├── .directory
├── .gitignore
├── .idea
├── encodings.xml
├── misc.xml
├── modules.xml
├── two-stream-action-recognition.iml
└── vcs.xml
├── Action Recognition Walkthrough.ipynb
├── LICENSE
├── Live_Demo_Two_steam_net.ipynb
├── UCF_list
├── classInd.txt
├── testlist01.txt
├── testlist02.txt
├── testlist03.txt
├── trainlist01.txt
├── trainlist02.txt
└── trainlist03.txt
├── average_fusion_demo.py
├── configs
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-36.pyc
│ └── spatial_configs.cpython-36.pyc
├── motion_configs.py
└── spatial_configs.py
├── evaluate_streams.py
├── evaluation
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-36.pyc
│ └── evaluation.cpython-36.pyc
└── evaluation.py
├── frame_dataloader
├── UCF_splitting_kernel.py
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-36.pyc
│ ├── motion_dataloader.cpython-36.pyc
│ ├── spatial_dataloader.cpython-36.pyc
│ ├── visual_motion_feature_dataloader.cpython-36.pyc
│ └── visual_spatial_feature_dataloader.cpython-36.pyc
├── dic
│ └── frame_count.pickle
├── helpers.py
├── motion_dataloader.py
├── spatial_dataloader.py
├── visual_motion_feature_dataloader.py
└── visual_spatial_feature_dataloader.py
├── generate_motion_feature_dataset.py
├── generate_spatial_feature_dataset.py
├── models
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-36.pyc
│ └── spatial_models.cpython-36.pyc
├── motion_models.py
└── spatial_models.py
├── motion_trainer.py
├── readme.md
├── recurrent_fusion_trainer.py
├── spatial_trainer.py
├── testing video samples
├── v_Archery_g02_c02.avi
├── v_BabyCrawling_g18_c06.avi
├── v_BabyCrawling_g19_c01.avi
├── v_BalanceBeam_g08_c03.avi
├── v_BalanceBeam_g13_c05.avi
├── v_BasketballDunk_g22_c04.avi
├── v_BenchPress_g01_c03.avi
├── v_Biking_g01_c04.avi
├── v_Biking_g10_c02.avi
├── v_Biking_g19_c01.avi
├── v_Biking_g20_c06.avi
├── v_Billiards_g15_c01.avi
├── v_BlowDryHair_g07_c02.avi
├── v_BlowDryHair_g13_c03.avi
├── v_BodyWeightSquats_g01_c03.avi
├── v_BodyWeightSquats_g04_c03.avi
├── v_Bowling_g22_c04.avi
├── v_BoxingPunchingBag_g01_c01.avi
├── v_BoxingPunchingBag_g18_c03.avi
├── v_BoxingSpeedBag_g04_c04.avi
├── v_BoxingSpeedBag_g09_c01.avi
├── v_BoxingSpeedBag_g12_c04.avi
├── v_BoxingSpeedBag_g23_c04.avi
├── v_BreastStroke_g03_c03.avi
├── v_BrushingTeeth_g17_c02.avi
├── v_BrushingTeeth_g20_c03.avi
├── v_CliffDiving_g02_c03.avi
├── v_CricketBowling_g02_c01.avi
├── v_CuttingInKitchen_g20_c04.avi
├── v_CuttingInKitchen_g25_c05.avi
├── v_Diving_g02_c02.avi
├── v_Diving_g03_c07.avi
├── v_Diving_g04_c04.avi
├── v_Diving_g16_c04.avi
├── v_Diving_g20_c04.avi
├── v_Fencing_g15_c01.avi
├── v_Fencing_g15_c04.avi
├── v_FieldHockeyPenalty_g11_c03.avi
├── v_FieldHockeyPenalty_g13_c03.avi
├── v_FrontCrawl_g23_c04.avi
├── v_Haircut_g07_c01.avi
├── v_HammerThrow_g10_c03.avi
├── v_HammerThrow_g23_c05.avi
├── v_Hammering_g12_c03.avi
├── v_Hammering_g17_c05.avi
├── v_HighJump_g02_c01.avi
├── v_HighJump_g19_c05.avi
├── v_HorseRace_g24_c05.avi
├── v_JavelinThrow_g05_c05.avi
├── v_JavelinThrow_g21_c03.avi
├── v_JavelinThrow_g22_c01.avi
├── v_JavelinThrow_g23_c04.avi
├── v_JavelinThrow_g24_c01.avi
├── v_Kayaking_g12_c03.avi
├── v_Knitting_g20_c01.avi
├── v_LongJump_g04_c03.avi
├── v_LongJump_g15_c02.avi
├── v_LongJump_g15_c03.avi
├── v_MoppingFloor_g03_c03.avi
├── v_PizzaTossing_g01_c04.avi
├── v_PizzaTossing_g14_c04.avi
├── v_PizzaTossing_g18_c01.avi
├── v_PlayingCello_g02_c03.avi
├── v_PlayingDaf_g10_c01.avi
├── v_PlayingDhol_g17_c06.avi
├── v_PlayingFlute_g05_c02.avi
├── v_PlayingGuitar_g22_c04.avi
├── v_PlayingTabla_g14_c02.avi
├── v_PoleVault_g04_c02.avi
├── v_PommelHorse_g17_c03.avi
├── v_Punch_g22_c07.avi
├── v_RockClimbingIndoor_g09_c04.avi
├── v_RockClimbingIndoor_g11_c02.avi
├── v_RockClimbingIndoor_g25_c03.avi
├── v_RopeClimbing_g01_c02.avi
├── v_RopeClimbing_g04_c01.avi
├── v_Rowing_g14_c04.avi
├── v_Rowing_g24_c01.avi
├── v_SalsaSpin_g12_c03.avi
├── v_ShavingBeard_g03_c05.avi
├── v_ShavingBeard_g24_c02.avi
├── v_Shotput_g13_c03.avi
├── v_Skiing_g14_c03.avi
├── v_Skijet_g07_c02.avi
├── v_SkyDiving_g05_c04.avi
├── v_SoccerPenalty_g17_c04.avi
├── v_StillRings_g03_c01.avi
├── v_StillRings_g18_c01.avi
├── v_Surfing_g05_c04.avi
├── v_Surfing_g17_c07.avi
├── v_Swing_g14_c04.avi
├── v_TennisSwing_g14_c03.avi
├── v_ThrowDiscus_g02_c04.avi
├── v_Typing_g16_c03.avi
├── v_VolleyballSpiking_g17_c02.avi
├── v_WalkingWithDog_g15_c01.avi
├── v_WallPushups_g01_c04.avi
├── v_WallPushups_g04_c02.avi
├── v_WritingOnBoard_g11_c02.avi
└── v_YoYo_g25_c03.avi
├── upload.sh
└── utils
├── __init__.py
├── __pycache__
├── __init__.cpython-36.pyc
├── drive_manager.cpython-36.pyc
├── training_utils.cpython-36.pyc
└── zip_manager.cpython-36.pyc
├── drive_manager.py
├── training_utils.py
└── zip_manager.py
/.directory:
--------------------------------------------------------------------------------
1 | [Dolphin]
2 | Timestamp=2018,11,14,20,45,31
3 | Version=4
4 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | ./**/__pycache__/
2 |
3 |
4 | # Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
5 | # Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
6 |
7 | .idea/**
8 |
9 | # User-specific stuff
10 | .idea/**/workspace.xml
11 | .idea/**/tasks.xml
12 | .idea/**/usage.statistics.xml
13 | .idea/**/dictionaries
14 | .idea/**/shelf
15 |
16 | # Generated files
17 | .idea/**/contentModel.xml
18 |
19 | # Sensitive or high-churn files
20 | .idea/**/dataSources/
21 | .idea/**/dataSources.ids
22 | .idea/**/dataSources.local.xml
23 | .idea/**/sqlDataSources.xml
24 | .idea/**/dynamic.xml
25 | .idea/**/uiDesigner.xml
26 | .idea/**/dbnavigator.xml
27 |
28 | # Gradle
29 | .idea/**/gradle.xml
30 | .idea/**/libraries
31 |
32 | # Gradle and Maven with auto-import
33 | # When using Gradle or Maven with auto-import, you should exclude module files,
34 | # since they will be recreated, and may cause churn. Uncomment if using
35 | # auto-import.
36 | # .idea/modules.xml
37 | # .idea/*.iml
38 | # .idea/modules
39 | # *.iml
40 | # *.ipr
41 |
42 | # CMake
43 | cmake-build-*/
44 |
45 | # Mongo Explorer plugin
46 | .idea/**/mongoSettings.xml
47 |
48 | # File-based project format
49 | *.iws
50 |
51 | # IntelliJ
52 | out/
53 |
54 | # mpeltonen/sbt-idea plugin
55 | .idea_modules/
56 |
57 | # JIRA plugin
58 | atlassian-ide-plugin.xml
59 |
60 | # Cursive Clojure plugin
61 | .idea/replstate.xml
62 |
63 | # Crashlytics plugin (for Android Studio and IntelliJ)
64 | com_crashlytics_export_strings.xml
65 | crashlytics.properties
66 | crashlytics-build.properties
67 | fabric.properties
68 |
69 | # Editor-based Rest Client
70 | .idea/httpRequests
71 |
72 | # Android studio 3.1+ serialized cache file
73 | .idea/caches/build_file_checksums.ser
74 |
75 |
76 |
77 | # Byte-compiled / optimized / DLL files
78 | __pycache__/
79 | *.py[cod]
80 | *$py.class
81 |
82 | # C extensions
83 | *.so
84 |
85 | # Distribution / packaging
86 | .Python
87 | build/
88 | develop-eggs/
89 | dist/
90 | downloads/
91 | eggs/
92 | .eggs/
93 | lib/
94 | lib64/
95 | parts/
96 | sdist/
97 | var/
98 | wheels/
99 | pip-wheel-metadata/
100 | share/python-wheels/
101 | *.egg-info/
102 | .installed.cfg
103 | *.egg
104 | MANIFEST
105 |
106 | # PyInstaller
107 | # Usually these files are written by a python script from a template
108 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
109 | *.manifest
110 | *.spec
111 |
112 | # Installer logs
113 | pip-log.txt
114 | pip-delete-this-directory.txt
115 |
116 | # Unit test / coverage reports
117 | htmlcov/
118 | .tox/
119 | .nox/
120 | .coverage
121 | .coverage.*
122 | .cache
123 | nosetests.xml
124 | coverage.xml
125 | *.cover
126 | .hypothesis/
127 | .pytest_cache/
128 |
129 | # Translations
130 | *.mo
131 | *.pot
132 |
133 | # Django stuff:
134 | *.log
135 | local_settings.py
136 | db.sqlite3
137 | db.sqlite3-journal
138 |
139 | # Flask stuff:
140 | instance/
141 | .webassets-cache
142 |
143 | # Scrapy stuff:
144 | .scrapy
145 |
146 | # Sphinx documentation
147 | docs/_build/
148 |
149 | # PyBuilder
150 | target/
151 |
152 | # Jupyter Notebook
153 | .ipynb_checkpoints
154 |
155 | # IPython
156 | profile_default/
157 | ipython_config.py
158 |
159 | # pyenv
160 | .python-version
161 |
162 | # pipenv
163 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
164 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
165 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
166 | # install all needed dependencies.
167 | #Pipfile.lock
168 |
169 | # celery beat schedule file
170 | celerybeat-schedule
171 |
172 | # SageMath parsed files
173 | *.sage.py
174 |
175 | # Environments
176 | .env
177 | .venv
178 | env/
179 | venv/
180 | ENV/
181 | env.bak/
182 | venv.bak/
183 |
184 | # Spyder project settings
185 | .spyderproject
186 | .spyproject
187 |
188 | # Rope project settings
189 | .ropeproject
190 |
191 | # mkdocs documentation
192 | /site
193 |
194 | # mypy
195 | .mypy_cache/
196 | .dmypy.json
197 | dmypy.json
198 |
199 | # Pyre type checker
200 | .pyre/
201 |
202 |
203 |
204 |
--------------------------------------------------------------------------------
/.idea/encodings.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/two-stream-action-recognition.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/UCF_list/classInd.txt:
--------------------------------------------------------------------------------
1 | 1 ApplyEyeMakeup
2 | 2 ApplyLipstick
3 | 3 Archery
4 | 4 BabyCrawling
5 | 5 BalanceBeam
6 | 6 BandMarching
7 | 7 BaseballPitch
8 | 8 Basketball
9 | 9 BasketballDunk
10 | 10 BenchPress
11 | 11 Biking
12 | 12 Billiards
13 | 13 BlowDryHair
14 | 14 BlowingCandles
15 | 15 BodyWeightSquats
16 | 16 Bowling
17 | 17 BoxingPunchingBag
18 | 18 BoxingSpeedBag
19 | 19 BreastStroke
20 | 20 BrushingTeeth
21 | 21 CleanAndJerk
22 | 22 CliffDiving
23 | 23 CricketBowling
24 | 24 CricketShot
25 | 25 CuttingInKitchen
26 | 26 Diving
27 | 27 Drumming
28 | 28 Fencing
29 | 29 FieldHockeyPenalty
30 | 30 FloorGymnastics
31 | 31 FrisbeeCatch
32 | 32 FrontCrawl
33 | 33 GolfSwing
34 | 34 Haircut
35 | 35 Hammering
36 | 36 HammerThrow
37 | 37 HandstandPushups
38 | 38 HandstandWalking
39 | 39 HeadMassage
40 | 40 HighJump
41 | 41 HorseRace
42 | 42 HorseRiding
43 | 43 HulaHoop
44 | 44 IceDancing
45 | 45 JavelinThrow
46 | 46 JugglingBalls
47 | 47 JumpingJack
48 | 48 JumpRope
49 | 49 Kayaking
50 | 50 Knitting
51 | 51 LongJump
52 | 52 Lunges
53 | 53 MilitaryParade
54 | 54 Mixing
55 | 55 MoppingFloor
56 | 56 Nunchucks
57 | 57 ParallelBars
58 | 58 PizzaTossing
59 | 59 PlayingCello
60 | 60 PlayingDaf
61 | 61 PlayingDhol
62 | 62 PlayingFlute
63 | 63 PlayingGuitar
64 | 64 PlayingPiano
65 | 65 PlayingSitar
66 | 66 PlayingTabla
67 | 67 PlayingViolin
68 | 68 PoleVault
69 | 69 PommelHorse
70 | 70 PullUps
71 | 71 Punch
72 | 72 PushUps
73 | 73 Rafting
74 | 74 RockClimbingIndoor
75 | 75 RopeClimbing
76 | 76 Rowing
77 | 77 SalsaSpin
78 | 78 ShavingBeard
79 | 79 Shotput
80 | 80 SkateBoarding
81 | 81 Skiing
82 | 82 Skijet
83 | 83 SkyDiving
84 | 84 SoccerJuggling
85 | 85 SoccerPenalty
86 | 86 StillRings
87 | 87 SumoWrestling
88 | 88 Surfing
89 | 89 Swing
90 | 90 TableTennisShot
91 | 91 TaiChi
92 | 92 TennisSwing
93 | 93 ThrowDiscus
94 | 94 TrampolineJumping
95 | 95 Typing
96 | 96 UnevenBars
97 | 97 VolleyballSpiking
98 | 98 WalkingWithDog
99 | 99 WallPushups
100 | 100 WritingOnBoard
101 | 101 YoYo
102 |
--------------------------------------------------------------------------------
/average_fusion_demo.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | this is a demo fusion of the output predictions of the two streams (the softmax outputs are summed and used for the final score)
6 | those predictions are obtained from the model trained on colab
7 | """
8 | import pickle
9 |
10 | from evaluation.evaluation import video_level_eval
11 | from frame_dataloader import DataUtil
12 |
13 |
14 | def eval_pickles(pickle_files, weights):
15 | if not isinstance(pickle_files, list):
16 | pickle_files = [pickle_files]
17 |
18 | initialized = False
19 | test_video_level_preds = {}
20 | testing_samples_per_video = 0
21 | for index, pickle_file in enumerate(pickle_files):
22 | with open(pickle_file, 'rb') as f:
23 | test_video_level_preds_, testing_samples_per_video_ = pickle.load(f)
24 | if initialized:
25 | if testing_samples_per_video_ != testing_samples_per_video or len(test_video_level_preds) != len(test_video_level_preds_) or set(test_video_level_preds.keys()) != set(test_video_level_preds_.keys()):
26 | print("Pickles doesn't match")
27 | return
28 | else:
29 | for key in test_video_level_preds:
30 | test_video_level_preds[key] += weights[index] * test_video_level_preds_[key]
31 | else:
32 | initialized = True
33 | test_video_level_preds = test_video_level_preds_
34 | for key in test_video_level_preds_:
35 | test_video_level_preds_[key] *= weights[index]
36 | testing_samples_per_video = testing_samples_per_video_
37 |
38 | for key in test_video_level_preds:
39 | test_video_level_preds[key] /= len(pickle_files)
40 |
41 | data_util = DataUtil(path='./UCF_list/', split='01')
42 | _, test_video_to_label_ = data_util.get_train_test_video_to_label_mapping()
43 |
44 | video_level_loss, video_level_accuracy_1, video_level_accuracy_5 = video_level_eval(test_video_level_preds=test_video_level_preds,
45 | test_video_level_label=test_video_to_label_,
46 | testing_samples_per_video=testing_samples_per_video)
47 |
48 | print("prec@1", video_level_accuracy_1, "prec@5", video_level_accuracy_5, "loss", video_level_loss)
49 |
50 |
51 | if __name__ == '__main__':
52 | # Epoch 10 prec@1 0.86122125 prec@5 0.9698652 loss 0.52952474
53 | eval_pickles("../pickles/mot-xception-adam-5e-05-imnet-0.84140.preds", [1])
54 | eval_pickles("../pickles/spa-xception-adam-5e-05-imnet-0.86122.preds", [1])
55 | print("")
56 | eval_pickles("../pickles/mot-xception-adam-5e-05-imnet-0.84140.preds", [5])
57 | eval_pickles("../pickles/spa-xception-adam-5e-05-imnet-0.86122.preds", [5])
58 | print("")
59 | eval_pickles(["../pickles/mot-xception-adam-5e-05-imnet-0.84140.preds"] * 10, [1] * 10)
60 | eval_pickles(["../pickles/spa-xception-adam-5e-05-imnet-0.86122.preds"] * 10, [1] * 10)
61 | print("")
62 | eval_pickles(["../pickles/mot-xception-adam-5e-05-imnet-0.84192.preds", "../pickles/spa-xception-adam-5e-05-imnet-0.86122.preds"], [1] * 2)
63 | eval_pickles(["../pickles/mot-xception-adam-5e-05-imnet-0.84192.preds", "../pickles/spa-xception-adam-5e-06-imnet-0.85964.preds"], [1] * 2)
64 | eval_pickles(["../pickles/mot-xception-adam-5e-05-imnet-0.84192.preds", "../pickles/spa-xception-adam-5e-06-imnet-0.86016.preds"], [1] * 2)
65 | # eval_model_from_disk("spatial.h5", spatial=True, testing_samples_per_video=19)
66 | # eval_model_from_disk("motion.h5", spatial=False, testing_samples_per_video=19)
67 |
--------------------------------------------------------------------------------
/configs/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | """
--------------------------------------------------------------------------------
/configs/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/configs/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/configs/__pycache__/spatial_configs.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/configs/__pycache__/spatial_configs.cpython-36.pyc
--------------------------------------------------------------------------------
/configs/motion_configs.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Configs for motion trainer
6 | comment/uncomment one of these blocks
7 | this includes: pretrained and from scratch resnet/xception/vgg19/mobile net hyper parameters
8 | """
9 | ###############################################################################
10 | """ medium,adam,pretrained,5e-5,resnet """
11 | # is_adam = True
12 | # pretrained = True
13 | # testing_samples_per_video = 19
14 | # lr = 5e-5
15 | # model_name = "resnet" # resnet xception vgg mobilenet
16 | # epochs = 100
17 | # validate_every = 5
18 | # stacked_frames = 10
19 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
20 | ###############################################################################
21 | """ medium,sgd,pretrained,5e-5,resnet """
22 | # is_adam = False
23 | # pretrained = True
24 | # testing_samples_per_video = 19
25 | # lr = 5e-5
26 | # model_name = "resnet" # resnet xception vgg mobilenet
27 | # epochs = 100
28 | # validate_every = 5
29 | # stacked_frames = 10
30 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
31 | ###############################################################################
32 | """ medium,adam,scratch,5e-5,resnet """
33 | # is_adam = True
34 | # pretrained = False
35 | # testing_samples_per_video = 19
36 | # lr = 5e-5
37 | # model_name = "resnet" # resnet xception vgg mobilenet
38 | # epochs = 100
39 | # validate_every = 5
40 | # stacked_frames = 10
41 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
42 | ###############################################################################
43 | """ medium,adam,pretrained,5e-5,xception """
44 | # is_adam = True
45 | # pretrained = True
46 | # testing_samples_per_video = 19
47 | # lr = 5e-5
48 | # model_name = "xception" # resnet xception vgg mobilenet
49 | # epochs = 200
50 | # validate_every = 5
51 | # stacked_frames = 10
52 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
53 | ###############################################################################
54 | """ medium,sgd,pretrained,5e-5,xception """
55 | # is_adam = False
56 | # pretrained = True
57 | # testing_samples_per_video = 19
58 | # lr = 5e-5
59 | # model_name = "xception" # resnet xception vgg mobilenet
60 | # epochs = 100
61 | # validate_every = 5
62 | # stacked_frames = 10
63 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
64 | ###############################################################################
65 | """ medium,adam,pretrained,5e-6,xception"""
66 | # is_adam = True
67 | # pretrained = True
68 | # testing_samples_per_video = 19
69 | # lr = 5e-6
70 | # model_name = "xception" # resnet xception vgg mobilenet
71 | # epochs = 350
72 | # validate_every = 5
73 | # stacked_frames = 10
74 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
75 | ###############################################################################
76 | """ heavy,adam,pretrained,10e-6,xception"""
77 | is_adam = True
78 | pretrained = True
79 | testing_samples_per_video = 19
80 | lr = 10e-6
81 | model_name = "xception" # resnet xception vgg mobilenet
82 | epochs = 350
83 | validate_every = 1
84 | stacked_frames = 10
85 | augmenter_level = 0 # 0 heavy , 1 medium,2 simple
86 | ###############################################################################
87 | """ medium,sgd,pretrained,5e-6,xception"""
88 | # is_adam = False
89 | # pretrained = True
90 | # testing_samples_per_video = 19
91 | # lr = 5e-6
92 | # model_name = "xception" # resnet xception vgg mobilenet
93 | # epochs = 100
94 | # validate_every = 5
95 | # stacked_frames = 10
96 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
97 |
--------------------------------------------------------------------------------
/configs/spatial_configs.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Configs for spatial trainer
6 | comment/uncomment one of these blocks
7 | this includes: pretrained and from scratch resnet/xception/vgg19/mobile net hyper parameters
8 | """
9 | ###############################################################################
10 | """ medium,adam,pretrained,5e-5,resnet 80 ~ 81.2%"""
11 | # is_adam = True
12 | # pretrained = True
13 | # testing_samples_per_video = 19
14 | # lr = 5e-5
15 | # model_name = "resnet" # resnet xception vgg mobilenet
16 | # epochs = 100
17 | # validate_every = 5
18 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
19 | ###############################################################################
20 | """ medium,sgd,pretrained,5e-5,resnet 78.5 ~ 80"""
21 | # is_adam = False
22 | # pretrained = True
23 | # testing_samples_per_video = 19
24 | # lr = 5e-5
25 | # model_name = "resnet" # resnet xception vgg mobilenet
26 | # epochs = 100
27 | # validate_every = 5
28 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
29 | ###############################################################################
30 | """ medium,adam,scratch,5e-5,resnet 0.42215174"""
31 | # is_adam = True
32 | # pretrained = False
33 | # testing_samples_per_video = 19
34 | # lr = 5e-5
35 | # model_name = "resnet" # resnet xception vgg mobilenet
36 | # epochs = 100
37 | # validate_every = 5
38 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
39 | ###############################################################################
40 | """ medium,adam,pretrained,5e-5,xception 86.12%"""
41 | # is_adam = True
42 | # pretrained = True
43 | # testing_samples_per_video = 19
44 | # lr = 5e-5
45 | # model_name = "xception" # resnet xception vgg mobilenet
46 | # epochs = 100
47 | # validate_every = 5
48 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
49 | ###############################################################################
50 | """ medium,sgd,pretrained,5e-5,xception 82%"""
51 | # is_adam = False
52 | # pretrained = True
53 | # testing_samples_per_video = 19
54 | # lr = 5e-5
55 | # model_name = "xception" # resnet xception vgg mobilenet
56 | # epochs = 100
57 | # validate_every = 5
58 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
59 | # ###############################################################################
60 | # """ medium,adam,pretrained,5e-6,xception"""
61 | # is_adam = True
62 | # pretrained = True
63 | # testing_samples_per_video = 19
64 | # lr = 5e-6
65 | # model_name = "xception" # resnet xception vgg mobilenet
66 | # epochs = 175
67 | # validate_every = 5
68 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
69 | # ###############################################################################
70 | """ heavy,adam,pretrained,10e-6,xception"""
71 | is_adam = True
72 | pretrained = True
73 | testing_samples_per_video = 19
74 | lr = 10e-6
75 | model_name = "xception" # resnet xception vgg mobilenet
76 | epochs = 175
77 | validate_every = 1
78 | augmenter_level = 0 # 0 heavy , 1 medium,2 simple
79 | ###############################################################################
80 | """ medium,sgd,pretrained,5e-6,xception"""
81 | # is_adam = False
82 | # pretrained = True
83 | # testing_samples_per_video = 19
84 | # lr = 5e-6
85 | # model_name = "xception" # resnet xception vgg mobilenet
86 | # epochs = 100
87 | # validate_every = 5
88 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
89 | ###############################################################################
90 | """ medium,adam,pretrained,5e-5,vgg"""
91 | # is_adam = True
92 | # pretrained = True
93 | # testing_samples_per_video = 19
94 | # lr = 5e-5
95 | # model_name = "vgg" # resnet xception vgg mobilenet
96 | # epochs = 100
97 | # validate_every = 5
98 | # augmenter_level = 1 # 0 heavy , 1 medium,2 simple
99 |
--------------------------------------------------------------------------------
/evaluate_streams.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Evaluate motion and spatial streams
6 | """
7 | import frame_dataloader
8 | from evaluation import legacy_load_model, get_batch_size
9 | from evaluation.evaluation import *
10 | from utils.drive_manager import DriveManager
11 |
12 | """
13 | Evaluate spatial stream
14 | """
15 | # download
16 | drive_manager = DriveManager("spa-xception-adam-5e-06-imnet")
17 | drive_manager.download_file('1djGzpxAYFvNX-UaQ7ONqDHGgnzc8clBK', "spatial.zip")
18 |
19 | # load into ram
20 | print("Spatial stream")
21 | spatial_model_restored = legacy_load_model(filepath="spatial.h5", custom_objects={'sparse_categorical_cross_entropy_loss': sparse_categorical_cross_entropy_loss, "acc_top_1": acc_top_1, "acc_top_5": acc_top_5})
22 | spatial_model_restored.summary()
23 |
24 | # evaluate
25 | _, spatial_test_loader, test_video_level_label = frame_dataloader.SpatialDataLoader(
26 |
27 | width=int(spatial_model_restored.inputs[0].shape[1]), height=int(spatial_model_restored.inputs[0].shape[2]), batch_size=get_batch_size(spatial_model_restored, spatial=True), testing_samples_per_video=19
28 | ).run()
29 |
30 | video_level_loss, video_level_accuracy_1, video_level_accuracy_5, test_video_level_preds = eval_model(spatial_model_restored, spatial_test_loader, test_video_level_label, 19)
31 | print("Spatial Model validation", "prec@1", video_level_accuracy_1, "prec@5", video_level_accuracy_5, "loss", video_level_loss)
32 |
33 | """
34 | Evaluate motion stream
35 | """
36 | # download
37 | drive_manager = DriveManager("heavy-mot-xception-adam-1e-05-imnet")
38 | drive_manager.download_file('1kvslNL8zmZYaHRmhgAM6-l_pNDDA0EKZ', "motion.zip") # the id of the zip file contains my network
39 |
40 | # load into ram
41 | print("Motion stream")
42 | motion_model_restored = legacy_load_model(filepath="motion.h5", custom_objects={'sparse_categorical_cross_entropy_loss': sparse_categorical_cross_entropy_loss, "acc_top_1": acc_top_1, "acc_top_5": acc_top_5})
43 | motion_model_restored.summary()
44 |
45 | # evaluate
46 | _, motion_test_loader, test_video_level_label = frame_dataloader.MotionDataLoader(
47 |
48 | width=int(motion_model_restored.inputs[0].shape[1]), height=int(motion_model_restored.inputs[0].shape[2])
49 | ,
50 | batch_size=get_batch_size(motion_model_restored, spatial=True)
51 | , testing_samples_per_video=19).run()
52 |
53 | video_level_loss, video_level_accuracy_1, video_level_accuracy_5, _ = eval_model(motion_model_restored, motion_test_loader, test_video_level_label, 19)
54 |
55 | print("Motion Model validation", "prec@1", video_level_accuracy_1, "prec@5", video_level_accuracy_5, "loss", video_level_loss)
56 |
--------------------------------------------------------------------------------
/evaluation/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | This contains helper functions needed by evaluation
6 | """
7 | import json
8 | import logging
9 | import os
10 |
11 | import h5py
12 | from tensorflow.python.keras import optimizers
13 | from tensorflow.python.keras.engine.saving import model_from_config, load_weights_from_hdf5_group
14 |
15 | is_tesla_k80 = os.path.isdir("/content")
16 |
17 |
18 | # from tensorflow.keras.models import load_model # 1.11.1.rc2
19 | # load model in the new version of tensorflow doesnt work for me and i can't re install older tensorflow-gpu with older cuda for every colab machine :DDD
20 | def legacy_load_model(filepath, custom_objects=None, compile=True): # pylint: disable=redefined-builtin
21 | """
22 | legacy load model since my pretrained models could't be loaded to newer versions of tensorflow
23 | """
24 | if h5py is None:
25 | raise ImportError('`load_model` requires h5py.')
26 |
27 | if not custom_objects:
28 | custom_objects = {}
29 |
30 | def convert_custom_objects(obj):
31 | if isinstance(obj, list):
32 | deserialized = []
33 | for value in obj:
34 | deserialized.append(convert_custom_objects(value))
35 | return deserialized
36 | if isinstance(obj, dict):
37 | deserialized = {}
38 | for key, value in obj.items():
39 | deserialized[key] = convert_custom_objects(value)
40 | return deserialized
41 | if obj in custom_objects:
42 | return custom_objects[obj]
43 | return obj
44 |
45 | opened_new_file = not isinstance(filepath, h5py.File)
46 | if opened_new_file:
47 | f = h5py.File(filepath, mode='r')
48 | else:
49 | f = filepath
50 |
51 | try:
52 | # instantiate model
53 | model_config = f.attrs.get('model_config')
54 | if model_config is None:
55 | raise ValueError('No model found in config file.')
56 | model_config = json.loads(model_config.decode('utf-8'))
57 | model = model_from_config(model_config, custom_objects=custom_objects)
58 |
59 | # set weights
60 | load_weights_from_hdf5_group(f['model_weights'], model.layers)
61 |
62 | if compile:
63 | # instantiate optimizer
64 | training_config = f.attrs.get('training_config')
65 | if training_config is None:
66 | logging.warning('No training configuration found in save file: '
67 | 'the model was *not* compiled. Compile it manually.')
68 | return model
69 | training_config = json.loads(training_config.decode('utf-8'))
70 | optimizer_config = training_config['optimizer_config']
71 | optimizer = optimizers.deserialize(
72 | optimizer_config, custom_objects=custom_objects)
73 |
74 | # Recover loss functions and metrics.
75 | loss = convert_custom_objects(training_config['loss'])
76 | metrics = convert_custom_objects(training_config['metrics'])
77 | sample_weight_mode = training_config['sample_weight_mode']
78 | loss_weights = training_config['loss_weights']
79 |
80 | # Compile model.
81 | model.compile(
82 | optimizer=optimizer,
83 | loss=loss,
84 | metrics=metrics,
85 | loss_weights=loss_weights,
86 | sample_weight_mode=sample_weight_mode)
87 |
88 | # Set optimizer weights.
89 | if 'optimizer_weights' in f:
90 | # Build train function (to get weight updates).
91 | model._make_train_function()
92 | optimizer_weights_group = f['optimizer_weights']
93 | optimizer_weight_names = [
94 | n.decode('utf8')
95 | for n in optimizer_weights_group.attrs['weight_names']
96 | ]
97 | optimizer_weight_values = [
98 | optimizer_weights_group[n] for n in optimizer_weight_names
99 | ]
100 | try:
101 | model.optimizer.set_weights(optimizer_weight_values)
102 | except ValueError:
103 | logging.warning('Error in loading the saved optimizer '
104 | 'state. As a result, your model is '
105 | 'starting with a freshly initialized '
106 | 'optimizer.')
107 | finally:
108 | if opened_new_file:
109 | f.close()
110 | return model
111 |
112 |
113 | def get_batch_size(model_restored, spatial):
114 | """
115 | Helper function to get batch size per model
116 | """
117 | if spatial:
118 | if model_restored.layers[2].__dict__["_name"] == 'resnet50':
119 | batch_size = 76 if is_tesla_k80 else 48
120 | elif model_restored.layers[2].__dict__["_name"] == 'xception':
121 | batch_size = 24 if is_tesla_k80 else 24
122 | elif model_restored.layers[2].__dict__["_name"] == 'vgg19':
123 | batch_size = 36 if is_tesla_k80 else 36
124 | else:
125 | batch_size = 100 if is_tesla_k80 else 100
126 | else:
127 | if model_restored.layers[2].__dict__["_name"] == 'resnet50':
128 | batch_size = 20 if is_tesla_k80 else 20
129 | else:
130 | batch_size = 18 if is_tesla_k80 else 18
131 |
132 | return batch_size
133 |
--------------------------------------------------------------------------------
/evaluation/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/evaluation/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/evaluation/__pycache__/evaluation.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/evaluation/__pycache__/evaluation.cpython-36.pyc
--------------------------------------------------------------------------------
/evaluation/evaluation.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | This contains helper functions needed to
6 | evaluate the model while training
7 | evaluate the model loaded from the disk
8 | evaluate prediction file in pickle format
9 | """
10 |
11 | import multiprocessing
12 | import os
13 | from collections import defaultdict
14 |
15 | import numpy as np
16 | import tensorflow as tf
17 | import tqdm
18 | from tensorflow import keras
19 |
20 | """ Global variables for evaluation """
21 | num_actions = 101
22 | workers = min(multiprocessing.cpu_count(), 4)
23 | is_tesla_k80 = os.path.isdir("/content") # this is true if you are on colab :D
24 |
25 | # keras placeholder used for evaluation
26 | video_level_labels_k = keras.backend.placeholder([None, 1], dtype=tf.float32)
27 | video_level_preds_k = keras.backend.placeholder([None, num_actions], dtype=tf.float32)
28 |
29 | # tensors representing top-1 top-5 and cost function in symbolic form
30 | val_loss_op = keras.backend.mean(keras.metrics.sparse_categorical_crossentropy(video_level_labels_k, video_level_preds_k))
31 | acc_top_1_op = keras.backend.mean(keras.metrics.sparse_top_k_categorical_accuracy(video_level_labels_k, video_level_preds_k, k=1))
32 | acc_top_5_op = keras.backend.mean(keras.metrics.sparse_top_k_categorical_accuracy(video_level_labels_k, video_level_preds_k, k=5))
33 |
34 |
35 | def acc_top_5(y_true, y_pred):
36 | """Helper function for top-5 accuracy reported in UCF"""
37 | y_true = keras.backend.cast(y_true, dtype='int32')
38 |
39 | return keras.backend.mean((tf.keras.metrics.sparse_top_k_categorical_accuracy(y_true, y_pred, k=5)))
40 |
41 |
42 | def acc_top_1(y_true, y_pred):
43 | """Helper function for top-1 accuracy/(traditional accuracy) reported in UCF"""
44 | print(y_true, y_pred)
45 | y_true = keras.backend.cast(y_true, dtype='int32')
46 | return keras.backend.mean((tf.keras.metrics.sparse_top_k_categorical_accuracy(y_true, y_pred, k=1)))
47 |
48 |
49 | # compile the model (should be done *after* setting layers to non-trainable)
50 | def sparse_categorical_cross_entropy_loss(y_true, y_pred):
51 | """Custom loss function:I changed it a little bit but observed no difference"""
52 | print(y_true, y_pred)
53 | y_true = keras.backend.cast(y_true, dtype='int32')
54 | return keras.backend.mean(keras.losses.sparse_categorical_crossentropy(y_true, y_pred))
55 |
56 |
57 | def eval_model(model, test_loader, test_video_level_label, testing_samples_per_video):
58 | """
59 | runs a progressor showing my custom validation per epoch, returning the metrics
60 | """
61 | print("loader",len(test_loader))
62 | progress = tqdm.tqdm(test_loader, total=len(test_loader))
63 | test_video_level_preds = defaultdict(lambda: np.zeros((num_actions,)))
64 |
65 | for i,(video_names, sampled_frame) in enumerate(progress): # i don't need frame level labels
66 | if i == len(progress):
67 | break
68 |
69 | frame_preds = model.predict_on_batch(sampled_frame)
70 | _batch_size = frame_preds.shape[0] # last batch wont be batch_size :3
71 |
72 | for video_id in range(_batch_size): # in batch
73 | video_name = video_names[video_id] # ApplyMakeup_g01_c01 for example
74 | test_video_level_preds[video_name] += frame_preds[video_id]
75 |
76 | video_level_loss, video_level_accuracy_1, video_level_accuracy_5 = video_level_eval(test_video_level_preds=test_video_level_preds,
77 | test_video_level_label=test_video_level_label,
78 | testing_samples_per_video=testing_samples_per_video)
79 |
80 | return video_level_loss, video_level_accuracy_1, video_level_accuracy_5, test_video_level_preds
81 |
82 |
83 | def video_level_eval(test_video_level_preds, test_video_level_label, testing_samples_per_video):
84 | """
85 | video level validation applying accuracy scoring top-5 and top-1 using predictions and labels fed as dictionaries
86 | """
87 | video_level_preds_np = np.zeros((len(test_video_level_preds), num_actions)) # each video per 101 class (prediction)
88 | video_level_labels_np = np.zeros((len(test_video_level_preds), 1))
89 |
90 | for index, video_name in enumerate(sorted(test_video_level_preds.keys())): # this should loop on test videos = 3783 videos
91 | video_summed_preds = test_video_level_preds[video_name] / testing_samples_per_video # average on
92 | video_label = test_video_level_label[video_name] # 0 based label
93 |
94 | video_level_preds_np[index, :] = video_summed_preds
95 | video_level_labels_np[index, 0] = video_label
96 |
97 | video_level_loss, video_level_accuracy_1, video_level_accuracy_5 = keras.backend.get_session().run(
98 | [val_loss_op, acc_top_1_op, acc_top_5_op], feed_dict={video_level_labels_k: video_level_labels_np, video_level_preds_k: video_level_preds_np})
99 |
100 | return video_level_loss, video_level_accuracy_1, video_level_accuracy_5
101 |
--------------------------------------------------------------------------------
/frame_dataloader/UCF_splitting_kernel.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | This contains :
6 | the class responsible for train-test split(video to label mapping) given by UCF101 authors
7 |
8 | look at the notes below
9 | """
10 |
11 | import os
12 | import pickle
13 |
14 |
15 | class DataUtil:
16 | """
17 | Gets video name to label mapping using UCF101 splits
18 | """
19 |
20 | def __init__(self, path, split):
21 | self.path = path
22 | self.split = split
23 |
24 | self.action_to_label = {}
25 | self.init_action_to_label_mapping()
26 |
27 | def init_action_to_label_mapping(self):
28 | with open(os.path.join(self.path, 'classInd.txt')) as f:
29 | class_index_mapping = f.readlines()
30 | class_index_mapping = [x.strip('\n') for x in class_index_mapping]
31 |
32 | for line in class_index_mapping:
33 | label, action = line.split(' ')
34 | self.action_to_label[action] = int(label) - 1 # without v_ or avi(has HandstandPushups) # make it zero based
35 |
36 | def get_train_test_video_to_label_mapping(self):
37 | train_to_label = self.get_video_to_label_mapping("trainlist")
38 | test_to_label = self.get_video_to_label_mapping("testlist")
39 |
40 | return train_to_label, test_to_label
41 |
42 | def get_video_to_label_mapping(self, file):
43 | """warning: trainlist, testlist contains video names called v_HandStandPushups_g16_c03.avi"""
44 | with open(os.path.join(self.path, '{file}{split}.txt'.format(file=file, split=self.split))) as f:
45 | content = f.readlines()
46 | content = [x.strip('\n') for x in content]
47 |
48 | each_video_to_label = {}
49 | for line in content:
50 | video_name = line.split('/', 1)[1] # get video name after /
51 | video_name = video_name.split(' ', 1)[0] # ignore class number 0>1>..> 101 (only trainlist)
52 | video_name = video_name.split('_', 1)[1] # remove v_
53 | video_name = video_name.split('.', 1)[0] # remove .avi
54 | video_name = video_name.replace("HandStandPushups", "HandstandPushups") # look at the warning <
55 | label = self.action_to_label[line.split('/')[0]] # get label index from video_name.. [without v_ or avi get (has HandstandPushups)]
56 | each_video_to_label[video_name] = label # zero based now
57 | return each_video_to_label
58 |
59 | def get_video_frame_count(self):
60 | with open(os.path.join(self.path, "..", "frame_dataloader/dic/frame_count.pickle"), 'rb') as file:
61 | old_video_frame_count = pickle.load(file) # has HandstandPushups_g25_c01 for example (small)
62 |
63 | video_frame_count = {}
64 | for old_video_name in old_video_frame_count:
65 | new_video_name = old_video_name.split('_', 1)[1].split('.', 1)[0] # remove v_ and .avi
66 | video_frame_count[new_video_name] = int(old_video_frame_count[old_video_name]) # name without v_ or .avi (has HandstandPushups)
67 |
68 | return video_frame_count
69 |
70 |
71 | if __name__ == '__main__':
72 | path = '../UCF_list/'
73 | split = '01'
74 | data_util = DataUtil(path=path, split=split)
75 | train_video, test_video = data_util.get_train_test_video_to_label_mapping()
76 | print(len(train_video), len(test_video))
77 |
78 | frames = data_util.get_video_frame_count()
79 |
80 | frame_test, frame_train = {}, {}
81 |
82 | test, train, other = 0, 0, 0
83 | for key, value in frames.items():
84 | if key in test_video:
85 | test += value
86 | frame_test[key] = value
87 | elif key in train_video:
88 | train += value
89 | frame_train[key] = value
90 | else:
91 | other += value
92 | print(test, train, other)
93 |
94 | print(sum(value for key, value in frames.items()))
95 | print(sorted(frame_train.values())[:20])
96 | print(sorted(frame_test.values())[:20])
97 |
98 | # SequenceLoader(sequence_class=CustomSequence, queue_size=100, num_workers=4, use_multiprocessing=True, do_shuffle=True, data=list(range(5)))
99 |
100 |
101 | """Some Important Notes to understand the conflict between the datafolders and splitfile.txt"""
102 | ##########################
103 | # HandstandPushups/v_HandStandPushups_g01_c01.avi (in actual data)
104 | # HandstandPushups/v_HandStandPushups_g01_c01.avi 37 (in train list) <<<< make me small to work with the frame and processed data on disk
105 | ##########################
106 | # v_HandstandPushups_g01_c01.avi(in frame count dict)
107 | # HandstandPushups_g01_c01 (in valid and train dictionaries)
108 | # v_HandstandPushups_g01_c01 (in processed data)
109 | ##########################
110 | # Trainin: mini-batch stochastic gradient descent with momentum (set to 0.9). At each iteration, a mini-batch
111 | # of 256 samples is constructed by sampling 256 training videos (uniformly across the classes), from
112 | # each of which a single frame is randomly selected. In spatial net training, a 224 × 224 sub-image is
113 | # randomly cropped from the selected frame; it then undergoes random horizontal flipping and RGB
114 | # jittering. The videos are rescaled beforehand, so that the smallest side of the frame equals 256. We
115 | # note that unlike [15], the sub-image is sampled from the whole frame, not just its 256 × 256 center.
116 | # In the temporal net training, we compute an optical flow volume I for the selected training frame as
117 | # described in Sect. 3. From that volume, a fixed-size 224 × 224 × 2L input is randomly cropped and
118 | # flipped.
119 | ##########################
120 | # Testing. At test time, given a video, we sample a fixed number of frames (25 in our experiments)
121 | # with equal temporal spacing between them. From each of the frames we then obtain 10 ConvNet
122 | # inputs [15] by cropping and flipping four corners and the center of the frame. The class scores for the
123 | # whole video are then obtained by averaging the scores across the sampled frames and crops therein.
124 | ##########################
125 | # v = vertical
126 | # u = horizontal
127 |
--------------------------------------------------------------------------------
/frame_dataloader/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | """
6 |
7 | from .motion_dataloader import *
8 | from .spatial_dataloader import *
9 |
10 | from .visual_motion_feature_dataloader import *
11 | from .visual_spatial_feature_dataloader import *
12 |
13 |
14 |
--------------------------------------------------------------------------------
/frame_dataloader/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/frame_dataloader/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/frame_dataloader/__pycache__/motion_dataloader.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/frame_dataloader/__pycache__/motion_dataloader.cpython-36.pyc
--------------------------------------------------------------------------------
/frame_dataloader/__pycache__/spatial_dataloader.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/frame_dataloader/__pycache__/spatial_dataloader.cpython-36.pyc
--------------------------------------------------------------------------------
/frame_dataloader/__pycache__/visual_motion_feature_dataloader.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/frame_dataloader/__pycache__/visual_motion_feature_dataloader.cpython-36.pyc
--------------------------------------------------------------------------------
/frame_dataloader/__pycache__/visual_spatial_feature_dataloader.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/frame_dataloader/__pycache__/visual_spatial_feature_dataloader.cpython-36.pyc
--------------------------------------------------------------------------------
/frame_dataloader/helpers.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | This Contains:
6 | Helper function for data loaders and augmentation
7 | the sequence loader class: multiprocess/multithread approach for dataloading
8 | """
9 | import os
10 |
11 | import cv2
12 | import numpy as np
13 | from imgaug import augmenters as iaa
14 | from imgaug import parameters as iap
15 |
16 |
17 | def stack_opticalflow(start_frame_index, video_name, data_root_path, stacked_frames): # returns numpy (h,w,stacked*2) = one sample
18 | """
19 | Stacks "stacked_frames" u/v frames on a single numpy array : (h,w,stacked*2)
20 | """
21 | first_optical_frame_u = cv2.imread(os.path.join(data_root_path, "u", "v_" + video_name, 'frame{}'.format(str(start_frame_index).zfill(6)) + '.jpg'), cv2.IMREAD_GRAYSCALE) # horizontal
22 | first_optical_frame_v = cv2.imread(os.path.join(data_root_path, "v", "v_" + video_name, 'frame{}'.format(str(start_frame_index).zfill(6)) + '.jpg'), cv2.IMREAD_GRAYSCALE) # vertical
23 |
24 | stacked_optical_flow_sample = np.zeros(first_optical_frame_u.shape + (2 * stacked_frames,), dtype=np.uint8) # with channel dimension of stacked_frames(u)+ stacked_frames(v)
25 |
26 | stacked_optical_flow_sample[:, :, 0] = first_optical_frame_u
27 | stacked_optical_flow_sample[:, :, 0 + stacked_frames] = first_optical_frame_v
28 |
29 | for index, optical_frame_id in enumerate(range(start_frame_index + 1, start_frame_index + stacked_frames), 1): # index starts at 1 placed after the first one
30 | stacked_optical_flow_sample[:, :, index] = cv2.imread(os.path.join(data_root_path, "u", "v_" + video_name, 'frame{}'.format(str(optical_frame_id).zfill(6)) + '.jpg'), cv2.IMREAD_GRAYSCALE)
31 | stacked_optical_flow_sample[:, :, index + stacked_frames] = cv2.imread(os.path.join(data_root_path, "v", "v_" + video_name, 'frame{}'.format(str(optical_frame_id).zfill(6)) + '.jpg'), cv2.IMREAD_GRAYSCALE)
32 |
33 | return stacked_optical_flow_sample
34 |
35 |
36 | def get_noise_augmenters(augmenter_level):
37 | """
38 | Gets an augmenter object of a given level
39 | """
40 | # 0 heavy , 1 medium,2 simple
41 | if augmenter_level == 0:
42 | ####################################################### heavy augmentation #########################################################################
43 | return [iaa.Sometimes(0.9, iaa.Crop(
44 | percent=((iap.Clip(iap.Normal(0, .5), 0, .6),) * 4) # random crops top,right,bottom,left
45 | )),
46 | # some noise
47 | iaa.Sometimes(0.9, [iaa.GaussianBlur(sigma=(0, 0.3)), iaa.Sharpen(alpha=(0.0, .15), lightness=(0.5, 1.5)), iaa.Emboss(alpha=(0.0, 1.0), strength=(0.1, 0.2))]),
48 | iaa.Sometimes(0.9, iaa.Add((-12, 12), per_channel=1))] # rgb jittering
49 | elif augmenter_level == 1:
50 | ####################################################### medium augmentation #######################################################################
51 | return [iaa.Sometimes(0.9, iaa.Crop(percent=((0.0, 0.15), (0.0, 0.15), (0.0, 0.15), (0.0, 0.15)))), # random crops top,right,bottom,left
52 | # some noise
53 | iaa.Sometimes(0.5, [iaa.GaussianBlur(sigma=(0, 0.25)), iaa.Sharpen(alpha=(0.0, .1), lightness=(0.5, 1.25)), iaa.Emboss(alpha=(0.0, 1.0), strength=(0.05, 0.1))]),
54 | iaa.Sometimes(.7, iaa.Add((-10, 10), per_channel=1))] # rgb jittering
55 | elif augmenter_level == 2:
56 | ######################################################## simple augmentation #######################################################################
57 | return [iaa.Sometimes(0.6, iaa.Crop(percent=((0.0, 0.1), (0.0, 0.1), (0.0, 0.1), (0.0, 0.1)))), # random crops top,right,bottom,left
58 | # some noise
59 | iaa.Sometimes(0.35, [iaa.GaussianBlur(sigma=(0, 0.17)), iaa.Sharpen(alpha=(0.0, .07), lightness=(0.35, 1)), iaa.Emboss(alpha=(0.0, .7), strength=(0.1, 0.7))]),
60 | iaa.Sometimes(.45, iaa.Add((-7, 7), per_channel=1))] # rgb jittering
61 | ###################################################################################################################################################
62 |
63 |
64 | def get_validation_augmenter(height, width):
65 | """
66 | for validation we don't add any stochasticity just resize them to height*width
67 | """
68 | aug = iaa.Sequential([
69 | iaa.Scale({"height": height, "width": width})
70 | ])
71 |
72 | return aug
73 |
74 |
75 | def get_training_augmenter(height, width, augmenter_level):
76 | """
77 | Get validation augmenter according to the level of stochasticity added
78 | """
79 | aug = iaa.Sequential([
80 | iaa.Fliplr(0.5), # horizontal flips
81 | *get_noise_augmenters(augmenter_level), # noisy heavy or simple
82 | iaa.Scale({"height": height, "width": width})
83 | ], random_order=True) # apply augmenters in random order
84 |
85 | return aug
86 |
--------------------------------------------------------------------------------
/frame_dataloader/motion_dataloader.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Motion Dataloader implementing sequence api from keras (defines how to load a single item)
6 | this loads batches of images for each iteration it returns [batch_size, height, width ,stacked_frames*2] ndarrays
7 | 2*stacked_frames since we have u,v optical flow
8 | """
9 | import copy
10 | import random
11 | import sys
12 |
13 | import numpy as np
14 | import tensorflow.keras as keras
15 |
16 | from .UCF_splitting_kernel import *
17 | from .helpers import stack_opticalflow, get_training_augmenter, get_validation_augmenter
18 |
19 |
20 | class MotionSequence(keras.utils.Sequence):
21 | def __init__(self, data_to_load, data_root_path, batch_size, is_training, augmenter, stacked_frames):
22 | """get data structure to load data"""
23 | # list of (video names,frame/max_frame,label)
24 | self.data_to_load = copy.deepcopy(data_to_load)
25 | self.batch_size = batch_size
26 | self.is_training = is_training
27 |
28 | self.augmenter = copy.deepcopy(augmenter)
29 |
30 | self.data_root_path = data_root_path
31 | self.stacked_frames = stacked_frames
32 | self.video_names, self.frames, self.labels = [list(one_of_three_tuples) for one_of_three_tuples in zip(*self.data_to_load)] # three lists
33 |
34 | def __len__(self):
35 | """Denotes the number of batches per epoch"""
36 | return (len(self.video_names) + self.batch_size - 1) // self.batch_size # ceiling div
37 |
38 | def get_actual_length(self):
39 | """Denotes the total number of samples"""
40 | return len(self.video_names)
41 |
42 | def __getitem__(self, batch_start):
43 | """Gets one batch"""
44 | batch_video_names = self.video_names[batch_start * self.batch_size:(batch_start + 1) * self.batch_size]
45 | batch_frames = self.frames[batch_start * self.batch_size:(batch_start + 1) * self.batch_size]
46 | batch_y = np.array(self.labels[batch_start * self.batch_size:(batch_start + 1) * self.batch_size])
47 |
48 | batch_x = [] # could be less or equal batch size
49 |
50 | for vid_id, _ in enumerate(batch_y): # for each sample here
51 |
52 | if self.is_training: # max frame is given
53 | first_optical_frame_id = random.randint(1, batch_frames[vid_id]) # random frame (one based)
54 | else:
55 | first_optical_frame_id = batch_frames[vid_id] # just as selected
56 |
57 | batch_x.append( # append one sample which is (h,w,stacked*2)
58 | stack_opticalflow(start_frame_index=first_optical_frame_id, video_name=batch_video_names[vid_id], data_root_path=self.data_root_path, stacked_frames=self.stacked_frames)
59 | )
60 |
61 | if self.is_training:
62 | return np.array(self.augmenter.augment_images(batch_x), dtype=np.float32) / 255.0, batch_y
63 | else:
64 | # no label needed since (test_video_to_label mapping) (dictionary of name to label) is returned
65 | return batch_video_names, np.array(self.augmenter.augment_images(batch_x), dtype=np.float32) / 255.0
66 |
67 | def shuffle_and_reset(self):
68 | """
69 | new data for the next epoch
70 | """
71 | random.shuffle(self.data_to_load)
72 | self.video_names, self.frames, self.labels = [list(one_of_three_tuples) for one_of_three_tuples in zip(*self.data_to_load)] # shuffle all
73 |
74 |
75 | class MotionDataLoader:
76 | def __init__(self, batch_size, testing_samples_per_video, width, height, augmenter_level=1, log_stream=open("/tmp/null.log", "w"), data_root_path='./tvl1_flow/', ucf_list_path='./UCF_list/', ucf_split='01', stacked_frames=10):
77 | """
78 | get the mapping and initialize the augmenter
79 | """
80 | self.batch_size = batch_size
81 | self.width, self.height = width, height
82 | self.stacked_frames = stacked_frames
83 | self.data_root_path = data_root_path
84 | self.testing_samples_per_video = testing_samples_per_video
85 | self.log_stream = log_stream
86 | # split the training and testing videos
87 | data_util_ = DataUtil(path=ucf_list_path, split=ucf_split)
88 | self.train_video_to_label, self.test_video_to_label = data_util_.get_train_test_video_to_label_mapping() # name without v_ or .avi and small s .. name to numeric label starts at 0
89 |
90 | # get video frames
91 | self.video_frame_count = data_util_.get_video_frame_count() # name without v_ or .avi and small s
92 | self.augmenter_level = augmenter_level
93 |
94 | def run(self):
95 | """
96 | get the data structure for training and validation
97 | """
98 | train_loader = self.get_training_loader()
99 | val_loader = self.get_testing_loader()
100 |
101 | return train_loader, val_loader, self.test_video_to_label
102 |
103 | def get_training_data_structure(self):
104 | """
105 | get the data structure for training
106 | """
107 | training_data_structure = [] # list of (video names,frame/max_frame,label)
108 | for video_name in self.train_video_to_label: # sample from the whole video frames
109 | training_data_structure.append((video_name, self.video_frame_count[video_name] - self.stacked_frames + 1, self.train_video_to_label[video_name])) # we need 10 frames to stack together
110 |
111 | return training_data_structure
112 |
113 | def get_testing_data_structure(self):
114 | """
115 | get the data structure for validation
116 | """
117 | test_data_structure = [] # list of (video names,frame/max_frame,label)
118 | for video_name in self.test_video_to_label:
119 | nb_frame = self.video_frame_count[video_name] - self.stacked_frames + 1 # we need 10 frames to stack together (this will be inclusive)
120 | interval = nb_frame // self.testing_samples_per_video
121 |
122 | if interval == 0: # for videos shorter than self.testing_samples_per_video
123 | interval = 1
124 |
125 | # range is exclusive add one to be inclusive
126 | # 1 > self.testing_samples_per_video * interval inclusive
127 | for frame_idx in range(1, min(self.testing_samples_per_video * interval, nb_frame) + 1, interval):
128 | test_data_structure.append((video_name, frame_idx, self.test_video_to_label[video_name]))
129 |
130 | return test_data_structure
131 |
132 | def get_training_loader(self):
133 | """
134 | an instance of sequence loader for motion model for parallel dataloading using keras sequence
135 | """
136 | loader = MotionSequence(data_to_load=self.get_training_data_structure(),
137 | data_root_path=self.data_root_path,
138 | batch_size=self.batch_size,
139 | is_training=True,
140 | augmenter=get_training_augmenter(height=self.height, width=self.width, augmenter_level=self.augmenter_level),
141 | stacked_frames=self.stacked_frames
142 | )
143 |
144 | print('==> Training data :', len(loader.data_to_load), 'videos', file=self.log_stream)
145 | print('==> Training data :', len(loader.data_to_load), 'videos')
146 | return loader
147 |
148 | def get_testing_loader(self):
149 | """
150 | an instance of sequence loader for motion model for parallel dataloading using keras sequence
151 | """
152 | loader = MotionSequence(data_to_load=self.get_testing_data_structure(),
153 | data_root_path=self.data_root_path,
154 | batch_size=self.batch_size,
155 | is_training=False,
156 | augmenter=get_validation_augmenter(height=self.height, width=self.width),
157 | stacked_frames=self.stacked_frames)
158 |
159 | print('==> Validation data :', len(loader.data_to_load), 'frames', file=self.log_stream)
160 | print('==> Validation data :', len(loader.data_to_load), 'frames')
161 | return loader
162 |
163 |
164 | if __name__ == '__main__':
165 | data_loader = MotionDataLoader(batch_size=64, use_multiprocessing=True,
166 | testing_samples_per_video=19, width=224, height=224, num_workers=1, log_stream=sys.stdout, augmenter_level=1)
167 | train_loader, test_loader, test_video_level_label = data_loader.run()
168 |
169 | print(len(train_loader))
170 | print(len(test_loader))
171 |
172 | print(train_loader.get_actual_length())
173 | print(test_loader.get_actual_length())
174 |
175 | print(train_loader[0][0].shape, train_loader[0][1])
176 |
177 | # import tqdm
178 | # progress = tqdm.tqdm(train_loader.get_epoch_generator(), total=len(train_loader))
179 |
180 | # for (sampled_frame, label) in progress:
181 | # pass
182 |
183 | import matplotlib.pyplot as plt
184 |
185 |
186 | # preview raw data
187 | def preview(data, labels):
188 | # 3 channels
189 | fig, axeslist = plt.subplots(ncols=8, nrows=8, figsize=(10, 10))
190 |
191 | for i, sample in enumerate(data):
192 | axeslist.ravel()[i].imshow(data[i], cmap='gray')
193 | axeslist.ravel()[i].set_title(labels[i])
194 | axeslist.ravel()[i].set_axis_off()
195 |
196 | plt.subplots_adjust(wspace=.4, hspace=.4)
197 |
198 |
199 | for batch in test_loader.get_epoch_generator():
200 | print(batch[0], batch[1].shape, batch[2].shape)
201 | preview(batch[1][:, :, :, 0], batch[2])
202 | preview(batch[1][:, :, :, 1], batch[2])
203 | preview(batch[1][:, :, :, 2], batch[2])
204 | preview(batch[1][:, :, :, 3], batch[2])
205 |
206 | preview(batch[1][:, :, :, 10], batch[2])
207 | preview(batch[1][:, :, :, 11], batch[2])
208 | preview(batch[1][:, :, :, 12], batch[2])
209 | preview(batch[1][:, :, :, 13], batch[2])
210 | break
211 |
212 | for batch in train_loader.get_epoch_generator():
213 | print(batch[0].shape, batch[1].shape)
214 | preview(batch[0][:, :, :, 0], batch[1])
215 | preview(batch[0][:, :, :, 1], batch[1])
216 | preview(batch[0][:, :, :, 2], batch[1])
217 | preview(batch[0][:, :, :, 3], batch[1])
218 |
219 | preview(batch[0][:, :, :, 10], batch[1])
220 | preview(batch[0][:, :, :, 11], batch[1])
221 | preview(batch[0][:, :, :, 12], batch[1])
222 | preview(batch[0][:, :, :, 13], batch[1])
223 | break
224 |
--------------------------------------------------------------------------------
/frame_dataloader/spatial_dataloader.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Spatial Dataloader implementing sequence api from keras (defines how to load a single item)
6 | this loads batches of images for each iteration it returns [batch_size, height, width ,3] ndarrays
7 | """
8 | import copy
9 | import random
10 |
11 | import cv2
12 | import numpy as np
13 | import tensorflow.keras as keras
14 |
15 | from .UCF_splitting_kernel import *
16 | from .helpers import get_training_augmenter, get_validation_augmenter
17 |
18 |
19 | class SpatialSequence(keras.utils.Sequence):
20 | def __init__(self, data_to_load, data_root_path, batch_size, is_training, augmenter):
21 | """get data structure to load data"""
22 | # list of (video names,frame/max_frame,label)
23 | self.data_to_load = copy.deepcopy(data_to_load)
24 | self.batch_size = batch_size
25 | self.is_training = is_training
26 |
27 | self.augmenter = copy.deepcopy(augmenter)
28 |
29 | self.data_root_path = data_root_path
30 |
31 | self.video_names, self.frames, self.labels = [list(one_of_three_tuples) for one_of_three_tuples in zip(*self.data_to_load)] # three lists
32 |
33 | def __len__(self):
34 | """Denotes the number of batches per epoch"""
35 | return (len(self.video_names) + self.batch_size - 1) // self.batch_size # ceiling div
36 |
37 | def get_actual_length(self):
38 | """Denotes the total number of samples"""
39 | return len(self.video_names)
40 |
41 | def __getitem__(self, batch_start):
42 | """Gets one batch"""
43 | batch_video_names = self.video_names[batch_start * self.batch_size:(batch_start + 1) * self.batch_size]
44 | batch_frames = self.frames[batch_start * self.batch_size:(batch_start + 1) * self.batch_size]
45 | batch_y = np.array(self.labels[batch_start * self.batch_size:(batch_start + 1) * self.batch_size])
46 |
47 | batch_x = [] # could be less or equal batch size
48 | #
49 | for vid_id, _ in enumerate(batch_y):
50 | if self.is_training: # max frame is given
51 | frame_id = random.randint(1, batch_frames[vid_id]) # random frame (one based)
52 | else:
53 | frame_id = batch_frames[vid_id] # just as selected
54 |
55 | batch_x.append(
56 | cv2.cvtColor(cv2.imread(os.path.join(self.data_root_path, "v_" + batch_video_names[vid_id], 'frame{}'.format(str(frame_id).zfill(6)) + '.jpg')), cv2.COLOR_BGR2RGB)
57 | )
58 |
59 | if self.is_training:
60 | return np.array(self.augmenter.augment_images(batch_x), dtype=np.float32) / 255.0, batch_y
61 | else:
62 | # no label needed since (test_video_to_label mapping) (dictionary of name to label) is returned
63 | return batch_video_names, np.array(self.augmenter.augment_images(batch_x), dtype=np.float32) / 255.0
64 |
65 | def shuffle_and_reset(self):
66 | """
67 | new data for the next epoch
68 | """
69 | random.shuffle(self.data_to_load)
70 | self.video_names, self.frames, self.labels = [list(one_of_three_tuples) for one_of_three_tuples in zip(*self.data_to_load)] # shuffle all
71 |
72 |
73 | class SpatialDataLoader:
74 | def __init__(self, batch_size, testing_samples_per_video, width, height, log_stream=open("/tmp/null.log", "w"), augmenter_level=1, data_root_path='./jpegs_256/', ucf_list_path='./UCF_list/', ucf_split='01'):
75 | """
76 | get the mapping and initialize the augmenter
77 | """
78 | self.batch_size = batch_size
79 | self.width, self.height = width, height
80 | self.data_root_path = data_root_path
81 | self.testing_samples_per_video = testing_samples_per_video
82 | self.log_stream = log_stream
83 | # split the training and testing videos
84 | data_util_ = DataUtil(path=ucf_list_path, split=ucf_split)
85 | self.train_video_to_label, self.test_video_to_label = data_util_.get_train_test_video_to_label_mapping() # name without v_ or .avi and small s .. name to numeric label starts at 0
86 |
87 | # get video frames
88 | self.video_frame_count = data_util_.get_video_frame_count() # name without v_ or .avi and small s
89 |
90 | self.augmenter_level = augmenter_level
91 |
92 | def run(self):
93 | """
94 | get the data structure for training and validation
95 | """
96 | train_loader = self.get_training_loader()
97 | val_loader = self.get_testing_loader()
98 |
99 | return train_loader, val_loader, self.test_video_to_label
100 |
101 | def get_training_data_structure(self):
102 | """
103 | get the data structure for training
104 | """
105 | training_data_structure = [] # list of (video names,frame/max_frame,label)
106 | for video_name in self.train_video_to_label: # sample from the whole video frames
107 | training_data_structure.append((video_name, self.video_frame_count[video_name], self.train_video_to_label[video_name]))
108 |
109 | return training_data_structure
110 |
111 | def get_testing_data_structure(self):
112 | """
113 | get the data structure for validation
114 | """
115 | test_data_structure = [] # list of (video names,frame/max_frame,label)
116 | for video_name in self.test_video_to_label:
117 | nb_frame = self.video_frame_count[video_name]
118 | interval = nb_frame // self.testing_samples_per_video
119 |
120 | if interval == 0: # for videos shorter than self.testing_samples_per_video
121 | interval = 1
122 |
123 | # range is exclusive add one to be inclusive
124 | # 1 > self.testing_samples_per_video * interval
125 | for frame_idx in range(1, min(self.testing_samples_per_video * interval, nb_frame) + 1, interval):
126 | test_data_structure.append((video_name, frame_idx, self.test_video_to_label[video_name]))
127 |
128 | return test_data_structure
129 |
130 | def get_training_loader(self):
131 | """
132 | an instance of sequence loader for spatial model for parallel dataloading using keras sequence
133 | """
134 | loader = SpatialSequence(data_to_load=self.get_training_data_structure(),
135 | data_root_path=self.data_root_path,
136 | batch_size=self.batch_size,
137 | is_training=True,
138 | augmenter=get_training_augmenter(height=self.height, width=self.width, augmenter_level=self.augmenter_level),
139 | )
140 |
141 | print('==> Training data :', len(loader.data_to_load), 'videos', file=self.log_stream)
142 | print('==> Training data :', len(loader.data_to_load), 'videos')
143 | return loader
144 |
145 | def get_testing_loader(self):
146 | """
147 | an instance of sequence loader for spatial model for parallel dataloading using keras sequence
148 | """
149 |
150 | loader = SpatialSequence(data_to_load=self.get_testing_data_structure(),
151 | data_root_path=self.data_root_path,
152 | batch_size=self.batch_size,
153 | is_training=False,
154 | augmenter=get_validation_augmenter(height=self.height, width=self.width),
155 | )
156 |
157 | print('==> Validation data :', len(loader.data_to_load), 'frames', file=self.log_stream)
158 | print('==> Validation data :', len(loader.data_to_load), 'frames')
159 | return loader
160 |
161 |
162 | if __name__ == '__main__':
163 | data_loader = SpatialDataLoader(batch_size=64, use_multiprocessing=True, # data_root_path="data",
164 | ucf_split='01',
165 | testing_samples_per_video=19, width=224, height=224, num_workers=2)
166 | train_loader, test_loader, test_video_level_label = data_loader.run()
167 |
168 | print(len(train_loader))
169 | print(len(test_loader))
170 |
171 | print(train_loader.get_actual_length())
172 | print(test_loader.get_actual_length())
173 |
174 | print(train_loader.sequence[0][0].shape, train_loader.sequence[0][1].shape)
175 | print(train_loader[0][0].shape, train_loader[0][1].shape)
176 | # import tqdm
177 | # progress = tqdm.tqdm(train_loader.get_epoch_generator(), total=len(train_loader))
178 |
179 | # for (sampled_frame, label) in progress:
180 | # pass
181 |
182 | import matplotlib.pyplot as plt
183 |
184 |
185 | # preview raw data
186 | def preview(data, labels):
187 | # 3 channels
188 | fig, axeslist = plt.subplots(ncols=8, nrows=8, figsize=(10, 10))
189 |
190 | for i, sample in enumerate(data):
191 | axeslist.ravel()[i].imshow(data[i])
192 | axeslist.ravel()[i].set_title(labels[i])
193 | axeslist.ravel()[i].set_axis_off()
194 |
195 | plt.subplots_adjust(wspace=.4, hspace=.4)
196 |
197 |
198 | print("train sample")
199 | for batch in train_loader.get_epoch_generator():
200 | print(batch[0].shape, batch[1].shape)
201 | print(batch[1])
202 | preview(batch[0], batch[1])
203 |
204 | break
205 | print("test sample") # same name will be displayed testing_samples_per_video with no shuffling
206 | for batch in test_loader.get_epoch_generator():
207 | print(batch[1].shape, batch[2].shape)
208 | print(batch[0], batch[2])
209 | preview(batch[1], batch[2])
210 |
211 | break
212 |
--------------------------------------------------------------------------------
/frame_dataloader/visual_motion_feature_dataloader.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Motion visual feature Dataloader implementing sequence api from keras (defines how to load a single item)
6 | we sample "samples_per_video" per video on equal intervals for validation or randomly for training
7 | this loads batches of stacked images(representing a video) for each iteration it returns [samples_per_video, height, width ,stacked_frames*2] ndarrays
8 | 2*stacked_frames since we have u,v optical flow
9 | """
10 | import random
11 | import sys
12 |
13 | import numpy as np
14 | import tensorflow.keras as keras
15 |
16 | from .UCF_splitting_kernel import *
17 | from .helpers import get_training_augmenter, get_validation_augmenter, stack_opticalflow
18 |
19 |
20 | class MotionSequenceFeature(keras.utils.Sequence):
21 | def __init__(self, data_to_load, data_root_path, samples_per_video, is_training, augmenter, stacked_frames):
22 | """get data structure to load data"""
23 | # list of (video names,[frame]/max_frame,label)
24 | self.data_to_load = data_to_load
25 | self.samples_per_video = samples_per_video
26 | self.is_training = is_training
27 |
28 | self.augmenter = augmenter
29 |
30 | self.data_root_path = data_root_path
31 | self.stacked_frames = stacked_frames
32 | self.video_names, self.frames, self.labels = [list(one_of_three_tuples) for one_of_three_tuples in zip(*self.data_to_load)] # three lists
33 |
34 | def __len__(self):
35 | """Denotes the number of batches per epoch"""
36 | return len(self.video_names)
37 |
38 | def get_actual_length(self):
39 | """Denotes the total number of samples"""
40 | return len(self)
41 |
42 | def __getitem__(self, video_index):
43 | """Gets one sample""" # (samples_per_video,h,w,stacked*2)
44 | video_label = self.labels[video_index]
45 | video_name = self.video_names[video_index]
46 |
47 | # start index of each frame so i will stack 19 samples each sample is 20 frames stacked ._.
48 | if self.is_training: # max frame is given
49 | video_frames_start_idx = sorted(random.sample(range(1, self.frames[video_index] + 1), self.samples_per_video)) # sample random frames (samples_per_video) and sort them
50 | else:
51 | video_frames_start_idx = self.frames[video_index] # just as selected list of samples_per_video
52 |
53 | video_frames = [] # could be less or equal batch size
54 |
55 | for video_frame_start_idx in video_frames_start_idx: # for each sample here
56 | video_frames.append(stack_opticalflow(start_frame_index=video_frame_start_idx, video_name=video_name, data_root_path=self.data_root_path, stacked_frames=self.stacked_frames)) # append one sample which is (h,w,stacked*2)
57 |
58 | return np.array(self.augmenter.augment_images(video_frames), dtype=np.float32) / 255.0, video_label
59 |
60 | def shuffle_and_reset(self):
61 | """
62 | new data for the next epoch
63 | """
64 | random.shuffle(self.data_to_load)
65 | self.video_names, self.frames, self.labels = [list(one_of_three_tuples) for one_of_three_tuples in zip(*self.data_to_load)] # shuffle all
66 |
67 |
68 | class MotionDataLoaderVisualFeature:
69 | def __init__(self, samples_per_video, width, height, num_workers, use_multiprocessing, augmenter_level=0, log_stream=open("/tmp/null.log", "w"), data_root_path='./tvl1_flow/', ucf_list_path='./UCF_list/', ucf_split='01', queue_size=10, stacked_frames=10):
70 | """
71 | get the mapping and initialize the augmenter
72 | """
73 | self.samples_per_video = samples_per_video
74 | self.use_multiprocessing = use_multiprocessing
75 | self.queue_size = queue_size
76 | self.num_workers = num_workers
77 |
78 | self.width, self.height = width, height
79 | self.stacked_frames = stacked_frames
80 | self.data_root_path = data_root_path
81 | self.log_stream = log_stream
82 | # split the training and testing videos
83 | data_util_ = DataUtil(path=ucf_list_path, split=ucf_split)
84 | self.train_video_to_label, self.test_video_to_label = data_util_.get_train_test_video_to_label_mapping() # name without v_ or .avi and small s .. name to numeric label starts at 0
85 |
86 | # get video frames
87 | self.video_frame_count = data_util_.get_video_frame_count() # name without v_ or .avi and small s
88 | self.augmenter_level = augmenter_level
89 |
90 | def run(self):
91 | """
92 | get the data structure for training and validation
93 | """
94 | train_loader = self.get_training_loader()
95 | val_loader = self.get_testing_loader()
96 |
97 | return train_loader, val_loader
98 |
99 | def get_training_data_structure(self):
100 | """
101 | get the data structure for training
102 | """
103 | training_data_structure = [] # list of (video names,[frame]/max_frame,label)
104 | for video_name in self.train_video_to_label: # sample from the whole video frames
105 | training_data_structure.append((video_name, self.video_frame_count[video_name] - self.stacked_frames + 1, self.train_video_to_label[video_name])) # we need 10 frames to stack together
106 |
107 | return training_data_structure
108 |
109 | def get_testing_data_structure(self):
110 | """
111 | get the data structure for validation
112 | """
113 | test_data_structure = [] # list of (video names,[frame]/max_frame,label)
114 | for video_name in self.test_video_to_label:
115 | nb_frame = self.video_frame_count[video_name] - self.stacked_frames + 1 # we need 10 frames to stack together (this will be inclusive)
116 | interval = nb_frame // self.samples_per_video
117 |
118 | if interval == 0: # for videos shorter than self.testing_samples_per_video
119 | interval = 1
120 |
121 | # range is exclusive add one to be inclusive
122 | # 1 > self.testing_samples_per_video * interval inclusive
123 | sampled_frames = []
124 | for frame_idx in range(1, min(self.samples_per_video * interval, nb_frame) + 1, interval):
125 | sampled_frames.append(frame_idx)
126 |
127 | test_data_structure.append((video_name, sampled_frames, self.test_video_to_label[video_name]))
128 |
129 | return test_data_structure
130 |
131 | def get_training_loader(self):
132 | """
133 | an instance of sequence loader for motion model for parallel dataloading using keras sequence
134 | """
135 | loader = MotionSequenceFeature(data_to_load=self.get_training_data_structure(),
136 | data_root_path=self.data_root_path,
137 | samples_per_video=self.samples_per_video,
138 | is_training=True,
139 | augmenter=get_training_augmenter(height=self.height, width=self.width, augmenter_level=self.augmenter_level),
140 | stacked_frames=self.stacked_frames)
141 |
142 | print('==> Training data :', len(loader.data_to_load), 'videos', file=self.log_stream)
143 | print('==> Training data :', len(loader.data_to_load), 'videos')
144 | return loader
145 |
146 | def get_testing_loader(self):
147 | """
148 | an instance of sequence loader for motion model for parallel dataloading using keras sequence
149 | """
150 | loader = MotionSequenceFeature( data_to_load=self.get_testing_data_structure(),
151 | data_root_path=self.data_root_path,
152 | samples_per_video=self.samples_per_video,
153 | is_training=False,
154 | augmenter=get_validation_augmenter(height=self.height, width=self.width),
155 | stacked_frames=self.stacked_frames
156 | )
157 | print('==> Validation data :', len(loader.data_to_load), 'frames', file=self.log_stream)
158 | print('==> Validation data :', len(loader.data_to_load), 'frames')
159 | return loader
160 |
161 |
162 | if __name__ == '__main__':
163 | data_loader = MotionDataLoaderVisualFeature(samples_per_video=19, use_multiprocessing=True, ucf_list_path='../UCF_list/',
164 | width=224, height=224, num_workers=1, log_stream=sys.stdout, heavy=False)
165 | train_loader, test_loader, test_video_level_label = data_loader.run()
166 |
167 | print(len(train_loader))
168 | print(len(test_loader))
169 |
170 | print(train_loader.get_actual_length())
171 | print(test_loader.get_actual_length())
172 |
173 | print(train_loader[0][0].shape, train_loader[0][1])
174 |
175 | # import tqdm
176 | # progress = tqdm.tqdm(train_loader.get_epoch_generator(), total=len(train_loader))
177 |
178 | # for (sampled_frame, label) in progress:
179 | # pass
180 |
181 | import matplotlib.pyplot as plt
182 |
183 |
184 | # preview raw data
185 | def preview(data, labels):
186 | # 3 channels
187 | fig, axeslist = plt.subplots(ncols=8, nrows=8, figsize=(10, 10))
188 |
189 | for i, sample in enumerate(data):
190 | axeslist.ravel()[i].imshow(data[i], cmap='gray')
191 | axeslist.ravel()[i].set_title(labels[i])
192 | axeslist.ravel()[i].set_axis_off()
193 |
194 | plt.subplots_adjust(wspace=.4, hspace=.4)
195 |
196 |
197 | for batch in test_loader.get_epoch_generator():
198 | print(batch[0], batch[1].shape, batch[2].shape)
199 | preview(batch[1][:, :, :, 0], batch[2])
200 | preview(batch[1][:, :, :, 1], batch[2])
201 | preview(batch[1][:, :, :, 2], batch[2])
202 | preview(batch[1][:, :, :, 3], batch[2])
203 |
204 | preview(batch[1][:, :, :, 10], batch[2])
205 | preview(batch[1][:, :, :, 11], batch[2])
206 | preview(batch[1][:, :, :, 12], batch[2])
207 | preview(batch[1][:, :, :, 13], batch[2])
208 | break
209 |
210 | for batch in train_loader.get_epoch_generator():
211 | print(batch[0].shape, batch[1].shape)
212 | preview(batch[0][:, :, :, 0], batch[1])
213 | preview(batch[0][:, :, :, 1], batch[1])
214 | preview(batch[0][:, :, :, 2], batch[1])
215 | preview(batch[0][:, :, :, 3], batch[1])
216 |
217 | preview(batch[0][:, :, :, 10], batch[1])
218 | preview(batch[0][:, :, :, 11], batch[1])
219 | preview(batch[0][:, :, :, 12], batch[1])
220 | preview(batch[0][:, :, :, 13], batch[1])
221 | break
222 |
--------------------------------------------------------------------------------
/frame_dataloader/visual_spatial_feature_dataloader.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Spatial visual feature Dataloader implementing sequence api from keras (defines how to load a single item)
6 | we sample "samples_per_video" per video on equal intervals for validation or randomly for training
7 | this loads batches of stacked images(representing a video) for each iteration it returns [samples_per_video, height, width ,3] ndarrays
8 | """
9 | import random
10 |
11 | import cv2
12 | import numpy as np
13 | import tensorflow.keras as keras
14 |
15 | from .UCF_splitting_kernel import *
16 | from .helpers import get_training_augmenter, get_validation_augmenter
17 |
18 |
19 | class SpatialSequenceFeature(keras.utils.Sequence):
20 | def __init__(self, data_to_load, data_root_path, samples_per_video, is_training, augmenter):
21 | """get data structure to load data"""
22 | # list of (video names,[frame]/max_frame,label)
23 | self.data_to_load = data_to_load
24 | self.samples_per_video = samples_per_video
25 | self.is_training = is_training
26 |
27 | self.augmenter = augmenter
28 |
29 | self.data_root_path = data_root_path
30 |
31 | self.video_names, self.frames, self.labels = [list(one_of_three_tuples) for one_of_three_tuples in zip(*self.data_to_load)] # three lists
32 |
33 | def __len__(self):
34 | """Denotes the number of batches per epoch"""
35 | return len(self.video_names)
36 |
37 | def get_actual_length(self):
38 | """Denotes the total number of samples"""
39 | return len(self)
40 |
41 | def __getitem__(self, video_index):
42 | """Gets one batch"""
43 | video_label = self.labels[video_index]
44 | video_name = self.video_names[video_index]
45 |
46 | if self.is_training: # max frame is given
47 | video_frames_idx = sorted(random.sample(range(1, self.frames[video_index] + 1), self.samples_per_video)) # sample random frames (samples_per_video) and sort them
48 | else:
49 | video_frames_idx = self.frames[video_index] # just as selected list of samples_per_video
50 |
51 | video_frames = [] # could be less or equal batch size
52 |
53 | for video_frame_id in video_frames_idx: # for each sample here
54 | video_frames.append(
55 | cv2.cvtColor(cv2.imread(os.path.join(self.data_root_path, "v_" + video_name, 'frame{}'.format(str(video_frame_id).zfill(6)) + '.jpg')), cv2.COLOR_BGR2RGB)
56 | )
57 |
58 | return np.array(self.augmenter.augment_images(video_frames), dtype=np.float32) / 255.0, video_label
59 |
60 | def shuffle_and_reset(self):
61 | """
62 | new data for the next epoch
63 | """
64 | random.shuffle(self.data_to_load)
65 | self.video_names, self.frames, self.labels = [list(one_of_three_tuples) for one_of_three_tuples in zip(*self.data_to_load)] # shuffle all
66 |
67 |
68 | class SpatialDataLoaderFeature:
69 | def __init__(self, samples_per_video, width, height, num_workers, use_multiprocessing, log_stream=open("/tmp/null.log", "w"), augmenter_level=0, data_root_path='./jpegs_256/', ucf_list_path='./UCF_list/', ucf_split='01', queue_size=10):
70 | """
71 | get the mapping and initialize the augmenter
72 | """
73 | self.samples_per_video = samples_per_video
74 | self.use_multiprocessing = use_multiprocessing
75 | self.queue_size = queue_size
76 | self.num_workers = num_workers
77 |
78 | self.width, self.height = width, height
79 | self.data_root_path = data_root_path
80 |
81 | self.log_stream = log_stream
82 | # split the training and testing videos
83 | data_util_ = DataUtil(path=ucf_list_path, split=ucf_split)
84 | self.train_video_to_label, self.test_video_to_label = data_util_.get_train_test_video_to_label_mapping() # name without v_ or .avi and small s .. name to numeric label starts at 0
85 |
86 | # get video frames
87 | self.video_frame_count = data_util_.get_video_frame_count() # name without v_ or .avi and small s
88 |
89 | self.augmenter_level = augmenter_level
90 |
91 | def run(self):
92 | """
93 | get the data structure for training and validation
94 | """
95 | train_loader = self.get_training_loader()
96 | val_loader = self.get_testing_loader()
97 |
98 | return train_loader, val_loader
99 |
100 | def get_training_data_structure(self):
101 | """
102 | get the data structure for training
103 | """
104 | training_data_structure = [] # list of (video names,[frame]/max_frame,label)
105 | for video_name in self.train_video_to_label: # sample from the whole video frames
106 | training_data_structure.append((video_name, self.video_frame_count[video_name], self.train_video_to_label[video_name]))
107 |
108 | return training_data_structure
109 |
110 | def get_testing_data_structure(self):
111 | """
112 | get the data structure for validation
113 | """
114 | test_data_structure = [] # list of (video names,[frame]/max_frame,label)
115 | for video_name in self.test_video_to_label:
116 | nb_frame = self.video_frame_count[video_name]
117 | interval = nb_frame // self.samples_per_video
118 |
119 | if interval == 0: # for videos shorter than self.testing_samples_per_video
120 | interval = 1
121 |
122 | # range is exclusive add one to be inclusive
123 | # 1 > self.testing_samples_per_video * interval inclusive
124 | sampled_frames = []
125 | for frame_idx in range(1, min(self.samples_per_video * interval, nb_frame) + 1, interval):
126 | sampled_frames.append(frame_idx)
127 |
128 | test_data_structure.append((video_name, sampled_frames, self.test_video_to_label[video_name]))
129 |
130 | return test_data_structure
131 |
132 | def get_training_loader(self):
133 | """
134 | an instance of sequence loader for motion model for parallel dataloading using keras sequence
135 | """
136 | loader = SpatialSequenceFeature(data_to_load=self.get_training_data_structure(),
137 | data_root_path=self.data_root_path,
138 | samples_per_video=self.samples_per_video,
139 | is_training=True,
140 | augmenter=get_training_augmenter(height=self.height, width=self.width, augmenter_level=self.augmenter_level),
141 | )
142 |
143 | print('==> Training data :', len(loader.data_to_load), 'videos', file=self.log_stream)
144 | print('==> Training data :', len(loader.data_to_load), 'videos')
145 | return loader
146 |
147 | def get_testing_loader(self):
148 | """
149 | an instance of sequence loader for motion model for parallel dataloading using keras sequence
150 | """
151 |
152 | loader = SpatialSequenceFeature(data_to_load=self.get_testing_data_structure(),
153 | data_root_path=self.data_root_path,
154 | samples_per_video=self.samples_per_video,
155 | is_training=False,
156 | augmenter=get_validation_augmenter(height=self.height, width=self.width),
157 | )
158 |
159 | print('==> Validation data :', len(loader.data_to_load), 'frames', file=self.log_stream)
160 | print('==> Validation data :', len(loader.data_to_load), 'frames')
161 | return loader
162 |
163 |
164 | if __name__ == '__main__':
165 | data_loader = SpatialDataLoaderFeature(samples_per_video=19, use_multiprocessing=True, # data_root_path="data",
166 | ucf_split='01', ucf_list_path='../UCF_list/',
167 | width=299, height=299, num_workers=2)
168 | train_loader, test_loader, test_video_level_label = data_loader.run()
169 |
170 | print(len(train_loader))
171 | print(len(test_loader))
172 |
173 | print(train_loader.get_actual_length())
174 | print(test_loader.get_actual_length())
175 |
176 | print(train_loader.sequence[0][0].shape, train_loader.sequence[0][1].shape)
177 | print(train_loader[0][0].shape, train_loader[0][1].shape)
178 | # import tqdm
179 | # progress = tqdm.tqdm(train_loader.get_epoch_generator(), total=len(train_loader))
180 |
181 | # for (sampled_frame, label) in progress:
182 | # pass
183 |
184 | import matplotlib.pyplot as plt
185 |
186 |
187 | # preview raw data
188 | def preview(data, labels):
189 | # 3 channels
190 | fig, axeslist = plt.subplots(ncols=8, nrows=8, figsize=(10, 10))
191 |
192 | for i, sample in enumerate(data):
193 | axeslist.ravel()[i].imshow(data[i])
194 | axeslist.ravel()[i].set_title(labels[i])
195 | axeslist.ravel()[i].set_axis_off()
196 |
197 | plt.subplots_adjust(wspace=.4, hspace=.4)
198 |
199 |
200 | print("train sample")
201 | for batch in train_loader.get_epoch_generator():
202 | print(batch[0].shape, batch[1].shape)
203 | print(batch[1])
204 | preview(batch[0], batch[1])
205 |
206 | break
207 | print("test sample") # same name will be displayed testing_samples_per_video with no shuffling
208 | for batch in test_loader.get_epoch_generator():
209 | print(batch[1].shape, batch[2].shape)
210 | print(batch[0], batch[2])
211 | preview(batch[1], batch[2])
212 |
213 | break
214 |
--------------------------------------------------------------------------------
/generate_motion_feature_dataset.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Here I'm generating visual features from my pretrained motion stream having 84% top-1 accuracy
6 | these visual features are just the layer below the softmax prediction, layer have 2048 features for each input image
7 | the data generated are stored into a big list and then dumped as pickle file for each epoch of data (more data augmentation)
8 | then this data are fed into a recurrent network implemented in recurrent_fusion_trainer.py file to train a video level classifier instead of frame level classier
9 |
10 | I expect a pre-trained xception model here to be downloaded from drive
11 | -------------------
12 | In this file I do what I call model surgery which is removing or adding some layer from a model
13 | Here I load my trained model whose architecture is
14 |
15 | Input_image > batch_norm >> xception model as layer >>> softmax layer of 101 classes
16 |
17 |
18 | so I can change the model a little bit and make it have 2 outputs which are the features just below the softmax and the softmax
19 | so the model becomes
20 |
21 | Input_image > batch_norm >> xception model as layer >>> softmax layer of 101 classes
22 | # >>> feature field of 2048 features
23 |
24 | which are two outputs now
25 | """
26 | import pickle
27 |
28 | from tensorflow.python.keras import Model, Input
29 |
30 | import frame_dataloader
31 | from evaluation import legacy_load_model
32 | from evaluation.evaluation import *
33 | from utils.drive_manager import DriveManager
34 |
35 | #####################################################
36 | feature_field_size = 2048
37 | testing_samples_per_video = 19
38 | #####################################################
39 | """Managed"""
40 | evaluate = False
41 | generate_test = False
42 |
43 | drive_manager = DriveManager("motion_feature_dataset")
44 | drive_manager.download_file('1O8OM6Q01az_71HdMQmWM3op1qJhfsQoI', "motion.zip") # the id of the zip file contains my network
45 |
46 | motion_model_restored = legacy_load_model(filepath="motion.h5", custom_objects={'sparse_categorical_cross_entropy_loss': sparse_categorical_cross_entropy_loss, "acc_top_1": acc_top_1, "acc_top_5": acc_top_5})
47 | motion_model_restored.summary()
48 | # xception here is a layer
49 | # The architecture summary is
50 | # input_image > batch_norm > xception layer
51 | xception_rebuilt = Model(
52 | motion_model_restored.layers[-1].layers[0].input, # input image to xception layer itself not my wrapper model
53 | [layer.output for layer in motion_model_restored.layers[-1].layers[-2:]] # two outputs of xception layer itself visual features, softmax output
54 | )
55 |
56 | motion_model_with_2_outputs = Model(
57 | motion_model_restored.inputs[0], # input of my wrapper model
58 | xception_rebuilt(motion_model_restored.layers[1](motion_model_restored.inputs[0])) # the two outputs obtained from xception layer are connected to the original input of the wrapper model
59 |
60 | )
61 |
62 | data_loader = frame_dataloader.MotionDataLoaderVisualFeature(
63 | num_workers=workers, samples_per_video=19,
64 | width=int(motion_model_restored.inputs[0].shape[1]), height=int(motion_model_restored.inputs[0].shape[2])
65 | , use_multiprocessing=True, augmenter_level=0, # heavy augmentation
66 | )
67 | train_loader, test_loader = data_loader.run()
68 |
69 | """
70 | Evaluate and check
71 | """
72 | if evaluate:
73 | progress = tqdm.tqdm(test_loader, total=len(test_loader))
74 | inp = Input(shape=(2048,), name="dense")
75 | dense_layer = Model(inp, motion_model_restored.layers[-1].layers[-1](inp))
76 |
77 | video_level_preds_np = np.zeros((len(progress), num_actions)) # each video per 101 class (prediction)
78 | video_level_labels_np = np.zeros((len(progress), 1))
79 |
80 | for index, (video_frames, video_label) in enumerate(progress): # i don't need frame level labels
81 | feature_field, frame_preds = motion_model_with_2_outputs.predict_on_batch(video_frames)
82 | assert np.allclose(frame_preds, dense_layer.predict(feature_field))
83 |
84 | video_level_preds_np[index, :] = np.mean(frame_preds, axis=0)
85 | video_level_labels_np[index, 0] = video_label
86 |
87 | video_level_loss, video_level_accuracy_1, video_level_accuracy_5 = keras.backend.get_session().run(
88 | [val_loss_op, acc_top_1_op, acc_top_5_op], feed_dict={video_level_labels_k: video_level_labels_np, video_level_preds_k: video_level_preds_np})
89 |
90 | print("Motion Model validation", "prec@1", video_level_accuracy_1, "prec@5", video_level_accuracy_5, "loss", video_level_loss)
91 |
92 | """
93 | Generate the data and save into pickles
94 | """
95 | ##############################################################################
96 | # test data generation
97 | if generate_test:
98 | test_progress = tqdm.tqdm(test_loader, total=len(test_loader))
99 |
100 | samples, labels = np.zeros([len(test_loader), testing_samples_per_video, feature_field_size], dtype=np.float32), np.zeros([len(test_loader), ], dtype=np.float32)
101 |
102 | last_access = 0
103 | for index, (video_frames, video_label) in enumerate(test_progress): # i don't need frame level labels
104 | feature_field, _ = motion_model_with_2_outputs.predict_on_batch(video_frames)
105 | samples[index] = feature_field
106 | labels[index] = video_label
107 | last_access = index
108 |
109 | print("test samples:", samples.shape)
110 | print("test labels:", labels.shape)
111 | assert last_access == len(test_progress) - 1
112 |
113 | with open("test_features_motion.pickle", 'wb') as f:
114 | pickle.dump((samples, labels), f)
115 |
116 | del samples, labels
117 | drive_manager.upload_project_file("test_features_motion.pickle")
118 |
119 | ##############################################################################
120 | # train data generation
121 | for epoch in range(1):
122 | train_progress = tqdm.tqdm(train_loader, total=len(train_loader))
123 | samples, labels = np.zeros([len(train_loader), testing_samples_per_video, feature_field_size], dtype=np.float32), np.zeros([len(train_loader), ], dtype=np.float32)
124 |
125 | last_access = 0
126 | for index, (video_frames, video_label) in enumerate(train_progress): # i don't need frame level labels
127 | feature_field, _ = motion_model_with_2_outputs.predict_on_batch(video_frames)
128 | samples[index] = feature_field
129 | labels[index] = video_label
130 | last_access = index
131 |
132 | print("train samples:", samples.shape)
133 | print("train labels:", labels.shape)
134 | assert last_access == len(train_loader) - 1
135 |
136 | with open("train_features_motion.pickle", 'wb') as f:
137 | pickle.dump((samples, labels), f)
138 |
139 | del samples, labels
140 | drive_manager.upload_project_file("train_features_motion.pickle")
141 | ##############################################################################
142 |
--------------------------------------------------------------------------------
/generate_spatial_feature_dataset.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Here I'm generating visual features from my pretrained spatial stream having 8% top-1 accuracy
6 | these visual features are just the layer below the softmax prediction, layer have 2048 features for each input image
7 | the data generated are stored into a big list and then dumped as pickle file for each epoch of data (more data augmentation)
8 | then this data are fed into a recurrent network implemented in recurrent_fusion_trainer.py file to train a video level classifier instead of frame level classier
9 |
10 | I expect a pre-trained xception model here to be downloaded from drive
11 | -------------------
12 | In this file I do what I call model surgery which is removing or adding some layer from a model
13 | Here I load my trained model whose architecture is
14 |
15 | Input_image > batch_norm >>> ...... very deep series of convs from xception model ... >>> softmax layer of 101 classes
16 |
17 | so I can change the model a little bit and make it have 2 outputs which are the features just below the softmax and the softmax
18 | so the model becomes
19 |
20 | Input_image > batch_norm >>> ...... very deep series of convs from xception model ... >>> softmax layer of 101 classes
21 | # >>> feature field of 2048 features
22 |
23 | which are two outputs now
24 | """
25 | import pickle
26 |
27 | from tensorflow.keras.models import Model
28 | from tensorflow.python.keras import Input
29 |
30 | import frame_dataloader
31 | from evaluation import legacy_load_model
32 | from evaluation.evaluation import *
33 | from utils.drive_manager import DriveManager
34 |
35 | #####################################################
36 | feature_field_size = 2048
37 | testing_samples_per_video = 19
38 | #####################################################
39 |
40 | """Managed"""
41 | evaluate = False
42 | generate_test = False
43 |
44 | drive_manager = DriveManager("spatial_feature_dataset")
45 | drive_manager.download_file('17O8JdvaSNJFmbvZtQPIBYNLgM9Um-znf', "spatial.zip")
46 | spatial_model_restored = legacy_load_model(filepath="spatial.h5", custom_objects={'sparse_categorical_cross_entropy_loss': sparse_categorical_cross_entropy_loss, "acc_top_1": acc_top_1, "acc_top_5": acc_top_5})
47 |
48 | spatial_model_restored.summary()
49 |
50 | spatial_model_with_2_outputs = Model(
51 | spatial_model_restored.inputs, # input image
52 | [layer.output for layer in spatial_model_restored.layers[-2:]] # visual features, softmax output
53 | )
54 |
55 | data_loader = frame_dataloader.SpatialDataLoaderFeature(
56 | num_workers=workers, samples_per_video=19,
57 | width=int(spatial_model_restored.inputs[0].shape[1]), height=int(spatial_model_restored.inputs[0].shape[2])
58 | , use_multiprocessing=True, augmenter_level=0, # heavy augmentation
59 | )
60 | train_loader, test_loader = data_loader.run()
61 |
62 | """
63 | Evaluate and check
64 | """
65 | if evaluate:
66 | progress = tqdm.tqdm(test_loader, total=len(test_loader))
67 | inp = Input(shape=(2048,), name="dense")
68 | dense_layer = Model(inp, spatial_model_restored.layers[-1](inp))
69 |
70 | video_level_preds_np = np.zeros((len(progress), num_actions)) # each video per 101 class (prediction)
71 | video_level_labels_np = np.zeros((len(progress), 1))
72 |
73 | for index, (video_frames, video_label) in enumerate(progress): # i don't need frame level labels
74 | feature_field, frame_preds = spatial_model_with_2_outputs.predict_on_batch(video_frames)
75 |
76 | assert np.allclose(frame_preds, dense_layer.predict(feature_field))
77 | video_level_preds_np[index, :] = np.mean(frame_preds, axis=0)
78 | video_level_labels_np[index, 0] = video_label
79 |
80 | video_level_loss, video_level_accuracy_1, video_level_accuracy_5 = keras.backend.get_session().run(
81 | [val_loss_op, acc_top_1_op, acc_top_5_op], feed_dict={video_level_labels_k: video_level_labels_np, video_level_preds_k: video_level_preds_np})
82 |
83 | print("Spatial Model validation", "prec@1", video_level_accuracy_1, "prec@5", video_level_accuracy_5, "loss", video_level_loss)
84 |
85 | """
86 | Generate the data and save into pickles
87 | """
88 | ##############################################################################
89 | # test data generation
90 | if generate_test:
91 | test_progress = tqdm.tqdm(test_loader, total=len(test_loader))
92 |
93 | samples, labels = np.zeros([len(test_loader), testing_samples_per_video, feature_field_size], dtype=np.float32), np.zeros([len(test_loader), ], dtype=np.float32)
94 |
95 | last_access = 0
96 | for index, (video_frames, video_label) in enumerate(test_progress): # i don't need frame level labels
97 | feature_field, _ = spatial_model_with_2_outputs.predict_on_batch(video_frames)
98 | samples[index] = feature_field
99 | labels[index] = video_label
100 | last_access = index
101 |
102 | print("test samples:", samples.shape)
103 | print("test labels:", labels.shape)
104 | assert last_access == len(test_progress) - 1
105 |
106 | with open("test_features_spatial.pickle", 'wb') as f:
107 | pickle.dump((samples, labels), f)
108 |
109 | del samples, labels
110 | drive_manager.upload_project_file("test_features_spatial.pickle")
111 |
112 | ##############################################################################
113 | # train data generation
114 | for epoch in range(1):
115 | train_progress = tqdm.tqdm(train_loader, total=len(train_loader))
116 | samples, labels = np.zeros([len(train_loader), testing_samples_per_video, feature_field_size], dtype=np.float32), np.zeros([len(train_loader), ], dtype=np.float32)
117 |
118 | last_access = 0
119 | for index, (video_frames, video_label) in enumerate(train_progress): # i don't need frame level labels
120 | feature_field, _ = spatial_model_with_2_outputs.predict_on_batch(video_frames)
121 | samples[index] = feature_field
122 | labels[index] = video_label
123 | last_access = index
124 |
125 | print("train samples:", samples.shape)
126 | print("train labels:", labels.shape)
127 | assert last_access == len(train_loader) - 1
128 |
129 | with open("train_features_spatial.pickle", 'wb') as f:
130 | pickle.dump((samples, labels), f)
131 |
132 | del samples, labels
133 | drive_manager.upload_project_file("train_features_spatial.pickle")
134 | ##############################################################################
135 |
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | """
--------------------------------------------------------------------------------
/models/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/models/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/models/__pycache__/spatial_models.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/models/__pycache__/spatial_models.cpython-36.pyc
--------------------------------------------------------------------------------
/models/motion_models.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | This Contains two keras models as motion stream:
6 | motion streams expects data tensors in the form [batch_size,height,width,stacked_frames(u/v=10*2)]
7 | 1) Xception model
8 | 2) resnet 50
9 | """
10 | """
11 | To understand what is going look at this https://keras.io/applications/
12 | """
13 |
14 | import h5py
15 | import numpy as np
16 | import tensorflow.keras.backend as K
17 |
18 |
19 | from tensorflow.keras.applications.resnet50 import ResNet50
20 |
21 | from tensorflow.keras.layers import *
22 | #
23 | from tensorflow.keras.models import Model
24 |
25 | from tensorflow.python.keras.applications.xception import Xception
26 | from tensorflow.python.keras.engine.saving import load_attributes_from_hdf5_group
27 | from tensorflow.python.keras.utils import get_file
28 |
29 | # from keras.applications.resnet50 import WEIGHTS_PATH_NO_TOP can't be imported in newer versions so I copied it
30 | WEIGHTS_PATH_NO_TOP = 'https://github.com/fchollet/deep-learning-models/releases/download/v0.2/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5'
31 |
32 | # from keras_applications.xception import TF_WEIGHTS_PATH_NO_TOP can't be imported in newer versions so I copied it
33 | TF_WEIGHTS_PATH_NO_TOP = (
34 | 'https://github.com/fchollet/deep-learning-models/'
35 | 'releases/download/v0.4/'
36 | 'xception_weights_tf_dim_ordering_tf_kernels_notop.h5')
37 |
38 | def is_same_shape(shape1, shape2):
39 | """Checks if two structures[could be list or single value for example] have the same shape"""
40 | if len(shape1) != len(shape2):
41 | return False
42 | else:
43 | for i in range(len(shape1)):
44 | if shape1[i] != shape2[i]:
45 | return False
46 |
47 | return True
48 |
49 |
50 | # This piece of code is inspired by keras source
51 | def compare_layers_weights(first_model_layers, second_model_layers):
52 | """Compare layers weights: I use them to test the pre trained models are loaded correctly"""
53 | for i in range(len(first_model_layers)):
54 | weights1 = first_model_layers[i].get_weights()
55 | weights2 = second_model_layers[i].get_weights()
56 | if len(weights1) == len(weights2):
57 | if not all([is_same_shape(weights2[w].shape, weights1[w].shape) and np.allclose(weights2[w], weights1[w]) for w in range(len(weights1))]):
58 | print(first_model_layers[i].name, "!=", second_model_layers[i].name)
59 | else:
60 | print(first_model_layers[i].name, "!=", second_model_layers[i].name)
61 |
62 |
63 | # This piece of code is inspired by keras source
64 | def get_symbolic_filtered_layer_weights_from_model(model):
65 | """For the given model get the symbolic(tensors) weights"""
66 | symbolic_weights = []
67 | for layer in model.layers:
68 | if layer.weights:
69 | symbolic_weights.append(layer.weights)
70 | return symbolic_weights # now you can load those weights with tensorflow feed
71 |
72 |
73 | # This piece of code is inspired by keras source
74 | def get_named_layer_weights_from_h5py(h5py_file):
75 | """decodes h5py for a given model downloaded by keras and gets layer weight name to value mapping"""
76 | with h5py.File(h5py_file) as h5py_stream:
77 | layer_names = load_attributes_from_hdf5_group(h5py_stream, 'layer_names')
78 |
79 | weights_values = []
80 | for name in layer_names:
81 | layer = h5py_stream[name]
82 | weight_names = load_attributes_from_hdf5_group(layer, 'weight_names')
83 | if weight_names:
84 | weight_values = [np.asarray(layer[weight_name]) for weight_name in weight_names]
85 | weights_values.append((name, weight_values))
86 | return weights_values
87 |
88 |
89 | # This piece of code is inspired by keras source
90 | def load_layer_weights(weight_values, symbolic_weights):
91 | """loads weight_values which is a list ot tuples from get_named_layer_weights_from_h5py()
92 | into symbolic_weights obtained from get_symbolic_filtered_layer_weights_from_model()
93 | """
94 | if len(weight_values) != len(symbolic_weights): # they must have the same length of layers
95 | raise ValueError('number of weights aren\'t equal', len(weight_values), len(symbolic_weights))
96 | else: # similar to keras source code :D .. load_weights_from_hdf5_group
97 | print("length of layers to load", len(weight_values))
98 | weight_value_tuples = []
99 |
100 | # load layer by layer weights
101 | for i in range(len(weight_values)): # list(layers) i.e. list of lists(weights)
102 | assert len(symbolic_weights[i]) == len(weight_values[i][1])
103 | # symbolic_weights[i] : list of symbolic names for layer i
104 | # symbolic_weights[i] : list of weight ndarrays for layer i
105 | weight_value_tuples += zip(symbolic_weights[i], weight_values[i][1]) # both are lists with equal lengths (name,value) mapping
106 |
107 | K.batch_set_value(weight_value_tuples) # loaded a batch to be efficient
108 |
109 |
110 | def cross_modality_init(in_channels, kernel):
111 | """
112 | Takes a weight computed for RGB and produces a new wight to be used by motion streams which need about 20 channels !
113 | kernel is (x, y, 3, 64)
114 | """
115 | # if in_channels == 3: # no reason for cross modality
116 | # return kernel
117 | print("cross modality kernel", kernel.shape)
118 | avg_kernel = np.mean(kernel, axis=2) # mean (x, y, 64)
119 | weight_init = np.expand_dims(avg_kernel, axis=2) # mean (x, y, 1, 64)
120 | return np.tile(weight_init, (1, 1, in_channels, 1)) # mean (x, y, in_channels, 64)
121 |
122 |
123 | def CrossModalityResNet50(num_classes, pre_trained, cross_modality_pre_training, input_shape):
124 | """Pretrained Resnet50 model from keras which uses cross modality pretraining to obtain a convolution weight which suits 20 channels needed by motion stream"""
125 | cross_modality_pre_training = cross_modality_pre_training and pre_trained
126 |
127 | # create the model
128 | model = ResNet50(classes=num_classes, weights=None, input_shape=input_shape, include_top=True)
129 | channels = input_shape[2]
130 |
131 | # load weight file >>> downloads some file from github
132 | weights_path = get_file(
133 | 'resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5',
134 | WEIGHTS_PATH_NO_TOP,
135 | cache_subdir='models',
136 | md5_hash='a268eb855778b3df3c7506639542a6af')
137 |
138 | # get the named weights of each layer
139 | weight_values_ = get_named_layer_weights_from_h5py(weights_path)
140 | # get the symbolic weights of each layer
141 | symbolic_weights_ = get_symbolic_filtered_layer_weights_from_model(model)[:len(weight_values_)]
142 |
143 | if cross_modality_pre_training: # use a pretrained convolution weight
144 | # update it (name,[kernel,bias])
145 | # cross modality pre-training for kernel
146 | # leave bias as is of course
147 | weight_values_[0] = ("conv1_cross_modality",
148 | [cross_modality_init(kernel=weight_values_[0][1][0], in_channels=channels), # 0 = first layer , 1 = weight_value , 0 = kernel
149 | weight_values_[0][1][1]] # 0 = first layer , 1 = weight_value , 1 = bias
150 | )
151 |
152 | else: # start the first convolution layer as random glorot
153 | symbolic_weights_ = symbolic_weights_[1:]
154 | weight_values_ = weight_values_[1:]
155 |
156 | if pre_trained:
157 | # do weight loading
158 | load_layer_weights(weight_values=weight_values_, symbolic_weights=symbolic_weights_)
159 |
160 | return model
161 |
162 |
163 | class ResNet50MotionCNN:
164 | """
165 | ResNet model used for motion stream which is (input layer >> norm layer >> resnet50 model)
166 | """
167 | """
168 | pretrained+adam:
169 | scratch+adam:
170 |
171 | pretrained+MSGD:80%
172 | scratch+MSGD:
173 | """
174 |
175 | def __init__(self, num_classes, is_tesla_k80, stacked_frames, pre_trained=True, cross_modality_pre_training=True):
176 | self.is_teslaK80 = is_tesla_k80
177 | # input layer
178 | self.inputs = Input(shape=(224, 224, 2 * stacked_frames), name="input_motion")
179 |
180 | # data normalization
181 | self.data_norm = BatchNormalization(3, name='data_norm', center=False, scale=False)
182 | # create the base pre-trained model
183 | self.resnet = CrossModalityResNet50(num_classes=num_classes, pre_trained=pre_trained, cross_modality_pre_training=cross_modality_pre_training, input_shape=(224, 224, 2 * stacked_frames))
184 |
185 | def get_keras_model(self):
186 | # keras functional api
187 | return Model(self.inputs, self.resnet(self.data_norm(self.inputs)), name="motion_resnet")
188 |
189 | def get_loader_configs(self):
190 | return {"width": 224, "height": 224, "batch_size": 28 if self.is_teslaK80 else 24}
191 |
192 |
193 | def CrossModalityXception(num_classes, pre_trained, cross_modality_pre_training, input_shape, include_feature_fields=False):
194 | cross_modality_pre_training = cross_modality_pre_training and pre_trained
195 |
196 | # create the model
197 | model = Xception(classes=num_classes, weights=None, input_shape=input_shape, include_top=True)
198 | channels = input_shape[2]
199 |
200 | # load weight file >>> downloads some file from github
201 | weights_path = get_file(
202 | 'xception_weights_tf_dim_ordering_tf_kernels_notop.h5',
203 | TF_WEIGHTS_PATH_NO_TOP,
204 | cache_subdir='models',
205 | file_hash='b0042744bf5b25fce3cb969f33bebb97')
206 |
207 | weight_values_ = get_named_layer_weights_from_h5py(weights_path)
208 | symbolic_weights_ = get_symbolic_filtered_layer_weights_from_model(model)[:len(weight_values_)]
209 |
210 | if cross_modality_pre_training: # use a pretrained convolution weight
211 | # update it (name,[kernel,bias])
212 | # cross modality pre-training for kernel
213 | # leave bias as is of course
214 | weight_values_[0] = ("conv1_cross_modality",
215 | [cross_modality_init(kernel=weight_values_[0][1][0], in_channels=channels), # 0 = first layer , 1 = weight_value , 0 = kernel
216 | # Xception has no bias
217 | ]
218 | )
219 |
220 | else: # start the first convolution layer as random glorot
221 | symbolic_weights_ = symbolic_weights_[1:]
222 | weight_values_ = weight_values_[1:]
223 |
224 | if pre_trained:
225 | # do weight loading
226 | load_layer_weights(weight_values=weight_values_, symbolic_weights=symbolic_weights_)
227 |
228 | if include_feature_fields:
229 | return Model(model.inputs, [layer.output for layer in model.layers[-2:]])
230 | else:
231 | return model
232 |
233 |
234 | class XceptionMotionCNN:
235 | """
236 | Xception model used for motion stream which is (input layer >> norm layer >> xception model)
237 | """
238 | """
239 | pretrained+adam: 84.4%
240 | scratch+adam:
241 |
242 | pretrained+MSGD:
243 | scratch+MSGD:
244 | """
245 |
246 | def __init__(self, num_classes, is_tesla_k80, stacked_frames, pre_trained=True, cross_modality_pre_training=True, include_feature_fields=False):
247 | self.is_teslaK80 = is_tesla_k80
248 | # input layer
249 | self.inputs = Input(shape=(299, 299, 2 * stacked_frames), name="input_motion")
250 | # data normalization
251 | self.data_norm = BatchNormalization(3, name='data_norm', center=False, scale=False)
252 |
253 | # create the base pre-trained model
254 | self.xception = CrossModalityXception(num_classes=num_classes, cross_modality_pre_training=cross_modality_pre_training, pre_trained=pre_trained, input_shape=(299, 299, 2 * stacked_frames), include_feature_fields=include_feature_fields)
255 |
256 | def get_keras_model(self):
257 | # keras functional api
258 | return Model(self.inputs, self.xception(self.data_norm(self.inputs)), name="motion_xception")
259 |
260 | def get_loader_configs(self):
261 | return {"width": 299, "height": 299, "batch_size": 28 if self.is_teslaK80 else 28}
262 |
263 |
264 | if __name__ == '__main__':
265 | # test :D
266 | model1 = ResNet50MotionCNN(num_classes=101, stacked_frames=10, is_tesla_k80=True)
267 | model2 = ResNet50MotionCNN2(num_classes=101, stacked_frames=10, is_tesla_k80=True)
268 | model3 = ResNet50()
269 | print(model1.layers)
270 | print(model2.layers)
271 | print(model3.layers)
272 | print(" ")
273 | compare_layers_weights(model1.layers[1].layers, model2.layers[1].layers)
274 | print(" ")
275 | compare_layers_weights(model3.layers, model2.layers[1].layers)
276 | print(" ")
277 | compare_layers_weights(model3.layers, model1.layers[1].layers)
278 | print(" ")
279 |
280 | print("xception test")
281 | model4 = Xception(input_shape=(299, 299, 3))
282 | model5 = XceptionMotionCNN(num_classes=101, is_tesla_k80=True, stacked_frames=10)
283 |
284 | print(model4.layers)
285 | print(model5.layers)
286 | compare_layers_weights(model4.layers, model5.layers[1].layers)
287 |
288 | print("values")
289 | print(model4.layers[1].weights)
290 | print(model4.layers[1].get_weights()[0][0, 0, :, 0])
291 | print(model5.layers[1].layers[1].get_weights()[0][0, 0, :, 0])
292 |
--------------------------------------------------------------------------------
/models/spatial_models.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | This Contains four keras models as spatial stream:
6 | motion streams expects data tensors in the form [batch_size,height,width,3)]
7 | 1) Xception model
8 | 2) resnet 50
9 | 3) VGG19
10 | 4) MobileNet
11 | """
12 | """
13 | To understand what is going look at this https://keras.io/applications/
14 | """
15 | from tensorflow.keras.applications.mobilenet import MobileNet
16 | from tensorflow.keras.applications.resnet50 import ResNet50
17 | from tensorflow.keras.applications.vgg19 import VGG19
18 | from tensorflow.keras.applications.xception import Xception
19 | from tensorflow.keras.models import Model
20 | from tensorflow.python.keras import Input
21 | from tensorflow.python.keras.layers import Reshape, Activation, Dropout, GlobalAveragePooling2D, Conv2D, Flatten, Dense, BatchNormalization
22 |
23 |
24 | class ResNet50SpatialCNN:
25 | """
26 | ResNet model used for spatial stream which is
27 | (input layer >> norm layer >> resnet50 without prediction layers(look at keras docs https://keras.io/applications/) >> flatting >> softmax projection)
28 | """
29 | """
30 | pretrained+adam: 80 ~ 81.2
31 | scratch+adam: 0.42215174 !!! imagenet pre training is really important
32 |
33 | pretrained+MSGD: 78.5 ~ 80
34 | scratch+MSGD:
35 | """
36 |
37 | def __init__(self, num_classes, is_tesla_k80, pre_trained=True):
38 | self.is_teslaK80 = is_tesla_k80
39 |
40 | # input layer
41 | self.inputs = Input(shape=(224, 224, 3), name="input_spatial")
42 | # data normalization
43 | self.data_norm = BatchNormalization(3, name='data_norm', center=False, scale=False)
44 |
45 | # create the base pre-trained model
46 | self.resnet = ResNet50(weights='imagenet' if pre_trained else None, include_top=False)
47 |
48 | # print(self.base_model.get_layer('avg_pool').__dict__)
49 | self.flat = Flatten(name="flatten")
50 |
51 | # self.drop_out_fc = keras.layers.Dropout(.75)
52 | self.fc_custom = Dense(num_classes, name="fc_custom", activation="softmax")
53 |
54 | def get_keras_model(self):
55 | # keras functional api
56 | def model(inputs):
57 | return self.fc_custom(self.flat(self.resnet(self.data_norm(inputs))))
58 |
59 | return Model(self.inputs, model(self.inputs), name="spatial_resnet50")
60 |
61 | def get_loader_configs(self):
62 | return {"width": 224, "height": 224, "batch_size": 76 if self.is_teslaK80 else 48}
63 |
64 |
65 | class XceptionSpatialCNN:
66 | """
67 | ResNet model used for spatial stream which is
68 | (input layer >> norm layer >> xception without prediction layers (look at keras docs https://keras.io/applications/) >> GlobalAveragePooling2D >> softmax projection)
69 | """
70 | """
71 | pretrained+adam: 86.12% <3
72 | scratch+adam:
73 |
74 | pretrained+MSGD:82%
75 | scratch+MSGD:
76 | """
77 |
78 | def __init__(self, num_classes, is_tesla_k80, pre_trained=True):
79 | self.is_teslaK80 = is_tesla_k80
80 | # input layer
81 | self.inputs = Input(shape=(299, 299, 3), name="input_spatial")
82 | # data normalization
83 | self.data_norm = BatchNormalization(3, name='data_norm', center=False, scale=False)
84 |
85 | # create the base pre-trained model
86 | self.xception = Xception(weights='imagenet' if pre_trained else None, include_top=False, input_shape=(299, 299, 3))
87 |
88 | self.GlobalAveragePooling2D = GlobalAveragePooling2D(name='avg_pool')
89 |
90 | # self.drop_out_fc = keras.layers.Dropout(.75)
91 | self.fc_custom = Dense(num_classes, name="predictions", activation="softmax")
92 |
93 | def get_keras_model(self):
94 | # print(inputs)
95 | def model(inputs):
96 | return self.fc_custom(self.GlobalAveragePooling2D(self.xception(self.data_norm(inputs))))
97 |
98 | return Model(self.inputs, model(self.inputs), name="spatial_xception")
99 |
100 | def get_loader_configs(self):
101 | return {"width": 299, "height": 299, "batch_size": 28 if self.is_teslaK80 else 28} # 28
102 |
103 |
104 | class VGGSpatialCNN:
105 | """
106 | VGG19 model used for spatial stream which is
107 | (input layer >> norm layer >> VGG19 without prediction layers (look at keras docs https://keras.io/applications/) >> GlobalAveragePooling2D >> softmax projection)
108 | """
109 | """
110 | pretrained+adam:
111 | scratch+adam:
112 |
113 | pretrained+MSGD: 70%
114 | scratch+MSGD:
115 | """
116 |
117 | def __init__(self, num_classes, is_tesla_k80, pre_trained=True):
118 | self.is_teslaK80 = is_tesla_k80
119 | # input layer
120 | self.inputs = Input(shape=(224, 224, 3), name="input_spatial")
121 | # data normalization
122 | self.data_norm = BatchNormalization(3, name='data_norm', center=False, scale=False)
123 |
124 | # create the base pre-trained model
125 | self.vgg19_no_top = VGG19(weights='imagenet' if pre_trained else None, include_top=False)
126 |
127 | self.flat = Flatten(name='flatten')
128 | self.Dense_1 = Dense(4096, activation='relu', name='fc1')
129 | self.Dense_2 = Dense(4096, activation='relu', name='fc2')
130 | self.Dense_3 = Dense(num_classes, activation='softmax', name='predictions')
131 |
132 | def get_keras_model(self):
133 | # print(inputs)
134 | def model(inputs):
135 | x = self.vgg19_no_top(self.data_norm(inputs))
136 | x = self.flat(x)
137 | x = self.Dense_1(x)
138 | x = self.Dense_2(x)
139 | prediction = self.Dense_3(x)
140 | return prediction
141 |
142 | return Model(self.inputs, model(self.inputs), name="spatial_vgg19")
143 |
144 | def get_loader_configs(self):
145 | return {"width": 224, "height": 224, "batch_size": 40 if self.is_teslaK80 else 40}
146 |
147 |
148 | class MobileSpatialCNN:
149 | """
150 | MobileNet model used for spatial stream which is
151 | (input layer >> norm layer >> MobileNet without prediction layers (look at keras docs https://keras.io/applications/) >> GlobalAveragePooling2D >> softmax projection)
152 | """
153 | """
154 | pretrained+adam:
155 | scratch+adam:
156 |
157 | pretrained+MSGD:
158 | scratch+MSGD:
159 | """
160 |
161 | def __init__(self, num_classes, is_tesla_k80, alpha=1, dropout=1e-3, pre_trained=True):
162 | self.is_teslaK80 = is_tesla_k80
163 |
164 | # input layer
165 | self.inputs = Input(shape=(224, 224, 3), name="input_spatial")
166 | # data normalization
167 | self.data_norm = BatchNormalization(3, name='data_norm', center=False, scale=False)
168 |
169 | # create the base pre-trained model
170 | self.mobile_net = MobileNet(weights='imagenet' if pre_trained else None, include_top=False)
171 |
172 | self.GlobalAveragePooling2D = GlobalAveragePooling2D()
173 |
174 | shape = (1, 1, int(1024 * alpha))
175 | self.Reshape_1 = Reshape(shape, name='reshape_1')
176 | self.Dropout = Dropout(dropout, name='dropout')
177 | self.Conv2D = Conv2D(num_classes, (1, 1), padding='same', name='conv_preds')
178 | self.Activation = Activation('softmax', name='act_softmax')
179 | self.Reshape_2 = Reshape((num_classes,), name='reshape_2')
180 |
181 | def get_keras_model(self):
182 | def model(inputs):
183 | x = self.mobile_net(self.data_norm(inputs))
184 | x = self.GlobalAveragePooling2D(x)
185 | x = self.Reshape_1(x)
186 | x = self.Dropout(x)
187 | x = self.Conv2D(x)
188 | x = self.Activation(x)
189 | prediction = self.Reshape_2(x)
190 | return prediction
191 |
192 | return Model(self.inputs, model(self.inputs), name="spatial_mobilenet")
193 |
194 | def get_loader_configs(self):
195 | return {"width": 224, "height": 224, "batch_size": 100 if self.is_teslaK80 else 100}
196 |
--------------------------------------------------------------------------------
/motion_trainer.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Here I'm training motion stream CNN in the following steps:
6 | 1. load configs from configs.motion_configs (indicating architecture/optimizer/lr/pretrained..)
7 | 2. initialize your dataloader >> feeding the data efficiently to the model
8 | 3. load the latest snapshot of the model from drive (It's public and will be downloaded for you)..
9 | note: folders are identified on my drive with their experiment_identifier
10 | for example heavy-mot-xception-adam-1e-05-imnet is (heavy augmentation,motion stream,xception architecture,adam optimizer with lr = 1e-05 pretrained on imagenet)
11 | this long experiment_identifier is given to drive manager and downloaded automatically and continue training from that checkpoint
12 | view my experiments :https://drive.google.com/drive/folders/1B82anWV8Mb4iHYmOp9tIR9aOTlfllwsD
13 | to make your own experiments on your drive you will need to modify DriveManager at utils.drive_manager and use some other long experiment_identifier
14 | for example make this personal.heavy-mot-xception-adam-1e-05-imnet as suffix at line 31
15 |
16 | 4. As the checkpoint is downloaded or not found the trainer will start from scratch or to continue from where it stopped (the checkpoint)
17 |
18 | note: validation is done by MotionValidationCallback which validates on the given dataset evaluation section
19 | """
20 | from functools import partial
21 |
22 | import frame_dataloader
23 | import utils.training_utils as eval_globals
24 | from configs.motion_configs import *
25 | from evaluation import legacy_load_model, get_batch_size
26 | from evaluation.evaluation import *
27 | from models.motion_models import *
28 | from utils import log, get_augmenter_text
29 | from utils.drive_manager import DriveManager
30 |
31 | ################################################################################
32 | """Files, paths & identifier"""
33 | suffix = "" # put your name or anything(your crush :3) :D
34 | experiment_identifier = suffix + ("" if suffix == "" else "-") + get_augmenter_text(augmenter_level) + "-mot-" + model_name + "-" + ("adam" if is_adam else "SGD") + "-" + str(lr) + "-" + ("imnet" if pretrained else "scrat")
35 | log_file = "motion.log"
36 | log_stream = open("motion.log", "a")
37 | h5py_file = "motion.h5"
38 | pred_file = "motion.preds"
39 | ################################################################################
40 | """Checking latest"""
41 | print(experiment_identifier)
42 | num_actions = 101
43 | print("Number of workers:", workers, file=log_stream)
44 | drive_manager = DriveManager(experiment_identifier)
45 | checkpoint_found, zip_file_name = drive_manager.get_latest_snapshot()
46 | ################################################################################
47 | # you need to send it as callback before keras reduce on plateau
48 | MotionValidationCallback = partial(eval_globals.get_validation_callback,
49 | log_stream=log_stream,
50 | validate_every=validate_every,
51 | testing_samples_per_video=testing_samples_per_video,
52 | pred_file=pred_file, h5py_file=h5py_file, drive_manager=drive_manager, log_file=log_file)
53 |
54 | data_loader = partial(frame_dataloader.MotionDataLoader,
55 | testing_samples_per_video=testing_samples_per_video,
56 | augmenter_level=augmenter_level,
57 | log_stream=log_stream, stacked_frames=stacked_frames)
58 |
59 | if checkpoint_found:
60 | # restore the model from the checkpoint
61 | log("Model restored")
62 | eval_globals.best_video_level_accuracy_1 = float(zip_file_name.split("-")[1])
63 | log("Current Best", eval_globals.best_video_level_accuracy_1)
64 |
65 | motion_model_restored = legacy_load_model(filepath=h5py_file, custom_objects={'sparse_categorical_cross_entropy_loss': sparse_categorical_cross_entropy_loss, "acc_top_1": acc_top_1, "acc_top_5": acc_top_5})
66 | # init data loader
67 | train_loader, test_loader, test_video_level_label = data_loader(width=int(motion_model_restored.inputs[0].shape[1]),
68 | height=int(motion_model_restored.inputs[0].shape[2]),
69 | batch_size=get_batch_size(motion_model_restored,
70 | spatial=False)).run()
71 |
72 | # training
73 | motion_model_restored.fit_generator(train_loader,
74 | steps_per_epoch=len(train_loader), # generates a batch per step
75 | epochs=epochs,
76 | use_multiprocessing=False, workers=workers,
77 | # validation_data=gen_test(), validation_steps=len(test_loader.dataset)
78 | callbacks=[MotionValidationCallback(model=motion_model_restored, test_loader=test_loader, test_video_level_label=test_video_level_label), # returns callback instance
79 | keras.callbacks.ReduceLROnPlateau(monitor='val_loss', patience=validate_every, verbose=1)],
80 | initial_epoch=int(zip_file_name.split("-")[0])) # get epoch number
81 |
82 | else:
83 | # init the model from scratch
84 | log("Starting from scratch")
85 |
86 | if model_name == "resnet":
87 | model = ResNet50MotionCNN(num_classes=num_actions,
88 | is_tesla_k80=is_tesla_k80,
89 | pre_trained=True if pretrained else False,
90 | stacked_frames=stacked_frames)
91 | elif model_name == "xception":
92 | model = XceptionMotionCNN(num_classes=num_actions,
93 | is_tesla_k80=is_tesla_k80,
94 | pre_trained=True if pretrained else False,
95 | stacked_frames=stacked_frames)
96 |
97 | # noinspection PyUnboundLocalVariable
98 | keras_motion_model = model.get_keras_model()
99 |
100 | # init data loader
101 | train_loader, test_loader, test_video_level_label = data_loader(**model.get_loader_configs()).run() # batch_size, width , height)
102 |
103 | keras_motion_model.compile(optimizer=keras.optimizers.Adam(lr=lr) if is_adam else keras.optimizers.SGD(lr=lr, momentum=0.9),
104 | loss=sparse_categorical_cross_entropy_loss,
105 | metrics=[acc_top_1, acc_top_5])
106 |
107 | keras_motion_model.summary(print_fn=lambda *args: print(args, file=log_stream))
108 | keras_motion_model.summary()
109 | log_stream.flush()
110 |
111 | # training
112 | keras_motion_model.fit_generator(train_loader,
113 | steps_per_epoch=len(train_loader), # generates a batch per step
114 | epochs=epochs,
115 | use_multiprocessing=False, workers=workers,
116 | # validation_data=gen_test(), validation_steps=len(test_loader.dataset)
117 | callbacks=[MotionValidationCallback(model=keras_motion_model, test_loader=test_loader, test_video_level_label=test_video_level_label), # returns callback instance
118 | keras.callbacks.ReduceLROnPlateau(monitor='val_loss', patience=validate_every * 10, verbose=1)],
119 | )
120 |
--------------------------------------------------------------------------------
/readme.md:
--------------------------------------------------------------------------------
1 | # Action Recognition [no longer maintained]
2 |
3 |
4 | 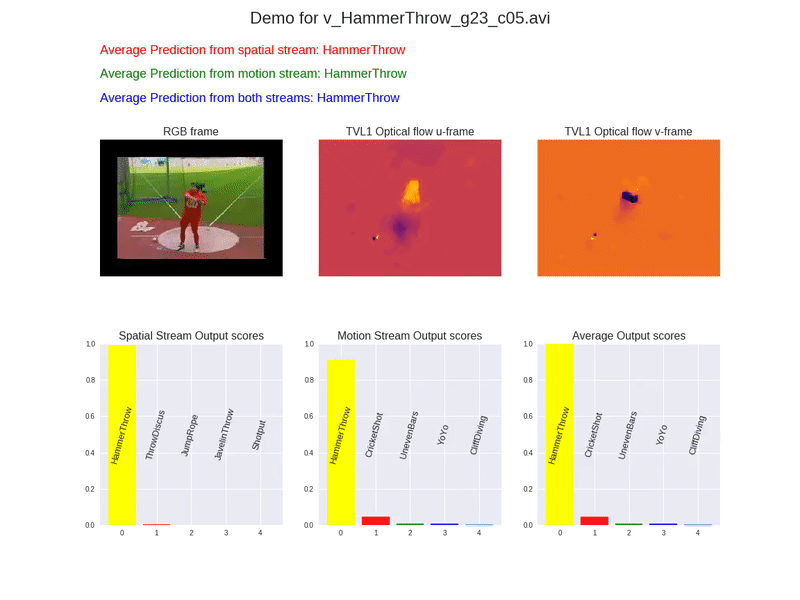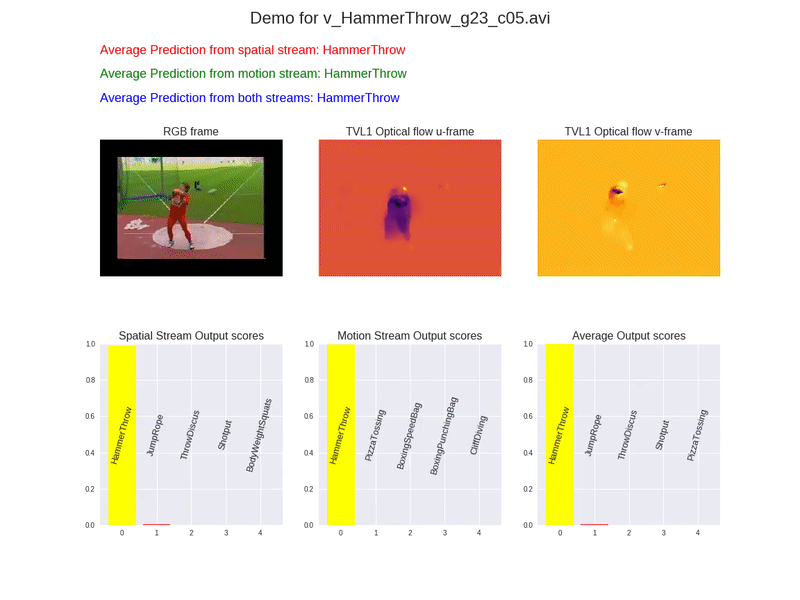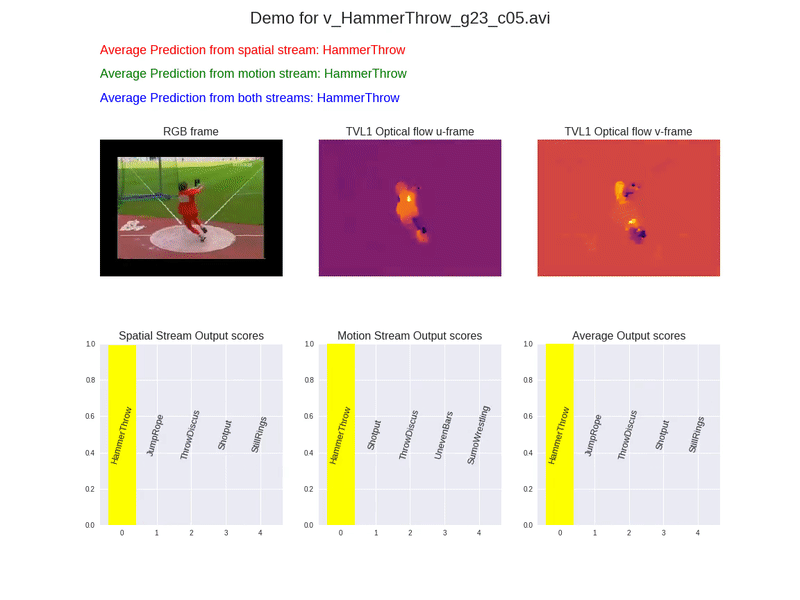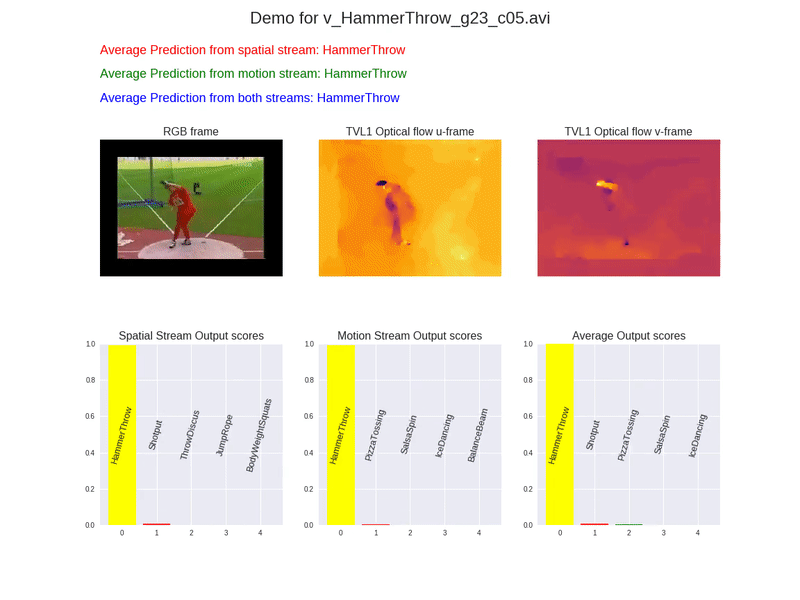 5 |
5 |
6 |
7 | In this repo we study the problem of action recognition(recognizing actions in videos) on UCF101 famous dataset.
8 |
9 | Here, I reimplemented two-stream approach for action recognition using pre-trained Xception networks for both streams(Look at references).
10 |
11 | # Live demo on Colab
12 | Just clone **Live Demo Two-steam net.ipynb** notebook to your drive and run the cells on Google Colab (Something like the demo gif will be generated in video format)
13 |
14 | # Get started:
15 | A full demo of the code in the repo can be found in **Action_Recognition_Walkthrough.ipynb** notebook.
16 |
17 | Please clone **Action_Recognition_Walkthrough.ipynb** notebook to your drive account and run it on Google Colab on python3 GPU-enabled instance.
18 |
19 | ## Environment and requirements:
20 | This code requires python 3.6,
21 | ```
22 | Tensorflow 1.11.0 (GPU enabled-the code uses keras associated with Tensorflow)
23 | Imgaug 0.2.6
24 | opencv 3.4.2.17
25 | numpy 1.14.1
26 | ```
27 | All of these requirements are satisfied by (python3 Colab GPU-enabled instance) Just use it and the notebook **Action_Recognition_Walkthrough.ipynb** will install the rest :)
28 |
29 |
30 | ## Dataset:
31 | I used UCF101 dataset originally found [here](https://www.crcv.ucf.edu/datasets/human-actions/ucf101/UCF101.rar).
32 |
33 | Also the dataset is processed and published by [feichtenhofer/twostreamfusion](https://github.com/feichtenhofer/twostreamfusion))
34 | * RGB images(single zip file split into three parts)
35 | ```
36 | wget http://ftp.tugraz.at/pub/feichtenhofer/tsfusion/data/ucf101_jpegs_256.zip.001
37 | wget http://ftp.tugraz.at/pub/feichtenhofer/tsfusion/data/ucf101_jpegs_256.zip.002
38 | wget http://ftp.tugraz.at/pub/feichtenhofer/tsfusion/data/ucf101_jpegs_256.zip.003
39 | ```
40 | * Optical Flow u/v frames(single zip file split into three parts)
41 | ```
42 | wget http://ftp.tugraz.at/pub/feichtenhofer/tsfusion/data/ucf101_tvl1_flow.zip.001
43 | wget http://ftp.tugraz.at/pub/feichtenhofer/tsfusion/data/ucf101_tvl1_flow.zip.002
44 | wget http://ftp.tugraz.at/pub/feichtenhofer/tsfusion/data/ucf101_tvl1_flow.zip.003
45 | ```
46 |
47 | ## Code Features:
48 | * You have variety of models to exchange between them easily.
49 | * Saves checkpoints on regular intervals and those checkpoints are synchronized to google drive using Drive API which means you can resume training anywhere for any Goggle Colab Instance.
50 | * Accesses the public models on my drive and you can resume and fine-tune them at different time stamps.
51 | Where the name of every checkpoint is as follows, **EPOCH.BEST_TOP_1_ACC.CURRENT_TOP_1_ACC**
52 | for example [this](https://drive.google.com/open?id=1N697z8uvAHICBbFNOJyKn4nbT64rUTcB)
53 | which is **300-0.84298-0.84166.zip** in folder **heavy-mot-xception-adam-1e-05-imnet**
54 | at this checkpoint,
55 | * **epoch=300**
56 | * **best top 1 accuracy was 0.84298** (obtained in checkpoint before 300)
57 | * **the current accuracy is 0.84166**
58 | * in the experiment **heavy-mot-xception-adam-1e-05-imnet**
59 | ## Models:
60 | I used pre-trained models on imagenet provided by keras applications [here](https://keras.io/applications/).
61 |
62 | The best results are obtained using Xception architecture.
63 |
64 |
65 | Network | Top1-Acc |
66 | --------------|:-------:|
67 | Spatial VGG19 stream | ~75% |
68 | Spatial Resnet50 stream | 81.2% |
69 | Spatial Xception stream | 86.04%|
70 | ------------------------|-------|
71 | Motion Resnet50 stream | ~75% |
72 | Motion xception stream | 84.4% |
73 | ------------------------|-------|
74 | Average fusion| **91.25%** |
75 | ------------------------|-------|
76 | Recurrent network fusion| **91.7%** |
77 |
78 | ## Pre-trained Model
79 | All the pre-trained models could be found [here](https://drive.google.com/drive/folders/1B82anWV8Mb4iHYmOp9tIR9aOTlfllwsD).
80 |
81 | It's the same drive folder accessed by the code while training and resuming training from a checkpoint.
82 |
83 | ## Reference Papers:
84 | * [[1] Two-stream convolutional networks for action recognition in videos](https://arxiv.org/pdf/1406.2199.pdf)
85 | * [[2] Real-time Action Recognition with Enhanced Motion Vector CNNs](https://arxiv.org/pdf/1604.07669.pdf)
86 | * [[3] Towards Good Practices for Very Deep Two-Stream ConvNets](https://arxiv.org/pdf/1507.02159.pdf)
87 |
88 |
89 | ## Nice implementations of two-stream approach:
90 | * [[1] Nice two-stream reimplementation using pytorch using resnets](https://github.com/jeffreyhuang1/two-stream-action-recognition)
91 | My code is inspired by this repo.
92 | * [[2] Two-stream-pytorch](https://github.com/bryanyzhu/two-stream-pytorch)
93 | * [[3] Hidden-Two-Stream](https://github.com/bryanyzhu/Hidden-Two-Stream)
94 |
95 |
96 | ## Future directions:
97 | * [[1] Hidden-Two-stream](https://arxiv.org/pdf/1704.00389.pdf)
98 | Which achieves real-time performance by using a deep neural net for generating the optical flow.
99 | * [[2] Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?](https://arxiv.org/pdf/1711.09577.pdf)
100 | Discuses how 3d convolutions is the perfect architecture for videos and Kinetics dataset pre-training could retrace imagenet pre-training.
101 | * [[3] Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset](https://arxiv.org/pdf/1705.07750.pdf)
102 |
103 | ## Useful links:
104 | * [[1] awesome-action-recognition](https://github.com/jinwchoi/awesome-action-recognition)
105 |
--------------------------------------------------------------------------------
/recurrent_fusion_trainer.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Here I'm training video level network based on recurrent networks(frames from CNN are concatenated into a 3d tensor and feed to RNN):
6 | 1. setting configs (considering concatenation will have feature of 4096 = 2048 *2)
7 | 2. generating experiment_identifier and creating files
8 | 3. downloading pickled data from drive each pickled file is a big numpy array whose shape is [instances, samples per video,features(2048 or 4096) ]
9 | """
10 | import glob
11 | import pickle
12 | import random
13 | import shutil
14 |
15 | from tensorflow.keras import backend as K
16 | from tensorflow.python.keras import Model
17 | from tensorflow.python.keras.layers import Dense, Softmax, GRU
18 |
19 | import utils.training_utils as eval_globals
20 | from evaluation.evaluation import *
21 | from utils import log
22 | from utils.drive_manager import DriveManager
23 |
24 | ################################################################################
25 | """Configs"""
26 | lr = 1e-6
27 | hidden_state = 128
28 | feature_field = 2048
29 | testing_samples_per_video = 19
30 | epochs = 1200
31 | save_every = 25
32 | batch_size = 64
33 |
34 | num_training_samples = 9537
35 | num_testing_samples = 3783
36 |
37 | is_spatial = True
38 | is_motion = True
39 |
40 | if is_spatial and is_motion:
41 | feature_field *= 2
42 | ################################################################################
43 | """Files, paths & identifier"""
44 | suffix = "" # put your name or anything :D
45 | experiment_identifier = suffix + "recurrent_fusion_selu_atten_simple" + str(lr)
46 | ################
47 | log_file = experiment_identifier + ".log"
48 | log_stream = open(log_file, "a")
49 | checkpoint_dir = "./fusion/"
50 | checkpoints = checkpoint_dir + "fusion_chk"
51 | try:
52 | shutil.rmtree(checkpoint_dir)
53 | except:
54 | pass
55 | drive_manager = DriveManager(experiment_identifier)
56 | checkpoint_found, zip_file_name = drive_manager.get_latest_snapshot()
57 | ################################################################################
58 | """sanity check"""
59 | if not is_motion and not is_spatial:
60 | exit()
61 | ################################################################################
62 | """Downloads the files and makes sure files aren't re-downloaded with every run if no one is missed"""
63 | if is_spatial:
64 | drive_manager_spatial = DriveManager("spatial_feature_dataset")
65 | test_spatial = drive_manager_spatial.search_file("test_features_spatial.pickle")
66 | train_spatial = drive_manager_spatial.search_file("train_features_spatial.pickle")
67 |
68 | if len(test_spatial) == 0:
69 | print("Please run 'generate_spatial_feature_dataset.py' and generate 'test_features_spatial.pickle'..this file will be saved to your drive in '/spatial_feature_dataset'".format(drive_manager_spatial.personal_dfolder))
70 | exit()
71 |
72 | if len(train_spatial) == 0:
73 | print("Please run 'generate_spatial_feature_dataset.py' and generate 'train_features_spatial.pickle'..those files will be saved to your drive in '/spatial_feature_dataset'".format(drive_manager_spatial.personal_dfolder))
74 | exit()
75 |
76 | drive_manager_spatial.download_file(test_spatial[0]["id"], "test_features_spatial.pickle", unzip=False)
77 |
78 | if len(glob.glob("train_features_spatial.pickle*")) != len(train_spatial):
79 | drive_manager_spatial.download_files_list(train_spatial, False, False)
80 |
81 | if is_motion:
82 | drive_manager_motion = DriveManager("motion_feature_dataset")
83 |
84 | test_motion = drive_manager_motion.search_file("test_features_motion.pickle")
85 | train_motion = drive_manager_motion.search_file("train_features_motion.pickle")
86 |
87 | if len(test_motion) == 0:
88 | print("Please run 'generate_motion_feature_dataset.py' and generate 'test_features_motion.pickle'..this file will be saved to your drive in '/motion_feature_dataset'".format(drive_manager_motion.personal_dfolder))
89 | exit()
90 |
91 | if len(train_motion) == 0:
92 | print("Please run 'generate_motion_feature_dataset.py' and generate 'train_features_motion.pickle'..those files will be saved to your drive in '/motion_feature_dataset'".format(drive_manager_motion.personal_dfolder))
93 | exit()
94 |
95 | drive_manager_motion.download_file(test_motion[0]["id"], "test_features_motion.pickle", unzip=False)
96 |
97 | if len(glob.glob("train_features_motion.pickle*")) != len(train_motion):
98 | drive_manager_motion.download_files_list(train_motion, False, False)
99 | ################################################################################
100 | seen_spatial_files = set()
101 | seen_motion_files = set()
102 |
103 |
104 | def train_generator():
105 | while True:
106 | train_samples_spatial, train_labels_spatial, train_samples_motion, train_labels_motion = [0] * 4
107 | """Choose file to read while being downloaded then read files"""
108 |
109 | """load spatial data"""
110 | if is_spatial:
111 | spatial_features_files = glob.glob("train_features_spatial.pickle*")
112 | if len(spatial_features_files) == len(seen_spatial_files):
113 | seen_spatial_files.clear()
114 |
115 | while True:
116 | spatial_features_file = random.sample(spatial_features_files, k=1)[0]
117 | if spatial_features_file not in seen_spatial_files:
118 |
119 | try:
120 | with open(spatial_features_file, 'rb') as f:
121 | train_samples_spatial, train_labels_spatial = pickle.load(f)
122 |
123 | # print("chose:", spatial_features_file)
124 | seen_spatial_files.add(spatial_features_file)
125 | break
126 | except:
127 | pass
128 |
129 | """load motion data"""
130 | if is_motion:
131 | motion_features_files = glob.glob("train_features_motion.pickle*")
132 | if len(motion_features_files) == len(seen_motion_files):
133 | seen_motion_files.clear()
134 |
135 | while True:
136 | motion_features_file = random.sample(motion_features_files, k=1)[0]
137 | if motion_features_file not in seen_motion_files:
138 |
139 | try:
140 | with open(motion_features_file, 'rb') as f:
141 | train_samples_motion, train_labels_motion = pickle.load(f)
142 |
143 | # print("chose:", motion_features_file)
144 | seen_motion_files.add(motion_features_file)
145 | break
146 | except:
147 | pass
148 |
149 | """generation loop"""
150 | permutation = list(range((num_training_samples + batch_size - 1) // batch_size))
151 | random.shuffle(permutation)
152 |
153 | if is_spatial != is_motion: # xor
154 | # single stream motion or spatial
155 | if is_spatial:
156 | train_samples, train_labels = train_samples_spatial, train_labels_spatial
157 | assert train_samples_spatial.shape[0] == num_training_samples
158 | else:
159 | train_samples, train_labels = train_samples_motion, train_labels_motion
160 | assert train_samples_motion.shape[0] == num_training_samples
161 |
162 | for batch_index in permutation:
163 | yield train_samples[batch_index * batch_size:(batch_index + 1) * batch_size], train_labels[batch_index * batch_size:(batch_index + 1) * batch_size]
164 | else:
165 | # concatenate samples from motion and spatial
166 | assert np.allclose(train_labels_spatial, train_labels_motion)
167 | assert train_samples_spatial.shape[0] == num_training_samples
168 | assert train_samples_motion.shape[0] == num_training_samples
169 |
170 | for batch_index in permutation:
171 | yield np.concatenate([train_samples_spatial[batch_index * batch_size:(batch_index + 1) * batch_size], train_samples_motion[batch_index * batch_size:(batch_index + 1) * batch_size]], axis=2), train_labels_spatial[batch_index * batch_size:(batch_index + 1) * batch_size]
172 |
173 |
174 | def test_generator():
175 | """load spatial test data"""
176 | if is_spatial:
177 | with open("test_features_spatial.pickle", 'rb') as f:
178 | test_samples_spatial, test_labels_spatial = pickle.load(f)
179 |
180 | """load motion test data"""
181 | if is_motion:
182 | with open("test_features_motion.pickle", 'rb') as f:
183 | test_samples_motion, test_labels_motion = pickle.load(f)
184 |
185 | while True:
186 | if is_spatial != is_motion: # xor
187 | # single stream motion or spatial
188 | if is_spatial:
189 | # noinspection PyUnboundLocalVariable
190 | test_samples, test_labels = test_samples_spatial, test_labels_spatial
191 | assert test_samples_spatial.shape[0] == num_testing_samples
192 | else:
193 | # noinspection PyUnboundLocalVariable
194 | test_samples, test_labels = test_samples_motion, test_labels_motion
195 | assert test_samples_motion.shape[0] == num_testing_samples
196 |
197 | for batch_index in range((test_samples.shape[0] + batch_size - 1) // batch_size):
198 | yield test_samples[batch_index * batch_size:(batch_index + 1) * batch_size], test_labels[batch_index * batch_size:(batch_index + 1) * batch_size]
199 |
200 | else:
201 | # concatenate samples from motion and spatial
202 | assert np.allclose(test_labels_motion, test_labels_spatial)
203 | assert test_samples_spatial.shape[0] == num_testing_samples
204 | assert test_samples_motion.shape[0] == num_testing_samples
205 |
206 | for batch_index in range((num_testing_samples + batch_size - 1) // batch_size):
207 | yield np.concatenate([test_samples_spatial[batch_index * batch_size:(batch_index + 1) * batch_size], test_samples_motion[batch_index * batch_size:(batch_index + 1) * batch_size]], axis=2), test_labels_spatial[batch_index * batch_size:(batch_index + 1) * batch_size]
208 |
209 |
210 | class saver_callback(tf.keras.callbacks.Callback):
211 | """
212 | save checkpoint with tensorflow saver not h5py since my model implementation is supclass api not function >> function implementation is left as TODO
213 | also logging model state and uploading the file
214 | """
215 |
216 | def on_epoch_end(self, epoch, logs={}):
217 | epoch_one_based = epoch + 1
218 | if epoch_one_based % save_every == 0 and epoch_one_based > 0:
219 | log("=" * 100 + "\n(Training:)Epoch", epoch_one_based, "prec@1", logs["acc_top_1"], "prec@5", logs["acc_top_5"], "loss", logs["loss"], file=log_stream)
220 | log("(Validation:)Epoch", epoch_one_based, "prec@1", logs["val_acc_top_1"], "prec@5", logs["val_acc_top_5"], "loss", logs["val_loss"], file=log_stream)
221 |
222 | if logs["val_acc_top_1"] > eval_globals.best_video_level_accuracy_1:
223 | log("Epoch", epoch_one_based, "Established new baseline:", logs["val_acc_top_1"], file=log_stream)
224 | eval_globals.best_video_level_accuracy_1 = logs["val_acc_top_1"]
225 |
226 | # save the model and pickle
227 | #
228 | else:
229 | log("Epoch", epoch_one_based, "Baseline:", eval_globals.best_video_level_accuracy_1, "but got:", logs["val_acc_top_1"], file=log_stream)
230 |
231 | saver.save(tf.keras.backend.get_session(), checkpoints)
232 |
233 | drive_manager.upload_project_files(
234 | files_list=[log_file],
235 | dir_list=[checkpoint_dir],
236 | snapshot_name=str(epoch_one_based) + "-" + "{0:.5f}".format(eval_globals.best_video_level_accuracy_1) + "-" + "{0:.5f}".format(logs["val_acc_top_1"]))
237 |
238 |
239 | class Model(tf.keras.Model):
240 | def __init__(self):
241 | super(Model, self).__init__()
242 |
243 | self.gru_1 = GRU(hidden_state, return_sequences=True, input_shape=(testing_samples_per_video, feature_field), dropout=.5) # recurrent layer
244 | # self.gru_2 = GRU(hidden_state, return_sequences=True)
245 |
246 | self.attention_layer = Dense(1) # gets attention weight for time step
247 | self.attention_normalizer = Softmax(axis=1) # normalizes the 3d tensor to give weight for each time step
248 |
249 | self.FC_1 = Dense(hidden_state // 2, activation='selu')
250 | # recurrent_fusion_model.add(BatchNormalization())
251 | # self.FC_2 = Dense(hidden_state // 4, activation='selu')
252 | # self.BN_1 = BatchNormalization()
253 | self.classification_layer = Dense(num_actions, activation='softmax')
254 |
255 | def call(self, input_visual_feature, training=None, mask=None):
256 | internal = self.gru_1(input_visual_feature) # returns a sequence of vectors of dimension feature_field
257 | # in self attention i will return_sequences of course
258 | # internal = self.gru_2(internal) # returns a sequence of vectors of dimension feature_field
259 |
260 | un_normalized_attention_weights = self.attention_layer(internal)
261 | normalized_attention_weights = self.attention_normalizer(un_normalized_attention_weights) # normalize on timesteps dimension
262 | internal = normalized_attention_weights * internal
263 | print(internal)
264 | attention_vector = K.sum(internal, axis=1) # sum on timesteps
265 | print(attention_vector)
266 | # recurrent_fusion_model.add(Dense(hidden_state // 2, activation='relu'))
267 | # recurrent_fusion_model.add(BatchNormalization())
268 | internal = self.FC_1(attention_vector)
269 | # internal = self.FC_2(internal)
270 | final_output = self.classification_layer(internal)
271 |
272 | return final_output
273 |
274 |
275 | # create the model
276 | recurrent_fusion_model = Model()
277 | recurrent_fusion_model.compile(optimizer=keras.optimizers.Adam(lr=lr), loss=sparse_categorical_cross_entropy_loss, metrics=[acc_top_1, acc_top_5])
278 |
279 | # build internal tensors
280 | recurrent_fusion_model.fit(*next(train_generator()), batch_size=1, epochs=1, verbose=0)
281 |
282 | # get tensorflow saver ready > will be used if a checkpoint found on drive
283 | saver = tf.train.Saver(recurrent_fusion_model.variables)
284 |
285 | if checkpoint_found:
286 | # restore the model from the checkpoint
287 | log("Model restored")
288 | eval_globals.best_video_level_accuracy_1 = float(zip_file_name.split("-")[1])
289 | log("Current Best", eval_globals.best_video_level_accuracy_1)
290 |
291 | saver.restore(tf.keras.backend.get_session(), checkpoints) # use tensorflow saver
292 | initial_epoch = int(zip_file_name.split("-")[0]) # get epoch number
293 | else:
294 | # init the model from scratch, it's already done
295 | log("Starting from scratch")
296 | # expected input data shape: (batch_size, timesteps, data_dim)
297 | recurrent_fusion_model.summary()
298 | initial_epoch = 0
299 |
300 | # training
301 | recurrent_fusion_model.fit_generator(train_generator(), use_multiprocessing=False,
302 | epochs=epochs, steps_per_epoch=(num_training_samples + batch_size - 1) // batch_size,
303 | validation_data=test_generator(), validation_steps=(num_testing_samples + batch_size - 1) // batch_size,
304 | callbacks=[saver_callback(), keras.callbacks.ReduceLROnPlateau(monitor='val_loss', patience=50, verbose=1, min_lr=lr / 10)],
305 | initial_epoch=initial_epoch)
306 |
--------------------------------------------------------------------------------
/spatial_trainer.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Here I'm training spatial stream CNN in the following steps:
6 | 1. load configs from configs.spatial (indicating architecture/optimizer/lr/pretrained..)
7 | 2. initialize your dataloader >> feeding the data efficiently to the model
8 | 3. load the latest snapshot of the model from drive (It's public and will be downloaded for you)..
9 | note: folders are identified on my drive with their experiment_identifier
10 | for example heavy-spa-xception-adam-1e-05-imnet is (heavy augmentation,spatial stream,xception architecture,adam optimizer with lr = 1e-05 pretrained on imagenet)
11 | this long experiment_identifier is given to drive manager and downloaded automatically and continue training from that checkpoint
12 | view my experiments :https://drive.google.com/drive/folders/1B82anWV8Mb4iHYmOp9tIR9aOTlfllwsD
13 | to make your own experiments on your drive you will need to modify DriveManager at utils.drive_manager and use some other long experiment_identifier
14 | for example make this personal.heavy-mot-xception-adam-1e-05-imnet as suffix at line 31
15 |
16 | 4. As the checkpoint is downloaded or not found the trainer will start from scratch or to continue from where it stopped (the checkpoint)
17 |
18 | note: validation is done by spatialValidationCallback which validates on the given dataset evaluation section
19 | """
20 | from functools import partial
21 |
22 | import frame_dataloader
23 | import utils.training_utils as eval_globals
24 | from configs.spatial_configs import *
25 | from evaluation import legacy_load_model, get_batch_size
26 | from evaluation.evaluation import *
27 | from models.spatial_models import *
28 | from utils import get_augmenter_text
29 | from utils.drive_manager import DriveManager
30 |
31 | ################################################################################
32 | """Files, paths & identifier"""
33 | suffix = "test" # put your name or anything(your crush :3) :D
34 | experiment_identifier = suffix + ("" if suffix == "" else "-") + get_augmenter_text(augmenter_level) + "-spa-" + model_name + "-" + ("adam" if is_adam else "SGD") + "-" + str(lr) + "-" + ("imnet" if pretrained else "scrat")
35 | log_file = "spatial.log"
36 | log_stream = open("spatial.log", "a")
37 | h5py_file = "spatial.h5"
38 | pred_file = "spatial.preds"
39 | ################################################################################
40 | """Checking latest"""
41 | print(experiment_identifier)
42 | num_actions = 101
43 | print("Number of workers:", workers, file=log_stream)
44 | drive_manager = DriveManager(experiment_identifier)
45 | checkpoint_found, zip_file_name = drive_manager.get_latest_snapshot()
46 | ################################################################################
47 | # you need to send it as callback before keras reduce on plateau
48 | SpatialValidationCallback = partial(eval_globals.get_validation_callback,
49 | log_stream=log_stream,
50 | validate_every=validate_every,
51 | testing_samples_per_video=testing_samples_per_video,
52 | pred_file=pred_file, h5py_file=h5py_file, drive_manager=drive_manager, log_file=log_file)
53 |
54 | data_loader = partial(frame_dataloader.SpatialDataLoader,
55 | testing_samples_per_video=testing_samples_per_video,
56 | augmenter_level=augmenter_level,
57 | log_stream=log_stream)
58 |
59 | if checkpoint_found:
60 | # restore the model
61 | print("Model restored")
62 | eval_globals.best_video_level_accuracy_1 = float(zip_file_name.split("-")[1])
63 | print("Current Best", eval_globals.best_video_level_accuracy_1)
64 | spatial_model_restored = legacy_load_model(filepath=h5py_file, custom_objects={'sparse_categorical_cross_entropy_loss': sparse_categorical_cross_entropy_loss, "acc_top_1": acc_top_1, "acc_top_5": acc_top_5})
65 |
66 | # init data loader
67 | train_loader, test_loader, test_video_level_label = data_loader(width=int(spatial_model_restored.inputs[0].shape[1]), height=int(spatial_model_restored.inputs[0].shape[2]), batch_size=get_batch_size(spatial_model_restored, spatial=True)).run()
68 |
69 | # training
70 | spatial_model_restored.fit_generator(train_loader,
71 | steps_per_epoch=len(train_loader), # generates a batch per step
72 | epochs=epochs,
73 | use_multiprocessing=False, workers=workers,
74 | # validation_data=gen_test(), validation_steps=len(test_loader.dataset)
75 | callbacks=[SpatialValidationCallback(model=spatial_model_restored, test_loader=test_loader, test_video_level_label=test_video_level_label), # returns callback instance
76 | keras.callbacks.ReduceLROnPlateau(monitor='val_loss', patience=validate_every, verbose=1)],
77 | initial_epoch=int(zip_file_name.split("-")[0])) # get epoch number
78 |
79 | else:
80 | # init the model
81 | print("Starting from scratch")
82 |
83 | if model_name == "resnet":
84 | model = ResNet50SpatialCNN(num_classes=num_actions, is_tesla_k80=is_tesla_k80, pre_trained=True if pretrained else False)
85 | elif model_name == "xception":
86 | model = XceptionSpatialCNN(num_classes=num_actions, is_tesla_k80=is_tesla_k80, pre_trained=True if pretrained else False)
87 | elif model_name == "vgg":
88 | model = VGGSpatialCNN(num_classes=num_actions, is_tesla_k80=is_tesla_k80, pre_trained=True if pretrained else False)
89 | elif model_name == "mobilenet":
90 | model = MobileSpatialCNN(num_classes=num_actions, is_tesla_k80=is_tesla_k80, pre_trained=True if pretrained else False)
91 |
92 | # noinspection PyUnboundLocalVariable
93 | keras_spatial_model = model.get_keras_model()
94 |
95 | # init data loader
96 | train_loader, test_loader, test_video_level_label = data_loader(**model.get_loader_configs()).run() # batch_size, width , height)
97 |
98 | keras_spatial_model.compile(optimizer=keras.optimizers.Adam(lr=lr) if is_adam else keras.optimizers.SGD(lr=lr, momentum=0.9), loss=sparse_categorical_cross_entropy_loss, metrics=[acc_top_1, acc_top_5])
99 |
100 | keras_spatial_model.summary(print_fn=lambda *args: print(args, file=log_stream))
101 | keras_spatial_model.summary()
102 | log_stream.flush()
103 |
104 | # training
105 | keras_spatial_model.fit_generator(train_loader,
106 | steps_per_epoch=len(train_loader), # generates a batch per step
107 | epochs=epochs,
108 | use_multiprocessing=False, workers=workers,
109 | # validation_data=gen_test(), validation_steps=len(test_loader.dataset)
110 | callbacks=[SpatialValidationCallback(model=keras_spatial_model, test_loader=test_loader, test_video_level_label=test_video_level_label), # returns callback instance
111 | keras.callbacks.ReduceLROnPlateau(monitor='val_loss', patience=validate_every, verbose=1)],
112 | )
113 |
--------------------------------------------------------------------------------
/testing video samples/v_Archery_g02_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Archery_g02_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_BabyCrawling_g18_c06.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BabyCrawling_g18_c06.avi
--------------------------------------------------------------------------------
/testing video samples/v_BabyCrawling_g19_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BabyCrawling_g19_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_BalanceBeam_g08_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BalanceBeam_g08_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_BalanceBeam_g13_c05.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BalanceBeam_g13_c05.avi
--------------------------------------------------------------------------------
/testing video samples/v_BasketballDunk_g22_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BasketballDunk_g22_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_BenchPress_g01_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BenchPress_g01_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_Biking_g01_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Biking_g01_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_Biking_g10_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Biking_g10_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_Biking_g19_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Biking_g19_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_Biking_g20_c06.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Biking_g20_c06.avi
--------------------------------------------------------------------------------
/testing video samples/v_Billiards_g15_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Billiards_g15_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_BlowDryHair_g07_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BlowDryHair_g07_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_BlowDryHair_g13_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BlowDryHair_g13_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_BodyWeightSquats_g01_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BodyWeightSquats_g01_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_BodyWeightSquats_g04_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BodyWeightSquats_g04_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_Bowling_g22_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Bowling_g22_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_BoxingPunchingBag_g01_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BoxingPunchingBag_g01_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_BoxingPunchingBag_g18_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BoxingPunchingBag_g18_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_BoxingSpeedBag_g04_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BoxingSpeedBag_g04_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_BoxingSpeedBag_g09_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BoxingSpeedBag_g09_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_BoxingSpeedBag_g12_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BoxingSpeedBag_g12_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_BoxingSpeedBag_g23_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BoxingSpeedBag_g23_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_BreastStroke_g03_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BreastStroke_g03_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_BrushingTeeth_g17_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BrushingTeeth_g17_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_BrushingTeeth_g20_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_BrushingTeeth_g20_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_CliffDiving_g02_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_CliffDiving_g02_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_CricketBowling_g02_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_CricketBowling_g02_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_CuttingInKitchen_g20_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_CuttingInKitchen_g20_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_CuttingInKitchen_g25_c05.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_CuttingInKitchen_g25_c05.avi
--------------------------------------------------------------------------------
/testing video samples/v_Diving_g02_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Diving_g02_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_Diving_g03_c07.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Diving_g03_c07.avi
--------------------------------------------------------------------------------
/testing video samples/v_Diving_g04_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Diving_g04_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_Diving_g16_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Diving_g16_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_Diving_g20_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Diving_g20_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_Fencing_g15_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Fencing_g15_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_Fencing_g15_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Fencing_g15_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_FieldHockeyPenalty_g11_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_FieldHockeyPenalty_g11_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_FieldHockeyPenalty_g13_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_FieldHockeyPenalty_g13_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_FrontCrawl_g23_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_FrontCrawl_g23_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_Haircut_g07_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Haircut_g07_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_HammerThrow_g10_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_HammerThrow_g10_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_HammerThrow_g23_c05.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_HammerThrow_g23_c05.avi
--------------------------------------------------------------------------------
/testing video samples/v_Hammering_g12_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Hammering_g12_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_Hammering_g17_c05.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Hammering_g17_c05.avi
--------------------------------------------------------------------------------
/testing video samples/v_HighJump_g02_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_HighJump_g02_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_HighJump_g19_c05.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_HighJump_g19_c05.avi
--------------------------------------------------------------------------------
/testing video samples/v_HorseRace_g24_c05.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_HorseRace_g24_c05.avi
--------------------------------------------------------------------------------
/testing video samples/v_JavelinThrow_g05_c05.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_JavelinThrow_g05_c05.avi
--------------------------------------------------------------------------------
/testing video samples/v_JavelinThrow_g21_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_JavelinThrow_g21_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_JavelinThrow_g22_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_JavelinThrow_g22_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_JavelinThrow_g23_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_JavelinThrow_g23_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_JavelinThrow_g24_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_JavelinThrow_g24_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_Kayaking_g12_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Kayaking_g12_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_Knitting_g20_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Knitting_g20_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_LongJump_g04_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_LongJump_g04_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_LongJump_g15_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_LongJump_g15_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_LongJump_g15_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_LongJump_g15_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_MoppingFloor_g03_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_MoppingFloor_g03_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_PizzaTossing_g01_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_PizzaTossing_g01_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_PizzaTossing_g14_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_PizzaTossing_g14_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_PizzaTossing_g18_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_PizzaTossing_g18_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_PlayingCello_g02_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_PlayingCello_g02_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_PlayingDaf_g10_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_PlayingDaf_g10_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_PlayingDhol_g17_c06.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_PlayingDhol_g17_c06.avi
--------------------------------------------------------------------------------
/testing video samples/v_PlayingFlute_g05_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_PlayingFlute_g05_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_PlayingGuitar_g22_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_PlayingGuitar_g22_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_PlayingTabla_g14_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_PlayingTabla_g14_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_PoleVault_g04_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_PoleVault_g04_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_PommelHorse_g17_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_PommelHorse_g17_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_Punch_g22_c07.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Punch_g22_c07.avi
--------------------------------------------------------------------------------
/testing video samples/v_RockClimbingIndoor_g09_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_RockClimbingIndoor_g09_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_RockClimbingIndoor_g11_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_RockClimbingIndoor_g11_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_RockClimbingIndoor_g25_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_RockClimbingIndoor_g25_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_RopeClimbing_g01_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_RopeClimbing_g01_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_RopeClimbing_g04_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_RopeClimbing_g04_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_Rowing_g14_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Rowing_g14_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_Rowing_g24_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Rowing_g24_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_SalsaSpin_g12_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_SalsaSpin_g12_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_ShavingBeard_g03_c05.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_ShavingBeard_g03_c05.avi
--------------------------------------------------------------------------------
/testing video samples/v_ShavingBeard_g24_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_ShavingBeard_g24_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_Shotput_g13_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Shotput_g13_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_Skiing_g14_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Skiing_g14_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_Skijet_g07_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Skijet_g07_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_SkyDiving_g05_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_SkyDiving_g05_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_SoccerPenalty_g17_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_SoccerPenalty_g17_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_StillRings_g03_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_StillRings_g03_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_StillRings_g18_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_StillRings_g18_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_Surfing_g05_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Surfing_g05_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_Surfing_g17_c07.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Surfing_g17_c07.avi
--------------------------------------------------------------------------------
/testing video samples/v_Swing_g14_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Swing_g14_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_TennisSwing_g14_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_TennisSwing_g14_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_ThrowDiscus_g02_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_ThrowDiscus_g02_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_Typing_g16_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_Typing_g16_c03.avi
--------------------------------------------------------------------------------
/testing video samples/v_VolleyballSpiking_g17_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_VolleyballSpiking_g17_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_WalkingWithDog_g15_c01.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_WalkingWithDog_g15_c01.avi
--------------------------------------------------------------------------------
/testing video samples/v_WallPushups_g01_c04.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_WallPushups_g01_c04.avi
--------------------------------------------------------------------------------
/testing video samples/v_WallPushups_g04_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_WallPushups_g04_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_WritingOnBoard_g11_c02.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_WritingOnBoard_g11_c02.avi
--------------------------------------------------------------------------------
/testing video samples/v_YoYo_g25_c03.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/testing video samples/v_YoYo_g25_c03.avi
--------------------------------------------------------------------------------
/upload.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 |
3 | # get drive credentials files
4 | cp -a "/media/mohammed-alaa/Core/current tasks/Storage/drive/." ./utils
5 |
6 | # create zipped file of the code
7 | zip upload.zip -r utils/*.txt *.py */*.py
8 |
9 | # use transfer sh to upload the zipped file
10 | curl --upload-file ./upload.zip https://transfer.sh/upload.zip --silent
11 |
12 | # clean and print the link
13 | rm upload.zip
14 |
15 | rm ./utils/cred*.txt
16 | printf "\n"
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | Some helper functions for logging and named constants
6 | """
7 |
8 | import sys
9 |
10 |
11 | def log(*args, file=None):
12 | """log to a file and console"""
13 | if file:
14 | print(*args, file=file)
15 | file.flush()
16 | print(*args)
17 | sys.stdout.flush()
18 |
19 |
20 | def get_augmenter_text(augmenter_level):
21 | """augmenter level text"""
22 | if augmenter_level == 0:
23 | augmenter_text = "heavy"
24 | elif augmenter_level == 1:
25 | augmenter_text = "medium"
26 | else: # 2
27 | augmenter_text = "simple"
28 |
29 | return augmenter_text
30 |
--------------------------------------------------------------------------------
/utils/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/utils/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/utils/__pycache__/drive_manager.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/utils/__pycache__/drive_manager.cpython-36.pyc
--------------------------------------------------------------------------------
/utils/__pycache__/training_utils.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/utils/__pycache__/training_utils.cpython-36.pyc
--------------------------------------------------------------------------------
/utils/__pycache__/zip_manager.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mohammed-elkomy/two-stream-action-recognition/803128ed2d765d987bc2429514ba974c0c58a7f4/utils/__pycache__/zip_manager.cpython-36.pyc
--------------------------------------------------------------------------------
/utils/training_utils.py:
--------------------------------------------------------------------------------
1 | """
2 | Created by mohammed-alaa
3 | """
4 | import pickle
5 |
6 | import tensorflow as tf
7 |
8 | from evaluation.evaluation import eval_model
9 | from utils import log
10 |
11 | """Evaluation best value over the course of training"""
12 | best_video_level_accuracy_1 = 0
13 | last_video_level_loss = 5.0
14 |
15 |
16 | def get_validation_callback(log_stream, validate_every, model, test_loader, test_video_level_label, testing_samples_per_video, log_file, pred_file, h5py_file, drive_manager):
17 | """
18 | Validation callback: keeps track of validation over the course of training done by keras
19 | """
20 |
21 | class ValidationCallback(tf.keras.callbacks.Callback):
22 | # def on_batch_end(self, batch, logs={}):
23 | #
24 | # metrics_log = ''
25 | # for k in self.params['metrics']:
26 | # if k in logs:
27 | # val = logs[k]
28 | # if abs(val) > 1e-3:
29 | # metrics_log += ' - %s: %.4f' % (k, val)
30 | # else:
31 | # metrics_log += ' - %s: %.4e' % (k, val)
32 | # print('{} ... {}'.format(
33 | # self.params['samples'],
34 | # metrics_log))
35 | #
36 | # print(batch)
37 | # print("="*50)
38 |
39 | def on_epoch_end(self, epoch, logs=None):
40 | """
41 | View validation metrics every "validate_every" epochs
42 | since training epoch is just very short compared to validation epoch >> frame level training >> video level validation
43 | """
44 | global best_video_level_accuracy_1
45 | global last_video_level_loss
46 | epoch_one_based = epoch + 1
47 | log("Epoch", epoch_one_based, file=log_stream)
48 |
49 | if epoch_one_based % validate_every == 0 and epoch_one_based > 0:
50 | video_level_loss, video_level_accuracy_1, video_level_accuracy_5, test_video_level_preds = eval_model(model=model,
51 | test_loader=test_loader,
52 | test_video_level_label=test_video_level_label,
53 | testing_samples_per_video=testing_samples_per_video) # 3783*(testing_samples_per_video=19)= 71877 frames of videos
54 | if video_level_accuracy_1 > best_video_level_accuracy_1:
55 | log("Epoch", epoch_one_based, "Established new baseline:", video_level_accuracy_1, file=log_stream)
56 | best_video_level_accuracy_1 = video_level_accuracy_1
57 |
58 | # save the model and pickle
59 | #
60 | else:
61 | log("Epoch", epoch_one_based, "Baseline:", best_video_level_accuracy_1, "but got:", video_level_accuracy_1, file=log_stream)
62 |
63 | last_video_level_loss = video_level_loss
64 |
65 | log("=" * 100 + "\n(Training:)Epoch", epoch_one_based, "prec@1", logs["acc_top_1"], "prec@5", logs["acc_top_5"], "loss", logs["loss"], file=log_stream)
66 | log("(Validation:)Epoch", epoch_one_based, "prec@1", video_level_accuracy_1, "prec@5", video_level_accuracy_5, "loss", video_level_loss, file=log_stream)
67 |
68 | logs['val_loss'] = video_level_loss
69 |
70 | log_stream.flush()
71 | with open(pred_file, 'wb') as f:
72 | pickle.dump((dict(test_video_level_preds), testing_samples_per_video), f)
73 | model.save(h5py_file)
74 |
75 | drive_manager.upload_project_files(
76 | files_list=[log_file, pred_file, h5py_file],
77 | snapshot_name=str(epoch_one_based) + "-" + "{0:.5f}".format(best_video_level_accuracy_1) + "-" + "{0:.5f}".format(video_level_accuracy_1))
78 |
79 | else:
80 | logs['val_loss'] = last_video_level_loss
81 | log_stream.flush()
82 |
83 | return ValidationCallback() # returns callback instance to be consumed by keras
84 |
--------------------------------------------------------------------------------
/utils/zip_manager.py:
--------------------------------------------------------------------------------
1 | """
2 | ********************************
3 | * Created by mohammed-alaa *
4 | ********************************
5 | a simple class adds set of files and folders into single zip file .. used extensively in saving checkpoints,logs or predictions
6 | """
7 | import datetime
8 | import os
9 | import zipfile
10 |
11 |
12 | class ZipFile:
13 | def __init__(self, file_name):
14 | self.zipf = zipfile.ZipFile(file_name, 'w', zipfile.ZIP_DEFLATED)
15 |
16 | def get_true_size(self):
17 | size = sum([zinfo.file_size for zinfo in self.zipf.filelist])
18 | zip_mb = float(size) / 1024 / 1024 # kB
19 | return zip_mb
20 |
21 | def get_compressed_size(self):
22 | size = sum([zinfo.compress_size for zinfo in self.zipf.filelist])
23 | zip_mb = float(size) / 1024 / 1024 # kB
24 | return zip_mb
25 |
26 | def print_info(self, verbose=False):
27 | print("%s,total data size is :%.3f mb,compressed :%.3f mb" % (self.zipf.filename, self.get_true_size(), self.get_compressed_size()))
28 | print("Files are :")
29 | for info in self.zipf.infolist():
30 | print(info.filename)
31 | if verbose:
32 | print(' Comment :', info.comment)
33 | mod_date = datetime.datetime(*info.date_time)
34 | print(' Modified :', mod_date)
35 | if info.create_system == 0:
36 | system = 'Windows'
37 | elif info.create_system == 3:
38 | system = 'Unix'
39 | else:
40 | system = 'UNKNOWN'
41 | print(' System :', system)
42 | print(' ZIP version :', info.create_version)
43 |
44 | print(' Compressed :', info.compress_size, 'bytes')
45 | print(' Uncompressed:', info.file_size, 'bytes')
46 | print()
47 |
48 | def add_directory(self, path):
49 | for root, dirs, files in os.walk(path):
50 | for file in files:
51 | self.zipf.write(os.path.join(root, file))
52 |
53 | def add_file(self, path):
54 | self.zipf.write(path)
55 |
56 | def __del__(self):
57 | # self.print_info()
58 | self.zipf.close()
59 |
60 | # import tarfile
61 |
62 | # USAGE
63 | # myzipfile = ZipFile("comp.zip")
64 | # myzipfile.addDir('./Bot/')
65 | # #myzipfile.addFile('./Bot/')
66 | # myzipfile.print_info()
67 | #
68 | # for root, dirs, files in os.walk('./Bot'):
69 | # print((root, dirs, files))
70 | #
71 | #
72 |
73 | #
74 | # tar = tarfile.open("TarName.tar.gz", "w:gz")
75 | # tar.add("comp.zip", arcname="comp.zip")
76 | # tar.close()
77 |
--------------------------------------------------------------------------------