├── requirements.in
├── README.md
├── .gitignore
├── speech
└── asr
│ ├── deepspeech
│ ├── ds-transcriber.py
│ └── mozilla_deepspeech_api_notebook.ipynb
│ └── python_speech_recognition_notebook.ipynb
├── requirements.txt
└── gpt
├── nlp_with_gpt_notebook.ipynb
└── translate_natural_language_query_to_sql_notebook.ipynb
/requirements.in:
--------------------------------------------------------------------------------
1 | # Python 3.10.14
2 | dask==2024.9.1
3 | datetime==5.5
4 | faker==30.8.0
5 | fastapi[all]==0.111.1
6 | gpustat==1.0.0
7 | httpx==0.27.0
8 | jax-metal==0.1.0
9 | jax==0.4.26
10 | jaxlib==0.4.26
11 | jsonschema==4.22.0
12 | line-profiler==4.1.3
13 | matplotlib==3.7.5
14 | networkx==3.3
15 | numba==0.60.0
16 | numpy==1.26.4
17 | openai[datalib]==1.35.14
18 | openpyxl==3.1.5
19 | pandarallel==1.6.5
20 | pandas==2.2.3
21 | perfplot==0.10.2
22 | pypdf==5.0.1
23 | python-dotenv==1.0.1
24 | SQLAlchemy==2.0.30
25 | swifter==1.4.0
26 | tensorflow-macos==2.16.1
27 | tensorflow-metal==1.1.0
28 | tensorflow==2.16.1
29 | torch==2.4.0
30 | torchaudio==2.4.0
31 | torchvision==0.19.0
32 | xlrd==2.0.1
33 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # ML4Devs — Notebooks
2 |
3 | This repository hosts companion notebooks and code snippets for [ML4Devs.com](https://www.ml4devs.com) website:
4 |
5 | - GPT
6 | - [`nlp_with_gpt_notebook.ipynb`](gpt/nlp_with_gpt_notebook.ipynb) : Sentiment Analysis, Language Translation, and Named-Entity Recognition with GPT
7 | - [`translate_natural_language_query_to_sql_notebook.ipynb`](gpt/translate_natural_language_query_to_sql_notebook.ipynb) : Translate Natural Language Queries to SQL, and execute it on a database
8 | - Pandas
9 | - [`pandas_apply_fn_on_dataframe.ipynb`](pandas/pandas_apply_fn_on_dataframe.ipynb) : Better ways to [apply a function to each row in Pandas DataFrame](https://www.ml4devs.com/articles/pandas-dataframe-apply-function-iterate-over-rows/)
10 | - Speech
11 | - [`mozilla_deepspeech_api_notebook.ipynb`](speech/asr/deepspeech/mozilla_deepspeech_api_notebook.ipynb) : Automatic [speech recognition with Mozilla DeepSpeech](https://www.ml4devs.com/articles/how-to-build-python-transcriber-using-mozilla-deepspeech/)
12 | - [`ds-transcriber.py`](speech/asr/deepspeech/ds-transcriber.py) : Code for a [Python transcriber](https://www.ml4devs.com/articles/how-to-build-python-transcriber-using-mozilla-deepspeech/) that process streaming audio with DeepSpeech
13 | - [`python_speech_recognition_notebook.ipynb`](speech/asr/python_speech_recognition_notebook.ipynb) : Comparing most prominent alternatives for [speech recognition with Python](https://www.ml4devs.com/articles/speech-recognition-with-python/)
14 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Databases
2 | *.db
3 | *.zip
4 |
5 | # Byte-compiled / optimized / DLL files
6 | __pycache__/
7 | *.py[cod]
8 | *$py.class
9 |
10 | # C extensions
11 | *.so
12 |
13 | # Distribution / packaging
14 | .Python
15 | build/
16 | develop-eggs/
17 | dist/
18 | downloads/
19 | eggs/
20 | .eggs/
21 | lib/
22 | lib64/
23 | parts/
24 | sdist/
25 | var/
26 | wheels/
27 | pip-wheel-metadata/
28 | share/python-wheels/
29 | *.egg-info/
30 | .installed.cfg
31 | *.egg
32 | MANIFEST
33 |
34 | # PyInstaller
35 | # Usually these files are written by a python script from a template
36 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
37 | *.manifest
38 | *.spec
39 |
40 | # Installer logs
41 | pip-log.txt
42 | pip-delete-this-directory.txt
43 |
44 | # Unit test / coverage reports
45 | htmlcov/
46 | .tox/
47 | .nox/
48 | .coverage
49 | .coverage.*
50 | .cache
51 | nosetests.xml
52 | coverage.xml
53 | *.cover
54 | *.py,cover
55 | .hypothesis/
56 | .pytest_cache/
57 |
58 | # Translations
59 | *.mo
60 | *.pot
61 |
62 | # Django stuff:
63 | *.log
64 | local_settings.py
65 | db.sqlite3
66 | db.sqlite3-journal
67 |
68 | # Flask stuff:
69 | instance/
70 | .webassets-cache
71 |
72 | # Scrapy stuff:
73 | .scrapy
74 |
75 | # Sphinx documentation
76 | docs/_build/
77 |
78 | # PyBuilder
79 | target/
80 |
81 | # Jupyter Notebook
82 | .ipynb_checkpoints
83 |
84 | # IPython
85 | profile_default/
86 | ipython_config.py
87 |
88 | # pyenv
89 | .python-version
90 |
91 | # pipenv
92 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
93 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
94 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
95 | # install all needed dependencies.
96 | #Pipfile.lock
97 |
98 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
99 | __pypackages__/
100 |
101 | # Celery stuff
102 | celerybeat-schedule
103 | celerybeat.pid
104 |
105 | # SageMath parsed files
106 | *.sage.py
107 |
108 | # Environments
109 | .env
110 | .venv
111 | env/
112 | venv/
113 | ENV/
114 | env.bak/
115 | venv.bak/
116 |
117 | # Spyder project settings
118 | .spyderproject
119 | .spyproject
120 |
121 | # Rope project settings
122 | .ropeproject
123 |
124 | # mkdocs documentation
125 | /site
126 |
127 | # mypy
128 | .mypy_cache/
129 | .dmypy.json
130 | dmypy.json
131 |
132 | # Pyre type checker
133 | .pyre/
134 |
--------------------------------------------------------------------------------
/speech/asr/deepspeech/ds-transcriber.py:
--------------------------------------------------------------------------------
1 | # (c) Copyright 2020-2022 Satish Chandra Gupta
2 | #
3 | # MIT License
4 | #
5 | # Permission is hereby granted, free of charge, to any person obtaining a copy
6 | # of this software and associated documentation files (the "Software"), to deal
7 | # in the Software without restriction, including without limitation the rights
8 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | # copies of the Software, and to permit persons to whom the Software is
10 | # furnished to do so, subject to the following conditions:
11 | #
12 | # The above copyright notice and this permission notice shall be included in
13 | # all copies or substantial portions of the Software.
14 | #
15 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | # SOFTWARE.
22 | #
23 |
24 |
25 | # For more explanation, check following blog posts:
26 | # - https://www.ml4devs.com/articles/how-to-build-python-transcriber-using-mozilla-deepspeech/
27 | # - https://www.ml4devs.com/articles/speech-recognition-with-python/
28 |
29 | import stt
30 | import numpy as np
31 | import os
32 | import pyaudio
33 | import time
34 |
35 | # DeepSpeech parameters
36 | DEEPSPEECH_MODEL_DIR = 'coqui-stt-1.0.0-models'
37 | MODEL_FILE_PATH = os.path.join(DEEPSPEECH_MODEL_DIR, 'model.tflite')
38 | SCORER_FILE_PATH = os.path.join(DEEPSPEECH_MODEL_DIR, 'large_vocabulary.scorer')
39 | LM_ALPHA = 0.75
40 | LM_BETA = 1.85
41 | BEAM_WIDTH = 500
42 |
43 | # Make DeepSpeech Model
44 | model = stt.Model(MODEL_FILE_PATH)
45 | model.enableExternalScorer(SCORER_FILE_PATH)
46 | model.setScorerAlphaBeta(LM_ALPHA, LM_BETA)
47 | model.setBeamWidth(BEAM_WIDTH)
48 |
49 | # Create a Streaming session
50 | stt_stream = model.createStream()
51 |
52 | # Encapsulate DeepSpeech audio feeding into a callback for PyAudio
53 | text_so_far = ''
54 | def process_audio(in_data, frame_count, time_info, status):
55 | global text_so_far
56 | data16 = np.frombuffer(in_data, dtype=np.int16)
57 | stt_stream.feedAudioContent(data16)
58 | text = stt_stream.intermediateDecode()
59 | if text != text_so_far:
60 | print('Interim text = {}'.format(text))
61 | text_so_far = text
62 | return (in_data, pyaudio.paContinue)
63 |
64 | # PyAudio parameters
65 | FORMAT = pyaudio.paInt16
66 | CHANNELS = 1
67 | RATE = 16000
68 | CHUNK_SIZE = 1024
69 |
70 | # Feed audio to deepspeech in a callback to PyAudio
71 | audio = pyaudio.PyAudio()
72 | stream = audio.open(
73 | format=FORMAT,
74 | channels=CHANNELS,
75 | rate=RATE,
76 | input=True,
77 | frames_per_buffer=CHUNK_SIZE,
78 | stream_callback=process_audio
79 | )
80 |
81 | print('Please start speaking, when done press Ctrl-C ...')
82 | stream.start_stream()
83 |
84 | try:
85 | while stream.is_active():
86 | time.sleep(0.1)
87 | except KeyboardInterrupt:
88 | # PyAudio
89 | stream.stop_stream()
90 | stream.close()
91 | audio.terminate()
92 | print('Finished recording.')
93 | # DeepSpeech
94 | text = stt_stream.finishStream()
95 | print('Final text = {}'.format(text))
96 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | #
2 | # This file is autogenerated by pip-compile with Python 3.10
3 | # by the following command:
4 | #
5 | # pip-compile requirements.in
6 | #
7 | absl-py==2.1.0
8 | # via
9 | # keras
10 | # tensorboard
11 | # tensorflow
12 | annotated-types==0.7.0
13 | # via pydantic
14 | anyio==4.6.2.post1
15 | # via
16 | # httpx
17 | # openai
18 | # starlette
19 | # watchfiles
20 | astunparse==1.6.3
21 | # via tensorflow
22 | attrs==24.2.0
23 | # via
24 | # jsonschema
25 | # referencing
26 | blessed==1.20.0
27 | # via gpustat
28 | certifi==2024.8.30
29 | # via
30 | # httpcore
31 | # httpx
32 | # requests
33 | charset-normalizer==3.4.0
34 | # via requests
35 | click==8.1.7
36 | # via
37 | # dask
38 | # typer
39 | # uvicorn
40 | cloudpickle==3.1.0
41 | # via dask
42 | contourpy==1.3.0
43 | # via matplotlib
44 | cycler==0.12.1
45 | # via matplotlib
46 | dask[array,dataframe]==2024.9.1
47 | # via
48 | # -r requirements.in
49 | # dask-expr
50 | # swifter
51 | dask-expr==1.1.15
52 | # via dask
53 | datetime==5.5
54 | # via -r requirements.in
55 | dill==0.3.9
56 | # via pandarallel
57 | distro==1.9.0
58 | # via openai
59 | dnspython==2.7.0
60 | # via email-validator
61 | email-validator==2.2.0
62 | # via fastapi
63 | et-xmlfile==2.0.0
64 | # via openpyxl
65 | exceptiongroup==1.2.2
66 | # via anyio
67 | faker==30.8.0
68 | # via -r requirements.in
69 | fastapi[all]==0.111.1
70 | # via -r requirements.in
71 | fastapi-cli==0.0.5
72 | # via fastapi
73 | filelock==3.16.1
74 | # via torch
75 | flatbuffers==24.3.25
76 | # via tensorflow
77 | fonttools==4.54.1
78 | # via matplotlib
79 | fsspec==2024.10.0
80 | # via
81 | # dask
82 | # torch
83 | gast==0.6.0
84 | # via tensorflow
85 | google-pasta==0.2.0
86 | # via tensorflow
87 | gpustat==1.0.0
88 | # via -r requirements.in
89 | grpcio==1.67.1
90 | # via
91 | # tensorboard
92 | # tensorflow
93 | h11==0.14.0
94 | # via
95 | # httpcore
96 | # uvicorn
97 | h5py==3.12.1
98 | # via
99 | # keras
100 | # tensorflow
101 | httpcore==1.0.6
102 | # via httpx
103 | httptools==0.6.4
104 | # via uvicorn
105 | httpx==0.27.0
106 | # via
107 | # -r requirements.in
108 | # fastapi
109 | # openai
110 | idna==3.10
111 | # via
112 | # anyio
113 | # email-validator
114 | # httpx
115 | # requests
116 | importlib-metadata==8.5.0
117 | # via dask
118 | itsdangerous==2.2.0
119 | # via fastapi
120 | jax==0.4.26
121 | # via
122 | # -r requirements.in
123 | # jax-metal
124 | jax-metal==0.1.0
125 | # via -r requirements.in
126 | jaxlib==0.4.26
127 | # via
128 | # -r requirements.in
129 | # jax-metal
130 | jinja2==3.1.4
131 | # via
132 | # fastapi
133 | # torch
134 | jsonschema==4.22.0
135 | # via -r requirements.in
136 | jsonschema-specifications==2024.10.1
137 | # via jsonschema
138 | keras==3.6.0
139 | # via tensorflow
140 | kiwisolver==1.4.7
141 | # via matplotlib
142 | libclang==18.1.1
143 | # via tensorflow
144 | line-profiler==4.1.3
145 | # via -r requirements.in
146 | llvmlite==0.43.0
147 | # via numba
148 | locket==1.0.0
149 | # via partd
150 | markdown==3.7
151 | # via tensorboard
152 | markdown-it-py==3.0.0
153 | # via rich
154 | markupsafe==3.0.2
155 | # via
156 | # jinja2
157 | # werkzeug
158 | matplotlib==3.7.5
159 | # via
160 | # -r requirements.in
161 | # matplotx
162 | # perfplot
163 | matplotx==0.3.10
164 | # via perfplot
165 | mdurl==0.1.2
166 | # via markdown-it-py
167 | ml-dtypes==0.3.2
168 | # via
169 | # jax
170 | # jaxlib
171 | # keras
172 | # tensorflow
173 | mpmath==1.3.0
174 | # via sympy
175 | namex==0.0.8
176 | # via keras
177 | networkx==3.3
178 | # via
179 | # -r requirements.in
180 | # torch
181 | numba==0.60.0
182 | # via -r requirements.in
183 | numpy==1.26.4
184 | # via
185 | # -r requirements.in
186 | # contourpy
187 | # dask
188 | # h5py
189 | # jax
190 | # jaxlib
191 | # keras
192 | # matplotlib
193 | # matplotx
194 | # ml-dtypes
195 | # numba
196 | # openai
197 | # pandas
198 | # pandas-stubs
199 | # perfplot
200 | # scipy
201 | # tensorboard
202 | # tensorflow
203 | # torchvision
204 | nvidia-ml-py==11.495.46
205 | # via gpustat
206 | openai[datalib]==1.35.14
207 | # via -r requirements.in
208 | openpyxl==3.1.5
209 | # via -r requirements.in
210 | opt-einsum==3.4.0
211 | # via
212 | # jax
213 | # tensorflow
214 | optree==0.13.0
215 | # via keras
216 | orjson==3.10.10
217 | # via fastapi
218 | packaging==24.1
219 | # via
220 | # dask
221 | # keras
222 | # matplotlib
223 | # tensorflow
224 | pandarallel==1.6.5
225 | # via -r requirements.in
226 | pandas==2.2.3
227 | # via
228 | # -r requirements.in
229 | # dask
230 | # dask-expr
231 | # openai
232 | # pandarallel
233 | # swifter
234 | pandas-stubs==2.2.3.241009
235 | # via openai
236 | partd==1.4.2
237 | # via dask
238 | perfplot==0.10.2
239 | # via -r requirements.in
240 | pillow==11.0.0
241 | # via
242 | # matplotlib
243 | # torchvision
244 | protobuf==4.25.5
245 | # via
246 | # tensorboard
247 | # tensorflow
248 | psutil==6.1.0
249 | # via
250 | # gpustat
251 | # pandarallel
252 | # swifter
253 | pyarrow==18.0.0
254 | # via dask-expr
255 | pydantic==2.9.2
256 | # via
257 | # fastapi
258 | # openai
259 | # pydantic-extra-types
260 | # pydantic-settings
261 | pydantic-core==2.23.4
262 | # via pydantic
263 | pydantic-extra-types==2.9.0
264 | # via fastapi
265 | pydantic-settings==2.6.1
266 | # via fastapi
267 | pygments==2.18.0
268 | # via rich
269 | pyparsing==3.2.0
270 | # via matplotlib
271 | pypdf==5.0.1
272 | # via -r requirements.in
273 | python-dateutil==2.9.0.post0
274 | # via
275 | # faker
276 | # matplotlib
277 | # pandas
278 | python-dotenv==1.0.1
279 | # via
280 | # -r requirements.in
281 | # pydantic-settings
282 | # uvicorn
283 | python-multipart==0.0.17
284 | # via fastapi
285 | pytz==2024.2
286 | # via
287 | # datetime
288 | # pandas
289 | pyyaml==6.0.2
290 | # via
291 | # dask
292 | # fastapi
293 | # uvicorn
294 | referencing==0.35.1
295 | # via
296 | # jsonschema
297 | # jsonschema-specifications
298 | requests==2.32.3
299 | # via tensorflow
300 | rich==13.9.3
301 | # via
302 | # keras
303 | # perfplot
304 | # typer
305 | rpds-py==0.20.1
306 | # via
307 | # jsonschema
308 | # referencing
309 | scipy==1.14.1
310 | # via
311 | # jax
312 | # jaxlib
313 | shellingham==1.5.4
314 | # via typer
315 | six==1.16.0
316 | # via
317 | # astunparse
318 | # blessed
319 | # google-pasta
320 | # gpustat
321 | # jax-metal
322 | # python-dateutil
323 | # tensorboard
324 | # tensorflow
325 | # tensorflow-metal
326 | sniffio==1.3.1
327 | # via
328 | # anyio
329 | # httpx
330 | # openai
331 | sqlalchemy==2.0.30
332 | # via -r requirements.in
333 | starlette==0.37.2
334 | # via fastapi
335 | swifter==1.4.0
336 | # via -r requirements.in
337 | sympy==1.13.3
338 | # via torch
339 | tensorboard==2.16.2
340 | # via tensorflow
341 | tensorboard-data-server==0.7.2
342 | # via tensorboard
343 | tensorflow==2.16.1
344 | # via
345 | # -r requirements.in
346 | # tensorflow-macos
347 | tensorflow-io-gcs-filesystem==0.37.1
348 | # via tensorflow
349 | tensorflow-macos==2.16.1
350 | # via -r requirements.in
351 | tensorflow-metal==1.1.0
352 | # via -r requirements.in
353 | termcolor==2.5.0
354 | # via tensorflow
355 | toolz==1.0.0
356 | # via
357 | # dask
358 | # partd
359 | torch==2.4.0
360 | # via
361 | # -r requirements.in
362 | # torchaudio
363 | # torchvision
364 | torchaudio==2.4.0
365 | # via -r requirements.in
366 | torchvision==0.19.0
367 | # via -r requirements.in
368 | tqdm==4.66.6
369 | # via
370 | # openai
371 | # swifter
372 | typer==0.12.5
373 | # via fastapi-cli
374 | types-pytz==2024.2.0.20241003
375 | # via pandas-stubs
376 | typing-extensions==4.12.2
377 | # via
378 | # anyio
379 | # faker
380 | # fastapi
381 | # openai
382 | # optree
383 | # pydantic
384 | # pydantic-core
385 | # pypdf
386 | # rich
387 | # sqlalchemy
388 | # tensorflow
389 | # torch
390 | # typer
391 | # uvicorn
392 | tzdata==2024.2
393 | # via pandas
394 | ujson==5.10.0
395 | # via fastapi
396 | urllib3==2.2.3
397 | # via requests
398 | uvicorn[standard]==0.32.0
399 | # via
400 | # fastapi
401 | # fastapi-cli
402 | uvloop==0.21.0
403 | # via uvicorn
404 | watchfiles==0.24.0
405 | # via uvicorn
406 | wcwidth==0.2.13
407 | # via blessed
408 | websockets==13.1
409 | # via uvicorn
410 | werkzeug==3.1.0
411 | # via tensorboard
412 | wheel==0.44.0
413 | # via
414 | # astunparse
415 | # jax-metal
416 | # tensorflow-metal
417 | wrapt==1.16.0
418 | # via tensorflow
419 | xlrd==2.0.1
420 | # via -r requirements.in
421 | zipp==3.20.2
422 | # via importlib-metadata
423 | zope-interface==7.1.1
424 | # via datetime
425 |
426 | # The following packages are considered to be unsafe in a requirements file:
427 | # setuptools
428 |
--------------------------------------------------------------------------------
/gpt/nlp_with_gpt_notebook.ipynb:
--------------------------------------------------------------------------------
1 | {"cells":[{"cell_type":"markdown","metadata":{"id":"EV0cfuXJeO-8"},"source":["Common NLP Tasks with GPT: Sentiment Analysis, Language Translation, and Named-Entity Recognition
\n","© Satish Chandra Guptascgupta ,\n","Twitter: scgupta \n"," \n"," \n","\n","---\n","\n","## Setup\n","\n","### Install Pip Packages\n","\n","You need Python 3.7 or higher to install [OpenAI Python API library](https://github.com/openai/openai-python)."]},{"cell_type":"code","execution_count":1,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":770,"status":"ok","timestamp":1701355793267,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"iZkQzDDxeO_A","outputId":"4824a891-78f6-47d5-c78b-5f51c7566483","vscode":{"languageId":"shellscript"}},"outputs":[{"name":"stdout","output_type":"stream","text":["Python 3.10.14\n"]}],"source":["# You should have Python 3.7 or higher\n","\n","!python --version\n"]},{"cell_type":"code","execution_count":2,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":5781,"status":"ok","timestamp":1701355799502,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"1Y6r5ieIeO_C","outputId":"c6a9c2b8-42a5-4749-d018-df48a804223e","vscode":{"languageId":"shellscript"}},"outputs":[],"source":["!pip install openai python-dotenv &> /dev/null\n"]},{"cell_type":"markdown","metadata":{"id":"cYfbkKGPeO_D"},"source":["### Upload `.env` File with API Keys\n","\n","You can either use GPT directly from OpenAI, or you can use Azure OpenAI from Microsoft. You need to create a `.env` file and add the environment variables needed for OpenAI api.\n","\n","If you are using OpenAI, check your [OpenAI account](https://platform.openai.com/api-keys) for creating API key. Your `.env` file will look like following:\n","\n","```sh\n","$ cat .env\n","OPENAI_API_KEY='sk-YourOpenAiApiKeyHere'\n","```\n","\n","If you are using Microsoft Azure OpenAI:\n","- Go to [Azure Portal](https://portal.azure.com/) > **All Resources**\n","- Filter the list with Type == Azure OpenAI\n","- Select the one you plan to use\n","- If there are none, you can [create and deploy an Azure OpenAI Service resource](https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/create-resource?pivots=web-portal#create-a-resource)\n","- Click on **Keys and Endpoint** on the left menu\n","- Get `AZURE_OPENAI_API_KEY` and `AZURE_OPENAI_ENDPOINT`\n","- Next click **Model deployments** on the left menu, and then click **Manage Deployment** button\n","- Alternatively, you can go to [Azure OpenAI Studio](https://oai.azure.com/), and click **Deployments** on the left menu\n","- Find (the latest) API version for [Azure OpenAI Service](https://learn.microsoft.com/en-us/azure/ai-services/openai/reference#rest-api-versioning)\n","\n","Your `.env` file will look like following:\n","```sh\n","$ cat .env\n","AZURE_OPENAI_API_KEY=yourAzureOpenAiApiKey\n","AZURE_OPENAI_ENDPOINT=https://your-azure-deployment.openai.azure.com/\n","AZURE_OPENAI_DEPLOYMENT_ID=your-deployment-name\n","AZURE_OPENAI_API_VERSION=2023-10-01-preview\n","```\n","\n","Upload `.env` using Upload File button in Google Colab (or Jupyter Notebook). In worst case scenario, uncomment and modify the relevant lines in the following cell to create `.env` file. Please note that it is dangerous to share such notebooks or check them into git."]},{"cell_type":"code","execution_count":3,"metadata":{"id":"XKy_X1wdeO_D","vscode":{"languageId":"shellscript"}},"outputs":[],"source":["# Upload or create a .env file with (Azure) OpenAI API creds\n","\n","#!echo \"OPENAI_API_KEY=sk-YourOpenApiKeyHere\" >> .env\n","\n","#!echo \"AZURE_OPENAI_API_KEY=yourAzureOpenAiApiKey\" >> .env\n","#!echo \"AZURE_OPENAI_ENDPOINT=https://your-azure-deployment.openai.azure.com/\" >> .env\n","#!echo \"AZURE_OPENAI_DEPLOYMENT_ID=your-deployment-name\" >> .env\n","#!echo \"AZURE_OPENAI_API_VERSION=2023-10-01-preview\" >> .env\n"]},{"cell_type":"markdown","metadata":{"id":"KcPWLtAWeO_E"},"source":["### Load `.env` File and Specify (Azure) OpenAI GPT Model\n","\n","Load environment variables from `.env` file:"]},{"cell_type":"code","execution_count":4,"metadata":{"id":"tIT35MxGeO_F"},"outputs":[],"source":["from dotenv import load_dotenv, find_dotenv\n","\n","_ = load_dotenv(find_dotenv())\n"]},{"cell_type":"markdown","metadata":{"id":"cVN8Z7wQeO_F"},"source":["Set `IS_AZURE_OPENAI` flag to `True`, if you are using Azure OpenAI:"]},{"cell_type":"code","execution_count":5,"metadata":{"id":"KfXGuwQZeO_G"},"outputs":[],"source":["IS_AZURE_OPENAI: bool = False\n"]},{"cell_type":"markdown","metadata":{"id":"2mY86GV2eO_G"},"source":["Specify model name:"]},{"cell_type":"code","execution_count":6,"metadata":{"id":"GK1r2VFVeO_G"},"outputs":[],"source":["from datetime import datetime\n","\n","GPT35_TURBO: str = \"gpt-3.5-turbo-1106\" if datetime.now() < datetime(2023, 12, 11) else \"gpt-3.5-turbo\"\n"]},{"cell_type":"markdown","metadata":{"id":"87QWD_kLeO_G"},"source":["---\n","\n","## Create an OpenAI Client and Specify GPT Model"]},{"cell_type":"code","execution_count":7,"metadata":{"id":"J3gYa6czeO_H"},"outputs":[],"source":["import os\n","import openai\n"]},{"cell_type":"code","execution_count":8,"metadata":{"id":"yTp0GKx9eO_H"},"outputs":[],"source":["def create_open_ai_client():\n"," if IS_AZURE_OPENAI:\n"," return openai.AzureOpenAI(\n"," api_key=os.getenv(\"AZURE_OPENAI_API_KEY\"),\n"," api_version=os.getenv(\"AZURE_OPENAI_API_VERSION\"),\n"," azure_endpoint=os.getenv(\"AZURE_OPENAI_ENDPOINT\"),\n"," azure_deployment=os.getenv(\"AZURE_OPENAI_DEPLOYMENT_ID\")\n"," )\n"," else:\n"," return openai.OpenAI(\n"," api_key=os.getenv('OPENAI_API_KEY')\n"," )\n"]},{"cell_type":"code","execution_count":9,"metadata":{"id":"Hes3w6mfeO_H"},"outputs":[],"source":["openai_client = create_open_ai_client()\n","openai_model = os.getenv(\"AZURE_OPENAI_DEPLOYMENT_ID\") if IS_AZURE_OPENAI else GPT35_TURBO\n","\n","def get_gpt_response(prompt, model=openai_model, temperature=0):\n"," messages = [{\"role\": \"user\", \"content\": prompt}]\n"," response = openai_client.chat.completions.create(\n"," model=model,\n"," #response_format={\"type\": \"json_object\"}, # Uncomment it if your chosen model supports it\n"," messages=messages,\n"," temperature=temperature,\n"," )\n"," return response.choices[0].message.content\n"]},{"cell_type":"code","execution_count":10,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":831,"status":"ok","timestamp":1701355800331,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"5JrKbCv7eO_H","outputId":"0202742f-4049-4f17-f581-9d2508d021c8"},"outputs":[{"name":"stdout","output_type":"stream","text":["{\n"," \"message\": \"This is a test\"\n","}\n"]}],"source":["print(get_gpt_response(\"Say this is test in JSON\"))\n"]},{"cell_type":"markdown","metadata":{"id":"Mu09cyaLeO_I"},"source":["You are all set to use GPT for common NLP tasks such as Sentiment Analysis, Language Translation, Intent/Entity Recognition."]},{"cell_type":"markdown","metadata":{"id":"eOmv1Y7OeO_I"},"source":["---\n","\n","## Sentiment Analysis\n","\n","Let's do sentiment analysis for food reviews. In classical ML, you will need to build a supervised classification model for sentiment analysis. You need to:\n","\n","- Clean and label the data (this takes significant amount of effort)\n","- Divide it into train, validate, and test sets\n","- Preprocessing: remove stop words, stemming, etc.\n","- Train multiple models\n","- Measure inference accuracy\n","- Select a model, and tune its hyper-parameters\n","- Deploy the final model\n","\n","This whole endeavour may take a couple of weeks and sometime months!\n","\n","But Large Language Models (LLMs) like GPT eliminates ML model training or train it with just few examples. It is called [Zero or Few Shot Learning](https://en.wikipedia.org/wiki/Zero-shot_learning). This is because foundational LLM models are capable of doing multiple tasks.\n","\n","This effectively makes many NLP capabilities accessible to developers who may not have data science and machine learning expertise. And, they can do it in few hours or days (instead of weeks and months)!\n","\n","See it yourself. Here is your food review sentiment analyzer with few lines of code."]},{"cell_type":"code","execution_count":11,"metadata":{"id":"CTkZo8K7eO_I"},"outputs":[],"source":["food_reviews = [\n"," \"The food is great, ambience is just right, but service is slow.\",\n"," \"खाना बहुत स्वादिष्ट है, बैंगन भरता और काबुली चिकन कबाब जरूर खाएँ\",\n"," \"starters soggy and लस्सी बिलकुल पानी, बकवास खाना, waste of money\",\n","]\n"]},{"cell_type":"code","execution_count":12,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":971,"status":"ok","timestamp":1701355801300,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"FsiUsSlXeO_I","outputId":"f8eee039-b029-4552-f5df-51604627f1af"},"outputs":[{"name":"stdout","output_type":"stream","text":["{\n"," \"sentiment\": \"mixed\"\n","}\n"]}],"source":["prompt = f\"\"\"\n","What is the sentiment of the following review that is delimited with triple backticks?\n","\n","Format your response in JSON.\n","\n","Review text: ```{food_reviews[0]}```\n","\"\"\"\n","\n","print(get_gpt_response(prompt))\n"]},{"cell_type":"markdown","metadata":{"id":"ClX5SA-reO_J"},"source":["Voilà! It worked like a charm! With just 20-word long prompt! Now let's improve the prompt to get the response in a structure that you specify."]},{"cell_type":"code","execution_count":13,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":1749,"status":"ok","timestamp":1701355803046,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"n6BXbiIAeO_J","outputId":"d4cdea6f-805f-498e-f438-04e5442a451f"},"outputs":[{"name":"stdout","output_type":"stream","text":["{\n"," \"sentiment\": \"mixed\",\n"," \"stars\": 3,\n"," \"emotions\": [\"positive\", \"neutral\"],\n"," \"summary\": \"Great food and ambience, but slow service.\"\n","}\n"]}],"source":["prompt = f\"\"\"\n","Identify following items from the review text that is delimited with triple backticks:\n","- Sentiment: (positive, mixed, or negative)\n","- Stars: a number rating characterizing overall sentiment, 1 star being the lowest and 5 star being the highest\n","- Emotions: top emotion(s), maximum 3 emotions\n","- Summary: human readable summary of the review and sentiments in less than 255 characters\n","\n","Format your response as JSON with \"sentiment\", \"stars\", \"emotions\", and \"summary\" as the keys.\n","\n","Review text: ```{food_reviews[0]}```\n","\"\"\"\n","\n","print(get_gpt_response(prompt))\n"]},{"cell_type":"markdown","metadata":{"id":"GzjaaFRkeO_J"},"source":["---\n","\n","## Language Translation\n","\n","Now, let's make this sentiment analyzer multi-lingual.\n","\n","GPT has language identification and translation capabilities, and you can invoke them with a simple prompt."]},{"cell_type":"code","execution_count":14,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":2852,"status":"ok","timestamp":1701355805897,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"qCMoL5CteO_J","outputId":"b99460b9-a078-482e-82e8-a80a61c3a0ff"},"outputs":[{"name":"stdout","output_type":"stream","text":["{\n"," \"text\": \"खाना बहुत स्वादिष्ट है, बैंगन भरता और काबुली चिकन कबाब जरूर खाएँ\",\n"," \"language\": \"Hindi\",\n"," \"translation\": \"The food is very delicious, be sure to try Baingan Bharta and Kabuli Chicken Kebab\"\n","}\n"]}],"source":["prompt = f\"\"\"\n","Translate the input text into English.\n","\n","Format your response as JSON with values for following keys:\n","- text: input text as is\n","- language: the language of the input text\n","- translation: input text translated in English\n","\n","Input text: ```{food_reviews[1]}```\n","\"\"\"\n","\n","print(get_gpt_response(prompt))\n"]},{"cell_type":"markdown","metadata":{"id":"FljOMrZqeO_J"},"source":["You can see the pattern:\n","- Breakdown the task into smaller steps\n","- Give specific instructions for each step\n","- Include input with clear demarcation\n","- Specify the desired structure of the output\n","\n","It is almost like how you will teach a smart kid to do a specific task.\n","\n","You can change the functionality by changing the prompt. You can experiment and craft an effective prompt for your NLP task.\n","\n","Now let's put together sentiment analysis and translation."]},{"cell_type":"code","execution_count":15,"metadata":{"id":"bCCDancUeO_J"},"outputs":[],"source":["def infer_sentiment(text):\n"," prompt = f\"\"\"\n"," Identify following items from the review text:\n"," - Language: language of the review text\n"," - Translation: review text translated in English\n"," - Sentiment: (positive, mixed, or negative)\n"," - Stars: a number rating characterizing overall sentiment, 1 star being the lowest and 5 star being the highest\n"," - Emotions: top emotion(s), maximum 3 emotions\n"," - Summary: human readable summary of the review and sentiments in less than 255 characters\n","\n"," Format your response as JSON with \"language\", \"translation\", \"sentiment\", \"stars\", \"emotions\", and summary as the keys.\n","\n"," Review text: '''{text}'''\n"," \"\"\"\n","\n"," return get_gpt_response(prompt)\n"]},{"cell_type":"code","execution_count":16,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":8417,"status":"ok","timestamp":1701355814312,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"xsrC5eoneO_K","outputId":"344be55d-2164-4353-eace-726ab9459a1f"},"outputs":[{"name":"stdout","output_type":"stream","text":["{\n"," \"language\": \"English\",\n"," \"translation\": \"The food is great, ambience is just right, but service is slow.\",\n"," \"sentiment\": \"mixed\",\n"," \"stars\": 3,\n"," \"emotions\": [\"satisfaction\", \"disappointment\"],\n"," \"summary\": \"Enjoyable experience with great food and ambience, but service could be improved.\"\n","}\n","{\n"," \"language\": \"Hindi\",\n"," \"translation\": \"The food is very delicious, do try the stuffed eggplant and Kabul chicken kebab\",\n"," \"sentiment\": \"positive\",\n"," \"stars\": 5,\n"," \"emotions\": [\"delight\", \"satisfaction\"],\n"," \"summary\": \"Delicious food with must-try stuffed eggplant and Kabul chicken kebab, highly satisfying experience with a 5-star rating\"\n","}\n","{\n"," \"language\": \"English\",\n"," \"translation\": \"starters soggy and lassi completely watery, terrible food, waste of money\",\n"," \"sentiment\": \"negative\",\n"," \"stars\": 1,\n"," \"emotions\": [\"disappointment\", \"disgust\"],\n"," \"summary\": \"Extremely disappointing experience with watery lassi and soggy starters, terrible food quality, complete waste of money.\"\n","}\n"]}],"source":["for t in food_reviews:\n"," print(infer_sentiment(t))\n"]},{"cell_type":"markdown","metadata":{"id":"i7yG6NszeO_K"},"source":["---\n","\n","## Intent/Entity Extraction"]},{"cell_type":"markdown","metadata":{"id":"L2Rv8bKpeO_K"},"source":["[Named-Entity Recognition (NER)](https://en.wikipedia.org/wiki/Named-entity_recognition) is another very common NLP task. For example, Chatbots and Voice Assistants have to:\n","\n","- Infer what you want (intent)\n","- Extract the named entities from your sentences that are needed to fulfill your request\n","- Perform that request\n","\n","For example, each of these commands to Alexa have different intent, and entities associated with it:\n","- Play songs by Taylor Swift\n","- Set an alarm for 30 minutes\n","- How is the weather\n","\n","Let's build a multilingual intent/entity extractor for a travel assistant that can enquire, book, and cancel bus, train, and flight tickets."]},{"cell_type":"code","execution_count":17,"metadata":{"id":"7GTL-q4xeO_K"},"outputs":[],"source":["travel_messages = [\n"," \"I want to fly from Bangalore to Delhi\",\n"," \"मुझे कल कानपुर से लखनऊ के लिए बस टिकट बुक करना है\",\n"," \"ನನ್ನ ಬಸ್ ಟಿಕೆಟ್ ರದ್ದು ಮಾಡಿ\",\n","]\n"]},{"cell_type":"code","execution_count":18,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":2483,"status":"ok","timestamp":1701355816794,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"rhQIzyhWeO_K","outputId":"96f23626-b6ad-44f8-d6d8-cadd8c945a9b"},"outputs":[{"name":"stdout","output_type":"stream","text":["{\n"," \"language\": \"Hindi\",\n"," \"translation\": \"I want to book a bus ticket from Kanpur to Lucknow for tomorrow\",\n"," \"intent\": \"book\",\n"," \"mode\": \"bus\",\n"," \"date\": \"2023-10-25\",\n"," \"source\": \"Kanpur\",\n"," \"destination\": \"Lucknow\"\n","}\n"]}],"source":["prompt = f\"\"\"\n","Act as a travel assistant clerk. Your job is to help customers by bus, train, or flight.\n","Identify following items from a customer message:\n","- Language: language of the customer message\n","- Translation: customer message translated in English\n","- Intent: (inquire, book, or cancel)\n","- Mode: (bus, train, or flight)\n","- Date: the travel date in YYYY-MM-DD\n","- Source: starting place of the journey\n","If the information isn't present, use null as the value.\n","\n","Format your response as JSON with \"language\", \"translation\", \"intent\", \"mode\", \"source\", and \"destination\".\n","\n","Review test: '''{travel_messages[1]}'''\n","\"\"\"\n","\n","print(get_gpt_response(prompt))\n"]},{"cell_type":"markdown","metadata":{"id":"sgzgjdvveO_L"},"source":["Well, it almost got everything right, except the date. It inferred \"tomorrow\" incorrectly, maybe because \"today\" for the model is when it was trained or deployed.\n","\n","That is another important lesson: your prompt must have the needed context. Let's tell it what the date today is."]},{"cell_type":"code","execution_count":19,"metadata":{"id":"HqsgF3g3eO_L"},"outputs":[],"source":["def travel_assistant(text):\n"," prompt = f\"\"\"\n"," Act as a travel assistant clerk. Your job is to help customers by bus, train, or flight.\n"," Identify following items from a customer message:\n"," - Language: language of the customer message\n"," - Translation: customer message translated in English\n"," - Intent: (inquire, book, or cancel)\n"," - Mode: (bus, train, or flight)\n"," - Date: the travel date in YYYY-MM-DD\n"," - Source: starting place of the journey\n"," If the information isn't present, use null as the value.\n","\n"," The current date and time is {datetime.now().strftime(\"%d %b %Y %I:%M %p\")}\n","\n"," Format your response as JSON with \"language\", \"translation\", \"intent\", \"mode\", \"source\", and \"destination\".\n","\n"," Review test: '''{text}'''\n"," \"\"\"\n","\n"," return get_gpt_response(prompt)\n"]},{"cell_type":"code","execution_count":20,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":6788,"status":"ok","timestamp":1701355823568,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"6UyObQVfeO_L","outputId":"e3815064-3811-48ea-d654-971e55df4ccc"},"outputs":[{"name":"stdout","output_type":"stream","text":["{\n"," \"language\": \"English\",\n"," \"translation\": \"I want to fly from Bangalore to Delhi\",\n"," \"intent\": \"book\",\n"," \"mode\": \"flight\",\n"," \"date\": null,\n"," \"source\": \"Bangalore\",\n"," \"destination\": \"Delhi\"\n","}\n","{\n"," \"language\": \"Hindi\",\n"," \"translation\": \"I want to book a bus ticket from Kanpur to Lucknow tomorrow\",\n"," \"intent\": \"book\",\n"," \"mode\": \"bus\",\n"," \"date\": \"2024-10-25\",\n"," \"source\": \"Kanpur\",\n"," \"destination\": \"Lucknow\"\n","}\n","{\n"," \"language\": \"Kannada\",\n"," \"translation\": \"Cancel my bus ticket\",\n"," \"intent\": \"cancel\",\n"," \"mode\": \"bus\",\n"," \"date\": null,\n"," \"source\": null,\n"," \"destination\": null\n","}\n"]}],"source":["for t in travel_messages:\n"," print(travel_assistant(t))\n"]},{"cell_type":"markdown","metadata":{"id":"f5BQT17FeO_L"},"source":["LLMs are one of the most powerful models, and yet most accessible for developers. It reduces the time to experiment, prototype, and deploy sophisticated NLP-assisted applications."]},{"cell_type":"markdown","metadata":{"id":"-_oyoZAkeO_L"},"source":["---\n","Copyright © 2023 Satish Chandra Gupta .
\n"," CC BY-NC-SA 4.0 International License.
"]}],"metadata":{"colab":{"provenance":[{"file_id":"https://github.com/ml4devs/ml4devs-notebooks/blob/master/gpt/nlp_with_gpt_notebook.ipynb","timestamp":1701355922767},{"file_id":"https://github.com/ml4devs/ml4devs-notebooks/blob/master/gpt/nlp_with_gpt_notebook.ipynb","timestamp":1701352821148}]},"kernelspec":{"display_name":"kaggle","language":"python","name":"python3"},"language_info":{"codemirror_mode":{"name":"ipython","version":3},"file_extension":".py","mimetype":"text/x-python","name":"python","nbconvert_exporter":"python","pygments_lexer":"ipython3","version":"3.10.14"}},"nbformat":4,"nbformat_minor":0}
2 |
--------------------------------------------------------------------------------
/gpt/translate_natural_language_query_to_sql_notebook.ipynb:
--------------------------------------------------------------------------------
1 | {"cells":[{"cell_type":"markdown","metadata":{"id":"EV0cfuXJeO-8"},"source":["Translate Natural Language Queries to SQL with GPT
\n","© Satish Chandra Guptascgupta ,\n","Twitter: scgupta \n"," \n"," \n","\n","---\n","\n","## Setup Environment\n","\n","### Install Pip Packages\n","\n","You need Python 3.7 or higher to install [OpenAI Python API library](https://github.com/openai/openai-python)."]},{"cell_type":"code","execution_count":1,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":770,"status":"ok","timestamp":1701355793267,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"iZkQzDDxeO_A","outputId":"4824a891-78f6-47d5-c78b-5f51c7566483","vscode":{"languageId":"shellscript"}},"outputs":[{"name":"stdout","output_type":"stream","text":["Python 3.10.14\n"]}],"source":["# You should have Python 3.7 or higher\n","\n","!python --version\n"]},{"cell_type":"code","execution_count":2,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":5781,"status":"ok","timestamp":1701355799502,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"1Y6r5ieIeO_C","outputId":"c6a9c2b8-42a5-4749-d018-df48a804223e","vscode":{"languageId":"shellscript"}},"outputs":[],"source":["!pip install openai python-dotenv SQLAlchemy &> /dev/null\n"]},{"cell_type":"markdown","metadata":{"id":"cYfbkKGPeO_D"},"source":["### Upload `.env` File with API Keys\n","\n","You can either use GPT directly from OpenAI, or you can use Azure OpenAI from Microsoft. You need to create a `.env` file and add the environment variables needed for OpenAI api.\n","\n","If you are using OpenAI, check your [OpenAI account](https://platform.openai.com/api-keys) for creating API key. Your `.env` file will look like following:\n","\n","```sh\n","$ cat .env\n","OPENAI_API_KEY='sk-YourOpenAiApiKeyHere'\n","```\n","\n","If you are using Microsoft Azure OpenAI:\n","- Go to [Azure Portal](https://portal.azure.com/) > **All Resources**\n","- Filter the list with Type == Azure OpenAI\n","- Select the one you plan to use\n","- If there are none, you can [create and deploy an Azure OpenAI Service resource](https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/create-resource?pivots=web-portal#create-a-resource)\n","- Click on **Keys and Endpoint** on the left menu\n","- Get `AZURE_OPENAI_API_KEY` and `AZURE_OPENAI_ENDPOINT`\n","- Next click **Model deployments** on the left menu, and then click **Manage Deployment** button\n","- Alternatively, you can go to [Azure OpenAI Studio](https://oai.azure.com/), and click **Deployments** on the left menu\n","- Find (the latest) API version for [Azure OpenAI Service](https://learn.microsoft.com/en-us/azure/ai-services/openai/reference#rest-api-versioning)\n","\n","Your `.env` file will look like following:\n","```sh\n","$ cat .env\n","AZURE_OPENAI_API_KEY=yourAzureOpenAiApiKey\n","AZURE_OPENAI_ENDPOINT=https://your-azure-deployment.openai.azure.com/\n","AZURE_OPENAI_DEPLOYMENT_ID=your-deployment-name\n","AZURE_OPENAI_API_VERSION=2023-10-01-preview\n","```\n","\n","Upload `.env` using Upload File button in Google Colab (or Jupyter Notebook). In worst case scenario, uncomment and modify the relevant lines in the following cell to create `.env` file. Please note that it is dangerous to share such notebooks or check them into git."]},{"cell_type":"code","execution_count":3,"metadata":{"id":"XKy_X1wdeO_D","vscode":{"languageId":"shellscript"}},"outputs":[],"source":["# Upload or create a .env file with (Azure) OpenAI API creds\n","\n","#!echo \"OPENAI_API_KEY=sk-YourOpenApiKeyHere\" >> .env\n","\n","#!echo \"AZURE_OPENAI_API_KEY=yourAzureOpenAiApiKey\" >> .env\n","#!echo \"AZURE_OPENAI_ENDPOINT=https://your-azure-deployment.openai.azure.com/\" >> .env\n","#!echo \"AZURE_OPENAI_DEPLOYMENT_ID=your-deployment-name\" >> .env\n","#!echo \"AZURE_OPENAI_API_VERSION=2023-10-01-preview\" >> .env\n"]},{"cell_type":"markdown","metadata":{"id":"KcPWLtAWeO_E"},"source":["### Load `.env` File and Specify (Azure) OpenAI GPT Model\n","\n","Load environment variables from `.env` file:"]},{"cell_type":"code","execution_count":4,"metadata":{"id":"tIT35MxGeO_F"},"outputs":[],"source":["from dotenv import load_dotenv, find_dotenv\n","\n","_ = load_dotenv(find_dotenv())\n"]},{"cell_type":"markdown","metadata":{"id":"cVN8Z7wQeO_F"},"source":["Set `IS_AZURE_OPENAI` flag to `True`, if you are using Azure OpenAI:"]},{"cell_type":"code","execution_count":5,"metadata":{"id":"KfXGuwQZeO_G"},"outputs":[],"source":["IS_AZURE_OPENAI: bool = False\n"]},{"cell_type":"markdown","metadata":{"id":"2mY86GV2eO_G"},"source":["Specify model name:"]},{"cell_type":"code","execution_count":6,"metadata":{"id":"GK1r2VFVeO_G"},"outputs":[],"source":["from datetime import datetime\n","\n","GPT35_TURBO: str = \"gpt-3.5-turbo-1106\" if datetime.now() < datetime(2023, 12, 11) else \"gpt-3.5-turbo\"\n","GPT4: str = \"gpt-4\"\n"]},{"cell_type":"markdown","metadata":{"id":"87QWD_kLeO_G"},"source":["---\n","\n","## Setup OpenAI Client with GPT Model"]},{"cell_type":"code","execution_count":7,"metadata":{"id":"J3gYa6czeO_H"},"outputs":[],"source":["import json\n","import os\n","import openai\n"]},{"cell_type":"code","execution_count":8,"metadata":{"id":"yTp0GKx9eO_H"},"outputs":[],"source":["def create_open_ai_client():\n"," if IS_AZURE_OPENAI:\n"," return openai.AzureOpenAI(\n"," api_key=os.getenv(\"AZURE_OPENAI_API_KEY\"),\n"," api_version=os.getenv(\"AZURE_OPENAI_API_VERSION\"),\n"," azure_endpoint=os.getenv(\"AZURE_OPENAI_ENDPOINT\"),\n"," azure_deployment=os.getenv(\"AZURE_OPENAI_DEPLOYMENT_ID\")\n"," )\n"," else:\n"," return openai.OpenAI(\n"," api_key=os.getenv('OPENAI_API_KEY')\n"," )\n"]},{"cell_type":"code","execution_count":9,"metadata":{"id":"Hes3w6mfeO_H"},"outputs":[],"source":["openai_client = create_open_ai_client()\n","openai_model = os.getenv(\"AZURE_OPENAI_DEPLOYMENT_ID\") if IS_AZURE_OPENAI else GPT4\n","\n","def get_gpt_response(messages, model=openai_model, temperature=0) -> dict:\n"," response = openai_client.chat.completions.create(\n"," model=model,\n"," #response_format={\"type\": \"json_object\"}, # Uncomment it if your chosen model supports it\n"," messages=messages,\n"," temperature=temperature,\n"," )\n"," response_str = response.choices[0].message.content\n","\n"," try:\n"," response_dict = json.loads(response_str)\n"," except json.JSONDecodeError:\n"," print(f\"Failed to decode response: {response_str}\")\n"," raise\n","\n"," return response_dict\n"]},{"cell_type":"code","execution_count":10,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"elapsed":831,"status":"ok","timestamp":1701355800331,"user":{"displayName":"","userId":""},"user_tz":-330},"id":"5JrKbCv7eO_H","outputId":"0202742f-4049-4f17-f581-9d2508d021c8"},"outputs":[{"name":"stdout","output_type":"stream","text":["{'message': 'this is test'}\n"]}],"source":["print(get_gpt_response([\n"," {\"role\": \"user\", \"content\": \"Say this is test. Format response in JSON\"}\n","]))\n"]},{"cell_type":"markdown","metadata":{"id":"Mu09cyaLeO_I"},"source":["You are all set to use GPT for common NLP tasks such as Sentiment Analysis, Language Translation, Intent/Entity Recognition."]},{"cell_type":"markdown","metadata":{"id":"eOmv1Y7OeO_I"},"source":["---\n","\n","## Setup Database\n","\n","You need a dataset that you will query using natural language. You also need a SQL database that will host that dataset."]},{"cell_type":"markdown","metadata":{},"source":["### Example Dataset: DVD Rental\n","\n","Sakila example dataset is commonly used for teaching and testing RDBMS concept. It has data of fictitious DVD Rental Store. We will use [SQLite](https://www.sqlite.org/index.html) as the database. Python has [sqlite3](https://docs.python.org/3/library/sqlite3.html) package, so it does not require anything to installed and deployed locally or on cloud."]},{"cell_type":"markdown","metadata":{},"source":["1. Download the dataset using `curl` or `wget` command from [SQLite Tutorial](https://www.sqlitetutorial.net/sqlite-sample-database/). Alternatively, you can download from [Kaggle](https://www.kaggle.com/datasets/atanaskanev/sqlite-sakila-sample-database/data) too."]},{"cell_type":"code","execution_count":11,"metadata":{},"outputs":[],"source":["# Clear previously downloaded and unzipped files\n","\n","!rm -f ./chinook.zip ./chinook.db"]},{"cell_type":"code","execution_count":12,"metadata":{},"outputs":[{"name":"stdout","output_type":"stream","text":[" % Total % Received % Xferd Average Speed Time Time Time Current\n"," Dload Upload Total Spent Left Speed\n","100 298k 100 298k 0 0 273k 0 0:00:01 0:00:01 --:--:-- 273k\n"]}],"source":["!curl -L0 https://www.sqlitetutorial.net/wp-content/uploads/2018/03/chinook.zip --output ./chinook.zip\n","\n","#!wget https://www.sqlitetutorial.net/wp-content/uploads/2018/03/chinook.zip\n"]},{"cell_type":"markdown","metadata":{},"source":["2. Unzip the db file"]},{"cell_type":"code","execution_count":13,"metadata":{},"outputs":[{"name":"stdout","output_type":"stream","text":["Archive: chinook.zip\n"," inflating: chinook.db \n"]}],"source":["!unzip chinook.zip\n"]},{"cell_type":"markdown","metadata":{},"source":["3. The db file will be stored at `./chinook.db`. This is the path you will need when using `sqlite3` package."]},{"cell_type":"code","execution_count":14,"metadata":{},"outputs":[{"name":"stdout","output_type":"stream","text":["-rw-r--r--@ 1 scgupta staff 884736 Nov 29 2015 ./chinook.db\n"]}],"source":["!ls -l ./chinook.db\n"]},{"cell_type":"markdown","metadata":{},"source":["4. Extract DB Metadata"]},{"cell_type":"code","execution_count":15,"metadata":{},"outputs":[],"source":["import sqlite3\n"]},{"cell_type":"code","execution_count":16,"metadata":{},"outputs":[],"source":["DB_FILE_PATH = \"./chinook.db\"\n"]},{"cell_type":"code","execution_count":17,"metadata":{},"outputs":[],"source":["def extract_sqlite3_db_metadata(sqlite_db_file_path: str):\n"," db_metadata = {}\n","\n"," # Connect to the SQLite database\n"," conn = sqlite3.connect(sqlite_db_file_path)\n"," cursor = conn.cursor()\n","\n"," # Get a list of all tables in the database\n"," cursor.execute(\"SELECT name FROM sqlite_master WHERE type='table';\")\n"," tables = cursor.fetchall()\n","\n"," # Loop through each table and get its columns\n"," for table in tables:\n"," table_name = table[0]\n"," primary_keys = []\n"," foreign_keys = {}\n"," columns_info = {}\n","\n"," # Get table details\n"," cursor.execute(f\"PRAGMA table_info({table_name});\")\n"," columns = cursor.fetchall()\n","\n"," # Extract info about the columns of the current table\n"," for column in columns:\n"," column_name = column[1]\n"," column_type = column[2]\n"," is_primary = (column[5] == 1)\n","\n"," columns_info[column_name] = {\n"," \"type\": column_type,\n"," \"primary\": is_primary,\n"," \"foreign\": {}\n"," }\n","\n"," # Primary Keys\n"," primary_keys = [\n"," c_name\n"," for c_name, c_attrs in columns_info.items()\n"," if c_attrs[\"primary\"] == True\n"," ]\n","\n"," # Get foreign key details\n"," cursor.execute(f\"PRAGMA foreign_key_list({table_name});\")\n"," fk_constraints = cursor.fetchall()\n","\n"," for fk in fk_constraints:\n"," fk_constraint_id = fk[0]\n"," fk_to_table = fk[2]\n"," fk_from_column = fk[3]\n"," fk_to_column = fk[4]\n","\n"," fk_info = {\n"," \"constraint_id\": fk_constraint_id,\n"," \"to_table\": fk_to_table,\n"," \"to_column\": fk_to_column\n"," }\n"," foreign_keys[fk_from_column] = fk_info\n"," columns_info[fk_from_column][\"foreign\"] = fk_info\n","\n"," db_metadata[table_name] = {\n"," \"columns\": columns_info,\n"," \"primary_keys\": primary_keys,\n"," \"foreign_keys\": foreign_keys\n"," }\n","\n"," # Close the connection\n"," conn.close()\n","\n"," # Remove tables with names staring with \"sqlite\" as those are not part of applications\n"," tables_to_remove = [t for t in db_metadata if t.startswith(\"sqlite\")]\n"," for t in tables_to_remove:\n"," del db_metadata[t]\n","\n"," # Done!\n"," return db_metadata\n"]},{"cell_type":"markdown","metadata":{},"source":["5. Check out if the database metadata has been extracted correctly."]},{"cell_type":"code","execution_count":18,"metadata":{},"outputs":[],"source":["def table_info_str(t_name, t_info) -> str:\n"," column_info_str = \"\\n \".join([\n"," f\"{c_name}: {c_info['type']}\"\n"," for c_name, c_info in t_info[\"columns\"].items()\n"," ])\n","\n"," primary_key_info_str = \"\"\n"," if len(t_info[\"primary_keys\"]) > 0:\n"," primary_key_info_str = f\"Primary Keys: {','.join(t_info['primary_keys'])}\"\n","\n"," foreign_key_info_str = \"\"\n"," if len(t_info[\"foreign_keys\"]) > 0:\n"," foreign_key_info_str = \"\\n Foreign Keys:\\n \" + \"\\n \".join([\n"," f\"{fk_from_col} => {fk_info['to_table']}.{fk_info['to_column']}\"\n"," for fk_from_col, fk_info in t_info[\"foreign_keys\"].items()\n"," ])\n","\n"," return f\"\"\"Table Name: {t_name}\n"," Columns:\n"," {column_info_str}\n"," \"\"\" + primary_key_info_str + foreign_key_info_str\n"]},{"cell_type":"code","execution_count":19,"metadata":{},"outputs":[],"source":["chinook_db_metadata = extract_sqlite3_db_metadata(DB_FILE_PATH)\n"]},{"cell_type":"code","execution_count":20,"metadata":{},"outputs":[{"name":"stdout","output_type":"stream","text":["Table Name: albums\n"," Columns:\n"," AlbumId: INTEGER\n"," Title: NVARCHAR(160)\n"," ArtistId: INTEGER\n"," Primary Keys: AlbumId\n"," Foreign Keys:\n"," ArtistId => artists.ArtistId\n","\n","Table Name: artists\n"," Columns:\n"," ArtistId: INTEGER\n"," Name: NVARCHAR(120)\n"," Primary Keys: ArtistId\n","\n","Table Name: customers\n"," Columns:\n"," CustomerId: INTEGER\n"," FirstName: NVARCHAR(40)\n"," LastName: NVARCHAR(20)\n"," Company: NVARCHAR(80)\n"," Address: NVARCHAR(70)\n"," City: NVARCHAR(40)\n"," State: NVARCHAR(40)\n"," Country: NVARCHAR(40)\n"," PostalCode: NVARCHAR(10)\n"," Phone: NVARCHAR(24)\n"," Fax: NVARCHAR(24)\n"," Email: NVARCHAR(60)\n"," SupportRepId: INTEGER\n"," Primary Keys: CustomerId\n"," Foreign Keys:\n"," SupportRepId => employees.EmployeeId\n","\n","Table Name: employees\n"," Columns:\n"," EmployeeId: INTEGER\n"," LastName: NVARCHAR(20)\n"," FirstName: NVARCHAR(20)\n"," Title: NVARCHAR(30)\n"," ReportsTo: INTEGER\n"," BirthDate: DATETIME\n"," HireDate: DATETIME\n"," Address: NVARCHAR(70)\n"," City: NVARCHAR(40)\n"," State: NVARCHAR(40)\n"," Country: NVARCHAR(40)\n"," PostalCode: NVARCHAR(10)\n"," Phone: NVARCHAR(24)\n"," Fax: NVARCHAR(24)\n"," Email: NVARCHAR(60)\n"," Primary Keys: EmployeeId\n"," Foreign Keys:\n"," ReportsTo => employees.EmployeeId\n","\n","Table Name: genres\n"," Columns:\n"," GenreId: INTEGER\n"," Name: NVARCHAR(120)\n"," Primary Keys: GenreId\n","\n","Table Name: invoices\n"," Columns:\n"," InvoiceId: INTEGER\n"," CustomerId: INTEGER\n"," InvoiceDate: DATETIME\n"," BillingAddress: NVARCHAR(70)\n"," BillingCity: NVARCHAR(40)\n"," BillingState: NVARCHAR(40)\n"," BillingCountry: NVARCHAR(40)\n"," BillingPostalCode: NVARCHAR(10)\n"," Total: NUMERIC(10,2)\n"," Primary Keys: InvoiceId\n"," Foreign Keys:\n"," CustomerId => customers.CustomerId\n","\n","Table Name: invoice_items\n"," Columns:\n"," InvoiceLineId: INTEGER\n"," InvoiceId: INTEGER\n"," TrackId: INTEGER\n"," UnitPrice: NUMERIC(10,2)\n"," Quantity: INTEGER\n"," Primary Keys: InvoiceLineId\n"," Foreign Keys:\n"," TrackId => tracks.TrackId\n"," InvoiceId => invoices.InvoiceId\n","\n","Table Name: media_types\n"," Columns:\n"," MediaTypeId: INTEGER\n"," Name: NVARCHAR(120)\n"," Primary Keys: MediaTypeId\n","\n","Table Name: playlists\n"," Columns:\n"," PlaylistId: INTEGER\n"," Name: NVARCHAR(120)\n"," Primary Keys: PlaylistId\n","\n","Table Name: playlist_track\n"," Columns:\n"," PlaylistId: INTEGER\n"," TrackId: INTEGER\n"," Primary Keys: PlaylistId\n"," Foreign Keys:\n"," TrackId => tracks.TrackId\n"," PlaylistId => playlists.PlaylistId\n","\n","Table Name: tracks\n"," Columns:\n"," TrackId: INTEGER\n"," Name: NVARCHAR(200)\n"," AlbumId: INTEGER\n"," MediaTypeId: INTEGER\n"," GenreId: INTEGER\n"," Composer: NVARCHAR(220)\n"," Milliseconds: INTEGER\n"," Bytes: INTEGER\n"," UnitPrice: NUMERIC(10,2)\n"," Primary Keys: TrackId\n"," Foreign Keys:\n"," MediaTypeId => media_types.MediaTypeId\n"," GenreId => genres.GenreId\n"," AlbumId => albums.AlbumId\n","\n"]}],"source":["for t_name, t_info in chinook_db_metadata.items():\n"," print(table_info_str(t_name, t_info))\n"," print()\n"]},{"cell_type":"markdown","metadata":{},"source":["---\n","\n","## Database Table Schema Documents\n","\n","GPT can create a SQL query only if it understands various tables and their columns. While creating the GPT prompt, you must include this info of relevant tables.\n","\n","The `CREATE TABLE` statement of [SQL DDL](https://en.wikipedia.org/wiki/Data_definition_language) captures all necessary info. Ideally, table description and column descriptions should also be captured as comments to assist document search and GPT.\n","\n","Let's create a mapping of table name and their `CREATE TABLE` statements."]},{"cell_type":"code","execution_count":21,"metadata":{},"outputs":[],"source":["def create_table_ddl_stmt_str(t_name, t_info) -> str:\n"," column_defs = \",\\n \".join([\n"," f\"{c_name} \\t{c_info['type']}\"\n"," for c_name, c_info in t_info[\"columns\"].items()\n"," ])\n","\n"," primary_key_def = \"\"\n"," if len(t_info[\"primary_keys\"]) > 0:\n"," primary_key_def = f\",\\n\\n PRIMARY KEY ({', '.join(t_info['primary_keys'])})\"\n","\n"," foreign_key_def =\"\"\n"," if len(t_info[\"foreign_keys\"]) > 0:\n"," fk_stmts = \",\\n\".join([\n"," f\" FOREIGN KEY({fk_from_col}) REFERENCES {fk_info['to_table']}({fk_info['to_column']})\"\n"," for fk_from_col, fk_info in t_info[\"foreign_keys\"].items()\n"," ])\n"," foreign_key_def = f\",\\n\\n{fk_stmts}\"\n","\n"," return f\"\"\"CREATE TABLE {t_name} (\n"," {column_defs}{primary_key_def}{foreign_key_def}\n",");\"\"\"\n"]},{"cell_type":"markdown","metadata":{},"source":["Let's sequence the tables so that the definition of every table referred to in a `FOREIGN KEY` constraint comes before the constraint. While one can write code to analyze foreign key constraint graph and perform a topological sort to get a partial order, I decided to just hand code it as it does not have relevance for this tutorial.\n","\n","You can check the [Entity Relation Model](https://en.wikipedia.org/wiki/Entity%E2%80%93relationship_model) for all tables drawn using Crow's Foot notation:\n","\n","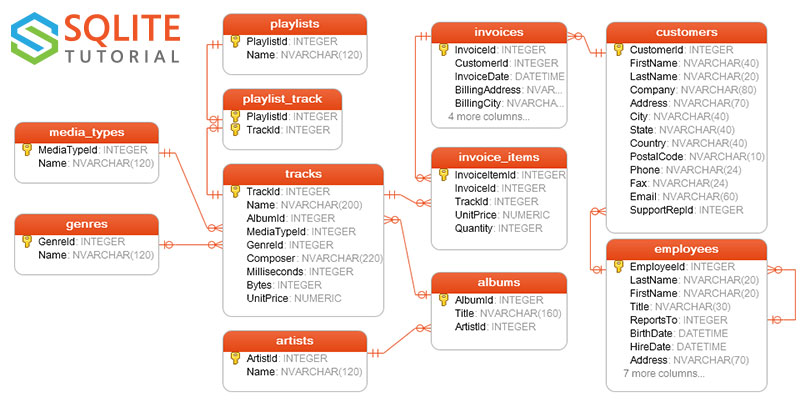"]},{"cell_type":"code","execution_count":22,"metadata":{},"outputs":[],"source":["# Table list in Topological Order for foreign key constraints\n","\n","chinook_db_table_names = [\n"," \"artists\", \"albums\",\n"," \"media_types\", \"genres\", \"tracks\",\n"," \"playlists\", \"playlist_track\",\n"," \"employees\",\n"," \"customers\", \"invoices\", \"invoice_items\"\n","]\n"]},{"cell_type":"code","execution_count":23,"metadata":{},"outputs":[],"source":["all_chinook_db_table_documents: dict[str, str] = {\n"," t_name: create_table_ddl_stmt_str(t_name, chinook_db_metadata[t_name])\n"," for t_name in chinook_db_table_names\n","}\n"]},{"cell_type":"code","execution_count":24,"metadata":{},"outputs":[],"source":["#for t_name in chinook_db_table_names:\n","# print(all_chinook_db_table_documents[t_name])\n","# print()\n"]},{"cell_type":"markdown","metadata":{},"source":["---\n","\n","## Natural Language Query to SQL\n","\n","General flow of building applications using Large Language Models (LLMs) and Retrieval Augmented Generation (RAG) has three parts:\n","\n","- **Embeddings**: Data Preprocessing\n"," - Break private data or documents into chunks\n"," - Convert chunks to vectors using an embedding model\n"," - Store vectors in a Vector DB\n","- **Retrieval**: Prompt Construction\n"," - Convert user query into a vector using the same embedding model\n"," - Search the Vector DB for chunk with similar embeddings and rank them\n"," - Craft a prompt using the user query and the document chunks found in the search\n","- **Inference**: Prompt Execution\n"," - Submit the prompt to a LLM\n"," - Post-process (check, augment) the LLM response\n"," - Send the response to the user\n","\n","For converting a natural language query to SQL, RAG pattern will translate to:\n","\n","- Embeddings:\n"," - Consider a `CREATE TABLE` statement for a table as one document chunk\n"," - Convert each `CREATE TABLE` statement to a vector embedding\n"," - Save (embedding, table name) mapping in a Vector DB\n","- Retrieval:\n"," - Convert incoming user query to a vector embedding\n"," - Search Vector DB and find tables with top similarity score\n"," - Craft a prompt using the user query and `CREATE TABLE` statements of all top-matching tables\n","- Inference:\n"," - Submit prompt to GPT to get the equivalent SQL\n"," - Execute the returned SQL on the database\n"," - Present the results to the user\n"]},{"cell_type":"markdown","metadata":{},"source":["### RAG: Vector DB Document Search\n","\n","For sake of simplicity, we will skip the embedding and Vector DB search. Since there are only 11 tables, with not too many columns, we can send DDL for all tables in the prompt."]},{"cell_type":"code","execution_count":25,"metadata":{},"outputs":[],"source":["def find_tables(nl_query: str) -> dict[str, str]:\n"," # Bypassing\n"," # - Convert nl_query => embeddings\n"," # - Search Vector DB for documents (table's CREATE TABLE statement) with similar embeddings\n"," # - Return {table_name: document} mapping for all matching tables\n"," #\n"," # Instead return all documents\n","\n"," return all_chinook_db_table_documents\n"]},{"cell_type":"markdown","metadata":{},"source":["### Prompt Construction\n","\n","Craft a prompt using the user query and the documents returned from Vector DB search"]},{"cell_type":"code","execution_count":26,"metadata":{},"outputs":[],"source":["def nl2sql_system_prompt(documents: dict[str, str], sql_flavor: str = \"Python sqlite3\") -> str:\n"," metadata = \"\\n\".join([\n"," f\"# SQL DDL Schema for `{table_name}` table:```sql\\n{table_schema}```\\n\"\n"," for table_name, table_schema in documents.items()\n"," ])\n","\n"," system_prompt = f\"\"\"\n"," You are a data analyst and data engineer. You are an expert in writing SQL queries\n"," for {sql_flavor} database.\n","\n"," You have following tables in the database. The table name is in single backquote, and\n"," the DDL code to create that table with schema and metadata details are in triple backquote.\n","\n"," ### Database Table Schemas:\n"," \\n{metadata}\n"," ###\n","\n"," User ask you queries in natural language, and you job is to write equivalent\n"," SQL queries in following steps:\n"," 1. Identify the tables that have data relevant for the query\n"," 2. Identify relevant columns in those tables\n"," 3. Craft a SQL query that selects, filters, groups, joins in an optimal order\n"," that is equivalent to the user's natural language query.\n","\n"," Format your response as a JSON dictionary with following key, value:\n"," - tables: a dictionary with the name of relevant tables as keys, and the\n"," list of relevant columns in that as value.\n"," - sql: the sql query that you crafted.\n"," \"\"\"\n","\n"," return system_prompt\n"]},{"cell_type":"code","execution_count":27,"metadata":{},"outputs":[],"source":["def nl2sql_user_prompt(nl_query: str):\n"," return f\"Write a SQL that computes natural language query in triple backquotes: ```{nl_query}```\"\n"]},{"cell_type":"markdown","metadata":{},"source":["### Prompt Execution"]},{"cell_type":"code","execution_count":28,"metadata":{},"outputs":[],"source":["def write_sql_query(nl_query: str) -> dict:\n"," # Vectorize nl_query and find matching documents (tables and their DDL)\n"," documents = find_tables(nl_query)\n"," # Craft prompt using the natural language queries and matching documents\n"," system_prompt = nl2sql_system_prompt(documents)\n"," user_prompt = nl2sql_user_prompt(nl_query)\n","\n"," messages = [\n"," {\"role\": \"system\", \"content\": system_prompt},\n"," {\"role\": \"user\", \"content\": user_prompt}\n"," ]\n"," response_dict = get_gpt_response(messages)\n","\n"," return response_dict\n"]},{"cell_type":"markdown","metadata":{},"source":["### Post-processing: Execute SQL"]},{"cell_type":"code","execution_count":29,"metadata":{},"outputs":[],"source":["def execute_sql_query_on_sqlite3(sql_query: str):\n"," conn = sqlite3.connect(DB_FILE_PATH)\n"," cursor = conn.cursor()\n"," result = cursor.execute(sql_query)\n"," rows = result.fetchall()\n"," conn.close()\n","\n"," return rows\n"]},{"cell_type":"code","execution_count":30,"metadata":{},"outputs":[],"source":["import sqlalchemy\n"]},{"cell_type":"code","execution_count":31,"metadata":{},"outputs":[],"source":["sql_engine = sqlalchemy.create_engine(\n"," f\"sqlite:///{os.path.abspath(os.path.join(os.getcwd(), DB_FILE_PATH))}\",\n"," echo=True\n",")\n"]},{"cell_type":"code","execution_count":32,"metadata":{},"outputs":[],"source":["def execute_sql_query(connection, query):\n"," result_obj = connection.execute(sqlalchemy.text(query))\n"," return result_obj.fetchall()\n"]},{"cell_type":"code","execution_count":33,"metadata":{},"outputs":[],"source":["def execute_nl_query(nl_query: str):\n"," response = write_sql_query(nl_query)\n","\n"," #response[\"rows\"] = execute_sql_query_on_sqlite3(response[\"sql\"])\n"," with sql_engine.connect() as conn:\n"," response[\"rows\"] = execute_sql_query(conn, response[\"sql\"])\n","\n"," return response\n"]},{"cell_type":"markdown","metadata":{},"source":["### Try"]},{"cell_type":"code","execution_count":34,"metadata":{},"outputs":[],"source":["test_nl_queries = [\n"," \"Who is the artist with the most albums?\",\n"," \"List the top 3 tracks with maximum sale.\",\n"," \"Name the employee who supports maximum number of customers.\"\n","] \n"]},{"cell_type":"code","execution_count":35,"metadata":{},"outputs":[{"name":"stdout","output_type":"stream","text":["2024-10-24 11:49:14,428 INFO sqlalchemy.engine.Engine BEGIN (implicit)\n","2024-10-24 11:49:14,430 INFO sqlalchemy.engine.Engine SELECT artists.Name, COUNT(albums.AlbumId) as AlbumCount FROM artists JOIN albums ON artists.ArtistId = albums.ArtistId GROUP BY artists.ArtistId ORDER BY AlbumCount DESC LIMIT 1;\n","2024-10-24 11:49:14,431 INFO sqlalchemy.engine.Engine [generated in 0.00248s] ()\n","2024-10-24 11:49:14,433 INFO sqlalchemy.engine.Engine ROLLBACK\n","2024-10-24 11:49:17,800 INFO sqlalchemy.engine.Engine BEGIN (implicit)\n","2024-10-24 11:49:17,802 INFO sqlalchemy.engine.Engine SELECT t.Name, SUM(ii.Quantity) as Total_Sales FROM invoice_items ii JOIN tracks t ON ii.TrackId = t.TrackId GROUP BY ii.TrackId ORDER BY Total_Sales DESC LIMIT 3\n","2024-10-24 11:49:17,802 INFO sqlalchemy.engine.Engine [generated in 0.00232s] ()\n","2024-10-24 11:49:17,807 INFO sqlalchemy.engine.Engine ROLLBACK\n","2024-10-24 11:49:20,924 INFO sqlalchemy.engine.Engine BEGIN (implicit)\n","2024-10-24 11:49:20,925 INFO sqlalchemy.engine.Engine SELECT e.FirstName, e.LastName FROM employees e WHERE e.EmployeeId = (SELECT c.SupportRepId FROM customers c GROUP BY c.SupportRepId ORDER BY COUNT(*) DESC LIMIT 1)\n","2024-10-24 11:49:20,925 INFO sqlalchemy.engine.Engine [generated in 0.00116s] ()\n","2024-10-24 11:49:20,926 INFO sqlalchemy.engine.Engine ROLLBACK\n"]}],"source":["results = []\n","for nl_q in test_nl_queries:\n"," response = execute_nl_query(nl_q)\n"," response[\"query\"] = nl_q\n"," results.append(response)\n"]},{"cell_type":"code","execution_count":36,"metadata":{},"outputs":[{"name":"stdout","output_type":"stream","text":["User Query: Who is the artist with the most albums?\n"," Tables:\n"," {\"artists\": [\"ArtistId\", \"Name\"], \"albums\": [\"ArtistId\"]}\n"," SQL:\n"," SELECT artists.Name, COUNT(albums.AlbumId) as AlbumCount FROM artists JOIN albums ON artists.ArtistId = albums.ArtistId GROUP BY artists.ArtistId ORDER BY AlbumCount DESC LIMIT 1;\n"," Rows:\n"," [('Iron Maiden', 21)]\n","\n"," \n","User Query: List the top 3 tracks with maximum sale.\n"," Tables:\n"," {\"invoice_items\": [\"TrackId\", \"Quantity\"], \"tracks\": [\"TrackId\", \"Name\"]}\n"," SQL:\n"," SELECT t.Name, SUM(ii.Quantity) as Total_Sales FROM invoice_items ii JOIN tracks t ON ii.TrackId = t.TrackId GROUP BY ii.TrackId ORDER BY Total_Sales DESC LIMIT 3\n"," Rows:\n"," [('Balls to the Wall', 2), ('Inject The Venom', 2), ('Snowballed', 2)]\n","\n"," \n","User Query: Name the employee who supports maximum number of customers.\n"," Tables:\n"," {\"employees\": [\"EmployeeId\", \"FirstName\", \"LastName\"], \"customers\": [\"SupportRepId\"]}\n"," SQL:\n"," SELECT e.FirstName, e.LastName FROM employees e WHERE e.EmployeeId = (SELECT c.SupportRepId FROM customers c GROUP BY c.SupportRepId ORDER BY COUNT(*) DESC LIMIT 1)\n"," Rows:\n"," [('Jane', 'Peacock')]\n","\n"," \n"]}],"source":["for t in results:\n"," print(\n"," f\"\"\"User Query: {t['query']}\n"," Tables:\n"," {json.dumps(t['tables'])}\n"," SQL:\n"," {t['sql']}\n"," Rows:\n"," {str(t['rows'])}\\n\n"," \"\"\")\n"]},{"cell_type":"markdown","metadata":{},"source":["## Cleanup"]},{"cell_type":"code","execution_count":37,"metadata":{},"outputs":[],"source":["sql_engine.dispose()\n"]},{"cell_type":"markdown","metadata":{"id":"-_oyoZAkeO_L"},"source":["---\n","Copyright © 2023 Satish Chandra Gupta .
\n"," CC BY-NC-SA 4.0 International License.
"]}],"metadata":{"colab":{"provenance":[{"file_id":"https://github.com/ml4devs/ml4devs-notebooks/blob/master/gpt/nlp_with_gpt_notebook.ipynb","timestamp":1701355922767},{"file_id":"https://github.com/ml4devs/ml4devs-notebooks/blob/master/gpt/nlp_with_gpt_notebook.ipynb","timestamp":1701352821148}]},"kernelspec":{"display_name":"kaggle","language":"python","name":"python3"},"language_info":{"codemirror_mode":{"name":"ipython","version":3},"file_extension":".py","mimetype":"text/x-python","name":"python","nbconvert_exporter":"python","pygments_lexer":"ipython3","version":"3.10.14"}},"nbformat":4,"nbformat_minor":0}
2 |
--------------------------------------------------------------------------------
/speech/asr/deepspeech/mozilla_deepspeech_api_notebook.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "colab_type": "text",
7 | "id": "view-in-github"
8 | },
9 | "source": [
10 | "Python Speech-to-Text Transcriber with Mozilla Deepspeech
\n",
22 | "© Satish Chandra Guptascgupta ,\n",
24 | "Twitter: scgupta \n",
25 | " \n",
26 | " \n",
27 | "\n",
28 | "---\n",
29 | "\n",
30 | "Blog post: [How to Build Python Transcriber Using Mozilla Deepspeech](https://www.ml4devs.com/articles/how-to-build-python-transcriber-using-mozilla-deepspeech/)\n",
31 | "\n",
32 | "Update: [Mozilla DeepSpeech](https://github.com/mozilla/DeepSpeech) is no longer maintaned, and its new home is [Coqui STT](https://github.com/coqui-ai/STT), which has same [APIs in C, Java, .NET, Python, and JavaScript](https://stt.readthedocs.io/) (and also appears that the team has moved too). This notebook is tested with the [Coqui STT 1.4.0](https://github.com/coqui-ai/STT/releases/tag/v1.4.0).\n",
33 | "\n",
34 | "From Colab menu, select: **Runtime** > **Change runtime type**, and verify that it is set to Python3, and select GPU if you want to try out GPU version.\n",
35 | "\n",
36 | "You can [pip-install Coqui STT](https://pypi.org/project/stt/):"
37 | ]
38 | },
39 | {
40 | "cell_type": "code",
41 | "execution_count": 1,
42 | "metadata": {
43 | "colab": {
44 | "base_uri": "https://localhost:8080/"
45 | },
46 | "id": "iemeuv-jKR3P",
47 | "outputId": "ae86dd81-81c2-4417-e76f-178b3e1150ad"
48 | },
49 | "outputs": [
50 | {
51 | "name": "stdout",
52 | "output_type": "stream",
53 | "text": [
54 | "Python 3.7.15\n"
55 | ]
56 | }
57 | ],
58 | "source": [
59 | "!python --version\n"
60 | ]
61 | },
62 | {
63 | "cell_type": "code",
64 | "execution_count": 2,
65 | "metadata": {
66 | "colab": {
67 | "base_uri": "https://localhost:8080/"
68 | },
69 | "id": "zABV65yhNJ0M",
70 | "outputId": "8023c889-f59a-44a9-99e0-702e94416ebf"
71 | },
72 | "outputs": [
73 | {
74 | "name": "stdout",
75 | "output_type": "stream",
76 | "text": [
77 | "Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/\n",
78 | "Requirement already satisfied: stt==1.4.0 in /usr/local/lib/python3.7/dist-packages (1.4.0)\n",
79 | "Requirement already satisfied: numpy>=1.14.5 in /usr/local/lib/python3.7/dist-packages (from stt==1.4.0) (1.21.6)\n"
80 | ]
81 | }
82 | ],
83 | "source": [
84 | "!pip install stt==1.4.0\n"
85 | ]
86 | },
87 | {
88 | "cell_type": "markdown",
89 | "metadata": {
90 | "id": "lbWIPOUwNVyI"
91 | },
92 | "source": [
93 | "## Download Models and Audio Files\n",
94 | "\n",
95 | "Mozilla has released models for US English, we will use those in this code lab.\n",
96 | "\n",
97 | "1. **Download the models:**\n",
98 | "Models can be downloaded from [Coqui Model repository](https://coqui.ai/models), for example, [English STT v1.0.0 (Large Vocabulary)](https://coqui.ai/english/coqui/v1.0.0-large-vocab) that is used here."
99 | ]
100 | },
101 | {
102 | "cell_type": "code",
103 | "execution_count": 3,
104 | "metadata": {
105 | "id": "-Z0dSoLJPKKY"
106 | },
107 | "outputs": [],
108 | "source": [
109 | "!mkdir coqui-stt-1.0.0-models\n"
110 | ]
111 | },
112 | {
113 | "cell_type": "code",
114 | "execution_count": 4,
115 | "metadata": {
116 | "colab": {
117 | "base_uri": "https://localhost:8080/"
118 | },
119 | "id": "cF1uB0zSNk-O",
120 | "outputId": "11c223bb-f1f3-43d5-f064-475b254f8bfc"
121 | },
122 | "outputs": [
123 | {
124 | "name": "stdout",
125 | "output_type": "stream",
126 | "text": [
127 | "--2022-11-01 08:48:10-- https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/model.tflite\n",
128 | "Resolving coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)... 54.70.21.136, 35.155.221.103\n",
129 | "Connecting to coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)|54.70.21.136|:443... connected.\n",
130 | "HTTP request sent, awaiting response... 302 Found\n",
131 | "Location: https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/model.tflite [following]\n",
132 | "--2022-11-01 08:48:10-- https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/model.tflite\n",
133 | "Resolving github.com (github.com)... 140.82.113.3\n",
134 | "Connecting to github.com (github.com)|140.82.113.3|:443... connected.\n",
135 | "HTTP request sent, awaiting response... 302 Found\n",
136 | "Location: https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/e6d0f95f-97dc-43ac-ac08-38660209ebbc?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084810Z&X-Amz-Expires=300&X-Amz-Signature=d7092fcaf803d854ad039a5acba46750ea0aee7c807a1673d6583d9ab4debe8f&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3Dmodel.tflite&response-content-type=application%2Foctet-stream [following]\n",
137 | "--2022-11-01 08:48:10-- https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/e6d0f95f-97dc-43ac-ac08-38660209ebbc?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084810Z&X-Amz-Expires=300&X-Amz-Signature=d7092fcaf803d854ad039a5acba46750ea0aee7c807a1673d6583d9ab4debe8f&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3Dmodel.tflite&response-content-type=application%2Foctet-stream\n",
138 | "Resolving objects.githubusercontent.com (objects.githubusercontent.com)... 185.199.109.133, 185.199.108.133, 185.199.111.133, ...\n",
139 | "Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.109.133|:443... connected.\n",
140 | "HTTP request sent, awaiting response... 200 OK\n",
141 | "Length: 47332120 (45M) [application/octet-stream]\n",
142 | "Saving to: ‘model.tflite’\n",
143 | "\n",
144 | "model.tflite 100%[===================>] 45.14M 87.1MB/s in 0.5s \n",
145 | "\n",
146 | "2022-11-01 08:48:11 (87.1 MB/s) - ‘model.tflite’ saved [47332120/47332120]\n",
147 | "\n"
148 | ]
149 | }
150 | ],
151 | "source": [
152 | "!wget https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/model.tflite\n"
153 | ]
154 | },
155 | {
156 | "cell_type": "code",
157 | "execution_count": 5,
158 | "metadata": {
159 | "colab": {
160 | "base_uri": "https://localhost:8080/"
161 | },
162 | "id": "mwqvk3jUFblh",
163 | "outputId": "b82099d7-9a54-4064-efeb-f868acc6f7ad"
164 | },
165 | "outputs": [
166 | {
167 | "name": "stdout",
168 | "output_type": "stream",
169 | "text": [
170 | "--2022-11-01 08:48:11-- https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/large_vocabulary.scorer\n",
171 | "Resolving coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)... 54.70.21.136, 35.155.221.103\n",
172 | "Connecting to coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)|54.70.21.136|:443... connected.\n",
173 | "HTTP request sent, awaiting response... 302 Found\n",
174 | "Location: https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/large_vocabulary.scorer [following]\n",
175 | "--2022-11-01 08:48:11-- https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/large_vocabulary.scorer\n",
176 | "Resolving github.com (github.com)... 140.82.112.3\n",
177 | "Connecting to github.com (github.com)|140.82.112.3|:443... connected.\n",
178 | "HTTP request sent, awaiting response... 302 Found\n",
179 | "Location: https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/1df256c5-336b-424b-b7b9-a33d8262eb24?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084812Z&X-Amz-Expires=300&X-Amz-Signature=8c3f53e036ebc62959f82f7ed932926af817fe3648c7ee8a9c25d52e50365cf3&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3Dlarge_vocabulary.scorer&response-content-type=application%2Foctet-stream [following]\n",
180 | "--2022-11-01 08:48:12-- https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/1df256c5-336b-424b-b7b9-a33d8262eb24?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084812Z&X-Amz-Expires=300&X-Amz-Signature=8c3f53e036ebc62959f82f7ed932926af817fe3648c7ee8a9c25d52e50365cf3&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3Dlarge_vocabulary.scorer&response-content-type=application%2Foctet-stream\n",
181 | "Resolving objects.githubusercontent.com (objects.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...\n",
182 | "Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.108.133|:443... connected.\n",
183 | "HTTP request sent, awaiting response... 200 OK\n",
184 | "Length: 132644544 (126M) [application/octet-stream]\n",
185 | "Saving to: ‘large_vocabulary.scorer’\n",
186 | "\n",
187 | "large_vocabulary.sc 100%[===================>] 126.50M 94.8MB/s in 1.3s \n",
188 | "\n",
189 | "2022-11-01 08:48:13 (94.8 MB/s) - ‘large_vocabulary.scorer’ saved [132644544/132644544]\n",
190 | "\n"
191 | ]
192 | }
193 | ],
194 | "source": [
195 | "!wget https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/large_vocabulary.scorer\n"
196 | ]
197 | },
198 | {
199 | "cell_type": "code",
200 | "execution_count": 6,
201 | "metadata": {
202 | "colab": {
203 | "base_uri": "https://localhost:8080/"
204 | },
205 | "id": "55gHX_5zP9JY",
206 | "outputId": "582181eb-373a-4f28-ba71-db0d2a508228"
207 | },
208 | "outputs": [
209 | {
210 | "name": "stdout",
211 | "output_type": "stream",
212 | "text": [
213 | "--2022-11-01 08:48:13-- https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/alphabet.txt\n",
214 | "Resolving coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)... 54.70.21.136, 35.155.221.103\n",
215 | "Connecting to coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)|54.70.21.136|:443... connected.\n",
216 | "HTTP request sent, awaiting response... 302 Found\n",
217 | "Location: https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/alphabet.txt [following]\n",
218 | "--2022-11-01 08:48:13-- https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/alphabet.txt\n",
219 | "Resolving github.com (github.com)... 140.82.112.3\n",
220 | "Connecting to github.com (github.com)|140.82.112.3|:443... connected.\n",
221 | "HTTP request sent, awaiting response... 302 Found\n",
222 | "Location: https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/17a8ffed-fd5a-4225-bb12-884c66c87c62?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084814Z&X-Amz-Expires=300&X-Amz-Signature=8774cf570daf9851962725458248903ce58515741f34f5e61ac9f5292599a002&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3Dalphabet.txt&response-content-type=application%2Foctet-stream [following]\n",
223 | "--2022-11-01 08:48:14-- https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/17a8ffed-fd5a-4225-bb12-884c66c87c62?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084814Z&X-Amz-Expires=300&X-Amz-Signature=8774cf570daf9851962725458248903ce58515741f34f5e61ac9f5292599a002&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3Dalphabet.txt&response-content-type=application%2Foctet-stream\n",
224 | "Resolving objects.githubusercontent.com (objects.githubusercontent.com)... 185.199.111.133, 185.199.110.133, 185.199.109.133, ...\n",
225 | "Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.111.133|:443... connected.\n",
226 | "HTTP request sent, awaiting response... 200 OK\n",
227 | "Length: 329 [application/octet-stream]\n",
228 | "Saving to: ‘alphabet.txt’\n",
229 | "\n",
230 | "alphabet.txt 100%[===================>] 329 --.-KB/s in 0s \n",
231 | "\n",
232 | "2022-11-01 08:48:14 (7.53 MB/s) - ‘alphabet.txt’ saved [329/329]\n",
233 | "\n"
234 | ]
235 | }
236 | ],
237 | "source": [
238 | "!wget https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/alphabet.txt\n"
239 | ]
240 | },
241 | {
242 | "cell_type": "code",
243 | "execution_count": 7,
244 | "metadata": {
245 | "colab": {
246 | "base_uri": "https://localhost:8080/"
247 | },
248 | "id": "6RLXmm1FQABI",
249 | "outputId": "b0d0ba6d-cba3-46b1-ae0b-018db6b9ba3f"
250 | },
251 | "outputs": [
252 | {
253 | "name": "stdout",
254 | "output_type": "stream",
255 | "text": [
256 | "--2022-11-01 08:48:14-- https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/MODEL_CARD\n",
257 | "Resolving coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)... 54.70.21.136, 35.155.221.103\n",
258 | "Connecting to coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)|54.70.21.136|:443... connected.\n",
259 | "HTTP request sent, awaiting response... 302 Found\n",
260 | "Location: https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/MODEL_CARD [following]\n",
261 | "--2022-11-01 08:48:14-- https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/MODEL_CARD\n",
262 | "Resolving github.com (github.com)... 140.82.112.3\n",
263 | "Connecting to github.com (github.com)|140.82.112.3|:443... connected.\n",
264 | "HTTP request sent, awaiting response... 302 Found\n",
265 | "Location: https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/b03c95a9-30e2-420d-b07e-413b44525bf0?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084814Z&X-Amz-Expires=300&X-Amz-Signature=0db67a4c622257f9e0519088f224f6b6ad96376357365549458c93ef7a804a15&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3DMODEL_CARD&response-content-type=application%2Foctet-stream [following]\n",
266 | "--2022-11-01 08:48:14-- https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/b03c95a9-30e2-420d-b07e-413b44525bf0?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084814Z&X-Amz-Expires=300&X-Amz-Signature=0db67a4c622257f9e0519088f224f6b6ad96376357365549458c93ef7a804a15&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3DMODEL_CARD&response-content-type=application%2Foctet-stream\n",
267 | "Resolving objects.githubusercontent.com (objects.githubusercontent.com)... 185.199.111.133, 185.199.110.133, 185.199.109.133, ...\n",
268 | "Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.111.133|:443... connected.\n",
269 | "HTTP request sent, awaiting response... 200 OK\n",
270 | "Length: 4244 (4.1K) [application/octet-stream]\n",
271 | "Saving to: ‘MODEL_CARD’\n",
272 | "\n",
273 | "MODEL_CARD 100%[===================>] 4.14K --.-KB/s in 0s \n",
274 | "\n",
275 | "2022-11-01 08:48:14 (39.3 MB/s) - ‘MODEL_CARD’ saved [4244/4244]\n",
276 | "\n"
277 | ]
278 | }
279 | ],
280 | "source": [
281 | "!wget https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/MODEL_CARD\n"
282 | ]
283 | },
284 | {
285 | "cell_type": "code",
286 | "execution_count": 8,
287 | "metadata": {
288 | "colab": {
289 | "base_uri": "https://localhost:8080/"
290 | },
291 | "id": "FOv1BfpaQB6S",
292 | "outputId": "a42f3fd0-c5ca-4e81-af6e-dd83aaf3eb47"
293 | },
294 | "outputs": [
295 | {
296 | "name": "stdout",
297 | "output_type": "stream",
298 | "text": [
299 | "--2022-11-01 08:48:15-- https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/LOG_TESTING\n",
300 | "Resolving coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)... 54.70.21.136, 35.155.221.103\n",
301 | "Connecting to coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)|54.70.21.136|:443... connected.\n",
302 | "HTTP request sent, awaiting response... 302 Found\n",
303 | "Location: https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/LOG_TESTING [following]\n",
304 | "--2022-11-01 08:48:15-- https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/LOG_TESTING\n",
305 | "Resolving github.com (github.com)... 140.82.112.3\n",
306 | "Connecting to github.com (github.com)|140.82.112.3|:443... connected.\n",
307 | "HTTP request sent, awaiting response... 302 Found\n",
308 | "Location: https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/f33b2c5a-c27e-47b1-9870-4f2a190a4a83?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084815Z&X-Amz-Expires=300&X-Amz-Signature=98154462951673f376188791445b1886a32b40f6a686e289c8c124fad0afa4f2&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3DLOG_TESTING&response-content-type=application%2Foctet-stream [following]\n",
309 | "--2022-11-01 08:48:15-- https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/f33b2c5a-c27e-47b1-9870-4f2a190a4a83?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084815Z&X-Amz-Expires=300&X-Amz-Signature=98154462951673f376188791445b1886a32b40f6a686e289c8c124fad0afa4f2&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3DLOG_TESTING&response-content-type=application%2Foctet-stream\n",
310 | "Resolving objects.githubusercontent.com (objects.githubusercontent.com)... 185.199.111.133, 185.199.110.133, 185.199.109.133, ...\n",
311 | "Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.111.133|:443... connected.\n",
312 | "HTTP request sent, awaiting response... 200 OK\n",
313 | "Length: 25391 (25K) [application/octet-stream]\n",
314 | "Saving to: ‘LOG_TESTING’\n",
315 | "\n",
316 | "LOG_TESTING 100%[===================>] 24.80K --.-KB/s in 0.001s \n",
317 | "\n",
318 | "2022-11-01 08:48:15 (19.6 MB/s) - ‘LOG_TESTING’ saved [25391/25391]\n",
319 | "\n"
320 | ]
321 | }
322 | ],
323 | "source": [
324 | "!wget https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/LOG_TESTING\n"
325 | ]
326 | },
327 | {
328 | "cell_type": "code",
329 | "execution_count": 9,
330 | "metadata": {
331 | "colab": {
332 | "base_uri": "https://localhost:8080/"
333 | },
334 | "id": "WPBYunv5QC_A",
335 | "outputId": "412e8f27-3fa0-4f29-d494-97d55cffc166"
336 | },
337 | "outputs": [
338 | {
339 | "name": "stdout",
340 | "output_type": "stream",
341 | "text": [
342 | "--2022-11-01 08:48:15-- https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/LICENSE\n",
343 | "Resolving coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)... 54.70.21.136, 35.155.221.103\n",
344 | "Connecting to coqui.gateway.scarf.sh (coqui.gateway.scarf.sh)|54.70.21.136|:443... connected.\n",
345 | "HTTP request sent, awaiting response... 302 Found\n",
346 | "Location: https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/LICENSE [following]\n",
347 | "--2022-11-01 08:48:16-- https://github.com/coqui-ai/STT-models/releases/download/english/coqui/v1.0.0-large-vocab/LICENSE\n",
348 | "Resolving github.com (github.com)... 140.82.112.3\n",
349 | "Connecting to github.com (github.com)|140.82.112.3|:443... connected.\n",
350 | "HTTP request sent, awaiting response... 302 Found\n",
351 | "Location: https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/dc69c571-83ca-48c1-9b31-408e9be73bc1?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084816Z&X-Amz-Expires=300&X-Amz-Signature=ded931fa9d8b592ee69283a4664a5c4a88b447e2dd65f3446426f5eff806d1b7&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3DLICENSE&response-content-type=application%2Foctet-stream [following]\n",
352 | "--2022-11-01 08:48:16-- https://objects.githubusercontent.com/github-production-release-asset-2e65be/351871871/dc69c571-83ca-48c1-9b31-408e9be73bc1?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20221101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20221101T084816Z&X-Amz-Expires=300&X-Amz-Signature=ded931fa9d8b592ee69283a4664a5c4a88b447e2dd65f3446426f5eff806d1b7&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=351871871&response-content-disposition=attachment%3B%20filename%3DLICENSE&response-content-type=application%2Foctet-stream\n",
353 | "Resolving objects.githubusercontent.com (objects.githubusercontent.com)... 185.199.111.133, 185.199.110.133, 185.199.109.133, ...\n",
354 | "Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.111.133|:443... connected.\n",
355 | "HTTP request sent, awaiting response... 200 OK\n",
356 | "Length: 11358 (11K) [application/octet-stream]\n",
357 | "Saving to: ‘LICENSE’\n",
358 | "\n",
359 | "LICENSE 100%[===================>] 11.09K --.-KB/s in 0s \n",
360 | "\n",
361 | "2022-11-01 08:48:16 (77.9 MB/s) - ‘LICENSE’ saved [11358/11358]\n",
362 | "\n"
363 | ]
364 | }
365 | ],
366 | "source": [
367 | "!wget https://coqui.gateway.scarf.sh/english/coqui/v1.0.0-large-vocab/LICENSE\n"
368 | ]
369 | },
370 | {
371 | "cell_type": "code",
372 | "execution_count": 10,
373 | "metadata": {
374 | "id": "dmxn7NKYGqRR"
375 | },
376 | "outputs": [],
377 | "source": [
378 | "!mv model.tflite large_vocabulary.scorer alphabet.txt MODEL_CARD LOG_TESTING LICENSE coqui-stt-1.0.0-models/\n"
379 | ]
380 | },
381 | {
382 | "cell_type": "code",
383 | "execution_count": 11,
384 | "metadata": {
385 | "colab": {
386 | "base_uri": "https://localhost:8080/"
387 | },
388 | "id": "flAYDslHHVZK",
389 | "outputId": "d88df0bd-8021-404b-822e-bf39b9e5b002"
390 | },
391 | "outputs": [
392 | {
393 | "name": "stdout",
394 | "output_type": "stream",
395 | "text": [
396 | "total 175816\n",
397 | "-rw-r--r-- 1 root root 329 Dec 7 2021 alphabet.txt\n",
398 | "-rw-r--r-- 1 root root 132644544 Dec 7 2021 large_vocabulary.scorer\n",
399 | "-rw-r--r-- 1 root root 11358 Dec 7 2021 LICENSE\n",
400 | "-rw-r--r-- 1 root root 25391 Dec 7 2021 LOG_TESTING\n",
401 | "-rw-r--r-- 1 root root 4244 Dec 7 2021 MODEL_CARD\n",
402 | "-rw-r--r-- 1 root root 47332120 Dec 7 2021 model.tflite\n"
403 | ]
404 | }
405 | ],
406 | "source": [
407 | "!ls -l coqui-stt-1.0.0-models\n"
408 | ]
409 | },
410 | {
411 | "cell_type": "markdown",
412 | "metadata": {
413 | "id": "_g5hZVWXO1wl"
414 | },
415 | "source": [
416 | "2. **Download audio data files**"
417 | ]
418 | },
419 | {
420 | "cell_type": "code",
421 | "execution_count": 12,
422 | "metadata": {
423 | "colab": {
424 | "base_uri": "https://localhost:8080/"
425 | },
426 | "id": "GdOxbBycM-Hf",
427 | "outputId": "d213f2ce-013b-4746-a59b-9e67fd0a3c57"
428 | },
429 | "outputs": [
430 | {
431 | "name": "stdout",
432 | "output_type": "stream",
433 | "text": [
434 | " % Total % Received % Xferd Average Speed Time Time Time Current\n",
435 | " Dload Upload Total Spent Left Speed\n",
436 | " 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0\n",
437 | "100 193k 100 193k 0 0 609k 0 --:--:-- --:--:-- --:--:-- 609k\n"
438 | ]
439 | }
440 | ],
441 | "source": [
442 | "!curl -LO https://github.com/coqui-ai/STT/releases/download/v1.4.0/audio-1.4.0.tar.gz\n"
443 | ]
444 | },
445 | {
446 | "cell_type": "markdown",
447 | "metadata": {
448 | "id": "m4yZaht2PH_5"
449 | },
450 | "source": [
451 | "4. **Unzip audio files**"
452 | ]
453 | },
454 | {
455 | "cell_type": "code",
456 | "execution_count": 13,
457 | "metadata": {
458 | "colab": {
459 | "base_uri": "https://localhost:8080/"
460 | },
461 | "id": "82DLg4JpPOVX",
462 | "outputId": "84c10407-6370-47c7-d721-ba73faba1537"
463 | },
464 | "outputs": [
465 | {
466 | "name": "stdout",
467 | "output_type": "stream",
468 | "text": [
469 | "._audio\n",
470 | "tar: Ignoring unknown extended header keyword 'LIBARCHIVE.xattr.com.apple.quarantine'\n",
471 | "audio/\n",
472 | "audio/._2830-3980-0043.wav\n",
473 | "tar: Ignoring unknown extended header keyword 'LIBARCHIVE.xattr.com.apple.quarantine'\n",
474 | "audio/2830-3980-0043.wav\n",
475 | "audio/._Attribution.txt\n",
476 | "tar: Ignoring unknown extended header keyword 'LIBARCHIVE.xattr.com.apple.quarantine'\n",
477 | "audio/Attribution.txt\n",
478 | "audio/._4507-16021-0012.wav\n",
479 | "tar: Ignoring unknown extended header keyword 'LIBARCHIVE.xattr.com.apple.quarantine'\n",
480 | "audio/4507-16021-0012.wav\n",
481 | "audio/._8455-210777-0068.wav\n",
482 | "tar: Ignoring unknown extended header keyword 'LIBARCHIVE.xattr.com.apple.quarantine'\n",
483 | "audio/8455-210777-0068.wav\n",
484 | "audio/._License.txt\n",
485 | "tar: Ignoring unknown extended header keyword 'LIBARCHIVE.xattr.com.apple.quarantine'\n",
486 | "audio/License.txt\n"
487 | ]
488 | }
489 | ],
490 | "source": [
491 | "!tar -xvzf audio-1.4.0.tar.gz\n"
492 | ]
493 | },
494 | {
495 | "cell_type": "code",
496 | "execution_count": 14,
497 | "metadata": {
498 | "colab": {
499 | "base_uri": "https://localhost:8080/"
500 | },
501 | "id": "zExydudVPU4r",
502 | "outputId": "19830ed2-cfd2-4eff-8f6a-c2a2338ec33c"
503 | },
504 | "outputs": [
505 | {
506 | "name": "stdout",
507 | "output_type": "stream",
508 | "text": [
509 | "total 260\n",
510 | "-rw-r--r-- 1 501 staff 63244 Nov 18 2017 2830-3980-0043.wav\n",
511 | "-rw-r--r-- 1 501 staff 87564 Nov 18 2017 4507-16021-0012.wav\n",
512 | "-rw-r--r-- 1 501 staff 82924 Nov 18 2017 8455-210777-0068.wav\n",
513 | "-rw-r--r-- 1 501 staff 340 May 14 2018 Attribution.txt\n",
514 | "-rw-r--r-- 1 501 staff 18652 May 12 2018 License.txt\n"
515 | ]
516 | }
517 | ],
518 | "source": [
519 | "!ls -l ./audio/\n"
520 | ]
521 | },
522 | {
523 | "cell_type": "markdown",
524 | "metadata": {
525 | "id": "dIiwclaXPzfm"
526 | },
527 | "source": [
528 | "5. **Test that it all works**"
529 | ]
530 | },
531 | {
532 | "cell_type": "code",
533 | "execution_count": 15,
534 | "metadata": {
535 | "colab": {
536 | "base_uri": "https://localhost:8080/"
537 | },
538 | "id": "ZJlSpiHSPebH",
539 | "outputId": "b7cd1790-a7c3-4fc9-df9f-50abbd09e1a3"
540 | },
541 | "outputs": [
542 | {
543 | "name": "stdout",
544 | "output_type": "stream",
545 | "text": [
546 | "usage: stt [-h] --model MODEL [--scorer SCORER] --audio AUDIO\n",
547 | " [--beam_width BEAM_WIDTH] [--lm_alpha LM_ALPHA] [--lm_beta LM_BETA]\n",
548 | " [--version] [--extended] [--json]\n",
549 | " [--candidate_transcripts CANDIDATE_TRANSCRIPTS]\n",
550 | " [--hot_words HOT_WORDS]\n",
551 | "\n",
552 | "Running Coqui STT inference.\n",
553 | "\n",
554 | "optional arguments:\n",
555 | " -h, --help show this help message and exit\n",
556 | " --model MODEL Path to the model (protocol buffer binary file)\n",
557 | " --scorer SCORER Path to the external scorer file\n",
558 | " --audio AUDIO Path to the audio file to run (WAV format)\n",
559 | " --beam_width BEAM_WIDTH\n",
560 | " Beam width for the CTC decoder\n",
561 | " --lm_alpha LM_ALPHA Language model weight (lm_alpha). If not specified,\n",
562 | " use default from the scorer package.\n",
563 | " --lm_beta LM_BETA Word insertion bonus (lm_beta). If not specified, use\n",
564 | " default from the scorer package.\n",
565 | " --version Print version and exits\n",
566 | " --extended Output string from extended metadata\n",
567 | " --json Output json from metadata with timestamp of each word\n",
568 | " --candidate_transcripts CANDIDATE_TRANSCRIPTS\n",
569 | " Number of candidate transcripts to include in JSON\n",
570 | " output\n",
571 | " --hot_words HOT_WORDS\n",
572 | " Hot-words and their boosts.\n"
573 | ]
574 | }
575 | ],
576 | "source": [
577 | "!stt --help\n"
578 | ]
579 | },
580 | {
581 | "cell_type": "code",
582 | "execution_count": 16,
583 | "metadata": {
584 | "colab": {
585 | "base_uri": "https://localhost:8080/"
586 | },
587 | "id": "wCn27zQOOM3Y",
588 | "outputId": "6d5fe457-cf6a-4009-9b3a-d255571264a4"
589 | },
590 | "outputs": [
591 | {
592 | "name": "stdout",
593 | "output_type": "stream",
594 | "text": [
595 | "Loading model from file coqui-stt-1.0.0-models/model.tflite\n",
596 | "TensorFlow: v2.9.1-11-gf8242ebc005\n",
597 | " Coqui STT: v1.4.0-0-gfcec06bd\n",
598 | "INFO: Created TensorFlow Lite XNNPACK delegate for CPU.\n",
599 | "Loaded model in 0.00167s.\n",
600 | "Loading scorer from files coqui-stt-1.0.0-models/large_vocabulary.scorer\n",
601 | "Loaded scorer in 0.000265s.\n",
602 | "Running inference.\n",
603 | "experience proves this\n",
604 | "Inference took 0.795s for 1.975s audio file.\n"
605 | ]
606 | }
607 | ],
608 | "source": [
609 | "!stt --model coqui-stt-1.0.0-models/model.tflite --scorer coqui-stt-1.0.0-models/large_vocabulary.scorer --audio ./audio/2830-3980-0043.wav\n"
610 | ]
611 | },
612 | {
613 | "cell_type": "code",
614 | "execution_count": 17,
615 | "metadata": {
616 | "colab": {
617 | "base_uri": "https://localhost:8080/"
618 | },
619 | "id": "V-kHdWHZPHyG",
620 | "outputId": "6193a383-fbbd-4280-92ef-854098810687"
621 | },
622 | "outputs": [
623 | {
624 | "name": "stdout",
625 | "output_type": "stream",
626 | "text": [
627 | "Loading model from file coqui-stt-1.0.0-models/model.tflite\n",
628 | "TensorFlow: v2.9.1-11-gf8242ebc005\n",
629 | " Coqui STT: v1.4.0-0-gfcec06bd\n",
630 | "INFO: Created TensorFlow Lite XNNPACK delegate for CPU.\n",
631 | "Loaded model in 0.00149s.\n",
632 | "Loading scorer from files coqui-stt-1.0.0-models/large_vocabulary.scorer\n",
633 | "Loaded scorer in 0.000223s.\n",
634 | "Running inference.\n",
635 | "why should one halt on the way\n",
636 | "Inference took 0.910s for 2.735s audio file.\n"
637 | ]
638 | }
639 | ],
640 | "source": [
641 | "!stt --model coqui-stt-1.0.0-models/model.tflite --scorer coqui-stt-1.0.0-models/large_vocabulary.scorer --audio ./audio/4507-16021-0012.wav\n"
642 | ]
643 | },
644 | {
645 | "cell_type": "code",
646 | "execution_count": 18,
647 | "metadata": {
648 | "colab": {
649 | "base_uri": "https://localhost:8080/"
650 | },
651 | "id": "2lZBwBRDPHtu",
652 | "outputId": "347ed959-e590-4de3-e763-f920221095fd"
653 | },
654 | "outputs": [
655 | {
656 | "name": "stdout",
657 | "output_type": "stream",
658 | "text": [
659 | "Loading model from file coqui-stt-1.0.0-models/model.tflite\n",
660 | "TensorFlow: v2.9.1-11-gf8242ebc005\n",
661 | " Coqui STT: v1.4.0-0-gfcec06bd\n",
662 | "INFO: Created TensorFlow Lite XNNPACK delegate for CPU.\n",
663 | "Loaded model in 0.00148s.\n",
664 | "Loading scorer from files coqui-stt-1.0.0-models/large_vocabulary.scorer\n",
665 | "Loaded scorer in 0.000231s.\n",
666 | "Running inference.\n",
667 | "your power is sufficient i said\n",
668 | "Inference took 0.889s for 2.590s audio file.\n"
669 | ]
670 | }
671 | ],
672 | "source": [
673 | "!stt --model coqui-stt-1.0.0-models/model.tflite --scorer coqui-stt-1.0.0-models/large_vocabulary.scorer --audio ./audio/8455-210777-0068.wav\n"
674 | ]
675 | },
676 | {
677 | "cell_type": "markdown",
678 | "metadata": {
679 | "id": "_4m0A8-VTPQG"
680 | },
681 | "source": [
682 | "Examine the output of the last three commands, and you will see results “experience proof this, “why should one halt on the way”, and “your power is sufficient i said” respectively. You are all set.\n",
683 | "\n",
684 | "If you want the breakup and timestamp, you can use `--json` flag:"
685 | ]
686 | },
687 | {
688 | "cell_type": "code",
689 | "execution_count": 19,
690 | "metadata": {
691 | "colab": {
692 | "base_uri": "https://localhost:8080/"
693 | },
694 | "id": "DohT6qE5SvXF",
695 | "outputId": "0721c87b-2d9b-4e91-ee0a-d0ceb41509b6"
696 | },
697 | "outputs": [
698 | {
699 | "name": "stdout",
700 | "output_type": "stream",
701 | "text": [
702 | "Loading model from file coqui-stt-1.0.0-models/model.tflite\n",
703 | "TensorFlow: v2.9.1-11-gf8242ebc005\n",
704 | " Coqui STT: v1.4.0-0-gfcec06bd\n",
705 | "INFO: Created TensorFlow Lite XNNPACK delegate for CPU.\n",
706 | "Loaded model in 0.00152s.\n",
707 | "Loading scorer from files coqui-stt-1.0.0-models/large_vocabulary.scorer\n",
708 | "Loaded scorer in 0.000266s.\n",
709 | "Running inference.\n",
710 | "{\n",
711 | " \"transcripts\": [\n",
712 | " {\n",
713 | " \"confidence\": -31.462177276611328,\n",
714 | " \"words\": [\n",
715 | " {\n",
716 | " \"word\": \"your\",\n",
717 | " \"start_time\": 0.72,\n",
718 | " \"duration\": 0.2\n",
719 | " },\n",
720 | " {\n",
721 | " \"word\": \"power\",\n",
722 | " \"start_time\": 0.98,\n",
723 | " \"duration\": 0.2\n",
724 | " },\n",
725 | " {\n",
726 | " \"word\": \"is\",\n",
727 | " \"start_time\": 1.28,\n",
728 | " \"duration\": 0.1\n",
729 | " },\n",
730 | " {\n",
731 | " \"word\": \"sufficient\",\n",
732 | " \"start_time\": 1.44,\n",
733 | " \"duration\": 0.36\n",
734 | " },\n",
735 | " {\n",
736 | " \"word\": \"i\",\n",
737 | " \"start_time\": 1.92,\n",
738 | " \"duration\": 0.12\n",
739 | " },\n",
740 | " {\n",
741 | " \"word\": \"said\",\n",
742 | " \"start_time\": 2.1,\n",
743 | " \"duration\": 0.08\n",
744 | " }\n",
745 | " ]\n",
746 | " },\n",
747 | " {\n",
748 | " \"confidence\": -36.81807327270508,\n",
749 | " \"words\": [\n",
750 | " {\n",
751 | " \"word\": \"our\",\n",
752 | " \"start_time\": 0.76,\n",
753 | " \"duration\": 0.16\n",
754 | " },\n",
755 | " {\n",
756 | " \"word\": \"power\",\n",
757 | " \"start_time\": 0.98,\n",
758 | " \"duration\": 0.2\n",
759 | " },\n",
760 | " {\n",
761 | " \"word\": \"is\",\n",
762 | " \"start_time\": 1.28,\n",
763 | " \"duration\": 0.1\n",
764 | " },\n",
765 | " {\n",
766 | " \"word\": \"sufficient\",\n",
767 | " \"start_time\": 1.44,\n",
768 | " \"duration\": 0.36\n",
769 | " },\n",
770 | " {\n",
771 | " \"word\": \"i\",\n",
772 | " \"start_time\": 1.92,\n",
773 | " \"duration\": 0.12\n",
774 | " },\n",
775 | " {\n",
776 | " \"word\": \"said\",\n",
777 | " \"start_time\": 2.1,\n",
778 | " \"duration\": 0.08\n",
779 | " }\n",
780 | " ]\n",
781 | " },\n",
782 | " {\n",
783 | " \"confidence\": -37.49082565307617,\n",
784 | " \"words\": [\n",
785 | " {\n",
786 | " \"word\": \"your\",\n",
787 | " \"start_time\": 0.72,\n",
788 | " \"duration\": 0.2\n",
789 | " },\n",
790 | " {\n",
791 | " \"word\": \"power\",\n",
792 | " \"start_time\": 0.98,\n",
793 | " \"duration\": 0.2\n",
794 | " },\n",
795 | " {\n",
796 | " \"word\": \"is\",\n",
797 | " \"start_time\": 1.28,\n",
798 | " \"duration\": 0.1\n",
799 | " },\n",
800 | " {\n",
801 | " \"word\": \"sufficient\",\n",
802 | " \"start_time\": 1.44,\n",
803 | " \"duration\": 0.36\n",
804 | " },\n",
805 | " {\n",
806 | " \"word\": \"i\",\n",
807 | " \"start_time\": 1.92,\n",
808 | " \"duration\": 0.12\n",
809 | " },\n",
810 | " {\n",
811 | " \"word\": \"said\",\n",
812 | " \"start_time\": 2.1,\n",
813 | " \"duration\": 0.1\n",
814 | " }\n",
815 | " ]\n",
816 | " }\n",
817 | " ]\n",
818 | "}\n",
819 | "Inference took 1.324s for 2.590s audio file.\n"
820 | ]
821 | }
822 | ],
823 | "source": [
824 | "!stt --json --model coqui-stt-1.0.0-models/model.tflite --scorer coqui-stt-1.0.0-models/large_vocabulary.scorer --audio ./audio/8455-210777-0068.wav \n"
825 | ]
826 | },
827 | {
828 | "cell_type": "markdown",
829 | "metadata": {
830 | "id": "p61UrYSvQrOd"
831 | },
832 | "source": [
833 | "# DeepSpeech API\n",
834 | "\n",
835 | "1. **Import deepspeech**"
836 | ]
837 | },
838 | {
839 | "cell_type": "code",
840 | "execution_count": 20,
841 | "metadata": {
842 | "id": "LKwSvpvaRFIe"
843 | },
844 | "outputs": [],
845 | "source": [
846 | "import stt\n"
847 | ]
848 | },
849 | {
850 | "cell_type": "markdown",
851 | "metadata": {
852 | "id": "xqd6bQ_gRPOB"
853 | },
854 | "source": [
855 | "2. **Create a model**"
856 | ]
857 | },
858 | {
859 | "cell_type": "code",
860 | "execution_count": 21,
861 | "metadata": {
862 | "id": "jKDVOmbFRR1A"
863 | },
864 | "outputs": [],
865 | "source": [
866 | "model_file_path = 'coqui-stt-1.0.0-models/model.tflite'\n",
867 | "model = stt.Model(model_file_path)\n"
868 | ]
869 | },
870 | {
871 | "cell_type": "markdown",
872 | "metadata": {
873 | "id": "VNRxsb2zRgeJ"
874 | },
875 | "source": [
876 | "3. **Add scorer and other parameters**"
877 | ]
878 | },
879 | {
880 | "cell_type": "code",
881 | "execution_count": 22,
882 | "metadata": {
883 | "colab": {
884 | "base_uri": "https://localhost:8080/"
885 | },
886 | "id": "6FRX1EvDRnLH",
887 | "outputId": "7be32767-0dc6-45cc-f4c0-80dac13b7e2a"
888 | },
889 | "outputs": [
890 | {
891 | "data": {
892 | "text/plain": [
893 | "0"
894 | ]
895 | },
896 | "execution_count": 22,
897 | "metadata": {},
898 | "output_type": "execute_result"
899 | }
900 | ],
901 | "source": [
902 | "scorer_file_path = 'coqui-stt-1.0.0-models/large_vocabulary.scorer'\n",
903 | "model.enableExternalScorer(scorer_file_path)\n",
904 | "\n",
905 | "lm_alpha = 0.75\n",
906 | "lm_beta = 1.85\n",
907 | "model.setScorerAlphaBeta(lm_alpha, lm_beta)\n",
908 | "\n",
909 | "beam_width = 500\n",
910 | "model.setBeamWidth(beam_width)\n"
911 | ]
912 | },
913 | {
914 | "cell_type": "markdown",
915 | "metadata": {
916 | "id": "tWbHnlwCRuDo"
917 | },
918 | "source": [
919 | "## Batch API\n",
920 | "\n",
921 | "1. **Read an input wav file**\n"
922 | ]
923 | },
924 | {
925 | "cell_type": "code",
926 | "execution_count": 23,
927 | "metadata": {
928 | "id": "PRshwTMoSFEL"
929 | },
930 | "outputs": [],
931 | "source": [
932 | "import wave\n",
933 | "filename = 'audio/8455-210777-0068.wav'\n",
934 | "w = wave.open(filename, 'r')\n",
935 | "rate = w.getframerate()\n",
936 | "frames = w.getnframes()\n",
937 | "buffer = w.readframes(frames)\n"
938 | ]
939 | },
940 | {
941 | "cell_type": "markdown",
942 | "metadata": {
943 | "id": "cAowLS39SNC_"
944 | },
945 | "source": [
946 | "Checkout sample rate and buffer type"
947 | ]
948 | },
949 | {
950 | "cell_type": "code",
951 | "execution_count": 24,
952 | "metadata": {
953 | "colab": {
954 | "base_uri": "https://localhost:8080/"
955 | },
956 | "id": "NHvatdmxSYGu",
957 | "outputId": "ad0916d8-26bc-4d6c-eaef-428759cc9164"
958 | },
959 | "outputs": [
960 | {
961 | "name": "stdout",
962 | "output_type": "stream",
963 | "text": [
964 | "16000\n",
965 | "16000\n",
966 | "\n"
967 | ]
968 | }
969 | ],
970 | "source": [
971 | "print(rate)\n",
972 | "print(model.sampleRate())\n",
973 | "print(str(type(buffer)))\n"
974 | ]
975 | },
976 | {
977 | "cell_type": "markdown",
978 | "metadata": {
979 | "id": "uOhbO3iTS3ft"
980 | },
981 | "source": [
982 | "As you can see that the speech sample rate of the wav file is 16000hz, same as the model’s sample rate. But the buffer is a byte array, whereas DeepSpeech model expects 16-bit int array.\n",
983 | "\n",
984 | "2. **Convert byte array buffer to int16 array**"
985 | ]
986 | },
987 | {
988 | "cell_type": "code",
989 | "execution_count": 25,
990 | "metadata": {
991 | "colab": {
992 | "base_uri": "https://localhost:8080/"
993 | },
994 | "id": "XYXF6AU2S8m2",
995 | "outputId": "4a504ca4-4ee7-4b08-f240-03676261881c"
996 | },
997 | "outputs": [
998 | {
999 | "name": "stdout",
1000 | "output_type": "stream",
1001 | "text": [
1002 | "\n"
1003 | ]
1004 | }
1005 | ],
1006 | "source": [
1007 | "import numpy as np\n",
1008 | "data16 = np.frombuffer(buffer, dtype=np.int16)\n",
1009 | "print(str(type(data16)))\n"
1010 | ]
1011 | },
1012 | {
1013 | "cell_type": "markdown",
1014 | "metadata": {
1015 | "id": "yyIxzx1zTVFp"
1016 | },
1017 | "source": [
1018 | "3. **Run speech-to-text in batch mode to get the text**"
1019 | ]
1020 | },
1021 | {
1022 | "cell_type": "code",
1023 | "execution_count": 26,
1024 | "metadata": {
1025 | "colab": {
1026 | "base_uri": "https://localhost:8080/"
1027 | },
1028 | "id": "XdzZteC7TZDP",
1029 | "outputId": "32a71587-11f0-43b0-f14e-eb18090521df"
1030 | },
1031 | "outputs": [
1032 | {
1033 | "name": "stdout",
1034 | "output_type": "stream",
1035 | "text": [
1036 | "your power is sufficient i said\n"
1037 | ]
1038 | }
1039 | ],
1040 | "source": [
1041 | "text = model.stt(data16)\n",
1042 | "print(text)\n"
1043 | ]
1044 | },
1045 | {
1046 | "cell_type": "markdown",
1047 | "metadata": {
1048 | "id": "VUCXp-5uTh0L"
1049 | },
1050 | "source": [
1051 | "## Streaming API\n",
1052 | "\n",
1053 | "Now let’s accomplish the same using streaming API. It consists of 3 steps: open session, feed data, close session.\n",
1054 | "\n",
1055 | "1. **Open a streaming session**"
1056 | ]
1057 | },
1058 | {
1059 | "cell_type": "code",
1060 | "execution_count": 27,
1061 | "metadata": {
1062 | "id": "uMSQ2VYCTyao"
1063 | },
1064 | "outputs": [],
1065 | "source": [
1066 | "stt_stream = model.createStream()\n"
1067 | ]
1068 | },
1069 | {
1070 | "cell_type": "markdown",
1071 | "metadata": {
1072 | "id": "YK4QDAZtT3QZ"
1073 | },
1074 | "source": [
1075 | "2. **Repeatedly feed chunks of speech buffer, and get interim results if desired**"
1076 | ]
1077 | },
1078 | {
1079 | "cell_type": "code",
1080 | "execution_count": 28,
1081 | "metadata": {
1082 | "colab": {
1083 | "base_uri": "https://localhost:8080/"
1084 | },
1085 | "id": "ScS6c2QQT72-",
1086 | "outputId": "c7ea4b0c-9df2-491d-8d67-3705ce1f4ed1"
1087 | },
1088 | "outputs": [
1089 | {
1090 | "name": "stdout",
1091 | "output_type": "stream",
1092 | "text": [
1093 | "\n",
1094 | "\n",
1095 | "your power \n",
1096 | "your power is suff\n",
1097 | "your power is sufficient i said\n",
1098 | "your power is sufficient i said\n"
1099 | ]
1100 | }
1101 | ],
1102 | "source": [
1103 | "buffer_len = len(buffer)\n",
1104 | "offset = 0\n",
1105 | "batch_size = 16384\n",
1106 | "text = ''\n",
1107 | "while offset < buffer_len:\n",
1108 | " end_offset = offset + batch_size\n",
1109 | " chunk = buffer[offset:end_offset]\n",
1110 | " data16 = np.frombuffer(chunk, dtype=np.int16)\n",
1111 | " stt_stream.feedAudioContent(data16)\n",
1112 | " text = stt_stream.intermediateDecode()\n",
1113 | " print(text)\n",
1114 | " offset = end_offset\n"
1115 | ]
1116 | },
1117 | {
1118 | "cell_type": "markdown",
1119 | "metadata": {
1120 | "id": "zeV7x1NgUK-p"
1121 | },
1122 | "source": [
1123 | "3. **Close stream and get the final result**"
1124 | ]
1125 | },
1126 | {
1127 | "cell_type": "code",
1128 | "execution_count": 29,
1129 | "metadata": {
1130 | "colab": {
1131 | "base_uri": "https://localhost:8080/"
1132 | },
1133 | "id": "aS0WtnF5UM4n",
1134 | "outputId": "153dc742-c1f1-4d00-f59e-f1800d3d9fac"
1135 | },
1136 | "outputs": [
1137 | {
1138 | "name": "stdout",
1139 | "output_type": "stream",
1140 | "text": [
1141 | "your power is sufficient i said\n"
1142 | ]
1143 | }
1144 | ],
1145 | "source": [
1146 | "text = stt_stream.finishStream()\n",
1147 | "print(text)\n"
1148 | ]
1149 | },
1150 | {
1151 | "cell_type": "markdown",
1152 | "metadata": {
1153 | "id": "Q-vbd5CmUmsY"
1154 | },
1155 | "source": [
1156 | "Verify that the output is same as as the batch API output: \"your power is sufficient i said.\""
1157 | ]
1158 | },
1159 | {
1160 | "cell_type": "markdown",
1161 | "metadata": {
1162 | "id": "wVNGdkq0fV-n"
1163 | },
1164 | "source": [
1165 | "# Recap\n",
1166 | "\n",
1167 | "DeepSpeech has two modes: batch and streaming. First step is to create a model object, and then either call `stt()` or `feedAudioContnet()` to transcribe audio to text."
1168 | ]
1169 | },
1170 | {
1171 | "cell_type": "markdown",
1172 | "metadata": {
1173 | "id": "YJp2Lkt8WNoN"
1174 | },
1175 | "source": [
1176 | "---\n",
1177 | "Copyright © 2020 - 2022 Satish Chandra Gupta .
\n",
1178 | " CC BY-NC-SA 4.0 International License.
"
1179 | ]
1180 | }
1181 | ],
1182 | "metadata": {
1183 | "colab": {
1184 | "collapsed_sections": [],
1185 | "include_colab_link": true,
1186 | "name": "mozilla_deepspeech_api_notebook.ipynb",
1187 | "provenance": []
1188 | },
1189 | "gpuClass": "standard",
1190 | "kernelspec": {
1191 | "display_name": "Python 3",
1192 | "name": "python3"
1193 | },
1194 | "language_info": {
1195 | "name": "python",
1196 | "version": "3.7.12"
1197 | }
1198 | },
1199 | "nbformat": 4,
1200 | "nbformat_minor": 0
1201 | }
1202 |
--------------------------------------------------------------------------------
/speech/asr/python_speech_recognition_notebook.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "colab_type": "text",
7 | "id": "view-in-github"
8 | },
9 | "source": [
10 | "Speech Recognition with Python
\n",
22 | "© Satish Chandra Guptascgupta ,\n",
24 | "Twitter: scgupta \n",
25 | " \n",
26 | " \n",
27 | "\n",
28 | "---\n",
29 | "\n",
30 | "# Introduction\n",
31 | "\n",
32 | "Blog Post: [Speech Recognition With Python](https://www.ml4devs.com/articles/speech-recognition-with-python/)\n",
33 | "\n",
34 | "There are several Automated Speech Recognition (ASR) alternatives, and most of them have bindings for Python. There are two kinds of solutions:\n",
35 | "\n",
36 | "- **Service:** These run on the cloud, and are accessed either through REST endpoints or Python library. Examples are cloud speech services from Google, Amazon, Microsoft.\n",
37 | "- **Software:** These run locally on the machine (not requiring network connection). Examples are CMU Sphinx and Mozilla DeepSpeech.\n",
38 | "\n",
39 | "Speech Recognition APIs are of two types:\n",
40 | "- **Batch:** The full audio file is passed as parameter, and speech-to-text transcribing is done in one shot.\n",
41 | "- **Streaming:** The chunks of audio buffer are repeatedly passed on, and intermediate results are accessible.\n",
42 | "\n",
43 | "All packages support batch mode, and some support streaming mode too.\n",
44 | "\n",
45 | "One common use case is to collect audio from microphone and passes on the buffer to the speech recognition API. Invariably, in such transcribers, microphone is accessed though [PyAudio](https://people.csail.mit.edu/hubert/pyaudio/), which is implemented over [PortAudio](http://www.portaudio.com/).\n",
46 | "\n",
47 | "From Colab menu, select: **Runtime** > **Change runtime type**, and verify that it is set to Python3, and select GPU if you want to try out GPU version."
48 | ]
49 | },
50 | {
51 | "cell_type": "markdown",
52 | "metadata": {
53 | "id": "7H6HFpi_LCBt"
54 | },
55 | "source": [
56 | "## Common Setup\n",
57 | "\n",
58 | "1. **Install google cloud speech package**\n",
59 | "\n",
60 | "You may have to restart the runtime after this."
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": null,
66 | "metadata": {
67 | "colab": {
68 | "base_uri": "https://localhost:8080/",
69 | "height": 492
70 | },
71 | "id": "RhIMRXQPLaaA",
72 | "outputId": "ee11bcc4-44ab-4f96-ec5e-84d5b2f630b3"
73 | },
74 | "outputs": [
75 | {
76 | "name": "stdout",
77 | "output_type": "stream",
78 | "text": [
79 | "Collecting google-cloud-speech\n",
80 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/0c/81/c59a373c7668beb9de922b9c4419b793898d46c6d4a44f4fe28098e77623/google_cloud_speech-1.3.1-py2.py3-none-any.whl (88kB)\n",
81 | "\r\u001b[K |███▊ | 10kB 33.9MB/s eta 0:00:01\r\u001b[K |███████▍ | 20kB 2.0MB/s eta 0:00:01\r\u001b[K |███████████▏ | 30kB 3.0MB/s eta 0:00:01\r\u001b[K |██████████████▉ | 40kB 2.0MB/s eta 0:00:01\r\u001b[K |██████████████████▋ | 51kB 2.5MB/s eta 0:00:01\r\u001b[K |██████████████████████▎ | 61kB 2.9MB/s eta 0:00:01\r\u001b[K |██████████████████████████ | 71kB 3.4MB/s eta 0:00:01\r\u001b[K |█████████████████████████████▊ | 81kB 3.9MB/s eta 0:00:01\r\u001b[K |████████████████████████████████| 92kB 3.4MB/s \n",
82 | "\u001b[?25hRequirement already satisfied: google-api-core[grpc]<2.0.0dev,>=1.14.0 in /usr/local/lib/python3.6/dist-packages (from google-cloud-speech) (1.15.0)\n",
83 | "Requirement already satisfied: googleapis-common-protos<2.0dev,>=1.6.0 in /usr/local/lib/python3.6/dist-packages (from google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (1.6.0)\n",
84 | "Requirement already satisfied: protobuf>=3.4.0 in /usr/local/lib/python3.6/dist-packages (from google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (3.10.0)\n",
85 | "Requirement already satisfied: requests<3.0.0dev,>=2.18.0 in /usr/local/lib/python3.6/dist-packages (from google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (2.21.0)\n",
86 | "Requirement already satisfied: setuptools>=34.0.0 in /usr/local/lib/python3.6/dist-packages (from google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (42.0.2)\n",
87 | "Requirement already satisfied: pytz in /usr/local/lib/python3.6/dist-packages (from google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (2018.9)\n",
88 | "Requirement already satisfied: google-auth<2.0dev,>=0.4.0 in /usr/local/lib/python3.6/dist-packages (from google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (1.4.2)\n",
89 | "Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.6/dist-packages (from google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (1.12.0)\n",
90 | "Requirement already satisfied: grpcio<2.0dev,>=1.8.2; extra == \"grpc\" in /usr/local/lib/python3.6/dist-packages (from google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (1.15.0)\n",
91 | "Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests<3.0.0dev,>=2.18.0->google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (3.0.4)\n",
92 | "Requirement already satisfied: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests<3.0.0dev,>=2.18.0->google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (2.8)\n",
93 | "Requirement already satisfied: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests<3.0.0dev,>=2.18.0->google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (1.24.3)\n",
94 | "Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests<3.0.0dev,>=2.18.0->google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (2019.11.28)\n",
95 | "Requirement already satisfied: rsa>=3.1.4 in /usr/local/lib/python3.6/dist-packages (from google-auth<2.0dev,>=0.4.0->google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (4.0)\n",
96 | "Requirement already satisfied: pyasn1-modules>=0.2.1 in /usr/local/lib/python3.6/dist-packages (from google-auth<2.0dev,>=0.4.0->google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (0.2.7)\n",
97 | "Requirement already satisfied: cachetools>=2.0.0 in /usr/local/lib/python3.6/dist-packages (from google-auth<2.0dev,>=0.4.0->google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (4.0.0)\n",
98 | "Requirement already satisfied: pyasn1>=0.1.3 in /usr/local/lib/python3.6/dist-packages (from rsa>=3.1.4->google-auth<2.0dev,>=0.4.0->google-api-core[grpc]<2.0.0dev,>=1.14.0->google-cloud-speech) (0.4.8)\n",
99 | "Installing collected packages: google-cloud-speech\n",
100 | "Successfully installed google-cloud-speech-1.3.1\n"
101 | ]
102 | },
103 | {
104 | "data": {
105 | "application/vnd.colab-display-data+json": {
106 | "pip_warning": {
107 | "packages": [
108 | "google"
109 | ]
110 | }
111 | }
112 | },
113 | "metadata": {
114 | "tags": []
115 | },
116 | "output_type": "display_data"
117 | }
118 | ],
119 | "source": [
120 | "!pip3 install google-cloud-speech"
121 | ]
122 | },
123 | {
124 | "cell_type": "markdown",
125 | "metadata": {
126 | "id": "QUjuKePpRJt5"
127 | },
128 | "source": [
129 | "2. **Download audio files for testing**\n",
130 | "\n",
131 | "Following files will be used as test cases for all speech recognition alternatives covered in this notebook."
132 | ]
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": null,
137 | "metadata": {
138 | "colab": {
139 | "base_uri": "https://localhost:8080/",
140 | "height": 286
141 | },
142 | "id": "t3_2z6qMRXcY",
143 | "outputId": "c155e814-439b-4fb0-d26f-307516b3ab97"
144 | },
145 | "outputs": [
146 | {
147 | "name": "stdout",
148 | "output_type": "stream",
149 | "text": [
150 | " % Total % Received % Xferd Average Speed Time Time Time Current\n",
151 | " Dload Upload Total Spent Left Speed\n",
152 | "100 608 0 608 0 0 2632 0 --:--:-- --:--:-- --:--:-- 2620\n",
153 | "100 192k 100 192k 0 0 310k 0 --:--:-- --:--:-- --:--:-- 310k\n",
154 | "audio/\n",
155 | "audio/2830-3980-0043.wav\n",
156 | "audio/Attribution.txt\n",
157 | "audio/4507-16021-0012.wav\n",
158 | "audio/8455-210777-0068.wav\n",
159 | "audio/License.txt\n",
160 | "total 260\n",
161 | "-rw-r--r-- 1 501 staff 63244 Nov 18 2017 2830-3980-0043.wav\n",
162 | "-rw-r--r-- 1 501 staff 87564 Nov 18 2017 4507-16021-0012.wav\n",
163 | "-rw-r--r-- 1 501 staff 82924 Nov 18 2017 8455-210777-0068.wav\n",
164 | "-rw-r--r-- 1 501 staff 340 May 14 2018 Attribution.txt\n",
165 | "-rw-r--r-- 1 501 staff 18652 May 12 2018 License.txt\n"
166 | ]
167 | }
168 | ],
169 | "source": [
170 | "!curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.6.0/audio-0.6.0.tar.gz\n",
171 | "!tar -xvzf audio-0.6.0.tar.gz\n",
172 | "!ls -l ./audio/"
173 | ]
174 | },
175 | {
176 | "cell_type": "markdown",
177 | "metadata": {
178 | "id": "wXzH4pu9Kxr4"
179 | },
180 | "source": [
181 | "3. **Define test cases**"
182 | ]
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": null,
187 | "metadata": {
188 | "id": "nbzYo01kRi8P"
189 | },
190 | "outputs": [],
191 | "source": [
192 | "TESTCASES = [\n",
193 | " {\n",
194 | " 'filename': 'audio/2830-3980-0043.wav',\n",
195 | " 'text': 'experience proves this',\n",
196 | " 'encoding': 'LINEAR16',\n",
197 | " 'lang': 'en-US'\n",
198 | " },\n",
199 | " {\n",
200 | " 'filename': 'audio/4507-16021-0012.wav',\n",
201 | " 'text': 'why should one halt on the way',\n",
202 | " 'encoding': 'LINEAR16',\n",
203 | " 'lang': 'en-US'\n",
204 | " },\n",
205 | " {\n",
206 | " 'filename': 'audio/8455-210777-0068.wav',\n",
207 | " 'text': 'your power is sufficient i said',\n",
208 | " 'encoding': 'LINEAR16',\n",
209 | " 'lang': 'en-US'\n",
210 | " }\n",
211 | "]"
212 | ]
213 | },
214 | {
215 | "cell_type": "markdown",
216 | "metadata": {
217 | "id": "f-23iCNLvBIx"
218 | },
219 | "source": [
220 | "4. **Utility Functions**"
221 | ]
222 | },
223 | {
224 | "cell_type": "code",
225 | "execution_count": null,
226 | "metadata": {
227 | "id": "Ujeuvj35Ksv8"
228 | },
229 | "outputs": [],
230 | "source": [
231 | "from typing import Tuple\n",
232 | "import wave\n",
233 | "\n",
234 | "def read_wav_file(filename) -> Tuple[bytes, int]:\n",
235 | " with wave.open(filename, 'rb') as w:\n",
236 | " rate = w.getframerate()\n",
237 | " frames = w.getnframes()\n",
238 | " buffer = w.readframes(frames)\n",
239 | "\n",
240 | " return buffer, rate\n",
241 | "\n",
242 | "def simulate_stream(buffer: bytes, batch_size: int = 4096):\n",
243 | " buffer_len = len(buffer)\n",
244 | " offset = 0\n",
245 | " while offset < buffer_len:\n",
246 | " end_offset = offset + batch_size\n",
247 | " buf = buffer[offset:end_offset]\n",
248 | " yield buf\n",
249 | " offset = end_offset"
250 | ]
251 | },
252 | {
253 | "cell_type": "markdown",
254 | "metadata": {
255 | "id": "9wFdQoEUQH-3"
256 | },
257 | "source": [
258 | "\n",
259 | "---\n",
260 | "\n",
261 | "# Google\n",
262 | "\n",
263 | "Google has [speech-to-text](https://cloud.google.com/speech-to-text/docs) as one of the Google Cloud services. It has [libraries](https://cloud.google.com/speech-to-text/docs/reference/libraries) in C#, Go, Java, JavaScript, PHP, Python, and Ruby. It supports both batch and stream modes."
264 | ]
265 | },
266 | {
267 | "cell_type": "markdown",
268 | "metadata": {
269 | "id": "GjcnbQvvY3Xu"
270 | },
271 | "source": [
272 | "## Setup\n",
273 | "\n",
274 | "1. **Upload Google Cloud Cred file**\n",
275 | "\n",
276 | "Have Google Cloud creds stored in a file named **`gc-creds.json`**, and upload it by running following code cell. See https://developers.google.com/accounts/docs/application-default-credentials for more details.\n",
277 | "\n",
278 | "This may reqire enabling **third-party cookies**. Check out https://colab.research.google.com/notebooks/io.ipynb for other alternatives."
279 | ]
280 | },
281 | {
282 | "cell_type": "code",
283 | "execution_count": null,
284 | "metadata": {
285 | "colab": {
286 | "base_uri": "https://localhost:8080/",
287 | "height": 87,
288 | "resources": {
289 | "http://localhost:8080/nbextensions/google.colab/files.js": {
290 | "data": "Ly8gQ29weXJpZ2h0IDIwMTcgR29vZ2xlIExMQwovLwovLyBMaWNlbnNlZCB1bmRlciB0aGUgQXBhY2hlIExpY2Vuc2UsIFZlcnNpb24gMi4wICh0aGUgIkxpY2Vuc2UiKTsKLy8geW91IG1heSBub3QgdXNlIHRoaXMgZmlsZSBleGNlcHQgaW4gY29tcGxpYW5jZSB3aXRoIHRoZSBMaWNlbnNlLgovLyBZb3UgbWF5IG9idGFpbiBhIGNvcHkgb2YgdGhlIExpY2Vuc2UgYXQKLy8KLy8gICAgICBodHRwOi8vd3d3LmFwYWNoZS5vcmcvbGljZW5zZXMvTElDRU5TRS0yLjAKLy8KLy8gVW5sZXNzIHJlcXVpcmVkIGJ5IGFwcGxpY2FibGUgbGF3IG9yIGFncmVlZCB0byBpbiB3cml0aW5nLCBzb2Z0d2FyZQovLyBkaXN0cmlidXRlZCB1bmRlciB0aGUgTGljZW5zZSBpcyBkaXN0cmlidXRlZCBvbiBhbiAiQVMgSVMiIEJBU0lTLAovLyBXSVRIT1VUIFdBUlJBTlRJRVMgT1IgQ09ORElUSU9OUyBPRiBBTlkgS0lORCwgZWl0aGVyIGV4cHJlc3Mgb3IgaW1wbGllZC4KLy8gU2VlIHRoZSBMaWNlbnNlIGZvciB0aGUgc3BlY2lmaWMgbGFuZ3VhZ2UgZ292ZXJuaW5nIHBlcm1pc3Npb25zIGFuZAovLyBsaW1pdGF0aW9ucyB1bmRlciB0aGUgTGljZW5zZS4KCi8qKgogKiBAZmlsZW92ZXJ2aWV3IEhlbHBlcnMgZm9yIGdvb2dsZS5jb2xhYiBQeXRob24gbW9kdWxlLgogKi8KKGZ1bmN0aW9uKHNjb3BlKSB7CmZ1bmN0aW9uIHNwYW4odGV4dCwgc3R5bGVBdHRyaWJ1dGVzID0ge30pIHsKICBjb25zdCBlbGVtZW50ID0gZG9jdW1lbnQuY3JlYXRlRWxlbWVudCgnc3BhbicpOwogIGVsZW1lbnQudGV4dENvbnRlbnQgPSB0ZXh0OwogIGZvciAoY29uc3Qga2V5IG9mIE9iamVjdC5rZXlzKHN0eWxlQXR0cmlidXRlcykpIHsKICAgIGVsZW1lbnQuc3R5bGVba2V5XSA9IHN0eWxlQXR0cmlidXRlc1trZXldOwogIH0KICByZXR1cm4gZWxlbWVudDsKfQoKLy8gTWF4IG51bWJlciBvZiBieXRlcyB3aGljaCB3aWxsIGJlIHVwbG9hZGVkIGF0IGEgdGltZS4KY29uc3QgTUFYX1BBWUxPQURfU0laRSA9IDEwMCAqIDEwMjQ7Ci8vIE1heCBhbW91bnQgb2YgdGltZSB0byBibG9jayB3YWl0aW5nIGZvciB0aGUgdXNlci4KY29uc3QgRklMRV9DSEFOR0VfVElNRU9VVF9NUyA9IDMwICogMTAwMDsKCmZ1bmN0aW9uIF91cGxvYWRGaWxlcyhpbnB1dElkLCBvdXRwdXRJZCkgewogIGNvbnN0IHN0ZXBzID0gdXBsb2FkRmlsZXNTdGVwKGlucHV0SWQsIG91dHB1dElkKTsKICBjb25zdCBvdXRwdXRFbGVtZW50ID0gZG9jdW1lbnQuZ2V0RWxlbWVudEJ5SWQob3V0cHV0SWQpOwogIC8vIENhY2hlIHN0ZXBzIG9uIHRoZSBvdXRwdXRFbGVtZW50IHRvIG1ha2UgaXQgYXZhaWxhYmxlIGZvciB0aGUgbmV4dCBjYWxsCiAgLy8gdG8gdXBsb2FkRmlsZXNDb250aW51ZSBmcm9tIFB5dGhvbi4KICBvdXRwdXRFbGVtZW50LnN0ZXBzID0gc3RlcHM7CgogIHJldHVybiBfdXBsb2FkRmlsZXNDb250aW51ZShvdXRwdXRJZCk7Cn0KCi8vIFRoaXMgaXMgcm91Z2hseSBhbiBhc3luYyBnZW5lcmF0b3IgKG5vdCBzdXBwb3J0ZWQgaW4gdGhlIGJyb3dzZXIgeWV0KSwKLy8gd2hlcmUgdGhlcmUgYXJlIG11bHRpcGxlIGFzeW5jaHJvbm91cyBzdGVwcyBhbmQgdGhlIFB5dGhvbiBzaWRlIGlzIGdvaW5nCi8vIHRvIHBvbGwgZm9yIGNvbXBsZXRpb24gb2YgZWFjaCBzdGVwLgovLyBUaGlzIHVzZXMgYSBQcm9taXNlIHRvIGJsb2NrIHRoZSBweXRob24gc2lkZSBvbiBjb21wbGV0aW9uIG9mIGVhY2ggc3RlcCwKLy8gdGhlbiBwYXNzZXMgdGhlIHJlc3VsdCBvZiB0aGUgcHJldmlvdXMgc3RlcCBhcyB0aGUgaW5wdXQgdG8gdGhlIG5leHQgc3RlcC4KZnVuY3Rpb24gX3VwbG9hZEZpbGVzQ29udGludWUob3V0cHV0SWQpIHsKICBjb25zdCBvdXRwdXRFbGVtZW50ID0gZG9jdW1lbnQuZ2V0RWxlbWVudEJ5SWQob3V0cHV0SWQpOwogIGNvbnN0IHN0ZXBzID0gb3V0cHV0RWxlbWVudC5zdGVwczsKCiAgY29uc3QgbmV4dCA9IHN0ZXBzLm5leHQob3V0cHV0RWxlbWVudC5sYXN0UHJvbWlzZVZhbHVlKTsKICByZXR1cm4gUHJvbWlzZS5yZXNvbHZlKG5leHQudmFsdWUucHJvbWlzZSkudGhlbigodmFsdWUpID0+IHsKICAgIC8vIENhY2hlIHRoZSBsYXN0IHByb21pc2UgdmFsdWUgdG8gbWFrZSBpdCBhdmFpbGFibGUgdG8gdGhlIG5leHQKICAgIC8vIHN0ZXAgb2YgdGhlIGdlbmVyYXRvci4KICAgIG91dHB1dEVsZW1lbnQubGFzdFByb21pc2VWYWx1ZSA9IHZhbHVlOwogICAgcmV0dXJuIG5leHQudmFsdWUucmVzcG9uc2U7CiAgfSk7Cn0KCi8qKgogKiBHZW5lcmF0b3IgZnVuY3Rpb24gd2hpY2ggaXMgY2FsbGVkIGJldHdlZW4gZWFjaCBhc3luYyBzdGVwIG9mIHRoZSB1cGxvYWQKICogcHJvY2Vzcy4KICogQHBhcmFtIHtzdHJpbmd9IGlucHV0SWQgRWxlbWVudCBJRCBvZiB0aGUgaW5wdXQgZmlsZSBwaWNrZXIgZWxlbWVudC4KICogQHBhcmFtIHtzdHJpbmd9IG91dHB1dElkIEVsZW1lbnQgSUQgb2YgdGhlIG91dHB1dCBkaXNwbGF5LgogKiBAcmV0dXJuIHshSXRlcmFibGU8IU9iamVjdD59IEl0ZXJhYmxlIG9mIG5leHQgc3RlcHMuCiAqLwpmdW5jdGlvbiogdXBsb2FkRmlsZXNTdGVwKGlucHV0SWQsIG91dHB1dElkKSB7CiAgY29uc3QgaW5wdXRFbGVtZW50ID0gZG9jdW1lbnQuZ2V0RWxlbWVudEJ5SWQoaW5wdXRJZCk7CiAgaW5wdXRFbGVtZW50LmRpc2FibGVkID0gZmFsc2U7CgogIGNvbnN0IG91dHB1dEVsZW1lbnQgPSBkb2N1bWVudC5nZXRFbGVtZW50QnlJZChvdXRwdXRJZCk7CiAgb3V0cHV0RWxlbWVudC5pbm5lckhUTUwgPSAnJzsKCiAgY29uc3QgcGlja2VkUHJvbWlzZSA9IG5ldyBQcm9taXNlKChyZXNvbHZlKSA9PiB7CiAgICBpbnB1dEVsZW1lbnQuYWRkRXZlbnRMaXN0ZW5lcignY2hhbmdlJywgKGUpID0+IHsKICAgICAgcmVzb2x2ZShlLnRhcmdldC5maWxlcyk7CiAgICB9KTsKICB9KTsKCiAgY29uc3QgY2FuY2VsID0gZG9jdW1lbnQuY3JlYXRlRWxlbWVudCgnYnV0dG9uJyk7CiAgaW5wdXRFbGVtZW50LnBhcmVudEVsZW1lbnQuYXBwZW5kQ2hpbGQoY2FuY2VsKTsKICBjYW5jZWwudGV4dENvbnRlbnQgPSAnQ2FuY2VsIHVwbG9hZCc7CiAgY29uc3QgY2FuY2VsUHJvbWlzZSA9IG5ldyBQcm9taXNlKChyZXNvbHZlKSA9PiB7CiAgICBjYW5jZWwub25jbGljayA9ICgpID0+IHsKICAgICAgcmVzb2x2ZShudWxsKTsKICAgIH07CiAgfSk7CgogIC8vIENhbmNlbCB1cGxvYWQgaWYgdXNlciBoYXNuJ3QgcGlja2VkIGFueXRoaW5nIGluIHRpbWVvdXQuCiAgY29uc3QgdGltZW91dFByb21pc2UgPSBuZXcgUHJvbWlzZSgocmVzb2x2ZSkgPT4gewogICAgc2V0VGltZW91dCgoKSA9PiB7CiAgICAgIHJlc29sdmUobnVsbCk7CiAgICB9LCBGSUxFX0NIQU5HRV9USU1FT1VUX01TKTsKICB9KTsKCiAgLy8gV2FpdCBmb3IgdGhlIHVzZXIgdG8gcGljayB0aGUgZmlsZXMuCiAgY29uc3QgZmlsZXMgPSB5aWVsZCB7CiAgICBwcm9taXNlOiBQcm9taXNlLnJhY2UoW3BpY2tlZFByb21pc2UsIHRpbWVvdXRQcm9taXNlLCBjYW5jZWxQcm9taXNlXSksCiAgICByZXNwb25zZTogewogICAgICBhY3Rpb246ICdzdGFydGluZycsCiAgICB9CiAgfTsKCiAgaWYgKCFmaWxlcykgewogICAgcmV0dXJuIHsKICAgICAgcmVzcG9uc2U6IHsKICAgICAgICBhY3Rpb246ICdjb21wbGV0ZScsCiAgICAgIH0KICAgIH07CiAgfQoKICBjYW5jZWwucmVtb3ZlKCk7CgogIC8vIERpc2FibGUgdGhlIGlucHV0IGVsZW1lbnQgc2luY2UgZnVydGhlciBwaWNrcyBhcmUgbm90IGFsbG93ZWQuCiAgaW5wdXRFbGVtZW50LmRpc2FibGVkID0gdHJ1ZTsKCiAgZm9yIChjb25zdCBmaWxlIG9mIGZpbGVzKSB7CiAgICBjb25zdCBsaSA9IGRvY3VtZW50LmNyZWF0ZUVsZW1lbnQoJ2xpJyk7CiAgICBsaS5hcHBlbmQoc3BhbihmaWxlLm5hbWUsIHtmb250V2VpZ2h0OiAnYm9sZCd9KSk7CiAgICBsaS5hcHBlbmQoc3BhbigKICAgICAgICBgKCR7ZmlsZS50eXBlIHx8ICduL2EnfSkgLSAke2ZpbGUuc2l6ZX0gYnl0ZXMsIGAgKwogICAgICAgIGBsYXN0IG1vZGlmaWVkOiAkewogICAgICAgICAgICBmaWxlLmxhc3RNb2RpZmllZERhdGUgPyBmaWxlLmxhc3RNb2RpZmllZERhdGUudG9Mb2NhbGVEYXRlU3RyaW5nKCkgOgogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAnbi9hJ30gLSBgKSk7CiAgICBjb25zdCBwZXJjZW50ID0gc3BhbignMCUgZG9uZScpOwogICAgbGkuYXBwZW5kQ2hpbGQocGVyY2VudCk7CgogICAgb3V0cHV0RWxlbWVudC5hcHBlbmRDaGlsZChsaSk7CgogICAgY29uc3QgZmlsZURhdGFQcm9taXNlID0gbmV3IFByb21pc2UoKHJlc29sdmUpID0+IHsKICAgICAgY29uc3QgcmVhZGVyID0gbmV3IEZpbGVSZWFkZXIoKTsKICAgICAgcmVhZGVyLm9ubG9hZCA9IChlKSA9PiB7CiAgICAgICAgcmVzb2x2ZShlLnRhcmdldC5yZXN1bHQpOwogICAgICB9OwogICAgICByZWFkZXIucmVhZEFzQXJyYXlCdWZmZXIoZmlsZSk7CiAgICB9KTsKICAgIC8vIFdhaXQgZm9yIHRoZSBkYXRhIHRvIGJlIHJlYWR5LgogICAgbGV0IGZpbGVEYXRhID0geWllbGQgewogICAgICBwcm9taXNlOiBmaWxlRGF0YVByb21pc2UsCiAgICAgIHJlc3BvbnNlOiB7CiAgICAgICAgYWN0aW9uOiAnY29udGludWUnLAogICAgICB9CiAgICB9OwoKICAgIC8vIFVzZSBhIGNodW5rZWQgc2VuZGluZyB0byBhdm9pZCBtZXNzYWdlIHNpemUgbGltaXRzLiBTZWUgYi82MjExNTY2MC4KICAgIGxldCBwb3NpdGlvbiA9IDA7CiAgICB3aGlsZSAocG9zaXRpb24gPCBmaWxlRGF0YS5ieXRlTGVuZ3RoKSB7CiAgICAgIGNvbnN0IGxlbmd0aCA9IE1hdGgubWluKGZpbGVEYXRhLmJ5dGVMZW5ndGggLSBwb3NpdGlvbiwgTUFYX1BBWUxPQURfU0laRSk7CiAgICAgIGNvbnN0IGNodW5rID0gbmV3IFVpbnQ4QXJyYXkoZmlsZURhdGEsIHBvc2l0aW9uLCBsZW5ndGgpOwogICAgICBwb3NpdGlvbiArPSBsZW5ndGg7CgogICAgICBjb25zdCBiYXNlNjQgPSBidG9hKFN0cmluZy5mcm9tQ2hhckNvZGUuYXBwbHkobnVsbCwgY2h1bmspKTsKICAgICAgeWllbGQgewogICAgICAgIHJlc3BvbnNlOiB7CiAgICAgICAgICBhY3Rpb246ICdhcHBlbmQnLAogICAgICAgICAgZmlsZTogZmlsZS5uYW1lLAogICAgICAgICAgZGF0YTogYmFzZTY0LAogICAgICAgIH0sCiAgICAgIH07CiAgICAgIHBlcmNlbnQudGV4dENvbnRlbnQgPQogICAgICAgICAgYCR7TWF0aC5yb3VuZCgocG9zaXRpb24gLyBmaWxlRGF0YS5ieXRlTGVuZ3RoKSAqIDEwMCl9JSBkb25lYDsKICAgIH0KICB9CgogIC8vIEFsbCBkb25lLgogIHlpZWxkIHsKICAgIHJlc3BvbnNlOiB7CiAgICAgIGFjdGlvbjogJ2NvbXBsZXRlJywKICAgIH0KICB9Owp9CgpzY29wZS5nb29nbGUgPSBzY29wZS5nb29nbGUgfHwge307CnNjb3BlLmdvb2dsZS5jb2xhYiA9IHNjb3BlLmdvb2dsZS5jb2xhYiB8fCB7fTsKc2NvcGUuZ29vZ2xlLmNvbGFiLl9maWxlcyA9IHsKICBfdXBsb2FkRmlsZXMsCiAgX3VwbG9hZEZpbGVzQ29udGludWUsCn07Cn0pKHNlbGYpOwo=",
291 | "headers": [
292 | [
293 | "content-type",
294 | "application/javascript"
295 | ]
296 | ],
297 | "ok": true,
298 | "status": 200,
299 | "status_text": ""
300 | }
301 | }
302 | },
303 | "id": "qXquL3Y7bLQ6",
304 | "outputId": "5a46b013-8b39-4227-ba5b-28677885d763"
305 | },
306 | "outputs": [
307 | {
308 | "data": {
309 | "text/html": [
310 | "\n",
311 | " \n",
313 | " Upload widget is only available when the cell has been executed in the\n",
314 | " current browser session. Please rerun this cell to enable.\n",
315 | " \n",
316 | " "
317 | ],
318 | "text/plain": [
319 | ""
320 | ]
321 | },
322 | "metadata": {
323 | "tags": []
324 | },
325 | "output_type": "display_data"
326 | },
327 | {
328 | "name": "stdout",
329 | "output_type": "stream",
330 | "text": [
331 | "Saving gc-creds.json to gc-creds.json\n",
332 | "User uploaded file \"gc-creds.json\" with length 2314 bytes\n"
333 | ]
334 | }
335 | ],
336 | "source": [
337 | "from google.colab import files\n",
338 | "\n",
339 | "uploaded = files.upload()\n",
340 | "\n",
341 | "for fn in uploaded.keys():\n",
342 | " print('User uploaded file \"{name}\" with length {length} bytes'.format(\n",
343 | " name=fn, length=len(uploaded[fn])))"
344 | ]
345 | },
346 | {
347 | "cell_type": "code",
348 | "execution_count": null,
349 | "metadata": {
350 | "colab": {
351 | "base_uri": "https://localhost:8080/",
352 | "height": 50
353 | },
354 | "id": "-emXbdQ1bTDg",
355 | "outputId": "2a343cc2-8a58-476c-ee89-8717954a08dd"
356 | },
357 | "outputs": [
358 | {
359 | "name": "stdout",
360 | "output_type": "stream",
361 | "text": [
362 | "/content\n",
363 | "-rw-r--r-- 1 root root 2314 Jan 30 00:20 ./gc-creds.json\n"
364 | ]
365 | }
366 | ],
367 | "source": [
368 | "!pwd\n",
369 | "!ls -l ./gc-creds.json"
370 | ]
371 | },
372 | {
373 | "cell_type": "markdown",
374 | "metadata": {
375 | "id": "o-80JnSyMWEV"
376 | },
377 | "source": [
378 | "2. **Set environment variable**"
379 | ]
380 | },
381 | {
382 | "cell_type": "code",
383 | "execution_count": null,
384 | "metadata": {
385 | "colab": {
386 | "base_uri": "https://localhost:8080/",
387 | "height": 34
388 | },
389 | "id": "msFTMyUWgtEv",
390 | "outputId": "ead40fcc-e41f-4ff6-e79d-418aad093c66"
391 | },
392 | "outputs": [
393 | {
394 | "name": "stdout",
395 | "output_type": "stream",
396 | "text": [
397 | "-rw-r--r-- 1 root root 2314 Jan 30 00:20 /content/gc-creds.json\n"
398 | ]
399 | }
400 | ],
401 | "source": [
402 | "import os\n",
403 | "os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/content/gc-creds.json'\n",
404 | "\n",
405 | "!ls -l $GOOGLE_APPLICATION_CREDENTIALS"
406 | ]
407 | },
408 | {
409 | "cell_type": "markdown",
410 | "metadata": {
411 | "id": "fljBsBFHWCMi"
412 | },
413 | "source": [
414 | "## Batch API"
415 | ]
416 | },
417 | {
418 | "cell_type": "code",
419 | "execution_count": null,
420 | "metadata": {
421 | "colab": {
422 | "base_uri": "https://localhost:8080/",
423 | "height": 168
424 | },
425 | "id": "7dlm4CWyQPeR",
426 | "outputId": "d5bfd6f5-e16a-4944-ad36-4325f9021935"
427 | },
428 | "outputs": [
429 | {
430 | "name": "stdout",
431 | "output_type": "stream",
432 | "text": [
433 | "\n",
434 | "audio file=\"audio/2830-3980-0043.wav\" expected text=\"experience proves this\"\n",
435 | "google-cloud-batch-stt: \"experience proves this\"\n",
436 | "\n",
437 | "audio file=\"audio/4507-16021-0012.wav\" expected text=\"why should one halt on the way\"\n",
438 | "google-cloud-batch-stt: \"why should one halt on the way\"\n",
439 | "\n",
440 | "audio file=\"audio/8455-210777-0068.wav\" expected text=\"your power is sufficient i said\"\n",
441 | "google-cloud-batch-stt: \"your power is sufficient I said\"\n"
442 | ]
443 | }
444 | ],
445 | "source": [
446 | "from google.cloud import speech_v1\n",
447 | "from google.cloud.speech_v1 import enums\n",
448 | "\n",
449 | "def google_batch_stt(filename: str, lang: str, encoding: str) -> str:\n",
450 | " buffer, rate = read_wav_file(filename)\n",
451 | " client = speech_v1.SpeechClient()\n",
452 | "\n",
453 | " config = {\n",
454 | " 'language_code': lang,\n",
455 | " 'sample_rate_hertz': rate,\n",
456 | " 'encoding': enums.RecognitionConfig.AudioEncoding[encoding]\n",
457 | " }\n",
458 | "\n",
459 | " audio = {\n",
460 | " 'content': buffer\n",
461 | " }\n",
462 | "\n",
463 | " response = client.recognize(config, audio)\n",
464 | " # For bigger audio file, the previous line can be replaced with following:\n",
465 | " # operation = client.long_running_recognize(config, audio)\n",
466 | " # response = operation.result()\n",
467 | "\n",
468 | " for result in response.results:\n",
469 | " # First alternative is the most probable result\n",
470 | " alternative = result.alternatives[0]\n",
471 | " return alternative.transcript\n",
472 | "\n",
473 | "# Run tests\n",
474 | "for t in TESTCASES:\n",
475 | " print('\\naudio file=\"{0}\" expected text=\"{1}\"'.format(t['filename'], t['text']))\n",
476 | " print('google-cloud-batch-stt: \"{}\"'.format(\n",
477 | " google_batch_stt(t['filename'], t['lang'], t['encoding'])\n",
478 | " ))"
479 | ]
480 | },
481 | {
482 | "cell_type": "markdown",
483 | "metadata": {
484 | "id": "pGhaFWC7rN9b"
485 | },
486 | "source": [
487 | "## Streaming API"
488 | ]
489 | },
490 | {
491 | "cell_type": "code",
492 | "execution_count": null,
493 | "metadata": {
494 | "colab": {
495 | "base_uri": "https://localhost:8080/",
496 | "height": 991
497 | },
498 | "id": "h9wMydkzrdX-",
499 | "outputId": "53c3427b-6a1e-4520-939b-a9bc34515760"
500 | },
501 | "outputs": [
502 | {
503 | "name": "stdout",
504 | "output_type": "stream",
505 | "text": [
506 | "\n",
507 | "audio file=\"audio/2830-3980-0043.wav\" expected text=\"experience proves this\"\n",
508 | "interim results: \n",
509 | "not final: next\n",
510 | "not final: iSpy\n",
511 | "not final: Aspira\n",
512 | "not final: Xperia\n",
513 | "not final: Experian\n",
514 | "not final: experience\n",
515 | "not final: experience proved\n",
516 | "not final: experience proves\n",
517 | "not final: experience proves the\n",
518 | "not final: experience proves that\n",
519 | "not final: experience\n",
520 | "final: experience proves this\n",
521 | "google-cloud-streaming-stt: \"experience proves this\"\n",
522 | "\n",
523 | "audio file=\"audio/4507-16021-0012.wav\" expected text=\"why should one halt on the way\"\n",
524 | "interim results: \n",
525 | "not final: what\n",
526 | "not final: watch\n",
527 | "not final: why should\n",
528 | "not final: why should we\n",
529 | "not final: why should one\n",
530 | "not final: why should one who\n",
531 | "not final: why should one have\n",
532 | "not final: why should\n",
533 | "not final: why should\n",
534 | "not final: why should\n",
535 | "not final: why should\n",
536 | "not final: why should one\n",
537 | "not final: why should one\n",
538 | "not final: why should one\n",
539 | "not final: why should one\n",
540 | "not final: why should one halt\n",
541 | "not final: why should one halt on\n",
542 | "not final: why should one halt on the\n",
543 | "final: why should one halt on the way\n",
544 | "google-cloud-streaming-stt: \"why should one halt on the way\"\n",
545 | "\n",
546 | "audio file=\"audio/8455-210777-0068.wav\" expected text=\"your power is sufficient i said\"\n",
547 | "interim results: \n",
548 | "not final: you're\n",
549 | "not final: your pie\n",
550 | "not final: your power\n",
551 | "not final: your power is\n",
552 | "not final: your power is so\n",
553 | "not final: your power is a\n",
554 | "not final: your\n",
555 | "not final: your power\n",
556 | "not final: your power\n",
557 | "not final: your power is\n",
558 | "not final: your power is\n",
559 | "not final: your power is\n",
560 | "not final: your power is\n",
561 | "not final: your power is sufficient\n",
562 | "final: your power is sufficient I said\n",
563 | "google-cloud-streaming-stt: \"your power is sufficient I said\"\n"
564 | ]
565 | }
566 | ],
567 | "source": [
568 | "from google.cloud import speech\n",
569 | "from google.cloud.speech import enums\n",
570 | "from google.cloud.speech import types\n",
571 | "\n",
572 | "def response_stream_processor(responses):\n",
573 | " print('interim results: ')\n",
574 | "\n",
575 | " transcript = ''\n",
576 | " num_chars_printed = 0\n",
577 | " for response in responses:\n",
578 | " if not response.results:\n",
579 | " continue\n",
580 | "\n",
581 | " result = response.results[0]\n",
582 | " if not result.alternatives:\n",
583 | " continue\n",
584 | "\n",
585 | " transcript = result.alternatives[0].transcript\n",
586 | " print('{0}final: {1}'.format(\n",
587 | " '' if result.is_final else 'not ',\n",
588 | " transcript\n",
589 | " ))\n",
590 | "\n",
591 | " return transcript\n",
592 | "\n",
593 | "def google_streaming_stt(filename: str, lang: str, encoding: str) -> str:\n",
594 | " buffer, rate = read_wav_file(filename)\n",
595 | "\n",
596 | " client = speech.SpeechClient()\n",
597 | "\n",
598 | " config = types.RecognitionConfig(\n",
599 | " encoding=enums.RecognitionConfig.AudioEncoding[encoding],\n",
600 | " sample_rate_hertz=rate,\n",
601 | " language_code=lang\n",
602 | " )\n",
603 | "\n",
604 | " streaming_config = types.StreamingRecognitionConfig(\n",
605 | " config=config,\n",
606 | " interim_results=True\n",
607 | " )\n",
608 | "\n",
609 | " audio_generator = simulate_stream(buffer) # buffer chunk generator\n",
610 | " requests = (types.StreamingRecognizeRequest(audio_content=chunk) for chunk in audio_generator)\n",
611 | " responses = client.streaming_recognize(streaming_config, requests)\n",
612 | " # Now, put the transcription responses to use.\n",
613 | " return response_stream_processor(responses)\n",
614 | "\n",
615 | "# Run tests\n",
616 | "for t in TESTCASES:\n",
617 | " print('\\naudio file=\"{0}\" expected text=\"{1}\"'.format(t['filename'], t['text']))\n",
618 | " print('google-cloud-streaming-stt: \"{}\"'.format(\n",
619 | " google_streaming_stt(t['filename'], t['lang'], t['encoding'])\n",
620 | " ))"
621 | ]
622 | },
623 | {
624 | "cell_type": "markdown",
625 | "metadata": {
626 | "id": "S8Fg2BE75Qoo"
627 | },
628 | "source": [
629 | "\n",
630 | "---\n",
631 | "\n",
632 | "# Microsoft Azure\n",
633 | "\n",
634 | "Microsoft Azure [Speech Services](https://azure.microsoft.com/en-in/services/cognitive-services/speech-services/) have [Speech to Text](https://azure.microsoft.com/en-in/services/cognitive-services/speech-to-text/) service."
635 | ]
636 | },
637 | {
638 | "cell_type": "markdown",
639 | "metadata": {
640 | "id": "mk8NgzQIlwwX"
641 | },
642 | "source": [
643 | "## Setup\n",
644 | "\n",
645 | "1. **Install azure speech package**"
646 | ]
647 | },
648 | {
649 | "cell_type": "code",
650 | "execution_count": null,
651 | "metadata": {
652 | "colab": {
653 | "base_uri": "https://localhost:8080/",
654 | "height": 121
655 | },
656 | "id": "2A5YJHlswQSs",
657 | "outputId": "4f2e7f65-dfcc-450e-cb26-c9ca780957c7"
658 | },
659 | "outputs": [
660 | {
661 | "name": "stdout",
662 | "output_type": "stream",
663 | "text": [
664 | "Collecting azure-cognitiveservices-speech\n",
665 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/a0/d8/690896a3543b7bed058029b1b3450f4ce2e952d19347663fe570e6dec72c/azure_cognitiveservices_speech-1.9.0-cp36-cp36m-manylinux1_x86_64.whl (3.9MB)\n",
666 | "\u001b[K |████████████████████████████████| 3.9MB 3.4MB/s \n",
667 | "\u001b[?25hInstalling collected packages: azure-cognitiveservices-speech\n",
668 | "Successfully installed azure-cognitiveservices-speech-1.9.0\n"
669 | ]
670 | }
671 | ],
672 | "source": [
673 | "!pip3 install azure-cognitiveservices-speech"
674 | ]
675 | },
676 | {
677 | "cell_type": "markdown",
678 | "metadata": {
679 | "id": "K4ME2jnAimEQ"
680 | },
681 | "source": [
682 | "2. **Set service credentials**\n",
683 | "\n",
684 | "You can enable Speech service and find credentials for your account at [Microsoft Azure portal](https://portal.azure.com/). You can open a free account [here](https://azure.microsoft.com/en-in/free/ai/)."
685 | ]
686 | },
687 | {
688 | "cell_type": "code",
689 | "execution_count": null,
690 | "metadata": {
691 | "id": "rSqzFx-lwyz7"
692 | },
693 | "outputs": [],
694 | "source": [
695 | "AZURE_SPEECH_KEY = 'YOUR AZURE SPEECH KEY'\n",
696 | "AZURE_SERVICE_REGION = 'YOUR AZURE SERVICE REGION'"
697 | ]
698 | },
699 | {
700 | "cell_type": "markdown",
701 | "metadata": {
702 | "id": "ZVvMt_qylUjF"
703 | },
704 | "source": [
705 | "## Batch API"
706 | ]
707 | },
708 | {
709 | "cell_type": "code",
710 | "execution_count": null,
711 | "metadata": {
712 | "colab": {
713 | "base_uri": "https://localhost:8080/",
714 | "height": 168
715 | },
716 | "id": "rRMjNB68wYYN",
717 | "outputId": "7539fb6e-1625-4931-f981-96874628c934"
718 | },
719 | "outputs": [
720 | {
721 | "name": "stdout",
722 | "output_type": "stream",
723 | "text": [
724 | "\n",
725 | "audio file=\"audio/2830-3980-0043.wav\" expected text=\"experience proves this\"\n",
726 | "azure-batch-stt: \"Experience proves this.\"\n",
727 | "\n",
728 | "audio file=\"audio/4507-16021-0012.wav\" expected text=\"why should one halt on the way\"\n",
729 | "azure-batch-stt: \"Whi should one halt on the way.\"\n",
730 | "\n",
731 | "audio file=\"audio/8455-210777-0068.wav\" expected text=\"your power is sufficient i said\"\n",
732 | "azure-batch-stt: \"Your power is sufficient I said.\"\n"
733 | ]
734 | }
735 | ],
736 | "source": [
737 | "import azure.cognitiveservices.speech as speechsdk\n",
738 | "\n",
739 | "def azure_batch_stt(filename: str, lang: str, encoding: str) -> str:\n",
740 | " speech_config = speechsdk.SpeechConfig(\n",
741 | " subscription=AZURE_SPEECH_KEY,\n",
742 | " region=AZURE_SERVICE_REGION\n",
743 | " )\n",
744 | " audio_input = speechsdk.AudioConfig(filename=filename)\n",
745 | " speech_recognizer = speechsdk.SpeechRecognizer(\n",
746 | " speech_config=speech_config,\n",
747 | " audio_config=audio_input\n",
748 | " )\n",
749 | " result = speech_recognizer.recognize_once()\n",
750 | "\n",
751 | " return result.text if result.reason == speechsdk.ResultReason.RecognizedSpeech else None\n",
752 | "\n",
753 | "# Run tests\n",
754 | "for t in TESTCASES:\n",
755 | " print('\\naudio file=\"{0}\" expected text=\"{1}\"'.format(t['filename'], t['text']))\n",
756 | " print('azure-batch-stt: \"{}\"'.format(\n",
757 | " azure_batch_stt(t['filename'], t['lang'], t['encoding'])\n",
758 | " ))"
759 | ]
760 | },
761 | {
762 | "cell_type": "markdown",
763 | "metadata": {
764 | "id": "aXd7OC7plbAu"
765 | },
766 | "source": [
767 | "## Streaming API"
768 | ]
769 | },
770 | {
771 | "cell_type": "code",
772 | "execution_count": null,
773 | "metadata": {
774 | "colab": {
775 | "base_uri": "https://localhost:8080/",
776 | "height": 521
777 | },
778 | "id": "IzfBW4kczY9l",
779 | "outputId": "8694efbf-5886-4359-ec6c-5b6f3c970372"
780 | },
781 | "outputs": [
782 | {
783 | "name": "stdout",
784 | "output_type": "stream",
785 | "text": [
786 | "\n",
787 | "audio file=\"audio/2830-3980-0043.wav\" expected text=\"experience proves this\"\n",
788 | "interim text: \"experience\"\n",
789 | "interim text: \"experienced\"\n",
790 | "interim text: \"experience\"\n",
791 | "interim text: \"experience proves\"\n",
792 | "interim text: \"experience proves this\"\n",
793 | "azure-streaming-stt: \"Experience proves this.\"\n",
794 | "\n",
795 | "audio file=\"audio/4507-16021-0012.wav\" expected text=\"why should one halt on the way\"\n",
796 | "interim text: \"huaisheng\"\n",
797 | "interim text: \"white\"\n",
798 | "interim text: \"whi should\"\n",
799 | "interim text: \"whi should one\"\n",
800 | "interim text: \"whi should one halt\"\n",
801 | "interim text: \"whi should one halt on\"\n",
802 | "interim text: \"whi should one halt on the\"\n",
803 | "interim text: \"whi should one halt on the way\"\n",
804 | "azure-streaming-stt: \"Whi should one halt on the way.\"\n",
805 | "\n",
806 | "audio file=\"audio/8455-210777-0068.wav\" expected text=\"your power is sufficient i said\"\n",
807 | "interim text: \"you're\"\n",
808 | "interim text: \"your\"\n",
809 | "interim text: \"your power\"\n",
810 | "interim text: \"your\"\n",
811 | "interim text: \"your power is\"\n",
812 | "interim text: \"your power is sufficient\"\n",
813 | "interim text: \"your power is sufficient i\"\n",
814 | "interim text: \"your power is sufficient i said\"\n",
815 | "azure-streaming-stt: \"Your power is sufficient I said.\"\n"
816 | ]
817 | }
818 | ],
819 | "source": [
820 | "import time\n",
821 | "import azure.cognitiveservices.speech as speechsdk\n",
822 | "\n",
823 | "def azure_streaming_stt(filename: str, lang: str, encoding: str) -> str:\n",
824 | " speech_config = speechsdk.SpeechConfig(\n",
825 | " subscription=AZURE_SPEECH_KEY,\n",
826 | " region=AZURE_SERVICE_REGION\n",
827 | " )\n",
828 | " stream = speechsdk.audio.PushAudioInputStream()\n",
829 | " audio_config = speechsdk.audio.AudioConfig(stream=stream)\n",
830 | " speech_recognizer = speechsdk.SpeechRecognizer(\n",
831 | " speech_config=speech_config,\n",
832 | " audio_config=audio_config\n",
833 | " )\n",
834 | "\n",
835 | " # Connect callbacks to the events fired by the speech recognizer\n",
836 | " speech_recognizer.recognizing.connect(lambda evt: print('interim text: \"{}\"'.format(evt.result.text)))\n",
837 | " speech_recognizer.recognized.connect(lambda evt: print('azure-streaming-stt: \"{}\"'.format(evt.result.text)))\n",
838 | "\n",
839 | " # start continuous speech recognition\n",
840 | " speech_recognizer.start_continuous_recognition()\n",
841 | "\n",
842 | " # push buffer chunks to stream\n",
843 | " buffer, rate = read_wav_file(filename)\n",
844 | " audio_generator = simulate_stream(buffer)\n",
845 | " for chunk in audio_generator:\n",
846 | " stream.write(chunk)\n",
847 | " time.sleep(0.1) # to give callback a chance against this fast loop\n",
848 | "\n",
849 | " # stop continuous speech recognition\n",
850 | " stream.close()\n",
851 | " time.sleep(0.5) # give chance to VAD to kick in\n",
852 | " speech_recognizer.stop_continuous_recognition()\n",
853 | " time.sleep(0.5) # Let all callback run\n",
854 | "\n",
855 | "# Run tests\n",
856 | "for t in TESTCASES:\n",
857 | " print('\\naudio file=\"{0}\" expected text=\"{1}\"'.format(t['filename'], t['text']))\n",
858 | " azure_streaming_stt(t['filename'], t['lang'], t['encoding'])"
859 | ]
860 | },
861 | {
862 | "cell_type": "markdown",
863 | "metadata": {
864 | "id": "5ASpAymRMzOz"
865 | },
866 | "source": [
867 | "---\n",
868 | "\n",
869 | "# IBM Watson\n",
870 | "\n",
871 | "For IBM [Watson Speech to Text](https://www.ibm.com/in-en/cloud/watson-speech-to-text) is ASR service with .NET, Go, JavaScript, [Python](https://cloud.ibm.com/apidocs/speech-to-text/speech-to-text?code=python), Ruby, Swift and Unity API libraries, as well as REST endpoints.\n"
872 | ]
873 | },
874 | {
875 | "cell_type": "markdown",
876 | "metadata": {
877 | "id": "atuGghM2RxWd"
878 | },
879 | "source": [
880 | "## Setup\n",
881 | "\n",
882 | "1. **Install IBM Watson package**"
883 | ]
884 | },
885 | {
886 | "cell_type": "code",
887 | "execution_count": null,
888 | "metadata": {
889 | "colab": {
890 | "base_uri": "https://localhost:8080/",
891 | "height": 490
892 | },
893 | "id": "nG5jW68yRWGk",
894 | "outputId": "b3beae11-4775-430c-8f5b-57ad5809bd93"
895 | },
896 | "outputs": [
897 | {
898 | "name": "stdout",
899 | "output_type": "stream",
900 | "text": [
901 | "Collecting ibm-watson\n",
902 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/da/f4/7e256026ee22c75a630c6de53eb45b6fef4840ac6728b80a92dd2e523a1a/ibm-watson-4.2.1.tar.gz (348kB)\n",
903 | "\u001b[K |████████████████████████████████| 358kB 3.4MB/s \n",
904 | "\u001b[?25hRequirement already satisfied: requests<3.0,>=2.0 in /usr/local/lib/python3.6/dist-packages (from ibm-watson) (2.21.0)\n",
905 | "Requirement already satisfied: python_dateutil>=2.5.3 in /usr/local/lib/python3.6/dist-packages (from ibm-watson) (2.6.1)\n",
906 | "Collecting websocket-client==0.48.0\n",
907 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/8a/a1/72ef9aa26cfe1a75cee09fc1957e4723add9de098c15719416a1ee89386b/websocket_client-0.48.0-py2.py3-none-any.whl (198kB)\n",
908 | "\u001b[K |████████████████████████████████| 204kB 43.6MB/s \n",
909 | "\u001b[?25hCollecting ibm_cloud_sdk_core==1.5.1\n",
910 | " Downloading https://files.pythonhosted.org/packages/b7/f6/10d5271c807d73d236e6ae07b68035fed78b28b5ab836704d34097af3986/ibm-cloud-sdk-core-1.5.1.tar.gz\n",
911 | "Requirement already satisfied: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests<3.0,>=2.0->ibm-watson) (2.8)\n",
912 | "Requirement already satisfied: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests<3.0,>=2.0->ibm-watson) (1.24.3)\n",
913 | "Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests<3.0,>=2.0->ibm-watson) (3.0.4)\n",
914 | "Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests<3.0,>=2.0->ibm-watson) (2019.11.28)\n",
915 | "Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/dist-packages (from python_dateutil>=2.5.3->ibm-watson) (1.12.0)\n",
916 | "Collecting PyJWT>=1.7.1\n",
917 | " Downloading https://files.pythonhosted.org/packages/87/8b/6a9f14b5f781697e51259d81657e6048fd31a113229cf346880bb7545565/PyJWT-1.7.1-py2.py3-none-any.whl\n",
918 | "Building wheels for collected packages: ibm-watson, ibm-cloud-sdk-core\n",
919 | " Building wheel for ibm-watson (setup.py) ... \u001b[?25l\u001b[?25hdone\n",
920 | " Created wheel for ibm-watson: filename=ibm_watson-4.2.1-cp36-none-any.whl size=343298 sha256=3fcdea1185ceb522ed5f080ad4d66048d9286cd28e8d9bc86094b08a84cb6211\n",
921 | " Stored in directory: /root/.cache/pip/wheels/ce/4d/6e/ae352b7c7acdddf073aeb06617fbfeefaea9fcb6d7ae98800b\n",
922 | " Building wheel for ibm-cloud-sdk-core (setup.py) ... \u001b[?25l\u001b[?25hdone\n",
923 | " Created wheel for ibm-cloud-sdk-core: filename=ibm_cloud_sdk_core-1.5.1-cp36-none-any.whl size=44492 sha256=8fbd5fdfa4ca15217877ee44671387c23ce61f390cd15d8006200d502d56dc63\n",
924 | " Stored in directory: /root/.cache/pip/wheels/6a/42/50/f96888116b329578304f9dda4693cef6f3e76e18272d22cb6c\n",
925 | "Successfully built ibm-watson ibm-cloud-sdk-core\n",
926 | "Installing collected packages: websocket-client, PyJWT, ibm-cloud-sdk-core, ibm-watson\n",
927 | "Successfully installed PyJWT-1.7.1 ibm-cloud-sdk-core-1.5.1 ibm-watson-4.2.1 websocket-client-0.48.0\n"
928 | ]
929 | }
930 | ],
931 | "source": [
932 | "!pip install ibm-watson"
933 | ]
934 | },
935 | {
936 | "cell_type": "markdown",
937 | "metadata": {
938 | "id": "bntnwqJ3Q99Z"
939 | },
940 | "source": [
941 | "2. **Set service credentials**\n",
942 | "\n",
943 | "You will need to [sign up/in](https://cloud.ibm.com/docs/services/text-to-speech?topic=text-to-speech-gettingStarted), and get API key credential and service URL, and fill it below."
944 | ]
945 | },
946 | {
947 | "cell_type": "code",
948 | "execution_count": null,
949 | "metadata": {
950 | "id": "cdl6Y7MJPtoT"
951 | },
952 | "outputs": [],
953 | "source": [
954 | "WATSON_API_KEY = 'YOUR WATSON API KEY'\n",
955 | "WATSON_STT_URL = 'YOUR WATSON SERVICE URL'"
956 | ]
957 | },
958 | {
959 | "cell_type": "markdown",
960 | "metadata": {
961 | "id": "8jqxI2XrRmKz"
962 | },
963 | "source": [
964 | "## Batch API"
965 | ]
966 | },
967 | {
968 | "cell_type": "code",
969 | "execution_count": null,
970 | "metadata": {
971 | "colab": {
972 | "base_uri": "https://localhost:8080/",
973 | "height": 168
974 | },
975 | "id": "QFWX40PYRogi",
976 | "outputId": "6feb0b03-8ca4-485e-bf25-5042340f8ed7"
977 | },
978 | "outputs": [
979 | {
980 | "name": "stdout",
981 | "output_type": "stream",
982 | "text": [
983 | "\n",
984 | "audio file=\"audio/2830-3980-0043.wav\" expected text=\"experience proves this\"\n",
985 | "watson-batch-stt: \"experience proves this \"\n",
986 | "\n",
987 | "audio file=\"audio/4507-16021-0012.wav\" expected text=\"why should one halt on the way\"\n",
988 | "watson-batch-stt: \"why should one hold on the way \"\n",
989 | "\n",
990 | "audio file=\"audio/8455-210777-0068.wav\" expected text=\"your power is sufficient i said\"\n",
991 | "watson-batch-stt: \"your power is sufficient I set \"\n"
992 | ]
993 | }
994 | ],
995 | "source": [
996 | "import os\n",
997 | "\n",
998 | "from ibm_watson import SpeechToTextV1\n",
999 | "from ibm_cloud_sdk_core.authenticators import IAMAuthenticator\n",
1000 | "\n",
1001 | "def watson_batch_stt(filename: str, lang: str, encoding: str) -> str:\n",
1002 | " authenticator = IAMAuthenticator(WATSON_API_KEY)\n",
1003 | " speech_to_text = SpeechToTextV1(authenticator=authenticator)\n",
1004 | " speech_to_text.set_service_url(WATSON_STT_URL)\n",
1005 | "\n",
1006 | " with open(filename, 'rb') as audio_file:\n",
1007 | " response = speech_to_text.recognize(\n",
1008 | " audio=audio_file,\n",
1009 | " content_type='audio/{}'.format(os.path.splitext(filename)[1][1:]),\n",
1010 | " model=lang + '_BroadbandModel',\n",
1011 | " max_alternatives=3,\n",
1012 | " ).get_result()\n",
1013 | "\n",
1014 | " return response['results'][0]['alternatives'][0]['transcript']\n",
1015 | "\n",
1016 | "# Run tests\n",
1017 | "for t in TESTCASES:\n",
1018 | " print('\\naudio file=\"{0}\" expected text=\"{1}\"'.format(t['filename'], t['text']))\n",
1019 | " print('watson-batch-stt: \"{}\"'.format(\n",
1020 | " watson_batch_stt(t['filename'], t['lang'], t['encoding'])\n",
1021 | " ))"
1022 | ]
1023 | },
1024 | {
1025 | "cell_type": "markdown",
1026 | "metadata": {
1027 | "id": "vOsBdku-RpB-"
1028 | },
1029 | "source": [
1030 | "## Streaming API\n",
1031 | "\n",
1032 | "Streaming API works over websocket."
1033 | ]
1034 | },
1035 | {
1036 | "cell_type": "code",
1037 | "execution_count": null,
1038 | "metadata": {
1039 | "colab": {
1040 | "base_uri": "https://localhost:8080/",
1041 | "height": 672
1042 | },
1043 | "id": "Pwb0uZjPR0rX",
1044 | "outputId": "97e95e3f-053e-46b7-c459-13697a6eb872"
1045 | },
1046 | "outputs": [
1047 | {
1048 | "name": "stdout",
1049 | "output_type": "stream",
1050 | "text": [
1051 | "\n",
1052 | "audio file=\"audio/2830-3980-0043.wav\" expected text=\"experience proves this\"\n",
1053 | "not final: X. \n",
1054 | "not final: experts \n",
1055 | "not final: experience \n",
1056 | "not final: experienced \n",
1057 | "not final: experience prove \n",
1058 | "not final: experience proves \n",
1059 | "not final: experience proves that \n",
1060 | "not final: experience proves this \n",
1061 | "final: experience proves this \n",
1062 | "watson-cloud-streaming-stt: \"experience proves this \"\n",
1063 | "\n",
1064 | "audio file=\"audio/4507-16021-0012.wav\" expected text=\"why should one halt on the way\"\n",
1065 | "not final: why \n",
1066 | "not final: what \n",
1067 | "not final: why should \n",
1068 | "not final: why should we \n",
1069 | "not final: why should one \n",
1070 | "not final: why should one whole \n",
1071 | "not final: why should one hold \n",
1072 | "not final: why should one hold on \n",
1073 | "not final: why should one hold on the \n",
1074 | "not final: why should one hold on the way \n",
1075 | "final: why should one hold on the way \n",
1076 | "watson-cloud-streaming-stt: \"why should one hold on the way \"\n",
1077 | "\n",
1078 | "audio file=\"audio/8455-210777-0068.wav\" expected text=\"your power is sufficient i said\"\n",
1079 | "not final: your \n",
1080 | "not final: your power \n",
1081 | "not final: your power is \n",
1082 | "not final: your power is the \n",
1083 | "not final: your power is sufficient \n",
1084 | "not final: your power is sufficient I \n",
1085 | "not final: your power is sufficient I saw \n",
1086 | "not final: your power is sufficient I said \n",
1087 | "not final: your power is sufficient I set \n",
1088 | "final: your power is sufficient I set \n",
1089 | "watson-cloud-streaming-stt: \"your power is sufficient I set \"\n"
1090 | ]
1091 | }
1092 | ],
1093 | "source": [
1094 | "import json\n",
1095 | "import logging\n",
1096 | "import os\n",
1097 | "from queue import Queue\n",
1098 | "from threading import Thread\n",
1099 | "import time\n",
1100 | "\n",
1101 | "from ibm_watson import SpeechToTextV1\n",
1102 | "from ibm_watson.websocket import RecognizeCallback, AudioSource\n",
1103 | "from ibm_cloud_sdk_core.authenticators import IAMAuthenticator\n",
1104 | "\n",
1105 | "# Watson websocket prints justs too many debug logs, so disable it\n",
1106 | "logging.disable(logging.CRITICAL)\n",
1107 | "\n",
1108 | "# Chunk and buffer size\n",
1109 | "CHUNK_SIZE = 4096\n",
1110 | "BUFFER_MAX_ELEMENT = 10\n",
1111 | "\n",
1112 | "# A callback class to process various streaming STT events\n",
1113 | "class MyRecognizeCallback(RecognizeCallback):\n",
1114 | " def __init__(self):\n",
1115 | " RecognizeCallback.__init__(self)\n",
1116 | " self.transcript = None\n",
1117 | "\n",
1118 | " def on_transcription(self, transcript):\n",
1119 | " # print('transcript: {}'.format(transcript))\n",
1120 | " pass\n",
1121 | "\n",
1122 | " def on_connected(self):\n",
1123 | " # print('Connection was successful')\n",
1124 | " pass\n",
1125 | "\n",
1126 | " def on_error(self, error):\n",
1127 | " # print('Error received: {}'.format(error))\n",
1128 | " pass\n",
1129 | "\n",
1130 | " def on_inactivity_timeout(self, error):\n",
1131 | " # print('Inactivity timeout: {}'.format(error))\n",
1132 | " pass\n",
1133 | "\n",
1134 | " def on_listening(self):\n",
1135 | " # print('Service is listening')\n",
1136 | " pass\n",
1137 | "\n",
1138 | " def on_hypothesis(self, hypothesis):\n",
1139 | " # print('hypothesis: {}'.format(hypothesis))\n",
1140 | " pass\n",
1141 | "\n",
1142 | " def on_data(self, data):\n",
1143 | " self.transcript = data['results'][0]['alternatives'][0]['transcript']\n",
1144 | " print('{0}final: {1}'.format(\n",
1145 | " '' if data['results'][0]['final'] else 'not ',\n",
1146 | " self.transcript\n",
1147 | " ))\n",
1148 | "\n",
1149 | " def on_close(self):\n",
1150 | " # print(\"Connection closed\")\n",
1151 | " pass\n",
1152 | "\n",
1153 | "def watson_streaming_stt(filename: str, lang: str, encoding: str) -> str:\n",
1154 | " authenticator = IAMAuthenticator(WATSON_API_KEY)\n",
1155 | " speech_to_text = SpeechToTextV1(authenticator=authenticator)\n",
1156 | " speech_to_text.set_service_url(WATSON_STT_URL)\n",
1157 | "\n",
1158 | " # Make watson audio source fed by a buffer queue\n",
1159 | " buffer_queue = Queue(maxsize=BUFFER_MAX_ELEMENT)\n",
1160 | " audio_source = AudioSource(buffer_queue, True, True)\n",
1161 | "\n",
1162 | " # Callback object\n",
1163 | " mycallback = MyRecognizeCallback()\n",
1164 | "\n",
1165 | " # Read the file\n",
1166 | " buffer, rate = read_wav_file(filename)\n",
1167 | "\n",
1168 | " # Start Speech-to-Text recognition thread\n",
1169 | " stt_stream_thread = Thread(\n",
1170 | " target=speech_to_text.recognize_using_websocket,\n",
1171 | " kwargs={\n",
1172 | " 'audio': audio_source,\n",
1173 | " 'content_type': 'audio/l16; rate={}'.format(rate),\n",
1174 | " 'recognize_callback': mycallback,\n",
1175 | " 'interim_results': True\n",
1176 | " }\n",
1177 | " )\n",
1178 | " stt_stream_thread.start()\n",
1179 | "\n",
1180 | " # Simulation audio stream by breaking file into chunks and filling buffer queue\n",
1181 | " audio_generator = simulate_stream(buffer, CHUNK_SIZE)\n",
1182 | " for chunk in audio_generator:\n",
1183 | " buffer_queue.put(chunk)\n",
1184 | " time.sleep(0.5) # give a chance to callback\n",
1185 | "\n",
1186 | " # Close the audio feed and wait for STTT thread to complete\n",
1187 | " audio_source.completed_recording()\n",
1188 | " stt_stream_thread.join()\n",
1189 | "\n",
1190 | " # send final result\n",
1191 | " return mycallback.transcript\n",
1192 | "\n",
1193 | "# Run tests\n",
1194 | "for t in TESTCASES:\n",
1195 | " print('\\naudio file=\"{0}\" expected text=\"{1}\"'.format(t['filename'], t['text']))\n",
1196 | " print('watson-cloud-streaming-stt: \"{}\"'.format(\n",
1197 | " watson_streaming_stt(t['filename'], t['lang'], t['encoding'])\n",
1198 | " ))"
1199 | ]
1200 | },
1201 | {
1202 | "cell_type": "markdown",
1203 | "metadata": {
1204 | "id": "M7W8nsP45IUx"
1205 | },
1206 | "source": [
1207 | "\n",
1208 | "---\n",
1209 | "\n",
1210 | "# CMU Sphinx\n",
1211 | "\n",
1212 | "[CMUSphinx](https://cmusphinx.github.io/) is has been around for quite some time, and has been adapting to advancements in ASR technologies. [PocketSphinx](https://github.com/cmusphinx/pocketsphinx-python) is speech-to-text decoder software package."
1213 | ]
1214 | },
1215 | {
1216 | "cell_type": "markdown",
1217 | "metadata": {
1218 | "id": "eSdcTyoTl3XL"
1219 | },
1220 | "source": [
1221 | "## Setup\n",
1222 | "\n",
1223 | "1. **Install swig**\n",
1224 | "\n",
1225 | "For macOS:"
1226 | ]
1227 | },
1228 | {
1229 | "cell_type": "code",
1230 | "execution_count": null,
1231 | "metadata": {
1232 | "id": "nMWqogsSSk2H"
1233 | },
1234 | "outputs": [],
1235 | "source": [
1236 | "!brew install swig\n",
1237 | "!swig -version"
1238 | ]
1239 | },
1240 | {
1241 | "cell_type": "markdown",
1242 | "metadata": {
1243 | "id": "tn_LqRxjSoMT"
1244 | },
1245 | "source": [
1246 | "For Linux:"
1247 | ]
1248 | },
1249 | {
1250 | "cell_type": "code",
1251 | "execution_count": null,
1252 | "metadata": {
1253 | "colab": {
1254 | "base_uri": "https://localhost:8080/",
1255 | "height": 806
1256 | },
1257 | "id": "ID2AUZX4SqkU",
1258 | "outputId": "01770ecb-4b8d-4047-c1a2-2f1490c2f74b"
1259 | },
1260 | "outputs": [
1261 | {
1262 | "name": "stdout",
1263 | "output_type": "stream",
1264 | "text": [
1265 | "Reading package lists... Done\n",
1266 | "Building dependency tree \n",
1267 | "Reading state information... Done\n",
1268 | "The following package was automatically installed and is no longer required:\n",
1269 | " libnvidia-common-430\n",
1270 | "Use 'apt autoremove' to remove it.\n",
1271 | "The following additional packages will be installed:\n",
1272 | " libpulse-mainloop-glib0 swig3.0\n",
1273 | "Suggested packages:\n",
1274 | " swig-doc swig-examples swig3.0-examples swig3.0-doc\n",
1275 | "The following NEW packages will be installed:\n",
1276 | " libpulse-dev libpulse-mainloop-glib0 swig swig3.0\n",
1277 | "0 upgraded, 4 newly installed, 0 to remove and 7 not upgraded.\n",
1278 | "Need to get 1,204 kB of archives.\n",
1279 | "After this operation, 6,538 kB of additional disk space will be used.\n",
1280 | "Get:1 http://archive.ubuntu.com/ubuntu bionic-updates/main amd64 libpulse-mainloop-glib0 amd64 1:11.1-1ubuntu7.4 [22.1 kB]\n",
1281 | "Get:2 http://archive.ubuntu.com/ubuntu bionic-updates/main amd64 libpulse-dev amd64 1:11.1-1ubuntu7.4 [81.5 kB]\n",
1282 | "Get:3 http://archive.ubuntu.com/ubuntu bionic/universe amd64 swig3.0 amd64 3.0.12-1 [1,094 kB]\n",
1283 | "Get:4 http://archive.ubuntu.com/ubuntu bionic/universe amd64 swig amd64 3.0.12-1 [6,460 B]\n",
1284 | "Fetched 1,204 kB in 1s (1,336 kB/s)\n",
1285 | "Selecting previously unselected package libpulse-mainloop-glib0:amd64.\n",
1286 | "(Reading database ... 145674 files and directories currently installed.)\n",
1287 | "Preparing to unpack .../libpulse-mainloop-glib0_1%3a11.1-1ubuntu7.4_amd64.deb ...\n",
1288 | "Unpacking libpulse-mainloop-glib0:amd64 (1:11.1-1ubuntu7.4) ...\n",
1289 | "Selecting previously unselected package libpulse-dev:amd64.\n",
1290 | "Preparing to unpack .../libpulse-dev_1%3a11.1-1ubuntu7.4_amd64.deb ...\n",
1291 | "Unpacking libpulse-dev:amd64 (1:11.1-1ubuntu7.4) ...\n",
1292 | "Selecting previously unselected package swig3.0.\n",
1293 | "Preparing to unpack .../swig3.0_3.0.12-1_amd64.deb ...\n",
1294 | "Unpacking swig3.0 (3.0.12-1) ...\n",
1295 | "Selecting previously unselected package swig.\n",
1296 | "Preparing to unpack .../swig_3.0.12-1_amd64.deb ...\n",
1297 | "Unpacking swig (3.0.12-1) ...\n",
1298 | "Setting up libpulse-mainloop-glib0:amd64 (1:11.1-1ubuntu7.4) ...\n",
1299 | "Setting up libpulse-dev:amd64 (1:11.1-1ubuntu7.4) ...\n",
1300 | "Setting up swig3.0 (3.0.12-1) ...\n",
1301 | "Setting up swig (3.0.12-1) ...\n",
1302 | "Processing triggers for man-db (2.8.3-2ubuntu0.1) ...\n",
1303 | "Processing triggers for libc-bin (2.27-3ubuntu1) ...\n",
1304 | "\n",
1305 | "SWIG Version 3.0.12\n",
1306 | "\n",
1307 | "Compiled with g++ [x86_64-pc-linux-gnu]\n",
1308 | "\n",
1309 | "Configured options: +pcre\n",
1310 | "\n",
1311 | "Please see http://www.swig.org for reporting bugs and further information\n"
1312 | ]
1313 | }
1314 | ],
1315 | "source": [
1316 | "!apt-get install -y swig libpulse-dev\n",
1317 | "!swig -version"
1318 | ]
1319 | },
1320 | {
1321 | "cell_type": "markdown",
1322 | "metadata": {
1323 | "id": "yZlvnjsfSu-3"
1324 | },
1325 | "source": [
1326 | "2. **Install poocketsphinx using pip**"
1327 | ]
1328 | },
1329 | {
1330 | "cell_type": "code",
1331 | "execution_count": null,
1332 | "metadata": {
1333 | "colab": {
1334 | "base_uri": "https://localhost:8080/",
1335 | "height": 222
1336 | },
1337 | "id": "XzOkKfgKS789",
1338 | "outputId": "116c7a60-cf24-4ba9-f3ac-ab09a5da0145"
1339 | },
1340 | "outputs": [
1341 | {
1342 | "name": "stdout",
1343 | "output_type": "stream",
1344 | "text": [
1345 | "Collecting pocketsphinx\n",
1346 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/cd/4a/adea55f189a81aed88efa0b0e1d25628e5ed22622ab9174bf696dd4f9474/pocketsphinx-0.1.15.tar.gz (29.1MB)\n",
1347 | "\u001b[K |████████████████████████████████| 29.1MB 102kB/s \n",
1348 | "\u001b[?25hBuilding wheels for collected packages: pocketsphinx\n",
1349 | " Building wheel for pocketsphinx (setup.py) ... \u001b[?25l\u001b[?25hdone\n",
1350 | " Created wheel for pocketsphinx: filename=pocketsphinx-0.1.15-cp36-cp36m-linux_x86_64.whl size=30126870 sha256=d111bc1a768251e9b8b4bea71f05b498955eda209f5d5650f7e68cc336bb5075\n",
1351 | " Stored in directory: /root/.cache/pip/wheels/52/fd/52/2f62c9a0036940cc0c89e58ee0b9d00fcf78243aeaf416265f\n",
1352 | "Successfully built pocketsphinx\n",
1353 | "Installing collected packages: pocketsphinx\n",
1354 | "Successfully installed pocketsphinx-0.1.15\n",
1355 | "pocketsphinx 0.1.15 \n"
1356 | ]
1357 | }
1358 | ],
1359 | "source": [
1360 | "!pip3 install pocketsphinx\n",
1361 | "!pip3 list | grep pocketsphinx"
1362 | ]
1363 | },
1364 | {
1365 | "cell_type": "markdown",
1366 | "metadata": {
1367 | "id": "weYD8oA-S-vu"
1368 | },
1369 | "source": [
1370 | "## Create Decoder object"
1371 | ]
1372 | },
1373 | {
1374 | "cell_type": "code",
1375 | "execution_count": null,
1376 | "metadata": {
1377 | "id": "TEpNoVUiTK4k"
1378 | },
1379 | "outputs": [],
1380 | "source": [
1381 | "import pocketsphinx\n",
1382 | "import os\n",
1383 | "\n",
1384 | "MODELDIR = os.path.join(os.path.dirname(pocketsphinx.__file__), 'model')\n",
1385 | "\n",
1386 | "config = pocketsphinx.Decoder.default_config()\n",
1387 | "config.set_string('-hmm', os.path.join(MODELDIR, 'en-us'))\n",
1388 | "config.set_string('-lm', os.path.join(MODELDIR, 'en-us.lm.bin'))\n",
1389 | "config.set_string('-dict', os.path.join(MODELDIR, 'cmudict-en-us.dict'))\n",
1390 | "\n",
1391 | "decoder = pocketsphinx.Decoder(config)"
1392 | ]
1393 | },
1394 | {
1395 | "cell_type": "markdown",
1396 | "metadata": {
1397 | "id": "a6s9CCA9WvIZ"
1398 | },
1399 | "source": [
1400 | "## Batch API"
1401 | ]
1402 | },
1403 | {
1404 | "cell_type": "code",
1405 | "execution_count": null,
1406 | "metadata": {
1407 | "colab": {
1408 | "base_uri": "https://localhost:8080/",
1409 | "height": 168
1410 | },
1411 | "id": "klStePTBWxO7",
1412 | "outputId": "c06996f3-5da9-4b1a-a5bc-a18c584da3e8"
1413 | },
1414 | "outputs": [
1415 | {
1416 | "name": "stdout",
1417 | "output_type": "stream",
1418 | "text": [
1419 | "\n",
1420 | "audio file=\"audio/2830-3980-0043.wav\" expected text=\"experience proves this\"\n",
1421 | "sphinx-batch-stt: \"experience proves this\"\n",
1422 | "\n",
1423 | "audio file=\"audio/4507-16021-0012.wav\" expected text=\"why should one halt on the way\"\n",
1424 | "sphinx-batch-stt: \"why should one hold on the way\"\n",
1425 | "\n",
1426 | "audio file=\"audio/8455-210777-0068.wav\" expected text=\"your power is sufficient i said\"\n",
1427 | "sphinx-batch-stt: \"your paris sufficient i said\"\n"
1428 | ]
1429 | }
1430 | ],
1431 | "source": [
1432 | "def sphinx_batch_stt(filename: str, lang: str, encoding: str) -> str:\n",
1433 | " buffer, rate = read_wav_file(filename)\n",
1434 | " decoder.start_utt()\n",
1435 | " decoder.process_raw(buffer, False, False)\n",
1436 | " decoder.end_utt()\n",
1437 | " hypothesis = decoder.hyp()\n",
1438 | " return hypothesis.hypstr\n",
1439 | "\n",
1440 | "# Run tests\n",
1441 | "for t in TESTCASES:\n",
1442 | " print('\\naudio file=\"{0}\" expected text=\"{1}\"'.format(t['filename'], t['text']))\n",
1443 | " print('sphinx-batch-stt: \"{}\"'.format(\n",
1444 | " sphinx_batch_stt(t['filename'], t['lang'], t['encoding'])\n",
1445 | " ))"
1446 | ]
1447 | },
1448 | {
1449 | "cell_type": "markdown",
1450 | "metadata": {
1451 | "id": "gQJ82tkTTyX3"
1452 | },
1453 | "source": [
1454 | "## Streaming API"
1455 | ]
1456 | },
1457 | {
1458 | "cell_type": "code",
1459 | "execution_count": null,
1460 | "metadata": {
1461 | "colab": {
1462 | "base_uri": "https://localhost:8080/",
1463 | "height": 168
1464 | },
1465 | "id": "iGfmRd6qTzq9",
1466 | "outputId": "65acfc30-d65e-432b-8abe-ed101ae4ee00"
1467 | },
1468 | "outputs": [
1469 | {
1470 | "name": "stdout",
1471 | "output_type": "stream",
1472 | "text": [
1473 | "\n",
1474 | "audio file=\"audio/2830-3980-0043.wav\" expected text=\"experience proves this\"\n",
1475 | "sphinx-streaming-stt: \"experience proves this\"\n",
1476 | "\n",
1477 | "audio file=\"audio/4507-16021-0012.wav\" expected text=\"why should one halt on the way\"\n",
1478 | "sphinx-streaming-stt: \"why should one hold on the way\"\n",
1479 | "\n",
1480 | "audio file=\"audio/8455-210777-0068.wav\" expected text=\"your power is sufficient i said\"\n",
1481 | "sphinx-streaming-stt: \"your paris sufficient i said\"\n"
1482 | ]
1483 | }
1484 | ],
1485 | "source": [
1486 | "def sphinx_streaming_stt(filename: str, lang: str, encoding: str) -> str:\n",
1487 | " buffer, rate = read_wav_file(filename)\n",
1488 | " audio_generator = simulate_stream(buffer)\n",
1489 | "\n",
1490 | " decoder.start_utt()\n",
1491 | " for chunk in audio_generator:\n",
1492 | " decoder.process_raw(chunk, False, False)\n",
1493 | " decoder.end_utt()\n",
1494 | "\n",
1495 | " hypothesis = decoder.hyp()\n",
1496 | " return hypothesis.hypstr\n",
1497 | "\n",
1498 | "# Run tests\n",
1499 | "for t in TESTCASES:\n",
1500 | " print('\\naudio file=\"{0}\" expected text=\"{1}\"'.format(t['filename'], t['text']))\n",
1501 | " print('sphinx-streaming-stt: \"{}\"'.format(\n",
1502 | " sphinx_streaming_stt(t['filename'], t['lang'], t['encoding'])\n",
1503 | " ))"
1504 | ]
1505 | },
1506 | {
1507 | "cell_type": "markdown",
1508 | "metadata": {
1509 | "id": "awZEgZKG5cWg"
1510 | },
1511 | "source": [
1512 | "\n",
1513 | "---\n",
1514 | "\n",
1515 | "# Mozilla DeepSpeech\n",
1516 | "\n",
1517 | "Mozilla released [DeepSpeech 0.6](https://hacks.mozilla.org/2019/12/deepspeech-0-6-mozillas-speech-to-text-engine/) software package in December 2019 with [APIs](https://github.com/mozilla/DeepSpeech/releases/tag/v0.6.0) in C, Java, .NET, [Python](https://deepspeech.readthedocs.io/en/v0.6.0/Python-API.html), and JavaScript, including support for TensorFlow Lite models for use on edge devices."
1518 | ]
1519 | },
1520 | {
1521 | "cell_type": "markdown",
1522 | "metadata": {
1523 | "id": "Ilmp9i-ql7V1"
1524 | },
1525 | "source": [
1526 | "## Setup\n",
1527 | "\n",
1528 | "1. **Install DeepSpeech**\n",
1529 | "\n",
1530 | "You can install DeepSpeech with pip (make it deepspeech-gpu==0.6.0 if you are using GPU in colab runtime)."
1531 | ]
1532 | },
1533 | {
1534 | "cell_type": "code",
1535 | "execution_count": null,
1536 | "metadata": {
1537 | "colab": {
1538 | "base_uri": "https://localhost:8080/",
1539 | "height": 138
1540 | },
1541 | "id": "gbWPbs_27f3Y",
1542 | "outputId": "583f2b3c-cdea-4027-b859-13118fc4b538"
1543 | },
1544 | "outputs": [
1545 | {
1546 | "name": "stdout",
1547 | "output_type": "stream",
1548 | "text": [
1549 | "Collecting deepspeech==0.6.0\n",
1550 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/26/f4/1ef0397097e8a8bbb7e24caabecbdb226b4e027e5018e9353ef65af14672/deepspeech-0.6.0-cp36-cp36m-manylinux1_x86_64.whl (9.6MB)\n",
1551 | "\u001b[K |████████████████████████████████| 9.6MB 3.0MB/s \n",
1552 | "\u001b[?25hRequirement already satisfied: numpy>=1.7.0 in /usr/local/lib/python3.6/dist-packages (from deepspeech==0.6.0) (1.17.5)\n",
1553 | "Installing collected packages: deepspeech\n",
1554 | "Successfully installed deepspeech-0.6.0\n"
1555 | ]
1556 | }
1557 | ],
1558 | "source": [
1559 | "!pip install deepspeech==0.6.0"
1560 | ]
1561 | },
1562 | {
1563 | "cell_type": "markdown",
1564 | "metadata": {
1565 | "id": "fIe7haLO7yo4"
1566 | },
1567 | "source": [
1568 | "2. **Download and unzip models**"
1569 | ]
1570 | },
1571 | {
1572 | "cell_type": "code",
1573 | "execution_count": null,
1574 | "metadata": {
1575 | "colab": {
1576 | "base_uri": "https://localhost:8080/",
1577 | "height": 286
1578 | },
1579 | "id": "eT-n1jLj8Ff4",
1580 | "outputId": "eb58aab5-aafe-4d3c-97dc-58ad4fd7e6b9"
1581 | },
1582 | "outputs": [
1583 | {
1584 | "name": "stdout",
1585 | "output_type": "stream",
1586 | "text": [
1587 | " % Total % Received % Xferd Average Speed Time Time Time Current\n",
1588 | " Dload Upload Total Spent Left Speed\n",
1589 | "100 620 0 620 0 0 2857 0 --:--:-- --:--:-- --:--:-- 2857\n",
1590 | "100 1172M 100 1172M 0 0 48.9M 0 0:00:23 0:00:23 --:--:-- 56.8M\n",
1591 | "deepspeech-0.6.0-models/\n",
1592 | "deepspeech-0.6.0-models/lm.binary\n",
1593 | "deepspeech-0.6.0-models/output_graph.pbmm\n",
1594 | "deepspeech-0.6.0-models/output_graph.pb\n",
1595 | "deepspeech-0.6.0-models/trie\n",
1596 | "deepspeech-0.6.0-models/output_graph.tflite\n",
1597 | "total 1350664\n",
1598 | "-rw-r--r-- 1 501 staff 945699324 Dec 3 06:51 lm.binary\n",
1599 | "-rw-r--r-- 1 501 staff 188914896 Dec 3 09:03 output_graph.pb\n",
1600 | "-rw-r--r-- 1 501 staff 188915850 Dec 3 09:49 output_graph.pbmm\n",
1601 | "-rw-r--r-- 1 501 staff 47335752 Dec 3 09:05 output_graph.tflite\n",
1602 | "-rw-r--r-- 1 501 staff 12200736 Dec 3 06:51 trie\n"
1603 | ]
1604 | }
1605 | ],
1606 | "source": [
1607 | "!curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.6.0/deepspeech-0.6.0-models.tar.gz\n",
1608 | "!tar -xvzf deepspeech-0.6.0-models.tar.gz\n",
1609 | "!ls -l ./deepspeech-0.6.0-models/"
1610 | ]
1611 | },
1612 | {
1613 | "cell_type": "markdown",
1614 | "metadata": {
1615 | "id": "uGGaM4wp8Ykp"
1616 | },
1617 | "source": [
1618 | "3. **Test that it all works**\n",
1619 | "\n",
1620 | "Examine the output of the last three commands, and you will see results *“experience proof less”*, *“why should one halt on the way”*, and *“your power is sufficient i said”* respectively. You are all set."
1621 | ]
1622 | },
1623 | {
1624 | "cell_type": "code",
1625 | "execution_count": null,
1626 | "metadata": {
1627 | "colab": {
1628 | "base_uri": "https://localhost:8080/",
1629 | "height": 222
1630 | },
1631 | "id": "3pPnZssj8fPY",
1632 | "outputId": "5ebaeec2-f484-4047-9766-026a3f53d730"
1633 | },
1634 | "outputs": [
1635 | {
1636 | "name": "stdout",
1637 | "output_type": "stream",
1638 | "text": [
1639 | "Loading model from file deepspeech-0.6.0-models/output_graph.pb\n",
1640 | "TensorFlow: v1.14.0-21-ge77504a\n",
1641 | "DeepSpeech: v0.6.0-0-g6d43e21\n",
1642 | "Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.\n",
1643 | "2020-01-30 00:27:46.675441: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\n",
1644 | "Loaded model in 0.13s.\n",
1645 | "Loading language model from files deepspeech-0.6.0-models/lm.binary ./deepspeech-0.6.0-models/trie\n",
1646 | "Loaded language model in 0.000221s.\n",
1647 | "Running inference.\n",
1648 | "experience proof less\n",
1649 | "Inference took 2.418s for 1.975s audio file.\n"
1650 | ]
1651 | }
1652 | ],
1653 | "source": [
1654 | "!deepspeech --model deepspeech-0.6.0-models/output_graph.pb --lm deepspeech-0.6.0-models/lm.binary --trie ./deepspeech-0.6.0-models/trie --audio ./audio/2830-3980-0043.wav"
1655 | ]
1656 | },
1657 | {
1658 | "cell_type": "code",
1659 | "execution_count": null,
1660 | "metadata": {
1661 | "colab": {
1662 | "base_uri": "https://localhost:8080/",
1663 | "height": 222
1664 | },
1665 | "id": "gvxm5RE68zu4",
1666 | "outputId": "84c877c7-d1fd-4bd9-ae96-56f63bf37dba"
1667 | },
1668 | "outputs": [
1669 | {
1670 | "name": "stdout",
1671 | "output_type": "stream",
1672 | "text": [
1673 | "Loading model from file deepspeech-0.6.0-models/output_graph.pb\n",
1674 | "TensorFlow: v1.14.0-21-ge77504a\n",
1675 | "DeepSpeech: v0.6.0-0-g6d43e21\n",
1676 | "Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.\n",
1677 | "2020-01-30 00:27:53.427469: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\n",
1678 | "Loaded model in 0.131s.\n",
1679 | "Loading language model from files deepspeech-0.6.0-models/lm.binary ./deepspeech-0.6.0-models/trie\n",
1680 | "Loaded language model in 0.000188s.\n",
1681 | "Running inference.\n",
1682 | "why should one halt on the way\n",
1683 | "Inference took 2.941s for 2.735s audio file.\n"
1684 | ]
1685 | }
1686 | ],
1687 | "source": [
1688 | "!deepspeech --model deepspeech-0.6.0-models/output_graph.pb --lm deepspeech-0.6.0-models/lm.binary --trie ./deepspeech-0.6.0-models/trie --audio ./audio/4507-16021-0012.wav"
1689 | ]
1690 | },
1691 | {
1692 | "cell_type": "code",
1693 | "execution_count": null,
1694 | "metadata": {
1695 | "colab": {
1696 | "base_uri": "https://localhost:8080/",
1697 | "height": 222
1698 | },
1699 | "id": "1Hq_tEFQ8254",
1700 | "outputId": "7f4a4720-72da-442a-ea4d-d7f08a66ec0f"
1701 | },
1702 | "outputs": [
1703 | {
1704 | "name": "stdout",
1705 | "output_type": "stream",
1706 | "text": [
1707 | "Loading model from file deepspeech-0.6.0-models/output_graph.pb\n",
1708 | "TensorFlow: v1.14.0-21-ge77504a\n",
1709 | "DeepSpeech: v0.6.0-0-g6d43e21\n",
1710 | "Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.\n",
1711 | "2020-01-30 00:28:00.365841: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\n",
1712 | "Loaded model in 0.129s.\n",
1713 | "Loading language model from files deepspeech-0.6.0-models/lm.binary ./deepspeech-0.6.0-models/trie\n",
1714 | "Loaded language model in 0.000228s.\n",
1715 | "Running inference.\n",
1716 | "your power is sufficient i said\n",
1717 | "Inference took 2.839s for 2.590s audio file.\n"
1718 | ]
1719 | }
1720 | ],
1721 | "source": [
1722 | "!deepspeech --model deepspeech-0.6.0-models/output_graph.pb --lm deepspeech-0.6.0-models/lm.binary --trie ./deepspeech-0.6.0-models/trie --audio ./audio/8455-210777-0068.wav"
1723 | ]
1724 | },
1725 | {
1726 | "cell_type": "markdown",
1727 | "metadata": {
1728 | "id": "PTcABJ2c9CRa"
1729 | },
1730 | "source": [
1731 | "## Create model object"
1732 | ]
1733 | },
1734 | {
1735 | "cell_type": "code",
1736 | "execution_count": null,
1737 | "metadata": {
1738 | "colab": {
1739 | "base_uri": "https://localhost:8080/",
1740 | "height": 34
1741 | },
1742 | "id": "tU41WTEr9G-X",
1743 | "outputId": "8c4f73ad-f61f-4467-a3fa-23ef5375de74"
1744 | },
1745 | "outputs": [
1746 | {
1747 | "data": {
1748 | "text/plain": [
1749 | "0"
1750 | ]
1751 | },
1752 | "execution_count": 27,
1753 | "metadata": {
1754 | "tags": []
1755 | },
1756 | "output_type": "execute_result"
1757 | }
1758 | ],
1759 | "source": [
1760 | "import deepspeech\n",
1761 | "\n",
1762 | "model_file_path = 'deepspeech-0.6.0-models/output_graph.pbmm'\n",
1763 | "beam_width = 500\n",
1764 | "model = deepspeech.Model(model_file_path, beam_width)\n",
1765 | "\n",
1766 | "# Add language model for better accuracy\n",
1767 | "lm_file_path = 'deepspeech-0.6.0-models/lm.binary'\n",
1768 | "trie_file_path = 'deepspeech-0.6.0-models/trie'\n",
1769 | "lm_alpha = 0.75\n",
1770 | "lm_beta = 1.85\n",
1771 | "model.enableDecoderWithLM(lm_file_path, trie_file_path, lm_alpha, lm_beta)"
1772 | ]
1773 | },
1774 | {
1775 | "cell_type": "markdown",
1776 | "metadata": {
1777 | "id": "gB4wl_9P9ilW"
1778 | },
1779 | "source": [
1780 | "## Batch API"
1781 | ]
1782 | },
1783 | {
1784 | "cell_type": "code",
1785 | "execution_count": null,
1786 | "metadata": {
1787 | "colab": {
1788 | "base_uri": "https://localhost:8080/",
1789 | "height": 168
1790 | },
1791 | "id": "MTaKt_rm9wY_",
1792 | "outputId": "8bc1dc02-3c8b-4a66-ddb4-b61f362167e0"
1793 | },
1794 | "outputs": [
1795 | {
1796 | "name": "stdout",
1797 | "output_type": "stream",
1798 | "text": [
1799 | "\n",
1800 | "audio file=\"audio/2830-3980-0043.wav\" expected text=\"experience proves this\"\n",
1801 | "deepspeech-batch-stt: \"experience proof less\"\n",
1802 | "\n",
1803 | "audio file=\"audio/4507-16021-0012.wav\" expected text=\"why should one halt on the way\"\n",
1804 | "deepspeech-batch-stt: \"why should one halt on the way\"\n",
1805 | "\n",
1806 | "audio file=\"audio/8455-210777-0068.wav\" expected text=\"your power is sufficient i said\"\n",
1807 | "deepspeech-batch-stt: \"your power is sufficient i said\"\n"
1808 | ]
1809 | }
1810 | ],
1811 | "source": [
1812 | "import numpy as np\n",
1813 | "\n",
1814 | "def deepspeech_batch_stt(filename: str, lang: str, encoding: str) -> str:\n",
1815 | " buffer, rate = read_wav_file(filename)\n",
1816 | " data16 = np.frombuffer(buffer, dtype=np.int16)\n",
1817 | " return model.stt(data16)\n",
1818 | "\n",
1819 | "# Run tests\n",
1820 | "for t in TESTCASES:\n",
1821 | " print('\\naudio file=\"{0}\" expected text=\"{1}\"'.format(t['filename'], t['text']))\n",
1822 | " print('deepspeech-batch-stt: \"{}\"'.format(\n",
1823 | " deepspeech_batch_stt(t['filename'], t['lang'], t['encoding'])\n",
1824 | " ))"
1825 | ]
1826 | },
1827 | {
1828 | "cell_type": "markdown",
1829 | "metadata": {
1830 | "id": "9v3jT8NR-qGb"
1831 | },
1832 | "source": [
1833 | "## Streaming API"
1834 | ]
1835 | },
1836 | {
1837 | "cell_type": "code",
1838 | "execution_count": null,
1839 | "metadata": {
1840 | "colab": {
1841 | "base_uri": "https://localhost:8080/",
1842 | "height": 454
1843 | },
1844 | "id": "EU7lHQ2A-svH",
1845 | "outputId": "8fc02288-a1a9-4709-ef25-bd42c4c99bf8"
1846 | },
1847 | "outputs": [
1848 | {
1849 | "name": "stdout",
1850 | "output_type": "stream",
1851 | "text": [
1852 | "\n",
1853 | "audio file=\"audio/2830-3980-0043.wav\" expected text=\"experience proves this\"\n",
1854 | "inetrim text: i\n",
1855 | "inetrim text: e\n",
1856 | "inetrim text: experi en\n",
1857 | "inetrim text: experience pro\n",
1858 | "inetrim text: experience proof les\n",
1859 | "deepspeech-streaming-stt: \"experience proof less\"\n",
1860 | "\n",
1861 | "audio file=\"audio/4507-16021-0012.wav\" expected text=\"why should one halt on the way\"\n",
1862 | "inetrim text: i\n",
1863 | "inetrim text: why shou\n",
1864 | "inetrim text: why should one\n",
1865 | "inetrim text: why should one haul\n",
1866 | "inetrim text: why should one halt \n",
1867 | "inetrim text: why should one halt on the \n",
1868 | "deepspeech-streaming-stt: \"why should one halt on the way\"\n",
1869 | "\n",
1870 | "audio file=\"audio/8455-210777-0068.wav\" expected text=\"your power is sufficient i said\"\n",
1871 | "inetrim text: i\n",
1872 | "inetrim text: your p\n",
1873 | "inetrim text: your power is\n",
1874 | "inetrim text: your power is suffi\n",
1875 | "inetrim text: your power is sufficient i\n",
1876 | "inetrim text: your power is sufficient i said\n",
1877 | "deepspeech-streaming-stt: \"your power is sufficient i said\"\n"
1878 | ]
1879 | }
1880 | ],
1881 | "source": [
1882 | "def deepspeech_streaming_stt(filename: str, lang: str, encoding: str) -> str:\n",
1883 | " buffer, rate = read_wav_file(filename)\n",
1884 | " audio_generator = simulate_stream(buffer)\n",
1885 | "\n",
1886 | " # Create stream\n",
1887 | " context = model.createStream()\n",
1888 | "\n",
1889 | " text = ''\n",
1890 | " for chunk in audio_generator:\n",
1891 | " data16 = np.frombuffer(chunk, dtype=np.int16)\n",
1892 | " # feed stream of chunks\n",
1893 | " model.feedAudioContent(context, data16)\n",
1894 | " interim_text = model.intermediateDecode(context)\n",
1895 | " if interim_text != text:\n",
1896 | " text = interim_text\n",
1897 | " print('inetrim text: {}'.format(text))\n",
1898 | "\n",
1899 | " # get final resut and close stream\n",
1900 | " text = model.finishStream(context)\n",
1901 | " return text\n",
1902 | "\n",
1903 | "# Run tests\n",
1904 | "for t in TESTCASES:\n",
1905 | " print('\\naudio file=\"{0}\" expected text=\"{1}\"'.format(t['filename'], t['text']))\n",
1906 | " print('deepspeech-streaming-stt: \"{}\"'.format(\n",
1907 | " deepspeech_streaming_stt(t['filename'], t['lang'], t['encoding'])\n",
1908 | " ))"
1909 | ]
1910 | },
1911 | {
1912 | "cell_type": "markdown",
1913 | "metadata": {
1914 | "id": "3aqlb4wEcdOx"
1915 | },
1916 | "source": [
1917 | "\n",
1918 | "---\n",
1919 | "\n",
1920 | "# SpeechRecognition Package\n",
1921 | "\n",
1922 | "The [SpeechRecognition](https://pypi.org/project/SpeechRecognition/) package provide a nice abstraction over several solutions. In this notebook we explore using CMU Sphinx (i.e. model running locally on the machine), and Google (i.e. service accessed over the network/cloud), but both through SpeechRecognition package APIs."
1923 | ]
1924 | },
1925 | {
1926 | "cell_type": "markdown",
1927 | "metadata": {
1928 | "id": "QpxAVH5OmPtn"
1929 | },
1930 | "source": [
1931 | "## Setup\n",
1932 | "\n",
1933 | "We need to install SpeechRecognition and pocketsphinx python packages, and download some files to test these APIs.\n",
1934 | "\n",
1935 | "1. **Install SpeechRecognition py package**"
1936 | ]
1937 | },
1938 | {
1939 | "cell_type": "code",
1940 | "execution_count": null,
1941 | "metadata": {
1942 | "colab": {
1943 | "base_uri": "https://localhost:8080/",
1944 | "height": 121
1945 | },
1946 | "id": "kJ0rokUuby2i",
1947 | "outputId": "c0d99348-92e9-49f7-edf0-20493983a1e8"
1948 | },
1949 | "outputs": [
1950 | {
1951 | "name": "stdout",
1952 | "output_type": "stream",
1953 | "text": [
1954 | "Collecting SpeechRecognition\n",
1955 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/26/e1/7f5678cd94ec1234269d23756dbdaa4c8cfaed973412f88ae8adf7893a50/SpeechRecognition-3.8.1-py2.py3-none-any.whl (32.8MB)\n",
1956 | "\u001b[K |████████████████████████████████| 32.8MB 92kB/s \n",
1957 | "\u001b[?25hInstalling collected packages: SpeechRecognition\n",
1958 | "Successfully installed SpeechRecognition-3.8.1\n"
1959 | ]
1960 | }
1961 | ],
1962 | "source": [
1963 | "!pip3 install SpeechRecognition"
1964 | ]
1965 | },
1966 | {
1967 | "cell_type": "markdown",
1968 | "metadata": {
1969 | "id": "TBjNf3GoTU1l"
1970 | },
1971 | "source": [
1972 | "Pocketsphinx has already been installed in earlier sections."
1973 | ]
1974 | },
1975 | {
1976 | "cell_type": "markdown",
1977 | "metadata": {
1978 | "id": "piIB_P7CXey4"
1979 | },
1980 | "source": [
1981 | "## Batch API\n",
1982 | "\n",
1983 | "SpeechRecognition has only batch API. First step to create an audio record, eithher from a file or from mic, and the second step is to call `recognize_` function. It currently has APIs for [CMU Sphinx, Google, Microsoft, IBM, Houndify, and Wit](https://github.com/Uberi/speech_recognition)."
1984 | ]
1985 | },
1986 | {
1987 | "cell_type": "code",
1988 | "execution_count": null,
1989 | "metadata": {
1990 | "colab": {
1991 | "base_uri": "https://localhost:8080/",
1992 | "height": 218
1993 | },
1994 | "id": "0aia5lFgb-vV",
1995 | "outputId": "bdf84ea8-98f0-43b9-e5f5-305c9745795e"
1996 | },
1997 | "outputs": [
1998 | {
1999 | "name": "stdout",
2000 | "output_type": "stream",
2001 | "text": [
2002 | "\n",
2003 | "audio file=\"audio/2830-3980-0043.wav\" expected text=\"experience proves this\"\n",
2004 | "sphinx: \"experience proves that\"\n",
2005 | "google: \"experience proves this\"\n",
2006 | "\n",
2007 | "audio file=\"audio/4507-16021-0012.wav\" expected text=\"why should one halt on the way\"\n",
2008 | "sphinx: \"why should one hold on the way\"\n",
2009 | "google: \"why should one halt on the way\"\n",
2010 | "\n",
2011 | "audio file=\"audio/8455-210777-0068.wav\" expected text=\"your power is sufficient i said\"\n",
2012 | "sphinx: \"your paris official said\"\n",
2013 | "google: \"your power is sufficient I said\"\n"
2014 | ]
2015 | }
2016 | ],
2017 | "source": [
2018 | "import speech_recognition as sr\n",
2019 | "from enum import Enum, unique\n",
2020 | "\n",
2021 | "@unique\n",
2022 | "class ASREngine(Enum):\n",
2023 | " sphinx = 0\n",
2024 | " google = 1\n",
2025 | "\n",
2026 | "def speech_to_text(filename: str, engine: ASREngine, language: str, show_all: bool = False) -> str:\n",
2027 | " r = sr.Recognizer()\n",
2028 | "\n",
2029 | " with sr.AudioFile(filename) as source:\n",
2030 | " audio = r.record(source)\n",
2031 | "\n",
2032 | " asr_functions = {\n",
2033 | " ASREngine.sphinx: r.recognize_sphinx,\n",
2034 | " ASREngine.google: r.recognize_google,\n",
2035 | " }\n",
2036 | "\n",
2037 | " response = asr_functions[engine](audio, language=language, show_all=show_all)\n",
2038 | " return response\n",
2039 | "\n",
2040 | "# Run tests\n",
2041 | "for t in TESTCASES:\n",
2042 | " filename = t['filename']\n",
2043 | " text = t['text']\n",
2044 | " lang = t['lang']\n",
2045 | "\n",
2046 | " print('\\naudio file=\"{0}\" expected text=\"{1}\"'.format(filename, text))\n",
2047 | " for asr_engine in ASREngine:\n",
2048 | " try:\n",
2049 | " response = speech_to_text(filename, asr_engine, language=lang)\n",
2050 | " print('{0}: \"{1}\"'.format(asr_engine.name, response))\n",
2051 | " except sr.UnknownValueError:\n",
2052 | " print('{0} could not understand audio'.format(asr_engine.name))\n",
2053 | " except sr.RequestError as e:\n",
2054 | " print('{0} error: {0}'.format(asr_engine.name, e))"
2055 | ]
2056 | },
2057 | {
2058 | "cell_type": "markdown",
2059 | "metadata": {
2060 | "id": "66lLoLCaL_nE"
2061 | },
2062 | "source": [
2063 | "### API for other providers\n",
2064 | "\n",
2065 | "For other speech recognition providers, you will need to create API credentials, which you have to pass to `recognize_` function, you can checkout [this example](https://github.com/Uberi/speech_recognition/blob/master/examples/audio_transcribe.py).\n",
2066 | "\n",
2067 | "It also has a nice abstraction for Microphone, implemented over PyAudio/PortAudio. Here is an example to capture input from mic in [batch](https://github.com/Uberi/speech_recognition/blob/master/examples/microphone_recognition.py) and continously in [background](https://github.com/Uberi/speech_recognition/blob/master/examples/background_listening.py)."
2068 | ]
2069 | },
2070 | {
2071 | "cell_type": "markdown",
2072 | "metadata": {
2073 | "id": "cTfKgcgF0uzz"
2074 | },
2075 | "source": [
2076 | "---\n",
2077 | "\n",
2078 | "# Summary\n",
2079 | "\n",
2080 | "This note covers various available speech recognition:\n",
2081 | "\n",
2082 | "- services: Google, Azure, Watson\n",
2083 | "- software: CMU Sphinx, Mozilla DeepSpeech\n",
2084 | "\n",
2085 | "All of these have two kind of Speech-to-Text APIs:\n",
2086 | "\n",
2087 | "- batch: the audio data is fed in one go\n",
2088 | "- streaming: the audio data is fed in chunks (very useful for transcribing microphone input)\n",
2089 | "\n",
2090 | "The Python SpeechRecognition package provides abstraction over several speech recognition services and softwares.\n",
2091 | "\n",
2092 | "I hope to include following in future:\n",
2093 | "\n",
2094 | "- services: [Amazon Transcribe](https://aws.amazon.com/transcribe/), and [Nuance](https://nuancedev.github.io/samples/http/python/)\n",
2095 | "- software: [Kaldi](https://pykaldi.github.io/), and [Facebook wav2letter](https://ai.facebook.com/blog/online-speech-recognition-with-wav2letteranywhere/)\n",
2096 | "\n",
2097 | "Copyright © 2020 Satish Chandra Gupta .
\n",
2101 | " CC BY-NC-SA 4.0 International License.
"
2102 | ]
2103 | }
2104 | ],
2105 | "metadata": {
2106 | "accelerator": "GPU",
2107 | "colab": {
2108 | "authorship_tag": "ABX9TyOugDdFcqekLlzo1yrW03ry",
2109 | "collapsed_sections": [],
2110 | "include_colab_link": true,
2111 | "name": "python_speech_recognition_notebook.ipynb",
2112 | "provenance": [],
2113 | "toc_visible": true
2114 | },
2115 | "kernelspec": {
2116 | "display_name": "Python 3.7.12 64-bit ('kaggle')",
2117 | "language": "python",
2118 | "name": "python3"
2119 | },
2120 | "language_info": {
2121 | "name": "python",
2122 | "version": "3.7.12"
2123 | },
2124 | "vscode": {
2125 | "interpreter": {
2126 | "hash": "180997e3444791da3f2b3061c2f2c1b4404ea4925238c499191fa40f3054d99b"
2127 | }
2128 | }
2129 | },
2130 | "nbformat": 4,
2131 | "nbformat_minor": 0
2132 | }
2133 |
--------------------------------------------------------------------------------
