on LAION-400M.
64 |
65 | ```Shell
66 | cd vision_benchmark
67 |
68 | python commands/zeroshot.py \
69 | --ds resources/datasets/imagenet-1k.yaml \
70 | --model resources/model/react_vitb32_CLIP.yaml \
71 | --save-predictions False \
72 | MODEL.CLIP_FP32 False
73 | ```
74 |
75 | ## Training
76 |
77 | ### Download Retrieved Pairs
78 |
79 | 1. Download the retrieved pairs meta data from [here](https://huggingface.co/datasets/react-vl/react-retrieval-datasets/blob/main/imagenet_10m.parquet). This is a parquet file with 10M retrieved pairs from LAION-400M dataset for ImageNet-1K.
80 |
81 | 2. Install [img2dataset](https://github.com/rom1504/img2dataset): `pip install img2dataset`
82 |
83 | 3. Set up DNS resolver following [img2dataset](https://github.com/rom1504/img2dataset#setting-up-a-high-performance-dns-resolver) guidelines. It is crucial for a high success rate for retrieval so as to have a retrieved dataset that is as complete as possible!
84 |
85 | 4. Download the pairs dataset with `img2dataset`.
86 |
87 | ```Shell
88 | img2dataset --url_list ./imagenet_10m.parquet --input_format "parquet"\
89 | --url_col "URL" --caption_col "TEXT" --output_format webdataset\
90 | --output_folder ./imagenet_10m --processes_count 64 --thread_count 12 --image_size 384 \
91 | --resize_only_if_bigger=True --resize_mode="keep_ratio" --skip_reencode=True \
92 | --enable_wandb True
93 | ```
94 |
95 | ### Gated-image Locked-text tuning on 8x V100s
96 | ```Shell
97 | torchrun --nproc_per_node 8 -m training.main \
98 | --save-frequency 1 \
99 | --zeroshot-frequency 1 \
100 | --name React_gi-clip_b32-lr_5e-4-b_512-grad_ckpt-v100_8-aug_on-p_amp-wds-wk_4 \
101 | --train-data '/path/to/imagenet_10m/{00000..00897}.tar' \
102 | --dataset-type webdataset \
103 | --train-num-samples 8530639 \
104 | --imagenet-val=/path/to/imagenet/val/ \
105 | --warmup 5000 \
106 | --batch-size=512 \
107 | --grad-checkpointing \
108 | --lr=5e-4 \
109 | --wd=0.1 \
110 | --epochs=32 \
111 | --workers=4 \
112 | --model react_ViT-B-32-quickgelu \
113 | --resume ./checkpoints/ViT-B-32.pt \
114 | --lock-image-unlock-gated \
115 | --lock-text \
116 | --aug-cfg \
117 | use_timm=True \
118 | scale='(0.08,1.0)' \
119 | ratio='(0.75,1.3333333)' \
120 | hflip=0.5 \
121 | interpolation=bicubic \
122 | color_jitter=0.4 \
123 | "auto_augment='rand-m9-mstd0.5-inc1'" \
124 | re_prob=0.25 \
125 | re_count=1
126 | ```
127 |
128 |
129 | ### Locked-text tuning on 8x V100s
130 | ```Shell
131 | torchrun --nproc_per_node 8 -m training.main \
132 | --save-frequency 1 \
133 | --zeroshot-frequency 1 \
134 | --report-to wandb \
135 | --name React_lt-clip_b32-lr_5e-5-b_512-grad_ckpt-v100_8-aug_on-p_amp-wds-wk_4 \
136 | --train-data '/path/to/imagenet_10m/{00000..00897}.tar' \
137 | --dataset-type webdataset \
138 | --train-num-samples 8530639 \
139 | --imagenet-val=/path/to/imagenet/val/ \
140 | --warmup 5000 \
141 | --batch-size=512 \
142 | --grad-checkpointing \
143 | --lr=5e-5 \
144 | --wd=0.1 \
145 | --epochs=32 \
146 | --workers=4 \
147 | --model ViT-B-32-quickgelu \
148 | --resume ./checkpoints/ViT-B-32.pt \
149 | --lock-text \
150 | --aug-cfg \
151 | use_timm=True \
152 | scale='(0.08,1.0)' \
153 | ratio='(0.75,1.3333333)' \
154 | hflip=0.5 \
155 | interpolation=bicubic \
156 | color_jitter=0.4 \
157 | "auto_augment='rand-m9-mstd0.5-inc1'" \
158 | re_prob=0.25 \
159 | re_count=1
160 | ```
161 |
162 | ## Details in the adaptation to OpenCLIP codebase
163 |
164 | The initial development of REACT customization originated from an internal code base at Microsoft. For public release, we adapted our work to the open-source OpenCLIP code base. Although there might be subtle differences in implementation and training, we have confirmed that the final results are comparable when using the CLIP ViT-B/32 backbone. We provide more details here.
165 |
166 | The primary cause for the difference in results is due to changes in data availability on the web over time. Our internal implementation utilized a retrieval set from the LAION-400M dataset in December 2021. Upon re-implementation with OpenCLIP in February 2023, we found that some retrieved pairs were no longer available online, resulting in a reduced "Feb 2023 set" containing only ~8.5M pairs, compared to the initial 10M in "Dec 2021 set".
167 |
168 | We trained REACT using CLIP ViT-B/32 backbone on OpenCLIP with both "Dec 2021 set" and "Feb 2023 set", yielding comparable results. For "Dec 2021 set", there was a 0.2% performance drop with gated-image tuning and a 0.1% improvement with locked-text tuning. On "Feb 2023 set", despite utilizing only 85% of the original data, there was a minor 0.4% performance drop with gated-image tuning and equivalent performance with locked-text tuning. Detailed results are provided below, along with training logs on [wandb.ai](https://api.wandb.ai/links/lht/nu5eexpi).
169 |
170 | As an effort to facilitate the research community, we are seaking to release the image-text pairs that we retrieved from LAION-400M dataset in Dec 2021. We will update this repo once the data is released.
171 |
172 | | | Paper (Dec 2021 set) | OpenCLIP (Dec 2021 set) | OpenCLIP (Feb 2023 set) |
173 | |-------------|----------------------|-------------------------|-------------------------|
174 | | Baseline | 63.2 | 63.2 | 63.2 |
175 | | Locked-text | 66.9 | 67.0 | 66.9 |
176 | | Gated-image | 68.6 | 68.4 | 68.2 |
177 |
178 |
179 |
--------------------------------------------------------------------------------
/react_customization/pytest.ini:
--------------------------------------------------------------------------------
1 | [pytest]
2 | markers =
3 | regression_test
4 |
--------------------------------------------------------------------------------
/react_customization/requirements-test.txt:
--------------------------------------------------------------------------------
1 | pytest-split==0.8.0
2 | pytest==7.2.0
3 | transformers
4 | timm==0.6.11
5 |
--------------------------------------------------------------------------------
/react_customization/requirements-training.txt:
--------------------------------------------------------------------------------
1 | torch>=1.9.0
2 | torchvision
3 | webdataset>=0.2.5
4 | regex
5 | ftfy
6 | tqdm
7 | pandas
8 | braceexpand
9 | huggingface_hub
10 | transformers
11 | timm
12 | fsspec
13 |
--------------------------------------------------------------------------------
/react_customization/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=1.9.0
2 | torchvision
3 | regex
4 | ftfy
5 | tqdm
6 | huggingface_hub
7 | sentencepiece
8 | protobuf<4
9 | timm
10 |
--------------------------------------------------------------------------------
/react_customization/setup.py:
--------------------------------------------------------------------------------
1 | """ Setup
2 | """
3 | from setuptools import setup, find_packages
4 | from codecs import open
5 | from os import path
6 |
7 | here = path.abspath(path.dirname(__file__))
8 |
9 | # Get the long description from the README file
10 | with open(path.join(here, 'README.md'), encoding='utf-8') as f:
11 | long_description = f.read()
12 |
13 | def _read_reqs(relpath):
14 | fullpath = path.join(path.dirname(__file__), relpath)
15 | with open(fullpath) as f:
16 | return [s.strip() for s in f.readlines() if (s.strip() and not s.startswith("#"))]
17 |
18 | REQUIREMENTS = _read_reqs("requirements.txt")
19 | TRAINING_REQUIREMENTS = _read_reqs("requirements-training.txt")
20 |
21 | exec(open('src/open_clip/version.py').read())
22 | setup(
23 | name='open_clip_torch',
24 | version=__version__,
25 | description='OpenCLIP',
26 | long_description=long_description,
27 | long_description_content_type='text/markdown',
28 | url='https://github.com/mlfoundations/open_clip',
29 | author='',
30 | author_email='',
31 | classifiers=[
32 | # How mature is this project? Common values are
33 | # 3 - Alpha
34 | # 4 - Beta
35 | # 5 - Production/Stable
36 | 'Development Status :: 3 - Alpha',
37 | 'Intended Audience :: Education',
38 | 'Intended Audience :: Science/Research',
39 | 'License :: OSI Approved :: Apache Software License',
40 | 'Programming Language :: Python :: 3.7',
41 | 'Programming Language :: Python :: 3.8',
42 | 'Programming Language :: Python :: 3.9',
43 | 'Programming Language :: Python :: 3.10',
44 | 'Topic :: Scientific/Engineering',
45 | 'Topic :: Scientific/Engineering :: Artificial Intelligence',
46 | 'Topic :: Software Development',
47 | 'Topic :: Software Development :: Libraries',
48 | 'Topic :: Software Development :: Libraries :: Python Modules',
49 | ],
50 |
51 | # Note that this is a string of words separated by whitespace, not a list.
52 | keywords='CLIP pretrained',
53 | package_dir={'': 'src'},
54 | packages=find_packages(where='src'),
55 | include_package_data=True,
56 | install_requires=REQUIREMENTS,
57 | extras_require={
58 | "training": TRAINING_REQUIREMENTS,
59 | },
60 | python_requires='>=3.7',
61 | )
62 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/__init__.py:
--------------------------------------------------------------------------------
1 | from .coca_model import CoCa
2 | from .constants import OPENAI_DATASET_MEAN, OPENAI_DATASET_STD
3 | from .factory import create_model, create_model_and_transforms, create_model_from_pretrained, get_tokenizer, create_loss
4 | from .factory import list_models, add_model_config, get_model_config, load_checkpoint
5 | from .loss import ClipLoss, DistillClipLoss, CoCaLoss
6 | from .model import CLIP, CustomTextCLIP, CLIPTextCfg, CLIPVisionCfg, \
7 | convert_weights_to_lp, convert_weights_to_fp16, trace_model, get_cast_dtype
8 | from .openai import load_openai_model, list_openai_models
9 | from .pretrained import list_pretrained, list_pretrained_models_by_tag, list_pretrained_tags_by_model, \
10 | get_pretrained_url, download_pretrained_from_url, is_pretrained_cfg, get_pretrained_cfg, download_pretrained
11 | from .push_to_hf_hub import push_pretrained_to_hf_hub, push_to_hf_hub
12 | from .tokenizer import SimpleTokenizer, tokenize, decode
13 | from .transform import image_transform, AugmentationCfg
14 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/bpe_simple_vocab_16e6.txt.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/microsoft/react/a1a796fbcd61838042dff43902007af2408959cb/react_customization/src/open_clip/bpe_simple_vocab_16e6.txt.gz
--------------------------------------------------------------------------------
/react_customization/src/open_clip/constants.py:
--------------------------------------------------------------------------------
1 | OPENAI_DATASET_MEAN = (0.48145466, 0.4578275, 0.40821073)
2 | OPENAI_DATASET_STD = (0.26862954, 0.26130258, 0.27577711)
3 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/generation_utils.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/microsoft/react/a1a796fbcd61838042dff43902007af2408959cb/react_customization/src/open_clip/generation_utils.py
--------------------------------------------------------------------------------
/react_customization/src/open_clip/hf_configs.py:
--------------------------------------------------------------------------------
1 | # HF architecture dict:
2 | arch_dict = {
3 | # https://huggingface.co/docs/transformers/model_doc/roberta#roberta
4 | "roberta": {
5 | "config_names": {
6 | "context_length": "max_position_embeddings",
7 | "vocab_size": "vocab_size",
8 | "width": "hidden_size",
9 | "heads": "num_attention_heads",
10 | "layers": "num_hidden_layers",
11 | "layer_attr": "layer",
12 | "token_embeddings_attr": "embeddings"
13 | },
14 | "pooler": "mean_pooler",
15 | },
16 | # https://huggingface.co/docs/transformers/model_doc/xlm-roberta#transformers.XLMRobertaConfig
17 | "xlm-roberta": {
18 | "config_names": {
19 | "context_length": "max_position_embeddings",
20 | "vocab_size": "vocab_size",
21 | "width": "hidden_size",
22 | "heads": "num_attention_heads",
23 | "layers": "num_hidden_layers",
24 | "layer_attr": "layer",
25 | "token_embeddings_attr": "embeddings"
26 | },
27 | "pooler": "mean_pooler",
28 | },
29 | # https://huggingface.co/docs/transformers/model_doc/mt5#mt5
30 | "mt5": {
31 | "config_names": {
32 | # unlimited seqlen
33 | # https://github.com/google-research/text-to-text-transfer-transformer/issues/273
34 | # https://github.com/huggingface/transformers/blob/v4.24.0/src/transformers/models/t5/modeling_t5.py#L374
35 | "context_length": "",
36 | "vocab_size": "vocab_size",
37 | "width": "d_model",
38 | "heads": "num_heads",
39 | "layers": "num_layers",
40 | "layer_attr": "block",
41 | "token_embeddings_attr": "embed_tokens"
42 | },
43 | "pooler": "mean_pooler",
44 | },
45 | }
46 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/hf_model.py:
--------------------------------------------------------------------------------
1 | """ huggingface model adapter
2 |
3 | Wraps HuggingFace transformers (https://github.com/huggingface/transformers) models for use as a text tower in CLIP model.
4 | """
5 |
6 | import re
7 |
8 | import torch
9 | import torch.nn as nn
10 | from torch import TensorType
11 |
12 | try:
13 | import transformers
14 | from transformers import AutoModel, AutoTokenizer, AutoConfig, PretrainedConfig
15 | from transformers.modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, \
16 | BaseModelOutputWithPoolingAndCrossAttentions
17 | except ImportError as e:
18 | transformers = None
19 |
20 |
21 | class BaseModelOutput:
22 | pass
23 |
24 |
25 | class PretrainedConfig:
26 | pass
27 |
28 | from .hf_configs import arch_dict
29 |
30 |
31 | # utils
32 | def _camel2snake(s):
33 | return re.sub(r'(? torch.Tensor:
90 | # calculated ground-truth and cache if enabled
91 | if self.prev_num_logits != num_logits or device not in self.labels:
92 | labels = torch.arange(num_logits, device=device, dtype=torch.long)
93 | if self.world_size > 1 and self.local_loss:
94 | labels = labels + num_logits * self.rank
95 | if self.cache_labels:
96 | self.labels[device] = labels
97 | self.prev_num_logits = num_logits
98 | else:
99 | labels = self.labels[device]
100 | return labels
101 |
102 | def get_logits(self, image_features, text_features, logit_scale):
103 | if self.world_size > 1:
104 | all_image_features, all_text_features = gather_features(
105 | image_features, text_features,
106 | self.local_loss, self.gather_with_grad, self.rank, self.world_size, self.use_horovod)
107 |
108 | if self.local_loss:
109 | logits_per_image = logit_scale * image_features @ all_text_features.T
110 | logits_per_text = logit_scale * text_features @ all_image_features.T
111 | else:
112 | logits_per_image = logit_scale * all_image_features @ all_text_features.T
113 | logits_per_text = logits_per_image.T
114 | else:
115 | logits_per_image = logit_scale * image_features @ text_features.T
116 | logits_per_text = logit_scale * text_features @ image_features.T
117 |
118 | return logits_per_image, logits_per_text
119 |
120 | def forward(self, image_features, text_features, logit_scale, output_dict=False):
121 | device = image_features.device
122 | logits_per_image, logits_per_text = self.get_logits(image_features, text_features, logit_scale)
123 |
124 | labels = self.get_ground_truth(device, logits_per_image.shape[0])
125 |
126 | total_loss = (
127 | F.cross_entropy(logits_per_image, labels) +
128 | F.cross_entropy(logits_per_text, labels)
129 | ) / 2
130 |
131 | return {"contrastive_loss": total_loss} if output_dict else total_loss
132 |
133 |
134 | class CoCaLoss(ClipLoss):
135 | def __init__(
136 | self,
137 | caption_loss_weight,
138 | clip_loss_weight,
139 | pad_id=0, # pad_token for open_clip custom tokenizer
140 | local_loss=False,
141 | gather_with_grad=False,
142 | cache_labels=False,
143 | rank=0,
144 | world_size=1,
145 | use_horovod=False,
146 | ):
147 | super().__init__(
148 | local_loss=local_loss,
149 | gather_with_grad=gather_with_grad,
150 | cache_labels=cache_labels,
151 | rank=rank,
152 | world_size=world_size,
153 | use_horovod=use_horovod
154 | )
155 |
156 | self.clip_loss_weight = clip_loss_weight
157 | self.caption_loss_weight = caption_loss_weight
158 | self.caption_loss = nn.CrossEntropyLoss(ignore_index=pad_id)
159 |
160 | def forward(self, image_features, text_features, logits, labels, logit_scale, output_dict=False):
161 | clip_loss = super().forward(image_features, text_features, logit_scale)
162 | clip_loss = self.clip_loss_weight * clip_loss
163 |
164 | caption_loss = self.caption_loss(
165 | logits.permute(0, 2, 1),
166 | labels,
167 | )
168 | caption_loss = caption_loss * self.caption_loss_weight
169 |
170 | if output_dict:
171 | return {"contrastive_loss": clip_loss, "caption_loss": caption_loss}
172 |
173 | return clip_loss, caption_loss
174 |
175 |
176 | class DistillClipLoss(ClipLoss):
177 |
178 | def dist_loss(self, teacher_logits, student_logits):
179 | return -(teacher_logits.softmax(dim=1) * student_logits.log_softmax(dim=1)).sum(dim=1).mean(dim=0)
180 |
181 | def forward(
182 | self,
183 | image_features,
184 | text_features,
185 | logit_scale,
186 | dist_image_features,
187 | dist_text_features,
188 | dist_logit_scale,
189 | output_dict=False,
190 | ):
191 | logits_per_image, logits_per_text = \
192 | self.get_logits(image_features, text_features, logit_scale)
193 |
194 | dist_logits_per_image, dist_logits_per_text = \
195 | self.get_logits(dist_image_features, dist_text_features, dist_logit_scale)
196 |
197 | labels = self.get_ground_truth(image_features.device, logits_per_image.shape[0])
198 |
199 | contrastive_loss = (
200 | F.cross_entropy(logits_per_image, labels) +
201 | F.cross_entropy(logits_per_text, labels)
202 | ) / 2
203 |
204 | distill_loss = (
205 | self.dist_loss(dist_logits_per_image, logits_per_image) +
206 | self.dist_loss(dist_logits_per_text, logits_per_text)
207 | ) / 2
208 |
209 | if output_dict:
210 | return {"contrastive_loss": contrastive_loss, "distill_loss": distill_loss}
211 |
212 | return contrastive_loss, distill_loss
213 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/RN101-quickgelu.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "quick_gelu": true,
4 | "vision_cfg": {
5 | "image_size": 224,
6 | "layers": [
7 | 3,
8 | 4,
9 | 23,
10 | 3
11 | ],
12 | "width": 64,
13 | "patch_size": null
14 | },
15 | "text_cfg": {
16 | "context_length": 77,
17 | "vocab_size": 49408,
18 | "width": 512,
19 | "heads": 8,
20 | "layers": 12
21 | }
22 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/RN101.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": [
6 | 3,
7 | 4,
8 | 23,
9 | 3
10 | ],
11 | "width": 64,
12 | "patch_size": null
13 | },
14 | "text_cfg": {
15 | "context_length": 77,
16 | "vocab_size": 49408,
17 | "width": 512,
18 | "heads": 8,
19 | "layers": 12
20 | }
21 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/RN50-quickgelu.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "quick_gelu": true,
4 | "vision_cfg": {
5 | "image_size": 224,
6 | "layers": [
7 | 3,
8 | 4,
9 | 6,
10 | 3
11 | ],
12 | "width": 64,
13 | "patch_size": null
14 | },
15 | "text_cfg": {
16 | "context_length": 77,
17 | "vocab_size": 49408,
18 | "width": 512,
19 | "heads": 8,
20 | "layers": 12
21 | }
22 | }
23 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/RN50.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": [
6 | 3,
7 | 4,
8 | 6,
9 | 3
10 | ],
11 | "width": 64,
12 | "patch_size": null
13 | },
14 | "text_cfg": {
15 | "context_length": 77,
16 | "vocab_size": 49408,
17 | "width": 512,
18 | "heads": 8,
19 | "layers": 12
20 | }
21 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/RN50x16.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 768,
3 | "vision_cfg": {
4 | "image_size": 384,
5 | "layers": [
6 | 6,
7 | 8,
8 | 18,
9 | 8
10 | ],
11 | "width": 96,
12 | "patch_size": null
13 | },
14 | "text_cfg": {
15 | "context_length": 77,
16 | "vocab_size": 49408,
17 | "width": 768,
18 | "heads": 12,
19 | "layers": 12
20 | }
21 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/RN50x4.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 640,
3 | "vision_cfg": {
4 | "image_size": 288,
5 | "layers": [
6 | 4,
7 | 6,
8 | 10,
9 | 6
10 | ],
11 | "width": 80,
12 | "patch_size": null
13 | },
14 | "text_cfg": {
15 | "context_length": 77,
16 | "vocab_size": 49408,
17 | "width": 640,
18 | "heads": 10,
19 | "layers": 12
20 | }
21 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/RN50x64.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "vision_cfg": {
4 | "image_size": 448,
5 | "layers": [
6 | 3,
7 | 15,
8 | 36,
9 | 10
10 | ],
11 | "width": 128,
12 | "patch_size": null
13 | },
14 | "text_cfg": {
15 | "context_length": 77,
16 | "vocab_size": 49408,
17 | "width": 1024,
18 | "heads": 16,
19 | "layers": 12
20 | }
21 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-B-16-plus-240.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 640,
3 | "vision_cfg": {
4 | "image_size": 240,
5 | "layers": 12,
6 | "width": 896,
7 | "patch_size": 16
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 640,
13 | "heads": 10,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-B-16-plus.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 640,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 896,
7 | "patch_size": 16
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 640,
13 | "heads": 10,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-B-16.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 768,
7 | "patch_size": 16
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 512,
13 | "heads": 8,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-B-32-plus-256.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 640,
3 | "vision_cfg": {
4 | "image_size": 256,
5 | "layers": 12,
6 | "width": 896,
7 | "patch_size": 32
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 640,
13 | "heads": 10,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-B-32-quickgelu.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "quick_gelu": true,
4 | "vision_cfg": {
5 | "image_size": 224,
6 | "layers": 12,
7 | "width": 768,
8 | "patch_size": 32
9 | },
10 | "text_cfg": {
11 | "context_length": 77,
12 | "vocab_size": 49408,
13 | "width": 512,
14 | "heads": 8,
15 | "layers": 12
16 | }
17 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-B-32.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 768,
7 | "patch_size": 32
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 512,
13 | "heads": 8,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-H-14.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 32,
6 | "width": 1280,
7 | "head_width": 80,
8 | "patch_size": 14
9 | },
10 | "text_cfg": {
11 | "context_length": 77,
12 | "vocab_size": 49408,
13 | "width": 1024,
14 | "heads": 16,
15 | "layers": 24
16 | }
17 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-H-16.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 32,
6 | "width": 1280,
7 | "head_width": 80,
8 | "patch_size": 16
9 | },
10 | "text_cfg": {
11 | "context_length": 77,
12 | "vocab_size": 49408,
13 | "width": 1024,
14 | "heads": 16,
15 | "layers": 24
16 | }
17 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-L-14-280.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 768,
3 | "vision_cfg": {
4 | "image_size": 280,
5 | "layers": 24,
6 | "width": 1024,
7 | "patch_size": 14
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 768,
13 | "heads": 12,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-L-14-336.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 768,
3 | "vision_cfg": {
4 | "image_size": 336,
5 | "layers": 24,
6 | "width": 1024,
7 | "patch_size": 14
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 768,
13 | "heads": 12,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-L-14.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 768,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 24,
6 | "width": 1024,
7 | "patch_size": 14
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 768,
13 | "heads": 12,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-L-16-320.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 768,
3 | "vision_cfg": {
4 | "image_size": 320,
5 | "layers": 24,
6 | "width": 1024,
7 | "patch_size": 16
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 768,
13 | "heads": 12,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-L-16.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 768,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 24,
6 | "width": 1024,
7 | "patch_size": 16
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 768,
13 | "heads": 12,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-M-16-alt.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 384,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 512,
7 | "patch_size": 16,
8 | "ls_init_value": 1e-4
9 | },
10 | "text_cfg": {
11 | "context_length": 77,
12 | "vocab_size": 49408,
13 | "width": 384,
14 | "heads": 6,
15 | "layers": 12
16 | }
17 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-M-16.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 512,
7 | "patch_size": 16
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 512,
13 | "heads": 8,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-M-32-alt.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 384,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 512,
7 | "patch_size": 32
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 384,
13 | "heads": 6,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-M-32.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 512,
7 | "patch_size": 32
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 512,
13 | "heads": 8,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-S-16-alt.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 256,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 384,
7 | "patch_size": 16
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 256,
13 | "heads": 4,
14 | "layers": 10
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-S-16.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 384,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 384,
7 | "patch_size": 16
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 384,
13 | "heads": 6,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-S-32-alt.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 256,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 384,
7 | "patch_size": 32
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 256,
13 | "heads": 4,
14 | "layers": 10
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-S-32.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 384,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 384,
7 | "patch_size": 32
8 | },
9 | "text_cfg": {
10 | "context_length": 77,
11 | "vocab_size": 49408,
12 | "width": 384,
13 | "heads": 6,
14 | "layers": 12
15 | }
16 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-bigG-14.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1280,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 48,
6 | "width": 1664,
7 | "head_width": 104,
8 | "mlp_ratio": 4.9231,
9 | "patch_size": 14
10 | },
11 | "text_cfg": {
12 | "context_length": 77,
13 | "vocab_size": 49408,
14 | "width": 1280,
15 | "heads": 20,
16 | "layers": 32
17 | }
18 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-e-14.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1280,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 56,
6 | "width": 1792,
7 | "head_width": 112,
8 | "mlp_ratio": 8.5715,
9 | "patch_size": 14
10 | },
11 | "text_cfg": {
12 | "context_length": 77,
13 | "vocab_size": 49408,
14 | "width": 1280,
15 | "heads": 20,
16 | "layers": 36
17 | }
18 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/ViT-g-14.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 40,
6 | "width": 1408,
7 | "head_width": 88,
8 | "mlp_ratio": 4.3637,
9 | "patch_size": 14
10 | },
11 | "text_cfg": {
12 | "context_length": 77,
13 | "vocab_size": 49408,
14 | "width": 1024,
15 | "heads": 16,
16 | "layers": 24
17 | }
18 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/coca_ViT-B-32.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 768,
7 | "patch_size": 32,
8 | "attentional_pool": true,
9 | "attn_pooler_heads": 8,
10 | "output_tokens": true
11 | },
12 | "text_cfg": {
13 | "context_length": 76,
14 | "vocab_size": 49408,
15 | "width": 512,
16 | "heads": 8,
17 | "layers": 12,
18 | "embed_cls": true,
19 | "output_tokens": true
20 | },
21 | "multimodal_cfg": {
22 | "context_length": 76,
23 | "vocab_size": 49408,
24 | "width": 512,
25 | "heads": 8,
26 | "layers": 12,
27 | "attn_pooler_heads": 8
28 | },
29 | "custom_text": true
30 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/coca_ViT-L-14.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 768,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 24,
6 | "width": 1024,
7 | "patch_size": 14,
8 | "attentional_pool": true,
9 | "attn_pooler_heads": 8,
10 | "output_tokens": true
11 | },
12 | "text_cfg": {
13 | "context_length": 76,
14 | "vocab_size": 49408,
15 | "width": 768,
16 | "heads": 12,
17 | "layers": 12,
18 | "embed_cls": true,
19 | "output_tokens": true
20 | },
21 | "multimodal_cfg": {
22 | "context_length": 76,
23 | "vocab_size": 49408,
24 | "width": 768,
25 | "heads": 12,
26 | "layers": 12,
27 | "attn_pooler_heads": 12
28 | },
29 | "custom_text": true
30 | }
31 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/coca_base.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "multimodal_cfg": {
4 | "width": 768,
5 | "context_length": 76,
6 | "vocab_size": 64000,
7 | "mlp_ratio": 4,
8 | "layers": 12,
9 | "dim_head": 64,
10 | "heads": 12,
11 | "n_queries": 256,
12 | "attn_pooler_heads": 8
13 | },
14 | "vision_cfg": {
15 | "image_size": 288,
16 | "layers": 12,
17 | "width": 768,
18 | "patch_size": 18,
19 | "output_tokens": true
20 | },
21 | "text_cfg": {
22 | "context_length": 76,
23 | "vocab_size": 64000,
24 | "layers": 12,
25 | "heads": 12,
26 | "width": 768,
27 | "embed_cls": true,
28 | "output_tokens": true
29 | },
30 | "custom_text": true
31 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/coca_roberta-ViT-B-32.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 768,
7 | "patch_size": 32,
8 | "output_tokens": true
9 | },
10 | "text_cfg": {
11 | "hf_model_name": "roberta-base",
12 | "hf_tokenizer_name": "roberta-base",
13 | "proj": "linear",
14 | "width": 768,
15 | "output_tokens": true
16 | },
17 | "multimodal_cfg": {
18 | "context_length": 76,
19 | "width": 768,
20 | "heads": 8,
21 | "layers": 12
22 | },
23 | "custom_text": true
24 | }
25 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/convnext_base.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "timm_model_name": "convnext_base",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "timm_drop": 0.0,
9 | "timm_drop_path": 0.1,
10 | "image_size": 224
11 | },
12 | "text_cfg": {
13 | "context_length": 77,
14 | "vocab_size": 49408,
15 | "width": 512,
16 | "heads": 8,
17 | "layers": 12
18 | }
19 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/convnext_base_w.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 640,
3 | "vision_cfg": {
4 | "timm_model_name": "convnext_base",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "timm_drop": 0.0,
9 | "timm_drop_path": 0.1,
10 | "image_size": 256
11 | },
12 | "text_cfg": {
13 | "context_length": 77,
14 | "vocab_size": 49408,
15 | "width": 640,
16 | "heads": 10,
17 | "layers": 12
18 | }
19 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/convnext_base_w_320.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 640,
3 | "vision_cfg": {
4 | "timm_model_name": "convnext_base",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "timm_drop": 0.0,
9 | "timm_drop_path": 0.1,
10 | "image_size": 320
11 | },
12 | "text_cfg": {
13 | "context_length": 77,
14 | "vocab_size": 49408,
15 | "width": 640,
16 | "heads": 10,
17 | "layers": 12
18 | }
19 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/convnext_large.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 768,
3 | "vision_cfg": {
4 | "timm_model_name": "convnext_large",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "timm_drop": 0.0,
9 | "timm_drop_path": 0.1,
10 | "image_size": 224
11 | },
12 | "text_cfg": {
13 | "context_length": 77,
14 | "vocab_size": 49408,
15 | "width": 768,
16 | "heads": 12,
17 | "layers": 12
18 | }
19 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/convnext_large_d.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 768,
3 | "vision_cfg": {
4 | "timm_model_name": "convnext_large",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "mlp",
8 | "timm_drop": 0.0,
9 | "timm_drop_path": 0.1,
10 | "image_size": 256
11 | },
12 | "text_cfg": {
13 | "context_length": 77,
14 | "vocab_size": 49408,
15 | "width": 768,
16 | "heads": 12,
17 | "layers": 16
18 | }
19 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/convnext_large_d_320.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 768,
3 | "vision_cfg": {
4 | "timm_model_name": "convnext_large",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "mlp",
8 | "timm_drop": 0.0,
9 | "timm_drop_path": 0.1,
10 | "image_size": 320
11 | },
12 | "text_cfg": {
13 | "context_length": 77,
14 | "vocab_size": 49408,
15 | "width": 768,
16 | "heads": 12,
17 | "layers": 16
18 | }
19 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/convnext_small.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "timm_model_name": "convnext_small",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "timm_drop": 0.0,
9 | "timm_drop_path": 0.1,
10 | "image_size": 224
11 | },
12 | "text_cfg": {
13 | "context_length": 77,
14 | "vocab_size": 49408,
15 | "width": 512,
16 | "heads": 8,
17 | "layers": 12
18 | }
19 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/convnext_tiny.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "vision_cfg": {
4 | "timm_model_name": "convnext_tiny",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "timm_drop": 0.0,
9 | "timm_drop_path": 0.1,
10 | "image_size": 224
11 | },
12 | "text_cfg": {
13 | "context_length": 77,
14 | "vocab_size": 49408,
15 | "width": 512,
16 | "heads": 8,
17 | "layers": 12
18 | }
19 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/convnext_xlarge.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "vision_cfg": {
4 | "timm_model_name": "convnext_xlarge",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "timm_drop": 0.0,
9 | "timm_drop_path": 0.1,
10 | "image_size": 256
11 | },
12 | "text_cfg": {
13 | "context_length": 77,
14 | "vocab_size": 49408,
15 | "width": 1024,
16 | "heads": 16,
17 | "layers": 20
18 | }
19 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/convnext_xxlarge.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "vision_cfg": {
4 | "timm_model_name": "convnext_xxlarge",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "timm_drop": 0.0,
9 | "timm_drop_path": 0.1,
10 | "image_size": 256
11 | },
12 | "text_cfg": {
13 | "context_length": 77,
14 | "vocab_size": 49408,
15 | "width": 1024,
16 | "heads": 16,
17 | "layers": 24
18 | }
19 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/convnext_xxlarge_320.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "vision_cfg": {
4 | "timm_model_name": "convnext_xxlarge",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "timm_drop": 0.0,
9 | "timm_drop_path": 0.1,
10 | "image_size": 320
11 | },
12 | "text_cfg": {
13 | "context_length": 77,
14 | "vocab_size": 49408,
15 | "width": 1024,
16 | "heads": 16,
17 | "layers": 24
18 | }
19 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/mt5-base-ViT-B-32.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 768,
7 | "patch_size": 32
8 | },
9 | "text_cfg": {
10 | "hf_model_name": "google/mt5-base",
11 | "hf_tokenizer_name": "google/mt5-base",
12 | "proj": "mlp",
13 | "pooler_type": "mean_pooler"
14 | }
15 | }
16 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/mt5-xl-ViT-H-14.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 32,
6 | "width": 1280,
7 | "head_width": 80,
8 | "patch_size": 14
9 | },
10 | "text_cfg": {
11 | "hf_model_name": "google/mt5-xl",
12 | "hf_tokenizer_name": "google/mt5-xl",
13 | "proj": "mlp",
14 | "pooler_type": "mean_pooler"
15 | }
16 | }
17 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/react_ViT-B-16.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 768,
7 | "patch_size": 16,
8 | "react_cfg": {
9 | "enabled": true,
10 | "last_k_layers": 6
11 | }
12 | },
13 | "text_cfg": {
14 | "context_length": 77,
15 | "vocab_size": 49408,
16 | "width": 512,
17 | "heads": 8,
18 | "layers": 12
19 | }
20 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/react_ViT-B-32-quickgelu.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "quick_gelu": true,
4 | "vision_cfg": {
5 | "image_size": 224,
6 | "layers": 12,
7 | "width": 768,
8 | "patch_size": 32,
9 | "react_cfg": {
10 | "enabled": true,
11 | "last_k_layers": 6
12 | }
13 | },
14 | "text_cfg": {
15 | "context_length": 77,
16 | "vocab_size": 49408,
17 | "width": 512,
18 | "heads": 8,
19 | "layers": 12
20 | }
21 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/react_ViT-B-32.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 768,
7 | "patch_size": 32,
8 | "react_cfg": {
9 | "enabled": true,
10 | "last_k_layers": 6
11 | }
12 | },
13 | "text_cfg": {
14 | "context_length": 77,
15 | "vocab_size": 49408,
16 | "width": 512,
17 | "heads": 8,
18 | "layers": 12
19 | }
20 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/react_ViT-L-14.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 768,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 24,
6 | "width": 1024,
7 | "patch_size": 14,
8 | "react_cfg": {
9 | "enabled": true,
10 | "last_k_layers": 6
11 | }
12 | },
13 | "text_cfg": {
14 | "context_length": 77,
15 | "vocab_size": 49408,
16 | "width": 768,
17 | "heads": 12,
18 | "layers": 12
19 | }
20 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/react_ViT-bigG-14.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1280,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 48,
6 | "width": 1664,
7 | "head_width": 104,
8 | "mlp_ratio": 4.9231,
9 | "patch_size": 14,
10 | "react_cfg": {
11 | "enabled": true,
12 | "last_k_layers": 12
13 | }
14 | },
15 | "text_cfg": {
16 | "context_length": 77,
17 | "vocab_size": 49408,
18 | "width": 1280,
19 | "heads": 20,
20 | "layers": 32
21 | }
22 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/roberta-ViT-B-32.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "quick_gelu": true,
4 | "vision_cfg": {
5 | "image_size": 224,
6 | "layers": 12,
7 | "width": 768,
8 | "patch_size": 32
9 | },
10 | "text_cfg": {
11 | "hf_model_name": "roberta-base",
12 | "hf_tokenizer_name": "roberta-base",
13 | "proj": "mlp",
14 | "pooler_type": "mean_pooler"
15 | }
16 | }
17 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/swin_base_patch4_window7_224.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 640,
3 | "vision_cfg": {
4 | "timm_model_name": "swin_base_patch4_window7_224",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "image_size": 224
9 | },
10 | "text_cfg": {
11 | "context_length": 77,
12 | "vocab_size": 49408,
13 | "width": 640,
14 | "heads": 10,
15 | "layers": 12
16 | }
17 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/vit_medium_patch16_gap_256.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "timm_model_name": "vit_medium_patch16_gap_256",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "image_size": 256
9 | },
10 | "text_cfg": {
11 | "context_length": 77,
12 | "vocab_size": 49408,
13 | "width": 512,
14 | "heads": 8,
15 | "layers": 12
16 | }
17 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/vit_relpos_medium_patch16_cls_224.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "timm_model_name": "vit_relpos_medium_patch16_cls_224",
5 | "timm_model_pretrained": false,
6 | "timm_pool": "",
7 | "timm_proj": "linear",
8 | "image_size": 224
9 | },
10 | "text_cfg": {
11 | "context_length": 77,
12 | "vocab_size": 49408,
13 | "width": 512,
14 | "heads": 8,
15 | "layers": 12
16 | }
17 | }
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/xlm-roberta-base-ViT-B-32.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 512,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 12,
6 | "width": 768,
7 | "patch_size": 32
8 | },
9 | "text_cfg": {
10 | "hf_model_name": "xlm-roberta-base",
11 | "hf_tokenizer_name": "xlm-roberta-base",
12 | "proj": "mlp",
13 | "pooler_type": "mean_pooler"
14 | }
15 | }
16 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/model_configs/xlm-roberta-large-ViT-H-14.json:
--------------------------------------------------------------------------------
1 | {
2 | "embed_dim": 1024,
3 | "vision_cfg": {
4 | "image_size": 224,
5 | "layers": 32,
6 | "width": 1280,
7 | "head_width": 80,
8 | "patch_size": 14
9 | },
10 | "text_cfg": {
11 | "hf_model_name": "xlm-roberta-large",
12 | "hf_tokenizer_name": "xlm-roberta-large",
13 | "proj": "mlp",
14 | "pooler_type": "mean_pooler"
15 | }
16 | }
17 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/modified_resnet.py:
--------------------------------------------------------------------------------
1 | from collections import OrderedDict
2 |
3 | import torch
4 | from torch import nn
5 | from torch.nn import functional as F
6 |
7 | from open_clip.utils import freeze_batch_norm_2d
8 |
9 |
10 | class Bottleneck(nn.Module):
11 | expansion = 4
12 |
13 | def __init__(self, inplanes, planes, stride=1):
14 | super().__init__()
15 |
16 | # all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
17 | self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)
18 | self.bn1 = nn.BatchNorm2d(planes)
19 | self.act1 = nn.ReLU(inplace=True)
20 |
21 | self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)
22 | self.bn2 = nn.BatchNorm2d(planes)
23 | self.act2 = nn.ReLU(inplace=True)
24 |
25 | self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()
26 |
27 | self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)
28 | self.bn3 = nn.BatchNorm2d(planes * self.expansion)
29 | self.act3 = nn.ReLU(inplace=True)
30 |
31 | self.downsample = None
32 | self.stride = stride
33 |
34 | if stride > 1 or inplanes != planes * Bottleneck.expansion:
35 | # downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1
36 | self.downsample = nn.Sequential(OrderedDict([
37 | ("-1", nn.AvgPool2d(stride)),
38 | ("0", nn.Conv2d(inplanes, planes * self.expansion, 1, stride=1, bias=False)),
39 | ("1", nn.BatchNorm2d(planes * self.expansion))
40 | ]))
41 |
42 | def forward(self, x: torch.Tensor):
43 | identity = x
44 |
45 | out = self.act1(self.bn1(self.conv1(x)))
46 | out = self.act2(self.bn2(self.conv2(out)))
47 | out = self.avgpool(out)
48 | out = self.bn3(self.conv3(out))
49 |
50 | if self.downsample is not None:
51 | identity = self.downsample(x)
52 |
53 | out += identity
54 | out = self.act3(out)
55 | return out
56 |
57 |
58 | class AttentionPool2d(nn.Module):
59 | def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
60 | super().__init__()
61 | self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)
62 | self.k_proj = nn.Linear(embed_dim, embed_dim)
63 | self.q_proj = nn.Linear(embed_dim, embed_dim)
64 | self.v_proj = nn.Linear(embed_dim, embed_dim)
65 | self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
66 | self.num_heads = num_heads
67 |
68 | def forward(self, x):
69 | x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3]).permute(2, 0, 1) # NCHW -> (HW)NC
70 | x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
71 | x = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NC
72 | x, _ = F.multi_head_attention_forward(
73 | query=x, key=x, value=x,
74 | embed_dim_to_check=x.shape[-1],
75 | num_heads=self.num_heads,
76 | q_proj_weight=self.q_proj.weight,
77 | k_proj_weight=self.k_proj.weight,
78 | v_proj_weight=self.v_proj.weight,
79 | in_proj_weight=None,
80 | in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
81 | bias_k=None,
82 | bias_v=None,
83 | add_zero_attn=False,
84 | dropout_p=0.,
85 | out_proj_weight=self.c_proj.weight,
86 | out_proj_bias=self.c_proj.bias,
87 | use_separate_proj_weight=True,
88 | training=self.training,
89 | need_weights=False
90 | )
91 |
92 | return x[0]
93 |
94 |
95 | class ModifiedResNet(nn.Module):
96 | """
97 | A ResNet class that is similar to torchvision's but contains the following changes:
98 | - There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
99 | - Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
100 | - The final pooling layer is a QKV attention instead of an average pool
101 | """
102 |
103 | def __init__(self, layers, output_dim, heads, image_size=224, width=64):
104 | super().__init__()
105 | self.output_dim = output_dim
106 | self.image_size = image_size
107 |
108 | # the 3-layer stem
109 | self.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
110 | self.bn1 = nn.BatchNorm2d(width // 2)
111 | self.act1 = nn.ReLU(inplace=True)
112 | self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)
113 | self.bn2 = nn.BatchNorm2d(width // 2)
114 | self.act2 = nn.ReLU(inplace=True)
115 | self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)
116 | self.bn3 = nn.BatchNorm2d(width)
117 | self.act3 = nn.ReLU(inplace=True)
118 | self.avgpool = nn.AvgPool2d(2)
119 |
120 | # residual layers
121 | self._inplanes = width # this is a *mutable* variable used during construction
122 | self.layer1 = self._make_layer(width, layers[0])
123 | self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
124 | self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
125 | self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
126 |
127 | embed_dim = width * 32 # the ResNet feature dimension
128 | self.attnpool = AttentionPool2d(image_size // 32, embed_dim, heads, output_dim)
129 |
130 | self.init_parameters()
131 |
132 | def _make_layer(self, planes, blocks, stride=1):
133 | layers = [Bottleneck(self._inplanes, planes, stride)]
134 |
135 | self._inplanes = planes * Bottleneck.expansion
136 | for _ in range(1, blocks):
137 | layers.append(Bottleneck(self._inplanes, planes))
138 |
139 | return nn.Sequential(*layers)
140 |
141 | def init_parameters(self):
142 | if self.attnpool is not None:
143 | std = self.attnpool.c_proj.in_features ** -0.5
144 | nn.init.normal_(self.attnpool.q_proj.weight, std=std)
145 | nn.init.normal_(self.attnpool.k_proj.weight, std=std)
146 | nn.init.normal_(self.attnpool.v_proj.weight, std=std)
147 | nn.init.normal_(self.attnpool.c_proj.weight, std=std)
148 |
149 | for resnet_block in [self.layer1, self.layer2, self.layer3, self.layer4]:
150 | for name, param in resnet_block.named_parameters():
151 | if name.endswith("bn3.weight"):
152 | nn.init.zeros_(param)
153 |
154 | def lock(self, unlocked_groups=0, freeze_bn_stats=False):
155 | assert unlocked_groups == 0, 'partial locking not currently supported for this model'
156 | for param in self.parameters():
157 | param.requires_grad = False
158 | if freeze_bn_stats:
159 | freeze_batch_norm_2d(self)
160 |
161 | @torch.jit.ignore
162 | def set_grad_checkpointing(self, enable=True):
163 | # FIXME support for non-transformer
164 | pass
165 |
166 | def stem(self, x):
167 | x = self.act1(self.bn1(self.conv1(x)))
168 | x = self.act2(self.bn2(self.conv2(x)))
169 | x = self.act3(self.bn3(self.conv3(x)))
170 | x = self.avgpool(x)
171 | return x
172 |
173 | def forward(self, x):
174 | x = self.stem(x)
175 | x = self.layer1(x)
176 | x = self.layer2(x)
177 | x = self.layer3(x)
178 | x = self.layer4(x)
179 | x = self.attnpool(x)
180 |
181 | return x
182 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/openai.py:
--------------------------------------------------------------------------------
1 | """ OpenAI pretrained model functions
2 |
3 | Adapted from https://github.com/openai/CLIP. Originally MIT License, Copyright (c) 2021 OpenAI.
4 | """
5 |
6 | import os
7 | import warnings
8 | from typing import List, Optional, Union
9 |
10 | import torch
11 |
12 | from .model import build_model_from_openai_state_dict, convert_weights_to_lp, get_cast_dtype
13 | from .pretrained import get_pretrained_url, list_pretrained_models_by_tag, download_pretrained_from_url
14 |
15 | __all__ = ["list_openai_models", "load_openai_model"]
16 |
17 |
18 | def list_openai_models() -> List[str]:
19 | """Returns the names of available CLIP models"""
20 | return list_pretrained_models_by_tag('openai')
21 |
22 |
23 | def load_openai_model(
24 | name: str,
25 | precision: Optional[str] = None,
26 | device: Optional[Union[str, torch.device]] = None,
27 | jit: bool = True,
28 | cache_dir: Optional[str] = None,
29 | ):
30 | """Load a CLIP model
31 |
32 | Parameters
33 | ----------
34 | name : str
35 | A model name listed by `clip.available_models()`, or the path to a model checkpoint containing the state_dict
36 | precision: str
37 | Model precision, if None defaults to 'fp32' if device == 'cpu' else 'fp16'.
38 | device : Union[str, torch.device]
39 | The device to put the loaded model
40 | jit : bool
41 | Whether to load the optimized JIT model (default) or more hackable non-JIT model.
42 | cache_dir : Optional[str]
43 | The directory to cache the downloaded model weights
44 |
45 | Returns
46 | -------
47 | model : torch.nn.Module
48 | The CLIP model
49 | preprocess : Callable[[PIL.Image], torch.Tensor]
50 | A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input
51 | """
52 | if device is None:
53 | device = "cuda" if torch.cuda.is_available() else "cpu"
54 | if precision is None:
55 | precision = 'fp32' if device == 'cpu' else 'fp16'
56 |
57 | if get_pretrained_url(name, 'openai'):
58 | model_path = download_pretrained_from_url(get_pretrained_url(name, 'openai'), cache_dir=cache_dir)
59 | elif os.path.isfile(name):
60 | model_path = name
61 | else:
62 | raise RuntimeError(f"Model {name} not found; available models = {list_openai_models()}")
63 |
64 | try:
65 | # loading JIT archive
66 | model = torch.jit.load(model_path, map_location=device if jit else "cpu").eval()
67 | state_dict = None
68 | except RuntimeError:
69 | # loading saved state dict
70 | if jit:
71 | warnings.warn(f"File {model_path} is not a JIT archive. Loading as a state dict instead")
72 | jit = False
73 | state_dict = torch.load(model_path, map_location="cpu")
74 |
75 | if not jit:
76 | # Build a non-jit model from the OpenAI jitted model state dict
77 | cast_dtype = get_cast_dtype(precision)
78 | try:
79 | model = build_model_from_openai_state_dict(state_dict or model.state_dict(), cast_dtype=cast_dtype)
80 | except KeyError:
81 | sd = {k[7:]: v for k, v in state_dict["state_dict"].items()}
82 | model = build_model_from_openai_state_dict(sd, cast_dtype=cast_dtype)
83 |
84 | # model from OpenAI state dict is in manually cast fp16 mode, must be converted for AMP/fp32/bf16 use
85 | model = model.to(device)
86 | if precision.startswith('amp') or precision == 'fp32':
87 | model.float()
88 | elif precision == 'bf16':
89 | convert_weights_to_lp(model, dtype=torch.bfloat16)
90 |
91 | return model
92 |
93 | # patch the device names
94 | device_holder = torch.jit.trace(lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])
95 | device_node = [n for n in device_holder.graph.findAllNodes("prim::Constant") if "Device" in repr(n)][-1]
96 |
97 | def patch_device(module):
98 | try:
99 | graphs = [module.graph] if hasattr(module, "graph") else []
100 | except RuntimeError:
101 | graphs = []
102 |
103 | if hasattr(module, "forward1"):
104 | graphs.append(module.forward1.graph)
105 |
106 | for graph in graphs:
107 | for node in graph.findAllNodes("prim::Constant"):
108 | if "value" in node.attributeNames() and str(node["value"]).startswith("cuda"):
109 | node.copyAttributes(device_node)
110 |
111 | model.apply(patch_device)
112 | patch_device(model.encode_image)
113 | patch_device(model.encode_text)
114 |
115 | # patch dtype to float32 (typically for CPU)
116 | if precision == 'fp32':
117 | float_holder = torch.jit.trace(lambda: torch.ones([]).float(), example_inputs=[])
118 | float_input = list(float_holder.graph.findNode("aten::to").inputs())[1]
119 | float_node = float_input.node()
120 |
121 | def patch_float(module):
122 | try:
123 | graphs = [module.graph] if hasattr(module, "graph") else []
124 | except RuntimeError:
125 | graphs = []
126 |
127 | if hasattr(module, "forward1"):
128 | graphs.append(module.forward1.graph)
129 |
130 | for graph in graphs:
131 | for node in graph.findAllNodes("aten::to"):
132 | inputs = list(node.inputs())
133 | for i in [1, 2]: # dtype can be the second or third argument to aten::to()
134 | if inputs[i].node()["value"] == 5:
135 | inputs[i].node().copyAttributes(float_node)
136 |
137 | model.apply(patch_float)
138 | patch_float(model.encode_image)
139 | patch_float(model.encode_text)
140 | model.float()
141 |
142 | # ensure image_size attr available at consistent location for both jit and non-jit
143 | model.visual.image_size = model.input_resolution.item()
144 | return model
145 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/push_to_hf_hub.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import json
3 | from pathlib import Path
4 | from tempfile import TemporaryDirectory
5 | from typing import Optional, Tuple
6 |
7 | import torch
8 |
9 | try:
10 | from huggingface_hub import (
11 | create_repo,
12 | get_hf_file_metadata,
13 | hf_hub_download,
14 | hf_hub_url,
15 | repo_type_and_id_from_hf_id,
16 | upload_folder,
17 | )
18 | from huggingface_hub.utils import EntryNotFoundError
19 | _has_hf_hub = True
20 | except ImportError:
21 | _has_hf_hub = False
22 |
23 | from .factory import create_model_from_pretrained, get_model_config, get_tokenizer
24 | from .tokenizer import HFTokenizer
25 |
26 |
27 | def save_config_for_hf(
28 | model,
29 | config_path: str,
30 | model_config: Optional[dict]
31 | ):
32 | preprocess_cfg = {
33 | 'mean': model.visual.image_mean,
34 | 'std': model.visual.image_std,
35 | }
36 | hf_config = {
37 | 'model_cfg': model_config,
38 | 'preprocess_cfg': preprocess_cfg,
39 | }
40 |
41 | with config_path.open('w') as f:
42 | json.dump(hf_config, f, indent=2)
43 |
44 |
45 | def save_for_hf(
46 | model,
47 | tokenizer: HFTokenizer,
48 | model_config: dict,
49 | save_directory: str,
50 | weights_filename='open_clip_pytorch_model.bin',
51 | config_filename='open_clip_config.json',
52 | ):
53 | save_directory = Path(save_directory)
54 | save_directory.mkdir(exist_ok=True, parents=True)
55 |
56 | weights_path = save_directory / weights_filename
57 | torch.save(model.state_dict(), weights_path)
58 |
59 | tokenizer.save_pretrained(save_directory)
60 |
61 | config_path = save_directory / config_filename
62 | save_config_for_hf(model, config_path, model_config=model_config)
63 |
64 |
65 | def push_to_hf_hub(
66 | model,
67 | tokenizer,
68 | model_config: Optional[dict],
69 | repo_id: str,
70 | commit_message: str = 'Add model',
71 | token: Optional[str] = None,
72 | revision: Optional[str] = None,
73 | private: bool = False,
74 | create_pr: bool = False,
75 | model_card: Optional[dict] = None,
76 | ):
77 | if not isinstance(tokenizer, HFTokenizer):
78 | # default CLIP tokenizers use https://huggingface.co/openai/clip-vit-large-patch14
79 | tokenizer = HFTokenizer('openai/clip-vit-large-patch14')
80 |
81 | # Create repo if it doesn't exist yet
82 | repo_url = create_repo(repo_id, token=token, private=private, exist_ok=True)
83 |
84 | # Infer complete repo_id from repo_url
85 | # Can be different from the input `repo_id` if repo_owner was implicit
86 | _, repo_owner, repo_name = repo_type_and_id_from_hf_id(repo_url)
87 | repo_id = f"{repo_owner}/{repo_name}"
88 |
89 | # Check if README file already exist in repo
90 | try:
91 | get_hf_file_metadata(hf_hub_url(repo_id=repo_id, filename="README.md", revision=revision))
92 | has_readme = True
93 | except EntryNotFoundError:
94 | has_readme = False
95 |
96 | # Dump model and push to Hub
97 | with TemporaryDirectory() as tmpdir:
98 | # Save model weights and config.
99 | save_for_hf(
100 | model,
101 | tokenizer=tokenizer,
102 | model_config=model_config,
103 | save_directory=tmpdir,
104 | )
105 |
106 | # Add readme if it does not exist
107 | if not has_readme:
108 | model_card = model_card or {}
109 | model_name = repo_id.split('/')[-1]
110 | readme_path = Path(tmpdir) / "README.md"
111 | readme_text = generate_readme(model_card, model_name)
112 | readme_path.write_text(readme_text)
113 |
114 | # Upload model and return
115 | return upload_folder(
116 | repo_id=repo_id,
117 | folder_path=tmpdir,
118 | revision=revision,
119 | create_pr=create_pr,
120 | commit_message=commit_message,
121 | )
122 |
123 |
124 | def push_pretrained_to_hf_hub(
125 | model_name,
126 | pretrained: str,
127 | repo_id: str,
128 | image_mean: Optional[Tuple[float, ...]] = None,
129 | image_std: Optional[Tuple[float, ...]] = None,
130 | commit_message: str = 'Add model',
131 | token: Optional[str] = None,
132 | revision: Optional[str] = None,
133 | private: bool = False,
134 | create_pr: bool = False,
135 | model_card: Optional[dict] = None,
136 | ):
137 | model, preprocess_eval = create_model_from_pretrained(
138 | model_name,
139 | pretrained=pretrained,
140 | image_mean=image_mean,
141 | image_std=image_std,
142 | )
143 |
144 | model_config = get_model_config(model_name)
145 | assert model_config
146 |
147 | tokenizer = get_tokenizer(model_name)
148 |
149 | push_to_hf_hub(
150 | model=model,
151 | tokenizer=tokenizer,
152 | model_config=model_config,
153 | repo_id=repo_id,
154 | commit_message=commit_message,
155 | token=token,
156 | revision=revision,
157 | private=private,
158 | create_pr=create_pr,
159 | model_card=model_card,
160 | )
161 |
162 |
163 | def generate_readme(model_card: dict, model_name: str):
164 | readme_text = "---\n"
165 | readme_text += "tags:\n- zero-shot-image-classification\n- clip\n"
166 | readme_text += "library_tag: open_clip\n"
167 | readme_text += f"license: {model_card.get('license', 'mit')}\n"
168 | if 'details' in model_card and 'Dataset' in model_card['details']:
169 | readme_text += 'datasets:\n'
170 | readme_text += f"- {model_card['details']['Dataset'].lower()}\n"
171 | readme_text += "---\n"
172 | readme_text += f"# Model card for {model_name}\n"
173 | if 'description' in model_card:
174 | readme_text += f"\n{model_card['description']}\n"
175 | if 'details' in model_card:
176 | readme_text += f"\n## Model Details\n"
177 | for k, v in model_card['details'].items():
178 | if isinstance(v, (list, tuple)):
179 | readme_text += f"- **{k}:**\n"
180 | for vi in v:
181 | readme_text += f" - {vi}\n"
182 | elif isinstance(v, dict):
183 | readme_text += f"- **{k}:**\n"
184 | for ki, vi in v.items():
185 | readme_text += f" - {ki}: {vi}\n"
186 | else:
187 | readme_text += f"- **{k}:** {v}\n"
188 | if 'usage' in model_card:
189 | readme_text += f"\n## Model Usage\n"
190 | readme_text += model_card['usage']
191 | readme_text += '\n'
192 |
193 | if 'comparison' in model_card:
194 | readme_text += f"\n## Model Comparison\n"
195 | readme_text += model_card['comparison']
196 | readme_text += '\n'
197 |
198 | if 'citation' in model_card:
199 | readme_text += f"\n## Citation\n"
200 | if not isinstance(model_card['citation'], (list, tuple)):
201 | citations = [model_card['citation']]
202 | else:
203 | citations = model_card['citation']
204 | for c in citations:
205 | readme_text += f"```bibtex\n{c}\n```\n"
206 |
207 | return readme_text
208 |
209 |
210 | if __name__ == "__main__":
211 | parser = argparse.ArgumentParser(description="Push to Hugging Face Hub")
212 | parser.add_argument(
213 | "--model", type=str, help="Name of the model to use.",
214 | )
215 | parser.add_argument(
216 | "--pretrained", type=str,
217 | help="Use a pretrained CLIP model weights with the specified tag or file path.",
218 | )
219 | parser.add_argument(
220 | "--repo-id", type=str,
221 | help="Destination HF Hub repo-id ie 'organization/model_id'.",
222 | )
223 | parser.add_argument(
224 | '--image-mean', type=float, nargs='+', default=None, metavar='MEAN',
225 | help='Override default image mean value of dataset')
226 | parser.add_argument(
227 | '--image-std', type=float, nargs='+', default=None, metavar='STD',
228 | help='Override default image std deviation of of dataset')
229 | args = parser.parse_args()
230 |
231 | print(f'Saving model {args.model} with pretrained weights {args.pretrained} to Hugging Face Hub at {args.repo_id}')
232 |
233 | # FIXME add support to pass model_card json / template from file via cmd line
234 |
235 | push_pretrained_to_hf_hub(
236 | args.model,
237 | args.pretrained,
238 | args.repo_id,
239 | image_mean=args.image_mean, # override image mean/std if trained w/ non defaults
240 | image_std=args.image_std,
241 | )
242 |
243 | print(f'{args.model} saved.')
244 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/timm_model.py:
--------------------------------------------------------------------------------
1 | """ timm model adapter
2 |
3 | Wraps timm (https://github.com/rwightman/pytorch-image-models) models for use as a vision tower in CLIP model.
4 | """
5 | import logging
6 | from collections import OrderedDict
7 |
8 | import torch
9 | import torch.nn as nn
10 |
11 | try:
12 | import timm
13 | from timm.models.layers import Mlp, to_2tuple
14 | try:
15 | # old timm imports < 0.8.1
16 | from timm.models.layers.attention_pool2d import RotAttentionPool2d
17 | from timm.models.layers.attention_pool2d import AttentionPool2d as AbsAttentionPool2d
18 | except ImportError:
19 | # new timm imports >= 0.8.1
20 | from timm.layers import RotAttentionPool2d
21 | from timm.layers import AttentionPool2d as AbsAttentionPool2d
22 | except ImportError:
23 | timm = None
24 |
25 | from .utils import freeze_batch_norm_2d
26 |
27 |
28 | class TimmModel(nn.Module):
29 | """ timm model adapter
30 | # FIXME this adapter is a work in progress, may change in ways that break weight compat
31 | """
32 |
33 | def __init__(
34 | self,
35 | model_name,
36 | embed_dim,
37 | image_size=224,
38 | pool='avg',
39 | proj='linear',
40 | proj_bias=False,
41 | drop=0.,
42 | drop_path=None,
43 | pretrained=False,
44 | ):
45 | super().__init__()
46 | if timm is None:
47 | raise RuntimeError("Please `pip install timm` to use timm models.")
48 |
49 | self.image_size = to_2tuple(image_size)
50 | timm_kwargs = {}
51 | if drop_path is not None:
52 | timm_kwargs['drop_path_rate'] = drop_path
53 | self.trunk = timm.create_model(model_name, pretrained=pretrained, **timm_kwargs)
54 | feat_size = self.trunk.default_cfg.get('pool_size', None)
55 | feature_ndim = 1 if not feat_size else 2
56 | if pool in ('abs_attn', 'rot_attn'):
57 | assert feature_ndim == 2
58 | # if attn pooling used, remove both classifier and default pool
59 | self.trunk.reset_classifier(0, global_pool='')
60 | else:
61 | # reset global pool if pool config set, otherwise leave as network default
62 | reset_kwargs = dict(global_pool=pool) if pool else {}
63 | self.trunk.reset_classifier(0, **reset_kwargs)
64 | prev_chs = self.trunk.num_features
65 |
66 | head_layers = OrderedDict()
67 | if pool == 'abs_attn':
68 | head_layers['pool'] = AbsAttentionPool2d(prev_chs, feat_size=feat_size, out_features=embed_dim)
69 | prev_chs = embed_dim
70 | elif pool == 'rot_attn':
71 | head_layers['pool'] = RotAttentionPool2d(prev_chs, out_features=embed_dim)
72 | prev_chs = embed_dim
73 | else:
74 | assert proj, 'projection layer needed if non-attention pooling is used.'
75 |
76 | # NOTE attention pool ends with a projection layer, so proj should usually be set to '' if such pooling is used
77 | if proj == 'linear':
78 | head_layers['drop'] = nn.Dropout(drop)
79 | head_layers['proj'] = nn.Linear(prev_chs, embed_dim, bias=proj_bias)
80 | elif proj == 'mlp':
81 | head_layers['mlp'] = Mlp(prev_chs, 2 * embed_dim, embed_dim, drop=(drop, 0), bias=(True, proj_bias))
82 |
83 | self.head = nn.Sequential(head_layers)
84 |
85 | def lock(self, unlocked_groups=0, freeze_bn_stats=False):
86 | """ lock modules
87 | Args:
88 | unlocked_groups (int): leave last n layer groups unlocked (default: 0)
89 | """
90 | if not unlocked_groups:
91 | # lock full model
92 | for param in self.trunk.parameters():
93 | param.requires_grad = False
94 | if freeze_bn_stats:
95 | freeze_batch_norm_2d(self.trunk)
96 | else:
97 | # NOTE: partial freeze requires latest timm (master) branch and is subject to change
98 | try:
99 | # FIXME import here until API stable and in an official release
100 | from timm.models.helpers import group_parameters, group_modules
101 | except ImportError:
102 | raise RuntimeError(
103 | 'Please install latest timm `pip install git+https://github.com/rwightman/pytorch-image-models`')
104 | matcher = self.trunk.group_matcher()
105 | gparams = group_parameters(self.trunk, matcher)
106 | max_layer_id = max(gparams.keys())
107 | max_layer_id = max_layer_id - unlocked_groups
108 | for group_idx in range(max_layer_id + 1):
109 | group = gparams[group_idx]
110 | for param in group:
111 | self.trunk.get_parameter(param).requires_grad = False
112 | if freeze_bn_stats:
113 | gmodules = group_modules(self.trunk, matcher, reverse=True)
114 | gmodules = {k for k, v in gmodules.items() if v <= max_layer_id}
115 | freeze_batch_norm_2d(self.trunk, gmodules)
116 |
117 | @torch.jit.ignore
118 | def set_grad_checkpointing(self, enable=True):
119 | try:
120 | self.trunk.set_grad_checkpointing(enable)
121 | except Exception as e:
122 | logging.warning('grad checkpointing not supported for this timm image tower, continuing without...')
123 |
124 | def forward(self, x):
125 | x = self.trunk(x)
126 | x = self.head(x)
127 | return x
128 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/tokenizer.py:
--------------------------------------------------------------------------------
1 | """ CLIP tokenizer
2 |
3 | Copied from https://github.com/openai/CLIP. Originally MIT License, Copyright (c) 2021 OpenAI.
4 | """
5 | import gzip
6 | import html
7 | import os
8 | from functools import lru_cache
9 | from typing import Union, List
10 |
11 | import ftfy
12 | import regex as re
13 | import torch
14 |
15 | # https://stackoverflow.com/q/62691279
16 | import os
17 | os.environ["TOKENIZERS_PARALLELISM"] = "false"
18 |
19 |
20 | @lru_cache()
21 | def default_bpe():
22 | return os.path.join(os.path.dirname(os.path.abspath(__file__)), "bpe_simple_vocab_16e6.txt.gz")
23 |
24 |
25 | @lru_cache()
26 | def bytes_to_unicode():
27 | """
28 | Returns list of utf-8 byte and a corresponding list of unicode strings.
29 | The reversible bpe codes work on unicode strings.
30 | This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
31 | When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
32 | This is a significant percentage of your normal, say, 32K bpe vocab.
33 | To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
34 | And avoids mapping to whitespace/control characters the bpe code barfs on.
35 | """
36 | bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
37 | cs = bs[:]
38 | n = 0
39 | for b in range(2**8):
40 | if b not in bs:
41 | bs.append(b)
42 | cs.append(2**8+n)
43 | n += 1
44 | cs = [chr(n) for n in cs]
45 | return dict(zip(bs, cs))
46 |
47 |
48 | def get_pairs(word):
49 | """Return set of symbol pairs in a word.
50 | Word is represented as tuple of symbols (symbols being variable-length strings).
51 | """
52 | pairs = set()
53 | prev_char = word[0]
54 | for char in word[1:]:
55 | pairs.add((prev_char, char))
56 | prev_char = char
57 | return pairs
58 |
59 |
60 | def basic_clean(text):
61 | text = ftfy.fix_text(text)
62 | text = html.unescape(html.unescape(text))
63 | return text.strip()
64 |
65 |
66 | def whitespace_clean(text):
67 | text = re.sub(r'\s+', ' ', text)
68 | text = text.strip()
69 | return text
70 |
71 |
72 | class SimpleTokenizer(object):
73 | def __init__(self, bpe_path: str = default_bpe(), special_tokens=None):
74 | self.byte_encoder = bytes_to_unicode()
75 | self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
76 | merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
77 | merges = merges[1:49152-256-2+1]
78 | merges = [tuple(merge.split()) for merge in merges]
79 | vocab = list(bytes_to_unicode().values())
80 | vocab = vocab + [v+'' for v in vocab]
81 | for merge in merges:
82 | vocab.append(''.join(merge))
83 | if not special_tokens:
84 | special_tokens = ['', '']
85 | else:
86 | special_tokens = ['', ''] + special_tokens
87 | vocab.extend(special_tokens)
88 | self.encoder = dict(zip(vocab, range(len(vocab))))
89 | self.decoder = {v: k for k, v in self.encoder.items()}
90 | self.bpe_ranks = dict(zip(merges, range(len(merges))))
91 | self.cache = {t:t for t in special_tokens}
92 | special = "|".join(special_tokens)
93 | self.pat = re.compile(special + r"""|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""", re.IGNORECASE)
94 |
95 | self.vocab_size = len(self.encoder)
96 | self.all_special_ids = [self.encoder[t] for t in special_tokens]
97 |
98 | def bpe(self, token):
99 | if token in self.cache:
100 | return self.cache[token]
101 | word = tuple(token[:-1]) + ( token[-1] + '',)
102 | pairs = get_pairs(word)
103 |
104 | if not pairs:
105 | return token+''
106 |
107 | while True:
108 | bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float('inf')))
109 | if bigram not in self.bpe_ranks:
110 | break
111 | first, second = bigram
112 | new_word = []
113 | i = 0
114 | while i < len(word):
115 | try:
116 | j = word.index(first, i)
117 | new_word.extend(word[i:j])
118 | i = j
119 | except:
120 | new_word.extend(word[i:])
121 | break
122 |
123 | if word[i] == first and i < len(word)-1 and word[i+1] == second:
124 | new_word.append(first+second)
125 | i += 2
126 | else:
127 | new_word.append(word[i])
128 | i += 1
129 | new_word = tuple(new_word)
130 | word = new_word
131 | if len(word) == 1:
132 | break
133 | else:
134 | pairs = get_pairs(word)
135 | word = ' '.join(word)
136 | self.cache[token] = word
137 | return word
138 |
139 | def encode(self, text):
140 | bpe_tokens = []
141 | text = whitespace_clean(basic_clean(text)).lower()
142 | for token in re.findall(self.pat, text):
143 | token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
144 | bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
145 | return bpe_tokens
146 |
147 | def decode(self, tokens):
148 | text = ''.join([self.decoder[token] for token in tokens])
149 | text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('', ' ')
150 | return text
151 |
152 |
153 | _tokenizer = SimpleTokenizer()
154 |
155 | def decode(output_ids: torch.Tensor):
156 | output_ids = output_ids.cpu().numpy()
157 | return _tokenizer.decode(output_ids)
158 |
159 | def tokenize(texts: Union[str, List[str]], context_length: int = 77) -> torch.LongTensor:
160 | """
161 | Returns the tokenized representation of given input string(s)
162 |
163 | Parameters
164 | ----------
165 | texts : Union[str, List[str]]
166 | An input string or a list of input strings to tokenize
167 | context_length : int
168 | The context length to use; all CLIP models use 77 as the context length
169 |
170 | Returns
171 | -------
172 | A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
173 | """
174 | if isinstance(texts, str):
175 | texts = [texts]
176 |
177 | sot_token = _tokenizer.encoder[""]
178 | eot_token = _tokenizer.encoder[""]
179 | all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
180 | result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
181 |
182 | for i, tokens in enumerate(all_tokens):
183 | if len(tokens) > context_length:
184 | tokens = tokens[:context_length] # Truncate
185 | tokens[-1] = eot_token
186 | result[i, :len(tokens)] = torch.tensor(tokens)
187 |
188 | return result
189 |
190 |
191 | class HFTokenizer:
192 | """HuggingFace tokenizer wrapper"""
193 |
194 | def __init__(self, tokenizer_name: str):
195 | from transformers import AutoTokenizer
196 | self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
197 |
198 | def save_pretrained(self, dest):
199 | self.tokenizer.save_pretrained(dest)
200 |
201 | def __call__(self, texts: Union[str, List[str]], context_length: int = 77) -> torch.Tensor:
202 | # same cleaning as for default tokenizer, except lowercasing
203 | # adding lower (for case-sensitive tokenizers) will make it more robust but less sensitive to nuance
204 | if isinstance(texts, str):
205 | texts = [texts]
206 | texts = [whitespace_clean(basic_clean(text)) for text in texts]
207 | input_ids = self.tokenizer(
208 | texts,
209 | return_tensors='pt',
210 | max_length=context_length,
211 | padding='max_length',
212 | truncation=True,
213 | ).input_ids
214 | return input_ids
215 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/transform.py:
--------------------------------------------------------------------------------
1 | import warnings
2 | from dataclasses import dataclass, asdict
3 | from typing import Any, Dict, Optional, Sequence, Tuple, Union
4 | import logging
5 |
6 | import torch
7 | import torch.nn as nn
8 | import torchvision.transforms.functional as F
9 |
10 | from torchvision.transforms import Normalize, Compose, RandomResizedCrop, InterpolationMode, ToTensor, Resize, \
11 | CenterCrop
12 |
13 | from .constants import OPENAI_DATASET_MEAN, OPENAI_DATASET_STD
14 |
15 |
16 | @dataclass
17 | class AugmentationCfg:
18 | hflip: Optional[float] = 0.
19 | scale: Tuple[float, float] = (0.9, 1.0)
20 | ratio: Optional[Tuple[float, float]] = None
21 | color_jitter: Optional[Union[float, Tuple[float, float, float]]] = None
22 | interpolation: Optional[str] = None
23 | re_prob: Optional[float] = None
24 | re_count: Optional[int] = None
25 | use_timm: bool = False
26 | auto_augment: Optional[str] = None
27 |
28 |
29 | class ResizeMaxSize(nn.Module):
30 |
31 | def __init__(self, max_size, interpolation=InterpolationMode.BICUBIC, fn='max', fill=0):
32 | super().__init__()
33 | if not isinstance(max_size, int):
34 | raise TypeError(f"Size should be int. Got {type(max_size)}")
35 | self.max_size = max_size
36 | self.interpolation = interpolation
37 | self.fn = min if fn == 'min' else min
38 | self.fill = fill
39 |
40 | def forward(self, img):
41 | if isinstance(img, torch.Tensor):
42 | height, width = img.shape[:2]
43 | else:
44 | width, height = img.size
45 | scale = self.max_size / float(max(height, width))
46 | if scale != 1.0:
47 | new_size = tuple(round(dim * scale) for dim in (height, width))
48 | img = F.resize(img, new_size, self.interpolation)
49 | pad_h = self.max_size - new_size[0]
50 | pad_w = self.max_size - new_size[1]
51 | img = F.pad(img, padding=[pad_w//2, pad_h//2, pad_w - pad_w//2, pad_h - pad_h//2], fill=self.fill)
52 | return img
53 |
54 |
55 | def _convert_to_rgb(image):
56 | return image.convert('RGB')
57 |
58 |
59 | def image_transform(
60 | image_size: int,
61 | is_train: bool,
62 | mean: Optional[Tuple[float, ...]] = None,
63 | std: Optional[Tuple[float, ...]] = None,
64 | resize_longest_max: bool = False,
65 | fill_color: int = 0,
66 | aug_cfg: Optional[Union[Dict[str, Any], AugmentationCfg]] = None,
67 | ):
68 | mean = mean or OPENAI_DATASET_MEAN
69 | if not isinstance(mean, (list, tuple)):
70 | mean = (mean,) * 3
71 |
72 | std = std or OPENAI_DATASET_STD
73 | if not isinstance(std, (list, tuple)):
74 | std = (std,) * 3
75 |
76 | if isinstance(image_size, (list, tuple)) and image_size[0] == image_size[1]:
77 | # for square size, pass size as int so that Resize() uses aspect preserving shortest edge
78 | image_size = image_size[0]
79 |
80 | if isinstance(aug_cfg, dict):
81 | aug_cfg = AugmentationCfg(**aug_cfg)
82 | else:
83 | aug_cfg = aug_cfg or AugmentationCfg()
84 | normalize = Normalize(mean=mean, std=std)
85 | if is_train:
86 | aug_cfg_dict = {k: v for k, v in asdict(aug_cfg).items() if v is not None}
87 | use_timm = aug_cfg_dict.pop('use_timm', False)
88 | if use_timm:
89 | from timm.data import create_transform # timm can still be optional
90 | if isinstance(image_size, (tuple, list)):
91 | assert len(image_size) >= 2
92 | input_size = (3,) + image_size[-2:]
93 | else:
94 | input_size = (3, image_size, image_size)
95 | # by default, timm aug randomly alternates bicubic & bilinear for better robustness at inference time
96 | aug_cfg_dict.setdefault('interpolation', 'random')
97 | aug_cfg_dict.setdefault('hflip', 0.)
98 | aug_cfg_dict.setdefault('color_jitter', None) # disable by default
99 |
100 | logging.info(f'Using timm_aug: {aug_cfg_dict}')
101 |
102 | train_transform = create_transform(
103 | input_size=input_size,
104 | is_training=True,
105 | # hflip=0.,
106 | mean=mean,
107 | std=std,
108 | re_mode='pixel',
109 | **aug_cfg_dict,
110 | )
111 | else:
112 | train_transform = Compose([
113 | RandomResizedCrop(
114 | image_size,
115 | scale=aug_cfg_dict.pop('scale'),
116 | interpolation=InterpolationMode.BICUBIC,
117 | ),
118 | _convert_to_rgb,
119 | ToTensor(),
120 | normalize,
121 | ])
122 | if aug_cfg_dict:
123 | warnings.warn(f'Unused augmentation cfg items, specify `use_timm` to use ({list(aug_cfg_dict.keys())}).')
124 | return train_transform
125 | else:
126 | if resize_longest_max:
127 | transforms = [
128 | ResizeMaxSize(image_size, fill=fill_color)
129 | ]
130 | else:
131 | transforms = [
132 | Resize(image_size, interpolation=InterpolationMode.BICUBIC),
133 | CenterCrop(image_size),
134 | ]
135 | transforms.extend([
136 | _convert_to_rgb,
137 | ToTensor(),
138 | normalize,
139 | ])
140 | return Compose(transforms)
141 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/utils.py:
--------------------------------------------------------------------------------
1 | from itertools import repeat
2 | import collections.abc
3 |
4 | from torch import nn as nn
5 | from torchvision.ops.misc import FrozenBatchNorm2d
6 |
7 |
8 | def freeze_batch_norm_2d(module, module_match={}, name=''):
9 | """
10 | Converts all `BatchNorm2d` and `SyncBatchNorm` layers of provided module into `FrozenBatchNorm2d`. If `module` is
11 | itself an instance of either `BatchNorm2d` or `SyncBatchNorm`, it is converted into `FrozenBatchNorm2d` and
12 | returned. Otherwise, the module is walked recursively and submodules are converted in place.
13 |
14 | Args:
15 | module (torch.nn.Module): Any PyTorch module.
16 | module_match (dict): Dictionary of full module names to freeze (all if empty)
17 | name (str): Full module name (prefix)
18 |
19 | Returns:
20 | torch.nn.Module: Resulting module
21 |
22 | Inspired by https://github.com/pytorch/pytorch/blob/a5895f85be0f10212791145bfedc0261d364f103/torch/nn/modules/batchnorm.py#L762
23 | """
24 | res = module
25 | is_match = True
26 | if module_match:
27 | is_match = name in module_match
28 | if is_match and isinstance(module, (nn.modules.batchnorm.BatchNorm2d, nn.modules.batchnorm.SyncBatchNorm)):
29 | res = FrozenBatchNorm2d(module.num_features)
30 | res.num_features = module.num_features
31 | res.affine = module.affine
32 | if module.affine:
33 | res.weight.data = module.weight.data.clone().detach()
34 | res.bias.data = module.bias.data.clone().detach()
35 | res.running_mean.data = module.running_mean.data
36 | res.running_var.data = module.running_var.data
37 | res.eps = module.eps
38 | else:
39 | for child_name, child in module.named_children():
40 | full_child_name = '.'.join([name, child_name]) if name else child_name
41 | new_child = freeze_batch_norm_2d(child, module_match, full_child_name)
42 | if new_child is not child:
43 | res.add_module(child_name, new_child)
44 | return res
45 |
46 |
47 | # From PyTorch internals
48 | def _ntuple(n):
49 | def parse(x):
50 | if isinstance(x, collections.abc.Iterable):
51 | return x
52 | return tuple(repeat(x, n))
53 | return parse
54 |
55 |
56 | to_1tuple = _ntuple(1)
57 | to_2tuple = _ntuple(2)
58 | to_3tuple = _ntuple(3)
59 | to_4tuple = _ntuple(4)
60 | to_ntuple = lambda n, x: _ntuple(n)(x)
61 |
--------------------------------------------------------------------------------
/react_customization/src/open_clip/version.py:
--------------------------------------------------------------------------------
1 | __version__ = '2.15.0'
2 |
--------------------------------------------------------------------------------
/react_customization/src/training/.gitignore:
--------------------------------------------------------------------------------
1 | logs/
2 |
--------------------------------------------------------------------------------
/react_customization/src/training/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/microsoft/react/a1a796fbcd61838042dff43902007af2408959cb/react_customization/src/training/__init__.py
--------------------------------------------------------------------------------
/react_customization/src/training/calculate_data_size.py:
--------------------------------------------------------------------------------
1 | import json
2 | from tqdm import tqdm
3 |
4 | total = 0
5 |
6 | pbar = tqdm(range(986))
7 | for i in pbar:
8 | stat_file = f'/mnt/mydata/cvinwild/react/imagenet_10m/{i:05d}_stats.json'
9 | with open(stat_file, 'r') as fp:
10 | stats = json.load(fp)
11 |
12 | total += stats['successes']
13 | pbar.set_description(f'Total: {total}')
14 |
15 | print(total)
--------------------------------------------------------------------------------
/react_customization/src/training/distributed.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import torch
4 | import torch.distributed as dist
5 |
6 | try:
7 | import horovod.torch as hvd
8 | except ImportError:
9 | hvd = None
10 |
11 |
12 | def is_global_master(args):
13 | return args.rank == 0
14 |
15 |
16 | def is_local_master(args):
17 | return args.local_rank == 0
18 |
19 |
20 | def is_master(args, local=False):
21 | return is_local_master(args) if local else is_global_master(args)
22 |
23 |
24 | def is_using_horovod():
25 | # NOTE w/ horovod run, OMPI vars should be set, but w/ SLURM PMI vars will be set
26 | # Differentiating between horovod and DDP use via SLURM may not be possible, so horovod arg still required...
27 | ompi_vars = ["OMPI_COMM_WORLD_RANK", "OMPI_COMM_WORLD_SIZE"]
28 | pmi_vars = ["PMI_RANK", "PMI_SIZE"]
29 | if all([var in os.environ for var in ompi_vars]) or all([var in os.environ for var in pmi_vars]):
30 | return True
31 | else:
32 | return False
33 |
34 |
35 | def is_using_distributed():
36 | if 'WORLD_SIZE' in os.environ:
37 | return int(os.environ['WORLD_SIZE']) > 1
38 | if 'SLURM_NTASKS' in os.environ:
39 | return int(os.environ['SLURM_NTASKS']) > 1
40 | return False
41 |
42 |
43 | def world_info_from_env():
44 | local_rank = 0
45 | for v in ('LOCAL_RANK', 'MPI_LOCALRANKID', 'SLURM_LOCALID', 'OMPI_COMM_WORLD_LOCAL_RANK'):
46 | if v in os.environ:
47 | local_rank = int(os.environ[v])
48 | break
49 | global_rank = 0
50 | for v in ('RANK', 'PMI_RANK', 'SLURM_PROCID', 'OMPI_COMM_WORLD_RANK'):
51 | if v in os.environ:
52 | global_rank = int(os.environ[v])
53 | break
54 | world_size = 1
55 | for v in ('WORLD_SIZE', 'PMI_SIZE', 'SLURM_NTASKS', 'OMPI_COMM_WORLD_SIZE'):
56 | if v in os.environ:
57 | world_size = int(os.environ[v])
58 | break
59 |
60 | return local_rank, global_rank, world_size
61 |
62 |
63 | def init_distributed_device(args):
64 | # Distributed training = training on more than one GPU.
65 | # Works in both single and multi-node scenarios.
66 | args.distributed = False
67 | args.world_size = 1
68 | args.rank = 0 # global rank
69 | args.local_rank = 0
70 | if args.horovod:
71 | assert hvd is not None, "Horovod is not installed"
72 | hvd.init()
73 | args.local_rank = int(hvd.local_rank())
74 | args.rank = hvd.rank()
75 | args.world_size = hvd.size()
76 | args.distributed = True
77 | os.environ['LOCAL_RANK'] = str(args.local_rank)
78 | os.environ['RANK'] = str(args.rank)
79 | os.environ['WORLD_SIZE'] = str(args.world_size)
80 | elif is_using_distributed():
81 | if 'SLURM_PROCID' in os.environ:
82 | # DDP via SLURM
83 | args.local_rank, args.rank, args.world_size = world_info_from_env()
84 | # SLURM var -> torch.distributed vars in case needed
85 | os.environ['LOCAL_RANK'] = str(args.local_rank)
86 | os.environ['RANK'] = str(args.rank)
87 | os.environ['WORLD_SIZE'] = str(args.world_size)
88 | torch.distributed.init_process_group(
89 | backend=args.dist_backend,
90 | init_method=args.dist_url,
91 | world_size=args.world_size,
92 | rank=args.rank,
93 | )
94 | else:
95 | # DDP via torchrun, torch.distributed.launch
96 | args.local_rank, _, _ = world_info_from_env()
97 | torch.distributed.init_process_group(
98 | backend=args.dist_backend,
99 | init_method=args.dist_url)
100 | args.world_size = torch.distributed.get_world_size()
101 | args.rank = torch.distributed.get_rank()
102 | args.distributed = True
103 |
104 | if torch.cuda.is_available():
105 | if args.distributed and not args.no_set_device_rank:
106 | device = 'cuda:%d' % args.local_rank
107 | else:
108 | device = 'cuda:0'
109 | torch.cuda.set_device(device)
110 | else:
111 | device = 'cpu'
112 | args.device = device
113 | device = torch.device(device)
114 | return device
115 |
116 |
117 | def broadcast_object(args, obj, src=0):
118 | # broadcast a pickle-able python object from rank-0 to all ranks
119 | if args.horovod:
120 | return hvd.broadcast_object(obj, root_rank=src)
121 | else:
122 | if args.rank == src:
123 | objects = [obj]
124 | else:
125 | objects = [None]
126 | dist.broadcast_object_list(objects, src=src)
127 | return objects[0]
128 |
129 |
130 | def all_gather_object(args, obj, dst=0):
131 | # gather a pickle-able python object across all ranks
132 | if args.horovod:
133 | return hvd.allgather_object(obj)
134 | else:
135 | objects = [None for _ in range(args.world_size)]
136 | dist.all_gather_object(objects, obj)
137 | return objects
138 |
--------------------------------------------------------------------------------
/react_customization/src/training/file_utils.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import os
3 | import multiprocessing
4 | import subprocess
5 | import time
6 | import fsspec
7 | import torch
8 | from tqdm import tqdm
9 |
10 | def remote_sync_s3(local_dir, remote_dir):
11 | # skip epoch_latest which can change during sync.
12 | result = subprocess.run(["aws", "s3", "sync", local_dir, remote_dir, '--exclude', '*epoch_latest.pt'], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
13 | if result.returncode != 0:
14 | logging.error(f"Error: Failed to sync with S3 bucket {result.stderr.decode('utf-8')}")
15 | return False
16 |
17 | logging.info(f"Successfully synced with S3 bucket")
18 | return True
19 |
20 | def remote_sync_fsspec(local_dir, remote_dir):
21 | # FIXME currently this is slow and not recommended. Look into speeding up.
22 | a = fsspec.get_mapper(local_dir)
23 | b = fsspec.get_mapper(remote_dir)
24 |
25 | for k in a:
26 | # skip epoch_latest which can change during sync.
27 | if 'epoch_latest.pt' in k:
28 | continue
29 |
30 | logging.info(f'Attempting to sync {k}')
31 | if k in b and len(a[k]) == len(b[k]):
32 | logging.debug(f'Skipping remote sync for {k}.')
33 | continue
34 |
35 | try:
36 | logging.info(f'Successful sync for {k}.')
37 | b[k] = a[k]
38 | except Exception as e:
39 | logging.info(f'Error during remote sync for {k}: {e}')
40 | return False
41 |
42 | return True
43 |
44 | def remote_sync(local_dir, remote_dir, protocol):
45 | logging.info('Starting remote sync.')
46 | if protocol == 's3':
47 | return remote_sync_s3(local_dir, remote_dir)
48 | elif protocol == 'fsspec':
49 | return remote_sync_fsspec(local_dir, remote_dir)
50 | else:
51 | logging.error('Remote protocol not known')
52 | return False
53 |
54 | def keep_running_remote_sync(sync_every, local_dir, remote_dir, protocol):
55 | while True:
56 | time.sleep(sync_every)
57 | remote_sync(local_dir, remote_dir, protocol)
58 |
59 | def start_sync_process(sync_every, local_dir, remote_dir, protocol):
60 | p = multiprocessing.Process(target=keep_running_remote_sync, args=(sync_every, local_dir, remote_dir, protocol))
61 | return p
62 |
63 | # Note: we are not currently using this save function.
64 | def pt_save(pt_obj, file_path):
65 | of = fsspec.open(file_path, "wb")
66 | with of as f:
67 | torch.save(pt_obj, file_path)
68 |
69 | def pt_load(file_path, map_location=None):
70 | if file_path.startswith('s3'):
71 | logging.info('Loading remote checkpoint, which may take a bit.')
72 | of = fsspec.open(file_path, "rb")
73 | with of as f:
74 | out = torch.load(f, map_location=map_location)
75 | return out
76 |
77 | def check_exists(file_path):
78 | try:
79 | with fsspec.open(file_path):
80 | pass
81 | except FileNotFoundError:
82 | return False
83 | return True
84 |
--------------------------------------------------------------------------------
/react_customization/src/training/logger.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 |
4 | def setup_logging(log_file, level, include_host=False):
5 | if include_host:
6 | import socket
7 | hostname = socket.gethostname()
8 | formatter = logging.Formatter(
9 | f'%(asctime)s | {hostname} | %(levelname)s | %(message)s', datefmt='%Y-%m-%d,%H:%M:%S')
10 | else:
11 | formatter = logging.Formatter('%(asctime)s | %(levelname)s | %(message)s', datefmt='%Y-%m-%d,%H:%M:%S')
12 |
13 | logging.root.setLevel(level)
14 | loggers = [logging.getLogger(name) for name in logging.root.manager.loggerDict]
15 | for logger in loggers:
16 | logger.setLevel(level)
17 |
18 | stream_handler = logging.StreamHandler()
19 | stream_handler.setFormatter(formatter)
20 | logging.root.addHandler(stream_handler)
21 |
22 | if log_file:
23 | file_handler = logging.FileHandler(filename=log_file)
24 | file_handler.setFormatter(formatter)
25 | logging.root.addHandler(file_handler)
26 |
27 |
--------------------------------------------------------------------------------
/react_customization/src/training/precision.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from contextlib import suppress
3 |
4 |
5 | def get_autocast(precision):
6 | if precision == 'amp':
7 | return torch.cuda.amp.autocast
8 | elif precision == 'amp_bfloat16' or precision == 'amp_bf16':
9 | # amp_bfloat16 is more stable than amp float16 for clip training
10 | return lambda: torch.cuda.amp.autocast(dtype=torch.bfloat16)
11 | else:
12 | return suppress
13 |
--------------------------------------------------------------------------------
/react_customization/src/training/profile.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | import torch
4 | import open_clip
5 | import pandas as pd
6 | from fvcore.nn import FlopCountAnalysis, flop_count_str, ActivationCountAnalysis
7 |
8 |
9 | parser = argparse.ArgumentParser(description='OpenCLIP Profiler')
10 |
11 | # benchmark specific args
12 | parser.add_argument('--model', metavar='NAME', default='',
13 | help='model(s) to profile')
14 | parser.add_argument('--results-file', default='', type=str, metavar='FILENAME',
15 | help='Output csv file for results')
16 |
17 |
18 | def profile_fvcore(
19 | model,
20 | image_input_size=(3, 224, 224),
21 | text_input_size=(77,),
22 | batch_size=1,
23 | detailed=False,
24 | force_cpu=False
25 | ):
26 | if force_cpu:
27 | model = model.to('cpu')
28 | device, dtype = next(model.parameters()).device, next(model.parameters()).dtype
29 | example_image_input = torch.ones((batch_size,) + image_input_size, device=device, dtype=dtype)
30 | example_text_input = torch.ones((batch_size,) + text_input_size, device=device, dtype=torch.int64)
31 | fca = FlopCountAnalysis(model, (example_image_input, example_text_input))
32 | aca = ActivationCountAnalysis(model, (example_image_input, example_text_input))
33 | if detailed:
34 | fcs = flop_count_str(fca)
35 | print(fcs)
36 | return fca.total(), aca.total()
37 |
38 |
39 | def profile_fvcore_text(
40 | model,
41 | text_input_size=(77,),
42 | batch_size=1,
43 | detailed=False,
44 | force_cpu=False
45 | ):
46 | if force_cpu:
47 | model = model.to('cpu')
48 | device = next(model.parameters()).device
49 | example_input = torch.ones((batch_size,) + text_input_size, device=device, dtype=torch.int64)
50 | fca = FlopCountAnalysis(model, example_input)
51 | aca = ActivationCountAnalysis(model, example_input)
52 | if detailed:
53 | fcs = flop_count_str(fca)
54 | print(fcs)
55 | return fca.total(), aca.total()
56 |
57 |
58 | def profile_fvcore_image(
59 | model,
60 | image_input_size=(3, 224, 224),
61 | batch_size=1,
62 | detailed=False,
63 | force_cpu=False
64 | ):
65 | if force_cpu:
66 | model = model.to('cpu')
67 | device, dtype = next(model.parameters()).device, next(model.parameters()).dtype
68 | example_input = torch.ones((batch_size,) + image_input_size, device=device, dtype=dtype)
69 | fca = FlopCountAnalysis(model, example_input)
70 | aca = ActivationCountAnalysis(model, example_input)
71 | if detailed:
72 | fcs = flop_count_str(fca)
73 | print(fcs)
74 | return fca.total(), aca.total()
75 |
76 |
77 | def count_params(model):
78 | return sum([m.numel() for m in model.parameters()])
79 |
80 |
81 | def profile_model(model_name):
82 | model = open_clip.create_model(model_name, force_custom_text=True, pretrained_hf=False)
83 | model.eval()
84 | if torch.cuda.is_available():
85 | model = model.cuda()
86 |
87 | if isinstance(model.visual.image_size, (tuple, list)):
88 | image_input_size = (3,) + tuple(model.visual.image_size[-2:])
89 | else:
90 | image_input_size = (3, model.visual.image_size, model.visual.image_size)
91 | text_input_size = (77,)
92 |
93 | results = {}
94 | results['model'] = model_name
95 | results['image_size'] = image_input_size[1]
96 |
97 | model_cfg = open_clip.get_model_config(model_name)
98 | if model_cfg:
99 | vision_cfg = open_clip.CLIPVisionCfg(**model_cfg['vision_cfg'])
100 | text_cfg = open_clip.CLIPTextCfg(**model_cfg['text_cfg'])
101 | results['image_width'] = int(vision_cfg.width)
102 | results['text_width'] = int(text_cfg.width)
103 | results['embed_dim'] = int(model_cfg['embed_dim'])
104 | else:
105 | results['image_width'] = 0
106 | results['text_width'] = 0
107 | results['embed_dim'] = 0
108 |
109 | retries = 2
110 | while retries:
111 | retries -= 1
112 | try:
113 | macs, acts = profile_fvcore(
114 | model, image_input_size=image_input_size, text_input_size=text_input_size, force_cpu=not retries)
115 |
116 | image_macs, image_acts = profile_fvcore_image(
117 | model.visual, image_input_size=image_input_size, force_cpu=not retries)
118 |
119 | text_macs, text_acts = profile_fvcore_text(
120 | model.text, text_input_size=text_input_size, force_cpu=not retries)
121 |
122 | results['gmacs'] = round(macs / 1e9, 2)
123 | results['macts'] = round(acts / 1e6, 2)
124 | results['mparams'] = round(count_params(model) / 1e6, 2)
125 | results['image_gmacs'] = round(image_macs / 1e9, 2)
126 | results['image_macts'] = round(image_acts / 1e6, 2)
127 | results['image_mparams'] = round(count_params(model.visual) / 1e6, 2)
128 | results['text_gmacs'] = round(text_macs / 1e9, 2)
129 | results['text_macts'] = round(text_acts / 1e6, 2)
130 | results['text_mparams'] = round(count_params(model.text) / 1e6, 2)
131 | except RuntimeError as e:
132 | pass
133 | return results
134 |
135 |
136 | def main():
137 | args = parser.parse_args()
138 |
139 | # FIXME accept a text file name to allow lists of models in txt/csv
140 | if args.model == 'all':
141 | parsed_model = open_clip.list_models()
142 | else:
143 | parsed_model = args.model.split(',')
144 |
145 | results = []
146 | for m in parsed_model:
147 | row = profile_model(m)
148 | results.append(row)
149 |
150 | df = pd.DataFrame(results, columns=results[0].keys())
151 | df = df.sort_values('gmacs')
152 | print(df)
153 | if args.results_file:
154 | df.to_csv(args.results_file, index=False)
155 |
156 |
157 | if __name__ == '__main__':
158 | main()
159 |
--------------------------------------------------------------------------------
/react_customization/src/training/scheduler.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | def assign_learning_rate(optimizer, new_lr):
5 | for param_group in optimizer.param_groups:
6 | param_group["lr"] = new_lr
7 |
8 |
9 | def _warmup_lr(base_lr, warmup_length, step):
10 | return base_lr * (step + 1) / warmup_length
11 |
12 |
13 | def const_lr(optimizer, base_lr, warmup_length, steps):
14 | def _lr_adjuster(step):
15 | if step < warmup_length:
16 | lr = _warmup_lr(base_lr, warmup_length, step)
17 | else:
18 | lr = base_lr
19 | assign_learning_rate(optimizer, lr)
20 | return lr
21 | return _lr_adjuster
22 |
23 |
24 | def const_lr_cooldown(optimizer, base_lr, warmup_length, steps, cooldown_steps, cooldown_power=1.0, cooldown_end_lr=0.):
25 | def _lr_adjuster(step):
26 | start_cooldown_step = steps - cooldown_steps
27 | if step < warmup_length:
28 | lr = _warmup_lr(base_lr, warmup_length, step)
29 | else:
30 | if step < start_cooldown_step:
31 | lr = base_lr
32 | else:
33 | e = step - start_cooldown_step
34 | es = steps - start_cooldown_step
35 | # linear decay if power == 1; polynomial decay otherwise;
36 | decay = (1 - (e/es)) ** cooldown_power
37 | lr = decay * (base_lr - cooldown_end_lr) + cooldown_end_lr
38 | assign_learning_rate(optimizer, lr)
39 | return lr
40 | return _lr_adjuster
41 |
42 |
43 | def cosine_lr(optimizer, base_lr, warmup_length, steps):
44 | def _lr_adjuster(step):
45 | if step < warmup_length:
46 | lr = _warmup_lr(base_lr, warmup_length, step)
47 | else:
48 | e = step - warmup_length
49 | es = steps - warmup_length
50 | lr = 0.5 * (1 + np.cos(np.pi * e / es)) * base_lr
51 | assign_learning_rate(optimizer, lr)
52 | return lr
53 | return _lr_adjuster
54 |
--------------------------------------------------------------------------------
/react_customization/src/training/zero_shot.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 | import torch
4 | import torch.nn.functional as F
5 | from tqdm import tqdm
6 |
7 | from open_clip import get_cast_dtype, get_tokenizer
8 | from .precision import get_autocast
9 | from .imagenet_zeroshot_data import imagenet_classnames, openai_imagenet_template
10 |
11 |
12 | def zero_shot_classifier(model, classnames, templates, args):
13 | tokenizer = get_tokenizer(args.model)
14 | with torch.no_grad():
15 | zeroshot_weights = []
16 | for classname in tqdm(classnames):
17 | texts = [template(classname) for template in templates] # format with class
18 | texts = tokenizer(texts).to(args.device) # tokenize
19 | if args.distributed and not args.horovod:
20 | class_embeddings = model.module.encode_text(texts)
21 | else:
22 | class_embeddings = model.encode_text(texts)
23 | class_embedding = F.normalize(class_embeddings, dim=-1).mean(dim=0)
24 | class_embedding /= class_embedding.norm()
25 | zeroshot_weights.append(class_embedding)
26 | zeroshot_weights = torch.stack(zeroshot_weights, dim=1).to(args.device)
27 | return zeroshot_weights
28 |
29 |
30 | def accuracy(output, target, topk=(1,)):
31 | pred = output.topk(max(topk), 1, True, True)[1].t()
32 | correct = pred.eq(target.view(1, -1).expand_as(pred))
33 | return [float(correct[:k].reshape(-1).float().sum(0, keepdim=True).cpu().numpy()) for k in topk]
34 |
35 |
36 | def run(model, classifier, dataloader, args):
37 | autocast = get_autocast(args.precision)
38 | cast_dtype = get_cast_dtype(args.precision)
39 | with torch.no_grad():
40 | top1, top5, n = 0., 0., 0.
41 | for images, target in tqdm(dataloader, unit_scale=args.batch_size):
42 | images = images.to(args.device)
43 | if cast_dtype is not None:
44 | images = images.to(dtype=cast_dtype)
45 | target = target.to(args.device)
46 |
47 | with autocast():
48 | # predict
49 | if args.distributed and not args.horovod:
50 | image_features = model.module.encode_image(images)
51 | else:
52 | image_features = model.encode_image(images)
53 | image_features = F.normalize(image_features, dim=-1)
54 | logits = 100. * image_features @ classifier
55 |
56 | # measure accuracy
57 | acc1, acc5 = accuracy(logits, target, topk=(1, 5))
58 | top1 += acc1
59 | top5 += acc5
60 | n += images.size(0)
61 |
62 | top1 = (top1 / n)
63 | top5 = (top5 / n)
64 | return top1, top5
65 |
66 |
67 | def zero_shot_eval(model, data, epoch, args):
68 | if 'imagenet-val' not in data and 'imagenet-v2' not in data:
69 | return {}
70 | if args.zeroshot_frequency == 0:
71 | return {}
72 | if (epoch % args.zeroshot_frequency) != 0 and epoch != args.epochs:
73 | return {}
74 |
75 | logging.info('Starting zero-shot imagenet.')
76 |
77 | logging.info('Building zero-shot classifier')
78 | classifier = zero_shot_classifier(model, imagenet_classnames, openai_imagenet_template, args)
79 |
80 | logging.info('Using classifier')
81 | results = {}
82 | if 'imagenet-val' in data:
83 | top1, top5 = run(model, classifier, data['imagenet-val'].dataloader, args)
84 | results['imagenet-zeroshot-val-top1'] = top1
85 | results['imagenet-zeroshot-val-top5'] = top5
86 | if 'imagenet-v2' in data:
87 | top1, top5 = run(model, classifier, data['imagenet-v2'].dataloader, args)
88 | results['imagenetv2-zeroshot-val-top1'] = top1
89 | results['imagenetv2-zeroshot-val-top5'] = top5
90 |
91 | logging.info('Finished zero-shot imagenet.')
92 |
93 | return results
94 |
--------------------------------------------------------------------------------
/react_retrieval/.gitignore:
--------------------------------------------------------------------------------
1 | # IntelliJ project files
2 | .idea
3 | *.iml
4 | out
5 | gen
6 |
7 | ### Vim template
8 | [._]*.s[a-w][a-z]
9 | [._]s[a-w][a-z]
10 | *.un~
11 | Session.vim
12 | .netrwhist
13 | *~
14 |
15 | ### IPythonNotebook template
16 | # Temporary data
17 | .ipynb_checkpoints/
18 |
19 | ### Python template
20 | # Byte-compiled / optimized / DLL files
21 | __pycache__/
22 | *.py[cod]
23 | *$py.class
24 |
25 | # C extensions
26 | *.so
27 |
28 | # Distribution / packaging
29 | .Python
30 | env/
31 | build/
32 | develop-eggs/
33 | dist/
34 | downloads/
35 | eggs/
36 | .eggs/
37 | #lib/
38 | #lib64/
39 | parts/
40 | sdist/
41 | var/
42 | *.egg-info/
43 | .installed.cfg
44 | *.egg
45 |
46 | # PyInstaller
47 | # Usually these files are written by a python script from a template
48 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
49 | *.manifest
50 | *.spec
51 |
52 | # Installer logs
53 | pip-log.txt
54 | pip-delete-this-directory.txt
55 |
56 | # Unit test / coverage reports
57 | htmlcov/
58 | .tox/
59 | .coverage
60 | .coverage.*
61 | .cache
62 | nosetests.xml
63 | coverage.xml
64 | *,cover
65 |
66 | # Translations
67 | *.mo
68 | *.pot
69 |
70 | # Django stuff:
71 | *.log
72 |
73 | # Sphinx documentation
74 | docs/_build/
75 |
76 | # PyBuilder
77 | target/
78 |
79 | # *.ipynb
80 | *.params
81 | .vscode/
82 | *.code-workspace/
83 |
84 | */azcopy/cache
85 |
86 | /data/
87 |
--------------------------------------------------------------------------------
/react_retrieval/README.MD:
--------------------------------------------------------------------------------
1 | # :globe_with_meridians: REACT: Retrieval Stage
2 |
3 |
4 | - [1. Download Retrieved Pairs for Standard Benchmarks](#1.-Download-Retrieved-Pairs-for-Standard-Benchmarks)
5 | - [2. Build and Retrieve on Customized Image-Text Pairs](#2.-Build-and-Retrieve-from-Customized-Image-Text-Pairs)
6 | - [2.1 Download CC3M Dataset](#2.1-Download-CC3M-Dataset)
7 | - [2.2 Build Index](#2.2-Build-Index)
8 | - [2.3 Retrieve Image-Text Pairs](#2.3-Retrieve-Image-Text-Pairs)
9 |
10 | ## Installation
11 |
12 | ```Shell
13 | conda create -n react_retrieval python=3.7 -y
14 | conda activate react_retrieval
15 | pip install torch==1.7.0+cu110 torchvision==0.8.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html
16 | pip install -r requirements.txt
17 | pip install -e .
18 | ```
19 |
20 | ## 1. Download Retrieved Pairs for Standard Benchmarks
21 |
22 | If you want to focus on building customized models on standard benchmarks like ImageNet-1K and ELEVATER, you may skip the following steps and directly download our retrieved pairs.
23 |
24 | See instructions [here](../react_customization).
25 |
26 | ## 2. Build and Retrieve from Customized Image-Text Pairs
27 | We use CC3M as an example to demonstrate how to build indexing system and retrieve from the indexed dataset.
28 |
29 | ### 2.1 Download CC3M Dataset
30 |
31 | Follow the instructions [here](https://github.com/rom1504/img2dataset/blob/main/dataset_examples/cc3m.md) to download CC3M dataset. You can also find [examples](https://github.com/rom1504/img2dataset#examples) for other datasets.
32 |
33 | ### 2.2 Build Index
34 | We use CC-3M as an example for the retrieval system itself, as it is much smaller and more accessible for all kinds of hardware setups.
35 |
36 | 1. Extract features. This step may take a while. You can split the dataset into multiple chunks by specifying `--tsv_chunks` and run the script in parallel to speed up the process.
37 |
38 | ```Shell
39 | python commands/extract_feature_pairs.py \
40 | --model 'ViT-B/32' \
41 | --dataset_dir '/path/to/CC3M' \
42 | --save_dir '/path/to/save/features' \
43 | --tsv_chunk_idx=0 \
44 | --tsv_chunks=1 \
45 | --tsv_padzero=5 \
46 | --batch_size=128 \
47 | --workers=8
48 | ```
49 |
50 | 2. Train index.
51 |
52 | Note that `--feature_mode` can be either `image` or `text`. If you want to build a retrieval system with texts as the **keys**, you can set `--feature_mode=text`. For example, for T2I retrieval, we use `feature_mode=image`.
53 |
54 | ```Shell
55 | python commands/train_index.py \
56 | --d=512 \
57 | --dataset_size=3000000 \
58 | --metafile '/path/to/save/features/metafile.json' \
59 | --data_root '/path/to/save/features' \
60 | --index_train_features '/path/to/save/features/train_features.npy' \
61 | --faiss_index '/path/to/save/index' \
62 | --base_index_path '/path/to/save/base_index' \
63 | --feature_mode '{image,text}'
64 | ```
65 |
66 | ### 2.3 Retrieve Image-Text Pairs
67 |
68 | After the index is built, you can retrieve image-text pairs efficiently.
69 |
70 | #### Preprocess
71 |
72 | 1. Create filelist for fast indexing between multiple chunked files.
73 |
74 | ```Shell
75 | python create_filelist_webdataset.py \
76 | --dataset_dir '/path/to/CC3M' \
77 | --filelist '/path/to/save/filelist.pkl'
78 | ```
79 |
80 | 2. We find scattering the retrieved pairs (originally in `tar` format) to separate files typically gives us better throughput.
81 |
82 | ```Shell
83 | python extract_webdataset_scattered.py \
84 | --dataset_dir '/path/to/CC3M' \
85 | --scatter_dir '/path/to/save/scattered' \
86 | --tsv_padzero=5
87 | ```
88 |
89 | #### Examples
90 | We provide two examples for retrieval:
91 | 1. a Jupyter notebook ([here](./notebook/retrieve_pairs.ipynb)) for exploring the retrieval results interactively, and
92 | 2. a sample script (see below) that allows you to retrieve image-text pairs in batch.
93 |
94 | ```Shell
95 | python commands/retrieve_pairs_sep_prompts.py \
96 | --metafile '/path/to/save/filelist.pkl' \
97 | --scatter_dir '/path/to/save/scattered' \
98 | --faiss_index '/path/to/save/index' \
99 | --output_dir '/path/to/save/retrieved_pairs' \
100 | --dataset caltech-101 \
101 | --images_per_class 200
102 | ```
103 |
--------------------------------------------------------------------------------
/react_retrieval/commands/create_filelist_webdataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import glob
3 | import argparse
4 | from tqdm import tqdm
5 |
6 | import torch
7 |
8 | from tarfile import TarFile
9 |
10 | from collections import OrderedDict
11 |
12 | import pickle
13 |
14 |
15 | def get_argument_parser():
16 | parser = argparse.ArgumentParser(description='Extract features from Vision-Language datasets.')
17 | parser.add_argument('--dataset_dir', required=True, help='Dataset directory.', type=str)
18 | parser.add_argument('--filelist', required=True, help='Output feature directory.', type=str)
19 | parser.add_argument('--tsv_padzero', default=5, help='TSV file name padding.', type=int)
20 | parser.add_argument('--batch_size', default=128, help='Batch size.', type=int)
21 | parser.add_argument('--workers', default=8, help='Number of workers.', type=int)
22 | parser.add_argument('--print_freq', default=20, help='Print frequency.', type=int)
23 | return parser
24 |
25 |
26 | def collate_fn(batch):
27 | images, texts, metas = list(zip(*batch))
28 | images = torch.stack(images, dim=0)
29 | texts = torch.stack(texts, dim=0)
30 | return images, texts, metas
31 |
32 |
33 | def main(args):
34 | tarfile_list = sorted(f for f in os.listdir(args.dataset_dir) if f.endswith('.tar'))
35 |
36 | filelist = OrderedDict()
37 |
38 | pbar = tqdm(enumerate(tarfile_list), total=len(tarfile_list))
39 | for tsv_idx, tarfile_name in pbar:
40 | assert tarfile_name == f'{tsv_idx:0{args.tsv_padzero}d}.tar'
41 | pbar.set_description(tarfile_name)
42 |
43 | tarf = TarFile(os.path.join(args.dataset_dir, f'{tsv_idx:0{args.tsv_padzero}d}.tar'))
44 | filelist[f'{tsv_idx:0{args.tsv_padzero}d}'] = []
45 | cur_list = filelist[f'{tsv_idx:0{args.tsv_padzero}d}']
46 |
47 | for f in tarf:
48 | if not f.name.endswith('.jpg'):
49 | continue
50 | cur_list.append(f.name)
51 |
52 | pickle.dump(filelist, open(args.filelist, "wb"))
53 |
54 |
55 | if __name__ == "__main__":
56 | args = get_argument_parser().parse_args()
57 |
58 | main(args)
59 |
--------------------------------------------------------------------------------
/react_retrieval/commands/extract_feature_pairs.py:
--------------------------------------------------------------------------------
1 | import os
2 | import glob
3 | import argparse
4 | from tqdm import tqdm
5 |
6 | import torch
7 | from torch.utils import data
8 | import clip
9 |
10 | import webdataset as wds
11 |
12 | from react_retrieval.data.tsv import TSVWriter
13 | from react_retrieval.data.datasets import *
14 |
15 |
16 | def get_argument_parser():
17 | parser = argparse.ArgumentParser(description='Extract features from Vision-Language datasets.')
18 | parser.add_argument('--model', default='ViT-B/32', help='VL model name.', type=str)
19 | parser.add_argument('--dataset_dir', required=True, help='Dataset directory.', type=str)
20 | parser.add_argument('--save_dir', required=True, help='Output feature directory.', type=str)
21 | parser.add_argument('--tsv_chunk_idx', default=0, help='TSV file index.', type=int)
22 | parser.add_argument('--tsv_chunks', default=8, help='TSV file index.', type=int)
23 | parser.add_argument('--tsv_padzero', default=5, help='TSV file name padding.', type=int)
24 | parser.add_argument('--batch_size', default=128, help='Batch size.', type=int)
25 | parser.add_argument('--workers', default=8, help='Number of workers.', type=int)
26 | parser.add_argument('--print_freq', default=20, help='Print frequency.', type=int)
27 | return parser
28 |
29 |
30 | def collate_fn(batch):
31 | images, texts, metas = list(zip(*batch))
32 | images = torch.stack(images, dim=0)
33 | texts = torch.stack(texts, dim=0)
34 | return images, texts, metas
35 |
36 |
37 | def main(args, model, preprocess):
38 | pairs_wds = wds.WebDataset(os.path.join(args.dataset_dir, f'{args.tsv_idx:0{args.tsv_padzero}d}.tar')) \
39 | .decode("pilrgb") \
40 | .rename(image="jpg;png;jpeg;webp", text="txt") \
41 | .map_dict(image=preprocess, text=lambda text: clip.tokenize([text], context_length=77, truncate=True)[0]) \
42 | .to_tuple("image", "text", "json")
43 |
44 | pairs_wds_loader = data.DataLoader(pairs_wds, batch_size=args.batch_size,
45 | num_workers=args.workers, drop_last=False, pin_memory=True,
46 | shuffle=False, collate_fn=collate_fn)
47 |
48 | feature_file = os.path.join(args.save_dir, f'{args.tsv_idx:0{args.tsv_padzero}d}.tsv')
49 |
50 | feature_writer = TSVWriter(feature_file)
51 |
52 | for images, texts, metas in pairs_wds_loader:
53 | images = images.cuda(non_blocking=True)
54 | texts = texts.cuda(non_blocking=True)
55 |
56 | with torch.no_grad():
57 | image_embeddings = model.encode_image(images)
58 | text_embeddings = model.encode_text(texts)
59 |
60 | for i in range(image_embeddings.shape[0]):
61 | feature_writer.write([
62 | metas[i]['key'],
63 | metas[i]['sha256'],
64 | encode_as_string(image_embeddings[i]),
65 | encode_as_string(text_embeddings[i]),
66 | ])
67 |
68 | feature_writer.close()
69 |
70 |
71 | if __name__ == "__main__":
72 | args = get_argument_parser().parse_args()
73 | n_shards = len(glob.glob(os.path.join(args.dataset_dir, '*.tar')))
74 | n_shard_per_chunk = n_shards // args.tsv_chunks
75 |
76 | torch.cuda.set_device(args.tsv_chunk_idx)
77 |
78 | os.makedirs(args.save_dir, exist_ok=True)
79 |
80 | if args.model in clip.available_models():
81 | model, preprocess = clip.load(args.model)
82 | model.cuda().eval()
83 |
84 | pbar = tqdm(range(n_shard_per_chunk*args.tsv_chunk_idx, min(n_shard_per_chunk*(args.tsv_chunk_idx+1), n_shards)))
85 | for i in pbar:
86 | args.tsv_idx = i
87 | pbar.set_description(f'{args.tsv_idx:0{args.tsv_padzero}d}.tar')
88 | main(args, model, preprocess)
89 |
--------------------------------------------------------------------------------
/react_retrieval/commands/extract_webdataset_scattered.py:
--------------------------------------------------------------------------------
1 | import os
2 | import argparse
3 | from multiprocessing.pool import ThreadPool as Pool
4 |
5 | import subprocess
6 | from tqdm import tqdm
7 |
8 |
9 | def get_argument_parser():
10 | parser = argparse.ArgumentParser(description='Extract features from Vision-Language datasets.')
11 | parser.add_argument('--dataset_dir', required=True, help='Dataset directory.', type=str)
12 | parser.add_argument('--scatter_dir', required=True, help='Output directory.', type=str)
13 | parser.add_argument('--tsv_padzero', default=5, help='TSV file name padding.', type=int)
14 | return parser
15 |
16 |
17 | def untar(args):
18 | src, dst = args
19 |
20 | os.makedirs(dst, exist_ok=True)
21 |
22 | untar_command = f"tar -xf {src} -C {dst}"
23 |
24 | p = subprocess.Popen(untar_command, stdout=subprocess.PIPE, shell=True)
25 |
26 | p.wait()
27 |
28 |
29 | def main(args):
30 | tarfile_list = sorted(f for f in os.listdir(args.dataset_dir) if f.endswith('.tar'))
31 |
32 | TASKS = []
33 | pool = Pool(36)
34 |
35 | for tsv_idx, tarfile_name in enumerate(tarfile_list):
36 | assert tarfile_name == f'{tsv_idx:0{args.tsv_padzero}d}.tar'
37 |
38 | src_file = os.path.join(args.dataset_dir, tarfile_name)
39 | dst_dir = os.path.join(args.scatter_dir, tarfile_name.replace('.tar', ''))
40 |
41 | TASKS.append((src_file, dst_dir))
42 |
43 | return list(tqdm(pool.imap(untar, TASKS), total=len(TASKS)))
44 |
45 | if __name__ == "__main__":
46 | args = get_argument_parser().parse_args()
47 |
48 | main(args)
49 |
--------------------------------------------------------------------------------
/react_retrieval/commands/retrieve_pairs.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from tqdm import tqdm
3 |
4 | import faiss
5 | import torch
6 | import torch.nn.functional as F
7 | import clip
8 | import numpy as np
9 | import os
10 | import shutil
11 | from functools import partial
12 |
13 | from react_retrieval.utils.prompts import *
14 | from react_retrieval.data.filelist_controller import FileListController
15 |
16 | from autofaiss.utils.decorators import Timeit
17 |
18 | from multiprocessing.pool import ThreadPool as Pool
19 |
20 | import logging
21 |
22 |
23 | def setup_logging(logging_level: int):
24 | """Setup the logging."""
25 | logging.config.dictConfig(dict(version=1, disable_existing_loggers=False))
26 | logging_format = "%(asctime)s [%(levelname)s]: %(message)s"
27 | logging.basicConfig(level=logging_level, format=logging_format)
28 |
29 |
30 | def get_argument_parser():
31 | parser = argparse.ArgumentParser(description='Extract features from Vision-Language datasets.')
32 | parser.add_argument('--model', type=str, default='vitb32')
33 | parser.add_argument('--metafile', type=str)
34 | parser.add_argument('--scatter_dir', type=str)
35 | parser.add_argument('--faiss_index', type=str)
36 | parser.add_argument('--output_dir', type=str)
37 | parser.add_argument('--dataset', type=str, help='ICinW dataset name.')
38 | parser.add_argument('--images_per_class', type=int, default=50, help='number of images per class')
39 | return parser
40 |
41 |
42 | def query_by_text(texts, model, index, k):
43 | assert type(texts) is list, "Please wrap texts into List[str]."
44 |
45 | texts = clip.tokenize(texts, context_length=77, truncate=True).cuda()
46 | with torch.no_grad():
47 | text_embeddings = model.encode_text(texts)
48 | text_embeddings = F.normalize(text_embeddings)
49 |
50 | queries = text_embeddings.data.cpu().numpy().astype('float32')
51 | dists, knns = index.search(queries, k)
52 |
53 | return dists, knns
54 |
55 |
56 | def copyfile(args):
57 | image_file, text_file, subdir = args
58 | shutil.copy2(image_file, os.path.join(subdir, os.path.basename(image_file)))
59 | shutil.copy2(text_file, os.path.join(subdir, os.path.basename(text_file)))
60 |
61 |
62 | def collect_retrieved_images(file_list_controller, knns, output_dir, pool=None):
63 | tasks = []
64 | for idx in range(knns.shape[0]):
65 | subdir = os.path.join(output_dir, f'{idx:03d}')
66 | os.makedirs(subdir, exist_ok=True)
67 |
68 | for knn_idx in knns[idx]:
69 | image_file, text_file = file_list_controller[knn_idx]
70 | if pool is not None:
71 | tasks.append((image_file, text_file, subdir))
72 | else:
73 | copyfile((image_file, text_file, subdir))
74 |
75 | if pool is not None:
76 | pool.map(copyfile, tasks)
77 |
78 | def main():
79 | args = get_argument_parser().parse_args()
80 |
81 | setup_logging(logging.INFO)
82 |
83 | with Timeit(f"Loading index: {args.faiss_index}"):
84 | index = faiss.read_index(args.faiss_index)
85 |
86 | with Timeit(f"Loading file list controller: {args.metafile}"):
87 | file_list_controller = FileListController(args.metafile, args.scatter_dir)
88 |
89 | class_names = class_map[args.dataset]
90 | templates = template_map[args.dataset]
91 |
92 | model_name = {
93 | "vitb32": "ViT-B/32",
94 | "vitb16": "ViT-B/16",
95 | "vitl14": "ViT-L/14",
96 | }[args.model]
97 |
98 | with Timeit(f"Loading model: {model_name}"):
99 | if model_name in clip.available_models():
100 | model, preprocess = clip.load(model_name)
101 | model.cuda().eval()
102 |
103 | pool = Pool(128)
104 |
105 | pbar = tqdm(class_names)
106 | for class_name in pbar:
107 | pbar.set_description(f'Fetching for {class_name}')
108 | texts = [template.format(class_name) for template in templates]
109 |
110 | dists, knns = query_by_text(texts, model, index, k=args.images_per_class)
111 | collect_retrieved_images(file_list_controller, knns,
112 | output_dir=os.path.join(args.output_dir, args.dataset, f'{args.images_per_class}nn', class_name), pool=pool)
113 |
114 |
115 | if __name__ == "__main__":
116 | main()
117 |
--------------------------------------------------------------------------------
/react_retrieval/commands/retrieve_pairs_sep_prompts.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from tqdm import tqdm
3 |
4 | import faiss
5 | import torch
6 | import torch.nn.functional as F
7 | import clip
8 | import numpy as np
9 | import os
10 | import shutil
11 | from functools import partial
12 |
13 | from react_retrieval.utils.prompts import *
14 | from react_retrieval.data.filelist_controller import FileListController
15 |
16 | from autofaiss.utils.decorators import Timeit
17 |
18 | from multiprocessing.pool import ThreadPool as Pool
19 |
20 | import logging
21 |
22 | import re
23 | import json
24 |
25 |
26 | def setup_logging(logging_level: int):
27 | """Setup the logging."""
28 | logging.config.dictConfig(dict(version=1, disable_existing_loggers=False))
29 | logging_format = "%(asctime)s [%(levelname)s]: %(message)s"
30 | logging.basicConfig(level=logging_level, format=logging_format)
31 |
32 |
33 | def get_argument_parser():
34 | parser = argparse.ArgumentParser(description='Extract features from Vision-Language datasets.')
35 | parser.add_argument('--model', type=str, default='vitb32')
36 | parser.add_argument('--metafile', type=str)
37 | parser.add_argument('--scatter_dir', type=str)
38 | parser.add_argument('--faiss_index', type=str)
39 | parser.add_argument('--output_dir', type=str)
40 | parser.add_argument('--dataset', type=str, help='ICinW dataset name.')
41 | parser.add_argument('--images_per_class', type=int, default=50, help='number of images per class')
42 | return parser
43 |
44 |
45 | def query_by_text(texts, model, index, k):
46 | assert type(texts) is list, "Please wrap texts into List[str]."
47 |
48 | texts = clip.tokenize(texts, context_length=77, truncate=True).cuda()
49 | with torch.no_grad():
50 | text_embeddings = model.encode_text(texts)
51 | text_embeddings = F.normalize(text_embeddings)
52 |
53 | queries = text_embeddings.data.cpu().numpy().astype('float32')
54 | dists, knns = index.search(queries, k)
55 |
56 | return dists, knns
57 |
58 |
59 | def copyfile(args):
60 | image_file, text_file, subdir = args
61 | shutil.copy2(image_file, os.path.join(subdir, os.path.basename(image_file)))
62 | shutil.copy2(text_file, os.path.join(subdir, os.path.basename(text_file)))
63 |
64 |
65 | def format_cls_name(cls_name):
66 | new_name = cls_name
67 | new_name = re.sub(r'[^0-9a-zA-Z_]', '_', new_name)
68 | new_name = re.sub(r'_+', '_', new_name).strip('_')
69 | return new_name
70 |
71 |
72 | def main():
73 | args = get_argument_parser().parse_args()
74 |
75 | setup_logging(logging.INFO)
76 |
77 | with Timeit(f"Loading index: {args.faiss_index}"):
78 | index = faiss.read_index(args.faiss_index)
79 |
80 | with Timeit(f"Loading file list controller: {args.metafile}"):
81 | file_list_controller = FileListController(args.metafile, args.scatter_dir, is_tar=True)
82 |
83 | class_names = class_map[args.dataset]
84 | templates = template_map[args.dataset]
85 |
86 | model_name = {
87 | "vitb32": "ViT-B/32",
88 | "vitb16": "ViT-B/16",
89 | "vitl14": "ViT-L/14",
90 | }[args.model]
91 |
92 | with Timeit(f"Loading model: {model_name}"):
93 | if model_name in clip.available_models():
94 | model, preprocess = clip.load(model_name)
95 | model.cuda().eval()
96 |
97 | KNNS, DISTS, LABELS = [], [], []
98 | for class_idx, class_name in enumerate(class_names):
99 | texts = [template.format(class_name) for template in templates]
100 | dists, knns = query_by_text(texts, model, index, k=args.images_per_class)
101 | KNNS.append(knns)
102 | DISTS.append(dists)
103 | LABELS.append(np.full_like(knns, class_idx, dtype=np.int64))
104 |
105 | KNNS = np.stack(KNNS)
106 | DISTS = np.stack(DISTS)
107 | LABELS = np.stack(LABELS)
108 |
109 | n_classes, n_prompts, n_neighbors = KNNS.shape
110 |
111 | output_image_dir = os.path.join(args.output_dir, 'images', args.dataset)
112 | output_meta_dir = os.path.join(args.output_dir, 'metas', args.dataset)
113 | os.makedirs(output_image_dir, exist_ok=True)
114 | os.makedirs(output_meta_dir, exist_ok=True)
115 |
116 | TASKS = []
117 |
118 | for cls_idx in range(n_classes):
119 | class_name = class_names[cls_idx]
120 | if type(class_name) == list:
121 | class_name = '_and_'.join(class_name)
122 | class_name = format_cls_name(class_name)
123 | cls_images = os.path.join(output_image_dir, class_name)
124 | os.makedirs(cls_images, exist_ok=True)
125 |
126 | metadata = dict()
127 |
128 | for prompt_idx in range(n_prompts):
129 | for neighbor_idx in range(n_neighbors):
130 | index = KNNS[cls_idx, prompt_idx, neighbor_idx]
131 | dist = DISTS[cls_idx, prompt_idx, neighbor_idx].tolist()
132 | image_file, text_file = file_list_controller[index]
133 | filename = os.path.basename(image_file)
134 | if filename not in metadata:
135 | metadata[filename] = {'search_meta': []}
136 | TASKS.append((image_file, text_file, cls_images))
137 | cur_meta = metadata[filename]
138 | query_class = class_names[cls_idx]
139 | if type(query_class) == list:
140 | query_class = query_class[0]
141 | cur_meta['search_meta'].append({
142 | 'query': templates[prompt_idx].format(query_class),
143 | 'dist': dist,
144 | })
145 |
146 | with open(os.path.join(output_meta_dir, f'{class_name}.json'), 'w') as fp:
147 | json.dump(metadata, fp)
148 |
149 | with Pool(128) as pool:
150 | r = list(tqdm(pool.imap(copyfile, TASKS), total=len(TASKS)))
151 |
152 | if __name__ == "__main__":
153 | main()
154 |
--------------------------------------------------------------------------------
/react_retrieval/commands/train_index.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from tqdm import tqdm
3 |
4 | import json
5 | import os
6 | import faiss
7 | import time
8 |
9 | from collections import OrderedDict
10 |
11 | import numpy as np
12 |
13 | from react_retrieval.data.datasets import TSVFile, TSVDataset, decode_pairs_feature
14 | from react_retrieval.index import index_utils
15 |
16 | from autofaiss.utils.decorators import Timeit
17 |
18 | import logging
19 |
20 | def setup_logging(logging_level: int):
21 | """Setup the logging."""
22 | logging.config.dictConfig(dict(version=1, disable_existing_loggers=False))
23 | logging_format = "%(asctime)s [%(levelname)s]: %(message)s"
24 | logging.basicConfig(level=logging_level, format=logging_format)
25 |
26 | def get_argument_parser():
27 | parser = argparse.ArgumentParser(description='Extract features from Vision-Language datasets.')
28 | parser.add_argument('--d', default=512, type=int)
29 | parser.add_argument('--dataset_size', default=3_000_000, type=int)
30 | parser.add_argument('--metafile', type=str)
31 | parser.add_argument('--data_root', type=str)
32 | parser.add_argument('--index_train_features', type=str)
33 | parser.add_argument('--faiss_index', required=True, type=str)
34 | parser.add_argument('--base_index_path', type=str)
35 | parser.add_argument('--feature_mode', type=str)
36 | parser.add_argument('--index_key', default=None, type=str)
37 | parser.add_argument('--metric_type', default="IP", type=str)
38 | parser.add_argument('--select_n_per_tsv', default=16384, type=int)
39 | return parser
40 |
41 |
42 | def sample_train_features(args):
43 | with open(args.metafile, "r") as fp:
44 | metafile = json.load(fp, object_pairs_hook=OrderedDict)
45 |
46 | n_total_entries = len(metafile) * args.select_n_per_tsv
47 | n_total_entries = min(n_total_entries, sum(metafile.values()))
48 | all_features = np.zeros((n_total_entries, args.d), dtype=np.float32)
49 | pbar = tqdm(sorted(metafile.keys()))
50 | current_idx = 0
51 | processed_tsv = 0
52 | os.makedirs(os.path.dirname(args.index_train_features), exist_ok=True)
53 | for tsv_idx in pbar:
54 | num_entries = metafile[tsv_idx]
55 | tsv_file_name = f'{tsv_idx}.tsv'
56 | tsv_file_path = os.path.join(args.data_root, tsv_file_name)
57 | pbar.set_description(f'Current: {tsv_file_name}, Loaded: {current_idx} vectors, Processed: {processed_tsv} files')
58 | dataset = TSVDataset(tsv_file_path, transform=decode_pairs_feature)
59 | select_n_per_tsv = min(args.select_n_per_tsv, num_entries)
60 | sample_idx = np.arange(num_entries)
61 | if num_entries > select_n_per_tsv:
62 | sample_idx = np.random.choice(sample_idx, size=select_n_per_tsv, replace=False)
63 | results = [dataset[idx] for idx in sample_idx]
64 | if args.feature_mode == 'image':
65 | features = [x[2].astype(np.float32) for x in results]
66 | elif args.feature_mode == 'text':
67 | features = [x[3].astype(np.float32) for x in results]
68 | else:
69 | assert False, f"Unknown feature type: {args.feature_mode}"
70 | features = np.stack(features, axis=0)
71 | features = features / np.linalg.norm(features, axis=1, keepdims=True)
72 | all_features[current_idx:current_idx+select_n_per_tsv] = features
73 | current_idx += select_n_per_tsv
74 | processed_tsv += 1
75 | np.save(args.index_train_features, all_features)
76 | return all_features
77 |
78 |
79 | def build_base_index(args):
80 | if args.index_key is None:
81 | args.index_key = index_utils.get_best_index(args.dataset_size, args.d)
82 | base_index = index_utils.create_empty_index(args.d, args.index_key, args.metric_type)
83 | if index_utils.check_if_index_needs_training(args.index_key):
84 | assert args.index_train_features is not None, "Need to train index, `--index_train_features` must not be empty"
85 | if os.path.isfile(args.index_train_features):
86 | print(f'Loading train features')
87 | start = time.time()
88 | train_features = np.load(args.index_train_features)
89 | print('Loaded train features in {} s'.format(time.time() - start))
90 | if train_features.dtype == np.float16:
91 | print('Find train features in np.float16, converting to np.float32')
92 | train_features = train_features.astype('float32')
93 | np.save(args.index_train_features, train_features)
94 | else:
95 | train_features = sample_train_features(args)
96 |
97 | print(f'Training index on {train_features.shape[0]} features')
98 | start = time.time()
99 | base_index.train(train_features)
100 | print('Training took {} s'.format(time.time() - start))
101 |
102 | print('Writing index after training')
103 | start = time.time()
104 | faiss.write_index(base_index, args.base_index_path)
105 | print('Writing index took {} s'.format(time.time()-start))
106 |
107 | return base_index
108 |
109 |
110 | def retrieve_features(tsv_idx, args):
111 | tsv_file_name = f'{tsv_idx}.tsv'
112 | tsv_file_path = os.path.join(args.data_root, tsv_file_name)
113 | dataset = TSVDataset(tsv_file_path, transform=decode_pairs_feature)
114 | results = [dataset[idx] for idx in range(len(dataset))]
115 | if args.feature_mode == 'image':
116 | features = [x[2].astype(np.float32) for x in results]
117 | elif args.feature_mode == 'text':
118 | features = [x[3].astype(np.float32) for x in results]
119 | else:
120 | assert False, f"Unknown feature type: {args.feature_mode}"
121 | features = np.stack(features, axis=0)
122 | features = features / np.linalg.norm(features, axis=1, keepdims=True)
123 | return features
124 |
125 |
126 | def create_meta_file(args):
127 | tsv_list = sorted(x.replace('.tsv', '') for x in os.listdir(args.data_root) if x.endswith('.tsv'))
128 |
129 | metadata = OrderedDict()
130 | for tsv_idx in tqdm(tsv_list):
131 | metadata[tsv_idx] = len(TSVFile(os.path.join(args.data_root, f'{tsv_idx}.tsv')))
132 |
133 | with open(args.metafile, "w") as fp:
134 | json.dump(metadata, fp)
135 |
136 |
137 | def add_features_to_index(trained_index, args):
138 | with open(args.metafile, "r") as fp:
139 | metafile = json.load(fp, object_pairs_hook=OrderedDict)
140 |
141 | tsv_indices = sorted(metafile.keys())
142 |
143 | pbar = tqdm(range(len(tsv_indices)))
144 | for idx in pbar:
145 | tsv_idx = tsv_indices[idx]
146 | pbar.set_description(f'{tsv_idx}.tsv')
147 |
148 | features = retrieve_features(tsv_idx, args)
149 | trained_index.add(features)
150 |
151 | with Timeit(f"Saving index to disk", indent=0):
152 | faiss.write_index(trained_index, args.faiss_index)
153 | return trained_index
154 |
155 |
156 | def main():
157 | args = get_argument_parser().parse_args()
158 |
159 | setup_logging(logging.INFO)
160 |
161 | if not os.path.isfile(args.metafile):
162 | create_meta_file(args)
163 |
164 | if os.path.isfile(args.base_index_path):
165 | base_index = faiss.read_index(args.base_index_path)
166 | else:
167 | base_index = build_base_index(args)
168 |
169 | add_features_to_index(base_index, args)
170 |
171 | if __name__ == "__main__":
172 | main()
173 |
--------------------------------------------------------------------------------
/react_retrieval/react_retrieval/data/datasets.py:
--------------------------------------------------------------------------------
1 | from io import BytesIO
2 | import base64
3 | from PIL import Image
4 | import json
5 | import logging
6 |
7 | from torch.utils import data
8 | import clip
9 | import numpy as np
10 |
11 | from .tsv import TSVFile
12 |
13 | import os
14 | from zipfile import ZipFile, BadZipFile
15 |
16 |
17 | class ICinWJsonDataset(data.Dataset):
18 | def __init__(self, data_root, infolist, transform=None):
19 | super().__init__()
20 |
21 | logging.info(f'Initializing ICinW JSON dataset with {infolist}')
22 | with open(infolist, 'r') as fp:
23 | self.infolist = json.load(fp)
24 | self.data_root = data_root
25 | self.zipfiles = {}
26 | self.transform = transform
27 |
28 | def __len__(self):
29 | return len(self.infolist)
30 |
31 | def load_zipfile(self, zipfile):
32 | zipfile = os.path.join(self.data_root, zipfile)
33 | if zipfile not in self.zipfiles:
34 | self.zipfiles[zipfile] = ZipFile(zipfile)
35 | return self.zipfiles[zipfile]
36 |
37 | def read_image(self, index):
38 | img_info = self.infolist[index]
39 | zipfile, imagefile = img_info['img_path'].split('@')
40 | zipfile = self.load_zipfile(zipfile)
41 |
42 | try:
43 | image = Image.open(BytesIO(zipfile.read(imagefile))).convert('RGB')
44 | except BadZipFile:
45 | assert False, f"bad zip file in reading {img_info['img_path']}"
46 |
47 | return image
48 |
49 | def __getitem__(self, index):
50 | image = self.read_image(index)
51 | if self.transform is not None:
52 | return self.transform(image)
53 | return image
54 |
55 |
56 | class TSVDataset(data.Dataset):
57 | def __init__(self, file_name, transform=None):
58 | super().__init__()
59 |
60 | self.tsv_file = TSVFile(file_name)
61 | self.transform = transform
62 |
63 | def __len__(self):
64 | return len(self.tsv_file)
65 |
66 | def __getitem__(self, index):
67 | item = self.tsv_file[index]
68 | if self.transform is not None:
69 | return self.transform(item)
70 | return item
71 |
72 |
73 | class PairsDataset(data.Dataset):
74 | def __init__(self, image_file_name, text_file_name, image_transform=None, text_transform=None):
75 | super().__init__()
76 |
77 | self.image_dataset = TSVDataset(image_file_name, image_transform)
78 | self.text_dataset = TSVDataset(text_file_name, text_transform)
79 |
80 | assert len(self.image_dataset) == len(self.text_dataset)
81 |
82 | def __len__(self):
83 | return len(self.image_dataset)
84 |
85 | def get_image(self, index):
86 | raw_image_data = self.image_dataset.tsv_file[index]
87 | return Image.open(BytesIO(base64.b64decode(raw_image_data[1]))).convert('RGB')
88 |
89 | def get_image_raw(self, index):
90 | raw_image_data = self.image_dataset.tsv_file[index]
91 | return raw_image_data[1]
92 |
93 | def get_text(self, index):
94 | raw_text_data = self.text_dataset.tsv_file[index]
95 | return json.loads(raw_text_data[1])['captions'][0]
96 |
97 | def __getitem__(self, index):
98 | image_filename, image = self.image_dataset[index]
99 | text_filename, text = self.text_dataset[index]
100 |
101 | assert image_filename == text_filename
102 |
103 | return image, text, {
104 | 'index': index,
105 | 'filename': image_filename,
106 | }
107 |
108 |
109 | def decode_image(image_item, fn):
110 | return image_item[0], fn(Image.open(BytesIO(base64.b64decode(image_item[1]))).convert('RGB'))
111 |
112 |
113 | def decode_text(text_item):
114 | text_captions_first = json.loads(text_item[1])['captions'][0]
115 | if text_captions_first is None:
116 | text_captions_first = ""
117 | print(f'Found null caption in file {text_item[0]}, using empty string.')
118 | texts = clip.tokenize([text_captions_first], context_length=77, truncate=True)
119 | return text_item[0], texts.squeeze()
120 |
121 |
122 | def encode_as_string(arr):
123 | if type(arr) != np.ndarray:
124 | arr = arr.data.cpu().numpy()
125 | return base64.b64encode(arr.tobytes()).decode('utf-8')
126 |
127 |
128 | def decode_pairs_feature(item):
129 | index, filename, image_feature, text_feature = item
130 | index = int(index)
131 | image_feature = np.frombuffer(base64.b64decode(image_feature), dtype='float16')
132 | text_feature = np.frombuffer(base64.b64decode(text_feature), dtype='float16')
133 | return index, filename, image_feature, text_feature
134 |
--------------------------------------------------------------------------------
/react_retrieval/react_retrieval/data/filelist_controller.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | from collections import OrderedDict
4 | import numpy as np
5 |
6 |
7 | class FileListController:
8 | def __init__(self, metafile, scatter_dir, is_tar=False) -> None:
9 | self.scatter_dir = scatter_dir
10 | self.is_tar = is_tar
11 |
12 | with open(metafile, "rb") as fp:
13 | self.meta = pickle.load(fp)
14 | self.cumsum = self.get_cumsum()
15 |
16 | def __getitem__(self, index):
17 | tsv_idx, sample_idx = self.parse_index(index)
18 | filename = self.meta[tsv_idx][sample_idx]
19 | if self.is_tar:
20 | image_filepath = os.path.join(self.scatter_dir, tsv_idx, filename)
21 | else:
22 | image_filepath = os.path.join(self.scatter_dir, tsv_idx, filename[0], filename[1], filename)
23 | caption_filepath = image_filepath.replace('.jpg', '.txt')
24 | return image_filepath, caption_filepath
25 |
26 | def get_cumsum(self):
27 | accum = 0
28 | cumsum = OrderedDict()
29 | for tsv_idx, filelist in self.meta.items():
30 | accum += len(filelist)
31 | cumsum[tsv_idx] = accum
32 | self.tsv_indices = list(cumsum.keys())
33 | self.cumsum_np = np.asarray(list(cumsum.values()))
34 | return cumsum
35 |
36 | def search_cumsum(self, index):
37 | tsv_idx = np.searchsorted(self.cumsum_np, index, side="right")
38 | return self.tsv_indices[tsv_idx]
39 |
40 | def parse_index(self, index):
41 | tsv_idx = self.search_cumsum(index)
42 | sample_idx = index - (self.cumsum[tsv_idx] - len(self.meta[tsv_idx]))
43 | return tsv_idx, sample_idx
44 |
45 | def get_item_with_index(self, index):
46 | return index, self[index]
47 |
--------------------------------------------------------------------------------
/react_retrieval/react_retrieval/data/tsv.py:
--------------------------------------------------------------------------------
1 | import os
2 | import os.path as op
3 | import gc
4 | import json
5 | from typing import List
6 | import logging
7 |
8 |
9 | def generate_lineidx(filein: str, idxout: str) -> None:
10 | idxout_tmp = idxout + '.tmp'
11 | with open(filein, 'r') as tsvin, open(idxout_tmp, 'w') as tsvout:
12 | fsize = os.fstat(tsvin.fileno()).st_size
13 | fpos = 0
14 | while fpos != fsize:
15 | tsvout.write(str(fpos) + "\n")
16 | tsvin.readline()
17 | fpos = tsvin.tell()
18 | os.rename(idxout_tmp, idxout)
19 |
20 |
21 | def read_to_character(fp, c):
22 | result = []
23 | while True:
24 | s = fp.read(32)
25 | assert s != ''
26 | if c in s:
27 | result.append(s[: s.index(c)])
28 | break
29 | else:
30 | result.append(s)
31 | return ''.join(result)
32 |
33 |
34 | class TSVFile(object):
35 | def __init__(self,
36 | tsv_file: str,
37 | if_generate_lineidx: bool = False,
38 | lineidx: str = None,
39 | class_selector: List[str] = None):
40 | self.tsv_file = tsv_file
41 | self.lineidx = op.splitext(tsv_file)[0] + '.lineidx' \
42 | if not lineidx else lineidx
43 | self.linelist = op.splitext(tsv_file)[0] + '.linelist'
44 | self.chunks = op.splitext(tsv_file)[0] + '.chunks'
45 | self._fp = None
46 | self._lineidx = None
47 | self._sample_indices = None
48 | self._class_boundaries = None
49 | self._class_selector = class_selector
50 | self._len = None
51 | # the process always keeps the process which opens the file.
52 | # If the pid is not equal to the currrent pid, we will re-open the file.
53 | self.pid = None
54 | # generate lineidx if not exist
55 | if not op.isfile(self.lineidx) and if_generate_lineidx:
56 | generate_lineidx(self.tsv_file, self.lineidx)
57 |
58 | def __del__(self):
59 | self.gcidx()
60 | if self._fp:
61 | self._fp.close()
62 |
63 | def __str__(self):
64 | return "TSVFile(tsv_file='{}')".format(self.tsv_file)
65 |
66 | def __repr__(self):
67 | return str(self)
68 |
69 | def gcidx(self):
70 | logging.debug('Run gc collect')
71 | self._lineidx = None
72 | self._sample_indices = None
73 | #self._class_boundaries = None
74 | return gc.collect()
75 |
76 | def get_class_boundaries(self):
77 | return self._class_boundaries
78 |
79 | def num_rows(self, gcf=False):
80 | if (self._len is None):
81 | self._ensure_lineidx_loaded()
82 | retval = len(self._sample_indices)
83 |
84 | if (gcf):
85 | self.gcidx()
86 |
87 | self._len = retval
88 |
89 | return self._len
90 |
91 | def seek(self, idx: int):
92 | self._ensure_tsv_opened()
93 | self._ensure_lineidx_loaded()
94 | try:
95 | pos = self._lineidx[self._sample_indices[idx]]
96 | except:
97 | logging.info('=> {}-{}'.format(self.tsv_file, idx))
98 | raise
99 | self._fp.seek(pos)
100 | return [s.strip() for s in self._fp.readline().split('\t')]
101 |
102 | def seek_first_column(self, idx: int):
103 | self._ensure_tsv_opened()
104 | self._ensure_lineidx_loaded()
105 | pos = self._lineidx[idx]
106 | self._fp.seek(pos)
107 | return read_to_character(self._fp, '\t')
108 |
109 | def get_key(self, idx: int):
110 | return self.seek_first_column(idx)
111 |
112 | def __getitem__(self, index: int):
113 | return self.seek(index)
114 |
115 | def __len__(self):
116 | return self.num_rows()
117 |
118 | def _ensure_lineidx_loaded(self):
119 | if self._lineidx is None:
120 | logging.debug('=> loading lineidx: {}'.format(self.lineidx))
121 | with open(self.lineidx, 'r') as fp:
122 | lines = fp.readlines()
123 | lines = [line.strip() for line in lines]
124 | self._lineidx = [int(line) for line in lines]
125 |
126 | # read the line list if exists
127 | linelist = None
128 | if op.isfile(self.linelist):
129 | with open(self.linelist, 'r') as fp:
130 | linelist = sorted(
131 | [
132 | int(line.strip())
133 | for line in fp.readlines()
134 | ]
135 | )
136 |
137 | if op.isfile(self.chunks):
138 | self._sample_indices = []
139 | self._class_boundaries = []
140 | class_boundaries = json.load(open(self.chunks, 'r'))
141 | for class_name, boundary in class_boundaries.items():
142 | start = len(self._sample_indices)
143 | if class_name in self._class_selector:
144 | for idx in range(boundary[0], boundary[1] + 1):
145 | # NOTE: potentially slow when linelist is long, try to speed it up
146 | if linelist and idx not in linelist:
147 | continue
148 | self._sample_indices.append(idx)
149 | end = len(self._sample_indices)
150 | self._class_boundaries.append((start, end))
151 | else:
152 | if linelist:
153 | self._sample_indices = linelist
154 | else:
155 | self._sample_indices = list(range(len(self._lineidx)))
156 |
157 | def _ensure_tsv_opened(self):
158 | if self._fp is None:
159 | self._fp = open(self.tsv_file, 'r')
160 | self.pid = os.getpid()
161 |
162 | if self.pid != os.getpid():
163 | logging.debug('=> re-open {} because the process id changed'.format(self.tsv_file))
164 | self._fp = open(self.tsv_file, 'r')
165 | self.pid = os.getpid()
166 |
167 |
168 | class TSVWriter(object):
169 | def __init__(self, tsv_file):
170 | self.tsv_file = tsv_file
171 | self.lineidx_file = op.splitext(tsv_file)[0] + '.lineidx'
172 | self.tsv_file_tmp = self.tsv_file + '.tmp'
173 | self.lineidx_file_tmp = self.lineidx_file + '.tmp'
174 |
175 | self.tsv_fp = open(self.tsv_file_tmp, 'w')
176 | self.lineidx_fp = open(self.lineidx_file_tmp, 'w')
177 |
178 | self.idx = 0
179 |
180 | def write(self, values, sep='\t'):
181 | v = '{0}\n'.format(sep.join(map(str, values)))
182 | self.tsv_fp.write(v)
183 | self.lineidx_fp.write(str(self.idx) + '\n')
184 | self.idx = self.idx + len(v)
185 |
186 | def close(self):
187 | self.tsv_fp.close()
188 | self.lineidx_fp.close()
189 | os.rename(self.tsv_file_tmp, self.tsv_file)
190 | os.rename(self.lineidx_file_tmp, self.lineidx_file)
191 |
--------------------------------------------------------------------------------
/react_retrieval/react_retrieval/index/index_factory.py:
--------------------------------------------------------------------------------
1 | """ functions that fixe faiss index_factory function """
2 | # pylint: disable=invalid-name
3 |
4 | import re
5 | from typing import Optional
6 |
7 | import faiss
8 |
9 |
10 | def index_factory(d: int, index_key: str, metric_type: int, ef_construction: Optional[int] = None):
11 | """
12 | custom index_factory that fix some issues of
13 | faiss.index_factory with inner product metrics.
14 | """
15 |
16 | if metric_type == faiss.METRIC_INNER_PRODUCT:
17 |
18 | # make the index described by the key
19 | if any(re.findall(r"OPQ\d+_\d+,IVF\d+,PQ\d+", index_key)):
20 | params = [int(x) for x in re.findall(r"\d+", index_key)]
21 |
22 | cs = params[3] # code size (in Bytes if nbits=8)
23 | nbits = params[4] if len(params) == 5 else 8 # default value
24 | ncentroids = params[2]
25 | out_d = params[1]
26 | M_OPQ = params[0]
27 |
28 | quantizer = faiss.index_factory(out_d, "Flat", metric_type)
29 | assert quantizer.metric_type == metric_type
30 | index_ivfpq = faiss.IndexIVFPQ(quantizer, out_d, ncentroids, cs, nbits, metric_type)
31 | assert index_ivfpq.metric_type == metric_type
32 | index_ivfpq.own_fields = True
33 | quantizer.this.disown() # pylint: disable = no-member
34 | opq_matrix = faiss.OPQMatrix(d, M=M_OPQ, d2=out_d)
35 | # opq_matrix.niter = 50 # Same as default value
36 | index = faiss.IndexPreTransform(opq_matrix, index_ivfpq)
37 | elif any(re.findall(r"OPQ\d+_\d+,IVF\d+_HNSW\d+,PQ\d+", index_key)):
38 | params = [int(x) for x in re.findall(r"\d+", index_key)]
39 |
40 | M_HNSW = params[3]
41 | cs = params[4] # code size (in Bytes if nbits=8)
42 | nbits = params[5] if len(params) == 6 else 8 # default value
43 | ncentroids = params[2]
44 | out_d = params[1]
45 | M_OPQ = params[0]
46 |
47 | quantizer = faiss.IndexHNSWFlat(out_d, M_HNSW, metric_type)
48 | if ef_construction is not None and ef_construction >= 1:
49 | quantizer.hnsw.efConstruction = ef_construction
50 | assert quantizer.metric_type == metric_type
51 | index_ivfpq = faiss.IndexIVFPQ(quantizer, out_d, ncentroids, cs, nbits, metric_type)
52 | assert index_ivfpq.metric_type == metric_type
53 | index_ivfpq.own_fields = True
54 | quantizer.this.disown() # pylint: disable = no-member
55 | opq_matrix = faiss.OPQMatrix(d, M=M_OPQ, d2=out_d)
56 | # opq_matrix.niter = 50 # Same as default value
57 | index = faiss.IndexPreTransform(opq_matrix, index_ivfpq)
58 |
59 | elif any(re.findall(r"Pad\d+,IVF\d+_HNSW\d+,PQ\d+", index_key)):
60 | params = [int(x) for x in re.findall(r"\d+", index_key)]
61 |
62 | out_d = params[0]
63 | M_HNSW = params[2]
64 | cs = params[3] # code size (in Bytes if nbits=8)
65 | nbits = params[4] if len(params) == 5 else 8 # default value
66 | ncentroids = params[1]
67 |
68 | remapper = faiss.RemapDimensionsTransform(d, out_d, True)
69 |
70 | quantizer = faiss.IndexHNSWFlat(out_d, M_HNSW, metric_type)
71 | if ef_construction is not None and ef_construction >= 1:
72 | quantizer.hnsw.efConstruction = ef_construction
73 | index_ivfpq = faiss.IndexIVFPQ(quantizer, out_d, ncentroids, cs, nbits, metric_type)
74 | index_ivfpq.own_fields = True
75 | quantizer.this.disown() # pylint: disable = no-member
76 |
77 | index = faiss.IndexPreTransform(remapper, index_ivfpq)
78 | elif any(re.findall(r"HNSW\d+", index_key)):
79 | params = [int(x) for x in re.findall(r"\d+", index_key)]
80 | M_HNSW = params[0]
81 | index = faiss.IndexHNSWFlat(d, M_HNSW, metric_type)
82 | assert index.metric_type == metric_type
83 | elif index_key == "Flat" or any(re.findall(r"IVF\d+,Flat", index_key)):
84 | index = faiss.index_factory(d, index_key, metric_type)
85 | else:
86 | index = faiss.index_factory(d, index_key, metric_type)
87 | # raise ValueError(
88 | # (
89 | # "Be careful, faiss might not create what you expect when using the "
90 | # "inner product similarity metric, remove this line to try it anyway. "
91 | # "Happened with index_key: " + str(index_key)
92 | # )
93 | # )
94 | import logging
95 | logging.warning(
96 | (
97 | "Be careful, faiss might not create what you expect when using the "
98 | "inner product similarity metric, remove this line to try it anyway. "
99 | "Happened with index_key: " + str(index_key)
100 | )
101 | )
102 |
103 | else:
104 | index = faiss.index_factory(d, index_key, metric_type)
105 |
106 | return index
107 |
--------------------------------------------------------------------------------
/react_retrieval/react_retrieval/index/index_utils.py:
--------------------------------------------------------------------------------
1 | from typing import Union, NamedTuple, Optional, List
2 |
3 | import faiss
4 | import autofaiss
5 |
6 | from .index_factory import index_factory
7 |
8 | def to_faiss_metric_type(metric_type: Union[str, int]) -> int:
9 | """convert metric_type string/enum to faiss enum of the distance metric"""
10 |
11 | if metric_type in ["ip", "IP", faiss.METRIC_INNER_PRODUCT]:
12 | return faiss.METRIC_INNER_PRODUCT
13 | elif metric_type in ["l2", "L2", faiss.METRIC_L2]:
14 | return faiss.METRIC_L2
15 | else:
16 | raise ValueError("Metric currently not supported")
17 |
18 | def create_empty_index(vec_dim: int, index_key: str, metric_type: Union[str, int]) -> faiss.Index:
19 | """Create empty index"""
20 |
21 | # Convert metric_type to faiss type
22 | metric_type = to_faiss_metric_type(metric_type)
23 |
24 | # Instanciate the index
25 | return index_factory(vec_dim, index_key, metric_type)
26 |
27 |
28 | def check_if_index_needs_training(index_key: str) -> bool:
29 | """
30 | Function that checks if the index needs to be trained
31 | """
32 |
33 | if "IVF" in index_key:
34 | return True
35 | elif "IMI" in index_key:
36 | return True
37 | else:
38 | return False
39 |
40 |
41 | def get_best_index(nb_vectors, dim_vector, max_index_memory_usage='100G'):
42 | best_indexes = autofaiss.external.optimize.get_optimal_index_keys_v2(
43 | nb_vectors = nb_vectors,
44 | dim_vector = dim_vector,
45 | max_index_memory_usage = max_index_memory_usage,
46 | flat_threshold = 1000,
47 | quantization_threshold = 10000,
48 | force_pq = None,
49 | make_direct_map = False,
50 | should_be_memory_mappable = False,
51 | ivf_flat_threshold = 1_000_000,
52 | use_gpu = False,
53 | )
54 |
55 | return best_indexes[0]
56 |
--------------------------------------------------------------------------------
/react_retrieval/requirements.txt:
--------------------------------------------------------------------------------
1 | yacs~=0.1.8
2 | scikit-learn
3 | timm~=0.4.12
4 | numpy~=1.21.0
5 | sharedmem
6 | git+https://github.com/openai/CLIP.git
7 | torch~=1.7.0
8 | PyYAML~=5.4.1
9 | Pillow~=9.0.1
10 | torchvision~=0.8.0
11 | tqdm~=4.62.3
12 | protobuf~=3.20.1
13 | faiss-cpu~=1.7.2
14 | requests~=2.28.1
15 | azure-storage-blob~=12.13.1
16 | autofaiss~=2.15.3
--------------------------------------------------------------------------------
/react_retrieval/setup.py:
--------------------------------------------------------------------------------
1 | import setuptools
2 |
3 | VERSION = '0.0.1'
4 |
5 | setuptools.setup(
6 | name='react_retrieval',
7 | author='Haotian Liu',
8 | author_email='lht@cs.wisc.edu',
9 | version=VERSION,
10 | python_requires='>=3.6',
11 | packages=setuptools.find_packages(exclude=['test', 'test.*']),
12 | package_data={'': ['resources/*']},
13 | install_requires=[
14 | 'yacs~=0.1.8',
15 | 'scikit-learn',
16 | 'timm>=0.3.4',
17 | 'numpy>=1.18.0',
18 | 'sharedmem',
19 | 'PyYAML~=5.4.1',
20 | 'Pillow',
21 | ],
22 | )
23 |
--------------------------------------------------------------------------------